cloud integrator: uma plataforma para composição de...
TRANSCRIPT

UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE CIÊNCIAS EXATAS E DA TERRA
DEPARTAMENTO DE INFORMÁTICA E MATEMÁTICA APLICADA
PROGRAMA DE PÓS-GRADUAÇÃO EM SISTEMAS E COMPUTAÇÃO
MESTRADO ACADÊMICO EM SISTEMAS E COMPUTAÇÃO
Cloud Integrator:
Uma Plataforma para Composição de Serviços
em Ambientes de Computação em Nuvem
Everton Ranielly de Sousa Cavalcante
Natal, RN, Brasil
Janeiro, 2013

Everton Ranielly de Sousa Cavalcante
Cloud Integrator:
Uma Plataforma para Composição de Serviços em
Ambientes de Computação em Nuvem
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Sistemas e
Computação do Departamento de Informática e
Matemática Aplicada da Universidade Federal do
Rio Grande do Norte como requisito parcial para
a obtenção do grau de Mestre em Sistemas e
Computação.
Linha de pesquisa:
Sistemas Integrados e Distribuídos
Orientadora
Prof.ª Dra. Thais Vasconcelos Batista
PPgSC – Programa de Pós-Graduação em Sistemas e Computação
DIMAp – Departamento de Informática e Matemática Aplicada
CCET – Centro de Ciências Exatas e da Terra
UFRN – Universidade Federal do Rio Grande do Norte
Natal, RN, Brasil
Janeiro, 2013

Catalogação da Publicação na Fonte. UFRN / SISBI / Biblioteca Setorial
Especializada do Centro de Ciências Exatas e da Terra – CCET.
Cavalcante, Everton Ranielly de Sousa.
Cloud Integrator: Uma Plataforma para Composição de Serviços em Ambientes
de Computação em Nuvem / Everton Ranielly de Sousa Cavalcante – Natal, RN,
Brasil, 2013.
129 f. : il.
Orientadora: Profª. Dra. Thais Vasconcelos Batista.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro de Ciências Exatas e da Terra. Departamento de Informática e Matemática Aplicada.
Programa de Pós-Graduação em Sistemas e Computação.
1. Sistemas distribuídos – Dissertação. 2. Computação Orientada a Serviços –
Dissertação. 3. Computação em nuvem – Dissertação. 4. Web Semântica –
Dissertação. 5. Plataforma de middleware – Dissertação. I. Batista, Thais
Vasconcelos. II. Título.
RN/UF/BSE-CCET CDU 004.75


a Deus, porque dEle, e por Ele, e para Ele são todas as coisas;
a Ele seja a glória para sempre.
(Romanos 11.36)

Agradecimentos
Agradecer é admitir que houve um momento em que se precisou de alguém, é
reconhecer que o homem jamais poderá lograr para si o dom de ser autossuficiente. Ninguém e
nada cresce sozinho; sempre é preciso um olhar de apoio, uma palavra de incentivo, um gesto
de compreensão, uma atitude de amor. Talvez seja difícil fazer isto em forma de palavras, mas
gostaria de externar sinceros agradecimentos a diversas pessoas que, de alguma forma,
contribuíram, diretamente ou não, para que eu pudesse estar escrevendo estas palavras. É
possível ainda que existam outras pessoas que deveriam ser citadas aqui, mas, por disfunção
da minha memória, infelizmente não foram; a tais pessoas, desde já peço sinceras desculpas.
Não tenho palavras para agradecer a Deus, o Autor da Vida, meu motivo, minha razão
de viver e existir. Sem a Sua graça, força, bondade, misericórdia e fidelidade, de maneira
alguma teria chegado até aqui, e tudo o que eu disser será muito pouco diante de tudo isso.
Agradeço a Ele pela oportunidade concedida e por me fazer quem sou hoje, pelas conquistas
alcançadas em meio às adversidades, por concretizar aquilo que parecia longínquo ou até
mesmo impossível aos meus olhos limitados, e pela determinação e perseverança concedida em
situações nas quais tudo parecia conspirar pelo fracasso. “O SENHOR é o meu rochedo, e o
meu lugar forte, e o meu libertador; o meu Deus, a minha fortaleza, em quem confio; o meu
escudo, a força da minha salvação e o meu alto refúgio. Porque quem é Deus senão o
SENHOR?” (Salmos 18.2,31).
Agradeço aos meus pais, Maria Gorete e José Cavalcante (in memoriam), pelo esforço
sob grandes dificuldades que tiveram de ser ultrapassadas para proporcionar uma boa
formação, pelos ensinamentos e valores que não passam e que, sem dúvida, são elementos que
levarei comigo pelo resto da minha existência. Obrigado também a todos os meus familiares
pelo apoio e incentivo e pela compreensão que tiveram em muitos momentos nos quais estive
ausente devido à intensa rotina de estudos. Minha gratidão a todos vocês por me ensinarem
como viver a vida com dignidade e honestidade, por iluminarem os caminhos escuros com
afeto e dedicação para que eu pudesse trilhá-los sem medo e cheio de esperança. Afinal, é
preciso força para sonhar e perceber que a estrada vai além do que se vê.
Agradeço especial e imensamente a Thais Batista, minha orientadora, professora,
amiga, conselheira e às vezes até mãe (risos). Nosso maior desejo na vida é encontrar alguém
que nos faça fazer o melhor que pudermos e, sem dúvida, ela é essa pessoa, de modo que tudo o
que eu disser aqui será muito pouco para agradecê-la. Obrigado, Thais, por tudo, tudo mesmo;
tenho certeza que, sem você, muito dificilmente eu teria chegado até aqui. Obrigado pelo
privilégio de poder trabalhar com você ao longo desses quase três anos (antes mesmo de iniciar
o Mestrado), pela amizade, atenção, disponibilidade, ensinamentos, conselhos (profissionais e
pessoais), paciência, confiança, por acreditar em mim mesmo quando nem eu acreditava, pelas
inúmeras portas que diante de mim foram abertas e oportunidades proporcionadas, e por estar
comigo e me ajudar nos momentos em que mais precisei. Sim, essas ações, apesar de às vezes

parecerem tão simples, não têm preço; tenha certeza que as levarei na memória e no coração
para sempre.
Ao amigo e professor Frederico Lopes por esses dois anos e meio de trabalho juntos,
ainda mesmo antes de iniciar o Mestrado. Obrigado por contribuir diretamente com este
trabalho desde a sua concepção e acompanhar todo o seu desenvolvimento e pela parceria,
cooperação e disponibilidade em me ajudar e sanar as minhas constantes dúvidas,
principalmente quando tudo estava ainda começando. Também agradeço a você pela amizade,
paciência, companheirismo, conselhos profissionais e pessoais, e até mesmo pelas brincadeiras
que você fazia só para perturbar o meu juízo (risos), mas eram apenas para descontrair.
Às professoras Noemi Rodriguez e Ana Lúcia de Moura, pela disponibilidade,
paciência e acolhida no tempo (ainda que curto) em que estive como pesquisador visitante na
PUC-Rio – Pontifícia Universidade Católica do Rio de Janeiro (Rio de Janeiro, Brasil), uma
universidade simplesmente maravilhosa. Obrigado pela oportunidade de trabalhar com vocês,
por toda a ajuda dispensada e pelas ideias e contribuições que só fizeram enriquecer este
trabalho.
Aos professores Nélio Cacho, Flavia Delicato e Paulo Pires pela contribuição
inestimável neste trabalho, pelas ideias que só fizeram agregar valor, e pela parceria nos
diversos trabalhos que desempenhamos juntos.
Aos colegas (e amigos) do ConSiste – Laboratório de Concepção de Sistemas, com os
quais tive a oportunidade de trabalhar, aprender e também rir bastante. Em especial, gostaria
de agradecer aos queridos amigos Ana Luisa Medeiros e Gustavo Alves, pessoas que admiro e
que tive o prazer de conhecer nesse ambiente de trabalho. Obrigado por me fazerem uma
pessoa feliz ao saber que tenho amigos como vocês com os quais posso contar, por me
proporcionarem momentos tão bons ao lado de vocês e por dividirem comigo as cargas dos que
pareciam ruins. Além da parceria nos projetos de pesquisa, a amizade, o companheirismo e as
palavras de apoio e incentivo de vocês também serviram de combustível fundamental para
prosseguir nesse bom combate. Mesmo com o tempo e/ou a distância, espero levar a amizade
desse trio para o resto da vida.
Às amigas Camila Oliveira e Juliana Araújo, companhias sempre presentes desde a
Graduação em Ciência da Computação na UFRN. Obrigado pela amizade e por sempre me
apoiarem, incentivarem e torcerem por mim, e também pelos nossos almoços mensais que me
fazem tão bem.
Aos colegas de Pós-Graduação que tive o prazer de conhecer nas disciplinas cursadas e
fazer novas amizades. Em especial, agradeço aos amigos Larissa Sobral, Fillipe Rodrigues e
Daniel Alencar, companheiros dessa mesma trajetória; muito obrigado pela amizade, apoio,
incentivo, torcida e por serem pessoas ímpares nesse mundo.
A Larissa Leite e Rebeca Maia, que, neste momento, estão em diferentes lugares do
mundo alçando voos cada vez mais altos. Obrigado pela amizade, carinho, torcida e pelos
incontáveis momentos divertidos nos quais eu tinha a companhia de vocês. Voltem logo!

A Reginaldo Mendes que, apesar da distância, forneceu auxílio indispensável neste
trabalho. Obrigado pela contribuição, paciência e constante disponibilidade, às vezes mesmo
sem tempo, para atender às minhas várias chamadas e sanar diversas dúvidas.
Aos meus segundos pais, Vanduir e Kátia Oliveira, pelo apoio, carinho, atenção,
conselhos e por dividirem comigo momentos tão especiais e me tratarem realmente como um
filho. Também agradeço ao amigo e professor Edson Moreira Neto por ter sido um dos
primeiros incentivadores dessa conquista e também pelo apoio, atenção, conselhos e pelo
exemplo de pessoa e profissional que é.
Aos amigos de perto e de longe, aos que vejo quase todos os dias e aos que “vejo”
apenas pela Internet; infelizmente não vou poder citar o nome de todos vocês, mas recebam
aqui as minhas palavras de gratidão. Em especial, agradeço aos queridos amigos do Pavilhão,
amigos ainda da época do Ensino Médio no CEFET-RN e que acompanham essa trajetória; no
sucesso de cada um de vocês, no potencial de cada um de vocês, encontro verdadeiros
guerreiros e, principalmente, verdadeiros vencedores.
Por fim, às Instituições que incentivaram a execução deste projeto e forneceram o apoio
financeiro fundamental para o desenvolvimento deste trabalho:
− CNPq – Conselho Nacional de Desenvolvimento Científico e Tecnológico;
− RNP – Rede Nacional de Ensino e Pesquisa, através do Projeto AltoStratus do
CTIC – Centro de Pesquisa e Desenvolvimento em Tecnologias Digitais para
Informação e Comunicação, e;
− INCT Web Science Brazil – Brazilian Institute for Web Science Research.
So, to everyone who has helped me over this time,
directly or not, here your “thank you”.

Este trabalho foi desenvolvido com recursos financeiros das seguintes Instituições:
− CNPq – Conselho Nacional de Desenvolvimento Científico e Tecnológico;
− RNP – Rede Nacional de Ensino e Pesquisa, através do Projeto AltoStratus do
CTIC – Centro de Pesquisa e Desenvolvimento em Tecnologias Digitais para
Informação e Comunicação, e;
− INCT Web Science Brazil – Brazilian Institute for Web Science Research.

O sucesso é você fazer o melhor que você pode, nas diversas maneiras que você
puder; é sempre se deter para o que está à frente e nunca para o que ficou para
trás; é nunca se dar por vencido naquilo que você faz; é acreditar no melhor que
você pode ser e ter fé nas coisas que você faz. Olhar para trás, após uma longa
caminhada, pode fazer perder a noção da distância que percorremos. Mas, se
nos detivermos em nossa imagem, quando a iniciamos e ao término dela,
certamente nos lembraremos de quanto custou chegar até o ponto final,
e hoje, temos a impressão de que tudo começou ontem; não somos os mesmos.
Digamos, então, que nada se perderá, pelo menos dentro de nós.
Valeu a pena? Tudo vale a pena se a alma não é pequena.

Cloud Integrator:
Uma Plataforma para Composição de Serviços em
Ambientes de Computação em Nuvem
Autor: B.Sc. Everton Ranielly de Sousa Cavalcante
Orientadora: Prof.ª Dra. Thais Vasconcelos Batista
RESUMO
Com o avanço do paradigma de Computação em Nuvem, um único serviço
oferecido por uma plataforma de nuvem pode não ser suficiente para satisfazer
todos os requisitos da aplicação. Para satisfazer tais requisitos, ao invés de um único
serviço, pode ser necessária uma composição que agrega serviços providos por
diferentes plataformas de nuvem. A fim de gerar valor agregado para o usuário, essa
composição de serviços providos por diferentes plataformas de Computação em
Nuvem requer uma solução em termos de integração de plataformas, envolvendo a
manipulação de um vasto número de APIs e protocolos não interoperáveis de
diferentes provedores. Nesse cenário, este trabalho apresenta o Cloud Integrator, uma
plataforma de middleware para composição de serviços providos por diferentes
plataformas de Computação em Nuvem. Além de prover um ambiente que facilita o
desenvolvimento e a execução de aplicações que utilizam tais serviços, o Cloud
Integrator funciona como um mediador provendo mecanismos para a construção de
aplicações através da composição e seleção de serviços Web semânticos que
consideram metadados acerca dos serviços, como QoS (Quality of Service), preços etc.
Adicionalmente, a plataforma de middleware proposta provê um mecanismo de
adaptação que pode ser disparado em caso de falha ou degradação da qualidade de
um ou mais serviços utilizados pela aplicação em questão, a fim de garantir sua a
qualidade e disponibilidade. Neste trabalho, através de um estudo de caso que
consiste de uma aplicação que utiliza serviços providos por diferentes plataformas
de nuvem, o Cloud Integrator é avaliado em termos da eficiência dos processos de
composição de serviços, seleção e adaptação realizados, bem como da potencialidade
do seu uso em cenários de nuvens computacionais heterogêneas.
Palavras-chave: Computação Orientada a Serviços. Computação em Nuvem.
Workflows semânticos. Composição de serviços Web semânticos. Seleção de serviços
de nuvem. Adaptação.

Cloud Integrator:
A Platform for Composition of Services in
Cloud Computing Environments
Author: Everton Ranielly de Sousa Cavalcante, B.Sc.
Supervisor: Prof. Thais Vasconcelos Batista, Ph.D.
ABSTRACT
With the advance of the Cloud Computing paradigm, a single service offered by a
cloud platform may not be enough to meet all the application requirements. To fulfill
such requirements, it may be necessary, instead of a single service, a composition of
services that aggregates services provided by different cloud platforms. In order to
generate aggregated value for the user, this composition of services provided by
several Cloud Computing platforms requires a solution in terms of platforms
integration, which encompasses the manipulation of a wide number of non-
interoperable APIs and protocols from different platform vendors. In this scenario,
this work presents Cloud Integrator, a middleware platform for composing services
provided by different Cloud Computing platforms. Besides providing an
environment that facilitates the development and execution of applications that use
such services, Cloud Integrator works as a mediator by providing mechanisms for
building applications through composition and selection of semantic Web services
that take into account metadata about the services, such as QoS (Quality of Service),
prices, etc. Moreover, the proposed middleware platform provides an adaptation
mechanism that can be triggered in case of failure or quality degradation of one or
more services used by the running application in order to ensure its quality and
availability. In this work, through a case study that consists of an application that use
services provided by different cloud platforms, Cloud Integrator is evaluated in terms
of the efficiency of the performed service composition, selection and adaptation
processes, as well as the potential of using this middleware in heterogeneous
computational clouds scenarios.
Keywords: Service-Oriented Computing. Cloud Computing. Semantic workflows.
Composition of semantic Web services. Cloud services selection. Adaptation.

Lista de figuras
Figura 1. Relacionamentos entre os elementos envolvidos em SOA. ........................... 27
Figura 2. Uso de padrões baseados em XML para relacionamento entre os elementos
em SOA. ............................................................................................................. 29
Figura 3. Principais tecnologias da Web Semântica. ...................................................... 30
Figura 4. Dialetos da OWL, definidos pelo de expressividade que representam. ...... 31
Figura 5. Ontologia OWL-S. ............................................................................................. 32
Figura 6. Trecho da ontologia OWL-S do serviço Web ReservarVooService. ................ 34
Figura 7. Representação de serviços simples e compostos. ........................................... 35
Figura 8. Ilustração do Cloud Integrator como mediador entre diferentes plataformas
de Computação em Nuvem e as aplicações que fazem uso dos serviços
providos por elas. .............................................................................................. 38
Figura 9. Representação parcial da ontologia de domínio Ecommerce. ........................ 40
Figura 10. Representação parcial da ontologia de nuvem CloudOntology.................... 41
Figura 11. Grafo direcionado acíclico que representa um conjunto de possíveis
planos de execução para um workflow. .......................................................... 42
Figura 12. Arquitetura do Cloud Integrator...................................................................... 43
Figura 13. Trecho de código referente à interface Application Interface......................... 44
Figura 14. Arquitetura do QoMonitor. ............................................................................. 48
Figura 15. Ilustração de workflow e de serviços coincidentes presentes nos planos de
execução. .......................................................................................................... 51
Figura 16. Exemplo de arquivo de configuração XML com pesos atribuídos aos
parâmetros de qualidade................................................................................ 55
Figura 17. Ponto de coincidência em um grafo direcionado acíclico que representa o
conjunto de planos de execução para um workflow. ..................................... 59
Figura 18. Diagrama UML de sequência que ilustra o processo de adaptação
disparado por falha de um serviço. ............................................................... 61
Figura 19. Diagrama UML de sequência que ilustra o processo de adaptação
disparado por degradação de qualidade. ..................................................... 63
Figura 20. Ilustração do assistente provido pelo Cloud Integrator para especificação de
atividades (tarefas e objetos) a compor um workflow. .................................. 69

Figura 21. Ilustração do assistente provido pelo Cloud Integrator para identificação de
entradas, saídas, precondições e efeitos no momento de adição de uma
atividade ao workflow. ..................................................................................... 70
Figura 22. Ilustração da interface gráfica do Cloud Integrator que mostra: (i) o plano
de execução selecionado para execução, acima; (ii) as entradas
selecionadas pelo usuário, à esquerda; (iii) as saídas a serem produzidas, à
direita, e; (iv) informações referentes aos processos executados. ............... 71
Figura 23. Ilustração da interface gráfica do Cloud Integrator para registro
(importação) de serviços Web semânticos (ontologias de serviço OWL-S).
.......................................................................................................................... 72
Figura 24. Assinaturas do serviço PaymentService e da operação makePayment. ......... 73
Figura 25. Trecho de descrição WSDL do serviço PaymentService, estando em
destaque a operação makePayment e suas respectivas entradas (c e v) e
saída (return). ................................................................................................... 74
Figura 26. Ontologia OWL-S da operação makePayment (parte 1 de 3). ....................... 75
Figura 27. Ontologia OWL-S da operação makePayment (parte 2 de 3). ....................... 76
Figura 28. Ontologia OWL-S da operação makePayment (parte 3 de 3). ....................... 77
Figura 29. Descrição de um workflow em OWL (parte 1 de 2). ...................................... 78
Figura 30. Descrição de workflow em OWL (parte 2 de 2). ............................................. 79
Figura 31. Consulta semântica em RDQL que retorna os serviços que atendem à
atividade <Consult, Inventory>. ...................................................................... 79
Figura 32. Descrição parcial em OWL de um plano de execução. ................................ 80
Figura 33. Fluxo de execução das atividades do estudo de caso. ................................. 81
Figura 34. Representação parcial da ontologia de domínio FlightBooking. .................. 82
Figura 35. Grafo direcionado acíclico com possíveis planos de execução para o
workflow do estudo de caso em questão – 2 planos de execução e 6 serviços
coincidentes. .................................................................................................... 83
Figura 36. Grafo direcionado acíclico com possíveis planos de execução para o
workflow do estudo de caso em questão – 4 planos de execução e 5 serviços
coincidentes. .................................................................................................... 83
Figura 37. Grafo direcionado acíclico com possíveis planos de execução para o
workflow do estudo de caso em questão – 8 planos de execução e 4 serviços
coincidentes. .................................................................................................... 84

Figura 38. Grafo direcionado acíclico com possíveis planos de execução para o
workflow do estudo de caso em questão – 12 planos de execução e 4
serviços coincidentes. ..................................................................................... 84
Figura 39. Grafo direcionado acíclico com possíveis planos de execução para o
workflow do estudo de caso em questão – 18 planos de execução e 4
serviços coincidentes ...................................................................................... 85

Lista de tabelas
Tabela 1. Exemplos de funções de agregação de parâmetros de qualidade................ 54
Tabela 2. Perfis de adaptação definidos para os pesos atribuídos à utilidade inicial e
ao custo de adaptação. ..................................................................................... 65
Tabela 3. Valores mínimo e máximo, média e desvio padrão (em milissegundos)
para o desempenho do processo de composição de serviços. ...................... 86
Tabela 4. Valores mínimo e máximo, média e desvio padrão (em milissegundos)
para a recuperação de metadados do QoMonitor e para o processo de
seleção de planos de execução. ....................................................................... 87
Tabela 5. Valores mínimo e máximo, média e desvio padrão (em milissegundos)
para o algoritmo de identificação de serviços coincidentes. ........................ 87
Tabela 6. Valores mínimo e máximo, média e desvio padrão (em milissegundos)
para o processo de adaptação propriamente dito. ........................................ 89
Tabela 7. Valores mínimo e máximo, média e desvio padrão (em segundos) para o
tempo de execução das versões das aplicações sem e com Cloud Integrator.
........................................................................................................................... 90

Lista de algoritmos
Algoritmo 1. Algoritmo para identificação de serviços coincidentes .......................... 51
Algoritmo 2. Algoritmo de seleção de planos de execução .......................................... 52

Lista de abreviaturas e siglas
API Application Programming Interface
AWS Amazon Web Services
BPEL Business Process Execution Language
CP Constraint Programming
FSM Finite State Machine
GAE Google App Engine
HTTP HyperText Transfer Protocol
IaaS Infrastructure as a Service
MILP Mixed-Integer Linear Programming
OGF Open Grid Forum
OWL Web Ontology Language
OWL-S Web Ontology Language for Web Services
PaaS Platform as a Service
PLIM Programação Linear Inteira Mista
QoS Quality of Service
RDF Resource Description Framework
RDQL RDF Data Query Language
REST REpresentational State Transfer
RPC Remote Procedure Call
SaaS Software as a Service
SAW Simple Additive Weighting
SCA Service Component Architecture
SLA Service-Level Agreement
SOA Service-Oriented Architecture
SOAP Simple Object Access Protocol
SOC Service-Oriented Computing
SPARQL SPARQL Protocol and RDF Query Language
SWRL Semantic Web Rule Language

TI Tecnologia da Informação
UDDI Universal Description, Discovery and Integration
UML Unified Modeling Language
URI Uniform Resource Identifier
WSDL Web Service Description Language
WSMO Web Service Modeling Ontology
W3C World Wide Web Consortium
XML eXtended Markup Language
XSL eXtensible Stylesheet Language
XSLT eXtensible Stylesheet Language for Transformation

Sumário
1 Introdução ...................................................................................................................... 21
1.1 Motivação ................................................................................................................. 22
1.2 Objetivos ................................................................................................................... 24
1.3 Organização do trabalho ......................................................................................... 25
2 Fundamentação teórica ................................................................................................. 26
2.1 Computação Orientada a Serviços.......................................................................... 26
2.1.1 SOA e serviços Web ........................................................................................ 26
2.2 Web Semântica ......................................................................................................... 29
2.2.1 Ontologias ........................................................................................................ 30
2.2.2 Serviços Web semânticos ................................................................................ 32
2.1.3 Composição de serviços Web semânticos ..................................................... 35
2.1.3.1 Composição baseada em workflows .................................................... 36
3 Cloud Integrator ............................................................................................................. 38
3.1 Elementos básicos .................................................................................................... 39
3.2 Arquitetura ............................................................................................................... 43
3.2.1 Service Layer ...................................................................................................... 44
3.2.2 Integration Layer ............................................................................................... 46
3.3 Monitoramento de metadados de qualidade ......................................................... 46
3.4 Seleção de serviços ................................................................................................... 49
3.5 Adaptação ................................................................................................................. 55
3.5.1 Fatores que disparam uma adaptação ........................................................... 56
3.5.2 Fatores a serem considerados em uma adaptação ....................................... 57
3.5.3 Disparando uma adaptação............................................................................ 59
3.5.4 Processo de adaptação .................................................................................... 64
3.5.4.1 Questões relevantes no processo de adaptação por degradação de
qualidade ............................................................................................. 65
4 Implementação .............................................................................................................. 68
4.1 Especificação de workflows semânticos ................................................................... 68
4.2 Representação de serviços ....................................................................................... 71
4.3 Composição de serviços .......................................................................................... 77
5 Avaliação ........................................................................................................................ 81
5.1 Estudo de caso .......................................................................................................... 81
5.2 Composição e seleção de serviços........................................................................... 85
5.3 Adaptação ................................................................................................................. 88

5.4 Execução de serviços ................................................................................................ 89
6 Trabalhos relacionados................................................................................................. 91
6.1 Integração/interoperabilidade entre plataformas de Computação em Nuvem. 91
6.2 Composição e seleção de serviços de nuvem ........................................................ 93
6.3 Estratégias de adaptação para aplicações em nuvem ........................................... 96
7 Considerações finais ..................................................................................................... 98
7.1 Contribuições ............................................................................................................ 99
7.2 Limitações ............................................................................................................... 102
7.3 Trabalhos em andamento e futuros ...................................................................... 103
Referências ...................................................................................................................... 106
Apêndice A – Ontologias OWL do estudo de caso ................................................... 115
A.1 Ontologia de domínio FlightBooking .................................................................... 115
A.2 Ontologia de nuvem Cloud Ontology ................................................................... 126

21
1 Introdução
Nos tempos modernos, serviços de utilidade pública como água, eletricidade,
gás e telefonia são considerados essenciais nas rotinas diárias, de modo que eles
estão geralmente disponíveis sempre que os consumidores necessitam [1]. Esses
serviços são providos por companhias específicas de maneira transparente para
residências, empresas, instituições, etc., que consomem tais serviços e pagam apenas
pela quantidade utilizada dos mesmos. Aplicando essa lógica de negócio à
Computação, a Computação em Nuvem, do inglês Cloud Computing [2, 3, 4], pode ser
definida como um modelo que possibilita o acesso ubíquo, conveniente e sob
demanda, via rede, a um conjunto de recursos de computação compartilhados e
configuráveis (e.g. redes, servidores, facilidades de armazenamento, aplicações e
serviços) tipicamente denominado nuvem [5, 6]. Tais recursos podem ser
rapidamente provisionados e liberados com o mínimo de esforço de gerenciamento
ou interação com o provedor de serviços e são oferecidos sob demanda para o
usuário, que passa a pagar pelo seu uso (pay-per-use model).
Supercomputadores com uma alta produtividade de computação e um grande
volume de memória são bastante utilizados na solução de algumas de problemas
complexos em diferentes campos da Ciência, mas o seu alto preço por vezes limita
sua aquisição e utilização comercial. Assim, o desenvolvimento de sistemas de
computação distribuída mais baratos que executem praticamente as mesmas funções
vem sendo amplamente aplicado ao redor do mundo [7]. Nessa perspectiva, a
Computação em Nuvem vai ao encontro dessas questões no contexto atual de
Tecnologia de Informação (TI), exigindo um avanço que praticamente os atuais
modelos de computação não conseguem acompanhar de maneira plenamente
satisfatória. Outra desvantagem do atual modelo de computação é o fato de que os
usuários precisam lidar com várias instalações, configurações e atualizações de
software, sem falar no fato de que recursos computacionais e de hardware são, por
natureza, propensos a desatualização em um espaço de tempo muito curto [8].
Segundo esse novo paradigma, desenvolvedores de serviços na Internet não
precisam mais investir muito capital em hardware e em recursos humanos para
manter o serviço em operação. Mais do que isso, organizações que necessitem de um
alto poder de processamento podem obter seus resultados tão rapidamente quanto
seus programas possam ser dimensionados, uma vez que, por exemplo, usar uma
quantidade de mil servidores por uma hora pode custar o mesmo que usar um único
servidor por mil horas. Essa elasticidade de recursos sem a necessidade de pagar mais
por usar poder computacional em alta escala é inédita na indústria de TI [2]. Do
ponto de vista do usuário, infraestruturas de Computação em Nuvem
disponibilizam sistemas operacionais que possibilitam que os usuários, utilizando

