introdução a banco de dados · 5 prefácio esta apostila foi desenvolvida para ajudar na...
TRANSCRIPT

Técnico em Redes de ComputadoresCentro Educacional Lagoa do Piau
Programa de Educação Profissional – MG
Introdução a Banco de Dados

2
1 INTRODUÇÃO.........................................................................................6
1.1 Modelos de Dados ................................................................................................................... 6 1.1.1 Modelo Hierárquico ............................................................................................................. 6 1.1.2 Modelo em Rede.................................................................................................................. 7 1.1.3 Modelo Relacional ............................................................................................................... 7 1.1.4 Modelo Orientado Objetos ...................................................................................................8 1.1.5 Sistemas Objeto-Relacionais ................................................................................................9
1.2 Arquiteturas de Banco Dados.................................................................................................9 1.2.1 Introdução............................................................................................................................9 1.2.2 Arquiteturas .........................................................................................................................9 1.2.3 Resumo das arquiteturas de SGBDs.................................................................................... 10
1.3 Ambiente de Implementação Cliente-Servidor .................................................................... 12
2 DEFINIÇÃO GERAL..............................................................................14
2.1 Propriedades:........................................................................................................................ 14
2.2 Características da Abordagem da Base de Dados x Processamento tradicional de Arquivos 15
2.3 Profissionais e Atividades envolvidas em um SGBD............................................................ 15
2.4 Profissionais de Apoio........................................................................................................... 16
2.5 Capacidades do SGBD.......................................................................................................... 16
2.6 Vantagens Adicionais da Abordagem da Base de Dados ..................................................... 17
2.7 Quando não utilizar um SGBD ............................................................................................ 18
3 CONCEITOS E ARQUITETURAS DE SGBD’S ....................................19
3.1 Modelos de Dados, Esquemas e Instâncias........................................................................... 19 3.1.1 Categorias de Modelos de Dados........................................................................................ 19 3.1.2 Esquemas e Instâncias ........................................................................................................ 19
3.2 Arquitetura e Independência de Dados de SGBD’s ............................................................. 20 3.2.1 Arquitetura “Three-Schema” (conhecida como arquitetura ANSI/SPARC - Tsichritzis e Klug, 1978) 20 3.2.2 Independência de dados...................................................................................................... 21
3.3 Linguagens de Base de Dados............................................................................................... 21
4 MODELAGEM DE DADOS USANDO O MODELO ENTIDADE-RELACIONAMENTO (MER) ............................................................................22
4.1 Modelo de Dados Conceitual de Alto-Nível e Projeto de Base Dados.................................. 22
4.2 Um Exemplo ......................................................................................................................... 22
4.3 Conceitos do Modelo Entidade-Relacionamento.................................................................. 23

3
4.3.1 Entidades e Atributos ......................................................................................................... 23 4.3.2 Tipos de Entidades, Conjunto de Valores e Atributos-Chaves ............................................. 24 4.3.3 Relacionamentos, Papéis e Restrições Estruturais ............................................................... 25 4.3.4 Tipo de Entidade-Fraca ...................................................................................................... 30 4.3.5 Projeto da Base de Dados COMPANHIA utilizando o MER ............................................... 31
4.4 Diagrama Entidade-Relacionamento (DER)........................................................................ 31
4.5 Tipos de Relacionamentos de Grau maior que Dois ............................................................ 34
4.6 Questões para a Síntese ........................................................................................................ 37
5 O MODELO DE DADOS RELACIONAL ...............................................38
5.1 Conceitos do Modelo Relacional........................................................................................... 38 5.1.1 Notação do Modelo Relacional........................................................................................... 39 5.1.2 Atributos-chaves de uma Relação....................................................................................... 40 5.1.3 Esquemas de Bases de Dados Relacionais e Restrições de Integridade................................. 41 5.1.4 Operações de Atualizações sobre Relações ......................................................................... 44
6 MAPEAMENTO DO MER PARA O MODELO DE DADOS RELACIONAL ..................................................................................................45
7 ÁLGEBRA RELACIONAL.....................................................................49
7.1 Operações SELECT e PROJECT ........................................................................................ 49 7.1.1 O Operador SELECT ......................................................................................................... 49 7.1.2 O Operador PROJECT ....................................................................................................... 50
7.2 Seqüência de Operações ....................................................................................................... 51
7.3 Renomeando Atributos......................................................................................................... 52
7.4 Operações da Teoria dos Conjuntos..................................................................................... 52 7.4.1 A Operação JOIN............................................................................................................... 54 7.4.2 Conjunto completo de Operações da Álgebra Relacional..................................................... 56 7.4.3 A Operação DIVISION ...................................................................................................... 57 7.4.4 Operações Relacionais Adicionais ...................................................................................... 58 7.4.5 Operações de Clausura Recursiva ....................................................................................... 59
7.5 Exemplos de Consultas na Álgebra Relacional .................................................................... 60
7.6 Questões de Revisão.............................................................................................................. 62
8 CONSULTAS EM SQL..........................................................................63
8.1 Consultas SQL básicas.......................................................................................................... 63
9 DEPENDÊNCIAS FUNCIONAIS E NORMALIZAÇÃO DE BASE DE DADOS RELACIONAIS ...................................................................................66
9.1 Diretrizes para o Projeto Informal de Esquemas de Relações............................................. 66 9.1.1 Semântica de atributos de relação ....................................................................................... 66 9.1.2 Informação redundante em tuplas e anomalias de atualizações ............................................ 67 9.1.3 Valores null em tuplas........................................................................................................ 69

4
9.2 Dependências Funcionais...................................................................................................... 71 9.2.1 Definição de Dependência Funcional.................................................................................. 71 9.2.2 Formas Normais Determinados pelas Chaves Primárias ...................................................... 73
10 REFERÊNCIAS BIBLIOGRÁFICAS......................................................76

5
Prefácio
Esta apostila foi desenvolvida para ajudar na aprendizagem e desenvolvimento dos alunos nas
disciplinas de Introdução a Banco de Dados do Curso Técnico de Redes de Computadores do
Colégio Piau. Seu conteúdo é uma pesquisa de vários autores, sendo em partes transcrições e
traduções dos mesmos.
Esta apostila visa ser uma primeira leitura para os alunos e tenta sempre mostrar os temas abordados
de forma simples e clara. Todas as referências bibliográficas utilizadas na construção desta apostila
se encontram no final do texto.

6
Base de Dados
1 Introdução O primeiro Sistema Gerenciador de Banco de Dados(SGBD) comercial surgiu no final de 1960. Este evoluiu dos sistemas de arquivos. Entretanto os sistemas de arquivos não controlavam o acesso concorrente por vários usuários ou processos. Os SGBDs evoluíram dos sistemas de armazenamento em disco criando novas estruturas de dados para armazenamento de informações. Esses SGBD's usam vários modelos de dados diferentes para descrever a estrutura de informação nos banco de dados tais como: os modelos hierárquicos, de redes, modelo relacional, que é amplamente usado, e o modelo orientado a objetos.
1.1 Modelos de Dados
1.1.1 Modelo Hierárquico É o primeiro reconhecido como modelo de dados. Foi desenvolvida devido à consolidação dos discos de armazenamento endereçáveis, sua estrutura utiliza as organizações de endereçamento físicos dos discos. Os dados estão estruturados em hierarquias ou árvores. Os nós das hierarquias contêm ocorrências de registros, onde cada registro é uma coleção de campos (atributos) cada um contendo apenas uma informação. O registro que em uma hierarquia precede outros, designa-se registro-pai dos outros registros que são chamados de registros-filhos. Uma ligação é uma associação entre dois registros. O relacionamento entre um registro-pai e registros-filhos é de 1:N. Os dados estão organizados e podem ser acessados segundo uma seqüência hierárquica com uma navegação do topo para as folhas e da esquerda para a direita. Um registro pode estar associado a vários registros diferentes. Para que exista esta condição este registro deve ser replicado. A replicação possui duas grandes desvantagens: pode causar inconsistência de dados quando houver atualização e o desperdício de espaço é inevitável. O Sistema comercial mais divulgado no modelo hierárquico foi Informativo Management System da IBM Corp(IMS). Grande parte das restrições e consistências de dados estavam contidas dentro nos programas escritos para as aplicações. Era necessário escrever programas na ordem para acessar o banco de dados. Um diagrama de estrutura da árvore é o esquema para um banco de dados hierárquico. Tal diagrama consiste em dois componentes básicos: Caixas - que correspondem ao tipo de registro e Linhas - que correspondem às ligações. Exemplo:
Figura 1.1 - Diagrama de estrutura de árvore Cliente - Conta Corrente

7
1.1.2 Modelo em Rede Aparece como uma extensão do modelo hierárquico. Elimina o conceito de hierarquia e permite que um mesmo registro esteja envolvido em várias associações. No modelo em rede os registros estão organizados em grafos. Nele aparece um único tipo de associação(set), que define uma relação de 1: N entre 2 tipos de registros: proprietário e membro. Desta maneira dados dois relacionamentos 1:N entre os registros A e D e entre os registros C e D é possível construir um relacionamento M:N entre A e D. O gerenciador Data Base Task Group (DBTG) da CODASYL (Committee on Data Systems and Languages) estabeleceu uma norma para este modelo de banco de dados, com linguagem própria para definição e manipulação de dados. Os dados tinham uma forma limitada de independência física. A única garantia era que o sistema deveria recuperar os dados para as aplicações como se eles estivessem armazenados na maneira indicada nos esquemas. Os geradores do relatório da CODASYL também definiram sintaxes para dois aspectos chaves dos sistemas gerenciadores de dados: Concorrência e segurança. O mecanismo de segurança fornecia uma facilidade na qual parte do banco de dados (áreas) pudessem ser bloqueadas para prevenir acessos simultâneos quando isto fosse necessário. A sintaxe da segurança permitia que uma senha fosse associada com cada objeto descrito no esquema. Ao contrário do Modelo Hierárquico, em que qualquer acesso aos dados passa pela raiz, o modelo em rede pode-se ter acesso a qualquer nó da rede. Estes dois modelos: Hierárquico e Rede são Orientados a Registros, isto é qualquer acesso à base de dados, inserção, consulta, alteração ou remoção é feito com um registro de cada vez. No Modelo em Rede o sistema comercial mais divulgado CA-IDMS da Computer Associates. O diagrama para representar os conceitos do modelo de rede consiste em dois componentes básicos: Caixas - as quais correspondem os registros e Linhas - as quais correspondem as associações. Exemplo:
Figura 1.2 - Diagrama de estrutura de dados Cliente - Conta Corrente
1.1.3 Modelo Relacional O modelo relacional apareceu devido a seguintes necessidades: aumentar a independência de dados nos sistemas gerenciadores de banco de dados; prover um conjunto de funções apoiadas em álgebra relacional para armazenamento e recuperação de dados; permitir processamento ad hoc1. O modelo relacional resultou de um estudo teórico realizado por CODD[Codd70] (investigador da IBM), tendo por base a teoria dos conjuntos e álgebra relacional. O modelo foi apresentado num artigo publicado em 1970, mas que só nos anos 80, foi implementado. O Modelo relacional revelou-se ser o mais flexível e adequado ao solucionar os vários problemas que se colocam ao nível da concepção e implementação da base de dados. A estrutura fundamental do modelo relacional é a relação. Uma relação é constituída por um ou mais atributos (campos), que traduzem o tipo de dados a armazenar. Cada instância
1 processamento dedicado, exclusivo

8
do esquema (linha), designa-se por tupla (registro). O modelo relacional não tem caminhos pré-definidos para acessar dados como no modelo de redes ou hierárquicos. O modelo relacional implementa estruturas de dados organizadas em relações (tabelas). Porém para trabalhar com essas tabelas algumas restrições tiveram que ser impostas para evitar aspectos indesejáveis no modelo relacional tais como: Repetição de informação, Incapacidade de representar parte da informação e perda de informação. Essas restrições são : integridade referencial, chaves, integridade de junções de relações.
Figura 1.3 Tabelas do modelo relacional Cliente - Conta Corrente
1.1.4 Modelo Orientado Objetos Os bancos de dados orientados a objeto, começaram a se tornar comercialmente viáveis em meados de 1980. Eles começaram a ser desenvolvidos em função dos limites de armazenamento e representações semântica dos modelos relacionais. Alguns exemplos são os sistemas de informações geográficas (SIG) , os sistemas CAD e CAM. Esses sistemas são mais facilmente construídos usando tipos complexos de dados. A habilidade para criar os tipos de dados necessários é uma característica da linguagens de programação orientada a objetos. Estes sistemas porém , necessitam guardar representações das estruturas de dados que eles usam no armazenamento permanente. A estrutura padrão para os banco de dados objeto foi feita pelo Grupo de gerenciamento dados objetos (ODMG). Esse grupo é formado por representações da maioria dos fabricantes no mercado de banco de dados objeto. Membros do grupo estão comprometidos a incorporar o padrão em seus produtos. O termo Modelo Orientado Objetos é usado para o documento padrão que contém a descrição geral das facilidades de um conjunto de linguagens de programação orientadas a objetos e a biblioteca de classes que pode formar a base para o Sistema de banco de Dados. Quando os banco de dados orientados a objetos foram introduzidos, algumas das falhas perceptíveis do modelo relacional parecem ter sido solucionados com esta tecnologia e acreditava-se que tais banco de dados ganhariam grande parcela do mercado. Porém hoje acredita-se que os Banco de Dados Orientados a Objetos serão usados em aplicações especializadas, enquanto os sistemas relacionais continuarão a sustentar os negócios tradicionais nos quais as estruturas de dados baseadas em relações são suficientes. Um diagrama UML é geralmente o esquema para o modelo orientado a objetos. Exemplo:
Figura 1.4 - Diagrama UML Cliente - Conta Corrente

9
1.1.5 Sistemas Objeto-Relacionais A área de atuação dos sistemas Objeto-Relacional tenta suprir a dificuldade dos sistemas relacionais convencionais, que é o de representar e manipular dados complexos. A solução proposta é a adição de facilidades para manusear tais dados utilizando-se das facilidades SQL existentes. Para isso foi necessário adicionar: extensões dos tipos básicos no contexto SQL; representações para objetos complexos no contexto SQL ; herança no contexto SQL; sistema para produção de regras.
1.2 Arquiteturas de Banco Dados
1.2.1 Introdução Atualmente, no desenvolvimento de aplicativos para atendimentos a usuários nos mais variados domínios de aplicações (automação de escritórios, sistemas de apoio a decisões, controle de reserva de recursos, controle e planejamento de produção, alocação e estoque de recursos, etc) alguns aspectos relevantes devem ser considerandos para se atingir a eficiência e a eficácia do sistema informatizado: a) Os projetos Lógico e Funcional do Banco de Dados devem ser capazes de prever o volume
de informações armazenadas a curto, médio e longo prazo. Os projetos devem ter uma grande capacidade de adaptação para os três casos mencionados;
b) Deve-se ter generalidade e alto grau de abstração de dados, possibilitando confiabilidade e
eficiência no armazenamento dos dados e permitindo a utilização de diferentes tipos de gerenciadores de dados através de linguagens de consultas padronizadas;
c) Projeto de uma interface ágil e com uma " rampa ascendente" de aprendizado suave para o
usuário; d) Implementação de um projeto de interface compatível com múltiplas plataformas (UNIX,
Windows NT, Windows Workgroup, etc); e) Independência da Implementação da Interface em relação aos servidores de dados que
darão condições às operações de armazenamento de informações (ORACLE, SYSBASE, INFORMIX, PADRÃO XBASE, etc).
f) Conversão e mapeamento da diferença semântica entre os paradigmas utilizados no
desenvolvimento de interfaces (Imperativo, Orientado a Objeto, Orientado a evento), servidores de dados (Relacional) e programação dos aplicativos (Imperativo, Orientado a Objetos).
1.2.2 Arquiteturas As primeiras arquiteturas usavam mainframes para executar o processamento principal para todos as funções do sistema, incluindo os programas aplicativos, programas de interface com o usuário, bem como a funcionalidade dos SGBDs. Esta é a razão pela qual a maioria dos usuários acessava os sistemas via terminais que não possuíam poder de processamento, apenas capacidade de visualização. Todos os processamentos eram feitos remotamente, e apenas as informações a serem visualizadas e os controles eram enviados do mainframe para os terminais de visualização, que eram conectados a ele através de várias redes de comunicação. Como os preços do hardware foram decrescendo, muitos usuários trocaram seus terminais por computadores pessoais (PC) e estações de trabalho. No começo os SGBDs usavam esses computadores da mesma maneira que usavam os terminais, ou seja o SGBD era centralizado e toda sua funcionalidade, execução de programas aplicativos e

10
processamento da interface do usuário eram executados em apenas uma máquina. Gradualmente os SGBDs começaram a explorar a disponibilidade do poder de processamento no lado do usuário, o que levou a arquitetura cliente-servidor. A arquitetura cliente-servidor foi desenvolvida para dividir ambientes de computação onde um grande número de PCs, estações de trabalho, servidores de arquivos, impressoras, servidores de banco de dados e outros equipamentos estão conectados juntos por uma rede. A idéia é definir servidores especializados tais como servidor de arquivos que mantém os arquivos de máquinas clientes ou servidores de impressão que podem estar conectados a várias impressoras, assim quando se deseja imprimir, todas as requisições de impressão são enviadas a este servidor. As máquinas clientes disponibilizam para o usuário as interfaces apropriadas para utilizar esses servidores, bem como poder de processamento para executar aplicações locais. Esta arquitetura se tornou muito popular por algumas razões. Primeiro a facilidade de implementação dada à clara separação de funcionalidade e o servidor. Segundo um servidor é inteligentemente utilizado porque as tarefas mais simples são delegadas as máquinas clientes mais baratas. Terceiro o usuário pode executar uma interface gráfica que já lhe é familiar ao invés de usar a interface do servidor. Desta maneira a arquitetura cliente-servidor foi incorporada nos SGBDs comerciais. Diferentes técnicas foram propostas sendo uma bastante adotada por muitos Sistemas Gerenciadores de Banco de Dados Relacionais (SGBDRs) comerciais a inclusão da funcionalidade de um SGBD centralizado no lado do servidor. As consultas e a funcionalidade transacional permanecem no servidor, sendo que este é chamado de servidor de consulta ou servidor de transação. Desta maneira um servidor de SQL é fornecido para os clientes. Cada cliente tem que formular suas consultas SQL, e prover a interface do usuário e a funções de interface para linguagem de programação. O cliente pode também se referir a um dicionário de dados que incluem informações sobre a distribuição dos dados em vários servidores SQL, bem como os módulos para a decomposição de uma consulta global em um número de consultas locais que podem ser executadas em vários sítios. Comumente o servidor SQL também é chamado de back-end machine e o cliente de front-end machine. Como SQL provê uma linguagem padrão para SGBDRs, ele criou o ponto de divisão lógica entre o cliente e o servidor. Existem várias tendências para Banco de Dados atualmente, nas mais diversas direções.
1.2.3 Resumo das arquiteturas de SGBDs • Plataformas centralizadas . Na arquitetura centralizada, existe um computador com grande capacidade de processamento que é o hospedeiro do SGBD e emuladores para os vários aplicativos. Esta arquitetura tem como principal vantagem a segurança em poder manipular grande volume de dados com muitos usuários. Sua principal desvantagem está no fato de se ter alto custo, pois se deve ter ambiente especial para mainframes e soluções centralizadas. • Sistemas de Computador Pessoal - PC. Os computadores pessoais trabalham em sistema stand-alone, ou seja fazem seus processamentos sozinhos. No começo esse processamento era bastante limitado, porém com a evolução do hardware temos hoje PCs com grande capacidade de processamento. Eles utilizam o padrão Xbase e quando se trata de SGBDs funcionam como hospedeiros e terminais, desta maneira possuem um único aplicativo a ser executado na máquina. A principal vantagem desta arquitetura é a simplicidade. • Banco de Dados Cliente-Servidor. Na arquitetura Cliente-Servidor o cliente (front_end) executa as tarefas do aplicativo, ou seja fornece a interface com o usuário (tela, e processamento de entrada e saída). O servidor (back_end) executa as consultas no DBMS e retorna os resultados ao cliente. Apesar de ser uma arquitetura bastante popular, para poder implementá-la são necessárias soluções de softwares sofisticados que possibilitem: tratamento de transações, confirmações de transações (commits), desfazer uma transação (rollbacks), linguagens de consultas (stored procedures) e gatilhos (triggers). A principal vantagem desta arquitetura é dividir o processamento entre dois sistemas reduzindo o tráfego de dados na rede. • Banco de Dados Distribuídos (N camadas). Nesta arquitetura a informação esta distribuída em diversos servidores. Cada servidor atua como no sistema cliente-servidor, porém as

11
consultas oriundas dos aplicativos são feitas para qualquer servidor indistintamente. Caso a informação solicitada seja mantida por outro servidor ou servidores, o sistema encarrega-se de obter a informação necessária, de maneira transparente para o aplicativo, que passa a atuar consultando a rede, independente de conhecer seus servidores. Exemplos típicos são bases de dados corporativas, em que o volume de informação é muito grande e deve ser distribuído por diversos servidores. Porém não é dependente de aspectos lógicos de carga de acesso aos dados, ou base de dados fracamente acopladas, em que uma informação solicitada vai sendo coletada numa propagação da consulta numa cadeia de servidores. A característica básica é a existência de diversos programas aplicativos consultando a rede para acessar os dados necessários, sem o conhecimento explícito de quais servidores dispõem desses dados.
Figura 1.5 - Arquitetura Distribuída N camadas

12
1.3 Ambiente de Implementação Cliente-Servidor
Figura 1.6 - Ambiente genérico para desenvolvimento de aplicativos A figura 1.6 ilustra um ambiente genérico de desenvolvimento de aplicativos. Nesta figura, a diferença (gap semântico) entre os paradigmas utilizados para a construção de interfaces, para o armazenamento de informações e para a programação dos aplicativos, é detalhada para ressaltar a importância de estruturas " Case" e "Cursores". As estruturas "Case" são utilizadas para converter as alterações e solicitações ocorridas na interface do aplicativo em uma linguagem que seja capaz de ser processada pelos servidores de dados. A construção da linguagem é feita através da composição de cadeias de caracteres usualmente utilizando o padrão "SQL" (Structured Query Language) utilizado nos servidores de dados relacionais. Quando um acesso ao SGBD é requerido, o programa estabelece uma conexão com o SGBD que está instalado no servidor. Uma vez que a conexão é criada, o programa cliente pode se comunicar com o SGBD. Um padrão chamado de Conectividade Base de Dados Aberta (Open DataBase Connectivity - ODBC) provê uma Interface para Programação de Aplicações (API) que permite que os programas no lado cliente possam chamar o SGBD, desde que tanto as máquinas cliente como servidor tenham o software necessário instalado. Muitos vendedores de SGBDs disponibilizam drivers específicos para seus sistemas. Desta maneira um programa cliente pode se conectar a diversos SGBDRs e enviar requisições de consultas e transações usando API, que são processados nos servidores. Após o processamento de uma chamada de função (levando uma cadeia de caracteres ou programas armazenados), o resultado é fornecido pelo servidor de dados através de tabelas em memória. Os resultados das consultas são enviados para o programa cliente, que pode processá-lo ou visualiza-lo conforme a necessidade. O conjunto de tuplas retornado por uma consulta pode ser uma tabela com zero, uma ou múltiplas linhas, dependendo de quantas linhas foram encontradas com o critério de busca. Quando uma consulta retorna múltiplas linhas, é necessário declarar um "CURSOR" para processar as linhas. Um cursor é similar a uma variável de arquivo ou um ponteiro de arquivo, que aponta para uma única linha (tupla) do resultado da consulta. Em SQL os cursores são controlados por três comandos: OPEN, FETCH, CLOSE. O cursor é inicializado com o comando OPEN, que executa a consulta, devolve o conjunto resultante de linhas e coloco o cursor para a posição anterior a primeira linha do resultado da consulta. O comando FETCH

13
quando executado pela primeira vez, devolve a primeira linha nas variáveis do programa e coloca o cursor para apontar para aquela linha. Subseqüentes execuções do comando FETCH avançam o cursor para a próxima linha no conjunto resultante e retornam a linha nas variáveis do programa. Quando a última linha é processada, o cursor é desalocado com o comando CLOSE. Os cursores existem principalmente para que linguagens como "C" que não permitem abstração para conjunto de registros, possam receber as linhas da resposta de uma consulta SQL uma de cada vez. Com a utilização de "CURSORES" apresentam-se esses dados como resultados das consulta, através de itens que representam os elementos de interface com o usuário, atendendo os preceitos impostos pelos diferentes paradigmas possivelmente envolvidos (imperativo, orientado a objeto e orientado a evento). Com isso os resultados são mostrados utilizando o objeto padrão da interface, disponíveis nas ferramentas de construção de interfaces. Dessa forma o ciclo de busca de informação nos mais variados servidores tem início e fim na interface com o usuário. É de fundamental importância a construção de aplicativos cujo projeto de interface seja "ortogonal" ao projeto de implementação de acesso aos servidores de dados. Na implementação de sistemas de informação deve-se utilizar uma arquitetura de base de dados relacional que seja independente de um determinado repositório de dados (gerenciadores Access, Oracle, Sybase, Informix, etc). A figura 1.7 ilustra a utilização de conversores genéricos tanto para interfaces como para os servidores de dados. Estes conversores são construídos para padronizar o controle de compartilhamento de dados, independente da ferramenta de interface ou do servidor de dados. Em situações práticas esses conversores são denominados comumente de drivers.
Figura 1.7 - Conversor genérico para interface e servidores de dados

14
2 Definição Geral Base de Dados: Coleção de dados relacionados; Dados: sinônimo de informação;
2.1 Propriedades:
• Uma base de dados é uma coleção de dados logicamente relacionados, com algum significado. Associações aleatórias de dados não podem ser chamadas de base de dados;
• Uma base de dados é projetada, construída e preenchida com dados para um propósito específico. Ela tem um grupo de usuários e algumas aplicações pré-concebidas para atender esses usuários;
• Uma base de dados representa algum aspecto do mundo real, algumas vezes chamado de “mini-mundo”. Mudanças no mini-mundo provocam mudanças na base de dados.
Uma base de dados tem alguma fonte de dados, algum grau de interação com eventos do mundo real e uma audiência que está ativamente interessada no conteúdo da base de dados. Um Sistema Gerenciador de Base de Dados (SGBD) é uma coleção de programas que permitem aos usuários criarem e manipularem uma base de dados. Um SGBD é, assim, um sistema de software de propósito geral que facilita o processo de definir, construir e manipular bases de dados de diversas aplicações. Definir uma base de dados envolve a especificação de tipos de dados a serem armazenados
na base de dados. Construir uma base de dados é o processo de armazenar os dados em algum meio que seja
controlado pelo SGBD. Manipular uma base de dados indica a utilização de funções como a de consulta, para
recuperar dados específicos, modificação da base de dados para refletir mudanças no mini-mundo, e geração de relatórios.
A base de dados e o software de gerenciamento da base de dados compõem o chamado Sistema de Base de Dados.

