institucional | devops: cultura, automação e monitoramento – daniel semedo, da microsoft
TRANSCRIPT

DevOpsCultura, automação e monitoramento

Cultura Automação Monitoramento
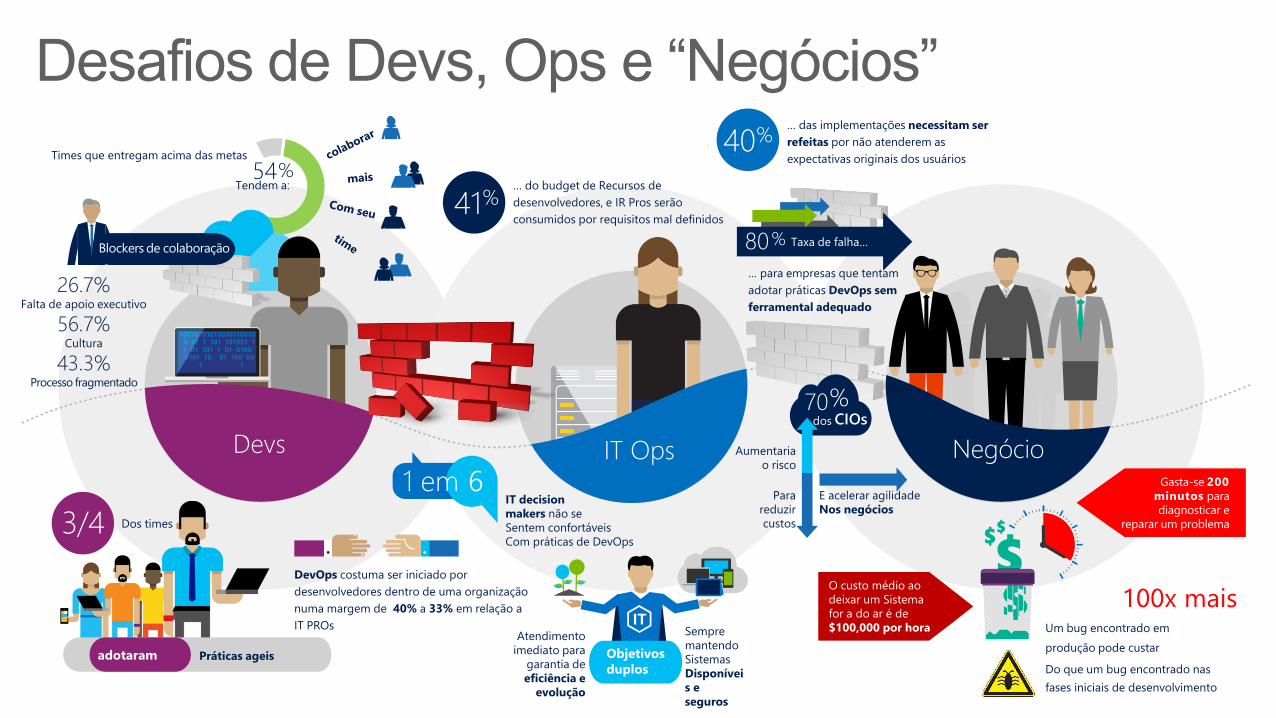
Times que entregam acima das metas
54%Tendem a:
Devs
26.7%Falta de apoio executivo
56.7%Cultura
43.3%Processo fragmentado
Blockers de colaboração
DevOps costuma ser iniciado por
desenvolvedores dentro de uma organização
numa margem de 40% a 33% em relação a
IT PROs
Práticas ageisadotaram
3/4 Dos times
NegócioIT Ops
O custo médio ao
deixar um Sistema
for a do ar é de
