inteligência computacional - renatomaia.net · no valor de x para que se obtenha um menor valor de...
TRANSCRIPT

Inteligência Computacional
Renato Dourado MaiaFaculdade de Ciência e Tecnologia de Montes Claros
Fundação Educacional Montes Claros
REDES NEURAIS ARTIFICIAIS – ADALINE

24/08/15 Inteligência Computacional – Renato Dourado Maia 2/36
Adaline
• Adaline = Adaptive Linear Neuron ou Adaptive Line-ar Element.
• Surgiu na literatura quase que simultaneamente com o Perceptron ao final da década de 50.
• Assim como o Perceptron, é um modelo baseado em elementos que executam operações sobre a soma ponderada de suas entradas.– Operações não-lineares, no caso do Perceptron, e pura-
mente lineares, no cado do Adaline.

24/08/15 Inteligência Computacional – Renato Dourado Maia 3/36
Adaline
• Apesar das semelhanças, os trabalhos que descreve-ram o Perceptron e o Adaline surgiram em áreas di-ferentes e com enfoques diferentes:– Frank Rosenblatt, que era psicólogo, enfocou a descrição
do Perceptron em aspectos cognitivos do armazenamen-to da informação e da organização cerebral, enquanto Bernard Widrow e Marcian Hoff enfocaram a descrição do Adaline na construção de filtros lineares.
Perceptron = Separador LinearAdaline = Aproximador Linear de Funções

24/08/15 Inteligência Computacional – Renato Dourado Maia 4/36
Adaline
• O algoritmo de treinamento do Adaline utiliza a in-formação contida no gradiente do erro para obter calcular o ajuste ΔW a ser aplicado ao vetor de pe-sos.
• Esse algoritmo, conhecido como Regra Delta, deu o-rigem, anos mais tarde, ao primeiro algoritmo de treinamento de redes Perceptron de múltiplas ca-madas, o Backpropagation.

24/08/15 Inteligência Computacional – Renato Dourado Maia 5/36
Arquitetura do Adaline.
W=[w0 w1 w2 ⋯ wm]T
X=[+1 x1 x2 ⋯ xm]T }
Função deAtivação
JunçãoSomadora
SaídaΣ f (u)yu
+ 1
.
.
.
w0
w1
wm
x1
xm
Pesos dasConexões
y= f (u)= f (∑j=0
m
w j x j)=uVetores
Aumentados
{u → Saída Lineary → Saída de Ativação
u
f (u)
1
1

24/08/15 Inteligência Computacional – Renato Dourado Maia 6/36
Análise Matemática do Adaline
y= f (u)= f (∑j=0
m
w j x j)= f (W⋅X)=u=w0+w1 x1+w2 x2+⋯+wm xm
Combinação Linear das Entradas
Adaline com Uma Entrada y=w0+ w1 x1
Reta!

