cap. 5 – objetos distribuídos e invocação remota · • precisam invocar operações em...
TRANSCRIPT

1 SD Cap. 5-6 1 SD Cap. 5-6
Cap. 5 – Objetos Distribuídos e Invocação Remota Aplicação distribuída: conjunto de processos que cooperam entre si; • Precisam invocar operações em processos remotos para realizar
serviços. Modelos de programação usados: • Chamada de procedimentos: extendida no RPC para permitir a
chamada de procedimentos remotos; • Invocação de métodos: extendida no RMI para permitir a
invocação de métodos em objetos remotos; • Programação orientada a eventos: permite a objetos receber
notificações de eventos em objetos onde registraram interesse. Extendida para permitir notificação sobre eventos distribuídos.
Middleware
Aplicações RMI, RPC e eventos
Protocolo request – reply Representação externa de dados
Sistema operacional Aspectos importantes: • Transparência de localização: no RPC, quem chama uma
função não sabe se ela é local ou não, se roda no mesmo processo ou num diferente. Se for remota, não se sabe onde está o processo que vai ser executado. Recebendo um evento
distribuído, o processo não sabe onde está o processo que o gerou.
• Protocolos: são independentes do sistema de comunicação básico.
• Diferenças de hardware: são encobertas por operações de marshalling com EDR.
• Sistema operacional: a aplicação que usa o middleware não depende do SO local.
• Linguagens diferentes: alguns middlewares permitem independência de linguagem. Um objeto escrito numa linguagem pode invocar métodos em objetos escritos em outra.
5.1.1 Interfaces Na programação por módulos, o relacionamento entre módulos é feito via uma interface. Nela, relaciona-se quais métodos estão disponíveis para acessar determinado módulo. Enquanto a interface permanecer igual, o acesso ao módulo não é alterado, mesmo que a implementação mude. Interfaces em SDs Num programa distribuído, um módulo não pode acessar variáveis de outro. A interface de um módulo não pode especificar acesso a variáveis. O IDL do CORBA permite especificar atributos, mas o acesso não é direto. A plataforma insere funções de consulta e atualização de variáveis automaticamente.
Middleware

2 SD Cap. 5-6 2 SD Cap. 5-6
Os mecanismos de passagem de parâmetros das chamadas locais não se aplicam em programas distribuídos (passagem por valor ou por referência). Na interface, a especificação de parâmetros indica apenas input e/ou output:
• Input: parâmetros passados para a função invocada que fornecem valores para o seu algoritmo;
• Output: parâmetros que recebem resultados da função invocada.
Ponteiros não podem ser usados em invocações de funções. Diferença entre RPC e RMI: • Interface de serviço: conjunto de funções disponíveis para
acessar os serviços de um servidor no modelo cliente-servidor; • Interface remota: métodos de um objeto disponíveis para
invocação por outros objetos; o Define parâmetros e forma de acesso; o Aceita passagem de objetos como argumentos; o Permite passagem de referências para objetos.
5.2 Comunicação entre objetos distribuídos
5.2.1 Modelo de Objetos Exceções
Tipos de erros que um processo pode encontrar durante sua execução: • Erros controláveis: valores inconsistentes de argumentos, falha
em encontrar um dado num BD, etc. • Erros externos: falha em acessar arquivos ou sockets, etc. • Erros internos: divisão por zero, endereços de memória
inválidos, etc. • Erros de dependência: ocorrem em processos hierarquicamente
superiores. O modelo de objetos permite colocar tratamento de erros através de comandos throw. Isso evita que o programador insira todos os testes no meio do código de um serviço. O tratamento é colocado em blocos separados e a execução desvia para esses blocos quando um evento é catched pelo programa. Garbage collection Objetos ocupam espaço e devem ser liberados quando não são mais necessários. Algumas linguagens (ex. Java) possuem mecanismos para liberar objetos quando não são mais referenciados. Outras não possuem e obrigam o programador a fazer esse controle (ex. C++). Operação sujeita a erros.
5.2.2 Objetos distribuídos Objetos distribuídos podem se organizar de várias formas. A invocação de seus métodos segue modelos previamente estudados.

3 SD Cap. 5-6 3 SD Cap. 5-6
Um dos pontos importantes é verificar se um determinado objeto (ou método) pode ser invocado concorrentemente (+ de uma invocação no mesmo intervalo – uma invocação feita antes da anterior ser executada). O fato de que os dados de um objeto são acessados apenas pelos seus métodos permite aplicar técnicas de controle: • Ex.: Java - métodos sinchronized; • Objetos podem ser copiados para caches locais, sendo acessados
diretamente; • Invocação via RMI permite acesso ao mesmo objeto por
plataformas diferentes – possíveis conversões são feitas por EDR.
5.2.3 O modelo de objetos distribuídos Tipos de invocação: • Local: feitas dentro do mesmo processo; • Remota: feita entre processos diferentes – podem residir ou não
em máquinas diferentes. Para ser acessado remotamente, um objeto deve ter uma referência remota. Cada objeto remoto deve ter uma interface remota, que especifica quais dos seus métodos podem ser acessados remotamente. Referência a objeto remoto Identificador que permite acessar um objeto remotamente.
É único no sistema inteiro e permite identificar um objeto determinado, independente de sua localização. Seu formato é diferente de uma referência local. Referências remotas podem ser passadas como argumentos. Interfaces remotas A classe de um objeto remoto implementa os métodos de sua interface remota. Outros objetos só podem invocar métodos de um objeto que pertencem a sua interface remota.
5.2.4 Quetões de projeto para RMI Diferenças entre chamadas locais e remotas: • Chamadas locais são executadas exatamente 1 vez; sobre
chamadas remotas já não é sempre assim; • O nível de transparência do RMI precisa ser definido. Semânticas de invocação RMI Escolhas sobre protocolos request-reply: • Mensagens retry: até quando retransmitir uma requisição, antes
de receber a resposta ou assumir que o servidor falhou; • Filtro de duplicados: com a possibilidade de retransmissões, se
o servidor deve usar um filtro; • Retransmissão de resultados: se um histórico deve ser mantido
em vez de re-executar sempre cada comando;

4 SD Cap. 5-6 4 SD Cap. 5-6
Medidas de tolerância a falhas Retransmitir requisições
Filtro de duplicados
Re-executar ou retransmitir
reply
Semânticas de
invocação
Não Não aplicável Não aplicável Maybe Sim Não Re-executar At-least-once Sim Sim Retransmite At-most-once
Obs.: para invocação de métodos locais, a semântica é exactly-once! Transparência No RPC, certas atividades (marshalling, envio de mensagens, retransmissão da requisição após um timeout) são escondidas do programador e realizadas de forma transparente. Com objetos distribuídos, isso é extendido para localizar e contactar objetos remotos. Invocações remotas são diferentes das locais porque envolvem redes. Pode haver falhas de rede ou máquina sem que se possa distinguir uma da outra. A grande questão é se a máquina destino recebeu a msg e se conseguiu executá-la. Isso obriga os objetos remotos a tratamentos para recuperação de cada caso. O atraso de uma invocação remota é enorme comparado a uma operação local. Então, é interessante minimisar esse custo.
Apesar de se procurar por transparência, é interessante que a diferença entre invocações locais e remotas sejam explícitas, já que as implicações são grandes. Ex.: • Corba repassa ao programa erros de comunicação como exceção; • A IDL também permite especificar o tipo de semântica que se
deseja – isso informa o projetista sobre que tipo de operação o objeto deve realizar;
• Java RMI separa invocações locais de remotas.
5.2.5 Implementação de RMI Módulo de comunicação • Executa o protocolo request-reply; • Especifica tipo de msg, requestId, referência remota; • Determina a semântica; • No servidor, seleciona o dispatcher. Módulo de referência remota • Tradução entre referências remotas e locais; • Cria referências remotas; • Mantém uma tabela de objetos remotos:
o Entradas para todos os objetos remotos relacionados ao processo;
o Entradas para cada proxy local.

