classificaÇÃo e indexaÇÃo de artigos cientÍficos...
TRANSCRIPT

Fabio Oliveira Teixeira
CLASSIFICAÇÃO E INDEXAÇÃO DE ARTIGOS CIENTÍFICOS INTERNACIONAIS DE INFORMÁTICA EM SAÚDE
Tese apresentada a Universidade Federal
de São Paulo para a obtenção do título
de Mestre em Ciências.
São Paulo
2011

Fabio Oliveira Teixeira
CLASSIFICAÇÃO E INDEXAÇÃO DE ARTIGOS CIENTÍFICOS INTERNACIONAIS DE INFORMÁTICA EM SAÚDE
Tese apresentada a Universidade Federal de São
Paulo para obtenção do título de Mestre em Ciências.
Orientador: Prof. Dr. Ivan Torres Pisa
Coorientador: Prof. Dr. Luciano Vieira de Araujo
São Paulo
2011

Teixeira, Fabio Oliveira
Classificação e indexação de artigos científicos internacionais de Informática em Saúde/Fabio Oliveira Teixeira.-- São Paulo, 2011.
xii, 77f.
Tese (Mestrado) - Universidade Federal de São Paulo. Escola Paulista de Medicina. Programa de pós-graduação em Gestão e Informática em Saúde.
Título em Inglês: Classification and indexing of international scientific articles in Health Informatics
1.Informática médica. 2.Classificação 3.Teorema de Bayes 4.Resumos e Indexação como Assunto

iii
UNIVERSIDADE FEDERAL DE SÃO PAULO (UNIFESP)
ESCOLA PAULISTA DE MEDICINA (EPM)
DEPARTAMENTO DE INFORMÁTICA EM SAÚDE
Chefe do Departamento: Prof. Dr. Paulo Bandiera Paiva
Coordenadora do Curso de pós-graduação: Profa. Dra. Heimar de Fátima Marin

iv
Fabio Oliveira Teixeira
CLASSIFICAÇÃO E INDEXAÇÃO DE ARTIGOS CIENTÍFICOS INTERNACIONAIS DE INFORMÁTICA EM SAÚDE
Presidente da banca: Prof. Dr. Ivan Torres Pisa
BANCA EXAMINADORA
Prof. Dr. Evandro Eduardo Seron Ruiz
Profa. Dra. Fátima de Lourdes dos Santos Nunes Marques
Prof. Dr. Paulo Schor
Aprovada em: 03 / 10 / 2011

v
DEDICATÓRIA
A minha amada esposa, Angela Cristina Sergio Teixeira,
a meus filhos, Rafael, Melissa e Fabiano,
motivo de paixão pela vida.

vi
Agradecimentos
Esta dissertação envolveu o esforço de muitas pessoas, que dedicaram seu
tempo a fim de transmitir conhecimento, ensinamentos de vida e apoio nos momentos
de incerteza. Espero ser capaz de retribuir a ajuda que me foi doada por todos que
participaram desta importante etapa da minha vida.
Gostaria de agradecer com ênfase meu orientador Prof. Dr. Ivan Torres Pisa, pela
orientação, confiança, paciência, amizade, dedicação e exemplo profissional,
qualidades que o tornam além de um excelente professor e orientador, também um
grande amigo.
Aos amigos do grupo de pesquisa, que tive o orgulho de participar, Alex E. J.
Falcão, Amanda Reis, Anderson D. Hummel, Felipe Mancini, Fernando S. Sousa,
Frederico M. Cohrs, Gabriela Araujo, Kellen Aureliano, Roberto Baptista e Thiago M. da
Costa, compartilhamos momentos felizes, desafios, companheirismo, discussões,
churrascos, publicações e, acima de tudo, amizade.
Ao professor Doutor Luciano Vieira de Araujo, pelo acolhimento nas reuniões
promovidas na USP-Leste e pelas contribuições que me ajudaram a concluir este
trabalho.
Aos professores Dr. Paulo Bandiera Paiva, Dr. Daniel Sigulem e Profa. Dra.
Heimar F. Marin que, durante o período do meu projeto, conduziram o departamento e
a Pós-graduação com maestria.
Aos docentes, Prof. Dr. Jacques Wainer, Profa. Dra. Claudia G. N. Barsottini, Prof.
Dr. Marcio B. Amaral, Prof. Dr. Carlos J. R. Campos, Prof. Roberto M Cesar Jr (USP) e
Prof. Dr. Evaldo Oliveira (USP) pelo conhecimento transferido por meio das disciplinas
lecionadas.
Andre Mattos, Homero Visani e Michel Seller, o apoio de vocês foi fundamental
para a realização deste trabalho. Muito obrigado!
Valdice P. S. Ribeiro muito obrigado pelo apoio administrativo durante o meu
projeto.
Aos amigos Bruno Monteiro, Luciano R. Lopes, D. Ana, Luciene Amorim, Maria
Zilda de Souza que de alguma forma colaboraram com esta pesquisa.
A minha esposa Angela, que incondicionalmente me apoiou na realização deste
trabalho, com paciência e amor, dividimos igualmente o sucesso alcançado.
Agradeço também a CAPES pela bolsa de pesquisa concedida.

vii
SUMÁRIO
DEDICATÓRIA ................................................................................................................. V
SUMÁRIO ...................................................................................................................... VII
LISTA DE FIGURAS ....................................................................................................... IX
LISTA DE TABELAS ....................................................................................................... XI
LISTA DE QUADROS ................................................................................................... XIII
LISTA DE ABREVIATURAS E SÍMBOLOS ................................................................. XIV
LISTA DE PUBLICAÇÕES ............................................................................................ XV
APOIO FINANCEIRO ................................................................................................... XVI
RESUMO .................................................................................................................... XVII
ABSTRACT ................................................................................................................ XVIII
1 INTRODUÇÃO .............................................................................................................. 1
1.1 Declaração do problema ............................................................................................ 2
1.2 Estado da Arte ........................................................................................................... 3
1.3 Classificação e indexação .......................................................................................... 4
1.4 Justificativa ................................................................................................................. 5
1.5 Organização da dissertação ...................................................................................... 6
2 OBJETIVOS .................................................................................................................. 7
2.1 Objetivo 1: Classificação de artigos científicos .......................................................... 7
2.2 Objetivo 2: Indexação de artigos científicos............................................................... 7
3 MATERIAIS E MÉTODOS ............................................................................................ 8
3.1 Materiais ..................................................................................................................... 8
3.2 Métodos ..................................................................................................................... 8
3.3 Composição da base de dados avaliada ................................................................. 10
3.4 Extração de características dos artigos ................................................................... 12
3.4.1 Métodos supervisionados de extração de características .................................... 13
3.4.2 Métodos não-supervisionados de extração de características ............................. 15

viii
3.5 Classificador de padrões probabilístico ................................................................... 17
3.6 Objetivo 1: Classificação de artigos científicos ........................................................ 19
3.7 Objetivo 2: Indexação de artigos científicos............................................................. 21
3.7.1 Indexação por meio de votação e competição de técnicas .................................. 23
3.8 Medidas de desempenho aplicadas ......................................................................... 24
3.9 Análises estatísticas ................................................................................................. 28
4 RESULTADOS ............................................................................................................ 30
4.1 Objetivo 1: Classificação de artigos científicos ........................................................ 30
4.1.1 Método supervisionado de extração de características ........................................ 30
4.1.2 Método não-supervisionado de extração de características ................................. 31
4.1.3 Comparação entre os métodos de classificação .................................................. 32
4.2 Objetivo 2: Indexação de artigos científicos............................................................. 35
4.2.1 Método supervisionado de extração de características ........................................ 35
4.2.2 Métodos não-supervisionados de extração de características ............................. 36
4.2.3 Indexação por meio de votação e competição de técnicas .................................. 37
4.2.4 Comparação entre as técnicas de indexação ....................................................... 38
5 DISCUSSÃO ............................................................................................................... 40
5.1 Objetivo 1: Classificação de artigos científicos ........................................................ 40
5.2 Objetivo 2: Indexação de artigos científicos............................................................. 43
5.2.1 Distribuição das categorias após indexação ......................................................... 46
6 CONCLUSÕES ........................................................................................................... 51
6.1 Objetivo 1: Classificação de artigos científicos ........................................................ 51
6.2 Objetivo 2: Indexação de artigos científicos............................................................. 51
7 APLICAÇÕES E TRABALHOS FUTUROS ................................................................. 53
8 ANEXOS ..................................................................................................................... 54
8.1 Aprovação do Comitê de Ética em Pesquisa ........................................................... 54
9 REFERÊNCIAS ........................................................................................................... 55

ix
LISTA DE FIGURAS
Figura 1 - Crescimento do volume de publicações relacionadas à Informática em
Saúde no período de 1987 a 2006 (20 anos) (Extraído do artigo de DeShazo et al.)[2]. . 1
Figura 2 - Disciplinas que contribuem para a interdisciplinaridade da Informática em
Saúde (Figura traduzida e adaptada)[5]. ........................................................................... 2
Figura 3 - Exemplo da definição teórica de classificação e indexação abordada neste
estudo. ............................................................................................................................. 5
Figura 4 - Recursos de hardware e software utilizados no estudo. ................................ 8
Figura 5 - Ilustração do método proposto para a realização do trabalho. ....................... 9
Figura 6 - Detalhamento das etapas de construção e avaliação do classificador de
artigos científicos nos domínios estudados. .................................................................. 20
Figura 7 - Detalhamento das etapas de construção e avaliação do indexador de artigos
científicos. ...................................................................................................................... 22
Figura 8 - Resumo das análises estatísticas utilizadas no estudo. ............................... 29
Figura 9 - Comparação da medida f0,5-score para os métodos jdi e tf. ......................... 33
Figura 10 - Comparação da medida f1-score para os métodos jdi e tf. ......................... 34
Figura 11 - Comparação da medida f2-score para os métodos jdi e tf. ......................... 34
Figura 12 - Comparação gráfica entre as maiores medidas de desempenho alcançadas
pelos métodos utilizados para indexação dos artigos científicos. ................................. 39
Figura 13 - Quantidade de termos (35.484) e respectiva intersecção presente nos
conjuntos de artigos científicos dos domínios da Ciência da Computação, Informática
em Saúde e Saúde. ....................................................................................................... 41
Figura 14 - Medidas f0,5-score, f1-score e f2-score de desempenho de classificação
alcançadas com o método supervisionado JDI.............................................................. 42
Figura 15 - Comparação entre a precisão dos métodos supervisionado e não-
supervisionados em relação à indexação de artigos. .................................................... 44
Figura 16 - Comparação entre a revocação dos métodos supervisionado e não-
supervisionados em relação à indexação de artigos. .................................................... 45
Figura 17 - Distribuição dos artigos científicos e descritores em relação aos domínios
estudados, de acordo com indexação sugerida pelo Portal ISI Web of Knowledge. ..... 48
Figura 18 - Distribuição dos artigos científicos e descritores em relação aos domínios
estudados, de acordo com a indexação sugerida pelo método de competição de
técnicas. ......................................................................................................................... 49

x
Figura 19 – Exemplo de indexações sugeridas pelo portal ISI Web of Knowledge e
método que utilizou a competição de técnicas atribuídas a um artigo científico coletado
da base de dados de validação. .................................................................................... 50

xi
LISTA DE TABELAS
Tabela 1 - Categorias e respectivos valores de relevância associadas a um artigo, de
acordo com o método utilizado pelo classificador Naive Bayes. ................................... 24
Tabela 2 - Exemplicação da medida f-score por meio da variação das pontuações de
Precisão e Revocação. .................................................................................................. 26
Tabela 3 - Matriz de confusão obtida quando o método supervisionado foi utilizado para
classificar artigos. ........................................................................................................... 30
Tabela 4 - Valores de precisão, revocação e f-score obtidos quando o método
supervisionado foi utilizado para classificar artigos. ...................................................... 30
Tabela 5 - Matriz de confusão obtida quando o método não-supervisionado foi utilizado
para classificar artigos. .................................................................................................. 31
Tabela 6 - Valores de precisão, revocação e f-score obtidos quando o método não-
supervisionado foi utilizado para classificar artigos. ...................................................... 32
Tabela 7 - Quadro resumo das medidas de desempenho abordadas e maiores
pontuações de desempenho alcançadas pelas técnicas utilizadas em relação aos
domínios estudados. ...................................................................................................... 32
Tabela 8 - Valores de p calculados para identificar a diferença estatística entre os
resultados a partir do teste Chi-quadrado. ..................................................................... 33
Tabela 9 - Resultados obtidos utilizando o método supervisionado de extração de
características. ............................................................................................................... 35
Tabela 10 - Valores de significância estatística quanto à distribuição normal dos
resultados. ...................................................................................................................... 36
Tabela 11 - Resultados obtidos utilizando os métodos não-supervisionados de extração
de características. .......................................................................................................... 36
Tabela 12 - Valores de significância estatística quanto à distribuição normal dos
resultados. ...................................................................................................................... 36
Tabela 13 - Diferença estatística entre os métodos quando avaliado f-score. .............. 37
Tabela 14 - Resultados obtidos utilizando a votação e competição de técnicas. ......... 37
Tabela 15 - Valores de significância estatística quanto à distribuição normal dos
resultados. ...................................................................................................................... 38
Tabela 16 - Diferença estatística entre os métodos quando avaliados os valores f-
score. ............................................................................................................................. 38

xii
Tabela 17 - Diferença estatística entre os resultados quando avaliados os valores f-
score. ............................................................................................................................. 39

xiii
LISTA DE QUADROS
Quadro 1 - Domínios e categorias utilizadas para construção da base de dados
provenientes do portal ISI Web of Knowledge. .............................................................. 10
Quadro 2 - Revistas selecionadas para a construção da base de dados. .................... 11
Quadro 3 - Relação final das categorias que compõem a base de dados avaliada neste
estudo provenientes do portal ISI Web of Knowledge. .................................................. 12
Quadro 4 - Matriz de relevância dos 35.484 termos para as 30 categorias do portal ISI
Web of Knowledge. ........................................................................................................ 14
Quadro 5 - Matriz de características construída utilizando a técnica supervisionada
para os artigos da base de dados de treino e validação. .............................................. 15
Quadro 6 - Descrição das técnicas não-supervisionadas de extração de características.
....................................................................................................................................... 16
Quadro 7 - Matriz de características construída para o método não supervisionado. .. 17
Quadro 8 - Matriz das relevâncias entre artigos e categorias, na qual 퐴푖 foi utilizado
para representar os artigos e 퐶푗 as categorias. ............................................................. 21
Quadro 9 - Vetores de relevância associados ao artigo científico. ............................... 23
Quadro 10 - Exemplificação das medidas de precisão, revocação e f-score para a
indexação de artigos. ..................................................................................................... 28
xiv
LISTA DE ABREVIATURAS E SÍMBOLOS
bo Binary occurrence
IMIA International Medical Informatics Association IS Informática em Saúde
JDI Journal Descriptor Indexing
MeSH Medical Subject Headings
NB/JDI Classificador Naive Bayes aliado a técnica JDI.
NB/tf Classificador Naive Bayes aliado a Term frequency
NB/tf.idf Classificador Naive Bayes aliado a Term frequency inverse document frequency
NB/tf.rf Classificador Naive Bayes aliado a Term frequency inverse relevance frequency
NB/to Classificador Naive Bayes aliado a Term occurrency
STI Semantic Type Indexing
tf Term frequency
tf.idf Term frequency inverse document frequency
tf.rf Term frequency inverse relevance frequency
to Term occurrency
UMLS Unified Medical Language System
UNIFESP Universidade Federal de São Paulo

xv
LISTA DE PUBLICAÇÕES
Teixeira F, Falcão AJ, Sousa FS, Hummel AD, da Costa TM, Mancini F, et al. Similarity-
based scoring method for classification of Health Informatics content. Journal of Health
Informatics. 2011;3:35-42.
Teixeira F, Hummel AD, de Domenico EBL, Araújo LV, Pisa IT. Statistical approach for
categorizing content in Medical Informatics, Computer Science and Health Domains. In:
AMIA 2011. Washington, DC: 2011.
Teixeira F, Hummel AD, Sousa FS, Mancini F, Falcão AEJ, de Domenico EBL, et al.
Abordagem Estatística Amparada na Teoria Bayesiana para Classificação de
Conteúdos de Artigos Científicos. In: 28º Colóquio Brasileiro de Matemática IMPA, Rio
de Janeiro: 2011.
Teixeira F, Falcão AJ, Hummel AD, Mancini F, da Costa TM, Sousa FS, et al. A method
for automatic content classification in health informatics based on specialized
thesaurus. In: MedInfo 2010. Cidade do Cabo: 2010. p. 1524.
Teixeira F, Falcão AEJ, Hummel AD, Mancini F, Costa TM, Sousa FS, et al. Using a
Health Informatics Thesaurus for automatic labeling articles. In: XII Congresso
Brasileiro de Informática em Saúde. CBIS 2010. Porto de Galinhas: 2010.
Teixeira F, Colepicolo E, Mancini F, Pisa IT. EpistemIS-XML: Modelo XML para
Disseminação e Padronização de Tesauro Epistemológico de Informática em Saúde.
In: XI Congresso Brasileiro de Informática em Saúde. CBIS 2008. Campos do Jordão,
São Paulo: 2008.

xvi
APOIO FINANCEIRO
Este projeto recebeu apoio financeiro por meio da concessão da bolsa:
CAPES-REUNI entre março/2010 e fevereiro/2011.
CAPES-Demanda social entre março/2011 e setembro/2011.

xvii
RESUMO
Teixeira FO. Classificação e indexação de artigos científicos internacionais de
Informática em Saúde [tese – Mestrado]. São Paulo: Departamento de Informática em
Saúde, Escola Paulista de Medicina, Universidade Federal de São Paulo; 2011. 77f.
Objetivo: O crescimento das bibliotecas virtuais é significativo ao longo dos últimos
anos, bem como os acervos responsáveis pelo armazenamento de artigos científicos.
Este cenário requer diferentes tipos de tratamento e representação dos dados, como a
classificação e indexação automática de documentos, a fim de contribuir para uma
recuperação de informação eficiente. O objetivo deste estudo foi propor um mecanismo
automatizado para a classificação e indexação de artigos científicos sob o domínio
interdisciplinar da Informática em Saúde. Métodos: Este estudo contemplou a
construção de uma base de dados com 10.800 títulos e resumos de artigos científicos
distribuídos uniformemente entre os domínios da Informática em Saúde, Ciência da
Computação e Saúde. Foi utilizado o modelo de espaço vetorial para identificar cada
artigo, no qual os vetores de características criados foram calculados a partir das
técnicas Journal Descriptor Indexing, term frequency inverse document frequency, term
frequency, term occurrence e binary occurrence. O classificador de padrões
probabilístico Naive Bayes recebeu como parâmetro tais vetores e foi utilizado para
classificar e indexar os artigos. A avaliação foi realizada por meio da medida de
desempenho f-score, bem como suas variações em relação aos pesos atribuídos à
precisão e revocação. Testes de significância estatística foram realizados a fim de
avaliar a independência das variáveis utilizadas. Resultados: A classificação e a
indexação de artigos entre os domínios que compuseram a base de validação
alcançaram valores de f-score superiores a 80% e 70%, respectivamente.
Conclusões: Os resultados foram expostos a medidas de validação amplamente
discutidas na literatura e, embora os artigos submetidos às tarefas de classificação e
indexação, neste estudo, pertencerem a um escopo interdisciplinar, o método proposto
foi capaz de caracterizá-los de acordo com sua área de interesse, com taxas de
acertos satisfatórias.
Palavras-chave: Informática médica. Classificação. Teorema de Bayes. Resumos e Indexação como Assunto.

