instrumentacao controle avancado renato spandri
TRANSCRIPT

1
Controle Avançado
Renato Spandri
agosto 2006

2
Estas notas são uma versão atualizada de vários textos anteriores, utilizados para os cursos de engenharia eletrônica e engenharia de processamento. O texto foi elaborado de modo a apresentar os conceitos de controle de um modo simples. O controle avançado é uma área de engenharia que está acontecendo de maneira intensa na PETROBRÁS. A contribuição das diversas áreas de engenharia para as questões de controle de processos é muito importante, o que motivou o preparo de um texto sem formalismos ou detalhes matemáticos, um texto dedicado aos que ainda não trabalhem com controle. Para os profissionais particularmente interessados no assunto, há quantidade grande de bons textos para leitura (alguns mencionados nestas notas) e que exploram minuciosamente todas as particularidades da teoria de controle de processos. Esta versão foi especialmente revisada para o curso de aperfeiçoamento de engenharia, turma de 2006. Na revisão, foram muito importantes os comentários e sugestões das turmas anteriores; envio a todos os engenheiros dessas turmas um grande abraço de agradecimento e um incentivo para que construam uma carreira sempre produtiva e muito feliz. Renato Spandri REPLAN – agosto 2006.

3
(1) Controle avançado: Antigamente só existiam controladores pneumáticos. Com recurso tão limitado, podia ser controlada apenas uma variável, manipulando-se (alterando-se) outra: por exemplo, controlar temperatura, manipulando abertura de válvula. As figuras seguintes mostram controladores pneumáticos:
[1] Coughanowr, D.R., Koppel, L.B. (1965): Process Analysis and Control. Mc Graw Hill, New York.

4

5
A lei natural desses dispositivos, montados com bico de ar, palhetas e alavancas, era uma lei de proporcionalidade (braço de alavancas) ao erro da variável controlada. Incorporando-se foles, o dispositivo passava a ter também comportamento adicional, proporcional à soma acumulada (integral) do erro. Nessa época, portanto, o controle era mono-variável e do tipo PI (proporcional + integral). Tudo mais era considerado um controle avançado (complexo, muito difícil de conseguir com dispositivos mecânicos). Tudo evoluiu. Hoje os controladores são computadores, o que permite fazer muitos tipos de cálculos. Os computadores podem funcionar como controladores do tipo PI (cálculos PI), podem trabalhar como controladores relativamente simples (cálculos simples) ou podem ser controladores bastante complexos (cálculos não tão simples). Daquela época pioneira, ficou o termo: avançado. Se o computador executar cálculos PI será considerado controlador PI; se o computador fizer qualquer outro tipo de cálculo, pode ser considerado controlador elaborado (avançado).

6
(2) elementos do controle clássico:
(2.1) representação de sistemas A representação matemática de um sistema (processo) é importante em controle. Um tanque para aquecimento de líquido será usado como exemplo.
Uma corrente de líquido é alimentação para um tanque. A vazão de líquido é w e sua temperatura é Ti. A vazão de entrada de líquido é igual à vazão de saída (balanço de massa em regime estacionário do tanque). Um fluido é usado para aquecimento da massa de líquido no tanque até a temperatura T. Não vai se supor que o sistema esteja em regime térmico permanente. Usando-se o balanço térmico do regime dinâmico, ou seja:

7
qTTwdtdT
i +−= )(CV)C( PPρ
Admitem-se propriedades constantes (massa e calor específicos) e apenas os termos térmicos do balanço de energia são levados em conta (termos predominantes em relação aos de energia mecânica). Uma referência termodinâmica conveniente e o uso de entalpias são suficientes para o propósito de modelagem.
O calor trocado é um grau de liberdade na operação do tanque. Abrindo-se a válvula de fluido de aquecimento, a temperatura do tanque sobe, passando por um transiente de aumento até um nível térmico final permanente e mais elevado. Fechando-se a válvula de fluido de aquecimento, a temperatura do tanque cai, passando por um transiente de diminuição até um nível térmico definitivo e mais baixo. Por enquanto não se considera qualquer controlador. Pode-se analisar o tanque sem controle para verificar seu comportamento ao longo do tempo (dinâmica) em consequência de alterações manuais na válvula de fluido de aquecimento, ou seja, no calor trocado. Se não houver alteração no calor trocado na camisa (válvula de fluido de aquecimento com abertura constante) nem alteração na temperatura da corrente de entrada, a temperatura do tanque fica constante e pode se escrever a equação de balanço térmico no estado estacionário (derivada temporal da temperatura nula):
( ( )ρV)C CP PdTdt
w T T qsis s s= = − +0
O índice s nas variáveis indica estado estacionário (steady-state). Usando o artifício matemático de subtrair a segunda expressão da primeira, resulta:
( ( ) ( ) ( ) ( )ρV)C C CP P Pd T T
dtw T T w T T q qs
i i s ss
−= − − − + −

8
Fazendo a seguinte mudança de notação (variáveis cheias substituídas por variáveis de desvio em relação ao estado estacionário):
y T Ts= − desvio da temperatura do tanque
sqqu −=′ desvio do fluxo térmico na camisa
d T Ti i s= − desvio da temperatura de entrada
a equação de balanço fica:
(ρV)C C CP P Pdydt
w d w y u= − + ′ ou (ρV)
wdydt
d y uwCp
= − +′
Redefinindo convenientemente algumas das variáveis do sistema:
resulta uma equação diferencial de primeira ordem com coeficientes constantes:
τ dydt
y u d+ = +
Essa equação expressa o comportamento dinâmico do tanque. Conforme u (desvio do fluxo térmico através das paredes da camisa) ou d (desvio de temperatura da corrente de entrada no tanque) variam, a solução da equação diferencial fornece a variação temporal de y (desvio de temperatura no tanque, ou seja, da corrente de saída).
Como toda equação diferencial de primeira ordem com coeficientes constantes, a solução dessa equação requer também a especificação das condições iniciais de temperatura.
τ ρ=
Vw
tempo de residência no tanque
u uwC p
=′
variável "normalizada"

9
Estando o tanque em estado estacionário inicial, temos o seguinte problema matemático a ser resolvido (ao longo do tempo):
τ dydt
y u d+ = +
com condições iniciais: t = 0 ⇒ y = 0 ( )T Ts= Uma forma muito comum e útil de representação do sistema é através de uma figura como a seguinte:
processo deaquecimento
yu
d
O tanque de aquecimento (o processo) é representado através de uma caixa ou bloco. Ignoram-se os detalhes do processo. Indicam-se com flechas de entrada as variáveis que se alteram independentemente do comportamento do tanque (variáveis independentes ou entradas), como o fluxo térmico através da camisa ou a temperatura da corrente de alimentação. Indicam-se com flechas de saída as variáveis cujas alterações dependem do comportamento do tanque frente às variações de entrada. Essas variáveis são dependentes (saídas), como a temperatura da massa de líquido no tanque. A figura é chamada diagrama de blocos do sistema e é uma representação abstrata, pictórica e de acordo com a notação de teoria de sistemas. Ela apenas nos dá uma idéia geral das relações de causa e efeito do processo que estudamos. Um bom exemplo de ocorrência nas variáveis de entrada é o seguinte:
• aumento súbito de uma unidade do fluxo térmico para o tanque (u = 1); • temperatura da corrente de entrada constante (d = 0).

10
Como prever o efeito dessas entradas, dessas causas?
u
t
y
t
?1
Manter constante a temperatura do líquido da corrente de entrada implica d=0 porque d é o desvio em relação ao estado estacionário inicial. Por outro lado, foi alterado o fluxo térmico, pela abertura da válvula de líquido de aquecimento para a camisa. O fluxo se alterou em uma unidade, ou seja, a variável de desvio u subiu uma unidade de uma só vez. Essa variação é chamada degrau unitário (observe-se o aspecto de degrau da primeira figura). Quanto à variável de saída, podemos no máximo ter alguma intuição sobre sua evolução no tempo (dinâmica do sistema). Aumentando o fluxo térmico, aumenta a temperatura do tanque. Mas, com que rapidez e em quantas unidades de temperatura vai se alterar a variável y (desvio em relação ao estado estacionário inicial)?
Para responder a essa pergunta, temos que resolver a equação diferencial.
τ dydt
y u d+ = +
com: d = 0 e u = 1
Uma das diversas formas de resolver a equação é a seguinte:
τ dydt
y+ = 1 e sendo: τ τdydt
y d ydt
y+ = −−
+ =( )1 1

11
⇒ d y
ydt( )1
1−
−= −
τ
Integrando a última expressão entre os limites t = 0 com y = 0 (inicio da perturbação do sistema) e t = t com y = y (momento genérico):
ln ( )1 − = −y tτ ⇒ y e
t
= −−
1 τ
A última expressão é a solução matemática do problema, sendo uma função assintótica (exponencial crescente) cujo gráfico vem a seguir.
Ganho é o quociente de duas variações: a variação total da saída, após o processo ter atingido novo estado estacionário, dividida pela variação total da entrada, que foi provocada num instante, instante esse que foi assumido como o inicial. A diferença entre o novo estado estacionário da saída e a saída inicial dividida pela diferença de variação da entrada é o ganho. Ele tem unidades de engenharia, por exemplo: oC / (kcal/h)
A constante de tempoτ , que no exemplo é um tempo de residência, aparece na solução da equação diferencial. Substituindo na equação de solução o tempo t por τ , tem-se:
63.0111 1 =−=→−=→−= −−−
eyeyeyt
ττ
τ
Isso mostra que a constante de tempo de primeira ordem, associada a uma equação diferencial também de primeira ordem (daí o nome da constante) é o tempo que transcorre desde o momento em que a temperatura do tanque

12
começa a subir até o instante em que chega a 63% da resposta total final (a do estado estacionário).
Esse exemplo pode ser generalizado para incluir o aspecto de ganhos que nem sempre são unitários e para a importante questão de tempo morto entre a alteração de variável de entrada e o início da consequente alteração de variável de saída. No caso geral, o gráfico da solução é o dado na figura seguinte:
Os sistemas químicos envolvem balanços. O balanço de massa envolve uma derivada temporal da massa, ou do volume (se a densidade é constante) ou da altura (se a densidade é constante e a área de seção transversal também).
Aww
dtdhww
dtdAhww
dtdVww
dtVdww
dtdm iii
ii ρρρρ ----- =→=→=→=→=
O balanço de energia envolve uma derivada temporal de temperatura. Nos dois casos, as equações diferenciais resultantes têm uma derivada primeira, motivo por que os sistemas são denominados de primeira ordem. Para perturbação do tipo degrau unitário na entrada, a saída dos sistemas químicos tem o comportamento típico mostrado no gráfico acima. O acúmulo de massa ou energia é progressivo e assintótico. Há uma demora inicial (tempo

13
morto ou dead time, atraso de resposta ou delay time - td) devido a uma não instantaneidade, típica de qualquer processo. Há também uma inércia típica de qualquer sistema e medida pela constante de tempoτ (constante de tempo de equação diferencial de primeira ordem). Há um ganho, expresso pelo quociente entre a variação total final da variável de saída dividida pela variação total inicial da variável de entrada. Outros sistemas, mecânicos ou elétricos, são modelados com equações de ordem mais elevada porque envolvem derivadas superiores (normalmente de ordem dois). Um sistema de massa que oscila, presa a uma mola e sujeita a um atrito amortecedor, pode ser modelado pela equação:
fkxdtdxC
dtxdmfkx
dtdxC
dtxdm =++⇒+−−=
2
2
2
2
onde aparece a lei de Newton (massa vezes aceleração, que é uma derivada segunda), a lei de atrito (proporcional à velocidade, que é uma derivada primeira), a lei de Hooke (constante de mola vezes deslocamento) e uma força de excitação do sistema f. Um bom exemplo é o de uma suspensão de automóvel. Um circuito com fonte de tensão elétrica, resistência, capacitor e indutor em série, que pode ser modelado pela equação:
EiCdt
diRdt
idLCQ
dtdiLRiE &=++⇒=−−−
102
2
em que a lei de Kirchoff foi aplicada em conjunto com as leis de Ohm, de Ampere e com a equação da diferença de potencial elétrico entre as placas de um capacitor. O termo E é a tensão elétrica fornecida pela fonte.

14
Programas de computador resolvem numericamente as equações diferenciais. Para isso, é necessário representá-las. A representação de um sistema em softwares normalmente usa a notação das transformadas de Laplace (anexo 1). Sem intenção de entrar no detalhe dessa transformada, vejamos como pode ser feita uma representação da equação diferencial:
τ dy tdt
y t K u tp( ) ( ) ( )+ =
O operador derivada pode ser substituído ou representado pela letra s (o que é possível porque se usam variáveis na forma de desvio em relação ao estado estacionário) e a equação diferencial fica:
)()()(.. suKsysys p=+τ O processo pode, então, ser representado pela expressão resumida:
G sy su s
Ks
p( )( )( )
= =+τ 1
G(s)y(s)u(s)
Alguns preferem chamar essa expressão de função de transferência. Esse nome tem certa inspiração no diagrama de blocos, quando se tem a impressão de que o sistema tem a função de transferir o sinal de entrada num sinal de saída. Essa transferência, no fundo, é dada pela solução da equação diferencial.

15
Exemplo: o topo de uma fracionadora
pode ser representado pelas funções de transferência:
y sy s
u su s
es
es
es
es
s s
s s
1
2
4 0550 1
17760 1
53950 1
57260 1
1
2
5 15
10 6
( )( )
( )( )
. .
. .
⎡
⎣⎢
⎤
⎦⎥=
⎡
⎣⎢
⎤
⎦⎥⋅
⎡
⎣⎢
⎤
⎦⎥
− −
− −+ +
+ +
onde as variáveis na forma de variação (desvio) têm o seguinte significado:
• y1 – ponto final ASTM D-86 da nafta (ver dispositivo do laboratório na figura acima) • y2 - ponto final ASTM D-86 do querosene • u1 - retirada de nafta • u2 - retirada de querosene
O processo envolve sempre várias variáveis: é denominado multivariável. Nesse caso, o processo é composto de duas entradas e duas saídas. As duas entradas influenciam simultaneamente as duas saídas.

16
Aumentando a retirada de nafta, mantendo-se constante a retirada de querosene, observa-se que os dois pontos finais de ebulição se elevam. O aumento da retirada de nafta significa incorporar pesados na nafta, o que ocorre através da incorporação da parte mais leve do querosene à corrente de nafta: o ponto final da nafta se eleva. Mantida constante a retirada de querosene, há uma compensação pela perda da parte mais leve (foi para a nafta) pela incorporação de uma fração inicial do diesel: o ponto final do querosene se eleva. O tempo morto para a elevação do ponto final do querosene é mais alto que o tempo morto para elevação do ponto final da nafta. Isso decorre do volume maior entre a retirada de nafta e a panela de querosene.
Aumentando a retirada de querosene mantendo-se constante a retirada de nafta, observa-se que os dois pontos finais de ebulição se elevam. O aumento da retirada de querosene provoca uma redução no refluxo abaixo da panela de querosene. Isso piora o fracionamento em toda a região superior à panela de querosene pela passagem de pesados para as seções superiores da torre e o ponto final da nafta também se eleva. O tempo morto para elevação do ponto final da nafta é mais alto que o tempo morto para elevação do ponto final do querosene. Isso decorre do volume maior entre a retirada de querosene e o ponto de retirada de nafta. Tudo isso pode ser representado por diagramas de blocos do processo:

17
(2.2) solução numérica das equações Esse tipo de equações diferenciais (ordinárias) é resolvido numericamente por métodos matemáticos denominados métodos Runge-Kutta. Não cabe aqui detalhar demais esses métodos. Apenas se discutirá uma noção, escrevendo inicialmente a equação diferencial de primeira ordem com coeficientes constantes na forma:
dydt
u t y t=
−( ) ( )τ
⇓ dy t
dtf t u t y
( )( , ( ), )=
A equação reorganizada expressa uma forma de calcular derivada. A taxa de variação – derivada – da variável dependente é função da variável tempo e das variáveis de entrada e saída do processo. A figura seguinte ressalta que a derivada (taxa de variação) é uma tangente da curva de solução.
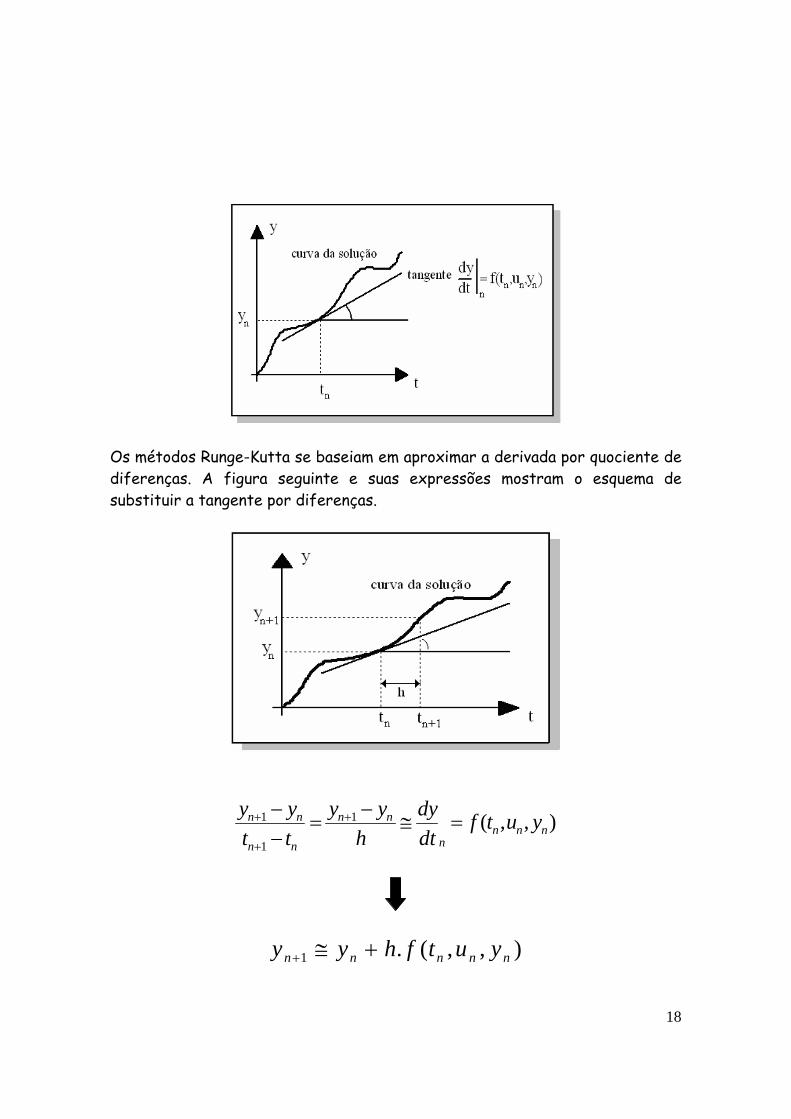
18
Os métodos Runge-Kutta se baseiam em aproximar a derivada por quociente de diferenças. A figura seguinte e suas expressões mostram o esquema de substituir a tangente por diferenças.
),,(1
1
1nnn
n
nn
nn
nn yutfdtdy
hyy
ttyy
=≅−
=−− +
+
+
),,(.1 nnnnn yutfhyy +≅+

19
Para resolver numericamente a equação diferencial, divide-se o intervalo de tempo total num número conveniente de passos e faz-se uma montagem da curva de resposta, sucessivamente avançando-se pelas sucessivas tangentes. A derivada num ponto n pode ser calculada com os dados desse ponto. Pela derivada do ponto n, avança-se um passo, estimando-se o valor da variável y no ponto seguinte n+1. O método é, pois, recursivo. Estima-se cada ponto sucessivo pelo avanço a partir da derivada do ponto anterior. A solução total aproximada pode ser ilustrada com uma tabela:
Tempo
variável y
Derivada dydt
t0 0= y0 0= f t y( , )0 0 t h1 = y y hf t y1 0 0 0= + ( , ) f t y( , )1 1
t h2 2= y y hf t y2 1 1 1= + ( , ) f t y( , )2 2 t h3 3= y y hf t y3 2 2 2= + ( , ) f t y( , )3 3
M M M t nhn = y y hf t yn n n n= +− − −1 1 1( , ) f t yn n( , )
M M M Uma questão muito importante é a escolha do passo h. Ele é um passo de avanço para ir construindo a solução ao longo de todo o tempo de integração. Se esse passo for muito grande, o erro da aproximação da derivada e da saída pela tangente é exagerado. Se o passo for muito pequeno, o tempo de computação pode ser muito grande e a resolução inviável. Há muitas propostas para uso desse passo. Passo variável, cálculo de várias derivadas dentro do mesmo passo, avanço num passo e ajuste para a derivada ao final do passo. Todos eles formam a classe de métodos de Runge-Kutta. O método direto e mais simples foi dedicado ao matemático Euler e as modificações formam a classe de métodos Runge-Kutta, que se baseia em calcular várias derivadas aproximadas a cada passo de integração:
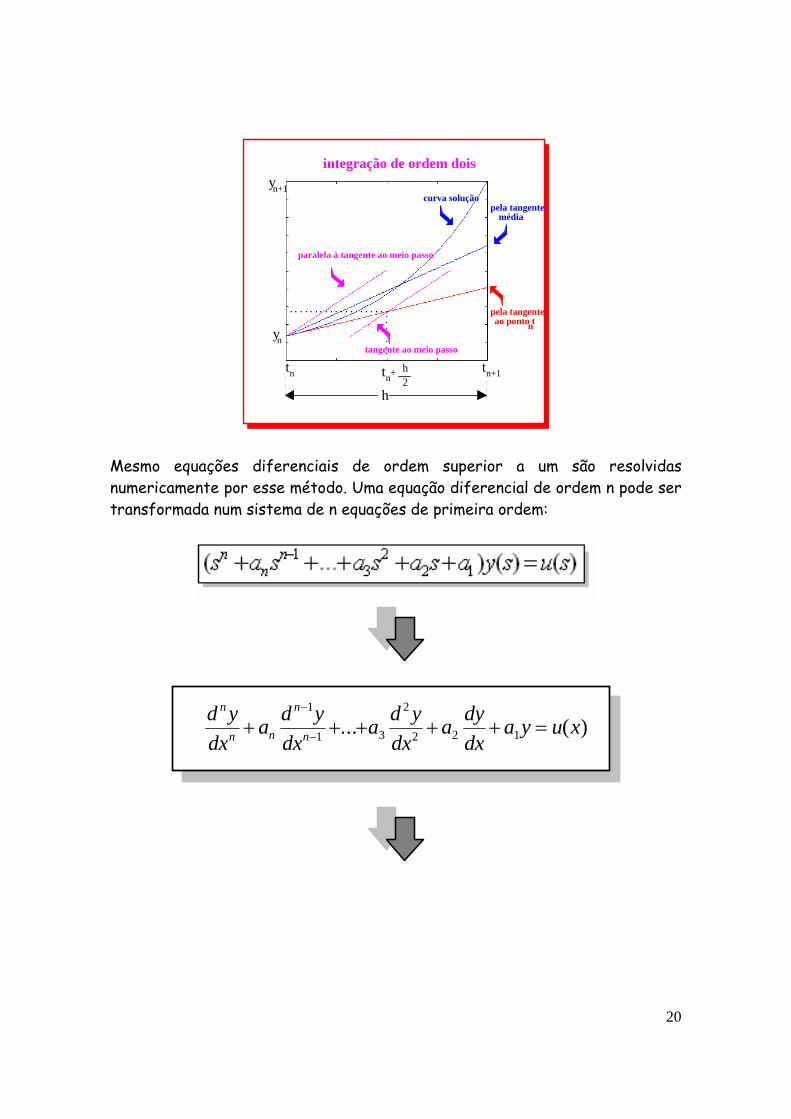
20
h
integração de ordem dois
tn tn+1tn+ h2
pela tangente
média
curva solução
tangente ao meio passo
paralela à tangente ao meio passo
yn
yn+1
pela tangente
ao ponto tn
Mesmo equações diferenciais de ordem superior a um são resolvidas numericamente por esse método. Uma equação diferencial de ordem n pode ser transformada num sistema de n equações de primeira ordem:
d ydx
a d ydx
a d ydx
a dydx
a y u xn
n n
n
n+ + + + + =−
−
1
1 3
2
2 2 1... ( )

21
y y1 =
y dydx
dydx2
1= =
y dydx
d ydx3
22
2= =
y dydx
d ydx4
33
3= =
y dydx
d ydxn
nn
n−−
−
−= =12
2
2
y dydx
d ydxn
nn
n= =−−
−1
1
1
...
dydx
y12=
dydx
y23=
dydx
y34=
...dydx
ynn
− =1
dydx
u x a y a y a y a ynn n n n= − − − − −− −( ) ...1 1 2 2 1 1
sistema de equaçõesde primeira ordem
[2] Carnahan, B., Luther, H. R. and Wilkes, J. D. (1969): Applied Numerical Methods. John Wiley & Sons Inc., New York.
(2.3) sistemas com controle
Um controlador é um sistema que possui sua dinâmica própria. Controlador e processo interagem, o que significa que suas dinâmicas ficam acopladas.
Todo controlador:
• recebe medições, sinais indicativos sobre as condições do sistema que ele controla;
• compara a situação do sistema que ele controla com alguma condição desejada;
• atua sobre o sistema, com o objetivo de corrigir, tanto quanto possível, para aproximar o sistema real da situação desejada.

