
Universidade de São Paulo Instituto de Matemática e Estatística Curso de Matemática Aplicada e Computacional
Rafael Klanfer Nunes
Um curso de inferência e seleção estatística de cadeias de alcance variável
Trabalho de Conclusão de Curso
São Paulo – SP 2014

Rafael Klanfer Nunes
Um curso de inferência e seleção estatística de
cadeias de alcance variável
Trabalho de conclusão de curso apresentado ao Curso de Matemática Aplicada e Computacional da USP, como requisito para a obtenção do grau de bacharel em Matemática Aplicada e Computacional com habilitação em Estatística Econômica.
Orientador: Prof. Dr. Antonio Galves
MAE – IME – USP
São Paulo – SP 2014

Resumo
O presente trabalho teve como principal motivação a percepção de que há uma escassez de materiais didáticos que abordem de forma mais abrangente o tema da seleção e inferência estatística de cadeias de alcance variável, em especial na língua portuguesa. Além disso, constata-se uma necessidade crescente de apresentar esse e demais assuntos correlatos à alunos de graduação em áreas relacionadas à estatística. Dessa forma, procurou-se aproveitar a oportunidade de reunir o conteúdo oferecido pela disciplina MAE0699 – Tópicos de Probabilidade e Estatística – ministradas pelo professor Antonio Galves no Instituto de Matemática e Estatística (IME-USP) de forma a elaborar um material que suprisse tais lacunas. O projeto consistiu em organizar o curso no formato de livro-texto, através do uso do software Latex, tomando as notas de aula da disciplina MAE0699 como principal referência. Foram também aproveitados artigos complementares de apoio à disciplina. De maneira geral, tentou-se trazer para um livro-texto a fluidez, didaticidade e coerência do conteúdo do curso. Tendo isso em mente, tomamos especial atenção à alguns pontos críticos para a compreensão do leitor: Alguns detalhes de notação foram modificados e padronizados de forma a evitar erros de interpretação. O conteúdo foi dividido em capítulos de forma a apresentar no capítulo anterior as ideias necessárias para o entendimento do capítulo seguinte. Ao final de cada capítulo foram inseridos diversos exercícios que captam as ideias fundamentais do conteúdo apresentado. Por fim, o trabalho está em constante atualização, motivado em especial pelo “feedback” fornecido por alguns alunos do IME, os quais tiveram contato com versões preliminares desse texto. Contato motivado tanto pela busca de um melhor entendimento da própria disciplina MAE0699, como também de forma a fazer uso desse material como suporte ao seus próprios trabalhos de conclusão de curso. Assim, espera-se com este trabalho contribuir tanto para um melhor aprendizado dos alunos de graduação, bem como propiciar a difusão dos temas aqui abordados. Palavras-chave: cadeias de markov, cadeias de alcance variável, estatística, algoritmo contexto, seleção estatística.

Curso de inferência
e seleção estatística
de cadeias de
alcance variável
Professor Dr. Antonio Galves
Transcrito por: Rafael Klanfer Nunes

Copyright c� 2014 Rafael Klanfer Nunes
PUBLISHED BY PUBLISHER
HTTP://WWW.IME.USP.BR/ GALVES/CURSOSHTTP://WWW.IME.USP.BR/ DOUGLASR
Licensed under the Creative Commons Attribution-NonCommercial 3.0 UnportedLicense (the “License”). You may not use this file except in compliance with theLicense. You may obtain a copy of the License at http://creativecommons.org/licenses/by-nc/3.0. Unless required by applicable law or agreed to inwriting, software distributed under the License is distributed on an “AS IS” BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either expressor implied. See the License for the specific language governing permissions andlimitations under the License.informationFirst printing, 2014

Conteúdo
1 Revisão de alguns conceitos estatísticos . . . . . . . . . . . . . 5
1.1 Comentário inicial 5
1.1.3 Lei fraca dos grandes números . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Cadeias de Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1 Objetivo do curso 9
2.2 Pseudo-algoritmo de simulação de uma cadeia de Markov10
2.2.1 Simulação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Conceitos importantes 11
2.3.1 Probabilidade invariante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 Modelo de Ehrenfest 19
2.5 Inferência estatística em cadeias de Markov 19
2.5.1 Caso geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5.2 Caso de alcance k � 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27

2.6 Exercícios de fixação 28
2.7 Exercícios teste 34
3 Cadeias de alcance variável . . . . . . . . . . . . . . . . . . . . . . 41
3.1 Neurociências: Modelo simples de um sistema de neurôniosinteragindo entre si. 41
3.2 Árvore de contextos 45
3.2.1 Contexto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.3 Conceitos importantes 51
3.4 Estimação de ‘p’ por máxima verossimilhança 53
3.5 Considerações Importantes 56
3.6 Exercícios de fixação 60
3.7 Exercícios teste 64
4 Seleção estatística de modelos . . . . . . . . . . . . . . . . . . . . 69
4.1 Introdução 69
4.2 Critério de Schwarz 72
4.3 Seleção de modelos 79
4.3.1 Selecionando uma árvore de contextos . . . . . . . . . . . . . . . . . . 85
4.3.2 Algoritmo "Contexto
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
4.4 Considerações importantes 89
4.5 Exercícios de fixação 90
4.6 Algoritmos de simulação em R 92
5 Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97

Comentário inicialLei fraca dos grandes números
1 — Revisão de alguns conceitos estatísticos
1.1 Comentário inicial
Antes de tratar dos problemas de interesse deste curso, vamos fazer uma pequenarevisão acerca de algumas ferramentas básicas que serão necessárias para o bomentendimento do que virá nos demais capítulos.
1.1.1 Variáveis Aleatórias1
Seja (W,F ,P) um espaço de probabilidade. Denominamos de variável aleatóriaqualquer função X : W ! R tal que:
X�1(I) = {w 2 W : X(w) 2 I} 2 F
para todo intervalo I ⇢R. Dito de outra forma, X é variável aleatória se sua imageminversa para intervalos I ⇢ R pertencerem à sigma-álgebra F .Portanto, uma variável aleatória é uma função do espaço amostral W nos reais, paraa qual é possível calcular a probabilidade de ocorrência de seus valores. Assim,para cada elemento w 2 W temos um número real X(w), além de certa probabilidadeP{X = X(w)} associada.
1Ver Magalhães(2011)

6 Revisão de alguns conceitos estatísticos
1.1.2 Cadeias de Markov2
Seja uma sequência de variáveis aleatórias X0,X1, ..., que assumem valores dentro doconjunto {0,1, ...,k}. Interpreta-se Xn como o estado de algum sistema no instante‘n’, de tal forma que o sistema encontra-se no estado ‘i’ no instante ‘n’ se Xn = i.Diz-se que a sequência de variáveis aleatórias forma uma cadeia de Markov se,cada vez que o sistema estiver no estado ‘i’, existir uma probabilidade fixa - Pi j -de que o sistema passe para o estado ‘j’. Ou seja, para i0, ..., in�1, i, j :
P{Xn+1 = j|Xn = i,Xn�1 = in�1, ...,X0 = i0}= Pi j
Chama-se Pi j de probabilidades de transição da cadeia de Markov, tal que:
Pi j � 0k
Âj=0
Pi j = 1 i = 0,1, ...,k
Também é conveniente arranjar as probabilidades de transição de tal forma a obter-mos a matriz de probabilidades de transição P:
��������
P00 P01 ... P0kP10 P11 ... P1k... ... ... ...Pk0 Pk1 ... Pkk
��������
Note que se conhecermos a composição da matriz de probabilidades de transição,bem como a distribuição de X0, poderemos calcular todas as probabilidades deinteresse. Por exemplo, a função de probabilidade conjunta de X0, ...Xn é dada por:
P{Xn = in,Xn�1 = in�1, ...,X1 = i1,X0 = i0}=P{Xn = in|Xn�1 = in�1, ...,X0 = i0}.P{Xn�1 = in�1, ...,X0 = i0}=
Pin�1,inP{Xn�1 = in�1, ...,X0 = i0}= ...=
Pin�1,in .Pin�2,in�1 ....P{X0 = i0}
Uma definição útil neste curso3 para cadeia de Markov diz: O processo em tempodiscreto (Xn)n2N tendo E como espaço de estados é uma cadeia de Markov seexistir uma função F : E ⇥ [0,1]! E tal que para todo n � 1 : Xn = F(Xn�1,Un),onde U1,U2, ... é uma sequência de variáveis aleatórias i.i.d. no intervalo [0,1].
2Ver Ross(2007)3Ver Ferrari, P. A.; Galves, A(1997)

1.1 Comentário inicial 7
1.1.3 Lei fraca dos grandes números
Para demonstrar a lei fraca dos grandes números iremos primeiramente nos valerde duas ferramentas importantes, a desigualdade de Markov e a desigualdade deChebyshev.
Desigualdade de Markov
Seja Z 2 {0,1,2,3, ...} uma variável aleatória. Então P{Z > u} E(Z)u .
Demonstração:
E(Z) =•
Âz=1
zP{Z = z}=u�1
Âz=1
zP{Z = z}+•
Âz=u
zP{Z = z}�
•
Âz=u
zP{Z = z}�•
Âz=u
uP{Z = z}=
u•
Âz=u
P{Z = z}= uP{Z � u}
Assim: P{Z > u} E(Z)u
Desigualdade de Chebyshev
Seja Z uma variável aleatória com valores reais, com E(|Z|)< • e V (Z) = s
2 < •,então 8e > 0 P{|Z �E(Z)|> e} Var(Z)
e
2 .
Demonstração: Segue da desigualdade de Markov
• P{|Z �E|� e}= P{(Z �E(Z))2 � e
2}
• W = [Z �E(Z)]2
Usando a notação: P{W � e
2}, onde e > 0 )W � 0, então usando a desigualdadede Markov:
P{W > e
2} E(W )
e
2 )

8 Revisão de alguns conceitos estatísticos
P{|Z �E(Z)|> e}
Var(Z)z }| {E{[Z �E(Z)]2}
e
2
Demonstração da LFGN usando as desigualdades apresentadas
P{|1n
n
Âi=1
yi �qz }| {
E(Yi) |> e}= P{|1n(
n
Âi=1
Yi �nq)|> e}=
P{|1n
n
Âi=1
(Yi �q)|> e}= P{|Â(Yi �q)| {z }
Z
|> ne|{z}e
}
Usando Chebyshev ! P{|Â(Yi �q)|> ne} Var(Z)(ne)2 =
Var(Âi.i.d.z }| {
(Yi �q))
(ne)2 =
indep. de (Y1,Y2, ...) =Ân
i=1
s
2z }| {Var(Yi �q)
(ne)2 =ns
2
n2e
2 =1n
s
2
e
2|{z}!0n!•
Assim, obtemos o seguinte resultado:
P{|1n
n
Âi=1
yi �qz }| {
E(Yi) |> e} 1n
Var(Yi)
e
2 ! 0n!•

Objetivo do cursoPseudo-algoritmo de simulação de umacadeia de Markov
Simulação
Conceitos importantesProbabilidade invariante
Modelo de EhrenfestInferência estatística em cadeias deMarkov
Caso geral
Caso de alcance k � 1Exercícios de fixaçãoExercícios teste
2 — Cadeias de Markov
2.1 Objetivo do curso
Interpretar séries de 0’s e 1’s, associando um modelo probabilístico a cada umadessas séries através de procedimento estatístico: Seleção estatística de modelos.
Discretização: Spike sorting
Notação:
X(i)n =
⇢1, há disparo do neurônio i no instante de tempo n0, caso contrário

10 Cadeias de Markov
2.2 Pseudo-algoritmo de simulação de uma cadeia de Markov
• Este algoritmo irá assumir sempre valores num alfabeto ‘A’ finito.1. Atribuir um valor escolhido em A a X0.2. Para todo n � 1.
2.1. Selecionar um número aleatório Un 2 [0;1], com distribuição uniformeindependente do passado.
2.2. Xn = f (Xn�1,Un) onde f : A⇥ [0;1]! A.
2.2.1 Simulação
Seja (X (0)n )n�0 uma evolução Markoviana assumindo valores no alfabeto A = {0,1}
e que pode ser simulada através do seguinte algoritmo:
Passo 1. X (0)0 = 0;
Passo 2. Para n � 1, definimos1:(
X (0)n = 0, se Un 0,7
X (0)n = 1, se Un > 0,7
! Note que o subscrito a, em X (b)a , indica o instante do tempo que estamos
tratando. Já o subscrito b, indica qual o valor inicial da sequência. Neste casoa sequência assume o valor inicial b. Usaremos o parênteses para indicar osímbolo inicial da sequência. Se a cadeia considera apenas 1 passo para trás,então chamamos de cadeia de Markov de alcance, ou ordem, 1. Isso ficarámais claro ao longo do texto.
⌅ Exemplo 2.1 Considere a seguinte série: (2,1,1,2,1,1,2,1,1). Ela simula a batidade uma valsa. Veja que as seguintes possibilidades são possíveis:
se
8<
:
Xn�1 = 2 ! Xn = 1
Xn�1 = 1 !⇢
Xn�2 = 1 ! Xn�1 = 1 ! Xn = 2Xn�2 = 2 ! Xn�1 = 1 ! Xn = 1
Veja que para saber opróximo passo preci-samos considerar até2 passos atrás. As-sim, a cadeia de Mar-kov da valsa é de or-dem 2!
⌅
1onde (Un)n�1 é uma sequência de variáveis aleatórias i.i.d. com distribuição uniforme em [0;1].

2.3 Conceitos importantes 11
2.3 Conceitos importantes
Definição 2.3.1 Uma cadeia de Markov é de alcance ‘k’ se possuir o seguintealgoritmo:
• Inicialização: Escolho valores para X�k, ...,X�1.• Para n � 0: Xn = f (Xn�1,Xn�2, ...,Xn�k;Un), onde (Un)n é uma sequência
de variáveis aleatórias i.i.d. com distribuição uniforme em [0;1].
Definição 2.3.2 Seja a cadeia da Markov de alcance 1: Xn = f (Xn�1;Un) comfunção f : A⇥ [0;1]! A. Então P{Xn = b|Xn�1 = a} é dado por:
P{Xn = b|Xn�1 = a}= P{ f (Xn�1,Un) = b|Xn�1 = a}=P{ f (a,Un) = b|Xn�1 = a}= P{ f (a,Un) = b}
⌅ Exemplo 2.2 Considere o seguinte exemplo onde, a partir das funções, calcula-mos a probabilidade de transição: ⌅
f (0,u) =⇢
0 se u 0,71 se u > 0,7
f (1,u) =⇢
0 se u 0,41 se u > 0,4
• p(1|0) = P{ f (0,u) = 1}= p(u > 0,7) = 0,3
• p(0|0) = P{ f (0,u) = 0}= p(u 0,7) = 0,7
• p(1|1) = P{ f (1,u) = 1}= p(u > 0,4) = 0,6
• p(0|1) = P{ f (1,u) = 0}= p(u 0,4) = 0,4
Note que: p(1|0)+ p(0|0) = p(1|1)+ p(0|1) = 1.
Ou seja, dada a função: f : A⇥ [0;1]! A, calculamos a probabilidade de transição:p(b|a) = P{f(a|u) = b}

12 Cadeias de Markov
! Como convenção definimos a probabilidade de transição ‘p’ como sendo:
p =
✓P(0|0) P(1|0)P(0|1) P(1|1)
◆
Cada linha representa o valor que aconteceu no instante anterior, enquantoque cada coluna representa o valor que irá acontecer no instante seguinte.Além disso, note que a probabilidade de transição ‘p’ é unicamente determi-nada pela função ‘f’.
⌅ Exemplo 2.3 Neste exemplo a função não é dada. Tem-se que o alfabeto consi-derado é o conjunto: A = {1,2,3}. Assim, a matriz de probabilidades é:
p=
1 2 3 !1 0,2 0,2 0,6
2 0,7 0,1 0,23 0,5 0,4 0,1
⌅
! Note que a escolha de f não é única.
Exercício 2.1 Monte uma outra função f que também represente as probabili-dades da matriz de transição p anterior. ⌅
Para montar a função ‘f’ é importante observar que:
f (a,u) = Âx2A
x.1{u2Iax }
onde Iax (x 2 A) é a partição disjunta de [0;1] para cada a 2 A.
Condição :
8<
:
Sx2A Ia
x = [0;1]|Ia
x |= p(a|x).se x 6= x0 , Ia
xT
Iax0 = /0

2.3 Conceitos importantes 13
⌅ Exemplo 2.4 Este exemplo servirá para mostrar como uma cadeia de Markovnão tem memória de seu valor inicial. Para tanto, considere a notação X (a)
n emque o subscrito ‘a’ representa o valor inicial da cadeia. Assim, distinguiremosduas sequências através deste símbolo. Agora, considere a seguinte matriz ‘p’ detransição, bem como um esquema das probabilidades:
p =
0 1✓ ◆0 0,7 0,31 0,3 0,7
0 1 00
1
0,3 0,60 1 1
u
!Veja com atenção a forma como o esquema foi criado. Do lado esquerdo, osnúmeros 0 e 1 indicam o estado no instante Xn�1. A reta indica os valoresque a variável aleatória Un pode assumir no intervalo [0;1]. Note que a partede cima da reta indica qual o valor que Xn assume no instante n. Há umaprobabilidade de Xn assumir o valor 1 de 30%, ou seja, 0,6 - 0,3. Da mesmaforma, dado que Xn�1 = 0, a probabilidade de Xn = 0 é 70%.
Na parte de baixo da reta é exibido o que pode acontecer com a variávelaleatória, dado que no instante Xn�1 ela assumiu o valor 1. Verifique queesta representação das probabilidades é exatamente a mesma que a exibidana matriz de probabilidades ‘p’!
Continuando, vamos simular ao mesmo tempo o par (X (0)n ,X (1)
n ) 2 A2, onde A ={0,1}. Ou seja, duas sequências regidas pela mesma matriz de probabilidades detransição, porém com valores iniciais distintos.2 Dessa forma teremos dois casospossíveis:
• Se (X (0)n�1,X
(1)n�1) = (0,1) ou (1,0)
– Se un 0,3 ) (X (0)n ,X (1)
n ) = (0,0)
– Se 0,3 < un 0,6 ) (X (0)n ,X (1)
n ) = (1,1)
– Se 0,6 < un 1 ) (X (0)n ,X (1)
n ) = (0,1)
• Se (X (0)n�1,X
(1)n�1) = (0,0) ou (1,1)
2(X (0)n ,X (1)
n ) = f (X (0)n ,X (1)
n ,Un)

14 Cadeias de Markov
– Se un 0,3 ) (X (0)n ,X (1)
n ) = (0,0)
– Se 0,3 < un 0,6 ) (X (0)n ,X (1)
n ) = (1,1)
– Se 0,6 < un 1 ) (X (0)n ,X (1)
n ) = (0,0)
Ou seja, se X (0)n�1 = X (1)
n�1 então X (0)n = X (1)
n . Assim, no instante em que os estados dacadeia se igualam as probabilidades ficam as mesmas. Observe a cadeia redutívelcom uma classe fechada (Pontilhado).
(0,0)
(1,1)
(1,0)
(0,1)
? Qual o valor da probabilidade P{X (0)n 6= X (1)
n }?
P{X (0)n 6= X (1)
n }=P{u0 > 0,6;u1 > 0,6; ...;un > 0,6}=
P{u0 > 0,6}.P{u1 > 0,6}...P{un > 0,6}= 0,4n+1
Portanto, para n ! •, P{X(0)n 6= X(1)
n }= 0
Ou seja, a cadeia de Markov perde a memória do valor inicial.
! Consequência da perda de memória da cadeia de Markov:
9 única medida de probabilidade µ em A tal que 8 a e b:
|P{X (a)n = b}�µ(b)| (0,4)n+1
⌅