xviii
ABSTRACT
Teixeira FO. Classification and indexing of international scientific articles in Health
Informatics [tese – Mestrado]. São Paulo: Departamento de Informática em Saúde,
Escola Paulista de Medicina, Universidade Federal de São Paulo; 2011. 77f.
Objectives: The virtual libraries' growth is considerable in the past few years, as well
the digital repositories which are responsible to store scientific papers. This scenario
requires different treatments and representation of the data, such as automatic
document classification and indexing to contribute to efficient information retrieval. The
purpose of this study was present an automatic engine to classifying and indexing
scientific papers under interdisciplinary domain of Health Informatics. Methods: This
study included a database's construction, divided into training and validation, consisting
of articles included in Health Informatics, Computer Science, and Health domains, in
order to represent the interdisciplinary nature of the proposed job. The feature vectors
of each paper were calculated using techniques to compute the word frequency. A
probabilistic pattern classifier was applied to classify and index articles. Measures of
precision, recall, and F-score, as well statistical significance were applied to results.
Results: The articles classification and indexing between domains used to build
validation database, reached f-score values above 80% and 70%, respectively.
Conclusions: Results were faced to validation measures broadly discussed in literature
and although the articles submitted to sorting and indexing tasks, in this study, come
from interdisciplinary scope, the proposed method was able to define them according to
their interest area, with satisfactory accuracy rates.
Keywords: Medical Informatics. Classification. Bayes Theorem. Abstracting and
Indexing as Topic.
1
1 INTRODUÇÃO
A interdisciplinaridade da Informática em Saúde (IS) e a amplitude dos temas
abordados em seu contexto, que ultrapassam barreiras previamente definidas por
domínios de conhecimento, diversificando fontes de armazenamento e recuperação de
informações, dificultam caracterizá-la sob um arcabouço de termos, conceitos e limites
de atuação[1].
No entanto, esforços são destinados à identificação de conhecimento relacionado
a IS, como o trabalho de DeShazo et al [2] que recuperou artigos publicados na
biblioteca virtual Medline/Pubmed (http://www.ncbi.nlm.nih.gov/pubmed) sob a
indexação do descritor “Medical Informatics” e sua respectiva árvore, oriunda do
vocabulário controlado Medical Subject Headings (MeSH,
http://www.ncbi.nlm.nih.gov/mesh), no período de 1987 a 2006.
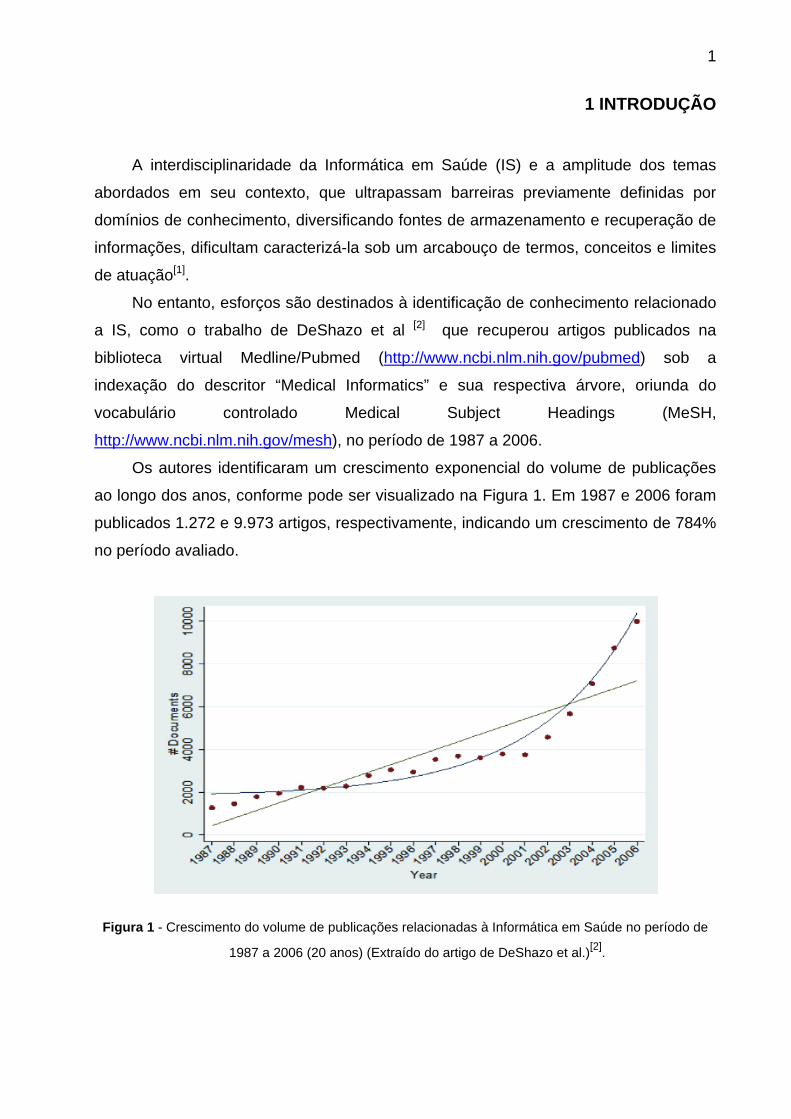
Os autores identificaram um crescimento exponencial do volume de publicações
ao longo dos anos, conforme pode ser visualizado na Figura 1. Em 1987 e 2006 foram
publicados 1.272 e 9.973 artigos, respectivamente, indicando um crescimento de 784%
no período avaliado.
Figura 1 - Crescimento do volume de publicações relacionadas à Informática em Saúde no período de
1987 a 2006 (20 anos) (Extraído do artigo de DeShazo et al.)[2].
2
1.1 Declaração do problema
A consequência de um domínio interdisciplinar, como o da IS, é a dificuldade para
a recuperação de informação pertinente ao seu contexto, uma vez que o conhecimento
está diluído sob diversas áreas, tais como Saúde, Ciência da Computação, Ciência da
Informação e Engenharia Biomédica[3,4].
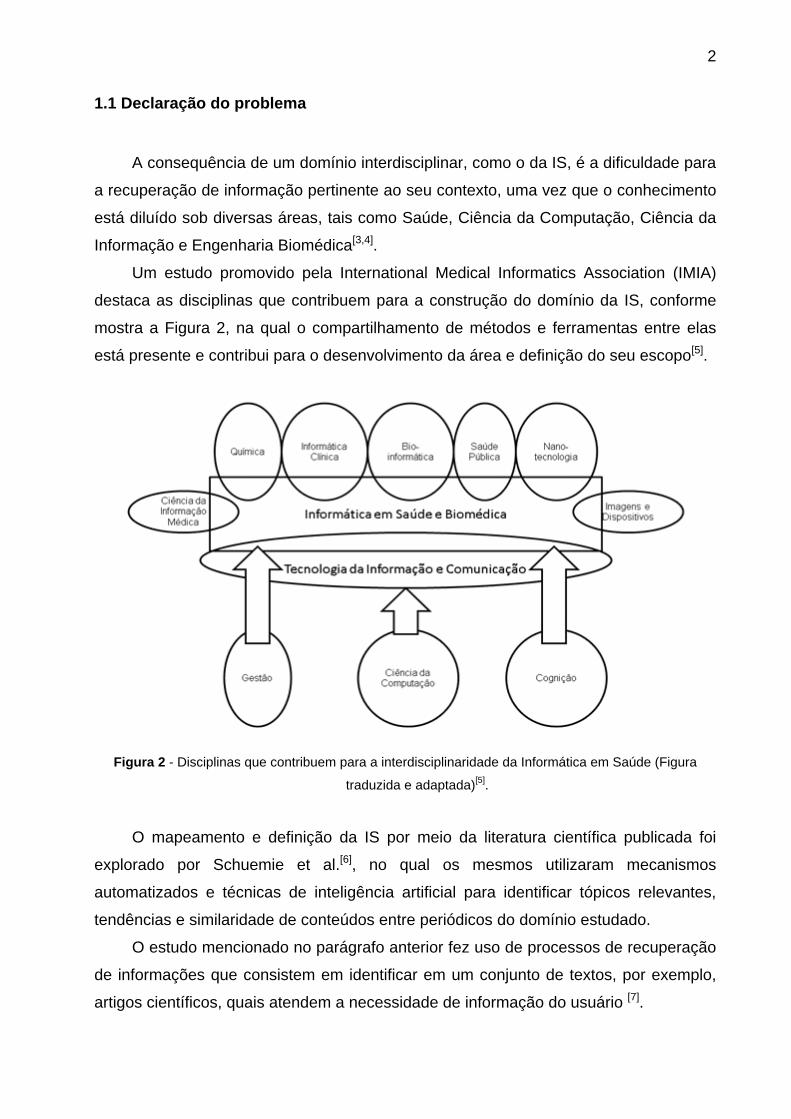
Um estudo promovido pela International Medical Informatics Association (IMIA)
destaca as disciplinas que contribuem para a construção do domínio da IS, conforme
mostra a Figura 2, na qual o compartilhamento de métodos e ferramentas entre elas
está presente e contribui para o desenvolvimento da área e definição do seu escopo[5].
Figura 2 - Disciplinas que contribuem para a interdisciplinaridade da Informática em Saúde (Figura
traduzida e adaptada)[5].
O mapeamento e definição da IS por meio da literatura científica publicada foi
explorado por Schuemie et al.[6], no qual os mesmos utilizaram mecanismos
automatizados e técnicas de inteligência artificial para identificar tópicos relevantes,
tendências e similaridade de conteúdos entre periódicos do domínio estudado.
O estudo mencionado no parágrafo anterior fez uso de processos de recuperação
de informações que consistem em identificar em um conjunto de textos, por exemplo,
artigos científicos, quais atendem a necessidade de informação do usuário [7].

3
Tais mecanismos automatizados são necessários devido ao crescimento das
bibliotecas virtuais e a grande quantidade de artigos científicos armazenados em tal
arquitetura, dificultando os processos de classificação e indexação manual de textos.
1.2 Estado da Arte
Há um amplo corpo de conhecimento disponível na literatura referente à
classificação e indexação automática de documentos. Neste contexto, podemos citar
os trabalhos de Kastrin[8] e Vasuki[9], que utilizaram técnicas probabilísticas e
vocabulários controlados para classificar e indexar artigos científicos cujo conteúdo
estava relacionado a temas do domínio da Saúde.
Outra fonte de extrema relevância para pesquisadores interessados no tema é o
projeto Text Categorization[10], mantido pela National Library of Medicine
(http://www.nlm.nih.gov/). Baseado em vocabulários controlados, tais como Medical
Subject Headings (MeSH, http://www.ncbi.nlm.nih.gov/mesh) e Unified Medical
Language System (UMLS, http://www.nlm.nih.gov/research/umls/), tem como objetivo
indexar artigos científicos relacionados à saúde por meio da associação estatística e
semântica entre palavras e descritores. Subdivide-se em duas iniciativas denominadas
Journal Descriptor Indexing (JDI) e Semantic Type Indexing (STI) [11–15].
O método JDI foi criado a partir de 121 descritores, presentes no vocabulário
MeSH, e a relação estatística dos mesmos com palavras presentes nos títulos e
resumos de artigos científicos publicados em cerca de 4.000 periódicos do domínio da
saúde.
Por outro lado, o método STI identifica relações semânticas entre textos, por meio
do cálculo da similaridade entre vetores criados a partir de 135 tipos semânticos
oriundos da UMLS.
Os trabalhos de Zhang et al [16] e Lan [17] preocuparam-se com a tarefa de
representação dos textos, fundamental para a classificação e indexação de conteúdo.
Embora os autores não tenham direcionado seus estudos para um domínio específico,
como o da Informática em Saúde, a avaliação realizada pelos mesmos em relação às
diferentes técnicas de extração de características textuais é relevante.

4
Métodos probabilísticos aplicados a recuperação de informações foram avaliados
por Sohn et al [18] e Aiguzhinov [19], nos quais os mesmos utilizaram a teoria de decisão
bayesiana como um dos pilares para seus trabalhos.
A particularidade da avaliação dos resultados de classificadores responsáveis
pela recuperação de informações textuais é abordada nos trabalhos de Gehanno et
al[20], Magdy [7] e Radlinski [21], nos quais medidas como precisão, revocação e f-score
são analisadas.
1.3 Classificação e indexação
Uma vez que a recuperação de informação em bases textuais é amparada por
mecanismos automatizados de classificação e indexação, torna-se relevante
compreendermos a definição teórica e as diferenças entre eles.
Neste trabalho adotaremos a definição teórica de Zhang [16] e Hanson [22], que tem
como pilares questões semânticas e estatísticas. De acordo com os autores, a
classificação tem a propriedade de reunir componentes de um grupo que possuem
relação semântica entre os mesmos. Por outro lado, a indexação trata apenas da
caracterização unitária dos componentes do grupo, abstendo o relacionamento entre
eles.
A Figura 3 exemplifica a definição teórica de classificação e indexação abordada
neste estudo, na qual 6 artigos foram classificados nos grupos Informática em Saúde,
Saúde e Ciência da Computação, respeitando a relação semântica entre os mesmos.
Na mesma figura, podemos visualizar a indexação sugerida para cada artigo, por
exemplo, a categoria Inteligência artificial, que foi utilizada nos 3 grupos. Portanto, a
sua utilização considerou apenas a análise individual de cada artigo, desconsiderando
os membros do respectivo grupo.

5
Figura 3 - Exemplo da definição teórica de classificação e indexação abordada neste estudo.
A recuperação de informação lida com informações semi ou não estruturadas que
dependem de uma representação específica para que o processo de classificação ou
indexação seja executado por classificadores de padrões [16]. A criação de um modelo
de espaço vetorial [23], cuja dimensão pode ser formada pelo número de termos
presentes no conjunto de documentos avaliados, possibilita que cada texto seja
identificado numericamente por meio de técnicas que calculam a relevância de cada
termo em relação ao documento.
1.4 Justificativa
O volume de artigos armazenados em bibliotecas virtuais e o aumento substancial
do mesmo sugerem mecanismos automatizados que auxiliem a tarefa humana de
classificação, indexação e recuperação de documentos.
Especificamente para o domínio da Informática em Saúde, no qual a
interdisciplinaridade intrínseca à mesma provoca um aumento da granularidade das
fontes de publicação de conteúdo e volume de publicações[2,24], o desafio atual é
oferecer mecanismos capazes de recuperar informações de maneira eficiente neste
domínio.
Portanto, os resultados deste trabalho pretendem responder à seguinte questão:
É possível a criação de mecanismos que possam classificar e indexar conteúdos
relacionados à Informática em Saúde em diferentes fontes de publicação, como
Informática em Saúde
Inteligência artificial
Mineração de textos
Engenharia biomédica
Saúde
Inteligência artificial
Oncologia
Biologia celular
Ciência da Computação
Inteligência artificial
Engenharia de software
Mineração de textos
Classificação Classificação Classificação
Artigo indexado
Artigo indexado
Artigo indexado
Artigo indexado
Artigo indexado
Artigo indexado

6
bibliotecas virtuais de Ciência da Computação ou Saúde, impedindo que informações
relevantes sejam descartadas?
1.5 Organização da dissertação
Esta dissertação está organizada da seguinte forma:
Capítulo 1: o capítulo corrente abordou elementos que subsidiaram os objetivos
gerais e específicos do presente trabalho, no qual foram explorados tópicos como
a representatividade da Informática em Saúde na comunidade científica, bem
como conceitos introdutórios de temas relacionados à recuperação de informação
textual;
Capítulo 2: são apresentados ao leitor os objetivos gerais e específicos.
Capítulo 3: os materiais e métodos utilizados para atingir os objetivos são
descritos neste capítulo. Os materiais contam com a relação de equipamentos,
softwares e bases de dados que ampararam a sequencia de passos que
caracterizaram os métodos, nos quais foram detalhadas as técnicas e análises
estatísticas que proporcionaram alcançar os objetivos previamente definidos;
Capítulo 4: são apresentados os resultados dos experimentos realizados;
Capítulo 5: discussão e comparação dos resultados obtidos nos diferentes
experimentos realizados, conduzindo o leitor a uma reflexão sobre a eficiência
das técnicas utilizadas;
Capítulo 6: conclusões do trabalho realizado
Capítulo 7: impactos científicos e trabalhos futuros.

7
2 OBJETIVOS
O objetivo principal deste trabalho é investigar a classificação e indexação de
artigos científicos a partir de técnicas vetoriais de extração de características de textos
aliadas a um classificador probabilístico. Para tanto, os seguintes objetivos específicos
foram estabelecidos:
2.1 Objetivo 1: Classificação de artigos científicos
Investigar mecanismos de classificação automática de artigos científicos entre os
domínios da Informática em Saúde, Ciência da Computação e Saúde, amparado em
técnicas vetoriais de extração de características de textos utilizadas como parâmetro
do classificador probabilístico Naive Bayes.
2.2 Objetivo 2: Indexação de artigos científicos
Propor um método capaz de indexar artigos científicos a partir de um conjunto de
categorias pré-definidas, delimitadas pelos domínios da Informática em Saúde, Ciência
da Computação e Saúde, utilizando técnicas de extração de características como
parâmetro do classificador probabilístico Naive Bayes.

8
3 MATERIAIS E MÉTODOS
Este capítulo conta com a descrição dos materiais utilizados para a condução
desta pesquisa, bem como, dos métodos realizados para alcançar os resultados
definidos nos objetivos específicos deste trabalho.
Este estudo foi analisado e aprovado pelo Comitê de Ética em Pesquisa da
Universidade Federal de São Paulo (UNIFESP), sob o protocolo de número 0247/09
em 13 de março de 2009 (Anexo 8.1 Aprovação do Comitê de Ética em Pesquisa).
O autor declarou não haver conflito de interesse na condução dessa pesquisa.
O projeto utilizou bases de dados digitais de artigos científicos, com o objetivo de
criar métodos computacionais que não exigem a participação de voluntários. Portanto
não houve necessidade de obtenção do Termo de Consentimento Livre e Esclarecido.
3.1 Materiais
Os recursos de hardware e software utilizados neste estudo são de propriedade
do Departamento de Informática em Saúde da UNIFESP e são compartilhados entre os
pesquisadores. A Figura 4 resume os recursos utilizados.
Figura 4 - Recursos de hardware e software utilizados no estudo.
3.2 Métodos
A Figura 5 mostra o método realizado, na qual são abordadas, de forma
sequencial, as etapas necessárias para a elaboração deste trabalho. Primeiramente, os

9
esforços concentraram-se na construção da base de dados de treinamento e validação,
descritos com detalhes na seção 3.3. Uma vez construída a base de dados, esta
suportou a criação dos vetores de características dos artigos científicos, baseados em
técnicas supervisionadas e não-supervisionadas, descritas na seção 3.4. O
classificador de padrões Naive Bayes escolhido para realizar a tarefa de classificação e
indexação dos artigos, que recebeu como parâmetro os vetores de características, é
abordado na seção 3.5. As seções 3.6 e 3.7 elucidam a relação entre os métodos e os
objetivos do trabalho e, finalmente, as análises de desempenho e estatística são
expostas nas seções 3.8 e 3.9.
Figura 5 - Ilustração do método proposto para a realização do trabalho.