22
Um bom exemplo de controlador é um motorista. O automóvel é um sistema, dinâmico, um processo, que tem seu comportamento típico e particularidades especiais. O motorista é, por assim dizer, outro sistema, também dinâmico e também com suas peculiaridades, e que interage com o carro. O motorista manipula, mexe em várias variáveis do carro (acelerador, freio, volante de direção: variáveis manipuladas) para atender a diversas necessidades (regras de trânsito, trajetória desejada, contorno de complicações: variáveis controladas). Para isso, o motorista recebe medições através de seus órgãos de sentido, compara os sinais recebidos com valores desejados, codificados em sua mente, e decide com intensidade proporcional ao afastamento da condição desejada (e, preferencialmente, com antecipação) como manipular o carro. Todo motorista tem que ter bom desempenho, o que significa, antes de tudo, primordialmente, atender às restrições das diversas variáveis controladas. Regras de trânsito impõem máximos e mínimos, a trajetória de percurso é uma seqüência de limites, o contorno de complicações exige re-estabelecimento de limites, máximos e mínimos... Dirigir é isso, é controlar, é um constante obedecer a limites, a restrições, ao longo de toda a viagem. Para atender a tais limites, o motorista precisa fazer uso de suas atribuições, suas liberdades, seus graus de liberdade, que são as diversas variáveis manipuladas (aceleração, freio, direção, comandos de painel). Um bom motorista, entretanto, não fica somente nisso. Um bom motorista sempre se esforça para não mexer demais nas manipuladas. As variáveis manipuladas sempre representam algum custo (combustível, freio...). O ideal em toda viagem é economizar, não gastando muito nas variáveis manipuladas. O caso ideal extremo de controle (inatingível?) seria o de tudo controlar sem em nada mexer. Todas as variáveis controladas sob controle (perto da referência desejada – set-point, dentro de faixas de tolerância – mínimos e máximos), alterando o menos possível as variáveis manipuladas (ou até - um sonho - sem alterar nada das variáveis manipuladas).

23
Um sistema só pode ser controlado se houver medições do seu estado para que o controlador tenha informação sobre suas condições. O projeto do processo prevê as medições necessárias, relacionadas com a finalidade do sistema. No exemplo anterior, como o tanque é de aquecimento, nada mais natural do que ele dispor de, pelo menos, um dispositivo para medição da temperatura do líquido. O sinal de um medidor de temperatura é usado pelo controlador para informação sobre o estado do sistema. Evidentemente, o dispositivo para medir a temperatura deve ser confiável, de boa qualidade, deve indicar a temperatura com fidelidade e precisão adequada. Afinal de contas, é com base nessa medição que o controlador vai tomar decisões. Medições ruins implicam em atuações precárias.
(2.4) sensibilidade do controlador O controlador examina a temperatura continua e permanentemente. A cada instante, ele compara a medição com o valor desejado para essa temperatura. Se a temperatura medida estiver abaixo da desejada, ele abre um pouco a válvula de fluido de aquecimento, provocando liberação de um tanto a mais de calor na camisa, atuando para aquecer o que falta. Se a temperatura medida estiver acima da desejada, ele fecha um pouco a válvula, provocando uma redução do calor trocado na camisa, atuando para resfriar um pouco o tanque. A intensidade do abrir ou fechar a válvula é uma sensibilidade do controlador. Essa sensibilidade pode ser ajustada, pode ser melhorada e a questão de quão sensível deve ser o controlador depende das necessidades do processo, do sistema. Em princípio, diferentes graus de sensibilidade seriam requeridos em diferentes circunstâncias: diferentes momentos ou diferentes conjunturas. A sensibilidade deve ser sempre atualizada, ajustada, o que é uma sintonia da intensidade de atuação do controlador. Falta de sensibilidade pode deixar o sistema sem controle e, nesse caso, o controlador precisa de mais agilidade de resposta. Excesso de sensibilidade pode ser prejudicial ao sistema, porque o controlador pode provocar oscilações ao tentar corrigir muito drasticamente na correção de um sentido, levando o sistema a erro para o sentido oposto. A sensibilidade está associada à lógica que o controlador usa para, conforme a comparação entre o valor medido e o desejado, atuar no processo. As lógicas

24
dos primeiros controladores eram consequência natural de seus detalhes construtivos. Esses primeiros controladores eram engenhocas mecânicas construídas com sistemas de alavancas, palhetinhas articuladas sujeitas a movimentações de espirais dilatantes, fluxos de ar, enchimentos de foles e outros dispositivos diversos. A figura seguinte ilustra um controlador desse tipo (fora de escalas) para regular a temperatura do tanque de aquecimento:
Um elemento de medição de temperatura pode ser uma espiral que se dilata por efeito térmico. Essa espiral pode estar ligada a um jogo de palhetas, que forma um sistema de alavancas. Uma das palhetas se move em relação a um bico de um sistema com ar comprimido. Continuamente, ar comprimido flui através do bico; pelo afastamento da palheta, mais ar é liberado, aliviando a pressão na antecâmara do bico de ar; pela aproximação da palheta, o bico vai se tampando progressivamente, o que provoca aumento de pressão na antecâmara do bico de ar. A pressão na antecâmara determina o esforço sobre uma membrana construída num sistema acoplado a uma válvula. Sobre a membrana atua também uma mola. Dependendo do jogo mecânico entre a pressão do ar (consequência da posição das palhetas, do grau de dilatação da espiral e, portanto, da temperatura no tanque) e a mola, a membrana move uma haste de válvula, provocando abertura ou fechamento da mesma pela aproximação ou afastamento de um plug em relação à sede.

25
A ação proporcional é tão mais intensa quanto maior a sensibilidade do controlador. Se o sistema de palhetas for construído mais próximo do bico de ar, o controlador fica mais sensível; se for construído mais distante, o controlador fica menos sensível.
(2.5) classes de finalidades do controlador:
• caso em que o mecanismo é regulador ou regulatório: havendo aumento de temperatura no tanque, a espiral se dilata, movendo as palhetas para a direita, obstruindo o orifício, aumentando a pressão na cabeça da válvula, vencendo a ação da mola, empurando a haste para baixo, fazendo o plug se aproximar da sede da válvula e ocasionando uma redução na quantidade de vapor para a serpentina. O efeito de todos esses eventos é o de tentar um abaixamento da temperatura no tanque. No sentido contrário, havendo redução de temperatura, todos os efeitos concorrem para aumentar o vapor para a serpentina. Desse modo, a engenhoca é reguladora da temperatura do tanque.
• caso em que o mecanismo é servo para seguir valor desejado: se o botão de valor desejado para temperatura ou ponto de referência de temperatura (set-point) for torcido para a direita, por efeito de alavanca todo o conjunto fica mais distante do bico de ar. A pressão sobre a cabeça da válvula abaixa, a mola age empurrando a membrana para cima, erguendo a haste, afastando o plug da sede, permitindo que mais vapor passe pela serpentina e faça o líquido do tanque ficar mais quente. Ou seja, torcer o botão para a direita é uma forma de pedir líquido mais quente e torcer o botão para a esquerda é uma forma de pedir líquido mais frio. Desse modo, a engenhoca é seguidora de set-points. A engenhoca é um controlador. Ela se baseia num sistema de dilatação que mede uma variável do tanque, temperatura, importante porque o tanque é um tanque de aquecimento. A engenhoca compara o estado térmico com um valor desejado de temperatura pela sua própria natureza de palhetinhas articuladas. E, finalmente, a engenhoca age sobre uma válvula de controle conforme uma lei de proporcionalidade. Essa proporcionalidade é consequência natural das regras de braços de alavancas e de dilatação térmica.

26
No final das contas, a lógica de atuação dessa engenhoca é a de uma lei de correção do fluxo térmico na serpentina proporcional ao erro entre o valor de temperatura medido e o valor desejado. Essa interação entre o processo (tanque) de aquecimento e o controlador (engenhoca), pode ser representada de maneira mais interessante através de diagrama de blocos. O diagrama de blocos ilustra as relações de entrada e saída entre processo e controlador, permitindo imaginar as relações de informação e atividades entre esses dois elementos, que possuem suas características e dinâmicas próprias. A figura seguinte mostra um diagrama de blocos para um processo com controlador:
A saída do bloco que representa o processo é o sinal de temperatura. Esse sinal é recebido e comparado a um valor desejado (set-point SP), gerando um erro. A saída do bloco que representa o controlador é um sinal proporcional ao erro, que será destinado ao processo. Esse tipo de controlador atua sobre o processo com base em um erro, uma discordância entre o valor medido e o valor desejado para a temperatura. Sua ação é, portanto, baseada numa realimentação do sinal de temperatura para compor uma comparação e gerar uma atuação. Esse é o motivo pelo qual ele se diz um controlador cuja atuação depende da realimentação (feed-back) da variável controlada. A variável controlada é a temperatura, que deve ser mantida próxima de um valor desejado, dentro de uma faixa tolerável em torno do valor desejado e que é a grande finalidade do tanque de aquecimento. A proporcionalidade da ação de controle em relação ao erro, natural do sistema de alavancas, justifica denominá-lo controlador proporcional (P).

27
(2.6) off-set: Já na época do controlador pneumático, percebeu-se um comportamento curioso do controlador proporcional. Quando a medição da variável controlada se altera, ou seja, no momento em que aparece novo erro relativo ao valor desejado para a variável controlada, o controlador proporcional aumenta ou diminui o fluido de aquecimento, proporcionalmente à alteração do erro. E isso é tudo o que ele faz. O aparecimento desse erro na temperatura pode ser devido a alguma perturbação no tanque de aquecimento ou pode ser consequência de uma alteração de set-point. Afinal de contas, alterar o set-point faz aparecer repentinamente um novo erro de temperatura num tanque que vinha em estado estacionário. Aparecendo novo erro, o controlador faz uma proporcional correção na abertura da válvula de fluido de aquecimento. Nova correção só será feita quando novo erro aparecer. De qualquer modo, aparecendo um erro, o controlador acrescenta uma parcela adicional de vapor para a camisa (seja para cima ou para baixo) e fica nisso. Mesmo que a parcela adicional não seja suficiente para corrigir totalmente o erro, o controlador só acrescentará nova parcela ao aparecer novo erro. Caso não apareça novo erro, mesmo com a persistência de certo erro residual antigo, constante, o controlador não acrescenta qualquer parcela a mais. Controladores mais intensos (mais sensíveis) podem levar a um erro residual persistente menor. Controladores menos intensos deixam um erro residual persistente maior. Mas, sempre há um erro residual persistente se o controlador for de lei apenas proporcional. Qualquer controlador apenas proporcional acaba deixando o sistema sempre com certo erro, ou seja, a variável controlada pode ficar fora do set-point (fora=off), que é o denominado off-set. Esse fato é devido à natureza da correção proporcional, que é feita apenas quando aparece um erro, e não considera a persistência do erro. Persistência é diferente de aparecimento. Apareceu, corrigiu. Persistiu, não faz nada, porque persistir não é aparecer. Se apareceu um erro e corrigiu, mas um tanto de erro persistir, o controlador só proporcional não toma mais ações, adicionais. Logicamente, se um outro erro aparecer mais à frente, ai sim, nova ação proporcional é tomada no momento do

28
aparecimento. Mas também esta segunda ação é insuficiente para correção do segundo erro. Off-sets podem se acumular (ou até se cancelar) ao longo do tempo. O off-set aparece tanto no caso de atuação do controlador como regulador quanto no caso servo-mecanismo. Neste último caso – alterações de set-point – os operadores logo adquiriram o hábito de reajustar o set-point (reset) para eliminar de forma manual off-sets indesejáveis. Para solucionar o problema de off-set, os técnicos de instrumentação da época inventaram uns foles que, acoplados ao sistema de palhetas, iam acumulando erros persistentes e provocando movimentações adicionais das palhetas, proporcionais ao erro persistente acumulado. Essas engenhocas modificadas permitiam eliminação automática do off-set.
[3] Perry, R.H., Green, D.W. (1999): Chemical Engineers Handbook. Mc-Graw Hill, New York (on-line site Universidade Petrobras)
Esses dispositivos modificados proporcionavam uma parcela adicional de ação sobre a válvula, parcela correspondente e proporcional ao erro adicional acumulado. Por esse motivo, o novo controlador passou a estar sujeito a duas ações simultâneas: a ação proporcional ao erro, normal, mais ação proporcional à integral do erro. Isso justifica denominar o controlador de proporcional mais integral (PI).

29
(2.7) leis matemáticas do controlador: A lei de proporcionalidade para um controlador proporcional e integral pode ser expressa matematicamente através da seguinte equação, que usa a notação de entrada e saída (em variáveis de desvio) já utilizada para o tanque de aquecimento:
∫ −+−=t
SPiSPc dtyykyyku0
)()(
Nessa expressão, observam-se duas constantes de proporcionalidade (kc e ki) que se relacionam à sensibilidade do controlador. A escolha de diferentes valores para essas constantes significa regular a sensibilidade do controlador. A constante kc é a que permite sintonizar ou ajustar a parcela proporcional do controlador (ganho proporcional do controlador). A constante ki é a que permite sintonizar a parcela integral do controlador (ganho integral do controlador). Valores baixos para as constantes amenizam as respectivas ações de controlador. Valores elevados intensificam as ações (e podem deixar o controlador muito sensível, muito nervoso). Quando temos um tanque de aquecimento, com sua dinâmica própria e sua equação diferencial, controlado por uma engenhoca de dinâmica e equação diferencial próprias, resolvemos simultaneamente duas equações:
uydtdy
=+τ
∫ −+−=t
SPiSPc dtyykyyku0
)()(

30
A entrada de uma é saída da outra e vice-versa e essas duas equações podem até ser reunidas numa única expressão:
∫ −+−=+t
SPiSPc dtyykyykydtdy
0
)()(τ
que, derivada dos dois lados:
→−+−=+ ykykdtdyk
dtdyk
dtdy
dtyd
iSPicSP
c2
2
τ
SPiSP
cic ykdt
dykykdtdyk
dtyd
+=+++→ )1(2
2
τ
Essa expressão mostra que os sistemas químicos sem controlador podem até ser de primeira ordem (balanços de massa e energia), mas um controlador pode provocar elevação da ordem do sistema. Isso é decorrência das dinâmicas acopladas do processo e do controlador, que se expressa matematicamente através da equação diferencial do processo sob ação de controlador. O diagrama de blocos também traduz esse acoplamento físico e matemático:

31
(2.8) controlador PID na prática
À expressão matemática do controlador proporcional + integral até aqui utilizada:
∫ −+−=t
SPiSPc dtyykyyku0
)()(
ou à sua equivalente mais comum na prática de controle:
∫+=t
i
cc dxxekteku
0
)()(τ
pode se acrescentar uma parcela proporcional à taxa de variação do erro:
dttdekdxxekteku dd
t
i
cc
)()()(0
ττ
++= ∫
Trata-se de uma parcela proporcional à derivada do erro, motivo por que é denominada parcela da ação derivativa. Sendo proporcional à taxa de variação, ela é, em sua essência, proporcional a uma previsão do erro futuro (tangente ou estimativa pela tendência linearizada para o erro). O controlador é corriqueiramente expresso através de sua transformada de Laplace (ver anexo 1):
)()()()( ssekses
kseksu dci
cc τ
τ++=
A ação derivativa acrescentada dessa forma, como uma parcela adicional às ações proporcional e integral, faz desse controlador um controlador PID (proporcional + integral + derivativo), denominado padrão. Ele também é conhecido como PID não-interagente, uma vez que as três parcelas são adicionadas de modo independente. Com as constantes das partes integral e derivativa definidas da forma:

32
ele é denominado controlador PID na forma paralela. Uma versão ligeiramente diferente é a mais comum em muitos controladores comerciais e se traduz pela equação:
Um controlador PID com essa equação matemática é denominado PID na forma interagente, uma vez que a parcela de ação derivativa influencia as duas outras. Também é denominado PID na forma série. Há razões históricas para a forma em série do PID: os detalhes construtivos dos controladores pneumáticos levavam naturalmente à forma série, que foi mantida nas gerações de controladores eletrônicos e muitos dos digitais. Na prática, é importante conhecer a forma PID usada pelo fabricante do controlador, consultando com cuidado a documentação fornecida. É possível converter os parâmetros de um controlador da forma série para a forma paralela e vice-versa através das expressões seguintes:
O controlador PID gera um sinal de controle a partir do erro da variável controlada, ou seja, da diferença:
)()()( tytyte SP −=
)()()()( ssekses
kseksu dci
cc τ
τ++= ( ) )(111)( ses
sksu d
ic τ
τ′+⎟⎟
⎠
⎞⎜⎜⎝
⎛′
+′=
i
dicc kk
τττ′
′+′′= ⎟
⎟⎠
⎞⎜⎜⎝
⎛−+=′
i
dcc
kk
ττ
4112
dii τττ ′+′= ⎟⎟⎠
⎞⎜⎜⎝
⎛−+=′
i
dii τ
τττ 411
2
di
did ττ
τττ
′+′′′
= ⎟⎟⎠
⎞⎜⎜⎝
⎛−−=′
i
did τ
τττ 411
2

33
Esse sinal de controle é aplicado ao processo. A realimentação do sinal da variável controlada faz dele um controlador com feed-back de erro tanto para os casos de set-point constante como para os casos de alteração de set-point. Há uma estrutura mais flexível de controlador PID, em que o set-point (ySP) e a medição (y) são tratados de modo distinto através das expressões:
O controlador PID definido desse modo funciona como o PID padrão na regulação ou caso regulatório, ou seja, nas rejeições de perturbações. Nesse caso, não há alteração de set-point. A resposta para alterações de set-point, entretanto, dependem dos parâmetros β eα . Esses parâmetros podem variar entre zero e um e ponderam a influência do set-point na composição do erro para as partes proporcional e derivativa do controlador. O valor zero cancela totalmente essa influência e o valor 1 mantém totalmente a influência, transformando o controlador num PID padrão também para o caso servo-mecanismo. Esse tipo de PID é denominado PID com dois graus de liberdade (two degrees of freedom PID controller). Também podem ser denominados:
• controlador I-PD quando 0=β e 0=α • controlador PI-D quando 1=β e 0=α • controlador PID – padrão - quando 1=β e 1=α
A vantagem dos controladores com dois graus de liberdade é a de se poder ajustar a influência das variações de set-point na regulagem, evitando ações drásticas sobre o processo.
)()()( tytyte SPP −= β para a parte proporcional )()()( tytyte SP −= para a parte integral
)()()( tytyte SPd −= α para a parte derivativa
)()()()( ssekses
kseksu ddci
cPc τ
τ++=

34
(3) controle por computador:
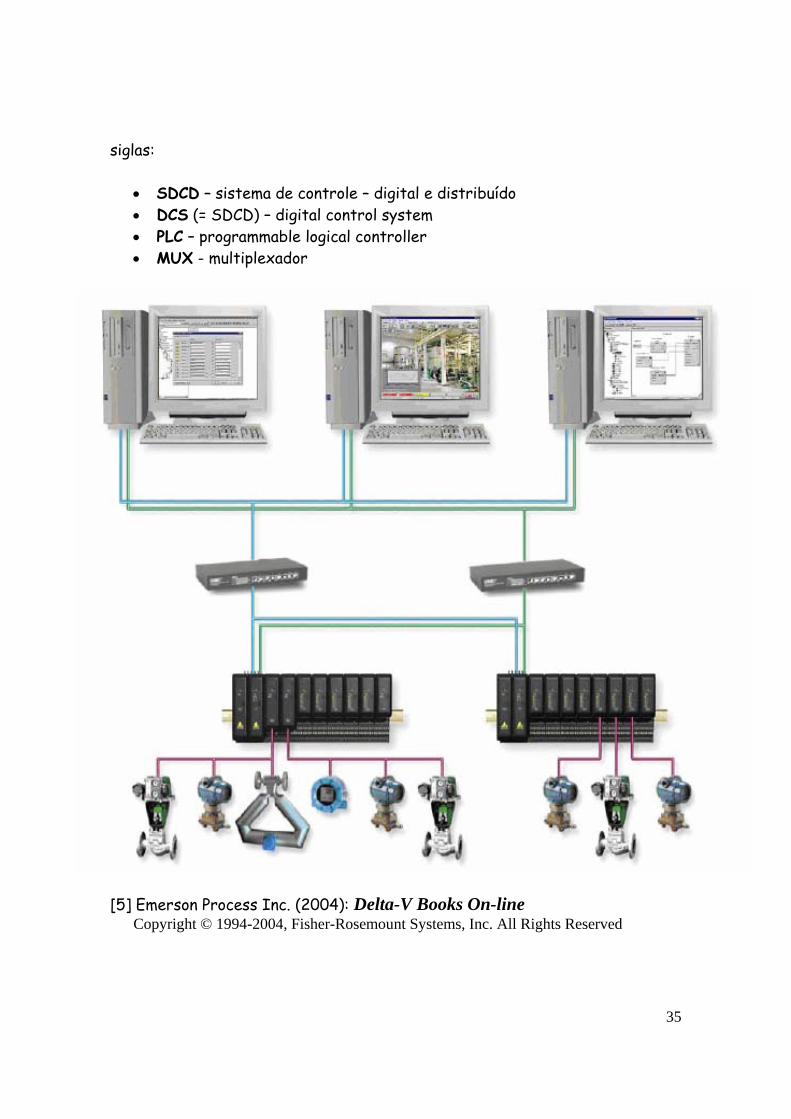
(3.1) SDCD e rede de computadores: Atualmente, os controladores digitais são computadores que ficam em rede como as seguintes figuras ilustram:
[4] Perry, R.H., Green, D.W. (1999): op. cit.
35
siglas:
• SDCD – sistema de controle – digital e distribuído • DCS (= SDCD) – digital control system • PLC – programmable logical controller • MUX - multiplexador
[5] Emerson Process Inc. (2004): Delta-V Books On-line
Copyright © 1994-2004, Fisher-Rosemount Systems, Inc. All Rights Reserved

36
[6] Emerson Process Inc. (2004): op. cit.

