banco de dados - lrocha.com.brlrocha.com.br/arquivos/arquivos/bdweb (postgresql)/bibliografia... ·...
TRANSCRIPT

Recife, 2010
Banco de Dados
UNIVERSIDADE FEDERAL RURAL DE PERNAMBUCO (UFRPE)
COORDENAÇÃO GERAL DE EDUCAÇÃO A DISTÂNCIA (EAD/UFRPE)
Sandra de Albuquerque Siebra
Volume 3

Universidade Federal Rural de Pernambuco
Reitor: Prof. Valmar Corrêa de AndradeVice-Reitor: Prof. Reginaldo BarrosPró-Reitor de Administração: Prof. Francisco Fernando Ramos CarvalhoPró-Reitor de Extensão: Prof. Paulo Donizeti SiepierskiPró-Reitor de Pesquisa e Pós-Graduação: Prof. Fernando José FreirePró-Reitor de Planejamento: Prof. Rinaldo Luiz Caraciolo FerreiraPró-Reitora de Ensino de Graduação: Profª. Maria José de SenaCoordenação Geral de Ensino a Distância: Profª Marizete Silva Santos
Produção Gráfica e EditorialCapa e Editoração: Rafael Lira, Italo Amorim e Arlinda TorresRevisão Ortográfica: Elias VieiraIlustrações: Noé AprígioCoordenação de Produção: Marizete Silva Santos

Sumário
Apresentação ................................................................................................................. 4
Conhecendo o Volume 3 ................................................................................................ 5
Capítulo 7 – O Modelo Relacional .................................................................................. 7
O Modelo Relacional (MR) ..............................................................................................7
Conceitos do Modelo Relacional .....................................................................................8
Regras de Integridade Fundamentais ............................................................................14
As 12 Regras de Codd ....................................................................................................18
Capítulo 8 – Derivando o MR a partir do MER .............................................................. 25
Algumas Informações Iniciais ........................................................................................25
Regras para Derivar o Modelo Relacional a partir do MER ............................................26
Capítulo 9 – Normalização de Dados ............................................................................ 41
Dependências Funcionais ..............................................................................................41
Anomalias de Atualização ..............................................................................................43
O que é Normalização?..................................................................................................45
Primeira Forma Normal (1FN) .......................................................................................47
Segunda Forma Normal .................................................................................................49
Terceira Forma Normal ..................................................................................................52
Forma Normal de Boyce-Codd ......................................................................................55
Quarta Forma Normal ...................................................................................................56
Quinta Forma Normal ....................................................................................................58
Um Roteiro para a Normalização ...................................................................................60
Algumas Informações Adicionais ...................................................................................60
Considerações Finais .................................................................................................... 67
Conheça a Autora ........................................................................................................ 69

4
Apresentação
Caro(a) cursista,
Seja bem-vindo(a) ao terceiro módulo do curso Banco de Dados!
Neste terceiro módulo, vamos estudar o modelo relacional e todas as suas nuances. O modelo relacional é o resultado da modelagem lógica do Banco de Dados e é a etapa seguinte a modelagem conceitual.
Dentro deste contexto, estudaremos como tranformar a modelagem conceitual em modelagem lógica, como otimizar o modelo criado através das regras de normalização e como fazer as checagens de integridade referencial.
Bons estudos!
Sandra de Albuquerque Siebra
Autora

5
Banco de Dados
Conhecendo o Volume 3
Neste terceiro volume, você irá encontrar o Módulo 3 da disciplina de Banco de Dados. Para facilitar seus estudos, veja a organização deste segundo módulo.
Módulo 3 – Modelagem Lógica e Projeto de Banco de Dados
Carga horária do Módulo 3: 15 h/aula
Objetivo do Módulo 3:
» Introduzir os principais conceitos e definições relacionados à modelagem lógica de dados.
» Examinar os principais conceitos envolvidos no modelo relacional.
» Estudar como derivar a modelagem lógica a partir da modelagem conceitual.
» Estudar como otimizar a modelagem de dados através da normalização.
Conteúdo Programático do Módulo 3:
» O Modelo Relacional.
» As 12 Regras de Codd.
» Transformação do Modelo E-R para o Modelo Relacional.
» Restrições de Integridade.
» Dependências Funcionais.
» Normalização de Dados.

6
Banco de Dados
Capítulo 7
O que vamos estudar neste capítulo?
Neste capítulo, vamos estudar os seguintes temas:
» O Modelo Relacional.
» Restrições de Integridade.
» As 12 Regras de Codd.
Metas
Após o estudo deste capítulo, esperamos que você consiga:
» Identificar as particularidades e os componentes do Modelo Relacional.
» Fazer a checagem de integridade do modelo.
» Reconhecer as 12 regras de Codd.

7
Banco de Dados
Capítulo 7 – O Modelo Relacional
Vamos conversar sobre o assunto?
No projeto de Banco de Dados, a modelagem lógica ou projeto lógico é a terceira etapa (vide Figura 1), antecedida pela análise de requisitos e pela modelagem conceitual. O produto dessa etapa é o modelo relacional ou esquema relacional e este é justamente o assunto desse capítulo! Esse modelo já é dependente do SGBD que for ser escolhido para a implementação do banco de dados. Logo, atente para o fato de que esse é o momento dessa decisão ser tomada.
Neste capítulo, vamos falar sobre o modelo relacional, que é um exemplo de modelo lógico de dados, e sobre os conceitos a ele relacionados.
Figura 1 - Etapas do Projeto de Banco de Dados
O Modelo Relacional (MR)
Vamos relembrar... o que é o modelo lógico? É um modelo que vai especificar a representação/declaração dos dados de acordo com o SGBD escolhido, definindo assim a estrutura de registros do BD (onde cada registro define número fixo de campos (atributos) e cada campo possui tamanho fixo). Um exemplo de modelo lógico é o modelo relacional (MR). Os SGBDs que utilizam o MR são denominados SGBDs Relacionais e, nesta disciplina, trataremos do projeto lógico apenas desse tipo de SGBD.

8
Banco de Dados
O Modelo Relacional foi introduzido por Ted Codd, da IBM Research, em 1970, em um artigo clássico (Codd, 1970) que imediatamente atraiu a atenção em virtude de sua simplicidade e base matemática. O modelo usa o conceito de uma relação matemática – algo como uma tabela de valores – como seu bloco de construção básica e tem sua base teórica na teoria dos conjuntos.
As primeiras implementações comerciais do modelo relacional tornaram-se disponíveis no início da década de 80, antes disso, eram utilizados os modelos de redes e hierárquico (sobre os quais estudamos no Volume 1, capítulo 1).
O modelo relacional tem como objetivos: prover esquemas de fácil utilização; melhorar a independência lógica e física de dados; prover os usuários com linguagens de manipulação de BD de alto nível, permitindo o seu uso por usuários não experientes; otimizar o acesso aos BDs e melhorar a integridade e segurança dos dados.
O MR representa os dados do BD como relações1 (tabelas) de nomes únicos. O conceito de tabelas está intimamente ligado ao conceito de uma relação matemática – de onde se origina o nome deste modelo. Vamos apresentar, na seção a seguir, cada um dos conceitos relevantes dentro do contexto do modelo relacional.
Conceitos do Modelo Relacional
Em um ambiente de banco de dados relacional utilizamos alguns conceitos muito importantes para a correta implantação e operação de qualquer sistema de banco de dados. Por exemplo, na terminologia do modelo relacional, cada tabela é chamada relação e vai possuir um nome único que a identifica, cada linha da tabela é chamada tupla, cada cabeçalho de coluna é conhecido como atributo (vide Figura 2).
Figura 2 - Exemplos de Terminologias do Modelo Relacional
Alguns desses novos termos originam-se diretamente da Teoria de Conjuntos, outros são decorrentes da utilização de elos lógicos para implementar os relacionamentos entre os dados armazenados no banco de dados. A seguir, cada um dos conceitos fundamentais do modelo relacional será descrito.
Tabela ou Relação
No modelo relacional, a estrutura que armazena os dados referentes a cada uma das ocorrências de uma entidade ou relacionamento com atributos do MER é chamada de tabela ou relação.
Uma tabela é uma representação bi-dimensional de dados composta de linhas e colunas. Por exemplo, a tabela de empregados de uma empresa (vide Tabela 1) onde
Comentário
1 A palavra relação é utilizada no sentido de lista ou rol de informações e não no sentido de associação ou relacionamento.

9
Banco de Dados
poderiam ser armazenados dados como o CPF, o nome e o telefone de cada empregado. A tabela como um todo representaria os empregados da empresa. Cada coluna representaria um atributo (ex: a primeira coluna da Tabela 1 é o CPF ). E cada linha da tabela representa os dados de um empregado. Por exemplo, a primeira linha da Tabela 1 se refere à empregada de CPF número 987675456-98, de nome Ana Marques e cujo telefone é 3245-8976.
Tabela 1 - Tabela ou Relação Empregado
CPF Nome Telefone
987675456-98 Ana Marques 3245-8976
765456243-45 João Pontes 3124-5645
213415467-89 Marcos Alves 3456-8923
567324980-03 Tânia Gomes 3455-9098
Matematicamente, define-se uma relação como um subconjunto de um produto cartesiano de uma lista de domínios2. Assim, suponha que D1 denote o domínio do atributo A1, D2 denote o domínio do atributo A2 e Dn denote o domínio do atributo N da tabela T1. Qualquer linha da tabela que possui estes atributos é denotada pela tupla3 (d1,d2,...,dn) em que d1, d2 e dn têm como valores possíveis (domínios), respectivamente D1, D2 e Dn. Em geral, uma instância de T1 é um subconjunto de D1 X D2 X ... X Dn.
O conjunto de atributos de uma relação é chamado de esquema da relação. O esquema de uma relação é denotado por : R[A1 D1, ..., An Dn] onde:
R é o nome da relação;
A1, ..., An é a lista de atributos da relação R e
D1, ..., Dn são os domínios de cada um dos atributos da relação R.
Frequentemente, é utilizada uma notação simplificada em que é omitida a definição do domínio de cada atributo da relação: R[A1, ..., An]. Por exemplo, o esquema da relação representada na Tabela 1 seria: Empregado[CPF char4(11), Nome char(50), Telefone char(9)] ou, na notação simplificada, teríamos Empregado[CPF, Nome, Telefone].
Na criação dos esquemas das relações o nome das relações ou tabelas devem ser únicos no banco de dados, devem ser escritos no singular e, de preferência, devem ser nomes curtos. Se for usado um nome composto, este deve ser separado por um underline (_), por exemplo Pessoa_Fisica ou Pessoa_Juridica.
O atributo identificador da relação é apresentado sublinhado (esse atributo identificador dará origem à chave primária da relação, como veremos mais a frente). Assim, se CPF fosse o atributo identificador teríamos: Empregado[CPF, Nome, Telefone].
O grau de uma relação é o número de atributos que a compõe. Por exemplo, o grau da relação Empregado[CPF, Nome, Telefone] é três, porque essa relação possui 3 atributos.
Uma particularidade referente à definição de relação é que, nesta definição, não existe qualquer tipo de ordenação ou de definição de ordenação. Assim, por exemplo, as duas relações representadas pelas Tabelas 1 e 2 são consideradas idênticas. Afinal, o que mudou de uma tabela para outra foi apenas a ordem em que os valores de preenchimento da tabela aparecem.
Comentário
2 Um domínio contém os valores possíveis para um determinado atributo da relação.
Comentário
3 Uma tupla é uma ocorrência particular de um elemento da tabela. Falaremos sobre esse conceito, em detalheas, mais a frente.
Comentário
4 O tipo char equivale ao tipo string das linguagens de programação, onde você pode digitar letras, números e símbolos. Quando você define um tipo char, você tem de especificar o tamanho do que preencherá o mesmo. Esse tipo pode variar de nome de SGBD para SGBD mas sempre vai ter um correspondente.

10
Banco de Dados
Tabela 2 - Tabela ou Relação Empregado
CPF Nome Telefone
213415467-89 Marcos Alves 3456-8923
567324980-03 Tânia Gomes 3455-9098
765456243-45 João Pontes 3124-5645
987675456-98 Ana Marques 3245-8976
Linha (Tupla)
Uma ocorrência em particular de dados em uma tabela ocupa uma linha dessa tabela. Por exemplo, na Tabela 3, os dados de cada um dos empregados que a compõe ocupam uma linha diferente da tabela. Como existem 4 empregados, a Tabela 3 possui 4 linhas (ou tuplas ou registros). O número de linhas ou tuplas de uma relação é chamado de cardinalidade da relação. Logo, a cardinalidade da relação expressa na Tabela 3 é quatro.
Cada linha da tabela deve ser única e deve possuir um atributo identificador. No caso da Tabela 3, esse identificador é o CPF do empregado. O atributo identificador, no modelo relacional, passa a ser chamado de chave primária (PK) - detalharemos melhor esse ponto mais a frente.
Tabela 3 - Exemplos de Atributos e Tuplas
Outra definição que pode ser dada para linha ou tupla é: um conjunto de pares (<atributo>,<valor>), em que cada par fornece o valor do mapeamento de um atributo Ai para um valor Vi, tal que cada valor Vi seja um elemento do domínio Di ou um valor nulo.
Algumas regras para tuplas são: em uma tabela ou relação não devem existir tuplas ou linhas duplicadas. As linhas de uma tabela não seguem uma ordem específica. Dessa forma, as tuplas ou linhas abaixo seriam idênticas:
T = <(CPF, 987675456-98), (Nome, Ana Marques), (Telefone, 3245-8976)> e
T = <(Telefone, 3245-8976), (CPF, 987675456-98), (Nome, Ana Marques)>
Coluna (Atributo)
Cada tipo de informação armazenada em uma tabela é uma coluna. Ou seja, cada

11
Banco de Dados
atributo que caracteriza a relação é expresso em uma coluna. Toda coluna de uma tabela deve possuir um nome pelo qual será referenciada sempre que necessário. Na verdade, ao criarmos uma tabela definimos, para cada uma de suas colunas, o seu nome (nome do atributo) e também o seu tipo (numérico, alfabético, data, etc). Por exemplo, CPF, Nome e Telefone são atributos (colunas ou campos) da Tabela Empregado, expressos na Tabela 3.
Um nome de atributo deve ser único em uma tabela e deve expressar o tipo de informação que ele representa. E o valor de um atributo não deve poder ser decomposto em mais de uma coluna.
Domínio do Atributo
Domínio de um atributo é a faixa de valores que esse atributo pode conter. Em outras palavras, é o conjunto de valores que um determinado atributo pode assumir. Por exemplo, para o atributo CPF da Tabela 3, o domínio seria o conjunto dos números naturais. Em outras tabelas quaisquer, por exemplo, o domíno do atributo “dia do mês”seria o conjunto dos números entre 1 e 31. O atributo “sexo” teria como domínio os mnemônicos M (para masculino) ou F (para feminino) e assim por diante.
Sempre que identificamos um atributo de uma tabela, temos também uma ideia de qual o tipo de informação que ele poderá vir a conter.
Chaves
Uma chave5 é um atributo (ou conjunto de atributos) que identifica univocamente cada entrada de uma relação. Ou seja, por meio de chaves podemos diferenciar as diversas tuplas pertencentes a uma relação. Como consequência dessa definição, temos que os atributos chaves não podem apresentar valores duplicados, nem podem ser nulos.
NULO - Não devemos confundir o conceito de nulo com espaços em branco ou o número zero, por exemplo, que são valores conhecidos. Nulo é a ausência de informação.
Uma coluna de preenchimento obrigatório numa tabela deve possuir todos os seus valores não-nulos. Se, por exemplo, uma linha da tabela Empregado contiver um nulo na coluna Telefone, significa que o telefone do empregado correspondente àquela linha é desconhecido. Assim, ou o telefone não foi informado por algum motivo ou o empregado não possui telefone, de qualquer forma, a informação está ausente na tabela.
Uma definição mais formal para chave seria: seja R um esquema de relação. Se dissermos que um subconjunto K de atributos de R é uma superchave6 para R, estaremos considerando restrições para as relações r(R), nas quais não existem duas tuplas distintas com mesmos valores em todos os atributos de K. Isto é, se as tuplas t1 e t2 fazem parte da relação r e t1 <> t2, então t1[K] <> t2[K].
Quando há a possibilidade de mais de um atributo (isoladamente) poder ser chave em uma relação, dizemos que esses atributos são chaves candidatas. Por exemplo, na Tabela 4, CPF e Nome poderiam ser chaves candidatas, porque poderiam ser atributos usados para localizar uma entrada na tabela.
Comentário
5 O conceito de chave está diretamente ligado ao de identificador da entidade ou relacionamento que foi estudado no volume anterior, quando foram detalhados os componentes do MER.
Comentário
6 Superchave é o conjunto de um ou mais atributos que nos permitem identificar de maneira unívoca uma tupla de uma relação.