5 SD Cap. 5-6 5 SD Cap. 5-6
Software RMI Camada entre objetos da aplicação e módulos de comunicação e referência remota. Função de seus componentes: • Proxy:
o Torna transparente para o cliente as invocações (comporta-se como um objeto local, mas repassa as invocações para os objetos remotos);
o Esconde detalhes da referência remota, marshalling, unmarshalling, envio e recepção de msgs;
o Um proxy para cada objeto remoto que o processo usa. • Dispatcher:
o Servidores possuem um dispatcher e um skeleton para cada classe de objetos remotos;
o Recebe requisições; methodId diz que método deve ser chamado; passa a requisição.
• Skeleton: o Implementa os métodos de uma interface; o Faz unmarshall da requisição e invoca o método
correspondente do objeto remoto; o Faz marshall do resultado (e exceções); o Passa a msg reply para o proxy para transmissão.
Métodos fábricas • Interfaces não incluem construtores; • Assim, objetos remotos não podem ser criados por invocação
remota;
• São criados na inicialização de processos ou em métodos de interfaces remotas;
• Um método fábrica é aquele que cria objetos remotos; • Objeto fábrica é aquele que possui métodos fábricas. Binder Serviço de um SD que mantém tabelas de mapeamento entre nomes de serviços e referências remotas. Permite aos servidores se registrarem e aos clientes procurar um serviço. • Corba: Corba Name Service; • Java: RMIregistry. Ativação de objetos remotos As aplicações necessitam que as informações sejam mantidas por longos períodos. Isso não justifica manter objetos em processos se eles não são necessários todo o tempo. Assim, os processos são disparados quando necessário. Um objeto remoto que pode ser invocado é chamado de ativo. Se ele não está ativo, mas pode ser ativado, é chamado de passivo. Um objeto passivo: • Implementação dos métodos; • Seu estado na forma marshalled. Processos que disparam servidores para manter objetos remotos são chamados de ativadores.

6 SD Cap. 5-6 6 SD Cap. 5-6
Armazéns de objetos persistentes Objeto persistente: pode manter seu estado e informações entre períodos de ativação. Ex.: • Serviço de objetos persistentes Corba; • Java Persistente. O processo de ativação é transparente. O estado dos objetos é salvo periodicamente em pontos íntegros para fins de tolerância a falhas. Duas abordagens para decidir se um objeto é persistente ou não: • Raízes persistentes: objetos acessíveis através de uma raiz
persistente é um objeto persistente. Ex.: Java Persistente e PerDis;
• Classes persistentes: objetos persistentes são instâncias dessas classes ou derivados delas. Ex.: Arjuna.
Alguns armazéns permitem a ativação de objetos em caches dos clientes. Ex.: PerDis e Khazana. Isso exige um protocolo de consistência de caches.
5.3 Remote Procedure Calling - RPC Programa distribuído: • Conjunto de componentes de software; • Executam sobre um número de computadores da rede.
Modelo cliente-servidor: • Uma aplicação pode ser cliente de qualquer serviço da rede; • Um servidor pode ser cliente de outros serviços; • Cada serviço possui um conjunto de operações que podem ser
invocadas pelos clientes; • A comunicação entre clientes e servidores é baseada no
protocolo requisição-resposta; • O cliente sempre espera pela resposta para continuar, mesmo que
não haja retorno de valor (pode haver erro!). RPC: • Integração entre clientes e servidores de forma conveniente; • Clientes se comunicam com servidores através da chamada de
procedimentos; • A chamada é feita no programa local; • A execução ocorre num programa remoto. Serviço ao nível RPC: • Uma interface que é exportada para os programas de um sistema; • Conjunto de funções que operam sobre certos dados ou recursos; Aspectos semânticos de RPC: • Parâmetros de entrada e saída:
• Parâmetros de entrada são passados para o servidor; • Valores enviados na requisição e copiados nas variáveis do
servidor; • Parâmetros de saída são enviados para o cliente na resposta; • Substituem as variáveis da chamada; • Parâmetros podem ser I/O.

7 SD Cap. 5-6 7 SD Cap. 5-6
• Parâmetros de entrada ~ passagem por valor • Se passagem por referência (ptr em C):
• Indicar se é I, O ou I/O; • Motivo para uma linguagem de definição de interface.
• Procedimento remoto:
• Executado em ambiente diferente de quem chama; • Não pode acessar dados do cliente (ex.: globais); • Endereços de memória do cliente não tem significado para o
servidor; Conclusão: parâmetros não podem incluir ponteiros! Referência opaca: • Referência que o cliente passa para o servidor; • Endereço do servidor; • Não tem significado para o cliente. Estruturas complexas podem ser serializadas: • Ex.: uma árvore pode ser convertida em uma expressão.
Questões de projeto Histórico: • 1981 - Xerox Courier RPC: padrão de desenvolvimento de
aplicações remotas; • 1984 - Birrel e Nelson:
• RPC para o ambiente de programação Cedar; • Datagramas sobre a Internet da Xerox; • Linguagem Mesa.
Classes de RPC: 1. o mecanismo RPC é integrado com uma linguagem específica;
• inclui uma notação de definição de interface; • ex.: Cedar, Argus, Arjuna; • pode incluir construções específicas para RPC (ex.:
exceções); 2. linguagem de definição de interfaces (pré-compilador ?!).
• ex.: SUN RPC (base do NFS); • Matchmaker (Jones e Rashid, 1986): pode ser usado com C,
Pascal, LISP, MIG (Mach Interface Generator); • Não é ligado a um ambiente particular.
Linguagem de definição de interfaces: • Especifica as características do servidor que são visíveis para o
cliente; • Nomes de procedimentos, tipos dos parâmetros; • Tipo de acesso a um parâmetro: I, O ou I/O; • O acesso indica se o valor precisa ser encapsulado na requisição
ou na resposta (marshaling); Compiladores de interfaces podem gerar descrições que podem ser usadas em diferentes linguagens, permitindo a comunicação de clientes e servidores de plataformas diferentes.

8 SD Cap. 5-6 8 SD Cap. 5-6
Tratamento de exceções: • Qualquer RPC pode falhar:
• Falha no servidor; • Sobrecarga do servidor (atraso na resposta).
• RPC deve devolver erros: • Timeouts (inerente à distribuição); • Erros de execução (FD inválido, leitura após EOF, divisão
por zero, etc.). • Erros detectados pelos procedimentos (códigos inválidos,
datas erradas, etc.). Obs.: na falta de um mecanismo de indicação de erros (como exceções em JAVA), o sistema pode usar um método bem definido de indicação de problemas (retorno de 0 ou –1 em UNIX). Garantia de entrega: Implementações possíveis do DoOperation: • Repetição da requisição: até receber uma resposta ou assumir
que o servidor falhou; • Filtro de duplicados: usado com retransmissão, para evitar
duplicação no servidor; • Retransmissão da resposta: evita a reexecução de uma
requisição. Garantia de Entrega Semântica RPC Repete Req. N S S
Filtra Duplic. - N S
Reexec/Retrans - Reexecuta Retransmite
Maybe At-least-once At-most-once
Tipos de semânticas RPC: 1. Maybe: sem tolerância a falhas. Não há garantias de que o
procedimento foi executado. Não se pode saber se o servidor executou a requisição ou se a resposta foi perdida.
2. At-least-once: o cliente é informado de que um timeout ocorreu e retransmite a requisição. Eventualmente o servidor receberá uma requisição duplicada. Se ele for projetado para executar operações idempotentes, não há problema.
3. At-most-once: o servidor filtra requisições duplicadas e retransmite as respostas.
Transparência: • O modelo Birrel e Nelson garante que a chamada a
procedimentos remotos é igual à chamada dos locais; • RPC Cedar:
• identifica os procedimentos remotos; • acrescenta o código necessário para o marshalling e
unmarshalling; • faz retransmissão da requisição após um timeout; • a duração de uma chamada é indefinida desde que o servidor
permaneça ativo. RPC é mais vulnerável do que chamadas locais: • envolve redes, outros computadores e outro processos; • consome muito mais tempo do que chamadas locais; • deve tratar erros que não acontecem nas chamadas locais.

