iris.sel.eesc.usp.briris.sel.eesc.usp.br/wvc2005/anaiswvc2005-v2.pdf · este trabalho discute uma...
TRANSCRIPT

!"
#

$%&'
() *" !
+ ,-
$) .
,/0'
!"

1$2# 1
)" &. -
0 + *1*
!"#$3"& 1 $"0
% & 4.
& '%( #
) ,$5 *
)&*,'+ 1

.'%#% !"
+$
#% !"6778.9# 6+7*8*&7.971- - , "6778.9
#% !"#%"$ &4 6&8.9
#% ++)68&9&%# 6+7*8*&7.9#%71- - , "6778.9
#%( 6778.9#%$7: ; *6&8.9
#%- 1*6&8.9#%& . 16778.9#%< & !;6&8.9#% <,6778.9
,
=$>"
, "# ,& 71-%-%, "
( 2,?$"(( ;:( 2.! $7%%; *- 1*&&
& . 1& "!- ! )< & !;.:
, "< 1 .! 1 %&%, "
#% !"#

!@" " ) , .A' B %7BC ) " 1C ?" C': : "@A" :' ?" % 7 1 2 '@1 @)1 1 ' DD%7& C 2 " = ' =: "? %" ) ) " 5 C 1@'C @ 1 1 A@ B % )) 2 @ 1) @ 1 B % 7 "@C) ) ! 1 %7= ) @B, ) ' E 5 2F0 1:%< @AB 1 " C 2: C C @C C %%% 7' 1C ) ': " B @ "@ ' !C2 2%
G=2H 1! 11 8 1 .2 ; C1 I1"2 "@ ) 1"@ !% ) ' 1 C 2 ! B ? * 6; ,.9C 6.,C C %%%9 ? 6777.&C .,C%%%9% 7CC 2 '@ ? !@ 1C 5 @2 0 " ' :%
< J ,J 1 C ) "" 2 B "@ 2 C , 1@ %
$-,
. /0112,-&,0112

&3%4*+
&56&'7#*&&'*+@A#&) 7#'B1 K8B ## E L 7<.%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
,@#"#+(;7>8 !17.%%%6. / 9%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
7@# " #, "' <?" .& *# "? ##@. %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% !"# !$ %
M
7+8 ' !# "7 ' B-+<*+8 !<&)7 "'%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% &!'( )
+," ;<-#<&**N N NNNNNNNNNNN%%%%%%%%%%%%
&'** 4+," N N NNNNNNNNNNNNNNNNNNNN%%
O
;!%% ' @#.A7"8 !,* ' -P%%%%%%%%%%%%%%%%%%* ++,
Q
, #+*8,* 7.%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% ! -&
' '! . .
@#+7"# " 8 !,* ' &-.%%%%%%%%%%%%%%%%%%% ('#*' /
R
&" .7=@#: 1 S,@7"#A# " %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%0
O
&'***@ # ,1 . ; . 7 ' @ # "&) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%1!2. #2+
OO
- 7B #4=%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%*)
OQ
.@(*,@#".>%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%2. 2 +
4) #' *, #%%%%%%%%%%%%%%%%%%%%%%%%&3 &
R
&" .7=@#: B #&8 %%%P !C4%-% C%$%< 1C+%$%''77%-%-%, "
R
# +& 7 @A*4= #7) " %%%%%%%%%%%%%%%%&
RO

&'*8 ! .@#:%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%& 45. 65 7 53 -
RQ
8 &) 7' # "@ # T ; * 4' # # E 7 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
U
& "V8.#P !@#( "1)#& #%%%%%2
UR
@###"#*;;7>78;#"8<7@#,"7(1%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%!*' '
Q
&'. # 8 ( " . # : . ,@ #";7>%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%-38
QO
(+# 8 " " N N NNNNNNNNN%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
@#A# " 1)#+@## E &) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%2+2
M
#@#+(7"# " K8" ;7-?" **8,
MR
4 +2// ' "." ". "%%%% * ( 2 ! 2* &
&56&+&'&&8* @#4'17,* .#@#+%%%%%%%%%%%%%%%%%%%%%%%%%%9# 8*8#*'8
O
, #+(;7;17.%%%%%%%%%%%%%%%%%%%%%%%, 5'
Q
.72 @#"#:. ( "## E#;%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%8!& 2
2 . 7=@ # : 1 7 " ; B 8 !# 1#-?" ."B1## %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% ". :28!
R
,@#"#+(;7>1)#1%%%%%%%%%% #! + '. # &
&8 )(

&8**7 1 ' #LV8.#&" # !@#..<= # "? %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%2;7 2 ''
! 7 ; # " &) 7 . !@#'@%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%2 7 2''
U
7=@#& ; ) 7*1#L"+ " %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%&
- !@#: + 8.5@A( ! 7 %%%%%%%%%%%%%%%%%%%%%%%%%+'!&8 &%8
<'# 71 8 " ' " 2 #8 &&/<"
M
&8***P !@#*4) (7"## " %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%,8&
O
,#8"## " 8 !#< @%%%%%%%%%%%%%%%%%%%%%%%%%%& &
OU
<;/ 7, #.A 7 "#;.#"%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%3' "#
#=4!, =4 #%
, 3 & 3!
:
"@#.7"8 !,* %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%&W %%+%;!
M

FUNÇÕES DE MÉRITO EM CONTORNOS DEFORMÁVEIS: UMA ANÁLISE GLOBAL DA
DISTÂNCIA ÓTIMA ENTRE OS PONTOS
A. M. Santana, R. A. C. Altafim, A. Gonzaga e R. F. Oliveira Departamento de Engenharia Elétrica, Escola de Engenharia de São Carlos
Universidade de São Paulo, USP [email protected]
Resumo
Este trabalho discute uma metodologia inédita para otimização dos contornos deformáveis paramétricos. Pela intervenção dinâmica na evolução da curva ele supera um problema inerente à snake tradicional de modo a possibilitar,quando do uso de snakes leves, a obtenção de contornos mais fiéis. Em fato, a diferença essencial para a tradicional snake GVF é a definição de uma função de mérito que destaca particularidades no aspecto da curva. O método proposto resolve o problema do agrupamento indevido dos pontos em grandes porções da snake e acessa a potencialidade das forças externas no alcance das regiões côncavas. Será também mostrado para um conjunto de imagens bem parametrizadas que a solução proposta implica em melhores resultados em convergência e casamento.
1. Introdução
A idéia de se promover a identificação de elementos em imagens por meio da deformação de modelos foi vislumbrada já na década de 70. Os contornos deformáveis ativos conhecidos como snakes, entretanto, foram apresentados por Kass et all [1] somente na década seguinte. Desde sua apresentação, as snakes têm tido vasto uso e definido uma das áreas mais prolíficas em processamento de imagens e visão computacional.
Estes modelos simulam materiais elásticos que se deformam de modo a conformarem-se dinamicamente ao aspecto dos objetos de interesse na
imagem. A deformação ocorre em resposta a forças de origem interna e externa e a constantes definidas pelo usuário. Grasping [2] e tracking [3] são exemplos bastante ilustrativos de seu uso.
A snake foi definida originalmente como uma curva ))(),(()( sysxsX = ,
]1,0[∈s que evolui sobre o domínio especial da imagem para minimizar uma função energia. Apesar de seu uso ser vasto e crescente, sua formulação original é inadequada a imagens com grandes concavidades e geometrias complexas. Estas questões têm sido registradas e trabalhos recentes têm sido propostos em melhoria destes aspectos da formulação original [4].
WVC´2005 - I Workshop de Visão Computacional
1

Ainda que responsáveis pela consecução de melhores resultados, as contribuições falham em promover uma análise global da distância ótima entre os pontos da snake. Em acréscimo, a limitação é tratada apenas à luz da inserção de restrições mais rígidas ou pelo uso de formulações essencialmente diferentes [5].
A solução apresentada aqui é um algoritmo adaptativo que, de forma inédita, acessa o problema pela análise global das distâncias ótimas. Os resultados obtidos mostram que o método proposto melhora grandemente a precisão na determinação do contorno e permite o uso de curvas significativamente mais leves e, conseqüentemente, rápidas. 2. Solução Proposta
O princípio da adaptação proposta é a definição de novas posições ótimas ao longo da snake que minimizam uma função morfológica de energia )(Xξ apresentada na equação 1.
dsXvhdXXhs
uXX
∫ ∫ +∂∂
= )()()(2
ξ (1)
Na qual h(X) representa a função de
mérito e u e v são constantes definidas pelo usuário.
A função de mérito é definida de modo a apresentar mínimos locais nas regiões de interesse. Deste modo, o reposicionamento dos pontos implica em melhor fidelidade na representação destas regiões críticas do contorno. A equação 2 apresenta um exemplo de uma função de mérito.
2
)( ⎟⎟⎠
⎞⎜⎜⎝
⎛
−−−−+−
=Δ−Δ+
Δ−Δ+Δ+Δ−
SSSS
SSSSSSSSS
xxxxxxxx
xh (2)
Conforme ilustra a figura 1, pela aplicação da função de mérito, pontos da snake aos quais maiores densidades de ponto implicam em maior fidelidade na detecção do contorno correspondem a valores menores da função de mérito. Com efeito, a minimização da função morfológica de energia implica no reposiciomento dos pontos da snake de modo a torná-los mais próximos nas regiões críticas e, mais esparsos nas regiões às quais correspondem maiores suavidades no contorno.
2040
6080
100120
140160
180
0
50
100
150
200-16
-14
-12
-10
-8
-6
-4
-2
0
Merit Function
Deformable Contour
Figure 1 – Função de mérito (---) e contorno deformável (-+-)
3. Resultados Experimentais
A figura 2 apresenta, para 2 imagens bem parametrizadas, a comparação entre os resultados obtidos pela snake GVF [6] e pelo método adaptativo proposto. Com o objetivo de ressaltar as diferenças foi utilizada uma snake pobre (30 pontos para ambos). Do que se pode observar nos resultados, o algoritmo proposto melhora significativamente a qualidade do contorno identificado.
WVC´2005 - I Workshop de Visão Computacional
2

Figura 2 - Snake GVF (---) tradicional e otimizada pela função de mérito (-+-), ambas com 30 pontos: imagem curva/curva (a), imagem plana/plana (b) e imagem curva/plana (c)
4. Conclusões
Os resultados experimentais demonstram que o posicionamento criterioso dos pontos da snake implica na obtenção de contornos mais fiéis e, conseqüente,
possibilita o uso de snakes mais leves e rápidas.
O mérito da proposta destaca-se sobremaneira pela inédita avaliação global das distâncias ótimas entre os constituintes e, com efeito, resolve por uso da
20 40 60 80 100 120 140 160 18040
60
80
100
120
140
160
180Iteração 25000
20 40 60 80 100 120 140 1600
20
40
60
80
100
120
140
160
180
200Iteração 45000
(a)
40 60 80 100 120 140 160 18040
60
80
100
120
140
160Iteração 40000
(b)
(c)
WVC´2005 - I Workshop de Visão Computacional
3

abordagem variacional o problema típico dos contornos deformáveis paramétricos que é o agrupamento indesejado de pontos.
A sensibilidade do método a particularidades do aspecto, ao alocar pontos em regiões usualmente desprestigiadas pela metodologia tradicional, aborda outra limitação das snakes aumentando a efetividade da força externa no alcance de regiões côncavas. 5. Referências Bibliográficas [1] M. Kass, A. Witkin e D. Terzopoulos, “Snakes: active contour models”, International Journal of Computer Vision, Vol 1, N. 4, 1987. [2] D. P. Perrin, E. Kadioglu, S. A. Stoeter and N. Papanikolopoulos, “Grasping and Tracking Using Constant Curvature Dynamic Contours”, The International Journal of Robotics Research, Vol 22, No. 10-11, October-November 2003. [3] K. Seo, T. Choi and J. Lee, “Adaptive Color Snake Model for Real-Time Object Tracking”, Proceedings of the 2004 IEEE International Conference on Robotics & Automation, New Orleans, LA, April, 2004. [4] X. Xie and M. Mirmehdi, “RAGS: Region-Aided Geometric Snake”, IEEE Transactions on Image Processing, Vol. 13, No. 5, May 2004. [5] D. Geiger, A. Gupta, L A. Costa e J Vlontzos, “Dynamic Programming for Detecting, Tracking and Matching Deformable Contours”, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 17, No. 3, Março, 1995. [6] C. Su, J. L. Prince, “Snakes, Shapes, and Gradient Vector Flow”, IEEE Transactions on Image Processing, Vol. 7, No. 3, March 1998.
WVC´2005 - I Workshop de Visão Computacional
4

RECUPERAÇÃO DE IMAGENS DE FACES HUMANAS BASEADA EM CONTEÚDO UTILIZANDO WAVELETS E P.C.A. (PRINCIPAL COMPONENT ANALYSIS)
Marcelo Franceschi de Bianchi, Adilson Gonzaga
Departamento de Engenharia Elétrica, Escola de Engenharia de São Carlos, Universidade de São Paulo
Av. Trabalhador São Carlense 400, 13560-970, São Carlos, SP, Brasil Email: [email protected]
ABSTRACT
This work describes a novel and efficient algorithm for content-based image retrieval based on the discrete Wavelet Transform (DWT) and Principal Component Analysis (PCA), together with inputs drawn from the Euclidian distance operator, a common criterion for distance measurement. The former is used to produce a signature vector from the query input image, a compressed and codified vector that holds the key features of the original image, and the latter is used to make projection of the images onto proper subspaces. Interestingly, the tests state that, for every particular query, the worse the frequency response of the wavelet filter, the better the classification, where the accuracy the algorithm up to 98,61 %. The system´s input consists of a query image and its output corresponds to the most similar image found in the data base, according to the distance criterion adopted. Keywords: CBIR Content -Based Image Retrieval, Wavelet, PCA Principal Component Analisys, Biometry, Facial Recognition.
1. INTRODUÇÃO Uma grande quantidade de trabalhos tem aparecido recentemente descrevendo algoritmos que utilizam recuperação de imagens baseada em conteúdo [1], [2], [3] e esta técnica é utilizada em identificação de pessoas, segurança e entre outras mais. Este trabalho apresenta um novo algoritmo para este propósito baseado na Transformada Wavelet Discreta (DWT) [4], [5], [6], [7] e na Análise de Componentes Principais (PCA) [8], [9]. Por último a distância Euclidiana é utilizada [1], como critério de classificação para a medida de distância entre os vetores, é usada para encontrar a imagem consulta com a imagem que possui maior similaridade, pela menor distância. A entrada no sistema é a imagem consulta em tons de cinza, então é comparada com todas as outras imagens armazenadas na base de imagens. Na verdade, o sistema armazena somente um único vetor de assinatura para cada image m. Cada vetor obtido utilizando a DWT consiste de uma versão com uma resolução mais baixa da imagem original para que o tempo de busca seja otimizado no sistema.
Os testes foram feitos com diferentes expressões faciais e diferentes transformadas Wavelets. O percentual de recuperação de imagens chegou a cerca de 98% com um algoritmo que tem ordem linear de complexidade. A implementação utiliza o MATLAB 6.5 rodando sobre o sistema operacional Windows XP Professional.
2. O PROCEDIMENTO PROPOSTO A tabela 1 descreve o algoritmo proposto. Todos os sujeitos usados estão em imagens em tons de cinza, com 128x128 pixels de resolução. O banco de imagens utilizado contém 504 imagens de faces humanas sendo que são de 28 sujeitos diferentes. Existem 18 imagens diferentes para cada sujeito. As imagens contém diferentes expressões faciais, existem imagens com ruído gaussiano [10] e rotação de 10 a -10 graus relativo a face.
3. TESTES E RESULTADOS O resultados do algoritmo proposto estão resumidos nas tabelas de 2 a 6. A figura 1 ilustra alguns resultados em particular. As imagens mostram a recuperação de diferentes expressões faciais no qual contém imagens consultas rotacionadas entre 10 e -10 graus de inclinação frontal e também com expressões faciais diferentes. Somente o último exemplo mostra uma falha no processo do algoritmo.
4. CONCLUSÕES Foi proposto um algoritmo para recuperação de imagens baseada em conteúdo com DWT e PCA. De acordo com os testes, o melhor nível de decomposição e a Wavelet para este propósito foi a Wavelet Symlet com o 2º nível. Isto indica uma taxa de compressão [11] de 1:4 entre a imagem original e o vetor de assinatura correspondente. Uma discussão interessante deste resultado é que quanto mais o filtro se aproxima do filtro ideal, a recuperação de imagens piora. Isto pode indicar que as altas freqüências são importantes para a seleção desde que os banco de filtros utilizados tenham uma resposta em freqüência distante do que seria a resposta em freqüência ideal, fazendo com que a seletividade seja pobre, isto é, as baixas freqüências são contaminadas com as altas freqüências.
WVC´2005 - I Workshop de Visão Computacional
5

• INICIO • Passo P-1: Todas as 504 imagens são
normalizadas e colocadas na resolução 128 x 128 pixels, 256 tons de cinza.
• Passo P-2: São agrupadas em 28 classes as
504 imagens. Cada classe contém 18 imagens da mesma pessoa. A imagem difere em relação a expressões faciais, ruído gaussiano, posição da face entre outras de acordo com as condições que são mencionadas logo abaixo:
• Passo P-3: Escolher m imagens para
representar cada classe (1<=m<=18). Esta escolha pode ser feita randomicamente ou manualmente, isto pode causar muita diferença no resultado.
• Passo P-4: Gerados e armazenados os
vetores de assinaturas para as 28 classes com as m imagens escolhidas, um para cada imagem. Cada vetor de características consiste da aplicação da transformada Wavelet [4] na imagem, variando a própria transformada e o nível da mesma que foi escolhido. Os testes foram realizados usando j-nível de cada DWT, de acordo com as tabelas 2 a 6.
• Passo P-5: É realizado a entrada do vetor de
assinatura da imagem consulta q. • Passo P-6: Aplica-se o algoritmo PCA para
todas os vetores de assinaturas no passo P-4 e para cada vetor vindo do passo anterior. Para cada vetor deste processo é então calculada a matriz de covariância e então são gerados os auto vetores e os auto valores.
• Passo S-7: O grupo de auto vetores é
ordenado, de acordo com a norma de cada vetor.
• Passo S-8: Todos os vetores na base de
imagens são projetados em um subespaço no qual contém o maior dos auto vetores.
• Passo S-9: Encontrar o vetor de assinatura x
no qual é o menor valor da distancia Euclidiana (a,q). Esta é a saída do sistema.
• FINAL
Tabela 1: O algoritmo para recuperação de imagens através de transformada Wavelet e PCA utilizando a distância Euclidiana entre os vetores.
Figura 1 (do topo ao final): Seis testes que foram realizados com o algoritmo proposto, um por linha. A entrada para o sistema que é a imagem consulta está logo à esquerda de cada linha e a saída é a imagem recuperada que está logo à direita de
WVC´2005 - I Workshop de Visão Computacional
6

cada linha. A última linha consiste de uma falha no processo, as outras correspondem a resultados positivos do algoritmo.
M (Passo P-3, tabela 1)
Dimensão do Subespaço
% Recuperação
2 23 75,59 % 6 23 89,88 %
12 23 95,83 % 18 23 97,42 % 2 53 80,95 % 6 53 94,04 %
12 53 98,01 % 18 53 98,41 % 2 73 81,34 % 6 73 94,24 %
12 73 98,21 % 18 73 98,41 % 2 103 81,34 % 6 103 94,24 %
12 103 98,41 % 18 103 98,41 %
Tabela 2: % de Recuperação do algoritmo proposto utilizando o segundo nível da transformada Wavelet Symmlet com suporte 8.
M (Passo P-3, tabela 1)
Dimensão do Subespaço
% Recuperação
2 23 59,12 % 6 23 69,84 %
12 23 77,77 % 18 23 77,57 % 2 53 60,71 % 6 53 74,60 %
12 53 80,95 % 18 53 81,54 % 2 73 60,51 % 6 73 75,19 %
12 73 81,15 % 18 73 81,94 % 2 103 60,51 % 6 103 75,39 %
12 103 81,74 % 18 103 82,34 %
Tabela 3: % de Recuperação do algoritmo proposto utilizando o segundo nível da transformada Wavelet de Daubechies com suporte 20.
M (Passo P-3, tabela 1)
Dimensão do Subespaço
% Recuperação
2 23 77,38 % 6 23 90,87 %
12 23 92,83 % 18 23 97,61 % 2 53 81,34 % 6 53 93,45 %
12 53 97,61 % 18 53 98,41 % 2 73 81,94 % 6 73 93,84 %
12 73 97,61 % 18 73 98,41 % 2 103 81,94 % 6 103 93,84 %
12 103 98,01 % 18 103 98,41 %
Tabela 4: % de Recuperação do algoritmo proposto utilizando o segundo nível da transformada Wavelet Reverse Birothogonal com suporte 4.
M (Passo P-3, tabela 1)
Dimensão do Subespaço
% Recuperação
2 23 75,39 % 6 23 90,47 %
12 23 96,03 % 18 23 97,42 % 2 53 81,54 % 6 53 93,45 %
12 53 98,01 % 18 53 98,41 % 2 73 81,15 % 6 73 93,45 %
12 73 98,01 % 18 73 98,41 % 2 103 81,15 % 6 103 93,84 %
12 103 98,01 % 18 103 98,41 %
Tabela 5: % de Recuperação do algoritmo proposto utilizando o segundo nível da transformada Wavelet Coiflet com suporte 6.
WVC´2005 - I Workshop de Visão Computacional
7

M (Passo P-3, tabela 1)
Dimensão do Subespaço
% Recuperação
2 23 71,03 % 6 23 88,09 %
12 23 95,83 % 18 23 97,22 % 2 53 78,76 % 6 53 92,26 %
12 53 97,61 % 18 53 98,21 % 2 73 78,96 % 6 73 92,65 %
12 73 98,01 % 18 73 98,41 % 2 103 78,96 % 6 103 93,65 %
12 103 98,01 % 18 103 98,61 %
Tabela 6: % de Recuperação do algoritmo proposto utilizando o segundo nível da transformada Wavelet Biorthogonal com suporte 4.
M (Passo P-3, tabela 1)
Dimensão do Subespaço
% Recuperação
2 23 76,19 % 6 23 91,46 %
12 23 95,83 % 18 23 97,61 % 2 53 81,34 % 6 53 93,84 %
12 53 97,81 % 18 53 98,41 % 2 73 81,34 % 6 73 94,04 %
12 73 98,21 % 18 73 98,41 % 2 103 81,34 % 6 103 94,44 %
12 103 98,01 % 18 103 98,41 %
Tabela 7: % de Recuperação do algoritmo proposto utilizando o segundo nível da transformada Wavelet Haar.
6- Referências [1] S. Deb. “Multimedia Systems and Content-Based Image Retrieval”. Hershey-US: Idea Group Publishing, 2003. [2] S. Deb., Y. Zhang: “An overview of content-based image retrieval techniques”. In AINA 2004 – 18th International Conference on Advanced Information Networking and Applications. (2004), v.1, pp. 59-64. [3] I. Andreou, N. M. Sgouros. “Computing, explaining and visualizing shape similarity in a content -based image retrieval”. Elsevier Information Processing and Management, v. 41, n. 5, pp. 1121-1139, 2005. [4] P. S. Addison. “The illustrated Wavelet Transform Handbook: Introductory Theory and applications in science, engineering, medicine and finance”. Edinburg: institute of Physics Publishing, 2002. [5] G. Strang, T. Nguyen, “Wavelets and Filter Banks Wellesley: Wellesley Cambridge Press, 1997. [6] R.C. Guido, J.C. Pereira, E. Fonseca, L.S. Vieira, F.L. Sanches. “Trying different wavelets on the search for voice disorders sorting”. In 37 th IEEE International southeastern Symposium on system Theory, Turkegee-AL-US, v.1 (2005) p. 495-499. [7] R.C. Guido, J.F.W. Slaets, L.O.B. Almeida, R. Koberle, J. C. Pereira, “A new technique to construct a wavelet transform matching a specified signal with applications to digital , real time, spike and overlap pattern recognition”. Digital Signal Processing, Elsevier, v.15, (2005), n.-, pp. – (article in press, available on www.sciencedirect.com website, to appear in 2005). [8] I.T. Jolliffe. “Principal Component Analysis”. 2.ed. Springer, 2002. [9] A . Hyvrinen, J. Karhunen, E. Oja, “Independent Component Analysis”, Wiley-Intersicence, 2001. [10] R. C. Gonzals, R. E. Woods. “Processamento de Imagens Digitais”. São Paulo: Edgard Blusher, 200. [11] D. Hankerson, G. A. Harris, P.D. Johson, “Introduction to Information Theory and Data Compression”, 2nd ed. BocaRaton: CRC Press, 2003.
WVC´2005 - I Workshop de Visão Computacional
8

ALINHAMENTO E SUBTRAÇÃO DIGITAL DE RADIOGRAFIAS ODONTOLÓGICAS PARA MELHORIA NO DIAGNÓSTICO DA DOENÇA PERIODONTAL
Rodrigues, E. B. *1;
Schiabel, H. 1; [email protected]
Escarpinati, M. C. 1;
Rubira_Bullen, I. R. F. 2 [email protected]
1 - Departamento de Engenharia Elétrica – Universidade de São Paulo, São Carlos, Brasil
Avenida Trabalhador São-carlense, 400 - Centro - CEP 13566-590 - São Carlos - SP Tel: (16) 3373-9363 - Fax: (16) 3373-9372.
2 - Estomatologia – Universidade de São Paulo, Bauru, Brasil
Al. Octávio Pinheiro Brisola, 9-75 - Bauru - SP - CEP 17012-901 - Tel: (14) 3235-8000.
Abstract
The radiography is one of the primary features to aid in the diagnosis and to monitor the treatment of the periodontal diseases. However, the subjective analysis of these radiographs done by the dentist can just identify a lesion above 30% of mineral loss, leading to a serious challenge for the practice of Odontology. A practical solution for this problem that has being widely researched [MARUKO, 1993; WEBBER, 1982; WEBBER, 1984] is the employment of computational techniques to aid in the diagnosis of digital odontologic radiographs. This way, this work presents an algorithm to quantify the bone loss or gain through the analysis of digital odontologic radiographs. The computational algorithm developed utilizes the image subtraction technique to realize the necessary measurements. First, two digital odontologic radiographs, taken at different times are aligned to allow that common structures on both images be represented by the same pixels addresses. Then they are subtracted to obtain only the differences of the structures represented by the analised images. The subtraction provides the detection of subtle changes, about 5%, leading to an early diagnosis of the disease and so enlarging the healing and the success of its treatment. Descrição da Proposta do estudo Este trabalho tem como objetivo gerar uma imagem na qual será visível somente estruturas que diferem de uma radiografia anterior em relação a uma radiografia tirada posteriormente, podendo auxiliar e melhorar o diagnóstico de doenças periodontais, fazendo com que esta seja detectada precocemente, bem como ajudar o dentista a seguir um método mais apropriado de tratamento ao doente periodontal de acordo com o grau da doença. Materiais e Métodos Um problema encontrado para que a subtração pudesse ser realizada foi que ambas as imagens deveriam possuir suas estruturas representadas exatamente pelos mesmos endereços de pixels. Para
WVC´2005 - I Workshop de Visão Computacional
9

tal, foi implementado o processo de alinhamento dessas imagens, onde a projeção geométrica (diferenças de translação e rotação) da imagem subseqüente é corrigida em relação à imagem referência. Este processo é feito através da seleção manual de quatro pontos, escolhidos pelo dentista. O primeiro ponto, que deve ser marcado em ambas as imagens, é chamado de ponto pivô e os três restantes são os pontos subseqüentes. Estes pontos devem ser marcados em regiões de alto contraste na imagem. Depois dos pontos serem selecionados, é calculado o fator de translação através da diferença encontrada entre o valor das coordenadas dos pontos pivôs em ambas as imagens (Figura 1).
Figura 1 – Esquema de translação das imagens.
Posteriormente calcula-se o fator de rotação, que é feito traçando uma reta entre cada ponto subseqüente e o ponto pivô em ambas as imagens. Os ângulos de inclinação entre os pontos pivôs e cada reta formada pelos pontos subseqüentes foram calculados, e a média desses ângulos foi encontrada para ambas as imagens. Finalmente, a diferença entre as médias determinou o valor da angulação final pela qual a imagem subseqüente deverá ser rotacionada (Figura 2).
Figura 2 – Esquema de rotação das imagens.
Depois do alinhamento, as imagens podem ser subtraídas através da subtração digital de radiografias (DSR – Digital Subtraction Radiography), pois elas estarão devidamente alinhadas e as regiões nas quais tiverem mudanças ósseas poderão ser localizadas. Resultados Para o teste do alinhamento, algumas imagens digitais de determinados objetos foram geradas, digitalizando-se o objeto duas vezes, sendo que na segunda ele foi transladado e rotacionado em relação à sua posição anterior. As imagens desses objetos foram submetidas à subtração antes de passarem pelo processo de alinhamento, resultando em uma imagem subtraída formada pela sobreposição de ambos os objetos, cheia de artefatos e de difícil interpretação. Posteriormente, as imagens passaram pelo processo de alinhamento antes de seguirem para a subtração. Desta forma a imagem subseqüente estaria com a mesma projeção geométrica da imagem referência. O resultado foi satisfatório e esperado, produzindo uma imagem subtraída em níveis de cinza homogêneos, devido a ambas as imagens serem exatamente iguais, exceto o erro que
WVC´2005 - I Workshop de Visão Computacional
10
é incorporado pelo próprio digitalizador. Depois de verificadas que as imagens estavam realmente sendo alinhadas pela rotina de alinhamento, através das imagens dos objetos - que são mais fáceis de serem interpretadas - os testes passaram a ser feitos nas imagens de radiografias odontológicas, como pode ser visto em uma amostra na Tabela 1.
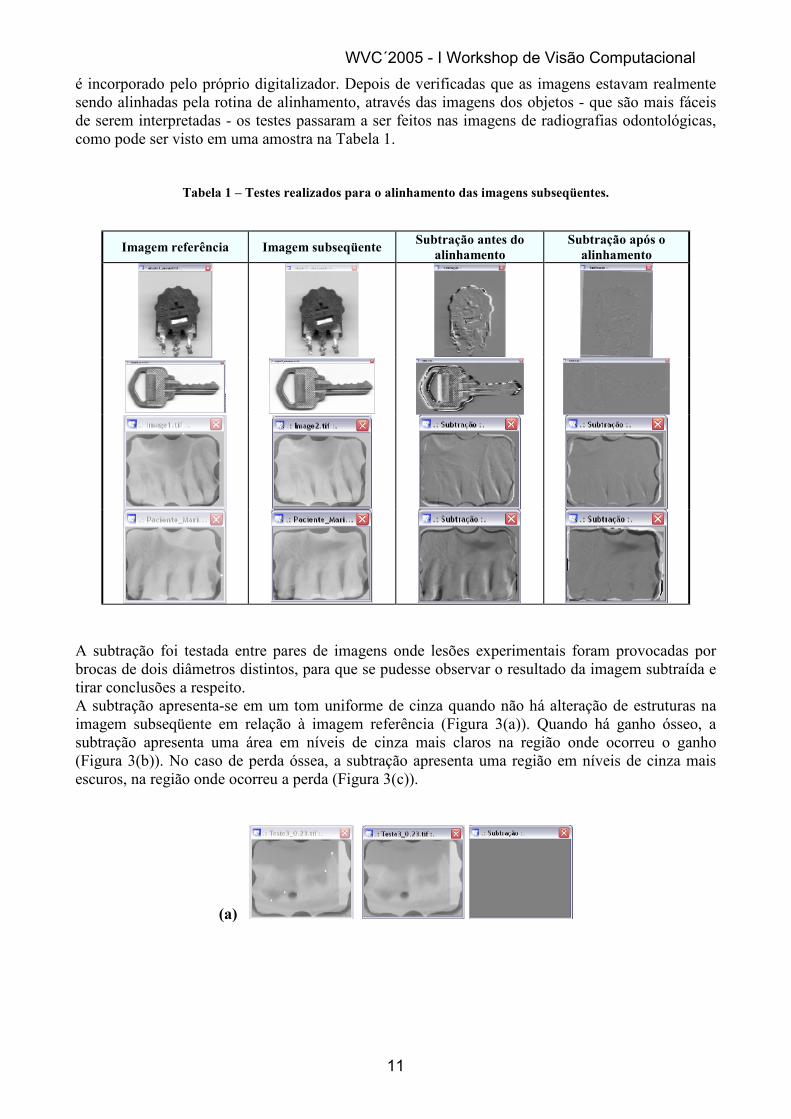
Tabela 1 – Testes realizados para o alinhamento das imagens subseqüentes.
Imagem referência Imagem subseqüente Subtração antes do alinhamento
Subtração após o alinhamento
A subtração foi testada entre pares de imagens onde lesões experimentais foram provocadas por brocas de dois diâmetros distintos, para que se pudesse observar o resultado da imagem subtraída e tirar conclusões a respeito. A subtração apresenta-se em um tom uniforme de cinza quando não há alteração de estruturas na imagem subseqüente em relação à imagem referência (Figura 3(a)). Quando há ganho ósseo, a subtração apresenta uma área em níveis de cinza mais claros na região onde ocorreu o ganho (Figura 3(b)). No caso de perda óssea, a subtração apresenta uma região em níveis de cinza mais escuros, na região onde ocorreu a perda (Figura 3(c)).
(a)
WVC´2005 - I Workshop de Visão Computacional
11

(b)
(c) Figura 3 - Subtração com nenhuma mudança apreciável (a), subtração com ganho ósseo (b) e subtração com
perda óssea (c).
De fato, pode-se observar que a subtração mostrou um ótimo resultado, resultando em uma imagem subtraída onde somente áreas que realmente tiveram mudança são visíveis. Conclusão O trabalho apresentou ótimos resultados tanto no alinhamento da imagem subseqüente em relação à imagem referência, quanto na subtração de ambas as imagens radiográficas, pois o sucesso da subtração está intimamente ligado ao bom alinhamento da imagem. Como pôde ser observada na Tabela 1, a subtração aplicada em uma imagem sem passar pela rotina de alinhamento produz uma imagem subtraída sobreposta e cheia de artefatos, fazendo com que apareçam estruturas que não estão verdadeiramente presentes. O resultado da subtração após o alinhamento da imagem resulta em uma imagem subtraída mais uniforme e com níveis de cinza homogêneos, resultado esperado, pois as duas imagens que foram subtraídas são as mesmas, somente com eventuais alterações que podem ser incorporadas pelo digitalizador, portanto, a imagem subtraída não poderia apresentar grandes variações. A diferença entre a imagem subtraída gerada antes e depois do alinhamento mostra que o alinhamento da imagem subseqüente é de suma importância para o resultado final da imagem subtraída. A imagem subtraída gerada após o alinhamento demonstrou um resultado muito confiável, conseguindo ressaltar somente estruturas que realmente obtiveram modificações entre a imagem referência e a subseqüente, como pode ser observado na Figura 3. Bibliografia GONZALEZ, R. C.; WOODS, R. E. Processamento de Imagens Digitais. 2000. Ed. Edgard Blücher Ltda. 1. ed. MARUKO, E. Y.; FORBES, D. P. Digital subtraction radiography for assessing alveolar bone grafts: diagnostic accuracy and sensitivity. Northwest Dent Res. 1993 Spring; 4(1):21-3.
WEBBER R.; RUTTIMANN U.; GRÖNDAHL H. X-ray image subtraction as a basis for assessment of periodontal changes. J Perio Res 1982; 17:509-11. WEBBER, R. L.; RÜTTIMANN E. U.; GROENHUIS R. A. J. Computer correction of projective distortions in dental radiographs. J. Dent. Res. 1984; 63:1032:1036.
WVC´2005 - I Workshop de Visão Computacional
12

E-Faces - Um classificador capaz de analisar imagens e classifica-lascomo faces ou nao faces utilizando o metodo Eigenfaces
Eder Augusto Penharbel, Erdiane L. G. Wutzke,Murilo dos S. Silva, Reinaldo A.C. Bianchi
Centro Universitario da FEI - UNIFEIDepartamento de Ciencia da Computacao
Av. Humberto de Alencar Castelo Branco, n.o 3972, Sao Bernardo do Campo,Sao Paulo, Brasil - CEP 09850-901 - Fone: (11) 4353 2900 - Fax: (11) 4109 5994
[email protected],ewutzke,msilva,[email protected]
Resumo
A classificacao de imagens como face ou nao face pode ser um passo inicial na implementacao deum sistema de deteccao de faces. Este artigo descreve a implementacao de um classificador capaz deanalisar uma imagem e classifica-la como face ou nao face. O E-Faces foi implementado utilizandoo metodoeigenfaces, um metodo que necessita de poucas imagens para o treinamento e foi capaz dealcancar uma taxa de 95% de classificacoes corretas.
Palavras-chave: Visao Computacional, Classificacao de Imagens, PCA,Eigenfaces, Deteccao Fa-cial.
1 Introduc ao
Faces de pessoas sao extremamente importantes nas iteracoes humanas. Uma grande parte das pessoasque conhecemos estao relacionadas a imagens de faces em nossa mente. Atraves dessa relacao podemosidentificar pessoas em contatos visuais, fotografias, vıdeos, pinturas, etc.Essa relacao face/pessoa pode ser utilizada em diversas situacoes. Um exemploe quando abrimos a portade nossa casa para algum amigo ou quando somos reconhecidos em um ambiente.E com base nessas situacoes que torna-seutil a implementacao de sistemas computacionais de classificacao,deteccao e reconhecimento facial.A classificacao, deteccao e reconhecimento facial vem atraindo a atencao de diversos pesquisadores [1]para que sistemas rapidos, confiaveis e robustos sejam criados.A implementacao desses sistemas computacionais pode ser utilizada no desenvolvimento de sistemasautonomos de seguranca de ambientes, na criacao de portas ”inteligentes”, na criacao de sistemas quereconhecam seus usuarios atraves de faces e muitas outras aplicacoes.Este trabalho descreve a implementacao de um classificador de imagens como faces ou nao faces atravesdo metodoeigenfaces[2]. O metodoeigenfacese um metodo baseado na analise de componentes princi-pais, ouPrincipal Component Analysis - PCA, e necessita de poucas imagens para criacao de uma basede treinamento.Nas secoes seguintes serao descritos o PCA, o metodo eigenfaces, a implementacao do sistema declassificacao e os resultados obtidos.
WVC´2005 - I Workshop de Visão Computacional
13

2 Desenvolvimento
O classificador E-Facese um sistema que aceita uma imagem como entrada e gera uma resposta queclassifica a imagem como face ou nao face.O E-faces foi implementado atraves do metodoeigenfacesna linguagem C++, utilizando o compiladorGNU G++ e a biblioteca GNU GSL. O E-Faces necessita de um banco de imagens de faces para extracaodas caracterısticas. Esse banco de facese criado e visualizado por uma interface feita em PHP e BashScripting. A secao seguinte explicara o PCA, fornecendo a base de entendimento do metodoeigenfacescom a finalidade de tornar claro o modo de funcionamento do classificador.
2.1 PCA
A Principal Component Analysis, analise de componentes principais ou expansao de Karhunen-Loeve,talvez seja uma das maiores contribuicoes daalgebra linear e estatıstica aplicadas [3] [4].E um metodolinear que pode ser aplicado na eliminacao da redundancia ou deteccao de padroes em um conjunto dedados.Quando visto pelo ponto de vista de transformada [5], o seu resultadoe uma mudanca de base, umaprojecao em um novo espaco onde cada componente esteja livre de redundancia e esteja expresso emordem de variancia ou contribuicao ao conjunto de dados.Na deteccao de padroes pode-se empregar a distancia euclidiana como criterio de classificacao. Nareducao do conjunto utiliza-se as componentes que mais contribuem nessa variacao do espaco, ou seja,as componentes cujos auto-vetores estejam relacionados com os maiores auto-valores da matriz de co-variancia do conjunto sendo analisado, desprezando os auto-vetores com baixos auto-valores associados.O algoritmo do PCAe o seguinte:
1. Organize os dados em uma matriz D onde a primeira linha sera formada pelas componentes daprimeira amostra, a segunda a linha formada pelas componentes da segunda amostra e a N-esimalinha sera formada pelas componentes da N-esima amostra, como na matriz abaixo:
D =
c1a1 c2a1 . . . cMa1c1a2 c2a2 . . . cMa2
......
......
c1aN c2aN . . . cMaN
(1)
2. Crie um vetor media E, formado pelas medias de cada coluna:
E =
µ1 µ2 . . . µM
(2)
3. Subtraia de cada item de cada coluna M da matriz D a mediaµM correspondente a coluna da qualo item pertenca
4. Calcule a matriz de covariancia COVD:
COV D =1
N − 1DDT (3)
WVC´2005 - I Workshop de Visão Computacional
14

5. Calcule os auto-vetores e auto-valores da matriz COVD gerando um vetor AVAL e uma matrizAVET.
6. Ordene os auto-vetores na matriz AVET de auto-vetores pela ordem crescente dos auto-valores novetor AVAL correspondentes.
2.2 Eigenfaces
O metodoeigenfacese um metodo baseado em aparencia segundo [1] que busca as componentes princi-pais de uma distribuicao facial, ou os auto-vetores da matriz de covariancia de um conjunto de imagensde faces.O nomeeigenfacese atribuıdo aos auto-vetores (eigenvectors) da matriz de covariancia das imagens dasfaces do banco de faces de treinamento por possuırem aspectos de faces.Seu funcionamentoe similar ao funcionamento do PCA, entretantoe utilizada uma leve otimizacao parareduzir a matriz de covariancia, reduzindo o processamento necessario para fazer o calculo de seus auto-vetores e auto-valores.Este metodo possibilita a classificacao de imagens a partir do calculo da distancia euclidiana entre aimagem sendo analisada e a imagem sendo analisada projetada no novo espaco. Se o valor da distanciaeuclidiana estiver dentro de uma distancia limite, a imagem sendo analisadae considerada face, casocontrario e considerada como nao face.O metodoeigenfacese interessante por possibilitar, alem da classificacao, a reconstrucao e a compactacaode imagens de faces.
2.2.1 Geracao das eigenfaces
1. Tendo em maos um conjunto de M faces,
Γ =(
Γ1 Γ2 . . . ΓM
)ondeΓi e cada face do conjunto
2. Calcule a face mediaΨ
Ψ =
M∑i=1
Γi
M
3. Crie uma matriz com as faces de treino com os pixeis dispostos em linhas e as M faces do conjuntode treinamento dispostas em colunas.
4. Subtraia a imagem mediaΨ de cada imagem deΓ, gerando uma nova matriz
Φ = Γ−Ψ
5. Sendo M menor que a dimensionalidade (largura * altura das imagens de treinamento) das imagensemΦ, calcule a matriz de covariancia
C = ΦT Φ
WVC´2005 - I Workshop de Visão Computacional
15

6. Calcule os auto-vetoresν e auto-valoresλ da matriz C
7. Crie a matriz de transformacaoµ = νΦ,
onde a matrizµ contera M - 1 auto-vetores significativos. Entretanto aindae possıvel realizar aeliminacao de alguns desses M - 1 auto-vetores pela ordem de importancia de seus correspondentesauto-valoresλ, gerando M’ auto-vetores escolhidos.
8. Para finalizar, normalize os M’ vetores da matrizµ.
A Figura 1 ilustra o conjunto de treinamento, a imagem media e as 41eigenfacesobtidas de 42 imagensde faces.
Figura 1: A esquerda: banco de faces para criacao daseigenfaces. A direita: primeira imageme aimagem media, as restantes sao aseigenfaces.
2.2.2 Reconstrucao de faces
A reconstrucao de facese feita da seguinte forma:
1. Subtraia a face mediaΨ da faceΓ a ser reconstruıda
Φnova = Γ−Ψ
WVC´2005 - I Workshop de Visão Computacional
16

2. Faca a transformacao daΦnova, projetando-a no espaco de faces
ω = µT Φnova
3. Faca a transformacao inversaΩ = µω
A Figura 2 ilustra a reconstrucao de uma imagem.
Figura 2: Da esquerda para direita: imagem a ser reconstruıda, imagem reconstruıda com 20 componen-tes, imagem reconstruıda com 30 componentes e imagem reconstruıda com 40 componentes.
2.2.3 Classificacao de faces
A Classificacao de facese feita da seguinte forma:
1. Subtraia a face mediaΨ da imagemΓ a ser classificada
Φnova = Γ−Ψ
2. Faca a transformacao daΦnova, projetando-a no espaco de faces
ω = µT Φnova
3. Faca a transformacao inversaΩ = µω
4. Calcule a distancia euclidianaε = ‖Φnova − Ω‖
Se o valorε estiver abaixo de um certo limiteθ, considere a imagemΓ como sendo uma imagem de face,caso contrario considere a imagemΓ como sendo uma imagem de nao face.
2.3 Interface
Como ja dito anteriormente o classificadore um conjunto de programas em C++ que sao manipulados poruma interface web em PHP e Bash Scripting. Essa interface permite montar um conjunto de treinamento,gerar e visualizar aseigenfaces, classificar imagens e fazer a deteccao em uma imagem. Um screenshotda interface desenvolvida pode ser visualizada nas figura 3.
WVC´2005 - I Workshop de Visão Computacional
17

Figura 3: Interface para criacao do banco de faces.
3 Resultados
Nossos experimentos nos mostraram que o metodo foi capaz de classificar corretamente 95% das facespresentes em um banco de imagens de 2429 faces, gerando 5% de deteccoes falso-negativo.Foi feita tambem a avaliacao em um banco de imagens de nao faces para determinacao da quantidade deerros falso-positivo, onde foram corretamente classificadas 93% das nao faces presentes em um banco deimagens de 4548 nao faces, gerando 7% de deteccoes falso-positivos.Por fim, foi feito um teste onde o metodo foi aplicado exaustivamente para busca de faces frontais emimagens. Esse teste foi realizado da seguinte forma:
1. Faca x = 0 e y = 0.
2. Retire uma sub-janela no ponto (x,y) com a mesma dimensao das faces apresentadas ao classifica-dor durante a etapa de treino.
3. Apresente a sub-janela ao classificador.
4. Se a sub-janela foi classificada como face entao marque aquela posicao como sendo uma face.
5. Incremente x.
6. Se x maior do que a largura da imagem entao faca x = 0 e incremente y.
7. Se y maior do que a altura da imagem entao faca y = 0 e reduza a imagem em 20%.
8. Se a dimensao da imagem for maior ou igual a dimensao da sub-janela volte ao passo 1, senaofinalize a busca.
A Figura 4 exibe o resultado do teste feito em duas imagens utilizando esse metodo.
WVC´2005 - I Workshop de Visão Computacional
18

Figura 4: Resultado do teste em duas imagens.
4 Conclusao
Neste trabalho foi possıvel visualizar a maior fragilidade do metodo: a determinacao do valorθ parao limite da distancia euclidiana, pois essa distancia determina quando uma imageme face ou nao face.A escolha de um valorθ incorreto pode fazer com que a taxa de erro seja muito elevada resultando naineficiencia do metodo.Tambem foi possıvel concluir empiricamente que estee um metodo que apresenta uma boa relacao entreo tamanho do conjunto de faces de treinamento com os resultados obtidos.
Referencias
[1] Ming-Hsuan Yang, David J. Kriegman, and Narendra Ahuja. Detecting faces in images: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002.
[2] Matthew Turk and Alex Pentland. Eigenfaces for recognition.Journal of Cognitive Neuroscience,1991.
[3] Lindsay Smith. A tutorial on principal component analysis. 2002.
[4] Jon Shlens. A tutorial on principal component analysis. 2003.
[5] Rafael C. Gonzalez and Richard E. Woods.Processamento de Imagens Digitais. Edgard Blucher,2000.
WVC´2005 - I Workshop de Visão Computacional
19

Face Recognition Based on LDA and SOM Neural Nets
Anderson Rodrigo dos Santos and Adilson Gonzaga
Department of Electrical Engineering - University of Sao Paulo - Sao Carlos, Brazil
[email protected] and [email protected]
Abstract
The use of biometric technique for automatic personal identification is one of the biggest challengesin the security field. The process is complex, because it is influenced by many factors related tothe form, position, illumination, rotation, translation, disguise and occlusion of face characteristics.This work presents a searching method to identify a face in a training database. We have proposedan algorithm for face recognition based on LDA subspace using a SOM neural net to memorizeeach class (face) in the stage of classification/ identification. The interaction between the number ofeigenvectors in the PCA and LDA subspaces has been analyzed to establish the rate recognition.
1 Introduction
The recognition of human faces is one area that searches to develop mathematical algorithms forauthentication or identification extracting important characteristics for the recognition and directingthe search in the database. Two of the most popular techniques in the face recognition are: PrincipalComponents Analysis (PCA) and Linear Discriminant Analysis (LDA). In the literature we can findsome works exploring the applications of LDA subspace in face recognition. [4], [8], [9] and [1]compared PCA with LDA subspace using some diversified face databases with innumerable situations(translation, scales, rotation, illumination, etc). [6], [7] and [3] analyzed the effect in face recognitionthat is related with the number of training samples.
In this work, we have implemented a face recognition algorithm applying LDA subspace with anintermediate PCA space and a set of SOM neural nets in the stage of classification. We hope thatthe SOM nets present a good results in the face memorization with soft light variations of rotation,because [5] has implemented SOM in the classification stage of face and satellite images.
1.1 PCA, LDA and SOM Neural Net
The PCA technique based on face recognition finds eigenvectors that constitute the face sub-spacebases (eigenspace) that are gotten through the covariance matrix formed by the correlation betweenpixels. In summary, each image of a human face in the training set can be represented in terms ofa linear combination of eigenvectors, and the coefficients of this combination will be the new facerepresented in the eigenspace.
The Linear Discriminant Analysis (LDA) searches for those vectors in the underlying space thatbest discriminate among classes (rather than those that best describe the data). More formally, givena number of independent features relative to which the data is described, LDA creates a linear com-bination of these which yields the largest mean differences between the desired classes.
WVC´2005 - I Workshop de Visão Computacional
20

The SOM nets are auto-organized maps constituted by neurons on a flat structures either 1-D or2-D. The learning method is based on ”competitive learning”, whose purpose is to discover patternsinto input data. An input vector of arbitrary dimension is taken in a discrete neuron map in accordancewith the proximity of the patterns in the original dimension [2].
2 Methodology
Training phase diagram is showed in the figure 1. The diagram shows the stages related to theconstruction of PCA subspace and LDA subspace based on the training samples and the classificationstage implemented by individual SOM neural nets.
Figure 1. Proposed algorithm - training phase.
The training stage of LDA module is built after the calculation of the coefficients related to eachprojected face in the PCA subspace. The weights of one same class (or coefficients LDA of the facesof one exactly individual in the training) feed an only SOM neural net representing the class.
The ORL database made byOlivetti Research Laboratory in Cambridge, UK, with 10 differentimages of 40 distinct individuals (total of 400 images) was applied to evaluate the performance of thepresented system (figure 2). Increasing the size database, the images have been flipped horizontallyto produce more 400 images.
Figure 2. Exemple of faces in the face database.
3 Experiments
To evaluate the PCA and LDA interaction, we proposed to analyze the PCA and LDA algorithm’sperformance, choosing the eigenvectors interval, which define from 60% to 99% of the energy amountto construct the PCA subspace and from 70% to 90% to the LDA, varying the eigenvectors numberby 2 for the PCA and considering all the eigenvectors included into the LDA energy interval.
we made a random selection with equal possibilities among the 20 faces to each particular person,performing different test and training groups that were submitted to the algorithm to elaborate the
WVC´2005 - I Workshop de Visão Computacional
21

efficiency and interaction curves between PCA and LDA. Six different combinations of the selectedfaces to training were evaluated, creating groups with 5, 6, 7, 8, 9 and 10 faces of each individual, andthe remnant ones were used to constitute the test group. Looking for improving the test confidence, weperformed 10 times the same test for each combination, enabling us to construct an average result witha 95% confidence interval, supposing a normal distribution (t-student) to the random faces selectionover the recognition rates.
In figures 3, 4, 5, 6, 7 and 8 are showed the recognition rates acquired to the PCA + LDA, varyingthe quantity of PCA eigenvectors to build a subspace with the early defined energy limits, and usingthe Euclidian distance as classifier. Each PCA subspace generates a greatly variety of LDA subspacescombination, represented by the LDA eigenvectors included in the pre-defined energy interval, butthe graphics show only the combinations that resulted in the maximum recognition rate for each PCAsubspace.
Figure 3. (5 training faces). Figure 4. (6 training faces). Figure 5. (7 training faces).
Figure 6. (8 training faces). Figure 7. (9 training faces). Figure 8. (10 training faces).
Analyzing the graphics showed by figures 3, 4, 5, 6, 7 and 8, we obtain some characteristics aboutthe applied algorithm in the proposed database. Following below there are more details:
1. The results related to the PCA stage revealed a transitory phase followed by one phase withstationary recognition rates, and the last eigenvectors do not carry meaningful information tothe global training group.
2. LDA stage was able to increase recognition rates over the PCA.
3. An intrinsic deficiency related to the LDA method can be observed in figures 4 and 5, when wehave few training samples to each individual class with a large number of PCA eigenvectors.
4. the recognition rates pikes to the PCA method are not the same for the LDA.
To analyze the recognition rates behavior to the LDA subspace + SOM algorithm over the LDAeigenvectors (considering the limits of energy concentration in the subspace), we picked some PCA
WVC´2005 - I Workshop de Visão Computacional
22

subspaces near to the region that had the biggest recognition rates of the algorithm. Figure 9 showsthe results.
Figure 9. LDA + SOM algorithm (8 faces of training).
4 Conclusions
The purpose of this work has been to classify/ identify one face with its respective representativeon the database connecting to the particular individual (one-to-many application). A computationalsystem to face recognition was implemented based in results showed by recent techniques using theLDA subspace algorithm (holistic method) to codify the images, and many SOM neural networkstogether to classify the faces set.
Formalizing the LDA subspace method, LDA and PCA stages are much important to construct ahigh-performance algorithm to face recognition. The tests were performed with many training groups,and the results showed that there is no need to use all the PCA eigenvectors to reach high recognitionrates (nearly to 97% to the ORL face database).
References
[1] P. N. BELHUMEUR, J. P. HESPANHA, and D. J. KRIEGMAN. Eigenfaces vs. fisherfaces: recognitionusing class specific linear projection.IEEE Transactions On Pattern Analysis And Machine Intelligence,vol. 19, no. 7, 1997.
[2] T. KOHONEN. The self-organizing map.Vision, 1988.[3] J. LU, K. N. PLATANIOTIS, and A. N. VENETSANOPOULOS. Face recognition using lda-based algo-
rithms. IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 14, NO. 1, 2003.[4] A. M. MARTNEZ and A. C.KAK. Pca versus lda.IEEE Transactions On Pattern Analysis And Machine
Intelligence, VOL. 23, NO. 2, 2001.[5] V. E. NEAGOE and A. D. ROPOT. Concurrent self-organizing maps for pattern classification.IEEE
International Conference on Cognitive Informatics, 2002.[6] X. WANG and X. TANG. Random sampling lda for face recognition. —, 2002?[7] X. WANG and X. TANG. Dual-space linear discriminant analysis for face recognition.in Proceedings of
CVPR, 2004.[8] W. ZHAO, R. CHELLAPPA, and A. KRISHNASWAMY. Discriminant analysis of principal components
for face recognition.In Proceedings, International Conference on Automatic Face and Gesture Recogni-tion. 336-341, 1998.
[9] W. ZHAO, R. CHELLAPPA, and N. NANDHAKUMAR. Empirical performance analysis of linear dis-criminant classifiers. —, 2002?
WVC´2005 - I Workshop de Visão Computacional
23