12
Banco de Dados
Tabela 4 - Tabela ou Relação Empregado
CPF (PK) Nome Telefone
213415467-89 Marcos Alves 3456-8923
567324980-03 Tânia Gomes 3455-9098
765456243-45 João Pontes 3124-5645
987675456-98 Ana Marques 3245-8976
Um dos princípios do modelo relacional diz que uma linha de uma tabela deve sempre poder ser referenciada de forma única. Por isso, entre as chaves candidatas, uma delas deve ser eleita para ser a principal, a chave primária da tabela (Primary Key ou PK), aquela que realmente identifica univocamente cada tupla da tabela. No caso, para a Tabela 4, a melhor escolha para chave primária seria o atributo CPF, já que essa informação não se repetiria, de forma alguma, em dois empregados distintos da tabela.
A escolha da chave primária (PK) da tabela é influenciada pelas necessidades do domíno do mundo real que está sendo modelado.
Chaves primárias são geralmente indicadas na tabela pela sigla PK (Primary Key) e podem também ser sublinhadas (vide Tabela 4).
As outras chaves candidatas que não forem escolhidas para chave primária, são chamadas de chaves secundárias. Por exemplo, na Tabela 4, o atributo Nome seria uma chave secundária.
Muitas vezes, uma tabela não possui, entre seus atributos, um que por si só seja suficiente para identificar univocamente uma ocorrência. Nesses casos deve sempre ser possível que a combinação de dois ou mais atributos tenha a capacidade de se constituir numa chave primária. Chamamos a essas chaves primárias formadas pela combinação de vários atributos de chaves primárias compostas. Ou seja, uma chave primária composta é uma chave primária que é formada por mais de um atributo ou coluna. Geralmente, uma tabela que represente um relacionamento entre outras duas tabelas (originada de um relacionamento do MER) irá possuir chaves primárias compostas. Por exemplo, a tabela Alocação (vide Tabela 5), terá como chaves primárias os atributos CPF e Cod_Projeto. Isso, porque para descobrir qual a função de um empregado em um projeto, precisamos dessas duas informações. Nenhum dos atributos isoladamente poderia fornecer essa informação.
Tabela 5 - Tabela ou Relação Alocação
CPF (PK) Cod_projeto (PK) Função
213415467-89 002 Analista
567324980-03 001 Consultor
765456243-45 003 Suporte
987675456-98 002 Programador

13
Banco de Dados
Tabela 6 - Tabela ou Relação Empregado
CPF (PK) Nome Telefone
213415467-89 Marcos Alves 3456-8923
567324980-03 Tânia Gomes 3455-9098
765456243-45 João Pontes 3124-5645
987675456-98 Ana Marques 3245-8976
Tabela 7 - Tabela ou Relação Projeto
Cod_projeto (PK) Nome Projeto
001 SOFTHOUSE
002 GEOPROC
003 LINUX WORLD
Uma tabela pode incluir entre seus atributos a chave primária de outra tabela. Essa chave é chamada chave estrangeira. Ou seja, uma chave estrangeira é uma coluna (ou combinação de colunas) que indica um valor que deve existir como chave primária em uma outra tabela (chamada de Tabela Pai). Por exemplo, na tabela Alocação (vide Tabela 5), as colunas CPF e Cod_Projeto são chaves estrangeiras, porque elas são chave primária, respectivamente, das tabelas Empregado (vide Tabela 6) e Projeto (vide Tabela 7).
Vamos definir novamente com outras palavras: uma chave estrangeira de uma relação R1 é um atributo (ou conjunto de atributos) que referencia a chave primária de uma outra relação R2. Dessa forma, para qualquer tupla de R1, o valor da chave estrangeira deve ser igual ao valor da chave primária de alguma tupla da relação R2 referenciada, ou deve ser o valor nulo (se a chave estrangeira não fizer parte da chave primária da relação R1). Com isso queremos dizer que o atributo que é chave estrangeira em uma relação R1, pode ou não fazer parte da chave primária de R1. No exemplo de chave estrangeira dado anteriormente, as chaves estrangeiras CPF e Cod_Projeto fazem parte da chave primária da tabela Alocação (vide Tabela 5). Porém, a chave estrangeira pode não fazer parte da chave primária. Observe a tabela Funcionário (vide Tabela 8). Ela possui um campo Cod_Depto que é chave primária da tabela Departamento (vide Tabela 9). Logo, na tabela Funcionário, o atributo Cod_Depto é uma chave estrangeira. Chaves estrangeiras são indicadas pela sigla FK (Foreign Key).
Tabela 8 - Tabela ou Relação Funcionário
CPF (PK) Nome Cod_Depto (FK)
213415467-89 Marcos Alves 11
567324980-03 Tânia Gomes 22
765456243-45 João Pontes 11
987675456-98 Ana Marques 22

14
Banco de Dados
Tabela 9 - Tabela ou Relação Departamento
Cod_Depto (PK) Nome
11 Vendas
22 Financeiro
Uma chave estrangeira formada por mais de uma coluna é chamada de chave estrangeira composta.
No modelo relacional os relacionamentos representados no MER passam a ser representados através de chaves estrangeiras. Ou seja, as chaves estrangeiras tornam possível a associação lógica entre tabelas distintas. Isso ficará mais claro no próximo capítulo quando forem apresentadas as regras de derivação do MR a partir do MER.
Regras de Integridade Fundamentais
O modelo relacional, ao definir conceitos como Tabela, Tupla, Atributo, Nulo, Domínio, Chave Primária e Chave Estrangeira deixa implícitas algumas regras fundamentais para a manutenção da consistência do banco de dados. Elas são chamadas de Regras de Integridade e tratam dos cuidados que analistas, projetistas e programadores devem observar ao implementar as rotinas de Inclusão, Alteração e Exclusão de dados nas bases de dados. Na prática, as restrições de integridade fornecem meios para assegurar que mudanças feitas no banco de dados não resultem na perda da consistência sobre estes dados.
Vamos ver agora dois dos principais tipos de integridade a serem mantidas em um banco de dados adequadamente projetado: a Integridade de Entidade e a Integridade Referencial. Posteriormente, discutiremos regras de integridade complementares e regras de integridade semântica.
Integridade de Entidade (ou de Identidade ou Existencial)
Refere-se às chaves primárias e procura garantir que toda e qualquer linha de uma tabela deve poder ser acessada com base apenas no conteúdo de sua chave primária. Para isso, algumas regras devem ser observadas:
» Toda tupla tem um conjunto de atributos que a identifica de maneira única na relação (Integridade de Chave).
» Nenhum atributo que faça parte de uma chave primária pode ter valor nulo (eles devem ser NN = not null).
» Não se deve permitir que em uma mesma tabela existam duas ocorrências (tuplas) com chaves primárias iguais. Ou seja, os atributos que são chave primária devem ser únicos (ND = No Duplicate ou Unique).
Isso significa que os conteúdos de todos os atributos que constituem uma chave primária devem ser conhecidos e únicos. Um conteúdo nulo representa uma informação desconhecida ou, em outras palavras, a ausência da informação, o que não pode ser permitido em qualquer elemento de uma chave primária.
Algumas recomendações para se alcançar a integridade de entidade são:

15
Banco de Dados
» Selecione chaves primárias que realmente tenham preenchimento único no domínio do problema.
» Se possível, prefira chaves primárias simples e numéricas.
» Se não houver nenhuma coluna que possa ser uma chave candidata, utilize chaves primárias sequenciais, geralmente, atribuídas pelo sistema.
Integridade Referencial
Diz respeito às chaves estrangeiras e visa manter a integridade dos relacionamentos previstos no banco de dados. Ou seja, a integridade referencial cuida para que uma relação possa ter um conjunto de atributos que contém valores com mesmo domínio de um conjunto de atributos que forma a chave primária de outra relação. Este conjunto é chamado chave estrangeira.
Na definição dos cuidados referentes a esse tipo de integridade, utilizaremos dois conceitos:
» Tabela-Pai (Parent Table): é aquela onde o atributo de relacionamento desempenha o papel de chave primária.
» Tabela-Filho (Dependent Table): tabela onde o atributo de relacionamento desempenha o papel de chave estrangeira.
Para manter a integridade referencial, a regra básica é: o conteúdo de uma chave estrangeira deve, necessariamente, ser igual ao de uma ocorrência da Tabela-Pai ou então ser nulo. Vale ressaltar que o valor da chave estrangeira só poderá ser nulo na Tabela-Filho, se o atributo que for chave estrangeira não fizer parte da chave primária da Tabela-Filho.
Por exemplo, na última tupla da tabela Funcionário (vide Tabela 10), temos que o Cod_Depto é NULL. Isso é possível apenas porque o atributo Cod_Depto não faz parte da chave primária da tabela Funcionário. E deve significar que, por enquanto, a funcionária Ana Marques não foi alocada em nenhum departamento (vamos supor que ela acabou de ser contratada). Já todas as outras tuplas da tabela Funcionário possuem o Cod_Depto preenchido e, para que a integridade referencial seja mantida, como esse atributo é chave estrangeira, ele deve existir como chave primária em alguma outra tabela. No caso, na tabela Departamento (vide Tabela 9). Nesse exemplo fornecido, a tabela Funcionário é a Tabela-Filho e a tabela Departamento é a Tabela-Pai.
Tabela 10 - Tabela ou Relação Funcionário
CPF (PK) Nome Cod_Depto (FK)
213415467-89 Marcos Alves 11
567324980-03 Tânia Gomes 22
765456243-45 João Pontes 11
987675456-98 Ana Marques NULL

16
Banco de Dados
Observação
Uma chave estrangeira pode referenciar-se a um atributo da sua própria tabela (caso que ocorrerá com os auto-relacionamentos do MER). Por exemplo, a tabela Funcionário (vide Tabela 11) poderia ter, para cada funcionário, quem é o seu supervisor direto. Assim, o campo CPF_Supervisor, que é considerado chave estrangeira, é a chave primária da própria tabela Funcionário e não de outra tabela qualquer.
Tabela 11 - Tabela ou Relação Funcionário
CPF (PK) Nome CPF_Supervisor (FK)
213415467-89 Marcos Alves 765456243-45
567324980-03 Tânia Gomes 765456243-45
765456243-45 João Pontes NULL
As consequências da Integridade Referencial refletem-se nas consistências necessárias ao se proceder às operações de Inclusão, Alteração e Exclusão de dados nas Tabelas Pai e Filho. Veja as regras no Quadro 1.

17
Banco de Dados
Quadro 1 - Regras de Inclusão, Alteração e Exclusão para manter a Integridade Referencial
Operação Tabela_Pai Tabela-Filho
InclusãoA inclusão de dados na tabela-pai não tem nenhuma implicação ou problema.
A inclusão de dados na Tabela-Filho deve atentar para o fato de que não será possível incluir uma nova tupla se o valor do campo que for chave estrangeira já não estiver cadastrado na Tabela-Pai.
Alteração
Se a alteração envolver o valor da chave primária, deve-se utilizar um dos seguintes critérios:
» A chave não deve ser alterada se estiver sendo utilizada em alguma tabela-filho.
» A chave deve ser alterada e deve-se colocar NULL nas chaves estrangeiras presentes na(s) Tabela(s)-Filho (contanto que o valor em questão não faça parte da chave primária da(s) Tabela(s)-Filho correspondente(s)).
» A chave deve ser alterada e o novo valor deve ser colocado no campo que é chave estrangeira em todas as tabelas-filho relacionadas.
Se a alteração envolver o atributo que é chave estrangeira, a alteração só deve ser realizada usando valores que existam na tabela pai (podendo também usar o valor NULL, se essa chave estrangeira não fizer parte da chave primária da Tabela-Filho).
Exclusão
Para excluir uma tupla dessa tabela, deve-se utilizar um dos seguintes critérios:
» Não deletar, se a tupla estiver sendo utilizada em uma Tabela-Filho.
» Deletar a tupla e colocar NULL nas chaves estrangeiras das Tabelas-Filhos afetadas (isso se o atributo envolvido não fizer parte da chave-primária da Tabela-Filho).
» Deletar e, também, eliminar todas as tuplas das Tabelas-Filho que façam uso do valor da tupla sendo eliminada.
A exclusão de Dados na Tabela-Filho não tem nenhuma implicação ou problema.
As restrições de integridade devem ser implementadas pelo SGBD. Muitos SGBD’s implementam integridade de entidade, mas não implementam integridade referencial.
Regras de Integridade Complementares
Além das regras de integridade de entidade e referencial, um banco de dados relacional pode suportar um conjunto adicional de regras (ou restrições) cuja finalidade

18
Banco de Dados
é especificar aspectos próprios de cada coluna e respectivo domínio, complementando com isso a definição de suas características lógicas. As principais restrições de integridade complementares tratam da obrigatoriedade e unicidade de valores e sobre conjuntos de valores permitidos. Vamos às regras:
» Obrigatoriedade - Indica se deve ou não ser permitida a existência de nulos em uma coluna (ou seja, se um atributo pode ou não ser nulo). Colunas que não aceitam nulos são de preenchimento obrigatório como, por exemplo, o nome de um funcionário na tabela de funcionários. Campos que não possuam obrigatoriedade de preenchimento são considerados campos opcionais. Por exemplo, o número do telefone poderia ser um campo opcional, dependendo do domínio, visto que ainda podem haver pessoas que não possuem número de telefone. A definição de se um campo será de preenchimento obrigatório ou não, vai depender muito do domínio do mundo real sendo modelado.
» Unicidade - Indica se deve ser permitido ou não que uma coluna possua valores idênticos em duas ou mais linhas. Uma coluna que não pode possuir valores repetidos é uma coluna de valores únicos.
» Verificação de Valores Específicos - Indica explicitamente qual o conjunto de valores permitidos para uma determinada coluna. Por exemplo, para a coluna Sexo de uma tabela Empregado só poderiam ser aceitos os valores ‘M’ ou ‘F’. Qualquer outro valor deveria ser recusado.
Restrições de Integridade Semântica
São restrições especificadas e mantidas num banco de dados relacional pelo programa de aplicação e que são inerentes a aplicação sendo desenvolvida. Ou seja, são as regras de negócio do domínio do mundo real sendo implementado. Por exemplo, em um determinado sistema pode-se querer implementar a restrição que “o salário de um empregado não pode ser maior do que o salário do seu supervisor direto” ou que “o número máximo de horas por semana que um empregado pode trabalhar em projetos é de 40 horas” (suponha que a empresa não permite horas extras) ou, ainda, “a data de entrega de um pedido não pode ser inferior à data em que o pedido foi realizado”. Tais restrições, como dito, são específicas do domínio sendo implementado e necessitam ser programadas em cada aplicação que vá fazer uso do banco de dados.
As 12 Regras de Codd
Edgard F. Codd, em 1985, estabeleceu as 12 regras de Codd que determinam o quanto um banco de dados é relacional. Algumas vezes as regras se tornam uma barreira e nem todos os SGBDs relacionais fornecem suporte a elas. De qualquer forma, a título de conhecimento, vamos apresentá-las a seguir. Lembramos que nem todas as regras serão completamente compreendidas nesse momento, mas o serão até o final da disciplina.
Regra 1 - Regra das informações em tabelas: As informações a serem armazenadas no banco de dados devem ser apresentadas como relações (tabelas formadas por linhas e colunas) e o vínculo de dados entre as tabelas deve ser estabelecido por meio de valores de campos comuns (chaves estrangeiras).
Regra 2 - Regra de acesso garantido: Todo e qualquer valor atômico em um BD relacional possui a garantia de ser logicamente acessado pela combinação do nome da tabela, do valor da chave primária e do nome do campo/coluna que deseja acessar. Isso