9 SD Cap. 5-6 9 SD Cap. 5-6
Implementação O software de suporte ao RPC tem 3 funções: • Processamento da interface:
• marshalling e unmarshalling; • despacho das requisições.
• Tratamento da comunicação: • Transmitir requisições e receber as respostas;
• Binding: • Localização de um servidor para um serviço qualquer.
Processamento da interface: Requisição Cliente Servidor Chamada Marshall Send Receive Unmarsh. Executa Seleção! Retorno Unmarsh Receive Send Marshall Retorno Resposta Cada procedimento de uma interface é numerado com um número único (0, 1, 2, 3, ...). Construindo um programa cliente: • Stub:
• converte chamada local em remota; • faz o casamento dos parâmentros.
Construindo o programa servidor: • entregador (despatcher); • conjunto de stubs servidores. Compilador de interfaces: • processa as definições de uma IDL.
1. Gera os stubs do cliente; 2. Gera os stubs do servidor; 3. Gera as operações de marshall e unmarshall; 4. Fornece os cabeçalhos das funções (o corpo – o que a função
faz – deve ser fornecido pelo programador).
Binding Mapeamento de um nome para um objeto determinado (identificador de comunicação). Ex.: no Unix, um socket com número IP e Porta. Ex.: Mach, Chorus e Amoeba, uma porta independente de localização. Evita a recompilação dos clientes quando o servidor muda de porta. Se o endereço inclui a identificação do host, o cliente precisa ser recompilado toda vez que o servidor mudar de host. Num sistema distribuído, o binding é um serviço separado que mantém tabelas associando nomes de serviços com portas de servidores. Ex.: o próprio Binding, DNS, etc. Funções: • Register(serviço: string, porta: port, versão: integer); • Withdraw(serviço: string; pota: port; versão: integer); • LookUp(serviço: string; versão: integer): port.

10 SD Cap. 5-6 10 SD Cap. 5-6
Quando um servidor inicia seus serviços, ele envia uma mensagem para o Binding para se registrar. Quando ele encerra suas atividades, ele pede para ser retirado das tabelas do Binding. Quando um cliente quer usar um serviço, manda uma mensagem ao Binding para descobrir o endereço do servidor. Se o servidor falha, o cliente pode requisitar ao Binding a porta de outro servidor do mesmo serviço. Se o sistema usa portas independentes de localização, um servidor pode se mover para outro host sem informar o Binding. Os clientes não são afetados pela mudança. Se o identificador de porta inclui o host, o Binding deve ser informado toda vez que o servidor for movido. Os clientes vão ter requisições ignoradas. Eles devem contatar o Binding para descobrir o novo endereço do serviço. Serviço único: todos os outros dependem dele: • Tolerante a falhas (ex.: salvando as tabelas em arquivos toda vez
que elas são alteradas); Um sistema distribuído dependente de um único Binder não é escalável: • As tabelas podem ser particionadas (maior desempenho); • Também podem ser replicadas em um grupo de Binders
(tolerância a falhas).
Alguns serviços são representados por múltiplos servidores, cada um rodando em um host diferente: • Cada um deles é uma instância de um serviço; • Um Binder deve ser capaz de registrar as várias instâncias de um
serviço; • Se o Binder não usa a instância de um serviço, o cliente deve
informar qual delas ele quer usar (número seqüencial); • Numa falha, o cliente pega a próxima instância.
• Se o Binder usar a instância, ele pode distribuir os clientes pelas diversas instâncias de um serviço (balanceamento de carga)
Exportação: registro de um nome de interface associado com a porta de um servidor. Importação: pergunta ao Binder pelo nome de um serviço retornando um número de porta. Localização do Binder: • Endereço bem definido, compilado em todos os clientes;
• Clientes e servidores precisam ser recompilados se o Binder for mudado;
• O Kernel informa o endereço do Binder (ex.: variável de ambiente). Permite a relocação ocasional do Binder;
• Quando clientes ou servidores iniciam, mandam mensagens de broadcast para localizar o Binder (ex.: no Unix, o Binder fica numa porta bem conhecida. Num broadcast, o Binder que receber informa qual é o seu host).

11 SD Cap. 5-6 11 SD Cap. 5-6
RPC Assíncrono Ex.: sistema de janelas X-11 Utiliza uma forma assíncrona de RPC: X-11 é um servidor de janelas; As aplicações que querem mostrar alguma coisa na tela (texto,
gráficos, etc.) são os clientes. Características: Para gerar ou atualizar a informação de uma janela, o cliente
envia várias requisições ao servidor, cada uma delas com uma pequena quantidade de informações: Strings, troca de fonte, um caracter.
O cliente não recebe respostas para suas requisições; Cliente e servidor trabalham em paralelo; Algumas requisições podem exigir intensa computação - há
ganhos em realizá-las enquanto o servidor atende requisições anteriores;
O servidor pode manipular requisições de vários clientes; Ou mesmo de dispositivos; O servidor tem uma performance melhor se ele não precisa
enviar respostas para as requisições. RPC sem respostas e sem bloqueio é chamado de assíncrono. Comparação: • No RPC síncrono, não existe paralelismo; • No RPC assíncrono, o cliente faz todas as requisições de que
necessita; só então espera pelos resultados;
• A espera no lado do cliente se resume ao intervalo entre a última requisição e a recepção da primeira resposta;
• Se não houver necessidade de resposta às requisições, o tempo de espera não existe.
Otimização possível: • Armazenar as requisições no lado do servidor até que ocorra um
timeout ou que o cliente peça uma resposta; • Só então as requisições são enviadas como uma comunicação só; • Isto reduz a latência de rede.
Requisições paralelas para vários servidores Ex.: considere um banco com vários servidores, cada um responsável por registrar os lançamentos feitos em uma agência. • Para saber o saldo de uma conta, é preciso consultar os
lançamentos de todas as agências; RPC síncrono: • O cliente faz requisições para um servidor de cada vez,
esperando a resposta; • Só após chegar uma resposta, ele manda a requisição para o
próximo. RPC assíncrono: • O cliente envia as requisições para todos os servidores em
seqüência e depois espera por todas as respostas; • Os servidores trabalham em paralelo. Comparação entre RPC síncrono e assíncrono:
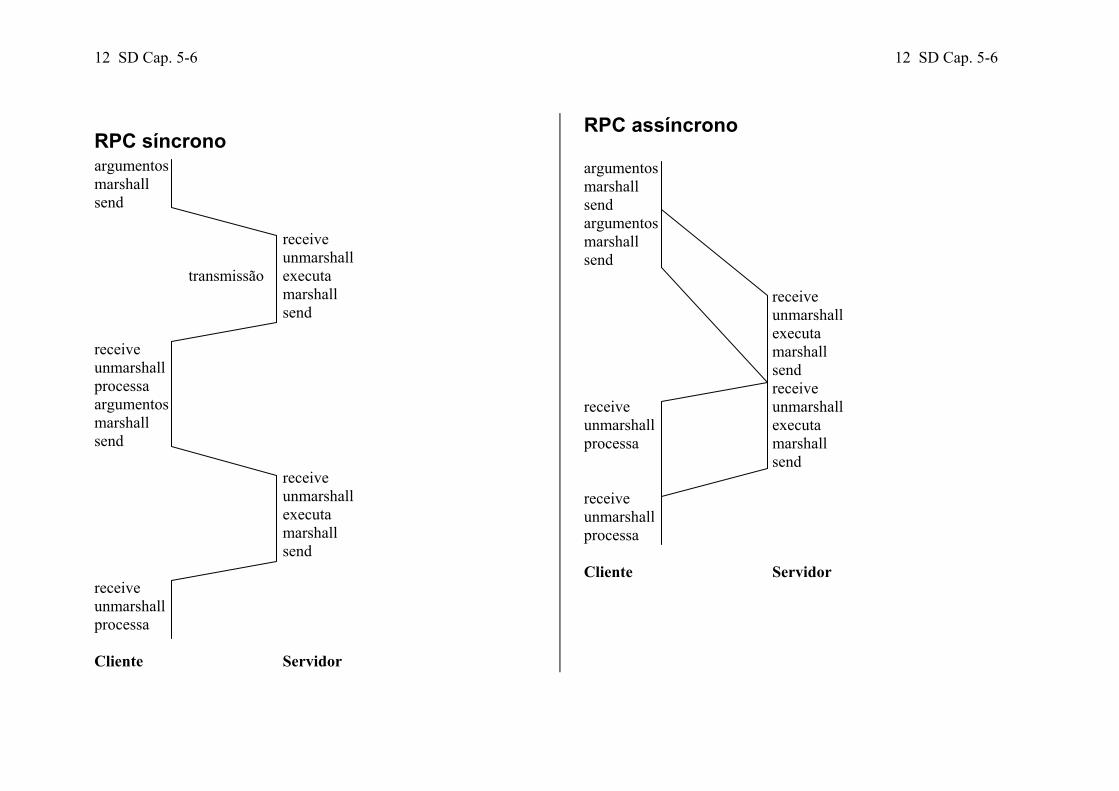
12 SD Cap. 5-6 12 SD Cap. 5-6
RPC síncrono argumentos marshall send receive unmarshall transmissão executa marshall send receive unmarshall processa argumentos marshall send receive unmarshall executa marshall send receive unmarshall processa Cliente Servidor
RPC assíncrono argumentos marshall send argumentos marshall send receive unmarshall executa marshall send receive receive unmarshall unmarshall executa processa marshall send receive unmarshall processa Cliente Servidor

