cálculo de score
TRANSCRIPT

Ordenação e Recuperação de Dados
Prof. Alexandre Duarte - http://alexandre.ci.ufpb.br
Centro de Informática – Universidade Federal da Paraíba
Aula 8: Cálculo de Score
11

Agenda
❶ Revisão
❶ Por que rankear?
❹ Implementação de classificação
❺ Um sistemas de buscas completo
2

Agenda
❶ Revisão
❶ Por que rankear?
❹ Implementação de classificação
❺ Um sistemas de buscas completo
3

4
Peso da frequência de termo
A frequência logarítimica de um termo t em um documento d é definida da seguinte maneira:
4
5
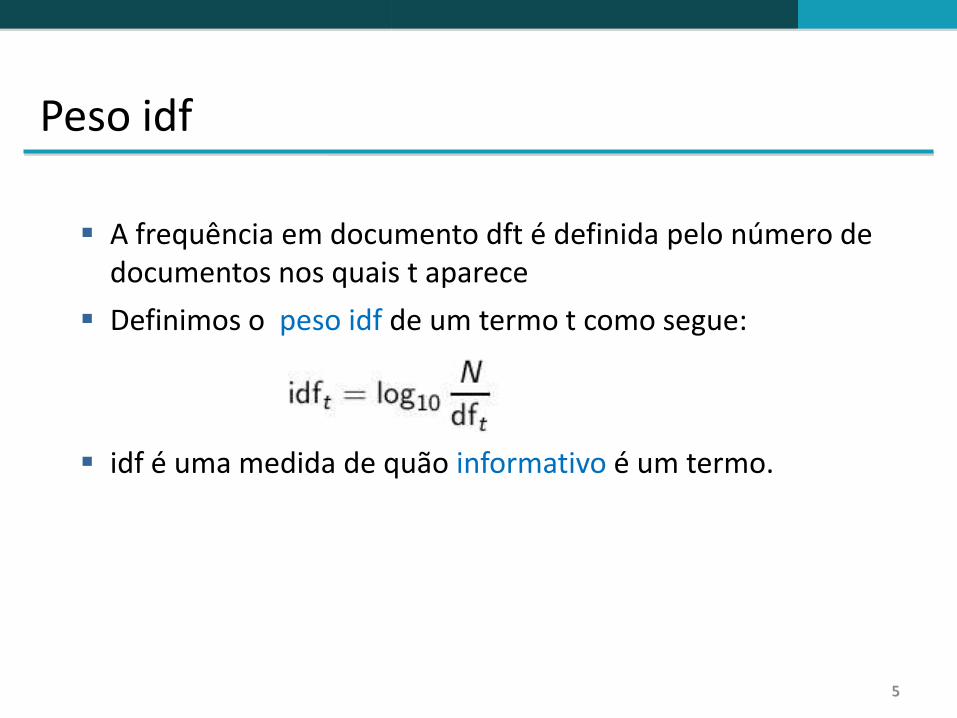
Peso idf
A frequência em documento dft é definida pelo número de documentos nos quais t aparece
Definimos o peso idf de um termo t como segue:
idf é uma medida de quão informativo é um termo.
5

