hemir da cunha santiago - ufpe
TRANSCRIPT

Pós-Graduação em Ciência da Computação
HEMIR DA CUNHA SANTIAGO
RECONHECIMENTO DE EXPRESSÕES FACIAIS
UTILIZANDO ESTIMAÇÃO DE MOVIMENTO
Universidade Federal de Pernambuco
www.cin.ufpe.br/~posgraduacao
RECIFE
2017

HEMIR DA CUNHA SANTIAGO
RECONHECIMENTO DE EXPRESSÕES FACIAIS
UTILIZANDO ESTIMAÇÃO DE MOVIMENTO
Tese apresentada ao Programa de Pós-
Graduação em Ciência da Computação da
Universidade Federal de Pernambuco, como
requisito parcial para a obtenção do título de
Doutor em Ciência da Computação.
Orientador: Prof. Dr. Tsang Ing Ren
Recife
2017

Catalogação na fonte
Bibliotecária Monick Raquel Silvestre da S. Portes, CRB4-1217
S235r Santiago, Hemir da Cunha
Reconhecimento de expressões faciais utilizando estimação de movimento / Hemir da Cunha Santiago. – 2017.
140 f.: il., fig., tab. Orientador: Tsang Ing Ren. Tese (Doutorado) – Universidade Federal de Pernambuco. CIn, Ciência da
Computação, Recife, 2017. Inclui referências.
1. Inteligência artificial. 2. Processamento de imagens. I. Ren, Tsang Ing (orientador). II. Título. 006.31 CDD (23. ed.) UFPE- MEI 2017-82

Hemir da Cunha Santiago
Reconhecimento de Expressões Faciais Utilizando Estimação de Movimento
Tese de Doutorado apresentada ao Programa
de Pós-Graduação em Ciência da
Computação da Universidade Federal de
Pernambuco, como requisito parcial para a
obtenção do título de Doutora em Ciência da
Computação
Aprovado em: 07/02/2017.
__________________________________________________ Orientador: Prof. Dr. Tsang Ing Ren
BANCA EXAMINADORA
________________________________________________
Prof. Dr. Cleber Zanchettin
Centro de Informática / UFPE
________________________________________________
Prof. Dr. Carlos Alexandre Barros de Mello
Centro de Informática / UFPE
_________________________________________________
Prof. Dr. Francisco Madeiro Bernardino Júnior
Escola Politécnica de Pernambuco / UPE
_______________________________________________________
Prof. Dr. Hae Yong Kim
Departamento de Engenharia de Sistemas e Eletrônicos/USP
_________________________________________________________________
Prof. Dr. Robson Cavalcanti Lins
Departamento de Estatística e Informática / UNICAP

AGRADECIMENTOS
Agradeço a todos os amigos e colegas que me ajudaram na realização deste trabalhoe também aos que me incentivaram e me apoiaram durante o curso de doutorado. Par-ticularmente, agradeço ao amigo e colega de trabalho Guilherme Melo, pelas conversas ediscussões que tiveram contribuição significativa neste trabalho.
Em especial, agradeço ao professor Dr. Tsang Ing Ren, meu orientador, pela sua dedica-ção, pela sua orientação, pela sua paciência e por tudo o que eu pude aprender com ele nasáreas de Processamento de Imagens, Inteligência Computacional e na vida acadêmica.
Faço um agradecimento especial também aos meus pais, Dalva e Hemir, que sempreacreditaram em mim, pelo incentivo ao estudo e à formação profissional.
Também agradeço à minha esposa Cristina pelo apoio, pela paciência e por ser extre-mamente solidária nos momentos mais importantes para que eu conseguisse cumprir osprazos regimentais do curso.
Finalmente, agradeço ao meu pequeno filho Benjamin que por muitas vezes abriu mãoda atenção do seu pai quando este precisou se dedicar às atividades deste doutorado.
HEMIR DA CUNHA SANTIAGO

"A vida do homem não é nada mais do que um simplespiscar de olhos, um curto momento... Nesse pouco
tempo, as pessoas nascem, riem, choram, lutam, sãoferidas, sentem alegria, tristeza, odeiam alguém, amam
alguém... Tudo em um só momento."
— Masami Kurumada

RESUMO
As expressões faciais fornecem informações sobre a resposta emocional e exercem um pa-
pel fundamental na interação humana e como forma de comunicação não-verbal. Contudo,
o reconhecimento das expressões ainda é algo considerado complexo para o computador.
Neste trabalho, propomos um novo extrator de características que utiliza a estimação de
movimento para o reconhecimento de expressões faciais. Nesta abordagem, o movimento
facial entre duas expressões é codificado usando uma estimação dos deslocamentos de re-
giões entre duas imagens, que podem ser da mesma face ou de faces similares. A imagem
da expressão facial é comparada a outra imagem mais similar em cada expressão facial da
base de treinamento, a maior similaridade é obtida usando a medida de Similaridade Estru-
tural (SSIM - Structural Similarity Index). Após a identificação das imagens mais similares
na base de treinamento, são calculados os vetores de movimento entre a imagem cuja ex-
pressão facial será reconhecida e a outra mais similar em uma das expressões da base. Para
calcular os vetores de movimento é proposto o algoritmo MARSA (Modified Adaptive Reduc-
tion of the Search Area). Todos os vetores de movimento são comparados às coordenadas com
as maiores ocorrências dentre todos os vetores de movimento obtidos durante a fase de trei-
namento, a partir dessa comparação são gerados os vetores de características que servem
de dados de entrada para uma SVM (Support Vector Machine), que irá realizar a classificação
da expressão facial. Diversas bases de imagens e vídeos de faces, reproduzindo expressões
faciais, foram utilizadas para os experimentos. O critério adotado para a escolha das ba-
ses foi a frequência com que são utilizadas em outros trabalhos do estado da arte, portanto
foram escolhidas: Cohn-Kanade (CK), Extended Cohn-Kanade (CK+), Japanese Female Facial Ex-
pression (JAFFE), MMI e CMU Pose, Illumination, and Expression (CMU-PIE). Os resultados
experimentais demostram taxas de reconhecimento das expressões faciais compatíveis a
outros trabalhos recentes da literatura, comprovando a eficiência do método apresentado.
Palavras-chave: Extração de característica. Casamento de blocos. Estimação de movimento.
Reconhecimento de expressões faciais.

ABSTRACT
Facial expressions provide information on the emotional response and play an essential
role in human interaction and as a form of non-verbal communication. However, the recog-
nition of expressions is still something considered complex for the computer. In this work,
it is proposed a novel feature extractor that uses motion estimation for Facial Expression
Recognition (FER). In this approach, the facial movement between two expressions is co-
ded using an estimation of the region displacements between two images, which may be of
the same face or the like. The facial expression image is compared to another more similar
image in each facial expression of the training base, the best match is obtained using the
Structural Similarity Index (SSIM). After identifying the most similar images in the training
base, the motion vectors are calculated between the reference image and the other more si-
milar in one of the expressions of the base. To calculate the motion vectors is proposed the
MARSA (Modified Adaptive Reduction of the Search Area) algorithm. All motion vectors
are compared to the coordinates with the highest occurrences of all motion vectors obtai-
ned during the training phase, from this comparison the feature vectors are generated that
serve as input data for a SVM (Support Vector Machine), which will perform the classifi-
cation of facial expression. Several databases of images and videos of faces reproducing
facial expressions were used for the experiments, the adopted criteria for selection of the
bases was the frequency which they are used in the state of the art, then were chosen: Cohn-
Kanade (CK), Extended Cohn-Kanade (CK+), Japanese Female Facial Expression (JAFFE), MMI,
and CMU Pose, Illumination, and Expression (CMU-PIE). The experimental results demons-
trate that the recognition rates of facial expressions are compatible to recent literature works
proving the efficiency of the presented method.
Keywords: Feature extraction. Block matching. Motion Estimation. Facial Expression Re-
cognition.

LISTA DE FIGURAS
1.1 Comparação entre técnicas padrões de reconhecimento e Deep Learning. Fonte:[1] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.1 Um sistema genérico de reconhecimento de expressões faciais. Fonte: autor. . 262.2 Faces da base de imagens JAFFE. Fonte: [2]. . . . . . . . . . . . . . . . . . . . . 282.3 Exemplo de sequência da base CK partindo da expressão neutra (esquerda)
para a expressão medo (direita). Fonte: [3]. . . . . . . . . . . . . . . . . . . . . 282.5 Exemplo de sequência da base CK+ partindo da expressão neutra (esquerda)
para a expressão de desprezo (direita). Fonte: [4]. . . . . . . . . . . . . . . . . 282.4 Faces da base de imagens CK. ”sem imagem” indica que o indivíduo não
possui imagem para aquela expressão na base. Fonte: [3]. . . . . . . . . . . . . 292.6 Exemplo de sequência da base MMI partindo da expressão neutra (esquerda)
para a expressão de nojo (direita). Fonte: [5]. . . . . . . . . . . . . . . . . . . . 292.7 Frames da base de vídeos MMI. ”sem imagem” indica que o indivíduo não
possui imagem para aquela expressão na base. Fonte: [5]. . . . . . . . . . . . . 302.8 Exemplo de imagens da base CMU-PIE, da esquerda para a direita e de cima
para baixo as imagens das câmeras: 05, 07, 09, 27 e 29. Fonte: [6]. . . . . . . . 312.9 Linha do tempo das bases de imagens de faces. As bases sublinhadas foram
utilizadas nos experimentos deste trabalho. Fonte: autor. . . . . . . . . . . . . 322.10 Um sistema genérico de detecção de faces. Fonte: autor. . . . . . . . . . . . . . 332.11 Exemplos de detecção de faces e carros. Fonte: [7]. . . . . . . . . . . . . . . . . 342.12 Cima: modelo do CANDIDE-1. Baixo: modelo do CANDIDE-2. Fonte: [8]. . . 352.13 Saída do detector de Viola e Jones em algumas imagens de testes. Fonte: [9]. . 372.14 Sequência de testes do descritor CNN em cascata: da esquerda pada a di-
reita, como as janelas de detecção são reduzidas e calibradas em cada estágio.Fonte: [10]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.15 Linha do tempo das técnicas de detecção de faces. A técnica sublinhada foiutilizada nos experimentos deste trabalho. Fonte: autor. . . . . . . . . . . . . . 38
2.16 Distribuição de brilho ao longo de uma linha vertical cruzando a íris. Fonte:[11]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.17 13 linhas verticais para obtenção das informações faciais. Fonte: [11]. . . . . . 402.18 Modelos de componentes faciais multi-estado de uma face na posição frontal.
Fonte: [12]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41

2.19 Pontos faciais na visão frontal (esquerda) e na visão lateral (direita). Fonte: [13]. 422.20 Posições típicas dos pontos fiduciais: (a) 34 pontos (b) 19 pontos. Fonte: [14]. 432.21 Modelo dos pontos-chave faciais. Fonte: [15]. . . . . . . . . . . . . . . . . . . . 432.22 (a) Características extraídas dos olhos, das sobrancelhas e do queixo (b) Ca-
racterísticas extraídas da boca e dos lábios. Fonte: [16]. . . . . . . . . . . . . . 442.23 Um exemplo do método de particionamento de regiões faciais: a imagem da
face dividida em 1, 4, 16 e 64 sub-regiões faciais. Fonte: [17]. . . . . . . . . . . 452.24 Exemplo de 49 pontos faciais de referência localizados por ASM (active shape
model). Fonte: [18]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.25 Linha do tempo das técnicas de extração baseadas em características geomé-
tricas. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462.26 Amostras de imagens extraídas da base de imagens JAFFE e respectivas ca-
racterísticas extraídas (olhos e boca). Fonte: [19]. . . . . . . . . . . . . . . . . . 472.27 Exemplo de características Haar-like sobrepostas em uma imagem de face.
Fonte: [20]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482.28 (Esquerda) Uma face dividida em 6 × 7 sub-regiões. (Direita) Quadrados
pretos indicam peso 0, cinza escuros 1, cinza claros 2 e brancos 4. Fonte: [21]. 492.29 Resultados da detecção de bordas usando o algoritmo de Canny. Fonte: [22]. . 502.30 Descritor de face LSDP. Fonte da Imagem: [23] . . . . . . . . . . . . . . . . . . 502.31 Ilustração de uma decomposição 4 escalas de Curvelet. Fonte da Imagem: [24] 522.32 Representações de planos de bits de imagem de face. Fonte da Imagem: [25] . 532.33 Linha do tempo das técnicas de extração de características de aparência. Fonte:
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 542.34 Amostras de saídas do sistema para um segmento de 10 segundos de vídeo,
contendo as AUs: 1, 2, 6 e 9. Com início, ápice e fim das AUs. Fonte: [26]. . . 562.35 Linha do tempo das técnicas de classificação utilizadas no reconhecimento de
expressões faciais. O trabalho sublinhado descreve o classificador utilizadonos experimentos desta tese. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . 59
3.1 Sistema desenvolvido para o reconhecimento de expressões faciais. Fonte:autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.2 Imagens da base Cohn-Kanade Extendida (CK+) convertidas para níveis decinza. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.3 Imagens da base Cohn-Kanade (CK) e respectivas faces recortadas utilizandoa localização dos olhos implementada pelos filtros ASEF. Fonte: autor. . . . . 64
3.4 Treinamento dos filtros ASEF. Fonte: [27] . . . . . . . . . . . . . . . . . . . . . 653.5 A imagem do centro representa a imagem-referência. As demais imagens
representam as melhores comparações em cada expressão facial da base deimagens Cohn-Kanade. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . 67
3.6 Exemplo de como os MVs são calculados entre a imagem-referência e a ima-gem mais similar em cada expressão da base Cohn-Kanade. Fonte: autor. . . 69

3.7 Representação de como é obtido o vetor de movimento entre duas imagens.Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.8 Procedimento para classificação de informação de bloco. Fonte: [28] (modifi-cada pelo autor). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
3.9 Regiões da face selecionadas para a extração de características faciais, consi-derando a proporcionalidade da distância entre os olhos e entre cada olho ea boca. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
3.10 Regiões da face selecionadas para a extração de características faciais. Umaimagem de cada base (da esquerda para a direita): CK, JAFFE, MMI, CK+ eCMU-PIE. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.11 O algoritmo Modificado de Redução Adaptativa da Área de Busca (MARSA).Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
3.12 As cinco fases do treinamento. Fonte: autor. . . . . . . . . . . . . . . . . . . . . 783.13 Busca da imagem mais similar em cada expressão facial. Fonte: autor. . . . . 793.14 Representação do MV. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . 793.15 Framework de testes. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . . 823.16 Visão do hiperplano separador de classes na SVM linear. Fonte: autor. . . . . 843.17 Visão geral do classificador em aprendizado supervisionado. Fonte: autor. . . 853.18 Conjunto de dados não linear. Fonte: autor. . . . . . . . . . . . . . . . . . . . . 85
4.1 Validação Cruzada 10-folds. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . 894.2 Taxas de reconhecimento para cada expressão facial da base JAFFE. Fonte:
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 934.3 Quantidade de HOVs X Respectivas taxas médias de acertos no reconheci-
mento de expressões faciais na base de imagens JAFFE. Fonte: autor. . . . . . 944.4 Taxas de reconhecimento para cada expressão facial da base CK. Fonte: autor. 994.5 Quantidade de HOVs X Respectivas taxas médias de acertos no reconheci-
mento de expressões faciais na base de imagens CK. Fonte: autor. . . . . . . . 1004.6 Taxas de reconhecimento para cada expressão facial da base CK+. Fonte: autor.1064.7 Quantidade de HOVs X Respectivas taxas médias de acertos no reconheci-
mento de expressões faciais na base de imagens CK+. Fonte: autor. . . . . . . 1064.8 Taxas de reconhecimento para cada expressão facial da base MMI. Fonte: autor.1114.9 Quantidade de HOVs X Respectivas taxas médias de acertos no reconheci-
mento de expressões faciais na base de imagens e vídeos MMI. Fonte: autor. . 1124.10 Imagens de faces segmentadas da base CMU-PIE. Fonte: autor. . . . . . . . . 1154.11 Taxas de reconhecimento para cada expressão facial da base CMU-PIE. Fonte:
autor. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1174.12 Quantidade de coordenadas de maiores ocorrências nos vetores de movi-
mento x Respectivas taxas de reconhecimento da expressões faciais na basede imagens CMU-PIE. Fonte: autor. . . . . . . . . . . . . . . . . . . . . . . . . 117

LISTA DE TABELAS
1.1 Exemplos de aplicações de reconhecimento de expressões faciais . . . . . . . 19
3.1 Para cada imagem, um MV para cada expressão da base de treinamento. . . . 793.2 Representação dos HOVs de cada expressão facial da base de treinamento. . 803.3 Cálculo do HOV para a base de imagens alegria. . . . . . . . . . . . . . . . . . 803.4 Cálculo do EDV para cada imagem da base de treinamento. . . . . . . . . . . 813.5 Cálculo do FV para uma imagem da base de treino. . . . . . . . . . . . . . . . 81
4.1 Tempos de detecção e recorte da face usando os filtros ASEF para cada basee para cada imagem utilizada nos experimentos. . . . . . . . . . . . . . . . . . 90
4.2 Tempos de busca da imagem de maior semelhança usando a função SSIMpara cada base e para cada imagem utilizada nos experimentos. . . . . . . . . 90
4.3 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 1 HOV. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.4 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 2 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.5 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 4 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
4.6 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 6 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.7 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 8 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.8 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 10 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
4.9 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 12 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.10 Matriz de confusão do reconhecimento de expressões faciais na base JAFFE,utilizando 14 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.11 Taxas médias de reconhecimento dos algoritmos de estimação de movimentopara tamanhos diferentes de blocos, utilizando a base JAFFE. . . . . . . . . . . 95
4.12 Tempos de processamento dos algoritmos de estimação de movimento paratamanhos diferentes de blocos, utilizando a base JAFFE. . . . . . . . . . . . . . 96

4.13 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 1 HOV. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.14 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 2 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.15 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 4 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
4.16 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 6 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.17 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 8 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.18 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 10 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.19 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 12 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
4.20 Matriz de confusão do reconhecimento de expressões faciais na base CK, uti-lizando 14 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
4.21 Taxas médias de reconhecimento dos algoritmos de estimação de movimentopara tamanhos diferentes de blocos, utilizando a base CK. . . . . . . . . . . . 101
4.22 Tempos de processamento dos algoritmos de estimação de movimento paratamanhos diferentes de blocos, utilizando a base CK. . . . . . . . . . . . . . . 102
4.23 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 1 HOV. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.24 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 2 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.25 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 4 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.26 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 6 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.27 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 8 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.28 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 10 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.29 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 12 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.30 Matriz de confusão do reconhecimento de expressões faciais na base CK+,utilizando 14 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
4.31 Taxas médias de reconhecimento dos algoritmos de estimação de movimentopara tamanhos diferentes de blocos, utilizando a base CK+. . . . . . . . . . . . 107
4.32 Tempos de processamento dos algoritmos de estimação de movimento paratamanhos diferentes de blocos, utilizando a base CK+. . . . . . . . . . . . . . . 108
4.33 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 1 HOV. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109

4.34 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 2 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
4.35 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 4 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
4.36 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 6 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
4.37 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 8 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
4.38 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 10 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
4.39 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 12 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
4.40 Matriz de confusão do reconhecimento de expressões faciais na base MMI,utilizando 14 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
4.41 Taxas médias de reconhecimento dos algoritmos de estimação de movimentopara tamanhos diferentes de blocos, utilizando a base MMI. . . . . . . . . . . 113
4.42 Tempos de processamento dos algoritmos de estimação de movimento paratamanhos diferentes de blocos, utilizando a base MMI. . . . . . . . . . . . . . 114
4.43 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 1 HOV. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.44 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 2 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.45 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 4 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
4.46 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 6 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.47 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 8 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.48 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 10 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.49 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 12 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.50 Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 14 HOVs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.51 Taxas médias de reconhecimento dos algoritmos de estimação de movimentopara tamanhos diferentes de blocos, utilizando a base CMU-PIE. . . . . . . . . 119
4.52 Tempos de processamento dos algoritmos de estimação de movimento paratamanhos diferentes de blocos, utilizando a base CMU-PIE. . . . . . . . . . . . 119
4.53 Comparação com outros métodos da literatura, utilizando a base de imagensJAFFE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
4.54 Comparação com outros métodos da literatura, utilizando a base de imagensCK. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121

4.55 Comparação com outros métodos da literatura, utilizando a base de imagensCK+. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
4.56 Comparação com outros métodos da literatura, utilizando a base de vídeosMMI. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
4.57 Comparação com outros métodos da literatura, utilizando a base de imagensCMU-PIE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125

SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.1 Reconhecimento de Expressões Faciais . . . . . . . . . . . . . . . . . . . . . . . . 181.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211.2.1 Objetivos Específicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.3 Organização da Tese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222 REVISÃO DA LITERATURA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.1 Sistemas de Reconhecimento de Expressões Faciais . . . . . . . . . . . . . . . . 252.1.1 Bases de Imagens de Faces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.1.2 Detecção e Rastreamento da Face . . . . . . . . . . . . . . . . . . . . . . . . . . . . 322.1.3 Extração de Características . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.1.4 Classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 543 MÉTODO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 603.1 Pré-processamento para as Bases de Expressões Faciais . . . . . . . . . . . . . . 633.1.1 Filtros de Correlação ASEF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 643.2 Busca da Maior Semelhança . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 663.2.1 SSIM - Structural Similarity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 673.3 Extração de Características . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 683.3.1 Algoritmo de Busca Exaustiva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 713.3.2 Algoritmo de Redução Adaptativa da Área de Busca . . . . . . . . . . . . . . . . 723.3.3 Algoritmo Modificado de Redução Adaptativa da Área de Busca . . . . . . . . . 753.4 Transformação de Características . . . . . . . . . . . . . . . . . . . . . . . . . . . 773.4.1 Treinamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 783.4.2 Testes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 823.5 Classificação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 833.5.1 SVM - Support Vector Machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 834 EXPERIMENTOS E RESULTADOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . 874.1 Etapas de Pré-processamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 894.2 Reconhecimento de Expressões Faciais Utilizando a Base JAFFE . . . . . . . . . 904.2.1 Comparação dos algoritmos de estimação de movimento por casamento de blo-
cos na base JAFFE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 944.3 Reconhecimento de Expressões Faciais Utilizando a Base CK . . . . . . . . . . 96

4.3.1 Comparação dos algoritmos de estimação de movimento por casamento de blo-cos na base CK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.3.2 A Segunda Versão da Base Cohn-Kanade: CK+ . . . . . . . . . . . . . . . . . . . . 1024.4 Reconhecimento de Expressões Faciais Utilizando a Base MMI . . . . . . . . . 1084.4.1 Comparação dos algoritmos de estimação de movimento por casamento de blo-
cos na base MMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1124.5 Reconhecimento de Expressões Faciais Utilizando a Base CMU-PIE . . . . . . 1144.5.1 Comparação dos algoritmos de estimação de movimento por casamento de blo-
cos na base CMU-PIE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1184.6 Comparação com Outros Métodos . . . . . . . . . . . . . . . . . . . . . . . . . . . 1195 CONCLUSÕES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1275.1 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131

CAPÍTULO 1
INTRODUÇÃO
"Se cheguei até aqui foi porque me apoiei nos
ombros de gigantes."
— Isaac Newton
AEmoção representa um estado psicológico da mente humana. Pesquisas em diversas
áreas defendem opiniões distintas sobre o processo de desenvolvimento da emo-
ção [29]. Alguns filósofos acreditam que a emoção é resultado de mudanças (positivas ou
negativas) em situações pessoais ou no ambiente. Entretanto, alguns biólogos consideram
os sistemas nervoso e hormonal como principais responsáveis pelo desenvolvimento das
emoções. Embora não haja um consenso sobre o que causa a emoção, é fato que a sua
excitação é geralmente acompanhada de alguma manifestação em nossa aparência, como
alterações na expressão facial, voz, gesto, postura e outras condições fisiológicas [29].
As expressões faciais fornecem informações relevantes sobre o estado emocional do in-
divíduo e exercem um papel fundamental na interação humana e como forma de comunica-
ção não-verbal. Elas podem complementar a comunicação verbal, ou até mesmo transmitir
uma mensagem completa por si só. Pesquisas afirmam que a parte verbal ou palavras fa-
ladas de uma mensagem contribuem apenas com 7% para o efeito da mensagem como um
todo, a parte vocal (entonação) contribui em 38%, enquanto a expressão facial de quem fala
contribui com 55% para o efeito da mensagem falada [30].
O reconhecimento da emoção a partir da expressão facial frequentemente induz a infe-

18
rências imprecisas, particularmente por duas razões. Primeiro, a expressão pode não cor-
responder verdadeiramente à excitação de uma determinada emoção. Segundo, medições
de expressões requerem ferramentas de alta precisão. O primeiro problema é insolúvel pois
depende dos indivíduos, sobre os quais as experiências são realizadas, que podem suprimir
sua emoção, ou mesmo fingir falsas emoções. Presumindo que os indivíduos envolvidos
nos experimentos são propícios à pesquisa sobre o reconhecimento de expressões faciais,
apenas o segundo problema é considerado, pois pode ser resolvido por sistemas automati-
zados de reconhecimento.
Os seres humanos em geral realizam o reconhecimento das expressões faciais baseados
em características identificadas em certas regiões da face, especificamente nas regiões dos
olhos e da boca. Da mesma forma, um sistema computacional deve ser capaz de detectar
essas regiões e de extrair as características necessárias para identificar a expressão facial
sendo manifestada. Na aprendizagem de máquina, no reconhecimento de padrões e no
processamento de imagens, a extração de características começa a partir de um conjunto
inicial de dados e cria valores derivados que devem ser informativos e não redundantes.
As características podem ser estruturas específicas na imagem, como pontos, bordas ou ob-
jetos. Outros exemplos estão relacionados com: o movimento identificado entre imagens
pertencentes a uma sequência, as formas definidas por curvas e limites entre regiões dife-
rentes na imagem, e as cores ou texturas de determinadas regiões. É possível perceber que
o conceito de característica é bastante genérico, portanto a escolha de características em um
sistema de visão computacional pode depender do problema em questão.
1.1 Reconhecimento de Expressões Faciais
Atualmente, imagens de faces são cada vez mais utilizadas como forma de reconheci-
mento de emoções. A informação da face é uma poderosa ferramenta para aplicações como
segurança, entretenimento, entre outras. Existe uma grande variedade de aplicações tais
como sistemas de reconhecimento de faces humanas, sistemas de vigilância e sistemas de
vídeo conferência, que têm como pré-requisito a localização da face e a extração de suas
características. Por isso, a comunidade científica tem dedicado esforços para ampliar os es-
tudos e encontrar melhores técnicas para o problema de localizar uma face e extrair suas
características. De acordo com Wong et al. [31], detectar faces humanas e extrair as carac-
terísticas faciais de uma imagem sem restrição é um grande desafio. Uma série de fatores

19
dificulta a detecção, tais como as cores da pele, uso de óculos, barba ou bigode e, em es-
pecial, as expressões faciais. Isso faz com que a extração de características faciais torne-se
difícil e desafiadora. Várias pesquisas sobre técnicas de reconhecimento de expressões fa-
ciais estão sendo desenvolvidas com o propósito de obter soluções para esses problemas.
Essas técnicas são muito úteis, pois não exigem a interação do usuário ou o conhecimento
dele.
A Tabela 1.1 apresenta algumas aplicações do reconhecimento de expressões faciais.
Tabela 1.1: Exemplos de aplicações de reconhecimento de expressões faciais
ÁREAS APLICAÇÕES ESPECÍFICAS
Entretenimento Jogos de videogame cujos personagens reagem a determinadas expressões do jogador.
Educação Avaliação de interesse do aluno em aulas presenciais e de ensino à distância.
Saúde Monitoramento de pacientes em hospitais.
Vigilância Fiscalização de vídeo avançada, monitorando pessoas com expressões suspeitas.
As expressões faciais são geradas a partir de contrações de músculos faciais, que re-
sultam na deformação de características faciais, tais como pálpebras, sobrancelhas, nariz
e boca, e também resultam em mudanças nas suas posições relativas. A partir destas de-
formações, modelos de representações podem ser definidos, onde imagens com deforma-
ções semelhantes podem pertencer a um determinado modelo. Este processo caracteriza-se
como reconhecimento de expressão facial. A forma para representar uma determinada ex-
pressão facial é analisar as suas distinções ou variações entre a imagem da expressão e a
sua imagem correspondente sob uma expressão normal. Portanto, alguns métodos de re-
conhecimento de expressão facial são baseados em uma sequência de imagens ou imagens
de um vídeo. Contudo, apenas imagens estáticas estão disponíveis para alguns tipos de
aplicações.
O movimento da face é uma característica que pode ser extraída. Alguns trabalhos
apresentam abordagens baseadas em estimação de movimento por casamento de blocos
(block-matching) para reconhecimento de expressões faciais [32], [33]. Karpouzis et al. [32]
propuseram um sistema que compara a evidência de ativação muscular da face humana a
dados obtidos a partir de um modelo 3D de uma cabeça. O algoritmo de estimação de mo-
vimento utilizado no trabalho de Karpouzis et al. é o 3SS (Three-Step Exhaustive Search) [34].
Shermina e Vasudevan [33] propuseram um sistema de reconhecimento de faces baseado
em oclusão e expressão parcial, usando EMD (Empirical Mode Decomposition) e Redes Neu-
rais Artificiais para a extração de características. O algoritmo de estimação de movimento

20
utilizado durante o processo de reconhecimento da expressão é o FS (Full Search) [34].
Recentemente, os sistemas automáticos de reconhecimento de emoções baseados em ex-
tração de características têm apresentado melhorias na precisão da classificação, devido em
parte aos avanços em métodos de seleção de características. No entanto, muitos desses mé-
todos capturam apenas relações lineares ou, alternativamente, requerem o uso de dados
rotulados. Por isso, as técnicas de Deep Learning [35] têm se tornado cada vez mais popu-
lares na áreas de visão e inteligência computacional. Essas técnicas podem superar essas
limitações dos métodos baseados em extração de características através da captura explícita
de complexas interações de características não-lineares em dados multimodais. Isso vem
ocorrendo devido principalmente à descoberta recente de algoritmos de aprendizado mais
efetivos em um contexto não-supervisionado [36]. A Figura 1.1 ilustra uma comparação
entre as técnicas de reconhecimento baseadas em extração de características e as técnicas
de Deep Learning, os níveis das características são relativos às suas complexidades, desde a
detecção de curvas e linhas (nível-baixo) até a detecção de faces ou a classificação de ativi-
dades humanas (nível-alto), por exemplo.
Figura 1.1: Comparação entre técnicas padrões de reconhecimento e Deep Learning. Fonte: [1]
Nesta Tese é apresentada uma nova técnica de extração de característica, baseada em
estimação de movimento por casamento de blocos (block-matching), utilizada no reconheci-
mento padrão tradicional, obtendo taxas de reconhecimento de expressões faciais compatí-
veis com as técnicas de reconhecimento que utilizam o padrão moderno e com as técnicas

21
de Deep Learning. Contudo, com uma abordagem menos complexa.
Na fase de treinamento, o movimento entre duas expressões da mesma face (ou faces
similares) é estimado. Para cada imagem de face da base de treinamento é buscada uma
outra imagem de maior similaridade em cada expressão facial do banco de imagens (por
exemplo: raiva, nojo, medo, felicidade, tristeza, surpresa), então é calculado um vetor de
movimento entre as duas imagens.
Após o cálculo dos vetores de movimento de todas as imagens em todas as expressões,
são calculadas as coordenadas que ocorreram mais vezes nesses vetores, elas são armaze-
nadas nos chamados ’vetores de maiores ocorrências’. A fase de treinamento é encerrada
após a obtenção desses vetores. Na fase de testes, a imagem que terá a expressão facial
reconhecida é comparada com todas as imagens utilizadas no treinamento, a imagem mais
similar dentro de cada expressão facial da base, também calculada a partir da métrica SSIM,
é utilizada para o cálculo do vetor de movimento. Então, os vetores de movimento são com-
parados aos vetores de maiores ocorrências calculados para cada expressão facial durante
a fase de treinamento, a partir dessa comparação são gerados os vetores de características
usados para o reconhecimento da expressão facial.
Finalmente, foi realizada uma análise da precisão do método apresentado neste trabalho
através de diversos experimentos com cinco bases de imagens comumente utilizadas no
estado da arte: Cohn-Kanade (CK) [3], Cohn-Kanade Extendida (CK+) [4], Japanese female facial
expression (JAFFE) [2], MMI [5] e CMU Pose, Illumination, and Expression (CMU-PIE) [6]. Para
a classificação da expressão facial foi utilizada a SVM (Support Vector Machine) [37]. Os
resultados experimentais mostram a eficiência da técnica proposta, sendo compatíveis ou
superiores a trabalhos recentes da literatura.
1.2 Objetivos
O objetivo desta Tese é apresentar um novo método de extração de característica para o
reconhecimento de movimento aplicável em expressões faciais, que obtenha maiores taxas
de acertos na classificação das expressões, e que seja mais simples, em termos de implemen-
tação, do que os métodos vigentes na literatura recente.