13 SD Cap. 5-6 13 SD Cap. 5-6
RPC assíncrono no sistema Mercury Otimizações necessárias no paradigma RPC:
• Se não há necessidade de resposta, o cliente pode fazer um RPC e continuar sua execução;
• Se não há necessidade de resposta, várias requisições podem ser armazenadas e enviadas no mesmo send;
• Se há necessidade de resposta, o cliente pode processar até que ela seja necessária para só então requisitá-la.
Sistema Mercury – MIT, 1988: • Call-stream: combina RPC síncronos e assíncronos; • As diferenças nos métodos de comunicação não são visíveis para
os servidores: • Eles só recebem requisições e devolvem respostas.
• Simplifica o projeto dos servidores; • O cliente determina o método que vai utilizar; • Diferente de outros sistemas onde a interface define o método e
o servidor precisa ser projetado de acordo; • Se o cliente não precisa da resposta a uma requisição, o call-
stream não a devolve para o cliente.
Promessas • Liskov e Shrira, 1988; • Uma promessa é criada no momento de uma chamada a um
servidor; • Pode assumir dois estados possíveis:
• Bloqueado; • Pronto.
• Quando criada, a promessa fica no estado bloqueado; • Uma promessa é associada com uma requisição específica; • Quando chega a resposta a essa requisição, ela é armazenada na
promessa correspondente; • Neste caso, o estado da promessa passa para pronto; Funções: • claim(): extrai a resposta de uma promessa;
• se ela estiver no estado bloqueado, o cliente bloqueia até que a promessa passe para o estado de pronto ou que ocorra uma exceção.
• ready(): testa o estado de uma promessa.
5.4 Eventos e notificações • Objetos que geram eventos numa plataforma distribuída
publicam os eventos disponíveis para observação por outros objetos;
• Objetos que querem receber notificações de eventos publicados assinam tipos de eventos em que têm interesse;
• Objetos que representam eventos são chamados de notificações. Sistemas baseados em eventos têm 2 características principais: • Heterogêneos: permite que objetos não projetados para
interoperação trabalhem em conjunto. Um sistema de eventos que permite publicação e assinatura pode permitir trabalho conjunto para objetos que não foram projetados com esse fim;

14 SD Cap. 5-6 14 SD Cap. 5-6
• Assíncronos: permite notificação de eventos aos assinantes sem necessidade de sincronismo, o que significa bloqueio dos envolvidos.
5.4.1 Participantes em notificações de eventos distribuídos Arquitetura que permite independência entre autores e assinantes: • Banco de dados com eventos publicados e interesse dos
assinantes; • Quando ocorre um evento que possui interessados, uma
notificação é enviada. Participantes: • Objetos de interesse: aqueles que possuem métodos que podem
alterar estados – isso gera eventos que podem ter interessados; • Evento: ocorre como resultado da execução de um método; • Notificação: objeto que contém informações sobre um evento: • Assinante: assina algum tipo de evento em outro objeto – recebe
notificações dele; • Observadores: objetos que isolam autores de assinantes. Eles
monitoram os eventos e notificam aqueles assinados; • Autor: objeto que declara que vai gerar notificações de certos
tipos de eventos. Pode ser um objeto de interesse ou um observador.
Possíveis casos de comportamento em um serviço de eventos:
• Objetos de Interesse enviam notificações diretamente aos assinantes;
• OdI enviam notificações via observadores aos assinantes; • OdI fora do serviço de eventos. Observadores fazem consultas ao
OdI para descobrir quando ocorre um evento. Ele é notificado aos assinantes.
Papéis dos observadores • Encaminhar notificações para os assinantes de um ou + objetos
de interesse. São os objetos de interesse que informam os observadores sobre seus assinantes;
• Filtros de notificações: aplicados pelos observadores para reduzir a quantidade de notificações. São baseados em regras informadas pelos assinantes. Ex.: num banco, retiradas, mas apenas as maiores que 10000,00;
• Padrões de eventos: relação de eventos entre si. Ex.: num banco, quero ser informado sempre que houver 3 retiradas sem um depósito;
• Caixas de correio para notificações: usadas para encaminhar notificações sem que o assinante receba na hora. Ex.: ele não possui uma conexão permanente, ou tornou-se passivo. As notificações são recuperadas mais tarde.

15 SD Cap. 5-6 15 SD Cap. 5-6
Cap. 6 – Suporte dos Sistemas Operacionais
6.1 Introdução Função importantes de um SD: compartilhamento de recursos. • Clientes invocam operações sobre recursos em outros nós ou
outros processos. Middleware: permite a interação entre aplicações clientes e recursos (gerentes). • O SO fica abaixo do middleware; • O que importa aqui é o relacionamento entre os dois; • Como o SO permite ao middleware o acesso aos recursos físicos,
como ele implementa políticas de acesso, etc. Abstrações: • SO fornece modelos para manipular certos recursos; • Ex.: arquivos x blocos de disco; • Ex.: sockets x fluxo de redes. Num SO de rede (Unix, NT, etc.), o usuário que precisa executar um programa numa máquina diferente precisa se envolver: • Telnet, fornece senha, executa o programa. SO Distribuído:
• O usuário não se preocupa com o nó em que seu programa executa;
• Não importa onde estão os recursos; • O usuário vê uma única imagem do sistema; • A esolha de um nó para executar um programa depende da
política de escalonamento. Caracterização de um SOD: • Permite a programação de um SD, permitindo a implementação
de uma grande gama de aplicações; • Apresenta para as aplicações abstrações genéricas e orientadas
aos problemas dos recursos do sistema; • Num SD aberto, o SOD é implementado como um conjunto de
kernels e servidores. • Não há uma distinção clara entre os serviços do sistema e as
aplicações que rodam no topo do SOD. Exemplos: Mach e Chorus. • Resultados de grandes períodos de pesquisa nos anos 80 e 90; • Alto nível de interesse técnico e comercial; Outros exemplos técnicos: • Amoeba, Clouds, V System; • Não aceitos para uso geral; Todos esses projetos empregam microkernel. SOD: • Infraestrutura de gerenciamento genérico de recursos e
transparente em rede;