$100,000 por hora
Gasta-se 200
minutos para
diagnosticar e
reparar um problema
Um bug encontrado em
produção pode custar
Do que um bug encontrado nas
fases iniciais de desenvolvimento
100x mais
IT decision
makers não se
Sentem confortáveis
Com práticas de DevOps
61 em
40%… das implementações necessitam ser
refeitas por não atenderem as
expectativas originais dos usuários
… do budget de Recursos de
desenvolvedores, e IR Pros serão
consumidos por requisitos mal definidos41%
Atendimento
imediato para
garantia de
eficiência e
evolução
Sempre
mantendo
Sistemas
Disponívei
s e
seguros
Objetivos
duplos
… para empresas que tentam
adotar práticas DevOps sem
ferramental adequado
80% Taxa de falha…
CIOs70%
Para
reduzir
custos
Aumentaria
o risco
E acelerar agilidade
Nos negócios
dos
Desafios de Devs, Ops e “Negócios”
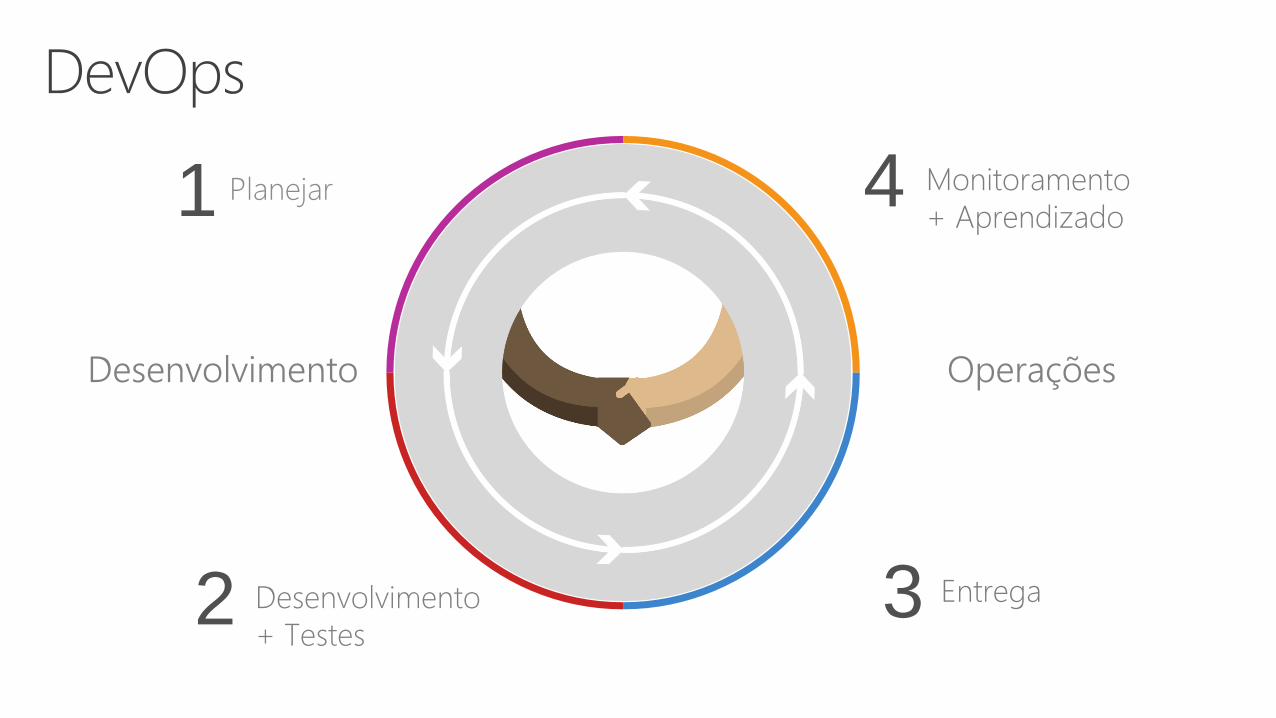
Planejar1 Monitoramento
+ Aprendizado
EntregaDesenvolvimento
+ Testes2
Desenvolvimento Operações
4
3
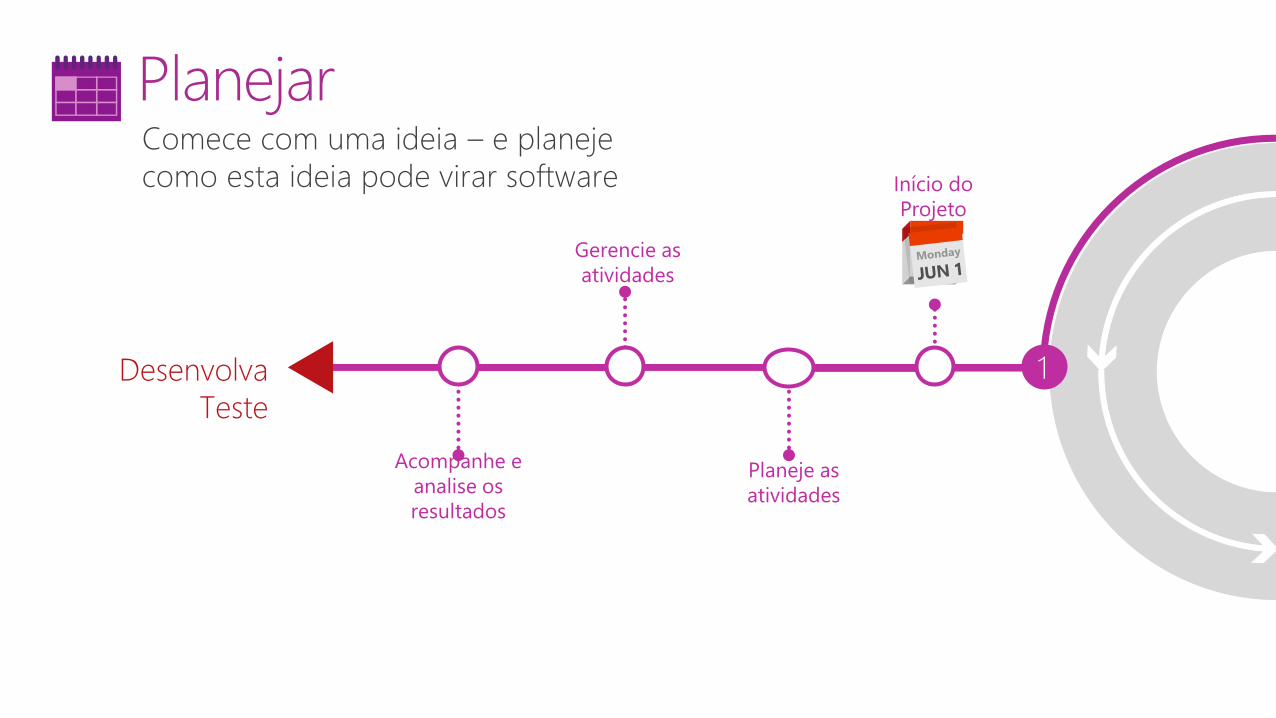
Comece com uma ideia – e planeje
como esta ideia pode virar software
Gerencie as
atividades
Desenvolva
Teste
1
Planejar
Início do
Projeto
Planeje as
atividades
Acompanhe e
analise os
resultados