2.3 Conceitos importantes 15
2.3.1 Probabilidade invariante
Retomando a definição 1.3.2, temos que:
Seja a cadeia da Markov de alcance 1: Xn = f (Xn�1;Un) para dada função f :A⇥ [0;1]! A. Qual a probabilidade de Xn = b, dado que Xn�1 = a?3
p(b|a) = P{Xn = b|Xn�1 = a}= P{ f (Xn�1,Un) = b|Xn�1 = a}=
P{ f (a,Un) = b|Xn�1 = a}= P{ f (a,Un) = b}
• Dada a função f, existe uma única matriz p : Ak ⇥A ! [0;1] tal que4:
p(b|a�1�k) = P{ f (a�1
�k ,Un) = b}= P{Xn = b|Xn�1n�k = a�1
�k}=
= P{ f (Xn�1n�k ,Un) = b|Xn�1
n�k = a�1�k} ! Depende só de Un
Assim, a matriz de probabilidades de transição de ordem k tem a seguinte proprie-dade:
0 p(b|a�1�k) 1
8a�1�k , Â
b2Ap(b|a�1
�k) = 1
Reciprocamente:Dada a matriz p : Ak ⇥A ! [0;1], existem muitas funções f : Ak ⇥ [0;1]! A quefornecem o algoritmo de simulação para uma cadeia de Markov de alcance k ematriz p.
3a�1�k = (a�k, ...,a�1)
4Cuidado com a notação. Veja que agora os subscritos indicam quais elementos estamos tratando:{Xn�1
n�k = a�1�k}= {Xn�k = a�k, ...,Xn�1 = a�1}

16 Cadeias de Markov
Caso k=1:mProbabilidade invariante com a matriz p. A probabilidade µ : A ![0;1] é invariante com respeito a p se, 8b 2 A:
µ(b) = Âa2A
µ(a)p(b|a)
Ou seja, escolhemos o estado inicial com a medida de probabilidade µ:Inicialização: X�1 ! a com probabilidade µ(a).Escolhi o elemento ‘a’ com probabilidade µ(a) e quero saber p(b|a).
a b
-1 0p(b|a)
1 Passo
Quero saber a probabilidade de no instante ‘0’ aparecer o símbolo ‘b’.
P{Xµ
0 = b}= f ( X�1|{z}Escolho com µ
,U0)
Graficamente:
A A
a
b
-1 0
Qual a probabilidade de termos‘b’ após o primeiro passo.p(b|a)
X−1 =
P{Xµ
0 = b}= Âa2A
µ0(a)p(b|a)
? Dado ‘p’, como selecionar µ0 de forma que: µ1 = µ0 (Invariante).5
5µ0: Distribuição inicial. µ1 Dist. após 1 passo. ! µ1(·) = Âa µ0(a)p(·|a)

2.3 Conceitos importantes 17
• Mostrar que qualquer cadeia de Markov tem sempre um único estado invariante esempre é possível alcançá-lo. Dados: A = {0,1}. p : A2 ! [0;1]
Simular as 2 cadeias ao mesmo tempo:
p =
0 1✓ ◆0 0,2 0,81 0,6 0,4
0 1 10
1
0,2 0,60 1 0
u
Definir:
(X (0)0 ,X (1)
0 ) = f ((0,1),U0) =
8<
:
(0,0) U0 < 0,2(1,1) 0,2 <U0 < 0,6(1,0) 0,6 <U0 < 1
Se X (0)m = X (1)
n para algum n, então X (0)m+1 = X (1)
n+1
Assim: P{X (0)0 6= X (1)
0 }= 0,4. Generalizando: P{X (0)n 6= X (1)
n }= (0,4)n+1
Distribuição após o instante ‘n’ da cadeia que começou com símbolo ‘a’:
µ
(a)n (·) = P{X (a)
n = ·}
Proposição 2.3.1 |µ(0)n (x)�µ
(1)n (x)| !|{z}
n!•
0
Demonstração:Primeiro veja que: P(F) = E(1F) = 1.P{1F = 1}+0.P{1F = 0}= P(F)
Agora, pela definição temos:
|µ(0)n (x)�µ
(1)n (x)|= |P{X (0)
n = x}�P{X (1)n = x}|=
= |E(1X (0)
n =x)�E(1
X (1)n =x
)|= |E(1X (0)
n =x)�1
X (1)n =x
|=
= E(1X (0)
n 6=X (1)n) = P{X (0)
n 6= X (1)n }= (0,4)n+1 ! 0
Ou seja:limn!•
µ
(0)n (x) = lim
n!•µ
(1)n (x) = µ(x)
Vamos chamar essa probabilidade limite comum de µ (Probabilidade Invariante).

18 Cadeias de Markov
Voltando ao exemplo:
p =
0 1✓ ◆0 0,2 0,81 0,6 0,4
0,2 0,6
min{p(0|0), p(0|1)}
min{p(0|1), p(1|1)}
p(1|0)− p(1|1) =
p(0|0)− p(0|1)
0,4Assim6:
|µ(0)n (x)�µ
(1)n (x) = |p(1|0)� p(1|1)|(n+1)
!• Mas no caso em que Xn são v.a. independentes: p(1|0) = p(1|1), ou seja,o passo atual não depende dos anteriores.
• No caso k=0: Xn = f (Un), ou seja, não depende dos valores anteriores(· · · ,Xn�2,Xn�1).
Problema 2.1 Tenho 2 urnas com N bolas numeradas de 1 a N. Jogo uma moedahonesta e se sair cara troco de urna a bola cujo número foi sorteado. Se sair coroanão faço nada e recomeço. Após um número grande de rodadas, como será adistribuição das bolas nas duas urnas? Ela depende da forma como inicialmenteestavam distribuídas as bolas entre as duas urnas? Esse problema é uma motivaçãopara o próximo assunto.
URNA A URNA B
1
9 22
NURNA
BOLA1 2 3 4
A A B A = Xn
6Se o tamanho do alfabeto for |A|> 3, ao invés do sinal de igualdade teremos .

2.4 Modelo de Ehrenfest 19
2.4 Modelo de Ehrenfest
Proposto em 1907 por Paul e Tatjana Ehrenfest, o modelo descreve a evoluçãode um gás entre dois compartimentos fechados7. Considere dois compartimentosinterligados, em que a conexão é regulada por uma válvula. Inicialmente todogás está num único compartimento. A experiência começa quando se permite acomunicação das duas câmaras. Se indicarmos o primeiro compartimento com osímbolo ‘0’ e o segundo por ‘1’, e supondo que N é o número de moléculas dogás, então o passeio pode ser visto como uma descrição detalhada da posição das Nmoléculas. Para tanto, define-se a variável aleatória X (a)
n (i) que representa o númerodo compartimento que a molécula i se encontra no instante n, em que a descrevea posição inicial da molécula (a(i) = 0 i = 1, ...,N). A partir desse modelo, sãolevantadas algumas perguntas de interesse:
• Qual a situação típica do modelo? Qual a probabilidade invariante dessaevolução?
• Se o modelo é reversível, quanto tempo leva para o gás voltar todo para ocompartimento inicial?
• Quanto tempo leva para o sistema voltar à configuração inicial? Sabe-se queo número de avogrado é de 1023 e que o tempo para cada molécula mudar detanque é de 1 segundo... (Poderia levar bilhões de anos!!!)
2.5 Inferência estatística em cadeias de Markov
Problema 2.2 Dada uma amostra (X�k = a�k, ...,X�1 = a�1,X0 = a0, ...,Xn = an),gerada por uma cadeia de Markov de alcance ‘k’ conhecido e matriz de probabilidadede transição desconhecida, como podemos estimar a matriz?
Método: Estimação por máxima verossimilhança. A ideia é que a matriz esti-mada pn seja aquela que maximiza a ‘verossimilhança’ da amostra, ou seja, aprobabilidade de ocorrência da amostra!
Vamos supor que a matriz probabilidade de transição seja: p 2 Mk(A). Repare que a7Ver Ferrari, P. A.; Galves, A.(1997)

20 Cadeias de Markov
notação de Mk(A) refere-se a toda classe de matrizes de transição de alcance k sobo alfabeto finito A.Para ilustrar, vamos resolver este problema usando o alfabeto A = {0,1}, traba-lhando com uma cadeia de alcance k=1 e supondo ter selecionado a seguinteamostra:
X�1 = 0,X0 = 0,X1 = 1,X2 = 0,X3 = 0,X4 = 1,X5 = 1,X6 = 0,X7 = 0,X8 = 0,X9 = 1,X10 = 1
Notação 2.1. As seguintes igualdades serão usadas de agora em diante:
• {Xn�1 = an
�1}= {X�1 = a�1,X0 = a0, ...,Xn = an}
• P{Xr = ar|Xr�1 = ar�1}= p(ar|ar�1)
Agora observe que:
P{Xn�1 = an
�1}= P{X�1 = a�1}.P{Xn0 = an
0|X�1 = a�1}=P{X�1 = a�1}.P{X0 = a0|X�1 = a�1}.P{Xn
1 = an1|X0
�1 = a0�1}=
P{X�1 = a�1}.n
’r=0
. P{Xr = ar|Xr�1�1 = ar�1
�1 }| {z }a última informação é que importa
Voltando ao nosso exemplo:
P{Xn�1 = an
�1}= P{X�1 = 0}.p(0|0).p(1|0).p(0|1).p(0|0).p(0|1).p(1|1).p(0|1).p(0|0).p(0|0).p(1|0).p(1|1) =
= P{X�1 = 0}.p(0|0)4.p(1|0)3.p(0|1)2.p(1|1)2
Veja que a potência 4 em p(0|0)4 diz respeito ao número de transições de 0 para0 na amostra X10
�1. Além disso, se somarmos 4+3+2+2=11, obtemos o número devezes que temos transições.Portanto, generalizando temos que:
P{Xn�1 = an
�1}= P{X�1 = a�1}. ’(x,y)2A2
.p(y|x)Nn(x,y)

2.5 Inferência estatística em cadeias de Markov 21
Notação 2.2. A seguinte notação é muito útil e diz respeito a forma como fazemosa contagem:
• Nn(x,y) = Ânt=01{Xt�1=x,Xt=y}
⌅ Exemplo 2.5 Primeiro vamos considerar a amostra até o instante n: X1, ...,Xn.
Agora sejam:
• Nn(x,y) : (x,y) 2 A2.• Xn = z.• Xn+1 = w.
Nn+1(x,y) =
8<
:
Nn(x,y) se x 6= zNn(z,y) se x = z mas Xn+1 = w 6= yNn(z,y)+1 quando Xn = z e Xn+1 = w
Chamamos a verossimilhança da amostra Xn�1 = an
�1 relativamente à matriz ‘p’ ovalor:
P{X�1 = a�1}. ’(x,y)2A2
.p(y|x)Nn(x,y)
Vamos indicar a matriz p como índice de P:
Pp{Xn�1 = an
�1}= P{X�1 = a�1}. ’(x,y)2A2
.p(y|x)Nn(x,y)
Assim dada a amostra an�1 e supondo P{X�1 = a�1} = 1, queremos calcular p 2
M1(A) que maximiza:
Pp{Xn�1 = an
�1}= 1. ’(x,y)2A2
.p(y|x)Nn(x,y)
Portanto:
p = argmax{Pp{Xn�1 = an
�1} : p 2 M1(A)}

22 Cadeias de Markov
Voltando ao exemplo numérico do problema 2.2:
Pp{X10�1 = a10
�1}= p(0|0)4| {z }
a
p(0|1)3| {z }
1�a
p(1|0)2| {z }
1�b
p(1|1)2| {z }
b
Supondo a matriz:
p=✓
a 1�a
1�b b
◆
Quero achar a matriz:
p =
✓a 1� a
1� b b
◆
Que maximiza Pp{X10�1 = a10
�1}
Para achar o máximo, bastar derivar e igualar a zero a função. Para facilitar, vamosrenomear e aplicar o logaritmo antes de derivar:
log(P(a,b ){X10�1 = a10
�1}) = log(a4 +(1�a)3 +(1�b )2 +b
2) =
= 4loga +3log(1�a)+2log(1�b )+2logb
Derivando e igualando a zero:
∂
∂a
log(a,b ) =4a
� 31� a
= 0 ! a =47
∂
∂b
log(a,b ) = 2⇣ 1
b
� 11� b
⌘= 0 ! b =
12
• Finalmente, veja que8:
a
1� a
=43=
N10(0,0)N10(0,1)
b
1� b
=22=
N10(1,1)N10(1,0)
a =4
4+3=
N10(0,0)N10(0,0)+N10(0,1)
b =N10(1,1)
N10(1,1)+N10(1,0)⌅
8 p(0|0) = 47 : Proporção de vezes que aparece um 0 seguido de outro 0.

2.5 Inferência estatística em cadeias de Markov 23
Resumindo:Fixada a amostra Xn
�1 = an�1, temos:
log({p(y|x) : (x,y) 2 A2}) = logP{Xn�1 = an
�1}= Â(x,y)
Nn(x,y) log p(y|x)
Queremos encontrar o máximo valor de log({p(y|x) : (x,y) 2 A2}) como função dep = {p(y|x) : (x,y) 2 A2}.
Assim, temos um problema de otimização com vínculo!
0 p(y|x) 1 e 8x Ây2A
p(y|x) = 1
Exercício 2.2 Tendo em vista o que foi visto até agora, e supondo que p 2M2(A), calcule uma expressão para Pp{Xn
�2 = an�2}.
⌅
Problema 2.3 Este problema irá motivar a construção de um caso geral a seguir.
Pergunta: Suponha que seja dada a amostra Xn�1 = an
�1. Queremos estimar a matrizque gerou a amostra.
Critério: Máxima verossimilhança. Vamos usar a matriz estimada p, aquela quemaximiza a chance de ocorrência daquela amostra em particular.
• M1(A) é a classe de matrizes probabilidade de transição de alcance 1 noconjunto A.
• p = argmax{Pp{Xn�1 = an
�1} : p 2 M1(A)}. Supondo que P{X�1 = a�1}= 1
Considere:• Alfabeto A = {0,1}• Matriz de probabilidade de transição p 2 Ma(A) tal que:
p =
✓a 1�a
1�b b
◆a,b 2 [0;1]

24 Cadeias de Markov
Agora seja a função a maximizar:
L(a,b ) = P(a,b ){Xn�1 = an
�1}= a
Nn(0,0)(1�a)Nn(0,1)b
Nn(1,1)(1�b )Nn(1,0)
O objetivo é calcular a e b que maximizam a verossimilhança da função L(a,b ).Para tanto, vamos otimizar derivando e igualando a zero:∂L∂a
= 0 e ∂L∂b
= 0
Finalmente iremos obter:
a =Nn(0,0)
Nn(0,0)+Nn(0,1)e b =
Nn(1,1)Nn(1,1)+Nn(1,0)
!Veja que b indica a proporção estimada de vezes que a partir do elemento 1obtemos o símbolo 1 no passo seguinte.
Notação 2.3. O contador Nn(1,0) indica que no primeiro instante temos o elemento1, e no instante seguinte o elemento 0. Portanto sempre deve-se ler da esquerdapara a direita, como sendo o passado para o futuro.
Nn(1,1) + Nn(1,0) = Número de vezes que o símbolo 1 aparece nas posições(X�1, ...,Xn�1) seguido por qualquer outro símbolo.
Notação 2.4. Assim, para amostras de tamanho ‘n’ temos:
pn(1|1) =Nn(1,1)Nn�1(1)
?Será que se a amostra for gerada por cadeia de matriz p, o estimador pn !
n!•p? Ou seja, estimador é não viesado?
É possível provar que o estimador é consistente usando a lei dos grandesnúmeros!

2.5 Inferência estatística em cadeias de Markov 25
2.5.1 Caso geral• Conjunto A finito
• Amostra dada: Xn�1 = an
�1
• p = argmax{ ’(a,b)2A2
.p(b|a)Nn(a,b) : p 2 M1(A)}
Cálculo do argmax(log{’ p(b|a)Nn(a,b)}) = Â(a,b)2A2
Nn(a,b) log(p(b|a))
Dificuldade: Vínculo0 p(b|a) 1, 8a, Â
bp(b|a) = 1
Usando multiplicadores de Lagrange, vamos obter o máximo da função de verossi-milhança:• F(p(b|a),la,a 2 A,b 2 A) =
= Âa2A
{Âb2A
Nn(a,b) log(p(b|a))+la{1� Âb2A
p(b|a)}}=
= Â(a,b)2A2
Nn(a,b) log(p(b|a))+ Âa2A
la{1� Âb2A
p(b|a)}
Derivando e igualando a zero:
∂F∂ p(u,v)
! se (a,b) 6= (u,v)! ∂F∂ p(u,v)
= 0
então:
∂F =∂Nn(u,v) log p(v|u)
∂ p(u,v)+
∂lu{Âb6=v p(b|u)� p(v|u)}∂ p(u,v)
Antes de continuar: Observação Importante!
Seja o alfabeto: A={0,1}.
e considere a notação: p(0|0) =x, p(1|0) =y, p(0|1) =z, p(1|1)=w

26 Cadeias de Markov
Assim, montamos a seguinte função:
F(x,y,z,w,l0,l �1) = N(0,0) logx+N(0,1) logy+
N(1,0) logz+N(1,1) logw+l0[1� (x+ y)]+l1[1� (z+w)]
O que resulta nas seguintes derivadas:
∂F∂x
= 0 ) Nn(0|0).1x�l0 = 0
∂F∂y
= 0 ) Nn(0|1).1y�l0 = 0
· · ·
Retomando, e tendo em mente a observação anterior temos:
∂F∂ p(b|a) = 0 ) Nn(a,b)
p(b|a) �la = 0 ) p(b|a) = Nn(a,b)
la
Vamos achar o valor de la:
∂F∂la
= 0 ) 1� [Â p(b|a) = 0]) Â p(b|a) = 1
{da equação anterior:} Âb
Nn(a,b)
la= 1
) la = Âb2A
Nn(a,b)
Inserindo o resultado, obtemos:
p(b|a) = Nn(a,b)Âc2A Nn(a,c)