15
Sistema de Base de Dados
Usuários/Programadores
Consultas/Programas de Aplicações
SGBD
Software p/ processar consultas/programas
Software p/ acessar a Base de Dados
BaseBase
Meta
Figura 2.1
2.2 Características da Abordagem da Base de Dados x Processamento tradicional de Arquivos
Processamento tradicional de Arquivos
Base de Dados
Definição dos dados é parte do código de programas de aplicação
Meta Dados eliminação de redundâncias
Dependência entre aplicação específica e dados
Capaz de permitir diversas aplicações
eliminação de redundâncias
independência entre dados e programas
facilidade de manutenção
Representação de dados ao nível físico
Representação conceitual através de dados e programas
facilidade de manutenção
Cada visão é implementada por módulos específicos
Permite múltiplas visões facilidade de consultas
2.3 Profissionais e Atividades envolvidas em um SGBD • Administrador da Base de Dados: em qualquer organização onde muitas pessoas
compartilham muitos recursos, existe a necessidade de um administrador chefe para supervisionar e gerenciar estes recursos. Num ambiente de base de dados, o recurso primário é a própria base de dados e os recursos secundários são o próprio SGBD e softwares relacionados. A administração desses recursos é de responsabilidade do DBA (“Database Administrator”). O DBA é responsável por autorizar acesso à base de dados e coordenar e monitorar seu uso. O DBA é responsável por problemas, tais como, quebra de segurança ou baixo desempenho. Em grandes organizações, o DBA é auxiliado por técnicos;
• Projetistas da Base de Dados: os projetistas de base de dados têm a responsabilidade de identificar os dados a serem armazenados na Base de Dados e escolher estruturas apropriadas para representar e armazenar tais dados. Estas tarefas são geralmente executadas antes que a base de dados seja utilizada. É responsabilidade destes projetistas

16
obter os requisitos necessários dos futuros usuários da base. Tipicamente, os projetistas interagem com cada grupo de usuários em potencial e definem visões da base de dados para adequar os requisitos e processamentos de cada grupo. Estas visões são então analisadas e, posteriormente, integradas para que, ao final, o projeto da base de dados possa ser capaz de dar subsídio aos requisitos de todos os grupos de usuários;
• Usuários Finais: existem profissionais que precisam ter acesso à base de dados para consultar, modificar e gerar relatórios. A base de dados existe para estes usuários. Existem algumas categorias de usuários finais:
⇒ usuários ocasionais: ocasionalmente fazem acesso à base de dados, mas eles podem necessitar de diferentes informações a cada vez que fazem acesso. Eles podem usar uma linguagem de consulta sofisticada para especificar suas requisições e são, tipicamente, gerentes de médio ou alto-nível;
⇒ usuários comuns ou paramétricos: estes usuários realizam operações padrões de consultas e atualizações, chamadas TRANSAÇÕES PERMITIDAS, que foram cuidadosamente programadas e testadas. Estes usuários constantemente realizam recuperações e modificações na base de dados;
⇒ usuários sofisticados: incluem engenheiros, analistas de negócios e outros que procuraram familiarizar-se com as facilidades de um SGBD para atender aos seus complexos requisitos;
• Analistas de Sistemas e Programadores de Aplicação: ⇒ analistas de sistemas determinam os requisitos de usuários finais, especialmente
dos usuários comuns, e desenvolvem especificações das transações para atender a estes requisitos;
⇒ programadores de aplicações implementam estas especificações produzindo programas e, então, testam, depuram, documentam e mantêm estes programas. Analistas e programadores devem estar familiarizados com todas as capacidades fornecidas pelo SGBD para desempenhar estas tarefas.
2.4 Profissionais de Apoio • Projetistas e Implementadores de SGBD • Desenvolvedores de Ferramentas • Operadores de Manutenção
2.5 Capacidades do SGBD • Controle de Redundância: no processamento tradicional de arquivos, muitos grupos de
usuários mantêm seus próprios arquivos para manipular suas aplicações de processamento. Isso pode provocar o armazenamento de informações redundantes;
Problemas: ⇒ Duplicação de esforços; ⇒ Desperdício de espaço; ⇒ Inconsistência: alteração em alguns arquivos e em outros não, ou em todos os
arquivos, porém de maneira independente; • Compartilhamento de Dados: SGBD’s multiusuários devem fornecer controle de
concorrência para assegurar que atualizações simultâneas resultem em modificações corretas. Um outro mecanismo que permite a noção de compartilhamento de dados em um SGBD multiusuário é a facilidade de definir visões de usuário, que é usada para especificar a porção da base de dados que é de interesse para um grupo particular de usuários;
• Restrições de Acesso Multiusuário: quando múltiplos usuários compartilham uma base de dados, é comum que alguns usuários não autorizados não tenham acesso a todas as informações da base de dados. Por exemplo, os dados financeiros são freqüentemente considerados confidenciais e, desse modo, somente pessoas autorizadas devem ter

17
acesso. Além disso, pode ser permitido, a alguns usuários, apenas a recuperação dos dados. Já, para outros, são permitidas a recuperação e a modificação. Assim, o tipo de operação de acesso - recuperação ou modificação - pode também ser controlado. Tipicamente, usuários e grupos de usuários recebem uma conta protegida por palavras-chaves, que é usada para se obter acesso à base de dados, o que significa dizer que contas diferentes possuem restrições de acesso diferentes. Um SGBD deve fornecer um subsistema de autorização e segurança, que é usado pelo DBA, para criar contas e especificar restrições nas contas. O SGBD deve então obrigar estas restrições automaticamente. Note-se que, controle similar pode ser aplicado ao software do SGBD;
• Fornecimento de Múltiplas Interfaces: devido a muitos tipos de usuários, com variados níveis de conhecimento técnico, um SGBD deve fornecer uma variedade de interfaces para usuários. Os tipos de interfaces incluem linguagens de consulta para usuários ocasionais, interfaces de linguagem de programação para programadores de aplicações, formulários e interfaces dirigidas por menus para usuários comuns;
• Representação de Relacionamento Complexo entre Dados: uma base de dados pode possuir uma variedade de dados que estão inter-relacionados de muitas maneiras. Um SGBD deve ter a capacidade de representar uma variedade de relacionamentos complexos entre dados, bem como recuperar e modificar dados relacionados de maneira fácil e eficiente;
• Reforçar Restrições de Integridade: muitas aplicações de base de dados terão certas restrições de integridade de dados. A forma mais elementar de restrição de integridade é a especificação do tipo de dado de cada item. Existem tipos de restrições mais complexas. Um tipo de restrição que ocorre freqüentemente é a especificação de que um registro de um arquivo deve estar relacionado a registros de outros arquivos. Um outro tipo de restrição especifica a unicidade sobre itens de dados. Estas restrições são derivadas da semântica dos dados e o mini-mundo que eles representam. Algumas restrições podem ser especificadas ao SGBD e automaticamente executadas. Outras restrições podem ser verificadas pelos programas de atualização ou no tempo da entrada de dados. Note que um item de dados pode ser “entrado” erroneamente, mas ainda atender as restrições de integridade;
• Fornecer Backup e Restauração: Um SGBD deve fornecer recursos para restauração caso ocorra falhas de hardware ou software. O subsistema de backup e restauração do SGBD é o responsável pela restauração. Por exemplo, se o sistema de computador falhar no meio da execução de um programa que esteja realizando uma alteração complexa na base de dados, o subsistema de restauração é responsável em assegurar que a base de dados seja restaurada no estado anterior ao início da execução do programa. Alternativamente, o subsistema de restauração poderia assegurar que o programa seja re-executado a partir do ponto em que havia sido interrompido.
2.6 Vantagens Adicionais da Abordagem da Base de Dados • Potencial para obrigar a Padronização: a abordagem de base de dados permite que o DBA
defina e obrigue a padronização entre os usuários da base de dados em grandes organizações. Isso facilita a comunicação e a cooperação entre vários departamentos, projetos e usuários. Padrões podem ser definidos para formatos de nomes, elementos de dados, telas, relatórios, terminologias, etc. O DBA pode obrigar a padronização em um ambiente de base de dados centralizado, muito mais facilmente que em um ambiente onde cada usuário ou grupo tem o controle de seus próprios arquivos e softwares;
• Flexibilidade: mudanças na estrutura de uma base de dados podem ser necessárias devido a mudanças nos requisitos. Por exemplo, um novo grupo de usuários pode surgir com necessidade de informações adicionais, não disponíveis atualmente na base de dados. Alguns SGBD’s permitem que tais mudanças na estrutura da base de dados sejam realizadas sem afetar a maioria dos programas de aplicações existentes;
• Redução do Tempo de Desenvolvimento de Aplicações: uma das principais características de venda da abordagem de base de dados é o tempo reduzido para o desenvolvimento de novas aplicações, tal como a recuperação de certos dados da base de dados para a impressão de novos relatórios. Projetar e implementar uma nova base de dados pode tomar mais tempo do que escrever uma simples aplicação de arquivos especializada.

18
Porém, uma vez que a base de dados esteja em uso, geralmente o tempo para se criar novas aplicações, usando-se os recursos de um SGBD, é bastante reduzido. O tempo para se desenvolver uma nova aplicação em um SGBD é estimado em 1/4 a 1/6 do que o tempo de desenvolvimento, usando-se apenas o sistema de arquivos tradicional, devido às facilidades de interfaces disponíveis em um SGBD;
• Disponibilidade de Informações Atualizadas: tão logo um usuário modifique uma base de
dados, todos os outros usuários “sentem” imediatamente esta modificação. Esta disponibilidade de informações atualizadas é essencial para muitas aplicações, tais como sistemas de reservas de passagens aéreas ou bases de dados bancárias. Isso somente é possível devido ao subsistema de controle de concorrência e restauração do SGBD;
• Economia de Escala: a abordagem de SGBD’s permite a consolidação de dados e de aplicações reduzindo-se, desse modo, o desperdício em atividades redundantes de processamento em diferentes projetos ou departamentos. Isto possibilita à organização como um todo investir em processadores mais poderosos, e periféricos de armazenamento e de comunicação mais eficientes.
2.7 Quando não utilizar um SGBD ° bases de dados e aplicações simples, bem definidas e nenhuma expectativa de mudança; ° existem restrições de tempo que não podem ser encontradas em SGBD’s; ° não necessitar de acesso multiusuário.

19
3 Conceitos e Arquiteturas de SGBD’s
3.1 Modelos de Dados, Esquemas e Instâncias Uma das características fundamentais da abordagem de base de dados é que ela fornece algum nível de abstração de dados, pela omissão de detalhes de armazenamento de dados que não são necessários para a maioria dos usuários. O modelo de dados é a principal ferramenta que fornece esta abstração. Um Modelo de Dados é um conjunto de conceitos que podem ser usados para descrever a estrutura de uma base de dados. Por estrutura de uma base de dados entende-se os tipos de dados, relacionamentos e restrições pertinentes aos dados. Muitos modelos de dados também definem um conjunto de operações para especificar como recuperar e modificar a base de dados.
3.1.1 Categorias de Modelos de Dados Muitos modelos de dados têm sido propostos. Pode-se classificar os modelos de dados baseando-se nos tipos de conceitos que fornecem para descrever a estrutura da base de dados. Modelos de Dados Conceituais ou de Alto-Nível fornecem conceitos próximos à percepção dos usuários. Já os Modelos de Dados Físicos ou de Baixo-Nível fornecem conceitos que descrevem os detalhes de como os dados são armazenados no computador. Modelos de alto-nível utilizam conceitos tais como Entidades, Atributos e Relacionamentos. Uma entidade é um objeto que é representado na base de dados. Um atributo é uma propriedade que descreve algum aspecto de um objeto. Relacionamentos entre objetos são facilmente representados em modelos de dados de alto-nível, que são algumas vezes chamados de Modelos Baseados em Objetos devido, principalmente, à sua característica de descreverem objetos e seus relacionamentos. Modelos de Dados de Baixo-Nível descrevem como os dados são armazenados no computador, representando informações em formato de registros, ordem dos registros e caminho de acesso. Um Caminho de Acesso é uma estrutura de que facilita a busca de um registro particular na base de dados.
3.1.2 Esquemas e Instâncias Em qualquer modelo de dados é importante distinguir entre descrição da base de dados da própria base de dados. A descrição de uma base de dados é chamada Esquema da Base de Dados. Um esquema de base de dados é especificado durante o projeto da base de dados, sendo que a expectativa de mudanças não é grande. A forma de visualização de um esquema é chamada Diagrama do Esquema. Muitos modelos de dados têm certas convenções para, diagramaticamente, mostrar esquemas especificados no modelo. Os dados atualmente existentes em uma base de dados podem mudar com relativa freqüência. Os dados da base de dados em um particular momento do tempo são chamados Instâncias da Base de Dados (ou Ocorrências ou Estados). A base-esquema é algumas vezes chamada de Base-Intencional e uma instância é chamada de Base-Extensional do esquema.

20
3.2 Arquitetura e Independência de Dados de SGBD’s
3.2.1 Arquitetura “Three-Schema” (conhecida como arquitetura ANSI/SPARC - Tsichritzis e Klug, 1978)
A meta desta arquitetura é separar as aplicações de usuários da base de dados física. Nesta arquitetura, esquemas podem ser definidos em três níveis: 1. O nível interno tem um esquema interno que descreve a estrutura de armazenamento físico
da base de dados. O esquema interno usa um modelo de dados físico e descreve todos os detalhes de armazenamento de dados e caminhos de acesso à base de dados;
2. O nível conceitual tem um esquema conceitual que descreve a estrutura de toda a base de dados. O esquema conceitual é uma descrição global da base de dados, que omite detalhes da estrutura de armazenamento físico e se concentra na descrição de entidades, tipos de dados, relacionamentos e restrições. Um modelo de dados de alto-nível ou um modelo de dados de implementação podem ser utilizados neste nível.
3. O nível externo ou visão possui esquemas externos ou visões de usuários. Cada esquema externo descreve a visão da base de dados de um grupo de usuários da base de dados. Cada visão descreve, tipicamente, à parte da base de dados que um particular grupo de usuários está interessado e esconde o resto da base de dados do mesmo. Um modelo de dados de alto-nível ou um modelo de dados de implementação podem ser usados neste nível.
BASE DE DADOS ARMAZENADA
ESQUEMA INTERNO
ESQUEMA CONCEITUAL
VISÃOEXTERNA 1
VISÃOEXTERNA N
USUÁRIOS FINAIS
NÍVEL EXTERNO
NÍVEL CONCEITUAL
NÍVEL INTERNO
mapeamento externo/conceitual
mapeamento conceitual/interno
Figura 3.1 Muitos SGBD’s não separam os três níveis completamente. Pode acontecer que alguns SGBD’s incluam detalhes do nível interno no esquema conceitual. Em muitos SGBD’s que permitem visões, os esquemas externos são especificados com o mesmo modelo de dados usado no nível conceitual. Note que os três esquemas são apenas descrições dos dados.

21
3.2.2 Independência de dados A arquitetura “three-schema” pode ser utilizada para explicar conceitos de independência de dados, que podem ser definidos como a capacidade de alterar o esquema de um nível sem ter que alterar o esquema no próximo nível superior. Dois tipos de independência de dados podem ser definidos: • Independência Lógica de Dados: É a capacidade de alterar o esquema conceitual sem ter
que mudar os esquemas externos ou programas de aplicação. Pode-se mudar o esquema conceitual para expandir a base de dados, adicionando novos tipos de registros ou de itens de dados, ou reduzir a base de dados removendo um tipo de registro ou itens de dados. Neste último caso, esquemas externos que se referem a apenas aos dados remanescentes não devem ser afetados;
• Independência Física de Dados: É a capacidade de alterar o esquema interno sem ter que
alterar o esquema conceitual externo. Mudanças no esquema interno podem ser necessárias devido a alguma reorganização de arquivos físicos para melhorar o desempenho nas recuperações e/ou modificações. Após a reorganização, se nenhum dado foi adicionado ou perdido, não haverá necessidade de modificar o esquema conceitual.
3.3 Linguagens de Base de Dados • Linguagem de Definição de Dados (“Data Definition Language” - DDL): é utilizada pelo DBA
e projetistas de base de dados para definir seus esquemas. O SGBD tem um compilador para processar descrições em DDL e construir a descrição do esquema armazenado no catálogo;
• Linguagem de Manipulação de Dados (“Data Manipulation Language” - DML): uma vez que o esquema é compilado e a base de dados preenchida com dados, os usuários têm que ter algum modo de manipular os dados. Manipulações comuns como recuperação, inserção, remoção e modificação de dados são realizadas pela DML.

22
4 Modelagem de Dados Usando o Modelo Entidade-Relacionamento (MER)
O MER é um modelo de dados conceitual de alto-nível. Assim, os conceitos do MER foram projetados para serem compreensíveis a usuários, descartando detalhes de como os dados são armazenados. Atualmente, o MER é usado principalmente durante o processo de projeto da base de dados. Existem expectativas para que uma classe de SGBD’s baseados diretamente no MER esteja disponível no futuro.
4.1 Modelo de Dados Conceitual de Alto-Nível e Projeto de Base Dados
Mini-Mundo
OBTENÇÃO E ANÁLISE DE REQUISITOS
Requisitos da Base de Dados
PROJETO CONCEITUAL
Esquema Conceitual(em um Modelo de Dados de Alto-Nível)
MAPEAMENTO DO MODELO DE DADOS
Esquema Conceitual(em um Modelo de Dados de um SGBD específico)
PROJETO FÍSICO
Esquema Interno(para o mesmo SGBD)
Independente de qualquer SGBD
SGBD específico
Figura 4.1
4.2 Um Exemplo Neste exemplo, é descrita uma base de dados COMPANHIA que será utilizada para ilustrar o processo de projeto de base de dados. São listados os requisitos da base de dados e criado o seu esquema conceitual passo-a-passo ao mesmo tempo em que são introduzidos os conceitos de modelagem usando o MER. A base de dados COMPANHIA armazena os dados dos empregados, departamentos e projetos. Supõe-se que após a Obtenção e Análise dos Requisitos, os projetistas da base de dados produziram a seguinte descrição do mini-mundo - parte da companhia a ser representada na base de dados:

23
• A companhia é organizada em departamentos. Cada departamento tem um nome, um número e um empregado que gerencia o departamento. Armazena-se a data de início que o empregado começou a gerenciar o departamento. Um departamento pode ter diversas localizações;
• Um departamento controla inúmeros projetos, sendo que cada um tem um nome, um número e uma localização;
• Do empregado armazena-se o nome, o número do seguro social, endereço, salário, sexo e data de nascimento. Todo empregado é associado a um departamento, mas pode trabalhar em diversos projetos, que não são necessariamente controlados pelo mesmo departamento. Armazena-se, também, o número de horas que o empregado trabalha em cada projeto. Mantém-se, ainda, a indicação do supervisor direto de cada projeto;
• Os dependentes de cada empregado são armazenados para propósito de garantir os benefícios do seguro. Para cada dependente será armazenado o nome, sexo, data de nascimento e o relacionamento com o empregado.
4.3 Conceitos do Modelo Entidade-Relacionamento
4.3.1 Entidades e Atributos O objeto básico que o MER representa é a entidade. Uma entidade é algo do mundo real que possui uma existência independente. Uma entidade pode ser um objeto com uma existência física - uma pessoa, carro ou empregado - ou pode ser um objeto com existência conceitual - uma companhia, um trabalho ou um curso universitário. Cada entidade tem propriedades particulares, chamadas atributos, que o descrevem. Por exemplo, uma entidade empregado pode ser descrita pelo seu nome, o trabalho que realiza, idade, endereço e salário. Uma entidade em particular terá um valor para cada um de seus atributos. Os valores de atributos que descrevem cada entidade ocupam a maior parte dos dados armazenados na base de dados. A figura 4.2 ilustra duas entidades. A entidade EMPREGADO e1 tem quatro atributos: Nome, Endereço, Idade e Telefone residencial. Os seus valores são: “João da Silva”, Rua Goiás 711, São Paulo, SP, 1301100”, “55” e “713-749”, respectivamente. A entidade companhia c1 tem três atributos: Nome, Sede e Presidente. Seus valores são: “Cooper Sugar”, “Ribeirão Preto”, “João da Silva”.
e1
Nome=João da Silva
Endereço=Rua Goiás 711,
Idade=55
Telefone residencial=713-749
c1
Nome=Cooper Sugar
Sede=Ribeirão Preto
Presidente=João da Silva
São Paulo, SP, 1301100
Figura 4.2 Alguns atributos podem ser divididos em subpartes com significados independentes. Por exemplo, Endereço da entidade e1 pode ser dividido em Endereço da Rua, Cidade, Estado e CEP. Um atributo que é composto de outros atributos mais básicos é chamado composto. Já, atributos que não são divisíveis são chamados simples ou atômicos. Atributos compostos podem formar uma hierarquia:

24
Endereço
Endereço da Rua Cidade Estado CEP
Nome da Rua Número Apartamento Figura 4.3 Atributos compostos são úteis quando os usuários referenciam o atributo composto como uma unidade e, em outros momentos, referenciam especificamente a seus componentes. Se o atributo composto for sempre referenciado como um todo, não existe razão para subdividi-lo em componentes elementares. Muitos atributos têm apenas um único valor. Tais atributos são chamados atributos univalorados (exemplo, Idade da entidade e1). Em outros casos, um atributo pode ter um conjunto de valores. Tais atributos são chamados de atributos multivalorados (exemplo, Telefone). Atributos multivalorados podem possuir uma multiplicidade, indicando as quantidades mínima e máxima de valores. Em alguns casos, dois ou mais atributos são relacionados. Por exemplo, Idade e Data de Nascimento de uma pessoa. Para uma entidade pessoa em particular, a Idade pode ser determinada a partir da data atual e da Data de Nascimento. Atributos como Idade são chamados atributos derivados. Alguns valores de atributos podem ser derivados de entidades relacionadas. Por exemplo, um atributo Número de Empregados de uma entidade departamento que pode ser calculado contando-se o número de empregados relacionados com o departamento. Outras situações: uma entidade pode não ter quaisquer valores para um atributo. Por exemplo, o atributo Apartamento aplica-se somente aqueles empregados que residam em algum prédio. Para tais situações, um valor especial chamado null é criado. O valor null pode também ser utilizado para denotar que o valor é desconhecido. O significado para o primeiro uso do null é “não aplicável” e, para o segundo, “desconhecido”.
4.3.2 Tipos de Entidades, Conjunto de Valores e Atributos-Chaves Uma base de dados irá conter normalmente grupos de entidades que são similares. Uma companhia com centenas de empregados pode querer agrupar as informações similares com respeito a empregados. Estas entidades empregados compartilham os mesmos atributos, mas cada entidade terá seus próprios valores para cada atributo. Tais entidades similares definem o tipo de entidade, que é um conjunto de entidades que têm os mesmos atributos. Na maioria das bases de dados pode-se identificar muitos tipos de entidades. A figura 4.4 mostra dois tipos de entidades denominadas EMPREGADO e COMPANHIA, e uma lista de atributos. Algumas entidades são também ilustradas, juntamente com os seus valores de atributos:

25
ESQUEMA(INTENÇÃO)
EMPREGADO COMPANHIANome, Idade, Salário Nome, Sede, Presidente
e1
e2
e3
(João da Silva, 55, 800)
(Roberto Carlos, 40, 300)
(Camélia Colina, 25, 200)
c1
c2
(Cooper Sugar, Ribeirão Preto, João da Silva)
(FastCom, Dallas, Paulo Paz)
INSTÂNCIAS(EXTENSÃO)
Figura 4.4 A descrição do tipo de entidade é chamada esquema do tipo de entidade e especifica uma estrutura comum compartilhada por todas as entidades individuais. O esquema especifica o nome do tipo de entidade, o significado de cada um de seus atributos e qualquer restrição que exista sobre entidades individuais. O conjunto de instâncias de entidades em um particular momento do tempo é chamado extensão do tipo de entidade. O esquema não é alterado com freqüência porque descreve a estrutura das entidades individuais. A extensão pode mudar com freqüência, por exemplo, quando se adiciona ou remove-se uma entidade de um tipo de entidade. • Atributo-Chave de um Tipo de Entidade: Uma restrição importante sobre entidades de um
tipo de entidade é a restrição de atributo-chave ou unicidade. Um tipo de entidade tem, normalmente, atributos cujos valores são distintos para cada entidade. Tal atributo é chamado atributo-chave, e seu valor pode ser usado para identificar cada entidade unicamente. Algumas vezes, um conjunto de atributos pode formar uma chave. Nestes casos, os atributos podem ser agrupados em um atributo composto, que virá a ser um atributo-chave do tipo de entidade.
A especificação de um atributo-chave para um tipo de entidade significa que a propriedade
de unicidade deve valer para quaisquer extensões deste tipo de entidade. Assim, esta restrição proíbe que duas entidades tenham, simultaneamente, o mesmo valor para o atributo-chave.
Alguns tipos de entidades podem ter mais que um atributo-chave.
4.3.3 Relacionamentos, Papéis e Restrições Estruturais • Tipo e Instância de Relacionamento: Um tipo de relacionamento R entre n tipos de
entidades E1, E2, ..., En é um conjunto de associações entre entidades desses tipos. Diz-se que cada entidade E1, E2, ..., En participa no tipo de relacionamento R e que as
entidades individuais e1, e2, ..., en participam na instância do relacionamento ri=(e1, e2, ..., en). O índice i indica que podem existir várias instâncias de relacionamento.
Por exemplo, considere-se que um tipo de relacionamento TRABALHA-PARA exista entre
tipos de entidades EMPREGADO e DEPARTAMENTO,. Este relacionamento associa cada

26
empregado com o departamento em que o empregado trabalha. Cada instância de relacionamento em TRABALHA-PARA associa uma entidade empregado e uma entidade departamento. A figura 4.5 ilustra este exemplo, onde cada instância de relacionamento ri é
conectada à uma entidade empregado e à uma entidade departamento. No mini-mundo representado nesta figura, os empregados e1, e3 e e6 trabalham para o departamento d1; e2 e e4 trabalham para d2; e e5 e e7 trabalham para d3.
EMPREGADOTRABALHA-PARA
DEPARTAMENTO
e1
e2
e3
e4
e5
e6
e7
♦
♦
♦
♦
♦
♦
♦
n
r1
n
r2
n
r3
n
r4
n
r5
n
r7
n
r6
d1
d2
d3
♦
♦
♦
Figura 4.5 • O Grau de um Tipo de Relacionamento: O grau de um tipo de relacionamento indica o
número de tipos de entidades participantes. Assim, o tipo de relacionamento TRABALHA-PARA é de grau dois. Um tipo de relacionamento de grau dois é chamado binário e de grau três de ternário. Um exemplo de um tipo de relacionamento ternário é FORNECE, ilustrado na figura 4.6. Cada instância de relacionamento ri associa três entidades - um fornecedor s, uma peça p e um projeto j - onde o fornecedor s fornece a peça p para o projeto j. Podem existir tipos de relacionamento de qualquer grau, porém é mais freqüente encontrar o tipo de relacionamento de grau dois.
FORNECEDOR
FORNECE
PROJETO
s1
s2
♦
♦
n
r1
n
r2
n
r3
n
r4
n
r5
n
r7
n
r6
j1
j2
j3
♦
♦
♦
p1
p2
p3
♦
♦
♦
PEÇA
Figura 4.6

27
Em geral, um tipo de relacionamento ternário representa mais informação do que três tipos de relacionamentos binários. Por exemplo, considere os três tipos de relacionamentos binários: PODE-FORNECER, USA e FORNECE-ALGO. Supõe-se que:
a. PODE-FORNECER, entre os tipos de entidades FORNECEDOR e PEÇA, possui uma instância (s, p) com o significado: "o fornecedor s pode fornecer a peça p" (para qualquer projeto);
b. USA, entre os tipos de entidades PROJETO e PEÇA, possui uma instância (j, p) com o significado: "o projeto j usa a peça p"; e
c. FORNECE-ALGO, entre os tipos de entidades FORNECEDOR e PROJETO, possui uma instância (s, j) com o significado: "o fornecedor s fornece alguma peça para o projeto j".
A existência dessas três instâncias de relacionamentos (s, p), (j, p) e (s, j) em PODE-
FORNECER, USA e FORNECE-ALGO, respectivamente, não necessariamente implica que uma instância (s, j, p) exista no tipo de relacionamento ternário FORNECE. Isto tem sido chamado armadilha de conexão.
· Relacionamento como Atributo: Convém, algumas vezes, pensar em um tipo de
relacionamento em termos de atributos. Considere-se o tipo de relacionamento TRABALHA-PARA discutido anteriormente. Pode-se pensar em colocar um atributo chamado Departamento no tipo de entidade EMPREGADO onde o valor deste atributo em cada entidade empregado é a entidade departamento em que ele trabalha. Quando se pensa em um tipo de relacionamento binário como atributo, existem duas alternativas: Departamento como atributo do tipo de entidade EMPREGADO ou Empregado como atributo do tipo de entidade DEPARTAMENTO. Neste último caso, o atributo Empregado é um atributo multivalorado, onde os valores pertencem ao tipo de entidade EMPREGADO. Qualquer uma dessas alternativas é representada pelo tipo de relacionamento TRABALHA-PARA.
· Nomes de Papéis e Relacionamentos Recursivos: Cada tipo de entidade que participa de
um tipo de relacionamento possui um papel específico no relacionamento. O nome do papel indica o papel que uma entidade de um tipo de entidade tem para cada instância de relacionamento. Por exemplo, no tipo de relacionamento TRABALHA-PARA, EMPREGADO tem o papel empregado ou trabalhador e DEPARTAMENTO tem o papel de departamento ou empregador. A escolha do nome nem sempre é simples. Para o tipo de relacionamento ternário FORNECE, é difícil encontrar-se um nome. O nome de papel não é exclusividade do tipo de relacionamento onde os tipos de entidades participantes são distintos. Em alguns casos, um mesmo tipo de entidade participa mais que uma vez em um tipo de relacionamento com diferentes papéis. Nesses casos, é essencial identificar os nomes dos papéis a fim de distinguir o significado de cada participação. Tais tipos de relacionamentos são chamados recursivos. Para ilustrar, considere a figura 4.7:
EMPREGADO
SUPERVISIONA
e1
e2
e3
♦
♦
♦
n
r1
n
r2
n
r3
1
1
1
e4
♦
2
2
2
Figura 4.7
O tipo de relacionamento SUPERVISIONA relaciona um empregado com o seu supervisor, onde ambas entidades são membros do mesmo tipo de entidade EMPREGADO. Assim, o tipo de entidade EMPREGADO participa duas vezes: uma vez no papel de supervisor e outra no papel de supervisionado. Na 4.7 acima, as linhas marcadas com "1" representam

28
o papel de supervisor e os marcados com "2" representam o papel de supervisionado. Assim, e1 supervisiona e2, e2 supervisiona e3 e e3 supervisiona e4.
· Restrições sobre Tipos de Relacionamentos: Os tipos de relacionamento possuem certas
restrições que limitam as combinações possíveis de entidades participando nas instâncias de relacionamento. Estas restrições são determinadas pelas situações do mini-mundo que os relacionamentos representam. Por exemplo, na figura 4.5, se existir uma regra que um empregado trabalha para apenas um departamento, então esta restrição deve ser descrita no esquema. Pode-se distinguir dois principais tipos de restrições de relacionamento que ocorrem com relativa freqüência: razão de cardinalidade e participação.
A restrição razão de cardinalidade especifica a quantidade de instâncias de
relacionamento que uma entidade pode participar. No tipo de relacionamento binário TRABALHA-PARA, DEPARTAMENTO:EMPREGADO tem razão de cardinalidade 1:N. Isto significa que cada entidade departamento pode estar relacionada a inúmeras entidades empregado (muitos empregados podem trabalhar para um departamento) mas uma entidade empregado pode estar relacionada a apenas um departamento (um empregado pode trabalhar apenas para um departamento). As razões de cardinalidade mais comuns para tipos de relacionamento binário são 1:1, 1:N e M:N.
Um exemplo de um tipo de relacionamento binário 1:1 entre DEPARTAMENTO e
EMPREGADO é GERENCIA, que relaciona uma entidade departamento com o empregado que gerencia esse departamento. Este relacionamento é 1:1 pois sabe-se que um empregado pode gerenciar apenas um departamento e que um departamento pode ter apenas um gerente.
EMPREGADOGERENCIA
DEPARTAMENTO
e1
e2
e3
e4
e5
e6
e7
♦
♦
♦
♦
♦
♦
♦
n
r1
n
r2
n
r3
d1
d2
d3
♦
♦
♦
Figura 4.8 O tipo de relacionamento TRABALHA-EM entre EMPREGADO e PROJETO tem a razão de
cardinalidade M:N considerando que um empregado pode trabalhar em diversos projetos e que diversos empregados podem trabalhar em um projeto.

29
EMPREGADOTRABALHA-EM
PROJETO
e1
e2
e3
e4
♦
♦
♦
♦
n
r1
n
r2
n
r3
p1
p2
p3
♦
♦
♦
n
r4
n
r5
n
r6
n
r7
p4♦
Figura 4.9 A restrição de participação especifica se a existência de uma entidade depende dela estar
relacionada com outra entidade através de um relacionamento. Existem dois tipos de restrições de participação: total e parcial. Se uma companhia estabelece a regra de que todo empregado deve trabalhar para um departamento, então uma entidade empregado somente pode existir se ele participar em uma instância de relacionamento TRABALHA-PARA. A participação de EMPREGADO em TRABALHA-PARA é chamada total, o que significa que toda entidade empregado deve estar relacionada a uma entidade departamento via TRABALHA-PARA. A restrição de participação total é algumas vezes chamada dependência existencial. Não é esperado, na figura 4.8, que todo empregado gerencie um departamento, assim a participação de EMPREGADO no tipo de relacionamento GERENCIA é parcial. Isso significa que algumas entidades, do conjunto de entidades EMPREGADO, poderão estar relacionadas a uma entidade departamento via GERENCIA, mas não necessariamente todas.
As restrições de participação e razão de cardinalidade podem ser derivadas da restrição
estrutural de um tipo de relacionamento. É simples especificar as restrições estruturais, embora não seja tão intuitiva quanto às restrições de participação e razão de cardinalidade. Pode-se associar um par de números inteiros (min, max) para cada participação de um tipo de entidade E em um tipo de relacionamento R, onde 0 ≤ min ≤ max e max ≥1. Os números indicam que para cada entidade e em E, e deve participar ao menos min e no máximo max vezes em instâncias de relacionamento de R. Note-se, que se min=0 então a restrição de participação é parcial e se min>0 então a participação é total. A vantagem de usar este método é que ele é mais preciso e pode ser usado facilmente para especificar restrições estruturais para tipos de relacionamentos de qualquer grau.
• Atributos em Tipos de Relacionamento: Os tipos de relacionamento também podem ter
atributos da mesma maneira que os tipos de entidades. Por exemplo, pode haver a necessidade de se representar à quantidade de horas semanais trabalhadas por um empregado em um dado projeto. Isto pode ser representado em cada instância de relacionamento TRABALHA-EM na forma de atributo denominado Horas. Um outro exemplo é o caso de representar a data em que um gerente começou a gerenciar um

30
departamento através de um atributo DataInício para o tipo de relacionamento GERENCIA (figura 4.8).
Note-se que atributos de tipos de relacionamento 1:1 ou 1:N podem ser incluídos como
atributos de um dos tipos de entidades participantes. Por exemplo, o atributo DataInício para o tipo de relacionamento GERENCIA pode ser um atributo tanto de EMPREGADO quanto de DEPARTAMENTO; embora, conceitualmente, ele pertença ao relacionamento GERENCIA. Isso ocorre porque GERENCIA é um relacionamento 1:1. Assim, toda entidade departamento ou empregado participam em apenas uma instância de relacionamento e, dessa forma, o valor do atributo DataInício pode ser representado em uma das entidades participantes.
Para um tipo de relacionamento 1:N, um atributo de relacionamento pode somente ser
colocado no tipo de entidade que está do lado N do relacionamento. Por exemplo, na figura 4.5, se o relacionamento TRABALHA-PARA tiver um atributo DataInício indicando quando um empregado começou a trabalhar para um departamento, este atributo pode ser colocado como atributo de EMPREGADO. Isto acontece porque o relacionamento é 1:N, tal que cada entidade empregado participa apenas uma única vez em uma instância de TRABALHA-PARA. Em ambos os tipos de relacionamento 1:1 e 1:N, a decisão de onde colocar um atributo de relacionamento é determinada subjetivamente pelo projetista de esquemas.
Se o valor de um atributo é determinado pela combinação das entidades participantes em
uma instância de relacionamento, e não apenas por uma das entidades, então o atributo deve ser especificado como um atributo de relacionamento. Esta condição aplica-se a atributos de tipos de relacionamentos M:N, porque as entidades dos tipos de entidades participantes podem participar em inúmeras instâncias de relacionamento. Um exemplo disso é o atributo Horas do relacionamento M:N TRABALHA-EM (figura 4.9). O número de horas que um empregado trabalha em um projeto é determinado pela combinação empregado-projeto e não separadamente.
4.3.4 Tipo de Entidade-Fraca Alguns tipos de entidades podem não ter quaisquer atributos-chaves. Isto implica que não se pode distinguir as entidades porque a combinação dos valores de atributos podem ser idênticas. Tais tipos de entidades são chamadas tipos de entidades-fracas. Entidades que pertencem a um tipo de entidade-fraca são identificados por estarem associadas a entidades específicas de um outro tipo de entidade em combinação com alguns de seus valores de atributos. Este outro tipo de entidade é denominado proprietário da identificação, e o tipo de relacionamento que relaciona um tipo de entidade-fraca com o proprietário da identificação é chamado relacionamento de identificação do tipo de entidade-fraca. Um tipo de entidade-fraca sempre tem uma restrição de participação total (dependência existencial) com respeito ao seu relacionamento de identificação, porque não é possível identificar uma entidade-fraca sem a correspondente entidade proprietária. Por exemplo, considere o tipo de entidade DEPENDENTE, relacionado a EMPREGADO, que é usado para representar os dependentes de cada empregado através do relacionamento 1:N. Os atributos de DEPENDENTE são Nome (apenas o primeiro nome do dependente), DataNasc, Sexo e Relação com o empregado (esposa, marido, filho, sogra, etc.). Dois dependentes de empregados distintos podem ter os mesmos valores para os atributos, mesmo assim eles ainda serão entidades distintas. Os dependentes serão identificados como entidades distintas após a determinação da entidade empregado com a qual cada um está relacionado. Um tipo de entidade-fraca tem uma chave-parcial, que é um conjunto de atributos que pode univocamente identificar entidades-fracas relacionadas à mesma entidade proprietária. No

31
exemplo, assume-se que nenhum dependente de um mesmo empregado terá o mesmo nome, então o atributo Nome de DEPENDENTE será a chave-parcial. Um tipo de entidade-fraca pode, algumas vezes, ser representado como atributo composto e multivalorado. No exemplo, pode-se especificar um atributo composto e multivalorado denominado Dependente para EMPREGADO, onde os atributos componentes são Nome, DataNasc, Sexo e Relação, substituindo-se assim, o tipo de entidade-fraca DEPENDENTE. A escolha de qual representação usar é determinada pelo projetista da base de dados. Um critério usado para se adotar a representação de tipo de entidade-fraca é quando o tipo de entidade-fraca tem muitos atributos ou participa, independentemente, em outros tipos de relacionamentos além de seu tipo de relacionamento que o identifica.
4.3.5 Projeto da Base de Dados COMPANHIA utilizando o MER Tendo visto os conceitos pertinentes ao MER, pode-se agora especificar os seguintes tipos de relacionamentos extraídos do exemplo apresentado na seção 4.2. a. GERENCIA (1:1) entre EMPREGADO e DEPARTAMENTO. A participação de
EMPREGADO é parcial. A participação de DEPARTAMENTO é total. O atributo DataInício é associado a este tipo de relacionamento.
b. TRABALHA-PARA (1:N) entre DEPARTAMENTO e EMPREGADO. Ambos têm participação total.
c. CONTROLA (1:N) entre DEPARTAMENTO e PROJETO. A participação de PROJETO é total e de DEPARTAMENTO é parcial.
d. SUPERVISIONA (1:N) entre EMPREGADO (no papel de supervisor) e EMPREGADO (no papel de supervisionado). A participação de ambos é parcial, pois nem todo empregado é supervisor e nem todo empregado tem um supervisor.
e. TRABALHA-EM (M:N) entre EMPREGADO e PROJETO com o atributo Horas. Ambos têm participação total.
f. DEPENDENTE-DE (1:N) entre EMPREGADO e DEPENDENTE. É um tipo de relacionamento de identificação para o tipo de entidade-fraca DEPENDENTE. A participação de EMPREGADO é parcial e de DEPENDENTE é total.
Nas figuras de 4.5 a 4.9 foram representados os tipos de entidades e relacionamentos mostrando suas extensões (as entidades e instâncias de relacionamentos). Em diagramas do MER, ou simplesmente DER, a ênfase está na representação de esquemas ao invés de instâncias. Isso porque o esquema de uma base de dados raramente sofre mudanças, já instâncias podem mudar freqüentemente. Também, o esquema é de fácil visualização por conter menor quantidade de elementos visuais.
4.4 Diagrama Entidade-Relacionamento (DER) A figura 4.10 ilustra um DER para o esquema da base de dados COMPANHIA. Os tipos de entidades tais como EMPREGADO, DEPARTAMENTO e PROJETO são mostrados em retângulos. Tipos de relacionamentos tais como TRABALHA-PARA, GERENCIA, CONTROLA e TRABALHA-EM são mostrados em losângulos interligados a tipos de entidades participantes. Atributos são mostrados em elipses conectadas a tipos de entidades ou relacionamentos. Os componentes de um atributo composto são também representados em elipses, porém conectadas ao atributo o qual ele pertence (atributo Nome de EMPREGADO). Atributos multivalorados são denotados em elipses com linhas duplas (atributo Localização de DEPARTAMENTO). Os atributos-chaves são sublinhados. Atributos derivados em elipses com linhas tracejadas (atributo NumeroDeEmpregados de DEPARTAMENTO).