22
1.2.1 Objetivos Específicos
• Desenvolver um extrator de características que possa ser utilizado em bases de ima-
gens estáticas e vídeos;
• Desenvolver um método capaz de ser treinado para reconhecer expressões faciais uti-
lizando algoritmos de estimação de movimentos por casamento de blocos;
• Desenvolver um método capaz de reconhecer outros tipos de movimento.
1.3 Organização da Tese
O conteúdo desta Tese está dividido em cinco capítulos. As referências encontram-se
nas páginas finais. A seguir, um resumo dos próximos capítulos:
Capítulo 2. Revisão da literatura recente na área de reconhecimento de expressões faciais,
descrevendo trabalhos de detecção de faces em imagens, extração de características e
classificadores de expressões.
Capítulo 3. Descrição da metodologia utilizada para o desenvolvimento deste trabalho.
Toda a arquitetura do processo de reconhecimento de expressões faciais é descrita de-
talhadamente, desde o pré-processamento até o processo de classificação.
Capítulo 4. Apresentação dos resultados obtidos nos experimentos realizados usando as
bases de imagens Cohn-Kanade (CK), Extended Cohn-Kanade (CK+), Japanese female facial
expression (JAFFE), MMI e CMU Pose, Illumination, and Expression (CMU-PIE). Tam-
bém são apresentados diversos dados estatísticos, como tempo de pré-processamento,
comparação de desempenho entre algoritmos diferentes de estimação de movimento,
resultados obtidos com a alteração de valores de diversos parâmetros no sistema pro-
posto, etc. Esses resultados são analisados e algumas considerações são expostas.
Capítulo 5. Discussões e conclusões obtidas dos experimentos realizados no Capítulo 4.
Também são apresentados os trabalhos futuros.

CAPÍTULO 2
REVISÃO DA LITERATURA
"Há riqueza bastante no mundo para as ne-
cessidades do homem, mas não para a sua am-
bição"
— Mahatma Gandhi
OEstudo das expressões faciais remete à era dos filósofos gregos (século IV A.C.), que
tentavam determinar a personalidade e o caráter de um indivíduo baseados na sua
aparência e visual, especialmente a partir de sua expressão facial [29].
Uma abordagem científica foi realizada por Paul Ekman [38], na década de setenta, que
realizou um estudo sobre a representação da expressão facial em diferentes culturas. Na
época, acreditava-se que as pessoas utilizavam seus músculos faciais de acordo com um
conjunto de convenções sociais e expressões aprendidas, de forma similar ao que ocorre
com os idiomas, onde cada região tem sua própria interpretação das expressões faciais. Ek-
man tirou fotos de homens e mulheres realizando diversas expressões faciais e viajou para
Brasil, Argentina e Japão com essas fotografias. Para a sua surpresa, as pessoas dos diferen-
tes países que participaram de seu experimento, concordaram com o que significava cada
uma das expressões nas fotografias. Ele então estendeu seus experimentos do mundo de-
senvolvido para as florestas em Papua-Nova Guiné, para as vilas mais remotas, e descobriu
que mesmo com os habitantes dessas vilas não havia dificuldade para identificar as expres-
sões nas fotografias. Essa descoberta foi um marco importante no estudo das expressões

24
faciais.
Outra contribuição importante do trabalho de Ekman [38] foi a criação do Facial Ac-
tion Coding System (FACS), um sistema para descrever expressões faciais humanas. É um
padrão para categorizar sistematicamente a expressão física das emoções, e tem sido útil
a psicólogos e a animadores. Usando FACS, rotuladores humanos podem manualmente
rotular quase qualquer expressão facial anatomicamente possível, desconstruindo-as em
Action Units (AU - Unidades de Ação) específicas e seus segmentos temporais que causa-
ram a expressão. Como as AUs são independentes de qualquer interpretação, elas podem
ser usadas em processos de decisões gerais incluindo reconhecimento de emoções básicas,
ou comandos pré-programados em um ambiente inteligente. O manual FACs tem mais de
1000 páginas e fornece as AUs, bem como as interpretações do Dr. Ekman do seu signi-
ficado. As AUs são utilizadas em alguns sistemas automatizados de reconhecimento de
expressões faciais [12], [13].
A necessidade de um sistema de reconhecimento de expressões faciais robusto tem se
tornado cada vez mais evidente com o avanço recente nas áreas de robótica e softwares au-
tomatizados. Os seres humanos em geral são responsivos aos estados emocionais uns dos
outros, portanto espera-se que computadores e sistemas automatizados também adquiram
essa habilidade. Através do avanço do estudo da interação homem-máquina, pesquisa-
dores têm conseguido melhorar significativamente essa interação com o uso de sensores.
Consoles de videogames como o Kinect [39] e Wii [40] podem detectar o movimento humano
e reagir de acordo, conectando os mundos físico e virtual. Sensores de detecção de sono em
automóveis podem identificar quando um motorista está sonolento e agir para reduzir o
risco de acidentes [41]. Robôs inteligentes vêm sendo desenvolvidos para fazer companhia
aos seres humanos [42]. A análise das expressões faciais é bastante útil para essas aplica-
ções.
Na Seção 2.1 é discutido o processo genérico de reconhecimento de expressões faciais
e são apresentados trabalhos e abordagens recentes sobre a análise de expressões faciais.
Na Subseção 2.1.1 são apresentadas algumas bases de imagens de faces, na Subseção 2.1.2
são apresentados alguns trabalhos sobre detecção de faces em imagens, a Subseção 2.1.3
revisa alguns trabalhos sobre extração de características e a Subseção 2.1.4 apresenta alguns
classificadores utilizados para a identificação das expressões.

25
2.1 Sistemas de Reconhecimento de Expressões Faciais
O foco de qualquer algoritmo de reconhecimento de faces é mitigar as mudanças relaci-
onadas à expressão [43]. O que pode ajudar a projetar um agente que percebe uma emoção
em uma pessoa e projeta uma expressão apropriada como resposta [44]. A habilidade de re-
conhecer o estado afetivo de um humano através de uma máquina inteligente irá capacitá-la
a interpretar, entender e responder às emoções, aos humores e às intenções, de forma similar
ao que acontece entre as pessoas [45]. O objetivo principal dos sistemas de reconhecimento
de expressões faciais é automaticamente analisar e reconhecer os movimentos faciais e as
mudanças de características faciais a partir de informações visuais [46].
Todo sistema de reconhecimento de expressões faciais deve executar alguns passos an-
tes da classificação da expressão em uma emoção específica. Primeiro é preciso definir a
base de imagens ou vídeos que será utilizada para treinar e testar o sistema. Cada base pos-
sui características específicas, como posição da face nas imagens, iluminação ambiente etc.
Um sistema de reconhecimento de expressões pode apresentar desempenhos diferentes, em
termos de precisão no reconhecimento das expressões, para cada tipo de base. Após a de-
finição da base, é preciso encontrar a face do indivíduo na imagem ou no vídeo que serve
de entrada para o sistema. Então, o sistema precisa rastrear as mudanças nos músculos fa-
ciais ou na aparência para detectar onde a expressão está sendo mostrada. Provavelmente
haverá obstáculos que podem encobrir a face parcial ou totalmente, o que dificulta tanto
o processo de localização quanto o de rastreamento da região da face onde a expressão é
mostrada. Uma vez que a face é detectada, o sistema deve procurar por características,
como lábios, sobrancelhas e movimentos das bochechas, para a classificação da expressão a
partir de características específicas que são detectadas e possa ocorrer uma decisão sobre a
emoção sendo mostrada.
Contudo, o sistema ’aprende’ a partir de uma base de imagens que é utilizada no seu
treinamento para o reconhecimento de expressões independente da idade, sexo, etnia ou
cor da pele do indivíduo. Resumidamente, os sistemas de reconhecimento de expressões
faciais podem ser divididos nos quatro módulos mostrados na Figura 2.1.

26
Figura 2.1: Um sistema genérico de reconhecimento de expressões faciais. Fonte: autor.
O sistema de reconhecimento de expressões faciais apresentado nesta Tese selecionou as
bases de imagens JAFFE, CK, CK+ e CMU-PIE e a base de vídeos MMI, conforme menci-
onado no Capítulo 1, para treinamento e testes. Para a detecção de faces nas imagens são
utilizados os filtros de correlação ASEF (Average of Synthetic Exact Filters) [27]. A técnica de
extração de características apresentada neste trabalho é baseada na mudança da aparência
da face com o movimento entre as expressões faciais, esse movimento é calculado a partir
de algoritmos de estimação por casamento de blocos. O classificador utilizado no último
módulo é o Support Vector Machine (SVM) [37].
A seguir, é apresentada a revisão da literatura para cada um dos quatro módulos do
sistema genérico mostrado na Figura 2.1.
2.1.1 Bases de Imagens de Faces
A escolha da base de imagens é uma etapa importante para o desenvolvimento de qual-
quer sistema de reconhecimento de expressões faciais. Se todos os pesquisadores pudessem
utilizar uma mesma base de imagens, tornaria mais fácil a realização de testes e compara-
ções entre os diversos sistemas desenvolvidos. Após a seleção da base, os pesquisadores
utilizam uma abordagem baseada em características para rastrear aquelas que são perma-
nentes ou transitórias. Existem rastreadores específicos para as características permanentes
da face, como olhos e lábios, por exemplo. Enquanto os métodos de detecção de bordas são
utilizados para as características transitórias da face, como as rugas, por exemplo. Entre-
tanto, tudo depende da disponibilidade de uma boa base de imagens.
A base FERET (Facial Recognition Technology) [47] é uma base de imagens de faces, divi-
dida em dois grupos: desenvolvimento e isolado. O grupo de desenvolvimento está dis-
ponível para os pesquisadores de diversas áreas e o grupo isolado é reservado para testes
de algoritmos de reconhecimento facial. O procedimento de avaliação FERET é um teste
de algoritmos de reconhecimento facial administrado de forma independente. O teste foi
desenvolvido para: (1) permitir a comparação direta entre diferentes algoritmos, (2) identi-

27
ficar as abordagens mais promissoras, (3) avaliar o estado da arte em reconhecimento facial,
(4) identificar futuras direções de pesquisa, e (5) auxiliar no avanço do estado da arte em
reconhecimento facial.
As imagens da base FERET foram coletadas em 15 sessões, entre agosto de 1993 e julho
de 1996. Ela contém 1.564 conjuntos de imagens para um total de 14.126 imagens que in-
cluem 1.199 indivíduos e 365 conjuntos duplicados de imagens. Um conjunto duplicado é o
segundo conjunto de imagens de uma pessoa que já está na base, mas teve novas fotos tira-
das em um dia diferente. Para alguns indivíduos, houve um intervalo de dois anos entre o
primeiro e o segundo conjunto de fotografias. Essa passagem de tempo foi importante pois
possibilitou aos pesquisadores, pela primeira vez, o estudo das mudanças na aparência do
indivíduo após um ano ou mais [47].
A base Japanese female facial expression (JAFFE) [2] está entre as bases de imagens de fa-
ces mais utilizadas em experimentos de sistemas de reconhecimento de expressões faciais.
Esta base possui 213 imagens de sete expressões faciais: raiva, nojo, medo, alegria, neutra,
tristeza e surpresa, com aproximadamente o mesmo número de imagens para cada catego-
ria de expressão facial. Cada imagem possui resolução de 256 × 256 pixels. Dez modelos
japonesas posaram paras as fotos, para cada uma das modelos há em média três imagens
diferentes da mesma expressão facial. Outra característica desta base é a pouca variação en-
tre as diferentes expressões faciais, o que dificulta o reconhecimento. A Figura 2.2 mostra
alguns exemplos dessa base, que foi utilizada nos experimentos do sistema proposto nesta
tese.
Outra base de imagens de expressões faciais bastante utilizada foi apresentada por Ka-
nade et al. [3]. A base foi nomeada como CMU-Pittsburgh AU-Coded Facial Expression, mas
é popularmente conhecida por Cohn-Kanade (CK). Ela foi criada para pesquisa em aná-
lise automática de faces e está disponível em duas versões. A primeira versão inclui 486
sequências de 97 indivíduos. Cada sequência começa com a expressão neutra e segue até
o ápice da expressão. Todas as sequências são codificadas de acordo com o FACS (Facial
Action Coding System) [38] e foram rotuladas com a emoção representada. Contudo, a ex-
pressão que identifica a sequência se refere à expressão que foi solicitada ao indivíduo e
não necessariamente à expressão que foi representada. As sequências de imagens partindo
da expressão neutra para a expressão-alvo foram digitalizadas em imagens com resoluções
de 640 × 480, 640 × 490 e 720 × 480 pixels, todas em níveis de cinza (ver Figura 2.3). Para

28
Figura 2.2: Faces da base de imagens JAFFE. Fonte: [2].
alguns indivíduos não há imagem para uma determinada expressão facial. A Figura 2.4
mostra alguns exemplos dessa base, utilizada nos experimentos do sistema proposto nesta
tese.
Figura 2.3: Exemplo de sequência da base CK partindo da expressão neutra (esquerda) para a expressão medo
(direita). Fonte: [3].
A base de imagens Cohn-Kanade (CK) possui ainda uma segunda versão, conhecida
como CK+ [4], que inclui tanto expressões representadas quanto expressões espontâneas.
Para as expressões representadas, o número de sequências é 22% maior do que a primeira
versão e a quantidade de indivíduos é 27% maior. Também foi representada uma expressão
facial a mais: desprezo (contempt). Na Figura 2.5 é mostrado um exemplo de sequência de
imagens para a expressão de desprezo. A base CK+ possui sequências de imagens coloridas.
Figura 2.5: Exemplo de sequência da base CK+ partindo da expressão neutra (esquerda) para a expressão de
desprezo (direita). Fonte: [4].

29
Figura 2.4: Faces da base de imagens CK. ”sem imagem” indica que o indivíduo não possui imagem para
aquela expressão na base. Fonte: [3].
A base de vídeos de expressões faciais MMI [5] é um projeto em andamento, seus ide-
alizadores têm como objetivo disponibilizar uma grande quantidade de dados visuais de
expressões faciais para a comunidade científica. A base MMI foi concebida no ano de 2002
como recurso para a construção e avaliação de algoritmos de expressões faciais, ela tenta
solucionar um problema comum às outras bases de expressões faciais que é a falta de um
padrão temporal completo das expressões, ou seja, da ausência de expressão (expressão
neutra), passando pela transição da expressão até o seu ápice, voltando novamente para
uma face sem expressão (neutra) (ver Figura 2.6).
Figura 2.6: Exemplo de sequência da base MMI partindo da expressão neutra (esquerda) para a expressão de
nojo (direita). Fonte: [5].
Enquanto as outras bases focam nas seis expressões básicas, a base MMI contém além
delas outras expressões com uma única unidade de ação (AU) FACS ativada, com todas
as AUs existentes e com muitos outros descritores de ação. Essa base é composta de 2.900
vídeos e imagens de alta resolução de 75 indivíduos. Ela é totalmente rotulada para a pre-

30
sença de AUs nos vídeos, e parcialmente codificada em nível de frame, indicando para cada
frame se uma AU está na expressão neutra, em transição ou ápice da expressão. A base MMI
está totalmente disponível para a comunidade. A Figura 2.7 mostra alguns exemplos dessa
base, também utilizada nos experimentos do sistema proposto nesta tese.
Figura 2.7: Frames da base de vídeos MMI. ”sem imagem” indica que o indivíduo não possui imagem para
aquela expressão na base. Fonte: [5].
A base de imagens CMU Pose, Illumination, and Expression (CMU-PIE) [6] possui mais
de 40.000 imagens de face de 68 pessoas. Usando o CMU (Carnegie Mellon University) 3D
Room, cada indivíduo foi fotografado em 13 poses diferentes, sob 43 condições de ilumi-
nação diferentes e com quatro expressões diferentes: neutra, sorrindo, fechando os olhos e
falando. Essas são provavelmente as quatro expressões faciais que mais ocorrem no cotidi-
ano das pessoas. As imagens da base têm resolução de 640× 486 pixels, disponibilizadas no
padrão de cores RGB. A Figura 2.8 mostra alguns exemplos dessa base, também utilizada
nos experimentos do sistema proposto nesta tese.

31
Figura 2.8: Exemplo de imagens da base CMU-PIE, da esquerda para a direita e de cima para baixo as imagens
das câmeras: 05, 07, 09, 27 e 29. Fonte: [6].
Sebe et al. [48] construíram uma base de imagens de faces com expressões espontâneas.
Eles pesquisaram sobre os principais problemas que estão associados com a captura de ex-
pressões espontâneas e observaram que as pessoas manifestam as mesmas expressões em
diferentes intensidades em diferentes ocasiões. Eles também perceberam que se as pessoas
estão cientes de que estão sendo filmadas ou fotografadas, as suas expressões perdem a
autenticidade. Então, eles propuseram uma solução: foi preparado um ambiente onde as
pessoas podiam assistir vídeos que induziam emoções. Suas expressões faciais foram fil-
madas com uma câmera escondida. Após o término da gravação as pessoas assinaram um
termo de consentimento para que seus vídeos e imagens capturados pudessem ser utiliza-
dos para propósito de pesquisa. Aqueles que assinaram o termo foram questionados sobre
qual emoção sentiram durante diversos momentos da filmagem.
Sebe et al. construíram uma grande base de imagens e vídeos de faces com os rótulos das
expressões que as pessoas vivenciaram. Contudo, eles descobriram que era muito difícil in-
duzir certas expressões, como tristeza e medo, por exemplo. Eles também obtiveram alguns
dados incorretos onde pessoas pareciam tristes, mas estavam sentindo alegria. Isso ocorreu
porque alguns filmes eram muito emotivos, mas tinham finais felizes. Curiosamente, eles
também descobriram que estudantes e jovens em geral estavam mais dispostos a dar seus
consentimentos para o uso de suas imagens em pesquisas do que professores mais velhos.
Para ilustrar a evolução das bases de imagens de faces, a Figura 2.9 mostra uma linha
do tempo com as bases citadas nesta seção. 1
1O critério para seleção das bases utilizadas nos experimentos foi a maior ocorrência nos trabalhos recentes da literatura.

32
Figura 2.9: Linha do tempo das bases de imagens de faces. As bases sublinhadas foram utilizadas nos experi-
mentos deste trabalho. Fonte: autor.
2.1.2 Detecção e Rastreamento da Face
Após a seleção da base de imagens, o primeiro passo na análise de expressões faciais é
detectar a face em uma imagem ou frame e então rastreá-la ao longo dos diferentes frames de
um vídeo. Os algoritmos de detecção e rastreamento de faces são baseados nas técnicas de
extração de características que buscam por uma determinada representação dentro de uma
imagem.
A detecção de faces possibilita a localização de faces em uma imagem arbitrária, sendo
utilizada para a detecção automática de faces em uma imagem digital ou em um frame de
um vídeo que serve como entrada em um sistema. Avanços recentes nas técnicas de pro-
cessamento de imagens tornaram possível a detecção de faces em tempo real, o que tornou
possível o seu uso em tecnologias biométricas, vídeos de vigilância e interação homem-
máquina. A detecção de faces é uma tarefa desafiadora que requer métodos de alta efici-
ência, confiáveis e rápidos. O método proposto deve ser capaz de detectar regiões da face
com um alto grau de acuracidade e erros mínimos [49]. Um sistema de detecção de faces
consiste basicamente de três fases: aquisição da imagem, pré-processamento da imagem e
classificação da imagem, como mostrado na Figura 2.10.

33
Figura 2.10: Um sistema genérico de detecção de faces. Fonte: autor.
Em 1991, Kanade e Lucas [50] apresentaram um dos métodos mais populares desenvol-
vidos para rastrear faces: o rastreador Kanade-Lucas-Tomasi. Anteriormente, Kanade e Lucas
haviam desenvolvido um algoritmo de extração de característica [51] que compara duas
imagens e assume que o segundo frame em uma sequência é uma translação do primeiro
devido à pouca variação de movimento entre os frames. Esta versão do algoritmo funcio-
nava satisfatoriamente sob supervisão humana, mas ainda ocorriam alguns erros que foram
solucionados na versão atualizada desenvolvida em [50]. O novo algoritmo funciona sem
a necessidade de supervisão, é mais rápido e simples do que a sua versão básica [51], re-
presentando a característica como uma função de três variáveis: x, y e t, onde x, y são as
coordenadas espaciais e t define o tempo. A técnica se mostrou eficiente para a determina-
ção de movimento e de forma nos experimentos realizados.
Em 2000, Kanade continuou sua pesquisa sobre métodos de detecção de objetos e pu-
blicou com Schneiderman [7] um método estatístico para detecção de objetos 3D. Eles re-
presentaram os dados estatísticos para a aparência do objeto e do ’não-objeto’ usando um
produto de histogramas, que também foram utilizados para representar uma grande va-
riedade de atributos visuais. Foram realizados experimentos para detectar faces humanas
e carros. O método proposto obteve sucesso na detecção de ambos. Kanade e Schneider-
man documentaram os desafios de detectar um objeto com características uniformes. Por
exemplo, carros têm diferentes tamanhos, formas, cores e tipos que são algumas das maio-
res diferenças e também possuem diferenças menores como tipos de faróis, luzes traseiras,
adesivos etc. De forma similar, as faces humanas também possuem diferentes atributos,
como etnia ou cor de pele. Um detector de objetos deve acumular todas essas propriedades
para ser capaz de detectar um determinado objeto em toda essa variedade de combinações.

34
Mesmo sem ser um fator de diferenciação em um objeto, o objeto a ser detectado pode pos-
suir diferentes ângulos de visualização. Por exemplo, a face humana vista de perfil ou de
frente é bastante diferente. O método apresentado por Kanade e Schneiderman lida com
isso utilizando uma abordagem baseada em visualização com vários detectores, em dife-
rentes posições, que detectam objetos em diferentes orientações.
A técnica apresentada em [7] foi capaz de detectar de 78% a 92% das faces de perfil e
95% das faces com vista frontal a partir de uma base com 208 imagens, com 441 faces, esco-
lhidas aleatoriamente na Internet. Em uma base com 213 carros e uma grande variedade de
cenários, cores, clima, condições de iluminação, tamanhos e modelos, o modelo proposto
foi capaz de detectar de 83% a 92% dos carros. A variação na detecção é baseada no parâ-
metro definido pela razão da probabilidade de uma forma detectada ser um ’não-objeto’ ou
um objeto. A Figura 2.11 mostra alguns exemplos da detecção obtida em [7].
Figura 2.11: Exemplos de detecção de faces e carros. Fonte: [7].
Em 2001, foi apresentado outro método utilizado para detecção de faces chamado mo-
delo de CANDIDE [8], que foi desenvolvido especificamente para codificação de faces hu-
manas baseada em modelo. O modelo de CANDIDE é construído usando um conjunto de
polígonos e teve a sua primeira versão apresentada no ano de 1987. Posteriormente, foram
desenvolvidos três diferentes modelos - CANDIDE 1, 2 e 3, cada um é uma atualização do
anterior, sendo o CANDIDE 3 o mais utilizado pela maioria dos pesquisadores. O CAN-
DIDE é controlado por unidades de ação global que rotacionam em três eixos e unidades
de ação local que consideram as faces com diferentes expressões. Unidade de ação é a ação

35
que pode ser realizada com um único músculo de ativação, por exemplo: fechar os olhos
ou piscar. O modelo original do CANDIDE tem 75 vértices e 100 triângulos, o CANDIDE-
1 foi atualizado para 79 vértices, 108 triângulos e 11 unidades de ação, o CANDIDE-2 foi
atualizado para 160 vértices e 238 triângulos e seis unidades de ação, ele também pode de-
tectar os ombros. A Figura 2.12 mostra os modelos de cada método (CANDIDE-1 e 2). O
CANDIDE-3 [8] introduz um novo tipo de unidade: a unidade de forma, foram definidas
12 unidades de forma, que permitem a detecção de diferentes formas de cabeças. As formas
das cabeças incluem a altura da cabeça, o tamanho dos olhos, a posição vertical dos olhos
etc. A lista completa das unidades de forma, unidades de ação, vértices, e como todos estão
relacionados com as versões anteriores do CANDIDE, pode ser encontrada em [8].
Figura 2.12: Cima: modelo do CANDIDE-1. Baixo: modelo do CANDIDE-2. Fonte: [8].
Em 2004, Viola e Jones [9] desenvolveram um método de aprendizado para detectar fa-
ces na posição frontal. Esse método é baseado no algoritmo de aprendizado AdaBoost [52]
e se mostrou veloz e preciso. Eles computaram uma nova representação de imagem cha-
mada ”imagem integral”, que permite um processamento ainda mais veloz das caracte-
rísticas usadas pelo detector apresentado, a partir de uma ’imagem-fonte’ usando poucas
operações por pixel baseadas em um conjunto de características que eles queriam detectar.
Essas características podem ser computadas em qualquer escala ou localização em tempo

36
constante. Após a detecção das características, Viola e Jones construíram uma classificador
simples e eficiente para selecionar um número pequeno de características importantes a
partir de uma grande biblioteca de potenciais características usando o AdaBoost. Entretanto,
o espaço de características era muito grande, muito maior do que o número de pixels. Para
garantir uma classificação veloz, foi proposto um processo de aprendizado que exclui a
grande maioria de características disponíveis. Foi utilizado o AdaBoost para restringir cada
classificador a depender de uma única característica. Então o processo de classificação se
tornou um processo de detecção de características visuais, que também é bastante veloz e
preciso.
Para tornar o seu método ainda mais rápido, Viola e Jones [9] combinaram classifica-
dores mais complexos em uma estrutura em cascata. Esses classificadores em sequência
aumentam a velocidade do detector focando a ’atenção’ do sistema de reconhecimento em
regiões promissoras da imagem. Por exemplo, um classificador de detecção de faces pode
facilmente filtrar 50% da imagem enquanto preserva mais de 99% das faces (de acordo com
os resultados dos experimentos realizados), assim a limitação da área para detecção de faces
torna o processo mais fácil e rápido para o sistema. No total, a cascata do método proposto
possui 38 classificadores e cada um deles é mais complexo do que o anterior. A área da ima-
gem que não for rejeitada por um classificador será analisada pelo próximo e a área que for
rejeitada não será analisada pelos demais classificadores. A classificação em cascata tornou
o detector final bastante veloz. A Figura 2.13 mostra exemplos da precisão da detecção de
faces obtida.

