lucas hipper˛ stuart boden arquiteturas deep learning ... · a área de deep learning é...
TRANSCRIPT

Universidade Federal Fluminense
Instituto de Computação
Departamento de Ciência da Computação
Lucas Hipper� Stuart Boden
ARQUITETURAS DEEP LEARNING APLICADAS EM
VEÍCULOS AUTÔNOMOS
Niterói-RJ
2017

ii
LUCAS HIPPERTT STUART BODEN
ARQUITETURAS DEEP LEARNING
APLICADAS EM VEÍCULOS AUTÔNOMOS
Monografia apresentada ao Departamento
de Ciência da Computação da Universidade
Federal Fluminense, como requisito parcial
para obtenção do Grau de Bacharel em
Ciência da Computação.
Orientador: Prof. Dr. Luis Martí Orosa
Niterói-RJ
2017

Ficha Catalográfica elaborada pela Biblioteca da Escola de Engenharia e Instituto de Computação da UFF
B666 Boden, Lucas Hippertt Stuart
Arquiteturas deep learning aplicadas em veículos autônomos /
Lucas Hippertt Stuart Boden. – Niterói, RJ : [s.n.], 2017.
42 f.
Projeto Final (Bacharelado em Ciência da Computação) –
Universidade Federal Fluminense, 2017.
Orientador: Luis Martí Orosa.
1. Veículo autônomo. 2. Aprendizado de máquina. 3.
Inteligência artificial. I. Título.
CDD 629.892


v

vi
Agradecimentos
Gostaria de agradecer à minha avó Lucia, que foi como mãe e pai para mim e meus
irmãos, que ela esteja bem aonde quer que esteja. À minha mãe Marcelle por toda luta e
sacrifício para conseguir formar os seus três filhos e ser o exemplo que é para todos os três.
Aos meus tios Márcia e Ruben por terem cuidado de mim enquanto morei com eles e por
sempre estarem perto em momentos de necessidade. À minha avó Laura por ser esse exemplo
de amor ao próximo, por todas as vezes que acordou cedo e me viu com sono e me animava
com um abraço, um beijo e um pão com manteiga. À minha namorada Jaqueline, por ser meu
suporte e meus sorrisos quando o desespero me alcançava. Ao meu orientador, professor Luis
Martí, por todo o esforço e dedicação ao me orientar para que esse trabalho fosse feito da
melhor forma possível. E a todos os que confiaram em mim e me auxiliaram de alguma forma
para que conseguisse alcançar o meu objetivo.

vii
Resumo
Existem diversos modelos e parâmetros que podem ser utilizados ao classificarmos
imagens utilizando Deep Learning. Essas diversas variações afetam diretamente a qualidade
das predições realizadas, e no contexto de veículos autônomos, esses valores podem ser a dife-
rença entre o carro se manter na estrada ou não. Por este motivo, este projeto visa realizar um
estudo de como a utilização de diferentes técnicas e arquiteturas de Deep Learning afetam a
qualidade da predição do ângulo que o veículo deve tomar para a tarefa de direção autônoma,
através da realização de experimentos teóricos e práticos, com o intuito de obter resultados
que possam ser utilizados tanto na tarefa de direção autônoma de veículos quanto em tarefas
semelhantes.
Palavras-chave: Deep Learning. Veículos Autônomos. Aprendizado de Máquina. Inteligência
Artificial

viii
Abstract
There are several models and parameters that can be used to classify images using
Deep Learning. These variations directly a�ect the quality of the assumptions made, and
in context of autonomous vehicles, these values can be deferred in the car whether to stay
on the road or not. For this reason, this project aims to perform a study of how the use
of techniques and architectures of Deep Learning a�ect the quality of the angle prediction
that the vehicle must take to the task of autonomous steering, through the realization of
theoretical experiments and practical, in order to obtain results that are used both in the task
of autonomous steering of vehicles and in similar tasks.
Keywords: Deep Learning. Self Driving Cars. Machine Learning. Artificial Intelligence

Sumário
Resumo vii
Abstract viii
Lista de Figuras xi
1 Introdução 1
1.1 Descrição do problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Organização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Conceitos Básicos 4
2.1 Aprendizado de Máquina . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Redes Neurais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Multilayer Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3.1 Função de erro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3.2 Backpropagation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.3 Overfi�ing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Aprendizagem profunda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4.1 Funções de ativação . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4.2 Redes neurais convolucionais . . . . . . . . . . . . . . . . . . . . . . . 13
3 Deep Learning para Veículos Autônomos 16
3.1 Obtenção dos dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 Pré-processamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.2.1 Aumento de dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
ix

x
3.2.2 Recorte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Treinamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4 Experimentos e Resultados 24
5 Conclusões 29
5.1 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29

xi
Lista de Figuras
2.1 Exemplo do funcionamento do dropout. Fonte: [Srivastava et al. 2014]. . . . . 9
2.2 Exemplo de uma arquitetura CNN para classificação de imagens. Fonte: [Britz
2015] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Exemplo de camada de convolução. Fonte: [Pacheco 2017]. . . . . . . . . . . 14
2.4 Exemplo de camada de agrupamento utilizando a função de máximo. Fonte:
[Boureau, Ponce e LeCun 2010]. . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1 Arquitetura original. CNN com 9 camadas, aproximadamente 27 milhões de
conexões e 250 mil parâmetros. Fonte: [Bojarski et al. 2016] . . . . . . . . . . 18
3.2 Vistas laterais e central das câmeras do veículo no simulador. Fonte: Próprio
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Distribuição inicial dos dados obtidos. Fonte: [Pagadala 2017]. . . . . . . . . . 20
3.4 Exemplo de imagem após a operação de rotação. Fonte: [Pagadala 2017] . . . 21
3.5 Exemplo de imagem após a operação de ajuste de brilho. Fonte: [Pagadala
2017] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.6 Exemplo de imagem após a operação de crop. Fonte: [Pagadala 2017] . . . . . 22
3.7 Arquitetura CNN simplificada utilizada no experimento. Fonte: Próprio autor 23
4.1 Gráfico dos erros de validação em cada configuração estudada. Fonte: Próprio
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25

Capítulo 1
Introdução
Uma das principais causas do estresse nos dias atuais está relacionada ao trânsito
[Ibope 2016]. Dirigir tornou-se uma tarefa complexa, exigindo paciência e removendo das
pessoas horas do seu dia por causa do trânsito, fazendo com que muitos prefiram nem sair de
casa para evitar o estresse, enquanto outros optam por entrar em ônibus com a esperança de
irem sentados para poder evitar um pouco do estresse causado pela direção.
A introdução de veículos autônomos no mercado, com capacidade para dirigir de forma
igual ou até melhor do que humanos, faria com que o número de acidentes fosse reduzido e o
tempo gasto dirigindo fosse gasto com outras tarefas, como por exemplo dormir, melhorando
assim a qualidade de vida da população.
Atualmente muitos estudos são feitos na área de veículos autônomos, e uma das técni-
cas mais utilizadas recentemente, e sobre a qual esse trabalho se desenvolveu, é a de utilizar
diferentes tecnologias da área de Deep Learning para fazer com que o so�ware responsável
pela direção do veículo aprenda a dirigir a partir de dados obtidos em simulações com pessoas
reais. Essa técnica onde o so�ware aprende uma determinada tarefa a partir da observação do
comportamento de seres humanos solucionando essa tarefa é chamado de aprendizado por
imitação.
1.1 Descrição do problema
Ao se estudar alguns dos modelos e técnicas atuais que utilizam Deep Learning para a
tarefa de predição de direção para veículos autônomos, observa-se a necessidade da utilização
de diferentes técnicas que visam solucionar problemas comuns de Machine Learning, além de
1

2
otimizar o processo de simular a ação humana na direção de veículos. Ao estudar as soluções
adotadas para a resolução dos problemas nessa simulação, observa-se que os métodos de
resolução de problemas e de otimização não se aplicam apenas à tarefa de direção de veículos,
eles são replicáveis para quase todas as outras tarefas que utilizam Machine Learning.
1.2 Motivação
A área de Deep Learning é atualmente uma das mais promissoras segundo o Pane�a
2017 e ao se estudar essa área, observa-se um aumento nos estudos sobre a mesma muito
recente, guiado pelo barateamento e aumento no poder de processamento de sistemas com-
putacionais e no grande aumento da disponibilidade de dados.
Dentro dessa área, uma das aplicações mais estudadas é a de veículos autônomos.
Grandes empresas do setor tecnológico, como a Google, e do setor automobilístico, como a
Tesla, investem fortemente no desenvolvimento de novos modelos que possam fazer com que
um carro não precise de nenhuma interferência humana para ser dirigido. Recentemente,
observando a qualidade das tecnologias que utilizam inteligência artificial, a Volkswagen fez
uma parceria com a NVIDIA para utilizar essa tecnologia em diferentes campos de sua em-
presa, além da aplicação em veículos autônomos [Gabriel 2017].
Estudando e observando modelos já existentes para a tarefa de simulação de direção
de veículos, observa-se a frequente necessidade de combinações de técnicas para solução de
problemas, que muitas vezes não são solucionados, são apenas minimizados.
1.3 Objetivo
Neste trabalho iremos estudar como diferentes técnicas e algoritmos de Deep Learning
podem ser utilizados para prever qual direção um veículo autônomo deve tomar, ou seja, se ele
deve virar para a esquerda, para a direita ou seguir reto, baseado em imagens obtidas através
de câmeras acopladas ao mesmo. Será realizado um experimento através da combinação da
utilização de diferentes valores na função de dropout e quatro diferentes funções de ativação;
ReLU, SELU, ELU e LReLU, aplicando esses valores e essas funções em dois modelos distin-
tos utilizando redes neurais convolucionais, o primeiro com nove camadas e o segundo com
apenas três.