2.5 Inferência estatística em cadeias de Markov 27
2.5.2 Caso de alcance k � 1• Conjunto A finito. Amostra dada: Xn
�k = an�k
• Matriz p 2 Mk(A) e p = Ak ⇥A ! [0;1]• Âb2A p(b|a�1
�k) = 1; 8a�1�k e 0 p(b|a�1
�k) 1Temos dada a amostra Xn
�k = an�k e conhecemos o alcance k. Queremos estimar
p 2 Mk(A) supondo que P{X�1�k = a�1
�k}= 1.
Pp{Xn�k = an
�k}=P{X�1�k = a�1
�k}.n
’t=0
p(at |at�1t�k)
| {z }agrupando termos iguais
=⇠⇠⇠⇠⇠⇠⇠:1P{X�1
�k = a�1�k}. ’
(x�1�k ,y)2Ak⇥A
p(y|x�1�k)
Nn(x�1�k ,y)
Portanto queremos: p = argmax ’(x�1
�k ,y)
p(y|x�1�k)
Nn(x�1�k ,y)
| {z }L(p)
.
Para facilitar as contas, vamos aplicar o log na função L(p), o que permite trocar oprodutório pelo somatório, sem perder a generalidade do processo de maximização.
logL(p) = Â(x�1
�k ,y)
Nn(x�1�k ,y). log p(y|x�1
�k)
Usando a seguinte notação: l = (l{x�1�k}
: x�1�k 2 Ak)
Escrevemos o Lagrangeano com o problema de vínculo da seguinte forma:
F(p,l ) = logL(p)+Âlx�1�k[1� Â
y2Ap(y|x�1
�k)]
Para obter o máximo, derivamos e igualamos a zero como o usual:
∂F∂ p(y|x�1
�k)= 0 e
∂F∂lx�1
�k
= 0
E a partir dos resultados apresentado obtemos:
Nn(x�1�k ,y)
lx�1�k
= p(y|x�1�k)
Ây
p(y|x�1�k) = 1
) p(y|x�1�k) =
Nn(x�1�k ,y)
Âz2A N(x�1�k ,z)

28 Cadeias de Markov
2.6 Exercícios de fixação
1. Seja (X (a)n )n�0 (Dado a 2 A = {0,1}) uma evolução Markoviana assumindo
valores no alfabeto A e que pode ser simulada através do seguinte algoritmo:
Passo 1. X (a)0 = a;
Passo 2. Para n � 1, definimos X (a)n = 0, se Un h(X (a)
n�1), onde h(0) = 1/3e h(1) = 1/5, e X (a)
n = 1, se Un > h(X (a)n�1),
onde (Un)n�1 é uma sequência de variáveis aleatórias i.i.d com distribuiçãouniforme em [0,1].
(i) Qual é a matriz de probabilidades de transição desta cadeia de Markov?(ii) Calcule P(X (1)
2 = 1) = P(X (1)2 = 1|X (1)
0 = 1).
2. Dado a 2 {1,2,3} definimos a sequência {X (a)n }•
n=0 por:
X (a)0 = a
X (a)n = F(X (a)
n�1,Un), 8n � 1
onde {Un}•n=1 é uma sequência de variáveis aleatórias i.i.d com distribuição
uniforme em (0,1) e F(x,u) está definida por:
F(x,u) =
8><
>:
1, se 0 u < h1(x)2, se h1(x) u < h2(x)3, se h2(x) u 1
onde
h1(x) =
8><
>:
1/2, se x = 11/3, se x = 21/4, se x = 3
e
h2(x) =
8><
>:
3/4, se x = 12/3, se x = 21/2, se x = 3

2.6 Exercícios de fixação 29
(i) Calcule as probabilidades de transição desta cadeia de Markov.(ii) Calcule sua ou suas probabilidades invariantes.
(iii) Diga tudo que puder sobre essa cadeia de Markov (irredutibilidade,etc.).
3. Seja p a matriz de probabilidades de transição em A= {1,2,3}, assim definida
0
@
1 2 31 0 1/2 1/22 1/3 1/3 1/33 1/4 1/4 1/2
1
A .
Queremos simular uma realização da cadeia de Markov (X (1)n )n�0 assumindo
valores no alfabeto A e tendo o símbolo 1 como estado inicial (ou seja,X (1)
0 = 1).(i) Proponha um algoritmo de simulação para esta cadeia.
(ii) A partir do algoritmo proposto em (a), simule uma realização dos dezprimeiros símbolos desta cadeia, ou seja, simule uma realização dasequência (X (1)
1 , . . . ,X (1)10 ).
(iii) A cadeia é irredutível? É aperiódica?(iv) A cadeia admite alguma probabilidade invariante? Se a resposta for sim,
calcule-a. Ela é única?
4. Como você simularia a cadeia de Markov assumindo valores no conjunto{0,1, . . . ,N} e com probabilidades de transição
p(x+1|x) = N � xN
p(x�1|x) = xN,
para todo x = 1, . . . ,N �1 e p(N �1|N) = p(1|0) = 1?

30 Cadeias de Markov
5. Seja (X (1,0)n )n�0 uma evolução Markoviana com memória de alcance 2 as-
sumindo valores no alfabeto A = {0,1} e que pode ser simulada através doseguinte algoritmo:
Passo 1. X (1,0)�2 = 1 e X (1,0)
�1 = 0;Passo 2. Para n � 0, definimos
X1,0n =
(0, se Un h(X (1,0)
n�2 ,X (1,0)n�1 )
1, se Un > h(X (1,0)n�2 ,X (1,0)
n�1 )
onde h(0,0) = 1/2, h(0,1) = 1/3, h(1,0) = 1/4 h(1,1) = 1/5 e (Un)n�1 éuma sequência de variáveis aleatórias i.i.d com distribuição uniforme em[0,1].
(i) Qual é a matriz de probabilidades de transição desta cadeia de Markovde ordem 2?
(ii) Calcule P(X (1,0)2 = 1).
6. Considere a cadeia estocástica (X (1,0)n )n�0 definida no exercício anterior. Seja
(Y (1,0)n )n�2 a cadeia estocástica tomando valores no alfabeto S = {0,1}2
satisfazendo Y (1,0)n = (X (1,0)
n�2 ,X (1,0)n�1 ).
(i) Observe que (Y (1,0)n )n�2 é uma cadeia de Markov de ordem 1.
(ii) Determine a matriz de transição desta cadeia de Markov.(iii) O que podemos dizer a respeito de cadeias de Markov de alcance 1 em
Ak construidas a partir de cadeias de alcance k em A?
7. Seja (X (1)n )n�0 uma cadeia de Markov assumindo valores no alfabeto A =
{0,1}, tendo o símbolo 1 como estado inicial e tendo matriz de probabilidadesde transição p assim definida:
p =
✓0.7 0.30.4 0.6
◆.
(i) Calcule (se existir) a probabilidade invariante desta cadeia. Ela é única?(ii) Construa simultaneamente as cadeias (X (0)
n ,X (1)n ) com estado inicial 0 e
1, respectivamente, utilizando o algorítmo
(X (0)n ,X (1)
n ) = f (X (0)n�1,X
(1)n�1,Un)

2.6 Exercícios de fixação 31
onde (Un)n�0 é uma sequência iid de variáveis aleatórias com distribui-ção uniforme em [0,1] e f : A⇥A⇥ [0,1]! A⇥A. Verifique que
P(X (0)n 6= X (1)
n ) = (0.3)n
8. Seja (Xn)n�0 uma cadeia de Markov assumindo valores num alfabeto finitoA com a matrix de probabilidades de transição p = (p(i| j) : i, j 2 A). Umamedida de probabilidade µ definida em A é dita reversível com respeito a pse para todo par de elementos i e j de A valer a igualdade
µ(i)p( j|i) = µ( j)p(i| j).
(i) Mostre que se µ é reversível com respeito a matrix p, então µ é invari-ante com respeito a p.
9. Seja (Xn)n�0 a sequência definida por
Xn =
⇢2 se n = 3k,k = 0,1,2...1 caso contrário.
Seja (xn)n�0 uma sequência de variáveis aleatórias independentes e iden-ticamente distribuidas tomando valores no alfabeto A = {0,1}, tais queP(x = 0) = e . Considere a cadeia de estocástica (Yn)n�0 definida como
Yn =
⇢Xn se Xn = 2Xnxn caso contrário.
Mostre que (Yn)n�0 é uma cadeia de Markov de ordem 2.
10. Seja (X (1)n )n�0 a cadeia de Markov de ordem 1 assumindo valores no alfabeto
A = {0,1}, tendo como estado inicial o símbolo 1 e tendo como matriz deprobabilidades de transição
p =
✓0,8 0,20,4 0,6
◆.

32 Cadeias de Markov
Dada uma amostra X (1)1 , . . . ,X (1)
n , para todo a 2 A definimos o estimadorempírico
µn(a) =1n
n
Ât=1
1{X (1)t =a}
da proporção de ocorrências do símbolo a na amostra. Nestas condições, olimite lim
n!+•µn(1) existe? Se a resposta for sim, calcule-o.
11. Considere uma realização aleatória (Xn)n=0,...,100 de uma cadeia de Markovassumindo valores no alfabeto A = {0,1} e com matriz de probabilidades detransição
p =
✓1/4 3/43/5 2/5
◆.
Obteve-se as contagens de todas as sequências de tamanho 2 na amostra:
N100(00) = 15,N100(01) = 48,N100(10) = 21,N100(11) = 16 .
Assumindo que P(X0 = 1) = 1:(i) Calcule a verossimilhança da amostra.
(ii) Obtenha os estimadores de máxima verossimilhança das probabilidadesde transição da matriz p.
(iii) Calcule o maior valor que a verossimilhança da amostra pode assumir.
12. Temos uma amostra X0,X1, . . .X100 de símbolos pertencendo ao alfabetoA = {0,1}. Suponhamos que os valores para o número de ocorrência dassequências de tamanho 2 e 3, foram obtidos e registrados, respectivamente,conforme as tabelas abaixo:
a0 N100(a0,0) N100(a0,1)0 12 401 39 9
a0 a1 N100(a0,a1,0) N100(a0,a1,1)0 0 3 90 1 32 71 0 9 311 1 7 2
(i) Estime as matrizes de probabilidades de transição de alcance 0 (casoindependente), 1 e 2 que maximizam a verossimilhança da amostra.

2.6 Exercícios de fixação 33
(ii) Escreva explicitamente as fórmulas para o maior valor que a verossimi-lhança da amostra pode assumir, supondo que ela seja produzida poruma cadeia de Markov de alcance 0 (caso independente), 1 e 2, respecti-vamente, supondo, no caso em k = 1, que X0 = 1 com probabilidade 1e, no caso em que k = 2, que X0 = X1 = 0 com probabilidade 1.
13. Seja (X (1)n )n�0 a cadeia de evolução Markoviana assumindo valores no al-
fabeto A = {0,1}, tendo como estado inicial o símbolo 1, isto é, X (1)0 = 1.
Suponhamos que este processo tenha matriz de probabilidades de transiçãodada por
p =
✓1�a a
b 1�b
◆
onde 0 < a < 1 e 0 < b < 1.(i) Calcule, se existir, a medida de probabilidade invariante µ para esta
cadeia.(ii) O tempo do primeiro retorno da cadeia (X (1)
n )n�0 ao símbolo 1, T 1!1, édefinido como
T 1!1 = inf{n � 1 : Xn = 1}.
Quanto vale a esperança E[T 1!1]?
14. Sejam I1, I2, . . . variáveis aleatórias i.i.d., cada uma delas com distribuiçãouniforme no conjunto {1,2,3}, e V1,V2, . . . variáveis aleatórias i.i.d., cadauma delas assumindo valores em A = {0,1} e com P(Vn = 1) = 1/2 paratodo n � 1. As sequências (In)n�1 e (Vn)n�1 são independentes entre si.Construímos agora a cadeia de Markov (Xn)n�0 assumindo valores em A3 ecom Xn = (Xn(1),Xn(2),Xn(3)) , onde Xn(i) 2 A para i = 1,2,3, da seguintemaneira:
Passo 1: X0(i) = 0 para todo i = 1,2,3 ;Passo 2: Para todo n � 1,
Xn(i) =
(Xn�1(i) , se In 6= iVn , se In = i .
(i) Construa a matriz de probabilidade de transição desta cadeia.(ii) Calcule a probabilidade invariante para esta cadeia utilizando as equa-
ções de reversibilidade .

34 Cadeias de Markov
2.7 Exercícios teste
1. Seja p a matriz de probabilidades de transição no alfabeto A = {1,2,3}, assimdefinida: 0
@1/4 1/2 1/41/3 1/3 1/31/4 1/4 1/2
1
A
Queremos simular uma cadeia de Markov (X (a)n )n�0, tendo essa matriz de
probabilidades de transição, usando o seguinte algoritmo:Passo 1. Dado a 2 {1,2,3}, X (a)
0 = a;Passo 2. Para n � 1, definimos X (a)
n = F(X (a)n�1,Un), onde (Un)n�1 é uma
sequência de variáveis aleatórias i.i.d com distribuição uniforme em [0,1] eF(x,u) está definida por:
F(x,u) =
8><
>:
1, se 0 u < h1(x)2, se h1(x) u < h2(x)3, se h2(x) u 1 .
Diga qual das linhas abaixo, definindo h1(1) e h2(1), está correta:(A) h1(1) = 1/3, h2(1) = 2/3(B) h1(1) = 1/4, h2(1) = 3/4(C) h1(1) = 1/4, h2(1) = 1/2(D) Nenhuma das anteriores
2. Seja (X (1)n )n�0, uma cadeia de Markov assumindo valores no alfabeto A =
{1,2,3}, tendo o símbolo 1 como estado inicial, isto é X (1)0 = 1, e tendo como
probabilidades de transição:
p(1 | 1) = p(2 | 1) = 1/2 e p(3 | 2) = p(1 | 3) = 1
Queremos calcular a distribuição da cadeia três passos depois do início. Isto é,queremos calcular a distribuição de X (1)
3 . Diga qual das afirmações seguintesé verdadeira:(A) P(X (1)
3 = 1) 1/4(B) P(X (1)
3 = 1) = 5/8(C) P(X (1)
3 = 2) = 0(D) Nenhuma das anteriores

2.7 Exercícios teste 35
3. Sejam (X (a)n )n�0 uma cadeia de Markov assumindo valores no alfabeto
A = {1,2}, tendo o símbolo a 2 A como estado inicial e tendo matriz deprobabilidades de transição p assim definida:
p =
✓0.8 0.20.4 0.6
◆.
Construímos simultaneamente as cadeias (X (1)n )n�0 e (X (2)
n )n�0 com estadosiniciais 1 e 2, respectivamente, utilizando para todo n � 1, o algoritmo
(X (1)n ,X (2)
n ) = f (X (1)n�1,X
(2)n�1,Un)
onde (Un)n�1 é uma sequência iid de variáveis aleatórias com distribuiçãouniforme em [0,1] e f : A⇥A⇥ [0,1]! A⇥A.Diga qual das seguintes afirmações é correta:(A) P(X (1)
n 6= X (2)n ) = (0.3)n
(B) P(X (1)n 6= X (2)
n ) = (0.4)n
(C) P(X (1)n 6= X (2)
n ) = (0.5)n
(D) Nenhuma das anteriores
4. Seja (Xn)n�0 a cadeia de Markov de alcance 1 tem o que assume valores noalfabeto A = {0,1,2,3} com matriz de probabilidades de transição
p =
0
BB@
1/2 1/4 1/4 01/3 2/3 0 0
0 0 1/3 2/30 0 1/2 1/2
1
CCA
e que tem símbolo a 2 A como estado inicial. Diga qual das seguintesalternativas abaixo é correta:(A) P(X (3)
n = 1) = 0 para todo n � 1.(B) P(X (1)
n = 2) = 0 para todo n � 1.(C) P(X (3)
n = 0)> 0 para todo n suficientemente grande.(D) Nenhuma das anteriores
5. Seja (X (1)n )n�0 uma evolução Markoviana assumindo valores no alfabeto
A = {1,2,3} e que pode ser simulada através do seguinte algoritmo:
Passo 1. X (1)0 = 1;

36 Cadeias de Markov
Passo 2. Para n � 1, definimos
X (1)n =
8><
>:
1, se Un h1(X(1)n�1)
2, se h1(X(1)n�1)< Un h2(X
(1)n�1)
3, se Un > h2(X(1)n�1)
onde
h1(x) =
8<
:
1/5, se x = 11/3, se x = 21/2, se x = 3
e h2(x) =
8<
:
4/5, se x = 12/3, se x = 25/6, se x = 3.
Sob essas hipóteses, podemos concluir que a matriz de probabilidades de
transição desta cadeia é:
(A)
0
@1/5 1/5 3/51/3 1/3 1/31/2 1/6 1/3
1
A
(B)
0
@3/5 1/5 1/51/3 1/3 1/31/3 1/2 1/6
1
A
(C)
0
@1/5 3/5 1/51/3 1/3 1/31/2 1/3 1/6
1
A
(D) Nenhuma das anteriores
6. Sejam I1, I2, . . . variáveis aleatórias i.i.d., cada uma delas com distribuiçãouniforme no conjunto {1, · · · ,10}, e V1,V2, . . . variáveis aleatórias i.i.d., cadauma delas assumindo valores em A = {0,1} e com P(Vn = 1) = 1/2 paratodo n � 1. As sequências (In)n�1 e (Vn)n�1 são independentes entre si.Construímos agora a cadeia de Markov (Xn)n�0 assumindo valores em A10 ecom
Xn = (Xn(1), · · · ,Xn(10)) ,
Xn(i) 2 A para i = 1, · · · ,10, da seguinte maneira:
1. Inicialização: escolhemos a sequência X0 = (X0(1), · · · ,X0(10)) usandouma certa distribuição µ sobre o conjunto A10 de todas as sequências detamanho 10 com símbolos 0 e 1.

2.7 Exercícios teste 37
2. Para todo n � 1,
Xn(i) =
(Xn�1(i) , se In 6= iVn , se In = i .
Qual deve ser a distribuição µ para que a distribuição de Xn seja igual adistribuição de X0 para todo n � 1:(A) µ deve escolher com probabilidade 1 a sequência X0(i) = 0 para todo
i = 1, · · · ,10.(B) µ deve escolher com probabilidade 1 uma sequência que tenha exata-
mente 5 símbolos iguais a zero e 5 símbolos iguais a 1.(C) µ deve escolher com probabilidade (1/2)10 uma sequência qualquer de
A10.(D) Nenhuma das anteriores
7. Seja X0,X1 · · · , a sequência, assumindo valores no conjunto {�1,+1}, assimdefinida:1. X0 é escolhido aleatoriamente com P(X0 =+1) = P(X0 =�1) = 1/22. Para todo n � 1, Xn =�Xn�1.Seja também (xn)n�1 uma sequência de variáveis aleatórias iid e indepen-dentes de X0 assumindo valores no conjunto { “apaga”,“mantém”} comP(xn = “apaga”) = e , onde e 2 (0,1) é um parâmetro fixado.Definimos a cadeia estocática Yn assumindo valores no conjunto {�1,0,+1}da seguinte maneira:
Yn =
⇢0, se Xn =�1 e xn = “apaga”Xn, caso contrário.
Usando esse mecanismo geramos a sequência:
(Y0, · · · ,Y9) = (0,+1,�1,+1,0,+1,�1,+1,0,+1)
Nessas condições, o valor de e que maximiza a probabilidade dessa sequênciaé:(A) e = 1/2.(B) e = 3/10.(C) e = 1.(D) Nenhuma das anteriores

38 Cadeias de Markov
8. Seja (Xn)n�0 uma cadeia de Markov de alcance 2 em A = {0,1}, com P(X0 =1|X�1
�2 = a�1�2) 6= 0.5 para todo a�1
�2 2 A2. Definimos Zn = (Xn�1,Xn) 2 A2.Diga quais das seguintes afirmações é verdadeira(A) (Zn)n�0 é uma sequência de variáveis aletatórias iid em A2.(B) (Zn)n�0 é uma cadeia de Markov de alcance 1 em A2.(C) (Zn)n�0 é uma cadeia de Markov de alcance 2 em A2.(D) Nenhuma das anteriores
9. Seja (0,1,1,0,1,0,0,0,1,0,0) uma amostra de símbolos que assumem valo-res no alfabeto A = {0,1}. Assumindo que P(X0 = 0) = 1 e que a amostrafoi gerada por uma cadeia de Markov (Xn)n�0 de alcance 1, qual o maiorvalor que a probabilidade da amostra pode assumir?(A) (1/2)6(3/4)3(1/4)(B) (1/2)10
(C) 1(D) Nenhuma das anteriores
10. Seja (0,1,1,0,1,0,0,0,1,0,0) uma amostra de símbolos que assumem va-lores no alfabeto A = {0,1}. Assumindo que P(X0 = 0,X1 = 1) = 1 e quea amostra foi gerada por uma cadeia de Markov (Xn)n�0 de alcance 2. Sobestas condições a máxima verossimilhança da amostra é:(A) 1(B) (1/2)10
(C) (1/2)2(2/3)4(1/3)2
(D) Nenhuma das anteriores
11. Seja (Xn)n�0 uma cadeia de Markov assumindo valores no alfabeto A= {0,1},com matriz de transição dada por
✓p 1� p
1� p p
◆,
onde 0 < p 1/2. Para n suficientemente grande podemos afirmar que(A) 0,45 P(X (0)
n = 1) 0,55.(B) P(X (0)
n = 1)� 0,95.(C) P(X (0)
n = 1) = 1� p.(D) Nenhuma das anteriores.