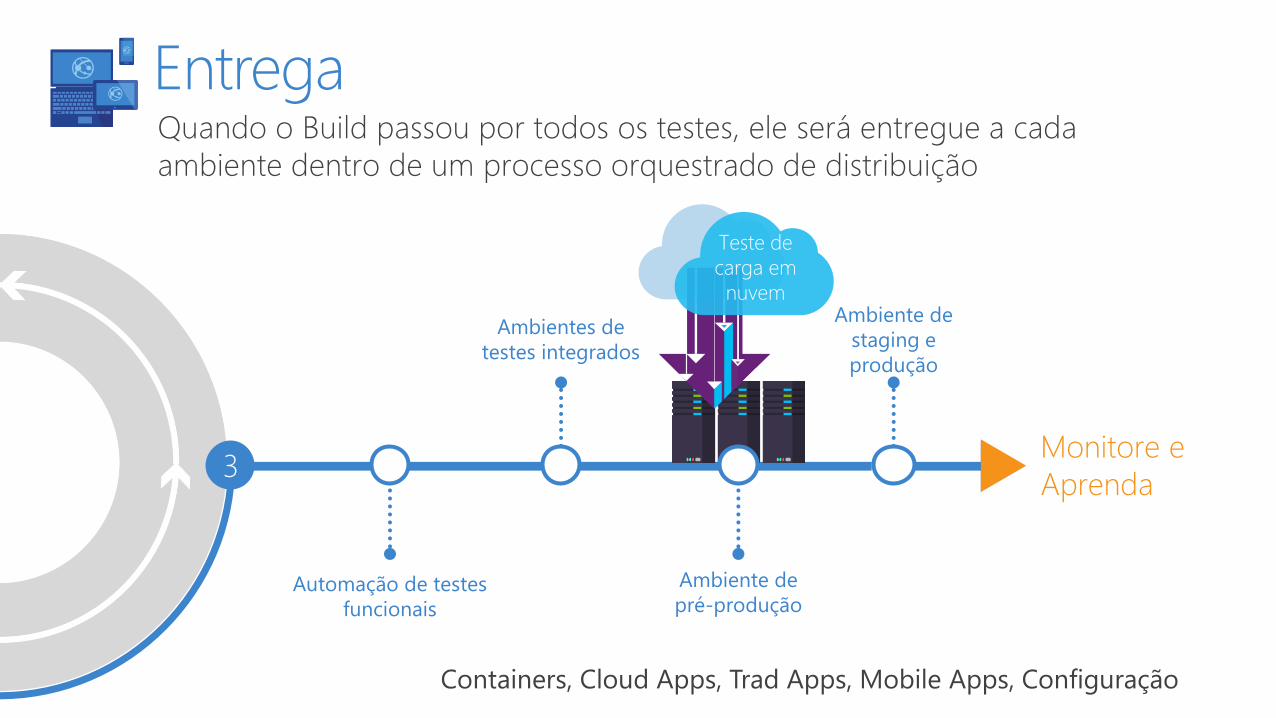
Teste de
carga em
nuvem
Ambientes de
testes integrados
Automação de testes
funcionais
3
Ambiente de
pré-produção
Ambiente de
staging e
produção
Monitore e
Aprenda
Quando o Build passou por todos os testes, ele será entregue a cada
ambiente dentro de um processo orquestrado de distribuição
Entrega
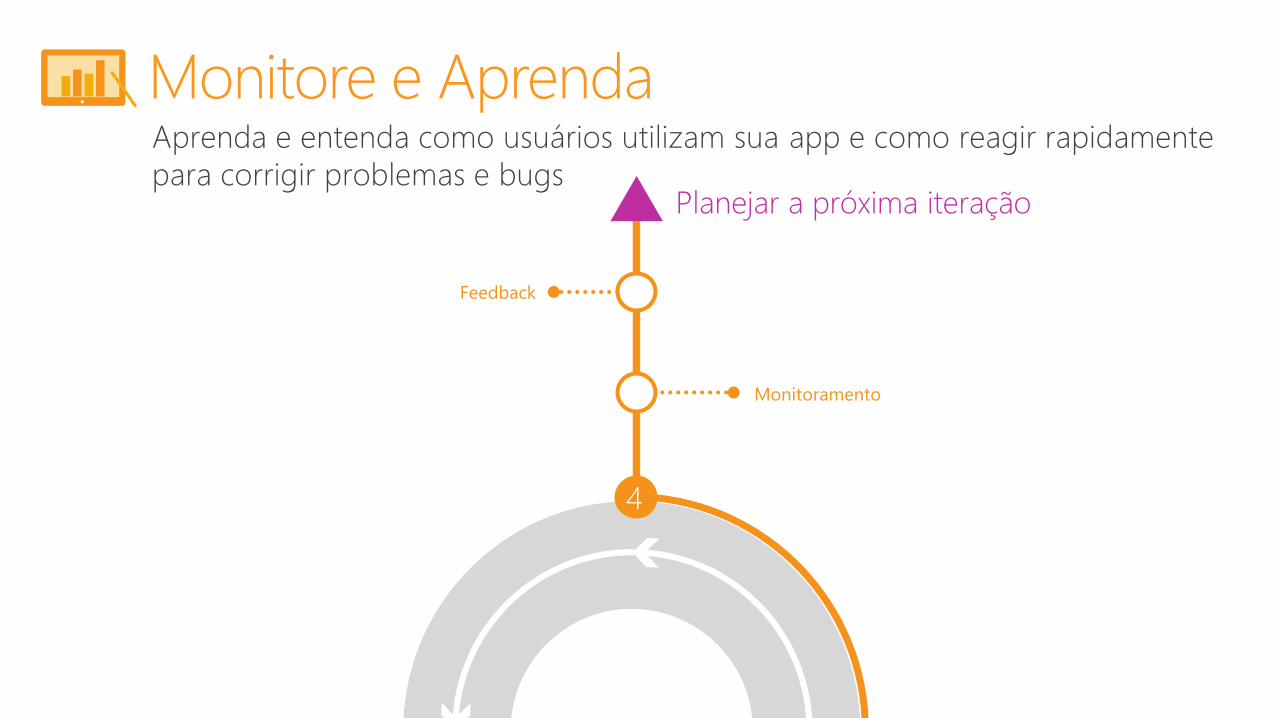
Aprenda e entenda como usuários utilizam sua app e como reagir rapidamente
para corrigir problemas e bugs
Monitore e Aprenda
4
Monitoramento
Feedback
Planejar a próxima iteração

Estou atendendo os meus KPIs
de SLA?