10
3.3 Composição da base de dados avaliada
Os dados avaliados no estudo foram coletados a partir do portal ISI Web Of
Knowledge (http://apps.isiknowledge.com), que concentra bancos de dados de
publicações científicas de diferentes domínios de conhecimento.
O escopo da coleta concentrou-se em títulos e resumos de artigos científicos do
idioma inglês, classificados sob um conjunto de categorias, relacionadas no Quadro 1 ,
associadas às revistas e disponíveis no portal utilizado.
A escolha das categorias foi arbitrária, no entanto, buscou refletir a abrangência
conceitual dos domínios de conhecimento estabelecidos neste estudo, os quais foram
Ciência da Computação, Informática em Saúde e Saúde.
O critério para seleção das categorias, utilizado neste estudo, foi similar ao
explorado por Spreckelsen et al. [24].
Quadro 1 - Domínios e categorias utilizadas para construção da base de dados provenientes do portal
ISI Web of Knowledge.
Ciência da Computação Informática em Saúde Saúde
Computer Science, Artificial Intelligence; Medical Informatics Anatomy & Morphology Computer Science, Cybernetics Biochemistry & Molecular Biology Computer Science, Hardware & Architecture Biology Computer Science, Information Systems Clinical Neurology Computer Science, Interdisciplinary Applications Medicine, Research & Experimental Computer Science, Software Engineering Microbiology Computer Science, Theory & Methods Nursing Oncology Pediatrics
Foram selecionados 10.800 artigos científicos dispostos uniformemente entre as
27 revistas relacionadas no Quadro 2 . Portanto, cada revista contribuiu com 400
artigos, que posteriormente foram subdivididos em 2 conjuntos, treino e validação, por
meio da distribuição de 75% e 25%, respectivamente. Esta subdivisão resultou em
8.100 artigos para a base de treinamento e 2.700 para a base de validação.
As revistas com maior fator de impacto foram escolhidas, no entanto, deveriam
possuir a quantidade mínima de 400 artigos publicados.

11
Quadro 2 - Revistas selecionadas para a construção da base de dados.
Domínio Revistas
Ciência da Computação
ACM COMPUTING SURVEYS ACM TRANSACTIONS ON GRAPHICS COMPUTATIONAL INTELLIGENCE IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION IEEE TRANSACTIONS ON FUZZY SYSTEMS IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE IEEE TRANSACTIONS ON SOFTWARE ENGINEERING INTERNATIONAL JOURNAL OF COMPUTER VISION MIS QUARTERLY MIS QUARTERLY
Informática em Saúde
IEEE TRANSACTIONS ON INFORMATION TECHNOLOGY IN BIOMEDICINE INTERNATIONAL JOURNAL OF MEDICAL INFORMATICS INTERNATIONAL JOURNAL OF TECHNOLOGY ASSESSMENT IN HEALTH CARE JOURNAL OF BIOMEDICAL INFORMATICS JOURNAL OF MEDICAL INTERNET RESEARCH JOURNAL OF THE AMERICAN MEDICAL INFORMATICS ASSOCIATION MEDICAL & BIOLOGICAL ENGINEERING & COMPUTING METHODS OF INFORMATION IN MEDICINE STATISTICS IN MEDICINE
Saúde
BRAIN CA-A CANCER JOURNAL FOR CLINICIANS CELL INTERNATIONAL JOURNAL OF NURSING STUDIES JOURNAL OF ANATOMY JOURNAL OF THE AMERICAN ACADEMY OF CHILD AND ADOLESCENT PSYCHIATRY NATURE MEDICINE PLOS BIOLOGY PLOS PATHOGENS
Um fator levou a alteração da relação de categorias definidas originalmente
(Quadro 1 ) para a seleção de revistas utilizadas neste estudo: As revistas disponíveis
no portal utilizam uma ou mais categorias para sua indexação, a fim de refletir com
maior amplitude o conteúdo abordado nas mesmas.
Como exemplo, podemos utilizar o periódico Journal of the American Academy of
Child and Adolescent Psychiatry, que inicialmente foi selecionado por ser indexado pela
categoria “Pediatrics” e possuir um alto fator de impacto. No entanto, a ele estão
vinculadas outras duas categorias, “Psychiatry” e “Psychology, Developmental”, que
foram adicionadas à relação final. A nova configuração das categorias é mostrada no
Quadro 3 .
A heurística utilizada para a seleção de revistas e respectivos títulos e resumos
de artigos científicos contemplou um número significativo de exemplos. Embora haja
categorias relacionadas aos domínios estudados que não foram contempladas na
relação final (Quadro 3 ), as mesmas não comprometeram a generalidade dos
experimentos executados.
12
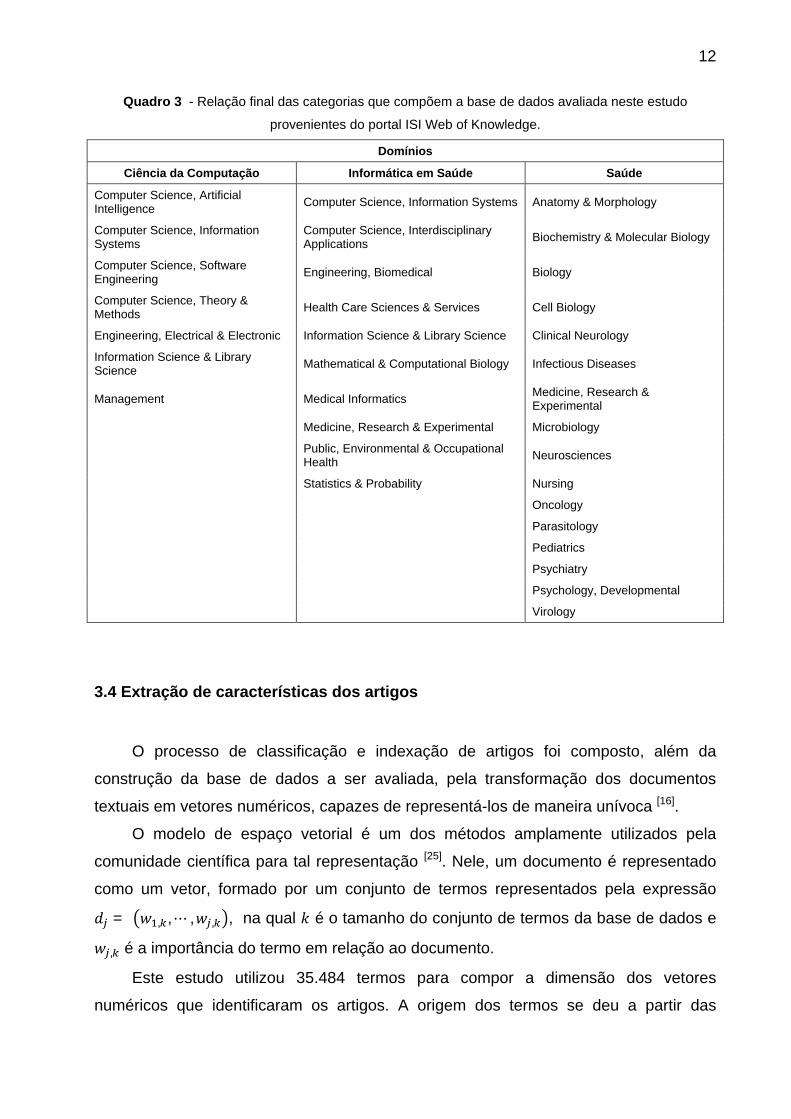
Quadro 3 - Relação final das categorias que compõem a base de dados avaliada neste estudo
provenientes do portal ISI Web of Knowledge.
Domínios
Ciência da Computação Informática em Saúde Saúde
Computer Science, Artificial Intelligence Computer Science, Information Systems Anatomy & Morphology
Computer Science, Information Systems
Computer Science, Interdisciplinary Applications Biochemistry & Molecular Biology
Computer Science, Software Engineering Engineering, Biomedical Biology
Computer Science, Theory & Methods Health Care Sciences & Services Cell Biology
Engineering, Electrical & Electronic Information Science & Library Science Clinical Neurology
Information Science & Library Science Mathematical & Computational Biology Infectious Diseases
Management Medical Informatics Medicine, Research & Experimental
Medicine, Research & Experimental Microbiology
Public, Environmental & Occupational Health Neurosciences
Statistics & Probability Nursing
Oncology
Parasitology
Pediatrics
Psychiatry
Psychology, Developmental
Virology
3.4 Extração de características dos artigos
O processo de classificação e indexação de artigos foi composto, além da
construção da base de dados a ser avaliada, pela transformação dos documentos
textuais em vetores numéricos, capazes de representá-los de maneira unívoca [16].
O modelo de espaço vetorial é um dos métodos amplamente utilizados pela
comunidade científica para tal representação [25]. Nele, um documento é representado
como um vetor, formado por um conjunto de termos representados pela expressão
푑 = 푤 , ,⋯ ,푤 , , na qual 푘 é o tamanho do conjunto de termos da base de dados e
푤 , é a importância do termo em relação ao documento.
Este estudo utilizou 35.484 termos para compor a dimensão dos vetores
numéricos que identificaram os artigos. A origem dos termos se deu a partir das

13
palavras únicas presentes nos títulos e resumos dos artigos que compuseram a base
de dados.
Para alcançar o número total de termos utilizados foram executados
processamentos preliminares, como:
1. Remoção de palavras presentes em uma lista de stopwords [26].
2. Aplicação de stemming [27] para cada palavra.
O processo de remoção de stopwords conta com a identificação, nos textos da
base de dados, de pronomes, conjunções, preposições e artigos que são irrelevantes
para a tarefa de classificação ou indexação. Este trabalho utilizou a lista de stopwords
disponível na ferramenta RapidMiner (http://rapid-i.com), utilizada para a mineração dos
textos. O stemming das palavras refere-se à redução das mesmas a sua raiz
morfológica, por meio da eliminação de prefixos e sufixos.
O modelo de espaço vetorial pode ser construído utilizando técnicas
supervisionadas ou não-supervisionadas, que serão detalhadas nas subseções
seguintes.
3.4.1 Métodos supervisionados de extração de características
A utilização de conhecimento prévio, no qual o conjunto de termos está
relacionado a um determinado grupo ou categoria, caracteriza o método
supervisionado de extração de características.
As técnicas supervisionadas presentes neste método utilizam, por exemplo, a
categoria dos documentos, associadas aos mesmos pelo portal ISI Web of Knowledge,
como um denominador para o cálculo da relevância dos termos.
O trabalho de Lan [17] apresentou a técnica term frequency inverse relevance
frequency (tf.rf) e comparou-a com as alternativas não-supervisionadas, detalhadas na
subseção seguinte, e obteve, em alguns cenários, resultados superiores de
classificação de textos.
Outra técnica caracterizada pela característica supervisionada é o Journal
Descriptor Indexing (JDI) [11–15], na qual os títulos e resumos dos artigos da base de
dados de treino “herdam” a categoria atribuída às revistas que os publicaram.

14
A Equação 1 mostra o cálculo utilizado pelo método JDI para obter a pontuação
de relevância dos termos em relação à categoria avaliada, que pode variar entre 0 e 1,
sendo os valores próximos de 1 os mais relevantes.
Na equação, o numerador 푛 , representa a soma do número de artigos nos quais
o termo 푡 co-ocorre com a categoria 푐 , que indexou a revista e o artigo, por meio da
relação de herança. O parâmetro 푗: 푡 ∈ 푑 expressa a soma do número de artigos
nos quais o termo 푡 ocorre independentemente da indexação herdada da revista.
퐽퐷퐼 , =푛 ,
푗: 푡 ∈ 푑
Equação 1 - Método JDI para extração de características dos documentos.
Neste estudo, cada termo da base de dados de treinamento foi associado a um
vetor, cuja dimensão foi definida pelo número de categorias relacionadas no Quadro 3
(página 12). Os elementos de tal vetor armazenaram o valor de relevância do termo em
relação à respectiva categoria.
O Quadro 4 mostra a matriz construída após o cálculo expresso na Equação 1
para o conjunto de termos da base de treinamento avaliada, cujo número de elementos
foi igual a 35.484.
Quadro 4 - Matriz de relevância dos 35.484 termos para as 30 categorias do portal ISI Web of
Knowledge.
푡 푡 ... 푡 퐶 퐽퐷퐼 , 퐽퐷퐼 , ... 퐽퐷퐼 ,
퐶 퐽퐷퐼 , 퐽퐷퐼 , ... 퐽퐷퐼 ,
... ... ... ... ...
퐶 퐽퐷퐼 , 퐽퐷퐼 , ... 퐽퐷퐼 ,
Para a construção do vetor de características de cada artigo das bases de dados
de treinamento e validação foi calculada a média aritmética da relevância dos termos,
presentes nos respectivos títulos e resumos dos artigos, em relação às categorias
avaliadas no estudo.
Cada dimensão de tal vetor foi obtida por meio da fórmula expressa na Equação
2, na qual ∑ 퐽퐷퐼 ,. representa o somatório dos valores de relevância dos termos,
presentes no título e resumo do artigo avaliado, em relação a uma determinada

15
categoria. O parâmetro ∑1, 푠푒 퐽퐷퐼 , > 00, 푠푒 퐽퐷퐼 , = 0 , da mesma equação, é o somatório da
quantidade de termos associados à categoria avaliada.
O Quadro 5 mostra a matriz de características construída para os artigos das
bases de dados de treino e validação. As linhas de tal matriz, representadas pelo vetor
multidimensional 푆 , , armazenam os valores de relevância das categorias em relação
aos artigos, cuja dimensão se limitou ao número de categorias avaliadas.
푆,
∑ ,.
∑, ,, ,
Equação 2 - Média aritmética dos termos em relação às categorias.
Quadro 5 - Matriz de características construída utilizando a técnica supervisionada para os artigos da
base de dados de treino e validação.
퐶 퐶 ... 퐶
퐴 푆 , 푆 , ... 푆 ,
퐴 푆 , 푆 , ... 푆 ,
... ... ... ... ...
퐴 푆 , 푆 , ... 푆 ,
Este método foi explorado nos experimentos deste estudo e comparado com as
técnicas não-supervisionadas de extração de características que serão apresentadas a
seguir.
3.4.2 Métodos não-supervisionados de extração de características
As técnicas tradicionais term frequency (tf), binary occurrence (bo), term
occurrence (to) e term frequency inverse document frequency (tf.idf) [28] caracterizam o
método não-supervisionado, uma vez que o cálculo da relevância é realizado sem
considerar classificações previamente estabelecidas.
A descrição de cada técnica, bem como suas restrições, é mostrada no Quadro 6
.

16
Quadro 6 - Descrição das técnicas não-supervisionadas de extração de características.
Técnica Descrição
푡푓 Dado um documento, a técnica calcula a divisão entre o nº de ocorrências de um determinado termo e a quantidade de termos existentes no mesmo documento.
푏표 Dado o conjunto de termos de um documento, a técnica indica a presença ou não de um determinado termo no mesmo.
푡표 Esta técnica utiliza a quantidade de vezes que um termo ocorreu em documento para compor o vetor de características do mesmo. Não ocorre a divisão pela quantidade de termos do documento avaliado, como na técnica tf.
푡푓. 푖푑푓 Esta técnica explora a relação entre a quantidade de vezes que um termo ocorre em um documento e a ocorrência do mesmo em todos os documentos avaliados.
A Equação 3, Equação 4, Equação 5 e Equação 6 ilustram os técnicas abordadas
nesta subseção, nas quais 푛 , é o número de ocorrências de um determinado termo
em um documento, ∑ 푛 , representa a quantidade de termos do documento, |퐷| é a
quantidade de documentos avaliados e 푗: 푡 ∈ 푑 é o número de documentos nos
quais o termo 푡 ocorre.
푡푓 , =푛 ,
∑ 푛 ,
Equação 3 - Term frequency (tf)
푏표 , =1, 푡푓 , > 00, 푡푓 , = 0
Equação 4 - Binary occurrence (bo)
푡표 , = 푛 ,
Equação 5 - Term occurrence (to)
푡푓. 푖푑푓 , = 푡푓 × log|퐷|
푗: 푡 ∈ 푑
Equação 6 - Term frequency inverse document frequency (tf.idf)
A matriz de características construída para cada técnica abordada nesta seção é
mostrada no Quadro 7 .
A dimensão de tal matriz foi composta pela quantidade de termos
푡 e artigos 퐴 encontrados na base de dados avaliada neste estudo. Cada elemento
do vetor multidimensional 푁푆 , armazenou o cálculo da relevância, que variou entre 0

17
e 1, de cada termo em relação aos artigos, de acordo com a respectiva técnica de
extração de características utilizada e expressa nas equações abordadas nesta
subseção.
Quadro 7 - Matriz de características construída para o método não supervisionado.
푡 푡 ... 푡 .
퐴 푁푆 , 푁푆 , ... 푁푆 , .
퐴 푁푆 , 푁푆 , ... 푁푆 , .
... ... ... ...
퐴 . 푁푆 . , 푁푆 . , ... 푁푆 . , .
3.5 Classificador de padrões probabilístico
A variedade de classificadores disponíveis na literatura é substancial, dentre eles
podemos citar as Artificial Neural Networks [29], Support Vector Machines [30], K-nearest
neighbours [31], Decision Trees [32] e Naive bayes [33]. Os exemplos citados reúnem um
pequeno número de opções disponíveis e sua aplicação depende do tipo de problema
enfrentado pelo pesquisador.
De acordo com a subdivisão proposta por Theodoridis [34], podemos agrupar os
classificadores em probabilísticos, lineares e não lineares.
Dentre os classificadores probabilísticos destacam-se àqueles baseados na teoria
de decisão bayesiana, como o Naive bayes. A premissa deste grupo concentra-se na
natureza da distribuição estatística dos atributos dos exemplos a serem classificados.
O grupo dos classificadores lineares, como as Support Vector Machines, ampara-
se em funções polinomiais de primeiro grau. Neste caso, a densidade probabilística dos
dados ou funções de probabilidade utilizadas pelo grupo citado no parágrafo anterior
não são consideradas.
Finalmente, podemos citar as Decision Trees e Artificial Neural Networks como
representantes do grupo de classificadores não lineares. Este grupo poderá ser útil
quando os limites das classes não puderem ser definidos por meio de probabilidades
ou funções lineares.
Este estudo concentrou-se na aplicação do classificador Naive Bayes e na sua
variação denominada Multinomial [33], que permite capturar o cálculo da relevância dos
termos. A escolha baseou-se na simplicidade do método e na sua eficiência para a

18
tarefa supervisionada de classificação e indexação de textos, comprovada, ao longo
dos anos, por meio de estudos científicos [18,35–38].
Uma vez criadas as matrizes de características dos documentos que compõem a
base de treino, as mesmas foram apresentadas como parâmetro de entrada do
classificador de padrões probabilístico Naive Bayes, a fim de realizar as tarefas de
classificação e indexação dos artigos que compuseram a porção de validação da base
de dados utilizada nos experimentos deste projeto.
O classificador Naive Bayes assume que os termos que compõem a base de
dados são independentes e, portanto, o adjetivo naive, “ingênuo” em português, é
atribuído a fim de considerar que a premissa da independência não ocorre, por
exemplo, ao avaliarmos a semântica de um texto.
O modelo bayesiano utilizado neste estudo é fundamentado na teoria das
probabilidades [39], regida pela Equação 7.
푃(퐶 = 푐 |푋 = 푥) = 푃(퐶 = 푐 ) ×푃(푋 = 푥|퐶 = 푐 )
푃(푥)
na qual,
푃(푋 = 푥) = 푃(푋 = 푥|퐶 = 푐 ´) × 푃(퐶 = 푐 ´)´
Equação 7 - Teorema de probabilidade de Bayes (a).
O denominador 푃(푥) representa o somatório da probabilidade de todos os
eventos possíveis. Neste estudo, significa documentos pertencerem a uma
determinada classe 푐 , … , 푐 , … , 푐 . O parâmetro 푋 reúne o conjunto de
características de um documento, 푥 = 푥 , … , 푥 , … , 푥 .
O numerador 푃(푋 = 푥|퐶 = 푐 ) é obtido considerando a premissa da
independência das características dos documentos, na qual os elementos contidos no
vetor 푥 são estatisticamente independentes. A Equação 8 apresenta este cálculo.
푃(푋 = 푥|퐶 = 푐 ) = 푃 푥 푐
Equação 8 - Teorema de probabilidade de Bayes (b).