2.7 Exercícios teste 39
12. Sejam N bolas numeradas de 1 a N distribuídas aleatoriamente em duas urnasA e B. Executamos o seguinte experimento: a cada instante de tempo jogouma moeda honesta. Se der cara, sorteio uma bola e a troco de urna. Seder coroa, não faço nada. Seja (Xn)n�0 o número de bolas na urna A após an-ésima repetição do experimento. Se µ(·) É a probabilidade invariante dacadeia, então podemos afirmar que(A) A cadeia (Xn)n�0 É reversível e µ(0) = 1/2N .(B) A cadeia (Xn)n�0 É reversível e µ(0) = 1/N.(C) A cadeia (Xn)n�0 não É reversível.(D) Nenhuma das anteriores.
13. A partir de uma amostra X0, . . . ,X100 gerada por uma cadeia de Markov deordem 1 e assumindo valores no alfabeto A = {0,1}, calculamos para todopar (a,b) 2 A2 as estatísticas N100(ab) assim definidas
Nn(ab) =n�1
Ât=0
1{Xt=a,Xt+1=b}
e obtemos N100(11) = 29, N100(10) = 11, N100(01) = 15. Seja p o estimadorde máxima verossimilhança da matriz de probabilidades p calculado a partirdessa amostra. Nessas condições, diga qual das seguintes afirmações éverdadeira:(A) p(1|1) = 29/55.(B) p(1|1) = 29/100.(C) p(0|0) = 3/4.(D) Nenhuma das anteriores.
14. Sejam X1,X2, . . . variáveis aleatórias independentes e identicamente distribuí-das, cada uma delas assumindo valores no conjunto {0,1} com P(X1 = 1) =2/3. Nessas condições, assinale a alternativa correta:
(A) P⇣ n
Âi=1
Xi � n56
⌘ 0,8 para todo n � 1.
(B) P⇣ n
Âi=1
Xi � n56
⌘ 0,01 para todo n � 1.
(C) P⇣ n
Âi=1
Xi � n56
⌘> 0,99 para todo n � 1.
(D) Nenhuma das anteriores.

40 Cadeias de Markov
15. Seja (X (1)n )n�0 uma cadeia de Markov assumindo valores no alfabeto A =
{1,2,3}, tendo o símbolo 1 como estado inicial e tendo matriz de probabili-dades de transição p assim definida:
p =
0
@1/2 1/2 00 0 11 0 0
1
A .
Diga qual das afirmações seguintes, referentes a essa cadeia, é verdadeira:(A) P(X (1)
3 = 1) 1/4(B) P(X (1)
3 = 1) = 5/8(C) P(X (1)
3 = 2) = 0(D) Nenhuma das anteriores.
16. Ainda sobre a cadeia de Markov do exercício 15, assinale a alternativa correta:(A) A cadeia não admite uma única probabilidade invariante.(B) A cadeia admite uma única probabilidade invariante µ , com µ(1) = 1/2
e µ(2) = µ(3) = 1/4.(C) A cadeia não admite probabilidade(s) invariante(s).(D) Nenhuma das anteriores.
17. Seja (Xn)n�0 uma cadeia de Markov assumindo valores no alfabeto A ={0,1,2}, com matriz de transição dada por
0
@1� p p 0
0 1� p pp 0 1� p
1
A .
onde 0 < p < 1. Então podemos afirmar que(A) A cadeia é reversível para todo p 2 [0,1].(B) A cadeia não é reversível para nenhum p 2 [0,1].(C) A cadeia é reversível somente para p = 1/2.(D) Nenhuma das anteriores.

Neurociências: Modelo simples de um sis-tema de neurônios interagindo entre si.Árvore de contextos
Contexto
Conceitos importantesEstimação de ‘p’ por máximaverossimilhançaConsiderações ImportantesExercícios de fixaçãoExercícios teste
3 — Cadeias de alcance variável
3.1 Neurociências: Modelo simples de um sistema de neurôniosinteragindo entre si.
Notação:
Xn =
⇢1, há disparo do neurônio na n-ésima janela0, caso contrário
No capítulo anterior vimos que o disparo de um neurônio funciona como umabarreira que vai retendo água até chegar num ponto em que não consegue maissegurar, liberando toda a água (disparo do neurônio). Até então utilizamos cadeiasde Markov para modelar tal fenômeno. Já a partir desse capítulo passaremos a usarcadeias de alcance variável em nosso estudo.

42 Cadeias de alcance variável
Notação 3.1. Vamos definir o sistema com dois neurônios da seguinte forma:
• I: Conjunto dos neurônios. I = {1;2}
• Xn: Sistema no instante n. Xn = {Xn(1),Xn(2)}
•Xn(i) =
⇢1, há disparo do neurônio i na n-ésima janela0, caso contrário
O caso mais simples conta com 2 neurônios, sendo que o neurônio de símbolo 2 sódepende dele próprio para disparar, enquanto que o disparo do neurônio 1 dependetanto da evolução passada do neurônio 2 quanto dele próprio.
Instante n:
P{Xn(1) = a,Xn(2) = b|Xn�1�• (1),Xn�1
�• (2)}=P{Xn(2) = b|Xn�1
�• (2)}.P{Xn(1) = a|Xn�1�• (1),Xn�1
�• (2)}
Condicionalmente ao passado os neurônios 1 e 2 escolhem disparar ou não inde-pendentemente. O neurônio 2 toma decisão sem depender do neurônio 1.
• Probabilidade do neurônio 1 disparar ((a,b) 2 {0;1}):
P{Xn(1) = 1|Xn�1�• (1),Xn�1
�• (2)}= f (N2[L1n,n�1])
Notação 3.2. Importante:
• N2[L1n,n� 1] é o número de disparos do neurônio 2 no intervalo de tempo
entre [L1n,n�1]
• L1n é o instante do último disparo do neurônio antes do instante n, ou seja:
sup{s n�1|Xs(1) = 1}

3.1 Neurociências: Modelo simples de um sistema de neurônios
interagindo entre si. 43
⌅ Exemplo 3.1 Vamos supor que (Xn(2))n seja uma cadeia de Markov de alcance1:
Neuronio 1
Neuronio 2
1 0 0 0 0 0 ?
0 1 1 0 0 1 n
P{Xn(1) = 1|∗} = f(3)
N2[L1n,n−1] = ∑n−1
s=L1nXs(1) = 3
⌅
Exercício 3.1 Suponha que a função f : N! [0;1] fosse do tipo: f(k) = ek
1+ek .Você consegue verificar que f (k)! 1 quando k ! •?
⌅
⌅ Exemplo 3.2 Considere, para os dois itens subsequentes, o processo estocástico(Xn)n2Z = (Xn(1),Xn(2))n2Z assumindo valores em A2, onde A = {0,1} e cujadistribuição conjunta é definida por:
P(Xn(1) = 1,Xn(2) = 1|Xn�1�• (1) = an�1
�• ,Xn�1�• (2) = bn�1
�• ) =
P(Xn(1) = 1|Xn�1�• (1) = an�1
�• ,Xn�1�• (2) = bn�1
�• )| {z }
Disparo do neurônio 1 depende do neurônio 2 e dele mesmo
.P(Xn(2) = 1|Xn�1�• (2) = an�1
�• )| {z }
Neurônio 2 só depende dele mesmo
sendo
P{Xn(1) = 1|Xn�1�• (1) = an�1
�• ,Xn�1�• (2) = bn�1
�• }= f (N2[L1n,n�1]),
onde Lin = sup{t < n : Xt(i) = 1}, para i = 1,2,
é o instante do último disparo do neurônio i antes do instante n
e Ni[s, t] =t
Âj=s1{Xj(i)=1}, para i = 1,2,
é o número de disparos do neurônio dentro do intervalo [s, t].⌅

44 Cadeias de alcance variável
No modelo simples de um sistema com 2 neurônios interagindo, vamos supor que:
f (k) = 1�⇣1
2
⌘k+1, para k = 0,1, . . . .
Nestas condições, qual é o valor da expressão:
P(X4(1) = 1|X30 (1) = 1100,X3
0 (2) = 0001)
Solução:
Primeiro vamos representar graficamente a expressão P(X4(1)= 1|X30 (1)= 1100,X3
0 (2)=0001), tomando cuidado com o fato de que vamos ler sempre da direita paraa esquerda como sendo o instante mais antigo para o mais recente. Por exem-plo, em X3
0 (2) = 0001, sabemos que para t = 0 ! X(2) = 1, t = 1 ! X(2) = 0,t = 2 ! X(2) = 0 e t = 3 ! X(2) = 0.
N1
N2
0 1 2 3 n=4
P{X4(1) = 1}=?0 0 1 1
0 1 2 3
1 0 0 0
último disparo
L1n = 3
N2[3,4] = 0 disparos
P(X4(1) = 1|·) = f (0) = 1� 12 = 1
2
Note que agora estamos falando de cadeias de alcance variável. A memória évariável uma vez que precisamos considerar um número indefinido de passos atráspara verificar se houve disparo. Note que não podemos chamar tal processo de cadeiade Markov, pois neste último há um número fixo e finito de passos a considerar!

3.2 Árvore de contextos 45
3.2 Árvore de contextos
Vamos começar esta seção com um exemplo. Na verdade retomaremos o exemplo davalsa, que era modelada por uma cadeia de Markov, fazendo com que ela incorporeum termo aleatório. Assim, mostraremos como essa valsa modificada pode sermodelada por uma cadeia de memória de alcance variável.
⌅ Exemplo 3.3 Considere a seguinte série: (2,1,1,2,1,1,2,1,1). Ela simula a batidade uma valsa. Veja que as seguintes possibilidades são possíveis:
se
8<
:
Xn�1 = 2 ! Xn = 1
Xn�1 = 1 !⇢
Xn�2 = 1 ! Xn�1 = 1 ! Xn = 2Xn�2 = 2 ! Xn�1 = 1 ! Xn = 1
Representação por árvores:
Xn
2
112
1 1
Xn−1Xn−2 Presente
Último passo
Penútimo passo1
1
2
2
⌅
Mais uma vez, a batida forte é representada pelo símbolo ‘2’, enquanto que a fracapelo símbolo 1. Mas suponha, agora, que introduzimos um componente novo detal forma que as batidas fracas são ‘apagadas’ aleatoriamente. Também vamosintroduzir o símbolo 0 que irá representar uma batida ‘apagada’!
Vamos chamar essa nova cadeia de Yn, enquanto que o componente aleatório seráchamado de yn:
Yn =
⇢Xn, se Xn = 2Xnyn, se Xn = 1
Onde yn 2 [0;1], v.a. i.i.d., independente de Xn.⇢
P{yn = 1}= 1� e = 0,9P{yn = 0}= e = 0,1

46 Cadeias de alcance variável
• Como fazer para predizer o próximo símbolo? Vamos usar uma árvore! t
?
0,1 0,9 00 1 2
0 1 2
0,1 0,9 00 1 2
0 0 10,10 1 2
0,9 0
0 1 2
0 0 1
0 1 2
0 1 20 0 1
0 0 1
Resultado
Probabilidade
0 1 2
01 2 0 1 2
n
n-1
n-2
Definimos a árvore probabilística de contextos: (t, p)
Na figura tem-se: (t, p) 8w 2 t e p(·,w) probabilidade em A={0,1,2}.
O símbolo ‘w’ é chamado de folha, ou seja, o pedaço do passado que eu tenho queconsiderar para poder predizer o próximo símbolo. Cada folha tem uma medida deprobabilidades associada.
O termo ‘contexto’ ficará mais claro a seguir. É uma ideia chave que liga o conceitode cadeia de alcance variável com cadeias de Markov. O contexto é caracterizadopor tudo o que foi observado até o momento e seu tamanho depende do passado.
3.2.1 Contexto• Primeira ideia:
Considere a seguinte frase:
“O ga_o_o _r_ _eg_”
Você consegue identificar qual será a próxima letra, depois do g? Se nãoconseguiu, vamos acrescentar alguma informação...
“O ga_o_o _ra _eg_”
Melhorou? E agora?
“O garo_o era ceg_”
Agora já dá para saber? A pergunta que fazemos é: Qual o menor bloco depassado que eu preciso considerar para acertar o futuro?

3.2 Árvore de contextos 47
• Segunda ideia:
Considere uma lâmpada, que acende (1) e apaga (0) seguindo uma cadeia deMarkov Xn. Essa lâmpada emite luz para um observador, porém entre eles háuma janela que abre (1) e fecha (0) independentemente da lâmpada.
A janela é modelada por yn, de tal forma que:
yn =
⇢1 ,1� e
0 ,e
Sendo que e 2 [0; 12 ]. Há que se dizer também que a matriz de transição ‘p’ da
cadeia Xn é:
p =
✓a 1�a
1�b b
◆
O processo que representa o observador sendo capaz de enxergar a luz da lâmpada(1), ou não poder ver luz alguma (0), seja pois a lâmpada estava apagada ou então ajanela fechada, é representado pela cadeia de alcance variável Yn = Xn.yn.
? Dito isto, qual o menor trecho de passado Yn�2,Yn�1, ... que devemos conhe-cer para poder predizer Yn? (Da melhor forma possível é claro!)

48 Cadeias de alcance variável
Para resolver este problema, primeiro temos que descobrir qual foi o último instanteem que o observador conseguiu ver luz, ou seja, o instante ‘t’ em que Yt = 1.
Xn
ψn
Yn
0 1 0 1 0 0 ?
1
1
Descobrimos o último símbolo 1
Antes de prosseguir considere duas notações importantes!
Notação 3.3.
• Nas probabilidades de transição, o passado é indicado do símbolo mais recenteao símbolo mais remoto:
p(b|a�1, ...,a�k) = p(b|a�1�k) = P{X0 = b|X�1 = a�1 · · · ,X�k = a�k},
, para a 2 A e a�1�k = (a�1, ...,a�k) 2 Ak.
• Já os contextos são indicados na ordem “natural”:
a�k, ...,a�1 = {X�k = a�k, ...,X�1 = a�1}
Portanto, pela figura acima descobrimos que em n-4 ocorre a última vez em que oobservador consegue ver luz. Assim, queremos descobrir:
P{Yn = 1| 0n�1
0n�2
0n�3
1n�4
}= ÂP{Yn = 1,yn = 1,Y n�1n�4 = y�1
�n,yn�1n�4 = s�1
�4}ÂP{Y n�1
n�4 = yn�1n�4,y
n�1n�4 = s�1
�4}

3.2 Árvore de contextos 49
A árvore de contextos é uma maneira de representar a busca pelo último símbolo 1.Ela mostra quando podemos parar de ver o passado, e indica qual é o contexto, ouseja, o passado relevante para o nosso problema.
0 1 Aqui não precisamos continuar procurando
00 10
100000
O passado relevante tem o símbolo 1, e depois o 0.
Se não encontrarmos o símbolo 1 até aqui
devemos continuar descendo na raiz da árvore
Presente
Passado
Note que a árvore é infinita! Porém, quando descobrimos qual o passado relevante,podemos trabalhar com um caso mais simples, modelado por uma cadeia de Markov.
!Veja que na vida real é muito comum encontrar elementos como a janelaque abre e fecha, o que por sua vez torna difícil a modelagem por cadeias deMarkov. No entanto, quando utilizamos a árvore de contextos para encontraro último símbolo 1, e assim definir o passado relevante, conseguimos fazer amodelagem do fenômeno.
⌅ Exemplo 3.4 Este exemplo irá mostrar que ao se calcular as probabilidades,devemos ignorar toda a informação irrelevante, e considerar apenas o contexto:
Primeiro, considere a seguinte árvore, com as respectivas probabilidades de transiçãoassociada:
0 1
1000
p(1|1) =0,3
p(1|00)=0,8
p(1|01)=0,5

50 Cadeias de alcance variável
Agora suponha a seguinte sequência gerada:
-2 -1 0 1 2 3 4 5 6 7 8 n
0 0 0 1 0 1 0 0 Xn1 1
Queremos obter a verossimilhança da amostra:
P{X50 = 1
X71X6
0X5
0X4
1X3
0X2
1X1
0X0|X�1 = 0,X�2 = 0}
Portanto basta calcular:
P{X70 = 11001010|X�1 = 0,X�2 = 0}= P{X0 = 0|X�1 = X�2 = 0}.
P{X1 = 1|X0 = X�1 = 0}.P{X2 = 0|X1 = 1,X0 = 0}.P{X3 = 1|X2 = 0,X1 = 1}.P{X4 = 0|X3 = 1,X2 = 0}.P{X5 = 0|X4 = 0,X3 = 1}.P{X6 = 1|X5 = 0,X4 = 0}.
P{X7 = 1|X6 = 1,X5 = 0}
Veja que neste exemplo estamos sempre considerando 2 passos atrás uma vez que aaltura da árvore que representa essa sequência foi escolhida como de tamanho 2.Entretanto, veja que há informação desnecessária, se considerarmos que o passadorelevante que interessa é aquele que vai até o momento em que o último símbolo 1aparece.
P{X2 = 0|X1 = 1, X0 = 0irrelevante
}
P{X4 = 0|X3 = 1, X2 = 0irrelevante
}
P{X7 = 1|X6 = 1, X5 = 0irrelevante
}
⌅

3.3 Conceitos importantes 51
Assim, podemos rescrever1:
P{X70 = 11001010|X�1 = 0,X�2 = 0}= ’
a2{0,1}.’
w2t
.p(a|w)Nn(wa) =
=P(1|1)N(11)=1.P(0|1)N(10)=2.P(1|00)N(001)=2.P(0|00)N(000)=1.P(1|01)N(101)=1.P(0|01)N(100)=1...
Proposição 3.2.1 Considerando o que foi visto até agora temos que:
Âa2A
Âw2t
Nn(wa) = n+1
3.3 Conceitos importantes
1
1 1
N
NN
FolhaFolha
Folha
Cada nó ou tem N filhosou então é marcado como folha
Árvore τ
Definição 3.3.1 Na árvore completa, cada nó ou é uma folha, ou então tem Nfilhos marcados com os N símbolos do alfabeto.
Definição 3.3.2 Dada uma sequência X�1�k (eventualmente infinita), um su-
fixo da sequência é qualquer outra sequência Y�1� j , onde j k, tal que y�1 =
x�1, ...,y� j = x� j.
1Veja que o símbolo ‘w’ irá representa o contexto. Também repare que quando usamos o símboloN(ab), estamos considerando que o símbolo ‘a’ é o mais antigo e ‘b’ o mais recente. Por fim, emp(.|ba), o símbolo mais recente é ‘b’ enquanto o mais antigo é ‘a’.