37
Figura 2.13: Saída do detector de Viola e Jones em algumas imagens de testes. Fonte: [9].
Em 2010, Suri e Verma [53] implementaram um detector de faces robusto com um novo
conceito chamado histogramas integrais de Haar com CMBLBP (circular multi block local bi-
nary operator). Eles propuseram uma mudança simples na regra de Haar: a definição de
uma região circular de codificação em vez de blocos de um retângulo por operador binário.
No método proposto, o valor do pixel central é subtraído do valor dos pixels da vizinhança.
Então a informação é apresentada sem perda, como uma distribuição conjunta do valor do
pixel central e as diferenças. O problema de escalonamento do LBP circular é reduzido pela
propriedade de multi bloco, o sistema pode detectar diversas estruturas na imagem (como
bordas, linhas, pontos e quinas). O detector proposto funciona em aplicações de tempo real.
Os resultados mostraram que é um detector rápido e com boa acuracidade mesmo com fa-
ces de vários tamanhos, variação de iluminação, variação de ângulo, diferentes expressões
faciais, rotação e mudança de escala.
Em 2015, Li et al. [10] apresentaram uma técnica para solucionar dois problemas con-
flitantes: o primeiro trata da detecção de faces no mundo real em imagens com variações
visuais na pose, expressão ou iluminação, utilizando um modelo discriminativo avançado
que possa distinguir de forma precisa as faces nos cenários. Consequentemente, modelos
efetivos para esse problema tendem a ser custosos computacionalmente. Para solucionar o
segundo problema, foi apresentada uma arquitetura em cascata construída em redes neu-
rais convolucionais (CNNs) com uma capacidade discriminativa poderosa, mantendo a alta

38
desempenho. A CNN em cascata proposta opera em múltiplas resoluções, rapidamente re-
jeita regiões de cenário nos estágios rápidos de baixa resolução, e cuidadosamente avalia
um número pequeno de candidatos no último estágio de alta resolução. Para aprimorar a
efetividade da localização, e reduzir o número de candidatos nos estágios finais, foi intro-
duzido um estágio com CNN baseada em calibração após cada um dos estágios de detecção
na cascata. A saída de cada estágio de calibração é usada para ajustar a posição da janela
de detecção que será a entrada do estágio seguinte. A Figura 2.14 mostra um exemplo de
como o detector CNN em cascata funciona.
Figura 2.14: Sequência de testes do descritor CNN em cascata: da esquerda pada a direita, como as janelas de
detecção são reduzidas e calibradas em cada estágio. Fonte: [10].
Para ilustrar a evolução das técnicas de detecção e rastreamento de faces, a Figura 2.15
mostra uma linha do tempo com as abordagens citadas nesta seção.
Figura 2.15: Linha do tempo das técnicas de detecção de faces. A técnica sublinhada foi utilizada nos experi-
mentos deste trabalho. Fonte: autor.
2.1.3 Extração de Características
Após a detecção da face na imagem ou vídeo, uma técnica de extração de característica
facial computa características relevantes e distintas da face com o propósito de diminuir a
quantidade de dados a serem processados. A escolha da característica a ser extraída está re-

39
lacionada à qualidade do reconhecimento e ao esforço computacional, algumas abordagens
para extrair esses pontos faciais a partir de imagens digitais e sequências de vídeos de faces
foram propostas, resultando em duas categorias de técnicas: baseadas em características
geométricas e baseadas em aparência [54].
Características Geométricas
As técnicas baseadas em características geométricas medem os deslocamentos de certas
partes da face, como sobrancelhas e cantos da boca. Os pontos de características faciais
são armazenados em um vetor de características que representa a geometria da face. As
abordagens baseadas em característica calculam a distância entre as unidades de ação fa-
ciais extraídas. As características faciais relevantes são extraídas usando posições relativas
e tamanhos dos componentes da face. Independente do tipo de característica, os sistemas
de reconhecimento de expressões faciais podem ser divididos pelo tipo de entrada que po-
dem ser imagens estáticas ou sequências de imagens. A principal atribuição da medição
de características geométricas é a análise da região facial, particularmente encontrando e
rastreando pontos cruciais na região da face [54]. A seguir, são citados alguns trabalhos do
estado da arte sobre técnicas baseadas em características geométricas.
Em 1992, uma tecnologia de reconhecimento de expressões faciais em tempo real é apre-
sentada no método de Kobayashi e Hara [11]. Uma câmera dentro de olho esquerdo de um
robô é posicionada a um metro de distância do indivíduo, capturando a imagem da face
do mesmo. O principal objetivo do trabalho de Kobayashi e Hara foi o desenvolvimento
de tecnologias de reconhecimento de expressões faciais em tempo real e a reprodução des-
sas expressões faciais em um robô. Primeiramente, a íris deve ser detectada na imagem.
A posição de cada íris é encontrada na face da imagem usando uma técnica de correlação
cruzada de distribuição de brilho, como se pode visualizar na Figura 2.16.
Figura 2.16: Distribuição de brilho ao longo de uma linha vertical cruzando a íris. Fonte: [11].

40
Kobayashi e Hara utilizaram uma técnica de distribuição de brilho para encontrar a
informação facial. Os movimentos dos FCPs (Facial Characteristics Points) mostram as mu-
danças nas linhas de borda das expressões faciais. Portanto, foi definida a distribuição de
brilho de 13 linhas verticais passando por esses pontos FCP. Esses pontos foram definidos
como sobrancelhas, olhos e boca, como pode ser visto na Figura 2.17. As faces foram nor-
malizadas a fim de compensar a diferença no tamanho de cada face, fazendo com que a
distância entre os centros das íris ficasse em 20 pixels. Com os valores da distância entre os
olhos e a posição central das íris obtidos, o tamanho das linhas verticais foi definido empiri-
camente, a fim de enquadrar as regiões das sobrancelhas, olhos e boca. Com as informações
da face coletadas, uma rede neural com aprendizagem back-propagation foi utilizada para o
treinamento. Utilizou-se um banco de 30 indivíduos com imagens recortadas na face nor-
mal (sem expressão ou neutra) e nas outras expressões faciais. Dos 30 indivíduos, 15 foram
usados como treinamento. O reconhecimento em tempo real é feito iniciando a imagem
na expressão normal e finalizando em uma das seis expressões básicas (feliz, triste, raiva,
medo, surpreso, nojo). O resultado do reconhecimento chegou a uma taxa média de 85,0%.
Figura 2.17: 13 linhas verticais para obtenção das informações faciais. Fonte: [11].
Em 2001, Tian et al. [12] desenvolveram um sistema para analisar expressões baseado nas
características permanentes e transitórias da face. O sistema pode reconhecer seis unidades
de ação da parte superior da face e dez unidades de ação da parte inferior com mais de 96%
de taxa de acerto. O sistema proposto não necessita de alinhamento das imagens e pode
lidar com movimentos da cabeça. Para o sistema de reconhecimento de características, foi
desenvolvido um modelo componente multi-estados da face, por exemplo: um modelo de

41
lábios de três estados pode descrever o estado de lábios abertos, o estado de lábios fechados
ou o estado de lábios cerrados. Similarmente, olhos, testa, bochechas, todos têm diferentes
modelos multi-estados. A Figura 2.18 mostra alguns exemplos de modelos para o lábio
e o olho. Para características transitórias, rugas, por exemplo, é utilizado um detector de
bordas em uma região determinada. O sistema foi testado com a base Cohn-Kanade [3].
Figura 2.18: Modelos de componentes faciais multi-estado de uma face na posição frontal. Fonte: [12].
Em 2004, o método de Pantic [13] define um modelo de face baseado em pontos com-
posto de duas visões faciais, a visão frontal e a visão lateral. Os modelos de visão frontal e
lateral, quando considerados separadamente, não possuem informações redundantes sobre
as características faciais. Contudo, quando utilizados de forma conjugada, eles revelam in-
formações redundantes sobre a expressão facial. As características definidas pelos modelos
frontal e lateral são extraídas automaticamente. As deformações das características ocorri-
das no modelo frontal revelam mudanças na aparência dos olhos, sobrancelhas, nariz, boca
e queixo. Já as deformações ocorridas no modelo lateral revelam mudanças na aparência
da testa, nariz, boca, mandíbula e queixo. É possível estabelecer relações únicas entre as
características dos modelos e as unidades de ação (AUs). O modelo de face de visão fron-

42
tal é composto de 30 características, sendo 25 delas definidas em correspondência com um
conjunto de 19 pontos faciais e o resto são algumas formas específicas da boca e do queixo.
O modelo de face lateral é composto de 10 pontos de perfil. Esses pontos correspondem aos
picos e vales da curvatura da função de contorno do perfil. Os modelos frontal e lateral são
mostrados na Figura 2.19.
Figura 2.19: Pontos faciais na visão frontal (esquerda) e na visão lateral (direita). Fonte: [13].
A fase de classificação do método de Pantic [13] é feita comparando as descrições das
AUs codificadas da expressão mostrada a cada uma das descrições das AUs da expressão
que caracteriza uma categoria específica de emoção. A taxa média de acerto do método é
de 86%.
Em 2008, o trabalho de Koutlas e Dimitrios [14] investigou o despenho do Banco de Fil-
tros de Gabor multi-escala e multi-orientação construído de forma a evitar informação re-
dundante. Uma abordagem baseada em região foi empregada usando tamanhos diferentes
de vizinhança nas localização dos 34 pontos fiduciais. Além disso, um conjunto reduzido
de 19 pontos fiduciais foi usado para modelar a geometria da face. O uso de PCA (Principal
Component Analysis) foi avaliado. A metodologia proposta foi avaliada a partir da classifi-
cação das seis emoções básicas propostas por Ekman [38], considerando a expressão neutra
como a sétima emoção.

43
Figura 2.20: Posições típicas dos pontos fiduciais: (a) 34 pontos (b) 19 pontos. Fonte: [14].
Os autores utilizaram a base JAFFE [2] para os experimentos do método proposto. Con-
siderando as seis expressões básicas, a taxa média de acerto obtida foi de 92,3% usando
34 pontos fiduciais e de 90,1% usando 19 pontos fiduciais. Quando a expressão neutra foi
incluída, as taxas caíram para 87,8% usando 34 pontos fiduciais e 86,9% usando 19 pontos
fiduciais.
Em 2010, os autores em [15] apresentaram um sistema que utiliza 28 pontos-chave de
características faciais em detecção de imagens e filtros Gabor Wavelet com cinco frequências
e oito orientações. Os pontos-chave faciais são caraterísticas importantes para um número
de tarefas diferentes no reconhecimento automático de expressões faciais. Esses pontos
são usados para derivar as outras características faciais. Os modelos de forma mostrados
na Figura 2.21 são usados para relacionar as características faciais para cara conjunto de
pontos-chave. Existem quatro pontos na testa, seis pontos na sobrancelha, seis pontos no
olho, três pontos no nariz, oito pontos na boca e um ponto no queixo. Consequentemente,
as posições detectadas na imagem podem ser usadas para dividir a face em 28 regiões onde
cada um dos pontos pode ser localizado.
Figura 2.21: Modelo dos pontos-chave faciais. Fonte: [15].

44
Os filtros de Gabor podem ser usados para reconhecimento de objetos e de expressões
faciais. No trabalho de Ou et al. [15] os filtros foram aplicados a vários problemas de re-
conhecimento de imagens para extração de características devido às suas propriedades de
localização nos domínios espacial e de frequência. Para testar o método proposto, foi utili-
zada a base Cohn-Kanade [3] e as seis expressões faciais básicas: raiva, medo, nojo, alegria,
tristeza e surpresa. A taxa média de acerto foi de 80%.
Em 2011, os autores em [16] utilizaram análise quantitativa para encontrar as caracte-
rísticas de movimento mais efetivas entre os pontos de características faciais selecionados,
a Figura 2.22 mostra alguns dos pontos selecionados. As características são extraídas com
base em estudos psicológicos e também em métodos quantitativos para melhorar a precisão
dos reconhecimentos. A normalização das faces é uma etapa importante, pois é onde ocorre
a remoção do efeito de distância do objeto a partir da câmera e os movimentos rígidos da
cabeça do indivíduo. A distância entre os cantos dos olhos é definida como o parâmetro
principal de medida. Portanto, todos os pontos de características são normalizados ba-
seados nessa distância. Além disso, o modelo proposto utiliza lógica fuzzy e algoritmos
genéticos para classificar as expressões. Os algoritmos genéticos são um atributo exclusivo
do modelo proposto, eles são usados para funções de pertinência e aumento da precisão.
Figura 2.22: (a) Características extraídas dos olhos, das sobrancelhas e do queixo (b) Características extraídas
da boca e dos lábios. Fonte: [16].
Em 2014, os autores em [17] apresentaram uma nova técnica multi-view de reconheci-
mento de expressões faciais. Nessa abordagem, cada imagem de face é dividida em um
conjunto de sub-regiões, como mostrado na Figura 2.23, a extração de características é rea-

45
lizada em cada uma dessas sub-regiões. Para gerenciar as expressões, a estratégia proposta
usa um novo modelo Group Sparse Reduced-Rank Regression (GSRRR) para descrever o rela-
cionamento entre vetores faciais multi-view e o rótulo do vetor de classificação da expressão.
Para resolver o problema de otimização do GSRRR um algoritmo efetivo é proposto utili-
zando a abordagem do Augmented Legrangian Multiplier (ALM) [17].
Figura 2.23: Um exemplo do método de particionamento de regiões faciais: a imagem da face dividida em 1, 4,
16 e 64 sub-regiões faciais. Fonte: [17].
Para testar o método proposto, foi utilizada a base CMU-PIE [6]. Para cada indivíduo da
base, existem seis expressões faciais: nojo, neutra, grito, sorriso, olhos cerrados e surpresa.
Para cada indivíduo, foram consideradas sete visualizações para os experimentos: 0º, 15º,
30º, 45º, 60º, 75º e 90º. A taxa média de acerto foi de 81,7%.
Em 2016, Zheng et al. [18] propuseram um novo método de aprendizado transdutivo
de transferência subespaço, onde um conjunto de imagens de face rotuladas de um do-
mínio fonte são combinadas com um conjunto de imagens de faces auxiliares sem rótulos
do domínio alvo para aprender em conjunto um subespaço discriminativo e fazer a predi-
ção dos rótulos das classes de imagens faciais sem rótulos, onde um modelo de regressão
de mínimos quadrados regularizados transdutivo de transferência (TTRLSR - transductive
transfer regularized least-squares regression) é proposto para este fim. Então, baseado no con-
junto de imagens faciais auxiliares, um classificador SVM (Support Vector Machine) [37] foi
treinado para a classificação de expressões de outras imagens faciais no domínio alvo. Além
disso, foi investigado o uso de cores de características faciais para avaliar a desempenho do
reconhecimento do método de reconhecimento de expressões faciais proposto, onde carac-

46
terísticas de CSIFT (color scale invariant feature transform) associadas com 49 pontos faciais de
referência são extraídas para descrever cada cor da imagem de face. A Figura 2.24 mostra
a localização dos pontos em uma imagem de face.
Figura 2.24: Exemplo de 49 pontos faciais de referência localizados por ASM (active shape model). Fonte: [18].
Finalmente, foram realizados experimentos nas bases de expressões faciais BU-3DFE
[55] e CMU-PIE [6] para avaliar a desempenho do reconhecimento de expressões, cruzando
as bases e as posições da face, do método proposto.
Para ilustrar a evolução das técnicas de extração baseadas em características geométri-
cas, a Figura 2.25 mostra uma linha do tempo com as abordagens citadas nesta seção.
Figura 2.25: Linha do tempo das técnicas de extração baseadas em características geométricas. Fonte: autor.
Características de Aparência
As técnicas baseadas em características de aparência descrevem a mudança na textura
da face, quando uma ação particular é realizada, como protuberâncias, testa, rugas, regiões
ao redor dos olhos e da boca. Esse tipo de técnica utiliza toda a região da face usando trans-
formações e abordagens estatísticas para encontrar os vetores de características básicas que

47
representam a face [54]. A seguir, são citadas algumas técnicas baseadas em características
de aparência.
Em 2006, Lin [19] propôs uma modificação do método PCA (Principal Component Analy-
sis) [56] para realizar o reconhecimento de expressões faciais. Um framework de uma rede
HRBFN (hierarchical radial basis function network) também é proposto para classificar as ex-
pressões faciais baseado na extração de características locais, usando a técnica PCA, dos
lábios e olhos das imagens. Os dados obtidos são decompostos em conjuntos pequenos de
características. O objetivo do trabalho proposto foi desenvolver uma abordagem mais efici-
ente para identificar a expressão correta para a imagem em análise entre as sete expressões
faciais básicas (felicidade, raiva, surpresa, medo, nojo, tristeza e neutra). O desempenho do
sistema desenvolvido foi avaliada na base de imagens faciais pública JAFFE [2]. A Figura
2.26 mostra exemplos de imagens da base e características extraídas.
Figura 2.26: Amostras de imagens extraídas da base de imagens JAFFE e respectivas características extraídas
(olhos e boca). Fonte: [19].
Foi concluído que imagens locais de lábios e olhos podem ser tratadas como pistas para
as expressões faciais. Nos experimentos realizados para o método proposto, a taxa média
de acerto obtida foi de 92,09% quando usadas apenas as características de olhos e lábios, e
82,73% quando usado apenas um estágio da HRBFN.
Em 2007, Yang et al. [20] apresentaram uma nova abordagem de unidades de ação fa-
ciais (AUs) e reconhecimento de expressões baseada em características dinâmicas codifica-

48
das. Para capturar as características dinâmicas dos eventos faciais, as características harr-
like dinâmicas foram projetadas para representar as variações temporais dos eventos faciais.
Além disso, as características faciais harr-like dinâmicas foram codificadas em característi-
cas de padrão binário, que são úteis para construir classificadores fracos para impulsionar
a aprendizagem. Por fim, o Adaboost é executado para aprender um conjunto de caracterís-
ticas dinâmicas codificadas discriminantes para unidades de ação faciais e reconhecimento
de expressões faciais. Portanto, o framework proposto tem três componentes: extração de ca-
racterísticas dinâmicas, codificação de características dinâmicas e aprendizado Adaboosting.
Figura 2.27: Exemplo de características Haar-like sobrepostas em uma imagem de face. Fonte: [20].
O método proposto teve a sua eficiência avaliada através de experimentos que foram re-
alizados na base de imagens Cohn-Kanade Facial Expression (CK) [3], a taxa média de acertos
foi de 96,62% para seis classes de expressões: raiva, medo, alegria, nojo, tristeza e surpresa.
Em 2009, Shan et al. [21] apresentaram um trabalho onde de forma empírica avaliaram a
representação facial baseada em estatísticas de características locais, LBP (Local Binary Pat-
terns), para o reconhecimento de expressões faciais independente de pessoa. Métodos dife-
rentes de aprendizagem de máquina foram examinados em algumas bases de imagens. Os
diversos experimentos mostraram que as características LBP são efetivas e eficientes para
o reconhecimento de expressões faciais. Também foi formulado o Boosted-LBP para extrair
as características LBP mais discriminantes, a melhor desempenho de reconhecimento foi
obtida usando os classificadores SVM (Support Vector Machine) [37] com as características
Boosted-LBP. Além disso, foram investigadas as características LBP para reconhecimento de
expressões faciais em baixa resolução, que é um problema crítico mas raramente investi-
gado nos trabalhos existentes.
A correlação de templates foi utilizada para classificar as expressões faciais devido à
simplicidade da técnica. No treinamento, os histogramas das imagens de expressões em
uma determinada classe foram usadas para o cálculo de uma imagem média, que serviu

49
de template para essa classe. Foi observado que algumas regiões locais da face contém mais
informações relevantes para a classificação da expressão do que outras. Por exemplo, ca-
racterísticas faciais que contribuem mais para expressões faciais se concentram nas regiões
dos olhos e boca. Portanto, um peso pode ser definido para cada sub-região baseado em
sua importância. O conjunto de pesos que foi utilizado no método proposto é mostrado
na Figura 2.28, os pesos foram definido de forma empírica, baseados em observação dos
experimentos.
Figura 2.28: (Esquerda) Uma face dividida em 6 × 7 sub-regiões. (Direita) Quadrados pretos indicam peso 0,
cinza escuros 1, cinza claros 2 e brancos 4. Fonte: [21].
As características LBP obtiveram desempenho estável e robusto em várias imagens de
baixa resolução, e tiveram um desempenho promissor em sequências de vídeos comprimi-
das de baixa resolução capturadas em ambientes do mundo real. O método proposto foi
aplicado para o reconhecimento de seis e sete classes na base Cohn-Kanade Facial Expres-
sion (CK) [3], obtendo taxas médias de acerto de 84,5% e 79,1%, respectivamente. As bases
MMI [5] e JAFFE [2] também foram usadas nos experimentos, obtendo taxas médias de
acerto de 86,9% e 81%, respectivamente, em ambas as expressões foram classificadas em
sete classes.
Em 2011, os Thai et al. [22] propuseram uma nova abordagem para o reconhecimento de
expressões faciais usando Canny, PCA (Principal Component Analysis) e RNA (Redes Neurais
Artificiais). Primeiramente, na fase de pré-processamento, Canny é usado para detecção da
região local nas imagens de faces, como mostrado na Figura 2.29. Então cada característica
de região local será baseada no PCA. Na última etapa do método, uma RNA é aplicada para
a classificação da expressão facial.

50
Figura 2.29: Resultados da detecção de bordas usando o algoritmo de Canny. Fonte: [22].
O método proposto foi aplicado para o reconhecimento das seis expressões básicas na
base de imagens JAFFE [2]. A taxa média de acerto foi de 85,7%.
Em 2012, Castillo et al. [23] propuseram um novo descritor de características: o Padrão
Direcional de Sinal Local (LSDP - Local Sign Directional Pattern), para reconhecimento de
expressões. O método LSDP codifica a informação direcional das texturas da face, isto é, a
estrutura da textura, em uma forma compacta, produzindo um código mais discriminante
do que outros métodos do estado da arte. A estrutura de cada micro-padrão é codificada
usando suas direções e sinal proeminentes, o que permite distinguir entre padrões de estru-
turas similares que têm diferentes transições de intensidade. Para tal, a face é dividida em
regiões, a partir das quais são extraídas distribuições de características LSDP. Essas carac-
terísticas são concatenadas em um vetor de características e usadas como um descritor de
face. Cada face é representada por um histograma LSDP, como mostrado na Figura 2.30.
Figura 2.30: Descritor de face LSDP. Fonte da Imagem: [23]
O método proposto teve a sua eficiência avaliada através de experimentos que foram re-
alizados nas bases de imagens CK [3] e JAFFE [2]. Como classificador para reconhecimento
da expressão facial, foi adotada a SVM (Support Vector Machine). Na base CK, a taxa média
de acertos foi de 94, 8%± 3, 1% para sete classes de expressões, e de 99, 2%± 0, 8% para seis
classes de expressões. Na base JAFFE, a taxa média de acertos foi de 89, 2% ± 2, 8% para
sete classes de expressões, e de 92, 3%± 1, 6% para seis classes de expressões.

51
Em 2013, Chakrabarti e Dutta [57] apresentaram um método para o reconhecimento de
expressões faciais chamado Eigenspace [58] que é uma modificação da abordagem original
do Eigenface [56]. Ele começa a partir da visão humana como ponto de referência padrão,
fazendo uso da base de imagens JAFFE [2], e identifica a expressão mostrada por uma face
em uma imagem de teste. Para demonstrar a viabilidade do uso de Eigenspaces para o re-
conhecimento de expressões faciais, o método de reconstrução PCA [19] foi utilizado com
o método snapsort para reduzir a dimensionalidade. As imagens da base foram divididas
em seis classes baseadas nas seis expressões faciais universais que elas representam e então
o Eigenspace de cada classe foi calculado. A imagem de teste foi projetada no Eigenspace
de cada classe, uma de cada vez. Então a distância Euclidiana/similaridade do Eigenspace
de cada imagem de teste projetada com o Eigenspace de cada uma das expressões da base.
A imagem de teste é classificada como pertencendo à classe com a qual apresenta a maior
similaridade. Antes de iniciar a entrada das imagens de treino e testes para a reconstrução
PCA, a parte facial da imagem é extraída deixando de fora as partes marginais da face, como
cabelo, ouvidos, etc. Isso reduz as partes irrelevantes da imagem da face que não represen-
tam nenhuma expressão e também compensam os movimentos da cabeça do indivíduo na
imagem.
No método original Eigenface, a face média de cada classe é determinada e cada imagem
de teste é comparada com essas faces médias. Essa abordagem apresentou uma taxa média
de acerto de 65,8% que é menor do que a taxa do método modificado proposto Eigenspace,
onde a taxa média de acerto é de 84,16%.
Em 2014, os autores em [24] apresentaram algoritmos baseados em características lo-
cais que exploram a forma como um localizador de ponto-chave extrai pontos relevantes
na região da face e como descritores de superfícies locais multi-escala podem separar par-
ticularidades ao redor dos pontos-chaves localizados. A transformada discreta de curvelet
decompõe cada imagem em um conjunto de frequências e partes de decomposição de ân-
gulos, como mostra a Figura 2.31. Para isso ocorrer, o coeficiente de curvelet é determinado
usando Fast Discrete Curvelet Transform (FDCT), a equação utilizada é mostrada em [24].
Então, um conjunto de ’chaves-foco’ são obtidas. Por meio de contraste das chaves-foco
no conjunto, pontos-chaves dominantes são escolhidos com foco ao redor da magnitude
dos componentes de decomposição. Uma vez que os pontos chaves dominantes são reco-
nhecidos, os descritores de superfícies locais multi-escala são separados ao redor de cada

52
ponto-chave. O passo principal é extrair os sub patches. Testes demonstraram que sub patches
com dimensões 5 × 5 são ideais. Os patches são reorganizados utilizando trocas circulares.
Finalmente, um vetor de características é gerado.
Figura 2.31: Ilustração de uma decomposição 4 escalas de Curvelet. Fonte da Imagem: [24]
O método proposto foi aplicado para o reconhecimento nas bases de imagens FRGC
v2 [59], que possui scans de faces 3D, e BU-3DFE [55], obtendo taxas médias de acerto de
97,83% e 98,21%, respectivamente.
Em 2015, Ahmed et al. [25] apresentaram um novo método para o reconhecimento de
expressões faciais que utiliza descrição de imagem local específica para plano de bits em
uma fusão de nível de pontuação ponderada. A motivação é utilizar uma parte do plano
de bits para destacar a sua contribuição particular para a aparência holística da face, que
é então usada em uma fusão de nível de pontuação ponderada para impulsionar a desem-
penho do reconhecimento. Um exemplo de representações de planos de bits é mostrado
na Figura 2.32. Um novo descritor de imagem local é proposto especificamente para ex-
trair as características locais das representações do bit plano de bits, esse descritor utiliza
discriminante linear de Fisher para maximizar a distância interclasse, enquanto minimiza a
variância intraclasse.

53
O método de reconhecimento de expressões faciais proposto em [25] possui sete eta-
pas. Primeiramente, é aplicado o algoritmo Viola-Jones [9] para detectar as faces em uma
imagem e as faces detectadas são então recortadas das imagens originais. Então, um par-
ticionamento é aplicado para obter os planos de bits a partir das imagens de faces recorta-
das. A codificação de imagem local LBP-like proposta é aplicada para cada plano de bit e
descritores de característica individual são obtidos. Esses descritores de características são
utilizados em uma fusão de nível de pontuação ponderada para a decisão final.
Figura 2.32: Representações de planos de bits de imagem de face. Fonte da Imagem: [25]
O método proposto foi aplicado para o reconhecimento de seis classes nas bases JAFFE
[2] e CK [3], obtendo taxas médias de acerto de 90% e 94%, respectivamente.
Para ilustrar a evolução das técnicas de extração de características de aparência, a Figura
2.33 mostra uma linha do tempo com as abordagens citadas nesta seção.

54
Figura 2.33: Linha do tempo das técnicas de extração de características de aparência. Fonte: autor.
2.1.4 Classificação
Após os processos de detecção da face e extração de características acontece a última
etapa do sistema de reconhecimento de expressões faciais: a classificação. Nesta etapa as
características extraídas são classificadas em expressões específicas. A seguir, são citados
alguns trabalhos do estado da arte sobre classificadores utilizados no reconhecimento de
expressões faciais.
Em 2003, Cohen et al. [60] introduziram um sistema de reconhecimento de expressões
faciais, em vídeos ao vivo, baseado em classificadores Bayesianos [61] e no Modelo Oculto
de Markov [62], portanto o sistema foi testado com dois tipo de classificadores: estáticos
e dinâmicos. Os classificadores estáticos, isto é, Naive-Bayes e Naive-Bayes Aumentado em
Árvore, classificam um frame em uma categoria de expressão facial dependendo dos resul-
tados obtidos apenas do próprio frame. Contudo, os classificadores dinâmicos, baseados
no Hidden Markov Model (HMM), consideram o padrão temporal entre os frames. A razão
da escolha dos classificadores Bayesianos para análise estática ocorreu porque eles podem
lidar com dados perdidos durante o treinamento.
Entre os classificadores estáticos, o Naive-Bayes assume que todas as características são
condicionalmente independentes. Já no classificador Naive-Bayes Aumentado em Árvore,
cada característica tem um ’pai’ resultando em uma estrutura baseada em árvore. Por exem-
plo, em um texto em inglês após a palavra ”thank” a probabilidade de aparecer a palavra
”you” é maior do que outras palavras, mas os classificadores Naive-Bayes não consideram
essa probabilidade. Cohen et al. [60] perceberam que essa propriedade também é aplicável
a sistemas de reconhecimento de expressões faciais. Eles identificaram que o classificador

55
Naive-Bayes Aumentado em Árvore tinha um melhor desempenho em termos de precisão
na classificação. Para a estrutura da árvore, eles desenvolveram um algoritmo que gera
uma estrutura otimizada. Os classificadores usam esse algoritmo e selecionam a melhor es-
trutura entre todas que obtêm a valor máximo em uma função de similaridade. Entretanto,
se a base de imagens é consideravelmente pequena, o classificador Naive-Bayes funcionará
melhor do que o baseado em árvore porque não haverá dados suficientes disponíveis para
o classificador baseado em árvore buscar pela relação de dependência ’pai-filho’. Para os
classificadores dinâmicos, Cohen et al. desenvolveram um classificador HMM que usa a
informação temporal para obter melhores resultados de classificação. Finalmente, eles in-
tegraram esses classificadores para construir um sistema de reconhecimento de expressões
faciais em tempo real.
Em 2005, Bartlett et al. [26] desenvolveram um sistema automático e em tempo-real que
pode identificar sete emoções e até 17 unidades de ação (AUs). Eles propuseram um sistema
baseado em aprendizagem de máquina que obteve os melhores resultados usando um sub-
conjunto de filtros de Gabor com AdaBoost e então treinaram os classificadores baseados em
Support Vector Machine (SVM) com as saídas dos filtros do AdaBoost. A representação Ga-
bor Wavelet das imagens são custosas tanto em tempo quanto em consumo de memória. A
extração de características foi realizada pelo AdaBoost que usa filtros de Gabor como clas-
sificadores. O AdaBoost seleciona o próximo filtro baseado nos erros do filtro anterior. Ele
tenta escolher o filtro que obterá a melhor desempenho a partir do erro dos filtros anteri-
ores. Bartlett et al. também treinaram outros dois tipos de classificadores - Support Vector
Machine e Linear Discriminant Analysis. Esses classificadores foram treinados nas caracterís-
ticas selecionadas pelo AdaBoost. A partir dos resultados experimentais foi observado que o
AdaBoost obteve melhor desempenho com os classificadores SVM. O sistema proposto clas-
sifica 17 unidades de ação, ocorrendo isoladamente ou em combinação com outras ações,
com uma taxa média de acerto de 94,8%. Um exemplo de classificação das unidades de ação
é mostrado na Figura 2.34.
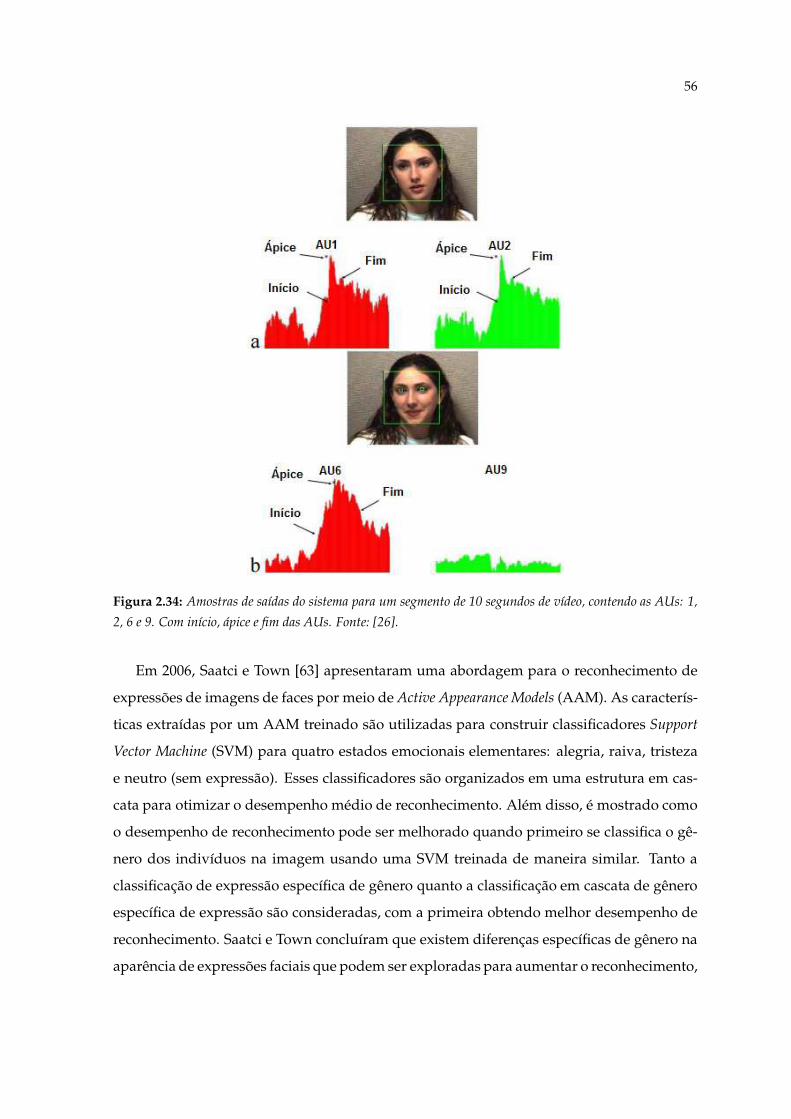
56
Figura 2.34: Amostras de saídas do sistema para um segmento de 10 segundos de vídeo, contendo as AUs: 1,
2, 6 e 9. Com início, ápice e fim das AUs. Fonte: [26].
Em 2006, Saatci e Town [63] apresentaram uma abordagem para o reconhecimento de
expressões de imagens de faces por meio de Active Appearance Models (AAM). As caracterís-
ticas extraídas por um AAM treinado são utilizadas para construir classificadores Support
Vector Machine (SVM) para quatro estados emocionais elementares: alegria, raiva, tristeza
e neutro (sem expressão). Esses classificadores são organizados em uma estrutura em cas-
cata para otimizar o desempenho médio de reconhecimento. Além disso, é mostrado como
o desempenho de reconhecimento pode ser melhorado quando primeiro se classifica o gê-
nero dos indivíduos na imagem usando uma SVM treinada de maneira similar. Tanto a
classificação de expressão específica de gênero quanto a classificação em cascata de gênero
específica de expressão são consideradas, com a primeira obtendo melhor desempenho de
reconhecimento. Saatci e Town concluíram que existem diferenças específicas de gênero na
aparência de expressões faciais que podem ser exploradas para aumentar o reconhecimento,

