apostila probabilidade estatistica aluno
TRANSCRIPT

APOSTILA DA DISCIPLINA DE
PROBABILIDADE E ESTATÍSTICA
Aluno(a):______________________________________
Curso: ________________________________________
Turma:________________________________________
2° Semestre/2012

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
1
I – CONCEITOS INICIAIS
1.1- INTRODUÇÃO
A Estatística é a parte da matemática aplicada que apresenta processos próprios
para coletar, apresentar e interpretar adequadamente conjuntos de dados, sejam eles
numéricos ou não. Podemos dizer que seu objetivo é o de apresentar informações
sobre dados em análise para que tenhamos maior compreensão dos fatos que os
mesmos representam.
As aplicações da estatística estão presentes em todos os campos de estudo: na
medicina (por exemplo, no controle de doenças que antecipam epidemias), na biologia
(por exemplo, no caso de espécies ameaçadas de extinção, onde são criados
regulamentos e leis para a proteção das mesmas a partir das estimativas estatísticas
de modificação de tamanho destas populações), nas ciências sociais (para o
planejamento de ações que busquem o equilíbrio social), na física, na administração,
na economia, na política, e em muitas outras áreas do conhecimento.
Na engenharia, um dos maiores usos está no controle de processos, produtos e
serviços. Podemos observar isso, por exemplo, nas técnicas de controle de qualidade.
Com base nas análises estatísticas temos melhores justificativas para propor medidas
de controle como as que regem a poluição ambiental, as inspeções de automóveis, a
utilização de equipamentos de proteção individual, etc. A estatística pode ser aplicada
na produção para acompanhar a estabilidade dos processos, por meio das cartas de
acompanhamento (cartas de controle estatístico de processo). Também utilizamos a
estatística para analisar ensaios destrutivos e não destrutivos, onde pode ser verificada
a porcentagem de peças não conformes ou probabilidade de vida útil de equipamentos
ou peças. Utilizamos a estatística em calibração de equipamentos de medição e na
verificação da condição de uso desses meios de medição e em muitas outras
aplicações.
As informações estatísticas são concisas, específicas e eficazes, fornecendo
assim subsídios imprescindíveis para as tomadas racionais de decisão. Neste sentido,
a Estatística fornece ferramentas importantes para que as empresas e instituições
possam definir melhor suas metas, avaliar seu desempenho, identificar seus pontos
fracos e atuar na melhoria contínua de seus produtos e serviços.
A estatística descritiva, cujo objetivo básico é o de sintetizar uma série de
valores de mesma natureza, permitindo dessa forma que se tenha uma visão global da
variação desses valores, organiza e descreve os dados de três maneiras: por meio de
tabelas, de gráficos e de medidas descritivas, que serão vistos neste e nos próximos
módulos.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
2
1.2- O MÉTODO, A COLETA DE DADOS EM ENGENHARIA E OS CONCEITOS
FUNDAMENTAIS
Primeiramente vamos tratar do método de engenharia, que é a abordagem para
formular e resolver problemas. Segundo Montgomery (2009), as etapas do método de
engenharia são dadas por:
I – Desenvolver uma descrição clara e concisa do problema;
II – Identificar os fatores importantes que afetam esse problema ou que possam
desempenhar um papel em sua solução;
III – Propor um modelo para o problema, usando o conhecimento científico ou de
engenharia do fenômeno estudado. Estabelecer qualquer limitação ou suposição do
problema;
IV – Conduzir experimentos apropriados e coletar dados para testar ou validar o
modelo-tentativa ou conclusões feitas nas etapas II e III;
V – Refinar o modelo com base nos dados observados;
VI – Tratar do modelo (manipular) de modo a ajudar no desenvolvimento da
solução do problema;
VII – Conduzir um experimento apropriado para confirmar que a solução
proposta para o problema é efetiva e eficiente;
VIII – Tirar conclusões ou fazer recomendações baseadas na solução do
problema.
Analisando estas etapas podemos ver o quanto o engenheiro tem de saber
como planejar eficientemente os experimentos, coletar dados, analisar e interpretar os
mesmos, entendendo como os dados observados estão relacionados com o modelo
que foi proposto para o problema em estudo.
Os métodos estatísticos são usados para nos ajudar a entender a variabilidade.
Vamos conhecer agora conceitos importantes para nossos estudos, com aplicações em
engenharia:
Variabilidade: é quando sucessivas observações de um sistema ou fenômeno
não produzem exatamente o mesmo resultado. Por exemplo, considere o desempenho
do consumo de gasolina em seu carro. Em cada tanque de combustível o desempenho
pode variar consideravelmente, dependendo de muitos fatores como o tipo de estrada,
as condições do veículo, a marca da gasolina, as condições climáticas, etc. Esses
fatores representam as fontes potenciais de variabilidade.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
3
O raciocínio (inferência estatística) do engenheiro para analisar os fatores é de
uma amostra para uma população.
População: é todo conjunto de elementos, finito ou infinito, que tem pelo menos
uma característica em comum.
Amostra: é uma parte da população adequadamente selecionada de acordo
com uma regra ou um plano. Este subconjunto deve ter dimensão menor que o da
população e seus elementos devem ser representativos da população.