24/08/15 Inteligência Computacional – Renato Dourado Maia 7/36
Função Quadrática de Erro
• O objetivo do treinamento será minimizar a função de custo J(W):– Para uma condição inicial qualquer W(0), deseja-se obter
a direção do ajuste a ser aplicado ao vetor de pesos, de forma que o valor de custo a ele associado se aproxime do mínimo da função de custo J (W).
J (W )=12∑i=1
N
(d i− y i )2=
12∑i=1
N
(d i−(W⋅X i ))2=
12∑i=1
N
(d i−(WT Xi))2=
12∑i=1
N
(e i )2
Como?
24/08/15 Inteligência Computacional – Renato Dourado Maia 8/36
A Regra Delta
Qual é o significado do vetor gradiente
de uma função?
24/08/15 Inteligência Computacional – Renato Dourado Maia 9/36
-4 -3 -2 -1 0 1 2 3 42
4
6
8
10
12
14
16
18
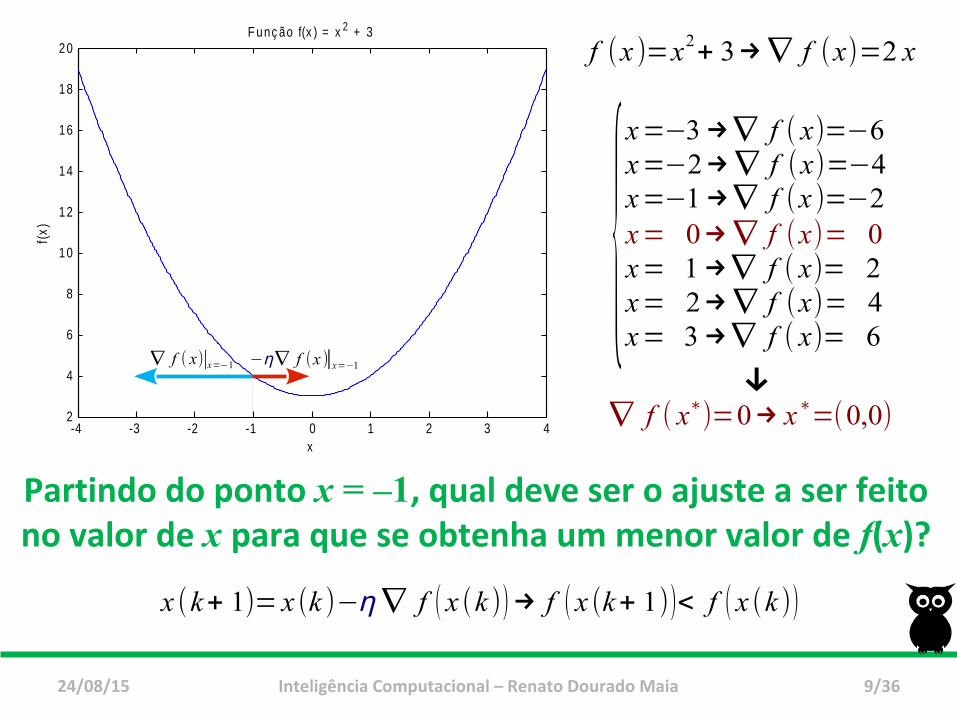
20F unç ão f(x ) = x 2 + 3
x
f(x)
f (x )=x2+ 3→∇ f (x)=2 x
{x=−3→∇ f ( x)=−6x=−2→∇ f (x)=−4x=−1→∇ f (x )=−2x= 0→∇ f (x)= 0x= 1→∇ f ( x)= 2x= 2→∇ f (x)= 4x= 3→∇ f ( x)= 6
↓∇ f ( x∗)=0→ x∗=(0,0)
Partindo do ponto x = –1, qual deve ser o ajuste a ser feito no valor de x para que se obtenha um menor valor de f(x)?
x (k+ 1)= x (k )−η ∇ f ( x (k ))→ f ( x (k+ 1))< f ( x (k ))
−η∇ f (x )|x=−1∇ f ( x)∣x=−1
24/08/15 Inteligência Computacional – Renato Dourado Maia 10/36
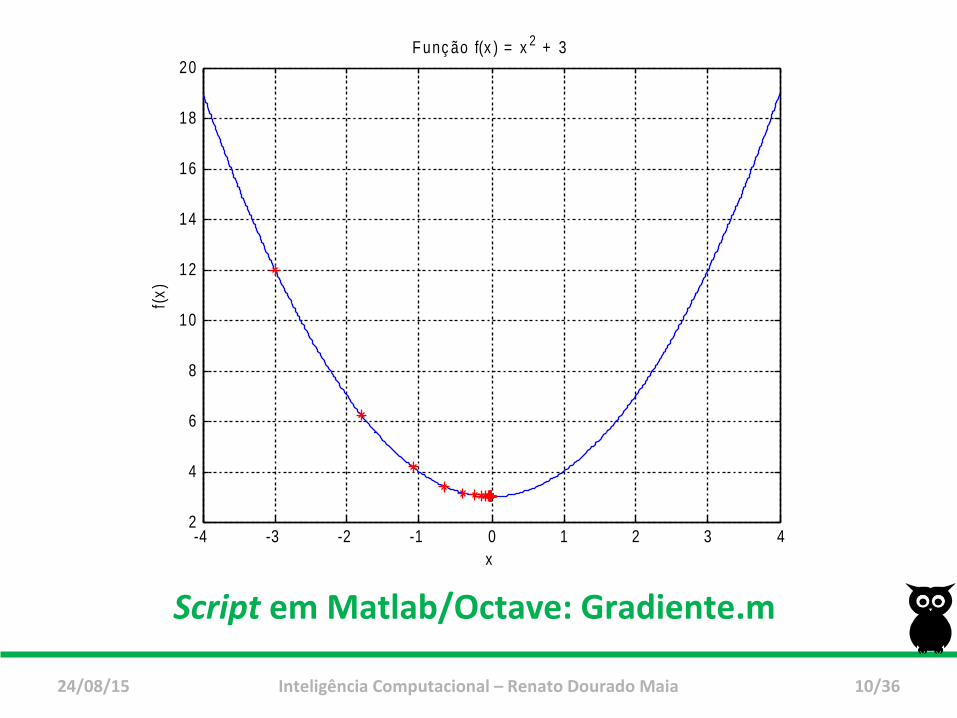
-4 -3 -2 -1 0 1 2 3 42
4
6
8
10
12
14
16
18
20F unç ão f(x ) = x 2 + 3
x
f(x)
Script em Matlab/Octave: Gradiente.m