52 Cadeias de alcance variável
⌅ Exemplo 3.5 Para elucidar melhor o que é um sufixo, considere a sequência:X�1�5 =10100. (Lembrando que lemos da direita para a esquerda para ver do mais
antigo ao mais recente).
A seguir os sufixos próprios sublinhados:
0 0 1 0 1
0 1 0 1
1 0 1
0 1
1
Cada vez que aparece o símbolo 1, a cadeia esquece o passado e gera o próximosímbolo (1 ou 0) com probabilidade q e (1-q) ! processo de renovação.
⌅
Proposição 3.3.1 t é uma árvore no alfabeto A, então qualquer sequência infinitade símbolos tem um único sufixo que é folha de t .
• A árvore t define uma partição do passado. Essa partição pode ser infinita, ouseja, dada a sequência X�1
�•, o sufixo que é folha de t é X�1�L onde:
Lcomprimento do contexto
= inf{k � 1|x�k = 1} no caso A = {0,1}

3.4 Estimação de ‘p’ por máxima verossimilhança 53
⌅ Exemplo 3.6 Cada vez que aparece o símbolo 1, a cadeia esquece o passadoe gera o próximo símbolo (1 ou 0) com probabilidade q e (1-q) ! processo derenovação.2
⌅
1
10
10k
p(1|0k1) =qk ∈ [0;1]
0k
3.4 Estimação de ‘p’ por máxima verossimilhança
? Suponha que a árvore t seja conhecida e que seja dada a amostra Xn�k = xn
�k.Como fazemos para estimar ‘p’ por máxima verossimilhança?
pn = argmax{’w2t
’a2A
p(a|w)Nn(wa)|p 2 Mt
(A)}
Mt
(A)! Conjunto das famílias de probabilidadesp = {p(·|w)|w 2 t} Indexadas pelas filhas de t
Mais uma vez, usando multiplicadores de Lagrange calculamos pn, para cadacontexto w 2 t e a 2 A:3
pn(a|w) =Nn(wa)
Âb2A Nn(wb)
Observação importante: Âb2A
Nn(wb) = Nn�1(w)
2Não confunda, 0k=0000.... k vezes.3Vínculo: 8w 2 t, Âa p(a|w) = 1

54 Cadeias de alcance variável
Teorema 3.4.1 — Teorema da consistência do estimador. Se a amostraXn�k = xn
�k for gerada por uma cadeia de alcance variável de árvore probabilísticade contexto (t, p), então 8w 2 t, 8a 2 A:
pn(a|w) !n!•
p(a|w) Estimador consistente
Demonstração: Segue diretamente da lei fraca dos grandes números.LFGNSejam Y1,Y2, ...Yn v.a. ⇠ i.i.d., e E(Yi) = q , V (Yi) = s
2, finitos. Então para8e > 0 :
P{|1n
n
Âi=1
Yi �q |> e} !n!•
0
• Lei Fraca: A probabilidade de grande discrepância tende a zero, ou seja, aprobabilidade de que a média empírica ÂYi
n esteja longe da média teórica µ tendea zero quando a amostra é grande!
Relembrando a propriedade da Binomial:
Seja Y1, ...,Yn v.a. i.i.d., com Yn 2 {0,1}, e P{Yn = 1}= p 2 [0;1].
Define-se: P{Âni=1Yi = k}=
�nk
�pk(1� p)n�k
E(ÂYi) = ÂE(Yi) = Â(1.P{Yi = 1}+0.P{Yi = 0}) =
E(ÂYi) = ÂP{Yi = 1}= n.p
Assim:
Var(ÂYi) = ÂVar(Yi) = nVar(Yi) = n(p�p2) = np(1� p)
Pois
Var(Yi) = [E(Y 2i )�E(Yi)]
2 = E(Yi)�E(Yi)2 = p�p2

3.4 Estimação de ‘p’ por máxima verossimilhança 55
⌅ Exemplo 3.7 Jogo uma moeda honesta 100 vezes. Usando a desigualdade deChebyshev calcular a probabilidade da frequência do número total de caras sedistanciar de 50 em mais do que 20 sorteios?
P{|ÂYi �50|� 20} 1100
14⇣
210
⌘2 =1
16= 6%
Portanto a probabilidade desse evento ocorrer é menor do que 6%.⌅
⌅ Exemplo 3.8 Considere a realização de ‘n’ experimentos idênticos independentesuns dos outros. Considere:
Yi =
⇢1 se a i-ésima experiência teve sucesso0 caso contrário
Agora vamos supor que P{Yi = 1} = p. Queremos estimar ‘p’ a partir de umaamostra de ‘n’ experimentos.
pn =ÂYi
n! é a proporção de sucesso das ‘n’ experiências.
• E(Yi) = 1.P{Yi = 1}+0.P{Yi = 0}= P{Yi = 1}= p
Assim: P{| 1n ÂYi � p|> d} 1
nVar(Yi)
d
2 = 1n(1�p)p
d
2
Como p é desconhecido, sei que o valor máximo que p(1-p) assume é 0,25:
14
120 1
p
(1-p)p
Portanto: 1n(1�p)p
d
2 1n
14
d
2
⌅

56 Cadeias de alcance variável
Problema 3.1 Sabendo que Yi ⇠ i.i.d. assumindo valores em {0,1}, qual o tamanhomínimo n que deve ter a amostra para que o valor correto P{Yi = 1} esteja nointervalo [pn �0,1; pn +0,1] com probabilidade maior que 0,95?
Note que a desigualdade de Chebyshev não fornece diretamente o valor mínimo!
P{|pn � p|� 0,1} 1n
14
(0,1)2 0,05 )
Assim:
1n
14
(0,1)2 =5
100) n = 500
3.5 Considerações Importantes
Suponha amostra X�n�k gerada por p 2 Mk(A), tal que: {p(b|a�1
�k) : b 2 A,a�1�k 2 Ak}.
Então o Estimador de Máxima Verossimilhança:
pn(b|a�1�k) =
Nn(a�1�kb)
Âz2A Nn(a�1�kz)
=Nn(a�1
�kb)
Nn�1(a�1�k)
! pn(b|a�1�k)
! Porém há algumas complicações a serem consideradas:
• (Xn)n não é uma sequência independente.
• O denominador é uma variável aleatória.

3.5 Considerações Importantes 57
Antes:
pn
n! número de sucessos numa sequência independente
! tamanho da amostra
• Para simular a cadeia nós gerávamos números aleatórios independentes e seguindoa distribuição uniforme.
Gero a primeira vez:
x−k x−1 a−k a−1
=b
= b?
Gero U1
p(b|a−1−k)Próximo é b Próximo não é b
Quando escrevemos: Nn(a�1�kb) = Â
Nn�1(a�1�k)
j=1 y j
y j =
(1 se u
a�1�k
j p(b|a�1�k)
0 c.c.
Então y j é o resultado da j-ésima decisão após encontrar pela j-ésima vez o passadoa�1�k .
Nn(a�1�kb) =
Nn�1(a�1�k)
Âj=1
y j =Nn�1(a�1
�k)
Âj=0
1{u
a�1�k
j <p(b|a�1�k)}
Assim temos Nn�1(a�1�k) = m.
y j = 1{u
a�1�k
j <p(b|a�1�k)}
LFGN: Comparar 1m Ây j com E(y1) = 1.P{y1 = 1}+0.P{y1 = 0}= p(b|a�1
�k)

58 Cadeias de alcance variável
Lei Fraca dos Grandes Números:
P{| 1m Ây j � p(b|a�1
�k)|> d} 1m
14
d
2
Uma vez que: p(b|a�1�k)[1� p(b|a�1
�k)]14
? Última dúvida: O denominador ‘m’ é variável aleatória!
Hipótese: A cadeia (Xn)n é irredutível e recorrente positiva, ou seja, ela voltainfinitas vezes à sequência a�1
�k .
+Nn�1(a�1
�k) !n!•
•
+
Função crescente em n: " n =" Nn�1(·)
• Vamos tomar k=1 e supor que p(v|u)> 0 8u,v 2 A.
Então seja a = min{p(v|u) : (u,v) 2 A2}, A = {1,2, ...|A|} e |A|.d = 1.
Portanto:
1 = Âv2A
p(v|u)� Âv2A
d = |A|d
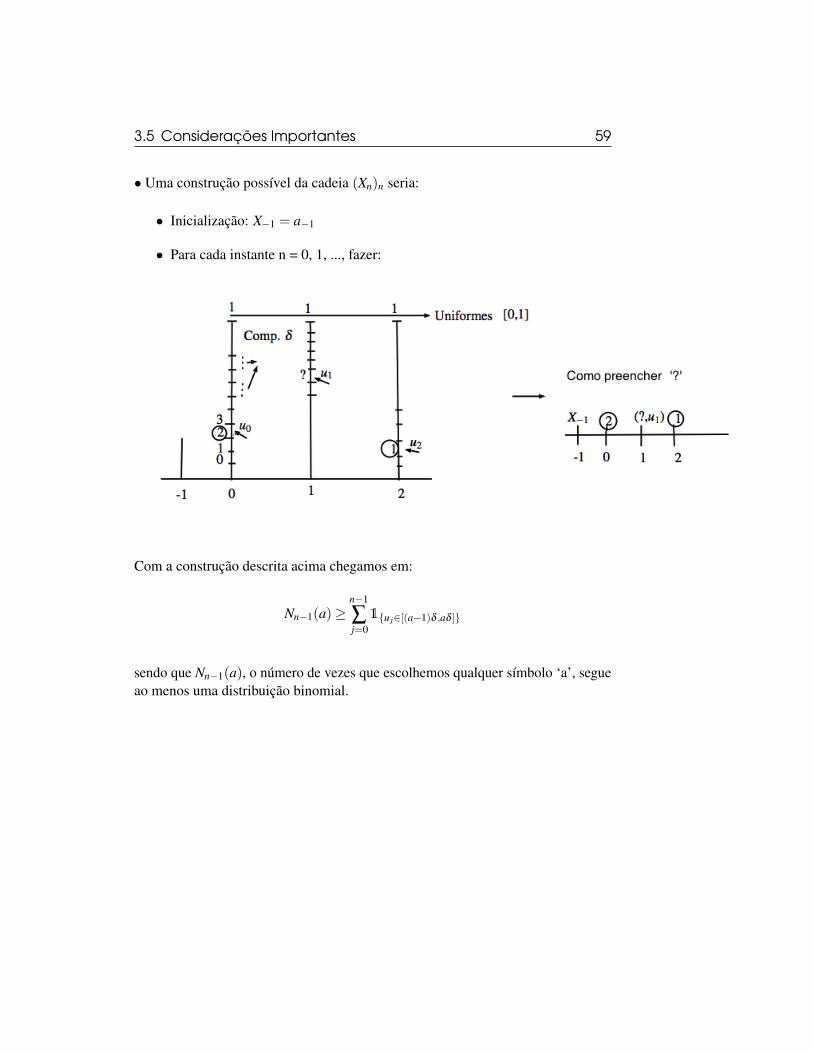
3.5 Considerações Importantes 59
• Uma construção possível da cadeia (Xn)n seria:
• Inicialização: X�1 = a�1
• Para cada instante n = 0, 1, ..., fazer:
Com a construção descrita acima chegamos em:
Nn�1(a)�n�1
Âj=0
1{u j2[(a�1)d ,ad ]}
sendo que Nn�1(a), o número de vezes que escolhemos qualquer símbolo ‘a’, segueao menos uma distribuição binomial.

60 Cadeias de alcance variável
3.6 Exercícios de fixação
1. Seja (Zn)n�0 uma cadeia de Markov de alcance 1 assumindo valores noalfabeto B = {0,1}2 e com matriz de probabilidades de transição Q dada por
0
BB@
00 01 10 1100 1/3 2/3 0 001 0 0 1/6 5/610 1/3 2/3 0 011 0 0 3/4 1/4
1
CCA .
Nessas condições, verifique que a matriz Q define uma cadeia de alcancevariável que assume valores no alfabeto A = {0,1} e com árvore de contextosdada por
t = {{w�1 = 0},{w�2 = 0,w�1 = 1},{w�2 = 1,w�1 = 1}}.
2. Sejam (Xn)n�0 uma cadeia de Markov assumindo valores no alfabeto A ={0,1} e (xn)n�0 uma sequência de variáveis aleatórias independentes, iden-ticamente distribuídas e assumindo valores no conjunto A, independente dacadeia (Xn)n e tal que
P(xn = 1) = 1� e ,
onde 0 < e < 1. Definimos uma nova sequência (Zn)n�0 da seguinte forma:
Zn = Xnxn para todo n � 0.
Sob estas condições, mostre queP(Zn = 1|Zn�1 = 1) = P(Zn = 1|Zn�1 = 1,Zn�2 = 0)
= P(Zn = 1|Zn�1 = 1,Zn�2 = 1)eP(Zn = 1|Zn�1 = 0,Zn�2 = 1) = P(Zn = 1|Zn�1 = 0,Zn�2 = 1,Zn�3 = 0)
= P(Zn = 1|Zn�1 = 0,Zn�2 = 1,Zn�3 = 1)
3. Sejam k,n � 1 dois números inteiros, Xn�k = (X�k, . . . ,Xn) uma amostra de
uma cadeia com memória de alcance variável definida em um alfabeto Afinito com árvore de contextos t . Suponhamos que X�1
�k = w 2 t , isto é, X�1�k

3.6 Exercícios de fixação 61
é um contexto da árvore t , definimos para cada a 2 A,
N[0,n](wa) =n
Ât=0
1{Xt�1t�|w| = w,Xt = a},
como sendo o número de vezes que o símbolo a é precedido pelo contexto wna amostra Xn
0 .Seja (Xk) uma cadeia com memória de alcance variável, assumindo valoresno alfabeto finito A = {0,1}, tendo como árvore de contextos
t = {{w�1 = 1},{w�2 = 1,w�1 = 0},{w�2 = 0,w�1 = 0}}
e tendo família associada de probabilidades de transição definida por
p(1 |1) = a , p(1 |01) = b e p(1 |00) = g ,
onde a , b e g são tres parâmetros pertencentes ao intervalo aberto (0,1).(i) Suponhamos que a amostra gerada foi
X10�1 = x10
�1 = (1,0,0,1,1,0,1,1,0,0,1,0).
Supondo que P(X�1 = 1) = 1, diga quanto vale P(X101 = x10
�1).(ii) Verifique que Âa2A N[0,n](wa) = N[0,n�1](w).
(iii) Verifique que Âw2t
Âa2A N[0,n](wa) = n+1
4. Nas condições do Exercício 3, encontre as estimativas de máxima verossimi-lhança dos parâmetros a , b e g .
5. No modelo simples de um sistema com 2 neurônios interagindo, suponha que(Xn(2))n é uma cadeia de Markov de alcance 1 em A = {0,1}. Verifique quea árvore de contextos de Xn = (Xn(1),Xn(2)) em A2 é dada pelos pares desequências w�1 =(w�1(1),w�1(2))= (1,b), w�(k+1) = (w�1
�(k+1)(1),w�1�(k+1)(2))=
(10k,b�1�(k+1)), para todo k � 1, b 2 A e b�1
�(k+1) 2 Ak+1.
6. Para todo inteiro n � 1, consideramos a variável aleatória Sn assumindovalores no conjunto {0, . . . ,n} e com distribuição dada por
P(Sn = k) =n!
k!(n� k)!
✓15
◆k✓45
◆n�k
.
(Observe que Sn tem distribuição binomial de parâmetros n e 1/5.) Usando

62 Cadeias de alcance variável
a desigualdade de Chebyshev, calcule n tal que para todo n � n tenhamos adesigualdade
P{|Sn
n�0.2|� 0.2)} 0.01 .
Observação: (Desigualdade de Chebyshev.) Para uma variável aleatória Xcom média E(X) e variância Var(X) finitas, vale que
P(|X �E(X)|> e) Var(X)
e
2
para todo e > 0.
7. Sejam X1,X2, . . . ,Xn variáveis aleatórias i.i.d. assumindo valores em A ={0,1} e com distribuição dada por
P(Xi = 1) = p e P(Xi = 0) = 1� p, para i = 1,2, . . .
Para n = 1000 e p = 0.5, para quais valores de d > 0 o majorante da desi-gualdade de Chebyshev é menor ou igual a 0.05?
8. Sejam X1,X2, . . . ,Xn variáveis aleatórias iid assumindo valores em A = {0,1}e com P(Xi = 1) = p, para i = 1, . . . ,n. Se p = 0.5 e d = 0.02, encontre Ntal que para todo n � N temos
P⇣���
1n
n
Âi=1
Xi �E(X1)���� d
⌘ 0.05.
9. Sejam X1,X2, . . . ,Xn variáveis aleatórias i.i.d. assumindo valores em A ={1, · · · , |A|} com distribuição dada por
P(Xi = a) = p(a), 8a 2 A
onde p(a) é conhecido para todo a 2 A. Definimos para cada a 2 A e n � 0,
pn(a) =n
Ât=1
1{Xt=a},
o número de vezes que a cadeia (Xt)t�0 visita o símbolo a até o instante n.

3.6 Exercícios de fixação 63
Usando a desigualdade de chebyshev, sabemos que para todo d > 0 e n � 0
P(| pn(a)� p(a)|> d ) (a(1� p(a))2
nd
2 .
Mostre, a partir da desigualdade acima, que para qualquer e > 0 e a 2 A,existe n = n(e,a) tal que,
P(pn(a)�d p(a) pn(a)+d )� 1� e.
10. Sejam X1,X2, . . . ,Xn variáveis aleatórias iid assumindo valores em A= {1, · · · , |A|}com distribuição dada por
P(Xi = a) = p(a), 8a 2 A
onde p(a) é desconhecido para todo a 2 A. Usando a desigualdade dechebyshev, sabemos que para todo d > 0 e n � 0
P(|pn(a)� p(a)|> d ) 14nd
2 .
Mostre, a partir da desigualdade acima, que para qualquer e > 0, existen = n(e) tal que para todo a 2 A,
P(pn(a)�d p(a) pn(a)+d )� 1� e.

