Download - Banco Dados Completa

74
Introdução
Um Sistema Gerenciador de Banco de Dados (SGBD) é constituído por um conjunto de dados associados a
um conjunto de programas para acesso a esses dados. O conjunto de dados, comumente chamado banco de
dados, contém informações sobre uma empresa em particular. O principal objetivo de um SGBD é proporcionar
um ambiente tanto conveniente quanto eficiente para a recuperação e armazenamento das informações dos
bancos de dados.
Sistemas de banco de dados são projetados para gerir grandes volumes de informações. O gerenciamento
de informações implica a definição das estruturas de armazenamento de informações e a definição dos
mecanismos para a manipulação dessas informações. Ainda, um sistema de banco de dados deve garantir a
segurança das informações armazenadas contra eventuais problemas com o sistema, além de impedir tentativas
de acesso não autorizadas. Se os dados são compartilhados por diversos usuários, o sistema deve evitar a
ocorrência de resultados anômalos.
A importância da informação na maioria das organizações – que estabelece o valor do banco de dados –
tem determinado o desenvolvimento de um grande conjunto de conceitos e técnicas para a administração eficaz
desses dados.
Objetivos de um Sistema de Banco de dados
Considere a área de um banco responsável por todas as informações de seus cliente e de suas contas-
poupança. Um modo de guardar as informações no computador é armazená-las em sistemas de arquivos
permanentes. Para permitir aos usuários a utilização dessas informações, o sistema deve apresentar um conjunto
de programas de aplicações que tratam esses arquivos, incluindo:
• Um programa para débito e crédito na contabilidade.
• Um programa para incluir novos registros na contabilidade.
• Um programa para balanço da contabilidade.
• Um programa para gerar relatórios mensais.
Essas aplicações foram desenvolvidas por programadores a fim de atender às necessidades das
organizações bancárias.
Novos programas foram incorporados a esses sistemas para atender a necessidades que foram surgindo.
Por exemplo, suponha que novas regras sejam promulgadas pelo governo obrigando que os bancos ofereçam
meios para a checagem de suas contas. Com isso, novos arquivos permanentes serão criados contendo dados
para checagem de todas as contas mantidas pelo banco e novos programas de aplicações serão necessários a fim
de adequar-se a nova situação, que de fato não foi originada pela caderneta de poupança, como o tratamento de
saldos negativos. Assim, conforme passa o tempo, mais arquivos e mais programas de aplicações são adicionados
ao sistema.
O sistema de processamento de arquivos típico que acabamos de descrever pode ser aceito pelos
sistemas operacionais convencionais. Registros permanentes são armazenados em vários arquivos e diversos
programas de aplicação são escritos para extrair e gravar registros nos arquivos apropriados. Antes do advento
dos SGBDs, as organizações usavam esses sistemas para armazenar informações.
Obter informações organizacionais em sistemas de processamento de arquivos apresenta numerosas
desvantagens:
• Inconsistência e redundância de dados. Já que arquivos e aplicações são criados mantidos por diferentes
programadores, em geral durando longos períodos de tempo, é comum que os arquivos possuam
formatos diferentes e os programas sejam escritos em diversas linguagens de programação. Ainda mais, a
mesma informação pode ser repetida em diversos lugares (arquivos). Por exemplo, o endereço e o
telefone de um cliente em particular pode aparecer tanto no arquivo de contas quanto no arquivo de
checagem de contas. Esta redundância aumenta os custos de armazenamento e acesso. Ainda, pode
originar inconsistência de dados; isto é, as várias cópias dos dados poderão divergir ao longo do tempo.

75
Por exemplo, a mudança de endereço de um cliente pode refletir nos arquivos de contas, mas não ser
alterada no sistema como um todo.
• Dificuldade de acesso aos dados. Suponha que um dos empregados da empresa precise de uma relação
com os nomes de todos os cliente que moravam em determinada área de acidade cujo CEP é 78733. O
empregado pede, então, ao departamento de processamento de dados que crie tal relação. Como esse
tipo de solicitação não foi prevista no projeto do sistema não há nenhuma aplicação disponível para
atende-la. No entanto, há uma aplicação para gerar a relação de todos os clientes da empresa. Assim, o
empregado tem duas alternativas: separar manualmente da lista de todos os clientes aqueles de que
necessita ou requisitar ao departamento de processamento de dados um programador para escrever o
programa necessário. Ambas as alternativas são, obviamente, insatisfatórias. Suponha que o tal programa
seja escrito e que dias depois o mesmo empregado necessite selecionar os clientes que possuem saldo
superior a dez mil dólares. Como esperado, tal programa não existe. Novamente o empregado tem as
mesmas duas opções, nenhuma delas insatisfatória. O fato é que um ambiente com um sistema de
processamento de arquivos convencional não atende às necessidades de recuperação de informações de
modo eficiente. Sistemas mais efetivos (com respostas mais rápidas e adequadas) para a recuperação de
informações precisam ser desenvolvidos.
• Isolamento de dados. Como os dados estão dispersos em vários arquivos, e estes arquivos podem
apresentar diferentes formatos, é difícil escrever novas aplicações para recuperação apropriada dos
dados.
• Problema de integridade. Os valores dos dados atribuídos e armazenados em um banco de dados devem
satisfazer certas restrições para manutenção da consistência. Por exemplo, o balanço de uma conta
bancaria não pode cair abaixo de um determinado valor. Os programadores determinam o cumprimento
dessas restrições por meio da adição de código apropriado aos vários programas de aplicações.
Entretanto, quando aparecem novas restrições é difícil alterar todos os programas para incrementá-las. O
problema é ampliado quando as restrições atingem diversos itens de dados em diferentes arquivos.
• Problemas de atomicidade. Um sistema computacional, como qualquer outro dispositivo mecânico ou
elétrico, está sujeito a falhas. Em muitas aplicações é crucial assegurar que, uma vez detectada uma falha,
os dados sejam salvos em seu último estado consistente, anterior a ela. Considere um programa para
transferir 50 dólares da conta A para uma conta B. Se ocorrer falha no sistema durante sua execução, é
possível que os 50 dólares sejam debitados da conta A sem serem creditados na conta B, criando um
estado inconsistente no banco de dados. Logicamente, é essencial para a consistência do banco de dados
que ambos, débito e crédito, ocorram ou nenhum deles seja efetuado. Isto é, a transferência de fundos
deve ser uma operação atômica – deve ocorrer por completo ou não ocorrer. É difícil garantir essa
propriedade em um sistema convencional de processamento de arquivos.
• Anomalias no acesso concorrente. Muitos sistemas permitem atualizações simultâneas nos dados para
aumento do desempenho do sistema como um todo e para melhores tempos de resposta. Nesses tipos
de ambiente, a interação entre atualizações concorrentes pode resultar em inconsistência de dados.
Suponha que o saldo de uma conta bancária A seja 500 dólares. Se dois clientes retiram fundos da conta
A (digamos 50 e 100 dólares, respectivamente), essas operações, ocorrendo simultaneamente, podem
resultar em erro (ou gerar inconsistência). Suponha que, na execução dos programas, ambos os clientes
leiam o saldo antigo e retirem, cada um, seu valor correspondente, sendo o resultado armazenado. Os
dois programas concorrendo, ambos leem o valor 500 dólares, resultado, em 450 e 400 dólares,
respectivamente. Dependendo de qual deles registre seu resultado primeiro, o saldo da conta A será 450
ou 400 dólares, em vez do valor correto de 350 dólares. Para resguardar-se dessa possiblidade, o sistema
deve manter algum tipo de supervisão. Como os dados podem sofrer acesso de diferentes programas, os
quais não foram coordenados previamente, a supervisão é bastante dificultada.
• Problemas de segurança. Nem todos os usuários de banco de dados estão autorizados ao acesso a todos
os dados. Por exemplo, em um sistema bancário, os funcionários do departamento pessoal devem ter

76
acesso apenas ao conjunto de pessoas que trabalham no banco. Uma vez que os programas de aplicação
são inseridos no sistema como um todo, é difícil garantir a efetividade das regras de segurança.
Estas dificuldades, entre outras, provocaram o desenvolvimento dos SGBDs. A seguir mostraremos os
conceitos e algoritmos que foram desenvolvidos para os sistemas de banco de dados que resolvem os problemas
mencionados anteriormente. Uma aplicação típica em banco de dados armazena um grande número de registros,
sendo que estes registros são frequentemente simples e pequenos.
Visão dos Dados
Um SGBD é uma coleção de arquivos e programas inter-relacionados que permitem ao usuário o acesso
para consultas e alterações desses dados. O maior benefício de um banco de dados é proporcionar ao usuário
uma visão abstrata dos dados. Isto é, o sistema acaba por ocultar determinados detalhes sobre a forma de
armazenamento e manutenção desses dados.
Abstração de Dados
Para que se possa usar um sistema, ele precisa ser eficiente na recuperação de informações. Esta
eficiência está relacionada à forma pela qual foram projetadas as complexas estruturas de representação desses
dados no banco de dados. Já que muitos dos usuários dos sistemas de banco de dados não são treinados em
computação, os técnicos em desenvolvimento de sistemas omitem essa complexidade desses usuários por meio
dos diversos níveis de abstração de modo a facilitar a interação dos usuários com o sistema:
• Nível físico. É o mais baixo nível de abstração que descreve como esses dados estão de fato
armazenados. No nível físico, estruturas de dados complexas de nível baixo são descritas em detalhes.
• Nível lógico. Este nível médio de abstração descreve quais dados estão armazenados no banco de dados
e quais os inter-relacionamentos entre eles. Assim, o banco de dados como um todo é descrito em
termos de um número relativamente pequeno de estruturas simples. Embora a implementação dessas
estruturas simples no nível lógico possa envolver estruturas complexas no nível físico, o usuário do nível
lógico não necessariamente precisa estar familiarizado com essa complexidade. O nível lógico de
abstração é utilizado pelos administradores do banco de dados que precisam decidir quais informações
devem pertencer ao banco de dados.
• Nível de visão. O mais alto nível de abstração descreve apenas parte do banco de dados. A despeito das
estruturas simples do nível lógico, alguma complexidade permanece devido ao tamanho dos banco de
dados. Muitos dos usuários do banco de dados não precisam conhecer todas as suas informações. Pelo
contrário, os usuários normalmente utilizam apenas parte do banco de dados. Assim, para que estas
interações sejam simplificadas, um nível de visão é definido. O sistema pode proporcionar diversas visões
do mesmo banco de dados.

77
O inter-relacionamento entre esses três níveis de abstração está ilustrado na fig. 1.1.
Uma analógica com o conceito de tipos de dados em linguagens de programação pode ajudar a esclarecer
a distinção entre os níveis de abstração. As linguagens de programação de mais alto nível dão suporte à noção de
tipos de dados. Por exemplo, nas linguagens semelhantes ao Pascal, podemos declarar um registro como se
segue:
Esse código define um novo registro chamado cliente com quatro campos. Cada campo tem um nome e
um tipo a ele associado. Um banco pode ter diversos tipos de registro, incluindo:
• conta, com os campos número_conta e saldo;
• empregado, com os campos nome_empregado e salario.
No nível físico, um registro de cliente, conta ou empregado pode ser descrito como um bloco consecutivo
de memória (p.e., palavras ou bytes). O compilador esconde esse nível de detalhes dos programadores.
Analogamente, o sistema de banco de dados esconde muitos dos detalhes de armazenamento em nível mais
baixo dos programadores do banco de dados. Os administradores de banco de dados podem estar familiarizados
com certos detalhes da organização física dos dados.
No nível lógico, cada registro é descrito por um tipo definido, como ilustrado no segmento de código de
programa visto, assim como é definida a inter-relação entre esses tipos de registros. Os programadores trabalham
com a linguagem de programação nesse nível de abstração. Da mesma forma, os administradores de banco de
dados, usualmente, trabalham nesse nível de abstração.
Finalmente, no nível de visão, os usuários do computador veem um conjunto de programas de aplicação
que esconde os detalhes dos tipos de dados. Nesse nível, algumas visões do banco de dados são definidas e os
usuários têm acesso a essas visões. Mais do que esconder detalhes próprios do nível lógico, essas visões também
fornecem mecanismos de segurança, de modo a restringir o acesso dos usuários a determinadas partes do banco
de dados. Por exemplo, em um banco, as telefonistas devem ter acesso apenas às informações dos extratos
bancários dos clientes, não devem ter acesso a informações salariais dos empregados do banco.
Instâncias e Esquemas
Um banco de dados muda ao longo do tempo por meio das informações que neles são inseridas ou
excluídas. O conjunto de informações contidas em determinado banco de dados, em um dado momento é
chamado instância do banco de dados. O projeto geral do banco de dados é chamado esquema. Os esquemas são
alterados com pouca frequência.
Analogias com conceitos de linguagem de programação, como tipos de dados, variáveis e valores, são
úteis aqui. Voltando à definição do registro clientes, note que, na declaração de seu tipo, não definimos qualquer
variável. Para declarar uma variável em linguagens semelhantes ao Pascal, escrevemos
var cliente1: cliente;
A variável cliente1 corresponde agora a uma área de memória que contém um registro tipo cliente.
Um esquema de banco de dados corresponde à definição do tipo em uma linguagem de programação.
Uma variável de um tipo tem um valor em particular em dado instante. Assim, esse valor corresponde a uma
instância do esquema do banco de dados.
Os sistemas de banco de dados apresentam diversos esquemas, referentes aos níveis de abstração que
discutimos. No nível mais baixo há o esquema físico; no nível intermediário, o esquema lógico; e no nível mais

78
alto, os subesquemas. Em geral, os sistemas de banco de dados dão suporte a um esquema físico, um esquema
lógico e vários subesquemas.
Independência de Dados
Os sistemas de banco de dados apresentam diversos esquemas, referentes ao níveis de abstração já
discutidos. No nível mais baixo há o esquema físico; no nível intermediário, o esquema lógico; e no nível mais
alto, os subesquemas. Em geral, os sistemas de banco de dados dão suporte a um esquema físico, um esquema
lógico e vários subesquemas.
Independência de Dados
A capacidade de modificar a definição dos esquemas em determinado nível, sem afetar o esquema
superior, é chamado independência de dados. Existem dois níveis de independência de dados:
1. Independência de dados física é a capacidade de modificar o esquema físico sem que, com isso, qualquer
programa de aplicação precise ser reescrito. Modificações no nível físico são necessárias, ocasionalmente,
para aprimorar o desempenho.
2. Independência de dados lógica é a capacidade de modificar o esquema lógica sem que, com isso,
qualquer programa de aplicação precise ser reescrito. Modificações no nível lógico são necessárias
sempre que uma estrutura lógica do banco de dados é alterada (p.e., quando novas moedas são inseridas
no sistema de um banco).
A independência de dados lógica é mais difícil de ser alcançada que a independência física, uma vez que
os programas de aplicação são mais fortemente dependentes da estrutura lógica dos dados do que de seu acesso.
O conceito de independência de dados é de várias formas similar ao conceito de tipo de dados
empregado nas linguagens modernas de programação. Ambos os conceitos omitem detalhes de implementação
do usuário, permitindo que ele se concentre em sua estrutura geral em vez de se concentrar nos detalhes
tratados no nível mais baixo.
Modelo de Dados
Sob a estrutura do banco de dados está o modelo de dados: um conjunto de ferramentas conceituais
usadas para a descrição dos dados, relacionamentos entre dados, semântica de dados e regras de consistência.
Os vários modelos que vêm sendo desenvolvidos são classificados em três diferentes grupos: modelos lógicos
com base em objetos, modelos lógicos com base em registros e modelos físicos.
Modelos Lógicos com Base em Objetos
Os modelos lógicos com base em objetos são usados na descrição do nível lógico e de visões. São
caracterizados por dispor de recursos de estruturação bem mais flexíveis e por viabilizar a especificação explícita
das restrições de dados. Existem vários modelos nessa categoria, e outros ainda estão por surgir. Alguns são
amplamente conhecidos, como:
• Modelo entidade-relacionamento.
• Modelo orientado a objeto.
• Modelo semântico de dados.
• Modelo funcional de dados.
Modelo Entidade-Relacionamento
O modelo de dados entidade-relacionamento (E-R) tem por base a percepção do mundo real como um
conjunto de objetos básicos, chamados entidades, e do relacionamento entre eles. Uma entidade é uma “coisa”
ou um “objeto” do mundo real que pode ser identificado por outros objetos. Por exemplo, cada pessoa é uma
entidade, as contas dos clientes de um banco também podem ser consideradas entidades. As entidades soa

79
descritas no banco de dados por meio de seus atributos. Por exemplo, os atributos número_conta e saldo
descrevem uma conta bancária em particular. Um relacionamento é uma associação entre entidades. Por
exemplo, um relacionamento depositante associa um cliente a cada conta que ele possui. O conjunto de todas as
entidades de um mesmo tipo, assim como o conjunto de todos os relacionamentos de mesmo tipo são
denominados conjunto de entidades e conjunto de relacionamentos, respectivamente.
Além das entidades e dos relacionamento, o modelo E-R representa certas regras, as quais o conteúdo do
banco de dados precisa respeitar. Uma regra importante é o mapeamento das cardinalidades, as quais expressam
o número de entidades às quais a outra entidade se relaciona por meio daquele conjunto de relacionamentos.
Toda estrutura lógica do banco de dados pode ser expressa graficamente por meio do diagrama E-R, cujo
construtores dos seguintes componentes são:
• Retângulos, que representam os conjuntos de entidades.
• Elipses, que representam os atributos.
• Losangos, que representam os relacionamentos entre os conjuntos de entidades.
• Linhas, que unem os atributos aos conjuntos de entidades e o conjunto de entidades aos seus
relacionamentos.
Cada componente é rotulado com o nome da entidade ou relacionamento que representa. Como ilustração,
considere uma parte do sistema bancário composta pelos clientes e suas respectivas contas. O diagrama E-R
correspondente é mostrado na fig. 1.2.
Modelo Orientado a Objetos
Como o modelo E-R, o modelo orientado a objetos tem por base um conjunto de objetos. Um objeto
contém valores armazenados em variáveis instâncias dentro do objeto. Um objeto também contém conjuntos de
códigos que operam esse objeto. Esses conjuntos de códigos são chamados métodos.
Os objetos que contêm os mesmos tipos de valores e os mesmos métodos são agrupados em classes.
Uma classe pode ser vista como uma definição de tipo para objetos. Essa combinação compacta de dados e
métodos abrangendo uma definição de tipo é similar ao tipo abstrato em uma linguagem de programação.
O único modo pelo qual um objeto pode conseguir acesso aos dados de outro objeto é por meio do
método desse outro objeto. Essa ação é chamada de enviar mensagem ao objeto. Assim, a interface de métodos
de um objeto define a parte externa visível de um objeto. A parte interna de um objeto – as instâncias variáveis e
o código do método – não são visíveis externamente. O resultado são dois níveis de abstração de dados.
Modelos Lógicos com Base em Registros
Modelos lógicos com base em registros são usados para descrever os dados no nível lógico e de visão. Em
contraste com os modelos com base em objetos, este tipo de modelo é usado tanto para especificar a estrutura
lógica do banco de dados quanto para implementar uma descrição de alto nível.

80
Os modelos com base em registro são assim chamados porque o banco de dados é estruturado por meio
de registros de formato fixo de todos os tipos. Cada registro define um número fixo de campos ou atributos, e
cada atributo tem um tamanho fixo.
Modelo Relacional
O modelo relacional usa um conjunto de tabelas para representar tanto os dados com a relação entre
eles. Cada tabela possui múltiplas colunas e cada uma possui um nome único. A fig. 1.3 apresenta um exemplo de
banco de dados relacional condensado em duas tabelas: uma mostrando os clientes do banco e a outra, suas
contas.
Modelo de Rede
Os dados no modelo de rede são representados por um conjunto de registros (como no Pascal) e as
relações entre estes registros são representados por links (ligações), as quais podem ser vistas pelos ponteiros. Os
registros são organizados no banco de dados por um conjunto arbitrário de gráficos. A fig. 1.4 apresenta um
exemplo de banco de dados em rede, usando as mesmas informações da fig. 1.3.
Modelo Hierárquico
O modelo hierárquico é similar ao modelo em rede, pois os dados e suas relações são representados,
respectivamente, por registros e links. A diferença é que no modelo hierárquico os registros estão organizados em
arvores em vez de gráficos arbitrários. A fig. 1.5 apresenta um exemplo de modelo de banco de dados
hierárquico, usando as mesmas informações da fig. 1.4.

81
Diferença entre Modelos
O modelo relacional difere dos modelos hierárquico e em rede por não usar nem ponteiros nem links. Ele
relaciona os registros por valores próprios a eles. Como não é necessário o uso de ponteiros, houve a
possibilidade do desenvolvimento de fundamentos matemáticos para sua definição.

82
Modelos Físicos de Dados
Os modelos físicos de dados são usados para descrevê-los no nível mais baixo. Em contraste com os
modelos lógicos, há poucos modelos físicos de dados em uso. Dois deles são amplamente conhecidos: o modelo
unificado (unifying model) e o modelo de partição de memória (frame-memory model).
Os modelos físicos captam os aspectos de implementação do sistema de banco de dados.
Linguagens de Banco de Dados
Um sistema de banco de dados proporciona dois tipos de linguagens: uma específica para os esquemas
do banco de dados e outra para expressar consultas e atualizações.
Linguagens de Definicao de Dados
Um esquema de dados é especificado por um conjunto de visões expressas por uma linguagem especial
chamada linguagem de definição de dados (data-definition language – DDL). O resultado da compilação dos
parâmetros DDLs é armazenado em um conjunto de tabelas que constituem um arquivo especial chamado
dicionário de dados ou diretório de dados.
Um dicionário de dados é um arquivo de metadados – isto é, dados a respeito de dados. Em um sistema
de banco de dados, esse arquivo ou diretório é consultado antes que o dado real seja modificado.
A estrutura de memória e o método de acesso usados pelo banco de dados são especificados por um
conjunto de definições em um tipo especial de DDL, chamado linguagem de definição e armazenamento de dados
(data storage and definition language). O resultado da compilação dessas definições é um conjunto de instruções
para especificar os detalhes de implementação dos esquemas do banco de dados – os detalhes normalmente são
ocultados dos usuários.
Linguagem de Manipulação dos Dados
Os níveis de abstração já discutidos não se aplicam apenas à definição ou à estrutura dos dados, mas
também a sua manipulação.
Por manipulação de dados entendemos:

83
• A recuperação das informações armazenadas no banco de dados.
• Inserção de novas informações no banco de dados.
• A remoção de informações do banco de dados.
• A modificação das informações do banco de dados.
No nível físico, precisamos definir algoritmos que permitam o acesso eficiente aos dados. Nos níveis mais
altos de abstração, enfatizamos a facilidade de uso. O objetivo é proporcionar uma interação eficiente entre
homens e sistema.
A linguagem de manipulação de dados (DML) é a linguagem que viabiliza o acesso a manipulação dos
dados de forma compatível ao modelo de dados apropriado. São basicamente dois tipos:
• DMLs procedurais exigem que o usuário especifique quais dados são necessários e como obtê-los.
• DMLs não procedurais exige que o usuário especifique quais dados são necessários, sem especificar
como obtê-los.
As DMLs não procedurais são normalmente mais fáceis de aprender e de usar. Entretanto, como o
usuário não especifica como obter os dados, essas linguagens pode gerar código menos eficiente que os gerados
por linguagens procedurais. Podemos resolver esse tipo de problema por meio de várias técnicas de otimização.
Uma consulta é uma solicitação para recuperação de informações. A parte de uma DML responsável pela
recuperação de informação é chamada linguagem de consultas (query language). Embora tecnicamente incorreto,
é comum o uso do termo linguagem de consultas como sinônimo de linguagem de manipulação de dados.
Gerenciamento de Transações
Frequentemente, muitas operações em um banco de dados constituem uma única unidade lógica de
trabalho. Voltamos ao exemplo usado na transferência de fundos entre contas bancárias, responsável pelo débito
na conta A e crédito na conta B. Antes de mais nada, é essencial que ocorram ambas as operações, de crédito e
débito, ou nenhuma delas deverá ser realizada. Isto é, ou a transferência de fundos acontece como um todo ou
nada deve ser feito. Esse tudo-ou-nada é chamado atomicidade. Ainda mais, é necessário que a transferência de
fundos preserve a consistência do banco de dados. Ou seja, a soma de A+B deve ser preservada. Essas exigências
de corretismo são chamadas de consistência. Finalmente, depois da execução com sucesso da transferência de
fundos, os novos valores de A e B devem persistir, a despeito das possibilidades de falhas no sistema. Esta
persistência é chamada durabilidade.
Uma transação é uma coleção de operações que desempenha uma função lógica única dentro de uma
aplicação do sistema de banco de dados. Cada transação é uma unidade de atomicidade e consistência. Assim,
exigimos que as transações não violem nenhuma das regras de consistência do banco de dados. Ou seja, o banco
de dados estava consistente antes do início da transação e deve permanecer consistente após o término com
sucesso de uma transação. Entretanto, durante a execução de uma transação, será necessário aceitar
inconsistências temporariamente. Essa inconsistência temporária, embora necessária pode gerar problemas caso
ocorra uma falha.
É responsabilidade do programador definir, de modo apropriado, as diversas transações, tais que cada
uma preserve a consistência do banco de dados. Por exemplo, a transação para a transferência de fundos da
conta A para a conta B poderia ser composta por dois programas distintos: um para débito na conta A e outro
para crédito na conta B. A execução destes dois programas um após o outro irá manter a consistência do banco
de dados. Entretanto, cada programa executado isoladamente não leva o banco de dados de um para outro
estado inconsistente. Logo, esses programas separados não são transações.
Assegurar as propriedades de atomicidade e durabilidade é também responsabilidade do sistema de
banco de dados – especialmente, os componentes de gerenciamento de transações. Na ausência de falhas, todas
as transações se completam com sucesso e a atomicidade é garantida. No entanto, devido aos vários tipos de
falhas possíveis, uma transação pode não se completar com sucesso. Se estivermos empenhados em garantir a

84
atomicidade, uma transação incompleta não poderá comprometer o estado do banco de dados. Assim, o banco
de dados precisa retornar ao estado anterior em que se encontrava antes do início dessa transação.
É responsabilidade do sistema de banco de dados detectar as falhas e recuperar o banco de dados,
garantindo seu retorno a seu último estado consistente.
Por fim, quando muitas transações atualizam o banco de dados concorrentemente, a consistência do
banco de dados pode ser violada, mesmo que essas transações, individualmente, estejam corretas. É
responsabilidade do gerenciador de controle de concorrência controlar a interação entre transações concorrentes
de modo a garantir a consistência do banco de dados.
Os sistemas de banco de dados projetados para o uso em computadores pessoais podem não apresentar
todas essas funções.
Administração de Memória
Normalmente, os banco de dados exigem um grande volume de memória. Um banco de dados
corporativo é usualmente medido em termos de gigabytes ou, para banco de dados de grande porte (largest
database), terabytes. Um gigabyte corresponde a 1000 megabytes (1 bilhão de bytes) e um terabyte é 1 milhão
de megabytes (1 trilhão de bytes). Já que a memória do computador não pode armazenar volumes tão grandes de
dados, as informações são armazenadas em discos. Os dados são transferidos dos discos para a memória quando
necessário. Uma vez que essa transferência é relativamente lenta comparada à velocidade do processador, é
imperativo que o sistema de banco de dados estruture os dados de forma a minimizar a necessidade de
movimentação entre disco e memória.
O objetivo de um sistema de banco de dados é simplificar e facilitar o acesso aos dados. Visões de alto
nível ajudam a alcançar esses objetivos. Os usuários do sistema não devem desnecessariamente importunados
com detalhes físicos relativos à implementação do sistema. Todavia, um dos fatores mais importantes de
satisfação ou insatisfação do usuário com um sistema de banco de dados é justamente seu desempenho. Se o
tempo de resposta é demasiado, o valor do sistema diminui. O desempenho de um sistema de banco de dados
depende da eficiência das estruturas usadas para a representação dos dados, e do quanto esse sistema está apto
a operar essas estruturas de dados. Como acontece com outras áreas dos sistemas computacionais, não se trata
somente do consumo de espaço e tempo, mas também da eficiência de um tipo de operação sobre outra.
Um gerenciador de memória é um módulo de programas para interface entre o armazenamento de dados
em um nível baixo e consultas e programas de aplicação submetidos ao sistema. O gerenciamento de memória é
responsável pela interação com o gerenciamento de arquivos. Uma linha de dados é armazenada no disco usando
os sistema de arquivos que, convencionalmente, é fornecido pelo sistema operacional. O gerenciador de memória
traduz os diversos comandos DML em comandos de baixo nível de sistema de arquivos. Assim, o gerenciador de
memória é responsável pelo armazenamento, recuperação e atualização de dados no banco de dados.
O Administrador de Banco de Dados
Uma das principais razoes que motivam o uso do SGBDs é o controle centralizado tanto dos dados quanto
dos programas de acesso a esses dados. A pessoa que centraliza esse controle do sistema é chamado
administrador de dados (DBA). Dentre as funções de um DBA destacamos as seguintes:
• Definicao do esquema. O DBA cria o esquema do banco de dados original escrevendo um conjunto de
definições que são transformadas pelo compilador DDL em um conjunto de tabelas armazenadas de
modo permanente no dicionário de dados.
• Esquema e modificações na organização física. Os programadores realizam relativamente poucas
alterações no esquema do banco de dados ou na descrição da organização física de armazenamento por
meio de um conjunto de definições que serão usadas ou pelo compilador DDL ou pelo compilador de
armazenamento de dados e definição de dados, gerando modificações na tabela apropriada, interna ao
sistema (p.e., no dicionário de dados).

85
• Fornecer autorização de acesso ao sistema. O fornecimento de diferentes tipos de autorização no acesso
aos dados permite que o administrador de dados regule o acesso dos diversos usuários às diferentes
partes do sistema. Os dados referentes à autorização de acesso são armazenados em uma estrutura
especial do sistema que é consultada pelo sistema de banco de dados toda vez que o acesso àquele dado
for solicitado.
• Especificação de regras de integridade. Os valores dos dados armazenados no banco de dados devem
satisfazer certas restrições para manutenção de sua integridade. Por exemplo, o número de horas que um
empregado pode trabalhar durante uma semana não deve ser superior a um limite especificado
(digamos, 40 horas). Tal restrição precisa ser explicitada pelo administrador de dados. As regras de
integridade são tratadas por uma estrutura especial do sistema que é consultada pelo sistema de banco
de dados sempre que uma atualização está em curso no sistema.
Usuários de Banco de Dados
A meta básica de um sistema de banco de dados é proporcionar um ambiente para recuperação de
informações e para o armazenamento de novas informações no banco de dados. Há quatro tipos de usuários de
sistemas de banco de dados, diferenciados por suas expectativas de interação com o sistema.
• Programadores de aplicação: são profissionais em computação que interagem com o sistema por meio
de chamadas DML, as quais são envolvidas por programas escritos na linguagem hospedeira (p.e., COBOL,
PL/1, C). Esses programas são comumente referidos como programas de aplicação. Exemplos em um
sistema bancário incluem programas para gerar relação de cheques pagos, para crédito em contas, para
débitos em conta ou para transferência de fundos entre contas.
Uma vez que a sintaxe da DML é, em geral, completamente diferente de uma linguagem hospedeira, as chamadas
DML são, normalmente, precedidas por um caractere especial antes que o código apropriado possa ser gerado.
Um pré-processamento, chamado pré-compilador DML, converte os comandos DML para as chamadas normais
em procedimentos da linguagem hospedeira. O programa resultante é, então, submetido ao compilador da
linguagem hospedeira, a qual gera o código de objeto apropriado.
Existem tipos especiais de linguagem de programação que combinam estruturas de controle de
linguagens semelhantes ao Pascal com estruturas de controle para manipulação dos objetos do banco de dados
(p.e., relações). Estas linguagens, muitas vezes chamadas linguagens de quarta geração, frequentemente incluem
recursos especiais para facilitar a geração de formulários e a apresentação de dados no monitor. A maior parte
dos sistemas de banco de dados comerciais inclui linguagens de quarta geração.
• Usuários sofisticados: interagem com o sistema sem escrever programas. Formulam suas solicitações ao
banco de dados por meio de linguagens de consultas. Cada uma dessas solicitações é submetida ao
processador de consultas cuja função é quebrar as instruções DML em instruções que o gerenciador de
memória entenda. Os analistas que submetem consultas para explorar dados no banco de dados caem
nessa categoria.
• Usuários especialistas: são usuários sofisticados que escrevem aplicações tradicionais especializadas de
banco de dados que não podem ser classificadas como aplicações tradicionais em processamento de
dados. Dentre elas estão os sistemas para projetos auxiliados por computador, sistemas especialistas e
sistemas de base de conhecimento, sistemas que armazenam dados de tipos complexos (por exemplo,
dados gráficos e de áudio) e sistemas para modelagem de ambiente (environment-modeling systems).
• Usuários navegantes: são usuários comuns que interagem com o sistema chamando um dos programas
aplicativos permanentes já escritos, como, por exemplo, um usuário que pede a transferência de 50
dólares da conta A para a B por telefone, usando para isso um programa chamado transfer. Esse
programa pede ao usuário o valor a ser transferido, o número da conta para crédito e o número da conta
para débito.
Visão Geral da Estrutura do Sistema

86
Um sistema de banco de dados está dividido em módulos específicos, de modo a atender a todas as
funções do sistema. Algumas das funções do sistema de banco de dados podem ser fornecidas pelo sistema
operacional. Na maioria das vezes, o sistema operacional do computador fornece apenas as funções essenciais, e
o sistema de banco de dados deve ser construído nessa base. Assim, o projeto do banco de dados deve considerar
a interface entre o sistema de banco de dados e o sistema operacional.
Os componentes funcionais do sistema de banco de dados podem ser divididos pelos componentes de
processamento de consultas e pelos componentes de administração de memória. Os componentes de
processamento de consultas incluem:
• Compilador DML, que traduz comando DML da linguagem de consulta em instruções de baixo nível,
inteligíveis ao componente de execução de consultas. Além disso, o compilador DML tenta transformar a
solicitação do usuário em uma solicitação equivalente, mas mais eficiente, buscando, assim, uma boa
estratégia para execução da consulta.
• Pré-compilador para comandos DML inseridos em programas de aplicação, que convertem comandos
DML em chamadas de procedimentos normais da linguagem hospedeira. O pré-compilador precisa
interagir com o compilador DML de modo a gerar o código apropriado.
• Interpretador DDL, que interpreta os comandos DDL e registra-os em um conjunto de tabelas que
contêm metadados.
• Componentes para o tratamento de consultas, que executam instruções de baixo nível geradas pelo
compilador DML.
Os componentes para administração do armazenamento de dados proporcionam a interface entre os dados de
baixo nível, armazenados no banco de dados, os programas de aplicações e as consultas submetidas ao sistema.
Os componentes de administração de armazenamento de dados incluem:
• Gerenciamento de autorizações e integridade, que testam o cumprimento das regras de integridade e a
permissão ao usuário no acesso ao dado.
• Gerenciamento de transações, que garante que o banco de dados permanecerá em estado consistente
(correto) a despeito de falhas no sistema e que transações concorrentes serão executadas sem conflitos
em seus procedimentos.
• Administração de arquivos, que gerencia a alocação de espaço no armazenamento em disco e as
estruturas de dados usadas para representar estas informações armazenadas em disco.
• Administração de buffer, responsável pela intermediação de dados do disco para a memória principal e
pela decisão de quais dados colocar em memória cache.
Além disso, algumas estruturas de dados são exigidas como parte da implementação física do sistema:
• Arquivo de dados, que armazena o próprio banco de dados.
• Dicionário de dados, que armazena os metadados relativos à estrutura do banco de dados. O dicionário
de dados é muito usado. Portanto, grande ênfase é dada ao desenvolvimento de um bom projeto com
uma implementação eficiente do dicionário.
• Índices, que proporcionam acesso rápido aos itens de dados que são associados a valores determinados.
• Estatísticas de dados, armazenam as informações estatísticas relativas aos dados contidos no banco de
dados. Essas informações são usadas pelo processador de consultas para seleção de meios eficientes para
execução de uma consulta.

87
Modelo Entidade-Relacionamento
O modelo entidade-relacionamento (E-R) tem por base a percepção de que o mundo real é formado por
um conjunto de objetos chamados entidades e pelo conjunto dos relacionamentos entre esses objetos. Foi
desenvolvido para facilitar o projeto do banco de dados, permitindo a especificação do esquema da empresa, que
representa toda estrutura lógica do banco de dados. O modelo E-R é um dos modelos com maior capacidade
semântica; os aspectos semânticos do modelo se referem à tentativa de representar o significado dos dados. O
modelos E-R é extremamente útil para mapear, sobre um esquema conceitual, o significado e interações das
empresas reais. Devido a essa utilidade, muitas das ferramentas de projeto foram concebidas para o modelo E-R.
Conceitos Básicos
Existem três noções básicas empregadas pelo modelo E-R: conjunto de entidades, conjunto de
relacionamentos e os atributos.
Conjunto de Entidades
Um entidade é uma “coisa” ou um “objeto” no mundo real que pode ser identificada de forma unívoca
em relação a todos os outros objetos. Por exemplo, cada pessoa na empresa é uma entidade. Uma entidade tem
um conjunto de propriedades, e os valores para alguns conjuntos dessas propriedades devem ser únicos. Por
exemplo, o número social 677-89-9011 identifica uma única pessoa na empresa. Também, pode-se pensar em
empréstimos como entidades, e o empréstimo número L-15 referente à agência Perryridge identifica
univocamente uma entidade empréstimo. Uma entidade pode ser concreta, como uma pessoa ou um livro, ou
pode ser abstrata, como um empréstimo, uma viagem de férias ou um conceito.
Um conjunto de entidades é um conjunto que abrange entidades de mesmo tipo que compartilham as
mesmas propriedades: os atributos. O conjunto de todas as pessoas que são clientes de um banco de dados, por
exemplo, pode ser definido como o conjunto de entidades clientes. Analogamente, o conjunto de entidades
empréstimo poderia representar o conjunto de todos os empréstimos que o banco em questão viabiliza. As
entidades individuais que constituem um conjunto são chamadas extensões do conjunto de entidades. Assim,
todos os clientes do banco são as extensões do conjunto de entidades cliente.
Os conjuntos de entidades não são necessariamente separados. Por exemplo, é possível definir um
conjunto de entidades com todos os empregados do banco (empregado) e um conjunto de entidades com todos
os clientes do banco (cliente). A entidade pessoa pode pertencer ao conjunto de entidades empregado, ou ao
conjunto de entidades cliente, ou a ambos, ou a nenhum.
Uma entidade é representada por um conjunto de atributos. Atributos são propriedades descritivas de
cada membro de um conjunto de entidades. A designação de um atributo para um conjunto de entidades
expressa que o banco de dados mantém informações similares de cada uma das entidades do conjunto de
entidades; entretanto, cada entidade pode ter seu próprio valor em cada atributo. Atributos possíveis ao
conjunto de entidades clientes são nome_cliente, seguro_social, rua_cliente, e cidade_cliente. Atributos possíveis
para o conjunto de entidades empréstimo são número_empréstimo e conta. Para cada atributo existe um
conjunto de valores possíveis, chamado domínio, ou conjunto de valores, daquele atributo. O domínio do atributo
nome_cliente pode ser o conjunto de todos os textos string de um certo tamanho. Similarmente, o domínio do
atributo número_empréstimo pode ser o conjunto de todos os inteiros positivos.
Desse modo, um banco de dados inclui uma coleção de conjuntos de entidades, cada qual contendo um
número de entidades de mesmo tipo. A fig. 2.1 mostra parte do banco de dados de uma empresa bancária
contendo dois conjuntos entidades: cliente e empréstimo.

88
Formalmente, um atributo de um conjunto de entidades é uma função que relaciona o conjunto de
entidades a seu domínio. Desde que um conjunto de entidades possua alguns atributos, cada entidade pode ser
descrita pelo conjunto formado pelos pares (atributos, valores de dados), um par para cada atributo do conjunto
de entidades. Por exemplo, uma entidade em particular de cliente pode ser descrita pelo conjunto {(nome,
Hayes), (seguro_social, 677-89-9011), (rua_cliente, Main), (cidade_cliente, Harrison)}, o que significa que essa
entidade descreve o cliente Hayes, que possui o seguro social número 677-89-90211 e mora na Rua Main em
Harrison. Podemos notar, a esta altura, uma integração entre o esquema abstrato e a empresa real que está
sendo modelada. Os valores dos atributos que descrevem as entidades constituem uma porção significativa dos
dados que serão armazenados no banco de dados. Um atributo, como é usado no modelo E-R, pode ser
caracterizado pelos seguintes tipos:
• Atributos simples ou compostos. Em nosso exemplo anterior, todos os atributos eram simples: isto é, não
eram divididos em partes. Os atributos compostos, por outro lado, podem ser divididos em partes (isto é,
outros atributos). Por exemplo, nome_cliente pode ser estruturado em prenome, nome_intermediario e
sobrenome. O uso de atributos compostos ajudam-nos a agrupar atributos correlacionados, tornando o
modelo mais claro.
Note que os atributos compostos podem estar hierarquizados. Retornando o exemplo do atributo
composto endereço_cliente, seu atributo rua pode vir a ser subdividido posteriormente em número_rua,
nome_rua, e número_apto. Esses exemplos de atributos compostos para clientes são apresentados na fig. 2.2.
• Atributos monovalorados ou multivalorados. Os atributos usados em nossos exemplos foram todos de
valores simples para uma entidade em particular. Ou seja, o atributo número_empréstimo de uma
entidade específica refere-se apenas a um número de empréstimo. Esses atributos são chamados
monovalorados. Pode haver instâncias em que um atributo possua um conjunto de valores para uma
única entidade. Considere o conjunto de entidades empregado com o atributo nome_dependente.
Qualquer empregado em particular pode ter um, nenhum ou vários dependentes; entretanto, diferentes
entidades empregado dentro do conjunto e empregados terão diferentes números de valores para o
atributo nome_dependente. Esse tipo de atributo é dito multivalorado. Quando necessário, pode-se
estabelecer limites inferiores e superiores para o número de ocorrências em um atributo multivalorado.
Por exemplo, um banco pode ter um número limite de registros de endereços para um cliente normal,
um ou dois endereços. O estabelecimento de limites, neste caso, exprime que o atributo
endereço_cliente do conjunto de entidades cliente pode possuir de zero a dois valores.
• Atributos nulos. Um atributo nulo é usado quando uma entidade não possui valor para determinado
atributo. Por exemplo, se um empregado em particular não possui dependentes, o valor do atributo

89
nome_dependente para esse dependente deverá ser nulo, e isso significa que esse atributo “não é
aplicável”. Nulo também pode significar que o valor do atributo é desconhecido. Um valor desconhecido
pode caracterizar omissão (o valor existe de fato, mas não temos essa informação) ou não conhecimento
(não sabemos se o valor existe de fato). Por exemplo, se o valor do seguro_social de determinado cliente
é nulo, assume-se que seu valor foi omitido, já que é exigido para efeitos de impostos. Um valor nulo para
o atributo número_apartamento pode significar que o número do apartamento foi omitido, ou que o
número existe mas não sabemos qual é, ou que o endereço não é um prédio de apartamentos e,
portanto, não faz parte do endereço do cliente.
• Atributo derivado. O valor desse tipo de atributo pode ser derivado de outros atributos ou entidades a
ele relacionados. Por exemplo, digamos que o conjunto de entidades cliente possui o atributo
empréstimos_tomados, que representa o número de empréstimos tomados do banco por um cliente.
Podemos derivar o valor desse atributo contando o número das entidades empréstimos associadas ao
cliente em questão. Como outro exemplo, consideremos que o conjunto de entidades empregado está
relacionado aos atributos data_contratação e tempo_de_casa, os quais representam o primeiro dia de
emprego no banco e o tempo total que o empregado está trabalhando, respectivamente. O valor do
tempo_de_casa pode ser derivado do valor da data_contratação e tempo_de_casa, os quais representam
o primeiro dia de emprego no banco e o tempo total que o empregado está trabalhando,
respectivamente. O valor do tempo_de_casa pode ser derivado do valor data_contratação e da
data_corrente. Neste caso, a data_contratação pode ser referida como um atributo da base ou um
atributo armazenado.
Um banco de dados para uma empresa bancária pode incluir um número diferente de conjuntos de entidades.
Por exemplo, aliado ao que foi dito sobre clientes e empréstimos, um banco também possui contas, que estão
representadas pelo conjunto de entidades conta com os atributos número_conta e saldo. Também, se um banco
tem um número diferente de agências, então deveríamos captar informações sobre todas essas agências. Cada
conjunto de entidades agência pode ser descrito pelos atributos nome_agência, cidade_agência e fundos.
Conjuntos de Relacionamentos
Um relacionamento é uma associação entre uma ou várias entidades. Por exemplo, podemos definir um
relacionamento que associa o cliente Hayes com o empréstimo L-15. Esse relacionamento especifica que o cliente
Hayes é cliente com o empréstimo número L-15.
Um conjunto de relacionamentos é um conjunto de relacionamentos do mesmo tipo. De modo formal, é a
relação matemática com n≥2 conjunto de entidades (podendo ser não-distintos). Se E1, E2, ..., Em são conjuntos
de entidades, então um conjunto de relacionamentos R é um subconjunto de
em que (e1, e2, ..., en) são relacionamentos.
Considere dois conjuntos de entidades da fig. 2.1, cliente e empréstimo. Definimos o conjunto de
relacionamentos devedor para denotar a associação entre clientes e empréstimos bancários contraídos pelo
clientes. Essa associação é apresentada na fig. 2.3.

90
Como exemplo, consideremos dois tipos de conjuntos de entidades, empréstimo e agência. Podemos
definir o conjunto de relacionamento agência_empréstimo denotando a associação entre um empréstimo
bancário e a agência onde esse empréstimo é mantido.
A associação entre os conjuntos de entidades é referida como uma participação; isto é, o conjunto de
entidade E1, E2, ..., En participa do conjunto de relacionamentos R. Uma instância de relacionamento em um
esquema E-R representa a existência de uma associação entre essa entidade e o mundo real no qual insere a
empresa que está sendo modelada. Ilustramos a entidade cliente chamada Hayes, que possui o seguro social
número 677-89-9011, e a entidade empréstimo L-15 participam na instância do relacionamento devedor.
Essa instância do relacionamento representa que, no mundo real da empresa, uma pessoa chamada
Hayes que possui o seguro social número 677-89-9011 tomou um empréstimo que tem o número L-15.
A função que uma entidade desempenha em um relacionamento é chamada papel. Uma vez que os
conjunto de entidades participantes em um conjunto de relacionamentos são geralmente distintos, papéis são
implícitos e não são, em geral, especificados. Entretanto, são uteis quando o significado de um relacionamento
precisa ser esclarecido. Este é o caso quando os conjuntos de entidades e os conjuntos de relacionamentos mais
de uma vez, em diferentes papéis.
Nesse tipo de conjunto de relacionamentos, que algumas vezes é chamado conjunto de relacionamentos
recursivos, nomes explícitos de papéis são necessários para especificar como uma entidade participa de uma
instância de relacionamento. Por exemplo, considere o conjunto de entidades empregado que mantém
informações sobre todos os empregados do banco. Podemos ter um conjunto de relacionamentos trabalha_para
que é modelado para ordenar os pares de entidades de empregado. O primeiro empregado de um par tem o
papel de gerente, enquanto o outro tem o papel de empregado. Deste modo, todos os relacionamentos de
trabalha_para são caracterizados pelos pares (gerente, empregado); os pares (empregado, gerente) são
excluídos.
Um relacionamento também pode ter atributos descritos. Considere o conjunto de relacionamentos
depositante com o conjunto das entidades cliente e conta. Poderemos associar o atributo data_acesso a essa
relação para especificar a data do último aceso feito pelo cliente em sua conta. O relacionamento depositante
entre as entidades correspondentes ao cliente Jones e à conta A-217 é descrita por {(data-acesso, 23 de maio de
2013)}, a qual significa que o mais recente acesso que Jones fez a sua conta A-217 foi em 23 de maio de 2013.
O conjunto de relacionamentos devedor e agência_empréstimo é um exemplo de conjunto de
relacionamentos binário – isto é, um relacionamento que envolve dois conjuntos de entidades. A maior parte dos
conjuntos de relacionamentos nos sistemas de banco de dados são binários. Ocasionalmente, entretanto, os
conjuntos de relacionamentos envolvem mais de dois conjuntos de entidades. Como exemplo, podemos
combinar os conjuntos de relacionamentos devedor e agência_empréstimo formado o conjunto de

91
relacionamentos CEA, envolvendo os conjuntos de entidades cliente, empréstimo e agência. Assim, o
relacionamento ternário entre as entidades correspondente ao cliente Hayes, o empréstimo número L-15, e a
agência Perryridge especifica que o cliente Hayes tem o empréstimo L-15 na agência Perryridge.
O número de conjuntos de entidades que participa de um conjunto de relacionamento é também o grau
desse conjunto de relacionamento. Um conjunto de relacionamento binário é de grau dois; um relacionamento
ternário é de grau três.
Metas de Projeto
Um conjunto de entidades e um conjunto de relacionamento não são noções precisas e é possível definir
um conjunto de entidades e de relacionamentos entre eles de várias formas diferentes.
Uso de Conjuntos de Entidades ou Atributos
Considere o conjunto de entidades empregado com os atributos nome_empregado e número_telefone.
Pode ser facilmente verificado que o telefone é uma entidade sujeita a seus próprios atributos, como
número_telefone e localização (o escritório onde o telefone está instalado). Sob esse ponto de vista, o conjunto
de entidades deve ser redefinido, conforme segue:
• O conjunto de entidades empregado com o atributo nome_empregado.
• O conjunto de entidades telefone com os atributos número_telefone e localização.
• O conjunto de relacionamentos emp_telefone, o qual denota a associação entre os empregados e os
telefones que podem ter.
Qual é, então, a principal diferença entre essas duas definições de um empregado? No primeiro caso, a definição
implica que todo empregado possui, precisamente, um número de telefone a ele associado. No segundo caso,
entretanto, a definição estabelece que o empregado pode ter vários números de telefones (incluindo zero) a ele
associados. Assim, a segunda definição é mais geral que a primeira e pode refletir com maior precisão as
situações reais.
Mesmos se nos for dado que cada empregado tem, precisamente, um número de telefone a ele
associado, a segunda definição pode, ainda assim, ser mais apropriada, caso um mesmo telefone possa ser
compartilhado por diversos empregados.
Não seria apropriado, no entanto, aplicar a mesma técnica ao atributo nome_empregado; é difícil
sustentar que nome_empregado seja uma entidade por si só (em contraste com telefone). Assim, é apropriado
manter nome_empregado como atributo do conjunto de entidades empregado.
Duas questões aparecem naturalmente: o que constitui um atributo e o que constitui um conjunto de
entidades? Infelizmente, não existe uma resposta simples. As distinções dependem, principalmente, da estrutura
real da empresa que está sendo modelada e da semântica associada aos atributos em questão.
Uso dos Conjuntos de Entidades e Conjunto de Relacionamentos
Nem sempre fica claro se um objeto é melhor expresso por um conjunto de entidades ou por um
conjunto de relacionamentos. Já assumimos anteriormente que um empréstimo bancário é modelado como uma
entidade. Uma alternativa é modelar o empréstimo não como uma entidade, mas como um relacionamento entre
clientes e agências, com número_empréstimo e conta como atributos descritivos. Cada empréstimo é
representado por um relacionamento entre um cliente e uma agência.
Se todo empréstimo é tomado por exatamente um cliente e está associado a exatamente uma agência,
podemos resolver o projeto de modo satisfatório caso o empréstimo seja representado como relacionamento.
Entretanto, com um projeto assim, não poderemos representar convenientemente uma situação na qual vários
clientes tomam um empréstimo conjunto. Precisaremos definir um relacionamento em separado para cada
componente de um empréstimo conjunto. Então, precisaremos replicar os valores dos atributos descritivos,
número_empréstimo e conta, para cada um dos relacionamentos. Dois problemas são consequência dessa

92
replicação: (1) os dados são armazenados diversas vezes, desperdiçando espaço em memória; e (2) as
atualizações deixam, potencialmente, os dados em um estado inconsistente, quando os valores diferem nos
atributos de dois relacionamentos que deveriam, supostamente, possuir valores iguais. O meio pelo qual se
evitam tais replicações é aplicado formalmente pela teoria da normalização.
Uma linha mestra possível na opção pelo uso de um conjunto de entidades ou pelo uso de um conjunto
de relacionamentos é recorrer ao conjunto de relacionamentos para descrever uma ação que ocorre entre
entidades. Essa abordagem pode ser útil também para decidir se certos atributos podem ser expressos de
maneira mais apropriada como relacionamentos.
Conjunto de relacionamentos Binários versus n-ésimos
É sempre possível recompor um conjunto de relacionamentos não-binários (n-ésimos, com n>2) por um
número de conjuntos de relacionamentos binários distintos. Para simplificar, considere o conjunto de
relacionamento ternário (n=3) abstrato R, relacionados aos conjuntos de entidades A, B e C. Poderemos recompor
o conjunto R em um conjunto de entidades E, e criar três conjuntos de relacionamentos:
• RA, relacionando E e A
• RB, relacionando E e B
• RC, relacionando E e C
Se o conjunto de relacionamentos R possui quaisquer atributos, estes são designados pelo conjunto de entidades
E (já que todo o conjunto de entidades deve ter ao menos um atributo para distinguir seus membros). Para cada
relacionamento (ai, bi, ci) do conjunto de relacionamentos R, podemos criar uma nova entidade ei no conjunto de
entidades E. Então, em cada um dos três novos conjuntos de relacionamentos, inserimos um relacionamento,
como segue:
• (ei, ai) em RA
• (ei, bi) em RA
• (ei, ci) em RA
Podemos generalizar esse processo de modo direto para os conjuntos de relacionamentos n-ésimo.
Assim, conceitualmente podemos restringir o modelo E-R para conter apenas conjuntos de relacionamentos
binários. Entretanto, essa restrição nem sempre é desejável.
• Pode ser que seja necessária a criação de um atributo de identificação para o conjunto de entidades
criado para substituir o conjunto de relacionamentos. Este atributo, juntamente com o conjunto extra de
relacionamentos criados, aumenta a complexidade do projeto e as necessidades de armazenamento
como um todo.
• Um conjunto de relacionamentos n-ésimo mostra claramente todos os conjuntos de entidades que
participam de uma determinada relação. O projeto correspondente, usando somente conjunto de
relacionamentos binários, torna mais difícil estabelecer as restrições dessa participação.
Mapeamento de Restrições
O esquema E-R de uma empresa pode definir certas restrições, as quais o conteúdo do banco de dados
deve respeitar.
Mapeamento das Cardinalidades
O mapeamento das cardinalidades, ou rateio de cardinalidades, expressa o número de entidades às quais
outra entidade pode estar associada via um conjunto de relacionamentos.
O mapeamento de cardinalidades é mais útil na descrição dos conjuntos de relacionamentos binários,
embora, ocasionalmente, possam contribuir para a descrição de conjuntos de relacionamentos que envolvam
mais de dois conjuntos de entidades.

93
Para um conjunto de relacionamentos R binário entre os conjuntos de entidades A e B, o mapeamento
das cardinalidades deve seguir uma das instruções abaixo:
• Um para um. Uma entidade em A está associada no máximo a uma entidade em B, e uma entidade em B
está associada a no máximo uma entidade em A (fig. 2.4a).
• Um para muitos. Uma entidade em A está associada a várias entidades em B. Uma entidade em B,
entretanto, pode estar associada a qualquer número de entidades em B e uma entidade em B está
associada a um número qualquer de entidades em A (fig. 2.5a).
O mapeamento apropriado de cardinalidades para um conjunto de relacionamentos em particular é,
obviamente, dependente das situações reais que estão sendo modeladas pelo conjunto de relacionamentos.
Como ilustração, considere o conjunto de relacionamentos devedor. Se, em um banco em particular, um
empréstimo pode se destinar a apenas um cliente e um cliente pode contrair diversos empréstimos, então o
conjunto de relacionamentos entre cliente e empréstimo é de um para muitos. Esse tipo de relacionamento é
apresentado na fig. 2.3. Se um empréstimo puder ser tomado por mais de um cliente (como normalmente
acontece com os vários sócios de um negócio), o relacionamento seria de muitos para muitos.
O rateio de cardinalidades de um relacionamento pode afetar a colocação dos atributos nos
relacionamentos. Atributos em conjuntos de relacionamentos um para um ou um para muitos deve ser
associados a um dos conjuntos de entidades participantes, em vez de serem associados ao conjunto de
relacionamentos. Por exemplo, consideremos depositante como um conjunto de relacionamentos um para
muitos, tal que um cliente pode possuir diversas contas, mas cada conta está vinculada a apenas um cliente.
Nesse caso, o atributo data_acesso poderia estar associado ao conjunto de entidades conta, como mostrados na

94
fig. 2.6; de modo a tornar a figura mais clara, são apresentados apenas alguns dos atributos dos dois conjuntos de
entidades. Já que cada entidade conta participa de um relacionamento com no máximo uma instância de cliente,
fazer esta designação de atributo pode ter o mesmo significado que colocar data_acesso no conjunto de
relacionamentos depositante. Atributos de conjuntos de relacionamentos um para muitos podem apenas ser
reposicionados no conjunto de entidades do lado “muitos” desse relacionamento. Em conjuntos de
relacionamentos um para um, o atributo do relacionamento pode ser associado a qualquer uma das entidades
participantes.
As decisões de projeto, como decidir onde colocar atributos descritivos – como um atributo de entidade
ou relacionamento – devem refletir as características da empresa que está sendo modelada. O projetista pode
optar por manter data_acesso como um atributo de depositante para explicitar que um acesso ocorreu em uma
interação entre os conjuntos de entidades cliente e conta.
A escolha de onde colocar um atributo é mais clara quando se trata de conjuntos de relacionamentos
muitos para muitos. Retornando ao exemplo, especifiquemos o que talvez seja um dos mais realísticos casos de
conjuntos de relacionamentos muitos para muitos, depositante, que expressa que um cliente pode ter uma ou
mais contas e que uma conta pode estar vinculada a um ou mais clientes.
Se quisermos expressar a data do último acesso de um cliente a uma dada conta, o atributo data_acesso
deverá ser atribuído ao conjunto de relacionamentos depositante, em vez de ser alocado a uma das duas
entidades participantes. Se data_acesso fosse atributo de conta, não poderíamos determinar qual dos clientes é
responsável pelo acesso mais recente à conta em questão.
Quando um atributo é determinado pela combinação dos conjuntos de entidades participantes em vez de
estar associado a cada uma das entidades, separadamente, esse atributo precisa ser associado ao conjunto de
relacionamentos muitos para muitos. A colocação de data_acesso como atributo do conjunto de relacionamentos
é mostrada na fig. 2.7; novamente, para tornar a figura mais simples, são apresentados apenas alguns dos
atributos dos dois conjuntos de entidades.

95
Dependência de Existência
Outra classe importante de restrições é a dependência de existência. Especificamente, se a existência da
entidade x depende da existência da entidade y, então x é dito dependente da existência de y. Operacionalmente,
se y for excluído, o mesmo deve acontecer com x. A entidade y é chamada entidade dominante e a x é chamada
entidade subordinada. Como ilustração, considere o conjunto de entidades empréstimo e o conjunto de
entidades pagamento, que mantém todas as informações dos pagamentos realizados para um determinado
empréstimo. O conjunto de entidades pagamento é descrito pelos atributos número_pagamento,
data_pagamento e total_pagamento. Criamos um conjunto de relacionamentos pagamento_empréstimo entre
esses dois conjuntos de entidades pagamento é descrito pelos atributos número_pagamento, data_pagamento e
total_pagamento. Criamos um conjunto de relacionamentos pagamento_empréstimo entre estes dois conjuntos
de entidade que é de um para muitos do empréstimo para o pagamento. Toda entidade pagamento está
associada a uma entidade empréstimo. Se uma entidade empréstimo é excluída, então todas as entidades
pagamento a ela associadas deverão ser excluídas também. Em contraste, uma entidade pagamento pode ser
excluída do banco de dados sem afetar em nada qualquer empréstimo. O conjunto de entidades empréstimo,
portanto, é dominante e pagamento é subordinado ao conjunto de relacionamentos pagamento_empréstimo.
A participação de um conjunto de entidades E no conjunto de relacionamentos R é dita total se todas as
entidades em E participam de pelo menos um relacionamento R. Se somente algumas entidades em E participam
do relacionamento R, a participação do conjunto de entidades em E participam do relacionamento R, a
participação do conjunto de entidades E no relacionamento R é dito parcial. A participação total está
estreitamente relacionada à existência de dependência. Por exemplo, desde que toda entidade pagamento esteja
associada a alguma entidade empréstimo pelo relacionamento pagamento_empréstimo, a participação de
pagamento no conjunto de relacionamentos pagamento_empréstimo é total. Por outro lado, um indivíduo pode
ser cliente de um banco, tendo ou não contraído um empréstimo nele. Daí, é possível que apenas parte do
conjunto de entidades cliente esteja relacionada ao conjunto de entidades empréstimo e a participação de cliente
no conjunto de relacionamentos devedor é, portanto, parcial.
Chaves

96
É importante especificar como as entidades dentro de um dado conjunto de entidades e os
relacionamentos dentro de um conjunto de relacionamentos podem ser identificados. Conceitualmente,
entidades e relacionamentos individuais são distintos, entretanto, na perspectiva do banco de dados, a diferença
entre ambos deve ser estabelecida em termos de seus atributos. O conceito de chave permite-nos fazer tais
distinções.
Conjunto de Entidades
Uma superchave é um conjunto de um ou mais atributos que, tomados coletivamente, nos permitem
identificar de maneira unívoca uma entidade em um conjunto de entidades. Por exemplo, o atributo
seguro_social do conjunto de entidades cliente é suficiente para distinguir uma entidade cliente de outra. Assim,
o seguro_social é uma superchave. Do mesmo modo, a combinação de nome_cliente e seguro_social é
superchave para o conjunto de entidades cliente. O atributo nome_cliente não é superchave de cliente, pois
algumas pessoas podem ter o mesmo nome.
O conceito de superchave não é suficiente para nossos propósitos, já que, como vimos, uma superchave
pode conter atributos externos. Se K é uma superchave, entoa é qualquer superconjunto de K. Nosso interesse é
por superchaves para as quais nenhum subconjunto possa ser uma superchave. Essas superchaves são chamadas
chaves candidatas. É possível que vários conjuntos diferentes de atributos possam servir como superchave.
Suponha que uma combinação de nome_cliente e rua_cliente seja suficiente para distinguir todos os membros do
conjunto de entidades cliente. Então, (seguro_social) e (nome_cliente, rua_cliente) são chaves candidatas.
Embora os atributos seguro_social e nome_cliente, juntos, possam distinguir as entidades cliente, sua
combinação não forma uma chave candidata, uma vez que seguro_social, sozinho, é uma chave candidata.
Chaves candidatas precisam ser escolhidas com cuidado. Como notamos, obviamente o nome de uma
pessoa não é suficiente, já que homônimos são possíveis. Nos Estados Unidos, o número de seguro_social pode
ser uma chave candidata. Em outros países onde os habitantes normalmente não possuem número de seguro
social, as empresas podem gerar seu próprio número de identificação, como número do cliente ou número de
identificação de estudantes ou número de identificação, como número do cliente ou número de identificação de
estudantes ou qualquer outra combinação única de outros atributos como chave. Uma das combinações mais
frequentemente usadas é o nome, data de nascimento e endereço, já que é extremamente difícil que mais de
uma pessoa tenha os mesmos valores para todos esses atributos.
Podemos usar o termo chave primária para caracterizar a chave candidata que é escolhida pelo projetista
do banco de dados como de significado principal para a identificação de entidades dentro de um conjunto de
entidades. Uma chave (primária, candidata e super) é duas entidades individuais em um conjunto não podem ter,
simultaneamente, mesmos valores em seus atributos-chave. A especificação de uma chave representa uma
restrição ao mundo real da empresa que está sendo modelada.
Conjuntos de Relacionamentos
A chave primária de um conjunto de entidades permite-nos distinguir as várias entidades de um conjunto.
Precisamos, de modo similar, de um mecanismo para a identificação dos vários relacionamentos em um conjunto
de relacionamentos.
Seja R um conjunto de relacionamentos envolvendo os conjuntos de entidades E1, E2, ..., En. Seja uma
chave_primária (Ei) denotando o conjunto de atributos que formam a chave primárias sejam únicos (se não
forem, use um esquema apropriado para rebatizá-los). A composição da chave primária para um conjunto de
relacionamentos depende de uma estrutura de atributos associada ao conjunto de relacionamentos R.
Se o relacionamento R não possui atributo, então o conjunto de atributos:
descreve um relacionamento individual do conjunto R.
Se o conjunto de relacionamento r possui os atributos a1, a2, ..., an a ele associados, então o conjunto de
atributos:

97
descreve um relacionamento em particular do conjunto R.
Em ambos os casos acima, o conjunto de atributos:
forma uma superchave do conjunto de relacionamentos.
A estrutura da chave primária para o conjunto de relacionamentos depende do mapeamento da
cardinalidade do conjunto de relacionamentos. Como ilustração, considere o conjunto de entidades cliente e
empregado e um conjunto de relacionamentos cliente_bancário que representa a associação entre um cliente e
um bancário (uma entidade empregado). Suponha que um conjunto de relacionamentos seja de muitos para
muitos, suponha também que o conjunto de relacionamentos possui o atributo tipo a ele associado,
representando a natureza do relacionamento (como um agente de empréstimo ou como um atendente pessoal).
A chave primária cliente_bancário constitui-se da união das chaves primárias de cliente e empregado. Entretanto,
se um cliente pode ser atendido exclusivamente por um bancário – isto é, se um relacionamento cliente_bancário
é muitos para um – então, a chave primária de cliente_bancário é simplesmente a chave primária de cliente. Para
relacionamentos um para um, qualquer uma das chaves primárias pode ser usada.
A designação de chaves primárias é mais complicada para relacionamentos não-binários.
Diagrama Entidade-Relacionamento
Toda estrutura lógica do banco de dados pode ser expressa graficamente pelo diagrama E-R. A relativa
simplicidade e clareza desta técnica de diagramação pode explicar, em grande parte, a ampla disseminação do
uso do modelo E-R.
A seguir são apresentados seus principais componentes:
• Retângulos, que representam os conjuntos de entidades.
• Elipses, que representam os atributos.
• Losangos, que representam os conjuntos de relacionamentos.
• Linhas, que unem os atributos aos conjuntos de entidades e os conjuntos de entidades aos conjuntos de
relacionamentos.
• Elipses duplas, que representam atributos multivalorados.
• Linhas duplas, que indicam a participação total de uma entidade em um conjunto de relacionamentos.
Como é mostrado na fig. 2.8, os atributos de um conjunto de entidades que são membros de uma chave
primária devem ser sublinhados.
Considere o diagrama entidade-relacionamento da fig. 2.8, que consiste de dois conjuntos de entidades,
cliente e empréstimo, relacionados pelo conjunto de relacionamentos devedor. Os atributos associados a cliente
são nome_cliente, seguro_social, rua_cliente e cidade_cliente. Os atributos associados a empréstimo são
número_empréstimo e total.
O conjunto de relacionamentos devedor pode ser muitos para muitos, um para um, muitos para um ou
um para um. Para fazer a distinção entre esses tipos, desenhamos uma linha direcionada (�) ou uma linha sem
direcionamento (-) entre o conjunto de relacionamentos e o conjunto de entidades em questão.
• Uma linha direcionada do conjunto de relacionamentos devedor para o conjunto de entidades
empréstimo especifica que devedor é um conjunto de relacionamentos um para um ou muitos para um,
de cliente para empréstimo; devedor não pode ser um conjunto de relacionamentos muitos para muitos
ou um para muitos, de cliente para empréstimo.
• Uma linha não direcionada do conjunto de relacionamentos devedor para o conjunto de entidades
empréstimo especifica que devedor é um conjunto de relacionamentos muitos para muitos ou um para
muitos, de cliente para empréstimo.

98
Voltando ao diagrama E-R da fig. 2.8, podemos ver que o conjunto de relacionamentos devedor é muitos
para muitos. Se o conjunto de relacionamentos dever for um para muitos, de cliente para empréstimo, então a
linha de devedor para cliente deveria ser direta, com a seta apontando para o conjunto de entidades cliente (fig.
2.9a). Similarmente, se o conjunto de relacionamentos devedor for muitos para um, de cliente para empréstimo,
então a linha de devedor para empréstimo deveria ser uma seta pontando para o conjunto de entidades
empréstimo (fig. 2.9b).
Finalmente, se o conjunto de relacionamentos devedor for um para um, então ambas as linhas de
devedor deveriam ser setas: uma apontando para o conjunto de entidades empréstimo e outra apontando para o
conjunto de entidades clientes (fig. 2.10).
Se um conjunto de relacionamentos também tem atributos a ele relacionados, então deveremos fazer a
ligação desses atributos com o conjunto de relacionamentos. Por exemplo, na fig. 2.11, temos o atributo descrito
data_acesso atrelado ao conjunto de relacionamentos depositante para especificar a data mais recente de acesso
do cliente à conta.
Indicamos os papeis desempenhados no diagrama E-R por meio da denominação nas linhas que ligam os
losangos aos retângulos. A fig. 2.12 mostra os papeis desempenhados, gerente e empregado, entre o conjunto de
entidades empregado e o conjunto de relacionamentos trabalha_para.
Conjuntos de relacionamentos não-binários podem ser facilmente especificados no diagrama E-R. A fig.
2.13 apresenta três conjuntos de entidades, cliente, empréstimo e agência, interligados pelo conjunto de
relacionamentos CEA.
Esse diagrama especifica que um cliente pode contrair diversos empréstimos e que um empréstimo pode
pertencer a diferentes clientes.
Esse diagrama especifica que um cliente pode contrair diversos empréstimos e que um empréstimo pode
pertencer a diferentes clientes.
A seguir, vemos uma seta apontando para agência indicando que cada par empréstimo-cliente está
associado a uma agência bancária específica. Se o diagrama tem uma seta apontando para cliente e outra
apontando para agência, o diagrama especificaria que cada empréstimo está associado a um cliente específico de
uma determinada agência bancária.

99

100
Conjunto de Entidades Fracas
Um conjunto de entidades pode não ter atributos suficientes para formar uma chave primária. Esse tipo
de conjunto de entidades é denominado conjunto de entidades fracas. Um conjunto de entidades que tem uma
chave primária é chamado um conjunto de entidades fortes. Como ilustração, considere o conjunto de entidades
pagamento, com três atributos: número_pagamento, data_pagamento e total_pagamento. Embora cada

101
entidade pagamento seja distinta, os pagamentos de empréstimos não tem uma chave primária; este é um
conjunto de entidades fracas. Para um conjunto de entidades fracas ser significativo, ele deve fazer parte de um
conjunto de relacionamentos um para muitos. Esse conjunto de relacionamentos não deve ter nenhum atributo
significativo, já que qualquer atributo exigido pelo conjunto de relacionamentos não deve ter nenhum atributo
significativo, já que qualquer atributo exigido pelo conjunto de relacionamentos pode ser associado ao conjunto
de entidades fracas.
Os conceitos de conjuntos de entidades fortes e fracas não possuir chave primária, precisamos, todavia,
de um significado para a distinção entre todas aquelas entidades em um conjunto de entidades que dependem de
uma entidade forte em particular. O identificador de um conjunto de entidades fracas é um conjunto de atributos
que permite que essa distinção seja feita. Por exemplo, o identificador do conjunto de entidades fracas
pagamento é o atributo número_pagamento, assim, para cada empréstimo, um número de pagamento identifica
um determinado pagamento para aquele empréstimo. O identificador de um conjunto de entidades fracas é
também chamado de chave parcial de um conjunto de entidades fracas é também de chave parcial de um
conjunto de entidades.
A chave primaria de um conjunto de entidades fracas é formado pela chave primária, precisamos, todavia,
de um significado para a distinção entre todas aquelas entidades fortes ao qual a existência do conjunto de
entidades fracas está vinculada mais o identificador do conjunto de entidades fracas. No caso do conjunto de
entidades pagamento, sua chave primária é {número_empréstimo, número_pagamento}, em que
número_empréstimo identifica a entidade dominante pagamento e número_pagamento identifica a entidade
pagamento dentro de determinado empréstimo.
O conjunto de entidades dominantes de identificação é dito proprietário do conjunto de entidades fracas
por ele identificada. O relacionamento que associa o conjunto de entidades fracas a seu proprietário é o
relacionamento identificador. Em nosso exemplo, pagamento_empréstimo é o relacionamento identificador de
pagamento.
Um conjunto de entidades fracas é identificado no diagrama E-R pela linha dupla usada no retângulo e no
losango do relacionamento correspondente. Na fig. 2.14, o conjunto de entidades fracas pagamento é
dependente do conjunto de entidades fortes empréstimo pelo conjunto de relacionamentos
pagamento_empréstimo. A figura também apresenta o uso de linhas duplas para identificar participação total – a
participação do conjunto de entidades (fracas) pagamento no relacionamento pagamento_empréstimo é total,
significando que todo pagamento precisa estar relacionado via pagamento_empréstimo a alguma conta.
Finalmente, a seta de pagamento_emprestimo para empréstimo indica que cada pagamento é para um único
empréstimo. O identificador de um conjunto de entidades fracas. Mesmo que um conjunto de entidades fracas
tenha sempre sua existência dependente de uma entidade dominante, a dependência de existência não resulta,
necessariamente, em um conjunto de entidades fracas; isto é, o conjunto de entidades subordinadas pode ter
uma chave primária.

102
Em alguns casos, o projetista do banco de dados pode optar por expressar um conjunto de entidades
fracas como um atributo composto multivalorado do conjunto de entidades proprietário. Em nosso exemplo, essa
alternativa exigiria que o conjunto de entidades empréstimo tivesse um atributo composto multivalorado
pagamento, consistindo de número_pagamento, data_pagamento e total_pagamento. Um conjunto de entidades
fracas pode ser modelado de forma mais apropriada, como um atributo, se ele apenas participar da identificação
do relacionamento e ele tiver poucos atributos. Por outro lado, será mais conveniente optar por um conjunto de
entidades fracas quando os conjuntos participantes no relacionamento não constituírem o relacionamento
identificador e quando o conjunto de entidades fracas possuir diversos atributos.
Recursos de Extensão do E-R
Apesar de ser possível modelar a maioria dos banco de dados apenas com os conceitos básicos do E-R,
alguns aspectos de um banco de dados podem ser expressos de modo mais conveniente por meio de algumas
extensões do modelo básico do E-R.
Especialização
Um conjunto de entidades pode conter subgrupos de entidades que são, de alguma forma, diferentes de
outras entidades do conjunto. Por exemplo, um subconjunto de entidades dentro de um conjunto de entidades
pode possuir atributos que não são compartilhados pelas demais entidades do conjunto. O modelo E-R
proporciona um significado para a representação desses agrupamentos distintos entre as entidades.
Considere o conjunto de entidades conta com os atributos número_conta e saldo. Um saldo é
futuramente classificado como um dos seguintes grupos:
• conta_poupança
• conta_movimento
Cada um desses tipos de contas é descrito como um conjunto de atributos que, além de todos os
atributos do conjunto de entidades conta, possui outros atributos adicionais. Por exemplo, as entidades
conta_poupança podem ser descritas pelo atributo taxa_juros, enquanto as entidades conta_movimento poderão
possuir o limite_cheque_especial. O processo de especialização de conta permite-nos distinguir os tipos de
contas.
Um conjunto de entidades pode ser especializado por mais de uma característica de diferenciação. Em
nosso exemplo, a distinção entre as entidades conta é seu tipo. Em nosso exemplo, a distinção entre as entidades
conta é seu tipo. Outra especialização coexistente poderia ser estabelecida entre os cheques especiais, resultando
nos conjuntos de entidades pessoa_física e pessoa_juridica. Quando mais de um tipo de especialização é formado
em um conjunto de entidades, uma entidade em particular pode pertencer a pessoa_fisica e conta_movimento.
Podemos aplicar o agrupamento por especialização, repetidamente, para refinar o esquema que está
sendo projetado. Por exemplo, um banco pode oferecer os três tipos de conta movimento:
1. Conta movimento padrão com taxa de três dólares mensais e 25 folhas de cheques por mês gratuitas.
Para essas contas, o banco emite o extrato bancário mensal com os números dos cheques.
2. Conta movimento especial que exige um saldo mínimo de mil dólares, pagando 2% em juros, e sem
limites na emissão de cheques. Neste caso, o banco monitora o saldo mínimo e os juros mensais pagos.
3. Conta movimento sênior para clientes com idade superior a 65 anos que não pagam taxa de serviços e
permite uso ilimitado de cheques, sem custo. Um registro sobre a data de aniversario do cliente é
associado a esse tipo de conta.
A especialização da conta_movimento pelo tipo de conta cria os seguintes conjuntos de entidades:
1. Padrão, com o atributo número_cheque.
2. Especial, com o atributo saldo_mínimo e taxa_juros.
3. Sênior, com o atributo data_aniversário.

103
Em termos de diagrama E-R, a especialização é representada pelo triângulo rotulado de ISA, como demonstrado
na fig. 2.15. Este rótulo-padrão ISA indica que, por exemplo, uma conta poupança “é uma” conta. Este
relacionamento ISA pode ser também entendido como um relacionamento de super ou subclasse. Os conjuntos
de entidades em nível superior e inferior são representados do mesmo modo que os conjuntos de entidades
regulares, ou seja, por um retângulo contendo o nome do conjunto de entidades.
Generalização
O refinamento do conjunto de entidades em níveis sucessivos de subgrupos indica um processo top-down
de projeto, no qual as diferenciações são feitas de modo explícito. O projeto pode ser realizado de modo bottom-
up, no qual vários conjuntos de entidades são sintetizados em um conjunto de entidades em alto nível, com base
em atributos comuns. O projetista do banco de dados poderia identificar, em uma primeira modelagem, o
conjunto de entidades conta_padrão com os atributos número_conta, saldo e saldo_negativo e o conjunto de
entidades conta_poupanca com os atributos número_conta, saldo e taxa_juros.
Existem similaridades entre o conjunto de entidades conta_movimento e o conjunto de entidades
conta_poupança, já que possuem atributos comuns. Esse compartilhamento de atributos pode ser expresso pela
generalização, que exprime o relacionamento existente entre os conjuntos de entidades de nível superior e um
ou mais conjuntos de entidades de nível inferior. E no nosso exemplo, conta é um conjunto de entidades de nível
superior e conta_poupança e conta)movimento são conjuntos de entidades de nível inferior. Conjuntos de
entidades superiores e inferiores podem também ser designados em termos de super e subclasses,
respectivamente. O conjunto de entidades conta é uma superclasse de conta_poupanca e conta_movimento são
subclasses.
Na prática, a generalização é simplesmente o inverso da especialização. Aplicaremos ambos os processos,
combinados, ao longo do projeto do esquema E-R de uma empresa. Em termos do diagrama E-R propriamente

104
dito, não faremos distinção entre a especialização e a generalização. Novos níveis de representação de entidades
serão diferenciadas (especialização) ou sintetizadas (generalização) de modo que o esquema possa expressar
totalmente a aplicação do banco de dados e atender às necessidades de seus usuários. As diferenças das duas
abordagens podem ser caracterizadas pelo ponto de partida e seus objetivos gerais.
A especialização parte de um único conjunto de entidades; ela enfatiza as diferenças entre as entidades
pertencentes ao conjunto por meio do estabelecimento das diferenças expressas nos conjuntos de entidades de
nível inferior. Estes conjuntos de entidades de nível inferior podem possuir atributos, ou mesmo participar de
relacionamentos que não podem ser aplicados a todas as entidades do conjunto de entidades de nível superior.
De fato, o projetista usa especialização justamente para representar tais distinções. Se conta_poupança e
conta_movimento não possuem atributos únicos; não há necessidade de especializar o conjunto de entidades
conta.
O uso da generalização procede para o reconhecimento de um número de conjunto de entidades que
compartilham características comuns (são descritos pelos mesmos atributos e participam dos mesmos conjuntos
de relacionamentos). Com base nessas características comuns, a generalização sintetiza esses conjuntos de
entidades de nível superior. A generalização é suada para enfatizar as similaridades entre os conjuntos de
entidades de nível inferior, omitindo suas diferenças; isso permite também uma representação mais econômica,
evitando repetições de atributos compartilhados.
Herança de Atributos
Uma propriedade decisiva das entidades de níveis superior e inferior criadas pela especialização e pela
generalização é a herança de atributos. Os atributos dos conjuntos de entidades de nível superior são herdados
pelos conjuntos de entidade de nível inferior. Por exemplo, conta_poupança e conta_movimento herdam os
atributos de conta. Assim, conta_poupança é identificado por seus atributos número_conta, saldo e taxa_juros;
conta_movimento é identificado por seus atributos número_conta, saldo e limite_cheque_especial. Os conjuntos
de entidade de nível inferior (ou subclasses) também herdam a participação em conjuntos de relacionamentos
dos quais participam seus conjuntos de entidades de nível superior(ou superclasse). Tanto que o conjunto de
entidades conta_poupança e conta_movimento participam do conjunto de relacionamentos depositante. Os
conjuntos de entidades padrão, especial e sênior de nível inferior herdam os atributos e a participação nos
relacionamentos de conta_movimento e conta.
Se uma dada porção do modelo E-R chegou à especialização ou à generalização, os resultados são
basicamente os mesmos:
• Conjuntos de entidades de nível superior com atributos e relacionamentos que são aplicados a todos os
seus conjuntos de entidades de nível inferior.
• Conjunto de entidades de nível inferior com características distintas que são apenas aplicadas a um
conjunto de entidades de nível inferior em particular.
Como se percebe, embora frequentemente nos refiramos apenas à generalização, as propriedades que
discutimos pertencem totalmente a ambos os processos.
A fig. 2.15 apresenta uma hierarquia nos conjuntos de entidades. Na figura, conta_movimento é um
conjunto de entidades de nível superior aos conjuntos de entidades padrão, especial e sênior. Hierarquicamente,
um dado conjunto de entidades somente poderá ser envolvido, como um conjunto de entidades de nível inferior,
por meio de um relacionamento ISA. Se um conjunto de entidades é um conjunto de entidades de nível inferior
em mais de um relacionamento ISA, a estrutura resultante é chamada reticulada.
Restrições de Projeto
Para modelagem mais apurada de uma empresa, o projetista do banco de dados pode optar por definir
algumas restrições em uma generalização em particular. Um tipo de restrição envolve a determinação das

105
entidades que podem participar de um dado conjunto de entidades de nível inferior. Tais escolhas podem ser
uma das seguintes:
• Definida por condição. Um conjunto de entidades de nível inferior definido por condição é selecionado
com base na satisfação ou não de condições ou predicados preestabelecidos. Por exemplo, considere que
o conjunto de entidades de nível superior conta possui o atributo tipo_conta. Todas as entidades conta
evoluem para um dos atributos tipo_conta. Somente aquelas entidades que satisfaçam a condição
tipo_conta = “conta_poupança”, podem pertencer ao conjunto de entidades de nível inferior
conta_poupança. Todas as entidades que satisfaçam a condição tipo_conta = “conta_movimento” são
incluídas em conta movimento. Desde que todas as entidades de nível inferior sejam classificadas com
base nos mesmos atributos (neste caso, tipo_conta), esse tipo de generalização é chamado
definida_por_atributo.
• Definida pelo usuário. Um conjunto de entidades de baixo nível definido pelo usuário não tem seus
membros classificados por uma condição; as entidades são designadas a um determinado conjunto de
entidades por usuários do banco de dados. Por exemplo, suponhamos que, depois de três meses de
trabalho, os empregados do banco sejam convocados para compor um dentre os quatro grupo de
trabalho existentes. Esses grupos são representados por quatro conjuntos de entidades de baixo nível,
derivados do conjunto de entidades de alto nível empregado. A escolha de um determinado empregado
para participar de um conjunto de entidades de um grupo específico não é originada automaticamente
pela definição de uma condição explícita. Pelo contrário, a escolha para compor determinado grupo é
feita por critérios individuais, pesando na decisão a opinião do usuário, e sua implementação é feita por
uma operação que adiciona a entidade ao conjunto de entidades.
O segundo tipo de restrição determina se uma entidade pode ou não pertencer a mais de um conjunto de
entidades de nível inferior dentro de uma generalização simples. Os conjuntos de entidades de nível inferior
podem ser um dos seguintes:
• Manutenção exclusivos. Restrições mutuamente exclusivas exigem que uma entidade pertença a apenas
um conjunto de entidades de nível inferior. Em nosso exemplo, uma entidade conta pode satisfazer a
apenas uma condição para o atributo tipo_conta; uma entidade pode ser tanto uma conta poupança
como uma conta movimento, mas nunca ambas.
• Sobrepostos. Em generalizações sobrepostas, uma mesma entidade pode pertencer a mais de um
conjunto de entidades de nível inferior dentro de uma generalização simples. Para ilustração, retornemos
ao exemplo dos grupos de trabalho dos empregados do banco e suponhamos que determinados gerentes
participem de mais de um desses grupos. Um determinado empregado pode, portanto, pertencer a mais
de um conjunto de entidades formadas pelos grupos de trabalho.
Conjuntos de entidades de nível inferior com sobreposição é o caso-padrão; restrições mutuamente
exclusivas devem ser apresentadas explicitamente em uma generalização (ou especialização).
Uma restrição final, a restrição de totalidade em uma generalização, determina se uma entidade de nível
superior pertence ou não a, no mínimo, um dos conjuntos de entidades de nível inferior dentro da generalização.
Essa restrição pode ser uma das seguintes:
• Total. Cada entidade do conjunto de entidades de nível superior deve pertencer a um conjunto de
entidades de nível inferior.
• Parcial. Qualquer entidade de nível superior pode pertencer a qualquer um dos conjuntos de entidades
de nível inferior.
A generalização conta é total: todas as entidades contas devem ser contas de poupança ou contas movimento.
Como os conjuntos de entidades de alto nível de uma generalização são, geralmente, compostos somente pelas
entidades de nível inferior. O conjunto de entidades dos grupos de trabalho ilustram uma especialização parcial.