3
Iremos analisar como a utilização dessas técnicas, tais como o dropout, o aumento de
dados e diferentes funções de ativação afetam a predição da direção que o carro deve tomar
baseado em imagens tiradas de diferentes ângulos do carro sendo dirigido por humanos. Fa-
remos um estudo empírico acerca deste assunto, demonstrando o resultado obtido através de
experimentos.
O objetivo geral deste projeto é obter resultados e análises que possam ajudar a solu-
cionar problemas recorrentes em modelos de Deep Learning na tarefa de simulação da direção
de veículos autônomos, para posteriormente replicar as soluções encontradas especificamente
para essa tarefa, para outras tarefas utilizando modelos semelhantes e estudar seus compor-
tamentos.
1.4 Organização
Neste capítulo foi apresentado o tema da monografia, sua importância e a motivação
por trás da mesma.
No capítulo 2 será feita a introdução a alguns conceitos importantes de serem com-
preendidos, antes de se aprofundar mais na leitura da monografia.
No capítulo 3 é apresentado o modelo base utilizado e o processo de obtenção e tra-
tamento de imagens. A partir do modelo, são demonstradas as alterações feitas no mesmo,
gerando novos modelos, com parâmetros diferentes.
No capítulo 4 são demonstrados os dados do experimento, explicando como o mesmo
foi obtido e quais informações podem ser obtidas a partir do experimento.
No capítulo 5 é realizada a conclusão do trabalho, apresentando como a experimenta-
ção abordada contribui para o objetivo do projeto, as limitações dos experimentos realizados
e quais devem ser os próximos passos para o estudo do tema proposto.

Capítulo 2
Conceitos Básicos
Neste capítulo abordaremos questões básicas que devem ser compreendidas para en-
tendimento do restante do trabalho.
2.1 Aprendizado de Máquina
Aprendizado de Máquina, tradução do inglês Machine Learning, é uma área da ciência
da computação, sendo subárea da inteligência artificial, que estuda como um computador
pode exercer funções de forma mais natural possível, sem que pareça que foi explicitamente
programado para isso. De forma simples, os algoritmos de Machine Learning permitem que os
computadores tomem decisões inteligentes baseados em comportamento que não foi direta-
mente programado, mas sim aprendido ou adaptado por meio de algum conhecimento [Reis
2017].
Existem diversas classes de problemas de Machine Learning, sendo as mais comuns a
classificação (onde ao se entregar um determinado dado nunca visto antes para o algoritmo
de Machine Learning, ele deve ser capaz de dizer à qual ou quais das já conhecidas classes
do problema esse novo dado pertence), clusterização (onde o objetivo é agrupar os dados em
classes de acordo com suas semelhanças, sem conhecer previamente as classes existentes) e
regressão (que é semelhante à classificação, mas os valores a serem previstos são contínuos e
não discretos como na classificação), que será o que possuirá mais enfoque neste trabalho.
4

5
2.2 Redes Neurais
Existem diferentes algoritmos e técnicas de Machine Learning, sendo uma das princi-
pais delas as redes neurais artificiais, ou simplesmente redes neurais.
O trabalho com redes neurais tem sido motivado desde o começo pelo reconhecimento
de que o cérebro de animais processa informações de uma forma inteiramente diferente do
computador digital convencional. O cérebro é um computador, um sistema de processamento
de informação altamente complexo, não linear e paralelo [Haykin 1994].
Além disso, o cérebro possui a capacidade de se adaptar ao ambiente em que se en-
contra e aprender com os experimentos passados. Somos capazes de, por exemplo, identificar
um rosto conhecido no meio de um ambiente não conhecido em questão de milissegundos,
ou então um morcego que é capaz, através do sinal recebido pelo seu sonar, identificar o ta-
manho da sua presa, a velocidade em que ela se encontra e a distância até a mesma [Suga
1990].
Com a percepção desse alto poder de processamento do cérebro, cientistas começaram
a tentar replicar esse processamento para os computadores, criando assim as redes neurais.
A primeira rede neural conhecida foi criada em 1943 [McCulloch e Pi�s 1943], utilizando
circuitos digitais para replicar o funcionamento dos neurônios.
A rede então é composta por vários neurônios, onde cada neurônio é uma unidade
de processamento de informação. Para realizar esse processamento, são enviados para esses
neurônios sinais de entrada relativos aos dados que estamos utilizando para realizar o trei-
namento da rede. Esses sinais são então multiplicados por pesos que são relacionados a cada
canal de entrada do neurônio. A atualização desses pesos é o que é chamado de aprendizado.
Após a multiplicação entre os pesos e os sinais de entrada, é adicionado um valor de viés,
visando permitir uma melhor adaptação, por parte da rede neural, ao conhecimento a ela
fornecido. No final, o resultado dessas operações é dado como entrada para uma função, cha-
mada de função de ativação, que serve para definir se a informação obtida naquele neurônio
é importante ou não para a tarefa a ser realizada.
A maneira pela qual os neurônios são estruturados está intimamente relacionada com
o algoritmo de aprendizagem utilizado para treinar a rede [Haykin 1994].
Existem três tipos principais de estruturas para redes neurais. A estrutura de redes
alimentadas adiante com duas camadas, onde os neurônios são organizados em camadas,
é estruturada de forma que haja uma camada de entrada e uma camada de saída, sendo

6
que a camada de entrada recebe os sinais de entrada dos dados e a camada de saída recebe
como entrada a saída da camada de entrada. Essa estrutura é conhecida como Perceptron
[Rosenbla� 1961].
Outro tipo são as redes alimentadas diretamente com múltiplas camadas, onde além
das camadas de entrada e saída, são adicionadas camadas intermediárias, também conhecida
como camada oculta, que possuem o objetivo de extrair estatísticas de ordem elevada, o que
é muito útil em problemas com uma grande quantidade de neurônios na camada de entrada.
Esse tipo de estrutura é geralmente conhecido como Multilayer Perceptron.
A terceira forma estrutural são as redes neurais recorrentes, onde pelos menos uma
saída de um dos neurônios das camadas posteriores é utilizado como entrada para neurônios
de camadas anteriores, processo esse chamado de realimentação. Essa terceira estrutura é
conhecida comumente como rede recorrente (Recurrent Neural Network).
2.3 Multilayer Perceptron
Como visto na seção anterior, o Multilayer Perceptron é uma topologia de rede neural
que funciona com três ou mais camadas de neurônios [Rumelhart, Hinton e Williams 1985].
No Multilayer Perceptron, o processo de aprendizagem é realizado de uma maneira supervi-
sionada, onde os dados de treinamento possuem conhecimento prévio do valor ou classe a
ser estimada, conhecido como retropropagação (mais comumente chamado pelo seu termo
em inglês backpropagation), que utiliza uma função de erro para calcular a diferença entre o
resultado obtido e o esperado.
Entretanto, o uso dessa técnica de aprendizado costuma causar um grande problema
para o treinamento de redes neurais, o sobreajuste, que é mais conhecido pelo seu termo em
inglês overfi�ing.
2.3.1 Função de erro
A função de erro é a unidade de medida utilizada para saber o quão bem a rede neural
está em relação aos dados de treinamento e o resultado esperado [Phylliida 2016].
A função de erro mais utilizada para o backpropagation é a função conhecida como
erro quadrático médio ou MSE (do inglês mean squared error). Ela é calculada realizando a
substração entre o resultado obtido pela rede neural e o resultado esperado e elevando esse

7
valor obtido ao quadrado. Esse processo é realizado para todos os exemplos de entrada da
rede e então são somados e é calculada uma média para obter o valor final do erro para aquela
etapa do treinamento.
A função MSE é equacionada conforme
E =∑N
k=1(yk − y ′k)
2)N
. (2.1)
2.3.2 Backpropagation
O backpropagation é um algoritmo para aprendizado supervisionado que utiliza uma
estratégia conhecida como descida do gradiente. Dada uma rede neural artificial e uma função
de erro, o método calcula o gradiente da função de erro com respeito aos pesos da rede neural
[Rumelhart, Hinton e Williams 1985].
O algoritmo de treinamento de uma rede neural utilizando backpropagation funciona
em três etapas. Na primeira etapa, conhecida como passagem dos padrões de treinamento (ou
pelo termo em inglês feedforward, os sinais de entrada são passados para a primeira camada
da rede. Esses sinais são passados para a camada seguinte, de forma que o valor recebido por
cada neurônio seja de acordo com
in = v +N∑i=1
wi,jxi , (2.2)
onde v é o valor do viés associado ao neurônio que está recebendo o sinal, wi,j é o valor do
peso relacionado à conexão entre o neurônio i da camada anterior e o neurônio j da camada
que está recebendo o sinal e xi é o valor da saída da camada anterior. Esse valor então é
passado para a função de ativação do neurônio, encontrando um valor f (in) que passará esse
novo valor para a camada seguinte, até chegar na última camada, que é a camada de saída.
Na camada de saída, cada neurônio realizará o mesmo cálculo que os neurônios das camadas
ocultas, chegando a um resultado final y .
Na segunda etapa, cada neurônio de saída calcula um valor ∂ = (ye− y)f ′(in), onde ye
é a saída esperada para aquele neurônio, y é a saída efetiva do neurônio, f ′() é a derivada da
função de ativação do neurônio e in é a entrada recebida pelo neurônio, calculado na etapa
1. Após achar esse valor, o neurônio deve calcular o seu termo de correção de pesos, utili-
zando a fórmula ∆w = α∂f (in), onde α é chamado de taxa de aprendizagem, um parâmetro