64 Cadeias de alcance variável
3.7 Exercícios teste1. Seja X1000
1 = (X1, · · · ,X1000) uma realização de uma cadeia de Markov dealcance 2 assumindo valores no alfabeto A = {0,1}. A partir da amostra,obteve-se os valores das seguintes funções de contagem:
N[0,1000](000) = 150; N[0,1000](001) = 54; N[0,1000](010) = 167;N[0,1000](011) = 116;
N[0,1000](100) = 55; N[0,1000](101) = 229; N[0,1000](110) = 116.
Com base nessas informações, assinale a alternativa correta:(A) p1000(1 |11) = 112/227(B) p1000(1 |11) = 112/228(C) p1000(1 |11) = 111/227(D) Nenhuma das anteriores
2. Seja (Zn)n�0 uma cadeia de Markov de alcance 1 assumindo valores noalfabeto B = {0,1}2 e com matriz de probabilidades de transição Q dada por
0
BB@
00 01 10 1100 0.3 0.7 0 001 0 0 0.8 0.210 0.6 0.4 0 011 0 0 0.8 0.2
1
CCA .
Nessas condições, assinale a alternativa correta.(A) A matriz Q define uma cadeia de alcance variável que assume valores
no alfabeto A = {0,1} e com árvore de contextos dada por t = {{X�1 =1},{X�2 = 1,X�1 = 0},{X�2 = 0,X�1 = 0}}.
(B) A matriz Q define uma cadeia de alcance variável que assume valoresno alfabeto A = {0,1} e com árvore de contextos dada por t = {{X�1 =0},{X�2 = 1,X�1 = 1},{X�2 = 0,X�1 = 1}}.
(C) A matriz Q define uma cadeia de alcance variável que assume valoresno alfabeto A = {0,1} e com árvore de contextos dada por t = {{X�1 =0},{X�1 = 1}}.
(D) Nenhuma das anteriores

3.7 Exercícios teste 65
3. Seja (Xk)k�0 uma cadeia com memória de alcance variável, assumindo valoresno alfabeto A = {0,1}, tendo como árvore de contextos
t = {{X�1 = 0},{X�2 = 0,X�1 = 1},{X�2 = 1,X�1 = 1}}
e tendo família associada de probabilidades de transição definida por
P(Xn = 1 |Xn�1 = 0) = a
P(Xn = 1 |Xn�1 = 1,Xn�2 = 0) = b
P(Xn = 1 |Xn�1 = 1,Xn�2 = 1) = g ,
onde a , b e g são três parâmetros pertencentes ao intervalo aberto (0,1).A partir de uma amostra X12
�1 = (0,0,1,1,1,0,0,0,1,0,1,1,1,1), gerada poresta cadeia e supondo que P(X�1 = 0) = 1, podemos afirmar que a verossimi-lhança da amostra é igual a:(A) (1/2)13
(B) a
3(1�a)3b
2(1�b )1g
3(1� g)1
(C) a
3(1�a)3b
1(1�b )2g
1(1� g)3
(D) Nenhuma das anteriores
4. Seja (Xn)n�0 uma sequência de símbolos pertencentes ao alfabeto finitoA = {0,1} e gerada por uma cadeia com memória de alcance variável comárvore
t = {{X�1 = 0},{X�2 = 0,X�1 = 1},{X�2 = 1,X�1 = 1}}
e família de probabilidades de transição p desconhecida. Dada a amostra
X12�1 = (0,0,1,1,1,0,0,0,1,0,1,1,1,1) .
gerada por esta cadeia, os estimadores de máxima verossimilhança parap(1 |0), p(1 |10) e p(1 |11) são, respectivamente:(A) 1/2, 1/2 e 1/3.(B) 1/3, 1/3 e 1/2.(C) 1/3, 1/3 e 1/9.(D) Nenhuma das respostas anteriores.

66 Cadeias de alcance variável
5. Seja (X0, . . . ,Xn) uma amostra de uma cadeia de alcance variável assumindovalores no alfabeto A = {0,1}, com árvore de contextos:
t = {{X�1 = 0},{X�2 = 0,X�1 = 1},{X�2 = 1,X�1 = 1}}
e com família de probabilidades de transição p dada por
p(0 |0) = 0,4 , p(0 |10) = 0,2 e p(0 |11) = 0,6 .
Nessas condições, assinale a alternativa correta.
(A) limn!•
N[0,n](000)N[0,n�1](00)
= 0.2
(B) limn!•
N[0,n](000)N[0,n�1](00)
= 0.4
(C) limn!•
N[0,n](000)N[0,n�1](00)
= 0.6
(D) Nenhuma das anteriores
6. Seja (Xk)k�0 uma cadeia de Markov de alcance 1, assumindo valores noalfabeto A= {0,1} e com matriz de probabilidades de transição p= {p(b |a) :(a,b) 2 A2} irredutível e aperiódica. Seja também (Yk)k�0 uma sequência devariáveis aleatórias independentes, identicamente distribuídas e assumindovalores no conjunto B = {0,1}, independente da cadeia (Xk)k�0 e tal que
P(Yk = 1) = 1� e ,
onde 0 < e < 1. Definimos uma nova sequência (Zk)k�0 da seguinte forma:
Zk = XkYk para todo n � 0.
Nessas condições a probabilidade condicional
P(Z2 = 1,Z1 = 0 |Z0 = 1) .
vale:(A) 1/2(B) p(1 |0)[p(1 |0)]2 p(1 |1)p(0 |1)(1� e)3
e
3
(C) [p(1 |1)]2(1� e)e + p(0 |1)p(1 |0)(1� e)(D) Nenhuma das respostas anteriores.

3.7 Exercícios teste 67
7. No modelo simples de um sistema com 2 neurônios interagindo, sem assumirnada sobre f (0), f (1), . . . , diga qual é o maior valor que a probabilidadecondicional
P{X1(1) = X2(1) = 0,X3(1) = X4(1) = X5(1) = 1|X0(1) = 1,X0(2) = X2(2) = X4(2) = 0,X1(2) = X3(2) = 1}
pode assumir:(A) (1
2)2(1
3)(23)
2
(B) ( 12)
2(13)
2(23)
(C) 1(D) Nenhuma das anteriores
8. No modelo simples de um sistema com 2 neurônios interagindo, vamos agorasupor que
f (k) =12
e�2k, para k = 0,1, . . . .
Nestas condições, o valor da expressão
P{X4(1) = 1|X3(1) = 0,X2(1) = 1,X1(1) = 0,X0(1) = 1,X3(2) = 0,X2(2) = 0,X1(2) = 0,X0(2) = 1}
(A) 0.25(B) 0.50(C) 0.75(D) Nenhuma das anteriores
9. Considere uma variável aleatória Z assumindo valores em {0,1, · · · ,104}com distribuição dada por
P(Z = k) =✓
104
k
◆✓12
◆104
.
Diga qual das seguintes afirmações é verdadeira:(A) P(4500 Z 5500)� 0.99(B) P(4500 Z 5500) 0.01(C) P(4500 Z 5500) = 0.5(D) Nenhuma das anteriores


IntroduçãoCritério de SchwarzSeleção de modelos
Selecionando uma árvore de contextos
Algoritmo "Contexto
Considerações importantesExercícios de fixaçãoAlgoritmos de simulação em R
4 — Seleção estatística de modelos
4.1 Introdução
Neste capítulo queremos associar um modelo| {z }critério estatístico
de uma classe de modelos| {z }cadeias de Markov
a uma
amostra de dados.
Até agora nós sabemos:
• Estimar uma matriz de probabilidade de transição p 2 Mk(A).
• Estimar p 2 Mt
(A) onde Mt
representa uma família de probabilidades noalfabeto A indexada pelo contexto w em t .
!Porém como fazer para selecionar ‘k’ e t para uma dada amostra?
• Uma primeira resposta poderia ser escolher k (ou t) de forma a maximizar averossimilhança da amostra. Porém essa resposta estaria errada! Imagine que paramaximizar a verossimilhança escolhêssemos um k igual ao tamanho da amostramenos 1. Neste caso o poder de previsão do modelo estaria bastante comprometido,estaríamos incorrendo no problema de ‘overfitting’.
70 Seleção estatística de modelos
k=1overfittingk=3
Problema de interesse
• Selecionar o grau k do polinômio.
• Escolher a0, ...,ak coeficientes que melhor se ajustam aos dados.
f (x) = a0 +a1x+ ...+akxk
Escolhido k buscamos a0, ...ak que minimizam o erro: E(xn1; a0, ..., ak).
Seja dada a amostra Xn1 = an
1, em que para cada k=0,1,2.. calculamos p(0)n , p(1)n , p(2)n , ...
onde p(0)n = Ânt=11{Xt=a}.
p(k)n (b[a�1�k ]) =
N[1,n](a�1�kb)
N[1,n�1](a�1�k)
) pMV (k)(Xn1 = an
1) = P{Xk1 = ak
1} ’a�k�12Ak
’b2A
p(k)n (b|a�1�k)
N[1,n](aa�1�kb)
A função de log-verossimilhança:
Lk(ak1)= log(PMV (k){Xn
1 = an1})=Â
a�1�k
Âb
N[1,n](a�1�kb) log p(k)n (b|a�1
�k)= c.Â[N(a�1�kb)]⇡ c.n
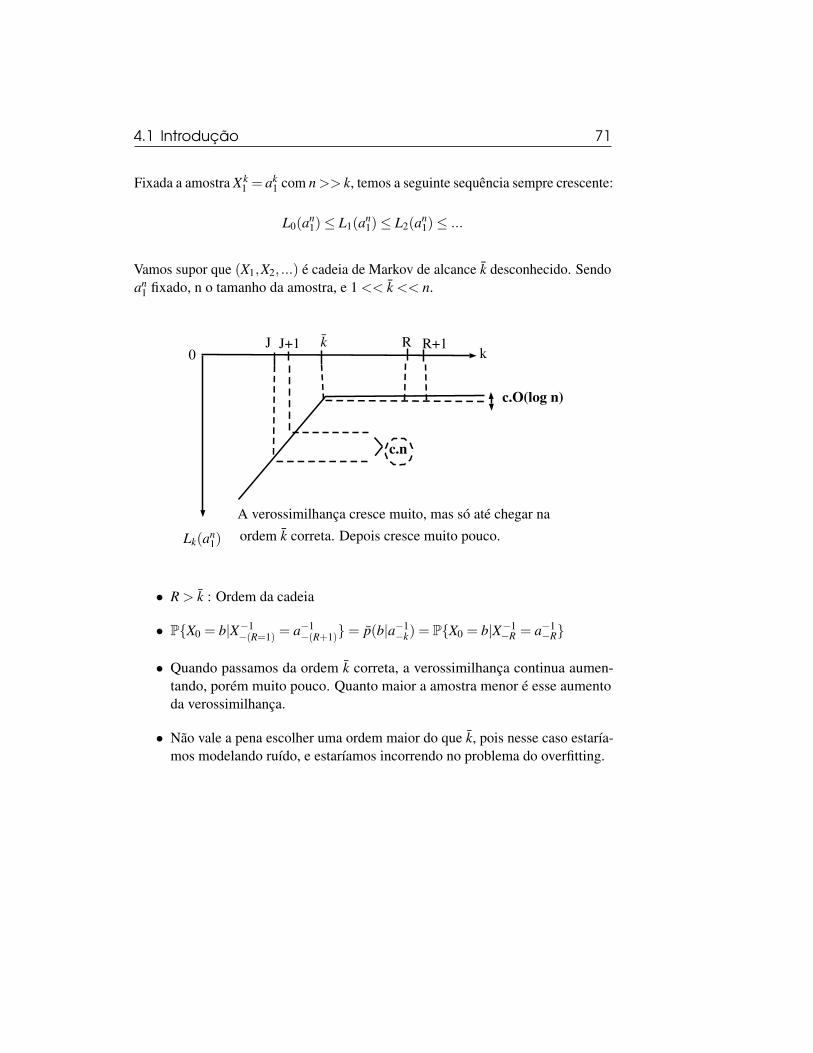
4.1 Introdução 71
Fixada a amostra Xk1 = ak
1 com n>> k, temos a seguinte sequência sempre crescente:
L0(an1) L1(an
1) L2(an1) ...
Vamos supor que (X1,X2, ...) é cadeia de Markov de alcance k desconhecido. Sendoan
1 fixado, n o tamanho da amostra, e 1 << k << n.
0J J+1 k R R+1
k
Lk(an1)
A verossimilhança cresce muito, mas só até chegar na
ordem k correta. Depois cresce muito pouco.
c.n
c.O(log n)
• R > k : Ordem da cadeia
• P{X0 = b|X�1�(R=1) = a�1
�(R+1)}= p(b|a�1�k) = P{X0 = b|X�1
�R = a�1�R}
• Quando passamos da ordem k correta, a verossimilhança continua aumen-tando, porém muito pouco. Quanto maior a amostra menor é esse aumentoda verossimilhança.
• Não vale a pena escolher uma ordem maior do que k, pois nesse caso estaría-mos modelando ruído, e estaríamos incorrendo no problema do overfitting.

72 Seleção estatística de modelos
4.2 Critério de Schwarz
O critério de Schwarz, ou critério de informação Bayesiano (BIC), é um critérioque seleciona o alcance k ótimo levando em consideração a relação custo benefício,como se segue:
log⇣ PMV (k)(Xk
1 )
custo do modelo de alcance k
⌘= Lk(Xn
1 )� log(custo(k))
• Cálculo do custo: Aumentar k até não valer mais a pena.
k
≥ c.n.Lk(an1)
Gráfico de Lk(an1) ≤ c.O(log(n))
Custo =
⇢<< c.n se k k>> c.O(log(n)) se k >> k
c(k,n) = c. |A|k.(|A|�1)| {z }Num. g.l. de um modelo em Mk(A)
.log(n)
Notação 4.1. BIC(k;Xn1 ) = log PMV (k)(Xn
1 )� c[|A|k(|A|�1)] logn
Critério: kn = argmax{BIC(k;Xk1 ) : k � 1}

4.2 Critério de Schwarz 73
⌅ Exemplo 4.1 Este exemplo tem como objetivo determinar o alcance k de umacadeia. Vamos supor, portanto, um alfabeto A = {0,1}, e uma matriz:
p =
0 1✓ ◆0 0,9 0,11 0,1 0,9
Simulando a cadeia, teríamos: (1 1 1 ... 1 1 0 0 ... 0 0 1 1 .... 1 1 0 0 ...)
Primeira tentativa: Alcance 0.
Como estimar p(0)n (1) = N[1,n](1)n ⇡ 1
2 = p(0)n (0)
Apesar de p = 12 , não é uma binomial! Para n grande, PMV (0)(Xn
1 ) =⇣
12
⌘n
Segunda tentativa: Alcance 1.
pn(1|1)⇡ 0,9
pn(0|0)⇡ 0,9
PMV (1)(Xn1 )⇡ (0,9)Nn(11).(0,9)Nn(00).(0,1)Nn(01).(0,1)Nn(10)
Onde: Nn(11)⇡ Nn(00) = n2 .0,9 e Nn(10)⇡ Nn(01) = n
2 .0,1
Substituímos na equação anterior e comparamos para ver qual fornece um resultadomaior.
⌅
!No que diz respeito ao critério BIC, em geral utiliza-se, como convenção, aconstante 1
2 na equação: log(PMV (k)(Xn1 ))�
12 |A|
k(|A|�1). log|A| n

74 Seleção estatística de modelos
⌅ Exemplo 4.2 Seja a matriz
p =
0 1✓ ◆0 0,9 = a 0,11 0,1 0,9
q(n) = P{Xn1 =
n vezesz }| {0....0,Xn+1 = 1|X0 = 0}= (0,9)n(1� 0,9|{z}
a
) = a
n(1�a)
Média de zeros:•
Ân=0
na
n(1�a) = a(1�a)+2a
2(1�a)+3a
3(1�a)+ ...=
=(1�a).
0
@a +a
2 +a
3 ...+a
2 +a
3 ...a
3 ...
1
A =(1�a)
(1�a)
ha
1�a
+a
2
1�a
+a
3
1�a
i=
a
(1�a)
Assim:
0 0 1 10,1 0,5
Comp. Médioα
1−α
Comp. Médio
(1− 12)∑n( 1
2)n = 0,5
1−0,5 = 1
Ou seja:
000 000 11 000 0011000 00
Longa seq. de zeros Seq. curta de uns
Geométricas independentes

4.2 Critério de Schwarz 75
!Antes de continuar o exemplo, devemos ter em mente o cálculo da medidade probabilidade invariante da cadeia. Seja a,b 2]0,1[, e:
Q =
✓1�a a
b 1�b
◆
Procuramos µ : {0,1}! [0,1].
µ(0)Q(1|0) = µ(1)Q(0|1)
⇢µ(0)a = µ(1)bµ(0)+µ(1) = 1
Assim: (µ(0) = b
b+a
µ(1) = a
b+a
Voltando ao exemplo:
p =
✓1� e e
e 1� e
◆
a = b = e . Então: µ(0) = µ(1) = 12 8e > 0
Se e for muito pequeno, então teremos longas sequências de zeros seguido porlongas sequências de uns.
Amostra 00 01 10 01..
Nós sabemos que a amostra foi gerada por uma cadeia de Markov, no alfabetoA = {0,1}, com matriz probabilidade de transição p.
Tentativa: Alcance 0 (n = 104)
p0n(1) =
Nn(1)n
⇡ 0,5
p0n(0) =
Nn(0)n
⇡ 0,5 = 1� pn(1)

76 Seleção estatística de modelos
Poderíamos pensar que a sequência é resultado dos lançamentos num jogo de cara ecoroa, já que temos o mesmo número de zeros e uns.
Verossimilhança da amostra de 104 elementos (Alcance 0):
PMV (0)(Xn1 )⇡
⇣12
⌘n
Vamos calcular a probabilidade de transição da cadeia de Markov:
) p(1)n (1|1) = Nn(11)Nn�1(1)
= 1� p(1)n (0|1)
) p(1)n (1|0) = Nn(01)Nn�1(0)
= 1� p(1)n (0|0)
• pn(1|1)⇡ p(1|1) = 1� e (O estimador chega próximo do valor verdadeiro).
Verossimilhança para alcance 1.
pMV (1)(Xn1 ) = ’
(a,b)2{0,1}2
pn(b|a)Nn(ab)
pn(1|1)Nn(11) ⇡ 1� e
n2 .(1�e)
Note antes que pela LGN:
Nn(11)n
⇡ P{X0 = 1,X1 = 1}= P{X0 = 1}P{X1 = 1|X0 = 1}= 12(1� e)
Assim:
• pn(0|0)Nn(00)⇡ 1�e
n2 .(1�e)
• pn(1|0)Nn(01) ⇡ e
n2 .e
• pn(0|1)Nn(10) ⇡ e
n2 .e
) PMV (1)(Xn1 )⇡ (1� e)n(1�e)
e
ne
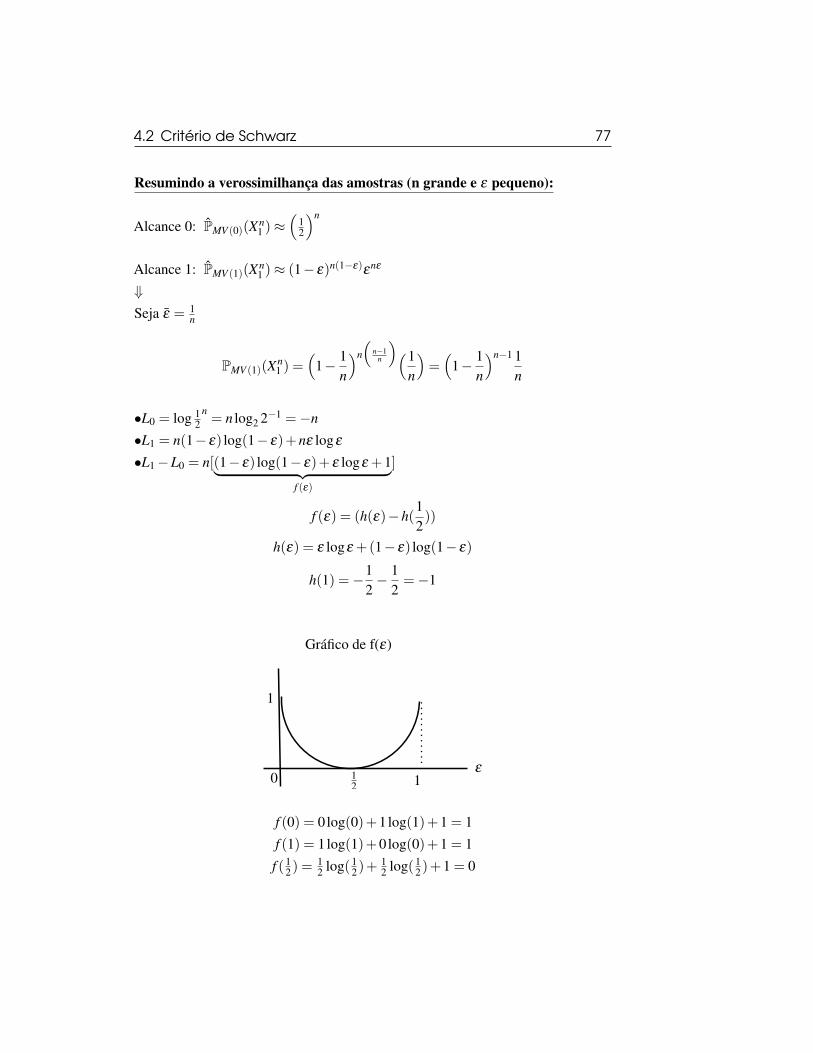
4.2 Critério de Schwarz 77
Resumindo a verossimilhança das amostras (n grande e e pequeno):
Alcance 0: PMV (0)(Xn1 )⇡
⇣12
⌘n
Alcance 1: PMV (1)(Xn1 )⇡ (1� e)n(1�e)
e
ne
+Seja e = 1
n
PMV (1)(Xn1 ) =
⇣1� 1
n
⌘n
⇣n�1
n
⌘⇣1
n
⌘=⇣
1� 1n
⌘n�1 1n
•L0 = log 12
n= n log2 2�1 =�n
•L1 = n(1� e) log(1� e)+ne loge
•L1 �L0 = n[(1� e) log(1� e)+ e loge +1| {z }f (e)
]
f (e) = (h(e)�h(12))
h(e) = e loge +(1� e) log(1� e)
h(1) =�12� 1
2=�1
1
0 12 1
ε
Gráfico de f(ε)
f (0) = 0log(0)+1log(1)+1 = 1f (1) = 1log(1)+0log(0)+1 = 1f (1
2) =12 log(1
2)+12 log(1
2)+1 = 0