16 SD Cap. 5-6 16 SD Cap. 5-6
• Recursos de baixo nível: processadores, memória, placas de rede, periféricos em geral;
• Plataforma para recursos de alto nível: planilhas, troca de mensagens eletrônicas, janelas;
• Oferecidos aos clientes pelos serviços do sistema; Acesso aos recursos pelo sistema: • Feito de forma transparente; • Identificadores independentes de localização; • Uso das mesmas propriedades; • Transparência fornecida no nível mais baixo, para que não
precise ser feita em cada serviço; Um SOD deve fornecer ferramentas para encapsular recursos: • De forma modular; • Modo protegido; • Amplo acesso via rede. Encapsulamento de recursos: • Interface padronizada – implementação escondida do usuário; • Concorrência – recursos compartilhados por vários usuários; • Proteção – segurança contra acesso ilegítimo. Os clientes acessam os recursos através da passagem de identificadores como argumentos: • Em system calls para o kernel; • RPC para um servidor. Invocação: acesso a um recurso encapsulado.
Tarefas relacionadas com a invocação de recursos: • Resolução de nomes – localização; • Comunicação para acesso aos recursos; Escalonamento: processamento das invocações no kernel. Middleware x SOs de rede • Não há SOs distribuídos em uso corrente hoje; • Apenas SOs de rede (Unix, NT, MacOS, etc.); • Motivos:
o Usuários se preocupam com suas aplicações de uso comum;
o Não trocam seus SOs por melhor que seja um outro produto se não puderem executar suas aplicações;
o Usuários preferem ter um certo controle sobre suas máquinas;
o A idéia de entregar os recursos a outros usuários sem controle é estranha.
Por outro lado, o uso de um middleware com um SO de rede é + versátil e aceitável: • O usuário consegue rodar seus programas favoritos; • Ele tem controle sobre os recursos de sua máquina; • Os usuários remotos têm um certo grau de transparência no
acesso aos recursos da rede; • É possível acessar recursos compartilhados com um certo grau
de concorrência.

17 SD Cap. 5-6 17 SD Cap. 5-6
6.2 Camada de sistema operacional
Aplicações, serviços
Middleware
OS1 Processos, threads, comunicação, etc.
OS2 Processos, threads, comunicação, etc.
Hardware do computador e rede
Hardware do computador e rede
Nó 1
Nó 2 As interfaces apresentadas por kernels e servidores devem apresentar pelo menos o seguinte: • Encapsulamento: conjunto mínimo de operações fornecidas aos
clientes. Detalhes de implementação escondidos; • Proteção: evita acessos indevidos; • Concorrência: clientes devem acessar os recursos de forma
concorrente. Isso deve ser transparente para eles.
Kernel Kernels e proteção: • O Kernel executa com privilégio de acesso total;
• Ex.: pode controlar a unidade de MM; • Pode conceder privilégio de acesso a recursos físicos; • Determina o espaço de endereçamento:
• Permite que os processos se protejam uns dos outros; • Evita que um processo invada áreas indevidas.
• Modo supervisor e usuário: • Processos usuários podem rodar em modo supervisor quando
tem acesso direto a um dispositivo; • System call trap: mecanismo de invocação de recursos
gerenciados pelo kernel; Kernel monolítico e microkernel – um SOD aberto deve permitir: • Executar apenas o suficiente para tornar o ambiente operacional
(módulos supérfluos gastam recursos); • Alterações no software ou sistema que implementa um serviço,
independentemente de outros elementos; • Alternativas do mesmo serviço para atender usuários ou
aplicações diferentes; • Introdução de novos serviços sem prejudicar os existentes. Um certo grau de abertura é obtido com a utilização de kernels tradicionais como base. Ex.: o DCE da OSF usa Unix, VMS, OS/2, etc. • Permitem a execução de processos servidores; • Suportam protocolos (ex.: RPC); • Possuem binding e serviços de nomes; • Serviços de tempo (sincronização); • Segurança; • Threads.

18 SD Cap. 5-6 18 SD Cap. 5-6
Unix: • Monolítico; • Sugere um sistema massivo; • Executa todas as operações básicas do sistema; • 1 MB de código e dados; • Não diferenciável: codificado de forma não modular; • Intratável: a alteração de um módulo para adequação a novos
requisitos é muito difícil.
Carregado dinamicamente
Kernel monolítico MicroKernel Principais funções de um microkernel: • Processos; • Memória; • IPC; • Todos os outros serviços carregados dinamicamente em
servidores específicos; • Um serviço extra só é carregado na máquina que precisa dele; • Acesso via invocação (RPC). O microkernel na hierarquia de um sistema:
Comparação: • Abertura; • Modularidade; • Um kernel pequeno tem mais chances de ter menos bugs; • Mais fácil de manter; • Kernel monolítico é mais difícil de ser modular; • Impossível extrair um módulo para execução remota; • Um bug num módulo pode se espalhar para os demais; • Alterar um módulo implica em recompilar o kernel e reiniciá-lo; • Vantagem: eficiência para realizar as tarefas.
Arquitetura de um microkernel Em princípio, não há uma definição clara de quais módulos um microkernel deve ter. Todos os produtos dessa categoria incluem: Gerência de processos; Gerência de memória;
Sn
S1 S2 S3 S3S2S1
Microkernel
Hardware
Serviços abertos processos/objetos das aplicações
Suporte de linguagem
Suporte de linguagem
Emulação de OS

19 SD Cap. 5-6 19 SD Cap. 5-6
Passagem de mensagens local. Tamanho: 10 KB até várias centenas de KB de código e dados
estáticos. Microkernels são projetados para serem portáveis: A maior parte de seu código é escrito em linguagem de alto nível
(C, C++, etc.); Recursos físicos são agrupados em camadas; Componentes dependentes de máquina são reduzidos:
Manipulação do processador, unidade de gerência de memória, registradores da unidade de ponto flutuante;
Tratamento de interrupções; Traps; Exceções.
A arquitetura de um microkernel geral pode ser visto na figura:
Aplicações Hardware
Gerente de processos: criação, interface, etc. Gerente de Threads: criação, sincronização, escalonamento.
Processadores disponíveis. Política de escalonamento a critério do usuário.
Gerente de comunicação: IPC. Gerente de memória: memória física, MMU, caches. Supervisor: tratamento de interrupções, system calls, exceções.
6.4 Processos e threads Unix: 1 processo, 1 atividade de processamento (1980). Processo: recurso caro para criar e manter. O compartilhamento entre atividades relacionadas é caro e complexo. Solução: generalização do conceito de processo. Associar mais de uma atividade ao mesmo processo. Processo: ambiente de execução + 1 ou mais threads. Thread: abstração de atividade do sistema operacional. "Thread of execution".
Ambiente de execução: unidade de gerenciamento de recursos. Coleção de recursos gerenciados pelo kernel local, aos quais suas
threads têm acesso; Ambiente de execução: Espaço de endereçamento; Sincronização de threads e IPC, como semáforos; interfaces de
comunicação (portas); Recursos de alto nível (arquivos, janelas, etc.).
Gerente de Processos
Supervisor
Gerente de Threads
Gerente de Memória
Gerente de
Comunicações