6
Peso tf-idf
O peso tf-idf de um termo é o produto de seus pesos tf e idf.
6

7
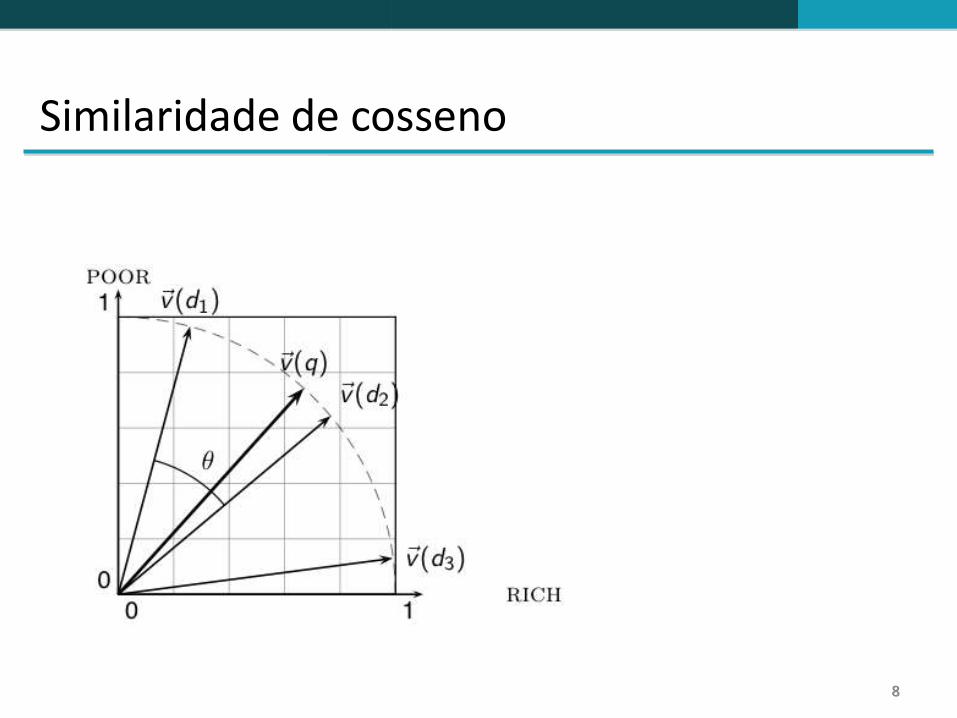
Similaridade de cosseno entre uma consulta e um documento
qi é o peso tf-idf do termo i na consulta.
di é o peso tf-idf do termo i no documento.
e são as normas dos vetores e
7
8
Similaridade de cosseno
8

9
Aula de hoje
A importância da classificação: Estudos do Google
Implementação de classificação
Um sistema de buscas completo
9
Agenda
❶ Revisão
❶ Por que rankear?
❹ Implementação de classificação
❺ Um sistemas de buscas completo
10

11
Por que classificação é tão importante?