8
geralmente entre (0, 1], ∂ o valor obtido anteriormente e f (in) o valor da saída da camada an-
terior. O neurônio também deve calcular o seu termo de correção de viés, conforme fórmula
∆b = ∂α.
Nos neurônios da camada oculta, o cálculo deve ser feito da seguinte forma. Primeiro
calcula o ∂, conforme fórmula ∂in =∑N
k=i(∂kwk), onde ∂k é o valor calculado nos neurônios da
camada superior que possuem conexão com o neurônio k onde está sendo realizado o cálculo
e wko peso do neurônio que possui relação com o neurônio onde está sendo feito o cálculo.
Após esse cálculo, é encontrado o valor ∂j = ∂inf ′(in), que então é multiplicado pelo
valor da taxa de aprendizagem e pelo valor de entrada no neurônio, achando um valor de taxa
de correção de peso ∆w e achando o valor da taxa de correção de viés através da fórmula
∆v = α∂k . Na terceira fase, os pesos e viéses antigos são adicionados às taxas de correção de
peso e vieses, respectivamente, para então encontrar os novos valores.
2.3.3 Overfi�ing
O sobre-ajuste, ou overfi�ing, é um dos principais problemas em redes com múltiplas
camadas e do aprendizagem de máquina em geral. O overfi�ing se dá quando uma rede sim-
plesmente decora o comportamento dos dados de entrada no treinamento e tenta replicá-los
sempre. Dessa forma, a rede funciona muito bem para dados similares aos utilizados no trei-
namento, mas não tão bem para entradas com comportamentos diferentes dos já conhecidos.
Existem diferentes técnicas utilizadas para evitar esse comportamento indesejado, como pa-
rar o treinamento quando o desempenho nos dados de validação está ficando pior, ou técnicas
de penalização de pesos como a regularização L1 e L2. [Srivastava et al. 2014] Entretanto, ire-
mos utilizar uma técnica conhecida como dropout, que funciona permitindo que os valores de
saída dos neurônios na camada anterior ao dropout apenas sejam passados para a camada se-
guinte se um valor gerado aleatoriamente for maior do que o parâmetro do dropout, chamado
de probabilidade de permanência (em inglês keep probability).
2.4 Aprendizagem profunda
Aprendizagem profunda, tradução do seu termo em inglês Deep Learning, é uma téc-
nica de Machine Learning que visa ensinar ao computador a fazer o que os humanos fazem
naturalmente: aprender a partir de exemplos [Goodfellow, Bengio e Courville 2016]. Com o

9
(a) Rede completamente conectada. (b) Rede depois do dropout.
Figura 2.1 – Exemplo do funcionamento do dropout. Fonte: [Srivastava et al. 2014].
estudo e experiências em Machine Learning, foi observado que a utilização de mais camadas
dentro de uma rede neural gera resultados muito mais precisos para as tarefas desejadas. Isso
se deve ao fato de que redes com mais camadas possuem maiores níveis de não-linearidade,
enquanto que redes com menos camadas possuem maior dificuldade para obter esses níveis.
Com isso, muitos cientistas pensaram que bastaria adicionar novas camadas aos seus mode-
los que resolveriam o problema. Porém, isso não ocorre de fato. Um dos motivos para que
isso não ocorra é devido à natureza do backpropagation.
O backpropagation é realizado utilizando derivadas. Pelo que foi visto no tópico de
backpropagation, se possuirmos muitas camadas na rede, a regra da cadeia aplicada para cal-
cular o fator de correção daquela camada se tornará uma multiplicação tão grande quanto o
número de camadas após a camada onde estamos calculando o fator na rede. Dessa forma,
caso o valor das derivadas seja um número pequeno, a multiplicação de diversos números
pequenos convergirá para um número muito próximo de 0, que mesmo que não chegue a
zero, devido a limitação de representação dos computadores, este número será tratado como
0, fazendo com que os pesos das camadas inicias não sejam alterados, ou seja, não há apren-
dizado nas camadas iniciais, tornando elas camadas inúteis. Esse tipo de problema é chamado
de problema do desaparecimento do gradiente, ou em inglês vanishing gradient problem [Ho-
chreiter 1991, Hochreiter et al. 2001]. Para minimizar esse problema, são utilizadas funções
de ativação que apresentem menos problema de saturação, dependendo da necessidade do
aumento no número de camadas da rede.

10
Outro problema do Deep Learning é a necessidade de uma grande quantidade de da-
dos. �anto maior for a necessidade de generalização do problema, maior a quantidade de
dados necessários. O problema da necessidade de grande quantidade de dados não é a obten-
ção dos dados em si, pois com a internet, muitos dados estão disponíveis, mas as arquiteturas
de Deep Learning funcionam melhor se os dados disponíveis forem classificados com rela-
ção à tarefa que desejamos, e esses dados são mais difíceis de arrumar, pois requisitam um
especialista que classifique-os antes de serem enviados para treinamento na rede. Por isso,
geralmente se recorre a técnicas que visam ajustar os dados que já se possui de forma que
eles funcionem como novos dados, como por exemplo rotacionar uma imagem de um gato na
tarefa de reconhecer uma figura. A figura contínua sendo a de um gato, mas para a rede é
como uma nova figura. Isso serve também para informar indiretamente à rede que a posição
do gato na figura não interfere na tarefa de classificação.
Existem diferentes técnicas de Deep Learning. A primeira já foi vista no tópico anterior,
que são os Multilayer Perceptrons. Outras duas muito populares são as redes neurais convo-
lucionais (CNN, do inglês Convolutional Neural Network) e redes neurais recorrentes (RNN,
do inglês Recurrent Neural Networks). E existe também uma quarta, que tem ganhado muita
força nos últimos anos que são as redes geradoras adversárias (GANs, do inglês Generative
Adversarial Nets), que possuem esse nome pelo fato de possuírem duas redes sendo treina-
das ao mesmo tempo, uma primeira, que gera instâncias falsas, e uma segunda, que tenta
diferenciar entre tais instâncias falsas (aquelas geradas pela primeira rede) e as entradas de
fato. [Goodfellow et al. 2014]
2.4.1 Funções de ativação
Como visto anteriormente, um dos principais problemas dos modelos de Deep Lear-
ning é o vanishing gradient problem. Para solucionar esse problema, muitos estudos estão
sendo feitos, em sua maioria voltados para a utilização de diferentes funções de ativação nos
neurônios das camadas. A seguir são demonstradas algumas dessas funções e como ela auxi-
liam na minimização desse problema, visto que ele ainda é um problema sem solução.

11
2.4.1.1 Unidade linear retificada (ReLU)
A função de ativação ReLU, do inglês Rectified Linear Unit é dada conforme
f (x) = max(0, x) . (2.3)
Essa função é bastante utilizada, pois como visto anteriormente, para treinarmos redes
neurais é necessário tanto fazer cálculos com a função de ativação quanto com a derivada da
mesma. Observando a função ReLU, observa-se que calcular o valor da função é simples
computacionalmente, e a derivada dela também, pois a derivada será 1 se x for positivo e 0
se x for negativo. Dessa forma, mesmo que tenhamos um grande número de multiplicações,
o cálculo será simples e rápido. Porém, essa função tem um problema. Os neurônios com
essa função de ativação são desativados quando a entrada deles é negativa. Isso pode em
muitos casos bloquear o processo de backpropagation pois o valor dos gradientes será 0 após
uma entrada negativa para a função de ativação [Maas, Hannun e Ng 2013]. Além disso,
ela não é derivável para o valor 0, de forma que pode causar problemas para o processo de
backpropagation.
2.4.1.2 Unidade linear retificada vazada (LReLU)
A fórmula para a função de ativação LReLU, do inglês Leaky Rectified Linear Unit, é
dada abaixo:
f (x) = max(αx , x) (2.4)
e derivada:
f ′(x) =
1 se x ≥ 0,
α em caso contrário.(2.5)
Essa função foi proposta [Maas, Hannun e Ng 2013] como uma forma de solucionar
o problema da ReLU, multiplicando o valor de entrada por um número muito pequeno, ge-
ralmente próximo a 0.2, fazendo com que tanto o valor da função para entradas negativas
quanto a sua derivada não zerem. Entretanto, essa função não soluciona o vanishing gradient
problem visto que a derivada para números negativos também será um número pequeno.

