econometria ii introduÇÃo o modelo...
TRANSCRIPT

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
ECONOMETRIA II – INTRODUÇÃO
O MODELO CLÁSSICO DE REGRESSÃO LINEAR (MCRL), O TEOREMA DE GAUSS-
MARKOV E A VIOLAÇÃO DOS PRESSUPOSTOS.
Lindomar Pegorini Daniel1
1. O Modelo Clássico de Regressão Linear (MCRL)
O termo regressão foi criado por Francis Galton. Em um artigo famoso de 1886, Galton
verificou que os filhos de pais mais altos e os filhos de pais mais baixos tendiam a apresentar uma
altura que se assemelhava a altura média da população. Em outras palavras, a estatura dos filhos de
pais com certa altura tendia a “regredir” para a altura média da população como um todo.
A análise de regressão tornou-se a base da econometria e, atualmente, refere-se ao estudo da
dependência de uma variável (dependente), em relação a outras variáveis (explicativas). A análise de
regressão é uma ferramenta interessante, pois consegue aproximar a Função de Esperança
Condicional (Conditional Expectation Function – CEF) ou Função de Regressão Populacional (RFP)
ou ainda Função de Média Condicional. A partir disso, ela é utilizada para estimar e/ou prever o valor
médio da variável dependente em termos dos valores conhecidos ou fixados (em amostras repetidas)
das variáveis explicativas.
CEF:
1 Professor Assistente da Universidade do Estado de Mato Grosso (UNEMAT) – Campus de Sinop.

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
Segundo Angrist e Pischke (2008), a CEF será causal quando descrever as diferenças na média
condicional da variável de interesse para uma população de referência fixa. Isso leva a hipótese de
independência condicional (Conditional Independence Assumption - CIA) que muitas vezes fornece
base para interpretações causais. Essa hipótese garante que a regressão pode representar relações
causais, caso essa relação seja independente de outros resultados potenciais. Em outras palavras,
pode-se estabelecer um contra factual desde que se possa controlar outros fatores, assim os grupos
sendo comparados são realmente comparáveis.
Pela teoria ou conhecimento “a priori”:
𝑌𝑖 = 𝑓(𝑋1, 𝑋2, … , 𝑋𝑚)
Por vários motivos, dentre eles a ausência de variáveis que representam certos fatores e o
tratamento de relações inexatas pela economia, adicionamos um termo de erro aleatório:
𝑌𝑖 = 𝑓(𝑋1, 𝑋2, … , 𝑋𝑘, 𝜀), (𝑘 < 𝑚)
onde 𝜀 é o termo de erro aleatório.
Além disso, temos de definir uma forma funcional para a relação, geralmente o modelo linear
(padrão):
𝑌𝑖 = 𝛽1𝑋1𝑖 + 𝛽2𝑋2𝑖 + ⋯+ 𝛽𝑘𝑋𝑘𝑖 + 𝜀𝑖
onde 𝑖 = 1,2, … , 𝑛.
As incógnitas 𝛽′𝑠 representam o efeito médio da variável 𝑋𝑖 sobre 𝑌.
𝜕𝑌
𝜕𝑋2= 𝛽2
efeito marginal de 𝑋2 sobre 𝑌, ceteris paribus.
Em termos matriciais pode-se representar o modelo de regressão linear como:
𝑌 = 𝑋𝛽 + 𝜀

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
O principal problema a ser abordado pela econometria é a estimação dos parâmetros e, para
isso, queremos encontrar um estimador adequado que apresente propriedades2 desejáveis (não
tendenciosidade, consistência e eficiência) dado o problema em questão.
Estimador de Mínimos Quadrados Ordinários:
A teoria ou a estrutura básica da análise de regressão é o Modelo Clássico de Regressão Linear
(MCRL), que trata das hipóteses ou pressupostos subjacentes ao estimador de Mínimos Quadrados
Ordinários (MQO). Sob a validade desses pressupostos é possível mostrar que o estimador de MQO
é BLUE (Best Linear Unbiased Estimator).
Além disso, as estruturas dos dados ditam ou impõem novos desafios à estimação
econométrica. A base da econometria é a análise de regressão a partir da estrutura de dados seccionais,
em outras palavras, toda a teoria econométrica é construída a partir dessa estrutura de dados. Nesse
sentido, a utilização de dados com estrutura temporal, longitudinal ou espacial incluem novas
hipóteses à estimação do modelo. Por esse motivo, tais estruturas de dados devem ser expostas e
trabalhadas de forma separada.
2 Propriedades referentes à distribuição do estimador.

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
PRESSUPOSTOS OU HIPÓTESES SUBJACENTES AO MCRL
1) A relação entre 𝒀e os 𝑿′𝒔 é linear.
𝑌 = 𝑋𝛽 + 𝜀
Linear significando linearidade nos parâmetros. Relações não lineares (intrinsecamente
lineares) que podem ser linearizadas podem ser estimadas pelos MQO, contudo a violação desse
pressuposto, ou seja, modelos não lineares nos parâmetros (intrinsecamente não lineares) devem ser
estimados por métodos não lineares.
2) Não há relação linear perfeita entre as variáveis explicativas.
𝑝𝑜𝑠𝑡𝑜(𝑋) = 𝑘
Indica ausência de multicolinearidade perfeita entre as variáveis explicativas, esse pressuposto
garante que a matriz (𝑋′𝑋) é não singular e, portanto, assegura a existência da matriz (𝑋′𝑋)−1. Caso
𝑝𝑜𝑠𝑡𝑜(𝑋) < 𝑘 a matriz (𝑋′𝑋)−1 é singular, o que impossibilita a estimação dos parâmetros.
Outras hipóteses relacionadas a esse pressuposto são a de que o número de observações deve
ser no mínimo maior que o número de parâmetros estimados (𝑛 > 𝑘) e a de que as variáveis
explicativas possuam variabilidade suficiente.
A violação desse pressuposto impossibilita a estimação dos parâmetros e torna os erros padrão
infinitos. A presença de multicolinearidade forte não viola o pressuposto, nesse caso os estimadores
de MQO preservam suas propriedades de BLUE, contudo os erros padrão tornam-se grandes e os
testes de significância individual (𝑡) tendem a aceitar a hipótese nula.
3) A matriz 𝑿 é não estocástica, ou seja, os 𝑿′𝒔 são fixos em amostras repetidas.
Esse pressuposto indica que para cada valor fixo de 𝑋 existe uma distribuição de probabilidade
associada. Estamos interessados no valor médio condicional de 𝑌 para cada valor fixo de 𝑋. Caso 𝑋
seja estocástico pressupõe-se que o mesmo não está correlacionado com o termo de erro 𝑋′𝜀 = 0.