Últimas aulas: Problemas com recuperação sem classificação
Os usuários quem analisar poucos resultados – e não milhares.
É muito difícil escrever consultas que resultem em poucos resultados.
Mesmo para pesquisadores experientes
→ classificação é importante porque ela reduz um grande conjunto de resultados para um conjunto muito menor.
A seguir: mais sobre “usuários querem analisar poucos resultados”
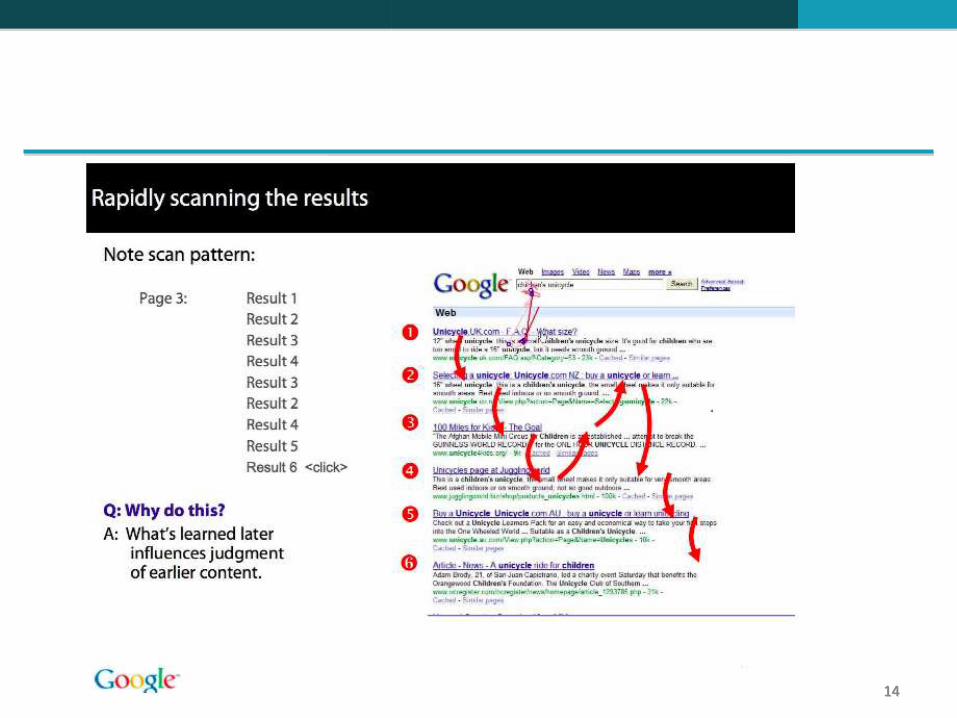
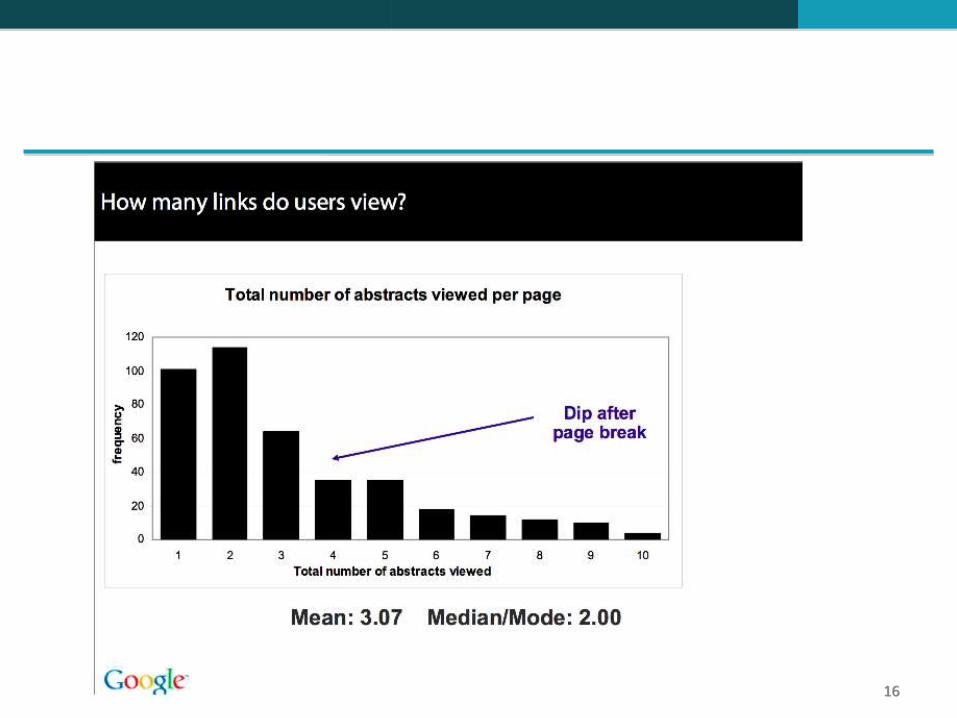
Na verdade, na grande maioria dos casos, os usuários só examinam 1, 2 ou 3 resultados.
11