57
e que cascatas são uma forma eficiente e efetiva de realizar o reconhecimento multi-classe
de expressões faciais.
Em 2008, Wen e Zhan [64] estudaram os classificadores Hidden Markov Model (HMM) e
K Nearest Neighbor (KNN) e realizaram uma combinação de ambos para o reconhecimento
de expressões faciais. Eles propuseram utilizar os classificadores HMM e KNN em série.
Primeiro, um classificador Double Hidden Markov Model (DHMM) é usado para calcular as
probabilidades de seis expressões. Então, se baseando nos dois resultados mais possíveis
de classificação por DHMM, o classificador KNN é utilizado para realizar a decisão final
enquanto a diferença entre a maior probabilidade e a segunda maior é maior do que a di-
ferença média. Os experimentos mostraram que o desempenho deste método é superior ao
método baseado apenas em HMM.
Em 2011, Meng et al. [65] apresentaram um sistema para classificar expressões faciais em
vídeos. Primeiramente, dois tipos de descritores básicos de aparência facial são extraídos.
O primeiro tipo de descritor, chamado Motion History Histogram (MHH), é utilizado para
detectar mudanças temporais de cada pixel da face. O segundo tipo de descritor, chamado
Histogram of Local Binary Patterns (LBP), é aplicado para cada frame do vídeo e então usado
para capturar os padrões de textura local. Em segundo lugar, a partir desses dois tipos de
descritores, duas novas características dinâmicas de expressões faciais são propostas. Essas
duas características incorporam ambas as informações: dinâmica e local. Finalmente, o clas-
sificador Two View SVK 2K foi construído para integrar essas duas características dinâmicas
de forma eficiente. Os resultados experimentais mostraram que esse método superou os re-
sultados do trabalho base apresentado no FG 2011 Facial Expression Recognition and Analysis
Challenge (FERA2011) [66].
Em 2014, Song et al. [67] desenvolveram um método para o reconhecimento de expres-
sões faciais em tempo real para smartphones. Eles treinaram uma rede neural convolucional
profunda em uma GPU (Graphics Processing Unit) para classificar expressões faciais. A rede
tem 65.000 neurônios e consiste de 5 camadas. Uma rede deste tamanho apresenta uma
sobrecarga substancial, em termos de número de operações, quando quantidade de exem-
plos de treinamento é pequena. Para combater essa sobrecarga, foi aplicado o aumento de
dados e uma técnica recentemente introduzida na literatura chamada "dropout". Com a rede
treinada, foi desenvolvido uma aplicativo de smatphone que reconhece a expressão facial do
usuário.

58
Em 2015, Li et al. [68] propuseram uma abordagem baseada em deep-learning para o re-
conhecimento de expressões faciais em imagens espontâneas, usando Redes Neurais Con-
volucionais (Convolutional Neural Networks - CNNs). Para avaliar o desempenho da técnica
no reconhecimento de expressões faciais espontâneas em tempo real, Li et al. criaram um
banco de imagens de expressões faciais (Candid Image Facial Expression - CIFE), com sete
tipos de expressões em mais de 10.000 imagens obtidas na Internet. Foram testadas duas
abordagens baseadas em características na base de imagens: Local Binary Pattern (LBP) +
Support Vector Machine (SVM) e Scale-Invariant Feature Transform (SIFT) + SVM. Uma técnica
de aumento da quantidade de dados também é proposta com o objetivo de gerar uma quan-
tidade suficiente de amostras de treinamento. Os experimentos realizados mostraram que
o desempenho usando as abordagens baseadas em características é próximo ao estado da
arte quando testado com as bases de dados padrão, mas falha quando tem que lidar com
imagens espontâneas. Entretanto, a abordagem baseada em CNN é muito efetiva no reco-
nhecimento de expressões em imagens espontâneas, sendo superior de forma significativa
a outras abordagens da literatura.
Em 2016, Nomiya et al. [69] também se preocuparam com o reconhecimento de expres-
sões faciais em imagens espontâneas para aplicações que não lidam apenas com as seis
expressões faciais básicas. Então, eles propuseram um método efetivo para o reconheci-
mento de expressões faciais espontâneas utilizando o "aprendizado combinado", ou seja
uma combinação de classificadores Naive Bayes. Além disso, Nomiya et al. também pro-
põem um método para estimar a intensidade das expressões usando os resultados dos clas-
sificadores. Para estimar essa intensidade é utilizado o peso de cada classificador usado
na votação ponderada. O que significa que não é necessário aumento no custo computa-
cional para estimar a intensidade das expressões faciais. Nomiya et al. conduziram vários
experimentos para avaliar o método proposto com foco na acurácia e na eficiência do reco-
nhecimento das expressões e na estimação da intensidade das expressões faciais. Uma base
de imagens composta de vários vídeos de expressões faciais espontâneas foi utilizada nos
experimentos.
Para ilustrar a evolução das técnicas de classificação utilizadas no reconhecimento de
expressões faciais, a Figura 2.35 mostra uma linha do tempo com os trabalhos citados nesta
seção.

59
Figura 2.35: Linha do tempo das técnicas de classificação utilizadas no reconhecimento de expressões faciais.
O trabalho sublinhado descreve o classificador utilizado nos experimentos desta tese. Fonte: autor.

CAPÍTULO 3
MÉTODO
"Sei que o meu trabalho é uma gota no oceano,
mas sem ela o oceano seria menor."
— Madre Teresa de Calcutá
NEste trabalho é proposto um extrator de características, baseado na estimação de mo-
vimento por casamento de blocos, para o reconhecimento de expressões faciais. O
sistema proposto codifica a informação da direção do movimento da expressão facial. Esse
movimento é codificado a partir da diferença entre duas imagens (similares) de expressões
faciais.
Na fase de treinamento, o movimento entre duas expressões da mesma face (ou faces si-
milares) é estimado, a similaridade é calculada utilizando a métrica SSIM (Structural Simila-
rity Index) [70], descrita em detalhes na Seção 3.2. Para cada imagem de face do treinamento
é realizada uma busca por uma outra imagem de maior similaridade em cada expressão fa-
cial do banco de imagens (raiva, nojo, medo, felicidade, tristeza, surpresa etc.) e então é
calculado um vetor de movimento (MV - Motion Vector) entre as duas imagens. O MV é
calculado utilizando uma versão modificada, proposta neste trabalho, do algoritmo Redu-
ção Adaptativa da Área de Busca [28] (Adaptive Reduction of the Search Area - ARSA), uma
otimização do tradicional Full Seach [34], chamada MARSA (Modified Adaptive Reduction of
the Search Area). Outros algoritmos de estimação de movimento por casamento de blocos
poderiam ser utilizados para o cálculo do MV entre duas imagens de faces, contudo as

61
melhores taxas de reconhecimento de expressões faciais foram obtidas usando o MARSA,
pois é um algoritmo que leva em consideração as características do movimento produzidos
pelas expressões apenas em determinadas regiões da face. Os algoritmos de estimação de
movimento são apresentados na Seção 3.3.
Após o cálculo dos MVs para todas as imagens em todas as expressões, são calculadas
as coordenadas que ocorreram mais vezes em cada i-ésima posição de todos os MVs, essas
coordenadas são armazenadas nos vetores de maiores ocorrências (HOV - Highest Occur-
rences Vector), cada expressão facial da base de imagens passa a ter tantos HOVs quanto são
as expressões faciais da base. É possível utilizar mais HOVs em cada expressão da base,
para isso é preciso calcular as coordenadas que possuem a segunda maior quantidade de
ocorrências na i-ésima posição dos MVs, também podem ser calculadas as coordenadas que
possuem a terceira maior quantidade de ocorrências e assim sucessivamente. Esse processo
é descrito em detalhes no Capítulo 4, assim como são mostrados e discutidos os resultados
dos experimentos variando a quantidade de HOVs.
Na etapa seguinte, cada MV é comparado por Distância Euclidiana com os HOVs de
todas as expressões, gerando um vetor de distâncias (EDV - Euclidean Distance Vector) para
cada expressão facial. Finalmente, para cada imagem são identificados os menores valores
de cada i-ésima posição em cada um dos seus EDVs, então a expressão facial a qual per-
tencer o EDV com o menor valor naquela posição incrementa a mesma posição no vetor de
características da imagem (FV - Feature Vector). Esse vetor será a entrada do classificador
que identificará a expressão facial da imagem.
Na fase de testes o procedimento é o mesmo do treinamento, exceto que os MVs das
imagens a serem testadas não participaram do cálculo dos HOVs obtidos na fase de treina-
mento.
Existem cinco módulos no sistema desenvolvido para o reconhecimento de expressões
faciais:
1. Pré-processamento: as imagens são convertidas para o mesmo padrão de cores (256
níveis de cinza), então a região da face é recortada a partir da localização dos olhos,
resultando em imagens com dimensões 128 × 160.
2. Busca da Maior Semelhança: para cada imagem é realizada uma busca por outra ima-
gem de maior semelhança em cada expressão facial da base de imagens.
3. Extração de Características Faciais: a característica a ser extraída é o movimento cal-

62
culado entre duas imagens, representado pelos vetores de movimento (MVs) obtidos
a partir da estimação de movimento por casamento de blocos.
4. Transformação das Características: são obtidas as coordenadas do movimento de maior
ocorrência nos MVs de cada expressão facial da base. Então é gerado um vetor (HOV),
para cada expressão, apenas com essas coordenadas.
5. Classificação: Todos os MVs da base de treinamento são comparados, usando a Dis-
tância Euclidiana, com os HOVs calculados no módulo anterior. Os MVs são utiliza-
dos para a obtenção dos HOVs. Então a distância obtida é armazenada em um EDV,
calculado para cada expressão facial. O menor valor de distância indica qual expres-
são pode estar reconhecida naquela posição do vetor. Para a classificação, a expressão
facial que mais ocorrer no EDV será reconhecida.
A Figura 3.1 sintetiza o sistema desenvolvido:

63
Figura 3.1: Sistema desenvolvido para o reconhecimento de expressões faciais. Fonte: autor.
3.1 Pré-processamento para as Bases de Expressões Faciais
Na fase de pré-processamento, foi preciso converter as imagens das bases de expressões
faciais para níveis de cinza, pois algumas delas foram disponibilizadas no modelo de cores
RGB. Para a detecção de olhos e o recorte automático da região da face nas imagens são
utilizados os filtros de correlação ASEF (Average of Synthetic Exact Filters) [27], eles realizam
a localização automática dos centros dos olhos em vídeos e imagens. Dependendo da base
escolhida, as dimensões das imagens variaram bastante, desde 256 × 256 pixels até 640 ×
490 pixels. No sistema apresentado, as imagens de faces devem ter a mesma proporção
de tamanho, então, ainda utilizando os filtros ASEF, realizou-se o recorte automático das
faces das imagens em dimensões padronizadas: 128 × 160 pixels, o que evitou a captura de

64
informações de características indevidas para a formação do modelo de representação. As
imagens das faces também devem ser frontais, ou seja, sem movimento angular da cabeça.
As etapas do pré-processamento estão ilustradas nas Figuras 3.2 e 3.3.
Figura 3.2: Imagens da base Cohn-Kanade Extendida (CK+) convertidas para níveis de cinza. Fonte: autor.
Figura 3.3: Imagens da base Cohn-Kanade (CK) e respectivas faces recortadas utilizando a localização dos
olhos implementada pelos filtros ASEF. Fonte: autor.
3.1.1 Filtros de Correlação ASEF
Os filtros ASEF simplificam o mapeamento entre a imagem de treinamento de entrada e
o plano de correlação de saída. O cálculo é realizado no domínio da frequência, contudo o
resultado do cálculo é transladado para o domínio espacial. A saída da correlação pode ser
especificada por cada imagem de treinamento [27].
Na Figura 3.4, as imagens fi e gi são, respectivamente, a imagem de treinamento e
a saída desejada. A saída gi é definida como uma Gaussiana bi-dimensional centrada na
posição do alvo (xi, yi) e com radiância σ, como mostrada na Equação 3.1. A imagem hi é o

65
filtro de correlação produzido no domínio da frequência que transforma fi para gi. O filtro
de correlação final é obtido a partir da média dos filtros hi.
Figura 3.4: Treinamento dos filtros ASEF. Fonte: [27]
gi(x, y) = e−(x − xi)
2 + (y − yi)2
σ2 (3.1)
A Equação 3.2 mostra a relação entre a convolução no domínio espacial e no domínio da
frequência. Segundo o Teorema da Convolução, a Transformada de Fourier de duas funções
convoluídas no domínio do espaço é igual ao produto das duas funções no domínio da
Frequência [27].
g(x, y) = ( f ⊗ g)(x, y) = F−1(F(ω, υ)H(ω, υ)), (3.2)
onde f , h e g são, respectivamente, a imagem de entrada, o filtro e a saída da correlação
no domínio espacial. As letras F, H e G correspondem as suas transformadas de Fourier
2-D e ⊗ corresponde ao operador de convolução. A partir desta equação forma-se a base

66
para calcular os filtros sintéticos exatos.
A seguir, a Equação 3.3 substitui o complexo conjugado de H na Equação 3.2:
G(ω, υ) = F(ω, υ)H∗(ω, υ), (3.3)
Em seguida, é mostrada a Equação 3.4 que realizará a divisão entre a saída do padrão
transformada e a imagem transformada:
H∗i (ω, υ) =
Gi(ω, υ)
Fi(ω, υ)(3.4)
O próximo passo é calcular a média dos filtros exatos. Este passo serve para criar um
filtro que se generalize em todo um conjunto de treinamento. A média enfatiza as caracte-
rísticas semelhantes das imagens do conjunto de treinamento e suprime as características
idiossincráticas de instâncias de treinamento únicas. Este passo foi ilustrado na Figura 3.4.
Como a Transformada de Fourier é linear, a média pode ser calculada tanto no domínio
da frequência, como no domínio espacial. As Equações 3.5 e 3.6 mostram o cálculo da média
no domínio da frequência e no domínio espacial, respectivamente. Hµ e hµ são os resultados
finais dos filtros ASEF.
H∗µ(ω, υ) =
1N
N
∑i=1
H∗i (ω, υ), (3.5)
h∗µ(x, y) =1N
N
∑i=1
h∗i (x, y), (3.6)
3.2 Busca da Maior Semelhança
Nesta etapa, para cada imagem de face a ter a expressão reconhecida (imagem-referência)
é realizada uma busca por outra imagem de maior semelhança em cada expressão facial da
base de imagens. Para comparar as imagens, foi utilizada a métrica SSIM (Structural Simila-
rity Index) [70], quanto mais próximo do valor 1 for o resultado do cálculo da métrica entre
duas imagens, maior a similaridade entre elas.
Na fase de treinamento, para cada imagem-referência é selecionada uma outra ima-
gem de maior semelhança em cada expressão facial da base, por exemplo, nas imagens
da expressão raiva, apenas uma é identificada como a de maior semelhança com a imagem-
referência e assim sucessivamente para as demais expressões: alegria, tristeza, desgosto,

67
surpresa, medo etc. Na fase de testes, o mesmo procedimento de busca é realizado, con-
tudo a expressão facial da imagem-referência é desconhecida.
A identificação dessas imagens será fundamental para o módulo seguinte: Extração de
Características. Na Figura 3.5 é mostrado um exemplo de resultado da busca de maior
semelhança para uma das imagens de uma das bases utilizadas nos experimentos deste
trabalho.
Figura 3.5: A imagem do centro representa a imagem-referência. As demais imagens representam as melhores
comparações em cada expressão facial da base de imagens Cohn-Kanade. Fonte: autor.
3.2.1 SSIM - Structural Similarity
O Índice de Similaridade Estrutural (SSIM - Structural Similarity) [70] é um método para
mensurar a similaridade entre duas imagens. Neste trabalho ele é utilizado para identificar
as imagens de faces mais similares, dentro da base de treinamento, para o cálculo dos MVs.
Outras medidas como GSSIM (Gradient-based Structural Similarity) [71] e MESSIM (Mean-
Edge Structural Similarity) [72] foram consideradas, entretanto essas métricas são aprimora-
mentos do SSIM apenas para os casos em que as imagens comparadas estão borradas ou

68
apresentam ruídos, o que não se aplica às imagens utilizadas nos experimentos desta Tese.
O método SSIM foi então escolhido pela menor quantidade de operações matemáticas, o
que resulta em um menor tempo de processamento.
A medição da qualidade é realizada com base em uma imagem não compactada ou
sem distorção inicial como referência. A diferença para os métodos tradicionais PSNR [73]
e MSE [74] está no fato de que essas abordagens estimam erros percebidos, enquanto a
técnica SSIM considera a degradação da imagem como mudança percebida na informação
estrutural. A informação estrutural é a ideia de que os pixels têm forte interdependência
especialmente quando eles estão espacialmente próximos. Essas dependências possuem
informações importantes sobre a estrutura dos objetos na imagem.
A medida SSIM é calculada em várias janelas de uma imagem. A medida entre duas
janelas x e y de tamanho comum N × N é definida pela função a seguir:
SSIM(x, y) =(2µxµy + c1)(2σxy + c2)
(µ2x + µ2
y + c1)(σ2x + σ2
y + c2), (3.7)
onde:
• µx é a média de x;
• µy é a média de y;
• σ2x é a variância de x;
• σ2y é a variância de y;
• σxy é a covariância de x e y;
• c1 = (k1L)2, c2 = (k2L)2 são duas variáveis para estabilizar a divisão com denominador
fraco;
• L é o intervalo dos valores de pixel (normalmente: 2numerodebitsporpixel − 1);
• k1 = 0, 01 e k2 = 0, 03 por padrão.
O índice SSIM resultante é um valor decimal entre -1 e 1, o valor 1 só é obtido no caso
de dois conjuntos idênticos de dados (duas imagens iguais) [70].
3.3 Extração de Características
Nesta etapa é extraído o movimento entre duas imagens semelhantes. O movimento é
estimado pelo deslocamento de um mesmo bloco de pixels em duas imagens de uma mesma

69
sequência. Esse deslocamento é representado pelo vetor de movimento (MV) calculado
por meio de um algoritmo de estimação de movimento por casamento de blocos (block-
matching), cada par de coordenadas (x, y) do vetor indica o deslocamento de um bloco de
pixels entre as imagens. Portanto, para cada imagem é calculado um MV para cada expres-
são facial da base, como ilustrado na Figura 3.6. Esse procedimento será realizado tanto na
fase de treinamento quanto na fase de testes.
Figura 3.6: Exemplo de como os MVs são calculados entre a imagem-referência e a imagem mais similar em
cada expressão da base Cohn-Kanade. Fonte: autor.
As técnicas do tipo casamento de blocos detectam os movimentos ocorridos em uma
sequência de imagens, realizando uma análise de duas a duas imagens consecutivas dentro
dessa sequência. A imagem atual é segmentada em diversos blocos de tamanhos L × H.
Cada bloco tem uma área de busca correspondente localizada na imagem anterior. Esta
área de busca tem tamanho (2DMAX + L) × (2DMAX + H), onde DMAX é um valor pré-
fixado que representa o deslocamento máximo a ser percorrido tanto na direção horizontal
quanto na vertical. A Figura 3.7 ilustra uma busca feita por um bloco de tamanho L× H em
relação a sua área de busca. Neste caso, a coordenada a ser pesquisada é o ponto no centro
do bloco. Todos os pixels localizados em um único bloco geram um mesmo deslocamento,
sendo este movimento independente em relação aos deslocamentos ocorridos por outros
blocos entre duas imagens [34].

70
Figura 3.7: Representação de como é obtido o vetor de movimento entre duas imagens. Fonte: autor.
Existem algumas funções para comparar os blocos, da imagem em análise e da imagem
com maior similaridade na base, sendo a diferença média absoluta (Mean Absolute Difference
- MAD) [34] aquela com menor custo computacional, ela é calculada pela equação a seguir:
MAD(x, y) =
H−1∑
i=0
L−1∑
j=0|sk(k + i, l + j)− sk−1(k + x + i, l + y + j)|
n, (3.8)
onde:
• sk(, ) é o nível de luminância do pixel na imagem atual;
• sk−1(, ) é o nível de luminância do pixel na imagem anterior;
• (k, l) é a coordenada do canto superior esquerdo relacionada à imagem atual;
• (x, y) é o deslocamento em pixels a ser pesquisado na imagem anterior com relação à
posição explorada da imagem atual;
• n é o total de pixels do bloco.
Outra função para comparação de blocos, também bastante utilizada em técnicas de
estimação de movimento por casamento de blocos, é o erro médio quadrático (Mean Squared
Error - MSE), calculada pela equação a seguir:

71
MSE(x, y) =
H−1∑
i=0
L−1∑
j=0|sk(k + i, l + j)− sk−1(k + x + i, l + y + j)|2
n, (3.9)
O movimento a ser encontrado em cada bloco é estipulado por um procedimento de
busca. Este procedimento estabelece pontos de pesquisa dentro da área de busca. Com
esses pontos, são feitos os cálculos da função MAD, escolhida para os experimentos desta
Tese pelo seu menor tempo de processamento. O ponto de pesquisa que obtiver o menor
valor será procurado pelo procedimento, determinando o MV.
Inicialmente, nos experimentos deste trabalho, foi utilizado o algoritmo de Busca Exaus-
tiva (Full Search - FS) [34]. Posteriormente, o algoritmo ARSA - Adaptive Reduction Search
Area [28] substituiu o FS por apresentar menor tempo de processamento. Então foram reali-
zadas algumas alterações no ARSA para adequá-lo à extração de movimento de expressões
faciais. Os algoritmos de busca utilizados nos experimentos serão descritos a seguir.
3.3.1 Algoritmo de Busca Exaustiva
O algoritmo de Busca Exaustiva (Full Seach - FS) [34] foi o marco inicial para o desen-
volvimento das técnicas do tipo casamento de blocos (block-matching). Ele é o algoritmo de
estimação de movimento por casamento de blocos com o maior tempo de processamento,
pois os pixels dos blocos candidatos da imagem em análise (imagem 1 na Figura 3.7) são
comparados com todos os pixels da área de busca na imagem com maior similaridade na
base (imagem 2 na Figura 3.7). Cada bloco desloca-se de pixel em pixel na área de busca até
chegar ao último pixel a ser pesquisado. Para isto ocorrer, o bloco se desloca de −DMAX a
+DMAX na função MAD estabelecida dentro do algoritmo, sendo DMAX o deslocamento
máximo do pixel. São procurados, portanto, (2DM + 1)2 blocos na área de busca. Portanto,
o algoritmo FS encontra o melhor casamento de blocos possível entre as duas imagens.
A maior desvantagem do FS é que quanto maior a área de busca, maior o tempo de
processamento. Por isso outros algoritmos tentam obter os mesmos resultados do FS com
o mínimo de custo computacional possível [28], [75], [76]. Neste trabalho, é proposta uma
versão modificada do algoritmo de Redução Adaptativa da Área de Busca (Adaptive Reduc-
tion of the Search Area - ARSA) [28], que é explicado a seguir.

72
3.3.2 Algoritmo de Redução Adaptativa da Área de Busca
Oh e Lee [28] propuseram um algoritmo de estimação de movimento com tamanho va-
riável da área de busca para reduzir o custo computacional do FS explorando as correlações
espaço-temporais nas sequências de vídeo. Particularmente, o método proposto abrange
aplicações com vídeos de baixa resolução, como vídeo-conferências e vídeos de celulares.
Os frames dos vídeos dessas aplicações contêm um ou mais indivíduo(s) e cenários fixos.
A quantidade de pixels a serem pesquisados pode ser reduzida selecionando uma pequena
área de busca para um bloco dentro de uma região de cenário fixo e uma área maior para
um bloco em região com movimento. Essa variação possibilita uma redução significativa
no tempo de processamento do algoritmo FS. A partir da análise de sequências de vídeo de
baixa resolução, um frame pode possuir quatro tipos de blocos: cenário, movimento ativo,
mudança de cenário para região ativa e vice-versa.
As sequências de vídeo de baixa resolução possuem correlações significantes entre fra-
mes consecutivos por geralmente possuírem um único indivíduo com regiões de pouco mo-
vimento, causado pelo próprio indivíduo. Portanto, um bloco em uma região específica
no frame anterior da sequência tende a permanecer na mesma região no frame atual. Os
experimentos de Oh e Lee mostraram que a correlação temporal entre frames consecutivos
é bastante alta, ou seja, se um bloco de um frame anterior pertence à região de cenário ou
região ”ativa” (com movimento), então o bloco localizado na mesma posição do frame atual
pode ser classificado como um bloco de cenário ou bloco de região ativa.
Essa correlação permite a implementação do método de redução adaptativa da área de
busca (adaptive reduction of the search area - ARSA) [28]. Para o bloco de cenário e bloco de
mudança de região ativa para cenário, é definida uma área de busca menor, e para o bloco
de região ativa e bloco de mudança de cenário para região ativa, é definida uma área de
busca maior. Para classificar o bloco, é utilizada a informação de classificação de bloco (block
classification information - BCI) no frame anterior e a diferença de bloco deslocado (displaced
block difference - DBD) no frame atual.
A estimação de movimento proposta é realizada através das etapas a seguir:
1. Estimar os valores iniciais dos limiares (thresholds) para determinar o BCI de um de-
terminado bloco;
2. Determinar o tamanho da área de busca usando os parâmetros DBD e BCI, e então

73
executar o algoritmo de casamento de blocos dentro dessa área;
3. Atualizar os thresholds para uma adaptação às características da sequência de vídeo.
Estimar os thresholds iniciais
Três parâmetros são utilizados para a classificação de bloco: BCI(i), DBDbg, and DBDar.
BCI(i) é a informação de classificação do i-ésimo bloco em um frame, DBDbg é a diferença
média de bloco deslocado dos blocos que são classificados como blocos de cenário no frame
anterior, e DBDar é a diferença média de bloco deslocado dos blocos que são classificados
como blocos ativos no frame anterior. Os valores iniciais desses parâmetros são estimados a
partir dos resultados do primeiro frame usando o algoritmo FS.
No primeiro frame, o BCI(i) é determinado apenas pelo MV. Os blocos que possuem
valor zero no MV são classificados como blocos de cenário e os outros blocos são classifi-
cados como ativos. O DBDbg é definido como a média dos DBDs dos blocos de cenário e
o DBDar é a média dos DBDs dos blocos ativos. O DBDbg geralmente é pequeno quando
comparado com o DBDar. Esses parâmetros são atualizados constantemente para refletir
de forma adaptativa as características das sequências de vídeo à medida que o processo de
codificação progride.
Determinar o tamanho da área de busca e executar o algoritmo de casamento de blocos
A classificação de blocos no frame atual é realizada através do uso do BCI(i) do frame
anterior, DBDbg e DBDar. O tamanho da área de busca é determinado dependendo do BCI
do bloco. A classificação de um determinado bloco no frame atual ocorre como mostrado na
Figura 3.8. Na figura, o BCI(i) é a informação de classificação do i-ésimo bloco no frame
anterior, o DBDbg e o DBDar são a média dos DBDs dos blocos de cenário e blocos ativos
também no frame anterior, respectivamente. A diferença de bloco de deslocamento zero
(zero displaced block difference - ZDBD) é a diferença entre um determinado bloco no frame
atual e um bloco candidato no frame anterior na mesma coordenada (deslocamento zero).
Para determinar o BCI do i-ésimo bloco no frame atual, o algoritmo observa o BCI naquela
mesma posição no frame anterior. Se o BCI(i) é uma "bloco de cenário", então o ZDBD no
frame atual é comparado com o DBDbg para decidir se o bloco é classificado como bloco de
cenário ou bloco de mudança de cenário para região ativa. Se o BCI(i) é um "bloco ativo",
então o bloco pode ser classificado como bloco ativo ou como bloco de mudança de região