37
(3.2) os controladores do SDCD: Os controladores PID do SDCD envolvem três variáveis importantes: • variável de processo (PV): valor lido para a propriedade controlada; • set-point (SP): valor desejado para a propriedade controlada; • analog output ou saída analógica (AO): sinal de saída do controlador, sinal de
atuação que normalmente vai para válvula ou para outro controlador. Eles comportam cinco modos principais de trabalho: • modo manual: MAN - sem computador de processo no esquema. Nesse caso,
o operador altera o sinal de saída do controlador (para a válvula); • modo automático: AUTO - sem computador de processo no esquema. Nesse
caso, o operador altera o set-point, valor desejado para a propriedade controlada;
• modo remoto ou cascata: RSP ou CAS - sem computador de processo e dois
controladores envolvidos no esquema. Nesse caso, outro controlador do SDCD altera o set-point, valor desejado para a propriedade controlada;
• modo supervisório ou cascata remota: SUP ou RCAS - computador de
processo envolvido no esquema. O set-point do controlador vem do computador de processo;
AOSP
PV
controlador em modo supervisório somente computador altera set-point
controle supervisóriocomputador

38
• modo controle digital direto: DDC ou ROUT - computador de processo envolvido no esquema. O sinal de saída do controlador vem do computador de processo:
AOSP
PV
controlador em modo DDC somente computador altera saída AO
controle digital diretocomputador
(3.3) o computador de processo: Computador de processo é o nome que se dá à máquina que processa o controle avançado: • em sistemas mais modernos, ele está ligado diretamente à rede SDCD, como
a estação Application das figuras anteriores. Os atuais computadores de processo são microcomputadores industriais com sistema operacional Windows. Os softwares para aplicações de engenharia para tais estações de trabalho usam intensamente o recurso OPC (object linking and embedding for process control).
• em alguns sistemas mais antigos, o computador de processo podia ficar
ligado à rede SDCD diretamente ou indiretamente através da rede administrativa. Os computadores de processo mais antigos eram máquinas especiais como VAX, Alpha (Digital Inc., atual H.P.) com sistema operacional VMS ou estações H.P. com sistema operacional Unix. Esse tipo de hardware e software está progressivamente sendo substituído por estações tipo microcomputador com Windows.
Obs: VAX (Virtual Access eXtended); VMS (virtual memory system)

39
A rede do SDCD podia ser ligada à rede administrativa de computadores:
Esse exemplo é o do antigo sistema Provox da Fisher. O fluxo de informações nesse tipo de configuração é o seguinte: • caso 1: dados para sistema administrativo de informações de processo:

40
• caso 2: dados do sistema de controle avançado:
Os desenhos representam os computadores e três softwares: • software CHIP da Fisher (computer-highway interface package). O CHIP
trabalha em conjunto com a HDL na coleta de dados de processo e envio de set-points para os controladores do SDCD;
• o primeiro caso mostra uma parte do P.I. (plant information) que fica no
computador de processo. Essa parte prepara dados do CHIP que vão para a parte histórica do P.I.;
• o segundo caso mostra o software de controle avançado. O controle avançado roda a cada minuto, os cálculos são concluídos em fração de segundo e resultam novos set-points, que são enviados para os controladores do SDCD.

41
O controle avançado é um supervisor. Ele envia set-points para controladores do SDCD. Esses controladores devem obedecer ao supervisor sendo necessário que:
- estejam funcionando bem (manutenção excelente); - estejam apropriadamente sintonizados; - fiquem no denominado modo supervisório (ou cascata remota).
Costuma-se representar a relação recíproca entre controladores do SDCD e demais aplicativos através de um diagrama com camadas (pirâmide):
A camada de controle regulatório corresponde a controladores tipo PID que ficam na rede do SDCD. A camada de controle avançado inclui: • controladores mais simples, que podem ficar na rede do SDCD ou no
computador de processo; • controladores mais complexos (como o preditivo e multivariável), que
normalmente ficam no computador de processo. A camada de otimização fica normalmente no computador de processo e é um outro software (otimizador on-line), que define rumos ótimos, valores ideais para o controle avançado. Esses valores são estimados através de modelos

42
matemáticos rigorosos do processo. São os denominados ideal resting values (IRV) do otimizador para o controle avançado.
(3.4) exemplos:
A figura seguinte é um esquema de controle para torre debutanizadora.
O controle regulatório (no SDCD) consiste em quatro controladores tipo PID: 1. controle da vazão de refluxo de topo; 2. controle da vazão de fluido de aquecimento no reboiler; 3. controle da temperatura de um prato da seção de fundo da torre; 4. controle da pressão de topo da coluna. Sem controle avançado, os controladores 1, 3 e 4 ficam em modo automático. O controlador número 2 fica em modo remoto. Os controladores 2 e 3 atuam em conjunto. Para controlar temperatura de prato, o controlador número 3 envia sinal de set-point para o controlador de vazão de fluido de aquecimento no reboiler (controlador 2). Este último, por receber set-point de um outro PID, fica em modo remoto (RSP).

43
Com controle avançado, o computador de processo envia set-points para os três controladores PID regulatórios (1, 3 e 4). Todos os três ficarão em modo supervisório, ou seja, o set-point de cada um deles é alterado pelo computador de processo. A relação entre os controladores e o computador de processo fica muito parecida com uma cascata. Os controladores ficam escravos do computador de processo e devem obedecer rigorosamente bem ao set-point que lhes é enviado pelo mestre. Os controladores costumam ser configurados para comutarem seu próprio modo de supervisório para outro modo quando o computador de processo deixe de enviar os tais set-points por mais de três minutos. Esse recurso é denominado watchdog (cão-de-guarda) dos controladores. O controle avançado altera os set-points a cada minuto. As alterações de set-point têm por finalidade controlar as temperaturas da torre, controlar o intemperismo do GLP, controlar a PVR da nafta, agir no sentido de evitar o fenômeno de inundação na coluna e otimizar a fracionadora. Neste último sentido, por exemplo, o controle avançado pode estar sempre fazendo um esforço para minimizar o refluxo de topo e o consumo de energia no reboiler. Os projetos de controle avançado podem abranger apenas parte da unidade, como o exemplo anterior ilustra. Eles também podem ter abrangência maior, envolvendo a unidade inteira. A figura seguinte mostra esquema de controle avançado (set-points alterados pelo computador de processo) para uma unidade inteira de FCC. Referências sobre o assunto: [7] Astrom, K. J. and Wittenmark (1984): Computer-Controlled Systems –
Theory and Design. Prentice-Hall, Englewood Cliffs, New Jersey. [8] Astrom, K. J. and Hagglund, T. (1995): PID Controllers: Theory, Design
and Tuning. ISA Publication, Research Triangle Park, North Carolina.

44

45
(4) inferências - cálculos por computador:
(4.1) o conceito Na área de automação e controle de processos, a palavra inferência significa cálculo de propriedade de produto. Esse cálculo é feito por um programa de computador que utiliza equações, correlações para estimar propriedades como:
- destilação (ASTM D-86) de produtos diversos; - PVR de naftas ou ponto de fulgor de médios; - intemperismo do GLP; - teor de C3
+ no gás combustível.
Os cálculos são feitos sempre com medidas de pressão, temperatura ou vazão. Recebem o nome de inferência: inferir é um termo da Lógica que significa tirar uma conclusão sobre algo com base em certas hipóteses e conhecimentos disponíveis. Deduções e induções são os dois tipos principais de inferências. Por exemplo, com base em medidas de temperaturas, pressões ou vazões da torre estabilizadora (debutanizadora), um programa de computador infere, estima o valor do intemperismo do GLP e da PVR da nafta.

46
[9] Standard Test Method for Volatility of Liquified Petroleum (LP) Gases.
American Society for Testing Materials D1837-02A [10] Standard Test Method for Vapor Pressure of Petroleum Products (Reid
Method). American Society for Testing Materials D323-99A

47
Um programa de computador para estimar propriedade de produtos envolve:
• cálculo propriamente dito da propriedade; • lógica de adaptação de parâmetros da equação (calibração).
cálculo da propriedade:
Os cálculos são feitos on-line, automaticamente, a cada minuto e exigem o denominado computador de processo - estação de aplicativos -, que deve ter bom porte e deve estar ligado direta ou indiretamente ao sistema digital, a rede de controle. As inferências funcionam como um sensor virtual ou sensor-software (soft-sensor), que funciona independentemente do controle avançado e faz o papel de um analisador on-line. Atualmente, na área de refino da Petrobrás, o valor calculado (estimado ou inferido) on-line de propriedades de produtos é disponibilizado para o controle avançado, como se fosse a medição de uma variável controlada do controlador através de um sensor.
atualização do bias: Há sempre um mecanismo adaptativo. Tal mecanismo corresponde a uma atualização ou calibração (baseada em resultado de análise de laboratório) de algum parâmetro da correlação. Esse parâmetro é normalmente um coeficiente linear denominado bias. O mecanismo adaptativo é, por isso, chamado de atualização de bias. Em casos muito específicos pode ser mais interessante corrigir um parâmetro fortemente embutido na equação, de um modo não linear: nesses casos, as expressões inversas para a correção do parâmetro devem ser codificadas no software de inferência para permitir a calibração. O resultado de laboratório, base para calibração da inferência, deve ser conseqüência não só de amostragem e procedimento analítico apropriados mas também de adequação da amostra sob o ponto de vista de representatividade. A questão de calibração de inferências é muito semelhante às necessidades de manutenção e calibração de analisadores on-line.

48
(4.2) correlações (inferências) mais comuns:
inferência do intemperismo do GLP: O intemperismo é calculado conforme a expressão abaixo:
biasVLaTaTay ptopo +++= ).(.. 321
a- a correção da temperatura pela pressão é calculada com expressão de
pressão de vapor: 273
2731ln.
1−−
++⎟⎟
⎠
⎞⎜⎜⎝
⎛= topo
topob
topo
v
p T
TPP
HR
T
b- a relação (L/V) é calculada a partir de um balanço no vaso de topo:
onde: a1, a
2, a
3 constantes experimentais
y intemperismo inferido (oC) topoT temperatura em prato da seção de topo (oC)
pT correção da temperatura pela pressão (oC)
VL relação molar líquido-vapor no prato 1 da coluna
onde: R 1.9872 kcal/kgmol/K Hv calor de vaporização do GLP: (~ 4468 kcal/kgmol) Ptopo pressão real no topo da torre (kgf/cm2 abs) Pb pressão de referência para topo da torre Ttopo temperatura real do topo da torre (oC)
L
V
- a vazão de vapor que sai do prato 1 é igual à soma das vazões de refluxo de topo e de retirada de GLP (balanço). ( ) mRDV ρ.+=
V vazão de vapor no prato (kgmol/h) R vazão de destilado em m3/h D vazão de refluxo em m3/h ρm densidade molar do refluxo: 102 kgmol/m3
refluxo D retirada R
V

49
- no ponto de retorno ao prato 1, o refluxo mais frio condensa parte do vapor que borbulha através do líquido do prato. Assim, a vazão de líquido do prato 1 para o 2 é a vazão de refluxo de topo, acrescida da parcela condensada conforme o seguinte balanço térmico:
( )⎥⎦
⎤⎢⎣
⎡−+= rtopo
v
pm TT
HC
DL .1..ρ
inferência da PVR da nafta craqueada:
Utilizam-se as equações:
( ) ( ) ( ) ( )log log . log .int10 10 101PVR P x P x= − +
x T T TT T T
=+⎛
⎝⎜⎞⎠⎟
+ −+ −
⎛⎝⎜
⎞⎠⎟int
int.. .230
267 777837 7778Δ
Δ
onde: L vazão de líquido no prato (kgmol/h) Cp
calor específico do refluxo: 37.6 kcal/kgmol/K Tr temperatura do refluxo (oC)
onde: P pressão no fundo da coluna - kgf/cm2 T temperatura no fundo da coluna - oC ΔT correção aplicada em T em função do resultado de laboratório

50
obs: Tint e Pint representam a temperatura e a pressão do ponto de intersecção das curvas de pressão de vapor para os componentes leve e pesado.
A constante ΔT é o parâmetro de ajuste da correlação. Nesse caso, em particular, a constante de ajuste não é um termo linear (bias), mas também é atualizado com resultados de laboratório através das expressões:
amostTy
T −−=Δ 2301
( )8.267
1
log
230.8.26778.37.log
int10
int
int10
+
⎟⎟⎠
⎞⎜⎜⎝
⎛
⎥⎦
⎤⎢⎣
⎡+
−⎟⎟⎠
⎞⎜⎜⎝
⎛
=
PPVR
TT
PVRP
ylab
lab
amos
Essas expressões para a correção do parâmetro de ajuste podem ser obtidas pela inversão da expressão direta para a inferência e são utilizadas pela subrotina de calibração.
inferência de temperatura ASTM D-86 de retirada lateral: O cálculo da temperatura de um ponto da destilação ASTM D-86 de retiradas laterais de fracionadora baseia-se nas vazões e temperaturas de retirada de correntes vizinhas: a do produto em questão e, geralmente, a do produto imediatamente inferior. As vazões são utilizadas para converter a escala individual de destilação dos dois produtos (0-100%), numa escala única que vai desde o ponto 30% vaporizados ASTM D-86 de um até o ponto 30% vaporizados ASTM D-86 do outro. As temperaturas dos pratos de retirada são utilizadas para estimar a temperatura correspondente aos 30% vaporizados ASTM D-86 de cada produto.
onde: Pamost pressão de fundo no snapshot (momento de amostragem) Tamost temperatura de fundo no snapshot PVRlab resultado de laboratório para a PVR.

51
Q
Q
sup
inf
T
T
sup
inf
.
..(inferida)
a- temperatura dos 30% vaporizados ASTM D-86: Essa temperatura pode ser estimada a partir das temperaturas dos pratos de retirada conforme a expressão:
• T i T b30%sup sup sup sup= × + (retirada superior)
• T i T b30%inf inf inf inf= × + (retirada inferior) onde os quatro parâmetros (inclinações e coeficiente linear) devem ser ajustados para cada fracionadora. As inclinações podem ser calculadas com a expressão:
( )iretiradaT
Tretirada
retirada= 30%
2
b- cálculo da temperatura ASTM D-86 a outra percentagem vaporizada: Para usar uma escala de destilação ASTM D-86 conjunta das duas correntes, usa-se a expressão:
V x QQ Q= − ×
× + ×( . )
. .sup
sup inf
0307 03 ou V
Q x QQ Q= × + − ×
× + ×0 7 1
0 7 0 3. ( )
. .sup inf
sup inf

52
onde Qsup é a vazão da corrente superior e Qinf é a vazão da corrente inferior. O valor de x varia entre 0.3 (30%) e 1 (100%) para estimativas de temperaturas de destilação ASTM D-86 da retirada superior ou entre 1 (0%) e 1.3 (30%) para estimativas relativas à retirada inferior. Essa escala permite interpolação desde 30% até 100% vaporizados do produto da retirada superior, e interpolação desde 0% até 30% vaporizados do produto da retirada inferior.
T T T V i T% sup( )inf sup sup
= − × + ×30% 30% 30%
inferência de temperatura ASTM D-86 de retirada de topo: Usa-se expressão na forma posicional:
biasVLaTaTaT ptopox +++= ).(.. 321%
onde: a
1, a
2 e a
3 constantes experimentais
%xT temperatura dos x % vaporizados ASTM D-86
topoT temperatura de topo da fracionadora
pT correção da temperatura pela pressão
VL relação molar líquido/vapor no prato 1 da fracionadora
As constantes dependem do produto em questão, devendo-se fazer ajuste de dados obtidos com cada fracionadora particular em questão. Dados típicos para inferir os pontos 90% e final ASTM D-86 de nafta craqueada são os seguintes:

53
90% a
1 = 0.685 a
2 = 2.032 a
3 = -14.324
PFE a1 = 0.895 a
2 = 0.9257 a
3 = -76.385
a- correção da temperatura com a pressão: 273
2731ln.
1−−
++⎟⎟
⎠
⎞⎜⎜⎝
⎛= topo
topob
topo
v
p T
TPP
HR
T
b- relação líquido/vapor:
( )]1[.rH
CM
D TTLv
p
r
r −⋅+= ρ
L vazão de líquido no prato 1 kgmol/h Qr vazão de refluxo m3/h ρ r massa específica do refluxo 738 kg/m3 Mr peso molecular do refluxo 108.7 kg/kgmol Cp calor específico do refluxo 52 kcal/kgmol/K Tr temperatura do refluxo oC
V Q Q
M rQ Qr d
r
g v= ⋅ + ++( ).ρ 22 4 18
Controle inferencial é um assunto tratado dentro do formalismo de controle clássico, o que pode ser constatado nas seguintes excelentes referências: [11] Luyben, W. L. (1995): Process Modeling, Simulation and Control for
Chemical Engineers 2nd. Ed., McGraw Hill, New York. [12] Seborg, D.E., Edgar, T.F. and Mellichamp, D.A. (1989): Process Dynamics
and Control John Wiley & Sons Inc., New York.
R constante dos gases 1.987 kcal/kgmol/K Hv calor de vaporização do vapor de topo da torre 9740 kcal/kgmol Ptopo pressão real no topo da fracionadora kgf/cm2 Pb pressão de referência no topo da fracionadora 2.145 kgf/cm2 Ttopo temperatura real no topo da fracionadora oC
V vazão de vapor no prato 1 kgmol/h Qd vazão de destilado do vaso de topo m3/h Qg vazão de gás produzido Nm3/h Qv vazão de vapor de água injetado no sistema kg/h

54
(5) identificação do processo:
(5.1) modelos de processo: O tipo de controle avançado que está se implementando na Petrobrás é denominado preditivo. Trata-se de um controle que calcula as tendências futuras para as variáveis controladas, tendo um caráter antecipatório (feed-forward). Todo controle antecipatório exige um modelo do processo para fazer a predição. Identificar o processo é levantar o modelo do mesmo. O modelo do processo é a relação numérica, quantitativa ou matemática, entre suas entradas e suas saídas:
uk ykprocesso
dk
Muitas regras práticas, heurísticas simples e usadas no dia-a-dia, já podem ser vistas como modelos do processo. Por outro lado, certos modelos matemáticos mais complicados também são modelos. Os dois casos são importantes na área de controle. Os modelos matemáticos podem ser de dois tipos principais: • modelos teóricos: são dados por equações algébricas ou diferenciais, cuja
solução fornece o comportamento dinâmico ou em estado estacionário do sistema;
• modelos empíricos: obtidos através da análise de dados obtidos por
experimentação com um sistema existente. Essa experimentação envolve a alteração de algumas entradas (excitação do processo) e exame do comportamento das saídas do sistema.
Na atual prática em refinaria, a identificação de processos será entendida como levantamento de dados experimentais e seu tratamento matemático, visando a obter um modelo empírico do sistema. Em última análise, a

55
identificação de processos é aqui entendida como uma atividade de ajuste de curvas ou análise de regressão.
(5.2) resposta ao degrau unitário: Os processos químicos são caracterizados por balanço de massa e de energia, sendo tipicamente sistemas de primeira ordem com atraso:
sistemau y
)()()(dp ttuKty
dttdy
−=+τ
A previsão dos valores futuros é feita com as respostas da unidade frente a um degrau:
A resposta mostra três importantes parâmetros do modelo
• ganho do processo: variação total final (estado estacionário) da variável de
saída (y), dividida pela variação inicial (tamanho do degrau) da variável de entrada. O ganho é uma razão, possui unidades e pode ser calculado pela expressão:
uyKp Δ
Δ=
A variação na saída demanda certo tempo para se completar. A rapidez dessa variação é medida através de duas constantes de tempo: o tempo morto e o tempo de primeira ordem.