22
qualquer tipo de dispositivo conectado à Internet, possam ter acesso aos serviços,
arquivos, informações e programas situados na nuvem, de modo que esses
dispositivos utilizados pelos usuários não necessitam de grandes recursos
computacionais, aproximando-se assim de simples terminais. Dessa forma, a ideia
essencial da Computação em Nuvem reside no fato de permitir a transição da
Computação dita tradicional para um novo modelo no qual o consumo de recursos
computacionais (e.g. armazenamento, processamento, largura de banda, entrada e
saída de dados, etc.) é realizado através de serviços, que podem ser acessados de
modo simples e pervasivo [8]. Esses recursos podem estar disponíveis e serem
usados sob demanda, praticamente sem limitações, através da Internet e de acordo
com um modelo de pagamento por uso, provendo-se elasticidade, customização,
garantias de QoS (Quality of Service) e infraestruturas de baixo custo.
1.1 Motivação
Apesar de a Computação em Nuvem propiciar benefícios ausentes nas
tecnologias atuais, como a elasticidade das aplicações, que podem rapidamente
aumentar ou diminuir o uso de infraestrutura computacional sem incorrer em custos
desnecessários com recursos ociosos ou subutilizados, o desenvolvimento da
Computação em Nuvem ainda está em emergência [9] e há vários novos desafios que
precisam ser tratados. Um deles diz respeito à composição de serviços, que se torna
uma questão relevante no contexto de Computação em Nuvem visto que, com o
avanço desse novo paradigma, pode ser necessária uma composição de serviços que
agrega serviços providos por diferentes plataformas de nuvem para satisfazer os
requisitos de uma aplicação. A fim de gerar valor agregado para o usuário, essa
composição de serviços providos por diferentes plataformas de Computação em
Nuvem requer uma solução em termos de integração de plataformas para,
consequentemente, possibilitar essa integração de serviços.
Em geral, plataformas de nuvem prometem uma alta disponibilidade para
seus clientes e, de acordo com Armbrust et al. [2], a única solução plausível para se
prover uma disponibilidade realmente alta seria utilizar múltiplos provedores de
serviços de nuvem. Contudo, as plataformas de Computação em Nuvem atuais não
são implementadas utilizando padrões comuns, de modo que cada uma possui sua
própria API (Application Programming Interface), ferramentas de desenvolvimento,
mecanismos de virtualização, características de governança, etc. [10]. Isso torna
difícil para os usuários realizarem tarefas integrando informações ou serviços
providos por diferentes plataformas, como, por exemplo, utilizar um serviço de
armazenamento de dados provido por uma plataforma de nuvem X e transportar
esses dados para uma plataforma Y na qual esses dados serão processados para
serem finalmente utilizados por uma aplicação implantada em outra plataforma de
nuvem Z. Isso acontece porque a Computação em Nuvem ainda é uma área

23
emergente e não possui modelos tecnológicos comuns, padronizados, de modo que
cada provedor oferece suas próprias tecnologias de desenvolvimento, implantação e
gerenciamento dos recursos que disponibilizam. Consequentemente, os usuários
desses recursos devem implementar suas aplicações visando um conjunto específico
de tecnologias, tornando-as assim altamente dependentes de um único provedor de
nuvem, problema conhecido como cloud lock-in [2].
Nesse processo de composição de serviços, não apenas a funcionalidade dos
mesmos deve ser considerada na seleção dos serviços a serem incluídos na composição.
Além do cumprimento de SLAs (Service-Level Agreements) [11, 12], que são contratos
estabelecidos entre o provedor de serviço e o cliente, é necessário considerar
metadados acerca dos serviços, tais como QoS, preços, etc., uma vez que podem existir
vários serviços equivalentes oferecidos pelo conjunto de plataformas de nuvem que
estão sendo integradas. Por exemplo, considere-se uma situação na qual uma
aplicação necessita fazer uso de um serviço de armazenamento de dados e, dentre as
plataformas de nuvem disponíveis, duas delas, A e B, oferecem esse tipo de serviço,
porém com diferentes tempos de resposta, que é o tempo entre o envio de uma
requisição de serviço pelo cliente e o recebimento da resposta. Sendo o tempo de
resposta do serviço provido pela plataforma A menor que o provido pela plataforma
B, no processo de seleção de serviços é preferível que o serviço provido por A seja
escolhido para entrar na composição a ser executada. Todavia, não só esse critério
deve ser levado em consideração, mas também os preços de utilização desses
serviços, outros parâmetros de qualidade, e os próprios requisitos da aplicação.
Como no contexto da Computação em Nuvem o pagamento é baseado no uso
dos serviços, o custo deles pode ser algo tão relevante para o usuário que, para a
composição, seja considerado um custo máximo como fator limitante. Assim, se for
especificado pelo usuário que a composição não deva custar mais que um dado
valor, o mecanismo de composição de serviços deve levar esse fator em consideração
no momento da composição a fim de incluir serviços cujos custos somados não
ultrapassem o valor estabelecido pelo usuário. Se for considerado tanto o fator custo
como também parâmetros de qualidade de serviço (e.g. disponibilidade, tempo de
resposta, etc.), esse mecanismo poderá fazer um trade-off entre esses metadados
possibilitando que seja feita uma melhor escolha levando em consideração esses
fatores.
Por fim, além desses mecanismos relacionados à composição e integração de
serviços providos por diferentes plataformas de nuvem, é necessário também prover
meios de adaptação para garantir que, em caso de falha ou degradação de qualidade
de um serviço que esteja envolvido em uma composição, a aplicação possa ser
adaptada, i.e. possa usar automaticamente outro serviço equivalente, se possível,
ainda considerando os requisitos estabelecidos pelo usuário.

24
A fim de mitigar essas questões, este trabalho propõe o Cloud Integrator, uma
plataforma de middleware orientada a serviços para composição, execução e
gerenciamento de serviços providos por diferentes plataformas de Computação em
Nuvem. O cerne do Cloud Integrator fundamenta-se na integração complementar dos
paradigmas de Computação Orientada a Serviços [13] e de Computação em Nuvem,
que, em conjunto, têm o potencial de gerar uma grande sinergia [14]. Nessa
perspectiva, o Cloud Integrator é baseado no paradigma de Arquitetura Orientada a
Serviços (SOA – Service-Oriented Architecture, em inglês) [15] e sua implementação
utiliza a tecnologia de serviços Web, explorando assim padrões e linguagens abertos e
possibilitando a integração de serviços providos por vários provedores de maneira
transparente e automática, além de oferecer um ambiente que facilita o
desenvolvimento e a execução de aplicações que fazem uso de serviços de nuvem.
A composição de serviços realizada pelo Cloud Integrator é especificada em
termos de um workflow semântico que descreve de forma abstrata a ordem na qual um
conjunto de tarefas deve ser executado por vários serviços de nuvem a fim de
atender aos objetivos de negócio da aplicação. No contexto do Cloud Integrator, tais
serviços podem ser classificados como recursos de nuvem, que se referem a recursos de
nuvem propriamente ditos providos por plataformas de nuvem, ou como serviços de
aplicação, que são serviços de mais alto nível que podem ser serviços de terceitos que
utilizam recursos de nuvem ou mesmo serviços tradicionais que não utilizam
recursos de nuvem.
Como será apresentado posteriormente, o modelo de composição de serviços
adotado pelo Cloud Integrator é baseado na funcionalidade de cada serviço bem como
nos seus respectivos metadados (como parâmetros de qualidade e preços), permitindo
uma melhor escolha entre os serviços disponíveis. Além disso, a fim de garantir a
disponibilidade e a qualidade da aplicação, esse mecanismo de composição
contempla a adaptação de aplicações em situações típicas que podem ocorrer no
cenário de serviços de nuvem, tais como: (i) falha de um serviço disponível no
momento da composição e que se torna indisponível em tempo de execução; (ii)
degradação de qualidade de algum serviço envolvido na composição, ou; (iii)
surgimento de novos serviços. Desses três casos, os dois primeiros são endereçados
neste trabalho.
1.2 Objetivos
Considerando as questões supramencionadas, o objetivo principal deste
trabalho é propor, especificar, implementar e avaliar uma plataforma de middleware
para composição, execução e gerenciamento de serviços oferecidos por diferentes
plataformas de nuvem de maneira transparente para o usuário. Tal plataforma deve
oferecer:

25
(i) estratégias de composição e seleção de serviços que considerem tanto
requisitos funcionais (i.e. funcionalidades propriamente ditas)
quanto não funcionais (e.g. metadados dos serviços como
parâmetros de QoS, preços, etc.) dos serviços, de modo que a própria
plataforma seja capaz de escolher, de acordo com as preferências do
usuário e/ou requisitos das aplicações, que serviços devem ser
utilizados;
(ii) um mecanismo de adaptação eficiente que garanta a disponibilidade e
a qualidade das aplicações em condições que afetem a sua execução,
tais como falha ou degradação da qualidade de um serviço
envolvido na composição em questão, ou ainda em caso de adição ou
remoção de serviços no ambiente, de modo que outro serviço
equivalente possa ser utilizado, ainda considerando os requisitos do
usuário;
(iii) um ambiente que facilite o desenvolvimento e a execução de
aplicações que utilizem os serviços providos pelas plataformas de
nuvem que estão sendo integradas, permitindo inclusive que tais
aplicações sejam construídas em um alto nível de abstração,
independentemente dos serviços concretos que possam ser
utilizados, e;
(iv) a integração, transparente e automática do ponto de vista do usuário,
de serviços providos por diferentes plataformas, em um cenário de
nuvens computacionais heterogêneas.
1.3 Organização do trabalho
A presente Dissertação de Mestrado possui seis capítulos que se somam a esta
introdução. O Capítulo 2 apresenta os conceitos básicos que alicerçam a matéria
apresentada neste trabalho, basicamente organizados em termos de SOA, serviços
Web, Web Semântica e composição de serviços Web semânticos. O Capítulo 3 trata
acerca do Cloud Integrator, sendo apresentados os elementos básicos necessários ao
seu entendimento e a arquitetura da plataforma, bem como descritos os processos de
composição e seleção de serviços, monitoramento de metadados e adaptação. No
Capítulo 4 são detalhados aspectos relacionados ao funcionamento e implementação
do Cloud Integrator. No Capítulo 5 é reportado um estudo experimental realizado
com o objetivo de avaliar os processos de composição, seleção e adaptação realizados
pelo Cloud Integrator. No Capítulo 6 são relacionados propostas existentes na
literatura em integração de plataformas, composição e seleção, e mecanismos de
adaptação para serviços em Computação em Nuvem. Por fim, no Capítulo 7 são
delineadas algumas considerações finais, contribuições e limitações deste trabalho,
bem como apontadas as direções para os trabalhos em andamento e futuros.

26
2 Fundamentação teórica
2.1 Computação Orientada a Serviços
A Computação Orientada a Serviços (ou, em inglês, SOC – Service-Oriented
Computing) é um paradigma que utiliza serviços como elementos fundamentais para o
desenvolvimento de aplicações/soluções. Nesse contexto, serviços são elementos
computacionais autônomos, autodescritivos, reusáveis e altamente portáveis,
diferindo assim de artefatos de software tradicionais. De maneira rápida e com um
baixo custo, serviços podem ser descritos, publicados, descobertos e dinamicamente
agregados para desenvolver sistemas distribuídos, interoperáveis e capazes de
evoluir, podendo executar funções que vão desde responder a simples requisições
até mesmo executar processos de negócio mais sofisticados [16, 17].
Qualquer pedaço de código e/ou qualquer componente de aplicação
implantado em um sistema pode ser reusado e transformado em um serviço
disponível na rede, reduzindo assim a necessidade de desenvolver novos
componentes de software toda vez que um novo processo de negócio surge [14].
Assim, serviços refletem uma abordagem de programação orientada a serviços baseada
na ideia de compor aplicações através da descoberta e invocação de serviços
disponíveis através da rede para realizar alguma dada tarefa [13, 17, 18]. Em geral,
serviços são construídos de maneira a serem independentes do contexto no qual eles
são utilizados e de linguagens de programação ou sistemas operacionais específicos,
ou seja, o provedor de serviço e o cliente que o consome são fracamente acoplados.
2.1.1 SOA e serviços Web
Dentro da Computação Orientada a Serviços, o paradigma de SOA, acrônimo
de Service-Oriented Architecture (Arquitetura Orientada a Serviços, em português),
estabelece que as aplicações sejam construídas através de serviços (ou operações)
específicos e bem definidos, serviços esses disponibilizados por um ou mais
provedores de serviço. Essa abordagem arquitetural é particularmente conveniente
quando múltiplas aplicações que são executadas em diferentes tecnologias e
plataformas precisam comunicar-se umas com as outras [19]. Assim, SOA promove a
interoperabilidade entre esses elementos de software fundamentais para o
desenvolvimento de aplicações mediante a utilização de tecnologias e protocolos
padronizados, de forma que o acoplamento seja mínimo entre eles devido ao fato de
que cada elemento responsável por uma unidade lógica de software define sua
própria interface de acesso, na qual a implementação é isolada da interface, ficando
assim transparente aos clientes. Além disso, a abordagem permite que serviços
individuais sejam combinados para fornecer funcionalidades agregadas e de mais
alto nível de abstração.

27
Em SOA, os agentes de software trocam mensagens entre si. Os clientes são os
agentes que requisitam a execução de um serviço enquanto que os provedores são os
agentes que proveem os serviços. Um provedor de serviços é responsável por
publicar a descrição dos serviços que provê, de modo que, como explicam Papazoglou
e Georgakopoulos [20], em SOC/SOA, tais descrições de serviços são utilizadas para
publicar funcionalidades, interface, comportamento e qualidade dos mesmos. A
publicação de tais informações acerca dos serviços disponíveis fornece assim os
meios necessários para a descoberta, seleção, ligação (binding) e composição de
serviços. Em particular, a descrição das capacidades de um serviço declara o
propósito conceitual e os resultados esperados do mesmo. A descrição da interface
de um serviço publica a sua assinatura, em termos de seus parâmetros de entrada,
saída e erro e tipos de mensagem. O comportamento de um serviço durante a sua
execução é descrita pela descrição de seu comportamento, por exemplo, como um
processo de workflow. Por fim, a descrição da qualidade de um serviço (QoS) publica
atributos funcionais e não funcionais importantes relacionados à qualidade de um
serviço, tais como custo, medidas de desempenho (e.g. tempo de resposta), atributos
de segurança, integridade, confiabilidade, escalabilidade e disponibilidade.
Por sua vez, clientes devem ser aptos a encontrar a descrição dos serviços
requisitados e receber as respostas a estas requisições. Desse modo, em SOA: (i)
serviços são publicados pelos provedores de serviços em um mecanismo de
descoberta de serviços, denominado registro (registry), que gerencia as descrições de
serviços; (ii) clientes buscam pelos serviços nesse registro, e; (iii) ocorre a ligação
entre o cliente e o provedor do serviço escolhido. A Figura 1, adaptada de Dan et al.
[21], ilustra esses relacionamentos existentes entre os elementos envolvidos em SOA.
Figura 1. Relacionamentos entre os elementos envolvidos em SOA.
Em toda essa perspectiva, SOA expressa abstratamente os conceitos que
regem a orientação a serviços. Qualquer tecnologia padronizada baseada na Web
pode ser usada para implementar SOA, porém a mais largamente utilizada pela
comunidade é a tecnologia de serviços Web, definida pelo W3C (World Wide Web
Consortium) como um sistema de software identificado por um URI (Uniform Resource

28
Identifier) cujas interfaces e ligações são definidas, descritas, publicadas e descobertas
via um contrato de uso e que interage com outros sistemas usando mensagens
transportadas por protocolos de Internet.
A tecnologia de serviços Web surgiu como uma nova forma de desenvolver
aplicações distribuídas baseadas em SOA. Por ser uma tecnologia totalmente baseada
em padrões abertos, os serviços Web possibilitaram a integração de aplicações
heterogêneas justamente por proverem interoperabilidade entre elas via Internet.
Cada serviço Web é construído de modo a ser independente do contexto no qual será
empregado, possuindo assim um baixo acoplamento. Qualquer parte de código ou
componente de um sistema pode ser transformado em um serviço Web, o qual pode,
portanto, oferecer desde uma simples funcionalidade, como operações aritméticas ou
conversão de temperaturas, por exemplo, até funcionalidades mais complexas e que
envolvem a interação e composição com outros serviços.
Com o objetivo de garantir interoperabilidade, a tecnologia de serviços Web
apoia-se em três padrões derivados de XML (eXtended Markup Language) [22]:
(i) SOAP (Simple Object Access Protocol) [23], um protocolo para o envio
de mensagens e fazer chamadas remotas de procedimentos (RPCs –
Remote Procedure Calls) que funciona sobre um protocolo de
transporte da Internet (por exemplo, HTTP – HyperText Transfer
Protocol);
(ii) WSDL (Web Service Description Language) [24], uma linguagem
utilizada para descrever serviços Web e especificar algumas de suas
propriedades, como o que ele faz, onde está localizado e como deve ser
invocado, e;
(iii) UDDI (Universal Description, Discovery and Integration) [25], um
diretório público que armazena as especificações WSDL dos serviços
Web disponíveis a fim de permitir a descoberta dos mesmos.
Juntos, esses três padrões permitem que os serviços Web sejam implementados e
acessados de qualquer plataforma usando qualquer linguagem de programação.
Como ilustra a Figura 2, adaptada de Barry [26], tipicamente um serviço Web
tem a sua funcionalidade descrita em WSDL, publicada em um repositório UDDI por
um provedor de serviço. O cliente faz consultas ao repositório UDDI para obter a
localização desse serviço Web utilizando como critérios o nome do provedor ou o
tipo de serviço desejado, e esse repositório então retorna a descrição WSDL do
serviço Web requisitado pelo cliente, que finalmente realiza a chamada remota ao
serviço Web com base na descrição obtida. Toda a comunicação entre o cliente, o
provedor de serviço e o repositório UDDI é realizada por meio de trocas de
mensagens SOAP.

29
Figura 2. Uso de padrões baseados em XML para relacionamento entre os elementos em SOA.
2.2 Web Semântica
A Web Semântica [27, 28] é considerada por muitos uma evolução da Web
tradicional (sendo inclusive denominada Web 3.0) que busca melhorar a qualidade
de acesso às informações a partir do processamento de conteúdo semântico das
mesmas. Ao adicionar um significado (i.e. semântica) bem definido a qualquer recurso
disponibilizado na Internet (uma página Web, por exemplo), a Web Semântica torna
mais fácil para uma máquina inferir um novo tipo de informação que envolva um
determinado recurso, pois ela elimina ambiguidades no tratamento desses
significados.
Para prover a estruturação semântica do conteúdo da Internet, a Web
semântica propõe o uso de três tecnologias, ilustradas na Figura 3, adaptada de Silva
[29]. A primeira tecnologia é a metalinguagem XML, que torna possível a estruturação
e organização de conteúdos na Internet de forma customizada através de marcações.
A segunda tecnologia tem como propósito atribuir sentido lógico às informações,
sobre as quais são aplicados esquemas sintáticos como, por exemplo, RDF (Resource
Description Framework) [30], que é um modelo de representação para fazer asserções
sobre XML a respeito dos recursos disponíveis na Web. Por fim, a terceira tecnologia
principal são as ontologias, utilizadas explicitamente para conceituar e representar um
determinado domínio, utilizando mecanismos de inferência para a realização de
consultas sobre tais ontologias. No contexto da Web Semântica, inferir representa a
capacidade de extrair um conhecimento que está armazenado de maneira implícita
em uma base de conhecimento através de um raciocínio lógico.

30
Figura 3. Principais tecnologias da Web Semântica.
Nas subseções a seguir serão apresentadas algumas noções básicas sobre
ontologias e como elas agregam semântica às descrições de serviços Web de modo a
favorecer a descoberta e a composição automática dos mesmos.
2.2.1 Ontologias
Uma ontologia é definida como uma especificação formal e explícita de uma
conceituação compartilhada [31]. Em outras palavras, uma ontologia tenta descrever
de maneira exata um modelo abstrato do mundo real a partir de conceitos,
propriedades, relações, funções e regras, todos definidos explicitamente por seres
humanos com o propósito de tornar esse modelo interpretável por agentes de
software. O diferencial de se utilizar ontologias é que elas fornecem um vocabulário
comum para a representação de um domínio específico, cujos termos são descritos
formalmente sem haver interpretações ambíguas. As ontologias permitem também
que o conhecimento seja compartilhado por outras ontologias como forma de reusar
e aperfeiçoar o vocabulário definido.
Para poder representar um dado conhecimento através de uma ontologia, é
necessária a utilização de linguagens formais baseadas em lógica capazes de
expressar satisfatoriamente o conhecimento desejado e de inferir sobre o mesmo. O
W3C desenvolve um conjunto de linguagens que têm como objetivo principal
promover a interoperabilidade entre aplicações na Web. Dentre essas linguagens,
OWL (Web Ontology Language) [32] é a linguagem de marcação semântica proposta
como padrão para ser utilizado pela Web Semântica para descrever ontologias;
devido ao seu nível suficiente de expressivade e pelo fato de ser um padrão para a
Web Semântica, essa linguagem foi escolhida para ser utilizada neste trabalho.
Fundamentada em RDF [30], que permite a identificação de recursos e construção de
predicados sobre eles, OWL permite que usuários escrevam o vocabulário de um
dado domínio em termos de classes, indivíduos e propriedades.
Dependendo do grau de expressividade desejado para descrever um
determinado domínio, OWL pode limitar ou não a utilização de seus construtores e,
por consequência, sua capacidade de inferência pode se tornar mais ou menos

31
eficiente. A rigor, quanto maior o grau de expressividade da linguagem, mais rica é a
sua semântica e menos eficiente é a sua capacidade de inferência e, assim, OWL pode
ser dividida em três sublinguagens (espécies ou dialetos), a saber, OWL-Lite, OWL-
DL e OWL-Full, ilustradas na Figura 4. OWL-Lite é a menos expressiva e destina-se a
situações em que apenas são necessárias restrições e uma hierarquia de classes
simples. OWL-Full é a mais expressiva e apropriada para situações nas quais se ter
uma alta expressividade é mais importante do que garantir a decidibilidade ou a
completude da linguagem, pois não é possível realizar inferências sobre a mesma.
Por sua vez, OWL-DL situa-se entre essas anteriores e é a que melhor apresenta
equilíbrio entre expressividade semântica e poder de raciocínio. OWL-DL é baseada
em lógica descritiva, que representa um conjunto de formalismos para representação
de conhecimento que são baseados em lógica de primeira ordem, possibilitando a
especificação dos construtores da linguagem OWL e para o desenvolvimento de
métodos automáticos de dedução utilizados pelas máquinas de inferência durante as
consultas aplicadas sobre as ontologias [33].
Figura 4. Dialetos da OWL, definidos pelo de expressividade que representam.
Apesar de possuir um conjunto rico de construtores, OWL não provê formas
de expressar associações envolvendo apenas as propriedades descritas em uma
ontologia. Por exemplo, seja temPai uma propriedade que representa a relação pai e
filho entre duas pessoas e sejam A, B, C e D instâncias da classe Pessoa. Para
representar as relações A é pai de B e B é pai de C, as propriedades das instâncias que
representam os filhos são definidas respectivamente como sendo temPai(B, A) e
temPai(C, B) (lê-se: B tem pai A e C tem pai B). Nesse caso, como se trata de uma
hierarquia, é possível inferir que A é avô de C devido à transitividade da propriedade
temPai sem a necessidade de criar a propriedade temAvo. Todavia, se existir uma
propriedade temIrmao na qual seja definido que D é irmão de B, não se pode inferir
que D é tio de C, pois não existe uma regra que represente a propriedade temTio. Para
solucionar esse problema, a linguagem SWRL (Semantic Web Rule Language) [34] foi
desenvolvida para representar predicados de regras através de OWL. As regras
aumentam a capacidade de inferência das linguagens de ontologias, permitindo
expressar associações entre propriedades e inferir informações implícitas a partir de

32
axiomas (sentenças verdadeiras) embutidos nas próprias ontologias. No caso do
exemplo anterior, ao invés de criar uma propriedade temTio para todas as instâncias
da classe Pessoa, pode-se definir a regra temPai(?x, ?y) de modo que temIrmao(?y, ?z),
implica em temTio(?x, ?z) para representar a propriedade desejada.
2.2.2 Serviços Web semânticos
A necessidade de acrescentar conteúdo semântico às descrições de serviços
Web fez com que as tecnologias dos serviços Web e da Web Semântica fossem
combinadas resultando nos chamados serviços Web semânticos [35]. Um serviço Web
semântico é definido por uma ontologia de serviço que permite interpretar
semanticamente as funcionalidades providas pelo serviço Web, bem como a
integração da descrição do serviço Web com o conhecimento de domínio (ou seja, a
terminologia de negócio).
Uma das propostas que estão sendo utilizadas com frequência na literatura da
área de Web Semântica como solução para o problema da descoberta e composição
dinâmica de serviços é OWL-S (Web Ontology Language for Web Services) [36]. OWL-S
descreve semanticamente as propriedades e as funcionalidades de um serviço Web
através da linguagem OWL, visando facilitar a automatização de tarefas na Web
Semântica, incluindo a descoberta, execução, interoperabilidade, composição e o
monitoramento da execução de serviços Web. OWL-S foi escolhida para este
trabalho, em detrimento de outras ontologias para descrição de serviços Web
semânticos (a exemplo de WSMO – Web Service Modeling Ontology [37]), devido à
simplicidade de OWL-S e pelo fato de utilizar OWL, padrão adotado pelo W3C.
A ontologia OWL-S consiste de três subontologias, a saber, ServiceProfile,
ServiceProcess e ServiceGrounding, ilustradas na Figura 5.
Figura 5. Ontologia OWL-S.