Qual é a causa raiz?
A minha aplicação está rápida o
suficiente?
Minha aplicação está UP ou
DOWN?
Quantas pessoas foram
impactadas?
Minha aplicação está
estável e disponível?
Quais funcionalidades meus clients
estão utilizando?
Qual o tempo de resposta dos meus
serviços dependentes?
Como está a experiência de uso?
Você já teve estes questionamentos?
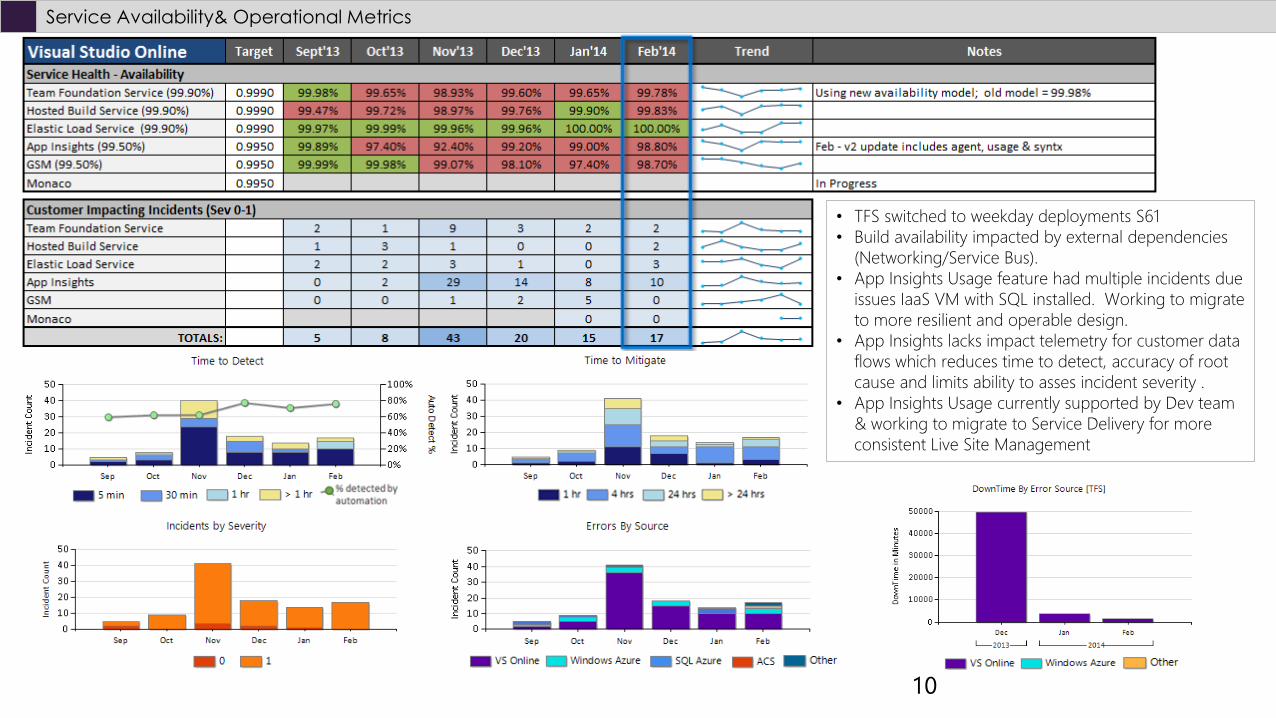
Service Availability& Operational Metrics
• TFS switched to weekday deployments S61
• Build availability impacted by external dependencies
(Networking/Service Bus).
• App Insights Usage feature had multiple incidents due
issues IaaS VM with SQL installed. Working to migrate
to more resilient and operable design.
• App Insights lacks impact telemetry for customer data
flows which reduces time to detect, accuracy of root
cause and limits ability to asses incident severity .