56
• tempo morto (td - delay time) é o tempo que leva para o processo começar a responder à variação em degrau.
• tempo de primeira ordem é o tempo que o processo demora, uma vez
iniciada a variação, para chegar aos 63% da variação total final.
Cada unidade tem suas respostas características. Levantar tais respostas é fazer um levantamento da identidade da unidade: identificação de processo. Para melhor identificar a unidade, são feitos testes, os chamados testes de identificação. O mais comum consiste em se alterar as variáveis livres (entrada) com o padrão de degrau, registrando-se as variáveis dependentes (saída) para obtenção da resposta frente ao degrau unitário.
Exemplo 1:
O gráfico seguinte mostra uma aplicação prática em sistema de topo de torre fracionadora GLP-gasolina:
• aumentou-se em 400 m3/d (de 3200 m3/d para 3600 m3/d) a vazão de
refluxo de topo da coluna, mantidas constantes as condições no reboiler e na pressão da torre. A torre esfriou e o intemperismo caiu de 0 para –1.6oC. O ganho do processo, portanto, vale:
dm
o
dm
o
pCCK 33 004.0
4006.1
−=−
=

57
• na abscissa pode-se verificar, de modo aproximado, tempo morto de 1 minuto. O tempo de primeira ordem vale 18 minutos, ou seja, iniciado o teste e decorrido o tempo morto de 1 minuto, o intemperismo começa a cair e atinge 0 – 0.63x1.6 = -1oC após 18 minutos.
Os três parâmetros do modelo podem variar conforme as condições operacionais da unidade. Tanto o tempo de primeira ordem como o tempo morto estão relacionados a tempo de residência (relação entre volume do equipamento e vazão de carga): para vazões mais altas, esse tempo diminui (volume constante). Também o ganho do processo, que expressa a sensibilidade do mesmo, pode variar conforme o ponto operacional da unidade. Algumas das formas de expressar esse modelo são:
equação diferencial )1(004.0)()(18 −×−=+ tutydt
tdy
função de transferência 118004.0
)()(
+−
=−
se
susy s
coeficientes de resposta ao degrau
coeficientes de resposta da planta

58
Exemplo 2: O gráfico seguinte mostra uma aplicação prática em sistema de fundo de torre fracionadora GLP-gasolina:
Neste caso, tem-se o resultado de um teste no sistema de fundo da torre. Reduziu-se em 200 m3/d (de 3460 m3/d para 3260 m3/d) a vazão de fluido de aquecimento do reboiler da coluna, mantidas constantes condições no refluxo e na pressão da torre. A torre esfriou e a temperatura da região de fundo caiu 3oC (de 154 para 151oC). Há várias maneiras de tratamento de dados para modelagem. No exemplo anterior, seguiu-se um método aproximado e, basicamente, visual. Estatísticas, matemáticas e diversos recursos de informática podem ser usados para aprimorar a modelagem. Planilhas de cálculo podem ser usadas para modelagem, examinando-se o comportamento de modelo de primeira e de segunda ordem.

59
(a) Modelo de 1ª ordem: a figura seguinte mostra parte de planilha com modelo de primeira ordem na forma integrada.
A primeira coluna contém a variável tempo em minutos contados desde a aplicação do teste em degrau no reboiler. Embora o teste tenha sido executado com redução da vazão de fluido de aquecimento, na segunda coluna da planilha reproduziram-se os dados para o degrau unitário e positivo, dividindo-se os desvios de temperatura por -200 m3/d. Na terceira coluna está codificado o modelo de primeira ordem integrado e na quarta coluna está codificado o erro quadrático ponto a ponto. O solver da planilha foi utilizado para, ajustando os parâmetros ganho e tempo de primeira ordem, obter o modelo correspondente que minimiza a soma dos quadrados dos erros (modelo x dados experimentais). O gráfico ilustra o melhor modelo obtido.

60
O modelo de primeira ordem também pode ser codificado em forma diferencial pelo uso das equações:
( )214321
−− +−= iiii yyy
hdtdy ( ) piii Kyy
hy
h=+−+⎟
⎠⎞
⎜⎝⎛ + −− 214
21
23 ττ
(b) Modelo de 2ª ordem: a figura seguinte mostra parte de planilha com
modelo de segunda ordem codificado na forma diferencial.
As duas primeiras colunas são semelhantes ao caso anterior: tempo decorrido desde aplicação do degrau e variação de temperatura decorrente (normalizada pelo tamanho do degrau). Na terceira coluna está codificado o modelo de segunda ordem na forma da equação diferencial discretizada (modelo diferencial):
• )(11−−= ii
i yyhdt
dy
• )2(12122
2
−− +−= iiii yyy
hdtyd
• piii Kyh
yhh
yhh
=+⎟⎟⎠
⎞⎜⎜⎝
⎛+−⎟⎟
⎠
⎞⎜⎜⎝
⎛+ −− 22
2
12
2
2
2 222 τζττζττ

61
Na quarta coluna está codificado o erro quadrático ponto a ponto. Também neste caso, o solver da planilha foi utilizado para, ajustando os parâmetros ganho, tempo de segunda ordem e fator de amortecimento (damping), obter o modelo correspondente que minimiza a soma dos quadrados dos erros (modelo x dados experimentais). O gráfico ilustra o modelo obtido. Uma pequena adaptação prática do modelo obtido seria a de eliminar o início de oscilação - conseqüência das características do modelo - obtendo a seqüência de coeficientes resposta ao degrau unitário do gráfico seguinte:

62
(5.3) experimentos com outras excitações: No esforço de modelagem, dados práticos podem ser levantados com testes experimentais em que se utilizem outras excitações, diferentes do degrau, para o sinal de entrada. Nesse caso, estatísticas de séries temporais são comumente usadas para obtenção dos modelos matemáticos. O modelo matemático, então, pode ser usado para simular a resposta ao degrau unitário.
Há muitas teorias sobre diferentes modos de excitação do processo através de sinal de entrada. A idéia é de excitar o sistema com sinal de entrada que permita melhor identificá-lo. Trata-se de um assunto complexo e que depende muito do tipo de processo envolvido e suas peculiaridades.

63
Teoricamente, uma forma de excitação freqüentemente aceita é pelo uso de PRBS - sequência binária pseudo-randômica. Parece tratar-se de um sinal com espectro largo, próximo do ruído branco, que permite cobrir a faixa de frequências de muitos processos. O sinal PRBS é periódico com 31 ou 43 sub-períodos de tempo:
PRBS de 31 pontos
-1
1
1
PRBS de 43 pontos
-1
1
1
Os sinais PRBS seriam recomendados para identificação de sistemas com várias variáveis de entrada e várias variáveis de saída (sistemas ditos multivariáveis). Nesses casos, recomenda-se excitação simultânea de mais de uma variável de entrada, registrando-se as diversas variáveis de saída (efeitos). Teoricamente, os sinais PRBS de 31 ou 43 pontos foram especialmente concebidos para permitir respostas experimentais mais favoráveis do sistema, respostas mais adequadas para aplicação de uma estatística de modelagem multivariável. Qualquer que seja o tipo de sinal PRBS, a duração de cada pulso que compõe a sequência depende de uma análise do tempo de resposta do sistema:
y k
tempo1 2 3T
T - constante de tempo do sistema
-1
1
tempo1 2 3
TPRBS
= T4

64
adota-se, geralmente, a quarta parte da constante de tempo do sistema para duração de cada pulso da PRBS. O valor da amplitude do sinal PRBS é escolhido de acordo com a amplitude do ruído de saída do sistema. Examinando a saída do sistema com sinal de entrada constante:
yk
a
recomenda-se que a amplitude da PRBS seja superior a dez vezes a amplitude do sinal de saída a. Muitos sistemas de refino de petróleo apresentam elevadas constantes de tempo (podendo chegar a horas). Isso pode elevar bastante o tempo total de experiência previsto pelas receitas PRBS. Várias ocorrências podem acontecer no decorrer de um longo teste, sendo necessária análise cuidadosa de representatividade das condições do experimento como um todo. [13] Box, G.E.P., Jenkins, G.M. (1976): Time Series Analysis – Forecasting and
Control. Holden-Day, Oakland. [14] Aguirre, L.A. (2000): Introdução à Identificação de Sistemas - Técnicas
Lineares e Não-Lineares Aplicadas a Sistemas Reais Editora da UFMG, Belo Horizonte.

65
(5.4) modelos discretos: Nestas notas, o sistema será representado por equações que envolvem as variáveis de entrada e saída do sistema. Serão envolvidos os termos das séries no tempo das variáveis de entrada e saída: • (... uk-3, uk-2, uk-1, uk) - série no tempo da variável de entrada • (... yk-3, yk-2, yk-1, yk) - série no tempo da variável de saída Supondo inicialmente um sistema mono-variável, as expressões que usaremos são de alguma das seguintes formas: 1. modelo AR: y a y a y a y ek k k n k n ka a
+ + + + =− − −1 1 2 2. . ... . Nesse caso, aparece apenas a variável de saída - yk. Foi feita regressão dessa variável consigo mesma em vários instantes de tempo. Ou seja, foi feita regressão linear dos termos da série temporal da variável de saída, motivo pelo qual esse modelo é dito modelo de auto-regressão (AR). Observar a existência de um termo ek, uma espécie de erro obtido ao se assumir que pode ser feita regressão linear dos termos da série temporal de yk. Demonstra-se que esse erro está associado à possibilidade de se compor um sinal temporal a partir de um ruído branco e que é uma forma de considerar as perturbações não medidas para o processo. 2. modelo ARX:
knnknnknknk
nknkkk
eubububub
yayayay
bkbkkk
aa
+++++
=++++
−+−−−−−−
−−−
123121
2211
.......
......
nesse caso, aparecem tanto a variável de saída (yk) como a variável de entrada (uk). Há regressão linear da variável de saída yk consigo mesma, motivo por que também este modelo é denominado auto-regressivo. Nota-se haver regressão linear na variável de entrada. Essa variável é denominada exógena, motivo para o modelo acima ser conhecido como modelo auto-regressivo com auto-regressão na variável exógena (ARX).

66
Observar a presença de um tempo morto (nk) entre a variável exógena (entrada) e a variável dependente (saída). 3. modelo ARMAX:
cc
bkbkkk
aa
nknkkk
nnknnknknk
nknkkk
ececece
ubububub
yayayay
−−−
−+−−−−−−
−−−
++++
+++++
=++++
......
.......
......
2211
123121
2211
esse caso é muito parecido com o ARX: auto-regressão para variável de entrada e de saída. Aqui, entretanto, foi feita regressão linear também para a série temporal dos erros. O propósito desse artifício é o de melhorar a correlação entre yk e uk, tentando-se segregar interferência de perturbações (dk) na modelagem, através da série de ek. No fundo, foi feita a auto-regressão na variável de saída, na exógena e ainda se fez uma média móvel do erro da regressão ARX. Esse termo média móvel (moving average) motiva o nome deste terceiro método: ARMAX. Para os modelos lineares, é comum representar os coeficientes ai e bi através de polinômios. Isso está de acordo com propriedade da transformada Z. Interessa principalmente por simplificar a notação. Desse modo, podemos representar os modelos anteriores através das seguintes notações simplificadas:
• )(.)......1.(...... 122
112211
−−−−−−− =++++=++++ zAyzazazayyayayay k
nnknknkkk
a
aaa
• )(.).......(...... 1123
1211121
−−
+−−−−−−+−−− =++++=+++ zBuzbzbzbbuububub
k
b
bkbkbkk nkn
nnknnknnknk
• )(.).....1.(...... 122
112211
−−−−−−− =++++=++++ zCezczczceececece k
nnknknkkk
c
ccc
Esta notação é apenas um formalismo; z-1 significa voltar um instante de tempo atrás, ou seja, yk.z-1 é o mesmo que yk-1. Os três modelos de regressão ficam escritos de modo mais compacto: • AR: kk ezAy =− )(. 1 • ARX: knkk ezBuzAy
k+= −
−− )(.)(. 11
• ARMAX: )(.)(.)(. 111 −−−
− += zCezBuzAy knkk k

67
4. outros modelos lineares: Já se comentou que o próprio modelo ARMAX inclui uma espécie de artifício matemático, o polinômio C(q-1). Outros modelos foram propostos para identificação, todos eles incluindo novos polinômios que também são artifícios matemáticos para tentar melhorar o ajuste de dados. Por exemplo, o modelo de Box-Jenkins (BJ) é bem completo e se traduz pela expressão:
knkk ezDzCu
zFzBy
k⋅+⋅= −
−
−−
−
)()(
)()(
1
1
1
1
Todos esses modelos envolvem os coeficientes dos polinômios como parâmetros, sendo chamados modelos paramétricos. Um caso particular é o modelo denominado FIR. O modelo FIR é da forma:
knkk ezBuyk
+= −− )(. 1
ou seja, não envolve o polinômio )( 1−zA . Apesar de envolver os coeficientes do polinômio )( 1−zB , a literatura se refere a tal caso como modelo não- paramétrico. “Os métodos não-paramétricos são aqueles que não resultam em modelo matemático tal como uma função de transferência, mas sim numa representação gráfica que caracteriza a dinâmica do sistema em estudo. Exemplos típicos de tais representações são a resposta ao impulso e a resposta em freqüência”. É fácil demonstrar que os coeficientes do polinômio )( 1−zB (parâmetros de Markov do sistema) são a resposta do sistema frente a uma excitação na forma de impulso. 5. modelo NARX (ARX não-linear): ),..,,...,( 11 parametrosuyfy kkk −−=
Trata-se de uma modificação que envolve o ajuste dos termos da série temporal com modelos não lineares. Dentre as muitas formas, as redes neurais são modelos não-lineares (função f) particularmente atraentes para identificação de processos.

68
(5.5) estimação dos parâmetros: Resolver o problema formulado por qualquer dos modelos citados significa pesquisar o valor dos parâmetros que minimize erro de ajuste de dados. Como seria de se esperar, o critério é o de minimizar a soma dos quadrados dos erros do ajuste, método de mínimos quadrados. No anexo 2 discutem-se alguns aspectos do método de mínimos quadrados para ajuste de modelos lineares. As expressões para os diversos modelos foram escritas de modo simplificado. Os textos sobre identificação costumam ser mais rigorosamente formais, acompanhados de um tratamento matemático que resulta naturalmente na forma de erro de ajuste a ser minimizado. Apenas analisaremos o resultado final aplicado aos três modelos de maior interesse, ou seja, os modelos lineares AR, ARX e ARMAX. O erro de ajuste relaciona-se com o valor atual do erro ek para cada instante de ajuste dos dados, ou seja, k=1, 2, ..., n e é dado pela somatória:
V ekk
n
( )Θ ==
∑ 2
1
Nessa expressão aparece como variável livre o vetor Θ , também denominado vetor dos parâmetros dos modelos, notação padrão na área de identificação de processos. No fundo, esse vetor engloba os parâmetros ai, bi, ci ... dos diversos polinômios envolvidos nos modelos citados anteriormente: • modelo AR: [ ]Θ = a a an
T
a1 2 L
• modelo ARX: [ ]Θ = a a a b b bn n
T
a b1 2 1 2L L
• modelo ARMAX: [ ]Θ = a a a b b b c c cn n n
T
a b c1 2 1 2 1 2L L L Esse vetor está associado ao vetor dos regressores, assim definido:
• modelo AR: [ ]ϕ Tk k k nk y y y
a( ) = − − −− − −1 2 L
• modelo ARX: [ ]ϕ Tk k k n k k k nk y y y u u u
a b( ) = − − −− − − − − −1 2 1 2L L
• modelo ARMAX: [ ]ϕTk k k n k k k n k k k nk y y y u u u e e e
a b c( , )Θ = − − −− − − − − − − − −1 2 1 2 1 2L L L

69
de tal modo que todos os modelos podem ser escritos de modo geral como:
y ekT
k= +ϕ .Θ ou e yk kT= − ϕ .Θ
É interessante observar que nos dois primeiros modelos, o vetor ϕ não depende de Θ . Entretanto, para o modelo ARMAX, estando envolvida a série histórica de erros, o vetor ϕ depende também de Θ . Isso significa que, para os modelos AR e ARX, a determinação de Θ é direta. A aplicação das condições de mínimo para V ( )Θ leva a um sistema de equações que pode ser resolvido diretamente:
∂∂
∂∂
V VΘ Θ1 2
0= = = ⇒L sistema de equações lineares
Ou seja, montam-se as matrizes de dados para o método de mínimos quadrados e, sendo o problema linear, a resolução é direta. Isso está ilustrado através do exemplo 3 do anexo 2. No modelo ARMAX o procedimento é diferente. A montagem das matrizes de dados envolve valores passados do erro ek-i. Estes valores, por sua vez, dependem dos parâmetros do modelo, que estão sendo estimados. A regressão é não-linear e a pesquisa dos valores para Θ é iterativa, envolvendo métodos de pesquisa numérica para a determinação de mínimo de função erro.
(5.6) seleção e validação do modelo: Como escolher o tipo de modelo e suas ordens? Não existem regras definitivas para escolha de modelo, sendo essa uma decisão que depende de bom senso em análise de engenharia. A estatística propõe algumas medidas de adequação de modelos. A base da maioria delas é a função erro de ajuste (loss error function):
N
yy
f
N
iiisim
e∑ −== 1
2)( )(
onde N é o número de pontos da série temporal, yi são as medições e ysim(i) são os valores calculados com o modelo.

70
Essa função expressa a perda de representação dos dados pelo modelo. A soma de erros quadráticos (diferença entre previsão com o modelo e resultado experimental) expressa a maior ou menor capacidade do modelo em traduzir os dados experimentais. Pesquisam-se modelos de várias ordens, escolhendo-se o que apresentar menor perda de representação (modelo ótimo). É boa prática estatística fazer ajuste de modelo com um conjunto de dados e examinar sua função de erro de ajuste com outro conjunto de dados: fazer a chamada validação cruzada. Não sendo feita validação cruzada, ou seja, usando-se o mesmo conjunto de dados para ajuste e para teste do modelo, a função erro de ajuste pode ser enganosa. Ordens muito elevadas podem levar a modelos com melhor ajuste mas com ônus de modelagem dos ruídos. Para resolver esse problema, há três modificações da função erro: 1- critério de Akaike: Uma medida estatística modificada para seleção de modelo é o denominado information theoretic criterion proposto por Akaike . Trata-se de um critério que transforma a lost error function segundo a expressão seguinte:
( )[ ]e e efn
N fn
N fmodlog ( )= + × ≅ + ×1 12 2
onde n é o número de parâmetros do modelo e N é o número de pontos da série temporal. 2- critério de Rissanen: Outra medida modificada de seleção de modelo é o denominado minimum description lenght proposto por Rissanen. O critério transforma a lost error function segundo a expressão seguinte:
e N efnN fmod
( log( ) )= + × ×1 onde, também nesse caso, n é o número de parâmetros do modelo e N é o número de pontos da série temporal.

71
3- final prediction error: Medida de seleção de modelo que se baseia na expressão:
fNnNn
f efpee ×−+
==11
mod
com n - número de parâmetros do modelo e N - número de pontos da série temporal. Nos três casos, efmod
é a lost error function modificada para correção por não se fazer a validação cruzada. Quando é feita a validação cruzada, pode-se usar apenas apenas a lost error function não-modificada. Todas as propostas anteriores se baseiam em alguma forma de erro total de ajuste do modelo aos dados experimentais.
Análise de resíduos Um critério interessante para seleção de modelo se baseia na análise de cada erro, ponto a ponto da série temporal. São os denominados resíduos do ajuste de modelo à série. Os resíduos são as diferenças entre os valores experimentais e os valores calculados com o modelo (simulados). Assim como as variáveis de entrada e de saída formam séries no tempo, também os próprios resíduos formam uma série no tempo.