32
Os tipos de entidades-fracas são distinguidos por retângulos com linhas duplas e os relacionamentos de identificação por losângulos com linhas duplas (tipo de entidade-fraca DEPENDENTE e tipo de relacionamento de identificação DEPENDENTE-DE). A chave-parcial de um tipo de entidade-fraca é sublinhada com linha tracejada.
TRABALHA-PARA
GERENCIA
Pnome Mnome Snome
Nome
Nss
DataNasc
Endereço
SalárioSexo
DEPARTAMENTO
Nome
Número
Localização
NúmeroDeEmpregadosDataInício
CONTROLA
PROJETO
EMPREGADO
TRABALHA-EM
HorasSUPERVISIONA
DEPENDENTE-DE
DEPENDENTE
Nome Sexo DataNasc Relação
supervisor
supervisiona
1 N
1
N
M N
1
N
1 1
N 1
Nome
Número Localização
Figura 4.10 Na figura 4.10 são mostradas as razões de cardinalidade para cada tipo de relacionamento binário. A razão de cardinalidade de DEPARTAMENTO:EMPREGADO em GERENCIA é 1:1, para DEPARTAMENTO:EMPREGADO em TRABALHA-PARA é 1:N e M:N para TRABALHA-EM. As restrições de participação parcial são especificadas por linhas simples. As linhas paralelas denotam participação total (dependência existencial). Na figura 4.10 foram mostrados os nomes de papéis para o tipo de relacionamento SUPERVISIONA porque o tipo de entidade EMPREGADO ocupa dois papéis neste relacionamento. Na figura 4.11 é mostrado o mesmo esquema da figura 4.10, porém com a utilização da notação alternativa para ilustrar as restrições estruturais de tipos de relacionamentos.
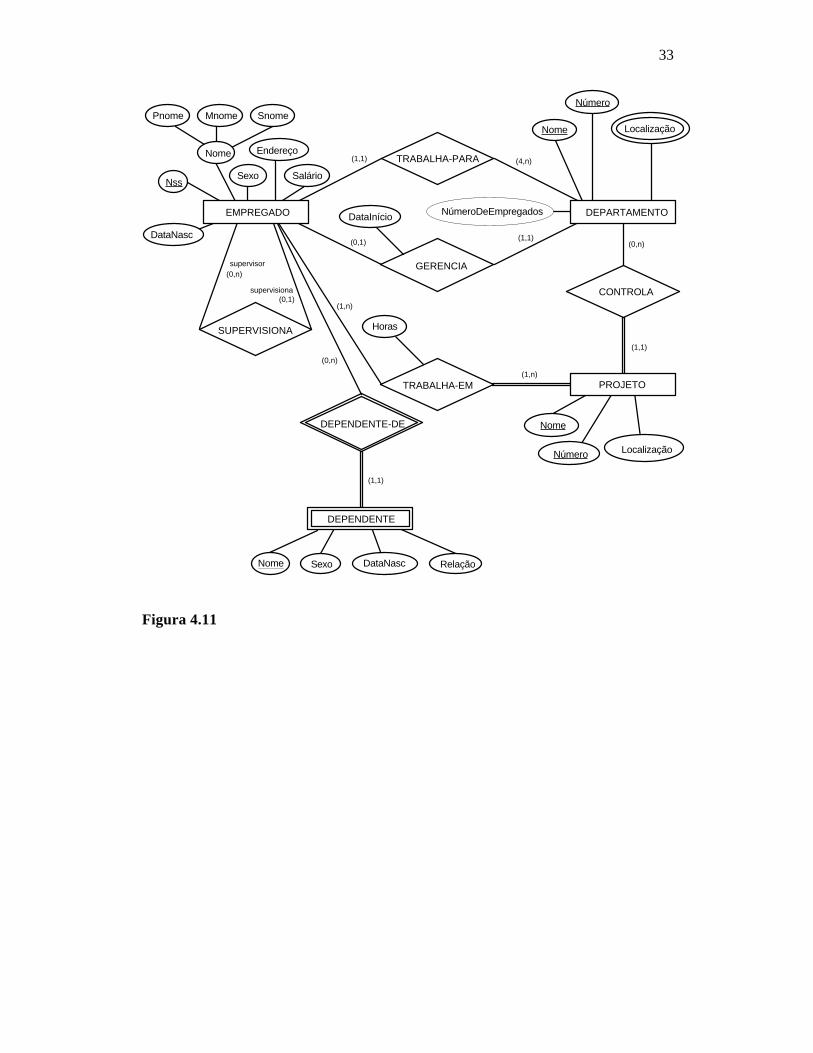
33
TRABALHA-PARA
GERENCIA
Pnome Mnome Snome
Nome
Nss
DataNasc
Endereço
SalárioSexo
DEPARTAMENTO
Nome
Número
Localização
NúmeroDeEmpregadosDataInício
CONTROLA
PROJETO
EMPREGADO
TRABALHA-EM
HorasSUPERVISIONA
DEPENDENTE-DE
DEPENDENTE
Nome Sexo DataNasc Relação
supervisor
supervisiona
(0,n)
(0,1)
(0,n)
(1,1)
(1,n)
(1,n)
(0,n)
(1,1)
(0,1)(1,1)
(1,1) (4,n)
Nome
Número Localização
Figura 4.11

34
Sumário da Notação do Diagrama Entidade-Relacionamento (DER) Símbolo Significado
Tipo de Entidade
Tipo de Entidade-Fraca
Tipo de Relacionamento
Tipo de Relacionamento Identificador
Atributo
Atributo-Chave
Atributo Multivalorado
Atributo Composto ....
Atributo Derivado
E1 R E2Participação Total de E2 em R
Razão de Cardinalidade 1:N para E1:E2 em RE1 R E2
1 N
R E(min, max) Restrição Estrutural (min, max)
na participação de E em R
Figura 4.12
4.5 Tipos de Relacionamentos de Grau maior que Dois Na seção 4.3.3 definiu-se grau de um tipo de relacionamento como o número de tipos de entidades participantes e chamou-se o tipo de relacionamento de grau dois de binário e de grau três de ternário. A notação do DER para um tipo de relacionamento ternário é mostrada na figura 4.13(a), que mostra o esquema para o tipo de relacionamento FORNECE que foi mostrado no nível de extensão na figura 4.6. Em geral, um tipo de relacionamento R de grau n irá ter n arestas no DER, cada um conectando R para cada tipo de entidade participante. A figura 4.13(b) mostra um DER para os tipos de relacionamento binário PODE-FORNECER, USA E FORNECE-ALGO. Como discutido na seção 4.3.3, estes três tipos de relacionamento binário não são equivalentes ao tipo de relacionamento ternário FORNECE. É freqüentemente

35
difícil decidir se um determinado relacionamento deve ser representado como um tipo de relacionamento de grau n ou dividido em muitos tipos de relacionamentos de menor grau. O projetista da base de dados deve guiar-se na semântica, ou no significado da situação particular que estiver representando, para decidir qual alternativa adotar. Um outro exemplo é mostrado na figura 4.13(c). O tipo de relacionamento ternário OFERECE representa a informação sobre os instrutores que oferecem cursos em um dado semestre. Assim, ele possui uma instância de relacionamento (i, s, c) onde o instrutor i oferece o curso c durante o semestre s. Os três tipos de relacionamento binários mostrados na figura 4.13(c) têm os seguintes significados: a. PODE-DAR: relaciona os instrutores que podem dar um dado curso. b. DÁ: relaciona os instrutores que dão algum curso num dado semestre. c. OFERECIDO: relaciona os cursos oferecidos num dado semestre por algum professor. Em geral, os relacionamentos binários e ternários representam informações diferentes, mas certas restrições podem ser feitas entre estes relacionamentos. Por exemplo, uma instância de relacionamento (i, s, c) somente irá existir em OFERECE se a instância (i, s) em DÁ, a instância (s, c) em OFERECIDO e a instância (i, c) em PODE-DAR existirem. No entanto, o inverso não é sempre verdade; pode ser que existam instâncias (i, s), (s, c) e (i, c) nos três tipos de relacionamentos binários e, mesmo assim, não existir nenhuma instância (i, s, c) em OFERECE. Sobre certas restrições adicionais (i, s, c) pode existir, por exemplo, se o tipo de relacionamento PODE-DAR for 1:1, ou seja, se um instrutor somente puder dar aulas em apenas um curso e um curso puder ter apenas um instrutor. O projetista da base de dados deve analisar cada situação específica para decidir qual tipo de relacionamento binário e ternário irá necessitar.

36
FORNECEDOR
Nome
PEÇA
PROJETO
Número
Quantidade Nome
FORNECE
FORNECEDOR
Nome
PEÇA
PROJETO
Número
NomeFORNECE-ALGO
PODE-FORNECER USA
M N
M
N
M
N
INSTRUTOR
Nome
CURSO
SEMESTRE
Número
M N
M
N
M
N
FORNECE
DÁ
PODE-DAR OFERECIDO
Semestre Ano
Sem-Ano
Figura 4.13 Note-se que é possível ter um tipo de entidade-fraca com um tipo de relacionamento de identificação ternário (ou n-ário). Neste caso, o tipo de entidade-fraca pode ter muitos tipos de entidades proprietárias da identificação. Um exemplo é mostrado na figura 4.14. As razões de cardinalidade também são aplicáveis em tipos de relacionamentos n-ários.
CANDIDATO
Nome
COMPANHIA
Dept/Data
Quantidade Nome
REALIZA
ENTREVISTA
Departamento Data
RESULTA TRABALHO
Figura 4.14

37
4.6 Questões para a Síntese 1. Discuta o papel de um modelo de dados de alto-nível no processo de projeto de base de
dados. 2. Cite alguns casos onde o valor null pode ser aplicado. 3. Defina os seguintes termos: entidade, atributo, valor de atributo, instância de
relacionamento, atributo composto, atributo multivalorado, atributo derivado e atributo-chave.
4. O que é um tipo de entidade? Descreva as diferenças entre entidade e tipo de entidade. 5. O que é um tipo de relacionamento? Descreva as diferenças entre instância e tipo de
relacionamento. 6. Quando é necessário utilizar nome de papéis na descrição de tipos de relacionamentos? 7. Descreva as duas alternativas para especificar as restrições estruturais sobre tipos de
relacionamentos. Quais são as vantagens e desvantagens de cada uma? 8. Sobre quais condições pode um atributo de um tipo de relacionamento binário ser
promovido a um atributo de um dos tipos de entidades participantes? 9. Sobre quais condições um tipo de relacionamento pode se tornar um atributo de um tipo de
entidade? 10. Qual o significado de um tipo de relacionamento recursivo? Dê alguns exemplos disso. 11. Quando o conceito de entidade-fraca é útil na modelagem de dados? Defina os termos: tipo
de entidade proprietário, tipo de relacionamento de identificação e chave-parcial. 12. Um tipo de relacionamento de identificação pode ter grau maior que dois? 13. Discuta as condições em que um tipo de relacionamento ternário pode ser representado
por um número de tipos de relacionamentos binários.

38
5 O Modelo de Dados Relacional O Modelo de Dados Relacional foi introduzido por Codd(1970). Entre os modelos de dados de implementação, o modelo relacional é o mais simples, com estrutura de dados uniforme e o mais formal.
5.1 Conceitos do Modelo Relacional O modelo de dados relacional representa os dados da base de dados como uma coleção de relações. Informalmente, cada relação pode ser entendida como uma tabela ou um simples arquivo de registros. Por exemplo, a base de dados de arquivos representada pela figura 5.1, é considerada estando no modelo relacional. Porém, existem diferenças importantes entre relações e arquivos.
ESTUDANTE Nome Número Classe Departamento Soares 17 1 DCC Botelho 8 2 DCC
CURSO Nome Número Créditos Departamento Introd. Ciências de Comp. DCC1310 4 DCC Estrutura de Dados DCC3320 4 DCC Matemática Discreta MAT2410 4 MAT Base de Dados DCC3380 4 DCC
PRÉ-REQUISITO Número Pré-requisito DCC3380 DCC3320 DCC3380 MAT2410 DCC3320 DCC1310
SEÇÃO Número Curso Semestre Ano Professor 85 MAT2410 1 86 Kotaro 92 DCC1310 1 86 Alberto 102 DCC3320 2 87 Kleber 112 MAT2410 1 87 Carlos 119 DCC1310 1 87 Alberto 135 DCC3380 1 87 Souza
HISTÓRICO NúmeroEstudante NúmeroSeção Nível 17 112 B 17 119 C 8 85 A 8 92 A 8 102 B 8 135 A
Figura 5.1 Quando uma relação é vista como uma tabela de valores, cada linha representa uma coleção de valores relacionados. Esses valores podem ser interpretados como um fato que descreve uma entidade ou uma instância de relacionamento. O nome da tabela e os nomes das colunas são usados para ajudar a interpretar o significado dos valores em cada linha da tabela. Por exemplo, na figura 5.1 anterior, a primeira tabela é chamada ESTUDANTE porque cada linha representa o fato sobre uma particular entidade estudante. Os nomes das colunas - Nome,

39
Número, Classe, Departamento - especificam como interpretar os valores em cada linha baseando-se nas colunas que cada um se encontra. Todos os valores de uma mesma coluna são, normalmente, do mesmo tipo. Na terminologia de base de dados relacional, a linha é chamada de tupla, a coluna é chamada de atributo e a tabela de relação. O tipo de dado que especifica o tipo dos valores que podem aparecer em uma coluna é chamado de domínio. Uma relação esquema R, denotada por R(A1, A2, ..., An), é um conjunto de atributos R={A1, A2, ..., An}. Cada atributo Ai indica o nome do papel de algum domínio D na relação esquema
R. D é chamado domínio de Ai e denotado por dom(Ai). Uma relação esquema é utilizada para descrever uma relação e R é o nome dessa relação. O grau de uma relação é o número de atributos da relação. Considere o exemplo de uma relação esquema de grau 7, que descreve estudantes universitários: ESTUDANTE(Nome, NSS, Telefone, Endereço, TelComercial, Anos, MPA) Nesta relação esquema, ESTUDANTE é o nome da relação esquema, que tem 7 atributos. Pode-se especificar alguns domínios para atributos da relação ESTUDANTE:
dom(Nome)=Nomes dom(NSS)=Número do seguro social dom(Telefone)=Número de telefone nacional dom(TelComercial)=Número de telefone nacional dom(MPA)=Média dos Pontos Acumulados
Uma relação r (ou instância de relação) da relação esquema R(A1, A2, ..., An), também
denotado por r(R), é um conjunto de tuplas r={ t1, t2, ..., tm}. Cada tupla t é uma lista ordenada
de n valores t=<v1, v2, ..., vn>, onde cada valor vi, 1 ≤ i ≤ n, é um elemento do dom(Ai) ou um valor especial null. São utilizados, com freqüência, os termos intenção da relação para o esquema R e extensão da relação para a instância r(R). Atributos
ESTUDANTE Nome NSS Telefone Endereço TelComercial Anos MPA Joaquim 305 555-444 R. X, 123 null 19 3.21 Katarina 381 555-333 Av. K, 43 null 18 2.89 tuplas Daví 422 null R. D, 12 555-678 25 3.53 Carlos 489 555-376 R. H, 9 555-789 28 3.93 Barbara 533 555-999 Av. f, 54 null 19 3.25
Figura 5.2 A figura 5.2 mostra um exemplo de uma relação ESTUDANTE, que corresponde ao esquema estudante especificada anteriormente. Cada tupla na relação representa uma entidade estudante. A relação é mostrada em forma de tabela, onde cada tupla é representada pelas linhas e cada atributo na linha de cabeçalho indicando os papéis ou a interpretação dos valores encontrados em cada coluna.
5.1.1 Notação do Modelo Relacional As seguintes notações serão utilizadas para apresentar alguns conceitos do modelo relacional:
• Uma relação esquema R de grau n é representada como R(A1, A2, ..., An).

40
• Uma tupla t em uma relação r(R) é representada como t=<v1, v2, ..., vn>, onde vi é
o valor correspondente para atributos Ai. Serão utilizadas as seguintes notações
para se referir aos valores dos componentes de tuplas: • t[Ai] indica o valor de vi em t para o atributo Ai.
• t[Au, Aw, ..., Az] onde Au, Aw, ..., Az é uma lista de atributos de R, indica o conjunto de valores <vu, vw, ..., vz> de t correspondentes aos atributos
especificados na lista. • As letras Q, R e S denotam nomes de relação. • As letras q, r e s denotam instâncias de relação. • As letras t, u e v denotam tuplas. • Em geral, o nome de uma relação tal como ESTUDANTE indica o conjunto atual de
tuplas na relação - instância corrente da relação - e ESTUDANTE(Nome, NSS, ...) refere-se à relação esquema.
• Os nomes de atributos são algumas vezes qualificados com o nome da relação na qual pertencem, por exemplo, ESTUDANTE.Nome ou ESTUDANTE.Anos.
Considere uma tupla t=<'Barbara', '533', '555-999', 'Av. f, 54', null, 19, 3.25> da relação ESTUDANTE da figura 5.2; t[Nome]=<'Barbara'> e t[NSS, MPA, Anos]=<'533', 3.25, 19>.
5.1.2 Atributos-chaves de uma Relação Uma relação é definida como um conjunto de tuplas. Pela definição, todos os elementos de um conjunto são distintos. Assim, todas as tuplas de uma relação também são distintas. Isto significa que nenhuma tupla pode ter a mesma combinação de valores para todos os seus atributos. Normalmente, existem subconjuntos de atributos de uma relação esquema R com a propriedade de que nenhuma tupla de uma relação r de R tenha a mesma combinação de valores para esses atributos. Suponha que esse subconjunto seja denotado por SC; então para quaisquer tuplas t1 e t2 em r de R, deve valer a regra:
t1[SC]≠t2[SC] Assim, SC é chamada super-chave da relação esquema R. Toda relação tem ao menos uma super-chave, que é o conjunto de todos os seus atributos. Uma chave C, de uma relação esquema R, é uma super-chave de R com a propriedade adicional de não se poder remover qualquer atributo A de K e continuar a ser super-chave de R. Assim, uma chave é uma super-chave mínima; uma super-chave da qual não se pode remover qualquer atributo. Por exemplo, considere a relação ESTUDANTE da figura 5.2. O conjunto de atributos {NSS} é uma super-chave de ESTUDANTE porque sabe-se que nenhum estudante irá ter o mesmo valor para NSS e também é uma chave, pois não se pode remover nenhum atributo. Qualquer conjunto de atributos que inclua NSS - por exemplo, {NSS, Nome, Anos} - será uma super-chave. No entanto, o conjunto {NSS, Nome, Anos} não é uma chave de ESTUDANTE porque removendo Nome ou Anos, ou ambos, o conjunto resultante será ainda uma super-chave. O valor de um atributo-chave pode ser usado para identificar unicamente uma tupla em uma relação. Por exemplo, o valor 533, do atributo NSS, identifica unicamente a tupla correspondente à 'Barbara' na relação ESTUDANTE. Note-se, que a indicação de quais atributos formam a chave deve ser feita na relação esquema, a fim de restringir qualquer duplicação de tuplas em quaisquer instâncias do esquema. A chave deve ser determinada pelo significado dos atributos na relação esquema e deve ser invariante ao tempo. Por exemplo, o atributo Nome da relação ESTUDANTE não pode ser indicada como chave, uma vez que nada garante a ocorrência de homônimos. Em geral, uma relação esquema pode ter mais que uma chave. Nestes casos, cada chave é chamada chave-candidata. Por exemplo, o esquema da relação ESTUDANTE poderia ter um

41
atributo adicional Código, para indicar o código interno de estudantes na escola. Assim, o esquema teria duas chaves candidatas: NSS e Código. É comum designar uma das chaves candidatas como a chave-primária da relação. A indicação de qual chave-candidata é a chave-primária é realizada sublinhado-se os atributos que formam a chave-candidata escolhida. Quando uma relação esquema tem muitas chaves-candidatas, a escolha da chave-primária é arbitrária; no entanto, é sempre melhor escolher a chave-primária com o menor número de atributos.
5.1.3 Esquemas de Bases de Dados Relacionais e Restrições de Integridade • Definição de um esquema de base de dados relacional e base de dados relacional: um
esquema da base de dados relacional S é um conjunto de relações esquemas S={R1,
R2, ..., Rm} e um conjunto de restrições de integridade RI. Uma instância da base de dados relacional DB de S é um conjunto de instâncias de relações DB={r1, r2, ..., rm} tal que ri é uma instância de Ri e que satisfaz as restrições de integridade especificadas em
RI. A figura 5.3 ilustra um esquema da base de dados relacional denominada COMPANHIA. O termo base de dados relacional refere-se, implicitamente, ao esquema e à instância.
EMPREGADO PNOME MNOME SNOME NSS DATANASC ENDEREÇO SEXO SALARIO NSSSUPER NDEP
DEPARTAMENTO DNOME DNÚMERO SNNGER DATINICGER
LOCAIS_DEPTO DNÚMERO DLOCALIZAÇÃO
PROJETO PNOME PNÚMERO PLOCALIZAÇÃO DNUM
TRABALHA_EM NSSEMP PNRO HORAS
DEPENDENTE NSSEMP NOMEDEPENDENTE SEXO DATANIV RELAÇÃO
Figura 5.3 Observa-se, na figura 5.3 acima, que o atributo DNÚMERO tanto de DEPARTAMENTO
quanto de LOCAIS_DEPTO referem-se ao mesmo conceito do mundo real - o número dado a um departamento. Este mesmo conceito é chamado NDEP em EMPREGADO e DNUM em PROJETO. Isto significa que é permitido dar nomes de atributos distintos para um mesmo conceito do mundo real. Permite-se, também, que atributos que representam conceitos diferentes tenham o mesmo nome desde que em relações diferentes. Por exemplo, poderia ter sido usado NOME ao invés de PNOME e DNOME nas relações esquemas PROJETO e DEPARTAMENTO, respectivamente.
• Restrições de Integridade sobre um Esquema de Base de Dados Relacional: as restrições
de chave especificam as chaves-candidatas de cada relação esquema; os valores das chaves-candidatas devem ser únicos para todas as tuplas de quaisquer instâncias da relação esquema. Além da restrição de chave, dois outros tipos de restrições são consideradas no modelo relacional: integridade de entidade e integridade referencial.
A restrição de integridade de entidade estabelece que nenhum valor da chave-primária
pode ser nulo. Isso porque, o valor de uma chave-primária é utilizado para identificar tuplas
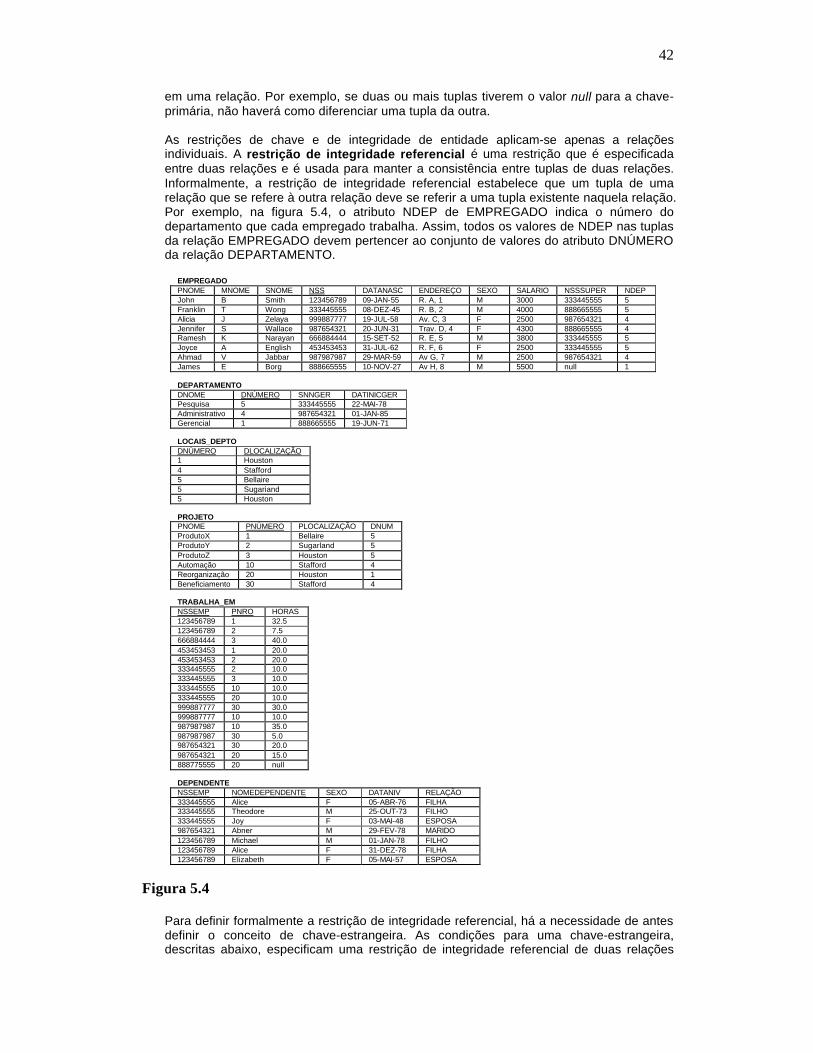
42
em uma relação. Por exemplo, se duas ou mais tuplas tiverem o valor null para a chave-primária, não haverá como diferenciar uma tupla da outra.
As restrições de chave e de integridade de entidade aplicam-se apenas a relações
individuais. A restrição de integridade referencial é uma restrição que é especificada entre duas relações e é usada para manter a consistência entre tuplas de duas relações. Informalmente, a restrição de integridade referencial estabelece que um tupla de uma relação que se refere à outra relação deve se referir a uma tupla existente naquela relação. Por exemplo, na figura 5.4, o atributo NDEP de EMPREGADO indica o número do departamento que cada empregado trabalha. Assim, todos os valores de NDEP nas tuplas da relação EMPREGADO devem pertencer ao conjunto de valores do atributo DNÚMERO da relação DEPARTAMENTO.
EMPREGADO PNOME MNOME SNOME NSS DATANASC ENDEREÇO SEXO SALARIO NSSSUPER NDEP John B Smith 123456789 09-JAN-55 R. A, 1 M 3000 333445555 5 Franklin T Wong 333445555 08-DEZ-45 R. B, 2 M 4000 888665555 5 Alicia J Zelaya 999887777 19-JUL-58 Av. C, 3 F 2500 987654321 4 Jennifer S Wallace 987654321 20-JUN-31 Trav. D, 4 F 4300 888665555 4 Ramesh K Narayan 666884444 15-SET-52 R. E, 5 M 3800 333445555 5 Joyce A English 453453453 31-JUL-62 R. F, 6 F 2500 333445555 5 Ahmad V Jabbar 987987987 29-MAR-59 Av G, 7 M 2500 987654321 4 James E Borg 888665555 10-NOV-27 Av H, 8 M 5500 null 1
DEPARTAMENTO DNOME DNÚMERO SNNGER DATINICGER Pesquisa 5 333445555 22-MAI-78 Administrativo 4 987654321 01-JAN-85 Gerencial 1 888665555 19-JUN-71
LOCAIS_DEPTO DNÚMERO DLOCALIZAÇÃO 1 Houston 4 Stafford 5 Bellaire 5 Sugariand 5 Houston
PROJETO PNOME PNÚMERO PLOCALIZAÇÃO DNUM ProdutoX 1 Bellaire 5 ProdutoY 2 Sugarland 5 ProdutoZ 3 Houston 5 Automação 10 Stafford 4 Reorganização 20 Houston 1 Beneficiamento 30 Stafford 4
TRABALHA_EM NSSEMP PNRO HORAS 123456789 1 32.5 123456789 2 7.5 666884444 3 40.0 453453453 1 20.0 453453453 2 20.0 333445555 2 10.0 333445555 3 10.0 333445555 10 10.0 333445555 20 10.0 999887777 30 30.0 999887777 10 10.0 987987987 10 35.0 987987987 30 5.0 987654321 30 20.0 987654321 20 15.0 888775555 20 null
DEPENDENTE NSSEMP NOMEDEPENDENTE SEXO DATANIV RELAÇÃO 333445555 Alice F 05-ABR-76 FILHA 333445555 Theodore M 25-OUT-73 FILHO 333445555 Joy F 03-MAI-48 ESPOSA 987654321 Abner M 29-FEV-78 MARIDO 123456789 Michael M 01-JAN-78 FILHO 123456789 Alice F 31-DEZ-78 FILHA 123456789 Elizabeth F 05-MAI-57 ESPOSA
Figura 5.4 Para definir formalmente a restrição de integridade referencial, há a necessidade de antes
definir o conceito de chave-estrangeira. As condições para uma chave-estrangeira, descritas abaixo, especificam uma restrição de integridade referencial de duas relações

