exercício 1 resolvido - mauricio-camargo.github.io · exercício 1 resolvido mauricio camargo 13...
TRANSCRIPT
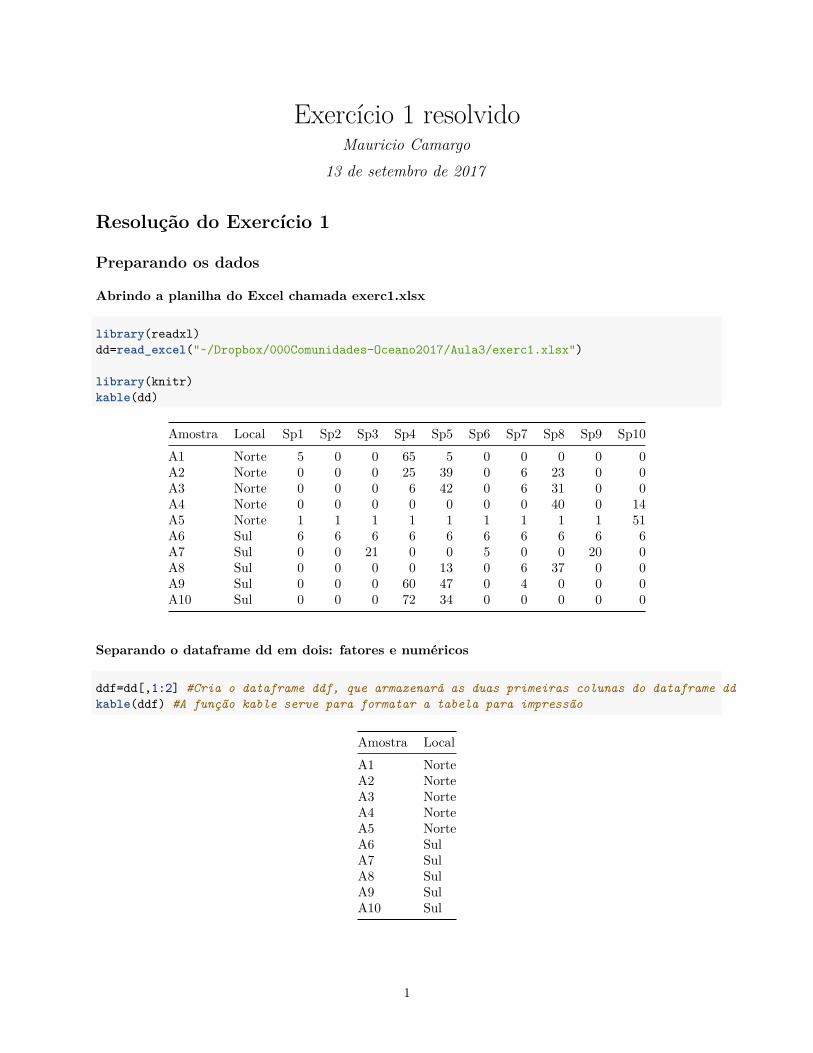
Exercício 1 resolvidoMauricio Camargo
13 de setembro de 2017
Resolução do Exercício 1
Preparando os dados
Abrindo a planilha do Excel chamada exerc1.xlsx
library(readxl)dd=read_excel("~/Dropbox/000Comunidades-Oceano2017/Aula3/exerc1.xlsx")
library(knitr)kable(dd)
Amostra Local Sp1 Sp2 Sp3 Sp4 Sp5 Sp6 Sp7 Sp8 Sp9 Sp10A1 Norte 5 0 0 65 5 0 0 0 0 0A2 Norte 0 0 0 25 39 0 6 23 0 0A3 Norte 0 0 0 6 42 0 6 31 0 0A4 Norte 0 0 0 0 0 0 0 40 0 14A5 Norte 1 1 1 1 1 1 1 1 1 51A6 Sul 6 6 6 6 6 6 6 6 6 6A7 Sul 0 0 21 0 0 5 0 0 20 0A8 Sul 0 0 0 0 13 0 6 37 0 0A9 Sul 0 0 0 60 47 0 4 0 0 0A10 Sul 0 0 0 72 34 0 0 0 0 0
Separando o dataframe dd em dois: fatores e numéricos
ddf=dd[,1:2] #Cria o dataframe ddf, que armazenará as duas primeiras colunas do dataframe ddkable(ddf) #A função kable serve para formatar a tabela para impressão
Amostra LocalA1 NorteA2 NorteA3 NorteA4 NorteA5 NorteA6 SulA7 SulA8 SulA9 SulA10 Sul
1