• App Insights Usage currently supported by Dev team
& working to migrate to Service Delivery for more
consistent Live Site Management
10
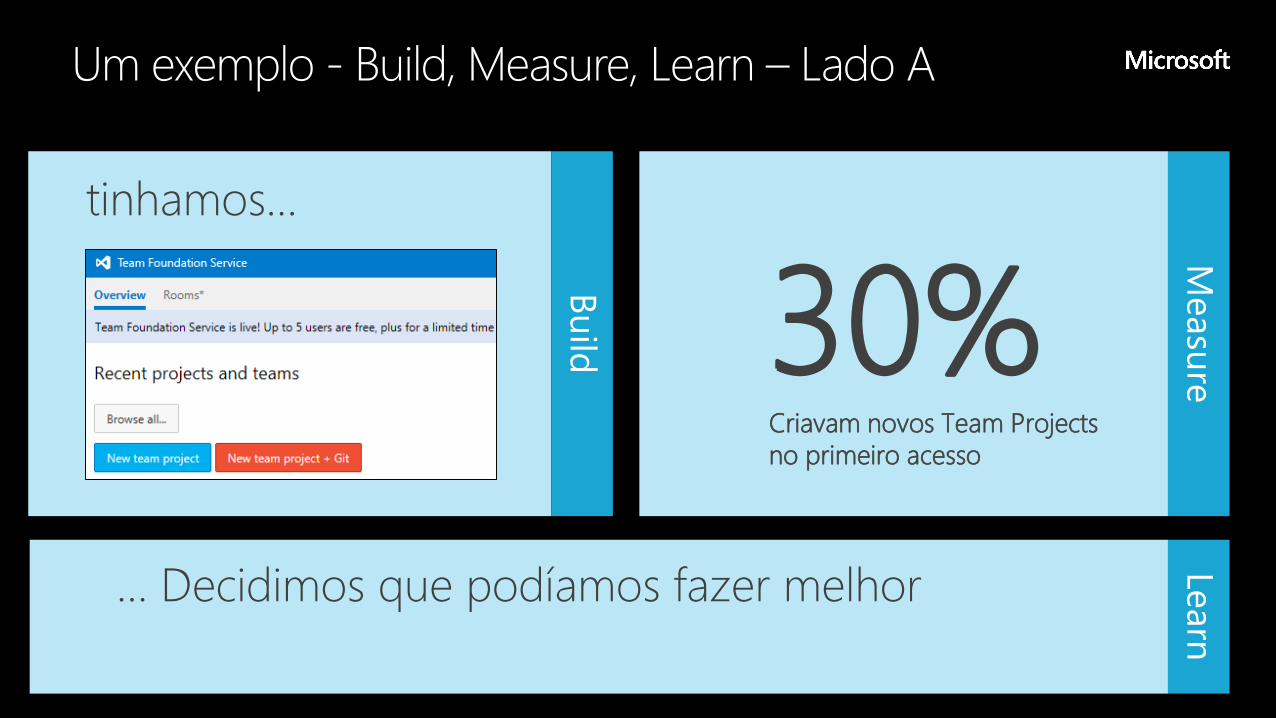
tinhamos…
… Decidimos que podíamos fazer melhor
30%Criavam novos Team Projects
no primeiro acesso
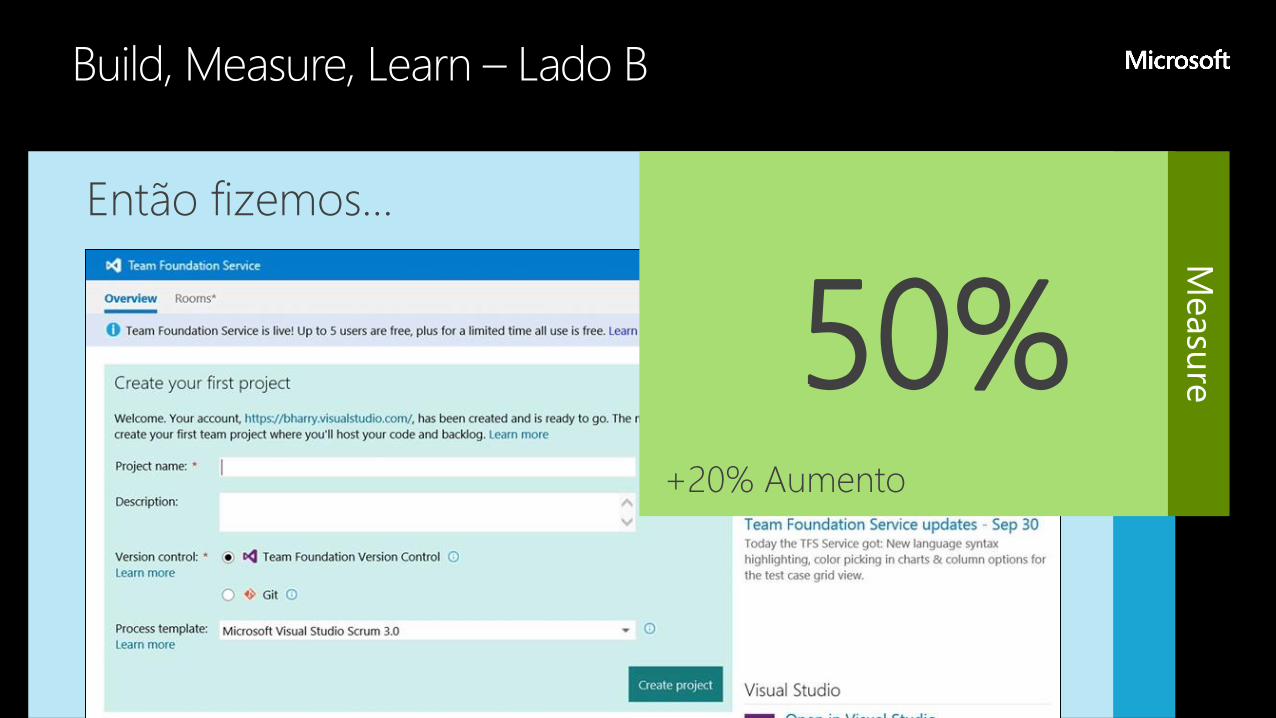
Então fizemos…
50%+20% Aumento
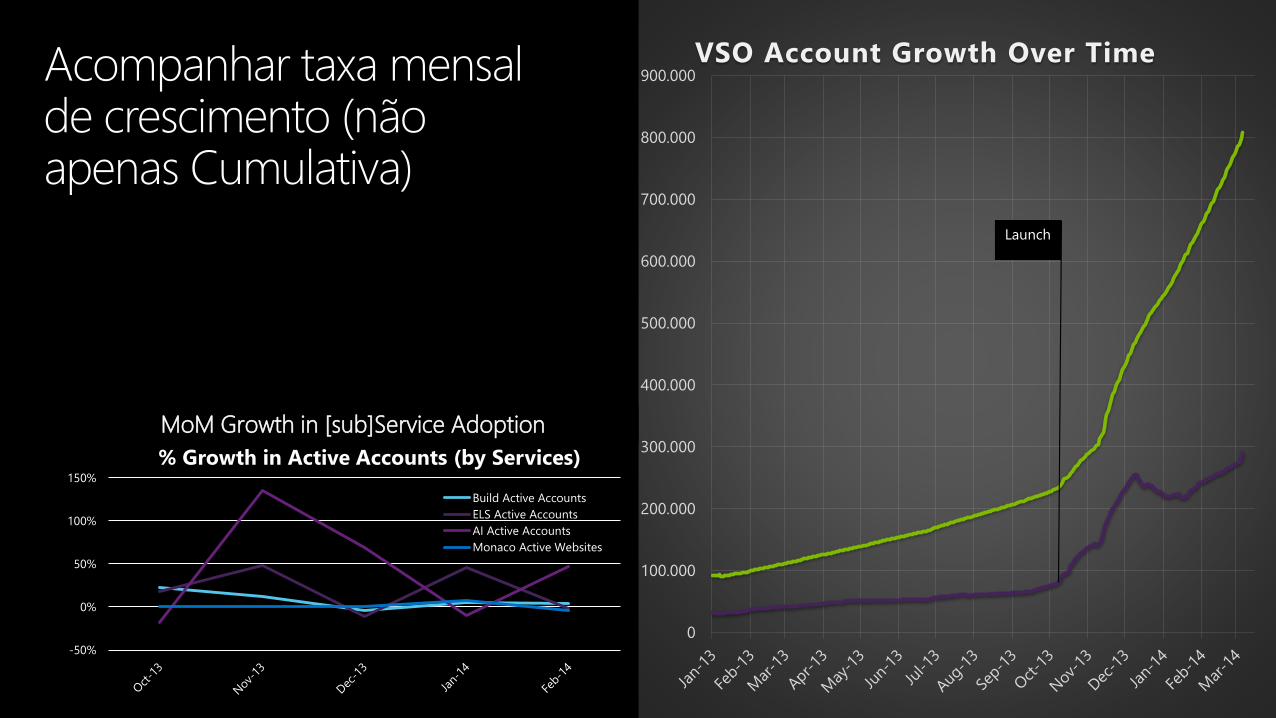
-50%
0%
50%
100%
150%
% Growth in Active Accounts (by Services)
Build Active Accounts
ELS Active Accounts
