inteligência competitiva na web: uma análise bibliométrica ... · destacada a relevância do...
TRANSCRIPT

1
Inteligência Competitiva na Web: uma Análise Bibliométrica do Estado da Literatura
Autoria: Maurílio Tiago Brüning Schmitt, Juliana Clementi, João Artur de Souza, Gertrudes Aparecida Dandolini, Pierry Teza, Patrícia Fernanda Dorow
Resumo: Esta pesquisa consiste numa revisão da literatura sobre a inteligência competitiva na web a partir de uma análise bibliométrica. A bibliometria é um estudo quantitativo da atividade científica. Utilizou-se as bases de dados Scopus, Engineering Village, Web of Science, EBSCO, IEEE Xplore. A partir de 968 artigos resultantes das buscas, selecionou-se 149 artigos relacionados ao tema, identificados, sobretudo pela leitura de resumos. Apresentou-se os principais artigos, os autores, países, journals, conferências que mais publicam e as palavras-chave mais utilizadas. Com base na análise dos artigos mais relevantes e citados, concluiu-se que há possibilidades de estudos na área, evidenciando-se lacunas.

2
1 Introdução
A inteligência competitiva (IC) é importante para as organizações, pode ser utilizada para antecipar mudanças no mercado, verificar ações de competidores, entender mudanças políticas, legislativas e regulatórias que podem afetar o negócio (KAHANER, 1996). Além de identificar ameaças, a IC serve para buscar oportunidades por meio do monitoramento da opinião de consumidores sobre produtos (inclusive dos concorrentes), beneficiando a geração de novas ideias.
Além das fontes usuais que a IC emprega, como entrevistas com detentores de conhecimento relevante, é possível utilizar a web para o desenvolvimento da inteligência competitiva, principalmente coletando informações em blogs, redes sociais e fóruns. Porém, verifica-se que os estudos que relacionam a IC e a web ainda são incipientes, principalmente aqueles que fazem uma ligação coerente entre os temas.
Esta pesquisa, a partir de uma análise bibliométrica, tem como objetivo identificar os principais artigos, autores com mais publicações, journals, conferências, palavras-chave relacionados ao tema IC na Web. Procura-se expandir o conhecimento na área e clarear a relação com outros temas, tais como inovação, aquisição de conhecimento e inteligência coletiva. Analisa-se os artigos mais relevantes e busca-se identificar lacunas para pesquisas futuras. O trabalho está estruturado em sete seções, incluindo esta introdução. Na próxima seção são apresentados os conceitos básicos sobre Inteligência Competitiva na Web. O método de pesquisa é explicado na terceira seção. Nas seções 4 e 5 são detalhadas as etapas de coleta de dados e de análise bibliométrica. Os artigos considerados mais relevantes são analisados na seção 6. Por fim, são apresentadas as considerações finais. 2 Inteligência competitiva na web: aspectos conceituais
Segundo Kahaner (1996, p.16), “Inteligência Competitiva é um programa sistemático
de coleta e análise da informação sobre atividades dos competidores e tendências gerais dos negócios, visando atingir as metas da empresa”. Buscam-se informações externas sobre competidores, mercado, produtos, clientes, tecnologia, ambiente, para então transformar bits em conhecimento estratégico (TYSON, 2002).
As fontes de informações da Inteligência Competitiva podem ser primárias ou secundárias. Fontes primárias são inalteradas, vêm diretamente da fonte (KAHANER, 1996), como a partir de apresentações em conferências, entrevistas com stakeholders e experts. Já as secundárias são encontradas em bancos de dados: publicações, sites, feeds, entre outros (FEHRINGER; HOHHOF; JOHNSON, 2006).
Destaca-se que “[...] um dos focos da maioria das empresas é adquirir a IC a partir da Web” (JIE; PEIQUAN, 2009, p.126). A grande dificuldade é filtrar informação relevante nesta imensa montanha de dados (TEO; CHOO, 2001). Para isso, as empresas fazem uso de técnicas como spider (CHEN; CHAU; ZENG, 2002), também chamados de crawlers, para coletar informação e utilizam a mineração de dados para a análise da informação (HEINRICHS; LIM, 2003). É importante também observar a necessidade de veículos eficazes para a disseminação da Inteligência Competitiva (MARIN; POULTER, 2004).
Ainda dentro da Web, há a possibilidade de utilizar as Redes Sociais ou Mídias Sociais como fontes de informações. Neste contexto, identifica-se o termo Sentimental Analysis (Análise Sentimental) ou também chamado de Opinion Mining (Mineração de Opinião). A “Análise Sentimental tenta identificar e analisar opiniões e emoções” (ABBASI; CHEN; SALEM, 2008, p.2); grandes oportunidades de negócio podem ser identificadas por meio da opinião das pessoas (LAU; LAI; YUEFENG, 2009).