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
4) A variável 𝜺 tem média zero.
𝐸(𝜀𝑖|𝑋𝑖) = 0
Implica que:
𝐸(𝑌) = 𝐸(𝑋𝛽) + 𝐸(𝜀)
Como 𝑋 é fixo e 𝛽 é constante 𝐸(𝑋𝛽) = 𝑋𝛽. Dado que 𝐸(𝜀) = 0, tem-se que:
𝐸(𝑌) = 𝑋𝛽
Em outras palavras, as variáveis incluídas no termo de erro não influenciam sistematicamente
o valor médio de 𝑌, ou seja, em média a influência do termo de erro para explicar 𝑌 é nula.
Outras hipóteses relacionadas a esse pressuposto são as de que o modelo está bem
especificado, ou seja, não existem erros de medida nas variáveis dependente e explicativas, não há
variáveis relevantes omitidas ou relações endógenas entre regressor e regressores (𝑋′𝜀 = 0) e (𝑌′𝜀 =
0).
A violação desse pressuposto torna os estimadores de MQO tendenciosos e inconsistentes,
porém mantém a eficiência dos estimadores.
5) Os erros 𝜺𝒊 são variáveis aleatórias com variância constante (homocedasticidade).
𝑉𝑎𝑟(𝜀𝑖) = 𝜎2
𝑉𝑎𝑟(𝜀𝑖) = 𝐸[𝜀𝑖 − 𝐸(𝜀𝑖)]2
Dado 𝐸(𝜀) = 0:
𝑉𝑎𝑟(𝜀𝑖) = 𝐸(𝜀2) = 𝜎2 𝑞𝑢𝑒 é 𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡𝑒

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
O pressuposto de homocedasticidade garante que a dispersão dos diferentes níveis fixos de 𝑋
em torno da média é constante, ou seja, é a mesma. Esse pressuposto assegura que a média condicional
de 𝑌 possui a mesma precisão para os diferentes níveis da variável 𝑋.
A violação desse pressuposto mantém as propriedades de não tendencioso e consistente dos
estimadores de MQO, contudo eles não são mais eficientes e os testes estatísticos deixam de ser
válidos.
6) Ausência de autocorrelação no erro.
𝐶𝑜𝑣(𝜀𝑖𝜀𝑗) = 0 𝑝𝑎𝑟𝑎 𝑖 ≠ 𝑗
O pressuposto de ausência de autocorrelação ou correlação serial no termo de erro assegura
que não existe uma relação sistemática entre o termo de erro e a variável dependente, em outras
palavras, o valor médio de 𝑌 não é afetado pelo termo de erro de forma sistemática, ou seja, um
choque aleatório em um período que causa um aumento na média de 𝑌 não afetará o valor do mesmo
nos próximos períodos.
A violação desse pressuposto mantém as propriedades de não tendencioso e consistente dos
estimadores de MQO, contudo eles não são mais eficientes e os testes estatísticos deixam de ser
válidos.
Observações: pressupostos 5 e 6 em forma matricial.
Considere o produto 𝜀𝜀′
𝜀𝜀′ =
[ 𝜀1
𝜀2...
𝜀𝑛]
𝑛𝑥1
[𝜀1𝜀2
. . . 𝜀𝑛]1𝑥𝑛
𝜀𝜀′ = [𝜀1
2 ⋯ 𝜀1𝜀𝑛
⋮ ⋱ ⋮𝜀𝑛𝜀1 ⋯ 𝜀𝑛
2]
𝑛𝑥𝑛

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
𝐸(𝜀𝜀′) = [𝐸(𝜀1
2) ⋯ 𝐸(𝜀1𝜀𝑛)⋮ ⋱ ⋮
𝐸(𝜀𝑛𝜀1) ⋯ 𝐸(𝜀𝑛2)
]
𝐸(𝜀𝜀′) = [𝑉𝑎𝑟(𝜀1) ⋯ 𝐶𝑜𝑣(𝜀1𝜀𝑛)
⋮ ⋱ ⋮𝐶𝑜𝑣(𝜀𝑛𝜀1) ⋯ 𝑉𝑎𝑟(𝜀𝑛)
]
Dadas as pressuposições 5 (𝑉𝑎𝑟(𝜀𝑖) = 𝜎2) e 6 (𝐶𝑜𝑣(𝜀𝑖𝜀𝑗) = 0 𝑝𝑎𝑟𝑎 𝑖 ≠ 𝑗), tem-se:
𝐸(𝜀𝜀′) = [𝜎2 ⋯ 0⋮ ⋱ ⋮0 ⋯ 𝜎2
]
Com 𝜎2 em evidência:
𝐸(𝜀𝜀′) = 𝜎2 [𝜔1 ⋯ 0⋮ ⋱ ⋮0 ⋯ 𝜔𝑛
] = 𝜎2Ω = Σ
Para os pressupostos 5 e 6, Ω = I:
𝐸(𝜀𝜀′) ≡ 𝑉𝑎𝑟 − 𝐶𝑜𝑣(𝜀) = 𝜎2𝐼
7) Os erros têm distribuição normal.
Esse pressuposto é necessário apenas para os testes de hipóteses, ou seja, ele não influencia
as propriedades dos estimadores de MQO. A adição desse pressuposto ao MCRL gera o MCRL
normal (MCRLN).
Esses pressupostos são, portanto, a base da análise de regressão utilizando os estimadores de
MQO.