Automatic Clusters to Face Recognition
Anderson Rodrigo dos Santos and Adilson Gonzaga
Department of Electrical Engineering - University of Sao Paulo - Sao Carlos, Brazil
[email protected] and [email protected]
Abstract
In this paper we consider to study the distribution of the vectors of face in the dimensional space(n x m pixels of the image), and we have developed a face recognition that works under varying posedealing with N different individual given under M different view/ poses and illumination. We constructan automatic algorithm that computes and finds clusters within the training group preserving intrinsichuman face characteristics. The algorithm named K-PCA applies a SOM neural network in thecluster stage and applies the PCA method into each cluster, that is, each cluster forms an eigenface.The recognition rate using the data base Umist and Essex are 85% and 99%.
1 Introduction
Though most of the algorithms achieve good recognition rates with the frontal views of faces,they fail when the pose of the face in the database and that in the query are different. Some authorshave presented methods to recognize human faces with variations in rotation (or pose). The mostsignificative works are Beymer and Poggio [1], Vetter [9], Lu and Jain [6], Huang et al. [4], Nayar etal. [7], Graham and Allinson [2], Pentland and Moghaddam [8].
The PCA technique based on face recognition finds eigenvectors that constitute the face sub-spacebases (eigenspace) that are gotten through the covariance matrix formed by the correlation betweenpixels. In summary, each image of a human face in the training set can be represented in terms ofa linear combination of eigenvectors, and the coefficients of this combination will be the new facerepresented in the eigenspace. Mathematically, each face image defined by a matrix of pixels withintensities in the gray scale defines vectors likeΓ1, Γ2, Γ3, ... ΓM , which are associated to pixels ofimagesIm(x, y)nxn concatenated by row or column. The average can be calculated by equation (1).
Ψ =1
M·
M∑n=1
Γn (1)
Every image differs from the mean by a vector:
φn = Γn − Ψ (2)
The vectorsµk and scalarλk are the eigenvectors and eigenvalues, respectively, of the covariancematrix C (equation 3).
C =1
M·
M∑n=1
φnφTn = A.AT (3)
WVC´2005 - I Workshop de Visão Computacional
24

Where the matrix A = [φ1, φ2,...φM ] and C are wxh dimension having w and h like image wideand height. So the eigenvectors are calculated by(A.AT ).µk = λk.µk. The eigenvectors calculatedthrough covariance matrix make the orthonormal bases of eigenspace. The training faces can beprojected onto the eigenspace by:
ωn = µTn .(Γ − ψ) paran = 1, ...M . (4)
Therefore, theωn define a pattern vectorΩT (i) = [ωi1, ω
i2, ....ω
in], i= 1,...M (where M is the number
of images), that represent each training face in the eigenspace.The SOM nets are auto-organized maps constituted by neurons on a flat structures either 1-D or
2-D. The learning method is based on ”competitive learning”, whose purpose is to discover patternsinto input data. An input vector of arbitrary dimension is taken in a discrete neuron map in accordancewith the proximity of the patterns in the original dimension [5].
When an input pattern is presented to the net, each unit in the first layer assumes the input value andthe units of the second layer add its input and compete to find an only unit winning. Thus, assumingan input pattern that was presented to the characteristics map of Kohonen is denoted like:
X = [x1, x2, ..., xm] (5)
And the weights are given by Wj = [wj1, wj2, ... , wjm], with j= 1, 2, ... , L. Where‖X‖ = ‖W‖ =1, j identifies the unit on the competitive layer, and L is the number of neurons in the net.
In the training, the first step is to calculate the similarity for each unit in the competitive layer withthe input data. The Euclidian Distance (d) between the vectors X and Wj can be calculated by:√∑
j
(xk − wjk)2 (6)
The unit with the major similarity wins the competition. That is equivalent to maximize the internalproductWj.XT [3]. If the index i(X) is used to identify the winner neuron corresponding to the input,i(X) will be set applying the condition (equation 7):
i(X) = argminj
(‖X −Wj‖) (7)
After that the winner unit is identified, the next step is to identify the neighborhood around of itand update them.
2. Methodology
To construct the sub-spaces of eigenfaces, we trained the SOM neural net with the training faces.After that, we defined the region of clusters and finally separated the training face that is similar foreach cluster computing the eigenface independent for each eigenspace (figure 1). In the identification,the first step is to determine the best one cluster to classify the input image. This is reached calculatingthe face projection into each eigenspace, doing the reconstruction of image and calculating the errorbetween the reconstructed and original image. The eigenspace that presents the lesser error in theimage reconstruction will be used to make the recognition.
The Algorithm K-PCA is an extension of PCA with the advantage to simplify the calculations ofthe eigenvectors, because it parallels the process when applied in big database.
The face database Umist1 and Essex2 had been used separately to evaluate the algorithm K-PCA.
1http://images.ee.umist.ac.uk/danny/database.html2http://www.essex.ac.uk/allfaces/faces94.html
WVC´2005 - I Workshop de Visão Computacional
25

Figure 1. Flowchart of training to K-PCA.
Umist database has 20 different people covering a scale of poses from profile to frontal view. Forthe test, 20 faces of each person had been selected and flipped horizontally to produce more 20 images.The images was divided in a set of training images (12 for each person) and another set of test images(28 for each person). Essex database has 132 individuals with 20 faces for each person had beenselected, and this set was divided in 10 faces for training and 10 for test (figure 2).
Figure 2. Exemples of faces in the database.
SOM neural net has been trained with 21 neurons distributed in a linear map. The weight distribu-tion of neurons converges to the characteristics of illumination and pose with relation to the averagefaces of the set however it does not converge to the faces of each person. After SOM training, three re-gions (clusters) were established applying the K-means algorithm. Figure 3 shows the vectors relatedto each neuron and transformed into faces for the database Umist and Essex.
Figure 3. SOM’s neurons after training.
In the test phase, the faces of testing set images are presented to the algorithm to effect the recog-nition. Figure 4 shows the recognition rate for the two databases.
The results presented for the database Essex are better than the presented ones for the databaseUmist, because this last one presents great variations with relation to the illumination and rotation.
WVC´2005 - I Workshop de Visão Computacional
26

Figure 4. Recognition rate for K-PCA.
3. Conclusions
The experiment that we report appeals an efficient method to brighten up the variations of rotationand illumination, and to parallel the PCA algorithm applied in the face recognition. The algorithmforms training sets with relation to the rotation, illumination or scales automatically separating thetraining face in accordance with these characteristics.
SOM neural net revealed efficient in the identification of the position of face rotation, and distribu-tion of the illumination in the face databases. It makes possible a study of the scattering vectors offaces in dimensional space n x m.
References
[1] D. BEYMER and T. POGGIO. Face recognition from one model view.Proc. Fifth Intl Conf. ComputerVision, 1995.
[2] D. GRAHAM and N. ALLINSON. Face recognition from unfamiliar views: subspace methods and posedependency.IEEE Intl Conf. On Automatic Face and Gesture Recognition, 1998.
[3] S. HAYKIN. Neural networks: a comprehensive foundation. Prentice Hall, New York, 1998.[4] J. HUANG, X.SHAO2, and H. WECHSLER. Face pose discrimination using support vector machines
(svm). Proc. of 14th International Conference on Pattern Recognition, 1998.[5] T. KOHONEN. The self-organizing map.Vision, 1988.[6] J. LU, K. N. PLATANIOTIS, and A. N. VENETSANOPOULOS. Face recognition using lda-based algo-
rithms. IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 14, NO. 1, 2003.[7] S. NAYAR, H. MURASE, and S. NENE. Parametric appearance representation.Early Visual Learning,
—.[8] A. PENTLAND, B. MOGHADDAM, and T. STARNER. View-based and modular eigenspaces for face
recognition.In Proceedings, IEEE Conference on Computer Vision and Pattern Recognition, 1994.[9] T. VETTER and T. POGGIO. Linear object classes and image synthesis from a single example image.
IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 19, No. 7, 1997.
WVC´2005 - I Workshop de Visão Computacional
27

Blz..Classificação de padrões em imagens utilizando redes neurais artificiais LVQ
André de Souza Tarallo, Deise Mota Alves, Thiago Crivelaro do Nascimento, Adilson Gonzaga
Universidade de São Paulo - USP Escola de Engenharia de São Carlos
Departamento de Engenharia Elétrica
[email protected], [email protected], [email protected], [email protected]
Abstract The goal of this work is to demonstrate the efficiency of an artificial neural network LVQ
(Learning Vector Quantization) as simple method for pattern classification in digital images. The extraction process of the most important characteristics of the images will not be mentioned here, because the study has been done about databases previously constructed and available to researchers of all world. The development of the present work, therefore, will be given by means of two applications: one is the use of Winsconsin breast cancer data [2] and the another one is the use of Fisher´s iris data [2].
1. Introdução
Todo problema que envolve classificação de padrões exige um estudo detalhado do problema. Deve-se levar em consideração a quantidade e natureza dos dados, a complexidade do problema, tempo de desenvolvimento, entre outros, a fim de que se opte pelo método que requeira o menor esforço computacional e dê bons resultados, constituindo a solução ótima para o problema em análise.
A base de dados de Winsconsin(1991) [2] contém 699 amostras com 9 características extraídas de imagens de células das mamas. Cada amostra, a partir da análise humana, foi classificada como pertencente a uma das duas classes possíveis: maligno ou benigno. As características observadas são: densidade do agrupamento, uniformidade do tamanho da célula, uniformidade da forma da célula, adesão marginal, tamanho das células epiteliais simples, núcleos desencapados, cromatina benigna, nucleoli normal, mitoses.
A base de dados de Fisher(1936) [2], é uma coleção de 150 amostras, com 4 características cada, sendo a largura e o comprimento da pétala e da sépala. Tais amostras são classificadas em três classes: Íris Virgínica, Íris Versicolor, Íris Setosa. 2. Solução do problema
Em algumas situações em que se deseja classificar padrões, uma simples rede neural artificial que seja capaz de se auto-organizar, promovendo um treinamento competitivo que detecte similaridades e conexões entre os padrões do conjunto de entrada, é suficiente para a solução do problema. As redes LVQ constituem, exatamente, estruturas deste tipo.
O objetivo principal da utilização destas redes reside na divisão do espaço amostral de entrada em diversos subespaços disjuntos, sendo que cada um dos vetores de entrada (padrões) deve pertencer somente a um desses subespaços, os quais representarão as classes associadas ao problema considerado.
Portanto, cada subespaço (classe) é associado a um vetor quantizador que representa todos os padrões vinculados àquela classe. Desta forma, quando um novo padrão de teste é apresentado ao
WVC´2005 - I Workshop de Visão Computacional
28

sistema, o mesmo ativa o vetor quantizador representante daquela classe a qual ele supostamente deva pertencer.
Para o ajuste de seus pesos, esta rede utiliza um processo competitivo, ao término do qual tais pesos estarão representando os respectivos vetores quantizadores.
Dessa forma, conhecem-se todas as N-classes associadas aos padrões de entrada do sistema. O objetivo da rede é a quantização ótima do espaço de entrada em N-subespaços.
Após a rede estar treinada (treinamento este que é supervisionado), ela pode ser utilizada para classificar outros padrões de entrada entre as várias classes do sistema.
Nas redes LVQ-1 considera-se que cada vetor de entrada utilizado no treinamento pertença a uma classe j. O algoritmo de aprendizagem é idêntico ao de Kohonen [15], modificando apenas o processo de ajuste dos pesos, o qual é aplicado apenas ao neurônio vencedor.
Dadas as características deste tipo de rede, bem como a natureza dos dados disponíveis (possibilidade de um treinamento supervisionado), utilizou-se uma rede LVQ-1 sobre a base de Winsconsin, bem como sobre a base de Fisher. Neste último caso, entretanto, bons resultados apenas foram alcançados por meio de algumas modificações no algoritmo, podendo-se citar:
• Utilização de dois neurônios para cada classe; • Inicialização dos vetores de pesos de acordo com os primeiros padrões de cada classe. Somente após tais adaptações, é que se obteve resultados satisfatórios. Há de se ressaltar ainda
que a base de Fisher foi parcialmente utilizada, uma vez que apenas duas características foram apresentadas à entrada da rede. Justifica-se esta atitude pelos maus resultados obtidos em testes realizados sobre a mesma rede para as quatro características de entrada. Observou-se que a largura e o comprimento da sépala constituem características relevantes e bastam para esta arquitetura de rede. A inclusão das demais características apenas dificulta o processo de treinamento da rede.
O treinamento para ambas as bases se deu sobre 50% dos dados disponíveis, o que representa prática comum dentre outros métodos publicados [1].
3. Resultados Computacionais Os resultados finais obtidos para a correta classificação das amostras da base de dados de Winsconsin foram:
• 95,6% para “benigno”; • 100,0% para “maligno”. A média aritmética fornece o resultado de 97,8%. O treinamento não atingiu valores maiores do
que 20 épocas de treinamento para diversas inicializações dos pesos. Os resultados finais obtidos para a classificação dos três tipos de Flor de Íris foram: • 100% de acerto para Setosa; • 94% de acerto para Versicolor; • 98% de acerto para Virgínica. A média aritmética fornece o resultado de 97,33%. O treinamento não atingiu valores maiores
do que 10 épocas de treinamento. Esses resultados podem ser melhor analisados à vista de resultados de outros métodos propostos
por diversos autores para os mesmos problemas, conforme indicam as tabelas 1 e 2.
WVC´2005 - I Workshop de Visão Computacional
29

Algoritmo Resultado (%) Kwok´s SVM with gaussian kernel [3] 91,60
Kwok´s SVM with polynomial kernel [3] 93,60 Setiono´s neuro classifier [4] 93,99
MSC [5] 94,90 FEBFC [6] 95,14 IRSS [1] 95,89
Rede Neural LVQ-1 97,80 Tabela 1. Classificação da rede LVQ-1 para a base de Winsconsin
em comparação a outros métodos.
Padrão Algoritmos
Setosa (%)
Versicolor (%)
Virgínica (%)
Média (%)
IVSM [7] 100 93.33 94.00 95.78 GVS [8] 100 94.00 94.00 96.00
NT-Growth [7] 100 93.50 91.13 94.87 Dasarathy [7] 100 98.00 86.00 94.67
C4 [7] 100 91.07 90.61 93.87 FCC [9] 100 94.00 92.00 95.33
AFLC [10] 100 86.00 100 95.33 Wu e Chen [11] 100 93.38 95.24 96.21 Hong e Lee [12] 100 94.00 92.72 95.57
FEBFC [6] 97.12 Nozaki et al. [13] 95.57 k-vizinhos [14] 94.67
Fisher ratios [14] 96.00 IRSS [1] 100 92.00 96.00 96.00
LVQ-1 Modificada 100 94.00 98.00 97.33 Tabela 2 – Resultados de diversos métodos para a base de Fisher.
4. Conclusão
Diante dos resultados obtidos, observa-se que nem sempre há uma análise detalhada do problema antes da escolha de determinada técnica a ser empregada para a solução do mesmo.
Esta consciência deve existir em todos os casos. Da mesma forma, seria um exagero, por exemplo, utilizar uma rede neural artificial como aproximadora de funções quando o problema poderia ser facilmente modelado por uma equação de segundo grau.
Cabe ao projetista ter discernimento para, diante de um problema, decidir pela técnica mais adequada, evitando constrangimentos e péssimos resultados.
Como pôde ser visto, a solução proposta nesse artigo alcançou resultados superiores àqueles apresentados nas tabelas 1 e 2, mostrando-se como uma opção rápida e eficaz.
5. Referências Bibliográficas [1] Chatterjee, A. e Rakshit, A., “Influential Rule Search Scheme (IRSS) – A New Fuzzy Pattern
Classifier”, IEEE Transactions on knowledge and Data Engineering, vol. 16, no. 8, pp. 881-893, agosto de 2004.
WVC´2005 - I Workshop de Visão Computacional
30

[2] C.L. Blake e C.J. Merz, “UCI Repository of Machine Learning Databases,” Univ. of California, Irvine, Dept. of Information and Computer Science, http://www.ics.uci.edu/~mlearn/MLRepository.html, 1998.
[3] J.T-Y. Kwok, “The Evidence Framework Applied to Support Vector Machines,” IEEE Trans. Neural Networks, vol. 11, no. 5, pp. 1162-1173, setembro de 2000.
[4] R. Setiono, “Extracting M-of-N Rules from Trained Neural Networks,” IEEE Trans. Neural Networks, vol. 11, no. 2, pp. 512-519, março de 2000.
[5] B.C. Lovel e A.P. Bradley, “The Multiscale Classifier,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 18, no. 2, pp. 124-137, fevereiro de 1996.
[6] H.-M. Lee, C.-M. Chen, J.-M. Chen, e Y.-L. Jou, “An Efficient Fuzzy Classifier with Feature Selection Based on Fuzzy Entropy,” IEEE Trans. Systems, Man, and Cybernetics - Part B: Cybernetics, vol. 31, no. 3, pp. 426-432, junho de 2001.
[7] T.P. Hong e J.B. Chen, “Processing Individual Fuzzy Attributes for Fuzzy Rule Induction,” Fuzzy Sets and Systems, vol. 112, pp. 127-140, 2000.
[8] T-P. Hong e S.-S. Tseng, “A Generalised Version Space Learning Algorithm for Noisy and Uncertain Data,” IEEE Trans. Knowledge and Data Eng., vol. 9, no. 2, pp. 336-340, março-abril de 1997.
[9] I.H. Suh, J.H. Kim, e F.C.H. Rhee, “Convex-Set-Based Fuzzy Clustering,” IEEE Trans. Fuzzy Systems, vol. 7, no. 3, pp. 271-285, junho de 1999.
[10] S.C. Newton, S. Pemmaraju, e S. Mitra, “Adaptive Fuzzy Leader Clustering of Complex Data Sets in Pattern Recognition,” IEEE Trans. Neural Networks, vol. 3, no. 5, pp. 794-800, setembro de 1992.
[11] T.P. Wu e S.M. Chen, “A New Method for Constructing Membership Functions and Fuzzy Rules from Training Examples,” IEEE Trans. System, Man, and Cybernetics - Part B: Cybernetics, vol. 29, no. 1, pp. 25-40, fevereiro de 1999.
[12] T.P. Hong e C.Y. Lee, “Induction of Fuzzy Rules and Membership Functions from Training Examples,” Fuzzy Sets and Systems, vol. 84, pp. 33-47, 1996.
[13] H. Ishibuchi e T. Nakashima, “Effect of Rule Weights in Fuzzy Rule-Based Classification Systems,” IEEE Trans. Fuzzy Systems, vol. 9, no. 4, pp. 506-515, agosto de 2001.
[14] S. Fahlman e C. Lebiere, “The Cascade-Correlation Learning Architecture,” Carnegie Mellon Univ., School of Computer Science, Technical Report CMU-CS-90-100, fevereiro de 1990.
[15] Haykin, S. – “Neural Networks”, Prentice Hall, 1999
WVC´2005 - I Workshop de Visão Computacional
31

Reconhecimento de Faces Neutras Usando Redes Neurais em Paralelo
Evandro A. Silva, Armando Marin, Adilson Gonzaga, Fabiana C. Bertoni Kelton A.P. Costa, Luciana A.L. Albuquerque
Universidade de São Paulo Av. Trabalhador São-carlense, 400 – CEP: 13566-590 Fone/FAX (16) 3373-9371– São Carlos / SP – Brasil
[email protected],[email protected],adilson,bertoni,[email protected], [email protected]
Abstract
This paper presents an approach to perform neutral facial image recognition through expression facial image using Hopfield neural networks. The dimension of neutral facial image is reduced and the image is sliced into gray levels, from the most significant bits to the less significant bits. The same process is applied to the expression facial image. The proposed approach using eight parallel Hopfield neural networks, one for each gray level, to recognition and recover the neutral facial image based in the expression facial image. 1. Introdução
As pesquisas em reconhecimento de faces são tão antigas quanto à própria área de Visão Computacional, com trabalhos datados a mais de trinta anos. Assim a literatura sobre o assunto é bastante extensa e contém as mais variadas técnicas e também as mais variadas aplicações [1], como por exemplo: detecção de faces em imagens, detecção de pele e não-pele, de faces em posições não-regulares e de faces com e sem expressão.
Dentre as motivações neste segmento de pesquisa pode-se citar: identificação pessoal para bancos, passaportes e fichas criminais; sistemas de segurança e controles de acesso; monitoramento de multidões em estações, shoppings, criação de retratos falados; e envelhecimento computadorizado para auxiliar na busca de desaparecidos. Em reconhecimento de expressões faciais têm-se, além das motivações citadas, o desenvolvimento de interfaces perceptuais homem-máquina e a identificação em bancos de imagens criminais ou de identificação pessoal caso a imagem coletada em flagrantes tenha alguma expressão.
Existem métodos bastante sofisticados para a detecção de expressões e reconhecimento de faces. Desde segmentação de partes como a boca, os olhos e o nariz até as que segmentam a movimentação dos músculos faciais [1].
As redes neurais artificiais têm contribuído no desenvolvimento de sistemas de reconhecimento e classificação de padrões em processamento de imagens e são utilizadas em vários trabalhos voltados ao reconhecimento de expressões faciais [2]. As mais variadas topologias e arquiteturas de redes neurais artificiais são utilizadas, dentre as quais destacamos a PMC (Multi-Layer Perceptron) [3], RBF (Radial Base Fuction) [4] e também trabalhos que usam redes de Hopfield, com o objetivo de detectar mudanças de expressões em uma face [5] [6] e classificação apenas de cores em imagens [7].
O artigo de Ma et.al. [3] propõe um reconhecimento de expressão facial usando PMC aliado a técnicas de compactação de imagem, algoritmos de otimização como quasi-newton e técnicas de poda (pruning technique). Na tentativa de desenvolver um modelo para identificar uma face neutra a partir de faces com expressões, adotou-se algumas idéias do trabalho de Ma et.al. [3], porém, enquanto o trabalho citado busca reconhecer qual a expressão facial de cada imagem apresentada à rede, o presente
WVC´2005 - I Workshop de Visão Computacional
32

trabalho busca encontrar qual imagem de face neutra armazenada corresponde à imagem de face com expressão apresentada. 2. Abordagem proposta
Imagens com expressão são geralmente as imagens encontradas nas situações comuns e imagens neutras são geralmente aquelas armazenadas nos bancos de imagens como, por exemplo, em sistemas de segurança. A Figura 1 mostra com clareza a diferença entre imagens de faces neutras em relação a imagens de faces com expressões.
Figura 1 – Faces Neutras e com Expressões
O problema a ser resolvido pela abordagem proposta neste trabalho consiste em reconhecer e
recuperar a imagem da face neutra a partir da imagem com expressão facial, utilizando-se a característica de memória associativa da rede neural artificial de Hopfield. O esquema da Figura 2 apresenta as fases e etapas da abordagem proposta para solução do problema descrito. A Fase 1 realiza o tratamento das imagens de faces neutras através das etapas da abordagem (Redução de Dimensionalidade, Criação de Vetor Coluna, Fatiamento do Vetor Coluna e Redes Neurais de Hopfield) necessário para o armazenamento das imagens na memória das redes neurais artificiais. A Fase 2 utiliza-se das mesmas etapas da Fase 1 para tratar as imagens de faces com expressão e apresentar para as redes neurais. O processo inverso é realizado para recuperar as imagens de faces neutras correspondentes.
Figura 2 – Fases e Etapas da abordagem proposta.
Todas as imagens apresentadas como padrão de entrada para a rede neural artificial passa pela
etapa de Redução de Dimensionalidade. A redução da dimensão dessas imagens, de 350 x 275 pixels para a dimensão de 32 x 32 pixels é realizada através da técnica “nearest” (vizinho mais próximo). A redução da dimensão não ocasiona perdas significativas nas características da imagem e é necessária
WVC´2005 - I Workshop de Visão Computacional
33

para redução dos números de neurônios utilizados nas redes neurais. Após a Redução de Dimensionalidade, é realizada a Criação de Vetor Coluna de 1024 posições.
As linhas da matriz da imagem reduzida para a dimensão de 32 x 32 pixels, com as informações de cada pixel, são enfileiradas em uma única coluna de 1024 posições.
Nos primeiros testes utilizou-se o vetor coluna como entrada da rede neural artificial de Hopfield, usando uma topologia com 1024 neurônios. Os testes resultaram em uma confusão da rede neural artificial em relação aos níveis inferiores de cinza das imagens. Para solucionar este problema optou-se por separar as imagens em níveis de cinza e criar uma rede neural para tratar cada nível. Assim o vetor de dimensão 1 x 1024 pixels foi fatiado em 8 bits, um para cada nível de cinza, dando origem a 8 vetores diferentes, conforme apresenta a Figura 3.
Figura 3 – Fatiamento do vetor de 1 x 1024 em 8 vetores.
Novos testes foram realizados com oito redes neurais artificiais em paralelo, uma para cada
nível de cinza. Cada rede neural possui 1024 neurônios e suas entradas são os vetores contendo os bits mais e menos significativos para cada nível de cinza, respeitando a ordem do mais significativo para o menos significativo. Assim, cada rede neural artificial trabalha com apenas um nível de cinza da imagem e, recupera o mesmo nível de bit da imagem neutra armazenada.
Na Fase 2 da abordagem, o mesmo processo é aplicado para obter 8 vetores com os níveis de cinza da imagem de face com expressão. As redes neurais artificiais utilizam as entradas para procurar cada fatia da imagem de face neutra correspondente. Ao encontrar, cada rede neural artificial retorna o vetor correspondente ao nível de cinza armazenado. O processo inverso é realizado para que a imagem da face neutra seja reconstruída e visualizada. 3. Resultados obtidos
De posse de uma base de dados contendo 100 imagens, onde cada grupo de 10 imagens é composto por 1 imagem de face neutra e 9 imagens com expressões faciais, na Fase 1 as 10 imagens de faces neutras foram armazenadas nas redes neurais artificiais. Em seguida, na Fase 2, foram apresentadas as imagens de faces com expressões para recuperação das imagens de faces neutras correspondentes.
Para todas as imagens com expressão facial apresentadas, foi recuperada, de forma perceptível ao olho humano, a imagem de face neutra correspondente. Nos casos com expressões mais acentuadas (proporcionando maior ruído à imagem) ocorreram pequenas distorções, mas ainda assim, foi possível reconhecer a imagem neutra recuperada. A ação da abordagem proposta fica evidente através do cálculo da distância euclidiana entre as imagens armazenadas e as recuperadas.
WVC´2005 - I Workshop de Visão Computacional
34

Além dos testes com os 8 níveis de bits, realizou-se testes retirando-se os bits menos significativos com o intuito de economizar custo computacional. Observou-se que, quando retirados 2 bits menos significativos recupera-se uma imagem muito próxima da imagem de face neutra armazenada, pois as características presentes nestes bits não influenciam na recuperação da imagem. Os testes também revelaram que com apenas os 3 bits mais significativos é possível obter um resultado não ótimo, mas satisfatório. Não é necessário a utilização dos 8 níveis de bits das imagens para que as redes neurais artificiais possam armazenar e recuperar os padrões corretamente.
Observou-se a partir dos testes realizados que, em todos os casos, a abordagem proposta retorna a imagem de face neutra esperada. 4. Conclusões
O presente trabalho propôs uma abordagem que viabiliza a utilização de redes neurais artificiais
de Hopfield para classificação e reconhecimento de faces neutras a partir de faces com expressões e evidencia que o “fatiamento” da imagem, em níveis de cinza, contribui para a redução do custo computacional sem prejuízo nos resultados.
A redução do tamanho da imagem também contribui para a redução do custo computacional, mas implica na redução da qualidade da imagem, fato que pode comprometer os resultados.
A abordagem proposta se mostrou estável e funcional, com baixo custo computacional e fácil implementação, incentivando a continuidade deste trabalho de pesquisa. Como trabalhos futuros, novos testes serão realizados com uma base de imagens maior para validar a abordagem proposta e sua utilização em situações reais na área de visão computacional. 5. Referências [1] DONATO, G.; BARTLETT, M. S.; HAGER, J. C.; EKMAN, P.; SEJNOWSKI, T. J. “Classifying facial actions”, IEEE Trans. Pattern Anal. Machine Intell., vol. 21, pp. 974–989, Oct. 1999. [2] XIAO, Y.; CHANDRASIRI, N. P.; TADOKORO, Y.; ODA, M. “Recognition of facial expressions using 2-d dct and neural network,” Electron. Commun.Jpn., vol. 82, no. 7, pp. 1–11, 1999. [3] MA, L.; KHORASANI, K.; “Facial expression recognition using constructive feedforward neural networks”. Systems, Man and Cybernetics, Part B, IEEE Transactions on Volume 34, Issue 3, June 2004 Page(s):1588 – 1595. [4] ROSENBLUM, M.; YACOOB, Y.; DAVIS, L. S. “Human expression recognition from motion using a radial basis function network architecture,” IEEE Trans. Neural Networks, vol. 7, pp. 1121–1138, Sept. 1996. [5] YONEYAMA, M.; IWANO, Y.; OHTAKE, A.; SHIRAI, K. “Facial Expressions Recognition Using Discrete Hopfield Neural Network”. International Conference on Image Processing (ICIP '97) 3-Volume Set-Volume 1; p. 117, 1997 [6] YING D; SHIBATA, Y.; NAKANO, Y.; HASHIMOTO, K.; “Recognition of facial expressions based on the Hopfield memory model”. Multimedia Computing and Systems, 1999. IEEE International Conference on Volume 2, 7-11 June 1999 Page(s):133 - 137 vol.2 [7] CAMPADELLI, P.; MORA, P.; SCHETTINI, R. “Using Hopfield networks in the nominal color coding of classified images”. Conference B: Computer Vision & Image Processing., IEEE CNF Proceedings of the 12th IAPR.
WVC´2005 - I Workshop de Visão Computacional
35

Subtração de fundo em imagens digitais utilizando redes neurais
artificiais MLP
Gouveia, Wellington da Rocha Alameda dos Crisântemos, 407 Cidade Jardim - São Carlos-SP
Lorencetti, Adriano Aparecido Rua nove de Julho, 891
Centro – Adamantina – SP [email protected]
Olivete, André Luís Rua Brig. Luiz Antonio, 300
Jd Paulista – Adamantina – SP [email protected]
Abstract
Artificial neural networks has been used in the most diverse research areas, this paper has the objective of the background subtraction in digital images using multilayers perceptrons networks (MLP, multilayer perceptron).
1. Introdução
Uma rede neural artificial é uma rede de muitos elementos com operações paralelas simples. As RNAs são inspiradas na eficiente comunicação entre os neurônios biológicos: os neurônios são locados em sucessivas camadas que são interconectadas de forma maciça pelas conexões sinápticas, permitindo transmissões de sinais elétricos.
A subtração de fundo em imagens é de grande importância para a detecção de objetos em movimento em vídeos e em imagens digitais, que tem a sua principal aplicação na área de segurança [1].
Normalmente os sistemas de captura de movimento, que utilizam dispositivos mecânicos, eletromagnéticos e acústicos, apresentam uma série de problemas, tais como a necessidade do uso de equipamentos especiais e a ocorrência de perda de dados de movimento [1]. O presente trabalho apresenta uma proposta da utilização de redes MLP para gerar um padrão de subtração de fundo em imagens digitais possibilitando assim a detecção de movimento nas mesmas.
O desenvolvimento desse trabalho consistiu na captura das imagens para o padrão de treinamento da rede e de imagens para o teste da rede, pré-processamento das imagens, realização do treinamento dos padrões para geração das matrizes de pesos da rede, teste da imagem para a subtração do fundo, detecção e visualização do objeto em movimento.
Na sessão 2 são apresentadas algumas definições sobre a subtração de fundo, os conceitos de redes neurais artificiais e redes perceptrons multicamadas (MLP) são apresentados na sessão 3. A sessão 4 apresenta a definição do problema encontrado, seguido pelo desenvolvimento do trabalho para a resolução do problema que está presente na sessão 5. Na sessão 6 são apresentados os resultados encontrados e é realizada uma discussão sobre eles, na sessão 7, as conclusões alcançadas com esse trabalho são apresentadas.
2. Subtração de Fundo
Os seres humanos tendem a associar uma cor constante a um objeto mesmo que este esteja sob a influencia de variações de luminosidade. A fidelidade à cor é importante na remoção do fundo da cena independente da projeção de sombras sobre eles. A subtração de fundo consiste em subtrair a imagem atual de uma imagem usada como referência, contendo apenas o fundo da cena e construída a partir de uma seqüência de imagens durante um período de treinamento. A subtração deixa visível apenas objetos não estáticos e novos objetos que não estavam na cena original.
A subtração de fundo faz uso de um modelo de cor capaz de separar a variação de luminosidade, a partir de uma imagem de referência e da imagem atual.
3. Redes Neurais Artificiais
A técnica de redes neurais artificiais tenta simular o cérebro humano, mas o cérebro processa informações de uma forma totalmente diferente do computador digital convencional. O cérebro humano é um computador altamente complexo, não linear e paralelo. Ele tem a capacidade de organizar seus neurônios, de forma a realizar certos processamentos muito mais rapidamente que o mais rápido computador digital hoje existente. [2]
Na sua forma mais geral, uma rede neural é uma maquina que é projetada para modelar a maneira como o cérebro realiza uma tarefa particular ou função de interesse; a rede é normalmente implementada utilizando-se componentes
WVC´2005 - I Workshop de Visão Computacional
36

eletrônicos ou é simulada por programação em um computador digital. Para alcançarem bom desempenho, as redes neurais empregam uma interligação maciça de células computacionais simples denominadas de “neurônios” ou “unidades de processamento”. Podemos então oferecer a seguinte definição de uma rede neural vista como uma maquina adaptativa:
Uma rede neural é um processador maciçamente paralelamente distribuído de unidades de processamento simples, que têm a propensão natural para armazenar conhecimento experimental e torná-lo disponível para o uso. Ela se assemelha ao cérebro em dois aspectos:
1- O conhecimento é adquirido pela rede a partir de seu ambiente através de um processo de aprendizagem.
2- Forças de conexão entre neurônios, conhecidos como pesos sinápticos, são utilizadas para armazenar o conhecimento adquirido.
O procedimento utilizado para realizar o treinamento da rede é chamado de algoritmo de aprendizagem, cuja função é modificar os pesos sinápticos da rede de uma forma ordenada para alcançar o objetivo desejado[3].
3.1. Perceptrons de Multicamadas
A rede perceptrons multicamadas consiste de um conjunto de unidades sensoriais (nós de fonte) que formam a camada de entrada, uma ou mais camadas ocultas de nós computacionais e uma camada de saída. O sinal de entrada se propaga para frente através da rede, camada por camada como apresentado na Fig. 1.
Os perceptrons multicamadas têm sido aplicados com sucesso para resolver diversos problemas difíceis, através
do seu treinamento de forma supervisionada com um algoritmo muito popular conhecido como algoritmo de retro propagação de erro (error back-propagation)[2].
4. Definição do problema
O problema tratado nesse artigo consiste na subtração do fundo de imagens digitais com variação da iluminação em um ambiente, onde a iluminação não deve ter grandes alterações de intensidade, possibilitando desta forma a detecção de objetos em movimento nessas imagens.
5. Desenvolvimento
A solução para o problema apresentado é a utilização de um algoritmo que utiliza a arquitetura de rede perceptrons multicamada com algoritmo de treinamento backpropagation para realizar o treinamento dos pesos da rede. A rede implementada nesse trabalho apresenta 01 camada de entrada com 04 entradas, 01 camada escondida com 08 neurônios e uma camada de saída com um neurônio.
Esse algoritmo foi desenvolvido utilizando o MATLAB (Matrix Laboratory) que é um software interativo e de alta performance voltado para cálculos numéricos e científicos.O modelo de fundo é composto por uma rede MLP para cada pixel de teste, onde cada pixel da imagem terá sua própria matriz de pesos da rede.
O treinamento da rede MLP é realizado gerando uma matriz de padrão de treinamento para cada pixel, onde esse pixel corresponde ao mesmo pixel na próxima imagem de treinamento como ilustrado na fig. 2. Dessa forma é gerada a
Si
nal de
Sinal de saída (resposta)
Camada de
entrada
Primeira camada oculta
Segunda camada oculta
Camada de saída
Figura 1 – Grafo arquitetural de um perceptron multicamadas com duas camadas ocultas.
WVC´2005 - I Workshop de Visão Computacional
37

Imagem
Imagem Imagem
Imagem
Figura 2 – A matriz de padrão de treinamento é gerada a partir de todos os pixel’s da mesma posição em um intervalo de imagens do conjunto de imagens de treinamento.
matriz de treinamento para o pixel, portanto para uma imagem de 120x160 pixels são geradas 19.200 matrizes de pesos. A implementação do algoritmo utilizado neste trabalho teve como base os algoritmos de subtração de fundo em imagens que utilizam os modelos de mistura de gaussianas (GMM), esses modelos apresentam a mesma estrutura de analise do plano de fundo implementa para a realização do presente trabalho[4,5].
A realização da subtração de fundo da imagem é realizada através do algoritmo de teste de classificação em cada pixel da imagem de teste com a sua matriz de pesos correspondente, desta forma é gerada uma nova imagem contendo o objeto onde foi detectado o movimento em relação ao fundo.
Os treinamentos das redes utilizada nesse trabalho foram realizados utilizando uma seqüência de 30 imagens de fundo valido com uma pequena variação de iluminação e 15 imagens de não fundo. Esse conjunto de imagens foi utilizado para a geração das matrizes de padrão de treinamento da rede.
6. Resultados e Discussões
O treinamento da rede requer um grande esforço computacional, pois a rede MLP é treinada para cada pixel da imagem, gerando assim uma grande quantidade de treinamento, como pode ser visto na sessão anterior. A subtração do fundo da imagem de teste é extremamente rápida e exige pouco esforço computacional, pois é realizada utilizando operações matemáticas simples entre as matrizes com os pesos da rede e o pixel corresponde da imagem.
Após o treinamento de todas as redes correspondentes ao plano de fundo verificou-se que foi realizada uma grande quantidade de épocas nas redes localizadas no centro da imagem conforme é ilustrado na fig. 3, realizando uma analise das imagens utilizadas como padrão de treinamento verificou-se que o ambiente que as imagens foram geradas era um ambiente aberto e o fundo sofria pequenas alterações.
Analisando a matriz de erro quadrático médio que foi gerada durante o treinamento de todas as redes para o plano de fundo verificou-se que nos pontos, onde foram utilizadas grandes quantidades de épocas, os erros foram menores em relação às outras redes que obtiveram uma quantidade menor de épocas como é ilustrado na fig. 4. Realizando a análise do gráfico de erros gerado após o teste de classificação em uma imagem de teste, verificou-se que o não foi detectado nenhum erro na realização do teste de classificação.
Figura 3 – Gráfico das de épocas de treinamento da rede gerado pelo padrão de treinamento.
Figura 4 – Gráfico do erro quadrático médio das redes gerado pelo padrão de Figura 5– Gráfico de tempo no teste de classificação.
WVC´2005 - I Workshop de Visão Computacional
38

Após o teste de classificação, a partir da imagem de teste foi gerado um gráfico referente ao tempo em segundos. Analisando esse gráfico verificou-se que em alguns pixels o tempo gasto foi muito abaixo de um segundo conforme ilustrado na fig. 5, onde totalizando esses tempos gastos na realização do teste conseguiu-se um valor também abaixo de um segundo.
Analisando a qualidade das imagens geradas na Figura 6, após o teste de classificação, detectou-se que o algoritmo implementado para a solução do problema teve um bom resultado.
Figura 6 – As imagens a), c) e e) são as imagens originais utilizadas
para teste e as imagens b), d) e f) são o resultado do teste pela rede MLP.
7. Conclusão
Este trabalho propôs um método de subtração de fundo em imagens utilizando rede perceptrons multicamadas (MLP), a subtração do fundo utilizando o método implementado é bastante eficiente em comparação com alguns métodos estudados, pois com a utilização da Rede MLP teve esforço computacional foi bastante baixo para a realização do teste de classificação da imagem. Para a obtenção de resultados coerentes existe a necessidade da implementação de outros métodos para a realização de teste de comparação entre os métodos.
Com os resultados obtidos pode-se verificar sua fácil aplicação, flexibilidade em relação ao tipo de ambiente utilizado para obtenção das imagens e agilidade na realização da subtração de fundos mesmo tendo um alto esforço computacional para o treinamento das matrizes de peso da rede.
Como proposta para continuação deste trabalho, encontra-se a implementação do algoritmo proposto em análise de vídeo para a detecção de movimentos.
8. Referências
[1] Chien, S.; Ma, S; Chen, L., Efficient Moving Object Segmentation Algorithm Using Background Registration Technique;, IEEE Transactions on circuits and systems for video technology, vol. 12, n. 7, Jul 2002.
[2] Haykin, Simon, Redes Neurais: princípios e prática, trad. Paulo Martins Engel, 2º ed., Porto Alegre: Bookman, 2001.
[3] Daigle A.; et al., Automatic Detection of Expanding H i Shells Using Artificial Neural Networks, The Astronomical Society of the Pacific, p. 115:662– 674, U.S.A., 2003.
[4] Sun, Y. and Yuan, B., Hierarchical GMM to handle sharp changes in moving object detection. Eletronics Letters, vol. 40, n. 13, jun 05.
[5] Zivkovic, Z., Improved Adaptive Gaussian Mixture Model for Background Subtraction. Intelligent and Autonomous Systems Group, University of Amsterdam, The Netherlands. 2004.
[6] Fernandes, L.A.F.; Gomes, P.C.R.; Remoção de Fundo da Cena e Identificação da Silhueta Humana para a Captura Óptica de Movimento; XI SEMINCO – Seminário de computação, p. 77-90, 2005.
WVC´2005 - I Workshop de Visão Computacional
39

Metodologia para extração de características invariantes à rotação em Imagens de Impressões Digitais
Cristina Mônica Dornelas Mazetti ([email protected], Rua dos Trevos 581, Jardim Seixas, São José do Rio Preto/SP, Telefone (17) 3211-3055)
Dr.Adilson Gonzaga ([email protected], Rua Libório Marino 383, Jardim Paulistano, São Carlos/SP, Telefone (16) 3373-9326)
Abstract
The objective of this research is to present algorithms that can be applied on images containing fingerprints in order to extract certain features, which are invariant to an eventual rotation in the given image. In the preprocessing stage, the "Canny" Border Detector is used, resulting in a binary, fine tuned image. For the minutiae extraction, the Crossing Number method is used, which extracts local aspects such as minutiae endings and bifurcations. The direction of local ridges is ignored because, in rotated images, the permanence conditions of the biometric attributes are not fulfilled. The process of matching fingerprints uses two arrays (one for ridge endings and the other for bifurcations), which are generated by the extraction of the minutiae, considering the (x,y) coordinate of the given minutiae stored in the arrays, and calculating its Euclidian Distance relating to the Center of Mass of the minutiae distribution, for each of its types (ending or bifurcation). Thus, both images are similar when the Euclidian Distance between the arrays of each image, distinct by the type of each minutiae, is minimal. The problems found in the initial experimental results are also mentioned, along with suggestions for solutions to be presented in this masters degree research.
1. Pré-processamento
As imagens de impressões digitais raramente possuem uma boa qualidade, geralmente são irregulares com elementos de ruídos, devido a muitos fatores, incluindo variações nas condições da pele, marcas de nascimento, cortes, uso de cremes e também devido aos dispositivos de aquisição. Esses fatores influenciam significativamente a qualidade das imagens, ou seja, nem sempre as estruturas das minúcias são bem definidas, portanto não podem ser detectadas ou podem resultar um número significativo de minúcias falsas. Assim, o primeiro passo a ser realizado como procedimento geral é a aplicação do limiar ou binarização (threshold), ou seja, tendo como entrada uma imagem de impressão digital em tons de cinza é necessário transformá-la em uma imagem binária. O segundo passo trata-se da aplicação do afinamento, ou seja, as cristas das impressões digitais passam por um processo de emagrecimento (JAIN et al, 1997). Essas duas técnicas de pré-processamento devem ser efetuadas antes da extração das minúcias para obter uma estimativa mais confiante de posições das minúcias detalhadas como cristas finais e cristas bifurcadas.
1.1. Detecção de Bordas pelo Detector de “Canny”
Este método encontra as bordas procurando máximos locais do gradiente da imagem. O gradiente é calculado usando a derivada do Filtro Gaussiano. O método usa dois “thresholds” (limiar), para detectar bordas fortes e fracas, e considera as bordas fracas que são conectadas às bordas fortes. A imagem de entrada para este método é uma imagem em níveis de cinza e a saída é uma imagem binarizada e afinada. 2. Extração das Minúcias Para localizar as cristas finais e cristas bifurcadas há necessidade de seguir as linhas do esqueleto na imagem. Neste conjunto de pixels são encontradas características, denominadas minúcias, que são usadas para a verificação. O conceito de Número de Cruzamentos (Crossing Number - CN)
WVC´2005 - I Workshop de Visão Computacional
40

(THAI, 2003) é muito usado para detecção destes aspectos ou minúcias e determinam as propriedades de um pixel simplesmente contando o número de transições preto e branco existentes na vizinhança de 8 do pixel que está sendo processado. 2.1. Número de Cruzamentos (Crossing Number - CN) (THAI, 2003) O processo de extração de minúcias permite sintetizar propriedades inerentes da imagem, que serão utilizadas no processo de armazenagem e recuperação baseada em seu conteúdo.
Um dos métodos mais utilizado para extração das minúcias é o Número de Cruzamentos (CN) (AMENGUAL apud THAI, 2003). Esse método extrai as minúcias fazendo uma varredura na vizinhança de 8 pixels usando uma janela 3x3. O valor de CN é definido como a metade da soma das diferenças entre os pares de pixels adjacentes na vizinhança de 8.
O CN para o pixel P é dado pela equação (2.1): PPPPi
iiCN 1
8
191 ,5.0 =−= ∑
=+
O pixel com CN igual a 1 corresponde à crista final, e com CN igual a 3 corresponde à crista bifurcada. Para cada ponto de minúcia extraída, a seguinte informação é armazenada: Coordenadas x e y, Direção da crista local (θ ), e Tipo de minúcia (crista final ou bifurcada = CN).
Minúcias Finais (vermelha) e
Bifurcadas (azul) Imagem pré-processada com Minúcias Finais e Bifurcadas
Figura 4: Extração de Minúcias Finais e Bifurcadas Neste trabalho os vetores gerados pela extração das minúcias são separados por tipo (Figura 4)
para minimizar o problema causado pela rotação das impressões digitais. Portanto, é gerado um vetor de minúcias do tipo final e outro vetor de minúcias do tipo bifurcada, e cada vetor contendo dados referentes ao quadrante, à coordenada x, coordenada y, e o tipo de minúcia.
3. Vetorização
Extraindo-se as minúcias gera-se um vetor, chamado vetor de registro. As minúcias finais são
separadas das minúcias bifurcadas, gerando-se um vetor específico para cada tipo. O Centro de Massa da distribuição espacial de cada tipo de minúcia é calculado e armazenado no respectivo vetor. Considerando-se o Centro de Massa como origem do sistema de coordenadas, a Distância Euclidiana entre cada ponto de minúcia e o respectivo Centro de Massa é calculada e armazenada no Vetor Distância, seguindo a ordem de quadrantes, como mostrado na Figura 5:
WVC´2005 - I Workshop de Visão Computacional
41

Minúcias Finais Minúcias Bifurcadas
Figura 5: Minúcias com a origem deslocada para o Centro de Massa O Vetor Distância por tipo de minúcia conterá, na ordem do primeiro elemento ao último, a
Distância Euclidiana ao Centro de Massa da primeira minúcia encontrada até a última, através de uma varredura nas coordenadas no sentido horário do primeiro ou quarto quadrante.
Esta forma de organização do Vetor Distância permitirá gerar o mesmo vetor rotacionado para a mesma impressão digital, rotacionada de um determinado ângulo.
Através de sucessivas rotações do Vetor Distância estabelece-se a menor distância entre os vetores da Base. Teoricamente, se nenhum ruído influenciar o processamento, é possível ter distância zero entre dois vetores de uma mesma imagem rotacionada, utilizando a Distância de Minkowsky que retorna zero se ambos vetores forem idênticos e um valor positivo que aumenta quanto maior a distância (ou dissimilaridade) .
4. Resultados Iniciais
Os resultados iniciais obtidos para autenticação automática da impressão digital entre imagens que sofreram algum tipo de rotação e as imagens originais, mostram a viabilidade da proposta, sendo que os principais problemas encontrados referem-se a minúcias espúrias extraídas e que poderão ser solucionadas. 5. Problemas Encontrados
Os principais problemas encontrados referem-se a minúcias espúrias extraídas. Estes problemas ocorridos no processo de extração de minúcias das imagens de impressões digitais que sofreram algum tipo de rotação, causam um aumento no valor da Distância de Minkowsky, mostrando dissimilaridade entre vetores que deveriam ser idênticos.
A primeira proposta de solução desse problema foi, calcular uma média dos valores de Distância Euclidiana de 3 em 3 pontos, filtrando os picos esporádicos dentro do vetor. Após a implementação e testes, foi detectado que a diferença na quantidade de pontos entre os dois vetores, continuava existindo, assim, não diminuindo o valor da Distância de Minkowsky entre os vetores idênticos.
4º Quadrante
1º Quadrante
2º Quadrante3º Quadrante
x x
2º Quadrante 3º Quadrante
4º Quadrante 1º Quadrante
y y
WVC´2005 - I Workshop de Visão Computacional
42