3
Observa-se que as opiniões dos consumidores geralmente comparam os pontos fortes e fracos entre produtos com funcionalidades similares (XU et al., 2011). Desta forma, é possível utilizar estas informações para projetar produtos melhores, vender mais e aumentar a satisfação do cliente.
Destacada a relevância do tema e conceituado o termo de IC na WEB, apresenta-se a seguir o método desta pesquisa.
3 Método
O método utilizado nesta pesquisa é composto pelas etapas de coleta de dados (busca
sistemática), seleção dos artigos e análise bibliométrica. Na etapa de coleta de dados foram definidos as bases de dados, os termos de busca e
os tipos de publicações. As bases de dados utilizadas foram Scopus, Engineering Village, Web of Science, EBSCO, IEEE Xplore. Dentre os termos de busca, definiram-se os seguintes: “competitive intelligence” + web; “competitive intelligence” + internet; “competitive intelligence” + social media; “competitive intelligence” + social networks; “Intelligence 2.0”. As buscas foram realizadas nos dias 28 e 29 de fevereiro de 2012, pesquisando os termos em Títulos, Resumos e Palavras-chave. Limitou-se a artigos de journals e de conferências.
As bases de dados retornaram 1770 publicações (contando os duplicados) distribuídas da seguinte forma: Scopus (498); Engineering Village (571); Web of Science (42); EBSCO (17); IEEE Xplore (642). Após a eliminação dos duplicados, gerou-se um portfólio de 968 artigos. Na segunda etapa, foram selecionados 149 artigos relevantes sobre o assunto, com base nos Títulos, Palavras-chave e Abstracts do portfólio de 968 artigos. Foram categorizadas as palavras-chave, nome de autores, journals, nome de conferências, para então realizar a última etapa, a análise bibliométrica.
A bibliometria é “[...] um instrumento quantitativo, que permite minimizar a subjetividade inerente à indexação e recuperação das informações, produzindo conhecimento, em determinada área de assunto” (GUEDES; BORSCHIVER, 2005, p.15). Na etapa de bibliometria geraram-se gráficos relacionados à produtividade de autores, à dispersão da literatura periódica científica e dos artigos mais citados na área de inteligência competitiva na web.
Na etapa de bibliometria foram gerados gráficos relacionados à produtividade de autores, à dispersão da literatura periódica científica e dos artigos mais citados na área de inteligência competitiva na web.
Utilizando-se dessas informações, selecionou-se os artigos encontrados mais citados e relevantes para analisa-los na íntegra. Os objetivos dessa fase são o de apresentar as diferentes abordagens sobre o tema de e de identificar lacunas para futuras pesquisas. 4 Coleta de dados
Na etapa de coleta de dados foram determinados os termos de buscas (Figura 1) com
base na leitura de artigos relevantes sobre o tema Inteligência Competitiva na Web. O termo intelligence 2.0 foi buscado no intuito de verificar se ele é utilizado e está relacionado ao tema.

4
Figura 1. Palavras utilizadas na busca
As buscas foram realizadas nos dias 28 e 29 de fevereiro de 2012 nas bases Scopus, EBSCO, Engineering Village, Web of Science e IEEE Xplore. Os termos definidos na Tabela 1 foram procurados em Título de Artigos, Abstracts, Palavras-chave. Além disso, o tipo de documento foi definido como Artigo ou Conference Paper, no intuito de não perder algum conteúdo relevante que foi apresentado em conferências. A Tabela 1 apresenta o resultado das buscas realizadas nas bases de dados.
Tabela 1 Resultados das buscas
Palavra buscas \
Base
Competitive intelligence +
web
Competitive intelligence +
internet
Competitive intelligence
+ social media
Competitive intelligence
+ social
networks
Intelligence 2.0 TOTAL
SCOPUS 258 193 10 33 4 498
Engineering Village 292 223 6 42 8 571
Web of Science 23 12 1 3 3 42
EBSCO 9 5 1 2 0 17 IEEE
Explore 322 266 12 40 2 642
TOTAL 904 699 30 120 17 1770
No total foram retornados 1770 artigos, contando os duplicados. Em seguida, os
resultados de cada busca foram importados na ferramenta EndNote® para eliminação dos artigos duplicados entre bases, restando 968 publicações. Além disso, foram adicionados 2 artigos relevantes, encontrados por meio da ferramenta Google Scholar. De início, já se percebeu que o termo Intelligence 2.0 é pouco utilizado. Após esta etapa, foram identificados os artigos não relevantes sobre o assunto Inteligência Competitiva na Web. Para realizar a seleção dos artigos, foram analisados os Títulos, Palavras-chave e Abstracts. Nos casos em que se havia dúvida da pertinência de um artigo para a pesquisa, analisou-se a publicação na íntegra.