72
A estatística propõe análise de auto-correlação da série dos resíduos e análise de correlação cruzada entre a série dos resíduos e a série da variável de entrada do sistema. A auto-correlação da série dos resíduos é calculada com a expressão:
∑−=
∞→ ++
=N
NiNee lieie
Nlr )()(
121lim)(
e a correlação cruzada da série dos resíduos com a série da variável de entrada é calculada com a expressão:
∑−=
∞→ ++
=N
NiNue lieiu
Nlr )()(
121lim)(
Nas duas expressões aparece o lag time (atraso) – l – que varia de zero a um valor apropriadamente selecionado (normalmente 25 períodos) para análise de correlação das duas séries. Se a série dos resíduos não formar um ruído branco, há fortes evidências de que o modelo é enviesado (tendencioso) e, portanto, fortes evidências a favor de sua rejeição. Pelo contrário, não havendo evidências suficientes para rejeição, a escolha do modelo ainda estará sujeita a risco. Não existe um teste de aceitação de modelo, apenas testes de rejeição, típicos da estatística. Aplica-se teste da hipótese de a série dos resíduos formar um ruído branco e independente da série dos dados de entrada do sistema: • série resíduos forma um ruído branco: para lag time de 1 a l , examinar os
l coeficientes de auto-correlação. Se a série dos resíduos não formar um ruído branco, pelo menos um dos coeficientes é diferente de zero com certo nível de confiança (ex: 99%) e a hipótese de ruído branco deve ser rejeitada. Nesse caso, o modelo de processo proposto deve ser rejeitado;
• para lag time igual a zero, evidentemente, o coeficiente de auto-correlação
de qualquer série temporal é 1;

73
• série dos resíduos é independente da série dos dados de entrada: para lag time de 0 a l , examinar os coeficientes de correlação cruzada u x e. Se as duas séries não forem independentes, pelo menos um dos coeficientes é diferente de zero com certo nível de confiança (ex: 99%) e a hipótese de independência deve ser rejeitada. Também nesse caso, o modelo de processo proposto deve ser rejeitado.
A não-rejeição do modelo de processo proposto por qualquer dos dois critérios não significa aceitação do modelo. A estatística do teste de hipóteses norteia apenas a rejeição; não há critério para aceitação. Gráficos dos coeficientes de auto-correlação dos resíduos x lag time e dos coeficientes de correlação cruzada resíduos-entrada x lag time são úteis para análise de resíduos:
Sob o ponto de vista estocástico, o erro de identificação consiste de duas partes: • erro de bias decorrente de um modelo insuficiente; • erro de variança em razão de perturbações que causaram impacto no
sistema. Geralmente, um modelo é considerado adequado se a auto-correlação de seus resíduos for considerada um ruído branco; além disso, a correlação dos resíduos com o sinal de entrada deve ser nula. Nesse caso, o erro de identificação é devido inteiramente a erro de variança (erro de bias nulo).
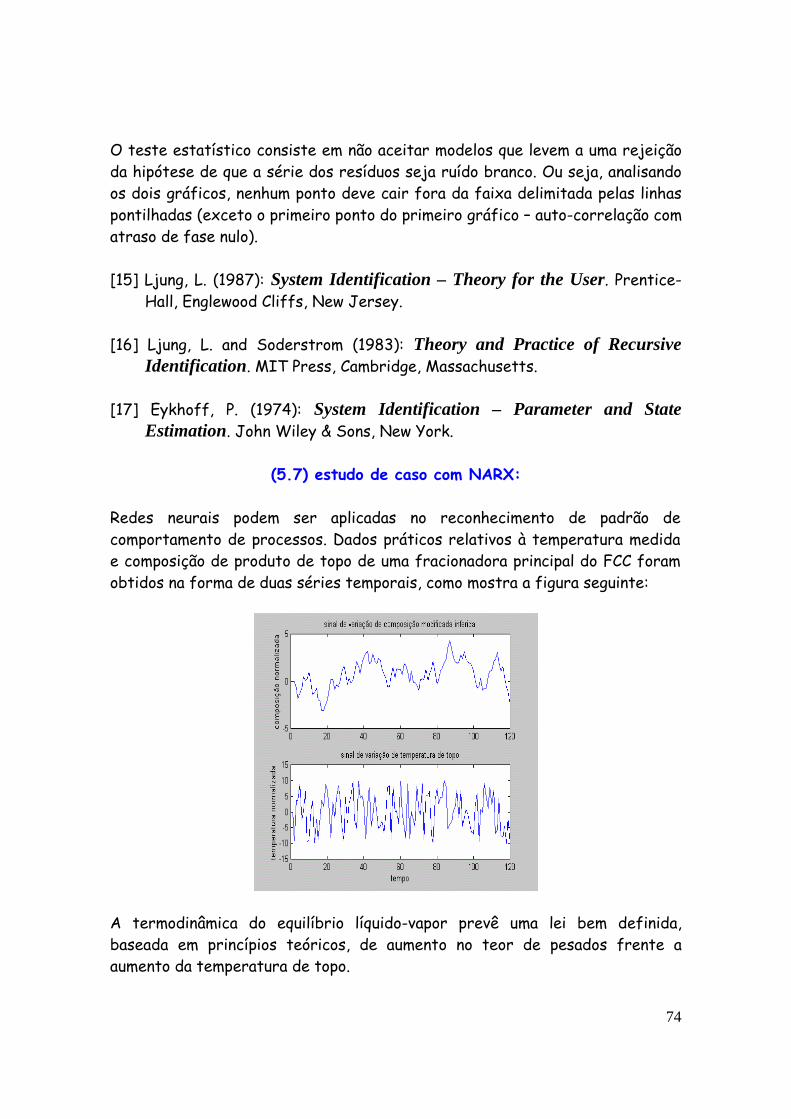
74
O teste estatístico consiste em não aceitar modelos que levem a uma rejeição da hipótese de que a série dos resíduos seja ruído branco. Ou seja, analisando os dois gráficos, nenhum ponto deve cair fora da faixa delimitada pelas linhas pontilhadas (exceto o primeiro ponto do primeiro gráfico – auto-correlação com atraso de fase nulo). [15] Ljung, L. (1987): System Identification – Theory for the User. Prentice-
Hall, Englewood Cliffs, New Jersey. [16] Ljung, L. and Soderstrom (1983): Theory and Practice of Recursive
Identification. MIT Press, Cambridge, Massachusetts. [17] Eykhoff, P. (1974): System Identification – Parameter and State
Estimation. John Wiley & Sons, New York.
(5.7) estudo de caso com NARX:
Redes neurais podem ser aplicadas no reconhecimento de padrão de comportamento de processos. Dados práticos relativos à temperatura medida e composição de produto de topo de uma fracionadora principal do FCC foram obtidos na forma de duas séries temporais, como mostra a figura seguinte:
A termodinâmica do equilíbrio líquido-vapor prevê uma lei bem definida, baseada em princípios teóricos, de aumento no teor de pesados frente a aumento da temperatura de topo.

75
Portanto, os dados práticos envolvem variáveis cujo relacionamento mútuo é regido por algum princípio científico, o que torna muito atraente a possibilidade de poderem ser ajustados modelos estatísticos empíricos para correlacionar as duas variáveis do sistema. Os dados práticos anteriores foram submetidos a treinamento com rede neural não-linear pelo uso do Matlab mediante o uso das seguintes instruções: nu = 3; ny = 1; z=[y u]; ncaso = max(nu,ny); t = z(ncaso+1:n,1); p = []; for i = 1:ny p = [p z(ncaso+1-i:n-i,1)]; end for i = 1:nu p = [p z(ncaso+1-i:n-i,2)]; end
No exemplo, quatro são as variáveis de entrada para a rede, estando organizadas em quatro linhas. As variáveis correspondem à própria série histórica deslocada num horizonte de até três intervalos de tempo para a variável temperatura (uk) e de um intervalo de tempo para a variável composição (yk).
A variável de saída para a rede é a série histórica da composição de produto de topo. Em termos estatísticos, diz-se ter sido empregado um modelo do tipo autoregressivo-exógeno (ARX) com na = 1 e nb = 3. Foi usada uma rede com uma primeira camada de dois neurônios com função de transferência tipo tansig e uma segunda camada (saída) cujo neurônio único tem função linear. Os resultados parciais ao longo das épocas de treinamento estão na figura seguinte.

76
O treinamento foi concluído em 26 épocas. As dez primeiras épocas permitiram um ajuste inicial mais rápido e as dezesseis últimas foram necessárias para um refinamento do ajuste dentro da precisão requerida. A rede neural treinada para identificar o sistema permitiu uma simulação de resposta do mesmo frente ao degrau unitário. O resultado, confirmado através de testes com a fracionadora, foi o seguinte:

77
Referências: [18] Bishop, M. B. (1990): Neural Networks and Pattern Recognition.
Oxford University Press, Boston. [19] Demuth, H. and Beale, M. (1997): Neural Network Toolbox User’s Guide
(v.3.0). The MathWorks, Inc., Natick.
[20] Ljung, L. (1994): System Identification Toolbox User’s Guide The MathWorks, Inc., Natick.

78
(6) controle avançado:
(6.1) estrutura do controlador:
O controle avançado faz três cálculos diferentes:
cálculo das previsõesvariáveis
controladas
variáveis manipuladasotimização do valor para
cálculo de set-points aproximando-se do
manipuladasótimo para
cálculo das previsõesvariáveis controladas
variáveis manipuladascálculo dos targets para
cálculo de set-points
(programação linear)
pelo DMC
• registra as alterações ocorridas nos set-points de todas as variáveis manipuladas. Com isso, ele pode fazer previsões do valor futuro para as variáveis controladas, usando as respostas ao degrau levantadas na identificação da unidade.
• pesquisa quais as variações necessárias em todas as variáveis manipuladas (vários set-points para o SDCD) para deixar as previsões futuras das variáveis controladas dentro de faixas aceitáveis (mínimo e máximo). Nos cálculos, também considera restrições de máximo e mínimo para variáveis manipuladas. Em consequência da escolha de pesos, os cálculos naturalmente levam a maximização ou minimização de variáveis manipuladas. Isso é uma

79
otimização que usa programação linear (ou quadrática) e que define objetivos (targets para variáveis manipuladas) para a unidade.
• encaminha a unidade suavemente, ao longo do tempo, para os objetivos
(targets) definidos pela otimização. Trata-se de um refinamento de cálculo de set-points a serem efetivamente enviados para o SDCD. Usa-se uma técnica matemática denominada controle pela matriz dinâmica (DMC - dynamic matrix control).
A sequência de cálculo do controle avançado se acopla ao software do SDCD, através do qual são feitos a leitura de dados e o envio de set-points para os controladores regulatórios.
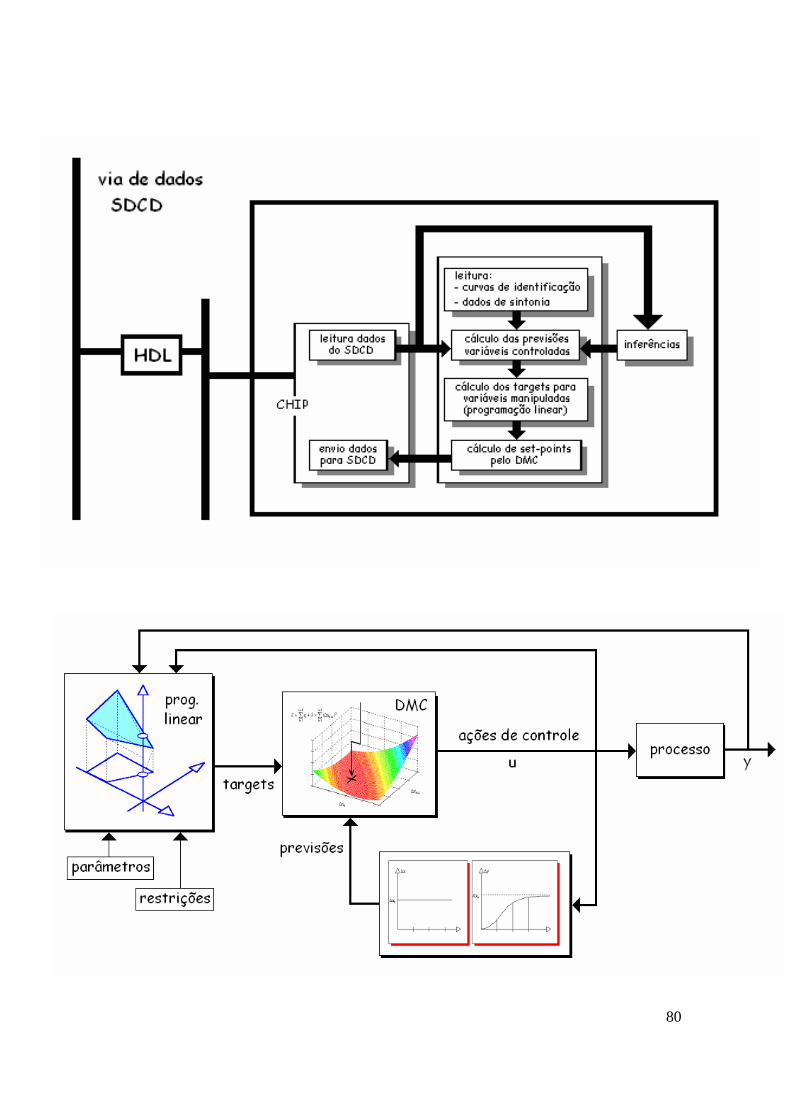
80
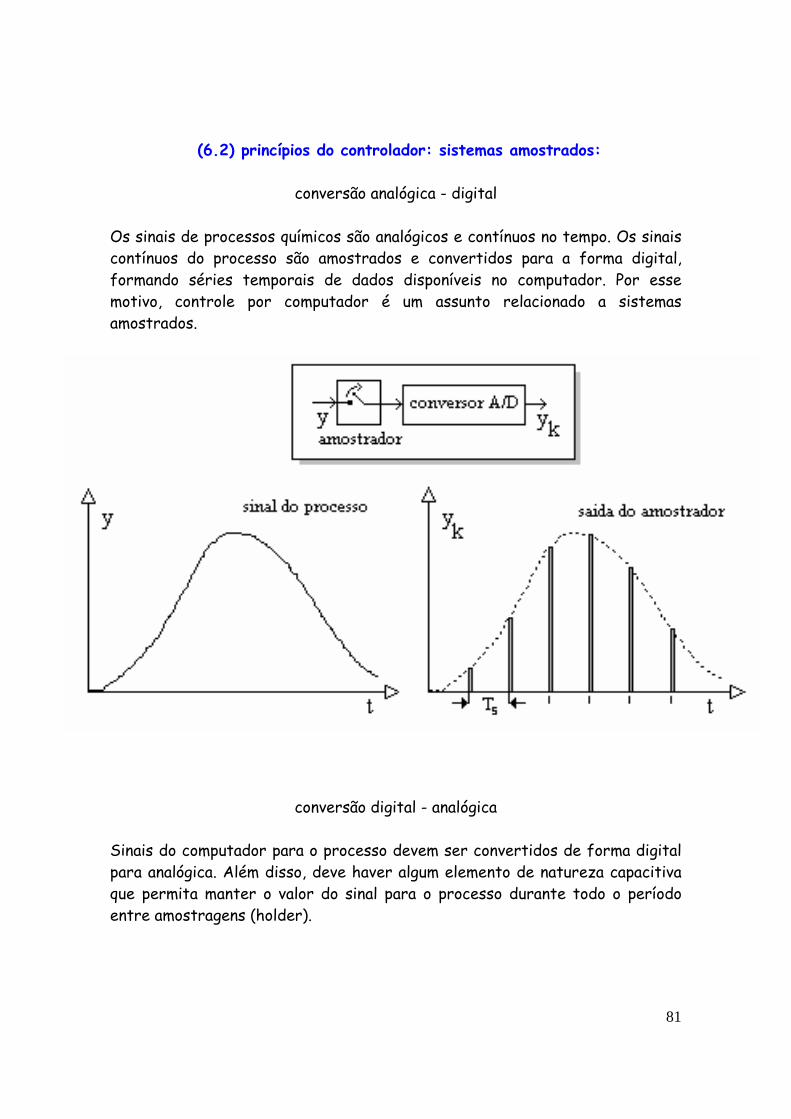
81
(6.2) princípios do controlador: sistemas amostrados:
conversão analógica - digital Os sinais de processos químicos são analógicos e contínuos no tempo. Os sinais contínuos do processo são amostrados e convertidos para a forma digital, formando séries temporais de dados disponíveis no computador. Por esse motivo, controle por computador é um assunto relacionado a sistemas amostrados.
conversão digital - analógica
Sinais do computador para o processo devem ser convertidos de forma digital para analógica. Além disso, deve haver algum elemento de natureza capacitiva que permita manter o valor do sinal para o processo durante todo o período entre amostragens (holder).

82
Em sistemas com amostragem, os eventos ocorrem em determinados momentos e formam uma série no tempo:
k k+1 k+2 k+3
y
k+4k-1k-2 tempo O índice k serve para fazer referência ao instante de amostragem:
• k se refere ao instante atual; • k-1, k-2, k-3 ... se referem aos instantes passados; • k+1, k+2, k+3 ... se referem aos instantes futuros.

83
O período de amostragem deve ser escolhido cuidadosamente, conforme o propósito dos sistemas. Esse cuidado está relacionado ao fato de que sempre é perdida a informação entre os momentos de amostragem, perda que não deve comprometer o desempenho do sistema. Para uma série temporal correspondente a um evento, define-se a transformação matemática z (Lofti Zahdeh) como:
...)()]([ 33
22
110
0
++++=== −−−∞
=
−∑ zyzyzyyzyzykyZk
kk
Uma propriedade importante é a da transformada da função:
)]([)]([00 0
)( kyZzzyzzzyzzyzynkyZj
njj
n
nj
njj
k k
nnknk
knk ∑∑∑ ∑
∞
=
−−−∞
−=
−−∞
=
∞
=
−−−−
−− =====−
ou seja, o termo nz− funciona como um operador de atraso no tempo (backward operator) para o sinal amostrado y(k). Essa propriedade é interessante para economia de notação, seja no caso de teoria de identificação de sistema, seja no de controle preditivo.

84
Um controle proporcional e integral na forma paralela é implementado em computador (sistema amostrado) através da codificação da seguinte lei, que é uma equação de diferenças:
( ) ki
ckkckk ekeekuu
τ+−+= −− 11
ou
( ) ( )kki
ckkkkckk ysp
kyspyspkuu −++−−+= −−− τ111
que resulta da discretização da equação diferencial do PID para sistemas contínuos (analógicos).
Essa equação está na forma velocidade, é a base do controle clássico para sistemas amostrados e expressa a idéia de que a atual ação de controle (uk) é calculada como a ação de controle na varredura anterior (uk-1) mais uma parcela proporcional ao valor atual da variável controlada (yk embutido no erro ek).
Discutir os princípios do controle avançado significa argumentar uma lei alternativa para a lei PID. Em particular, nestas notas se argumentam os princípios que permitem usar previsão futura das variáveis controladas (yk+j j=1, 2, ... n) em substituição ao mero valor atual. Também se argumentam os princípios de otimização definidores de valores futuros para os set-points das variáveis controladas (denominados targets).
[21] Deshpande, P. (1982): Elements of computer process control with
advanced control applications Instrument Society of America, Research Triangle Park.

85
(6.3) resposta de um sistema ao pulso unitário
O controlador se baseia na idéia de expressar a saída atual do sistema como ponderação de entradas históricas.
SISTEMAS MONOVARIÁVEIS
sistemauk yk
Isso pode ser expresso como:
$y huk ii
k i+=
∞
+ −= ∑11
1
onde aparece a função ponderal hi, i = 1, 2, ... Essa função ponderal é a resposta do sistema ao pulso unitário em sua entrada (coeficientes de resposta ao impulso ou parâmetros de Markov):
u y
1 2 3 41 2 3 4
1 pulso unitário
h 1
h 2
h 3
h 4
t t

86
A função pulso unitário é dada por: u0 = 1, u1 = 0, u2 = 0 ... Admite-se que o sistema é estável, ou seja, ele não se deixa perturbar permanentemente pelo pulso e a resposta tende assintoticamente a 0. A argumentação para esse fato passa pela transformada Z da função de transferência do sistema. Representando-a como:
G z y zu z
( ) ( )( )
=
para o caso do pulso unitário tem-se u(z)=1, já que u z u z ukk
k
( ) .= = =−
=
∞
∑0
0 1
Isso quer dizer que a transformada Z da função de transferência do sistema é a transformada Z da resposta do sistema a um pulso unitário em sua entrada. Chamaremos essa resposta h(z). Então, tem-se G z h z( ) = ( ) , ou, no caso geral: y z h z u z( ) = ( ). ( ) Desenvolvendo a última expressão:
y y z y z h h z h z u u z u z0 11
22
0 11
22
0 11
22+ + + = + + + + + +− − − − − −. . ... ( . . ...).( . . ...) ou
y y z y z h u h u h u z h u h u h u z0 1
12
20 0 0 1 1 0
10 2 1 1 2 0
2+ + + = + + + + + +− − − −. . ... . ( . . ) ( . . . ) ...
o termo genérico da série pode ser escrito como: y h uk i k ii
k
= −=∑ .
1
O estado inicial do sistema é estacionário em relação à perturbação pulso unitário, o que significa h0=0. A representação do sistema por convolução usa uma série infinita. Como os sistemas que nos interessam são estáveis, a convolução pode se restringir a um número de termos adequados para representação do sistema:

87
resposta ao impulso
assintótica para zero
$y h uk ii
N
k i+=
+ −= ∑11
1
Vale relembrar graficamente como se obteriam os valores da função ponderal:
uk
tempo
1
1 2 3
yk
tempo
1
1 2 3
entrada: pulso unitário saida: resposta ao pulso na entrada
h1
h2
h3
O levantamento dessa função, portanto, envolveria a perturbação do sistema com um pulso unitário. Lembrando que a escala discreta de tempo (granularidade) refere-se à unidade de tempo escolhida (entre k e k+1 pode ter decorrido 1 segundo, 1 minuto ou qualquer outra unidade) verifica-se que o teste com o sistema envolve uma duração de pulso coerente com a unidade escolhida.

88
(6.4) resposta de um sistema ao degrau unitário
O teste mais comum para identificação de sistemas é o de se injetar uma perturbação degrau em sua entrada. Por esse motivo, interessa conhecer como fica a representação do sistema em termos de sua resposta a perturbação degrau.
uk
tempo
1
1 2 3
yk
tempo
1
1 2 3
entrada: degrau unitário saida: resposta ao degrau na entrada
a1
a2a3
Novamente, a argumentação baseia-se na transformada Z da perturbação. Para
o degrau unitário tem-se: u z u z z z zzk
k
k
( ) . ...= = + + + + =−
−
=
∞− − −
−∑0
1 2 311 1
1
Isso significa que a resposta do sistema - a(z) - a um degrau unitário em sua
entrada pode ser escrita como G z y zu z
h z z a z h z( ) ( )( )
( ) ( ). ( ) ( )= = ⇒ − =−1 1 .
Os coeficientes ak podem ser obtidos como se verifica no gráfico acima, e sua relação com hk é dada por: h a ak k k= − −1 . Esta última expressão decorre de propriedade da transformada Z:
)]([.)]1([ 1 kfZzkfZ −=−

89
Conclui-se que se pode representar a saída de um sistema através de suas entradas passadas, ponderadas por uma função ponderal que envolve a resposta do sistema a uma perturbação degrau unitário em sua entrada (a0 = 0):
y a a uk i i k ii
ncalc
= − − −=∑ ( ).1
1
(6.5) aplicação da convolução para previsão: Controle preditivo pressupõe previsão. Essa previsão baseia-se na convolução aplicada a dois instantes:
onde: Δu u uk i k i k i+ − + − −= −1 1
$y huk ii
N
k i+=
+ −= ∑11
1
$ $y y h uk k ii
N
k i+=
+ −− =∑11
1Δ
$y huk ii
N
k i==
−∑1
modelo com a variável na forma de variação (variável não cheia)

90
Fazendo uma correção da estimativa futura com o erro verificado para a estimativa atual (feita no passado):
correção da estimativa:
y y h ukc
k i k ii
N
+ + −=
= + ∑1 11
Δ
erro da estimativano instante k
válido para k+1
$ $y y y yk kc
k k+ +− = −1 1
(6.6) valor desejado para variável controlada: O valor desejado para a previsão da variável geralmente consiste numa ponderação entre o valor atual e um valor desejado. Essa ponderação suaviza as ações de controle, aumentando robustez (estabilidade) do controlador:
α → 1
α → 0
0 1≤ ≤ααrk
y y rkd
k k+ = + −1 1α α( )
valor desejado para y k + 1
set-pointconstante de filtração
t
yrk
trajetória suaveações de controle suaves
ações de controle drásticas

91
(6.7) fechamento da malha: previsão x valor desejado: Ao estabelecer que o valor desejado da variável controlada seja atingido mediante ajuste de variável manipulada:
caso ideal - previsão é o desejado
y ykc
kd
+ +=1 1 y h u y rk ii
N
k i k k+ = + −=
+ −∑1
1 1Δ α α( )
h u h u r y Ek ii
N
k i k k k12
1 1 1Δ Δ+ = − − = −=
+ −∑ ( )( ) ( )α α erro atual
u uh
Eh
h uk k k i k ii
N
= +−
−− + −=∑1
1 11
2
1 1( )αΔ
chega-se a um controlador monovariável preditivo com predição para apenas um intervalo futuro. Esse controlador apresentaria um problema para sistemas com tempo morto superior ao intervalo de amostragem do controlador, uma vez que devido à operação de divisão pelo termo h1.