Em se tratando de conjuntos-subconjuntos, estes podem ser finitos quando
possuem um número limitado de elementos e infinitos quando possuem um número
ilimitado de elementos.
Um Parâmetro é a medida numérica que descreve uma característica da
população.
Uma Estatística é uma é a medida numérica que descreve uma característica
da amostra.
Vamos observar o esquema abaixo que apresenta alguns parâmetros como a
média, a variância, o desvio padrão, a proporção, que veremos detalhadamente ao
longo do nosso curso.
1.3- PLANEJAMENTO DE UM ESTUDO ESTATÍSTICO
Após a definição do problema a ser estudado e o estabelecimento do
planejamento da pesquisa, que inclui a forma pela qual os dados serão coletados, o
cronograma das atividades, o levantamento dos custos envolvidos, o exame das
informações disponíveis, o delineamento da amostra, etc., o passo seguinte é a coleta
de dados, que consiste na busca ou aplicação dos dados das variáveis, componentes
do fenômeno a ser estudado.
A coleta de dados chamada de direta quando os dados são obtidos na fonte
originária. Os valores assim compilados são chamados de dados primários, como, por
exemplo, dados obtidos em pesquisas de opinião pública, vendas registradas em notas
fiscais da empresa, medição de chuva em pluviômetros, contagem do número de
carros que passa por dia em um cruzamento, etc.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
4
A coleta de dados é dita indireta quando os dados obtidos provêm de coleta
direta. Os valores assim compilados são denominados de dados secundários, como,
por exemplo, o cálculo do tempo de vida média de um produto, obtido por pesquisa, em
tabelas publicadas.
Quanto ao tempo, a coleta pode ser classificada em:
Contínua: quando é realizada permanentemente, sem interrupção,
automaticamente e na vigência de um determinado período, por exemplo, consumo de
energia elétrica em uma residência, medida mensalmente;
Periódica: quando é feita em intervalos de tempo curtos determinados, por
exemplo, o censo industrial e o controle de tráfego em feriados;
Ocasional: quando é efetuada sem época preestabelecida, atendendo a uma
conjuntura qualquer ou a uma emergência, por exemplo, dados de desastres naturais.
Os métodos possíveis de coleta de dados em um estudo estatístico são:
Censo: é uma avaliação direta de um parâmetro, utilizando-se dados relativos a
todos os elementos da população. É 100% confiável, porém caro, lento, às vezes
desatualizado (dependendo do tempo gasto para realização) e nem sempre viável.
Estimação: é uma avaliação indireta de um parâmetro populacional com base
em um estimador. Tem menos de 100% de confiabilidade, porém barato, rápido e
atualizado.
Simulação: é o uso de um modelo físico ou matemático para reproduzir as
condições de uma determinada situação, por exemplo, teste para eficiência de airbags
em automóveis.
Experimentação: quando é aplicado um tratamento a uma parte da população
e são verificadas as respostas, por exemplo, uso de medicamentos.
Estudo observacional: são observadas e medidas características específicas,
mas os objetos do estudo não são modificados, por exemplo, uma pesquisa de
satisfação de clientes
Na coleta de dados a amostra deve ser representativa da população. Devemos
usar técnicas de amostragem apropriadas para que se garanta que as inferências
sobre a população sejam válidas. As regras de amostragem podem ser classificadas
em duas categorias gerais:
Probabilísticas: são amostragens em que a seleção é aleatória onde cada
elemento tenha uma chance conhecida, mas não necessariamente igual, de ser
selecionado para a amostra.
Em uma amostra aleatória, membros de uma população são selecionados de tal
modo que cada membro individual tem chance igual de ser selecionado.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
5
Uma amostra aleatória simples de tamanho n é selecionada de tal modo que
toda a amostra possível de mesmo tamanho n tenha a mesma chance de ser
escolhida.
Não-probabilísticas ou intencionadas: são amostragens em que há uma
escolha deliberada dos elementos da amostra.
A revisão crítica dos dados tem a finalidade de descartar os valores estranhos
ao levantamento, os quais são capazes de provocar futuros enganos. É importante
sempre identificarmos todos os possíveis erros.
A apresentação dos dados é o próximo passo, que pode ser feita por meio das
tabelas e dos gráficos. A tabela é um quadro que resume um conjunto de observações,
enquanto os gráficos são formas de apresentação dos dados, cujo objetivo é o de
produzir uma impressão mais rápida e viva do fenômeno em estudo.
Para ressaltar as tendências características observadas nas tabelas,
isoladamente, ou em comparação com outras, é necessário expressar tais tendências
através de números ou medidas descritivas. As medidas descritivas são conhecidas
como medidas de posição, medidas de dispersão, de assimetria e de curtose, e
veremos todas essas detalhadamente nos próximos módulos.
A análise dos dados permite a emissão da conclusão final do estudo.
A Estatística Descritiva pode assim ser resumida no diagrama a seguir:
1.4. VARIÁVEIS
Após a determinação dos elementos nos perguntamos: o que fazer com estes?