33
A subontologia ServiceProfile é uma superclasse para todos os tipos de
descrição em alto nível a respeito de um serviço. Essa classe contém as informações
básicas necessárias para vincular qualquer instância de Profile, uma subclasse da
subontologia ServiceProfile, com uma instância de Service, que representa o serviço em
si. A classe Profile especifica de maneira global as funcionalidades que o serviço
oferece, em termos de suas entradas (inputs) e saídas (outputs), bem como as
precondições (preconditions) requeridas e os efeitos (effects) esperados da execução do
serviço.
Para especificar detalhadamente como interagir com um serviço, tem-se a
classe Process, uma subclasse da subontologia ServiceModel. Para efeito de
entendimento, uma instância da classe Process pode ser vista como um processo que
define a interação com o serviço Web. É possível descrever o funcionamento de um
serviço de três maneiras: (i) como um AtomicProcess (processo atômico), contendo um
único passo de execução; (ii) como um CompositeProcess (processo composto),
composto de vários passos, ou; (iii) um SimpleProcess (processo simples), uma visão
comum abstrata dos dois primeiros.
Por último, a subontologia ServiceGrounding fornece os meios necessários para
representar os dados semânticos serializados em mensagens XML a serem
transportadas pela rede, e também especifica como o receptor pode interpretar essas
mensagens XML e transformá-las novamente em dados semânticos. Para tal, tem-se a
subclasse WsdlGrounding que especifica os detalhes de como acessá-lo em termos de
detalhes acerca do protocolo e formato de mensagens que são utilizados,
serialização, transporte e endereçamento. Além disso, essa subclasse também pode
ser vista como um mapeamento da especificação abstrata para uma concreta dos
elementos que compõem a descrição WSDL do serviço que são necessários para
interagir com o mesmo.
A Figura 6, adaptada de Mendes Júnior [38], apresenta parte da ontologia de
um serviço de reserva de voos denominado ReservarVooService, mostrando assim um
exemplo de como OWL-S descreve semanticamente um serviço Web que exibe parte
da ontologia de um serviço. Esse serviço é apresentado por um ReservarVooProfile,
descrito por um ReservarVooProcess e suportado por um ReservarVooGrounding. O
primeiro elemento da ontologia contém informações sobre a utilidade do serviço,
enquanto o segundo descreve o funcionamento do serviço como um processo de um
único passo, que exige as entradas Origem, Destino, Data, Hora e Voo, e produz a saída
Localizador. Finalmente, o último elemento descreve a forma de acessar esse serviço
via WSDL, especificando a URI da operação (reservarVoo) que deverá ser invocada.

34
Figura 6. Trecho da ontologia OWL-S do serviço Web ReservarVooService.

35
2.1.3 Composição de serviços Web semânticos
O enfoque dado ultimamente às tecnologias de serviços Web e da Web
Semântica tem proporcionado o desenvolvimento de vários projetos de pesquisa
abordando de diferentes maneiras a composição de serviços Web. Uma composição de
serviços é uma agregação coordenada de serviços que são montados para prover
alguma funcionalidade requerida para automatizar um processo ou tarefa específicos
de negócio [15]. Nessa perspectiva, a composição de serviços é necessária quando
não existe um serviço que sozinho atenda aos requisitos solicitados pela aplicação, de
modo que serviços podem ser compostos em um novo serviço para que em
cooperação agreguem valor para satisfazer as necessidades dos clientes.
Uma representação de composições de serviços ao lado de serviços simples
pode ser vista na Figura 7, na qual os círculos no plano superior da figura
representam serviços simples, atômicos, e os polígonos no plano inferior
compreendem conjuntos de serviços simples que, juntos, satisfazem uma
necessidade mais complexa. No paradigma de SOA, qualquer elemento definido no
mesmo deve ser capaz de participar como membro de uma composição, a não ser
que sejam explicitamente restringidos em suas especificações.
Figura 7. Representação de serviços simples e compostos.
Apesar de todos os esforços realizados nessa área, a composição de serviços
Web ainda é uma tarefa altamente complexa. Tal complexidade, em geral, deve-se: (i)
ao crescimento do número de serviços Web disponíveis na Internet nos últimos anos,
criando um imenso repositório de busca; (ii) aos próprios serviços Web que podem
ser criados e atualizados de forma dinâmica (on-the-fly), tornando necessário que o
processo de composição seja capaz de detectar essa atualização em tempo de
execução com base na especificação atual do processo de negócio, e; (iii) ao fato dos
serviços Web serem desenvolvidos por várias organizações, que usam modelos
conceituais diferentes para descrever tais serviços, não se estabelecendo uma
linguagem exclusiva para definir e avaliar os serviços Web de uma forma idêntica
[39].
Como discute Mendes Júnior [38], em parte os problemas supracitados estão

36
diretamente relacionados à falta de significado na sintaxe de WSDL. Sem semântica,
as descrições WSDL dos serviços Web não podem ser interpretadas por agentes de
software, requerendo sempre a presença de pessoas para realizar tal interpretação.
Consequentemente, a composição não pode ser feita de forma automática, pois não é
possível para uma máquina de inferência compreender o real significado de uma
operação provida pelo serviço simplesmente analisando os tipos de dados descritos
na interface WSDL do mesmo. A solução para esse problema está nas ontologias de
serviço OWL-S sugeridas pela Web Semântica, que proveem descrições semânticas
para os serviços Web.
De fato, as ontologias de serviço agregam significados às descrições WSDL
tornando os serviços Web interpretáveis tanto para máquinas de inferência quanto
para seres humanos, além de elas oferecem aos agentes de software a possibilidade de
compor serviços Web de forma automática. Tal composição pode ser dividida em
quatro etapas: (i) a descoberta e combinação (ou matching) dos serviços; (ii) a geração
do plano de composição; (iii) a execução do plano gerado; e (iv) o monitoramento da
execução. Na primeira etapa os serviços Web são descobertos e combinados com
base nas suas propriedades funcionais (entradas, saídas, precondições e pós-
condições) e não funcionais (qualidade do serviço, custo, etc.), as quais são
requeridas por um dado processo de negócio. Com isso, os mecanismos de
inferências aplicados sobre as ontologias de serviço permitem a um raciocinador
(reasoner) concluir que serviços são adequados para implementar um processo de
negócio. A segunda etapa consiste em gerar o plano de composição que atenda às metas
ou objetivos de um processo de negócio, i.e. sintetizar uma especificação de como
coordenar os serviços Web descobertos inicialmente para atender tal processo de
negócio. Já na terceira etapa, o plano de composição gerado é instanciado por uma
máquina de execução da qual serão invocados os serviços Web escolhidos para realizar
o processo de negócio. Na última etapa, o plano de composição é monitorado em
tempo de execução para que seja possível substituir um dado serviço Web que
porventura ficou indisponível ou mudou de descrição WSDL, sem ter que modificar
a especificação atual desse plano [38].
2.1.3.1 Composição baseada em workflows
A necessidade de combinar serviços simples para gerar serviços compostos
despertou interesse em encontrar soluções que suportem a composição de serviços e,
com isso, várias técnicas de composição têm sido propostas na literatura. Uma delas
é a técnica de composição baseada em workflows [40], que são automações de
processos de negócio ou de parte deles. Um processo de negócio é um conjunto de
atividades interligadas e que coletivamente realizam um objetivo ou uma meta de
negócio [38].
Para que seja possível realizar a especificação de um serviço composto, é

37
necessário incluir um conjunto de serviços atômicos juntamente com o controle e o
fluxo de dados entre esses serviços; do mesmo modo, a definição de processo em um
sistema de workflow precisa descrever o fluxo de atividades. Para facilitar a tarefa de
especificar um workflow, o agente compositor permite a busca por um serviço Web
que implemente uma funcionalidade desejada pelo processo de negócio. Esse
processo de busca envolve quatro etapas: (i) identificação da funcionalidade
requerida; (ii) combinação semântica de serviços Web; (iii) criação ou atualização do
workflow, e; (iv) execução e monitoramento do workflow.
Workflows podem ser concretos ou abstratos. Um workflow é dito concreto
quando define o próprio processo ou plano que define a execução da composição de
serviços. Já um workflow é dito abstrato quando define um processo abstrato através
de atividades para cumprir um determinado objetivo de negócio do usuário, de modo
que essas atividades ainda não estejam ligadas diretamente aos serviços que as
realizam. A separação em workflow concreto e abstrato é interessante uma vez que,
para o usuário, o workflow concreto possui muitos detalhes que não necessitam ser
conhecidos e nem muito menos descritos por esses usuários. Assim, basta que os
usuários descrevam um workflow abstrato contendo as atividades, de modo que esse
workflow abstrato pode ser dinamicamente transformado em workflows concretos
através de seleção de serviços em tempo de execução, permitindo ainda a adaptação
dinâmica do workflow.
Relacionando à Web Semântica, um workflow abstrato pode ser chamado de
workflow semântico. Esses workflows semânticos são processados por uma máquina de
workflow para transformá-los em workflows concretos, chamados planos de execução.
Assim, um plano de execução consiste de um conjunto de serviços Web descobertos
de compostos dinamicamente e em tempo de execução para realizarem as atividades
especificadas no workflow semântico (abstrato). Para cada atividade do workflow
semântico, é realizada uma busca por um serviço Web que seja capaz de atendê-la, e
caso não exista um serviço que faça isso, tenta-se então compor um conjunto de
serviços para atender a essa dada atividade.

38
3 Cloud Integrator
Este capítulo apresenta o Cloud Integrator, uma plataforma de middleware
orientada a serviços para composição, execução e gerenciamento de serviços
providos por diferentes plataformas de Computação em Nuvem. O Cloud Integrator é
baseado no paradigma de SOA e em workflows semânticos, integrando serviços de
nuvem de maneira transparente e automática, além de oferecer um ambiente que
facilita o desenvolvimento e a execução de aplicações que fazem uso desse tipo de
serviço. Nessa perspectiva, plataformas de nuvem são provedores de serviços que
proveem serviços às aplicações em nuvem (clientes), e o Cloud Integrator funciona
como um mediador entre esses elementos, provendo mecanismos para a construção
de aplicações através da composição e seleção de serviços Web semânticos. A Figura
8 ilustra esse papel do Cloud Integrator como um elemento intermediário entre
plataformas de Computação em Nuvem (nomeadas apenas para fins ilustrativos) e
as aplicações que fazem uso dos serviços providos pelas mesmas.
Figura 8. Ilustração do Cloud Integrator como mediador entre diferentes plataformas de Computação em Nuvem e as aplicações que fazem uso dos serviços providos por elas.
A Seção 3.1 trata de termos e elementos necessários ao entendimento da
operação do Cloud Integrator, cuja arquitetura é apresentada na Seção 3.2. A Seção 3.3
apresenta o processo de monitoramento de metadados de qualidade, metadados
esses que são utilizados pelo Cloud Integrator principalmente nos processos de
seleção e adaptação, detalhados respectivamente nas Seções 3.4 e 3.5.

39
3.1 Elementos básicos
No contexto do Cloud Integrator, uma aplicação é especificada através de um
workflow semântico (ou simplesmente workflow), que é descrito em termos de atividades
e define a sequência na qual tais atividades devem ser executadas a fim de satisfazer
o objetivo de negócio da aplicação. As aplicações especificadas por workflows
semânticos no Cloud Integrator tipicamente são aplicações determinísticas, i.e. com
fluxo de atividades e início/término bem definidos.
Cada uma das atividades que compõem um workflow semântico é especificada
por uma tupla <tarefa, objeto> (e.g. <armazenar, arquivo>, <enviar, mensagem>, etc.) na
qual uma tarefa representa uma operação implementada por um ou mais serviços,
enquanto um objeto pode ser um elemento físico ou conceitual, incluindo pessoas,
equipamentos, entidades computacionais, mensagens, locais, etc., bem como pode
ser usado para descrever entradas, saídas, precondições e efeitos relacionados a uma
tarefa. Dessa forma, os serviços que realizam cada atividade do workflow podem ser
descobertos dinamicamente em tempo de execução apenas com base nas tuplas
<tarefa, objeto>.
Os conceitos tarefa e objeto são representados em termos de ontologias. O Cloud
Integrator emprega duas modalidades de ontologias para a representação de
conceitos no contexto de aplicações em Computação em Nuvem, todas descritas
utilizando a linguagem OWL [32]. A primeira delas é chamada ontologia de domínio,
que modela conceitos específicos relacionados a uma dada classe de aplicações e é
estruturada em termos de tarefas e objetos [41]. A Figura 9 mostra uma representação
parcial da ontologia de domínio Ecommerce, que descreve os conceitos tarefa e objeto
relacionados a aplicações de comércio eletrônico (e-commerce). Essa ontologia
apresenta relacionamentos do tipo tarefa–objeto, como o existente entre a tarefa
Consult e o objeto Inventory, significando que o estoque de produtos pode ser
consultado acerca da disponibilidade de produtos. Além disso, também podem ser
observados nessa ontologia relacionamentos do tipo objeto–objeto, como o
relacionamento purchase entre os objetos Client e Product, significando que um dado
cliente adquire um dado produto.

40
Figura 9. Representação parcial da ontologia de domínio Ecommerce.
A segunda modalidade de ontologias empregada pelo Cloud Integrator é
chamada ontologia de nuvem (Figura 10) e se refere especificamente ao contexto de
Computação em Nuvem. Essa ontologia genérica e extensível é inspirada na
ontologia de nuvem proposta no trabalho de Han e Sim [42] e tem por objetivo
representar os serviços providos por plataformas de nuvem e os relacionamentos
entre eles. Na versão adotada pelo Cloud Integrator, tais serviços são classificados
em1:
(i) recursos de nuvem, que se referem a recursos propriamente ditos
providos por plataformas de nuvem, como, por exemplo, serviços
IaaS (Infrastructure as a Service)2, e;
(ii) serviços de aplicação, que são serviços de mais alto nível que podem
ser serviços de terceiros que utilizam recursos de nuvem, serviços
SaaS (Software as a Service)3 e/ou PaaS (Platform as a Service)4, ou
1 A motivação principal para fazer essa distinção entre tipos de serviços providos pelas plataformas de nuvem se deve ao fato de que alguns tipos de recursos providos como serviços não podem entrar uma composição de serviços feita em tempo de execução e sim em tempo de projeto.
2 Plataformas de nuvem classificadas como IaaS (Infrastructure as a Service, ou infraestrutura como um serviço, em português) tipicamente proveem recursos físicos tais como máquinas virtuais, servidores, redes, etc. A Amazon Web Services (AWS) [43] é um dos exemplos mais conhecidos de plataformas IaaS.
3 Serviços SaaS (Software as a Service, ou software como um serviço, em português) basicamente consistem de aplicações de software que são executadas na nuvem e os usuários podem acessá-las acessando um navegador Web (browser), por exemplo. Um exemplo bastante popular de serviços SaaS é a suíte de aplicativos do Google, chamada Google Apps [68].
4 Plataformas PaaS (Platform as a Service, ou plataforma como um serviço, em português) tipicamente proveem uma infraestrutura subjacente para permitir o desenvolvimento, implantação, execução e gerenciamento de aplicações baseadas em nuvem. Um exemplo de plataforma PaaS é o Google App Engine (GAE) [44].

41
mesmo serviços tradicionais que não utilizam recursos de nuvem.
Como mostrado na Figura 10, recursos de nuvem são representados
genericamente nessa ontologia pelo conceito CloudResource, do qual derivam os
conceitos que representam tais recursos, como os conceitos Storage e Database, que
representam serviços de armazenamento e de banco de dados. Esses conceitos, por
sua vez, se especializam em conceitos associados diretamente aos serviços específicos
providos pelas plataformas de nuvem, como, por exemplo, os conceitos AmazonS3 e
AmazonRDS que dizem respeito, respectivamente, aos serviços de armazenamento e
de banco de dados relacional providos pela plataforma Amazon Web Services (AWS)
[43]. Por sua vez, serviços de aplicação são representados genericamente pelo
conceito ApplicationService, do qual derivam serviços de aplicação em nuvem. Os
elementos presentes nessa ontologia de nuvem são utilizados para enriquecer a
descrição dos serviços Web semânticos que realizam as atividades que compõem o
workflow referente à aplicação. A descrição OWL dessa ontologia consta no Apêndice
A.2 deste trabalho.
Figura 10. Representação parcial da ontologia de nuvem CloudOntology.
Os serviços que realizam as atividades especificadas são descritos como
serviços Web semânticos [35] utilizando a ontologia de serviço OWL-S [36], que
permite a descrição de serviços Web utilizando a linguagem OWL de maneira não
ambígua e interpretável por máquina, possibilitando um aumento do grau de
automação da composição de serviços. Além disso, máquinas de inferência podem
ser utilizadas para descobrir automaticamente e compor serviços através de suas
entradas, saídas, precondições e efeitos, de modo que o desenvolvedor de aplicações
não necessita escolher diretamente, em tempo de desenvolvimento, os serviços
concretos a serem utilizados. Quando um workflow é executado, o Cloud Integrator

42
realiza inferências considerando a especificação abstrata do workflow e os serviços
Web semânticos, executando assim uma composição de serviços e identificando que
serviços devem ser selecionados para satisfazer os objetivos de negócio do workflow
em questão. Para fazer isso, o Cloud Integrator utiliza o algoritmo de composição
apresentado no trabalho de Mendes et al. [47], que compõe serviços Web semânticos
a partir da especificação abstrata de um workflow considerando as entradas e
precondições requeridas e as saídas e efeitos produzidos para cada atividade.
A fim de executar um workflow semântico, é necessário criar no mínimo uma
especificação concreta para o mesmo, i.e. um plano de execução que contenha um
conjunto de serviços Web orquestrados. Os planos de execução são construídos
através de um processo dinâmico de descoberta e composição de serviços de acordo
com a interface semântica dos serviços selecionados e a especificação do workflow
semântico. Uma vez que o usuário tenha especificado abstratamente o workflow
semântico que representa as atividades de sua aplicação, o Cloud Integrator realiza
uma composição de serviços com base nessa especificação, i.e. procura pelos serviços
que realizam cada uma das atividades especificadas no workflow com base na
descrição semântica dos mesmos, e cria possíveis planos de execução compondo
esses serviços.
No Cloud Integrator, os planos de execução de um workflow são representados
por um grafo direcionado acíclico no qual cada nó intermediário representa um
serviço e as arestas direcionadas representam a sequência de execução dos serviços,
de modo que um plano de execução é um caminho (sequência de nós) entre os nós
inicial e final, que servem apenas para identificar respectivamente o início e o fim do
grafo e não representam serviços em si. A Figura 11 mostra um exemplo de grafo
direcionado acíclico que representa um conjunto de quatro possíveis planos de
execução para um workflow com sete atividades (indicadas pelas raias).
Figura 11. Grafo direcionado acíclico que representa um conjunto de possíveis planos de execução para um workflow.

43
Uma vez que diferentes serviços com funcionalidade similar podem estar
disponíveis no ambiente em um dado momento, mais de um plano de execução pode
ser criado para um workflow. Dessa forma, é necessário executar um algoritmo de
seleção que seleciona um plano de execução, dentre os disponíveis, para ser
executado. Para guiar essa seleção, o algoritmo de seleção executado pelo Cloud
Integrator utiliza metadados acerca dos serviços, tais como parâmetros de QoS e preço,
conforme apresentado na Seção 3.4 deste trabalho. Após selecionar um plano de
execução, o Cloud Integrator executa-o invocando sequencialmente os serviços que
compõem esse plano de execução.
3.2 Arquitetura
Figura 12. Arquitetura do Cloud Integrator.

44
A arquitetura do Cloud Integrator, apresentada na Figura 12, envolve duas
camadas, a saber, Service Layer e Integration Layer, cujos componentes são descritos
nas Seções 3.2.1 e 3.2.2. Este trabalho possui enfoque nos componentes da camada
Service Layer, mais precisamente os responsáveis pelas atividades de criação,
execução e gerenciamento de workflows, envolvendo os processos de composição e
seleção de serviços, bem como o de adaptação de aplicações, conforme apresentado a
seguir.
3.2.1 Service Layer
A camada Service Layer é responsável por gerenciar as abstrações (descrições
OWL-S) dos serviços que são utilizadas pelos componentes dessa camada para criar
e executar workflows e para os processos de composição, seleção e adaptação.
Localizado no topo da camada Service Layer, o elemento Application Façade é
responsável por receber requisições das aplicações que utilizam os serviços providos
pelas plataformas de nuvem integradas pelo Cloud Integrator e as encaminhar para os
componentes da camada Service Layer. Esse elemento implementa a interface
Application Interface, ilustrada no trecho de código apresentado na Figura 13, que
mostra as operações básicas providas pelo Cloud Integrator, que permitem o usuário
criar, abrir e executar um workflow, bem como especificar suas preferências com
relação aos parâmetros utilizados nos processos de seleção e adaptação (detalhados
nas Seções 3.4 e 3.5).
Figura 13. Trecho de código referente à interface Application Interface.
O componente Workflow Manager gerencia workflows e é composto por quatro
subcomponentes, que oferecem suporte à especificação de workflows semânticos e à
geração e execução de planos de execução. O componente Service Manager é
responsável por importar e validar descrições OWL-S e por prover capacidades de
busca por conceitos na base de conhecimento utilizando entradas, saídas,
precondições e efeitos dos serviços Web semânticos disponíveis. O componente
Semantic Composer é responsável por descobrir e compor serviços Web de acordo com
a especificação do workflow semântico, realizando o mapeamento entre atividades
abstratas e serviços Web. Primeiramente esse componente tenta descobrir os serviços
que podem ser utilizados para compor o plano de execução dentre os disponíveis no

45
componente Semantic Repository, que armazena as ontologias que descrevem os
serviços Web e as especificações dos workflows e dos planos de execução. A seguir,
ele tenta combinar os serviços descobertos a fim de consumir todas as entradas e
precondições e produzir todas as saídas e efeitos especificados no workflow. Os
serviços combinados são então orquestrados (organizados) de acordo com o fluxo de
mensagem entre as saídas de um serviço e as entradas do serviço subsequente. Por
fim, o componente Workflow Executor provê suporte à execução de workflows,
recebendo os planos de execução selecionados pelos componentes Selection Manager
(no processo de seleção, descrito na Seção 3.4) e Adaptation Manager (no processo de
adaptação, descrito na Seção 3.5). No momento da execução do workflow, o
componente Workflow Executor executa o plano de execução selecionado fazendo
chamadas aos serviços providos pelas plataformas de nuvem integradas.
O componente Metadata Manager é responsável por gerenciar os metadados
acerca dos serviços de nuvem utilizados pelas aplicações e por torná-los disponíveis
aos processos de seleção e adaptação executados respectivamente pelos componentes
Selection Manager e Adaptation Manager. Exemplos de metadados são: (i) parâmetros de
QoS, e.g. tempo de resposta, disponibilidade, desempenho, etc., e; (ii) preços (custos)
dos serviços [48]. Para adquirir e monitorar esses metadados, o Cloud Integrator
interage com um sistema de monitoramento externo chamado QoMonitor,
brevemente apresentado na Seção 3.3.
O componente Selection Manager é responsável por selecionar planos de
execução com base nos metadados referentes aos serviços que compõem tais planos
de execução. Quando esses planos de execução são gerados pelo componente
Workflow Manager, o componente Selection Manager seleciona um deles para ser
executado analisando os metadados providos pelo componente Metadata Manager e
as preferências do usuário. Feito isso, o plano de execução selecionado é
encaminhado para o componente Workflow Manager para execução. O processo de
seleção realizado pelo componente Selection Manager é descrito com detalhes na
Seção 3.4 e no trabalho de Cavalcante et al. [49].
Conforme descrito na Seção 3.5, o componente Adaptation Manager é
encarregado de executar o processo de adaptação em caso de (i) falha de serviços, (ii)
degradação na qualidade de serviço, ou (iii) surgimento de novos serviços. No
contexto do Cloud Integrator, uma adaptação de uma aplicação significa substituir um
plano de execução em estado de execução por outro que realize as mesmas
atividades, a fim de cumprir o objetivo de negócio do workflow em questão. Esse
componente funciona de maneira conjunta com os componentes Metadata Manager e
Workflow Manager para identificar uma condição que possa disparar uma adaptação e
para mudar automaticamente o plano de execução de uma aplicação. Neste trabalho,
o processo de adaptação executado pelo componente Adaptation Manager endereça

46
apenas a substituição de serviços de aplicação.
3.2.2 Integration Layer
A camada Integration Layer é responsável por integrar plataformas de nuvem
(provedores de serviços) que são ligadas ao Cloud Integrator através da interface
Integration Interface, que é implementada pelo elemento Integration Façade para
intermediar a interação entre o Cloud Integrator e as plataformas subjacentes.
Para permitir a comunicação do Cloud Integrator com as plataformas de
Computação em Nuvem que estão sendo integradas, faz-se necessário desenvolver
binders para cada plataforma de nuvem. Esses binders abstraem as APIs específicas de
cada plataforma, de modo a permitir o acesso a recursos providos, como, por
exemplo, possibilitando iniciar e instanciar de maneira automática e/ou
programática máquinas virtuais. Na Figura 12, por exemplo, os binders AWSBinder e
GAEBinder referem-se respectivamente às plataformas de nuvem pública Amazon
Web Services (AWS) [43] e Google App Engine (GAE) [44] que estão sendo
integradas pelo Cloud Integrator. De maneira similar, o binder OCCIBinder é um binder
de caráter mais genérico a ser utilizado por plataformas de nuvem que adotam a
especificação OCCI (Open Cloud Computing Interface)5 [46], a exemplo da plataforma
de nuvem privada OpenStack [45].
O componente Service Discovery é responsável por descobrir serviços de
nuvem no ambiente e registrá-los no Cloud Integrator. Por sua vez, o componente
Service Factory é responsável por criar serviços que encapsulam as APIs específicas
das plataformas de nuvem, enquanto o componente Service Bridge insere-os no
componente Semantic Repository, um dos subcomponentes do componente Workflow
Manager na camada Service Layer. Assim, cada serviço provido através de uma API
de plataforma de nuvem é representado por um serviço Web criado pelo
componente Service Factory para representar a respectiva API do serviço, de modo
que cada um desses serviços Web que são criados utiliza um binder desenvolvido
especificamente para a plataforma de nuvem subjacente.
3.3 Monitoramento de metadados de qualidade
Após selecionar um plano de execução para uma aplicação, os metadados
utilizados são ainda necessários para decidir se é preciso substituir um serviço
5 OCCI (Open Cloud Computing Interface) é uma iniciativa proposta pelo OGF (Open Grid Forum) como uma API padrão para acessar recursos IaaS providos por diferentes plataformas de nuvem. Na especificação OCCI, recursos podem ser identificados unicamente por um URI e acessados via REST (REpresentational State Transfer) através das operações (verbs) definidas no protocolo HTTP (POST, GET, PUT, DELETE). Maiores detalhes sobre a OCCI podem ser encontrados em: http://occi-wg.org/about/specification/.

47
selecionado anteriormente por outro serviço equivalente em casos de falha ou
degradação de qualidade desse serviço, ou ainda caso surja um serviço alternativo
com melhor qualidade, situações típicas de ambientes dinâmicos detalhadas na Seção
3.5.1. Nessa perspectiva, é necessário prover meios eficientes para obter e monitorar
periodicamente metadados referentes à qualidade dos serviços utilizados pela
aplicação, bem como para detectar variações consideráveis em tais metadados. Com
isso, esse monitoramento de metadados em tempo de execução permite que
aplicações utilizem serviços que melhor satisfaçam seus requisitos de qualidade
durante sua execução.
Para adquirir e monitorar tais informações, o Cloud Integrator utiliza o
QoMonitor [50, 51], um sistema genérico de monitoramento de metadados para
computação distribuída implementado como um serviço Web. O QoMonitor recebe
requisições de clientes (aplicações e/ou plataformas de middleware como, no caso, o
Cloud Integrator), recupera metadados de qualidade (e.g. parâmetros de QoS) dos
provedores de serviços e os encaminha para os clientes, de modo que, utilizando esse
sistema de monitoramento, o Cloud Integrator passa a não ter a responsabilidade de
lidar com as complexidades relacionadas ao monitoramento de metadados. No Cloud
Integrator, os metadados providos pelo QoMonitor são encaminhados ao componente
Metadata Manager, que é responsável por gerenciar tais metadados e os tornar
disponíveis aos componentes responsáveis pelos processos de seleção e de
adaptação.
A Figura 14 apresenta a arquitetura do QoMonitor, detalhada no trabalho de
Alves [51]. O QoMonitor consiste de dois repositórios: (i) o Repositório de Metadados,
que persiste em uma base de dados todos os metadados de qualidade dos serviços
monitorados, bem como os metadados disponibilizados pelos provedores de serviço,
e; (ii) o Repositório de Serviços, que armazena informações acerca de todos os serviços
que estão sendo monitorados e dos parâmetros necessários para se comunicar com os
provedores dos mesmos.