20 SD Cap. 5-6 20 SD Cap. 5-6
Obs.: num microkernel, recursos de alto nível como arquivos e janelas não fazem parte dos recursos de um ambiente de execução. São acessados via servidores. Ambientes de execução são caros e difíceis de criar; Várias threads podem compartilhar o mesmo ambiente; Threads podem ser criadas e destruídas dinamicamente; Objetivo: maximizar o grau de concorrência entre operações
relacionadas. Threads: lightweight process.
6.4.1 Espaços de endereçamento • Os espaços não são contíguos. • Gaps permitem o crescimento das regiões. • Componente mais caro de um ambiente de execução; • Grande (232 é um valor típico); • Consiste de uma ou mais regiões; • Região: área contígua de memória virtual acessível pelas threads
do processo; Regiões não se sobrepõem; Propriedades das regiões: • Extensão: endereço mais baixo e tamanho; • Permissões para as threads: read/write/execute; • Direção de crescimento: para cima ou para baixo; Analogia para processos e threads:
• Um ambiente de execução consiste de um jarro com água e comida;
• A 1ª thread desse processo é uma mosca dentro do jarro; • A mosca pode gerar filhos (outras threads) ou matá-los; • As moscas podem consumir a água e/ou a comida; 2N Memória Gaps Virtual (ex.: 232) 0
♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦
Regiões Auxiliares
♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦♦
♦♦♦♦♦♦♦♦Stack♦♦♦♦♦♦♦♦
♦♦♦♦♦♦♦♦Heap♦♦♦♦♦♦♦♦
♦♦♦♦♦♦♦♦♦Text♦♦♦♦♦♦♦♦

21 SD Cap. 5-6 21 SD Cap. 5-6
• Uma mosca não pode sair de seu jarro para entrar em outros jarros;
• As moscas podem colidir, quando resultados imprevisíveis poderão ocorrer;
• As moscas podem consumir toda a água e comida – o ambiente passa a ser inviável.
O sistema com um número indefinido de regiões permite o mapeamento de arquivos no espaço de endereçamento: • Um arquivo mapeado é acessado como um array de bytes; • O sistema VM garante que as atualizações se reflitam no sistema
de arquivos.
6.4.2 Criação de um novo processo Unix: • Um processo que chama o comando fork() cria um novo
processo copiando o seu espaço de endereçamento; • A diferença é o valor retornado pelo fork(); • O comando exec() transforma o programa que chama num
processo do arquivo em disco passado como parâmetro. Num SD, há duas novas considerações: • Múltiplos computadores; • A infraestrutura de suporte reside em serviços separados. Aspectos de criação de processos em um SD: • Escolha do host alvo (onde o novo processo vai residir); • Criação de um ambiente de execução;
• Criação de uma thread, com um ponteiro de pilha default e um contador de instruções.
Escolha de um host alvo Depende do sistema: • V System: executa um processo num host determinado ou no
mais ocioso; • Amoeba: escolhe um dos processadores do pool onde o processo
vai residir. É transparente. Depende da necessidade. Se é necessário trabalhar com paralelismo explícito, pode ser necessário indicar hosts específicos. Tipos de políticas: • Política de transferência: diz se um novo processo é local ou é
executado num host remoto. Depende da carga; • Política de localização: determina o host remoto que recebe um
novo processo; o Depende da carga, da arquitetura e de possíveis recursos
especializados que o host tem. As políticas podem ser estáticas ou adaptativas: • Estáticas não consideram o estado atual do sistema;
o Podem ser deterministas (a transferência sempre ocorre de A para B);
o Ou probabilísticas (a transferência ocorre de A para um entre B-E – escolha aleatória).
• Adaptativas: usam heurísticas sobre fatores momentâneos.

22 SD Cap. 5-6 22 SD Cap. 5-6
Sistemas de carga compartilhada: • Centralizados: um gerente de carga para o sistema; • Hierárquicos: vários gerentes, organizados em árvore; • Decentralizados: todos são gerentes. Tipos de algoritmos de carga compartilhada: • Iniciados pelo transmissor: disparado quando a carga local
atinge um limite máximo; • Iniciados pelo receptor: quando a carga local cai abaixo de um
certo valor, o nó avisa os demais que passou a ser um receptor de carga.
Sistemas migratórios: a carga pode ser distribuída a qualquer momento: • Recurso pouco usado; • O custo para transferir um processo é muito alto; • Extrair o estado de um processo do kernel é muito difícil. Criação de um novo ambiente de execução Opções: • O sistema inicia um espaço de endereçamento genérico, baseado
em certos parâmetros que ele possui: tamanho da área de código, stack, etc.
• Geração a partir de um já existente: fork() • Pai e filho compartilham a área de código! • Isto é feito pelo mapeamento da região de texto do pai dentro
do espaço de endereçamento do filho. • Stack e heap são copiados do pai para o filho.
• Mach e Chorus: usam copy-on-write: • Regiões herdadas do pai são copiadas apenas logicamente; • A cópia física só ocorre quando um dos processos tenta
escrever sobre a região: • O compartilhamento é desfeito; • Ocorre a cópia física; • Esta cópia pode acontecer em disco, caso ocorra um page
fault. Obs.: herança é um problema caso haja uma ou mais portas em uso pelo processo pai. Dois processos não podem compartilhar fluxos de mensagens.
6.4.3 Threads Considere um servidor com uma ou mais threads. Assumimos que uma requisição qualquer utiliza 2 msegs de tratamento e 8 msegs de I/O (sem o uso de cache). O computador possui apenas um processador. Máximo throughput dependendo do número de threads: • 1: 2 + 8 = 10 msegs. 100 requisições por segundo. • 2: uma thread pode processar enquanto a outra está esperando. As threads de um processo não podem fazer I/O em paralelo. Assim, todos os I/Os devem ser feitos seqüencialmente. Se todas as requisições de I/O forem serializadas, temos 1000/8 = 125 requisições por segundo.

23 SD Cap. 5-6 23 SD Cap. 5-6
Considere agora um cache de blocos de disco. O servidor mantém blocos em buffers em seu espaço de endereçamento. Se há uma requisição, ele 1º verifica se o bloco está no cache. Se estiver, a requisição é atendida com I/O zero. Considerando uma taxa de acerto de 75%, Tempo médio por requisição = 0,25 * 8 + 0,75 * 0 = 2 msegs. Máximo throughput = 500 requisições por segundo. Entretanto, há um acréscimo de tempo pela pesquisa no cache. Vamos supor que o tempo médio por requisição real seja de 2,5 msegs. Máximo throughput = 400 requisições por segundo. Arquiteturas para servidores multi-thread Pool de trabalhadores: • O servidor mantém um pool de trabalhadores para processar as
requisições; • Em geral, uma thread de I/O recebe as msgs através de várias
conexões; • As requisições são colocadas em filas para tratamento. Threads-por-requisição: • A thread de I/O cria uma thread para cada requisição que chega; • Ela se destrói quando a tarefa está feita; • Maximiza o I/O; • Custo de criação e destruição de threads.
Threads-por-conexão: • O servidor coloca uma thread para cada conexão de cliente; • Em uma conexão, cada cliente pode fazer várias requisições. Threads-por-objeto: • Uma thread associada a cada objeto remoto; • Cada objeto possui sua fila. Threads nos clientes Nos clientes, o uso de threads é interessante para evitar bloqueios indesejáveis em certas operações: • Em requisições a um servidor; • Em RMI (ou RPC), quando se faz invocação a um objeto
remoto. Formas organização de threads nos clientes: • Por requisição: para cada requisição feita no cliente é disparada
uma thread que gerencia o processo; • Por conexão: cada conexão estabelecida com um servidor
remoto recebe uma thread – toda comunicação nessa conexão é feita por meio dela;
• Por objeto: para cada objeto remoto usado pelo cliente é disparada uma thread – cada uma faz as invocações remotas para o seu objeto.
Threads x múltiplos processos A mesma sobreposição pode ser alcançada por múltiplos processos. Por que um sistema multithread é preferível?