Podemos medi-los, observá-los, contá-los surgindo um conjunto de respostas que
receberá a denominação de variável.
Variável: é a característica que vai ser observada, medida ou contada nos
elementos da população ou da amostra e que pode variar, ou seja, assumir um valor
diferente de elemento para elemento. Dividem-se em:
I) Variável Qualitativa (ou dados categóricos): podem ser separados em
diferentes categorias, atributos, que se distinguem por alguma característica não
numérica. Divide-se em:
COLETA DOS
DADOS
CRÍTICA DOS
DASDOS
APRESENTAÇÃO DOS DADOS
TABELAS ANÁLISE
GRÁFICOS ANÁLISE

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
6
Variável Qualitativa Nominal: é uma variável que assume como possíveis
valores, atributos ou qualidades e estes não apresentam uma ordem natural de
ocorrência. Exemplo: meios de informação: televisão, revista, internet, jornal.
Variável Qualitativa Ordinal: é uma variável que assume como possíveis valores
atributos ou qualidades e estes apresentam uma ordem natural de ocorrência. Por
exemplo: estado civil (solteiro, casado, separado, divorciado).
II) Variável Quantitativa: consistem em números que representam contagens
ou medidas. Divide-se em:
Variáveis Quantitativas Discretas: resultam de um conjunto finito, enumerável de
valores possíveis. Por exemplo: número de filhos, número de provas, número de
acidentes do trabalho, etc.
Variáveis Quantitativas Contínuas: resultam de números infinitos de valores
possíveis que podem ser associados a pontos em uma escala contínua, e em geral,
resultantes de mensurações. Por exemplo: temperatura, altura, peso, comprimento de
uma estrada, etc.
Resumidamente, quanto ao nível de mensuração temos as variáveis:
Exemplo 1.1:
Classificar as variáveis abaixo segundo o nível de mensuração:
a) Cor de sinalização de segurança:
b) Número de peças defeituosas:
c) Área de uma construção:
d) Profissão:
Variáveis
QUALITATIVAS: SUAS REALIZAÇÕESSÃO ATRIBUTOS DOS
ELEMENTOS PESQUISADOS
NOMINAIS: APENAS IDENTIFICA AS CATEGORIAS
ORDINAIS: É POSSÍVEL ORDENAR AS CATEGORIAS
QUANTITATIVAS (INTERVALARES): SUAS
REALIZAÇÕES SÃO NÚMEROS
RESULTANTES DE CONTAGEM OU MENSURAÇÃO
DISCRETAS: PODEM ASSUMIR APENAS ALGUNS VALORES
CONTÍNUAS: PODEM ASSUMIR INFINITOS
VALORES

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
7
e) Número de empregados de uma fábrica:
f) Tipo sanguíneo:
g) Sexo:
h) Valor obtido na face superior de um dado:
i) Salário dos Empregados de uma empresa:
j) Resultado da extração da loteria Federal:
k) Comprimento de um seguimento de reta:
l) Área de um Círculo:
m) Raça:
n) Volume de água contido numa piscina:
o) Letras do alfabeto:
1.5. SÉRIES ESTATÍSTICAS
É importante organizar os dados de maneira prática e racional, para o melhor
entendimento do fenômeno que se está estudando. A Estatística Descritiva pode extrair
e apresentar a informação contida nos dados coletados e apresentá-los de três formas
(tabelas, gráficos e medidas descritivas), que possibilitam uma rápida visão geral do
fenômeno estudado. Neste módulo veremos as tabelas representadas pelas séries
estatísticas.
As tabelas podem ser consideradas quadros em que estão resumidos um
conjunto de dados organizados e dispostos sistematicamente em linhas e colunas.
Assim como existem algumas regras e normas que devem ser observadas
quando vamos elaborar um texto científico ou acadêmico, para organizar os dados em
séries estatísticas ou em distribuição de frequências, existem algumas normas
nacionais definidas pela Associação Brasileira de Normas Técnicas (ABNT) que devem
ser respeitadas. Dessa forma, toda tabela estatística deve conter elementos essenciais
e elementos complementares, quando necessário.
Temos como elementos essenciais:
Título: no título é indicada a natureza do fato estudado, ou seja, o que foi
estudado. Também deve conter as variáveis escolhidas na análise do fato, o local e a
época em que os dados foram obtidos.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
8
Corpo: é formado pelo conjunto de linhas e colunas, em que podemos observar
as séries horizontais e verticais de informações.
Cabeçalho: no início de cada coluna devemos designar a natureza do conteúdo
de que a coluna trata.
Coluna indicadora: nessa coluna devemos evidenciar a natureza do conteúdo de
cada linha.
Temos como elementos complementares:
Fonte: onde se indica a entidade responsável pela sua organização ou que
forneceu dos dados primários. Deve ficar no rodapé da tabela.
Notas: quando é necessário algum outro esclarecimento além dos essenciais,
eles devem ser colocados em forma de notas no rodapé da tabela.
Chamadas: são colocadas também no rodapé da tabela e são necessárias para
esclarecer pormenores ou detalhes em relação às células, colunas ou linhas.