74
ativa para cenário dependendo do ZDBD e DBDar.
Figura 3.8: Procedimento para classificação de informação de bloco. Fonte: [28] (modificada pelo autor).
Para cada tipo de bloco, a área de busca é definida como (2DMAX + L)× (2DMAX + H)
para o bloco ativo e o bloco de mudança de cenário para região ativa, [(2DMAX + L) ×
(2DMAX + H)]/4 para o bloco de cenário, e [(2DMAX + L)× (2DMAX + H)]/2 para o bloco
de mudança de região ativa para cenário. Ou seja, a maior área de busca é alocada para
a região ativa, que contém blocos com muito movimento, e a menor área de busca é dada
para os blocos de cenário.
Após determinar o tamanho da área de busca para cada bloco, o algoritmo de casamento
de blocos é executado utilizando a redução logarítmica da área de busca. Primeiramente, o
algoritmo FS é executado dentro da área de busca determinada. Se o bloco correspondente
no frame anterior for encontrado dentro dessa área, a estimação de movimento é interrom-
pida. Caso contrário (MV aponta para os limites da área de busca), o algoritmo FS é exe-
cutado, com uma nova origem de busca apontada pelo MV no primeiro estágio, dentro de
uma área de busca que tem metade do tamanho da primeira área. O procedimento continua
até o MV não apontar mais para os limites da área de busca. Esse processo reduz a degra-
dação da qualidade da estimação de movimento causada pela classificação errada dos tipos
de bloco.
Atualizar os thresholds
Finalmente, após um frame passar pelo algoritmo de casamento de blocos, o BCI de cada
bloco é atualizado usando o BCI do bloco na mesma posição no frame atual, que é usado

75
para o próximo frame. Ao mesmo tempo, o DBDbg e o DBDar são estimados novamente
usando os DBDs dos blocos de cenário e dos blocos ativos do frame atual.
3.3.3 Algoritmo Modificado de Redução Adaptativa da Área de Busca
Com o objetivo de melhorar a precisão do processo de extração de características faci-
ais, neste trabalho são propostas algumas alterações no algoritmo ARSA. O algoritmo FS
percorre todos os pixels (agrupados em blocos) das imagens comparadas, identificando os
blocos de maior semelhança para calcular o vetor de movimento. Contudo, mesmo com o
recorte da face realizado no pré-processamento utilizando os filtros ASEF, algumas regiões
da face que não possuem informação relevante para o reconhecimento da expressão facial,
testa e nariz, por exemplo, podem ser ignoradas.
Para realizar a seleção das regiões cujos vetores de movimento serão calculados de forma
automática, novamente são utilizados os filtros ASEF: para cada base de imagens de face, é
calculada a média da coordenada y de localização dos pontos centrais dos olhos em todas as
imagens. A partir dessa média, foi definido que para cada imagem serão calculados apenas
os vetores de movimento para os pixels localizados nas regiões dos olhos e da boca, na Fi-
gura 3.9 é ilustrado um exemplo das regiões selecionadas para a extração de características.
Figura 3.9: Regiões da face selecionadas para a extração de características faciais, considerando a proporciona-
lidade da distância entre os olhos e entre cada olho e a boca. Fonte: autor.
A definição das coordenadas de início e término das regiões de olhos e boca foi realizada
de forma empírica, considerando a estrutura da face humana e as distâncias proporcionais
de ambos os olhos até a boca, como mostrado na Figura 3.9. Considerando yolho a coorde-
nada y média da localização do centro dos olhos, as regiões dos olhos e boca foram definidas
da seguinte forma (para imagens com dimensões 128 × 160):

76
• Coordenadas de início da região dos olhos:
Ciro = (0, yolho ∗ 0, 5), (3.10)
• Coordenadas de término da região dos olhos:
Ctro = (128, yolho + (yolho ∗ 0, 25)), (3.11)
• Coordenadas de início da região da boca:
Cirb = (0, yolho ∗ 0, 6), (3.12)
• Coordenadas de término da região da boca:
Ctrb = (128, 160). (3.13)
Para comprovar a efetividade das equações acima, a Figura 3.10 ilustra exemplos de
imagens obtidas em cada base.
Figura 3.10: Regiões da face selecionadas para a extração de características faciais. Uma imagem de cada base
(da esquerda para a direita): CK, JAFFE, MMI, CK+ e CMU-PIE. Fonte: autor.
Anteriormente, foi mencionado que o algoritmo ARSA classifica os blocos de busca
em quatro tipos. Contudo, alguns tipos não são aplicados a imagens de face, após o pré-
processamento não existe mais cenário nas imagens. A versão modificada proposta neste
trabalho (Modified Adaptive Reduction of the Search Area - MARSA), diminui o número de
pontos de busca usando as características das expressões faciais: uma área pequena é de-
terminada para blocos com pouco ou nenhum movimento (micro-expressões) e uma área
maior é definida para blocos com muito movimento (macro-expressões), como pode ser
visto na Figura 3.11. A classificação de blocos é realizada para determinar o tamanho da
área de busca para cada tipo de bloco, a área de busca tem tamanho DMAX para blocos de
macro-expressões e DMAX/2 para blocos de micro-expressões. Portanto, além da definição

77
das 2 regiões (olhos e boca) em que o algoritmo será executado, dentro dessas regiões a área
de busca pelo bloco de maior semelhança também pode ser reduzida.
Figura 3.11: O algoritmo Modificado de Redução Adaptativa da Área de Busca (MARSA). Fonte: autor.
3.4 Transformação de Características
Nesta Seção são descritas as etapas de treinamento e testes do sistema de reconheci-
mento de expressões faciais proposto neste trabalho.

78
3.4.1 Treinamento
Figura 3.12: As cinco fases do treinamento. Fonte: autor.
PRIMEIRA FASE
Na Figura 3.12 são mostradas as fases do processo de transformação de características.
O símbolo σ representa a base de imagens e f representa a expressão facial identificada.
Para cada imagem de treino, a imagem com maior similaridade em cada expressão facial
da base é obtida usando a medida Structural Similarity index (SSIM), como mostrado na
Figura 3.13.

79
Figura 3.13: Busca da imagem mais similar em cada expressão facial. Fonte: autor.
As imagens similares são usadas para calcular os vetores de movimento (MV), compa-
rando a imagem de treino Xi à imagem com maior similaridade em cada expressão facial
(Xa, Xb, ..., Xg) da base de imagens, como mostrado na Figura 3.14.
Figura 3.14: Representação do MV. Fonte: autor.
A Tabela 3.1 mostra que para cada imagem, um MV é calculado em cada expressão
facial da base de treinamento.
Tabela 3.1: Para cada imagem, um MV para cada expressão da base de treinamento.
imagens Xa, alegria Xb, medo ... Xg, raiva
Xi MV1i MV2i ... MV7i
Xj MV1j MV2j ... MV7j
... ... ... ... ...
Xn MV1n MV2n ... MV7n
SEGUNDA FASE
Na segunda fase do treinamento, os ’Vetores de Maiores Ocorrências’ (HOV) são cal-
culados para cada expressão facial da base, esses vetores representam as coordenadas que

80
possuem as maiores ocorrências nos vetores de movimento MV em cada expressão da base
de treino, como mostrado na Tabela 3.1.
Tabela 3.2: Representação dos HOVs de cada expressão facial da base de treinamento.
alegria medo ... raiva
imagem 1 MV11 MV21 ... MV71
imagem 2 MV12 MV22 ... MV72
... ... ... ... ...
imagem n MV1n MV2n ... MV7n
HOV1 HOV2 ... HOV7
A Tabela 3.3 mostra como é gerado o HOV da primeira coluna da Tabela 3.2, corres-
pondente aos MVs da base de imagens alegria. As coordenadas (xn, yn)′ do HOV1 são as
coordenadas de maiores ocorrências naquela posição dos vetores MVs.
Tabela 3.3: Cálculo do HOV para a base de imagens alegria.
alegria
imagem 1 MV11 = [(x11, y11), (x21, y21), ..., (xn1, yn1)]
imagem 2 MV12 = [(x12, y12), (x22, y22), ..., (xn2, yn2)]
... ...
imagem n MV1n = [(x1n, y1n), (x2n, y2n), ..., (xnn, ynn)]
HOV1 = [(x1, y1)′, (x2, y2)
′, ..., (xn, yn)′]
Cada imagem de treino possui tantos HOVs quanto são as expressões faciais na base de
treino. Por exemplo, se existem sete expressões faciais (raiva, nojo, medo, alegria, neutra,
tristeza e surpresa) na base de treino, haverá sete HOVs para cada expressão facial (49
vetores para toda a base de treino).
TERCEIRA FASE
Nesta fase, o objetivo é obter as distâncias absolutas entre dois pontos na mesma posição
em cada vetor MV da base de treinamento e todos os vetores HOVs de cada expressão facial
da base de treinamento. A Distância Euclidiana é utilizada para o cálculo da distância entre
esses pontos, como mostrado na Tabela 3.4:

81
Tabela 3.4: Cálculo do EDV para cada imagem da base de treinamento.
expressão
alegria EDV11 =√
(MV11 − HOV1)2,
medo EDV21 =√
(MV21 − HOV2)2
... ...
raiva EDVn1 =√
(MVn1 − HOVn)2
onde EDV é o ’Vetor de Distâncias Euclidianas’ calculado para a i-ésima posição do MV
e do HOV. Os índices em EDVij, MVij e HOVi indicam (i) a expressão da base a qual per-
tence o vetor e (j) a imagem a qual pertence o vetor. Para cada imagem, são gerados tantos
EDVs quanto são as expressões faciais da base de treino.
QUARTA FASE
Nesta fase, o menor valor de cada i-ésima posição do EDV (ai, bi, ..., zi), incrementa uma
variável Qtd do ’Vetor de Características’ (Feature Vector - FV) relacionado à expressão facial
a qual o EDV pertence. Para cada imagem, existem tantas variáveis Qtd (posições no FV)
quantas são as expressões na base de treino. Esse procedimento é demonstrado na Tabela
3.5:
Tabela 3.5: Cálculo do FV para uma imagem da base de treino.
expressão
alegria EDV11 = [a1, b1, ..., z1]
medo EDV21 = [a2, b2, ..., z2]
... ...
raiva EDVn1 = [an, bn, ..., zn]
FVimagem = [Qtdalegria, Qtdmedo, ..., Qtdraiva]
QUINTA FASE
Na última fase do treinamento, ocorre a classificação da expressão facial. O FV de cada
imagem (última linha da Tabela 3.5) calculado na etapa anterior será a entrada do classifi-
cador que reconhece a expressão facial representada na imagem sendo analisada.
Finalmente, é realizado o reconhecimento independente do indivíduo usando a SVM
(Support Vector Machine) [37], a seção seguinte explica este procedimento.

82
3.4.2 Testes
Na Figura 3.15 é mostrado o framework utilizado para a realização dos testes do método
proposto.
Figura 3.15: Framework de testes. Fonte: autor.
1. Para cada imagem de teste é obtida a imagem com maior similaridade em cada ex-
pressão facial da base usando a métrica Structural Similarity index (SSIM). Os pares de
imagens com maior similaridade são usados para calcular os MVs, cada imagem de
teste possui um MV calculado entre ela e uma imagem de cada expressão facial da
base de treino.
2. O MV calculado para a imagem de teste é comparado, por Distância Euclidiana, a cada
HOV de cada expressão facial da base de treino.
3. As fases seguintes são idênticas às fases quatro e cinco do framework do treinamento.

83
3.5 Classificação
As técnicas de AM (Aprendizado de Máquina) adotam um mecanismo denominado de
indução ou inferência, onde pode-se obter conclusões genéricas a partir de um conjunto
particular de exemplos. Este tipo de aprendizado está dividido em dois subtipos: supervi-
sionado e não supervisionado. No aprendizado supervisionado, temos o que chamamos de
um agente externo que apresenta o conhecimento do ambiente e o representa de uma deter-
minada forma. A partir deste conhecimento, os algoritmos de AM extraem essas informa-
ções a partir desses conjuntos. Esses conjuntos são chamados de ’base de treinamento’. O
objetivo dessa representação é conseguir produzir saídas corretas para entradas não apre-
sentadas ao conjunto de treinamento. Já no aprendizado não supervisionado, não existe a
representação do agente externo. Nesse caso, os algoritmos de AM aprendem a representar
os dados a partir de uma medida de qualidade [77].
Nesta etapa do método proposto, as entradas são os dados de saída da transforma-
ção das características, que foram calculadas utilizando o algoritmo de estimação por casa-
mento de blocos MARSA, e a saída do classificador é a identificação da expressão de uma
imagem de face. Para realizar a classificação dos dados, foi escolhida a técnica SVM (Sup-
port Vector Machine) [37] por ser uma técnica robusta e bastante utilizada na literatura para
a classificação de expressões faciais.
3.5.1 SVM - Support Vector Machine
A classificação de dados é uma tarefa comum no AM. No caso das SVMs, um dado é
visto como um vetor p-dimensional (uma lista de números p), esses dados devem ser sepa-
rados por um hiperplano (p− 1)-dimensional. Classificadores que separam dados por meio
de um hiperplano são chamados de lineares. O objetivo das SVMs lineares é a obtenção de
fronteiras lineares para a separação de dados de duas classes. Essas classes são linearmente
separáveis se for possível separar os dados das classes a partir de um hiperplano. Pode-se
visualizar na Figura 3.16 a projeção do hiperplano separador das classes.

84
Figura 3.16: Visão do hiperplano separador de classes na SVM linear. Fonte: autor.
Existem muitos hiperplanos que podem classificar os dados. Uma SVM constrói um
hiperplano, ou conjunto de hiperplanos, em um espaço hiper dimensional, que pode ser
usado para classificação, regressão, ou outras tarefas. Uma boa separação de dados é al-
cançada pelo hiperplano que possuir a maior distância para o dado de treinamento mais
próximo de qualquer classe, por isso que quanto maior a margem, menor o erro de genera-
lização do classificador.
As SVMs são modelos de aprendizado supervisionado onde dado um conjunto de exem-
plos de treinamento, cada exemplo é rotulado como pertencente a uma categoria, um algo-
ritmo de treinamento constrói um modelo que atribui novos exemplos a uma categoria,
tornando-o um classificador linear binário não-probabilístico. Dado um conjunto de treina-
mento rotulado da forma (xi, yi), onde xi representa o dado de treinamento e yi representa o
seu rótulo, será produzido um modelo ou hipótese capaz de predizer precisamente o rótulo
de novos dados. Quando os rótulos possuírem valores discretos 1, ..., k, será um problema
de classificação. Para o caso de rótulos com valores contínuos, será um problema de regres-
são [78].
Um requisito bastante importante para as técnicas de AM é a capacidade que elas têm de
lidar com a presença de ruídos e ’outliers’. Os outliers são dados do conjunto de treinamento
muito distintos ou discrepantes em relação ao restante do domínio. A técnica de AM deverá
ser robusta o bastante para tratar esses tipos de dados. A Figura 3.17 ilustra uma visão geral
dos conceitos referentes à geração de um classificador.

85
Figura 3.17: Visão geral do classificador em aprendizado supervisionado. Fonte: autor.
Quando os dados não são rotulados, o aprendizado supervisionado não é possível, por-
tanto uma abordagem não supervisionada é necessária. Essa abordagem tenta estabelecer
o agrupamento (clustering) dos dados em grupos, e então mapear novos dados para esses
grupos. O algoritmo de agrupamento que permite uma melhora nas SVMs é chamado sup-
port vector clustering [79] e é utilizado com frequência em aplicações industriais quando os
dados não são rotulados, ou quando apenas alguns dados são rotulados, como um pré-
processamento para a classificação.
As SVMs não lineares são utilizadas quando não há possibilidade de se dividir os dados
de treinamento por um hiperplano. Na Figura 3.18 é mostrado um exemplo onde o uso
de uma fronteira curva seria mais adequado para separar as classes. As SVMs não lineares
tratam os dados mapeando o conjunto de treinamento de seu espaço original para um novo
espaço hiper dimensional, chamado de espaço de características (feature space).
Figura 3.18: Conjunto de dados não linear. Fonte: autor.
Para o treinamento da SVM foi utilizado nos experimentos desta Tese o algoritmo SMO
(Sequencial Minimal Optimization) [80], com o Kernel RBF (Radial-Basis Function) [81]. Este
kernel é uma função que recebe dois pontos xi e xj do espaço de entradas e computa o
produto escalar desses dados no espaço de características. O kernel RBF possui o parâmetro
Gamma (γ), que determina a flexibilidade da SVM na obtenção dos dados, ele foi variado

86
de 1 a 200, e o parâmetro C, que também foi variado de 1 a 200, em busca dos melhores
resultados de classificação.
Todas as etapas descritas nas Seções deste Capítulo compõem uma nova arquitetura de-
senvolvida para identificar o movimento produzido pelas expressões faciais. No Capítulo
4 são descritos os experimentos realizados nas bases de imagens e vídeos, mencionadas na
Seção 2.1, bem como apresentados os resultados obtidos.

CAPÍTULO 4
EXPERIMENTOS E
RESULTADOS
"O que sabemos é uma gota, o que ignoramos
é um oceano."
— Isaac Newton
APós o fim do processo de desenvolvimento e implementação do sistema de reconhe-
cimento de expressões faciais, foi iniciado o processo de elaborar um conjunto de
testes que permita a obtenção de resultados qualitativos e quantitativos. Para os experi-
mentos de reconhecimento de expressões faciais, foram utilizadas cinco bases de imagens
de faces: Cohn-Kanade (CK) [3], Cohn-Kanade Extendida (CK+) [4], Japanese female facial ex-
pression (JAFFE) [2], MMI [5] e CMU Pose, Illumination, and Expression (CMU-PIE) [6]. Os
experimentos são detalhados nas próximas seções deste capítulo.
O sistema apresentado neste trabalho foi implementado na linguagem de programação
Java SE, da empresa Sun Microsystems. As rotinas de pré-processamento das imagens fo-
ram implementadas na linguagem de programação Python (filtros ASEF), gerenciada pela
organização Python Software Foundation, e no MatLab R2015b (métrica SSIM), da MathWorks.
Todos os experimentos foram realizados em um computador desktop com configuração: pro-
cessador Intel(R) Core(TM) i3-2100 CPU 3,10GHz e memória RAM de 8,00 GB.
A sequência de treinamento e testes, do método de reconhecimento proposto neste tra-

88
balho, pode ser resumida em seis etapas:
1. Imagens de treinamento são lançadas no sistema para que os MVs sejam calculados, a
partir desses vetores são calculados os HOVs;
2. Os MVs gerados são comparados com os HOVs para gerar os EDVs;
3. Para finalizar o treinamento, a partir dos EDVs, são calculados os FVs de todas as
imagens da base, eles são usados como dados de treinamento na SVM;
4. Imagens de teste são lançadas no sistema para que sejam calculados os MVs;
5. Os MVs são comparados com os HOVs, obtidos na fase de treinamento, para gerar os
EDVs;
6. Finalmente, a partir dos EDVs, são calculados os FVs de todas as imagens da base de
treinamento. Os FVs são utilizados como dados de entrada na SVM.
O algoritmo de estimação de movimento MARSA é utilizado na primeira etapa. Ele
realiza uma busca pelos blocos de maior semelhança entre duas imagens, necessários para o
cálculo do MV. Os algoritmos de estimação ARSA e FS também foram utilizados para testes
e comparação de performance e tempo de processamento, com o objetivo de comprovar a
melhor eficiência e acuracidade do algoritmo MARSA.
Na terceira e sexta etapas, são gerados os arquivos de entrada para a SVM. A classifica-
ção foi realizada com um tipo de validação: Cross Validation 10-folds. Este tipo de validação
seleciona 10% dos indivíduos da base de imagens para gerar a base de testes, os demais
indivíduos fazem parte da base de treinamento, ver a Figura 4.1. Os indivíduos da base
de teste são testados individualmente. Ainda sobre o método de validação utilizado, ele
consiste em dividir o conjunto total de dados em dez subconjuntos mutuamente exclusi-
vos do mesmo tamanho e, a partir disto, um subconjunto é utilizado para teste e os nove
restantes são utilizados para estimação dos parâmetros e calcula-se a acurácia do modelo.
Este processo é realizado 10 vezes (rodadas) alternando de forma circular o subconjunto de
teste.

89
Figura 4.1: Validação Cruzada 10-folds. Fonte: autor.
A técnica de validação Cross Validation 10-folds determina que a escolha das imagens
de treinamento e de teste seja feita de forma aleatória. O sistema implementado separa as
imagens de treinamento (90% da base de imagens) das imagens de teste (10% da mesma
base).
Também é importante ressaltar que é possível melhorar a acuracidade da classificação
das expressões faciais variando a quantidade de coordenadas que são utilizadas no cálculo
dos HOVs, ou seja, pode-se considerar não apenas a coordenada de movimento que mais
ocorreu na i-ésima posição dos MVs, mas também a segunda, a terceira, a quarta coorde-
nada que mais ocorreu e assim sucessivamente. Portanto, foram realizados experimentos
variando a quantidade de HOVs.
Nas Seções a seguir são mostrados os resultados obtidos paras as bases de imagens e
vídeos utilizadas nos experimentos deste trabalho.
4.1 Etapas de Pré-processamento
Todas as imagens das bases utilizadas nos experimentos apresentados neste capítulo ti-
veram que passar por pré-processamento para que pudessem ser analisadas pelo método
apresentado. O pré-processamento é dividido em duas etapas: (1) detecção e recorte da face
na imagem, realizada utilizando os filtros ASEF; (2) busca da imagem de maior semelhança
para o cálculo do MV, realizada utilizando a função SSIM. Essas etapas já foram detalhada-
mente explicadas no capítulo anterior. Nas Tabelas 4.1 e 4.2 são apresentados os tempos de
processamento de cada etapa para cada uma das bases de imagens de faces utilizadas nos
experimentos deste trabalho.

90
Tabela 4.1: Tempos de detecção e recorte da face usando os filtros ASEF para cada base e para cada imagem
utilizada nos experimentos.
Bases de imagensTempos da 1ª etapa de pré-processamento
Total de imagens ASEF(base) ASEF(imagem)
JAFFE 213 1,42 min. 0,4 seg.
CK 1287 8,58 min. 0,4 seg.
CK+ 1722 11,48 min. 0,4 seg.
MMI 648 4,32 min. 0,4 seg.
CMU-PIE 778 5,19 min. 0,4 seg.
Tabela 4.2: Tempos de busca da imagem de maior semelhança usando a função SSIM para cada base e para
cada imagem utilizada nos experimentos.
Bases de imagensTempos da 2ª etapa de pré-processamento
Total de imagens SSIM(base) SSIM(imagem)
JAFFE 213 3,9 min. 1,10 seg.
CK 1287 12,80 hrs. 35,8 seg.
CK+ 1722 17,26 hrs. 36,1 seg.
MMI 648 2,92 hrs. 16 seg.
CMU-PIE 778 51,26 min. 3,95 seg.
O pré-processamento da base de imagens é realizado apenas uma vez, na fase de treina-
mento. Após o treinamento, o pré-processamento é realizado apenas para a imagem a ser
analisada pelo sistema. Os tempos de pré-processamento variam de acordo com o tamanho
da base, quanto mais imagens, maior o tempo de pré-processamento.
4.2 Reconhecimento de Expressões Faciais Utilizando a Base JAFFE
O primeiro conjunto de testes, efetuado com o intuito de averiguar o sucesso do sistema
desenvolvido, foi realizado com as imagens da base JAFFE. Esta base possui 213 imagens
de sete expressões faciais: raiva, nojo, medo, alegria, neutra, tristeza e surpresa, com apro-
ximadamente o mesmo número de imagens para cada categoria de expressão facial. Todas
as imagens da base foram utilizadas nos experimentos do método apresentado.
Nas Tabelas 4.3 a 4.10 são apresentadas as matrizes de confusão com os resultados dos
experimentos de reconhecimento das expressões faciais dentro da base de imagens JAFFE,
variando a quantidade de HOVs e com tamanho fixo de bloco 8× 8 para o cálculo dos MVs.

91
Tabela 4.3: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 1 HOV.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 100 0 0 0 0 0 0
Nojo 6,9 89,66 3,45 0 0 0 0
Medo 0 6,25 81,25 3,12 0 6,25 0
Alegria 0 3,12 0 96,88 0 0 0
Neutra 0 0 0 3,33 93,33 0 3,33
Tristeza 0 6,67 10 0 13,33 66,67 0
Surpresa 0 0 3,33 0 0 3,33 93,33
Tabela 4.4: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 2 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 96,67 3,33 0 0 0 0 0
Nojo 3,45 82,76 13,80 0 0 0 0
Medo 0 6,25 78,13 3,12 0 9,37 3,12
Alegria 0 0 0 100 0 0 0
Neutra 0 0 0 3,33 93,33 3,33 0
Tristeza 0 3,33 16,67 0 13,33 66,67 0
Surpresa 0 3,33 3,33 0 3,33 0 90
Tabela 4.5: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 4 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 100 0 0 0 0 0 0
Nojo 3,45 86,21 10,35 0 0 0 0
Medo 0 3,12 84,38 3,12 0 9,37 0
Alegria 0 0 0 100 0 0 0
Neutra 0 0 0 3,33 96,67 0 0
Tristeza 0 3,33 16,67 0 13,33 66,67 0
Surpresa 0 0 10 0 0 0 90

92
Tabela 4.6: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 6 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 96,67 3,33 0 0 0 0 0
Nojo 3,45 82,76 13,80 0 0 0 0
Medo 0 6,25 81,25 3,12 3,12 6,25 0
Alegria 0 0 0 96,88 3,12 0 0
Neutra 0 0 0 3,33 96,67 0 0
Tristeza 0 0 3,33 0 6,67 86,67 3,33
Surpresa 0 0 6,67 0 0 0 93,33
Tabela 4.7: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 8 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 96,67 3,33 0 0 0 0 0
Nojo 3,45 89,66 6,90 0 0 0 0
Medo 0 3,12 81,25 0 3,12 12,5 0
Alegria 0 0 0 90,63 9,37 0 0
Neutra 0 0 0 3,33 96,67 0 0
Tristeza 0 0 3,33 0 3,33 90 3,33
Surpresa 0 0 3,33 0 3,33 0 93,33
Tabela 4.8: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 10 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 96,67 3,33 0 0 0 0 0
Nojo 20,69 72,41 6,90 0 0 0 0
Medo 0 0 81,25 0 0 15,62 3,13
Alegria 0 0 0 90,63 9,37 0 0
Neutra 0 0 0 3,33 93,33 3,33 0
Tristeza 0 0 6,66 0 6,66 86,67 0
Surpresa 0 0 6,66 0 0 3,33 90

93
Tabela 4.9: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 12 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 93,33 6,67 0 0 0 0 0
Nojo 17,24 68,97 10,34 0 0 3,45 0
Medo 0 0 75 0 0 18,75 6,25
Alegria 0 0 0 96,88 3,12 0 0
Neutra 0 0 0 3,33 96,67 0 0
Tristeza 0 0 6,66 0 6,66 83,33 3,33
Surpresa 0 0 3,33 0 0 0 96,67
Tabela 4.10: Matriz de confusão do reconhecimento de expressões faciais na base JAFFE, utilizando 14 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 93,33 6,67 0 0 0 0 0
Nojo 13,79 79,31 6,70 0 0 0 0
Medo 0 0 71,88 0 0 21,87 6,25
Alegria 0 0 0 93,75 6,25 0 0
Neutra 0 0 3,33 0 96,67 0 0
Tristeza 0 0 13,33 0 3,33 80 0
Surpresa 0 0 10 3,33 0 0 86,67
A Figura 4.2 mostra a taxa de acertos no reconhecimento de cada expressão facial da
base JAFFE, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
70
80
90
100
Quantidade de HOVs
Taxa
de
acer
tos
(%)
raivanojo
medoalegrianeutratristeza
surpresa
Figura 4.2: Taxas de reconhecimento para cada expressão facial da base JAFFE. Fonte: autor.