Após a seleção, montou-se um portfólio de 149 artigos e foi realizado o refinamento e padronização das referências. Com base nestes artigos é que foi feita a análise bibliométrica a seguir.
5
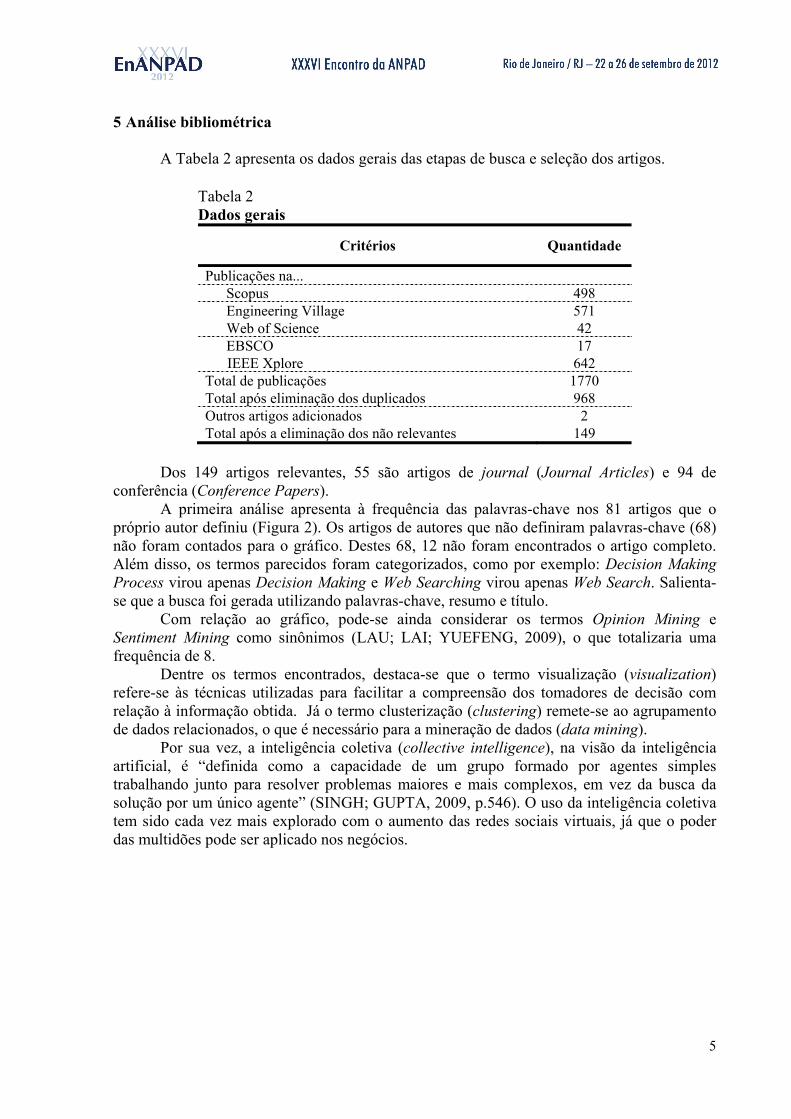
5 Análise bibliométrica A Tabela 2 apresenta os dados gerais das etapas de busca e seleção dos artigos.
Tabela 2 Dados gerais
Critérios Quantidade
Publicações na... Scopus 498 Engineering Village 571 Web of Science 42 EBSCO 17
IEEE Xplore 642 Total de publicações 1770 Total após eliminação dos duplicados 968 Outros artigos adicionados 2 Total após a eliminação dos não relevantes 149
Dos 149 artigos relevantes, 55 são artigos de journal (Journal Articles) e 94 de
conferência (Conference Papers). A primeira análise apresenta à frequência das palavras-chave nos 81 artigos que o
próprio autor definiu (Figura 2). Os artigos de autores que não definiram palavras-chave (68) não foram contados para o gráfico. Destes 68, 12 não foram encontrados o artigo completo. Além disso, os termos parecidos foram categorizados, como por exemplo: Decision Making Process virou apenas Decision Making e Web Searching virou apenas Web Search. Salienta-se que a busca foi gerada utilizando palavras-chave, resumo e título.
Com relação ao gráfico, pode-se ainda considerar os termos Opinion Mining e Sentiment Mining como sinônimos (LAU; LAI; YUEFENG, 2009), o que totalizaria uma frequência de 8.
Dentre os termos encontrados, destaca-se que o termo visualização (visualization) refere-se às técnicas utilizadas para facilitar a compreensão dos tomadores de decisão com relação à informação obtida. Já o termo clusterização (clustering) remete-se ao agrupamento de dados relacionados, o que é necessário para a mineração de dados (data mining).