19
Banco de Dados
porque, com o nome da tabela, se localiza a tabela desejada. Com o valor da chave primária a tupla desejada dentro da tabela é localizada. E com o nome do campo/coluna se acessa a parte desejada da tupla.
Regra 3 - Regra de tratamento sistemático de valores nulos: Valores nulos devem ser suportados de forma sistemática e independente do tipo de dado para representar informações inexistentes e informações inaplicáveis. Deve-se sempre lembrar que valores nulos devem ter um tratamento diferente de “valores em branco”.
Regra 4 - Regra do catálogo relacional ativo: Toda a estrutura do banco de dados (domínios, campos, tabelas, regras de integridade, índices, etc) deve estar disponível em tabelas (também referenciadas como catálogo). Sua manipulação é possível por meio de linguagens específicas (por exemplo, SQL). Essas tabelas são, geralmente, manipuladas pelo próprio sistema no momento em que o usuário efetua alterações na estrutura do banco de dados (por exemplo, a inclusão de um novo atributo em uma tabela).
Regra 5 - Regras de atualização de alto-nível: Essa regra diz que o usuário deve ter capacidade de manipular as informações do banco de dados em grupos de registros, ou seja, ser capaz de inserir, alterar e excluir vários registros ao mesmo tempo7.
Regra 6 - Regra de sub-linguagem de dados abrangente: Pelo menos uma linguagem, com sintaxe bem definida, deve ser suportada, para que o usuário possa manipular a estrutura do banco de dados (como criação e alteração de tabelas), assim como extrair, inserir, atualizar ou excluir dados, definir restrições de integridade e de acesso e controle de transações (commit e rollback8, por exemplo). Deve ser possível ainda a manipulação dos dados por meio de programas aplicativos.
Regra 7 - Regra de independência física: Quando for necessária alguma modificação na forma como os dados estão armazenados fisicamente, nenhuma alteração deve ser necessária nas aplicações que fazem uso do banco de dados (isolamento), assim como devem permanecer inalterados os mecanismos de consulta e manipulação de dados utilizados pelos usuários finais.
Regra 8 - Regra de independência lógica: Qualquer alteração efetuada na estrutura do banco de dados como inclusão ou exclusão de campos de uma tabela ou alteração no relacionamento entre tabelas não deve afetar o aplicativo utilizado ou ter um baixo impacto sobre o mesmo. Da mesma forma, o aplicativo somente deve manipular visões9 dessas tabelas.
Regra 9 - Regra de atualização de visões: Uma vez que as visões dos dados de uma ou mais tabelas são, teoricamente, suscetíveis a atualizações, então um aplicativo que faz uso desses dados deve ser capaz de efetuar alterações, exclusões e inclusões neles. Essas atualizações, no entanto, devem ser repassadas automaticamente às tabelas originais. Ou seja, a atualização em uma visão deve refletir na atualização das tabelas representadas por essa visão.
Regra 10 - Regra de independência de integridade: As várias formas de integridade de banco de dados (integridade de entidade, integridade referencial e restrições de integridade complementares) precisam ser estabelecidas dentro do catálogo do sistema ou dicionário de dados e serem totalmente independentes da lógica dos aplicativos. Assim, os aplicativos não devem ser afetados quando ocorrerem mudanças nas regras de restrições de integridade.
Regra 11 - Regra de independência de distribuição: Alguns SGBDs, notadamente os que seguem o padrão SQL, podem ser distribuídos em diversas plataformas/equipamentos que se encontrem interligados em rede. Essa capacidade de distribuição não pode afetar a funcionalidade do sistema e dos aplicativos que fazem uso do banco de dados. Em resumo,
Comentário
7 Veremos como fazer isso no último volume desta disicplina, quando estivermos estudando a linguagem SQL.
Comentário
8 Commit serve para confirmar as operações realizadas no banco de dados. Rollback serve para desfazer uma operação que ainda não tenha sido confirmada.
Comentário
9 Visão: é uma relação virtual que não faz parte do esquema conceitual do BD, mas que é visível a um grupo de usuários. Em outras palavras, uma visão é uma tabela virtual que é definida a partir de outras tabelas, contendo sempre os dados atualizados.

20
Banco de Dados
as aplicações não são logicamente afetadas quando ocorrem mudanças geográficas dos dados (caso dos BDs distribuídos).
Regra 12 - Regra não-subversiva: O sistema deve ser capaz de impedir qualquer usuário ou programador de transgredir os mecanismos de segurança, regras de integridade do banco de dados e restrições, utilizando algum recurso de linguagem de baixo nível que eventualmente possam ser oferecidos pelo próprio sistema.
Conheça Mais
Neste capítulo foram vistos conceitos básicos do modelo relacional. Para obter mais informações ou materiais diversificados para o que foi visto aqui, você pode proceder a uma pesquisa usando o Google (www.google.com.br) com as palavras chaves “Modelagem Lógica” + “Banco de Dados” ou “Modelo Relacional” ou ainda “Esquema Relacional”. Você vai ver que virá muito material. Entre eles: apostilas, notas de aula, reportagens, etc.
Adicionalmente, você pode consultar qualquer livro sobre banco de dados, pois qualquer um deles terá um ou mais capítulos voltados para a explicação do modelo relacional. Entre os livros que podemos indicar estão:
HEUSER, CARLOS ALBERTO. Projeto De Banco De Dados – Série Livros Didáticos, V.4. Bookman Companhia Ed., 6ª Edição - 2009
SILBERSCHATZ, Abraham; KORTH, Henry F; SUDARSHAN, S. Sistema de banco de dados. Traduzido por Daniel Vieira. Rio de Janeiro: Elsevier;Campus, 2006.
ELMASRI, Ramez; NAVATHE, Shamkant B. Sistemas de banco de dados. 4a. ed. São Paulo: Pearson Education do Brasil, 2005.
DATE, C. J. Introdução a sistemas de bancos de dados. Rio de Janeiro: Campus, 2000.
ALVES, W.P. Fundamentos de Bancos de Dados. Editora Érica, 2004.
Você Sabia?
A linguagem padrão dos Bancos de Dados Relacionais é a Structured Query Language, ou simplesmente SQL, como é mais conhecida. Ela será assunto do próximo volume (Volume 4) da disciplina.
Aprenda Praticando
Vamos dar uma olhada novamente em questões de concurso?
NCE-UFRJ - 2001 - TRE-RJ - Analista Judiciário - Especialidade - Análise de Sistemas - Desenvolvimento
1) Sobre os conceitos de domínio, atributo e relacionamento, é correto afirmar que:
a) um domínio é definido pelo conjunto dos atributos pertencentes a um relacionamento;

21
Banco de Dados
b) domínio e atributo representam um único conceito semântico;
c) um atributo é considerado identificador se pertencer ao domínio que define um relacionamento;
d) todos os atributos de uma relação devem pertencer a um mesmo domínio;
e) domínio são os valores possíveis que um atributo pode assumir.
2) A cardinalidade de uma relação é caracterizada por:
a) Número de atributos dessa relação;
b) Número de campos dessa relação;
c) Quantidade de chaves estrangeiras da relação;
d) Número de tuplas de uma relação;
e) Nenhuma das respostas anteriores.
3) Uma chave estrangeira:
a) Pode conter valores que não existem na Tabela-Pai (tabela referenciada);
b) Pode não pertencer à chave primária;
c) Tem de pertencer, obrigatoriamente, à chave primária;
d) Podem sempre assumir o valor nulo;
e) Nenhuma das respostas anteriores.
Fundação Getúlio Vargas – 2008
4) No contexto de Banco de Dados, um conceito assegura que um valor que aparece em uma tabela para um determinado conjunto de atributos apareça em outro conjunto de atributos de outra tabela. Por exemplo, se cristalina é o nome de uma agência que aparece em uma tupla da tabela conta, então deve existir uma tupla cristalina na tabela agencia. Esse conceito é definido como um sistema de regras, utilizado para garantir que os relacionamentos entre tuplas de tabelas relacionadas sejam válidas e que não exclui ou altera, acidentalmente, dados relacionados. Trata-se do seguinte conceito:
a) Integridade Funcional;
b) Dependência Funcional;
c) Integridade Relacional;
d) Dependência Referencial;
e) Integridade Referencial.
(Técnico de Tecnologia da Informação/UFT/FCC/2005)
5) Os dois principais tipos de integridade a serem mantidos em um banco de dados relacional adequadamente projetado são:
a) Integridade Existencial e Integridade Permanente;
b) Integridade de Entidade e Integridade de Relacionamento;
c) Integridade de Entidade e Integridade Referencial;
d) Integridade Permanente e Integridade Referencial;
e) Integridade Existencial e Integridade de Entidade.
(Administrador/PM SANTOS/FCC/2005)

22
Banco de Dados
6) Um tipo de dado específico, como por exemplo Nome do Funcionário, é armazenado numa localização da estrutura do banco de dados denominada.
a) Tabela;
b) Linha;
c) Planilha;
d) Coluna;
e) Registro.
Respostas:
1) E – O domínio de um atributo são os valores que ele pode assumir. Ou seja, é o tipo deste atributo. Por exemplo, o atributo dia do mês tem como domínio os valores naturais entre 1 e 31.
2) C – A cardinalidade de uma relação é o número de linhas ou tuplas dessa relação. Assim, uma relação com quatro tuplas, tem cardinalidade 4.
3) B – Uma chave estrangeira pode não pertencer à chave primária, não pode conter valores que não existam na tabela-pai e só podem assumir valor nulo se não pertencer à chave primária da tabela onde é chave estrangeira.
4) E – Integridade Referencial. Ela checa todas as validações necessárias referentes ao uso de chaves estrangeiras.
5) C – os dois principais tipos de integridade que podem ser verificados em um BD relacional são a integridade de entidade (que se referem às checagens da chave primária) e a integriadade referencial (que se refere às checagens da chave estrangeira).
6) D – Nome do funcionário é tipicamente um atributo e um atributo é representado no BD relacional por uma coluna.
Atividades e Orientações de Estudo
Agora vamos exercitar o que foi estudado neste capítulo. Assim sendo, faça as atividades sugeridas a seguir. Lembre que exercitar vai ajudá-lo(a) a fixar melhor o conteúdo estudado. E o conteúdo desse capítulo é fundamental para o capítulo seguinte, onde vamos aprender a construir o Modelo Relacional. Mãos à obra!
Atividades Práticas:
Responda as questões a seguir em um documento de texto (doc) e poste as respostas no ambiente virtual, no local indicado. Esse trabalho deve ser feito individualmente. (Exercícios adaptados do livro de Carlos Heuser (1998) - capítulo 4).
Exercício 1: Abaixo aparecem diversos esquemas de relação que compõem um banco de dados relacional. Identifique nestes esquemas, da maneira apropriada, as chaves primárias e chaves estrangeiras:
Aluno (CodigoAluno,Nome,CodigoCurso)
Curso(CodigoCurso,Nome)

23
Banco de Dados
Disciplina(CodigoDisciplina,Nome,Creditos,CodigoDepartamento)
Curriculo(CodigoCurso,CodigoDisciplina,Obrigatória-Opcional)
Conceito(CodigoAluno,CodigoDisciplina,Ano-Semestre,Conceito)
Departamento(CodigoDepartamento,Nome)
Exercício 2: Considere o esquema das relações de um BD relacional a seguir:
Paciente(CodigoConvenio (FK), NumeroPaciente, Nome)
Convenio(CodigoConvenio, Nome)
Medico(CRM, Nome, Especialização)
Consulta(CodigoConvenio (FK), NumeroPaciente (FK), CRM(FK), Data-Hora)
A partir desse esquema, explique que verificações/checagens deveriam ser feitas pelo SGBD para garantir integridade referencial nas seguintes situações:
a) Uma linha é incluída na tabela Consulta.
b) Uma linha é excluída da tabela Paciente.
Vamos Revisar?
Você estudou, neste capítulo, os conceitos básicos referentes ao modelo relacional. Entre eles, os conceitos de tabela ou relação, tuplas ou linhas, atributos ou colunas e chaves (chave candidata, primária, secundária e estrangeira). Esses conceitos serão todos utilizados no próximo capítulo onde você aprenderá a derivar o modelo relacional a partir do modelo entidade-relacionamento. Adicionalmente, foram vistos também neste capítulo os principais tipos de integridade (de entidade e referencial), além de integridades complementares e integridade semântica.

24
Banco de Dados
Capítulo 8
O que vamos estudar neste capítulo?
Neste capítulo, vamos estudar os seguintes temas:
» Como derivar o MR a partir do MER.
Metas
Após o estudo deste capítulo, esperamos que você consiga:
» Derivar o MR a partir do MER.
» Verificar a corretude do modelo derivado.

25
Banco de Dados
Capítulo 8 – Derivando o MR a partir do MER
Vamos conversar sobre o assunto?
“Vimos no capítulo anterior os conceitos básicos do modelo relacional. Porém, ainda não vimos como gerar o modelo relacional, que faz parte da modelagem lógica do banco de dados, que é a terceira etapa do projeto de banco de dados como um todo. A melhor maneira de produzir o modelo relacional é derivá-lo a partir do modelo entidade-relacionamento. Para fazer isso, existem algumas regras. São justamente essas regras que discutiremos neste capítulo.”
Neste capítulo, você vai aprender como derivar o MR a partir do MER, para isso, todas as instruções de como fazer isso serão dadas. Vamos lá?
Algumas Informações Iniciais
A terceira fase do projeto de banco de dados é o projeto lógico que objetiva mapear o modelo de dados conceitual para o modelo de dados relacional. Essa fase dá origem ao esquema lógico representado pelo modelo relacional que já é um modelo que depende do SGBD e será usado para implementar o banco de dados.
É comum, em projetos de banco de dados, se realizar a modelagem dos dados através de um modelo de dados de alto-nível. O modelo de dados de alto-nível normalmente adotado é o Modelo Entidade-Relacionamento (MER) e o esquema das visões e de toda a base de dados são especificados em diagramas entidade-relacionamento (DER). O passo seguinte à modelagem dos dados conceitual é o mapeamento do diagrama da base de dados global para um modelo de dados de implementação. Existem três tipos de modelos de dados de implementação: hierárquico, rede e relacional. Para cada um desses modelos, podem-se definir estratégias de tradução a partir do DER. A estratégia de tradução, ou de mapeamento, que trataremos neste capítulo e nesta disciplina será apenas para o modelo de dados relacional.
O Modelo Relacional é a representação do modelo lógico do projeto de banco de dados, sendo que a forma de representação dos conceitos necessários ao projeto deve passar a ser mais detalhada e se aproximar um pouco mais da representação física. Dessa forma, várias mudanças devem ser realizadas no DER gerado na fase de modelagem conceitual, como, por exemplo: entidades passam a ser representadas por relações ou tabelas. Atributos passam a ser representados em colunas. O atributo identificador passa a ser a chave primária (PK) da tabela. Os relacionamentos e as dependências passam a ser representados por chaves estrangeiras (FK) e assim por diante. Na Figura 3, pode ser visto um exemplo do resultado da transformação de um MER em MR. Cada etapa desse mapeamento será estudada na seção a seguir.

26
Banco de Dados
Figura 3 - Passagem do MER para o MR
Regras para Derivar o Modelo Relacional a partir do MER
Agora, iremos estudar cada uma das etapas de derivação do MR a partir do MER.
» Mapeamento de Entidades Fortes – Cada conjunto de entidades fortes é mapeado como uma relação que envolve todos os atributos da entidade correspondente do DER. Assim, para cada entidade regular E no DER, criar uma relação R que inclua todos os atributos simples de E. Se houver atributos compostos, inclua apenas os atributos simples que compõem o atributo composto (ou seja, decomponha o atributo composto). O(s) atributo(s) identificador(es) da entidade E deve(m) ser marcado(s) como chave primária da relação R. Por exemplo, suponha a entidade Aluno que possui dois atributos CPF e Nome, sendo o CPF o atributo identificador da entidade (vide Figura 4). No MR, seria criada uma relação ou tabela de nome Aluno, com duas colunas (atributos) CPF, que deveria ser marcado como chave primária (PK) e Nome. Como, anteriormente explicado, se houvesse atributos compostos, esses deveriam ser substituídos pelos atributos simples que o compõem (vide Figura 5). Assim, o atributo Endereço, que é composto pelos atributos Rua, Numero e Bairro, seria representado na relação apenas por estes últimos.
Figura 4 - Exemplo de Mapeamento de Entidade Forte

27
Banco de Dados
Figura 5 - Exemplo de mapeamento de atributo composto
» Mapeamento de Atributos Multivalorados – Os atributos multivalorados vão se tornar relações cujas chaves primárias serão compostas pela chave da entidade possuidora do atributo mais o atributo multivalorado. Ou seja, para cada atributo A multivalorado, deve-se criar uma nova relação R que inclua o atributo multivalorado A e a chave-primária K da relação que representa o tipo de entidade ou o tipo de relacionamento que tem A como atributo. O detalhe é que a chave-primária da relação R será composta por K e pelo atributo A. Se o atributo multivalorado for composto, você deve seguir a instrução anteriormente dada de decompô-lo (usar os atributos simples que o compõem). Por exemplo, suponha a entidade Empregado (vide Figura 6). Ela possui os atributos CPF e Nome simples e o atributo Telefone que é multivalorado. Essa entidade seria mapeada para a relação Empregado (pela regra já descrita anteriormente) e o atributo mutivalorado Telefone daria origem a outra relação, que chamamos de Telefone_Empregado, contendo a chave primária da relação Empregado (que originou-se da entidade possuidora do atributo) e o atributo valorado, também fazendo parte da chave primária dessa nova relação.
Figura 6 - Exemplo mapeamento de atributo multivalorado
» Mapeamento de Entidades Fracas – São mapeadas em uma relação formada por todos os atributos da entidade fraca mais os atributos que formam a chave primária da relação da qual a entidade fraca depende. O relacionamento não é mapeado. Assim, para cada tipo de entidade fraca EF do DER, criar uma relação R e incluir todos os atributos simples (ou os componentes simples de atributos compostos) de EF como atributos de R. Além disso, incluir como a chave-estrangeira de R a