A segunda proposta seria utilizar o método “Missing Data” proposto por Dixon (1979) apud Jain (1998), substituindo o valor da característica faltante do vetor rotacionado pela média das características dos K vizinhos mais próximos do vetor origem. Ou por outra técnica que, calcula a distância entre dois vetores xi e xk e onde existem características faltantes substituindo o valor da distância por “zero”.
A terceira proposta seria diminuir o raio de abrangência da extração das minúcias para 80% da imagem. 5.5. Conclusão Neste trabalho foi apresentada a proposta de um algoritmo para extração de características invariantes à rotação em imagens de impressões digitais. A etapa de pré-processamento da imagem, utiliza o detector de bordas de “Canny” e tem como resultado uma imagem binarizada e afinada. A etapa de extração de minúcias adota a Número de Cruzamentos como metodologia, e gera um vetor para as minúcias finais e outro para as minúcias bifurcadas. Considerando-se a posição (x,y) da minúcia e a Distância Euclidiana dessa posição (x,y) ao Centro de Massa do vetor para cada tipo de minúcia (final e bifurcada), são gerados dois vetores de distâncias com seus elementos dispostos em ordem de quadrantes e no sentido anti-horário. Essa metodologia permitirá a invariância com relação à rotação das imagens. Portanto, duas imagens serão similares quando a Distância de Minkowsky entre os vetores de cada imagem e por tipo de minúcia forem próximas de zero, considerando-se a rotação do vetor. Foi apresentada então, a metodologia proposta e os resultados iniciais obtidos para autenticação automática da impressão digital entre imagens que sofreram algum tipo de rotação e as imagens originais. Os resultados mostram a viabilidade da proposta, sendo que os principais problemas encontrados referem-se a minúcias espúrias extraídas e que poderão ser facilmente solucionadas. Várias soluções estão sendo implementadas e testadas objetivando um maior desempenho do algoritmo. 5. Bibliografia
JAIN, A.K.; HONG, L.; BOLLE, R. On–Line Fingerprint Verification. IEEE Transactions on Pattern
Analysis and Machine Intelligence, vol.19, nº 4, pp. 302-313, 1997. THAI, Raymond. Fingerprint Image Enhancement and Minutiae Extraction. In: School of Computer
Science and Software Engineering, The University of Western Australia, 2003. Disponível em: <www.csse.uwa.edu.au/~pk/studentprojects/raymondthai/RaymondThai.pdf>. Acesso em: 28 dez. 2004.
AMENGUAL, J. C.; JUAN, A.; PREZ, J. C.; PRAT, F.; SEZ, S.; VILAR, J. M. Real-time minutiae extraction in fingerprint images. In: Proc. of the 6th Int. Conf. on Image Processing and its Applications (July 1997), pp. 871–875 apud THAI, Raymond. Fingerprint Image Enhancement and Minutiae Extraction. School of Computer Science and Software Engineering, The University of Western Australia, 2003. Disponível em: <www.csse.uwa.edu.au/~pk/studentprojects/ raymondthai/RaymondThai.pdf>. Acesso em: 28 dez. 2004.
DIXON, J.K. Pattern recognition with partly missing data. IEEE Transactions on System, Man and Cybernetics SMC 9, 617-621 apud JAIN, Anil; DUBES, Richard C. Algorithms for Clustering Data. Prentice Hall Advanced Reference Series. New Jersey, 1998.
FARINA, A.; KOVÁCS-VAJNA, Z.M.; LEONE, A. Fingerprint minutiae extraction from skeletonized binary images. Pattern Recognition, 32, pp. 877-889, 1999.
WVC´2005 - I Workshop de Visão Computacional
43

Seleção de Atributos Relevantes para Busca por Similaridade e Classificação de Imagens Médicas
Marcela X. Ribeiro 1 Joaquim C. Felipe 2 Agma J. M. Traina 1
1Departamento de Ciência da Computação, Instituto de Ciências Matemáticas e de Computação, USP
Av. Trabalhador São-carlense, 400, São Carlos, SP, CEP 13560-970, fone 16-33739674 2Departamento de Física e Matemática, Faculdade de Filosofia, Ciências e Letras de Ribeirão Preto, USP
Av. Bandeirantes, 3900, Ribeirão Preto, SP, CEP 14040-901, fone 16-36023770
[mxavier,jfelipe,agma]@icmc.usp.br
Abstract
This paper presents a new method to identify relevant features to discriminate images into categories. Shape features of a set of medical images are represented by Zernike moments. MinERA (Minerador Estátistico de Regras de Associação) is a new algorithm that identifies the most relevant features to discriminate images into categories (benign and malignant tumours, for instance), through mining association rules. The algorithm uses statistical measures that describe the behaviour of the attributes, considering the image categories, in order to find rules of interest. An experiment with images of tumoral masses of mammograms compares the accuracy of MinERA and C4.5 algorithms to determine a set of relevant Zernike moments, capable to classify the images into benign and malignant. The results show that MinERA reaches a higher precision to perform this task. 1. Introdução
A crescente quantidade de imagens digitais geradas atualmente em hospitais e centros de saúde exige a implementação de mecanismos automáticos de armazenamento e recuperação das mesmas. Os sistemas PACS (Picture Archiving and Communication System) [BUENO '02] tendem a incorporar cada vez mais recursos que permitam a recuperação dessas imagens de forma ágil. Técnicas de CBIR (Content-Based Image Retrieval) [MÜLLER '04] tradicionais utilizam as características visuais intrínsecas das imagens, tais como cor, forma e textura, para organizá-las e recuperá-las.
Em alguns contextos, as características intrínsecas das imagens podem ser utilizadas para separá-las dentro de um número pré-definido de classes distintas. Um exemplo é a classificação de massas tumorais detectadas em exames de mamografia, como benignas ou malignas. O radiologista realiza esta classificação, numa avaliação inicial, baseando-se no formato apresentado pela lesão. Tumores malignos geralmente infiltram-se pelo tecido adjacente, resultando em contornos irregulares ou difíceis de se distinguir, enquanto tumores benignos apresentam contornos bem definidos.
Neste trabalho são utilizados momentos de Zernike [KHOTANZAD '90] para reter a informação de padrões relacionados com a forma das imagens. Os momentos de Zernike possuem características que são importantes para essa tarefa, tais como invariância a rotação, translação e escala, além de serem capazes de reter as informações mais significativas utilizando uma quantidade reduzida de descritores. Outra vantagem importante apresentada por este método é que, para determinados tipos de imagem, a análise é realizada sem a necessidade de segmentação prévia da imagem.
Este trabalho está focado no estudo de técnicas automáticas de seleção das características que melhor discriminam as imagens médicas de acordo com suas categorias. O objetivo é reduzir a dimensionalidade do conjunto de características que representam as imagens através da mineração de
WVC´2005 - I Workshop de Visão Computacional
44

regras de associação estatística, usando o algoritmo MinERA, e usar os resultados obtidos para melhorar o desempenho e a precisão da busca por conteúdo nestas imagens. 2. Indutores de Árvores de Decisão
Aprendizado de Máquina é a área da Inteligência Artificial responsável pelo estudo e modelagem de processos computadorizados de aprendizado indutivo. A indução de árvores de decisão é um processo de aprendizado de máquina no qual pode-se obter a classificação de um conjunto de dados, por meio da geração de um conjunto de regras que podem ser visualizadas num formato de árvore. Um algoritmo de indução bastante conhecido é o C4.5 [QUINLAN '86], que, dentre diversos métodos existentes para construção de classificadores, apresentam vantagens tais como esforço computacional reduzido, simplicidade na interpretação das regras e seleção automática de atributos relevantes, quando comparados com redes neurais, por exemplo. 3. O Algoritmo MinERA e o Uso de Regras de Associação para a Seleção de Atributos
O problema de mineração de regras de associação tem sido bastante pesquisado atualmente. A maior parte dos trabalhos referem-se ao problema de mineração de regras envolvendo itens categóricos, segundo a abordagem original apresentada em [AGRAWAL '93]. No entanto, em se tratando de imagens médicas, vetores de características são previamente extraídos das imagens e são os dados desses vetores que são submetidos ao processo de mineração. As características extraídas são dados numéricos e contínuos que descrevem características visuais intrínsecas das imagens, tais como cor, forma e textura. Assim uma abordagem para extrair regras de associação envolvendo dados quantitativos é mais adequada do que a abordagem tradicional para a mineração de regras de associação nesse domínio de dados. O algoritmo MinERA propõe uma extensão das técnicas de mineração estatísticas apresentadas em [AUMANN '99] aplicada para a obtenção de padrões em imagens médicas.
O objetivo do algoritmo MinERA é implementar a mineração de regras de associação estatística para encontrar os atributos que melhor discriminam a imagem em categorias. O formato geral da regra é x Ai e as regras mineradas pelo algoritmo devem satisfazer a seguintes condições:
• O atributo Ai deve apresentar um comportamento distinto para as imagens da categoria x em relação às demais imagens;
• O atributo Ai deve apresentar um comportamento uniforme para todas as imagens da categoria x. As condições anteriores são implementadas no algoritmo MinERA através da incorporação das
restrições de interesse apresentadas a seguir no processo de mineração. Seja uma base de imagens médicas T, x uma categoria de imagens, Tx ⊂ T o subconjunto de imagens da base da categoria x e Ai o i-ésimo atributo da imagem, as restrições de interesse usadas no algoritmo MinERA são:
1. |MédiaAi(Tx) – MédiaAi(T-Tx)| mindif ≥o MédiaAi(Z): média aritmética dos valores do atributo Ai para o subconjunto de imagens Z. o mindif: parâmetro de entrada que indica a diferença mínima permitida entre a média dos valores de Ai para as imagens da categoria x e a média dos valores de Ai para as imagens restantes.
2. Realizar testes de hipóteses. H0 deve ser rejeitada com confiança maior ou igual a minconf. o H0: MédiaAi(Tx) = MédiaAi(T-Tx) o H1: MédiaAi(Tx) ≠ MédiaAi(T-Tx) o minconf: parâmetro de entrada que indica a confiança mínima com a qual a hipótese H0 deve ser rejeitada.
3. σAi(Tx) ≤ maxstd o σAi(Tx): desvio padrão dos valores do atributo Ai para o subconjunto de imagens Tx.
WVC´2005 - I Workshop de Visão Computacional
45

o maxstd: parâmetro de entrada que indica o máximo desvio padrão permitido aos valores de Ai para as imagens da categoria x.
A aplicação do algoritmo MinERA sobre o conjunto de imagens, permite que sejam obtidas regras que envolvam atributos com alto poder de discriminação, uma vez que os atributos contidos nas regras apresentam um comportamento particular e distinto para imagens de uma determinada categoria. A redução da dimensionalidade do conjunto de características é conseguida eliminando os atributos das imagens que não geram regras. Os atributos que não geram regras apresentam um comportamento uniforme para todas as imagens, independente da categoria e, portanto, não contribuem para a discriminação das imagens, devendo ser eliminados. 4. Experimento e Resultados
Uma base de dados contendo 250 imagens foi utilizada para testar e validar o método proposto. Exemplos das imagens contidas na base são apresentados na Figura 1. Estas imagens são regiões de interesse (ROIs) contendo massas tumorais, obtidas a partir de exames de mamografia. As lesões apresentadas pelas imagens são classificadas ou como benignas ou como malignas, de acordo com a análise do seu formato. Massas benignas possuem contornos bem definidos, enquanto massas malignas apresentam contornos fracamente distintos do parênquima mamário. Todos os casos foram previamente analisados e classificados por médicos radiologistas. Com o objetivo de realçar as regiões das imagens e executar a extração dos momentos sem a necessidade de segmentação prévia, um pré-processamento foi executado sobre as imagens, consistindo em uma sequência de operações de auto-nivelamento, redução do número de níveis de cinza e aplicação de filtro da mediana. A seguir, foram extraídos momentos de Zernike de ordens variando de 0 a 30, gerando um total de 256 momentos para cada imagem. Dessa forma, cada imagem passou a ser representada por um vetor de 256 características juntamente com a sua respectiva classe (benigna ou maligna).
A seguir, o algoritmo C4.5 foi aplicado aos vetores de características de cada imagem da base, gerando uma árvore de decisão em cujos nós figuram os momentos mais relevantes, ou seja, com maior poder de discriminação para a classificação das imagens. Desta árvore, um conjunto de 38 momentos foram identificados como relevantes. Por outro lado, o algoritmo MinERA também foi executado sobre os mesmos vetores de características das imagens, lembrando que os vetores possuem 256 atributos. Os parâmetros do MinERA foram calibrados para gerar também um conjunto de 38 momentos relevantes.
Séries de consultas aos k vizinhos mais próximos foram aplicadas às imagens da base, variando os valores de k e selecionando randomicamente as imagens de referência, considerando ambos os conjuntos de 38 momentos relevantes obtidos com o algoritmo C4.5 e com o algoritmo MinERA.
Para analisar os resultados, foram aplicados os conceitos de precision/recall [YAMAMOTO '99] e as médias dos valores obtidos foram usadas para gerar curvas precision x recall mostradas na Figura 2. Deve-se lembrar que para tais curvas, o melhor método é o que gera curvas mais próximas do topo do gráfico. Como pode ser visto nos gráficos, a redução da dimensionalidade, seja com o algoritmo C4.5, seja com o MinERA, leva a uma maior precisão dos resultados, quando comparados com os resultados obtidos com os 256 atributos originais. Isso evidencia que o uso de momentos irrelevantes pode levar a uma degradação dos resultados, onde os atributos irrelevantes "enfraquecem" o poder de discriminação dos relevantes. Além disso, comparando-se os resultados obtidos com os dois algoritmos, vemos que o MinERA levou a uma maior precisão dos resultados, mostrando-se, dessa forma, mais eficiente do que o algoritmo C4.5.
5. Conclusões
Um novo método para seleção de atributos relevantes foi apresentado, o qual baseia-se na mineração de regras de associação estatística para encontrar os atributos que melhor discriminam uma
WVC´2005 - I Workshop de Visão Computacional
46

imagem em categorias. Foi realizado um experimento de recuperação e classificação de imagens médicas, no qual as
imdmMdrcpp
R[
[
[
[
[
[
[
WVC´2005 - I Workshop de Visão Computacional
magens são representadas por meio de momentos de Zernike. De um conjunto inicial de 256 omentos, os algoritmos C4.5 e MinERA são utilizados para processar uma redução de
imensionalidade para 38 atributos. Os resultados de precision x recall para consultas aos vizinhos ais próximos sobre uma base contendo 250 imagens de tumor de mama mostram que o algoritmo inERA gerou um conjunto de atributos mais eficientes para a tarefa de recuperação e classificação
as imagens, revelando sua capacidade para a tarefa de redução da dimensionalidade. Vale também essaltar que o custo computacional do C4.5 para construir a árvore de decisão é maior que o custo omputacional do MinERA para gerar as regras de associação. Enquanto cada atributo pode ser rocessado inúmeras vezes no C4.5 para computar o ganho de informação, o algoritmo MinERA rocessa cada atributo somente uma vez computando sua média e desvio padrão.
0.0
0.2
0.4
0.6
0.8
1.0
0.0 0.2 0.4 0.6 0.8 1.0
recallpr
ecis
ion
256 MOMENTOS
38 MOMENTOSC4.5
38 MOMENTOSMinERA
Figura 1. Exemplo de imagens de mama com tumores benignos e malignos usadas no experimento. Figura 2. Precision x recall para 256 momentos, para 38
momentos resultantes da aplicação do C4.5 e para 38 momentos resultantes da aplicação do MinERA.
eferências AGRAWAL '93] Agrawal, R., T. Imielinski and A. N. Swami. Mining Association Rules between Sets of Items in Large
Databases. SIGMOD International Conference on Management of Data, Washington, D.C. 1993 AUMANN '99] Aumann, Y. and Y. Lindell. A Statistical Theory for Quantitative Association Rules. Fifth SIGKDD
International Conference on Knowledge Discovery and Data Mining, San Diego, California. 1999 BUENO '02] Bueno, J. M., F. Chino, A. J. M. Traina, J. C. Traina and P. M. d. A. Marques. How to Add Content-based
Image Retrieval Capability in a PACS. IEEE International Conference on Computer Based Medical Systems - CBMS, Maribor, Slovenia. pp. 321-326. 2002
KHOTANZAD '90] Khotanzad, A. and Y. H. Hong. Invariant Image Recognition by Zernike Moments. Transactions on Pattern Analysis and Machine Inteligence vol.12(5): 489 - 497.IEEE. 1990
YAMAMOTO '99] H. Yamamoto, H. Iwasa, N. Yokoya, and H. Takemura, "Content-based Similarity Retrieval of Images Based on Spatial Color Distributions," Proc. 10th Intl. Conference on Image Analysis and Processing, September 1999, pp. 951-956.
MÜLLER '04] Müller, H., N. Michoux, D. Bandon and A. Geissbuhler. A review of content-based image retrieval systems in medical applications - clinical menefits and future directions. International Journal of Medical Informatics vol.73: 1 - 23.Elsevier. 2004
QUINLAN '86] Quinlan, J. R. Induction of Decision Trees. Machine Learning. 1(1): 81 - 106. 1986
47

Lacunaridade Aplicada em Análise de Textura
André Ricardo BackesOdemir Martinez Bruno
Instituto de Ciências Matemáticas e de Computação – USPSão Carlos - SP
[backes,bruno]@icmc.usp.br
AbstractThis article presents a study about lacunarity applied to texture analysis. Lacunarity is a counterpart tothe fractal dimension that describes the texture of a fractal. In this work this concept is adapted fortexture analysis, more specifically to the problem of pattern recognition, where lacunarity is consideredas a texture signature and could be used to quantify and to classify a texture. The work still presents anexperiment that illustrates the potential of the technique for the pattern recognition using the textureattribute.
1. IntroduçãoDiversas aplicações relacionadas ao reconhecimento de padrões necessitam de métodos que
possibilitem quantificar, atributos visuais obtidos em processos de análise de imagem.Dentre os principais atributos visuais, temos a textura. Este atributo está relacionado a
distribuição e a organização dos pixels de uma determinada região da imagens. A textura pode serutilizada para segmentar regiões ou ainda como métrica que pode ser utilizada no reconhecimento depadrões. Na literatura encontramos diversas abordagens que analisam este atributo visual, das quais sedestacam: Campo Aleatório de Markov [8], Redes Neurais [9], Wavelet [10] e momentos Invariantes[6]. Neste trabalho é explorado o uso do método de lacunaridade para a análise de texturas.
A lacunaridade se baseia no grau de invariância a translação que um fractal apresenta, obtendoassim uma medida de como o espaço está preenchido. Desse modo, a lacunaridade atua como umcomplemento da Dimensão Fractal, que mede o quanto do espaço está preenchido. Ela consiste de umamedida da distribuição espacial dos “gaps” ou buracos existentes na textura. Por meio dela é possívelquantificar o quão homogênea é uma determinada textura, de maneira que se possa compará-la comoutras texturas [1,11,12].
Esse artigo apresenta um estudo sobre o uso da lacunaridade como método para obter assinaturade textura, o que permite quantificar, identificar, segmentar e classificar texturas. O método e suaimplementação são discutidos, bem como os resultados obtidos, que ilustram o potencial da técnica.
2. Lacunaridade e TexturaA lacunaridade é uma medida que se baseia no grau de invariância a translação que um fractal
apresenta. Fractais, por sua vez, são formas geométricas incapazes de serem classificadas nos moldesda Geometria Euclidiana, uma vez que apresentam três características fundamentais que os definem eos distinguem de outras formas: auto-semelhança em diferentes níveis de escala, Dimensão Fractal esua complexidade infinita [7]. Ela constitui uma medida de como os pixels estão distribuídos e organizados em umadeterminada região da imagem, ou seja, ela quantifica como o espaço está preenchido, diferente daDimensão Fractal, que mede o quão preenchido está o espaço. Na verdade, a lacunaridade pode ser
WVC´2005 - I Workshop de Visão Computacional
48

compreendida com um complemento da Dimensão Fractal, uma vez que formas com a mesmaDimensão Fractal podem possuir lacunaridades diferentes [11].
A lacunaridade é obtida medindo a distribuição espacial dos “gaps” ou buracos existentes naimagem. Por meio dela é possível quantificar o quão homogênea é a textura dessa imagem, de maneiraque se possa compará-la com outras texturas [1,11].
A textura é uma característica diretamente relacionada com as propriedades físicas que asuperfície de um objeto apresenta, descrevendo o padrão de variação de tons de cinza e cor numadeterminada área. Trata-se de um termo intuitivo e de largo emprego, mas que apesar de sua grandeimportância, não possui uma definição precisa [5].
Uma textura se caracteriza pela repetição de um modelo sobre uma região, sendo que estemodelo pode ser repetido de forma exata ou com pequenas variações. Por meio de sua análise épossível distinguir regiões que apresentem as mesmas características de refletância (e portando mesmascores em determinada combinação de bandas). Isso faz da textura um excelente descritor regional,contribuindo na melhoria da exatidão do processo de reconhecimento, descrição e classificação deimagens. No entanto, seu processo de reconhecimento exige grande sofisticação e complexidadecomputacional [5]. Diversas abordagens na literatura operaram em textura, realizando análise ousegmentação. Estes métodos em geral são baseados na análise estatística dos pixels de uma região [8],em técnicas baseadas em análise de espectro [2], utilizando wavelets [10] e dimensão fractal [4].Recentemente foi proposto a utilização da lacunaridade para estimar a textura [1,11]. Neste trabalho éexplorada a lacunaridade como uma medida para estimar texturas através de assinaturas.
Diversos métodos tem sido desenvolvidos para estimar a lacunaridade, sendo os mais popularesbaseados no uso do algoritmo gliding-box. Esse algoritmo utiliza os momentos de probabilidade deprimeira e segunda ordem da imagem a fim de estimar a sua lacunaridade.
O algoritmo do Gliding-box é similar ao algoritmo do BoxCounting utilizado para estimar aDimensão Fractal. Nele, uma caixa de lado r é colocada sobre o canto superior esquerdo da imagem e onúmero de pontos da imagem é contado. Esse processo é repetido para todas as linha e colunas daimagem, produzindo uma distribuição de freqüência da massa da imagem. O número de caixas de lador contendo uma massa S da imagem é designado por n(S,r) e o total de caixas contadas por N(r). Essadistribuição de freqüência é então convertida para uma distribuição de probabilidade Q(S,r), onde
)(/),(),( rNrSnrSQ =O primeiro e o segundo momentos dessa distribuição são determinados como:
∑= ),()1( rSSQZ
∑= ),(2)2( rSQSZA lacunaridade para uma caixa de tamanho r é então definida como:
2)1()2( )/()( ZZr =ΛOutras características relativas a lacunaridade podem ser obtidas alterando o tamanho da caixa utilizadano gliding-box [11].
3. AssinaturaA assinatura de uma imagem pode ser definida como uma função ou matriz simplificada que
consiga representar ou caracterizar a mesma. Em geral as técnicas utilizadas realizam transformaçõesRIT →2: ou IIT →2: , onde a função ou vetor de caraterísticas obtido é capaz de representar e
caracterizar a imagem. Exemplos e teorias sobre assinaturas podem ser encontrados em [3,6].
WVC´2005 - I Workshop de Visão Computacional
49

Este trabalho estuda a possibilidade de considerar a lacunaridade como uma técnica plausível decaracterizar uma imagem pela sua textura e deste modo se constituir uma assinatura de textura deimagens.
Ao se realizar o cálculo da lacunaridade para diferentes tamanhos de caixas, pode-se estudar ocomportamento da textura segundo a escala. Isso ocorre pelo fato da lacunaridade ser umacaracterística dependente da escala. Assim, é possível representar o comportamento da textura de umaimagem por uma função 1-D que relaciona o tamanho da caixa utilizada no cálculo com o valor dalacunaridade obtido (Figura 1).
Figura 1: Gráfico log-log da lacunaridade pelo tamanho da caixa utilizada.
4. ResultadoVisando comprovar a eficiência do uso da lacunaridade na classificação de texturas, foram
selecionadas quatro imagens (A,B,C,D), sendo que cada uma possuía uma textura diferente. Essasimagens foram então subdivididas em quatro partes de mesmo tamanho, sendo a seguir calculada aassinatura de lacunaridade de cada parte.
Separando as amostras de texturas em dois conjuntos, cada qual com duas amostras de cadatextura, pode-se comparar as assinaturas das texturas de um conjunto com as do outro conjunto pormeio da distancia euclidiana, sendo o erro entre as duas assinaturas apresentado na Tabela 1. Comopode ser observado, a técnica apresentou bons resultados quantificando e realizando o reconhecimentode padrões das texturas.
Erro A1 A2 B1 B2 C1 C2 D1 D2A3 0,0297 0,1059 2,2862 1,6804 2,7688 3,1294 3,1470 2,9164A4 0,2049 0,3011 2,0934 1,4886 2,5762 2,9368 2,9536 2,7231B3 1,7160 1,8144 0,5785 0,0939 1,0592 1,4202 1,4383 1,2077B4 1,9826 2,0815 0,3303 0,3001 0,7904 1,1539 1,1773 0,5477C3 2,8077 2,9062 0,5203 1,1264 0,0427 0,3296 0,3564 0,1415C4 2,6027 2,7013 0,3208 0,9208 0,1725 0,5333 0,5582 0,3317D3 2,9377 3,0360 0,6469 1,2614 0,1858 0,2250 0,2168 0,0208D4 3,0930 3,1914 0,8026 1,4154 0,3302 0,1118 0,0617 0,1704
Tabela 1: Distância Euclidiana entre as assinaturas de lacunridadedas das amostras.
WVC´2005 - I Workshop de Visão Computacional
50

5. Conclusão Neste trabalho foi apresentado um estudo da utilização do método de estimativa de lacunaridadeem análise de textura, mais especificamente para o reconhecimento de padrões. A lacunaridade é umamedida complementar a dimensão fractal e realiza uma análise da disposição e tamanho das lacunas nopreenchimento do fractal. Embora tradicionalmente a lacunaridade apresente uma medida pontual,neste trabalho o método de estimativa de lacunaridade foi aperfeiçoado para extrair um vetor durante aanálise e deste modo caracterizar e quantificar a textura. Esta abordagem permitiu utilizar alacunaridade como uma assinatura de textura. Foi realizado um experimento de classificação de texturas com o método proposto. Osresultados demonstraram que o método possui um grande potencial para a análise de textura. Osresultados foram satisfatórios, uma vez que foi adotado um método simples de comparação de vetoresatravés de sua norma. Embora eles poderiam ter sido melhorados significativamente se fossemadotadas técnicas mais elaboradas de análise tais como, descritores de fourier ou wavelet e mecanismosmais eficientes de classificação, como por exemplo, redes neurais artificias, os resultados atenderam aopropósito do trabalho, que consistiu na proposta de um novo método e na investigação de seu potencial.
6. Referência Bibliográfica[1] C. Allain, M. Cloitre, Characterizing the lacunarity of random and deterministic fractals sets, Phys.Rev. A 44 (6) (1991) 3552.[2] N. P. Ângelo,V. haertel, “INVESTIGAÇÃO COM RESPEITO A APLICAÇÃO DOS FILTROSDE GABOR NA CLASSIFICAÇÃO SUPERVISIONADA DE IMAGENS DIGITAIS”, Anais XSBSR, Foz do Iguaçu, 21-26 abril 2001, INPE, p. 1193-1200, Sessão Técnica Oral[3] K. R. Castleman, Digital Image Processing. Englewood Cliffs, NJ, 1996[4] B. B. CHAUDHURI, N. SARKAR, Texture Segmentation Using Fractal Dimension. IEEETransactions on Pattern Analysis and Machine Intelligence, n.17, p. 72-76, 1995.[5] D.S. Ebert (Ed.), Texturing and Modeling: A Procedural Approach, Academic Press, Cambridge,MA, 1994.[6] R. C. Gonzalez, R. E. Woods, Digital Imaging Processing, Addison-Wesley, Reading,Massachusetts, USA, 1992.[7] D. Gulick, “Encounters with Chaos”, McGraw-Hill International Editions - Mathematics andStatistics Series, 1992.[8] S.Z. Li, Markov Random Field, Modeling in Computer Vision, Springer-Verlag,ISBN 0-387-70145-1, 1995.[9] F. LIBERMANN, Classificação de Imagens Digitais por Textura usando Redes Neurais. PortoAlegre: CPGCC da UFRGS, 1997. 86p. Dissertação de Mestrado.[10] D. M. Moura, L. V. Silva, M. S. Nery, P. S. S. Rodrigues, “Recuperação de Imagens Baseado emConteúdo”, Anais do IV Workshop em Tratamento de Imagens, NPDI/DCC/ICEx/UFMG, p. 101-109,Junho de 2003.[11] R.E. Plotnick, R.H. Gradner, W.W. Hargrove, K. Prestegaard, M. Perlmutter, Lacunarity analysis:a general technique for the analysis of spatial patterns, Phys. Rev. E 53 (5) (1996) 5461.[12] T.G. Smith Jr., G.D. Lange, W.B. Marks, Fractal methods and results in cellular morphology—dimensions, lacunarity, and multifractals, J. Neurosci. 69 (1996) 123–136.
WVC´2005 - I Workshop de Visão Computacional
51

A Percepção Humana na Recuperação de Imagens por Conteúdo
Joselene Marques, Agma Juci Machado Traina
Instituto de Ciências Matemáticas e de Computação (ICMC) - Universidade de São Paulo (USP)
Caixa Postal 668 – CEP 13560-970 – São Carlos – SP – Brasil [email protected] (16 3373-8159), [email protected] (16 3373-9674)
Abstract. The Relevance Feedback (RR) approach is a powerful mechanism to refine and improve the techniques for content-based image retrieval (CBIR) considering the subjectivity introduced by the human analysis. Traditionally, in this process the human analyst weighs the images retrieved, considering their degree of relevance to the query posed. By doing so, the subjectivity of human perception is introduced in the CBIR, and the semantic gap inherent to this process is diminished. This work discusses the use of Relevance Feedback in a real CBIR system under development at the ICMC-USP, which aims at minimizing the negative effect on the user acceptance of a CBIR system when false negative images are retrieved. A new approach on RR is proposed, which aims at taking advantage of the computation of the similarity function between the images to improve the set of relevant images retrieved.
1. Introdução A computação é uma das ciências que mais tem auxiliado no desenvolvimento da medicina
[Dev_1999]. Em sistemas de apoio a diagnóstico, por exemplo, utilizar a comparação de imagens é importante para encontrar imagens similares que já foram previamente analisadas e laudadas, podendo auxiliar a elaboração de novos laudos e diagnósticos, além de auxiliar no ensino de radiologia.
Para adequar sistemas de apoio a diagnóstico a efetuar consultas por similaridade são utilizadas técnicas de recuperação que levem em consideração o conteúdo das imagens. Para realizar a busca por similaridade sobre imagens, faz-se necessário capturar o que há de mais representativo nas mesmas, de modo a extrair informações que as representem sucinta e adequadamente. Tais informações são armazenadas em vetores de características da imagem [Aslandogan_1999]. O grau de similaridade/dissimilaridade entre as imagens é medido através de uma função de distância aplicada sobre os vetores de características das imagens sendo comparadas. A partir do resultado da comparação, as imagens mais similares, ou seja, com menor grau de dissimilaridade são retornadas ao usuário.
2. Motivação e objetivos A recuperação de imagens utilizando suas características inerentes e usualmente de baixo nível
apenas, como é a proposta das técnicas de recuperação de imagens baseada em conteúdo (CBIR), não é capaz de extrair e representar todo o conteúdo semântico presente em uma imagem. Logo, a precisão do conjunto de respostas significativas pode não atingir as necessidades e anseios do usuário.
A Realimentação de Relevância (RR) [Rui_1998] tem sido considerada uma ferramenta poderosa para o refinamento de técnicas de CBIR, introduzindo o fator humano no processo. O usuário fornece um grau de adequação para cada imagem recuperada considerada como relevante e o processo de recuperação é refeito, procurando capturar a subjetividade da percepção humana.
A partir das informações fornecidas pelo usuário, o sistema pode mover o centro de consulta para um novo local que seja mais "próximo" aos resultados relevantes, e "distante" dos resultados não-
WVC´2005 - I Workshop de Visão Computacional
52

relevantes, tentando adequá-la o máximo possível às intenções do usuário. Uma alternativa a usar um único centro de consulta p, é considerar múltiplos objetos (centros) de consulta, pois neste paradigma faz sentido procurar por objetos similares a mais que um exemplo ao mesmo tempo.
Este trabalho avalia o tratamento de RR em sistemas que utilizam recuperação de imagens por conteúdo para responder consultas por similaridade em imagens médicas [Zhang_2002]. A abordagem proposta neste trabalho combina técnicas de movimentação do centro de consulta [Rocchio_1971] com o uso de múltiplos centros de consulta [Ishikawa_1998].
3. Metodologia A QPM (Query Point Moviment), chamada assim por mover o centro de consulta, é uma técnica
tradicional em RR. Na abordagem original, em cada iteração do processo, o centro que representa a consulta é movido para o centróide da região onde o usuário marcou como relevante (figura 1a). Uma modificação natural nesta técnica consiste em atribuir pesos à contribuição de cada objeto relevante. O usuário define quais são as imagens relevantes selecionando um determinado peso. O centro de consulta tende a se aproximar dos objetos com maior peso como ilustrado na figura 1b.
Nossa proposta para a estratégia de movimentação do centro de consulta, chamada de QPM by Weight and Distance, considera, além dos pesos atribuídos a cada objeto, as distâncias dos objetos selecionados como relevante até o objeto original de consulta para determinar a posição do novo ponto de consulta. Observe na figura 1c que o centro de consulta é movido para a região do objeto com a maior distância considerando também o peso.
Figura 1: Movimentação do Centro de Consulta a) Técnica tradicional b) Técnica utilizando pesos c) Técnica proposta utilizando pesos e
distâncias (QPM by Weight and Distance)
O uso da distância em técnicas de RR supõe que, se uma imagem originalmente considerada
como relevante encontra-se distante do objeto de consulta, alguma característica importante para o usuário não está sendo devidamente valorizada pela função de distância. Nossa nova abordagem procura acrescentar essa subjetividade definida somente pela percepção humana ao cálculo de similaridade, identificando características particulares que podem melhorar a precisão da consulta.
A MPQ (Multiple Point Query) se baseia no uso de múltiplos centros de consulta e uma função de distância que agrega suas distâncias individuais. Cada centro de consulta pode fornecer não somente uma visão diferente do objeto procurado, como também tais visões podem levar à bases cognitivas diferentes. A quantidade e a posição dos centros influenciam no formato da consulta e no espaço de características fornecendo uma flexibilidade enorme à consulta. (figura 2).
O uso de múltiplas técnicas de RR mostra que cada técnica pode produzir consultas modificadas diferentes, e cada consulta
t
WVC´2005 - I Workshop de Visão Computacional
Figura 2: Múltiplos Centros de Consulta
pode recuperar objetos distintos, então usar uma combinação de écnicas pode levar à recuperação de mais objetos relevantes.53

Após experiências comparando a técnica que utiliza somente o peso na determinação da nova posição do objeto de consulta e nossa nova proposta que utiliza também a distância como fator de ponderação, foi desenvolvida uma nova técnica, chamada de MPQ by Weight and Distance, que combina a movimentação do centro de consulta com o uso de múltiplos centros de consulta visando a recuperar os objetos relevantes distintos que cada abordagem oferece.
O MPQ by Weight and Distance define cada objeto selecionado como relevante como um novo objeto de consulta. Além destes, um novo objeto é criado, tendo seu vetor de característica calculado a partir dos vetores dos objetos selecionados e os seus respectivos pesos. Assim, para r objetos selecionados como relevantes são definidos r+1 centros de consulta. A partir daí, novas consultas são realizadas utilizando os mesmos parâmetros da consulta original. Para a ordenação do resultado, uma nova distância é calculada baseada: na distância do objeto resultante ao seu respectivo centro, nos pesos definidos pelo usuário e nas distâncias originais de cada objeto relevante ao objeto de consulta inicial (equação 1). Os objetos com menores distâncias ponderadas são retornados como resultado da consulta.
d ' a d WiW
b d DiD
Equação 1: Fórmula da distância ponderada, onde d’ = distância ponderada, d = distância do objeto retornada pelo algoritmo de RR, Wi = peso do i-ésimo objeto relevante, Di = distância original do i-ésimo objeto relevante, a e b = coeficientes de ponderação
4. Testes e Resultados
A aplicação implementada visa a auxiliar o processo de diagnóstico médico por meio de busca por similaridade de imagens. A base de dados do sistema foi montada a partir de exames de mamografia, já com seus respectivos laudos, provenientes do Hospital das Clínicas de Ribeirão Preto -USP. Na base, com um total de 1274 imagens, foram identificados seis tipos de projeções nos exames, incluindo imagens da região torácica adjacente às mamas. As dimensões das imagens variam em torno de 2000 por 2000 pixels, gerando arquivos ao redor de 11 MBytes para cada imagem.
As consultas podem ser realizadas utilizando como características das imagens sua textura ou histograma. Após o resultado inicial, o usuário pode selecionar a partir da interface da aplicação qual técnica de RR deseja aplicar à consulta. A aplicação permite ainda que várias iterações sejam realizadas até que se encontre um resultado adequado. A cada nova iteração o usuário pode identificar novas imagens relevantes e selecionar uma técnica de RR diferente.
A figura 3 mostra o resultado original de uma consulta utilizando a textura como característica. O resultado é ordenado de maneira crescente pela distância ao centro da consulta. A primeira imagem do resultado, com distância 0 (zero) é a imagem exemplo (centro da consulta). Observe que abaixo de cada imagem considerada como relevante foi atribuído um peso que varia de 1(um – menos relevante) a 5(cinco – mais relevante). Figura 3: Resultado original da consulta
WVC´2005 - I Workshop de Visão Computacional
54

Figura 4: Resultado da consulta após processamento do algoritmo de RR proposto
A figura 4 mostra o resultado da consulta logo após a primeira iteração de (RR) executando a técnica MPQ by Weight and Distance. Observe a eliminação de um falso positivo presente no conjunto resposta original (figura 3) e o aumento da precisão da consulta considerando a relevância fornecida pelo usuário.
O estado default é de irrelevância, sendo que na figura 4 estão todas as imagens neste estado inicial.
5. Conclusões A abordagem mostrada neste trabalho indica que a combinação de técnicas de realimentação de
relevância pode trazer melhorias significativas na eficácia de métodos e sistemas CBIR. Com os experimentos realizados pôde-se verificar que o uso de RR na recuperação de imagens
por similaridade pode minimizar a descontinuidade semântica e aumentar a precisão da consulta levando em consideração a subjetividade que somente pode ser definida pela percepção humana.
6. Referências [Aslandogan_1999] Y. Alp Aslandogan and Clement T. Yu, “Techniques and Systems for Image and
Vídeo Retrieval,” IEEE Transactions on Knowledge and Data Engineering, vol. 11,Jan/Feb 1999, pp. 56-63.
[Ishikawa_1998] Yoshiharu Ishikawa, Ravishankar Subramanya and Christos Faloutsos, “MindReader: Querying Databases Through Multiple Examples”, Proc. 24th Int. Conf. Very Large Data Bases (VLDB), New York City, New York, USA, August 1998, pp. 218-227
[Dev_1999] Parvatia Dev, "Imaging in Medical education - Guest Editors' Introduction." IEEE Computer Graphics and Applications , vol.19, Mai/Jun 1999, pp. 20.
[Rocchio_1971] J. J. Rocchio. “Relevance Feedback in Information Retrieval”. In G. Salton, editor, “The SMART Retrieval System: Experiments in Automatic Document Processing”, Prentice-Hall, Englewood Cliffs, NJ, 1971, pp. 313-323.
[Rui_1998] Y. Rui, T. S. Huang, et al., “Relevance Feedback: A Power Tool for Interactive Content-Based Image Retrieval”, IEEE Trans. on Circuits and Video Tech., Special Issue on Segmentation Description, and Retrieval of Video Content, 8(5), Sep. 1998
[Zhang_2002] Zhang, H. and Z. Su (2002). Relevance Feedback in CBIR. Sixth IFIP Working Conference on Visual Database Systems, Brisbane, Australia, Kluwer Academic Publishers.
WVC´2005 - I Workshop de Visão Computacional
55

Técnicas de Afinamento Aplicadas no Reconhecimento de Caracteres Impressos
Rodrigo de Oliveira Plotze, Mário Augusto Pazoti e Odemir Martinez Bruno
Instituto de Ciências Matemáticas e de Computação
Universidade de São Paulo (ICMC-USP) Caixa Postal 688 – Cep 13560-90 São Carlos – São Paulo - Brasil
roplotze,pazoti, [email protected]
Resumo: Este trabalho apresenta um estudo realizado sobre a eficiência dos algoritmos de afinamento no reconhecimento automático de caracteres impressos. Foram implementados e avaliados cinco algoritmos de afinamento: Hiltidtch, Stentiford, Zhang-Suen, Holt e Multiescala. Um conjunto de caracteres impressos diferentes foi utilizado nos experimentos computacionais. As informações resultantes do processo de afinamento são transformadas em vetores de características por meio de uma técnica de reamostragem. Esses dados são utilizados como entrada para uma rede neural artificial visando ao reconhecimento dos caracteres. Para cada algoritmo implementado são relatadas as taxas de acerto na classificação, determinando assim a potencialidade de cada técnica. Abstract: This work describes a thinning algorithms study for automatic recognition of printed characters. A group of five thinning techniques were implemented: Hilditch algorithm’s, Stentiford algorithm’s, Zhang-Suen algorithm’s, Holt algorithm’s and multiscale thinning. A set of distinct printed characters was used in computational experiments. The resulted information of thinning process (the skeleton) was transformed in a feature vector through a remonstration technique. A neural network was trained to perform the character recognition. Every one developed thinning algorithms was evaluated with score classification (correct / incorrect printed characters recognition).
1. Introdução A técnica de afinamento é o processo de redução de uma forma para uma versão simplificada que ainda retém as características do objeto original. A versão afinada da forma é chamada de esqueleto. Os algoritmos de afinamento excluem, de forma sucessiva, diversas camadas da extremidade (borda) de um padrão até que permaneça apenas o esqueleto da forma. A exclusão de um determinado ponto p dependerá dos pontos que estão na sua vizinhança. Esses algoritmos podem ser classificados como iterativos e não-iterativos, de acordo com o modo com que esses pontos da vizinhança são examinados.
Desde a década de 50 muitos algoritmos de afinamento foram desenvolvidos e diversas abordagens para esses métodos foram propostas (LAM, LEE et al., 1992; PLOTZE e BRUNO, 2004). Os trabalhos pioneiros da área foram concentrados no reconhecimento de padrões em caracteres manuscritos na década de 1950. Atualmente, diversas aplicações podem ser encontradas para os algoritmos de afinamento como: impressões digitais, reconhecimento de caracteres, entre outras.
Neste trabalho é apresentando um estudo sobre a eficiência dos algoritmos de afinamento no reconhecimento automático de caracteres. O reconhecimento de caracteres é útil por causa do volume
WVC´2005 - I Workshop de Visão Computacional
56

que informações ainda armazenadas em meios impressos. Uma visita a uma biblioteca já é o bastante para se convencer da utilização de um sistema de visão computacional que possa analisar “visualmente” palavras impressas. Além disso, os caracteres aparecem em qualquer cena do mundo real, impressos em pôsteres, placas, entre outros (PARKER, 1997).
2. Técnicas de Afinamento No início da evolução dos computadores uma das suas principais aplicações era o reconhecimento de padrões. Entretanto, a grande quantidade de informações e o baixo poder computacional motivaram diversos pesquisadores ao desenvolvimento de algoritmos capazes de reduzir a quantidade de dados a ser processada. Esses métodos computacionais são conhecidos como algoritmos de afinamento. Na literatura é possível encontrar uma infinidade de trabalhos descrevendo novos métodos, bem como aplicações, dessas técnicas de afinamento. A seguir são descritos, sucintamente, alguns dos principais métodos encontrados na literatura. O método de afinamento de Hilditch (RUTOVITZ, 1966) é um algoritmo iterativo baseado nos pixels da imagem. O funcionamento do algoritmo consiste na aplicação de um conjunto de regras para decidir se o valor do pontos deve ser mudado de preto (0) para branco (1). Inicialmente devemos considerar uma janela 3x3, cujo ponto central é chamado de P1 com seus respectivos vizinhos. Denota-se por A(P1) o número de transições de 0 (zero) para 1 (um) na seqüência ordenada de P2...P9, P2; e B(P1) o número de vizinhos diferentes de 0 (zero) de P1. A cada passada do algoritmo (em paralelo) são removidos os pontos que satisfaçam as condições do processo.
O algoritmo de Stentiford (STENTIFORD, 1983) introduziu uma nova abordagem para os algoritmos de afinamento: o conceito de máscaras. Para executar o afinamento de uma imagem binária o algoritmo utiliza quatro máscaras que devem ser aplicadas sucessivamente na imagem.
Em 1984, Zhang e Suen (ZHANG e SUEN, 1984) publicaram um artigo no qual foi proposto um novo algoritmo paralelo de afinamento. O algoritmo de Zhang e Suen consiste em sucessivas aplicações de duas regras ao contorno da imagem, sendo que os pontos do contorno são quaisquer pontos com valor 1 (um) que tenham ao menos um dos seus 8 (oito) vizinhos iguais a 0 (zero). Assim, o algoritmo é composto por duas iterações que são aplicadas paralelamente na imagem para remoção dos pontos.
Durante vários anos, a maioria dos algoritmos de afinamento funcionava através da aplicação sucessiva de um conjunto de regras em uma imagem. Em 1987, Holt (HOLT et al., 1987) sugeriu um novo algoritmo que não envolvia iteração e, além disso, era um dos mais rápidos na época. A idéia proposta por Holt consiste em transformar os dois conjuntos de regras de Zhang-Suen em expressões lógicas.
Uma outra técnica de afinamento muito importante encontrada na literatura é o método multiescala (COSTA e CESAR, 2000). Simples e relativamente eficiente, o afinamento multiescala é uma técnica baseada no conceito de dilatações exatas. O processo de afinamento multiescala inicia rotulando a borda da imagem com valores inteiros de forma sucessiva. Na Figura 1(a) é mostrada uma imagem e na Figura 1(b), a respectiva borda. O resultado do processo de rotulação da borda é ilustrado na Figura 1(c). A rotulação sucessiva dos elementos da borda pode ser obtida aproveitando-se da aplicação dos algoritmos para extração de contornos. O próximo passo é a propagação dos elementos através da dilatação exata. Uma vez terminada a propagação dos rótulos por toda imagem, a diferença máxima entre cada valor e seus respectivos vizinhos (vizinhança de 4) é determinada e colocada em uma matriz. Por fim, os esqueletos espaço-escala podem ser obtidos através de um simples limiar T aplicados nessa matriz. Diferentes valores de T resultam em esqueletos diferentes como pode ser
WVC´2005 - I Workshop de Visão Computacional
57

observado nas Figuras 1(d) e 1(e). Na Figura 1 é apresentada uma visão geral de todo processo de afinamento usando o método multiescala.
(a) (b) (c) (d) (e) Figura 1: Processo de Afinamento Multiescala. (a) imagem original; (b) extração da borda; (c) rotulação sucessiva da
borda com valores inteiros; (d) esqueleto da imagem para o limiar = 5; (e) esqueleto da imagem para o limiar =30.
3. Experimentos Na literatura podem ser encontrados inúmeros métodos de afinamento, que de modo geral, produzem esqueletos a partir de imagens binárias. A principal diferença entre essas técnicas é o resultado do processo, ou seja, esses métodos resultam em esqueletos diferentes. Na Figura 2 são mostrados os resultados de diversos métodos de afinamento aplicados a uma imagem binária.
(a) (b) (c) (d) (e) (f) Figura 2: Resultados dos algoritmos de afinamento utilizados nos experimentos. (a) imagem original; esqueleto
obtido através do algoritmo de: (b) hilditch; (c) holt; (d) multiescala; (e) stentiford e (f) zhang-suen.
Com base nessa problemática, foram realizados experimentos para determinar, dentre os métodos de afinamento estudados, qual a melhor técnica para reconhecimento de caracteres impressos. Assim, foram implementados os seguintes métodos de afinamento: Hilditch, Holt, Multiescala, Stentiford e Zhang-Suen. Todas as imagens binárias de caracteres do conjunto original (10 classes contendo 10 amostras por classes) foram processadas aplicando-se os métodos de afinamento implementados. Dessa maneira, foram gerados cinco grupos de esqueletos, com cada grupo contendo 100 imagens resultantes do processo de afinamento: (i) grupo 1 – resultado do algoritmo de Hilditch; (ii) grupo 2 – resultado do algoritmo de Holt; (iii) grupo 3 – resultado do algoritmo Multiescala; (iv) grupo 4 – resultado do algoritmo de Stentiford e (v) grupo 5 – resultado do algoritmo de Zhang-Suen. Para cada grupo de imagens, foram extraídas características aplicando-se um método estatístico conhecido como reamostragem (PARKER, 1997). Nesse método uma imagem de nxm pontos pode ser reamostrada em uma imagem menor, ou maior, de pxq pontos. O método de reamostragem é utilizado para reduzir o número de características utilizadas para representar a imagem. Nos experimentos, as imagens que originalmente possuíam tamanho de 200x200 pontos foram reduzidas para 40x40 pontos, e em seguida reamostradas para 4x4 pontos (16 regiões). As 16 regiões resultantes do processo de reamostragem foram utilizadas como vetor de entrada para rede neural
WVC´2005 - I Workshop de Visão Computacional
58

artificial. A rede foi treinada utilizando o algoritmo back-propagation, com uma topologia de 16x32x4. A taxa de aprendizado adotada foi de 0.1, para um número de épocas de treinamento igual a 1000. As taxas de acerto/erro da rede foram estimadas por meio de método de validação cruzada conhecido como k-fold cross validation. Na Figura 3 são apresentados os resultados de classificação (reconhecimento) dos caracteres impressos para os cinco algoritmos utilizados. As barras em preto representam as predições corretas para cada algoritmo, ou seja, quando a rede neural artificial consegue reconhecer corretamente o caractere com base no seu esqueleto. As barras em cinza estão relacionadas às predições incorretas.
81
50
8086
94
19
50
2014
6
0
10
20
30
40
50
60
70
80
90
100
Hild it c h S t e nt if o rd Zhang - S ue n Ho lt M ult iEs c a la
% acerto% erro
Figura 3: Resultados da rede neural no reconhecimento de caracteres impressos.
4. Conclusões Neste trabalho foi apresentado um estudo comparativo da potencialidade de diversos algoritmos de afinamento no reconhecimento de caracteres impressos. As informações resultantes do processo de afinamento − o esqueleto − foram transformadas em vetores de características por meio de uma técnica de reamostragem. Esses dados serviram de entrada para uma rede neural artificial que determinou a eficiência de cada algoritmo no processo de reconhecimento. O algoritmo melhor avaliado foi a técnica de afinamento multiescala com taxa de acerto de 94%, o que demonstra a qualidade dos esqueletos gerados com o método multiescala.
Referências (COSTA e CESAR, 2000) COSTA, L. F. e R. M. CESAR. Shape Analysis and Classification: Theory and Practice.
Pennsylvania: CRC Press. 659 p., 2000. (HOLT et al., 1987) HOLT, C. M., A. STEWART, M. CLINT e R. H. PERROT. An Improved Parallel Thinning
Algorithm. Communications of the ACM, v.30, p.156-160. 1987. (LAM, LEE et al., 1992) LAM, L., S.-W. LEE e C. Y. SUEN. Thinning Methodologies - A Comprehensive Survey. IEEE
Transactions on Pattern Analysis and Machine Intelligence, v.14, n.9, p.869-885. 1992. (MELHI et al., 2001) MELHI, S. S., S. S. IPSON e W. BOOTH. A Novel Triangulation Procedure for Thinning Hand-
Written Text. Pattern Recognition Letters, v.22, p.1059-1071. 2001. (PARKER, 1997) PARKER, J. R. Algorithms for Image Processing and Computer Vision. NY: John Wiley & Sons, 1997. (PLOTZE e BRUNO, 2004) PLOTZE, R. O. e O. M. BRUNO. Estudo e Comparação de Algoritmos de Esqueletonização
para Imagens binárias. IV Congresso Brasileiro de Computação - CBComp. Itajaí-SC, p., 2004 (RUTOVITZ, 1966) RUTOVITZ, D. Pattern recognition. Journal of the Royal Statistical Society, v.129, p.504-530. 1966. (STENTIFORD, 1983) STENTIFORD, F. Some new heuristics for thinning binary handprinted characters for OCR. IEEE
Transactions on Systems, Man and Cybernetics, v.13, n.1, p.81-84. 1983. (ZHANG e SUEN, 1984) ZHANG, T. Y. e C. Y. SUEN. A fast parallel algorithm for thinning digital patterns.
Communications of the ACM, v.27, n.3, p.236-239. 1984.
WVC´2005 - I Workshop de Visão Computacional
59