106
Desde que os empregados participem de um dos grupos somente após três meses de trabalho, algumas
entidades empregados podem não ser membros de qualquer um dos conjuntos de entidades de grupos de nível
inferior.
Podemos caracterizar os conjuntos de entidades de grupos de modo completo como especialização
parcial e sobreposta de empregado. A generalização conta_movimento e conta_poupança de conta é total,
generalização mutuamente exclusiva. As restrições de totalidade e de sobreposição, entretanto, ano são
dependentes uma das outra. Os padrões de generalização podem ser parcial-mutuamente-exclusivas e total-
sobrepostas.
Podemos ver que certas exigências para inserções e exclusões seguem restrições que são aplicadas a
dadas generalizações ou especializações. Por exemplo, quando uma restrição total é aplicada, uma entidade
inserida em um conjunto de entidades de nível superior deverá ser inserida em pelo menos um de seus conjuntos
de entidades de nível inferior. Em restrições definidas por condição, todas as entidades de nível superior que
satisfaçam tal condição devem ser inseridas nos conjuntos de entidades de nível inferior. Finalmente, uma
entidade excluída de um conjunto de entidades de nível superior também deverá ser excluída de todos os
conjuntos de entidades de nível inferior às quais pertencem.
Agregação
Uma das limitações do modelo E-R é que não é possível expressar relacionamentos entre
relacionamentos. Para ilustrar a necessidade desse tipo de construtor, consideremos novamente um banco de
dados descrevendo informações sobre clientes e seus empréstimos. Suponha que cada par empréstimo-cliente
possui um bancário, ou agente-empréstimo, responsável pelo acompanhamento de determinado empréstimo.
Usando os construtores do modelo E-R básico, obteríamos o diagrama apresentado na fig. 2.16. Nota-se que o
conjunto de relacionamentos devedor e agente_empréstimo poderia ser combinado em um único conjunto de
relacionamentos. No entanto, não podemos fazê-lo, porque isso tornaria obscura a estrutura lógica desse
esquema. Por exemplo, se combinarmos os conjuntos de relacionamentos devedor e agente_emprestimo, essa
combinação deveria especificar que um agente-empréstimo específico é responsável por uma par empréstimo-
cliente, o que não ocorre. A separação em dois conjuntos de relacionamentos distintos resolve esse problema.
Entretanto, existe redundância de informações na figura resultante, uma vez que todo par empréstimo-
cliente em agente_empréstimo está também em devedor. Se o agente_empréstimo fosse um valor, em vez de
uma entidade de empregado, poderíamos fazer de agente_empréstimo um atributo multivalorado do
relacionamento devedor. Mas, assim, seria ainda mais difícil (nos custos de lógica e execução) encontrar, por
exemplo, o par empréstimo-cliente pelo qual determinado bancário é responsável.
Já que um agente de empréstimo é uma entidade empregado, essa alternativa é descartada em qualquer
caso.

107
O melhor modo de modelar a situação acima descrita é usando a agregação. Agregação é a abstração por
meio da qual os relacionamentos são tratados como entidades de nível superior. Assim, em nosso exemplo,
simbolizamos o conjunto de relacionamentos devedor e o conjunto de entidades cliente e empréstimo como um
conjunto de entidades de nível superior, chamado devedor.
Como é um conjunto de entidades, é tratado da mesma forma que qualquer outro conjunto de entidades.
A notação mais comum para a agregação é mostrada na fig. 2.17.

108
Projeto de um Esquema de Banco de Dados E-R
O modelo de dados E-R nos dá uma flexibilidade substancial par ao projeto de um esquema de banco de
dados na modelagem de determinada empresa. Vamos agora considerar quais as opções possíveis para o
projetista dentre o grande número de possibilidades. Algumas das possíveis opções são:
• Optar pelo uso de um atributo ou de um conjunto de entidades para representação de um objeto.
• Se uma concepção real é expressa de modo mais preciso por um conjunto de entidades ou por um
conjunto de relacionamentos.
• Optar por um conjunto de relacionamentos ternário ou por um par de relacionamento binário.
• Se se deve usar um conjunto de entidades forte. Um conjunto de entidades forte e seus conjuntos de
entidades fracas dependentes podem ser visto como um único “objeto” do banco de dados, já que as
entidades fracas têm sua existência vinculada à de uma entidade forte.
• Se o uso da generalização é apropriado. A generalização, ou uma hierarquia de relacionamentos ISA,
contribui para a modularidade, já que atributos comuns a conjuntos de entidades similares podem ser
representados em apenas um local do diagrama E-R.
• Se o uso da agregação for apropriado, agregar grupos de uma parte do diagrama E-R em um conjunto de
entidades simples, permitindo-nos tratar do conjunto de entidades agregadas como uma unidade
simples, sem abordar os detalhes de suas estruturas internas.
Podemos notar que um projetista de banco de dados necessidade de um bom entendimento da empresa
que está sendo modelada para que possa tomar essas decisões.
Fases de Projeto

109
Um modelo de dados de alto nível proporciona ao projetista uma base conceitual na qual se pode
especificar, de modo sistemático, quais as necessidades dos usuários do banco de dados e como este banco de
dados será estruturado para atender plenamente a todas estas necessidades. A fase inicial do projeto é
caracterizar todos os dados necessários na perspectiva do usuário. O resultado dessa fase é a especificação das
necessidades do usuário (ou levantamento de requisitos).
A seguir, o projetista escolhe o modelo de dados e, por meio da aplicação de seus conceitos, transcreve as
necessidades especificadas em um esquema conceitual de banco de dados. O esquema desenvolvido nessa fase é
chamado projeto conceitual e proporcional uma visão detalhada da empresa. Como só estudamos o modelo E-R
até agora, iremos usá-lo para o desenvolvimento do esquema conceitual. Empregando os termos do modelo E-R,
o esquema deve especificar todos os conjuntos de entidades, relacionamentos, atributos e o mapeamento das
restrições. O projetista revê o esquema para confirmar se todos os dados exigidos estão de fato representados e
se não há conflitos entre eles. Ele deverá também examinar o projeto para remover qualquer tipo de
redundância. Neste momento, seu enfoque é descrever os dados e seus relacionamentos, em vez de especificar
os detalhes físicos de armazenamento.
O desenvolvimento completo do esquema conceitual irá indicar também as necessidades funcionais da
empresa. Na especificação das necessidades funcionais, os usuários descrevem os tipos de operações (ou
transações) que serão realizados nos dados. Os exemplos dessas operações incluem modificação para atualização
dos dados, pesquisa para recuperação de um determinado dado e remoção de dados. Deverá ser feita, nesse
estágio do projeto conceitual, uma revisão do esquema dos dados em função das necessidades funcionais.
O transporte do modelo de dados abstrato, para sua implementação, ocorre nas duas fases finais do
projeto. Na fase de projeto lógico, o esquema conceitual de alto nível é mapeado para o modelo de
implementação de dados do SGBD que será usado. O esquema de dados resultante é usado para a fase
subsequente, que é a do projeto físico, especificamente dependente dos recursos do SGBD usado. Esses recursos
incluem as formas de organização de arquivos e estruturas internas de armazenamento.
Vamos abordar somente os conceitos do modelo E-R como usados na fase do projeto do esquema
conceitual.
Dados Necessários a uma Empresa da Área Bancária
A especificação dos requisitos dos usuários pode ser apurada por meio de entrevistas unidas à própria
avaliação do projetista sobre a empresa.
A descrição resultante dessa fase do projeto é a base para a especificação da estrutura conceitual do
banco de dados. A lista de itens que se segue apresenta as principais necessidades de uma empresa da área
bancária.
• Um banco é organizado em agências. Cada agência é localizada em uma cidade e é identificada por um
nome único. O banco controla os fundos de cada uma dessas agências.
• Os clientes do banco são identificados pelo número do seu seguro social. O banco mantém dados como
nome, rua, e cidade do cliente. Os clientes podem possuir contas e contrair empréstimos. O cliente pode
estar associado a um bancário específico que cuida de seus negócios ou atua como um agente de
empréstimos.
• Os empregados do banco também são identificados por meio do seu seguro social. A administração do
banco mantém o nome e o número do telefone de cada um de seus empregados, os nomes de seus
dependentes e o número do seguro social de seu gerente. O banco também possui a data de contrata do
empregado e, com isso, seu tempo de trabalho.
• O banco oferece dois tipos de contas – contas poupança e contas movimento. As contas movimento
podem possuir mais de um correntista, e um correntista pode possuir mais de uma conta. Cada conta
possui um único número. O banco controla o saldo de cada conta, assim como a data mais recente de
acesso a essa conta. Por outro lado, cada conta poupança possui a taxa de juros associada, assim como
são também registrados os excessos nos limites da conta movimento.

110
• Um empréstimo originado em uma agência em particular pode ter sido obtido por um ou mais clientes.
Um empréstimo é identificado por um número único. Para cada empréstimo o banco mantém o
montante emprestado, assim como os pagamentos das parcelas. Embora o número das parcelas de um
empréstimos não identifique de modo único um pagamento específico dentre os muitos realizados no
banco, o número da parcela identifica um pagamento específico dentre os muitos realizados no banco, o
número da parcela identifica um pagamento efetuado para um empréstimo em particular. A data e o
montante são registrados no pagamento de cada parcela.
Em um banco real, poderia ser de interesse manter informações sobre depósitos e retiradas tanto para as contas
poupança quanto para as contas movimento, assim como se mantêm informações sobre o pagamento de
parcelas dos empréstimos. Uma vez que a modelagem dos requisitos dos usuários nas necessidades descritas a
pouco são semelhantes àquelas feitas no início, podemos optar por um exemplo de aplicação mais reduzido, não
fazendo, em nosso modelo, o acompanhamento dos depósitos e das retiradas.
Designação de Conjuntos de Entidades em Empresas Bancárias
Nossa especificação dos requisitos de dados servem como base inicial para a construção de um esquema
conceitual do banco de dados.
Para as especificações relacionadas, começamos por identificar os conjuntos de dados e seus atributos.
• O conjunto de entidades agência, com os atributos:
nome_agência, cidade_agência, e fundos
• O conjunto de entidades cliente, com os atributos:
nome_cliente, seguro_social, rua_cliente e cidade_cliente
Com a possibilidade do atributo adicional nome_bancário.
• O conjunto de entidades empregado, com os atributos:
seguro_social_empregado, nome_empregado, número_telefone, salario e gerente.
Recursos adicionais descritivos são os atributos multivalorados nome_dependentes, o atributo básico
data_início e o atributo descritivo tempo_de_trabalho.
• Dois conjuntos de entidades contas – conta_poupança e conta_movimento – com os atributos comuns
número_conta e saldo; também, conta_poupança possui o atributo taxa_de_juros e conta_movimento, o
atributo limite_cheque_especial.
• O conjunto de entidades empréstimo, com os atributos:
número_empréstimo, total e agência_origem
São possíveis os seguintes atributos adicionais: pagamento_empréstimo, composto multivalorado; com os
seguintes atributos componentes:
número_pagamento, data_pagamento e total_pagamento
Designação dos conjuntos de Relacionamentos de uma Empresa da Área Bancária
Retornemos agora ao esquema do projeto descrito para especificar os seguintes conjuntos de
relacionamentos e mapeamentos de cardinalidades:
• devedor, como conjunto de relacionamentos muitos para um que indica qual a agência responsável pelo
empréstimo.
• pagamento_empréstimo, relacionamento um para muitos entre empréstimo e pagamento, que
documento que um pagamento está sendo feito para um determinado empréstimo.
• depositante, com os atributos de relacionamento data_acesso, um conjunto de relacionamentos muitos
para muitos entre cliente e conta, indicando que um cliente possui uma conta.

111
• agente_cliente, com o atributo de relacionamento tipo, um conjunto de relacionamentos muitos para um
expressando que um cliente pode ser atendido por determinado empregado do banco e que um
empregado do banco pode atender a um ou mais clientes.
• trabalha_para, conjunto de relacionamentos entre entidades empregado que determina se se trata de
gerente ou empregado; o mapeamento da cardinalidade expressa que um empregado trabalha para um
gerente específico e que um gerente supervisiona um ou mais empregados.
Note que trocamos o atributo nome_agente do conjunto de entidades cliente pelo conjunto de relacionamentos
agente_cliente, e o atributo gerente do conjunto de entidades empregado pelo conjunto de relacionamentos
trabalha_para. Optamos por manter o conjunto de entidades empréstimo. O conjunto de relacionamentos
agência_empréstimo e pagamento_empréstimo foi substituído, respectivamente, pelos atributos agência_origem
e pagamento_empréstimo do conjunto de entidades empréstimo.
Digrama E-R de uma Empréstimo de uma Empresa da Área Bancária
Esquematizando, apresentamos agora o diagrama E-R completo para nosso exemplo de empresa da área
bancária. A fig. 2.18 mostra a representação de um modelo conceitual de um banco, expresso nos termos
conceituais de E-R. O diagrama inclui os conjuntos de entidades, atributos, conjuntos de relacionamentos e o
mapeamento das cardinalidades concluídas durante o processo descrito anteriormente, e já refinado.

112
Redução de um Esquema E-R a Tabelas
Um banco de dados em conformidade com o esquema de banco de dados E-R pode ser representado por
uma coleção de tabelas. Para cada conjunto de entidades e para cada relacionamentos, dentro de um banco de
dados, existe uma tabela única registrando o nome do conjunto de entidades ou relacionamentos
correspondentes. Cada tabela possui várias colunas, cada uma delas com um único nome.
Tanto o modelo E-R quanto o modelo relacional são abstratos, ou seja, representações lógicas de
empresas reais. Como esses dois modelos empregam princípios de projetos similares, podemos converte o
projeto E-R em projeto relacional. Converter a representação de um banco de dados de um diagrama E-R para um
formato de tabela é a base para a derivação de um diagrama E-R de um projeto a partir de um banco de dados
relacional. Embora existam importantes diferenças entre uma relação e uma tabela, informalmente, uma relação
pode ser considerada uma tabela de valores.
Representação Tabular dos Conjuntos de Entidades Fortes

113
Seja E um conjunto de entidades fortes descrito pelos atributos a1, a2, ..., an. Representamos essa
entidade por uma tabela chamada E com n colunas distintas, cada uma delas correspondendo a um dos atributos
de E. Cada linha da tabela corresponde a uma entidade do conjunto de entidades E.
Como ilustração, considere o conjunto de entidades empréstimo do diagrama E-R mostrado na fig. 2.8.
Esse conjunto de entidades possui dois atributos: número_empréstimo e total. Representaremos esse conjunto
de entidades pela tabela chamada empréstimo, com duas colunas, como mostra a fig. 2.19. A linha (L-17, 1000)
da tabela empréstimo significa que o empréstimo de número L-17 é de mil dólares. Podemos adicionar uma nova
entidade ao banco de dados pela inserção de uma linha na tabela. Também podemos excluir ou modificar as
linhas.
Denotaremos como D1 o conjunto de todos os números de empréstimos e D2 o conjunto de todos os
saldos. Qualquer linha da tabela empréstimo deve consistir de uma 2-tupla (v1, v2), em que v1 é um empréstimo
(isto é, v1 está no conjunto D1) e v2 é um total (isto é, v2 está no conjunto D2). No geral, a tabela empréstimo
conterá somente o subconjunto de todas as linhas possíveis. Iremos nos referir ao conjunto de todas as linhas
possíveis de empréstimo como o produto cartesiano de D1 e D2, denotado por: D1xD2.
No geral, se tivermos uma tabela com n colunas, denotaremos o produto cartesiano de D1, D2, ..., Dn por:
Como outro exemplo, considere o conjunto de entidades cliente do diagrama E-R mostrado na fig. 2.8.
Esse conjunto de entidades tem os atributos nome_cliente, seguro_social, rua_cliente e cidade_cliente. A tabela
correspondente a cliente tem quatro colunas, como mostra a fig. 2.20.
Representação Tabular dos Conjuntos de Entidades Fracas
Seja A um conjunto de entidades fracas com os atributos a1, a2, ..., an. Seja B um conjunto de entidades
fortes, do qual A é dependente. Seja a chave primária de B composta pelos atributos b1, b2, ..., bn. Representamos
o conjunto de entidades A pela tabela chamada A com uma coluna para cada um dos atributos do conjunto:

114
Como ilustração, considere o conjunto de entidades pagamento mostrado no diagrama E-R da fig. 2.14.
Esse conjunto de entidades tem três atributos: número_pagamento, data_pagamento e total_pagamento. A
chave primária do conjunto de entidades empréstimo, do qual pagamento é dependente, é o
número_empréstimo. Assim, pagamento é representado por uma tabela com quatro colunas chamadas
número_empréstimo, número_pagamento, data_pagamento e total_pagamento, como mostrado na fig. 2.21.
Representação Tabular do Conjunto de Relacionamentos
Seja R um conjunto de relacionamentos; seja a1, a2, ..., an o conjunto de atributos formado pela união das
chaves primarias de cada um dos conjuntos de entidades participantes de R; e seja os atributos descritivos b1, b2,
..., bn (se houver) de R. Representamos esse conjunto de relacionamentos pela tabela chamada R, com uma
coluna para cada atributo do conjunto:
Para ilustrar, considere o conjunto de relacionamentos devedor no diagrama E-R da fig. 2.8. Esse conjunto
de relacionamentos envolve os dois conjuntos de entidades seguintes:
• cliente, com a chave primária seguro_social.
• Empréstimo, com a chave primária número_empréstimo.
Uma vez que o conjunto de relacionamentos não possui atributos próprios, a tabela devedor possui duas colunas,
a de seguro_social e número_empréstimo, como mostra a fig. 2.22.
Tabelas Redundantes

115
O caso do conjunto de relacionamentos unindo um conjunto de entidades fracas ao seu conjunto de
entidades fortes correspondente é um caso especial. Como pudemos ver anteriormente, esses relacionamentos
são muitos para um e não possuem atributos descritivos. Além disso, a chave primária de um conjunto de
entidades fracas inclui a chave primária do conjunto de entidades fortes. No diagrama E-R da fig. 2.14, o conjunto
de entidades fracas pagamento é dependente do conjunto de entidades fortes empréstimo por meio do conjunto
de relacionamentos pagamento_empréstimo. A chave primária de pagamento é {número_empréstimo,
número_pagamento} e a chave primária de empréstimo é {número_empréstimo}. Desde que
pagamento_empréstimo não possui atributos descritivos, a tabela para pagamento_empréstimo poderia ter duas
colunas, número_empréstimo e número_pagamento. A tabela para o conjunto de entidades pagamento tem
quatro colunas, número_empréstimo, número_pagamento, data_pagamento e total_pagamento. Assim, a tabela
pagamento_empréstimo é redundante. Em geral, a tabela para o conjunto de relacionamentos unindo o conjunto
de entidades fracas com seu conjunto de entidades fortes correspondente é redundante e não precisa ser
apresentada em uma representação tabular do diagrama E-R.
Combinação de tabelas
Considere um conjunto de relacionamento muitos para um AB entre os conjuntos de entidades A e B.
Usando nosso esquema de construção de tabelas previamente descrito, teremos três tabelas: A, B e AB.
Entretanto, se existe dependência de A sobre B (isto é, para cada entidade a em A, a existência de a depende da
existência de alguma entidade b em B), então podemos combinar as tabelas A e AB para formar uma tabela
simples consistindo da união das colunas de ambas as tabelas.
Como ilustração, considere o diagrama E-R da fig. 2.23. O conjunto de relacionamentos entre conta e
agência, agência_conta, é muitos para um. Daqui para frente, uma linha dupla no diagrama E-R indica que a
participação de conta em conta_agência é total. Daí, uma conta não pode existir sem que esteja associada a uma
agência em particular. Portanto, necessitamos somente de duas tabelas:
• conta, com os atributos número_conta, saldo e nome_agência.
• agência, com atributos nome_agência, cidade_agência e fundos.
Atributos Multivalorados
Vimos que, em geral, os atributos do diagrama E-R são mapeados diretamente em colunas nas tabelas
apropriadas. Atributos multivalorados, entretanto, constituem uma exceção; novas tabelas são criadas para esses
tipos de atributos.
Para um atributo multivalorado M, criamos a tabela T com uma coluna C que corresponde a M e as
colunas correspondentes à chave primária do conjunto de entidades ou conjunto de relacionamento do qual M é
atributo. Como ilustração, considere o diagrama E-R apresentado na fig. 2.18. o diagrama inclui o atributo
multivalorado nome_dependente. Para esse atributo multivalorado, criamos a tabela nome_dependente com as
colunas nomed, referente ao atributo nome_dependente do empregado, e seguro_social_empregado,

116
representando a chave primária do conjunto de entidades empregado. Cada dependente de um empregado é
representado por uma única linha na tabela.
Representação Tabular da Generalização
Existem dois modos diferentes de transformar um diagrama E-R que contenha generalização em tabelas.
Embora nos refiramos à generalização mostrada na fig. 2.15, preferimos simplificar essa discussão incluindo
somente o primeiro grupo dos conjuntos de entidades de nível inferior – isto é, os atributos conta_poupança e
conta_movimento.
1. Criar a tabela para o conjunto de entidades de nível superior. Para cada conjunto de entidades de nível
inferior, criar uma tabela que inclua uma coluna para cada um dos coluna para cada um dos atributos
daquele conjunto de entidades mais uma coluna para cada atributo da chave primária do conjunto de
entidades mais uma coluna para cada atributo da chave primária do conjunto de entidades de nível
superior. Assim, para o diagrama da fig. 2.15, teremos três tabelas:
• conta, com os atributos número_conta e saldo.
• conta_poupança, com os atributos número_conta e taxa_juros.
• conta_movimento, com os atributos número_conta e limite_cheque_especial.
2. Se a generalização é mutuamente exclusiva e total – isto é, se nenhuma entidade é membro de mais de
um conjunto de entidades de nível imediatamente inferior ao conjunto de entidades de nível superior e
se todas as entidades do conjunto de entidades de nível inferior –, então, uma outra representação
alternativa é possível. Para cada conjunto de entidades de nível inferior, cria-se uma tabela que inclua
uma coluna para cada um dos atributos do conjunto de entidades mais uma coluna para cada atributo do
conjunto de entidades de nível superior. Então, para o diagrama E-R da fig. 2.15, teremos duas tabelas.
• Conta_poupança, com atributos número_conta, saldo e taxa_juros.
• Conta_movimento, com os atributos número_conta, saldo e limite_cheque_especial.
As relações correspondentes a conta_poupança e conta_movimento para essas tabelas têm, ambas, saldo
como chave primária.
Se o segundo método for usado para generalizações com sobreposição, alguns valores, como saldo,
podem ser armazenados duas vezes sem necessidade. Similarmente, se a generalização não for total – isto é, se
algumas contas não forem nem de poupança nem de movimento, então tais contas não poderão ser
representadas usando o segundo método.
Representação Tabular da Agregação
A transformação de um diagrama E-R com agregação para forma tabular é bastante direta. Considere o
diagrama da fig. 2.17. A tabela para o conjunto de relacionamentos agente_empréstimo inclui uma coluna para
cada atributo, uma para a chave primária do conjunto de entidades empregado e uma para o conjunto de
relacionamentos devedor. Poderia também incluir uma coluna para cada um dos atributos descritivos do
conjunto de relacionamentos agente_empréstimo, se eles existirem. Usando o mesmo procedimento anterior
para o resto do diagrama, criamos as seguintes tabelas:
• cliente, com os atributos nome_cliente, seguro_social, rua_cliente e cidade_cliente.
• empréstimo, com os atributos número_empréstimo e total.
• devedor, com os atributos seguro_social e número_empréstimo.
• empregado, com os atributos seguro_social_empregado, nome_empregado, e número_telefone.
• agente_empréstimo, com os atributos seguro_social, número_empréstimo e seguro_social_empregado.

117
Arquiteturas de Sistemas de Banco de Dados
A arquitetura de um sistema de banco de dados é fortemente influenciada pelo sistema básico
computacional sobre o qual o sistema de banco de dados é executado. Aspectos da arquitetura de computadores
– como rede, paralelismo e distribuição – têm influência na arquitetura do banco de dados.
• Rede de computadores permite que algumas tarefas sejam executadas no servidor do sistema e outras
sejam executadas no cliente. Essa divisão de trabalho tem levado ao desenvolvimento de sistemas de
banco de dados cliente-servidor.
• Processamento paralelo em um sistema de computadores permite que atividades do sistema de banco de
dados sejam realizadas com mais rapidez, reduzindo o tempo de resposta das transações e, assim,
aumentando o número de transações processadas por segundo. Consultas podem ser processadas de
forma a explorar o paralelismo oferecido pelo sistema operacional. A necessidade de processamento
paralelo de consultas tem levado ao desenvolvimento de sistemas de banco de dados paralelos.
• A distribuição de dados pelos nós da rede ou pelos diversos departamentos de uma organização
permitem que esses dados residam onde são gerados ou mais utilizados, mas, ainda assim, estejam
acessíveis para outros nós de outros departamentos. Dispor de diversas cópias de um banco de dados em
diferentes nós também permite a organizações de grande porte manter operações em seus bancos de
dados mesmo quando um nó é afetado por um desastre natural, como inundações, incêndios ou
terremotos. Sistemas de banco de dados distribuídos têm se desenvolvido para tratar dados distribuídos
geográfica ou administrativamente por diversos sistemas de banco de dados.
Vamos agora estudar a arquitetura dos sistemas de banco de dados, começando com os sistemas
centralizados tradicionais e passando por sistemas de banco de dados cliente-servidor, paralelos e distribuídos.
Sistemas Centralizados
Sistemas de banco de dados centralizados são aqueles executados sobre um único sistema computacional
que n ao interagem com outros sistemas. Tais sistemas podem ter a envergadura de um sistema de banco de
dados de um só usuário executado em um computador pessoal até sistemas de alto desempenho em sistema de
grande porte.
Um sistema computacional genérico moderno consiste em uma ou poucas CPUs e dispositivos de controle
que são conectados por meio de um bus comum que proporciona acesso à memória compartilhada (fig. 16.1). As
CPUs têm memórias cache locais que armazenam cópias de partes da memória para acesso rápido aos dados.
Cada dispositivo de controle atende a um tipo específico de dispositivo (por exemplo, um drive de disco, um
dispositivo de áudio ou de vídeo). A CPU e os dispositivos de controle podem trabalhar concorrentemente,
competindo pelo acesso à memória. A memória cache parcialmente reduz a contenção de acesso à memória,
uma vez que reduz o número de tentativas de acesso da CPU à memória compartilhada.

118
Dividimos em dois modos a forma pela qual os computadores são usados: por um sistema de um único
usuário e sistemas multiusuários. Computadores pessoais e estações de trabalho caem na primeira categoria. Um
sistema monousuário típico é uma unidade de trabalho de uma única pessoa, com uma única CPU e um ou dois
discos rígidos, com um sistema operacional que pode dar suporte a apenas um único usuário. Um sistema
multiusuário típico, por outro lado, possui um número maior de discos e área de memória, podendo ter diversas
CPUs e um sistema operacional multiusuário. Atende a um grande número de usuários que estão conectados ao
sistema por meio de terminais. Tais sistemas são frequentemente chamados de sistemas servidor.
Sistemas de banco de dados projetados para ser monousuários, como os de computadores pessoais,
normalmente não proporcionam muitos recursos comuns aos banco de dados multiusuários. Em particular, ele
não dão suporte ao controle de concorrência, o que não é necessário quando somente um usuário pode gerar
atualizações.
A recuperação de perdas nesse tipo de sistema é, senão inexistente, primitiva – por exemplo, fazendo um
backup do banco de dados antes de qualquer atualização. Muitos desses sistemas não dão suporte à SQL,
fornecendo linguagens de consulta bem mais simples, como uma variante da QBE.
Embora os sistemas de computadores de propósito geral possuam atualmente múltiplos processadores,
eles têm paralelismo de granulação-grossa, com um número limitado de processadores (entre dois e quatro,
normalmente), todos compartilhando a memória principal. Os banco de dados rodando em tais equipamentos
normalmente não promovem o particionamento de uma consulta entre processadores: ao contrário, cada
consulta roda em um único processador, permitindo que diversas consultas sejam executada concorrentemente.
Assim, tais sistemas proporcionam alto throughput, isto é, um grande número de transações é processador por
segundo, embora uma transação, individualmente, não seja necessariamente processada com maior rapidez.
Banco de dados processados em equipamento de um só processador já dispõem de recursos multitarefas,
nos quais diversos processos podem ser executados em um mesmo processador de modo compartilhado, dando
ao usuário a impressão de que diversos processos são executados em paralelo. Assim, equipamentos com
paralelismo de granulação-grossa parecem, na lógica, idênticos a um equipamento de um único processador;
sistemas de banco de dados projetados para equipamentos time-shared podem facilmente ser adaptados para
esse ambiente.
Em contrate, os equipamentos de granulação-fina têm um grande número de processadores, e os
sistemas de banco de dados rodando nesse tipo de equipamento podem processar unidades de tarefas
(consultas, por exemplo) submetidas pelos usuários em paralelo.

119
Sistemas Cliente-Servidor
Como os computadores pessoais têm se tornado mais rápidos, mais poderosos e baratos, há uma
tendência de seu uso nos sistemas centralizados. Terminais conectados a sistemas centralizados estão sendo
substituídos por computadores pessoais. Simultaneamente, interfaces com o usuário usadas funcionalmente para
manuseio direto com sistemas centralizados estão sendo adequadas ao trato com computadores pessoais.
Como resultado, sistemas centralizados atualmente agem como sistemas servidores que atendem a
solicitações de sistemas clientes. A estrutura geral de um sistema cliente-servidor é exibida na fig. 16.2.
As funcionalidades de um banco de dados podem ser superficialmente divididas em duas categorias –
front-end e back-end – como mostra a fig. 16.3. O back-end gerencia as estruturas de acesso, desenvolvimento e
otimização de consultas, controle de concorrência e recuperação. O front-end dos sistemas de banco de dados
consiste em ferramentas como formulários, gerador de relatórios e recursos de interface gráfica. A interface
entre front-end e o back-end é feita por meio da SQL ou de um programa de aplicação.
Sistemas servidores podem ser caracterizados, de modo geral, como servidores de transações e
servidores de dados.
• Sistemas servidores de transações, também chamados sistemas servidores de consultas (query-server),
proporcionam uma interface por meio da qual os clientes podem enviar pedidos para determinada ação
e, em resposta, eles executam a ação e mandam de volta os resultados ao cliente. Usuários podem
especificar pedidos por SQL ou por meio de um programa de aplicação usando um mecanismo de
chamada de procedimento remota (remote-procedure-call).
• Sistemas servidores de dados permitem que os servidores interajam com clientes que fazem solicitações
de leitura e atualização de dados em unidades como arquivos ou páginas. Por exemplo, servidores de
arquivos que proporcionam uma interface sistema-arquivo na qual os clientes podem criar, atualizar, ler e
remover arquivos. Servidores de dados para sistemas de banco de dados oferecem muito mais recursos:
dão suporte a unidades de dados – como páginas, tuplas ou objetos – menores que um arquivo.
Proporcionam meios para indexação de dados e transações, tal que os dados nunca se tornem
inconsistentes se um equipamento cliente ou processo falhar.

120
Servidores de Transações
Em sistemas centralizados, o front-end e o back-end são ambos executados dentro de um único sistema.
Entretanto, a arquitetura de servidores de transações segue a divisão funcional entre front-end e back-end.
Devido à grande exigência de processamento para código de interface gráfica e ao aumento do poder de
processamento dos computadores pessoais, o recurso para front-end é possível em computadores pessoais. Os
computadores pessoais agem como clientes de sistemas servidores, os quais armazenam grandes volumes de
dados e dão suporte aos recursos de back-end. Clientes enviam solicitações ao sistema servidor no qual essas
transações são executadas e os resultados são enviados de volta ao cliente que tem a responsabilidade de exibir
esses dados.
Padrões do tipo ODBC (open database connectivity) visam atender à interface de clientes e servidores.
ODBC são programas de aplicação de interface que possibilitam aos clientes a criação de comandos SQL que são
enviados para o servidor, no qual são executados. Qualquer cliente que use uma interface ODBC pode se conectar
a qualquer servidor que forneça essa interface. Nas primeiras gerações de sistemas de banco de dados, a falta
desse tipo de padrão levou ao uso de software de mesmo fabricante tanto para back-end quanto para front-end.
Com a difusão de padrões para interfaces, diversos fabricantes passaram a disponibilizar ferramentas de
front-end e os servidores back-end. Gupta SQL e PowerBuilder são exemplos de sistemas front-end
independentes dos servidores back-end. Logo, alguns programas de aplicação, como as planilhas eletrônicas e
pacotes para análise estatística, usarão interfaces cliente-servidor para acesso direto aos dados de um servidor
back-end. Com efeito, eles funcionam como front-ends especializados para tarefas específicas.
Interfaces cliente-servidor não ODBC são também usadas para alguns sistemas de processamento de
transações. São definidas por uma interface de programa de aplicação na qual os clientes enviam chamadas de
procedimento transacional remota (transactional remote procedure call) para o servidor. Essas chamadas
parecem chamadas de procedimentos simples feitas por programas, mas, na verdade, todas as chamadas de
procedimentos simples feitas por programas, mas, na verdade, todas as chamadas de procedimentos remotas
feitas pelo cliente são encapsuladas em uma única transação para o servidor. Assim, se a transação for abortada,
o servidor poderá reverter os resultados da chamada de procedimento remota.
Como os equipamentos pequenos e individuais apresentam atualmente custo bem menor de aquisição e
manutenção, as grandes corporações tendem a adotar o down-sizing. Muitas empresas estão substituindo seus
equipamentos de grande porte por redes de computadores com estacoes de trabalho ou computadores pessoais
conectados a equipamentos servidores back-end. Algumas das vantagens são a maior funcionalidade e o menor
custo, mais flexibilidade na disseminação, expansão e alocação dos recursos, melhores interfaces com os usuários
e manutenção mais fácil.
Servidores de dados
Sistemas servidores de dados são usados em redes locais, nas quais há conexões de alta velocidade entre
clientes e servidores, os equipamentos clientes são comparáveis, em poder de processamento, aos equipamentos
servidores e as tarefas executadas são do tipo processamento intensivo. Em tal ambiente, faz sentido o tráfego de
dados para o equipamento cliente, para o processamento local (o que pode levar certo tempo) e então o envio
dos dados de volta para o servidor. Note que essa arquitetura exige ampla funcionalidade back-end (fig. 16.3) nos
clientes. Arquiteturas de servidores de dados têm sido comuns nos sistemas de banco de dados orientados a
objetos.
A origem do interesse nesse tipo de arquitetura surge a partir do momento em que o custo, relativo ao
consumo de tempo, da comunicação entre cliente e servidor é alta comparada ao tempo de referência à memória
local (milissegundos versus menos de cem nanossegundos).
• Transmissão de páginas versus transferência de itens. A unidade de comunicação para os dados pode ser
de granularidade grossa, como uma página, ou de granularidade fina, como uma tupla (ou um objeto, no
contexto de banco de dados orientado a objetos).

121
Se a unidade de comunicação é um único item, o overhead para a troca de mensagens é alto se
comparado ao volume de dados transmitido. Quando um item é solicitado, faz sentido também enviar
outros itens que certamente serão usados em um futuro próximo. A busca de itens antes mesmo que
sejam solicitados é chamada prefetching. A transferência de páginas pode ser considerada uma forma de
prefetching se diversos itens residirem em uma mesma página, já que todos os itens na página são
transferidos quando um processo deseja ter acesso a um único item de uma página.
• Bloqueio. Os bloqueios, em geral, são utilizados pelo servidor em itens de dados transitando entre
clientes. Uma desvantagem da transferência de páginas é que as máquinas clientes precisam bloquear a
unidade da granularidade – um bloqueio de uma página implica o bloqueio de todos os itens dessa
página. Mesmo que o cliente não esteja acessando mais de um item dessa página, fica implícito o
bloqueio sobre todos os itens reservados. Outro cliente que solicite bloqueio nesses itens será impedido
desnecessariamente. Algumas técnicas para escala de liberação de bloqueio (lock deescalation) já foram
propostas, nas quais o servidor pode solicitar de volta para seus clientes a transferência dos bloqueios
dos itens reservados. Se o cliente não precisar de um item reservado, ele pode transferir o bloqueio do
item de volta ao servidor, que então pode ser bloqueado por outro cliente.
• Data caching. Os dados que navegam para um cliente durante uma transação pode ser cached no cliente,
mesmo depois de completada a transação, se houver espaço suficiente disponível. Transações sucessivas
em um mesmo cliente podem acarretar o uso de dados cached. Entretanto, o uso de cache exige certa
coerência: mesmo que uma transação ache um dado cached, é preciso ter certeza de que esse dado
esteja atualizado, uma vez que ele pode ter sido alterado por um outro cliente depois de ter sido
colocado em cache. Assim, uma mensagem precisará ainda ser trocada com o servidor para checar a
validade e conseguir um bloqueio sobre o dado.
• Bloqueio cache (lock caching). Se os dados forem bem particionados entre os clientes, com um cliente
raramente solicitando um dado ao mesmo tempo que outro, os bloqueios podem também ser
armazenados localmente (cached) no equipamento cliente. Suponha que um item de dado esteja em
cache e que o bloqueio solicitado para acesso a esse dado também esteja em cache. Então, o acesso pode
ser realizado sem qualquer comunicação com o servidor. Entretanto, o servidor precisa controlar os
bloqueios em cache: se um cliente solicita um bloqueio ao servidor, o servidor precisa recuperar todos os
bloqueios em conflito de itens de dados de qualquer outro equipamento cliente que possua bloqueio em
cache. Essa tarefa torna-se muito mais complicada quando são consideradas as falhas de equipamento.
Essa técnica difere da escala de liberação de bloqueios apenas pelo fato de ser realizada ao longo da
transação; de resto, ambas as técnicas são similares.
Sistemas Paralelos
Sistemas paralelos imprimem velocidade ao processamento e à I/O por meio do uso em paralelos de
diversas CPUs e discos. Equipamentos paralelos estão se tornando bastante comuns, fazendo com que o estudo
de sistema de bancos de dados paralelos seja também cada vez mais importante. O direcionamento das atenções
para os sistemas de banco de dados paralelos proveem da demanda de aplicações que geram consultas em banco
de dados muito grandes (da ordem de terabytes – isto é, 1012 bytes) ou que tenham de processar um volume
enorme de transações por segundo (da ordem de milhares de transações por segundo). Sistemas de banco de
dados centralizados e cliente-servidor não são poderosos o suficiente para tratar desse tipo de aplicação.
No processamento paralelo, muitas operações são realizadas simultaneamente, ao contrário do
processamento serial, no qual os passos do processamento são sucessivos. Um equipamento paralelo de
granulação-grossa consiste em poucos e poderosos processadores; um paralelismo intensivo ou de granulação-
fina usa milhares de pequenos processadores; um paralelismo intensivo ou de granulação-fina usa milhares de
pequenos processadores. A maioria das máquinas high-end, atualmente, oferece algum grau de paralelismo de
granulação-grossa: dois a quatro processadores em uma única máquina já é comum. Computadores de
paralelismo intensivo podem ser diferenciados dos equipamentos de paralelismo de granulação-grossa pelo grau

122
de paralelismo muito mais alto que podem oferecer. Computadores paralelos com centenas de CPUs e discos já
estão disponíveis comercialmente.
São duas as principais formas de avaliar o desempenho de um sistema de banco de dados. A primeira é o
throughput: o número de tarefas realizadas em um dado intervalo de tempo. A segunda é o tempo de resposta: o
tempo total que o sistema leva para completar uma única tarefa. Um sistema que processa um grande número de
pequenas transações pode aumentar o throughput por meio do processamento de diversas transações em
paralelo. Um sistema que processa um grande volume de transações pode aumentar o tempo de resposta, assim
como o throughput por meio do processamento em paralelo.
Aceleração e Escalabilidade
Duas metas são importantes no estudo do paralelismo, a aceleração e a escalabilidade. A aceleração
refere-se à redução do tempo de execução de uma tarefa por meio do aumento do grau de paralelismo. A
escalabilidade diz respeito ao manuseio de um maior número de tarefas por meio do aumento do grau de
paralelismo.
Considere uma aplicação de banco de dados rodando em um sistema paralelo com um certo número de
processadores e discos. Agora, suponha que incrementemos o número de processadores ou discos e outros
componentes do sistema. A meta é processar a tarefa em tempo inversamente proporcional aos processadores e
discos alocados. Suponha que o tempo de execução de uma tarefa em um equipamento de grande porte seja TL e
que o tempo de execução da mesma tarefa em uma máquina de menor porte seja TS. A aceleração em função do
paralelismo é definida por Ts/TL.
O sistema paralelo apresenta um comportamento de aceleração linear se a aceleração for N quando um
sistema de maior porte tiver N vezes mais recursos (CPU, disco e assim por diante) que o sistema de menor porte.
Se a aceleração é menor que N, diz-se que o sistema apresenta comportamento de aceleração sublinear. A fig.
16.4 ilustra as acelerações linear e sublinear.
A escalabilidade relaciona-se à capacidade de processar grande volume de tarefas em um mesmo
intervalo de tempo por meio do aumento dos recursos. Seja Que uma tarefa e QN uma tarefa que é N vezes maior
que Q. Suponha que o tempo de execução de Que em um determinado equipamento MS seja TS e o tempo de
execução da tarefa QN em um equipamento paralelo ML, que é N vezes maior que MS, seja TL.
A escalabilidade é, então, definida como TS /TL. o sistema paralelo ML apresenta um comportamento de
escalabilidade linear na tarefa Q se TL = TS. Se TL > TS, o sistema apresenta um comportamento de escalabilidade
sublinear. A fig. 16.5 ilustra a escalabilidade linear e sublinear. Há dois tipos de escalabilidade relevantes em
sistemas de banco de dados paralelos, dependendo de como se mede a tarefa:
• Na escalabilidade em lote (batch), o tamanho do banco de dados aumenta e as tarefas são grandes jobs
cujo tempo de execução depende do tamanho do banco de dados. Um exemplo de tarefa desse tipo é a
pesquisa em uma relação cujo tamanho é proporcional ao tamanho do banco de dados. Assim, o
tamanho do banco de dados é determinante para a medição do problema. A escalabilidade no

123
processamento em lote também vale para as aplicações científicas, como na execução de uma consulta
com refinamento de N vezes ou a execução de uma simulação com N repetições.
• Na escalabilidade de transação, a taxa de submissão das transações para o banco de dados aumenta e o
tamanho do banco de dados aumenta proporcionalmente à taxa de transações. Esse tipo de
escalabilidade é o que é relevante nos sistemas de processamento de transações nos quais as transações
são pequenas atualizações – por exemplo, um depósito ou saque de uma conta – e a taxa de transações
cresce à medida que mais contas são criadas. Esse tipo de processamento de transações é especialmente
adequado para execução em paralelo, uma vez que as transações podem ser executadas concorrente e
independentemente em processadores separados, e cada transação leva, aproximadamente, o mesmo
tempo, até mesmo se o banco de dados crescer.
A escalabilidade é a mais importante métrica para medir a eficiência de um sistema de banco de dados
paralelo. Normalmente, o objetivo do paralelismo em sistemas de banco de dados é garantir um desempenho
aceitável, mesmo se o tamanho do banco de dados e o volume de transações crescerem. O aumento da
capacidade do sistema em função do paralelismo proporciona um caminho mais suave para o crescimento de
uma empresa que a transferência do sistema centralizado para um equipamento mais rápido (mesmo supondo
que tal máquina exista).
Entretanto, devemos também dar uma olhada nos números relativos ao desempenho absoluto quando
avaliamos a escalabilidade: uma máquina cujo crescimento da escalabilidade seja linear pode resultar em um
desempenho pior que outra cuja escala de crescimento seja menor que a linear, porque se partiu de uma
premissa indevida.
Alguns fatores trabalham contra a eficiência das operações em paralelo e podem reduzir tanto a
aceleração quanto a escalabilidade.
• Custo inicial. Existe um custo inicial associado à inicialização de um processo. Em operações paralelas
consistindo de milhares de processos, o tempo de iniciação (startup time) pode se sobrepor ao tempo
real de processamento, afetando de modo negativo a aceleração.
• Interferência. Uma vez que os processos executando em um sistema paralelo frequentemente mantem
seus acessos a recursos compartilhados, alguma lentidão pode resultar da interferência de cada novo
processo, já que ele disputará os recursos comuns com os processos existentes, tais como cabos, discos
compartilhados ou mesmo bloqueios. Tanto a aceleração quanto a escalabilidade são afetadas por esse
fenômeno.
• Distorção (skew). Com a quebra de uma tarefa em um número determinado de passos paralelos
reduzimos o tamanho do passo médio. Nem sempre o tempo de serviço do passo mais lento determinará
o tempo de serviço para a tarefa como um todo. Frequentemente, é difícil dividir uma tarefa em partes
iguais e o modo de estabelecer essas partes é, portanto, distorcido. Por exemplo, se uma tarefa de
tamanho menor que 10 ou de tamanho maior que 10; mesmo que uma tarefa tenha tamanho 20, a

124
aceleração obtida executando as tarefas em paralelo é de apenas 5, em vez de 10, como poderia ser
esperado.
Interconexão de Redes
Os sistemas paralelos são conjuntos de componentes (processadores, memória, e discos) que podem se
comunicar entre si via redes interconectadas. Exemplos de interconexão de redes incluem:
• Bus. Todos os componentes do sistema podem enviar e receber dados em um único bus (cabo) de
comunicação. O bus pode ser uma ethernet ou um interconector paralelo. Arquiteturas com bus
trabalham bem com um pequeno número de processadores. Entretanto, não respondem bem ao
aumento do paralelismo, já que o bus só pode servir a uma comunicação por vez.
• Malha (mesh). Os componentes são organizados como nós de uma grade, e cada componente é
conectado na grade a todos os componentes adjacentes. Em uma malha bidimensional, cada nó é
conectado a quatro nós adjacentes, enquanto em uma malha tridimensional, cada nó é conectado a seis
nós adjacentes. Os nós que não estão diretamente interconectados podem se comunicar roteando
mensagens por meios dos nós intermediários. O número de ligações para comunicação cresce com o
crescimento do número de componentes e a capacidade de comunicação da malha, portanto responde
melhor ao aumento do paralelismo.
• Hipercúbica (hypercube). Os componentes são numerados em binários e um componente é conectado a
outro se a representação binaria de seus números diferirem em exatamente um bit. Assim, cada um dos n
componentes está conectado a log(n) outros componentes. Isso pode ser verificado quando em uma
interconexão hipercúbica uma mensagem de um componente pode alcançar outro por meio de, no
máximo, log(n) ligações. Em contraste, em uma malha, um componente pode manter √�-1 ligacoes com
algum outro componente (ou √�/2 ligacoes, se a interconexão pela malha alcançar as bordas da grade).
Assim, atrasos na comunicação em um hipercubo são significativamente menores que em uma malha.
Arquiteturas de Banco de Dados Paralelo
Há diversos modelos arquitetônicos para máquinas paralelas. Entre elas, as mais promissoras são
mostradas na fig. 16.6 (na figura, M denota memória, P, processador e os discos são representados por cilindros):
• Memória compartilhada. Todos os processadores compartilham uma mesma memória. Esse modelo é
mostrado na fig. 16.6a.
• Disco compartilhado. Todos os processador compartilham o mesmo disco. Esse modelo é mostrado na
fig. 16.6b. Sistemas com discos compartilhados são, às vezes, chamados de clusters.
• Ausência de compartilhamento. Os processadores não compartilham nem a memória nem disco. Esse
modelo é apresentado na figura 16.6c.
• Hierárquico. Esse modelo é mostrado na fig. 16.6d; ele é um hibrido das arquiteturas anteriores.

125
Memória compartilhada
Na arquitetura com memória compartilhada, os processadores e os discos acessam a memória comum,
normalmente, por meio de cabo ou por meio de rede de interconexão. A vantagem da memória compartilhada é
sua extrema eficiência na comunicação entre processadores – qualquer processador pode ter acesso aos dados
em memória compartilhada sem necessidade de ser movido por software. Um processador pode enviar
mensagens a outro processador usando a memória. Essas trocas de mensagens são bem mais rápidas
(normalmente, menos de um microssegundo) se comparadas às que usam mecanismos de comunicação. O
problema das máquinas com memória compartilhada é que a arquitetura não é adequada ao uso de mais de 32
ou 64 processadores, uma vez que o bus ou a interconexão por rede torna-se um gargalo (pois é compartilhado
por todos os processadores). Após determinado ponto, adicionar mais processadores não resolve; eles gastarão a
maior parte de seu tempo esperando sua vez de usar o bus para acesso à memória. Arquiteturas de memória
compartilhada utilizam, normalmente, grande memória cache em cada processador para que o acesso à memória
compartilhada seja evitado sempre que possível. Porém, pelo menos alguns desses dados não estarão em
memória cache e os acessos serão dirigidos à memória compartilhada. Consequentemente, máquinas com
memória compartilhada não possibilitam aumento de escala além de determinado ponto; as máquinas de
memória compartilhada, atualmente, não dão suporte a mais de 64 processadores.
Disco Compartilhado
No modelo de disco compartilhado, todos os processadores podem ter acesso direto a todos os discos, via
interconexão por rede, mas os processadores possuem memórias próprias. Há duas vantagens da arquitetura de
discos compartilhados sobre a de memória compartilhada. Primeiro, uma vez que cada processador possui
memória exclusiva, o bus de memória não representa um gargalo. Segundo, essa arquitetura oferece um modo
barato de aumentar a tolerância a falhas: se o processador (ou sua memória) falha, o outro processador pode
assumir suas tarefas, já que o banco de dados residente nos discos é acessível a todos os processadores. Podemos
fazer o subsistema de discos, ele próprio, tolerante a falhas usando a arquitetura RAID. A arquitetura de discos
compartilhados vem obtendo aceitação em diversos tipos de aplicações; os sistemas construídos sobre
arquitetura desse tipo são frequentemente chamados de clusters.

126
O principal problema dos sistemas de discos compartilhados é, novamente, o grau de crescimento.
Embora o bus de memória não represente mais um gargalo, a restrição é agora a interconexão com o subsistema
de discos; esse caso é particularmente determinante quando o banco de dados acessa muito os discos.
Comparando aos sistemas de memória compartilhada, os sistemas de discos compartilhados podem ser usados
com um número maior de processadores, mas a comunicação entre os processadores é lenta (um pouco acima de
milissegundos quando não há hardware específico para a comunicação), uma vez que ela tem de atravessar a
rede.
Cluster DEC rodando Rdb foi um dos primeiros usuários comerciais a utilizar a arquitetura de discos
compartilhados (o Rdb é atualmente propriedade da Oracle e é chamado de Oracle Rdb).
Ausência de Compartilhamento
Em um sistema sem compartilhamento, cada equipamento de um nó consiste em um processador, uma
memória e discos. O processador de um nó pode comunicar-se com outros processadores de outros nós usando
intercomunicação de rede de alta velocidade. Um nó serve de servidor dos dados alocados em seus discos. Uma
vez que as referências aos discos são atendidas em cada processador por discos locais, o modelo sem
compartilhamento transpõe os percalços de submeter todos os I/Os por meio de uma única rede de
interconexão; somente consultas, acessos a discos remotos e o resultado das relações são transportados por
meio da rede. Além disso, as redes de interconexão dos sistemas sem compartilhamento são normalmente
projetadas para permitir o crescimento de escala, o que significa que sua capacidade aumenta quanto mais nós
são acrescidos. Consequentemente, arquiteturas sem compartilhamento são mais flexíveis quanto à escala e
podem, facilmente, dar suporte a um grande número de processadores. Os principais problemas dos sistemas
sem compartilhamento são os custos de comunicação e os acessos a discos remotos, que são maiores que não
arquitetura com memória ou discos compartilhados, já que a transmissão de dados envolve interação feita por
software em ambos os lados.
A máquina de banco de dados Teradata foi um dos primeiros sistemas comerciais a usar a arquitetura de
banco de dados com ausência de compartilhamento.
Hierárquica
A arquitetura hierárquica combina as características das arquiteturas de compartilhamento de memória e
discos com a arquitetura sem compartilhamento. Em seu nível mais alto, o sistema constitui-se de nós que são
conectados por uma rede sem compartilhar discos ou memória entre si. O topo de linha é um sistema sem
compartilhamento. Cada nó do sistema pode ser um sistema com memória compartilhada entre poucos
processadores. Alternativamente, cada nó poderia ser um sistema de discos compartilhados e cada um desses
sistemas que compartilham um conjunto de discos poderia também compartilhar memória. Desse modo, o
sistema poderia ser construído obedecendo a uma hierarquia, com o compartilhamento de memória por alguns
processadores na base e sem compartilhamento algum no nível mais alto, com possivelmente uma arquitetura de
compartilhamento de discos intermediaria. A fig. 16.6d ilustra uma arquitetura hierárquica de nós com memória
compartilhada conectada por uma arquitetura com ausência de compartilhamento. Sistemas de banco de dados
paralelos comerciais atualmente rodam em diversas dessas arquiteturas.
Tentativas para redução da complexidade de programação desse tipo de sistema resultaram em
arquiteturas de memória virtual distribuída, nas quais há uma única memória lógica compartilhada, mas
fisicamente há diversos sistemas de memória separados; o acoplamento de hardware com mapeamento da
memória virtual por meio de suporte extra de memória oferece uma visa única de área de memória virtual dessas
memórias separadas.
Sistemas Distribuídos
Em um sistema de banco de dados distribuído, o banco de dados é armazenado em diversos
computadores. Os computadores de um sistema de banco de dados distribuído comunica-se com outros por

127
intermédio de vários meios de comunicações, como redes de alta velocidade ou linhas telefônicas. Eles não
compartilha memória principal ou discos. Os computadores em um sistema de banco de dados distribuído podem
variar, quanto ao tamanho e funções, desde estacoes de trabalho até sistemas de grande porte (mainframe).
Os computadores de um sistema de banco de dados distribuído recebem diversos nomes, como sites ou
nós, dependendo do contexto no qual são inseridos. Usaremos preferencialmente o termo site (local, sítio) para
enfatizar a distribuição física desses sistemas. A estrutura geral do sistema distribuído é mostrada na fig. 16.7.
As principais diferenças entre os banco de dados paralelos sem compartilhamento e os banco de dados
distribuídos são que, nos banco de dados distribuídos, há a distribuição física geográfica, administração separada
e uma intercomunicação menor. Outra importante diferença é que, nos sistemas distribuídos, distinguimos
transações locais de globais. Uma transação local acessa um único site, justamente no qual ela se inicia. Uma
transação global, por outro lado, é aquela que busca acesso a diferentes sites, ou a outro site além daquele em
que se inicia.
Exemplo Ilustrativo
Considere o sistema de uma empresa da área bancária que consiste em quatro agências em quatro
cidades diferentes. Cada agência possui seu próprio computador, com um banco de dados abrangendo todas as
contas referentes àquela agência.
Cada uma dessas instalações é, assim, um site. Há também um único site que mantem informações sobre
todas as agências do banco. Cada agência mantém (entre outras) uma relação conta (Esquema_conta), em que:
Esquema_conta = (nome_agência, número_conta, saldo)
O site que mantém informações sobre as quatro agências possui a relação agência(Esquema_agência), em
que:
Esquema_agência = (nome_agência, cidade_agência, fundos)
Há outras relações nos diversos sites; nós a ignoramos em nosso exemplo.
Para ilustrar a diferença entre os dois tipos de transações, consideramos a transação de adicionar 50
dólares à conta A-177 localizada na agência Valleyview. Se uma transação foi iniciada na agência Valleyview, ela é
então considerada local; caso contrário, será considerada global. Uma transação para transferir 50 dólares da
conta A-177 para a conta A-305, a qual está localizada na agência Hillside, é uma transação global, uma vez que
conta em sites diferentes sofrem acessos como resultado de sua execução.
O que faz dessa configuração um sistema de banco de dados distribuído são os seguintes aspectos:

128
• Os vários sites estão disponíveis entre si.
• Os sites compartilham um esquema global comum, embora algumas relações possam estar armazenadas
em alguns sites.
• Cada site proporciona um ambiente para execução tanto de transações locais quanto de transações
globais.
• Cada site roda o mesmo software para o gerenciamento de banco de dados.
Se houver sistemas gerenciadores de banco de dados diferentes rodando nos sites, torna-se difícil o
gerenciamento de transações globais. Tais sistemas são chamados de sistemas de banco de dados múltiplos
(multidatabase) ou sistemas de banco de dados distribuídos heterogêneos.
Tradeoffs
Há diversas razoes para a utilização de sistemas de banco de dados distribuídos, como o
compartilhamento de dados, a autonomia e a disponibilidade.
• Compartilhamento de dados. A maior vantagem de um sistema de banco de dados distribuído é criar um
ambiente no qual os usuários de um site podem ter acesso a dados residentes em outros sites. Por
exemplo, no sistema distribuído bancário usado como exemplo, os usuários de uma agência podem ter
acesso aos dados de outra agência. Sem essa disponibilidade, um usuário que desejasse transferir fundos
de uma agência para outra teria de recorrer a algum mecanismo externo.
• Autonomia. A primeira vantagem do compartilhamento dos dados por meio da distribuição dos dados é
que cada site pode manter certo nível de controle sobre os dados que estão armazenados localmente. Em
sistemas centralizados, o administrado do banco de dados central é quem gerencia o banco de dados. Em
sistemas de banco de dados distribuídos há um administrador geral responsável pelo banco como um
todo. Uma parte dessa responsabilidade é delegada ao administrador local de cada site. Dependendo do
projeto do banco de dados distribuído, os administradores podem possuir diferentes graus de autonomia
local é provavelmente uma das maiores vantagens dos banco de dados distribuídos.
• Disponibilidade. Se um site sai do ar em um sistema distribuído, os demais sites podem continuar em
operação. Particularmente, se os itens de dados são replicados em diversos sites, uma transação que
precise de um item de dado em particular pode encontrar tal item presente em diversos sites. Assim, a
queda de um site não implica, necessariamente, a queda do sistema.
A queda de um site precisa ser detectada pelo sistema, assim como determinadas ações devem ser
executadas para recuperá-lo da falha. O sistema não poderá mais usar os serviços do site fora do ar. Finalmente,
quando um site volta a funcionar ou quando é consertado, é necessário dispor de mecanismos para integrá-lo
paulatinamente ao sistema.
Embora a recuperação de uma falha seja mais complexa nos sistemas distribuídos que nos sistemas
centralizados, a capacidade da maioria dos sistemas manter-se em operação a despeito da falha de um site acaba
por aumentar a disponibilidade. A disponibilidade é crucial para os sistemas de banco de dados usados em
aplicações de tempo real. A perda do acesso aos dados em, por exemplo, uma companhia aérea pode fazer com
que um cliente em potencial prefira viajar com uma companhia concorrente.
A principal desvantagem dos sistemas de banco de dados distribuídos é o acréscimo de complexidade
necessário para assegurar a coordenação entre os sites. Esse aumento de complexidade toma diversas formas:
• Custo de desenvolvimento de software. É mais difícil implementar sistemas de banco de dados
distribuídos, portanto, o custo é mais alto.
• Maior possibilidade de bugs. Uma vez que os sites que constituem o sistema distribuído operam em
paralelo, é difícil assegurar a precisão dos algoritmos, especialmente durante a ocorrência e recuperação
de falha em parte do sistema. Há, potencialmente, a chance de bugs extremamente sutis.

129
• Aumento do processamento e overhead. A troca de mensagens e processamento adicional necessários à
coordenação entre sites são uma forma de overhead que não ocorre nos sistemas centralizados.
Na escolha do projeto do sistema de banco de dados, o projetista deve ponderar as vantagens e
desvantagens da distribuição dos dados. Há diversas abordagens para um projeto de banco de dados distribuído,
partindo de projetos totalmente distribuídos até os que mantêm alto nível de centralização.
Tipos de Redes
Sistemas de banco de dados distribuídos e sistemas cliente-servidor são apoiados em redes de
comunicação. Há basicamente dois tipos de redes: redes locais (local-area networks – LAN) e redes de longa
distância (wide-area networks – WAN). A principal diferença entre as duas é o modo pelo qual são distribuídas
geograficamente. Redes locais são compostas por processadores distribuídos sobre pequenas extensões
geográficas, como um único edifício ou alguns prédios próximos. Redes de longa distância, por outro lado, são
compostas por determinado número de processadores autônomos, distribuídos por uma extensa área geográfica.
Essas diferenças envolvem maiores variações na velocidade e confiabilidade das redes de comunicação e se
refletem no projeto do sistema operacional.
Redes Locais
As redes locais (LANs) apareceram no início dos anos 70 como meio de comunicação entre computadores
e para compartilhamento de dados. Percebeu-se que, em diversas empresas, numerosos pequenos
computadores, cada um com suas próprias aplicações, são mais econômicos que um único grande sistema. Como
cada pequeno equipamento provavelmente necessita de acesso a um grande número de dispositivos periféricos
(como discos e impressoras) e como a necessidade de alguma forma de compartilhamento de dados é
frequentemente em uma empresa, a consequência natural foi a conexão desses pequenos sistemas em uma rede
de computadores.
As LANs são normalmente projetadas para cobrir uma pequena área geográfica e são, geralmente, usadas
me escritórios. Todos os sites deste tipo de sistema estão próximos entre si, assim a comunicação entre eles
tende a manter velocidades mais altas e menores taxas de erro que as apresentadas pelas redes de longa
distância. O tipo de ligação mais comum entre os computadores de uma rede local é o par trançado, cabo coaxial
de banda larga e fibra ótica. A velocidade de comunicação gira em torno de um megabyte por segundo, para rede
como Appletalk e IBM, redes lentas em anel (token ring), até um gigabit por segundo, para redes óticas
experimentais. Dez megabits por segundo é bastante comum, é essa a velocidade da Ethernet. As redes de fibra
ótica FDDI (optical-fiber-based) e Fast Ethernet rodam a cem megabits por segundo. Redes com base no
protocolo chamado protocolo assíncrono (asynchronous transfer mode – ATM) podem alcançar velocidades
superiores, como 144 megabits por segundo, e estão se tornando bastante populares.
Uma LAN típica consiste em diferentes estações de trabalho, um ou mais sistemas servidores, vários
dispositivos periféricos compartilhados (como impressora a laser ou unidades de fita magnética) e um ou mais
gateways (processadores especializados) que proporcionam acesso a outras redes (fig. 16.8). o esquema Ethernet
é usado com frequência em LANs.

130
Redes de Longa Distância
As redes de longa distância (WANs) apareceram no final da década de 1960, principalmente em projetos
de pesquisas acadêmicas para comunicação eficiente entre sites, permitindo que o hardware e o software
pudessem ser compartilhados conveniente e economicamente entre a grande comunidade de usuários. Os
sistemas que permitiram a conexão de terminais remotos com um computador central via linhas telefônicas
foram desenvolvidos no início da década de 1960, embora não fossem de fato uma WAN. A primeira WAN
projetada e desenvolvida foi a Arpanet. Os trabalhos na Arpanet começaram em 1968. A Arpanet desenvolveu-se
a partir de quatro redes experimentais até chegar à rede mundial, a Internet, compreendendo milhões de
sistemas computacionais. A ligação característica da WAN são circuitos telefônicos que usam linhas de fibra ótica
e (por vezes) canais de satélite.
Como exemplo, consideremos a Internet, que conecta computadores pelo mundo. O sistema possibilita
que hosts em sites geograficamente separados comuniquem-se entre si. Os computadores hosts diferem uns dos
outros no tipo, velocidade, tamanho da palavra, sistema operacional, etc. Os hosts são, geralmente, LANs
conectadas a redes regionais. As redes regionais são interligadas a roteadores para formar a rede mundial. As
conexões entre as redes usam frequentemente o serviço de telefonia chamado T1, que oferece taxas de
transferência de cerca de 44.736 megabits por segundo. As mensagens enviadas para a rede são roteadas por
sistemas chamados de roteadores, que controlam o caminho percorrido por cada mensagem através da rede.
Esse roteamento pode ser dinâmico, para aumentar a eficiência da comunicação, ou estático, para reduzir riscos
ou permitir que a carga de comunicação seja processada mais facilmente.
Outras WANs em operação usam linhas telefônicas padrão como principal meio de comunicação. Os
modems são dispositivos que recebem sinal digital de um computador e convertem esses dados em sinais
analógicos, que são usados pelo sistema de telefonia. Um modem no site de destino converte o sinal analógico
em digital e, assim, o equipamento de destino recebe o dado. A velocidade dos modems varia de 2400 bips a 32
kilobits por segundo. Os sistemas de telefonia que aceitam o padrão Rede Digital de Serviços Integrados
(Integrated Services Digital Network – ISDN) permitem que os dados sejam transferidos ponto a ponto a altas
taxas, normalmente 128 kilobits por segundo.
A rede UNIX, UUCCP, permite que os sistemas se comuniquem uns com os outros um número limitado de
vezes (e, geralmente, predeterminado), via modems, para troca de mensagens. Essas mensagens são roteadas
para outro sistema próximo e, dessa forma, propagadas para todos os hosts da rede (mensagens publicas) ou
transferidas para seu destino (mensagens particulares).

131
As WANs são classificadas em dois tipos:
• WAN conexão descontínua, como aquelas que têm por base a UUCP, em que os hosts estão conectados à
rede somente por determinados períodos.
• WAN conexão contínua, como a Internet, cujos hosts estão conectados à rede o tempo todo.
O projeto de um sistema de banco de dados distribuído é fortemente influenciado pelo tipo de WAN de
apoio. Os verdadeiros sistemas de banco de dados distribuídos podem rodar apenas sobre as redes conectadas
continuamente – pelo menos durante as horas em que o banco de dados distribuído está operacional.
Redes que não estão continuamente conectadas, geralmente, não permitem transações entre sites, mas
tomam cópias locais dos dados remotos e atualizam periodicamente essas cópias (toda noite, por exemplo). Para
aplicações cuja consistência não seja crítica, como compartilhamento de documentos, sistemas de trabalho em
grupo (groupware systems) como o Lotus Notes, permitem atualizações em dados remotos feitos localmente e
essas atualizações retornam periodicamente ao site remoto. Há conflito potencial de atualizações entre sites que
precisa ser detectado e resolvido. Um mecanismo para detecções de atualizações conflitantes existe; o
mecanismo para resolução de conflitos de atualização, entretanto, é dependente da aplicação.
Arquitetura de sistemas de bancos de dados
INTRODUÇÃO
Agora temos condições de apresentar uma arquitetura para um sistema de bancos de dados. Nosso
objetivo ao apresentar essa arquitetura é fornecer um arcabouço sobre o qual possamos desenvolver os capítulos
subsequentes. Esse arcabouço é útil para descrever conceitos gerais de bancos de dados e explicar a estrutura de
sistemas de bancos de dados específicos — mas não afirmamos que todo sistema pode se enquadrar bem nesse
arcabouço em particular, nem queremos sugerir que essa arquitetura prevê o único arcabouço possível. Em
especial, é provável que sistemas “pequenos” (ver Capítulo 1) não ofereçam suporte para todos os aspectos da
arquitetura. Porém, a arquitetura em questão de fato parece se ajustar razoavelmente bem à maior parte dos
sistemas; além disso, ela é basicamente idêntica à arquitetura proposta pelo ANSI/SPARC Study Group on Data
Base Management Systems (a chamada arquitetura ANSI/SPARC — consulte as referências [2.1-2.2]). Contudo,
optamos por não seguir a terminologia ANSI/SPARC em todos os detalhes.
OS TRÊS NÍVEIS DA ARQUITETURA
A arquitetura ANSI/SPARC se divide em três níveis, conhecidos como nível interno, nível conceitual e nível
externo, respectivamente (ver Figura 2.1). De modo geral:
• O nível interno (também conhecido como nível físico) é o mais próximo do meio de armazenamento físico — ou
seja, é aquele que se ocupa do modo como os dados são fisicamente armazenados.
• O nível externo (também conhecido como nível lógico do usuário) é o mais próximo dos usuários — ou seja, é
aquele que se ocupa do modo como os dados são vistos por usuários individuais.
• O nível conceitual (também conhecido como nível lógico comunitário, ou às vezes apenas nível indireto, sem
qualificação) é um nível de “simulação” entre os outros dois.
Observe que o nível externo se preocupa com as percepções dos usuários individuais, enquanto o nível
conceitual está preocupado com uma percepção da comunidade de usuários. Em outras palavras, haverá muitas
“visões externas” distintas, cada qual consistindo em uma representação mais ou menos abstrata de alguma
parte do banco de dados completo, e haverá exatamente uma “visão conceitual”, consistindo em uma
representação analogamente abstrata do banco de dados em sua totalidade.* (Lembre-se de que a maioria dos
usuários não estará interessada em todo o banco de dados, mas somente em alguma porção restrita do banco de
dados.) Do mesmo modo, haverá precisamente uma “visão interna”, representando o modo como o banco de
dados está fisicamente armazenado.

132
Um exemplo ajudará a esclarecer essas ideias. A Figura 2.2 mostra a visão conceitual, a visão interna
correspondente e duas visões externas correspondentes (uma para um usuário PL/I e outra para um usuário
COBOL), todas para um simples banco de dados de pessoal. É claro que o exemplo é inteiramente hipotético —
ele não pretende se assemelhar a qualquer sistema real — e muitos detalhes irrelevantes foram deliberadamente
omitidos. Explicação:
• No nível conceitual, o banco de dados contém informações relativas a um tipo de entidade chamada
EMPREGADO. Cada empregado individual tem um NUMERO_EMPREGADO (seis caracteres), um
NUMERO_DEPARTAMENTO (quatro caracteres) e um SALARIO (cinco dígitos decimais).
• No nível interno, os empregados são representados por um tipo de registro armazenado, denominado
EMP_ARMAZENADO, com vinte bytes de comprimento. EMP_ARMAZENADO contém quatro campos
armazenados: um prefixo de seis bytes (presumivelmente contendo informações de controle, tais como flags ou
ponteiros) e três campos de dados correspondentes às três propriedades de empregados. Além disso, os registros
EMP_ARMAZENADO são indexados sobre o campo EMP# por um índice chamado EMPX, cuja definição não é
mostrada.
• O usuário PL/I tem uma visão externa do banco de dados na qual cada empregado é representado por um
registro PL/I que contém dois campos (números de departamentos não são de interesse para esse usuário, e por
isso foram omitidos da visão). O tipo de registro é definido por uma declaração de estrutura PL/I comum, de
acordo com as regras normais de PL/I.
• De modo semelhante, o usuário COBOL tem uma visão externa em que cada empregado é representado por um
registro COBOL contendo, mais uma vez, dois campos (agora, foram omitidos os salários). O tipo de registro é
definido por uma descrição comum de registro COBOL, de acordo com as regras normais do COBOL.
Observe que itens de dados correspondentes podem ter nomes diferentes em pontos diferentes. Por
exemplo, a referência ao número do empregado é chamada EMP# na visão externa de PL/I, EMPNO na visão
externa COBOL, NUMERO EMPREGADO na visão conceitual e novamente EMP# na visão interna. É claro que o
sistema deve estar ciente das correspondências; por exemplo, ele tem de ser informado de que o campo EMPNO
do COBOL é derivado do campo conceitual Por abstrata, queremos dizer nesse caso apenas que a representação

133
em questão envolve construções como registros e campos, mais orientadas para o usuário, em oposição a
construções como bits e bytes, mais orientadas para a máquina.
Observe que faz pouca diferença para as finalidades deste capítulo saber se o sistema que está sendo
considerado é relacional ou não. Contudo, pode ser útil indicar de forma resumida como os três níveis da
arquitetura são em geral percebidos especificamente em um sistema relacional:
• Primeiro, o nível conceitual em tal sistema será definitivamente relacional, no sentido de que os objetos visíveis
nesse nível serão tabelas relacionais, e os operadores serão operadores relacionais (incluindo, em especial, os
operadores de restrição e projeção examinados de forma abreviada no Capítulo 1).
• Em segundo lugar, uma determinada visão externa também será tipicamente relacional, ou algo muito próximo
disso; por exemplo, as declarações de registros PL/I ou COBOL da Figura 2.2 podem ser consideradas de maneira
informal, respectivamente, os equivalentes PL/I ou COBOL da declaração de uma tabela relacional em um sistema
relacional.
Nota: devemos mencionar de passagem que o termo “visão externa” (em geral abreviado apenas como “visão”)
infelizmente tem um significado bastante específico em contextos relacionais que não é idêntico ao significado
atribuído ao termo neste capítulo. Consulte os Capítulos 3 e 9 para ver uma explicação e uma descrição do
significado relacional.
• Terceiro, o nível interno não será relacional, porque os objetos nesse nível não serão apenas tabelas relacionais
(armazenadas) — em vez disso, eles serão os mesmos tipos de objetos encontrados no nível interno de qualquer
outra espécie de sistema (registros armazenados, ponteiros, índices, hashing etc.). De fato, o modelo relacional
em si não tem absolutamente nenhuma relação com o nível interno; ele se preocupa, como vimos no Capítulo 1,
com o modo como o banco de dados é visto pelo usuário.
Agora vamos prosseguir com o exame dos três níveis da arquitetura com um nível muito maior de
detalhes, começando pelo nível externo. Em toda a nossa descrição, faremos repetidas referências à Figura 2.3,
que mostra os principais componentes da arquitetura e seus inter-relacionamentos pelo administrador de banco
de dados (DBA) .