12
2.4.1.3 Unidade linear exponencial (ELU)
A função ELU, do inglês Exponential Linear Unit [Clevert, Unterthiner e Hochreiter
2015] é dada conforme à fórmula:
f (x ,α) =
x se x ≥ 0,
α(ex − 1), em caso contrário.(2.6)
f ′(x ,α) =
1 se x ≥ 0,
f (x ,α) + α em caso contrário.(2.7)
ELU também soluciona o problema da ReLU de desativar um neurônio com entrada
negativa, entretanto, por ser necessário realizar cálculos de exponencial, ela se torna um mé-
todo mais lento se comparado a LReLU e ReLU, mas conforme mostrado no artigo de proposta
da mesma [Maas, Hannun e Ng 2013], ela possui melhor performance quando comparadas
com as outras duas.
2.4.1.4 Unidade linear exponencial escalonada (SELU)
A função SELU, do inglês scaled exponential linear unit, é bem parecida com a fun-
ção ELU, mas ela possui uma pequena diferença conforme mostrado nas fórmulas abaixo, da
função e de sua respectiva derivada, onde por convenção, λ = 1.0507 e α = 1.6732.
f (x) = λ
x se x > 0
α(ex − 1), em caso contrário.(2.8)
e derivada:
f ′(x) = λ
1 se x > 0
αex , em caso contrário.(2.9)
A ideia principal dessa função é realizar a normalização dos dados dentro da função,
não sendo necessário técnicas externas para realizar essa tarefa.

13
Figura 2.2 – Exemplo de uma arquitetura CNN para classificação de imagens. Fonte: [Britz2015]
2.4.2 Redes neurais convolucionais
Redes neurais convolucionais (CNN, do inglês Convolutional Neural Networks) [LeCun
et al. 1989], são um tipo de modelo de Deep Learning amplamente utilizado para tarefas de
classificação e aprendizado através de imagens. A ideia do modelo é diminuir o tamanho das
imagens ao mesmo tempo que extrai-se delas características não conhecidas das camadas
anteriores e então, a partir dessas características, obter a informação desejada, como por
exemplo reconhecer qual objeto está presente na imagem, ou, no exemplo deste trabalho,
descobrir qual direção o veículo deve seguir.
Elas foram primeiramente propostas em 1998 [LeCun et al. 1989], sendo utilizada para
reconhecer dígitos escritos a mão, atingindo uma taxa de acerto de de 99,2%, atingindo assim
um novo estado da arte. A Figura 2.2 mostra uma arquitetura típica de CNN.
2.4.2.1 Camada de convolução
Essa camada é a camada mais importante da rede (Figura 2.3). Ela possui a maior
parte do processamento da rede convolucional, sendo também responsável por dar o nome
ao modelo. Nela, é passada uma matriz de filtro de tamanho definido, contendo valores que
podem ser interpretados como pesos. Essa matriz é multiplicada pela entrada da camada,
fazendo multiplicações matriciais percorrendo toda a imagem, da esquerda para a direita
e de baixo para cima, sempre andando um número pré-definido de pixeis, conhecido como
passo, ou em inglês stride. Essa camada é capaz de identificar características específicas de
pequenas partes da imagem. Ela também é capaz de aprender, já que os valores da matriz de
filtros são tratados como pesos, e como o filtro é o mesmo em todas as partes da imagem, esse
peso é chamado de peso compartilhado, tipo de peso que reduz a quantidade de operações
de aprendizagem.

14
Figura 2.3 – Exemplo de camada de convolução. Fonte: [Pacheco 2017].
2.4.2.2 Camada de agrupamento
A camada de agrupamento, tradução do inglês para pooling layer, é uma camada seme-
lhante à camada de convolução, onde é passado um filtro pelos dados de entrada da camada
sendo guiado pelo stride. Entretanto, ao contrário da camada de convolução onde é feito uma
multiplicação matricial, o filtro da camada de agrupamento é uma função que é aplicada ao
dado de entrada. Existem diferentes funções utilizadas para essa tarefa, sendo a mais utili-
zada a função de máximo, que faz com que, dentro do pedaço do dado sendo analisado pelo
filtro, apenas o maior valor seja passado para a camada seguinte, fazendo assim com que
seja passado apenas o valor que em tese possuiria mais impacto para a tarefa desejada na
utilização do modelo. A Figura 2.4 mostra um exemplo do processo antes descrito.

15
Figura 2.4 – Exemplo de camada de agrupamento utilizando a função de máximo. Fonte:[Boureau, Ponce e LeCun 2010].
2.4.2.3 Camada totalmente conectada
A camada totalmente conectada, como o próprio nome já sugere, é completamente
conectada com a camada anterior [Pacheco 2017], ou seja, todos os neurônios de uma ca-
mada se conectam com todos os neurônios da camada seguinte. Como todos os neurônios de
uma camada precisam se conectar com todos os da anterior, e geralmente as camadas total-
mente conectadas vem após as camadas de convolução, e as camadas de convolução possuem
saídas com profundidade, é necessário que seja realizado um processo de aplainar, também
conhecido como sua pronuncia em inglês fla�en, para que todos os neurônios da camada de
convolução consigam se conectar aos neurônios da camada totalmente conectada. O principal
objetivo dessa camada é realizar as tarefas que desejamos na nossa rede, tanto de classificação
quanto de regressão, baseados nas características extraídas pelas camadas anteriores.

Capítulo 3
Deep Learning para Veículos
Autônomos
Veículos autônomos são há muito tempo temas de ficção científica e discutidos pela
população. Entretanto, eles não estão apenas no mundo das ideias. Grandes empresas de tec-
nologia e do ramo automobilístico estão unindo forças para concretizar essa ideia, já havendo
alguns modelos capazes de dirigir durante longos períodos de tempo sem acidentes provo-
cados pelo mesmo, sob determinadas condições, como é o caso do carro desenvolvido pela
Google [Waymo 2017], que atualmente já dirigiu mais de 126.000 milhas sem ação externa.
Existem cinco diferentes níveis de autonomia na direção de veículos. Autonomia de
funções específicas, como estacionamento, autonomia de funções integradas, como manter o
veículo no centro da pista, autonomia limitada, quando o veículo transfere para o usuário a
direção do veículo, por se encontrar em uma situação de perigo ou que não possui conheci-
mento, autonomia sobre condições específicas, quando o veículo dirige sem a ajuda externa,
mas apenas em condições específicas, como pistas com marcações, e autonomia total, quando
o veículo é capaz de dirigir sem qualquer necessidade de intervenção humana sobre qualquer
condição [Litman 2017].
Atualmente, o estado da arte para veículos autônomos é a utilização de combinações
de técnicas de Deep Learning para realizar tarefas como detecção de pedestres, detecção de
pista, detecção de veículos, identificação de sinais luminosos, etc. Como as principais tarefas
de direção podem ser traduzidas como tarefas de reconhecimento de imagens, os modelos
mais utilizados são CNN, que foram recentemente impulsionados pelo grande poder de pa-
ralelismo de processamento das GPU e pela massiva quantidade de dados disponível através
16

17
da internet.
Os primeiros estudos feitos utilizando Deep Learning para a tarefa de simular a direção
humana de um veículo foram feitos por Pormelau [Pormelau 1989], que utilizou um modelo
com três camadas totalmente conectadas para, tendo como entradas para a sua rede vídeos
feitos por uma câmera acoplada ao veículo e uma distância entre o veículo e os objetos da
cena, calculada através de um sensor de laser acoplado ao veículo. Como foi um estudo de
1989, houveram dificuldades relacionadas à obtenção de dados, armazenamento dos dados,
processamento, o que dificultou o funcionamento do modelo, mas de qualquer forma ele ser-
viu como base para estudos futuros. Esse modelo criado por Pormelau ficou conhecido como
Alvinn, sigla em inglês para veículo terrestre autônomo utilizando redes neurais.
Cientistas da Agência de Projetos de Pesquisa Avançada de Defesa (DARPA) [DARPA
2017] dos Estados Unidos, utilizando os estudos de Pormelau como base, desenvolveram um
projeto conhecido como DAVE, sigla em inglês para veículo autonômo da Darpa, que foi trei-
nado utilizando vídeos capturados por duas câmeras acopladas a um veículo guiado por hu-
manos, que apenas davam o sinal de esquerda ou direita para o veículo, como forma de simular
a direção. Entretanto, DAVE não obteve marcas tão expressivas, conseguindo apenas andar
em média vinte metros em estradas complexas.
Alguns meses depois, o projeto DAVE foi retomado por uma equipe da NVIDIA, co-
mandada pela Karol Zieba [Bojarski et al. 2016], visando aplicar os estudos anteriores para
realizar testes em estradas públicas. Eles desenvolveram um modelo CNN com cinco camadas
de convolução e três camadas totalmente conectadas, além de uma camada inicial de norma-
lização, utilizada para acelerar e otimizar o processo de treinamento. O modelo utilizado se
encontra na figura 3.1.
Com esse modelo, foi possível percorrer dez mil milhas em uma estrada sem nenhuma
intervenção humana. Também foi possível percorrer ruas urbanas com apenas 2% do tempo
sendo necessária intervenção humana, sem contar as mudanças de faixa. Esses resultados
foram obtidos com apenas setenta e duas horas de captura de vídeo para treinamento da
rede.
A partir desse estudo da NVIDIA, foram desenvolvidas diferentes implementações que
visam replicar ou melhorar os resultados obtidos pela equipe.
Os modelos estudados para esse projeto utilizaram de uma ideia conhecida como
aprendizagem por imitação, que visa imitar o comportamento humano em uma determinada