Metodologia para Extração de Características Automáticas da Mão Usando Assinatura Vertical
A. C. Queiroz, T. L. Gaspar, C. J. Olivete, F. J. Affonso e E. L. L. Rodrigues
Escola de Engenharia de São Carlos (EESC) – Universidade de São Paulo (USP)
São Carlos – SP – Brasil Av. Trabalhador Sãocarlense, 400 – Centro – CEP 13566-590 - São Carlos – SP
Tel: (16) 3373-9366 - Ramal 226 – Fax: (16) 3373-9372
aqueiroz, tlgaspar, olivete, faffonso, [email protected]
Abstract: This paper presents a methodology to extract features of hand’s bones in an automatic manner. Fundaments on a process to locate the regions of interest using the vertical signature’s method in digitalized images of hand, with the purpose of dimensions calculating of the phalanxes and metacarpus. Based on these informations it’s possible to estimate the age of the bones with the Eklof & Ringertz’s simplified method. The algorithm was developed on Matlab version 6.5, using the toolbox of image processing.
1. Introdução
A estimativa da idade óssea através da radiografia carpal é freqüentemente utilizada para avaliar
desordens no crescimento em pacientes pediátricos, obtendo o quanto o seu crescimento evoluiu em relação à sua maturidade óssea. A idade cronológica não é um bom indicador para avaliar o desenvolvimento e o crescimento, pois além de existirem diferenças relacionadas ao sexo, fatores genéticos, ambientais e nutricionais podem influenciar na análise.
Existem vários métodos para avaliação da idade óssea, os mais difundidos e utilizados no Brasil são Greulich & Pyle, que faz uma avaliação inspecional dos ossos da mão através de um Atlas onde os sexos são analisados separadamente [1]; o método Tanner & Whitehouse, que analisa 20 ossos da mão e punho atribuindo um escore específico para cada osso, de acordo com o sexo, onde através da soma dos escores obtém-se a idade óssea [2]; o método Eklof & Ringertz tradicional, o qual baseia-se em medidas de comprimento e/ou largura de 10 centros de ossificação [3]; e o método simplificado [4], que baseia-se em dimensões de 5 centros de ossificação, sendo estes falanges e metacarpos. Este método é o mais adequado na utilização da metodologia descrita neste trabalho, por não utiliza a região do punho, a qual dificulta a análise devido à sobreposição de ossos. Um outro critério importante deste método é o fato de não utilizar uma análise inspecional e comparativa através do uso de Atlas.
Uma das maiores dificuldades em automatizar métodos computacionais para determinar a idade óssea está na extração das características, pois existe uma grande dificuldade em localizar as regiões de interesse de maneira precisa. Neste trabalho será descrito um método baseado em assinatura vertical
WVC´2005 - I Workshop de Visão Computacional
60
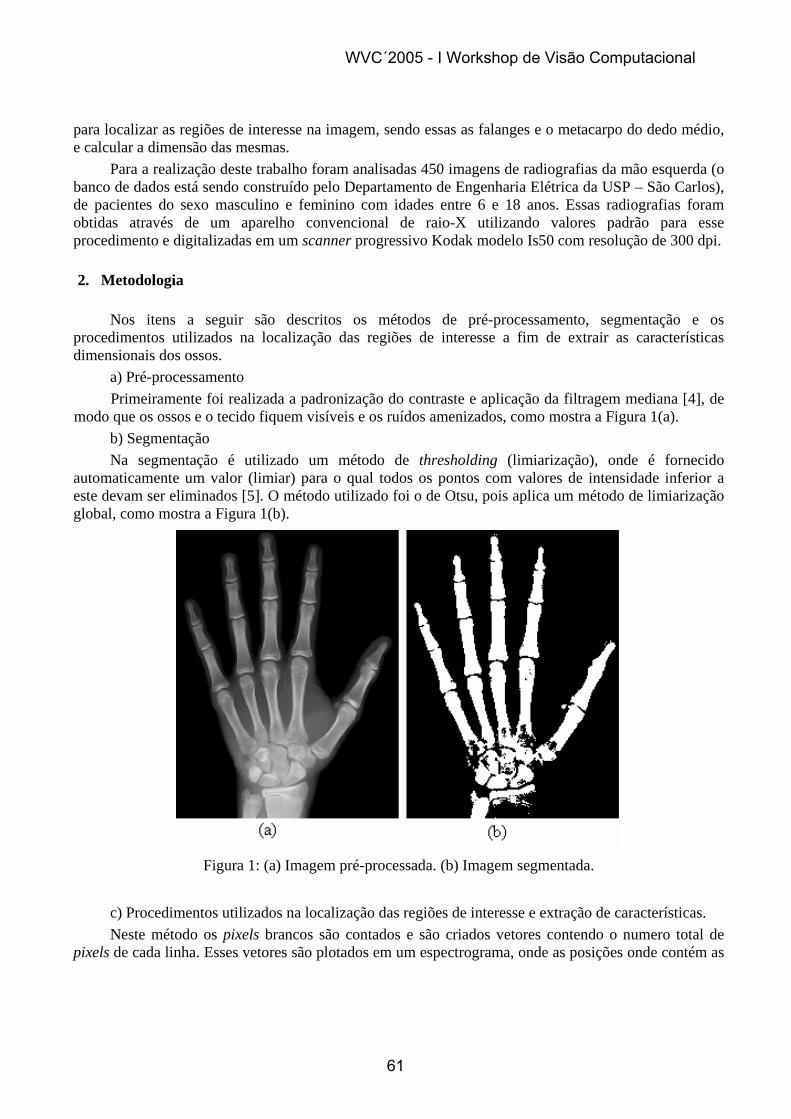
para localizar as regiões de interesse na imagem, sendo essas as falanges e o metacarpo do dedo médio, e calcular a dimensão das mesmas.
Para a realização deste trabalho foram analisadas 450 imagens de radiografias da mão esquerda (o banco de dados está sendo construído pelo Departamento de Engenharia Elétrica da USP – São Carlos), de pacientes do sexo masculino e feminino com idades entre 6 e 18 anos. Essas radiografias foram obtidas através de um aparelho convencional de raio-X utilizando valores padrão para esse procedimento e digitalizadas em um scanner progressivo Kodak modelo Is50 com resolução de 300 dpi.
2. Metodologia
Nos itens a seguir são descritos os métodos de pré-processamento, segmentação e os
procedimentos utilizados na localização das regiões de interesse a fim de extrair as características dimensionais dos ossos.
a) Pré-processamento Primeiramente foi realizada a padronização do contraste e aplicação da filtragem mediana [4], de
modo que os ossos e o tecido fiquem visíveis e os ruídos amenizados, como mostra a Figura 1(a). b) Segmentação Na segmentação é utilizado um método de thresholding (limiarização), onde é fornecido
automaticamente um valor (limiar) para o qual todos os pontos com valores de intensidade inferior a este devam ser eliminados [5]. O método utilizado foi o de Otsu, pois aplica um método de limiarização global, como mostra a Figura 1(b).
Figura 1: (a) Imagem pré-processada. (b) Imagem segmentada.
c) Procedimentos utilizados na localização das regiões de interesse e extração de características. Neste método os pixels brancos são contados e são criados vetores contendo o numero total de
pixels de cada linha. Esses vetores são plotados em um espectrograma, onde as posições onde contém as
WVC´2005 - I Workshop de Visão Computacional
61
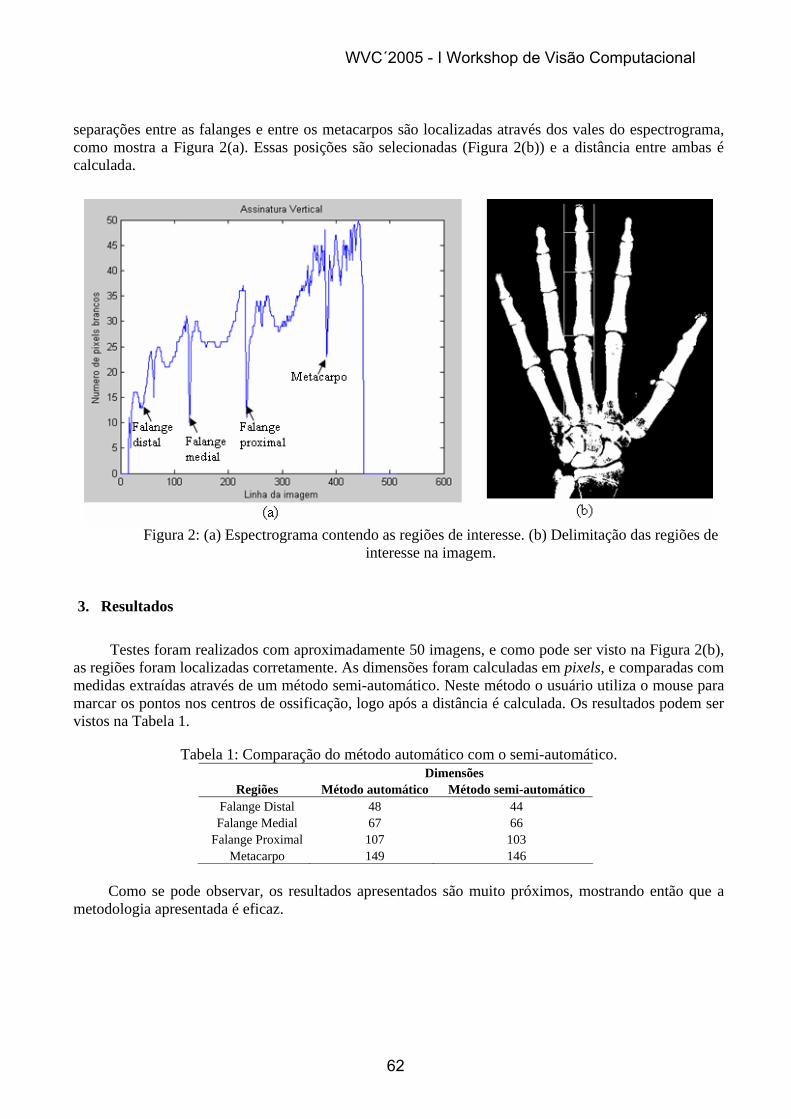
separações entre as falanges e entre os metacarpos são localizadas através dos vales do espectrograma, como mostra a Figura 2(a). Essas posições são selecionadas (Figura 2(b)) e a distância entre ambas é calculada.
Figura 2: (a) Espectrograma contendo as regiões de interesse. (b) Delimitação das regiões de
interesse na imagem. 3. Resultados
Testes foram realizados com aproximadamente 50 imagens, e como pode ser visto na Figura 2(b), as regiões foram localizadas corretamente. As dimensões foram calculadas em pixels, e comparadas com medidas extraídas através de um método semi-automático. Neste método o usuário utiliza o mouse para marcar os pontos nos centros de ossificação, logo após a distância é calculada. Os resultados podem ser vistos na Tabela 1.
Tabela 1: Comparação do método automático com o semi-automático. Dimensões
Regiões Método automático Método semi-automático Falange Distal 48 44 Falange Medial 67 66
Falange Proximal 107 103 Metacarpo 149 146
Como se pode observar, os resultados apresentados são muito próximos, mostrando então que a
metodologia apresentada é eficaz.
WVC´2005 - I Workshop de Visão Computacional
62

4. Conclusões
Com base nos estudos conclui-se que é possível utilizar essa metodologia para extração de características de maneira automática a fim de usá-la para estimar a idade óssea através do método de Eklof & Ringertz simplificado [4]. Ressalta-se que esta metodologia deve ser aplicada a todos os centros de ossificação utilizados pelo método.
Os resultados obtidos foram satisfatórios, pois quando comparado com o método semi-automático as variações são pequenas, validando assim a sua eficiência.
Referências Bibliográficas
[1] HAITER NETO, F,; ALMEIDA, S. M.; LEITE, C. C. (2000). “Estudo comparativo dos métodos de estimativa da idade óssea de Greulich & Tanner & Whitehouse”. Pesquisa Odontológica Brasileira, vol 14, nº 4, pp 378-384.
[2] TANNER, J. M.; WHITEHOUSE, R. W.; HEALVY (1969). A New System for Estimating Skeletal Maturity from Hand and Wrist, with Standarts Derived From a Study Of 2600 Healthy British Children, Departament of Growth and Development Institute of Child Health, University of London; and Departament of Statistics, Rothamsted Experimental Station, Harpenden. [3] TAVANO, O. (2001). Radiografias Carpal e Cefalométrica como Estimadores da Idade Óssea e do Crescimento e Desenvolvimento, Bauru – Brasil.
[4] OLIVETE, C. J.; QUEIROZ, A. C.; RODRIGUES, E. L. L. (2005) – Software automático para determinação da idade óssea baseado na simplificação do método de Eklof & Ringertz. In: CONGRESSO BRASILEIRO DE FÍSICA MÉDICA, 2005 Salvador. Disponível em: http://www.abfm.org.br/c2005/trabalhos/Sord09.pdf
[5] GONZALEZ, R. C.; WOODS, R. E. (1993). Digital Image Processing Techniques. Addison Wesley, New York.
WVC´2005 - I Workshop de Visão Computacional
63

Dimensão Fractal Multiescala e suas Aplicações na Taxonomia de Espécies Vegetais
Rodrigo de Oliveira Plotze, Odemir Martinez Bruno
Instituto de Ciências Matemáticas e de Computação
Universidade de São Paulo (ICMC-USP) Caixa Postal 688 – Cep 13560-90 São Carlos – São Paulo - Brasil
roplotze,[email protected]
Resumo: O riquíssimo reino vegetal, com sua abundante diversidade de espécies, torna o processo de identificação de órgãos foliares um verdadeiro desafio para pesquisadores. Este trabalho descreve uma nova metodologia, baseada em técnicas de análise de imagens e extração de características, capaz de realizar a taxonomia de espécies vegetais. Os métodos desenvolvidos se concentram em informações coletadas da parte interna dos órgãos foliares, o conjunto de nervuras. São extraídas características relativas à dimensão fractal multiescala, tanto das nervuras quanto do esqueleto das espécies. A eficiência das técnicas é comprovada a em casos reais de taxonomia de espécies vegetais. Abstract: The immeasurable diversity of species in vegetable kingdom becomes the leaves identification process a very complex task. This work presents a new methodology based in image analysis and feature extraction techniques, for vegetable species taxonomy. The developed methods are concentrated in internal features of leaves, the venation system. Attributes relatives of multiscale fractal dimension are collected of the venation system and the skeletons (result of thinning process). The techniques efficiency was evaluated with real cases of species identification.
1. Introdução
A imensa variabilidade de características taxonômicas presentes nas espécies vegetais, torna o processo de identificação morfológica um desafio para os pesquisadores. Os modelos tradicionais de taxonomia necessitam de profissionais especializados e, em grande parte é uma árdua tarefa realizada manualmente. Por outro lado, a identificação de espécies vegetais em florestas, além de ser um dos alicerces para o estudo e pesquisa científica em diversas áreas da ciência associadas à botânica, apresenta ainda importância vital para a manutenção e preservação ecológica.
Nesse contexto surge a necessidade do desenvolvimento de modelos matemáticos e computacionais, que sejam capazes de auxiliar os taxonomistas na tarefa de identificação das espécies vegetais. O intuito de se desenvolver novos métodos, não se concentra em momento algum na substituição dos profissionais de botânica, mais especificamente os taxonomistas, na tarefa de caracterização das espécies. Esses instrumentos, ou novas tecnologias, têm como único e principal
WVC´2005 - I Workshop de Visão Computacional
64

objetivo auxiliar esses profissionais, servindo como ferramental durante a complexa tarefa de identificação vegetal.
Este trabalho apresenta uma nova metodologia para identificação de espécies vegetais através de características internas de seus órgãos foliares. São coletadas informações do conjunto de nervuras das espécies utilizando uma técnica de análise de imagens conhecida como dimensão fractal multiescala. Para verificar a potencialidade da abordagem desenvolvida, foram realizados experimentos com casos reais de órgãos foliares, mais especificamente espécies da Mata Atlântica e do Cerrado brasileiro.
2. Dimensão Fractal Multiescala
A dimensão fractal multiescala é uma importante característica para identificação de órgãos foliares (PLOTZE et al., 2004; PLOTZE et al., 2005). O método de estimação da dimensão fractal multiescala possibilita a análise da variação da dimensão fractal de um objeto, em função do espaço métrico no qual este objeto se encontra. Diferentes dos métodos tradicionais para estimação da dimensão fractal que resultam em um único valor, a dimensão fractal multiescala é uma função de escala espacial (COSTA, 1999).
O processo para estimar a dimensão fractal através da abordagem multiescala se inicia com a dilatação sucessiva do objeto em análise por um raio d (método de dilatações exatas). Considerando as áreas A(d) assumida pelo objeto enquanto ele é dilatado em função do raio, é possível calcular um gráfico bi-log que é obtido plotando )log()(log dxdA . Para obtenção da análise multiescala da dimensão fractal é necessário que seja obtido um gráfico )'log()log( Axd , no qual A’ é o resultado da derivada numérica do ponto ))(,( dAd do gráfico bi-log. A Figura 1 ilustra o processo para estimativa da dimensão fractal através do método multiescala.
(a) (b) (c)
(d)
Figura 1: Processo da estimativa da dimensão fractal multiescala. (a) imagem original;
(b) dilatações sucessivas da imagem; (c) gráfico bi-log )log()(log dxdA ;
(d) gráfico da dimensão fractal multiescala. 0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
1,1
1,2
1,3
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100
log(d)
log
(A')
3,0
3,2
3,4
3,6
3,8
4,0
4,2
4,4
4,6
4,8
5,0
5,2
5,4
5,6
0,0 0,2 0,4 0,6 0,8 1,0 1,2 1,4 1,6 1,8 2,0 2,2 2,4 2,6
log(d)
log
A(d
)
WVC´2005 - I Workshop de Visão Computacional
65

3. Experimentos
Os experimentos para taxonomia das espécies vegetais foram divididos em três fases: (i) processamento; (ii) extração de características e (iii) reconhecimento de padrões. A Figura 2 apresenta um diagrama com as fases dos experimentos com órgãos foliares.
Figura 2: Fases do experimento sobre complexidade dos órgãos foliares
Inicialmente a base de imagens, contendo 10 espécies da Mata Atlântica e do Cerrado foi processada para adequar as figuras para a fase de extração de características. Nessa etapa as nervuras são segmentadas através de uma abordagem semi-automatizada, porém algumas deficiências durante a segmentação fazem com que as nervuras apresentem variações no diâmetro em determinadas posições da folha. Para solucionar este problema, de maneira que essa diferença não influencie no processo de extração de características, as nervuras foram reduzidas para 1 (um) pixel de largura utilizando um algoritmo de afinamento (PARKER, 1997).
A segunda fase do experimento coletou as características através da análise multiescala da dimensão fractal, aplicada nas imagens de nervuras. Com base na curva resultante ( )'log()log( Axd ) seis características são extraídas em três pontos de interesse diferentes (P1, P2 e P3), como ilustrado na Figura 3a. Esses pontos foram escolhidos devido ao comportamento padronizado das curvas da dimensão fractal multiescala, Figura 3b.
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
1,00
1,10
1,20
1,30
1,40
1,50
1,60
1,70
1,80
0 10 20 30 40 50 60 70 80 90 100 (a) (b)
Figura 3: Extração de características através da curva fractal multiescala. (a) Pontos de interesse extraídos da curva fractal multiescala. As coordenadas x e y de cada ponto são consideradas como características. (b) comportamento
da curva multiescala de cinco espécies vegetais.
Na fase de reconhecimento de padrões foram utilizadas redes neurais artificiais treinadas com algoritmo back-propagation. A topologia adota foi 6x5x4. O conjunto de dados, contendo cinqüenta
WVC´2005 - I Workshop de Visão Computacional
66
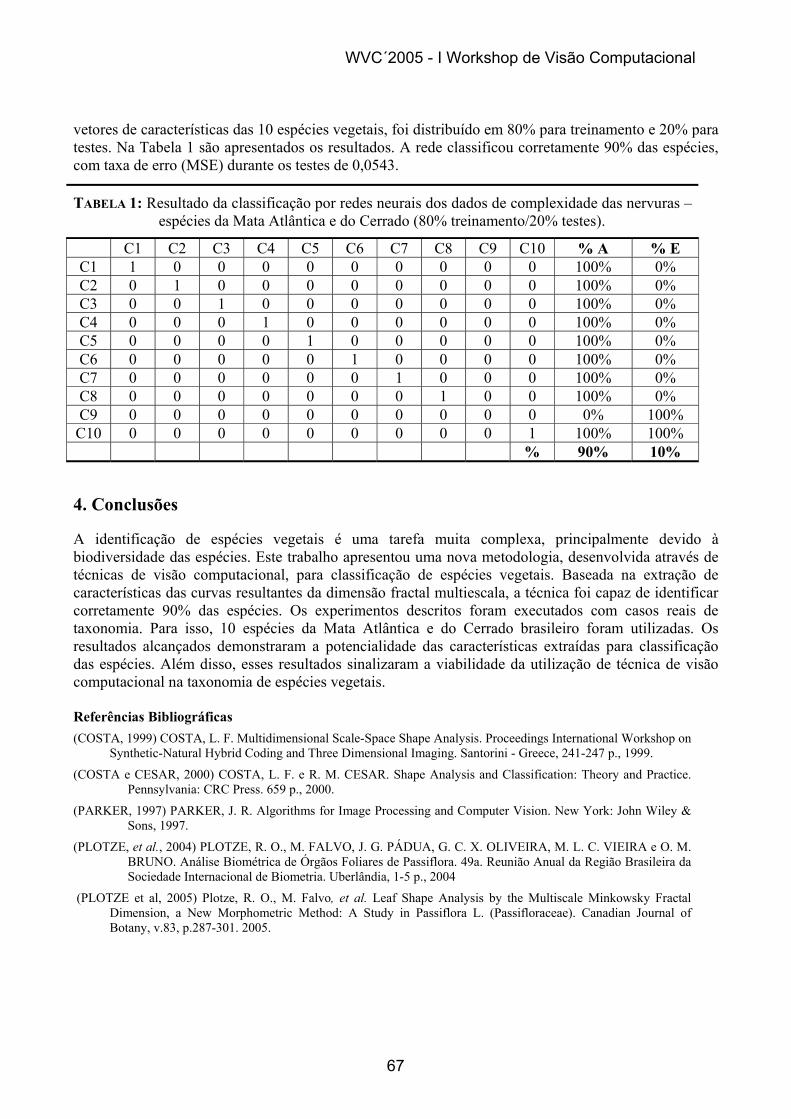
vetores de características das 10 espécies vegetais, foi distribuído em 80% para treinamento e 20% para testes. Na Tabela 1 são apresentados os resultados. A rede classificou corretamente 90% das espécies, com taxa de erro (MSE) durante os testes de 0,0543.
TABELA 1: Resultado da classificação por redes neurais dos dados de complexidade das nervuras – espécies da Mata Atlântica e do Cerrado (80% treinamento/20% testes).
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 % A % E C1 1 0 0 0 0 0 0 0 0 0 100% 0% C2 0 1 0 0 0 0 0 0 0 0 100% 0% C3 0 0 1 0 0 0 0 0 0 0 100% 0% C4 0 0 0 1 0 0 0 0 0 0 100% 0% C5 0 0 0 0 1 0 0 0 0 0 100% 0% C6 0 0 0 0 0 1 0 0 0 0 100% 0% C7 0 0 0 0 0 0 1 0 0 0 100% 0% C8 0 0 0 0 0 0 0 1 0 0 100% 0% C9 0 0 0 0 0 0 0 0 0 0 0% 100%
C10 0 0 0 0 0 0 0 0 0 1 100% 100% % 90% 10%
4. Conclusões
A identificação de espécies vegetais é uma tarefa muita complexa, principalmente devido à biodiversidade das espécies. Este trabalho apresentou uma nova metodologia, desenvolvida através de técnicas de visão computacional, para classificação de espécies vegetais. Baseada na extração de características das curvas resultantes da dimensão fractal multiescala, a técnica foi capaz de identificar corretamente 90% das espécies. Os experimentos descritos foram executados com casos reais de taxonomia. Para isso, 10 espécies da Mata Atlântica e do Cerrado brasileiro foram utilizadas. Os resultados alcançados demonstraram a potencialidade das características extraídas para classificação das espécies. Além disso, esses resultados sinalizaram a viabilidade da utilização de técnica de visão computacional na taxonomia de espécies vegetais. Referências Bibliográficas
(COSTA, 1999) COSTA, L. F. Multidimensional Scale-Space Shape Analysis. Proceedings International Workshop on Synthetic-Natural Hybrid Coding and Three Dimensional Imaging. Santorini - Greece, 241-247 p., 1999.
(COSTA e CESAR, 2000) COSTA, L. F. e R. M. CESAR. Shape Analysis and Classification: Theory and Practice. Pennsylvania: CRC Press. 659 p., 2000.
(PARKER, 1997) PARKER, J. R. Algorithms for Image Processing and Computer Vision. New York: John Wiley & Sons, 1997.
(PLOTZE, et al., 2004) PLOTZE, R. O., M. FALVO, J. G. PÁDUA, G. C. X. OLIVEIRA, M. L. C. VIEIRA e O. M. BRUNO. Análise Biométrica de Órgãos Foliares de Passiflora. 49a. Reunião Anual da Região Brasileira da Sociedade Internacional de Biometria. Uberlândia, 1-5 p., 2004
(PLOTZE et al, 2005) Plotze, R. O., M. Falvo, et al. Leaf Shape Analysis by the Multiscale Minkowsky Fractal Dimension, a New Morphometric Method: A Study in Passiflora L. (Passifloraceae). Canadian Journal of Botany, v.83, p.287-301. 2005.
WVC´2005 - I Workshop de Visão Computacional
67

Utilizando a Visão Computacional para a Condução de Veículos Marcelo P. Guimarães1, Ezequiel R. Zorzal1, Eduardo A. Queiroz1, Cláudio Kirner1,2
Centro Universitário Adventista de São Paulo1 Estrada de Itapecerica, 5859 CEP 05858-001 São Paulo – SP - Brasil
Universidade Metodista de Piracicaba – UNIMEP2 Faculdade de Ciências Exatas da Natureza
Programa de Pós Graduação em Ciência da Computação Rodovia do Açúcar, km 156 – CEP 13400-911- Piracicaba – SP - Brasil
[email protected], [email protected], [email protected], [email protected] Abstract. This paper describes a system of conduction of vehicles based on images from a wireless camera. It was used Computational Visional to find signals spread on the road. When a signal is found, the system detects it and emits the appropriated command to the car. It was used a toy car to develop a prototype.
1. Introdução
A Realidade Aumentada permite a inserção de objetos virtuais tridimensionais nos ambientes dos usuários. Desta forma, ela complementa a realidade em lugar de a substituir, como faz Realidade Virtual, onde o usuário não vê o mundo real que o rodeia. Ao decompor um sistema típico de Realidade Aumentada nos seus vários subsistemas, torna-se evidente o caráter multidisciplinar e integrador desta área de investigação, que envolve conhecimento, tecnologias e metodologias de diferentes áreas, dentre elas, da Visão Computacional, que possibilita a localização dos objetos reais e o alinhamento espacial do mundo real com o virtual [1,2,3,4]. Este trabalho apresenta um exemplo de aplicação dos recursos fornecidos pela área de Visão Computacional para desenvolvimento de um sistema para condução de veículos. Neste caso, utilizou-se um veículo de brinquedo. Além de conduzir o veículo, o sistema apresenta para o operador objetos virtuais sobrepostos ao mundo real (Realidade Aumentada). A figura 1 descreve o funcionamento do sistema. Ao longo da pista existem diversos marcadores (placas de sinalização), com sinais como: pare, vire a esquerda, vire a direita e siga em frente. Inicialmente, o sistema obtém as imagens da pista, por intermédio de uma câmera sem fio acoplada ao veículo (1). A seguir as imagens são enviadas (2) para a central (computador). Ao receber, a central processa as imagens para a localização dos marcadores - são utilizados algoritmos de Visão Computacional (3). Quando um marcador é encontrado, o comando associado a ele é enviado para o veículo. No mesmo instante, o veículo executa o comando e é mostrado para o operador a imagem real da pista com um mapa virtual da posição do veículo.
Placas de sinalização
Obtém as imagens
Algoritmos Visão Computacional
1 2
Pista Câmera acoplada no veículo Central
Posição na pista
3 +
Real
Virtual
+
Conduz o veículo
Figura 1 – Sistema de Visão Computacional para a condução do veículo
WVC´2005 - I Workshop de Visão Computacional
68

Os detalhes desta pesquisa serão apresentados nas próximas seções. A seção 2 apresenta a ferramenta ARToolKit [3]. Esta ferramenta forneceu para o sistema a posição e o alinhamento dos marcadores na imagem. A seção 3 descreve os recursos de Visão Computacional disponíveis neste software e que foram utilizados no protótipo. A seção 4 mostra o protótipo desenvolvido e, finalmente, na seção 5, são apresentadas as conclusões.
2. ARToolKit
ARToolKit é uma ferramenta em C/C++ voltada para o desenvolvimento de aplicações de Realidade Aumentada. Ela fornece técnicas de Visão Computacional para o cálculo da posição e da orientação da câmera em relação aos marcadores em tempo real, de tal forma que objetos virtuais tridimensionais possam ser sobrepostos a eles. Para o desenho dos objetos virtuais é utilizada a API (application programming interface) OpenGL[1]. A ferramenta ARToolKit permite a construção de sistemas do tipo see-through de Realidade Aumentada, tanto com visão ótica direta quanto com visão direta baseada em vídeo. Nestes sistemas os objetos virtuais são adicionados ao mundo real independente do dispositivo de visualização que está sendo utilizado. Por exemplo, para realizar a sobreposição quando o usuário está utilizando um capacete de visualização (HMD -Head Mounted Displays) acopla-se uma câmera de vídeo a ele. Embora um HMD com visão direta por vídeo possa ser utilizado para conduzir veículos, cabe ressaltar que o capacete com visão ótica direta é o mais indicado, por não oferecer perigo em caso de pane ou defeito no sistema computacional. Em caso de problemas, haveria a perda do complemento virtual, mas a visão do usuário continuaria mantida, permitindo o controle manual do veículo. Por outro lado, no caso de falhas, usando capacete com visão por vídeo, haveria a necessidade de retirada do capacete, deixando o motorista sem visão por alguns instantes. Atualmente, o ARToolKit executa nas plataformas SGI Irix, PC Linux, PC Windows 95/98/NT/2000/XP e Mac OS X. Há versões separadas para cada uma destas plataformas. A funcionalidade de cada versão do pacote é a mesma, mas o desempenho pode variar conforme as diferentes configurações de hardware [1]. Utilizou-se no protótipo o sistema operacional Windows 2000.
3. Sistema de Visão Computacional do ARToolKit
Uma das maiores dificuldades durante o desenvolvimento de sistemas de Realidade Aumentada é calcular, de maneira precisa, a visão da câmera do usuário em tempo real. Após ter esta informação, pode-se então acertar a câmera virtual. Somente quando as duas câmeras tornam-se as mesmas, o objeto virtual pode ser adicionado na posição correta da imagem do mundo real. Para resolver este problema, o ARToolKit, inicialmente, obtém a imagem do vídeo ao vivo e a converte em uma imagem binária (preto ou branco), baseando-se na determinação do valor de thresholding (separação dos pixels cujos valores são menores ou iguais a um certo limiar, daqueles com valores superiores a este mesmo limiar). Então, são localizadas as regiões quadradas na imagem. A imagem pode conter vários quadrados, contudo a maioria deles não é um marcador. Para cada quadrado encontrado, o padrão de dentro do quadrado é capturado e comparado com os modelos de padrões que foram previamente cadastrados. Todos os marcadores são previamente cadastrados. Se houver uma identificação positiva, o ARToolKit então usa o tamanho já conhecido do quadrado e do padrão de orientação para
WVC´2005 - I Workshop de Visão Computacional
69

calcular a posição da câmera de vídeo real em relação ao marcador. Em seguida uma matriz
3x4 é preenchida com as coordenadas da câmera de vídeo do mundo real em relação aos marcadores. Assim, a câmera virtual e a real tornam-se as mesmas, o que permite a adição do objeto virtual sobre o marcador [1,2]. A figura 2 ilustra o processo de funcionamento de um sistema de Realidade Aumenta utilizando ARToolkit. Na fase inicial, os marcadores são cadastrados (1). Em seguida o sistema pode iniciar a execução e a captura a imagens do ambiente real (2). Então, as imagens são transformadas em binárias (3). Logo após, são identificados os marcadores e a câmera virtual é configurada na mesma posição em que a real (4). Por fim, o objeto virtual é desenhado na imagem real e a imagem é apresentada para o usuário (5) .
4. O protótipo O sistema foi construído para demonstrar a condução de um veículo de brinquedo. Por isso, foi necessário interligar o controle remoto do veículo ao computador, por intermédio de um circuito que liga a porta paralela do computador ao controle. Assim, os sinais elétricos da porta paralela (comandos de controle do veículo) são enviados para o controle remoto, o qual transmite para o veículo. Na central é executado um aplicativo que tem as seguintes funções: ser a interface de interação e de visualização do operador; tratar as imagens da câmera; e gerar os comandos a serem executados pelo veículo. A interface do aplicativo desenvolvido é apresentada na figura 3(a). Note que é apresentada a imagem real da pista e um objeto virtual (mapa da pista com a posição do veículo). A figura 3 (b) mostra a pista com um marcador e o veículo com a câmera sem fio acoplada.
Captura a imagem
Transforma em
binária Realidade
Aumentada
Câmera Virtual
Ajuste da câmera
(1) (2) (3) (4)
Figura 2 – sistema de Realidade Aumenta utilizando ARToolkit
(5)
Cadastro dos marcadores
(a) Interface (b) Pista Figura 3 – Protótipo
WVC´2005 - I Workshop de Visão Computacional
70

A distância do veículo em relação aos marcadores varia no decorrer da simulação. Como conseqüência, o sistema detecta os marcadores de diversas distâncias. Além disso, quando o veículo recebe um comando, ele o executa imediatamente. Por isso, foi necessário calibrar o aplicativo para que este envie o comando a ser executado para o veículo somente quando o veículo estiver na distância correta. Assim, a Visão Computacional foi importante, neste projeto, tanto para detectar os marcadores, quanto para informar a distância do veículo ao marcador.
5. Conclusões
A Visão Computacional é uma área que oferece diversas oportunidades de aplicações, como na área educacional, de comércio e de controle industrial. Este artigo mostrou um exemplo de uso desta tecnologia. Foi apresentado um sistema de condução de veículos que se baseia nas imagens para decidir quais ações devem ser executadas pelo veículo. Para a implementação, utilizou-se a ferramenta ARToolKit.
No futuro, espera-se que os veículos sejam conduzidos por sistemas automáticos de controle, sem a necessidade de motorista. Isto proporcionará diversas vantagens à sociedade, como, por exemplo, facilitará a locomoção de idosos e de deficientes visuais. Além disso, têm outros valores agregados, como: o conforto (mais espaço no veículo, pois não há a necessidade de dispositivos de condução – pedais, volantes) e segurança (os pedais e volantes geralmente causam graves ferimentos nos motoristas).
6. Referências
[1]KATO,H & BILLINGHURST,M. & POUPYREV,I. ARToolKit. Version2.33. Tutorial. November 2000. Disponível em: http://www.hitl.washington.edu/artoolkit/. Acessado em: 15 julho de 2005.
[2]AZUMA,R.T. A Survey of Augmented Reality. Presence: Teleoperators and Virtual Environments. 355 - 385. ACM SIGGRAPH '95. Los Angeles. CA. August. 1995.
[3]KIRNER,C. & TORI,R.Introdução à Realidade Virtual, Realidade Misturada e Hiper-realidade. In: Claudio Kirner, Romero Tori (Ed.). Realidade Virtual: Conceitos, Tecnologia e Tendências. 1 ed. v.1, p.3-20. São Paulo.2004.
[4]SANTIN,R & KIRNER,C.Desenvolvimento de Técnicas de Interação para Aplicações de Realidade Aumentada com o ARToolKit. Anais do WRA 2004. I Workshop sobre Realidade Aumentada. Piracicaba. 2004.
WVC´2005 - I Workshop de Visão Computacional
71

Um método eficiente de segmentação de íris baseado na Transformada da Distância Euclidiana
Ronaldo Martins da Costa1, Eveline B. Rodrigues2, Adilson Gonzaga3
1 R. Galvão de Castro, 13-40 – Cond. Monte Castelo – Bloco C Apto 81 – Jd. Marambá – 17030-026 – Bauru – SP – Fone (14) 3203-6643 /
9712-2433 – [email protected] 2 Escola de Engenharia de São Carlos-USP – Departamento de Engenharia Elétrica – Av. Trabalhador São Carlense, 400 – 13566-590 –
São Carlos – SP – Fone/Fax (16) 3373-9371 – [email protected] 3 Escola de Engenharia de São Carlos-USP – Departamento de Engenharia Elétrica – Av. Trabalhador São Carlense, 400 – 13566-590 –
São Carlos – SP – Fone/Fax (16) 3373-9371 – [email protected]
Abstract. This work presents an efficient method for human iris segmentation using Euclidean Distance Transform. The goal is providing data within a Region of Interest (ROI), eliminating eyelid and eyelash, for applications that recognize people through the iris. The method was considered efficient, because its success was about 80% of iris database. The method was considered fast, because its medium processing time is about 1 second per image, executing on MatLab. We have used the CASIA iris database provided by the National Laboratory of Pattern Recognition (NLPR), Institute of Automation (IA) and Chinese Academy of Sciences (CAS), with 756 iris images.
Palavras Chaves: Segmentação de Íris, Transformada da Distância Euclidiana. 1. INTRODUÇÃO
Os recentes avanços da tecnologia de informação e o crescimento dos requisitos de segurança têm impulsionado o desenvolvimento de novas pesquisas para a identificação de usuários através de características biométricas [1],[2]. Todas as características biométricas têm sido amplamente estudadas, e dentre elas, o estudo e reconhecimento através da íris tem se destacado em virtude da riqueza de características que a mesma oferece [3]. Em virtude de suas características a íris oferece meios de identificar cada indivíduo de forma única. [4],[5].
No processo de identificação de um indivíduo através da íris, assim como em várias outras aplicações em visão computacional, o processamento requer primeiro a extração de estruturas específicas de interesse, nomeadas de segmentação da informação visual [9]. Ma [6] e outros desenvolveram um método de identificação baseado em três etapas, sendo elas Segmentação da Íris, Normalização, Realce da Imagem.
A proposta deste artigo é apresentar um método
eficiente e rápido para a segmentação da íris baseado na Transformada da Distância Euclidiana (TDE).
2. TRANSFORMADA DA DISTÂNCIA EUCLIDIANA (TDE)
A Transformada da Distância é uma função que converte os pixels de uma imagem digital binária em uma matriz na qual cada célula possui um valor correspondente à mínima distância do fundo através de uma função de distância [7]. A métrica utilizada neste trabalho para o cálculo da distância foi a da distância Euclidiana, dada por:
de(p,q) = v(x-u)2 + (y-v)2
onde, x e y representam as coordenadas do píxel p e u e v representam as coordenadas do píxel q.
A TDE é uma operação básica que é aplicável em muitos problemas de processamento de imagens como por ex., thinning, compressão de dados, seleção de regiões de interesse, diagramas digitais de Voronoi, etc.[8].
WVC´2005 - I Workshop de Visão Computacional
72

O método foi aplicado no banco de imagens de íris CASIA coletado pelo Laboratório Nacional de Reconhecimento de Padrões (NLPR), Instituto de Automação e Academia Chinesa de Ciências [10]. O banco utilizado dispõe de 756 imagens de 108 olhos. Para cada olho, 7 imagens foram capturadas.
3. MATERIAL E MÉTODO O método proposto é baseado na localização de um ponto de referência, que foi obtido através da TDE. A TDE gera uma matriz de distâncias de todo o olho ao fundo da imagem. Levando-se em consideração que as imagens estão em escala de cinza faz-se necessário a binarização. O limite utilizado foi de 50%. O resultado obtido foi satisfatório com a utilização deste nível médio (127) da escala de níveis de cinza. Após a binarização, a maior distância encontrada com a aplicação da TDE será o centro da pupila. A figura 1 apresenta o centro da pupila e o raio da mesma em destaque. Estes são obtidos diretamente através da TDE. É necessário estabelecer o limite entre a íris e a
esclera do olho, determinando-se uma região de interesse (ROI). A ROI é então obtida através da proporcionalidade do diâmetro da pupila em relação ao tamanho total da imagem, a Tabela 1 apresenta os fatores de multiplicação que foram utilizados para segmentar a região.
Proporção do diâmetro da pupila em relação ao tamanho da
imagem
Limite Inferior
Limite Superior
< 20% 2.70 4.25 = 20% e < 22% 2.50 4.00 = 22% e < 27% 2.00 3.25
= 27% e < 35% 1.70 2.70 = 35% 1.50 2.25
Tabela 1: Fatores de multiplicação para determinar a região de interesse da imagem A região de interesse então é segmentada aplicando-se o seguinte algoritmo: Se [distância-do-ponto-para-o-centro-da-pupila] = [raio-da-pupila × Limite-Inferior] e [distância-do-ponto-o-para-centro-da-pupila] = [raio-da-pupila × Limite-Superior] então selecione Fim-Se
A figura 2a apresenta a região de interesse segmentada e a figura 2b a binarização desta. Procede-se então, ao cálculo do diâmetro da íris. O cálculo é realizado de forma similar ao processo
executado para identificação da pupila. Primeiro calcula-se o raio da íris e então o diâmetro. Para obter o raio da íris, toma-se a distância euclidiana, entre o centro da pupila e um píxel da região de borda da ROI. Para tal é considerada a “região inferior” da imagem evitando assim que os cílios ou “sombras” interfiram nos resultados. A figura 3a apresenta uma imagem onde os cílios e sombras formadas na região mediana e superior da imagem poderiam distorcer o resultado. O píxel da ROI utilizado para cálculo do raio é obtido da “região inferior” com base na distância euclidiana. É traçada uma reta horizontal a 70% do raio da circunferência interna formada pela região de interesse. A linha vertical na figura 3a indica o raio da circunferência interna. A linha perpendicular a esta, no sentido horizontal é traçada a 70% da extensão total da linha vertical. As setas indicam as coordenadas externas.
(a) (b)
Figura 2: Resultado de binarização na região de interesse.
Figura 1: Centro e raio da pupila em destaque.
WVC´2005 - I Workshop de Visão Computacional
73

Através destas coordenadas é calculada a distância euclidiana. A íris então é segmentada, levando-se em consideração toda a região interna à figura 3b,
exceto a região da pupila. 3.1. Coeficiente de Variação O coeficiente de variação indica qual a variação existente de uma amostra em relação à média. A importância do coeficiente de variação está em analisar o comportamento de vários conjuntos de dados com suas respectivas médias e desvios padrões. Terá menor variabilidade aquele conjunto que apresenta menor coeficiente de variação. O coeficiente de variação é calculado por:
xS
cv ?
Onde S é: As pálpebras e os cílios são eliminados excluindo-se as janelas cujas médias excedam os limites de 50% acima ou abaixo do coeficiente de variação calculado para a imagem da íris segmentada.
4. RESULTADOS OBTIDOS O tempo total gasto para o processamento foi de 829.03 segundos, com um tempo médio de 1.0966 segundos por imagem. O equipamento utilizado foi microcomputador AMD 1050 MHz, 132 MB de memória RAM, sistema operacional Windows XP e MatLab 6.5 Release 13. A resolução das imagens é de 320 x 280 pixels.
No processo de identificação, algumas imagens foram identificadas com limites maiores ou menores ao devido. Estes resultados podem ser observados na Tabela 2.
Identificação do diâmetro externo da
íris
Imagens %
Não identificou 92 12,17 Maior que o devido 27 3,57
Identificou corretamente
637 84,26
Tabela 2: Avaliação quanto à identificação do diâmetro externo da íris. Isso ocorre devido a qualidade da imagem e o threshold utilizado para binarizar a região de interesse visto na figura 3 (a e b). Em virtude do limite entre íris e esclera não possuir uma diferenciação adequada dos níveis de cinza da imagem original o resultado final é comprometido. Tal problema não pode ser resolvido apenas alterando o limite para threshold, pois o utilizado foi escolhido em virtude da qualidade das imagens existentes na amostra. A Tabela 3 apresenta os resultados da operação de remoção de cílios e pálpebras.
Remoção da pálpebra e cílios
Imagens %
Não removeu corretamente
36 5,65%
Removeu corretamente
601 94,35%
Tabela 3: Avaliação quanto à remoção das pálpebras e cílios (considerando somente os 637 casos de sucesso do processo anterior). Novamente, isto ocorre em função da qualidade das imagens existentes na amostra. Neste ponto sugere-se um filtro para realce da imagem. Concluindo, das 756 imagens avaliadas, o total de imagens processadas corretamente, com a
1
)(1
2
?
??
??
n
xxS
n
ii
(a) (b)
Figura 3: Região utilizada para obter raio e diâmetro da íris e o resultado do processamento.
WVC´2005 - I Workshop de Visão Computacional
74

identificação correta do diâmetro externo da íris e remoção das pálpebras e cílios foram 601 imagens contra 155 imagens com erros. Estes dados são apresentados na Tabela 4.
Avaliação final Imagem % Sucesso na
segmentação 601 79,5%
Erros na segmentação 155 20,5% Tabela 4: Avaliação final das imagens processadas. A figura 4 apresenta o resultado final do método aplicado sobre uma imagem do banco casia.
4. CONCLUSÃO
O método aplicado foi considerado eficiente e rápido para a finalidade proposta, pois quando aplicado no banco de dados CASIA resultou em aproximadamente 80% de acerto, com um tempo médio de 1 segundo por imagem. O tempo de 1 segundo, também foi considerado satisfatório. O índice de aproximadamente 20% de erro foi considerado aceitável levando-se em consideração que o banco possui imagens imperfeitas, com problemas de resolução, foco, etc. Além do desempenho no tempo de processamento, a íris segmentada apresenta uma maior quantidade de dados isentos de interferências (cílios, pálpebras, etc.) o que contribui efetivamente para os algoritmos de extração de características que visam o reconhecimento. Na continuidade do trabalho, prevê-se a implementação de métodos de threshold dinâmicos, pois foi empregado aqui um threshold fixo, o que influencia parcialmente os 20% de erro do método.
Melhores resultados poderão ser também obtidos eliminando-se, de maneira automática ou manual, as imagens fora de foco e com ruídos.
REFERÊNCIAS [1] Biometrics: Personal Identification in a
Networked Society, A. Jain, R. Bolle and S. Pankanti, eds. Kluwer, 1999.
[2] D. Zhang, Automated Biometrics: Tecnologies and Systems. Kluwer, 2000.
[3] T. Mansfield, G. Kelly, D. Chandler, and J. Kane, “Biometric Product Testing Final Report”, issue 1.0, Nat’1 Physical Laboratory of UK, 2001.
[4] F. Adler, Physiology of the Eye: Clinical Application, fourth ed. London: The C.V. Mosby Company, 1965.
[5] Davision, The Eye. London: Academic, 1962. [6] L. Ma, T. Tan, Y. Wang, D. Zhang, Personal
Identification Based on Iris Texture Analysis, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 25, no. 12, Dez. 2003.
[7] SHIH F. Y., WU Y., “Fast Euclidean distance transformation in two scans using a 3 X 3 neighborhood”, Computer Vision and Image Understanding 93:195-205, 2004.
[8] EGGERS, H., “Two fast Euclidean distance transformations in Z2 based on sufficient propagation”, Computer Vision and Image Understanding 69:106-116, 1998.
[9] PARAGIOS N., ROUSSON M., RAMESH V., “Non – rigid registration using distance functions”, Computer Vision and Image Understanding 89:142-165, 2003.
[10] Banco de imagens de íris CASIA. Disponibilizado pelo Laboratório Nacional de Reconhecimento de Padrões (NLPR), Instituto de Automação (IA) e Academia Chinesa de Ciências. Disponível em: <http://www.sinobiometrics.com> em 10 de abril de 2004.
Figura 4: Resultado final do método para segmentação de íris.
WVC´2005 - I Workshop de Visão Computacional
75

Misturograma – Uma proposta de Quantização do Histograma através da Mistura de Cores
Severino Jr, Osvaldo IMES FAFICA – Catanduva - SP
Gonzaga, Adilson Escola de Engenharia de São Carlos - USP
Resumo
Inspirado na idéia da mistura de cores realizada por pintores, este artigo propõe uma nova metodologia para a quantização de cores em imagens digitais. Um pixel representado no espaço RGB com 24 bits é classificado como uma mistura das cores preto, azul, verde, ciano, vermelho, rosa, amarelo e branco. Uma vez que para cada pixel da imagem pode ser especificado um valor dado pela mistura dessas cores, definimos então o Misturograma para uma imagem. O Misturograma é um histograma quantizado das cores de uma imagem digital baseado no valor da mistura de cores. A aplicação implementada neste artigo demonstra o potencial do Misturograma na recuperação de imagens baseada em conteúdo. Além disso, como emprega a representação binária da cor do pixel, uma das principais características do Misturograma é a possibilidade de implementação através de hardware, o que o tornaria mais rápido e eficiente. 1. Introdução
Desde que considere a cor como uma informação visual causada por um estímulo físico e capturada pelos olhos e decodificada pelo cérebro, a entendemos exercendo influência na vida pessoal e particularmente em um processo de comunicação.
Quando se utiliza a cor como característica para classificação de imagens em CBIR (Content-Based Image Retrival Systems), há uma grande quantidade de valores possíveis, e em razão disso, a sensibilidade na variação ou percepção da cor, tornam a tarefa praticamente impossível. A solução é a quantização do histograma de cores em valores representativos para a classificação ou recuperação da imagem. A quantização do histograma de cores tem sido abordada na literatura de diversas maneiras, com maior ou menor eficiência em cada metodologia proposta. De uma maneira geral, os autores: Subdividem o espaço de cor RGB em 220 subespaços [1]; Subdividem cada canal do espaço de cor RGB em 16 níveis [2]; Reduzem de forma heurística o espaço de cor RGB [3]; Utilizam os dois bits mais significativos de cada canal do espaço de cor RGB [4]; Utilizam o Correlograma que analisa a relação entre as cores de uma imagem [5]; Mapeiam as cores da imagem RGB para o espaço de cor CIELUV [6]; Mapeiam as cores da imagem RGB para o espaço de cor CIELAB [7]; Definem processos adaptativos de clusters do espaço de cor RGB [8]; Utilizam a distância entre cores adjacentes [9]; Utilizam Lógica Fuzzy [10]; Fazem uma compressão do histograma de cores [11].
Por outro lado, analisando a maneira de como uma pintura artística é realizada, nota-se que ela não é executada em uma única vez. O artista utiliza um processo de composição em forma de camadas, ou seja, primeiramente ele introduz uma camada de tinta inicial denominada fundo da tela. Posteriormente, aplica diversas outras camadas constituídas por diferentes cores para, finalmente, alcançar o resultado final. O número de camadas de tinta aplicadas resultará em uma mistura de cores
WVC´2005 - I Workshop de Visão Computacional
76

distribuídas proporcionalmente pelo artista. Utilizando-se deste processo, ele consegue compor uma paleta de cores mais ampla do que as disponíveis comercialmente. Inspirado no processo de pintura artística e aplicando-se o mesmo conceito ao espaço de cor RGB, este trabalho propõe o termo Misturograma. Cada cor neste modelo será composta por uma mistura de cores, na forma de camadas distribuídas em seus canais: R (red), G (green) e B (blue). 2. Mistura de Cores no modelo RGB
Cada pixel no espaço RGB é representado por uma cor C constituída por um vetor de três elementos [12]. Supondo que cada canal seja composto por 8 bits, ou seja
)BBBBBBB,BGGGGGGG,GRRRRRRR (RC 012345670123456701234567=
e analogamente à pintura artística em camadas, estamos definindo uma cor C por 8 camadas ( )i
Bi
Gi
Ri
K ,,= para 7,,0 K=i
onde cada camada Ki é formada pela adição de Ri, Gi e Bi constituindo uma mistura das cores primárias dos canais conforme a Tabela 1.
Tabela 1 – Representação Binária da mistura de cores em uma camada do espaço RGB
( R , G , B ) Cor ( 0 , 0 , 0 ) Preto – ausência de vermelho, de verde e de azul ( 0 , 0 , 1 ) Azul – presença apenas de azul ( 0 , 1 , 0 ) Verde – presença apenas de verde ( 0 , 1 , 1 ) Ciano – mistura de verde com azul (1 , 0 , 0 ) Vermelho – presença apenas de vermelho ( 1 , 0 , 1 ) Rosa – mistura de vermelho com azul ( 1 , 1 , 0 ) Amarelo – mistura de vermelho com verde (1 , 1 , 1 ) Branco – mistura de vermelho com verde e com azul
Temos que:
• Cada camada representa uma proporção de mistura em relação à mistura final. Expressamos esta proporção por:
182
2
−=
i
iP para 7,,0K=i
• Qualquer mistura de cores é, então, discretizada a um valor escalar entre 0 e 7, onde 0 é o valor correspondente à terna (0,0,0) e 7 à terna (1,1,1). O valor V de uma mistura expressa, dessa forma, uma transformação do espaço RGB-3D para um escalar 1D, de acordo com a fórmula:
∑=
−
++=
7
0182
)222(2
i
iB
iG
iRi
V
Portanto, qualquer pixel de uma imagem RGB poderá ser representado por um valor de uma mistura composta por uma determinada porcentagem das cores preto, azul, verde, ciano, vermelho, rosa, amarelo e branco podendo ser utilizado para gerar um Misturograma. O Misturograma é um histograma quantizado das cores de uma imagem digital em função de V.
WVC´2005 - I Workshop de Visão Computacional
77