94
A Figura 4.3 mostra a taxa média de acertos no reconhecimento de todas as expressões
faciais da base JAFFE, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
86
88
90
88, 73
86, 79
89, 13
90, 6191, 17
87, 2887, 26
85, 94
Quantidade de HOVs
Taxa
méd
iad
eac
erto
s(%
)
Figura 4.3: Quantidade de HOVs X Respectivas taxas médias de acertos no reconhecimento de expressões
faciais na base de imagens JAFFE. Fonte: autor.
Nas Tabelas 4.3 a 4.10 e no gráfico da Figura 4.2 é possível observar que as expressões
faciais que apresentam as melhores taxa de reconhecimento são raiva e alegria, com taxas
médias de acertos de 96,67% e 95,71%, respectivamente. A expressão que apresenta a pior
taxa é tristeza, com taxa média de acerto de 78,33%, sendo bastante confundida com as
expressões medo e neutra. Por fim, no gráfico da Figura 4.3 é possível observar que quando
são utilizados dois HOVs, há uma diminuição na média de acertos do reconhecimento com
relação ao uso de apenas um HOV, contudo a média de acertos aumenta gradativamente a
partir do uso de quatro HOVs, mas diminui novamente com o uso de 10, 12 e 14 HOVs. Isso
ocorre pois a utilização de muitos HOVs significa que são consideradas muitas coordenadas
com maiores ocorrências, o que diminui a relevância das coordenadas que de fato ocorreram
mais vezes nos MVs de cada expressão facial da base de imagens.
4.2.1 Comparação dos algoritmos de estimação de movimento por
casamento de blocos na base JAFFE
Para verificar a eficiência do algoritmo de estimação de movimento proposto (MARSA),
foram realizados experimentos também com os algoritmos FS e ARSA, que são considera-
dos precursores do MARSA. Os três algoritmos foram utilizados no sistema implementado

95
com três tamanhos diferentes de blocos para o cálculo dos MVs: 4 × 4, 8 × 8 e 12 × 12.
Blocos de tamanho menor (2 × 2) não foram considerados, pois são formados por apenas
4 pixels, o que dificulta a detecção de movimento. Blocos de tamanhos maiores (16 × 16,
20 × 20, etc) dificultam a detecção de movimento pelo motivo oposto: são formados por
uma grande quantidade de pixels, o que pode gerar erro no cálculo dos MVs, visto que o
deslocamento obtido é considerado para todos os pixels do bloco.
As quantidades de HOVs também foram alteradas junto com os tamanhos dos blocos.
O tamanho de bloco 8× 8 gerou a maior taxa de reconhecimento, portanto foi utilizado para
o cálculo das matrizes de confusão para as respectivas quantidades de HOVs: 1, 2, 4, 6, 8,
10, 12 e 14. A quantidade de HOVs que forneceu as maiores taxas médias de acertos para
os três algoritmos foi oito, assim como é mostrado no gráfico da Figura 4.2.
Na Tabela 4.11 são mostradas as taxas médias de acerto para o reconhecimento de ex-
pressões faciais utilizando os três algoritmos de estimação de movimento no método pro-
posto: FS, ARSA e MARSA. É possível observar a superioridade do algoritmo MARSA, isso
se explica por ele ser aplicado apenas nas regiões dos olhos e da boca, onde ocorrem os
principais movimentos das expressões faciais. Os algoritmos FS e ARSA apresentam taxas
de reconhecimento um pouco menores por considerarem informações de movimento em
outras regiões da imagem da face (nariz e testa, por exemplo) que podem levar a algum
erro no reconhecimento das expressões.
Tabela 4.11: Taxas médias de reconhecimento dos algoritmos de estimação de movimento para tamanhos dife-
rentes de blocos, utilizando a base JAFFE.
AlgoritmoTamanho do bloco
4 × 4 (%) 8 × 8 (%) 12 × 12 (%)
FS 82,1 ± 6,4 87,8 ± 6,1 87,2 ± 6,1
ARSA 83,0 ± 6,2 88,2 ± 6,8 86,8 ± 3,0
MARSA 83,9 ± 5,5 91,2 ± 2,9 87,7 ± 3,0
Além da comparação das taxas médias de acertos entre os algoritmos de estimação, tam-
bém foi realizada a comparação dos tempos de processamento, a configuração do hardware
utilizado é informada no início do capítulo. A Tabela 4.12 mostra três tempos de proces-
samento: treinamento, teste e para uma única imagem. O treinamento inclui o cálculo dos
MVs para as imagens de treino, o cálculo de todos os HOVs, o cálculo dos EDVs para as
imagens de treino e o cálculo dos FVs. O teste inclui o cálculo dos MVs para as imagens de

96
teste, o cálculo dos EDVs e o cálculo dos FVs. O reconhecimento da expressão facial para
uma única imagem inclui os cálculos dos mesmos vetores calculados para as imagens de
teste. Também foram comparados os tempos de processamento para diferentes tamanhos
de blocos: 4 × 4, 8 × 8 e 12 × 12. É possível observar que algoritmo MARSA apresenta os
menores tempos de processamento no método proposto: sendo em média 10,5% mais veloz
no treinamento, 13,4% mais veloz nos testes e no reconhecimento da expressão facial em
uma única imagem, quando comparado com o segundo algoritmo mais veloz.
Tabela 4.12: Tempos de processamento dos algoritmos de estimação de movimento para tamanhos diferentes
de blocos, utilizando a base JAFFE.
Algor.(tam. do bloco)Tempo de processamento
treinamento(min.) teste(min.) imagem(seg.)
FS (4 × 4) 49,51 5,07 1,43
FS (8 × 8) 45,15 4,82 1,36
FS (12 × 12) 55,92 4,97 1,40
ARSA (4 × 4) 48,27 4,21 1,19
ARSA (8 × 8) 43,96 3,74 1,05
ARSA (12 × 12) 53,50 5,64 1,59
MARSA (4 × 4) 39,13 3,15 0,89
MARSA (8 × 8) 41,65 3,32 0,93
MARSA (12 × 12) 49,51 4,78 1,35
4.3 Reconhecimento de Expressões Faciais Utilizando a Base CK
Também foram realizados experimentos com as imagens da base Cohn-Kanade (CK).
Esta base é composta por 1.480 imagens, tendo como modelos 97 estudantes universitários,
com idades que variam de 18 a 30 anos, onde 65% são mulheres, 15% são Afro-americanos e
3% são asiáticos ou latinos. Todos foram instruídos a realizar alguma série de 23 mudanças
de expressões faciais, sete das quais baseadas nas emoções básicas: raiva, nojo, medo, ale-
gria, neutra, tristeza e surpresa. Sequências de imagens partindo da expressão neutra para a
expressão-alvo foram digitalizadas em imagens com resolução de 640 × 490 pixels, contudo
algumas imagens são disponibilizadas no padrão de cores RGB, como o sistema proposto
foi desenvolvido para processar imagens no padrão de 256 níveis de cinza foi necessária a
conversão dessas imagens para o mesmo padrão.
Nos experimentos deste trabalho, apenas as três últimas imagens das sequências, que

97
representam o ápice das expressões faciais, foram utilizadas para treinamento e testes.
Nas Tabelas 4.13 a 4.20 são apresentadas as matrizes de confusão com os resultados dos
experimentos do reconhecimento das expressões faciais dentro da base de imagens Cohn-
Kanade, variando a quantidade de HOVs e com tamanho fixo de bloco 8 × 8 para o cálculo
dos MVs.
Tabela 4.13: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 1 HOV.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 97,22 0 1,85 0 0,93 0 0
Nojo 1,71 91,45 1,71 0,85 2,56 1,71 0
Medo 0 2,34 94,15 0,58 1,17 0 1,75
Alegria 0 2,05 0 96,30 1,23 0 0,41
Neutra 0,70 2,77 0,35 0,35 94,10 1,40 0,70
Tristeza 0 0 0,71 0 0,71 98,58 0
Surpresa 0 0,46 0 0 0,91 0 98,63
Tabela 4.14: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 2 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 95,37 0,93 0,93 0 2,78 0 0
Nojo 1,71 90,60 2,56 2,56 1,71 0,85 0
Medo 1,17 2,92 91,81 0 2,34 0 1,75
Alegria 0 1,65 0,82 96,30 1,23 0 0
Neutra 0,69 0,35 0,35 0,69 95,83 1,05 1,05
Tristeza 0 0,71 0,71 0 1,42 97,16 0
Surpresa 0 0,46 0,46 0,46 0 0 98,63
Tabela 4.15: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 4 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 97,22 0,93 0,93 0 0 0 0,93
Nojo 1,71 91,45 1,71 2,56 0,85 0,85 0,85
Medo 0,58 1,75 95,90 0 1,17 0 0,58
Alegria 0 2,47 0,41 97,12 0 0 0
Neutra 0,35 1,04 0,35 0,70 96,88 0 0,70
Tristeza 0 1,43 0 0 0 98,57 0
Surpresa 0,46 0,91 0,46 0 0 0 98,17

98
Tabela 4.16: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 6 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 97,22 1,85 0,93 0 0 0 0
Nojo 1,71 93,16 0,85 2,56 0,85 0,85 0
Medo 0 3,51 94,15 0,58 1,17 0 0,58
Alegria 0 1,65 0 97,94 0 0 0,41
Neutra 0,35 1,04 0,35 0,70 96,88 0 0,70
Tristeza 0 0,71 0,71 0 0 98,58 0
Surpresa 0,46 0,46 0,46 0 0 0 98,63
Tabela 4.17: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 8 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 98,15 0 0 0 0,93 0,93 0
Nojo 0 94,02 0,85 2,56 2,56 0 0
Medo 0 3,51 94,15 0,58 1,75 0 0
Alegria 0 1,65 0 97,12 0,82 0 0,41
Neutra 0,69 0,35 0 0,35 97,92 0,35 0,35
Tristeza 0 1,43 0 0 0 97,86 0,71
Surpresa 0 0 0 0 0,46 0 99,54
Tabela 4.18: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 10 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 97,22 0,93 0,93 0 0,93 0 0
Nojo 2,56 91,45 2,56 1,71 0,85 0,85 0
Medo 0,58 2,34 94,74 1,17 0,58 0 0,58
Alegria 0 1,23 0,41 97,94 0 0 0,41
Neutra 0,69 1,39 0,35 0,35 96,88 0 0,35
Tristeza 0,71 0,71 0 0 0 98,58 0
Surpresa 0 0 0 0 0,46 0 99,54

99
Tabela 4.19: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 12 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 94,44 1,85 2,78 0 0,93 0 0
Nojo 2,56 89,74 5,13 1,71 1,71 1,71 0
Medo 0,58 4,09 91,81 0 2,92 0 0,58
Alegria 0 1,23 1,23 97,53 0 0 0
Neutra 0 1,04 1,04 0,35 96,88 0 0,69
Tristeza 0,42 0,42 0 0,42 0 98,75 0
Surpresa 0 0 0 0 0 0 100
Tabela 4.20: Matriz de confusão do reconhecimento de expressões faciais na base CK, utilizando 14 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 94,44 1,85 3,70 0 0 0 0
Nojo 2,56 82,91 8,55 1,71 2,56 1,71 0
Medo 0 2,92 90,06 0 5,85 0 1,17
Alegria 0 1,23 0,82 97,53 0,41 0 0
Neutra 0,35 1,39 0,69 0,69 95,83 0 1,04
Tristeza 0 0,71 2,14 0 1,43 95 0
Surpresa 0 0 0 0 0 0 100
A Figura 4.4 mostra a taxa de acertos no reconhecimento de cada expressão facial da
base CK, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
85
90
95
100
Quantidade de HOVs
Taxa
de
acer
tos
(%)
raivanojo
medoalegrianeutratristeza
surpresa
Figura 4.4: Taxas de reconhecimento para cada expressão facial da base CK. Fonte: autor.

100
A Figura 4.5 mostra a taxa média de acertos no reconhecimento de todas as expressões
faciais da base CK, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
94
95
96
97
95, 78
95, 1
96, 4796, 65
96, 9796, 62
95, 59
93, 68
Quantidade de HOVs
Taxa
méd
iad
eac
erto
s(%
)
Figura 4.5: Quantidade de HOVs X Respectivas taxas médias de acertos no reconhecimento de expressões
faciais na base de imagens CK. Fonte: autor.
Nas Tabelas 4.13 a 4.20 e no gráfico da Figura 4.4 é possível observar que as expres-
sões faciais que apresentam as melhores taxa de reconhecimento são surpresa e tristeza, com
taxas médias de acertos de 99,14% e 97,88%, respectivamente. A expressão que apresenta
a pior taxa é nojo, com taxa média de acerto de 90,60%, sendo bastante confundida com
as expressões medo e neutra. Em todas as tabelas, as taxas de acerto no reconhecimento de
cada expressão são superiores a 82%. Por fim, no gráfico da Figura 4.5 é possível observar
que quando são utilizados dois HOVs, há uma diminuição na média de acertos do reco-
nhecimento com relação ao uso de apenas um HOV, contudo a média de acertos aumenta
gradativamente a partir do uso de quatro HOVs, mas volta a diminuir com o uso de 10, 12
e 14 HOVs. Isso ocorre pois a utilização de muitos HOVs significa que são consideradas
muitas coordenadas com maiores ocorrências, o que diminui a relevância das coordenadas
que de fato ocorreram mais vezes nos MVs de cada expressão facial da base de imagens. O
mesmo foi observado nos experimentos da base JAFFE.

101
4.3.1 Comparação dos algoritmos de estimação de movimento por
casamento de blocos na base CK
Assim como foi feito para a base JAFFE, para verificar a eficiência do algoritmo de es-
timação de movimento proposto (MARSA), foram realizados experimentos também com
os algoritmos FS e ARSA. Seguindo os mesmos critérios para a definição dos tamanhos de
blocos para o cálculo dos MVs e para as quantidades de HOVs. O tamanho de bloco 8 × 8
gerou a maior taxa de reconhecimento, portanto foi utilizado para o cálculo das matrizes
de confusão para as respectivas quantidades de coordenadas com maiores ocorrências nos
vetores de movimento: 1, 2, 4, 6, 8, 10, 12 e 14. A quantidade de HOVs que forneceu as
maiores taxas médias de acertos para os três algoritmos foi oito, assim como é mostrado no
gráfico da Figura 4.5.
Na Tabela 4.21 são mostradas as taxas médias de acerto para o reconhecimento de ex-
pressões faciais utilizando os três algoritmos de estimação de movimento no método pro-
posto: FS, ARSA e MARSA. É possível observar a superioridade do algoritmo MARSA, pela
mesma razão apresentada na comparação dos algoritmos na base JAFFE.
Tabela 4.21: Taxas médias de reconhecimento dos algoritmos de estimação de movimento para tamanhos dife-
rentes de blocos, utilizando a base CK.
AlgoritmoTamanho do bloco
4 × 4 (%) 8 × 8 (%) 12 × 12 (%)
FS 95,4 ± 1,9 96,9 ± 1,3 94,6 ± 1,4
ARSA 95,6 ± 1,7 96,0 ± 1,3 94,9 ± 1,4
MARSA 95,8 ± 1,5 97,0 ± 1,0 94,9 ± 1,4
Além da comparação das taxas médias de acertos entre os algoritmos de estimação,
também foi realizada a comparação dos tempos de processamento, assim como foi feito com
a base de imagens JAFFE. A Tabela 4.22 mostra três tempos de processamento: treinamento,
teste e para uma única imagem. Também foram comparados os tempos de processamento
para diferentes tamanhos de blocos: 4× 4, 8× 8 e 12× 12. É possível observar que algoritmo
MARSA apresenta os menores tempos de processamento no método proposto: sendo em
média 13,8% mais veloz no treinamento, 13,3% mais veloz nos testes e no reconhecimento
da expressão facial em uma única imagem, quando comparado com o segundo algoritmo
mais veloz.

102
Tabela 4.22: Tempos de processamento dos algoritmos de estimação de movimento para tamanhos diferentes
de blocos, utilizando a base CK.
Algor.(tam. do bloco)Tempo de processamento
treinamento(min.) teste(min.) imagem(seg.)
FS (4 × 4) 290,71 31,79 8,96
FS (8 × 8) 264,08 28,22 7,95
FS (12 × 12) 315,08 36,14 10,18
ARSA (4 × 4) 290,31 30,79 8,67
ARSA (8 × 8) 260,05 28,02 7,89
ARSA (12 × 12) 309,70 33,15 9,34
MARSA (4 × 4) 218,87 25,84 7,28
MARSA (8 × 8) 231,08 23,21 6,54
MARSA (12 × 12) 292,34 30,94 8,72
4.3.2 A Segunda Versão da Base Cohn-Kanade: CK+
Como já foi mencionado no capítulo dois, a base de imagens Cohn-Kanade (CK) possui
uma segunda versão. Na versão CK+ há mais uma expressão facial: desprezo (contempt).
Da mesma forma que na base CK, sequências de imagens partindo da expressão neutra para
a expressão-alvo foram digitalizadas em imagens com resoluções de 640 × 480, 640 × 490 e
720× 480 pixels, portanto foi necessário redimensionar as imagens para um mesmo padrão:
640 × 490. Além disso, assim como na base CK, existem algumas imagens no padrão de
cores RGB, que precisaram ser convertidas para 256 níveis de cinza.
Nos experimentos deste trabalho, assim como na base CK, apenas as três últimas ima-
gens das sequências, que representam o ápice das expressões faciais, foram utilizadas para
treinamento e testes.
Nas Tabelas 4.23 a 4.30 são apresentadas as matrizes de confusão com os resultados dos
experimentos do reconhecimento das expressões faciais dentro da base de imagens CK+,
variando a quantidade de HOVs e com tamanho fixo de bloco 8 × 8 para o cálculo dos
MVs.
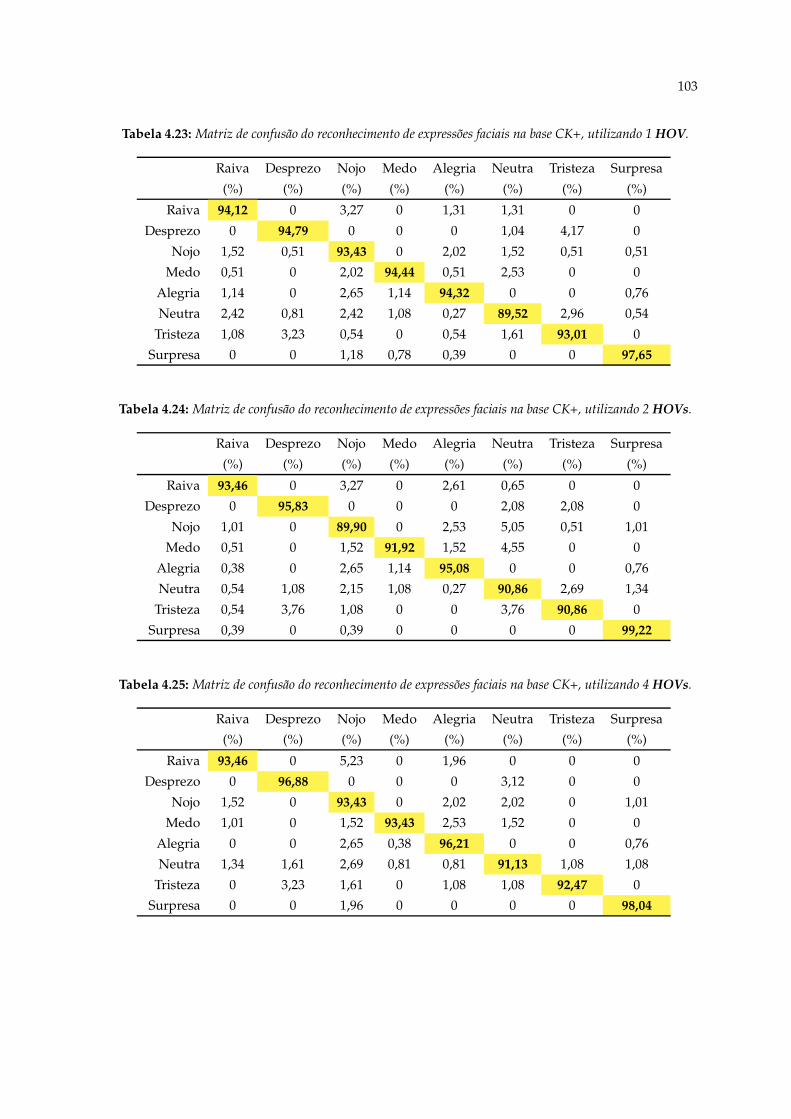
103
Tabela 4.23: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 1 HOV.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 94,12 0 3,27 0 1,31 1,31 0 0
Desprezo 0 94,79 0 0 0 1,04 4,17 0
Nojo 1,52 0,51 93,43 0 2,02 1,52 0,51 0,51
Medo 0,51 0 2,02 94,44 0,51 2,53 0 0
Alegria 1,14 0 2,65 1,14 94,32 0 0 0,76
Neutra 2,42 0,81 2,42 1,08 0,27 89,52 2,96 0,54
Tristeza 1,08 3,23 0,54 0 0,54 1,61 93,01 0
Surpresa 0 0 1,18 0,78 0,39 0 0 97,65
Tabela 4.24: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 2 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 93,46 0 3,27 0 2,61 0,65 0 0
Desprezo 0 95,83 0 0 0 2,08 2,08 0
Nojo 1,01 0 89,90 0 2,53 5,05 0,51 1,01
Medo 0,51 0 1,52 91,92 1,52 4,55 0 0
Alegria 0,38 0 2,65 1,14 95,08 0 0 0,76
Neutra 0,54 1,08 2,15 1,08 0,27 90,86 2,69 1,34
Tristeza 0,54 3,76 1,08 0 0 3,76 90,86 0
Surpresa 0,39 0 0,39 0 0 0 0 99,22
Tabela 4.25: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 4 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 93,46 0 5,23 0 1,96 0 0 0
Desprezo 0 96,88 0 0 0 3,12 0 0
Nojo 1,52 0 93,43 0 2,02 2,02 0 1,01
Medo 1,01 0 1,52 93,43 2,53 1,52 0 0
Alegria 0 0 2,65 0,38 96,21 0 0 0,76
Neutra 1,34 1,61 2,69 0,81 0,81 91,13 1,08 1,08
Tristeza 0 3,23 1,61 0 1,08 1,08 92,47 0
Surpresa 0 0 1,96 0 0 0 0 98,04

104
Tabela 4.26: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 6 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 93,46 0 3,92 0 1,96 0,65 0 0
Desprezo 0 96,88 0 0 0 3,12 0 0
Nojo 2,02 1,01 92,42 0 2,02 2,02 0 0,51
Medo 1,01 0 2,02 92,93 3,03 1,01 0 0
Alegria 0,76 0 1,89 0,76 95,83 0 0 0,76
Neutra 1,34 0 1,08 0,54 0,81 94,62 1,08 0,54
Tristeza 0,54 3,23 1,61 1,08 0,54 0,54 92,47 0
Surpresa 0 0 1,57 0 0 0,39 0 98,04
Tabela 4.27: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 8 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 94,77 0 2,61 0 2,61 0 0 0
Desprezo 0 96,88 0 0 0 3,12 0 0
Nojo 2,53 0,51 91,92 1,01 1,01 2,53 0 0,51
Medo 0 0 2,53 92,93 1,01 3,54 0 0
Alegria 0 0 1,14 0,38 96,59 0,76 0,38 0,76
Neutra 0,54 0 1,08 0,54 0,27 96,24 0,54 0,81
Tristeza 0 4,30 1,08 0,54 1,08 1,08 91,94 0
Surpresa 0 0 0,39 0 0 1,18 0 98,43
Tabela 4.28: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 10 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 94,12 0 2,61 0 1,31 1,31 0 0,65
Desprezo 0 94,79 1,04 0 0 4,17 0 0
Nojo 0,51 1,01 91,92 1,01 2,53 2,53 0 1,01
Medo 0,51 0 3,03 91,41 1,52 2,53 0,51 0
Alegria 0 0 1,52 1,14 94,70 1,89 0,38 0,38
Neutra 0,81 0,27 1,08 0,54 0 95,16 1,61 0,54
Tristeza 0 4,30 1,08 0,54 0,54 4,84 88,71 0
Surpresa 0 0 0,78 0 0 0,78 0 98,43

105
Tabela 4.29: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 12 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 90,20 0 6,54 0,65 1,31 1,31 0 0
Desprezo 0 92,71 0 0 0 6,25 1,04 0
Nojo 2,53 1,01 89,39 0,51 3,03 2,02 0 1,52
Medo 1,01 0,51 2,53 90,40 3,03 2,53 0 0
Alegria 0,38 0 2,65 0,38 94,70 1,14 0,38 0,38
Neutra 1,34 0,54 0,27 0,54 0 95,43 0,81 1,08
Tristeza 1,08 3,76 1,08 0 0 5,94 86,56 0
Surpresa 0,39 0 0,39 0,78 0 0,25 0 96,08
Tabela 4.30: Matriz de confusão do reconhecimento de expressões faciais na base CK+, utilizando 14 HOVs.
Raiva Desprezo Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%) (%)
Raiva 90,20 0 4,58 0,65 1,96 1,96 0,65 0
Desprezo 0 94,79 0 2,08 0 3,12 0 0
Nojo 1,52 1,01 86,87 0,51 4,55 4,04 0,51 1,01
Medo 0,51 0,51 3,03 87,37 3,03 5,56 0 0
Alegria 0 0 4,17 0,38 93,94 1,14 0,38 0
Neutra 1,08 0,27 1,34 0,81 0,54 93,55 1,08 1,34
Tristeza 0 4,30 1,61 1,08 0,54 8,06 84,41 0
Surpresa 0 0 0,78 0 0 2,75 0 96,47
A Figura 4.6 mostra a taxa de acertos no reconhecimento de cada expressão facial da
base CK+, para quantidades diferentes de HOVs.

106
0 2 4 6 8 10 12 14
85
90
95
100
Quantidade de HOVs
Taxa
de
acer
tos
(%)
raivadesprezo
nojomedoalegrianeutratristeza
surpresa
Figura 4.6: Taxas de reconhecimento para cada expressão facial da base CK+. Fonte: autor.
A Figura 4.7 mostra a taxa média de acertos no reconhecimento de todas as expressões
faciais da base CK+, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
91
92
93
94
95
93, 91
93, 39
94, 3894, 58
94, 96
93, 66
91, 93
90, 95
Quantidade de HOVs
Taxa
méd
iad
eac
erto
s(%
)
Figura 4.7: Quantidade de HOVs X Respectivas taxas médias de acertos no reconhecimento de expressões
faciais na base de imagens CK+. Fonte: autor.
Nas Tabelas 4.23 a 4.30 e no gráfico da Figura 4.6 é possível observar que as expressões
faciais que apresentam as melhores taxa de reconhecimento são surpresa e desprezo, com ta-
xas médias de acertos de 97,80% e 95,44%, respectivamente. As expressões que apresentam
as piores taxas são nojo e tristeza, com taxas médias de acertos de 91,16% e 90,05%, respec-
tivamente. Em todas as tabelas, as taxas de acerto no reconhecimento de cada expressão
são superiores a 84%. Por fim, no gráfico da Figura 4.7 é possível observar que quando

107
são utilizadas dois HOVs, há uma diminuição na média de acertos do reconhecimento com
relação ao uso de apenas 1 HOV, contudo a média de acertos aumenta gradativamente a
partir do uso de dois HOVs, mas volta a diminuir com o uso das 10, 12 e 14 HOVs. O
mesmo foi observado nos experimentos das bases JAFFE e CK.
Comparação dos algoritmos de estimação de movimento por casamento de blocos na base CK+
Assim como foi feito para as bases JAFFE e CK, para verificar a eficiência do algoritmo
de estimação de movimento proposto (MARSA), foram realizados experimentos também
com os algoritmos FS e ARSA. Seguindo os mesmos critérios para a definição dos tamanhos
de blocos para o cálculo dos vetores de movimento e para as quantidades de coordenadas
de maiores ocorrências nesses mesmos vetores. O tamanho de bloco 8 × 8 gerou a maior
taxa de reconhecimento, portanto foi utilizado para o cálculo das matrizes de confusão para
as respectivas quantidades de coordenadas com maiores ocorrências nos vetores de movi-
mento: 1, 2, 4, 6, 8, 10, 12 e 14. A quantidade de HOVs que forneceu as maiores taxas médias
de acertos para os três algoritmos foi oito, assim como é mostrado no gráfico da Figura 4.7.
Na Tabela 4.31 são mostradas as taxas médias de acerto para o reconhecimento de ex-
pressões faciais utilizando os três algoritmos de estimação de movimento no método pro-
posto: FS, ARSA e MARSA. É possível observar a superioridade do algoritmo MARSA, pela
mesma razão apresentada na comparação dos algoritmos nas bases anteriores.
Tabela 4.31: Taxas médias de reconhecimento dos algoritmos de estimação de movimento para tamanhos dife-
rentes de blocos, utilizando a base CK+.
AlgoritmoTamanho do bloco
4 × 4 (%) 8 × 8 (%) 12 × 12 (%)
FS 90,7 ± 2,4 93,4 ± 1,2 90,7 ± 2,4
ARSA 92,4 ± 1,6 94,1 ± 1,9 91,6 ± 1,6
MARSA 92,6 ± 1,1 95,0 ± 1,0 92,0 ± 1,9
Além da comparação das taxas médias de acertos entre os algoritmos de estimação,
também foi realizada a comparação dos tempos de processamento, assim como foi feito
com as bases de imagens JAFFE e CK. A Tabela 4.32 mostra três tempos de processamento:
treinamento, teste e para uma única imagem. Também foram comparados os tempos de
processamento para diferentes tamanhos de blocos: 4 × 4, 8 × 8 e 12 × 12. É possível ob-
servar que algoritmo MARSA apresenta os menores tempos de processamento no método

108
proposto: sendo em média 13,8% mais veloz no treinamento, 17,2% mais veloz nos testes e
no reconhecimento da expressão facial em uma única imagem, quando comparado com o
segundo algoritmo mais veloz.
Tabela 4.32: Tempos de processamento dos algoritmos de estimação de movimento para tamanhos diferentes
de blocos, utilizando a base CK+.
Algor.(tam. do bloco)Tempo de processamento
treinamento(min.) teste(min.) imagem(seg.)
FS (4 × 4) 517,95 57,35 16,16
FS (8 × 8) 461,65 51,25 14,44
FS (12 × 12) 567,82 75,38 21,23
ARSA (4 × 4) 500,28 54,17 15,26
ARSA (8 × 8) 448,47 50,41 14,20
ARSA (12 × 12) 539,90 62,65 17,65
MARSA (4 × 4) 381,12 41,57 11,71
MARSA (8 × 8) 393,08 42,67 12,02
MARSA (12 × 12) 511,65 54,45 15,34
4.4 Reconhecimento de Expressões Faciais Utilizando a Base MMI
A quarta rodada de testes foi realizada com as imagens da base MMI. Esta base é com-
posta por 30 indivíduos de ambos os sexos e idades entre 19 e 62 anos. A partir desses
indivíduos foram geradas mais de 1.500 amostras de imagens estáticas e vídeos de faces
nas visões frontal e de perfil, mostrando várias expressões faciais. Os vídeos que mostram a
transição da expressão neutra para a expressão-alvo possuem resolução de 720× 576 pixels.
Nos experimentos deste trabalho foram utilizados os vídeos da "Parte II"da base, da mesma
forma que em [82], que contém 238 clipes de 28 indivíduos (sessões 1.767 a 2.004) onde to-
das as expressões básicas (raiva, nojo, medo, alegria, tristeza e surpresa) foram gravadas
duas vezes. Pessoas usando óculos foram gravadas uma vez e mais uma vez sem óculos.
Como os vídeos foram disponibilizados no padrão de cores RGB, e o sistema proposto foi
desenvolvido para processar imagens no padrão de 256 níveis de cinza, foi necessária a
conversão das sequências de imagens extraídas para o mesmo padrão.
Nos experimentos deste trabalho, apenas três imagens de cada sequência, que represen-
tam o ápice das expressões faciais, foram utilizadas para treinamento e testes, assim como
nas bases CK e CK+, o que resultou em 648 imagens de expressões.
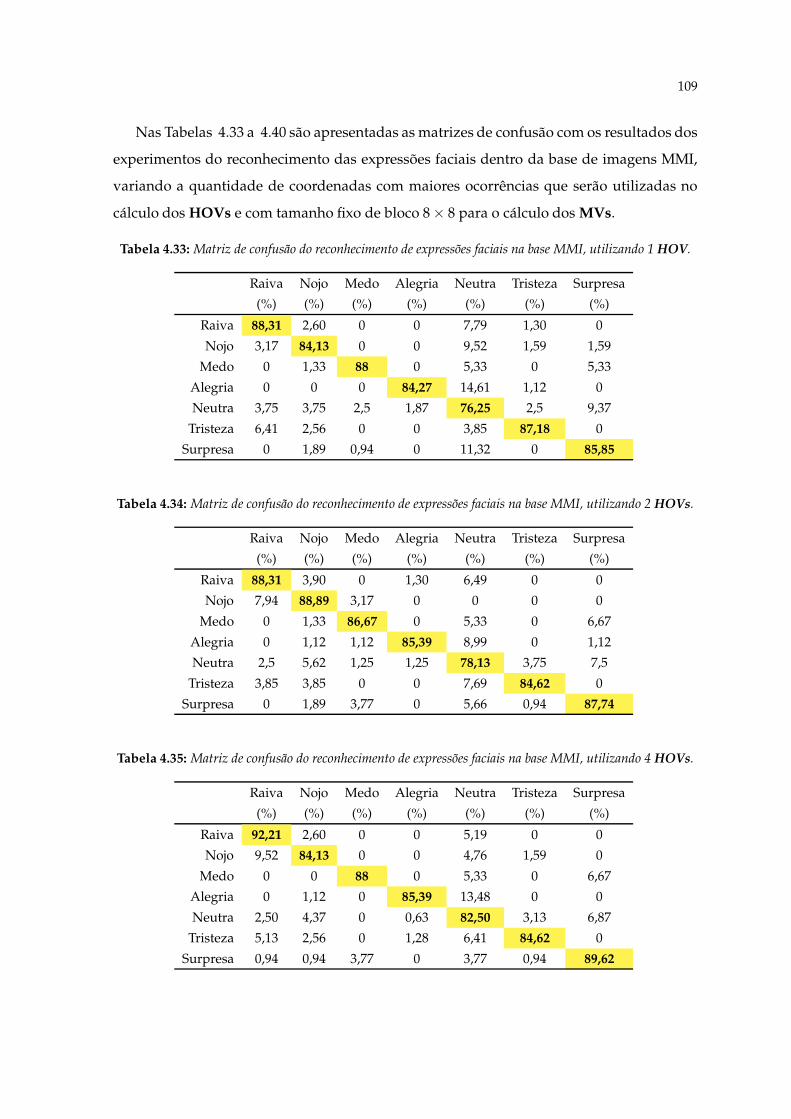
109
Nas Tabelas 4.33 a 4.40 são apresentadas as matrizes de confusão com os resultados dos
experimentos do reconhecimento das expressões faciais dentro da base de imagens MMI,
variando a quantidade de coordenadas com maiores ocorrências que serão utilizadas no
cálculo dos HOVs e com tamanho fixo de bloco 8 × 8 para o cálculo dos MVs.
Tabela 4.33: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 1 HOV.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 88,31 2,60 0 0 7,79 1,30 0
Nojo 3,17 84,13 0 0 9,52 1,59 1,59
Medo 0 1,33 88 0 5,33 0 5,33
Alegria 0 0 0 84,27 14,61 1,12 0
Neutra 3,75 3,75 2,5 1,87 76,25 2,5 9,37
Tristeza 6,41 2,56 0 0 3,85 87,18 0
Surpresa 0 1,89 0,94 0 11,32 0 85,85
Tabela 4.34: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 2 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 88,31 3,90 0 1,30 6,49 0 0
Nojo 7,94 88,89 3,17 0 0 0 0
Medo 0 1,33 86,67 0 5,33 0 6,67
Alegria 0 1,12 1,12 85,39 8,99 0 1,12
Neutra 2,5 5,62 1,25 1,25 78,13 3,75 7,5
Tristeza 3,85 3,85 0 0 7,69 84,62 0
Surpresa 0 1,89 3,77 0 5,66 0,94 87,74
Tabela 4.35: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 4 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 92,21 2,60 0 0 5,19 0 0
Nojo 9,52 84,13 0 0 4,76 1,59 0
Medo 0 0 88 0 5,33 0 6,67
Alegria 0 1,12 0 85,39 13,48 0 0
Neutra 2,50 4,37 0 0,63 82,50 3,13 6,87
Tristeza 5,13 2,56 0 1,28 6,41 84,62 0
Surpresa 0,94 0,94 3,77 0 3,77 0,94 89,62