Por sua vez, a inteligência coletiva (collective intelligence), na visão da inteligência artificial, é “definida como a capacidade de um grupo formado por agentes simples trabalhando junto para resolver problemas maiores e mais complexos, em vez da busca da solução por um único agente” (SINGH; GUPTA, 2009, p.546). O uso da inteligência coletiva tem sido cada vez mais explorado com o aumento das redes sociais virtuais, já que o poder das multidões pode ser aplicado nos negócios.

publiautor
Figura A segun
icam artigores Hsinchu
Fig
Comp
a 2. Frequên
nda análise s relacionad
un Chen e Ji
gura 3. Aut
Web u
SocS
SOp
Knowledge Informat
DeciDat
CompetitivCollective
Knowled
Dpetitive intellig
VSenti
BusinessCompetitive
012345678
Che
n, H
sinc
hun
ncia das pa
foi realizados à Inteliin Peiquan.
tores com m
usage miningWeb search
Webcial networksSocial mediaearch engineinion miningmanagementtion retrievalision makingta warehouseCompetitors
ve advantagee intelligence
Clusteringdge discovery
InternetData analysisgence systemVisualizationiment miningData miningText miningWeb mining
s intelligencee intelligence
Peiq
uan,
Jin
Vau
ghan
, L.
alavras-cha
ada com o gência Com
mais public
0 5
3333333333333334444
55
g,
Chu
ng, W
ingy
an
ave (corte d
intuito de mpetitiva na
cações (cor
10 15
67
11
Jie,
Zha
o
Bau
mga
rtner
, R.
de mínimo 3
identificar a Web (Figu
rte de no mí
5 20
17
Dey
, L.
Tan,
A. H
.
3 repetiçõe
os autoresura 3). Dest
ínimo 3)
25 30
27
6
es)
s que maistacam-se os
6
s s

UtilizNos Foramcitad
F
quan
Outra anzaram-se ascasos em qm considera
dos em duas
Figura 4. A Com bas
ntas vezes es
Figu
A
CHUNG; C
SRINIVA
012345678
nálise realizas bases de que o artigoados os arti
s bases, cons
Artigos mai
se nos gráficstes autores
ura 5. Ocor
CRIMGREGG;
PAWA
TAN
ARAYA; SILVVAUGHAN
CRHEIN
GOTPANT; SR
CHEN; NUNAJ
CHEN; CH
ASAN; MENCZHONG; JIM
Che
n, H
sinc
hun
Peiq
uan,
Jin
ada se referdados Scop
o não era enigos citadossiderou-se o
is citados (c
cos de autor apareceram
rrências do
MMINS et al.; WALCZAK
AR; SHARDATAN et al.
N; FOO; HUILIN et al.
PIKASVA; WEBER; GAO; KIPP
DOURONIN et al.
NRICHS; LIMTTLOB et al.RINIVASANAMAKER JRJINDAL; LIUHAU; ZENGTEO; CHOO
CZER; PANTMING; YIYU
Vau
ghan
, L.
Chu
ng, …
Jie
Zhao
re aos artigopus e IEEEncontrado ns no mínimoo maior núm
corte de no
res que maim (Figura 5)
os autores c
0
, 1999, 2007, 1997, 2004, 2002, 2008, 2005, 2004, 2006, 2004, 1994, 2003, 2004, 2006, 2005, 2006, 2002, 2001, 2005, 2002
Jie,
Zha
o
Bau
mga
rtner
, R.
Dey
, L.
os mais citaE Xplore panestas baseso 10 vezes emero.
o mínimo 10
is publicam).
com mais p
10 20
1010111111
1313
151516
1818
Tan,
A. H
.
ados por outara checar s, verificou-em uma das
0)
m e dos mais
ublicações
30 40
2731
3439
4141
NúmerArtigos
Ocorrêno Gradas Cit
tros autoreso número d-se a Web s bases. Par
s citados, rel
e citações
50 60
46
ro de s
ências afico tações
7
(Figura 4).de citações.of Science.a os artigos
lacionou-se
70
70
7
.
.
. s
e

do prnúme
Figu publipossu(SCIjourndefinmeno
Procurourimeiro autero de publi
ura 6. Publi
Dos 55 icações: Joui uma quMAGOLABnal; quanto nido pela CAos elevado -
0
5
10
15
20
25
30
35
40
45
Esta
dos U
nido
sC
hina
u-se tambémor (Figura 6icações.
icações por
artigos dournal of Sualificação B, 2012). maior o SJRAPES, é B5- com peso
Espa
nha
Índi
aC
anad
áSi
ngap
ura
Ale
man
ha
m verificar a6). Destaca
r país dos a
de Journal,Software e
4, o piorO SJR in
R, melhor é5, sendo quzero (CAPE
Ale
man
haR
eino
Uni
doÁ
ustri
aB
rasi
lFi
nlân
dia
as publicaçõa-se que os
rtigos selec
, examinoue Decision r na escal
ndica a influé o journal. ue o A1 é oES, 2012).