134
O NÍVEL EXTERNO O nível externo é o nível do usuário individual. Como foi explicado no Capítulo 1, um determinado usuário pode ser ou programador de aplicações ou um usuário final com qualquer grau de sofisticação. (O DBA é um caso especial importante; porém, diferentemente de outros usuários, o DBA também precisará estar interessado nos níveis conceitual e interno. Consulte as duas seções seguintes.)
Cada usuário tem uma linguagem à sua disposição: • Para o programador de aplicações, essa linguagem será uma linguagem de programação convencional (como PL/I, C+ +, Java) ou uma linguagem proprietária específica para o sistema em questão. Essas linguagens proprietárias são frequentemente chamadas de linguagens de “quarta geração” (L4Gs), pelo fato (muito difuso!) de que (a) o código de máquina, a linguagem assembler e a linguagem PL/I podem ser consideradas como três “gerações” mais antigas de linguagens e (b) as linguagens proprietárias representam o mesmo tipo de aperfeiçoamento em relação às linguagens de “terceira geração” (L3Gs) que essas linguagens representavam em relação à linguagem assembler e esta última, por sua vez, representava em relação ao código de máquina. • Para o usuário final, a linguagem será uma linguagem de consulta ou alguma linguagem de uso especial, talvez dirigida por formulários ou menus, adaptada aos requisitos desse usuário e com suporte de algum programa aplicativo on-line.
Para nossos propósitos, o ponto importante sobre todas essas linguagens é que elas incluirão uma sublinguagem de dados — isto é, um subconjunto da linguagem completa relacionado de modo específico aos objetos e às operações do banco de dados. A sublinguagem de dados (abreviada como DSL — data sublanguage — na Figura 2.3) é dita embutida na linguagem hospedeira correspondente. A linguagem hospedeira é responsável pelo fornecimento de diversos recursos não relacionados com bancos de dados, como variáveis locais, operações de cálculo, lógica de desvios condicionais (if-then-else), e assim por diante. Um dado sistema poderia admitir qualquer número de linguagens hospedeira e qualquer número de sublinguagens de dados; porém, uma determinada sublinguagem de dados reconhecida por quase todos os sistemas atuais é a linguagem SQL, discutida brevemente no Capítulo 1. A maioria desses sistemas permite que a SQL seja usada tanto de modo interativo como uma linguagem de consulta autônoma, quanto incorporada a outras linguagens como PL/I ou Java (consulte o Capítulo 4 para ver detalhes adicionais). Observe que, embora seja conveniente para propósitos arquiteturais distinguir entre a sublinguagem de dados e

135
a linguagem hospedeira que a contém, as duas podem de fato não ser distintas para o usuário; na verdade, talvez seja preferível sob a perspectiva do usuário que elas não sejam distintas. Se elas não forem distintas, ou se só puderem ser distinguidas com dificuldade, diremos que elas estão fortemente acopladas. Se forem clara e facilmente distinguíveis, dizemos que elas estão fracamente acopladas. Apesar de alguns sistemas comerciais (em especial sistemas de objetos — ver Capítulo 24) admitirem o acoplamento forte, a maioria não o aceita. Em particular, os sistemas SQL costumam oferecer suporte apenas para o acoplamento fraco. (O acoplamento forte oferece um conjunto de recursos mais uniforme para o usuário, mas sem dúvida envolve maior esforço por parte dos desenvolvedores de sistemas, um fato que presumivelmente contribui para o status quo.) Em princípio, qualquer sublinguagem de dados determinada é, na realidade, uma combinação de pelo menos duas linguagens subordinadas — uma linguagem de definição de dados (DDL — Data Definition Language), que dá suporte à definição ou à declaração de objetos dos bancos de dados, e uma linguagem de manipulação de dados (DML — Data Manipulation Language), que admite a manipulação ou o processamento desses objetos. Por exemplo, considere o usuário PL/I da Figura 2.2, na Seção 2.2. A sublinguagem de dados para esse usuário consiste nos recursos de PL/I utilizados para a comunicação com o SGBD: • A parte de DDL consiste nas construções declarativas de PL/I necessárias para se declararem objetos do banco de dados — a própria instrução DECLARE(DEL), certos tipos de dados de PL/I, possivelmente extensões especiais de PL/I para oferecer suporte a novos objetos não manipulados pela PL/I existente. • A parte da DML consiste nas instruções executáveis de PL/I que transferem informações de e para o banco de dados — mais uma vez incluindo, possivelmente, novas instruções especiais. Nota: mas precisamente, devemos dizer que a PL/I não inclui na realidade nenhum recurso específico de bancos de dados na época em que este livro foi escrito. Em particular, as instruções de “DML” costumam ser apenas instruções CALL de PL/I que invocam o SGBD (embora essas chamadas possam estar sintaticamente disfarçadas de algum modo, a fim de torná-las um pouco mais amistosas para o usuário — consulte a discussão sobre a SQL embutida no Capítulo 4).
Voltando à arquitetura: já indicamos que um usuário individual geralmente só estará interessado em alguma parte do banco de dados como um todo; além disso, a visão que esse usuário tem dessa parte será em geral um tanto abstrata quando comparada com o modo como os dados estão fisicamente armazenados. O termo ANSI/SPARC para a visão de um usuário individual é visão externa. Uma visão externa é, portanto, o conteúdo do banco de dados visto por algum usuário determinado (ou seja, para esse usuário a visão externa é o banco de dados). Por exemplo, um usuário do Departamento de Pessoal poderia considerar o banco de dados uma coleção de ocorrências de registros de departamentos e empregados, e ele poderia não ter nenhum conhecimento das ocorrências de registros de fornecedores e peças vistas pelos usuários do Departamento de Compras.
Nível Conceitual A visão conceitual é uma representação de todo conteúdo de informação de informações do banco de dados, mais uma vez (como no caso de uma visão externa) em uma forma um tanto abstrata, em comparação com o modo como os dados são visualizados por qualquer usuário em particular. Em termos gerais, a visão conceitual pretende ser uma visão dos dados “como eles realmente são”, em vez de forçar os usuários a vê-los pelas limitações (por exemplo) da linguagem ou do hardware que eles possam estar utilizando. A visão conceitual consiste em muitas ocorrências de cada um dos vários tipos de registros conceituais. Por exemplo, ela pode consistir em uma coleção de ocorrências de registros de departamentos, junto com uma coleção de ocorrências de registros de empregados, junto com uma coleção de ocorrências de registros de fornecedores, mais uma coleção de ocorrências de registros de peças, e assim por diante. Um registro conceitual não é necessariamente o mesmo que um registro externo, nem o mesmo que um registro armazenado. A visão conceitual é definida por meio do esquema conceitual, que inclui definições de cada um dos vários tipos de registros conceituais (mais uma vez, observe um exemplo simples da fig. 2.2). o esquema conceitual é escrito por meio de outra linguagem de definição de dados, a DDL conceitual. Se quisermos alcançar a independência física dos dados, então essas definições de DDL conceitual não deverão envolver quaisquer considerações sobre a representação física ou a técnica conceitual, não deverá haver nenhuma referência a representações de campos armazenados, sequencias de registros armazenados, índices, esquemas de hashing, ponteiros ou quaisquer outros detalhes de armazenamento e acesso. Se o esquema conceitual se tornar verdadeiramente independente de dados dessa maneira, então os esquemas externos, definidos em termos do esquema conceitual, também são independentes dos dados. Portanto, a visão conceitual é uma visão do conteúdo total do banco de dados, e o esquema conceitual é uma definição dessa visão. Porém, seria enganoso sugerir que o esquema conceitual nada mais é do que um

136
conjunto de definições muito semelhante às definições de registros simples, encontradas hoje em (por exemplo) um programa COBOL. As definições no esquema conceitual têm por finalidade incluir muitos recursos adicionais, como as restrições de segurança e integridade. Algumas autoridades no assunto chegariam até a sugerir que o objetivo final do esquema conceitual é descrever a empresa inteira – não apenas seus dados em si, mas também o modo como esses dados são usados; como eles fluem de um ponto para outro dentro da empresa, para q eles são usados em cada ponto, quais controles de auditoria ou outros controles devem ser aplicados em cada ponto, e assim por diante. No entanto, devemos enfatizar que nenhum sistema atual admite realmente um esquema conceitual q sequer se aproxime desse grau de complexidade; na maior parte dos sistemas existentes, o “esquema conceitual” é, na verdade, pouco mais que uma simples união de todos os esquemas externos individuais, juntamente com determinadas restrições de segurança e integridade. Porém, sem dúvida, é possível q sistemas futuros eventualmente se tornem muito mais sofisticados em seu suporte ao nível conceitual. O NÍVEL INTERNO
O terceiro nível da arquitetura é o nível interno. A visão interna é uma representação de baixo nível do banco de dados por inteiro; ela consiste em muitas ocorrências de cada um dos vários tipos de registros internos. “Registro interno” é o termo ANSI/SPARC que representa a construção que temos chamado de registro armazenado (e continuaremos a usar essa última forma). Assim, a visão interna ainda está muito afastada do nível físico, pois ela não lida com registros físicos — também chamados blocos ou páginas — nem com quaisquer considerações específicas de dispositivos, como tamanhos de cilindros ou trilhas. Em outras palavras, a visão interna pressupõe efetivamente um espaço de endereços linear infinito; os detalhes de como esse espaço de endereços é mapeado no meio de armazenamento físico são bastante específicos para cada sistema e foram deliberadamente omitidos da arquitetura geral. Nota: o bloco, ou a página, é a unidade de entrada e saída (E/S) — isto é, ele representa a quantidade de dados transferidos entre o meio de armazenamento secundário e a memória principal em uma única operação de E/S. Os tamanhos de páginas típicos são 1 K, 2 K ou 4 K bytes (K = 1.024). A visão interna é descrita por meio do esquema interno, que não somente define os diversos tipos de registros armazenados mas também especifica quais índices existem, como os campos armazenados estão representados, em que sequência física estão os registros armazenados, e assim por diante (mais uma vez, veja na Figura 2.2 um exemplo simples). O esquema interno é escrito usando-se ainda outra linguagem de definição de dados — a DDL interna. Nota: neste livro, usaremos normalmente os termos mais intuitivos “estrutura de armazenamento” ou “banco de dados armazenado” em vez de “visão interna”, e ainda “definição de estrutura de armazenamento” em lugar de “esquema interno”.
Para encerrar lembramos que, em certas situações excepcionais, os programas aplicativos — em particular as aplicações de natureza utilitária (ver Seção 2.11) — podem ter permissão para operar diretamente no nível interno, e não no nível externo. Não é preciso dizer que essa prática não é recomendável; ela representa um risco de segurança (pois as restrições de segurança são ignoradas) e um risco de integridade (pois também as restrições de integridade são ignoradas), e o programa terá uma inicialização dependente dos dados; porém, às vezes essa poderá ser a única maneira de obter a funcionalidade ou o desempenho exigido — do mesmo modo o usuário em uma linguagem de programação de alto nível poderia ter a necessidade ocasional de descer até a linguagem assembler para satisfazer certos objetivos de funcionalidade ou desempenho.
MAPEAMENTOS Além dos três níveis básicos, a arquitetura da Figura 2.3 envolve, em geral, certos mapeamentos — um mapeamento conceitual/interno e vários mapeamentos externos/conceituais: • O mapeamento conceitual/interno define a correspondência entre a visão conceitual e o banco de dados armazenado; ele especifica o modo como os registros e campos conceituais são representados no nível interno. Se a estrutura do banco de dados armazenado for alterada — isto é, se for efetuada uma mudança na definição do banco de dados armazenado – o mapeamento conceitual/interno terá de ser alterado de acordo, a fim de q o esquema conceitual possa permanecer invariável. (é responsabilidade do DBA, ou provavelmente, do SGBD, administrar tais alterações.) Em outras palavras, os efeitos dessas mudanças devem ser isolados abaixo do nível conceitual, a fim de preservar a independência de dados física. • Definir o esquema interno

137
O DBA também deve decidir como serão representados os dados no banco de dados armazenado. Em geral, esse processo é chamado projeto de banco de dados físico.* Tendo elaborado o projeto físico, o DBA deve então criar a definição da estrutura de armazenamento correspondente (isto é, o esquema interno), usando a DDL interna. Além disso, ele também deve definir o mapeamento conceitual/interno associado. Na prática, a DDL conceitual ou a DDL interna — mais provavelmente a primeira — deverá incluir os meios para definir esse mapeamento, mas as duas funções (criação do esquema, definição do mapeamento) devem ser claramente distinguíveis. Como no caso do esquema conceitual, o esquema interno e o mapeamento correspondente existirão tanto na forma de fonte quanto de objeto. • Ligação com usuários É tarefa do DBA fazer a ligação com os usuários, a fim de garantir que os dados de que eles necessitam estarão disponíveis, e escrever (ou ajudar os usuários a escreverem) os esquemas externos necessários, usando a DDL externa aplicável. (Como já foi dito, um dado sistema pode admitir várias DDLs externas distintas.) Além disso, os mapeamentos externos/conceituais correspondentes também devem ser definidos. Na prática, a DDL externa provavelmente incluirá os meios para especificar esses mapeamentos, mas, de novo, os esquemas e os mapeamentos devem ser claramente distinguíveis. Cada esquema externo e o mapeamento correspondente deverão existir tanto na forma de fonte quanto de objeto. Outros aspectos da função de ligação com o usuário incluem a consultoria em projeto de aplicações, o fornecimento de instrução técnica, a assistência para determinação e resolução de problemas e serviços profissionais semelhantes. • Definir restrições de segurança e integridade Como já vimos, as restrições de segurança e integridade podem ser consideradas uma parte do esquema conceitual. A DDL conceitual deve incluir recursos para a especificação de tais restrições. • Definir normas de descarga e recarga Uma vez que uma empresa esteja comprometida com um sistema de banco de dados, ela se torna dependente de modo crítico do sucesso desse sistema. Em caso de danos a qualquer parte do banco de dados — provocados por erro humano, digamos, ou por uma falha de hardware ou do sistema operacional — é essencial ser capaz de reparar os dados em questão com um mínimo de demora e com o menor efeito possível sobre o restante do sistema. Por exemplo, em condições ideais, a disponibilidade dos dados que não tenham sido danificados não deve ser afetada. O DBA tem de definir e implementar um esquema apropriado de controle de danos, em geral envolvendo (a) descarga periódica ou dumping do banco de dados para o meio de armazenamento de backup e (b) recarregamento do banco de dados quando necessário, a partir do dump mais recente. A propósito, a discussão anterior fornece uma razão pela qual seria uma boa ideia espalhar a coleção total de dados por vários bancos de dados, em vez de manter tudo em um único lugar; o banco de dados individual poderia muito bem formar a unidade para finalidades de descarga e recarregamento. Nessa linha, observe que já existem sistemas terabyte** — isto é, instalações de bancos de dados comerciais que armazenam bem mais de um trilhão de bytes de dados, em termos informais — e que os sistemas do futuro deverão ser muito maiores. E desnecessário dizer que tais sistemas VLDB (“banco de dados muito grande” — very large database) exigem administração muito cuidadosa e sofisticada, em especial se houver um requisito de disponibilidade contínua (que normalmente existe). Não obstante, por simplicidade, continuaremos a falar como se de fato houvesse um único banco de dados. * Observe a sequência: primeiro, defina que dados você deseja; depois, decida como representá-los no meio de armazenamento.
O projeto físico sempre deve ser feito depois do projeto lógico. **1.o24 bytes = um kilobyte (KB); 1.024 KB = um megabyte (MB); 1.024 MB = um gigabyte (GB); 1.024 GB um terabyte (TB); 1.024 TB = um petabyte (PB); 1.024 PB = um exabyte (EB). Observe que, informalmente, um gigabyte equivale a um bilhão de bytes (a abreviatura BB é empregada às vezes em lugar de GB).

138
• Monitorar o desempenho e responder a requisitos de mudanças Como foi indicado na Seção 1.4, o DBA é responsável pela organização do sistema de modo a
obter o desempenho que seja “o melhor para a empresa”, e por fazer os ajustes apropriados — isto é, a sintonia fina (tuning) — conforme os requisitos se alterarem. Por exemplo, poderia ser necessário reorganizar o banco de dados armazenado de tempos em tempos para assegurar que os níveis de desempenho permanecerão aceitáveis. Como já mencionamos, qualquer mudança no nível de armazenamento físico (interno) do sistema deve ser acompanhada por uma mudança correspondente na definição do mapeamento de nível conceitual/interno, de modo que o esquema conceitual possa permanecer constante. E claro que a lista anterior não esgota o assunto — ela pretende apenas dar uma ideia da extensão e da natureza das responsabilidades do DBA. O SISTEMA DE GERENCIAMENTO DE BANCOS DE DADOS
O sistema de gerenciamento de bancos de dados (SGBD) é o software que trata de todo o acesso ao banco de dados. Conceitualmente, o que ocorre é o seguinte (observe mais uma vez a Figura 2.3): 1. Um usuário faz um pedido de acesso usando uma determinada sublinguagem de dados (em geral, SQL). 2. O SGBD intercepta o pedido e o analisa. 3. O SGBD inspeciona, por sua vez, o esquema externo (ou as versões objeto desse esquema) para esse usuário, o mapeamento externo/conceitual correspondente, o esquema conceitual, o mapeamento conceitual/interno e a definição da estrutura de armazenamento. 4. O SGBD executa as operações necessárias sobre o banco de dados armazenado. Como exemplo, considere as ações relacionadas com a busca de uma determinada ocorrência de registro externo. Em geral, serão necessários campos de várias ocorrências de registros conceituais e, por sua vez, cada ocorrência de registro conceitual exigirá campos de várias ocorrências de registros armazenados. Então, conceitualmente, o SGBD deve primeiro buscar todas as ocorrências necessárias de registros armazenados, depois construir as ocorrências de registros conceituais exigidas e, em seguida, construir a ocorrência de registro externo. Em cada estágio, podem ser necessárias conversões de tipos de dados ou outras conversões. Naturalmente, a descrição anterior é muito simplificada; em particular, ela implica que todo o processo é interpretativo, à medida que sugere que os processos de análise do pedido, inspeção dos diversos esquemas etc., são todos realizados durante a execução. A interpretação, por sua vez, em geral implica um desempenho sofrível devido à sobrecarga em tempo de execução. Porém, na prática talvez seja possível fazer os pedidos de acesso serem compilados antes do momento da execução (em particular, diversos produtos atuais de SQL fazem isso — consulte as anotações relativas às referências [4.12] e [4.26] do Capítulo 4). Vamos examinar agora as funções do SGBD com um pouco mais de detalhes. Essas funções incluirão o suporte a pelo menos todos os itens a seguir (observe a Figura 2.4): • Definição de dados O SGBD deve ser capaz de aceitar definições de dados (esquemas externos, o esquema conceitual, o esquema interno e todos os mapeamentos associados) em forma fonte e convertê-los para a forma objeto apropriada. Em outras palavras, o SGBD deve incluir componentes de processador de DDL ou compilador de DDL para cada uma das diversas linguagens de definição de dados (DDLs). O SGBD também deve “entender” as definições da DDL, no sentido de que, por exemplo, ele “entende” que os registros externos EMPREGADO incluem um campo SALARIO; ele deve então ser capaz de usar esse conhecimento para analisar e responder a pedidos de manipulação de dados (por exemplo, “obtenha todos os empregados com salário < R$ 50.000,00”). • Manipulação de dados O SGBD deve ser capaz de lidar com solicitações do usuário para buscar, atualizar ou excluir dados existentes no banco de dados, ou para acrescentar novos dados ao banco de dados. Em outras

139
palavras, o SGBD deve incluir um componente processador de DML ou compilador de DML para lidar com a linguagem de manipulação de dados (DML — data manipulation language). Em geral, as solicitações de DML podem ser “planejadas” ou “não-planejadas”: a. Uma solicitação planejada é aquela para a qual a necessidade foi prevista com bastante antecedência em relação ao momento em que a solicitação é executada. O DBA provavelmente terá ajustado o projeto de banco de dados físico de modo a garantir um bom desempenho para solicitações planejadas. b. Em contraste, uma solicitação não-planejada é uma consulta ad hoc, isto é, uma solicitação cuja necessidade não foi prevista com antecedência mas, em vez disso, surgiu no último instante. O projeto de banco de dados físico pode estar ou não adaptado de forma ideal para a solicitação específica sendo considerada. Para usar a terminologia introduzida no Capítulo 1 (Seção 1.3), as solicitações planejadas são características de aplicações “operacionais” ou “de produção”, ao passo que as solicitações não-planejadas são características de aplicações para “apoio à decisão”. Além disso, as solicitações planejadas em geral serão emitidas a partir de programas aplicativos escritos previamente, enquanto as solicitações não-planejadas serão, por definição, emitidas de modo interativo por meio de algum processador de linguagem de consulta. Nota: como vimos no Capítulo 1, o processador de linguagem de consulta é na realidade uma aplicação on-line embutida, não uma parte do SGBD per se; ele foi incluído na Figura 2.4 por completitude. • Otimização e execução As requisições de DML, planejadas ou não-planejadas, devem ser processadas pelo componente otimizador, cujo propósito é determinar um modo eficiente de implementar a requisição. A otimização é discutida em detalhes no Capítulo 17. As requisições otimizadas são então executadas sob o controle do gerenciador em tempo de execução (run time). Nota: na prática, o gerenciador em tempo de execução provavelmente invocará algum tipo de gerenciador de arquivos para obter acesso aos dados armazenados. Os gerenciadores de arquivos são descritos resumidamente no final desta seção. • Segurança e integridade de dados O SGBD deve monitorar requisições de usuários e rejeitar toda tentativa de violar as restrições de segurança e integridade definidas pelo DBA (consulte a seção anterior). Essas tarefas podem ser executadas em tempo de compilação ou em tempo de execução, ou ainda em alguma mistura dos dois. • Recuperação e concorrência de dados O SGBD — ou, mais provavelmente, algum outro componente de software relacionado, cm geral chamado gerenciador de transações ou monitor de processamento de transações (monitor TP) — deve impor certos controles de recuperação e concorrência. Os detalhes desses aspectos do sistema estão além do escopo deste capítulo; consulte a Parte IV deste livro, que contém uma descrição em profundidade do assunto. Nota: o gerenciador de transações não é mostrado na Figura 2.4 porque, em geral, ele não faz parte do SGBD propriamente dito.
• Dicionário de dados O SGBD deve fornecer uma função de dicionário de dados. O dicionário de dados pode ser considerado um banco de dados em si (mas um banco de dados do sistema, não um banco de dados impõem restrições - de segurança e integridade do usuário), O dicionário contém “dados sobre os dados” (às vezes chamados metadados ou descritores) — ou seja, definições de outros objetos do sistema, em vez de “dados brutos” somente. Em particular, todos os vários esquemas e mapeamentos (externos, conceituais etc.) e todas as diversas restrições de segurança e integridade estarão armazenados, tanto na forma de fonte quanto de objeto, no dicionário. Um dicionário completo também incluirá muitas informações adicionais mostrando, por exemplo, os programas que utilizam determinadas partes do banco de dados, os usuários que exigem certos relatórios, os terminais conectados ao sistema, e assim por diante. O dicionário poderia até estar — na verdade, provavelmente deve estar — integrado ao banco de dados que define e, portanto, incluir sua própria definição. Por certo, deve haver a opção de consultar o dicionário como qualquer outro banco de dados para que, por exemplo, seja possível saber que programas e/ou usuários terão maior probabilidade de serem afetados

140
por alguma alteração proposta no sistema. Consulte o Capítulo 3 para ver uma discussão adicional sobre o assunto. Nota: estamos entrando agora em uma área sobre a qual existe muita confusão de terminologia. Algumas pessoas fariam referência ao que estamos chamando de dicionário como um diretório ou catálogo, o que implica que diretórios ou catálogos são de algum modo inferiores a um verdadeiro dicionário — e reservariam o termo dicionário para designar uma variedade específica (importante) de ferramenta para desenvolvimento de aplicações. Outros termos que também são algumas vezes empregados para designar essa última variedade de objetos são repositório de dados (ver Capítulo 13) e enciclopédia de dados.
É desnecessário dizer que o SGBD deve realizar todas as funções identificadas anteriormente de forma tão eficiente quanto possível.
Podemos resumir tudo o que foi mencionado antes afirmando que a função geral do SGBD é fornecer a interface do usuário para o sistema de banco de dados. A interface do usuário pode ser definida como a fronteira no sistema abaixo da qual tudo é invisível para o usuário. Por definição, portanto, a interface do usuário está no nível externo. Contudo, como veremos no Capítulo 9, há algumas situações em que é improvável que a visão externa seja significativamente diferente da porção relevante da visão conceitual subjacente, pelo menos nos produtos SQL comerciais de hoje.
Concluímos esta seção com uma breve comparação entre os sistemas de gerenciamento de bancos de dados discutidos anteriormente e os sistemas de gerenciamento de arquivos (gerenciadores de arquivos ou servidores de arquivos). Em linhas gerais, o gerenciador de arquivos é o componente do sistema operacional básico que administra arquivos armazenados; portanto, em termos informais, ele está “mais próximo ao disco” que o SGBD. (Na verdade, o SGBD costuma ser montado sobre algum tipo de gerenciador de arquivos.) Desse

141
modo, o usuário de um sistema de gerenciamento de arquivos será capaz de criar e destruir arquivos armazenados e de executar operações simples de busca e atualização sobre registros armazenados em tais arquivos. No entanto, em contraste com o SGBD: • Os gerenciadores de arquivos não têm conhecimento da estrutura interna dos registros armazenados e, por isso, não podem lidar com requisições que dependam de um conhecimento dessa estrutura. • Em geral, eles fornecem pouco ou nenhum suporte para restrições de segurança e integridade. • Em geral, eles fornecem pouco ou nenhum suporte para controles de recuperação e concorrência. • Não há verdadeiramente um conceito de dicionário de dados no nível do gerenciador de arquivos. • Eles proporcionam muito menos independência de dados que o SGBD. • Em geral, os arquivos não estão “integrados” ou “compartilhados” no mesmo sentido que o banco de dados (normalmente, eles são privativos de algum usuário ou alguma aplicação em particular). O GERENCIADOR DE COMUNICAÇÕES DE DADOS
Nesta seção, consideraremos resumidamente o tópico de comunicações de dados. As requisições a bancos de dados de um usuário final são, na verdade, transmitidas da estação de trabalho do usuário — que pode estar fisicamente afastada do próprio sistema de banco de dados — para alguma aplicação on-line (embutida ou não), e daí até o SGBD, sob a forma de mensagens de comunicação. De modo semelhante, as respostas do SGBD e da aplicação on-line para a estação de trabalho do usuário também são transmitidas sob a forma de mensagens. Todas essas transmissões de mensagens têm lugar sob o controle de outro componente de software, o gerenciador de comunicações de dados (gerenciador DE — data communications).
O gerenciador DE não faz parte do SGBD, mas é um sistema autônomo. Porém, como o gerenciador DE e o SGBD são claramente obrigados a trabalhar em harmonia, às vezes os dois são considerados parceiros de igual nível em um empreendimento cooperativo de nível mais alto, denominado sistema de banco de dados/comunicações de dados (sistema DB/DE), no qual o SGBD toma conta do banco de dados e o gerenciador DE manipula todas as mensagens de e para o SGBD ou, mais precisamente, de e para aplicações que utilizam o SGBD. Porém, neste livro, teremos pouco a dizer sobre o manejo de mensagens como essas (o que, por si só, é um assunto extenso). A Seção 2.12 descreve resumidamente a questão das comunicações entre sistemas distintos (ou seja, entre máquinas diferentes em uma rede de comunicações, como a Internet), mas esse é, na realidade, um tópico à parte. ARQUITETURA CLIENTE/SERVIDOR
Descrevemos até agora neste capítulo os sistemas de bancos de dados sob o ponto de vista da chamada arquitetura ANSI/SPARC. Em particular, a Figura 2.3 forneceu uma representação simplificada dessa arquitetura. Nesta seção, examinaremos os sistemas de bancos de dados sob uma perspectiva um pouco diferente. Naturalmente, o objetivo geral desses sistemas é fornecer suporte ao desenvolvimento e à execução de aplicações de bancos de dados. Portanto, sob um ponto de vista de mais alto nível, um sistema de banco de dados pode ser considerado como tendo uma estrutura muito simples em duas partes, consistindo em um servidor (também chamado back end) e um conjunto de clientes (também chamados front ends). Consulte a Figura 2.5. Explicação: • O servidor é o próprio SGBD. Ele admite todas as funções básicas de SGBDs discutidas na Seção 2.8 — definição de dados, manipulação de dados, segurança e integridade de dados, e assim por diante. Em particular, ele oferece todo o suporte de nível externo, conceitual e interno que examinamos nas Seções 2.3 a 2.6. Assim, o termo “servidor” neste contexto é tão-somente um outro nome para o SGBD. • Os clientes são as diversas aplicações executadas sobre o SGBD — tanto aplicações escritas por usuários quanto aplicações internas, ou seja, aplicações fornecidas pelo fabricante do SGBD ou por produtores independentes. No que se refere ao servidor, é claro que não existe nenhuma diferença entre aplicações escritas pelo usuário e aplicações internas — todas elas empregam a mesma interface para o servidor, especificamente a interface de nível externo discutida na Seção 2.3.

142
Nota: certas aplicações especiais chamadas “utilitários” poderiam constituir uma exceção ao que vimos antes, pois às vezes elas podem precisar operar diretamente no nível interno do sistema (conforme mencionamos na Seção 2.5). Esses utilitários devem ser considerados componentes integrais do SGBD, em vez de aplicações no sentido usual. Os utilitários serão discutidos com mais detalhes na próxima seção. Vamos aprofundar o exame da questão de aplicações escritas pelo usuário versus aplicações fornecidas pelo fabricante: • Aplicações escritas pelo usuário são basicamente programas aplicativos comuns, escritos (em geral) em uma linguagem de programação convencional de terceira geração (L3G), como C ou COBOL, ou então em alguma linguagem proprietária de quarta geração (L4G) — embora em ambos os casos a linguagem precise ser de algum modo acoplada a uma sublinguagem de dados apropriada, conforme explicamos na Seção 2.3. Banco de dados • Aplicações fornecidas por fabricante (chamadas frequentemente de ferramentas — tools) são aplicações cuja finalidade básica é auxiliar na criação e execução de outras aplicações! As aplicações criadas são aplicações adaptadas a alguma tarefa específica (elas podem não ser muito semelhantes às aplicações no sentido convencional; de fato, a finalidade das ferramentas é permitir aos usuários, em especial aos usuários finais, criar aplicações sem ter de escrever programas em uma linguagem de programação convencional). Por exemplo, uma das ferramentas fornecidas pelo fabricante será um gerador de relatórios, cuja finalidade é permitir que os usuários finais obtenham relatórios formatados a partir do sistema sob solicitação. Qualquer solicitação de relatório pode ser considerada um pequeno programa aplicativo, escrito em uma linguagem de geração de relatórios de nível muito alto (e finalidade especial). As ferramentas fornecidas pelo fabricante podem ser divididas em diversas classes mais ou menos distintas: a. Processadores de linguagem de consulta. b. Geradores de relatórios. c. Subsistemas gráficos de negócios. d. Planilhas eletrônicas. e. Processadores de linguagem natural. f. Pacotes estatísticos. g. Ferramentas para gerenciamento de cópias ou “extração de dados”. h. Geradores de aplicações (inclusive processadores L4G). i. Outras ferramentas para desenvolvimento de aplicações, inclusive produtos de engenharia de software auxiliada pelo computador (CASE — computer-aided software engineering). Os detalhes dessas ferramentas e de várias outras estão além do escopo deste livro; entretanto, observamos que, tendo em vista que (como foi dito antes) toda a importância de um sistema de banco de dados está em dar suporte à criação e à execução de aplicações, a qualidade das ferramentas disponíveis é, ou deve ser, um fator preponderante na “decisão sobre o banco de dados” (isto é, o processo de escolha do produto de banco de dados apropriado). Em outras palavras, o SGBD em si não é o único fator que precisa ser levado em consideração, nem mesmo é necessariamente o fator mais significativo. Encerramos esta seção com uma referência para o que se segue. Como o sistema por completo pode estar tão claramente dividido em duas partes, servidores e clientes, surge a possibilidade de executar os dois em

143
máquinas diferentes. Em outras palavras, existe o potencial para o processamento distribuído. O processamento distribuído significa que máquinas diferentes podem estar conectadas entre si para formar algum tipo de rede de comunicações, de tal modo que uma única tarefa de processamento de dados possa ser dividida entre várias máquinas na rede. Na verdade, essa possibilidade é tão atraente — por urna variedade de razões, principalmente de ordem econômica — que o termo “cliente/servidor” passou a se aplicar a quase exclusivamente ao caso em que o cliente e o servidor estão de fato localizados em máquinas diferentes. Examinaremos o processamento distribuído com mais detalhes na Seção 2.12. UTILITÁRIOS Utilitários são programas projetados para auxiliar o DBA com diversas tarefas administrativas. Como mencionamos na seção anterior, alguns programas utilitários operam no nível externo do sistema e, portanto, são na verdade apenas aplicações de uso especial; alguns podem nem mesmo ser fornecidos pelo fabricante do SGBD, mas sim por algum fabricante independente. Porém, outros utilitários operam diretamente no nível interno (em outras palavras, eles realmente fazem parte do servidor) e, desse modo, devem ser oferecidos pelo fornecedor do SGBD.
Aqui estão alguns exemplos dos tipos de utilitários que costumam ser necessários na prática: • Rotinas de carga, a fim de criar a versão inicial do banco de dados a partir de um ou mais arquivos do sistema operacional. • Rotinas de descarregamento/recarregamento, a fim de descarregar o banco de dados, ou partes dele, para o meio de armazenamento de backup e recarregar dados dessas cópias de backup (é claro que o “utilitário de recarregamento” é basicamente idêntico ao utilitário de carga que acabamos de mencionar). • Rotinas de reorganização, a fim de rearranjar os dados no banco de dados armazenado por várias razões (em geral, relacionadas com o desempenho) — por exemplo, para agrupar dados de algum modo particular no disco, ou para reaver o espaço ocupado por dados que se tornaram obsoletos. • Rotinas estatísticas, a fim de calcular diversas estatísticas de desempenho, tais como tamanhos de arquivos e distribuição de valores de dados ou contagens de E/S etc. • Rotinas de análise, a fim de analisar as estatísticas mencionadas antes. A lista precedente representa apenas uma pequena amostra das funções em geral oferecidas pelos utilitários; existe uma série de outras possibilidades. PROCESSAMENTO DISTRIBUÍDO Repetindo o que mencionamos na Seção 2.10, a expressão “processamento distribuído” significa que máquinas diferentes podem estar conectadas entre si em uma rede de comunicações como a Internet, de tal modo que uma única tarefa de processamento de dados possa se estender a várias máquinas na rede. (A expressão “processamento paralelo” também é utilizada algumas vezes com significado quase idêntico, exceto pelo fato de que as diferentes máquinas tendem a manter uma certa proximidade física em um sistema “paralelo” e não precisam estar tão próximas em um sistema “distribuído” — por exemplo, elas poderiam estar geograficamente dispersas no último caso.) A comunicação entre as várias máquinas é efetuada por algum tipo de software de gerenciamento de rede — possivelmente uma extensão do gerenciador DE discutido na Seção 2.9 ou, com maior probabilidade, um componente de software separado.
São possíveis muitos níveis ou variedades de processamento distribuído. Conforme mencionamos na Seção 2.10, um caso simples envolve a execução do back end do SGBD (o servidor) em uma das máquinas e dos front ends da aplicação (os clientes) em outra. Ver Figura 2.6.
Como vimos no final da Seção 2.10, o termo “cliente/servidor”, embora seja estritamente uma expressão relacionada com a arquitetura, passou a ser quase um sinônimo da disposição ilustrada na Figura 2.6, na qual o cliente e o servidor funcionam em máquinas diferentes. De fato, há muitos argumentos em favor de um esquema desse tipo: • O primeiro é basicamente o argumento usual sobre o processamento paralelo: especificamente, muitas unidades de processamento estão sendo agora aplicadas na tarefa global, enquanto o processamento do servidor (o banco de dados) e o processamento do cliente (a aplicação) estão sendo feitos em paralelo. O tempo de resposta e a vazão (throughput) devem assim ser melhorados. • Além disso, a máquina servidora pode ser uma máquina feita por encomenda para se ajustar à função de SGBD (uma “máquina de banco de dados”) e pode assim fornecer melhor desempenho de SGBD.

144
• Do mesmo modo, a máquina cliente poderia ser uma estação de trabalho pessoal, adaptada às necessidades do usuário final e, portanto, capaz de oferecer interfaces melhores, alta disponibilidade, respostas mais rápidas e, de modo geral, maior facilidade de utilização para o usuário.
• Várias máquinas clientes distintas poderiam ser capazes (na verdade, normalmente serão capazes) de obter acesso à mesma máquina servidora. Assim, um único banco de dados poderia ser compartilhado entre vários sistemas clientes distintos (ver Figura 2.7).
Além dos argumentos anteriores, existe também o fato de que a execução do(s) cliente(s) e do servidor em máquinas diferentes combina com a maneira como as empresas operam na realidade. E bastante comum que uma única empresa — um banco, por exemplo — opere muitos computadores, de tal modo que os dados correspondentes a uma parte da empresa sejam armazenados em um computador e os dados de outra parte sejam armazenados em outro computador. Prosseguindo com o exemplo do banco, é muito provável que os usuários de uma agência precisem ocasionalmente obter acesso a dados armazenados em outra agência. Portanto, observe que as máquinas clientes poderiam ter seus próprios dados armazenados, e a máquina servidora poderia ter suas próprias aplicações. Dessa forma, em geral caia maquina atuará como um servidor para alguns usuários e como cliente para outros (ver Figura 2.8); em outras palavras, cada máquina admitirá um sistema de banco de dados por inteiro, no sentido estudado em seções anteriores deste capítulo. O último ponto a mencionar é que uma única máquina cliente poderia ser capaz de obter acesso a várias máquinas servidoras diferentes (a recíproca do caso ilustrado na Figura 2.7). Esse recurso é desejável porque, como mencionamos antes, as empresas em geral operam de tal maneira que a totalidade de seus dados não fica armazenada em uma única máquina, mas se espalha por muitas máquinas diferentes, e as aplicações às vezes precisarão ter a capacidade de conseguir acesso a dados de mais de uma máquina. Basicamente, esse acesso pode ser fornecido de dois modos distintos: • Um dado cliente pode ser capaz de obter acesso a qualquer número de servidores, mas somente um de cada vez (ou seja, cada requisição individual ao banco de dados tem de ser direcionada para apenas um servidor). Em um sistema desse tipo não é possível, dentro de uma única requisição, combinar dados de dois ou mais servidores diferentes. Além disso, o usuário de tal sistema tem de saber qual máquina em particular contém cada um dos fragmentos de dados. • O cliente pode ser capaz de obter acesso a muitos servidores simultaneamente (isto é, uma única solicitação ao banco de dados poderia ter a possibilidade de combinar dados de vários servidores). Nesse caso, os servidores aparentam para o cliente — de um ponto de vista lógico — ser realmente um único servidor, e o usuário não precisa saber qual máquina contém cada um dos itens de dados.

145
Esse último caso constitui um exemplo daquilo que se costuma chamar sistema de banco de dados
distribuído, O tema de bancos de dados distribuídos é um grande tópico por si só; levado a sua conclusão lógica, o suporte completo a bancos de dados distribuídos implica que uma única aplicação deve ser capaz de operar “de modo transparente” sobre dados espalhados por uma variedade de bancos de dados diferentes, gerenciados por uma variedade de SGBDs diferentes, funcionando em uma variedade de máquinas distintas, com suporte de uma variedade de sistemas operacionais diferentes e conectados entre si por meio de uma variedade de redes de comunicações diferentes — onde “de modo transparente” significa que a aplicação opera, de um ponto de vista lógico, como se os dados fossem todos gerenciados por um único SGBD funcionando em uma única máquina. Esse recurso pode parecer algo muito difícil de conseguir, mas é altamente desejável de uma perspectiva prática, e os fabricantes estão trabalhando arduamente para tornar realidade esses sistemas. Discutiremos em detalhes os sistemas de bancos de dados distribuídos no Capítulo 20.

146
Normalização
O conceito de normalização foi introduzido por E. F. Codd em 1970 (primeira forma normal). Esta técnica
é um projeto matemático formal, que tem seus fundamentos na teoria dos conjuntos.
Através deste processo pode-se, gradativamente, substituir um conjunto de entidades e relacionamentos
por um outro, o qual se apresenta “purificado” em relação às anomalias de atualização (inclusão, alteração e
exclusão) as quais podem causar certos problemas, tais como: grupos repetitivos (atributos multivalorados) de
dados, dependências parciais em relação a uma chave concatenada, redundância de dados desnecessários,
perdas acidentais de informação, dificuldade na representação de fatos da realidade observada e dependências
transitivas entre atributos.
Os conceitos abordados podem ser aplicados às duas formas de utilização da normalização:
- sentido de cima para baixo (TOP-DOWN):
Após a definição de um modelo de dados, aplica-se a normalização para se obter uma síntese dos dados,
bem como uma decomposição das entidades e relacionamentos em elementos mais estáveis, tendo em vista sua
implementação física em um banco de dados;
- sentido de baixo para cima (BOTTON-UP):
Aplicar a normalização como ferramenta de projeto do modelo de dados, usando os relatórios,
formulários e documentos utilizados pela realidade em estudo, constituindo-se em uma ferramenta de
levantamento.
Anomalias de Atualização
Observando-se o formulário de PEDIDO apresentado na fig. 12.1, podemos considerar que uma entidade
formada com os dados presentes terá a seguinte apresentação:
• Atributos da entidade PEDIDO:
o número do pedido
o prazo de entrega
o cliente
o endereço
o cidade
o UF
o CGC
o inscrição estadual
o código do produto (*)
o unidade do produto (*)
o quantidade do produto (*)
o descrição do produto (*)
o valor unitário do produto (*)
o valor total do produto (*)
o valor total do pedido (*)
o código do vendedor
o nome do vendedor
(*) Atributos que se repetem no documento

147
Caso a entidade fosse implementada como uma tabela em um banco de dados, as seguintes anomalias
iriam aparecer:
• anomalia de inclusão: ao ser incluído um novo cliente, o mesmo tem que estar relacionado a uma venda;
• anomalia de exclusão: ao ser excluído um cliente, os dados referentes as suas compras serão perdidos;
• anomalia de alteração: caso algum fabricante de produto altere a faixa de preço de uma determinada
classe de produtos, será preciso percorrer toda a entidade para se realizar múltiplas alterações.
Primeira forma normal (1FN)
Em uma determinada realidade, às vezes encontramos algumas informações que se repetem (atributos
multivalorados), retratando ocorrências de um mesmo fato dentro de uma única linha e vinculadas a sua chave
primária.
Ao observarmos a entidade PEDIDO, apresentada acima, visualizamos um certo grupo de atributos
(produtos solicitados) se repete (número de ocorrências não definidas) ao longo do processo de entrada de dados
na entidade.
A 1FN diz que: cada ocorrência da chave primária deve corresponder a uma e somente uma informação
de cada atributo, ou seja, a entidade não deve conter grupos repetitivos (multivalorados).

148
Para se obter entidades na 1FN, é necessário decompor cada entidade não normalizada em tantas
entidades quanto for o número de conjuntos de atributos repetitivos. Nas novas entidades criadas, a chave
primária é a concatenação da chave primária da entidade original mais o(s) atributo(s) do grupo repetitivo
visualizado(s) como chave primária desse grupo.
Para a entidade PEDIDO, temos:
Entidade não normalizada:
Ao aplicarmos a 1FN sobre a entidade PEDIDO, obtemos mais uma entidade chamada de ITEM-DE-
PEDIDO, que herdará os atributos repetitivos e destacados da entidade PEDIDO.

149
Um PEDIDO possui no mínimo 1 e no máximo N elementos de ITEM-DE-PEDIDO e um ITEM-DE-PEDIDO
pertence a 1 e somente 1 PEDIDO, logo o relacionamento POSSUI é do tipo 1:N.
Variação Temporal e a Necessidade de Histórico
Observamos que normalmente, ao se definir um ambiente de armazenamento de dados, seja ele um
banco de dados ou não, geralmente se mantém a última informação cadastrada, que às vezes, por sua própria
natureza, possui um histórico de ocorrências. Mas como a atualização é sempre feita sobre esta última
informação, perdem-se totalmente os dados passados.
A não-observação deste fato leva a um problema na hora de uma auditoria de sistemas, que em vez de
utilizar uma pesquisa automatizada sobre os históricos, se vê obrigada a uma caçada manual cansativa sobre um
mar imenso de papeis e relatórios, e que na maioria das vezes se apresenta incompleta ou inconsistente devido a
valores perdidos (documentos extraviados) ou não documentados.
Com a não-utilização de históricos e a natural perda destas informações, a tomada de decisões por parte
da alta administração de uma empresa pode levar a resultados catastróficos para a corporação.
Toda vez que a decisão de armazenar o histórico de algum atributo for tomada, cria-se explicitamente um
relacionamento de um para muitos (1-N), entre a entidade que contém o atributo e a entidade criada para conter
o histórico deste atributo. Passa a existir então uma entidade dependente, contendo (no mínimo) toda data em
que houve alguma alteração do atributo bem como o respectivo valor do atributo para cada alteração. A chave
desta entidade de histórico será concatenada, e um de seus atributos será a data de referência.

150
Com base nesta necessidade de armazenamento de históricos, após a aplicação da 1FN devemos observar
para cada entidade definida, quais de seus atributos se transformarão com o tempo, se é preciso armazenar
dados históricos deste atributo e em caso afirmativo, observar o período de tempo que devemos conservar este
histórico, ou através de quantas alterações foram realizadas neste atributo.
Dependência Funcional
Para descrevermos as próximas formas normais, se faz necessária a introdução do conceito de
dependência funcional, sobre o qual a maior parte da teoria de normalização foi baseada.
Dada uma entidade qualquer, dizemos que um atributo ou conjunto de atributos A é dependente
funcional de um outro atributo B contido na mesma entidade, se a cada valor de B existir nas linhas da entidade
em que aparece, um único valor de A. Em outras palavras, A depende funcionalmente de B.
Ex.: Na entidade PEDIDO, o atributo PRAZO-DE-ENTREGA depende funcionalmente de NÚMERO-DO-
PEDIDO.
O exame das relações existentes entre os atributos de uma entidade deve ser feito a partir do
conhecimento (conceitual) que se tem sobre a realidade a ser modelada.
Dependência Funcional Total (Completa) e Parcial
Na ocorrência de uma chave primária concatenada, dizemos que um atributo ou conjunto de atributos
depende de forma completa ou total desta chave primária concatenada, se e somente se, a cada valor da chave (e
não parte dela), está associado um valor para cada atributo, ou seja, um atributo não (dependência parcial) se
apresenta com dependência completa ou total quando só dependente de parte da chave primária concatenada e
não dela como um todo.
Ex.: dependência total – na entidade ITEM-DO-PEDIDO, o atributo QUANTIDADE-DO-PRODUTO depende
de forma total ou completa da chave primária concatenada (NÚMERO-DO-PEDIDO+CODIGO-DO-PRODUTO).
A dependência total ou completa só ocorre quando a chave primária for composta por vários
(concatenados) atributos, ou seja, em uma entidade chave primária composta de um único atributo não ocorre
este tipo de dependência.
Dependência Funcional Transitiva
Quando um atributo ou conjunto de atributos A depende de outro atributo B que não pertence à chave
primária, mas é dependente funcional desta, dizemos que A é dependente transitivo de B.
Ex.: dependência transitiva – na entidade PEDIDO, os atributos ENDEREÇO, CIDADE, UF, CGC e INSCRIÇÃO-
ESTATUAL são dependentes transitivos do atributo CLIENTE. Nesta mesma entidade, o atributo NOME-DO-
VENDEDOR é dependente transitivo do atributo CODIGO-DO-VENDEDOR.
Com base na teoria sobre as dependências funcionais entre atributos de uma entidade, podemos
continuar com a apresentação das outras formas normais.
Segunda Forma Normal (2FN)
Devemos observar se alguma entidade possui chave primária concatenada, e para aqueles que
satisfizerem esta condição, analisar se existe algum atributo ou conjunto de atributos que dependem desta chave
parcial, ou seja, uma entidade para estar na 2FN não pode ter atributos com dependência parcial em relação à
chave primária.
Ex.: A entidade ITEM-DO-PEDIDO apresenta uma chave primária concatenada e por observação, notamos
que os atributos UNIDADE-DO-PRODUTO, DESCRIÇÃO-DO-PRODUTO e VALOR-UNITARIO depende de forma
parcial do atributo CODIGO-DO-PRODUTO, que faz parte da chave primária. Logo devemos aplicar a 2FN sobre
esta entidade. Quando aplicamos a 2FN sobre ITEM-DO-PEDIDO, será criada a entidade PRODUTO que herdará os
atributos UNIDADE-DO-PRODUTO, DESCRIÇÃO-DO-PRODUTO e VALOR-UNITÁRIO e terá como chave primária o
CODIGO-DO-PRODUTO.
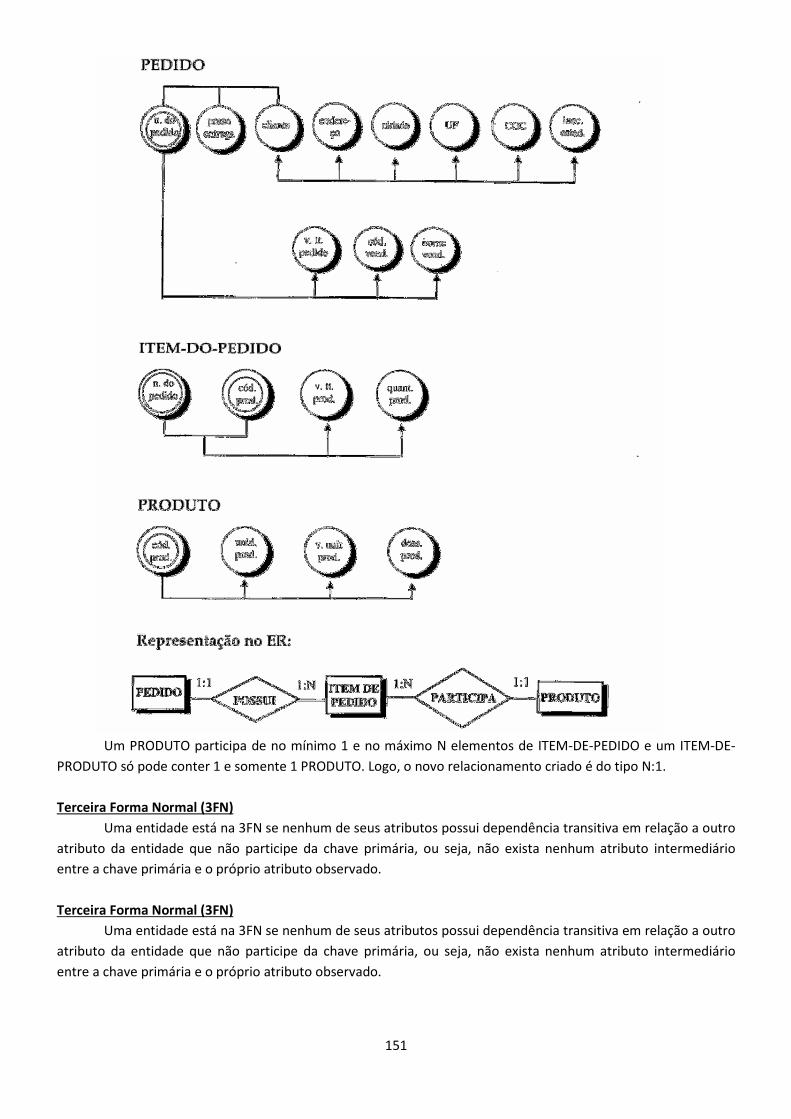
151
Um PRODUTO participa de no mínimo 1 e no máximo N elementos de ITEM-DE-PEDIDO e um ITEM-DE-
PRODUTO só pode conter 1 e somente 1 PRODUTO. Logo, o novo relacionamento criado é do tipo N:1.
Terceira Forma Normal (3FN)
Uma entidade está na 3FN se nenhum de seus atributos possui dependência transitiva em relação a outro
atributo da entidade que não participe da chave primária, ou seja, não exista nenhum atributo intermediário
entre a chave primária e o próprio atributo observado.
Terceira Forma Normal (3FN)
Uma entidade está na 3FN se nenhum de seus atributos possui dependência transitiva em relação a outro
atributo da entidade que não participe da chave primária, ou seja, não exista nenhum atributo intermediário
entre a chave primária e o próprio atributo observado.

152
Ao retirarmos a dependência transitiva, devemos criar uma nova entidade que contenha os atributos que
contenha os atributos que dependem transitivamente de outro e sua chave primária é o atributo que causou esta
dependência.
Além de não conter atributos com dependência transitiva, entidades na 3FN não devem conter atributos
que sejam o resultado de algum cálculo sobre outro atributo, que de certa forma pode ser encarada como uma
dependência funcional.
Ex.: Na entidade PEDIDO, podemos observar que o atributo NOME-DO-VENDEDOR depende
transitivamente do atributo CODIGO-DO-VENDEDOR que não pertence à chave primária. Para eliminarmos esta
anomalia devemos criar a entidade VENDEDOR, com o atributo NOME-DO-VENDEDOR e tendo como chave
primária o atributo CODIGO-DO-VENDEDOR.
Encontramos ainda o conjunto de atributos formados por ENDEREÇO, CIDADE, UF, CGC e INSCRIÇÃO-
ESTADUAL que dependem transitivamente do atributo CLIENTE. Neste caso, devemos criar a entidade
VENDEDOR, com o atributo NOME-DO-VENDEDOR e tendo como chave primária o atributo CODIGO-DO-
VENDEDOR.
Encontramos ainda o conjunto de atributos formados por ENDEREÇO, CIDADE, UF, CGC e INSCRIÇÃO-
ESTADUAL que dependem transitivamente do atributo CLIENTE. Neste caso, devemos criar a entidade CLIENTE
que conterá os atributos ENDEREÇO, CIDADE, UF, CGC e INSCRIÇÃO-ESTADUAL. Para chave primária desta
entidade vamos criar um atributo chamado CODIGO-DO-CLIENTE que funcionará melhor como chave primária do
que NOME-DO-CLIENTE, deixa este último como simples atributo da entidade CLIENTE.

153
Um PEDIDO só é feito por um e somente um CLIENTE e um CLIENTE pode fazer de zero (clientes que
devem ser contatados mais frequentemente pelos vendedores) até N elementos de PEDIDO. Um PEDIDO só é
tirado por um e somente um VENDEDOR e um VENDEDOR pode tirar de zero (vendedores que devem ser
reciclados em termos de treinamento, para aumentar o poder de venda) a N elementos de PEDIDO.
Forma Normal de BOYCE/CODD (FNBC)
As definições da 2FN e 3FN, desenvolvidas por Codd, não cobriam certos casos. Esta inadequação foi
apontada por Raymond Boyce em 1974. Os casos não cobertos pelas definições de Codd somente ocorrem
quando três condições aparecem juntas:
• a entidade tenha várias chaves candidatas;
• estas chaves candidatas sejam concatenadas (mais de um atributo);
• as chaves concatenadas compartilham pelo menos um atributo comum.
Na verdade, a FNBC é uma extensão da 3FN, que não resolvia certas anomalias presentes na informação contida
em uma entidade. O problema foi observado porque a 2FN e a 3FN só tratavam dos casos de dependência parcial
e transitiva de atributos fora de qualquer chave, porém quando o atributo observado estiver contido em uma
chave (primária ou candidata), ele não é captado pelo verificação da 2FN e 3FN.
A definição da FNBC é a seguinte: uma entidade está na FNBC se e somente se todos os determinantes
forem chaves candidatas. Notem que esta definição é em termos de chaves candidatas e não sobre chaves
primárias.
Considere a seguinte entidade FILHO:

154
Por hipótese, vamos assumir que um professor possa estar associado a mais de uma escola e uma sala.
Sob esta suposição, tanto a chave (candidata) concatenada NOME-DA-ESCOLA+SALA-DA-ESCOLA bem como
NOME-DA-ESCOLA+NOME-DO-PROFESSOR podem ser determinantes. Logo esta entidade atende às três
condições relacionadas anteriormente:
• as chaves candidatas para a entidade FILHO são: NOME-DO-FILHO+ENDEREÇO-DO-FILHO+NÚMERO-DA-
SALA e NOME-DO-FILHO+NOME-DO-PROFESSOR;
• todas as três chaves apresentam mais de um atributo (concatenados);
• todas as três chaves compartilham um mesmo atributo: NOME-DO-FILHO.
Neste exemplo, NOME-DO-PROFESSOR não é completamente dependente funcional do NÚMERO-DA-
SALA, nem NÚMERO-DA-SALA é completamente dependente funcional do NOME-DO-PROFESSOR. Neste caso,
NOME-DO-PROFESSOR é realmente completamente dependente funcional da chave candidata concatenada
NOME-DO-FILHO+NOME-DO-PROFESSOR.
Ao se aplicar FNBC, a entidade FILHO deve ser dividida em duas entidades, uma que contém todos os
atributos que descrevem o FILHO, e uma segunda que contém os atributos que designam um professor em uma
particular escola e número de sala.
Quarta Forma Normal (4FN)
Na grande maioria dos casos, as entidades normalizadas até a 3FN são fáceis de entender, atualizar e de
se recuperar dados. Mas às vezes podem surgir problemas com relação a algum atributo não chave, que recebe
valores múltiplos para um mesmo valor de chave. Esta nova dependência recebe o nome de dependência
multivalorada que existe somente se a entidade contiver no mínimo três atributos.
Uma entidade que esteja na 3FN também está na 4FN, se ela não contiver mais do que um fato
multivalorado a respeito da entidade descrita. Esta dependência não é o mesmo que uma associação M:N entre
atributos, geralmente descrita desta forma em algumas literaturas.

155
Ex.: Dada a entidade hipotética a seguir:
Como podemos observar, esta entidade tenta conter dois fatos multivalorados: as diversas peças
compradas e os diversos compradores. Com isso apresenta uma dependência multivalorada entre CODIGO-
FORNECEDOR e o CODIGO-PEÇA e entre CÓDIGO-FORNECEDOR e o CODIGO-COMPRADOR. Embora esteja na 3FN,
ao conter mais de um fato multivalor, torna sua atualização muito difícil, bem como a possibilidade de problemas
relativos ao espaço físico de armazenamento poderem ocorrer, causados pela ocupação desnecessária de área de
memória (primária ou secundária), podendo acarretar situações críticas em termos de necessidade de mais
espaço para outras aplicações.
Para passarmos a entidade acima para a 4FN, é necessária a realização de uma divisão da entidade
original, em duas outras, ambas herdando a chave CODIGO-FORNECEDOR e concatenado, em cada nova entidade,
com os atributos CODIGO-PEÇA e CODIGO-COMPRADOR.
Quinta Forma Normal (5FN)
Esta última forma normal trata do conceito de dependência de junção, quando a noção de normalização é
aplicada à decomposição, devido a uma operação de projeção, e aplicada na reconstrução devido a uma junção.
A 5FN trata de casos bastantes particulares, que ocorrem na modelagem de dados, que são os
relacionamentos múltiplos (ternários, quaternários, ..., n-ários). Ela fala que um registro está na sua 5FN, quando
o conteúdo deste mesmo registro não puder ser reconstruído (junção) a partir de outros registros menores,
extraídos deste registro principal. Ou seja, se ao particionar um registro, e sua junção posterior não conseguir
recuperar as informações contidas no registro original, então este registro está na 5FN.
Vamos ilustrar o uso da 5FN utilizando um exemplo de relacionamento ternário:
Ex.: Uma empresa constrói equipamentos complexos. A partir de desenhos de projeto desses
equipamentos, são feitos documentos de requisições de materiais, necessários para a construção do
equipamento; toda a requisição de um material dá origem a um ou mais pedidos de compra. A modelagem deste
exemplo, irá mostrar quais materiais de que requisições geraram quais pedidos. Na fig. 12.2 é apresentado este
relacionamento ternário.

156
A tabela 2, representante do relacionamento ternário M-R-P, poderia conter os seguintes dados:
Utilizando uma soma de visualização da dependência de junção, obtemos o seguinte gráfico de
dependência de junção, mostrado na fig. 12.3.
Uma pergunta surge sobre este problema: é possível substituir o relacionamento ternário por
relacionamentos binários, como os apresentados na fig. 12.4.
Como resposta, podemos dizer que geralmente não é possível criar esta decomposição sem perda de
informação, armazenada no relacionamento ternário.
Realizando uma projeção na tabela anterior, chegamos às entidades apresentadas na fig. 12.5.

157
Se realizarmos, agora, um processo de junção destas três entidades, teremos:
• Inicialmente, vamos juntar a entidade 1 com a entidade 2, através do campo pedido de compra. Obtemos
então a entidade 4, mostrada na fig. 12.6:
• Podemos observar que o registro apontado pela seta não existia na tabela original, ou seja, foi criado pela
junção das tabelas parciais. Devemos juntar a entidade 4, resultante da primeira junção, com a entidade
3, através dos campos material e requisição. Após esta última operação de junção, obtemos a entidade 5,
mostrada na fig. 12.7.

158
Como se pode notar, ao se juntar as três entidades, fruto da decomposição da entidade original, as
informações destas foram preservadas. Isto significa que o relacionamento M-R-P não está na 5FN, sendo
necessário decompô-lo em relacionamento binários, os quais estarão na 5FN.
A definição da 5FN diz que: uma relação de 4FN estará em 5FN, quando seu conteúdo não puder ser
reconstruído (existir perda de informação) a partir das diversas relações menores que não possuam a mesma
chave primária. Esta forma normal trata especificamente dos casos de perda de informação, quando da
decomposição de relacionamentos múltiplos.
Com a 5FN, algumas redundâncias podem ser retiradas, como a informação de que o “ROTOR 1BW” está
presente na requisição “R3192”, será armazenada uma única vez, a qual na forma não normalizada pode ser
repetida inúmeras vezes.
Roteiro de Aplicação da Normalização
Entidade ou documento não normalizado, apresentando grupos repetitivo e certas anomalias de
atualização.
• Aplicação da 1FN
- Decompor a entidade em uma ou mais entidades, sem grupos repetitivos;
- Destacar um ou mais atributos como chave primária da(s) nova(s) entidade(s), e este será concatenado com a
chave primária da entidade original;
- Estabelecer o relacionamento e a cardinalidade entre a(s) nova(s) entidade(s) gerada(s) e a entidade geradora;
- Verificar a questão da variação temporal de certos atributos e criar relacionamentos 1:N entre a entidade
original e a entidade criada por questões de histórico.
Entidades na 1FN
• Aplicação da 2FN
- Para entidades que contenham chaves primárias concatenadas, destacar os atributos que tenham dependência
parcial em relação à chave primária concatenada;
- Criar uma nova entidade que conterá estes atributos, e que terá como chave primária o(s) atributo(s) do(s)
qual(quais) se tenha dependência parcial;
- Serão criadas tantas entidades quanto forem os atributos da chave primária concatenada, que gerem
dependência parcial;
- Estabelecer o relacionamento e a cardinalidade entre a(s) nova(s) entidade(s) gerada(s) e a entidade geradora.
• Entidades na 2FN
- Verificar se existem atributos que sejam dependentes transitivos de outros que não pertencem à chave
primária, sendo ela concatenada ou não, bem como atributos que sejam dependentes de cálculo realizado a
partir de outros atributos;
- Destacar os atributos com dependência transitiva, gerando uma nova entidade com este atributo e cuja chave
primária é o atributo que originou a dependência;

159
- Eliminar os atributos obtidos através de cálculos realizados a partir de outros atributos.
• Entidades na 3FN
• aplicação da FNBC
- Só aplicável em entidades que possuam chaves primárias e candidatas concatenadas;
- Verificar se alguma chave candidata concatenada é um determinante, e em caso afirmativo, criar uma entidade
com os que dependam funcionalmente deste determinante e cuja chave primária é o própria determinante.
• Entidades na FNBC
- Aplicação da 4FN
- Para se normalizar em 4FN, a entidade tem que estar (obrigatoriamente) na 3FN;
- Verificar se a entidade possui atributos que não sejam participantes da chave primária e que sejam
multivalorados e independentes em relação a um mesmo valor da chave primária;
- Retirar estes atributos não chaves e multivalorados, criando novas entidades individuais para cada um deles,
herdando a chave primária da entidade desmembrada.
• Entidades na 4FN
- aplicação da 5FN
- Aplicada em elemento que estejam na 4FN;
- A ocorrência deste tipo de forma normal está vinculada aos relacionamentos múltiplos (ternários, etc.) ou
entidades que possuam chave primária concatenada com três ou mais atributos;
- Verificar se é possível reconstruir o conteúdo do elemento original a partir de elementos decompostos desta;
- Se não for possível, o elemento observado não está na 5FN, caso contrário os elementos decompostos
representam um elemento na 5FN.
• Entidades na forma normal final
O processo de normalização leva ao refinamento das entidades, retirando delas grande parte das redundâncias e
inconsistências. Naturalmente, para que haja uma associação entre entidades é preciso que ocorram
redundâncias mínimas de atributos que evidenciam estes relacionamentos entre entidades.
Desnormalização
Parece um tanto quanto incoerente apresentar um item falando sobre desnormalização. Porém os
processos de síntese de entidades vistos até aqui levam à criação de novas entidades e relacionamentos.
Os novos elementos criados podem trazer prejuízos na hora de serem implementados em um SGBD.
Devido as características de construção física de certos banco de dados, algumas entidades e relacionamentos
devem ser desnormalizados para que o SGBD tenha um melhor desempenho.
Hoje em dia, existe um grande debate sobre as chamadas semânticas da normalização, sua utilidade e
facilidade em relação à implementação física em um sistema operacional.
Vários estudos e algumas considerações estão sendo realizados, e se chega até a utilização de banco de
dados relacionais não normalizados, por apresentarem maior ligação com a realidade e por terem vínculos
matemáticos mais amenizados.
Outro aspecto da normalização é que todas as definições sobre as formas normais após a 1FN, ainda não
foram exaustivamente examinadas, propiciando assim grandes controvérsias. A redução das anomalias de
atualização devido às formas normais de alta ordem sofre os ataques óbvios dos grandes problemas (físicos) de
atualização, pois as relações estão excessivamente normalizadas e com isso uma simples alteração pode encadear
um efeito cascata bastante profundo no banco de dados, ocasionando um aumento bastante significativo no
tempo.

160
Infelizmente, os argumentos que podem viabilizar o processo de desmoralização sofrem de uma
deficiência e aderência matemática.
Pesquisas recentes indicam que as estruturas desnormalizadas (apelidadas de forma normal não primeira)
têm um atrativo matemático similar ao que foi o da normalização. Estas pesquisas estão provendo recentes
definições sobre álgebra relacional desnormalizada e extensões à linguagem SQL para a manipulação de relações
desnormalizadas.
Ao se optar pela desnormalização, deve-se levar em conta o custo da redundância de dados e as
anomalias de atualização decorrentes.
Chegou-se à conclusão também que o espírito da normalização contradiz vários princípios importantes,
relativos à modelagem semântica e à construção de bases de dados em SGBD orientados por objeto.
Considerações Finais sobre Normalização
Antes de qualquer conclusão, podemos observar que as formas normais nada mais são do que restrições
de integridade, e à medida que se alimenta este grau de normalização, torna-se cada vez mais restritivas.
Dependendo do SGBD relacional utilizado, essas restrições podem se tornar benéficas ou não.
A forma de atuação da normalização no ciclo de vida de um projeto de banco de dados pode ser mais
satisfatória no desenvolvimento (botton-up) de modelos preliminares, a partir da normalização da documentação
existente no ambiente analisado, bem como de arquivos utilizados em alguns processos automatizados neste
ambiente.
No caso do desenvolvimento top-down, no qual um modelo de dados é criado a partir da visualização da
realidade, a normalização serve para realizar um aprimoramento deste modelo, tornando-o menos redundante e
inconsistente. No caso desta visão, a normalização torna-se um poderoso aliado da implementação física do
modelo.
Por experiência, podemos afirmar que a construção de um modelo de dados já leva naturalmente ao
desenvolvimento de entidades e relacionamentos na 3FN, ficando as demais (FNBC, 4FN, e 5FN) para melhorias e
otimizações.
A criação de modelos de dados, partindo-se da normalização de documentos e arquivos pura e
simplesmente, não é o mais indicado, pois na verdade estaremos observando o problema e não dando uma
solução para ele. Neste caso, estaremos projetando estruturas de dados que se baseiam na situação atual (muitas
vezes caótica) e que certamente não vão atender às necessidades reais do ambiente em análise. Ao passo que, se
partimos para a criação do modelo de dados com entidades e relacionamentos aderentes à realidade em estudo
(mundo real), vamos naturalmente desenvolver uma base de dados ligada à visão da realidade e como
consequência iremos solucionar o problema de informação.
A aplicação da modelagem de dados, ao longo da nossa vida profissional, tem sido bastante gratificante,
mostrando principalmente, que a técnica de normalização é uma ferramenta muito útil como apoio ao
desenvolvimento do modelo de dados. Seja ela aplicada como levantamento inicial (documentos e arquivos) bem
como otimizador do modelo de dados, tendo em vista certas restrições quanto à implementação física nos banco
de dados conhecidos.
Todas as ideias sobre eficiência da normalização passam necessariamente sobre tempo e espaço físico,
em função, principalmente, das consultas efetuadas pelos usuários bem como a quantidade de bytes necessários
para guardar as informações.
Nota-se, através da observação, que o projeto do modelo conceitual nem sempre pode ser derivado para
o modelo físico final. Com isso, é de grande importância que o responsável pela modelagem (analista, AD, etc.)
não conheça só a teoria iniciada por Peter Chen, mas também tenha bons conhecimentos a respeito do ambiente
do banco de dados utilizado pelo local em análise.

161
Regras de Integridade
As regras de integridade fornecem a garantia de que mudanças feitas no banco de dados por usuários
autorizados não resultem em perda de consistência de dados. Assim, as regras de integridade protegem o banco
de dados de danos acidentais.
Já vimos regras de integridade para o modelo E-R. Essas regras possuem a seguinte forma:
• Declaração de variáveis – a determinação de certos atributos, como chave candidata, para um dado
conjunto de entidades. O conjunto de inserções e atualizações válidas é restrito àquelas que não criem
duas entidades com o mesmo valor de chave candidata.
• Forma de um relacionamento – muitos para muitos, um para muitos, um para um. O conjunto de
relacionamentos um para um ou um para muitos restringe o conjunto de relacionamentos válidos entre
os diversos conjuntos de entidades.
Em geral, uma regra de integridade constitui um predicado arbitrário pertencente ao banco de dados. Entretanto,
predicados arbitrários podem representar altos custos para serem testados. Assim, normalmente, as regras de
integridade são limitadas às que podem ser verificadas com o mínimo tempo de processamento.
Restrições de Domínios
Vimos que um domínio de valores válidos pode ser associado a qualquer atributo. Vimos tais restrições
são especificadas em SQL DDL. Restrições de domínio são as mais elementares formas de restrições de
integridade. Elas são facilmente verificadas pelo sistema sempre que um novo item de dado é incorporado ao
banco de dados.
É possível que diversos atributos tenham um mesmo domínio. Por exemplo, os atributos nome_cliente e
nome_empregado podem ter o mesmo domínio: o conjunto de todos os nomes de pessoas. Entretanto, os
domínios de saldo e nome_agência certamente serão distintos. Será, talvez, menos claro o caso nome_cliente e
nome_agência que podem ter o mesmo domínio. No nível de implementação, os nomes de agência e clientes são
strings de caracteres. No entanto, essas linguagens inibem os “quebra-galhos”, que são frequentemente
necessários na programação de sistemas. Uma vez que os sistemas de banco de dados são projetados para
atender a diversos usuários que não são especialistas em banco de dados, os benefícios de tipos fortemente
definidos geralmente apresentam mais desvantagens do que vantagens. Apesar disso, muito dos sistemas
existentes permitem apenas um reduzido número de domínios de tipos. Poucos sistemas, particularmente os
sistemas de banco de dados orientado a objeto, oferecem um conjunto rico de tipos de domínios que podem ser
facilmente ampliados.
A cláusula check da SQL-92 permite modos poderosos de restrições de domínios que a maioria dos
sistemas de tipos das linguagens de programação não permite. Especificamente, a cláusula check permite ao
projeto do esquema determinar um predicado que deva ser satisfeito por qualquer valor designado a uma
variável cujo tipo seja o domínio. Por exemplo, uma cláusula check pode garantir que o domínio relativo ao turno
de trabalho de um operário contenha somente valores maiores que um dado valor (turno mínimo), como
ilustrado aqui:
create domain turno_trabalho numeric (5,2)
o domínio de turno_trabalho é declarado como um número decimal com um total de cinco dígitos, dois
dos quais colocados após o ponto decimal, e o domínio possui uma restrição que assegura que o turno de
trabalho não seja inferior a 4,00. A cláusula constraint valor_teste_turno é opcional e é usada para dar o nome
valor_teste_turno à restrição. O nome é usado para indicar quais restrições foram violadas em determinada
atualização.
A cláusula check pode também ser usada para restringir os valores nulos em um domínio, como ilustrado
a seguir:

162
Como outro exemplo, o domínio pode ser restrito a determinado conjunto de valores por meio do uso da
cláusula in:
Integridade Referencial
Frequentemente, desejamos garantir que um valor que aparece em uma relação para um dado conjunto
de atributos também apareça para um certo conjunto de atributos de outra relação. Essa condição é chamada
integridade referencial
Conceitos Básicos
Considere um par de relações r(R) e s(S) e a junção natural . Pode existir uma tupla tr em r que não
possa ser combinada a nenhuma tupla em s. Isto é, não existe nenhum tS em s tal que . Tais
tuplas são chamadas de tuplas pendentes. Dependendo do conjunto de entidades ou relacionamentos que está
sendo modelado, tuplas pendentes podem ou não ser aceitáveis.
Sabemos que existe um tipo diferente de junção – a junção externa – para operar relações contendo
tuplas pendentes. Não estamos abordando consultas aqui, mas o modo de tratar a existência, quando desejada,
de tuplas pendentes no banco de dados.
Suponha que exista a tupla t1 na relação conta, com t1[nome_agência] = “Lunartown”, mas que não haja
nenhuma tupla na relação agência para Lunartown. Essa situação pode ser indesejável.
Esperamos que a relação agência possua todas as agências do banco. Portanto, a tupla t1 faz referência a
uma conta de uma agência inexistente. Obviamente, gostaríamos de implementar uma regra de integridade que
proíba tuplas pendentes desse tipo.
No entanto, nem todos os tipos de tuplas pendentes são indesejáveis. Suponha que exista uma tupla t2 na
relação agência, com t2[nome_agência]= “Mokan”, mas não há nenhuma tupla da relação conta com referência à
agência Mokan. Nesse caso, existe uma agência que não possui nenhum conta.
Embora essa seja uma situação incomum, pode ocorrer quando uma agência está sendo aberta ou
fechada. Assim, não devemos proibir esse tipo de situação.
A diferença entre esses dois exemplos tem origem em dois fatos:
• O atributo nome_agência do Esquema_conta é uma chave estrangeira (foreign key) cuja referência é a
chave primária do Esquema_agência.
• O atributo nome_agência do Esquema_agência não é uma chave estrangeira.
No exemplo de Lunartown, a tupla t1 de conta tem um valor para a chave estrangeira nome_agência que
não aparece em agência. No exemplo da agência Mokan, a tupla t2 de agência tem um valor nome_agência que
não aparece em conta, mas nome_agência não é uma chave estrangeira. Assim, a diferença entre nossos dois
exemplos de tuplas pendentes é a existência de uma chave estrangeira.
Seja r1(R1) e r2(R2) relações com chaves primárias K1 e K2, respectivamente. Dizemos que um subconjunto
α de R2 é uma chave estrangeira associada a K1 em relação a r1 se é garantido que, para todo t2 em r2, existe uma
tupla t1 em r1, tal que t1[K1] = t2[α]. Exigências desse tipo são chamadas de regras de integridade referencial ou
subconjunto dependente. O último termo advém do fato de ser possível escrever a regra de integridade
referencial anterior como (r1). Note que, para a regra de integridade referencial ter sentido, cada α
deve ser igual a K1.
Integridade Referencial no Modelo E-R
Regras de integridade referencial aparecem com frequência. Se derivarmos nosso esquema de bancos de
dados relacional em tabelas originadas de diagramas E-R, então toda relação resultante de um conjunto de
relacionamentos possui regras de integridade referencial. A fig. 6.1 mostra um conjunto de relacionamentos R de

163
n elementos, relacionando os conjuntos de entidades E1, E2, ..., En. Seja Ki a chave primária de Ei. Os atributos para
o esquema da relação referente ao conjunto de relacionamentos R incluem K1ǓK2Ǔ... ǓKn. Cada Ki do esquema de
R é uma chave estrangeira que leva a uma regra de integridade referencial.
Outra fonte de regras de integridade referencial são os conjuntos de entidades fracas. Vimos que o
esquema da relação para um conjunto de entidades fracas precisa incluir a chave primária do conjunto de
entidades do qual ele é dependente. Assim, o esquema da relação para cada conjunto de entidades fracas inclui
uma chave estrangeira que leva a uma regra de integridade referencial.
Modificações no Banco de Dados
As modificações no banco de dados podem originar violação das regras de integridade referencial.
Colocamos aqui a verificação necessária a cada tipo de modificação no banco de dados para que se possa
preservar a seguinte regra de integridade referencial:
• Inserção. Se uma tupla t2 é inserida em r2, o sistema deve garantir que exista uma tupla t1 em r1 tal que
t1[K]=t2[α]. Isto é:
• Remoção. Se uma tupla t1 é removida de r1, o sistema deve tratar também no conjunto de tuplas em r2
que são referidos por t1: .
Se esse conjunto é vazio, o comando de remoção foi rejeitado devido a algum erro ou a tupla que faz
referência a t1 deve ser removida. Esta última alternativa pode levar a uma remoção em cascata se
algumas tuplas fizerem referência a tuplas que se referem a t1 e assim por diante.
• Atualização. Precisamos considerar duas situações de atualizações: as que se referem à relação (r2) e as
referidas pela relação (r1).
o Se uma tupla t2 da relação r2 é atualizada e a atualização modifica os valores da chave estrangeira
α, então é feita uma verificação similar à inserção. Seja t2’ o novo valor da tupla t2. O sistema
deverá assegurar que:
o Se uma tupla t1 da relação r1 é atualizada e a atualização modifica os valores de uma chave
primária (K), então deverá ser feito um teste similar ao realizado para a remoção. O sistema
deverá computar usando o valor antigo de t1 (o valor existente antes da aplicação
da atualização). Se esse conjunto não for vazio, a atualização será rejeitada como uma ocorrência
de erro ou as atualizações serão realizadas em cascata, de modo similar ao que ocorre na
remoção.
Integridade Referencial em SQL
É possível definir chaves primárias, secundárias e estrangeiras como parte do comando create table da
SQL:

164
• A cláusula primary key do comando create table inclui a lista dos atributos que constituem a chave
primária.
• A cláusula unique do comando create table inclui a lista dos atributos que constituem uma chave
candidata.
• A cláusula foreign key do comando create table inclui a lista dos atributos que constituem a chave
estrangeira quanto o nome da relação à qual a chave estrangeira faz referência.
Ilustramos as declarações de chaves estrangeiras e primárias usando definições de parte de nosso banco em SQL
DDL, mostrado na fig. 6.2. Note que não nos detivemos em modelar de modo preciso o mundo real no exemplo
do banco de dados de uma empresa da área bancária. No mundo real, diversas pessoas podem ter o mesmo
nome, assim nome_cliente não pode ser chave primária para cliente. No mundo real, alguns outros atributos,
como o número do seguro social, ou uma combinação de atributos como nome e endereço, poderiam ser usados
como chave primária. Usamos nome_cliente como chave primária para conferir simplicidade e concisão a nosso
esquema de banco de dados.
Podemos usar a forma simplificada para declarar que uma única coluna é uma chave estrangeira:
A SQL também dá suporte a uma outra maneira de formular a cláusula chave estrangeira, em que uma
lista de atributos da relação por ela referida pode ser explicitamente especificada, e esses atributos são usados no
lugar da chave primária; essa lista de atributos precisa ser declarada como chave candidata de uma relação
referida.
Quando uma regra de integridade referencial é violada, o procedimento normal é rejeitar a ação que
ocasionou essa violação. Entretanto, a cláusula relativa a foreign key em SQL-92 pode especificar que, se uma
remoção ou atualização na relação a que ela faz referência violar uma regra de integridade, então, em vez de
rejeitar a ação, executam-se passos para modificação da tupla na relação que contém a referência, de modo a
garantir a regra de integridade. Considere a seguinte definição de regra de integridade para a relação conta:

165
Devido à cláusula on delete cascade associada à declaração da chave estrangeira, se a remoção de uma
tupla de agência resultar na violação da regra de integridade anterior, a remoção não será rejeitada. Ao contrário,
a remoção é feita em “cascata” na relação conta, de modo que as tuplas que se referirem a uma agência
removida sejam também removidas. De modo similar, a atualização de um campo referido por uma regra de
integridade não será rejeitada se ela violar uma regra de integridade; pelo contrário, o campo nome_agência das
tuplas da relação conta será também atualizado. A SQL-92 permite, também, que a cláusula foreign key
especifique outros tipos de ações além de “cascata”, como alterar o campo em questão (no caso, nome_agência)
com nulos, ou um valor-padrão, caso a regra seja violada.
Se houver uma cadeia de dependências entre chaves estrangeiras de diversas relações, uma remoção ou
uma atualização em uma das extremidades poderá propagar-se ao longo de toda a cadeia. Se uma atualização ou
remoção em cascata provoca a violação de uma regra de integridade que não pode ser tratada por uma operação
de cascata seguinte, o sistema aborta a transação. Como resultado, todas as mudanças causadas pela transação,
assim como as ações em cascata decorrentes, serão desfeitas.
A semântica de chaves em SQL torna-se mais complexa pelo fato da SQL permitir valores nulos. As
seguintes regras, algumas das quais arbitrárias, são usadas para tratar esses valores nulos.
• Todos os atributos de uma chave primária são declarados implicitamente como not null.
• Atributos de uma declaração unique (isto é, atributos de uma chave candidata) podem ser nulos,
contanto que não sejam declarados não-nulos de outro modo. A restrição para garantia da unicidade em
uma relação é violada somente se duas tuplas da relação têm o mesmo valor para todos os atributos da
regra unique e todos os valores forem não-nulos. Assim, qualquer número de tuplas pode ser igual em
todas as colunas declaradas como únicas, sem que haja violação da regra de integridade, contanto que ao
menos uma das colunas tenha um valor nulo.
• Atributos nulos em chaves estrangeiras são permitidos, contanto que não tenha sido declarados como
não-nulos de outro modelo. Se todas as colunas de uma chave estrangeira são não-nulas em uma
determinada tupla, a definição usual de regra de integridade em chave estrangeira será empregada
naquela tupla. Se qualquer uma das colunas da chave é nula, a tupla é automaticamente aprovada na
regra de integridade. Essa definição é arbitrária e nem sempre uma boa opção, assim a SQL fornece,
também, construtores que possibilitam mudança de comportamento em relação aos valores nulos.
Dada a complexidade e arbitrariedade natural das formas e comportamentos de restrições (ou regras) de
integridade SQL em relação a valores nulos, é melhor assegurar que todas as colunas especificadas em unique e
foreign key sejam declaradas, não permitindo nulos.
Asserções
Uma asserção é um predicado que expressa uma condição que desejamos que seja sempre satisfeita no
banco de dados. Restrições de domínio e regras de integridade referencial são formas especiais de asserções.
Dispensamos substancial atenção a essas formas de asserções, porque são facilmente verificadas e aplicadas em
grande parte das aplicações em banco de dados. Entretanto, existem muitas restrições que não podem ser
expressas usando somente essas formas especiais. Exemplos dessas restrições compreendem:
• A soma de todos os totais em conta empréstimo de cada uma das agências deve ser menor que a soma
de todos os saldos da contas dessa agência.

166
• Todo empréstimo deve ter ao menos um cliente que mantenha uma conta com saldo mínimo de mil
dólares.
Uma asserção em SQL-92 toma a seguinte forma:
As duas regras mencionadas podem ser escritas como mostrado a seguir. Já que a SQL não oferece um
construtor “para todo X, P(X)” (em que P é um predicado), somos forçados a implementar o construtor usando o
construtor “não existe X tal que nenhum P(X)”, pode ser escrito em SQL.
Quando uma asserção é criada, o sistema verifica sua validade. Se as asserções são válidas então qualquer
modificação posterior no banco de dados será permitida somente quando a asserção não for violada. Quando as
asserções são complexas, a verificação pode gerar um aumento significativo em tempo de processamento. Por
isso, as asserções são usadas com muito cuidado.
Esse grande overhead para teste e manutenção de asserções tem levado alguns profissionais ligados ao
desenvolvimento de sistemas de banco de dados a excluir as asserções gerais ou a fornecer apenas formas
especiais de asserções, que possam ser verificadas facilmente.
Gatilhos (Triggers)
Um gatilho é um comando que é executado pelo sistema automaticamente, em consequência de uma
modificação no banco de dados. Duas exigências devem ser satisfeitas para a projeção de um mecanismo de
gatilho:
1. Especificar as condições sob as quais o gatilho deve ser executado.
2. Especificar as ações que serão tomadas quando um gatilho for disparado.
Os gatilhos são mecanismos úteis para avisos a usuários ou para executar automaticamente determinadas
tarefas quando as condições para isso são criadas. Como ilustração, suponha que, em vez de permitir saldos
negativos em conta, o banco crie condições para que a conta corrente seja zerada e o saldo negativo seja
transferido para uma conta empréstimo. Essa conta empréstimo terá o mesmo número da conta corrente em
questão. Para esse exemplo, a condição para o disparo de um gatilho é uma atualização na relação conta que
resulta em um valor negativo para saldo.
Suponha que Jones tenha feito um resgate em uma conta que gerou um saldo negativo. Suponha que t
denote a tupla de conta com um valor negativo para saldo. As ações a tomar são as seguintes:
• Inserir uma nova tupla s na relação empréstimo com:

167
(Note que, se t[saldo] for negativo, impedimos que t[saldo] receba um valor positivo em um total de
empréstimo.)
• Inserir uma nova tupla u na relação devedor com:
• Tornar t[saldo] igual a 0.
O padrão SQL-92 não dispõe de gatilhos, embora a proposta original da SQL do Sistema R proponha
alguns recursos para gatilhos. Alguns sistemas existentes possuem seus próprios recursos de gatilho não
padronizados. Ilustraremos, aqui, como um gatilho para saldo negativo poderia ser escrito na versão original de
SQL.

168
A palavra-chave new usada antes de T.saldo indica que o valor de T.saldo após a atualização deverá ser
usado; se ele for omitido, o valor existente antes da atualização será, então, usado.
Os gatilhos são chamados, algumas vezes, de regras (rules), ou regras ativas (active rules), mas não devem
ser confundidos com as regras da Datalog, que tratam realmente de definições de visões.
Dependência Funcional
A noção de dependência funcional é uma generalização da noção de chave. Dependências funcionais
representam um papel importante no projeto de banco de dados.
Conceitos Básicos
Dependências funcionais são restrições ao conjunto de relações válidas. Elas permitem expressar
determinados fatos em nosso banco de dados relativos à empresa que desejamos modelar.
Eis o conceito de superchave como segue. Seja R o esquema de uma relação. Um subconjunto K de R é
uma superchave de R em qualquer relação válida r(R) para todos os pares de t1 e t2 de tuplas em r tal que t1≠t2,
então t1[K]≠t2[K]. isto é, nenhum par de tuplas em qualquer relação validade r(R) deve ter o mesmo valor no
conjunto de atributos K.
A noção de dependência funcional generaliza a noção de superchave. Seja α R e β R. A dependência
funcional: α � β realiza-se em R se, em qualquer relação validade r(R), para todos os pares de tuplas t1 e t2 em r,
tal que t1[α] = t2[α], t1[β] = t2[β] também será verdade.
Usando a notação de dependência funcional, dizemos que K é uma superchave de R se K�R. isto é, K é
uma superchave se, para todo t1[K]=t2[K], t1[R]=t2[R] (isto é, t1=t2).
A dependência funcional permite-nos expressar restrições que as superchaves não expressam. Considere
o esquema:
esquema_info_empréstimo=(nome_agência, número_empréstimo, nome_cliente, total)
O conjunto de dependências funcionais que queremos garantir para esse esquema relação é:
Entretanto, não esperamos realizar dependência funcional para:
já que, em geral, um empréstimo pode ser contraído por mais de um cliente (por exemplo, para ambos os
membros de um casal, marido-mulher).
Podemos usar dependência funcional de dois modos:
1. Usando-as para o estabelecimento de restrições sobre um conjunto de relações válidas. Devemos, assim,
concentrá-las somente àquelas relações que devem satisfazer um dado conjunto de dependências
funcionais. Se desejarmos restringi-las a relações do esquema R que satisfaçam um conjunto F de
dependências funcionais, dizemos que F realiza-se em R.
2. Usando-as para verificação de relações, de modo a saber se as últimas são válidas sob um dado conjunto
de dependências funcionais. Se desejarmos restringi-las a relações do esquema R que satisfaçam um
conjunto F de dependências funcionais, dizemos que r satisfaz F.
Consideremos a relação r da fig. 6.3 para verificar quais dependências funcionais são satisfeitas. Observe que
A�C é satisfeita. Duas tuplas têm valor a1 em A. essas tuplas têm um mesmo valor de C – denominado cI. de
modo similar, duas tuplas com valor a2 em A têm mesmo valor c2 em C, mas eles possuem valor diferentes em A,
a2 e a3, respectivamente. Assim, encontramos um par de tuplas t1 e t2 tal que t1[C]=t2[C], mas t1[A]≠t2[A].