24 SD Cap. 5-6 24 SD Cap. 5-6
Ambiente de execução (processo): • Espaço de endereçamento; • Portas, interfaces de comunicação, etc. • Semáforos, objetos de sincronização, etc. • Lista de threads. Thread: • Registradores salvos; • Estado (ex.: bloqueado) e prioridade; • Informação sobre tratamento de interrupções. Elementos comuns entre processos e threads: • Páginas residentes em memória; • Entradas de caches. Sumário: • Criar uma nova thread para um processo já existente é mais
barato do que criar um novo processo; • Chavear para outra thread de um processo é mais barato do que
para threads de processos diferentes; • O compartilhamento dos recursos de um processo por suas
threads é mais simples do que por processos separados; • O problema é que as threads não têm proteção uma das outras. Custo de criação de uma thread: Alocação da região da pilha; Valores iniciais para os registradores; Estado inicial: SUSPENDED ou RUNNABLE; Prioridade; Acréscimo de identificador no registro de threads.
Comparação de tempos: Sistema Unix; Arquitetura CVAX; Kernel Topaz; Anderson et al., 1991; Teste: processo ou thread criados para fazer uma chamada nula; Processo: 11 msegs; Thread: 1 mseg.
Memória: Um processo recebe page faults logo que inicia sua execução; Uma thread também! Entretanto, threads podem se beneficiar dos acessos feitos sobre
suas áreas por outras threads; Pode aproveitar áreas colocadas nos caches por outras threads.
Programação de Threads A programação de threads é Programação Concorrente! Conceitos desta seção: race conditions, seção crítica, variáveis de condição e semáforos. Ex.: Modula-3, Java: suporte direto à threads; C: extensão por biblioteca; P Threads: padrão de threads para o Posix desenvolvido pelo
IEEE; GNU Threads: padrão da Free Software Foundation para o
SunOS.

25 SD Cap. 5-6 25 SD Cap. 5-6
Chamadas Java para manipulação de Threads: • Thread(ThreadGroup grupo, Runnable alvo, String nome) – cria
uma nova thread no estado SUSPENDED, que pertence a grupo e é identificada como nome; passa a executar pela chamada do método run() de alvo.
• setPriority(int newPriority), getPriority() – muda ou retorna a prioridade da thread.
• Run() – executa o método run() de seu objeto alvo, se houver; ou seu próprio método run() (Thread implementa Runnable).
• start() – muda o estado da thread de SUSPENDED para RUNNABLE.
• sleep(int millisecs) – a thread passa para o estado SUSPENDED pelo tempo especificado.
• yield() – passa para o estado READY e chama o escalonador. • destroy() – destrói a thread. Obs.: • Grupos são isolados uns dos outros, no sentido de que não
podem ser gerenciados entre si; • Threads de um grupo não podem criar threads de outro; • Grupos podem ter prioridades limites estabelecidas pelo
processo. Chamadas da biblioteca C Threads: threadId = cthread_fork(func, arg) - permite criar uma thread a
partir de outra, que executa a função func passando um só argumento arg;
cthread_exit(result) - termina a thread atual; cthread_join(threadId) - a thread que criou threadId espera até o
seu término;
cthread_set_data(threadId, data) - associa dados globais exclusivamente com uma thread;
cthread_data(threadId) - libera os dados associados a uma thread;
cthread_yield() - permite que outra thread rode. Problemas com Threads: <stdio.h> em C; 1 buffer para cada stream de I/O (ex.: vídeo) o problema ocorre quando mais de uma thread tenta mandar
caracteres para um terminal; a ordem depende do escalonador; a biblioteca mantém um ponteiro para a posição no buffer onde o
próximo caracter deve ser colocado: pode levar a race conditions.
Chamadas de sincronização da biblioteca C Threads: mutex_lock(mutexId) mutex_unlock(mutexId) condition_wait(conditionId, mutexId) condition_signal(conditionId)
Escalonamento de Threads Preemptivo: uma thread pode ser suspensa pelo escalonador para
que outra execute; Não preemptivo (corrotina): uma thread executa até fazer uma
chamada que cause sua suspensão. Corrotinas:

26 SD Cap. 5-6 26 SD Cap. 5-6
Qualquer seção que não apresenta chamadas é uma seção crítica; Só servem para máquinas com 1 processador; Não servem para Real Time; Aplicações processor bound devem dar chances às outras (yield).
Implementação de Threads Alguns kernels permitem processos com apenas uma thread; Porém, há bibliotecas que permitem implementar processos
multithreads. Ex.: SunOS 4.1 Lightweight Processes (pacote) O kernel não reconhece as threads; Não há escalonamento de threads independentemente; Se alguém (o processo ou uma thread) faz uma sys call
bloqueante, todos bloqueiam; As threads de um processo nessas condições não podem executar
num sistema multiprocessador; A troca de contexto de threads dentro de um processo não
precisa ser feita via sys call; O escalonamento pode ser específico da aplicação;
Psyche (SO multiprocessador) - processador virtual (PV): Um PV é um recurso pertencente a um processo; Implementado no kernel; Associado com processadores reais; O processo controla esses recursos diretamente; Cada um executa uma função; O kernel informa o processo dos eventos; O processo pode trocar uma thread bloqueada em um PV; Ou pode trocar o PV de um processador real.
6.4 Nomes e proteção Um serviço em geral gerencia vários recursos: Cada um deles pode ser acessado independentemente pelos
clientes; Para esta finalidade, o serviço fornece identificadores para cada
um dos seus recursos; Serviços precisam ser reconfiguráveis - flexíveis:
Para um grupo de servidores gerenciar um recurso individual;
Para se localizar os servidores. Clientes acessam recursos através de requisições a um serviço, passando o identificador correto. Requisições são passadas a identificadores de comunicação, que
podem ser obtidos de um serviço de binding; Mach e Amoeba: portas; Chorus: grupos de portas.
Identificação de um recurso – deve-se fornecer: Porta (grupo) de acesso ao servidor que gerencia o recurso; Identificador específico.
• Identificadores independentes de localização fornecem
transparência de rede; • O formato dos identificadores é escolhido por quem implementa
o serviço; • É boa prática usar o mesmo formato para a mesma família de
serviços; • Facilita a administração e marshalling;

27 SD Cap. 5-6 27 SD Cap. 5-6
• Identificadores devem ser únicos num SD inteiro ou, ao menos, dentro de um serviço;
• Amoeba: identificadores únicos em todo o SD; • Permite usar um identificador sem saber de que serviço ele é!
Reconfigurabilidade Capacidade de um SD de se adaptar à evolução ou mudanças em suas condições, tais como carga de rede ou falhas: • Relocação de servidores: ocorre pela criação de novas instâncias
de servidores ou por migração; • Mobilidade de recursos: recursos migram de um servidor para
outro no mesmo serviço. • É preciso manter as transparências de localização e de migração; • Problema: como reconfigurar o serviço on-line?
Proteção de recursos Objetivo: garantir que os processos só possam acessar os recursos para os quais tenham permissão. Problemas: • As redes devem ter abertura; • Os computadores de um SD podem sofrer ataques que alterem
seu software; • A proteção deve ser específica por serviço; • Os servidores podem receber qualquer requisição de qualquer
computador/processo da rede;
Domínios de proteção • Já visto em SO I; • Conjunto de pares (recurso, direitos), relacionando todos os
recursos que podem ser acessados pelos processos que rodam nesse domínio;
Ex.: Unix – domínio determinado pelo grupo e usuário. Os direitos são determinados pelas operações RWX. Implementações: • Capabilities e Listas de controle de acesso.
6.5 Comunicação e invocação Formas de comunicação: • Produtor-consumidor; • Cliente-servidor; • Comunicação de grupo. Formas de qualidade de serviço: • Garantia de entrega; • Banda de transmissão; • Latência; • Segurança. Questões relacionadas aos serviços de comunicação: • Primitivas disponíveis;