110
Tabela 4.36: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 6 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 89,61 3,90 0 0 3,90 2,60 0
Nojo 6,35 84,13 0 0 7,94 1,59 0
Medo 0 0 88 0 6,67 0 5,33
Alegria 0 0 2,25 85,39 12,36 0 0
Neutra 1,88 4,37 1,25 0,63 80 3,13 8,75
Tristeza 5,13 2,56 0 1,28 6,41 84,62 0
Surpresa 0 0,94 2,83 0 6,60 0 89,62
Tabela 4.37: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 8 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 89,61 2,60 0 0 5,19 2,60 0
Nojo 6,35 87,30 0 0 4,76 1,59 0
Medo 0 1,33 88 0 5,33 0 5,33
Alegria 0 0 2,25 86,52 11,24 0 0
Neutra 1,88 2,5 1,25 1,25 80,63 3,13 9,37
Tristeza 2,56 2,56 1,28 0 8,97 84,62 0
Surpresa 0 1,89 3,77 0 6,60 0 87,74
Tabela 4.38: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 10 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 89,61 3,90 0 0 3,90 2,60 0
Nojo 9,52 79,37 1,59 1,59 7,94 0 0
Medo 0 0 88 0 6,67 0 5,33
Alegria 0 0 1,12 86,52 12,36 0 0
Neutra 1,88 2,5 2,5 1,25 80,63 3,13 8,12
Tristeza 3,85 1,28 1,28 0 6,41 87,18 0
Surpresa 0 0,94 4,72 0 7,55 0 86,79

111
Tabela 4.39: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 12 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 87,01 5,19 0 0 6,49 1,30 0
Nojo 1,59 84,13 1,59 3,18 4,76 1,59 1,59
Medo 0 1,33 88 0 6,67 0 4
Alegria 0 0 0 85,39 14,61 0 0
Neutra 2,5 3,12 0 1,25 83,13 2,5 7,5
Tristeza 3,85 2,56 0 0 11,54 83,33 0
Surpresa 0 1,89 2,83 0 7,55 0 87,74
Tabela 4.40: Matriz de confusão do reconhecimento de expressões faciais na base MMI, utilizando 14 HOVs.
Raiva Nojo Medo Alegria Neutra Tristeza Surpresa
(%) (%) (%) (%) (%) (%) (%)
Raiva 85,71 5,19 0 0 7,79 1,30 0
Nojo 1,59 88,89 0 0 7,94 0 1,59
Medo 0 1,33 84 0 10,67 0 4
Alegria 0 2,25 0 83,15 14,61 0 0
Neutra 1,87 5,63 0,62 0,62 80,63 1,87 8,75
Tristeza 2,56 2,56 0 0 12,82 82,05 1,27
Surpresa 0 0,94 1,89 0,94 15,09 0 87,74
A Figura 4.8 mostra a taxa de acertos no reconhecimento de cada expressão facial da
base MMI, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 1475
80
85
90
Quantidade de HOVs
Taxa
de
acer
tos
(%)
raivanojo
medoalegrianeutratristeza
surpresa
Figura 4.8: Taxas de reconhecimento para cada expressão facial da base MMI. Fonte: autor.

112
A Figura 4.9 mostra a taxa média de acertos no reconhecimento de todas as expressões
faciais da base MMI, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
84
85
86
87
84, 86
85, 68
86, 64
85, 91
86, 35
85, 4485, 53
83, 65
Quantidade de HOVs
Taxa
méd
iad
eac
erto
s(%
)
Figura 4.9: Quantidade de HOVs X Respectivas taxas médias de acertos no reconhecimento de expressões
faciais na base de imagens e vídeos MMI. Fonte: autor.
Nas Tabelas 4.33 a 4.40 e no gráfico da Figura 4.8 é possível observar que as expressões
faciais que apresentam as melhores taxa de reconhecimento são raiva e surpresa, com taxas
médias de acertos de 88,80% e 87,86%, respectivamente. A expressão que apresenta a pior
taxa é neutra, com taxa média de acerto de 80,24%. Em todas as tabelas, as taxas de acerto no
reconhecimento de cada expressão são superiores a 76%. Por fim, no gráfico da Figura 4.9
é possível observar que após um aumento gradativo nas taxas de acertos, variando a quan-
tidade de HOVs até seis, ocorre uma pequena oscilação (menos de 3%) nas taxas enquanto
a quantidade de HOVs é aumentada.
4.4.1 Comparação dos algoritmos de estimação de movimento por
casamento de blocos na base MMI
Assim como foi feito para as bases JAFFE, CK e CK+, para verificar a eficiência do al-
goritmo de estimação de movimento proposto (MARSA), foram realizados experimentos
também com os algoritmos FS e ARSA. Seguindo os mesmos critérios para a definição dos
tamanhos de blocos para o cálculo dos MVs e para as quantidades de HOVs. O tamanho
de bloco 8 × 8 gerou a maior taxa de reconhecimento, portanto foi utilizado para o cálculo
das matrizes de confusão para as respectivas quantidades de HOVs: 1, 2, 4, 6, 8, 10, 12 e

113
14. A quantidade de HOVs que forneceu as maiores taxas médias de acertos para os três
algoritmos foi quatro, assim como é mostrado no gráfico da Figura 4.9.
Na Tabela 4.41 são mostradas as taxas médias de acerto para o reconhecimento de ex-
pressões faciais utilizando os três algoritmos de estimação de movimento no método pro-
posto: FS, ARSA e MARSA. É possível observar a superioridade do algoritmo MARSA, pela
mesma razão apresentada na comparação dos algoritmos nas bases anteriores.
Tabela 4.41: Taxas médias de reconhecimento dos algoritmos de estimação de movimento para tamanhos dife-
rentes de blocos, utilizando a base MMI.
AlgoritmoTamanho do bloco
4 × 4 (%) 8 × 8 (%) 12 × 12 (%)
FS 84,2 ± 4,3 85,9 ± 3,2 85,2 ± 4,6
ARSA 84,2 ± 3,8 85,5 ± 3,1 85,2 ± 4,6
MARSA 84,5 ± 3,4 86,6 ± 3,1 86,3 ± 2,9
Além da comparação das taxas médias de acertos entre os algoritmos de estimação, tam-
bém foi realizada a comparação dos tempos de processamento, assim como foi feito com as
bases de imagens JAFFE, CK e CK+. A Tabela 4.42 mostra três tempos de processamento:
treinamento, teste e para uma única imagem. Também foram comparados os tempos de
processamento para diferentes tamanhos de blocos: 4 × 4, 8 × 8 e 12 × 12. É possível ob-
servar que algoritmo MARSA apresenta os menores tempos de processamento no método
proposto: sendo em média 10,86% mais veloz no treinamento, 14,24% mais veloz nos testes
e no reconhecimento da expressão facial em uma única imagem, quando comparado com o
segundo algoritmo mais veloz.

114
Tabela 4.42: Tempos de processamento dos algoritmos de estimação de movimento para tamanhos diferentes
de blocos, utilizando a base MMI.
Algor.(tam. do bloco)Tempo de processamento
treinamento(min.) teste(min.) p/ imagem(seg.)
FS (4 × 4) 151,74 16,51 4,65
FS (8 × 8) 138,27 14,05 3,96
FS (12 × 12) 168,69 16,83 4,74
ARSA (4 × 4) 151,01 15,34 4,32
ARSA (8 × 8) 134,99 13,96 3,93
ARSA (12 × 12) 167,93 17,31 4,88
MARSA (4 × 4) 125,66 12,34 3,48
MARSA (8 × 8) 122,10 12,37 3,48
MARSA (12 × 12) 157,47 15,80 4,45
4.5 Reconhecimento de Expressões Faciais Utilizando a Base CMU-
PIE
O sistema proposto também foi testado com a base de imagens CMU-PIE, esta base
contém 41.368 imagens de faces de 68 indivíduos realizando 13 poses, com 43 condições di-
ferentes de iluminação, e quatro expressões diferentes: neutra, sorriso, piscando, e falando.
Para os experimentos, foram testadas duas expressões faciais: neutra e sorriso, visto que as
expressões piscando e falando requerem informação temporal, o que está fora do escopo
deste trabalho. Além disso, foram usadas as poses que são próximas da frontal (câmera 27)
com rotação horizontal (câmeras 05 e 29) e vertical (câmeras 07 e 09), como mostrado na
Figura 2.8.
Para o reconhecimento de duas classes de expressões, cinco imagens representativas
foram tiradas de cada câmera, o que resultou em 778 imagens de expressões. As imagens
da base têm resolução de 640 × 486 pixels, contudo elas são disponibilizadas no padrão de
cores RGB, como o sistema proposto foi desenvolvido para processar imagens no padrão de
256 níveis de cinza foi necessária a conversão dessas imagens para o mesmo padrão, assim
como nas bases anteriores.
Como nesta base não há sequências de imagens representando as expressões faciais,
apenas imagens de diferentes posições, nos experimentos deste trabalho foram utilizadas
uma imagem de cada câmera para o treinamento. No pré-processamento, além de converter

115
as imagens para 256 níveis de cinza, também foi aplicada a função ASEF para localização
dos olhos e segmentação das faces em imagens com resolução 128 × 160 pixels, como pode
ser visto na Figura 4.10.
Figura 4.10: Imagens de faces segmentadas da base CMU-PIE. Fonte: autor.
Nas Tabelas 4.43 a 4.50 são apresentadas as matrizes de confusão com os resultados dos
experimentos do reconhecimento das expressões faciais dentro da base de imagens CMU-
PIE, variando a quantidade de coordenadas com maiores ocorrências que serão utilizadas
no cálculo dos HOVs e com tamanho fixo de bloco 12 × 12 para o cálculo dos MVs.
Tabela 4.43: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 1
HOV.
Neutra Sorriso
(%) (%)
Neutra 86,52 13,48
Sorriso 20,75 79,25
Tabela 4.44: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 2
HOVs.
Neutra Sorriso
(%) (%)
Neutra 88,91 11,19
Sorriso 23,27 76,73
Tabela 4.45: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 4
HOVs.
Neutra Sorriso
(%) (%)
Neutra 88,04 11,96
Sorriso 17,61 82,39

116
Tabela 4.46: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 6
HOVs.
Neutra Sorriso
(%) (%)
Neutra 91,96 8,04
Sorriso 26,10 73,90
Tabela 4.47: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 8
HOVs.
Neutra Sorriso
(%) (%)
Neutra 92,61 7,39
Sorriso 29,24 72,96
Tabela 4.48: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 10
HOVs.
Neutra Sorriso
(%) (%)
Neutra 93,26 6,74
Sorriso 25,16 74,84
Tabela 4.49: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 12
HOVs.
Neutra Sorriso
(%) (%)
Neutra 90,43 9,57
Sorriso 21,07 78,93
Tabela 4.50: Matriz de confusão do reconhecimento de expressões faciais na base CMU-PIE, utilizando 14
HOVs.
Neutra Sorriso
(%) (%)
Neutra 88,48 11,52
Sorriso 26,21 75,79
A Figura 4.11 mostra a taxa de acertos no reconhecimento de cada expressão facial da

117
base CMU-PIE, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
75
80
85
90
95
Quantidade de HOVs
Taxa
de
acer
tos
(%)
neutrasorriso
Figura 4.11: Taxas de reconhecimento para cada expressão facial da base CMU-PIE. Fonte: autor.
A Figura 4.12 mostra a taxa média de acertos no reconhecimento de todas as expressões
faciais da base CMU-PIE, para quantidades diferentes de HOVs.
0 2 4 6 8 10 12 14
82
83
84
85
82, 9982, 72
85, 22
82, 9382, 79
84, 05
84, 68
82, 14
Quantidade de HOVs
Taxa
méd
iad
eac
erto
s(%
)
Figura 4.12: Quantidade de coordenadas de maiores ocorrências nos vetores de movimento x Respectivas taxas
de reconhecimento da expressões faciais na base de imagens CMU-PIE. Fonte: autor.
Nas Tabelas 4.43 a 4.50 e no gráfico da Figura 4.11 é possível observar que a expressão
facial que apresenta a melhor taxa de reconhecimento é a neutra, com taxa média de acerto
de 90,03%. A expressão sorriso apresenta a pior taxa de reconhecimento, com taxa média
de acerto de 76,85%. Em todas as tabelas, as taxas de acerto no reconhecimento de cada

118
expressão são superiores a 72%. As taxas mais baixas para esta base de imagens, deve-se ao
fato de que os MVs são calculados entre duas imagens, da mesma face ou similar, de poses
diferentes, diferentemente das outras bases onde a pose é a mesma para todas as imagens.
Outro fato que leva a menores taxas de acertos é a presença de óculos e barba em algumas
imagens, o que dificulta a etapa de busca da imagem de maior semelhança para o cálculo
dos MVs.
Finalmente, no gráfico da Figura 4.12 é possível observar que quando são utilizados
dois HOVs, há uma pequena diminuição na média de acertos do reconhecimento com re-
lação ao uso de apenas um HOV, contudo a média de acertos aumenta quando são usados
quatro HOVs, então há uma oscilação quando são usados de 6 a 14 HOVs. Esse padrão é
diferente das demais bases de imagens utilizadas nos experimentos deste trabalho, devido
aos fatos mencionados no parágrafo anterior.
4.5.1 Comparação dos algoritmos de estimação de movimento por
casamento de blocos na base CMU-PIE
Assim como foi feito para as bases JAFFE, CK, CK+ e MMI, para verificar a eficiência do
algoritmo de estimação de movimento proposto (MARSA), foram realizados experimentos
também com os algoritmos FS e ARSA. Seguindo os mesmos critérios para a definição dos
tamanhos de blocos para o cálculo dos MVs e para os HOVs. O tamanho de bloco 12 × 12
gerou a maior taxa de reconhecimento, portanto foi utilizado para o cálculo das matrizes de
confusão para as respectivas quantidades de HOVs: 1, 2, 4, 6, 8, 10, 12 e 14. A quantidade de
HOVs que forneceu as maiores taxas médias de acertos para os três algoritmos foi quatro,
assim como é mostrado no gráfico da Figura 4.12.
Na Tabela 4.51 são mostradas as taxas médias de acerto para o reconhecimento de ex-
pressões faciais utilizando os três algoritmos de estimação de movimento no método pro-
posto: FS, ARSA e MARSA. É possível observar a superioridade do algoritmo proposto,
pela mesma razão apresentada na comparação dos algoritmos nas bases anteriores.

119
Tabela 4.51: Taxas médias de reconhecimento dos algoritmos de estimação de movimento para tamanhos dife-
rentes de blocos, utilizando a base CMU-PIE.
AlgoritmoTamanho do bloco
4 × 4 (%) 8 × 8 (%) 12 × 12 (%)
FS 79,8 ± 5,3 82,1 ± 4,5 83,5 ± 4,3
ARSA 78,7 ± 5,1 82,8 ± 3,5 83,3 ± 4,2
MARSA 80,5 ± 4,1 82,8 ± 3,1 85,2 ± 3,9
Além da comparação das taxas médias de acertos entre os algoritmos de estimação, tam-
bém foi realizada a comparação dos tempos de processamento, assim como foi feito com as
bases de imagens JAFFE, CK, CK+ e MMI. A Tabela 4.52 mostra três tempos de processa-
mento: treinamento, teste e para uma única imagem. Também foram comparados os tempos
de processamento para diferentes tamanhos de blocos: 4 × 4, 8 × 8 e 12 × 12. É possível ob-
servar que algoritmo MARSA apresenta os menores tempos de processamento no método
proposto: sendo em média 15,18% mais veloz no treinamento, 20,04% mais veloz nos testes
e no reconhecimento da expressão facial em uma única imagem, quando comparado com o
segundo algoritmo mais veloz.
Tabela 4.52: Tempos de processamento dos algoritmos de estimação de movimento para tamanhos diferentes
de blocos, utilizando a base CMU-PIE.
Algor.(tam. do bloco)Tempo de processamento
treinamento(min.) teste(min.) p/ imagem(seg.)
FS (4 × 4) 13,49 1,05 0,29
FS (8 × 8) 11,38 0,86 0,24
FS (12 × 12) 14,96 0,95 0,27
ARSA (4 × 4) 11,21 0,97 0,27
ARSA (8 × 8) 11,10 0,77 0,22
ARSA (12 × 12) 14,83 0,89 0,25
MARSA (4 × 4) 8,37 0,70 0,20
MARSA (8 × 8) 9,95 0,66 0,18
MARSA (12 × 12) 13,37 0,73 0,20
4.6 Comparação com Outros Métodos
As melhores taxas de reconhecimento para as bases JAFFE, CK, CK+, MMI e CMU-PIE
foram 91,17%, 96,97%, 94,96%, 86,64% e 85,22%, respectivamente. Todas as bases tiveram

120
taxas acima de 85%. A eficiência da técnica apresentada nesta Tese foi avaliada com a ob-
tenção de resultados satisfatórios.
As Tabelas 4.53, 4.54, 4.55, 4.56 e 4.57 a seguir mostram uma comparação dos me-
lhores resultados obtidos neste trabalho, para o reconhecimento de expressões faciais nas
bases utilizadas nos experimentos, com outros métodos recentes da literatura, que também
utilizaram a SVM para a classificação e a técnica de validação cruzada (cross-validation) para
avaliação. Os resultados dos métodos apresentados nas tabelas de comparação foram ob-
tidos nos artigos referenciados ao lado do nome de cada método, alguns resultados não
foram disponibilizados nos artigos referenciados e por isso não são apresentados nas tabe-
las de comparação.
Os resultados apresentados nas Tabelas 4.53, 4.54 e 4.55 foram obtidos utilizando oito
HOVs e tamanho de bloco 8 × 8 para o cálculo do MV. Os resultados apresentados nas
Tabelas 4.56 e 4.57 foram obtidos utilizando quatro HOVs e tamanho de bloco 8 × 8 e
12 × 12, respectivamente.
Tabela 4.53: Comparação com outros métodos da literatura, utilizando a base de imagens JAFFE.
MétodoJAFFE
6-classes (%) 7-classes (%)
LBP [21] 86,7 ± 4,1 80,7 ± 5,5
LDP [83] 85,8 ± 1,1 85,9 ± 1,8
Gabor [84] 85,1 ± 5,0 79,7 ± 4,2
LSDP [23] 92,3 ± 1,6 89,2 ± 2,8
LPTP [85] 90,2 ± 1,0 88,7 ± 0,5
LDNK [82] 92,3 ± 1,7 89,2 ± 2,8
LDNG0,3;0,6;0,9 [82] 92,9 ± 0,1 90,6 ± 0,4
LDNG0,5;1,0;1,5 [82] 92,4 ± 0,3 88,7 ± 0,2
LDNG1,0;1,3;1,6 [82] 93,4 ± 0,4 90,1 ± 0,2
Resultado da Tese 92,2 ± 4,4 91,2 ± 2,9
Foram calculados os intervalos de confiança (IC) de 99% 1 considerando as taxas médias
de reconhecimento obtidas para as 6 e 7-classes na base JAFFE, ou seja, na repetição de
amostras dessas populações, em 99% dos casos a média µ (a média da população para a
qual se deseja o IC) estará entre os valores calculados l1 (limite inferior do IC) e l2 (limite
superior do IC).
1Um intervalo de confiança é um intervalo estimado de um parâmetro de interesse de uma população. Em vez de estimar oparâmetro por um único valor, é dado um intervalo de estimativas prováveis [95].

121
Dados para o cálculo do IC para a base JAFFE (6-classes):
• n (número de elementos da amostra) = 18 (foi escolhido aleatoriamente 1 dos 10 folds
utilizados nos experimentos da base);
• σ (desvio-padrão) = 4,4;
• X̄ (taxa média de acertos dos valores da amostra) = 94,44%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base JAFFE (6-classes): 92, 02% 6 µ 6 96, 86% para
99% de confiança.
Dados para o cálculo do IC para a base JAFFE (7-classes):
• n = 21;
• σ = 2,9;
• X̄ = 90,48%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base JAFFE (7-classes): 89, 00% 6 µ 6 91, 96% para
99% de confiança.
Tabela 4.54: Comparação com outros métodos da literatura, utilizando a base de imagens CK.
MétodoCK
6-classes (%) 7-classes (%)
LBP [21] 92,6 ± 2,9 88,9 ± 3,5
LDP [83] 98,5 ± 1,4 94,3 ± 3,9
Gabor [84] 89,8 ± 3,1 86,8 ± 3,1
LSDP [23] 99,2 ± 0,8 94,8 ± 3,1
LPTP [85] 99,4 ± 1,1 95,1 ± 3,1
LDNK [82] 99,2 ± 0,8 94,8 ± 3,1
LDNG0,3;0,6;0,9 [82] 98,7 ± 0,3 95,6 ± 0,7
LDNG0,5;1,0;1,5 [82] 98,9 ± 0,2 96,6 ± 0,6
LDNG1,0;1,3;1,6 [82] 99,1 ± 0,2 96,6 ± 0,6
Resultado da Tese 97,2 ± 1,1 97,0 ± 1,7
Assim como foi feito para a base JAFFE, foram calculados os intervalos de confiança
(IC) de 99% considerando as taxas médias de reconhecimento obtidas para as 6 e 7-classes
na base CK.
Dados para o cálculo do IC para a base CK (6-classes):

122
• n = 100;
• σ = 1,1;
• X̄ = 97,00%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base CK (6-classes): 96, 74% 6 µ 6 97, 26% para
99% de confiança.
Dados para o cálculo do IC para a base CK (7-classes):
• n = 129;
• σ = 1,7;
• X̄ = 96,90%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base CK (7-classes): 96, 55% 6 µ 6 97, 25% para
99% de confiança.
Tabela 4.55: Comparação com outros métodos da literatura, utilizando a base de imagens CK+.
MétodoCK+
7-classes (%) 8-classes (%)
LBP [86] - 83,87(linear) 81,89(RBF)
SIFT [86] - 86,39(linear) 87,31(RBF)
HOG [86] - 89,53(linear) 88,61(RBF)
Gabor [86] - 88,61(linear) 85,09(RBF)
OR [86] - 91,44(linear)
AURF [86] - 92,22(linear)
AUDN [86] - 92,05(linear)
SPTS [4] 50,4(não informado) -
CAPP [4] 66,7(não informado) -
SPTS+CAPP [4] 83,3(não informado) -
CLM [87] 74,4(não informado) -
CLM-SRI [88] 88,6(não informado) -
EAI [89] 82,6(não informado) -
LDNK [82] 82,0±0,8(linear) 82,3±0,8(RBF) -
LDNG0,3;0,6;0,9 [82] 85,6±0,8(linear) 85,6±0,8(RBF) -
LDNG0,5;1,0;1,5 [82] 89,0±0,7(linear) 89,0±0,7(RBF) -
LDNG1,0;1,3;1,6 [82] 89,3±0,6(linear) 89,3±0,7(RBF) -
Resultado da Tese 95,3 ± 1,2(RBF) 95,0 ± 0,9(RBF)

123
Assim como foi feito para as bases JAFFE e CK, foram calculados os intervalos de con-
fiança (IC) de 99% considerando as taxas médias de reconhecimento obtidas para as 7 e
8-classes na base CK+.
Dados para o cálculo do IC para a base CK+ (7-classes):
• n = 136;
• σ = 1,2;
• X̄ = 95,49%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base CK+ (7-classes): 95, 25% 6 µ 6 95, 73% para
99% de confiança.
Dados para o cálculo do IC para a base CK+ (8-classes):
• n = 173;
• σ = 0,9;
• X̄ = 95,07%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base CK+ (8-classes): 94, 91% 6 µ 6 95, 23% para
99% de confiança.

124
Tabela 4.56: Comparação com outros métodos da literatura, utilizando a base de vídeos MMI.
MétodoMMI
6-classes (%) 7-classes (%)
LBP [21], [86] 86,9(não informado) 52,9(linear) 50,4(RBF)
CPL [90] 49,4(não informado) -
CSPL [90] 73,5(não informado) -
AFL [90] 47,7(não informado) -
ADL [90] 47,8(não informado) -
SIFT [86] - 57,8(linear) 61,5(RBF)
HOG [86] - 63,2(linear) 65,2(RBF)
Gabor [86] - 56,1(linear) 57,6(RBF)
CSPL [90] 73,5(não informado) -
OR [86] - 68,4(linear)
AURF [86] - 69,9(linear)
AUDN [86] - 74,8(linear)
LDNK [82] 92,9±3,0(linear) 93,8±3,1(RBF) -
LDNG0,3;0,6;0,9 [82] 94,9±3,2(linear) 94,1±2,9(RBF) -
LDNG0,5;1,0;1,5 [82] 95,2±2,7(linear) 94,6±3,2(RBF) -
LDNG1,0;1,3;1,6 [82] 95,5±3,0(linear) 94,1±3,9(RBF) -
Resultado da Tese 92,8±2,7(RBF) 86,6±2,4(RBF)
Assim como foi feito para as bases de imagens anteriores, foram calculados os intervalos
de confiança (IC) de 99% considerando as taxas médias de reconhecimento obtidas para as
6 e 7-classes na base MMI.
Dados para o cálculo do IC para a base MMI (6-classes):
• n = 50;
• σ = 2,7;
• X̄ = 92,00%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base MMI (6-classes): 91, 11% 6 µ 6 92, 89% para
99% de confiança.
Dados para o cálculo do IC para a base MMI (7-classes):
• n = 66;
• σ = 2,4;
• X̄ = 86,36%;

125
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base MMI (7-classes): 85, 67% 6 µ 6 87, 05% para
99% de confiança.
Tabela 4.57: Comparação com outros métodos da literatura, utilizando a base de imagens CMU-PIE.
MétodoCMU-PIE
2-classes (%)
LBP [91] 93,5(não informado)
LBPω [92] 90,3(não informado)
LTP [93] 87,6(não informado)
LDiP [83] 88,4(não informado)
LPQ [94] 90,9(não informado)
LDNK [82] 84,6±0,3(linear) 88,8±0,3(RBF)
LDNG0,3;0,6;0,9 [82] 91,9±0,3(linear) 92,9±0,2(RBF)
LDNG0,5;1,0;1,5 [82] 94,2±0,3(linear) 93,9±0,3(RBF)
LDNG1,0;1,3;1,6 [82] 94,4±0,2(linear) 94,3±0,2(RBF)
Resultado da Tese 85,2±0,9(RBF)
Assim como foi feito para as bases de imagens anteriores, foi calculado o intervalo
de confiança (IC) de 99% considerando a taxa média de reconhecimento obtida para as
2-classes na base CMU-PIE.
Dados para o cálculo do IC para a base CMU-PIE:
• n = 78;
• σ = 0,9;
• X̄ = 84,98%;
• 1 − α = 0, 99 ou alpha = 0, 01.
Intervalo de confiança obtido para a base CMU-PIE (2-classes): 84, 74% 6 µ 6 85, 22%
para 99% de confiança.
É possível observar que para o reconhecimento 7-classes (raiva, medo, alegria, surpresa,
tristeza, nojo e neutra), o método proposto apresenta as melhores taxas de reconhecimento
nas bases JAFFE, CK, CK+ e MMI. Para o reconhecimento 8-classes (que inclui a expressão
facial de desprezo) na base CK+ também foi obtida a melhor taxa de reconhecimento dentre
as técnicas utilizadas para comparação de resultados.
Entretanto, quando consideramos o reconhecimento 6-classes (que exclui a expressão
facial neutra) nessas mesmas bases, apesar do aumento na taxa média de reconhecimento

126
o método proposto apresenta resultados um pouco inferiores a algumas das técnicas utili-
zadas para comparação dos resultados. Na base JAFFE, a taxa média de reconhecimento
foi inferior aos resultados apresentados em [23], [82]. Na base CK, a taxa média de reco-
nhecimento do método proposto ficou abaixo das técnicas apresentadas em [23], [82], [83],
[85]. Na base MMI, a taxa média de reconhecimento do método proposto ficou abaixo dos
resultados obtidos por [82]. Quando considerado o reconhecimento de apenas 2-classes de
expressões faciais (neutra e sorriso) na base CMU-PIE, a taxa média de reconhecimento foi
inferior às taxas das demais técnicas. Indicando que a técnica apresentada neste trabalho
tem a acuracidade do reconhecimento comprometida quando há variação na posição da
face do indivíduo e a presença de ’obstáculos’ na face, como barba e óculos, e quando há
variação de iluminação nas imagens.
Finalmente, também foram calculados os intervalos de confiança (IC) para validar a
comparação dos resultados dos experimentos desta Tese e dos outros trabalhos da literatura
apresentados nas Tabelas 4.53, 4.54, 4.55, 4.56 e 4.57, considerando os valores de desvio-
padrão calculados. Os intervalos de confiança validam estatisticamente as taxas médias
de reconhecimento obtidas para todas as bases de imagens utilizadas nos experimentos.
Portanto, considerando que os intervalos de confiança são calculados a partir de amostras,
é seguro afirmar que na repetição das amostras de uma população, em 99% dos casos a
média µ estará entre os valores calculados l1 e l2 em todas as bases.