Obs: Nenhuma célula deve ficar em branco, deve sempre apresentar um número ou sinal. O
lado direito e esquerdo das tabelas devem sempre ser abertos (sem bordas).
Agora vamos a definição de série estatística:
Série Estatística é qualquer coleção de dados colocada numa tabela e
classificada segundo as variações do fenômeno observado.
As séries estatísticas podem ser divididas em série de dados não agrupados e
série de dados agrupados, como segue:
I) Série de dados não agrupados
Podem estar relacionadas a época de ocorrência, a localização, ou a um fator
específico relacionado ao problema estudado, ou ainda fazer referência a mais de um
destes fatores. São elas:
a) Série Cronológica, Temporal, Evolutiva ou Histórica: é a série estatística em
que os dados são observados segundo a época de ocorrência.
Exemplo 1.2:
Tabela 1.1 Taxa de domicílios particulares permanentes com acesso à internet, no Brasil, de 2005 a 2009
Período Domicílios particulares permanentes com acesso à internet
2005 13,7
2006 16,7
2007 20
2008 23,8
2009 27,4
Fonte: IBGE, Diretoria de Pesquisas, Coordenação de Trabalho e Rendimento, 2009

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
9
b) Série Geográfica ou de Localização: é a série estatística em que os dados são
observados segundo a localidade de ocorrência.
Exemplo 1.3:
Tabela 1.2. Chuva observada no Ceará relativa ao mês de maio de 2000
Região Precipitação (mm)
Litoral Norte 70,8
Litoral do Pecém 96,9
Litoral de Fortaleza 148,1
Maciço de Baturité 148,0
Sertão Central e Inhamuns 43,5
Fonte: www.funceme.br
c) Série Específica: é a série estatística em que os dados são agrupados
segundo a modalidade (espécie) de ocorrência.
Exemplo 1.4:
Tabela 1.3. Indicadores Conjunturais da Indústria, Índice Mês/Mês Anterior com ajustamento sazonal - Brasil - Outubro- 2011
Variáveis Índice Mês/Mês Anterior (1)
Ind. Geral Ind. Extrativa Ind. Transformação
Pessoal Ocupado Assalariado (2) 99,56 100,68 99,52
Número de Horas Pagas 99,08 99,64 99,06
Folha de Pagamento Real 97,84 86,26 98,97
Fonte: IBGE, Diretoria de Pesquisas, Coordenação de Indústria. (1) Base: Mês imediatamente anterior = 100. (2) Variável sem movimento sazonal significativo e, portanto, sem ajuste sazonal, nas indústrias extrativas.
d) Série Mista: é a série estatística em que os dados são agrupados com a variação do fenômeno em função de mais de uma das séries anteriores.
Exemplo 1.5:
Tabela 1.4 Incidência de acidentes de trabalho (número de acidentes típicos e de trajeto, por 1000 trabalhadores segurados no Brasil em 1997, 1998 e 2000
Incidência de acidentes de trabalho (n o de acidentes
típicos e de trajeto, por 1000 trabalhadores segurados
1997 1998 2000
Brasil 21,9 23,1 20,4
Região Norte 11,9 14,1 13,2
Região Nordeste 11,4 11 9,2
Região Sudeste 23,7 25,8 22,9
Região Sul 30,1 27,9 24,9
Região Centro-Oeste 13,1 15,1 13,4
Fonte: Ministério da Saúde, Secretaria de Políticas de Saúde (SPS).

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
10
II) Série de dados agrupados:
Dependendo do volume de dados, torna-se difícil ou impraticável tirar conclusões a respeito do comportamento das variáveis e, em particular, de variáveis quantitativas. Uma das maneiras de sumarizar os valores de uma variável discreta ou contínua é a montagem de uma distribuição de frequência.
Por definição, uma distribuição de frequência (ou tabela de frequência) lista os valores dos dados, juntamente com suas frequências correspondentes (ou contagens).
- Distribuição de Frequência por Intervalos: série estatística na qual a variável observada está dividida em subintervalos do intervalo total, neste caso temos uma variável contínua;
- Distribuição de Frequência por Pontos: série estatística na qual as frequências observadas estão associadas a um ponto real observado, neste caso temos uma variável discreta.
Para iniciar, podemos colocar os dados brutos de cada uma das variáveis quantitativas em uma ordem crescente ou decrescente, o que denominaremos de rol. A visualização de algum padrão ou comportamento pode continuar sendo de difícil observação ou até mesmo cansativa, mas conseguimos de forma rápida identificar maiores e menores valores ou concentrações de valores no caso de variáveis quantitativas.
Estes números (menor e maior valor observado) servem de ponto de partida para a construção de tabelas para estas variáveis. A seguir, estão alguns conceitos, aliados a procedimentos comuns para a representação das distribuições de frequências, onde:
Dados brutos
É o conjunto dos dados numéricos obtidos após a crítica dos valores coletados.
Exemplo 1.6:
24 – 23 – 22 – 28 – 35 – 21 – 23 – 33 – 34 – 24 – 21 – 25 – 36 – 26 – 22
30 – 32 – 25 – 26 – 33 – 34 – 21 – 31 – 25 – 31 – 26 – 25 – 35 – 33 – 31
Rol
É o arranjo dos dados brutos em ordem de frequências crescente ou decrescente. No exemplo 6 colocamos os dados brutos do exemplo 5 em rol (de forma crescente).