48
Figura 14. Arquitetura do QoMonitor.
O QoMonitor também contém um Tratador de Requisições, que trata requisições
síncronas e assíncronas dos clientes, obtém os metadados requisitados e responde
aos clientes. Associado ao Tratador de Requisições, o Módulo Publish-Subscribe é
responsável por notificar clientes quando ocorre o evento especificado por uma
determinada condição de retorno6 (fornecida na requisição assíncrona), ou seja, quando
tal condição de retorno é satisfeita.
O principal componente do QoMonitor é o Módulo de Aferição, que é
responsável por efetivamente monitorar e aferir os metadados de qualidade dos
serviços armazenados no Repositório de Serviços. Esse componente é basicamente
composto por três tipos de subcomponentes: (i) aferidores; (ii) Blackboard, e; (iii)
Controlador. Cada aferidor é responsável por aferir um parâmetro de qualidade
específico a partir de informações capturadas através de requisições aos serviços
monitorados, a saber, o tempo que a requisição levou para ser completada, se o
6 No contexto do QoMonitor, uma condição de retorno é uma tripla <expressão, tipo de comparação, valor> na qual: (i) a expressão é formada por variáveis e operações matemáticas que, aplicadas aos dados armazenados pelo QoMonitor, retorna um valor; (ii) o valor é um valor numérico qualquer, e; (iii) o tipo de comparação determina o operador de igualdade/desigualdade que será utilizado para fazer a comparação do valor da expressão com o valor fornecido pelo cliente.
Provedor de
Serviço A
Provedor de
Serviço B
Provedor de
Serviço N
Cliente 1 Cliente 2
QoMonitor
Fachada Servidor
Fachada Cliente
Cliente N
IServidor
...
ICliente
...
Módulo de Aferição
Aferidor
Parâmetro XAferidor
Parâmetro Z
Blackboard
Controlador
...Aferidor
Parâmetro Y
Tratador de Requisições
Requisição
Assíncrona
Requsição
Síncrona
Módulo Publish-Subscribe
Repositório de Metadados
Repositório de Serviços
Módulo de Ontologia

49
serviço está disponível, e o momento em que a requisição foi feita. O componente
Blackboard incorpora a ideia de um repositório de dados compartilhados, permitindo
que aferidores de diferentes parâmetros de qualidade dos serviços utilizem as
mesmas informações previamente listadas para calcular o valor desses parâmetros.
Por fim, a ideia do componente Controlador é controlar o acesso às informações
armazenadas no componente Blackboard e as informações obtidas a partir da aferição
dos parâmetros, de modo que os aferidores não conhecem a origem dos dados que
eles utilizam para aferição, modularizando assim a arquitetura.
Apesar de o QoMonitor não apresentar, em sua implementação original,
alguns aferidores necessários para que o mesmo possa ser plenamente aplicado no
contexto de Computação em Nuvem (visto que, por exemplo, pode ser necessário
monitorar o uso dos recursos das plataformas de nuvem integradas, tais como uso de
processamento, memória, rede, etc.), neste trabalho foram utilizados os parâmetros
de QoS que já são disponibilizados pelo QoMonitor, mais precisamente os parâmetros
tempo de resposta e disponibilidade. Contudo, a arquitetura do QoMonitor, concebida
para que ele seja um monitor genérico e possa então ser empregado em diferentes
classes de ambientes distribuídos, permite que novos aferidores sejam facilmente
implementados e acrescentados e/ou retirados, de modo que é possível desenvolver
facilmente esses novos aferidores relacionados a recursos no contexto de plataformas
de nuvem.
3.4 Seleção de serviços
Como mencionado anteriormente na Seção 3.1, uma vez que o usuário tenha
especificado um workflow, o Cloud Integrator pode então fazer a composição dos
serviços disponíveis para criar os possíveis planos de execução que atendam às
atividades do workflow especificado. Mesmo havendo diferentes opções de planos de
execução, apenas um deles deve ser selecionado para ser executado e assim satisfazer
os objetivos de negócio da aplicação. No Cloud Integrator, essa seleção é feita com
base em metadados dos serviços que estão envolvidos na composição, a saber: (i)
parâmetros de QoS, e.g. tempo de resposta, disponibilidade, desempenho, etc., e; (ii)
preços (custo) dos serviços [48].
Conforme apresentado no trabalho de Cavalcante et al. [48], o processo de
seleção realizado pelo Cloud Integrator envolve duas operações básicas, a saber: (i)
agregação, que computa o valor global de um dado parâmetro considerando um
plano de execução como um todo, e; (ii) normalização, que enquadra os parâmetros
em uma mesma faixa de valores para permitir uma medição uniforme da qualidade
dos planos de execução. Feito isso, o algoritmo de seleção avalia a utilidade de cada
plano de execução candidato com base nessas operações, considerando o custo e os
parâmetros de qualidade de cada serviço de nuvem incluído no plano de execução.

50
Todavia, dado que o algoritmo proposto no trabalho de Cavalcante et al. [48]
considera todos os serviços que compõem todos os planos de execução disponíveis, se
uma aplicação requerer um número relativamente grande de serviços (como é o caso
de aplicações em computação científica, por exemplo), o processo de seleção pode
tornar-se impraticável devido ao aumento do tempo despendido pelo algoritmo de
seleção de serviços, em termos de combinar tais serviços e calcular todos os valores
agregados para cada um dos parâmetros considerados para cada plano de execução.
De fato, a composição e seleção de serviços com base em parâmetros de qualidade é
um problema combinatório de difícil solução em termos de tempo computacional
para a determinação de soluções ótimas, como reportado em alguns trabalhos na
literatura [52, 53, 54]. Dessa forma, uma vez que o desempenho de tal algoritmo pode
ter influência considerável no desempenho geral do sistema [55] (i.e. o Cloud
Integrator), é necessário prover um meio de otimizar o processo de seleção de
serviços.
Nessa perspectiva, no trabalho de Cavalcante et al. [49] é apresentada uma
nova abordagem que tenta otimizar o processo de seleção realizado pelo Cloud
Integrator, para isso desconsiderando dos cálculos todos os serviços coincidentes. Tais
serviços coincidentes são serviços que estão presentes em todos os planos de execução
e, portanto, contribuem igualmente com os mesmos valores de custo e de qualidade
em qualquer plano de execução. Em não se considerando esses serviços, o processo
de seleção de serviços seria teoricamente executado mais rapidamente, por envolver
um número menor de serviços a serem considerados, porém com um trade-off em se
executar um algoritmo adicional para identificar de antemão os serviços coincidentes
para depois iniciar o processo de seleção de serviços. De fato, os resultados
experimentais preliminares reportados no trabalho de Cavalcante et al. [49] mostram
que essa nova abordagem de seleção de serviços é mais eficiente em termos de
desempenho e promoveu uma redução entre cerca de 13% e 15% no tempo
despendido pelo processo de seleção em si, em comparação à abordagem original
[48]. Além disso, o algoritmo para identificação dos serviços coincidentes também se
mostrou ser eficiente e capaz de fazer um bom trade-off entre o número de planos de
execução a serem analisados e o número de serviços coincidentes entre eles.
Contudo, é importante salientar que o algoritmo de seleção original apresentado no
trabalho de Cavalcante et al. [48] não sofreu qualquer modificação, i.e. o algoritmo de
identificação de serviços coincidentes é executado tão somente em um passo anterior
ao algoritmo de seleção propriamente dito, que passa então a considerar apenas os
serviços não-coincidentes ao invés de todos os serviços.
O Algoritmo 1 a seguir apresenta o algoritmo para identificação de serviços
coincidentes a serem desconsiderados dos cálculos realizados no processo de seleção.
Dada uma lista A de atividades que compõem o workflow, para cada atividade a do
workflow (a A), os serviços que realizam essa atividade a são recuperados pelo

51
procedimento recuperarServiçosPorAtividade (linha 3). Assim, se existe apenas um
serviço que realiza essa atividade a (linha 4), então tal serviço está necessariamente
em todos os planos de execução e, consequentemente, ele é marcado como um serviço
coincidente, sendo adicionado ao conjunto de serviços coincidentes SC (linha 5) a ser
retornado pelo algoritmo.
Algoritmo 1. Algoritmo para identificação de serviços coincidentes
Entrada: A – lista de atividades que compõem o workflow
Saída: SC – conjunto de serviços coincidentes
1: SC ← Ø
2: para cada atividade a A faça
3: S ← recuperarServiçosPorAtividade(a)
4: se |S| = 1 então
5: SC ← SC S
6: fim se
7: fim para
A Figura 15 ilustra um grafo direcionado acíclico que representa um conjunto
com seis possíveis planos de execução para um workflow com seis atividades
(indicadas pelas raias), sendo também destacados os serviços coincidentes nesses
planos de execução. Os serviços A, C, D e F, que atendem unicamente às atividades 1,
3, 4 e 6, respectivamente, estão presentes em todos os seis planos de execução e,
portanto, são enquadrados como serviços coincidentes.
Figura 15. Ilustração de workflow e de serviços coincidentes presentes nos planos de execução.

52
Após identificar os serviços coincidentes, o processo de seleção propriamente
dito é iniciado, conforme sumarizado no Algoritmo 2. Esse algoritmo recebe como
entrada uma lista PE com os planos de execução gerados para o workflow em questão,
o conjunto SC de serviços coincidentes, e uma lista W de pesos atribuídos pelo
usuário como preferências para os parâmetros. Os serviços coincidentes presentes no
conjunto SC não são considerados nas operações realizadas nesta etapa do processo
de seleção. Como será mostrado adiante, o processo de seleção de serviços com base
em parâmetros de qualidade (mais especificamente parâmetros de QoS) já é aplicado
em outros trabalhos na literatura, inclusive no contexto de Computação em Nuvem
[81, 83, 86].
Algoritmo 2. Algoritmo de seleção de planos de execução
Entrada: PE – lista de planos de execução gerados para o workflow
SC – conjunto de serviços coincidentes
W – lista de pesos atribuídos pelo usuário
Saída: s PE – plano de execução com utilidade maximal
1: para cada plano de execução p PE faça
2: calcularCustoAgregado(p, SC)
3: normalizarCustoAgregado(p, PE)
4: fim para
5: para cada plano de execução p PE faça
6: para cada parâmetro de qualidade q
7: calcularQualidadeGlobal(p, q, SC)
8: normalizarQualidadeGlobal(p, q, SC)
9: para cada
10: calcularUtilidade(p, W)
11: fim para
O Algoritmo 2 começa com o cálculo do custo (monetário) de cada plano de
execução p PE (linha 2) através de uma soma simples do custo de cada serviço que
compõe o plano de execução corrente. Feito isso, esse valor agregado é normalizado
(linha 3) a fim de enquadrá-lo na faixa de valores entre 0 e 1, utilizando a Equação 1:
minmax
minmax
imaxN cc
cc
pccpc
,
)( )( (1)
na qual cN(p) é o custo normalizado, ci(p) é o valor agregado de custo para o plano de
execução p, e cmax e cmin são os maior e menor valores agregados dos planos de
execução considerados, respectivamente (se cmax = cmin então cN(p) = 1). Conforme
apontado no trabalho de Cavalcante et al. [48], os parâmetros de custo e de
qualidade são considerados (nesta ordem) de maneira separada, visto que selecionar
um plano de execução com menor custo não implica necessariamente que tal plano
de execução tenha a melhor qualidade.
Em algumas situações, o usuário pode estabelecer que o custo total de uma

53
composição de serviços de nuvem não ultrapasse um dado valor θ, a sua escolha.
Dado que essa é uma restrição global para todo o workflow, planos de execução que
apresentarem valor agregado de custo superior ao valor θ especificado deverão ser
desconsiderados. Entretanto, com isso, é possível que muitos planos de execução,
incluindo planos que possam ter uma alta qualidade, sejam desconsiderados. Para
reverter tal efeito, o usuário pode configurar (previamente) algumas exceções, como,
por exemplo, autorizar que o processo de seleção aceite planos de execução que
extrapolem o limite em no máximo x% caso a alta qualidade desses planos
compense essa extrapolação. Dessa forma, se o usuário especificar o custo máximo ,
então cmax = .
No próximo passo, o algoritmo calcula a qualidade de cada plano de execução
como um todo, considerando os valores dos parâmetros de QoS providos pelo
QoMonitor7 referentes aos m serviços que o compõem. Primeiramente, o valor global
de cada parâmetro de qualidade q é computado para cada plano de execução p PE
(linha 7) através de funções de agregação específicas para cada parâmetro [53, 55],
como as apresentadas na Tabela 1:
(i) tempo de resposta é o parâmetro de QoS utilizado para medir o tempo
de resposta para executar cada serviço, de modo que o valor global
desse parâmetro qt(p) é dado pela soma dos valores qt(s) desse
parâmetro para cada serviço s que compõe o plano de execução p
considerado;
(ii) o parâmetro de QoS disponibilidade representa a probabilidade (valor
percentual) na qual o provedor de serviço está disponível, i.e. que o
serviço está pronto para uso imediato; seu valor global qa(p) pode ser
obtido através do produtório (multiplicação) do valor qa(s) de
disponibilidade de cada serviço s que compõe o plano de execução p
considerado;
(iii) desempenho é o parâmetro de QoS que descreve a quantidade de
requisições qd(p) atendidas pelo provedor de um serviço s em um
dado período de tempo, de modo que o desempenho qd(p) de um
plano de execução p é limitado pelo serviço s que apresente o menor
valor para esse parâmetro.
7 É importante salientar que são solicitados, para o QoMonitor, apenas os metadados de qualidade de serviços não coincidentes, visto que são esses metadados que de fato serão considerados nos cálculos do processo de seleção.

54
Tabela 1. Exemplos de funções de agregação de parâmetros de qualidade.
Tipo Exemplo de parâmetro Expressão
Somatório tempo de resposta
PEs
tt sqpq
)()(
Produtório disponibilidade
PEs
aa sqpq
)()(
Mínimo desempenho )(min)(
sqpq dPEs
d
Uma vez calculados os valores globais dos parâmetros para os planos de
execução disponíveis, apenas esses valores globais para os planos de execução serão
considerados e não mais os valores individuais dos parâmetros para os serviços.
Entretanto, apenas calcular os valores globais não é suficiente, visto que cada
parâmetro lida com diferentes grandezas, sendo, portanto, necessário fazer uma
normalização dos mesmos a fim de enquadrá-los em uma mesma faixa de valores para
permitir uma medição uniforme da qualidade dos planos de execução [53, 54, 55].
Dessa forma, no Algoritmo 2, o valor global dos parâmetros de qualidade é
normalizado (linha 8) a fim de enquadrá-lo na faixa de valores entre 0 e 1 [54].
Dependendo de sua natureza, alguns parâmetros são positivos, i.e. quanto maior o
seu valor, maior a sua qualidade (por exemplo, o parâmetro disponibilidade), e outros
parâmetros são negativos, i.e. quanto menor o seu valor, maior a sua qualidade (por
exemplo, o parâmetro tempo de resposta). As Equações 2 e 3 apresentam as fórmulas
para normalização de parâmetros positivos e negativos, respectivamente. Nessas
equações, qNi(p) é o valor normalizado para o parâmetro i, qi(p) é o valor global do
parâmetro i para o plano de execução p, e qmax e qmin são os maior e menor valores
para todos planos de execução considerados, respectivamente (se qmax = qmin então
qNi(p) = 1). Nesse processo, qNi(p) resulta em um valor entre 0 e 1.
minmax
minmax
miniNi qq
qpqpq
,
)()( (2)
minmax
minmax
imaxNi qq
pqqpq
,
)()( (3)
Por fim, tendo-se os valores normalizados de custo e de qualidade, a utilidade
u(p) de cada plano de execução p PE (linha 10) é calculada como uma soma
ponderada (Equação 4) entre os valores normalizados dos parâmetros e os
respectivos pesos w W atribuídos pelo usuário a esses parâmetros através de um
arquivo de configuração em XML. A Figura 16 mostra um exemplo de arquivo de
configuração XML no qual são atribuídos pesos iguais (valor 0.5) aos parâmetros de

55
QoS availability (disponibilidade) e response_time (tempo de resposta).
Figura 16. Exemplo de arquivo de configuração XML com pesos atribuídos aos parâmetros de qualidade.
Ao fim do processo de seleção, é selecionado o plano de execução com
utilidade maximal, e se existir mais de um plano de execução com utilidade
maximal, um deles é selecionado aleatoriamente. Na Equação 4, qNi(p) e cN(p) são,
respectivamente, os valores normalizados para o parâmetro de qualidade i e para o
custo considerando o plano de execução p, enquanto wi, wc W são os pesos
atribuídos pelo usuário a esses parâmetros, de modo que wi, wc [0, 1] e
1.1
c
m
ii ww
cN
m
iiNi wpcwpqpu *)(*)()(
1
(4)
Uma vez que um plano de execução é selecionado, o Cloud Integrator está apto
a iniciar a execução do mesmo através do componente Workflow Executor.
3.5 Adaptação
O modelo de composição de serviços adotado pelo Cloud Integrator é baseado
na funcionalidade de cada serviço e em seus respectivos metadados (como parâmetros
de qualidade e preço). Esse mecanismo de composição permite que o Cloud Integrator
lide com situações nas quais um serviço está disponível em tempo de composição e
se torna indisponível em tempo de execução, ou em caso de degradação de
qualidade de qualquer serviço que esteja incluído na composição. Se dois ou mais
serviços com funcionalidade similar estão disponíveis, o Cloud Integrator constrói
diferentes planos de execução para o workflow em questão, cada um deles utilizando
um desses serviços alternativos. Dessa forma, em caso de falha ou degradação de
qualidade de um serviço, outro plano de execução que contém um serviço
equivalente, de funcionalidade similar, pode então substituir o corrente a fim de
garantir a qualidade e a disponibilidade da aplicação em questão. Nesta seção é

56
descrito o processo de adaptação que oferece suporte a essa facilidade.
3.5.1 Fatores que disparam uma adaptação
Existem três classes de mudanças em ambientes de nuvem que podem
disparar um processo de adaptação: (i) falha de um ou mais serviços; (ii) degradação
da qualidade de um ou mais serviços, e; (iii) surgimento de novos serviços.
A perda da conexão entre o Cloud Integrator e um provedor de serviços ou
mesmo erros internos no serviço são causas típicas de falhas de serviço. Em ambos os
casos, o provedor de um serviço torna-se incapaz de responder a requisições e, com
isso, todos os planos de execução ativos que possuam tal serviço devem ser
analisados e substituídos por planos de execução alternativos que contenham
serviços com funcionalidade similar ao serviço em falha, quando possível. Por
exemplo, supondo que o plano de execução A → B → C1 → D → E está sendo
executado e o serviço C1 torna-se indisponível, o mecanismo de adaptação, nesse
caso, deve selecionar, da maneira mais transparente possível, um plano de execução
alternativo com um serviço equivalente a C1 (por exemplo, C2), evitando assim a
falha de toda a aplicação devido à indisponibilidade de C1.
A segunda classe de eventos que podem disparar uma adaptação é a
degradação da qualidade de um ou mais serviços. Ambientes de Computação em Nuvem
podem apresentar condições de execução altamente dinâmicas nas quais flutuações
na rede e uso extensivo de serviços podem afetar a qualidade dos serviços em
execução. Nesse caso, um plano de execução alternativo contendo um serviço que
proveja funcionalidade similar à do serviço degradado pode ser adotado se sua
utilidade8 for significativamente maior que a utilidade do plano de execução em
questão.
Ambientes de nuvem também são bastante dinâmicos no que diz respeito à
emergência de novos serviços, que podem ser dinamicamente descobertos. Uma vez
que esses novos serviços podem propiciar outros planos de execução alternativos
que sejam mais vantajosos às aplicações em execução, é necessário também analisar a
necessidade e a conveniência em se substituir o plano de execução corrente por um
alternativo que contenha um ou mais desses novos serviços. Como no caso de
degradação de qualidade, é importante considerar os ganhos em termos de utilidade
desses planos de execução alternativos e o impacto de se fazer a substituição do
plano de execução corrente.
No estado atual de desenvolvimento do Cloud Integrator, o processo de
8 Conforme apresentado na Seção 3.4, o cálculo da utilidade de um plano de execução considera tanto parâmetros de QoS quanto custos [monetários] dos serviços que o compõem.

57
adaptação é disparado apenas em casos de falha de serviços e degradação de
qualidade, porém apenas o primeiro tipo de adaptação foi implementado. Adaptação
de aplicações disparada pela descoberta de novos serviços é um tópico que poderá
ser endereçado em trabalhos futuros.
3.5.2 Fatores a serem considerados em uma adaptação
Quando um processo de adaptação substitui um dado plano de execução para
uma aplicação, é necessário garantir que os requisitos da aplicação continuem a ser
satisfeitos. Embora a qualidade de planos de execução alternativos seja um fator
essencial a ser considerado, ele não é suficiente para garantir uma adaptação
eficiente. Além disso, uma vez que a substituição do plano de execução corrente
pode levar à reexecução de serviços ou a outras ações de impacto considerável, a
decisão acerca dessa possível substituição deve considerar o custo de adaptação9, que é
o overhead decorrente da substituição do plano de execução corrente por um
alternativo. Por exemplo, se algum dos serviços incluídos no plano de execução em
questão já tiver sido executado, pode ser mais vantajoso selecionar um plano de
execução alternativo que possua mais serviços em comum com o atual, de modo que
esse plano de execução similar pode oferecer um baixo custo de adaptação devido ao
reuso das saídas dos serviços previamente executados, evitando assim a necessidade
de ações que possuam impacto considerável.
Os custos de adaptação referentes aos planos de execução alternativos são
tipicamente variáveis e o seu cálculo deve considerar os seguintes fatores:
(i) reuso de serviços executados – considerando que alguns serviços
possam estar presentes em dois ou mais planos de execução, pode
ser conveniente priorizar planos de execução alternativos que
reusem serviços que estejam incluídos no plano de execução corrente
e já tenham sido executados;
(ii) rollbacks – na substituição do plano de execução corrente, alguns
serviços que já tenham sido executados podem requerer rollbacks
para retornar a um estado de execução anterior10, e;
(iii) ações compensatórias – quando o plano de execução corrente é
substituído, se um serviço necessita retornar a um estado de
execução anterior porém não oferece suporte a rollbacking, ações
9 No processo de adaptação, o custo de adaptação não envolve o custo [monetário] dos serviços, mas sim o overhead imposto pelas ações que devem ser executadas a fim de permitir a continuidade da aplicação após a substituição do plano de execução corrente.
10 A descrição semântica do serviço registrado no Cloud Integrator deve informar se o serviço oferece suporte a rollbacking, de modo que o Cloud Integrator não é diretamente responsável por esse suporte.

58
compensatórias podem ser providas pelo componente Adaptation
Manager a fim de restaurar um estado de execução anterior à
execução de tal plano de execução.
É importante salientar que nem todos os serviços incluídos em planos de
execução requerem rollbacking ou ações compensatórias. Serviços que executam
operações que não modificam o ambiente de execução (e.g. operações de leitura) não
requerem tais ações. Por outro lado, serviços que modificam o ambiente de execução
(e.g. serviços que executam operações de escrita) tipicamente requerem esse tipo de
ações. A descrição da estratégia utilizada para rollbacks e ações compensatórias está
fora do escopo deste trabalho.
O cálculo do custo de adaptação de um plano de execução p começa com o
cálculo do seu custo de adaptação absoluto cabs(p) (Equação 5), definido como a soma do
número de serviços a serem executados após a substituição do plano de execução
corrente (e), do número de serviços que requerem rollbacks (r), e do número de
serviços que requerem ações compensatórias (a):
arepcabs )( (5)
Para determinar os valores das parcelas e, r e a na Equação 5, é adotada a
estratégia empregada no trabalho de Lopes [69], que utiliza o grafo direcionado
acíclico que representa o conjunto de planos de execução disponíveis para o workflow
em questão (Seção 3.1), sendo necessário identificar o ponto de coincidência entre o
plano de execução corrente, com o serviço em falha, e os planos de execução
alternativos. Esse ponto de coincidência define pontualmente a mudança de caminho
(dado que um plano de execução pode ser entendido como um caminho entre os nós
inicial e final no grafo) entre um plano de execução e outro, de modo que o próximo
serviço após tal ponto de coincidência é o primeiro serviço que precisa ser executado
uma vez concluído o processo de adaptação.
Por exemplo, considere-se o grafo direcionado acíclico mostrado na Figura 17
com cinco opções de plano de execução para um workflow, das quais o plano de
execução PE1: A → B1 → C1 → D1 → E1 → F tenha sido selecionado para ser
executado. Supondo que o serviço E1 torne-se indisponível, têm-se ainda três planos
de execução alternativos candidatos a substituir esse plano de execução, a saber: (i)
PE2: A → B1 → C1 → D1 → E2 → F; (ii) PE4: A → B1 → C2 → D1 → E2 → F, e; (iii) PE5:
A → B2 → C3 → D2 → E3 → F.
Como mostrado no grafo da Figura 17, o ponto de coincidência entre os
planos de execução PE1: A → B1 → C1 → D1 → E1 → F (com o serviço em falha) e, por
exemplo, PE4: A → B1 → C2 → D1 → E2 → F é o nó que representa o serviço B1.
Supondo que o serviço C1 requeira rollbacking em caso de adaptação, se o plano de

59
execução PE4 for selecionado para substituir o plano de execução PE1, as execuções
dos serviços A e B1 serão reaproveitadas e os serviços a serem executados serão C2,
D1, E2 e F, quatro no total. Assim, para o plano de execução alternativo PE4, e = 4, r =
1 (visto que o serviço C1 requer rollbacking) e a = 0, resultando em cabs(PE4) = 5.
Figura 17. Ponto de coincidência em um grafo direcionado acíclico que representa o conjunto de planos de execução para um workflow.
Por fim, o custo de adaptação c(p) de um plano de execução p é calculado
mediante uma normalização vetorial do valor do custo de adaptação absoluto cabs(p)
desse plano de execução, conforme definido pela Equação 6:
PEr abs
abs
rc
pcpc
2)(
1
)(
1
1)( (6)
na qual cabs(r) é o custo de adaptação absoluto de cada plano de execução r no
conjunto de planos de execução PE.
3.5.3 Disparando uma adaptação
Uma condição de falha de serviço é identificada quando uma invocação de
serviço não é realizada com sucesso. Nesse caso, o componente Workflow Manager
notifica o componente Adaptation Manager e o processo de adaptação é iniciado
imediatamente, visto que a execução da aplicação que realizou a invocação do
serviço em falha só pode continuar se o plano de execução corrente for substituído

60
por um alternativo que contenha um serviço equivalente. Se o serviço em falha está
presente em planos de execução utilizados por outras aplicações11, é também
necessário disparar o processo de adaptação para todas as aplicações cujos planos de
execução correntes contenham o serviço em falha.
A Figura 18 apresenta um diagrama UML de sequência que ilustra o processo
de adaptação realizado pelo Cloud Integrator em caso de falha de um serviço
envolvido no plano de execução que está sendo executado. As operações 1, 2 e 3
consistem na invocação de serviços que fazem parte desse plano de execução, porém
a invocação referente à operação 3 não é completada uma vez que o serviço C está
em situação de falha, ocasionada por algum dos fatores elencados na Seção 3.5.1.
Assim, o processo de adaptação é disparado (operação 4) para efetuar a mudança do
plano de execução atual por outro plano de execução. Na Figura 18, como os serviços
C e C’ são equivalentes e o serviço C está em situação de falha, o plano de execução
que contém o serviço C’ é selecionado para que assim o objetivo especificado pela
aplicação possa ser alcançado.
11 O Cloud Integrator é idealizado para oferecer suporte à execução concorrente de múltiplas aplicações utilizando os serviços providos pelas plataformas de nuvem que estão sendo integradas.
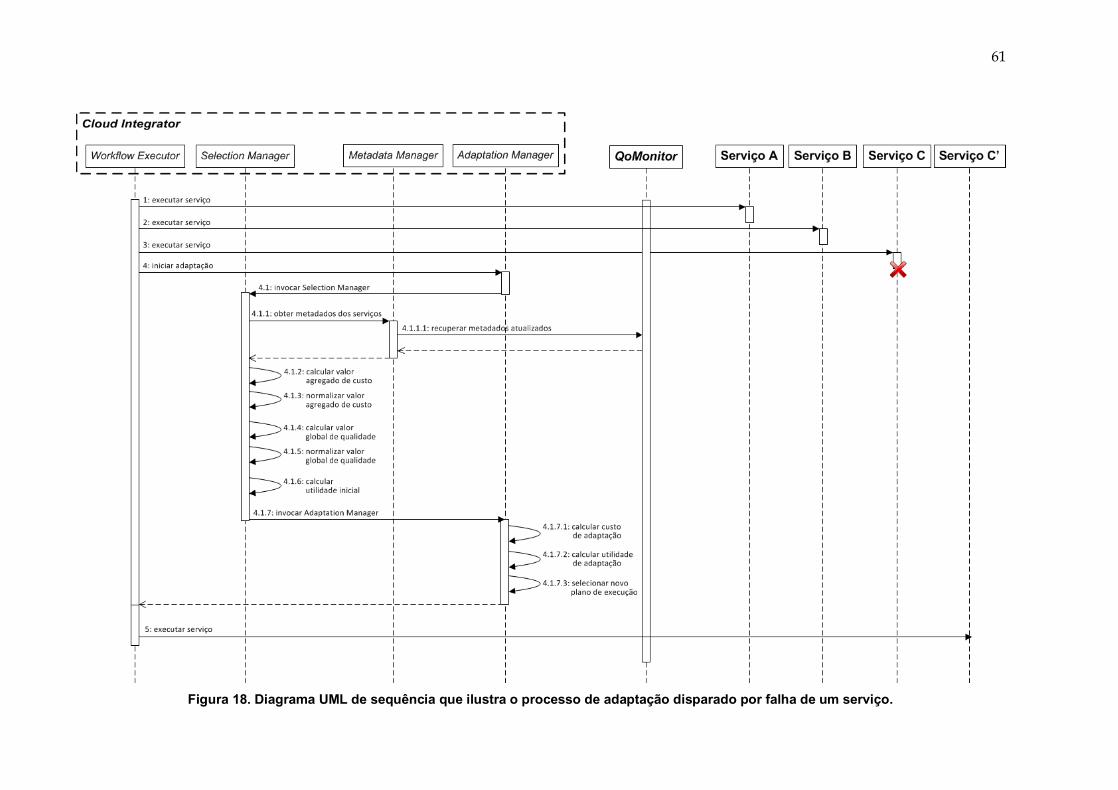
61
Figura 18. Diagrama UML de sequência que ilustra o processo de adaptação disparado por falha de um serviço.