18
Figure 4: CNN architecture. The network has about 27 million connections and 250 thousandparameters.
To remove a bias towards driving straight the training data includes a higher proportion of framesthat represent road curves.
5.2 Augmentation
After selecting the final set of frames we augment the data by adding artificial shifts and rotationsto teach the network how to recover from a poor position or orientation. The magnitude of theseperturbations is chosen randomly from a normal distribution. The distribution has zero mean, and thestandard deviation is twice the standard deviation that we measured with human drivers. Artificiallyaugmenting the data does add undesirable artifacts as the magnitude increases (see Section 2).
6 Simulation
Before road-testing a trained CNN, we first evaluate the networks performance in simulation. Asimplified block diagram of the simulation system is shown in Figure 5.
The simulator takes pre-recorded videos from a forward-facing on-board camera on a human-drivendata-collection vehicle and generates images that approximate what would appear if the CNN were,instead, steering the vehicle. These test videos are time-synchronized with recorded steering com-mands generated by the human driver.
5
Figura 3.1 – Arquitetura original. CNN com 9 camadas, aproximadamente 27 milhões deconexões e 250 mil parâmetros. Fonte: [Bojarski et al. 2016]
tarefa, no caso, a de dirigir um veículo. Nessa técnica, um agente (um modelo de Machine
Learning) é treinado para realizar tarefas a partir de exemplos, realizando um mapeamento
entre as observações e as ações. [Hussein et al. 2017]
Ao se estudar essas diferentes implementações, observou-se que em quase sua totali-
dade, as implementações tiveram a necessidade da utilização de uma camada de dropout, e
todas as estudadas apenas utilizaram as funções de ativação ReLU ou ELU. Observando isso,
desenvolveu-se a ideia desse projeto, que visa estudar como a utilização de diferentes funções
de ativação e de diferentes valores de keep probability utilizados na função de dropout afetam
a robustez dos diferentes modelos estudados na tarefa de predição angular do veículo.

19
(a) Vista da lateral esquerda. (b) Vista da lateral direita.
(c) Vista central.
Figura 3.2 – Vistas laterais e central das câmeras do veículo no simulador. Fonte: Próprioautor.
3.1 Obtenção dos dados
Para a obtenção dos dados e futuros testes, utilizou-se um simulador [Brown et al.
2017], tendo em vista que testes e obtenção de dados reais seriam inviáveis para esse trabalho.
Esse simulador possui duas pistas, com apenas o veículo que está sendo dirigido. Esse
veículo possui três câmeras acopladas a ele, sendo uma em seu centro e duas nas laterais,
todas mirando a frente do veículo. Essas imagens são então salvas como frames e é criado um
arquivo de log contendo as informações das pastas onde estão salvas as imagens, da veloci-
dade do veículo, ângulo de rotação do volante, profundidade do acelerador e profundidade do
freio.
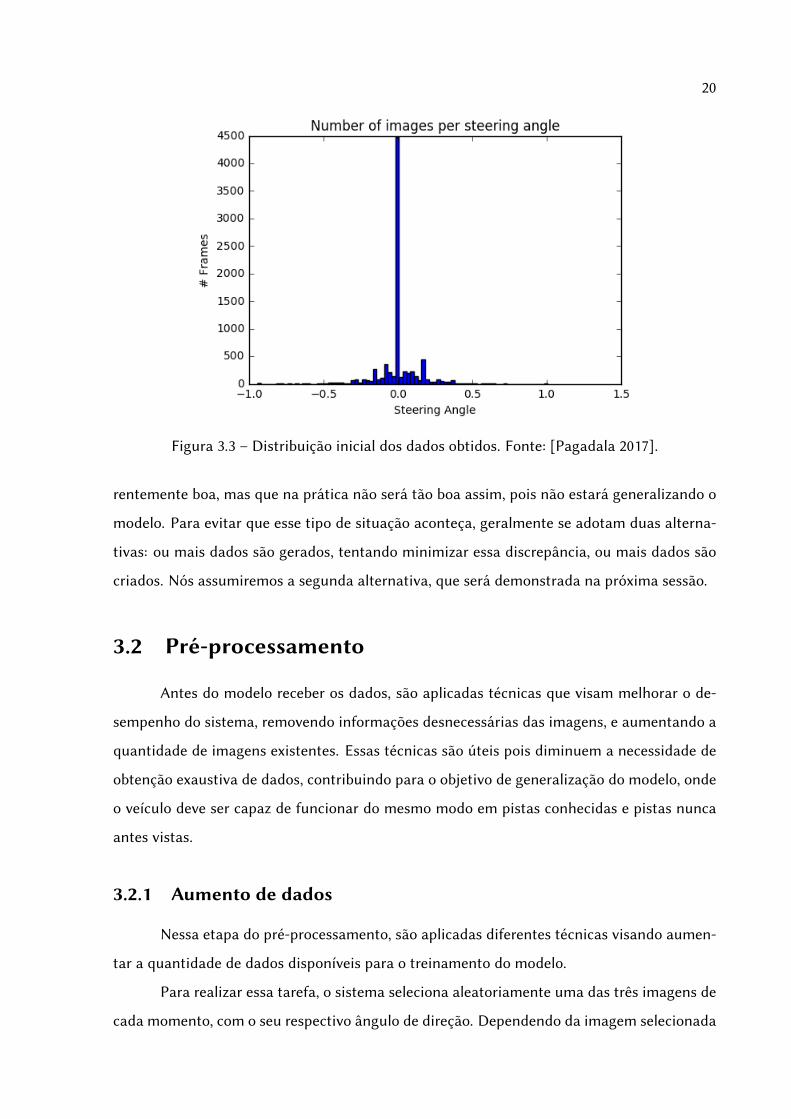
Ao final dessa simulação, os dados se encontram com a distribuição demonstrada na
figura 3.3.
Esse tipo de configuração, com muitos dados concentrados em um único ponto é ge-
ralmente ruim para fins de Machine Learning, pois pode influenciar o modelo a tomar a deci-
são de apenas tentar predizer que o dado de entrada vai possuir um valor igual à esse valor
mais concentrado, e mesmo assim acertar na maioria das vezes, ou seja, nesse caso o modelo
pode apenas retornar sempre um ângulo zero e mesmo assim ele irá ter uma resposta apa-
20
Figura 3.3 – Distribuição inicial dos dados obtidos. Fonte: [Pagadala 2017].
rentemente boa, mas que na prática não será tão boa assim, pois não estará generalizando o
modelo. Para evitar que esse tipo de situação aconteça, geralmente se adotam duas alterna-
tivas: ou mais dados são gerados, tentando minimizar essa discrepância, ou mais dados são
criados. Nós assumiremos a segunda alternativa, que será demonstrada na próxima sessão.
3.2 Pré-processamento
Antes do modelo receber os dados, são aplicadas técnicas que visam melhorar o de-
sempenho do sistema, removendo informações desnecessárias das imagens, e aumentando a
quantidade de imagens existentes. Essas técnicas são úteis pois diminuem a necessidade de
obtenção exaustiva de dados, contribuindo para o objetivo de generalização do modelo, onde
o veículo deve ser capaz de funcionar do mesmo modo em pistas conhecidas e pistas nunca
antes vistas.
3.2.1 Aumento de dados
Nessa etapa do pré-processamento, são aplicadas diferentes técnicas visando aumen-
tar a quantidade de dados disponíveis para o treinamento do modelo.
Para realizar essa tarefa, o sistema seleciona aleatoriamente uma das três imagens de
cada momento, com o seu respectivo ângulo de direção. Dependendo da imagem selecionada

21
Figura 3.4 – Exemplo de imagem após a operação de rotação. Fonte: [Pagadala 2017]
Figura 3.5 – Exemplo de imagem após a operação de ajuste de brilho. Fonte: [Pagadala 2017]
(esquerda, centro ou direita), é necessária uma alteração no ângulo da direção registrado no
arquivo de log, pois o que está registrado é o ângulo em relação a câmera central. Após a
seleção, a imagem é rotacionada em torno de seu eixo y, com uma probabilidade de 0,5. Caso
a imagem receba a rotação, é necessário também atualizar o ângulo da direção, que passa a
valer o negativo do ângulo anterior.
Outra tarefa de aumento de dados aplicada é a de ajustar o brilho da imagem aleatori-
amente. Dessa forma, o sistema consegue aprender a dirigir em qualquer tipo de iluminação,
o que é bom para o objetivo de generalização do modelo.
3.2.2 Recorte
O recorte, tradução do termo em inglês crop, é a técnica utilizada para remoção de
informações da imagem que não são de interesse do modelo. O crop realizado no sistema
remove da imagem o céu e a parte dianteira do veículo, pois para a tarefa de descobrir qual a