Exemplo 1.7:
21 – 21 – 21 – 22 – 22 – 23 – 23 – 24 – 24 – 25 – 25 – 25 – 26 – 26 – 26
28 – 30 – 31 – 31 – 31 – 32 – 33 – 33 – 33 – 34 – 34 – 34 – 35 – 35 – 36
Amplitude total (AT)
É a diferença entre o maior e o menor valor observados. No exemplo 6 temos:
AT = xmax – xmin

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
11
AT = 36 – 21 = 15.
Número de classes (k)
De modo a interpretar melhor o que esses números exprimem, devemos criar intervalos (classes), preferencialmente, igualmente espaçados. O número deles depende do número de observações (n) e o quão dispersos os dados estão. Não há uma fórmula exata para o cálculo do número de classes. Apresentamos a seguir, duas soluções.
O número de classes (k) será k = 5 para n ≤ 25 e k= √n , para n > 25.
Fórmula de Sturges: k ≈ 1 + 3,3 log n, em que n = tamanho da amostra.
Exemplo 1.8:
Para um total de 30 dados, n = 30, temos que:
k = √30 = 5,48 ou k ≈ 1 + 3,3 log 30 ≈ 5,87 .
Geralmente utilizamos k como um número inteiro, neste caso adotamos k = 5.
Amplitude das classes (h)
A especificação da largura do intervalo é uma consideração importante. Intervalos muito grandes resultam em um número menor de classes de intervalo. A amplitude das classes é dada pela relação:
Assim como no caso do número de classes (K), a amplitude das classes (h) deve ser aproximada para o maior inteiro.
A amplitude das classes (h) deve estar entre os números 1, 2, 3, 5, 7, 10 e os múltiplos de 5.
A amplitude das classes (h) é a diferença entre dois limites inferiores ou superiores de classe consecutivos.
Limites das classes
Limites inferiores de classe (Li) são os menores números que podem pertencer às diferentes classes.
Limites superiores de classe (Ls) são os maiores números que podem pertencer às diferentes classes.
Existem diversas maneiras de expressar os limites das classes. Apresentamos a seguir algumas:
21 26: compreende todos os valores entre 21 e 26 (incluindo-os);
21 26: compreende todos os valores entre 21 e 26, excluindo o 26;
21 26: compreende todos os valores entre 21 e 26; excluindo o 21.
Neste exemplo, temos Li = 21 e Ls = 26.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
12
Agora podemos introduzir os elementos de uma distribuição de frequências:
Pontos médios das classes (PM)
É a média aritmética entre o limite superior e o limite inferior da classe. Assim,
se a classe for, por exemplo de 21 26, temos:
=21+2
2= 23,5, como ponto médio da classe.
Frequência simples ou absoluta (Fi)
É o número de vezes que o elemento aparece na amostra, ou o número de elementos pertencentes a uma classe. No exemplo 6, F(21) = 3.
Frequência absoluta acumulada (Fac)
É a soma das frequências de todos os valores inferiores ao limite superior do intervalo de uma dada classe, mais a frequência simples da classe.
Frequência relativa (fi) e Frequência relativa percentual (fi%)
É a porcentagem daquele valor na amostra. Note que Σfi = 1. A frequência relativa de um valor é dada por:
ou
Passos para a montagem de uma Distribuição de Frequência por intervalos:
1° passo: ordenar os elementos em ordem crescente, indicando a frequência simples de cada elemento (distribuição de frequência por intervalos);
2° passo: Determinar a amplitude total (AT);
3° passo: Determinar o número de intervalos de classe (k);
4° passo: Determinar a amplitude da classe (h);
5° passo: Montagem da distribuição de frequência com título e fonte.