Irã
Itália
Japã
oM
alás
ia
ões por paísEstados Un
cionados (n
u-se que aSupport S
a de 1 a uência cienO estrato in
o mais eleva
Fran
çaH
ong
Kon
gH
ungr
iaR
omên
iaA
ustrá
lia
s. Foi consinidos e a C
n=149)
apenas 2 pSystems. O
4, com Sntífica médndicativo deado; A2; B
Aus
trália
Bós
nia
e …C
hile
Col
ômbi
aC
órei
a do
Sul
iderada a Unhina possue
periódicos O Journal oSJR 0,029
dia dos artie qualidade 1; B2; B3;
Cro
ácia
Din
amar
caG
réci
aIr
land
a
8
niversidadeem o maior
tiveram 3of Software
em 2011gos de umdo journal,B4; B5; C,
Portu
gal
Taiw
an
8
e r
e
m , ,

(SCICom obtiv(Figu
Figu TechComp 6 An
para no de autortema
In
Ha
Já o DeMAGOLAB
mputação (CACom bas
veram um mura 7).
ura 7. Confe
Verificouhnology, Texpetitive Inte
nálise dos a
Com basentão se reaesenvolvim
A referênres tratam das relaciona
Workshop o
nternational ST
Internati
Internation
Internat
InternationaMining a
Manag
awaii Internati
ecision SupB, 2012). OAPES, 2012se nos 94 a
maior númer
erências co
u-se que ext Mining, elligence, B
artigos
se na análisalizar uma a
mento da Intencia mais cida importânados na pers
n Intelligent IApplic
Symposium onTechnology A
ional Conferen
nal Conference
tional ConfereKnowledge
al Conferenceand their Busingement Inform
ional Confere
pport SysteO estrato C2). artigos de Cro de trabalh
om mais art
estas conferWeb Minin
Business Inte
se biblioméanálise sobreligência Coitada é a ob
ncia da webspectiva de
Information Tation
n Intelligent InApplication
nce on Web In
e on Informati
ence on Informe Managemen
e on Data, Texness Applicatimation Engine
nce on System
ems tem quCAPES é A
Conferênciahos apresen
tigos apres
rências posng, Social Melligence.
étrica, examre a abordagompetitiva.
bra dos autob para o des
negócio: w
0
Technology
nformation
ntelligence
ion Fusion
mation and t
xt and Web ions and eering
m Sciences
ualificação 1 para Inter
a, gerou-se ntados sobre
entados (co
ssuem tópiMedia, Opin
minou-se os gem utilizad
res Zhong, senvolvimenweb mining,
1
Q1, com rdisciplinar
um gráficoe Inteligênci
orte de no m
cos em Danion Mining
artigos mada por cada
Jiming e Ynto da intel, agentes w
2 3
SJR 0,054r e A2 para
o das conferia Competit
mínimo 3)
ata Miningg, Sentimen
is citados ea autor sobre
Yuyu (2002)ligência e d
web, interaçã
3 4
9
4 em 2011Ciência da
rências quetiva na Web
g, Decisionnt Analysis,
e relevantese o uso web
, na qual osdiscutem osão homem-
5
9
a
e b
n ,
s b
s s -

10
web, redes de conhecimento, infraestrutura e tecnologias emergentes, gestão da informação provinda da web, computação ubíqua, inteligência social, recuperação da informação.
Teo e Choo (2001) apresentam por meio de estudos empíricos que há uma relação entre a qualidade da informação da Inteligência Competitiva e a Internet. Os autores afirmam que “apesar das preocupações sobre a confiabilidade da informação publicada na internet, ela possui um dos melhores custos-benefícios para obtenção da informação" (TEO; CHOO, 2001, p. 80). Esta importância do uso da Internet como fonte para a inteligência competitiva é corroborada no artigo de Tan, Foo e Hui (2002). Os autores descrevem formas embrionárias do monitoramento da web, mesmo considerando que a “natureza dinâmica da web torna a tarefa de monitorar complicada e consumidora de tempo” (TAN; FOO; HUI, 2002, p. 225). Destaca-se que o potencial uso da internet para o desenvolvimento da IC já era discutido em 1994 (Cronin et al., 1994).