92
(6.8) extensão do horizonte de previsão:
Aplicando a convolução a R instantes futuros:
kk
cjkjk
N
iijkijk
yyyy
uhy
−=−
=
++
=−++ ∑
ˆˆ
ˆ1
Reorganizando algebricamente as expressões:
∑∑
∑∑
∑∑
∑∑
=−
=−++
=−
=−++
=−
=−++
=−
=−++
−+=
−+=
−+=
−+=
N
iiki
N
iiRkik
cRk
N
iiki
N
iikik
ck
N
iiki
N
iikik
ck
N
iiki
N
iikik
ck
uhuhyy
uhuhyy
uhuhyy
uhuhyy
11
1133
1122
1111
M⇒
∑
∑
∑
∑
=−+−++
=−+++
=−+++
=−++
Δ+=
Δ+=
Δ+=
Δ+=
N
iiRki
cRk
cRk
N
iiki
ck
ck
N
iiki
ck
ck
N
iikik
ck
uhyy
uhyy
uhyy
uhyy
11
1323
1212
111
M

93
O sistema de equações pode ser reescrito como:
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
Δ+Δ++Δ+Δ+=
Δ+Δ+Δ+Δ+=
Δ+Δ+Δ+=
Δ+Δ+=
∑
∑
∑
∑
+=−+++−+−++
=−+++++
=−++++
=−++
N
RiiRkikRRkRk
cRk
cRk
N
iikikkk
ck
ck
N
iikikk
ck
ck
N
iikikk
ck
uhuhuhuhyy
uhuhuhuhyy
uhuhuhyy
uhuhyy
122111
433122123
3221112
2111
...
M
⇒
RkRRkRkc
Rkc
Rk
kkkck
ck
kkck
ck
kkck
Suhuhuhyy
Suhuhuhyy
Suhuhyy
Suhyy
+Δ++Δ+Δ+=
+Δ+Δ+Δ+=
+Δ+Δ+=
+Δ+=
++−+−++
++++
+++
+
...22111
33122123
221112
111
M
⇒
com: ∑+=
−+Δ=N
jiijkij uhS
1 (termos históricos da entrada).

94
RkRRkRkkc
Rk
kkkkck
kkkck
kkck
SSSuhhhuhhuhyy
SSSuhhhuhhuhyy
SSuhhuhyy
Suhyy
++++Δ+++++Δ++Δ+=
+++Δ+++Δ++Δ+=
++Δ++Δ+=
+Δ+=
++−++
+++
++
+
...)...(...)(
)()(
)(
212122111
321321121213
2121112
111
M
A equivalência entre as respostas ao pulso unitário e ao degrau unitário permite fazer a substituição:
∑=
=i
jji ha
1
e reescrever as equações de convolução como:
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
+Δ++Δ+Δ+Δ+=
+Δ+Δ+Δ+=
+Δ+Δ+=
+Δ+=
−++−+−+
+++
++
+
RRkkRkRkRkc
Rk
kkkkck
kkkck
kkck
Puauauauayy
Puauauayy
Puauayy
Puayy
112211
3211233
21122
111
...M

95
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
+
+++
+
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
Δ
ΔΔΔ
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−+
+
+
−−+
+
+
+
Rk
k
k
k
Rk
k
k
k
RRRc
Rk
ck
ck
ck
Py
PyPyPy
u
uuu
aaaa
aaaaa
a
y
yyy
MMMOMMMM
3
2
1
1
2
1
121
123
12
1
3
2
1
...
0...0...00...00
Novamente utilizando o conceito de uma trajetória desejável para os valores futuros da variável controlada (suavizando seu percurso desde o valor atual até um valor desejado):
y y rk jd
j k j k+ = + −α α( )1escrevendo o valor desejado
na forma matricial
yyy
y
y ry ry r
y r
kd
kd
kd
k Rd
k k
k k
k k
R k R k
+
+
+
+
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
+ −+ −+ −
+ −
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
1
2
3
1 1
2 2
3 3
111
1M M
α αα αα α
α α
( )( )( )
( )
O valor previsto das saídas (y) pode ser alterado pela conveniente escolha de futuras entradas (u), buscando máxima coincidência com o valor desejado:
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−−−−−
+
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
Δ
ΔΔΔ
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−
−−−
−+
+
+
−−++
++
++
++
RkR
k
k
k
Rk
k
k
k
RRRc
Rkd
Rk
ck
dk
ck
dk
ck
dk
PE
PEPEPE
u
uuu
aaaa
aaaaa
a
yy
yyyyyy
)1(
)1()1()1(
...
0...0...00...00
33
22
11
1
2
1
121
123
12
1
33
22
11
α
ααα
MMMOMMMM

96
E A u E= − + ′.Δ
onde: E erro de previsão e ′E termo com fatores passados e erro atual. A matriz A é quadrada e, sendo adequadamente condicionada, pode ser invertida.
Se a matriz for inversível, o termo E pode ser igualado a zero, havendo então graus de liberdade necessários e suficientes para igualar os valores desejados e os previstos para a variável controlada. Nesse caso, o bom condicionamento está associado à idéia de que é possível selecionar todo um horizonte futuro para a variável manipulada de modo a não cometer erro entre o valor desejado e o previsto para a saída.
(6.9) redução do horizonte de controle O condicionamento da matriz A é fortemente determinado pela existência de
tempo morto no sistema:
0=E previsão corrigida igual ao valor desejado
EAu ′=Δ −1
? tempo morto faz 011 == ha (matriz singular)
Uma solução para esse problema consiste em aumentar os graus de liberdade da equação de erro para emprego de mínimos quadrados.

97
diminuição do número de ações de controle
introdução de um horizonte de controle (movimentação)
0=Δ +iku Li >
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−−−−−
+
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
Δ
ΔΔΔ
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−
−−−
−+
+
+
+−−−++
++
++
++
RkR
k
k
k
Lk
k
k
k
LRRRRc
Rkd
Rk
ck
dk
ck
dk
ck
dk
PE
PEPEPE
u
uuu
aaaa
aaaaa
a
yy
yyyyyy
)1(
)1()1()1(
...
0...0...00...00
33
22
11
1
2
1
121
123
12
1
33
22
11
α
ααα
MMMOMMMM
E A u E= − + ′.Δ
Essa equação não tem solução direta para E = 0 porque R>L. No entanto, ela permite uma solução através de pseudo-inversa como consequência da aplicação do método de mínimos quadrados. A solução consiste em determinar o perfil de ações de controle futuras que minimize a soma dos quadrados dos erros entre a trajetória desejada e os valores previstos para a variável controlada.
solução por mínimos quadrados:
J u E Et( )Δ =
função objetivo soma dos quadrados dos erros

98
J u A u E A u Et( ) ( . ) .( . )Δ Δ Δ= − + ′ − + ′
J u u A A u u A E E A u E Et t t t t( ) . . . . . . . .Δ Δ Δ Δ Δ= − ′ − ′ + ′ ′
para otimização: ∂∂
Ju
A A u A E A Et t t
ΔΔ= = − ′ − ′0 2 . . . .
Δu A A A Et t= ′−( . ) . .1
que é a expressão final do controlador preditivo que usa a dinâmica do sistema na forma de matriz (dynamic matrix control).
Vale lembrar que a lei de controle envolve parâmetros de sintonia como os horizontes (R da variável controlada e L da variável manipulada) e os filtros da trajetória desejada para a variável controlada. Vale também ressaltar mais uma vez o significado do vetor de ações de controle futuras:
Δ
ΔΔ
Δ
u
uu
u
k
k
k L
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
+
+ −
1
1
M

99
Dessas ações, que são reavaliadas a cada varredura, apenas a primeira é efetivada:
u u uk k k= +−1 Δ
As demais ações são recalculadas a cada varredura futura.
Uma modificação importante dessa lei de controle é a proposta de acrescentar a soma dos quadrados das movimentações (ações de controle) na minimização de erro, minimizar a função objetivo:
J u E Q E u ut t( ) . . .Δ Δ Δ= + λ
onde λ é matriz diagonal de pesos (supressão de movimentos)
Δu A Q A A Q Et t= + ′−( . . ) . . .λ 1
A nova lei de controle implica em ações mais suaves e ajuda a contornar imperfeições de modelo que podem introduzir condicionamento impróprio de matrizes.
(6.10) modificação do vetor de previsão E’ O cálculo do erro que utiliza a previsão dos valores futuros para variáveis controladas (vetor E’) pode ser simplificado pelo uso do algoritmo seguinte. Num instante qualquer de uma situação diária comum, o perfil futuro da variável controlada pode ser organizado numa tabela ou vetor (notação de matrizes):

100
yy
y
k
k
k n k
+
+
+
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
1
2
M
O índice k do vetor é indicativo de previsões que foram feitas para momento atual, mas na amostragem anterior. Valores futuros (para os instantes k+1, k+2, ... k+n) do vetor de índice k se referem a previsões que foram feitas 1 minuto atrás (amostragem anterior). Transcorrido um minuto a partir do momento atual, como ficará esse perfil de previsões? Ele se modifica em consequência de duas operações: 1. translação de posições fruto da mudança de momento de amostragem.
Transcorrido um minuto, o vetor de previsões deve ter suas posições alte-radas conforme ilustra a figura:
sistema estável
yyy
yy
k
k
k
k n
k n k
+
+
+
+ −
+ +
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
1
2
3
1
1
M
yyy
yy
k
k
k
k n
k n k
+
+
+
+ −
+
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
1
2
3
1
M
Essa translação corresponde à seguinte multiplicação:
yyy
yy
yyy
yy
k
k
k
k n
k n kn n
k
k
k
k n
k n
+
+
+
+ −
+ +×
+
+
+
+ −
+
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
←
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥⎥⎥
×
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤1
2
3
1
1
1
2
3
1
0 1 0 0 0 00 0 1 0 0 00 0 0 1 0 0
0 0 0 0 1 00 0 0 0 0 10 0 0 0 0 1
M
L
L
L
M M M M O M M
L
L
L
M
⎦
⎥⎥⎥⎥⎥⎥⎥
k
2. acréscimo das parcelas correspondentes a:

101
2.1- influência de uma variação de Δuk unidades na variável manipulada ocorrida no momento atual k. As variações consequentes na variável controlada serão proporcionais a Δuk e à resposta ao degrau unitário (a1, a2, ... an):
...
notaçãode
matrizes
ΔΔ
Δ
Δ
yy
y
aa
a
u
k
k
k n n
k
+
+
+
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
×
1
2
1
2
M M
Δ Δy a uk k+ = ×1 1
Δ Δy a uk k+ = ×2 2
Δ Δy a uk n n k+ = ×
2.2- refinamento da previsão em consequência do erro constatado para a
variável controlada no momento atual k:
d y yk k k= −
onde: dk - erro entre valor previsto e valor real
yk - valor real verificado no momento atual k
yk - valor que tinha sido previsto para o momento atual k
assumindo que esse erro seja válido para todo o horizonte futuro de previsão, a expressão final para previsão futura será:
rolagem do vetor de previsões do minuto atual para o posterior
vetor de previsõesque veio do momento anterior
vetor de previsõesdo momento atual para frente
influência davariável manipulada
na controlada
refinamento daprevisão
yyy
yy
yyy
yy
k
k
k
k n
k n kn n
k
k
k
k n
k n
+
+
+
+ −
+ +×
+
+
+
+ −
+
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥⎥⎥
×
⎡
⎣
⎢⎢⎢⎢⎢⎢
1
2
3
1
1
1
2
3
1
0 1 0 0 0 00 0 1 0 0 00 0 0 1 0 0
0 0 0 0 1 00 0 0 0 0 10 0 0 0 0 1
M
L
L
L
M M M M O M M
L
L
L
M
( )
⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
+
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
× +
⎡
⎣
⎢⎢⎢⎢
k
n
k
aa
a
u
kd1
2
M MΔ
⎤
⎦
⎥⎥⎥⎥
×n 1( )
kd
kd

102
Nesta expressão, observar a notação entre parênteses para indicar o tamanho da matrizes. Os índices k e k+1 dos vetores de previsão não estão entre parênteses por fazerem referência a instante de amostragem no tempo (não a tamanho de matriz). O vetor E’ passa a ser a diferença entre uma trajetória futura de set-points (vetor de targets) e o vetor de previsão calculado conforme o método acima descrito que, em resumo:
acréscimo parcelacom erro atual
rolar u rolar y p
previsão anterior nãorealizada
aa
a
u
R
k
1
2
M
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
. Δacréscimo parceladevida à entrada atual
rolagem do vetorde previsões
no início de operação do controlador, o preditor inicializa o perfil futuro com valor atual da saída do sistema
(6.11) inclusão de restrições: O controlador apresentado tem o inconveniente de que as ações de controle calculadas minimizam uma função erro, mas não apresentam qualquer restrição. Isso pode implicar em ações de controle muito drásticas (violação de restrições em variável manipulada) ou em off-set muito elevado (violação de

103
restrições em variável controlada). Restrições podem ser incluídas no controlador pela utilização de um otimizador para resolver a equação de erros.
formulação com otimizador para inclusão de restrições:
Uma alternativa freqüentemente adotada é a do uso de otimizador baseado em programação linear ou programação quadrática para resolver o problema de controle com restrições. Conforme o otimizador utilizado e sua relação com o problema de controle preditivo, diferentes métodos da classe DMC podem ser usados em controle avançado. Nestas notas será examinado o membro LDMC, em que programação linear é utilizada para resolver a equação de erro das previsões:
E A u E= − + ′.Δ
Partindo do caso ideal almejado pelo método de mínimos quadrados:
previsão corrigida = trajetória desejada E = 0
A u E.Δ = ′A A u A Et t. . .Δ = ′
( . ). .A A u A Et t+ = ′λ Δ
Pode-se trabalhar com um vetor residual decorrente da não realização do caso idealizado:

104
ρ λ= + − ′( . ). .A A u A Et tΔdefinindo vetor resíduo
min u ii
L
iΔ ( )φ ω ρ==
∑1
ω i
LDMC resolve:
pesos arbitrários
Como é tradicional em programação linear, variáveis que não são estritamente positivas podem ser decompostas através da diferença entre duas outras variáveis estritamente positivas:
ρ i pode assumir valores negativos
ρ i i ix z= −fazer xi ≥ 0
zi ≥ 0
Essa transformação, aplicada ao caso de controle em questão:
ω ρ ω ω ω ωii
L
i ii
L
i i ii
L
i ii
L
i ii
L
i ix z x z x z= = = = =∑ ∑ ∑ ∑ ∑= − ≤ + = +
1 1 1 1 1
. . . . .( )
φ ω= +=∑ ii
L
i ix z1
.( )

105
Essas considerações nos permitem resumir todo o problema em resolver o problema de otimização com 3L variáveis:
x x x xL i1 2 0, ,..., ;→ ≥z z z zL i1 2 0, ,..., ;→ ≥u u u uk k k L k i, ,..., ;+ + − +→ ≥1 1 0
3L variáveis
que se formula da maneira seguinte:
min x zii
L
i iφ ω= +=∑
1
.( )
x zx z
x z
A A
u uu u
u u
A E
L L
t
k k
k k
k L k L
t
1 1
2 2
1
1
1 2
−−
−
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
= +
−−
−
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
− ′
−
+
+ − + −
M M( . ). .λ
sujeita às restrições:
aproveitando-se para incluir as seguintes restrições:
Δ Δu u u umin k i k i max≤ − ≤+ + −1 i = 0, 1, ... , L-1 (delta das ações de controle); u u umin k i max≤ ≤+ i = 0, 1, ... , L-1 (manipuladas); y y ymin k i
cmax≤ ≤+ i = 1, ... , R (controladas).
no caso de yk i
c+ as variáveis dependem também de uk i+ :
y a u u y P ymin j k j k j kj
i
i max≤ − + + ≤+ − + −=
∑ ( )1 21

106
(6.12) extensão ao caso multivariável:
Nos sistemas com r variáveis controladas e s variáveis manipuladas há um total de r.s curvas de resposta ao degrau unitário. No sistema com uma só variável, a resposta ao degrau fica organizada na sequência de dados numéricos: ( )a a an1 2 L . Os índices se referem à posição da resposta ao degrau no primeiro, segundo... e demais instantes. Nos sistemas multivariáveis, as respostas ao degrau ficam organizadas na sequência de matrizes (notação com letras maiúsculas) com dados numéricos dos diversos testes:
( )A A An1 2 L onde os índices se referem à posição das respostas ao degrau no tempo e cada matriz tem a forma:
A
a n a n a na n a n a n
a n a n a n
n
s
s
r r rs
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
11 12 1
21 22 2
1 2
( ) ( ) ( )( ) ( ) ( )
( ) ( ) ( )
L
L
M M O M
L
O elemento aij(n) refere-se à resposta da variável controlada i ao degrau na variável manipulada j no instante n. Por exemplo, com três variáveis controladas e duas manipuladas, as matrizes A têm dimensão 3 x 2, seus elementos são obtidos de testes conforme mostra a figura seguinte:
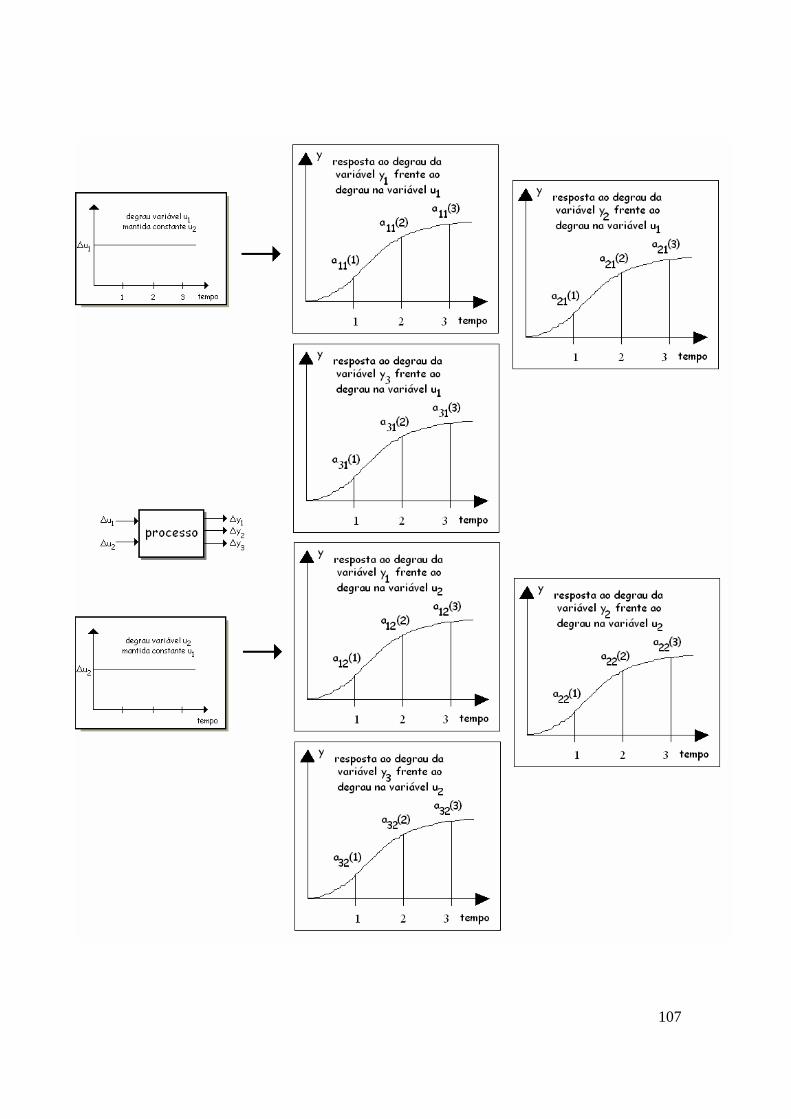
107

108
e se organizam do seguinte modo:
Aa aa aa a
1
11 12
21 22
31 32
1 11 11 1
=
⎡
⎣
⎢⎢⎢
⎤
⎦
⎥⎥⎥
( ) ( )( ) ( )( ) ( )
Aa aa aa a
2
11 12
21 22
31 32
2 22 22 2
=
⎡
⎣
⎢⎢⎢
⎤
⎦
⎥⎥⎥
( ) ( )( ) ( )( ) ( )
...... Aa n a na n a na n a n
n =
⎡
⎣
⎢⎢⎢
⎤
⎦
⎥⎥⎥
11 12
21 22
31 32
( ) ( )( ) ( )( ) ( )
No caso multivariável, usa-se a mesma expressão para cálculo de previsões do caso mono-variável.
YYY
YY
II
I
III
YYY
YY
k
k
k
k n
k n kn r n r
k
k
k
k n
k n
+
+
+
+ −
+ +×
+
+
+
+ −
+
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥⎥⎥
×
⎡
⎣
⎢⎢
1
2
3
1
1
1
2
3
1
0 0 0 0 00 0 0 0 00 0 0 0 0
0 0 0 0 00 0 0 0 00 0 0 0 0
M
L
L
L
M M M M O M M
L
L
L
M
( . . )
⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥⎥
+
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
× +
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
×
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
× × ×
k
n n r s
k
nr r
k
k
r k r
AA
A
U
II
I
dd
d
1
2
1
2
1
M M M
( . ) ( )
,
,
, ( )
Δ
Os elementos das matrizes dessa expressão são as pequenas matrizes com as respostas aos degraus (Ai). Também cabe lembrar que as variáveis Yk+i e Uk+i
são vetores, respectivamente das r variáveis controladas e das s variáveis manipuladas:
Y
yy
y
k i
k i
k i
r k i
+
+
+
+
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
1
2
,
,
,
M e U
uu
u
k i
k i
k i
s k i
+
+
+
+
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
1
2
,
,
,
M
[22] Deshpande, P. (1989): Multivariable Process Control Instrument Society
of America, Research Triangle Park.