169
Diversas outras dependências funcionais são satisfeitas por r, incluindo, por exemplo, a dependência
funcional AB � D. Note que usamos AB como notação simplificada para [A,B], reduzindo-se a um padrão mais
prático. Observe que não existe nenhum par de tuplas distintas t1 e t2 tal que t1[AB]=t2[AB]. Portanto, se
t1[AB]=t2[AB], entoa é necessário que t1=t2 e, assim, t1[D]=t2[D]. Logo, r satisfaz AB � D.
Algumas dependências funcionais são consideradas triviais porque são satisfeitas por todas as relações.
Por exemplo, A�A é satisfeita por todas as relações que contêm o atributo A. Na leitura literal da definição de
dependência funcional, podemos notar que, para todos os atributos t1 e t2 tal que t1[A]=t2[A] será também
verdade. De modo similar, AB � A é satisfeita para todas as relações envolvendo o atributo A. Em geral, uma
dependência funcional da forma α�β é trivial se β α.
Para distinguir os conceitos de uma relação que satisfaz uma dependência e de uma dependência
realizando-se em um esquema, retornaremos ao exemplo do banco. Se considerarmos a relação cliente (com o
esquema_cliente), como mostrado na fig. 6.4, notamos que rua_cliente � cidade_cliente é satisfeita. Entretanto,
acreditamos que, no mundo real, duas cidades podem possuir duas ou mais ruas com o mesmo nome. Assim, é
possível, em algum tempo, haver uma instância da relação cliente na qual rua_cliente � cidade_cliente não é
satisfeita. Logo, não incluiremos rua_cliente � cidade_cliente no conjunto das dependências funcionais que são
realizadas no Esquema_cliente.
Na relação empréstimo (do esquema_empréstimo) na fig. 6.5, vemos que número_empréstimo � total é
satisfeita. Ao contrário do que ocorre em cidade_cliente e rua_cliente no esquema_cliente, acreditamos que, em
empresas reais, eles são modelados de modo a garantir que cada conta tenha somente um total. Portanto,
queremos que a condição número_empréstimo� total seja sempre satisfeita para a relação empréstimo. Em
outras palavras, necessitamos da restrição número_empréstimo�total para o esquema_empréstimo.

170
Na relação agência da fig. 6.6, vemos que nome_agência�fundos é satisfeita, assim como
fundos�nome_agência. Gostaríamos de garantir que nome_agência�fundos fosse realizada em
esquema_agência. Entretanto, não queremos que fundos�nome_agência seja realiza, uma vez que é possível
haver diversas agências com o mesmo valor de fundos.
Embora a SQL não forneça um modo simples para especificação de dependência funcional podemos
escrever consultas para verificação de dependências funcionais, assim como criar asserções para garantia de
dependências funcionais.
Conforme segue, consideramos que, quando projetamos um banco de dados relacional, primeiro
relacionamos as dependências funcionais que sempre precisam ser realizadas. No exemplo do banco, nossa
relação de dependências funcionais engloba as seguintes:
• No esquema_agência:
nome_agência � cidade_agência
nome_agência � fundos
• No esquema_cliente:
nome_cliente � cidade_cliente
nome_cliente � rua_cliente
• No esquema_empréstimo:
número_empréstimo � total
número_empréstimo � nome_agência
• No esquema_devedor:
nenhuma dependência funcional

171
• No esquema_conta:
número_conta � nome_agência
número_conta � saldo
• No esquema_depositante:
nenhuma dependência funcional
Clausura de um Conjunto de Dependências Funcionais
Não basta considerar um dado conjunto de dependências funcionais. É preciso considerar todos os
conjuntos de dependências funcionais que são realizados. Podemos mostrar que, dado um conjunto F de
dependências funcionais, prova-se que outras dependências funcionais realizam-se. Dizemos que esse tipo de
dependência funcional é logicamente implícito em F.
Suponha um dado esquema de relação R = (A, B, C, G, H, I) é o conjunto de dependências funcionais:
A � B
A � C
CG �H
CG � I
B � H
A dependência funcional:
A � H
É logicamente implícita. Isto é, podemos mostrar que, sempre que um dado conjunto de dependências
funcionais se realiza, A�H também se realiza. Suponha que t1 e t2 são duas tuplas, tais que:
t1[A] = t2[A]
Já que é dado que A�B, dessa definição de dependência funcional decorre que:
t1[B] = t2[B]
Então, desde que B�H seja dada, decorre desta definição de dependência funcional que:
t1[H]=t2[H]
Portanto, mostramos que, sempre que t1 e t2 forem tuplas, tais que t1[A]=t2[A], necessariamente t1[H] =
t2[H]. Mas essa é exatamente a definição de A�H.
Seja F um conjunto de dependências funcionais. A clausura de F é o conjunto de todas as dependências
funcionais logicamente implícitas em F. Denotamos a clausura de F por F+. Dado F, podemos computar F+
diretamente da definição formal de dependência funcional. Se F for grande, esse processo pode tornar-se lento e
difícil. Tal qual a computação de F+, exige argumentos do tipo dado anteriormente para mostrar que A�H está
em clausura em nosso conjunto de exemplo de dependências. Existem técnicas mais simples para o raciocínio da
dependência funcional.
A primeira técnica tem por base três axiomas ou regras para inferência da dependência funcional. Para
aplicação dessas regras, precisamos encontrar todos os F+ de um dado F. Nas regras a seguir, adotamos a
convenção do uso de letras gregas para conjuntos de atributos e de letras maiúsculas do alfabeto romano para
atributos individuais. Usamos αβ para denotar .
• Regra de reflexividade. Se α é um conjunto de atributos e , então α�β realiza-se.
• Regra de incremento. Se α�β realiza-se e γ é um conjunto de atributos, então γα�γβ também realiza-
se.
• Regra de transitividade. Se α�β realiza-se e β�γ realiza-se, então α�γ realiza-se.

172
Essas regras são sólidas, porque elas não geram nenhuma dependência funcional incorreta. As regras são
completas, porque, para um dado conjunto F de dependências funcionais, elas nos permitem criar todo F+. Para
simplificar, relacionamentos regras adicionais:
• Regra de união. Se α�β e α�γ, então α�βγ também realiza-se.
• Regra de decomposição. Se α�βγ realiza-se, então α�β e α�γ também realizam-se.
• Regra pseudotransitiva. Se α�β e γβ�δ, então αγ�δ também realiza-se.
Apliquemos nossas regras ao esquema do exemplo apresentado anteriormente R=(A, B, C, G, H, I) e ao conjunto F
de dependências funcionais {A�B, A�C, CG�H, CG�I, B�H}. Relacionamos diversos membros de F+ aqui:
• A�H. Desde que A�B e B�H realizam-se, aplicamos a regra da transitividade. Observe que foi mais fácil
aplicar os axiomas de Armstrong para mostrar que A�H se realiza do que raciocinando diretamente
sobre as definições, como fizemos anteriormente.
• CG�HI. Já que CG�H e CG�I, a regra da pseudotransitividade implica a realização de AG�I.
Clausura de Conjunto de Atributos
Para verificar se um conjunto α é uma superchave, precisamos conceber um algoritmo para computar o
conjunto de atributos determinados funcionalmente por α. Podemos deduzir que esse algoritmo também é útil
como parte do processamento da clausura de um conjunto de dependências funcionais F.
Seja α um conjunto de atributos. Chamamos o conjunto dos atributos funcionalmente determinados por
α, sob um conjunto de dependências funcionais F, de clausura de α sob F, denotada por α+. A fig. 6.7 mostra um
algoritmo, escrito em pseudo-Pascal, para computar α+. O conjunto de dependências funcionais F e o conjunto α
de atributos funcionam como entrada. A saída é armazenada na variável resultado.
Para ilustração de como o algoritmo da fig. 6.7 funciona, iremos usá-lo para processar (AG)+ com as
dependências funcionais definidas anteriormente. Começaremos com resultado = AG. A primeira execução do
laço while para verificação da dependência funcional irá chegar a:
• A�B obriga-nos a incluir B no resultado. Para perceber esse fato, observemos que A�B está em F, A
resultado (o que é AG), assim, resultado := resultado B.
• A�C obriga que resultado se torne ABCG.
• CG�H obriga que resultado se torne ABCGH.
• CG�I obriga que resultado se torne ABCGHI.
Na segunda vez em que executamos o laço while, não será adicionado nenhum outro atributo a
resultado, e o algoritmo terminará.
Vejamos por que o algoritmo da fig. 6.7 está correto. Já que α�α sempre se realiza (pela regra da
reflexidade), o primeiro passo é correto. Exigimos que, para qualquer subconjunto β de resultado, α�β. Já que
começamos o laço while com α�resultado sendo verdadeiro, podemos adicionar γ ao resultado somente se β
resultado e β�γ. Mas, então, pela regra reflexiva, resultado�β e, pela transitividade, α�β. Outra aplicação
da transitividade mostra que α�γ (usando α�β e β�γ). A regra da união implica que α�resultado γ, assim
α determina, funcionalmente, qualquer resultado novo gerado pelo laço while. Dessa forma, qualquer atributo
obtido pelo algoritmo está em α+.

173
É fácil perceber que o algoritmo encontra todos os atributos de α+. Se há um atributo de α+ que não esteja
ainda em resultado, então é preciso que haja uma dependência funcional β�, para a qual β resultado, e que
ao menos um atributo em γ não esteja em resultado.
Por outro lado, no pior caso, esse algoritmo pode tomar tempo proporcional ao quadrado do tamanho de
F. Há um algoritmo mais rápido (embora ligeiramente mais complexo) que consome tempo proporcionalmente
linear ao tamanho de F.
Cobertura Canônica
Suponha que tenhamos um conjunto de dependências funcionais F sobre o esquema de uma relação.
Sempre que uma atualização é realizada na relação, o sistema de banco de dados deve garantir que todas as
dependências funcionais em F sejam satisfeitas no novo estado do banco de dados, ou deverá reverter as
alterações caso não o sejam.
Podemos reduzir os esforços exigidos para o teste por meio da simplificação de um dado conjunto de
dependências funcionais, com ou sem a alteração daquele conjunto de clausura. Qualquer banco de dados que
satisfaça um conjunto simplificado de dependências funcionais deve também satisfazer o conjunto original e vice-
versa, uma vez que os dois conjuntos têm a mesma clausura. Entretanto, o conjunto simplificado é mais
facilmente verificado. O conjunto simplificado pode ser construído com descrevemos a seguir. Primeiro,
precisamos de algumas definições.
Um atributo de uma dependência funcional é extrínseco se podemos removê-lo sem alterar a clausura do
conjunto de dependências funcionais. Formalmente, atributos extrínsecos são definidos conforme segue.
Considere um conjunto de dependências funcionais F e a dependência funcional α�β em F.
• O atributo A é extrínseco a α se A α, e F implica logicamente (F – {α�β}) {(α – A)�β}.
• O atributo A é extrínseco a β se A β, e o conjunto de dependências funcionais (F – {α�β}) {(β – A)}
implica logicamente F.
Uma cobertura canônica Fc para F é o conjunto de dependências tal que F implique logicamente todas as
dependências de FC e FC implique logicamente todas as dependências em F. Além disso, FC deve apresentar as
seguintes propriedades:
• Nenhuma dependência funcional em FC contém um atributo extrínseco.
• Cada lado esquerdo da dependência funcional em FC é único. Isto é, não há duas dependências α1� β1 e
α2� β2 em Fc tal que α1= α2.
Uma cobertura canônica para um conjunto de dependências funcionais F pode ser computada como:
Pode-se mostrar que a cobertura canônica de F, FC, possui a mesma clausura de F; então, verificar se F é
satisfeita. Entretanto, Fc é mínima em certo sentido – ela não contém atributos extrínsecos e as dependências
funcionais, com mesmo lado esquerdo, foram combinadas. É mais econômico verificar FC que testar o próprio F.
Considere o seguinte conjunto de dependências funcionais F do esquema (A, B, C):
A�BC
B�C
A�B
AB�C
Vejamos como computar a cobertura canônica para F.

174
• Há duas dependências funcionais com o mesmo conjunto de atributos do lado esquerdo da seta:
A�BC
A�B
Combinamos essas dependências funcionais em A�BC.
• A é extrínseco em AB�C porque F implica logicamente (F – {AB�C}) {B�C}. Essa asserção é verdadeira
porque B�C já está em nosso conjunto de dependências funcionais.
• C é extrínseco em A�BC, uma vez que A�BC está implícita logicamente por A�B e B�C.
Assim, nossa cobertura canônica é:
A�B
B�C
Dado um conjunto F de dependências funcionais, pode ser que uma dependência funcional total no
conjunto seja extrínseca, no sentido de que, tirando-as, não há mudança na clausura de F. podemos mostrar que
uma cobertura canônica FC de F não contém nenhuma dependência funcional extrínseca. Suponha que, de modo
contrário, houvesse tal dependência funcional extrínseca em FC. O lado direito dos atributos da dependência
poderia ser extrínseco, o que não é possível na definição da cobertura canônica.

175
Projeto e implementação de um banco de dados relacional
Genericamente, o objetivo do projeto de um banco de dados relacional é gerar um conjunto de esquemas
de relações que nos permita armazenar informações sem redundância desnecessária e, ainda, nos permita
recuperar informações facilmente. Uma das abordagens possíveis seria projetar esquemas na forma normal
apropriada. Para determinar se um esquema de relação atende a uma das formas normais, precisamos de
informações adicionais sobre a empresa real cujo banco de dados estamos modelando. Já vimos como podemos
usar dependências funcionais para expressar fatos acerca dos dados.
Armadilhas no Projeto de banco de dados Relacional
Antes de prosseguir com nossa discussão sobre formas normais e dependências de dados, vejamos o que
determina a qualidade de um projeto de banco de dados. Entre as propriedades indesejáveis em um bom projeto
de banco de dados de banco de dados temos:
• Informações repetidas.
• Inabilidade para representação de certas informações.
Podemos discutir esses problemas usando uma modificação no projeto de banco de dados. Entre as
propriedades indesejáveis em um bom projeto de banco de dados temos:
• Informações repetidas.
• Inabilidade para representação de certas informações.
Podemos discutir esses problemas usando uma modificação no projeto de banco de dados no exemplo que temos
usado de uma empresa de área bancária; diferente do usado anterior, a informação acerca de empréstimos será
agora representada em uma única relação, linha_de_crédito, que será definido pelo esquema de relação:
esquema_linha_de_crédito=(nome_agência, cidade_agência, fundos, nome_cliente, número_empréstimo, total)
A fig. 7.1 mostra uma instância da relação linha_de_crédito (esquema_linha_de_crédito). Uma tupla t da
relação linha_de_crédito tem o seguinte significado intuitivo:
• t[fundos] são os fundos totais de uma determinada agência cujo nome é t[nome_agência].
• t[cidade_agência] é a cidade onde determinada agência de nome t[nome_agência] está localizada.
• t[número_empréstimo] é o número atribuído ao empréstimo feito na agência denominada
t[nome_agência] para o cliente de nome t[nome_cliente].
• t[total] é o montante da dívida do empréstimo cujo número é t[número_empréstimo].
Suponha que desejamos adicionar um novo empréstimo ao nosso banco de dados. Digamos que o

176
empréstimo, no valor de 1,5 mil dólares, foi contraído na agência Perryridge para o cliente Adams. O
número_empréstimo será L-31. Em nosso projeto, precisamos de uma tupla com valores em todos os atributos do
esquema_linha_de_crédito. Assim, é necessário repetir os dados sobre fundos e cidade referentes à agência
Perryridge na adição da tupla
(Perryridge, Horseneck, 1700000, Adams, L-31, 1500)
na relação linha_de_crédito. De modo geral, dados sobre fundos e localização da agência devem aparecer toda
vez que um empréstimo é contraído naquela agência.
A necessidade de repetição de informações imposta pelo nosso projeto alternativo é indesejável.
Repetições desperdiçam espaço. Além disso, dificulta atualizações no banco de dados. Suponha, por exemplo,
que a agência Perryridge se mude de Horseneck para Newtown. Em nosso projeto original, uma tupla da relação
agência será alterada. Nesse projeto alternativo, diversas tuplas da relação linha_de_crédito deverão sofrer
alterações. Assim, as atualizações serão mais custosas no novo projeto que no original. Quando realizarmos a
alteração no projeto alternativo, precisamos ter certeza de que todas as tuplas pertencentes à agência Perryridge
serão alteradas, senão nosso banco de dados irá apresentar duas cidades para a agência Perryridge.
Essa observação é fundamental para entender por que o projeto é considerado ruim. Sabemos que uma
agência bancária está localizada em apenas uma cidade, naturalmente. Por outro lado, sabemos que uma agência
pode conceder diversos empréstimos. Em outras palavras, a dependência funcional
nome_agência�cidade_agência se realiza no esquema_linha_de_crédito, mas não esperamos que a dependência
funcional pode ser usada para especificação formal quando o projeto de banco de dados é bom.
Outro problema com o projeto esquema_linha_de_crédito é que não podemos representar diretamente a
informação relativa a uma agência (nome_agência, cidade_agência, fundos), salvo se houver ao menos um
empréstimo concedido pela agência. O problema é que as tuplas da relação linha_de_crédito exigem valores para
número_empréstimo, total e nome_cliente.
Uma solução para esse problema é introduzir valores nulos para tratar as atualizações por meio de visões.
Recorde-se, entretanto, de que é difícil trabalhar com valores nulos. Se não estamos dispostos a tratar com
valores nulos, então só poderemos criar informações sobre as agências quando o primeiro empréstimo na
agência for realizado. Pior, poderemos perder essa informação quando todos os empréstimos da agência forem
pagos. Logicamente, essa situação é impensável, já que, em nosso projeto original, as informações a respeito das
agências estão disponíveis independente de existirem ou não empréstimos mantidos pela agência, e sem a
necessidade de usar valores nulos.
Decomposição
O exemplo de um maus projeto sugere que poderíamos decompor um esquema de relação com diversos
atributos em vários esquemas com diversos atributos em vários esquemas com menor número de atributos.
Decomposições descuidadas, entretanto, podem gerar outro tipo de projeto de má qualidade.
Considere uma alternativa de projeto, em que esquema_linha_de_crédito é decomposto nos dois
esquemas que se seguem:
esquema_agência_cliente = (nome_agência, cidade_agência, fundos, nome_cliente)
esquema_cliente_empréstimo = (nome_cliente, número_empréstimo, total)
Usando a relação linha_de_crédito da fig. 7.1, construímos nossas novas relações cliente_agência
(esquema_agência_cliente) e cliente_empréstimo (esquema_cliente_empréstimo), como se segue:
Mostramos as relações resultados agência_cliente e nome_cliente nas fig. 7.2 e 7.3, respectivamente.
Naturalmente, há casos em que precisamos reconstruir a relação empréstimo. Por exemplo, suponha que
desejamos encontrar todas as agências que tenham empréstimos cujos totais sejam inferiores a mil dólares.

177
Nenhuma relação em nosso banco de dados alternativo contém esses dados. Precisamos reconstruir a relação
linha_de_crédito. Parece que podemos fazê-lo escrevendo:
A fig. 7.4 mostra o resultado do processamento de agência_cliente cliente_empréstimo. Quando
comparamos essa relação e a primeira relação linha_de_crédito (fig. 7.1), notamos algumas diferenças. Embora
todas as tuplas que aparecem em linha_de_crédito apareçam em agência_cliente cliente_empréstimo,
há tuplas em agência_cliente cliente_empréstimo que não estão em linha_de_crédito. Em nosso
exemplo, agência_cliente cliente_empréstimo tem as seguintes tuplas adicionais:

178
Considere a consulta “encontre todas as agências que tenham feito um empréstimo com totais menores
que mil dólares”. Se olharmos a fig. 7.1, veremos que somente as agências Mianus e Round Hill possuem totais de
empréstimo menores que mil dólares. Entretanto, quando aplicamos a expressão
obtemos três nomes de agências: Mianus, Round Hill e Downtown.
Examinaremos esse exemplo mais de perto. Se acontecer de um cliente contrariar vários empréstimo em
diferentes agências, não poderemos identificar a qual agência pertence qual empréstimo. Assim, da junção de
agência_cliente e cliente_empréstimo, não obtemos somente as tuplas que tínhamos originalmente em
linha_de_crédito, mas também diversas tuplas adicionais. Embora haja mais tuplas em agência_cliente
cliente_empréstimo, temos, na verdade, menos informação. De qualquer modo, não poderemos representar nas
informações do banco de dados quais clientes são devedores de quais agências. Devido a essa perda de
informação, chamamos a decomposição do esquema_linha_de_crédito em esquema_agência_cliente e
esquema_cliente_empréstimo de decomposição com perda (lossy decomposition), ou uma decomposição com
perda na junção (lossy-join decomposition). Quando a decomposição não implica perda de informação, ela é
chamada decomposição sem perda na junção (lossless-join decomposition). Deve estar claro diante de nosso
exemplo que uma decomposição com perda na junção é, em geral, uma má opção de projeto de banco de dados.
Examinaremos essa decomposição mais atentamente para descobrir por que ela representa perda. Há um
atributo comum entre esquema_agência_cliente e esquema_cliente_empréstimo:
O único modo de representarmos um relacionamento entre, por exemplo, número_empréstimo e
nome_agência é por meio de nome_cliente. Essa representação não é adequada, porque um cliente pode
contrair diversos empréstimos e, ainda, esses empréstimos não são necessariamente obtidos na mesma agência.
Consideremos outra alternativa de projeto, na qual esquema_linha_de_crédito é decomposta nos dois
esquemas seguintes:
Há um atributo em comum entre os dois esquemas:

179
Assim, o único modo de representar um relacionamento entre, por exemplo, nome_cliente e fundos é por
meio de nome_agência. A diferença entre esse exemplo e o precedente é que o valor dos fundos de uma agência
é o mesmo, qualquer que seja o cliente em questão, enquanto a linha de crédito oferecida pela agência,
especialmente no montante envolvido, depende do cliente em questão. Para um dado nome_agência, há
exatamente um valor de fundos e exatamente uma cidade_agência; já um tratamento similar não pode ser
oferecido para nome_cliente. Isto é, a dependência funcional:
nome_agência � fundos cidade_agência
realiza-se, mas nome_cliente não determina funcionalmente número_empréstimo.
A noção de junção sem perda é fundamental para a maioria dos projetos de banco de dados. Portanto,
refaremos o exemplo anterior de modo mais precisa e mais formal. Seja R um esquema de relação. Um conjunto
de esquemas de relações {R1, R2, ..., Rn} é uma decomposição de R se:
Isto é, {R1, R2, ..., Rn} é uma decomposição de R se, para i = 1, 2, ..., n, cada Ri é um subconjunto de R e
todo atributo de R aparece ao menos uma vez em Ri.
Seja r uma relação do esquema R, e seja ri = para i=1,2,..., n. Isto é, {r1, r2, ..., rn} é o banco de dados
que resulta da decomposição de R em {R1, R2, ..., Rn}. Neste caso, é sempre válido:
Para verificar se essa declaração é verdadeira, considere uma tupla t da relação r. quando computamos as
relações r1, r2, ..., rn, a tupla t origina uma tupla ti em cada ri, i=1, 2, ..., n. Essas n tuplas podem ser combinadas
para reconstruir t quando computamos r1 r2 ... rn. Portanto, toda tupla em r aparece em .
De modo geral, r≠ . Como ilustração, considere nosso exemplo anterior, no qual:
• n = 2
• R = esquema_linha_de_crédito
• R1 = esquema_agência_cliente
• R2 = esquema_cliente_empréstimo
• r = a relação mostrada na fig. 7.1.
• r1 = a relação mostrada na fig. 7.2.
• r2 = a relação mostrada na fig. 7.3.
• r1 r2 = a relação mostrada na fig. 7.4.
Note que as relações das fig. 7.1 a 7.4 não são as mesmas.
Para decomposições sem perda, precisamos impor restrições ao conjunto das relações possíveis.
Concluímos que a decomposição do esquema_linha_de_crédito em esquema_agência e
esquema_info_empréstimos ocorre sem perdas porque a dependência funcional
nome_agência � cidade_agência fundos
realiza-se em esquema_agência.
Seja C a representação de um conjunto de restrições do banco de dados. Uma decomposição {R1, R2, ...,
Rn} do esquema de relação R é uma decomposição sem perda na junção de R se para todas as relações r no
esquema R válido sob C:
Normalização usando dependências funcionais
Podemos usar um dado conjunto de dependências funcionais para projetar um banco de dados relacional,
evitando a maior das propriedades não desejadas, já discutidas. Quando projetamos tais sistemas, pode tornar-se
desnecessário decompor uma relação em diversas relações menores. Usando a dependência funcional, podemos
definir algumas formas normais que representam “bons” projetos de banco de dados.

180
Propriedades Desejáveis da Decomposição
Podemos ilustrar nossos conceitos por meio do esquema_linha_de_crédito:
O conjunto de dependências funcionais F que desejamos que se realizem para o
esquema_linha_de_crédito são:
nome_agência � fundos cidade_agência
número_empréstimo � total nome_agência
O esquema_linha_de_crédito é um exemplo de projeto ruim de banco de dados. Suponha que tenhamos
decomposto esse esquema nas três relações a seguir:
esquema_agência= (nome_agência, fundos, cidade_agência)
esquema_empréstimo= (nome_agência, número_empréstimo, total)
esquema_devedor= (nome_cliente, número_empréstimo)
Afirmamos que essa decomposição apresenta diversas propriedades desejáveis.
Decomposição sem Perda na Junção
Já sustentamos que, quando decompomos uma relação em outras relações menores, é crucial que a
decomposição não resulte em perda de informação. Afirmamos que a decomposição é crucial que a
decomposição não resulte em perda de informação.
Seja R um esquema de relação e F um conjunto de dependências funcionais sobre R. Sejam R1 e R2 formas
de decomposição de R. Essa decomposição é uma decomposição sem perda na junção de R se ao menos uma das
seguintes dependências funcionais está em F+:
Mostraremos agora que nossa decomposição para o esquema_linha_de_crédito é uma decomposição
sem perda na junção mostrando uma sequência de passos que geraram essa decomposição. Comecemos pela
decomposição do esquema_linha_de_crédito em dois esquemas:
esquema_agência = (nome_agência, cidade_agência, fundos)
esquema_info_empréstimo = (nome_agência, nome_cliente, número_empréstimo, total)
Uma vez que nome_agência�cidade_agência fundos, a regra incremental (augmentation) para a
dependência funcional implica:
nome_agência � nome_agência cidade_agência fundos
Já que esquema_agência esquema_info_empréstimo = {nome_agência}, então nossa decomposição
inicial é uma decomposição sem perda na junção.
A seguir, decomporemos esquema_info_empréstimo em:
Esse passo resulta em uma decomposição sem perda na junção, desde que número_empréstimo seja um
atributo comum e número_empréstimo�total nome_agência.
Preservação da dependência
Outra meta do projeto de um banco de dados relacional é a preservação da dependência. Quando ocorre
uma atualização no banco de dados, o sistema deve checar se ele criará uma relação ilegal – isto é, uma relação
que não que não satisfaça todas as dependências funcionais. Se checarmos de modo eficiente essas atualizações,

181
poderemos projetar esquemas de banco de dados relacionais capazes de validar atualizações sem necessidade de
junções.
Para decidir se uma junção é ou não necessária, precisamos determinar quais dependências funcionais
devem ser testadas, verificando cada uma das relações individualmente. Seja F um conjunto de dependências
funcionais de um esquema R e seja R1, R2, ..., Rn uma decomposição de R. A restrição de F para Ri é o conjunto Fi
de todas as dependências funcionais em F+ que contenha somente os atributos de Ri. Já que todas as
dependências funcionais em uma restrição contêm atributos de apenas um esquema de relação, é possível testar
se tais dependências são satisfeitas checando somente uma relação.
O conjunto de restrições F1, F2, ..., Fn é o conjunto das dependências que podem ser checadas
eficientemente. Agora precisamos nos certificar de que é suficiente testar somente as restrições. Seja F’ =
. F’ é um conjunto de dependências funcionais do esquema R, mas, em geral, F’≠F. Entretanto,
mesmo que F’≠F, pode ser que F’+=F+. Se o último é verdadeiro, então toda a dependência de F está
compreendida logicamente em F’, e, se verificarmos que F’ é satisfeita, podemos verificar que F também o é.
Dizemos que uma decomposição é decomposição com preservação da dependência se possui a propriedade
F’+=F+. A fig. 7.5 mostra um algoritmo para o teste da preservação da dependência. A entrada é o conjunto dos
esquemas das relações decompostas D = {R1, R2, ..., Rn} e um conjunto de dependências funcionais F.
Podemos agora mostrar que nossa decomposição do esquema_linha_de_crédito é uma decomposição
com preservação de dependência. Consideramos cada membro do conjunto F das dependências funcionais que
desejamos impostas sobre esquema_linha_de_crédito e mostraremos que cada uma pode ser testada em ao
menos uma relação da decomposição.
• Podemos testar a dependência funcional: nome_agência�cidade_agência fundos usando
esquema_agência= (nome_agência, cidade_agência, fundos).
• Podemos testar a dependência funcional: número_empréstimo�total nome_agência usando
esquema_empréstimo= (nome_agência, número_empréstimo, total).
Como no exemplo mostrado anteriormente, frequentemente é mais fácil não aplicar o algoritmo da fig.
7.5 para o teste da preservação da dependência, já que o primeiro passo, o processamento de F+, toma tempo
exponencial.
Redundância de Informações
A decomposição do esquema_linha_de_crédito não sofre o problema da repetição da informação que foi
discutido anteriormente. No esquema_linha_de_crédito é necessário repetir, em cada empréstimo, a cidade e os
fundos relativos à agência.

182
A decomposição separa os dados a respeito da agência e do empréstimo em relações distintas
eliminando, desse modo, a redundância. Similarmente, observe que, se um único empréstimo é feito para
diversos clientes, repetiremos o total do empréstimo para cada um dos clientes (assim como a cidade e os fundos
da agência). Na decomposição, a relação do esquema esquema_devedor contém o relacionamento
número_do_empréstimo e nome_do_cliente que nenhum outro esquema contém.
Temos, portanto, somente na relação do esquema esquema_devedor contém o relacionamento
número_do_empréstimo e nome_do_cliente que nenhum outro esquema contém.
Temos, portanto, somente na relação do esquema esquema_devedor, uma tupla para cada cliente com
um empréstimo. Nas outras relações que contêm o atributo número_empréstimo (as dos esquemas
esquema_empréstimo, e esquema_devedor) aparece somente uma tupla por empréstimo.
Evidentemente, é desejável a ausência de redundância mostrada nessa decomposição. O grau alcançado
por essa ausência de redundância é representado pelas diversas formas normais.
Forma Normal de Boyce-Codd
Uma das mais procuradas formas normais é a forma normal de Boyce-Codd (FNBC). Uma relação do
esquema R está na FNBC com respeito a um conjunto F de dependências funcionais se para todas as
dependências funcionais em F+ da forma α�β, em que α R e β R, ao menos uma das seguintes realiza-se:
• α�β é uma dependência funcional trivial (isto é, β α).
• α é uma superchave para o esquema R.
Um projeto de banco de dados está na FNBC se cada membro do conjunto de relações dos esquemas que
constituem o projeto está na FNBC.
Como exemplo, consideremos os seguintes esquemas de relações e suas respectivas dependências
funcionais:
Afirmamos que o esquema_cliente está na FNBC. Notamos que uma chave candidata para o esquema é
nome_cliente. A única dependência funcional não trivial no que se realiza no esquema_cliente tem nome_cliente
é chave candidata, dependências funcionais com nome_cliente do lado esquerdo da seta não violam a definição
da FNBC. Analogamente, pode-se mostrar facilmente que a relação do esquema esquema_agência está na FNBC.
O esquema esquema_info_empréstimo, entretanto, não está na FNBC. Primeiro, note que
número_empréstimo não é superchave do esquema_info_empréstimo, já que poderia haver um par de tuplas
representando um único empréstimo adquirido por duas pessoas – por exemplo:
Como não fizemos a lista das dependências funcionais que não são admitidas no caso precedente,
número_empréstimo não é uma chave candidata. Entretanto, a dependência funcional
número_empréstimo�total não é trivial. Portanto, esquema_info_esquema não satisfaz a definição FNBC.
Afirmamos que o esquema_info_empréstimo não é conveniente, uma vez que está sujeito ao problema
de informações redundantes já descrito. Observemos que, se existir diversos nomes de clientes associados a um
empréstimo, em uma relação do esquema_info_empréstimo, então somos forçadas a repetir o nome da agência
e o total do empréstimo a cada cliente.

183
Podemos eliminar essa redundância redesenhando nosso banco de dados de modo que todos os
esquemas estejam em FNBC. Uma abordagem para esse problema é tomar um projeto que não está na FNBC
como ponto de partida e decompor os esquemas necessários. Considere a decomposição do
esquema_info_empréstimo em dois outros esquemas:
Essa decomposição é uma decomposição sem perda na junção.
Para determinar se esses esquemas estão na FNBC, precisamos determinar quais dependências funcionais
se aplicam a elas. Nesse exemplo, é fácil perceber que:
número_empréstimo� total nome_agência
aplica-se a esquema_empréstimo e que somente dependências funcionais aplicam-se a esquema_devedor.
Embora número_empréstimo não seja uma superchave para esquema_info_empréstimo, ele é chave candidata
para esquema_empréstimo. Assim, ambos os esquemas de nossa decomposição estão em FNBC.
Assim, é possível evitar redundância quando há diversos clientes associados a um único empréstimo. Há
exatamente uma tupla para cada empréstimo na relação do esquema_empréstimo e uma tupla para cada
empréstimo de cada cliente na relação do esquema_devedor. Logo, não precisamos repetir o nome da agência e
o total para cada cliente associado a um empréstimo.
Podemos agora determinar um método geral para criar uma coleção de esquemas na FNBC. Se R não está
na FNBC, podemos decompor R em um grupo de esquemas R1, R2, ..., Rn na FNBC usando o algoritmo da fig. 7.6,
que não só gera decomposições na FNBC, como todas as decomposições sem perda na junção. Para perceber por
que nosso algoritmo gera somente decomposições sem perda na junção, note que, quando substituímos um
esquema Ri por (Ri – β) e (α,β), a dependência α�β realiza-se e .
Vejamos a aplicação do algoritmo de decomposição FNBC no esquema_linha_de_crédito que usamos
anteriormente como exemplo de um projeto deficiente de banco de dados:
esquema_linha_de_crédito = (nome_agência, cidade_agência, fundos, nome_cliente, número_empréstimo, total)
O conjunto de dependências funcionais que exigimos que se realizem são:
Uma chave candidata para esse esquema é {número_empréstimo, nome_cliente}.
Aplicamos o algoritmo da fig. 7.6 para o exemplo com esquema_linha_de_crédito, conforme segue:
• A dependência funcional nome_agência � fundos cidade_agência
realiza-se no esquema_linha_de_crédito, mas nome_agência não é uma superchave.
Assim, esquema_linha_de_crédito não está na FNBC. Substituímos o esquema_linha_de_crédito por:

184
• A única dependência funcional não trivial que se realiza no esquema_agência contém nome_agência no
lado esquerdo da seta. Uma vez que nome_agência é uma chave para o esquema_agência, a relação
esquema_agência está na FNBC.
• A dependência funcional
número_empréstimo � total nome_agência
realiza-se no esquema_info_empréstimo, mas número_empréstimo não é chave para o
esquema_info_empréstimo. Substituímos esquema_info_empréstimo por:
• esquema_empréstimo e esquema_devedor estão na FNBC.
Assim, a decomposição do esquema_linha_de_crédito resulta nos três esquemas de relações
esquema_agência, esquema_empréstimo, e esquema_devedor, cada um dos quais na FNBC. Esses esquemas de
relação são os mesmos já usados anteriormente.
Nem toda decomposição na forma FNBC tem dependência preservada. Considere a seguinte relação:
esquema_bancário= (agência_nome, nome_cliente, nome_bancário)
que informa que um cliente possui atendimento personalizado, de responsabilidade de um bancário
determinado, em uma dada agência. O conjunto F de dependências funcionais necessárias ao esquema_bancário
são:
Naturalmente, esquema_bancário não está na FNBC, uma vez que nome_bancário não é uma superchave.
Se aplicarmos o algoritmo da fig. 7.6, obtemos a seguinte decomposição em FNBC:
A decomposição dos esquemas preserva somente nome_bancário�nome_agência (e as dependências
triviais), mas a clausura {nome_bancário�nome_agência} não engloba nome_cliente nome_agência �
nome_bancário. Uma violação dessa dependência pode ser detectada somente por meio de uma junção.
Para verificar se a decomposição de esquema_bancário nos esquemas esquema_bancário_agência e
esquema_cliente_bancário não acontece com preservação da dependência, aplicamos o algoritmo da fig. 7.5.
Consideremos que as restrições F1 e F2 de F para cada um dos esquemas são:
Assim, uma cobertura canônica para o conjunto F’ é F1.
É fácil perceber que a dependência funcional nome_cliente nome_agência � nome_bancário não está
em F’+ mesmo que esteja em F+. Portanto, F’+≠F+ e a decomposição não preserva a dependência.
O exemplo precedente demostra que nem toda decomposição FNBC preserva a dependência. Além disso,
ela demonstra que nem sempre as três metas de projeto podem ser satisfeitas:
1. FNBC
2. Sem perda na junção
3. Preservação da dependência
Não podemos realiza-las neste exemplo porque toda decomposição FNBC do esquema_bancário falha na
preservação de nome_cliente nome_agência � nome_bancário.

185
Terceira Forma Normal
Nos caos em que não conseguimos alcançar todos os três critérios de projeto, abandonamos FNBC e
aceitamos uma forma normal mais fraca chamada terceira forma normal (3FN). Vemos que sempre é possível
alcançar decomposição sem perda na junção, decomposição com preservação da dependência que está na 3FN.
A FNBC exige que todas as dependências não triviais sejam da forma α�β, em que α é uma superchave. A
3FN suaviza essa restrição permitindo dependências funcionais não-triviais cujo lado esquerdo da seta não seja
superchave.
Um esquema de relação R está na 3FN com respeito a um conjunto de dependências funcionais F se, para
todas as dependências funcionais F+ da forma α�β, em que α R e β R, ao menos uma das seguintes
condições for realizada:
• α�β é uma dependência funcional trivial.
• α é uma superchave de R.
• Cada atributo de A em β – α está contido em uma chave candidata de R.
A definição da 3FN permite algumas dependências funcionais que não são permitidas na FNBC. A
dependência α�β, que satisfaz apenas a terceira condição da definição da 3FN, não é permitida na FNBC, mas é
permitida na 3FN. Essas dependências são um exemplo de dependências transitivas.
Observe que, se um esquema de relação está na FNBC, então todas as dependências funcionais são da
forma “superchave determina um conjunto de atributos”, ou a dependência é trivial. Assim, um esquema FNBC
não pode conter nenhuma dependência transitiva. Como resultado, todo esquema FNBC é também da 3FN, e a
FNBC, portanto, mantém regras mais restritivas que a 3FN.
Retornemos ao nosso exemplo do esquema_bancário. Mostramos que esse esquema de relação não tem
a dependência preservada, com decomposição sem perda da junção em FNBC. Esse esquema, entretanto, sai da
3FN. Para essa verificação, notamos que {nome_cliente, nome_agência} é uma chave candidata para
esquema_bancário, assim o único atributo não contido em chave candidata de esquema_bancário é
nome_bancário. As únicas dependências funcionais não-triviais da forma α�nome_bancário incluem
{nome_cliente, nome_agência} como parte de α. Já que {nome_cliente, nome_agência} é chave candidata, essas
dependências não violam a definição da 3FN.
A fig. 7.7 mostra um algoritmo para chegar à preservação de dependência, com decomposição sem perda
na junção em 3FN. O fato de cada esquema de relação Ri estar na 3FN decorre diretamente de nossa exigência de
que o conjunto de dependências funcionais F seja da forma canônica. O algoritmo assegura a preservação das
dependências explicitando um esquema para cada dependência. Ele assegura que a decomposição é sem perda
na junção por meio da garantia de que ao menos um esquema contém uma chave candidata para o esquema que
está sendo decomposto.
Para ilustrar o algoritmo da fig. 7.7 consideramos a seguinte extensão do esquema_bancário:
esquema_info_bancário= (nome_agência, nome_cliente, nome_bancário, número_seção)
A principal diferença aqui é que incluímos o número da seção do bancário como parte da informação. As
dependências funcionais para esse esquema de relação são:
Uma vez que esquema_bancário contém uma chave candidata para o esquema_info_bancário,
terminamos o processo de decomposição.

186
Comparação entre FNBC e 3FN
Vimos duas formas normais de esquemas de banco de dados relacionais: 3FN e FNBC. Uma vantagem de
um projeto na 3FN é saber que sempre é possível obtê-la sem sacrificar uma decomposição sem perda na junção
ou preservação da dependência. Apesar disso, há uma desvantagem na 3FN. Se não a eliminarmos todas as
dependências transitivas, teremos de usar valores nulos para representação de alguns dos possíveis
relacionamentos significativos entre itens de dados, e há ainda o problema da repetição da informação.
Como ilustração, considere novamente o esquema_bancário e suas dependências funcionais associadas.
Dado nome_bancário�nome_agência, podemos desejar representar em nosso banco de dados relacionamentos
entre valores de nome_bancário e valores de nome_agência. No entanto, se fizermos isso, será preciso ter um
valor correspondente para nome_cliente ou usar valores nulos para o atributo nome_cliente.
Outra dificuldade com esquema_bancário é a repetição da informação. Como ilustração, considere uma
instância de esquema_bancário mostrada na fig. 7.8. Note que a informação de que Johnson está trabalhando na
agência Perryridge é repetida.
Se formos forçados a escolher entre FNBC e preservação da dependência com 3FN, geralmente é
preferível optar pela 3FN. Se não pudermos verificar eficientemente a preservação da dependência, termos de
pagar alto custo em desempenho do sistema ou corremos riscos em relação à integridade de dados de nosso
banco de dados. Nenhuma dessas opções é atraente. Com tais alternativas, o limite à redundância imposto pelas
dependências transitivas sob a 3FN é o menos pior. Assim, normalmente optamos por manter a preservação da
dependência e sacrificar a FNBC.
Em resumo, repetimos que as três metas de projeto para um banco de dados relacional são:
1. FNBC

187
2. Junção sem perda
3. Preservação da dependência
Se não pudermos alcançar as três, aceitamos:
1. 3FN
2. Junção sem perda
3. Preservação da dependência
Normalização usando Dependências Multivaloradas
Há esquemas de relação na FNBC que não estão normalizados o bastante, no sentido de que eles ainda
sofrem de problemas de repetição de informação. Considere novamente nosso exemplo relativo ao banco.
Assuma que, como alternativa de projeto para o esquema de um banco de dados de uma empresa na área
bancária, tenhamos o esquema:
esquema_BC = (número_empréstimo, nome_cliente, rua_cliente, cidade_cliente)
Podemos perceber que esse esquema não está na FNBC por causa da dependência funcional
nome_cliente � rua_cliente cidade_cliente
que afirmamos anteriormente, e porque nome_cliente não é uma chave do esquema_BC. Entretanto,
consideremos que nosso banco está atraindo clientes ricos que possuem diversos endereços (digamos, casa de
inverno e casa de verão). Então, não desejaremos mais a dependência funcional nome_cliente�rua_cliente
cidade_cliente. Se retirarmos essa dependência funcional, concluiremos que o esquema_BC está na FNBC com
respeito ao nosso conjunto de dependências funcionais modificadas. Ainda, mesmo que o esquema_BC esteja na
FNBC com respeito ao nosso conjunto de dependências funcionais modificadas. Ainda, mesmo que o
esquema_BC esteja na FNBC, nós teremos o problema da repetição de informações que tínhamos anteriormente.
Para tratar esse problema, precisamos definir uma nova forma de restrição, chamada dependência
multivalorada. Como fizemos com as dependências funcionais, usaremos as dependências funcionais
multivaloradas para definir uma forma normal para os esquemas das relações. Essa forma normal, chamada
quarta forma normal (4FN), é mais restritiva que a FNBC. Podemos ver que todo esquema na 4FN está também na
FNBC, mas há esquemas na FNBC que não estão na 4FN.
Dependências Multivaloradas
As dependências funcionais rejeitam certas tuplas como participantes de uma relação. Se A�B, então
não podemos ter duas tuplas com os mesmos valores de A, mas diferentes valores de B. Dependências
multivaloradas não rejeitam a existência de certas tuplas. Pelo contrário, elas exigem que outras tuplas, de uma
certa forma, estejam presentes na relação. Por essa razão, por vezes, as dependências funcionais são chamadas
dependências geradas por igualdade (equality-generating dependencies) e dependências multivaloradas são
referidas como dependências geradas por tuplas (tuple-generating dependencies).
Seja R um esquema de relação e seja α R e β R. A dependência multivalorada α��β realiza-se em R
se, para qualquer relação r(R), para todos os pares de tuplas t1 e t2 de r, tal que t1[α] =t2 [α], existem tuplas t3 e t4
em r tal que
Essa definição é menos complexa do que parece. Na fig. 7.9, damos uma apresentação tabular para t1, t2,
t3 e t4. Intuitivamente, a dependência multivalorada α��β diz que um relacionamento entre α e β é
independente do relacionamento entre α e R – β. Se uma dependência multivalorada α��β é satisfeita para
todas as relações do esquema R, então α��β é uma dependência multivalorada trivial do esquema R. Assim,
α��β é trivial se β α β α=R.

188
Para ilustrar as diferenças entre dependência funcional e multivalorada, consideremos novamente o
esquema_BC e a relação bc (esquema_BC) da fig. 7.10. Precisamos repetir o número do empréstimo de um
mesmo cliente. Essa repetição é desnecessária, já que o relacionamento entre o cliente e seu endereço é
independente do relacionamento entre o cliente e um empréstimo. Se um cliente (digamos, Smith) tem um
empréstimo (digamos, o de número L-23), queremos que o empréstimo seja associado a todos os endereços de
Smith. Assim, a relação da fig. 7.11 não é validade. Para tornar essa relação válida, precisamos adicionar as tuplas
(L-23, Smith, Main, Manchester) e (L-27, Smith, North, Rye) à relação bc da fig. 7.11.
Comparando o exemplo anterior com nossa definição de dependência multivalorada, percebemos que
desejamos que a dependência multivalorada nome_cliente �� rua_cliente cidade_cliente se realize (a
dependência multivalorada nome_cliente ��número_empréstimo faz a mesma coisa. Assim, verificamos que
são equivalentes).
Como fizemos para as dependências funcionais, podemos usar a dependência multivalorada de dois
modos:
1. Para testar relações para determinar se elas são validades sob um dado conjunto de dependências
funcionais e multivaloradas.
2. Para especificar restrições sobre um conjunto de relações válidas; devemos, assim, nos restringir somente
àquelas relações que satisfazem um dado conjunto de dependências funcionais e multivaloradas.
Note que, se uma relação r não satisfaz uma dada dependência multivalorada, podemos criar uma relação r’ que
satisfaça a dependência multivalorada adicionando tuplas a r.
Teoria das Dependências Multivaloradas
Como foi feito para a dependência funcional, para 3FN e para FNBC, precisamos determinar todas as
dependências multivaloradas que estão logicamente implícitas em um dado conjunto de dependências
multivaloradas.
Adotamos o mesmo enfoque tomado anteriormente para as dependências funcionais. Seja D um
conjunto de dependências funcionais e multivaloradas. A clausura D+ de D é o conjunto de todas as dependências

189
funcionais e multivaloradas logicamente implícitas em D. Como fizemos para as dependências funcionais,
podemos computar D+ por meio de D, usando a definição formal de dependências funcionais e dependências
multivaloradas. Entretanto, é normalmente mais fácil ponderar acerca de conjuntos de dependências
multivaloradas. Entretanto, é normalmente mais fácil ponderar acerca de conjuntos de dependências usando um
sistema de regras de inferências.
A seguinte lista de regras de inferências para dependências funcionais e dependências multivaloradas é
sólida e completa. Recorde que as regras para solidez não criam qualquer dependência que não esteja
logicamente implícita em D e regras completas permite-nos criar todas as dependências em D+.
Seja R= (A, B, C, G, H, I) um esquema de relação. Suponha que A��BC realiza-se. A definição de
dependência multivalorada implica que, se t1[A] = t2[A], então existem as tuplas t3 e t4 tal que:
A regra de complementação coloca que, se A��BC, então A��GHI. Observe que t3 e t4 satisfazem a
definição de que A��GHI simplesmente mudando os subescritos.
Podemos proporcionar uma justificativa similar para as regras 5 e 6 usando a definição de dependência
multivalorada.
Regra 7, a regra da replicação, envolve dependências funcionais e multivaloradas. Suponha que A�BC
realiza-se em R. Se t1[A] =t2[A] e t1[BC] =t2[BC], então as próprias t1 e t2 podem ser as tuplas t3 e t4 exigidas na
definição da dependência multivalorada A��BC.
Regra 8, a regra da coalescência, é a mais difícil de se verificar entre as oito regras.
Podemos simplificar a computação da clausura de D usando as seguintes regras, as quais podemos provar
usando as regras 1 a 8.
• Regra da união multivalorada. Se α��β e α��γ realizam-se, então α�βγ também realiza-se.
• Regra da interseção. Se α��β e α��γ realizam-se, então α��β γ realiza-se.
• Regra da diferença. Se α��β e α��γ realizam-se, então α��β – γ realiza-se e α��γ – β realiza-se.
Apliquemos nossas regras no seguinte exemplo. Seja R = (A, B, C, G, H, I) com o seguinte conjunto de
dependências D dado:
Relacionamos alguns membros de D+ aqui:

190
• A��CGHI: desde que A��B, a regra da complementação (regra 4) implica que A��R – B – A, R – B –
A = CGHI, assim A��CGHI.
• A��HI: desde que A��B e B��HI, a regra da transitividade multivalorada (regra 6) implica que
A��HI – B. Desde que HI – B = HI, A��HI.
• B�H: para mostrar isso, precisamos aplicar a regra da transitividade multivalorada (regra 6) implica que
A��HI – B. Desde que HI – B = HI, A��HI.
• B�H: para mostrar isso, precisamos aplicar a regra da coalescência (regra 8). B�HI realiza-se. Desde que
H HI e CG�H e CG HI = , satisfazemos a regra da coalescência, com α estando em B, β estando em
HI, δ estando em CG e γ estando em H. Concluímos que B�H.
• A��CG: também sabemos que A��CGHI e A��HI. Pela regra da diferença, A��CGHI. Desde que
CGHI – HI = CG. A�CG.
Quarta Forma Normal
Retornemos a nosso exemplo esquema_BC no qual a dependência multivalorada nome_cliente ��
rua_cliente cidade_cliente realiza-se, mas nenhuma dependência funcional não-trivial realiza-se. Vimos
anteriormente que, embora esquema_BC esteja na FNBC, o projeto não é adequado, uma vez que precisamos
repetir as informações acerca do endereço do cliente a cada empréstimo. Podemos ver que é possível usar a
dependência multivalorada dada para melhorar o projeto do banco de dados, por meio da decomposição
esquema_BC em uma decomposição na quarta forma normal (4FN).
Um esquema de relação R está na 4FN com respeito a um conjunto D de dependências funcionais e
multivaloradas se, para todas as dependências multivaloradas em D+ da forma α��β, em que α R e β R, ao
menos uma das seguintes condições se realize:
• α��β é uma dependência multivalorada trivial.
• α é uma superchave para o esquema R.
Um projeto de banco de dados está na 4FN se cada membro do conjunto dos esquemas de relações que
constituem o projeto estiver na 4FN.
Note que a definição da 4FN difere da definição da FNBC somente no uso de dependências multivaloradas
em vez de dependências funcionais. Todo esquema na 4FN está na FNBC.
Para constatar esse fato, notamos que, se um esquema R não está na FNBC, então há uma dependência
funcional não-trivial α�β realizando-se em R, na qual α não é superchave. Desde que α�β implica que α��β
(pela regra da replicação), R não poderá estar na 4FN.
A analogia entre 4FN e FNBC aplica-se ao algoritmo para a decomposição de um esquema para a 4FN. A
fig. 7.12 mostra o algoritmo para a decomposição na 4FN. Ele é idêntico ao algoritmo de decomposição para FNBC
mostrado na fig. 7.6, exceto pelo fato de usar dependência multivalorada em vez da dependência funcional.
Se aplicarmos o algoritmo da fig. 7.12 para o esquema_BC, concluímos que nome_cliente � �
número_empréstimo é uma dependência multivalorada não-trivial e nome_cliente não é uma superchave para o
esquema_BC pelos dois esquemas:
esquema_devedor = (nome_cliente, número_empréstimo)
esquema_cliente = (nome_cliente, rua_cliente, cidade_cliente)
Esse par de esquemas, que estão na 4FN, eliminam o problema encontrado anteriormente em relação à
redundância do esquema_BC.
Como no caso em que tratamos somente das dependências funcionais, estamos interessados em
decomposições sem perda na junção e com preservação das dependências. Os fatos seguintes sobre
dependências multivaloradas e sem perda na junção mostram que o algoritmo da fig. 7.12 cria somente
decomposições sem perda na junção:

191
• Seja o esquema de relação R e seja D um conjunto de dependências funcionais e multivaloradas de R. Seja
R1 e R2 decomposições de R. Esta decomposição é sem perda na junção de R se e somente se ao menos
uma das seguintes dependências multivaloradas estiver em D+:
Lembre-se de que estabelecemos anteriormente que, se R1 R2�R1 ou R1 R2�R2, então R1 e R2 são
decomposições sem perda na junção de R. O fato precedente ressalta que as dependências multivaloradas
constituem uma forma mais genérica de junção sem perda. Ele indica que, para toda decomposição sem perda na
junção de R em dois esquemas R1 e R2, uma das duas dependência R1 R2 ��R1 ou R1 R2�R2 deve se realizar.
A questão da preservação da dependência quando temos dependência multivalorada não é tão simples
quanto quando temos somente dependências funcionais. Seja R um esquema de relação e sejam R1, R2, ..., Rn
decomposições de R. Lembre-se de que, para um conjunto de dependências funcionais F, a restrição F1 de F para
Ri são todas as dependências funcionais em F+ que incluem somente atributos de Ri. Agora, consideremos um
conjunto D, tanto de dependências funcionais quanto de dependências multivalorados. A restrição de D para R1 é
o conjunto Di, consistindo:
• Todas as dependências funcionais em D+ que incluem somente atributos de Ri.
• Todas as dependências multivaloradas da forma.
α��β Ri em que α Ri e α��β está em D+.
Uma decomposição do esquema R nos esquemas R1, R2, ..., Rn é uma decomposição com preservação da
dependência com respeito ao conjunto D de dependências funcionais e multivaloradas se, para todo conjunto de
relações r1(R1), r2(R2), ..., rn (Rn), tal que, para todo i, ri satisfaça Di, lá houver uma relação r(R) que satisfaça D e
para qual ri= Ri(r) para todo i.
Apliquemos o algoritmo para decomposição na 4FN da fig. 7.12 em nosso exemplo de R = (A, B, C, G, H, I)
com D = {A��B, B��HI, CG� H}. Podemos, então, testar a decomposição resultante em relação à preservação
da dependência.
R não está na 4FN. Observe que A��B não é trivial, ainda A não é uma superchave. Usando A��B na
primeira iteração do while, substituímos R por dois esquemas, (A, B) e (A, C, G, H, I). É fácil perceber que (A,B)
está na 4FN desde que todas as dependências multivaloradas que valem em (A, B) sejam triviais. Entretanto, o
esquema (A, C, G, H, I) não está na 4FN. Aplicando a dependência multivalorada CG��H (que decorre na
dependência funcional dada CG��H pela regra da replicação), substituímos (A, C, G, H, I) pelos dois esquemas,
(C, G, H) e (A, C, G, I). O esquema (C, G, H) está na 4FN, mas o esquema (A, C, G, I) não está. Para perceber que (A,
C, G, I) não está na 4FN, lembremos que foi mostrado anteriormente que A��HI está em D+. Portanto, A��I
está na restrição de D para (A, C, G, I). Assim, na terceira iteração do laço while, substituímos (A, C, G, I) pelos dois
esquemas (A, I) e (A, C, G). O algoritmo então termina e a decomposição 4FN é {(A, B), (C, G, H), (A, I), (A, C, G)}.

192
Essa decomposição para a 4FN não preserva a dependência, uma vez que ela falha na preservação da
dependência multivalorada B��HI. Considere a fig. 7.13m que mostra as quatro relações que poderiam resultar
da projeção de uma relação em (A, B, C, G, H, I) nos quatro esquemas de nossa decomposição. A restrição de D
para (A, B) é A��B e algumas dependências triviais. É fácil perceber que r1 satisfaz A��B porque não há
nenhum par de tuplas com o mesmo valor de A. Observe que r2 tenha os mesmos valores em qualquer atributo.
Um comando similar pode ser feito para r3 e r4. Portanto, a versão decomposta de nosso banco de dados satisfaz
a todas as dependências da restrição de D. Entretanto, não há nenhuma relação r em (A, B, C, G, H, I) que
satisfaça D e possa ser decomposta em r1, r2, r3 e r4. A fig. 7.14 mostra a relação r = . A relação
r não satisfaz B��HI. Qualquer relação s contendo r e satisfazendo B��HI deve incluir a tupla (a2, b1, c2, g2, h1,
i1). Entretanto, CGH(s) inclui uma tupla (c2, g2, h1) que não está em r2. Assim, nossa decomposição falha da
detecção da violação de B��HI.
Vimos que, se estamos definindo um conjunto de dependências funcionais e multivaloradas, é vantajoso
chegar a um projeto de banco de dados que tenha como critérios:
1. 4FN
2. Preservação de dependência
3. Junção sem perda
Se tudo o que tivermos forem dependências funcionais, então o primeiro critérios será apenas a FNBC.
Vimos também que nem sempre é possível alcançar todas as três condições. Obtivemos sucesso na
decomposição do exemplo do banco, mas falhamos no exemplo do esquema R= (A, B, C, G, H, I).
Quando não conseguimos alcançar as três metas, abrimos mão da 4FN aceitando FNBC ou mesmo 3FN, se
necessário, assegurando a preservação da dependência.
Normalização usando dependências na Junção

193
Vimos que a propriedade sem perda na junção é uma das diversas propriedades para o projeto de um
banco de dados. De fato, essa propriedade é essencial: sem ela, há perda de informação. Quando restringimos o
conjunto das relações válidas entre as que satisfazem um conjunto de dependências funcionais e multivaloradas,
podemos usar essas dependências para mostrar que certas decomposições são decomposições sem perda na
junção.
Por causa da importância desse conceito de “sem perda na junção”, é útil conseguir restringir um
conjunto de relações válidas sobre uma esquema R para aquelas relações para as quais uma dada decomposição
é uma decomposição sem perda na junção. Vamos agora definir o que é dependência de junção. Apenas como
tipos de dependências conduzidas por outras formas normais, dependências de junção serão direcionadas a uma
forma normal chamada forma normal de projeção de junção – Project-join normal form (FNPJ).
Dependências de junção (Join Dependencies)
Seja R um esquema de relação e R1, R2, ..., Rn seja uma decomposição de R. A dependência de junção *
(R1, R2, ..., Rn) é usada para restringir o conjunto de relações legais para aquelas para as quais R1, R2, ..., Rn é uma
decomposição sem perda na junção de R. Formalmente, se R= , dizemos que uma relação r(R)
satisfaz a dependência de junção * (R1, R2,..., Rn) se:
Uma dependência de junção é trivial se um dos Ri for o próprio R.
Considere a dependência de junção *(R1, R2) do esquema R. Essa dependência exige que, para toda
r(R)válida:
Seja r contendo duas tuplas t1 e t2, conforme segue:
Assim, t1[R1 R2]=t2[R1 R2], mas t1 e t2 têm diferentes valores em todos os outros atributos.
Computemos . A fig. 7.15 mostra e . Quando computamos a junção, temos duas
tuplas, além de t1 e t2, exigidas na fig. 7.16 por t3 e t4.
Se *(R1, R2) vale, então, sempre que tivermos as tuplas t1 e t2, devemos também ter t3 e t4. Assim, a fig.
7.16 mostra uma representação tabular da dependência de junção *(R1, R2). Compare a fig. 7.16 com a fig. 7.9, na
qual temos a representação tabular de α��β. Se tivermos e β=R1, podemos ver que as duas
representações tabulares nessas figuras são as mesmas. De fato, *(R1, R2) é apenas um outra forma de determinar
. Usando as regras da complementação e do incremento para dependências multivaloradas,
podemos mostrar que ��R1 implica ��R2. Assim, *(R1, R2) é equivalente a ��R2. Essa
observação não causa surpresa tendo em vista que, conforme observamos anteriormente, R1 e R2 formam uma
decomposição de R sem perda na junção se, e somente se, ��R2 ou ��R1.

194
Toda dependência de junção da forma *(R1, R2) é, portanto, equivalente a uma dependência
multivalorada. No entanto, há dependências de junção que não são equivalentes a nenhuma dependência
multivalorada. O exemplo mais simples desse tipo de dependência é o esquema R=(A, B, C). A dependência de
junção: *((A, B), (B, C), (A, C))
não é equivalente a nenhuma coleção de dependências multivaloradas. A fig. 7.17 mostra uma representação
tabular dessa dependência de junção. Para notar que nenhum conjunto de dependências multivaloradas
implicam logicamente *((A, B), (B, C), (A, C)), consideramos a fig. 7.17 como uma relação r(A, B, C), como mostra a
fig. 7.18.
A relação r satisfaz a dependência de junção *((A, B), (B, C), (A, C)), como podemos verificar computando:
e mostrando que o resultado é exatamente r. Entretanto, r não satisfaz qualquer dependência multivalorada não-
trivial. Para percebemos isso, verificamos que r não satisfaz nenhuma das A��B, A��C, B��A, B��C,
C��A, ou C��B.

195
Da mesma forma que a dependência multivalorada é um modo de estabelecer a independência de um
par de relacionamentos, uma dependência de junção é um modo de estabelecer que os membros de um conjunto
de relacionamentos são todos independentes. Essa noção de independência de relacionamentos é consequência
natural do modo pelo qual geralmente definimos uma relação. Considere:
esquema_info_empréstimo=(nome_agência, nome_cliente, número_empréstimo, total)
de nosso exemplo bancário. Podemos definir uma relação info_empréstimo (esquema_info_empréstimo) com o
conjunto de todas as tuplas do esquema_info_empréstimo) com o conjunto de todas as tuplas do
esquema_info_empréstimo, tal que:
• O empréstimo representado por número_empréstimo é feito pela agência de nome nome_agência.
• O empréstimo representado por número_empréstimo é feito pelo cliente chamado nome_cliente.
• O empréstimo representado por número_empréstimo está no total de nome total.
A definição anterior da relação info_empréstimo é uma conjugação de três predicados: um em
número_agência e nome_agência, um em número_empréstimo e nome_cliente e um em número_empréstimo e
total.
Supreendentemente, pode ser mostrado que a definição intuitiva anterior de info_empréstimo implica
logicamente a dependência de junção *((número_empréstimo, nome_agência), (número_empréstimo,
nome_cliente), (número_empréstimo, total)).
Assim, as dependências de junção têm um aspecto intuitivo e correspondem a um dos três critérios
apresentados para um bom projeto de banco de dados.
Para dependências funcionais e multivaloradas, temos de fornecer um sistema de regras de inferências
que devem ser válidas e completas. Infelizmente, nenhum conjunto de regras é conhecido para dependências de
junções. Esse fato nos leva a considerar classes mais genéricas de dependências que as dependências de junções
para construir um conjunto de regras de inferências sólido e completo.
Forma Normal de Projeção de Junção
Forma normal de projeção de junção (FNPJ) é definida de maneira similar a FNBC e a 4FN, exceto pelo
fato das dependências de junções serem usadas. Um esquema de relação r está em FNPJ com respeito a um
conjunto D de dependências funcionais, multivaloradas e de junção se, para todas as dependências de junções
em D+ na forma *(R1, R2, ..., Rn), em que cada Ri R e R = , ao menos uma das seguintes for
validade:
• *(R1, R2, ..., Rn) é uma dependência de junção trivial.
• Todo Ri é superchave para R.
Um projeto de banco de dados está na FNPJ se cada membro de um conjunto de esquemas de relações
que constituem o projeto estiver na FNPJ. A FNPJ é chamada quinta forma normal (5FN) em parte da literatura
sobre normalização de banco de dados.
Retornaremos ao nosso exemplo bancário. Dada a dependência de junção *((número_empréstimo,
nome_agência), (número_empréstimo, nome_cliente), (número_empréstimo, total)), esquema_info_empréstimo
não está na FNPJ. Para colocar esquema_info_empréstimo na FNPJ, precisamos decompô-la em três esquemas
específicos por meio da dependência de junção: (número_empréstimo, nome_agência), (número_empréstimo,
nome_cliente) e (número_empréstimo, total).
Como todas as dependências multivaloradas são também dependências de junção, é fácil perceber que
todo esquema na FNPJ está também na 4FN. Assim, em geral, não precisamos chegar à decomposição com
preservação de dependência na FNPJ para um dado esquema.
Forma Normal Domínio-chave

196
A abordagem que utilizamos para a normalização toma por base a definição de restrições (funcional,
multivalorada ou dependência de junção) e então usa essa restrição para definir a forma normal. A forma normal
domínio-chave (FNDC) baseia-se em três noções:
1. Declaração de domínio. Seja A um atributo e dom um conjunto de valores. A declaração de domínio A
dom exige que o valor de A em todas as tuplas seja um valor em dom.
2. Declaração de chaves. Seja R um esquema de relação com K R. A declaração da chave key(K)
necessita que K seja uma superchave do esquema R – isto é, K�R. Note que todas as declarações de
chaves são dependências funcionais, mas nem todas as dependências funcionais são declarações de
chaves.
3. Restrições gerais. Uma restrição geral é um predicado do conjunto de todas as relações de um dado
esquema. As dependências que estudamos nesse capítulo são exemplos de restrições gerais.
Normalmente, uma restrição geral é um predicado expresso em uma forma agregada, como a lógica de
primeira ordem.
Damos agora um exemplo de uma restrição geral que não é funcional, multivalorada ou dependente de
junção. Suponha que todas as contas que comecem com o dígito 9 sejam contas especiais com altas taxas de
juros, cujo saldo mínimo é 2500 dólares. Então incluímos como restrição geral: “se o primeiro dígito de
t[número_conta] for 9, então t[saldo]≥2500”.
Declarações de domínio e declarações de chave são fáceis de testar em um sistema de banco de dados
prático. Restrições gerais, entretanto, podem ser extremamente custosas (em termos de tempo de
processamento e espaço) para testar. O proposito de um projeto de banco de dados na FNPJ é permitir-nos o
teste de restrições gerais usando somente restrições de domínio e chaves.
Formalmente, seja D um conjunto de restrições de domínio e K, um conjunto de restrições por chaves
para o esquema de relação R. Suponha que G represente as restrições gerais de R. O esquema R está na FNDC se
D K implica logicamente G.
Retornemos às restrições gerais que demos para as contas. As restrições implicam que nosso projeto de
banco de dados não está na FNDC. Para criar um projeto na FNDC, precisamos de dois esquemas no lugar do
esquema_conta:
esquema_conta_regular=(nome_agência, número_conta, saldo)
esquema_conta_especial=(nome_agência, número_conta, saldo)
Conservamos, como restrições gerais, todas as dependências que tínhamos no esquema_conta. As
restrições de domínio para esquema_conta_especial exigem que, para cada conta:
• O número da conta comece por 9.
• O saldo da conta seja maior que 2500.
As restrições de domínio para esquema_conta_regular exigem que o número da conta não comece por 9.
O projeto resultante está na FNDC.
Comparemos a FNDC com outras formas normais estudadas. Nas outras formas normais, não levamos em
consideração restrições de domínio. Assumimos (de modo implícito) que o domínio de cada atributo possui
domínio infinito, como o conjunto de todos os inteiros ou conjunto de todas as cadeias de caracteres. Permitimos
restrições por chaves (de fato, permitimos dependências funcionais).
Para cada forma normal, permitimos uma forma específica de restrição geral (um conjunto de
dependências funcionais, multivaloradas ou de junção). Assim, podemos reescrever as definições de FNPJ, 4FN,
FNBC e 3FN de modo a mostra-las como casos especiais de FNDC.
A seguir reescreveremos nossa definição de FNPJ inspirada na FNDC. Seja o esquema da relação R = (A1,
A2, ..., An). Seja dom(Ai) o domínio do atributo Ai e sejam infinitos esses domínios. Então, todas as restrições de
domínio D são da forma Ai dom(Ai). Sejam as restrições gerais um conjunto G de dependências funcionais

197
multivaloradas ou de junção. Se F é um conjunto de dependências funcionais em G, seja o conjunto K de
restrições por chave aquelas dependências funcionais não triviais em F+ da forma α�R. O esquema R está na
FNPJ se e somente se ele estiver na FNDC com respeito a D, K e G.
Uma consequência da FNDC é que toda inserção e remoção anômala é eliminada.
A FNDC constitui a última forma normal porque permite restrições arbitrárias, em vez de dependências, e
permite ainda testes eficientes para essas restrições. Naturalmente, se um esquema não está na FNDC, podemos
alcançá-la por meio de decomposições, mas tais decomposições, como já foi visto, não são sempre
decomposições com preservação da dependência. Assim, embora a FNDC seja a meta de um projetista de banco
de dados, poderá ser sacrificada em projetos reais.
Abordagens Alternativas para Projeto de Banco de Dados
Vamos reexaminar a normalização de esquemas de relação com ênfase nos efeitos dessa normalização no
projeto de um banco de dados real.
Adotamos como abordagem começar com um único esquema de relação e, então, decompô-lo. Uma de
nossas metas é escolher uma decomposição que resulte em decomposição sem perda na junção. Para considerar
essa ausência de perda na junção, assumimos ser válido falar em junção de todas as relações de um banco de
dados decomposto.
Considere o banco de dados da fig. 7.19, representamos a relação info_empréstimo decomposta na FNPJ.
Na fig. 7.19, representamos uma situação na qual ainda não determinamos o total do empréstimo L-58, mas
desejamos registrar a existência do dado no empréstimo. Se computarmos uma junção natural dessas relações,
notaremos que todas as tuplas referentes ao empréstimo L-58 desaparecerão. Em outras palavras, não há
nenhuma relação info_empréstimo correspondente às relações da fig. 7.19. Tuplas que desaparecem quando
computamos a junção são tuplas pendentes. Formalmente, seja r1(R1), r2(R2), ..., rn(Rn) um conjunto de relações.
Uma tupla t de uma relação ri é uma tupla pendente se t não está na relação:
As tuplas pendentes podem ocorrer em aplicações de banco de dados reais. Representam informações
incompletas, como ocorreu em nosso exemplo quando desejamos armazenar dados sobre um empréstimo que
estava ainda em processo de negociação. A relação r1 r2 ... rn é chamada relação universal, uma vez que
envolve todos os atributos do universo definido por R1 R2 ... Rn.
O único modo por meio do qual podemos escrever uma relação universal para o exemplo da fig. 7.19 é
incluindo valores nulos na relação universal. Vimos que valores nulos originam sérias dificuldades. Pesquisas a
respeito de valores nulos e relações são discutidos em notas bibliográficas. Devido à dificuldade de manuseio de
valores nulos, pode ser mais adequado tratar as relações de um projeto decomposto como a representação do
banco de dados, em vez das relações universais cujos esquemas foram decompostos durante o processo de
normalização.

198
Note que não devemos introduzir informações incompletas no banco de dados da fig. 7.19 sem recorrer
ao uso de valores nulos. Por exemplo, não podemos introduzir um número de empréstimo se não conhecermos
ao menos uma das seguintes informações:
• O nome do cliente.
• O nome da agência.
• O total do empréstimo.
Assim, uma decomposição em particular define uma forma restritiva para uma informação incompleta
que é aceitável em nosso banco de dados.
A forma normal que definimos gera bons projetos de banco de dados do ponto de vista da representação
de informações incompletas. Retornando novamente ao exemplo da fig. 7.19, poderíamos desejar não permitir o
armazenamento do seguinte fato: “há empréstimos (cujo número é desconhecido) para Jones cujo montante é
cem dólares”. Uma vez que
número_empréstimo � nome_cliente total,
o único modo de podermos relacionar nome_cliente e total é por meio de número_empréstimo. Se desejarmos
saber o número do empréstimo, não poderemos diferenciar esse empréstimo de outros cujos números são
desconhecidos.
Em outras palavras, não conseguimos armazenar dados cujos atributos-chave sejam desconhecidos.
Observe que as formas normais que definimos não nos permitem armazenar esse tipo de informação sem a
utilização de valores nulos. Assim, nossas formas normais permitem a representação de informações incompletas
não desejáveis.
Se permitimos tuplas suspensas em nosso banco de dados, podemos preferir uma visão alternativa do
processo de projeto de banco de dados. Em vez de decompor uma relação universal, podemos sintetizar uma
coleção de esquemas na forma normal de um determinado conjunto de atributos. Estamos interessados nas
mesmas formas normais, independente de usar decomposição ou síntese. A abordagem da decomposição é
melhor entendida e mais largamente utilizada.
Outra consequência da abordagem usada no projeto de um banco de dados é que os nomes dos atributos
devem ser únicos nas relações universais. Não podemos usar nome para referência tanto para nome_cliente
quanto para nome_agência. Geralmente, é preferível usar nomes únicos, como vínhamos fazendo. Ainda assim,
se definíssemos nossos esquemas de relações diretamente, em vez de usarmos relações universais, obteríamos
relações com esquema tais como os que se seguem para nosso exemplo bancário:
agência_empréstimo (nome, número)
cliente_empréstimo (número, nome)
tot (número, total)
Observe que, com as relações anteriores, expressões como agência_empréstimo cliente_empréstimo
não têm sentido. Na verdade, a expressão, agência_empréstimo cliente_empréstimo aponta os empréstimos
feitos para clientes cujos nomes sejam os mesmos do nome da agência.
Em linguagens como SQL, entretanto, há operações de junção não-naturais, então, em uma consulta
envolvendo agência_empréstimo e cliente_empréstimo, precisamos de referências não ambíguas para nome
usando, para isso, o nome da relação como prefixo. Nesses ambientes, os diversos papeis de nome (como nome
da agência e nome do cliente), são menos problemáticos e provavelmente de utilização mais simples.
Acreditamos que usar o critério do papel único – cada nome de atributo tem um único significado no
banco de dados – é geralmente preferível que a utilização de um mesmo nome em diversos papeis. Quando o
critério do papel único não é adotado, o projetista do banco de dados deve ser cuidadoso durante a construção
de um projeto de banco de dados relacional normalizado.

199
SQL 2003
Durante o desenvolvimento do sistema R, a IBM desenvolveu a linguagem SEQUEL, primeira linguagem de
acesso aos SGBD´s relacionais. Com o desenvolvimento de um número cada vez maior de SGBD´s, fez-se
necessário especificar um padrão da linguagem, chamada SQL, em 1986. Esse lançamento foi um esforço
particular da ANSI em conjunto com a ISO. A padronização de uma linguagem de consulta foi responsável pelo
sucesso dos SGBD´s relacionais.
Em linhas gerais, os comandos da linguagem SQL podem ser divididos em sublinguagens, tais como a
Linguagem de Manipulação de Dados (DML) e a Linguagem de Definição de Dados (DDL). A DML trata dos
comandos ligados à manipulação de Dados, definindo comandos para a seleção, inclusão, alteração e exclusão
dos dados das tabelas. Já a DDL, reúne os comandos para a criação e manutenção de estruturas e objetos do
banco de dados, tais como tabelas, visões e índices.
Os fornecedores de Gerenciadores de Banco de Dados não hesitaram em adotar a SQL. Entretanto,
criaram variações próprias da linguagem, adicionando funções ou comandos que, muitas vezes, em virtude de seu
sucesso, acabaram se incorporando em versões posteriores do padrão. Contudo, a maior parte do padrão é
implementado de forma idêntica nos principais SGBD´s, possibilitando a portabilidade de aplicações e maior
facilidade para os conhecedores da linguagem.
A linguagem passou por aperfeiçoamento em 1989 e, em 1992, foi lançada a SQL-92, ou SQL2. Embora
muitos dos conceitos especificados na SQL-92 somente tenham sido implementados por SGBD´s relacionais
cresceu rapidamente.
A SQL:2003 é a mais nova versão do padrão SQL. Nesta versão foi feita uma grande revisão do padrão
SQL3 e adicionada uma nova parte, ligada ao tratamento de XML.
Tipos de Dados
Em banco de dados relacionais e relacionais estendidos, as informações ficam armazenadas em tabelas.
As tabelas são as materializações das relações do modelo relacional. Elas têm linhas e colunas, onde cada linha
representa a instância de um item armazenado e cada coluna uma informação relativa ao item em questão. A
cada coluna de uma tabela está associado um tipo de dados, fazendo com que somente dados do tipo adequado
sejam armazenados na coluna.
A SQL define alguns tipos de dados que são implementados em alguns SGBD´s. Ele define, também, os
comandos para criação, alteração e exclusão de tabelas.
Tipos de dados básicos
Em banco de dados relacionais e relacionais-estendidos, as informações são armazenadas em tabelas.
Cada tabela poderá conter várias colunas, as quais estão armazenados dados. A cada coluna existirá um tipo de
dados associado.
O tipo de dados de cada coluna é definido durante a criação da tabela. O padrão de SQL define vários
tipos de dados simples. Permite, também, que o usuário defina tipos de dados próprios, a partir da composição
de tipos definidos pela linguagem.
A tabela 2.1 apresenta os principais tipos de dados definidos no padrão da linguagem SQL. A partir desta,
podemos dividir os tipos de dados em cinco grupos: (i) relativos a cadeias de caracteres; (ii) relativos a dados
numéricos; (iii) para armazenamento de “objetos grandes”; (iv) para armazenamento de informação booleana e
(v) tipos de dados relativos a datas e horas.

200
Os vários fornecedores de SGBD´s utilizam variações próprias de dados definidos no SQL:2003.
Criando Tabelas
Uma tabela é a materialização de um local para armazenamento de dados. Tais dados são agrupados em
linhas. Cada linha contém um conjunto de uma ou mais colunas. Todas as linhas têm o mesmo número de
colunas. Cada coluna possui seu tipo de dados próprio, que é o mesmo para todas as linhas.
Ao criarmos uma tabela, devemos especificar o seu nome, quais colunas que a compõe e quais os tipos de
dados das colunas em questão. Além disso, podem ser definidas restrições de integridade e regras de domínio,
entre outros. Assim, podemos especificar, durante a criação de uma tabela, por exemplo, que uma coluna refere-
se à chave primária da tabela ou que uma dada coluna somente poderá conter determinados valores.
Quando uma tabela é criada, ela não contém dados, ou seja, linhas. Somente depois os dados são
inseridos. Entretanto, algumas colunas da tabela podem não ter o seu preenchimento obrigatório. Para estas,
quando nenhum dado for fornecido durante a inclusão, é incluído o valor NULL (nulo).
A princípio, todas as colunas, independente de seus tipos de dados, podem apresentar o valor NULL no
seu conteúdo, em uma ou mais linhas. Ou seja, uma coluna definida como de tipo INTEGER pode suportar
números inteiros ou o valor NULL. Da mesma forma, uma coluna CHAR suporta cadeia de caracteres ou o valor
NULL. Notamos que NULL indica ausência de valor definido. É diferente de zero ou de uma cadeia de caracteres
de comprimento zero. Ao criarmos uma tabela, podemos especificar que uma ou mais colunas não podem conter
o valor NULL. Ou seja, tais colunas têm o seu preenchimento obrigatório. Quando nada é informado para uma
coluna, ela aceita NULL no seu conteúdo.
Utilizamos o comando CREATE TABLE para criação de tabelas. A sintaxe básica do comando é a seguinte:
CREATE TABLE NOME_TABELA(
COL1 TIPO_COL1 [NOT NULL],
COL2 TIPO_COL2 [NOT NULL],
COLN TIPO_COLN [NOT NULL]

201
)
Exemplo de criação de tabela no Oracle 10g:
CREATE TABLE EDITORA (
CODIGO NUMBER(2) NOT NULL,
NOME VARCHAR2(80) NOT NULL
)
Podemos, na criação de tabelas, especificar vários tipos de restrições. Para uma dada coluna, a SQL:2003
nos permite que restrições sejam especificadas após o nome do tipo de dados da coluna em questão. As
principais restrições são:
• Chave primária: devemos posicionar a expressão PRIMARY KEY ao lado da definição do tipo de dados da coluna em questão.
• Chave estrangeira: posicionamos a expressão FOREIGN KEY REFERENCES NOME_TABELA ao lado da definição do tipo da coluna. FOREIGN KEY é opcional. NOME_TABELA deve ser substituído pelo nome da tabela que é referenciada pela chave estrangeira. A tabela referenciada pela chave estrangeira deve ser criada antes da criação da chave estrangeira.
• Chave alternada: a expressão UNIQUE deve ser usada ao lado da definição do tipo de dados da coluna. UNIQUE faz com que não seja possível inserir valores repetidos na coluna.
• Restrição de domínio: para verificar que o valor de uma coluna deve estar contido em uma lista ou faixa de valores, utilizamos a palavra CHECK, seguida de uma expressão booleana delimitada por parênteses.
CONSTRAINT NOME_RESTRICAO TIPO_RESTRICAO
Onde:
• Constraint – indica a definição de uma restrição de integridade.
• Nome_Restricao – nome dada a restrição (CONSTRAINT) que está sendo criada.
• Tipo_Restricao – tipo da restrição que está sendo criada: PRIMARY KEY, FOREIGN KEY OU UNIQUE, por exemplo. No caso de uma chave estrangeira, FOREIGN KEY é opcional e o comando deve ser complementado com a cláusula REFERENCES.
A designação de um nome para cada restrição é bastante útil para o controle de erros que porventura
ocorram. Suponha que, por exemplo, durante a execução de um programa que acessa um banco de dados, tente-
se incluir um valor repetido em linhas de uma coluna marcada como chave primária de uma tabela. Neste caso, o
SGBD não permite operação e um erro ocorre. O SGBD informa, na mensagem de erro, o nome da restrição que
foi violada. Isto permite que a aplicação trate o erro corretamente ou, ainda que seja mais facilmente detectado o
ponto onde a aplicação deve ser alterada de forma a não permitir que tal situação ocorra. Por isso, é interessante
que o nome da CONSTRAINT indique o tipo de restrição, a tabela a que se refere e, quando possível, a coluna que
sofre a restrição.
Consideremos a coluna CPF da tabela AUTOR. Esta coluna não deve aceitar valores repetidos. Para isso,
utilizamos a seguinte definição para a coluna:
CPF CHAR(11) NOT NULL UNIQUE
Por exemplo, para criar a tabela EDITORA no banco de dados Oracle 10g:
CREATE TABLE EDITORA (
CODIGO NUMBER(2) NOT NULL PRIMARY KEY,
NOME VARCHAR2 (80) NOT NULL )
Para criar a tabela ASSUNTO, definindo PK_ASSUNTO como nome para a CONSTRAINT chave primária, utilizamos,
no Oracle 10g:
CREATE TABLE ASSUNTO(
SIGLA CHAR(1) NOT NULL
CONSTRAINT PK_ASSUNTO PRIMARY KEY,
DESCRICAO VARCHAR2(50)

202
)
Vejamos agora, um exemplo da definição de chave estrangeira, a partir da criação da tabela LIVRO.
Atribuiremos o nome PK_LIVRO para a restrição de chave primária, FK_LIVRO_ASSUNTO para a restrição de chave
estrangeira da coluna que referencia a tabela ASSUNTO e FK_LIVRO_EDITORA para a restrição de chave
estrangeira da coluna que referencia a tabela EDITORA.
CREATE TABLE LIVRO(
CODIGO NUMBER(3) NOT NULL
CONSTRAINT PK_LIVRO PRIMARY KEY,
TITULO VARCHAR2(80) NOT NULL,
PRECO NUMBER(10,2),
LANCAMENTO DATE,
ASSUNTO CHAR(1)
CONSTRAINT FK_LIVRO_ASSUNTO
REFERENCES ASSUNTO,
EDITORA NUMBER(2)
CONSTRAINT FK_LIVRO_EDITORA
REFERENCES EDITORA
)
Restrições de domínio podem ser implementadas através da cláusula CHECK, seguida da expressão
booleana delimitada por parênteses. Para a montagem da expressão booleana podemos utilizar operadores de
comparação (<,>,>=,<=, =, <>) e predicados como LIKE e IN.
Exemplos:
• Para definirmos a coluna SIGLA, que não admite valores nulos, somente possa aceitar os valores “R”, “B” e “F”:
SIGLA CHAR(1) NOT NULL CHECK (SIGLA IN(‘R’, ‘B’, ‘F’))
• Para definirmos que a coluna MATRICULA somente aceitará valores maiores que 1000: MATRICULA INTEGER CHECK (MATRICULA > 1000)
Podemos, também, atribuir um valor padrão para as colunas de uma tabela. O valor padrão será
automaticamente atribuído à coluna durante a criação de uma linha, caso nenhum valor tenha sido fornecido.
Sua definição dá-se no momento da criação da tabela através da cláusula DEFAULT, conforme apresentado a
seguir:
COL1 TIPO_COLUNA DEFAULT VALOR_PADRAO
Por exemplo: SEXO CHAR(1) DEFAULT ‘M’
A utilização de restrições de integridade no banco de dados pode ser bastante útil para a manutenção da
correção das informações. A definição de chaves primárias e restrições UNIQUE impedem que sejam incluídos
valores repetidos em uma dada coluna. A definição de chaves estrangeiras faz com que somente sejam
permitidos valores que existam na tabela referenciada.
A tabela 2.6 apresenta um conteúdo da tabela EDITORA:

203
Na tabela LIVRO que criamos anteriormente, especificamos a coluna EDITORA como chave estrangeira
para a tabela EDITORA. Dessa forma, se considerarmos o conteúdo da tabela EDITORA apresentado na tabela
acima, então a coluna EDITORA da tabela LVIRO somente poderá conter os valores NULL, 1, 2, 3 e 4. Se tentarmos
incluir quaisquer outros valores, o SGBD gerará um erro e não permitirá a inclusão das informações.
Considere, agora, que existe uma linha na tabela LIVRO onde a coluna EDITORA possua o valor 2.
Consideremos que um usuário tente excluir, da tabela EDITORA, a linha de código 2. Se isto for possível, teremos
uma inconsistência nos dados, pois existirá um valor na chave estrangeira da tabela LIVRO que não existe na
chave primária da tabela EDITORA. De acordo com o padrão SQL é possível especificar, durante a definição da
restrição, três diferentes ações a serem tomadas pelo SGBD, quando tal situação ocorrer:
• Impedir a exclusão da linha da tabela pai (EDITORA) caso existam outras tabelas que referenciem o valor a ser excluído. A linha não é excluída e um erro é gerado. Esta é a situação padrão, a qual ocorrerá sempre que uma chave estrangeira for definida, a menos que declaremos o contrário. É especificada atraves da opção ON DELETE RESTRICT; ASSUNTO CHAR(1)
CONSTRAINT FK_LIVRO_ASSUNTO
REFERENCES ASSUNTO
ON DELETE RESTRICT
• Alterar o valor da coluna da chave estrangeira na tabela filho (LIVRO), tornando-o NULL para as linhas que possuam o valor que está sendo apagado na tabela pai. A linha da tabela pai também é apagada. Esta ação é especificada atraves da cláusula ON DELETE SET NULL; ASSUNTO CHAR(1)
CONSTRAINT FK_LIVRO_ASSUNTO
REFERENCES ASSUNTO
ON DELETE SET NULL
• Apagar as linhas da tabela filho onde existir, na coluna de chave estrangeira, o valor que está sendo apagado na tabela pai. A linha da tabela pai também é apagada. Esta ação é definida atraves da cláusula ON DELETE CASCADE. ASSUNTO CHAR(1)
CONSTRAINT FK_LIVRO_ASSUNTO
REFERENCES ASSUNTO
ON DELETE CASCADE
Existe, ainda, um outro formato para a especificação de restrições em tabelas. Podemos especificar
restrições após a declaração de todas as colunas. Neste caso, deveremos seguir o formato:
CONSTRAINT NOME_RESTRICAO TIPO_RESTRICAO
(COLUNA1_RESTRICAO, COLUNA2_RESTRICAO,...)