19
Portanto, 푃(퐶 = 푐 |푋 = 푥) é a probabilidade condicional de um determinado
documento em pertencer a uma classe, uma vez que o vetor de características 푥 é
conhecido.
Os valores presentes nos conjuntos de características dos documentos, variável
푋, foram obtidos pelas técnicas de extração abordadas na seção 3.4 e submetidos ao
classificador de padrões probabilístico definido neste estudo.
3.6 Objetivo 1: Classificação de artigos científicos
Um dos objetivos específicos deste estudo concentra-se na classificação de
artigos científicos entre os domínios da Informática em Saúde, Ciência da Computação
e Saúde.
Os artigos do subconjunto de treinamento, bem como seus respectivos vetores de
características, foram apresentados ao classificador de padrões definido na seção 3.5,
a fim de se realizar um treinamento supervisionado dos dados [40].
Os vetores de características dos artigos destinados à validação foram
submetidos à classificação e rotulados automaticamente em um dos 3 domínios
estudados.
Foram comparadas cinco estratégias de classificação, baseadas no tipo de
extração de características discutidas na seção 3.4. A Figura 6 detalha o processo de
construção do classificador para cada técnica utilizada.
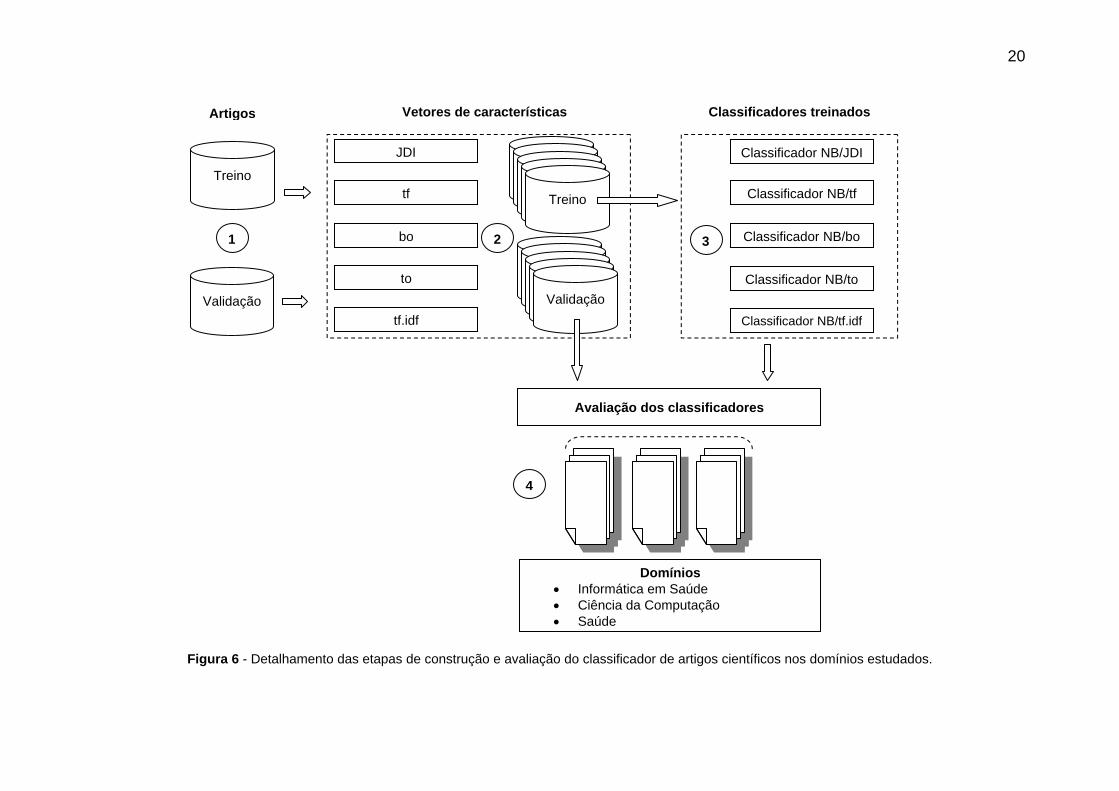
20
Figura 6 - Detalhamento das etapas de construção e avaliação do classificador de artigos científicos nos domínios estudados.
Validação
Treino JDI
Treino Treino Treino Treino
Treino Treino Treino Treino Validação tf.idf
to
bo
tf
Classificador NB/JDI
Classificador NB/tf.idf
Classificador NB/to
Classificador NB/bo
Classificador NB/tf
Classificadores treinados Vetores de características
Avaliação dos classificadores
Domínios Informática em Saúde Ciência da Computação Saúde
Artigos
Treino
1 2 3
4
21
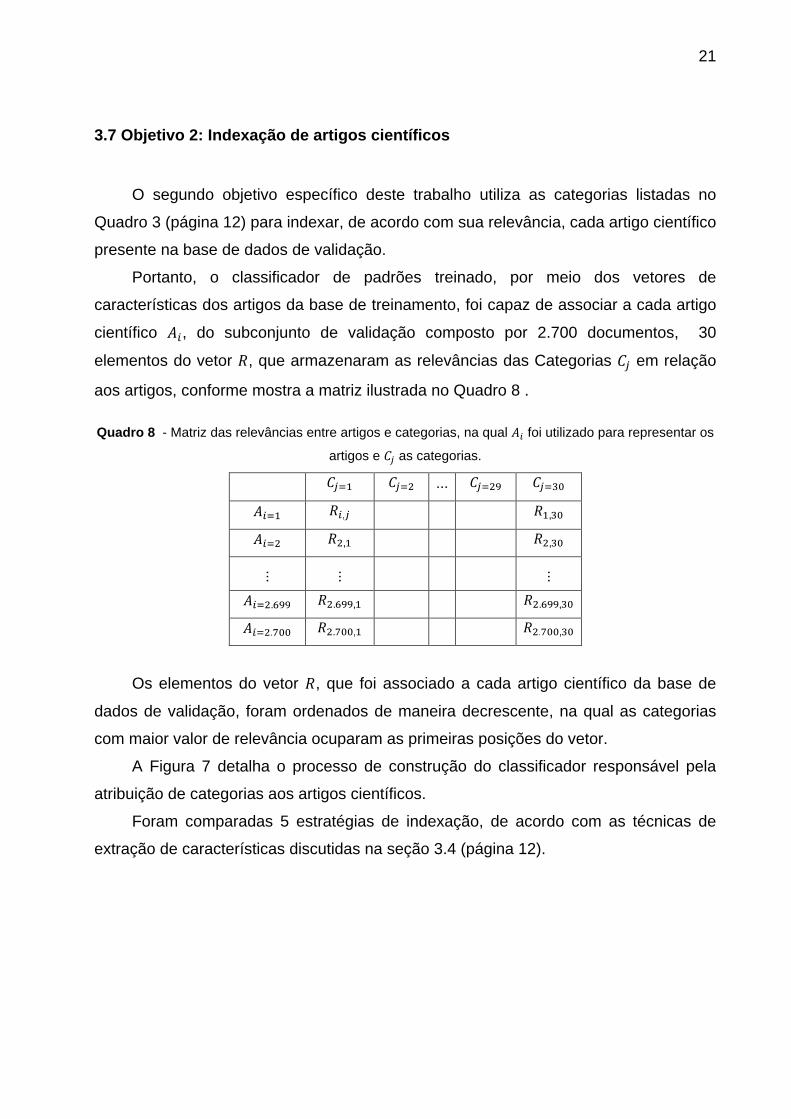
3.7 Objetivo 2: Indexação de artigos científicos
O segundo objetivo específico deste trabalho utiliza as categorias listadas no
Quadro 3 (página 12) para indexar, de acordo com sua relevância, cada artigo científico
presente na base de dados de validação.
Portanto, o classificador de padrões treinado, por meio dos vetores de
características dos artigos da base de treinamento, foi capaz de associar a cada artigo
científico 퐴 , do subconjunto de validação composto por 2.700 documentos, 30
elementos do vetor 푅, que armazenaram as relevâncias das Categorias 퐶 em relação
aos artigos, conforme mostra a matriz ilustrada no Quadro 8 .
Quadro 8 - Matriz das relevâncias entre artigos e categorias, na qual 퐴 foi utilizado para representar os
artigos e 퐶 as categorias.
퐶 퐶 ... 퐶 퐶
퐴 푅 , 푅 ,
퐴 푅 , 푅 ,
...
... ...
퐴 . 푅 . , 푅 . ,
퐴 . 푅 . , 푅 . ,
Os elementos do vetor 푅, que foi associado a cada artigo científico da base de
dados de validação, foram ordenados de maneira decrescente, na qual as categorias
com maior valor de relevância ocuparam as primeiras posições do vetor.
A Figura 7 detalha o processo de construção do classificador responsável pela
atribuição de categorias aos artigos científicos.
Foram comparadas 5 estratégias de indexação, de acordo com as técnicas de
extração de características discutidas na seção 3.4 (página 12).
22
Figura 7 - Detalhamento das etapas de construção e avaliação do indexador de artigos científicos.
Validação
Treino JDI
Treino Treino Treino Treino
Treino Treino Treino Treino Validação tf.idf
to
bo
tf
Classificador NB/JDI
Classificador NB/tf.idf
Classificador NB/to
Classificador NB/bo
Classificador NB/tf
Classificadores treinados Vetores de características
Avaliação dos classificadores
퐶푎푡푒푔표푟푖푎 , 퐶푎푡푒푔표푟푖푎 , ⋯, 퐶푎푡푒푔표푟푖푎 , 퐶푎푡푒푔표푟푖푎
Artigos
Treino
1 2 3
4
퐶푎푡푒푔표푟푖푎 , 퐶푎푡푒푔표푟푖푎 , ⋯, 퐶푎푡푒푔표푟푖푎 , 퐶푎푡푒푔표푟푖푎
⋮

23
3.7.1 Indexação por meio de votação e competição de técnicas
O segundo objetivo específico do estudo também explorou a eficiência da
indexação de artigos científicos quando diferentes técnicas de extração de
características foram utilizadas, em conjunto, para realizar tal tarefa.
O Quadro 9 mostra a análise de um artigo (퐴 ) da base de dados de validação
após a atribuição dos vetores ordenados de relevância das categorias, criados a partir
de cada técnica oriunda dos métodos supervisionado e não-supervisionado que
alimentaram os parâmetros de entrada do classificador Naive Bayes.
Foram considerados os vetores 푅 de cada artigo científico, conforme mostrado no
Quadro 9 , resultantes da aplicação do classificador de acordo com as técnicas de
extração de características abordadas, para propor a indexação final do mesmo.
A indexação por meio de votação considerou o índice do vetor e a ocorrência das
categorias para determinar a indexação dos artigos científicos. Dado o artigo 퐴 , na
qual a posição 푗 = 1 dos vetores 푅 , , 푅 , e 푅 ,. estão associadas à categoria “A” e,
na mesma posição 푗 = 1, os vetores 푅 , e 푅 ,. estão associados à categoria “B”, foi
considerada a categoria “A” como sugestão final para a indexação do artigo científico
nesta posição de relevância, uma vez que a mesma possui o maior número de
ocorrências. Nos casos em que não houve predominância de uma determinada
categoria foi considerada a que apresentou a maior pontuação de relevância.
A Competição de técnicas utilizou a maior pontuação de relevância atribuída à
posição do vetor e sua respectiva categoria para compor a indexação final do artigo.
Quadro 9 - Vetores de relevância associados ao artigo científico.
퐴
푅 , 푅 , 푅 , 푅 , 푅 ,.
푅 , 푅 , 푅 , 푅 , 푅 ,.
⋯ ⋯ ⋯ ⋯ ⋯
푅 , 푅 , 푅 , 푅 , 푅 ,.

24
A Tabela 1 foi utilizada para exemplificar a aplicação dos métodos, abordados
nesta subseção, a um determinado artigo. Nesta tabela, as letras de A a G foram
utilizadas para representar as categorias, os valores à direita de cada letra indicam a
pontuação de relevância da categoria em relação ao artigo científico, de acordo com a
técnica utilizada pelo classificador Naive Bayes.
Portanto, a indexação por meio de votação atribuiu ao artigo exemplo, de acordo
com a tabela, as categorias A, D, F, C e B como sugestão de indexação final, pois foi
contabilizada uma maior ocorrência das mesmas em sua respectiva posição de
relevância. O exemplo mostra que a categoria A foi sugerida por 3 das 5 técnicas
possíveis para a indexação da primeira posição de relevância em relação ao artigo
científico. Por outro lado, a lista final definida pela competição de técnicas foi C, B, F, G
e E, uma vez que as mesmas foram associadas às maiores pontuações de relevância
nas posições avaliadas dos vetores criados a partir das técnicas.
Tabela 1 - Categorias e respectivos valores de relevância associadas a um artigo, de acordo com o
método utilizado pelo classificador Naive Bayes.
Posição do vetor NB/JDI NB/tf.idf NB/tf NB/to NB/bo
1 A = 0,97 C = 0,99 E = 0,23 A = 0,75 A = 0,55 2 B = 0,90 D = 0,82 A = 0,18 D = 0,74 D = 0,50 3 F = 0,85 G = 0,60 F = 0,15 F = 0,62 F = 0,42 4 G = 0,70 A = 0,50 B = 0,14 C = 0,63 C = 0,30 5 C = 0,42 E = 0,44 C = 0,12 B = 0,43 B = 0,18
3.8 Medidas de desempenho aplicadas
Medidas convencionais de desempenho como precisão, revocação e f-score [20]
foram aplicadas aos resultados obtidos por meio do classificador de padrões construído
para os experimentos e suas respectivas variações nos parâmetros de entrada.
A precisão é definida pela razão entre exemplos classificados corretamente,
representado pelo parâmetro 푡 (true positive ou, em português, verdadeiros positivos)
presente no numerador da Equação 9, e todos aqueles que foram associados a uma
determinada classe pelo mecanismo avaliado, representado pelo denominador da
mesma equação, que calcula a soma entre 푡 e 푓 (false positive ou, em português,
falsos positivos).

25
푃 = 푡
푡 + 푓
Equação 9 - Cálculo da precisão.
A revocação é obtida por meio de todos os exemplos classificados corretamente,
representado pelo parâmetro 푡 presente no numerador da Equação 10, e todos
aqueles que deveriam ter sido associados a uma determinada classe pelo mecanismo
avaliado, representado pelo denominador da mesma equação, que calcula a soma
entre 푡 e 푓 (false negative ou, em português, falsos negativos).
푅 = 푡
푡 + 푓
Equação 10 - Cálculo da revocação.
O f-score [7], por sua vez, é uma medida harmônica entre Precisão e Revocação,
regida pela Equação 11, na qual 푃 e 푅 representam os valores de Precisão e
Revocação, respectivamente, e 훽 é um parâmetro de ponderação da Revocação em
relação à Precisão, determinando a importância da mesma para o sistema de
recuperação de informação avaliado. Neste estudo, os experimentos utilizaram três
variações para o parâmetro 훽, sendo 0.5, 2 e 1, que determinaram maior importância à
Precisão, Revocação e pesos iguais, respectivamente, aos parâmetros utilizados na
fórmula.
퐹 − 푠푐표푟푒 =(1 + 훽 ) ∗ (푃 ∗ 푅)
훽 ∗ 푃 + 푅
Equação 11 - Medida f-score.
Para exemplificar o cálculo da Equação 11 a Tabela 2 foi utilizada, na qual as
medidas de Precisão e Revocação alternaram os valores de 0,75 e 0,85,
respectivamente. Observa-se na coluna f-score1, que embora haja alternância nos
valores, o parâmetro 훽 igual a 1 garantiu pesos iguais à medida, atribuindo a mesma
pontuação (0,80) para variações equivalentes. Quando o peso da Revocação em
relação à Precisão é considerado, o balanceamento dos resultados também pode ser
observado na tabela.

26
Tabela 2 - Exemplicação da medida f-score por meio da variação das pontuações de Precisão e
Revocação.
Precisão Revocação f-score0,5 f-score1 f-score2 0,75 0,85 0,77 0,80 0,83 0,85 0,75 0,83 0,80 0,77
Uma variação das medidas de desempenho mencionadas no parágrafo anterior
foi utilizada para avaliar o classificador construído quanto à indexação de artigos
científicos, uma vez que a pontuação de relevância da categoria em relação aos
mesmos foi considerada [41].
A Equação 12, Equação 13 e Equação 14 mostram os cálculos da Precisão,
Revocação e f-score, respectivamente, utilizados quando um determinado intervalo 푘
de categorias, associadas pelo classificador a cada artigo 퐴 de acordo com sua
pontuação de relevância, representado pelo parâmetro 푅 , , foi utilizado para
determinar se a indexação sugerida pelo classificador foi correta.
Neste estudo, o intervalo de categorias foi avaliado apenas para o valor de 푘 igual
a 5. A escolha deste valor respeitou a quantidade máxima de categorias associadas
pelo Portal ISI Web of Knowledge aos artigos que compuseram a base de dados
utilizada nos experimentos.
A indexação de textos por meio do cálculo da relevância de índices também foi
explorado por Radlinski e Craswell [21], quando os mesmos avaliaram páginas web
retornadas a partir de consultas submetidas a um buscador.
푃@푘 =1
|퐶|∑ 푅푒푙푒푣푎푛푡푒푠 푒 푅푒푡표푟푛푎푑표푠 푅 ,
∑ 푅푒푡표푟푛푎푑표푠 푅 ,
Equação 12 - Precisão baseada em intervalo de avaliação.
푅@푘 =1
|퐶|∑ 푅푒푙푒푣푎푛푡푒푠 푒 푅푒푡표푟푛푎푑표푠 푅 ,
∑ 푅푒푙푒푣푎푛푡푒푠 푅 ,
Equação 13 - Revocação baseada em intervalo de avaliação.
퐹@푘 =(1 + 훽 ) ∗ (푃@푘 ∗ 푅@푘)
훽 ∗ 푃@푘 + 푅@푘
Equação 14 - F-score baseado em intervalo de avaliação.

27
O Quadro 10 foi utilizado para exemplificar os cálculos da Precisão, Revocação e
f-score, quando um intervalo 푘 de categorias foi considerado. Na primeira coluna deste
quadro, os artigos A, B, C e E exemplificam a indexação proposta pelo Portal ISI Web
of Knowledge, por meio da categoria “Statistics & Probability”. A coluna central reúne
os artigos A, C e D, nos quais a categoria “Statistics & Probability” foi associada pelo
classificador automatizado, representado pelo parâmetro ∑ 푅푒푡표푟푛푎푑표푠 푅 , na
Equação 12, considerando que a relevância da categoria em relação aos artigos pode
variar entre a primeira e quinta posição. De acordo com a indexação sugerida no
exemplo pelo Portal, disposta na primeira coluna do Quadro 10 , apenas 2 artigos, A e
C, desta associação automatizada foram categorizados corretamente, os quais foram
identificados como “verdadeiros positivos” na coluna central e alimentam o parâmetro
∑ 푅푒푙푒푣푎푛푡푒푠 푒 푅푒푡표푟푛푎푑표푠 푅 , das equações Equação 12 e Equação 13. O
artigo D, embora tenha sido indexado pelo mecanismo automatizado sob a categoria
“Statistics & Probability”, não alimenta o numerador das equações, uma vez que não foi
originalmente indexado pelo Portal sob a categoria avaliada. Portanto, obtivemos uma
precisão para esta categoria de 0,67.
Para a Revocação, o parâmetro ∑ 푅푒푙푒푣푎푛푡푒푠 푅 , expressa a quantidade de
artigos que deveriam ser retornados pelo classificador, no exemplo, estes foram
representados pelas letras A, B, C e E, que originalmente foram indexados pelo Portal
sob a categoria “Statistics & Probability”. Assumindo o intervalo 푘 de relevâncias das
categorias associadas aos artigos pelo mecanismo automatizado, esta medida assumiu
o valor de 0,50.
Uma vez calculadas as médias aritméticas da Precisão e Revocação das
categorias avaliadas no estudo, é possível, portanto, realizar o cálculo da medida f-
score demonstrada na Equação 14.