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
2. O Teorema de Gauss-Markov
Dadas as premissas do MCRL, os estimadores de MQO da classe dos estimadores lineares
não viesados têm variância mínima, isto é, são o melhor estimador linear não viesado BLUE. Em
outras palavras, sob a validade dos 6 primeiros pressupostos é possível demonstrar que o estimador
de MQO é BLUE.
i) o estimador de MQO é não tendencioso:
Dada a premissa 2 (ausência de multicolinearidade perfeita)
�̂� = (𝑋′𝑋)−1𝑋′𝑌
Dado 𝑌 = 𝑋𝛽 + 𝜀 (premissa 1 linearidade), substituindo:
�̂� = (𝑋′𝑋)−1𝑋′(𝑋𝛽 + 𝜀)
�̂� = (𝑋′𝑋)−1𝑋′𝑋𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Dado (𝑋′𝑋)−1𝑋′𝑋 = 𝐼:
�̂� = 𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Aplicando o operador de valor esperado:
𝐸[�̂�] = 𝐸[𝛽] + 𝐸[(𝑋′𝑋)−1𝑋′𝜀]
Dado que 𝑋 é fixo em amostras repetidas por pressuposição (premissa 3):
𝐸[�̂�] = 𝛽 + (𝑋′𝑋)−1𝑋′𝐸[𝜀]
Dado 𝐸[𝜀] = 0 por pressuposição (premissa 4):
𝐸[�̂�] = 𝛽
Comportamentos de estimadores: não tendencioso (𝜃1) e tendencioso (𝜃2):
ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
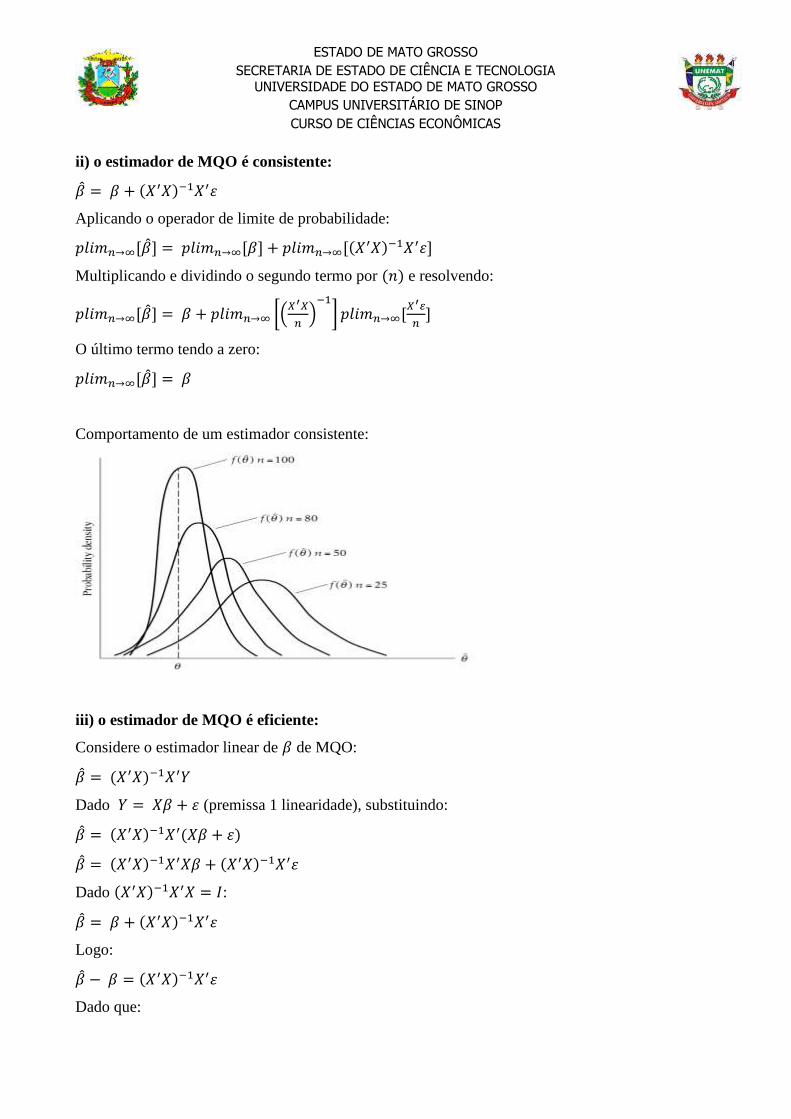
ii) o estimador de MQO é consistente:
�̂� = 𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Aplicando o operador de limite de probabilidade:
𝑝𝑙𝑖𝑚𝑛→∞[�̂�] = 𝑝𝑙𝑖𝑚𝑛→∞[𝛽] + 𝑝𝑙𝑖𝑚𝑛→∞[(𝑋′𝑋)−1𝑋′𝜀]
Multiplicando e dividindo o segundo termo por (𝑛) e resolvendo:
𝑝𝑙𝑖𝑚𝑛→∞[�̂�] = 𝛽 + 𝑝𝑙𝑖𝑚𝑛→∞ [(𝑋′𝑋
𝑛)−1
] 𝑝𝑙𝑖𝑚𝑛→∞[𝑋′𝜀
𝑛]
O último termo tendo a zero:
𝑝𝑙𝑖𝑚𝑛→∞[�̂�] = 𝛽
Comportamento de um estimador consistente:
iii) o estimador de MQO é eficiente:
Considere o estimador linear de 𝛽 de MQO:
�̂� = (𝑋′𝑋)−1𝑋′𝑌
Dado 𝑌 = 𝑋𝛽 + 𝜀 (premissa 1 linearidade), substituindo:
�̂� = (𝑋′𝑋)−1𝑋′(𝑋𝛽 + 𝜀)
�̂� = (𝑋′𝑋)−1𝑋′𝑋𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Dado (𝑋′𝑋)−1𝑋′𝑋 = 𝐼:
�̂� = 𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Logo:
�̂� − 𝛽 = (𝑋′𝑋)−1𝑋′𝜀
Dado que:

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[(�̂� − 𝛽)(�̂� − 𝛽)′]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[((𝑋′𝑋)−1𝑋′𝜀)((𝑋′𝑋)−1𝑋′𝜀)′]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[(𝑋′𝑋)−1𝑋′𝜀𝜀′𝑋(𝑋′𝑋)−1]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[(𝑋′𝑋)−1𝑋′𝜀𝜀′𝑋(𝑋′𝑋)−1]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = (𝑋′𝑋)−1𝑋′𝐸(𝜀𝜀′)𝑋(𝑋′𝑋)−1
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = (𝑋′𝑋)−1𝑋′(𝜎2Ω)𝑋(𝑋′𝑋)−1
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝜎2(𝑋′𝑋)−1𝑋′Ω𝑋(𝑋′𝑋)−1
Sob a validade dos pressupostos 5 e 6, Ω = I, então:
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝜎2(𝑋′𝑋)−1
Considere agora outro estimador linear de 𝛽 que não o de MQO:
�̂�∗ = [(𝑋′𝑋)−1𝑋′ + 𝐶]𝑌
Dado 𝑌 = 𝑋𝛽 + 𝜀
�̂�∗ = [(𝑋′𝑋)−1𝑋′ + 𝐶][𝑋𝛽 + 𝜀]
�̂�∗ = (𝑋′𝑋)−1𝑋′𝑋𝛽 + (𝑋′𝑋)−1𝑋′𝜀 + 𝐶𝑋𝛽 + 𝐶𝜀
Dado (𝑋′𝑋)−1𝑋′𝑋 = 𝐼 e o fato de que 𝐶𝑋 = 0 para que esse estimador seja não tendencioso:
�̂�∗ = 𝛽 + (𝑋′𝑋)−1𝑋′𝜀 + 𝐶𝜀
�̂�∗ − 𝛽 = (𝑋′𝑋)−1𝑋′𝜀 + 𝐶𝜀
Por definição, a matriz de variâncias e covariâncias de (�̂�∗) é:
Var − Cov(�̂�∗) = 𝐸[(�̂�∗ − 𝛽)(�̂�∗ − 𝛽)′]
Então:
Var − Cov(�̂�∗) = 𝐸[((𝑋′𝑋)−1𝑋′𝜀 + 𝐶𝜀 )((𝑋′𝑋)−1𝑋′𝜀 + 𝐶𝜀 )′]
Resolvendo:
Var − Cov(�̂�∗) = 𝐸[(𝑋′𝑋)−1𝑋′𝜀𝜀′𝑋(𝑋′𝑋)−1 + 𝐶𝜀𝜀′𝑋(𝑋′𝑋)−1 + (𝑋′𝑋)−1𝑋′𝜀𝜀′𝐶′ + 𝐶𝜀𝜀′𝐶′]
Var − Cov(�̂�∗) = (𝑋′𝑋)−1𝑋′𝐸[𝜀𝜀′]𝑋(𝑋′𝑋)−1 + 𝐶𝐸[𝜀𝜀′]𝑋(𝑋′𝑋)−1 + (𝑋′𝑋)−1𝑋′𝐸[𝜀𝜀′]𝐶′ +
+ 𝐶𝐸[𝜀𝜀′]𝐶′
Dado 𝐸[𝜀𝜀′] = 𝜎2 (premissas 5 e 6) e 𝐶𝑋 = 0:
Var − Cov(�̂�∗) = 𝜎2(𝑋′𝑋)−1 + 𝜎2𝐶𝐶′
Var − Cov(�̂�∗) = 𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) + 𝜎2𝐶𝐶′
A não ser que 𝐶 seja nulo, a variância de �̂�∗ será maior que a de �̂�.
ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
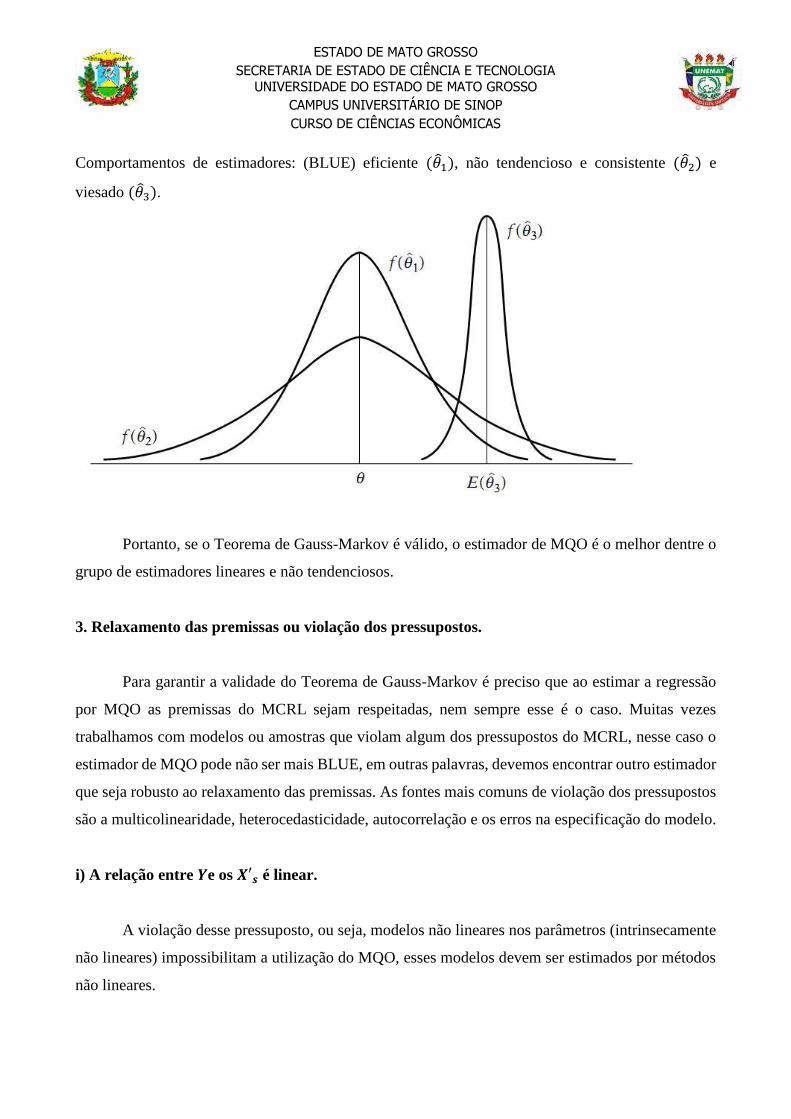
Comportamentos de estimadores: (BLUE) eficiente (𝜃1), não tendencioso e consistente (𝜃2) e
viesado (𝜃3).
Portanto, se o Teorema de Gauss-Markov é válido, o estimador de MQO é o melhor dentre o
grupo de estimadores lineares e não tendenciosos.
3. Relaxamento das premissas ou violação dos pressupostos.
Para garantir a validade do Teorema de Gauss-Markov é preciso que ao estimar a regressão
por MQO as premissas do MCRL sejam respeitadas, nem sempre esse é o caso. Muitas vezes
trabalhamos com modelos ou amostras que violam algum dos pressupostos do MCRL, nesse caso o
estimador de MQO pode não ser mais BLUE, em outras palavras, devemos encontrar outro estimador
que seja robusto ao relaxamento das premissas. As fontes mais comuns de violação dos pressupostos
são a multicolinearidade, heterocedasticidade, autocorrelação e os erros na especificação do modelo.
i) A relação entre 𝒀e os 𝑿′𝒔 é linear.
A violação desse pressuposto, ou seja, modelos não lineares nos parâmetros (intrinsecamente
não lineares) impossibilitam a utilização do MQO, esses modelos devem ser estimados por métodos
não lineares.