204
Eis a sintaxe do Oracle 10g:
CREATE TABLE LIVRO (
CODIGO NUMBER(3),
TITULO VARCHAR2(80) NOT NULL,
PRECO NUMBER(10,2),
LANCAMENTO DATE,
ASSUNTO CHAR(1),
EDITORA NUMBER(2)
CONSTRAINT PK_LIVRO PRIMARY KEY (CODIGO),
CONSTRAINT FK_LIVRO_ASSUNTO FOREIGN KEY (ASSUNTO)
REFERENCES ASSUNTO,
CONSTRAINT FK_LIVRO_EDITORA
FOREIGN KEY (EDITORA)
REFERENCES EDITORA
)
Alterando tabelas
A SQL:2003 nos dá a opção de alterar tabelas já existentes no banco de dados. Para isso, utilizamos o
comando ALTER TABLE. Este comando pode ser utilizado em conjunto com as cláusulas adicionais para executar,
entre outras, uma das seguintes opções:
• Incluir novas colunas em uma tabela existente;
• Excluir colunas existentes em uma tabela;
• Adicionar a definição de uma restrição a uma tabela existente;
• Excluir a definição de uma restrição existente em uma tabela.
Incluindo novas colunas em uma tabela já existente
Para incluir novas colunas em uma tabela, utilizamos o comando ALTER TABLE, conforme a seguir:
ALTER TABLE NOME_TABELA
ADD [COLUMN] NOME_COLUNA TIPO_COLUNA RESTRICOES
Por exemplo, vamos adicionar a coluna IDENTIDADE à tabela AUTOR, já criada no banco de dados.
ALTER TABLE AUTOR
ADD IDENTIDADE CHAR(10)
Excluindo colunas existentes em uma tabela
Para excluir colunas existentes em uma tabela, utilizamos o comando ALTER TABLE no formato
apresentado a seguir:
ALTER TABLE NOME_TABELA
DROP [COLUMN] NOME_COLUNA
Por exemplo, vamos remover a coluna IDENTIDADE da tabela AUTOR, já criada no banco de dados:
ALTER TABLE AUTOR
DROP COLUMN IDENTIDADE
Adicionando a definição de uma restrição a uma tabela existente
ALTER TABLE NOME_TABELA
ADD CONSTRAINT NOME_RESTRICAO TIPO_RESTRICAO
(COLUNA1_RESTRICAO, COLUNA2_RESTRICAO, ...)

205
Por exemplo, suponha que tenhamos criado a tabela LIVRO sem especificar nenhuma restrição. Vamos
agora adicionar essas restrições atraves de três comandos:
Adicionando a chave primária:
ALTER TABLE LIVRO
ADD CONSTRAINT PK_LIVRO PRIMARY KEY (CODIGO)
Adicionando a chave estrangeira a tabela ASSUNTO:
ALTER TABLE LIVRO
ADD CONSTRAINT FK_LIVRO_ASSUNTO FOREIGN KEY (ASSUNTO)
REFERENCES ASSUNTO
Adicionando a chave estrangeira para a tabela EDITORA:
ALTER TABLE LIVRO
ADD CONSTRAINT FK_LIVRO_EDITORA
FOREIGN KEY (EDITORA)
REFERENCES EDITORA
Excluindo a definição de uma restrição existente em uma tabela
Alterando tabelas
Podemos também alterar tabelas já definidas no banco de dados. Para isso utilizamos o comando ALTER
TABLE. Este comando pode ser utilizado em conjunto com as cláusulas adicionais para executar, entre outras,
uma das seguintes opções:
• Incluir novas colunas em uma tabela existente;
• Excluir colunas existentes em uma tabela;
• Adicionar a definição de uma restrição em uma tabela já existente;
• Excluir a definição de uma restrição existente em uma tabela.
Incluir novas colunas em uma tabela existente
Para incluir novas colunas em uma tabela existente, utilizamos o comando ALTER TABLE conforme a
seguir:
ALTER TABLE NOME_TABELA
ADD [COLUMN] NOME_COLUNA TIPO_COLUNA RESTRICOES
Por exemplo: vamos adicionar a coluna IDENTIDADE à tabela AUTOR, já criada no banco de dados.
ALTER TABLE AUTOR
ADD IDENTIDADE CHAR(10)
Excluindo colunas existentes em uma tabela, utilizamos o comando ALTER TABLE no formato apresentado a
seguir:
ALTER TABLE NOME_TABELA
DROP [COLUMN] NOME_COLUNA
Exemplo, vamos remover a coluna IDENTIDADE da tabela AUTOR, já criada no banco de dados:
ALTER TABLE AUTOR
DROP COLUMN IDENTIDADE
Adicionando a definição de uma restrição a uma tabela existente
Para incluir uma nova restrição a uma tabela existente, também utilizamos o comando ALTER TABLE. A
sintaxe básica utilizada é:

206
ALTER TABLE NOME_TABELA
ADD CONSTRAINT NOME_RESTRICAO TIPO_RESTRICAO
(COLUNA1_RESTRICAO, COLUNA2_RESTRICAO, ...)
Por exemplo: Suponha que tenhamos criado a tabela LIVRO sem especificar nenhuma restrição. Vamos,
agora, adicionar as restrições a essa tabela, através de três comandos.
Adicionando a chave primária:
ALTER TABLE LIVRO
ADD CONSTRAINT PK_LIVRO KEY(CODIGO)
Adicionando a chave estrangeira para a tabela ASSUNTO:
ALTER TABLE LIVRO
ADD CONSTRAINT FK_LIVRO_ASSUNTO FOREIGN KEY(ASSUNTO)
REFERENCES ASSUNTO
Adicionando a chave estrangeira para a tabela EDITORA:
ALTER TABLE EDITORA
ADD CONSTRAINT FK_LIVRO_EDITORA
FOREIGN KEY (EDITORA)
REFERENCES EDITORA
Excluindo a definição de uma restrição existente em uma tabela
O comando ALTER TABLE também pode ser utilizado para excluir uma restrição já existente em uma
tabela. Para isso, utilizamos o seguinte formato:
ALTER TABLE NOME_TABELA
DROP CONSTRAINT NOME_RESTRICAO
Por exemplo, desejamos excluir a chave primária da tabela LIVRO:
ALTER TABLE LIVRO
DROP CONSTRAINT PK_LIVRO
Desejamos destruir a chave estrangeira da tabela LIVRO que aponta para a tabela EDITORA.
ALTER TABLE LIVRO
DROP CONSTRAINT FK_LIVRO_EDITORA
Destruindo tabelas
Para destruir uma tabela utilizamos o comando DROP TABLE. Sua sintaxe básica é:
DROP NOME NOME_TABELA [CASCADE]
Exemplo: Para destruir a tabela LIVRO.
DROP TABLE LIVRO

207
Comandos Básicos
Inclusão de Dados
Para incluirmos dados em uma tabela, devemos utilizar o comando INSERT. Sua sintaxe básica, segundo a
qual inserimos uma linha em uma tabela é mostrada a seguir:
INSERT INTO NOME_TABELA (COL1, COL2, ..., COLN)
VALUES (VAL1, VAL2, ..., VALN)
Considere a tabela LIVRO já apresentada anteriormente. A tabela 3.1 apresenta um exemplo de instância
da tabela LIVRO apresentado. Notamos que existe um livro com valor nulo para o campo LANCAMENTO. Isso
significa que ele ainda não foi lançado.
A descrição completa dos assuntos está na tabela ASSUNTO. Nesta existem vários assuntos cadastrados,
independentemente se existe um livro do assunto em questão. Tomemos a tabela 3.2 como exemplo de instância
da tabela EDITORA.
Para concluirmos as três primeiras linhas na tabela LIVRO, devemos realizar os seguintes comandos
INSERT:
INSERT INTO LIVRO
(CODIGO, TITULO, PRECO, LANCAMENTO, ASSUNTO, EDITORA) VALUES
(1, ‘BANCO DE DADOS PARA WEB’, 31.2, ‘10/01/1999’, ‘B’, 1)
INSERT INTO LIVRO
(TITULO, CODIGO, LANCAMENTO, PRECO, ASSUNTO, EDITORA) VALUES
(‘PROGRAMANDO EM LINUGAGEM C’, 2, ‘01/10/1997’, 30, ‘P’, 1)
Notamos que a diferença dos dois primeiros comandos anteriores está na diferença da ordem. Quando
especificamos o nome não há uma limitação na ordenação das mesmas.
A especificação dos nomes das colunas permite, ainda, que não sejam inseridos dados para todas as
colunas de uma tabela. Considere o caso do livro de código ‘4’, que não possui data de lançamento. Ao inseri-lo,
podemos omitir a coluna LANCAMENTO do comando INSERT a ser utilizado:
INSERT INTO LIVRO (CODIGO, TITULO, PRECO, ASSUNTO, EDITORA) VALUES
(4, ‘BANCO DE DADOS PARA INFORMATICA’, 48, ‘B’, 2)

208
Neste caso, será inserido o valor NULL para LANCAMENTO. Note que, se essa coluna possuir uma
restrição para não aceitar valores nulos, e não estiver definido um valor padrão, o comando não poderá ser
executado.
Outra forma de executar o comando anterior, especificando todas as colunas da tabela, é através da
utilização da palavra NULL:
INSERT INTO LIVRO
(CODIGO, TITULO, PRECO, LANCAMENTO, ASSUNTO, EDITORA) VALUES
(4, ‘BANCO DE DADOS PARA BIOINFORMATICA’, 48, NULL, ‘B’, 21)
Caso estejamos inserindo valores para todas as colunas da tabela, podemos omitir seus nomes.
Entretanto, nesse caso, devemos especificar os valores a serem inseridos na mesma ordem em que as colunas da
tabela foram criadas:
Errado:
INSERT INTO LIVRO VALUES
(‘R’, 42, 5, ‘01/09/1996’, ‘REDES DE COMPUTADORES’, 2)
Correto:
INSERT INTO LIVRO
(CODIGO, TITULO, PRECO, LANCAMENTO, ASSUNTO, EDITORA) VALUES
(5, ‘REDES DE COMPUTADORES’, 42, ‘01/09/1996’, ‘R’, 2)
Quando incluímos dados em tabelas que possuem chaves estrangeiras referenciando outras tabelas, os
valores que estão sendo inseridos nas colunas da chave estrangeira já devem constar na chave primária da tabela
referenciada.
Consulta simples
A consulta simples a dados armazenados é, usualmente, a operação realizada com mais freqüência em
sistemas comerciais. À medida que a quantidade de linhas em tabelas cresce e que utilizamos varias tabelas em
uma mesma consulta, não só a complexidade do comando SQL aumenta, como também o tempo de resposta da
consulta pode ser muito alto, exigindo, assim, mais atenção na montagem do comando.
Para a realização de consulta ao banco de dados, utilizamos o comando SELECT. A sintaxe básica do
comando SELECT é:
SELECT COL1, COL2, ..., COLN
FROM NOME_TABELA
Considere a instância da tabela LIVRO apresentado anteriromente. Se quisermos recuperar as colunas
TITULO e CODIGO dessa tabela, devemos executar o comando:
SELECT CODIGO, TITULO
FROM LIVRO
Se quisermos recuperar todas as colunas da tabela LIVRO podemos especificá-la no comando SELECT ou
utilizar o caractere ‘*’.
As consultas:
SELECT CODIGO, TITULO, PRECO, LANCAMENTO, ASSUNTO, EDITORA
FROM LIVRO
e
SELECT * FROM LIVRO

209
Quando especificamos as colunas no comando SELECT, elas serão apresentadas no resultado, na ordem
especificada. Quando o caractere ‘*’ é utilizado, as colunas estarão ordenadas da mesma forma que o foram na
criação da tabela.
A cláusula WHERE
Os resultados de comandos como apresentado anteriormente possuem todas as linhas da tabela. No
entanto, na maioria das consultas queremos consultar apenas as informações referentes a algumas linhas. Essas
linhas devem atender a alguma condição.
A cláusula WHERE permite que sejam especificadas linhas sobre as quais será aplicada. A instrução pode
ser um comando SELECT ou comandos de atualização e exclusão de dados.
WHERE é sempre usada com expressões lógicas, a qual pode ser operadores de comparação (>,<,>=,<=, =,
<>), operadores lógicos (AND, OR e NOT) e predicados próprios de linguagem SQL, tais como IS(NOT) NULL, IS
(NOT) LIKE, IN e EXISTS. Os operadores lógicos AND e OR são usados para conectar comparações.
A expressão lógica terá um resultado que poderá assumir os valores verdadeiro ou falso. A instrução
especificada será executada para as linhas que tornarem o resultado da expressão lógica verdadeiro.
Por exemplo:
• Preço superior a R$ 50,00 WHERE PRECO > 50
• Preço igual a R$ 50,00 e de assunto ‘p’ WHERE PRECO > 50 AND ASSUNTO = ‘P’
• Preço inferior a R$ 50,00 ou de assunto ‘P’ WHERE PRECO < 50 OR ASSUNTO = ‘P’
• Lançamento é nulo WHERE LANCAMENTO IS NULL
Quando realizamos comparações com colunas de tipos cadeias de caracteres, frequentemente queremos
encontrar valores que possuem determinados caracteres ou sequencias de caracteres. Para tal, usamos o
predicado LIKE em conjunto com um ou mais caracteres coringa.
O caractere coringa é usado para substituir um ou mais caracteres que não conhecemos. Os caracteres
coringa são ‘%’ e ‘_’. O caractere % é utilizado para substituir uma cadeia ilimitada de caracteres onde ele é
posicionado, enquanto _ substitui zero ou apenas um caractere.
Por exemplo: WHERE TITULO IS LIKE ‘%BANCO_ DE DADOS%’
Atualização de informações
Os dados inseridos em tabelas do banco de dados podem ser modificados. Para tal, utiliza-se o comando
UPDATE. Sua sintaxe é:
UPDATE NOME_TABELA
SET COL1 = VAL1, COL2 = VAL2, ..., COLN = VALN
WHERE EXPRESSAO_LOGICA
Considerando a tabela LIVROS, temos os seguintes exemplos:
• Atualizar o preço de todos os livros fornecendo um aumento de 10%. UPDATE LIVRO
SET PRECO = PRECO * 1.1
• Atualizar o preço do livro Programando em Linguagem C para R$ 32,00. UPDATE LIVRO
SET PRECO = 32
WHERE TITULO = ‘PROGRAMANDO EM LINGUAGEM C’

210
• Alterar o titulo e o preço do livro de código 2 para Programação em Linguagem C e R$ 42,00, respectivamente.
UPDATE LIVRO
SET PRECO = 42,
TITULO = ‘PROGRAMACAO EM LINGUAGEM C’
WHERE CODIGO = 2
Quando atualizamos os dados de uma ou mais colunas marcadas como chaves estrangeiras, os novos
valores já devem constar na chave primária da tabela referenciada.
Exclusão de linhas
O comando DELETE é utilizado para excluir linhas de uma tabela. Sua sintaxe é a seguinte:
DELETE FROM NOME_TABELA
WHERE EXPRESSAO_LOGICA
Nos exemplos a seguir, utilizaremos novamente a tabela LIVROS:
• Excluir todos os livros da tabela. DELETE FROM LIVRO
• Excluir os livros que tenham preço superior a R$ 100,00 e que não tenham sido lançados. DELETE FROM LIVRO
WHERE LANCAMENTO IS NULL AND PRECO > 100
• Excluir os livros que tenham ‘R’ como assunto ou que ainda não tenham sido lançados. DELETE FROM LIVRO
WHERE ASSUNTO = ‘R’ OR LANCAMENTO IS NULL
Agrupamento Dados
Na linguagem SQL são definidas várias funções que operam sobre grupos de dados. Tais funções,
usualmente, realizam operações ou comparações sobre um conjunto de dados e retornam, como resultado, uma
relação de apenas uma linha ou uma coluna. São chamadas Funções Agregadas.
Contagem
Muitas vezes é necessário contar uma quantidade de linhas que satisfaz uma determinada condição. Para
isso, utilizamos a função COUNT. Assim como as outras funções que serão apresentadas mais adiante, a função
COUNT recebe um parâmetro e retorna um numero.
Como parâmetro para a função COUNT podemos utilizar o nome de uma coluna ou o caractere *. No caso
da utilização do caractere * o resultado obtido é a contagem do numero de linhas da tabela. No caso da utilização
de uma coluna como parâmetro, o reesultado obtido é o numero de ocorrências não nulas desta coluna na tabela
pesquisada.ç
Por exemplo:
• Contar a quantidade de linhas da tabela LIVRO: SELECT COUNT(*)
FROM LIVRO
• Contar a quantidade de linha da tabela LIVRO com a coluna de código preenchida: SELECT COUNT(CODIGO)
FROM LIVRO
A função COUNT retornará zero quando nenhuma linha atender ao critério utilizado.
Soma

211
Outra operação comumente utilizada é a soma. Para realizar a soma de valores de uma coluna para um
grupo de dados, utilizamos a função SUM.
Exemplo:
• Somatório dos preços da tabela de livros: SELECT SUM(PRECO)
FROM LIVRO
A função SUM retornará o somatório dos valores não-nulos da coluna utilizada como parâmetro.
Retornará NULL se todos os valores desta coluna forem nulos ou se nenhum valor atender ao critério de seleção.
Média
Para obter a média aritmética dos valores de uma coluna utilizada como parâmetro, utilizamos o
comando AVG, informando, como parâmetro para a mesma, o nome da coluna para a qual desejamos obter a
média.
A função AVG retornará a média considerando apenas os valores não-nulos da coluna especificada.
Exemplo:
SELECT AVG(PRECO)
FROM LIVRO
Valor Máximo
Para obter o valor máximo de uma coluna em um conjunto de dados, utilizamos a função MAX. Assim
como a função AVG, MAX recebe um parâmetro e retorna o valor NULL se em todas as linhas da tabela
consultada o valor da coluna em questão for nulo, ou se nenhuma linha atender ao valor do critério de seleção.
Exemplo:
SELECT MAX(PRECO)
FROM LIVRO
WHERE ASSUNTO = ‘P’
Valor mínimo
Em oposição à função MAX, temos a função MIN, que retorna o menor valor de uma coluna para a tabela
especificada.
• Menor preço da tabela de livros, para cujos livros o assunto seja ‘B’: SELECT MIN(PRECO)
FROM LIVRO
WHERE ASSUNTO = ‘B’
Outras funções
Podemos destacar:
• STDDEV_POP: desvio padrão da população;
• STDDEV_SAMP: desvio padrão da amostra;
• VAR_POP: variância calculada como o quadrado de STDDEV_POP;
• VAR_SAMP: variância calcula como o quadrado de STDDEV_SAMP.
Cláusula GROUP BY
Para utilizarmos uma função de agregação em conjunto com colunas da tabela na cláusula SELECT,
devemos utilizar a cláusula GROUP BY. A sintaxe de utilização da cláusula GROUP BY é a seguinte:
SELECT COL1, COL2, ..., COLN, FUNCAO1, …, FUNCAON
FROM NOME_TABELA
WHERE CONDICAO

212
GROUP BY COL1, COL2, ..., COLN
A utilização da cláusula GROUP BY faz com que os dados sejam sumarizados pelas colunas que são
especificadas na mesma. Assim, somente valores distintos destas colunas farao parte do resultado. Neste caso,
torna-se possível utilizar funções agregadas, as quais irão operar sobre as linhas que foram utilizadas para montar
cada grupo (sumarização) de dados. Vejamos alguns exemplos:
• Qual o preço médio dos livros de cada assunto? SELECT ASSUNTO, AVG(PRECO)
FROM LIVRO
GROUP BY ASSUNTO
• Quantos livros existem para cada assunto? SELECT ASSUNTO, COUNT(*)
FROM LIVRO
GROUP BY ASSUNTO
• Qual o preço do livro mais caro de cada assunto, dentre aqueles que já foram lançados? SELECT ASSUNTO, MAX(PRECO)
FROM LIVRO
WHERE LANCAMENTO IS NOT NULL
GROUP BY ASSUNTO
• Quantos livros já foram lançados para cada editora? SELECT EDITORA, COUNT(*)
FROM LIVRO
WHERE LANCAMENTO IS NOT NULL
GROUP BY EDITORA
Cláusula HAVING
A cláusula WHERE não nos permite realizar não nos permite realizar restrições com base nos resultados
das funções agregadas. Para isso, devemos utilizar a cláusula HAVING.
A cláusula HAVING será seguida de uma expressão lógica que poderá ser composta ou não, de forma
idêntica ao que foi apresentado na cláusula WHERE. Assim como a cláusula WHERE, a cláusula HAVING serve de
filtro para as linhas constantes do resultado do comando SQL.
A principal diferença entre essas cláusulas se dá no fato de que, no caso da cláusula WHERE, o filtro é
aplicado quando as linhas são recuperadas do banco de dados, fazendo com que estas nem cheguem a ser
consideradas quando da realização de agrupamentos ou na execução da função de agregação. Já as restrições
descritas na cláusula HAVING serão aplicadas somente após a recuperação das linhas no banco de dados, da
montagem dos grupos e da execução de funções agregadas. Por isso, é possível utilizar funções agregadas em
expressões lógicas da cláusula HAVING.
Sintaxe básica:
SELECT COL1, COL2, ..., COLN
FROM NOME_TABELA
WHERE EXPRESSAO_LOGICA_WHERE
GROUP BY COL1, COL2,..., COLN
HAVING EXPRESSAO_LOGICA_HAVING
Exemplo:
• Quais os assuntos cujo preço médio dos livros ultrapassa R$50,00?

213
SELECT ASSUNTO
FROM LIVRO
GROUP BY ASSUNTO
HAVING AVG(PRECO) > 50
• Quais os assuntos que possuem mais de dois livros? SELECT ASSUNTO, COUNT(*)
FROM LIVRO
GROUP BY ASSUNTO
HAVING COUNT(*) > 1
• Quais os assuntos que possuem mais de dois livros já lançados? SELECT ASSUNTO, COUNT(*)
FROM LIVRO
GROUP BY ASSUNTO
HAVING COUNT(*) > 1
• Quantos livros já foram lançados por assunto? SELECT ASSUNTO, COUNT(*)
FROM LIVRO
WHERE LANCAMENTO IS NULL
GROUP BY ASSUNTO

214
Operando, Ordenando e Formatando Resultados
Usando apelidos
Não é possível atribuir apelidos tanto a colunas quanto a tabelas, e referenciá-las através de seus apelidos.
Apelidos para colunas � atribuir um apelido a uma coluna resultante de uma consulta é extremamente fácil. Veja
a sintaxe:
SELECT COL1 AS MINHA_COLUNA
FROM NOME_TABELA
Quaisquer construções particionadas na cláusula SELECT, como as funções, podem receber apelidos. Por
exemplo:
• Considere a consulta que retorna o maior preço da tabela de livros para livros cujo assunto seja ‘P’: SELECT MAX(PRECO) AS PRECO_MAXIMO
FROM LIVRO
WHERE ASSUNTO = ‘P’
Apelidos para as tabelas � em nossas consultas ao banco de dados podemos fazer referência a uma coluna
explicitando a sua tabela de origem como uma construção no formato: NOME_TABELA.NOME_COLUNA. Na
verdade, há situações onde somos obrigados a utilizar esse tipo de construção.
Em alguns casos, as tabelas são representadas por nomes extensos e utilizar a construção anterior pode não
ser só cansativo quanto tornar o comando extenso e confuso. Nessas situações, possuir um apelido menor e
expressivo para a tabela é interessante. Na verdade, não se trata somente de questão de clareza de comando. Há
situações onde somos obrigados a utilizar apelidos para tabelas e relações. Vejamos, então, como fornecer
apelidos para tabelas:
SELECT COL1
FROM NOME_TABELA_ORIGINAL AS NOVO_NOME_TABELA
Abaixo, a tabela LIVRO é substituída pelo apelido L:
SELECT MAX(L.PRECO) AS PRECO_MAXIMO
FROM LIVRO L
WHERE L.ASSUNTO = ‘P’
Constantes e concatenação
A SQL permite definir constantes que serão repetidas em todas as linhas do resultado de uma consulta, o que
atende ao caso anterior. Para isso, basta especificar a constante desejada na cláusula SELECT do comando. Por
exemplo:
SELECT ‘LIVRO:’ AS TEXTO, TITULO
FROM LIVRO
Neste exemplo, a cadeia de caracteres ‘LIVRO:’ foi tratada como uma coluna independente. A linguagem SQL
define o operador de concatenação é ||, e deve ser utilizado entre as colunas ou textos que desejamos
concatenar.
Vejamos o exemplo da utilização de concatenação do exemplo anterior:
SELECT ‘LIVRO:’ || TITULO AS TEXTO
FROM LIVRO
Realizando operações aritméticas

215
Da mesma forma que utilizamos a cláusula SELECT, podemos realizar operações aritméticas sobre os
resultados de uma consulta. Os operadores +, -, *, e / podem ser utilizados em expressões matemáticas. Além
disso, parênteses também podem ser utilizados, para determinar prioridades na execução das operações. Por
exemplo:
• Listar os novos preços dos livros se os valores fossem reajustados em 10%. SELECT TITULO, PRECO*1.1 AS NOVO_PRECO
FROM LIVRO
Podemos reescrever a consulta para demonstrar a utilização de outros operadores mas obtendo o mesmo
resultado.
SELECT TITULO, PRECO + (PRECO/10) AS NOVO_PRECO
FROM LIVRO
Notamos que as operações realizadas modificam somente o resultado das consultas, não alterando os dados
das tabelas.
Aplicando Funções
Formatando os resultados de uma consulta através de funções do SGBD pode fornecer resultados mais
compreensíveis e, também, fazer com que a consulta retorne informações em formato adequado para exibição
ao usuário final. Além disso, muitas vezes, podemos utilizar funções que manipulam os resultados de consultas
SQL formatando-os ou alterando-os.
Cadeia de caracteres � o padrão SQL define várias funções que manipulam e formatam cadeias de caracteres.
Nesta seção são apresentadas as principais: UPPER, LOWER, TRIM, SUBSTRING e LENGHT.
As funções UPPER, LOWER, TRIM e LENGHT recebem uma cadeia de caracteres (ou uma coluna de dados do
tipo cadeia de caracteres) como parâmetro e retornam um resultado do mesmo tipo. Já a função SUBSTRING, que
também retorna uma cadeia de caracteres como resultado, recebe três parâmetros como entrada, sendo dois
numéricos e uma cadeia de caracteres.
A função UPPER retornam o seu parâmetro de entrada com todos os caracteres convertidos para maiúsculas.
Em oposição à função UPPER, a função LOWER retorna todos os caracteres convertidos para minúsculos. Vejamos
um exemplo:
SELECT UPPER(‘LIVRO:’) || LOWER(TITULO) AS TEXTO
FROM LIVRO
A função TRIM retira os caracteres ‘espaço’ contidos nas margens da cadeia de caracteres que recebe como
parâmetro. Exemplo:
Consulta:
SELECT TRIM(‘ LIVRO: ’) || TITULO AS TEXTO
FROM LIVRO
WHERE ASSUNTO = ‘P’
A função SUBSTRING retorna o trecho da cadeia de caracteres que ela recebe como parâmetro. O trecho a ser
retornado é definido por outros dois parâmetros de entrada: a posição de início do trecho e o seu comprimento.
Exemplo:
• Listar os dez primeiros caracteres dos títulos dos livros: SELECT SUBSTRING(TITULO, 1, 10) AS TRECHO
FROM LIVRO

216
LENGTH retorna o comprimento da cadeia de caracteres que recebe como parâmetro. Retornará nulo, caso
receba NULL como parâmetro. Exemplo:
SELECT LENGTH(TITULO) AS COMPRIMENTO
FROM LIVRO
WHERE ASSUNTO = ‘R’
Datas
A formatação de campos relacionados a datas e horários é uma das que apresenta o maior número de
variações entre as implementações dos SGBD´s padrões para SQL. Dentre as funções mais utilizadas, temos as
funções DAY, MONTH e YEAR. Estas funções recebem uma data como parâmetro e retornam o dia, o mês e o ano
da data, respectivamente. Exemplo:
• Selecionar o dia da publicação do livro de código 1 SELECT DAY(LANCAMENTO) AS DIAS
FROM LIVRO
WHERE CODIGO = 1
• Selecionar o mês e o ano da publicação dos livros cujo assunto é ‘R’: SELECT MONTH(LANCAMENTO) AS MÊS,
YEAR(LANCAMENTO) AS ANO
FROM LIVRO
WHERE ASSUNTO = ‘R’
Números
A linguagem SQL e os SGBD´s oferecem várias funções predefinidas para a manipulação de números.
Na tabela 5.1 são apresentadas as principais funções matemáticas definidas pela SQL. A maioria das funções
da tabela 5.1 recebe apenas um parâmetro de entrada numérico e retorna um número.
Também são comuns implementações de funções trigonométricas para a SQL. Dentre as principais funções
trigonométricas, temos as apresentadas na tabela 5.2:

217
A utilização das funções algébricas e trigonométricas apresentadas é semelhante à das funções de cadeias de
caracteres apresentadas anteriormente. Veja o exemplo para a função CEIL:
SELECT CEIL(PRECO)
FROM LIVRO
WHERE CODIGO = 3
Eliminando repetições
Quando utilizamos consultas sobre tabelas, podemos obter linhas repetidas. Para eliminar repetições, em
relações resultantes de consultas, foi definido o predicado DISTINCT. Este predicado poderá ser utilizado
isoladamente na cláusula SELECT ou em conjunto com outras funções SQL.
Para eliminar resultados distintos de uma consulta, basta posicionar o predicado DISTINCT após a cláusula
SELECT e antes da especificação das colunas a serem recuperados. Vejamos um exemplo:
• recuperar os assuntos distintos da tabela de livros: SELECT DISTINCT ASUNTO AS ASSUNTO
FROM LIVRO
O predicado DISTINCT pode ainda ser utilizado com a função COUNT, quando posicionado junto ao seu
parâmetro de entrada. Neste caso, é possível contar os valores distintos de uma coluna, por exemplo.
SELECT COUNT(DISTINCT ASSUNTO)
FROM LIVRO
Ordenando os resultados
Ao realizarmos consultas SQL não sabemos, a priori, quais e em que ordem as linhas do resultado serão
apresentadas. No entanto, muitas vezes, desejamos obter os resultados ordenados por uma ou mais colunas.
Para isso, devemos utilizar a cláusula ORDER BY.
A cláusula ORDER BY é sempre posicionada como a última de um comando SELECT. Vejamos um exemplo de
sintaxe:
SELECT COL1, COL2, ..., COLN
FROM NOME_TABELA
WHERE CONDICAO
GROUP BY COL1, COL2, ..., COLN
HAVING EXPRESSAO_LOGICA
ORDER BY COL1 [DESC,ASC], COL2 [DESC, ASC]
Consulta:
• Gerar a listagem dos livros contendo assunto, título, e preço. A listagem deverá estar ordenada em ordem crescente de assunto e decrescente de preço.
SELECT ASSUNTO, TITULO, PRECO

218
FROM LIVRO
ORDER BY ASSUNTO, PRECO DESC
• Gerar listagem dos livros contendo assunto, título e preço. A listagem deverá estar ordenada em ordem crescente de título e descente de preço.
SELECT ASSUNTO, TITULO, PRECO
FROM LIVRO
ORDER BY 2, PRECO DESC
A SQL:2003 nos permite, ainda, utilizar funções, como SUBSTRING, na cláusula ORDER BY.

219
Junções
Nos comandos apresentados anteriormente, somente uma tabela era acessada por vez. Entretanto, muitas
vezes precisamos acessar informações de mais de uma tabela em uma mesma consulta.
Para acessar mais de uma tabela em um mesmo comando SELECT, devemos realizar operações chamadas
junções. Existem vários tipos de juntos, como a interna, a externa e a natural. As diferenças entre as junções se
dão na forma como as tabelas da consulta são combinadas para a montagem dos resultados.
Para coletar informações de mais de uma tabela, realizamos junções. As junções são ligações entre tabelas,
realizadas através dos valores de uma ou mais colunas. Usualmente, essas ligações ocorrem entre a chave-
primária de uma tabela e a chave estrangeira de outra.
No caso de nosso exemplo, temos que a coluna ASSUNTO da tabela LIVRO é a chave estrangeira para a
coluna SIGLA, chave-primária da tabela ASSUNTO. Assim, neste caso, a ligação entre as informações de uma
tabela com a outra se dará através das colunas ASSUNTO e SIGLA.
A junção entre tabelas faz com que seja gerada uma relação resultante contendo todas as colunas das
tabelas originais. Para a junção entre as tabelas anteriores será gerada uma relação contendo as colunas CODIGO,
TITULO, PRECO, LANCAMENTO, ASSUNTO, EDITORA, SIGLA e DESCRICAO. Essa relação será gerada somente para
a execução da consulta e sobre ela poderão ser aplicadas as operações apresentadas anteriormente. As linhas
que participarão da relação resultante serão escolhidos com base no tipo de junção que está sendo realizada e
com o predicado de junção.
Junção Interna
A junção interna entre tabelas é a modalidade de junção que faz com que somente participarem da relação
resultante as linhas das tabelas de origem que atenderem à cláusula de junção. A sintaxe básica para a realização
da junção interna é:
SELECT COL1, COL2, ..., COLN, FUNCAO1, ..., FUNCAON
FROM NOME_TABELA
INNER JOIN NOME_TABELA2
ON NOME_TABELA.COL1 = NOME_TABELA2.COL1
WHERE CONDICAO
GROUP BY COL1, COL2, ..., COLN
HAVING EXPRESSAO_LOGICA
ORDER BY COL1, COL2, …, COLN
Por exemplo:
• Quais os títulos dos livros já lançados e a descrição dos seus assuntos? SELECT TITULO, DESCRICAO
FROM LIVRO
INNER JOIN ASSUNTO
ON SIGLA = ASSUNTO
WHERE LANCAMENTO IS NOT NULL
No exemplo anterior, nem todas as linhas da tabela ASSUNTO (cuja instância está representada na tabela 3.2)
fazem parte do resultado da consulta. Isto ocorre porque estamos utilizando uma junção interna, onde somente
participam do resultado as linhas nas quais os valores das colunas de junção possuem correspondente em ambas
as tabelas. As junções externas, apresentadas a seguir, permitirão que linhas onde não existam valores
correspondentes em ambas as tabelas participam.
Os primeiros SGBD´s possuíram a cláusula INNER JOIN. Mas as junções internas já eram utilizadas. Para tal, as
tabelas eram listadas na cláusula FROM, separadas por virgulas, e as condições de junção eram descritas na

220
cláusula WHERE. Nesta construção, as condições de junção são listadas juntamente com as condições de seleção.
Veja o exemplo da junção interna sem a cláusula INNER JOIN:
SELECT TITULO, DESCRICAO
FROM LIVRO, ASSUNTO
WHERE ASSUNTO = SIGLA
AND LANCAMENTO IS NOT NULL
Em consultas complexas formuladas dessa forma, é comum que alguma importante condição seja esquecida.
Embora bastante difundidas, é aconselhável que construções deste tipo sejam substituídas pela sintaxe contendo
a cláusula INNER JOIN.
Suponha que, agora, busquemos gerar uma listagem contendo o título do livro, o nome da editora que o
publicou e a descrição do assunto de que trata. Para isso, teremos que utilizar o acesso a três tabelas. Por
exemplo:
SELECT TITULO, NOME, DESCRICAO
FROM LIVRO
INNER JOIN EDITORA E
ON EDITORA = E.CONTEUDO
INNER JOIN ASSUNTO
ON ASSUNTO = SIGLA
Em consultas onde ocorrem junções, todas as cláusulas apresentadas anteriormente como (WHERE, GROUP
BY, HAVING e ORDER BY) continuam válidas. Por exemplo:
Montar a listagem das editoras e dos títulos dos livros que lançaram, ordenada pelo nome da editora e, em
seguida, pelo título do livro. Apresentar somente os livros já lançados.
Consulta:
SELECT NOME, TITULO
FROM EDITORA E
INNER JOIN LIVRO
ON EDITORA = E.CODIGO
WHERE LANCAMENTO IS NOT NULL
ORDER BY NOME, TITULO
Junções Externas
Nas consultas onde se realizam junções internas, somente participam dos resultados as linhas cujas colunas
de junção possuem os mesmos valores em ambas as tabelas participantes da junção.
Nesta seção, serão apresentadas três formas de executar a junção externa, modalidade de junção onde a não
inexistência de valores correspondentes não limita a participação de linhas no resultado de uma consulta.
Junção externa à esquerda
Suponha que desejamos obter uma listagem de todas as editoras cadastradas em nosso banco de dados e,
para aquelas que possuam livros publicados, o nome dos mesmos. Vamos ter que utilizar uma junção externa. Eis
a sintaxe da junção externa à esquerda:
SELECT COL1, COL2, ..., COLN, FUNCAO1, FUNCAO2
FROM NOME_TABELA
LEFT OUTER JOIN NOME_TABELA2
ON NOME_TABELA.COL1 = NOME_TABELA2. COL1
WHERE CONDICAO
GROUP BY COL1, COL2, ..., COLN
HAVING EXPRESSAO_LOGICA

221
ORDER BY COL1, COL2, …, COLN
A única diferença para sintaxe da junção interna é a substituição do termo INNER JOIN pelo termo LEFT
OUTER JOIN, indicador da junção externa à esquerda.
Em uma junção externa à esquerda, a junção ocorre de forma que todas as linhas pertencentes à tabela
posicionada à esquerda do termo LEFT OUTER JOIN no comando e que atendem aos critérios definidos na
cláusula WHERE farão parte do resultado, independente se existem valores correspondentes na coluna de junção
da tabela posicionada à direita do comando. Caso não existam valores correspondentes na tabela à direita, as
colunas selecionadas desta tabela, nas linhas onde não existe correspondência, terão valor NULL.
Montando a listagem de todas as editoras cadastradas em nossa base de dados e, para aquelas que possuam
livros publicados, relacionar, também, o título dos mesmos. Vamos ordenar os resultados pelo nome da editora e
pelo título do livro.
SELECT NOME, TITULO
FROM EDITORA E
LEFT OUTER JOIN LIVRO
ON EDITORA = E.CODIGO
ORDER BY NOME, TITULO
Outro exemplo: Mostrar a listagem completa de assuntos contendo, também, os títulos dos livros e seus
respectivos assuntos. Resultados ordenados pela descrição do assunto.
Consulta:
SELECT DESCRICAO, TITULO
FROM ASSUNTO
LEFT OUTER JOIN LIVRO
ON SIGLA = ASSUNTO
ORDER BY DESCRICAO
Junção externa à Direita
A junção externa à direita é extremamente parecida com a junção externa à esquerda. A única diferença
consta no fato de que a tabela da qual todas as linhas constarão do resultado está posicionada à direita do termo
RIGHT OUTER JOIN no comando. Sua sintaxe é:
SELECT COL1, COL2, ..., COLN, FUNCAO1, ..., FUNCAON
FROM NOME_TABELA
RIGHT OUTER JOIN NOME_TABELA2
ON NOME_TABELA.COL1 = NOME_TABELA2.COL1
WHERE CONDICAO
GROUP BY COL1, COL2, ..., COLN
HAVING EXPRESSAO_LOGICA
ORDER BY COL1, COL2, …, COLN
Onde, a única diferença em termos de sintaxe para a junção externa à esquerda é a substituição do termo
LEFT OUTER JOIN pelo termo RIGHT OUTER JOIN, indicador da junção externa à direita.
Se reescrevermos a consulta do exemplo anterior de forma a obtermos o mesmo resultado e com a utilização
da junção externa à direita, teremos a seguinte consulta:
SELECT DESCRICAO, TITULO
FROM LIVRO
RIGHT OUTER JOIN ASSUNTO
ON SIGLA = ASSUNTO

222
ORDER BY DESCRICAO
Note que para que as consultas sejam equivalentes, temos que inverter a ordem das tabelas na cláusula
FROM.
Junção Externa Completa
Podemos ainda querer montar as listagem de todas as linhas das tabelas participantes que atendam aos
critérios de seleção especificados na cláusula WHERE participem do resultado, independente da correspondência
de valores da cláusula de junção. A cláusula de junção atua de forma a montar a relação quando existir
correspondência entre valores. Quando não existir, as colunas da tabela onde inexiste o valor devem apresentar o
valor nulo. Esta é a junção externa completa.
A diferença da junção externa para as junções à direita e à esquerda se dá no fato de que, naquelas, uma das
tabelas somente apresentava os valores com correspondência à outra, a qual apresentava todos os seus valores.
Na junção externa completa, as duas tabelas poderão apresentar valores sem correspondentes. A sintaxe é:
SELECT COL1, COL2, ..., COLN, FUNCAO1, ..., FUNCAON
FROM NOME_TABELA
FULL OUTER JOIN NOME_TABELA2
ON NOME_TABELA.COL1 = NOME_TABELA2.COL1
WHERE CONDICAO
GROUP BY COL1, COL2, ..., COLN
HAVING EXPRESSAO_LOGICA
ORDER BY COL1, COL2, …, COLN
Onde a única diferença para a sintaxe da junção externa à esquerda é a substituição do termo FULL OUTER
JOIN, em detrimento de LEFT OUTER JOIN e RIGHT OUTER JOIN, respectivamente.
Consideremos agora, a tabela de editoras, cujo exemplo é apresentado na tabela 2.6, e a tabela de livros,
onde foram adicionados mais livros, ainda sem data prevista para o lançamento, sem editora definida e sem
preço. A nossa nova tabela de livros é apresentada na tabela 6.1. Vejamos, então um exemplo para a realização
da junção externa completa.
Listagem com a exibição de todos os títulos e de todas as editoras, relacionando a obra com a editora que a
publica, quando caso. A listagem deverá estar ordenada pelo título da obra.
Consulta:
SELECT TITULO, NOME
FROM LIVRO
FULL OUTER JOIN EDITORA
ON EDITORA.CODIGO = EDITORA
ORDER BY TITULO
Junção Cruzada

223
Algumas vezes queremos gerar todas as combinações possíveis entre elementos de duas tabelas. É uma
operação idêntica a um produto cartesiano dos elementos das tabelas. Para isso, podemos utilizar um tipo de
junção conhecida como CROSS JOIN. Sua sintaxe é:
SELECT COL1, COL2, ..., COLN, FUNCAO1, …, FUNCAON
FROM NOME_TABELA
CROSS JOIN NOME_TABELA2
WHERE CONDICAO
GROUP BY COL1, COL2, …, COLN
HAVING EXPRESSAO_LOGICA
ORDER BY COL1, COL2, …, COLN
Suponha um torneio onde seleções são divididas em dois grupos, A e B, e onde todos os membros do grupo A
jogam contra todos os membros do grupo B. A tabela 6.2 representa as seleções do Grupo A, euqunato a tabela
6.3, as do grupo B.
Consulta:
SELECT A.NOME AS TIME_A, B.NOME AS TIME_B
FROM GRUPO_A A CROSS JOIN GRUPO_B B
Resultado:
Junção Natural e Baseada em Nomes de Colunas
Anteriormente foram apresentadas as junções internas e externas. Agora vamos verificar a junção natural e a
junção baseada em nomes de colunas. Ambas são construções que podem ser aplicadas em conjunto com as
modalidades apresentadas anteriromente para substituir a utilização da cláusula ON.

224
Na verdade, como, em alguns casos, as tabelas sobre as quais queremos realizar a junção apresentam
colunas de mesmo nome e para que, nesses asos, não seja necessário explicitar o nome das colunas, é definida a
junção natural. Nesta modalidade de junção, todas as colunas de mesmo nome nas tabelas em questão
participam da condição de junção.
Para utilizar a junção natural, basta incluir a palavra reservada NATURAL antes das palavras INNER, LEFT,
OUTER ou FULL, de acordo com a situação. Então, não será necessário utilizar a cláusula ON.
Entretanto, realizar automaticamente a junção por todas as colunas de mesmo nome pode ser um problema.
Frequentemente encontramos tabelas com colunas de nomes intituladas “nome” e “descrição”. No entanto, não
é comum realizar junções por tais colunas.
Para solucionar essa questão, foi elaborada a junção baseada em nomes de colunas. Assim, como no caso da
junção natural, neste caso, as colunas de mesmo nome nas diferentes tabelas serão utilizadas para a junção.
Entretanto, agora, as colunas não serão utilizadas automaticamente. Será necessário especificar quais colunas
serão utilizadas.
A sintaxe da junção baseada em nomes de coluna é:
SELECT COL1, COL2, ..., COLN
FROM NOME_TABELA
[INNER, LEFT OUTER, RIGHT OUTER,
FULL OUTER] JOIN NAME_TABELA2
USING [NOME_COLUNA]
A principal diferença entre a junção natural e a baseada em nomes de colunas se dá no fato de que, na
junção natural, todas as colunas de mesmo nome nas tabelas serão utilizadas para realizar a junção, enquanto a
junção baseada em nomes de colunas, somente serão utilizadas as colunas que forem listadas.
Formatando a Saída e as junções externas
Quando utilizamos as funções externas, podemos obter vários valores nulos em uma ou mais coluna do
resultado. A função COALESCE nos permite substituir os valores nulos por outros que desejamos. Ela recebe uma
lista de parâmetros e retorna o primeiro que possuir um valor não-nulo. Frequentemente, é exigido que todos os
parâmetros sejam do mesmo tipo de dados.
Por exemplo:
Obter uma listagem com a descrição de todos os assuntos e os títulos dos livros de cada um. Quando não
existir um assunto associado, deve ser escrita a frase “SEM PUBLICAÇÕES”.
Consulta:
SELECT DESCRICAO, COALESCE(TITULO, ‘SEM PUBLICAÇÕES’) AS TITULO
FROM ASSUNTO
LEFT OUTER JOIN LIVRO
ON SIGLA = ASSUNTO
ORDER BY DESCRICAO

225
Combinando Comandos
Todos os commandos de consulta da linguagem SQL atuam sobre uma relação, que pode ou não estar
materializada em formato de uma tabela. O resultado dos comandos de seleção também é uma relação. Tanto as
relações de entrada quanto as relações de saída podem possuir diversos números de colunas e linhas.
Este tipo de construção permite que utilizemos consultas embutidas na cláusula FROM de uma consulta,
fazendo com que a saída de um comando SELECT seja utilizada como entrada para outro comando SELECT. Outras
formas de combinarmos os dois ou mais comandos SELECT para obter um único resultado final são subconsultas
da cláusula WHERE, correlacionadas ou não, e as operações baseadas nas operações de conjunto.
Subconsultas da cláusula WHERE
A utilização de subconsultas na cláusula WHERE é uma das formas de combinação de duas ou mais consultas
para um único resultado final. Nestas construções, o resultado da subconsulta não é apresentado ao usuário,
sendo construído de forma temporária pelo SGBD, o qual utiliza os resultados temporários em testes das
consultas mais externas. Existem dois tipos de subconsultas: correlacionadas e não-correlacionadas.
Subconsultas não-correlacionadas
Com a utilização do predicado IN era possível comparar o valor de uma coluna com uma lista de valores. Na
subconsulta não-correlacionada, substituímos a lista de valores do predicado IN por uma consulta.
A sintaxe básica do comando para utilização da subconsulta não-correlacionada é:
SELECT COL1, COL2, ..., COLN
FROM NOME_TABELA
WHERE COLM [NOT] IN (SELECT COLX FROM NOME_TABELA2)
Note que, à esquerda do predicado [NOT] IN continua posicionada uma coluna (a utilização do operador NOT
é opcional). A consulta interna ao predicado IN (aquela que substitui a lista de valores), não tem nenhuma ligação
com a consulta externa. Ambas as consultas poderão possuir todas as construções apresentadas anteriormente,
sem nenhuma restrição adicional devido à presença da subconsulta. A consulta interna deverá, no entanto,
retornar uma coluna apenas.
Exemplos:
Considerando a base de dados de publicações composta pelas tabelas ASSUNTO, LIVRO e EDITORA, conforme
anteriormente. Desejamos saber os nomes das editoras que possuem livros já lançados.
Consulta:
SELECT NOME
FROM EDITORA
WHERE CODIGO IN ( SELECT EDITORA
FROM LIVRO
WHERE LANCAMENTO IS NOT NULL)
Neste exemplo, a subconsulta gera uma relação temporária de uma única coluna (não exibida ao usuário em
nenhum momento) contendo os códigos de editoras que publicaram livros que já foram lançados. A consulta
externa procurará por nomes de editoras para as quais o código consta na relação produzida para subconsulta.
Desejamos saber quais assuntos não foram lançados livros.
SELECT DESCRICAO
FROM ASSUNTO
WHERE SIGLA NOT IN (SELECT ASSUNTO FROM LIVRO WHERE LANCAMENTO IS NOT NULL)
Neste exemplo, a subconsulta gera uma listagem de assuntos dos livros que já foram lançados. A consulta
externa procurará, na tabela de assuntos, quais assuntos não constam na listagem gerada pela subconsulta.

226
Também podemos utilizar subconsultas combinadas com operações de atualização e exclusão de dados. Por
exemplo:
Desejamos excluir as editoras que não publicaram os livros. O comando para tal operação é:
DELETE FROM EDITORA
WHERE CODIGO NOT IN (SELECT EDITORA FROM LIVRO)
Subconsultas Correlacionadas
É possivel utilizar o predicado IN em conjunto com um commando SQL em uma construção chamada de não-
correlacionada. Agora, veremos outro tipo de construção, chamado de subconsulta não-correlacionada. Agora,
veremos outro tipo de construção, chamada de subconsulta correlacionada, pois, neste caso, a subconsulta
possui dependência direta da consulta externa.
Na subconsulta correlacionada utilizaremos o predicado EXISTS. O predicado IN permitia testar se valores de
uma coluna constavam em uma listagem de valores. O predicado EXISTS testa se uma condição é verdadeira ou
falsa. Vejamos exemplo da sintaxe para sua utilização:
SELECT COL1, COL2, ..., COLN
FROM NOME_TABELA TAB_EXTERNA
WHERE [NOT] EXISTS
(SELECT COLX
FROM NOME_TABELA2 TAB_EXTERNA
WHERE TAB_EXTERNA.COLA = TAB_INTERNA.COLA)
Na subconsulta do exemplo anterior, existe uma comparação entre uma coluna da tabela externa com uma
coluna da tabela interna (em negrito). Este tipo de teste é possível em subconsultas, onde a consulta mais interna
poderá acessar uma coluna da coluna mais externa, usualmente utilizando o apelido (ou correlation name) da
tabela mencionada da coluna mais externa, usualmente utilizando o apelido da tabela mencionada da consulta
mais externa.
Esse comando começa a ser executado pela consulta mais externa. Então, para cada linha de NOME_TABELA,
a subconsulta será executada, substituindo-se o valor de TAB_EXTERNA.COLA por seu valor na linha em questão.
Se a subconsulta retornar algum valor a cláusula EXISTS será verdadeira e a linha recuperada na consulta mais
externa fará parte do resultado final. Em caso contrário, a consulta mais externa realiza o teste para a próxima
linha de TAB_EXTERNA.COLA.
Note que, na utilização do predicado EXISTS, não é posicionada nenhuma coluna à esquerda do mesmo, pois
ele não compara valores, e, sim, testa uma condição booleana. Assim, a coluna posicionada na cláusula SELECT da
subconsulta não influenciará no resultado do comando.
Devido à existência, na subconsulta, da utilização de uma coluna da consulta mais externa em uma
comparação, esta construção é chamada de consulta correlacionada.
Vejamos os exemplos anteriores reescritos para o formato de subconsultas correlacionadas:
• Desejamos saber os nomes das editoras que possuem livros lançados. SELECT NOME
FROM EDITORA ED
WHERE EXISTS (SELECT EDITORA
FROM LIVRO
WHERE LANCAMENTO IS NOT NULL
AND ED.CODIGO = EDITORA)
• Desejamos saber sobre quais assuntos nao foram lançados livros. SELECT DESCRICAO
FROM ASSUNTO ASS
WHERE NOT EXISTS (SELECT ASSUNTO

227
FROM LIVRO
WHERE LANCAMENTO IS NOT NULL
AND ASS.SIGLA = ASSUNTO)
Assim como no caso do predicado IN, poderemos utilizar EXISTS em commandos de atualização e exclusão de
dados. Vejamos a reescrita do comando para exclusão das editoras que não possuem livros associados, com a
utilização de EXISTS:
DELETE FROM EDITORA E
WHERE NOT EXISTS (
SELECT 1 FROM LIVRO WHERE EDITORA = E.CODIGO)
Subconsultas substituindo valores
Em uma consulta, para cada linha da relação resultante temos, em uma dada coluna, uma pequena relação
de uma linha e uma coluna que pode ser substituída por um comando SELECT que retorne apenas uma linha e
uma coluna. Tal comando SELECT pode ser formador tanto de uma consulta correlacionada quanto de uma
consulta não-correlacionada.
Considere que desejamos montar uma relação que contenha em uma coluna a descrição dos assuntos
existentes e, em outra, a quantidade de livros lançados de cada assunto.
Para obter a coluna ASSUNTOS basta realizar uma seleção sobre a coluna DESCRIÇÃO da tabela de assuntos e
utilizar o apelido ASSUNTOS para a coluna. Para obter a coluna LIVROS_LANCADOS devemos contar, para cada
assunto, quantos livros já lançados existem na tabela de livros do assunto em questão. O comando que monta o
resultado anterior é o seguinte:
SELECT DESCRICAO AS ASSUNTOS,
(SELECT COUNT(*)
FROM LIVRO L
WHERE L.ASSUNTO = A.SIGLA
AND LANCAMENTO IS NOT NULL
) AS LIVROS_LANCADOS
FROM ASSUNTO A
Note que, no comando anterior, foi utilizada uma subconsulta correlacionada substituindo um valor em um
comando SELECT e, para a qual, foi dado um apelido (LIVROS_LANCADOS). A subconsulta utilizada possui
somente uma coluna onde foi usada a função COUNT que retorna somente uma linha, de forma a atender ao
requisito apresentado anteriormente. Como a correlação desta com a tabela externa (L.ASSUNTO = A.SIGLA) faz
com que a contagem de livros seja feita para o assunto adequado.
Outro exemplo:
• Listar o nome das editoras e o preço médio das publicações de cada uma. SELECT NOME,
(SELECT AVG(PRECO)
FROM LIVRO V
WHERE V.EDITORA = E.CODIGO
AND LANCAMENTO IS NOT NULL) AS PRECO_MEDIO
FROM EDITORA E
ORDER BY NOME
Poderemos utilizar subconsultas que retornem uma relação de uma linha e uma coluna em vários comandos
e locais como, por exemplo, substituindo o valor no comando UPDATE TABELA SET COLUNA = VALOR.

228
Tabelas aninhadas
Uma tabela é a materialização de uma relação. Quando realizamos uma consulta e posicionamos uma tabela
na cláusula FROM, estamos fazendo uma consulta sobre uma relação. Logo, podemos substituir uma tabela por
uma subconsulta que retorne uma relação. A esta construção chamamos de tabelas aninhadas.
Para utilizarmos o resultado de uma consulta como uma tabela, devemos posicionar a consulta delimitada
por parênteses em local destinado a uma tabela. Para que possamos acessar as colunas do resultado da
subconsulta como se acessássemos as colunas de uma tabela, pode ser necessário atribuir um apelido para a
subconsulta. Vejamos um exemplo de sintaxe para a junção entre uma tabela aninhada e uma tabela:
SELECT COL1, COL2, COLN, COLX, COLY, COLZ
FROM
(SELECT COLX, COLY, COLZ FROM TAB_INTERNA) TAB_CONSULTA
INNER JOIN TAB_EXTERNA
ON TAB_CONSULTA.COLX = TAB_EXTERNA.COL1
Notamos que a expressão TAB_CONSULTA.COLX representa o acesso à coluna COLX do resultado da
subconsulta. Qualquer coluna da tabela aninhada poderá ser acessada como uma coluna de uma tabela.
• Listar o nome das editoras e as publicações das editoras que lançaram ao menos dois livros, ordenados por nome da editora e pelo título da publicação.
SELECT NOME, TITULO
FROM
(SELECT EDITORA, COUNT(*) AS QUANTIDADE
FROM LIVRO V
WHERE LANCAMENTO IS NOT NULL
GROUP BY EDITORA) EDITORA_QUANT
INNER JOIN LIVRO
ON EDITORA_QUANT.EDITORA = LIVRO.EDITORA
INNER JOIN EDITORA
ON EDITORA_QUANT.EDITORA = EDITORA.CODIGO
WHERE QUANTIDADE >= 2
ORDER BY NOME
Essa relação, que não é exibida ao usuário, é utilizada exatamente como uma tabela e referenciada pelo
nome EDITORA_QUANT.
• Listar os títulos dos livros dos assuntos para os quais o preço médio das publicações é superior a R$ 40,00, juntamente com os respectivos assuntos.
SELECT TITULO, DESCRICAO AS ASSUNTO
FROM ( SELECT ASSUNTO, AVG(PRECO) AS PRECO_MEDIO
FROM LIVRO V
GROUP BY SIGLA
HAVING AVG(PRECO) > 40) ASSUNTO_PRECO
INNER JOIN LIVRO
ON ASSUNTO_PRECO.ASSUNTO = LIVRO.ASSUNTO
INNNER JOIN ASSUNTO
ON ASSUNTO_PRECO.ASSUNTO = ASSUNTO.SIGLA
Operações de Conjunto
Podemos realizar as operações tradicionais sobre conjuntos: união, interseção, e diferença.
União

229
Quando realizamos junções entre tabelas, formamos uma relação resultante com as colunas que contêm as
colunas das tabelas originais. Por outro lado, podemos querer realizar um comando SQL que apresente, como
resultado, todas as linhas que foram recuperadas por outros dois comandos SQL realizados em separado. Para
unir as linhas resultantes de duas ou mais consultas, utilizamos o predicado UNION.
O predicado UNION é utilizado posicionado entre dois comandos de consulta, da seguinte forma:
SELECT COL1, COL2
FROM TABELA1
UNION [ALL]
SELECT COL3, COL4
FROM TABELA2
Observamos que os comandos poderão acessar tabelas diferentes e utilizar as mais diversas construções da
linguagem. Existem, somente, duas regras para utilização do UNION: (i) os comandos devem retornar o mesmo
número de colunas e (ii) as colunas correspondentes em cada comando devem possuir os mesmo tipos de dados.
O UNION irá atuar fazendo com que o resultado das consultas participante seja combinado com o resultado
final. Quando utilizamos o UNION isoladamente, no resultado final não constarão linhas repetidas. Se desejarmos
que linhas repetidas apareçam, devemos utilizar o predicado ALL logo após UNION, conforme mostrado antes.
* Listar os títulos dos livros que cujo assunto é “Banco de Dados” ou que foram lançados por editoras que
contenham “Mirandela” no nome.
SELECT TITULO
FROM LIVRO
INNER JOIN ASSUNTO
ON ASSUNTO = SIGLA
WHERE DESCRICAO = ‘BANCO DE DADOS’
UNION [ALL]
SELECT TITULO
FROM LIVRO
INNER JOIN EDITORA E
ON EDITORA = E.CODIGO
WHERE NOME LIKE “%MIRANDELA%”
Interseção
Para obtermos a interseção entre os resultados do comando SELECT, utilizamos o comando INTERSECT.
O INTERSECT é utilizado da mesma forma que o UNION, posicionado entre dois comandos SELECT, e atende
às mesmas regras: (i) os comandos devem retornar o mesmo número de colunas e (ii) as colunas correspondentes
em cada comando devem possuir os mesmos tipos de dados. Então, o INTERSECT retornará as linhas que estejam
presente nos resultados de todas as consultas participantes.
Da mesma forma que o UNION, o INTERSECT utilizado isoladamente eliminará as linhas repetidas. Para que
as linhas repetidas constem no resultado final, o predicado ALL deve ser utilizado.
• Listar os títulos dos livros cujo assunto é ‘Programação’ e que foram lançados por uma editora que contenha a palavra “Mirandela” no nome, sem repetições.
SELECT TITULO
FROM LIVRO
INNER JOIN ASSUNTO
ON ASSUNTO = SIGLA
WHERE DESCRICAO = ‘PROGRAMACAO’
INTERSECT
SELECT TITULO
FROM LIVRO

230
INNER JOIN EDITORA E
ON EDITORA = E.CODIGO
WHERE NOME LIKE “%MIRANDELA%”
Diferença
Também é possível realizar a diferença entre os resultados de comandos SELECT. Neste caso, o predicado
utilizado é o EXCEPT.
O EXCEPT será utilizado da mesma forma que o UNION e o INTERSECT (entre os comandos SELECT). Estará
sujeito às mesmas duas regras apresentadas nos casos anteriores sobre o número de colunas e os tipos de dados
das mesmas. Isoladamente, ele não permite linhas repetidas no resultado final. Da mesma forma que o UNION e
o INTERSECT, ele pode ser utilizado em conjunto com o predicado ALL.
Exemplo: Listar os títulos dos livros cujo assunto é “Banco de Dados” e que não foram lançados por uma editora
que contenha a palavra ‘Mirandela’ no nome.
SELECT TITULO
FROM LIVRO
INNER JOIN ASSUNTO
ON ASSUNTO = SIGLA
WHERE DESCRICAO = ‘BANCO DE DADOS’
EXCEPT
SELECT TITULO
FROM LIVRO
INNER JOIN EDITORA E
ON EDITORA = E.CODIGO
WHERE NOME LIKE ‘MIRANDELA’
Como o EXCEPT realiza a diferença entre conjuntos, a ordem de declaração das consultas com relação ao
predicado EXCEPT altera o resultado final, diferentemente do que acontece com os predicados UNION e
INTERSECT.
• Listar o título dos livros que foram lançados por editora que contenham a palavra ‘Mirandela’ em seu nome e cujo assunto não é ‘Banco de Dados’.
SELECT TITULO
FROM LIVRO
INNER JOIN EDITORA E
ON EDITORA = E.CODIGO
WHERE NOME LIKE ‘%MIRANDELA%’
EXCEPT
SELECT TITULO
FROM LIVRO
INNER JOIN ASSUNTO
ON ASSUNTO = SIGLA
WHERE DESCRICAO = ‘BANCO DE DADOS’
Comandos e Estruturas Avançadas
A seguir serão apresentadas construções da SQL:2003 que permitem a realização de consultas bastante
poderosas, como as consultas recursivas, ou de grande utilidade, como o predicado CASE e os comandos para
criação e exclusão de visões. Também é apresentado o comando MERGE, para inclusão e atualização de
informações em tabelas.
Visões e Visões Temporárias

231
Muitas vezes gostaríamos de utilizar os dados contidos em nosso banco de dados como se estivessem em um
formato diferente daquele em que realmente estão.
Consideremos uma situação em que queremos constantemente queremos consultar o título de um livro, seu
preço, o nome da editora que o publica e a descrição do assunto do livro. Estas informações estão contidas em
nosso banco de dados, mas espalhada em três tabelas. Para uni-las devemos realizar o comando SELECT com
junções entre as tabelas. Entretanto, como a consulta é realizada constantemente, gostaríamos de ter uma
diferente visão de nosso banco de dados: gostaríamos de ter uma visão onde as informações já aparecessem
unidas. A linguagem SQL nos permite isso através da criação de um objeto chamado visão.
Visões são tabelas artificiais cujo conteúdo provém de tabelas reais. Os dados que as compõem são definidos
através de comandos SELECT realizados sobre tabelas dos bancos de dados. Na verdade, os dados continuam
armazenados na tabela original. Cada vez que realizamos uma consulta sobre a visão, o SGBD se encarrega de
coletar os dados nas tabelas de origem, a partir do comando SELECT que definem a visão como se ela fosse uma
tabela.
Para criamos visões, utilizamos o comando CREATE VIEW, cuja estrutura básica é apresentada a seguir.
CREATE VIEW NOME_VISÃO
AS COMANDO DE CONSULTA
Vejamos, a seguir o comando para criação da visão que contém o título dos livros, seus preços, o nome da
editora que os publica e a descrição de seus assuntos.
CREATE VIEW LIVRO_EDITORA_ASSUNTO
AS
SELECT TITULO, PRECO, NOME AS EDITORA,
DESCRICAO AS ASSUNTO
FROM LIVRO
INNER JOIN EDITORA ED
ON EDITORA = ED.CODIGO
INNER JOIN ASSUNTO
ON ASSUNTO.SIGLA = LIVRO.ASSUNTO
Agora, poderemos consultar a visão como se consultássemos uma tabela de nosso banco de dados. Como
exemplo, vamos apresentar o comando para obtermos o título, o nome da editora, e a descrição do assunto dos
livros que possuem preço superior a R$ 45,00. Queremos a listagem ordenada por título do livro.
SELECT TITULO, EDITORA, ASSUNTO
FROM LIVRO_EDITORA_ASSUNTO
WHERE PRECO > 45
ORDER BY TITULO
A definição de uma visão permanece no banco de dados, de forma que a visão pode ser acessada a qualquer
momento. Para apagarmos uma visão, utilizamos o comando DROP VIEW, seguido do nome da visão. A seguir,
como exemplo, temos o comando para exclusão da visão
LIVRO_EDITORA_ASSUNTO
DROP VIEW LIVRO_EDITORA_ASSUNTO
Na exclusão da visão, somente sua definição é excluída. Os dados permanecem nas tabelas originais.
Por outro lado, podemos querer criar uma visão para ser utilizada em um comando somente, sem que sua
definição fique armazenada no banco de dados. Para isto, utilizamos o comando WITH. Uma estrutura simples
para o comando WITH é apresentada a seguir.
WITH NOME_VISÃO_TEMPORÁRIA [(NOME_COLUNAS_VISÃO)]
AS
(COMANDO_DEFINIÇÃO_VISÃO)
COMANDO_DE_CONSULTA

232
Vamos, agora, como exemplo, utilizar o mesmo comando que colocou a visão LIVRO_EDITORA_ASSUNTO na
definição de uma visão temporária. Usaremos, também, a mesma consulta sobre esta visão que utilizamos
anteriormente.
WITH CONSULTA_EDITORA_ASSUNTO AS (
SELECT TITULO, PRECO, NOME AS EDITORA, DESCRICAO AS ASSUNTO
FROM LIVRO
INNER JOIN EDITORA ED
ON EDITORA = ED.CODIGO
INNER JOIN ASSUNTO
ON ASSUNTO.SIGLA = LIVRO.ASSUNTO)
SELECT TITULO, EDITORA, ASSUNTO
FROM LIVRO_EDITORA_ASSUNTO
WHERE PRECO > 45
ORDER BY TITULO
Consultas recursivas
A inclusão de consultas na linguagem SQL permitiu a realização de comandos que antes deveriam ser
realizados somente através da utilização de linguagens de programação.
Vamos considerar um fórum de mensagens na Intenet. Neste fórum, o usuário pode enviar uma mensagem
ou responder a outra enviada anteriormente. O usuário pode, inclusive, responder a uma resposta anterior. Um
exemplo dessa estrutura é apresentado na figura 8.1. Notamos que essa estrutura pode ser visualizada em
formato de árvore.
Em termos de modelagem, consideremos que a mensagem seja representada por um auto-relacionamento,
conforme a figura 8.2. Todas as mensagens poderão estar contidas em uma única tabela do banco de dados, da
qual temos um exemplo na tabela 8.1. Nesta tabela, a coluna ID_MENSAGEM é chave primária, identificando
univocamente cada mensagem da tabela. A coluna ASSUNTO representa o assunto da mensagem. No caso de
uma mensagem estar respondendo à outra, na coluna ID_MENSAGEMPAI estará contido o identificador da
mensagem que está sendo respondida. Em caso contrário, esta coluna estará vazia.

233
Se desejarmos obter quais as respostas para a mensagem de número 1, basta realizarmos uma consulta
procurando as linhas onde a coluna ID_MENSAGEMPAI possui o valor 1. Entretanto, podemos querer obter todas
as mensagens originadas a partir da pergunta de mensagem de número 1, ou seja, todas aquelas que estão
diretamente respondendo à mensagem de número 1, aquelas que respondem a respostas da mensagem de
número 1 e assim por diante. Para obter todas essas mensagens, termos que utilizar uma consulta recursiva.
Consultas recursivas utilizam-se da cláusula WITH combina com os comandos SELECT e UNION ALL.
A construção a ser utilizada é semelhante à apresentada anteriormente. A principal diferença reside na
construção da consulta que define a visão. Esta deverá conter consultas, unidas via UNION ALL. A primeira, mais
básica, define a semente do comando, acessando a linha a partir da qual iremos querer disparar a recursão. A
segunda conterá uma segunda definição de tabela, ligada à primeira, montando a cláusula da recursão.
Assim, para o exemplo anterior, onde queremos obter todas as mensagens que foram originadas a partir da
mensagem de número 1, devemos utilizar o seguinte comando listado a seguir.
WITH JA_SELECIONADO
(ID_MENSAGEM, ASSUNTO, ID_MENSAGEM_PAI)
AS
(SELECT ID_MENSAGEM, ASSUNTO, ID_MENSAGEM_PAI
FROM MENSAGEM
WHERE ID_MENSAGEM = 1
UNION ALL
SELECT M.ID_MENSAGEM, M.ASSUNTO, M.ID_MENSAGEM_PAI
FROM JA_SELECIONADO J, MENSAGEM M
WHERE J.ID_MENSAGEM = M.ID_MENSAGEM_PAI)
SELECT * FROM JA_SELECIONADO
Note, no comando, que utilizamos a consulta
SELECT ID_MENSAGEM, ASSUNTO, ID_MENSAGEM_PAI
FROM MENSAGEM
WHERE ID_MENSAGEM = 1

234
Como semente da recursão, selecionando a primeira linha da tabela temporária JÁ_SELECIONADO. O
comando SELECT, que se une a este, acessa as tabelas MENSAGEM e JÁ_SELECIONADO, unindo-as pela chave
estrangeira e fazendo com que novas linhas sejam adicionadas à visão temporária.
Embora as consultas recursivas tenham sido um grande avanço, elas também criaram um novo problema a
ser tratado: o loop infinito. Assim, ao construirmos consultas recursivas, devemos estar atentos para montá-las de
forma a que tenham fim.
Predicado CASE
Algumas vezes queremos selecionar resultados diferentes em função de uma ou mais condições. O predicado
CASE, que pode ser utilizado em conjunto com comandos SELECT, permite que realizemos tal tarefa.
Existem duas diferentes construções para o predicado CASE. A construção mais simples possui o seguinte
formato:
CASE COLUNA
WHEN VALOR THEN RESULTADO
WHEN VALOR2 THEN RESULTADO2
...
[ELSE RESULTADO_ELSE]
END
• Para os livros cujo assunto é ‘B’, retornar o título concatenado com a expressão ‘-MUITO INTERESSANTE’. Para aqueles cujo assunto é ‘P’ retornar o título concatenado com a expressão ‘-INTERESSANTE MÉDIO’. Para os outros retornar a expressao ‘-SEM INTERESSE’ concatenada com seu título. Consideremos a Tabela 6.1 como a instância para a tabela LIVRO.
SELECT CASE ASSUNTO
WHEN ‘B’ THEN TITULO || ‘-MUITO INTERESSANTE’
WHEN ‘P’ THEN TITULO || ‘-INTERESSE MÉDIO’
ELSE TITULO || ‘-SEM INTERESSE’
END AS IMPORTANCIA
FROM LIVRO
O segundo formato da expressão CASE permite que testes envolvendo diferentes colunas, variáveis e
expressões sejam avaliados. Sua estrutura é a seguinte:
CASE
WHEN EXPRESSAO_BOOLEANA THEN RESULTADO
WHEN EXPRESSAO_BOOLEANA2 THEN RESULTADO2
...
[ELSE RESULTADO_ELSE]
END
• Consideremos, novamente, o exemplo de instância para a tabela LIVRO apresentado na tabela 6.1. Para os livros que possuem data de lançamento e o preço é superior a R$ 45,00 retornar o título concatenado com a expressão ‘-LIVRO CARO’. Para aqueles que não possuem data de lançamento, mas possuem editora, retornar o título concatenado com a expressão ‘- LANCAMENTO EM BREVE’. Para aqueles que não possuem editora, retornar o título concatenado com a expressao ‘-LIVRO BARATO’.
SELECT CASE
WHEN LANCAMENTO IS NOT NULL AND PRECO > 40
THEN TITULO || ‘ – LIVRO CARO’
WHEN LANCAMENTO IS NOT NULL AND EDITORA IS NOT NULL
THEN TITULO || ‘ – LANCAMENTO EM BREVE’

235
WHEN EDITORA IS NULL
THEN TITULO || ‘ – EM PREPARACAO’
ELSE TITULO || ‘ – LIVRO BARATO’
END AS IMPORTANCIA
FROM LIVRO
CASE pode ser utilizado em consultas SELECT que tenham complexidade que desejemos. Pode, inclusive, ser
utilizado na cláusula WHERE. Exemplo:
• As várias editoras estão estudando a aplicação de diferentes fatores a reajustes de preços. Queremos saber quais os títulos dos livros que custarão acima de R$50,00 caso a editora ‘VIA-NORTE’ aplique um reajuste de 10% nos preços de seus livros e a editora ‘ILHAS TIJUCAS’ aplique um reajuste de 25%.
SELECT TITULO
FROM LIVRO
INNER JOIN EDITORA
ON EDITORA = EDITORA.CODIGO
WHERE 50 < (CASE WHEN NOME= ‘EDITORA VIA-NORTE’
THEN PRECO *1.1
WHEN NOME = ‘EDITORA ILHAS TIJUCAS’
THEN PRECO * 1.25
ELSE PRECO
END)
Comando MERGE
Suponhamos que tenhamos uma tabela de clientes. A descrição da tabela de clientes será apresentada na
figura 8.3. Esta tabela possui várias linhas, sendo que, algumas delas são referentes a pessoas que também atuam
como atores e que também estão cadastradas na tabela de autores.
Foi decidido que todos os autores serão
cadastrados como clientes. Para os autores que já se encontram cadastrados como clientes, deveremos atualizar
as informações na tabela de clientes com base nos dados da tabela de autores.
Para realizar tais operações utilizando os comandos INSERT e UPDATE, teríamos que percorrer todas as linhas
da tabela de autores, verificando cada uma se o autor já está cadastrado como cliente. Caso não esteja, teríamos
que realizar um comando INSERT para cadastrá-lo. Caso o autor já estivesse cadastrado, teríamos que fazer um
comando UPDATE, para atualizar essas informações na tabela de clientes. Para simplificar situações como essa,
foi criado o comando MERGE (algumas vezes conhecidos como UPSERT, devido às suas circunstâncias).
MERGE faz, automaticamente, comparações entre informações de tabelas, inserindo as linhas que não existem e
atualizando as outras. Uma sintaxe simplificada para o comando MERGE é apresentado a seguir:
MERGE INTO TABELA_DESTINO [AS APELIDO_DESTINO]
USING TABELA_ORIGEM [AS APELIDO_ORIGEM]
ON (EXPRESSAO_BOOLEANA)
WHEN MATCHED THEN OPERAÇÃO_VERDADEIRO
WHEN NOT MATCHED THEN OPERAÇÃO_FALSO
Vejamos, a seguir, como exemplo, a realização da inclusão e atualização dos dados de autores como clientes,
conforme descrito anteriormente, através do comando MERGE.
MERGE INTO CLIENTE CLI

236
USING AUTOR AU
ON (AU.CPF = CLI.CPF)
WHEN MATCHED THEN
UPDATE SET CLI.NOME = AU.NOME
CLI.ENDERECO = AU.NOME,
CLI.DATA_NASCIMENTO = AU.DATA_NASCIMENTO
WHEN NOT MATCHED THEN
INSERT(CODIGO, NOME, CPF, ENDERECO, DATA_NASCIMENTO)
VALUES (AU.MATRICULA, AU.NOME, AU.CPF, AU.ENDERECO, AU.DATA_NASCIMENTO)
Transações e Concorrência
Uma transação é formada por um conjunto de comandos SQL que são atômicos no que diz respeito à sua
execução e à recuperação do banco de dados. Cada comando executado em um banco de dados faz parte de uma
transação, mesmo que unitária. As propriedades ACID (Atomicidade, Consistência, Isolamento e Durabilidade) são
importantes propriedades em transações. Para implementá-las, os SGBD´s utilizam mecanismos que podem
reduzir o nível de concorrência do sistema como um todo.
SGBD´s são sistemas que, em situações reais podem ser acessados por milhares de usuários
concorrentemente. São comuns situações onde vários usuários realizam consultas e atualizações nos mesmos
dados. Na situação ideal, cada usuário de um banco de dados deveria executar os seus comandos como se ele
fosse o único usuário. Esse é o maior nível de isolamento a ser obtido. Entretanto, é muito baixo o nível de
concorrência correspondente a tal nível de isolamento. Neste caso, usuários poderão ficar aguardando por
informações durante tempos relativamente longos, à espera do término de outras transações.
De forma a aumentar os níveis de concorrência em detrimento do isolamento, a SQL define quatro níveis de
isolamento: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ e SERIAZABLE.
Iniciando, Alterando e Concluindo Transações
Se uma transação for concluída com sucesso, as alterações por ele realizadas não poderão ser desfeitas.
Mesmo que ocorram falhas no sistema, o SGBD deve prover mecanismos para recuperação de informações de
forma a manter o estado que as mesmas possuíam quando da confirmação do término de uma transação.
De forma análoga, se uma transação é concluída com fracasso, o SGBD deve desfazer todas as operações de
atualização dos dados contidas na transação em questão, retornando o banco de dados para o estado em que
estava ao início da transação.
Iniciando uma Transação
O comando a seguir é uma simplificação do comando de início de uma transação no padrão SQL:2003:
START TRANSACTION [NIVEL_DE_ISOLAMENTO]
Concluindo uma Transação
Uma transação pode ser concluída com sucesso ou com fracasso. Para concluirmos uma transação com
sucesso, utilizamos o comando:
COMMIT [WORK]
Para terminar uma transação com fracasso, ou seja, para desfazer todas as ações ocorridas durante a
transação, retornando ao seu estado inicial, utilizamos o comando:
ROLLBACK [WORK]
Por exemplo: Considere a instância da tabela ASSUNTO representa na tabela 3.2. Considere que uma transação
foi iniciada e que os dois comandos a seguir foram executados:

237
INSERT INTO ASSUNTO (SIGLA, DESCRICAO)
VALUES (‘X’, ‘XML’)
UPDATE ASSUNTO SET DESCRICAO = ‘BIOINFORMATICA’ WHERE SIGLA = ‘B’
A nova instância da tabela é representada na tabela 9.1. No entanto, essa instância está sendo válida para a
transação em questão. Então, consideremos que os comando a seguir foi realizado.
ROLLBACK
Neste caso, todas as alterações foram desfeitas, ou seja, a tabela ASSUNTO voltou a ter o conteúdo da tabela
3.2.
Se, ao invés de desfazermos as alterações, quiséssemos mantê-las, tomando a instância representada pela
tabela 9.1 definitiva, bastaria realizar o comando COMMIT ao invés do comando ROLLBACK.
Inserindo figura da página 8.1
Marcando pontos de retorno
A SQL permitem que sejam definidos marcadores durante uma transação chamados de pontos de
salvamento (SAVEPOINT). A transação pode, então, ser desfeita até um ponto de salvamento, tornando sem
efeito os comandos que foram executados após o mesmo.
Os pontos de salvamento somente são validos dentro de transações que foram definidos. Não é possível
retornar um ponto de salvamento após a conclusão da transação, quer seja com sucesso ou com fracasso.
Um ponto de salvamento pode ser definido através do comando:
SAVEPOINT IDENTIFICADOR_DO_SAVEPOINT
Para retornar a um ponto de salvamento, devemos utilizar o comando ROLLBACK em conjunto com a cláusula
TO SAVEPOINT, conforme mostrado a seguir:
ROLLBACK [WORK] TO SAVEPOINT IDENTIFICADOR_DO_SAVEPOINT
• Consideremos a instância da tabela ASSUNTO representada na tabela 3.2. Considere que uma transação foi iniciada e que os três comandos a seguir foram executados.
INSERT INTO ASSUNTO (SIGLA, DESCRICAO)
VALUES (‘X’, ‘XML’)
SAVEPOINT PONTO1
UPDATE ASSUNTO SET DESCRICAO = ‘BIOINFORMATICA’
WHERE SIGLA = ‘B’
A nova instância da tabela está representada na tabela 9.1. Então, consideremos que o comando a seguir foi
realizado:
ROLLBACK TO SAVEPOINT PONTO1
Neste caso, o comando UPDATE foi desfeito. O conteúdo temporário da tabela ASSUNTO está representado
na tabela 9.2, mas a transação continua ativa. Neste caso, novos comandos podem ser realizados antes da
finalização da transação. Se, neste ponto, o comando COMMIT for executado, a tabela ASSUNTO será confirmada
com conteúdo idêntico ao da tabela 9.2. Se um comando ROLLBACK for executado, conteúdo da tabela ASSUNTO
voltará a ser da tabela 3.2.