28
Banco de Dados
chave-primária da relação que corresponde à entidade forte, da qual a entidade fraca depende. Logo, a chave primária da entidade fraca deverá ser formada pela chave primária da relação que representa a entidade forte da qual a entidade fraca depende e pelo atributo identificador da entidade fraca. Por exemplo, vide a Figura 7. A entidade forte Empregado foi mapeada para a relação Empregado, como explicado anteriormente. A entidade fraca Dependente deu origem a uma relação cuja chave primária é formada pela chave primária de empregado (CPF) e pelo identificador da própria entidade fraca (RG), além do atributo adicional Nome.
Figura 7 - Exemplo de mapeamento de entidade fraca
» Mapeamento de Relacionamentos Binários 1:1 – Esse tipo de relacionamento não é mapeado em uma nova relação. Seus atributos são colocados em qualquer uma das relações que mapeiem as entidades envolvidas. A entidade escolhida para receber os atributos do relacionamento receberá, também, a chave primária da outra entidade envolvida. Assim, temos que, para cada tipo de relacionamento binário 1:1 R do DER, devem-se criar as relações E1 e E2 que correspondem aos tipos de entidade participantes do relacionamento R. Depois, deve-se escolher uma das relações, por exemplo, E1, para incluir nela, como chave-estrangeira, a chave-primária de E2. Devem-se incluir também em E1 todos os atributos simples (ou os componentes simples de atributos compostos) do tipo de relacionamento R. Por exemplo, suponha que “Um empregado trabalha em uma empresa e uma empresa possui um único empregado” (vide Figura 8). Esse é um relacionamento binário 1:1. Para mapeá-lo para o MR, devem-se criar duas relações Empregado e Empresa, conforme a maneira anteriormente explicada (mapeamento de entidade forte). Depois, seria escolhida uma das relações (suponha que escolhemos a relação Empregado) para receber os atributos do relacionamento (no caso, Dt_admissao) e a chave primária da relação que não for a escolhida (no caso, o atributo Codigo, que pertence à relação Empresa). Se a entidade escolhida fosse a relação Empresa (a escolha é sua) seria necessário colocar a chave primária da entidade Empregado na relação Empresa, assim como o atributo do relacionamento. Todas as duas abordagens seriam possíveis.

29
Banco de Dados
Figura 8 - Exemplo de mapeamento de relacionamento binário 1:1
» Mapeamento de Relacionamentos Binários 1:N – Esse tipo de relacionamento não é mapeado em uma nova relação. Seus atributos são colocados na relação que mapeia a entidade com cardinalidade N. Os atributos-chaves da entidade com cardinalidade 1 são mapeados (passam a fazer parte) na entidade com cardinalidade N. Ou seja, para cada tipo de relacionamento binário 1:N (que não envolva entidades fracas) R, você deve identificar a relação S que representa o tipo de entidade que participa do lado N do tipo de relacionamento. Depois, deve incluir em S, como chave-estrangeira, a chave-primária da relação T que representa o outro tipo de entidade que participa em R. Por fim, devem-se incluir, também, quaisquer atributos simples (ou componentes simples de atributos compostos) do tipo de relacionamento 1:N como atributos de S. Por exemplo, suponha que “Uma empresa tem zero ou mais empregados e um empregado trabalha para uma e apenas uma empresa” (vide Figura 9). Esse é um relacionamento binário 1:N. Para mapeá-lo para o MR, devem-se criar duas relações Empregado e Empresa, conforme a maneira anteriormente explicada (mapeamento de entidade forte). Depois, deve-se incluir na relação que representa a entidade do lado N do relacionamento (no caso, Empregado), a chave primária da relação que representa a entidade do lado 1 (no caso, Empresa). Por fim, os atributos do relacionamento devem também ser incluídos na relação do lado N. Neste caso, obrigatoriamente o lado escolhido deveria ser o lado N do relacionamento.

30
Banco de Dados
Figura 9 - Exemplo de mapeamento de relacionamento binário 1:N
» Mapeamento de Relacionamentos Binários M:N – O relacionamento é mapeado em uma nova relação que recebe os atributos do relacionamento mais os atributos-chaves das entidades envolvidas no relacionamento. Assim, a chave da relação seria a concatenação das chaves das entidades envolvidas (e, em alguns casos, também o atributo identificador do próprio relacionamento10). Então teríamos que, para cada tipo de relacionamento binário M:N R, criar uma nova relação S para representar este relacionamento R. Nesta nova relação seriam incluídas, como chave-estrangeira, as chaves-primárias das relações que representam os tipos de entidade participantes do relacionamento. A combinação dessas chaves-primárias irá formar a chave primária da nova relação S. Também seriam incluídos na relação S qualquer atributo simples do tipo de relacionamento M:N (ou componentes simples dos atributos compostos). Relacionamentos M:N sempre derivam uma nova relação, para o tipo relacionamento. Por exemplo, temos que “Um projeto aloca zero ou mais empregados e um empregado pode trabalhar em zero ou mais projetos.” (vide Figura 10). Como o relacionamento é binário e M:N, seriam criadas três relações: Projeto, Empregado e Alocação (melhor passar o verbo para um substantivo, assim o relacionamento aloca passa a ser a relação alocação). As duas primeiras relações seriam criadas pela regra já vista de mapeamento de entidades fortes. Quanto ao relacionamento, seria criado para ele uma relação Alocação que teria como chave primária as chaves das duas relações que representam as entidades envolvidas no relacionamento (no caso, CPF e Código), além do atributo do próprio relacionamento (no caso, Dt_alocação).
Comentário
10 Isso ocorrerá quando for necessário que o relacionamento reflita algum aspecto temporal ou mantenha algum tipo de histórico. Consulte o capítulo 5 do Volume 2 da disciplina para mais informações a respeito.

31
Banco de Dados
Figura 10 - Exemplo de mapeamento de relacionamento binário M:N
Se, como mencionado anteriormente, fosse necessário armazenar algum aspecto temporal do relacionamento (no caso, guardar o histórico das alocações feitas), o atributo Dt_alocação do relacionamento viria no DER como identificador do relacionamento. Isso faria com que ele no mapeamento também passasse a fazer parte da chave primária da relação que representa esse relacionamento (no caso, a relação Alocação), conforme pode ser visto na Figura 11. Consegue perceber o que muda? (Observe as figuras 10 e 11).
Figura 11 - Exemplo de mapeamento de relacionamento binário M:N (guardando aspecto temporal)

32
Banco de Dados
» Mapeamento de Relacionamentos Ternários, Quaternários, etc – Usualmente, mapeamos tais relacionamentos como se todos fossem de cardinalidade M:N. A relação será formada pelos atributos do relacionamento e as chaves primárias das entidades envolvidas neste relacionamento. Por exemplo, suponha o relacionamento ternário da Figura 12. Cada entidade forte seria mapeada em uma relação, conforme regra já vista. E o relacionamento matricula, seria mapeado na relação Matricula que seria composta pelas chaves primárias de cada uma das relações que representam as entidades envolvidas no relacionamento (no caso, Sigla, CPF e Código), mais a o atributo existente no próprio relacionamento (no caso, Dt_matricula). Sendo que as chaves primárias comporiam as chaves primárias da própria relação.
Figura 12 - Exemplo de mapeamento de relacionamento ternário
» Mapeamento de Especialização/Generalização – Há dois casos. Primeiro, se a especialização for mutuamente exclusiva e total. Ou seja, nenhum elemento é membro de mais de uma entidade e se todas as entidades do nível superior forem membros dos níveis inferiores (por exemplo, todo cliente ou é pessoa física ou é pessoa jurídica, nunca será apenas um cliente). Neste caso são criadas relações apenas para as especializações (entidades filhas, no nível inferior) e elas usarão como chave primária o atributo identificador da entidade de nível superior. Por exemplo, atente para a Figura 13. Temos que o Cliente foi especializado em Pessoa_Fisica e Pessoa_Juridica e essa é uma especialização mutuamente exclusiva e total. Dessa forma, esse diagrama dará origem a duas relações. Ambas terão os atributos da entidade de nível superior (e a chave primária será o identificador da mesma – o código), além de seus próprios atributos.

33
Banco de Dados
Figura 13 - Exemplo de mapeamento de especialização/generalização total e mutuamente exclusiva
Se a especialização não for mutuamente exclusiva, deve ser criada uma tabela para cada entidade, todas tendo como chave primária o atributo identificador da entidade principal (de nível superior). Por exemplo, vide a Figura 14. Uma conta pode ser apenas uma conta normal, pode ser uma poupança ou uma conta de investimento. Assim, a especialização não é mutuamente exclusiva, como consequência, cada entidade dará origem a uma tabela e todas terão como chave primária a chave da entidade principal.

34
Banco de Dados
Figura 14 - Exemplo de mapeamento de especialização/generalização não exclusiva
» Agregação e Entidade Associativa – Envolvem um relacionamento entre relacionamentos. Para fazer o mapeamento, primeiro, criamos relações para todas as entidades envolvidas. Segundo, criamos uma relação para o primeiro relacionamento (a entidade associativa) que terá como chave primária as chaves primárias das entidades diretamente envolvidas. Terceiro, criamos uma relação para o relacionamento externo, contendo as chaves primárias de todas as entidades. Por exemplo, vide a Figura 15. Nela temos um exemplo de uso de entidade associativa para poder especificar que em uma consulta feita por um médico a um paciente, medicamentos podem ser prescritos. Cada entidade forte dará origem a uma relação. Depois, a entidade associativa Consulta também dará origem a uma relação que terá como chave primária as chaves das duas entidades diretamente envolvidas (no caso, Medico e Paciente) no relacionamento da entidade associativa. Por último, o relacionamento externo, que se liga com a entidade associativa (no caso, o relacionamento prescreve que passamos a chamar de prescrição no MR) também dará origem a uma relação que terá como chave primária a chave da entidade associativa e a chave da entidade que a ela se liga.

35
Banco de Dados
Figura 15 - Exemplo de mapeamento de diagrama envolvendo entidade associativa
» Mapeando Auto-Relacionamentos –. Existem duas maneiras de transformar um auto-relacionamento (vide Figura 16) em relações:
Figura 16 - Exemplo de auto-relacionamento
› A primeira é usar para representar a entidade e seu auto-relacionamento apenas uma relação com duas ocorrências da chave primária. Por exemplo, o auto-relacionamento da Figura 16 que representa que um empregado é gerenciado por zero ou um empregado e esse empregado-gerente pode gerenciar zero ou mais empregados, daria origem a uma única relação chamada Empregado, onde haveria duas ocorrências da chave primária CPF: uma para o próprio empregado e outra para o seu gerente, como apresentado a seguir:

36
Banco de Dados
› A outra opção é criar duas relações, uma para representar a entidade e outra para representar o auto-relacionamento. Dessa forma, o DER da Figura 16 daria origem a duas relações: Empregado e Gerência. A relação Empregado seria mapeada da forma já explicada para entidades fortes. E o auto-relacionamento seria mapeado em uma relação que conteria duas entradas da chave primária da entidade: uma para o empregado e outra para o seu gerente, como apresentado a seguir.
Considerações Finais
O principal ponto que deve ser considerado em um esquema relacional, quando comparado ao esquema do MER, é que os tipos de relacionamento não são representados explicitamente; eles são representados por dois atributos A e B, um para a chave-primária e outra para a chave-estrangeira – sobre o mesmo domínio – incluídos em duas relações S e T. Duas tuplas em S e T estão relacionadas quando elas tiverem o mesmo valor para A e B, ou seja, os relacionamentos são definidos pelos valores dos atributos A e B.
Uma vez que o modelo relacional esteja pronto, ele deve ser normalizado (otimizado). O como fazer isso é assunto do próximo capítulo. Depois, com o MR Normalizado, o projeto do banco de dados estará pronto para passar da sua fase lógica (Projeto Lógico), para a fase física, o Projeto Físico ou de Implementação.
Conheça Mais
Alguns livros que podem ser usados para aprofundar o estudo nesse capítulo são:
HEUSER, CARLOS ALBERTO. Projeto de Banco De Dados – Série Livros Didáticos, V.4. Bookman Companhia Ed., 6ª Edição - 2009
SILBERSCHATZ, Abraham; KORTH, Henry F; SUDARSHAN, S. Sistema de banco de dados. Traduzido por Daniel Vieira. Rio de Janeiro: Elsevier;Campus, 2006.
ELMASRI, Ramez; NAVATHE, Shamkant B. Sistemas de banco de dados. 4a. ed. São Paulo: Pearson Education do Brasil, 2005.
DATE, C. J. Introdução a sistemas de bancos de dados. Rio de Janeiro: Campus, 2000.
ALVES, W.P. Fundamentos de Bancos de Dados. Editora Érica, 2004.