43
esquemas R1 e R2. Um conjunto de atributos CE na relação esquema R1 será uma chave-estrangeira de R1 se ele satisfizer as seguintes regras:
1. Os atributos em CE têm o mesmo domínio dos atributos da chave-primária CP
da outra relação esquema R2. Diz-se que os atributos CE referenciam ou
referem-se para a relação R2.
2. Uma CE na tupla R1 ou tem um valor que ocorre como CP de alguma tupla t2 de R2 ou tem o valor null. No primeiro caso, tem-se t1[CE]=t2[CP], e diz-se que
t1 referencia ou refere-se para a tupla t2.
Uma base de dados tem muitas relações, e usualmente possuem muitas restrições de integridade referencial. Para especificar estas restrições, o projetista deve ter um claro entendimento do significado ou papel que os atributos desempenham nas diversas relações esquemas da base de dados. Normalmente, as restrições de integridade referencial são derivadas dos relacionamentos entre entidades representadas pelas relações esquemas. Por exemplo, considere a base de dados mostrada na 5.4. Na relação EMPREGADO, o atributo NDEP refere-se ao departamento em que cada empregado trabalha; desse modo, designa-se NDEP como a chave-estrangeira de EMPREGADO referenciando a relação DEPARTAMENTO. Isso significa que um valor de NDEP em alguma tupla t1 da relação EMPREGADO deve ter um
valor correspondente para a chave-primária da relação DEPARTAMENTO - o atributo DNÚMERO - em alguma tupla t2 da relação DEPARTAMENTO ou o valor de NDEP pode ser
null se o empregado não pertencer a nenhum departamento. Na figura 5.4, a tupla do empregado "John Smith" referencia a tupla departamento de "Pesquisa", indicando que "John Smith" trabalha para este departamento. Note-se que uma chave-estrangeira pode referenciar sua própria relação. Por exemplo, o atributo NSSSUPER em EMPREGADO refere-se ao supervisor de um empregado; isto é, um outro empregado. Pode-se, diagramaticamente, mostrar as restrições de integridade desenhando-se arcos direcionados partindo da chave-estrangeira para a relação referenciada. A figura 5.5 ilustra o esquema apresentado na figura 5.3 com as restrições de integridade referencial anotadas desta maneira.
EMPREGADO
PNOME MNOME SNOME NSS DATANASC
ENDEREÇO SEXO SALARIO
NSSSUPER NDEP
DEPARTAMENTO
DNOME DNÚMERO SNNGER DATINICGER
LOCAIS_DEPTO
DNÚMERO DLOCALIZAÇÃO
PROJETO
PNOME PNÚMERO PLOCALIZAÇÃO DNUM
TRABALHA_EM
NSSEMP PNRO HORAS
DEPENDENTE NSSEMP NOMEDEPENDENTE SEXO DATANIV RELAÇÃO
Figura 5.5 Todas as restrições de integridade deveriam ser especificadas no esquema da base de dados relacional se o projetista tiver interesse em manter essas restrições válidas para toda a base de dados. Assim, em um sistema relacional, a linguagem de definição de dados (DDL) deveria

44
fornecer recursos para especificar os vários tipos de restrições tal que o SGDB possa verificá-las automaticamente. Muitos sistemas de gerenciamento de base de dados relacionais permitem restrições de chave e de integridade de entidade mas, infelizmente, a maioria não permite a integridade referencial. Além dos tipos de restrições descritas acima, existem outras mais gerais, algumas vezes chamadas de restrições de integridade semânticas, que podem ser especificadas e verificadas numa base de dados relacional. Exemplos de tais restrições são "o salário de um empregado não deve ultrapassar o salário de seu supervisor" e "o número máximo de horas por semana que um empregado pode trabalhar num projeto é 56". Tais restrições não são verificadas por SGBD relacional atualmente encontrados no mercado.
5.1.4 Operações de Atualizações sobre Relações Existem três tipos básicos de operação de atualização sobre relações - inserção, remoção e modificação. A inserção é usada para inserir novas tuplas em uma relação, a remoção elimina tuplas e a modificação modifica os valores de alguns atributos. Quando são aplicadas operações de atualização, o projetista deve verificar que as restrições de integridade especificadas no esquema da base de dados relacional não sejam violadas.

45
6 Mapeamento do MER para o Modelo de Dados Relacional É comum, em projetos de banco de dados, realizar a modelagem dos dados através de um modelo de dados de alto-nível. Os produtos gerados por esse processo são os esquemas de visões que são posteriormente integradas para formar um único esquema. O modelo de dados de alto-nível normalmente adotado é o Modelo Entidade-Relacionamento (MER) e o esquema das visões e de toda a base de dados são especificados em diagramas entidade-relacionamento (DER). O passo seguinte à modelagem dos dados é o mapeamento do diagrama da base de dados global, obtido na fase anterior, para um modelo de dados de implementação. Existem três tipos de modelos de dados de implementação: hierárquico, rede e relacional. Para cada um desses modelos, pode-se definir estratégias de tradução a partir de um DER específico. A estratégia de tradução, ou de mapeamento, tratado neste capítulo é para o modelo de dados relacional. Para isso, considere o esquema relacional mostrado na figura 6.1 (semelhante à figura 5.5) que foi derivado do DER da figura 4.11 seguindo um procedimento de mapeamento. Este procedimento é apresentado passo-a-passo usando como exemplo o DER COMPANHIA.
EMPREGADO ce ce PNOME MNOME SNOME NSS DATANASC ENDEREÇO SEXO SALARIO NSSSUPER DNUM cp
DEPARTAMENTO Ce * DNOME DNÚMERO SNNGER DATINICGER cp
LOCAIS_DEPTO Ce DNÚMERO DLOCALIZAÇÃO \
_________________________/
cp
PROJETO ce PNOME PNÚMERO PLOCALIZAÇÃO DNUM Cp
TRABALHA_EM ce ce NSSEMP PNRO HORAS \_______________/ cp
DEPENDENTE ce NSSEMP NOMEDEPENDENTE SEXO DATANIV RELAÇÃO \___________________________/ cp
Figura 6.1

46
Passo 1: Para cada entidade regular E no DER, criar uma relação R que inclua todos os atributos simples de E. Para um atributo composto, inclua apenas os atributos simples que compõem o atributo composto. Escolha um dos atributos-chave de E como sendo a chave-primária de R. Se a chave escolhida de E for composta, então o conjunto de atributos simples que o compõem irão formar a chave-primária de R.
No exemplo, foram criadas as relações EMPREGADO, DEPARTAMENTO e
PROJETO correspondentes às entidades regulares EMPREGADO, DEPARTAMENTO e PROJETO presentes no DER. Os atributos indicados com ce (chave-estrangeira) ou * (atributos de relacionamento) não foram incluídos ainda; eles serão adicionados durante os passos subseqüentes. Foram escolhidas as chaves-primárias NSS, DNÚMERO e PNÚMERO para as relações EMPREGADO, DEPARTAMENTO e PROJETO respectivamente.
Passo 2: Para cada tipo de entidade fraca W do DER com o tipo de entidade de identificação
E, criar uma relação R e incluir todos os atributos simples (ou os componentes simples de atributos compostos) de W como atributos de R. Além disso, incluir como a chave-estrangeira de R a chave-primária da relação que corresponde ao tipo de entidade de identificação; isto resolve o problema do tipo do relacionamento de identificação de W. A chave-primária de R é a combinação da chave-primária do tipo de entidade de identificação e a chave-parcial do tipo de entidade fraca W.
No exemplo, foi criada a relação DEPENDENTE correspondente ao tipo de entidade
fraca DEPENDENTE do DER. Foi incluída a chave-primária da relação EMPREGADO - que corresponde ao tipo de entidade de identificação - como um atributo de DEPENDENTE; foi renomeado o atributo NSS para NSSEMP embora não seja necessário. A chave-primária da relação DEPENDENTE é a combinação {NSSEMP, NOMEDEPENDENTE} porque NOMEDEPENDENTE é a chave-parcial de DEPENDENTE.
Passo 3: Para cada tipo de relacionamento binário 1:1 R do DER, criar as relações S e T que
correspondem aos tipos de entidade participantes em R. Escolher uma das relações, por exemplo S, que inclua como chave-estrangeira de S a chave-primária de T. É melhor escolher o tipo de entidade com participação total em R como a relação S. Inclua todos os atributos simples (ou os componentes simples de atributos compostos) do tipo de relacionamento 1:1 R como atributos de S.
No exemplo, foi mapeado o tipo de relacionamento 1:1 GERENCIA da figura 4.10,
escolhendo o tipo de entidade participante DEPARTAMENTO para fazer o papel de S porque sua participação no tipo de relacionamento GERENCIA é total (todo departamento tem um gerente). Foi incluída a chave-primária da relação EMPREGADO como a chave-estrangeira na relação DEPARTAMENTO que foi chamado de SNNGER . Também foi incluído o atributo simples DataInício do tipo de relacionamento GERENCIA na relação DEPARTAMENTO e foi renomeado como DATINICGER.
Note-se que, uma alternativa para o mapeamento de um tipo de relacionamento 1:1
seria unir os dois tipos de entidades e o tipo de relacionamento numa única relação. Isto é particularmente apropriado quando ambas as participações são total e quanto os tipos de entidade não participam em quaisquer outros tipos de relacionamentos.
Passo 4: Para cada tipo de relacionamento binário regular 1:N (não fraca) R, identificar a
relação S que representa o tipo de entidade que participa do lado N do tipo de relacionamento. Inclua como chave-estrangeira de S a chave-primária da relação T que representa o outro tipo de entidade que participa em R; isto porque cada instância da entidade do lado N está relacionada a mais de uma instância de entidade no lado 1 do tipo de relacionamento. Por exemplo, no tipo de relacionamento 1:N TRABALHA-PARA cada empregado está relacionado a um único departamento. Inclua também quaisquer atributos simples (ou componentes simples de atributos compostos) do tipo de relacionamento 1:N como atributos de S.

47
No exemplo, foram mapeados os tipos de relacionamentos 1:N TRABALHA-PARA e
SUPERVISIONA. Para TRABALHA-PARA incluiu-se a chave-primária da relação DEPARTAMENTO como a chave-estrangeira na relação EMPREGADO e foi chamado DNUM. Para SUPERVISIONA incluiu-se a chave-primária da relação EMPREGADO como a chave-estrangeira na relação EMPREGADO e foi denominado NSSSUPER. O relacionamento CONTROLA é mapeado da mesma maneira.
Passo 5: Para cada tipo de relacionamento binário M:N R, criar uma nova relação S para
representar R. Incluir como chave-estrangeira em S as chaves-primárias das relações que representam os tipos de entidade participantes; sua combinação irá formar a chave-primária de S. Inclua também qualquer atributo simples do tipo de relacionamento M:N (ou componentes simples dos atributos compostos) como atributos de S. Note-se que não se pode representar um tipo de relacionamento M:N como uma simples chave-estrangeira em uma das relações participantes - como foi feito para os tipos de relacionamentos 1:1 e 1:N - por causa da razão de cardinalidade M:N.
No exemplo foi mapeado o tipo de relacionamento M:N TRABALHA-EM criando-se a
relação TRABALHA_EM na figura 4.6. Incluiu-se as chaves-primárias das relações PROJETO e EMPREGADO como chaves-estrangeiras em TRABALHA_EM e foi renomeado NSS para NSSEMP e Número para PNRO respectivamente. Também foi incluído um atributo HORAS para representar o atributo Horas do tipo de relacionamento. A chave-primária da relação TRABALHA_EM é a combinação das chaves-estrangeiras {NSSEMP, PNRO}.
Note-se que sempre é possível mapear relacionamentos 1:1 ou 1:N da mesma
maneira que os relacionamentos M:N. Esta alternativa pode ser adotada desde que existam poucas instâncias de relacionamento a fim de evitar valores null em chaves-estrangeiras.
Passo 6: Para cada atributo A multivalorado, criar uma nova relação R que inclua um atributo
correspondendo a A e a chave-primária K da relação que representa o tipo de entidade ou o tipo de relacionamento que tem A como atributo. A chave-primária de R é a combinação de A e K. Se o atributo multivalorado é composto inclua os atributos simples que o compõem.
No exemplo foi criada a relação LOCAIS_DEPTO. O atributo DLOCALIZAÇÃO
representa o atributo multivalorado Localização de DEPARTAMENTO, enquanto DNÚMERO - como chave-estrangeira - representa a chave-primária da relação DEPARTAMENTO. A chave-primária de LOCAIS_DEPTO é a combinação de {DNÚMERO, DLOCALIZAÇÃO}. Uma tupla irá existir em LOCAIS_DEPTO para cada localização que um departamento tiver.
A figura 6.1 mostra o esquema da base de dados relacional obtida aplicando-se os
passos acima e a figura 5.4 mostra uma instância deste esquema. Observa-se que não foi discutido o mapeamento de tipos de relacionamento n-ário (n > 2) porque não existem na figura 4.10. Estes tipos de relacionamentos podem ser mapeados da mesma forma que os tipos de relacionamentos M:N, apenas observando o seguinte passo adicional no procedimento de mapeamento.
Passo 7: Para cada tipo de relacionamento n-ário R, n>2, criar uma nova relação S para
representar R. Inclua como chave-estrangeira em S as chaves-primárias das relações que representam os tipos de entidades participantes. Incluindo-se também qualquer atributo simples do tipo de relacionamento n-ário (ou componentes simples dos atributos compostos) como atributo de S. A chave-primária de S é normalmente uma combinação de todas as chaves-estrangeiras e referenciam as relações que representam os tipos de entidades participantes. Porém, se a restrição de participação (min, max) de um dos tipos de entidades E que participa em R tiver max=1, então a chave-primária de S pode ser a chave-estrangeira que referencia a

48
relação E' correspondente a E; isto porque cada entidade e em E irá participar em apenas uma instância de R e, portanto, pode identificar univocamente esta instância de relacionamento.
Por exemplo, considere o tipo de relacionamento da figura 4.13a. Este
relacionamento triplo pode ser mapeado para a relação FORNECE mostrada na figura 6.2, onde a chave-primária é a combinação das chaves-estrangeiras {FNOME, PNOME, NÚMERO}.
FORNECEDOR SNOME ...
PROJETO PNOME ...
PEÇA NÚMERO ...
FORNECE SNOME PNOME NÚMERO QUANTIDADE
Figura 6.2 O principal ponto que deve ser considerado em um esquema relacional quando comparado ao esquema do MER é que os tipos de relacionamento não são representados explicitamente, eles são representados por dois atributos A e B, um para a chave-primária e outra para a chave-estrangeira - sobre o mesmo domínio - incluídos em duas relações S e T. Duas tuplas em S e T estão relacionadas quando elas tiverem o mesmo valor para A e B. Ou seja, os relacionamentos são definidos pelos valores dos atributos A e B.

49
7 Álgebra Relacional As discussões anteriores sobre o modelo relacional contemplaram apenas os aspectos estruturais. Agora, a atenção será voltada para a álgebra relacional, que é uma coleção de operações que são utilizadas para manipular relações. Essas operações são usadas para selecionar tuplas de uma determinada relação ou para combinar tuplas relacionadas a diversas relações com o propósito de especificar uma consulta - uma requisição de recuperação - sobre a base de dados. As operações da álgebra relacional são normalmente divididas em dois grupos. O primeiro deles inclui um conjunto de operações da teoria de conjuntos. As operações são UNION, INTERSECTION, DIFFERENCE e CARTESIAN PRODUCT. O segundo grupo consiste de operações desenvolvidas especificamente para bases de dados relacionais, tais como: SELECT, PROJECT e JOIN entre outras.
7.1 Operações SELECT e PROJECT
7.1.1 O Operador SELECT A operação SELECT é usada para selecionar um subconjunto de tuplas de uma relação. Estas tuplas devem satisfazer uma condição de seleção. Por exemplo, a seleção de um subconjunto de tuplas da relação EMPREGADOS que trabalham para o departamento 4 ou que tenham salário maior que 3000. Cada uma dessas condições é especificada individualmente usando a operação SELECT como segue:
NDEP = 4 (EMPREGADO) SALÁRIO > 3000 (EMPREGADO)
Em geral, a operação SELECT é denotada por:
<condição de seleção> (<nome da relação>) onde o símbolo é usado para denotar o operador SELECT, e a condição de seleção é uma expressão Booleana especificada sobre atributos da relação especificada. A relação resultante da operação SELECT tem os mesmos atributos da relação especificada em <nome da relação>. A expressão Booleana especificada em <condição de seleção> é construída a partir de cláusulas da forma: <nome de atributo> <operador de comparação> <valor constante>, ou <nome de atributo> <operador de comparação> <nome de atributo> Onde <nome de atributo> é o nome de um atributo da <nome da relação>, <operador de comparação> é normalmente um dos operadores relacionais {=, <, , , } e <valor constante> é um valor constante. As cláusulas podem ser utilizadas em conjunto com os operadores lógicos {AND, OR NOT} para formar uma condição de seleção composta. Por exemplo, suponha que se deseja selecionar as tuplas de todos os empregados que ou trabalham no departamento 4 e faz mais de 2500 ou trabalha no departamento 5 e faz mais que 3000. Neste caso, pode-se especificar a consulta da seguinte forma: (NDEP = 4 AND SALÁRIO > 2500) OR (NDEP = 5 AND SALÁRIO > 3000) (EMPREGADO)

50
O resultado é mostrado na figura 7.1a.
(a) PNOME MNOME SNOME NSS DATANASC ENDEREÇO SEXO SALARIO NSSSUPER NDEP Franklin T Wong 333445555 08-DEZ-45 R. B, 2 M 4000 888665555 5 Jennifer S Wallace 987654321 20-JUN-31 Trav. D, 4 F 4300 888665555 4 Ramesh K Narayan 666884444 15-SET-52 R. E, 5 M 3800 333445555 5
(b) SNOME PNOME SALARIO (c) SEXO SALARIO Smith John 3000 M 3000 Wong Franklin 4000 M 4000 Zelaya Alícia 2500 F 2500 Wallace Jennifer 4300 F 4300 Narayan Ramesh 3800 M 3800 English Joyce 2500 M 2500 Jabbar Ahmad 2500 M 5500 Borg James 5500
Figura 7.1 O operador SELECT é unário; isto é, ele é aplicado somente a uma relação. Assim, o SELECT não pode ser usado para selecionar tuplas de mais de uma relação. Note-se também que a operação de seleção é aplicada individualmente para cada tupla. Assim, as condições de seleção não podem ser aplicadas a mais que uma tupla. O grau da relação resultante é a mesma que a relação original. O número de tuplas da relação resultante é sempre menor ou igual ao número de tuplas da relação original. Note que o operador SELECT é comutativo; isto é,
<cond1> (<cond2> (R))= <cond2> (<cond1> (R)) Assim, uma seqüência de SELECTs pode ser aplicada em qualquer ordem. Além disso, pode-se sempre trocar operadores SELECT em cascata com a conjuntiva AND; isto é: <cond1> (<cond2> (...<condn> (R) ...))=<cond1> AND <cond2> AND ... AND <condn>(R)
7.1.2 O Operador PROJECT Pensando na relação como uma tabela, então o operador SELECT seleciona algumas linhas da tabela enquanto descarta outras. O operador PROJECT, por outro lado, seleciona certas colunas da tabela e descarta outras. Se existir o interesse sobre certos atributos da relação, pode-se usar o PROJECT para “projetar” a relação sobre esses atributos. Por exemplo, suponha a necessidade de listar, para cada empregado, os atributos PNOME, SNOME e SALÁRIO; então pode-se usar o PROJECT como segue: SNOME, PNOME, SALÁRIO (EMPREGADO) A relação resultante é mostrada na figura 7.1b. A forma geral do operador PROJECT é: <lista de atributos> (<nome da relação>) onde é o símbolo usado para representar o operador PROJECT e <lista de atributos> é uma lista de atributos da relação especificada por <nome da relação>. A relação resultante tem apenas os atributos especificados em <lista de atributos> e aparecem na mesma ordem que aparecem na lista. Assim, o grau é igual ao número de atributos em <lista de atributos>.