62
De maneira similar, a Figura 19 apresenta um diagrama UML de sequência
que ilustra o processo de adaptação realizado pelo Cloud Integrator em caso de
degradação de qualidade, mais precisamente com relação à utilidade do plano de
execução corrente. Conforme apresentado na Seção 3.3, no momento em que o Cloud
Integrator realiza uma requisição assíncrona ao QoMonitor, é fornecida uma condição
de retorno que, caso seja satisfeita, faz com que o Cloud Integrator seja notificado pelo
QoMonitor que o evento determinado por tal condição de retorno ocorreu. Dessa
forma, para detectar se houve uma degradação de qualidade de um ou mais serviços
e se essa degradação causou impacto significativo12 na utilidade inicial (computada
no processo de seleção) do plano de execução corrente, a expressão referente ao
cálculo da utilidade inicial é especificada na condição de retorno que é passada ao
QoMonitor no momento da requisição assíncrona.
Por exemplo, considere-se uma condição de retorno dada pela tripla
<utilidade_inicial, menor, 0.9 * utilidade_original>, na qual utilidade_inicial é a expressão
do cálculo da utilidade inicial. Se o valor da expressão utilidade_inicial, calculado com
os valores atuais providos pelo QoMonitor, for menor que 90% que a utilidade_original,
calculada ainda no processo de seleção, essa condição de retorno é então satisfeita.
Com isso, o QoMonitor notifica o Cloud Integrator (operação 1 na Figura 19) de que
houve tal degradação na utilidade inicial do plano de execução corrente (nesse caso
superior a 10% do valor original) e o processo de adaptação é então disparado.
12 O valor que representa um decréscimo significativo, demandando assim o disparo do processo de adaptação, pode ser configurado pelo usuário através de um limiar (threshold) aceitável com relação à utilidade inicial do plano de execução corrente. Assim, por exemplo, pode ser configurado que o processo de adaptação seja disparado quando a utilidade inicial sofrer uma degradação de 10% com relação ao seu valor original, calculado no processo de seleção desse plano de execução.

63
Figura 19. Diagrama UML de sequência que ilustra o processo de adaptação disparado por degradação de qualidade.

64
3.5.4 Processo de adaptação
O processo de adaptação executado pelo Cloud Integrator é inspirado no
AdaptUbiFlow (Adaptive Ubiquitous Workflow) [57], um mecanismo de adaptação
proposto no contexto de aplicações ubíquas. Esse processo basicamente consiste de
dois passos consecutivos: (i) selecionar um plano de execução alternativo para
substituir o plano de execução corrente, e; (ii) continuar a execução da aplicação após
substituir seu respectivo plano de execução pelo alternativo selecionado no passo
anterior.
A seleção de um plano de execução alternativo considera dois parâmetros
essenciais:
(i) a utilidade inicial dos planos de execução candidatos (u), que expressa
suas propriedades em termos de custo e dos parâmetros de
qualidade, e para o qual se deseja um valor alto, e;
(ii) o custo de adaptação (c), que pondera as ações que devem ser
executadas quando ocorre a substituição de um plano de execução,
para o qual se deseja um valor baixo.
Quando o processo de adaptação é disparado, o componente Selection Manager
é invocado para que seja refeito o cálculo da utilidade inicial dos planos de execução
alternativos, considerando valores atualizados dos parâmetros de qualidade
providos pelo QoMonitor (operação 4.1.1.1 na Figura 18 e operação 3.1.1 na Figura 19)
e utilizando os mesmos critérios originalmente considerados para a seleção do plano
de execução corrente, conforme a abordagem apresentada na Seção 3.4. Esse
recálculo (operações 4.1.2 a 4.1.6 na Figura 18 e operações 3.2 a 3.6 na Figura 19) é
necessário visto que é possível que alguns desses parâmetros considerados tenham
tido seus valores alterados com o tempo, de modo que novamente são solicitados ao
componente Metadata Manager os valores dos metadados (operação 4.1 na Figura 18 e
operações 3.1 na Figura 19). Ao término dessa etapa, esses valores de utilidade são
repassados (operação 4.1.7 na Figura 18 e operação 3.7 na Figura 19) ao componente
Adaptation Manager para que este faça os cálculos referentes ao custo de adaptação e
assim possa fazer a seleção do plano de execução substituto.
A seguir, o componente Adaptation Manager calcula o custo de adaptação para
cada plano de execução alternativo (operação 4.1.7.1 na Figura 18 e operação 3.7.1 na
Figura 19) com base na Equação 2, apresentada na Seção 3.5.2. No contexto do
processo de adaptação, a seleção de um plano de execução é baseada no cálculo da
utilidade de adaptação (p) de cada plano de execução alternativo p. Essa utilidade de
adaptação é definida como a soma ponderada da utilidade inicial u(p), calculada pelo
componente Selection Manager, e do custo de adaptação c(p), calculado pelo

65
componente Adaptation Manager. O usuário pode priorizar esses critérios atribuindo
diferentes pesos (prioridades) à utilidade inicial e ao custo de adaptação, a saber, wPE e
wCA, sendo 1 0,, CAPE ww e wPE + wCA = 1. Os valores atribuídos aos pesos wPE e wCA
são definidos em termos de cinco diferentes configurações que correspondem a perfis
de adaptação, apresentados na Tabela 2.
Tabela 2. Perfis de adaptação definidos para os pesos atribuídos à utilidade inicial e ao custo de adaptação.
Perfil de adaptação
Descrição Pesos atribuídos
Utilidade inicial (wPE)
Custo de adaptação (wCA)
máxima utilidade inicial
prioridade exclusiva à utilidade inicial do plano de execução
1,00 0,00
alta utilidade inicial
prioriza a utilidade inicial do plano de execução, considerando também o custo de adaptação
0,75 0,25
balanceado configuração padrão, com pesos iguais aos critérios
0,50 0,50
baixo custo de adaptação
prioriza o custo de adaptação, considerando também a utilidade inicial do plano de execução
0,25 0,75
mínimo custo de adaptação
exclusiva prioridade ao custo de adaptação
0,00 1,00
A Equação 7 mostra o cálculo da utilidade de adaptação (p) para cada plano
de execução alternativo p (operação 4.1.7.2 na Figura 18 e operação 3.7.2 na Figura
19), no qual o plano de execução alternativo com utilidade de adaptação maximal é
selecionado para substituir o plano de execução corrente (operação 4.1.7.3 na Figura
18 e operação 3.7.3 na Figura 19). Se dois ou mais planos de execução possuem a
mesma utilidade de adaptação, o processo de adaptação seleciona um deles de
maneira aleatória.
CAPE wpcwpup )()()μ( (7)
Quando a seleção do plano de execução alternativo é concluída, os rollbacks e
ações compensatórias necessários são executados de maneira transparente para o
usuário para que seja feita a substituição do plano de execução corrente. Feito isso, o
componente Adaptation Manager retorna o controle para o componente Workflow
Manager, que dá prosseguimento à execução da aplicação.
3.5.4.1 Questões relevantes no processo de adaptação por degradação de qualidade
Na Seção 3.5.3 argumentou-se que o processo de adaptação deve ser
disparado apenas se o decréscimo na utilidade de um plano de execução for maior
que um dado limiar provido pelo usuário. De maneira similar, pode ser conveniente

66
para o usuário definir outro limiar para filtrar o conjunto de planos de execução
alternativos para substituir o plano de execução corrente, de modo que apenas os
planos de execução alternativos que provejam um aumento significativo com relação
à utilidade do plano de execução corrente (por exemplo, em no mínimo 20%) são
candidatos a substituí-lo. Essa filtragem pode ser realizada pelo componente
Adaptation Manager quando este recebe os valores de utilidade inicial referentes aos
planos de execução alternativos, de modo que se não existe plano de execução
alternativo que satisfaça esse critério de filtragem, então o processo de adaptação é
abortado. O usuário também pode definir um limiar referente ao custo de adaptação;
nesse caso, os planos de execução alternativos com custos de adaptação maiores que
esse dado limite não serão então candidatos para a substituição do plano de execução
corrente.
Outra questão importante a ser ressaltada no contexto da adaptação de
aplicações é que, quando o processo de adaptação é disparado por uma falha de
serviço, a substituição dos planos de execução que incluem o serviço em falha é
mandatória, de modo a de garantir a disponibilidade das aplicações que o utilizam.
Entretanto, uma degradação na qualidade de um serviço, apesar de potencialmente
afetar o desempenho das aplicações, não necessariamente implica em sua falha.
Nesse caso, é importante analisar se os possíveis benefícios resultantes da
substituição do plano de execução corrente realmente justificam o custo de
adaptação decorrente de tal processo.
Quando é possível se ter o controle dos recursos subjacentes que compõem o
ambiente de execução do serviço (por exemplo, a instância de máquina virtual que
executa o serviço), uma melhor qualidade para esse serviço pode ser obtida com a
substituição de tais recursos. Nessa perspectiva, é possível fazer a distinção, no
contexto do processo de adaptação, entre dois tipos de serviços de acordo com a
disponibilidade desse controle. O primeiro deles são os serviços próprios, serviços que
podem ser diretamente instanciados através do Cloud Integrator em uma plataforma
de nuvem a fim de serem utilizados por uma aplicação, sendo possível ter o controle
sobre os recursos utilizados para sua execução. Por exemplo, considerando uma
aplicação de comércio eletrônico baseada em nuvem, o serviço de controle de
estoque, responsável por permitir consultas e atualizações no estoque, é um serviço
próprio provido por uma máquina virtual que está implantada em uma plataforma
de nuvem e que pode ser instanciada pelo Cloud Integrator. Desse modo, se por
algum motivo essa máquina virtual não estiver atendendo à demanda pelo serviço
(por exemplo, se o processamento estiver próximo aos 100% da capacidade da
máquina virtual), uma nova máquina virtual pode ser instanciada e o serviço
migrado para essa nova máquina ou ainda o serviço pode ser provido por ambas as
máquinas virtuais.

67
Por sua vez, o segundo tipo de serviço são os serviços de terceiros, previamente
disponibilizados em plataformas de nuvem e utilizados para a composição de
aplicações, de modo que, nesse caso, o Cloud Integrator não possui controle algum
sobre os recursos utilizados para a execução dos serviços. Exemplos dessa categoria
são serviços providos pelas diferentes plataformas de nuvem, como serviços de
banco de dados ou logging. Além de serviços providos pelas próprias plataformas de
nuvem, outro tipo de serviços de terceiros são aqueles serviços implantados por
terceiros em máquinas virtuais em plataformas de nuvem. Utilizando ainda como
exemplo uma aplicação de comércio eletrônico baseada em nuvem, um exemplo de
serviço de terceiros seria o serviço de efetuar pagamento por cartão de crédito, que é
de propriedade de uma instituição de crédito. Desse modo, o Cloud Integrator não
possui controle sobre o serviço, ficando assim impossibilitado de criar novas
máquinas virtuais para oferecer suporte a esse serviço.
Conforme o tipo do serviço com qualidade degradada, têm-se então diferentes
opções de substituição disponíveis ao processo de adaptação do Cloud Integrator.
Quando a qualidade de um serviço de terceiro sofre uma degradação significativa, a
única opção possível é a sua substituição por um serviço de funcionalidade
equivalente, i.e. por outra implementação desse serviço, seja na mesma plataforma
de nuvem ou em outra plataforma. Já no caso de um serviço próprio, é possível ter
uma opção de qualidade superior tanto pela escolha de uma implementação
alternativa desse serviço como através da substituição dos recursos de computação
utilizados. Essa substituição de recursos pode ser realizada de duas formas: (i)
através da migração do serviço para uma máquina virtual de configuração superior,
explorando as facilidades de elasticidade (elasticity) providas pelas plataformas de
nuvem, ou; (ii) através da criação de uma nova instância do serviço (replicação) em
uma nova máquina virtual, explorando facilidades de balanceamento de carga (load
balancing). O processo de adaptação endereçado neste trabalho trata da substituição
simples de serviços de terceiros, de modo que as facilidades de elasticidade e
balanceamento de carga das quais pode se fazer uso para o caso de serviços próprios
poderão ser abordadas em trabalhos futuros.

68
4 Implementação
Este capítulo apresenta alguns aspectos de implementação do Cloud Integrator.
A Seção 4.1 ilustra a especificação de workflows semânticos por meio de um assistente
gráfico provido pelo Cloud Integrator. A Seção 4.2 apresenta a representação de
serviços através das tecnologias WSDL e OWL-S. Finalmente, a Seção 4.3 ilustra a
composição de plano de execução.
4.1 Especificação de workflows semânticos
O Cloud Integrator provê um assistente que permite ao usuário especificar
(criar e/ou editar) um workflow semântico referente a uma aplicação selecionando as
atividades abstratas que irão compor tal workflow. Essas atividades são ditas abstratas
no sentido que a correspondência para os serviços concretos que irão realiza-las é
feita em tempo de execução. Além disso, o usuário não necessita criar as atividades
do workflow devido ao fato de que elas são predefinidas de acordo com o conjunto de
tarefas e objetos especificados na respectiva ontologia de domínio.
Para especificar um workflow, o assistente do Cloud Integrator mostra uma lista
de possíveis tarefas e uma lista de possíveis objetos, ambos recuperados da ontologia
de domínio, dentre os quais o usuário pode selecionar uma tupla <tarefa, objeto> para
descrever cada atividade do workflow. A Figura 20 mostra uma captura de tela do
assistente provido pelo Cloud Integrator para especificação de atividades (tarefas e
objetos) a compor um workflow, para o qual já foram adicionadas duas atividades
(Search_Flight e Select_Flight) e está sendo adicionada uma terceira atividade
composta pela tarefa Generate e pelo objeto Booking.

69
Figura 20. Ilustração do assistente provido pelo Cloud Integrator para especificação de atividades (tarefas e objetos) a compor um workflow.
Em seguida, o assistente mostra a lista de entradas, saídas, precondições e
efeitos relacionados à atividade que está sendo definida, permitindo que o usuário
selecione quais delas devam ser consideradas para essa atividade, para que, feito
isso, a atividade seja efetivamente adicionada ao workflow. A Figura 21 mostra uma
captura de tela do assistente do Cloud Integrator que, após a especificação da
atividade representada pela tupla Generate_Booking (Figura 20), mostra que o usuário
selecionou a entrada Client e a saída Booking para essa atividade. É importante
salientar que, se uma determinada atividade A1 utiliza um conceito C como entrada
ou saída, caso outra atividade subsequente A2 utilize esse mesmo conceito C, seja
como entrada ou como saída, ele não necessita ser incluído novamente na
especificação das entradas e saídas da atividade A2, pelo fato de já ter sido utilizado
anteriormente por outra atividade (no caso, a atividade A1).
Após confirmar a associação desses conceitos à atividade em questão, o
usuário pressiona o botão Finish e a atividade é efetivamente adicionada ao workflow.
Para adicionar uma nova atividade sequencial ao workflow em questão, o usuário
pressiona o botão O na área de especificação do workflow (Specification).

70
Figura 21. Ilustração do assistente provido pelo Cloud Integrator para identificação de entradas, saídas, precondições e efeitos no momento de adição de uma atividade ao workflow.
Conforme mostrado na Figura 20 e na Figura 21, o assistente do Cloud
Integrator também disponibiliza fluxos de controle para a especificação workflows
semânticos com nível de complexidade maior. São eles: (i) sequência (S), que
estabelece a ordem de execução das atividades; (ii) divisão-junção (D), que possibilita
a execução de atividades em paralelo; (iii) escolha (E), que cria a possibilidade de
escolher uma dada atividade a ser executada dentre um conjunto de opções; (iv)
condição (C), que estabelece regras (utilizando conceitos do tipo objeto) para que uma
dada atividade seja executada, e; (v) repetição (R), que possibilita a criação de laços de
repetição para um conjunto de atividades. Apesar de o usuário poder especificar,
utilizando o assistente do Cloud Integrator, workflows com esses diferentes tipos de
fluxo de controle, no presente trabalho são considerados apenas workflows com
atividades sequenciais, visto que a máquina (engine) de execução atualmente
utilizada oferece suporte apenas à execução desse tipo de workflow.
Após especificar o workflow utilizando o assistente provido pela plataforma, o
usuário pode solicitar a sua execução, pressionando o botão Execute (Figura 22). Para
tal, o Cloud Integrator executa o processo de composição semântica, i.e. realiza
inferências sobre as ontologias dos serviços disponíveis para descobrir que serviços
atendem a cada atividade que compõe o workflow semântico que especifica o
processo de negócio referente à aplicação em nuvem. Em seguida, os possíveis
planos de execução são gerados e então o melhor deles em termos dos metadados
relativos aos serviços que compõem tal plano é automaticamente selecionado e

71
exibido na tela.
Figura 22. Ilustração da interface gráfica do Cloud Integrator que mostra: (i) o plano de execução selecionado para execução, acima; (ii) as entradas selecionadas pelo usuário, à esquerda; (iii) as saídas a serem produzidas, à direita, e; (iv) informações referentes aos processos executados.
Para executar o plano de execução selecionado, o usuário insere as entradas
requeridas e solicita a execução propriamente dita, pressionando o botão Start. Tais
entradas referem-se às entradas de serviços que podem ser diretamente fornecidas,
i.e. que não são geradas pela execução de algum serviço incluído no plano de
execução corrente. Quando a execução é concluída, as saídas produzidas são exibidas
na tela, tais saídas referindo-se às saídas dos serviços que não são aproveitadas como
entradas de outros serviços incluídos no plano de execução em questão.
4.2 Representação de serviços
O Cloud Integrator integra diferentes plataformas de nuvem disponibilizando
os serviços oferecidos pelas mesmas de modo transparente para as aplicações. Para
tal, o Cloud Integrator abstrai esses serviços em dois níveis diferentes: (i)
representando os serviços em WSDL [24], o que permite a descoberta, seleção,
composição e invocação dos serviços de forma independente do ambiente e da
plataforma de implementação, e; (ii) representando os serviços através de ontologias

72
de serviço OWL-S [36], o que adiciona semântica à descrição dos serviços e permite
que as funcionalidades sejam descritas abstratamente, i.e. sem se referir diretamente
a serviços específicos. Para que o Cloud Integrator possa ter conhecimento da
existência dessas ontologias, elas são armazenadas no componente Semantic
Repository, que funciona como uma base de conhecimento (knowledge base) e é
responsável por armazenar as ontologias que são manipuladas pelos demais
componentes do Cloud Integrator. No estado atual de desenvolvimento do Cloud
Integrator, assume-se que os serviços já tenham sido previamente descobertos e
disponíveis no ambiente da plataforma, mediante registro (i.e. importação) das
ontologias de serviço OWL-S, como mostrado na Figura 23. Em trabalhos futuros,
poderá ser desenvolvido um mecanismo de descoberta dinâmica desses serviços a
ser realizado componente Service Discovery da camada Integration Layer do Cloud
Integrator.
Figura 23. Ilustração da interface gráfica do Cloud Integrator para registro (importação) de serviços Web semânticos (ontologias de serviço OWL-S).
Para implementar o componente Semantic Repository, foi utilizada a OWL-S
API [58], uma API na linguagem de programação Java (que é a utilizada na
implementação do Cloud Integrator) que oferece suporte à manipulação de descrições
OWL-S de serviços Web semânticos e de regras semânticas expressas em SWRL [34],
utilizada para representar predicados de regras através da linguagem OWL para
aumentar a capacidade de inferência sobre as ontologias. A OWL-S API é uma
extensão do framework Apache Jena [59], um framework implementado na linguagem
de programação Java que oferece suporte à manipulação de ontologias em OWL e a
execução de consultas em RDQL (RDF Data Query Language) [60] e SPARQL
(SPARQL Protocol and RDF Query Language) [61] sobre tais ontologias.
A fim de ilustrar os dois níveis de abstração supracitados, considere-se o

73
serviço PaymentService, que representa um serviço de pagamento via cartão de
crédito em uma aplicação de comércio eletrônico e cuja assinatura é mostrada na
Figura 24. Nesta seção serão apresentadas as abstrações WSDL e OWL-S para a
operação makePayment, responsável por efetuar o pagamento de uma compra que
está sendo realizada. Essa operação recebe como entrada uma referência para o
cliente que está realizando a compra e o valor da compra a ser debitado; caso a
operação seja realizada com sucesso, é retornado o valor verdadeiro, e em caso
contrário (e.g. alguma falha ocorrida durante a transação ou o saldo do cliente for
insuficiente para realizar a compra) é retornado o valor falso.
Figura 24. Assinaturas do serviço PaymentService e da operação makePayment.
Depois de implementado, o serviço precisa ser implantado em algum
framework de serviços Web. No contexto do desenvolvimento do Cloud Integrator, foi
escolhido o framework Apache Axis [62] para a implantação de serviços Web pelo fato
desse framework implementar o protocolo SOAP [23] e também disponibilizar
bibliotecas de classes para facilitar a comunicação e a publicação de serviços Web,
além de gerar automaticamente as descrições WSDL dos serviços implantados. A
Figura 25 apresenta um trecho da descrição WSDL do serviço PaymentService, na qual
estão destacadas a operação makePayment e suas respectivas entradas (c e v) e saída
(return).

74
Figura 25. Trecho de descrição WSDL do serviço PaymentService, estando em destaque a operação makePayment e suas respectivas entradas (c e v) e saída (return).
A Figura 26 mostra a ontologia de serviço OWL-S da operação makePayment,
na qual está destacada a entrada c do serviço (identificada como MakePaymentClient)
que faz referência ao conceito Client descrito na respectiva ontologia de domínio, no
caso, a ontologia Ecommerce.

75
Figura 26. Ontologia OWL-S da operação makePayment (parte 1 de 3).
A Figura 27 mostra outro trecho da ontologia de serviço OWL-S da operação
makePayment, na qual está destacado o elemento Profile do serviço Web semântico,
que especifica o que o serviço oferece através da representação dos seus parâmetros
de entrada e saída, precondições e efeitos, além de conter informações sobre a
categoria na qual o serviço se enquadra [36]. Dessa forma, tal elemento contém a
informação necessária para que um agente de busca determine se o serviço satisfaz
os requisitos de parte de uma dada especificação de processo. No trecho em destaque
na Figura 27, é possível observar que o serviço em questão, cujo nome é MakePayment
(dado pelo elemento serviceName), está associado à atividade composta pela tarefa
Make (dada pelo elemento serviceClassification) e pelo objeto Payment (dado pelo
elemento serviceProduct). Caso outro serviço também realize a atividade especificada
pela tupla <Make, Payment>, o elemento Profile da ontologia referente a esse segundo
serviço também possuirá referências à tarefa Make e ao objeto Payment. É a partir
dessa especificação que o processo de composição executado pelo Cloud Integrator
identifica que dois serviços realizam uma mesma atividade, i.e. são equivalentes.

76
Figura 27. Ontologia OWL-S da operação makePayment (parte 2 de 3).
A Figura 28 ilustra outro trecho da ontologia de serviço OWL-S da operação
makePayment, na qual está destacada uma especificação XSLT (eXtensible Stylesheet
Language for Transformation) [63], que é uma linguagem declarativa para
transformações de documentos baseados em XML em outros. No contexto das
ontologias de serviço, especificações XSLT (transformações XSL) são utilizadas para
fazer o mapeamento bidirecional entre os elementos presentes nas mensagens SOAP
(requisição/resposta) e definidos na descrição WSDL do serviço, em elementos OWL
(classes e propriedades) definidos nas ontologias. Esse mapeamento é necessário
para que a máquina de execução do workflow possa invocar os serviços a partir das
descrições semânticas dos mesmos. No trecho em destaque, é possível observar que o
objeto c, que representa um cliente, possui as propriedades clientId (identificador),
name (nome), email (endereço de e-mail) e creditCardNumber (número do cartão de
crédito).

77
Figura 28. Ontologia OWL-S da operação makePayment (parte 3 de 3).
4.3 Composição de serviços
No Cloud Integrator, um workflow representa a composição de atividades
abstratas que são responsáveis por atingir os objetivos do usuário, podendo ser
construído pelo próprio usuário através de um assistente que facilita esse processo,
conforme apresentado na Seção 4.1. Uma vez concluída a especificação de um
workflow pelo usuário, o Cloud Integrator gera uma representação do workflow na
linguagem OWL a ser persistida na base de conhecimento da plataforma. A Figura
29 apresenta um trecho de uma descrição em OWL que representa as atividades de
um workflow. Nessa figura é possível observar a atividade nomeada arbitrariamente
de Activity_1, que é composta pela tarefa Consult (representado pelo elemento
Task_2) e pelo objeto Inventory (representado pelo elemento Object_3), resultando na
tupla <Consult, Inventory>, que descreve a atividade em questão. Além disso,
também são especificadas a entrada requerida (Product, representado pelo elemento
Input_4) e a saída produzida (ConsultInventoryReturn, representado pelo elemento
Output_5).