109
(6.13) exemplo: Para o caso do sistema de topo de fracionadora de FCC, a temperatura de topo e a pressão de sucção do compressor de gases influenciam o ponto final ASTM D-86 da nafta e na corrente elétrica das bombas de refluxo. Os modelos obtidos a partir de testes (respostas a degraus) com a unidade para identificação foram os seguintes:
O controle avançado faz três cálculos importantes: • fazer a previsão, tendência futura de comportamento da unidade; • otimizar as variáveis envolvidas; • calcular os set-points necessários para melhor ajustar a unidade Ou seja, o controle avançado tem caráter:
• preditivo; • otimizador.
(1) caráter preditivo:
Para o par temperatura de topo da fracionadora principal x ponto final da nafta:

110
• um aumento de 1oC em TIC de topo provoca um aumento de 1.905oC (2oC) no ponto final da nafta;
• um aumento de 0.1 kgf/cm2 em PIC de topo provoca redução de 1.995oC (2oC) no ponto final da nafta.
Δ Δ ΔT T PPFE topo suc= × − ×2 20 Existem numerosas combinações de variação simultânea dos dois set-points. Por exemplo:
• ΔT Ctopoo= 1 e ΔP kgf cmsuc = 01 2. / => ΔT CPFE
o=0 com evolução dinâmica:
Observa-se uma variação intermediária que se anula após cerca de 50 minutos (compensação de efeitos). O transiente é devido às diferenças de tempos de primeira ordem das respostas do ponto final da nafta frente à temperatura e pressão de topo.
• ΔT Ctopoo= 1 e ΔP kgf cmsuc = −01 2. / => ΔT CPFE
o=4 com evolução dinâmica:

111
Observa-se uma superposição de efeitos no mesmo sentido: aumentar 1oC na temperatura de topo contribui com 2oC e reduzir 0.1 kgf/cm2 na pressão de topo contribui com 2oC adicionais para o ponto final inferido para a nafta. Nos dois casos do exemplo acima, as curvas de resposta do sistema de topo de torre foram usadas para se prever a evolução do ponto final da nafta para variações na temperatura de e pressão de topo. Essa é a base do caráter preditivo do controle avançado. Cada vez que acontecem variações nos set-points do TIC e do PIC de topo da torre, podem ser usadas as curvas de resposta para prever o comportamento futuro do ponto final da nafta. Mudanças sucessivas se superpõem, como pode ser visto no seguinte registro de quase duas horas de simulação teórica da operação:

112
• aos dez minutos, aumentou-se 2oC no TIC de topo para aproveitar a folga do
ponto final da nafta (especificação 220oC); já nesse momento se poderia prever elevação de 4oC (até 219oC em cerca de 14 minutos) no ponto final conforme a curva de resposta da unidade permite deduzir.
• aos vinte minutos reduziu-se 1oC e aos trinta reduziu-se 2oC no TIC de topo
e o ponto final foi caindo conforme se poderia prever com a curva de resposta. Observar a superposição dos efeitos.
• aos cinquenta minutos, reduziu-se em 0.3 kgf/cm2 a pressão de topo. Essa
redução drástica (válida só mesmo em exemplos) melhorou a recuperação de nafta e aliviou o soprador de ar.
• aos setenta minutos, para evitar depósito de sais, elevou-se a temperatura
no sistema de topo. Conhecedor da influência das duas variáveis no ponto final, o operador aproveitou para já elevar também a pressão de topo. Com isso, observou-se a dinâmica intermediária do ponto final da nafta; mas, transcorrido tempo suficiente, o ponto final ficou sob controle.
(2) caráter otimizador:
1o necessidade de produção de nafta craqueada:

113
Suponhamos que a inferência indique 224oC para o ponto final da nafta, desejando-se que ele esteja em 220oC. Ou seja, reduzir 4oC no ponto final. Os dados da curva de identificação revelam que isso pode ser feito, por exemplo, através da redução de 2oC na temperatura de topo da torre ou através da elevação de 0.2 kgf/cm2 na pressão. Também poderíamos fazer um misto de redução na temperatura de topo e elevação da pressão. Nesse caso, o número de combinações possíveis é bastante elevado, desde que:
Δ Δ ΔT T PPFE topo suc=− = × − ×4 2 20
2o critério econômico para fazer alteração na unidade: O critério para selecionar o par ΔTtopo e ΔPsuc é o de minimizar uma função objetivo de duas variáveis:
f T P T Ptopo suc topo suc( , )Δ Δ Δ Δ=− × + ×5 30
Essa função pode refletir uma questão econômica: - cada aumento de 1oC na temperatura de topo reduz algum custo em 5
unidades financeiras (maior recuperação de nafta craqueada). Reduções na temperatura de topo aumentam o custo.
- cada aumento de 1 kgf/cm2 na pressão aumenta algum custo em 30 unidades financeiras (maior trabalho de compressão em soprador de ar). Reduções na pressão diminuem o custo.
Minimizando a função objetivo, minimiza-se um custo de produção da nafta craqueada.
3o restrições para cumprir necessidade e atender critério econômico:

114
restrição 1: enquadrar o ponto final da nafta que está sendo inferido em 224oC (especificação máximo 220oC). Vale a expressão:
2 20 4× − × ≤−Δ ΔT Ptopo suc
obtida com os ganhos identificados na própria unidade (ganhos revelados pelos testes de identificação).
restrição 2: a variação na temperatura de topo não deve ser superior a 3oC, ou seja, − ≤ ≤3 3ΔTtopo . restrição 3: a elevação na pressão de topo não deve ser superior a 0.07 kgf/cm2, ou seja 0 0 07≤ ≤ΔPsuc . . Nos dois casos, as duas últimas restrições podem ser consequência de se limitar a taxa de variação do controle avançado (máximo de 3oC/min na temperatura de topo e máximo de 0.07 (kgf/cm2)/min na pressão). Tais restrições podem ser consequência, também, da folga máxima momentânea para tais variáveis; por exemplo, a temperatura de topo está em 123oC e o mínimo é de 120oC (problema de formação de sais no topo da torre).
De modo simplificado, portanto, o problema de otimização é o seguinte:
minimizar a função linear: f T P T Ptopo suc topo suc( , )Δ Δ Δ Δ=− × + ×5 30 com as restrições lineares: 2 20 4× − × ≤ −Δ ΔT Ptopo suc ΔTtopo ≤ 3 ΔPsuc ≤ 0 07. • as restrições 2 e 3 definem duas faixas de validade para ΔTtopo e ΔPsuc :
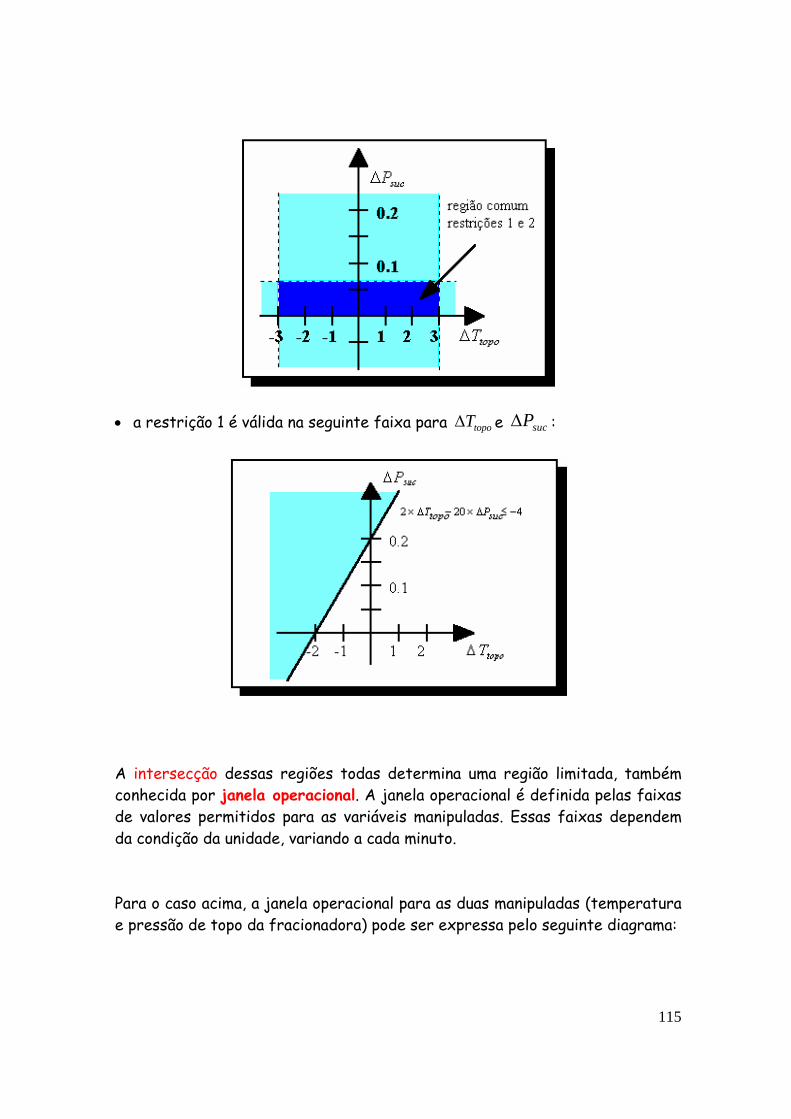
115
• a restrição 1 é válida na seguinte faixa para ΔTtopo e ΔPsuc :
A intersecção dessas regiões todas determina uma região limitada, também conhecida por janela operacional. A janela operacional é definida pelas faixas de valores permitidos para as variáveis manipuladas. Essas faixas dependem da condição da unidade, variando a cada minuto. Para o caso acima, a janela operacional para as duas manipuladas (temperatura e pressão de topo da fracionadora) pode ser expressa pelo seguinte diagrama:

116
e está definida pelos seguintes quatro vértices:
ΔT Ctopoo= −3 ΔP kgf cmsuc = 0 00 2. / f T Ptopo suc( , ) $15.Δ Δ = 00
ΔT Ctopoo= −3 ΔP kgf cmsuc = 0 07 2. / f T Ptopo suc( , ) $17.Δ Δ = 10
ΔT Ctopoo= −13. ΔP kgf cmsuc = 0 07 2. / f T Ptopo suc( , ) $8.Δ Δ = 60
ΔT Ctopoo= −2 ΔP kgf cmsuc = 0 00 2. / f T Ptopo suc( , ) $10.Δ Δ = 00
A tabela anterior mostra os vértices da janela operacional e traz também a função objetivo calculada em cada vértice. Os vértices são as intersecções de pares dentre as diversas restrições. Para esse exemplo, a função objetivo está expressando o aumento de custo associado à alteração das duas variáveis manipuladas. Assim, comparando-se as quatro alternativas dos quatro vértices, a que minimiza o aumento de custo é a correspondente ao vértice 3: diminuir 1.3oC na temperatura de topo e aumentar 0.07 kgf/cm2 na pressão. A opção correspondente ao vértice 3 é mínima, sendo inferior a qualquer outra opção do interior da janela operacional, como se pode constatar pela figura seguinte:

117
A cada minuto outras variações acontecem na unidade e devem ser consideradas. Ou seja, todos os cálculos são repetidos a cada minuto para incluir novos eventos que venham aparecendo.
(3) cálculo dos novos set-points:
O último módulo é o controlador propriamente dito. Ele é denominado DMC, uma sigla da expressão dynamic matrix control - controle com matriz dinâmica. Ele inclui os testes em degrau feitos na unidade (dinâmica da unidade). Os dados da figura seguinte poderiam, por exemplo, ser da influência da temperatura de topo (u) na composição (y) de produto de topo de uma fracionadora. O degrau foi de 1oC, tendo-se passado a temperatura de 70oC para 71oC; a composição se alterou 1.9%, passando de 4% para 5.9% em cerca de 6 minutos.

118
Para um controlador com horizontes de R = 5 e L = 1, a matriz dinâmica fica com o aspecto:
yyy
y
aa aa a a
a a a a
uuu
u
yyy
y
kp
kp
kp
k Rp
R R R R L
k
k
k
k L
k
k
k
k R
+
+
+
+ − − − +
+
+
+
+
+
+
+
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
×
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
+
⎡
⎣
1
2
3
1
2 1
3 2 1
1 2 1
1
2
1
2
3
0 0 00 0
0M
L
L
L
M M M O M
L
M M
ΔΔΔ
Δ
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
yyyyy
uu
yyyyy
kp
kp
kp
kp
kp
k
k
k
k
k
k
k
+
+
+
+
+
+
+
+
+
+
+
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
×⎡
⎣⎢
⎤
⎦⎥ +
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
1
2
3
4
5
1
1
2
3
4
5
0 2 00 5 0 214 0 517 1418 17
.
. .. .. .. .
ΔΔ

119
Assumindo:
• previsão para o ponto final no minuto anterior dada por: yk+1 = 7%; yk+2 = 7.5%; yk+3 = 7.2%; yk+4 = 7.0% e yk+5 = 6.8%
• valor desejado para o ponto final seja 5% (calculado pelo módulo de otimização do controle avançado). A formulação de matrizes do DMC fica na seguinte forma:
erro
eeeee
yyyyy
kp
kp
kp
kp
kp
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
+
+
+
+
+
1
2
3
4
5
1
2
3
4
5
55555
55555
0 2 00 5 0 21 4 0 51 7 1 41 8 1 7
.
. .. .. .. .
⎥⎥⎥⎥⎥⎥
×⎡
⎣⎢
⎤
⎦⎥ −
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
+
ΔΔ
uu
k
k 1
77 57 27
6 8
.
.
.
erro
eeeee
uu
k
k=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
−−−−−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
×⎡
⎣⎢
⎤
⎦⎥
+
1
2
3
4
5
1
22 52 22
18
0 2 00 5 0 21 4 0 51 7 1418 17
.
.
.
.
. .. .. .. .
ΔΔ
• há liberdade de escolha de duas variações de set-point de temperatura de
topo, uma para o momento atual ( Δuk ) e outra para o próximo minuto ( Δuk +1 ); • conforme a escolha, os erros ei variam, bem como a sua soma quadrática
( S e e e e e eii
i R
= + + + + ==
=
∑12
22
32
42
52
1).
A composição está em torno de 7% e se deseja reduzir para 5%. Como o aumento de 1oC aumenta cerca de 2%, normalmente se reduziria 1oC para enquadrar a composição. O controlador DMC vai dividir essa ação em duas parcelas, uma para o instante atual e outra para o próximo minuto. Há várias formas de se escolher essas

120
duas parcelas, implicando em diferentes erros. Por exemplo, podemos calcular alguns casos e formar uma tabela:
significado Δuk Δuk +1 S e e e e e ei
i
i R
= + + + + ==
=
∑12
22
32
42
52
1
método tradicional -1oC 0oC 7.97
abaixar bastante agora e compensar depois? -2oC 1oC 5.47 piorar, subindo agora e também depois? 2oC 1oC 146.35
não fazer nada? 0oC 0oC 22.33 ... ... ... ...
Calculando-se uma quantidade grande de casos mediante escolha de uma faixa para Δuk (-4oC a 0oC) e outra para Δuk +1 (0oC a 4oC), a soma quadrática dos erros apresenta o seguinte gráfico:
S eii
i R
==
=
∑1
Δuk
Δuk +1
mínimo para eΔuk = −2 87. Δuk + =1 2 04.
Pelo gráfico verifica-se que a opção que minimiza a soma dos quadrados dos erros previstos para a variável controlada é a de reduzir-se 2.87oC no momento atual, com a previsão de se aumentar 2oC no próximo minuto. Essa solução pode ser obtida diretamente, sem necessidade de análise gráfica, pelo uso da matriz pseudo-inversa do método dos mínimos quadrados:

121
⎥⎦
⎤⎢⎣
⎡ΔΔ
×
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−−
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=+1
5
4
3
2
1
7.18.14.17.15.04.12.05.0
02.0
8.122.25.2
2
00000
k
k
uu
eeeee
erro
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−−
=⎥⎦
⎤⎢⎣
⎡ΔΔ
×
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
+
8.122.25.2
2
7.18.14.17.15.04.12.05.0
02.0
1k
k
uu
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−−
×⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡ΔΔ
×
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
×⎥⎦
⎤⎢⎣
⎡
+
8.122.25.2
2
7.14.15.02.008.17.14.15.02.0
7.18.14.17.15.04.12.05.0
02.0
7.14.15.02.008.17.14.15.02.0
1k
k
uu
⎥⎦
⎤⎢⎣
⎡−−
=⎥⎦
⎤⎢⎣
⎡ΔΔ
×⎥⎦
⎤⎢⎣
⎡
+ 46.737.11
14.524.624.638.8
1k
k
uu
⎥⎦
⎤⎢⎣
⎡−=⎥
⎦
⎤⎢⎣
⎡−−
×⎥⎦
⎤⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡ΔΔ −
+ 04.287.2
46.737.11
14.524.624.638.8 1
1k
k
uu
• ação de controle Δuk atual é enviada para o controlador regulatório. • ação de controle Δuk +1 , entretanto, não será considerada no próximo
minuto. Todas as ações de controle futuras são descartadas. A cada minuto fatos diferentes ocorrem na unidade e a janela operacional se altera. No próximo minuto, o controlador vai refazer todos os cálculos: previsão, otimização e cálculo dos novos set-points pelo DMC. O critério usado para encontrar a solução ótima se baseia no erro para a variável controlada. Deseja-se que as previsões para a variável controlada

122
estejam tão próximas quanto seja possível de um valor definido (5% para composição). Esse critério é um critério de desempenho: baseia-se no objetivo primeiro do controlador, que é o de manter a variável controlada sob controle. Para isso, entretanto, haverá alteração de set-point. Em princípio, uma alteração para o momento atual e outra mais prevista para o próximo minuto. Diz-se que haverá movimentação da unidade, alteração da unidade. Um segundo objetivo de um controlador é o de reduzir essa movimentação. O ideal seria controlar sem precisar alterar nada e, para se aproximar um pouco mais desse ideal, também a variável manipulada deve participar no erro a ser minimizado. A idéia é de minimizar o erro da variável controlada e também minimizar a movimentação da variável manipulada. Isso pode ser feito, por exemplo, modificando-se a expressão de cálculo do erro para a seguinte:
S e e e e e u uk k= + + + + + × + × +1
222
32
42
52 2
12λ λ( ) ( )Δ Δ
Nessa nova expressão aparece um fator λ que pode assumir valores positivos arbitrários: o caso de λ = 0 corresponde ao da figura anterior. Para esse novo método de cálculo de erro, pode-se repetir a análise gráfica. Examinam-se alguns casos a seguir. • caso 1: com λ = 01.

123
Δuk
Δuk +1
mínimo para eΔuk = −2 37. Δuk + =1 140.
S e uii
i R
k ii
i L
= + ×=
=
+=
=
∑ ∑1
2
1λ ( )Δ
λ = 01.
• caso 2: com λ = 0 5.
Δuk
Δuk +1
mínimo para e
S e uii
i R
k ii
i L
= + ×=
=
+=
=
∑ ∑1
2
1λ ( )Δ
Δuk = −158. Δuk + =1 0 42.
λ = 0 5.
• caso 3: com λ = 1

124
Δuk
Δuk +1
mínimo para e
S e uii
i R
k ii
i L
= + ×=
=
+=
=
∑ ∑1
2
1λ ( )Δ
Δuk = −1 25. Δuk + =1 0.05
λ = 1
• caso 4: com λ = 5
Δuk
Δuk +1
mínimo para e
S e uii
i R
k ii
i L
= + ×=
=
+=
=
∑ ∑1
2
1λ ( )Δ
λ = 5
Δuk = −0 71. Δuk + = −1 0 30.

125
Os casos anteriores mostram que o ótimo se altera com a mudança da expressão do cálculo do erro, bem como com o aumento do fator λ . Observa-se que a inclusão dos termos Δuk e Δuk +1 na expressão a ser minimizada faz com que tais ações de controle sejam menores. Também se observa que o aumento do fator λ leva ações de controle menores, mais suaves. Esse é o motivo para se denominar λ como fator de supressão de movimentos. Trata-se de um parâmetro de sintonia, que deixa o controlador mais intenso ou mais suave.
(6.14) os atuais controladores nas refinarias: O controlador DMC para as refinarias tem duas características importantes, dentre os conceitos discutidos até aqui. • as ações de controle são reavaliadas a cada minuto; • o controlador é multivariável. ................................................................................................................................................... Quanto ao primeiro aspecto, o exemplo do item anterior nos revela que duas ações de controle (alterações de set-point de controlador de temperatura de topo) foram avaliadas, correspondendo a um ponto ótimo:
Δuk alteração de set-point para o momento atual Δuk +1 alteração de set-point para o próximo minuto
A ação de controle Δuk atual é enviada para o controlador regulatório. Por exemplo, no caso 4 da página anterior, Δu Ck
o= −0 71. e Δu Cko
+ = −1 0 30. . Se o set-point do controlador de temperatura de topo estiver, por exemplo, em 73oC, o controle avançado vai alterá-lo para 73-0.71=72.29oC. A ação de controle Δuk +1 , entretanto, não será considerada no próximo minuto. Todas as ações de controle futuras são descartadas. A cada minuto fatos diferentes ocorrem na unidade e a janela operacional se altera. No próximo minuto, o controlador vai refazer todos os cálculos: previsão, otimização por programação linear e cálculo do controlador DMC.

126
Quanto ao segundo aspecto, o fato de o controlador ser multivariável apenas significa o uso das matrizes Ai com as respostas ao degrau discutidas anteriormente. A expressão das previsões modificadas do DMC será a seguinte:
YYY
Y
AA AA A A
A A A A
UUU
U
YYY
Y
kp
kp
kp
k Rp
R R R R L
k
k
k
k L
k
k
k
k R
+
+
+
+ − − − +
+
+
+
+
+
+
+
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
×
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
+
⎡
⎣
1
2
3
1
2 1
3 2 1
1 2 1
1
2
1
2
3
0 0 00 0
0M
L
L
L
M M M O M
L
M M
ΔΔΔ
Δ
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
onde Ai,Yk+i e Uk+i foram definidos no item (6.12). Considerando o vetor de targets definidos pela programação linear:
Y
yy
y
tg
tg
tg
tgr
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
1
2
M
ele pode ser subtraído da expressão do controlador DMC:
YYY
Y
YYY
Y
YYY
Y
AA AA A A
A A A A
Utg
tg
tg
tg
kp
kp
kp
k Rp
tg
tg
tg
tg R R R R L
k
M M M
L
L
L
M M M O M
L
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
×
+
+
+
+ − − − +
1
2
3
1
2 1
3 2 1
1 2 1
0 0 00 0
0
ΔΔΔ
Δ
UU
U
YYY
Y
k
k
k L
k
k
k
k R
+
+
+
+
+
+
+
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
1
2
1
2
3
M M
EEE
E
AA AA A A
A A A A
UUU
U
Y YY YY Y
Y YR R R R R L
k
k
k
k L
tg k
tg k
tg k
tg k R
1
2
3
1
2 1
3 2 1
1 2 1
1
2
1
2
3
0 0 00 0
0M
L
L
L
M M M O M
L
M M
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
= −
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
×
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
−−−
−
⎡
− − − +
+
+
+
+
+
+
+
ΔΔΔ
Δ ⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
= − ×
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
−
−−−
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
+
+
+
+
+
+
+
A
UUU
U
Y YY YY Y
Y Y
k
k
k
k L
tg k
tg k
tg k
tg k R
ΔΔΔ
Δ
1
2
1
2
3
M M

127
onde se abreviou a notação da matriz dinâmica para:A
AA AA A A
A A A AR R R R L
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
− − − +
1
2 1
3 2 1
1 2 1
0 0 00 0
0
L
L
L
M M M O M
L
Calculam-se os valores de ΔUi que minimizam a soma dos erros ao quadrado (minimizar E E E E ER= + + + +1
222
32 2... ) pela expressão:
Δ
ΔΔ
Δ
UUU
U
A A A
Y YY YY Y
Y Y
k
k
k
k L
t t
tg k
tg k
tg k
tg k R
+
+
+
−
+
+
+
+
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
= × × ×
−−−
−
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
1
21
1
2
3
M M
( )
Tipicamente, há um total de s = 20 a 30 variáveis manipuladas. O horizonte de controle está em L=2 a 5 minutos. O horizonte de otimização típico é de R=100 para as R = 30 a 50 variáveis a serem controladas. Portanto, a cada minuto: • calculam-se as previsões para as 50 variáveis controladas ao longo de 100
minutos de horizonte futuro; • calculam-se 30 targets para variáveis manipuladas mediante otimização por
programação linear; • calculam-se os 30 set-points para variáveis manipuladas através do método
DMC. São estimados 30 set-points para o momento atual e 30 para os próximos 5 minutos. Os 30 set-points para o momento atual são enviados para os controladores do SDCD. Os 30 set-points para os próximos minutos são descartados: no próximo minuto tudo será recalculado.