3. Recuperação de Imagens por similaridade usando o Misturograma como característica Para validação da proposta implementamos uma aplicação em CBIR. Construiu-se um banco de 119 classes com 65 de homens e 54 de mulheres de tamanho 128 x 96 pixels no formato RGB com 24 bits. Previamente escolhidas, cada classe mantém 4 imagens com diferentes expressões, totalizando, desta forma, 476 imagens finais. A figura 1 mostra em a) uma imagem original, em b) e d) são dadas as imagens reduzidas para 8 e 64 cores, respectivamente, empregando simples proporcionalidades entre os canais; em c) e e) são apresentadas as imagens, também, reduzidas para 8 e 64 cores porém utilizando o valor da mistura de cores. Nota-se que a redução pelo valor da mistura de cores permite a segmentação de partes distintas da face como por exemplo cabelo, cílios, olhos e pele. Foram, então, obtidos o histograma de 8 e 64 cores da respectivas reduções para cada imagem do banco.
Figura 1 – Composição de imagens para a aplicação CBIR
A figura 2 mostra a curva precision x recall para as 4 situações anteriores. No caso de 8 cores o desempenho do emprego da nossa proposta é muito superior (ver distanciamento das curvas correspondentes); e próxima das curvas de 64 cores. Considerando o aspecto do espaço de armazenamento e que usando apenas 8 cores é substancialmente inferior ao uso de 64 concluímos a relevância da nossa proposta. Ainda que o número de testes realizados com outras imagens não relevantes, cerca de 2 centenas, as curvas de precision x recall apresentaram em todos os casos analisados os mesmos padrões da imagem apresentada neste trabalho.
Figura 2 – Precision-Recall para 8 e 64 cores nos dois métodos
WVC´2005 - I Workshop de Visão Computacional
78

5. Conclusões Criou-se com este trabalho um novo método de classificação de pixels de uma imagem RGB através da introdução do conceito do valor da mistura de cores primárias e secundárias acrescidas do branco e do preto. A obtenção do valor da mistura de cores pode ser paralelizável e implementado, também, em hardware, pois trabalha ao nível de bit, tornando um dos métodos mais eficientes para a quantização de histogramas RGB fornecendo um recurso de grande valia na composição de vetor de características associado à descrição de uma imagem digital. No momento o trabalho é limitado à característica cor para qual o método mostrou-se eficiente com vantagens no espaço de armazenamento comparativamente ao da proporcionalidade. Nossa intenção é ampliar o vetor de características para englobar, por exemplo, textura. Referências [1] Syeda-Mahmood, T. F. “Data and Model-Driven Selection Using Ccolor Regions”. MIT, 1992. [2] Hafner, J., Sawhney, H. S., Esquitz, W., et al. “Efficient color histogram indexing for quadratic from distance functions”. IEEE Trans. Pattern Analysis and Machine Intelligence, Vol. 17, pp. 729-736, 1995. [3] Mehtre, B. M., Kankanhalli, M. S., Narasimhalu, A. D., et al. “Color Matching for Image Retrieval”. Pattern Recognition Letters, Vol. 16, pp. 325-311, 1995. [4] Pass, G., Zabih, R., Miller, J. “Comparing Images Using Color Coherence Vectors”. Proc Fourth ACM Multimedia Conference, 1996. [5] Mitra, M., Huang J., Kumar, S. R. “Combining Supervised Learning with Color Correlograms for Content-Based Image Retrieval”. Proc. of Fifth ACM Multimedia Conference, 1997. [6] Sclaroff, S., Taycher, L., Cascia, M. L “Image-Rover: A Content-Based Image Browser for the World Wide”. Proc. IEEE Workshop on Content-based Access Image and Video Libraries, 1997. [7] Ciocca, G., Schettini, R. “A relevance feedback mechanism for content-based image retrieval”. Information Processing and Management, Vol. 35, pp. 605-632, 1999. [8] Papamarkos, N., Atsalakis, A. E., Strouthopoulos, C. P. “Adaptive Color Reduction”. IEEE Transactions on Systems, Man and Cybernectics, Vol. 32, No. 1, 2002. [9] Sirisathitkul, Y., Auwatanamongkol, S., Uyyanonvara, B. “Color Image Quantization Using Distances Between Adjacent Colors Along the Color Axis With Highest Color Variance”. Pattern Recognition Letters, Vol. 25, pp. 1025-1043, 2004. [10] Ito, N., Shimazu, Y., Yokoyama, T., et al. “Fuzzy Logic Based Non-Parametric Color Image Segmentation With Optional Block Prossing”. ACM, 1995. [11] Qiu, G., Feng, X., Fang, J. “Compressing Histogram Representations for Automatic Colour Photo Categorization”. Pattern Recognition, Vol. 37, pp. 2177-2193, 2004. [12] Gonzales, R. C., Woods, R. E., and Eddins, Steven L. Digital Image processing using Matlab. Pearson Education : 2004.
WVC´2005 - I Workshop de Visão Computacional
79

COMPARAÇÃO DO DESEMPENHO DOS AUTO-CORRELOGRAMAS DE COR NA BUSCA BASEADA EM CONTEÚDO EM UM BANCO DE
IMAGENS USANDO OS ESPAÇOS DE CORES RGB E HSV
DEPARTAMENTO DE ENGENHARIA ELÉTRICA - EESC - USP Av. Trabalhador São-carlense, 400 - Centro - CEP 13566-590 - São Carlos - SP
Robson Barcellos Tel: (16) 3373-9810 Fax: (16) 3373-9811
[email protected] Rogério Saranz Oliani Tel: (17) 3522-6737 Cel: (17) 9101-6694 [email protected]
Luciana Lorenzi Tel: (16) 3941-6299 Fax: (16) 3941-6299
[email protected] Adilson Gonzaga
Tel: 16) 3373-9326 Fax: (16) 3373-9372
[email protected] ABSTRACT Color auto-correlograms have been shown to excel color histograms, color coherence vectors and color co-occurrence matrices when used as feature vectors in content based image retrieval (CBIR) systems. This is due mainly to their ability to detect the spatial relation of colors. In this work we show that further improvement in the performance of auto-correlograms can be achieved by choosing an appropriate color space. Specifically, when robustness to illumination condition changes is an issue, HSV color space has been proven to be a good choice to work with. 1- INTRODUÇÃO O rápido avanço das tecnologias dos meios de comunicação, como Internet de alta velocidade, utilização de fibras ópticas até próximo das residências (FTTC- Fiber to the Curb ou FTTB Fiber to the Basement), aliado ao desenvolvimento paralelo das velocidades de processamento dos computadores e sua capacidade de armazenamento de dados, fez com que a quantidade de dados de imagens utilizadas nas diversas aplicações profissionais ou de entretenimento tenha crescido assombrosamente. A procura de imagens dentro destes bancos de imagens tornou-se uma tarefa não trivial. Muitas vezes a procura precisa ser feita fornecendo ao programa de pesquisa, uma imagem exemplo (query image) para que sejam extraídas do banco de imagens aquelas que se parecem com a imagem dada. Esta metodologia é conhecida pela sigla CBIR (Content Based Image Retrieval).
WVC´2005 - I Workshop de Visão Computacional
80

Uma discussão detalhada sobre a utilização dos auto-correlogramas de cor em CBIR usando o espaço RGB pode ser vista no trabalho de Huang et al [1], onde é feita uma comparação de desempenho entre auto-correlogramas, histogramas, vetores de coerência de cor (CCVs) e CCV melhorado (CCV/C). Este trabalho apresentada o estudo comparativo do desempenho do auto-correlograma nos espaços de cor RGB e HSV, procurando manter aproximadamente o mesmo número de cores usadas nas quantizações em ambos os espaços. 2- METODOLOGIA. 2.1 O AUTO-CORRELOGRAMA DE COR O auto-correlograma de cor expressa como a correlação espacial de cores muda com a distância, transmitindo a idéia da existência de áreas maiores ou menores de uma determinada cor na imagem. A expressão para o auto-correlograma de cor é dado por: (1) (1)
Em palavras, o valor do auto-correlograma de cor para a cor ci (onde i é o número de cores existentes na imagem) e para uma distância k, da imagem I, é a probabilidade de que, dado um pixel p1 de cor ci na imagem I, exista um pixel p2 também de cor ci a uma distância k do pixel p1. Neste trabalho, foi usado o auto-correlograma para os valores de k = [1,3,5,7]. Também se fez uma quantização de cores nas imagens consideradas com 64 cores para o espaço RGB e 75 cores para o espaço HSV, resultando em um auto-correlograma de 64 linhas e 4 colunas no caso do espaço RGB e uma matriz e 75 linhas por 4 colunas no caso do espaço HSV. 2.2 A QUANTIZAÇÃO DE CORES A quantização de cores é um dos recursos utilizados para reduzir o número de cores efetivamente utilizadas em uma imagem e que consiste em definir, num determinado espaço de cores, regiões que serão representadas por uma única cor escolhida segundo determinados critérios, dentro desta região do espaço. Neste projeto utilizou-se uma quantização linear dentro do cubo RGB, dividindo cada eixo em 4 partes e definindo que todas as cores dentro de cada um dos 64 sub-cubos formados neste processo serão mapeadas na cor que estiver no centro do sub-cubo. 2.3 A INDEXAÇÃO DAS IMAGENS Para simplificar o cálculo do auto-correlograma, utilizamos imagens indexadas. Para isto, numeramos seqüencialmente as linhas do mapa de cor, e atribuímos a cada pixel da imagem indexada, o número da linha do mapa de cores na qual o pixel da imagem original é mapeado. Assim, no nosso caso, cada pixel da imagem indexada assumirá um valor inteiro contido no intervalo de 1 a 64. No espaço HSV o processo é o mesmo, porém a quantização é feita para 75 cores (5 níveis para o eixo H, 3 níveis para o eixo S e 5 níveis para o eixo V) 2.4 O BANCO DE IMAGENS UTILIZADAS Para a formação do banco de imagens, foram obtidas 62 imagens genéricas encontradas em busca pela Internet, que foram ajustadas para o tamanho de 232 pixels de largura por 168 pixels de altura. Para demonstrar mais claramente a robustez do auto-correlograma a variações de luminosidade, usando o espaço HSV, cada uma das imagens foi usada para gerar mais três imagem do banco, semelhantes a primeira, porém com diferentes níveis de brilho. Assim usamos um banco com 248 imagens no total.
]212[Pr)(21 ,
)( kppIpΙ ciIpIcp
kc
ii =−∈=
∈∈γ
WVC´2005 - I Workshop de Visão Computacional
81

2.5 AS DISTÂNCIAS UTILIZADAS Adicionalmente e paralelamente ao estudo da robustez do auto-correlograma a variações de iluminação nos espaços RGB e HSV, analisamos a influência do tipo de distância utilizada para medir a semelhança entre dois vetores de característica (VCs), no desempenho de recuperação de imagens. As distâncias utilizadas foram a euclidiana (L2) e a relativa em L1, conforme descrito em [1] e definida por: onde e são os auto-correlogramas (2) das imagens I1 e I2 . 2.6 A AVALIAÇÃO - GRÁFICO PRECISION X RECALL Para comparar o desempenho do auto-correlograma nos espaços de cores RGB e HSV, quando as imagens sofrem variações de iluminação, usamos gráficos de Precision X Recall, gerando os auto-correlogramas a partir de imagens idênticas, nestes dois espaços de cor. Para gerar os gráficos, utilizou-se um k = 10, isto é, foram usados os valores de precision e recall para as imagens cujo auto-correlograma tem as 10 menores distâncias para o auto-correlograma da imagem base. O valor considerado no gráfico é a média dos valores encontrados. Este processo foi aplicado aos seguintes casos: (1) Base de dados reduzida (100 imagens) e distância Euclidiana; (2) Base de dados reduzida (100 imagens) e distância L1; (3) Base de dados total (248 imagens) com distância Euclidiana; (4) Base de dados total (248 imagens) com distância L1. 3- RESULTADOS Nas figuras Fig. 1 e Fig. 2 estão mostrados os gráficos Precision X Recall onde utilizamos apenas 100 imagens no banco e usamos as distâncias euclidiana (L2) e relativa (L1), respectivamente, para calcular a distância entre auto-correlogramas. Podemos notar que o auto-correlograma no espaço HSV superou em desempenho o auto-correlograma no espaço RGB e que a curva precision X recall no espaço RGB desempenhou levemente melhor com a distância L1. No espaço HSV, porém, a curva foi praticamente insensível ao tipo de distância utilizada. Nas figuras Fig. 3 e Fig. 4 estão mostrados os gráficos Precision X Recall onde utilizamos o banco completo de imagens (248 imagens) e usamos as distâncias euclidiana (L2) e relativa (L1), respectivamente, para calcular a distância entre auto-correlogramas. Podemos notar novamente que o auto-correlograma no espaço HSV superou em desempenho o auto-correlograma no espaço RGB. Fig. 1 Precision X Recall para 100 imagens Fig. 2 Precision X Recall para 100 imagens e e distância euclideana (L2) distância relativa (L1)
)( 1Iicγ )( 2Iicγ)()(1
)()(21
21
IIII
dii
ii
cc
cc
γγγγ++
−=
WVC´2005 - I Workshop de Visão Computacional
82

Notamos também que tanto nos espaços RGB como HSV houve uma ligeira melhoria de desempenho quando foi usada a distância relativa em L1. Porém esta melhora foi tão pequena que podemos considerar a curva insensível ao tipo de distância usada. Fig. 3 Precision X Recall para 248 imagens Fig. 4 Precision X Recall para 248 imagens e e distância euclideana (L2) distância relativa (L1)) Notamos, no entanto, uma queda de desempenho em ambos os espaços de cor, e com o uso de ambos os tipos de distância, quando o banco completo de imagens é utilizado. O fato de mais imagens serem utilizadas piorou os dois resultados. 4- CONCLUSÕES O fato mais marcante que pode ser observado em todos os gráficos é que o auto-correlograma no espaço HSV desempenha sensivelmente melhor do que no espaço RGB, independente do tamanho do banco de imagens e do tipo de distância utilizada. Fato marcante também, é que pudemos mostrar este fato usando um número de cores na quantização, aproximadamente igual nos dois espaços. Isto confirma nossa hipótese, assim como as conclusões das referências [2] e [3], que usam um número maior de cores. A melhora de desempenho quando usada a distância relativa L1 no espaço RGB é muito pequena e é praticamente inexistente no espaço HSV. Nossa conclusão é que o tipo de métrica adotada para calcular a distância entre os auto-correlogramas não é relevante neste caso. A queda de desempenho, tanto em RGB como em HSV, quando aumentamos o número de imagens do banco, deve ser atribuída a maior a probabilidade de que uma imagem, mesmo que diferente da imagem procurada, tenha um auto-correlograma cuja distância para o auto-correlograma da imagem procurada seja menor do que as distâncias de imagens semelhantes. 5- REFERÊNCIAS [1] HUANG, J. et al. (1997). Image indexing using color correlograms. Proc. IEEE ComputerSociety Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, p. 762-768. [2].OJALA, T et al. (2001). Semantic Image Retieval with HSV correlograms. Proc. 12th Scandinavian Conference on Image Analisys, Bergen, Norway, p. 621-627. [3]RAUTIAINEN, M; OJALA T (2002). Color Correlograms in Image and Video Retrieval. 10th Finnish Artificial Intelligence Conference, Oulu, Finland, p. 203-212
WVC´2005 - I Workshop de Visão Computacional
83

Proposta de um Histograma Perceptual de cores como característica para recuperação de
imagens baseada em conteúdo. Kátia Veloso Silva Adilson Gonzaga
Rua Felício Soubihe, 1-25 – Edifício Enseada Cep: 17012-623 Bauru/SP
Telefones: Cel. (14) 9793-3641 Res. (14) 3227-6643 Serv. (14) 4009-3647 E-mails: [email protected] [email protected] [email protected]
Abstract:
This work was developed with the intention of establishing a methodology for the classification of the colors of digital images in perception colors to generate a feature vector that allows to retrieve images by their content from a database. In related works and studies analyzed the methodologies of grouping the diverse possible colors of an image do not allow making an association between the digital colors perceived for human beings. Studies show that the in majority of the cultures human beings associate with the color perception only eleven terms: red, yellow, blue, green, pink, brow, black, white, purple, orange and gray.
Therefore, this work considers a methodology based on rules of the Fuzzy Logic, that allows to associate with all the possible colors of digital images one of the eleven defined cultural colors, thus creating a Perceptual Color Histogram. This will allow the generation of a feature vector for the Content-Based Images Retrieval in a Database.
Keywords: Content-Based Image Retrieval (CBIR); Color Perception; Color Models; Fuzzy Logic; Perception Histogram; Characteristics Vector.
A Recuperação de Imagens Baseada em Conteúdo (CBIR), tem sido bastante utilizada em diversas aplicações, tais como, em banco de imagens médicas, na localização de cópias de imagens na Internet, entre outras. A busca por conteúdo consiste em encontrar numa base de dados uma imagem similar àquela que foi dada como imagem de entrada, ou seja, àquela que se busca pesquisar por similaridade no banco de dados [1] e [2].
As características utilizadas na maioria dos trabalhos em CBIR são: cor, textura e forma. No entanto, a cor apresenta uma quantidade muito grande de valores (16777216 milhões de cores), dependendo da “paleta” utilizada. O uso de todos esses valores como características em um vetor torna assustador o problema da alta dimensionalidade.
Baseado em estudos da psicologia humana e da ciência das cores [10] e [11], este trabalho propõe a geração de um Histograma Perceptual de Cores onde cada uma das possíveis cores de uma imagem digital possa ser agrupada em uma das onze cores culturais concordes com a percepção humana.
No universo das cores, pesquisas mostram que todas as cores existentes podem ser classificadas em apenas onze categorias de cores culturais: vermelho, amarelo, azul, verde, rosa, marrom, preto, violeta, laranja e cinza [3].
Assim, um Histograma Perceptual [2] das Cores será gerado para cada imagem, informando o quanto de cada cor cultural cada imagem contém.
WVC´2005 - I Workshop de Visão Computacional
84

Testes comparativos deverão ser realizados na recuperação de imagens em banco de dados, usando o Histograma Perceptual, usando também todas as cores de uma imagem e comparando-se com outras metodologias que agrupam cores em imagens para a geração do vetor de características. O objetivo deste trabalho é a elaboração de uma metodologia para a classificação das diversas cores existentes em cores culturais (no total de onze cores) e assim buscar uma ou mais imagens iguais ou similares à fornecida como entrada. A metodologia estabelecida para se obter informações sobre o agrupamento das cores culturais foi disponibilizar um Site onde diversas pessoas pudessem acessar e votar na Internet estabelecendo os limites das onze cores culturais.
Isso permitirá a geração de um Histograma Perceptual [3] agrupando em apenas onze todas as cores que fazem parte de cada imagem. De acordo com a classificação de cada uma delas, será criado um vetor de características para a busca em uma base de dados.
As imagens utilizadas para os testes e validação da metodologia de CBIR [4] e [5] serão imagens encontradas na Internet, assim como imagens de faces humanas. Assim, será possível analisar e verificar a eficiência na busca em base de dados [9] utilizando somente as informações das cores, sem qualquer outra característica da imagem.
A metodologia para o agrupamento de todas as cores em apenas onze cores culturais será baseada em um modelo Fuzzy onde as regras serão estabelecidas através do conhecimento humano obtido por meio de uma pesquisa de classificação das cores disponibilizadas na Internet. Para isso foi desenvolvido um Site com o objetivo de se extrair o conhecimento sobre cores de um maior número de usuários possível e com isso estabelecer as regras Fuzzy [8] que classificassem as cores em cores culturais gerando assim o que chamamos de Histograma Perceptual de Cores.
Alguns trabalhos com classificação de imagens coloridas utilizam o conceito de cores culturais, no entanto, não se descreve a metodologia para a classificação das diversas cores de uma imagem em cores culturais (como por exemplo, nos trabalhos [6] e [7]).
Com o intuito de simplificar o processo de aquisição do conhecimento, antes de serem lançadas no Site, as cores foram classificadas preliminarmente. Algumas pessoas foram contactadas pessoalmente a dar sua opinião e de acordo com um consenso geral essas imagens não foram inseridas nas imagens do Site, pois tiveram cem por cento de votação em uma única cor, não havendo necessidade das mesmas serem inseridas, pois o universo de imagens seria muito grande. A Figura 1.0 mostra a paleta de cores que foi apresentada as pessoas para aquisição das informações. Aquelas que houve divergências foram inclusas no Site para votação.
Figura 1.0 – Paleta de cores
O modelo de cor utilizado foi o HSV (Hue/Saturation/Value). Esse modelo traz uma
visualização melhor que o modelo RGB(Red/Green/Blue) e é compreendido melhor pelos monitores do que modelo CIE, pelo fato do modelo CIE possuir mais cores do que o monitor de vídeo consegue
WVC´2005 - I Workshop de Visão Computacional
85

interpretar. Durante os testes, o modelo HSV mostrou-se mais nítido, mais claro perceptualmente e apresentam resultados melhores para se trabalhar com imagens coloridas.
O Site possui um total de 417 figuras e foi disponibilizado do servidor da USP, através do link: (http://iris.sel.eesc.sc.usp.br/tutorial). As páginas foram construídas em PHP (Hypertext Preprocessor), uma linguagem de programação utilizada para desenvolvimento de Web-Sites. Para o armazenamento das informações foi utilizado o banco de dados MySQL (My Structured Query Language), pela facilidade e segurança em se trabalhar com dados.
O Site foi disponibilizado em duas versões: Português e Inglês, conforme mostra a Figura 1.1.
Figura 1.1 – Versões do Site que foram disponibilizadas (Português e Inglês)
O total de dados colhidos das votações é mostrado no Gráfico 1.0. Os dados referem-se ao
período de Janeiro a Abril de 2005 totalizando 4.529 votos.
24 56 74 131 164
439 462 510 583711
1375
0200400600800
1000120014001600
Branc
oPre
to
Lara
nja
Amar
elo
Verm
elho
Mar
rom
Rosa
Cinza
Azul
Verde
Violet
a
Gráfico 1.0 – Resultado da Votação
Os resultados estão sendo avaliados principalmente no que se refere à interpretação humana de
acordo com um determinado contexto e como isso influencia na hora do reconhecimento. Uma mesma cor dependendo de um contexto pode parecer outra. As cores parecem mudar de tonalidade, a
WVC´2005 - I Workshop de Visão Computacional
86

percepção se mistura com o conhecimento adquirido de outras cores. Uma observação interessante é que parece haver dificuldades em classificar cores dos tons azul e violeta. Referências: [1] FLANK, S.; MARTIN, P.; BALOGH, A.; ROTHEY, J. (1995). A digital library for image retrieval. In: PROC. OF INTERNATIONAL CONFERENCE ON MULTIMEDIA COMPUTING AND SYSTEM. Washington: IEEE Computer Society. [2] WANG, S. (2001). A Robust CBIR Approach Using Local Color Histograms. Alberta: University of Alberta – Department of Computing Science. [3] BERLIN, B.; KAY, P. (1991). Basic Color Terms. California: Berkeley. [4] RUI Y., HUANG, T. S.,CHANG, S. F. (1999). Image retrieval: current techniques, promising, directions, and open issues. Journal of Visual Communications and Image Representation. p.39-62. [5] JACOBS, C. E.; FINKELSTEIN, A.; SALESIN, D. H. (1995). Fast Multiresolution Image Querying. Computer Graphics. p.277-286. [6] MENG, Y.; CHANG, E., LI, B. (2004). Enhanced DPF for Near-replica Image Recognition. Electrical & Computer Engineering Department. University of California. Santa Barbara. [7] QAMRA, A; MENG, Y; CHANG, E. (2004). Enhanced Perceptual Distance Functions and Indexing for image replica Recognition. Department of Computer Science and Electrical & Computer Engineering Department. University of California. Santa Barbara.
[8] KING, P. J.; MANDANI, E. H. (1977). The application of fuzzy control systems to industrial process. Automática. p.235-242. [9] GUIMARÃES, S. J. F.; ARAÚJO, A. A. (2003). Recuperação de Informação com base no conteúdo visual. Minas Gerais: Universidade Federal de Minas Gerais (UFMG) - Núcleo de Processamento Digital de Imagens. [10] EVANS, R. M. (1948). An Introduction to Color. New York: Wiley. [11] GOLDSTEIN, E. B. (1989). Sensation and Perception. 3.ed. California: Wadsworth Publishing Company.
WVC´2005 - I Workshop de Visão Computacional
87

Human Face Detection Using Genetic Algorithm
Matheus Borges Alves EESC/USP
Rua 38, 2212 Barretos-SP
(17) 3325-5268 [email protected]
Rodrigo Antonio Faccioli EESC/USP
Rua Tranquilo Pavan, 42 Sertãozinho-SP (16) 3945-5917
Adilson Gonzaga EESC/USP
Av. Trabalhador São-carlense, 400 São Carlos-SP (16) 3373-9326
Abstract A face detection algorithm is proposed. Using genetic algorithms, the face is approached to an ellipse and the image is detected. The following subjects will be board: genetic algorithm and face detection. Introduction Digital images have a huge information and characteristics quantities. But until today, a complete efficient mechanism to extract these characteristics in an automatic way, is yet unknown [1]. Referring to facial images, its detection in an image is a problem that requires a meticulous investigation due to its high complexivity. The usage of these images is very wide, such is the security systems case, where it can be used for remote conference, search in database, people identification, and so on [1]. The increase of terrorist attacks motivates countless works in this segment. Security cameras are placed in supermarkets, shopping centers, subways, downtown, parks, buses, and so on, trying to help the identification of guilty people, besides reducing crimes [2]. Unfortunately, until now, security systems need human supervisee, which causes a significant number of failures. Here, we propose an investigation of the Genetic Algorithms technique application in facial detection, one step to face recognition. According to [3] the Genetic Algorithms (GA's) are characterized as one search technique inspired by Darwin Evolutionist Theory, shaped using some selection mechanisms used in Nature, according with that individuals who
are abler in a population are those who have more survival possibility, when adapting themselves more easily to the changes that occur in their habitats. 1. Face Detection An important task to be carried out in the Systems of Recognition of Faces is to detect the presence of a face in a determined region of the image. To detect the face before trying to recognize it saves a lot of work, as only a restricted region of the image is analyzed, opposite to many algorithms which work considering the whole image. The techniques of face detention are divided in basically three main methods which are: Methods Based on Invariable Characteristics, Methods Based on the Appearance, Methods Based on Knowledge. 1.2 Methods Based on Knowledge The methods based on knowledge represent the techniques of detection of faces that use some basis of rules established from the previous knowledge about the problem, in other words, methods which have rules that define what a face is, according with the knowledge of the researcher [5]. Moreover, these elements are distributed in specific ways on the face. With this knowledge it is possible to establish rules to identify a human face. One example is the Methods Based on Templates [6]. One classic technique to detect objects is to look for them inside the image and to test if they correspond to a previous model belonging to their shapes. One of the most common ways to shape the form of an object is describing it by its basic geometric components, such as circles, squares or triangles, this technique is called template. The detection of the object, therefore, will consist of finding the best correspondence,
id18834500 pdfMachine by Broadgun Software - a great PDF writer! - a great PDF creator! - http://www.pdfmachine.com http://www.broadgun.com
WVC´2005 - I Workshop de Visão Computacional
88

defined by an energy function, from the object in the image and its mold (template). In the case of detection of faces the most used template is that one which treats the face as an ellipse [7]. The usage of this model usually involves the search for the object in the image that can be made by using heuristical or genetic algorithms. As such technique is extremely flexible being able to be used to detect any possible object that can be represented by geometric forms. A variation of this technique which shows better results is the deformable templates. These are flexible ones, making possible the adjustment of its size, width and other parameters to match with the data [8]. 2. Genetic Algorithms According to [2], Genetic Algorithms (GA´s) are characterized like a search technique inspired in the Evolutionist Theory by Darwin, shaped using some selection mechanism like used by Nature, in which individuals (chromosomes) more adapted of a population are the ones that have more survival chances, by getting used easily to changes that occur in its environment. This makes the algorithm strong and fast, being designate to a determined type of optimization, where the search space is too big and the conventional methods become inefficient [3]. Another GA´s important characteristic is that they result a set of solutions and not only one solution. An algorithm can be described in six steps: (1) Start a population of N size, with chromosomes generated randomly; (2) apply fitness to each chromosome of population; (3) Make new chromosomes through crossings of selected chromosomes of this population. Apply recombination and mutation in these chromosomes; (4) Eliminate members of old population, in order to have space to insert these new chromosomes, keeping the population with the same N chromosomes;
(5) Apply fitness in these chromosomes and insert them in the population; (6) If the ideal solution will be found or, if the time (or generation number) depleted, return the chromosome with best fitness. Otherwise, come back to the step 3. 2.2 Fitness Responsible for joining the genetic algorithm to the problem properly said, the fitness is used by the reproduction operators to evaluate the chromosomes. It has a chain of bites as entrance argument and as return a real value. Due to, not always, possess some method to evaluate how much a chromosome is far from the solution, a heuristic can be used to assist to find the solution ideal. 2.3 Selection The election occurs after the fitness application in the chromosomes, exercising the function of natural election in the evolution, choosing to survive and to reproduce, the organisms with better fitness value. There are countless methods of election, but it is certain that, in the most methods, the chromosomes that possess a better adaptation will have a higher probability to survival and reproduction. 2.4 Reproduction Is the way for which two new chromosomes is generated, from two old ones. This process depends on two parameters chosen a priori by the developer/operator, which are: the recombination probability ("crossover"), denoted for pc and the mutation probability, denoted for pm, being typical values for pc between 0.5 to 1,0 and for pm between 0,001 to 0,02 [4]. 3. Genetic algorithm face detention To follow will be presented a genetic algorithm for face detention. This process is divided in
WVC´2005 - I Workshop de Visão Computacional
89

two parts: the pre-processing and the application of the Genetic Algorithm. 3.1 Pre-processing phase This process consists basically of three steps: Reduction of the size of the image: The original size of the images is 256 by 256 pixels; this size is reduced to 128 by 128 pixels. Reduction of noises: It is necessary to use the median filter, the mask used is the 3 x 3, making the image cleaner and false positives are more difficult to be joined. Detection of edges: The method used for detection of edges was the application of the filters of Sobel. The result is a binary image: the background is black (0) and the edges are white (1).
The original and the pre-processed image.
3.2 Genetic Algorithm After performing the pre-processing phase it is possible to use the Genetic Algorithm, which consists basically of making a search in the image for the object that most resembles to an ellipse of a proportional ratio of 1.5:1, which will probably be the image of the face. In the literature it is common to adopt the frontal angle ratio as being 1.5:1. This is a Method Based on Knowledge, and to be more specific, it is the method of the deformable Templates, since it is known that the face resembles to an ellipse.
The individuals, in this case the ellipses, are written using a binary form, assuming that each individual has four chromosomes respectively: Position X, Position Y, Ratio of X, Ratio of Y. These chromosomes in conventional algorithms would be seen as variable with the coordinates of the ellipse; however in genetic algorithms these chromosomes form only one string (individual). Each chromosome has the size of 7 bits, as illustrated below:
Position of X = 112 1110000 Position of Y = 27 0011011 Ratio of X = 75 1001011 Ratio of Y = 50 0110010
Individual 1110000001101110010110110010
Image of the individual
The first step is to generate the initial population with 100 individuals. Each individual is generated of random form, with just one restriction the rays of X and Y must be in the proportional measurement of 1.5:1 no restriction is made regarding the ellipse size or position, because the image can have a very big face, or a very small one. The fitness function is defined by the number of white pixels present in the image of the individual and in the pre-processed image in same position X,Y (this value we will call NA), divided by the number of white pixels white contained in the image of the individual (this value we call NB).
WVC´2005 - I Workshop de Visão Computacional
90

In green the pixels present in the individual and in the pre-processed image in the same position.
NA / NB = Fitness value
The selection process is made in an automatic form, without passing for the match or roulette method, for example. The 20 individuals with the biggest value of fitness are selected for reproduction. However with 20 individuals, following the reproduction concept is only possible to generate others 20 new individuals. Because of that, the pairs are interchanged among themselves, until the new generation of 100 individuals is generated. The reproduction is made in two points, and these points are chosen in a random form. The mutation is made after the reproduction process. This process is repeated 150 generations, each generation with 100 individuals. At the end the individual with the highest value of fitness will be shown in the last generation, which will probably be the region where the face in the image is. Results The resolution of the tested images is 256 by 256 pixels, all of them compacted in the JPG format and gotten from the Internet in frontal angles. In the case of images with the non complex background, the algorithm showed to be efficient, even if the face has a beard, a mustache, long hair, glasses etc. However in the cases where we have a complex background the algorithm showed inefficiency in the great majority of the times. Due to the fact of the algorithm always compare each pixel of the images, this is a slow algorithm, it takes around three minutes to detect a face running in Mat lab 7.0, in a computer with a processor of 1.8 GHz and 256 of memory RAM. Conclusion In this paper, a method to detect human face regions was proposed. In the case of images with the non complex background, the algorithm showed to be efficient. Certainty, the
genetic algorithms can be used in such a way to solve an infinity of problems in computer vision and in other areas.
References [1] = Yen, G.G.; Nithianandan, N. (2002) Facial Feature Extraction Using Genetic Algorithm. IEEE. pp 1895-1900 [2]=Ambrósio P. E. (1997) Algoritmos Genéticos Uma Introdução. Revista da Universidade de Franca. pp 11-12 [3]=Pastorino A. S. - Algoritmos Genéticos: Aplicações e Perspectivas. UCPel. pp 1-9 [4]=Barcellos J. C. H. (2000) Algoritmos Genéticos Adaptativos: Um estudo comparativo. USP. pp 1-143 [5] = Chun-Hung; Ja-Ling.(1999) Automatic facial feature extraction by genetic algorithms. IEEE. [6] = Roberto B; Tomaso P. (1993) Face Recognition: Features versus Templates. IEEE. pp 1042 1052 [7] = Yuki Y; Masafumi H. (1996) - Human faces detection method using genetic algorithms. IEEE. pp 113 -118 [8] = Alan L. (1989) Feature extraction from faces using deformable templates. IEEE. pp 104 -109
WVC´2005 - I Workshop de Visão Computacional
91

Identificação de Impressões Digitais Através de Função de Distância Métrica
Evandro JardiniFundação Educacional de Fernandópolis
Departamento de Informática - [email protected]
Adilson GonzagaSEL/EESC-USP São Carlos
Caetano Traina Jr.ICMC-USP São [email protected]
Abstract
The individuals’ identification through fingerprint is very used. The fingerprint is formed since the first monthsof the human being’s life and it stays unaffected during its life. This paper presents an innovative method offingerprint identification based on metric distance function.
1 Introdução
O método tradicional de reconhecimento e validação de indivíduos recaem sobre um identificador e uma senha.Este método, apesar de ser muito utilizado, possui graves problemas que sugerem sua troca por outros. Algunsproblemas que podem ser citados é o esquecimento, roubo, cópia indevida, perda, etc. Muitos usuários de compu-tador, por exemplo, menosprezam uma situação de ataque via rede e não se preocupam e tomar atitudes básicas desegurança, como senhas seguras, configuração correta de arquivos compartilhados via rede, etc. O resultado distosão arquivos danificados ou roubados, débito indevido na conta bancária, etc. O ideal é o uso de uma tecnologiaque torna difícil uma pessoa não autorizada passar-se por outra. Devido estes problemas citados, o uso de caracte-rísticas biométricas vem sendo empregado em diversas situações através de equipamentos, algoritmos, técnicas deextração de características, etc.
A Biometria é um conjunto de métodos automatizados, com base em características comportamentais (gestos,voz, escrita manual, modo de andar e assinatura) e fisiológicas (impressão digital, face, geometria da mão, íris,veias da retina, voz e orelha). Estas características são chamadas de identificadores biométricos.
Este artigo propõe uma metodologia original de identificação de impressões digitais baseado em uma funçãode distância métrica.
2 Impressão Digital
A impressão digital é formada por sulcos presentes nos dedos. A parte alta dos sulcos é denominada de crista e abaixa de denominada de vale. Para o reconhecimento de impressões digitais, as cristas apresentam as característicasdesejadas. Seguindo o fluxo das cristas nota-se a formação de dois pontos característicos usado para a identificação
1
WVC´2005 - I Workshop de Visão Computacional
92

de indivíduos, as minúcias. Dos tipos existentes de minúcias, os dois mais utilizados para o reconhecimento deimpressões digitais são: i) minúcia do tipo cristas finais e ii) minúcia do tipo cristas bifurcadas.
A literatura de trabalhos biométricos realizados sobre impressões digitais é vasta. Freqüentemente, as pes-quisas recaem sobre as áreas de classificação de impressões digitais [1], detecção de minúcias [2] e processo dereconhecimento automático de impressões digitais [3]. Outra área que vem surgindo é o processo de indexação debanco de dados formados por impressões digitais [4], visto que existem grandes quantidades de impressões digitaise existem a necessidade de localização rápida.
3 Indexação em Banco de Dados de Imagens
As imagens são armazenadas com a finalidade de serem recuperadas por consultas realizadas sobre elas através deseus próprios atributos. Para suportar essas consultas, uma imagem armazenada em um Banco de Dados de Imagem(BDI) deve ser previamente processada para extração de suas características. Estas características são usadas parabusca no BDI e determinar qual imagem satisfaz o critério de seleção da consulta. Usualmente, existem doisgrupos de métodos para a indexação de imagens que são o Método de Acesso Espacial (MAE) e o Método deAcesso Métrico (MAM). O primeiro foca as buscas baseado em um vetor de espaços de coordenadas X e Y dosobjetos. O segundo é utilizado para indexar dados complexos usando as distâncias entre os objetos. Para isto, osobjetos devem estar contidos em um espaço métrico.
Um espaço métrico é uma coleção de objetos e uma função de distância definida sobre eles. Uma função dedistância
para um espaço métrico deve possuir as seguintes propriedades: i) simetria: d(
) = d(
), ii)
não negatividade: 0 < d(
) < se
e d(
) = 0 e iii) desigualdade triangular:
Uma vez que um objeto pertence a um espaço métrico, pode-se utilizar estrutura de indexação sobre eles paraacelerar o processo de busca. Das diversas estruturas existentes de indexação pertencentes aos MAMs, tem-se aSlim-tree. Esta estrutura foi criada por [5]. Ela, diferente de outras MAMs como a vp-tree, gh-tree e mvp-tree entreoutras, não é estática. Isto significa que permite que novos objetos sejam inseridos e retirados dinamicamente.A estrutura de dados da Slim-tree segue a mesma idéia de outras árvores métricas onde os dados são inseridosnas folhas e o balanceamento é feito pela altura. Outra semelhança é que a intersecção dos subespaços métricosdefinidos pelos nós de um mesmo nível pode não ser vazia. Ou seja, a divisão do espaço métrico não gera regiõesdisjuntas.
4 Identificação de Impressões Digitais
Este trabalho propõe uma função de distância para identificação de impressões digitais. A idéia principal dotrabalho pode ser observada pelo esquema do diagrama de blocos da figura 1.
A tarefa de identificação da impressão digital é dividida em duas fases denominadas de fase 1 e fase 2. Nafase 1, tem os objetivos de criar e armazenar em um banco de dados, os vetores de características das impressõesdigitais. As características extraídas de uma impressão digital dizem respeito as minúcias pertencentes a mesma esão: as coordenadas X e Y da minúcia, a direção da minúcia e uma lista de minúcias vizinhas contendo tambémsuas coordenadas e direções. Todas estas informações são armazenadas em um vetor de características e este éarmazenado em um banco de vetores de características.
Na fase 2, tem-se as mesmas operações da fase 1 além da aplicação de uma função de distância métrica (de-senvolvida neste trabalho) sobre os vetores de características. A função de distância métrica retorna a lista das 10
2
WVC´2005 - I Workshop de Visão Computacional
93

Fase 1
Imagem deImpressãoDigital
Extração dascaracterísticas
Criação e Amazenamentodo Vetor de Características da Impressão
Digital
Banco de Vetores deCaracterísticas
de Impressão Digital
Lista das 10 Impressões Digitaismais semelhantes
Fase 2
Imagem deImpressãoDigital
Extração dascaracterísticas
Cálculo daDistância Métricada Impressão
Digital
Criaçãodo Vetor de
Característicasda Impressão
Digital
Figura 1: Diagrama da Metodologia Proposta
impressões digitais mais semelhantes.
4.1 Resultados iniciais
Foram realizados testes em uma base de dados contendo em torno de 840 impressões digitais. Destas, 21 sãoimpressões digitais diferentes. Cada impressão digital foi capturada 8 vezes. Para cada imagem de impressãodigital, foram criadas 4 outras imagens, sendo que duas contém rotações (com um e dois graus respectivamente)para esquerda e duas com rotações para direita.
Para efeito do teste, foram consideradas somente as imagens das impressões digitais originais, sem o processode rotação o que resultou num universo de 163 impressões digitais. O objetivo deste teste é indicar a precisão doalgoritmo de verificação. O resultado pode ser observado no gráfico da figura 2.
Nota-se pela figura que a taxa de acerto foi de 94% das impressões digitais disponíveis contra uma taxa de errode 6%. Pelo teste realizado, há o indício que o algoritmo proposto está trabalhando de forma satisfatória. Um outrofator que está sendo levado em consideração é o tempo gasto no processo de verificação de uma impressão digital.Os testes de desempenho indicaram um tempo médio de 2 segundos para a verificação das 840 impressões digitais.Para este teste realizaram-se buscas seqüenciais de todas as impressões digitais.
5 Conclusão
Este artigo demonstrou uma proposta inovadora de identificação de impressões digitais através de função de dis-tância métrica. Os testes iniciais realizados apresentam resultados promissores. Este trabalho ainda está em desen-volvimento e deverão ser realizados testes em uma base de impressões digitais maior, além da inserção da funçãode distância métrica na estrutura de indexação Slim-tree.
3
WVC´2005 - I Workshop de Visão Computacional
94

Figura 2: Gráfico demonstrando as taxas de acerto e de erro do algoritmo para um universo de 163 impressõesdigitais
Referências
[1] D. Maio and D. Maltoni, “A structural approach to fingerprint classification,” IEEE Proceedings of ICPR’96,pp. 578–585, 1996.
[2] F. Zhao and X. Tang, “Preprocessing for skeleton-based fingerprint minutiae extration,” CISST InternationConference, pp. 742–745, 2002.
[3] A. Jain, L. Hong, S. Pankanti, and R. Bolle, “An identity authentication system using fingerprints,” Proceedingsof the IEEE, vol. 85, no. 9, pp. 1365–1388, september, 1997.
[4] R. S. Germain, A. Califano, and S. Colville, “Fingerprint matching using transformation paremeter clustering,”IEEE Computational Science and Engineering, vol. 4, no. 4, pp. 42–49, 1997.
[5] C. TRAINA Jr., A. Traina, B. Seeger, and C. Faloutsos, “Slim-Trees: High performance metric trees minimi-zing overlap between nodes,” Lecture Notes in Computer Science, vol. 1777, pp. 51–65, 2000.
4
WVC´2005 - I Workshop de Visão Computacional
95

DETECÇÃO DE FACES HUMANAS EM IMAGENS DIGITAIS: UM ALGORITMO BASEADO EM LÓGICA NEBULOSA.
Andréia Vieira do Nascimento - [email protected]
Adilson Gonzaga - [email protected] Laboratório de Visão Computacional – LAVI, Departamento de Engenharia Elétrica – SEL
Universidade de São Paulo – USP, Av. Trabalhador São-Carlense, 400 – 13566-590 São Carlos, São Paulo, Brasil, Tel/fax 3373 9371
Abstract
The present paper aims to develop a methodology based on Fuzzy Pattern to detect human faces in digital images.
Considering that “ people are easily able to recognize human faces”, this study foresees the research of the relative information to this recognition using the acquired results, in a “Fuzzy” scheme, for the identification of human faces in digital images. It´s proposed an algorithm which automatically classifies or not the regions of an image in human faces. It is based on the information acquired from people by means of a field research where the answers are stored numerically for the creation of the fuzzy classification. Drawings “line-draw” were created to represent human faces and were presented to the people interviewed to give information for the creation of the fuzzy rules. After that the algorithm was able to identify human faces in digitalized images.
Key Works: Face detection, Fuzzy Logic, Biometry, Image Processing.
1. Introdução A detecção e o reconhecimento de faces humanas é uma área muito promissora, é uma das áreas mais
desafiadoras no campo da visão computacional e do reconhecimento de padrões [YOW & CIPOLLA, 1997]. A face humana é o principal atributo anatômico através da qual as pessoas são reconhecidas. Este fato
sugere o desenvolvimento de sistemas automáticos de detecção, rastreamento e reconhecimento facial e promovem aplicações como autenticação de usuários, monitoramento de ambientes, controle de acesso, vigilância, etc.
Inserido no contexto do Sistema de Visão Artificial, o processo de detecção e reconhecimento de faces humanas em cenas tem crescido significativamente. No campo científico e no campo comercial, buscam-se melho-rias na interface entre homem e máquina, por meio do reconhecimento facial. 2. Metodologia 2.1 Pesquisa de campo
Para determinação dos graus de pertinência “Fuzzy”,foi desenvolvida uma pesquisa de campo realizada com 100 pessoas, durante quatro meses. Foram gerados 100 desenhos representativos de faces humanas (“line-draw”) medindo 5 x 5 cm, baseados em imagens processadas. Esses desenhos foram mostrados isoladamente a diferentes pessoas que classificaram dentro de uma escala de 0 a 100, cada um deles considerando semelhança com uma face humana ou não. A Tabela 1 mostra o resultado parcial dessa classificação.
Figuras 13 14 15 16 17
Graus de pertinência
50% 38% 55% 55% 64%
TABELA 1 Conjunto de faces, contendo o grau de pertinência.
WVC´2005 - I Workshop de Visão Computacional
96

Preenchimento de região erosão
2.2. Banco de imagens As imagens de entrada do algoritmo são compostas por dois bancos de imagens, o de Treinamento é
composto apenas de imagens de faces, adquirido do Departamento de Psicologia da Universidade de Stirling (PICS), o banco de imagens teste é composto de 76 imagens de faces e 24 imagens não-faces, formado por ima-gens adquiridas de alguns “sites” da Internet, como Galeria de Fotos, Símbolos de futebol, etc. Ambos são constitu-ídos de 100 imagens.
As imagens possuem resolução espacial aproximadamente de 274 x 350 pixels. Todas as imagens utili-zadas no algoritmo estão em níveis de cinza. A opção de utilizar imagens em escala de cinza baseou-se no fato de não haver necessidade do uso de cor durante a segmentação da imagem. 2.3. O algoritmo
O algoritmo de classificação desenvolvido nesta pesquisa foi implementado no MATLAB versão 6.5, dadas às facilidades dos “Toolboxes” de processamento de imagens e Lógica “fuzzy”. O algoritmo é composto de 3 etapas, conforme mostra a Figura 1.
FIGURA 1 Etapas do algoritmo
O pré-processamento aprimora a qualidade da imagem, corrigindo diversas imperfeições, por meio do
alargamento de contraste e o filtro da mediana. A segmentação divide a imagem em suas partes significativas. Primeiramente foi utilizado o operador de
Sobel para detecção das bordas. Depois foram aplicados filtros morfológicos como: dilatação, preenchimento de região e erosão para segmentar a imagem. Com a imagem segmentada foram realizadas a localização e a marcação com cores determinadas nas características faciais. Finalmente, o algoritmo, por meio de um classificador nebulo-so, classifica a imagem de entrada de acordo com o grau de pertinência.
2.3.1. Pré-Processamento
As técnicas de pré-processamento são utilizadas para corrigir diversas imperfeições, tais como: realce, contraste e/ou brilho inadequado, remoção de ruído, (especialmente as bordas) partes incompletas ou indevidamen-te conectadas. O pré-processamento foi constituído de 2 etapas como mostra a figura 2.
FIGURA 2. Etapas para realização do pré-processamento
O alargamento de contraste consiste no aumento da escala dinâmica dos níveis de cinza da imagem sen-do processada. Essa condição preserva a ordem dos níveis de cinza, impedindo a criação de artefatos na intensidade da imagem processada. A seguir, é aplicado o filtro da mediana, utilizando-se a vizinhança 3x3. Esse filtro não somente reduz ruído como preserva as bordas da imagem, forçando os pontos com intensidades distintas a asseme-lharem com seus vizinhos. 2.3.2. Segmentação
A tarefa básica da etapa de segmentação é de dividir uma imagem em suas unidades significativas.Para realizar a segmentação foram realizados quatro procedimentos básicos, como mostra a figura 3.
FIGURA 3 Etapas da segmentação
Pré-processamento Segmentação da imagem
Localização das características
Classificação da imagem
Imagem de entrada Alargamento de contrate Filtro da mediana Resultado do pré-
processamento
Operador de Sobel abertura
Imagem de entrada
WVC´2005 - I Workshop de Visão Computacional
97

As bordas na imagem caracterizam os contornos dos objetos e são bastante úteis para segmentação e i-dentificação das características. Para detecção e realce das bordas, foi aplicado o Operador Sobel, pois consegue um desempenho satisfatório na detecção das características faciais, como também o contorno.
As operações morfológicas utilizadas foram: a dilatação, em que uma pequena área relacionada a um pi-xel é alterada para um dado padrão; o preenchimento de região que preenche as regiões fechadas; e a erosão, onde os pixels que não atendem a um dado padrão são apagados da imagem. A imagem segmentada passou por 4 pas-sos para localização das características faciais como mostra a figura 4.
FIGURA 4 Localização das características faciais
A abertura de área visa à remoção de pequenos objetos e/ou ruídos da imagem binária. O redimensiona-mento da imagem para 350 linhas e 250 colunas padroniza as figuras para facilitar a busca das características faci-ais. A conversão da imagem em RGB prepara a imagem para receber as cores determinadas.
Realiza-se uma varredura na região mais provável de se encontrar os olhos, ou seja, nas linhas 155 até 180 e nas colunas 55 até 110 para encontrar o olho direito, nas linhas 155 até 180 e colunas 115 até 180, para o olho esquerdo. Localizando-se um agrupamento de pixels brancos esses são coloridos. No caso do olho esquerdo, em cor verde, e do direito, na cor azul claro. Após marcar essas regiões é realizada a contagem desses pixels para que sejam representados os olhos nas funções de pertinência. Foram alteradas as coordenadas para localizar a região do nariz e boca e marcá-las nas cores especificadas. Para o nariz, a cor foi o azul e, para a boca, a vermelha.
Após colorir as características faciais é feita a análise da assinatura vertical, essa técnica é uma espécie de histograma da imagem, mas ao invés de relacionar as cores da imagem, relaciona a quantidade de pontos brancos em cada linha possibilitando a detecção das coordenadas verticais. 2.4. Classificação
Para classificar as imagens é utilizado um classificador baseado na lógica “Fuzzy”. Essa abordagem foi proposta devido ao caráter dos dados, ou seja, as regras de inferência dependem do conhecimento humano obtidos por meio da pesquisa de campo. A classificação possui 3 principais passos:
A base de conhecimento compreende a base de regras e a base de dados. − A base de regras é formada por um conjunto de regras lingüísticas que definem a estratégia de contro-
le do sistema. − A base de dados é formada pelas definições dos conjuntos “Fuzzy” obtidos através da pesquisa de
campo. A máquina de inferência é responsável por obter conjuntos “fuzzy” de saída, infere ações de controle
empregando implicações “fuzzy”, operando com composições de máximo (OR) ou mínimo (AND). O processo de desfuzzificação é responsável por gerar uma saída precisa. Isso se dá por meio de diferen-
tes métodos, como a média dos máximos, altura máxima e centróide. A classificação das faces foi realizada utilizando os “toolboxes” de lógica “fuzzy” no MATLAB. Ele
possui uma série de comandos que permitem configurar um sistema, adequar o número de entradas e saídas, gerar as funções de pertinências para cada entrada e saída, especificar os métodos de máximo e mínimo, implicação a-gregação e centróide. O MATLAB cria um arquivo “.FIS”. Esses sistema possui comandos que possibilitam dar a entrada e obter a saída a um sistema nebuloso.
Abertura de área redimensiomento Segmentação das características
Assinatura das bordas
WVC´2005 - I Workshop de Visão Computacional
98