AI Active Accounts
Monaco Active Websites
0
100.000
200.000
300.000
400.000
500.000
600.000
700.000
800.000
900.000VSO Account Growth Over Time
Launch
MoM Growth in [sub]Service Adoption
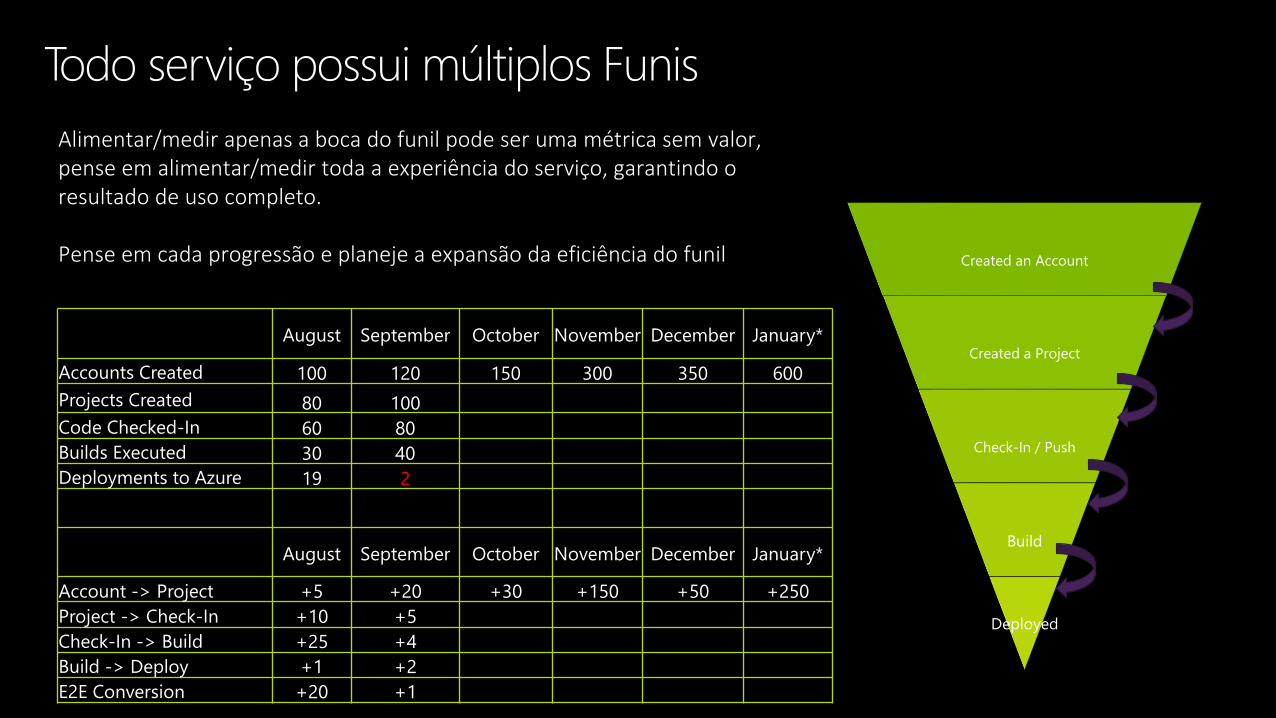
Alimentar/medir apenas a boca do funil pode ser uma métrica sem valor, pense em alimentar/medir toda a experiência do serviço, garantindo o resultado de uso completo.
Pense em cada progressão e planeje a expansão da eficiência do funil Created an Account
Created a Project
Check-In / Push
Build
Deployed
August September October November December January*
Accounts Created 100 120 150 300 350 600
Projects Created 80 100
Code Checked-In 60 80
Builds Executed 30 40
Deployments to Azure 19 2
August September October November December January*
Account -> Project +5 +20 +30 +150 +50 +250
Project -> Check-In +10 +5
Check-In -> Build +25 +4
Build -> Deploy +1 +2
E2E Conversion +20 +1

X
“Use ambas, inovação exige também criatividade e risco, aplique-as no caminho correto”

DEMO

Obrigado!