78
Figura 29. Descrição de um workflow em OWL (parte 1 de 2).
A Figura 30 ilustra outra parte de uma descrição OWL para um workflow,
agora mostrando a configuração do processo de execução das atividades. Nesse caso
específico, tem-se uma lista de atividades na qual a primeira atividade a ser
executada é representada pelo índice Activity_1; em seguida, a atividade
representada pelo índice Activity_7 é a próxima a ser executada, e assim
sucessivamente.

79
Figura 30. Descrição de workflow em OWL (parte 2 de 2).
Internamente, o Cloud Integrator utiliza o raciocinador (reasoner) semântico
Pellet [64] para realizar inferências sobre as ontologias dos serviços Web semânticos
disponíveis para identificar os serviços que atendem às atividades que compõem o
workflow semântico que especifica o processo de negócio de uma aplicação. Um
exemplo é ilustrado na Figura 31, que apresenta uma consulta semântica expressa em
RDQL [60] para descobrir os serviços (variável service, que é uma instância do
elemento Process utilizado nas ontologias de serviço OWL-S) que realizam a
atividade <Consult, Inventory> (variáveis task e object, cujo relacionamento é definido
pela propriedade concept:involves).
Figura 31. Consulta semântica em RDQL que retorna os serviços que atendem à atividade <Consult, Inventory>.
De maneira similar aos workflows, os planos de execução gerados também são
descritos utilizando a linguagem OWL. A Figura 32 mostra parte da descrição de um
plano de execução no qual, por exemplo, o serviço descrito pela ontologia de serviço
SendMessage.owl é executado imediatamente após o serviço descrito pela ontologia de

80
serviço MakePurchase.owl.
Figura 32. Descrição parcial em OWL de um plano de execução.

81
5 Avaliação
Neste capítulo é reportado um estudo experimental realizado com o objetivo
de avaliar o Cloud Integrator, utilizando como estudo de caso uma aplicação de
compra de passagens aéreas que utiliza serviços em nuvem (Seção 5.1). A avaliação
realizada contempla basicamente três aspectos: (i) os processos de composição e seleção
de serviços (Seção 5.2); (ii) o processo de adaptação em caso de falha de um serviço
envolvido no plano de execução corrente, de modo que outro plano de execução é
selecionado para ser executado para a aplicação (Seção 5.3), e; (iii) o overhead gerado
pelo Cloud Integrator (Seção 5.4), overhead esse que é natural pelo fato de a própria
plataforma representar uma camada a mais de abstração entre as plataformas de
nuvem que estão sendo integradas e as aplicações.
5.1 Estudo de caso
Considere-se uma aplicação simples de compra de passagens aéreas baseada
em Computação em Nuvem que é operada por uma agência de viagens com o
objetivo de gerenciar voos de diferentes companhias aéreas. Para reservar um voo, o
usuário primeiro procura por voos disponíveis baseado em critérios como aeroporto
e data de origem e de destino (atividade search flights). Se existem voos disponíveis, o
usuário seleciona os voos desejados (atividade select flights) e o sistema gera uma
reserva de acordo com os voos selecionados (atividade generate booking). Em seguida,
o pagamento através de cartão de crédito deve ser realizado (atividade make
payment), e uma vez que o pagamento é confirmado, o sistema deve gerar (atividade
generate receipt) e armazenar um recibo de pagamento (atividade update information)
contendo os dados dos voos reservados e do cliente. Finalmente, uma mensagem de
confirmação é enviada ao usuário (atividade send message). A Figura 33 apresenta o
fluxo de execução das atividades supracitadas.
Figura 33. Fluxo de execução das atividades do estudo de caso.

82
Conforme apresentado na Seção 3.1, o Cloud Integrator usa duas modalidades
de ontologias para representar os conceitos no contexto de Computação em Nuvem,
a saber: (i) a ontologia de domínio, na qual são modelados conceitos específicos
relativos a uma dada classe de aplicações, de modo que cada aplicação em nuvem
teria seus conceitos descritos por uma ontologia de domínio de aplicação específica,
estruturada em termos de tarefas e objetos, e; (ii) a ontologia de nuvem (ver Figura 10),
que representa os serviços providos por plataformas de nuvem e serviços de
aplicação que utilizam recursos de nuvem, de modo que os elementos presentes
nessa ontologia são utilizados para enriquecer a descrição dos serviços Web
semânticos que realizam as atividades que compõem o workflow referente à
aplicação. A Figura 34 apresenta uma representação parcial da ontologia de domínio
FlightBooking na qual estão descritas tarefas e objetos relacionados a esse tipo de
aplicação. As descrições OWL da ontologia de domínio FlightBooking e da ontologia
de nuvem CloudOntology constam respectivamente nos Apêndices A.1 e A.2 deste
trabalho.
Figura 34. Representação parcial da ontologia de domínio FlightBooking.
Da Figura 35 à Figura 39 são ilustrados grafos direcionados acíclicos que
representam conjuntos de possíveis planos de execução para o workflow do estudo de
caso em questão, cujas atividades são representadas pelas raias. Nesses grafos, A
abstrai um serviço de banco de dados relacional e contém operações para consultas e
atualizações sobre esse banco de dados, B representa um serviço de aplicação
responsável por fazer reserva de voos, C é um serviço de aplicação responsável por
efetuar pagamento por cartão de crédito, D abstrai um serviço para armazenar
arquivos referentes aos recibos gerados pela aplicação, e E é um serviço de aplicação
responsável por enviar mensagens para os usuários.
Na presente avaliação foram utilizados o serviço de banco de dados relacional
Amazon RDS [65] e o serviço de armazenamento de arquivos Amazon S3 [66], ambos

83
providos pela plataforma AWS, para implementar as funcionalidades da aplicação.
A fim de permitir um maior número de planos de execução, foram criadas réplicas
das ontologias associadas a tais serviços (simulando assim serviços equivalentes
providos por diferentes plataformas de nuvem), de modo que o processo de seleção
pudesse ser avaliado considerando um número variável de planos de execução
através da combinação desses serviços, resultando assim em configurações com 2, 4,
8, 12 e 18 planos de execução, conforme mostrado da Figura 35 à Figura 39.
Figura 35. Grafo direcionado acíclico com possíveis planos de execução para o workflow do estudo de caso em questão – 2 planos de execução e 6 serviços coincidentes.
Figura 36. Grafo direcionado acíclico com possíveis planos de execução para o workflow do estudo de caso em questão – 4 planos de execução e 5 serviços coincidentes.

84
Figura 37. Grafo direcionado acíclico com possíveis planos de execução para o workflow do estudo de caso em questão – 8 planos de execução e 4 serviços coincidentes.
Figura 38. Grafo direcionado acíclico com possíveis planos de execução para o workflow do estudo de caso em questão – 12 planos de execução e 4 serviços coincidentes.

85
Figura 39. Grafo direcionado acíclico com possíveis planos de execução para o workflow do
estudo de caso em questão – 18 planos de execução e 4 serviços coincidentes
5.2 Composição e seleção de serviços
Para avaliar os processos de composição semântica e de seleção de planos de
execução realizados pelo Cloud Integrator, foram realizados experimentos no sistema
operacional Linux Ubuntu 12.10 64-bits, utilizando um computador com processador
Intel® CoreTM i7-3612QM 2.10 GHz e 8 GB de memória RAM. Uma vez especificado
o workflow referente à aplicação, os processos de composição e seleção de serviços
foram executados vinte vezes. No processo de seleção de planos de execução, foram
considerados os parâmetros de QoS disponibilidade e tempo de resposta providos pelo
QoMonitor (apresentado na Seção 3.3), aos quais foram atribuídos pesos iguais (0.5)
no cálculo da utilidade dos planos de execução. Nos experimentos realizados, o
QoMonitor e o Cloud Integrator foram executados em computadores localizados na
mesma rede, a fim de minimizar os efeitos da mesma sobre os resultados observados.
O QoMonitor foi executado no sistema operacional Mac OS X 10.8.2, utilizando um
computador com processador Intel® CoreTM i5-2410M 2.3 GHz e 4 GB de memória
RAM.
Como anteriormente mencionado, no processo de composição de serviços
tem-se a transformação da especificação abstrata do workflow em termos de
atividades em composições de serviços concretos, os planos de execução. Nesse
processo, os serviços que atendem a cada uma das atividades que compõem o
workflow em termos de suas entradas, saídas, precondições e efeitos são identificados
a fim de serem compostos para formar os planos de execução. Feito isso, os serviços
são orquestrados a fim de criar os planos de execução seguindo a sequência de
atividades definida na especificação do workflow. Esse processo é o mais custoso

86
computacionalmente, visto que ele envolve a análise das ontologias de cada serviço
disponível, além de incluir o processamento de documentos XML, o que é
mandatório devido ao uso das tecnologias de serviços Web e Web Semântica.
A Tabela 3 apresenta os valores mínimo e máximo, média e desvio padrão em
milissegundos para o processo de composição de serviços, considerando diferentes
configurações de possíveis planos de execução. Para a configuração mais simples (2
planos de execução), o tempo médio despendido para o processo de composição de
serviços foi 502 ms, enquanto para a configuração mais complexa (18 planos de
execução) o tempo médio despendido 597 ms. Pelo exposto na Tabela 3, é possível
observar que, apesar do aumento do número de possíveis planos de execução devido
ao número de serviços disponíveis para atender às atividades do workflow, o tempo
despendido para realizar o processo de composição de serviços não aumenta
consideravelmente.
Tabela 3. Valores mínimo e máximo, média e desvio padrão (em milissegundos) para o desempenho do processo de composição de serviços.
Planos de execução Mínimo Máximo Média Desvio padrão
2 474 575 502 28,051
4 493 578 524 28,688
8 507 590 538 28,546
12 535 614 563 25,554
18 566 645 597 26,023
A Tabela 4 apresenta os valores mínimo (coluna Min) e máximo (coluna Max),
média (coluna Med) e desvio padrão (coluna DP) em milissegundos para a
recuperação de metadados provenientes do QoMonitor e para o processo de seleção
de planos de execução que desconsidera serviços coincidentes, considerando
diferentes configurações de possíveis planos de execução. Como mostrado na Tabela
4, para a configuração mais simples (2 planos de execução), o tempo médio
despendido foi 0,62373 ms, enquanto para a configuração mais complexa (18 planos
de execução) o tempo médio despendido foi 3,96914 ms, sendo possível concluir que
o tempo despendido pelo processo de seleção que desconsidera serviços coincidentes
é bastante pequeno. Além disso, a Tabela 4 também mostra o tempo despendido para
a recuperação de metadados provenientes do QoMonitor, que representa a diferença
de tempo entre o instante no qual a requisição é recebida pelo QoMonitor até o
instante no qual o Cloud Integrator recebe a resposta. Como pode ser observado na
Tabela 4, o tempo médio despendido para a recuperação de metadados também é
pequeno (sendo mais influenciado pelo tráfego da rede), de modo que é possível
concluir que o monitor de metadados não promove um impacto significativo no
processo de seleção de planos de execução.
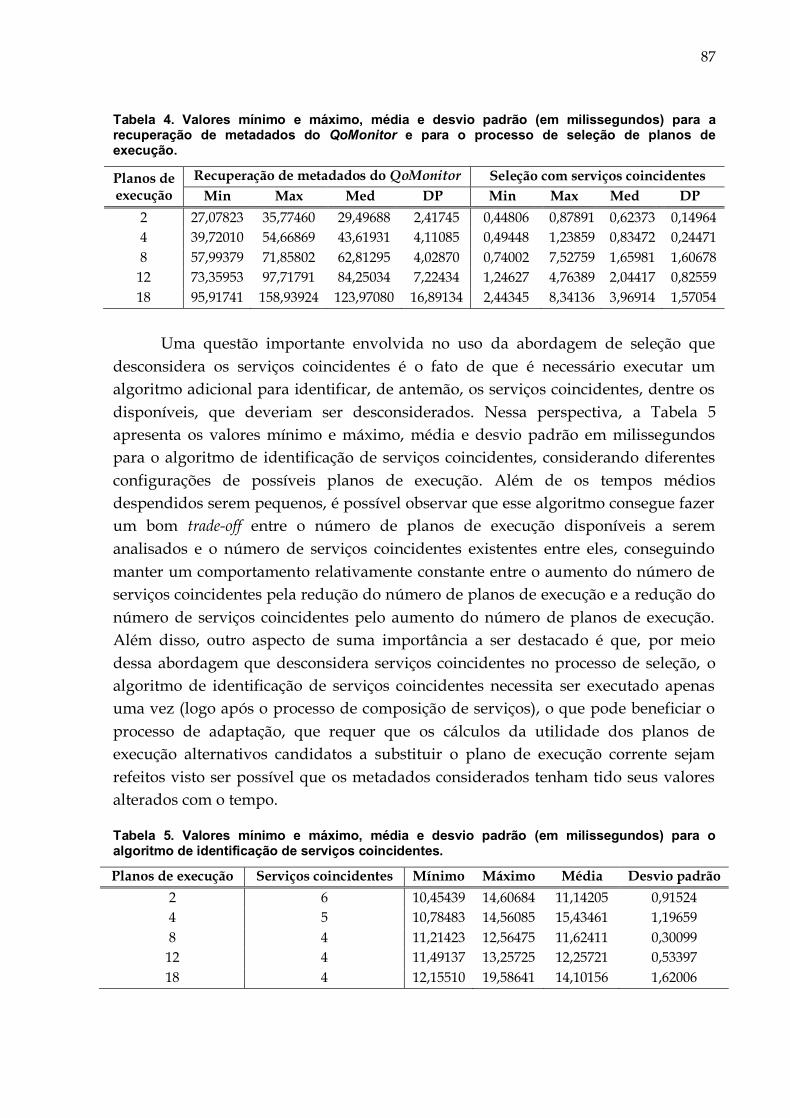
87
Tabela 4. Valores mínimo e máximo, média e desvio padrão (em milissegundos) para a recuperação de metadados do QoMonitor e para o processo de seleção de planos de execução.
Planos de execução
Recuperação de metadados do QoMonitor Seleção com serviços coincidentes
Min Max Med DP Min Max Med DP
2 27,07823 35,77460 29,49688 2,41745 0,44806 0,87891 0,62373 0,14964
4 39,72010 54,66869 43,61931 4,11085 0,49448 1,23859 0,83472 0,24471
8 57,99379 71,85802 62,81295 4,02870 0,74002 7,52759 1,65981 1,60678
12 73,35953 97,71791 84,25034 7,22434 1,24627 4,76389 2,04417 0,82559
18 95,91741 158,93924 123,97080 16,89134 2,44345 8,34136 3,96914 1,57054
Uma questão importante envolvida no uso da abordagem de seleção que
desconsidera os serviços coincidentes é o fato de que é necessário executar um
algoritmo adicional para identificar, de antemão, os serviços coincidentes, dentre os
disponíveis, que deveriam ser desconsiderados. Nessa perspectiva, a Tabela 5
apresenta os valores mínimo e máximo, média e desvio padrão em milissegundos
para o algoritmo de identificação de serviços coincidentes, considerando diferentes
configurações de possíveis planos de execução. Além de os tempos médios
despendidos serem pequenos, é possível observar que esse algoritmo consegue fazer
um bom trade-off entre o número de planos de execução disponíveis a serem
analisados e o número de serviços coincidentes existentes entre eles, conseguindo
manter um comportamento relativamente constante entre o aumento do número de
serviços coincidentes pela redução do número de planos de execução e a redução do
número de serviços coincidentes pelo aumento do número de planos de execução.
Além disso, outro aspecto de suma importância a ser destacado é que, por meio
dessa abordagem que desconsidera serviços coincidentes no processo de seleção, o
algoritmo de identificação de serviços coincidentes necessita ser executado apenas
uma vez (logo após o processo de composição de serviços), o que pode beneficiar o
processo de adaptação, que requer que os cálculos da utilidade dos planos de
execução alternativos candidatos a substituir o plano de execução corrente sejam
refeitos visto ser possível que os metadados considerados tenham tido seus valores
alterados com o tempo.
Tabela 5. Valores mínimo e máximo, média e desvio padrão (em milissegundos) para o algoritmo de identificação de serviços coincidentes.
Planos de execução Serviços coincidentes Mínimo Máximo Média Desvio padrão
2 6 10,45439 14,60684 11,14205 0,91524
4 5 10,78483 14,56085 15,43461 1,19659
8 4 11,21423 12,56475 11,62411 0,30099
12 4 11,49137 13,25725 12,25721 0,53397
18 4 12,15510 19,58641 14,10156 1,62006

88
5.3 Adaptação
Para avaliar o processo de adaptação realizado pelo Cloud Integrator, foi
considerado o tempo despendido por esse processo em caso de falha de um serviço
envolvido no plano de execução que está sendo executado, falha essa que é detectada
quando é atingido um tempo limite (timeout) no qual o serviço não responde à
requisição, significando que ele está indisponível. Nessa perspectiva, serviços
envolvidos nesse plano de execução foram forçados a falhar para que o processo de
adaptação fosse então disparado. Para a presente avaliação, foi considerada apenas a
substituição de serviços de aplicação, de modo que a substituição de serviços
classificados como recursos de nuvem poderá ser abordada em trabalhos futuros por
ser uma questão não trivial. Por exemplo, ser muito complexo e computacionalmente
custoso migrar uma base de dados implantada em uma plataforma de nuvem para
outra plataforma visto que tal migração exige: (i) realizar a exportação (dump) de
todos os dados existentes na base de dados, incluindo as estruturas das tabelas que o
compõem; (ii) criar a mesma base de dados no serviço de banco de dados provido
pela plataforma de nuvem para a qual se quer fazer essa migração, e; (iii) popular a
nova base de dados com as tuplas originais. O mesmo problema acontece com a
migração de uma máquina virtual criada em uma plataforma de nuvem que provê
serviços de processamento, de modo que a nova máquina virtual a ser criada na
plataforma de destino deve necessariamente disponibilizar as mesmas aplicações que
estão instaladas na máquina virtual na plataforma original.
Os experimentos (em um total de vinte execuções) foram realizados no
sistema operacional Linux Ubuntu 12.10 64-bits, utilizando um computador com
processador Intel® CoreTM i7-3612QM 2.10 GHz e 8 GB de memória RAM. Para esta
avaliação, diferentes configurações dos workflows (número de planos de execução)
referentes ao estudo de caso apresentado na Seção 5.1 foram consideradas. A Tabela
6 apresenta os valores mínimo e máximo, média e desvio padrão em milissegundos
para o processo de adaptação, contemplando a seleção de um plano de execução
alternativo para substituir o plano em falha. Na configuração mais simples (2 planos
de execução), o tempo médio despendido foi 0,4694 ms, enquanto na configuração
mais complexa (18 planos de execução), o tempo médio despendido foi 7,2724 ms.
Como mostrado na Tabela 6, esse tempo despendido para executar o processo de
adaptação (mesmo considerando o processo para selecionar um plano de execução
alternativo) é significativamente pequeno, sendo possível concluir que o processo de
adaptação não impacta significativamente na execução da aplicação. Além disso, o
processo de adaptação proposto funciona com o mínimo de ciência do usuário,
promovendo assim a autonomia da aplicação (em caso de falhas ou outras condições
que possam disparar uma adaptação) e garantindo que ela continue sendo
executada.

89
Tabela 6. Valores mínimo e máximo, média e desvio padrão (em milissegundos) para o processo de adaptação.
Planos de execução Mínimo Máximo Média Desvio padrão
2 0,2754 0,5950 0,4694 0,0708
4 0,4598 0,9522 1,2352 0,1626
8 0,7716 1,9416 1,7846 0,2574
12 1,4680 3,7006 3,2596 0,5168
18 4,0158 11,7134 7,2724 1,7644
5.4 Execução de aplicações
Outro aspecto analisado na avaliação realizada foi o tempo de execução da
aplicação. Uma vez que o Cloud Integrator representa uma camada a mais de
abstração entre as plataformas de nuvem subjacentes que estão sendo integradas e as
aplicações, é de se esperar que a adoção do Cloud Integrator faça com que o tempo de
processamento e, consequentemente, o tempo de resposta para os usuários aumente.
Dessa forma, é importante medir o impacto da plataforma no tempo de execução da
aplicação e se tal impacto é significativo ou não do ponto de vista do usuário.
A fim de permitir essa avaliação, duas versões da aplicação utilizada como
estudo de caso neste trabalho foram construídas. Na primeira delas, a aplicação foi
especificada através de um workflow semântico utilizando o Cloud Integrator, de modo
a ser executado o conjunto de serviços presentes no plano de execução selecionado
pelo processo de seleção realizado pela plataforma. A segunda versão, por sua vez,
consistiu de um código cliente implementado na linguagem de programação Java no
qual os mesmos serviços presentes no plano de execução selecionado pelo Cloud
Integrator eram invocados diretamente, através dos stubs gerados pelo Axis2 [62].
Ambas as versões da aplicação foram executadas vinte vezes no sistema operacional
Linux Ubuntu 12.10 64-bits, utilizando um computador com processador Intel®
CoreTM i7-3612QM 2.10 GHz e 8 GB de memória RAM.
A Tabela 7 apresenta os valores mínimo, máximo, médio e de desvio padrão,
em segundos, para o tempo de execução da aplicação nas versões com e sem o Cloud
Integrator. Na versão da aplicação sem o Cloud Integrator o tempo de execução da
aplicação foi, em média, 16,723 s, enquanto na versão da aplicação com o Cloud
Integrator o tempo de execução da aplicação foi, em média, 17,342 s. Todavia, essa
diferença de 0,619 s (i.e. 3,57% a mais) entre as duas versões da aplicação não é
significativa para esse tipo de aplicação, visto que, de acordo com Nah [67], atrasos
na ordem de 2 s são plenamente aceitáveis para aplicações Web. Além disso, foram
necessárias 505 linhas de código-fonte para implementar a versão da aplicação que
invoca os serviços de maneira direta, via código fonte, sendo necessário criar as
instâncias dos stubs referentes a cada um dos serviços a serem utilizados. Mais ainda,
é necessário conhecer os serviços disponíveis no ambiente e suas respectivas

90
interfaces, dificultando assim o desenvolvimento das aplicações, sem falar no fato de
que os serviços são selecionados de maneira estática e a adaptação dinâmica e
autônoma de tais aplicações quando ocorre uma falha ou degradação na qualidade
de um serviço torna-se impossível de se fazer. Em contrapartida, utilizando o Cloud
Integrator, o usuário apenas especifica abstratamente o workflow por meio das
atividades (tuplas <tarefa, objeto>) referentes à aplicação em questão, de modo que os
processos de composição de serviços, seleção de planos de execução e
(principalmente) de adaptação de aplicações são realizados com o mínimo de
intervenção do usuário e de maneira dinâmica, desacoplando-as dos serviços que
podem ser utilizados pelas mesmas.
Tabela 7. Valores mínimo e máximo, média e desvio padrão (em segundos) para o tempo de execução das versões das aplicações sem e com Cloud Integrator.
Versões da aplicação Mínimo Máximo Média Desvio padrão
sem o Cloud Integrator 14,475 20,401 16,723 1,559
com o Cloud Integrator 16,178 24,887 17,342 1,854

91
6 Trabalhos relacionados
As seções a seguir apresentam algumas propostas existentes na literatura
objetivando fornecer uma visão geral das mesmas e discutir aspectos que as
diferenciam do Cloud Integrator no tocante a: (i) integração de plataformas de
Computação em Nuvem; (ii) composição e seleção de serviços de nuvem, e; (iii)
estratégias de adaptação para aplicações em nuvem.
6.1 Integração/interoperabilidade entre plataformas de
Computação em Nuvem
Como anteriormente mencionado, dado que a Computação em Nuvem ainda
é uma área emergente, as plataformas de nuvem atuais não são implementadas
utilizando modelos tecnológicos comuns, padronizados [70, 71], de modo que cada
uma possui sua própria API e tecnologias de desenvolvimento, implantação e
gerenciamento dos recursos por elas providos, tornando difícil para os usuários a
realização de tarefas integrando informações ou serviços providos por diferentes
plataformas. Diante desse desafio, a literatura tem apresentado algumas iniciativas
com o objetivo de definir uma estratégia para integração e interoperabilidade que
não esteja atrelada a qualquer plataforma de nuvem específica, permitindo assim que
clientes (consumidores dos serviços) podem ser capazes de comparar e escolher entre
provedores de nuvem [72]. Contudo, o que se pode observar é que: (i) praticamente
não existem propostas em termos de integração de serviços PaaS; (ii) as propostas
que podem ser encontradas possuem maior enfoque em serviços IaaS, e; (iii) a
integração de serviços SaaS pode ser feita de maneira relativamente simples, através
do uso de serviços Web. Nesta seção são apresentadas algumas dessas propostas
para integração e interoperabilidade entre plataformas de Computação em Nuvem.
OCCI [46], acrônimo de Open Cloud Computing Interface, é uma iniciativa
proposta pelo OGF (Open Grid Forum) que tem como objetivo propor uma API
padrão para acessar recursos IaaS providos por diferentes plataformas de nuvem,
sendo previstas futuras extensões para endereçar serviços PaaS e SaaS. A
especificação OCCI é baseada em três modelos fundamentais: (i) OCCI Core
Specification, que define uma representação de tipos que abstraem recursos reais
(resources); (ii) OCCI HTTP Rendering Specification, que define que recursos definidos
no modelo OCCI Core Specification podem ser identificados unicamente por um URI
hierárquico e acessados via REST através das operações (verbs) definidas no
protocolo HTTP (POST, GET, PUT e DELETE), e; (iii) OCCI Infrastructure Specification, que
estende o modelo OCCI Core Specification e no qual são representadas as entidades de
infraestrutura propriamente ditas, a saber, Compute para recursos de processamento,
Storage para recursos de armazenamento e Network para recursos de rede.