238
Para destruir um ponto de salvamento, devemos utilizar o comando:
Concorrência e Níveis de isolamento
Cada transação realizada em um SGBD tem um nível de isolamento. São quatro os níveis de isolamento
definidos no padrão SQL: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, e SERIAZABLE. O nível de
isolamento mais alto, SERIAZABLE, faz com que as operações sejam executadas como se a transação em questão
fosse a única ocorrendo no sistema. Esse nível de isolamento diminui o nível de concorrência. Por outro lado, os
níveis de isolamento mais baixos, que aumentam os níveis de concorrência podem levar a aparentes problemas
de consistência das informações.
Consideremos um ambiente onde não existe isolamento entre as transações. As alterações realizadas por um
usuário são imediatamente vistas por todos. Neste caso, dentre os fenômenos possíveis de ocorrer, temos:
• Leitura Suja – leitura de dados não confirmados. Suponha que ocorram os seguintes passos: 1. Duas transações, T1 e T2 são iniciadas; 2. A transação T1 modifica a linha L1; 3. A transação T2 lê a linha L1 antes que T1 termine; 4. T1 termina com fracasso e suas operações são desfeitas;
Neste caso, T2 terá lido uma informação que nunca foi confirmada.
• Leitura Não-Repetida: duas leituras de dados da mesma transação não se repetem. Na segunda leitura, dados antigos não existem ou foram modificados. Suponha que ocorram os seguintes passos: 1. Duas transações T1 e T2 são iniciadas; 2. A transação T1 lê a linha L1; 3. A transação T2 modifica a linha L1, atualizando seus dados ou apagando a linha; 4. A transação T2 é concluída com sucesso e suas operações são confirmadas; 5. A transação T1 lê (ou tenta ler) a linha L1. T1 nunca modificou os dados da linha L2, mas não obteve a
mesma leitura duas vezes dentro da mesma transação.
• Leitura Fantasma: na leitura de um conjunto de dados, surgem novas informações no conjunto. Suponha que ocorram os seguintes passos: 1. Duas transações T1 e T2 são iniciadas; 2. A transação T1 lê um conjunto de linhas que atendem a uma condição C1; 3. A transação T2 executa uma operação de atualização que cria uma ou mais que atendem à condição
C1; 4. A transação T1 lê, novamente, um conjunto de linhas que atendem a uma condição C1. Embora T1
não tenha criado linhas que atendam à condição C1, novas linhas participarão do resultado da consulta;
• Perda de atualização: duas transações que ocorrem simultaneamente atualizam o mesmo dado no banco de dados. Isto pode ocorrer em uma sequencia segundo a qual uma das atualizações é perdida: 1. Duas transações, T1 e T2, são iniciadas; 2. A transação T1 lê o dado D1 e armazena seu valor na variável X; 3. A transação T2 lê o dado D1 e armazena seu valor na variável Y; 4. A transação T1 atualiza D1 com o valor de 6*X; 5. A transação T2 atualiza D1 com o valor de 0.5*Y;

239
6. A transação T1 termina com sucesso; 7. A transação T2 termina com sucesso.
Para a transação T1, ao seu final, o valor de D1 deveria ter sido multiplicado por seis. Já para T2, ao seu final,
o valor de D1 deveria ser a metade do seu valor original. Se as transações T1 e T2 fossem executadas em série,
independente da ordem, o valor final de D1 deveria ser a metade do valor original. Entretanto, na ordenação de
comandos demonstrada antes, o valor final de D1 é a metade do original, como se a atualização realizada por T1
nunca tivesse sido realizada.
Os quatros níveis de isolamento da SQL podem ser definidos de acordo com sua relação com os quatro
fenômenos listados. Essa relação é mostrada na tabela 9.3.
O nível de
isolamento a ser utilizado pode ser definido através de uma cláusula nos comandos de início de uma transação,
conforme foi apresentado. Pode, também, ser definido em um comando de alteração das propriedades da
transação, o comando:
SET TRANSACTION ISOLATION LEVEL NIVEL_DE_ISOLAMENTO
Por exemplo, alterar o nível de isolamento de uma transação para SERIAZABLE:
SET TRANSACTION ISOLATION LEVEL SERIAZABLE
Programas e Gatilhos Armazenados
A linguagem SQL é uma linguagem diferente das linguagens tradicionais, como C e Pascal. Ao contrário de
linguagens como estas, no SQL especificamos o resultado que queremos obter, sem nos preocuparmos com a
sequencia de passos a serem para obtenção do resultado. Por isso, a SQL é classificada como uma linguagem
declarativa.
Por outro lado, SGBD´s se tornaram pontos cruciais em ambientes coorporativos, sendo acessos por diversos
sistemas. A partir daí, surgiram, em algumas situações, duas necessidades: (i) mover a especificação e execução
de rotinas que verificam e implementam regras de negócio para o próprio SGBD, centralizando, assim, tais
operações e as disponibilizando para toda a empresa de uma só vez, e (ii) fornecer ao SGBD algum tipo de
comportamento ativo (ou reativo) a determinadas situações.
De forma a permitir a migração das regras de negócio para o gerenciador de banco de dados foram definidos,
na SQL, os conceitos de procedimento e função armazenados. Estes são pequenos programas compilados,
armazenados e executados diretamente no servidor de banco de dados. São invocados através de comandos SQL.
Já para adicionar ao SGBD comportamento reativo, foi introduzido, na linguagem SQL, o conceito de gatilho.
Este é um mecanismo que permite a execução automática de comandos ou, até mesmo, programas, a partir de
eventos que ocorrem na base de dados (como a atualização do conteúdo de uma célula, por exemplo).
Para permitir a definição de blocos de programas a serem armazenados no SGBD, a SQL foi estendida com
comandos típicos de linguagens não-declarativas, como comandos de iteração e de decisão, por exemplo. Estes
blocos compõem o corpo não só de procedimentos e funções armazenados nos servidores, mas, também, de

240
gatilhos. Os SGBD´s apresentam também, conjuntos próprios de comandos de controle. No Oracle, a linguagem
de programação, chama-se PL/SQL. Já no SQL Server, chama-se Transact SQL.
Bloco de Comandos
Para permitir a criação de programas com SQL, foi criado o conceito de blocos de comandos. Além disso,
foram incorporados à linguagem vários comandos de controle similares aos existentes em outras linguagens de
programação.
Blocos de comandos são pequenos programas compostos de um ou mais comandos SQL. Permitem a
especificação de variáveis e cursores próprios aos blocos. Sua estrutura é a seguinte:
BEGIN
DECLARAÇÃO DE VARIÁVEIS
DECLARAÇÃO DE CURSORES
LISTA DE COMANDOS SQL
END
Existe, ainda, no padrão SQL:2003, a possibilidade de declaração de handles, objetos que irão tratar exceções
ocorridas durante a execução de blocos de comandos.
Declaração de Variáveis: em um bloco de comandos, podemos declarar quantas variáveis locais forem
necessárias. Para isso, utilizamos a seguinte estrutura:
DECLARE NOME_VARIAVEL1, NOME_VARIAVEL2, ...,
NOME_VARIAVELN TIPO_DE_DADOS
Cursores OPEN, FETCH e CLOSE: cursores são mecanismos que permitem que as linhas de uma tabela sejam
manipuladas uma a uma. Atuam como ponteiros que apontam para as linhas que formam o resultado de uma
dada consulta. Podemos recuperar e manipular os valores de cada linha apontada por um cursor.
Desta forma, deve existir um comando SELECT associado a um cursor. Para declarar um cursor e seu
comando associado, utilizamos o comando DECLARE CURSOR, conforme mostrado a seguir:
DECLARE CURSOR
FOR COMANDO_SELECT
[FOR UPDATE]
Um cursor não deve ser, somente, declarado. Para manipularmos os dados, devemos, inicialmente, abrir um
cursor. Para isso, utilizaremos o comando OPEN seguido do nome do cursor, conforme a seguir:
OPEN NOME_CURSOR
Neste momento, o resultado do comando SQL que define o cursor estará pronto para ser manipulado. Então,
para posicionarmos o ponteiro, devemos utilizar o comando FETCH. Esse comando irá posicionar o ponteiro em
uma dada linha e atribuir as informações apontadas para um conjunto de variáveis. Então, após a atribuição,
poderemos manipular as variáveis que recebem o valor de um cursor como tratamos quaisquer outras. FETCH
terá a seguinte estrutura:
FETCH NOME_CURSOR
INTO VARIAVEL1, ..., VARIAVELN
O comando FETCH é, usualmente, utilizado em conjunto com um comando de iteração, como os comandos
REPEAT e WHILE, que serão apresentados ainda nesta seção.
Ao final de sua utilização, o cursor deve ser fechado. Para fechar o cursor, utilizamos o comando CLOSE
seguido do nome do cursor, conforme representado a seguir:

241
CLOSE NOME_CURSOR
Através do comando FOR, poderemos declarar, abrir, navegar, e fechar cursores em um único comando. O
comando FOR será apresentado mais adiante.
Atribuição de Valores: podemos utilizar variáveis em blocos de comandos. Para atribuirmos valores a variáveis,
utilizaremos o comando SET da seguinte forma:
SET NOME_VARIAVEL = VALOR;
Por exemplo: Bloco de comando contendo a declaração de uma variável X, de tipo caractere de comprimento
cinco, e atribuição do valor ‘OI’ a X.
BEGIN
DECLARE X CHAR(5);
SET X = ‘OI’;
END
Comando FOR: FOR é um comando bastante útil, pois permite que, através de um só comando, seja declarado
como cursor, que seu conteúdo seja percorrido e que tal cursor seja fechado. O cursor é fechado
automaticamente ao final do comando. FOR deve ser utilizado quando a navegação se faz de forma seqüencial e
através de todas as linhas do resultado da consulta de declaração do cursor. Sua estrutura é mostrado a seguir.
FOR
NOME_CURSOR [CURSOR FOR]
COMANDO_SELECT
DO LISTA DE COMANDOS SQL
END FOR
Ao início de FOR o cursor é declarado e aberto. O ponteiro é posicionado na primeira linha do resultado da
consulta. Então, os comandos SQL contidos na lista de comandos são executados. Ao chegar a END FOR, a
execução retorna para FOR que, desta vez, percebe que o cursor já está aberto e posiciona o ponteiro na próxima
linha do resultado da consulta. Novamente, o conjunto de comandos SQL é executado. O laço se repete até que
todas as linhas resultantes do comando SELECT tenham sido percorridas.
Comando SELECT INTO: atribui um valor a uma variável. O valor atribuído é recuperado a partir de uma consulta.
A consulta deve retornar somente uma linha. A seguir é apresentado um formato para o comando.
SELECT COL1, COL2, ..., COLN
INTO VAR1, VAR2, ..., VARN
FROM NOME_TABELA
Comando IF: para permitir decisões, foi incorporado à linguagem SQL o comando IF. Esta testa se uma condição
booleana é verdadeira e, em função do resultado dos testes, executa um determinado conjunto de comandos.
Sua estrutura é:
IF CONDICAO_BOOLEANA THEN
LISTA DE COMANDOS SQL
[ELSE IF CONDICAO_BOOLEANA THEN
LISTA DE COMANDOS SQL]
[ELSE LISTA DE COMANDOS SQL]
END IF

242
Comando WHILE: permite que a execução de um conjunto de comandos se repita enquanto determina se a
condição é verdadeira. Sua estrutura é:
WHILE CONDICAO_BOOLEANA DO
LISTA DE COMANDOS SQL
END WHILE
Comando REPEAT: permite que a execução de um conjunto de comandos se repita enquanto determinada
condição for falsa. Os comandos serão executados ao menos uma vez, independente do valor da condição.
REPEAT
LISTA DE COMANDOS SQL
UNTIL CONDICAO_BOOLEANA
END REPEAT
Comando LOOP: assim como WHILE e REPEAT, LOOP permite a repetição na execução de um conjunto de
comandos. Entretanto, no caso de LOOP, não existe uma condição a ser testada. Para que a repetição termine,
outro comando deve ser utilizado. Segundo a SQL, o comando LEAVE termina o laço. Na estrutura de LOOP, que é
apresentado a seguir, temos LOOP e END LOOP como delimitadores do comando e conjunto de comandos a
serem executados, representados por uma lista de comandos SQL. LEAVE deve ser posicionado na lista de
comandos SQL.
LOOP
LISTA DE COMANDOS SQL
END LOOP
Procedimentos armazenados e Funções
Os blocos e comandos apresentados anteriormente permitem a construção de rotinas que serão executadas
no servidor de banco de dados. Tais rotinas podem possuir código extenso e serem bastante complexas.
Armazenar tais rotinas no servidor e permitr que sejam invocadas a partir da própria linguagem SQL aumenta em
muito a utilidade de sua construção. Para permitir essa definição e armazenamento, estão definidas, na
linguagem SQL, os conceitos de procedimentos e funções armazenados no servidor.
Procedimentos armazenados
Procedimentos armazenados (stored procedures) são procedimentos análogos aos existentes em linguagens
de programação tradicionais, mas que terão seu código-fonte armazenado no servidor de banco de dados, o que
é capaz de compilá-lo e executá-lo.
Assim como em outras linguagens, os procedimentos poderão receber valores como parâmetros. Esses
parâmetros são definidos no cabeçalho de procedimentos. Eles têm um nome, um tipo de dados e um modo.
Existem três modos para os parâmetros na SQL:2003: (i) parâmetros que permitem apenas que os valores
externos das variáveis sejam passados dentro do procedimento (idêntico às passagens por valor de outras
linguagens); (ii) modo onde as variáveis internas ao procedimento referentes aos parâmetros não recebem
valores das variáveis externas correspondentes, mas alterações de valores ocorridas nos procedimentos são
efetivadas nas variáveis externas correspondentes; e (iii) os valores externos são passados para dentro do
procedimento e as modificações ocorridas internamente são efetivadas para as variáveis externas (modo
semelhante às passagens por referência de outras linguagens). Parâmetros do primeiro modo são identificados
pela palavra reservada IN. A palavra OUT identifica os parâmetros do segundo modo. Já os parâmetros que
pertencem ao terceiro modo são identificados pela palavra reservada INOUT. O primeiro passo para a utilização
de procedimentos armazenados é a sua criação no servidor. Para criar um procedimento armazenado, utilizamos
o comando CREATE PROCEDURE. Uma estrutura básica para este comando é apresentado a seguir.
CREATE PROCEDURE NOME_PROCEDURE(

243
MODO_PARAM1 NOME_PARAM1 TIPO_PARAM1,
MODO_PARAM2 NOME_PARAM2 TIPO_PARAM2,
...
MODO_PARAMN NOME_PARAMN TIPO_PARAMN
BLOCO_DE_COMANDOS_SQL
Consideremos, por exemplo, o procedimento PRECO_MEDIO apresentado a seguir. Ele possui dois
parâmetros. O primeiro, NÚMERO_LIVROS, é um parâmetro de entrada que recebe do ambiente externo o
número total de livros a ser considerado. O segundo parâmetro, PRECO_MEDIO, é um procedimento e este valor
estará visível para a variável externa correspondente ao parâmetro. Após a declaração da linguagem utilizada,
está sendo criado um bloco de comandos SQL. Neste bloco, é declarada uma variável (V_VALOR_TOTAL), é
utilizado um cursor (MEUCURSOR), manipulado através do comando FOR, e o valor médio dos preços dos livros é
calculado. Tal valor é atribuído à variável PRECO_MEDIO, segundo parâmetro do procedimento.
CREATE PROCEDURE PRECO_MEDIO
(IN NÚMERO_LIVROS INTEGER, OUT PRECO_MEDIO REAL)
LANGUAGE SQL
BEGIN
DECLARE V_VALOR_TOTAL REAL;
SET PRECO_MEDIO = 0;
SET V_VALOR_TOTAL = 0;
FOR MEU_CURSOR AS
SELECT PRECO FROM LIVRO
DO
SET V_VALOR_TOTAL = V_VALOR_TOTAL + PRECO;
END FOR;
SET PRECO_MEDIO = V_VALOR_TOTAL / NÚMERO_LIVROS
END
Após a criação do procedimento, este fica armazenado no servidor de banco de dados e está pronto para ser
utilizado, bastando acioná-lo a partir de um bloco de comandos. Para isso, devemos utilizar seu nome e variáveis
correspondentes aos parâmetros entre parênteses, quando for o caso. A seguir temos um exemplo de chamada
ao procedimento PRECO_MEDIO:
BEGIN
DECLARE V_NUMERO INTEGER;
DECLARE MÉDIA REAL;
...
PRECO_MEDIO(V_NUMERO, MÉDIA);
...
END
Para destruirmos um procedimento de nosso banco de dados, devemos utilizar o comando DROP
PROCEDURE seguido do nome do procedimento a ser destruído, conforme mostrado a seguir.
DROP PROCEDURE NOME_PROCEDIMENTO;
Como exemplo, vamos destruir o procedimento PRECO_MEDIO:
DROP PROCEDURE PRECO_MEDIO;
Funções Armazenadas

244
Além de procedimentos, o SQL permite que armazenemos funções no servidor de banco de dados. A função
pode receber e tratar diversos parâmetros de uma mesma maneira que o procedimento. A diferença entre um
procedimento e uma função reside no fato de que a função sempre retorna um valor. Assim, para criar uma
função, utilizamos o comando CREATE FUNCTION ao invés do comando CREATE PROCEDURE. Como a função
retorna um valor, no comando CREATE FUNCTION devemos especificar o tipo de dados retornado pela função. O
exemplo da estrutura de CREATE FUNCTION é similar a CREATE PROCEDURE. A única diferença, além do nome do
comando, reside na introdução da cláusula RETURNS, onde o TIPO_RETORNO representa o tipo de dados
retornado pela função.
CREATE FUNCTION NOME_FUNÇÃO (
MODO_PARAM1 NOME_PARAM1 TIPO_PARAM1,
MODO_PARAM2 NOME_PARAM2 TIPO_PARAM2,
...
MODO_PARAMN NOME_PARAMN TIPO_PARAMN
) RETURN TIPO_RETORNO [LANGUAGE NOME_LINGUAGEM]
BLOCO DE COMANDOS SQL
Dentro do bloco de comandos do corpo da função devemos ter um comando RETURN seguido do valor a ser
retornado pela mesma. Exemplo:
RETURN 3.65;
A chamada para execução de funções é um pouco diferente da chamada para execução de procedimentos.
Como funções retornam um valor, o nome da função aparece ao lado direito do comando de atribuição de
valores. Por exemplo:
BEGIN
DECLARE V_NUMERO INTEGER;
DECLARE MÉDIA REAL;
...
SET MÉDIA = FUNC_PRECO_MEDIO(V_NUMERO);
...
END
Funções armazenadas podem, ainda, ser utilizadas em comandos SQL da mesma forma que as funções da
própria linguagem, já apresentadas anteriormente.
Para destruirmos funções, utilizamos o comando DROP FUNCTION seguido do nome da função.
DROP FUNCTION FUNC_PRECO_MEDIO
Gatilhos
Gatilhos são especificações de ações a serem realizadas sempre que um dado evento ocorrer sobre um dado
objeto. Entre os eventos possíveis, temos a inclusão, atualização ou exclusão de informações de uma tabela.
Um gatilho executa um conjunto de comandos, definido num bloco de comandos similar aos apresentados
anteriormente. Este bloco pode ser executado uma vez para cada evento que disparou o gatilho ou uma vez para
cada linha afetada pelo evento em questão. No primeiro caso, dizemos que se trata de um evento ao nível de
comando e, no segundo, ao nível de linha.
Entretanto, podemos querer que o bloco de comandos seja acionado somente em algumas circunstâncias e
não todas as vezes que o evento disparador do gatilho ocorrer. A linguagem SQL nos permite realizar tal ação
através da inclusão de uma condição booleana na declaração do gatilho. Devido às suas características, os
gatilhos são conhecidos por atenderem à regra ECA – Evento, Condição e Ação.

245
Um gatilho pode ser executado antes ou após a execução do comando que o disparou. Entretanto, em ambos
os casos, podemos querer acessar os dados nos formatos que teriam antes ou após a execução de tal comando.
Ou seja, podemos, por exemplo, após a realização de uma atualização, querer testar se o novo valor de uma dada
coluna é diferente do valor anterior.
Para permitir o acesso à duas versões das informações de uma dada linha dentro de um gatilho, foram
definidas as tabelas de transição NEW e OLD. NEW contém a nova versão das informações e OLD, a versão antiga.
Note que os eventos podem ser operações de inclusão, atualização e exclusão. No caso de uma operação de
inclusão, OLD está vazia, pois a informação não existia antes do evento. Caso o evento seja um operação de
exclusão, NEW está vazia, pois a informação não mais existe após o comando. Quando o evento disparador é uma
operação de atualização, tanto NEW quanto OLD possuem dados. A seguir, apresentaremos a sintaxe básica para
a declaração de um gatilho:
CREATE TRIGGER NOME_GATILHO
MOMENTO_EXECUÇÃO
EVENTO_DISPARADOR
ON TABELA_EVENTO
[REFERENCING NEW AS NOVO_NOME_N OLD AS NOVO_NOME_O]
[NIVEL_GATILHO]
[CONDICAO_EXECUCAO]
BLOCO_DE_COMANDOS_SQL
Por exemplo: Suponha que desejamos armazenar, sempre que um livro sofra um aumento de preço superior a
20%, seu código, seu preço antigo e seu novo preço. Para isto, criamos uma tabela chamada AUDITORIA que tem
três colunas: uma para armazenar o código do livro que sofreu aumento (CODIGO_LIVRO), a segunda para
armazenar o preço do livro antes do aumento (VALOR_ANTIGO) e a última (VALOR_NOVO), para armazenar o
novo preço do livro.
Para que a rotina de armazenamento das mudanças de preço ocorra de forma automática, criamos um
gatilho, chamado TESTA_AUMENTO, que é disparado sempre que a coluna PREÇO, da tabela LIVRO, é atualizada.
Então, para cada linha afetada pelo comando de atualização, se o novo valor for superior a 20% do antigo valor, o
código do livro, o seu preço antigo e seu novo preço são inseridos na tabela auditoria. Nesse gatilho, utilizaremos
N1 como apelido para a tabela NEW e O1 para apelido para a tabela OLD.
O comando de criação do gatilho descrito encontra-se a seguir:
CREATE TRIGGER TESTA_AUMENTO
AFTER UPDATE OF PRECO ON LIVRO
REFERENCING NEW AS N1 OLD AS O1
FOR EACH ROW
WHEN (N1.PRECO > 1.2 * O1.PRECO)
BEGIN
INSERT INTO AUDITORIA (CODIGO_LIVRO, VALOR_ANTIGO, VALOR_NOVO) VALUES (:N1.CODIGO, :O1.PRECO,
:N1.PRECO)
END;
Note que, no exemplo, utilizamos o caractere ‘;’ para referenciar, a partir do bloco de comandos SQL, as
variáveis que representam a tabela de transição. Note, ainda, que, para acessarmos os valores das colunas,
podemos utilizar o formato NOME_TABELA_TRANSICAO.NOME_COLUNA.
Não podemos executar gatilhos através de chamadas diretas, como fazemos com procedimentos e funções
armazenadas. A única maneira de executá-los é através de seu evento disparador.
Para apagar um gatilho, utilizamos o comando DROP TRIGGER seguido do nome do gatilho. Exemplo:
DROP TRIGGER TESTA_AUMENTO;

246
Extensões ao Relacional
No final da década de 80, a programação orientada a objetos alcançou um grande número de adeptos. O
debate entre os que defendiam os SGBD´s orientados a objetos e entre os adeptos dos SGBD´s relacionais tomou
maior importância. A partir deste, surgiram SGBD´s que incorporaram características de orientação a objeto aos
modelos relacionais: os SGBD´s estendidos ou relacionais a objeto.
Vários SGBD´s Relacionais começaram a se tornar relacionais estendidos, até que a SQL incorporou
comandos para criação de tipos do usuário e manipulação de dados não-convencionais, entre outros.
Tipos de Dados do Usuário
A primeira características dos SGBD´s relacionais estendidos é a possibilidade do usuário poder criar seus
próprios tipos de dados.
Tipos de dados definidos pelo usuário podem conter um ou mais atributos, sendo que cada atributo possui,
por sua vez, um tipo de dados próprio, podendo este ser um tipo predefinido ou um tipo de dados do usuário.
Tipos de dados do usuário em conjunto com seus atributos formam estruturas análogas ao struct da linguagem C
ou ao RECORD da linguagem Pascal.
Podemos, também, atribuir métodos a tipos de dados do usuário. Métodos são rotinas (procedimentos ou
funções) que podem ser acionados para tratamento e manipulação de informações.
Outro importante conceito proveniente de orientação a objetos é o de herança. Na orientação a objetos,
uma classe, chamada de subclasse, pode herdar atributos e métodos de outra classe, sua superclasse. Na
SQL:2003, um tipo de dados do usuário pode ser classificado como NOT FINAL poderão ter herdeiros (ou
descendentes), ou seja, seus atributos e métodos poderão ser herdados por outros tipos de dados.
CREATE TYPE NOME_TIPO [UNDER NOME_SUPER_TIPO] AS (
ATRIBUTO1 TIPO_ATRIBUTO1,
ATRIBUTO2 TIPO_ATRIBUTO2,
...
ATRIBUTON TIPO_ATRIBUTON
)
[TIPO_FINAL]
[METHOD NOME_MÉTODO1 (PARAMETROS_METODO1),
METHOD NOME_METODO2 (PARAMETROS_METODO2),
...
METHOD NOME_METODON(PARAMETROS_METODON)]
Consideremos que nossa base de dados armazena a informação de endereços em diversas tabelas. Para
tornar a definição de um endereço mais completa, gostaríamos de dividi-lo em vários campos: logradouro,
número, complemento, CEP, bairro, cidade e estado.
Como temos várias tabelas com colunas que armazenam endereços, decidimos, por exemplo, criar um tipo
de dados chamado TYP_ENDERECO, que contém os campos citados anteriormente com seus atributos. A criação
do tipo de dados TYP_ENDERECO é apresentado a seguir:
CREATE TYP_ENDERECO (
LOGRADOURO VARCHAR(100),
NÚMERO INTEGER,
COMPLEMENTO VARCHAR(15),
CEP CHAR(8),
BAIRRO VARCHAR(30),
CIDADE VARCHAR(40),
ESTADO VARCHAR(2) )

247
FINAL
No exemplo anterior, o tipo de dados TYP_ENDERECO foi definido como FINAL. Isso significa que ele não
pode ter suas propriedades herdadas por outros tipos de dados. TYP_ENDERECO não apresenta nenhum método.
Consideremos, agora, como exemplo, que desejamos tornar a definição de nomes mais bem estruturada,
criando dois atributos para um nome e sobrenome. Chamemos nosso tipo de dados de TYP_NOME. Além disso,
muitas vezes, desejamos obter o nome completo de uma pessoa. Para tal, criamos um método que seja capaz de
concatenar nome e sobrenome. Os atributos e métodos desse tipo de dados podem ser herdados por outros
tipos. A definição do tipo de dados, contendo atributos e métodos, é apresentado a seguir:
CREATE TYPE TIP_NOME(
PRIMEIRO_NOME VARCHAR(30),
SOBRENOME VARCHAR(30)
) NOT FINAL
METHOD NOME_COMPLETO RETURNS VARCHAR
Utilizando tipo de dados do usuário
Os tipos de dados definidos pelo usuário podem ser utilizados na definição de colunas. Assim, podemos criar
uma tabela CLIENTE que possui, dentre as suas colunas, a coluna NOME, de tipo de dados TYP_NOME, e a coluna
ENDERECO que tem, como tipo de dados, tipo TYP_ENDERECO. O comando de criação da tabela CLIENTE é
apresentado a seguir:
CREATE TABLE CLIENTES(
CODIGO INTEGER PRIMARY KEY,
NOME TYP_NOME NOT NULL,
ENDERECO TYP_ENDERECO NOT NULL
CPF CHAR(11) CONSTRAINT UK_CPF UNIQUE,
DATA_NASCIMENTO DATE,
TELEFONE VARCHAR(12) )
Para utilizarmos colunas cujos tipos são definidos pelo usuários em comandos de seleção, inclusão,
atualização e exclusão, devemos utilizar o construtor do tipo, que podemos o nome do próprio tipo de dados.
Alterando o tipo de dados do usuário
Em varias situações pode ser necessários alterar um tipo de dados definido pelo usuário. Podemos, por
exemplo, querer: (i) adicionar atributos, (ii) remover atributos, (iii) adicionar novos métodos e (iv) remover
métodos existentes. Para atender a essas necessidades, foi definido o comando ALTER TYPE.
Podemos utilizar ALTER TYPE em diferentes construções. A estrutura a seguir deve ser utilizada para
adicionarmos um atributo a um tipo.
ALTER TYPE NOME_TIPO
ADD ATTRIBUTE NOME_ATRIBUTO TIPO_ATRIBUTO
Exemplo:
ALTER TYPE TYP_ENDERECO
ADD ATTRIBUTE PAIS VARCHAR(35)
Já para remover um atributo, utilizamos o comando ALTER TYPE com o formato abaixo.
ALTER TYPE NOME_TIPO
DROP ATTRIBUTE NOME_ATRIBUTO [RESTRICT]

248
RESTRICT reforça a idéia de que nenhum atributo pode ser apagado se o tipo de dados estiver sendo utilizado na
definição de qualquer objeto de b d.
Exemplo:
ALTER TYPE TYP_ENDERECO
DROP ATTRIBUTE PAIS
Para adicionar novos métodos, utilizamos o commando com o formato abaixo:
ALTER TYPE NOM_TIPO
ADD METHOD NOME_METODO [PARAMETROS_METODO]
RETURNS TIPO_RETORNO
Após a inclusão do método, seu corpo deve ser especificado. Tal especificação ocorre de forma análoga à
apresentada anteriormente.
Já para removermos um método do tipo definido pelo usuário, utilizamos o comando ALTER TYPE conforme
mostrado a seguir.
ALTER TYPE NOME_TIPO DROP METHOD NOME_METODO
Removendo tipos de dados do usuário
Tipos de dados do usuário podem ser excluídos. Para isso, utilizamos o comando DROP TYPE seguido do
nome do tipo de dados em questão. A seguir, teremos o exemplo de exclusão dos tipos TYP_CLIENTE e
TYP_ENDERECO.
DROP TYPE TYP_CLIENTE
DROP TYPE TYP_ENDERECO
Para que possamos excluir um tipo de dados, ele não deve estar sendo utilizado por nenhuma tabela e nem
por outro tipo de dados.
Armazenando e referenciando objetos
Os objetos (de dados) criados a partir dos tipos definidos pelo usuário possuem um identificador único,
chamado OID (object identifier). Podemos referenciar os objetos, através de seu OID, utilizando o tipo REF.
REF é um ponteiro para objetos de um determinado tipo de dados do usuário. Permite implementar vínculos
entre relações onde em um dos lados existe um objeto. Desta forma, podemos criar colunas ou atributos que
sejam do tipo REF e que armazenam um ponteiro para um objeto de um dado tipo. Ao valor da coluna, podemos
atribuir o valor NULL ou uma referência ao objeto. Podemos utilizar o valor contido em REF para recuperar o
objeto que é apontado e para atualizar seu valor.
Para criarmos um atributo ou coluna que armazene uma referência, devemos utilizar a construção:
NOME_COLUNA REF NOME_TIPO_DE_DADOS_USUARIO
Exemplo: Considere que tenhamos montado um banco de dados para armazenar as equipes que participam de
um torneio. De cada jogador, queremos armazenar o nome e a equipe a que pertence. De cada equipe,
desejamos armazenar o nome e o nome de seu capitão. Para isso, iremos criar dois tipos de dados.
Iniciamos criando o tipo que representa as informações de equipes que, por enquanto, contém apenas o
atributo nome.
CREATE TYPE TYP_EQUIPE AS (
NOME VARCHAR(30)
)
Então, criamos o tipo de dados para representar as informações de cada jogador. Este tipo contém dois
atributos: o nome, e uma referência para um objeto do tipo referenciado.

249
CREATE TYPE TIP_JOGADOR AS (
NOME VARCHAR(50),
EQUIPE REF(TYP_EQUIPE))
Por fim, alteramos TYP_EQUIPE para conter uma referência para um objeto que contém as informações do
capitão da equipe:
ALTER TYPE TYP_EQUIPE ADD ATTRIBUTE CAPITAO REF(TYP_JOGADOR)
A SQL:2003 nos permite criar tabela que sejam repositórios de objetos. Nestas tabelas, somente temos um
objeto. Uma sintaxe simplificada para sua criação é:
CREATE TABLE NOME_TABELA OF NOME_TIPO_DADOS (
REF IS NOME_COLUNA,
NOME_COLUNA_TIPO_REF WITH OPTIONS
SCOPE NOME_TABELA_REFERENCIADA,
NOME_COLUNA_TIPO_REF2 WITH OPTIONS
SCOPE NOME_TABELA_REFERENCIADA2,
NOME_COLUNA_TIPO_REFN WITH OPTIONS
SCOPE NOME_TABELA_REFERENCIADAN
)
Consideremos o tipo de dados TYP_EQUIPE e TYP_JOGADORES, mencionados anteriormente. Vamos, agora,
criar as tabelas EQUIPES e JOGADORES de forma a armazenar objeto dos dois tipos, respectivamente.
Inicialmente, criamos a tabela EQUIPES, definindo OID como nome da coluna de referência.
Comando:
CREATE TABLE EQUIPES OF TYP_EQUIPE (REF IS OID)
Então, criamos a tabela JOGADORES, definindo, também, uma coluna de nome OID como coluna de
referência. Na criação, definimos, ainda, que o atributo EQUIPE aponta para objetos contidos na tabela EQUIPES.
Comando:
CREATE TABLE JOGADORES OF TYP_JOGADOR (REF IS OID,
EQUIPE WITH OPTIONS SCOPE EQUIPES)
Agora, utilizamos o comando ALTER TABLE para modificar a tabela EQUIPES de forma a fazer com que a
coluna CAPITAO referencie objetos contidos na tabela JOGADORES. O comando a ser utilizado, apresentado a
seguir, permite alterar a definição de uma coluna, adicionando um escopo para sua referência.
ALTER TABLE EQUIPES ALTER CAPITAO ADD SCOPE JOGADORES
Vamos, agora, como exemplo, incluir equipes e jogadores nas tabelas. Começamos incluindo três equipes
chamadas ‘Equipe Azul’, ‘Equipe Verde’ e ‘Equipe Laranja’. Os comandos de inclusão são apresentados a seguir.
INSERT INTO EQUIPES (OID, NOME)
VALUES (TYP_EQUIPE(‘1’), ‘EQUIPE AZUL’)
INSERT INTO EQUIPES (OID, NOME)
VALUES (TYP_EQUIPE(‘2’), ‘EQUIPE VERDE’)
INSERT INTO EQUIPES (OID, NOME)
VALUES (TYP_EQUIPE(‘3’), ‘EQUIPE LARANJA’)
Note, nos comandos anteriores, que não incluímos valores para o atributo CAPITAO. Além disso, utilizamos o
nome do tipo de dados como construtor para a obtenção de um OID a partir dos valores ‘1’, ‘2’ e ‘3’.

250
Podemos, também, incluir dados na tabela de jogadores. Vamos incluir três jogadores para a Equipe Azul:
João, André, e Pedro. Para isso, executamos os comandos a seguir:
INSERT INTO JOGADORES (OID, NOME, EQUIPE)
VALUES (
TYP_JOGADOR(‘1’), ‘JOAO’, (SELECT OID FROM EQUIPES WHERE NOME= ‘EQUIPE AZUL’))
INSERT INTO JOGADORES (OID, NOME, EQUIPE) VALUES (
TYP_JOGADOR(‘2’), ‘ANDRÉ’, (SELECT OID FROM EQUIPES WHERE NOME= ‘EQUIPE AZUL’))
INSERT INTO JOGADORES (OID, NOME, EQUIPE) VALUES (
TYP_JOGADOR(‘3’), ‘PEDRO’, (SELECT OID FROM EQUIPES WHERE NOME= ‘EQUIPE AZUL’))
Nos comandos anteriores, utilizamos uma subconsulta para recuperar o objeto referente à equipe dos
jogadores e inseri-lo na tabela JOGADORES. Vamos, agora, marcar o jogador André como capitão da equipe Azul.
UPDATE EQUIPE
SET CAPITAO = ( SELECT OID FROM JOGADORES WHERE NOME = ‘ANDRÉ’)
WHERE NOME = ‘EQUIPE AZUL’
Podemos, também, realizar consultas sobre os dados contidos em JOGADORES e em EQUIPES. Vejamos
exemplos:
• Desejamos selecionar o nome do capitão da ‘Equipe Azul’. SELECT CAPITAO -> NOME
FROM EQUIPES
WHERE NOME = ‘EQUIPE AZUL’
• Desejamos selecionar o nome da equipe do jogador ‘JOAO’. SELECT EQUIPE -> NOME
FROM JOGADORES
WHERE NOME = ‘JOAO’
• Desejamos selecionar o nome do capitão da equipe do jogador ‘JOAO’. SELECT EQUIPE -> CAPITAO -> NOME
FROM JOGADORES
WHERE NOME = ‘JOAO’
Nestes comandos utilizamos ‘->’ para acessar os campos dos objetos referenciados pelas colunas de tipo REF.
No terceiro exemplo, a partir do objeto referente ao jogador ‘JOAO’ acessamos o objeto referente à ‘Equipe Azul’,
na tablea de equipes, e, então, acessamos o objeto referente ao jogdor capitão da equipe, ‘André’, para obter o
seu nome.
A SQL:2003 define, também, dois tipos de coleções de objetos: arrays e multisets. Arrays são coleções onde
cada elemento participante possui uma posição fixa e pode ser acessado por sua posição na coleção. Multisets
são coleções onde não existe ordenação dos elementos. Assim, Multisets são coleções onde não existe ordenação
dos elementos. Assim, não há um índice através do qual acessemos um dado elemento.
Extensão para OLAP
A SQL:2003 apresenta diferentes estruturas para atender a necessidades de aplicações OLAP. Dentre elas,
temos os elementos de agrupamento ROLLUP, CUBE e GROUPING SETS, que são apresentados a seguir.
Anteriormente foi apresentada a cláusula GROUP BY. Ela faz com que dados sejam agrupados através de uma
ou mais colunas e permite que se apliquem funções sobre as linhas que participam de cada grupo. ROLLUP, CUBE,

251
e GROUPING SETS são empregados em conjunto com GROUP BY, provendo diferentes comportamentos a essa
cláusula.
ROLLUP
Quando utilizamos ROLLUP, o resultado obtido contém linhas representando a realização do agrupamento
em vários níveis. Sua sintaxe de utilização é a seguinte:
SELECT COL1, COL2, ..., COLN, FUNCAO1, ..., FUNCAON
FROM NOME_TABELA
GROUP BY ROLLUP (COL1, ..., COLN)
Como exemplo, considere uma base de dados de vendas. Assuma que existe uma tabela onde são
armazenadas informações das vendas realizadas por uma empresa nos diversos estados do país. São
armazenados os produtos vendidos, a data das vendas e as quantidades vendidas em cada operação. Um
exemplo desta tabela é apresentado na Tabela 11.1.
Considere, como exemplo, que desejamos saber a quantidade total vendida em cada combinação de
<produto, mês, estado> existente na tabela. Desejamos que a listagem esteja ordenada por estado, mês de
venda, e nome do produto. Para isso, devemos utilizar a consulta a seguir.
SELECT ESTADO, MONTH(DATA) AS MÊS, PRODUTO, SUM(QUANTIDADE) AS TOTAL
FROM VENDA
GROUP BY ESTADO, MONTH(DATA), PRODUTO
ORDER BY ESTADO, MONTH(DATA), PRODUTO
Considere que, agora, desejamos montar uma listagem que apresente os totais de vendas, não só para as
diversas combinações de <produto, mês, estado>, mas, também, para cada par <mês, estado> e para cada estado
isoladamente. Vamos, então, utilizar o operador ROLLUP:
SELECT ESTADO, MONTH(DATA) AS MÊS, PRODUTO,
SUM(QUANTIDADE) AS TOTAL
FROM VENDA
GROUP BY ROLLUP (ESTADO, MONTH(DATA), PRODUTO)
ORDER BY ESTADO, MONTH(DATA), PRODUTO
Note a diferença entre os resultados da utilização da cláusula GROUP BY com e sem o operador ROLLUP.
Quando utilizamos o operador ROLLUP, além das linhas obtidas com a realização do agrupamento, são obtidas
novas linhas que contêm os subtotais para cada nível de agrupamento. Uma linha contendo o total geral também
participa do resultado.
Grouping Sets
Já a utilização do operador GROUPING SETS faz com que o agrupamento seja realizado, isoladamente, por
cada uma das expressões contidas na cláusula GROUP BY. Ou seja, o resultado de uma consulta com a utilização
de GROUPING SETS em um cláusula GROUP BY com n expressões é idêntico à união dos resultados de n
comandos com a cláusula GROUP BY utilizada isoladamente e, em cada um dos n comandos, somente uma das
colunas n originais está presente em GROUP BY.
GROUPING SETS é utilizado de forma idêntica a ROLLUP, bastando substituir no comando de consulta, ROLLUP
por GROUPING SETS. Vejamos, como exemplo, a utilização de GROUP SETS na nossa tabela de vendas.
SELECT ESTADO, MONTH(DATA) AO MÊS, PRODUTO, SUM(QUANTIDADE) AS TOTAL
FROM VENDA
GROUP BY GROUPING SETS (ESTADO, MONTH(DATA), PRODUTO)

252
ORDER BY ESTADO, MONTH(DATA), PRODUTO
Note, no exemplo, anterior, que o resultado final é idêntico ao que seria obtido se realizássemos a consulta
três vezes, onde, em cada uma, somente o comando GROUP BY e uma das três expressões de agrupamento
(ESTADO, MONTH(DATA), PRODUTO) fossem utilizados.
CUBE
Este operador realizar agrupamentos por cada combinação possível das expressões contidas na cláusula
GROUP BY. Ele apresenta, também, uma linha com informação condensada de toda a tabela. É utilizado de forma
idêntica a ROLLUP e a GROUP SETS. Vejamos um exemplo de consulta utilizando a tabela VENDA:
SELECT ESTADO, MONTH(DATA) AS MÊS, PRODUTO, SUM(QUANTIDADE) AS TOTAL
FROM VENDA
GROUP BY CUBE(ESTADO, MONTH(DATA), PRODUTO)
ORDER BY ESTADO, MONTH(DATA), PRODUTO
Notamos que estão presentes no resultado aqueles que seriam obtidos se realizássemos várias consultas
com a cláusula GROUP BY e diversas combinações entre as colunas ESTADO e PRODUTO e a expressão
MONTH(DATA).
Nos exemplos anteriores, utilizamos a função SUM. Comportamento análogo pode ser obtido se utilizarmos
outras funções agregadas, como SUM. No caso da utilização de AVG em conjunto com ROLLUP, por exemplo,
obtemos a média por produto, mês e estado, a média de vendas por mês e estado, a média por estado e, enfim, a
média final de vendas.
Privilégios e Papéis
Controle de privilégios é um importante mecanismo existente em SGBD´s. através dele é possível garantir
que os usuários realizem apenas as operações que lhe são permitidas.
Todo acesso a um SGBD é realizado em conjunto com a identificação de um usuário ou tipo de usuário, seja
de forma implícita ou explícita. A cada usuário podem estar associados diversos privilégios. De acordo com os
privilégios que possui, o usuário pode, por exemplo, se conectar ao banco de dados, criar outros usuários e ler,
alterar, incluir ou apagar dados de uma ou mais tabela.
É possível ainda, por exemplo, configurar o sistema de forma que um determinado usuário conectado ao
SGBD não saiba da existência de uma ou mais tabelas. Para isso, basta não atribuir a tal usuário os privilégios
mínimos para que tome conhecimento da existência das tabelas em questão.
De forma a facilitar o gerenciamento e a atribuição de privilégios a usuários, o padrão SQL define a
possibilidade de criação de papéis (roles), os quais podem ser tratados como conjuntos de privilégios que podem
ser atribuídos a usuários.
Usuários
O padrão SQL define o conceito de identificadores de usuários como a representação no SGBD de usuários do
mundo real. Desta forma, identificadores de usuários representam usuários do SGBD.
De acordo com o que foi definido no padrão SQL, toda sessão SQL possui um identificador de usuário a ela
associado. De acordo com os privilégios, que o identificador de usuário da sessão possuir, são definidos os
comandos que podem ou não ser executados na referida sessão.
É comum que usuários do banco de dados representem aplicações e não usuários reais. Do ponto de vista do
SGBD, no que se refere ao controle de acesso e segurança, esses tipos de usuários não são diferentes entre si,
devendo ser tratados de maneira similar, havendo também a necessidade de atribuição e revogação de
privilégios.

253
Privilégios
O padrão SQL define um privilegio como sendo uma autorização para que uma dada ação seja executada.
Estas ações geralmente incidem sobre um objeto de banco de dados, como tabelas, visões, gatilhos ou colunas,
por exemplo.
Dentre as possíveis ações indicadas no padrão SQL, temos:
• INSERT [LISTA_DE_COLUNAS] – LISTA DE COLUNAS é opcional. Permite incluir somente valores para as colunas especificadas na LISTA_DE_COLUNAS, caso esta lista tenha sido especificada, ou para todas as colunas de uma tabela/visão, caso a lista não tenha sido especificada.
• UPDATE [LISTA_DE_COLUNAS] – LISTA_DE_COLUNAS é opcional. Permite atualizar as colunas de uma tabela/visão especificadas na LISTA_DE_COLUNAS, caso essa lista tenha sido especificada, ou em todas as colunas, caso essa lista não tenha sido especificada.
• DELETE – Apagar dados em uma tabela.
• SELECT [LISTA_DE_COLUNAS] – LISTA_DE_COLUNAS é opcional. Permite selecionar valores de uma tabela/visão, somente para as colunas especificadas na LISTA_DE_COLUNAS, caso esta lista tenha sido especificada, ou para todas as colunas, caso essa lista não tenha sido especificada.
• REFERENCES [LISTA_DE_COLUNAS] – LISTA_DE_COLUNAS é opcional. Permite referenciar uma tabela na criação de chaves estrangeiras. Somente as colunas especificadas na LISTA_DE_COLUNAS poderão ser referenciadas, caso essa lista tenha sido especificada, ou qualquer coluna, caso a lista não tenha sido especificada.
De forma a melhorar os mecanismos de controle de acesso e segurança, os Gerenciadores de Banco de dados
apresentam diversos privilégios além dos especificados no padrão. Cada SGBD possui seu próprio modelo de
privilégios. Nesses modelos, os privilégios são classificados, geralmente, ao menos como privilégios de objeto e
privilégios de sistema.
De toda a forma, são comuns em SGBD´s privilégios específicos para:
• Conectar-se a uma instância do SGBD ou a uma de suas bases de dados;
• Criar e destruir objetos do banco de dados, como tabelas, índices, visões, gatilhos, e procedimentos armazenados, dentre outros.
• Consultar, atualizar, incluir e excluir dados em tabelas (e em visões, para gerenciadores que suportam a realização dessas operações nas mesmas).
• Executar procedimentos e funções armazenados.
• Alterar as características do sistema e de suas bases de dados, tais como parâmetros de inicialização.
• Realizar operações de geração de cópias de segurança (backup) e recuperação de tais cópias (restore).
Em geral, o usuário analista de sistema ou programador não necessitará possuir todos esses privilégios. A
maioria de tais privilégios se relaciona com ações que são realizadas especificamente pelo administrador do
banco de dados.
Usualmente, é o administrador do banco de dados que concede os privilégios necessários para que outros
usuários realizem suas ações.
Atribuindo privilégios a um usuário
Para atribuirmos um privilégio a um usuário (ou seja, para permitimos que um usuário realize uma
determinada ação), devemos utilizar o comando GRANT, cuja sintaxe é exibida a seguir:
GRANT PRIVILEGIOS
TO NOME_PRIVILEGIADO
[WITH HIERARCHY OPTION][WITH GRANT OPTION]
[GRANTED BY NOME_CONCEDENTE]
É importante notar que, para poder atribuir um privilégio a um dado usuário, o usuário concedente deve
possuir privilégios para tal.
Como exemplo, consideremos que deve ser permitido ao usuário MARIA realizar qualquer operação dentro
da tabela EDITORA. Para atribuir ao referido usuário tais privilégios, pode ser usada a cláusula ALL PRIVILEGES.

254
GRANT ALL PRIVILEGES ON EDITORA TO MARIA
Considere-se, ainda, que este usuário deveria poder, também, selecionar e atualizar dados da tabela LIVRO,
mas que não lhe deve ser permitido incluir ou apagar dados desta tabela. O usuário MARIA poderá, ainda,
conceder privilégios que possui na tabela LIVRO a outros usuários. Para permitir que o usuário MARIA realize tais
ações, executa-se o comando a seguir:
GRANT SELECT, UPDATE ON LIVRO TO MARIA WITH GRANT OPTION
Já no que se refere à tabela ASSUNTO, o usuário MARIA somente pode alterar apenas a coluna DESCRIÇÃO.
Para atribuir à Maria privilégios necessários para realizar essa operação, deve ser executado o seguinte comando:
GRANT UPDATE(DESCRIÇÃO) ON ASSUNTO TO MARIA
Conforme mencionado anteriormente, para que os comandos GRANT apresentados nos exemplos possam
ser executados com sucesso, devem ser executados por um usuário que possua os privilégios adequados.
Usualmente, esse usuário representa o administrador do banco de dados, o qual possui privilégios de sistema
que lhe permitem realizar todas, ou quase todas as operações do banco de dados. No entanto, podem, também,
ser executados por um usuário que tenha recebido tais privilégios com a opção WITH GRANT OPTION, que lhe
permite atribuir privilégios recebidos a outros usuários.
Privilégios referentes à manipulação de dados em objetos podem, ainda, ser executados pelo usuário ‘dono’
do objeto em questão. Usualmente, o ‘dono’ de um objeto de banco de dados é o usuário que o criou.
Removendo privilégios de um usuário
Após o usuário ter recebido o privilegio para executar uma ação, ele irá manter esse privilégio até que o
mesmo seja explicitamente revogado. Para revogar um ou mais privilégios de um usuário, deve-se utilizar o
comando REVOKE. Sua estrutura simplificada é mostrada a seguir:
REVOKE [GRANT OPTION FOR] PRIVILÉGIOS FROM NOME_PRIVILEGIADO
Como exemplo, consideremos que o usuário MARIA não deve mais possuir a habilidade de alterar dados da
tabela EDITORA. Para tal, pode-se executar comando como o apresentado a seguir.
REVOKE UPDATE ON EDITORA FROM MARIA
Consideremos, agora, que não deve mais ser permitido ao usuário MARIA atribuir a todos os outros usuários
o privilégio de atualização da tabela LIVRO. Para tal, pode-se executar o comando apresentado a seguir, que
revoga essa habilidade do usuário em questão, mas também a possibilidade que o referido usuário possa
atualizar dados na tabela LIVRO.
REVOKE GRANT OPTION FOR UPDATE ON LIVRO FROM MARIA
Podemos ainda considerar a situação onde não mais deve ser permitido ao usuário realizar quaisquer ações
na tabela ASSUNTO. Para tal, pode-se executar o comando a seguir, que retira do usuário os privilégios para
executar ações na tabela ASSUNTO.
REVOKE ALL PRIVILEGES ON ASSUNTO FROM MARIA
Papéis
Em um ambiente de banco de dados de produção podem existir diversos usuários e algumas centenas ou até
mesmo milhares de tabelas, entre outros objetos. Muitos dos usuários podem utilizar o mesmo conjunto de
objetos, devendo ter privilégios para executar conjuntos similares de ações.
Atribuir privilégios referentes a cada um dos objetos para cada usuário de forma individual pode ser uma
tarefa bastante trabalhosa. Além disso, a medida que aumenta o número de tabelas ou outros objetos sobre as
quais cada usuário deve ter privilégios, aumenta também a probabilidade de que, por erro ou por esquecimento

255
pode ficar desapercebido num primeiro momento. No entanto, poderá causar problemas mais graves, por
exemplo, quando a aplicação que utilize o usuário em questão para acessar o banco de dados esteja em
produção.
Para facilitar as tarefas de administração do banco de dados relacionadas com a atribuição e revogação de
privilégios, e reduzir o número de erros nessas operações, foi definido o conceito de Papel (Role).
Um Papel visa representar todas as ações que um ou mais usuários podem realizar no banco de dados.
Assim, após criar um papel, é necessário atribuir-lhe todas as ações que representa. Em seguida, esse papel pode
ser atribuído a um ou mais usuários. Todos os usuários a quem o papel for atribuído receberão todos os
privilégios que foram atribuídos ao papel em questão. A qualquer momento é possível atribuir ou revogar
privilégios de um papel, e atribuir ou revogar o papel de um ou mais usuários.
Desta forma, ao ser criado um novo usuário B que deva possuir os mesmos privilégios para execução de
ações que outro usuário A já existente, podemos atribuir ao usuário B os mesmos papéis que tiverem sido
atribuídos ao usuário A.
Criando e utilizando Papéis
Para criamos um papel, utilizamos o comando CREATE ROLE. Sua sintaxe simplificada é a seguinte:
CREATE ROLE NOME-ROLE
Consideremos a base de dados de livros que será utilizada por vários usuários que podem ser agrupados
segundo dois diferentes perfis: um denominado BIBLIOTECA e outro denominado VISITANTE. Para criar esses
papéis, utilizamos o comando a seguir:
CREATE ROLE BIBLIOTECA
CREATE ROLE VISITANTE
Os papéis somente serão úteis se a eles forem associados os privilégios aos quais correspondem. Para
aqueles que possuírem o papel BIBLIOTECA, deverá ser permitido realizar quaisquer operações sobre os dados
das tabelas ASSUNTO, EDITORA, AUTOR, LIVRO e AUTOR_LIVRO. É necessário, então, que tais privilégios sejam
atribuídos ao papel BIBLIOTECA. Isto pode ser feito pelo comando GRANT, de forma similar ao que foi realizado
para a atribuição de privilégios para um usuário. Nesse caso, deve-se usar o nome do papel na posição de NOME-
PRIVILEGIADO.
Os cinco comandos a seguir apresentam a atribuição dos privilégios para o papel BIBLIOTECA.
GRANT ALL PRIVILEGES ON ASSUNTO TO BIBLIOTECA
GRANT ALL PRIVILEGES ON EDITORA TO BIBLIOTECA
GRANT ALL PRIVILEGES ON AUTOR TO BIBLIOTECA
GRANT ALL PRIVILEGES ON LIVRO TO BIBLIOTECA
GRANT ALL PRIVILEGES ON AUTOR_LIVRO TO BIBLIOTECA
Além de atribuir os privilégios ao papel, faz-se necessário atribuir o papel a cada usuário que deva ter o perfil
em questão.
Caso deva ser permitido aos usuários MARIA, JOÃO e ANA o acesso completo aos dados das tabelas
ASSUNTO, EDITORA, AUTOR, LIVRO e AUTOR_LIVRO, podemos atribuir o papel BIBLIOTECA a tais usuários. Para
isso, utilizamos o comando GRANT de forma similar ao apresentado anteriormente. Porém, neste caso,
PRIVILÉGIOS será substituído pelo nome do papel. O NOME_PRIVILEGIADO irá se referir ao usuário que deverá
possuir os mesmos privilégios que foram atribuídos ao papel. O comando a seguir exemplifica a atribuição do
papel BIBLIOTECA aos usuários MARIA, JOÃO e ANA.
GRANT BIBLIOTECA TO MARIA, JOAO, ANA

256
Após a execução do comando anterior, os usuários MARIA, JOÃO e ANA poderão executar todas as ações
definidas nos privilégios atribuídos ao papel BIBLIOTECA.
Se considerarmos que, após uma reavaliação dos critérios de segurança do banco de dados, seja definido, por
exemplo, que o papel BIBLIOTECA não deve ter acesso aos dados da tabela EDITORA, podemos revogar os
privilégios que possui com a utilização do comando REVOKE.
A utilização do comando REVOKE, nesse caso, será similar à apresentada anteriormente, sendo necessário
que se utilize, como NOME_PRIVILEGIADO, o nome do papel em questão. O exemplo a seguir retira os privilégios
sobre a tabela EDITORA do papel BIBLIOTECA.
REVOKE ALL PRIVILEGES ON EDITORA FROM BIBLIOTECA
Ao executarmos o comando anterior, alguns privilégios para executar ações que são revogados do papel
BIBLIOTECA e, consequentemente, de todos os usuários que possuem o referido papel. Ou seja, segundo nosso
exemplo, os privilégios para executar ações sobre a tabela EDITORA foram removidos dos usuários MARIA, ANA e
JOÃO. De fato, se for necessário atribuir um novo privilégio ou revogar um privilégio do papel que os usuários
possuem.
É possível, também, revogar de um usuário a sua participação em um papel. Para isso, também é utilizado o
comando REVOKE. Neste caso, o nome do papel será utilizado em PRIVILEGIOS e o nome do usuário em
NOME_PRIVILEGIADO.
Consideremos que o usuário ANA não deva mais ter os privilégios definidos para o papel BIBLIOTECA. O
exemplo a seguir revoga o referido papel do usuário ANA.
REVOKE BIBLIOTECA FROM ANA
Removendo Papéis
Para removermos papéis, podemos utilizar o comando DROP ROLE. Sua sintaxe básica é:
DROP ROLE NOME_ROLE
O comando a seguir exemplifica a exclusão do papel BIBLIOTECA através do comando DROP ROLE.
DROP ROLE BIBLIOTECA
Ao removermos um papel, ele é automaticamente retirado de todos os usuários a quem tenha sido atribuído.
Desta forma, não será mais permitido aos usuários que executem as ações definidas no papel que foi removido, a
menos que os privilégios para tal sejam diretamente atribuídos aos usuários ou que sejam atribuídos através de
outros papéis.
Com base nos exemplos anteriores, pode-se dizer que ao removermos o papel BIBLIOTECA, o usuário JOÃO
não terá mais privilégios para realizar ações sobre as tabelas LIVROS e LIVRO_AUTOR, dentre outras. Isso porque
nenhum privilegio sobre tais tabelas tinha sido explicitamente atribuído a este usuário. Todas as ações que ele
podia realizar sobre essas tabelas eram permitidas pois o usuário possuía o papel BIBLIOTECA, ao qual foi, agora,
removido do sistema.

257
Transação e Concorrência
Normalmente, considera-se que um conjunto de várias operações no banco de dados é uma única
unidade do ponto de vista do usuário. Por exemplo, a transferência de fundos de uma conta corrente para uma
poupança é uma operação única sob o ponto de vista do cliente; dentro do sistema de banco de dados, porém,
ela envolve várias operações. Evidentemente, é essencial a conclusão de todo o conjunto de operações, ou que,
no caso de uma falha, nenhuma delas ocorra. Seria inaceitável o débito na conta sem o crédito na poupança.
As operações que formam uma única unidade lógica de trabalho são chamadas de transações. Um
sistema de banco de dados precisa garantir a execução apropriada das transações a despeito de falhas – ou a
transação é executada por completo ou nenhuma parte dela é executada. Além disso, ele deve administrar a
execução simultânea de transações de modo a evitar a ocorrência de inconsistências. Retornando a nosso
exemplo de transferência de fundos, uma transação que calcula o total de dinheiro do cliente poderia trabalhar
com o saldo da conta corrente antes do débito feito pela transação de transferência e, também, verificar o saldo
da poupança depois do crédito. Com isso, obteria um resultado incorreto.
Conceito de Transação
Uma transação é uma unidade de execução de programa que acessa e, possivelmente, atualiza vários
itens de dados. Uma transação, geralmente, é o resultado da execução de um programa de usuário escrito em
uma linguagem de manipulação de dados de alto nível ou em uma linguagem de programação (p.e., SQL, COBOL,
C ou Pascal), e é determinada por declarações (ou chamadas de função) da forma begin transaction e end
transaction. A transação consiste em todas as operações ali executadas, entre o começo e o fim da transação.
Para assegurar a integridade dos dados, exigimos que o sistema de banco de dados mantenha as
seguintes propriedades das transações:
• Atomicidade. Ou todas as operações da transação são refletidas corretamente no banco de dados ou
nenhuma o será.
• Consistência. A execução de uma transação isolada (ou seja, sem a execução concorrente de outra
transação) preserva a consistência do banco de dados.
• Isolamento. Embora diversas transações possam ser executadas de forma concorrente, o sistema garante
que, para todo par de transações Ti e Tj, Ti tem a sensação de que Tj terminou sua execução antes de Ti
começar, ou que Tj começou sua execução após Ti terminar. Assim, cada transação não toma
conhecimento de outras transações concorrentes no sistema.
• Durabilidade. Depois da transação completar-se com sucesso, as mudanças que ela faz no banco de
dados persistem, até mesmo se houver falhas no sistema.
Essas propriedades são chamadas frequentemente de propriedades ACID; o acrônimo é derivado da
primeira letra de cada uma das quatro propriedades.
Para obter um melhor entendimento das propriedades ACID e da necessidade dessas propriedades,
vamos considerar um sistema bancário simplificado que consiste em várias contas e um conjunto de transações
que acessam e atualizam essas contas. Por enquanto, vamos supor que o banco de dados reside
permanentemente em disco, mas que alguma parte dele reside, temporariamente, na memória principal.
O acesso ao banco de dados é obtido pelas duas seguintes operações:
• read(X), que transfere o item de dados X do banco de dados para um buffer local alocado à transação que
executou a operação de read.
• write(X), que transfere o item de dados X do buffer local da transação que executou a write de volta ao
banco de dados.
Em um sistema de banco de dados real, a operação write (escrita) não resulta necessariamente na
atualização imediata dos dados no disco; a operação write pode ser armazenada temporariamente na memória e
ser executada depois no disco. Mas, por enquanto, vamos supor que a operação write atualize o banco de dados
imediatamente.

258
Seja Ti uma transação que transfere 50 dólares da conta A para a conta B. Essa transação pode ser
definida como:
Vamos considerar cada uma das propriedades ACID (para facilidade de apresentação, vamos considera-las
em ordem diferente da ordem A-C-I-D).
• Consistência. A exigência de consistência aqui significa que a soma de A com B deve permanecer
inalterada após a execução da transação. Sem a exigência de consistência, uma soma em dinheiro poderia
ser criada ou destruída pela transação! Pode-se verificar facilmente que, se o banco de dados permanece
consistente depois da execução da transação.
Assegurar a permanência da consistência após uma transação em particular é responsabilidade do
programador da aplicação que codifica a transação.
• Atomicidade. Suponha que, exatamente antes da execução da transação Ti, os valores das contas A e B
sejam 1000 e 2000 dólares, respectivamente. Agora suponha que, durante a execução da transação Ti,
uma falha aconteceu impedindo Ti de se completar com sucesso. Exemplos desses tipos de falhas incluem
falta de energia, falhas de máquina e erros de software. Além disso, suponha que a falha tenha ocorrido
depois da execução da operação write(A), mas antes da operação write(B). Nesse caso, os valores das
contas A e B refletidas no banco de dados são 950 e 2000 dólares. Como resultado da falha sumiram 50
dólares. Em particular, notamos que a soma A+B já não é preservada.
Assim, como resultado da falha, o estado do sistema não reflete mais de um estado real do mundo que se
supõe representado no banco de dados. Chamamos esse estado de inconsistente. Devemos assegurar que essas
inconsistências não sejam perceptíveis em um sistema de banco de dados. Porém, observe que o sistema pode,
em algum momento, estar em um estado inconsistente. Mesmo que a transação Ti seja executada até o final, há
um ponto no qual o valor da conta A é 950 dólares e o valor da conta B é 2000 dólares, que é claramente um
estado inconsistente. Porém esse estado deverá ser substituído pelo estado consistente em que o valor da conta
A é 950 dólares e o valor da conta B é 2050 dólares. Assim, se a transação nunca se iniciou ou se for garantida sua
execução completa, esse estado incompatível não seria visível, exceto durante a execução da transação. Essa é a
razão da exigência da atomicidade: se a propriedade de atomicidade for garantida, todas as ações da transação
serão refletidas no banco de dados ou nenhuma delas o será.
A ideia básica por trás da garantia da atomicidade é a seguinte. O sistema de banco de dados mantém um
registro (em disco) dos antigos valores de quaisquer dados sobre os quais a transação executa uma gravação e, se
a transação não se completar, os valores antigos são restabelecidos para fazer com que pareça que ela nunca foi
executada. Assegurar a atomicidade é responsabilidade do próprio sistema de banco de dados, mais
especificamente ela é tratada por um componente chamado de componente de gerenciamento de transações.
• Durabilidade. Se a transação se completar com sucesso, e o usuário que a disparou for notificado da
transferência de fundos, isso significa que não houve nenhuma falha de sistema que tenha resultado em
perda de dados relativa a essa transferência de capitais.
A propriedade de durabilidade garante que, uma vez completada a transação com sucesso, todas as atualizações
realizadas no banco de dados persistirão, até mesmo se houver uma falha de sistema após a transação se
completar.
Suponha agora que uma falha do sistema possa resultar em perda de dados na MP, mas que os dados
gravados em disco nunca sejam perdidos. Podemos garantir a durabilidade observando um dos seguintes itens:

259
1. As atualizações realizadas pela transação foram gravadas em disco, antes da transação completar-se.
2. Informações gravadas no disco, sobre as atualizações realizadas pela transação, são suficientes para que o
banco de dados possa reconstruir essas atualizações quando o sistema de banco de dados for reiniciado
após uma falha.
Assegurar a durabilidade é responsabilidade de um componente do sistema de banco de dados chamado
de componente de gerenciamento de recuperação. O componente de gerenciamento de transação e o
componente de gerenciamento de transação estão estreitamente relacionados.
• Isolamento. Mesmo asseguradas as propriedades de consistência e de atomicidade para cada transação,
quando diversas transações concorrentes são executadas, suas operações podem ser intercaladas de
modo inconveniente, resultando em um estado inconsistente.
Por exemplo, conforme vimos, o banco de dados fica temporariamente inconsistente, enquanto a
transação transfere fundos de A para B, quando o total reduzido já está escrito em A e o total a ser acrescidos
ainda está aguardando ser escrito em B. Se uma segunda transação, em execução concorrente, ler A e B nesse
ponto intermediário e computar A+B, observará um valor inconsistente. Além disso, se essa segunda transação
executar em A e B atualizações baseadas nos valores inconsistentes que leu, o banco de dados pode ficar em um
estado inconsistente mesmo após ambas as transações se completarem.
Uma solução para o problema de execução concorrente de transações é executar as transações em série
– ou seja, uma após a outra. Entretanto, a execução simultânea de transações proporcionam uma melhoria de
desempenho significativa. Por isso, foram desenvolvidas opções que permitem que diversas transações sejam
executadas de modo concorrente.
Discutimos os problemas causados pela execução de transações concorrentes adiante. A propriedade de
isolamento de uma transação garante que a execução simultânea de transações resulte em uma situação no
sistema equivalente ao estado obtido caso as transações tivessem sidos executadas uma de cada vez, em
qualquer ordem. Assegurar a propriedade de isolamento é responsabilidade de um componente do sistema de
banco de dados chamado componente de controle de concorrência e bem como a obediência a seus princípios.
Estado da Transação
Na ausência de falhas, todas as transações completam-se com sucesso. Entretanto, como observamos
anteriormente, nem sempre uma transação pode completar-se com sucesso. Nesse caso, a transação é abortada.
Se asseguramos a propriedade de atomicidade, uma transação é abortada. Se assegurarmos a propriedade de
atomicidade, uma transação abortada não deve ter efeito sobre o estado do banco de dados. Assim, quaisquer
atualizações que a transação abortada tiver feito no banco de dados devem ser desfeitas. Uma vez que as
mudanças causadas por uma transação abortada sejam desfeitas, dizemos que a transação foi desfeita (rolled
back – retornada). Gerenciar transações abortadas é responsabilidade do esquema de recuperação.
Uma transação completada com sucesso é chamada efetivada (committed). Uma transação que foi
efetivada e que realizou atualizações transforma o banco de dados em um novo estado consistente que deve
persistir até mesmo se houver uma falha no sistema.
Uma vez que uma transação chegue à efetivação (commit), não podemos desfazer seus efeitos
abortando-a. O único modo de desfazer os efeitos de uma transação efetivada é executar uma transação de
compensação, porém nem sempre isso é possível. Logo, a responsabilidade pela criação e execução de uma
transação de compensação é deixada a cargo do usuário, não sendo tratada pelo sistema de banco de dados.
Precisamos ser mais precisos sobre o que queremos dizer com término com sucesso de uma transação.
Portanto, estabeleceremos um modelo de transação simples e abstrato. Uma transação deve estar em um dos
seguintes estados:
• Ativa, ou estado inicial; a transação permanece neste estado enquanto estiver executando.
• Em efetivação parcial, após a execução da última declaração.
• Em falha, após a descoberta de que a execução normal já não pode se realizar.

260
• Abortada, depois que a transação foi desfeita e o banco de dados foi restabelecido ao estado anterior do
início da execução da transação.
• Em efetivação, após a conclusão com sucesso.
O diagrama de estado correspondente a uma transação é mostrado na fig. 13.1. Dizemos que uma
transação foi efetivada somente se ela entrou no estado de efetivação. Analogamente, dizemos que uma
transação abortou somente se ela entrou no estado de abortada. Uma transação é dita concluída se estiver em
efetivação abortada.
Uma transação começa no estado ativo. Quando termina sua última declaração, ela entra no estado de
efetivação parcial.
Nesse momento, a transação completou sua execução, mas ainda é possível ser abortada, já que seus
efeitos ainda podem estar na MP, e com isso uma falha de hardware pode impedir que seja completada com
sucesso.
Então, o sistema de banco de dados escreve informações suficientes no disco, de forma que, até mesmo
em uma falha eventual, as atualizações realizadas pela transação possam ser recriadas quando o sistema for
reiniciado. Quando a última dessas informações for escrita, a transação entre no estado de efetivação.
Conforme mencionamos anteriormente, por enquanto estaremos supondo que as falhas não resultam em
perda de dados no disco. Técnicas para lidar com a perda de dados serão discutidas a seguir.
Uma transação entra no estado de falha quando o sistema determina que ela já não pode prosseguir sua
execução normal (p.e., por causa de erros de hardware ou erros lógicos). Essa transação deve ser desfeita. Ela
entra, então, no estado abortada. Nesse momento, o sistema tem duas opções:
• Ele pode reiniciar a transação, mas somente se ela foi abortada como resultado de algum erro de
hardware ou de software não criado pela lógica interna da transação. Uma transação reiniciada é
considerada uma transação nova.
• Ele pode matar a transação. Normalmente, isso é feito em decorrência de algum erro lógico interno que
só pode ser corrigido refazendo o programa de aplicação, ou porque a entrada de dados não era
adequada ou porque os dados desejados não foram encontrados no banco de dados.
Devemos ser cautelosos quando tratamos de escritas externas observáveis, como escrever em um
terminal ou em uma impressora. Uma escrita desse tipo não pode ser apagada, já que é vista externamente ao
sistema de banco de dados. A maioria dos sistemas permite que essas escritas aconteçam somente depois que
essas escritas aconteçam somente depois que a transação entra no estado de efetivação. Um modo de
implementar esse esquema é fazer com que o sistema de banco de dados armazene temporariamente, em um
meio de armazenamento não-volátil, qualquer valor associado a uma escrita externa, e fazer com que ele executa
a escrita real somente depois que a transação entra no estado de efetivação. Se o sistema falhar depois ter
entrado no estado de efetivação, mas antes de completar a escrita externa, quando o sistema for reiniciado, o

261
sistema de banco de dados executará a escrita externa (usando as informações do meio de armazenamento não-
volátil).
Para certas aplicações, pode ser conveniente permitir que transações ativas exibam dados aos usuários,
particularmente em transações de longa duração, de minutos ou horas. Infelizmente, não podemos permitir essas
saídas de dados, a menos que estejamos dispostos a comprometer a atomicidade da transação. A maioria dos
atuais sistemas de transação assegura a atomicidade e, por isso, proíbe essa forma de interação com usuários.
Implementação de Atomicidade e Durabilidade
O componente de gerenciamento de recuperação de um banco de dados implementa o suporte à
atomicidade e durabilidade. Consideraremos primeiro um esquema simples, mas extremamente ineficiente. Esse
esquema supõe que somente uma transação esteja ativa por vez, e baseia-se em cópias do banco de dados é
simplesmente um arquivo no disco. Um ponteiro chamado db_pointer é mantido no disco; ele aponta para a
cópia corrente do banco de dados.
No esquema de banco de dados shadow, uma transação que deseja atualizar o banco de dados primeiro
cria uma cópia completa dele. Todas as atualizações são feitas na nova cópia, deixando a cópia original, chamada
cópia shadow, intata. Se, em qualquer momento, a transação tiver de ser abortada, simplesmente apaga-se a
novo cópia.
Se a transação se completa, sua efetivação será feita conforme segue. Primeiro, o sistema operacional
precisa ter certeza de que todas as páginas da nova cópia do banco de dados tenham sido escritas no discos. Em
sistemas Unix, o comando flush (transportar, arrebatar) é usada para esse propósito. Depois que o flush se
completa, o ponteiro db_pointer é atualizado para apontar para a nova cópia do banco de dados e a esta se torna
a cópia atual. Então, a cópia velha é apagada. Esse esquema é mostrado graficamente na fig. 13.2, em que o
estado do banco de dados, antes e após a atualização, é indicado.
Diz-se que uma transação foi efetivada quando o db_pointer atualizado é escrito no disco. Discutiremos,
agora, como essa técnica trata as falhas de transação e de sistema. Primeiramente, consideremos a falha de
transação. Se a transação falhar antes da atualização do db_pointer, o conteúdo antigo do banco de dados não
será afetado. Simplesmente podemos abortar a transação apagando a cópia nova do banco de dados. Se a
transação foi efetivada, todas as atualizações que ela executou estão no banco de dados apontado pelo
db_pointer. Assim, ou todas as atualizações da transação são efetivadas ou nenhum de seus efeitos estarão
refletidos, a despeito da falha da transação.
Agora, considere uma falha do sistema. Suponha que a falha do sistema ocorra antes do db_pointer
atualizado ser escrito em disco. Quando o sistema reiniciar, ele lerá o db_pointer, verá o conteúdo original do
banco de dados e nenhum dos efeitos da transação será visível no banco de dados. Agora, suponha que o sistema
falha depois que o db_pointer tiver sido atualizado em disco. Antes de atualizar o ponteiro, todas as páginas
atualizadas da nova cópia do banco de dados foram escritas no disco. Como mencionamos anteriormente,
estamos supondo que, uma vez escrito no disco, o conteúdo de um arquivo não seja danificado, nem mesmo se

262
houver uma falha de sistema. Portanto, quando o sistema reiniciar, ele lerá o db_pointer e verá o conteúdo do
banco de dados depois de todas as atualizações executadas pela transação.
Na verdade, a implementação depende da atomicidade da gravação em db_pointer; ou seja, todos os
seus bytes são escritos ou nenhum de seus bytes o será. Se alguns dos bytes do ponteiro forem atualizados por
uma escrita, mas outros não, o ponteiro não será representativo, e tanto a versão antiga do banco de dados
quanto a versão nova podem não ser encontradas quando o sistema for reiniciado. Felizmente, os sistemas de
disco fornecem atualizações atômicas para blocos inteiros, ou pelo menos para um setor de disco. Em outras
palavras, o sistema de disco garante que atualizará o db_pointer atomicamente.
Assim, as propriedades de atomicidade e durabilidade das transações são garantidas na técnica de
implementação com cópia shadow, feita pelo componente de gerenciamento de recuperação.
Um exemplo simples de uma transação, fora do domínio de banco de dados, seria uma sessão de edição
de texto. Uma sessão de edição inteira pode ser modelada como uma transação. As ações executadas pela
transação são a leitura e a atualização de um arquivo. Salvar o arquivo ao término da edição corresponde à
efetivação da transação de edição; sair da sessão do editor sem salvar o arquivo corresponde a abortar a
transação de edição.
Muitos editores de texto usam essencialmente a implementação descrita acima, para garantir que a
sessão de edição seja transacional. Um arquivo novo é usado para armazenar o arquivo atualizado. Ao término da
sessão de edição, se o arquivo atualizado for salvo, um comando de arquivo rename é usado para rebatizar o
arquivo novo com seu nome corrente. Supõe-se que o rename seja implementado como uma operação atômica
pelo sistema de arquivo subjacente, e que ele também apagará o arquivo antigo.
Infelizmente, essa implementação é extremamente ineficiente no contexto dos grandes banco de dados,
já que a execução de uma única transação implica copiar o banco de dados inteiro. Além disso, essa
implementação não permite que transações concorram uma com as outras. Há maneiras práticas de implementar
a atomicidade e a durabilidade que são muito menos onerosas e mais poderosas.
Execuções Concorrentes
Os sistemas de processamento de transações, normalmente, permitem que diversas transações sejam
executadas de modo concorrente. Permitir que múltiplas transações concorram na atualização de dados traz
diversas complicações em relação à consistência desses dados, conforme vimos anteriormente. Assegura a
consistência, apesar da execução concorrente de transações, exige trabalho adicional; é muito mais fácil insistir
na execução de transações sequencialmente, uma de cada vez, cada uma começando somente depois que a
anterior se completou. Porém, há duas boas razoes para permitir a concorrência.
• Uma transação consiste em diversos passos. Alguns envolvem atividade de I/O; outros atividades de CPU.
A CPU e os discos em um sistema de computador podem operar em paralelo. Logo, a atividade de I/O
pode ser feita em paralelo com o processamento na CPU. Assim, o paralelismo entre CPU e o sistema de
I/O pode ser explorado para executar diversas transações em paralelo. Enquanto uma leitura ou escrita
solicitada por uma transação está em desenvolvimento em um disco, outra transação pode estar sendo
processada na CPU, e outro disco pode estar executando uma leitura ou escrita solicitada por uma
terceira transação. Desse modo, há um aumento no throughput do sistema – ou seja, no número de
transações que podem ser executadas em um determinado tempo. De forma correspondente, o uso do
processador e do disco também aumentam; em outras palavras, o processador e o disco ficam menos
tempo inativos ou sem executar trabalho útil.
• Pode haver uma mistura de transações em execução simultânea no sistema, algumas curtas e outras
longas. Se a execução das transações for sequencial, uma transação curta pode ser obrigada a esperar até
que uma transação longa precedente se complete, o que pode gerar atrasos imprevisíveis em sua
execução. Se as transações estão operando em diferentes partes do banco de dados, é melhor deixa-las
concorre de modo a compartilhar os ciclos de CPU e os acessos de disco entre si. A execução concorrente
reduz os atrasos imprevisíveis na execução. Se as transações estão operando em diferentes partes do

263
banco de dados, é melhor deixa-las concorrer de modo a compartilhar os ciclos de CPU e os acessos de
disco entre si. Além disso, reduz também o tempo médio de resposta: o tempo médio para uma
transação ser completada após ser submetida.
A motivação para usar a execução concorrente em um banco de dados é essencialmente a mesma para
usar a multiprogramação em um sistema operacional.
Quando várias transações são processadas de modo concorrente, a consistência do banco de dados pode
ser destruída, mesmo que cada transação individual seja executada com correção. Vamos agora apresentar o
conceito de escalas de execução (schedules), para ajudar na identificação de quais ordens de execução podem
garantir a manutenção da consistência.
O sistema de banco de dados deve controlar a interação entre as transações concorrentes para impedi-las
de destruir sua consistência. Isso é feito por meio de uma variedade de mecanismos chamados de esquemas de
controle de concorrência.
Considere, novamente, o sistema bancário simplificado já apresentado, que possui diversas contas, além
de um conjunto de transações que acessa e atualiza essa contas. Sejam T1 e T2 duas transações que transferem
fundos de uma conta para outra. A transação T1 transfere 50 dólares da conta A para a conta B e é definida da
seguinte forma:
A transação T2 transfere 10 por cento do saldo da conta A para a conta B e é definida da seguinte forma:
Sejam mil e dois mil dólares os valores correntes das contas A e B, respectivamente. Suponha que as duas
transações sejam executadas em sequência, T1 seguida de T2. Essa sequência de execução é representada na fig.
13.3. A sequência dos passos das instruções estão em ordem cronológica a partir do topo da figura, com as
instruções de T1 aparecendo na coluna à esquerda e as instruções de T2 aparecendo na coluna à direita. Depois
que a execução apresentada na fig. 13.3 terminar, os valores nas contas A e B são 855 e 2145 dólares,
respectivamente. Assim, o montante de dinheiro das contas A e B – ou seja, a soma A+B – é preservado depois da
execução de ambas as transações.