128
ANEXO 1: RESUMO DA TRANSFORMADA DE LAPLACE:
(a) transformada de Laplace de processo (malha aberta): A equação diferencial de um processo de primeira ordem:
τ dy tdt
y t K u tp( ) ( ) ( )+ =
pode ser representada com a técnica de transformada de Laplace. Aplica-se o seguinte artifício à equação (multiplicando por uma exponencial conveniente e integrando de zero a infinito):
edy tdt
dt e y t dt e K u t dtst st stp
−∞
− −∞∞
∫ ∫∫+ =τ( )
( ) ( )0 00
A função exponencial é escolhida como fator multiplicativo porque ela é a classe de funções de solução de equações diferenciais com coeficientes constantes: o espaço vetorial da solução. A integração imprópria visa a eliminar a variável t, deixando apenas a variável s, o que implica numa redefinição da função de t para s (mapeamento de domínio t para domínio s). Podemos encarar tudo isso como artifício matemático conveniente. A definição de transformada de Laplace facilita a notação:
e y t dt y sst−∞
=∫ ( ) ( )0
Recordando questões matemáticas:
• questão 1: regra da integração por partes
d uv
dtu
dvdt
vdudt
d uv udv vdu( )
( )= + ⇒ = + ⇒
⇒ = + ⇒ = + ⇒ = − ∫∫∫∫∫d uv udv vdu d uv udv vdu udv uv vdu( ) ( )

129
aplicada ao caso:
edy t
dtdt e dy e y yd est st st st− − − ∞
∞∞−
∞
= = −∫∫ ∫( )
( )0
00 0
• questão 2: regra da cadeia
d e
dts e d e s e dt
stst st st( )
. ( ) .−
− − −= − ⇒ = −
yd e y s e dt s e y t dt sy sst st st( ) ( ) ( ) ( )−∞
− −∞∞
∫ ∫∫= − = − = −0 00
Reunindo as duas questões numa só:
edy tdt
dt e dy e y yd e s y sst st st st− − − ∞∞∞
−∞
= = − =∫∫ ∫( )
( ) . ( )0
00 0
e a equação diferencial fica:
edy tdt
dt e y t dt e K u t dtst st stp
−∞
− −∞∞
∫ ∫∫+ =τ( )
( ) ( )0 00
⇓
τ. . ( ) ( ) ( )s y s y s K u sp+ = O processo pode, então, ser representado pela expressão resumida:
G sy su s
Ks
p( )( )( )
= =+τ 1

130
(b) transformada de Laplace de controlador:
A equação diferencial do controlador PID:
dttdekdxxektektu dc
t
i
cc
)()()()(0
ττ ∫ ++=
pode ser representada com a técnica de transformada de Laplace, de modo semelhante ao do caso anterior. Aplica-se o mesmo artifício matemático anteriormente usado:
)()()()(00
ssekdtdxxekeseksu dc
t
i
cstc τ
τ+⎥
⎦
⎤⎢⎣
⎡+= ∫∫
∞−
O termo intermediário pode ser estimado, igualmente ao já feito, através de integração por partes:
=⎥⎦
⎤⎢⎣
⎡−=⎥
⎦
⎤⎢⎣
⎡∫ ∫∫∫∞
−∞
−
0 000
)()()( stt
i
ct
i
cst eddxxes
kdtdxxekeττ
=⎥⎥⎦
⎤
⎢⎢⎣
⎡−⎥
⎦
⎤⎢⎣
⎡−= ∫∫
∞−
∞
−
000
)()( dtteedxxees
k stt
st
i
c
τ
)()(0
ses
kdttees
ki
cst
i
c
ττ=⎥
⎦
⎤⎢⎣
⎡−−= ∫
∞−
e a expressão final do controlador fica:
)()()()( ssekses
kseksu dci
cc τ
τ++=

131
ANEXO 2: MÉTODO DE MÍNIMOS QUADRADOS:
Ajuste de pontos experimentais: No método de mínimos quadrados estaremos ajustando dados de uma lista de variáveis independentes (x1, x2, ... , xni) para prever uma variável dependente y através de uma expressão que inclui parâmetros (p1, p2, ... , pnp) a serem determinados:
y f x x x p p pp ni np= ( , ,... , , ,... )1 2 1 2 que no caso de regressão linear se torna:
y p x p x p x bp ni ni= + + + +1 1 2 2. . ... . Como já lembramos no capítulo de controle preditivo, o método de mínimos quadrados envolve a derivada da função soma dos quadrados dos erros:
E e y f x x x p p p bii
nd
p ni npi
nd
= = −= =∑ ∑2
11 2 1 2
2
1
( ( , ,... , , ,... , ))
ou seja, impõe-se como condição de mínimo que:
∂∂Ep1
0= ∂∂
Ep2
0= ... ∂∂
Epnp
= 0 ∂∂Eb
= 0
No caso da regressão linear, essa condição leva a uma formulação final em termos de matrizes, que pode ser mais facilmente visualizada através do método que segue. Suponhamos que temos nd pontos experimentais (nd valores de y e nd listas de x1, x2, ... , xni associadas). Organizemos esses dados através da seguinte sequência de expressões: • p x p x p x b yni ni1 1 1 2 2 1 1 1. . ... .( ) ( ) ( )+ + + + = • p x p x p x b yni ni1 1 2 2 2 2 2 2. . ... .( ) ( ) ( )+ + + + = ... • p x p x p x b ynd nd ni ni nd nd1 1 2 2. . ... .( ) ( ) ( )+ + + + =

132
que pode ser escrita matricialmente na forma X p Y. = onde:
X
x x xx x x
x x x
ni
ni
nd nd ni nd
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
1 1 2 1 1
1 2 2 2 2
1 2
11
1
( ) ( ) ( )
( ) ( ) ( )
( ) ( ) ( )
L
L
M M O M M
L
p
pp
pbni
=
⎡
⎣
⎢⎢⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥⎥⎥
1
2
M e Y
yy
ynd
=
⎡
⎣
⎢⎢⎢⎢
⎤
⎦
⎥⎥⎥⎥
1
2
M
Observar que nd ni≠ , ou seja, a matriz X não é quadrada. O método de mínimos quadrados para regressões lineares pode ser facilmente aplicado usando-se um artifício algébrico bastante simples:
X p Y X X p X Y p X X X Yt t t t. . . . ( . ) . .= ⇒ = ⇒ = −1 Exemplo 1: uma regressão linear simples y=a+bx para os seguintes dados:
x y 1.1 9.0 2.3 16.0 3.4 20.0 5.5 30.0 6.3 32.0
temos, então:
1 111 2 31 3 41 551 6 3
9 016 020 030 032 0
1 1 1 1 111 2 3 3 4 55 6 3
1 111 2 31 3 41 551 6 3
1 1 1 1 111 2 3 34 55 6 3
9 0.....
.
.....
. . . . ..
.
....
.. . . . .
.
.⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⎛⎝⎜
⎞⎠⎟ =
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⇒⎛⎝⎜
⎞⎠⎟
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⎛⎝⎜
⎞⎠⎟ =
⎛⎝⎜
⎞⎠⎟
ab
ab
16 020 030 032 0
.
.
.
.
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⇒
5 18 618 6 88 0
107 04813
4 934 42
.. .
...
.
.⎛⎝⎜
⎞⎠⎟
⎛⎝⎜
⎞⎠⎟ =
⎛⎝⎜
⎞⎠⎟ ⇒
⎛⎝⎜
⎞⎠⎟ =
⎛⎝⎜
⎞⎠⎟
ab
ab
ou seja, a = 4.93 e b = 4.42

133
Exemplo 2: regressão linear múltipla y=a1.x1+a2.x2+b para os seguintes dados:
x1 x2 y 1.1 5.1 -6 2.5 3.3 7 4.7 -2.0 20 8.3 4.0 32
11 51 12 5 33 14 7 2 0 18 3 4 0 1
672032
11 2 5 4 7 8 351 33 2 0 4 01 1 1 1
11 51 12 5 33 14 7 2 0 18 3 4 0 1
11 2 5 41
2
1
2
. .
. .
. .
. .
.. . . .. . . . .
. .
. .
. .
. .
.. .
−
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
=
−⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
⇒ −⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟ −
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
=aab
aab
. .. . . . .
7 8 351 3 3 2 0 4 01 1 1 1
672032
−⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
−⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
⇒
98 44 37 66 16 6037 66 56 90 10 4016 60 10 40 4
370 5805530
4 90510154 469
1
2
1
2
. . .
. . .
. ..
...
...
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
=⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
⇒⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
= −−
⎛
⎝
⎜⎜⎜
⎞
⎠
⎟⎟⎟
aab
aab
ou seja a1=4.905, a2=-1.015 e b=-4.469.
Exemplo 3: ajuste linear de n termos de uma série temporal:
( , ,..., ,..., )y y y yn n nd1 2 1+ − com um modelo linear do tipo y a y a y a yk k k n k n= + + +− − − − +1 1 2 2 1 1. . ... . . Uma vez que temos nd+n-1 dados, podemos fazer a regressão sobre nd pontos correspondentes a fazer-se k=n, n+1, ... , nd+n-1. Notar que se trata de uma autoregressão da variável y sobre si mesma, típica de séries temporais. Nesse caso, o modelo é ainda linear do tipo y=a1.x1+a2.x2+...+an-1.xn-1 e sem coeficiente linear (bias).

134
O modelo é aplicado aos seguintes dados:
y y y yy y y yy y y y
y y y y
a
aa
yy
y
n n
n n
n n
nd nd nd n nd n
n n
n
nd n
1 2 2 1
2 3 1
3 4 1
1 3 2
1
2
1
1
1
L
L
L
M M O M M
L
M
M
− −
−
+
+ + − + −
−
+
+ −
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
=
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
⇒.
y y y yy y y y
y y y yy y y y
y y y yy y y yy y y y
y y y y
a
aa
y y ynd
nd
n n n nd n
n n n nd n
n n
n n
n n
nd nd nd n nd n
n1 2 3
2 3 4 1
2 1 3
1 1 2
1 2 2 1
2 3 1
3 4 1
1 3 2
1
2
1
1 2 3L
L
M M M O M
L
L
L
L
L
M M O M M
L
M
L
+
− − + −
− + + −
− −
−
+
+ + − + −
−
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
=. .
yy y y y
y y y yy y y y
yy
y
nd
nd
n n n nd n
n n n nd n
n
n
nd n
2 3 4 1
2 1 3
1 1 2
1
1
L
M M M O M
L
L
M
+
− − + −
− + + −
+
+ −
⎛
⎝
⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
⇒
xn-1 xn-2 ... x2 x1 y
y1 y2 ... yn-2 yn-1 yn y2 y3 ... yn-1 yn yn+1 y3 y4 ... yn yn+1 yn+2 : : : : :
ynd ynd+1 ... ynd+n-3 ynd+n-2 ynd+n-1

135
y y y y y y y
y y y y y y y
y y y y y y y
y y y y
ii
nd
i ii
nd
i ii
nd
i i ni
nd
i ii
nd
ii
nd
i ii
nd
i i ni
nd
i ii
nd
i ii
nd
ii
nd
i i ni
nd
i i ni
nd
i i
2
11
12
12
1
11
12
11 2
11 2
1
21
1 21
22
12 2
1
21
1
=+
=+
=+ −
=
+=
+=
+ +=
+ + −=
+=
+ +=
+=
+ + −=
+ −=
+ +
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
∑
. . .
. . .
. . .
. .
L
L
L
M M M O M
ni
nd
i i ni
nd
i ni
nd
ni i n
i
nd
i i ni
nd
i n i ni
nd
y y y
a
aa
y y
y y
y y−
=+ + −
=+ −
=
−+ −
=
+ + −=
+ − + −=∑ ∑ ∑
∑
∑
∑
⎛
⎝
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
=
⎛
⎝
⎜⎜⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟⎟⎟
⇒
21
2 21
22
1
1
2
1
11
1 11
2 11.
.
.
.
.L
M
M
a
aa
y y y y y y y
y y y y y y y
y y y y y y y
n
ii
nd
i ii
nd
i ii
nd
i i ni
nd
i ii
nd
ii
nd
i ii
nd
i i ni
nd
i ii
nd
i ii
nd
ii
nd
i i ni
nd
−
=+
=+
=+ −
=
+=
+=
+ +=
+ + −=
+=
+ +=
+=
+ + −=
⎛
⎝
⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟
=
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
1
2
1
2
11
12
12
1
11
12
11 2
11 2
1
21
1 21
22
12 2
1
M
L
L
L
M M M O M
. . .
. . .
. . .
y y y y y y y
y y
y y
y yi i n
i
nd
i i ni
nd
i i ni
nd
i ni
nd
i i ni
nd
i i ni
nd
i n i ni
nd
. . .
.
.
.+ −
=+ + −
=+ + −
=+ −
=
−
+ −=
+ + −=
+ − + −=∑ ∑ ∑ ∑
∑
∑
∑
⎛
⎝
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎛
⎝
⎜⎜⎜⎜⎜⎜⎜⎜
⎞
⎠
⎟⎟⎟⎟⎟⎟⎟⎟
21
1 21
2 21
22
1
1
11
1 11
2 11L
M

136
ANEXO 3: identificação com Matlab: O MATLAB inclui uma série de bibliotecas (toolbox) para cálculos de engenharia. Uma dessas bibliotecas refere-se à identificação de sistemas. Aqui vão algumas sugestões para uso dessa toolbox. As principais funções para identificação têm uma estrutura comum: • os dados envolvidos são colocados em colunas: [y u] onde y é a saída e u é a
entrada do sistema; • os parâmetros são calculados e colocados num vetor. O formato desse
vetor, ou seja, que dados ficam em quais posições, é denominado formatoΘ (referência ao vetor dos parâmetros);
• várias funções recuperam os dados a partir do vetor resposta em formato
Θ . Vamos ver como isso funciona, detalhando cada um desses três passos. 1. organização dos dados: esse item não apresenta maior problema. Tendo-se os dados de y e u na forma de vetores-colunas, podemos atribuí-los a uma variável auxiliar z.
z = [y u]; ou entrar na rotina do MATLAB diretamente com a forma [y u]. O uso da variável auxiliar z pode ser útil no uso posterior de outras rotinas do MATLAB, dentro do mesmo problema de identificação. Em identificação recomenda-se também eliminar tendências lineares dos dados, evitando-se que estas sejam modeladas. Isso pode ser feito através da função dtrend do MATLAB. Em geral, elimina-se a média, centrando cada variável ao redor de zero. zt = dtrend(z);

137
2. chamada da rotina principal: a chamada das rotinas de cálculo dos parâmetros é a mesma para todos os modelos discutidos: a- modelo AR:
th = AR(y,n); nesse caso não temos dado de entrada u e não faz sentido usar z. O número n é escolhido pelo usuário e refere-se ao tamanho do modelo escolhido (número de termos da série temporal). b- modelo ARX:
th = ARX(zt,[na nb nk]; nesse caso temos os dados colocados na variável z. O vetor nn inclui as escolhas feitas sobre o tamanho do modelo, ou seja, quantos coeficientes para a saída (na), quantos coeficientes para a entrada (nb) e o número de intervalos de tempo de atraso da resposta do sistema (tempo morto nk). Observe-se que o uso de um vetor nn para dimensionar o modelo não é obrigatório; as diversas ordens na, nb e nk podem ser fornecidas através de vetor na chamada da própria rotina. c- modelo ARMAX:
th = ARMAX(zt,[na nb nc nk]; esse caso é semelhante ao ARX, apenas mudando o vetor nn para incluir a ordem nc. No caso do uso de ARMAX, o software informa sobre o andamento da busca numérica do mínimo da função erro de ajuste, conforme discutimos anteriormente. Em todos os casos, o nome dado ao vetor resposta das chamadas às funções de identificação foi th (vetor Θ ). Evidentemente, outro nome qualquer poderia ser escolhido.

138
3. recuperação dos coeficientes: os dados calculados pelas funções de identificação ficam armazenados no vetor th. Há uma série de funções do MATLAB para extrair desse vetor os coeficientes calculados. Cada uma dessas funções está dirigida especialmente para determinados objetivos, dependendo, portanto, da aplicação desejada. A principal é a função th2tf: para quem deseja obter a função de transferência entre u (entrada) e y (saída) - do formato Θ para forma de função de transferência.
[B,A] = th2tf(th); observe-se que B (numerador) e A (denominador) são vetores, respostas da função th2tf, com os coeficientes da função objetivo dada por:
a
a
b
b
nn
nn
k
kk zazaza
zbzbzbuyG −−−
−−−
++++
+++==
......1......
22
11
22
11
Usando algumas das funções acima, uma sequência típica de comandos para se fazer identificação seria: yt = dtrend(y); ut = dtrend(u); zt=[yt ut]; na = input('ordem do polinômio A = '); nb = input('ordem do polinômio B = '); nk = input('atraso da saída em relação à entrada = '); nn = [na nb nk]; th = arx(zt,nn); [num,den]=th2tf(th); Tendo-se o modelo do sistema, pode-se obter a resposta ao degrau unitário através da função dstep do MATLAB:
ystep = dstep(num,den); O MATLAB disponibiliza alguns recursos para escolhas de ordens dos modelos.

139
Dentre eles, as funções: 1. funções arxstruc e selstruc: para sistemas com uma saída (monovariáveis);
essas funções aplicam-se aos modelos tipo ARX. A função arxstruc permite calcular de uma só vez o modelo ARX para um conjunto de valores diferentes de na, nb e nk. Isso pode ser definido numa matriz nn com três colunas e diversas linhas, cada uma das quais corresponde a um conjunto diferente de ordens escolhidas (ou seja, linhas do tipo [na nb nk]). Utilizar a função struc para gerar a matriz nn: nn = struc(na1:na2,nb1:nb2,nk1:nk2); Para cada ordem (cada linha de nn), é feito ajuste do modelo ARX aos dados z e testado o ajuste contra um segundo conjunto de dados zv (cross validation): v = arxstruc(z,zv,nn); A matriz v inclui os resultados dos ajustes. Para selecionar o caso com menor erro, pode-se usar uma função do MATLAB de seleção da melhor estrutura: no = selstruc(v,critério); Na chamada dessa função, 'critério' é uma variável tipo caracter que expressa o tipo de correção usada para compensar o fato de não se ter feito validação cruzada. Os critérios mais comuns para seleção de modelo são descritos a seguir. • critério = 'aic' - critério de Akaike (information theoretic criterion) • critério = 'mdl' - critério de Rissanen (minimum description lenght) • critério = 'plot' – critério da função perda por modelagem não modificada. ou seja, temos três opções principais: no = selstruc(v,'aic'); no = selstruc(v,'mdl'); no = selstruc(v,'plot');

140
2. função resid: válida para qualquer modelo, essa função se baseia no cálculo da correlação dos resíduos gerados pelo modelo ajustado. Os resíduos são as diferenças entre os valores experimentais e os valores calculados com o modelo, fazendo-se análise de auto-correlação dos resíduos e correlação cruzada destes com os dados de entrada do sistema.
A função resid é usada na forma:
e = resid(zt,th);
sendo desenhados dois gráficos, com as correlações de sinais mencionadas acima (coeficientes de correlação x lag). Nesses dois gráficos aparecem os intervalos (indicados com linhas pontilhadas) de 99% de confiança para que o resíduo seja considerado ruído branco. Sob o ponto de vista estocástico, o erro de identificação consiste de duas partes: • erro de bias decorrente de um modelo insuficiente; • erro de variança em razão de perturbações que causaram impacto no
sistema. Geralmente, um modelo é considerado adequado se a auto-correlação de seus resíduos for considerada um ruído branco; além disso, a correlação dos resíduos com o sinal de entrada deve ser nula. Nesse caso, o erro de identificação é devido inteiramente a erro de variança (erro de bias nulo). O teste estatístico consiste em não aceitar modelos que levem a uma rejeição da hipótese de que a série dos resíduos seja ruído branco. Ou seja, analisando os dois gráficos, nenhum ponto deve cair fora da faixa delimitada pelas linhas pontilhadas (exceto o primeiro ponto do primeiro gráfico – auto-correlação com atraso de fase nulo). A função resid devolve também o vetor com os resíduos calculados. Com os resíduos pode ser feita análise de erro de ajuste.

141
As versões mais recentes do Matlab apresentam uma graphical user interface para acionar a toolbox de identificação. Essa interface engloba todos os itens mencionados anteriormente e será usada em sala para exercitar levantamento de modelos dinâmicos. As três figuras seguintes mostram a interface gráfica de usuário para: • entrada dos dados a partir da área de trabalho (workspace) do Matlab; • pré-processamento dos dados (remoção de médias ou tendências); • estimação do modelo e análise de resultados (simulações e análise de
resíduos).

142

143

144
ANEXO 4: telas de engenharia – controle avançado: Seguem telas de configuração de controlador, de variáveis controladas, de variáveis manipuladas e variáveis perturbação dos sistemas SSP-Laplace e SICON.

145

146

147

148

149
150

151

152

153

154

155

156