51
Convém salientar que, caso a lista de atributos não contenha atributos chaves, então é provável que tuplas duplicadas apareçam no resultado. A operação PROJECT remove implicitamente quaisquer tuplas duplicadas, tal que o resultado da operação PROJECT seja um conjunto de tuplas e assim, uma relação válida. Por exemplo, considere a seguinte operação: SEXO, SALÁRIO (EMPREGADO) O resultado é mostrado na figura 7.1c, onde a tupla <F, 2500> aparece apenas uma vez, mesmo que esta combinação de valores apareça duas vezes na relação EMPREGADO. Dessa maneira, se duas ou mais tuplas aparecerem quando aplicada à operação PROJECT, apenas uma será mantida no resultado; isto é conhecido como eliminação de duplicidade e é necessária para assegurar que o resultado da operação também seja uma relação - um conjunto de tuplas. O número de tuplas na relação resultante sempre será igual ou menor que a quantidade de tuplas na relação original. Note-se que: <lista1> ( <lista2> (R)) = <lista1> (R) caso <lista2> contém os atributos de <lista1>; caso contrário, o lado esquerdo da igualdade acima estará incorreta. A comutatividade não é válida para PROJECT.
7.2 Seqüência de Operações As relações mostradas na figura 7.1 não possuem nomes. Em geral, existe a necessidade de se aplicar várias operações da álgebra relacional uma após a outra. Pode-se escrever essas operações em apenas uma única expressão da álgebra relacional ou aplicar uma única operação por vez e criar relações intermediárias. Neste último caso, deve-se dar nomes às relações intermediárias. Por exemplo, deseja-se recuperar o primeiro nome, o último nome e o salário de todos os empregados que trabalham no departamento 5;. Isto pode ser feito aplicando-se os operadores SELECT e PROJECT: PNOME, SNOME, SALÁRIO (NDEP=5 (EMPREGADO)) A figura 7.2a mostra o resultado desta expressão da álgebra relacional. Alternativamente, pode-se explicitar a seqüência de operações, dando um nome para cada relação intermediária:
DEP5_EMPS ← NDEP=5 (EMPREGADO) RESULT ← PNOME, SNOME, SALÁRIO (DEP5_EMPS)
(a) PNOME SNOME SALÁRIO John Smith 3000 Franklin Wong 4000 Alícia Zelaya 2500 Jennifer Wallace 4300 Ramesh Narayan 3800 Joyce English 2500 Ahmad Jabbar 2500 James Borg 5500

52
DEP5_EMPS (b) PNOME MNOME SNOME NSS DATANASC ENDEREÇO SEXO SALÁRIO NSSSUPER NDEP John B Smith 123456789 09-JAN-55 R. A, 1 M 3000 333445555 5 Franklin T Wong 333445555 08-DEZ-45 R. B, 2 M 4000 888665555 5 Ramesh K Narayan 666884444 15-SET-52 R. E, 5 M 3800 333445555 5 Joyce A English 453453453 31-JUL-62 R. F, 6 F 2500 333445555 5
RESULT
PRIMEIRO_NOME SOBRENOME SALÁRIO John Smith 3000 Franklin Wong 4000 Ramesh Narayan 3800 Joyce English 2500
Figura 7.2
7.3 Renomeando Atributos Normalmente, é mais simples dividir uma seqüência de operações especificando as relações intermediárias ao invés de escrever uma única expressão da álgebra relacional. Pode-se, também, utilizar a técnica de renomear atributos nas relações intermediárias. Para renomear atributos de uma relação, que resultou da aplicação de uma operação da álgebra relacional, basta listar os nomes dos atributos entre parênteses:
DEP5_EMPS ← NDEP=5 (EMPREGADO)
RESULT(PRIMEIRO_NOME, SOBRENOME, SALÁRIO)← PNOME, SNOME, SALÁRIO (DEP5_EMPS)
Os resultados das duas operações acima são ilustrados na figura 7.2b.
7.4 Operações da Teoria dos Conjuntos O próximo grupo de operações da álgebra relacional são as operações matemáticas padrões sobre conjuntos. Elas se aplicam ao modelo relacional porque uma relação é definida como um conjunto de tuplas. Por exemplo, suponha a necessidade de se recuperar o número do seguro social de todos os empregados que trabalham no departamento 5 ou, diretamente supervisione um empregado que trabalha no departamento 5. Esta operação pode ser realizada usando o operador UNION.
DEP5_EMPS ← NDEP=5 (EMPREGADO)
RESULT1← NSS (DEP5_EMPS) RESULT2(NSS)← NSSSUPER (DEP5_EMPS)
RESULT←RESULT1 ∪ RESULT2
A relação RESULT1 contém o número do seguro social de todos os empregados que trabalham no departamento 5. RESULT2 contém o número do seguro social de todos os empregados que diretamente supervisionam empregados que trabalham no departamento 5. A operação UNION gera uma relação que contém tanto as tuplas de RESULT1 quanto de RESULT2. A figura 7.3 ilustra este exemplo.
RESULT1 NSS RESULT2 NSS RESULT NSS 123456789 333445555 123456789 333445555 888665555 333445555 666884444 666884444 453453453 453453453 888665555
Figura 7.3

53
Existem várias operações da teoria de conjuntos que são utilizadas para agrupar elementos de dois conjuntos, entre elas estão: UNION, INTERSECTION e DEFFERENCE. Estas operações são binárias; isto é, elas necessitam de dois conjuntos. Quando essas operações são adaptadas para a base de dados relacional, deve-se assegurar que essas operações resultem sempre em relações válidas. Para conseguir isso, as duas relações aplicadas a qualquer uma das três operações acima devem ter o mesmo tipo de tuplas; esta condição é chamada união compatível. Duas relações R(A1, A2, ..., An) e S(B1, B2, ..., Bn) são união compatível se elas
tiverem o mesmo grau n, e dom(Ai)=dom(Bi) para 1 ≤ i ≤ n. Isso significa que as duas relações
têm o mesmo número de atributos e que cada par de atributos correspondentes tem o mesmo domínio. Pode-se definir as três operações UNION, INTERSECTION e DIFFERENCE sobre duas relações que sejam união compatível R e S:
• UNION O resultado da operação, denotado por R ∪ S, é uma relação que inclui todas as tuplas de R e todas as tuplas de S. Tuplas duplicadas são eliminadas.
• INTERSECTION O resultado desta operação, denotado por R ∩ S, é a relação que inclui todas as tuplas que são comuns a R e S.
• DIFFERENCE O resultado desta operação, denotado por R - S, é a relação que inclui todas as tuplas de R mas que não estão em S.
Note que as operações UNION e INTERSECTION são operações comutativas:
R ∪ S = S ∪ R, e R ∩ S = S ∩ R. Estas operações podem ser aplicadas a qualquer número de relações, e ambas são associativas:
R ∪ (S ∪ T) = (R ∪ S) ∪ T, e R ∩ (S ∩ T) = (R ∩ S) ∩ T.
A operação DIFFERENCE não é comutativa:
R - S ≠ S - R. A operação CARTESIAN PRODUCT, denotada por χ, é também uma operação de conjunto binária, mas as relações sobre as quais são aplicadas não necessitam ser união compatível. Esta operação é usada para combinar tuplas de duas relações tal que tuplas relacionadas possam ser identificadas. Em geral, o resultado de R(A1, A2, ..., An) χ S(B1, B2, ..., Bm) é a relação Q com n + m
atributos Q(A1, A2, ..., An, B1, B2, ..., Bm) nesta ordem. A relação resultante Q tem uma tupla
para cada combinação de tuplas. Assim, se R tem nR tuplas e S tem nS tuplas, então RχS terá nR*nS tuplas. Para ilustrar, considere que se deseja recuperar para cada empregado do sexo feminino uma lista de nomes de seus dependentes; isso pode ser feito da seguinte forma: EMP_FEM←σSEXO='F' (EMPREGADO)
EMP_NOMES←πPNOME, SNOME, NSS (EMP_FEM)
E0MP_DEP←EMP_NOMES χ DEPENDENTE DEP_ATUAL←σNSS=NSSEMP (EMP_DEP)
RESULT←πPNOME, SNOME, NOMEDEPENDENTE(DEP_ATUAL)

54
As tuplas geradas a partir da seqüência de operações acima são mostradas na figura 7.4. A relação EMP_DEP é o resultado da operação CARTESIAN PRODUCT entre EMP-NOMES da figura 7.4, e DEPENDENTE da figura 5.4. Em EMP_DEP, cada tupla de EMP_NOMES é combinada com todas as tuplas de DEPENDENTE, gerando um resultado que não tem muito significado. Deseja-se apenas combinar tuplas de empregado feminino com seus dependentes, o que significa dizer: tuplas de DEPENDENTES onde os valores de NSSEMP são iguais aos valores de NSS de EMPREGADO. Em DEP_ATUAL, foi obtido isto. O CARTESIAN PRODUCT cria tuplas com atributos combinados de duas relações. Pode-se então selecionar apenas as tuplas que estejam relacionadas especificando uma condição de seleção apropriada, como foi feita no exemplo. Devido à seqüência: CARTESIAN PRODUCT seguido de SELECT, ser muito comum para se identificar tuplas relacionadas de duas relações, uma operação especial JOIN foi criada para especificar esta seqüência como uma única operação. Assim, a operação CARTESIAN PRODUCT é raramente utilizada isoladamente.
EMP_FEM PNOME MNOME SNOME NSS DATANASC ENDEREÇO SEXO SALARIO NSSSUPER NDEP Alicia J Zelaya 999887777 19-JUL-58 Av. C, 3 F 2500 987654321 4 Jennifer S Wallace 987654321 20-JUN-31 Trav. D, 4 F 4300 888665555 4 Joyce A English 453453453 31-JUL-62 R. F, 6 F 2500 333445555 5
EMP_NOMES PNOME SNOME NSS Alicia Zelaya 999887777 Jennifer Wallace 987654321 Joyce English 453453453
EMP_DEP PNOME SNOME NSS NSSEMP NOMEDEPENDENTE SEXO DATANIV RELAÇÃO Alicia Zelaya 999887777 333445555 Alice F 05-ABR-76 FILHA Alicia Zelaya 999887777 333445555 Theodore M 25-OUT-73 FILHO Alicia Zelaya 999887777 333445555 Joy F 03-MAI-48 ESPOSA Alicia Zelaya 999887777 987654321 Abner M 29-FEV-78 MARIDO Alicia Zelaya 999887777 123456789 Michael M 01-JAN-78 FILHO Alicia Zelaya 999887777 123456789 Alice F 31-DEZ-78 FILHA Alicia Zelaya 999887777 123456789 Elizabeth F 05-MAI-57 ESPOSA Jennifer Wallace 987654321 333445555 Alice F 05-ABR-76 FILHA Jennifer Wallace 987654321 333445555 Theodore M 25-OUT-73 FILHO Jennifer Wallace 987654321 333445555 Joy F 03-MAI-48 ESPOSA Jennifer Wallace 987654321 987654321 Abner M 29-FEV-78 MARIDO Jennifer Wallace 987654321 123456789 Michael M 01-JAN-78 FILHO Jennifer Wallace 987654321 123456789 Alice F 31-DEZ-78 FILHA Jennifer Wallace 987654321 123456789 Elizabeth F 05-MAI-57 ESPOSA Joyce English 453453453 333445555 Alice F 05-ABR-76 FILHA Joyce English 453453453 333445555 Theodore M 25-OUT-73 FILHO Joyce English 453453453 333445555 Joy F 03-MAI-48 ESPOSA Joyce English 453453453 987654321 Abner M 29-FEV-78 MARIDO Joyce English 453453453 123456789 Michael M 01-JAN-78 FILHO Joyce English 453453453 123456789 Alice F 31-DEZ-78 FILHA Joyce English 453453453 123456789 Elizabeth F 05-MAI-57 ESPOSA
DEP_ATUAL PNOME SNOME NSS NSSEMP NOMEDEPENDENTE SEXO DATANIV RELAÇÃO Jennifer Wallace 987654321 987654321 Abner M 29-FEV-78 MARIDO
RESULT PNOME SNOME NOMEDEPENDENTE Jennifer Wallace Abner
Figura 7.4
7.4.1 A Operação JOIN A operação JOIN, denotada por ⌧, é usada para combinar tuplas relacionadas de relações em uma única tupla. Esta operação é muito importante para quaisquer bases de dados relacionais, pois permite processar relacionamentos entre relações. Para ilustrar a operação JOIN, suponha que se deseja recuperar os nomes dos gerentes de cada departamento. Para obter-se o nome dos gerentes, é necessário combinar cada tupla de departamento com tuplas de empregados cujo valor NSS seja igual ao valor de SNNGER na tupla departamento. Isto é feito usando a operação JOIN, então projeta-se o resultado sobre aqueles atributos necessários:

55
DEPT_GER←DEPARTAMENTO ⌧SNNGER=NSS EMPREGADO
RESULT←πDNOME, SNOME, PNOME (DEPT_GER) O resultado da primeira operação é mostrado na figura 7.5. O exemplo utilizado para ilustrar o CARTESIAN PRODUCT pode ser especificado usando o operador JOIN trocando as duas operações:
EMP_DEP←EMP_NOMES χ DEPENDENTE DEP_ATUAL←σNSS=NSSEMP (EMP_DEP)
por
DEP_ATUAL←EMP_NOME ⌧NSS=NSSEMP DEPENDENTE
DEPT_GER DNOME DNÚMERO SNNGER ... PNOME MNOME SNOME NSS ... Pesquisa 5 333445555 ... Franklin T Wong 333445555 ... Administrativo 4 987654321 ... Jennifer S Wallace 987654321 ... Gerencial 1 888665555 ... James E Borg 888665555 ...
Figura 7.5 A forma geral da operação JOIN sobre duas relações R(A1, A2, ..., An) e S(B1, B2, ..., Bm) é:
R ⌧<condição join> S. O resultado de JOIN é uma relação Q com n+m atributos Q(A1, A2, ..., An, B1, B2, ..., Bm)
nesta ordem; Q tem um tupla para cada combinação de tuplas uma de R e uma de S onde quer que a combinação satisfaça a condição join. Esta é a principal diferença entre CARTESIAN PRODUCT e JOIN; em JOIN, apenas combinações de tuplas que satisfazem a condição join é que aparecerá no resultado, já no CARTESIAN PRODUCT, todas as combinações de tuplas são incluídas no resultado. A condição join é especificada sobre atributos de R e de S, e é avaliada para cada combinação de tuplas. Uma condição join tem a forma: <condição> AND <condição> AND ... AND <condição> onde cada condição é da forma Ai θ Bj, Ai é um atributo de R, Bj é um atributo de S, Ai e Bj têm
o mesmo domínio e θ é um dos operadores de comparação <=, <, ≤, >, ≥, ≠}. Uma operação JOIN de condição especificada é denominada THETA JOIN. Tuplas cujos valores dos atributos join são null não aparecem no resultado. É muito comum encontrar JOIN que envolva condições joins com apenas a comparação de igualdade. Um JOIN, onde apenas o operador de comparação = é utilizado é chamado EQUIJOIN. Os dois exemplos anteriores eram EQUIJOIN. Note-se, que no resultado de uma EQUIJOIN sempre terá um ou mais pares de atributos que tem valores idênticos em todas as tuplas. Por exemplo, na figura 7.5 os valores dos atributos SNNGER e NSS são idênticos em todas as tuplas de DEPT_GER porque condição join de igualdade é especificada sobre estes atributos. Devido a esta duplicação ser desnecessária, uma nova operação chamada NATURAL JOIN foi criada. Denota-se o join natural por *, que é basicamente um equijoin seguido da remoção de atributos desnecessários. Um exemplo é:
PROJ_DEPT←PROJETO * DNUM=DNÚMERO DEPARTAMENTO
Os atributos DNUM e DNÜMERO são chamados atributos de união. A relação resultante é mostrada na figura 7.6a. Na relação PROJ_DEPT, cada tupla combina uma tupla de PROJETO

56
com a tupla de DEPARTAMENTO que controla o projeto. Na relação resultante, manteve-se apenas o primeiro atributo de união. Devido às comparações em uma condição join de um join natural serem sempre comparações de igualdade, pode-se descartar o operador de comparação e apenas listar os atributos de união como segue:
PROJ_DEPT←PROJETO * (DNUM),,(DNÚMERO) DEPARTAMENTO Assim, a forma geral de um NATURAL JOIN é: Q←R * (<lista1>),(<lista1>) S
Neste caso, <lista1> especifica uma lista de i atributos de R e <lista2> especifica uma lista de i atributos de S. Apenas os atributos da primeira relação R <lista1> serão mantidos na relação resultante Q. Se os atributos sobre os quais o join natural é especificado tiverem os mesmos nomes em ambas relações, pode-se tirar a condição join totalmente. Por exemplo, para aplicar um join natural sobre DNÚMERO de DEPARTAMENTO e LOCAIS_DEPTO, é suficiente escrever:
DEPT_LOCS←DEPARTAMENTO * LOCAIS_DEPTO A relação resultante é mostrada na figura 7.6b, que combina cada departamento com suas localizações e tem uma tupla para cada localização. Esta operação é executada igualando-se todos os pares de atributos que tenham o mesmo nome nas duas relações. Note que, se nenhuma combinação de tuplas satisfizer a condição join, então o resultado será uma relação vazia. Em geral, se R tiver nR tuplas e S tiver nS tuplas, o resultado de uma operação JOIN R ⌧ <condição join> S terá entre zero e nR*nS tuplas. Se não existir <condição join> para satisfazer, então todas as combinações de tuplas serão incluídas. Nestes casos, JOIN torna-se um CARTESIAN PRODUCT.
PROJ_DEPT (a) PNOME PNÚMERO PLOCALIZAÇÃO DNUM DNOME SNNGER DATINICGER ProdutoX 1 Bellaire 5 Pesquisa 333445555 22-MAI-78 ProdutoY 2 Sugarland 5 Pesquisa 333445555 22-MAI-78 ProdutoZ 3 Houston 5 Pesquisa 333445555 22-MAI-78 Automação 10 Stafford 4 Administrativo 987654321 01-JAN-85 Reorganização 20 Houston 1 Gerencial 888665555 19-JUN-71 Beneficiamento 30 Stafford 4 Administrativo 987654321 01-JAN-85
DEPT_LOCS (b) DNOME DNÚMERO SNNGER DATINICGER DLOCALIZAÇÃO Gerencial 1 888665555 19-JUN-71 Houston Administrativo 4 987654321 01-JAN-85 Stafford Pesquisa 5 333445555 22-MAI-78 Bellaire Pesquisa 5 333445555 22-MAI-78 Sugariand Pesquisa 5 333445555 22-MAI-78 Houston
Figura 7.6
7.4.2 Conjunto completo de Operações da Álgebra Relacional Será mostrado que o conjunto de operações da álgebra relacional {σ, π, ∪, -, χ} é um conjunto completo; isto é, quaisquer outras operações da álgebra relacional podem ser expressas como uma seqüência de operações deste conjunto. Por exemplo, a operação de INTERSECTION pode ser expressa usando UNION e DEFFERENCE como segue: R ∩ S ≡ (R ∪ S)-((R - S) ∪ (S - R)) Embora, estritamente falando, a INTERSECTION, seja desnecessária, é inconveniente especificar esta complexa expressão todas as vezes que for necessário utilizar a interseção.

57
Como um outro exemplo, uma operação JOIN pode ser especificada como uma CARTESIAN PRODUCT seguida pela operação SELECT como discutido anteriormente: R ⌧ <condição> S ≡ σ <condição> (R χ S)
Similarmente, uma operação NATURAL JOIN pode ser especificada como um CARTESIAN PRODUCT seguida pelas operações SELECT e PROJECT. Assim, as várias formas de JOIN também não são estritamente necessárias para expressar o poder da álgebra relacional. No entanto, elas são muito convenientes assim como a operação INTERSECTION porque elas são utilizadas com freqüência pelas aplicações de base de dados relacional. Outras operações foram incluídas por conveniência. Será discutida uma delas: DIVISION.
7.4.3 A Operação DIVISION A operação DIVISION é útil para um tipo especial de consulta que ocorre freqüentemente em aplicações de base de dados. Esta requisição pode ser ilustrada pela seguinte consulta: "Recupere os nomes dos empregados que trabalham em todos os projetos em que 'John Smith' trabalha. Para expressar esta consulta usando DIVISION deve-se fazer o seguinte: primeiro recuperar a lista de números de projetos em que 'John Smith' trabalha em uma relação intermediária SMITH_PNOS:
SMITH←σ PNOME = 'John' AND SNOME = 'Smith' (EMPREGADO)
SMITH_PNOS←π PNRO (TRABALHA_EM * NSSEMP = NSS SMITH)
Depois, criar uma relação que inclua tuplas da forma <PNRO, NSSEMP> que lista todos os empregados, cujo número do segura social é NSSEMP, que trabalham num determinado projeto PNRO:
NSS_PNRO←π PNRO, NSSEMP (TRABALHA_EM)
Finalmente, aplicar a operação DIVISION para as relações obtidas a fim de obter os números dos seguros sociais desejados:
NSS_DESEJADO(NSS)←NSS_PNRO ÷ SIMTH_PNOS RESULT←π PNOME, SNOME (NSS_DESEJADO * EMPREGADO)
Os resultados das operações acima são mostrados na figura 7.7a. Em geral, a operação DIVISION é aplicada para duas relação R(Z) ÷ S(X), onde X ⊆ Z. Seja Y=Z - X; isto é, Y é o conjunto de atributos de R que não são atributos de S. O resultado da divisão é uma relação T(Y) que incluirá uma tupla t se tR cujo tR[Y] = t aparecer em R com tR[X] = Ts para toda tupla tS em S. Isto significa que para uma tupla aparecer no resultado T da divisão, os valores em t devem aparecer em R em combinação com todas as tuplas de S. A figura 7.7b ilustra a utilização da operação DIVISON onde R = Z = {A, B}, S = X = {A}, e T = Y = {B}; isto é, X e Y são ambos atributos simples. A relação resultante T terá apenas um único atributo B = Z - X. Note que b1 e b4 aparecem em R em combinação com todas as três tuplas de S; por isso é que eles aparecem na relação resultado T. Todos os outros valores de B em R não apareceram com todas as tuplas de S e não foram selecionados b2 não aparece com a2 e b3 não aparece com a1. A operação de divisão pode ser expressa como uma seqüência de operações π, χ e -:
T1←πY (R)
T2←πY ((S χ T1) - R)
T←T1 - T2

58
(a) NSS_PNRO NSSEMP PNRO SMITH_PNO PNRO NSS_DESEJADO NSS 123456789 1 1 123456789 123456789 2 2 453453453 666884444 3 453453453 1 453453453 2 333445555 2 333445555 3 333445555 10 333445555 20 999887777 30 999887777 10 987987987 10 987987987 30 987654321 30 987654321 20 8886655555 20
(b)
R A B S A T B a1 b1 a1 b1 a2 b1 a2 b4 a3 b1 a3 a4 b1 a1 b2 a3 b2 a2 b3 a3 b3 a4 b3 a1 b4 a2 b4 a3 b4
Figura 7.7
7.4.4 Operações Relacionais Adicionais Existem algumas consultas comuns em bases de dados relacionais que não podem ser realizadas como as operações da álgebra descritas na seção anterior. Muitas linguagens de consulta de SGBD possuem a capacidade de realizar essas consultas. Nesta seção serão discutidas algumas dessas consultas e define-se operações adicionais que usadas para expressar essas consultas.
7.4.4.1 Funções de Agregação O primeiro tipo de consulta que não pode ser expressa na álgebra relacional é conhecido como funções agregadas sobre coleções de valores da base de dados. Por exemplo, pode-se querer recuperar a média ou total salarial de todos os empregados ou o número de tuplas de empregados. As funções normalmente aplicadas para coleções de valores numéricos são: SUM, AVERAGE, MAXIMUM e MINIMUM. A função de contagem de tuplas é normalmente chamada COUNT. Cada uma destas funções pode ser aplicada a todas as tuplas de uma relação. Um outro tipo comum de consulta envolve o agrupamento de tuplas de uma relação pelo valor de alguns de seus atributos e então a aplicação de alguma função agregada independente para cada grupo de tuplas. Um exemplo é o agrupamento de tuplas de empregados pelo NDEP. Pode-se então listar, para cada NDEP a média salarial de empregados num determinado departamento. Pode-se definir uma operação FUNCTION, que pode ser usada para especificar estes tipos de consultas.