264
Analogamente, se as transações forem executadas em outra sequência, desta vez T2 seguida de T1, então
a sequência de execução correspondente é mostrada na fig. 13.4. Novamente, conforme esperado, a soma A+B é
preservada, e os valores finais das contas A e B são 850 e 2150 dólares, respectivamente.
As sequências de execução descritas anteriormente são chamadas de escalas de execução ou escalas. Elas
representam a ordem cronológica por meio da qual as instruções são executadas no sistema. Claramente, uma
determinada escala de execução de um conjunto de transações consiste em todas as instruções dessas transações
e deve preservar a ordem na qual as instruções aparecem em cada transação individual. Por exemplo, na
transação T1, a instrução write(A) deve aparecer antes da instrução read(B), em qualquer escala válida. Na
discussão a seguir, iremos nos referir à primeira sequência de execução (T1 seguida de T2) como escala 1 e à
segunda sequência de execução (T2 seguida de T1) como escala 2.
Essas escalas de execução são sequenciais. Cada escala sequencial consiste em uma sequência de
instruções de várias transações em que as instruções que pertencem a uma única transação aparecem agrupadas.
Assim, para um conjunto de n transações, há n! escalas sequenciais válidas diferentes.
Quando várias transações são executadas simultaneamente, a escala correspondente pode já não ser
sequencial. Se duas transações são executadas simultaneamente, o sistema operacional pode executar uma
transação durante algum tempo e, então, voltar à primeira transação durante algum tempo e assim por diante,
alternadamente. Com diversas transações, o tempo de CPU é compartilhado entre todas.
Várias sequências de execução são possíveis, já que as várias instruções, de ambas as transações podem
ser intercaladas. Geralmente, não é possível exatamente prever quantas instruções de uma transação serão
executadas antes que a CPU alterne para outra transação. Assim, o número de escalas de execução possíveis para
um conjunto de n transações é muito maior que n!

265
Retornando ao nosso exemplo anterior, suponha que as duas transações sejam executadas de modo
concorrente. Uma escala de execução possível é mostrada na fig. 13.5. Após essa execução, chegamos ao mesmo
estado obtido durante a execução sequencial na ordem T1 seguida de T2. A soma A+B é preservada.
Nem todas as execuções concorrentes resultam em um estado correto. Para ilustrar, considere a escala
de execução da fig. 13.6. Depois de sua execução, chegamos a um estado tal que os valores para as contas A e B
são 950 e 2100 dólares, respectivamente. Esse estado final é um estado inconsistente, já que apareceram 50
dólares durante a execução concorrente. Realmente, a soma A+B não é preservada na execução das duas
transações.
Se o controle da execução concorrente é deixado completamente sob a responsabilidade do sistema
operacional, muitas escalas de execução possíveis, inclusive aquelas que deixam o banco de dados em um estado
inconsistente como a descrita anteriormente, são factíveis. É uma tarefa do sistema de banco de dados garantir
que qualquer escala executada deixe o banco de dados em estado consistente. O componente do sistema de
banco de dados que executa esta tarefa é chamado de componente de controle de concorrência.
Podemos assegurar a consistência do banco de dados, sob execução concorrente, garantindo que
qualquer escala executada tenho o mesmo efeito de outra que tivesse sido executada sem qualquer
concorrência. Isto é, uma escala de execução deve, de alguma forma, ser equivalente a uma escala sequencial.
Serialização
O sistema de banco de dados deve controlar a execução concorrente de transações para assegurar que o
estado do banco de dados permaneça consistente. Antes de examinarmos como o sistema de banco de dados
pode cumprir essa tarefa, temos de entender primeiro quais escalas de execução podem garantir a consistente e
quais não irão fazê-lo.

266
Considerando que as transações são programas, é difícil, pelo caráter da computação, determinar quais
são as operações exatas que uma transação executa, e como as operações de várias transações interagem. Por
essa razão, não faremos interpretações sobre o tipo de operações que uma transação pode executar em um item
de dados. Em vez disso, consideraremos apenas duas operações: read (leitura) e write (escrita). Supomos assim
que, entre uma instrução read (Q) e write(Q) em um item de dado Q, uma transação pode executar uma
sequência arbitrária de operações na cópia de Q, que está residindo no buffer local no qual se processa a
transação. Assim, as únicas operações significativas de uma transação, do ponto de vista da escala de execução,
são suas instruções de leitura e escrita. Por isso, mostraremos apenas as instruções read e write nas escalas de
execução, conforme fizemos na representação da escala 3 que é mostrada na fig. 13.7.
Vamos discutir formas de equivalência entre escalas de execução; elas conduzem às noções de
serialização de conflito e de visão serializada.
Serialização de Conflito
Vamos considerar uma escala de execução S com duas instruções sucessivas, Ii e Ij, das transações Ti e Tj
(i≠j), respectivamente. Se Ii e Ij referem-se a itens de dados diferentes, então podemos alternar Ii e Ij sem afetar os
resultados de qualquer instrução da escala. Porém, se Ii e Ij referem-se ao mesmo item de dados Q, então a
ordem de dois passos pode importar. Como estamos lidando apenas com instruções read e write, há quatro casos
a considerar:
Assim, apenas no caso em que ambas, Ii e Ij, são instruções de read a ordem relativa de suas execuções
não é importante.
Dizemos que Ii e Ij entram em conflito caso elas sejam operações pertencentes a diferentes transações,
agindo no mesmo item de dado, e pelo menos uma dessas instruções é uma operação de write.
Para ilustrar o conceito de operações conflitantes consideraremos a escala 3 mostrada na fig. 13.7. A
instrução write (A) de T1 entra em conflito com a instrução read(A) de T2. Porém, a instrução write(A) de T2 não
está em conflito com a instrução read(B) de T1, porque as duas instruções trabalham itens de dados diferentes.
Sejam Ii e Ij instruções consecutivas de uma escala de execução S. Se Ii e Ij são instruções de transações
diferentes e não entram em conflito, então podemos trocar a ordem de Ii e Ij para produzir uma nova escala de

267
execução S’. Esperamos que S seja equivalente a S’, já que todas as instruções aparecem na mesma ordem em
ambas as escalas de execução com exceção de Ii e Ij , cuja ordem não importa.
Como a instrução write(A) de T2 na escala 3 da fig. 13.7 não entra em conflito com a instrução read(B) de
T1, podemos trocar essas instruções para gerar uma escala de execução equivalente, a escala 5, conforme mostra
a fig. 13.8. A despeito do estado inicial do sistema, ambas as escalas, 3 e 5, produzem o mesmo estado final no
sistema.
Continuaremos a trocar instruções não-conflitantes conforme segue:
• Trocar a instrução read(B) de T1 pela instrução read(A) de T2.
• Trocar a instrução write(B) de T1 pela instrução write(A) de T2.
• Trocar a instrução write(B) de T1 pela instrução read(A) de T2.
O resultado final dessas trocas, conforme mostrado na escala 6 da fig. 13.9, é uma escala de execução
sequencial. Assim, mostramos que a escala 3 é equivalente a uma escala de execução sequencial. Essa
equivalência implica que, a despeito do estado inicial do sistema, a escala 3 produzirá o mesmo estado final
produzido por alguma escala sequencial.
Se uma escala de execução S puder ser transformada em outra, S’, por uma série de trocas de instruções
não-conflitantes, dizemos que S e S’ são equivalentes no conflito.
Retornando a nossos exemplos anteriores, observamos que a escala 1 não é equivalente no conflito à
escala 2. Entretanto, a escala 1 é equivalente no conflito à escala 3, porque as instruções read(B) e write(B) de T1
podem ser trocadas pelas instruções read(A) e write(A) de T2.
O conceito de equivalência no conflito leva ao conceito de serialização de conflito. Dizemos que uma
escala de execução S é conflito serializava se ela é equivalente no conflito a uma escala de execução sequencial.
Assim, a escala 3 é conflito serializava, já que ela é equivalente no conflito à escala sequencial 1.
Finalmente, considere a escala 7 da fig. 13.10; ela consiste somente nas operações significativas (ou seja,
read e write) das transações T3 e T4. Essa escala de execução não é conflito serializava, já que não é equivalente à
escala sequencial <T3, T4> ou à escala sequencial <T4, T3>.

268
É possível ter duas escalas de execução que produzam o mesmo resultado, mas que não sejam
equivalentes no conflito. Por exemplo, considere a transação T5, que transfere 10 dólares da conta B para a conta
A. Seja a escala 8 definida na fig. 13.11. Verificamos que a escala 8 não é equivalente no conflito à escala
sequencial <T1, T5>, já que, na escala 8, a instrução write(B) de T5 entra em conflito com a instrução read(B) de T1.
Assim, apenas pela troca de instruções consecutivas não conflitantes, não conseguimos mover todas as instruções
de T1 antes daquelas de T5. Porém, os valores finais das contas A e B depois da execução da escala 8 ou da escala
sequencial <T1, T5> são os mesmos – isto é, 960, e 2040 dólares, respectivamente.
Podemos ver nesse exemplo que há definições menos triviais de equivalência de escala que a
equivalência de conflito. Para o sistema determinar se a escala 8 produz o mesmo resultado que a escala
sequencial <T1, T5>, ele tem de analisar toda computação executada por T1 e T5, em vez de analisar apenas as
operações read e write. Em geral, tal análise é difícil de implementar e é onerosa em termos computacionais.
Porém, há outras definições de equivalência entre escalas de execução baseadas puramente nas operações read
e write.
Visão Serializada
Vamos considerar uma forma de equivalência que é menos restritiva que a equivalência de conflito,
embora, assim como a equivalência de conflito, esteja baseada apenas nas operações read e write das
transações.
Considere duas escalas de execução S e S’, com o mesmo conjunto de transações participando de ambas.
As escalas S e S’ são ditas equivalente na visão se as três condições seguintes forem satisfeitas:
1. Para cada item de dados Q, se a transação Ti fizer uma leitura no valor inicial de Q na escala S, então a
transação Ti também deve, na escala S’, ler o valor inicial de Q.
2. Para cada item de dados Q, se a transação Ti executar um read(Q) na escala S, e aquele valor foi
produzido por meio da transação Tj (se houver), então a transação Ti também deverá, na escala S’, ler o
valor de Q que foi produzido por meio da transação Tj.
3. Para cada item de dados Q, a transação (se houver) que executa a operação final write(Q) na escala S tem
de executar a operação write(Q) final na escala S’.

269
As condições 1 e 2 asseguram que cada transação lê os mesmos valores em ambas as escalas e, então,
executa a mesma computação. A condição 3, em conjunto com as condições 1 e 2, assegura que ambas as escalas
de execução resultem no mesmo estado final de sistema.
Retornando a nossos exemplos anteriores, notamos que a escala 1 não é equivalente em visão à escala 2,
já que, na escala 1, o valor da conta A lido pela transação T2 foi produzido por T1, enquanto isso não ocorre na
escala 2. Porém, a escala 1 é equivalente em visão à escala 3, porque os valor da conta A e B lidos pela transação
T2 foram produzidos por T1 em ambas as escalas.
O conceito de equivalência de visão leva ao conceito de serialização de visão. Dizemos que uma escala de
execução S tem visão serializada se for equivalente, em visão, a uma escala de execução sequencial.
Para ilustrar, suponha que aumentemos a escala 7 com a inclusão da transação T6 obtendo a escala 9,
conforme pode ser visto na fig. 13.12. A escala 9 é a visão serializada. De fato, ela é equivalente em visão à escala
sequencial <T3, T4, T6>, já que uma instrução read(Q) lê o valor inicial de Q em ambas as escalas, e T6 executa a
escrita final de Q em ambas as escalas.
Toda escala conflito serializava é visão serializava, mas há escala visão serializava que não são conflito
serializava. Realmente, a escala 9 não é conflito serializava, uma vez que qualquer par de instruções consecutivas
é conflitante e, assim, não é possível nenhuma troca de instruções.
Observe que, na escala 9, as transações T4 e T6 executam operações write(Q) sem terem executado uma
operação read(Q). Esse tipo de escrita é chamado de escrita cega (blind write). As escritas cegas aparecem em
algumas escalas visão serializava que não são conflito serializava.
Recuperação
Até o momento, estudamos quais escalas de execução são aceitáveis do ponto de vista da consistência do
banco de dados, supondo, de modo implícito, que não ocorram falhas de transação. Veremos agora os efeitos das
falhas de transação durante a execução concorrente.
Se uma transação Ti falhar, por qualquer razão, precisamos desfazer seus efeitos para garantir a
propriedade de atomicidade da transação. Em um sistema que permite execução concorrente, também é
necessário assegurar que qualquer transação Tj que seja dependente de Ti (quer dizer, Tj leu dados escritos por Ti)
também seja abortada. Para alcançar essa segurança, precisamos colocar restrições no tipo de escalas permitidas
no sistema.
Escala de Execução Recuperáveis
Considere a escala 11, mostrada na fig. 13.13, na qual T9 é uma transação que executa apenas uma
instrução: read(A). Suponha que o sistema permita que T9 seja efetivada imediatamente após executar a
instrução read(A). Assim, T9 é efetivada antes que T8 o seja. Agora, suponha que T8 falhe antes da efetivação.
Como T9 leu o valor do item de dados A escrito por T8, temos de abortar T9 para assegurar a atomicidade da
transação. Porém, T9 já foi efetivada e não poderá ser abortada. Assim, temos uma situação em que é impossível
se recuperar corretamente da falha de T8.

270
A escala 11, com a efetivação acontecendo imediatamente após a instrução read(A), é um exemplo de
escala de execução não-recuperável que, portanto, não deveria ser permitida. A maioria dos sistemas de banco
de dados exige que todas as escalas sejam recuperáveis. Uma escala recuperável é aquela na qual, para cada par
de transações Ti e Tj, tal que Tj leia itens de dados previamente escritos por Ti, a operação de efetivação de Ti
apareça antes da operação de efetivação de Tj.
Escalas sem cascata
Mesmo em uma escala recuperável, para o sistema recuperar-se corretamente da falha de transação Ti,
pode ser que seja necessário desfazer diversas transações. Tais situações ocorrem se as transações leram dados
escritos por Ti. Como ilustração, considere a escala parcial da fig. 13.14. A transação T10 escreve um valor para A
que é lido pela transação T11. A transação T11 escreve um valor para A que é lido pela transação T11. Suponha que,
nesse momento, T10 falhe. T10 deverá ser desfeita. Como T11 é dependente de T10, T11 deverá ser desfeita. Como
T12 é dependente de T11, T12 deverá ser desfeita. Esse fenômeno, no qual a falha de uma única transação conduz a
uma série de reversões de transação, é chamado de retorno em cascata (cascading rollback).
O retorno em cascata é indesejável, já que leva a desfazer uma quantia significativa de trabalho. É
conveniente restringir as escalas àquelas nas quais os retornos em cascata não possam acontecer. Tais escalas são
chamadas de escalas sem cascata. Uma escala sem cascata é aquela na qual cada par de transações Ti e Tj, tal que
Tj leia um item de dados previamente escrito por Ti, a operação de efetivação de Ti apareça antes da operação de
leitura de Tj. É fácil verificar que toda escala sem cascata também é recuperável.
Implementação do Isolamento
Até o momento, vimos quais propriedades uma escala deve ter para deixar o banco de dados em um
estado consistente e para permitir o tratamento seguro de possíveis falhas de transação. Especificamente, as
escalas que são conflito ou visão serializava e sem cascata satisfazem essas exigências.
Há vários esquemas de controle de concorrência que podemos usar para garantir que, até mesmo quando
diversas transações são executadas de modo concorrente, sejam geradas apenas escalas aceitáveis, a despeito de
como o sistema operacional compartilha os recursos (como o tempo de CPU) entre as transações.
Como um exemplo trivial de um esquema de controle de concorrência, considere este: uma transação
bloqueia (lock) o banco de dados inteiro antes de começar e libera o bloqueio após sua efetivação. Enquanto uma
transação mantém um bloqueio, nenhuma outra tem permissão para realizar um bloqueio, todas elas são
obrigadas a esperar sua liberação. Como resultado dessa política de bloqueio, apenas uma transação pode
executar um bloqueio de cada vez. Logo, são geradas apenas escalas sequenciais. Estas são trivialmente
serializáveis e é fácil verificar que são também sem cascata.

271
Um esquema de controle de concorrência como esse apresenta um desempenho pobre, já que força as
transações a esperarem o término das precedentes antes que possam começar. Em outras palavras, ele
possibilita um baixo grau de concorrência. A execução concorrente traz vários benefícios em relação ao
desempenho.
O objetivo dos esquemas de controle de concorrência é proporcionar um alto grau de concorrência,
enquanto garante que todas as escalas geradas sejam conflito serializava ou visão serializava, e também sejam
em cascata.
Os esquemas têm diferentes características em termos do grau de concorrência observado e da
quantidade de overhead em que incorrem. Alguns deles permite que apenas escalas conflito serializava sejam
geradas, outros permite que escalas visão serializável, que não são conflito serializava, também sejam geradas.
Definição de Transação em SQL
Uma linguagem de manipulação de dados deve possuir um construtor para especificar o conjunto de
ações que constitui uma transação.
O padrão SQL especifica que uma transação começa de modo subentendido. As transações são
terminadas por uma das seguintes declarações SQL:
• Commit work executa a efetivação da transação corrente e começa uma nova.
• Rollback work aborta a transação corrente.
A palavra-chave work é opcional em ambas as declarações. Se um programa termina sem um desses
comandos, as atualizações são efetivadas ou desfeitas – a escolha não é especificada pelo padrão, e é
dependente da implementação.
O padrão especifica também que o sistema deve assegurar a serialização e retorno sem cascata. A
definição de serialização usada pelo padrão é a que estabelece que uma escala deve ter o mesmo efeito de uma
escala sequencial. Assim, tanto serialização de conflito quanto serialização de visão são aceitáveis.
O padrão SQL-92 também permite que se estabeleça para uma transação uma execução de modo não
serializava em relação a outras transações. Por exemplo, uma transação pode operar em nível de read sem
efetivação (read uncommitted), permitindo que as transações leiam registros mesmo sem suas efetivações. Essa
características é oferecida para transações longas, cujos resultados não precisam ser exatos. Por exemplo, uma
informação aproximada é geralmente suficiente para estatísticas usadas na otimização de consultas. Se essas
transações forem executadas de uma maneira serializava, elas poderiam interferir em outras transações,
provocando atrasos.
O nível de consistência especificado pela SQL-92 é:
• Serializável é o default (padrão).
• Read repetitivo somente permite leitura de registros que sofreram efetivação e, além disso, exige que
nenhuma outra transação consiga atualizar um registro entre duas leituras feitas por uma transação.
Entretanto, a transação pode não ser serializava com respeito a outras transações. Por exemplo, quando
se está procurando registros que satisfaçam algumas condições, uma transação pode achar alguns dos
registros inseridos por uma transação que sofreu efetivação, mas não encontrar os outros.
• Read com efetivação permite que apenas registros que sofreram efetivação sejam lidos, mas não exige
read repetitivo. Por exemplo, entre duas leituras de um registro feitas por uma transação, os registros
podem ter sido atualizados por meio de transações que obtiveram efetivação.
• Read sem efetivação permite a leitura de registros que não sofreram efetivação. É o nível mais baixo de
consistência permitido pela SQL-92.
Teste de Serialização
Ao projetar esquemas de controle de concorrência, devemos mostrar que as escalas geradas por eles são
serializáveis. Para fazê-lo, primeiro temos de entender como determinar, para uma escala S em particular, se ela é
serializava. Nesta seção, apresentaremos métodos para determinar serialização de conflito e serialização de visão.

272
Mostraremos que há um algoritmo simples e eficiente para determinar a serialização de conflito. Entretanto, não
há nenhum algoritmo eficiente para determinar a serialização de visão.
Teste para Serialização de Conflito
Seja S uma escala. Construímos um gráfico direcionado, chamado gráfico de precedência de S. Esse
gráfico consiste em um par G=(V,E), em que V é um conjunto de vértices e E é um conjunto de arestas. O conjunto
de vértices consiste em todas as transações que participam da escala. O conjunto de arestas consiste em todas as
transações que participam da escala. O conjunto de arestas consiste em todas as arestas Ti�Tj para as quais uma
das seguintes condições se verifica:
1. Ti executa write(Q) antes de Tj executar read(Q).
2. Ti executa read(Q) antes de Tj executar write(Q).
3. Ti executa write(Q) antes de Tj executar write(Q).
Se há uma aresta Ti�Tj no gráfico de precedência, então, em qualquer escala sequencial S’ equivalente a
S, Ti deve aparecer antes de Tj.
Por exemplo, o gráfico de precedência para a escala 1 é mostrado na fig. 13.15a. Ele contém a única
aresta T1�T2, já que todas as instruções de T1 são executadas antes da primeira instrução de T2 ser executada. De
forma semelhante, a fig. 13.15b mostra o gráfico de precedência para a escala 2 com a única aresta T2�T1, já que
todas as instruções de T2 são executadas antes da primeira instrução de T1 ser executada.
O gráfico de precedência para a escala 4 é mostrado na fig. 13.16. Ele contém a aresta T1�T2, porque T1
executa read(A) antes de T2 executar write(A). Ele também contém a aresta T2�T1, porque T2 executa read(B)
antes de T1 executar write(B).
Se o gráfico de precedência para S tem um ciclo, então a escala S não é conflito serializava. A ordem de
serialização pode ser obtida por meio da classificação topológica, que estabelece uma ordem linear consistente
com a ordem parcial do gráfico de precedência. Em geral, várias ordens lineares possíveis podem ser obtidas por
meio da classificação topológica. Por exemplo, o gráfico da fig. 13.17a possui ordens lineares aceitáveis, conforme
é ilustrado pelas fig. 13.17b e 13.17c.
Assim, para testar a serialização de conflito, precisamos construir o gráfico de precedência e evocar um
algoritmo de detecção de ciclos. Algoritmos de detecção de ciclos podem ser encontrados em livros-texto sobre
algoritmos. Os algoritmos de detecção de ciclos, como aqueles baseados em depth-first search, são da ordem de
n2 operações, em que n é o número de vértices no gráfico (ou seja, o número de transações). Assim, temos um
esquema prático para determinar a serialização de conflito.
Retornando a nossos exemplos anteriores, observe que os gráficos de precedência para as escalas 1 e 2
(fig. 13.15) realmente não contêm ciclos. O gráfico de precedência para a escala 4 (fig. 13.16), por outro lado,
contém um ciclo que indica que essa escala não é conflito serializava.
Teste para Serialização de Visão
Podemos modificar o teste do gráfico de precedência para serialização de visão, conforme mostraremos a
seguir. Entretanto, o teste resultante é oneroso em relação ao tempo de CPU. De fato, testar serialização de visão
é um problema caro em termos computacionais, como veremos posteriormente.

273
No teste para serialização de conflito, sabemos que, se duas transações, Ti e Tj, têm acesso a um item de
dados Q, e pelo menos uma dessas transações escreve Q, então a aresta Ti�Tj ou a aresta Tj�Ti será inserida no
gráfico de precedência. Porém, isto não mais ocorre no teste para serialização de visão. Como veremos em breve,
essa diferença é a razão da incapacidade em se chegar a um algoritmo eficiente para esse teste.
Considere a escala 9 da fig. 13.12. Se seguirmos a regra do teste para serialização de conflito e criamos o
gráfico de precedência, obteremos o gráfico da fig. 13.18. O gráfico contém um ciclo indicando que a escala 9 não
é conflito serializava. Entretanto, como vimos anteriormente, a escala 9 é visão serializava, já que ela é
equivalente em visão à escala sequencial <T3, T4, T6>. A aresta T4�T3 não deveria ter sido inserida no gráfico, já
que os valores do item Q produzidos por T3 e T4 não foram usados por quaisquer outras transações, e T6 produziu
um valor final novo de Q. As instruções write(Q) de T3 e T4 são chamadas de gravações inúteis.
Com isso, mostramos que não podemos simplesmente usar o esquema de gráfico de precedência citado
anteriormente para testar serialização de visão. Precisamos desenvolver um esquema para decidir se uma aresta
deve ou não ser inserida no gráfico de precedência.
Seja S uma escala. Suponha que a transação Tj leia o valor do item de dado Q escrito por Ti. É claro que, se
S é visão serializava, então, em qualquer escalar que S’ seja equivalente a S, Ti deve preceder Tj. Suponha agora
que, na escala S, a transação Tk executou uma write(Q). Então, na escala S’, Tk deve preceder Ti ou deve seguir Tj.

274
Ela não poderá aparecer entre Ti e Tj, porque dessa forma Tj não leria o valor de Q escrito por Ti e, assim, S não
seria equivalente em visão a S’.
Tais requisitos não podem ser expressos no modelo simples de gráfico de precedência discutido
anteriormente. A dificuldade acontece porque sabemos que, no exemplo precedente, um dos pares de arestas,
Tk�Ti ou Tj�Tk, deverá ser inserido no gráfico, mas não temos, contudo, formulada a regra para determinar qual
a escolha apropriada.
Para formulá-la, precisamos expandir o gráfico de precedência de modo a incorporar as arestas rotuladas.
Chamamos esse gráfico de gráfico de precedência rotulado. Como antes, os nós do gráfico são as transações que
participam da escala. As regras para a inserção de arestas rotuladas são descritas a seguir.
Seja S uma escala que consiste nas transações {T1, T2, ..., Tn}. Sejam Tb e Tf duas transações fictícias, tais
que Tb execute write(Q) para todo Q que sofreu acesso em S e Tf, execute uma read(Q) para todo Q que sofreu
acesso em S. Construímos uma nova escala S’ a partir de S por meio da inserção de Tb no início de S e do
acréscimo de Tf no final de S. Construímos o gráfico de precedência rotulado para a escala S’ conforme segue:
1. Adicione uma aresta , se a transação Tj lê o valor do item de dados Q escrito pela transação Ti.
2. Remova todas as arestas que incidam em transações inúteis. Uma transação Ti é inútil se não houver
caminho, no gráfico de precedência, de Ti para a transação Tf.
3. Para todo item de dados Q, tal que Tj lê o valor de Q escrito por Ti, Tk executa um write(Q) e Tk≠Tb, faça o
seguinte:
a. Se Ti=Tb e Tj≠Tf, então insira a aresta no gráfico de precedência rotulado.
b. Se Ti≠Tb e Tj=Tf, então insira a aresta no gráfico de precedência rotulado.
c. Se Ti=Tb e Tj≠Tf, então insira o par de arestas e no gráfico de precedência rotulado,
em que p é um inteiro maior que 0 que não tenha sido usado anteriormente para rotular arestas.
A regra 3c determina que, se Ti escrever um item de dados lido por Tj, então uma transação Tk que escreva o
mesmo item de dados deve vir antes de Ti ou depois de Tj. As regras 3a e 3b são casos especiais resultantes do
fato de que, necessariamente, Tb e Tf são a primeira e a última transação, respectivamente. Quando aplicamos a
regra 3c, não estamos exigindo que Tk esteja simultaneamente antes de Ti e depois de Tj. Em vez disso,
poderemos escolher onde Tk aparecerá, em uma ordem sequencial equivalente.
Como ilustração, considere novamente a escala 7 (fig. 13.10). O gráfico construído pelos passos 1 e 2 é
mostrado na fig. 13.19a. Ele contém a aresta , já que T3 lê o valor de Q escrito por Tb. ele contém a aresta
, já que T3 foi a última transação que escreveu Q e, assim, Tf leu aquele valor. O gráfico final que
corresponde à escala 7 é mostrado na fig. 13.19b. Ele contém a aresta resultante do passo 3a. Ele contém
a aresta como resultado do passo 3b.

275
Agora, considere a escala 9 (fig. 13.12). O gráfico construído nos passos 1 e 2 é mostrado na fig. 13.20a. O
gráfico final é mostrado na fig. 13.20b. Ele contém as arestas e como resultado do passo 3a. Contém
as arestas (já no gráfico) e como resultado do passo 3b.
Finalmente, considere a escala 10 da fig. 13.21. A escala 10 é visão serializava, já que é equivalente em
visão à escala sequencial <T3, T4, T7>. O gráfico de precedência rotulado correspondente, construído nos passos 1
e 2 é mostrado na fig. 13.22a. O gráfico final é mostrado na fig. 13.22b. As arestas e foram inseridas
como resultado da regra 3a. O par de arestas e foi inserido como resultado de uma única
aplicação da regra 3c.

276
Os gráficos mostrados nas figuras 13.19b e 13.22b contêm os seguintes ciclos mínimos, respectivamente:
O gráfico da fig. 13.20b, por outro lado, não contém ciclos.
Se o gráfico não contém ciclos, a escala correspondente é visão serializava. Realmente, o gráfico da figura
13.20b não contém ciclos, e sua escala correspondente, escala 9, é visão serializava. Entretanto, se o gráfico
contiver um ciclo, essa condição não implica necessariamente que a escala correspondente não seja visão
serializava. Realmente, o gráfico da fig. 13.19b contém um ciclo, contudo sua escala correspondente, escala 7,
não é visão serializava. O gráfico da fig. 13.22b, por outro lado, contém um ciclo, mas sua escala correspondente,
escala 10, é visão serializava.
Como, então, determinamos se uma escala é visão serializava? A resposta está em uma intepretação
apropriada do gráfico de precedência. Suponha que haja n pares de arestas distintas. Ou seja, aplicamos n vezes a
regra 3c na construção do gráfico de precedência. Haverá então 2n gráficos diferentes, sendo que cada gráfico
contém apenas uma aresta de cada par. Se algum desses gráficos for acíclico, então a escala correspondente será
visão serializava. A ordem de serialização é determinada pela remoção das transações fictícias Tb e Tf e pela
classificação topológica do gráfico acíclico restante.
Volte ao gráfico da fig. 13.22b. como há exatamente um par distinto, há dois gráficos diferentes que
devem ser considerados. Os dois gráficos são mostrados na fig. 13.23. Como o gráfico da fig. 13.23a é acíclico,
sabemos que a escala correspondente, escala 10, é visão serializava.
O algoritmo descrito anteriormente obriga testar exaustivamente todos os possíveis gráficos distintos.
Para isso mostrou-se que o problema do teste de um gráfico acíclico nesse conjunto recai sobre a classe de

277
problemas NP-completos. Qualquer algoritmo para um problema NP-completo quase certamente tomará um
tempo exponencial proporcional ao tamanho do problema.
De fato, foi mostrado que o problema do teste para serialização de visão é, ele próprio, NP-completo.
Assim, muito provavelmente não há um algoritmo eficiente para testar serialização de visão. Entretanto, os
esquemas de controle de concorrência ainda podem usar as condições suficientes para serialização de visão. Ou
seja, se as condições suficientes forem satisfeitas, a escala é visão serializava, mas pode haver escalas visão
serializava que não satisfaçam as condições suficientes.

278
Controle de Concorrência
Já vimos que uma propriedade fundamental da transação é o isolamento. Quando diversas transações são
executadas de modo concorrente em um banco de dados, a propriedade do isolamento pode não ser preservada.
É necessário que o sistema controle a interação entre transações concorrentes; esse controle é alcançado por
meio de uma larga gama de mecanismo chamados esquemas de controle de concorrência.
Todos os esquemas de controle de concorrência têm por base a propriedade de serialização
(serializability). Isto é, todos os esquemas apresentados aqui garantem que a ordenação de processamento é
serializada.
Protocolo com Base em Bloqueios (Lock)
Um meio de garantir a serialização é obrigar que o acesso aos itens de dados seja feito de maneira
mutuamente exclusiva; isto é, enquanto uma transação acessa um item de dados, nenhuma outra transação pode
modifica-lo. O método mais usado para sua implementação é permitir o acesso a um item de dados somente se
ele estiver bloqueado.
Bloqueios
Há vários modos por meio dos quais um item de dado pode ser bloqueado. Vamos nos restringir a dois
deles:
1. Compartilhado. Se uma transação Ti obteve um bloqueio compartilhado (denotado por S) sobre o item Q,
então Ti pode ler, mas não escrever Q.
2. Exclusivo. Se uma transação Ti obteve um bloqueio exclusivo (denotado por X) do item Q, então Ti pode
tanto ler como escrever Q.
Precisamos que toda transação solicite o bloqueio do item Q de modo apropriado, dependendo do tipo
de operação realizada em Q. A solicitação é direcionada para o gerenciador do controle de concorrência. A
transação pode realizar suas operações somente depois que o gerenciador de controle de concorrência. A
transação pode realizar suas operações somente depois que o gerenciador de controle de concorrência conceder
(grants) o bloqueio para transação.
Dado um conjunto de bloqueios, podemos definir uma função de compatibilidade sobre eles. Seja A e B
uma representação arbitrária dos modos de bloqueio. Suponha que uma transação Ti solicite um bloqueio do
modo A sobre o item Q, sobre o qual a transação Tj (Ti≠Tj) mantém um bloqueio do modo B.
Se uma transação Ti consegue um bloqueio sobre Q imediatamente, a despeito da presença de um
bloqueio do modo B, então dizemos que o modo A é compatível com o modo B. Essa função pode ser
convenientemente representada por uma matriz. A relação de compatibilidade entre os dois modos de bloqueio
usados aqui é apresentada na matriz comp da fig. 14.1. Um elemento comp(A,B) da matriz possui valor
verdadeiro se, e somente se, o modo A é compatível com o modo B.
Note que o modo compartilhado é compatível com o modo compartilhado, mas não com o modo
exclusivo. A qualquer hora podem ser feitos diversos bloqueios compartilhados simultaneamente (por diferentes
transações) sobre um item de dado em particular. Uma solicitação de bloqueio exclusivo precisa esperar até que
um bloqueio compartilhado termine para ser efetivada.
Uma transação solicita um bloqueio compartilhado do item de dado Q executando a instrução lock-S(Q).
Analogamente, um bloqueio exclusivo é solicitado pela instrução lock-X(Q). um item de dado Q pode ser
desbloqueado por outra transação, o gerenciador de controle de concorrência não concederá o bloqueio até que
todos os bloqueios incompatíveis mantidos pela outra transação sejam desfeitos.

279
A transação Ti pode desbloquear um item de dado a qualquer momento. Note que uma transação precisa
manter o bloqueio do item de dado durante todo o tempo de acesso àquele item. Além disso, o desbloqueio
imediatamente após o acesso final nem sempre é interessante, já que pode comprometer a serialização.
Como ilustração, considere novamente o sistema bancário apresentado anteriormente.
Sejam A e B duas contas que são acessadas pelas transações T1 e T2. A transação T1 transfere 50 dólares
da conta A para a conta B e tem a forma:
A transação T2 apresenta o saldo total das contas A e B – isto é, a soma A+B – e é definida por:
Suponha que os saldos de A e B sejam 100 e 200 dólares, respectivamente. Se essas duas transações são
executadas serialmente, na ordem T1, T2 ou T2, T1, então a transação T2 mostrará o valor 300 dólares. Se, no
entanto, essas transações forem executadas concorrentemente, a escala de execução 1, mostrada na fig. 14.2,
pode ocorrer. Nesse caso, a transação T2 mostrará o resultado 250 dólares, que não é correto. A razão desse erro
provém da falta de bloqueio em tempo hábil do item de dado B, com isso T2 mostra uma situação inconsistente.
A escala de execução mostra as ações que são executadas pelas transações, assim como os pontos em
que os bloqueios são concedidos pelo gerenciador de controle de concorrência. Uma transação que pede um
bloqueio não pode executar sua próxima ação até que o bloqueio seja concedido pelo gerenciador de controle de
concorrência; daí o bloqueio precisa ser concedido no intervalo de tempo entre a operação de pedido de
bloqueio e a ação seguinte da transação. Em que momento, exatamente, o bloqueio é concedido imediatamente
antes da ação seguinte da transação. Assim, retiraremos a coluna que indica as ações do gerenciador de controle
de concorrência de todas as escalas de execução apresentadas.
Suponha, agora, que os desbloqueios sejam realizados ao final da transação. A transação T3 é similar à
transação T1, com desbloqueio ao final da transação, e é definida como:
A transação T2 apresenta o saldo total das contas A e B – isto é, a soma A+B – e é definida por:

280
Suponha que os saldos de A e B sejam 100 e 200 dólares, respectivamente. Se essas duas transações são
executadas serialmente, na ordem T1, T2 ou T2, T1, então a transação T2 mostrará o valor 300 dólares. Se, no
entanto, essas transações forem executadas concorrentemente, a escala de execução 1, mostrada na fig. 14.2,
pode ocorrer. Nesse caso, a transação T2 mostrará o resultado 250 dólares, que não é correto. A razão desse erro
provém da falta de bloqueio em tempo hábil do item de dado B, com isso T2 mostra uma situação inconsistente.
A escala de execução mostra as ações que são executadas pelas transações, assim como os pontos em
que os bloqueios são concedidos pelo gerenciador de controle de concorrência. Uma transação que pede um
bloqueio não pode executar sua próxima ação até que o bloqueio seja concedido pelo gerenciador de controle de
concorrência; daí o bloqueio precisa ser concedido no intervalo de tempo entre a operação de pedido de
bloqueio e a ação seguinte da transação. Em que momento, exatamente, o bloqueio é concedido dentro desse
intervalor não é importante; o bloqueio é considerado seguro mesmo que concedido imediatamente antes da
ação seguinte da transação. Assim, retiraremos a coluna que indica as ações do gerenciador de controle de
concorrência de todas as escalas de execução apresentadas aqui.
Suponha, agora, que os desbloqueios sejam realizados ao final da transação. A transação T3 é similar à
transação T1, com desbloqueio ao final da transação, e é definida como:
A transação T4 corresponde à T2, com desbloqueio ao final da transação, e é definida como:

281
Você pode notar que a sequência de leituras e escritas da escala de execução 1, que resulta no total
incorreto de 250 dólares, não ocorre usando T3 e T4. Outras escalas são possíveis. T4 não apresentará um
resultado inconsistente, qualquer que seja a escala de execução.
Infelizmente, o uso de bloqueio pode causar situações indesejáveis. Considere a escala parcial de T3 e T4
na fig. 14.3. Já que T3 mantém um bloqueio exclusivo sobre B, e T4 solicita um bloqueio compartilhado em B, e T4
solicita um bloqueio compartilhado em B, T4 espera que T3 libere B. Analogamente, como T4 mantém um bloqueio
compartilhado de A, e T3 está solicitando um bloqueio exclusivo em A, T3 está esperando que T4 libere A. Assim,
chegamos a uma situação em que nenhuma dessas transações pode processar em sua forma normal. Essa
situação é chamada de deadlock (impasse). Quando um deadlock ocorre, o sistema precisa desfazer uma das duas
transações. Uma vez desfeita a transação, os itens de dados são, então, avaliados por outras transações, que
podem continuar com suas execuções. Retornaremos aos meios de tratamento do deadlock mais adiante.
Se não usarmos o bloqueio, ou desbloqueio, dos itens de dados, tão logo seja possível, após sua leitura ou
escrita, poderemos chegar a resultados inconsistentes. Por outro lado, se não desbloquearmos um item de dados
antes de solicitarmos um bloqueio a outro item de dados, o deadlock poderá ocorrer. Há formas de evitar o
deadlock em algumas situações. Entretanto, em geral, deadlocks são problemas inerentes ao bloqueio, necessário
se desejarmos evitar estados inconsistentes. Os deadlocks podem ser preferíveis a estados inconsistentes, já que
podem ser tratados por meio do rollback (reversão) da transação, enquanto os estados inconsistentes podem
originar problemas reais, não tratados pelo sistema de banco de dados.
Exigimos que cada transação do sistema siga determinado conjunto de regras, chamado de protocolo de
bloqueio, indicando quando uma transação pode ou não bloquear ou desbloquear cada um dos itens de dados. O
protocolo de bloqueio restringe o número de escalas de execução possíveis. O conjunto de todas as escalas desse
tipo é um subconjunto de todas as escalas serializadas possíveis. Apresentaremos diversos protocolos de bloqueio
que permitem somente escalas com serialização de conflitos. Antes de fazê-lo, precisamos de algumas definições.
Seja {T0, T1, ..., Tn} um conjunto de transações participantes de uma escala de execução S. Dizemos que Ti
precede Tj em S, denotando Ti�Tj, se há um item de dado Q tal que Ti consegue bloqueio do tipo A sobre Q e
depois Tj consegue bloqueio do tipo B sobre Q e comp (A,B) = falso. Se Ti�Tj, então essa precedência implica que,
em qualquer escala serial equivalente, Ti precisa aparecer antes de Tj. Observe que esse gráfico é similar ao usado
anteriormente para testar serialização de conflito. Dizemos que um protocolo de bloqueio garante serialização de
conflito se, e somente se, para todas as escalas de execução legais, as relações associadas � são acíclicas.
Concessão de Bloqueios
Quando uma transação solicita bloqueio sobre um determinado item de dado em particular, e nenhuma
outra transação mantém o mesmo item de dado bloqueado de modo conflitante, tal bloqueio pode ser
concedido. Entretanto, é preciso ter cuidado para evitar o seguinte cenário. Suponha que a transação T2 tenha um
bloqueio compartilhado sobre um item de dado e outra transação T1 solicite um bloqueio exclusivo do mesmo

282
item. Claro que T1 terá de esperar até que o bloqueio compartilhado feito por T2 seja liberado. Enquanto isso,
uma transação T3 pode solicitar que um bloqueio compartilhado feito por T2 seja liberado. Enquanto isso, uma
transação T3 pode solicitar um bloqueio compartilhado sobre o mesmo item de dado. O bloqueio pedido é
compatível com o bloqueio concedido a T2, de modo que o bloqueio compartilhado pode ser concedido a T3.
Nessa altura, T2 pode liberar o bloqueio, mas T1 terá de esperar agora, até que T3 termine. Novamente, aparece
uma nova transação T4 que solicita um bloqueio compartilhado sobre o mesmo item de dado e ele é concedido
antes que T3 libere o dado. De fato, é possível que haja uma sequência de transações solicitando bloqueios
compartilhados sobre um item de dado, e que cada uma delas libere seu bloqueio um pouco antes de que novo
bloqueio seja concedido à outra transação, de modo que T1 nunca consegue seu bloqueio exclusivo. A transação
T1 poderá nunca ser processada, e ela é chamada de inane (starved).
Podemos evitar a inanição de transações da seguinte forma. Quando uma transação Ti solicita o bloqueio
do item de dados Q de um modo particular M, o bloqueio é concedido contato que:
1. Não haja nenhuma outra transação com bloqueio sobre Q cujo modo de bloqueio seja conflitante com
M.
2. Não haja nenhuma outra transação que esteja esperando um bloqueio sobre Q e que tenha feito sua
solicitação de bloqueio antes de Ti.
Protocolo de Bloqueio em Duas Fases
Um dos protocolos que garante a serialização é o protocolo de bloqueio em duas fases (two-phase locking
protocol). Esse protocolo exige que cada transação emita suas solicitações de bloqueio e desbloqueio em duas
fases:
1. Fase de expansão. Uma transação pode obter bloqueios, mas não pode liberar nenhum.
2. Fase de encolhimento. Uma transação pode liberar bloqueios, mas não consegue obter nenhum bloqueio
novo.
Inicialmente, uma transação está na fase de expansão. A transação adquire os bloqueios de que precisa.
Tão logo a transação libera um bloqueio, ela entra na fase de encolhimento e não poderá solicitar novos
bloqueios.
Por exemplo, as transações T3 e T4 têm duas fases. Por outro lado, as transações T1 e T2 não têm duas
fases. Note que as instruções de desbloqueio não precisam aparecer no final da transação. Por exemplo, no caso
da transação T3, podemos colocar a instrução unlock(B) logo após a instrução lock-X(A) e ainda assim manter a
propriedade do bloqueio em duas fases.
Podemos mostrar que o protocolo do bloqueio em duas fases garante a serialização de conflitos.
Considere qualquer transação. O ponto da escala no qual a transação obteve seu bloqueio final (o fim da fase de
expansão) é chamado de ponto de bloqueio da transação. Assim, as transações podem ser ordenadas de acordo
com seus pontos de bloqueio – essa ordenação é, de fato, uma ordenação serializada de transações.
O bloqueio em duas fases não garante a ausência de deadlock. Observe que as transações T3 e T4
possuem duas fases, mas na escala de execução 2 (fig. 14.3) elas estão em um deadlock.
Recordamos que, além de serem serializada, é desejável que as escalas de execução não sejam em
cascata. O rollback em cascata pode ocorrer sob o protocolo de bloqueio em duas fases. Como ilustração,
considere a escala da fig. 14.4. Cada transação observa o protocolo de bloqueio em duas fases, mas a falha de T5
depois do passo read(A) da transação T7 ocasiona o rollback em cascata de T6 e T7.

283
Os rollbacks em cascata podem ser evitados por uma modificação no bloqueio em duas fases chamado
protocolo de bloqueio em duas fases severo (strict two-phase locking). O protocolo de bloqueio em duas fases
severo exige, em adição ao bloqueio feito em duas fases, que todos os bloqueios de modo exclusivo tomados por
uma transação sejam mantidos até que a transação seja efetivada. Essa exigência garante que qualquer dado
escrito por uma transação que não foi ainda efetivada seja bloqueado de modo exclusivo até que a transação seja
efetivada, evitando que qualquer outra transação leia o dado em transação.
Outra variante do bloqueio em duas fases é o protocolo de bloqueio em duas fases rigoroso, que exige
que todos os bloqueios sejam mantidos até que a transação seja efetivada. Pode ser facilmente verificado que,
com o bloqueio em duas fases rigoroso, as transações podem ser serializadas na ordem de sua efetivação. A
maioria dos sistemas de banco de dados implementa ou o bloqueio em duas fases severo ou o rigoroso.
Considere as duas transações seguintes para as quais mostramos somente algumas das mais significativas
operações de leitura (read) e escrita (write). A transação T8 é definida como:
A transação T9 é definida como:
Se empregarmos o protocolo de bloqueio em duas fases, então T8 precisará bloquear a1 de modo
exclusivo. Portanto, qualquer execução concorrente de ambas as transações atinge uma execução serial. Note,
entretanto, que T8 precisa de um bloqueio exclusivo de a1 somente ao final de sua execução, quando ela escreve
a1. Assim, se T8 estiver bloqueando ai de modo compartilhado e depois mudar esse bloqueio para o modo
exclusivo, poderemos obter mais concorrência, já que T8 e T9 poderiam manter acesso simultâneo a a1 e a2.
Essa observação remete-nos ao refinamento do protocolo básico do bloqueio em duas fases, no qual a
conversão de bloqueios é permitida. Podemos proporcionar um mecanismo para promover um bloqueio
compartilhado para exclusivo de promoção (upgrade) e de exclusivo para compartilhamento de rebaixamento
(downgrade). A conversão de bloqueio não pode ser arbitrária. Pelo contrário, a promoção só pode acontecer
durante a fase de expansão, enquanto o rebaixamento somente ocorre na fase de encolhimento.
Retornando a nosso exemplo, as transações T8 e T9 podem ser executadas concorrentemente sob o
protocolo de bloqueio em duas fases refinado, como mostra a escala incompleta da fig. 14.5, em que somente
algumas das instruções de bloqueio são mostradas.
Note que uma transação tentando a promoção de um bloqueio do item Q pode ser forçada a esperar.
Essa espera forçada ocorre se Q estiver bloqueado por outra transação em modo compartilhado.

284
Tanto quanto o protocolo de bloqueio em duas fases, o bloqueio em duas fases com conversão de
bloqueio não pode ser arbitrária. Pelo contrário, a promoção só pode acontecer durante a fase de expansão,
enquanto o rebaixamento somente ocorre na fase de encolhimento.
Retornando a nosso exemplo, as transações T8 e T9 podem ser executadas concorrentemente sob o
protocolo de bloqueio em duas fases refinado, como mostra a escala incompleta da fig. 14.5, em que somente
algumas das instruções de bloqueio são mostradas.
Note que uma transação tentando a promoção de um bloqueio do item Q pode ser forçada a esperar.
Essa espera forçada ocorre se Q estiver bloqueado por outra transação em modo compartilhado.
Tanto quanto o protocolo de bloqueio em duas fases, o bloqueio em duas fases com conversão de
bloqueio só gera escalas com serialização de conflito, e as transações podem ser serializadas por seus pontos de
bloqueio. Além disso, se bloqueios exclusivos são mantidos até o final da transação, as escalas são em cascata.
Descreveremos agora um esquema simples, mas muito usado, que gera as instruções de bloqueio e
desbloqueio, automaticamente, para uma transação. Quando uma transação Ti emite uma operação read(Q), o
sistema emite uma instrução lock-S(Q) seguida de uma instrução read(Q). Quando Ti emite uma operação
write(Q), o sistema verifica se Ti ainda mantém um bloqueio compartilhado. Se ainda há, o sistema emite uma
instrução upgrade(Q), seguida de uma instrução write(Q). De outro modo, o sistema emite uma instrução lock-
X(Q), seguida de uma instrução write(Q). Todos os bloqueios obtidos por uma transação são desbloqueados
depois da transação ser efetivada ou abortada.
Para um conjunto de transações, pode haver escalas de serialização de conflito que não sejam obtidas por
meio do protocolo de bloqueio em duas fases. Entretanto, para obter escalas de serialização de conflito por meio
de protocolos de bloqueio sem usar duas fases, precisamos obter informações adicionais sobre as transações ou
impor alguma estrutura, ou ordem, sobre o conjunto de itens de dados dos banco de dados. Na ausência de tais
informações, o bloqueio em duas fases é necessário para a serialização de conflito – se Ti é uma transação que
não está em duas fases, é sempre possível encontrar outra transação Tj que esteja em duas fases, tal que haja
uma escala viável para Ti e Tj que não seja conflitante por serialização.
O bloqueio em duas fases severo e o bloqueio em duas fases rigoroso (com conversão de bloqueios) são
usados extensivamente em sistemas de banco de dados comerciais.
Protocolos com Base em Gráficos (Graph-Based Protocols)
Como dissemos, na ausência de informações a respeito do modo de acesso aos itens de dados, o
protocolo de bloqueio em duas fases é necessário e suficiente para garantir a serialização. Assim, se desejamos
desenvolver protocolos que não usam duas fases, precisamos de informações adicionais sobre como cada
transação desenvolverá seu acesso ao banco de dados. Há diversos modelos que diferem no tocante à quantidade
de informações a proporcionar. O modelo mais simples exige que tenhamos conhecimento anterior sobre a
ordem na qual os itens de banco de dados serão acessados. Fornecidas essas informações, é possível construir
protocolos de bloqueio que não sejam em duas fases, mas que, no entanto, garantem a serialização de conflito.
Para adquirir esse conhecimento prévio, impomos uma ordenação parcial � sobre o conjunto
D={d1,d2,...,dn} de todos os itens de dados. Se di�dj, então qualquer transação que mantenha acesso a ambos, di

285
e dj, deverá acessar primeiro di e depois dj. Essa ordenação parcial pode resultar da organização física ou lógica
dos dados, ou pode ser imposta somente para fins de controle de concorrência.
A ordenação parcial implica que o conjunto D pode ser visto agora como um gráfico acíclico, chamado
gráfico de banco de dados. Por maior simplicidade, restringiremos nossa atenção somente àqueles gráficos que
são árvores raízes. Apresentaremos um protocolo simples, chamado de protocolo de árvore, que é restrito para
emprego somente nos bloqueios exclusivos.
No protocolo de árvore é permitida somente a instrução de bloqueio lock-X. Cada transação Ti pode
bloquear um item de dado no máximo uma vez e deve observar as seguintes regras:
1. O primeiro bloqueio feito por Ti pode ser sobre qualquer dado.
2. Subsequentemente, um certo item de dado Q pode ser bloqueado por Ti somente se os pais de Q
estiverem bloqueados por Ti.
3. Itens de dados podem ser desbloqueados a qualquer momento.
4. Um item de dado que foi bloqueado e desbloqueado por Ti não pode ser rebloqueado por Ti
subsequentemente.
Como colocamos anteriormente, todas as escalas de execução que forem legais sob o protocolo de árvore
que serão conflito serializadas.
Para ilustrar esse protocolo, considere o gráfico do banco de dados da fig. 14.6. As quatro transações
seguintes respeitam o protocolo de árvore desse gráfico. Mostraremos somente as instruções de bloqueio e
desbloqueios:
Uma escala possível em que participam essas quatro transações é a mostrada na fig. 14.7. Note que,
durante a execução, a transação T10 mantém bloqueio sobre duas subárvores separadas.
Observe que a escala da fig. 14.7 é conflito serializada. Não apenas pode ser mostrado que o protocolo de
árvore garante a serialização de conflito, mas também que esse protocolo garante a ausência de deadlock.

286
O protocolo de bloqueio em árvore apresenta a vantagem de realizar o desbloqueio mais cedo do que é
feito no protocolo de bloqueio em duas fases. O desbloqueio feito mais cedo pode reduzir os tempos de espera e
aumentar a concorrência. Além disso, uma vez que o protocolo é resistente a deadlocks, nenhum rollback é
necessário. Entretanto, o protocolo tem a desvantagem de, em alguns casos, uma transação pode manter o
bloqueio de um item de dado que não acessa. Por exemplo, uma transação que precise do acesso aos itens de
dados A e J cujo gráfico do banco de dados é o da fig. 14.6, precisa não somente bloquear A e J, mas também os
itens de dados B, D e H. Esse bloqueio adicional resulta no aumento de overhead relativo aos bloqueios, na
possibilidade de tempo de espera adicional e decréscimo potencial da concorrência. Além disso, sem o
conhecimento prévio de como os itens de dados serão bloqueados, as transações terão de bloquear a raiz da
árvore, o que reduz consideravelmente a concorrência.
Para um conjunto de transações, há escalas conflitos serializadas que não podem ser obtidas pelo
protocolo de árvore. Ainda, há escalas possíveis sob o protocolo de bloqueio em duas fases que também não são
possíveis sob o protocolo de árvore, e vice-versa.
Protocolos com Base em Timestamp (Registro de Tempo)
Nos protocolos de bloqueio, descritos até agora, a ordem entre cada par de transações conflitantes é
determinada durante a execução do primeiro bloqueio que ambas solicitam e que envolve modos incompatíveis.
Outro método para a determinação da ordem serializada é selecionar uma ordenação entre transações em
andamento. O método mais usado é o esquema de ordenação por timestamp.
Timestamp
A cada transação Ti dos sistema associamos um único timestamp fixo, denotado por TS(Ti). Esse
timestamp é criado pelo sistema de banco de dados antes que a transação Ti inicie sua execução. Se uma
transação Ti recebeu o TS(Ti) em uma nova transação Tj entre no sistema, então TS(Ti)<TS(Tj).
Há duas formas simples de implementar esse esquema:
1. Usar a hora do relógio do sistema (clock) como timestamp, isto é, o timestamp de uma transação é igual à
hora em que a transação entra no sistema.
2. Usar um contador lógico que é incrementado sempre que se usa um novo timestamp, isto é, o timestamp
da transação é igual ao valor do contador no momento em que a transação entre no sistema.
Os timestamps das transações determinam a ordem de serialização. Assim, se TS(Ti)<TS(Tj), o sistema
precisa garantir que a escala produzida seja equivalente a uma escala serial em que a transação Ti aparece antes
da transação Tj.
Para implementação desse esquema, associamos a cada item Q dois valores para timestamp:
• W-timestamp(Q) denota o maior timestamp de qualquer transação que execute uma write(Q) com
sucesso.
• R-timestamp(Q) denota o maior timestamp de qualquer transação que execute uma read(Q) com
sucesso.
Esses timestamps são atualizados sempre que uma nova instrução read(Q) ou write(Q) for executada.
O Protocolo de Ordenação por Timestamp
O protocolo de ordenação por timestamp assegura que quaisquer operações de leitura e escrita sejam
executadas por ordem de timestamp. Esse protocolo opera da seguinte forma:
1. Suponha que a transação Ti emita uma read(Q).
a. Se TS(Ti)<W-timestamp(Q), então Ti precisa ler um valor de Q que já foi sobreposto. Assim, a
operação read é rejeitada e Ti é desfeita.
b. Se TS(Ti)≥W-timestamp(Q), então a operação read é executada e R-timestamp(Q) recebe o maior
valor entre R-timestamp(Q) e TS(Ti).
2. Suponha que a transação Ti emita um write(Q).

287
a. Se TS(Ti)<R-timestamp(Q), então o valor de Q que Ti está produzindo foi necessário antes e o
sistema assumiu que aquele valor nunca seria produzido. Logo, a operação write é rejeitada e Ti é
desfeita.
b. Se TS(Ti)<W-timestamp(Q), então Ti está tentando escrever um valor obsoleto em Q. Logo, essa
operação write é rejeitada e Ti é desfeita.
c. De outro modo, a operação write é executada e W-timestamp(Q) é registrado em TS(Ti).
Uma transação Ti que foi desfeita pelo esquema de controle de concorrência, decorrente de uma
operação read ou write, recebe um novo timestamp e é reiniciada.
Para ilustrar esse protocolo, considere as transações T14 e T15. A transação T14 mostra o conteúdo total das
contas A e B e é definida como:
A transação T15 transfere 50 dólares da conta A para a conta B e então apresenta o resultado de ambas:
Nas escalas criadas obedecendo ao protocolo de timestamp, assumimos que uma transação recebe um
timestamp imediatamente antes de sua primeira instrução. Assim, na escala 3 da fig. 14.8, TS(T14)<TS(T15) e a
escala é possível sob o protocolo de timestamp.
Notamos que a execução precedente pode também ser realizada pelo protocolo de bloqueio em duas
fases. Há, entretanto, escalas que são viáveis sob o protocolo de bloqueio em duas fases, mas inviáveis sob o
protocolo de timestamp, e vice-versa.
O protocolo de ordenação por timestamp garante a serialização de conflito. Essa asserção provém do fato
de que operações conflitantes são processadas pela ordem do timestamp. O protocolo garante também
resistência a deadlocks, já que uma transação nunca espera. O protocolo consegue gerar escalas que não podem
ser recuperadas (desfeitas), entretanto ele pode receber uma extensão para fazer escalas cascateadas.
Regra de Escrita de Thomas (Thomas’ Write Rule)
Apresentaremos agora uma modificação no protocolo de ordenação por timestamp que aumenta a
concorrência em potencial em relação àquele que descrevemos anteriormente. Consideremos a escala 4 da fig.
14.9 e apliquemos a ela o protocolo da ordenação por timestamp. Uma vez que T16 começa antes de T17, podemos
considerar que TS(T16)<TS(T17). A operação read(Q) de T16 é executada, assim como a operação write(Q) de T17.
Quando T16 tenta executar sua operação write(Q), descobrimos que TS(T16)<W-timestamp(Q), já que W-
timestamp(Q) = TS(T17). Assim, a operação write(Q) de T16 é rejeitada e a transação T16 precisa ser desfeita.

288
Embora o rollback de T16 seja requerido pelo protocolo da ordenação por timestamp, ele é desnecessário.
Uma vez que T17 já escreveu Q, o valor que T16 está tentando escrever nunca será lido. Qualquer transação Ti com
TS(Ti)<TS(T17) deverá ler o valor de Q que foi escrito por T17 em vez de o valor escrito por T16.
Essa observação sugere uma modificação no protocolo de ordenação por timestamp no qual operações
write obsoletas podem ser ignoradas sob determinadas circunstâncias. As regras de protocolo para as operações
read permanecem inalteradas. As regras de protocolo para as operações write, entretanto, são ligeiramente
diferentes das do protocolo de ordenação por timestamp vista anteriormente:
1. Se TS(Ti)<R-timestamp(Q), então o valor de Q que Ti está produzindo foi necessário anteriormente, e
assumiu-se que o valor nunca seria produzido. Logo, a operação write é rejeitada e Ti é desfeita.
2. Se TS(Ti)<W-timestamp(Q), então Ti está tentando escrever um valor obsoleto para Q. Logo, a operação
write pode ser ignorada.
3. De outro modo, a operação write é executada e W-timestamp(Q) recebe o valor de TS(Ti).
A diferença entre essas regras e as apresentadas anteriormente está na segunda regra. O protocolo de
ordenação por timestamp exige que Ti seja desfeita se emitir uma write(Q) e TS(Ti)<W-timestamp(Q). Entretanto,
aqui, nos casos em que TS(Ti)≥W-timestamp(Q). Entretanto, aqui, nos casos em que TS(Ti)≥R-timestamp(Q),
ignoramos writes obsoletas. Essa modificação no protocolo de ordenação por timestamp é chamada de regra de
escrita de Thomas.
A regra de escrita de Thomas faz uso da serialização de visão, eliminando, com efeito, as operações de
write obsoletas das transações que as emitem. Essa modificação torna possível a geração de escalas de execução
serializadas que não poderiam ocorrer sob outros protocolos apresentados aqui. Por exemplo, a escala 4 da fig.
14.9 é não-conflito serializada e, assim, não é viável sob qualquer protocolo de bloqueio em duas fases, protocolo
de árvore ou de ordenação por timestamp. Sob a regra escrita de Thomas, a operação write(Q) da T16 poderia ser
ignorada. O resultado é uma escala cuja visão é equivalente à escala serial <T16, T17>.
Protocolos com Base em Validação
Nos casos em que a maioria das transações é somente de leitura, a taxa de conflitos entre as transações
pode ser baixa. Assim, algumas dessas transações, se executadas sem a supervisão de um esquema de controle
de concorrência, poderiam deixar o sistema sempre em estado consistente. Um esquema de controle de
concorrência impõe overhead relativo à execução de mais código e possível atraso nas transações. Pode ser
interessante usar um esquema alternativo que resulte em menor overhead. Uma dificuldade enfrentada para a
redução de overhead é que não sabemos a priori quais transações serão envolvidas em conflito. Para obter essa
informação, precisamos de um esquema para a monitoração do sistema.
Consideramos que cada transação Ti é executada em duas ou três fases diferentes, dependendo se é uma
transação somente de leitura ou de atualização. Essas fases são, em ordem, as seguintes:
1. Fase de leitura. Durante essa fase, a execução da transação Ti tem início. Os valores de diversos itens de
dados são lidos e armazenados em variáveis locais para Ti. Todas as operações de escrita são processadas
com variáveis locais temporárias, sem alterar de fato o banco de dados.
2. Fase de validação. A transação Ti processa um teste de validação para determinar se pode copiar no
banco de dados as variáveis locais temporárias que mantêm os resultados das operações de escrita sem,
com isso, causar a violação da serialização.
3. Fase de escrita. Se a transação Ti obtém sucesso na validação (passo 2), então a atualização é aplicada de
fato ao banco de dados. Caso contrário, Ti é desfeita.
Cada transação precisa passar pelas três fases, na ordem mostrada. Entretanto, as três fases de
transações em execução concorrentes podem ser intercaladas.

289
As fases de leitura e escrita são autoexplicativas. A única fase que exige mais explicações é a de validação.
Para realizar os testes de validação, precisamos saber quando ocorreram as diversas fases da transação Ti.
Precisamos, portanto, associar três timestamps diferentes para a transação Ti:
1. Start(Ti), o momento em que Ti teve início.
2. Validation(Ti), o momento em que Ti terminou sua fase de leitura e começou sua fase de validação.
3. Finish(Ti), o momento em que Ti terminou sua fase de escrita.
Determinamos a ordem de serialização pela técnica de ordenação por timestamp, usando o valor do
timestamp da Validation(Ti). Assim, o valor de TS(Ti)=Validation(Ti) e, se TS(Tj)<TS(Tk), então qualquer escala criada
precisa ser equivalente à escala serializada na qual a transação Tj aparece antes da transação Tk. A razão para
escolhermos Validation(Ti) em vez de Start(Ti) como timestamp da transação Ti é que, com isso, podemos esperar
menor tempo de resposta, com a condição de que as taxas de conflito entre transações sejam com certeza
pequenas.
O teste de validação para Ti exige que, para todas as transações Ti com TS(Ti)<TS(Tj), uma das duas
condições a seguir seja realizada:
1. Finish(Ti)<Start(Ti). Já que Ti completa sua execução antes de Tj começar, a ordem de serialização é com
certeza mantida.
2. Não há interseção entre o conjunto de itens de dados escritos por Ti e o conjunto de dados lidos por Tj, e
Ti completa sua fase de escrita antes de Tj começar sua fase de validação
(Start(Tj)<Finish(Ti)<Validation(Tj)). Essa condição garante que as escritas de Ti e Tj não sejam sobrepostas.
Uma vez que a escrita de Ti não afeta a leitura de Tj e que Tj não pode afetar a leitura de Ti, a ordem de
serialização é com certeza mantida.
Como ilustração, considere novamente as transações T14 e T15. Suponha que TS(T14)<TS(T15). Então, a fase de
validação consegue produzir a escala de execução 5, que é apresentada na fig. 14.10. Note que a escrita das
variáveis reais é realizada somente após a fase de validação de T15. Assim, T14 lê valores desatualizados de A e B e
essa é serializada.
O esquema de validação evita, automaticamente, os rollbacks em cascata, já que as escritas reais
acontecem somente depois que a transação que emitiu a solicitação de escrita tenha sido efetivada.
Granularidade Múltipla
Nos esquemas de concorrência descritos até agora, estivemos usando cada item de dado individual como
uma unidade à qual a sincronização é aplicada.
Há circunstâncias, no entanto, em que pode ser vantajoso o agrupamento de diversos itens de dados,
tratando-os como uma unidade de sincronização individual. Por exemplo, se uma transação Ti precisa do acesso a
todo o banco de dados e um protocolo de bloqueio é usado, Ti precisará bloquear cada um dos itens do banco de
dados. Logicamente, esse bloqueio é um consumidor de tempo. Seria melhor Ti emitir uma única solicitação de
bloqueio a todo o banco de dados. Por outro lado, se uma transação Tj precisa do acesso a somente alguns itens
de dados, não é necessário bloquear todo o banco de dados, porque, desse modo, a concorrência é perdida.
É preciso um mecanismo que permita ao sistema definir diferentes múltiplos de granulação. Podemos
desenvolver um desses mecanismos permitindo diversos tamanhos aos itens de dados e definindo uma hierarquia

290
de granularidade de dados, em que as granulações menores sejam aninhadas às maiores. Tal hierarquia pode ser
representada graficamente como uma árvore. Note que a árvore que descrevemos aqui é bastante diferente da
usada no protocolo de árvore. O nó sem ramificações de uma árvore de granularidade múltipla representa o dado
associado a seus descendentes. No protocolo de árvore, cada nó representa um item de dado independente.
Como ilustração, considere a árvore da fig. 14.11, consistindo em nós em quatro níveis. O nível mais alto
representa o banco de dados como um todo. Abaixo, há nós do tipo área; o banco de dados é constituído
exatamente dessas áreas. Cada área, por sua vez, possui nós do tipo arquivo como filhos. Cada área é constituída
exatamente daqueles arquivos que são seus nós filhos. Nenhum arquivo está em mais de uma área. Finalmente,
cada arquivo possui nós do tipo registro. Como antes, o arquivo é constituído exatamente daqueles registros que
são seus nós filhos, e nenhum registro pode estar em mais de um arquivo.
Cada nó de uma árvore pode ter bloqueio individual. Como foi feito no protocolo de bloqueio em duas
fases, usaremos os modos de bloqueio exclusivo e compartilhado. Quando uma transação bloqueia um nó, tanto
no modo compartilhado quanto no exclusivo, a transação também bloqueará todos os descendentes daquele nó
no mesmo modo de bloqueio. Por exemplo, se a transação Ti bloqueio de forma explícita o arquivo Fc da fig.
14.11, no modo exclusivo, então ela está bloqueando de forma implícita, no modo exclusivo, todos os registros
pertencentes àquele arquivo. Ela não precisará fazer, de forma explícita, o bloqueio individual dos registros de Fc.
Suponha que uma transação Tj queira bloquear o registro rb6 do arquivo Fb. Dado que Ti bloqueou Fb de
forma explícita, segue que rb6 está também bloqueado (de forma implícita). Mas, quando Tj emite uma solicitação
de bloqueio para rb6, este não bloqueado de modo explícito! Como o sistema determinará se Tj pode bloquear rb6?
Tj precisará percorrer a árvore da raiz até o registro rb6. Se algum modo nó do caminho estiver bloqueado de
modo incompatível, então Tj precisará esperar.
Suponha, agora, que a transação Tk deseja bloquear todo o banco de dados. Para isso, ela precisa
simplesmente bloquear a raiz hierárquica. Note, entretanto, que Tk não deve conseguir o bloqueio no nó raiz, já
que Ti já está bloqueado, como acontece com parte da árvore (especificamente, o arquivo Fb). Mas, agora, como o
sistema determinará se o nó raiz poderá ser bloqueado? Uma solução seria pesquisar a árvore inteira. Essa
solução, entretanto, se antepõe ao proposito do esquema do bloqueio de granularidade múltipla. Um meio mais
eficiente seria introduzir uma nova classe de modo de bloqueio, chamado modo de bloqueio intencional. Se um
nó é bloqueado no modo intencional, o bloqueio explícito será feito no nível mais baixo da árvore (isto é, na
granularidade mais fina). Bloqueios intencionais serão feitos em todos os antecessores do nó antes que aquele nó
seja bloqueado de forma explícita. Assim, uma transação não precisa pesquisar a árvore inteira para determinar
se poderá bloquear um nó. Uma transação que queira bloquear um nó – digamos, Q – precisa percorrer o
caminho, pela árvore, do nó até Q. Enquanto se percorre a árvore, os bloqueios das transações são feitos de
modo intencional.
Há um modo intencional associado ao modo compartilhado e um relacionado ao modo exclusivo. Se um
nó é bloqueado no modo compartilhado-intencional (intention-shared – IS), o bloqueio explícito está sendo feito
no nível mais baixo da árvore, mas com somente bloqueios de modo compartilhado.
Analogamente, se um nó é bloqueado no modo exclusivo-intencional (intention-exclusive – IX), então o
bloqueio explícito está sendo feito no nível mais baixo, no modo exclusivo ou compartilhado. Finalmente, se um
nó está bloqueado nos modos de bloqueio é apresentada na fig. 14.12.

291
O protocolo de bloqueio de granularidade múltipla garante a serialização. Cada transação Ti pode
bloquear um nó Q, usando as seguintes regras:
1. A função de compatibilidade de bloqueio da fig. 14.12 precisa ser observada.
2. A raiz da árvore precisa ser bloqueada primeiro e pode ser bloqueada em qualquer modo.
3. Um nó Q pode ser bloqueado por Ti no modo S ou IS somente se o pai de Q for bloqueado por Ti no modo
IX ou IS.
4. Um nó Que pode ser bloqueado por Ti no modo X, SIX ou IX somente se o pai de Q estiver bloqueado por
Ti no modo IX ou no modo SIX.
5. Ti pode bloquear um nó somente se ele não desbloqueou outro nó anteriormente (isto é, Ti tem duas
fases).
6. Ti pode desbloquear um nó Que somente se nenhum dos filhos de Que estiver bloqueado por Ti.
Observe que o protocolo de granularidade múltipla exige que os bloqueios sejam feitos de cima para
baixo (top-down – da raiz para as folhas), enquanto a liberação deve ser de baixo para cima (bottom-up – das
folhas para a raiz).
Para ilustrar o protocolo, considere a árvore da fig. 14.11 e as seguintes transações:
• Suponha que a transação T18 leia o registro ra2 do arquivo Fa. Então, T18 precisa bloquear o banco de
dados, a área A1, o arquivo Fa no modo IS (nessa ordem) e, finalmente, bloquear ra2 no modo S.
• Suponha que a transação T19 altere o registro ra9 do arquivo Fa. Então, T19 precisa bloquear o banco de
dados, a área A1, o arquivo Fa no modo IX e, finalmente, bloquear ra9 no modo X.
• Suponha que a transação T20 leia todos os registros do arquivos Fa. Então, T20 precisa bloquear o banco de
dados e a área A1 (nesse ordem) no modo IS e, finalmente, bloquear Fa no modo S.
• Suponha que a transação T21 leia todo o banco de dados. Então, poderá fazê-lo depois de bloquear o
banco de dados no modo S.
Podemos notar que as transações T18, T20, e T21 mantêm acesso ao banco de dados concorrentemente. A
transação T19 pode concorrer com T18, mas não com T20 nem T21.
Esse protocolo aumenta a concorrência e reduz o overhead por bloqueio. Isso é particularmente útil em
aplicações que misturam:
• Transações curtas que mantêm acesso em poucos itens de dados.
• Transações longas que produzem relatórios a partir de um arquivo ou de um conjunto de arquivos.
Há protocolos de bloqueio similares que são aplicados a sistemas de banco de dados nos quais a
granularidade é organizada na forma de gráficos acíclicos.
Esquemas de Multiversão
Os esquemas de controle de concorrência discutidos até aqui garantem a serialização atrasando a
operação ou abortando a transação responsável por tal operação. Por exemplo, uma operação de read pode ser
retratada se o valor apropriado em questão ainda estiver sendo escrito; ou pode ser rejeitada se o valor
apropriado em questão ainda estiver sendo escrito; ou pode ser rejeitada (isto é, a transação que emitiu tal
solicitação deve ser abortada) porque o valor lido já foi alterado. Essas dificuldades podem ser evitadas se o
sistema providenciar cópias anteriores de cada item de dado.
Em um sistema de banco de dados multiversão, cada operação write(Q) cria uma nova versão de Q.
Quando é emitida uma operação read(Q), o sistema seleciona uma das versões de Q para ser lida seja tal que

292
assegure a serialização. É crucial, por razões de desempenho, que uma transação possa determinar fácil e
rapidamente qual versão do item de dados poderá ser lido.
Multiversão com Ordenação por Timestamp
A técnica mais usada nos esquemas de multiversão é o timestamp. A cada transação Ti do sistema é
associado um timestamp único e estático, denotado por TS(Ti). Esse timestamp é associado antes do início da
execução da transação, conforme já descrito.
Para cada idem de dado Q, uma sequência de versões < Q1, Q2, ..., Qm> é associada. Cada versão Qk
contém três campos de dados:
• Content (conteúdo) é o valor da versão Qk.
• W-timestamp(Qk) é o timestamp da transação que criou a versão Qk.
• R-timestamp(Qk) é o timestamp mais alto de alguma transação que tenha lido a versão Qk com sucesso.
Uma transação – digamos, Ti – cria uma nova versão Qk do item de dado Q emitindo uma operação
write(Q). O campo conteúdo da versão mantém o valor escrito por Ti. O W-timestamp e o R-timestamp são
inicializados por TS(Ti). O valor de R-timestamp é atualizado sempre que uma transação Tj lê o conteúdo de Qk e
R-timestamp é atualizado sempre que uma transação Tj lê o conteúdo de Qk e R-timestamp(Qk)<TS(Tj).
O esquema de multiversão com timestamp apresentado a seguir garante a serialização. O esquema opera
da forma descrita a seguir. Suponha que uma transação Ti emita uma operação read(Q) ou write(Q). Seja Qk a
versão de Q cujo timestamp de escrita é o mais alto timestamp, menor ou igual a TS(Ti).
1. Se a transação Ti emitir uma read(Q), então o valor recebido será o conteúdo da versão Qk.
2. Se a transação Ti emitir um write(Q) e TS(Ti)<R-timestamp(Qk), o conteúdo de Qk é sobreposto; caso
contrário, outra versão de Q é criada.
A justificativa para a regra 1 é clara. Uma transação lê a versão mais recente anterior a ela. A segunda
regra força o aborto de uma transação se for “tarde demais” para que se faça uma escrita. Mais precisamente, se
Ti tentar escrever uma versão que alguma outra transação já tenha lido, então não poderemos permitir que essa
escrita seja bem-sucedido.
As versões que não forem mais necessárias serão removidas conforme a regra seguinte. Suponha que
haja duas versões, QK e Qj, de um item de dados e que ambas as versões tenha o W-timestamp menor que o
timestamp da última transação do sistema. Então, a mais antiga entre as versões QK e Qj não será usada
novamente e pode ser eliminada.
O esquema multiversão ordenada por timestamp possui a adequada propriedade de garantir que uma
solicitação de leitura nunca falhe e nunca espere. Em um sistema de banco de dados típico, em que as operações
de leitura são mais frequentes que as de escrita, essa vantagem é de grande importância prática.
O esquema, entretanto, possui duas propriedades indesejáveis. Primeiro, a leitura de um item de dados
exige também a atualização do campo R-timestamp, resultando em dois acessos ao disco, em vez de apenas um.
Segundo, os conflitos entre transações são resolvidos por rollback, em vez da imposição de tempo de espera. Essa
alternativa pode ser onerosa. Um algoritmo para amenizar o problema será descrito na próxima seção.
Multiversão com Bloqueio em Duas Fases
O protocolo de multiversão com bloqueio em duas fases tenta combinar as vantagens do controle de
concorrência multiversão com as vantagens do bloqueio em duas fases. Esse protocolo diferencia transações
somente de leitura das transações de atualização. As transações de atualização executam um bloqueio em duas
fases rigorosas, isto é, elas mantêm todos os bloqueios até o final da transação. Assim, podem ser serializadas de
acordo com sua ordem de efetivação. Cada item de dado possui um único timestamp. O timestamp não é, nesse
caso, baseado no horário, mas em um contador, que será chamado de ts_counter, que é incrementado durante o
processo de efetivação.

293
Marcamos o timestamp das transações somente de leitura por meio do valor corrente do contador, ou
seja, lendo o valor de ts_counter antes de começar sua execução; para a leitura, elas seguem o protocolo de
multiversão ordenada por timestamp. Com isso, quando uma transação Ti desse tipo emite uma read(Q), o valor
recebido é o conteúdo da versão cujo timestamp é o inferior a TS(Ti) mais próximo.
Quando uma transação de atualização lê um item, ela impõe um bloqueio compartilhado ao item e lê a
última versão do item. Quando uma transação de atualização deseja escrever um item, ela primeiro consegue o
bloqueio exclusivo desse item e, então, cria uma nova versão do item de dados. A escrita é realizada a partir da
nova versão e o timestamp da nova versão recebe ∞ como valor inicial, que é maior que qualquer outro
timestamp possível.
Quando uma transação de atualização Ti completa suas ações, ela realiza o processo de efetivação da
seguinte forma: primeiro, Ti adiciona 1 ao valor de ts_counter e transfere esse valor aos timestamp de todas as
versões que criou; então, Ti adiciona 1 ao ts_counter. Somente uma transação de atualização por vez pode
realizar o processo de efetivação.
Como consequência, as transações somente de leitura que começarem depois de Ti incrementar o
ts_counter acessarão o valor atualizado por Ti, enquanto aquelas que começarem antes do incremento de
ts_counter, feito por Ti, verão o valor anterior à atualização de Ti. Nesse caso, as transações somente de leitura
jamais precisarão esperar por bloqueios.
As versões são eliminadas de modo similar à multiversão com ordenação por timestamp. Suponha que
haja duas versões, QK e Qj, de um item de dado e que ambas as versões tenham timestamp menor que o da
última transação somente de leitura processada no sistema. Logo, a mais antiga entre as duas versões QK e Qj
não será mais usada e pode ser eliminada.
A multiversão com bloqueio em duas fases ou variações são aplicadas a alguns sistemas de banco de
dados comerciais.
Manuseio do Deadlock
Um sistema está em estado de deadlock se há um conjunto de transações, tal que toda a transação desse
conjunto está esperando outra transação também nele contida. Mais precisamente, há um conjunto de
transações esperando {T0,T1,...,Tn}, tal que T0 está esperando um item de dado mantido por T1, T1 está esperando
um item de dado mantido por T2, ..., Tn-1 está esperando um item de dados mantido por Tn e Tn está esperando
por um item de dado mantido por T0. Nenhuma dessas transações poderá prosseguir em uma situação dessas. O
único remédio para essa situação indesejável é uma ação drástica do sistema, como reverter uma das transações
envolvidas no deadlock.
Há dois métodos principais para o tratamento do deadlock. Podemos usar o protocolo de prevenção de
deadlock para garantir que o sistema nunca entrará em tal situação. Ou podemos permitir que o sistema entre
em estado de deadlock e, então, removê-lo dessa situação, recuperando-o por meio dos esquemas de detecção
de deadlock e recuperação de deadlock. Como vimos, ambos os métodos podem acabar por reverter uma
transação (rollback). A prevenção é mais utilizada se a probabilidade do sistema que entrar deadlock for
relativamente alta; caso contrário, a detecção e recuperação são mais eficientes.
Note que os esquemas de detecção e recuperação implicam overhead relativo, não somente ao tempo de
processamento do sistema para manutenção das informações necessárias e para a execução do algoritmo de
detecção, mas também devido às perdas potenciais inerentes advindas da recuperação de um deadlock.
Prevenção de Deadlock
Há duas abordagens para a prevenção de deadlock. Uma garante que nenhum ciclo de espera poderá
ocorrer pela ordenação de solicitações de bloqueios, ou obrigando que todos os bloqueios sejam obtidos juntos.
Outra aproxima-se da recuperação do deadlock, fazendo com que a transação seja refeita, em vez de esperar um
bloqueio, sempre que a espera possa potencialmente ocorrer um deadlock.