Exemplo 1.9:
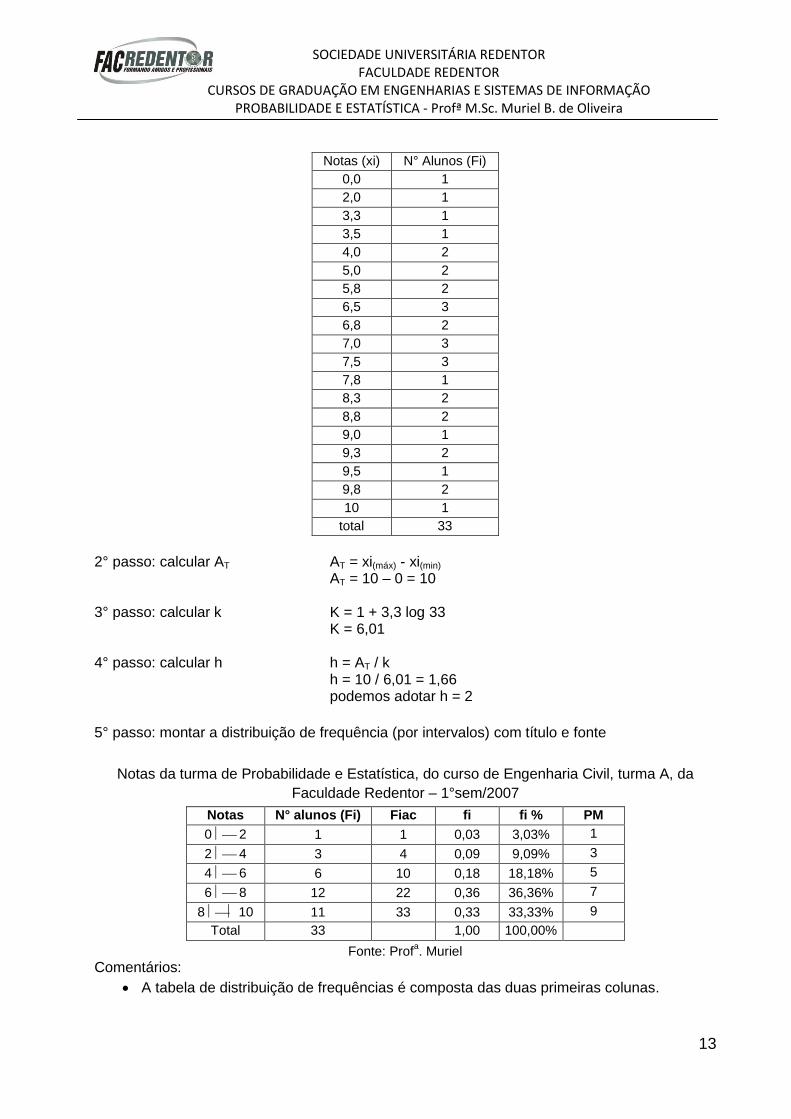
Com as notas da turma de Probabilidade e Estatística, do curso de Engenharia Civil, turma A, da Faculdade Redentor – 1°sem/2007, vamos montar uma distribuição de frequência.
5,0 – 4,0 – 5,8 – 3,3 – 6,8 – 3,5 – 4,0 – 7,0 – 7,0 - 8,3 – 9,3 – 9,8 – 7,5 – 8,8 – 7,5 – 6,8 - 10,0 – zero – 6,5 – 2,0 – 8,8 – 9,3 – 7,5 – 5,8 – 9,8 – 9,0 – 7,8 – 6,5 – 9,5 – 5,0 – 7,0 – 8,3 – 6,5
Solução:
1° passo: colocar os elementos em rol (crescente), aqui teremos uma distribuição de frequência por pontos.
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
13
Notas (xi) N° Alunos (Fi)
0,0 1
2,0 1
3,3 1
3,5 1
4,0 2
5,0 2
5,8 2
6,5 3
6,8 2
7,0 3
7,5 3
7,8 1
8,3 2
8,8 2
9,0 1
9,3 2
9,5 1
9,8 2
10 1
total 33
2° passo: calcular AT AT = xi(máx) - xi(min)
AT = 10 – 0 = 10
3° passo: calcular k K = 1 + 3,3 log 33 K = 6,01
4° passo: calcular h h = AT / k
h = 10 / 6,01 = 1,66 podemos adotar h = 2
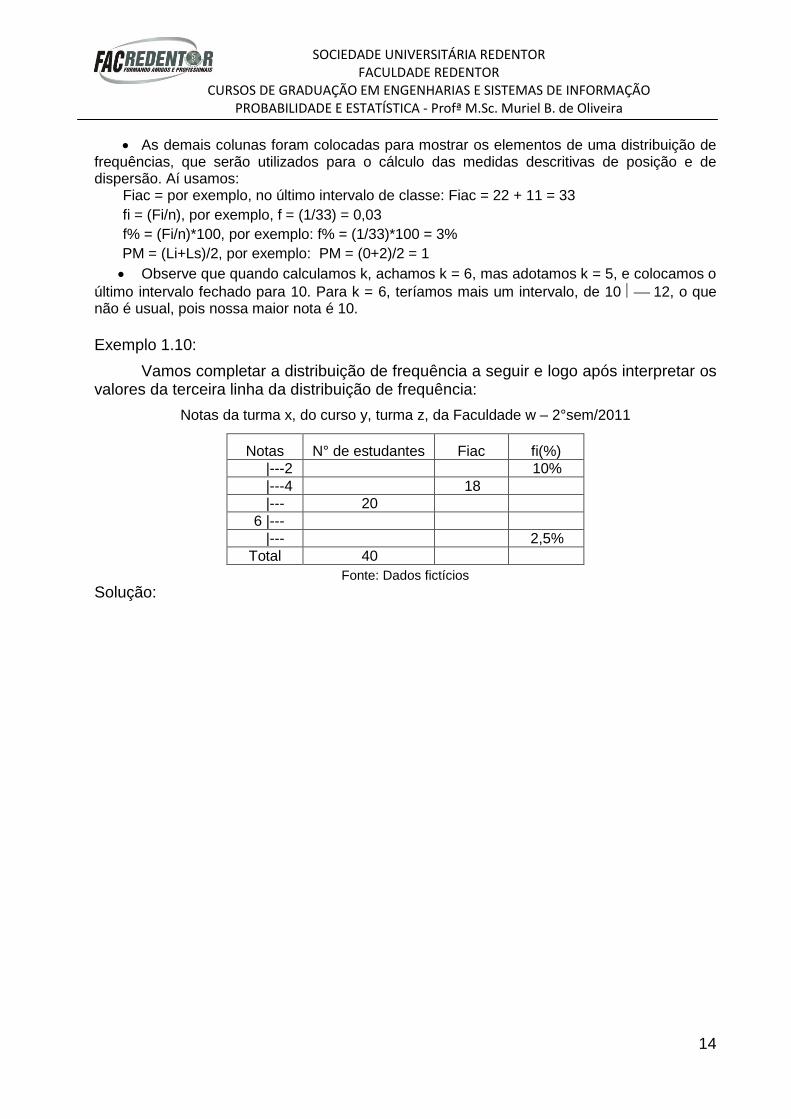
5° passo: montar a distribuição de frequência (por intervalos) com título e fonte
Notas da turma de Probabilidade e Estatística, do curso de Engenharia Civil, turma A, da
Faculdade Redentor – 1°sem/2007
Notas N° alunos (Fi) Fiac fi fi % PM
0 2 1 1 0,03 3,03% 1
2 4 3 4 0,09 9,09% 3
4 6 6 10 0,18 18,18% 5
6 8 12 22 0,36 36,36% 7
8 10 11 33 0,33 33,33% 9
Total 33 1,00 100,00%
Fonte: Profa. Muriel
Comentários:
A tabela de distribuição de frequências é composta das duas primeiras colunas.
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
14
As demais colunas foram colocadas para mostrar os elementos de uma distribuição de frequências, que serão utilizados para o cálculo das medidas descritivas de posição e de dispersão. Aí usamos:
Fiac = por exemplo, no último intervalo de classe: Fiac = 22 + 11 = 33
fi = (Fi/n), por exemplo, f = (1/33) = 0,03
f% = (Fi/n)*100, por exemplo: f% = (1/33)*100 = 3%
PM = (Li+Ls)/2, por exemplo: PM = (0+2)/2 = 1
Observe que quando calculamos k, achamos k = 6, mas adotamos k = 5, e colocamos o
último intervalo fechado para 10. Para k = 6, teríamos mais um intervalo, de 10 12, o que não é usual, pois nossa maior nota é 10.
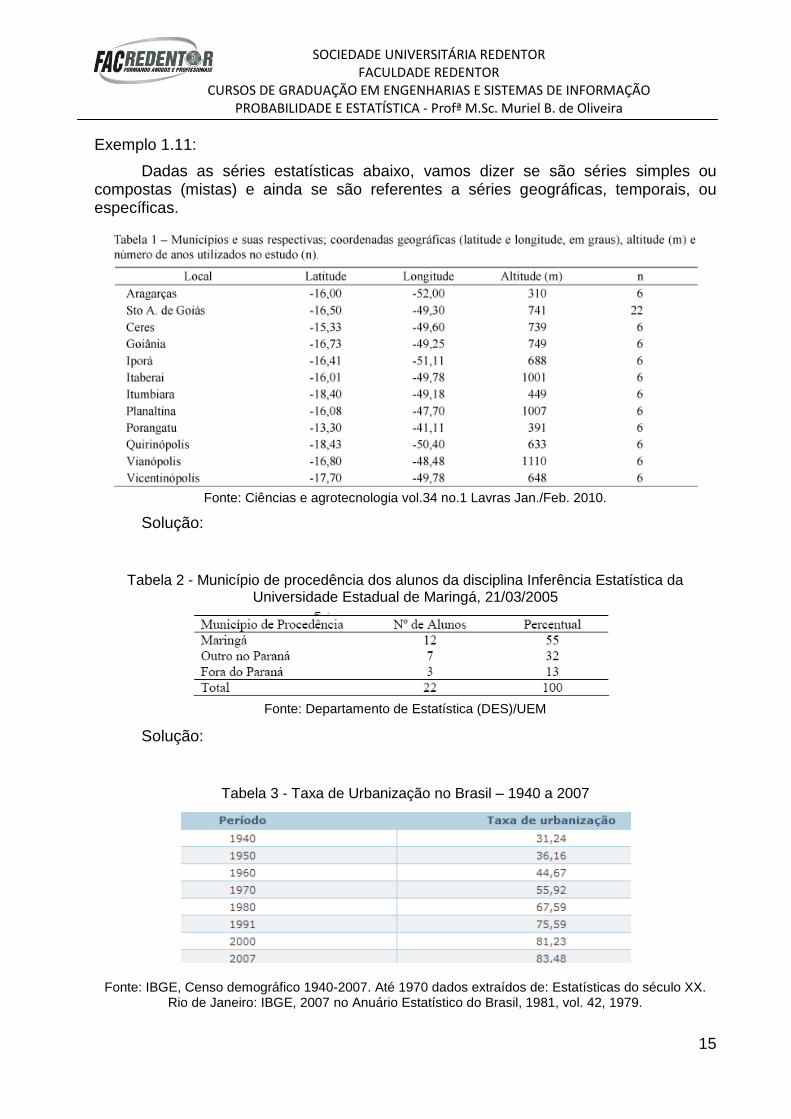
Exemplo 1.10:
Vamos completar a distribuição de frequência a seguir e logo após interpretar os valores da terceira linha da distribuição de frequência:
Notas da turma x, do curso y, turma z, da Faculdade w – 2°sem/2011
Notas N° de estudantes Fiac fi(%)
|---2 10%
|---4 18
|--- 20
6 |---
|--- 2,5%
Total 40
Fonte: Dados fictícios
Solução:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
15
Exemplo 1.11:
Dadas as séries estatísticas abaixo, vamos dizer se são séries simples ou compostas (mistas) e ainda se são referentes a séries geográficas, temporais, ou específicas.