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
ii) Não há relação linear perfeita entre as variáveis explicativas.
A violação desse pressuposto impossibilita a estimação dos parâmetros e torna os erros padrão
infinitos. A presença de multicolinearidade forte não viola o pressuposto, nesse caso os estimadores
de MQO preservam suas propriedades de BLUE, contudo os erros padrão tornam-se grandes e os
testes de significância individual (𝑡) tendem a aceitar a hipótese nula. Para ver isso, observe que
quando se pretende explicar determinada variável por meio de uma regressão múltipla é possível
mostrar que a variância do j-ésimo regressor pode ser expressa como:
𝑉𝑎𝑟(�̂�𝑗) =𝜎2
∑𝑥𝑗2 (
1
1−𝑅𝑗2)
onde 𝑅𝑗2 denota o coeficiente de determinação da regressão auxiliar do regressor j em função dos
demais regressores.
Nesse caso, 𝑅𝑗2 representa o grau de colinearidade da variável explicativa j para com as
demais. O segundo termo do lado direito da equação é conhecido como fator de inflação da variância
ou FIV, ele determina quanto a variância do parâmetro estimado aumenta em função do grau de
relação linear entre as variáveis explicativas. Quando existe correlação linear perfeita entre as
covariáveis, ou seja, 𝑅𝑗2 = 1, o FIV torna-se infinito e o pressuposto de ausência de relação linear
perfeita entre as variáveis explicativas é violado, o que impossibilita a estimação dos parâmetros por
MQO.
Com 𝑅𝑗2 < 1 os estimadores de MQO mantém a propriedade BLUE, contudo se a
multicolinearidade for alta isso pode incorrer em problemas para a análise de regressão, pois, não se
consegue retirar o efeito “líquido” da variação de uma variável explicativa (Xi) sobre a média da
variável dependente (Y). Apesar de que, mesmo na presença de multicolinearidade, os estimadores
de MQO ser os de variância mínima, isto não significa que essa variância seja pequena, ou seja, o
problema causa problemas de imprecisão nas estimativas.
Podem ser identificadas algumas causas para o problema de multicolinearidade forte como o
método de coleta dos dados, restrições ao modelo ou amostra (como no caso da regressão para
explicar o consumo de energia elétrica (Y) que inclui a renda (X2) e o tamanho da casa (X3) como
regressores, essas variáveis estarão relacionadas na medida em que famílias com maior nível de renda
possuem casas maiores), especificação do modelo (inclusão de termos polinomiais), pequeno número