24/08/15 Inteligência Computacional – Renato Dourado Maia 11/36
A Regra Delta
• O vetor gradiente aponta para a direção e o sentido de maior crescimento da função de custo.
• Portanto, o ajuste dos pesos deve considerar a mes-ma direção e o sentido contrário ao do vetor gradi-ente (método da descida mais íngreme) da função de custo J(W). Assim:
ΔW∝−∇ J (W (k ))=−η ∇ J (W (k ))
E agora? Contas! :-)

24/08/15 Inteligência Computacional – Renato Dourado Maia 12/36
ΔW∝−∇ J (W )→ΔW=−η ∇ J (W)
J (W )=12∑i=1
N
(d i−(WT Xi))2→∇ J (W)=
∂ J (W )
∂W=∑
i=1
N
(d i−(WT Xi ))(−X i )
∇ J (W )=∂ J (W )
∂W=∑
i=1
N
(d i−(WT X i ))(−Xi )=∑i=1
N
e i (−Xi )=−∑i=1
N
(e iX i )
∇ J (W )=−∑i=1
N
(e iX i )
ΔW=−η ∇ J (W)=η∑i=1
N
(e iX i )

24/08/15 Inteligência Computacional – Renato Dourado Maia 13/36
A Regra Delta
• O Algoritmo do Mínimo Quadrado Médio – LMS considera valores instantâneos para a função de cus-to: – Utiliza-se uma estimativa para o vetor gradiente.– A atualização dos pesos é realizada após a apresentação
de cada padrão de treinamento.
W(k+1)=W (k )+ΔW
ΔW=η e (k )X (k ) → {→ Taxa de Aprendizado (Constante Positiva)→ Erro=Saída Desejada (d )−Saída Obtida ( y )→ Padrão de Entrada

24/08/15 Inteligência Computacional – Renato Dourado Maia 14/36
ΔW∝−∇ J (W )→ΔW=−η ∇ J (W)
J (W )=12e(k )2
→∇ J (W)=∂ J (W)
∂W=e (k )
∂ e(k )∂W
e(k )=d (k )−W (k )T X (k )→∂e (k )∂W
=−X(k )
∇ J (W)=∂ J (W)
∂W=e(k )
∂ e(k )∂W
=−e (k )X(k )
ΔW=−η ∇ J (W)=η e (k )X(k )
↓W (k+1)=W (k )+ΔW=W (k )+η e (k )X(k )
{→ Taxa de Aprendizado (Constante Positiva)→ Erro=Saída Desejada (d )−Saída Obtida ( y )→ Padrão de Entrada

24/08/15 Inteligência Computacional – Renato Dourado Maia 15/36
Superfícies de Erro
• O conjunto dos (m+1) pesos a serem ajustados em uma rede neural pode ser visto como um ponto em um espaço (m+1)-dimensional – o espaço de pesos.
• Cada conjunto de pesos possui um valor associado de erro para cada padrão de entrada e também para o conjunto completo de padrões de treinamento.
• Os valores de erro para todos os conjuntos possíveis de pesos definem uma superfície no espaço de pe-sos – a superfície de erro.