59
<atributos de agrupamento> ℑ <lista de funções> (<nome da relação>) onde <atributos de agrupamento> é uma lista de atributos da relação especificada em <nome da relação> e <lista de funções> é uma lista de pares (<função><atributo>). Em cada par, <função> é uma das funções seguintes: SUM, AVERAGE, MAXIMUM, MINIMUM, COUNT, e <atributo> é um atributo da relação especificada por <nome da relação>. A relação resultante tem tantos atributos quanto aqueles que existirem em atributos de agrupamento além da lista de funções combinada. Por exemplo, para recuperar cada número de departamento, o número de empregados em departamento, e sua média salarial, escreve-se: R(DNO, NRO_EMPS, MÉDIA)←NDEP ℑ COUNT NSS, AVERAGE SALÁRIO (EMPREGADO)
O resultado desta operação é mostrado na figura 7.8a. No exemplo acima, foi especificada uma lista de nomes de atributos - entre parênteses - para a relação R. Se nenhuma lista tivesse sido especificada, então os atributos da relação resultante teriam como o nome à concatenação no nome da função com o nome do atributo especificado. Por exemplo, o resultado da seguinte operação é mostrado na figura 7.8b.
NDEP ℑ COUNT NSS, AVERAGE SALÁRIO (EMPREGADO) Se nenhum atributo de agrupamento for especificado, as funções serão aplicadas para todos os valores de tuplas na relação, tal que a relação resultante terá uma única tupla. Por exemplo, o resultado da seguinte operação é mostrado na figura 7.8
ℑ COUNT NSS, AVERAGE SALÁRIO (EMPREGADO) É importante destacar que o resultado da aplicação de qualquer função de agregação sempre será uma relação e não um número. (a)
R DNO NRO_EMPS MÉDIA 5 4 3325 4 3 3100 1 1 5500
(b)
NDEP COUNT_NSS AVERAGE_SALÁRIO 5 4 3325 4 3 3100 1 1 5500
(c)
COUNT_NSS AVERAGE_SALÁRIO 8 3512.5
Figura 7.8
7.4.5 Operações de Clausura Recursiva Um outro tipo de operação que, em geral, não pode ser definido na álgebra relacional é a clausula recursiva. Esta operação é aplicada em relacionamentos recursivos, como verificado no relacionamento entre empregado e supervisor. Este relacionamento é descrito por uma chave-estrangeira NSSSUPER da relação empregado nas figura 5.4 e 5.5, que relaciona cada tupla de empregado (no papel de supervisionado) a uma outra tupla empregado (no papel de supervisor). Um exemplo de uma operação recursiva é recuperar todos os supervisionados de um empregado e em todos os níveis, isto é, todos os empregados e' diretamente supervisionados por e, todos os empregados e'' diretamente supervisionados por e', todos os empregados e''' diretamente supervisionados por e'', e assim

60
por diante. Embora seja simples especificar, na álgebra relacional, todos os empregados supervisionados por e num nível específico, é difícil especificar todos os supervisionados em todos os níveis. Por exemplo, para especificar os NSSs de todos os empregados e' diretamente supervisionados no nível um por e cujo nome é 'James Borg' (veja figura 5.4), pode-se aplicar as seguintes operações:
BORG_NSS←πNSS (σ PNOME = 'James' AND SNOME = 'Borg' (EMPREGADO)) SUPERVISÃO(SSN1, SSN2)←πNSS, NSSSUPER (EMPREGADO)
RESULT1←πSSN1 (SUPERVISÃO ⌧SSN2 = NSS BORG_NSS)
Para recuperar todos os empregados supervisionados por Borg no nível dois, isto é, todos os empregados e'' supervisionados pelo empregado e' que é diretamente supervisionado por Borg, pode-se aplica um outro JOIN ao resultado da primeira consulta:
RESULT2←πSSN1 (SUPERVISÃO ⌧SSN2 = NSS RESULT1)
Para obter todos os empregados supervisionados nos níveis um e dois por 'James Borg', pode-se aplicar a operação UNION como segue:
RESULT3←(RESULT1 ∪ RESULT2) Embora seja possível recuperar os empregados supervisionados em cada nível, não é possível especificar uma consulta tal como " recupere todos os supervisionados de 'James Borg' em todos os níveis" se não for conhecido o número máximo de níveis.
7.5 Exemplos de Consultas na Álgebra Relacional Nesta seção serão apresentados exemplos para ilustrar o uso das operações da álgebra relacional. Todos os exemplos referem-se à base de dados da figura 5.4. Em geral, a mesma consulta pode ser realizada de várias maneiras usando diferentes operadores relacionais. Consulta 1: Encontrar o nome e o endereço de todos os empregados que trabalham para o
departamento 'Pesquisa'. PESQUISA_DEPTO←σ DNOME = 'Pesquisa' (DEPARTAMENTO)
PESQUISA_DEPTO_EMPS←(PESQUISA_DEPTO ⌧ DNÚMERO = NDEP EMPREGADO) RESULT←π PNOME, SNOME, ENDEREÇO (PESQUISA_DEPTO_EMPS)
Esta consulta poderia ser especificada de outra maneira; por exemplo, a ordem das operações JOIN e SELECT poderia ser invertida ou o JOIN poderia ser trocado pelo NATURAL JOIN.
Consulta 2: Para todo projeto localizado em 'Stafford', listar o número do projeto, o número do
departamento responsável, e o sobrenome, endereço e data de nascimento do gerente responsável pelo departamento.
STAFFORD_PROJS←σ PLOCALIZAÇÃO = 'Stafford' (PROJETO) CONTR_DEPT←(STAFFORD_PROJS ⌧ DNUM = DNÚMERO DEPARTAMENTO) PROJ_DEPT_MGR←(CONTR_DEPT ⌧ SSNGER = NSS EMPREGADO)
RESULT←π PNÚMERO, DNUM, SNOME, ENDEREÇO, DATANASC (PROJ_DEPT_MGR)

61
Consulta 3: Encontrar os nomes de empregados que trabalham em todos os projetos
controlados pelo departamento 5. DEPT5_PROJS(PNO)←π PNÚMERO (σ DNUM=5 (PROJETO)))
EMP_PROJ(NSS, PNO)←π NSSEMP, PNRO (TRABALHA_EM)
RESULT_EMP_SSNS←EMP_PROJ ÷ DEPT5_PROJS RESULT←π SNOME, PNOME (RESULT_EMP_SSNS * EMPREGADO)
Consulta 4: Fazer uma lista de números de projetos no qual um empregado, cujo sobrenome é
'Smith' , trabalha no projeto ou é gerente do departamento que controla o projeto. SMITH(NSSEMP)← π NSS (σ SNOME='Smith' (EMPREGADO))
SMITH_WORKER_PROJS← π PNRO (TRABALHA_EM * SMITH)
MGRS←π SNOME, DNÚMERO (EMPREGADO ⌧ NSS = SNNGER DEPARTAMENTO)
SMITH_MGS←σ SNOME = 'Smith' (MGRS) SMITH_MANAGED_DEPTS(DNUM)←π DNÚMERO (SMITH_MGRS)
SMITH_MGR_PROJS(PNRO)←π PNÚMERO (SMITH_MANAGED_DEPTS * PROJETO) RESULT←(SMITH_WORKER_PROJS ∪ SMITH_MGR_PROJS) Consulta 5: Listar os nomes de todos os empregados com dois ou mais dependentes. Esta consulta não pode ser realizada usando apenas a álgebra relacional. Deve-
se utilizar a operação FUNCTION com a função de agregação COUNT, que não é da álgebra relacional. Nas formulações que se seguirão, assume-se que dependentes de um mesmo empregado possuem nomes distintos.
T1(NSS, NO_DE_DEPS)←NSSEMP ℑ COUNT NOMEDEPENDENTE (DEPENDENTE)
T2←σ NO_DE_DEPS > 2 (T1) RESULT←π SNOME, PNOME (T2 * EMPREGADO) Consulta 6: Listar os nomes dos empregados que não possuem dependentes. TODOS_EMPS←π NSS (EMPREGADO) EMPS_COM_DEPS(NSS)←π NSSEMP (DEPENDENTE)
EMPS_SEM_DEPS←(TODOS_EMPS - EMPS_COM_DEPS) RESULT←π SNOME, PNOME (EMPS_SEM_DEPS * EMPREGADO)
Consulta 7: Listar os nomes dos gerentes que têm ao menos um dependente. MGRS(NSS)←π SNNGER (DEPARTAMENTO) EMPS_COM_DEPS(NSS)←π NSSEMP (DEPENDENTE)
MGRS_COM_DEPS←(MGRS ∩ EMPS_COM_DEPS) RESULT←π SNOME, PNOME (MGRS_COM_DEPS * EMPREGADO)

62
7.6 Questões de Revisão 1. O que é união compatível? Por que as operações UNION, INTERSECTION e
DIFFERENCE são operações que necessitam que as relações sejam união compatível? 2. Discuta algumas das consultas onde seja necessário renomear atributos a fim de
especificar consultas não ambíguas. 3. Discuta os vários tipos de operações JOIN. Resuma em forma de tabela que contenha o
nome da operação, o propósito da operação e a notação. 4. Especifique as seguintes consultas sobre a base de dados mostrada na figura 5.3 usando
operações relacionais discutidas neste capítulo. Mostra também os resultados de cada consulta se aplicada à base de dados da figura 5.4.
a) Recuperar os nomes de empregados do departamento 5 que trabalham mais
que 10 horas no projeto 'ProdutoX'. b) Listar os nomes dos empregados que tenham um dependente com o mesmo
nome (PNOME). c) Encontrar os nomes de empregados que são diretamente supervisionados por
'Franklin Wong'. d) Para cada projeto, listar o nome do projeto e o total de horas (de todos os
empregados) gastos em cada projeto. e) Recuperar os nomes dos empregados que trabalham em todos os projetos. f) Recuperar os nomes dos empregados que não trabalham em quaisquer
projetos. g) Para cada departamento, recuperar o nome do departamento e a média salarial
dos empregados que trabalham no departamento. h) Recuperar a média salarial de todos os empregados femininos. i) Encontrar os nomes e endereços de empregados que trabalham em ao menos
um projeto localizado em Houston mas cujo departamento não possua localização em Houston.
j) Listar os sobrenomes dos gerentes de departamentos que não tenham dependentes.
k) Generalize a consulta i) acima para listar os nomes e endereços de empregados que trabalham em um projeto em alguma cidade , mas que o departamento não tenha nenhuma localização nessa cidade.

63
8 Consultas em SQL O SQL tem um comando básico para recuperar informações numa base de dados: o comando SELECT. Note que o comando SELECT não tem nenhuma relação com a operação SELECT da álgebra relacional. O SQL permite que uma tabela (relação) tenha duas ou mais tuplas idênticas em todos os seus valores de atributos. Assim, em geral, uma relação SQL não é um conjunto de tuplas porque um conjunto não permite elementos idênticos. Ao invés disso, SQL é um multi-conjunto (algumas vezes chamado de bag) de tuplas. Algumas relações SQL podem ser restritas para se comportarem como um conjunto usando o comando CREATE UNIQUE INDEX ou usando a opção DISTINCT com o comando SELECT.
8.1 Consultas SQL básicas A forma básica do comando SELECT, algumas vezes chamada de mapping ou bloco SELECT FROM WHERE, é formada por três cláusulas - SELECT, FROM e WHERE: SELECT <lista de atributos> FROM <lista de tabelas> WHERE <condição> Para ilustrar a utilização do comando SELECT serão realizadas as mesmas consultas executadas nos exemplos da álgebra relacional, agora em SQL. Apenas as primeiras consultas não terão nenhuma relação com os exemplos anteriores. Consulta 0: Recuperar a data de nascimento e o endereço do empregado cujo nome é 'John
B. Smith'. Q0: SELECT DATANASC, ENDEREÇO FROM EMPREGADO WHERE PNOME = 'John' AND MNOME = 'B' AND SNOME = 'Smith' Esta consulta envolve apenas a relação EMPREGADO declarada na cláusula
FROM. A consulta seleciona as tuplas de EMPREGADO que satisfazem a condição da cláusula WHERE, e então projeta o resultado sobre os atributos listados na cláusula SELECT. Q0 é similar à expressão da álgebra relacional:
π DATANASC, ENDEREÇO (σ PNOME = 'John' AND MNOME = 'B' AND SNOME='Smith'
(EMPREGADO)) Assim, uma simples consulta SQL com uma única relação é similar ao par
SELECT-PROJECT. A única diferença da consulta SQL é que, na relação resultante, as tuplas podem estar duplicadas.
Consulta 1: Encontrar o nome e o endereço de todos os empregados que trabalham para o
departamento 'Pesquisa'. Q1: SELECT PNOME, SNOME, ENDEREÇO FROM EMPREGADO, DEPARTAMENTO WHERE DNOME = 'Pesquisa' AND DNÚMERO = NDEP Esta consulta é similar à seqüência SELECT-PROJECT-JOIN da álgebra
relacional. Na cláusula WHERE a condição DNOME='Pesquisa' é uma condição de seleção e corresponde à operação SELECT álgebra relacional. A condição DNÚMERO = NDEP é uma condição join, que corresponde à condição da operação JOIN.

64
Consulta 2: Para todo projeto localizado em 'Stafford', listar o número do projeto, o número do departamento responsável, e o sobrenome, endereço e data de nascimento do gerente responsável pelo departamento. Q2: SELECT PNÚMERO, DNUM, SNOME, ENDEREÇO, DATANASC FROM PROJETO, DEPARTAMENTO, EMPREGADO WHERE DNUM = DNÚMERO AND SSNGER = NSS AND PLOCALIZAÇÃO = 'Stafford' Consulta 3: Encontrar os nomes de empregados que trabalham em todos os projetos
controlados pelo departamento 5. Q3: SELECT PNOME, SNOME FROM EMPREGADO WHERE (( SELECT PNRO FROM TRABALHA_EM WHERE NSS = NSSEMP) CONTAINS ( SELECT PNÚMERO FROM PROJETO WHERE DNUM = 5)) O operador CONTAINS compara dois conjuntos de valores e retorna TRUE se um conjunto contém todos os valores do outro. A segunda consulta dentro dos parênteses recupera todos os números de projetos controlados pelo departamento 5. Para cada tupla de EMPREGADO, a primeira consulta dentro dos parênteses recupera os números de projetos sobre os quais os empregados trabalham. Se o resultado desta consulta contiver todos os projetos controlados pelo departamento 5, a tupla de EMPREGADO é selecionada e o nome deste empregado é recuperado. Note que a operação de comparação CONTAINS é similar em sua função à operação DIVISION da álgebra relacional. Consulta 4: Fazer uma lista de números de projetos no qual um empregado, cujo sobrenome é
'Smith' , trabalha no projeto ou é gerente do departamento que controla o projeto. Q4: (SELECT PNÚMRO FROM PROJETO, DEPARTAMENTO, EMPREGADO WHERE DNUM=DNÚMERO AND SNNGER=NSS AND SNOME='Smith') UNION (SELECT PNÚMERO FROM PROJETO, TRABALHA_EM, EMPREGADO WHERE PNÚMERO=PNRO AND NSSEMP=NSS AND SNOME='Smith') Consulta 5: Listar os nomes de todos os empregados com dois ou mais dependentes. Q5: SELECT SNOME, PNOME FROM EMPREGADO WHERE ( SELECT COUNT (*) FROM DEPENDENTE WHERE NSS=NSSEMP) >= 2 onde (*) indica o número de tuplas. Consulta 6: Listar os nomes dos empregados que não possuem dependentes. Q6: SELECT PNOME, SNOME FROM EMPREGADO WHERE NOT EXISTS ( SELECT * FROM DEPENDENTE WHERE NSS=NSSEMP) onde * indica todos os valores de atributos das tuplas selecionadas.

65
Consulta 7: Listar os nomes dos gerentes que têm ao menos um dependente. Q7: SELECT PNOME, SNOME FROM EMPREGADO WHERE EXISTS ( SELECT * FROM DEPENDENTE WHERE NSS=NSSEMP) AND EXISTS ( SELECT * FROM DEPARTAMENTO WHERE NSS=SNNGER)

66
9 Dependências Funcionais e Normalização de Base de Dados Relacionais
9.1 Diretrizes para o Projeto Informal de Esquemas de Relações Irá se discutir as métricas de qualidade informal para projeto de esquemas de relações. São elas:
• Semântica de atributos. • Redução de valores redundantes em tuplas. • Redução de valores nulos em tuplas. • Não permissão de tuplas espúrias.
Essas métricas não são sempre independentes uma das outras, como será visto.
9.1.1 Semântica de atributos de relação Assume-se que um certo significado esteja associado aos atributos, para todo agrupamento de atributos que formam uma relação esquema. Intuitivamente, verifica-se que cada relação pode ser interpretada como um conjunto de fatos ou declarações. Este significado, ou semântica, especifica como podem ser interpretados os valores de atributos armazenados em uma tupla da relação, em outras palavras, como os valores de atributos estão relacionados uns com os outros. Em geral, é mais simples descrever a semântica de relações, ao invés da semântica de atributos de uma relação. Para ilustrar, considere a versão simplificada da base de dados COMPANHIA da figura 5.4. O significado do esquema da relação é simples - cada tupla representa um empregado, com valores para nome, número do seguro social, data de aniversário, endereço, e o número do departamento em que cada empregado trabalha. Além desses atributos existem aqueles atributos que são utilizados para estabelecer um relacionamento entre relações. Assim, todas os esquemas de relações da figura 5.4. podem ser considerados como um bom ponto de partida para manter clara a semântica. Pode-se assim, estabelecer as seguintes diretrizes para projetar esquemas de relações: Diretriz 1ª: Projetar um esquema de relação de maneira que seja simples descrever seu significado. Normalmente, isso significa que não se pode combinar atributos de múltiplos tipos de entidades e tipos de relacionamentos numa simples relação. Intuitivamente, se um esquema de relação corresponde a um tipo de entidade ou tipo de relacionamento, o significado tende a ser claro. Por outro lado, tende ser uma mistura de múltiplas entidades e relacionamentos e, assim, semanticamente não-clara. A relação esquema da figura 9.1 a e b possuem semântica clara. Uma tupla na relação esquema EMP_DEPT da figura 9.1a representa um mero empregado mas inclui informações adicionais, tais como o nome do departamento em que o empregado trabalha (DNAME) e o número do seguro social do gerente do departamento (DMGRSSN). Na relação esquema EMP_PROJ da figura 9.1b, cada tupla relaciona um empregado a um projeto mas, também, incluem nome do empregado (ENAME), nome do projeto (PNAME) e a localização do projeto (PLOCATION). Embora não exista, logicamente, nada de errado com esses esquemas, eles são considerados um projeto pobre pois viola a Diretriz 1 porque mistura atributos de entidades distintas do mundo real; EMP_DEPT mistura atributos de empregados e departamentos, e EMP_PROJ mistura atributos de empregados e projetos. Eles podem ser usados como visões, mas podem causar problemas quando usados como relações da base de dados , como será discutido mais adiante.