3. Resultados Estabelecendo um limiar de 50%, o índice de desempenho do algoritmo com as imagens do banco de treinamento
foi de 86%, obtendo apenas dois falsos negativos como mostra a tabela 2, porque durante segmentação as características faciais foram perdidas, induzindo o classificador a um falso negativo.
Numero de Imagens
Graus de pertinência
Classificação
43 imagens 100% Face 11 imagens 86% Exatamente semelhante 23 imagens 64% Semelhante 09 imagens 50% Ligeiramente Semelhante 12 imagens 38% Nenhuma semelhança 02 imagens 12% Não face
Tabela 2 Resultados do Banco de imagens padrão
Para testar a eficiência do algoritmo, considerando que imagens com até 50% de grau de pertinência são pertencentes ao conjunto de faces, o desempenho do algoritmo foi de 62% de acerto. Das 27 imagens classificadas como não face, 19 foram classificadas corretamente, sendo 3 falsos positivos e 5 falsos negativos. 4. Conclusões
O sistema de detecção de faces através da metodologia proposta é inovador e demonstrou ser eficiente. O uso de um conjunto de imagens padronizadas apresentou um resultado com baixo nível de falsos positivos e, principalmente, ressaltou a capacidade do método de ser flexível, obtendo um índice de 86% de acerto.
No banco de imagens teste, foram obtidos bons resultados por serem imagens não padronizadas, mos-trando a versatilidade da metodologia aplicada. Dentre as 100 imagens testes, o algoritmo proposto obteve 62% de acerto, apresentando somente 3 falsos positivos e 5 falsos negativos.
A Lógica nebulosa mostrou-se como uma ferramenta importante de trabalho em um contexto de infor-mações, muitas vezes, incertas e imprecisas. O conhecimento humano mostrou-se fundamental para determinar as regras nebulosas, podendo facilitar os caminhos para se alcançar os resultados almejados. 5. Referências Bibliográficas CHELLAPPA, R.; WILSON, C. L.; SIROHEY, S. (1995). Human and Machine Recognition of Faces: A Survey.
IEEE Transaction on Pattern Analysis and Machine Intelligence, Vol. 83, nº 5. KLIR, George J.,YUAN, Bo. (1995) - “Fuzzy Sets and Fuzzy Logic” - Theory and Applications, Prentice Hall
PTR, New Jersey. MARQUES, O. F; VIEIRA H. N. (1999) Processamento Digital de Imagens: Brasport, Rio de Janeiro – Brasil. PICS Psychological Image Collection at Stirling. Disponível em :http//:pics. psych.stir.ac.uk/cgi-
bin/PICS/New/pics.cgi Acesso em 15 jun. 2004 SERRA, J (1982) Image Analysis and Mathematical Morphology, Academic Press, New York. YOW, K. C.; CIPOLLA, R. (1997). Feature-based human face detection. Image and Vision Computing, Vol. 15,
pp. 713-735. ZADEH, L.A. (1965) Fuzzy Sets. Information and Control. Vol. 8, pp. 338-353 GALERIA DE FOTOS Disponível em: http://plasurg.com/plasticurgery/gallery/skin_anti-aging.htm# Acesso em
15 sept. 2004.
Numero de Imagens
Graus de pertinência
Classificação
0 imagem 100% Face 05 imagens 86% Exatamente semelhante 31 imagens 64% Semelhante 07 imagens 50% Ligeiramente semelhante 30 imagens 38% Nenhuma semelhança 27 imagens 0% Não face
Tabela 3 Resultados do banco de imagens teste
WVC´2005 - I Workshop de Visão Computacional
99

E-mail: [email protected] and [email protected] Departamento de Engenharia Elétrica - EESC/USP
Avenida Trabalhador São-carlense, 400 13566-590 - São Carlos – SP
Abstract — An algorithm able to classify pathological and normal voice signals based on Daubechies Discrete Wavelet Transform (DWT–db) and Support Vector Machines (SVM) classifier is presented. DWT–db is used for time-frequency analysis giving quantitative evaluation of signal characteristics to identify pathologies in voice signals, mainly the nodule pathology in vocal folds, of subjects with different ages for both male and female. The signals mean square values of a particular scale from wavelet analysis are entries to a Least Square Support Vector Machine (LS-SVM) classifier. A non-linear LS-SVM leads to an adequate larynx pathology classifier (over 90% of classification accuracy) as far as nodule is concerned.
I. INTRODUCTION COUSTICALLY, pathologies related to the glottal tract are identified through perceptual standards like breathiness, hoarseness and harshness. However, due to the complex structure of the speech
system producer, pathologies with harsh characteristics may be confused with the perceptually defined as hoarse [1]. It is also possible “to hear” some acoustic standard, but no pathology is verified in more precise exams, such as video-laryngoscopy or stroboscope light. Nowadays, a large number of researches are done in order to measure the speech signals perturbations and to find their correlation with disease characteristics or pathologies. The turbulence in glottal flow resulting from malfunction of the vocal folds can be quantified by the noise in spectral components of speech [2]. The objective of the technique proposed here is to use time-frequency analysis for voice signals processing and artificial intelligence to identify the pathological ones.
The present work uses the Daubechies Discrete Wavelet Transform (DWT–db) [3], [4] for time-frequency processing of normal voice signals and pathological voice signals from patients with nodule in vocal folds. The most common family of wavelets, created by Ingrid C. Daubechies, is used, in this work, to decompose normal and pathological voice signals in order to give quantitative evaluation of voice characteristics. A sustained Brazilian Portuguese phoneme /a/ was extracted from 60 speakers divided into 30 pathological and 30 normal speakers. The DWT–db power spectrum, especially in a particular scale in high frequencies, showed distinct characteristics between the normal and pathological vowel sounds. That distinction is a consequence of the turbulence in glottal flow [2] resulting from the nodule pathology in vocal folds and quantified by the wavelet filter bank using Daubechies’ function basis. After decomposing until the fifth scale all the 60 voice signals using DWT–db and less orders, this distinction showed more evidence in the coefficient of detail in the second scale and using Daubechies’ basis of order 20 (db20). Most of the
Time-frequency Analysis and Artificial Intelligence in Pathological Voice Signals
Processing Everthon S. Fonseca, André C. Silvestre, Walison J. Barbera, José C. Pereira and Adilson Gonzaga
A
WVC´2005 - I Workshop de Visão Computacional
100

existing systems and algorithms for laryngeal pathology detection are based on neural maps and networks, fractal or wavelet classifiers [5]. Best-basis wavelet classifiers [6] may produce until 85% of classification accuracy, but it is improper to use in real-time because of their order of complexity.
Signals energy values of the particular scale from Daubechies wavelet analysis commented previously are used as entries to a Least Square Support Vector Machine (LS-SVM) classifier [7], [8], a kind of learning machine. SVM is a statistical learning technique for training classifiers and it was originally created for two-group classification problems using a hyper-linear separating plane. Some important advantages of the SVM compared to other artificial intelligence techniques are the good capacity of generalization, robustness in great dimensions, convexity of the objective function and a well-defined statistical and mathematical learning theory [9]. LS-SVM is a modified version of SVM classifier, proposed by Suykens and Vandewalle [7], Suykens et all [8], which resulted in a set of linear equations instead of a quadratic programming problem. Here in this work, the application of the non-linear LS-SVM lead to an adequate larynx pathology classifier increasing the percentage of pathological voice signals discrimination validated over 95 % for this database.
II. VOICE SIGNALS PROCESSING AND DATABASE The analyzed voices were obtained from 60 speakers divided into 30 patient’s voice signals with
nodule in vocal folds and 30 normal speakers for both male and female with ages varying from 4 to 72 years. The utterances of the normal speakers constituted the control group. Basically, the presence of nodules in vocal folds makes impossible they close completely, adding hoarseness in the voice signal and modifying its fundamental frequency similarly many other pathologies. However, there are not parameters that quantify surely these characteristics and their correlations with the pathology diagnosis.
The files were recorded in wav format using a wide-band microphone and a professional specific software, sampling the voices at 22050 Hz, 16 bits of quantisation, mono-channel. Each speaker was asked to pronounce the Brazilian Portuguese phoneme /a/ for nearly 5 seconds, in comfortable levels of pitch and magnitude which corresponded to his conversational natural voice. The algorithm proposed in this work uses around 3000 sample points (removing initial 1000 points) of the recorded files, corresponding from 20 to 40 periods of voice signals, in accordance with its fundamental frequency. The signals were also normalized in amplitude by its peak value. All patients were diagnosed by speech pathologists from the Otolaryngology sector and the Head and Neck Surgery sector of the Clinical Hospital of the Faculty of Medicine at Ribeirão Preto, Brazil. Video-laryngoscope and stroboscope light were used for the diagnosis.
III. LARYNX PATHOLOGY CLASSIFICATION It was analyzed the reconstructed signals of detail (Ds) of DWT–db with orders varying from 4 to
20 in scales 1 up to 5 for all the voices in this database. These details showed different characteristics between normal and pathological voices mainly for DWT–db20 in the second scale (D2).
It is possible to note major presence of noise in the reconstructed signals of detail in the second scale (D2) using DWT–db20 for pathological voices. The peak values noted in D2 for normal voices occur in a space of time corresponding to the pitch period of voice signals, which is obstructed by the noise in the pathological voices.
Energy values (or mean square values) of D2 were used as entries to a simple threshold algorithm classifier. In order to establish the best threshold value, we used 50 signals for training (25
WVC´2005 - I Workshop de Visão Computacional
101

pathological and 25 normal voices), corresponding to 83.3% of voice signals database. To improve the classification between normal and pathological voices, it is possible to use some of
these values for a supervised training bidimensional entry to a Least Square Support Vector Machine (LS-SVM) classifier. It was developed in software Matlab 6.0 using the toolbox LS-SVMlab1.5.
A Radial Base function (RBF) was used as kernel function in training process. RBF is given by: )exp(),(
/2 λ
jiji xxxxf −−=
where, λ is a parameter set in training.
Fig. 1. Example of bidimensional entry to a LS-SVM classifier.
In this algorithm, the Larynx Pathology Classifier was a unidimensional entry to a LS-SVM whose
entries are the D2 energy values commented previously. A lot of trainings were performed varying the parameters of the LS-SVM algorithm. With the best hyperplane and threshold found, a set test data composed by 10 signals (5 pathological and 5 normal voices), corresponding to 16.7 % of database, were used to validate these classifiers.
IV. RESULTS In the following table the set test data used for validation and chosen in a random way among the
60 values is presented. Using a threshold of 8.85, we found 82% of correct discrimination for the 50 voice signals used to
establish this threshold and 80% for the test data (table 1). With the unidimensional entry to a LS-SVM classifier, it was found 92% of correct discrimination
for the 50 voice signals used for training and 100% for the test data (table 1).
TABLE 1: TEST DATA. Voice samples
D2 energy
1 9.5778 2 11.8062 3 11.2360 4 10.3381
WVC´2005 - I Workshop de Visão Computacional
102

5 9.5637 6 7.7134 7 7.8989 8 7.2158 9 8.9659 10 9.1515
V. CONCLUSION AND DISCUSSION The presented techniques showed that the DWT–db20 reconstructed signal of detail in the second
scale (D2) for normal voices has minor energy values than patient’s voice signals with nodule in vocal folds for this database with 60 voice signals. Certainly, it is a consequence of the major presence of noise detected by DWT–db20. It is important to note that the order 20 was the best order for Daubechies’ wavelet function to accomplish this result analyzing the signal corresponding to the Brazilian Portuguese phoneme /a/.
LS-SVM classifier with a Radial Base function (RBF) as kernel could improve this classification to over 95% of correct discrimination in the validation test using the same database (50 for training and 10 for testing) with the D2 energy values as entries. The parameters values used for this training in the classifier were the best to avoid the overfitting process, when the classifier became very much specialized only for the database training that results in a failure for validation tests. Therefore, in this algorithm, LS-SVM has established an adequate result of generalization to distinguish normal and pathological voices using the D2 energy values.
This paper showed a technique that can help the speech pathologist to evaluate larynx diseases and identify them, mainly the nodule pathology in vocal folds. Certainly, a great database would be able to give a better generalization of this method and other base functions in DWT and different kinds of artificial intelligence must also be used for this application.
REFERENCES [1] N. Isshiki, H. Okamura, M. Tanabe, and M. Morimoto, “Differential diagnosis of hoarseness,” Folia
Phoniatrica, vol. 21, pp. 9–19, 1969. [2] M. O. Rosa, J. C. Pereira, and M. Grellet, “Adaptive estimation of residue signal for voice pathology
diagnosis”, IEEE Trans. On Biomedical Engineering, vol. 47, pp. 96-104, 2000. [3] I. C. Daubechies, “Ten lectures on wavelets,” SIAM, 1992. [4] S. G. Mallat, “A wavelet tour of signal processing,” San Diego: Academic Press, 1999. [5] Rodrigo C. Guido, José C. Pereira, Everthon S. Fonseca, Fabrício L. Sanchez, and Lucimar S. Vieira,
“Trying different wavelets on the search for voice disorders sorting,” IEEE Southeastern Symposium on System Theory, vol. 37, pp. 495–499, 2005.
[6] M. Akay, “Time frequency and wavelets in biomedical signal processing,” IEEE Press in Biomedical Engineering, New York, 1998.
[7] J. A. K. Suykens and J. Vandewalle, “Least squares support vector machine classifiers,” Neural Process. Lett. 9 (3), pp. 293–300, 1999.
[8] J. A. K. Suykens, T. Van Gestel, J. de Brabanter, B. De Moor and J. Vandewalle, “Least squares support vector machine classifiers,” World Scientific, Singapore, 2002.
[9] A. C. Lorena and A. C. P. L. F. de Carvalho, “Introdução às Máquinas de Vetores Suporte,” Instituto de Ciências Matemáticas e de Computação (ICMC-USP), São Carlos, Tech. Rep., April 2003.
WVC´2005 - I Workshop de Visão Computacional
103

Aplicação de Transformadas Wavelets e Redes Neurais para Detecção de Faces
Inês Ap G Boaventura Valéria M Volpe André L S Veltroni Adilson Gonzaga
IBILCE-UNESP UNIRP UNIRP EESC-USP Fone (17)3221-2205 Fone(17)3221-3330 Fone(17)3221-3330 Fone (16) 3373-9363 Fax(17)3221-2203 Fax (17) Fax (17) Fax (16)33739372 [email protected] [email protected] [email protected] [email protected]
Abstract
This paper presents an approach for detecting human faces in digital images. Two different techniques are combined and used to accomplish the face detection task. First of all, Wavelet Transforms are applied in the input image in order to extract particular features that are detected by a locally connected Multilayer Perceptron network.
1. Introdução
Reconhecimento de padrões é um problema clássico de visão computacional com várias aplicações práticas. O trabalho em questão apresenta uma técnica de detecção de padrões e características, baseado nos aspectos globais de imagens, para encontrar faces humanas. O sistema desenvolvido classifica imagens em faces e não faces.
Na abordagem proposta adota-se a transformada Wavelet [1],[2] para extração de características globais da imagem, e uma Rede Neural Perceptron Multi-Camadas (do inglês Multi-Layer Perceptron - MLP) localmente conectada para fazer a classificações dos padrões que representam face e não face. O objetivo do trabalho é melhorar e simplificar o processo de extração de características proposto em [3], onde foi utilizado uma arquitetura de rede neural convolutiva, inicialmente proposta por LeCun et al [4] para o reconhecimento de padrões de escrita. A arquitetura convolutiva funciona como um extrator de características, e também como um classificador de padrões, onde o sistema sintetiza automaticamente os extratores de características de um conjunto de padrões face e não face. A arquitetura da rede neural convolutiva é bastante complexa. Além disso, a rede é a responsável pela inferência das características relevantes para a classificação correta de faces e não faces, e nesse processo foi utilizado um esquema de combinação de imagens que tem pouco significado na área de visão computacional. Nas seções seguintes apresenta-se a abordagem proposta, resultados obtidos, discussões dos resultados e as conclusões do trabalho.
2. Solução do problema
Conforme já mencionado, o problema em questão trata de um sistema inteligente para reconhecer se uma dada imagem é ou não uma face. Assim, foi utilizada as funções Wavelets para extração de características das imagens e uma Rede Neural Perceptron Multi-Camadas (MLP) para a classificação das imagens. As entradas para a rede MLP consistem das imagens processadas através das funções Wavelets, com seus valores normalizados entre –1 e 1. Para cada imagem original de 32x32 pixels, produziu-se oito imagens 4x4 pixels, onde quatro delas são originadas do processamento da função
WVC´2005 - I Workshop de Visão Computacional
104

Haar e as outras quatro do processamento da função Symlet. Foi considerado, em ambos os casos, nível três de aplicação das Wavelets.
A rede neural MLP considerada possui duas camadas: uma camada escondida e uma camada de saída. Foi usada a tangente hiperbólica como função de ativação dos neurônios, em ambas as camadas. A camada escondida da rede é constituída de oito neurônios localmente conectados às entradas, ou seja, cada neurônio é responsável por tratar uma determinada imagem de entrada. É importante ressaltar que cada uma das oito imagens de entrada corresponde a uma única imagem, e são resultantes da aplicação da transformadas Wavelets. Em cada uma dessas oito imagens processadas foram ressaltadas características diferentes da imagem. Para cada uma das funções Wavelets, produz-se quatro imagens resultantes, onde correspondem respectivamente a filtragens passa baixa passa baixa (LL), passa baixa passa alta (LH), passa alta passa baixa (HL) e passa alta passa alta (HH). A figura 3 ilustra a arquitetura proposta, mostrando os seus detalhes.
Para o treinamento da rede foi produzida uma base de imagens com duzentas imagens, consistindo de imagens representativas de faces, extraídas da base de faces AR [5], e imagens não faces. Para a composição dessa base de dados, as imagens que representam faces foram recortadas manualmente, de forma a conter as características de olhos, nariz e boca. Assim, foram produzidas janelas de faces, todas elas de aproximadamente 186x194 pixels, onde foram enquadradas as características de face mencionadas. Foi aplicado o mesmo processo para as imagens não face. Para a aplicação das funções Wavelets, as imagens foram transformadas em tons de cinza e foram
1 Face -1 Não Face
MLP
LL
LH
HH
HL
LL
LH
HH
HL
Wavelet Symlets
Imagem 32x32
Wavelet Haar
Y
Imagem 4 x 4(nível = 3)
Figura 3. Arquitetura da rede proposta. redimensionadas para 32x32 pixels, utilizando o método de interpolação "vizinho mais próximo", a fim de reduzir a dimensionalidade das imagens de entrada, e conseqüentemente a dimensão das entradas para a rede neural e a diminuição da quantidade de pesos calculados pela rede.
A rede foi treinada utilizando o algoritmo backpropagation simples (sem momentum). A taxa de aprendizado utilizada foi 0.001 e a precisão foi de 0.5x10-6.
Para satisfazer a condição das entradas localmente conectadas, o algoritmo backpropagation foi alterado para que, durante o ajuste de pesos dos neurônios da camada escondida, fossem considerados somente o conjunto de entradas relativo ao seu respectivo neurônio.
WVC´2005 - I Workshop de Visão Computacional
105

4. Resultados Computacionais
Para a coleta de resultados, a rede neural foi treinada três vezes, com os pesos iniciais gerados aleatoriamente, com a finalidade de se obter a melhor generalização. Foram utilizadas 30 imagens para o teste, sendo que 16 delas contêm faces, com um certo grau de complexidade, e 14 delas são imagens que não contém faces.
O treinamento foi executado em um computador Pentium 4 Hyper Threading de 3.06 GHz, com 512 Mb de RAM DDR 333 MHz.
A tabela 1 mostra os resultados obtidos nos respectivos treinamentos.
Treinamento Épocas Tempo Taxa de acertos
1 2606 39.08s 100 % 2 3179 48.03s 96,6 % 3 1950 29.28s 96,6 %
Tabela 1. Resultados É importante ressaltar que as imagens de teste contêm faces em ambientes controlados, com fundo
neutro e iluminação variável com relação à posição e intensidade. 5. Análise dos Resultados
Durante os testes, observou-se que a rede tinha um alto índice de erros em imagens não-face. Para melhorar o desempenho da rede, a base de dados foi incrementada com uma quantidade maior de imagens não-faces, muitas vezes extraídas dos falsos positivos, resultantes de treinamentos anteriores.
Observou-se também que, na maioria das vezes que em que a rede classificava incorretamente, as imagens continham faces com óculos, cuja lente refletia a iluminação do ambiente, prejudicando a detecção de características de face. Em outros casos, a face estava excessivamente inclinada, fazendo com que os dados que caracterizam face, tais como olhos, nariz e boca, ficassem desalinhados, conforme observado na figura 4.
Figura 4: Face desalinhada com relação ao padrão
Por outro lado, a rede se mostrou eficaz na detecção de imagens complexas, tais como faces
sorrindo e com óculos, grandes variações na iluminação, caretas, conforme exemplificado na figura 5.
Figura 5. a) Sorrindo e com óculos, b) iluminação à direita e c) careta
WVC´2005 - I Workshop de Visão Computacional
106

6. Conclusões
Analisando-se os resultados finais, obtidos com a base de dados utilizada, pode-se dizer são bastante animadores, uma vez que a taxa de acertos é superior a 96% em todos os testes realizados.
Como continuidade deste trabalho, sugere-se o aumento das bases de treinamento e teste, inserindo faces parcialmente ocludidas, contendo óculos de sol, chapéus, barba, etc. Sugere-se, também, a criação de um método de varredura em imagens, com a finalidade de se obter a localização espacial de possíveis faces em imagens complexas, em ambientes não controlados, para que sejam classificadas pela rede proposta neste trabalho. 7. Referências Bibliográficas [1] P. C. De Lima, "Wavelets: uma introdução", Matemática Universitária, 33, pp. 13-44, 2002. [2] I. Daubechies, "Ten Lectures on Wavelets", CBMS-NSF Regional Conference Series in Applied
Mathematics, Rutgers University and AT&T Bell Laboratories, volume 61, 1992. [3] C. Garcia and M. Delakis, "Convolucional Face Finder: A Neural Architecture for Fast and Robust
Face Detection", IEEE Transactions on Pattern Analysis and Machine Intelligence, 26(11),pp. 1408-1422, 2004.
[4] Y. LeCun, Y. Bengio and P. Haffner, "Gradient-Based Learning Applied to Document Recognition", Proceedings of the IEEE, 86(11), pp.2278-2324, 1998.
[5] A. M. Martinez and R. Benavente, The AR Face Database, CVC Technical Report no. 24, June 1998.
WVC´2005 - I Workshop de Visão Computacional
107

RECONHECIMENTO DE FACES HUMANAS BASEADO EM SUB-BANDAS WAVELET E PCA-2D
Nogueira, A1. L., Gonzaga, A2. 1Unijales-Centro Universitário de Jales, [email protected]
2Departamento de Engenharia Elétrica, USP-SC, [email protected]
Abstract This work presents the SWPCA-2D algorithm for the recognition or recovery of images of human faces in image database. The proposal is to apply the wavelet transform to images considering all its subbands and frequencies followed by the two-dimension principal component analysis. The results are compared with the simple application of the two-dimension principal component analysis, demonstrating that the algorithm proposed has better performance. 1 Introdução Na análise de componentes principais unidimensional (PCA), as imagens são transformadas em vetores e sobre estes vetores é calculada a matriz de covariância, uma desvantagem evidente desta abordagem é o alto custo computacional. No caso da análise de componentes bidimensional a matriz de covariância é obtida diretamente da matriz associada à imagem, o que reduz significativamente o tempo de processamento. A transformada wavelet é aplicada à imagem, para que esta seja decomposta em sub-imagens, o reconhecimento é feito em cada um destes conjuntos de sub-imagens independentemente, utilizando-se estes resultados uma estrutura de decisão indicará a qual classe pertence a imagem submetida ao reconhecimento. A seguir é apresentada uma breve descrição da análise de componentes principais bi-dimensional e da transformada wavelet 1.1 PCA Bi-dimensional Seja X um vetor coluna n-dimensional, a idéia da PCA bi-dimensional [1] (PCA-2D) é projetar uma imagem W (uma matriz mxn) em X, utilizando a transformação linear
Y=XW (1) obtendo-se um vetor Y m-dimensional, como vetor de características da imagem W. Dessa forma, a técnica PCA-2D resume-se em encontrar os vetores X’s da equação (1). Sendo n as amostras de imagens de treinamento, a j-ésima imagem de treinamento será denotada por Aj (j=1,2,...,n), enquanto que a média de todas imagens será denotada por M. Então, a matriz imagem de covariância é:
)()(11
MAMAn
G j
Tn
jjt −−= ∑
=
(2)
Os vetores Xk (k=1,2,...d) são os autovetores de Gt, , que correspondem aos maiores autovalores. Dada uma imagem A, e utilizando a equação 3,
dkAXY kk ,...2,1, == (3) os componentes principais obtidos são usados para formar uma matriz B=[Y1, Y2,... Yd], que é denominada matriz característica ou imagem característica de A, utilizada para representar a imagem A.
WVC´2005 - I Workshop de Visão Computacional
108

Depois de aplicar a PCA-2D, uma matriz característica é obtida de cada imagem. A distância (euclidiana) entre duas matrizes características é definida por:
∑=
−=d
k
jk
ikji YYBBd
12
)()( ||||),( (4)
onde denota a distância euclidiana entre os dois componentes principais , . A classificação é feita utilizando o vizinho mais próximo.
2)()( |||| j
ki
k YY −)(i
kY )( jkY
1.2 Transformada Wavelet A Transformada Wavelet (TW) [2,3] é uma poderosa ferramenta na análise de imagens. Dada uma função f a TW LΨ é definida por [4]
Rba
dxa
bxxfa
fL
∈>
⎟⎠⎞
⎜⎝⎛ −
= ∫∞
∞−
,0
)(1 ψψ (5)
Os algoritmos da TW possuem uma estrutura de bancos de filtros em diferentes escalas, que decompõem um sinal em diferentes bandas para análise. Dada uma imagem de resolução NxN, ela é inicialmente filtrada (na direção das linhas) por 2 filtros, um passa alta (P-A) e outro passa baixa (P-B).As imagens obtidas são sub-amostradas na direção das colunas, obtendo assim imagens L (passa-baixa) e H (passa alta) NxN/2. Em seguida, realiza-se a filtragem na direção das colunas das imagens L e H, resultando em quatro sub-imagens, que serão sub-amostradas na direção das linhas. Na figura 1 tem-se o diagrama do algoritmo da decomposição da TW bidimensional. Observa-se que no caso bidimensional existem três tipos de coeficientes wavelets. O LH é obtido após a aplicação do filtro P-B nas linhas e P-A nas colunas contendo, portanto, detalhes na direção vertical. De maneira análoga, HL contém detalhes na direção horizontal, enquanto HH contém detalhes tanto na direção vertical como na horizontal e, finalmente, LL é uma aproximação da imagem original.
Figura 1: diagrama do algoritmo da decomposição da TW
Uma vez aplicada a TW em uma imagem, tem-se como resultado três imagens detalhes (HL, LH e HH) e uma imagem aproximação (LL) sendo, que todas possuem um quarto da resolução da imagem inicial. Aplicando-se a TW na imagem LL, obtém-se três imagens detalhes HL1, LH1, HH1 e uma imagem aproximação LL1. Aplicando-se a TW em LL1 obtém-se HL2, LH2, HH2, LL2 e assim sucessivamente.
WVC´2005 - I Workshop de Visão Computacional
109

2 Algoritmo SWPCA-2D O algoritmo proposto para reconhecimento de faces humanas baseado em Sub-bandas Wavelet e PCA-2D, divide-se em dois estágios: Estágio 1 (1) aplica-se a transformada wavelet às imagens do conjunto de treinamento, obtendo-se quatro sub-imagens para cada imagem do conjunto, formando 04 subconjuntos:
- CLL - contendo todas as imagens LL; - CLH - contendo todas as imagens LH; - CHL – contendo todas as imagens HL; - CHH – contendo todas as imagens HH;
(2) aplica-se a PCA-2D a cada um dos subconjuntos de imagens obtendo dessa forma, uma base (ou um subespaço SLL, SHL, SLH e SHH) para cada subconjunto de imagens; Estágio 2 (1) aplica-se a transformada wavelet à imagem a ser submetida ao reconhecimento, obtendo quatro sub-imagens (LL, HL, LH e HH); (2) cada sub-imagem (LL, HL, LH e HH) é projetada no subespaço correspondente, gerado pela PCA-2D, ou seja, a subimagem LL é projetada no subespaço gerado pelo conjunto CLL, a HL pelo CHL, etc; (3) calcula-se a distância euclidiana entre as médias de cada classe e a imagem submetida ao reconhecimento (para cada um dos subespaços); (4) em cada subespaço a imagem é recuperada, levando-se em conta a menor distância euclidiana das médias de cada classe; (5) Como o subespaço SLL é o que apresenta a maior taxa de reconhecimento [5], é proposto neste algoritmo uma estrutura de decisão baseada na maioria. Logo, se, - as imagens recuperadas dos quatro subespaços são do mesmo indivíduo em número maior ou igual a duas, então, estas são admitidas como recuperadas pelo método; - duas das imagens recuperadas forem de um indivíduo e outras duas de outro indivíduo ou então, se todas as imagens forem de indivíduos diferentes, será admitida como recuperada a imagem obtida do subespaço SLL. 3 Resultados Experimentais Os algoritmos SWPCA-2D e o PCA-2D [1] foram implementados utilizando-se o software Matlab 6.1@, em um microcomputador AMD de 1GHz, com 512M de memória RAM. O algoritmo PCA-2D é aplicado na sub-imagem LL, obtida após aplicação da transformada wavelet. Foram realizados testes utilizando-se uma base de 504 imagens dividida em 28 classes, com 18 imagens cada. Para que se possa comparar o algoritmo PCA-2D e o algoritmo SWPCA-2D na tarefa de reconhecimento de faces humanas, é necessário selecionar a dimensão dos subespaços (d), a resolução da imagem (r) e o número de imagens de treinamento (c). Os resultados apresentados nas figuras 7 mostram o desempenho das técnicas SWPCA-2D e PCA-2D. Na figura 7(a) tem-se o gráfico da taxa de reconhecimento versus a dimensão (d=2-8) utilizando-se os parâmetros r=8x8 e c=2. Os demais gráficos da figura 7 são obtidos fazendo c =6,10 e 14 respectivamente.
WVC´2005 - I Workshop de Visão Computacional
110

Dimensão versus Taxa de Reconhecimento
0
10
20
30
40
50
60
2 4 6 8(a)
PCA-2DSWPCA-2D
01020304050607080
2 4 6 8(c)
PCA-2DSWPCA-2D
01020304050607080
2 4 6 8(b)
PCA-2DSWPCA-2D
0102030405060708090
2 4 6 8(d)
PCA-2DSWPCA-2D
Figura 7: dimensão versus a taxa de reconhecimento para a base de dados BD1
4 Conclusão Os resultados mostram que o algoritmo SWPCA tem um desempenho superior ao algoritmo PCA-2D considerando a base utilizada. Como o desempenho do SWPCA-2D chega a ser aproximadamente 40% superior em relação ao PCA-2D em baixas resoluções o consumo de tempo não representa uma influência significativa no desempenho global do mesmo levando à conclusão que a metodologia proposta é superior ao método proposto por Yang et all.[1]. Refêrencias [1] Yang, J., Zhang, D., Frangi, A. F. "Two-Dimensional PCA: A New Approch to Appearance-Based Face Representation and Recognition" IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 26, no.1, 2004. [2] Dai, D. Q., Feng, G. C., Yuen, P. C. "Wavelet based PCA for Human Face Recognition". Department of Computing Studies, Hong Kong Baptist University, Hong Kong, 1998. [3] Choi, H., Kim, K., Oh S. "Facial Feature Extraction Using PCA and Wavelet Multi-Resolution Image". Proceedings of the 6th IEEE International Conference on Automatic Face and Gesture Recognition, 2004. [4] Chan A. K., Goswami, J. C. Fundamentals do Wavelets: Theory, Algorithms and Applications, John Wiley & Sons, Inc. [5] Chen Y., He T. N., Shen Y. Z. A Recognition Algorithm of Facial Image Based on Wavelet Subbands and Decision Fusion"", Proceedings of the Second International Conference on Machine Learning and Cybernetics, pp2956-2959, 2003
WVC´2005 - I Workshop de Visão Computacional
111

Processamento e Aquisição de Imagens de Vídeo para Correlacionar Histograma de cordas ao diâmetro de bolhas
Marcelo Marinho, e-mail: [email protected] Obac Roda, e-mail: [email protected]
Paulo Seleghim Jr., e-mail: [email protected] r Departamento de Engenharia Elétrica, Escola de Engenharia de São Carlos, Universidade de São Paulo,
Avenida Trabalhador São Carlense, 400, CEP 13566-590, Tel. 55 16 33739366 233
Abstract Probes are widely used in the study of multiphase systems, such as gas-liquid flows and fluidized beds, for improving the performance of industrial applications like distillation and fermentation columns. The problem consists in determining bubble size histograms from measured chords which may be critical due to large amount of noise in probe signal. This paper proposes a method of images acquisition and filtering for the determination of bubble size from images extracted from a standard video camera using a flash strobe. 1 Introdução Fluxo de bolhas é amplamente encontrado em uma grande variedade de equipamentos industriais utilizados na manipulação ou transporte de misturas com duas fases (gás-líquido ou gás-sólido) e tem importantes aplicações em colunas de gás-líquido usadas no processo de separação e reação, como por exemplo destilação e fermentação [1],[2]. Estes tipos de processos dependem fortemente do fluxo de bolhas, assim como da concentração, forma e tamanho de bolhas. Isso ocorre devido à relação entre a superfície de contato entre gás e líquido e a velocidade de reação ou taxa de transferência do processo. Alguns dos principais princípios físicos utilizados para a determinação do diâmetro de bolhas são: impedância elétrica, raios-X, atenuação de radiação gama, luz, capacitância e diferença de pressão [1], [3]. A proposta deste artigo é utilizar uma sonda elétrica que mede a condutividade do meio para obter um histograma de cordas em um fluxo de bolhas, e utilizar uma câmera de vídeo para capturar as respectivas imagens das bolhas do histograma. Através do histograma e das imagens é possível determinar uma função de distribuição de probabilidade dos diâmetros que são correlacionas ao tamanho das cordas medidas pela sonda elétrica.
Pcorda(y)
r
y
Figura 1 – Determinação das cordas de bolhas através de uma sonda condutiva.
WVC´2005 - I Workshop de Visão Computacional
112

2 Obtenção do Histograma de cordas Utilizando uma sonda elétrica ideal imersa na coluna de bolhas em um meio composto por água e ar, e uma excitação elétrica senoidal, é possível determinar o tamanho das cordas das bolhas que passam através da sonda. A figura 1 ilustra o processo de determinação das cordas. Como a condutividade medida diminui quando uma bolha está passando através da ponta sonda, é possível determinar o tempo que cada bolha leva para passar pela sonda medindo a largura dos pulsos que representam a variação de amplitude do sinal. Conhecendo-se a velocidade instantânea da bolha pode-se determinar o tamanho da corda:
tvY B ⋅= (1) Onde Y é a corda, a velocidade instantânea da bolha e t o tempo levado pela bolha para atravessar a ponta da sonda.
Bv
3 Correlação entre Corda e Raio A sonda nem sempre fura a bolha no centro, portanto os valores encontrados através da sonda não fornecem diretamente o raio de cada bolha que passa através da ponta de prova. Desta forma é preciso encontrar uma forma de relacionar as cordas obtidas aos raios. Através do histograma de cordas pode-se determinar a função de distribuição de probabilidade de cordas, ( )yPCorda , e relacioná-lo à função distribuição de probabilidade de raios, , através da equação integral abaixo [4]: )(rPBolha
( ) ( )∫∞
⋅⋅=0
)(| drrPryPyP BolhaCorda (2)
Onde ,y r e são a corda , o raio e a probabilidade condicional de se medir y de uma bolha de raio r, respectivamente.
( ryP | )
4 Captura das Imagens A velocidade das bolhas que atravessam a ponta de prova é relativamente alta quando comparada com o tempo de exposição à luz do sensor de uma câmera de vídeo convencional e ao tempo de varredura de cada quadro de imagem. É necessário compensar este inconveniente da câmera através de algum dispositivo ou processamento de imagens, a fim de que as imagens não apareçam borradas. Uma possibilidade é a utilização de uma câmera de vídeo de alta velocidade para realizar a captura de vídeo, mas este tipo de câmera apresenta um custo muito alto comparado às convencionais. Devido à sua simplicidade e custo, foi utilizado neste trabalho um flash estroboscópico sincronizado com uma câmera de vídeo,de tal forma que no início de cada quadro de vídeo, são disparados flashes de luz que sensibilizam a câmera apenas em um intervalo extremamente curto, evitando assim o borramento das imagens de vídeo. A figura 2 mostra imagens capturadas com uma câmera de vídeo convencional sem a utilização e com a utilização de um flash estroboscópico.
WVC´2005 - I Workshop de Visão Computacional
113

Figura 2 – À esquerda imagem obtida sem a utilização de um flash e à direita imagem obtida com a utilização de um flash estroboscópico. 5 Processamento das imagens Depois de realizar a aquisição das imagens, é necessário realizar algumas operações a fim de remover o ruído presente nas imagens e segmentar partes da imagem úteis para um processamento posterior. Primeiramente será realizada uma binarização [5] para remover informações das imagens que não são importantes, preservando as partes da imagem que serão utilizadas posteriormente. Foi escolhido experimentalmente um limiar e realizou-se a binarização das imagens da seguinte forma:
⎪⎩
⎪⎨⎧ ≤
=contrário caso1
215 j)Imagem(i, se 0j)(i,I B (3)
Onde Imagem(i,j) e representam os “pixels” da imagem original e da imagem binarizada, respectivamente. A figura 3 mostra um exemplo de binarização para uma imagem de bolha.
),( jiI B
Figura 3 – À esquerda imagem original e à direita imagem binarizada.
Devido à presença de ruído e de áreas espúrias da imagem, a binarização da imagem não segmentou totalmente a bolha da imagem original. Portanto é necessário realizar outra forma de processamento para que seja possível extrair apenas as partes da imagem que são realmente de interesse. Assim foi realizada uma operação de abertura [5] na imagem binarizada. A operação de abertura consiste em realizar uma operação de erosão seguida de uma operação de dilatação, definida da seguinte forma:
( ) BBABA ⊕= θo (4)
WVC´2005 - I Workshop de Visão Computacional
114

Onde BAo , θ e representam a operação de abertura em ⊕ A por um elemento estruturante , a operação morfológica de erosão e a operação morfológica de dilatação, respectivamente. O elemento estruturante foi definido da seguinte forma:
B
B
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
000111000
B (5)
A figura 4 mostra um exemplo da operação de abertura aplicada à imagem binarizada.
Figura 4 – Imagem binarizada à esquerda e imagem depois da aplicação da operação de abertura pelo elemento estruturante à direita. B 6 Conclusões É possível notar que o ruído da imagem original foi removido após as operações de binarização e abertura, preservando a parte da imagem que compõe a bolha sem perdas significativas da imagem original. Através da imagem segmentada é possível calcular o raio da bolha ou outras relações geométricas que permitem determinar características de um sistema composto por uma mistura gás líquido com uma maior precisão. Além disso, pode-se relacionar a distribuição de cordas obtidas através de uma sonda elétrica com a distribuição de raios encontrada através das imagens obtidas pela câmera de vídeo, possibilitando assim, através da equação (2), a determinação de um modelo matemático que relacione distribuição de cordas à distribuição de raios. Como continuação do trabalho está sendo desenvolvido um modelo para calcular o raio de uma bolha em “pixels”, convertê-lo em unidades físicas de comprimento para posterior comparação com os sinais elétricos provenientes da sonda . Bibliografia [1] Paulo Seleghim Jr., Fernando E. Milioli, Improving the determination of bubble size histograms by wavelet de-noising techniques, Powder Technology 115 (2001) 114-123. [2] N. N. Clark, Chord length distribution related to bubble size distribution in multiphase flows, Int. J. Multiphase Flow 14 (1988) 413-424. [3]R. Turton, N. N. Clark, Interpreting Probe Signals from fluidized beds, Powder Technology 59 (1989) 117-123. [4] Tai L, Chow, Mathematical Methods for Physicists: a concise introduction, Cambridge University Press 2000 [5] R. C. Gonzalez, R. E. Woods, Digital Image Processing 1987.
WVC´2005 - I Workshop de Visão Computacional
115

Arquitetura para extração de características invariantes em imagens binárias utilizando dispositivos de lógica programável de alta densidade
Guilherme Henrique Renó Jorge, Valentin Obac Roda
[email protected], [email protected], tel. 16 33739366 – R223
Abstract
A challenge for digital systems designers is to meet the balance between speed and flexibility. FPGAs and CPLDs where used as “glue logic”, reducing the number of components in a system. The use of programmable logic (CPLDs and FPGAs) as an alternative to microcontrollers and microprocessors is a real issue. Moments of the intensity function of a group of pixels have been used for the representation and recognition of objects in two dimensional images. Due to the high cost of computing the moments, the search for faster computing architectures is very important. A problem faced by nowadays developed architectures is the speed of computer communication buses. Simpler interfaces, as USB (Universal Serial Bus) and Ethernet, have their transfer rate in Megabytes per second. A solution for this problem is the use the PCI bus, where the transfer rate can achieve Gigabytes per second. This work proposes a soft core architecture, fully compatible with the Wishbone [1] standard, for the extraction of invariant characteristics from binary images using logic programmable devices. Introdução
Os projetistas de sistemas digitais enfrentam sempre o desafio de encontrar o balanço correto entre velocidade e generalidade de processamento de seu hardware. É possível desenvolver um chip genérico que realiza muitas funções diferentes, porém com sacrifício de desempenho (por exemplo: microprocessadores), ou chips dedicados a aplicações específicas, estes com uma velocidade muitas vezes superior aos chips genéricos[2].
Já na área de Visão Computacional, a representação e reconhecimento de objetos em imagens de duas dimensões em é um tópico importante. Uma forma comum de se fazer à representação de um objeto ou uma imagem é a utilização de momentos da função de intensidade de um grupo de pixels. Devido ao alto custo computacional para o calculo desses momentos tem sido importante a busca por arquiteturas que de alguma forma agilizassem o calculo dos mesmos. [3] [4] [5] [6]. Isso foi de certa forma beneficiado com o advento dos dispositivos de lógica programável complexa. A flexibilidade dos mesmos permite o desenvolvimento e simulação de novas arquiteturas a um custo acessível nos dias de hoje.
Esse trabalho vem propor uma arquitetura, em forma de soft core totalmente compatível com o padrão Wishbone [7], para a extração de características invariantes em imagens binárias utilizando-se de dispositivos de lógica programável complexa. Desse modo torna-se possível o uso do barramento PCI para a transmissão de dados para um microcomputador ou uma estação de trabalho. Dessa forma espera-se um ganho de desempenho no calculo dos momentos frente ao microcomputador e uma rápida e portável solução de transmissão utilizando-se o barramento PCI.
WVC´2005 - I Workshop de Visão Computacional
116

Reconhecimento de Padrões e Características Invariantes
A utilização de atributos invariantes a transformações é um método bastante utilizado no reconhecimento de padrões, sendo que a escolha destes na maioria das vezes influencia as taxas de reconhecimento alcançadas. Fatores como, tempo de cálculo dos atributos (na fase de pré-processamento) e redução de dados (compressão) devem também, ser levados em conta [8].
Os métodos para extração de características invariantes existentes possuem certas limitações, sendo a principal delas o alto custo computacional. Com isso surge a necessidade de desenvolvimento de um sistema de extração de características invariantes.
O principal motivo de ter-se escolhido utilizar momentos invariantes no processo de extração de características é o desta técnica ser capaz de representar propriedades, de imagens, que são invariantes em relação à rotação, translação e escala. Isto significa que uma imagem, após sofrer alguma das operações citadas (translação, rotação, ampliação e redução), será representada, por momentos invariantes, da mesma forma que a imagem original. A lógica a ser implementado tem por objetivo principal a extração dos Momentos invariantes de Hu [9].
Metodologia para o cálculo dos momentos invariantes
Atributos facilmente computados são as projeções horizontal e vertical, que são utilizados para imagens binárias. A projeção horizontal y(xi) é o número de pixels de objeto (pixels iguais a 1, por exemplo) que possuem a coordenada x igual a xi. A projeção vertical é similar, porém para as coordenadas y. Esses atributos, porém, não são capazes de capturar muitas informações sobre alguns aspectos importantes da imagem, como a forma do objeto, e são normalmente utilizados com outros objetivos, como correção de ângulo e segmentação de imagens binárias. Mesmo assim, projeções e mapas de bits são algumas das características muito utilizadas em sistemas de reconhecimento de padrões ainda hoje [10]. Na arquitetura proposta, o método, que já está sendo implementado, faz uso de projeções horizontal e vertical. Foram feitos testes preliminares através do uso de MATLAB, para a extração dos valores dos momentos invariantes de imagens binárias utilizando-se o mesmo algoritmo que está sendo implementado em hardware. Os resultados foram satisfatórios, comprovando a eficiência do algoritmo. Como demonstrado na Figura 1, gerando os resultados mostrados na Tabela 1, com os valores obtidos, a seguir:
| | Chave Alen
| | Alicate de Corte
Figura 1: Imagens utilizadas como exemplo para cálculo dos momentos invariantes
WVC´2005 - I Workshop de Visão Computacional
117

Tabela 1: Faixas de valores dos momentos obtidos para as imagens
Momento\Objeto Alen Alicate
1º momento 4.7324 à 4.7372 4.2600 à 4.26232º momento 9.4649 à 9.4745 8.5201 à 8.5245
3º momento 16.1911 à 16.2031 15.9496 à 15.9558
4º momento 16.1911 à 16.2031 15.9496 à 15.9558
5º momento 32.3568 à 32.3802 31.8834 à 31.8957
6º momento 20.9235 à 20.9403 20.2096 à 20.2181
7º momento 32.5602 à 32.5846 32.0694 à 32.0820 Arquitetura e Interface PCI
Com o advento de uma plataforma desenvolvida na Universidad de la Republica (Montevidéu, Uruguai)[11] o desenvolvimento de aplicações com interface PCI fica imensamente facilitado. Com a disponibilidade do core gratuitamente e de exemplos de aplicação, o desenvolvimento de novas aplicações ganha um grande estímulo. Vantagem ainda maior é a compatibilidade com o padrão Wishbone, que vêm ganhando força na comunidade de desenvolvimento de cores acadêmicos e gratuitos na Internet [7].
Propostas e Desenvolvimento
Figura 2: Esquema da Arquitetura Proposta A arquitetura para extração e armazenamento das imagens binárias a ser utilizada nesse projeto
tem como base o sistema desenvolvido por [12]. Uma nova placa de circuito impresso está sendo desenvolvida, utilizando componentes mais modernos e também a FPGA escolhida, um modelo da família Cyclone da ALTERA, assim como conectores para conexão com a placa PCI. Ou seja, à parte para fazer a extração e armazenamento de imagens da arquitetura final que será desenvolvida será essa mesma, apenas com a introdução de um limiar para a binarização da imagem (já feita), sendo desenvolvida no projeto uma nova parte, ou um novo módulo, para a extração de características
WVC´2005 - I Workshop de Visão Computacional
118

invariantes das imagens armazenadas, formando assim um sistema completo para extração, armazenamento e cálculo dos momentos invariantes. O esquema da Arquitetura Proposta está representado na Figura 2.
O cálculo dos momentos invariantes consiste em basicamente três etapas. O cálculo da área; O cálculo dos momentos centrais; O cálculo dos momentos invariantes em si. Uma vez que a arquitetura de extração e armazenamento prove a imagem já na forma binária e essa informação pode ser recuperada das memórias em forma de uma matriz de pixels, a metodologia de cálculo através de projeções horizontal e vertical é perfeitamente aplicável.
A interface Wishbone será criada de acordo com as normas do padrão Wishbone estabelecidas segundo [7]. Uma vez calculados os momentos centrais, que servem como base para o calculo dos momentos invariantes, é possível se fazer o calculo dos momentos invariantes de forma paralela, gerando um ganho de desempenho esperado frente às arquiteturas tradicionais. O trabalho encontra-se na faze de implementação do algoritmo para extração dos momentos invariantes em lógica programável. Já foram feitos testes preliminares através do uso de MATLAB, para a extração dos valores dos momentos invariantes de imagens binárias como apresentado anteriormente.
Referências bibliográficas:
[2] Cappelatti, E. A. (2001), Implementação do Padrão de Barramento PCI para interação Hardware/Software em Dispositivos Reconfiguráveis. Dissertação de Mestrado, Pontifícia Universidade Católica do Rio Grande do Sul. [3] ANDERSSON, R. (1985). Real-Time Gray-Scale Video Processing Using a Moment-Generating Chip. IEEE Journal of Robotics and Automation, vol. 1, no. 2, junho. pp. 79-85. [4] CHEN, K. (1990). Efficient Parallel Algorithms for the Computation of Two-Dimensional Image Moments. Pattern Recongnition, vol. 23, no. ½, 1990, pp. 109-119. [5] JIANG, X.; BUNKE, H. (1991). Simple and Fast Computation of Moments. Pattern Recognition, vol. 24, no. 8, 1991, pp. 801-806. [6] WONG, W. H.; SIU, W. C.; LAM, K. M. (1995). Generation of moment invariants and their uses for character recognition. Pattern Recognition Letters, vol 16, n. 2. [7] OPENCORES website, www.opencores.org. [8] YUCEER, C.; OFLAZER, K. (1993). A rotation, scaling and translation invariant pattern classification system. Pattern Recognition, v. 26, n. 5. [9] HU, M. (1961). Pattern recognition by invariant moments.Proc. IRE Transactions on Information Theory, 179–187. [10] Guingo, B. C. Reconhecimento Automático de Placas de Veículos Automotores. Dissertação de Mestrado, UFRJ, 2003. [11] Fernández, S. (2003) Una plataforma de desarrollo para el bus PCI. Projeto de final de curso, Faculdade de Engenharia, Instituto de Engenharia Elétrica, Montevideo, Uruguai. [12] Pedrino, E. C. (2003) Arquitetura Pipeline para Processamento Morfológico de Imagens Binárias em Tempo Real utilizando Dispositivos de Lógica Programável Complexa. Dissertação de Mestrado, EESC-USP.
WVC´2005 - I Workshop de Visão Computacional
119

RECUPERAÇÃO DE IMAGENS DE FACES HUMANAS BASEADA EM CONTEÚDO ATRAVÉS DE WAVELETS
Marcelo Franceschi de Bianchi,
Rodrigo Capobianco Guido, Thais Lorasqui Scarpa Paula Padovan, Vladisa S. Ramos,
Reinaldo Masuko, Wellington F. Bastos
Núcleo de Estudos de Computação, Centro Universitário do Norte Paulista, UNORP, R. Ipiranga 3460 – Jd. Alto Rio Preto – 15020-040 - São José do Rio Preto – SP – Brasil
E-mail: [email protected]
Abstract This work describes an efficient algorithm for content-based image retrieval based on discrete wavelet transform (DWT) filter banks and Euclidian distance operator, an ordinary criterion for distance measurement. The former is used to turn the query image into a signature-vector, a compressed frame which holds the main features of the original data, and the latter is used to calculate the lowest distance between the query signature vector, and all the signature-vectors stored in the data base, each on related to a particular image. Interestingly and according to the tests, we have found that, for one particular query, the worse the frequency response of the filter bank used for compression is, the better the classification is 96,73% being the best accuracy we have reached. The system´s input consists of a query image and its output corresponds to the most similar image found in the data-bank, according to the distance criterion adopted.
Keywords: Biometry, Facial Recognition, CBIR Content Based Image Retrieval. 1- Introdução
Muita literatura tem surgido recentemente descrevendo algoritmos para recuperação de imagens baseada em conteúdo, uma técnica de pesquisa usada em segurança, identificação pessoal e muitas outras aplicações. Este trabalho apresenta um novo algoritmo para este propósito baseado no classificador distancia Euclideana e Transformada Wavelet Discreta (DWT) [4],[5],[6],[7].
A saída do sistema é um banco de imagens em tons de
cinza, no qual é comparado com todos as outras imagens em tons de cinza armazenadas em um outro banco de imagens por meio do classificador distancia Euclideana. O sistema armazena somente um vetor de características para cada imagem além da imagem atual. Cada vetor obtido usando a DWT consiste em uma versão da imagem com uma menor resolução de modo que a busca por imagens similares seja otimizada.
Testamos diferentes DWT’s e diferentes expressões
faciais. A precisão dos resultados foi em torno de 96% com um simples algoritmo que tem ordem linear de complexidade. A implementação usa MATLAB 7.0 rodando em sistema operacional Windows XP Professional.
O restante deste artigo é constituído de 3 seções. A
seção 2 descreve o propósito do algoritmo para recuperação de imagens similares. A seção 3 lista os testes e os resultados. As conclusões estão descritas na seção 4, seguida com as e referências na seção 5. 2- O Procedimento Proposto A tabela 1 descreve o algoritmo proposto. Todas as imagens estão em tons de cinza, 128x128 pixels de resolução. Há dois bancos de dados de vetores de características, DB1 e DB2. O primeiro banco de dados consiste em 32 imagens cada uma para uma pessoa diferente. O último cont ém 153 imagens com expressões faciais diferentes, imagens (contaminada) com ruído Gaussiano [8] e imagens rotacionadas a 10 e -10 graus das 32 imagens de faces acima mencionadas. 3- Testes e Resultados O algoritmo produz os resultados resumidos na tabela 2. A figura 1 ilustra alguns resultados específicos. A primeira e a segunda linha mostram a recuperação de diferentes expressões faciais. A terceira linha contém um banco de imagens com ruído Gaussiano. A próximas duas linhas contém imagens rotacionadas. Somente o último exemplo mostra um erro de modo que o sistema de saída corresponde a face de uma outra pessoa.
WVC´2005 - I Workshop de Visão Computacional
120