24/08/15 Inteligência Computacional – Renato Dourado Maia 16/36
Superfícies de Erro
• A questão que resulta então é: – Qual é o papel do algoritmo de treinamento?
• A forma como como normalmente os algoritmos su-pervisionados operam é pela minimização de uma função de custo baseada no erro entre as saídas da rede e as saídas desejadas.– Problema de otimização, em geral não linear e irrestrito.– A superfície de erro possui, potencialmente, uma grande
quantidade de mínimos locais.– Diversos métodos de busca podem ser utilizados.

24/08/15 Inteligência Computacional – Renato Dourado Maia 17/36
-50
5
-50
50
50
w0
S uperfíc ie H ipo tét ic a de E rro
w1
Err
o
C urvas de N íve l da S uperfíc ie H ipo tét ic a de E rro
w 0
w1
-5 -4 -3 -2 -1 0 1 2 3 4 5-5
0
5
Script em Matlab/Octave: GradienteParaboloide.m

24/08/15 Inteligência Computacional – Renato Dourado Maia 18/36
Método da Descida mais Íngreme – Problemas?
-5 -4 -3 -2 -1 0 1 2 3 4 5
-1
0
1
2
3
4
F unç ão f(x ) = P (1)*x 5 + P (2)*x 4 + P (3)*x 3 + P (4)*x 2 + P (5)*x + P (6)
x
f(x)

24/08/15 Inteligência Computacional – Renato Dourado Maia 19/36
-5 -4 -3 -2 -1 0 1 2 3 4 5
-1
0
1
2
3
4
F unç ão f(x ) = P (1)*x 5 + P (2)*x 4 + P (3)*x 3 + P (4)*x 2 + P (5)*x + P (6)
x
f(x)
Script em Matlab/Octave: GradienteMomentum.m
Perigos?
Variação de η?

24/08/15 Inteligência Computacional – Renato Dourado Maia 20/36
"Convergence of Minimization Methods" from the Wolfram Demonstrations Project
http://demonstrations.wolfram.com/ConvergenceOfMinimizationMethods

24/08/15 Inteligência Computacional – Renato Dourado Maia 21/36
Algoritmo [W ] = Adaline(MaxEpocas ,η,X ,D , E)
{X ∈ℝm×N ; D ∈ ℝN×1 ; E ≥0 ; η > 0 ; MaxEpocas >0}
W← InicializaPesos(wLimite , m)
X← InserePolarizacao(X)Epoca←1ErroEpoca←0repita
ErroEpocaAnterior←ErroEpocaErroEpoca←0para i de 1 até N façayi←YAdaline (W ,Xi)
ei← d i− y iW←W+η ei Xi
ErroEpoca← ErroEpoca+e i2
fim paraErroEpoca← (ErroEpoca /N )Epoca←Epoca+1
até (| ErroEpoca−ErroEpocaAnterior|≤E ) ou (Epoca=MaxEpocas)fim algoritmo

24/08/15 Inteligência Computacional – Renato Dourado Maia 22/36
Algoritmo [ y ]= YAdaline (X ,W)
{X ∈ℝ(m+1 )×1 ; W ∈ ℝ
(m+1)×1}
y=W⋅Xfim algoritmo
Algoritmo [W ] = InicializaPesos (wLimite ,m)
{w limite > 0 ; m≥1}
para i de 1 até (m+1) façawi←U [−wLimite ,wLimite ]
fim parafim algoritmo

24/08/15 Inteligência Computacional – Renato Dourado Maia 23/36
No Laboratório de Circuitos...
• Suponha que você queira saber o valor de um resis-tor e que, para tanto, montou o circuito apresentado a seguir e tabulou os valores de tensão no resistor para diferentes valores da corrente de entrada.
i(t) R V R

24/08/15 Inteligência Computacional – Renato Dourado Maia 24/36
0 1 2 3 4 5 6 7 8 9 10-10
0
10
20
30
40
50
60
i(k )
VR
(k)
M ed iç ões - Tens ão x C orren te
Qual é o valor do resistor?