67
(a) EMP_DEPT ENAME NSS DATANASC ENDEREÇO DNÚMERO DNOME NSSGER
(b) EMP_PROJ NSS PNÚMERO HORAS ENAME PNOME PLOCALIZAÇÃO
Figura 9.1
9.1.2 Informação redundante em tuplas e anomalias de atualizações Uma das metas do projeto de esquemas é a minimização do espaço de armazenamento que relações da base ocupam. O agrupamento de atributos em esquemas de relações tem um efeito significativo no espaço de armazenamento. Por exemplo, compare o espaço usado pelas duas relações base EMPREGADO e DEPARTAMENTO na figura 9.2 com o espaço utilizado por EMP_DEPT na relação base da figura 9.3, que é o resultado da aplicação do JOIN NATURAL entre EMPREGADO e DEPARTAMENTO.
EMPREGADO ENAME NSS DATANASC ENDEREÇO DNÚMERO John Smith 123456789 09-JAN-55 R. A, 1 5 Franklin Wong 333445555 08-DEZ-45 R. B, 2 5 Alícia Zelaya 999887777 19-JUL-58 Av. C, 3 4 Jennifer Wallace 987654321 20-JUN-31 Trav. D, 4 4 Ramesh Narayan 666884444 15-SET-52 R. E, 5 5 Joyce English 453453453 31-JUL-62 R. F, 6 5 Ahmad Jabbar 987987987 29-MAR-59 Av G, 7 4 James Borg 888665555 10-NOV-27 Av H, 8 1 DEPARTAMENTO LOCAIS_DEPTO DNOME DNÚMERO SNNGER DNÚMERO DLOCALIZAÇÃO Pesquisa 5 333445555 1 Houston Administrativo 4 987654321 4 Stafford Gerencial 1 888665555 5 Bellaire 5 Sugariand 5 Houston
TRABALHA_EM PROJETO NSSEMP PNRO HORAS PNOME PNÚMERO PLOCALIZAÇÃ
O DNUM
123456789 1 32.5 ProdutoX 1 Bellaire 5 123456789 2 7.5 ProdutoY 2 Sugarland 5 666884444 3 40.0 ProdutoZ 3 Houston 5 453453453 1 20.0 Automação 10 Stafford 4 453453453 2 20.0 Reorganização 20 Houston 1 333445555 2 10.0 Beneficiamento 30 Stafford 4 333445555 3 10.0 333445555 10 10.0 333445555 20 10.0 999887777 30 30.0 999887777 10 10.0 987987987 10 35.0 987987987 30 5.0 987654321 30 20.0 987654321 20 15.0 888775555 20 null
Figura 9.2 EMP_DEPT
ENAME NSS DATANASC ENDEREÇO DNÚMERO DNOME NSSGER John Smith 123456789 09-JAN-55 R. A, 1 5 Pesquisa 333445555 Franklin Wong 333445555 08-DEZ-45 R. B, 2 5 Pesquisa 333445555 Alícia Zelaya 999887777 19-JUL-58 Av. C, 3 4 Administrativo 987654321 Jennifer Wallace 987654321 20-JUN-31 Trav. D, 4 4 Administrativo 987654321 Ramesh Narayan 666884444 15-SET-52 R. E, 5 5 Pesquisa 333445555 Joyce English 453453453 31-JUL-62 R. F, 6 5 Pesquisa 333445555 Ahmad Jabbar 987987987 29-MAR-59 Av G, 7 4 Administrativo 987654321 James Borg 888665555 10-NOV-27 Av H, 8 1 Gerencial 888665555
EMP_PROJ
NSS PNÚMERO HORAS ENAME PNOME PLOCALIZAÇÃO 123456789 1 32.5 John Smith ProdutoX Bellaire 123456789 2 7.5 John Smith ProdutoY Sugarland 666884444 3 40.0 Ramesh Narayan ProdutoZ Houston 453453453 1 20.0 Joyce English ProdutoX Bellaire 453453453 2 20.0 Joyce English ProdutoY Sugarland 333445555 2 10.0 Franklin Wong ProdutoY Sugarland 333445555 3 10.0 Franklin Wong ProdutoZ Houston 333445555 10 10.0 Franklin Wong Automação Stafford 333445555 20 10.0 Franklin Wong Reorganização Houston

68
999887777 30 30.0 Alícia Zelaya Beneficiamento Stafford 999887777 10 10.0 Alícia Zelaya Automação Stafford 987987987 10 35.0 Ahmad Jabbar Automação Stafford 987987987 30 5.0 Ahmad Jabbar Beneficiamento Stafford 987987987 30 20.0 Jennifer Wallace Beneficiamento Stafford 987987987 20 15.0 Jennifer Wallace Reorganização Houston 888665555 20 null James Borg Reorganização Houston
Figura 9.3 Em EMP_DEPT, os valores de atributos pertencentes a um particular departamento (DNÚMERO, DNOME, NSSGER) estão repetidos para todos os empregados que trabalham para um departamento. Em contraste, as informações de departamento aparecem apenas uma vez para cada departamento na relação DEPARTAMENTO da figura 9.2, e apenas o número do departamento (DNÚMERO) é repetido na relação EMPREGADO para cada empregado que trabalha no departamento. Similarmente, o mesmo comentário se aplica para a relação EMP_PROJ. Um outro problema sério identificado, quando se utilizam relações similares às encontradas na figura 9.3 como relações base, é o problema da anomalia de alterações. Podem ser classificadas em anomalias de inserção, remoção e modificações.
9.1.2.1 Anomalia de inserção Pode se diferenciar dois tipos de anomalias de inserção.
• Para inserir uma nova tupla empregado em EMP_DEPT, deve-se incluir valores de atributos do departamento em que o empregado trabalha, ou null se o empregado ainda não pertencer a um departamento. Por exemplo, para inserir uma nova tupla para o empregado que trabalha no departamento 5, deve-se tomar cuidado em assegurar que os valores de atributos sejam inseridos corretamente, tal que fiquem consistentes com os valores do departamento 5 em outras tuplas de EMP_DEPT. No projeto ilustrado na figura 9.2 esse cuidado não precisa ser tomado, uma vez que apenas o número do departamento é necessário em cada tupla de empregado; os outros valores de atributos do departamento 5 são registrados apenas uma vez na base de dados, como uma simples tupla na relação DEPARTAMENTO.
• É difícil inserir um novo departamento que ainda não tenha empregados na relação EMP_DEPT. A única maneira de fazer isso é colocar valores null em atributos de empregados. Isso provoca um problema pois NSS é a chave primária de EMP_DEPT, e supõe-se que cada tupla representa uma entidade empregado — não uma entidade departamento. Mais do que isso, quando o primeiro empregado for associado a esse departamento, não será mais necessário a tupla com valores null. Este problema não ocorre no projeto da figura 9.2, porque um departamento é inserido na relação DEPARTAMENTO sem que nenhum empregado trabalhe nele, e quando um empregado for associado ao departamento, uma tupla correspondente é inserida em EMPREGADO.
9.1.2.2 Anomalia de remoção Este problema está relacionado à segunda anomalia de inserção discutida acima. Se for removida uma tupla empregado de EMP_DEPT e esta tupla for à última de um particular departamento, a informação correspondente ao departamento será perdida. Este problema não ocorre na base de dados da figura 9.2 pois as tuplas de DEPARTAMENTO são armazenadas separadamente das tuplas de EMPREGADO, somente o atributo DNÙMERO de EMPREGADO relaciona os dois.

69
9.1.2.3 Anomalia de modificação Em EMP_DEPT, se for mudado o valor de um dos atributos de um departamento qualquer, por exemplo o gerente do departamento 5, deve ser mudado as tuplas de todos os empregados que trabalham neste departamento; por outro lado, a base de dados se tornará inconsistente.
9.1.2.4 Discussão De acordo com as anomalias acima, pode-se estabelecer a seguinte diretriz: Diretriz 2ª: Projetar esquemas de relações de maneira que nenhuma anomalia de alteração ocorra em relações. Se existir alguma anomalia, isso deverá ser considerado para que as modificações pelos programas ocorram corretamente. A segunda diretriz é consistente e reforça a primeira diretriz. Verifica-se, porém, que existe a necessidade de uma abordagem mais formal para auxiliar na avaliação de que projetos obedecem estas diretrizes. Nas seções seguintes isso será fornecido. É importante notar que estas diretrizes podem, algumas vezes, ter que ser violadas a fim de aumentar o desempenho de certas consultas. Por exemplo, se for importante recuperar, rapidamente, informações pertinentes ao departamento, através de atributos de um empregado que trabalhe no departamento, o esquema EMP_DEPT pode ser usado como uma relação base. No entanto, deve-se assegurar que as anomalias sejam bem conhecidas para que as modificações nesta relação base não a tornem inconsistente. Em geral é aconselhável utilizar relações base livre de anomalias e especificar visões utilizando JOIN´s para unir atributos freqüentemente referenciados em consultas importantes. Isso reduz o número de JOIN´s especificados em consultas, simplifica as consultas, e em alguns casos, eleva o desempenho.
9.1.3 Valores null em tuplas Em alguns projetos de esquemas pode-se agrupar atributos em uma “grande” relação. Se muitos atributos não se aplicarem a todas as tuplas da relação, ter-se-á muitos valores nulls na relação. Isto pode despender espaço armazenamento e pode também trazer problemas de entendimento do significado dos atributos na especificação de operações JOIN´s. Um outro problema com valores nulls é que não se pode contá-los quando operações de agregação, tais como COUNT ou SUM são aplicadas. Mais que isso, os valores nulls podem ter múltiplas interpretações, tais como:
• O atributo pode não se aplicar a tupla. • O valor de atributo para a tupla é desconhecido. • O valor é conhecido, porém não foi registrado ainda.
Ter a mesma representação, null, para diferentes significados pode comprometer as consultas. Assim, pode-se estabelecer uma outra diretriz: Diretriz 3ª: Tanto quanto possível, evite colocar atributos em um esquema de relação base cujos valores possam ser null. Se for inevitável os valores nulls, esteja seguro que eles se apliquem apenas em casos excepcionais e não se apliquem na maioria das tuplas da relação. Por exemplo. se apenas 10% dos empregados tiverem secretárias, não existe razão para incluir um atributo NÚMERO_SECRETÁRIA na relação EMPREGADO; ao invés disso, uma relação EMP_SEC(ESSN, NÚMERO_SECRETÁRIA) poderia ser criada para conter apenas as tuplas indicando o ESSN de empregados que possuem secretárias.

70
9.1.3.1 Tuplas espúrias Considere os esquemas de relação EMP_LOCS e EMP_PROJ1 da figura 9.4a, que pode substituir a relação EMP_PROJ da figura 9.1b. (a) EMP_LOCS ENAME PLOCALIZAÇÃO EMP_PROJ1 NSS PNÚMERO HORAS PNOME PLOCALIZAÇÃO
(b) EMP_LOCS
ENAME PLOCALIZAÇÃO John Smith Bellaire John Smith Sugarland Ramesh Narayan Houston Joyce English Bellaire Joyce English Sugarland Franklin Wong Sugarland Franklin Wong Houston Franklin Wong Stafford Alícia Zelaya Stafford Ahmad Jabbar Stafford Jennifer Wallace Stafford Jennifer Wallace Houston James Borg Houston
EMP_PROJ1
NSS PNÚMERO HORAS PNOME PLOCALIZAÇÃO 123456789 1 32.5 ProdutoX Bellaire 123456789 2 7.5 ProdutoY Sugarland 666884444 3 40.0 ProdutoZ Houston 453453453 1 20.0 ProdutoX Bellaire 453453453 2 20.0 ProdutoY Sugarland 333445555 2 10.0 ProdutoY Sugarland 333445555 3 10.0 ProdutoZ Houston 333445555 10 10.0 Automação Stafford 333445555 20 10.0 Reorganização Houston 999887777 30 30.0 Beneficiamento Stafford 999887777 10 10.0 Automação Stafford 987987987 10 35.0 Automação Stafford 987987987 30 5.0 Beneficiamento Stafford 987987987 30 20.0 Beneficiamento Stafford 987987987 20 15.0 Reorganização Houston 888665555 20 null Reorganização Houston
Figura 9.4 Uma tupla em EMP_LOCS significa que o empregado cujo nome é ENOME trabalha em algum projeto cuja localização é PLOCALIZAÇÂO. Uma tupla em EMP_PROJ1 significa que o empregado cujo número do seguro social é NSS trabalha HORAS por semana em um projeto cujo nome, número e localização são PNOME, PNÚMERO e PLOCALIZAÇÂO. A figura 9.4b mostra a extensão de EMP_LOCS e EMP_PROJ1 correspondente à relação extensão EMP_PROJ da figura 9.3, aplicando-se operações de projeção (¶) adequadas. Suponha agora que EMP_PROJ1 e EMP_LOCS sejam utilizadas como relações base ao invés de EMP_PROJ. Isto seria, particularmente, um projeto ruim, pois não se pode recuperar informações que existiam originalmente em EMP_PROJ a partir de EMP_PROJ1 e EMP_LOCS. Se uma operação JOIN-NATURAL for aplicada em EMP_PROJ1 e EMP_LOCS, surgirão mais tuplas que existiam em EMP_PROJ. A figura 9.5 ilustra o resultado obtido aplicando-se o join, considerando apenas as tuplas existentes acima da linha pontilhada, para reduzir o tamanho da relação resultante. As tuplas adicionais são chamadas tuplas espúrias porque elas representam informações espúrias ou erradas, e por isso não válidas. As tuplas espúrias estão marcadas por asteriscos (*) na figura 9.5. A decomposição de EMP_PROJ em EMP_PROJ1 e EMP_LOCS é ruim porque quando é aplicada a operação JOIN-NATURAL, não são obtidas as informações originais corretas. Isto

71
porque foi escolhido PLOCALIZAÇÃO como o atributo que relaciona EMP_LOCS e EMP_PROJ1, e PLOCALIZAÇÃO não é nem uma chave-primária e nem uma chave-estrangeira. Pode-se agora estabelecer uma outra diretriz para projeto: Diretriz 4ª: Projetar esquemas de relações tal que, quando aplicadas operações JOIN-NATURAIS, os atributos nas condições-joins envolvam atributos que sejam ou chaves-primárias ou chaves-estrangeiras de maneira a garantir que nenhuma tupla espúria seja gerada.
NSS PNÚMERO HORAS PNOME PLOCALIZAÇÃO ENAME 123456789 1 32.5 ProdutoX Bellaire John Smith * 123456789 1 32.5 ProdutoX Bellaire Joyce English 123456789 2 7.5 ProdutoY Sugarland John Smith * 123456789 2 7.5 ProdutoY Sugarland Joyce English * 123456789 2 7.5 ProdutoY Sugarland Franklin Wong 666884444 3 40.0 ProdutoZ Houston Ramesh Narayan * 666884444 3 40.0 ProdutoZ Houston Franklin Wong * 453453453 1 20.0 ProdutoX Bellaire John Smith 453453453 1 20.0 ProdutoX Bellaire Joyce English * 453453453 2 20.0 ProdutoY Sugarland John Smith 453453453 2 20.0 ProdutoY Sugarland Joyce English * 453453453 2 20.0 ProdutoY Sugarland Franklin Wong * 333445555 2 10.0 ProdutoY Sugarland John Smith * 333445555 2 10.0 ProdutoY Sugarland Joyce English 333445555 2 10.0 ProdutoY Sugarland Franklin Wong * 333445555 3 10.0 ProdutoZ Houston Ramesh Narayan 333445555 3 10.0 ProdutoZ Houston Franklin Wong 333445555 10 10.0 Automação Stafford Franklin Wong * 333445555 20 10.0 Reorganização Houston Ramesh Narayan 333445555 20 10.0 Reorganização Houston Franklin Wong
Figura 9.5 Obviamente, estas diretrizes informais necessitam ser estabelecidas de maneira mais formal.
9.2 Dependências Funcionais Um conceito simples, porém, muito importante em projetos de esquemas relacionais é o de dependência funcional. Nesta seção será definido formalmente este conceito, e na seção 9.2.2 será verificado como trabalhar com esquemas de relações em formas normais.
9.2.1 Definição de Dependência Funcional Dependências Funcionais são restrições ao conjunto de relações válidas. Elas permitem expressar determinados fatos em banco de dados relativos ao empreendimento que se deseja modelar. Anteriormente foi definido o conceito de superchave. Seja R o esquema de uma relação. Um subconjunto K de R é uma superchave de R em qualquer relação válida r(R) para todos os pares t1 e t2 de tuplas em r tal que t1≠ t2, então t1[K]≠ t2[K]. Isto é, nenhum par de tuplas em qualquer relação válida r(R) deve ter o mesmo valor no conjunto de atributos K. A noção de dependência funcional generaliza a noção de superchave. Seja α ⊆ R e β ⊆ R. A dependência funcional :
α→β realiza-se em R se, em qualquer relação válida r(R), para todos os pares de tuplas t1 e t2 em r tal que t1 [α] = t2 [α], t1 [β] = t2 [β] também será verdade.

72
Usando a notação de dependência funcional, dizemos que K é uma superchave de R se K → R. Isto é, K é uma superchave se, para todo t1[K] = t2[K], t1[R] = t2[R] (isto é t1 = t2). A dependência funcional permite expressar restrições que as superchaves não expressam. Considere o esquema: Esquema_info_empréstimo = (nome_agência, número_empréstimo, nome_cliente, total) O conjunto de dependências funcional que queremos garantir para esse esquema de relação é:
número_empréstimo→total número_empréstimo→nome_agência
Entretanto, não se espera realizar dependência funcional para:
número_empréstimo→nome_cliente já que, em geral, um empréstimo pode ser contraído por mais de um cliente (por exemplo para ambos os membros de um casal, marido-mulher). Podemos usar dependência funcional de dois modos:
1. Usando-as para o estabelecimento de restrições sobre um conjunto de relações válidas. Deve-se assim, concentrá-las somente àquelas que devem satisfazer um dado conjunto de dependências funcionais. Se desejasse restringi-las a relações do esquema em R que satisfaçam o conjunto F de dependências funcionais, diz-se que F realiza-se em R.
2. Usando-as para verificações de relações, de modo a saber se as últimas são válidas
sob um conjunto de dependências funcionais. Se uma relação r é legal sobre um conjunto F de dependências funcionais, diz-se que r satisfaz F.
Considera-se a relação r mostrada abaixo para verificar quais dependências funcionais são satisfeitas. Observa-se que A → C é satisfeita. Duas tuplas têm valor a1 em A. Essas tuplas têm o mesmo valor de C – denominado c1. De modo similar, duas tuplas com valor a2 em A têm o mesmo valor c2 em C. Não existe outro par de tuplas distintas que tenha, em A, os mesmos valores. A dependência funcional C → A, entretanto não é satisfeita. Para confirmar esta afirmação, considere as tuplas t1 = (a2, b2, c2, d3) e t2 = (a3, b3, c2, d4). Essas tuplas têm os mesmos valores c2 em C, mas elas possuem valores diferentes em A, a2 e a3, respectivamente. Assim, encontra-se um par de tuplas t1 e t2 tal que t1 [C] = t2 [C], mas t1 [A] ≠ t2 [A].
Figura 9.6 - Relação r de exemplo Uma dependência funcional é uma restrição entre dois conjuntos de atributos da base de dados. Considere-se que o esquema da base de dados relacional tenha n atributos A1, A2, ..., An ; e que toda a base de dados seja descrita por um único esquema de relação universal R = { A1, A2, ..., An }. Isso não significa que isso de fato deverá acontecer; esta suposição é feita apenas para desenvolver uma teoria formal sobre dependência de dados. Uma dependência funcional, denotada por XàY, entre dois conjuntos de atributos X e Y que são subconjuntos de R, especifica uma restrição sobre as possíveis tuplas que podem existir na relação instância r de R. A restrição estabelece que para quaisquer tuplas t1 e t2 em r, se
A B C D a1 b1 C1 d1 a1 b2 c1 d2 a2 b2 c2 d2 a2 b3 c2 d3 a3 b3 c2 d4

73
t1[X]= t2[X], então t1[Y]= t2[Y]. Isto significa que os valores da componente Y das tuplas em r dependem, ou são determinados pelos valores da componente X ou, alternativamente, os valores da componente X de uma tupla determinam de maneira única (ou funcionalmente) os valores da componente Y. Pode-se também dizer que existe uma dependência funcional de X para Y ou que Y é dependente funcionalmente de X. A abreviatura de dependência funcional é DF. Note que:
• Se uma restrição sobre R estabelece que não pode existir mais que uma tupla com um dado valor de X, em quaisquer instâncias de relação r(R) - isto é, X é uma chave-candidata de R - isto implica que XàY para quaisquer subconjuntos de atributos Y de R.
• Se XàY em R, isto não significa que YàX em R. Uma dependência funcional é uma propriedade do significado ou semântica dos atributos em um esquema de relação R. Utiliza-se o entendimento da semântica de atributos de R - isto é, como eles se relacionam - para especificar as dependências funcionais envolvidas em todas as instâncias da relação r (extensão) de R. As instâncias r que satisfazem as restrições de dependência funcional especificadas sobre atributos de R são chamadas extensões legais, pois obedecem as restrições de dependência funcional. Assim, a principal utilização das dependências funcionais é o de descrever um esquema de relação R especificando restrições sobre seus atributos que devem ser válidas todas às vezes. Isto significa que uma dependência funcional é uma propriedade do esquema da relação (intenção) R e não de uma instância particular legal r (extensão) de R. Assim, uma DF não pode ser automaticamente inferida a partir de uma extensão de relação r, mas deve ser definida por alguém que conheça a semântica dos atributos de R. Por exemplo, na figura 9.7, uma instância particular de um esquema de relação ENSINO é mostrada. Embora num primeiro momento possa parecer que TEXTOàCURSO, não se pode afirmar isso a menos que se conheça que isso seja verdade para todas as instâncias da relação ENSINO.
PROFESSOR CURSO TEXTO Smith Estrutura de Dados Bartram Smith Gerenciamento de dados Al-Nour Hall Compiladores Hoffman Brown Estrutura de Dados Augenthaler
Figura 9.7
9.2.2 Formas Normais Determinados pelas Chaves Primárias O processo de normalização foi proposto inicialmente por Codd em 1972. Esta é uma maneira mais formal de garantir as diretrizes descritas anteriormente.
9.2.2.1 Primeira Forma Normal (1FN) A primeira forma normal é agora genericamente considerada como parte da definição formal de uma relação; historicamente foi definida para não permitir atributos multivalorados, compostos e suas combinações.
9.2.2.2 Segunda Forma Normal (2FN) A segunda forma normal é baseada no conceito de dependência funcional total. Uma dependência funcional XàY é uma dependência funcional total se, na remoção de qualquer

74
atributo A de X significar que a dependência não mais existe; isto é, para todo atributo A ∈ X, (X-{A}) -xàY. Por exemplo, na figura 9.8b, {NSS, PNÚMERO}àHORAS é uma dependência funcional total (nem NSSàHORAS e nem PNÚMEROàHORAS são DF. Porém a dependência {NSS, PNÚMERO}àENOME é parcial pois NSSàENOME. Um esquema de relação R está na 2FN se qualquer atributo não-primo A de R for totalmente dependente funcionalmente de qualquer chave de R. Atributo não-primo é qualquer atributo que não seja membro de uma chave-candidata. A relação EMP_PROJ da figura 9.8b está na 1FN mas não na 2FN. O atributo não-primo ENOME viola a 2FN devido à df2, o mesmo acontece com os atributos não-primos PNOME e PLOCALIZAÇÃO em df3. As dependências funcionais df2 e df3 indicam a dependência parcial da chave-primária {NSS, PNÚMERO}, violando assim a 2FN. (a) EMP_DEPT ENAME NSS DATANASC ENDEREÇO DNÚMERO DNOME NSSGER df1
(b) EMP_PROJ NSS PNÚMERO HORAS ENAME PNOME PLOCALIZAÇÃO df1 df2 df3
Figura 9.8 Se uma relação não está na 2FN, ela pode ser normalizada em um número de relações na 2FN. As dependências funcionais df1, df2 e df3 indicadas na figura 9.9 podem ser consideradas para decompor a relação EMP_PROJ em 3 esquemas de relações EP1, EP2 e EP3, como mostra a figura 9.9a. Cada um desses esquemas de relação satisfaz a 2FN. Verifica-se que as relações EP1, EP2 e EP3 evitam as anomalias que estava sujeita a relação EMP_PROJ. (a) EMP_PROJ NSS PNÚMERO HORAS ENAME PNOME PLOCALIZAÇÃO df1 df2 df3 EP1 EP2 EP3 NSS PNÚMERO HORAS NSS ENAME PNÚMERO PNOME PLOCALIZAÇÃO df1 df2 df3
(b) EMP_DEPT ENAME NSS DATANASC ENDEREÇO DNÚMERO DNOME NSSGER df1

75
ED1 ED2 ENAME NSS DATANASC ENDEREÇO DNÚMERO DNÚMERO DNOME NSSGER
Figura 9.9
9.2.2.3 Terceira Forma Normal (3FN) A terceira forma normal é baseada no conceito de dependência transitiva. Uma dependência X→Y em uma relação R é uma dependência transitiva se existir um conjunto de atributos Z que não é um subconjunto de qualquer chave de R, e tanto X→Z quanto Z→Y. Por exemplo, a dependência NSS→NSSGER é uma dependência transitiva em EMP_DEPT da figura 9.9b. Diz-se que a dependência de NSSGER sobre o atributo chave NSS é transitiva via DNÚMERO. Intuitivamente, verifica-se que a dependência de NSSGER sobre DNÚMERO é indesejável uma EMP_DEPT desde que DNÚMERO não é chave de EMP_DEPT. Um esquema de relação R está na 3FN se ele estiver na 2FN e nenhum atributo não-primo de R é dependente transitivamente de qualquer chave de R. A relação EMP_DEPT da figura 9.9b está na 2FN, pois não há dependência parcial de nenhum atributo não-primo sobre a chave. Porém, não está na 3FN, pois NSSGER e DNOME são dependentes transitivos de NSS via DNÚMERO. Pode-se normalizar EMP_DEPT decompondo-o em dois esquemas de relação na 3FN, ED1 e ED2, como mostra a figura 9.9b.

76
10 Referências Bibliográficas [Codd00] E. F. Codd. A Relational Model of Data for Large Shared Data Banks. Revista CACM volume = 6,1970 [Date00] C. J. Date. Introdução a Sistema de Banco de Dados. Editora Campus, 2000 [SSK99] S. Sudarshan and A. Silberschatz and F. Henry Korth. Sistemas de Banco de Dados. Editora Makron Books, 1999. [NE01] B. Shamkant Navathe and E. Ramez Elmasri. Fundamentals of DataBase Systems. Editora Addison Wesley Pub, 2001 [WU97] Jennifer Widow and Jeffrey Ullman .A First Course in Database Systems. Editora Prentice Hall, 1997 [Jackson99] M Jackson .Thirty years(and more) of databases .Revista Information and Software Technology, volume = "41", páginas =969-978, 1999.