37
Banco de Dados
Aprenda Praticando
A partir das regras de mapeamento estudadas neste capítulo, mapeie o MER a seguir para o MR, apresentando o esquema das relações que são originadas.
Vamos começar o mapeamento pela especialização/generalização do lado esquerdo do diagrama. Se observar, a especialização do diagrama é mutuamente exclusiva e total. Um cliente não pode ser pessoa física e jurídica. Ele ou é pessoa física ou é pessoa jurídica. Também, ele não pode ser simplesmente um cliente. Dessa forma, precisamos criar relações apenas para as especializações (entidades filhas, no nível inferior), no caso Pessoa_Fisica e Pessoa_Juridica. E, essas relações usarão como chave primária o atributo identificador da entidade de nível superior (no caso Cliente).
Uma vez mapeada a especialização, vamos tratar agora de mapear o relacionamento
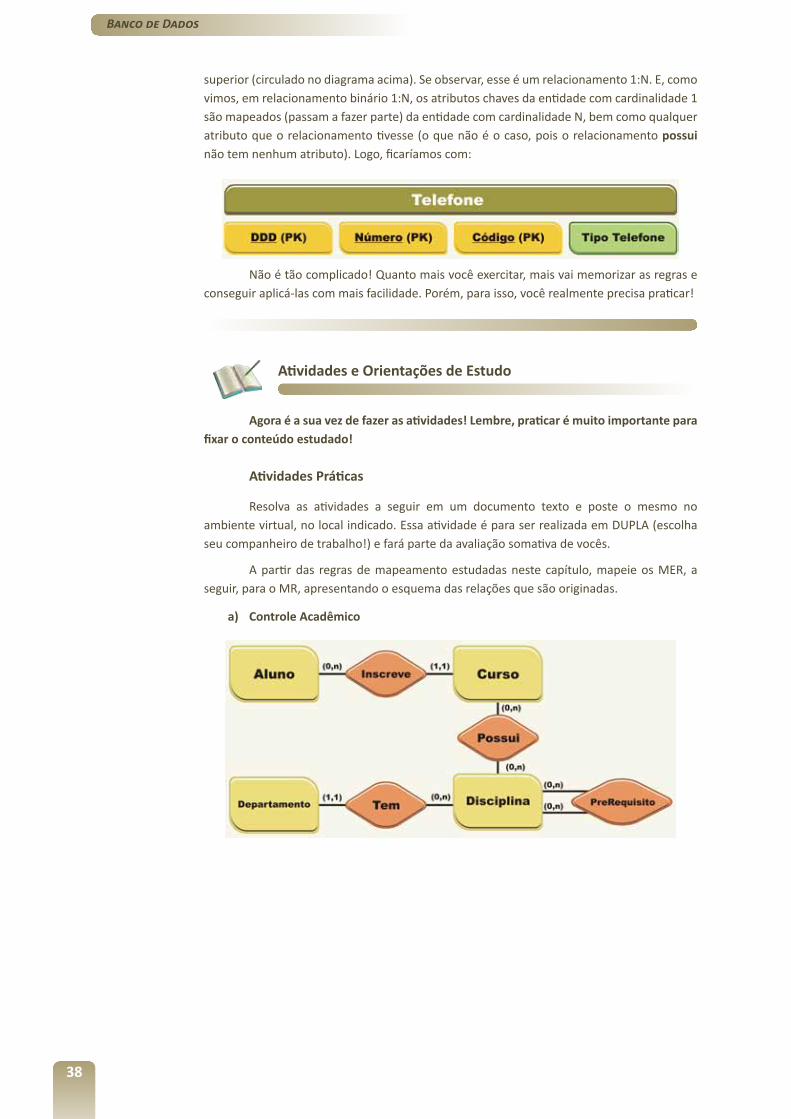
38
Banco de Dados
superior (circulado no diagrama acima). Se observar, esse é um relacionamento 1:N. E, como vimos, em relacionamento binário 1:N, os atributos chaves da entidade com cardinalidade 1 são mapeados (passam a fazer parte) da entidade com cardinalidade N, bem como qualquer atributo que o relacionamento tivesse (o que não é o caso, pois o relacionamento possui não tem nenhum atributo). Logo, ficaríamos com:
Não é tão complicado! Quanto mais você exercitar, mais vai memorizar as regras e conseguir aplicá-las com mais facilidade. Porém, para isso, você realmente precisa praticar!
Atividades e Orientações de Estudo
Agora é a sua vez de fazer as atividades! Lembre, praticar é muito importante para fixar o conteúdo estudado!
Atividades Práticas
Resolva as atividades a seguir em um documento texto e poste o mesmo no ambiente virtual, no local indicado. Essa atividade é para ser realizada em DUPLA (escolha seu companheiro de trabalho!) e fará parte da avaliação somativa de vocês.
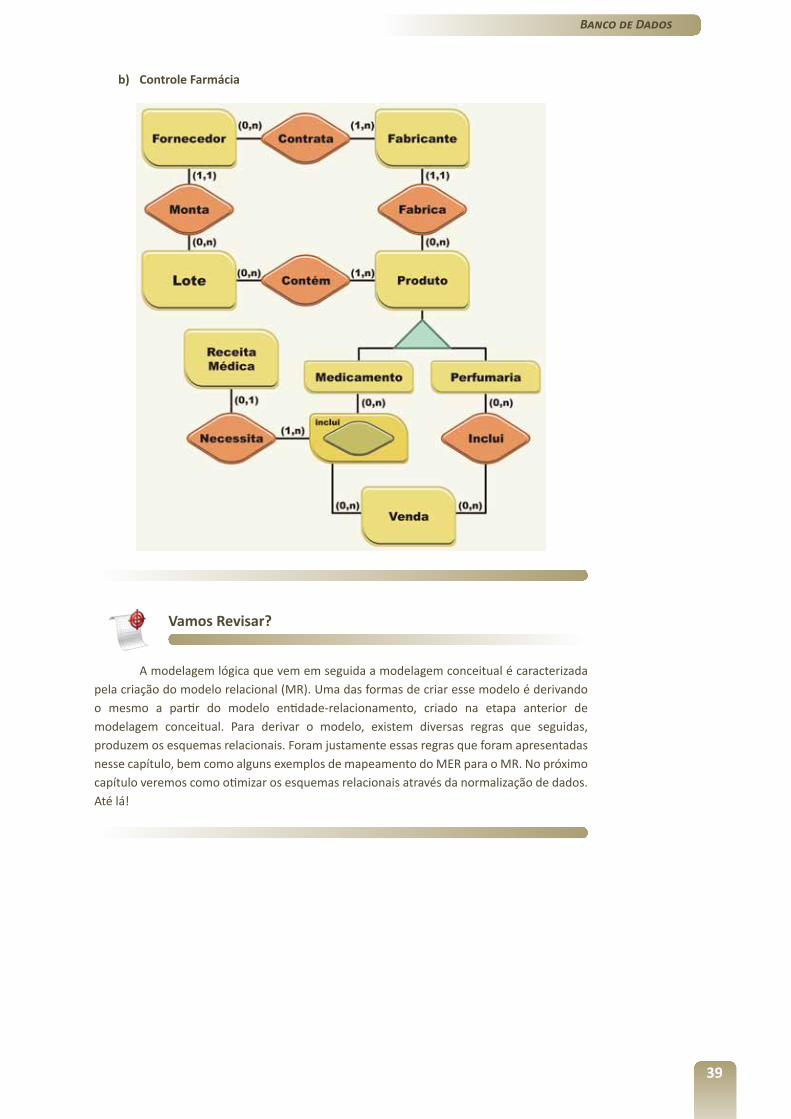
A partir das regras de mapeamento estudadas neste capítulo, mapeie os MER, a seguir, para o MR, apresentando o esquema das relações que são originadas.
a) Controle Acadêmico
39
Banco de Dados
b) Controle Farmácia
Vamos Revisar?
A modelagem lógica que vem em seguida a modelagem conceitual é caracterizada pela criação do modelo relacional (MR). Uma das formas de criar esse modelo é derivando o mesmo a partir do modelo entidade-relacionamento, criado na etapa anterior de modelagem conceitual. Para derivar o modelo, existem diversas regras que seguidas, produzem os esquemas relacionais. Foram justamente essas regras que foram apresentadas nesse capítulo, bem como alguns exemplos de mapeamento do MER para o MR. No próximo capítulo veremos como otimizar os esquemas relacionais através da normalização de dados. Até lá!

40
Banco de Dados
Capítulo 9
O que vamos estudar neste capítulo?
Neste capítulo, vamos estudar os seguintes temas:
» Dependências Funcionais.
» Normalização de Dados.
Metas
Após o estudo deste capítulo, esperamos que você:
» Saiba o que são dependências funcionais.
» Saiba normalizar o seu modelo relacional, pelo menos, até a 3ª Forma Normal.
» Conheça todas as formais normais (1FN, 2FN, 3FN, 4FN e 5FN), além da forma normal de Boyce-Codd.

41
Banco de Dados
Capítulo 9 – Normalização de Dados
Vamos conversar sobre o assunto?
Projetar um banco de dados relacional significa agrupar atributos para formar bons esquemas de relações. Mas o que seria um bom esquema? Em nível geral, poderíamos dizer que seria um esquema fácil de entender e em que as tuplas da relação fossem armazenadas e acessadas de forma eficiente. Para isso, é preciso que sejam minimizadas, ao máximo, a redundância nos dados e as anomalias de inserção, atualização e exclusão. Além disso, é preciso garantir a integridade dos dados, evitando que informações sem sentido sejam inseridas e é preciso organizar e dividir as tabelas da forma mais eficiente possível. Uma forma de colaborar com essas necessidades é fazer a normalização dos dados. Esse é justamente o assunto deste capítulo.
Neste capítulo estudaremos o que são dependências funcionais, seu impacto sobre os dados e como realizar a otimização do MR através da normalização dos dados. Vamos lá?
Dependências Funcionais
Sempre que um atributo X identifica um atributo Y dizemos que entre eles há uma dependência funcional11. Temos, portanto, que X é o determinante e que Y é o dependente. A representação é: X → Y. Em outras palavras, se o valor de um atributo X permite descobrir o valor de um outro atributo Y, dizemos que X determina funcionalmente Y. Por exemplo, dada uma determinada cidade (não considerando cidades homônimas) sabemos o seu estado e com o estado temos o país. Isso é representado da seguinte forma:
Cidade → estado
Estado → país
Em outras palavras, estado é funcionalmente dependente de cidade e país é funcionalmente dependente de estado. Ou ainda, cidade determina estado e estado determina país.
Logo, a dependência funcional é caracterizada pela existência de campos em uma determinada tabela relacional cuja ocorrência de valores está associada a valores que são preenchidos em outros campos na mesma tabela. Por exemplo, suponha uma tabela EMPREGADO que possui dois atributos CPF e NOME. O atributo NOME é funcionalmente dependente do atributo CPF. Assim, CPF → Nome. Com isso, queremos dizer que nome é função do CPF, ou seja, se eu tiver um número de CPF, poderei encontrar o nome da pessoa correspondente. Em outras palavras, CPF determina o Nome (vide Figura 17).
Você Sabia?
11 O Modelo Relacional pegou emprestado da teoria de funções da matemática o conceito de dependência funcional.

42
Banco de Dados
Figura 17 – CPF determina o Nome
Para efetuar a normalização de um modelo de dados relacional, como veremos daqui a pouco, alguns tipos de dependências funcionais são de extrema relevância:
» Dependência Parcial – Ocorre quando a chave primária é composta e existe um campo da relação que depende somente de parte desta chave primária composta. Por exemplo, veja a Relação Alocação (vide Tabela 12). Ela possui a chave composta CPF_Empregdo e Cod_Projeto. O ideal seria que todos os campos (atributos) da relação dependessem (fossem funcionalmente dependentes) da chave primária total, completa. Porém, o campo Nome_Empregado depende apenas de parte da chave primária (no caso, do CPF_Empregado). O mesmo ocorre com o atributo Nome_Projeto que só depende do atributo Cod_Projeto. Apenas o atributo Horas_Trabalhadas é funcionalmente dependente da chave primária completa (porque para determinar as horas trabalhadas, precisamos saber o CPF do empregado e para qual projeto ele está trabalhando através do código do projeto).
Tabela 12 - Relação Alocação
CPF_Empregado (PK)
Cod_Projeto (PK)
Nome_Empregado Nome_Projeto Horas_Trabalhadas
123456 11 Ana Maria Gomes SoftHouse 40
654321 22 José da Silva HardCore 20
789654 33 Cláudio Alencar LinuxP 40
» Dependência Transitiva – Ocorre quando uma coluna depende não somente da chave primária da tabela, mas também de uma segunda coluna (ou conjunto de colunas) da tabela, que não fazem parte da chave primária. Em outras palavras, a dependência funcional transitiva é a dependência funcional indireta existente entre dois ou mais atributos. Assim, se um atributo C depende funcionalmente de um atributo B e o atributo B depende funcionalmente de um atributo A, então diz-se que o atributo C depende indiretamente (transitivamente) do atributo A (vide Figura 18).

43
Banco de Dados
Figura 18 - Exemplo de dependência transitiva
Por exemplo, a relação Pedido_Venda (vide Tabela 13) tem como chave primária o atributo Cod_Pedido. Os atributos Data_Pedido, Situação_Pedido e CPF_Cliente dependem funcionalmente dessa chave primária. Porém, o atributo Nome_Cliente depende funcionalmente do CPF_Cliente (que não é a chave primária) e, apenas, indiretamente do Cod_Pedido, o que é uma anomalia, visto que, todos os atributos de uma relação deveriam depender funcionalmente apenas da sua chave primária.
Tabela 13 - Relação Pedido_Venda
Cod_Pedido (PK)
Data_Pedido Situação_Pedido CPF_Cliente Nome_Cliente
1 18/03/2010 Pendente 123456 Pedro Alves
2 22/02/2010 Entregue 654211 Carolina Dantas
3 10/01/2010 Entregue 987654 Olívia Duncan
» Dependência Multivalorada – Ocorre quando o valor de um atributo determina um conjunto de valores de um outro atributo. Por exemplo, até agora vimos que um atributo (que deve ser a chave primária da relação) determina outro atributo: CPF → Nome (ou seja, o CPF determina o nome, sendo um nome para cada CPF). Porém, se considerarmos: CPF → Dependente teremos um problema para expressar a realidade, porque através de um CPF poderia ocorrer de mais de um dependente ser determinado e não apenas um. Isso caracteriza uma dependência multivalorada. Uma dependência multivalorada é representada por X →→ Y (que quer dizer, X multidetermina Y ou Y é multidependente de X).
Uma dependência funcional (DF) é uma propriedade do esquema da relação e não de uma instância particular da relação (tupla). Assim, uma DF não pode ser automaticamente inferida a partir de algumas tuplas da relação, mas deve ser definida por alguém que conheça a semântica dos atributos da relação. Isso, porque a DF deve ser válida para todas as tuplas de uma relação, ou seja, para a definição do esquema da relação como um todo.
Anomalias de Atualização
A mistura de atributos de várias entidades pode gerar problemas conhecidos como anomalias de atualização e essas anomalias podem, por sua vez, causar problemas tais como a ocorrência de:

44
Banco de Dados
» Grupos repetitivos de dados;
» Dependências parciais de chave;
» Redundâncias desnecessárias de dados;
» Perdas acidentais de informações;
» Dificuldade de representação de fatos da realidade (modelos); e
» Dependências transitivas entre atributos.
As anomalias de atualização podem ser de 3 tipos:
» Anomalias de inserção – Causam a repetição desnecessária de dados (redundância);
» Anomalias de alteração – Levam as inconsistências e aumentam o esforço para a atualização dos dados;
» Anomalias de exclusão - Causam a perda de informações associadas a um dado registro.
Para ficar mais claro, vamos demonstrar essas anomalias através de exemplos.
Exemplo 1 - Considere uma única relação VENDAS para representar as informações sobre os negócios de uma loja de CDs (vide Tabela 14)
Tabela 14 - Relação Vendas
Nome_Cliente (PK)
Cod_CD (PK) Dt_Compra (PK) Nome_CD Cantor Preço
Carlos Veneza 22 20/05/2009 Tribalistas Tribalistas 22,00
Juliano Morais 10 13/02/2010 Siderado Skank 10,00
Joana Pena 45 10/10/2009 Amarantine Enya 18,00
Agora imagine a seguinte situação: o cliente João Pontes deseja comprar 5 CDs iguais (por exemplo, Perfil de Ivete Sangalo, que custa 15 reais). Como essa operação refletiria na Relação Vendas? Seria possível realizá-la?
O primeiro problema seria: como não podemos ter mais de uma tupla com a mesma chave primária, o cliente não poderia comprar os 5 cds no mesmo dia. Isso, porque, se comprasse, haveria 5 tuplas com a mesma chave primária (Nome_Cliente, Cod_CD e Dt_Compra), o que não seria possível. Se o cliente comprasse em dias diferentes, mesmo assim, poderiam ser observadas as seguintes anomalias:
» Anomalia de inserção – Redundância em quase todas as colunas (5 linhas praticamente iguais – mudando só o campo Dt_Compra - na tabela), afinal, é o mesmo CD e o mesmo cliente.
» Anomalia de alteração – se houvesse um aumento de preço do CD, a atualização do preço deveria ser feita em todas as linhas referentes àquele CD na tabela.
» Anomalia de exclusão – A tabela só guarda registro dos CDs que foram comprados. Dessa forma, se só ocorreu uma única venda de um CD e ela fosse apagada, não haveria na loja mais nenhuma informação sobre aquele CD.
Exemplo 2 – Suponha que você criou uma relação Empregado para armazenar as informações sobre os empregados de uma empresa X qualquer (vide Tabela 15).

45
Banco de Dados
Tabela 15 - Relação Empregado
CPF (PK) Nome_Emp Endereco_Emp Cod_Depto Nome_Depto
123456 Carlos Veneza R. das Flores, 10 12 Vendas
987654 Juliano Morais R. ABC, 230 55 Suporte
007654 Joana Pena Av. João XX, 11 43 Financeiro
Na relação criada dessa forma, é possível observar as seguintes anomalias de atualização:
» Anomalia de inserção - Para inserir uma nova tupla Empregado na relação Empregado, deve-se incluir, também, valores para os atributos do departamento em que o empregado trabalha ou colocar null em qualquer campo referente ao departamento. Além disso, deve-se tomar cuidado ao inserir dados de um departamento que já conste na tabela. Por exemplo, para inserir uma nova tupla para um empregado que trabalhe no departamento 55, é preciso tomar cuidado para poder assegurar que os valores dos atributos sejam inseridos corretamente, tal que fiquem consistentes com os valores do departamento 55 que já existe na relação (segunda linha da Tabela 15), senão, seriam inseridos dados inconsistentes na relação. Adicionalmente, seria difícil inserir um novo departamento que ainda não tivesse empregados na relação Empregado. A única maneira de fazer isso seria colocar valores null nos atributos relativos aos empregados. Porém, isso provocaria um problema, pois o CPF do empregado faz parte da chave primária da relação Empregado, e supõe-se que cada tupla deva representar um empregado e não um departamento.
» Anomalia de alteração - Se for mudado o valor de um dos atributos de um departamento qualquer, por exemplo, o nome do departamento 43 passar a ser “Administração”, esse valor precisaria ser mudado em todas as tuplas referentes a todos os empregados que trabalhassem neste departamento ou a base de dados se tornaria inconsistente.
» Anomalia de remoção - Se for removida uma tupla da relação Empregado e esta for a última ocorrência de um departamento em particular (por exemplo, remover o empregado “Carlos Veneza”), a informação correspondente ao departamento seria perdida (no caso, as informações sobre o departamento “Vendas”).
De acordo com as anomalias exemplificadas acima, pode-se verificar a importância de projetar esquemas de relações de maneira que nenhuma anomalia de atualização ocorra. Neste contexto, podem ser usadas as técnicas de normalização, pois um dos objetivos das mesmas é justamente evitar anomalias de atualização no banco de dados. Veremos essas técnicas ainda neste capítulo.
O que é Normalização?
Em 1970, o Professor Dr. Edgar F. Codd12, analista da IBM, desenvolveu uma série de estudos sobre como tratar os dados, a fim de eliminar as anomalias de atualização e as suas consequências desagradáveis para as organizações. Deste esforço surgiram duas inovações que revolucionaram a maneira de tratar os dados. A primeira destas inovações foi o Modelo Relacional, no qual se basearam os Sistemas Gerenciadores de Base de Dados
Comentário
12 Já falamos sobre ele, lembra?