92
Nessa mesma perspectiva de prover uma API que permita a utilização de
recursos providos por diferentes plataformas de nuvem, o jclouds [73] é uma
biblioteca open-source que permite o desenvolvimento de aplicações na linguagem de
programação Java que façam uso serviços providos por diferentes plataformas de
nuvem pública e privada, incluindo Amazon Web Services [43], GoGrid [74],
OpenStack [46], Eucalyptus [75] e Windows Azure [76]. O jclouds é estruturado sobre
duas APIs que podem ser utilizadas pelas aplicações, a saber: (i) Compute API, que
provê uma abstração sobre serviços de computação, permitindo, por exemplo, a
criação personalizada e o gerenciamento de máquinas virtuais de diferentes
plataformas de nuvem, e; (ii) Blobstore API, que provê meios para o gerenciamento de
serviços de armazenamento de arquivos, na forma de objetos binários (blobs). Para
utilizar os métodos providos por essas APIs, é necessário que o desenvolvedor inclua
(i.e. faça a importação, no código-fonte) os pacotes referentes às plataformas de
nuvem cujos recursos serão utilizados pela a aplicação, de modo que ele necessita
manipular apenas os tipos de dados e respectivos métodos providos pelas APIs do
jclouds, que, internamente, abstraem as APIs específicas das plataformas de nuvem.
O Cloudmux [77] é um serviço Web implementado na linguagem de
programação Python [78] para gerenciar recursos IaaS de nuvens distintas,
independentemente de suas interfaces específicas. O Cloudmux é fundamentado no
estilo arquitetural REST e na especificação OCCI e seus principais componentes são
basicamente: (i) o núcleo, que abstrai a localização dos recursos e apresenta a visão de
uma única nuvem para os clientes, além de tratar as representações informadas nas
requisições HTTP realizadas pelos mesmos, conforme o estilo arquitetural REST, e;
(ii) os drivers, que são componentes plugáveis responsáveis por se comunicarem
diretamente com as plataformas de nuvem a serem utilizadas. Assim, quando o
núcleo recebe requisições HTTP dos clientes para gerenciar recursos de uma dada
plataforma de nuvem, é feita uma chamada ao driver correspondente a essa nuvem,
que efetua a requisição propriamente dita.
Por fim, Maximilien et al. [79] apresentam o IBM Altocumulus, uma plataforma
de middleware para Computação em Nuvem que provê uma interface orientada a
serviços uniforme para implantação e gerenciamento de aplicações em várias
nuvens, bem como facilidades para a migração de instâncias entre nuvens. O IBM
Altocumulus, implementado utilizando o framework de desenvolvimento Web Ruby
on Rails [80], utiliza uma arquitetura distribuída que divide a plataforma em três
elementos básicos: (i) Dashboard, que permite aos usuários implantar e gerenciar
aplicações em diferentes nuvens; (ii) API, que expõe uma API REST para o IBM
Altocumulus, e; (iii) Core, que é o núcleo orquestrador da plataforma e contém um
conjunto elaborado de scripts, regras e adaptadores (adapters) para permitir a
execução de ações entre diferentes nuvens por diferentes usuários. São esses
adaptadores que permitem a comunicação do IBM Altocumulus com as plataformas

93
de nuvem subjacentes ao mesmo, sendo necessário desenvolver um adaptador
diferente para cada plataforma integrada.
Como é possível observar, todas as propostas enumeradas nesta seção têm por
objetivo prover algum elemento de abstração sobre as APIs das diferentes
plataformas de nuvem que podem ser utilizadas por uma aplicação, permitindo que
seja possível utilizar diferentes serviços apesar das especificidades de cada
plataforma. No caso da especificação OCCI e da biblioteca jclouds, são providas APIs
unificadas cujas operações fazem referência aos recursos propriamente ditos,
enquanto no IBM Altocumulus, no Cloudmux e no Cloud Integrator tal abstração sobre
os recursos se dá por meio de elementos adaptadores (respectivamente, adapters,
drivers e binders) que objetivam permitir essa integração das plataformas de nuvem
subjacentes à plataforma de middleware. Além disso, é importante salientar que esses
mecanismos, sejam eles adaptadores ou APIs unificadas, não são mutuamente
exclusivos e podem ser utilizados de maneira conjunta, como é o caso do binder
genérico provido pelo Cloud Integrator que pode ser utilizado para plataformas de
nuvem compatíveis com a especificação OCCI para acesso aos recursos de
infraestrutura via REST, bem como o acesso a recursos IaaS de diferentes nuvens por
intermédio do Cloudmux. Todavia, um diferencial importante proporcionado pelo
Cloud Integrator é a integração de serviços de nuvem de diferentes níveis (IaaS, PaaS e
SaaS) e, aliado a isso, a plataforma de middleware proposta neste trabalho também
oferece mecanismos fundamentais de suporte ao desenvolvimento de aplicações que
utilizam serviços providos por diferentes plataformas de nuvem, a saber,
composição e seleção de serviços e adaptação de aplicações.
6.2 Composição e seleção de serviços de nuvem
Composição e seleção de serviços são tópicos de pesquisa que têm sido
bastante estudados no contexto de serviços Web, e uma vez que a Computação
Orientada a serviços é considerada como o conceito subjacente que serve de base à
Computação em Nuvem, uma linha natural de pensamento seria estender ou
aproveitar abordagens tradicionais de seleção de serviços a fim de endereçar serviços
de nuvem, evidentemente considerando as especificidades introduzidas por esse
novo paradigma [85]. Diante disso, nesta seção são discutidos alguns desses
trabalhos e também destacadas algumas ideias interessantes apresentadas nos
mesmos.
Zeng et al. [10] propõem uma estratégia para composição de serviços Web
que, de acordo com os autores, pode ser adaptada para serviços em Computação em
Nuvem. Na abordagem proposta, primeiramente uma descrição de serviço em
WSDL é processada por um interpretador WSDL e seus elementos principais (nome,
função, descrição, operadores e parâmetros de entrada e saída do serviço) são

94
armazenadas em diferentes tabelas de bancos de dados relacionais, utilizadas no
intuito de se prover certa eficiência no processo de composição de serviços. Em
seguida, é utilizado um algoritmo que calcula o grau de casamento (matching) entre
os parâmetros de saída de um serviço Web com os parâmetros de entrada de outro
serviço Web, com base em consultas às tabelas relacionais. Esse problema de
casamento entre serviços é representado como um grafo direcionado ponderado, no
qual os nós representam serviços Web e as arestas ponderadas denotam o grau de
similaridade semântica entre dois serviços Web. Assim, o problema da composição
de serviços é reduzido ao problema de se determinar todos os caminhos entre dois
nós do grafo, de modo que os resultados desse algoritmo são ordenados com base
em informações de QoS acerca dos serviços, armazenados em uma tabela específica.
Embora a proposta pareça promissora, os autores não a aplicam de fato a qualquer
contexto de Computação em Nuvem. Além disso, há a ausência de mecanismos que
permitam uma composição dinâmica de serviços bem como adaptação em caso de
falha ou degradação de qualidade de serviços envolvidos na composição.
Finalmente, apesar de os autores argumentarem no trabalho que descrições de
serviços em WSDL podem não ser capazes atender completamente requisitos de
composição de serviços em Computação em Nuvem, na abordagem proposta eles
consideram apenas serviços descritos em WSDL.
Wang et al. [81] propõem uma abordagem de seleção de serviços baseada em
QoS para ambientes de nuvem. Os autores utilizam uma abordagem similar à
adotada neste trabalho (ver Seção 3.4) para calcular, com base em parâmetros de
QoS, a utilidade de composições de serviços (planos de execução) geradas, das quais
uma será selecionada. Adicionalmente, a abordagem emprega uma técnica de
Programação Linear Inteira Mista (PLIM) (ou, em inglês, MILP – Mixed-Integer Linear
Programming) [82] para considerar restrições sobre os processos de composição e
seleção. Entretanto, da maneira na qual essa abordagem é apresentada, é necessário
conhecer as transações internas dos serviços, e nem sempre esse tipo de informação
está disponível quando serviços de nuvem são considerados. Em contrapartida, na
estratégia adotada pelo Cloud Integrator, os serviços de nuvem a serem incluídos nos
planos de execução (processo de composição) a serem selecionados (processo de
seleção) são tratados em um nível mais alto de abstração, sob a perspectiva de
serviços Web semânticos. Além disso, em contraste à abordagem do Cloud Integrator,
que é mais simples, a adoção de uma técnica PLIM pode dificultar o entendimento
do problema, e um crescimento no número de variáveis inteiras pode fazer com que
o modelo pareça inadequado em cenários práticos, tornando muito dispendiosa a
resolução do problema sob o ponto de vista computacional, apesar de ser capaz de
determinar soluções ótimas.
Kouki et al. [83] propõem uma abordagem para endereçar a seleção de
serviços de nuvem considerando parâmetros de QoS e SLAs, que são utilizadas pelo

95
usuário para especificar restrições sobre tais parâmetros a serem considerados no
processo de seleção, restrições essas modeladas matematicamente em termos de
Programação por Restrições (ou, em inglês, CP – Constraint Programming) [84]. Os
autores também utilizam uma abordagem muito similar à adotada neste trabalho
para calcular valores agregados (globais) e normalizados para os metadados de
qualidade referentes aos serviços, de modo que o usuário pode especificar pesos aos
parâmetros de QoS a fim de selecionar os serviços mais apropriados de acordo com
as suas preferências. Todavia, a proposta de Kouki et al. [83] considera SLAs no
processo de seleção de serviços, o que não é feito no Cloud Integrator no seu estado
atual de desenvolvimento; SLAs são elementos muito importantes no cenário de
serviços em Computação em Nuvem e poderão ser considerados em trabalhos
futuros.
Por fim, no trabalho de Bao e Dou [86], uma composição de serviços Web é
modelada como uma máquina de estados finita (FSM – Finite State Machine), através
da qual é realizada uma busca pelos serviços concretos que irão atender ao processo
de negócio da composição (target process) utilizando uma árvore de composição,
gerando os possíveis caminhos (planos) de execução (execution paths). Feito isso, um
desses planos é selecionado utilizando uma estratégia bastante similar à empregada
neste trabalho, chamada SAW (Simple Additive Weighting), proposta por Zeng et al.
[56]. Primeiramente, os valores de um parâmetro de QoS são escalonados de acordo
com o seu caráter, se negativo ou positivo; em seguida, tais valores escalonados são
ponderados, sendo atribuído a cada parâmetro um peso, resultando em um valor de
avaliação (score) para cada caminho (plano) de execução, de modo que, ao final, será
escolhido o que apresentar maior valor de avaliação. Considerando a similaridade
entre as estratégias de seleção empregadas no trabalho de Bao e Dou [86] e no Cloud
Integrator, destacam-se, entretanto, algumas diferenças pertinentes. Primeiramente, a
composição de serviços no trabalho dos autores é modelada como uma FSM para
que, através dela, seja construída uma árvore de composição para possibilitar a
descoberta dos serviços concretos que irão realizar as atividades do processo de
negócio. Já no Cloud Integrator, esse processo de composição de serviços é feito de
maneira consideravelmente mais simples, na qual o usuário apenas especifica as
atividades do processo de negócio por meio de um workflow semântico e a própria
plataforma encarrega-se de, dinamicamente, descobrir os serviços que irão realizar as
atividades apenas com base na interface semântica dos mesmos e na especificação
das atividades. Além disso, no processo de seleção de serviços realizado na
abordagem de Bao e Dou [86] são considerados todos os serviços que compõem
todos os caminhos (planos) de execução, enquanto que, no Cloud Integrator, tal
processo de seleção procura ser otimizado (ver Seção 3.4) por não considerar serviços
coincidentes, que contribuem igualmente nos cálculos realizados pelo processo.

96
6.3 Estratégias de adaptação para aplicações em nuvem
Nesta seção são discutidos de maneira breve alguns trabalhos relacionados em
termos de estratégias de adaptação para aplicações em nuvem que estão relacionadas
à proposta do Cloud Integrator.
Behl et al. [87] apresentam um mecanismo de tolerância a falhas para a
execução de workflows baseados em serviços Web de nuvem, utilizando, para isso,
replicação de tais serviços. A proposta é avaliada em comparação a um mecanismo
de log associado a um workflow especificado na linguagem WS-BPEL (Web Services
Business Process Execution Language) [91], porém o custo total para a estratégia não é
endereçado. Além disso, a proposta não considera uma adaptação baseada em
parâmetros de QoS, não oferece suporte a múltiplas plataformas de nuvem, e, pelo
exposto no trabalho, não é possível dizer se diferentes modelos de serviços de nuvem
(i.e. se serviços de infraestrutura ou serviços de mais alto nível) são considerados,
como o Cloud Integrator se propõe a fazer. Por fim, o Cloud Integrator não se limita a
utilizar plataformas de nuvem privada, como é feito no trabalho dos autores, mas
sim possibilita utilizar plataformas de nuvem pública, que são mais suscetíveis a
problemas externos e mudanças relacionadas a parâmetros de qualidade.
Por sua vez, Merle et al. [88] propõem FraSCAti, uma plataforma de
middleware adaptativa e reflexiva que possibilita o desenvolvimento e a execução de
aplicações baseadas na abordagem de componentes SCA (Service Component
Architecture)13 [89], utilizando serviços de diferentes plataformas de nuvem. De
acordo com os autores, FraSCAti é capaz de realizar dois tipos de adaptação: (i)
adaptação em tempo de projeto, no qual o usuário pode selecionar previamente os
componentes em tempo de projeto, e; (ii) adaptação em tempo de execução, que é
baseada na implantação dinâmica de scripts de reconfiguração que permite vincular
ou desvincular componentes SCA em tempo de execução, porém com intervenção do
usuário no nível de componentes. Na estratégia de adaptação implementada pelo
Cloud Integrator, as aplicações não necessitam seguir um estilo arquitetural específico
a ser interceptada pela plataforma. Além disso, os autores também não consideram
adaptação baseada em parâmetros de qualidade ou mesmo em caso de falhas de
serviço, além do fato de que o processo de adaptação dinâmica necessita de
intervenção do usuário. Por fim, os custos da solução proposta ou uma descrição
13 SCA (Service Component Architecture) é um modelo de componentes que permite a construção de aplicações distribuídas baseadas em SOA, agregando diferentes tecnologias e especificações. Na abordagem SCA, os componentes são as unidades básicas (building blocks) para a construção das aplicações e podem ser compostos de serviços (ou interfaces providas), referências (ou interfaces requeridas) e expor propriedades. As referências de um componente são conectadas aos serviços de outros componentes por meio de conectores chamados wires.

97
mais detalhada do esforço necessário para o uso de tal plataforma de middleware não
são apresentados.
Por fim, Juhnke et al. [90] propõem uma abordagem para redundância de
serviços baseados em nuvem a fim de promover a substituição de serviços em falha
estrutural, como timeouts na rede e falhas de servidor. A abordagem dos autores é
baseada em políticas para configurar uma reconfiguração automática sem a
necessidade de adicionar mecanismos explícitos de tolerância a falhas a um processo
BPEL, que modela um workflow. Em caso de falha, tais políticas são utilizadas para
determinar a ação consecutiva a ser tomada, podendo ser a execução de uma nova
chamada ao serviço ou a substituição do mesmo por outro serviço alternativo
existente. Conforme apontado pelos próprios autores, a abordagem proposta não
envolve o monitoramento de parâmetros de QoS nem o processo de adaptação
disparado pela degradação dos mesmos. Por fim, não se é considerado o custo de
adaptação envolvido na execução das operações de reconfiguração, como é feito no
Cloud Integrator.

98
7 Considerações finais
Apesar de a Computação em Nuvem surgir como um novo paradigma de
computação que tem o potencial de proporcionar diversos benefícios ausentes nas
tecnologias atuais, o seu desenvolvimento ainda está em emergência e há vários
novos desafios que precisam ser tratados. Alguns desses desafios estão relacionados
às principais vertentes endereçadas neste trabalho, a saber:
(i) a necessidade de se realizar uma composição de serviços que agrega
serviços providos por diferentes plataformas de nuvem, a fim de
gerar valor agregado para o usuário e assim satisfazer os requisitos
das aplicações;
(ii) a necessidade de uma integração de tais serviços que permita o uso
transparente de diferentes plataformas de nuvem e abstraia as
especificidades de cada uma delas, em um ambiente
consideravelmente heterogêneo;
(iii) a necessidade de se considerar metadados acerca dos serviços (e.g.
parâmetros de QoS, preços etc.) que guie a seleção de serviços a serem
incluídos nas composições de serviços e possibilite escolher serviços
dentre os equivalentes (i.e. que proveem as mesmas funcionalidades)
oferecidos pelo conjunto de plataformas de nuvem que estão sendo
integradas;
(iv) a necessidade de meios de adaptação para garantir que, em caso de
falha ou degradação da qualidade de um serviço que esteja
envolvido em uma composição, a aplicação possa ser adaptada, i.e.
possa usar automaticamente outro serviço equivalente, se possível,
ainda considerando os requisitos estabelecidos pelo usuário, e;
(v) a necessidade um ambiente que facilite o desenvolvimento e a
execução de aplicações que utilizem os serviços providos pelas
plataformas de nuvem que estão sendo integradas, permitindo
inclusive que tais aplicações sejam construídas em um alto nível de
abstração, independentemente dos serviços concretos que possam
ser utilizados.
De modo a contribuir na redução do esforço para desenvolver aplicações que
façam uso de serviços de nuvem, facilitando assim a exploração de todo o potencial
desse paradigma, esta Dissertação de Mestrado propôs o Cloud Integrator, uma
plataforma de middleware orientada a serviços para composição, execução e
gerenciamento de serviços providos por diferentes plataformas de Computação em
Nuvem. O Cloud Integrator é baseado no paradigma de SOA e sua implementação

99
utiliza a tecnologia de serviços Web, explorando assim padrões e linguagens abertos
e possibilitando a integração de serviços providos por vários provedores de maneira
transparente e automática, além de oferecer um ambiente que facilita o
desenvolvimento e a execução de aplicações que fazem uso de serviços de nuvem.
De acordo com a abordagem SOA, plataformas de nuvem são provedores de serviço
que proveem serviços a aplicações em nuvem (clientes), e o Cloud Integrator atua como
um mediador entre esses elementos.
Utilizando um assistente gráfico provido pelo Cloud Integrator, depois de o
usuário especificar um workflow semântico composto por um conjunto de atividades
abstratas referentes à aplicação, atividades essas que devem ser realizadas por
serviços de nuvem a fim de satisfazer os objetivos de negócio da aplicação, o Cloud
Integrator executa uma composição de serviços baseada nessa especificação, i.e. procura
pelos serviços concretos que realizam cada atividade especificada no workflow,
gerando assim possíveis planos de execução com tais serviços. Como tipicamente há
mais de um plano de execução disponível, é necessário executar uma seleção de
serviços para escolher um desses planos de execução disponíveis para ser executado,
utilizando, para fazer tal seleção, metadados acerca dos serviços. Contudo, ambientes
de nuvem são caracterizados por alta dinamicidade e assim podem apresentar
condições que levem à falha ou degradação na qualidade dos serviços envolvidos na
execução da aplicação, sendo necessário um mecanismo de adaptação que visa
selecionar outro plano de execução que contenha um serviço equivalente para
substituir o corrente, a fim de garantir a qualidade e a disponibilidade da aplicação
em questão e que os serviços que estão sendo utilizados atendam aos requisitos da
aplicação.
7.1 Contribuições
A principal contribuição deste trabalho é a proposição, especificação e
implementação (ainda que parcial) do Cloud Integrator, para possibilitar a
composição, execução e gerenciamento de serviços providos por diferentes
plataformas de Computação em Nuvem, de maneira transparente para o usuário, em
um cenário de nuvens computacionais heterogêneas. De maneira a alcançar os
objetivos enumerados no início deste trabalho, foram desenvolvidas estratégias de
composição e seleção de serviços que considerem tanto requisitos funcionais (i.e.
funcionalidades propriamente ditas) quanto não funcionais (e.g. metadados dos
serviços como parâmetros de QoS, preços, etc.) dos serviços, de modo que a própria
plataforma seja capaz de escolher, de acordo com as preferências do usuário e/ou
requisitos das aplicações, que serviços devem ser utilizados. Além disso, também foi
desenvolvido um mecanismo de adaptação eficiente que garanta a disponibilidade e a
qualidade das aplicações em condições que afetem a sua execução, tais como falha ou
degradação da qualidade de um serviço envolvido na composição em questão, ou

100
ainda em caso de adição ou remoção de serviços no ambiente, de modo que outro
serviço equivalente possa ser utilizado. Por fim, o Cloud Integrator, através de um
ambiente gráfico, facilita o desenvolvimento e a execução de aplicações que utilizem
os serviços providos pelas plataformas de nuvem que estão sendo integradas,
permitindo inclusive que tais aplicações sejam construídas em um alto nível de
abstração, independentemente dos serviços concretos que possam ser utilizados.
Outra contribuição deste trabalho é a proposição de uma nova abordagem
para a seleção de serviços em nuvem, apresentada originalmente no trabalho de
Cavalcante et al. [49] e que se coloca como uma nova versão de um algoritmo
apresentado em um trabalho anterior [48]. Conforme apresentado na Seção 3.4, no
algoritmo de seleção original [48], todos os serviços que compõem todos os planos de
execução eram considerados, de modo que, se uma aplicação requeresse um número
relativamente grande de serviços, o processo de seleção poderia tornar-se
impraticável devido ao aumento do tempo despendido pelo algoritmo de seleção de
serviços. Essa nova abordagem proposta tenta então otimizar o processo de seleção
realizado pelo Cloud Integrator, para isso desconsiderando dos cálculos todos os
serviços coincidentes. Tais serviços coincidentes são serviços que estão presentes em
todos os planos de execução e, portanto, contribuem igualmente com os mesmos valores
de custo e de qualidade em qualquer plano de execução. Em não se considerando
esses serviços, o processo de seleção de serviços seria teoricamente executado mais
rapidamente, por envolver um número menor de serviços a serem considerados,
porém com um trade-off em se executar um algoritmo adicional para identificar de
antemão os serviços coincidentes para depois iniciar o processo de seleção de
serviços. Essa hipótese é confirmada pelos resultados reportados no trabalho de
Cavalcante et al. [49] e na Seção 5.2 deste trabalho, em que essa nova abordagem de
seleção de serviços é mais eficiente em termos de desempenho com relação à
abordagem original [48]. Além disso, o algoritmo para identificação dos serviços
coincidentes também se mostrou ser eficiente e capaz de fazer um bom trade-off entre
o número de planos de execução a serem analisados e o número de serviços
coincidentes entre eles. Mais ainda, optando-se por utilizar a abordagem que
desconsidera serviços coincidentes do processo de seleção, esse algoritmo para
identificar serviços coincidentes só necessita ser executado apenas uma vez (logo
após o processo de composição de serviços), o que beneficiou o processo de
adaptação, conforme apresentado na Seção 5.3, por requerer que os cálculos da
utilidade dos planos de execução alternativos candidatos a substituir o plano de
execução corrente sejam refeitos, devido ao fato de que os metadados considerados
tenham tido seus valores alterados com o tempo.
Também pode ser destacada como contribuição deste trabalho a proposição
de ontologias que podem ser utilizadas no contexto de Computação em Nuvem, de
maneira a possibilitar um vocabulário comum para a representação formal de

101
elementos desse domínio e também o compartilhamento e reuso do conhecimento
por elas expresso. Como descrito na Seção 3.1, o Cloud Integrator emprega duas
modalidades de ontologias para a representação de conceitos no contexto de
aplicações em Computação em Nuvem, todas descritas utilizando a linguagem OWL.
A primeira delas é chamada ontologia de domínio, que modela conceitos específicos
relacionados a uma dada classe de aplicações e é estruturada em termos de tarefas e
objetos, que são os conceitos utilizados para especificar as atividades do workflow
semântico referente à aplicação. A outra modalidade de ontologias empregada pelo
Cloud Integrator é chamada ontologia de nuvem e se refere especificamente ao contexto
de Computação em Nuvem. Essa segunda ontologia, genérica e extensível, tem por
objetivo representar os serviços providos por plataformas de nuvem e os
relacionamentos entre eles, de maneira que os conceitos presentes nessa última
ontologia podem ser utilizados para enriquecer a descrição dos serviços Web
semânticos que realizam as atividades que compõem o workflow referente à
aplicação.
De maneira adicional, este trabalho mostrou a integração do Cloud Integrator
com um sistema externo de monitoramento de metadados, o QoMonitor [50, 51], que
se mostrou ser eficiente para a recuperação de metadados referentes aos parâmetros
de qualidade dos serviços, metadados esses utilizados fundamentalmente nos
processos de seleção e adaptação realizados pelo Cloud Integrator. Além disso, o
QoMonitor possui papel crucial no processo de adaptação disparado por degradações
de qualidade dos serviços, visto que o Cloud Integrator pode ser notificado pelo
sistema de monitoramento de metadados quando ocorre uma degradação de
qualidade em um ou mais serviços que resulte em um impacto significativo na
utilidade inicial (computada no processo de seleção) do plano de execução corrente.
Por fim, conforme apresentado no Capítulo 5 deste trabalho, os processos de
composição, seleção e adaptação realizados pelo Cloud Integrator foram avaliados de
maneira a verificar o desempenho dos mesmos, de modo que foi possível concluir
que os tempos despendidos pelos mesmos são consideravelmente pequenos, não
impactando no desempenho da plataforma. Além disso, para avaliar o impacto (i.e. o
overhead) do Cloud Integrator sobre o tempo de execução da aplicação, visto que ele
representa uma camada a mais de abstração entre as plataformas de nuvem
subjacentes que estão sendo integradas e as aplicações, foram construídas duas
versões do estudo de caso empregado na avaliação (Seção 5.1). Na primeira delas, a
aplicação foi especificada através de um workflow semântico utilizando o Cloud
Integrator, de modo a ser executado o conjunto de serviços presentes no plano de
execução selecionado pelo processo de seleção realizado pela plataforma, enquanto
na segunda versão foi implementado um código cliente na linguagem de
programação Java através do qual os mesmos serviços presentes no plano de
execução selecionado pelo Cloud Integrator eram invocados diretamente. Os

102
resultados apresentados mostraram que a diferença observada com relação aos
tempos de execução dessas versões não foi significativa, em média 0,617 s. Além
disso, pôde ser observado um esforço considerável para desenvolver a versão da
aplicação que invoca diretamente os serviços. Mais ainda, nessa segunda versão, é
necessário conhecer os serviços disponíveis no ambiente e suas respectivas interfaces,
dificultando assim o desenvolvimento das aplicações, sem falar no fato de que os
serviços são selecionados de maneira estática e a adaptação dinâmica e autônoma de
tais aplicações quando ocorre uma falha ou degradação na qualidade de um serviço
torna-se impossível de se fazer. Em contrapartida, através do Cloud Integrator, os
processos de composição de serviços, seleção de planos de execução e
(principalmente) adaptação de aplicações podem ser realizados com o mínimo de
intervenção do usuário e de maneira dinâmica, desacoplando-as dos serviços que
podem ser utilizados pelas mesmas.
7.2 Limitações
Em seu estado atual de desenvolvimento, o Cloud Integrator apresenta algumas
limitações, sendo as principais:
(i) a arquitetura do Cloud Integrator, apesar de ter sido conceitualmente
apresentada por completo na Seção 3.2, não está totalmente
implementada; conforme explicitado nessa mesma seção, este
trabalho concentrou-se nos componentes da camada Service Layer,
mais precisamente os responsáveis pelas atividades de criação,
execução e gerenciamento de workflows, envolvendo os processos de
composição e seleção de serviços, bem como o de adaptação de
aplicações, de modo que os componentes da camada Integration
Layer, que é responsável por integrar as plataformas de nuvem
subjacentes, não foram implementados, impossibilitando, por
exemplo, a descoberta dinâmica de serviços a ser realizada pelo
componente Service Discoverer;
(ii) a interface de usuário da plataforma ainda é limitada no sentido de
não permitir o uso, de maneira simultânea, por múltiplos usuários,
além de necessitar de alguns aperfeiçoamentos;
(iii) o algoritmo de composição de serviços atualmente empregado no
Cloud Integrator, apresentado por Mendes et al. [47] possui limitações
com relação ao fato de que ele considera fundamentalmente entradas
e saídas para fazer a composição semântica dos serviços; dessa
forma, por exemplo, se dois serviços Web semânticos S1 e S2 que
realizam, respectivamente, as atividades A1 e A2 possuírem os
mesmos tipos de entradas e saídas em suas especificações, o