24/08/15 Inteligência Computacional – Renato Dourado Maia 25/36
Script em Matlab/Octave: AdalineReta.m
-2 -1 .5 -1 -0.5 0 0.5 1 1.5 2
-10
-5
0
5
10
E vo luç ão da A prox im aç ão O bt ida
x
f(x)
A m os tras
R eta O bt ida

24/08/15 Inteligência Computacional – Renato Dourado Maia 26/36
Script em Matlab/Octave: AdalineReta.m
0 5 10 1570
80
90
100
110
120
130
140
150
É poc a
Err
o Q
uadr
átic
o
E rro Q uadrá t ic o A c um ulado por É poc a de Tre inam ento

24/08/15 Inteligência Computacional – Renato Dourado Maia 27/36
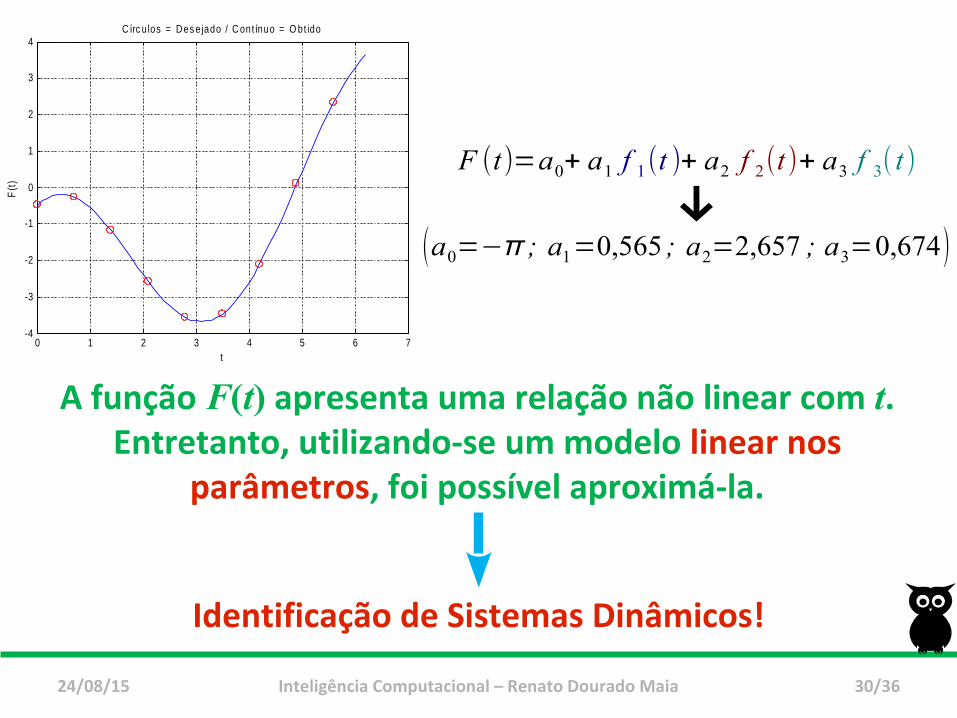
{→ f 1( t)=sen(t)→ f 2(t)=cos(t )→ f 3(t)=t
F (t)=a0+ a1 f 1(t )+ a2 f 2(t)+ a3 f 3( t)
↓(a0=−π ; a1=0,565 ; a2=2,657 ; a3=0,674)
Combinação Linear de Sinais

24/08/15 Inteligência Computacional – Renato Dourado Maia 28/36
F̂ (t )=w0+w1 f 1(t)+w2 f 2(t )+w3 f 3(t )
F̂ (t )=−3,133289+0,558704 f 1(t )+2,654937 f 2( t )+0,671218 f 3(t)
0 2 4 6-1
-0.5
0
0.5
1
S ina l 1 : f1
(t )
t
f 1(t)
0 2 4 6-1
-0 .5
0
0.5
1
S ina l 2 : f2
(t )
t
f 2(t)
0 2 4 60
2
4
6
S ina l 3 : f3
(t )
t
f 2(t)
0 2 4 6 8-4
-2
0
2
4C írc u los = D es e jado / C ont ínuo = O bt ido
t
F(t
)

24/08/15 Inteligência Computacional – Renato Dourado Maia 29/36
0 100 200 300 400 500 600 7000
5
10
15
20
25
30
35E rro Q uadrá t ic o A c um ulado por É poc a
É poc a
Err
o Q
uadr
átic
o
24/08/15 Inteligência Computacional – Renato Dourado Maia 30/36
0 1 2 3 4 5 6 7-4
-3
-2
-1
0
1
2
3
4C írc u los = D es e jado / C ont ínuo = O bt ido
t
F(t
)
F (t)=a0+ a1 f 1(t )+ a2 f 2(t)+ a3 f 3( t)
↓(a0=−π ; a1=0,565 ; a2=2,657 ; a3=0,674)
A função F(t) apresenta uma relação não linear com t.Entretanto, utilizando-se um modelo linear nos
parâmetros, foi possível aproximá-la.
Identificação de Sistemas Dinâmicos!