46
Banco de Dados
(SGBD) da metade da década de 1980 e início de 1990. A segunda inovação foi o processo de Normalização, sendo que ambas estão intimamente relacionadas.
O processo de normalização como foi proposto por Codd sujeita um esquema de relação a uma série de testes para certificar-se de que ele satisfaça certa forma normal. Na verdade, a normalização de dados pode ser vista como o processo de análise de determinados esquemas de relações com base em suas dependências funcionais e chaves primárias para alcançar as propriedades desejáveis de: (1) minimização de redundâncias e (2) minimização de anomalias de inserção, exclusão e alteração. Nesse processo, os esquemas de relações insatisfatórios, que não alcançam certas condições (no caso, os testes de forma normal) são decompostos em esquemas de relações menores que passam nos testes e, consequentemente, possuem as propriedades desejadas. Em outras palavras, quando uma tabela não atende ao critério de uma forma normal, sua estrutura é redesenhada através da projeção (jogar para fora) de alguns atributos, levando a construção de novas tabelas contendo algum atributo que possa refazer o conteúdo da tabela original através da junção (reunir) das tabelas resultantes.
Assim, podemos dizer que o processo de normalização tem as seguintes funções:
» Analisar tabelas e organizá-las de forma que a sua estrutura seja simples, relacional e estável, para que o gerenciamento delas possa ser também simples, eficiente e seguro;
» Evitar a perda e a repetição da informação;
» Conseguir uma forma de representação adequada para o que se deseja armazenar;
» Oferecer mecanismos para analisar o projeto do BD (identificação de erros e possibilidades de melhorias) e oferecer métodos para corrigir problemas que, por ventura, sejam encontrados.
E, com essas funções, pretende-se alcançar os seguintes objetivos:
» Garantir a integridade dos dados, evitando que informações sem sentido sejam inseridas no banco de dados;
» Organizar e dividir as tabelas da forma mais eficiente possível, diminuindo a redundância e permitindo a evolução do banco de dados com o mínimo de efeito colateral.
Inicialmente Codd propôs três formas normais que ele chamou de primeira (1FN), segunda (2FN) e terceira (3FN) forma normal. Uma definição mais forte da 3FN (chamada forma normal BOYCE-CODD - FNBC ou BCNF) foi depois proposta por Boyce e Codd. Todas essas formas normais são baseadas nas dependências funcionais entre os atributos de uma relação. Posteriormente, uma quarta (4FN) e quinta (5FN) forma normal foram propostas.
As formas normais são aplicadas para evitar redundância de dados, inconsistências e anomalias de atualização. Isso porque, redundância de dados é um fato gerador de inconsistências. Já as anomalias de atualização criam dificuldades operacionais para manutenção do banco de dados, quebrando a confiabilidade no dado ou ferindo a integridade dos dados.
Uma forma normal engloba todas as outras anteriores, ou seja, a hierarquia entre as formas normais indica que uma tabela só pode estar numa forma mais avançada se, além de atender as condições necessárias, já estiver na forma normal imediatamente anterior. Por exemplo, para que uma tabela esteja na 2FN, ela obrigatoriamente deve estar na 1FN e assim por diante.
Na prática, o mais comum é normalizar relações apenas até a 3FN. Isso porque as três primeiras formas normais (1FN, 2FN e 3FN) atendem à maioria dos casos de

47
Banco de Dados
normalização e já são suficientes para organizar as tabelas de um BD.
Apresentaremos cada uma das formas normais nas seções a seguir, ilustrando cada uma delas com exemplos.
Primeira Forma Normal (1FN)
Para o Modelo Relacional a Forma Normal mais importante consiste da Primeira Forma Normal, pois é considerada parte da própria definição de uma relação. Uma relação se encontra na Primeira Forma Normal (1FN) se todos os domínios de atributos possuem apenas valores atômicos (indivisíveis), e que o valor de cada atributo na tupla seja um valor simples. Ou seja, a 1FN não permite a construção de relações que apresentem atributos compostos (vide o atributo Graus das Lentes na Tabela 16) e nem possibilita a existência de atributos multivalorados (vide o atributo Cursos na Tabela 17) em suas tuplas. Os únicos valores de atributos permitidos devem ser simples e atômicos.
Tabela 16 - Relação Paciente (fora da 1FN)
CPF (PK) Nome Tipo_Sanguineo Graus_Lentes
123456 Jonas Borges AB+ 0.25, 0.50
987659 Cássia Lima O- 1.0,0.5
007543 Túlio Gomes A+ 0.0,0.25
Tabela 17 - Relação Matricula_Aluno (fora da 1FN)
CPF (PK) Nome Cursos
123456 Jonas Borges Programador, Arquiteto
987659 Cássia Lima Analista
007543 Túlio Gomes Operador, Programador, Analista
Para normalizar para a Primeira Forma Normal deve-se:
I) Atributos Compostos - cada um dos atributos compostos (ou não atômicos) devem ser “divididos” em seus atributos componentes. Por exemplo, na Tabela 16, o atributo “Graus_Lentes” poderia ser subdivido em Grau_LenteEsq e Grau_LenteDir, visto que temos de armazenar o grau de cada olho separadamente, quebrando assim o atributo composto nos dois outros que o compõe. Com essa quebra, ficaríamos com a relação apresentada na Tabela 18. Observe que, agora, todos os atributos são indivisíveis (atômicos).

48
Banco de Dados
Tabela 18 - Relação Paciente (na 1FN)
CPF (PK) Nome Tipo_Sanguineo Grau_LenteEsq Grau_LenteDir
123456 Jonas Borges AB+ 0.25 0.50
987659 Cássia Lima O- 1.0 0.5
007543 Túlio Gomes A+ 0.0 0.25
II) Atributos Multi-valorados – temos dois tratamentos possíveis:
a) Quando a quantidade de valores a serem preenchidos no atributo multivalorado for pequena e conhecida a priori, substitui-se o atributo multivalorado por um conjunto de atributos de mesmo domínio, cada um monovalorado representando uma ocorrência do valor. Por exemplo, na relação Matricula_Aluno representada na Tabela 17, suponha que a pessoa possa se matricular, no máximo, em três cursos. Dessa forma, poderíamos decompor o atributo Cursos em três colunas (vide Tabela 19). Essa opção é menos utilizada do que a opção que explicaremos a seguir, porque ela pode gerar colunas de valor Null e, com isso, desperdiçar espaço de armazenamento.
Tabela 19 - Relação Matricula (na 1FN, considerando quantidade pequena e conhecida de valores)
CPF (PK) Nome Curso1 Curso2 Curso3
123456 Jonas Borges Programador Arquiteto Null
987659 Cássia Lima Analista Null Null
007543 Túlio Gomes Operador Programador Analista
b) Quando a quantidade de valores for muito variável, desconhecida ou grande, retira-se da relação o atributo multivalorado, e cria-se uma nova relação que tem o mesmo conjunto de atributos chave, mais o atributo multivalorado também como chave, mas tomado como monovalorado. Em outras palavras, projetam-se os atributos com domínio multivalorado para fora da tabela, levando um atributo (geralmente a chave da tabela original) como elo para refazer a ligação e recuperar o conteúdo da tabela original. Por exemplo, na relação Matricula_Aluno representada, na Tabela 17, se não soubéssemos a quantidade de cursos nos quais um aluno pode se matricular, deveríamos tirar o atributo Cursos da relação Matricula_Aluno (vide Tabela 20). Depois, criar uma nova relação, que chamamos Aluno_Curso (vide Tabela 21), onde seria colocada a chave primária da relação Matricula_Aluno (no caso, o atributo CPF) e o atributo multivalorado (agora, como monovalorado), também como chave primária (no caso, o atributo Curso). Dessa forma, cada curso cursado pelo aluno, daria origem a uma tupla dessa nova relação (videTabela 21). Essa opção é a mais utilizada por não dar origem a campos de preenchimento null. Só seria usado o espaço de armazenamento necessário.

49
Banco de Dados
Tabela 20 - Relação Matricula_Aluno (na 1FN), considerando quantidade variável ou desconhecida de valores
CPF (PK) Nome
123456 Jonas Borges
987659 Cássia Lima
007543 Túlio Gomes
Tabela 21 - Relação Aluno_Curso – criada para atender a 1FN
CPF (PK) Curso (PK)
123456 Programador
123456 Arquiteto
987659 Analista
007543 Operador
007543 Programador
007543 Analista
Mesmo que uma relação esteja na 1FN, ela pode apresentar redundâncias e anomalias de atualização. Para eliminar ou minimizar estes problemas, devemos prosseguir no processo de normalização, aplicando as outras formas normais.
Segunda Forma Normal
Uma relação está na segunda forma normal quando duas condições são satisfeitas:
» A relação está na primeira forma normal;
» Todos os atributos que não fazem parte da chave-primária dependem funcionalmente de toda a chave primária, ou seja, nenhum dos atributos da relação possui dependência parcial. Em outras palavras, todo atributo A da relação R não é parcialmente dependente da chave-primária de R.
Dica
Relações na 1FN e que possuam chave primária simples estão, automaticamente, na 2FN.
Por exemplo, veja a Relação Alocação (vide Tabela 22). Ela possui a chave composta CPF_Empregdo e Cod_Projeto. Essa relação se encontra na 1FN porque não possui atributos multivalorados ou compostos. Porém, não está na 2FN porque o campo Nome_Empregado depende apenas de parte da chave primária (no caso, do CPF_Empregado) e o atributo

50
Banco de Dados
Nome_Projeto só depende do atributo Cod_Projeto. Apenas o atributo Horas_Trabalhadas é funcionalmente dependente da chave primária completa (porque para determinar as horas trabalhadas, precisamos saber o CPF do empregado e para qual projeto ele está trabalhando através do código do projeto). Dessa forma, como existe dependência parcial, a relação não está na 2FN.
Tabela 22 - Relação Alocação
CPF_Empregado (PK)
Cod_Projeto (PK)
Nome_Empregado Nome_Projeto Horas_Trabalhadas
123456 11 Ana Maria Gomes SoftHouse 40
654321 22 José da Silva HardCore 20
789654 33 Cláudio Alencar LinuxP 40
E como faríamos para passar uma relação para a 2FN? Para passarmos uma entidade da 1FN para a 2FN, devemos eliminar as dependências parciais. E como fazer isso?
1) Para cada atributo que não faça parte da chave primária da relação, analisar se existe dependência parcial da chave primária. Para identificar a dependência parcial de uma coluna em relação à chave primária, deve-se indagar: Para que o valor do atributo seja determinado, quais as partes da chave primária que devem ser conhecidas?
2) Para cada grupo de atributos que tenham a mesma dependência parcial da chave primária, devem-se criar novas relações (tabelas) que terão como chave primária a chave parcial que estava na relação original e todo o grupo de atributos que depende da mesma chave parcial;
3) Excluir da relação original o grupo de atributos para o qual foi criada uma nova relação;
4) Repetir esses procedimentos para cada grupo de atributos que tenha dependência parcial da chave primária da relação original, até que todas as relações somente contenham atributos que dependam de toda a chave primária.
Por exemplo, a relação Alocação (Tabela 22) daria origem a duas novas relações13 13(vide Tabelas 23 e 24), uma vez que há dois grupos e dependências parciais nesta relação: Cod_Projeto a NomeProjeto e CPF_Empregado a Nome_Empregado. Veja que em cada nova relação criada, foi colocada a parte da chave primária da tabela original da qual o atributo depende. E, posteriormente, os atributos que tinham dependência parcial foram retirados da relação original (vide Tabela 25), só ficando nela o atributo (no caso Horas_Trabalhadas) que dependia da chave primária completa.
Tabela 23 - Relação Empregado
CPF_Empregado (PK) Nome_Empregado
123456 Ana Maria Gomes
654321 José da Silva
789654 Cláudio Alencar
Dica
13 O nome das novas relações deve ser escolhido de acordo com suas chaves primárias.

51
Banco de Dados
Tabela 24 - Relação Projeto
Cod_Projeto (PK) Nome_Projeto
11 SoftHouse
22 HardCore
33 LinuxP
Tabela 25 - Relação Alocação
CPF_Empregado (PK) Cod_Projeto (PK) Horas_Trabalhadas
123456 11 40
654321 22 20
789654 33 40
Relações que não estão na 2FN podem apresentar problemas de inconsistência devido à duplicidade dos dados e à perda de dados em operações de remoção/alteração (anomalias de atualização). Por exemplo, veja a relação Turma na Tabela 26. Se a disciplina BD não for oferecida para nenhuma turma, isso levará à remoção da terceira tupla da relação Turma, o que ocasionaria a perda do número de horas da disciplina BD, pois esta informação não se encontra em outra relação ou tupla. Adicionalmente, outra anomalia é a duplicidade do número de horas das disciplinas, que pode levar à inconsistência (por exemplo, caso o número de horas da disciplina IP fosse atualizado na primeira tupla e não na segunda). Observe que esses problemas são causados porque o atributo Num_horas depende apenas de parte da chave primária (no caso, depende da Sigla_Disciplina).
Tabela 26 - Relação Turma (fora da 2FN)
Cod_Turma (PK) Sigla_Disciplina (PK) Num_SalaAula Num_Horas
11 IP S15 6
22 IP S16 6
11 BD S02 4
22 SO S10 4
22 SO S12 4
E, então, como ficaria essa relação Turma (Tabela 26) na 2FN? Observe as Tabelas 27 e 28 e reflita sobre como elas foram obtidas.

52
Banco de Dados
Tabela 27 - Relação Disciplina
Sigla_Disciplina (PK) Num_Horas
IP 6
BD 4
SO 4
Tabela 28 - Relação Turma (na 2FN)
Cod_Turma (PK) Sigla_Disciplina (PK) Num_SalaAula
11 IP S15
22 IP S16
11 BD S02
11 SO S10
22 SO S12
Terceira Forma Normal
Uma relação está na terceira forma normal quando duas condições são satisfeitas:
» A relação está na segunda forma normal;
» Não existir dependência transitiva na relação, ou seja, nenhum dos atributos não chave depende de outro atributo que também não é chave. Ou seja, se todos os atributos dependerem completa e exclusivamente da chave primária. Ou ainda, se não houver relação de identificação entre os atributos que não façam parte da chave primária (dependência transitiva).
Dica
Relações que estejam na 2FN e que não tenham nenhum ou apenas um atributo além da chave estão automaticamente na 3FN.
Por exemplo, observe a relação Funcionário (Tabela 29). Ela está na 2FN porque não contém chave composta. Porém, há uma dependência transitiva na mesma. O atributo Salário depende do atributo Cargo (que não faz parte da chave primária). Já o atributo Cargo, por sua vez, depende da chave primária Cod_Empregado. Assim, temos: Cod_Empregado → Cargo → Salário.