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
de observações (limita a variabilidade das variáveis explicativas ∑𝑥𝑗2) e alguma tendência comum
nas variáveis explicativas.
As consequências de alta multicolinearidade são intervalos de confiança mais amplos para os
estimadores, razões (𝑡) =�̂�𝑗
√𝑉𝑎𝑟(�̂�𝑗) insignificantes enquanto a regressão apresenta 𝑅2 alto e (𝐹)
significativo e sensibilidade dos estimadores a alterações nos dados.
A detecção do problema pode ser feito com a ajuda da matriz de correlações de ordem zero
entre as variáveis explicativas, com a identificação de 𝑅2 alto e (𝐹) significativo enquanto as razões
(𝑡) são não significativas, através das regressões auxiliares e do cálculo do FIV.
Após identificar o “problema” podem ser tomadas algumas medidas corretivas dentre as quais
estão não fazer nada (uma vez que de fato a colinearidade não perfeita não viola o pressuposto do
MCRL), utilizar alguma informação a priori quando conhecemos o padrão de relação linear entre as
variáveis (por exemplo, X1 = X2i + 0,3X3i), combinar dados de série temporal e corte transversal ou
aumentar o número de observações, fazer alguma transformação nas variáveis, ou excluir a variável
(contudo isso pode incorrer em viés de especificação do modelo que causa viés e inconsistência nos
estimadores, em outras palavras, a solução pode acabar incorrendo em problemas maiores).
iii) A matriz 𝑿 é não estocástica, ou seja, os 𝑿′𝒔 são fixos em amostras repetidas.
Esse pressuposto indica que para cada valor fixo de 𝑋 existe uma distribuição de probabilidade
associada. Estamos interessados no valor médio condicional de 𝑌 para cada valor fixo de 𝑋. Caso 𝑋
seja estocástico pressupõe-se que o mesmo não está correlacionado com o termo de erro 𝑋′𝜀 = 0,
caso esse pressuposto não se mantenha os estimadores de MQO serão viesados e inconsistentes e
torna-se necessário a utilização de outro estimador.
iv) A variável 𝜺 tem média zero.
Um dos pressupostos do MCRL é o de que a média do termo de erro é igual a zero, 𝐸(𝜀𝑖|𝑋𝑖) =
0. Em outras palavras, supõe-se que o modelo está bem especificado e que as variáveis omitidas ou

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
que não puderam ser incluídas no modelo e estão, portanto, presentes no termo de erro possuem um
efeito médio nulo sobre Y.
Se variáveis importantes forem omitidas pode-se violar esse pressuposto, pois a variável
omitida pode estar correlacionada com X, (𝑋′𝜀 ≠ 0), ou com Y, (𝑌′𝜀 ≠ 0), causando o viés ou erro
de especificação do modelo.
Podem-se listar alguns tipos de erros de especificação como a omissão de uma ou mais
variáveis relevantes, a inclusão de uma ou mais variáveis desnecessárias, a adoção da forma funcional
errada, erros de medida, especificação incorreta do termo de erro estocástico e a pressuposição de que
o erro distribui-se normalmente quando o processo gerador não é dessa forma.
Os erros de especificação do modelo trazem várias consequências. A omissão de variável
relevante, ou seja, estimar 𝑌 = 𝛼1 + 𝛼2𝑋2 + 𝜇𝑖 quando o verdadeiro modelo é 𝑌 = 𝛽1 + 𝛽2𝑋2 +
𝛽3𝑋3 + 𝜀𝑖 causará viés e inconsistência das estimativas de MQO se a variável 𝑋3 estiver
correlacionada com outra variável explicativa, ou seja, 𝐸(𝜀𝑖|𝑋𝑖) ≠ 0 pois (𝑋′𝜀 ≠ 0) uma vez que
𝜇𝑖 = 𝜀𝑖 + 𝛽3𝑋3. Mesmo que a variável 𝑋3 não esteja correlacionada com as demais o intercepto será
viesado. Outra consequência é a incorreta estimação da variância do erro e o consequente equívoco
no cálculo dos intervalos de confiança, erros padrão e testes de hipóteses.
A inclusão de variáveis desnecessárias, ou seja, estimar 𝑌 = 𝛽1 + 𝛽2𝑋2 + 𝛽3𝑋3 + 𝜀𝑖 quando
o verdadeiro modelo é 𝑌 = 𝛼1 + 𝛼2𝑋2 + 𝜇𝑖 incorrerá na perda de eficiência dos estimadores devido
a correlação (FIV) existente entre as covariáveis. Já os erros de medida quando na variável dependente
causam perda de eficiência nos estimadores e quando nas variáveis explicativas causam viés e
inconsistência por motivos análogos à omissão de variável relevante.
A especificação incorreta do termo de erro causa viés nos estimadores de MQO enquanto a
invalidade da pressuposição de distribuição normal torna os testes de hipóteses usuais inutilizáveis.
A identificação dos problemas de omissão de variável relevante, inclusão de variável
irrelevante e forma funcional equivocada podem ser feita por meio dos testes (𝑡), do teste (𝐹) restrito,
do exame dos resíduos, da estatística d de Durbin-Watson, do teste Reset de Ramsey e do teste
Multiplicador de Lagrange (ML). Os erros de medidas são difíceis de ser detectados uma vez que
geralmente trabalhamos com dados secundários, já os erros de especificação do termo de erro devem
ser tratados a partir de métodos de estimação não lineares. A normalidade do termo de erro pode ser
verificada a partir do teste de normalidade de Jarque-Bera.
Por fim, cabe ressaltar que a estimação de relações endógenas por MQO gera estimadores
viesados e inconsistentes devido a violação da pressuposição 𝐸(𝜀𝑖|𝑋𝑖) = 0, pois tanto (𝑋′𝜀 ≠ 0)