78 Seleção estatística de modelos
Assim, L1 �L0 � 0, ou seja, é 0 apenas se e = 12
Lembrando que:
p =
✓1� e e
e 1� e
◆
Quando e = 12 a cadeia de Markov tem alcance 0, ou seja, é uma cadeia indepen-
dente.
Já para e 6= 12 L1 > L0, a ordem 1 é melhor do que a ordem 0.
• Agora, para a mesma amostra, calcular a verossimilhança supondo cadeia deMarkov de alcance 2:
PMV (2)(Xn1 ) = ’
a�1�22A2
’b2A
pn(b|a�1�2)
Nn(a�1�2b)
pn(1|11)⇡ P{Xt = 1|Xt�1 = Xt�2 = 1}= P{Xt�2 = Xt�1 = Xt = 1}P{X�2 = Xt�1 = 1} =
=P{Xt�2 = 1}P{Xt�1 = 1|Xt�2 = 1}P{Xt = 1|Xt�1 = Xt�2 = 1}
P{Xt�2 = 1}P{Xt�1 = 1|Xt�2 = 1} =
P{Xt = 1|Xt�1 = Xt�2 = 1}= P{Xt = 1|Xt�1 = 1}= 1� e
então p(1|11) = 1� e , ou seja:
PMV (2)(Xn1 )⇡ PMV (1)(X
n1 ) com pequena flutuação
Assim o alcance mais adequado seria ‘1’, uma vez que alcance de maior ordem, porexemplo ‘2’ não acrescentaria nada de realmente relevante.
⌅

4.3 Seleção de modelos 79
4.3 Seleção de modelos
? Como identificar o alcance k de uma cadeia de Markov (De alcance kdesconhecido) que gera a amostra que observamos Xn
0 ?
• BIC(k,Xn0 ) = log PMV (k)(Xn
0 )�c[|A|k(|A|�1)] log|A| n| {z }Penalização
• Teorema da Consistência: Se Xn0 for gerado por uma matriz p 2 Mk(A), então
kn = k para todo n suficientemente grande, e pn(b|a�1�k) !
n!•p(b|a�1
�k) para
8b 2 A e 8a�1�k 2 Ak.
Temos que M(A) = [•k=0Mk(A), então o BIC seleciona k que melhor descreve a
amostra Xn0 , maximizando a relação qualidade (Verossimilhança), preço (Número
de parâmetros do modelo).
Queremos maximizar a relação1:
log|A|⇣ PMV (k)(Xn
0 )
(nc)|A|k(|A|�1)
⌘
• Veja que se p 2 Mk(A)
Akb ∈ A
a−1−k p(b|a−1
−k)
|A|k
éo
núm
ero
delin
has d
am
atriz
|A| colunas, mas |A|−1 par?metrosPara cada passado
• Assim, o número de parâmetros a ser fixado é: |A|k|{z}N. de linhas
. (|A|�1)| {z }N. de parâmetros
1Note que, como foi dito, em geral atribui-se o valor 12 para a constante c.

80 Seleção estatística de modelos
• Se o tamanho da amostra for ‘n’, então a precisão estatística não pode ser maisfina do que 1p
n , de acordo com o T.L.C.
• Procedimento Bayesiano: Para k fixado, escolhemos cada uma das |A|k.(|A|�1)caselas com uma uniforme no intervalo de comprimento 1p
n independentes.
• Escolhemos para cada a�1�k 2 A e b 2 {1,2, ..|A|�1} p(b|a�1
�k) 2 [0, 1pn ] unifor-
memente. A probabilidade dessa escolha é 1pn|A|k.(|A|�1), o que ao se aplicar o log,
obtém-se:� 12 .n.|A|
k.(|A|�1)
O número de graus de liberdade |A|k.(|A|�1) cresce exponencialmente com k.
• Motivação: Esse número exponencialmente grande de parâmetros a serem esti-mados para selecionar modelos em M(A) = [•
k=0Mk(A) nos leva a buscar modelosmais econômicos ! Classe das cadeias com memória de alcance variável.
Notação 4.2. Mt
(A) = {p(·|w)|A ! [0,1],w 2 t : Âb2A p(b|w) = 1}
⌅ Exemplo 4.3 Dada uma amostra gerada por p 2 Mt
(A), como identificar t?Seja A = {0,1} e p 2 M2(A) a probabilidade de transição de alcance 2. O númerode graus de liberdade do modelo |A|k(|A|�1) = 22(2�1) = 4.
A1 0X−2X−1 Soma
1
1
1
1
0,7
0,5
0,2
0,2
0 0
1 0
0 1
1 1
0,3
0,5
0,8
0,8
Passado FuturoA2
RedundanteContexto
Info inútil 4 graus de liberdade

4.3 Seleção de modelos 81
• Representação mais econômica desse modelo:
1
Próximo passo
0,7
0,5
0,2
0
0
1
0
1
X−2X−1
p = 3 graus de liberdade
Árvore10
0 1
00 10
=w
0,2 0,81 0
0,5 10,5 0
1 0,7
0 0,3
X0
X0X0
p(·|w)
(τ, p)
• Dada uma amostra X0, ...Xn (Com n grande), gerada por p, como estimar p?
pn(b|a�1�2) =
Nn(a�1�2b)
Nn�1(a�1�2)
Como n é grande, pn(b|a�1�2)⇡ p(b|a�1
�2).
Ou seja,
pn(1|00)⇡ 0,7 pn(1|01)⇡ 0,5
e,
pn(1|11)⇡ 0,2 pn(1|10)⇡ 0,2 são aproximadamente iguais, ou seja, se X�1 = 1então é inútil saber o valor de X�2.
⌅

82 Seleção estatística de modelos
?Perguntas a serem respondidas:
• Qual a altura máxima da árvore a ser considerada?
• O que significa, na prática, dizer que pn(1|10) é aproximadamenteigual a pn(1|11)?
Primeira pergunta:Se a amostra tem comprimento n, X1, ...,Xn, qual é o maior k que podemos conside-rar para fazer estatísticas? Usar o máximo absoluto não é boa solução!
• Pelo teorema de Shannon-McMillan-Breiman (Ver teorema 4.3.1 a seguir),sabemos que k log|A| n. Assim:
+
Fato geral: Vai além de cadeias de Markov
Se Xn : X0,X1,X2, ... for cadeia estocástica regida por um mecanismo aleatório quenão muda ao longo do tempo, como por exemplo:
Se para todo n � m:
Xn = f (Xn�1n�m,un)
Então
1n
logP{Xn1 = an
1} !n!•
h � 0 ! Todas as sequências longas tem mesmo peso
+
Ou seja, para n longo, todas as sequências de tamanho n vão ter aproximadamente amesma probabilidade.
P{Xn1 = an
1}⇡ e�n.h ,8Xn1 = an
1

4.3 Seleção de modelos 83
Teorema 4.3.1 — Teorema de Shannon-McMillan-Breiman. Sob determina-das hipóteses, 8e > 0 9 n = n(e) tal que 8n >> n existe um conjunto Rn ⇢ An
com P{Xn1 2 Rn} e e para todas as outras sequências an
1 * Rn
P{Xn1 = an
1}⇡ e�nh
Além disso, h log |A| e h = log |A| ()
P{Xn = a}= 1|A| , 8a 2 A
⌅ Exemplo 4.4 Seja A = {0,1}, e X1,X2, ... i.i.d., com P{Xi = 1} = 12 e Rn 6= ,
8a1,a2, ... elementos de A:
P{Xn1 = an
1}=12
n= e
log⇣
12
⌘n
= e�n. log(2)
Onde log(2) = h de acordo com a aproximação descrita anteriormente.
Veja que este é o único caso em que h = log |A|⌅
⌅ Exemplo 4.5 Seja (Xn)n cadeia de Markov com matriz p de alcance 1: p2M1(A):
P{Xn0 = an
0}= P{X0 = a0}.n
’t=1
p(Xt |Xt�1) =
= P{X0 = a0}. ’(u,v)
p(v|u)Nn(uv) =
Aplicando o log dos dois lados
1n
logP{Xn0 = an
0}=⇠⇠⇠⇠⇠⇠⇠⇠⇠:01n
logP{X0 = a0}+ Â(u,v)
=Nn(uv)
nlog p(v|u)
= Â(u,v)⇢
⇢⇢⇢>
converge parap(v|u)Nn(uv)
nlog p(v|u)

84 Seleção estatística de modelos
Assim:
1n
logP{Xn0 = an
0}= Â(u,v)
p(v|u) log p(v|u)
| {z }h: Entropia da cadeia: Mede o grau de incerteza da cadeia
P{Xn0 = an
0}⇡ e�nh
• O número de sequências de elementos de A de comprimento n é |A|n = en log |A|
que é exponencialmente maior que enh.
0 h < log |A|
O número de sequências que ocorrem é muito menor que o número de sequênciaspossíveis.
⌅
• Lema de RAC:
E(T ) =1
P{Xk�1 = ak
�1}
• Juntando os resultados, para fazer estatística sobre p(b|a�1�k) precisamos ter muitas
ocorências de a�1�k .
Queremos que h � ekh () elogn�ekh () k lognn e sabe-se que h < log |A|.
Se k lognlog |A| teremos repetições de a�1
�k .
Assim, começamos da seguinte altura da árvore:
k log|A| n

4.3 Seleção de modelos 85
4.3.1 Selecionando uma árvore de contextos
? Dada uma amostra, como selecionar uma árvore de contextos?
Ideia: Suponha X0,X1, ..Xn num alfabeto A = {0,1} gerado por (t, p) em que aárvore t:
1
1000
τ =
e p(1|00) = a , p(1|01) = b , p(1|1) = g .
pkn(b|a�1
�k) =Nn(a�1
�kb)
Nn�1(a�1�k)
Note que como (00) é contexto, então p(1|00z) o ‘z’ não adiciona informação poisa probabilidade não depende mais de X�3.
Da mesma forma: p3n(b|1z1z2) não vai variar muito em função de x e y, pois sabemos
que 1 é contexto.
Na verdade:
p3n(1|00z)⇡ p(1|00) = a
p3n(1|01z)⇡ p(1|01) = b
p3n(1|1z1z2)⇡ p(1|1) = g

86 Seleção estatística de modelos
4.3.2 Algoritmo "Contexto"
1. Calcular pkn(b|a�1
�k) para todo k log|A|n
• k = 12 log|A| n para ter suficientes repetições de a�1
�k , pois se obtivermossequências muito longas, não teremos repetições.
• a�1�k é candidato a contexto.
2. Para cada a�1�(k�1) decidimos se a informação é relevante.
3. Se for relevante, decidimos que a�1�k 2 tn
4. Se não for relevante essa informação a�1�k , recomeçamos no passo 1, mas
agora com a�1�(k�1) como novo candidato a contexto.
00
000 100pn(1|00) = 0,32
pn(1|001) = 0,34
pn(1|000) = 0,27
10k=3
!O próximo passo agora é verificar se a informação é relevante, ou seja,se os valores 0,32, 0,34 e 0,27 são estatisticamente diferentes. Se foremiguais, então não devemos procurar mais no passado, e definimos o contextorelevante.
• Relevância:Para verificarmos se a�k é relevante devemos comparar, para todos os valores de be para todos os valores a�k:
pkn(b|a�1
�k) e pk+1n (b|a�1
�(k�1))

4.3 Seleção de modelos 87
Regra geral:
D(a�1�(k�1)) = max
b2A,z2A|pk+1
n (b|a�1�(k�1)z)� pk+1
n (b|a�1�(k�1))|
• Se D(a�1�(k�1))> d então continuamos a podar os ramos.
• Se D(a�1�(k�1))< d então recomeçamos o processo, mas agora com D(a�1
�(k�2))
• Comprimento estimado do contexto:
L(a�1�c log|A| n
) = max{ j = 2, ..., log|A| n|D(a�1�( j+1)) d} mas D(a�1
� j > d )
Note que podamos os ramos a partir das folhas de comprimento log|A| n.
Agora suponha que a�1� j é contexto:
maxb,z2A
|p(b|a�1� j)� p(b|a�1
� j z)|= 0
Define-se:
Dn(a�1� j) = max
b,z2A|pn(b|a�1
� j)� pn(b|a�1� j z)|=
= maxb,z2A
|pn(b|a�1� j)
Soma e subtrai o valor teóricoz }| {�p(b|a�1
� j)+ p(b|a�1� j)�pn(b|a�1
� j z)|
maxb,z2A
|pn(b|a�1� j)� p(b|a�1
� j)|+ | p(b|a�1� j)� pn(b|a�1
� j z)| {z }Diferença entre valor teórico e estimado
| (1)
Primeiro termo em módulo da equação (1)Pela consistência do estimaodr pn, quando n ! • a diferença tende a zero.
P{maxb
|p(b|a�1� j)� pn(b|a�1
� j)|>d
2} Â
bP{|p(b|a�1
� j)� pn(b|a�1� j)|>
d
2}! 0
n!•

88 Seleção estatística de modelos
Segundo termo em módulo da equação (1)
|p(b|a�1� j z)� p(b|a�1
� j)| {z }a�1� j é contexto
|= |p(b|a�1� j z)� p(b|a�1
� j z)|
Juntando os termos:
P{maxb,z
|pn(b|a�1� j z)� p(b|a�1
� j z)|>d
2}! 0
n!•
Teorema 4.3.2 — Teorema da Consistência. Se a�1� j for contexto, 8d > 0
P{D(a�1� j)> d}! 0
n!•
Demonstração:
P{D(a�1� j)> d}
P{max |
D1z }| {pn(b|a�1
� j)� p(b|a�1� j) |+ | p(b|a�1
� j)� pn(b|a�1� j z)| {z }
D2
|> d}
Ou seja: P(D1 +D2 > d )������*! 0P(D1 >
12)+◆◆7
! 0P(D2 >
d
2)

4.4 Considerações importantes 89
4.4 Considerações importantes
Algoritmo "Contexto"
Dada uma amostra X1,X2, ...,Xn assumindo valores no alfabeto finito A, defina parax�1�(k+1) 2 Ak+1 e k < n�1 a seguinte quantidade
Dn(x�1�(k+1)) = max
a2A
��� p(a|x�1,x�2, ...,x�(k+1))� p(a|x�1,x�2, ...,x�k)���
para algum d 2 (0,1) fixado. Se Dn(x�1�(k+1)) < d , então podo o símbolo x�(k+1)
da sequência x�1�(k+1) e adoto x�1
�k como novo candidato a contexto. Caso contráriomantenho a sequência x�1
�(k+1).
Seleção de árvores de contextos usando o BIC:
Podemos usar o Critério da Informação Bayesiana (BIC) para selecionar uma árvoredentro de um conjunto de árvores: dada uma árvore de contextos t e uma amostra(X0, . . . ,Xn) de símbolos no alfabeto A finito,
1. Definimos
BIC(t|Xn0 ) = log PMV,t(Xn
0 )�12(|A|�1)|t| log(n),
onde PMV,t(Xn0 ) é a máxima verossimilhança da amostra quando a árvore de
contextos é t e |t| é o número de contextos associados a t .
2. Definimost(Xn
0 ) = argmax{BIC(t|Xn0 ) : t 2 Tn},
onde Tn é o conjunto das árvores indexadas por símbolos do alfabeto A e dealtura menos oi igual log|A| n.

90 Seleção estatística de modelos
4.5 Exercícios de fixação
Para os exercícios seguintes, considere a seguinte notação: dada uma amostraX�k, · · ·Xn de símbolos pertencendo a um alfabeto finito A, definimos as funções decontagem:
N[0,n](a0�k) =
n
Âi=t1{Xt
t�k=a0�k}
.
para k,n � 1.
1. Defina n = 1000 e gere uma amostra X0,X1, . . .Xn a partir de uma cadeia deMarkov de alcance 1 que assume valores no alfabeto A = {0,1,2} e que tema seguinte matriz de probabilidades de transição:
p =
0
@1/6 1/3 1/21/2 1/6 1/31/3 1/2 1/6
1
A .
Observação: Inicialize a simulação com X�1 = 1.
(i) Calcule as estimativas de máxima verossimilhança para as probabilida-des de transição da matriz p e o maior valor que a verossimilhança daamostra pode assumir. Assuma que P(X�1 = 1) = 1.
(ii) Verifique se o BIC (Critério da Informação Bayesiana) seleciona o al-cance correto da cadeia da Markov que gerou os dados. Considere comoúnicos candidatos os alcances 0 (caso i.i.d),1 e 2. Além disso assumaque P(X�2 = 1,X�1) = 1 para o cálculo da máxima verossimilhançasupondo que (Xn)n��2 é uma cadeia de Markov de alcance 2.
2. Tome n = 1000 e gere uma amostra X0,X1, . . .Xn a partir de uma cadeia deMarkov de alcance 2 que assume valores no alfabeto A = {0,1} e que tem pcomo matriz de probabilidades de transição definida pela seguinte tabela:
a0 a1 p(0 |a0,a1) p(1 |a0,a1)0 0 1/3 2/30 1 1/2 1/21 0 1/4 3/41 1 4/5 1/5
Observação: Inicialize a simulação com X�2 = X�1 = 1.