53
Banco de Dados
Tabela 29 - Relação Funcionário (fora da 3FN)
Cod_Empregado (PK) Nome_Empregado Cargo Salário
100 Carlos Alves Programador 2000
101 José Souza Analista 3500
102 Maria Ramos Programador 2000
E como faríamos para passar uma relação para a 3FN? Para passarmos uma entidade da 2FN para a 3FN, devemos eliminar as dependências transitivas. E como fazer isso?
1) Para cada atributo que não participe da chave primária da relação, analisar se existe dependência transitiva da chave primária. Para identificar a dependência transitiva de um atributo deve-se indagar: Qual outro atributo não pertencente à chave e poderia determinar o valor do atributo em análise? Ou seja, você vai analisar se o valor de um atributo não-chave pode ser determinado por algum outro atributo que também não pertença à chave primária da relação;
2) Para cada grupo de atributos não-chaves dependentes funcionalmente de outros atributos não-chaves, cria-se uma nova relação. Essa nova relação vai ter os atributos dependentes como não-chaves e os atributos que causam a dependência (determinantes) como chave primária. Ou seja, vai ser chave primária da nova relação os atributos dos quais os atributos não-chave da relação original dependem. O nome das novas relações deve ser escolhido de acordo com a chave primária das mesmas;
3) Repetir os passos anteriores até que todos os atributos restantes na relação original dependam diretamente de toda a chave primária. Em outras palavras, repete-se até que todas as relações não contenham atributos dependentes de atributos não-chaves;
4) Excluir da tabela original todos os atributos com dependência transitiva, mantendo o atributo determinante da transitividade. Deve-se excluir, também, os atributos derivados a partir de outros (atributos calculados), como por exemplo, se houver um atributo data de nascimento e outro atributo idade, o atributo idade deve ser excluído, uma vez que, a qualquer momento, ele poderá ser calculado a partir do atributo data de nascimento.
Vamos exemplificar. Para passar a Tabela 29 para a 3FN, iríamos criar uma nova relação (que chamamos de Salario_Cargo, vide Tabela 30) que terá como chave primária o atributo não-chave determinante da dependência transitiva (no caso, o Cargo) e o atributo não-chave dependente (no caso Salário), uma vez que Cargo a Salário na relação Funcionário original (vide Tabela 29). Depois, o atributo em dependência transitiva deve ser retirado da relação original (no caso, Salário é retirado da relação Funcionário – vide Tabela 31). Assim, a relação original fica apenas com atributos que dependem funcionalmente apenas da chave primária (no caso, Cod_Empregado).
Tabela 30 - Relação Salario_Cargo
Cargo (PK) Salário
Programador 2000
Analista 3500

54
Banco de Dados
Tabela 31 - Relação Funcionário (na 3FN)
Cod_Empregado (PK) Nome_Empregado Cargo
100 Carlos Alves Programador
101 José Souza Analista
102 Maria Ramos Programador
Relações que não estão na 3FN podem apresentar problemas de inconsistência devido à duplicidade dos dados e à perda de dados em operações de remoção/alteração (anomalias de atualização). Por exemplo, a relação Turma (vide Tabela 32) está na 2FN, mas não está na 3FN, pois o atributo Capacidade depende do atributo Sala e não da chave primária da relação que é Cod_Turma. Considerando que a sala S23 tivesse sua capacidade atualizada de 50 para 60 apenas na segunda tupla, teríamos um caso de anomalia de alteração, com consequente inconsistência nos dados armazenados (a segunda tupla marcaria que a sala S23 tem capacidade para 60 pessoas e a terceira tupla marcaria que essa mesma sala teria capacidade para 50 pessoas).
Tabela 32 - Relação Turma (fora da 3FN)
Cod_Turma (PK) Professor Sala Capacidade
IP501 Carlos Alves S09 40
BD210 José Souza S23 50
PR900 Maria Ramos S23 50
E, então, como ficaria essa relação Turma (Tabela 32) na 3FN? Observe as Tabelas 33 e 34 e reflita sobre como elas foram obtidas.
Tabela 33 - Relação Sala
Sala (PK) Capacidade
S09 40
S23 50
Tabela 34 - Relação Turma (na 3FN)
Cod_Turma (PK) Professor Sala
IP501 Carlos Alves S09
BD210 José Souza S23
PR900 Maria Ramos S23

55
Banco de Dados
Forma Normal de Boyce-Codd
Uma relação é considerada pertencente à FNBC quando estiver na Primeira Forma Normal (1FN) e para cada chave candidata, todos os atributos que não participam da chave candidata forem dependentes não transitivos de toda a chave candidata. Em outras palavras, quando todo determinante14, existente na tabela, fizer parte da chave.
A FNBC é uma forma mais restritiva de 3FN, isto é, toda relação em FNBC está também em 3FN; entretanto, uma relação em 3FN não está necessariamente em FNBC. Por exemplo, na relação Turma (vide Tabela 35) cada tupla informa que um aluno A estuda em uma disciplina D com um professor P. Para esta relação, considere as seguintes regras:
» Para cada disciplina, um aluno tem um único professor;
» Cada disciplina pode ser ensinada por mais de um professor; e
» Cada professor só pode ensinar uma disciplina.
Tendo em mente estas regras, quais são os determinantes dessa relação? Temos que (Aluno, Disciplina) → Professor (sabendo o aluno e a disciplina, podemos determinar o professor) que Professor → Disciplina (ou seja, através do professor, podemos descobrir/determinar a disciplina). Como não há dependência transitiva, ou seja, nenhum atributo não-chave é determinado por outro atributo não-chave, a relação está na 3FN. Porém, ela não está na FNBC, porque temos que Professor é um atributo determinante e ele não faz parte da chave primária. Isso acaba ocasionando anomalia de remoção. Vamos exemplificar: Observando a relação Turma na Tabela 35 temos que, se removermos a informação de que o aluno “Carlos Alves” está matriculado na disciplina de BD, não haveria mais no banco de dados nenhum registro de que “Paulo Bennet” leciona a disciplina de BD. A informação seria perdida.
Tabela 35 - Relação Turma
Aluno (PK) Disciplina (PK) Professor
Carlos Alves IP Joana Mendes
Carlos Alves BD Paulo Bennet
José Souza IP Joana Mendes
José Souza PRG Garcia Lopes
Maria Ramos PRG Rui Carneiro
Observação
Na prática, quando um esquema relacional está na 3NF, normalmente, também está na BCNF. A exceção é quando existe uma dependência X → A onde X não é uma superchave e A é um atributo da chave (vide Figura 19).
Comentário
14 Chamamos de determinante um atributo do qual algum outro atributo é funcionalmente dependente.

56
Banco de Dados
Figura 19 – Ocorrência da BCNF
Para Normalizar para a Forma Normal de Boyce-Codd seguem-se os mesmos passos da Terceira Forma Normal. Deve-se verificar se há algum determinante que não é chave primária e, em caso afirmativo, deve-se criar uma nova relação com os que dependem funcionalmente deste determinante e com o próprio determinante como chave primária da nova relação. Por exemplo, a relação Turma (Tabela 35) seria decomposta nas seguintes relações apresentadas nas tabelas 36 e 37, de acordo com os determinantes identificados.
Tabela 36 - Relação Aluno-Professor
Aluno (PK) Professor
Carlos Alves Joana Mendes
Carlos Alves Paulo Bennet
José Souza Joana Mendes
José Souza Garcia Lopes
Maria Ramos Rui Carneiro
Tabela 37 - Relação Professor-Disciplina
Professor (PK) Disciplina
Joana Mendes IP
Paulo Bennet BD
Garcia Lopes PRG
Rui Carneiro PRG
Quarta Forma Normal
Uma relação está na Quarta Forma Normal (4FN) se não possuir dois ou mais atributos multi-valorados independentes. Em outras palavras, se não possuir casos de multi-dependência funcional. Mas o que é mesmo multi-dependência funcional? Se cada valor de um Atributo A permite descobrir um conjunto de possíveis valores de um outro Atributo B, dizemos que A determina multi-funcionalmente B (A → → B). Por exemplo, geralmente, em uma universidade um professor ministra mais de uma disciplina. Logo, Nome_Prof → → Disciplina (Nome_Prof determina multi-funcionalmente disciplina) e, assim, sempre que o nome do professor for pesquisado será possível obter os nomes de suas disciplinas.

57
Banco de Dados
Observação
Para se verificar a 4FN a relação deve ter, no mínimo, três atributos.
Por exemplo, analise a relação Alocação_Professor (vide Tabela 35). Nela temos as seguintes multi-dependências funcionais: Nome_Prof → → Sigla_Disciplina (ou seja, a partir do nome do professor podemos saber as disciplina que ele ministra) e Nome_Prof → → Orientando (ou seja, a partir do nome do professor é possível saber os alunos que ele orienta).
Tabela 35 - Relação Alocação_Professor (fora da 4FN)
Nome_Prof (PK) Sigla_Disciplina (PK) Orientando (PK)
André Fernandes BD Tadeu Batista
André Fernandes ES Tadeu Batista
Jorge Macedo IP Otto Melo
Jorge Macedo IP Paulo Gouveia
Márcia Gadelha SO Jonas Bastos
Observe que as disciplinas que o professor leciona devem ser independentes dos alunos que ele orienta. Se a relação acima significasse que o professor orienta determinado aluno em uma determinada disciplina, a relação estaria correta e não necessitaria ser normalizada. Porém, estamos considerando multi-dependências funcionais entre atributos independentes.
Relações que não estão na 4FN podem apresentar problemas de inconsistências devido à duplicidade dos dados. Por exemplo, na Tabela 35, o professor “André Fernandes” só tem um orientando “Tadeu Batista”, mas ministra duas disciplinas. Devido a esse fato, o nome do orientando precisou ser duplicado sem necessidade. O mesmo ocorreu com o professor “Jorge Macedo” que só ministra uma disciplina “IP” e possui dois orientandos (houve duplicação da sigla da disciplina). Adicionalmente, relações desse tipo podem apresentar anomalias de atualização, por exemplo:
» Anomalia de inserção – um orientando só pode ser inserido se o professor estiver ministrando alguma disicplina (veja que todos os atributos são chaves, nenhum deles pode ficar com valor null);
» Anomalia de remoção – deletar uma disciplina ou um orientando levaria a perda de informação;
» Anomalia de alteração – se necessitássemos alterar o nome de um orientando, precisaríamos alterar o mesmo em todas as tuplas em que ele aparecesse.
Para Normalizar para a Quarta Forma Normal, você deve retirar da relação o atributo multi-valorado e criar uma nova relação, tendo-o como parte da chave, a fim de separar as dependências. Ou seja, deve-se usar o mesmo procedimento feito para passar uma relação para a 1FN, visto anteriormente. Uma observação importante é que, para se normalizar em 4FN, a entidade tem que estar (obrigatoriamente) na 3FN. Por exemplo, a

58
Banco de Dados
relação Alocação_Professor daria origem à nova relação Orientações_Professor (vide Tabela 36) e provocaria mudanças na relação original Alocação_Professor (vide Tabela 37).
Tabela 36 - Relação Orientações_Professor
Nome_Prof (PK) Orientando (PK)
André Fernandes Tadeu Batista
Jorge Macedo Otto Melo
Jorge Macedo Paulo Gouveia
Márcia Gadelha Jonas Bastos
Tabela 37 - Relação Alocação_Professor (na 4FN)
Nome_Prof (PK) Sigla_Disciplina (PK)
André Fernandes BD
André Fernandes ES
Jorge Macedo IP
Márcia Gadelha SO
Veja que, agora, assuntos diferentes são tratados em relações diferentes, evitando duplicações e anomalias.
É importante relembrar que a necessidade de aplicar a 4FN ocorre apenas quando se tem tabelas que mantêm relacionamentos ternários ou superiores e se detectam dependências funcionais multivaloradas independentes.
Quinta Forma Normal
Não vamos dar uma exposição abrangente sobre a quinta forma normal, vamos apenas apresentar uma noção da sua ideia central. A quinta forma normal (5FN) é também chamada de Forma Normal de Projeção / Junção (FNPJ) e trata de casos bastante particulares que ocorrem na modelagem de dados: os relacionamentos múltiplos (ternários, quaternários e n-ários).
Uma relação R está na quinta forma normal (5FN) se está na 4FN e não possui nenhuma dependência de junção. Mas o que é uma dependência de junção?
Dependência de Junção: Dada uma relação R e certas projeções (subconjuntos da relação) R1,..., Rn diz-se que há uma dependência de junção (de R em relação a R1,..., Rn) se R pode ser reconstituída com a junção de R1,..., Rn.
Em outras palavras, uma relação na 4FN estará na 5FN, quando seu conteúdo não puder ser reconstruído (junção), porque há perda de informação, a partir das diversas relações menores (subconjuntos extraídos da relação principal). Ou seja, se ao particionar

59
Banco de Dados
uma relação, sua junção posterior não conseguir recuperar as informações contidas na relação original, então esta relação está na 5FN.
Assim, se uma relação não está na 5ªFN, então, existe uma decomposição de R em um conjunto de projeções (subconjuntos) que estão na 5ªFN e cuja junção natural restabelece a relação original. Esta forma normal trata especificamente dos casos de perda de informação, quando da decomposição de relacionamentos múltiplos.
Para exemplificar, pode acontecer de uma tabela representar um relacionamento triplo que não pode ser simplificado, pois se for quebrado em relacionamentos binários poderá gerar informações incorretas. Neste caso, a tabela já está na 5FN. Para checar esse fato, pode-se utilizar a seguinte pergunta: é possível substituir o relacionamento ternário por relacionamentos binários?
Vamos a outro exemplo. Se um vendedor vende certo tipo de veículo e ele representa o fabricante daquele tipo de veículo, então ele vende aquele tipo de veículo para aquele fabricante (regra de simetria), tal como representado na relação Vendas (vide Tabela 41). Essa relação pode ser decomposta em três outras relações, portanto não está na 5NF (observe que há uma redundância de informações na relação, que irá requerer mais atenção na atualização de dados).
Tabela 41 - Relação Vendas
Vendedor (PK) Fabricante (PK) Veículo (PK)
André Fernandes Ford Automóvel
André Fernandes Ford Caminhão
André Fernandes GM Automóvel
André Fernandes GM Caminhão
Jorge Macedo Ford Automóvel
Assim, para transformar em 5FN podemos quebrar a relação Vendas em 3 relações diferentes, representadas nas Tabelas 42, 43 e 44. Essas relações não podem ser decompostas, estando assim na 5NF. Para conseguir recompor a relação Vendas originais seriam necessárias as três relações.
Tabela 42 - Relação Vendedor-Fabricante
Vendedor (PK) Fabricante (PK)
André Fernandes Ford
André Fernandes GM
Jorge Macedo Ford

60
Banco de Dados
Tabela 43 - Relação Vendedor-Veículo
Vendedor (PK) Veículo (PK)
André Fernandes Automóvel
André Fernandes Caminhão
Jorge Macedo Automóvel
Tabela 44 - Relação Fabricante-Veículo
Fabricante (PK) Veículo (PK)
Ford Automóvel
Ford Caminhão
GM Automóvel
GM Caminhão
Qualquer outra decomposição da relação original poderia ocasionar informações incorretas (tuplas espúrias). Como pôde ser observado, a 4NF decompõe uma relação aos pares (substitui uma relação por duas de suas projeções – em pares), enquanto que a 5NF é utilizada quando uma decomposição aos pares não é possível, como no caso anterior (a relação foi decomposta em três outras, sem perdas).
Um Roteiro para a Normalização
A partir do modelo relacional gerado a partir do modelo entidade relacionamento, construído na fase de modelagem conceitual, proceda os seguintes passos:
» Elimine os atributos repetidos (se houver), de modo a obter um modelo na 1FN;
» Elimine as dependências parciais da chave primária em suas relações (se houver) para obter o modelo na 2FN;
» Elimine as dependências transitivas nas tabelas (se houverem), obtendo um esquema na 3FN;
» Avalie se vale a pena aplicar mais algum tipo adicional de normalização 4FN, 5FN e FNBC.
Algumas Informações Adicionais
Para finalizar esse capítulo, vamos dar algumas informações adicionais sobre cuidados que você precisará ter no refinamento do seu modelo relacional.
» O que fazer se você não conseguir definir uma chave primária? Realmente, poderá haver algumas ocasiões que, no momento da geração da estrutura de tabelas, você não consiga determinar um ou mais atributos que garantam a identificação única de alguma relação, ou seja, não conseguirá definir uma chave primária. Nestes casos,