Neste contexto é que se identifica a importância dos crawlers para o desenvolvimento de ferramentas de inteligência competitiva, já que os crawlers facilitam a coleta de dados (SRINIVASAN; MENCZER; PANT, 2005). No artigo de Chen, Chau e Zeng (2002), por exemplo, é introduzido um crawler (também chamado de spider) específico para desenvolver a Inteligência Competitiva, permitindo a busca de páginas relevantes de acordo com as especificações do usuário. Ainda, Pant e Srinivasan (2006) examinaram os efeitos que o contexto de ligação (link context) das páginas causa nos crawlers focados na coleta de um único tópico (topical crawlers).
Um exemplo de coleta de dados é o do monitoramento de patentes que estão disponibilizadas na Internet, tratado no artigo de Dou (2004). O autor apresenta uma aplicação que permite o desenvolvimento da inteligência competitiva e do pensamento inovador por meio da busca e seleção de patentes em bancos de dados gratuitos. Além disso, essa coleta auxilia os usuários a compreenderem a relação entre os diferentes conjuntos de patentes (DOU, 2004).
No artigo de Gregg e Walczak (2007, p. 111) é apresentado um sistema de extração adaptativo que “deve ser resiliente, de modo que tenha a capacidade para continuar funcionando adequadamente, mesmo quando há mudanças nas páginas Web”. Esta solução é interessante, pois além de permitir o reuso auxilia na precisão dos dados.
Após a fase de coleta de dados na Inteligência Competitiva, é necessário que haja a mineração de dados. Heinrichs e Lim (2003, p. 104) afirmam que se “[...] podem usar estas ferramentas de inteligência e mineração de dados para oportunidades de mercado, monitorar o desempenho do produto, entender mudanças nas exigências do cliente e administrar o relacionamento com o cliente em tempo real”. Tan et al. (2004) abordam a questão da personalização, em que se define o monitoramento da informação relevante de acordo com o interesse e o perfil do usuário.
Um exemplo de framework para a descoberta de conhecimento na web apresentado é o de Chung, Chen e Nunamaker (2005). Ele incorpora as fases de coleta de dados, mineração, algoritmos de clusterização e visualização da informação. Na visão dos autores, este framework alivia o excesso de informações, permite a descoberta de inteligência de negócio a partir da web e busca melhores métodos para a visualização dessas informações.
Com relação aos artigos identificados que tratam do uso das mídias sociais (blogs, fóruns, redes sociais), destaca-se o artigo de Dey et al. (2011). Os autores afirmam que a “inteligência competitiva não está restrita apenas a coleta do conhecimento sobre o consumidor” (DEY et al., 2011, p. 1). Existem outras formas em que o conteúdo das mídias sociais pode contribuir com a inteligência competitiva, destacadas na Figura 8.

11
Figura 8. Monitoramento das mídias sociais Fonte: o autor (2012), baseado em Dey et al. (2011)
A grande dificuldade apontada por Dey et al. (2011) é lidar com o conteúdo web que
não interessa, removendo o chamado noise. Esse conteúdo caracteriza-se por propagandas, menus, links e também por elementos da linguagem que são difíceis de interpretação. Os autores ainda apresentam estudos de caso sobre a detecção de promoções de concorrentes com base no Twitter e da popularidade de marcas no Facebook.
Sobre outros artigos mais recentes (publicados no ano 2011), sobressai-se o artigo de Xu et al. (2011). Nesta publicação, os autores apontam uma lacuna de estudo, ao afirmarem que
Já existem estudos sobre a mineração das opiniões dos consumidores. Porém, estes estudos focam principalmente na identificação das polaridades do sentimento dos consumidores com relação a produtos. O problema mais importante da IC – coletar e analisar a informação sobre competidores para identificar riscos potenciais o quanto antes for possível e assim planejar estratégias - não foi tão bem estudado (XU et al., 2011, p. 743).

12
Nesse contexto, os autores propõem e aplicam um modelo que extrai opiniões de consumidores do site de vendas Amazon e exibe a partir de grafos (mapas comparativos) os resultados para a tomada de decisão do gestor (XU et al., 2011).
Outro artigo que merece destaque é o de Jie e Peiquan (2011), em que os autores apontam mais uma lacuna de estudo:
Existem poucos trabalhos focados na avaliação da credibilidade da inteligência competitiva. A maioria dos trabalhos anteriores relacionados concentra-se na credibilidade da informação. Basicamente, a inteligência competitiva deriva da informação. Mas a credibilidade da inteligência competitiva é diferente da credibilidade da informação. Existe relação entre esses dois tipos de credibilidade, que ainda é uma questão não descoberta na pesquisa sobre inteligência competitiva (JIE; PEIQUAN, 2011, p. 1515).