CAPÍTULO 5
CONCLUSÕES
"Aprendemos a voar como os pássaros e a na-
dar como os peixes, mas não aprendemos a
conviver como irmãos."
— Martin Luther King
NEsta Tese, é abordado o problema do reconhecimento de emoções por meio de um
sistema automatizado. Dessa forma, a interação homem-máquina pode evoluir de
forma significativa, pois se aproximaria da maneira como os seres humanos interagem entre
si. Além disso, pessoas com algum tipo de transtorno, como o autismo, podem se beneficiar
desse tipo de sistema aprendendo a reconhecer qual emoção está sendo manifestada por
outro indivíduo. Considerando que uma das formas de manifestação de emoções em seres
humanos são as expressões faciais, nesta tese é proposto um método de reconhecimento
da expressões por variações na aparência de certas regiões da face, particularmente olhos e
boca, provocadas pelo movimento dos músculos faciais.
Existem alguns tipos de características que podem ser analisados pelos sistemas de reco-
nhecimento de expressões, como: textura, cor, forma e movimento. O movimento dos mús-
culos faciais durante a mudança de uma expressão para a outra é praticamente o mesmo
em todos os indivíduos. Portanto, é possível identificar a expressão facial analisando o
movimento entre as expressões, independente da pessoa.
Neste trabalho, é apresentado um método para o reconhecimento de movimentos, parti-

128
cularmente de expressões faciais, utilizando algoritmos de estimação de movimento por ca-
samento de blocos. Esses algoritmos geralmente são utilizados em sistemas de codificação
de vídeos para a eliminação de informação redundante (regiões de cenário, por exemplo)
em uma sequência de imagens, possibilitando a compressão de vídeo. Um nova abordagem
é apresentada, onde a extração de características das imagens é feita a partir de uma versão
modificada da técnica de estimação ARSA, chamada MARSA (Modified Adaptative Reduction
of the Search Area). Também é apresentada neste trabalho uma nova forma de utilização de
algoritmos de estimação de movimento: os vetores de movimento (MVs) são calculados
a partir de duas imagens de uma mesma face (ou de faces similares), a expressão facial
representada na imagem é conhecida no treinamento, mas desconhecida na fase de testes.
A partir desses MVs são obtidas as coordenadas de movimento com maiores ocorrências
nesses vetores, que serão utilizadas para gerar informação de classificação das expressões
faciais. Para comprovar a eficiência e a assertividade do método proposto, foram realizados
experimentos em cinco bases de imagens de faces utilizadas em diversos trabalhos da litera-
tura recente sobre reconhecimento de expressões faciais: JAFFE, CK, CK+, MMI e CMU-PIE.
Cada base de imagens (ou vídeos) possui características específicas, ou seja, o sistema de-
senvolvido foi testado sob condições diferentes de iluminação, posição de câmera, variação
de expressões, etc. Foi verificado que as bases com mais imagens (CK e CK+) apresentaram
as maiores taxas de reconhecimento de expressões faciais, enquanto as bases com menos
imagens (JAFFE e MMI) apresentaram taxas de reconhecimento menores. Isso ocorre pois
quanto maior a quantidade de imagens na base, melhor para o treinamento do sistema.
Contudo, a base de imagens CMU-PIE apresentou as menores taxas de reconhecimento de-
vido à variação da posição das faces e da iluminação nas imagens.
Nos primeiros experimentos, foram utilizados os algoritmos de estimação de movi-
mento por casamento de blocos Busca Exaustiva (FS - Full Search) e Redução Adaptativa da
Área de Busca (ARSA - Adaptative Reduction of the Search Area). O primeiro é um algoritmo
tradicional de estimação e compensação de movimento, foi o primeiro apresentado para
uso na compressão de vídeos padrão MPEG (Moving Picture Experts Group) [96]. Depois do
FS, foram apresentados diversos algoritmos para otimizar a estimação de movimento man-
tendo a qualidade das imagens, dentre eles o ARSA, que propõe a redução adaptativa da
área de busca para regiões da imagem com pouco ou nenhum movimento, como o cená-
rio, por exemplo. Também foram apresentadas neste trabalho algumas alterações no ARSA

129
para adequá-lo à extração de movimento de expressões faciais, essas alterações resultaram
uma versão modificada chamada MARSA e são listadas a seguir, resumidamente:
1. Utilização dos filtros de correlação ASEF (Average of Synthetic Exact Filters) para defi-
nição das regiões dos olhos e da boca, apenas essas regiões são consideradas para a
extração da característica movimento;
2. Redução dinâmica da área de busca para diminuir o número de pontos de busca,
usando as características das expressões faciais: uma pequena área de busca é deter-
minada para o bloco com pouco (ou nenhum) movimento (micro expressões) e uma
grande área de busca para o bloco com maior quantidade de movimento (macro ex-
pressões).
Os três algoritmos de estimação (FS, ARSA e MARSA) foram testados nos experimen-
tos, confirmando o melhor desempenho do algoritmo MARSA em termos de acuracidade na
classificação das expressões faciais e menor tempo de processamento, desde o treinamento
do sistema até o uso para o reconhecimento da expressão em uma única imagem. Tam-
bém é importante ressaltar que os algoritmos de estimação de movimento por casamento
de blocos são de fácil implementação e ainda assim possibilitam a extração da característica
movimento com uma alta acuracidade, o que contribui de forma significativa para a obten-
ção de taxas de reconhecimento de expressões faciais compatíveis com outras técnicas da
literatura mais complexas, como Deep Learning, por exemplo.
Os resultados apresentados nesta Tese foram comparados com outros trabalhos da lite-
ratura, apresentando taxas médias de acerto no reconhecimento de expressões faciais equi-
paráveis e até mesmo superiores, dependendo da base de imagens utilizada.
Este trabalho foi publicado no artigo Facial Expression Recognition Based on Motion Estima-
tion [97], apresentado na IJCNN 2016 (International Joint Conference on Neural Networks) [98].
5.1 Trabalhos Futuros
Apesar de apresentar resultados compatíveis ou mesmo superiores se comparados com
outros trabalhos recentes no reconhecimento de expressões faciais, o método proposto tam-
bém deve ser testado com outras bases de imagens e/ou vídeos. A utilização de outras
bases para treinamento e testes é importante não apenas para comprovar a eficiência do

130
método proposto, mas também para analisar o seu desempenho em bases com característi-
cas diferentes de iluminação, posição da câmera, expressões faciais, oclusões parciais, etc.
A combinação do extrator da característica movimento apresentado neste trabalho com
outros extratores de diferentes características (textura e forma, por exemplo) também é uma
proposta de trabalho futuro. A combinação de métodos de extração de características é uti-
lizada em outros tipos de aplicações, como detecção de pedestres [99], por exemplo. A
escolha das características mais apropriadas para o reconhecimento de expressões continua
sendo um problema desafiador, visto que a acuracidade do reconhecimento depende princi-
palmente das características que são usadas para representar as expressões. De forma intui-
tiva, algumas características parecem mais apropriadas do que outras para a representação
das expressões. Contudo, ainda não há uma consenso na literatura sobre quais as melhores
características a serem combinadas, tanto no reconhecimento de expressões faciais quanto
em outras aplicações. A hipótese a ser provada é que a combinação de extratores de dife-
rentes características pode prover taxas ainda melhores de reconhecimento das expressões
faciais.
Finalmente, o uso do sistema proposto no reconhecimento de outros tipos de movimen-
tos também pode ser alvo de estudos futuros. As atividades humanas, por exemplo, tam-
bém são uma forma bastante efetiva de comunicação não-verbal. O reconhecimento des-
sas atividades é o processo de corretamente identificar as ações realizadas pelo indivíduo.
Existem várias aplicações nesta área, tais como: vídeos de vigilância, interação homem-
máquina (HCI - Human-Computer Interaction), análises estatísticas em esportes, cuidados
médicos, etc. Em vigilância, é usada para monitorar as atividades em casas inteligentes e
também para detectar atividades anormais e alertar as autoridades competentes. Similar-
mente, em HCI, esse tipo de reconhecimento fornece um método mais natural de interagir
com o computador do que os convencionais mouse e teclado. Em sistemas de cuidados mé-
dicos, as atividades dos pacientes podem ser monitoradas para facilitar uma recuperação
mais rápida. Devido à tamanha variedade de aplicações, o reconhecimento de atividades
humanas se tornou um tópico importante na comunidade científica, com muitas pesquisas
sendo realizadas em todo o mundo [100].

REFERÊNCIAS
[1] Y. LeCun. (2016) Nips 2016 deep learning symposium. [Online]. Available:
https://drive.google.com/file/d/0BxKBnD5y2M8NREZod0tVdW5FLTQ/view
[2] M. J. Lyons, J. Budynek, and S. Akamatsu, “Automatic classification of single facial
images,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 21, no. 12,
pp. 1357–1362, 1999.
[3] T. Kanade, J. F. Cohn, and Y. Tian, “Comprehensive database for facial expression
analysis,” in Automatic Face and Gesture Recognition, 2000. Proceedings. Fourth IEEE In-
ternational Conference on. IEEE, 2000, pp. 46–53.
[4] P. Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambadar, and I. Matthews, “The ex-
tended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-
specified expression,” in 2010 IEEE Computer Society Conference on Computer Vision and
Pattern Recognition-Workshops. IEEE, 2010, pp. 94–101.
[5] M. Pantic, M. Valstar, R. Rademaker, and L. Maat, “Web-based database for facial ex-
pression analysis,” in Multimedia and Expo, 2005. ICME 2005. IEEE International Confe-
rence on. IEEE, 2005, pp. 5–pp.
[6] T. Sim, S. Baker, and M. Bsat, “The cmu pose, illumination, and expression (pie) data-
base,” in Automatic Face and Gesture Recognition, 2002. Proceedings. Fifth IEEE Internati-
onal Conference on. IEEE, 2002, pp. 46–51.
[7] H. Schneiderman and T. Kanade, “A statistical method for 3d object detection applied
to faces and cars,” in Computer Vision and Pattern Recognition, 2000. Proceedings. IEEE
Conference on, vol. 1. IEEE, 2000, pp. 746–751.
[8] J. Ahlberg, “Candide-3-an updated parameterised face,” 2001.
131

132
[9] P. Viola and M. J. Jones, “Robust real-time face detection,” International journal of com-
puter vision, vol. 57, no. 2, pp. 137–154, 2004.
[10] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neural network cascade
for face detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, 2015, pp. 5325–5334.
[11] H. Kobayashi and F. Hara, “Recognition of six basic facial expression and their
strength by neural network,” in Robot and Human Communication, 1992. Proceedings.,
IEEE International Workshop on. IEEE, 1992, pp. 381–386.
[12] Y.-I. Tian, T. Kanade, and J. F. Cohn, “Recognizing action units for facial expression
analysis,” IEEE Transactions on pattern analysis and machine intelligence, vol. 23, no. 2,
pp. 97–115, 2001.
[13] M. Pantic and L. J. Rothkrantz, “Facial action recognition for facial expression analysis
from static face images,” IEEE Transactions on Systems, Man, and Cybernetics, Part B
(Cybernetics), vol. 34, no. 3, pp. 1449–1461, 2004.
[14] A. Koutlas and D. I. Fotiadis, “An automatic region based methodology for facial
expression recognition,” in Systems, Man and Cybernetics, 2008. SMC 2008. IEEE Inter-
national Conference on. IEEE, 2008, pp. 662–666.
[15] J. Ou, X.-B. Bai, Y. Pei, L. Ma, and W. Liu, “Automatic facial expression recognition
using gabor filter and expression analysis,” in Computer Modeling and Simulation, 2010.
ICCMS’10. Second International Conference on, vol. 2. IEEE, 2010, pp. 215–218.
[16] A. Jamshidnezhad and M. J. Nordin, “A classifier model based on the features quan-
titative analysis for facial expression recognition,” International Journal on Advanced
Science, Engineering and Information Technology, vol. 1, no. 4, pp. 391–394, 2011.
[17] W. Zheng, “Multi-view facial expression recognition based on group sparse reduced-
rank regression,” IEEE Transactions on Affective Computing, vol. 5, no. 1, pp. 71–85,
2014.
[18] W. Zheng, Y. Zong, X. Zhou, and M. Xin, “Cross-domain color facial expression re-
cognition using transductive transfer subspace learning.”

133
[19] D.-T. Lin, “Facial expression classification using pca and hierarchical radial basis func-
tion network,” Journal of information science and engineering, vol. 22, no. 5, pp. 1033–
1046, 2006.
[20] P. Yang, Q. Liu, and D. N. Metaxas, “Boosting coded dynamic features for facial action
units and facial expression recognition,” in 2007 IEEE Conference on Computer Vision
and Pattern Recognition. IEEE, 2007, pp. 1–6.
[21] C. Shan, S. Gong, and P. W. McOwan, “Facial expression recognition based on local
binary patterns: A comprehensive study,” Image and Vision Computing, vol. 27, no. 6,
pp. 803–816, 2009.
[22] L. H. Thai, N. D. T. Nguyen, and T. S. Hai, “A facial expression classification system
integrating canny, principal component analysis and artificial neural network,” arXiv
preprint arXiv:1111.4052, 2011.
[23] J. A. R. Castillo, A. R. Rivera, and O. Chae, “Facial expression recognition based on
local sign directional pattern,” in 2012 19th IEEE International Conference on Image Pro-
cessing. IEEE, 2012, pp. 2613–2616.
[24] S. Elaiwat, M. Bennamoun, F. Boussaid, and A. El-Sallam, “3-d face recognition using
curvelet local features,” IEEE Signal processing letters, vol. 21, no. 2, pp. 172–175, 2014.
[25] F. Ahmed, P. P. Paul, M. Gavrilova, and R. Alhajj, “Weighted fusion of bit plane-
specific local image descriptors for facial expression recognition,” in 2015 IEEE Inter-
national Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2015, pp. 1852–1857.
[26] M. S. Bartlett, G. Littlewort, M. Frank, C. Lainscsek, I. Fasel, and J. Movellan, “Recog-
nizing facial expression: machine learning and application to spontaneous behavior,”
in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition
(CVPR’05), vol. 2. IEEE, 2005, pp. 568–573.
[27] D. S. Bolme, B. A. Draper, and J. R. Beveridge, “Average of synthetic exact filters,” in
Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE,
2009, pp. 2105–2112.
[28] H.-S. Oh and H.-K. Lee, “Block-matching algorithm based on an adaptive reduction
of the search area for motion estimation,” Real-Time Imaging, vol. 6, no. 5, pp. 407–414,
2000.

134
[29] A. Konar and A. Chakraborty, Emotion Recognition: A Pattern Analysis Approach. John
Wiley & Sons, 2014.
[30] N. N. Khatri, Z. H. Shah, and S. A. Patel, “Facial expression recognition: A survey,”
IJCSIT) International Journal of Computer Science and Information Technologies, vol. 5,
no. 1, pp. 149–152, 2014.
[31] K.-W. Wong, K.-M. Lam, and W.-C. Siu, “An efficient algorithm for human face de-
tection and facial feature extraction under different conditions,” Pattern Recognition,
vol. 34, no. 10, pp. 1993–2004, 2001.
[32] K. Karpouzis, G. Votsis, G. Moschovitis, and S. Kollias, “Emotion recognition using
feature extraction and 3-d models,” Computational intelligence and applications. World
Scientific and Engineering Society Press, pp. 342–347, 1999.
[33] V. Vasudevan, “Face recognition system with various expression and occlusion ba-
sed on a novel block matching algorithm and PCA,” International Journal of Computer
Applications, vol. 38, no. 11, pp. 27–34, 2012.
[34] J. Jain and A. Jain, “Displacement measurement and its application in interframe
image coding,” IEEE Transactions on communications, vol. 29, no. 12, pp. 1799–1808,
1981.
[35] J. Schmidhuber, “Deep learning in neural networks: An overview,” Neural Networks,
vol. 61, pp. 85–117, 2015.
[36] Y. Kim, H. Lee, and E. M. Provost, “Deep learning for robust feature generation in
audiovisual emotion recognition,” in 2013 IEEE International Conference on Acoustics,
Speech and Signal Processing. IEEE, 2013, pp. 3687–3691.
[37] C. Cortes and V. Vapnik, “Support-vector networks,” Machine learning, vol. 20, no. 3,
pp. 273–297, 1995.
[38] P. Ekman and E. L. Rosenberg, What the face reveals: Basic and applied studies of spontane-
ous expression using the Facial Action Coding System (FACS). Oxford University Press,
USA, 1997.
[39] Z. Zhang, “Microsoft kinect sensor and its effect,” IEEE multimedia, vol. 19, no. 2, pp.
4–10, 2012.

135
[40] T. Schlömer, B. Poppinga, N. Henze, and S. Boll, “Gesture recognition with a wii con-
troller,” in Proceedings of the 2nd international conference on Tangible and embedded inte-
raction. ACM, 2008, pp. 11–14.
[41] R. Grace and S. Steward, “Drowsy driver monitor and warning system,” in Internati-
onal driving symposium on human factors in driver assessment, training and vehicle design,
vol. 8, 2001, pp. 201–208.
[42] S. Boucenna, P. Gaussier, P. Andry, and L. Hafemeister, “A robot learns the facial ex-
pressions recognition and face/non-face discrimination through an imitation game,”
International Journal of Social Robotics, vol. 6, no. 4, pp. 633–652, 2014.
[43] W. Zhao, R. Chellappa, P. J. Phillips, and A. Rosenfeld, “Face recognition: A literature
survey,” ACM computing surveys (CSUR), vol. 35, no. 4, pp. 399–458, 2003.
[44] G. McKeown, M. F. Valstar, R. Cowie, and M. Pantic, “The semaine corpus of emo-
tionally coloured character interactions,” in Multimedia and Expo (ICME), 2010 IEEE
International Conference on. IEEE, 2010, pp. 1079–1084.
[45] R. A. Calvo and S. D’Mello, “Affect detection: An interdisciplinary review of models,
methods, and their applications,” IEEE Transactions on affective computing, vol. 1, no. 1,
pp. 18–37, 2010.
[46] Z. Zeng, M. Pantic, G. I. Roisman, and T. S. Huang, “A survey of affect recognition
methods: Audio, visual, and spontaneous expressions,” IEEE transactions on pattern
analysis and machine intelligence, vol. 31, no. 1, pp. 39–58, 2009.
[47] P. J. Phillips, H. Wechsler, J. Huang, and P. J. Rauss, “The feret database and evaluation
procedure for face-recognition algorithms,” Image and vision computing, vol. 16, no. 5,
pp. 295–306, 1998.
[48] N. Sebe, M. S. Lew, Y. Sun, I. Cohen, T. Gevers, and T. S. Huang, “Authentic facial
expression analysis,” Image and Vision Computing, vol. 25, no. 12, pp. 1856–1863, 2007.
[49] J. P. Maurya, A. A. Waoo, P. Patheja, and S. Sharma, “A survey on face recognition
techniques,” 2013.
[50] C. Tomasi and T. Kanade, Detection and tracking of point features. School of Computer
Science, Carnegie Mellon Univ. Pittsburgh, 1991.

136
[51] B. D. Lucas, T. Kanade et al., “An iterative image registration technique with an appli-
cation to stereo vision.” in IJCAI, vol. 81, no. 1, 1981, pp. 674–679.
[52] Y. Freund and R. E. Schapire, “A desicion-theoretic generalization of on-line learning
and an application to boosting,” in European conference on computational learning theory.
Springer, 1995, pp. 23–37.
[53] P. Suri and E. A. Verma, “Robust face detection using circular multi block local binary
pattern and integral haar features,” IJACSA) International Journal of Advanced Computer
Science and Applications, Special Issue on Artificial Intelligence, June 2010.
[54] A. Rathi and B. N. Shah, “Facial expression recognition survey,” (IRJET) International
Research Journal of Engineering and Technology, April 2016, vol. 3, no. 4, pp. 540–545.
[55] L. Yin, X. Wei, Y. Sun, J. Wang, and M. J. Rosato, “A 3d facial expression database
for facial behavior research,” in 7th international conference on automatic face and gesture
recognition (FGR06). IEEE, 2006, pp. 211–216.
[56] M. Turk and A. Pentland, “Eigenfaces for recognition,” Journal of cognitive neuroscience,
vol. 3, no. 1, pp. 71–86, 1991.
[57] D. Chakrabarti and D. Dutta, “Facial expression recognition using eigenspaces,” Pro-
cedia Technology, vol. 10, pp. 755–761, 2013.
[58] G. Murthy and R. Jadon, “Recognizing facial expressions using eigenspaces,” in 2007
IEEE International Conference on Computational Intelligence and Multimedia Applications,
vol. 3. IEEE, 2007, pp. 201–207.
[59] P. J. Phillips, P. J. Flynn, T. Scruggs, K. W. Bowyer, J. Chang, K. Hoffman, J. Marques,
J. Min, and W. Worek, “Overview of the face recognition grand challenge,” in 2005
IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05),
vol. 1. IEEE, 2005, pp. 947–954.
[60] I. Cohen, N. Sebe, A. Garg, L. S. Chen, and T. S. Huang, “Facial expression recogni-
tion from video sequences: temporal and static modeling,” Computer Vision and image
understanding, vol. 91, no. 1, pp. 160–187, 2003.
[61] T. Mitchell, Machine Learning. McGraw Hill, 1997.

137
[62] L. R. Rabiner, “A tutorial on hidden markov models and selected applications in spe-
ech recognition,” Proceedings of the IEEE, vol. 77, no. 2, pp. 257–286, 1989.
[63] Y. Saatci and C. Town, “Cascaded classification of gender and facial expression using
active appearance models,” in 7th International Conference on Automatic Face and Ges-
ture Recognition (FGR06). IEEE, 2006, pp. 393–398.
[64] C. J. Wen and Y. Z. Zhan, “Hmm+ knn classifier for facial expression recognition,”
in 2008 3rd IEEE Conference on Industrial Electronics and Applications. IEEE, 2008, pp.
260–263.
[65] H. Meng, B. Romera-Paredes, and N. Bianchi-Berthouze, “Emotion recognition by
two view svm_2k classifier on dynamic facial expression features,” in Automatic Face
& Gesture Recognition and Workshops (FG 2011), 2011 IEEE International Conference on.
IEEE, 2011, pp. 854–859.
[66] SSPNET. (2011) Fg 2011 facial expression recognition and analysis challenge
(fera2011). [Online]. Available: http://sspnet.eu/fera2011/
[67] I. Song, H.-J. Kim, and P. B. Jeon, “Deep learning for real-time robust facial expres-
sion recognition on a smartphone,” in 2014 IEEE International Conference on Consumer
Electronics (ICCE). IEEE, 2014, pp. 564–567.
[68] W. Li, M. Li, Z. Su, and Z. Zhu, “A deep-learning approach to facial expression re-
cognition with candid images,” in Machine Vision Applications (MVA), 2015 14th IAPR
International Conference on. IEEE, 2015, pp. 279–282.
[69] H. Nomiya, S. Sakaue, and T. Hochin, “Recognition and intensity estimation of facial
expression using ensemble classifiers,” in Computer and Information Science (ICIS), 2016
IEEE/ACIS 15th International Conference on. IEEE, 2016, pp. 1–6.
[70] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment:
from error visibility to structural similarity,” IEEE transactions on image processing,
vol. 13, no. 4, pp. 600–612, 2004.
[71] G.-H. Chen, C.-L. Yang, and S.-L. Xie, “Gradient-based structural similarity for image
quality assessment,” in Image Processing, 2006 IEEE International Conference on. IEEE,
2006, pp. 2929–2932.

138
[72] L.-x. Liu and Y.-q. Wang, “A mean-edge structural similarity for image quality asses-
sment,” in Fuzzy Systems and Knowledge Discovery, 2009. FSKD’09. Sixth International
Conference on, vol. 5. IEEE, 2009, pp. 311–315.
[73] Q. Huynh-Thu and M. Ghanbari, “Scope of validity of psnr in image/video quality
assessment,” Electronics letters, vol. 44, no. 13, pp. 800–801, 2008.
[74] D. M. Allen, “Mean square error of prediction as a criterion for selecting variables,”
Technometrics, vol. 13, no. 3, pp. 469–475, 1971.
[75] C.-H. Cheung and L.-M. Po, “A novel block motion estimation algorithm with con-
trollable quality and searching speed,” in Circuits and Systems, 2002. ISCAS 2002. IEEE
International Symposium on, vol. 2. IEEE, 2002, pp. II–496.
[76] C.-K. Cheung and L.-M. Po, “Normalized partial distortion search algorithm for block
motion estimation,” IEEE Transactions on Circuits and Systems for Video Technology,
vol. 10, no. 3, pp. 417–422, 2000.
[77] T. Hastie, R. Tibshirani, and J. Friedman, “Unsupervised learning,” in The elements of
statistical learning. Springer, 2009, pp. 485–585.
[78] C. E. Rasmussen, “Gaussian processes for machine learning,” 2006.
[79] A. Ben-Hur, D. Horn, H. T. Siegelmann, and V. Vapnik, “Support vector clustering,”
Journal of machine learning research, vol. 2, no. Dec, pp. 125–137, 2001.
[80] J. C. Platt, “12 fast training of support vector machines using sequential minimal op-
timization,” Advances in kernel methods, pp. 185–208, 1999.
[81] M. D. Buhmann, “Radial basis functions,” Acta Numerica 2000, vol. 9, pp. 1–38, 2000.
[82] A. R. Rivera, J. R. Castillo, and O. O. Chae, “Local directional number pattern for
face analysis: Face and expression recognition,” IEEE transactions on image processing,
vol. 22, no. 5, pp. 1740–1752, 2013.
[83] T. Jabid, M. H. Kabir, and O. Chae, “Robust facial expression recognition based on
local directional pattern,” ETRI journal, vol. 32, no. 5, pp. 784–794, 2010.
[84] M. S. Bartlett, G. Littlewort, I. Fasel, and J. R. Movellan, “Real time face detection
and facial expression recognition: Development and applications to human computer

139
interaction.” in Computer Vision and Pattern Recognition Workshop, 2003. CVPRW’03.
Conference on, vol. 5. IEEE, 2003, pp. 53–53.
[85] A. R. Rivera, J. A. R. Castillo, and O. Chae, “Recognition of face expressions using
local principal texture pattern,” in 2012 19th IEEE International Conference on Image
Processing. IEEE, 2012, pp. 2609–2612.
[86] M. Liu, S. Li, S. Shan, and X. Chen, “Au-aware deep networks for facial expression re-
cognition,” in Automatic Face and Gesture Recognition (FG), 2013 10th IEEE International
Conference and Workshops on. IEEE, 2013, pp. 1–6.
[87] S. W. Chew, P. Lucey, S. Lucey, J. Saragih, J. F. Cohn, and S. Sridharan, “Person-
independent facial expression detection using constrained local models,” in Automatic
Face & Gesture Recognition and Workshops (FG 2011), 2011 IEEE International Conference
on. IEEE, 2011, pp. 915–920.
[88] L. A. Jeni, D. Takacs, and A. Lorincz, “High quality facial expression recognition in
video streams using shape related information only,” in Computer Vision Workshops
(ICCV Workshops), 2011 IEEE International Conference on. IEEE, 2011, pp. 2168–2174.
[89] S. Yang and B. Bhanu, “Understanding discrete facial expressions in video using an
emotion avatar image,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cy-
bernetics), vol. 42, no. 4, pp. 980–992, 2012.
[90] L. Zhong, Q. Liu, P. Yang, B. Liu, J. Huang, and D. N. Metaxas, “Learning active facial
patches for expression analysis,” in Computer Vision and Pattern Recognition (CVPR),
2012 IEEE Conference on. IEEE, 2012, pp. 2562–2569.
[91] T. Ahonen, A. Hadid, and M. Pietikainen, “Face description with local binary pat-
terns: Application to face recognition,” IEEE transactions on pattern analysis and ma-
chine intelligence, vol. 28, no. 12, pp. 2037–2041, 2006.
[92] Z. Xie and G. Liu, “Weighted local binary pattern infrared face recognition based
on weber’s law,” in Image and Graphics (ICIG), 2011 Sixth International Conference on.
IEEE, 2011, pp. 429–433.
[93] X. Tan and B. Triggs, “Enhanced local texture feature sets for face recognition under
difficult lighting conditions,” IEEE transactions on image processing, vol. 19, no. 6, pp.
1635–1650, 2010.

140
[94] C. H. Chan, J. Kittler, N. Poh, T. Ahonen, and M. Pietikäinen, “(multiscale) local phase
quantisation histogram discriminant analysis with score normalisation for robust face
recognition,” in Computer Vision Workshops (ICCV Workshops), 2009 IEEE 12th Interna-
tional Conference on. IEEE, 2009, pp. 633–640.
[95] P. Action. (2017) Intervalo de confiança. [Online]. Available: http://www.
portalaction.com.br/inferencia/intervalo-de-confianca
[96] D. Le Gall, “Mpeg: A video compression standard for multimedia applications,” Com-
munications of the ACM, vol. 34, no. 4, pp. 46–58, 1991.
[97] H. da Cunha Santiago, T. I. Ren, and G. D. Cavalcanti, “Facial expression recogni-
tion based on motion estimation,” in Neural Networks (IJCNN), 2016 International Joint
Conference on. IEEE, 2016, pp. 1617–1624.
[98] IJCNN. (2016) Ijcnn 2016 program. [Online]. Available: http://www.wcci2016.org/
document/ijcnn2016_4.pdf
[99] I. P. Alonso, D. F. Llorca, M. Á. Sotelo, L. M. Bergasa, P. R. de Toro, J. Nuevo, M. Ocaña,
and M. Á. G. Garrido, “Combination of feature extraction methods for svm pedestrian
detection,” IEEE Transactions on Intelligent Transportation Systems, vol. 8, no. 2, pp. 292–
307, 2007.
[100] J. K. Aggarwal and M. S. Ryoo, “Human activity analysis: A review,” ACM Computing
Surveys (CSUR), vol. 43, no. 3, p. 16, 2011.