61
Banco de Dados
será necessário criar um atributo artificial (por exemplo, um código, geralmente, sequencial) para servir como chave primária.
» Atributos Irrelevantes devem ser desconsiderados – Alguns atributos de um relatório não necessitam estar armazenados em um BD, pois serão determinados em tempo de execução. Por exemplo, número de páginas de um relatório ou a sua data de emissão. Estes dados não devem ser considerados atributos da estrutura de tabelas aninhadas.
» Atributos derivados também podem ser desconsiderados – Informações que são deduzidas a partir de dados do BD, como cálculos (somas, médias, valor máximo) ou a idade, que pode ser deduzida a partir da data do nascimento podem ser eliminadas do conjunto de atributos da estrutura de tabelas aninhadas. Esta afirmação não é uma exigência. Isso porque, às vezes, um somatório, por exemplo, é solicitado com tanta frequência em uma consulta, que se torna mais eficaz manter o seu resultado no BD, do que calculá-lo diversas vezes em pouco tempo.
» Valores Nulos em Tuplas – as relações devem ser projetadas de forma que suas tuplas tenham a menor quantidade possível de valores nulos. Normalmente, os atributos que possuem valores nulos podem ser colocados em relações separadas. E quais as razões para se usarem valores nulos? Quando o valor é não aplicável ou inválido, quando o valor é desconhecido (embora possa existir) ou está, temporariamente, indisponível (embora se saiba que ele exista).
» Tuplas Espúrias - projetos incorretos de bancos de dados relacionais podem gerar resultados inválidos (tuplas espúrias) em certas operações de junção de relações15 (Join). A propriedade de “junção sem perdas” é usada para garantir resultados corretos em operações de junção, de forma que nenhuma tupla espúria seja gerada.
Considerações Finais
O processo de Normalização pode ser considerado como a aplicação de uma série de regras, que constituem as Formas Normais, que irão provocar a decomposição de esquemas de dados insatisfatórios de algumas relações, em novas relações.
O processo de normalização é aplicado em uma relação por vez. Durante o processo, a relação vai sendo “quebrada”, criando-se outras relações. Geralmente, o processo de normalização é realizado em etapas, começando através das formas normais menos rígidas e depois através de refinamentos sucessivos, até chegar a uma normalização considerada satisfatória para a aplicação.
A decisão de normalizar ou não uma relação é um compromisso entre garantir a eliminação de inconsistências no BD e alcançar a eficiência de acesso (pois normalizar demais pode diminuir a eficiência dos aplicativos). Por isso mesmo, deve ser realizada alguma ponderação antes de se tomar uma decisão.
Saiba Mais
Existem diversos livros de Banco de Dados que possuem um capítulo específico sobre Normalização e Dependências Funcionais. Aqui vão o nome apenas de alguns:
RAMAKRISHNNAN, R.; GEHRKE, J. Database Management Systems. McGraw-Hill, 2003.
Comentário
15 Quando relações são combinadas a partir de um atributo (geralmente a chave primária) em comum.
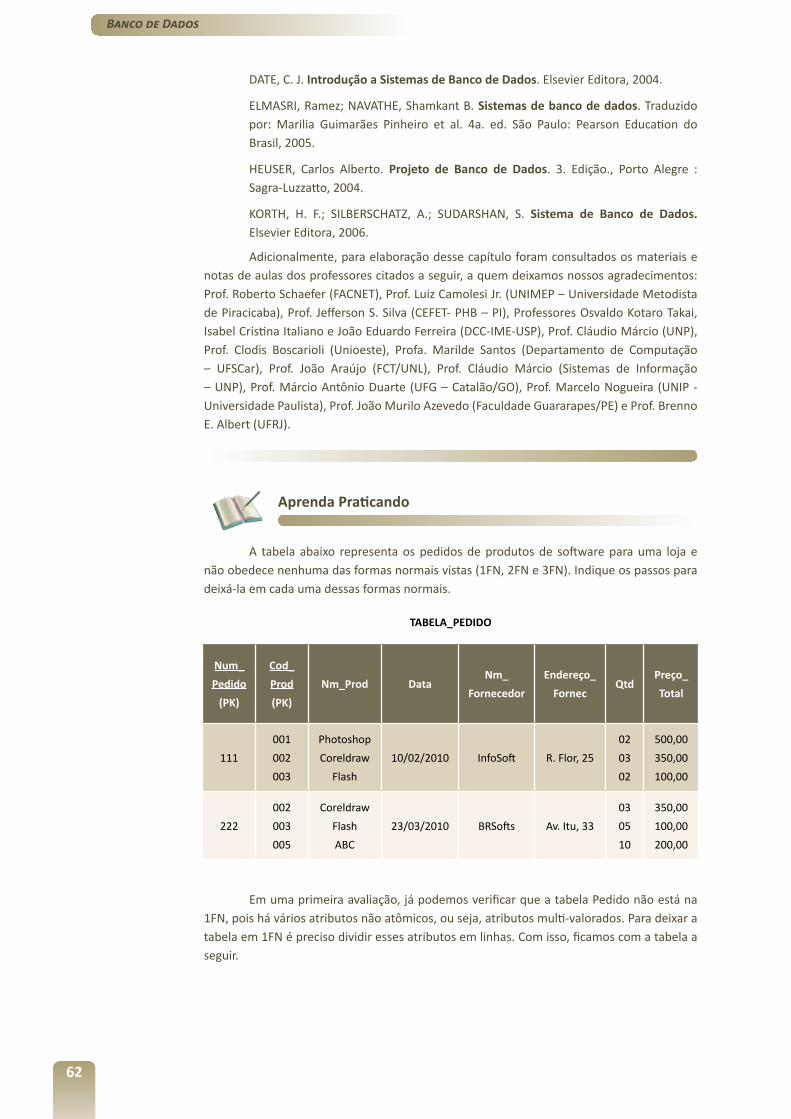
62
Banco de Dados
DATE, C. J. Introdução a Sistemas de Banco de Dados. Elsevier Editora, 2004.
ELMASRI, Ramez; NAVATHE, Shamkant B. Sistemas de banco de dados. Traduzido por: Marilia Guimarães Pinheiro et al. 4a. ed. São Paulo: Pearson Education do Brasil, 2005.
HEUSER, Carlos Alberto. Projeto de Banco de Dados. 3. Edição., Porto Alegre : Sagra-Luzzatto, 2004.
KORTH, H. F.; SILBERSCHATZ, A.; SUDARSHAN, S. Sistema de Banco de Dados. Elsevier Editora, 2006.
Adicionalmente, para elaboração desse capítulo foram consultados os materiais e notas de aulas dos professores citados a seguir, a quem deixamos nossos agradecimentos: Prof. Roberto Schaefer (FACNET), Prof. Luiz Camolesi Jr. (UNIMEP – Universidade Metodista de Piracicaba), Prof. Jefferson S. Silva (CEFET- PHB – PI), Professores Osvaldo Kotaro Takai, Isabel Cristina Italiano e João Eduardo Ferreira (DCC-IME-USP), Prof. Cláudio Márcio (UNP), Prof. Clodis Boscarioli (Unioeste), Profa. Marilde Santos (Departamento de Computação – UFSCar), Prof. João Araújo (FCT/UNL), Prof. Cláudio Márcio (Sistemas de Informação – UNP), Prof. Márcio Antônio Duarte (UFG – Catalão/GO), Prof. Marcelo Nogueira (UNIP - Universidade Paulista), Prof. João Murilo Azevedo (Faculdade Guararapes/PE) e Prof. Brenno E. Albert (UFRJ).
Aprenda Praticando
A tabela abaixo representa os pedidos de produtos de software para uma loja e não obedece nenhuma das formas normais vistas (1FN, 2FN e 3FN). Indique os passos para deixá-la em cada uma dessas formas normais.
TABELA_PEDIDO
Num_Pedido
(PK)
Cod_Prod (PK)
Nm_Prod DataNm_
FornecedorEndereço_
FornecQtd
Preço_Total
111001 002 003
Photoshop Coreldraw
Flash10/02/2010 InfoSoft R. Flor, 25
02 03 02
500,00 350,00 100,00
222002 003 005
Coreldraw Flash ABC
23/03/2010 BRSofts Av. Itu, 3303 05 10
350,00 100,00 200,00
Em uma primeira avaliação, já podemos verificar que a tabela Pedido não está na 1FN, pois há vários atributos não atômicos, ou seja, atributos multi-valorados. Para deixar a tabela em 1FN é preciso dividir esses atributos em linhas. Com isso, ficamos com a tabela a seguir.

63
Banco de Dados
TABELA_PEDIDO
Num_Pedido
(PK)
Cod_Prod (PK)
Nm_Prod DataNm_
FornecedorEndereço_
FornecQtd
Preço_Total
111 001 Photoshop 10/02/2010 InfoSoft R. Flor, 25 02 500,00
111 002 Coreldraw 10/02/2010 InfoSoft R. Flor, 25 03 350,00
111 003 Flash 10/02/2010 InfoSoft R. Flor, 25 02 100,00
222 002 Coreldraw 23/03/2010 BRSofts Av. Itu, 33 03 350,00
222 003 Flash 23/03/2010 BRSofts Av. Itu, 33 05 100,00
222 005 ABC 23/03/2010 BRSofts Av. Itu, 33 200,00
Reavaliando a tabela, podemos perceber que ela não se encontra na 2FN, pois há atributos que dependem apenas de parte da chave primária composta (dependência parcial). Quais seriam? Temos que: Data, Nm_Fornecedor e Endereco dependem apenas de Num_Pedido. Nm_Prod depende apenas de Cod_Produto. Apenas Qtd e Preco dependem da chave composta. Assim redividimos as tabelas, segundo essas dependências e ficamos com:
TABELA_PEDIDO
Num_Pedido (PK) Data Nm_Fornecedor Endereço_Fornec
111 10/02/2010 InfoSoft R. Flor, 25
222 23/03/2010 BRSofts Av. Itu, 33
TABELA_PRODUTO
Cod_Prod (PK) Nm_Prod
001 Photoshop
002 Coreldraw
003 Flash
005 ABC

64
Banco de Dados
TABELA_PRODUTOS_PEDIDO
Num_Pedido (PK) Cod_Prod (PK) Qtd Preço_Total
111 001 02 500,00
111 002 03 350,00
111 003 02 100,00
222 002 03 350,00
222 003 05 100,00
222 005 10 200,00
Agora, só falta avaliar se as tabelas já estão na 3FN, ou seja, se há alguma dependência transitiva. Se avaliarmos a Tabela_Pedido, o atributo Endereço_Fornec depende de um atributo não-chave (dependência transitiva), no caso, o Nm_Fornecedor. Dessa forma, é preciso criar uma nova tabela (Tabela_Fornecedor) e ajustar a Tabela_Pedido. As outras tabelas ficariam iguais, não haveria modificação nas mesmas.
TABELA_PEDIDO
Num_Pedido (PK) Data Nm_Fornecedor
111 10/02/2010 InfoSoft
222 23/03/2010 BRSofts
TABELA_FORNECEDOR
Nm_Fornecedor (PK) Endereço_Fornec
InfoSoft R. Flor, 25
BRSofts Av. Itu, 33
Agora, se reavaliar as tabelas, vai verificar que as mesmas se encontram na 3FN.
Você Sabia?
Você sabia que, algumas vezes, precisaremos fazer uma desnormalização do Banco de Dados? Mas o que é isso? Desnormalização é uma técnica usada para converter uma ou mais tabelas relacionadas em uma única tabela com informações possivelmente redundantes, a fim de melhorar o desempenho no acesso aos dados. Essa técnica é usada em casos particulares para evitar junções e proporcionar agilidade nas consultas aos dados, como no caso do projeto de data warehouses.

65
Banco de Dados
Atividades e Orientações de Estudos
Agora é a sua vez de fazer as atividades! Lembre que praticar é muito importante para fixar o conteúdo estudado!
Atividades Práticas:
Resolva as atividades a seguir em um documento texto e poste o mesmo no ambiente virtual, no local indicado. Essa atividade é para ser realizada em DUPLA (escolha seu companheiro de trabalho!) e fará parte da avaliação somativa de vocês.
I) Faça a Normalização, pelo menos até a 3FN, das relações a seguir. Atributos entre chaves indicam atributos multivalorados. Atributos sublinhados indicam as chaves primárias.
a) Tabela_Oficina (cod_cliente, nome, endereco, cod_carro, modelo, ano_fabricacao, {cod_servico, descricao}, data_servico,valor_servico,{cod_produto, nome_produto})
b) Tabela_Hospital (cod_paciente, nome, tel, endereco, crm, nome_med, tel_med, endereco_med, cod_especialidade, nome_espec, data_consulta, diagnostico)
c) Tabela_Locadora (cod_cliente, nome, tel, {cod_fita, nome_filme, duracao, cod_genero, descricao}, data_locacao, data_devolucao, valor)
d) Tabela_Estoque (cod_peca, descricao, quantidade_comprada, {cod_fornecedor, nome, telefone})
e) Tabela_Biblioteca (cod_aluno, nome, telefone, end, {cod_livro, titulo, editora, volume, cod_autor, nome, genero}, data_emprestimo, data_devolucao)
f) Tabela_Matricula (cod_aluno, cod_turma, cod_disciplina, nome_disciplina, nome_aluno, cod_localnascaluno, nome_localnascaluno)
g) Tabela_Consulta (cod_medico, nome_med, crm, fone, cod_paciente, nome_pac, fone_pac, end_pac, dt_consulta, diagnostico)
II) Considere a relação para livros publicados:
LIVRO (título_livro, nome_autor, tipo_livro, preço_tabela, afiliação_autor, editora)
Suponha as que existam as seguintes dependências:
título_livro → editora, tipo_livro
tipo_livro → preço_tabela
nome_autor → afiliação_autor
a) Em que forma normal está esta relação? Justifique sua resposta.
b) Aplique a normalização até que não possa mais decompor as relações. Justifique as razões de cada decomposição.

66
Banco de Dados
Vamos Revisar?
O Modelo Relacional, devido à sua natureza inerentemente formal, dispõe de uma ferramenta conceitual que permite modelar diversas formas de controle de consistência. O controle através da própria estrutura do BD é obtido no Modelo Relacional construindo-se as relações, segundo regras que garantam a manutenção de certas propriedades. Essas regras são chamadas Formas Normais.
As principais formas normais são a 1FN (que trata atributos compostos e multivalorados), a 2FN (que trata dependências parciais) e a 3FN (que trata dependências transitivas). E, geralmente, só normalizamos as relações até essa 3FN. Adicionalmente, existem a BCNF, a 4FN e a 5FN que só são aplicadas em casos especiais.
Qualquer um que projete um sistema a ser implementado em banco de dados relacional deve estar familiarizado com as técnicas básicas da normalização, pois elas podem contribuir para melhorar a qualidade do projeto do banco de dados.

67
Banco de Dados
Considerações Finais
Olá, cursista!
Esperamos que você tenha aproveitado este terceiro módulo da disciplina Banco de Dados. Com os assuntos vistos até agora, você já tem tudo para criar o seu banco de dados e começar a trabalhar com ele, armazenando, alterando, deletando e consultado os dados armazenados. É justamente isto que estudaremos no próximo módulo: a linguagem SQL que vai lhe ajudar a criar e manipular o seu banco de dados!
Aguardamos sua participação no próximo módulo.
Até lá e bons estudos!
Sandra de Albuquerque Siebra
Autora

68
Banco de Dados
Referências
BATINI, C.; CERI, S.; NAVATHE, S. B. Conceptual database design: an entity-relationship approach. San Francisco: Benjamim Cummings, 1992.
COUGO, Paulo Sérgio. Modelagem Conceitual e Projeto de Banco de Dados. Elsevier Editora, 1997.
DATE, C. J. Banco de dados: tópicos avançados. Rio de Janeiro : Campus, 1988.
DATE, C. J. Introdução a Sistemas de Banco de Dados. Elsevier Editora, 2004.
ELMASRI, Ramez; NAVATHE, Shamkant B. Sistemas de banco de dados. Traduzido por: Marilia Guimarães Pinheiro et al. 4a. ed. São Paulo: Pearson Education do Brasil, 2005.
HEUSER, Carlos Alberto. Projeto de Banco de Dados. 3. Edição., Porto Alegre: Sagra-Luzzatto, 2004.
KORTH, H. F.; SILBERSCHATZ, A.; SUDARSHAN, S. Sistema de Banco de Dados: Elsevier Editora, 2006.
KROENKE, David M. Banco de Dados: Fundamentos, Projeto e Implementação. 6ª Edição: Editora LTC, 1999.
LAENDER, A. H. F. ; CASANOVA, M. A. ; TUCHERMAN, L.. On the Design and Maintenance of Optimized Relational Representations of Entity-Relationship Schemas. Data & Knowledge Engineering, Amsterdam, v. 11, n. 1, p. 1-20, 1993
Revista SQL Magazine - http://www.sqlmagazine.com.br
SETZER, V. W. Banco de dados. 3.ed. São Paulo : Revista Edgard Blucher, 1989.
SILBERSCHATZ, Abraham; KORTH, Henry F;SUDARSHAN, S. Sistema de banco de dados. Traduzido por Daniel Vieira. Rio de Janeiro: Elsevier; Campus, 2006.

69
Banco de Dados
Conheça a Autora
Sandra de Albuquerque Siebra
Doutora em Ciência da Computação, pelo Centro de Informática da UFPE onde trabalhou com Ambientes Virtuais de Aprendizagem e Ambientes Colaborativos em Geral. Ensinou na Faculdade Integrada do Recife (FIR) e na Universidade Católica de Pernambuco (UNICAP), além de ter trabalhado como gerente de projetos no Centro de Estudos e Sistemas Avançados do Recife (CESAR). Atualmente, é professora da Universidade Federal Rural de Pernambuco (UFRPE). Atua na equipe de Educação a Distância da UFRPE e no Departamento de Estatística e Informática (DEINFO), como professora autora de materiais didáticos para cursos a distância, já tendo também atuado como coordenadora de curso e professora executora de disciplinas. Tem experiência, trabalhos desenvolvidos e artigos publicados nas áreas de Educação a Distância, Interfaces Homem- Máquina, Sistemas Colaborativos, Banco de Dados, Análise e Projeto de Sistemas Orientados a Objetos, Sistemas de Informação e Engenharia de Software. Atualmente, desenvolve pesquisas sobre contextualização de interações em ambientes virtuais de aprendizagem e trabalho cooperativo.