12
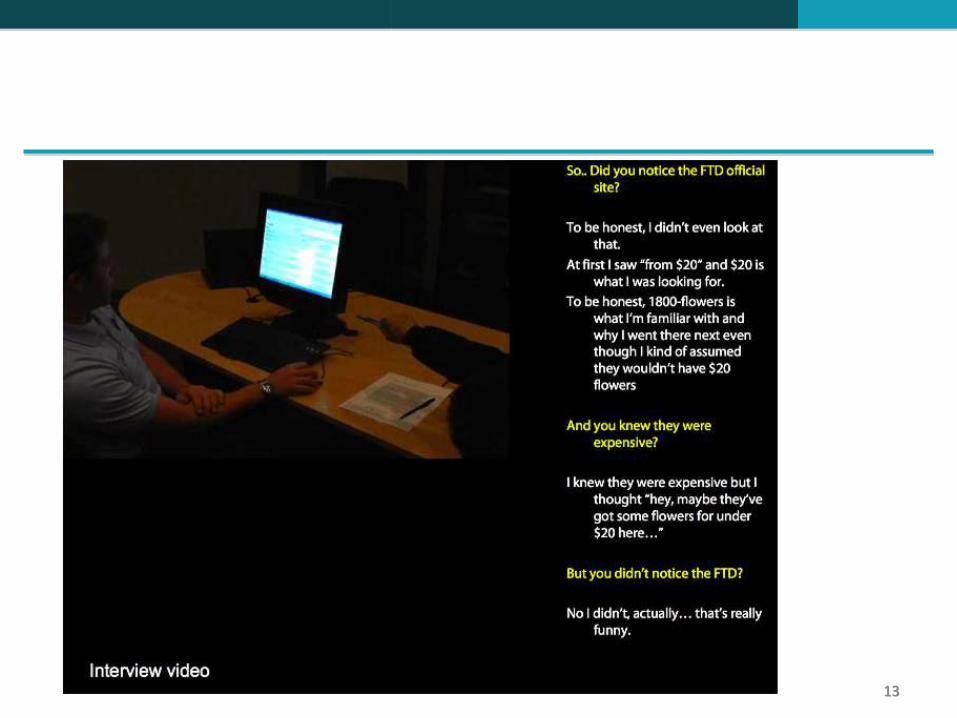
Investigação empírica sobre os efeitos da classificação de resultados Como poderíamos medir a importância da classificação de resultados de
consultas?
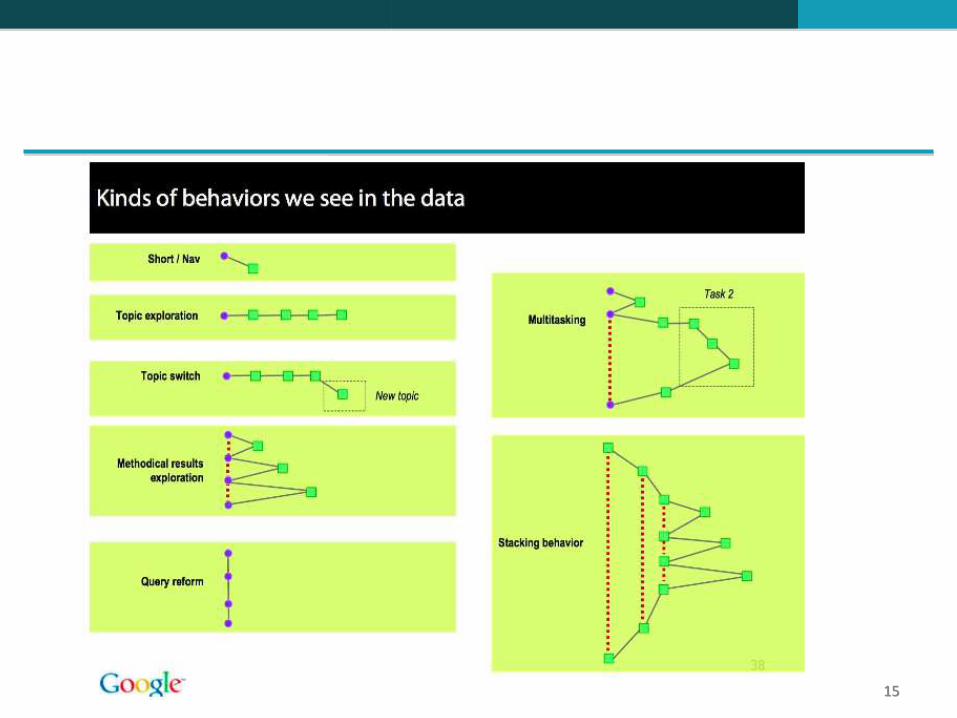
Observe em um ambiente controlado o que os usuários fazem enquanto estão pesquisando
Filme-os
Peça para “pensarem alto”
Entreviste-os
Monitore seus olhares
Monitore seu tempo
Grave e conte seus cliques de mouse
Os slides a seguir são da apresentação do Dan Russell na JCDL
Dan Russell é o guru da Google para “Qualidade de Busca & Felicidade dos Usuários”
12
1313
1414
1515
1616
1717
1818