28
Quadro 10 - Exemplificação das medidas de precisão, revocação e f-score para a indexação de artigos.
Categoria: Statistics & Probability
Portal ISI Web of Knowledge
Classificador Automatizado Relevância 1ª a 5ª posição
Classificador Automatizado Relevância 6ª a 30ª posição
Artigo A Artigo A (verdadeiro positivo) (1º posição)
Artigo B Artigo B (falso negativo) (8º posição)
Artigo C Artigo C (verdadeiro positivo) (3º posição)
Artigo D (falso positivo) (5º posição)
Artigo E Artigo E (falso negativo) (15º posição)
Artigo F (verdadeiro negativo) (6º posição)
Foram utilizadas duas classes de medidas, que avaliaram o desempenho do
classificador quanto a:
Classificação automática de artigos científicos entre os domínios da Saúde,
Informática em Saúde e Ciência da Computação.
Indexação automática de artigos científicos de acordo com a lista de
categorias definidas no estudo e ordem de relevância das mesmas
atribuídas pelo classificador de padrões.
3.9 Análises estatísticas
A análise da independência dos diferentes resultados alcançados pelas
combinações de parâmetros apresentadas ao classificador foi realizada por meio dos
testes Chi-quadrado [42], ao avaliarmos os resultados da classificação de artigos
científicos, e Wilcoxon signed-rank [43] e T pareado [44], quando a indexação foi o foco
da análise.
A restrição da distribuição normal das variáveis avaliadas, exigida pelo teste T
pareado, foi constatada pelo teste estatístico Shapiro-Wilk [45].
A escolha do teste Chi-quadrado se deu devido à característica categórica das
variáveis avaliadas, uma vez que a classificação dos artigos obteve dois valores, certo
ou errado. O teste avaliou o número de exemplos classificados corretamente entre
pares de estratégias de classificação, constatando a independência das mesmas.
Os testes T pareado e Wilcoxon signed-rank verificaram valores médios de acerto
entre os grupos avaliados quanto à indexação de artigos científicos. A opção pareada
de tais testes foi considerada a fim de realizar a correspondência de exemplos entre as
estratégias propostas.
29
A hipótese nula dos testes considerou que a diferença média entre os grupos foi
igual a zero. Portanto, valores de p < 0,05 (95% de confiança) rejeitaram tal hipótese.
A Figura 8 resume as análises estatísticas utilizadas no estudo de acordo com os
objetivos previamente definidos.
Figura 8 - Resumo das análises estatísticas utilizadas no estudo.
Classificação Dados categóricos
Exemplos independentes Chi-quadrado
Indexação Dados contínuos Exemplos pareados
Teste t pareado† ou Wilcoxon signed-
rank‡
† Teste paramétrico ‡ Teste não-paramétrico
Objetivo 2
Objetivo 1

30
4 RESULTADOS
A apresentação dos resultados obtidos neste estudo foi dividida em 2 partes, de
acordo com os objetivos previamente definidos. Primeiramente foram apresentados os
resultados da classificação de artigos científicos entre os domínios da Ciência da
Computação, Informática em Saúde e Saúde, presentes na seção 4.1. Finalmente, os
resultados quanto à categorização automática de artigos foi abordada na seção 4.2.
4.1 Objetivo 1: Classificação de artigos científicos
Os resultados da classificação automática de artigos científicos entre os domínios
da Ciência da Computação, Informática em Saúde e Saúde são explorados nesta
seção, bem como as estratégias de extração de características dos documentos
utilizadas como parâmetro de entrada do classificador de padrões.
4.1.1 Método supervisionado de extração de características
A matriz de confusão e o desempenho do classificador quando a extração de
características dos documentos utilizou o método supervisionado, por meio da técnica
JDI, são mostrados na Tabela 3 e Tabela 4 , respectivamente.
Tabela 3 - Matriz de confusão obtida quando o método supervisionado foi utilizado para classificar
artigos.
Técnica Classes Verdadeiro positivo
Verdadeiro negativo
Falso positivo
Falso negativo
JDI
Ciência da Computação 604 (27%) 1511 (67%) 115 (5%) 34 (2%)
Informática em Saúde 681 (30%) 1312 (58%) 123 (5%) 148 (7%)
Saúde 706 (31%) 1432 (63%) 35 (2%) 91 (4%)
Tabela 4 - Valores de precisão, revocação e f-score obtidos quando o método supervisionado foi
utilizado para classificar artigos.
f-score
Técnica Classes Precisão Revocação 0,5 1 2
JDI
Ciência da Computação 0,84 0,95 0,86 0,89 0,92
Informática em Saúde 0,85 0,82 0,84 0,83 0,83
Saúde 0,95 0,89 0,94 0,92 0,90
31
4.1.2 Método não-supervisionado de extração de características
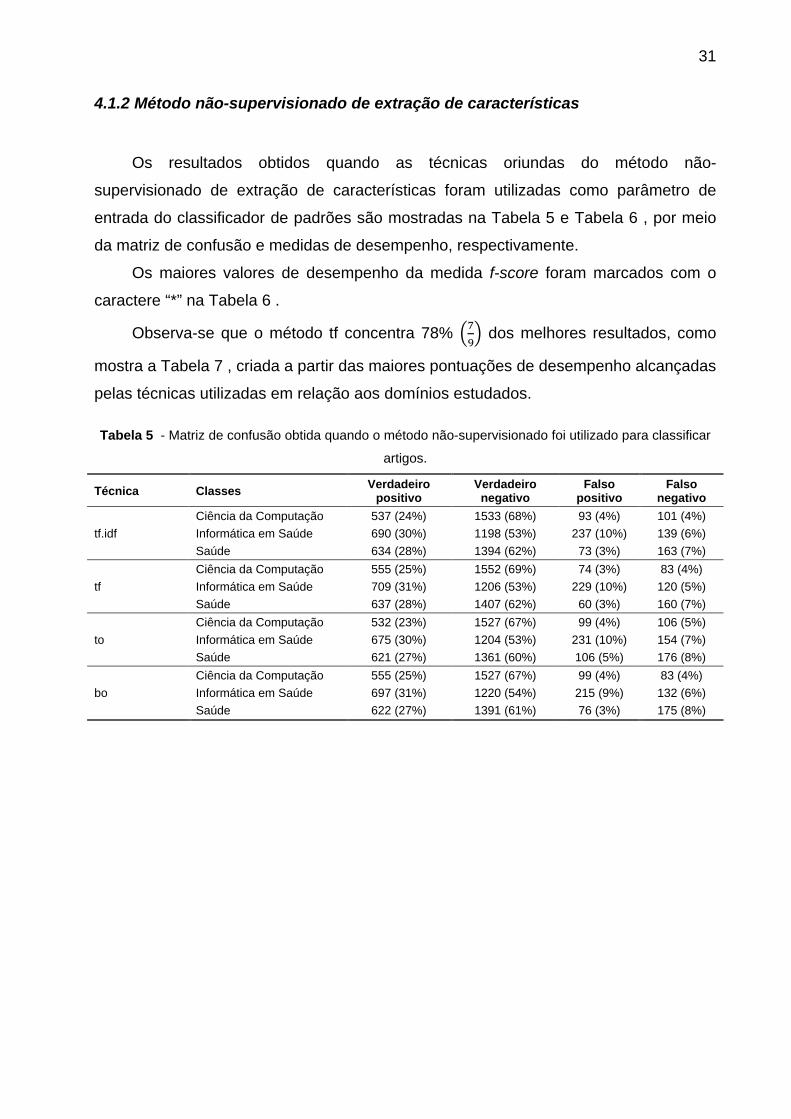
Os resultados obtidos quando as técnicas oriundas do método não-
supervisionado de extração de características foram utilizadas como parâmetro de
entrada do classificador de padrões são mostradas na Tabela 5 e Tabela 6 , por meio
da matriz de confusão e medidas de desempenho, respectivamente.
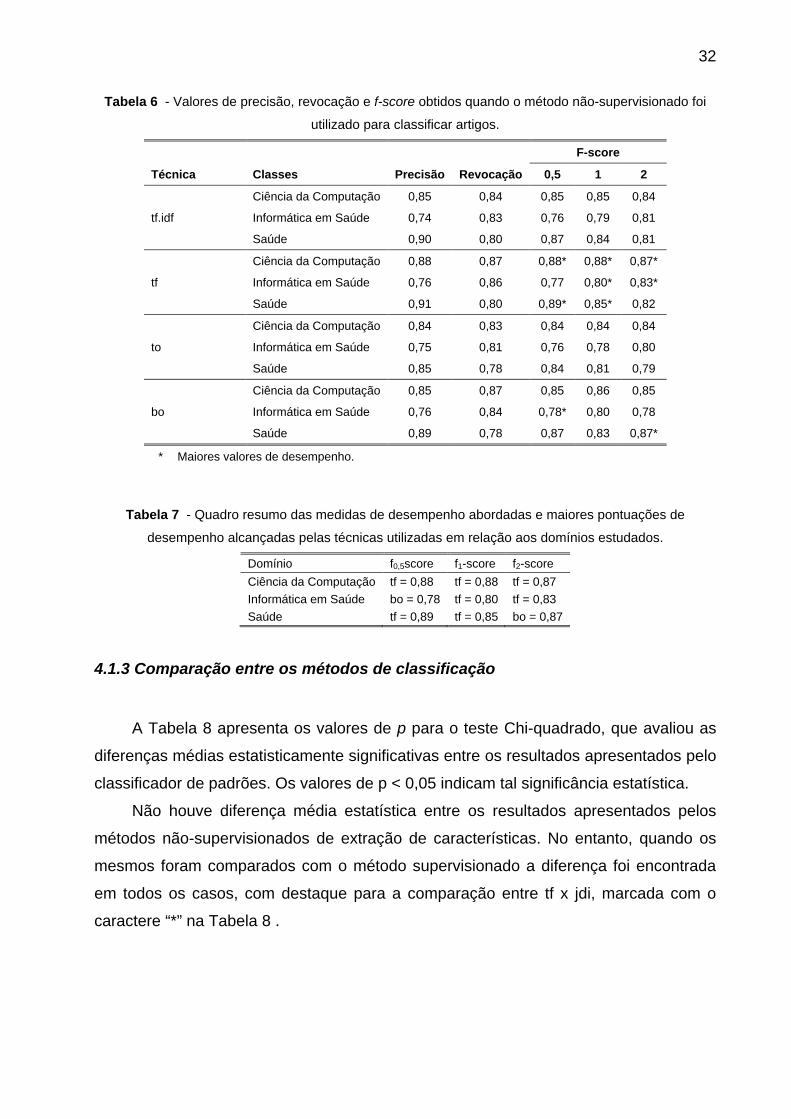
Os maiores valores de desempenho da medida f-score foram marcados com o
caractere “*” na Tabela 6 .
Observa-se que o método tf concentra 78% dos melhores resultados, como
mostra a Tabela 7 , criada a partir das maiores pontuações de desempenho alcançadas
pelas técnicas utilizadas em relação aos domínios estudados.
Tabela 5 - Matriz de confusão obtida quando o método não-supervisionado foi utilizado para classificar
artigos.
Técnica Classes Verdadeiro positivo
Verdadeiro negativo
Falso positivo
Falso negativo
tf.idf Ciência da Computação 537 (24%) 1533 (68%) 93 (4%) 101 (4%) Informática em Saúde 690 (30%) 1198 (53%) 237 (10%) 139 (6%) Saúde 634 (28%) 1394 (62%) 73 (3%) 163 (7%)
tf Ciência da Computação 555 (25%) 1552 (69%) 74 (3%) 83 (4%) Informática em Saúde 709 (31%) 1206 (53%) 229 (10%) 120 (5%) Saúde 637 (28%) 1407 (62%) 60 (3%) 160 (7%)
to Ciência da Computação 532 (23%) 1527 (67%) 99 (4%) 106 (5%) Informática em Saúde 675 (30%) 1204 (53%) 231 (10%) 154 (7%) Saúde 621 (27%) 1361 (60%) 106 (5%) 176 (8%)
bo Ciência da Computação 555 (25%) 1527 (67%) 99 (4%) 83 (4%) Informática em Saúde 697 (31%) 1220 (54%) 215 (9%) 132 (6%) Saúde 622 (27%) 1391 (61%) 76 (3%) 175 (8%)
32
Tabela 6 - Valores de precisão, revocação e f-score obtidos quando o método não-supervisionado foi
utilizado para classificar artigos.
F-score
Técnica Classes Precisão Revocação 0,5 1 2
tf.idf
Ciência da Computação 0,85 0,84 0,85 0,85 0,84
Informática em Saúde 0,74 0,83 0,76 0,79 0,81
Saúde 0,90 0,80 0,87 0,84 0,81
tf
Ciência da Computação 0,88 0,87 0,88* 0,88* 0,87*
Informática em Saúde 0,76 0,86 0,77 0,80* 0,83*
Saúde 0,91 0,80 0,89* 0,85* 0,82
to
Ciência da Computação 0,84 0,83 0,84 0,84 0,84
Informática em Saúde 0,75 0,81 0,76 0,78 0,80
Saúde 0,85 0,78 0,84 0,81 0,79
bo
Ciência da Computação 0,85 0,87 0,85 0,86 0,85
Informática em Saúde 0,76 0,84 0,78* 0,80 0,78
Saúde 0,89 0,78 0,87 0,83 0,87*
* Maiores valores de desempenho.
Tabela 7 - Quadro resumo das medidas de desempenho abordadas e maiores pontuações de
desempenho alcançadas pelas técnicas utilizadas em relação aos domínios estudados.
Domínio f0,5score f1-score f2-score Ciência da Computação tf = 0,88 tf = 0,88 tf = 0,87 Informática em Saúde bo = 0,78 tf = 0,80 tf = 0,83 Saúde tf = 0,89 tf = 0,85 bo = 0,87
4.1.3 Comparação entre os métodos de classificação
A Tabela 8 apresenta os valores de p para o teste Chi-quadrado, que avaliou as
diferenças médias estatisticamente significativas entre os resultados apresentados pelo
classificador de padrões. Os valores de p < 0,05 indicam tal significância estatística.
Não houve diferença média estatística entre os resultados apresentados pelos
métodos não-supervisionados de extração de características. No entanto, quando os
mesmos foram comparados com o método supervisionado a diferença foi encontrada
em todos os casos, com destaque para a comparação entre tf x jdi, marcada com o
caractere “*” na Tabela 8 .
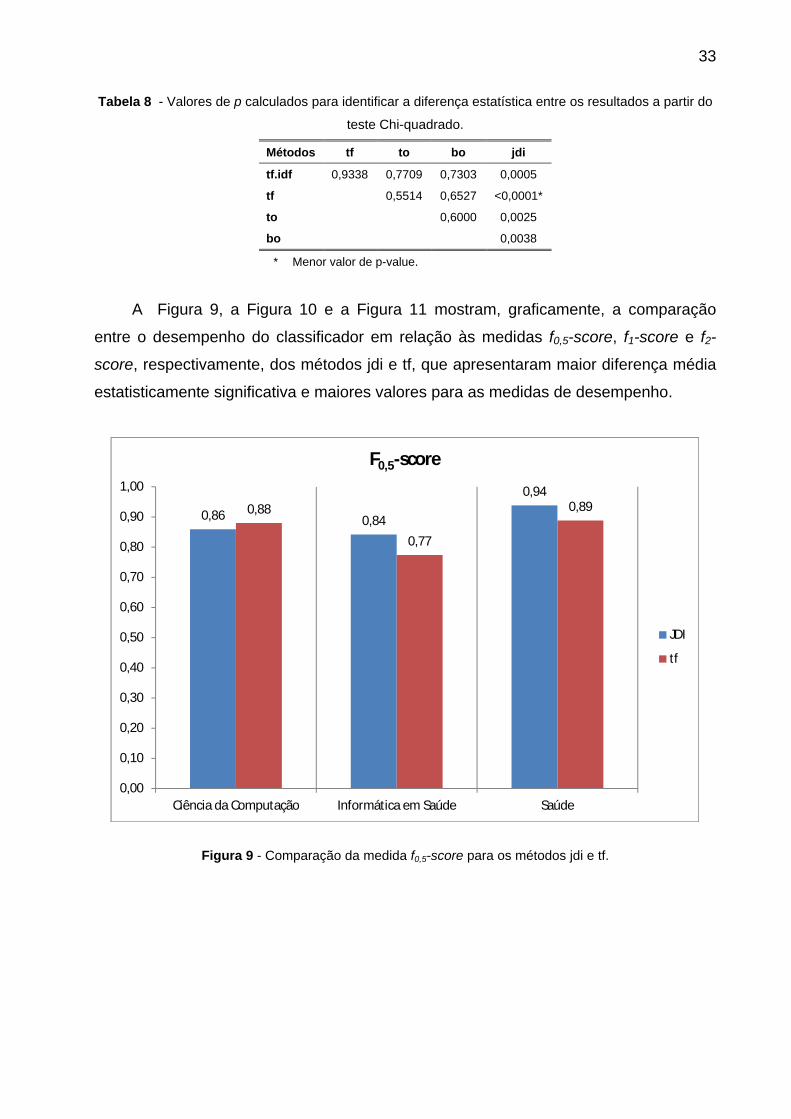
33
Tabela 8 - Valores de p calculados para identificar a diferença estatística entre os resultados a partir do
teste Chi-quadrado.
Métodos tf to bo jdi
tf.idf 0,9338 0,7709 0,7303 0,0005
tf 0,5514 0,6527 <0,0001*
to 0,6000 0,0025
bo 0,0038
* Menor valor de p-value.
A Figura 9, a Figura 10 e a Figura 11 mostram, graficamente, a comparação
entre o desempenho do classificador em relação às medidas f0,5-score, f1-score e f2-
score, respectivamente, dos métodos jdi e tf, que apresentaram maior diferença média
estatisticamente significativa e maiores valores para as medidas de desempenho.
Figura 9 - Comparação da medida f0,5-score para os métodos jdi e tf.
0,86 0,84
0,940,88
0,77
0,89
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
1,00
Ciência da Computação Informática em Saúde Saúde
F0,5-score
JDI
tf
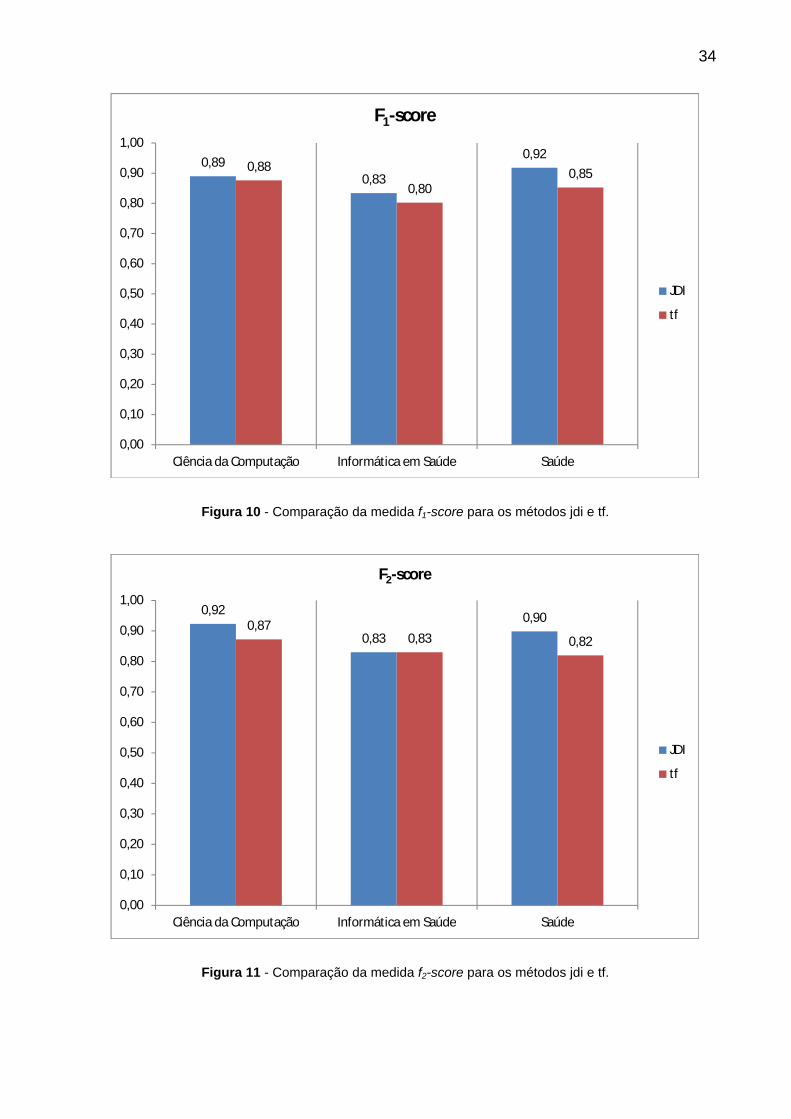
34
Figura 10 - Comparação da medida f1-score para os métodos jdi e tf.
Figura 11 - Comparação da medida f2-score para os métodos jdi e tf.
0,890,83
0,920,88
0,800,85
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
1,00
Ciência da Computação Informática em Saúde Saúde
F1-score
JDI
tf
0,92
0,83
0,900,87
0,83 0,82
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
1,00
Ciência da Computação Informática em Saúde Saúde
F2-score
JDI
tf