28 SD Cap. 5-6 28 SD Cap. 5-6
• Garantias de QoS; • Protocolos; • Abertura da implementação; • Procedimentos para aumentar a eficiência.
Primitivas de comunicação Formas de passagem de mensagens: • Send-receive; • DoOperation-GetRequest-SendReply. A implementação depende dos recursos disponíveis: • As primitivas podem ser confiáveis; • Se não forem, isso pode ser alcançado em níveis mais altos; • Uma das formas pode ser implementada usando a outra; • Isso pode ser feito em baixo nível (kernel) ou em alto nível (até
na aplicação).
Compartilhamento de memória • Comunicação local deve ser feita pela transferência do conteúdo
de áreas de memória entre os processos; • Feito pelo kernel através de operações especiais (Copy-on-
write); • Transfere dados de páginas de um espaço de endereçamento para
páginas de outro; • Regiões compartilhadas podem ser usadas para facilitar (dar
mais velocidade) a comunicação processo-kernel e/ou processo-processo;
• Problemas:
• Sincronismo; • Justifica se for bastante usado, já que o custo para estabelecer
é alto. Qualidade de Serviço O que é possível fazer com primitivas não confiáveis?
É possível construir uma versão confiável de um Send; Até um RPC com semântica at-least-once ou mesmo at-most-
once; Comunicação orientada a streams, com um sistema apropriado
de buffers; Multicast de alto nível; Segurança para a comunicação, passando por um serviço de
criptografia; Principal dificuldade é latência satisfatória: Há serviços que precisam de mais latência do que outros; Multimídia impõem restrições de tempo real; O SO deve atender as solicitações de um mínimo de qualidade
dos usuários ou recusar o serviço; Protocolos e abertura Alguns sistemas incorporam seus próprios protocolos:
Ex.: Amoeba - Amoeba RPC; V system - VMTP; Sprite - Sprite RPC.
Problema: esses protocolos não são usados em ambientes de uso geral;

29 SD Cap. 5-6 29 SD Cap. 5-6
TCP, UDP e IP não suportam RPC diretamente; Mach e Chorus têm outra estratégia:
Suportam apenas passagem de mensagens local; Usam servidores no topo do kernel para tratar os protocolos
de rede; Sistema aberto, já que qualquer um pode implementar seu
próprio servidor. Desempenho de Invocação Mecanismos de invocação: • Chamar um procedimento local; • System call; • Enviar uma mensagem; • RPC; • Chamar um método de um objeto, etc. Em todos os casos, código é executado fora dos limites de quem chama. É preciso passar argumentos e retornar dados para quem chama.
Tipos de operações entre espaços de endereçamento: Thread User kernel Thread 1 Thread 2 User 1 Kernel User 2 Thread 1 Thread 2 Rede User 1 Kernel 1 Kernel 2 User 2 Tipos de operação: • Síncronas: chamada local e RPC; • Assíncronas: operação sem retorno de valores. Desempenho de RPC RPC nulo: RPC sem parâmetros, que executa um procedimento nulo e não retorna valores. • Melhor tempo reportado para um RPC nulo entre 2 processos
usuários através de uma LAN: 1 milisegundo! • Uma chamada local de procedimento é executada numa fração
pequena deste tempo.
trap
Instruções privilegiadas
System Call
RPC (no mesmo computador
RPC (entre computadores)

30 SD Cap. 5-6 30 SD Cap. 5-6
• Um RPC nulo transfere cerca de 100 bytes, somando dados de cabeçalhos de pacotes de rede.
• A 100 Mbits/seg., o tempo total de rede para transferir essa quantidade é cerca de 0,1 milisegundos.
• A maioria do tempo é composta de atrasos impostos pelo SO e pelo código do RPC no nível do usuário.
Estudo sobre a média de RPCs chamados (Bershad, 1990 – 1,5 milhão de chamadas): • A chamada mais freqüente é de menos de 50 bytes do usuário; • A maioria das chamadas transfere menos que 200 bytes; • RPC que transfere blocos de disco tende a ter 1-8 kb; • O uso de caches tende a diminuir a freqüência dessas chamadas. A maioria das chamadas RPC cabe num pacote de rede (em torno de 1 KB). Um RPC nulo representa o overhead fixo que uma chamada apresenta. Figura 6.14: • O atraso de um RCP cresce proporcionalmente ao tamanho do
pacote; • Há um salto toda vez que é preciso acrescentar mais um pacote
na chamada. Throughput: • O atraso não é o único elemento de interesse no RPC; • Throughput: taxa na qual os dados podem ser transferidos entre
computadores;
• Na fig. 6.14, o throughput é pequeno para pequenas quantidades de dados;
• À medida que cresce a quantidade de dados, cresce o throughput, já que o overhead fixo torna-se menos significativo;
• Hutchinson, 1989 – máximo throughput = 750 KB/seg. (Ethernet 10 Mbits/seg!);
• O throughput para quantidades maiores de dados deve aumentar bastante com redes de 100 Mbits/seg (ou mais)!
• Mesmo assim, para quantidades pequenas o overhead fixo deve predominar;
Quais são esses overheads e o que fazer para minimizá-los? Passos de um RPC: • Stub do cliente:
• Marshalling dos argumentos; • Envio da requisição; • Recepção da resposta; • Unmarshalling da resposta.
• Servidor: • Dispatcher recebe a requisição; • Chama o stub apropriado do servidor.
• Stub do servidor:
• Unmarshall dos argumentos; • Chamada do procedimento correto; • Marshalling dos argumentos; • Envio da resposta.

31 SD Cap. 5-6 31 SD Cap. 5-6
Principais componentes do atraso de um RPC: • Marshalling: significa copiar e converter dados;
• Cresce à medida que a quantidade de dados aumenta. • Cópia de dados:
• Cópia de memória para memória fica em torno de 10 MB/seg. nos processadores mais rápidos;
• Mesma taxa de transferência de uma rede 100 Mbits/seg; • Uma mensagem pode ser copiada diversas vezes num RPC:
• Entre usuário e kernel; • Entre cliente e servidor; • Nos buffers do kernel; • Entre as camadas dos protocolos; • Entre as interfaces de rede e os buffers do kernel.
Obs.: no sentido interface-memória (na chegada), a transferência é feita por DMA. • Inicialização de pacotes (headers, checksums, etc.): custo
proporcional à quantidade de dados; • Escalonamento de threads e troca de contexto:
• RPC invoca sistema de comunicação do kernel; • Aplicação usa threads para fazer um RPC; • Se há um processo gerente de rede, um Send implica em
troca de contexto.
6.6 Memória virtual Objetivo: executar grandes problemas e combinações de programas cuja soma de código e dados é maior que a memória principal:
Parte da memória é usada como cache do sistema de armazenamento.
Por manter apenas as seções de código e dados atualmente em uso pelos processos, é possível: Executar programas maiores que a memória principal; Aumentar o nível de multiprogramação ao aumentar o número
de processos na memória principal; Liberar os programadores das limitações da memória física.
Idéia generalizada para abranger o acesso a arquivos mapeados em áreas de memória: Um processo lê ou grave dados no arquivo lendo ou gravando
num array em memória; Um arquivo aberto para uma linguagem de alto nível aparece
como um array; O kernel é responsável por trazer mais dados à medida que os
dados do array são lidos; O kernel transfere os dados para disco à medida que eles são
alterados Ex.: MULTICS, SunOS. Demand paging: uma página só é carregada por demanda (isto é, quando alguém precisa, ela é carregada para a memória principal). Gerenciadores externos Em um SD, o computador que recebe um page fault não precisa ser o mesmo que gerencia os dados: Ex.: o 1o pode ser diskless; O gerente é um servidor de arquivos remoto;

32 SD Cap. 5-6 32 SD Cap. 5-6
O uso de gerenciadores externos permite implementar esquemas
customizados de paginação; Uma abordagem para implementar memória compartilhada
distribuída; O kernel continua responsável por:
tratar page faults; gerência da memória principal; política de alocação; política de substituição.
Função do gerenciador externo: Receber e tratar dados de páginas purgadas pelo kernel; Fornecer páginas ao kernel conforme ele peça; Impor restrições aos diversos kernels que acessam uma área
(todos podem tentar manter caches de áreas modificáveis).
Espaço de endereça- mento
Kernel Kernelrede
Page fault msgs
Gerente externo