19
A importância da classificação: Sumário
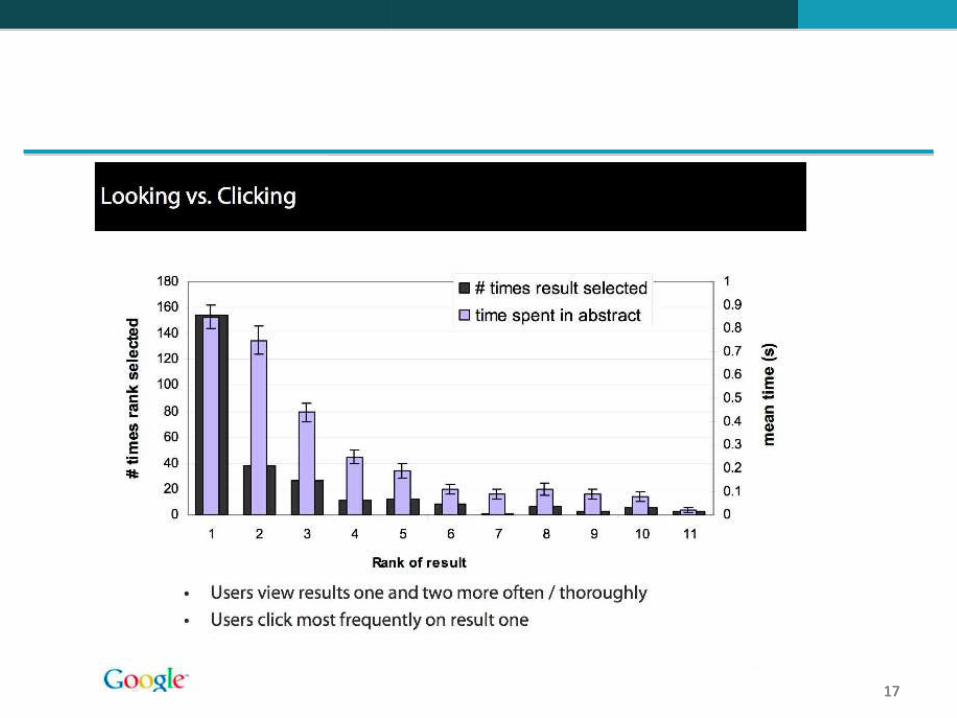
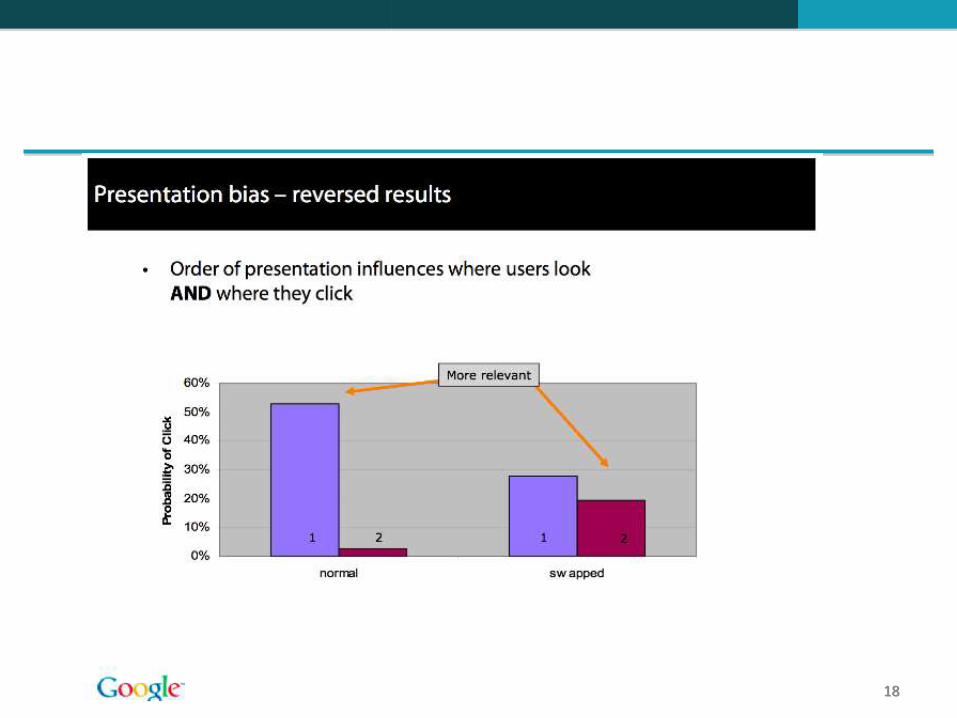
Leitura dos resumos: Os usuários preferem ler os resumos dos resultados mais bem classificados (1, 2, 3, 4) do que os resumos dos resultados com classificação inferior (7, 8, 9, 10).
Cliques: Essa distribuição é ainda mais desigual para os cliques
Em uma a cada duas consultas os usuários clicam no resultado número 1.
Mesmo que o resultado número 1 não seja relevante, 30% dos usuários clicaram nele.
→ Classificar de forma correta é importante.
→ Classificar corretamente os melhores resultados é ainda mais importante.
19
Agenda
❶ Revisão
❶ Por que rankear?
❹ Implementação de classificação
❺ Um sistemas de buscas completo
20