103
algoritmo de composição considerará S1 e S2 como serviços
equivalentes (i.e. capazes de atender à mesma atividade), o que pode
gerar planos de execução incorretos;
(iv) apenas um estudo de caso foi considerado na avaliação, utilizando
apenas uma plataforma de Computação em Nuvem, de modo que é
necessário aumentar o grau de avaliação do Cloud Integrator através
da realização de outros experimentos com outros estudos de caso e
utilizando de fato diferentes plataformas de nuvem, além de serem
feitas comparações quantitativas com outras abordagens
apresentadas na literatura principalmente no tocante à seleção de
serviços, visto que boa parte das abordagens apresentadas na
literatura é bastante similar à empregada neste trabalho (ver Seção
6.2);
(v) conforme explicitado na Seção 3.5, o escopo do processo de
adaptação apresentado neste trabalho limita-se apenas à substituição
de serviços classificados como serviços de aplicação, pelo fato de a
substituição de serviços classificados como recursos de nuvem (ver
Seção 3.1) não ser uma questão trivial;
(vi) o processo de adaptação disparado por degradação de qualidade,
apesar de completamente especificado neste trabalho, ainda não está
completamente implementado e, portanto, não pôde ser avaliado;
além disso, o processo de adaptação disparado pelo surgimento de
novos serviços ainda precisa ser especificado, e;
(vii) os workflows semânticos que podem ser especificados e executados
utilizando o assistente provido pelo Cloud Integrator são
essencialmente sequenciais, apesar de tal assistente permitir a
especificação de workflows mais complexos, que fazem uso de fluxos
de controle (e.g. repetição, divisão-junção, condição, etc.).
7.3 Trabalhos em andamento e futuros
Diante das limitações elencadas na Seção 7.2, diversos trabalhos futuros
poderão ser desenvolvidos a partir deste trabalho, e alguns deles já estão em
andamento. Por exemplo, para a aplicação de compra de passagens aéreas baseada
em nuvem (ver Seção 5.1), estão sendo desenvolvidos serviços contemplando outras
plataformas de Computação em Nuvem (visto que, na versão presentemente
apresentada, apenas os serviços de nuvem da plataforma AWS estão sendo
utilizados), de modo a permitir que o processo de composição de serviços possa
considerar, na construção dos planos de execução, serviços providos por diferentes
plataformas de nuvem, bem como, no caso de adaptação, um serviço de nuvem

104
provido por uma plataforma poder ser substituído por outro serviço provido por
outra plataforma. Além disso, já se encontra em andamento o desenvolvimento de
outros estudos de caso (inclusive utilizando serviços classificados como recursos de
nuvem, para que seja possível a instanciação de recursos a partir da própria
plataforma) que poderão ser utilizados em avaliações futuras dos processos
realizados pelo Cloud Integrator. Nessa perspectiva de permitir o gerenciamento de
recursos a partir da própria plataforma, pode ser criado um componente chamado
Resource Manager que, através dos binders específicos das plataformas integradas,
poderia interagir com as mesmas para gerenciar os recursos providos por elas.
Também se encontra em desenvolvimento a mudança do protocolo utilizado
para suporte a serviços Web. Conforme explanado na Seção 4.2, na implementação
atual do Cloud Integrator é utilizado o protocolo SOAP [23] em conjunto com a
linguagem WSDL [24] para descrição dos serviços Web. Para que seja possível
invocar as operações de tais serviços Web a partir dos seus respectivos serviços Web
semânticos descritos utilizando a ontologia OWL-S [36], são necessárias
especificações XSLT [63] para fazer o mapeamento bidirecional entre os elementos
presentes nas mensagens SOAP (requisição/resposta) e definidos na descrição
WSDL do serviço em elementos OWL (classes e propriedades) definidos nas
ontologias, de maneira que a máquina de execução do workflow possa invocar os
serviços a partir das descrições semânticas dos mesmos. Todavia, a produção de tais
especificações XSLT é um processo completamente manual, cansativo e altamente
propenso a erros. Diante disso, encontra-se em estudo a mudança do protocolo
SOAP para uma abordagem baseada em REST (REpresentational State Transfer) [97,
98, 99] que, devido ao fato ser baseada nas operações básicas definidas no protocolo
HTTP, pode proporcionar uma maior simplicidade por não ser necessário (pelo
menos em teoria) realizar o mapeamento entre os elementos das ontologias de
serviço e os elementos que descrevem os serviços propriamente ditos. Além disso,
Ferreira Filho [95] propõe uma abordagem baseada em REST para serviços Web
semânticos, estendendo a ontologia OWL-S para os serviços Web semânticos e
utilizando a linguagem WADL (Web Application Description Language) [96] para a
descrição sintática dos serviços, não impactando em mudanças profundas nas
tecnologias da Web Semântica que são atualmente empregadas pelo Cloud Integrator.
Finalmente, é necessário realizar uma atualização das tecnologias utilizadas na
implementação do Cloud Integrator, principalmente com relação à OWL-S API [58],
cuja versão empregada neste trabalho pode ser considerada desatualizada com
relação aos lançamentos recentes da mesma.
Outro trabalho futuro importante a ser desenvolvido é a implementação de
uma interface de usuário Web para o Cloud Integrator. A ideia é implantar a
plataforma de middleware em um servidor de aplicação de modo a permitir que um
número maior de usuários possa utilizá-la simultânea e remotamente. Além disso,

105
através dessa nova interface, duas classes de clientes poderão ser contempladas: (i)
os desenvolvedores de aplicações, que desejem criar aplicações que façam uso dos
serviços providos pelas plataformas de nuvem subjacentes que estão sendo
integradas pelo Cloud Integrator, sendo necessário prover meios para facilitar a
criação, edição e execução de workflows, e; (ii) os desenvolvedores de serviços de
nuvem, que porventura desejem integrar seus serviços ao Cloud Integrator, que, por
sua vez, deve prover meios para facilitar essa tarefa.
Por fim, um trabalho futuro a ser desenvolvido no âmbito do
desenvolvimento do Cloud Integrator é a implementação do processo de adaptação
que permite a substituição de serviços enquadrados como recursos de nuvem,
conforme discutido na Seção 5.3. Para endereçar essa questão não trivial,
checkpointers internos ao Cloud Integrator poderiam ser utilizados para armazenar o
estado desses serviços entre a execução dos serviços envolvidos no plano de execução
em questão. Checkpointing é uma técnica bastante conhecida no contexto de tolerância
a falhas que basicamente consiste no armazenamento de estados de processos em
determinados instantes de tempo (snapshots) [92, 93, 94]. Dessa forma, existiriam
diferentes checkpointers para as diferentes classes de serviços que representam os
recursos de nuvem (e.g. serviços de persistência em bancos de dados,
armazenamento de arquivos, etc.) cujos estados poderiam ser armazenados e
futuramente recuperados em caso de substituição de tais serviços na execução do
processo de adaptação, a fim de possivelmente minimizar o custo (overhead)
envolvido nessa operação.

106
Referências
[1] Rajkumar Buyya, Chee Sin Yeo, Srikumar Venugopal (2008) Market-oriented
Cloud Computing: Vision, hype and reality for delivering IT services as
computing utilities. Proceedings of the 10th IEEE International Conference on
High Performance Computing and Communications (HPCC’08), Dalian, China.
Washington, DC, USA: IEEE Computer Society, pp.5-13.
[2] Michael Armbrust et al. (2009) Above the clouds: A Berkeley view of Cloud
Computing – Technical report. Reliable Adaptive Distributed Systems
Laboratory, University of California at Berkeley, CA, USA.
[3] Qi Zhang, Li Cheng, Raouf Boutaba (2010) Cloud Computing: State-of-the-art
and research challenges. Journal of Internet Services and Applications, vol. 1,
no. 1, pp.7-18.
[4] Lizhe Wang, Gregor Von Laszewski, Marcel Kunze, Jie Tao (2010) Cloud
Computing: A perspective study. New Generation Computing, vol. 28, no. 2,
pp.137-146.
[5] Peter Mell, Timothy Grance (2011) The NIST Definition of Cloud Computing –
NIST Special Publication, Reports on Computer Systems Technology. National
Institute of Standards and Technology, Gaithersburg, MD, USA.
[6] Luis M. Vaquero, Luis Rodero-Merino, Juan Caceres, Maik Lindnet (2009) A
break in the clouds: Towards a cloud definition. ACM SIGCOMM Computer
Communication Review, vol. 39, no. 1, pp.50-55.
[7] Rashid Alakbarov (2010) Modern condition and development perspectives of
Cloud Computing technology. Proceedings of the 3rd International Conference
“Problems of Cybernetics and Informatics” (PCI’2010), Baku, Azerbaijan.
[8] Lizhe Wang, Gregor Von Laszewski, Marcel Kunze, Jie Tao (2010) Cloud
Computing: A perspective study. New Generation Computing, vol. 28, no. 2,
pp.137-146.
[9] John W. Rittinghouse, James F. Randsome (2010) Cloud Computing:
Implementation, management and security. USA: CRC Press.
[10] Cheng Zeng, Xiao Guo, Weijie Ou, Dong Han (2009) Cloud Computing service
composition and search based on semantic. Proceedings of the 1st International
Conference on Cloud Computing (CloudCom 2009), Beijing, China. In: Martin
Gilje Jaatun, Gansen Zhao, Chunming Rong (eds.) Lecture Notes in Computer
Science, v. 5931. Germany: Springer-Verlag Berlin/Heidelberg, pp.290-300.
[11] Alexander Keller, Heiko Ludwig (2003) The WSLA Framework: Specifying and
monitoring service level agreements for Web Services. Journal of Networks and

107
Systems Management, vol. 11, no. 1, pp.57-81.
[12] Sumit Bose, Anjaneyulu Pasala, Dheepak Ramanujam, Sridhar Murthy,
Ganesan Malaiyandisamy (2011) SLA management in Cloud Computing: A
service provider’s perspective. In: Rajkumar Buyya, James Broberg, Andrzej
Goscinski (eds.) Cloud Computing: Principles and paradigms. New Jersey,
USA: John Wiley & Sons, pp.413-436.
[13] Michael P. Papazoglou, Paolo Traverso, Schahram Dustdar, Frank Leymann
(2007) Service-Oriented Computing: State of the art and research challenges.
Computer, vol. 40, no. 1, pp.64-70.
[14] Yi Wei, M.B. Blake (2010) Service-Oriented Computing and Cloud Computing:
Challenges and Opportunities. Internet Computing, vol. 14, no. 6, pp.72-75.
[15] Thomas Erl (2007) SOA principles of service design. New Jersey, USA: Prentice
Hall.
[16] Mike P. Papazoglou (2003) Service-Oriented Computing: Concepts,
characteristics and directions. Proceedings of the 4th International Conference
on Web Information Systems and Engineering (WISE 2003), Rome, Italy.
Piscataway, NJ, USA: IEEE Computer Society, pp.3-12.
[17] Michael P. Papazoglou, Paolo, Schahram Dustdar, Frank Leymann, Bernd J.
Krämer (2005) Service-Oriented Computing research roadmap. In: F. Cubera,
Bernd, J. Krämer, Michael P. Papazoglou (eds.) Dagstuhl Seminar Proceedings
05462. Schloss Dagstuhl, Leibniz Center for Informatics, Leibniz, Germany,
pp.1-29.
[18] Mike P. Papazoglou (2007) Web Services: Principles and technology. USA:
Prentice-Hall.
[19] Michael P. Papazoglou, Jean-Jacques Dubray (2004) A survey of Web service
technologies – Technical report. University of Trento, Italy.
[20] Mike P. Papazoglou, Dimitris Georgakopoulos (2003) Service-Oriented
Computing. Communications of the ACM, vol. 46, no. 10, pp.25-28.
[21] Xie Dan et al. (2006) An approach for describing SOA. Proceedings of the 2006
International Conference on Wireless Communications, Networking and
Mobile Computing (WiCOM 2006), Wuhan, China. Washington, DC, USA: IEEE
Computer Society, pp.1-4.
[22] Aphrodite Tsalgatidou, Thomi Pilioura (2002) An overview of standards and
related technology in Web services. Distributed and Parallel Databases, vol. 12,
no. 1, pp.135-162.
[23] Simple Object Access Protocol (SOAP) 1.2:

108
http://www.w3.org/TR/2007/REC-soap12-part1-20070427/
[24] Web Services Description Language (WSDL) 1.1:
http://www.w3.org/TR/2001/NOTE-wsdl-20010315
[25] Universal Description, Discovery and Integration (UDDI):
http://www.w3schools.com/wsdl/wsdl_uddi.asp
[26] Douglas K. Barry (2003) Web services and Service-Oriented Architectures. San
Francisco, USA: Morgan Kaufmann Publishers/Elsevier Science.
[27] Tim Berners-Lee, James Hendler, Ora Lassila (2001) The Semantic Web.
Scientific American, vol. 284, no. 5, pp. 34-43.
[28] Nigel Shadbolt, Wendy Hall, Tim Berners-Lee (2006) The Semantic Web
revisited. IEEE Intelligent Systems, vol. 21, no. 3, pp. 96-101.
[29] Thiago Pereira da Silva (2012) AutoWebS: Um ambiente para modelagem a
geração automática de serviços Web semânticos – Dissertação de Mestrado
(Mestrado em Sistemas e Computação). Programa de Pós-Graduação em
Sistemas e Computação, Departamento de Informática e Matemática Aplicada,
Universidade Federal do Rio Grande do Norte, Natal, RN, Brasil.
[30] Resource Description Framework (RDF):
http://www.w3.org/RDF/
[31] Thomas R. Gruber (1993) A translation approach to portable ontology
specifications. Journal of Knowledge Acquisition, vol. 5, no. 2, pp.199-220.
[32] OWL Web Ontology Language Reference:
http://www.w3.org/TR/owl-ref/
[33] Matthew Hooridge, Simon Jupp, Georgina Moulton, Alan Rector, Robert
Stevens, Chris Wroe (2007) A practical guide to building OWL ontologies using
Protégé 4 and CO-ODE tools – Edition 1.1. University of Manchester,
Manchester, United Kingdom.
[34] SWRL: A Semantic Web Rule Language combining OWL and RuleML:
http://www.w3.org/Submission/SWRL/
[35] Sheila A. McIlraith, Tran Cao Son, Honglei Zeng (2001) Semantic Web services.
Intelligent Systems, vol. 16, no. 2, pp.46-53.
[36] David Martin et al. (2005) Bringing semantics to Web services: The OWL-S
approach. Proceedings of the First International Workshop on Semantic Web
Services and Web Process Composition (SWSWPC 2004), San Diego, CA, USA.
In: Jorge Cardoso, Amit Sheth (eds.) Lecture Notes in Computer Science, v.
3387. Germany: Springer-Verlag Berlin/Heidelberg, pp.26-42.
[37] Dumitru Roman et al. (2005) Web Service Modeling Ontology. Applied

109
Ontology, vol. 1, no. 1, pp. 77-106.
[38] José Reginaldo de Sousa Mendes Júnior (2008) WebFlowAH: Um ambiente para
especificação e execução ad-hoc de processos de negócio baseados em serviços
Web – Dissertação de Mestrado (Mestrado em Sistemas e Computação).
Programa de Pós-Graduação em Sistemas e Computação, Departamento de
Informática e Matemática Aplicada, Universidade Federal do Rio Grande do
Norte, Natal, RN, Brasil.
[39] Jinghai Rao, Xiaomeng Su (2005) A survey of automated Web Service
composition methods. Proceedings of the First International Workshop on
Semantic Web Services and Web Process Composition (SWSWPC 2004), San
Diego, CA, USA. In: Jorge Cardoso, Amit Sheth (eds.) Lecture Notes in
Computer Science, v. 3387. Germany: Springer-Verlag Berlin/Heidelberg,
pp.43-54.
[40] Rob Allen (2000) Workflow: An introduction. In: Layna Fischer (ed.) Workflow
Handbook 2001. Florida, USA: Future Strategies, Inc., pp. 15-38.
[41] Nicola Guarino (1998) Formal ontology and information systems. Proceedings
of the International Conference on Formal Ontology and Information Systems
(FOIS’98), Trento, Italy. Amsterdam, the Netherlands: IOS Press, pp. 3-15.
[42] Taekgyeong Han, Kwang Mong Sim (2010) An ontology-enhanced cloud
service discovery system. Proceedings of the 2010 International
MultiConference of Engineers and Computer Scientists (IMECS 2010), Hong
Kong, pp. 644-649.
[43] Amazon Web Services (AWS): http://aws.amazon.com/
[44] Google App Engine (GAE): http://developers.google.com/appengine/
[45] OpenStack Open Source Cloud Computing Software:
http://www.openstack.org/
[46] Open Cloud Computing Interface (OCCI): http://occi-wg.org/
[47] Reginaldo Mendes, Paulo F. Pires, Flavia C. Delicato, Thais Batista, Javid
Taheri, Albert Y. Zomaya (2011) Using Semantic Web to build and execute ad-
hoc processes. Proceedings of the 9th IEEE/ACS International Conference on
Computer Systems and Applications (AICCSA 2011), Sharm El-Sheikh, Egypt.
Washington, DC, USA: IEEE Computer Society, 2011, pp. 233-240.
[48] Everton Cavalcante, Frederico Lopes, Thais Batista, Nélio Cacho, Flavia C.
Delicato, Paulo F. Pires (2011) Cloud Integrator: Building value-added services
on the cloud. Proceedings of the First International Symposium on Network
Cloud Computing and Applications (NCCA 2011), Toulouse, France.
Piscataway, NJ, USA: IEEE Computer Society, pp.137-142.

110
[49] Everton Cavalcante, Thais Batista, Frederico Lopes, Noemi Rodriguez, Ana
Lúcia de Moura, Flávia C. Delicato, Paulo F. Pires, Reginaldo Mendes (2012)
Optimizing services selection in a cloud multiplatform scenario. Proceedings of
the 2012 IEEE Latin America Conference on Cloud Computing and
Communications (LatinCloud 2012), Porto Alegre, RS, Brazil. Piscataway, NJ,
USA: IEEE Computer Society, pp. 31-36.
[50] Caio Batista, Gustavo Alves, Everton Cavalcante, Thais Batista, Frederico Lopes,
Flavia C. Delicato, Paulo F. Pires (2012) A metadata monitoring system for
Ubiquitous Computing. Proceedings of the 6th International Conference on
Mobile Ubiquitous Computing, Systems, Services and Technologies
(UBICOMM 2012), Barcelona, Spain. Wilmington, DE, USA: IARIA, pp. 60-66.
[51] Gustavo Nogueira Alves (2013) Um sistema para monitoramento de metadados
para Computação Ubíqua. Monografia de Graduação (Bacharelado em Ciência
da Computação) – Departamento de Informática e Matemática Aplicada,
Universidade Federal do Rio Grande do Norte, Natal, RN, Brasil.
[52] Tao Yu, Yue Zhang, Kwei-Jay Li (2007) Efficient algorithms for Web services
selection with end-to-end QoS constraints. ACM Transactions on the Web, vol.
1, no. 1.
[53] Zheng Yanwei, Ni Hong, Deng Haojiang, Liu Lei (2010) A dynamic Web
services selection based on decomposition of global QoS constraints.
Proceedings of the 2010 IEEE Youth Conference on Information Computing and
Telecommunications (YC-ICT 2010), Beijing, China. Piscataway, NJ, USA: IEEE
Computer Society, pp. 77-80.
[54] Danilo Ardagna, Raffaela Mirandola (2010) Per-flow optimal service selection
for Web services based processes. Journal of Systems and Software, vol. 83, pp.
1512-1523.
[55] Yousri Kouki, Thomas Ledoux, Remi Sharrock (2011) Cross-layer SLA selection
for cloud services. Proceedings of the First International Symposium on
Network Cloud Computing and Applications (NCCA 2011), Toulouse, France.
Piscataway, NJ, USA: IEEE Computer Society, pp.143-147.
[56] Liangzhao Zeng, Boualem Benatallah, Anne H.H. Ngu, Marlon Dumas, Jayant
Kalagnanam, Henry Chang (2004) QoS-aware middleware for Web services
composition. IEEE Transactions on Software Engineering, vol. 30, no. 5, pp. 311-
327.
[57] Frederico Lopes, Thiago Pereira, Everton Cavalcante, Thais Batista, Flavia C.
Delicato, Paulo F. Pires, Paulo Ferreira (2011) AdaptUbiFlow: Selection and
adaptation in workflows for Ubiquitous Computing. Proceedings of the 9th
IEEE/IFIP International Conference on Embedded and Ubiquitous Computing

111
(EUC 2011), Melbourne, Australia. Piscataway, NJ, USA: IEEE Computer
Society, pp. 63-71.
[58] OWL-S API: http://www.mindswap.org/2004/owl-s/api/index.shtml
[59] Apache Jena: http://jena.apache.org/
[60] RDQL – A Query Language for RDF: http://www.w3.org/Submission/RDQL/
[61] SPARQL Query Language for RDF:
http://www.w3.org/TR/rdf-sparql-query/
[62] Apache Axis: http://axis.apache.org/
[63] XSL Transformations (XSLT): http://www.w3.org/TR/xslt/
[64] Pellet OWL Reasoner: http://clarkparsia.com/pellet
[65] Amazon Relational Database Service (Amazon RDS):
http://aws.amazon.com/rds/
[66] Amazon Simple Storage Service (Amazon S3): http://aws.amazon.com/pt/s3/
[67] Fiona F.H. Nah (2004) A study on tolerable waiting time: How long are Web
users willing to wait? Behavior and Information Technology, vol. 23, no. 3, pp.
153-163.
[68] Google Apps: http://apps.google.com
[69] Frederico Araújo da Silva Lopes (2011) Uma plataforma de integração de
middleware para Computação Ubíqua. Tese de Doutorado (Doutorado em
Ciência da Computação) – Programa de Pós-Graduação em Sistemas e
Informação, Departamento de Informática e Matemática Aplicada,
Universidade Federal do Rio Grande do Norte, Natal, RN, Brasil.
[70] Amit Sheth, Ajith Ranabahu (2010) Semantic modeling for Cloud Computing,
Part 1. IEEE Internet Computing, vol. 14, no. 3, pp. 81-83.
[71] Amit Sheth, Ajith Ranabahu (2010) Semantic modeling for Cloud Computing,
Part 2. IEEE Internet Computing, vol. 14, no. 4, pp. 81-84.
[72] Nikolaos Loutas, Eleni Kamateri, Filippo Bosi, Konstantinos Tarabanis (2011)
Cloud Computing interoperability: The state of play. Proceedings of the 3rd
IEEE International Conference on Cloud Computing Technology and Science
(CloudCom 2011), Athens, Greece. Piscataway, NJ, USA: IEEE Computer
Society, pp. 752-757.
[73] jclouds: http://www.jclouds.org/
[74] GoGrid IaaS Provider: http://www.gogrid.com
[75] Eucalyptus Open Source Private and Hybrid Cloud:

112
http://www.eucalyptus.com/
[76] Windows Azure Microsoft’s Cloud Platform: http://www.windowsazure.com
[77] Nabor Mendonça, Américo Sampaio, Karin Breitman, Silvio Meira, João Gabriel
Cabral, Ronaldo Pinheiro (2012) Cloudmux: Um serviço de adaptação para
acesso unificado a múltiplas plataformas de Computação em Nuvem. Relatório
técnico – Centro de Ciências Tecnológicas, Universidade de Fortaleza,
Fortaleza, CE, Brasil.
[78] Python Programming Language: http://www.python.org.br/
[79] E. Michael Maximilien, Ajith Ranabahu, Roy Engehausen, Laura Anderson
(2009) IBM Altocumulus: A cross-cloud middleware and platform. Proceedings
of the 24th Annual ACM SIGPLAN Conference on Object-Oriented
Programming, Systems, Languages, and Applications (OOPSLA 2009) Orlando,
USA.
[80] Ruby on Rails: http://rubyonrails.com.br/
[81] Wenying Zeng, Yuelong Zhao, Junwei Zeng (2009) Cloud model for service
selection. Proceedings of the First ACM/SIGEVO Summit on Genetic and
Evolutionary Computation (GEC 2009), Shanghai, China. New York, NY, USA:
ACM, pp. 1045-1048.
[82] Enrique Castillo, Antonio J. Gonejo, Pablo Pedregal, Ricardo García, Natalia
Alguacil (2002) Building and solving Mathematical Programming models in
Engineering and Science. John Wiley & Sons, Inc.
[83] Yousri Kouki, Thomas Ledoux, Remi Sharrock (2011) Cross-layer SLA selection
for cloud services. Proceedings of the First International Symposium on
Network Cloud Computing and Applications (NCCA 2011), Toulouse, France.
Piscataway, NJ, USA: IEEE Computer Society, pp. 143-147.
[84] Francesca Rossi, Peter van Beek, Toby Walsh (2006) Handbook of Constraint
Programming. New York, NY, USA: Elsevier Science, Inc.
[85] Andrzej Goscinski, Michael Brock (2010) Toward dynamic and attribute based
publication, discovery and selection for Cloud Computing. Future Generation
Computer Systems, vol. 26, pp. 947-970.
[86] Huihui Bao, Wanchun Dou (2012) A QoS-aware service selection method for
cloud service composition. Proceedings of the 26th IEEE International Parallel
and Distributed Processing Symposium (IPDPS 2012), Shanghai, China.
Piscataway, NJ, USA: IEEE Computer Society, pp. 2254-2261.
[87] Johannes Behl, Tobias Distler, Florian Heisig, Rüdigier Kapitza, Matthias
Schunter (2012) Providing fault-tolerant execution of Web service based

113
workflows within clouds. Proceedings of the 2nd International Workshop on
Cloud Computing Platforms (CloudCP 2012), Bern, Switzerland. New York,
NY, USA: ACM, 2012.
[88] Phillippe Merle, Romain Rouvoy, Lionel Seinturier (2011) A reflective platform
for highly adaptive multi-cloud systems. Proceedings of the 10th International
Workshop on Adaptive and Reflective Middleware (ARM 2011), Lisbon,
Portugal. New York, NY, USA: ACM, pp. 14-21.
[89] Jim Marino, Michael Rowley (2009) Understanding SCA (Service Component
Architecture). Addison-Wesley Professional.
[90] Ernst Juhnke, Tim Dörnemann, Bernd Freisleben (2009) Fault-tolerant BPEL
workflow execution via cloud-aware recovery policies. Proceedings of the 35th
EUROMICRO Conference on Software Engineering and Advanced
Applications (SEAA 2009), Patras, Greece. Washington, DC, USA: IEEE
Computer Society, pp. 31-38.
[91] Web Services Business Process Execution Language Version 2.0:
http://docs.oasis-open.org/wsbpel/2.0/OS/wsbpel-v2.0-OS.html
[92] Richard Koo, Sam Toueg (1986) Checkpointing and rollback-recovery for
distributed systems. Proceedings of the 1986 ACM Fall Joint Computer
Conference (ACM’86). Los Alamitos, CA, USA: IEEE Computer Society Press,
pp. 1150-1158.
[93] K. Mani Chandy, Leslie Lamport (1985) Distributed snapshots: Determining
global states of distributed systems. ACM Transactions on Computer Systems,
vol. 3, no. 1, pp. 63-75.
[94] E.N. (Mootaz) Elnozahy, Lorenzo Alvisi, Yi-Min Wang, David B. Johnson (2002)
A survey of rollback-recovery protocols in message-passing systems. ACM
Computing Surveys, vol. 34, no. 3, pp. 375-408.
[95] Otávio Freitas Ferreira Filho (2009) Serviços semânticos: Uma abordagem
RESTful. Dissertação de Mestrado (Mestrado em Engenharia Elétrica) – Escola
Politécnica da Universidade de São Paulo, São Paulo, SP, 2009.
[96] Web Application Description Language:
http://www.w3.org/Submission/wadl/
[97] Roy Fielding (2000) Architectural styles and the design of network-based
software architectures. PhD Dissertation – University of California - Irvine,
Irvine, CA, USA.
[98] Leonard Richardson, Sam Ruby (2007) RESTful Web services. Sebastopol, CA,
USA: O’Reilly.

114
[99] Jim Webber, Savas Parastatidis, Ian Robinson (2010) REST in practice:
Hypermedia and systems architecture. Sebastopol, CA, USA: O’Reilly.

115
Apêndice A –
Ontologias OWL do estudo de caso
A.1 Ontologia de domínio FlightBooking

116

117

118

119

120

121

122

123

124

125

126
A.2 Ontologia de nuvem Cloud Ontology

127

128