35
4.2 Objetivo 2: Indexação de artigos científicos
A segunda parte da apresentação dos resultados, detalhada nesta seção, aborda
a indexação automática, que utilizou as 30 categorias relacionadas no Quadro 3
(página 12) para rotular os artigos da base de validação construída para os
experimentos.
As medidas de desempenho obedeceram às métricas discutidas na seção 3.7
(página 21), nas quais a posição de relevância da categoria em relação ao artigo
científico, atribuída pelo classificador de padrões, contribuiu para a análise de
desempenho.
A análise dos resultados concentrou-se na posição de relevância igual a 5, uma
vez que a atribuição de categorias, realizada pelo portal ISI Web of Knowledge aos
artigos da base de dados de validação, variou entre uma e cinco categorias.
Foi comparado o desempenho do classificador quando diferentes métodos de
extração de características foram apresentados como parâmetro de entrada para o
mesmo. Finalmente, explorou-se a indexação utilizando as técnicas de votação e
competição, descritas na seção 3.7.1 (página 23).
4.2.1 Método supervisionado de extração de características
A média aritmética e desvio padrão dos resultados obtidos para a indexação de
artigos científicos, quando o método supervisionado de extração de características foi
utilizado, são mostrados na Tabela 9 . A média aritmética exposta na tabela refere-se
à razão entre a soma da pontuação das medidas de desempenho alcançadas pelo
classificador de padrões para cada categoria e o módulo da quantidade das mesmas.
A Tabela 10 apresenta o teste de significância estatística quanto à distribuição
normal dos resultados obtidos para o conjunto de medidas f-score, na qual o caractere
“*” foi utilizado para destacar a ocorrência da distribuição normal.
Tabela 9 - Resultados obtidos utilizando o método supervisionado de extração de características.
Relevância Precisão Revocação F0,5-score F1-score F2-score 5 0,61 ± 0,22 0,72 ± 0,28 0,63 ± 0,20 0,66 ± 0,21 0,70 ± 0,23

36
Tabela 10 - Valores de significância estatística quanto à distribuição normal dos resultados.
p-values
F0.5-score F1-score F2-score
0,5188* 0,0472 0,0092
* Distribuição normal.
4.2.2 Métodos não-supervisionados de extração de características
Esta subseção concentra a apresentação dos resultados da indexação de artigos
científicos quando os métodos não-supervisionados de extração de características
foram contemplados.
A Tabela 11 mostra a média aritmética e o desvio padrão das medidas de
desempenho aplicadas às técnicas utilizadas, quando a atribuição de categorias
realizada pelo classificador variou entre a primeira e a quinta posição de relevância. Os
maiores valores alcançados foram destacados com o caractere “*”.
A Tabela 12 apresenta a análise estatística referente à distribuição normal dos
resultados obtidos na tabela anterior. A normalidade foi destacada com o caractere “*”.
Tabela 11 - Resultados obtidos utilizando os métodos não-supervisionados de extração de
características.
Método Relevância Precisão Revocação F0,5-score F1-score F2-score tf.idf 5 0,62 ± 0,27 0,53 ± 0,31 0,60 ± 0,21* 0,57 ± 0,18 0,55 ± 0,21
tf 5 0,54 ± 0,28 0,44 ± 0,35 0,52 ± 0,17 0,49 ± 0,16 0,46 ± 0,22 to 5 0,50 ± 0,17 0,91 ± 0,07 0,55 ± 0,16 0,65 ± 0,14 0,78 ± 0,10* bo 5 0,53 ± 0,19 0,87 ± 0,11 0,58 ± 0,17 0,66 ± 0,13* 0,77 ± 0,10
* Maiores valores de desempenho. ± O desvio padrão considerou a variação de desempenho da indexação em relação a cada categoria.
Tabela 12 - Valores de significância estatística quanto à distribuição normal dos resultados.
p-values
Métodos F0.5-score F1-score F2-score
tf.idf 0,5688* 0,0154 0,0504*
tf 0,2804* 0,2327* 0,1112*
to 0,0127 0,0613* 0,3998*
bo 0,0099 0,0576* 0,2877*
* Distribuição normal.
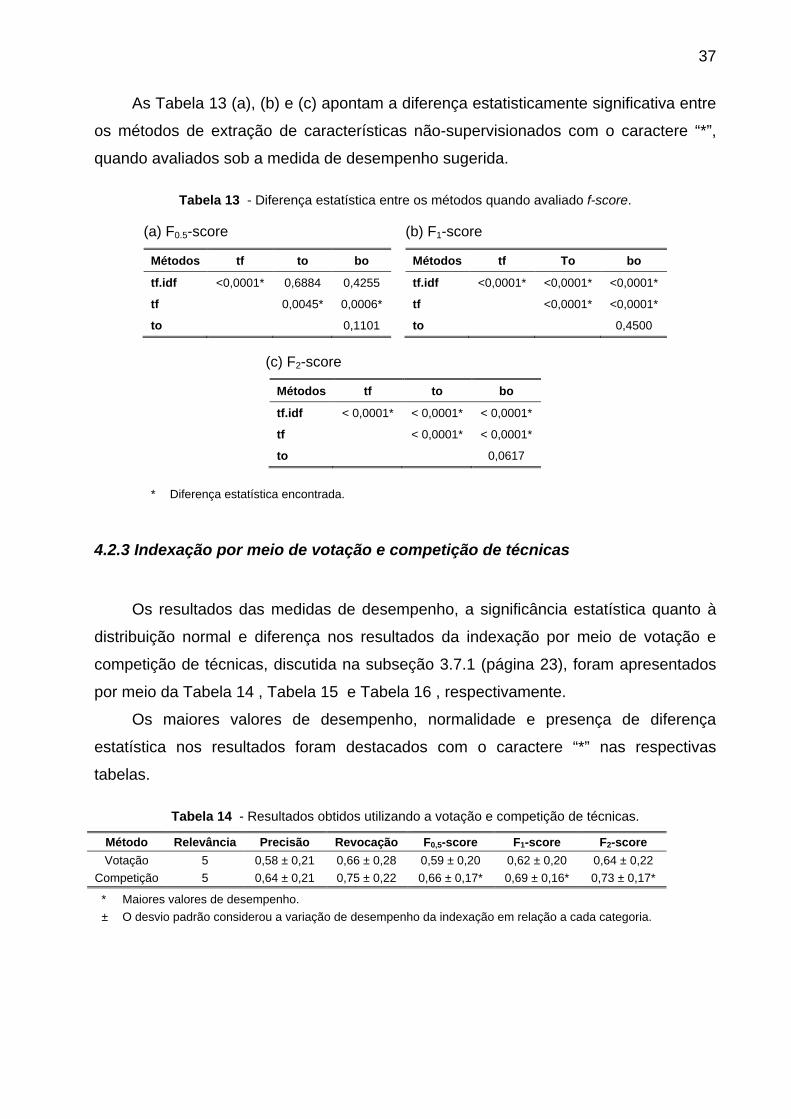
37
As Tabela 13 (a), (b) e (c) apontam a diferença estatisticamente significativa entre
os métodos de extração de características não-supervisionados com o caractere “*”,
quando avaliados sob a medida de desempenho sugerida.
Tabela 13 - Diferença estatística entre os métodos quando avaliado f-score.
(a) F0.5-score
Métodos tf to bo
tf.idf <0,0001* 0,6884 0,4255
tf 0,0045* 0,0006*
to 0,1101
(b) F1-score
Métodos tf To bo
tf.idf <0,0001* <0,0001* <0,0001*
tf <0,0001* <0,0001*
to 0,4500
(c) F2-score
Métodos tf to bo
tf.idf < 0,0001* < 0,0001* < 0,0001*
tf < 0,0001* < 0,0001*
to 0,0617
* Diferença estatística encontrada.
4.2.3 Indexação por meio de votação e competição de técnicas
Os resultados das medidas de desempenho, a significância estatística quanto à
distribuição normal e diferença nos resultados da indexação por meio de votação e
competição de técnicas, discutida na subseção 3.7.1 (página 23), foram apresentados
por meio da Tabela 14 , Tabela 15 e Tabela 16 , respectivamente.
Os maiores valores de desempenho, normalidade e presença de diferença
estatística nos resultados foram destacados com o caractere “*” nas respectivas
tabelas.
Tabela 14 - Resultados obtidos utilizando a votação e competição de técnicas.
Método Relevância Precisão Revocação F0,5-score F1-score F2-score Votação 5 0,58 ± 0,21 0,66 ± 0,28 0,59 ± 0,20 0,62 ± 0,20 0,64 ± 0,22
Competição 5 0,64 ± 0,21 0,75 ± 0,22 0,66 ± 0,17* 0,69 ± 0,16* 0,73 ± 0,17*
* Maiores valores de desempenho. ± O desvio padrão considerou a variação de desempenho da indexação em relação a cada categoria.

38
Tabela 15 - Valores de significância estatística quanto à distribuição normal dos resultados.
Métodos p-values
F0,5-score F1-score F2-score
Votação 0,3995* 0,6435* 0,0097*
Competição 0,5687* 0,2647* 0,0122
* Distribuição normal.
Tabela 16 - Diferença estatística entre os métodos quando avaliados os valores f-score.
p-values
Métodos F0,5-score F1-score F2-score
Competição X Votação 0,0020* 0,0005* <0,0001*
* Diferença estatística encontrada.
4.2.4 Comparação entre as técnicas de indexação
A seção “4.2 Objetivo 2: Indexação de artigos científicos” contou com a
apresentação de 7 resultados que avaliaram o desempenho do classificador de
padrões mediante a variação dos parâmetros de entrada, de acordo com a técnica de
extração de característica e utilização, em conjunto, de tais técnicas para compor a
indexação final.
Esta subseção concentrou esforços na comparação entre os melhores resultados
de desempenhos alcançados pela utilização dos métodos não-supervisionado e
supervisionado, bem como a votação e competição de técnicas, na tarefa de indexação
de artigos científicos.
A Figura 12 mostra a comparação gráfica entre os métodos JDI, bo e Competição
de técnicas, quando avaliadas as medidas de desempenho f-score e variações no
parâmetro 훽.
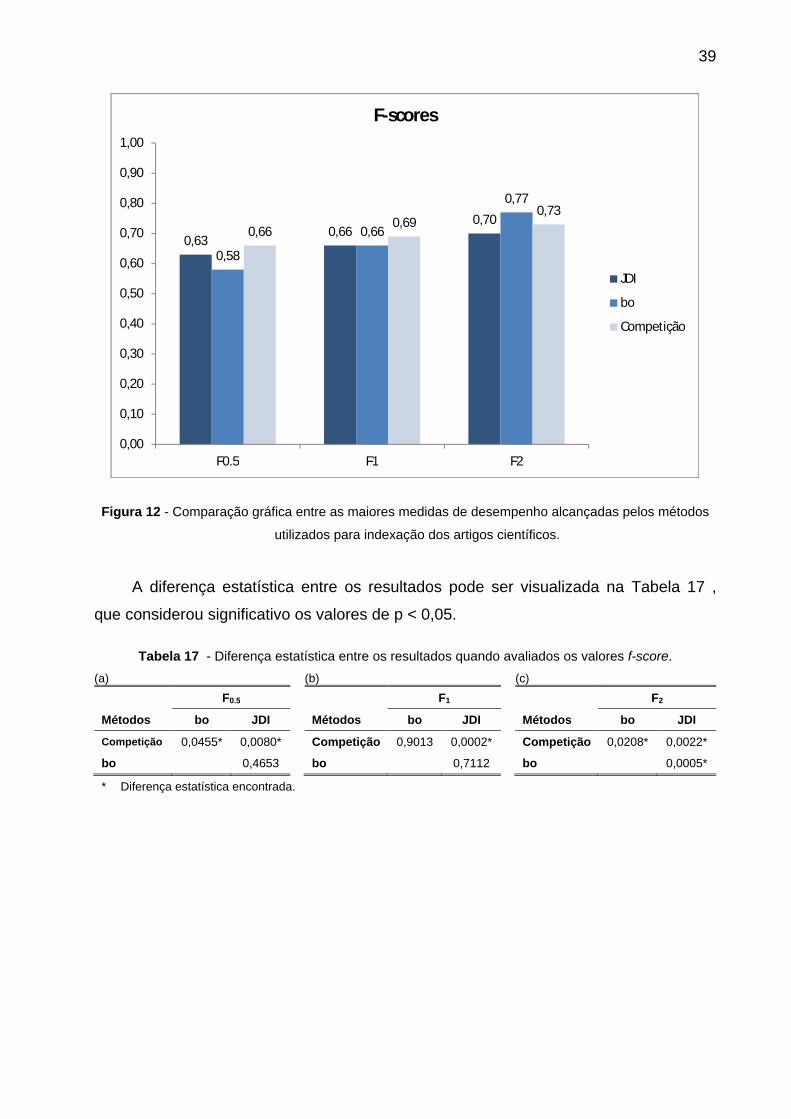
39
Figura 12 - Comparação gráfica entre as maiores medidas de desempenho alcançadas pelos métodos
utilizados para indexação dos artigos científicos.
A diferença estatística entre os resultados pode ser visualizada na Tabela 17 ,
que considerou significativo os valores de p < 0,05.
Tabela 17 - Diferença estatística entre os resultados quando avaliados os valores f-score. (a) (b) (c)
F0.5
Métodos bo JDI
Competição 0,0455* 0,0080*
bo 0,4653
F1
Métodos bo JDI
Competição 0,9013 0,0002*
bo 0,7112
F2
Métodos bo JDI
Competição 0,0208* 0,0022*
bo 0,0005*
* Diferença estatística encontrada.
0,630,66
0,70
0,58
0,66
0,77
0,660,69
0,73
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
1,00
F0.5 F1 F2
F-scores
JDI
bo
Competição

40
5 DISCUSSÃO
Este capítulo aborda a discussão dos resultados e métodos apresentados nos
capítulos anteriores, dividindo, em duas seções, a análise e confronto dos resultados. A
seção 5.1 discutirá a classificação de artigos científicos, fruto do primeiro objetivo deste
trabalho. Finalmente, a seção 5.2 concentrará as análises referentes ao segundo
objetivo, cujo propósito foi indexar artigos científicos.
5.1 Objetivo 1: Classificação de artigos científicos
Quanto à classificação de artigos científicos, as estratégias de extração de
características utilizadas como parâmetro de entrada do classificador probabilístico
apresentaram diferentes pontuações de desempenho, como pode ser observado na
Tabela 4 (página 30) e na Tabela 6 (página 32). No entanto, entre os métodos não-
supervisionados não houve diferenças estatísticas significativas, comprovadas pelo
teste Chi-quadrado e mostradas na Tabela 8 (página 33).
Quando tais estratégias foram comparadas com o método supervisionado,
apresentaram diferenças estatísticas significativas em todos os casos, com destaque
para a comparação entre tf X JDI, destacada na mesma tabela e utilizada nos gráficos
comparativos da Figura 9 (página 33), Figura 10 e Figura 11 (página 34).
A utilização de conhecimento prévio para a construção do vetor de características,
única variante do experimento, mostrou-se eficiente, uma vez que os gráficos citados
acima mostraram que o desempenho do método supervisionado foi melhor em 78%
das comparações. Esta estratégia também foi explorada nos trabalhos de Zhang [16] e
Lan et al [46], os quais demonstraram, por meio de experimentos similares, a eficácia do
método supervisionado de extração de características.
A quantidade, distribuição e intersecção dos 35.484 termos, oriundos da base de
dados construída para o estudo, em seus respectivos domínios são mostradas na
Figura 13. A partir desta figura é possível identificar que o domínio da Saúde possui a
maior quantidade de termos que não são compartilhados pelos outros domínios
(9.710). No entanto, o conjunto de termos que compõe exclusivamente o domínio da
Informática em Saúde é o menos representativo, com apenas 1.696 itens.