21
Precisaremos da frequência dos termos
Precisaremos também das posições, não ilustradas aqui.
21

22
Como encontrar os top k resultados no ranking?
Em muitas aplicações nós não precisamos de um ranking completo.
Precisamos apenas dos top k resultados para um kpequeno(e.g., k = 100).
Se não precisamos de um ranking completo, há alguma forma de eficiente para encontrar apenas os top k resultados?
Abordagem ingênua: Computar os scores para todos os N documentos Ordenar Retornar os top k documentos
Qual o problema com essa abordagem?
22

23
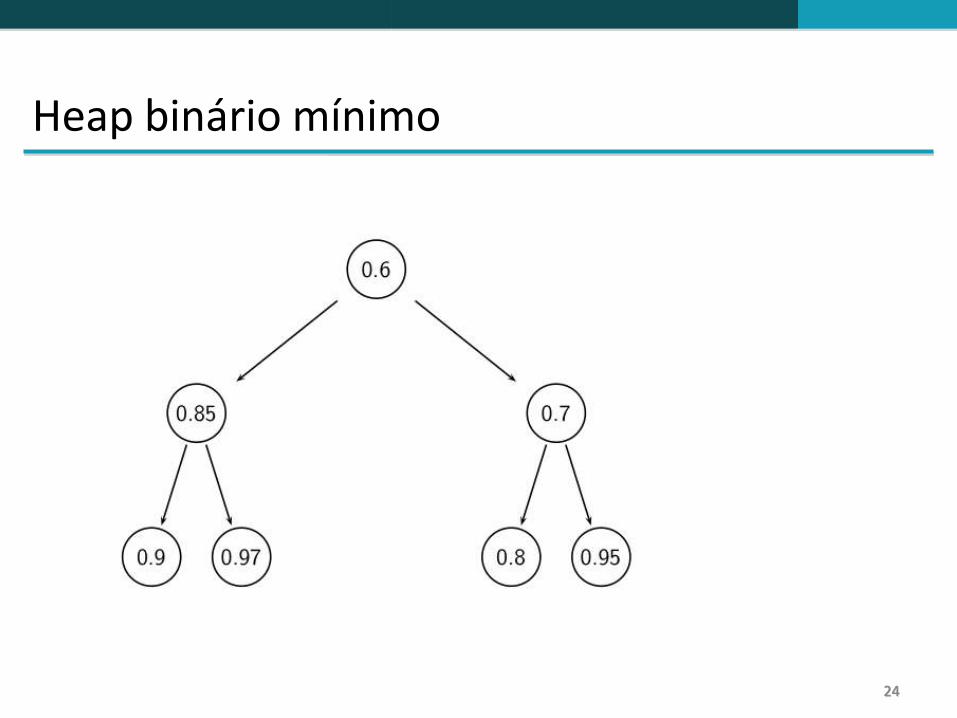
Use um heap mínimo para selecionar os top k documentos entre os N
Use um heap mínimo binário
Um heap binário mínimo é uma árvore binária na qual o valor de cada nó é menor do que o valor dos seus filhos.
Precisamos de O(N log k) operações para construir um heapmínimo (onde N é o número de documentos) . . .
. . . depois precisamos de O(k log k) operações para encontrar os top k resultados
23
24
Heap binário mínimo
24

25
Selecionado os top k documentos em O(N log k)
Objetivo: Manter os top k documentos encontrados até o momento
Usar um heap binário mínimo
Para processar um novo documento d’ com score s′:
Pegar o valor mínimo hm
do heap (O(1))
Se s′ h˂m processar o próximo documento
Se s′ > hm heap-delete-root (O(log k))
Heap-add s′ (O(log k))
25

26
Formas mais eficientes para encontrar os top k documentos: Heuristicas
Ideia 1: Reordenar as listas de postings
Ao invés de ordenar os postings pelo docID . . .
. . . ordenar de acordo com alguma medida da “expectativa de relevância”.
Ideia 2: Usar heurísticas para podar o espaço de buscas
Não dá garantias de corretude . . .
. . . mas falham com pouca frequência.
Na prática, próximo de tempo constante.
26

27
Ordenação independente do docID
Até agora: a lista de postings foi ordenada de acordo com o docID.
Alternativa: utilizar uma medida independente de consulta da “qualidade” de uma página
Exemplo: PageRank g(d) de uma página d, uma medida de quantas páginas “boas” tem links para a página d (capítulo 21)
Ordenar os documentos nas postings listings de acordo com o PageRank: g(d1) > g(d2) > g(d3) > . . .
Definir o score composto de um documento: net-score(q, d) = g(d) + cos(q, d)
Este esquema suporta terminação precoce: não precisamos processar totalmente as listas de postings para achar os top k.
27

28
Ordenação independente do docID
Ordenar os documentos nas listas de postings de acordo com o PageRank: g(d1) > g(d2) > g(d3) > . . .
Definir o score composto de um documento: net-score(q, d) = g(d) + cos(q, d)
Suponha: (i) g → [0, 1]; (ii) g(d) < 0.1 para o documento d que estamos processando; (iii) o menor ranking dos top kdocumentos encontrados até agora é 1.2
Portanto, todos os próximos scores serão < 1.1.
Já encontramos os top k resultados e podemos parar o processamento e ignorar o restante da lista de posting.
28