ddn=dd[,3:12] #Cria o dataframe ddn, que armazenará as colunas de 3 até 12.kable(ddn)
Sp1 Sp2 Sp3 Sp4 Sp5 Sp6 Sp7 Sp8 Sp9 Sp105 0 0 65 5 0 0 0 0 00 0 0 25 39 0 6 23 0 00 0 0 6 42 0 6 31 0 00 0 0 0 0 0 0 40 0 141 1 1 1 1 1 1 1 1 516 6 6 6 6 6 6 6 6 60 0 21 0 0 5 0 0 20 00 0 0 0 13 0 6 37 0 00 0 0 60 47 0 4 0 0 00 0 0 72 34 0 0 0 0 0
Questões
1. Calcule os principais descritores univariados: o número de indivíduos (N) e o número de espécies (S)library(vegan)S=specnumber(ddn)N=rowSums(ddn)kable(cbind(ddf,S,N))
Amostra Local S NA1 Norte 3 75A2 Norte 4 93A3 Norte 4 85A4 Norte 2 54A5 Norte 10 60A6 Sul 10 60A7 Sul 3 46A8 Sul 3 56A9 Sul 3 111A10 Sul 2 106
2. A seguir calcule o índice de riqueza de espécies de Margalef, usando N e SDmg=(S-1)/log(N) #Riqueza de Margalefkable(cbind(ddf,S,N,Dmg))
Amostra Local S N DmgA1 Norte 3 75 0.4632323A2 Norte 4 93 0.6618718A3 Norte 4 85 0.6752725A4 Norte 2 54 0.2506904A5 Norte 10 60 2.1981540A6 Sul 10 60 2.1981540A7 Sul 3 46 0.5223785A8 Sul 3 56 0.4968510A9 Sul 3 111 0.4246708
2

Amostra Local S N DmgA10 Sul 2 106 0.2144340
3. Depois, os índices de diversidade de espécies de Simpson (1 – D) e Shannon-Wienner (H), usando aabundância relativa das espéciesD=diversity(ddn, "simpson")D=1-D #Simpson é expresso como 1-DH=diversity(ddn, "shannon")
Esta é a tabela final dos Descritores Univariadostab=cbind(ddf,S,N,Dmg,D,H)kable(tab)
Amostra Local S N Dmg D HA1 Norte 3 75 0.4632323 0.7600000 0.4850941A2 Norte 4 93 0.6618718 0.3134466 1.2399358A3 Norte 4 85 0.6752725 0.3871280 1.0904531A4 Norte 2 54 0.2506904 0.6159122 0.5722807A5 Norte 10 60 2.1981540 0.7250000 0.7522928A6 Sul 10 60 2.1981540 0.1000000 2.3025851A7 Sul 3 46 0.5223785 0.4092628 0.9613195A8 Sul 3 56 0.4968510 0.5019133 0.8521577A9 Sul 3 111 0.4246708 0.4727701 0.8161717A10 Sul 2 106 0.2144340 0.5642577 0.6274370
4. Discuta sobre riqueza e diversidade das amostras A5 e A6
Resposta:Na amostra A5, todas as espécies possuíam apenas 1 indivíduo, exceto a última (sp10), que continha 51indivíduos.
Na amostra A6, todas as espécies continham 6 indivíduos.
Nota-se que a riqueza medida por S, N e Dmg são idênticas entre as amostras A5 e A6, mesmo com asdiscrepâncias na distribuição das espécies entre as duas amostras.
A diversidade de Simpson (D) é sensível a estas diferenças. Quando existe homogeneidade total entre asespécies, como em A6, D é igual a 0,1. Quando a abundância é diferente em apenas uma espécie, como emA5, D é igual a 0,725.
A diversidade de Shannon (H) é muito mais sensível a estas variações. Em situação de homogeneidade, comoem A6, H é igual 2,30. Quando a abundância difere em apenas uma espécies, como em A5, H é igual a 0,75.
5. Calcule a média e o desvio padrão entre os locais Norte e Sul, número de indivíduos (N) e número deespécies (S)library(doBy)kable(summaryBy(S+N~Local,FUN=c(mean,sd),data=tab))
Local S.mean N.mean S.sd N.sdNorte 4.6 73.4 3.130495 16.41036Sul 4.2 75.8 3.271085 30.33480
3