4.5 Exercícios de fixação 91
(i) A partir da amostra gerada, obtenha as estimativas de máxima veros-similhança para as probabilidades de transição da matriz p e o maiorvalor que a verossimilhança da amostra pode assumir. Assuma queP(X�1 = X�2 = 1) = 1.
(ii) Verifique se o BIC (Critério da Informação Bayesiana) seleciona oalcance correto da cadeia da Markov que gerou os dados. Considerecomo únicos candidatos os alcances 0, 1, 2 e 3. Além disso assumaque P(X�2 = 1,X�1) = 1 para o cálculo da máxima verossimilhançasupondo que (Xn)n��2 é uma cadeia de Markov de alcance 2 e queP(X�3 = 1,X�2 = 1,X�1) = 1 para o cálculo da máxima verossimi-lhança supondo que (Xn)n��3 é uma cadeia de Markov de alcance 3.
3. Seja (Xn)n�1 uma sequência de símbolos pertencentes ao alfabeto A = {0,1}e gerada por algum mecanismo aleatório. Obteve-se uma amostra dos 11primeiros símbolos dessa sequência:
(X1, . . . ,X11) = (0,0,1,1,0,1,0,0,0,0,1) .
Qual é a árvore de contextos t obtida a partir da aplicação da versão doAlgoritmo Contexto com d = 0.150 no critério de poda? (Observação: Use ofato de que 2 < ln11 < 3.)
4. Seja (Xn)n�0 uma cadeia com memória de alcance variável assumindo valoresno alfabeto A = {0,1} e com família de probabilidades de transição dada por:
p(1 |1) = 0,2; p(1 |00) = 0,5 e p(1 |01) = 0,7 .
(i) Gere uma amostra de tamanho n dessa cadeia. Assuma, por simplici-dade, que P(X0 = X1 = 0) = 1 e escolha o maior n tal que 3 < ln(n)< 4.
(ii) Use o Critério da Informação Bayesiana (BIC) para estimar a “melhor”árvore de contextos dentre todas as árvores com profundidade menor ouigual a 2 (incluindo a árvore que contém somente a raiz).

92 Seleção estatística de modelos
4.6 Algoritmos de simulação em R
1 # #######################################################2 # Codigo r e f e r e n t e ao e x e r c i c i o 1 ( i ) do c a p i t u l o a n t e r i o r3 # #######################################################4
5 # P r o b a b i l i d a d e r e a i s f o r n e c i d a s p e l o e x e r c i c i o6 p00 <� 1 / 67 p10 <� 1 / 38 p20 <� 1 / 29 p01 <� 1 / 2
10 p11 <� 1 / 611 p21 <� 1 / 312 p02 <� 1 / 313 p12 <� 1 / 214 p22 <� 1 / 615
16 # M a t r i z prob . de t r a n s i c a o r e a l17
18 # P r e e n c h e os v e t o r e s l i n h a19 p0 <� c ( p00 , p10 , p20 )20 p1 <� c ( p01 , p11 , p21 )21 p2 <� c ( p02 , p12 , p22 )22
23 # P r e e n c h e a m a t r i z de t r a n s i c a o24 p<�m a t r i x ( 0 , nrow =3 , ncol = 3 )25 p [ 1 , ] <� p026 p [ 2 , ] <� p127 p [ 3 , ] <� p228
29 # Comando p a r a c r i a r a s e q u e n c i a Xn ( I n c l u i n d o Xn�1 = 1)30 xn <� r e p ( 0 , 1001)31 xn [ 1 ]<�132 c o u n t <� r u n i f ( 1 , min = 0 , max = 1 )33 f l a g<�034
35 f o r ( i i n 1 : 1 0 0 1 ) {36 c o u n t <� r u n i f ( 1 , min = 0 , max = 1 )37
38 i f ( xn [ i ] == 0) {39 i f ( c o u n t < p [ 1 , 1 ] ) { f l a g <� 0}40 e l s e i f ( c o u n t > (1 � p [ 1 , 3 ] ) ) { f l a g <� 2}41 e l s e f l a g <� 142 }43
44 e l s e i f ( xn [ i ] == 1) {45 i f ( c o u n t < p [ 2 , 1 ] ) { f l a g <� 0}46 e l s e i f ( c o u n t > (1 � p [ 2 , 3 ] ) ) { f l a g <� 2}47 e l s e f l a g <� 1
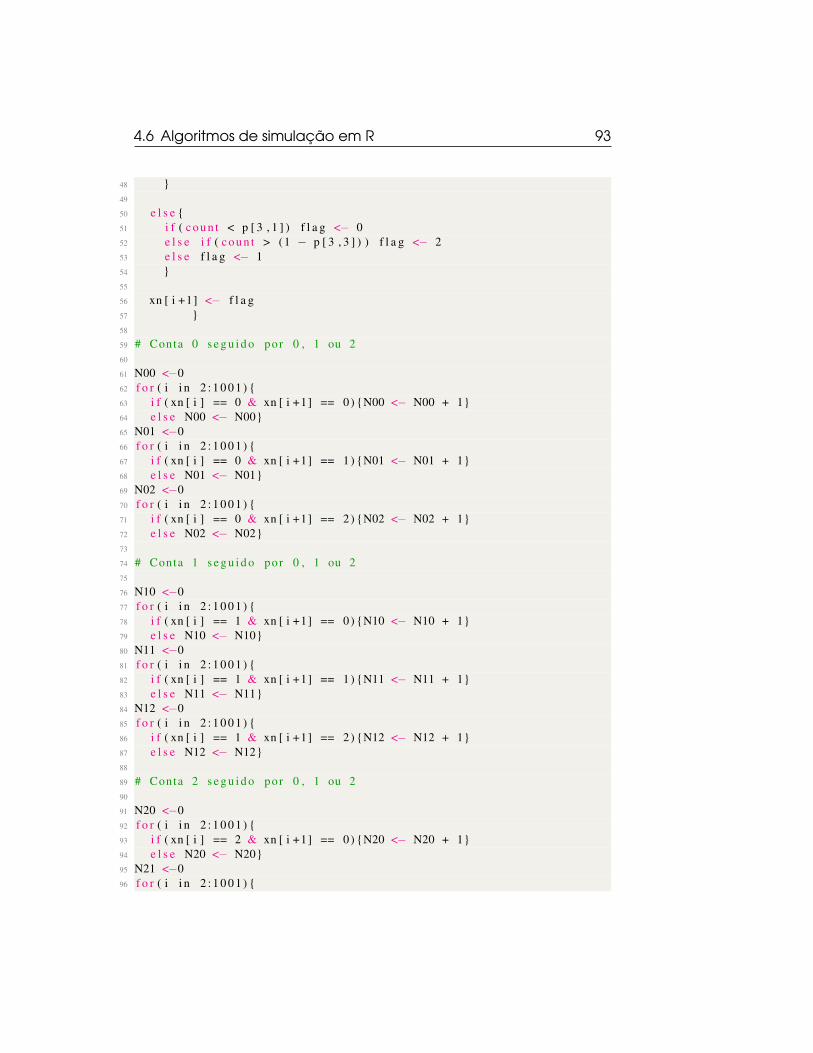
4.6 Algoritmos de simulação em R 93
48 }49
50 e l s e {51 i f ( c o u n t < p [ 3 , 1 ] ) f l a g <� 052 e l s e i f ( c o u n t > (1 � p [ 3 , 3 ] ) ) f l a g <� 253 e l s e f l a g <� 154 }55
56 xn [ i +1] <� f l a g57 }58
59 # Conta 0 s e g u i d o por 0 , 1 ou 260
61 N00 <�062 f o r ( i i n 2 : 1 0 0 1 ) {63 i f ( xn [ i ] == 0 & xn [ i +1] == 0) {N00 <� N00 + 1}64 e l s e N00 <� N00}65 N01 <�066 f o r ( i i n 2 : 1 0 0 1 ) {67 i f ( xn [ i ] == 0 & xn [ i +1] == 1) {N01 <� N01 + 1}68 e l s e N01 <� N01}69 N02 <�070 f o r ( i i n 2 : 1 0 0 1 ) {71 i f ( xn [ i ] == 0 & xn [ i +1] == 2) {N02 <� N02 + 1}72 e l s e N02 <� N02}73
74 # Conta 1 s e g u i d o por 0 , 1 ou 275
76 N10 <�077 f o r ( i i n 2 : 1 0 0 1 ) {78 i f ( xn [ i ] == 1 & xn [ i +1] == 0) {N10 <� N10 + 1}79 e l s e N10 <� N10}80 N11 <�081 f o r ( i i n 2 : 1 0 0 1 ) {82 i f ( xn [ i ] == 1 & xn [ i +1] == 1) {N11 <� N11 + 1}83 e l s e N11 <� N11}84 N12 <�085 f o r ( i i n 2 : 1 0 0 1 ) {86 i f ( xn [ i ] == 1 & xn [ i +1] == 2) {N12 <� N12 + 1}87 e l s e N12 <� N12}88
89 # Conta 2 s e g u i d o por 0 , 1 ou 290
91 N20 <�092 f o r ( i i n 2 : 1 0 0 1 ) {93 i f ( xn [ i ] == 2 & xn [ i +1] == 0) {N20 <� N20 + 1}94 e l s e N20 <� N20}95 N21 <�096 f o r ( i i n 2 : 1 0 0 1 ) {
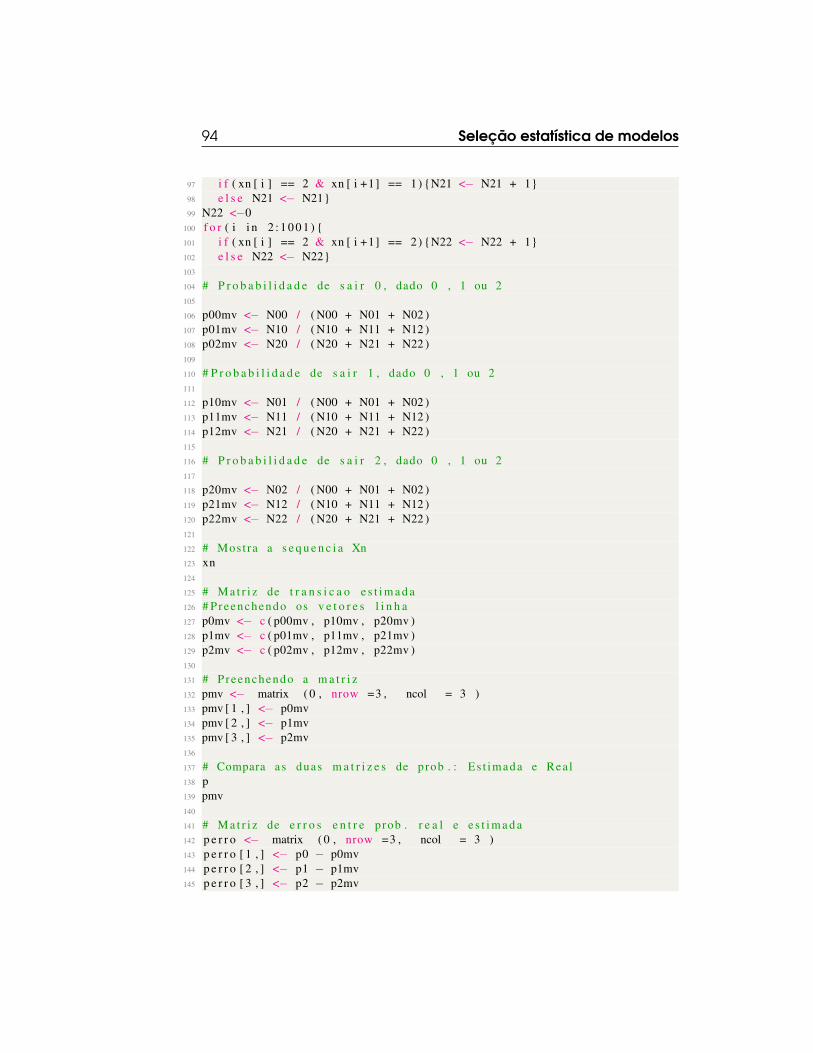
94 Seleção estatística de modelos
97 i f ( xn [ i ] == 2 & xn [ i +1] == 1) {N21 <� N21 + 1}98 e l s e N21 <� N21}99 N22 <�0
100 f o r ( i i n 2 : 1 0 0 1 ) {101 i f ( xn [ i ] == 2 & xn [ i +1] == 2) {N22 <� N22 + 1}102 e l s e N22 <� N22}103
104 # P r o b a b i l i d a d e de s a i r 0 , dado 0 , 1 ou 2105
106 p00mv <� N00 / ( N00 + N01 + N02 )107 p01mv <� N10 / ( N10 + N11 + N12 )108 p02mv <� N20 / ( N20 + N21 + N22 )109
110 # P r o b a b i l i d a d e de s a i r 1 , dado 0 , 1 ou 2111
112 p10mv <� N01 / ( N00 + N01 + N02 )113 p11mv <� N11 / ( N10 + N11 + N12 )114 p12mv <� N21 / ( N20 + N21 + N22 )115
116 # P r o b a b i l i d a d e de s a i r 2 , dado 0 , 1 ou 2117
118 p20mv <� N02 / ( N00 + N01 + N02 )119 p21mv <� N12 / ( N10 + N11 + N12 )120 p22mv <� N22 / ( N20 + N21 + N22 )121
122 # Most ra a s e q u e n c i a Xn123 xn124
125 # M a t r i z de t r a n s i c a o e s t i m a d a126 # Preenchendo os v e t o r e s l i n h a127 p0mv <� c ( p00mv , p10mv , p20mv )128 p1mv <� c ( p01mv , p11mv , p21mv )129 p2mv <� c ( p02mv , p12mv , p22mv )130
131 # Preenchendo a m a t r i z132 pmv <� matrix ( 0 , nrow =3 , ncol = 3 )133 pmv [ 1 , ] <� p0mv134 pmv [ 2 , ] <� p1mv135 pmv [ 3 , ] <� p2mv136
137 # Compara as duas m a t r i z e s de prob . : Es t imada e Rea l138 p139 pmv140
141 # M a t r i z de e r r o s e n t r e prob . r e a l e e s t i m a d a142 p e r r o <� matrix ( 0 , nrow =3 , ncol = 3 )143 p e r r o [ 1 , ] <� p0 � p0mv144 p e r r o [ 2 , ] <� p1 � p1mv145 p e r r o [ 3 , ] <� p2 � p2mv
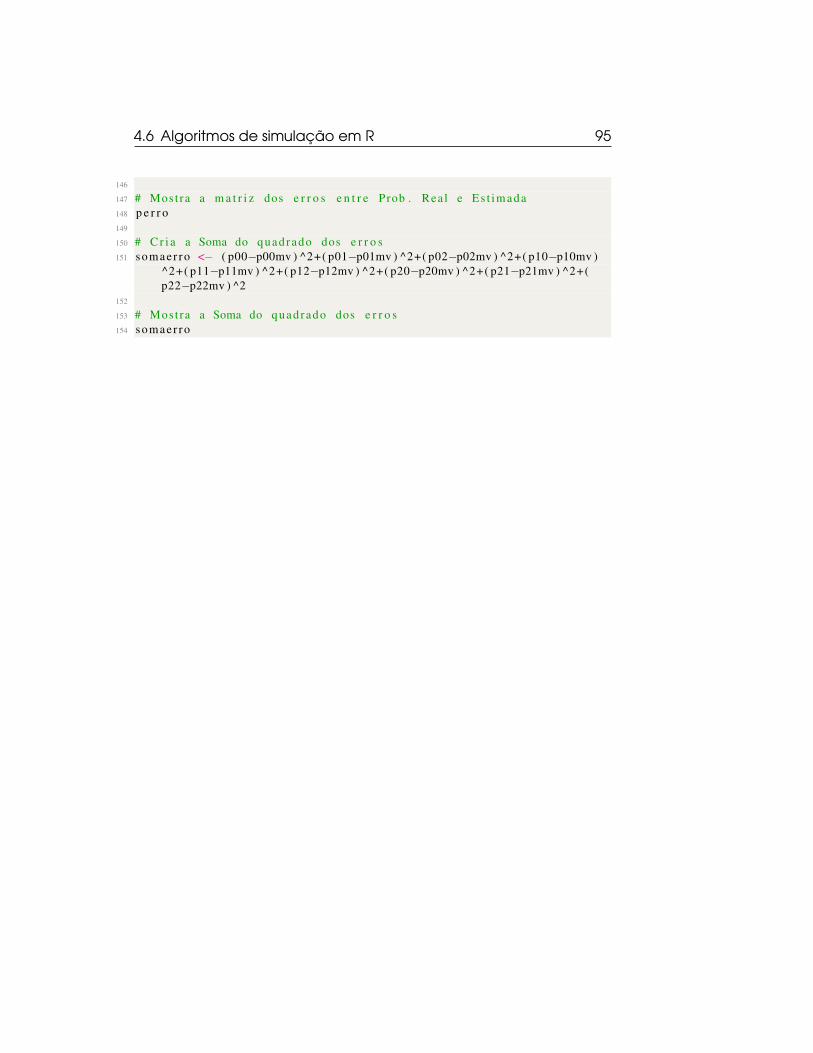
4.6 Algoritmos de simulação em R 95
146
147 # Most ra a m a t r i z dos e r r o s e n t r e Prob . Rea l e Es t imada148 p e r r o149
150 # C r i a a Soma do quadrado dos e r r o s151 somaer ro <� ( p00�p00mv ) ^2+( p01�p01mv ) ^2+( p02�p02mv ) ^2+( p10�p10mv )
^2+( p11�p11mv ) ^2+( p12�p12mv ) ^2+( p20�p20mv ) ^2+( p21�p21mv ) ^2+(p22�p22mv ) ^2
152
153 # Most ra a Soma do quadrado dos e r r o s154 somaer ro

5 — Bibliografia
Galves, Antonio, et al. "Context tree selection and linguistic rhythm retrieval fromwritten texts". The Annals of Applied Statistics 6.1 (2012): 186-209.
Magalhães, Marcos Nascimento. Probabilidade e Variáveis Aleatórias. EdUSP,2011.
Ross, Sheldon. Probabilidade: Um Curso Moderno com Aplicações. Bookman, n.d.
Billingsley, Patrick. "Statistical methods in Markov chains". The Annals of Mathe-matical Statistics (1961): 12-40.
Rissanen, Jorma. "A universal data compression system". IEEE Transactions oninformation theory 29.5 (1983): 656-664.
Galves, Antonio, and Eva Löcherbach. "Infinite Systems of Interacting Chainswith Memory of Variable Length—A Stochastic Model for Biological Neural Nets".Journal of Statistical Physics 151.5 (2013): 896-921.
Van den Heuvel, M. P., and O. Sporns. “Rich-Club Organization of the HumanConnectome”. Journal of Neuroscience 31, no. 44 (November 2, 2011)

98 Bibliografia
Ferrari, Pablo Augusto, and Antonio Galves. "Acoplamento e processos estocásti-cos". IMPA, 1997.
Rodriguez, Arias, and Azrielex Andres. “Modelagem estocástica de sequênciasde disparos de um conjunto de neurônios”. Universidade de São Paulo, 2013.http://www.teses.usp.br/teses/disponiveis/45/45133/tde-09012014-000601/.