Agenda
❶ Revisão
❶ Por que rankear?
❹ Implementação de classificação
❺ Um sistema de buscas completo
29
30
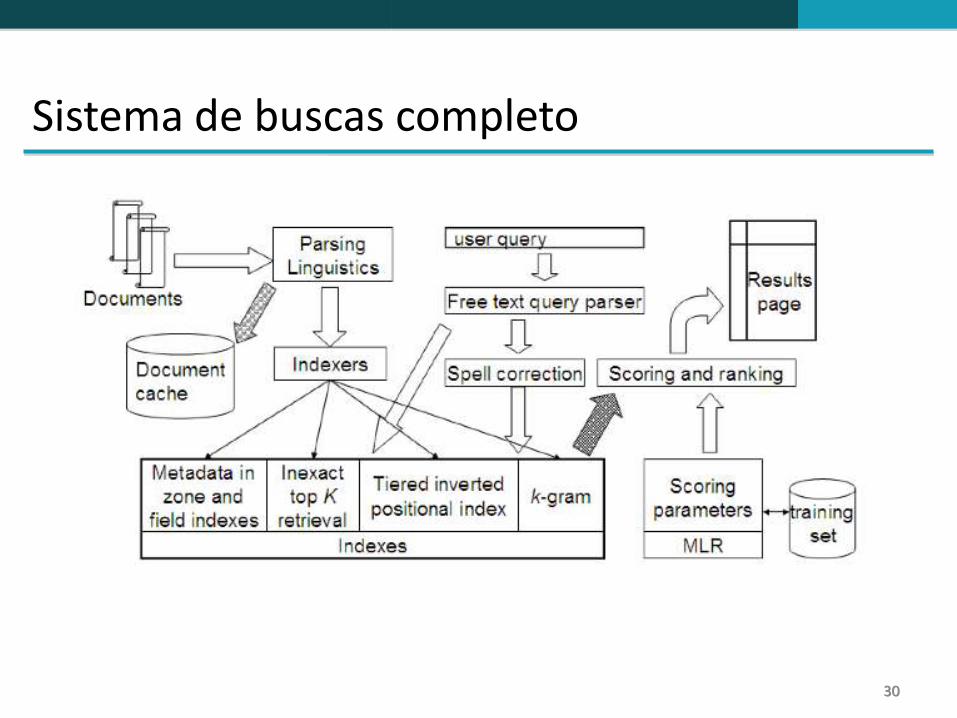
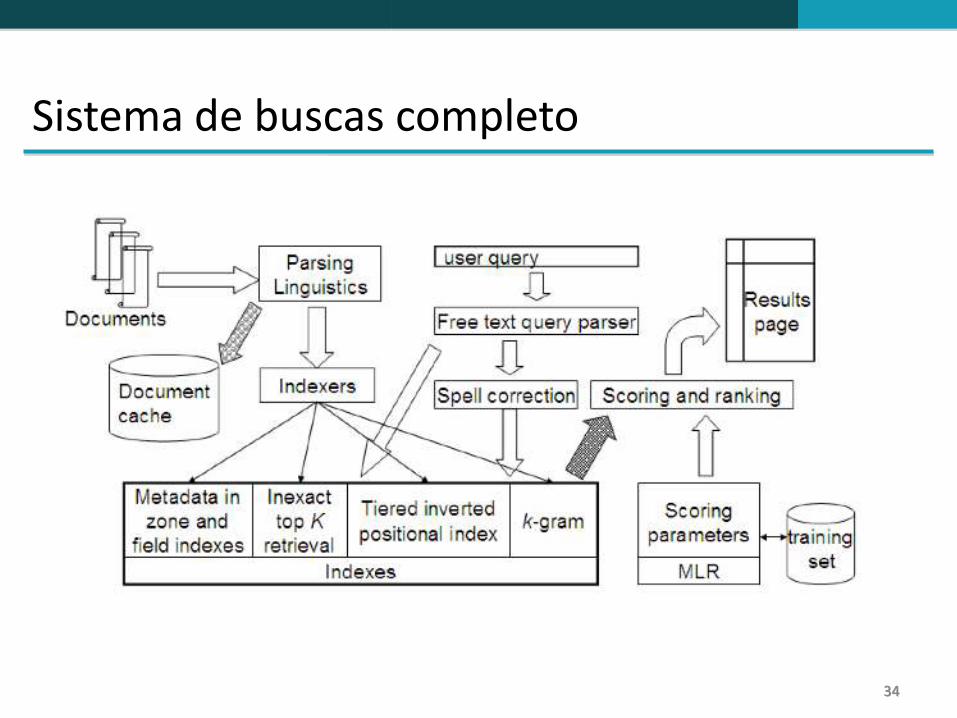
Sistema de buscas completo
30