6. Faça um gráfico de barras com barras de erro representadas pelo erro padrão, usando o pacote sciplot,comparando as amostras de Norte e Sul para todos os descritores univariadoslibrary(sciplot)par(mfrow=c(3,2)) #Cria uma grade para 6 gráficosbargraph.CI(tab$Local,tab$S,main='Número de espécies')bargraph.CI(tab$Local,tab$N,main='Número de indivíduos')bargraph.CI(tab$Local,tab$Dmg,main='Margalef')bargraph.CI(tab$Local,tab$D,main='Simpson')bargraph.CI(tab$Local,tab$H,main='Shannon')
Norte Sul
Número de espécies
04
Norte Sul
Número de indivíduos
060
Norte Sul
Margalef
0.0
Norte Sul
Simpson0.
00.
6
Norte Sul
Shannon
0.0
1.4
7. Faça um teste-t para cada um dos descritores univariados entre os locais norte e sul
7.1. Número de espécies
Aceita H0t.test(tab$S ~ tab$Local)
#### Welch Two Sample t-test#### data: tab$S by tab$Local## t = 0.19755, df = 7.9846, p-value = 0.8483## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## -4.270869 5.070869## sample estimates:## mean in group Norte mean in group Sul## 4.6 4.2
7.2. Número de indivíduos
Aceita H0
4

t.test(tab$N ~ tab$Local)
#### Welch Two Sample t-test#### data: tab$N by tab$Local## t = -0.1556, df = 6.1565, p-value = 0.8813## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## -39.9098 35.1098## sample estimates:## mean in group Norte mean in group Sul## 73.4 75.8
7.3. Margalef
Aceita H0t.test(tab$Dmg ~ tab$Local)
#### Welch Two Sample t-test#### data: tab$Dmg by tab$Local## t = 0.15716, df = 7.9857, p-value = 0.879## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## -1.074313 1.231406## sample estimates:## mean in group Norte mean in group Sul## 0.8498442 0.7712977
7.4. Simpson
Aceita H0t.test(tab$D ~ tab$Local)
#### Welch Two Sample t-test#### data: tab$D by tab$Local## t = 1.2441, df = 7.9239, p-value = 0.249## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## -0.1290695 0.4303827## sample estimates:## mean in group Norte mean in group Sul## 0.5602974 0.4096408
7.5. Shannon
Aceita H0t.test(tab$H ~ tab$Local)
#### Welch Two Sample t-test##
5

## data: tab$H by tab$Local## t = -0.84512, df = 5.7713, p-value = 0.4317## alternative hypothesis: true difference in means is not equal to 0## 95 percent confidence interval:## -1.113936 0.546090## sample estimates:## mean in group Norte mean in group Sul## 0.8280113 1.1119342
6