• INICIO
• Passo 1: Garantir que todas as imagens do DB1 e
DB2 estão normalizadas de acordo com as condições mencionadas acima (128x128 pixels, 256 níveis de cinza).
• Passo 2: Gerar e armazenar os vetores de assinaturas
para todas as imagens do DB1 e DB2. Cada vetor consiste da transformada wavelet da imagem de modo que a extensão da assinatura varia de acordo com o níveis da transformada wavelet aplicada aos dados. Os testes são realizados usando um j-nível da DWT’x, de acordo com a tabela 2.
• Passo 3: Entrada do banco de imagens do vetor
característica. • Passo 4: Para cada wavelet x na tabela 2:
o Passo 4.1: Para os níveis j = 1 até 3, de acordo coma tabela 2.
- Passo 4.1.1: Para imagens i = 1 até 153 do DB2.
- Passo 4.1.2: distancia[x][y] Euclidiana(q,i)100
• Passo 5: O menor valor no vetor distancia
corresponde a uma imagem especifica no DB2, que é a saída do sistema.
• FIM.
Tabela 1: O algoritmo completo para recuperação de imagens baseada em conteúdo. 4 Conclusões
Propomos um simples algoritmo de recuperação de imagem baseada em conteúdo que utiliza a Transformada Wavelet Discreta e o classificador distância Euclidiana. De acordo com os testes o melhor nível de decomposição e a melhor Wavelet para este propósito é a Haar com nível 1. Indica um nível de compressão [9] de 50% entre a imagem original e o correspondente vetor de assinatura.
Existe uma discussão interessante sobre este resultado: quanto mais o filtro se aproxima de valores que seriam considerados ideais, a recuperação da imagem piora. Isto indica que as freqüências maiores são importantes para a seleção de características, fazendo com que uma resposta em freqüência distante da que seja considera ideal realize melhor a busca de imagens por similaridade do que filtros que possuam considerado alto fator de seletividade.
.
Figura 1 (de cima para baixo): Seis testes realizados com o algoritmo proposto, um por linha. O sistema de entrada, o banco de imagem, é o da esquerda e o de saída, a imagem recuperada, é o da direita. A última linha consiste de um erro. A outras imagens correspondem a resultados bem sucedidos.
WVC´2005 - I Workshop de Visão Computacional
121

Nível (j) wavelet(x) e suporte precisão 1 Haar - 2 96.73% 1 Coiflet-6 96.72% 1 Coiflet-12 72.54% 1 Coiflet-18 31.37% 1 Coiflet-24 38.56% 1 Coiflet-30 42.48% 1 Symmelet -8 96.07% 1 Symmelet -16 27.45% 1 Daubechies - 4 95.42% 1 Daubechies - 20 36.60% 1 Daubechies - 60 79.73% 1 Daubechies - 80 86.92% 1 Daubechies – 90 70.58% 1 Biorthogonal –2 96.72% 1 Biorthogonal –4 94.11% 1 Biorthogonal –6 35.94% 1 Biorthogonal –8 31.37% 1 Biorthogonal –12 32.02% 2 Haar - 2 95.42% 2 Coiflet-6 94.11% 2 Coiflet-12 92.81% 2 Coiflet-18 88.23% 2 Coiflet-24 79.08% 2 Coiflet-30 45.75% 2 Symmelet -8 95.42% 2 Symmelet -16 88.88% 2 Daubechies - 4 95.42% 2 Daubechies - 20 77.12% 2 Daubechies - 60 82.35% 2 Daubechies - 80 86.27% 2 Daubechies – 90 64.05% 2 Biorthogonal –2 95.42% 2 Biorthogonal –4 94.11% 2 Biorthogonal –6 87.58% 2 Biorthogonal –8 75.81% 2 Biorthogonal –12 90.19% 3 Haar - 2 91.50% 3 Coiflet-6 94.77% 3 Coiflet-12 92.81% 3 Coiflet-18 92.15% 3 Coiflet-24 91.50% 3 Coiflet-30 90.84% 3 Symmelet -8 93.46% 3 Symmelet -16 92.15% 3 Daubechies - 4 93.46% 3 Daubechies - 20 92.15% 3 Daubechies - 60 79.73% 3 Daubechies - 80 88.88% 3 Daubechies – 90 80.39% 3 Biorthogonal –2 93.46% 3 Biorthogonal –4 92.81% 3 Biorthogonal –6 91.50% 3 Biorthogonal –8 90.19% 3 Biorthogonal –12 92.15%
5- Referências [1] S. Deb, “Multimedia Systems and Content-Based Image Retrieval”. Hersey-US: Idea Group Publishing,2003. [2] S.Deb, Y. Zhang. “An overview of content-based image retrieval techniques”. In AINA 2004 – 18 th International Conference on Advanced Information Networking and Applications, (2204), v.1,pp.59-64. [3] I. Andreou, N. M. Sgouros. “Computing explaining and visualizing shape similarity in content -based image retrieval”. Elsevier Information Processing and Managemente, v.41,n.5,pp.1121-1139,2005. [4] P. S. Addilson, “The Illustrated Wavelet Transform Handbook: Introductory theory and application in science, engineering, medicine and finance”. Edinburg: Institute of Physics Publishing,2002. [5] G. Strang,T. Nguyen, “Wavelets and Filter Banks”. Wellesley: Wellesley Cambrigde Press,1997. [6] R.C.Guido, J.C.Pereira, E. Fonseca, L.S. Vieira, F.L.Sanchez. “Trying different wavelets on the search for voice disorders sorting”, in 37th IEEE Intenational Southeastern Symposium on System Theory, Tuskegee-AL-US,v.1(2005) p.495-499 [7] R.C.Guido, J.F.W.Slaets, L.O.B.Almeida, R. Koberle, J.C.Pereira, “ A new technique to construct a wavelet transform matching a specified signal with applications to digital, real time, spike and overlap pattern recognition”, Digital Signal Processing, Elsevier, v.15, (2005), n. - ,pp. – (article in press, available on www.sciencedirect.com website, to appear in 2005. [8] R.C.Gonzales, R.E.Woods. “Processamento de Imagens Digitais”. São Paulo: Edgard Bluscher,2000. [9] D. Hankerson, G.A. Harris, P.D. Johnson, “Introduction to Information Theory and Data Compression”, 2 nd ed. Boca Raton: CRC Press,2003.
WVC´2005 - I Workshop de Visão Computacional
122

Estimativa simplificada da Idade Óssea – Uma proposta de Metodologia de automatização do processo para o auxilio ao diagnóstico
Olivete, J.C.; Queiroz A. C., Affonso, F. J., Rodrigues, E.L.L.
USP, Departamento de Engenharia Elétrica, São Carlos, SP, Brasil. Av. Trabalhador São-carlense, 400 - Centro - CEP 13566-590 - São Carlos – SP.
Fone: 33739366. Ramal: 226. olivete, queiroz, faffonso, [email protected]
Abstract This paper presents a automatic software to estimate a skeletal age using the Eklof & Ringertz method. It presents a methodology to isolate bone from hand’s tissue for dimension measurements. These dimensions were used as the information for skeletal age estimation of humans in the growth phase, in order to simplify the Eklof & Ringertz method. Word-Keys: Carpal Analysis, Skeletal Age, Computer Vision, Eklof & Ringertz. Introdução A estimativa da idade óssea através da radiografia carpal é freqüentemente utilizada para avaliar desordens no crescimento em pacientes pediátricos, obtendo o quanto o seu crescimento evoluiu em relação à sua maturidade óssea (Marques et al. 2001). Segundo Tavano (Tavano 2001), existem vários métodos para realizar essa estimativa, sendo que os mais difundidos e utilizados no Brasil são: Greulich& Pyle (Niemeijer, 2002), Tanner & Whitehouse (Moraes et al. 2003) e Eklof & Ringertz (Tavano, 2001). O software baseia-se no método de Eklof & Ringertz, onde são necessários apenas métodos computacionais não muito sofisticados para estimar a idade óssea baseando-se na análise das dimensões de alguns centros de ossificação (10 centros) da mão, punho e carpo (Eklof e Ringertz, 1967). A grande dificuldade desta análise está diretamente relacionada com a obtenção das dimensões dos centros do punho e do carpo por apresentarem grande concentração de tecido, prejudicando assim o isolamento correto dos mesmos. Por este motivo, estimou-se a idade óssea baseando-se na análise apenas dos ossos da mão (5 centros de ossificação), excluindo os do punho e do carpo. Neste trabalho foram utilizadas imagens radiográficas da mão que apresentavam laudo médico (num total de 250 imagens) do banco de dados do Depto de Engenharia Elétrica da USP – São Carlos. Método
- Banco de dados de imagens carpais – Armazena as imagens e suas informações (nome do paciente, idade cronológica, resolução em que foi digitalizada a imagem, laudo médico, sexo, entre outras).
- Banco de dados de medidas – armazena as medidas (em milímetros) de cada centro de ossificação e as suas idades correspondentes para os 10 centros utilizados por Eklof & Ringertz (Eklof e Ringertz, 1967).
- Marcação dos centros de ossificação – Delimita o início e o fim de cada osso - Obtenção das medidas e estimativa da idade – Após a seleção de todos os centros de
ossificação, é calculado o comprimento de cada um dos ossos utilizando a distância Euclidiana. Em seguida, é feita uma busca no banco de dados de medidas e estimada a idade óssea.
Resultados Na tela principal do software encontram-se todos os processamentos necessários para a estimativa da idade óssea, como por exemplo: abrir e segmentar uma imagem, cadastrar a
WVC´2005 - I Workshop de Visão Computacional
123
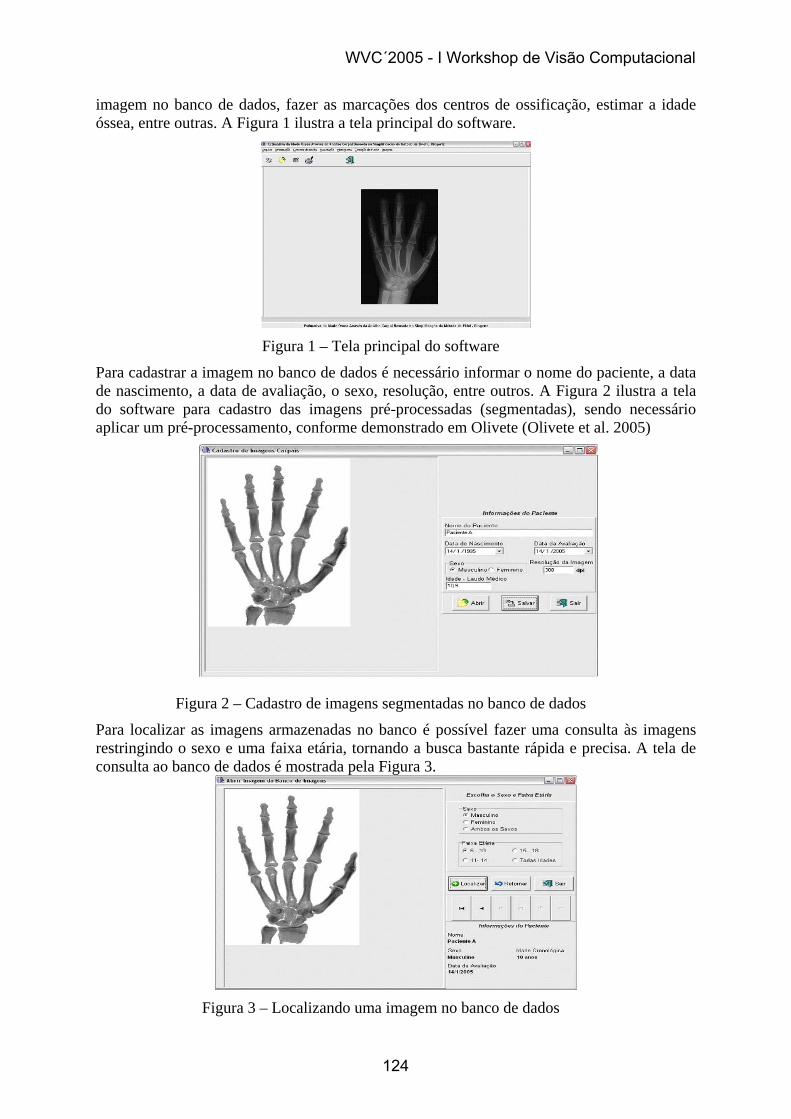
imagem no banco de dados, fazer as marcações dos centros de ossificação, estimar a idade óssea, entre outras. A Figura 1 ilustra a tela principal do software.
Figura 1 – Tela principal do software
Para cadastrar a imagem no banco de dados é necessário informar o nome do paciente, a data de nascimento, a data de avaliação, o sexo, resolução, entre outros. A Figura 2 ilustra a tela do software para cadastro das imagens pré-processadas (segmentadas), sendo necessário aplicar um pré-processamento, conforme demonstrado em Olivete (Olivete et al. 2005)
Figura 2 – Cadastro de imagens segmentadas no banco de dados
Para localizar as imagens armazenadas no banco é possível fazer uma consulta às imagens restringindo o sexo e uma faixa etária, tornando a busca bastante rápida e precisa. A tela de consulta ao banco de dados é mostrada pela Figura 3.
Figura 3 – Localizando uma imagem no banco de dados
WVC´2005 - I Workshop de Visão Computacional
124

O próximo passo é inserir os marcadores para os centros de ossificação utilizados pelo método de Eklof & Ringertz. Essas marcações são feitas automaticamente (ver Figura 4a) e, em seguida, é disponibilizado um mapa (ver Figura 4b) com as posições corretas dos centros de ossificação, sendo possível ajustá-los com o auxílio do mouse.
(a) (b)
Figura 4 – (a): Marcações estimadas dos centros de ossificação. (b): localização correta dos pontos utilizada por Eklof & Ringertz
Figura 5 – Relatório da estimativa da idade óssea gerado pelo software
Após inserir os marcadores (Figura 4) para os centros de ossificação, são obtidas as medidas (em milímetros) através da distância Euclidiana e estimada a idade para cada centro através de uma busca na tabela de medidas propostas por de Eklof & Ringertz. A idade óssea final é obtida através da média das idades encontradas para os cinco ossos. A Figura acima (Figura 5) ilustra todas essas medidas.
Resultados Obtidos - Laudo do software X laudo médico Para apresentar os resultados obtidos pelo software utilizando a simplificação, foram selecionadas 68 imagens do banco de dados, sendo 34 do sexo masculino e 34 do sexo feminino e estimadas as suas idades ósseas. Para medir a eficiência da simplificação utilizada no software, foram obtidas as idades ósseas para 68 imagens do banco de dados e, em seguida, realizou-se a confrontação entre os laudos do software e do médico. O desvio padrão utilizado variou de 0.1 a 0.5 anos. O gráfico da Figura 6a ilustra os resultados da simplificação para o sexo masculino e do da 6b, o do sexo feminino.
WVC´2005 - I Workshop de Visão Computacional
125

14,71%
32,35%
61,76%
94,12% 100,00%
Desvio0,1
Desvio0,2
Desvio0,3
Desvio0,4
Desvio0,5
[valores em anos]
17,65%
47,06%
76,47%
94,12% 100,00%
Desvio0,1
Desvio0,2
Desvio0,3
Desvio0,4
Desvio0,5
[valores em anos]
(a) (b)
Figura 6 – Porcentagem de acertos do software X laudo médico para o sexo feminino
Analisando o gráfico da Figura 6, nota-se que quando utilizado o desvio padrão de 0.1 a 0.3 anos ocorreu baixa taxa de concordância, ficando 23,53% abaixo do valor do laudo médico no melhor caso (desvio padrão de 0.3 anos e sexo feminino). Quando utilizado o desvio padrão de 0.4 anos o resultado foi excelente em ambos os casos. E, conseqüentemente, chegando a 100% quando o desvio padrão foi aumentado para 0.5 anos. Discussão e Conclusões Com base nos resultados alcançados através do software, conclui-se que é possível estimar com confiança a idade óssea baseando-se apenas nos ossos da mão (formados por 5 centros de ossificação), excluindo da análise os ossos do carpo e do punho, que são ossos necessários na análise completa do método de Eklof & Ringertz (10 centros de ossificação). Um dos softwares atualmente existentes para estimar a idade óssea, denominado Radiocef Studio 2.01, também está baseado no método de Eklof & Ringertz e é operado de forma manual. Todos os pontos que compõem os centros de ossificação são marcados manualmente, o que resulta em um tempo elevado para a fixação dos 20 pontos necessários para estimar a idade óssea. O software desenvolvido e apresentado aqui, trabalha de forma automática e simplificada, onde os marcadores são inseridos automaticamente e utiliza-se apenas 6 pontos (3 ossos) para a estimação da idade óssea. Referências Eklof, O.; Ringertz, H. 1967. A method for assessment of skeletal maturity. Ann Radiology. v. 10. p. 330. Marques, A. M. S et al. 2001. On Determining a Signature for Skeletal Maturity, Proceedings of the 14th Brazilian Symposium on Computer Graphics and Image Processing, p. 246-251. Moraes, M.E.L. et al. 2003. Reliability of Greulich & Pyle and Eklof & Ringertz methods for skeletal age evaluation in brazilian children. Rev. Odontol. UNESP, São Carlos, v. 32, n. 1, p. 9-17, Jan/Jun 2003. Niemeijer, M. 2002. Automating Skeletal Age Assessment, Master’s Thesis, University Utrecht. Olivete, C. J. et al. 2005. O efeito da correção do “Efeito Heel” em imagens radiográficas da mão. Revista Brasileira de Física Médica, v. 1, p. 38-51. Tavano, O. 2001. Radiografias Carpal e Cefalométrica como Estimadores da Idade Óssea e do Crescimento e Desenvolvimento, Bauru – Brasil. 1 - Radiocef Studio 2.0: fabricado em 1994 pela empresa Radio Memory Ltda., localizada em Belo Horizonte, MG, Brasil. Home Page: <http://www.radiomemory.com.br>.
WVC´2005 - I Workshop de Visão Computacional
126

ARMAZENAMENTO E BUSCA DE IMAGNES MÉDICAS EM SISTEMAS VOLTADOS PARA WEB COM CENTRALIZAÇÃO DA INFORMAÇÃO
F. J. Affonso1, A. C. Queiroz2 C. J. Olivete2 e E. L. L. Rodrigues2
1 Centro Universitário Central Paulista (UNICEP) - São Carlos - Brasil
Rua Miguel Petroni, Rua Miguel Petroni, 5111 - CEP. 13563-470, São Carlos - SP Telefone / Fax: (16) 3307-2111
2 Escola de Engenharia de São Carlos (EESC) - Universidade de São Paulo (USP)
São Carlos - SP - Brasil Av. Trabalhador São-carlense, 400 - Centro - CEP 13566-590 São Carlos - SP
Tels: (16) 3373-9366 - ramal 226 - Fax: (16) 3373-9372
e-mail: [email protected] e-mail: faffonso, aqueiroz, olivete, [email protected]
Abstract The computational techniques for analysis of medical images have been provided a great advance in the current medicine, mainly in the area of computational systems of assist to the diagnosis. In the esteem of the bones age these systems come growing significantly, because they are used in verification of the maturity of the children skeleton and adolescents. The automatization of the methods for esteem of the bones age needs a great number of images for tests. To organize this images a Web management system of images was developed, where the characteristics information are recorded in a database and the images are inserted in a set of directories previously established by the system administrator as file. 1. Introdução
A incorporação de técnicas computacionais para análise de imagens médicas proporcionou um grande avanço na medicina atual. Estruturas de difícil visualização podem ser realçadas, tais como os ossos da mão e do punho. Características como dimensão e volume podem ser medidas, auxiliando a análise do radiologista na determinação da idade óssea, contribuindo assim como uma segunda opinião ao fornecer o laudo.
O conceito de idade óssea é comumente utilizado para verificar o estado da maturidade do esqueleto de crianças e adolescentes. Cada indivíduo tem um desenvolvimento biológico particular onde nem sempre corresponde com o desenvolvimento cronológico, ou seja, dentro de um grupo de crianças do mesmo sexo e mesma idade cronológica, haverá variação na idade biológica [1, 2].
A automatização de métodos para estimação da idade óssea cresce significativamente, necessitando assim de um grande número de imagens para avaliar suas respectivas idades. De modo a atender essa necessidade, foi desenvolvida uma metodologia de organização e recuperação utilizando um sistema Web, que gerencia imagens radiográficas digitalizadas da mão e punho, e que pode ser adequado a qualquer tipo de imagem que se deseja armazenar ou recuperar.
2. Metodologia
O Sistema para Gerenciamento de Imagens Médicas (SGIM) foi desenvolvido utilizando a ferramenta Eclipse [3], que permite a confecção dos modelos de lógica e dos dados do sistema, além de ser uma plataforma para implementação desses modelos em linguagem de programação. Para executar esse sistema foi necessária a instalação e configuração de um servidor Web, TomCat [6], para
WVC´2005 - I Workshop de Visão Computacional
127

hospedagem das páginas escritas em HTML e das páginas escritas em JSP - JavaServer Pages [4], as quais permitem integrar os dados da interface com o usuário e o banco de dados do sistema.
A linguagem escolhida para implementação do sistema foi a JAVA pelos aspectos de portabilidade entre sistemas operacionais e de segurança. A arquitetura deste sistema é do tipo cliente-servidor, trabalhando sob thin-client, ou seja, toda a lógica e o banco de dados do sistema são armazenados no servidor, ficando o cliente somente com o processamento das páginas HTML.
Para mostrar o funcionamento do sistema, tem-se de maneira resumida, o Modelo Lógico como mostra a Figura 1. Nesse modelo são apresentadas as duas classes centrais, Usuário e Documento, bem como a relação entre ambas, permitindo apenas aos usuários cadastrados no sistema inserir, consultar e manipular imagens.
Figura 1: Modelo lógico do sistema
Com base na Figura 1 pode-se detalhar o funcionamento do sistema, que tem inicio com a tela de autenticação. Caso o usuário não esteja cadastrado, ele o pode fazer enviando seus dados através do formulário de cadastro e depois receber uma autorização de acesso via email, enviada pelo administrador do sistema. Essas telas não serão apresentadas neste artigo por motivos de insuficiência de espaço.
Após o processo de autenticação é exibida a tela de pesquisa ao usuário conforme mostra a Figura 2. Nessa tela, ao lado direito há um link (Imagem), que o direciona à tela de cadastro das características da imagem, conforme os atributos apresentados no Modelo Lógico da Figura 1, além da imagem como um arquivo.
Figura 2: Interface de busca de imagens Na Figura 3 são apresentadas as telas de inserção de características e da imagem como arquivo
no sistema. Neste sistema, as características das imagens são armazenadas no banco de dados MySQL [5] por possuir ótimo desempenho em termos de velocidade de acesso e tempo de resposta, além de atender plenamente os requisitos do sistema. A velocidade de acesso é um fator de destaque, devido ao número elevado de consultas que podem ser realizadas.
WVC´2005 - I Workshop de Visão Computacional
128

Figura 3: Cadastro das características e arquivos das imagens
Outra característica deste sistema está na atividade de inserção de imagens, destacando a maneira como elas são armazenadas e acessadas. Quando uma nova imagem é inserida, as informações textuais são gravadas no banco de dados e as imagens são armazenadas em um conjunto de diretórios organizados segundos critérios pré-estabelecidos pelo administrador do sistema. Essa organização auxilia a inserção e busca das imagens, pois apenas um caminho indicando a localização das mesmas é armazenado e o mesmo é referenciado numa consulta. Isso aumenta o desempenho do sistema de maneira acentuada, pois em se tratando de Web, onde as informações navegam do cliente para o servidor e vice-versa, nenhum processo de conversão para inserção de imagens no sistema e nem de reconstituição para apresentá-las aos usuários é utilizado, o qual pode retardar o acesso ao sistema.
O sistema de busca de imagens apresentado na Figura 2 possui o seguinte funcionamento: o usuário pode consultar o acervo de imagens digitando um conjunto de até 10 palavras separadas por espaços em branco. Os critérios de consultas das imagens percorrem seus atributos como descrição, sexo, idade, entre outros, identificando quais imagens satisfazem os requisitos de pesquisa digitados pelo usuário para serem retornados ao usuário. A Figura 4 mostra um resultado de consulta de imagens.
Figura 4: Interface de busca de imagens
Na tela apresentada na Figura 4, o usuário pode clicar sobre a imagem encontrada para que seja
aberta uma nova janela pop-up contendo a mesma imagem em seu tamanho original.
WVC´2005 - I Workshop de Visão Computacional
129

3. Resultados Com o desenvolvimento do SGIM para WEB, uma quantidade indefinida de usuários pode
armazenar e consultar imagens, contribuindo para o crescimento da base de pesquisa nesse ou em outros tipos de imagens. Na Figura 5 é apresentada a estrutura de armazenamento do sistema, em que se destacam os diretórios para armazenamento e o banco de dados para documentação de suas características descritivas.
Figura 5: Estrutura interna de armazenamento A separação em bases de dados distintas para o armazenamento das informações textuais e
arquivos é uma recomendação de desenvolvimento mesmo em sistema tradicionais [7], pois traz aumento significativo no desempenho sistema. Neste sistema, destaca-se o aprimoramento da técnica de armazenamento e busca, em que apenas informações que caracterizam as imagens e um link para o arquivo da mesma, são armazenadas. Dessa forma, pode-se notar a redução dos tempos de inserção e consultas, pois nenhum processo de conversão e busca na base de dados é utilizado. 4. Conclusões
Com base na execução do sistema notou-se um melhor gerenciamento e organização das imagens, que foram catalogadas com suas características, auxiliando em uma futura recuperação.
Outro fator de destaque que se alcançou com o sistema foi a centralização das imagens num servidor e a abrangência que pode ser oferecida, pois se tratando de uma arquitetura cliente-servidor Web, qualquer pessoa pode acessar e manipular suas respectivas imagens.
Quanto ao desenvolvimento, destaca-se a técnica empregada, o serviço de diretório e o não armazenamento em banco de dados [7], o que possibilitou um aumento no desempenho do sistema com a redução do tempo de acesso e resposta.
Estão sendo implementados os módulos para o tratamento e diagnóstico dessas imagens, que auxiliarão, por exemplo, a correção de ruídos, a reconstituição das mesmas antes de serem armazenadas, entre outras tarefas. Referências [1] ZEFERINO, A. M. B.; BARROS F. O.; A. A.; BETTIOL, H.; BARBIERI, M. A. (2003).
“Acompanhamento do crescimento”, Jornal de Pediatria, vol 79, supl. 1. [2] LONGUI, C. A. (2003). “Previsão da Estatura Final – Acertando no “Alvo” ”. Arquivo Brasileiro
Endocrinológico e Metabólico, vol 74, nº 6. [3] ECLIPSE, Internet site address: http://www.eclipse.org acessado em 30/05/2005. [4] JSP, Internet site address: http://www.sun.com acessado em 26/06/2005. [5] MYSQL, Internet site address: http://www.mysql.com acessado em 15/06/2005. [6] JAKARTA-TOMCAT, Internet site address: http://jakarta.apache.org/tomcat/ acessado em
10/07/2005. [7] ORACLE, Internet site address: http://www.oracle.com.br acessado em 10/08/2005.
Banco de Dados do Sistema
Caminho de inserção e pesquisa
//imagem/nome_da_imagem.extensão
WVC´2005 - I Workshop de Visão Computacional
130

Extração de Medidas Biométricas em Nervuras de Órgãos Foliares Vegetais
Rodrigo de Oliveira Plotze, Odemir Martinez Bruno
Instituto de Ciências Matemáticas e de Computação
Universidade de São Paulo (ICMC-USP) Caixa Postal 688 – Cep 13560-90 São Carlos – São Paulo - Brasil
roplotze,[email protected]
Resumo: Neste artigo são apresentados técnicas de visão computacional capazes de extrair medidas biométricas em estruturas de órgãos foliares. Os dados coletados estão concentrados nos conjuntos de nervuras das espécies. As técnicas foram empregadas em imagens reais de órgãos foliares, em dois conjuntos de espécies: (i) maracujás silvestres do gênero Passiflora e (ii) vegetais da Mata Atlântica e do Cerrado. As informações biométricas extraídas serviram de entrada para uma rede neural artificial visando à classificação das espécies. A taxa de acerto na discriminação das espécies foi superior a 90%. Os métodos desenvolvidos podem auxiliar os taxonomistas na extração de medidas biométricas em espécies vegetais. Abstract: Computer vision techniques utilized for extracting biometric features in plant leaf structures are described in this paper. The collected biometric data are concentrated in leaf venation system. The methods are applied in real images of plants in two species sets: (i) passion fruits species of genus Passiflora and (ii) vegetable species of Mata Atlântica and Cerrado. The biometric features extracted were introduced in a neural network to perform the classification of the species. The results exhibited a correctly species discrimination more than 90%. The developed methods can be used to assists the taxonomists to perform biometry in plant leaf structures.
1. Introdução
O crescimento do uso de imagens digitais em diversas áreas de aplicação tem demandado, cada vez mais, o desenvolvimento de métodos para análise de imagens. Necessariamente, esses métodos precisam ser altamente confiáveis e capazes de extrair informações úteis, além de interpretar resultados. A aplicabilidade é comprovada em diversas áreas de conhecimento como: agricultura (SOILLE, 2000), medicina (CHAMARTHY, STANLEY et al., 2004), robótica (WINTERS e SANTOS-VICTOR, 2002), indústria (SUN, 2004), dentre outras.
O conteúdo das imagens analisadas nas diferentes áreas de aplicação é completamente diferente, entretanto, os tipos de análise executados possuem muitas características em comum. Na maioria das vezes, o processo de análise envolve algumas etapas fundamentais como: distinção de partes de interesse na imagem (células, tumores, etc); medição de propriedades dessas partes e utilização dos atributos para classificar ou descrever partes (ROSENFELD, 2001).
WVC´2005 - I Workshop de Visão Computacional
131

Em botânica, sistemas de visão computacional capazes de efetuar análise de imagens podem contribuir substancialmente para o desenvolvimento de pesquisas na área. Hoje em dia, estudos relacionados a análise morfológica, padrão de crescimento e taxonomia de órgãos foliares tem consumido esforços de vários pesquisadores (BOCKHOFF, 2001; HOFER, GOURLAY et al., 2001).
Estudos envolvendo botânica são baseados na extração de medidas biométricas dos órgãos foliares, ou simplesmente biometria. Os métodos biométricos são utilizados para coletar e estudar medidas de estruturas em órgãos de seres vivos, bem como, analisar a funcionalidade dessas medidas. O principal problema relacionado à utilização dessas técnicas é que a maioria delas é realizada manualmente. Dessa forma, a implementação de técnicas biométricas em sistemas computacionais pode auxiliar a tarefa dos biometricistas na realização de diversas tarefas do dia-a-dia.
Este trabalho apresenta um conjunto de ferramentas computacionais capazes de realizar biometria de espécies vegetais. Inicialmente, os métodos foram aplicados especificamente na biometria do conjunto de nervuras dos órgãos foliares. Entretanto, é importante salientar que estes métodos poderão ser utilizados para biometria de outras estruturas. Para validação dos métodos desenvolvidos, as técnicas foram aplicadas em casos reais de biometria de espécies. Dois conjuntos de imagens de órgãos foliares foram utilizados: (i) imagens de espécies de maracujás silvestres do gênero Passiflora e (ii) imagens de órgãos foliares de espécies da Mata Atlântica e do Cerrado. Os resultados dos métodos são apresentados e discutidos na seção de Experimentos.
2. Biometria de Órgãos Foliares
Hoje em dia, sistemas envolvendo técnicas biométricas têm se tornado essenciais para as mais variadas aplicações em reconhecimento de padrões como: reconhecimento de faces, íris, voz, impressão digital, etc. Em botânica, os métodos biométricos podem ser aplicados em dois conjuntos principais de informações dos órgãos foliares: (i) área foliar - no qual inúmeras informações podem ser extraídas como: largura, altura, centro de massa, simetria, etc. e (ii) conjunto de nervuras - em que podem ser coletadas informações como: número de bifurcações, ângulos entre as bifurcações, tamanho da nervura principal, etc.
Este trabalho se concentra no desenvolvimento de métodos computacionais para extração de medidas biométricas especificamente do conjunto de nervuras dos órgãos foliares. As informações extraídas das nervuras foram definidas a partir de estudos realizados em protocolos de taxonomia de espécies vegetais (WING, 1999). Essa preocupação na definição dos dados a serem extraídos foi necessária para que as características realmente fossem significantes na taxonomia das espécies vegetais.
Os métodos desenvolvidos e implementados foram divididos em três categorias: (i) distâncias; (ii) comprimentos e (iii) ângulos. Na primeira categoria, os métodos biométricos referentes às distâncias, têm como objetivo extrair medidas com base na distância entre determinados pontos das nervuras. Por exemplo, uma medida que pode ser extraída é a distância média entre todas as bifurcações das nervuras. A segunda categoria é responsável por extrair medidas referentes ao comprimento. Um exemplo de característica extraída nessa categoria é o comprimento de uma determinada ramificação, ou, o comprimento da ramificação principal. Por fim, a terceira categoria é responsável por extrair medidas com bases nos ângulos. Com esses métodos é possível extrair, por exemplo, os ângulos entre duas ramificações de uma nervura. A Figura 1 ilustra alguns tipos de medidas biométricas que podem ser coletadas através dos métodos computacionais desenvolvidos: (a) distância entre as bifurcações das nervuras; (b) comprimento da nervura (ramificação) principal e (c) ângulos entre as ramificações.
WVC´2005 - I Workshop de Visão Computacional
132

(a) (b) (c) Figura 1: Extração de medidas biométricas em nervuras de órgãos foliares. (a) distância entre as bifurcações;
(b) comprimento da nervura principal e (c) ângulos entre as ramificações.
Experimentos
O objetivo dos experimentos envolvendo biometria dos órgãos foliares é classificar as espécies através de medidas biométricas extraídas a partir do conjunto de nervuras. De maneira geral, os experimentos com biometria podem ser divididos em três fases principais: (i) processamento; (ii) biometria (extração de características) e (iii) reconhecimento de padrões. A Figura 2 apresenta um diagrama contendo as fases do experimento sobre biometria do conjunto de nervuras.
Figura 2: Diagrama dos experimentos realizados para extração de medidas biométricas nas nervuras de órgãos
foliares das espécies de Passiflora e da Mata Atlântica. Foram utilizadas 90 imagens de espécies vegetais – 40 de maracujás silvestres (10 espécies) e 50 de espécies da Mata Atlântica e do Cerrado (10 espécies). Através dos métodos biométricos desenvolvidos, um conjunto de 19 características biométricas foi coletado, sendo algumas delas:
WVC´2005 - I Workshop de Visão Computacional
133

número de bifurcações, distância média entre as bifurcações; tamanho da nervura; número de ramificações; ângulos médios de abertura, dentre outras. Utilizando redes neurais artificiais, três arquiteturas foram treinadas visando a discriminação das espécies. Na primeira arquitetura a rede foi treinada apenas com os vetores de características biométricos das espécies de Passiflora. Na segunda, o treinamento foi realizado apenas com os 50 vetores das espécies da Mata Atlântica e de Cerrado. E por fim, na terceira rede todos os vetores foram utilizados para treinamento. O algoritmo para treinamento da rede foi o backpropagation e os erros foram estimados através da taxa MSE. A Tabela 1 apresenta os resultados obtidos da classificação das espécies através de rede neurais artificiais.
TABELA 1: Resultado da classificação por redes neurais dos dados de biometria das nervuras – espécies de Passiflora; e da Mata Atlântica e do Cerrado.
# espécies amostras para
treinamento amostras para teste
% acerto % erro MSE nos testes
rede 1 Passiflora 75% 25% 95% 5% 0.00123 rede 2 Mata Atlântica 75% 25% 90% 10% 0.05938 rede 3 Todas 75% 25% 90% 10% 0.05392
Conclusões
Este trabalho apresenta um conjunto de técnicas capazes de realizar a extração de medidas biométricas em órgãos foliares. Os métodos foram desenvolvidos com base em protocolos de taxonomia de espécies utilizados por botânicos, visando com isso a extração de medidas realmente significantes para classificação das espécies. Utilizando imagens reais de órgãos foliares a taxa de acerto, ou seja, taxonomia correta das espécies foi superior a 90%. Assim, estas técnicas podem ser utilizadas para auxiliar os botânicos na coleta de informações biométricas de espécies vegetais. Referências (BOCKHOFF, 2001) BOCKHOFF, R. C. Plant Morphology: The Historic Concepts of Wilhelm Troll, Walter
Zimmermann and Agnes Arber. Annals of Botanny, v.88, p.1153-1172. 2001. (CHAMARTHY, STANLEY et al., 2004) CHAMARTHY, P., R. J. STANLEY, G. CIZEK, R. LONG, S. ANTANI e
G. THOMA. Image Analysis Techniques for Characterizing Disc Space Narrowing in Cervical Vertebrae Interfaces. Computerized Medical Imaging and Graphics, v.28, n.1-2, p.39-50. 2004.
(HOFER, GOURLAY et al., 2001) HOFER, J. M. I., C. W. GOURLAY e T. H. N. ELIS. Genetic Control of Leaf Morphology: A Partial View. Annals of Botanny, v.88, p.1129-1139. 2001.
(ROSENFELD, 2001) ROSENFELD, A. From Image Analysis to Computer Vision: An Annotated Bibliography, 1955-1979. Computer Vision and Image Understanding, v.84, p.298-324. 2001.
(SOILLE, 2000) SOILLE, P. Morphological Image Analysis Applied to Crop Field Mapping. Image and Vision Computing, v.18, p.1025-1032. 2000.
(SUN, 2004) SUN, D. W. Computer Vision - An Objective, Rapid and Non-Contact Quality Evaluation Tool for the Food Industry. Journal of Food Engineering, v.61, n.1, p.1-2. 2004.
(WING, WILF et al., 1999) WING, S., P. WILF, K. JOHNSON, L. J. HICKEY, B. ELLIS e A. ASH. Manual of Leaf Architecture - Morphological Description and Categorization of Dicotyledonous and Net-veined Monocotyledonous Angiosperms by Leaf Architecture. Washington: Leaf Architecture Working Group. 65 p., 1999.
(WINTERS e SANTOS-VICTOR, 2002) WINTERS, N. e J. SANTOS-VICTOR. Information Sampling for Vision-Based Robot Navigation. Robotics and Autonomous Systems, v.41, n.2-3, p.145-159. 2002.
WVC´2005 - I Workshop de Visão Computacional
134

Localização de Características Faciais usando Projeções Horizontais e Verticais
Thiago Lombardi GASPAR, Maria Stela Veludo de PAIVA
Escola de Engenharia de São Carlos (EESC) – Universidade de São Paulo (USP)
São Carlos – SP – Brasil Av. Trabalhador Sãocarlense, 400 – Centro – CEP 13566-590 - São Carlos – SP
Tels: (16) 3373-9362 - (16) 3373-9347 – Fax: (16) 3373-9372
tlgaspar, [email protected]
Abstract. This paper presents an automatic methodology based on vertical and horizontal projection for facial features extraction. This methodology is applied on digital images of faces, to locate the eyes and nose. With these informations, the face features points are extracted and then is created a facial features vector. The algorithm was developed on Matlab version 6.5, using the toolbox of image processing.
1. Introdução
Métodos seguros para reconhecimento automático de indivíduos, baseados em características
biométricas, têm se tornado de extremo interesse, uma vez que essas características são únicas para cada indivíduo, não podendo ser transferidas de uma pessoa para outra. Dentre os métodos baseados em características biométricas, destaca-se aqueles que extraem as características faciais, que são medidas do rosto que nunca se alteram, tais como a distância entre os olhos, a distância entre os olhos, nariz e boca, a distância entre os olhos, queixo, boca e contorno dos cabelos [5]. Porém, alguns problemas podem dificultar o processo de localização dos componentes faciais, tais como a posição da face do indivíduo, face parcialmente ou totalmente obstruída por objetos, expressão facial, complexidade no fundo da imagem, etc. Essas características podem ser detectadas manualmente ou através de algoritmos automáticos [2].
Dentre os métodos existentes para a localização de características faciais, destaca-se o método baseado em projeção horizontal e vertical, utilizado por [1], pela sua simplicidade no que se refere à estrutura de implementação, baixo custo computacional na localização das características faciais. O trabalho apresentado neste artigo baseia-se nesse método e utiliza projeções horizontais e verticais para localizar características faciais.
A implementação do presente trabalho está dividida em três módulos:
• O primeiro módulo, o de pré-processamento é aplicado sobre as imagens de entrada, com o objetivo de reduzir o ruído, melhorar a qualidade da imagem e padronizar suas dimensões;
• O segundo módulo, o de segmentação destaca as características de interesse; • Essas características são então localizadas pelo terceiro módulo através das projeções
horizontais e verticais.
WVC´2005 - I Workshop de Visão Computacional
135

2. Metodologia Como imagem de entrada, foi utilizado um banco de aproximadamente 100 imagens faciais obtido
do Departamento de Psicologia da Universidade de Stirling [6]. Esse banco contém imagens de pessoas de ambos os sexos, dimensões de aproximadamente 350 x 274 pixels, em escala de cinza, e inclui diferentes tipos de imagens, tais como, frontais, de perfil, com expressões faciais diversas. Foram utilizadas somente as imagens frontais, por serem as imagens de interesse para documentos em geral. Um detalhe importante a ser mencionado, é que nessas imagens, as pessoas não têm bigode, barba ou óculos.
As imagens foram redimensionadas usando o Face Detector Software Web [3]. Esse software on-line permite um upload da imagem para a qual se deseja realizar a detecção da face em uma determinada cena, retornando somente a região facial de interesse.
Sobre as imagens redimensionadas foram aplicados métodos de pré-processamento, segmentação e a projeção horizontal e vertical para detectar os componentes faciais (os olhos e o nariz), que serão descritos a seguir:
1) Pré-processamento da imagem: primeiramente, foi utilizada a filtragem mediana para
reduzir ruídos e preservar as bordas da imagem, assim eliminando as imperfeições que influirão de forma negativa no processo de localização dos componentes faciais. Posteriormente, foi aplicado um processamento para aumentar o contraste da imagem e, impedindo a criação de artefatos da imagem processada.
2) Segmentação: nesta etapa, é aplicada a binarização global simples, seguido da operação
morfológica de abertura de área para a remoção de agrupamentos de pixels que estão interconectados, auxiliando na remoção de alguns pixels, que possam dificultar o processo de localização das características faciais. Após isso, é aplicado o detector de bordas de Sobel para ressaltar os contornos dos principais elementos da face (os olhos e o nariz), assim como todo o contorno da face. Por fim, é utilizada uma técnica de preenchimento, responsável por preencher de branco todos os pixels que estão totalmente conectados.
3) Projeções horizontais e verticais para a localização das características faciais. O
algoritmo das projeções localiza os olhos e o nariz, através da análise dos picos que representam valores das regiões com maior concentração de pixels brancos. Essas regiões foram definidas manualmente, através da análise dos espectrogramas. Em seguida, são aplicadas as projeções horizontais e verticais sobre a imagem binária, criando vários vetores contendo a quantidade de pixels brancos em cada linha e em cada coluna. Os vetores são então analisados pelo algoritmo para a identificação dos pontos de máximo e localização dos componentes faciais. Os componentes faciais estão localizados na região de coincidência dos máximos das assinaturas horizontais e verticais.
3. Resultados
Foram testadas algumas imagens do banco de dados [6], contendo faces frontais, sem oclusão das
características faciais onde as imagens possuem resolução de 189 x 168 pixels, de 8 bits/pixel. A Figura
WVC´2005 - I Workshop de Visão Computacional
136

1 mostra os resultados do pré-processamento e da segmentação, e na Figura 2 são apresentados os resultados das projeções horizontais e verticais.
(a) (b) (c) (d) (e)(a) (b) (c) (d) (e) Figura 1 - (a): Imagem de entrada. (b): Aplicação da filtragem mediana. (c): Aplicação do aumento de contraste. (d): Aplicação do detector de Sobel e da técnica de preenchimento
de pixels. (e): Resultado da localização das características faciais.
Figura 2 – Espectrograma das projeções horizontais e verticais sobre a imagem segmentada. (a):
Projeção horizontal (Figura 1 (d)). (b): Projeção vertical (Figura 1 (d)).
A Figura 1 (e) mostra os cruzamentos determinados pelas regiões de máximo das projeções horizontais e verticais. Uma vez identificada a região dos olhos e a região do nariz, determina-se através da média entre o olho esquerdo e o olho direito, a posição central da face e o ponto central do nariz. A partir da localização da posição dos pixels de cada característica facial, é possível extrair as características, criando assim o vetor de características faciais.
Banco de Dados Face normal Face sorrindo
Características faciais
34 imagens 43 imagens Olhos 85% 53% Nariz 76% 84% Olhos e Nariz 79% 49%
Tabela 1 – Porcentagem de acerto do algoritmo para o banco de dados PICS.
WVC´2005 - I Workshop de Visão Computacional
137

Na Tabela 1 é apresentada a porcentagem de acerto obtida com a aplicação do algoritmo das projeções horizontais e verticais sobre a imagem facial segmentada. A taxa de erro encontrada para as imagens normais, está relacionada com a inclinação e rotação da face. As imagens contendo faces sorrindo, apresentaram uma alta taxa de erro na localização dos olhos e do nariz, que deve-se ao problema da inclinação e rotação, e acrescido da expressão facial. Em algumas dessas, os olhos estavam parcialmente ou totalmente fechados, dificultando a segmentação do globo ocular. Nessas mesmas imagens, devido ao fato da face estar com expressão sorridente, o nariz foi confundido com a boca, pelo fato desta estar muito aberta. 4. Conclusões
As operações de pré-processamento contribuíram para eliminar ou atenuar pequenos ruídos que
prejudicavam a aplicação do método de segmentação e do algoritmo das projeções horizontais e verticais.
Analisando os resultados obtidos, conclui-se que é possível localizar as características faciais através do algoritmo das projeções horizontais e verticais de forma bastante satisfatória, desde que as imagens sejam anteriormente padronizadas, com a face centrada e que seja feita a correção da inclinação e rotação das faces. Além disso, a face não pode estar parcialmente ou totalmente obstruída por outros objetos.
A boca é importante em pesquisas relacionadas ao reconhecimento de expressões faciais, e nesse trabalho não foi utilizada, pelo fato da sua forma e tamanho se alterarem com a expressão facial. Outro fator que pode influenciar é a presença de bigode na região da boca [4].
Referências Bibliográficas [1] BASKAN, S.; BULUT, M.; ATALY, V. (2002). “Projection based method for segmentation of human face and its evaluation”, Pattern Recognition Letters / Elsevier Science, vol. 23, pp. 1623-1629. [2] BRUNELLI, R.; POGGIO, T. (1992). “Face recognition through geometrical features”, Proceedings 2nd European Conference Computer Vision, pp. 792-800. [3] FDSW Face Detector Software Web, http://aias.csd.uch.gr:8999/cff/Upload.html. [4] GU, H.; SU, G.; DU, C. (2003). “Feature Points Extraction from Faces”, Image and Vision Computing, New Zealand, pp. 154-158. [5] LEE, S. Y.; HAM, Y. K.; PARK, R. H. (1996). “Recognition of Human Front Faces Using Knowledge-Based Feature Extraction and Neuro-Fuzzy Algorithm”, Pattern Recognition, vol. 29, no. 11, pp. 1863-1876. [6] PICS Psychological Image Collection at Stirling (PICS), http://pics.psych.stir.ac.uk/cgi-bin/PICS/New/pics.cgi.
WVC´2005 - I Workshop de Visão Computacional
138

Automatic Creation of 3D Virtual Environments Using Artificial Intelligence and Scene Graphs
Juliana Gouveia Denipote1,3, Maria Stela Veludo de Paiva1, Patrícia Shirley Herrera Cateriano2,3
1Escola de Engenharia de São Carlos EESC/USP- São Carlos, Brazil [email protected], [email protected]
2Instituto de Ciências Matemáticas e de Computação ICMC/USP - São Carlos, Brazil [email protected]
3Cientistas Associados Ltda. - São Carlos, Brazil [email protected]
Abstract. The long time spent during the 3D modeling of the environment objects is the main problem of creating virtual environment (VE). Automatic generation tools represent good alternative ways to increase performance when a VE is being built. Furthermore, the representation of the VE needs to be of good quality and fast for an interaction in real time. This work describes an automatic generation tool using scene graphs and neural net to create a VE from a real city photographs. 1. Introduction The creation of virtual environments (VE) should replicate the most visual aspects as possible from the real objects that are being represented. A VE application, very cited in the nowadays literature, is the representation of real cities [1], [2]. That kind of VE is used in many fields, such as entertainment, tourism, 3D geographic information systems, among others. Although VE has been used in many areas of applications, its creation is a complex task because of the many objects that can be included in the 3D environment such as houses, squares, buildings, roads. The task complexity is aggravated when large urban areas have to been modeled. To solve that problem, the solution proposed is to model the city objects in an automatic way, using image segmentation methods and a neural net to recognize and classify city elements in urban aerial photographs. Another important issue is the definition of the criteria used during the navigation in VE. One interesting criterion is the detail level of the objects, in order to maintain as much as possible a realistic environment. For that purpose, this work considered the optimization of the rendering process through the representation of three-dimensional synthetic VE using scene graphs. It should allow a faster and more efficient processing of the VE by the application, maintaining a good quality in the visualization and allowing visualization and interaction in real time. 2. Virtual Environment Creation It was used a set of photos from an urban area, acquired in an easy and cheap way to guarantee the viability of the application. The photographs were the same used by Hughet [1] and were taken by a common digital camera Kodak DX3700 that has 3 Megapixels precision. However that camera is more accessible, being approximately forty times cheaper than the cameras of medium format usually used in application of this type, as those used in [3]. The photographs were taken in a low altitude, 500 meters from the ground. Figure 1(a) shows one of these photographs. Tests were made with images taken from
WVC´2005 - I Workshop de Visão Computacional
139

Google Earth [4] too, which is free tool for personal use and makes available photograph images taken by satellites and aircrafts in the last three years. Figure 1 (b) shows an example of Google Earth images.
Figure 1 – (a) São Paulo city’s aerial photograph taken from Google Earth. (b) Belo Horizonte city aerial photographs taken using a Kodak DX3700.
On images of Figure 1 are applied Computational Vision and Artificial Intelligence methods to obtain the expected result of the image processing as showed in Figure 2.
Figure 2 – Solution for creating a 3D Virtual City
In Figure 2, first, the Image Processing using Computational Vision techniques must be made. The image processing is divided in three activities: 1) pre-processing: the image’s noise is decreased and the quality is enhanced. 2) segmentation: objects of interest as buildings, pavements and green parks are found by segmentation methods. 3) characteristics extraction: some characteristics of the objects found in the segmentation activity are extracted such as color average, perimeter, height, width, pixel quantity, etc. Those characteristics will be the input parameters for the neural net. The characteristics found in the image processing will be the entrance patterns for the neural net, which has to classify the objects in three different classes: houses, buildings and squares. The neural net
WVC´2005 - I Workshop de Visão Computacional
140

architecture used in this work was Multi Layer Perceptron (MLP). For this work, the used net has the following topology: five entrance characteristics (height, width and pixel color represented by RGB standard); five neurons in the hidden layer due to the amount of patterns characteristics; and three neurons in the output layer, because the patterns were classified in the classes: houses, buildings and squares. There is a 3D models database to store different models for each of the three classes of objects. As long as each object of the image was properly identified and classified by the neural net, a 3D object is chosen in a random way in the database. For example, if it is identified that the object is a house, one 3D model is chosen among the ten house models. Then, the position of the model to be inserted in the VE is determined by the position of the corresponding object in the image. 3. Virtual Environment Navigation
An interesting and very efficient approach to optimize the process of visualization is the use of scene graphs. The scene graphs store data, creating a tree with the elements that conform the VE. This tree will allow a more accurate processing of the information that should be visualized, discarding those that are not in the user’s visual area. The leaves of the tree store the geometry of the scene and the nodes of higher levels store complementary information. Two techniques were used in the scene graphs in order to increment the render process speed: Impostor and LOD (Level Of Detail). Impostor works in scene graphs as a particular type of node that intends to substitute part of the scene’s geometry by images of the same geometry computed by the system. The substitution is determined by a distance parameter that is predetermined in the application (a threshold distance). The use of the Impostor technique represents a lower cost of processing, as it is not necessary to process over and again the complete geometry of the original scene. The LOD technique is implemented as another type of node, used as well by the Impostor technique. LOD allows the substitution of objects in the scene. In this technique are used two different models of the same object: one more detailed which have a high number of polygons and other simpler model, represented by a low number of polygons. The replacement of one by another depends on the threshold distance between the object and the viewpoint. 4. Tests and Results It was observed that the network reached an excellent classification with an estimative error of 9% for houses class, 12.28% for buildings class and 0,29% for square class. A momentum term was used to accelerate the neural net training processes. Analyzing the results, it is possible to observe that the samples quality influence the pattern classification. The patterns normalization is a way to enhance the samples, and it was confirmed that normalizing the dates, the accuracy of classification reached the rate of 100% of the tested samples, while without the normalization, the rate was 80%. The system implemented used the Open Scene Graph (OSG) library [5] to create and manipulate the VE. The use of LOD and Impostor techniques increase the performance in more than 50% of the visualization’s time. The experiments with an environment composed by over one million polygons reached a visualization time, before the optimization, about 32 and 42 fps (frame per second) for a dual Xeon machine with 1GB of RAM. This time was improved after the use of LOD and Impostor and it achieved a frame rate around 65 to 72 fps. Some scenes of this VE can be seen in the Figures 4 and 5. 5. Conclusion The MLP network is a good solution for the problem of the automatic VE creation with low error rates and an acceptable time for the network training processing after the momentum inclusion. For a best
WVC´2005 - I Workshop de Visão Computacional
141

performance of the MLP training, the image processing must reach a satisfactory accuracy during the segmentation stage in order to result on high quality samples for the network. The use of scene graphs with different techniques of computer graphics allows to create and visualize complex models, with a high number of polygons, in a much reduced time. The use of libraries based on scene graphs makes easier the development of graphic applications and allows the improvement of the performance in terms of the application’s time. The applications that use this kind of interface allow the user to better understand the data to be studied and obtaining more complex information, because it is possible to offer a great number of information in an organized way.
Figure 4: A house block inserted in the VE. (a) Close view of the building (b) Far view of the same building as sprite
generated by the system with Impostor (in detail)
Figure 5: Navigation from the VE. (a) A 3D model inserted in the VE represented by the LOD model of full detail (b) the
same building in a low level of detail. 6. References [1] A. Huguet, R. Carceroni and A. Albuquerque. Towards Automatic 3D Reconstruction of Urban
Scenes from Low-Altitude Aerial Images. ICIAP, 2003. [2] Sistema Computacional para Redução de Perdas em Redes de Distribuição de Energia com Interface
em Realidade Virtual, PIPE FAPESP Project, ICMC/USP e Cientistas Associados, http://www.icmc.usp.br/~energ_rv/, 2004.
[3] Istar, Aerial Data Acquisition Services, http://istar.photon.francenet.fr/services/acquisition.html, [Last visited on June, 2005].
[4] Google Earth Beta, http://earth.google.com/earth.html. [Last visited on July, 2005] [5] Open Scene Graph, http://openscenegraph.sourceforge.net/index.html. [Last visited on May, 2005].
WVC´2005 - I Workshop de Visão Computacional
142