41
O cenário visualizado na Figura 13 expõe a interdisciplinaridade da Informática
em Saúde, uma vez que a quantidade de termos compartilhados com os domínios da
Ciência da Computação e Saúde, 2.008 e 4.832, respectivamente, é maior do que seu
próprio conjunto não compartilhado, 1.696.
Figura 13 - Quantidade de termos (35.484) e respectiva intersecção presente nos conjuntos de artigos
científicos dos domínios da Ciência da Computação, Informática em Saúde e Saúde.
O desempenho alcançado para a classificação de artigos científicos no domínio
da Informática em Saúde foi menor em relação aos outros domínios. Acredita-se que a
quantidade de termos destinados exclusivamente ao seu conjunto influenciou as
pontuações de desempenho, como pode ser observado na Figura 14, que mostra os
resultados da classificação por meio do método supervisionado.
Quando a medida f-score considerou, para fins de desempenho do classificador,
maior importância à revocação (f2-score), o melhor resultado foi atribuído ao domínio
da Ciência da Computação (92%). No entanto, para a medida f0,5-score, na qual a
precisão foi alvo do desempenho do classificador, o domínio da Saúde alcançou o
melhor resultado (94%).
Os valores de “Falso positivo” iguais a 115 e 123, atribuídos aos domínios da
Ciência da Computação e Informática em Saúde, respectivamente, e superiores ao
Conjunto de termos da Ciência da
Computação
Conjunto de termos da
Saúde
Conjunto de termos da Informática em Saúde
4.979 923 9.710
11.336
2.008 4.832
1.696
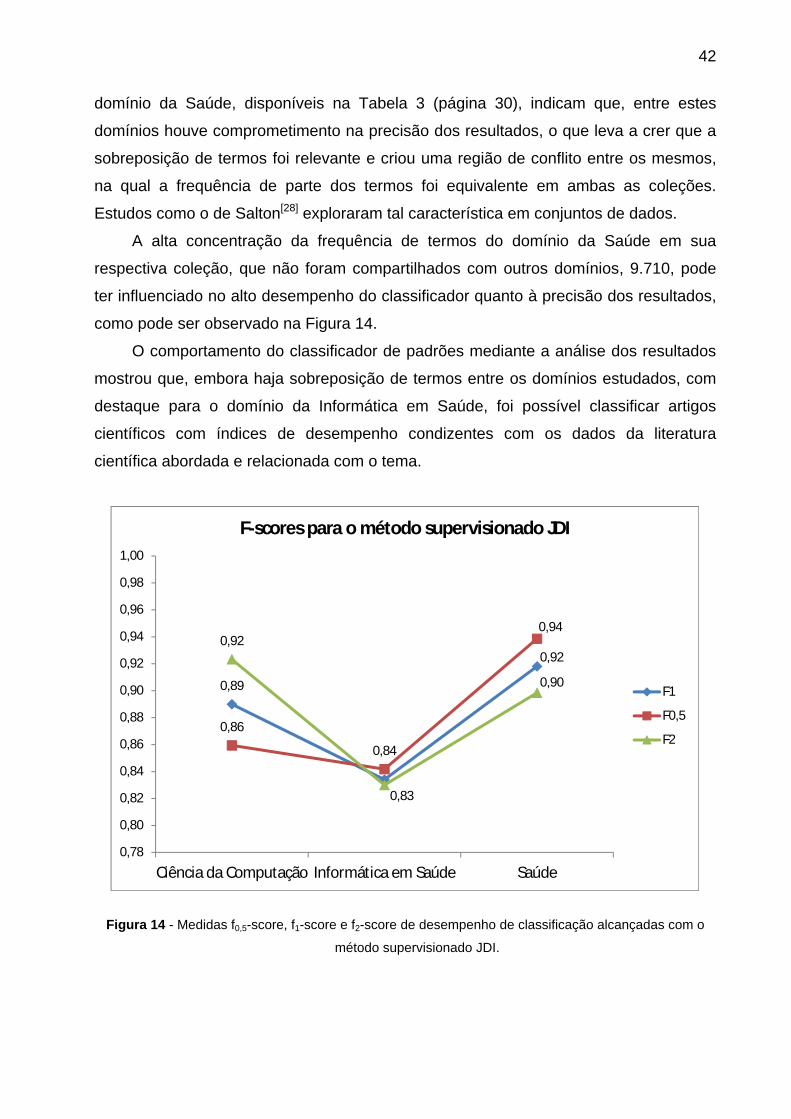
42
domínio da Saúde, disponíveis na Tabela 3 (página 30), indicam que, entre estes
domínios houve comprometimento na precisão dos resultados, o que leva a crer que a
sobreposição de termos foi relevante e criou uma região de conflito entre os mesmos,
na qual a frequência de parte dos termos foi equivalente em ambas as coleções.
Estudos como o de Salton[28] exploraram tal característica em conjuntos de dados.
A alta concentração da frequência de termos do domínio da Saúde em sua
respectiva coleção, que não foram compartilhados com outros domínios, 9.710, pode
ter influenciado no alto desempenho do classificador quanto à precisão dos resultados,
como pode ser observado na Figura 14.
O comportamento do classificador de padrões mediante a análise dos resultados
mostrou que, embora haja sobreposição de termos entre os domínios estudados, com
destaque para o domínio da Informática em Saúde, foi possível classificar artigos
científicos com índices de desempenho condizentes com os dados da literatura
científica abordada e relacionada com o tema.
Figura 14 - Medidas f0,5-score, f1-score e f2-score de desempenho de classificação alcançadas com o
método supervisionado JDI.
0,89
0,92
0,86
0,84
0,940,92
0,83
0,90
0,78
0,80
0,82
0,84
0,86
0,88
0,90
0,92
0,94
0,96
0,98
1,00
Ciência da Computação Informática em Saúde Saúde
F-scores para o método supervisionado JDI
F1
F0,5
F2

43
5.2 Objetivo 2: Indexação de artigos científicos
Esta seção aborda a discussão dos resultados apresentados quanto à indexação
de artigos científicos sob as categorias relacionadas no Quadro 3 (página 12). Foram
realizados 7 experimentos que avaliaram o classificador quanto às medidas de
desempenho f0,5-score, f1-score e f2-score, detalhadas na seção 3.8 (página 24).
Os experimentos contaram com a variação nos parâmetros de entrada do
classificador, mediante a utilização de diferentes métodos de extração de
características dos documentos oriundos da base de dados construída para o estudo e,
também, exploraram métodos de votação e competição de técnicas, definidos na
subseção 3.7.1 (página 23).
Os desvios-padrão encontrados nas avaliações de desempenho dos métodos
supervisionado e não-supervisionados motivaram a utilização da votação e competição
de técnicas.
Estudos como o de Lan et al [16] mostraram que diferentes técnicas de atribuição
de pesos aos termos que compõem os vetores de características utilizados pelos
classificadores podem ter um grau de influência maior nos resultados do que a escolha
do próprio classificador.
A Figura 15 e a Figura 16 mostram a comparação entre a precisão e revocação,
respectivamente, do método não-supervisionado e supervisionado em relação ao
desempenho alcançado por cada técnica ao atribuir as categorias corretas aos
respectivos artigos. É possível constatar, por meio das figuras, uma variação na
relação entre categoria versus método, explorada na votação e competição de
técnicas.
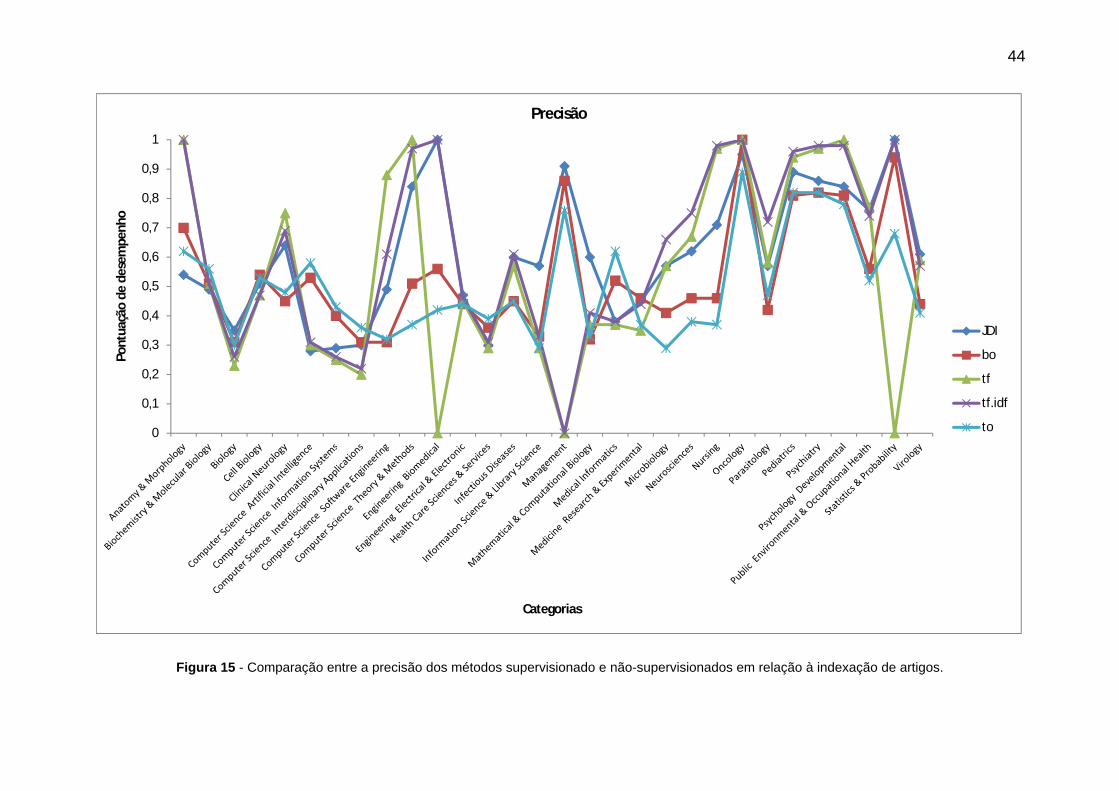
44
Figura 15 - Comparação entre a precisão dos métodos supervisionado e não-supervisionados em relação à indexação de artigos.
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1Po
ntua
ção
de d
esem
penh
o
Categorias
Precisão
JDI
bo
tf
tf.idf
to
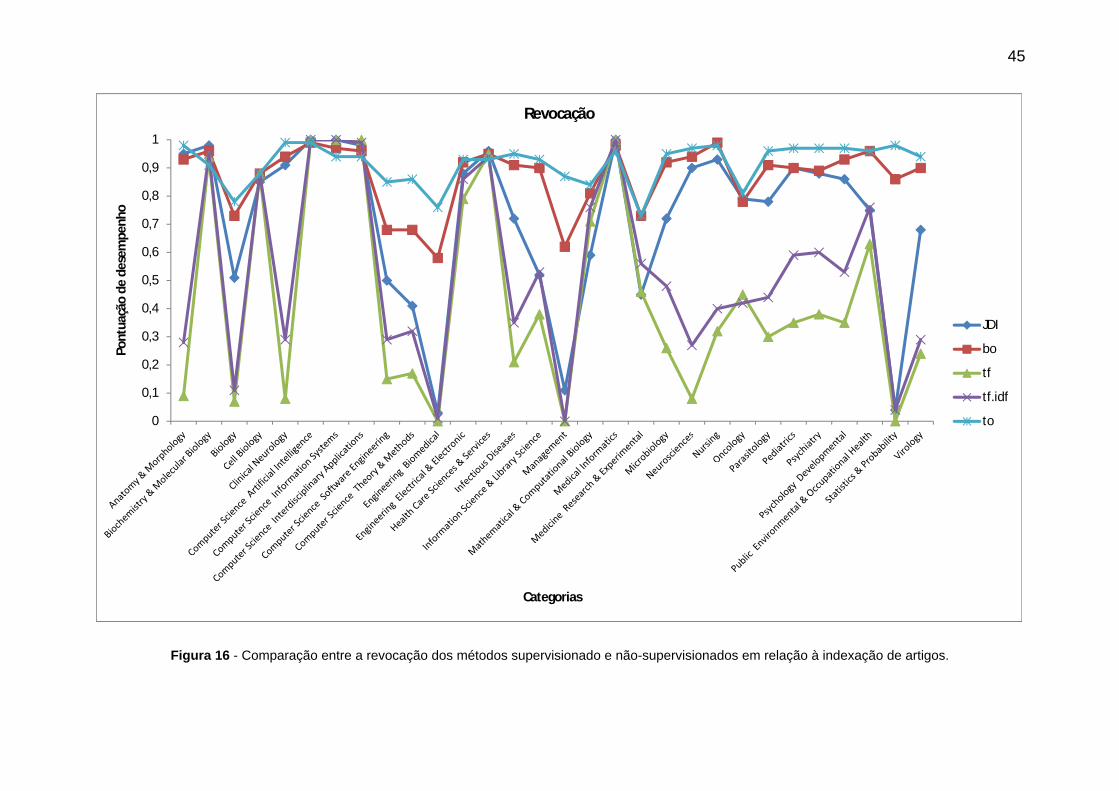
45
Figura 16 - Comparação entre a revocação dos métodos supervisionado e não-supervisionados em relação à indexação de artigos.
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1Po
ntua
ção
de d
esem
penh
o
Categorias
Revocação
JDI
bo
tf
tf.idf
to

46
A comparação entre os resultados mais expressivos obtidos por meio dos
experimentos destinados à indexação de artigos é mostrada na Figura 12 (página 39).
O método que utilizou a competição de técnicas apresentou melhores resultados
quando a precisão foi o alvo da medida de desempenho abordada, na qual a
pontuação f0,5-score alcançou o valor de 0,66. Quando a precisão e revocação
assumiram igual importância por meio da medida f1-score o método também superou
as outras estratégias, apresentando a pontuação igual a 0,69.
No entanto, quando a revocação foi avaliada por meio da medida f2-score a
estratégia de extração de características binary occurrence mostrou-se mais eficiente,
com pontuação igual a 0,77.
A diferença média estatisticamente significativa entre os resultados foi calculada
por meio dos testes T e Wilcoxon, respeitando a restrição de normalidade das variáveis
avaliadas exigida pelo primeiro teste citado. A Tabela 17 (página 39) mostra que os
resultados mais expressivos obtiveram valores de p significativos.
A partir dos resultados expostos, a medida de desempenho ligada a revocação
(f2-score) privilegiou as ocorrências de termos individualmente nos documentos. Tal
comportamento foi destacado por Salton [28] em seu trabalho. A competição de técnicas
favoreceu os resultados ligados à precisão (f0,5-score) e a equivalência entre a mesma
e a revocação (f1-score).
5.2.1 Distribuição das categorias após indexação
A Figura 17 mostra a distribuição dos artigos científicos e categorias em relação à
indexação sugerida às revistas pelo Portal ISI Web of Knowledge, de acordo com a
divisão dos domínios construída neste estudo (Quadro 3 , página 12).
Na figura, somente as categorias “Computer Science, Information Systems” e
“Information Science & Library Science” compartilham artigos publicados em revistas
dos domínios da Ciência da Computação e Informática em Saúde, enquanto apenas a
categoria “Medicine, Research & Experimental” foi compartilhada entre os artigos
publicados em revistas dos domínios da Saúde e Informática em Saúde.
A Figura 18 apresenta a distribuição após a aplicação do método de indexação
por meio de competição de técnicas. Neste cenário houve um maior compartilhamento
entre as categorias e domínios, o que sugere uma incompatibilidade entre a

47
categorização original das revistas sugeridas pelo portal ISI Web of Knowledge e a
proposta deste estudo. De acordo com os resultados, o método proposto indica que
uma parte dos artigos não reflete, ou reflete parcialmente, a categorização atribuída às
revistas pelo portal ISI Web of Knowledge.
A indexação incorreta e/ou incompleta de revistas ou artigos científicos pode
prejudicar a recuperação de informação, uma vez que as categorias são utilizadas
como parâmetros em sistemas de buscas construídos pelos Portais.
Spreckelsen [24], em seu trabalho, destacou a importância do corpo de
conhecimento de Informática em Saúde, disponível nas bibliotecas virtuais, ser
cuidadosamente delimitado por meio das revistas e artigos publicados, pois os índices
que medem o fator de impacto da área são amparados nos mesmos, sendo que uma
fraca indexação comprometeria tais índices.
A Figura 19 exemplifica as indexações sugeridas pelo portal ISI Web of
Knowledge e método que utilizou a competição de técnicas a um artigo científico
coletado da base de dados de validação, pertencente à revista Methods of Information
in Medicine, classificada sob o domínio da Informática em Saúde. Embora o método
proposto neste trabalho tenha indexado corretamente o artigo da figura nas 3 primeiras
posições de relevância, as categorias que ocupam as posições 4 e 5 também
mostraram-se relevantes, de acordo com o título e resumo do artigo. A categoria
“Computer Science Artificial Intelligence”, utilizada pelo mecanismo automatizado no
exemplo, foi atribuída a um artigo de um domínio no qual, originalmente, não havia
relação (Figura 17), expondo a deficiência discutida nos parágrafos anteriores.
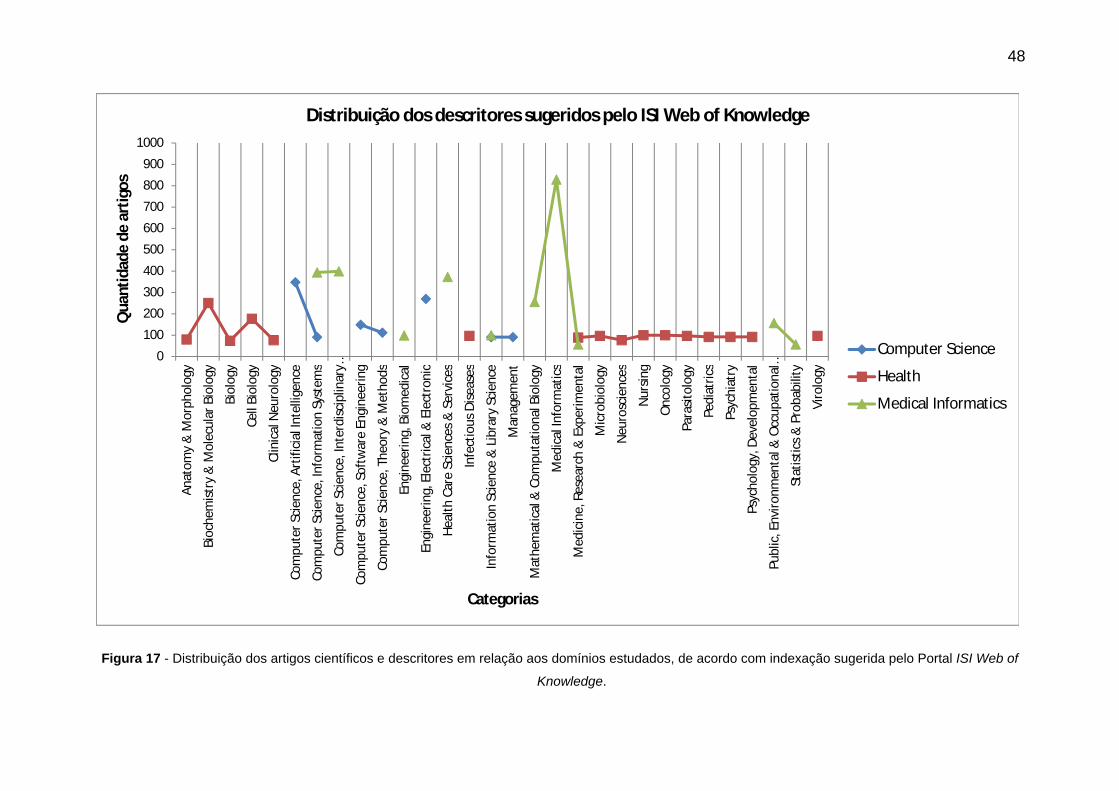
48
Figura 17 - Distribuição dos artigos científicos e descritores em relação aos domínios estudados, de acordo com indexação sugerida pelo Portal ISI Web of
Knowledge.
0
100
200
300
400
500
600
700
800
900
1000
Ana
tom
y &
Mor
phol
ogy
Bioc
hem
istr
y &
Mol
ecul
ar B
iolo
gy
Biol
ogy
Cell
Biol
ogy
Clin
ical
Neu
rolo
gy
Com
pute
r Sci
ence
, Art
ifici
al In
telli
genc
e
Com
pute
r Sci
ence
, Inf
orm
atio
n Sy
stem
s
Com
pute
r Sci
ence
, Int
erdi
scip
linar
y …
Com
pute
r Sci
ence
, Sof
twar
e En
gine
erin
g
Com
pute
r Sci
ence
, The
ory
& M
etho
ds
Engi
neer
ing,
Bio
med
ical
Engi
neer
ing,
Ele
ctri
cal &
Ele
ctro
nic
Hea
lth C
are
Scie
nces
& S
ervi
ces
Infe
ctio
us D
isea
ses
Info
rmat
ion
Scie
nce
& L
ibra
ry S
cien
ce
Man
agem
ent
Mat
hem
atic
al &
Com
puta
tiona
l Bio
logy
Med
ical
Info
rmat
ics
Med
icin
e, R
esea
rch
& E
xper
imen
tal
Mic
robi
olog
y
Neu
rosc
ienc
es
Nur
sing
Onc
olog
y
Para
sito
logy
Pedi
atri
cs
Psyc
hiat
ry
Psyc
holo
gy, D
evel
opm
enta
l
Publ
ic, E
nvir
onm
enta
l & O
ccup
atio
nal …
Stat
istic
s &
Pro
babi
lity
Viro
logy
Qua
ntid
ade
de a
rtig
os
Categorias
Distribuição dos descritores sugeridos pelo ISI Web of Knowledge
Computer Science
Health
Medical Informatics
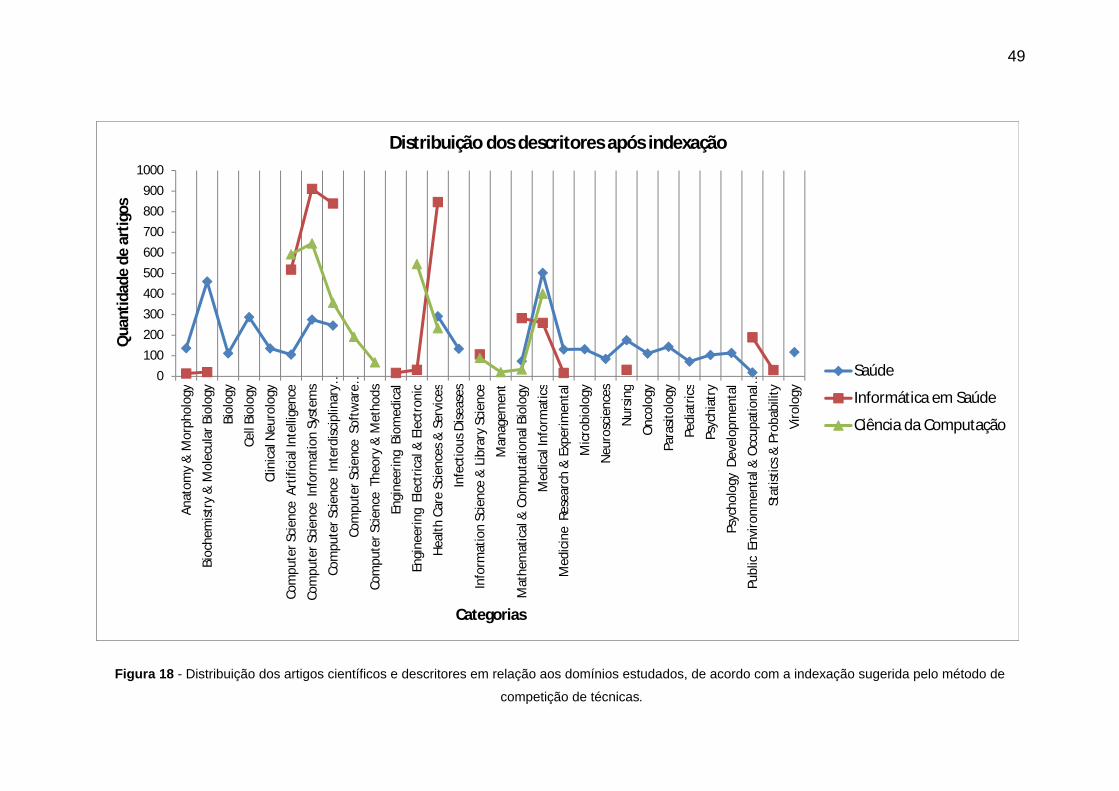
49
Figura 18 - Distribuição dos artigos científicos e descritores em relação aos domínios estudados, de acordo com a indexação sugerida pelo método de
competição de técnicas.
0
100
200
300
400
500
600
700
800
900
1000A
nato
my
& M
orph
olog
y
Bioc
hem
istr
y &
Mol
ecul
ar B
iolo
gy
Biol
ogy
Cell
Biol
ogy
Clin
ical
Neu
rolo
gy
Com
pute
r Sci
ence
Art
ifici
al In
telli
genc
e
Com
pute
r Sci
ence
Inf
orm
atio
n Sy
stem
s
Com
pute
r Sci
ence
Int
erdi
scip
linar
y …
Com
pute
r Sci
ence
Sof
twar
e …
Com
pute
r Sci
ence
The
ory
& M
etho
ds
Engi
neer
ing
Bio
med
ical
Engi
neer
ing
Ele
ctri
cal &
Ele
ctro
nic
Hea
lth C
are
Scie
nces
& S
ervi
ces
Infe
ctio
us D
isea
ses
Info
rmat
ion
Scie
nce
& L
ibra
ry S
cien
ce
Man
agem
ent
Mat
hem
atic
al &
Com
puta
tiona
l Bio
logy
Med
ical
Info
rmat
ics
Med
icin
e R
esea
rch
& E
xper
imen
tal
Mic
robi
olog
y
Neu
rosc
ienc
es
Nur
sing
Onc
olog
y
Para
sito
logy
Pedi
atri
cs
Psyc
hiat
ry
Psyc
holo
gy D
evel
opm
enta
l
Publ
ic E
nvir
onm
enta
l & O
ccup
atio
nal …
Stat
istic
s &
Pro
babi
lity
Viro
logy
Qua
ntid
ade
de a
rtig
os
Categorias
Distribuição dos descritores após indexação
Saúde
Informática em Saúde
Ciência da Computação