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
como (𝑌′𝜀 ≠ 0). Ao se detectar relações endógenas pelo teste de Hausman (que verifica se 𝑋′𝜀 ≠ 0)
é preciso recorrer a outros estimadores para superar o problema como o de Mínimos Quadrados
Indiretos (MQI), para equações exatamente identificadas, ou Mínimos Quadros em Dois Estágios
(MQ2E) e Variáveis Instrumentais (VI) para equações superidentificadas.
v) Os erros 𝜺𝒊 são variáveis aleatórias com variância constante (homocedasticidade).
Podemos representar a violação do pressuposto da seguinte forma:
Dada a premissa 2 (ausência de multicolinearidade perfeita)
�̂� = (𝑋′𝑋)−1𝑋′𝑌
Dado 𝑌 = 𝑋𝛽 + 𝜀 (premissa 1 linearidade), substituindo:
�̂� = (𝑋′𝑋)−1𝑋′(𝑋𝛽 + 𝜀)
�̂� = (𝑋′𝑋)−1𝑋′𝑋𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Dado (𝑋′𝑋)−1𝑋′𝑋 = 𝐼:
�̂� = 𝛽 + (𝑋′𝑋)−1𝑋′𝜀
Logo:
�̂� − 𝛽 = (𝑋′𝑋)−1𝑋′𝜀
Dado que:
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[(�̂� − 𝛽)(�̂� − 𝛽)′]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[((𝑋′𝑋)−1𝑋′𝜀)((𝑋′𝑋)−1𝑋′𝜀)′]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[(𝑋′𝑋)−1𝑋′𝜀𝜀′𝑋(𝑋′𝑋)−1]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝐸[(𝑋′𝑋)−1𝑋′𝜀𝜀′𝑋(𝑋′𝑋)−1]
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = (𝑋′𝑋)−1𝑋′𝐸(𝜀𝜀′)𝑋(𝑋′𝑋)−1
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = (𝑋′𝑋)−1𝑋′(𝜎2Ω)𝑋(𝑋′𝑋)−1
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝜎2(𝑋′𝑋)−1𝑋′Ω𝑋(𝑋′𝑋)−1
Sob a validade dos pressupostos 5 e 6, Ω = I, então:
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝜎2(𝑋′𝑋)−1
Caso os pressupostos 5 e/ou 6 não sejam válidos então Ω ≠ I, então:
𝑉𝑎𝑟 − 𝐶𝑜𝑣(�̂�) = 𝜎2(𝑋′𝑋)−1𝑋′Ω𝑋(𝑋′𝑋)−1

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
Dessa forma, caso não sejam válidas as premissas do MCRL a matriz de variância e
covariância dos parâmetros estimados será viesada. Não é possível afirmar se a mesma será maior ou
menor que a matriz quando os pressupostos são válidos, portanto, as inferências com base nos testes
𝑡 e 𝐹 não serão mais válidas.
A causa ou a natureza do problema pode ser a variabilidade entre os diferentes valores fixados
de X (exemplo renda e consumo), a presença de outliers, erros de especificação do modelo
(omissão de variável relevante), assimetria na distribuição da variável explicativa e observações
discrepantes (empresas pequenas, médias e grandes na mesma amostra).
Quando a pressuposição de variância constante é violada os estimadores de MQO continuam
a ser não tendenciosos e consistentes, contudo deixam de ser eficientes. Para o modelo 𝑌 = 𝛽1 +
𝛽2𝑋2 + 𝜀𝑖 a variância estimada de 𝛽2 será 𝑉(�̂�2) =�̂�2
∑𝑥𝑖2 enquanto a verdadeira variância seria
𝑉(�̂�2) =∑𝑥𝑖
2�̂�𝑖2
(∑𝑥𝑖2)2
.
Além da invalidade das inferências com base nos testes 𝑡 e 𝐹, os estimadores não serão mais
eficientes. Para detectar a violação do pressuposto de variância constante é possível recorrer a alguns
procedimentos informais como o gráfico do resíduo ao quadrado (𝜀2) em função das variáveis
explicativas ou dependente ou procedimentos formais como os testes de Park (a equação de teste
baseia-se na regressão do logaritmo do resíduo ao quadrado em função de alguma variável
explicativa), Glejser (a equação de teste baseia-se na regressão do resíduo absoluto em função de
alguma variável explicativa), Goldfeld-Quandt (baseia-se na comparação da variância entre grupos
diferentes da variável explicativa), Breusch-Pagan-Godfrey e o teste geral de heterocedasticidade de
White (a equação de teste baseia-se na regressão do resíduo ao quadrado em função das variáveis
explicativas, do quadrado e do produto cruzado dessas variáveis). A hipótese nula é de
homocedasticidade, caso seja identificado algum padrão de relação entre a variância e as variáveis
explicativas gera-se evidência da existência do problema.
A identificação do problema leva a conclusão de que os estimadores de MQO podem não ser
mais os melhores uma vez que não é possível garantir a validade do Teorema de Gauss-Markov.
Nesse caso, pode-se encontrar estimadores que sejam BLUE mesmo com a presença de
heterocedasticidade.
Para corrigir o problema é preciso levar em consideração se o padrão de heterocedasticidade
é conhecido ou não. Se o padrão de heterocedasticidade é conhecido estima-se o seguinte modelo:

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
𝑃𝑌 = 𝑃𝑋𝛽 + 𝑃𝜀 onde 𝑃 =
[ 1/√ω1.
.
.1/√ωn]
Ao estimar o modelo transformado por MQO damos origem aos estimadores de Mínimos
Quadrados Generalizados (MQG) ou Mínimos Quadrados Ponderados (MQP) que, nesse caso, são
BLUE.
Quando não se conhece o padrão de heterocedasticidade, quase a totalidade dos casos, pode-
se supor um padrão de heterocedasticidade com base nos testes e estimar por MQG ou utilizar a
correção de White que consiste na estimação da verdadeira variância por:
𝑉(�̂�2) =∑𝑥𝑖
2�̂�𝑖2
(∑𝑥𝑖2)2
Outra possibilidade quando não se conhece o padrão de heterocedasticidade é estimar a
variância utilizando, por exemplo, a especificação de Harvey’s (1976) (𝜎𝑖2 = 𝜎2exp (𝑋𝛽))
transformar as variáveis e aplicar o MQO dando origem aos Mínimos Quadrados Generalizados
Factíveis (MQGF).
vi) Ausência de autocorrelação no erro.
Como no caso da heterocedasticidade, caso não seja válida a premissas do MCRL de ausência
de autocorrelação no termo de erro a matriz de variância e covariância dos parâmetros estimados será
viesada. Não é possível afirmar se a mesma será maior ou menor que a matriz quando os pressupostos
são válidos, portanto, as inferências com base nos testes 𝑡 e 𝐹 não serão mais válidas.
A causa ou a natureza do problema pode ser a inércia presente nas séries de tempo como PIB
e inflação, erros de especificação do modelo (omissão de variável relevante ou forma funcional
inadequada), o fenômeno da teia de aranha, defasagens, manipulação e transformação nos dados e
ausência de estacionariedade.
Quando a pressuposição de ausência de autocorrelação é violada os estimadores de MQO
continuam a ser não tendenciosos e consistentes, contudo deixam de ser eficientes. Para o modelo

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
𝑌𝑡 = 𝛽1 + 𝛽2𝑋2𝑡 + 𝜀𝑡 a variância estimada de 𝛽2 será 𝑉(�̂�2) =�̂�2
∑𝑥𝑡2 enquanto a verdadeira variância
seria 𝑉(�̂�2) =�̂�2
∑𝑥𝑡2 (1 + 2𝜌
∑𝑥𝑡𝑥𝑡−1
∑𝑥𝑡2 + ⋯+ 2𝜌𝑛−1 ∑𝑥𝑡𝑥𝑡−𝑛
∑𝑥𝑡2 ).
Além da invalidade das inferências com base nos testes 𝑡 e 𝐹, os estimadores não serão mais
eficientes. Para detectar a violação do pressuposto de ausência de autocorrelação é possível recorrer
a alguns procedimentos informais como o gráfico do resíduo em função do tempo ou do resíduo em
função do resíduo defasado ou procedimentos formais como os testes de Durbin-Watson ou de
Breusch-Godfrey (a equação de teste baseia-se na estimação de uma regressão dos resíduos em função
das variáveis explicativas e das defasagens do resíduo).
A identificação do problema leva a conclusão de que os estimadores de MQO podem não ser
mais os melhores (quando a autocorrelação não é originada por erro de especificação do modelo) uma
vez que não é possível garantir a validade do Teorema de Gauss-Markov. Nesse caso, pode-se
encontrar estimadores que sejam BLUE mesmo com a presença de autocorrelação.
Para corrigir o problema é preciso levar em consideração se o coeficiente de autocorrelação
(𝜌) é conhecido ou não. Se (𝜌) é conhecido estima-se o seguinte modelo de diferenças generalizadas
(para o caso de um processo AR(1):
𝑌𝑡 − 𝜌𝑌𝑡−1 = 𝛽1(1 − 𝜌) + 𝛽2(𝑋𝑡 − 𝜌𝑋𝑡−1) + (𝜀𝑡 − 𝜌𝜀𝑡−1)
Ao estimar o modelo transformado por MQO damos origem aos estimadores de Mínimos
Quadrados Generalizados (MQG) que são BLUE.
Quando não se conhece (𝜌), quase a totalidade dos casos, podemos estimá-lo por meio de
algum procedimento como o de Durbin-Watson, Durbin Watson de 2 etapas, Cochrane-Orkutt de 2
etapas ou iterativo e estimar por MQGF a equação de diferenças generalizada ou ainda, pode-se
utilizar a correção de Newey-West que consiste na estimação da verdadeira variância. Outra
possibilidade é a estimação da equação com as variáveis em primeira diferença.
vii) Os erros têm distribuição normal.
Já tratada na seção iv, a violação desse pressuposto impossibilita a usual inferência estatística
baseada na distribuição normal. Contudo, caso a amostra possua tamanho razoável é possível invocar

ESTADO DE MATO GROSSO
SECRETARIA DE ESTADO DE CIÊNCIA E TECNOLOGIA
UNIVERSIDADE DO ESTADO DE MATO GROSSO
CAMPUS UNIVERSITÁRIO DE SINOP
CURSO DE CIÊNCIAS ECONÔMICAS
a teoria assintótica ou de grandes amostras que postula que a distribuição do erro tende para normal
conforme cresce o tamanho da amostra.
REFERÊNCIAS
ANGRIST, J. D.; PISCHKE, J. S. Mostly harmless econometrics: An empiricist's companion.
2008.
GALTON, F. Regression towards mediocrity in hereditary staturep. Anthropological Miscellanea,
p. 246-263, 1886.
GREENE, W. Econometric Analysis, 7a. Ed., Prentice Hall, 2000.
GUJARATI, Damodar N.; PORTER, Dawn C. Econometria Básica. 5a Ed., Porto Alegre: Bookman,
2011.