Melhoramento de compressão usando a quantização de bits na
técnica wavelet em imgem de impressão digital
Nilvana S. Reigota, Maria Stela V. Paiva, Everthon S. Fonseca, Deise Alves.
Universidade de São Paulo-USP
Escola de Engenharia Elétrica de São Carlos - Departamento de Engenharia Elétrica Programa de Pós-Graduação em Engenharia Elétrica
São Carlos – SP Av. Trabalhador São-carlense, 400 - Centro - CEP 13566-590 Tel: (16) 3373-9362, e-mail:
Abstract This paper presents a system based on compression of fingerprints. The work proposes a
compression with lossless in images visualization using wavelet Haar technique with quantization of bits.
1. Introdução
A compressão de imagens é o trabalho de reduzir a quantidade de dados desnecessários, para representar uma imagem digital, pela remoção de dados redundantes, diminuindo a quantidade de memória necessária para representar e armazenar uma imagem digital. Posteriormente a imagem é descomprimida obtendo a imagem original ou uma aproximação dela. 2. Compressão usando quantização e transformada de wavelet Haar
A compressão tem o pré-processamento e o pós-processamento. Para o procedimento de pré-processamento, utilizou-se a quantização da imagem com um algoritmo, para modificar a quantidade de níveis de cinza para cada componente R(red), G(green) e B(Blue). Para tanto, foi necessário basicamente dividir a imagem por 255 (28 bits) e multiplicar por um número que representasse a quantidade de níveis para a nova imagem. Usou-se potências de dois para representar a quantidade destes novos níveis. O algoritmo foi implementado em MATLAB, os níveis de cinza foram reescalonados, de 0 a 255, porém, é mantido o mesmo número, resultando num total de 2*2*2 = 8 níveis de cinza no máximo.
Ao aplicar a transformada da wavelet na imagem para um pós-processamento, é necessário analisar a imagem em filtragem de sub-bandas, este método tem sido largamente usado em codificações, cada sub-banda resultante da filtragem com banco de filtro é depois codificada usando um codificador que leva as características da sub-banda.
Uma solução típica usada devida á sua baixa complexidade consiste em dividir o espectro da imagem em duas metades iguais: a metade passa baixo e a metade passa – alto. A metade passa alto contém os detalhes mais finos da imagem que são os chamados detalhes (altas freqüências). A metade passa baixo pode ser novamente dividida em duas bandas também chamada de aproximação, obtendo–se assim três zonas de interesse no espectro do sinal. Esta iteração é realizada até se atingir o numero de bandas desejadas, onde a imagem é filtrada. A figura (a) abaixo mostra o banco de filtro que contém aproximação que é indicada pela letra (a), e o detalhe que indica a letra D. A figura (b) indica a
WVC´2005 - I Workshop de Visão Computacional
143

representação de uma decomposição da imagem, logo A1, A2, A3 são representação de aproximação e D1
1, D12 ... são detalhes.
(a) (b)
Figura 1: estas imagens representam um modo de detalhamento no andamento da compressão; (a) decomposição de imagem em forma de banco de filtro; (b) decomposição em forma de sub-bandas.
A wavelet usa compressão de banco para decomposição da imagem original, calculando a media dos pixels, onde todos os dados redundantes da imagem em processamento passam a ter perdas. Com isso a wavelet bidimensional de Haar faz uma média entre os pixels, por exemplo: a média entre [8 e 4 ] é 6; isso é aplicado em cada linha que coleta um par com valor de pixels e faz a media chamada de wavelet Haar com base unidimensional depois para cada par de colunas da imagem. Este método é chamado de decomposição padrão, como mostra a imagem 1(b). A seguir, repete-se o processo para a versão de baixa resolução da imagem obtida no passo anterior, e obtendo-se uma submatriz de A1[i, j] com intervalos, na qual se tem uma nova versão de baixa resolução da imagem (nas demais posições os coeficientes de wavelet). Prosseguindo desta forma, encontra-se uma submatriz de A, formada por A[0, 0] contendo a “média” de todos os pixels e nas demais posições estarão os coeficientes de wavelet.
O objetivo da compressão de wavelet é iniciar um grupo de dados usando soma em pequenos grupos de dados em base funcional. Este grupo de dados consiste de vários coeficientes. No fim deste procedimento ter-se á uma aproximação com menos coeficientes. Estendendo-se uma faixa de tolerância de erros, que reduze o numero de coeficientes. O método para aplicação de função unidimensional equaliza melhor a imagem, de coeficientes correspondendo à base bidimensional constante de variável flexível. A aproximação apresentada é o início para um tratamento completo de compressão de imagens wavelet. Neste trabalho interessa apenas a transformação e redução dos coeficientes e não como eles são codificados. A compressão de imagens usando wavelet e a norma L2 pode ser resumida em 3 passos:
1. Computar os coeficientes c1,...cm representando uma imagem em uma normalização de base Haar bidimensional. 2. Selecionar os coeficientes na ordem decrescente da magnitude para produzir a seqüência cΠ(1)...,cΠ(m).
3. Dado uma norma permissível (L2) e o erro ξ e começando com ^m = m, achar o pequeno
^m para
o qual:
WVC´2005 - I Workshop de Visão Computacional
144
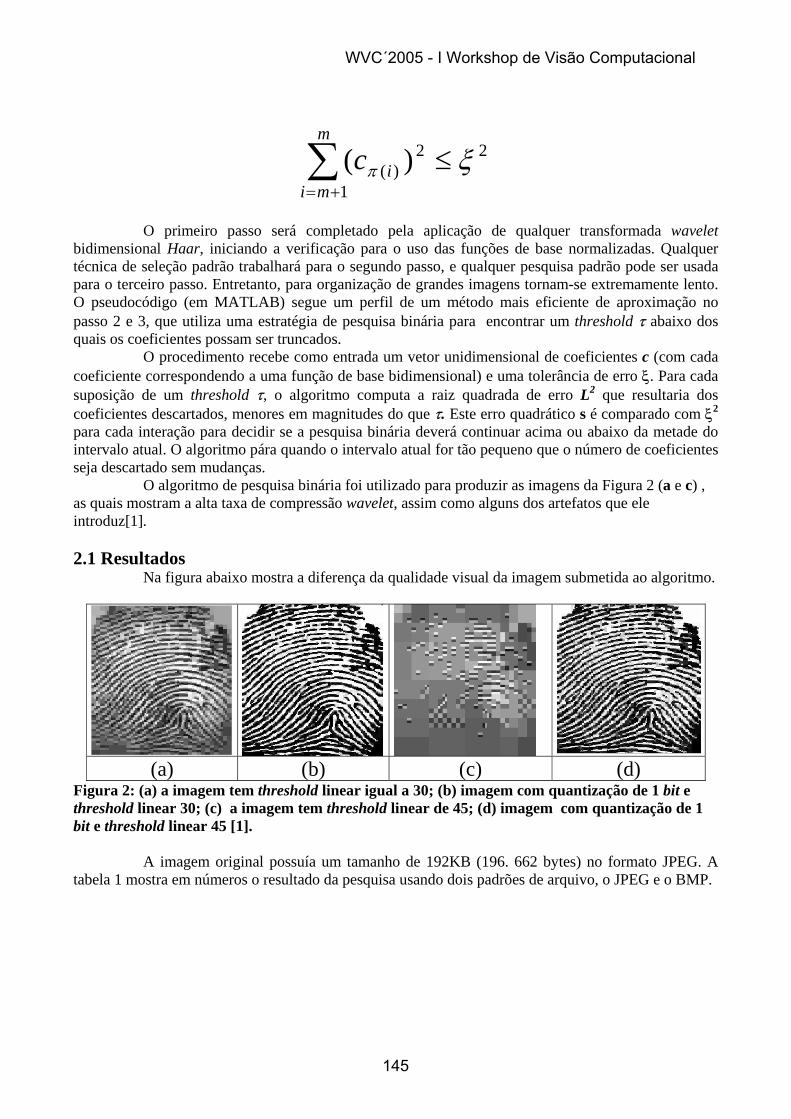
∑+=
≤m
miic
1
22)( )( ξπ
O primeiro passo será completado pela aplicação de qualquer transformada wavelet
bidimensional Haar, iniciando a verificação para o uso das funções de base normalizadas. Qualquer técnica de seleção padrão trabalhará para o segundo passo, e qualquer pesquisa padrão pode ser usada para o terceiro passo. Entretanto, para organização de grandes imagens tornam-se extremamente lento. O pseudocódigo (em MATLAB) segue um perfil de um método mais eficiente de aproximação no passo 2 e 3, que utiliza uma estratégia de pesquisa binária para encontrar um threshold τ abaixo dos quais os coeficientes possam ser truncados.
O procedimento recebe como entrada um vetor unidimensional de coeficientes c (com cada coeficiente correspondendo a uma função de base bidimensional) e uma tolerância de erro ξ. Para cada suposição de um threshold τ, o algoritmo computa a raiz quadrada de erro L2 que resultaria dos coeficientes descartados, menores em magnitudes do que τ. Este erro quadrático s é comparado com ξ2
para cada interação para decidir se a pesquisa binária deverá continuar acima ou abaixo da metade do intervalo atual. O algoritmo pára quando o intervalo atual for tão pequeno que o número de coeficientes seja descartado sem mudanças.
O algoritmo de pesquisa binária foi utilizado para produzir as imagens da Figura 2 (a e c) , as quais mostram a alta taxa de compressão wavelet, assim como alguns dos artefatos que ele introduz[1]. 2.1 Resultados
Na figura abaixo mostra a diferença da qualidade visual da imagem submetida ao algoritmo.
(a) (b) (c) (d)
Figura 2: (a) a imagem tem threshold linear igual a 30; (b) imagem com quantização de 1 bit e threshold linear 30; (c) a imagem tem threshold linear de 45; (d) imagem com quantização de 1 bit e threshold linear 45 [1].
A imagem original possuía um tamanho de 192KB (196. 662 bytes) no formato JPEG. A tabela 1 mostra em números o resultado da pesquisa usando dois padrões de arquivo, o JPEG e o BMP.
WVC´2005 - I Workshop de Visão Computacional
145

Tabela 1: resultados obtidos Imagem Número de
quantização Número de percentagem
de threshold linear Tamanho de arquivo em
extensão JPEG Tamanho de arquivo em
extensão BMP (a) 8 30% 26,0 KB (36.183 bytes) 65,0 KB (66,000 bytes) (b) 1 30% 35,0 KB (36.183 bytes) 67,0 KB (68,678 bytes) (c) 8 45% 13,8 KB (14.205 bytes) 66,5 KB (68,158 bytes) (d) 1 45% 34,6 KB (35.481 bytes) 66,3 KB (67,898 bytes)
3. Conclusão
Observou-se que as imagens com pequena quantidade de níveis de cinza ou de grande quantização são representadas de forma mais aceitável a olho nu, mesmo sendo um pouco maiores no tamanho. E o formato JPEG é o melhor para se arquivar imagens com um resultado de números menor de bytes. Para trabalhos futuros segue-se o uso de codificador e decodificador como o de Huffman, por não apresentar perdas, e um pré-processamento mais apurado na imagem com mais filtros de refinamento antes de se comprimi-la. Agradecimentos
A autora agradece ao Everthon Silva Fonseca, por ter fornecido e explicado o algoritmo de transformada wavelet Haar, a Deise pela tradução e correção e a orientadora Maria Stela Veludo de Paiva, pela orientação e correção. Referências [1] GREEN, W. B. “Digital image Processing”. New York, Van No strand Reinhold Company, 1983. [2] GUERRA S.; SCHUCKA.”Wavelets em compressão de dados”. Mestrado, do depto. De Engenharia Elétrica, Universidade Federal do Rio Grande do Sul, Porto Alegre, RS.,1990. [3] JANG E.; KINSNER W. ”Multifractal wavelet compression of fingerprints.” IEEE, 1997. [4] STRELA V.; HELLER P.; STRANG, G.; TOPIWALA, P.; HEIL C. “The Application of Multiwavelet Filterbanks to Image Processing.” IEEE, 1999. [5] STOLLNITZ, E; DEROSE, T; SALESIN D. “Wavelet for Computer graphics theory and applications”, 1996 [6] XU, S. ”Wavelet Analysis and FBI WSQ Standard for Gray – scale Fingerprint image Compression,” 1990.
WVC´2005 - I Workshop de Visão Computacional
146

Realce de uma Imagem de Impressão Digital utilizando Campo de Orientação.
Paulo Paulin Benzatti, Adilson Gonzaga
Universidade de São Paulo – USP
Escola de Engenharia de São Carlos Departamento de Engenharia Elétrica
[email protected]; [email protected]
Abstract In this paper, it is presented a new algorithm for the enhancement of fingerprint images based in
Orientation Field. This technique is used in the reconstruction of ridge of the Fingerprints that had been damaged in the process of acquisition of the image to recovery the redundant information that had been lost. The proposed algorithm is tested with FVC2000 fingerprint images database obtained of the Internet.
Introdução A performance de um sistema automático de identificação de impressão digital confia na
qualidade da imagem de entrada de uma impressão digital (ID). Imagens de baixa qualidade afetam a extração de minutiaes, causando declínio na performance. Para construir um sistema de identificação de ID efetivo, é necessário um algoritmo robusto de intensificação [5]. Dessa maneira, é freqüentemente necessário o pré-processamento de uma imagem de ID para melhorar a claridade dos detalhes característicos que possam representar corretamente na preparação do processo de classificação [7].
A proposta deste trabalho é implementar um algoritmo capaz de intensificar (realçar) uma imagem de impressão digital de forma que possa recuperar os detalhes dos cumes que foram degenerados no processo de aquisição das imagens originais.
Realce de uma Imagem de Impressão Digital Um algoritmo de intensificação/realce de uma imagem de impressão digital recebe uma imagem
de ID na entrada e aplica um conjunto de etapas de pré-processamento, para finalmente apresentar a imagem de saída realçada. A fim de introduzir o algoritmo de realce da imagem de ID, é apresentada uma série de procedimentos utilizados.
Normalização – efetua-se, por meio da definição prévia de valores constantes de média e variância, a remoção de influências dos ruídos quanto à deformação dos níveis de cinza adquiridos pelas diferentes pressões do dedo no sensor de captura [5]. Assim, o método utilizado para a etapa de normalização foi extraído dos métodos proposto por [6] e de [4].
Campo De Orientação - representa uma propriedade intrínseca de uma imagem de ID e é especificado pelas coordenadas invariantes das estruturas de cumes e vales em uma vizinhança local [8], e é definido como a orientação local das estruturas de cumes e vales em uma ID. Utiliza-se o método proposto em [1] para calcular o campo de orientação da imagem de ID. Para cada pixel da imagem normalizada, são calculados os gradientes GX e GY nas direções de x e y, respectivamente, através do operador de Sobel. Através do resultado das duas componentes do campo de orientação é aplicado um filtro passa-baixa na imagem devido à influência do ruído no cálculo do campo de
WVC´2005 - I Workshop de Visão Computacional
147

orientação. Após a realização da operação bloco a bloco, obtém-se o novo campo de orientação suavizado.
Segmentação - subdivide uma imagem em suas partes constituintes. Em uma imagem de ID, existem áreas onde não são de interesse na análise por não fazer parte da ID. Essas áreas devem ser separadas das áreas onde contenham informações relevantes sobre as estruturas de cumes e vales da ID. A diferença principal entre essas áreas, áreas espúrias e áreas relevantes de estruturas de cumes e vales são a variância do nível de cinza [7]. Nessa etapa de segmentação foi utilizado o módulo gradiente quadrático médio conforme a equação 1.
( ) ( ) ( )∑∑ ΓΓ−+⋅⋅=
22222, yxyx GGGGyxG
As áreas espúrias apresentam um valor absoluto de gradiente menor do que as áreas que representam as estruturas de cumes e vales, sendo possível remover áreas indesejadas utilizando um limiar. Esse valor define se a área pertence à área de interesse da imagem e é definido pela equação 2, sendo que Is(x,y) é a imagem segmentada.
(1)
( )( )( ) LimiaryxGse
LimiaryxGseIyxI N
s ≤
>
⎩⎨⎧
=,
,255
,
Binarização - realça certos pixels, ou determinadas regiões de uma imagem, através de um nível de threshold. Em uma imagem de impressão digital, o interesse é distinguir as linhas pretas das linhas brancas, sendo assim, faz-se uma comparação dos valores dos níveis de cinza dos pixels com um determinado nível de threshold. Se o valor do pixel de interesse tiver um valor inferior ao valor do nível de threshold, então o pixel será convertido para o valor zero (cor preta), caso o valor seja superior, então será convertido para o valor 1 (cor branca). Neste trabalho, o processo de binarização é realizado através da detecção de picos no perfil de intensidade em nível de cinza ao longo das seções ortogonais as orientações [6]. Neste processo foi utilizada uma janela orientada de tamanho 15x15 centrada em cada pixel (x,y). O perfil de nível de cinza é obtido através da projeção das intensidades dos pixels na seção central da janela. Além disso, o perfil é suavizado através de uma média local em cada uma das direções paralelas à orientação no pixel central. Para a determinação das estruturas de cumes são detectados os mínimos do perfil de nível de cinza ao longo da região ortogonal à orientação no pixel (x,y). Os pixels de mínimos e os dois vizinhos são fixados como pixels pretos.
(2)
Filtro Médio - para eliminar os pixels espúrios que surgiram após o processo de binarização, utiliza-se um filtro médio na imagem como o proposto por [2]. Uma janela de tamanho 3x3 foi aplicada pixel a pixel na imagem. Dessa forma, o novo valor do pixel é determinado de acordo com a quantidade de pixels pretos e brancos existentes na janela onde foi centralizada, ou seja, se o número de pixels pretos for maior do que o numero de pixels brancos dentro da janela, então o novo valor do pixel será convertido para preto, caso contrário, será convertido para branco.
Esqueletização – utiliza-se esse processo em uma imagem de ID com a finalidade de reduzir os dados redundantes e preservar a continuidade dos cumes da ID. Assim, os pixels indesejáveis são eliminados na imagem sem alterar sua estrutura. O algoritmo consiste na aplicação sucessiva de duas etapas. Na primeira etapa, de acordo com a definição de vizinhança mostrada na figura 1, é determinado que um ponto de contorno p deva ser eliminado caso satisfaçam as seguintes condições:
( ) ( ) ( )( ) ( ) ( ) 0;1
0;62
4860
8620
=••==••≤≤
pppdpSbpppcpNa (3)
Onde N(p0) é o número de vizinhos não-nulos de p0, ou seja:
( ) 87210 pppppN ++++= K
WVC´2005 - I Workshop de Visão Computacional
148
(4)

p1 p2 p3
p4 p0 p6
p5 p8 p7
Figura 1 - Vizinhança usada pelo algoritmo de esqueletização. Na segunda etapa, as condições anteriores, (a) e (b), permanecem as mesmas, porém as
condições (c) e (d) são modificadas para: 00 482462 =••=•• pppeppp
Se todas as condições forem satisfeitas, então o ponto deve ser marcado para ser apagado. Porém, o ponto não deve ser apagado até que todos os pontos de bordas tenham sido processados. Concluído a aplicação do primeiro passo a todos os pontos de bordas, então aqueles que foram marcados a serem apagados serão igualados a 0. Na seqüência, o segundo passo deve ser aplicado aos dados resultantes exatamente da mesma maneira que o primeiro passo.
(5)
Reconstrução Como o campo de orientação apresenta informações globais das estruturas que compõem uma impressão digital, é possível utiliza-lo para reconstruir algumas linhas das estruturas de cumes que foram perdidas durante todo o processo, desde a aquisição da imagem até a etapa de processamento. A proposta é utilizar uma janela variável (de 3x3 a 19x19 pixels) e orientada para recorrer a imagem esqueletizada e corrigir falsas minutiaes, possibilitando assim um melhoramento no processo posterior de identificação. Para determinar se dois pontos de fim de linha devem ser ligados, são verificados os pixels adjacentes aos pixels mais extremos que pertencem à orientação do pixel central da janela.
Figura 2 - Janela Orientada
Se for verificado que na região central existe um pixel branco e que há pelo menos um pixel adjacente em cada extremo da janela orientada é traçada uma reta ligando os dois extremos cujo ângulo tem o mesmo valor da orientação, conforme mostra a figura 2. Foi utilizada uma variação angular na orientação do pixel central da janela orientada com a intenção de tornar o modelo mais flexível, conforme a equação 6, e essa variação depende do tamanho da janela. Onde a janela corresponde ao tamanho da janela utilizada e ∆θ corresponde a variação da orientação.
( )122
+±=∆ janela
πθ
Consideramos a condição mostrada na equação 7 com a finalidade de evitar que o algoritmo preencha as linhas que não devem ser consideradas como pertencentes a uma linha da estrutura de cume que não existe.
(6)
⎩
⎨⎧
≤>
linhaapreenchedifOlinhaapreenchedifO
limnãolim
(7)
Onde difO é a diferença entre a orientação dos dois pixels adjacentes que podem ou não ser ligados, e é calculado de acordo com a equação 8.
⎪⎩
⎪⎨⎧
−−
<−−=
contráriocasoOO
OOOOdifO
DE
DEDE
π
π2 (8)
WVC´2005 - I Workshop de Visão Computacional
149

Onde OE e OD são as orientações dos extremos direito e esquerdo da orientação, respectivamente.
Figura 3 - Imagem original, imagem s/ a utilização do método, imagem c/ a utilização do método de reconstrução de cumes, respectivamente.
Para se fazer uma avaliação comparativa entre as imagens de ID que utilizaram o método de reconstrução de cumes com as imagens sem a utilização do método, foram feitas análises das minutiaes encontradas nas imagens de ID’s originais. Houve também uma análise comparativa entre as imagens melhoradas com as imagens originais para avaliar a existência de falsas minutiaes.
Nº total de minutiaes corretas: 364 (s/ o método) 373 (c/ o método) Nº total de falsas minutiaes: 395 (s/ o método) 268 (s/ o método)
Conclusão No método proposto houve uma melhora significativa nas imagens com relação à correção de
falsas minutiaes que surgiam de acordo com a deterioração da imagem ou pelo surgimento de ruídos através das etapas de processamento. Essas imagens apresentaram um resultado 32,2% melhores do que as imagens onde não apresentava o método de reconstrução de cumes. Com relação ao reconhecimento de minutiaes corretas, houve uma melhora de apenas 2,4% no total das imagens avaliadas. Referências [1] BAZEN, A.M. & GEREZ, S.H. “Systematic methods for the computation of the directional fields
and singular points of fingerprint” IEEE Trans. Pattern Analysis and Machine, Intelligence, vol 24, nº 7, pp 905-919, July 2002
[2] EMIROGLU, I. & AKHAN, M.B. “Pre-processing of fingerprint images” European Conference on Security and Detection, pp 28-30 University of Hertfordshire, UK. April 1997
[3] GONZALEZ, R. C. & WOODS, R. E. “Digital image processing” Addison-Wesley Publishing Company, Inc. 1993
[4] HONG, L, WAN, Y. & JAIN, A. “Fingerprint Image Enhancement: Algorithm and Performance Evaluation” vol. 20, nº 8 pp 777-789. August 1998
[5] HSIEH, C. T., LAI, E. & WANG, Y. C. “An Effective algorithm for fingerprint image enhancement based on wavelet transform” Pattern Recognition 36, pp 303-312, 2003
[6] MALTONI, D. et al. “Handbook of Fingerprint Recognition” Springer-Verlag New York, 2003 [7] RANDOLPH, T.R. & SMITH, M.J.T. “Fingerprint image enhancement using a binary angular
representation” Georgia Institute of Technology Center for Signal and Image Processing, pp 1561-1564, Atlanta USA 2001
[8] WANG, Y, CHEN, C. “An AFIS using fingerprint classification”. Palmerston North, Taiwan, pp 233-238, November 2003
[9] ZHOU, J. and GU, J. “A Novel Model for Orientation Field of Fingerprints”. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003
WVC´2005 - I Workshop de Visão Computacional
150

OPERADOR BAESYANO EM RECONHECIMENTO DE PADRÕES EM IMAGENS DE BOLSAS PARACOLETA DE SANGUE
Adilson GonzagaAv. Trabalhador São-carlense, 400
São Carlos – S.P.16 33739363
Cássio Avelino AdorniRua Orestes Morandini, 400
Ribeirão Preto – S.P.16 6241733
Luis Carlos H. CamposRua Maria Glória M. Santana, 256
Ribeirão Preto – S.P.16 6184053
Abstract
This paper presents a study to automation inspection visual to blood bag utilizing image withcolor representation RGB and Bayesian classifier with the histogram technique to find residue inblood bag images .
1. Introdução
Recentemente, há um interesse crescente na segmentação de regiões específicas deimagens, esta segmentação pode ser atribuída, por exemplo para detecção de “resíduos”indesejáveis em determinados produtos produzidos em escala industrial. Há aplicações deprocura de objetos de interesse em um espaço, como a presença de resíduos em bolsas para coletade sangue, para este fim a segmentação de região é muito efetiva, porque usualmente envolvepequena amostragem para computar, podendo ser feito sem levar em consideração a posição doobjeto de interesse.
2. Motivação
Três fatores motivam o setor produtivo industrial a buscar novas técnicas oumecanismos automáticos para detecção de imperfeições em seus produtos.
Como por exemplo: o controle de qualidade cada vez mais exigente; a grandeconcorrência crescente e impulsionada pela globalização mundial e a busca frenética de altospadrões de produtividade.
Este artigo, se deteve a buscar solução para um ramo industrial que necessita de altopadrão de qualidade que é a indústria farmacêutica.
WVC´2005 - I Workshop de Visão Computacional
151

Trataremos a presença de resíduos nas bolsas para coleta de sangue como “falhas” equando não ocorrerem estas falhas chamaremos de “não falhas”.
Mostrando a existência da técnica da segmentação de falhas envolvendo aclassificação individual do pixel da imagem que contém falha e não falha em categorias básicasde pixels coloridos.
Neste artigo, apresenta-se a análise de importantes assuntos para a classificação depixel coloridos, como sistemas de representação de cores e algoritmos de classificação. Utilizou-se a representação de cor através do sistema RGB e o algoritmo de classificação de pixelscoloridos, para dar sustentação a este estudo, foi criado um banco de imagens composto de 59imagens coloridas de bolsas para coleta de sangue.
O artigo é organizado da seguinte maneira: a representação de cor e algoritmo declassificação de pixels são descritos nos itens 3 e 4 respectivamente, resultado das análises ecomparações estão no item 7, e a conclusão no item 8.
3. Representação de Cores
Deve-se ressaltar, que existem diferentes sistemas de representação de cores, maismuitos deles têm características similares. Dentro deste estudo, concentrou-se na representaçãodo sistema de cor RGB pois, é habitualmente usado no campo de processamento de imagens.
O sistema de representação de cores RGB é formada por três cores primárias:vermelho, verde e azul, com essas três cores, é possível obter qualquer cor.
4. Algoritmo de Classificação
A regra para decisão baesyano para custo mínimo, é uma técnica estabelecida emclassificação de padrão estatístico. Usando esta regra de decisão, um pixel de cor x é consideradoum pixel de falha ou não falha se
Onde p ( x / falha ) p ( x / não falha) são os respectivos condicionadores de classePDFS de cor de falha e não falha, e T é um limiar. O valor teórico de T, que minimiza os custostotais de classificação dependem das probabilidades em princípio de falha e não falha e os várioscustos de classificação. |
No entanto, na prática T é freqüentemente determinado empiricamente. Oscondicionais de classe PDFS podem ser estimados usando técnicas estimativas de densidade dehistogramas ou paramétricas. O classificador baesyano com a técnica de histograma tem sidousado para detectar a falha.
5. Metodologia Aplicada para a Captura das Imagens
Para a capturar as imagens, foi necessário isolar as bolsas para coleta de sangue dasadversidades do ambiente, para isto foi desenvolvido uma caixa.
TñFalhaxPFalhaxP ≥
)|()|(
WVC´2005 - I Workshop de Visão Computacional
152

A caixa tem seu interior dividido em duas partes, a primeira é revestida em papelalumínio e com duas lâmpadas dicrôicas, estas lâmpadas estão com seu foco de luz direcionadopara o fundo da caixa, para que seja refletida pelo papel alumínio até uma tampa de acrílicobranco leitoso. A outra parte da caixa têm suas paredes pintadas em preto fosco.
Como fonte de energia elétrica foi utilizada uma bateria automotiva, para eliminar asoscilações de freqüência causadas pela corrente alternada.
Para capturar e digitalizar as imagens além da caixa desenvolvida, foi necessárioutilizar uma câmera digital , Mavica ( Sony ).
As imagens capturadas são de diversas bolsas para coleta de sangue, com diversascenas, desde bolsas limpas (padrão) até bolsas com resíduos e líquido anticoagulante, gerandovárias imagens com as mais variadas adversidade. As imagens têm a resolução de 640 x 480pixels, todas coloridas com a quantização de 256 cores e no formato JPEG.
Após a captura das imagens estas serão submetidas a um processamento para detectara existência ou não de resíduos
6. Banco de Imagens
O banco de imagens, foi gerado utilizando os equipamentos citados anteriormente noitem 5 e constituído com 30 imagens com resíduos, 12 imagens com resíduos, soluçãoanticoagulante e bolhas , 8 imagens de bolsas perfeitas, sem resíduos ou solução e 9 imagens comsolução e sem resíduos, totalizando assim, 59 imagens.
7. Resultados e Análise Experimentais
Depois de formar o banco de imagens, foi preciso analisar cada uma das imagens paradeterminar a presença de falhas ou não falhas, para isto, foi desenvolvido um algoritmo noMatlab, utilizando a técnica de operador baesyano, aliado a técnica de histograma e o sistema derepresentação de cores RGB .
Identificadas corretamente 78%Imagens sem resíduos e sem bolhas 90%Imagens com resíduos e bolhas 55%Imagens com resíduos e sem bolhas 82%Imagens perfeitas, com e sem bolhas, com e sem resíduos 74%Reconhecimento das imagens em até um segundo 99%
8. Conclusão
Analisando os resultados, verificamos que o procedimento de verificação das imagensé rápido pois, 99% das imagens foram processadas em até 1 segundo.
A técnica de operador baesyano com a técnica de histograma, mostrou-se eficientediante das adversidades encontradas nas imagens analisadas, pois há várias cenas onde é muitodifícil verificar resíduos, cenas como a de bolsas com solução anticoagulante, bolhas e resíduosou somente com bolhas que são facilmente confundidas com resíduos.
A técnica mostrou-se eficiente também em imagens com baixa resolução, uma vezque as imagens utilizadas têm 640 x 480 pixels de resolução.
WVC´2005 - I Workshop de Visão Computacional
153

Diante destes resultados, a técnica mostrou-se rápida e eficiente no reconhecimentode resíduos em bolsas para coleta de sangue.
Cabe aqui ressaltar, que os resultados obtidos sofrem influência direta devido àscondições de iluminação da cena.
9. Recursos Utilizados
Para a captura das imagens, foi utilizadas a câmera fotográfica Mavica (Sony) comresolução de 640 x 480 pixels.
Para o desenvolvimento do algoritmo, utilizou-se o Matlab versão 7.0 , e paraprocessar as imagens um computador Pentium III 650 Mhz, com 256 Mgb de memória Ram.
10. Referências Bibliográfica
PHUNG, S.L.; BOUZERDOUM, A.; CHAI, D. Skin Segemrntation Using Color PIxelClassification:Analysis and Comparison,Janeiro 2005. Anais:IEEE 2005. p . 148-154.
Rafael C. Gonzalez and Paul Wintz - Digital Image Processing,Addison-Wesley Pub. Co., 1987
B.G. Batchelor, D.A. Hill and D.G. Hodgson - Automated VisualInspection, North-Holland Pub. Co., 1985.
WVC´2005 - I Workshop de Visão Computacional
154

Aplicação dos Filtros Gabor na Classificação Supervisionada de Imagens de Sensoriamento Remoto
Ana Carolina Nicolosi da Rocha Gracioso, Ana Cláudia Paris
Fábio Fernando da Silva, Renata de Freitas Góes, Adilson Gonzaga Universidade de São Paulo - Departamento de Engenharia Elétrica – São Carlos, SP, Brasil
[email protected], [email protected], [email protected], [email protected], [email protected], Telefone/Fax +55 16 3373 9371
Abstract This work describes a technique of classification of remote sensing images using the texture attribute
as source of data. The processes of classification/segmentation are described and the use of Gabor Filters for the supervised classification of such images is proposed here, for the purpose of separating areas of water, vegetation and urban region. For an image characteristic extraction was chosen an spectrum approach, which try to identify a periodicity in the image, through an identification of peaks of high energy in the spectrum, what may be get with the Fourier Transform application. Thus, the properties of the Fourier spectrum were used in the recognition of the most representative frequencies of each area to separate the classes. Some routines to identify the frequencies were developed in Matlab and the classification of the images was done with the software tools MultiSpec and PRTools.
Palavras-Chave: Textura; Sensoriamento Remoto; Classificação Textural; Filtro de Gabor. 1. Introdução
O Brasil iniciou os investimentos na capacitação de profissionais e no desenvolvimento de infra-estrutura que viabilizasse a aplicação de técnicas de Sensoriamento Remoto (SR) ao final da década de 1960. Recentemente, com a disponibilidade de novos sensores que permitem a exploração de um maior número de faixas espectrais, novas possibilidades de aplicação das técnicas de SR têm surgido. No entanto, cabe observar que o tipo de sensor a bordo no satélite e os diferentes índices de refletância da energia eletromagnética (REM) dos objetos estudados, interferem nos tipos de dados obtidos.
No processo de análise e extração de características, pode-se utilizar algoritmos de classificação/ segmentação, os quais particionam a imagem em regiões correspondentes às áreas de interesse. Uma região pode ser definida como um conjunto de pixels contíguos, com espalhamento bidimensional, que apresentam uniformidade em relação a determinado atributo, como textura, por exemplo [5]. Nosso objetivo é explorar o atributo textura que pode ser definido como uma das características mais importantes para classificar e reconhecer objetos e cenas. O atributo textura pode ser caracterizado por variações locais em valores de pixels que se repetem de maneira regular ou aleatória ao longo do objeto ou imagem e oferece a impressão visual de rugosidade1 ou suavidade de uma superfície [3].
Para a extração de características de textura optamos por uma abordagem espectral, a qual tenta identificar uma periodicidade na imagem, através da análise dos picos de alta energia no espectro [3], o que pode ser obtido com a aplicação da Transformada de Fourier. Assim, neste estudo, utilizou-se a Transformada de Fourier aplicada sobre toda a imagem, para análise das componentes resultantes, uma vez que ela tende a localizar informações sobre padrões anteriormente globalizados na imagem.
1 Rugosidade é definida em termos da variação estatística da altura e largura das irregularidades da superfície.
WVC´2005 - I Workshop de Visão Computacional
155

Classificação de imagens é uma das principais tarefas envolvidas em um sistema de visão computacional. Seu objetivo é obter informações suficientes para distinguir diferentes objetos de interesse. No presente estudo, foram utilizados classificadores baseados em características de textura, obtendo informações sobre a distribuição espacial das variações de tonalidade de um objeto. Os algoritmos de classificação analisam individualmente os atributos numéricos de cada pixel na imagem, caracterizando assim uma abordagem quantitativa, com o intuito de encontrar as fronteiras de decisão entre as classes – água, vegetação e região urbana – [5]. Durante o processo de classificação supervisionada, o usuário indica amostras representativas para cada classe que deve ser identificada na imagem. Através de funções e parâmetros estatísticos, o algoritmo define a que classe cada pixel pertence, ou seja, todos os pixels que apresentam características semelhantes daquelas apresentadas pelos pixels indicados.
A segmentação de imagem é uma técnica de agrupamentos de dados, na qual somente as regiões espacialmente adjacentes podem ser agrupadas. Para realizar a segmentação é necessário definir o limiar de similaridade que é o limiar mínimo, abaixo do quais duas regiões são consideradas similares e agrupadas em uma única região; e o limiar de área que é o valor de área mínima, dado em número de pixels, para que uma região seja individualizada [2].
A interpretação visual, a segmentação e a classificação são métodos importantes e complementares, que freqüentemente são usados de forma combinada visando obter os melhores resultados na tarefa de extração de informação em imagens. [1]
2. Metodologia Neste estudo, a extração das características de textura nas diferentes regiões de uma imagem é
realizada por um processo de filtragem seletiva. Dentre as diversas alternativas, utilizamos os filtros de Gabor [6], pois são altamente eficientes no processo de análise de textura a partir de freqüências espaciais, simulando algumas características do sistema visual humano.
Os filtros de Gabor [6], [7], apresentam um bom desempenho na análise de textura, por terem a capacidade de caracterizar um sinal simultaneamente nos domínios temporal e das freqüências, que são limitados pela relação de incerteza conjunta, ou principio de Heisenberg:
( )( ) π≥ω∆∆ 4/1t onde, ∆τ e ∆ω representam incerteza nos domínios temporal e das freqüências respectivamente. Gabor determinou a família de funções que atingem este limite inferior de incerteza conjunta, como sendo:
( )
ω+
σ
−= tif 21
21
expt (1)
Essencialmente, a função determinada por Gabor descreve uma onda senoidal com freqüência ω modulada por um envelope Gaussiano com duração σ. O conjunto original de filtros proposto por Gabor foi estendido para o caso bidimensional por Daugman [7], podendo, portanto ser aplicado para dados do tipo imagem. O filtro bidimensional é representado pela função:
( ) ( ) 00
22
00 2exp21
exp2
1,,,,, vui
yxvuyxf
yxyxyx +π
σ+
σ−
σπσ=σσ (2)
A figura 1 no domínio das freqüências é especialmente ilustrativa do comportamento da
componente real de (2). Apresenta duas exponenciais Gaussianas centradas na freqüência selecionada (u0 , v0 ) e (-u0, -v0 ), com variâncias iguais a 2/1 xσ e 2/1 yσ .
WVC´2005 - I Workshop de Visão Computacional
156

Figura 1: Componente real da função de Gabor no domínio espacial e no domínio das freqüências respectivamente.
A abordagem adotada neste estudo consiste das seguintes etapas: seleção de áreas representativas de cada classe; identificação das freqüências espaciais mais representativas de cada classe; seleção das freqüências mais adequadas para fins de separação das classes; construção de filtros Gabor adequados a cada uma das freqüências selecionadas; convolução de cada filtro com a imagem, gerando um número igual de imagens filtradas que poderiam ser denominadas “bandas texturais”; classificação da imagem usando as “bandas texturais” e análise da performance da metodologia proposta.
3. Experimentos
A partir de imagens obtidas do satélite Landsat [8], utilizando-se o software MATLAB 7.0 para Windows, foram selecionados um conjunto de 80 amostras de 128 x 128, representativas de cada classe: água – 15 imagens –, vegetação – 28 imagens – e região urbana – 37 imagens –. Com o propósito de conhecer as freqüências mais representativas em cada uma das respectivas classes, visando tentar identificar quais destas freqüências formam as chamadas “bandas texturais” para definir os Filtros Gabor, primeiramente aplicou-se a Transformada de Fourier nas amostras. Aplicando um mapa de cores, que auxilia na identificação visual das freqüências encontradas isoladamente nas amostras, constatamos que a água é representada em vermelho, correspondente as baixas freqüências, a vegetação em azul, correspondente as médias freqüências e a área urbana em verde, identificando as altas freqüências. A figura 2 ilustra este processo com um grupo de amostras de cada classe que desejamos identificar.
(a) Água (b) Vegetação (c) Região urbana Figura 2: Amostras da classe (a) água, (b) vegetação e (c) região urbana e suas respectivas freqüências obtidas com a TF
No entanto, ao aplicar a Transformada de Fourier em imagens contendo diversas paisagens ou
mesmo um filtro circular, conforme mostrado nas figuras 3 e 4, usando os limiares identificados a partir da TF nas amostras, verificou-se que o resultado final varia consideravelmente, dependendo das características da imagem. Devido às dificuldades em identificar as freqüências ideais para gerar as bandas texturais, utilizando apenas a TF, optou-se por aplicar uma análise das energias e novamente notou-se que as distribuições das energias no espectro também variam sensivelmente dependendo do tipo da imagem e região que a imagem representa, por exemplo.
Para um conjunto de treinamento de imagens com características semelhantes, o processo funciona satisfatoriamente, ou seja, é possível identificar as freqüências a partir da aplicação de Fourier para formar as “bandas texturais” e gerar os filtros Gabor, porém se o conjunto de treinamento apresentar características muito distintas, o processo não apresenta resultados satisfatórios e mesmo usando um conjunto de treinamento com características semelhantes, ao aplicar o processo em imagens distintas os resultados variam muito e algumas vezes são satisfatórios e outras não. Para realizar este estudo um
WVC´2005 - I Workshop de Visão Computacional
157

banco com 120 imagens foi usado, contendo imagens de SR registradas pelo satélite Landsat das três classes separadamente e imagens englobando todas as classes. A dificuldade em obter resultados definitivos reside no fato de que o comportamento espectral dos objetos varia consideravelmente, pois a caracterização de como e de quanto um objeto reflete de REM, influencia nos resultados.
Figura 3: Separação da classe água em imagem do Rio, obtida através do satélite Landsat.
Figura 4: Separação da classe água em imagem da Argentina, obtida através do satélite Landsat.
4. Conclusões
Nossa proposta foi aplicar um método para classificação supervisionada de imagens digitais, com base no atributo textura, caracterizando as classes texturais presentes na imagem, pelas freqüências espaciais mais representativas identificadas nas amostras de cada classe. O desenvolvimento de rotinas para análise das imagens em MATLAB 7.0, provou ser um processo demorado, justificando assim o uso do Multispec [9] e PRTools [10], para obter resultados preliminares. Notou-se que há grande dificuldade para a separação das freqüências que representam cada classe de maneira única, pois dependendo da rugosidade da textura, as classes se entrelaçam, dificultando a geração dos filtros Gabor. Pode-se afirmar que ao utilizar imagens com características semelhantes, o método apresenta resultados satisfatórios, porém torna-se restritivo. Conclui-se que em imagens de sensoriamento remoto há muitas particularidades que devem ser consideradas. Cada elemento possui características próprias e não há como prever todas as possibilidades ou tentar elencá-las, relacionando-as a possíveis padrões em imagens orbitais. Assim, estar preparado para conviver com estas limitações e extrair dos produtos de sensoriamento remoto o máximo de informação confiável, não é uma tarefa trivial.
5. Referências [1] Novo, Evlyn Márcia L. M., Ponzoni, Flávio Jorge. Introdução ao Sensoriamento Remoto. INPE – Instituto Nacional de Pesquisas Espaciais, São José dos Campos, 2001 [2] Soler, Luciana de Souza Soler. Detecção de Manchas de Óleo na Superfície do Mar por meio de Técnicas de Classificação Textural de Imagens de Radar de Abertura Sintética (RADARSAT-1) [3] Nascimento, João Paulo R., Madeira, Heraldo M. F., Pedrini, Hélio. Classificação de Imagens Utilizando Descritores Estatísticos de Textura. Universidade Federal do Paraná, Anais XI SBSR, 2003. [4] Mello, Eliana M. K., Moreira, José C., Santos, João R., et al. Técnicas de Modelo de Mistura Espectral, Segmentação e Classificação de Imagens TMLANDSAT para o Mapeamento do Desflorestamento da Amazônia. INPE-Instituto Nacional de Pesquisas Espaciais, Anais XI SBSR, 2003. [5] Silva, Marcelino Pereira dos Santos. Mineração de Dados em Bancos de Imagens. INPE, Monografia do Exame de Qualificação do Doutorado em Computação Aplicada, 2003. São José dos Campos. [6] D. Gabor, Theory of Communication, Journal of the Institute of Electrical Engineers, v.93,pp.429-457, 1946. [7] J G. Daugman, Uncertainty Relation for Resolution in Space, Spatial Frequency and Orientation Optimized by Two-Dimensional Visual Cortical Filters, Journal of Optical Society of America, v.2, Nº7, pp.1160-69,1985. [8] LANDASAT 7, http://landsat.gsfc.nasa.gov/ [9] D. Landgrebe, Multispec, 2003, http://gcmd.na-sa.gov/records/MultiSpec.html [10] Prtools, Duin – Universidade de Delft, 2005, http://www.prtools.org.
WVC´2005 - I Workshop de Visão Computacional
158

Segmentação de pele em imagens utilizando redes neuraisMarc’ Antonio S. F. Bezerra
Escola de Engenharia de São Carlos, USPR. Padre Teixeira, 150 ap21
Jd. Alvorada - São Carlos - BrasilCEP: 13562-003
Fone: (16) 9766-5456 / (16) [email protected]
ResumoEste projeto visa estudar a classificação de padrões de pele em imagens digitais a fim desegmentá-las para posterior processamento. Esta classificação será feita através dealgoritmos de redes neurais utilizando treinamento supervisionado em imagens diversasobtidas da internet. Estas imagens serão inicialmente processadas para minimizar oprocessamento exigido da máquina e analisar o efeito deste processamento nos resultadosobtidos.
IntroduçãoAlgoritmos de segmentação de pele têm sido largamente utilizados como ferramenta paradetecção regiões de interesse em imagens. Este tipo de segmentação é empregado emprocessos de detecção de faces, análises de gestos pelas mãos e análise de conteúdo daimagem. Em aplicações como estas, a região de processamento fica reduzida a umnúmero de pixel pré selecionado pelo algoritmo de segmentação de pele.Para se fazer o processamento de uma imagem, indiferente do método selecionado,primeiramente deve-se analisar a representação de cores a ser utilizada. Abaixo está umabreve descrição das representações mais comuns:RGB: a cor do pixel é especificada pela intensidade de cada uma das três componentesprimárias, vermelho (R), verde (G) e azul (B).HSV: a cor do pixel é especificada em termos da matiz (H), saturação (S) e daintensidade (V). A transformação entre HSV e RGB é não linear.YCbCr: a cor do pixel é especificada em termos da luminância (Y) e crominância (Cb eCr).A grande dificuldade de segmentar regiões de pele é a variação de tonalidades devido acaracterísticas étnicas e variações de iluminação.
Definição do problemaO problema a ser solucionado é de criar uma rede neural capaz de identificar os pixel depele em uma imagem utilizando apenas as informações de cor em quaisquer condições deiluminação e para quaisquer tipo de cor de pele.Não serão abordados as informações de disposição espacial dos pixels nesta análise.
Solução do problemaPara solucionar este problema foi desenvolvida e treinada uma rede neural do tipo LVQ-1. Esta é uma rede do tipo supervisionada, isto é, necessita de um conjunto de dados detreinamento para os quais a saída é conhecida.
WVC´2005 - I Workshop de Visão Computacional
159

Este rede foi configurada com uma camada escondida com 4 neurônios e uma camada desaída com 2 neurônios.O conjunto de treinamento foi criado utilizando a imagem Fig1 onde todos os pixel depele foram segmentados manualmente e pintado de vermelho puro (Fig2). O programaentão processou esta imagem identificando o pixels em vermelho e classificando todos ospixels um duas classes, pele e não pele.Foi selecionada a representação RGB por já ter sido apresentada em outros estudos comoa melhor opção de representação das cores do pixel para processamento.Portanto as entradas da rede serão as três componentes vermelho, verde e azul de cadapixel. Os pixels da imagem serão reorganizados como uma matriz com o tamanho donúmero de pixels da imagem por 3 componentes de cores.O vetor de saída será processado para apresentar a região da imagem original detectadacomo pele.Será feito o treinamento da rede e posteriormente será feita a validação através da análisede sua eficiência.Todo o desenvolvimento e processamento foram feitos utilizando o programa MatLabcomo ferramenta.
Fig1: Imagem de treinamento
Fig2: Imagem de treinamento com pele segmentada manualmente
Resultados ComputacionaisA maior demora do treinamento foi efetuar o processamento da imagem segmentadamanualmente (Fig2) para poder extrair, classificar e gerar o vetor de saída conhecido noformato padrão do programa. Este tempo foi cerca de 10 min para uma imagem no
WVC´2005 - I Workshop de Visão Computacional
160

formato bitmap do windows com 512 x 384 x 3, onde cada componente de cor estavadefinida com 24 bits de profundidade. A máquina utilizada foi um Pentium4 2.80GHzcom 640MB de memória ram.Após o treinamento da rede LVQ-1, foi aplicada à entrada a imagem de verificação(Fig3).
Fig3: Imagem de verificação
Fig4: Imagem de verificação com pele segmentada manualmente
Análise dos ResultadosA eficiência desta rede neural foi analisada utilizando-se uma imagem de verificação. Ospixel de pele nesta imagem foram igualmente segmentados como na imagem detreinamento.Para efetuar a análise, esta imagem de verificação foi submetida à rede já treinada e osdados de saída foram comparados com segmentação manual, registrando o número dedetecções corretas (pixels não pele identificados como não pele e pixels de peleidentificados como pele) e falsas detecções (pixels não pele identificados como pele epixel de pele identificados como não pele).Convém ressaltar que diferenças de alguns pixel de pele identificados como pele ou pixelde não pele identificados como pele podem ser devidos não a erros de classificação pelarede, mas sim a erros de classificação manual. Este tipo de erro é de certa formainevitável pelo grande número de pixel e pelo fato de se confundir o limiar entre a regiãode pele e não pele, que pode estar ocultado por uma região de sombra na imagem. Como resultado da verificação da rede, obtivemos uma taxa de acerto na classificação de68,6%.
WVC´2005 - I Workshop de Visão Computacional
161

Devido à demora no processamento da imagem, descartou-se a aplicação deste métodoem imagens com maior número de pixels.
ConclusõesO método apresentado mostrou-se eficiente para o objetivo proposto, sendo capaz desegmentar regiões de pele com precisão suficiente para identificar partes do corpo comoum rosto ou uma mão.Este análise é válida para definir mais uma opção de ferramenta para segmentação de pelea ser utilizado juntamente com outros métodos de processamento de imagem. Porém ademora de processamento, mesmo com uma boa máquina, restringe o uso deste método.Além do objetivo proposto, é possível utilizar esta rede para outras aplicações por setratar de uma metodologia de análise sem abordagens específicas a um problema.Portanto cabe ressaltar que esta rede pode ser treinada com imagens relacionadas aquaisquer outras aplicações, utilizando até qualquer outra representação de cores.
Referências Bibliográficas
• Haykins, S – “Neural Networks”, Prentice Hall, 1999;• Freeman, James A. – “Simulating Neural Networks with Mathematica”, Addison
Wesley, 1994;• Batchelor, B. G. – “Automated Visual Inspection”, IFS, 1985;• Jones, Michael J., Rehg, James M. – “Statistical Color Models with Application to
Skin Detection”, Cambridge Center.
WVC´2005 - I Workshop de Visão Computacional
162