Os autores propõem um framework para extração da inteligência competitiva da web,
utilizando redes sociais na avaliação da credibilidade da informação e assim tentam melhorar a eficácia do processo. Como citado pelos autores, os detalhes da implementação e do experimento não são discutidos nesse artigo. 7 Considerações finais
Esta pesquisa teve como objetivo fazer uma análise bibliométrica da literatura sobre
Inteligência Competitiva na Web. Identificou-se os artigos mais citados, autores, journals e conferências com mais publicações, bem como as palavras-chave relacionadas ao tema IC na Web mais frequentes. Dentre os autores com mais publicações sobre o tema, destacaram-se os pesquisadores Hsinchun Chen (University of Arizona) e Jin Peiquan (University of Science and Technology of China). Identificou-se que a maioria dos artigos é produzida em Universidades localizadas nos Estados Unidos e China. A conferência que teve mais trabalhos apresentados foi a Hawaii International Conference on System Sciences. Esta conferência tem foco em tecnologias que apoiam a tomada de decisão (como data/web/text mining) e sistemas de conhecimento. Nesse sentido, analisando o número de publicações e eventos, pode-se considerar que os Estados Unidos são responsáveis pela maior produção de artigos sobre o tema. Com relação à frequência das palavras-chave, além dos termos inteligência competitiva (competitive intelligence) e inteligência de negócio (business inteligence), destaca-se os termos variados de mineração de dados (web, data, text, sentiment, opinion mining), descoberta de conhecimento (knowledge discovery), inteligência coletiva (collective intelligence), redes sociais (social networks), mídias sociais (social media), entre outros. Além disso, verificou-se que os journals com mais publicações são o Journal of Software e o Decision Support Systems. O journal Decision Support Systems é uma referência para estudos relacionados à atividade de apoio à decisão, considerado pela CAPES como um periódico de qualis A1 e A2 (os níveis mais altos).
Após a análise bibliométrica, os artigos mais citados e relevantes foram analisados na íntegra, no intuito de compreender a abordagem utilizada por cada autor. Destaca-se que o foco de muitos autores está na tecnologia e na elaboração de frameworks. Ainda, existem estudos que mostram a importância do uso da web para o desenvolvimento da inteligência competitiva, inclusive com a mineração da opinião dos consumidores em mídias sociais. Essas opiniões auxiliam no monitoramento das estratégias dos concorrentes, acontecimentos do mundo real e eventos promocionais.

13
Com base neste trabalho sobre inteligência competitiva na web, podem-se direcionar estudos futuros relacionando o tema com a inovação, o uso das redes sociais como fonte de informações e as técnicas de mineração de dados.
Dentre as lacunas identificadas estão a avaliação da credibilidade da inteligência competitiva desenvolvida a partir da web, o uso da opinião dos consumidores para avaliar riscos e criar estratégias, e a questão da visualização dos dados. Verificou-se que ainda existem dificuldades para filtrar as informações relevantes da web e a eliminação do chamado noise.
Referências ABBASI, A.; CHEN, H.; SALEM, A. Sentiment analysis in multiple languages: Feature selection for opinion classification in Web forums. ACM Trans. Inf. Syst. [S.I.], v. 26, n. 3, p. 1-34, 2008. ARAYA, S.; SILVA, M.; WEBER, R. A methodology for web usage mining and its application to target group identification. Fuzzy Sets and Systems [S.I.], v. 148, n. 1, p. 139-152, 2004. CAPES. WebQualis. Disponível em: <http://qualis.capes.gov.br/webqualis/>. Acesso em: 20 mar. 2012. CHEN, H.; CHAU, M.; ZENG, D. CI Spider: A tool for competitive intelligence on the Web. Decision Support Systems [S.I.], v. 34, n. 1, p. 1-17, 2002. CHUNG, W.; CHEN, H.; NUNAMAKER JR, J. F. A visual framework for knowledge discovery on the web: An empirical study of business intelligence exploration. Journal of Management Information Systems [S.I.], v. 21, n. 4, p. 57-84, 2005. CRIMMINS, F. et al. TetraFusion: information discovery on the Internet. Intelligent Systems and their Applications, IEEE [S.I.], v. 14, n. 4, p. 55-62, 1999. CRONIN, B. et al. The internet and competitive intelligence: A survey of current practice. International Journal of Information Management [S.I.], v. 14, n. 3, p. 204-222, 1994. DEY, L. et al. Acquiring competitive intelligence from social media. In: Joint Workshop on Multilingual OCR and Analytics for Noisy Unstructured Text Data, Beijing. 2011 Joint Workshop on Multilingual OCR and Analytics for Noisy Unstructured Text Data, J-MOCR-AND 2011, in Conjunction with the 11th International Conference on Document Analysis and Recognition, ICDAR 2011. DOU, H. J. M. Benchmarking R&D and companies through patent analysis using free databases and special software: A tool to improve innovative thinking. World Patent Information [S.I.], v. 26, n. 4, p. 297-309, 2004. FEHRINGER, D.; HOHHOF, B.; JOHNSON, T. State of the art: competitive intelligence. A Competitive Intelligence Foundation, Society of Competitive Intelligence Professionals, Alexandria, VA, Competitive Intelligence Foundation Research Report, 2006.