50
Title: Combining medical informatics and bioinformatics toward tools for personalized medicine
Abstract: Objectives. Key bioinformatics and medical informatics research areas need to be identified to advance knowledge
and understanding of disease risk factors and molecular disease pathology in the 21(st) century toward new diagnoses,
prognoses, and treatments. Methods: Three high-impact informatics areas are identified: predictive medicine (to identify
significant correlations within clinical data using statistical and artificial intelligence methods), along with pathway informatics and
cellular simulations (that combine biological knowledge with advanced informatics to elucidate molecular disease pathology).
Results. Initial predictive models have been developed for a pilot study in Huntington's disease. An initial bioinformatics platform
has been developed for the reconstruction and analysis of pathways, and work has begun on pathway simulation. Conclusions:
A bioinformatics research program has been established at GE Global Research Center as an important technology toward next
generation medical diagnostics. We anticipate that 21(st) century medical research will be a combination of informatics tools with
traditional biology wet lab research, and that this will translate to increased use of informatics techniques in the clinic.
Categorias sugeridas pelo ISI Web of Knowledge Categorias sugeridas pela competição de técnicas Computer Science, Information Systems 1. Medical Informatics
Health Care Sciences & Services 2. Computer Science Information Systems
Medical Informatics 3. Health Care Sciences & Services
4. Computer Science Interdisciplinary Applications
5. Computer Science Artificial Intelligence
Figura 19 – Exemplo de indexações sugeridas pelo portal ISI Web of Knowledge e método que utilizou a
competição de técnicas atribuídas a um artigo científico coletado da base de dados de validação.
A literatura científica que investiga técnicas capazes de indexar automaticamente
documentos é ampla e não esgotou os esforços direcionados à criação de novos
mecanismos. Os resultados obtidos neste estudo se comparam às pontuações de
desempenho alcançadas em trabalhos publicados recentemente sobre a indexação de
artigos científicos sob escopos de domínios de conhecimento específicos [15,19,47,48].

51
6 CONCLUSÕES
A exploração de técnicas de extração de características, classificadores de
padrões, medidas de desempenho aplicadas à classificação e indexação de textos,
bem como diferentes análises estatísticas foram contempladas neste trabalho.
O desenvolvimento do mesmo concentrou-se em dois objetivos específicos, cujas
conclusões foram abordadas nas seções abaixo.
6.1 Objetivo 1: Classificação de artigos científicos
Com relação ao objetivo 1, cuja proposta foi classificar artigos científicos entre os
domínios da Ciência da Computação, Informática em Saúde e Saúde, a comparação
de diferentes métodos para a construção dos vetores de características utilizados como
parâmetro de entrada do classificador probabilístico definido no estudo mostrou-se
relevante, uma vez que os resultados apresentados, de acordo com o método utilizado,
foram diferentes.
A utilização de conhecimento prévio, adotado pelo método supervisionado de
extração de características, alcançou as melhores pontuações de desempenho
avaliadas no estudo, superiores a 80%.
A interdisciplinaridade do domínio da Informática em Saúde, que poderia dificultar
a tarefa de classificação, foi absorvida pelas técnicas propostas e não comprometeu os
resultados.
6.2 Objetivo 2: Indexação de artigos científicos
A indexação de artigos científicos sob uma lista pré-definida de categorias
caracterizou o segundo objetivo proposto no trabalho.
Este objetivo também contou com a exploração de métodos para a construção
dos vetores de características e posterior utilização como parâmetro de entrada do
classificador utilizado no estudo, além disso, abordou uma nova proposta,
caracterizada pela votação e competição de técnicas.
Os valores alcançados pelas medidas de desempenho f0,5-score e f1-score foram
0,66 e 069, respectivamente, apresentados pelo método que explorou a competição de

52
técnicas. O método não-supervisionado, regido pela técnica binary occurrence,
apresentou o valor de 0,77 para a medida f2-score.

53
7 APLICAÇÕES E TRABALHOS FUTUROS
Este estudo contemplou a utilização de diferentes técnicas de extração de
características de documentos como parâmetro de entrada de um classificador
probabilístico, promovendo uma avaliação detalhada dos métodos aplicados, nos quais
os objetivos concentraram-se na classificação e indexação de artigos científicos do
idioma inglês entre os domínios da Informática em Saúde, Saúde e Ciência da
Computação.
Embora os resultados tenham sido condizentes com os dados da literatura,
alguns pontos merecem atenção especial, por exemplo, a dimensão (35 mil) dos
vetores de características utilizados para representarem os documentos. A literatura
expõe alternativas para a redução da dimensionalidade de tais vetores, que não foram
contempladas neste estudo, como o trabalho de Yang [49], que explora e compara
técnicas capazes de selecionar características de documentos para a tarefa de
classificação automática.
Outro ponto relevante é a análise de desempenho quanto ao tempo de
processamento da tarefa de classificação e indexação consumida pelo mecanismo
automatizado. Ao disponibilizar este serviço para o público, questões relacionadas a
este contexto emergirão e necessitarão ser avaliadas.
A motivação deste estudo amparou-se no crescimento exponencial da quantidade
de artigos científicos publicados no domínio da Informática em Saúde e na redução das
tarefas manuais de indexação e classificação de conteúdo pertinente a este contexto.
Trabalhos futuros serão destinados à disponibilização dos mecanismos
automatizados criados à comunidade científica, por meio de serviços que auxiliem
profissionais que atuam na classificação e indexação de conteúdos em bibliotecas
virtuais, pesquisadores que conduzem trabalhos científicos a encontrar informação
relevante e demais aplicações aplicadas à mineração de textos nos domínios
abordados neste estudo.

54
8 ANEXOS
8.1 Aprovação do Comitê de Ética em Pesquisa

55
9 REFERÊNCIAS
1. Bernstam EV, Smith JW, Johnson TR. What is biomedical informatics? J Biomed Inform 2010;43(1):104–10.
2. DeShazo J, LaVallie D, Wolf F. Publication trends in the medical informatics literature: 20 years of “Medical Informatics” in MeSH. BMC Medical Informatics and Decision Making 2009;9(1):7.
3. van Bemmel JH. Medical Informatics Is Interdisciplinary avant la Lettre. Methods Inf Med [Internet] 2008 [cited 2011 Mar 9];Available from: http://www.schattauer.de/index.php?id=246&L=1&schattauer_issue[issueId]=667&schattauer_issue[manuscriptId]=10163&schattauer_issue[manuscriptMode]=show&cHash=d6134beb4b
4. Knaup P, Dickhaus H. Perspectives of medical informatics: advancing health care requires interdisciplinarity and interoperability. Special topic on the occasion of the 35th anniversary of the Heidelberg/Heilbronn curriculum of medical informatics. Methods Inf Med 2009;48(1):1–3.
5. Mantas J, Ammenwerth E, Demiris G, Hasman A, Haux R, Hersh W, et al. Recommendations of the International Medical Informatics Association (IMIA) on Education in Biomedical and Health Informatics. Methods Inf Med [Internet] 2010 [cited 2011 Mar 9];Available from: http://www.schattauer.de/en/magazine/subject-areas/journals-a-z/methods/contents/archive/issue/special/manuscript/12538/show.html
6. Schuemie MJ, Talmon JL, Moorman PW, Kors JA. Mapping the Domain of Medical Informatics. Methods Inf Med [Internet] 2009 [cited 2011 Mar 9];Available from: http://www.schattauer.de/index.php?id=246&L=1&schattauer_issue[issueId]=661&schattauer_issue[manuscriptId]=10817&schattauer_issue[manuscriptMode]=show&cHash=c4211d4612
7. Magdy W, Jones G. PRES: a score metric for evaluating recall-oriented information retrieval applications [Internet]. In: Proceeding of the 33rd international ACM SIGIR conference on Research and development in information retrieval. Geneva, Switzerland: ACM; 2010 [cited 2011 May 5]. p. 611–8.Available from: http://dx.doi.org/10.1145/1835449.1835551
8. Kastrin A, Peterlin B, Hristovski D. Chi-square-based scoring function for categorization of MEDLINE citations. Methods Inf Med 2010;49(4):371–8.
9. Vasuki V, Cohen T. Reflective random indexing for semi-automatic indexing of the biomedical literature. J Biomed Inform 2010;43(5):694–700.
10. Text Categorization [Internet]. Text Categorization2011 [cited 2011 Jul 15];Available from: http://lexsrv3.nlm.nih.gov/LexSysGroup/Projects/tc/current/web/index.html

56
11. Humphrey SM. A New Approach to Automatic Indexing Using Journal Descriptors. Proceedings of the ASIS Annual Meeting 1998;35:496–500.
12. Humphreys BL, Lindberg DAB, Schoolman HM, Barnett GO. The Unified Medical Language System: An Informatics Research Collaboration. J Am Med Inform Assoc 1998;5(1):1–11.
13. Humphrey SM. Automatic Indexing of Documents from Journal Descriptors: A Preliminary Investigation. Journal of the American Society for Information Science 1999;50(8):661–74.
14. Humphrey SM, Rogers WJ, Kilicoglu H, Demner-Fushman D, Rindflesch TC. Word sense disambiguation by selecting the best semantic type based on Journal Descriptor Indexing: Preliminary experiment. J. Am. Soc. Inf. Sci. Technol. 2006;57(1):96–113.
15. Humphrey SM, Névéol A, Browne A, Gobeil J, Ruch P, Darmoni SJ. Comparing a rule-based versus statistical system for automatic categorization of MEDLINE documents according to biomedical specialty. Journal of the American Society for Information Science and Technology 2009;60(12):2530–9.
16. Zhang W, Yoshida T, Tang X. A comparative study of TF*IDF, LSI and multi-words for text classification. Expert Systems with Applications 2011;38(3):2758–65.
17. Lan M, Tan C-L, Low H-B. Proposing a new term weighting scheme for text categorization [Internet]. In: Proceedings of the 21st national conference on Artificial intelligence - Volume 1. AAAI Press; 2006 [cited 2011 Apr 29]. p. 763–8.Available from: http://portal.acm.org/citation.cfm?id=1597538.1597660
18. Sohn S, Kim W, Comeau DC, Wilbur WJ. Optimal training sets for Bayesian prediction of MeSH assignment. J Am Med Inform Assoc 2008;15(4):546–53.
19. Aiguzhinov A, Soares C, Serra AP. A similarity-based adaptation of naive bayes for label ranking: application to the metalearning problem of algorithm recommendation [Internet]. In: Proceedings of the 13th international conference on Discovery science. Berlin, Heidelberg: Springer-Verlag; 2010 [cited 2011 Jun 9]. p. 16–26.Available from: http://portal.acm.org/citation.cfm?id=1927300.1927302
20. Gehanno J-F, Rollin L, Jean T, Louvel A, Darmoni S, Shaw W. Precision and Recall of Search Strategies for Identifying Studies on Return-To-Work in Medline. J Occup Rehabil 2009;19(3):223–30.
21. Radlinski F, Craswell N. Comparing the sensitivity of information retrieval metrics. In: Proceeding of the 33rd international ACM SIGIR conference on Research and development in information retrieval. New York, NY, USA: ACM; 2010. p. 667–74.
22. Hanson AF. From classification to indexing: How automation transforms the way we think. Social Epistemology: A Journal of Knowledge, Culture and Policy 2004;18(4):333.

57
23. Salton G, McGill MJ. Introduction to Modern Information Retrieval [Internet]. McGraw-Hill, Inc.; 1986 [cited 2009 Feb 3]. Available from: http://portal.acm.org/citation.cfm?id=576628
24. Spreckelsen C, Deserno T, Spitzer K. Visibility of medical informatics regarding bibliometric indices and databases. BMC Medical Informatics and Decision Making 2011;11(1):24.
25. Salton G, Wong A, Yang CS. A vector space model for automatic indexing. Commun. ACM 1975;18:613–20.
26. Baeza-Yates RA, Ribeiro-Neto B. Modern Information Retrieval. in Text Operations: Addison-Wesley Longman Publishing Co., Inc.; 1999.
27. Porter M. An algorithm for suffix stripping. Program 1980;14(3):130–7.
28. Salton G, Buckley C. Term-weighting approaches in automatic text retrieval. INFORMATION PROCESSING AND MANAGEMENT 1988;24:513--523.
29. Haykin S. Neural Networks: A Comprehensive Foundation. 2nd ed. Prentice Hall; 1998.
30. Chang C, Lin C. LIBSVM: a library for support vector machines [Internet]. 2001 [cited 2009 Oct 1]. Available from: http://www.csie.ntu.edu.tw/~cjlin/libsvm
31. Aha DW, Kibler D, Albert MK. Instance-Based Learning Algorithms. Machine Learning 1991;6(1):37–66.
32. Quinlan JR. C4.5: programs for machine learning [Internet]. Morgan Kaufmann Publishers Inc.; 1993 [cited 2009 Oct 1]. Available from: http://portal.acm.org/citation.cfm?id=152181
33. Nigam K, McCallum. A comparison of event models for Naive Bayes text classification. 1998. p. 41–8.
34. Theodoridis S, Koutroumbas K. Pattern Recognition, Third Edition. Academic Press, Inc.; 2006.
35. Guthrie L, Walker E, Guthrie J. Document classification by machine: theory and practice [Internet]. In: Proceedings of the 15th conference on Computational linguistics - Volume 2. Stroudsburg, PA, USA: Association for Computational Linguistics; 1994 [cited 2011 May 18]. p. 1059–63.Available from: http://dx.doi.org/10.3115/991250.991322
36. Lewis DD, Gale WA. A sequential algorithm for training text classifiers [Internet]. In: Proceedings of the 17th annual international ACM SIGIR conference on Research and development in information retrieval. New York, NY, USA: Springer-Verlag New York, Inc.; 1994 [cited 2011 May 18]. p. 3–12.Available from: http://portal.acm.org/citation.cfm?id=188490.188495
37. Joachims T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. In ICML-97 1997;:143--151.

58
38. Li H, Yamanishi K. Document classification using a finite mixture model [Internet]. In: Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics; 1997 [cited 2011 May 18]. p. 39–47.Available from: http://dx.doi.org/10.3115/976909.979623
39. Lewis DD. Naive (Bayes) at Forty: The Independence Assumption in Information Retrieval. 1998;:4--15.
40. Duda RO, Hart PE, Stork DG. Pattern classification. Wiley; 2001.
41. Sebastiani F. Machine learning in automated text categorization. ACM Comput. Surv. 2002;34:1–47.
42. Hope ACA. A Simplified Monte Carlo Significance Test Procedure. Journal of the Royal Statistical Society. Series B (Methodological) 1968;30(3):582–98.
43. Bauer DF. Constructing Confidence Sets Using Rank Statistics. Journal of the American Statistical Association 1972;67(339):687–90.
44. Altman DG. Practical Statistics for Medical Research. 1st ed. Chapman and Hall/CRC; 1990.
45. Royston J. An Extension of Shapiro and Wilk’s W Test for Normality to Large Samples. Journal of the Royal Statistical Society. Series C (Applied Statistics) [Internet] 1982 [cited 2011 Jun 16];31(2). Available from: http://dx.doi.org/10.2307/2347973
46. Lan M, Tan C, Low H, Sung S. A comprehensive comparative study on term weighting schemes for text categorization with support vector machines. In: WWW ’05: Special interest tracks and posters of the 14th international conference on World Wide Web. Chiba, Japan: ACM Press; 2005. p. 1032–3.
47. Liang C-Y, Guo L, Xia Z-J, Nie F-G, Li X-X, Su L, et al. Dictionary-based text categorization of chemical web pages. Information Processing & Management 2006;42(4):1017–29.
48. Trieschnigg D, Pezik P, Lee V, de Jong F, Kraaij W, Rebholz-Schuhmann D. MeSH Up: effective MeSH text classification for improved document retrieval. Bioinformatics 2009;25(11):1412–8.
49. Yang Y, Pedersen J. A comparative study on feature selection in text categorization [Internet]. In: Proceedings of ICML-97, 14th International Conference on Machine Learning. Morgan Kaufmann Publishers, San Francisco, US; 1997 [cited 2011 Aug 20]. p. 412–20.Available from: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.32.9956