22
Figura 3.6 – Exemplo de imagem após a operação de crop. Fonte: [Pagadala 2017]
direção a ser tomada pelo veículo, esses dados não são importantes e poderiam atrapalhar o
treinamento.
3.3 Treinamento
Para o processo de treinamento, foram realizadas todas as combinações possíveis entre
os valores passados. Dessa forma, foi possível realizar diferentes combinações de diferentes
modelos, diferentes funções de ativação e diferentes valores de keep probability. Esses parâ-
metros foram escolhidos com o intuito de verificar o funcionamento da rede com os mesmos,
permitindo dessa forma saber se seria possível desenvolver modelos mais potentes sem que
ocorresse o problema do vanishing gradient. Além disso, deseja-se verificar o impacto do pa-
râmetro de keep probability na generalização do modelo, verificando se o aumento ou a dimi-
nuição desse parâmetro afeta tanto a qualidade da direção do veículo na pista utilizada para
treinamento quanto a qualidade na pista utilizada para testes, pista essa que não foi utilizada
na tarefa de obtenção dos dados.
Nesse processo, foram escolhidos dois modelos para serem utilizados. O primeiro é o
modelo demonstrado no artigo da NVIDIA [Bojarski et al. 2016], observado nos tópicos an-
teriores. O segundo, utiliza uma arquitetura CNN bastante simplificada, possuindo apenas
a camada de normalização, semelhante ao modelo da NVIDIA, uma camada de convolução
e uma camada totalmente conectada. A escolha desse modelo se deu visando observar se é
possível utilizar um modelo mais simples, que teoricamente será mais rápido e mais leve com-
putacionalmente, comparando os resultados obtidos com os resultados do modelo da NVIDIA.
Para realização do treinamento, os dados foram separados em dados de treinamento
e dados de validação. A cada etapa do treinamento, foram enviadas para a rede pequenas
quantidades de imagens, conhecidas como lotes, escolhidas aleatoriamente dentro dos dados
de treinamento, fazendo com que não fosse necessário que todos os dados de treinamento
estejam na memória ao mesmo tempo. Dessa forma, a rede aprende a cada passagem de lote,

23
Figura 3.7 – Arquitetura CNN simplificada utilizada no experimento. Fonte: Próprio autor
não sendo necessário atualizar a rede a cada imagem, o que, devido ao número de imagens
seria custoso computacionalmente. Ao final da passagem de uma determinada quantidade de
lotes pré-definida, conhecida como época, a rede é testada utilizando os dados de validação.
Caso o resultado desse teste seja o melhor entre os testes utilizando a combinação atual, o
modelo é salvo para realização dos testes no simulador.

Capítulo 4
Experimentos e Resultados
Todo o experimento foi realizado utilizando Python [Rossum 1995], a IDE Jupyter No-
tebook [Kluyver et al. 2016], Pandas [McKinney 2010] para carregamento dos dados e cri-
ação dos datasets, Matplotlib [Hunter 2007] para geração e visualização dos gráficos, Scikit
Learn [Pedregosa et al. 2011] para separar os dados em dados de validação, treinamento e
teste, Keras [Chollet et al. 2015] para criação das camadas dos modelos e Numpy [Walt, Col-
bert e Varoquaux 2011] para tratamento de matrizes.
Como visto no capítulo anterior, o experimento consiste combinação das funções de
ativação ReLU, LReLU, ELU, e SELU, dos valores de keep probability no dropout de 0.25, 0.5
e 0.75 e dos dois modelos apresentados, o modelo da NVIDIA [Bojarski et al. 2016] e o CNN
simplificado.
Essa combinação foi repetida 30 vezes, gerando um total de 720 modelos. Dentro des-
ses modelos foram pegos os que obtiveram a menor função de erro em relação aos dados de
validação, para cada uma das 24 combinações possíveis, e então foi feita uma comparação
entre eles.
Apenas o processo de treinamento das redes para o experimento levou um total de
186 horas aproximadamente, o que requisitou que, para evitar interferências no experimento,
fosse utilizada uma máquina com o intuito de não rodar nenhuma outra aplicação durante o
experimento, limitando assim a realização de uma maior quantidade de experimentos.
24
25
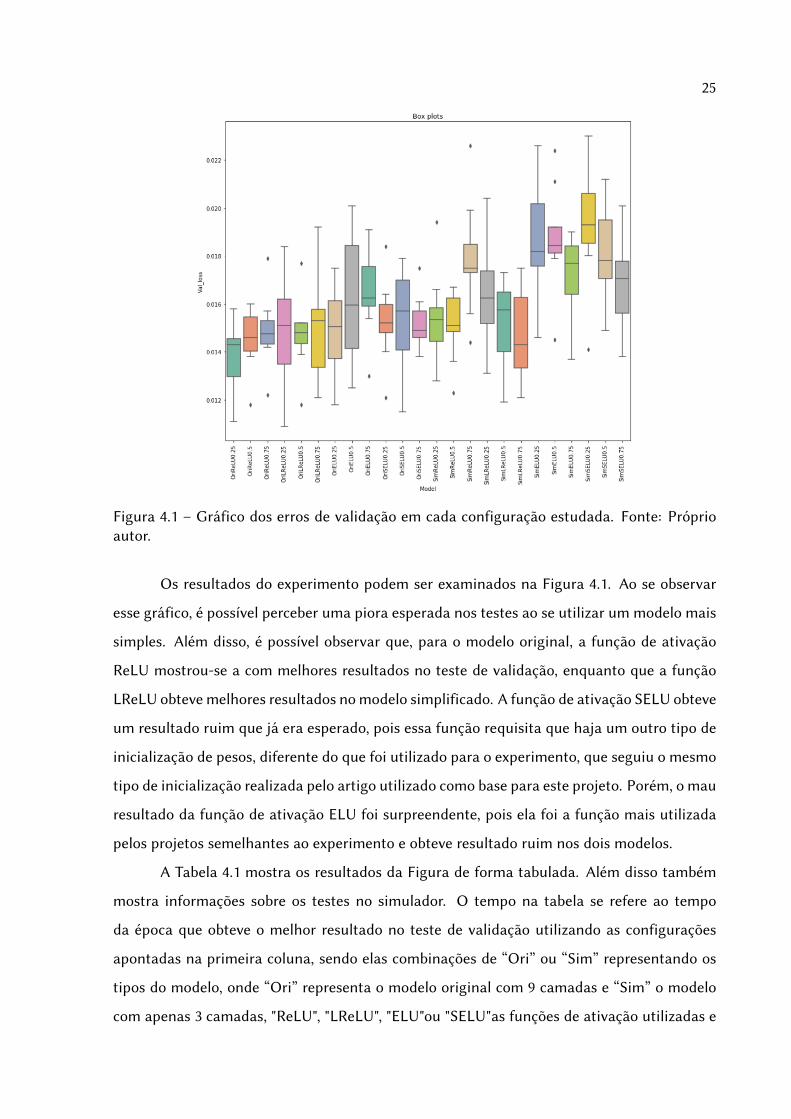
Figura 4.1 – Gráfico dos erros de validação em cada configuração estudada. Fonte: Próprioautor.
Os resultados do experimento podem ser examinados na Figura 4.1. Ao se observar
esse gráfico, é possível perceber uma piora esperada nos testes ao se utilizar um modelo mais
simples. Além disso, é possível observar que, para o modelo original, a função de ativação
ReLU mostrou-se a com melhores resultados no teste de validação, enquanto que a função
LReLU obteve melhores resultados no modelo simplificado. A função de ativação SELU obteve
um resultado ruim que já era esperado, pois essa função requisita que haja um outro tipo de
inicialização de pesos, diferente do que foi utilizado para o experimento, que seguiu o mesmo
tipo de inicialização realizada pelo artigo utilizado como base para este projeto. Porém, o mau
resultado da função de ativação ELU foi surpreendente, pois ela foi a função mais utilizada
pelos projetos semelhantes ao experimento e obteve resultado ruim nos dois modelos.
A Tabela 4.1 mostra os resultados da Figura de forma tabulada. Além disso também
mostra informações sobre os testes no simulador. O tempo na tabela se refere ao tempo
da época que obteve o melhor resultado no teste de validação utilizando as configurações
apontadas na primeira coluna, sendo elas combinações de “Ori” ou “Sim” representando os
tipos do modelo, onde “Ori” representa o modelo original com 9 camadas e “Sim” o modelo
com apenas 3 camadas, "ReLU", "LReLU", "ELU"ou "SELU"as funções de ativação utilizadas e
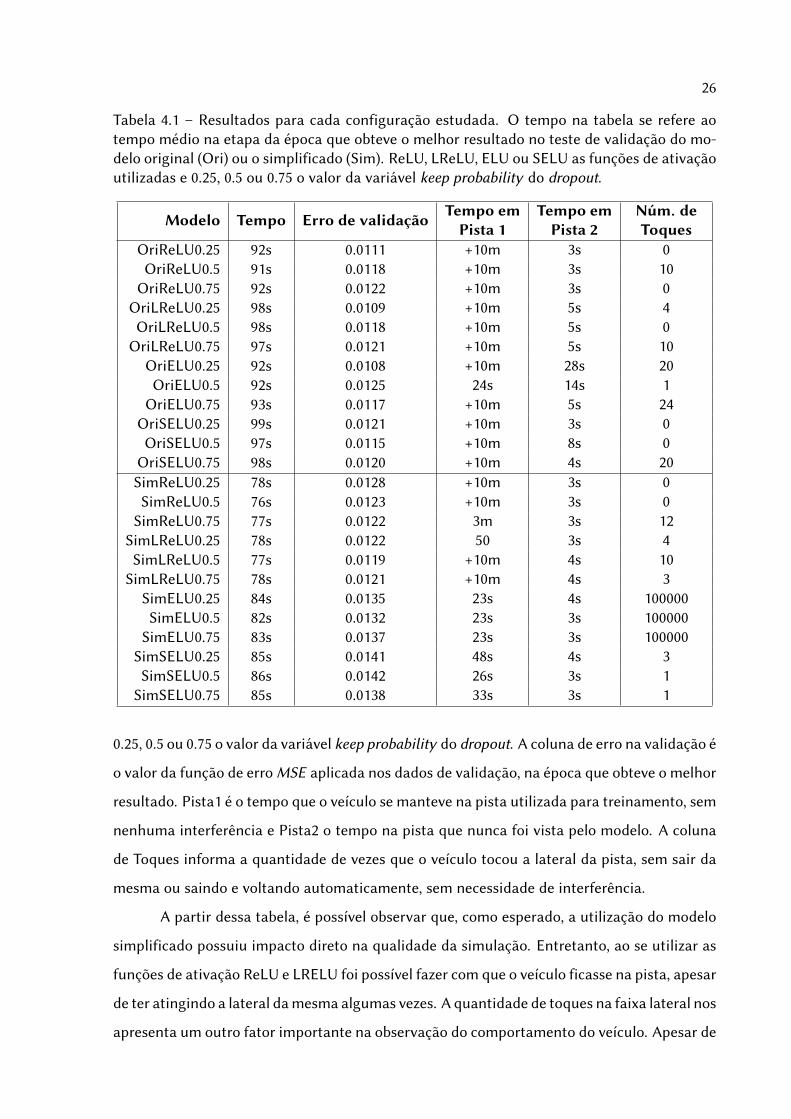
26
Tabela 4.1 – Resultados para cada configuração estudada. O tempo na tabela se refere aotempo médio na etapa da época que obteve o melhor resultado no teste de validação do mo-delo original (Ori) ou o simplificado (Sim). ReLU, LReLU, ELU ou SELU as funções de ativaçãoutilizadas e 0.25, 0.5 ou 0.75 o valor da variável keep probability do dropout.
Modelo Tempo Erro de validação Tempo emPista 1
Tempo emPista 2
Núm. deToques
OriReLU0.25 92s 0.0111 +10m 3s 0OriReLU0.5 91s 0.0118 +10m 3s 10
OriReLU0.75 92s 0.0122 +10m 3s 0OriLReLU0.25 98s 0.0109 +10m 5s 4OriLReLU0.5 98s 0.0118 +10m 5s 0
OriLReLU0.75 97s 0.0121 +10m 5s 10OriELU0.25 92s 0.0108 +10m 28s 20OriELU0.5 92s 0.0125 24s 14s 1
OriELU0.75 93s 0.0117 +10m 5s 24OriSELU0.25 99s 0.0121 +10m 3s 0OriSELU0.5 97s 0.0115 +10m 8s 0
OriSELU0.75 98s 0.0120 +10m 4s 20SimReLU0.25 78s 0.0128 +10m 3s 0SimReLU0.5 76s 0.0123 +10m 3s 0
SimReLU0.75 77s 0.0122 3m 3s 12SimLReLU0.25 78s 0.0122 50 3s 4SimLReLU0.5 77s 0.0119 +10m 4s 10
SimLReLU0.75 78s 0.0121 +10m 4s 3SimELU0.25 84s 0.0135 23s 4s 100000SimELU0.5 82s 0.0132 23s 3s 100000
SimELU0.75 83s 0.0137 23s 3s 100000SimSELU0.25 85s 0.0141 48s 4s 3SimSELU0.5 86s 0.0142 26s 3s 1
SimSELU0.75 85s 0.0138 33s 3s 1
0.25, 0.5 ou 0.75 o valor da variável keep probability do dropout. A coluna de erro na validação é
o valor da função de erro MSE aplicada nos dados de validação, na época que obteve o melhor
resultado. Pista1 é o tempo que o veículo se manteve na pista utilizada para treinamento, sem
nenhuma interferência e Pista2 o tempo na pista que nunca foi vista pelo modelo. A coluna
de Toques informa a quantidade de vezes que o veículo tocou a lateral da pista, sem sair da
mesma ou saindo e voltando automaticamente, sem necessidade de interferência.
A partir dessa tabela, é possível observar que, como esperado, a utilização do modelo
simplificado possuiu impacto direto na qualidade da simulação. Entretanto, ao se utilizar as
funções de ativação ReLU e LRELU foi possível fazer com que o veículo ficasse na pista, apesar
de ter atingindo a lateral da mesma algumas vezes. A quantidade de toques na faixa lateral nos
apresenta um outro fator importante na observação do comportamento do veículo. Apesar de