294
O esquema mais simples sob a primeira abordagem obriga cada transação a bloquear todos os itens de
dados antes de sua execução. Além disso, ou todos são bloqueados de uma vez ou nenhum o será. Há duas
desvantagens nesse protocolo. A premiria, normalmente, é a dificuldade em prever, antes da transação começar,
quais itens de dados precisarão de bloqueio. Segundo, a utilização do item de dados pode ser bastante reduzida,
já que muitos dos itens de dados podem ser bloqueados e não ser usados pro um longo período.
Outro esquema de prevenção de deadlock é feito pela imposição de ordenação parcial de todos os itens
de dados e pela obrigação de que a transação bloqueie um item de dado somente na ordem especificada na
ordenação parcial. Vimos um desses esquemas no protocolo de árvore.
A segunda abordagem para a prevenção de deadlock é a preempção e o rollback de transações. Na
preempção, quando uma transação T2 solicita um bloqueio que está sendo mantido pela transação T1, o bloqueio
concedido a T1 pode ser revisto por meio do rollback de T1, e concedido a T2. Para controle da preempção,
consideramos um único timestamp para cada transação. O sistema usa esses timestamps somente para decidir se
a transação pode esperar ou será revertida. O bloqueio é ainda usado para controle de concorrência. Se uma
transação for revertida, ela manterá seu timestamp antigo quando for reiniciada. São propostos dois esquemas
diferentes de prevenção de deadlock usando timestamp:
1. O esquema esperar-morrer (wait-die) tem por base uma técnica de não-preempção. Quando uma
transação Ti solicita um item de dado mantido por Tj, Ti pode esperar somente se possuir um timestamp
menor que o de Tj (isto é, Ti é mais antiga que Tj). Caso contrário, Ti será revertida (morta). Por exemplo,
suponha que as transações T22, T23 e T24 tenham timestamps 5, 10 e 15, respectivamente. Se T24 solicita
um item de dado mantido por T23, então T24 será desfeita. Se T24 solicitar um item de dado mantido por
T23, então T24 esperará.
Sempre que as transações forem revertidas, é importante garantir que não haja inanição (starvation) –
isto é, que nenhuma transação seja desfeita continuamente e jamais possa continuar seu processamento.
Ambos os esquemas, esperar-morrer e ferir-esperar, evitam a inanição: qualquer que seja o momento, é
possível encontrar a transação com menor timestamp. Essa transação não será revertida em nenhum dos
esquemas. Uma vez que os timestamps sempre crescem, e dado que as transações não recebem dois novos
timestamps se foram revertidas, a transação revertida, em determinado momento, terá o menor timestamp.
Assim, ela não será revertida novamente.
Há entretanto, diferenças significativas entre as formas dos dois esquemas operar.
• No esquema esperar-morrer, a transação mais antiga precisará esperar até que a mais nova libere seus
itens dados. Assim, quanto mais antiga a transação, maior a possibilidade de esperar. Em contraste, no
esquema ferir-esperar, a transação mais antiga nunca espera a mais nova.
• No esquema esperar-morrer, se uma transação Ti morre e é desfeita porque solicitou um item de dado
preso por uma transação Tj, então Ti pode reemitir a mesma sequência de solicitações quando for
reiniciada. Se os itens de dados ainda estiverem presos por Tj, então Ti morrerá novamente. Assim, Ti
poderá morrer diversas vezes antes de conseguir o item de dados necessário. Compare essa série de
eventos com o que acontece no esquema ferir-esperar. A transação Ti será ferida e revertida porque Tj
solicitou um item de dados preso por ela. Quando Ti reinicia e solicita o item de dado preso por Tj, Ti
esperará. Com isso, deve haver menos reversões do esquema ferir-esperar.
O maior problema com ambos os esquemas é que podem ocorrer rollbacks desnecessários.
Esquemas com Base em Tempo Esgotado (Timeout)
Outro enfoque simples para o tratamento de deadlocks tem por base o tempo esgotado para o bloqueio
(lock timeouts). Dessa forma, uma transação que tenha solicitado um bloqueio espera por ele determinado
período de tempo. Se o bloqueio não for conseguido dentro desse intervalo, é dito que o tempo da transação está
esgotado, assim ela mesma se reverte e se reinicia. Se de fato estiver ocorrendo um deadlock, uma ou mais
transações nele envolvidas terão seu tempo esgotado e se revertem, permitindo a continuação de outras. Esse

295
esquema pode ser considerado alguma coisa entre prevenção de deadlock, dado que o deadlock nunca ocorre, e
detecção e recuperação, já discutidas.
O esquema de tempo esgotado é particularmente fácil de ser implementado, trabalha bem se as
transações forem curtas e longas esperas são frequentemente em função dos deadlocks. Entretanto, em geral é
difícil decidir por quanto tempo a transação deve esperar. Esperas muito longas implicam atrasos desnecessários,
dado que esteja ocorrendo um deadlock. Esperas muito curtas resultam em transações sendo revertidas mesmo
sem deadlock, desperdiçando recursos. A inanição também é possível nesse esquema. Então ocorre a aplicação
limitada do esquema com base em tempo esgotado.
Detecção de Deadlock e Recuperação
Se um sistema não usa um protocolo resistente ao deadlock, ou seja, que garanta que deadlocks não
aconteçam, então um esquema para detecção e recuperação precisa ser aplicado. Um algoritmo que examina o
estado do sistema é evocado periodicamente para determinar se um deadlock está ocorrendo. Se estiver, então o
sistema precisa tentar recuperar-se. Para isso, ele precisa:
• Manter informações sobre a alocação corrente dos itens de dados para transações, assim como qualquer
solicitação de itens de dados pendente.
• Proporcionar um algoritmo que use essas informações para determinar se o sistema entrou em estado de
deadlock.
• Recuperar-se de um deadlock quando o algoritmo de detecção determinar que ele ocorreu.
Detecção de Deadlock
Os deadlocks podem ser precisamente descritos em, termos de um gráfico chamado gráfico de espera.
Esse gráfico consiste em um par G=(V,E), em que V é um conjunto de vértices e E, um conjunto de arestas. O
conjunto de vértices consiste em todas as transações do sistema. Cada elemento do conjunto E de arestas é um
par ordenado Ti�Tj. Se Ti�Tj está em E, então o sentido da aresta, da transação Ti para Tj, implica que a
transação Ti está esperando que a transação Tj libere o item de dado de que ela precisa.
Quando a transação Ti solicita um item de dado que está preso pela transação Tj, então a aresta Ti�Tj é
inserida no gráfico de espera. Essa aresta é removida somente quando a transação Tj não estiver mais esperando
um item de dado necessário à transação Ti.
Há um deadlock no sistema se, e somente se, o gráfico de espera contiver um ciclo. Cada transação
envolvida em um ciclo está em deadlock. Para detectar deadlocks, o sistema precisa manter o gráfico de espera e,
periodicamente, evocar um algoritmo que verifique a existência de ciclos.
Para ilustrar esses conceitos, considere o gráfico de espera da fig. 14.13, que exibe a seguinte situação:
• A transação T25 está esperando as transações T26 e T27.
• A transação T27 está esperando a transação T26.
• A transação T26 está esperando a transação T28.
Uma vez que não há ciclos, o sistema não está em estado de deadlock.
Suponha agora que a transação T28 esteja solicitando um item preso por T27. A aresta T28�T27 será
adicionada ao gráfico de espera, alterando o estado do sistema, como mostrado na fig. 14.14. A essa altura, o
gráfico contém o ciclo:
implicando que as transações T26, T27 e T28 estão todas em deadlock.

296
Consequentemente, impõe-se a questão: quando evocaremos o algoritmo de detecção será evocado com
mais frequência que o usual. Os itens de dados alocados nas transações em deadlock não estarão disponíveis para
outras transações até que o deadlock seja resolvido. Além disso, o número de ciclos no gráfico pode crescer
também. Na pior das hipóteses, evocaríamos o algoritmo de detecção sempre que uma solicitação de alocação
não puder ser atendida imediatamente.
Recuperação após um Deadlock
Quando um algoritmo de detecção determina a existência de um deadlock, o sistema precisa recuperar-
se desse deadlock. A solução mais comum é reverter uma ou mais transação para quebrar o deadlock. Devem ser
tomadas três ações:
1. Selecionar uma vítima. Dado um conjunto de transações em deadlock, precisamos determinar quais
transações (ou transação) serão desfeitas para quebrar o deadlock. Poderíamos reverter as transações
que representam o menor custo. Infelizmente, o termo mínimo custo não é preciso. Muitos fatores
podem determinar o custo de um rollback, incluindo:
a. A quanto tempo a transação está em processamento e quanto tempo será ainda necessário para
que a tarefa seja completada.
b. Quantos itens de dados a transação usou.
c. Quantos itens ainda a transação usará até que se complete.
d. Quantas transações serão envolvidas no rollback.
2. Rollback. Uma vez decidido que uma transação em particular será revertida, precisamos determinar até
que ponto ela deverá ser revertida. A solução mais simples é revertê-la totalmente: abortá-la para depois
reiniciá-la. Entretanto, é mais eficaz reverter a transação somente o suficiente para a quebra do deadlock.
Mas esse método exige que o sistema mantenha informações adicionais sobre o estado de todas as
transações em execução.
3. Inanição. Em um sistema no qual a seleção de vítimas tem por base fatores de custo, pode acontecer de
uma mesma transação ser sempre escolhida vítima. Assim, essa transação nunca se completa. Essa
situação é chamada de inanição. Precisamos garantir que uma transação seja escolhida vítima somente
um número finito (pequeno) de vezes. A solução mais comum é incluir o número de reversão no fator de
custos.
Operações de Inserção e Remoção
Até agora restringimos nossa atenção a operações read e write. Essas restrições limita a ação das
transações sobre os itens de dados existentes no banco de dados. Algumas transações precisam não somente de
acesso a itens de dados existentes, mas também da capacidade de criar novos itens de dados. Outras precisam
remover itens de dados. Para examinar como tais transações afetam o controle de concorrência, introduzimos as
seguintes operações adicionais:
• delete(Q) remove o item de dados Q do banco de dados.
• insert(Q) insere um novo item de dados Q em um banco de dados e designa um valor inicial para ele.
Uma transação Ti que queira operar uma read(Q) depois da remoção de Q resulta em erro lógico em Ti.
Analogamente, se uma transação Ti quiser realizar uma operação de read(Q) antes da inserção de Q, também
haverá erro lógico em Ti. Também será um erro lógico tentar remover um item de dados inexistente.

297
Remoção
Para entender como uma instrução de remoção (delete) afeta o controle de concorrência, precisamos
definir quando ela entra em conflito com outra instrução. Seja Ii e Ij instruções de Ti e Tj, respectivamente, que
aparecem nessa ordem na escala de execução S. Seja Ii= delete(Q). Consideremos as seguintes instruções Ij.
• Ij = read(Q). Ii e Ij entram em conflito. Se Ii começou antes de Ij, Tj incorrerá em erro lógico. Se Ij começou
antes de Ii, Tj poderá executar a operação read com sucesso.
• Ij = write(Q). Ii e Ij entram em conflito. Se Ii começou antes de Ij, Tj incorrerá em erro lógico. Se Ij começou
antes de Ii, Tj poderá executar a operação write com sucesso.
• Ij = delete(Q). Ii e Ij entram em conflito. Se Ii começou antes de Ij, Tj incorrerá em erro lógico. Se Ij começou
antes de Ii, Ti incorrerá em erro lógico.
• Ij = insert(Q). Ii e Ij entram em conflito. Suponha que o item de dado Q não exista antes da execução de Ii e
Ij. Então, se Ii começou antes de Ij, ocorrerá erro lógico em Ti. Se Ij começou antes de Ii não ocorrerá
nenhum erro lógico. Da mesma forma, se Q existir antes da execução de Ii e Ij, poderá ocorrer erro lógico
se Ij começou antes de Ii, caso contrário não.
Podemos concluir que, se o bloqueio em duas fases for usado, é preciso um bloqueio exclusivo sobre o
item de dados antes que ele possa ser removido. Sob o protocolo de ordenação por timestamp, um teste que ele
possa ser removido. Sob o protocolo de ordenação por timestamp, um teste similar ao indicado para a write
precisará ser realizado. Suponha que a transação Ti emita um delete(Q).
• Se TS(Ti)<R-timestamp(Q), então o valor de Q que Ti removeu já havia sido lido pela transação Tj com
TS(Tj)>TS(Ti). Então, a operação delete será rejeitada e Ti será revertida.
• Se TS(Ti)<W-timestamp(Q), então uma transação Tj com TS(Ti)>TS(Tj) já gravou Q. Com isso, essa operação
delete será rejeitada e Ti será desfeita.
• De outro modo a operação delete será executada.
Inserção
Vimos que uma operação insert(Q) entra em conflito com uma operação delete(Q). Analogamente,
insert(Q) entra em conflito com uma operação read(Q) ou uma operação write(Q). nenhuma read ou write pode
ser realizada sobre um item de dados antes que ele exista.
Uma vez que insert(Q) estabeleça um valor para o item de dado Q, a insert é tratada de modo similar à
write para efeito de controle de concorrência:
• Sob o protocolo de bloqueio em duas fases, se Ti realizar uma operação insert(Q), Ti estará impondo um
bloqueio exclusivo para o novo item de dado Q criado.
• Sob o protocolo de ordenação por timestamp, se Ti realizar uma operação insert(Q), os valores de R-
timestamp(Q) e W-timestamp(Q) serão registros em TS(Ti).
O Fenômeno do Fantasma
Considere a transação T29 que executa a consulta SQL a seguir:
A transação T29 obriga o acesso a todas as tuplas da relação conta pertencentes a agência Perryridge.
Seja T30 uma transação que executa a seguinte inserção SQL:
Seja S uma escala de execução envolvendo T29 e T30. Esperamos um conflito em potencial pelas seguintes
razões:
• Se T29 usar a tupla recentemente inserida por T30 para calcular sum(saldo), então T29 lerá o valor inserido
por T30. Assim, em uma escala de execução serializada equivalente a S, T30 deve começar antes de T29.

298
• Se T29 não usar a tupla recentemente inserida por T30 para calcular sum(saldo) em uma escala de
execução serializada equivalente a S, T29 deve começar antes de T30.
O segundo caso é curioso. T29 e T30 não acessam a nenhum tupla em comum, ainda assim entram em
conflito. Com efeito, T29 e T30 entram em conflito com uma tupla fantasma. Assim, o fenômeno que acabamos de
descrever é chamado de fenômeno do fantasma. Se o controle de concorrência é feito com granularidade de
tupla, esse conflito pode não ser detectado.
Para prevenir esse fenômeno, fazemos com que T29 evite que outras transações criem novas tuplas na
relação conta com nome_agência= “Perryridge”.
Para encontrar todas as tuplas de conta com nome_agência = “Perryridge”, T29 precisa pesquisar toda a
relação conta, ou ao menos um índice na relação. Até agora, consideramos de modo implícito que os itens de
dados aos quais a transação mantém acesso sejam somente tuplas. Entretanto, T29 é um exemplo de transação
que procura a informação de quantas tuplas há na relação e T30 exemplifica uma transação que atualiza essa
informação. É lógico que não é suficiente bloquear as tuplas que sofrem acesso; o bloqueio também é necessário
para informações sobre os quais tuplas estão na relação.
A solução mais simples para esse problema seria associar um item de dado à própria relação. Transações,
como a T29, que leem informações acerca de quais tuplas estão na relação deveriam, então, bloquear no modo
compartilhado o item de dado correspondente à relação conta. Transação, com a T30, que atualizam as
informações acerca de quais tuplas estão na relação deveriam bloquear o item de dado no modo exclusivo. Desse
modo, T29 e T30 entram em conflito devido a itens de dados reais, e não fantasmas.
Não confunda o bloqueio de uma relação inteira, como no bloqueio de granularidade múltipla, com o
bloqueio de um item de dado correspondente à relação. Por meio do bloqueio do item de dado, uma transação
impede somente que outras transações alterem informações sobre as tuplas que pertencem à relação. O
bloqueio das tuplas é ainda necessário. As transações que mantêm acesso direto a uma tupla podem conseguir o
bloqueio de uma tupla mesmo que outra transação tenha bloqueio exclusivo sobre um item de dado
correspondente àquela transação propriamente dita.
A maior desvantagem do bloqueio de um item de dado correspondente a uma relação é o baixo grau de
concorrência – duas transações que inserem tuplas diferentes em uma relação não podem ser concorrentes.
Uma solução melhor é a técnica do bloqueio de índices. Qualquer transação que inserir uma tupla em
uma relação deve inserir informações em todos os índices mantidos pela relação. Eliminamos o fenômeno do
fantasma por meio da imposição de um protocolo de bloqueios para os índices.
Todo valor da chave de pesquisa está associado a um registro do índice ou a um bucket. Uma consulta,
normalmente, usará um ou mais índices para o acesso à relação. Uma consulta, normalmente, usará um ou mais
índices para o acesso à relação. Uma inserção precisará introduzir uma nova tupla em todos os índices de uma
relação.
Em nosso exemplo, assumimos que há um índice em conta para nome_agência. Logo, T30 precisa
modificar o bucket de Perryridge. Se T29 lê o bucket de Perryridge para localizar todas as tuplas pertencentes à
agência Perryridge, então T29 e T30 entrarão em conflito naquele bucket.
O protocolo de bloqueio de índices possui a vantagem de criar índices sobre uma relação por meio da
troca de instâncias do fenômeno de fantasmas por conflito de bloqueios em índices bucket. O protocolo opera da
seguinte forma:
• Toda relação precisa ter ao menos um índice.
• Uma transação Ti pode bloquear em modo S uma tupla ti de uma relação somente se ela possui um
bloqueio modo S sobre o índice bucket que contém um ponteiro para ti.
• Uma transação Ti pode bloquear em modo X uma tupla ti de uma relação somente se ela possui um
bloqueio modo X sobre o índice bucket que contém um ponteiro para ti.
• Uma transação Ti não pode inserir uma tupla ti em uma relação r sem atualizar todos os índices de r. Ti
precisa obter um bloqueio modo X sobre todos os índices bucket que ela modifica.
• É preciso observar as regras do protocolo de bloqueio em duas fases.

299
Há variante da técnica de bloqueio de índices para a eliminação do fenômeno do fantasma em outros
protocolos de controle de concorrência já apresentados.
Concorrência em Estruturas de Índices
É possível tratar do acesso às estruturas de índices como qualquer outra estrutura de um banco de dados
e aplicar as técnicas de controle de concorrência discutidas anteriormente. Entretanto, uma vez que os índices
têm acesso frequente, eles se tornam ponto de grande contenção de bloqueios, originando um baixo nível de
concorrência. Felizmente, os índices não tem de receber o mesmo tipo de tratamento das demais estruturas do
banco de dados, já que não proporcionam um alto nível de abstração para o mapeamento de chaves de pesquisa
de tuplas do banco de dados. É perfeitamente aceitável que uma transação verifique um índice duas vezes e
perceba que essa estrutura de índice foi alterada nesse meio tempo, contanto que o índice aponte um conjunto
correto de tuplas. Assim, é aceitável manter acesso concorrente não-seriado em um índice, contanto que a
precisão do índice seja mantida.
Mostramos a técnica para o gerenciamento de acessos concorrentes em árvores-B+.
As técnicas que apresentamos para árvores-B+ têm por base o bloqueio, mas nem o bloqueio em duas
fases nem o protocolo de árvore são empregados.

300
Sistema de Recuperação
Um sistema de computador, como qualquer outro equipamento mecânico ou elétrico, está sujeito a
falhas. Há grande variedade de falhas, incluindo quebra de disco, falha de energia, erro de software, fogo na sala
de equipamento ou mesmo sabotagem. Em cada um desses casos, informações podem ser perdidas. Portanto, o
sistema de banco de dados deve precaver-se para garantir que as propriedades de atomicidade e durabilidade
das transações sejam preservadas, a despeito de tais falhas. Uma parte integrante de um sistema de banco de
dados é o esquema de recuperação que é responsável pela restauração do banco de dados para um estado
consistente que havia antes da ocorrência da falha.
Classificação de Falha
Vários tipos de falhas podem ocorrer em um sistema, cada um dos quais exigindo um tratamento
diferente. O tipo de falha mais simples de tratar é aquele que não resulta na perda de informação no sistema. As
falhas mais difíceis de tratar são aquelas que resulta em perda de informação. Vamos considerar somente os
seguintes tipos de falha:
• Falha de transação. Dois tipos de erros podem causar uma falha de transação:
o Erro lógico. A transação não pode mais continuar com sua execução normal devido a alguma
condição interna, como uma entrada inadequada, um dado encontrado, overflow ou limite de
recurso excedido.
o Erro de sistema. O sistema entrou em um estado inadequado (por exemplo, deadlock), com isso,
uma transação não pode continuar com sua execução normal. A transação, entretanto, pode ser
reexecutada posteriormente.
• Queda do sistema. Há algum mau funcionamento de hardware ou um bug no software de banco de
dados ou no sistema operacional que causou a perda do conteúdo no armazenamento volátil e fez o
processamento da transação parar. O conteúdo de armazenamento não-volátil permanece intato e não é
corrompido.
A condição originada por erros de hardware e bugs no software que fazem o sistema parar, mas não
corrompem o conteúdo do armazenamento não-volátil, é conhecida como condição falhar-parar. Sistemas bem
projetados têm numerosas verificações internas em nível de hardware e software que fazem o sistema parar
quando há um erro. Consequentemente, a condição falhar-parar é uma condição razoável.
• Falha de disco. Um bloco de disco perde seu conteúdo em função da quebra do cabeçote ou da falha
durante uma operação de transferência de dados. São usadas, para recuperação do sistema após a falha,
as cópias dos dados em outros discos ou backups de arquivos em meios terciários, como fitas.
Para determinar como o sistema deve recuperar-se das falhas, necessitamos identificar os modos de falha
possíveis dos equipamentos usados para armazenar dados. Depois, devemos considerar como esses modos de
falha afetam o conteúdo do banco de dados. Então, poderemos desenvolver algoritmos para assegurar a
consistência do banco de dados e a atomicidade da transação, a despeito das falhas. Esses algoritmos são
conhecidos como algoritmos de recuperação, embora tenham duas partes:
1. Ações tomadas durante o processamento normal da transação a fim de garantir que haja informação
suficiente para permitir a recuperação de falhas.
2. Ações tomadas em seguida à falha, recuperando o conteúdo do banco de dados para um estado que
assegure sua consistência, a atomicidade da transação e durabilidade.
Estrutura de Armazenamento
Os vários itens do banco de dados podem ser armazenados e sofre acesos em diferentes meios de
armazenamento. Para compreender como garantir propriedades de atomicidade e durabilidade de uma
transação, devemos compreender melhor como funcionam esses meios de armazenamento e seus métodos de
acesso.

301
Tipos de Armazenamento
Há vários tipos de meios de armazenamento; eles são distinguidos por sua velocidade relativa, capacidade
e resistência à falha.
• Armazenamento volátil. A informação residente em armazenamento volátil usualmente não sobrevive a
quedas no sistema. Exemplos de tal armazenamento são MP e memória cache. O acesso à armazenagem
volátil é extremamente rápido, tanto devido à velocidade de acesso da memória em si quanto ao acesso
direto a qualquer item de dado possível no armazenamento volátil.
• Armazenamento não-volátil. A informação residente em armazenamento não-volátil sobrevive a quedas
de sistema. Exemplos de tal armazenamento são o disco e fitas magnéticas. Os discos são usados para
armazenamento online, ao passo que as fitas são usadas para armazenamento de arquivo. Entretanto,
ambos estão sujeitos à falha (por exemplo, quebra de cabeçote), que pode resultar em perda de
informação. No atual estado da tecnologia, o armazenamento não-volátil é mais lento que o
armazenamento volátil por muitas ordens de magnitude. Essa distinção ocorre porque discos e fitas são
equipamentos eletromecânicos, em vez de inteiramente baseados em chips, como o armazenamento
volátil. Outros meios não-voláteis são usados, normalmente apenas no backup de dados.
• Armazenamento estável. A informação residente em armazenamento estável nunca é perdida (nunca é
entendida aqui como uma agulha no palheiro, já que teoricamente nunca não pode ser garantido – por
exemplo, é possível, embora extremamente improvável, que um buraco negro engula a Terra e destrua
permanentemente todos os dados!). Embora o armazenamento estável seja teoricamente impossível de
obter, pode-se chegar perto dele usando técnicas que torna extremamente improvável a perda de dados.
Frequentemente, as distinções entre os vários tipos de armazenamento são menos claras na prática que
em nossa apresentação. Certos sistemas fornecem backup de bateria, de forma que parte da MP pode resistir a
quedas de sistema e falhas de energia. Formas alternativas de armazenamento não-volátil, como meio ótico,
fornecem maior grau de confiabilidade que os discos.
Implementação do Armazenamento Estável
Para implementar o armazenamento estável, temos de replicar a informação em vários meios de
armazenamento ano-voláteis (usualmente discos), como modos possíveis de falha independentes, e controlar a
atualização das informações, garantindo que uma eventual falha durante a transferência de dados não danifique
as informações.
Os sistemas RAID garantem que a falha de um único disco (mesmo durante a transferência de dados) não
resulte em perda de dados. A forma mais simples e mais rápida de RAID é o disco espelhado, que mantém duas
cópias de cada bloco em discos separados. Outras formas de RAID oferecem custos menores, mas com menor
desempenho.
Os sistemas RAID, entretanto, não podem se proteger contra perda de dados devido a desastres como
incêndios ou enchentes. Muitos sistemas armazenam backups em fitas e diferentes locais para proteger-se contra
tais desastres. Entretanto, já que as fitas não podem ser transportadas continuamente, as atualizações ocorridas
entre o desastre e o último backup podem ser perdidas. Sistemas mais seguros mantêm uma cópia de cada bloco
de armazenamento estável em um site remoto, enviando-a por uma rede de computadores, além de armazenar o
bloco em um sistema de disco local. Já que os blocos são enviados ao sistema remoto, como e quando são
enviados para o armazenamento local, uma vez completada a operação de saída, essa saída não é perdida,
mesmo na ocorrência de um desastre, como um incêndio ou uma enchente.
Vamos discutir como o meio de armazenamento pode ser protegido de uma falha durante a transferência
de dados. A transferência de blocos entre a memória e o armazenamento de disco pode resultar em:
• Conclusão bem-sucedida. A informação transferida chegou de forma segura ao seu destino.
• Falha parcial. Uma falha ocorreu no meio de transferência e o bloco de destino contém informação
incorreta.

302
• Falha total. A falha ocorreu cedo o suficiente, de modo que o bloco de destino permanece intato.
Exigimos que, se uma falha na transferência de dados ocorrer, o sistema a detecte e chama um
procedimento de recuperação para restabelecer o bloco, levando-o a um estado consistente. Para isso, o sistema
deve manter dois blocos físicos para cada bloco lógico do banco de dados; no caso de discos espelhados, ambos
os blocos então no mesmo local; no caso de backup remoto, um dos blocos é local, enquanto o outro está em um
site remoto. Uma operação de saída é executa como segue:
1. Escreve a informação dentro do primeiro bloco físico.
2. Quando a primeira escrita se completar com sucesso, escreve a mesma informação no segundo bloco
físico.
3. A saída é completada somente após a segunda escrita completar-se com sucesso.
Durante a recuperação, cada par de blocos físico é examinado. Se ambos são iguais e não há erro detectável,
então nenhuma ação adicional é necessária. Se um bloco contém um erro detectável, então trocamos seu
conteúdo pelo conteúdo do segundo bloco. Se ambos os blocos não contêm erros detectáveis, mas diferem em
conteúdo, então trocamos o conteúdo do primeiro bloco pelo valor do segundo. Esse procedimento de
recuperação assegura que uma escrita em armazenamento estável seja bem-sucedida (isto é, atualize todas as
cópias), ou não resulte em mudança alguma.
Exigir a comparação entre cada par de blocos correspondentes durante a recuperação é custoso.
Podemos reduzir consideravelmente o custo mantendo uma varredura de escritas de bloco que estão em
progresso, usando uma pequena quantidade de RAM não-volátil.
Os protocolos para escrita de um bloco em um site remoto são similares aos protocolos para escrita de
blocos em sistema de disco espelhado.
Podemos facilmente expandir esse procedimento para que permita o uso de um número arbitrariamente
grande de cópias de cada bloco de armazenamento estável. Embora o uso de um número grande de cópias
reduza a probabilidade de uma falha para muitos menos que quando se usam duas cópias, em geral é suficiente
simular o armazenamento estável somente com duas cópias.
Acesso de dados
O sistema de banco de dados reside permanentemente em armazenamento não-volátil (usualmente
discos) e é particionado em unidades de armazenamento de comprimento fixo chamadas de blocos. Os blocos
são unidades de transferência de dados para e a partir do disco e podem conter vários itens de dados. Assumimos
que nenhum item de dado abrange dois ou mais blocos. Essa premissa é verdadeira para a maioria das aplicações
de processamento de dados, como em nosso exemplo bancário.
As transações transferem informações do disco para a MP e, então, reenviam essas informações de volta
para o disco. As operações de entrada e saída (entrar e sair da memória) são feitas em unidades de bloco. Os
blocos residentes no disco são chamados de blocos físicos; os blocos residentes temporariamente na MP são
chamados de blocos de buffer. A área de memória na qual os blocos residem temporariamente é chamada de
buffer de disco.
Movimentos de bloco entre disco e memória principal são iniciados por meio de duas operações
seguintes:
1. input(B) transfere o bloco físico B para a MP.
2. output(B) transfere o bloco de buffer B para o disco e troca-o, no disco, pelo físico apropriado.
Esse esquema é ilustrado na fig. 15.1.

303
Cada transação Ti tem uma área de trabalho privada na qual cópias de todos os itens de dados acessados
e atualizados são mantidas. Essa área de trabalho é criada quando a transação é iniciada; ele é removida quando
a transação é iniciada; ela é removida quando a transação é efetivada ou abortada. Cada item de dados x mantido
na área de trabalho da transação Ti é denotado por xi. A transação Ti interage com o sistema de banco de dados
pela transferência de dados para e de sua área de trabalho até o buffer de sistema. Transferimos os dados usando
as duas operações a seguir:
1. read(X) designa o valor do item de dado X para a variável local xi. Essa operação é executada como segue:
a. Se o bloco Bx no qual reside X não está na memória principal, então é emitido um input(Bx).
b. Designa a xi o valor de X a partir do bloco de buffer.
2. write(X) designa o valor da variável local xi para o item de dado X no bloco de buffer. Essa operação é
executada como segue:
a. Se o bloco Bx no qual reside X não está na memória principal, então emite um input(Bx).
b. Designa o valor de xi para X no buffer Bx.
Observe que ambas as operações podem exigir a transferência de um bloco do disco para a MP.
Entretanto, elas não exigem a transferência de um bloco da MP para o disco.
O bloco de buffer será eventualmente escrito no disco se o gerenciador de buffer necessitar de espaço
em memória para outros propósitos ou porque o sistema de banco de dados deseja refletir a mudança em B
sobre o disco. Dizemos que o sistema de banco de dados força saídas do buffer B se ele emite um output(B).
Quando uma transação necessita do acesso a um item de dado X pela primeira vez, ela deve executar
read(X). Todas as atualizações de X são, então, realizadas sobre xi. Após o último acesso X feito pela transação, ela
executará um write(X) para refletir a mudança em X no banco de dados propriamente dito.
A operação output(Bx) para o buffer de bloco Bx em que X reside não precisa ter efeito imediato após a
execução do write(X), já que o bloco Bx pode conter outros itens de dados que ainda estão sendo acessados.
Então, a saída real aparecerá mais tarde. Observe que, se o sistema cair após a operação write(X) ter sido
executada, mas antes do output(Bx), o novo valor de X nunca será escrito no disco e, portanto, é perdido.
Recuperação e Atomicidade
Considere novamente nosso sistema bancário simplificado e a transação Ti transfere 50 dólares da conta
A para a conta B, com valores iniciais de A e B sendo mil e dois mil dólares, respectivamente. Suponha que uma
queda de sistema tenha ocorrido durante a execução de Ti, após output(BA), mas antes do output(BB), em que BA
e BB denotam os blocos de buffer em que A e B residem. Já que os conteúdos de memória foram perdidos, não
sabemos o destino da transação; então, poderíamos chamar um dos dois possíveis procedimentos de
recuperação:
• Reexecutar Ti. Este faz com que o valor de A torne-se 900 dólares, em vez de 950 dólares. Então, o
sistema entra em um estado inconsistente.
• Não reexecutar Ti. No estado corrente do sistema, os valores A e B são de 950 e 2000 dólares,
respectivamente. Então, o sistema entra em um estado inconsistente.
Em ambos os casos, o banco de dados é deixado em estado inconsistente, logo esse esquema de recuperação
simples não funciona. Essa dificuldade ocorre porque modificamos o banco de dados sem ter certeza de que a

304
transação será efetivada de fato. Entretanto, se Ti realizou diversas modificações no banco de dados, podem ser
necessárias várias operações de saída e pode ocorrer uma falha após algumas dessas modificações terem sido
feitas, mas antes de todas serem realizadas.
Para atingir nosso objetivo de atomicidade, primeiro devemos mandar informações que descrevam essas
modificações para um armazenamento estável, sem modificar o banco de dados em si. Como veremos, esse
procedimento nos permitirá enviar todas as modificações feitas por uma transação efetivada, apesar de possíveis
falhas. Há duas maneiras de realizar tais saídas. Vamos assumir que as transações são executadas serialmente,
isto é, somente uma única transação está ativa de cada vez.
Recuperação Baseada em Log
A estrutura mais usada para gravar modificações no banco de dados é o log (diário). O log é uma
sequência de registros de log que mantém um arquivo atualizado das atividades no banco de dados. Há vários
tipos de registros de log que mantém um arquivo atualizado das atividades no banco de dados. Há vários tipos de
registro de log. Um registro de atualização de log descreve uma única escrita do banco de dados e tem os
seguintes campos:
• Identificador de transação é um identificador único da transação que realiza operação de escrita (write).
• Identificação de item de dado é um identificador único do item de dado escrito. Normalmente, é a
localização do item de dado no disco.
• Valor antigo é o valor do item de dado anterior à escrita.
• Valor novo é o valor que o item de dado terá após a escrita.
Há outros registros de log para arquivar eventos significativos durante o processamento de transação,
como o início da transação, sua efetivação ou aborto. Indicamos os vários tipos de registros de log como seguem:
• <Ti start>. A transação Ti começou.
• <Ti, Xj, V1, V2>. A transação Ti foi efetivada.
• <Ti abort>. A transação Ti foi abortada.
Sempre que uma transação realiza uma escrita, é essencial que o registro de log para aquela escrita seja
criado antes do banco de dados ser modificado. Havendo o registro de log, podemos enviar a modificação ao
banco de dados quando ela for conveniente. Também conseguiremos inutilizar (undo) uma modificação que já
tenha sido enviada ao banco de dados. Podemos desfazê-la usando o campo de valor antigo do registro de log.
Para que os registros de log sejam úteis na recuperação após falhas de sistema e disco, o log deve residir
em armazenamento estável. Por enquanto, assumiremos que todo registro de log será escrito no final do arquivo
de log em armazenamento estável, tão logo seja criado. Veremos quando é seguro afrouxar essa exigência para
reduzir o overhead imposto ao registro em log. Introduziremos também duas técnicas de uso de log para garantir
atomicidade de transações apesar das falhas. Repare que o log contém um registro completo de toda atividade
do banco de dados. Com isso, o volumo de dados armazenado no log pode tornar-se absurdamente grande.
Mostraremos quando é seguro apagar informações de log.
Modificações adiadas do banco de dados
A técnica de adiar modificações garante a atomicidade de transações quando todas as modificações do
banco de dados são escritas no log, adiando a execução de todas as operações write de uma transação até sua
efetivação parcial. Lembre-se de que uma transação é considerada parcialmente efetivada quando a última ação
da transação tiver sido executada. A versão da técnica de modificação que descrevemos aqui pressupõe que as
transações sejam executadas serialmente.
Quando uma transação é parcialmente efetivada, as informações no log associadas àquela transação são
usadas para a execução das escritas adiadas. Se o sistema cair antes de completar a transação ou se a transação
for abortada, então as informações do log serão simplesmente ignoradas.

305
A execução da transação Ti funciona como segue. Um registro <Ti start> é escrito no log antes de Ti ter
início. Uma operação write(X) feita por Ti resulta na escrita de um novo registro no log. Finalmente, quando Ti é
parcialmente efetivada, um registro <Ti commit> é escrito no log.
Quando uma transação Ti é parcialmente efetivada, os registros no log a ela associados são usados para
execução das escritas adiadas. Como uma falha pode ocorrer enquanto essa execução está em andamento,
devemos ter certeza, antes de começa-la, de que todos os registros de log estejam escritos em armazenamento
estável. Uma vez escritas, as atualizações reais podem ocorrer de fato e a transação entra no estado de
efetivação.
Observe que somente o novo valor do item de dado é necessário para a técnica de modificação adiada.
Logo, podemos simplificar a estrutura geral do registro de atualização do log, que vimos anteriormente, por meio
da omissão do campo de valor antigo.
Para ilustração, reconsidere nosso exemplo de sistema bancário simplificado. Seja T0 uma transação que
transfere 50 dólares da conta A para a conta B. Essa transação é definida como segue:
Seja T1 uma transação que debita cem dólares da conta C. Essa transação é definida como:
Suponha que essas transações sejam executadas serialmente, T0 é seguida por Ti e os valores das contas
A, B e C antes da execução, eram de 1000, 2000 e 700 dólares, respectivamente. A porção do log contendo as
informações relevantes sobre essas duas transações é apresentada 15.2.
Como resultado da execução de T0 e T1, há várias ordens possíveis em que as saídas reais podem ocorrer,
tanto para o sistema de banco de dados como para o log. Tal ordem é apresentada na fig. 15.3. Note que o valor
de A é alterado somente após o registro <T0, A, 950> ter sido colocado no log.
Usando o log, o sistema pode lidar com qualquer falha que resulte em perda de informação no
armazenamento volátil. O esquema de recuperação usa o seguinte procedimento:
• redo(Ti) define o valor de todos os itens de dados atualizados pela transação Ti para os novos valores.
O conjunto de itens de dados atualizados por Ti e seus respectivos novos valores podem ser encontrados
no log.

306
A operação redo (refazer) deve ser idempotente, isto é, executá-la várias vezes deve ser equivalente a
executá-la uma vez só. Essa característica é exigida se formos garantir comportamento correto, mesmo que uma
falha ocorra durante o processo de recuperação.
Após a ocorrência de uma falha, o subsistema de recuperação consulta o log para determinar quais
transações têm de ser refeitas. A transação Ti deverá ser refeita se, e somente se, o log contiver os registros <Ti
start> e <Ti commit>. Assim, se o sistema cair depois que a transação completar sua execução, as informações no
log serão usadas na restauração do sistema para o estado consistente anterior.
Como ilustração, retornemos a nosso exemplo bancário com as transações T0 e T1 executadas uma após a
outra, T0 seguida por T1. A figura 15.2 mostra o log resultante da execução completa de T0 e T1.
Suponhamos que o sistema caia antes que as transações terminem, de forma que possamos ver como a
técnica de recuperação restabelece o banco de dados para um estado consistente. Assuma que a queda logo após
o registro de log do passo write (B) da transação T0 ter sido escrito em armazenamento estável. O log, no
momento da queda, é mostrado na fig. 15.4a. Quando o sistema retorna, nenhuma ação refazer tem de ser
tomada, já que nenhum registro de efetivação aparece no log. Os valores das contas A e B permanecem mil e dois
mil dólares, respectivamente. Os registros de log da transação incompleta T0 podem ser removidos do log.
Agora, assumamos que a queda venha logo após o registro de log para o passo write(C) da transação T1
ter sido escrito em armazenamento estável. Nesse caso, o log, no momento da queda, está como na fig. 15.4.
Quando o sistema retorna, a operação redo (T0) é realizada, já que o registro <T0 commit> aparece no log em
disco. Após essa operação, os valores das contas A e B são 950 e 2050 dólares, respectivamente. O valor da conta
C permanece 700 dólares. Como antes, os registros de log da transação incompleta T1 podem ser removidos do
log.
Por último, assumamos que uma queda ocorra logo após o registro de log <T1 commit> ser escrito em
armazenamento estável. O log, no momento dessa queda, está como mostra a fig. 15.4c. Quando o sistema
retorna, dois registros de efetivação estão no log: um para T0 e um para T1. Portanto, as operações redo(T0) e
redo(T1) devem ser processadas. Após essas operações, os valores das contas A, B e C são, respectivamente, 950,
2050 e 600 dólares.
Finalmente, consideremos o caso em que uma segunda queda de sistema ocorre durante a recuperação
da primeira queda. Algumas mudanças devem ter sido feitas no banco de dados como resultado das operações
redo, mas pode ser que nem todas as alterações tenham ocorrido. Quando o sistema retornar da segunda queda,
a recuperação se dará exatamente como nos exemplos anteriores.
Para cada registro de efetivação <Ti commit> encontrado no log, a operação redo(Ti) será processada. Em
outras palavras, as ações de recuperação são reinicializadas a partir do começo. Já que redo escreve valores no
banco de dados independente de seus valores correntes, o resultado de uma segunda tentativa de redo será igual
ao alcançado caso o redo seja bem-sucedido já na primeiro vez.
Modificação Imediata de Banco de Dados
A técnica de atualização imediata permite que as modificações no banco de dados sejam enviadas
enquanto as transações ainda estão no estado ativo. As escritas emitidas por transações ativas são chamadas de
modificações não-efetivadas. Na ocorrência de uma queda ou de uma falha de transação, o sistema deverá usar o
campo relativo ao valor antigo dos registros de log para restauração dos itens de dados modificados, levando-os

307
ao valor anterior ao início da transação. Essa restauração é conseguida por meio da operação undo (desfazer)
descrita a seguir.
Antes que uma transação Ti inicie sua execução, o registro <Ti start> é escrito no log. Durante sua
execução, qualquer operação write(X) feita por Ti é precedida pela escrita apropriada do novo registro corrente
no log. Quando Ti é parcialmente efetivada, o registro <Ti commit> é escrito no log.
Já que as informações do log são usadas na reconstrução do estado do banco de dados, não podemos
permitir que a atualização real do banco de dados ocorra antes da escrita correspondente, em armazenamento
estável, do registro de log. Portanto, exigimos que, antes da execução de uma operação output(B), os registros de
log correspondentes a B sejam escritos em armazenamento estável.
Como ilustração, reconsideremos nosso sistema bancário simplificado, com transações T0 e T1 executadas
uma após a outra com T0 seguida por T1. A porção do log contendo as informações importantes relativas a essas
duas transações é apresentada na fig. 15.5.
Uma ordem possível de ocorrência das saídas reais, tanto para o sistema de banco de dados quanto para
o log, resultantes da execução de T0 e T1, é descrita na fig. 15.6. Observe que essa ordem não poderia ser obtida
na técnica de modificação adiada.
Usando o log, o sistema pode tratar de qualquer falha que não resulte na perda de informação em
armazenamento não-volátil. O esquema de recuperação usa dois procedimentos de recuperação:
• undo(Ti) retorna aos valores antigos todos os itens de dados atualizados pela transação Ti.
• redo(Ti) ajusta os valores de todos os itens de dados atualizados pela transação Ti para os valores novos.
O conjunto de itens de dados atualizados por Ti e seus respectivos valores antigos e novos podem ser
encontrados no log.
As operações undo e redo devem ser idempotentes para garantir o comportamento correto mesmo se
uma falha ocorrer durante o processo de recuperação.
Após a falha, o esquema de recuperação consulta o log para determinar quais transações necessitam ser
refeitas e quais necessitam ser inutilizadas. Essa classificação de transações é conseguida como segue:
• A transação Ti tem de ser inutilizada se o log contém o registro <Ti start>, mas não contém o registro <Ti
commit>.
• A transação Ti tem de ser refeita se o log contém tanto o registro <Ti start> quanto o registro <Ti commit>.
Como ilustração, retornaremos a nosso exemplo bancário, com as transações T0 é seguida por T1. Suponhamos
que o sistema caia antes do término das transações. Deveremos considerar três casos. O estado dos logs para
cada um desses casos é mostrado na fig. 15.7.

308
Primeiro, assumamos que a queda ocorra logo após o registro de log para o passo write(B) da transação
T0 ter sido escrito em armazenamento estável (fig. 15.7a). quando o sistema retorna, ele encontra o registro <T0
start> no log, mas nenhum registro <T0 commit> correspondente. Então, a transação T0 deverá ser inutilizada, de
modo que um undo(T0) será processado. Como resultado, os valores nas contas A e B (no disco) são restaurados
em mil e dois mil dólares, respectivamente.
A seguir, assumamos que a queda venha logo após o registro de log para o passo write(C) da transação T1
ter sido escrito em armazenamento estável (fig. 15.7b). Quando o sistema retornar, duas ações de recuperação
necessitam ser tomadas. A operação undo (T1) deve ser realizada, já que o registro <T1 start> aparece no log, mas
não há o registro <T1 commit>, e a operação redo(T0) também deve ser realizada, já que o log contém tanto o
registro <T0 start> como o registro <T0 commit>. No fim do processo de recuperação completo, os valores das
contas A, B e C serão 950, 2050 e 700 dólares, respectivamente. Observe que a operação undo(T1) é realizada
antes de redo(T0). Nesse exemplo, o resultado seria o mesmo se a ordem fosse revertida. Entretanto, fazer
primeiro as operações undo e depois as operações redo é importante no algoritmo de recuperação que veremos
adiante.
Finalmente, assumamos que a queda ocorra logo após o registro de log <T1 commit> ter sido escrito em
armazenamento estável (fig. 15.7c). Quando o sistema retorna, tanto T0 como T1 necessitam ser refeitas, já que os
registros <T0 start> e <T0 commit> aparecem no log, assim como os registros <T1 start> e <T1 commit>. Após os
procedimentos de recuperação redo(T0) e redo(T1), os valores nas contas A, B e C serão 950, 2050 e 600 dólares,
respectivamente.
Checkpoints
Quando uma falha de sistema ocorre, devemos consultar o log para determinar aquelas transações que
necessitam ser refeitas e aquelas que necessitem ser inutilizadas. A princípio, para isso, deveríamos pesquisar
todo o log. Há duas grandes dificuldades nessa abordagem:
1. O processo de pesquisa consome tempo.
2. Muitas das transações que, de acordo com nosso algoritmo, necessitam ser refeitas já escreveram suas
atualizações no banco de dados. Embora refazê-las não cause dano algum, a recuperação torna-se mais
longa.
Para reduzir esses tipos de overhead, introduzimos os checkpoints (pontos de controle). Durante a
execução, o sistema mantém o log usando uma das duas técnicas descritas anteriormente. Além disso, o sistema
cria checkpoints periodicamente, que exigem a execução da seguinte sequência de ações:
1. Saída, para armazenamento estável, de todos os registros residentes na memória principal;
2. Saída, para disco, de todos os blocos de buffer modificados.
3. Saída, para armazenamento estável, de um registros de log <checkpoint>.
Não é permitido às transações processar quaisquer ações de atualização, como escrever em um bloco de
buffer ou escrever um registro de log, enquanto um checkpoint está em progresso.
A presença de um registro <checkpoint> no log permite que o sistema dinamize seu procedimento de
recuperação. Considere uma transação Ti efetivada antes do checkpoint. Para tal transação, o registro <Ti
commit> aparece no log antes do registro <checkpoint>. Quaisquer modificações feitas por Ti ou já foram escritas
no banco de dados antes do checkpoint ou o foram como parte do checkpoint propriamente dito. Então, no
momento de recuperação, não haverá necessidade de uma operação redo sobre Ti.

309
Essa observação permite-nos refinar nossos esquemas de recuperação anteriores (continuamos a assumir
que as transações são executadas serialmente). Após uma falha, o esquema de recuperação examina o log para
determinar a última transação Ti anterior ao checkpoint mais recente. Isso poderá ser feito por uma pesquisa
retroativa no log, a partir de seu final até o primeiro registro <checkpoint> (já que estamos pesquisando em
ordem cronológica inversa, o registro encontrado será o último registro <checkpoint> do log); então o sistema
continuará a pesquisar retroativamente até encontrar o próximo registro <Ti start>. Esse registro identifica uma
transação Ti.
Uma vez identificada a transação Ti, as operações redo e undo devem ser aplicadas à transação Ti e a
todas as transações Tj que começaram depois da dela. Indiquemos essas transações pelo conjunto T. O restante
(parte anterior) do log pode ser ignorado e até mesmo apagado, se for conveniente. Quais operações de
recuperação devem, exatamente, ser processadas dependerá da técnica de modificação em uso, se imediata ou
adiada. As operações de recuperação exigidas, se a técnica de modificação imediata é empregada, são as
seguintes:
• Para todas as transações Tk em T que não têm nenhum registro <Tk commit> no log será executado
undo(Tk).
• Para todas as transações Tk em T tais que o registro <Tk commit> aparece no log será executado redo(Tk).
Obviamente, a operação undo não será aplicada caso a técnica de modificação adiada esteja em uso.
Como ilustração, considere o conjunto de transações {T0,T1,..., T100} executado na ordem dos subescritos.
Suponha que o checkpoint mais recente tenha ocorrido durante a execução da transação T67. Então, somente as
transações T67, T68, ..., T100 necessitam ser consideradas durante o esquema de recuperação. Cada uma delas será
refeita se tiver sido efetivada; caso contrário, será inutilizada.
Paginação Shadow
Uma alternativa às técnicas de recuperação de queda baseada em log é a paginação shadow (sombra). A
técnica de paginação shadow é essencialmente uma melhoria de técnica de cópia shadow. Sob certas
circunstâncias, a paginação shadow pode exigir menos acessos a disco que os métodos baseados em log que
acabamos de discutir. Entretanto, também há desvantagens nessa abordagem, como veremos. Por exemplo, é
difícil aplicar a paginação shadow pode exigir menos acessos a disco que os métodos baseados em log que
acabamos de discutir. Entretanto, também há desvantagens nessa abordagem, como veremos. Por exemplo, é
difícil aplicar a paginação shadow em transações concorrentes.
Como antes, o banco de dados é particionado em um número de blocos de comprimento fixo, chamados
de páginas. O termo página é emprestado dos sistemas operacionais, já que estamos usando um esquema de
paginação para gerenciamento de memória. Assumamos que haja n páginas, numeradas de 1 até n. (Na prática, n
pode ser da ordem de centenas de milhares.) Essas páginas não necessitam ser armazenadas em alguma ordem
particular no disco (há muitas razões para que isso não aconteça). Entretanto, deve haver uma forma de
encontrar, para um i qualquer, a i-ésima página do banco de dados. Usamos, para esse proposito, uma tabela de
página, como mostrado na fig. 15.8. A tabela de página tem n entradas – uma para cada página do banco de
dados. Cada entrada contém um ponteiro para uma página no disco. A primeira entrada contém um ponteiro
para a primeira página do banco de dados, a segunda entrada aponta para a segunda página e assim por diante. O
exemplo da fig. 15.8 mostra que a ordem lógica das páginas do banco de dados não necessita corresponder à
ordem física em que as páginas estão armazenadas no disco.
A ideia básica da técnica de paginação shadow é manter duas tabelas de página durante o processamento
da transação: a tabela de páginas atuais e a tabela de páginas shadow. Quando a transação começa, ambas as
tabelas são idênticas. A tabela de página shadow não é alterada durante toda a duração da transação. A tabela de
página atual é alterada quando a transação processa uma operação write. Todas as operações de entrada (input)
e saída (output) usam a tabela de páginas atuais para localizar páginas do banco de dados no disco.

310
Suponha que a transação processe uma operação write(X) e que X resida na i-ésima página. A operação
write é executada como segue:
1. Se a i-ésima página (isto é, a página em que X reside) ainda não está na MP, então será emitido um
input(X).
2. Se essa é a primeira escrita processada na i-ésima página por essa transação, então a tabela de páginas
atuais será modificada conforme segue:
a. Encontra-se uma página sem uso no disco. Normalmente, o sistema de banco de dados tem
acesso a uma lista de páginas sem uso (livres).
b. Remove-se a página encontrada no passo 2a a partir da lista de quadros de páginas livres.
c. Modifica-se a tabela de páginas atuais, tal que a i-ésima entrada aponte para a página encontrada
no passo 2a.
3. Designa-se o valor de xj para X na página de buffer.
Comparemos a ação precedente para a operação write com aquela já descrita. A única diferença é
adicionamos um novo passo. Os passos 1 e 3 anteriores correspondem aos passos 1 e 2 descritos anteriormente.
O passo adicional, passo 2, manipula a tabela de páginas atuais. A fig. 15.9 mostra as tabelas, shadow e atual,
para uma transação que realize uma escrita na quarta página de um banco de dados constituído de dez páginas.
Intuitivamente, a abordagem de recuperação por meio de páginas shadow consiste em manter uma
tabela de páginas atuais. A fig. 15.9 mostra as tabelas, shadow e atual, para uma transação que realize uma
escrita na quarta página de um banco de dados constituído de dez páginas.
Intuitivamente, a abordagem de recuperação por meio de páginas shadow consiste em manter uma
tabela de páginas shadow em armazenamento não-volátil, tal que se possa recuperar o estado do banco de dados
anterior à execução da transação, devido a uma queda ou aborto da transação. Quando uma transação é
efetivada, a tabela de páginas atuais é escrita em armazenamento não-volátil. A tabela de páginas atuais torna-se,
então, a nova tabela de páginas shadow e, então, uma nova transação pode começar. É importante que a tabela
de páginas shadow seja armazenada em meio não-volátil, já que ela fornece o único meio de localização das
páginas do banco de dados. A tabela de páginas atuais pode ser mantida na MP (armazenamento volátil). Não
importa se a tabela de páginas atuais é perdida em uma queda, já que o sistema se recupera usando a tabela de
página shadow.

311
Uma recuperação bem-sucedida exige que, após uma queda, encontremos a tabela de páginas shadow no
disco. Uma forma simples de encontra-la é manter, em uma localização fixa de armazenamento estável, o
endereço em disco da tabela de página shadow. Quando o sistema retornar após uma queda, copiamos a tabela
de páginas shadows na MP e a usamos para o processamento subsequente da transação. Devido a nossa
definição de operação write, garantimos que a tabela de páginas shadow apontará para as páginas do banco de
dados que correspondem ao estado do banco de dados anterior a qualquer transação ativa no momento da
queda. Então, o aborto de transações é automático. Ao contrário dos esquemas baseados em log, nenhuma
operação undo precisa ser chamada.
Para efetivar uma transação, devemos fazer o seguinte:
1. Garantir que todas as páginas de buffer da MP que foram alteradas pela transação sejam enviadas para a
saída em disco. (Observe que essas operações de saída não alterarão as páginas do banco de dados
apontadas pela tabela de páginas shadow.)
2. Enviar a tabela de páginas atuais para saída em disco. Observe que não devemos sobrescrever a tabela de
páginas atuais, já que poderemos precisar dela para a recuperação após uma queda.
3. Enviar os endereços de disco da tabela de página atuais para a localização fixa em armazenamento
estável que contém o endereço da tabela de páginas shadow. Essa ação sobrescreve o endereço da tabela
de páginas shadow antiga. Portanto, a tabela de páginas atuais tornou-se a tabela de páginas shadow e a
transação foi efetivada.
Se uma queda ocorrer antes do término do passo 3, reverteremos ao estado anterior ao da execução da
transação. Se a queda ocorrer após o término do passo 3, os efeitos da transação ainda assim serão preservados;
nenhuma operação redo precisará ser atividade.
A paginação shadow oferece diversas vantagens sobre as técnicas baseadas em log. O overhead relativo
ao envio dos registros de log é eliminado e a recuperação de falhas é significativamente mais rápida (já que
nenhum operação undo e redo é necessária). Entretanto, há também inconvenientes nessa técnica.
• Overhead de efetivação. A efetivação de uma única transação usando paginação shadow exige que
diversos blocos sejam enviados – blocos de dados reais, tabela de páginas atuais e o endereço de disco da
tabela de páginas atuais. Os esquemas baseados em log precisam enviar somente os registros de log que,
para as pequenas e mais comuns transações, cabem dentro de um bloco.
• Fragmentação de dado. Consideramos estratégias para manter próximas no disco as páginas do banco de
dados relacionadas fisicamente. Essa proximidade permite maior rapidez na transferência de dados. A
paginação shadow gera alterações na localização das páginas do banco de dados quando elas sofrem

312
atualizações. Com isso, ou perdemos a proximidade das páginas ou precisaremos recorrer a esquemas
mais complexos, com maior overhead para gerenciamento do armazenamento físico.
• Coleta de lixo. Cada vez que uma transação é efetivada, as páginas do banco de dados contendo a versão
antiga do dado, alterado pela transação, tornam-se inacessíveis. Na fig. 15.9, a página apontada pela
quarta entrada da tabela de páginas shadow se tornará inacessível se a transação daquele exemplo for
efetivada. Tais páginas são consideras lixo, já que elas não fazem parte do espaço livre nem contêm
informação útil. O lixo também pode ser um efeito colateral das quedas. Periodicamente, é necessário
encontrar todas as páginas lixo e adicioná-las à lista de páginas livres. Esse processo, chamado de coleta
de lixo, impõe overhead e complexidade adicionais ao sistema. Há vários algoritmos-padrão para coleta
de lixo.
Além dos inconvenientes que mencionamos, a adaptação da paginação shadow a sistemas com
transações concorrentes é mais difícil do que registro de log. Em tais sistemas, algum tipo de registro de log é
normalmente necessário, mesmo que a paginação shadow seja usada. O protótipo do Sistema R, por exemplo,
usava uma combinação de paginação shadow com um esquema de registro de log similar ao já apresentado. É
relativamente simples ampliar os esquemas de recuperação baseados em log para que trabalhem com transações
concorrentes. Por essas razões, a paginação shadow não é tão usada.
Recuperação com Transações Concorrentes
Até agora, consideramos a recuperação em um ambiente no qual uma única transação é executada por
vez. Agora, discutiremos como modificar o esquema de recuperação baseado em log para tratar de diversas
transações concorrentes. Independente do número de transações concorrentes, o sistema tem um único buffer
de disco e um único log. Os blocos de buffer são compartilhados por todas as transações. Permitiremos, além de
atualizações imediatas, que um bloco de buffer tenha itens de dados atualizados por uma ou mais transações.
Interação com Controle de Concorrência
O esquema de recuperação depende muito do esquema de controle de concorrência em uso. Para
reverter (rollback) uma transação com falha, devemos inutilizar as atualizações processadas por ela. Suponha que
uma transação T0 tenha de ser desfeita e um item de dado Q que foi atualizado por T0 tenha de recuperar seu
valor antigo. Usando os esquemas baseados em log, recuperamos esses valor usando as informações undo de um
registro de log.
Suponha agora que uma segunda transação T1 tenha também processado uma atualização sobre Q antes
de T0 ser desfeita. Então, a atualização processada por T1 será perdida quando T0 for revertida.
Portanto, exigimos que, se uma transação T atualizou um item de dado Q, nenhuma outra transação
consiga atualizar o mesmo item de dado até que T tenha sido efetivada ou revertida. Podemos facilmente cumprir
essa exigência pelo bloqueio em duas fases severo – isto é, bloqueio em duas fases com bloqueios exclusivos
mantidos até o final da transação.
Reversão de Transação
Revertemos uma transação com falha, Ti, usando o log. O log é reexaminado, do fim para o começo; e
para cada registro da forma <Ti, Xj, V1, V2> encontrado, o item de dado Xj é restaurado em seu valor antigo V1.
Esse exame termina quando o registro de log <Ti, start> é encontrado.
Reexaminar o log de trás para frente é importante, já que uma transação pode ter atualizado um item de
dados mais de uma vez. Como ilustração, considere o par de registros de log:
Os registros de log representam uma modificação do item de dado A por Ti, seguido de outra modificação
de A por Ti. Reexaminar o log do final para o começo ajusta A corretamente para 10. Se os logs fossem
examinados no sentido inverso, A seria ajustado para 20, cujo valor é incorreto.

313
Se o bloqueio em duas fases severo é usado para controle de concorrência, os bloqueios mantidos pela
transação T podem ser liberados somente após a transação ter sido revertida, como descrito. Uma vez que uma
transação T (que é revertida) tenha atualizado um item de dado, nenhuma outra transação poderá atualizar o
mesmo item de dado, devido às exigências de controle de concorrência mencionadas anteriormente. Portanto, a
recuperação do valor antigo do item de dado não apagará os efeitos de qualquer transação.
Checkpoints
Usamos checkpoints para reduzir o número de registros de log que devem ser examinados quando o
sistema se recupera de uma queda. Já que não tínhamos levado qualquer ocorrência em conta, foi necessário
considerar somente as seguintes transações durante a recuperação:
• Aquelas transações que iniciaram após o checkpoint mais recente.
• Aquela transação, se houver alguma, que estava ativa no momento da escrita do checkpoint mais
recente.
A situação é mais complexa quando as transações podem ser executadas de modo concorrente, já que
várias transações poderiam estar ativas no momento em que o checkpoint mais recente foi gerado.
Em um sistema com processamento de transações concorrentes, exigimos que o registro de log relativo
ao checkpoint seja da forma <checkpoint L>, em que L é a lista de transações ativas no momento do checkpoint.
Novamente, assumimos que as transações não processam atualizações tanto nos blocos de buffer como no log
enquanto o checkpoint está em andamento.
A exigência de que as transações não devem realizar quaisquer atualizações nos blocos de buffer, ou no
log, durante o checkpoint pode ser preocupante, já que o processamento de transação terá de parar enquanto
um checkpoint estiver em progresso. Um fuzzy checkpoint é aquele que é permitido às transações processarem
atualizações mesmo quando os blocos de buffer estão sendo escritos.
Recuperação por Reinício
Quando um sistema se recupera de uma queda, ele constrói duas listas: a lista inutilizar (undo-list), que
consiste em transações a serem inutilizadas, e a lista refazer (redo-list), que consiste em transações a serem
refeitas.
Essas duas listas são construídas na recuperação como segue. Inicialmente, ambas estão vazias.
Examinando o log de trás para frente, cada registro, até que seja encontrado o primeiro registro <checkpoint>:
• Para cada registro da forma <Ti commit> encontrado, adicionamos Ti à lista refazer.
• Para cada registro da forma <Ti start> encontrado, se Ti não estiver na lista refazer, então adicionamos Ti
na lista inutilizar.
Quando todos os registros de log apropriados tiverem sido examinados, checamos a lista L no registro de
checkpoint em questão. Para cada transação Ti em L, se Ti não estiver na lista refazer, então será adicionada à lista
inutilizar.
Uma vez construídas as listas refazer e inutilizar, os procedimentos de recuperação prosseguem como
segue:
1. Reexaminar o log a partir do registro mais recente e processar um undo para cada registro de log
pertencente à transação Ti na lista inutilizar. Os registros de log de transações na lista refazer serão
ignorados nessa fase. O exame para quando os registros <Ti start> são encontrados para cada
transação Ti na lista inutilizar.
2. Localizar o registro <checkpoint L> mais recente no log. Note que este passo pode implicar exame do
log na ordem cronológica crescente, se o registro de checkpoint foi ultrapassado no passo 1.
3. Examinar o log a partir do registro <checkpoint L> mais recente até o final e processar redo para cada
registro de log pertencente a uma transação Ti que está na lista refazer. Ignorar os registros de log de
transações na lista inutilizar nessa fase.

314
É importante processar o log no passo 1, na ordem cronológica decrescente, para garantir que o estado
resultante do banco de dados estará correto.
Após desfazer todas as transações da lista inutilizar, as transações da lista refazer são refeitas. É
importante, nesse caso, processar o log na ordem cronológica crescente. Completado o processo de recuperação,
o processamento da transação é reassumido.
Quando se usa o algoritmo precedente, é importante inutilizar uma transação da lista inutilizar antes de
refazer transações da lista refazer. De outra forma, o seguinte problema pode ocorrer. Suponha que o item de
dado A tenha inicialmente o valor 10. Suponha que uma transação Ti tenha atualizado o item de dado A para 20 e
depois foi abortada; a reversão da transação restauraria A para o valor 10. Suponha, então, que outra transação Tj
tenha atualizado o item de dado A para 30 e tenha sido efetivada; em seguida, o sistema cai. O estado do log no
momento da queda é:
Se o passo redo é processado primeiro, A será ajustado para 30; então, no passo undo, A será ajustado
para 10, o que está errado. O valor final de Q deveria ser 30, que podemos alcançar processando undo antes de
redo.
Gerenciamento de Buffer
Vamos considerar diversos detalhes sutis, embora essenciais, para a implementação de um esquema de
recuperação de queda que garanta consistência de dados e imponha uma quantidade mínima de overhead
devido a interações com o banco de dados.
Bufferização de Registro de Log
Anteriormente, assumimos que qualquer registro de log é enviado para a saída de armazenamento
estável no momento em que é criado. Essa situação impõe grande overhead à execução do sistema pelas
seguintes razões. Normalmente, a saída para armazenamento estável ocorre em unidades de blocos. Em muitos
casos, um registro de log é muito menor que um bloco. Então, a saída de cada registro de log se traduz em uma
saída muito maior no nível físico. Além do mais a saída de um bloco para armazenamento estável pode significar
várias operações de saída no nível físico.
O custo relativo ao processamento de uma saída de bloco para armazenamento estável é suficientemente
alto; é melhor que saiam diversos registros de log de uma só vez. Para isso, escrevemos os registros de log em um
buffer de log na MP, onde permanecem temporariamente, até serem enviados para armazenamento estável.
Múltiplos registros de log podem ser reunidos no buffer de log e enviados para armazenamento estável em uma
única operação de saída. A ordem dos registros de log no armazenamento estável deve ser exatamente a mesma
na qual foram escritos no buffer de log.
Em consequência do uso da bufferização do log, um registro de log pode residir somente em MP
(armazenamento volátil) por um tempo considerável antes de ser enviado para a saída em armazenamento
estável. Já que tais registros de log são perdidos se os sistema cair, devemos impor exigências adicionais às
técnicas de recuperação para garantia de atomicidade da transação:
• A transação Ti entra em estado de efetivação após o registro de log <Ti commit> ter sido enviado para
saída em armazenamento estável.
• Antes do registro de log <Ti commit> sofrer armazenamento estável, todos os registros de log
pertencentes à transação Ti deverão ter sido enviados para armazenamento estável.
• Antes de um bloco de dados na MP podem ser enviado para o banco de dados (em armazenamento não-
volátil), todos os registros de log pertencentes a dados naquele bloco devem ter sido enviados para
armazenamento estável.

315
• Antes de um bloco de dados na MP poder ser enviado para o banco de dados (em armazenamento não-
volátil), todos os registros de log pertencentes a dados naquele bloco devem ter sido enviados para
armazenamento estável.
A última regra é chamada de regra write-ahead logging (WAL). (Precedência de escrita do log, a regra WAL exige
somente a informação undo no log tenha sido enviada para saída em armazenamento estável, permitindo que a
informação redo seja escrita mais tarde. A diferença é relevante em sistemas nos quais a informação redo e undo
é armazenada em registros de log separados.)
Escrever o log bufferizado no disco às vezes é chamado de forçar o log (log force). As regras precedentes
criam situações em que certos registros de log devem ser enviados para saída em armazenamento estável. Não
há problema decorrente do envio dos registros de log mais cedo que o necessário. Logo, quando o sistema achar
necessário enviar um registro de log para armazenamento estável, ele enviará um bloco inteiro de registros de
log, se houver registros de log suficientes na MP para preencher um bloco. Se os registros de log forem
insuficientes na MP para preencher um bloco. Se os registros de logo forem insuficientes para preencher o bloco,
os registros de log na MP serão combinados a um bloco parcialmente completo e serão enviados para saída em
armazenamento estável.
Bufferização de Banco de Dados
Já descrevemos a hierarquia de armazenamento em dois níveis. O banco de dados está armazenado em
armazenamento não-volátil (disco) e os blocos de dados são levados à MP quando necessário. Já que a MP é
normalmente muito menor que o banco de dados inteiro, pode ser necessário sobrescrever um bloco B1 na MP
quando outro bloco B2 necessitar ser levado à memória. Se B1 tiver sido modificado, ele deverá ser enviado para o
banco de dados antes da entrada de B2. Essa hierarquia de armazenamento é o conceito-padrão de sistema
operacional de memória virtual.
As regras para a saída de registros de log limitam a liberdade do sistema para saída de blocos de dados. Se
a entrada do bloco B2 fizer com que o bloco B1 seja selecionado para a saída, todos os registros de log
pertencentes aos dados em B1 devem ser enviados para armazenamento estável antes de B1 ser enviado para
saída. Então, a sequência de ações pelo sistema, seria como segue:
• Enviar registros de log para armazenamento estável até acabarem os registros de log pertencentes ao
bloco B1.
• Enviar o bloco B1 para saída no disco.
• Enviar o bloco B2 do disco para a entrada em MP.
É importante que nenhuma gravação no bloco B1 esteja em progresso enquanto a sequência precedente
de ações estiver em execução. Essa condição é satisfeita quando se usa um meio especial de bloqueio, como
segue. Antes que uma transação escreva um item de dado, ela deve adquirir um bloqueio exclusivo sobre o bloco
no qual o item de dados reside. O bloqueio poderá ser liberado imediatamente após a atualização. Antes de um
bloco ser enviado para a saída, o sistema obtém um bloqueio exclusivo sobre o bloco, para garantir que nenhuma
transação o altere. Completada a saída do bloco, o bloqueio é liberado. Os bloqueios que são mantidos por pouco
tempo são frequentemente chamados de trancas (latches). As trancas são tratadas de forma distintas dos
bloqueios usados pelo sistema de controle de concorrência. Com isso, elas podem ser liberadas sem considerar
qualquer protocolo de bloqueio, como bloqueio em duas fases, exigido pelo sistema de controle de concorrência.
Para ilustrar a necessidade da sequência anterior de ações, consideremos nosso exemplo bancário com as
transações T0 e T1. Suponha que o estado do log seja:
e que a transação T0 emita uma read(B). Assuma que o bloco em que B reside não está na MP e que a MP esteja
completa. Suponha que o bloco em que reside A seja escolhido para ser enviado ao disco. Se o sistema envia esse
bloco para saída no disco e, então, o sistema cai, os valores no banco de dados para as contas A, B e C são 950,
2000 e 700 dólares, respectivamente. Esse estado do banco de dados é inconsistente. Entretanto, devido às
exigências precedentes, o registro de log <T0, A, 1000, 950> deverá ser enviado para armazenamento estável

316
antes da saída do bloco em que A reside. O sistema pode usar o registro de log durante a recuperação para levar
o banco de dados de volta a um estado consistente.
Regra de Sistema Operacional em Gerenciamento de Buffer
Podemos gerenciar o buffer do banco de dados usando uma das duas abordagens:
1. O sistema de banco de dados reserva parte da MP para servir como um buffer gerenciado por ele, e não
pelo sistema operacional. O sistema de banco de dados gerencia a transferência de bloco de dados, de
acordo com as exigências que já discutimos.
Essa abordagem tem o inconveniente de limitar a flexibilidade de uso da MP. O buffer deve ser mantido
pequeno o suficiente para que outras aplicações tenha MP suficiente para sua necessidades. Entretanto, mesmo
quando outras aplicações não estiverem rodando, o banco de dados não poderá fazer uso de todas a memória
disponível. Da mesma forma, aplicações que não sejam banco de dados podem não usar aquela parte da MP
reservada para o buffer de banco de dados, mesmo se algumas páginas no buffer do banco de dados não
estiverem em uso.
2. O sistema de banco de dados implementa seu buffer dentro da memória virtual do sistema operacional.
Já que o sistema operacional possui informações sobre as exigências de memória de todos os processos
no sistema, idealmente ele deveria estar capacitado a decidir quais blocos de buffer devem ser forçados à
saída para o disco e quando isso deve ser feito. Mas, para atender à precedência de escrita do log que
discutimos, o sistema operacional não poderia escrever páginas de buffer no banco de dados por si só,
mas, ao contrário, solicitar que o sistema de banco de dados forçasse a saída dos blocos do buffer. O
sistema de banco de dados, por sua vez, só forçaria a saída dos blocos do buffer para o banco de dados
após escrever os registros de log relevantes em armazenamento estável.
Infelizmente, quase todos os sistemas operacionais da geração atual mantêm controle completo sobre a
memória virtual. O sistema operacional reserva espaço em disco para armazenar páginas de memória virtual que
não estão na MP; este espaço é chamado de espaço de swap (troca). Se o sistema operacional decidir retirar da
memória um bloco Bx, ele será enviado para o espaço de swap no disco, e não há nenhuma forma do sistema de
banco de dados conseguir controle dessa saída de blocos do buffer.
No entanto, se o buffer de banco de dados estiver na memória virtual, as transferências entre arquivos de
banco de dados e o buffer na memória virtual são gerenciadas pelo sistema de banco de dados, que cumprirá as
exigências de precedência de escrita do log que discutimos.
Essa abordagem pode implicar saídas extras de dados para o disco. Se um bloco Bx é retirado pelo sistema
operacional, esse bloco não será enviado para o banco de dados. Ao contrário, ele será enviado para o banco de
dados. Quando o sistema de banco de dados tiver de enviar Bx para o disco, pode ser que o sistema operacional
tenha de, primeiro, retirar Bx de seu espaço de swap. Então, ao contrário de uma única saída de Bx da memória,
exigiremos duas saídas de Bx (uma pelo sistema operacional, e outra pelo sistema de banco de dados), além de
uma entrada extra de Bx na memória.
Embora ambas as abordagens padeçam de alguns inconvenientes, uma ou outra deverá ser escolhida, a
menos que o sistema operacional seja projetado para aceitar as exigências de log do banco de dados. Somente
uns poucos sistemas operacionais atuais, como o sistema operacional Mach, aceitam tais exigências.
Falha com Perda de Armazenamento Não-volátil
Até agora, consideramos somente falhas que têm como consequência a perda de informações residentes
em armazenamento volátil; o conteúdo do armazenamento não-volátil permanece intacto. Embora as falhas com
perda de armazenamento não-volátil sejam raras, precisamos estar preparados para trata-las. Vamos discutir, por
enquanto, apenas armazenamento em disco. Nossas discussões se aplicam também a outros tipos de
armazenamento não-volátil.
O esquema básico é descarregar (dump) todo conteúdo do banco de dados para armazenamento estável
periodicamente – digamos, uma vez por dia. Por exemplo, podemos descarregar o banco de dados para uma ou

317
mais fitas magnéticas. Se ocorrer uma falha que resulte na perda de blocos físicos do banco de dados, a descarga
mais recente será usada na restauração do banco de dados para seu último estado consistente possível. Uma vez
completada essa restauração, o sistema usa o log para trazer o sistema de banco de dados para um estado
consistente recente.
Mais precisamente, nenhuma transação pode estar ativa durante o procedimento de descarga, e um
procedimento similar para checkpoint (pontos de controle) deve ocorrer:
1. Enviar todos os registros de log residentes em MP para saída de armazenamento estável.
2. Enviar todos os blocos de buffer para saída em disco.
3. Copiar o conteúdo do banco de dados em armazenamento estável.
4. Enviar um registro de log <dump> para saída em armazenamento estável.
Os passos 1, 2 e 4 correspondem aos três passos usados para checkpoints anteriormente.
Para se recuperar da perda de armazenamento não-volátil, restauramos o banco de dados em disco
usando a descarga (dump) mais recente. O log é, então, consultado e todas as transações que foram efetivadas
desde a última descarga são refeitas. Observe que nenhuma operação undo precisa ser executada.
Uma descarga do conteúdo do banco de dados também é chamada de archival dump (descarga histórica),
já que podemos arquivar as descargas e usá-las mais tarde para examinar informações antigas do banco de
dados. Descargas de um banco de dados e checkpoints dos buffers são similares.
O procedimento de descarga simples aqui descrito é oneroso pelas seguintes razões. Primeiro, todo o
banco de dados deverá ser copiado em armazenamento estável, resultando em considerável transferência de
dados. Segundo, já que o processamento das transações é suspenso durante a descarga, ciclos de CPU são
perdidos. Têm sido desenvolvidos esquemas de fuzzy dump (descarga indistinta) que permitem a existência de
transações ativas enquanto a descarga está em progresso. São similares a esquemas de checkpoints.
Técnicas de Recuperação Avançadas
As técnicas de recuperação já descritas requerem que, enquanto uma transação atualização um item de
dado, nenhuma outra transação consiga atualizar o mesmo item de dado, até que a primeira seja efetivada ou
revertida. Satisfazemos essa condição por meio do bloqueio em duas fases severo. Embora o bloqueio em duas
fases severo seja aceitável para os registros de relações ele causa um significativo decréscimo de concorrência
quando aplicado a certas estruturas especiais, como páginas de índice de árvore-B+.
Para aumentar a concorrência, podemos usar o algoritmo de controle e de concorrência árvore-B+
permitindo que os bloqueios sejam liberados mais cedo, sem usar duas fases. Como isso, entretanto, as técnicas
de recuperação estudadas tornam-se inaplicáveis. Várias técnicas de recuperação alternativas têm sido propostas
tornam-se inaplicáveis. Várias técnicas de recuperação alternativas têm sido propostas, aplicáveis mesmo com
liberação prematura de bloqueio. Descrevemos uma dessas técnicas de recuperação agora.
Log com Undo Lógico
Para ações nas quais os bloqueios são liberados mais cedo, não podemos processar as ações undo
simplesmente regravando o valor antigo dos itens de dados. Considere uma transação T que insira uma entrada
em uma árvore-B+ e, seguindo o protocolo de controle de concorrência árvore-B+, libere alguns dos bloqueios
após o término da operação de inserção, mas antes da transação ser efetivada. Após a liberação dos bloqueios,
outras transações podem realizar inserções ou remoções adicionais, causando desse modo mudanças adicionais
nas páginas da árvore B+.
Mesmo que a operação libere alguns dos bloqueios previamente, ela deverá reter bloqueios suficientes
para garantir que não seja permitido a nenhuma outra transação executar qualquer operação conflitante (como
ler ou remover o valor inserido). Por essa razão, o protocolo de controle de concorrência árvore-B+ mantém os
bloqueios no nível de folha da árvore-B+ até o fim da transação.
Agora vamos considerar como processar os rollbacks de transações. Se os valores antigos dos nós
internos da árvore-B+ (antes da operação de inserção ser executada) forem restaurados durante a reversão da

318
transação, algumas das atualizações processadas pelas últimas operações de inserção ou exclusão executadas por
outras transações poderiam ser perdidas. Em vez disso, a operação de inserção tem de ser inutilizada logicamente
– isto é, pela execução de uma operação de remoção.
Portanto, quando a ação de inserção for completada, antes de liberar qualquer bloqueio, ela deverá
gravar um registro de log <Oi, operation-end, U>, em que U indica a informação de inutilização e Oi indica um
identificador para a operação. Por exemplo, se a operação inseriu uma entrada em uma árvore-B+, a informação
undo U indicaria o que remover da árvore-B+. Esse log de informação sobre operações é chamado de log físico e
os correspondentes registros de log são chamados de registros de log físicos.
As operações de inserção e remoção são exemplos de uma classe de operações que exige operações undo
lógicas, já que liberam os bloqueios previamente; chamamos tais operações de operações lógicas. Antes que uma
operação lógica tenha início, ela escreve um registro de log <Oi, operation-begin>, em que Oi é o identificador
para a operação. Enquanto a operação está sendo executada, o log é feito da maneira convencional para todas as
atualizações processadas pela operação. Então, as informações usuais dos valores antigos e novos são escritos
para cada atualização. Quando a operação termina, um registro de log de final de operação (operation-end) é
escrito como explicado anteriormente.
Reversão de Transação
Vamos considerar primeiro a reversão de transações durante operação normal (isto é, não durante a
recuperação do sistema após uma falha). O log é examinado de trás para a frente (ordem cronológica
decrescente) e os registros de log pertencente à transação são usado para restaurar os valores antigos dos itens
de dados. Ao contrário de antes, escrevemos registros especiais de log somente redo da forma <Ti, Xj, V> com o
valor V sendo sobreposto ao item de dado Xj durante a reversão. Esses registros de log algumas vezes são
chamados de registros de log de compensação. Sempre que um registro de log <Oi, operation-end, U> é
encontrado, ações especiais são tomadas:
1. Revertemos a operação usando a informação undo U do registro de log. As atualizações processadas
durante a reversão da operação são registradas no log exatamente da mesma forma que as atualizações
processadas quando a operação foi executada primeiro. Além do mais, registros de log referentes ao
início e ao final da operação são gerados exatamente como durante a execução normal da operação.
2. Quando a verificação retroativa do log continua, saltamos todos os registros de log da transação até
encontrados o registro de log <Oi, operation-begin>. Após o registro de log de início da operação ser
encontrado, os registros de log da transação são processados novamente de maneira usual.
Quando a transação Ti for revertida, um registro <Ti abort> será adicionado ao log.
Se ocorrerem falhas enquanto uma operação lógica está em progresso, o registro de logo de fim de
operação para aquela operação não será encontrado quando a transação for revertida. Entretanto, para cada
atualização processada pela operação, a informação undo – na forma do valor antigo nos registros de log físicos –
está disponível no log. Observe que saltar os registros de log físicos, quando o registro de log de fim de operação
é encontrado durante a reversão, garante que os valores antigos do registro de log físico não sejam usados na
reversão, uma vez que a operação terminou.
Se o bloqueio é usado para controle de concorrência, os bloqueios mantidos por uma transação T podem
ser liberados somente após a transação tiver sido revertida, conforme descrito.
Checkpoints
Os checkpoints são processados conforme já descrito. Atualizações no banco de dados são
temporariamente suspensas e as seguintes ações são executadas:
1. Enviar para saída em armazenamento estável todos os registros de log residentes na memória principal.
2. Enviar para saída em armazenamento estável um registro de log <checkpoint L>, em que L é uma lista de
todas as transações ativas.
3. Enviar para saída em disco todos os blocos de buffer modificados.

319
Recuperação de Reinício
As ações de recuperação, quando o sistema de banco de dados é reiniciado após uma falha, são
executadas em duas fases:
1. Na fase redo, reexecutamos as atualizações de todas as transações pela varredura do log avançando a
partir do último checkpoint. Os registros de log que serão reexecutados englobam os registros de log das
transações que foram revertidas antes do sistema cair e aquelas que não foram efetivas quando ocorreu
a queda do sistema. Os registros de log reexecutados incluem os registros de log usuais da forma <Ti, Xj,
V1, V2> e os registros de log especiais da forma <Ti, Xj, V2>; o valor V2 é escrito para o item de dados Xj em
qualquer caso. Essa fase também determina todas as transações que estão na lista de transações no
registro de checkpoint ou que foram iniciadas mais tarde, mas não têm nenhum registro <Ti abort> ou <Ti
commit> no log. Todas essas transações têm de ser revertidas e seus identificadores de transação são
colocados em uma lista undo.
2. Na fase undo, refazemos todas as transações da lista undo. Processamos a reversão reexaminando o log
do final para o começo. Sempre que um registro de log pertencente a uma transação da lista undo é
encontrado, as ações undo são processadas exatamente como se o registro de log fosse encontrado
durante a reversão de uma transação que falhou. Então, os registros de log de uma transação anteriores a
um registro final de operação, mas após o correspondente registro de início de operação, são ignorados.
Quando um registro de log <Ti start> é encontrado para uma transação Ti na lista undo, um registro de log
<Ti abort> é escrito no log. O exame do log para quando registros de log <Ti start> são encontrados para todas as
transações na lista undo.
A fase redo da recuperação de reinício reexecuta todos os registros de log físico, a partir do mais recente
registro de checkpoint. Em outras palavras, essa fase de recuperação de reinício repete todas as ações de
atualização que foram executadas após o checkpoint e cujos registros de log alcançaram log estável. Essas ações
incluem as transações incompletas e as ações executadas para reverter transações com falha. As ações são
repetidas na mesma ordem em que foram executas; consequentemente, esse processo é chamado de história
repetitiva (repeating history). A história repetitiva simplifica enormemente os esquemas de recuperação.
Fuzzy Checkpoint
A técnica checkpoint descrita exige que todas as atualizações ao banco de dados sejam temporariamente
suspensas enquanto o checkpoint está em progresso. É possível modificar a técnica para permite que as
atualizações iniciem no momento em que o registro checkpoint é escrito, mas antes dos blocos de buffer
modificados serem escritos no disco. Então, o checkpoint gerado é um fuzzy checkpoint (ponto de controle
indistinto).
A ideia é a seguinte. Em vez de reexaminar o log de trás para frente a fim de encontrar um registro de
checkpoint, armazenamos a localização em log do último registro de checkpoint em uma posição fixa no disco.
Entretanto, essa informação não é atualizada quando o registro checkpoint é escrito. Ao contrário, antes do
registro checkpoint ser escrito, uma lista com todos os blocos de buffer modificados é criada. A informação último
checkpoint é atualizada somente após todos os blocos de buffer, da lista de blocos de buffer modificados, terem
sido escritos no disco. O protocolo de precedência de escrita do log deve ser seguido quando os blocos de buffer
são enviados para saída.
Observe que, em nosso esquema, o registro de log lógico é usado somente para propósitos de undo, ao
passo que o registro de log físico é usado para propósitos redo (refazer) e undo (inutilizar). Há esquemas de
recuperação que usam registro de log lógico para propósitos redo. Entretanto, tais esquemas não podem ser
usados com fuzzy checkpoint e, portanto, não são muito empregados.