14
GOTTLOB, G. et al. The Lixto data extraction project - Back and forth between theory and practice, Paris. Proceedings of the Twenty-third ACM SIGMOD - SIGACT - SIGART Symposium on Principles of Database Systems, PODS 2004. 2004. p.1-12. GREGG, D. G.; WALCZAK, S. Exploiting the information web. IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews [S.I.], v. 37, n. 1, p. 109-125, 2007. GUEDES, Vânia L. S.; BORSCHIVER, Suzana. Bibliometria: uma ferramenta estatística para a gestão da informação e do conhecimento, em sistemas de informação, de comunicação e de avaliação científica e tecnológica. In: ENCONTRO NACIONAL DE CIÊNCIA DA INFORMAÇÃO, 6, 2005, Salvador. HEINRICHS, J. H.; LIM, J. S. Integrating web-based data mining tools with business models for knowledge management. Decision Support Systems [S.I.], v. 35, n. 1, p. 103-112, 2003. JIE, Z.; PEIQUAN, J. Towards the extraction of intelligence about competitor from the web. In: World Summit on the Knowledge Society, Chania, Crete, Greece. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer Verlag, 2009. p.118-127. _________________. Extraction and credibility evaluation of web-based competitive intelligence. Journal of Software [S.I.], v. 6, n. 8, p. 1513-1520, 2011. JINDAL, N.; LIU, B. Identifying comparative sentences in text documents, Seatttle, WA. 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2006. p. 244-251. KAHANER, Larry. Competitive intelligence: how to gather, analyze, and use information to move your business to the top. Nova York: Simon & Schuster, 1996. LAU, R. Y. K.; LAI, C. L.; YUEFENG, L. Leveraging the web context for context-sensitive opinion mining. In: International Conference on Computer Science and Information Technology, 8-11 Ago. 2009. p. 467-471. LIN, C. Y. et al. SmallBlue: People mining for expertise search. IEEE Multimedia [S.I.], v. 15, n. 1, p. 78-84, 2008. MARIN, J.; POULTER, A. Dissemination of competitive intelligence. Journal of Information Science [S.I.], v. 30, n. 2, p. 165-180, 2004. PANT, G.; SRINIVASAN, P. Link contexts in classifier-guided topical crawlers. Knowledge and Data Engineering, IEEE Transactions on [S.I.], v. 18, n. 1, p. 107-122, 2006. PAWAR, B. S.; SHARDA, R. Obtaining business intelligence on the Internet. Long Range Planning [S.I.], v. 30, n. 1, p. 110-121, Fev. 1997. PIKAS, C. K. BLOG searching for competitive intelligence, brand image, and reputation management. Online (Wilton, Connecticut) [S.I.], v. 29, n. 4, p. 16-21, 2005.

15
SCIMAGOLAB. SCImago Journal & Country Rank. Disponível em: <http://www.scimagojr.com/>. Acesso em: 20 mar. 2012. SINGH, V. K.; GUPTA, A. K. From artificial to collective intelligence: Perspectives and implications. In: International Symposium on Applied Computational Intelligence and Informatics, 2009, p.545-550. SRINIVASAN, P.; MENCZER, F.; PANT, G. A general evaluation framework for topical crawlers. Information Retrieval [S.I.], v. 8, n. 3, p. 417-447, 2005. TAN, A. H. et al. Towards personalised web intelligence. Knowledge and Information Systems [S.I.], v. 6, n. 5, p. 595-616, Set. 2004. TAN, B.; FOO, S.; HUI, S. C. Web information monitoring for competitive intelligence. Cybernetics and Systems [S.I.], v. 33, n. 3, p. 225-251, 2002. TEO, T. S. H.; CHOO, W. Y. Assessing the impact of using the Internet for competitive intelligence. Information and Management [S.I.], v. 39, n. 1, p. 67-83, 2001. TYSON, K. Guide to competitive intelligence: gathering, analyzing, and using competitive intelligence. Chicago: Kirk Tyson, 2002. VAUGHAN, L.; GAO, Y. J.; KIPP, M. Why are hyperlinks to business Websites created? A content analysis. Scientometrics [S.I.], v. 67, n. 2, p. 291-300, Maio 2006. XU, K. et al. Mining comparative opinions from customer reviews for Competitive Intelligence. Decision Support Systems [S.I.], v. 50, n. 4, p. 743-754, 2011. ZHONG, N.; JIMING, L.; YIYU, Y. In search of the wisdom web. Computer [S.I.], v. 35, n. 11, p. 27-31, 2002.