27
ele ter conseguido completar as voltas na pista, ele demonstrou uma instabilidade na direção
do veículo muito maior do que quando utilizado o modelo com mais camadas. Isso se deve ao
fato de o modelo simplificado obter menos características da pista do que o modelo com mais
camadas. Com isso, o modelo conseguiu aprender características como para não sair da pista
mas não conseguiu obter características suficientes para se manter a uma distância suficiente
do fim da mesma.
Outra importante informação obtida a partir do experimento e dos resultados conse-
guidos foi a da impossibilidade de se testar os modelos baseando-se apenas na primeira volta
da pista, pois no caso do modelo simplificado utilizando função ReLU com 0.75 de keep proba-
bility, o veículo completou uma volta, mas na terceira volta ele saiu da pista. Nos resultados
OriELU0.75, OriLReLU0.25, SimLReLU0.25 e SimLReLU0.75 esse comportamento também é
observável, pois o número de toques por volta na pista não se manteve constante. Nesses
casos, em algumas voltas o veículo chegava próximo à lateral da pista, mas não a tocava,
enquanto que em outras voltas, na mesma posição da pista, o veículo tocava a lateral. Esse
comportamento se deve ao fato de que as imagens obtidas no simulador durante as voltas não
eram as mesmas durante as voltas, nos mesmos pontos da pista, principalmente nos mode-
los que demonstraram uma maior instabilidade na direção do veículo. Foi colocado um valor
de cem mil na coluna de Toques nos modelos simplificados utilizando a função ELU pois no
curto período de tempo em que o veículo se manteve na pista, ele andou todo o tempo na
faixa lateral da mesma.
Comprovando os dados obtidos pelo gráfico, a função de ativação ELU se apresentou
a com piores resultados, tanto no modelo com nove camadas quanto no simplificado. No
modelo original essa função, apesar de conseguir completar mais do que dez voltas na pista,
ela tocou a lateral da pista pelo menos duas vezes em cada volta, demonstrando fragilidade
na realização de curvas. Entretanto, estudos mais profundos com as mesmas são necessários,
pois mesmo demonstrando instabilidade nas curvas da pista de treinamento, a configuração
utilizando essa função de ativação foi a única que conseguiu ultrapassar a segunda curva da
pista de testes, conseguindo chegar até a sexta curva, sendo as curvas da segunda pista curvas
mais fechadas e em ladeiras, enquanto que na primeira pista as curvas são mais abertas e não
possuem ladeiras.
Já a função SELU contrariou o esperado pelos testes teóricos, e se mostrou a função
com maior estabilidade na direção dentro do modelo original. Isso demonstra que essa é uma

28
função que pode substituir a função ELU como a mais utilizada, pois mesmo não trabalhando
essa função em seu estado ideal, utilizando uma inicialização de pesos diferente do proposto
pelo autor da mesma, ela obteve bons resultados na simulação.
Com os resultados do experimento, é possível intuir que a utilização de um modelo sim-
plificado é possível, como na utilização da função de ativação ReLU, que se mostrou com maior
velocidade no treinamento. Em um treinamento em maior escala, com maior quantidade de
dados, maior variedades de parâmetros a serem otimizados e maior carga de teste, esses pou-
cos segundos podem ter influência positiva na decisão de qual modelo escolher.Entretanto,
como na tarefa de direção de veículos autônomos, a principal é a estabilidade do veículo, uti-
lizar modelos com maior número de camadas deve ser priorizado, pois esse tipo de modelo se
mostrou possuidor de maior confiança do que o modelo simplificado.