31
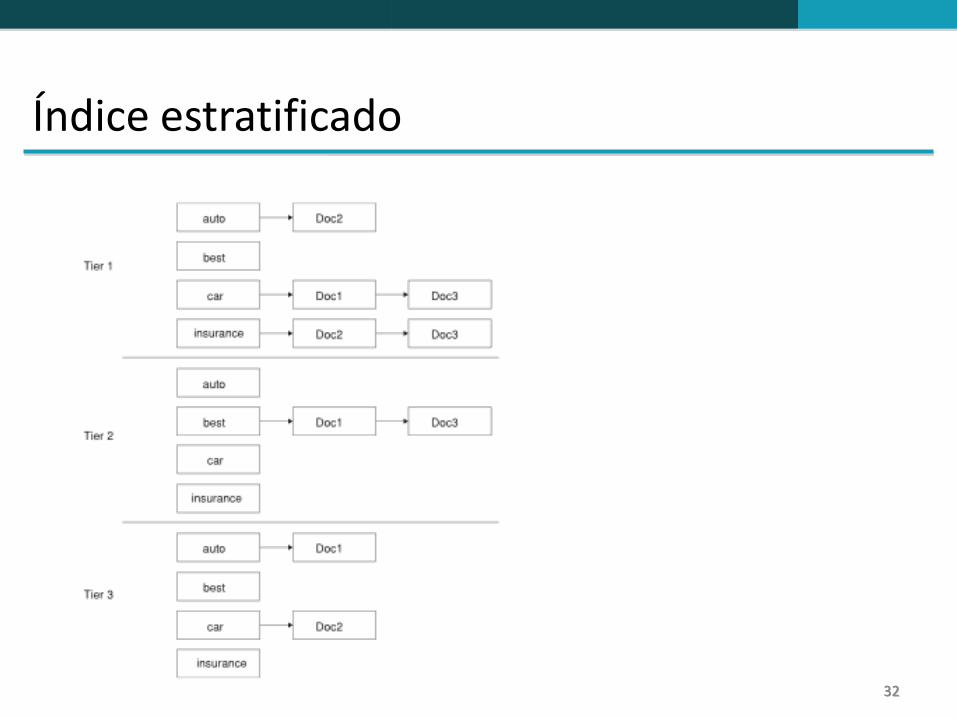
Índices estratificados Ideia básica:
Criar uma série de índices, correspondendo a importância dos termos indexados
Durante o processamento da consulta, iniciar pela séria de mais alta importância
Se a séria mais alta retornar pelo menos k resultados, encerrar o processamento
Se menos que k resultados forem encontrados: repetir o processo para a série seguinte
Exemplo: sistema com duas séries
Série 1: Índice com todos os títulos
Série 2: Índice com o resto dos documentos
Documentos que contem os termos da consulta no título são resultados melhores do que os que só contem os termos da consulta no corpo do texto. 31
32
Índice estratificado
32

33
Índices Estratificados
Acredita-se que o uso de índices estratificados foi uma das razões para o Google apresentar em seu lançamento uma melhor qualidade em seus resultados de busca que seus competidores.
juntamente com o PageRank
33
34
Sistema de buscas completo
34

35
Vimos até o momento
Pré-processamento de documentos (linguístico)
Índices posicionais
Índices estratificados
Correção ortográfica
Índices com k-gramas para correção ortográfica e consulta com coringas
Processamento de consulta
Classificação de documentos
35

36
Componentes que ainda não vimos
Cache de documentos: utilizado para gerar os sumários dos resultados
Índices por zona: separam os índices por diferentes zonas no documento: corpo, texto selecionado texto âncora, texto nos metadados, etc
Funções de classificação com aprendizagem de máquina
Classificação por proximidade (e.g., classificar melhor documentos onde os termos da consulta aparecem juntos numa mesma página em relação a documentos onde os termos aparecem em diferentes páginas)
Parsing da consulta
36