24/08/15 Inteligência Computacional – Renato Dourado Maia 31/36
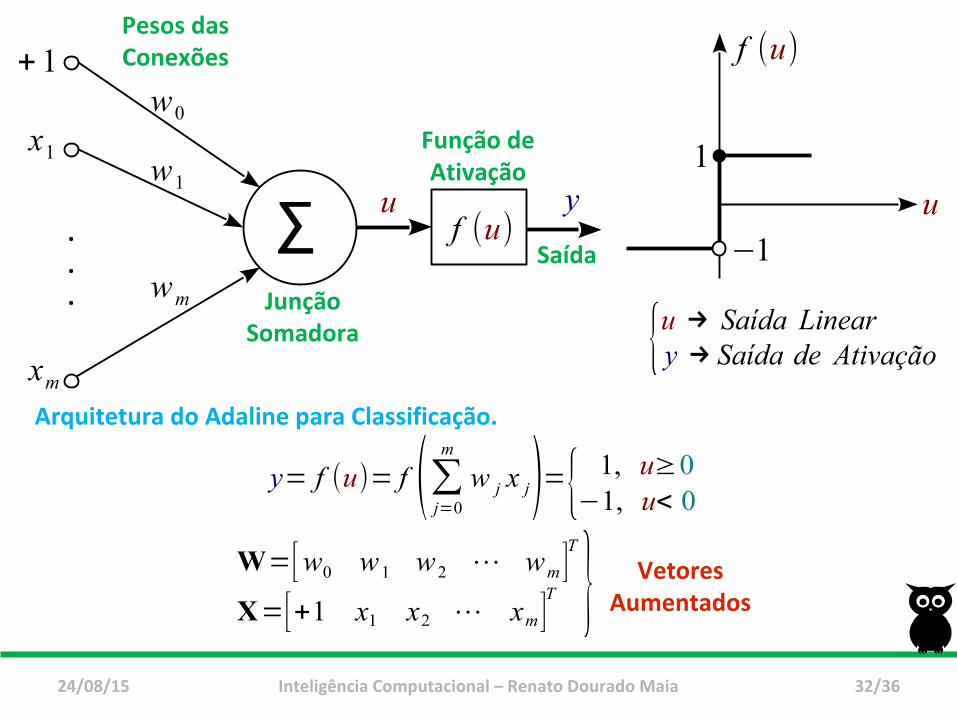
Adaline e Classificação
Pode-se utilizar o Adaline para
resolver problemas de classificação?
24/08/15 Inteligência Computacional – Renato Dourado Maia 32/36
Arquitetura do Adaline para Classificação.
W=[w0 w1 w2 ⋯ wm]T
X=[+1 x1 x2 ⋯ xm]T }
Função deAtivação
JunçãoSomadora
SaídaΣ f (u)yu
+ 1
.
.
.
w0
w1
wm
x1
xm
Pesos dasConexões
Vetores Aumentados
{u → Saída Lineary → Saída de Ativação
u
f (u)
−1
1
y= f (u)= f (∑j=0
m
w j x j)={ 1, u≥0−1, u< 0

24/08/15 Inteligência Computacional – Renato Dourado Maia 33/36
"Delta and Perceptron Training Rules for Neuron Training" from the Wolfram Demonstrations Project
http://demonstrations.wolfram.com/DeltaAndPerceptronTrainingRulesForNeuronTraining/

24/08/15 Inteligência Computacional – Renato Dourado Maia 34/36
Adaline para Classificação x Perceptron

24/08/15 Inteligência Computacional – Renato Dourado Maia 35/36
Adaline para Classificação x Perceptron

24/08/15 Inteligência Computacional – Renato Dourado Maia 36/36
Por enquanto, isso é tudo, pessoal!