Capítulo 5
Conclusões
Como dito anteriormente, o objetivo do experimento era observar e analisar o impacto
que diferentes técnicas de Deep Learning teriam na tarefa de simulação da direção de veículos
autônomos, através da combinação dessas técnicas aplicadas em diferentes arquiteturas.
Os resultados apresentados anteriormente demonstraram uma boa aproximação deste
objetivo. A partir deles é possível concluir que é possível utilizar modelos mais simples para a
tarefa de direção autônoma de veículos, acelerando assim o processo de treinamento, apesar
de possuir um alto grau de instabilidade no experimento, fazendo com que seja necessário
um estudo mais profundo visando aumentar a estabilidade dos veículos que utilizem essa
arquitetura.
Outro fato que deve ser melhor estudado é a utilização da função ELU, que não apre-
sentou resultados tão bons no experimento, tanto na parte teórica quanto na prática, apesar
de ser a única que conseguiu ser utilizada na tarefa de generalização.
5.1 Trabalhos Futuros
Com os resultados obtidos neste projeto, seria possível, através de aprendizado por
transferência [Pra� 2017], estender o problema para outros veículos, como caminhões ou mo-
tos, e avaliar os resultados. Com isso, não seria necessário começar esses estudos do zero,
podendo utilizar este projeto como base e apenas realizar as alterações necessárias para o
bom funcionamento em outros veículos.
Existem diversos outros parâmetros que poderiam ser estudados para detectar a in-
fluência dos mesmos na tarefa principal do projeto, como a taxa de aprendizagem, a iniciali-
29

30
zação dos pesos da rede, o tamanho do filtro nas camadas de convolução. Outra característica
que deve ser estudada é a estrutura da rede e o impacto dela na tarefa,visto que foi apontado
que essa característica afeta diretamente a qualidade da direção. Muitos estudos estão sur-
gindo visando utilizar modelos de redes neurais recorrentes e redes geradoras adversárias na
área de veículos autônomos. Esses estudos visam utilizar a característica de que a direção do
veículo em determinado momento seria baseada na direção do mesmo em momentos anterio-
res. Além disso, com as GANs, seria possível detectar outros problemas existentes na direção
de veículos, ignorados neste projeto por motivo de simplificação, como outros veículos nas
pistas, pedestres e sinais luminosos.
Baseado na implementação deste trabalho, é possível perceber que a utilização da
mesma metodologia para diferentes simuladores é possível, como a utilização destes modelos
em jogos de video game, pois seria necessário apenas implementar a captura de imagens no
simulador utilizado e o arquivo de conexão entre o simulador e o programa que utiliza o
modelo desenvolvido para direção.
Outra utilização que pode ser dada para este projeto é o desenvolvimento de um carro
de controle remoto com câmeras acopladas ao mesmo e a utilização do mesmo em algumas
pistas reduzidas, simulando veículos e pistas reais, o que seria uma maneira menos custosa
de se testar os resultados obtidos, quando comparado a utilização de veículos reais, além de
complementar os resultados obtidos neste projeto.
Com este trabalho, foi possível perceber que, com a utilização de redes neurais, está
sendo possível se obter excelentes resultados na área de veículos autônomos, demonstrando
assim que não está longe o dia em que a ficção científica se encontrará com a realidade, onde
não será mais necessário que nos preocupemos com o trânsito nem com acidentes, pois a
direção será toda automatizada.

Referências Bibliográficas
BOJARSKI, M. et al. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316,2016.
BOUREAU, Y.-L.; PONCE, J.; LECUN, Y. A theoretical analysis of feature pooling in visualrecognition. In: Proceedings of the 27th International Conference on Machine Learning(ICML-10). [S.l.: s.n.], 2010. p. 111–118.
BRITZ, D. Understanding Convolutional neural networks for NLP. [S.l.]: WildML, 2015.
BROWN, A. et al. Self Driving Car Simulator. [S.l.]: GitHub, 2017. <h�ps://github.com/udacity/self-driving-car-sim>.
CHOLLET, F. et al. Keras. [S.l.]: GitHub, 2015. <h�ps://github.com/fchollet/keras>.
CLEVERT, D.-A.; UNTERTHINER, T.; HOCHREITER, S. Fast and accurate deep networklearning by exponential linear units (ELUs). arXiv preprint arXiv:1511.07289, 2015.
DARPA. Defense Advanced Projects Agency. 2017. Último acesso em 13/12/2017. Disponívelem: <h�ps://www.darpa.mil/>.
GABRIEL, J. ao. Volkswagen e Nvidia fazem parceria para desenvolver IA alémdos carros autônomos. 2017. <h�ps://adrenaline.uol.com.br/2017/06/28/50413/volkswagen-e-nvidia-fazem-parceria-para-desenvolver-ia-alem-dos-carros-autonomos/>.Último acesso em 14/12/2017.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. [S.l.]: MIT Press, 2016.<h�p://www.deeplearningbook.org>.
GOODFELLOW, I. et al. Generative adversarial nets. In: Advances in Neural InformationProcessing Systems. [S.l.: s.n.], 2014. p. 2672–2680.
HAYKIN, S. Neural networks: A comprehensive foundation. [S.l.]: Prentice Hall PTR, 1994.
HOCHREITER, S. Untersuchungen zu dynamischen neuronalen netzen. Diploma, TechnischeUniversität München, v. 91, 1991.
HOCHREITER, S. et al. Gradient flow in recurrent nets: The di�iculty of learning longtermdependencies. In: . A Field Guide to Dynamical Recurrent Networks. Wiley-IEEEPress, 2001. p. 464–. ISBN 9780470544037. Disponível em: <h�p://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=5264952>.
HUNTER, J. D. Matplotlib: A 2d graphics environment. Computing In Science & Engineering,IEEE COMPUTER SOC, v. 9, n. 3, p. 90–95, 2007.
31

32
HUSSEIN, A. et al. Imitation learning: A survey of learning methods. ACM Comput. Surv.,ACM, New York, NY, USA, v. 50, n. 2, p. 21:1–21:35, abr. 2017. ISSN 0360-0300. Disponível em:<h�p://doi.acm.org/10.1145/3054912>.
IBOPE. Paulistano passa, em média, 1 mês e meio no trânsito por ano. 2016. <h�ps://veja.abril.com.br/brasil/paulistano-passa-em-media-1-mes-e-meio-no-transito-por-ano>.
KLUYVER, T. et al. Jupyter notebooks - a publishing format for reproducible computationalworkflows. In: ELPUB. [S.l.: s.n.], 2016.
LECUN, Y. et al. Backpropagation applied to handwri�en ZIP code recognition. Neuralcomputation, MIT Press, v. 1, n. 4, p. 541–551, 1989.
LITMAN, T. Autonomous Vehicle Implementation Predictions. 2017. <h�ps://www.vtpi.org/avip.pdf>. Último acesso em 13/12/2017.
MAAS, A. L.; HANNUN, A. Y.; NG, A. Y. Rectifier nonlinearities improve neural networkacoustic models. In: Proceedings International Conference on Machine Learning. [s.n.], 2013.v. 30, n. 1. Disponível em: <h�p://web.stanford.edu/~awni/papers/relu_hybrid_icml2013_final.pdf>.
MCCULLOCH, W. S.; PITTS, W. A logical calculus of the ideas immanent in nervous activity.The bulletin of mathematical biophysics, Springer, v. 5, n. 4, p. 115–133, 1943.
MCKINNEY, W. Data structures for statistical computing in python. In: WALT, S. van der;MILLMAN, J. (Ed.). Proceedings of the 9th Python in Science Conference. [S.l.: s.n.], 2010. p. 51– 56.
PACHECO, A. Redes Neurais Convolutivas – CNN. 2017. <h�p://www.computacaointeligente.com.br/artigos/redes-neurais-convolutivas-cnn/>. Último acesso em 13/12/2017.
PAGADALA, S. Deep Learning to Clone Driving Behavior. 2017. <h�ps://srikanthpagadala.github.io/serve/carnd-behavioral-cloning-p3-report.html>. Último acesso em 14/12/2017.
PANETTA, K. End to End Learning for Self-DrivingCars. 2017. <h�ps://www.gartner.com/smarterwithgartner/top-trends-in-the-gartner-hype-cycle-for-emerging-technologies-2017>. Último acesso em29/11/2017.
PEDREGOSA, F. et al. Scikit-learn: Machine learning in Python. Journal of Machine LearningResearch, v. 12, p. 2825–2830, 2011.
PHYLLIIDA. A list of cost functions used in neural networks, alongside applications. 2016. CrossValidated. URL:h�ps://stats.stackexchange.com/q/154880 (version: 2016-11-08). Disponívelem: <h�ps://stats.stackexchange.com/q/154880>.
PORMELAU, D. A. An Autonomous Land Vehicle In a Neural Network. 1989. <h�p://repository.cmu.edu/cgi/viewcontent.cgi?article=2874&context=compsci>. Último acessoem 13/12/2017.
PRATT, L. Y. Discriminability-Based Transfer between Neural Networks. 2017. <h�p://papers.nips.cc/paper/641-discriminability-based-transfer-between-neural-networks.pdf>.Último acesso em 14/12/2017.

33
REIS, L. Machine Learning: entendendo a evolução dos algoritmos. 2017.<h�p://blog.cedrotech.com/machine-learning-a-evolucao-dos-algoritmos/?gclid=EAIaIQobChMIq4Ta5ZWF2AIVVgWRCh1rBw29EAAYBCAAEgKcofD_BwE>. Último acessoem 12/12/2017.
ROSENBLATT, F. Principles of neurodynamics. perceptrons and the theory of brain mechanisms.Bu�alo, NY, USA, 1961.
ROSSUM, G. Python Reference Manual. Amsterdam, The Netherlands, The Netherlands,1995.
RUMELHART, D. E.; HINTON, G. E.; WILLIAMS, R. J. Learning internal representations byerror propagation. [S.l.], 1985.
SRIVASTAVA, N. et al. Dropout: A simple way to prevent neural networks from overfi�ing.Journal of Machine Learning Research, v. 15, n. 1, p. 1929–1958, 2014.
SUGA, N. Biosonar and neural computation in bats. Scientific American, v. 262, n. 6, p. 60–68,1990.
WALT, S. van der; COLBERT, S. C.; VAROQUAUX, G. The numpy array: A structure fore�icient numerical computation. Computing in Science Engineering, v. 13, n. 2, p. 22–30,March 2011. ISSN 1521-9615.
WAYMO. 2017. Último acesso em 13/12/2017. Disponível em: <h�ps://waymo.com/>.