Fonte: Ciências e agrotecnologia vol.34 no.1 Lavras Jan./Feb. 2010.
Solução:
Tabela 2 - Município de procedência dos alunos da disciplina Inferência Estatística da Universidade Estadual de Maringá, 21/03/2005
Fonte: Departamento de Estatística (DES)/UEM
Solução:
Tabela 3 - Taxa de Urbanização no Brasil – 1940 a 2007
Fonte: IBGE, Censo demográfico 1940-2007. Até 1970 dados extraídos de: Estatísticas do século XX. Rio de Janeiro: IBGE, 2007 no Anuário Estatístico do Brasil, 1981, vol. 42, 1979.
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
16
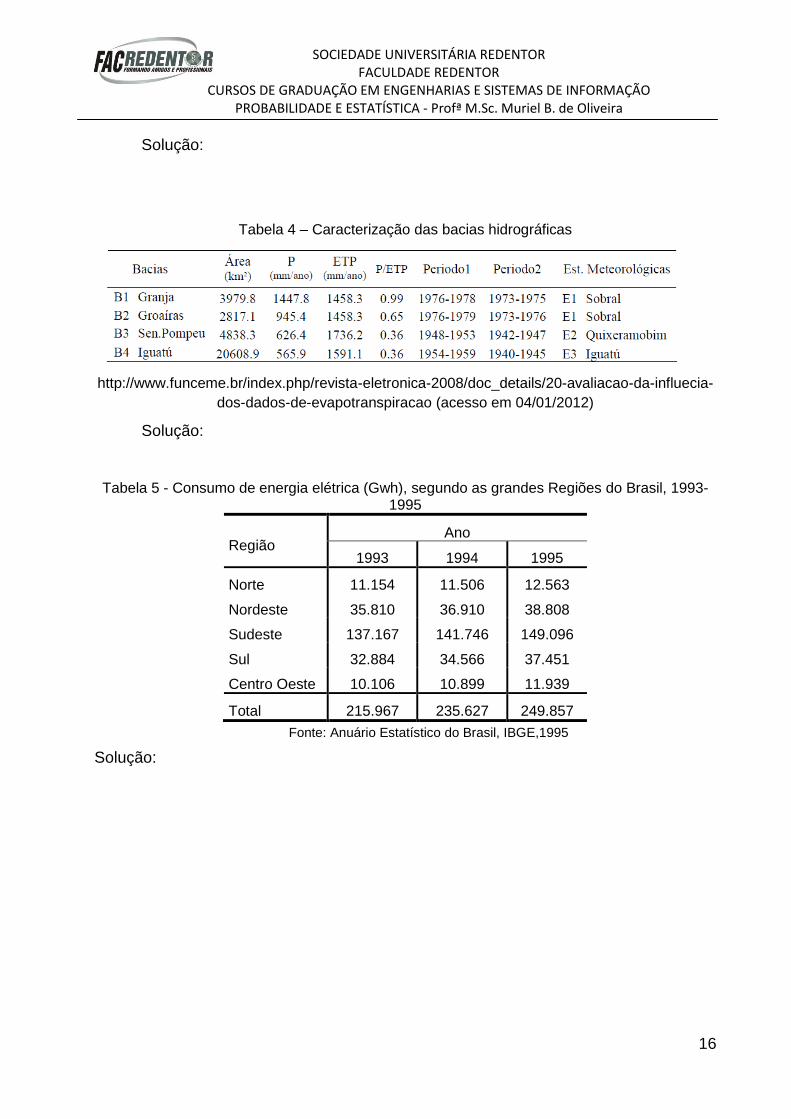
Solução:
Tabela 4 – Caracterização das bacias hidrográficas
http://www.funceme.br/index.php/revista-eletronica-2008/doc_details/20-avaliacao-da-influecia-
dos-dados-de-evapotranspiracao (acesso em 04/01/2012)
Solução:
Tabela 5 - Consumo de energia elétrica (Gwh), segundo as grandes Regiões do Brasil, 1993-1995
Região Ano
1993 1994 1995
Norte 11.154 11.506 12.563
Nordeste 35.810 36.910 38.808
Sudeste 137.167 141.746 149.096
Sul 32.884 34.566 37.451
Centro Oeste 10.106 10.899 11.939
Total 215.967 235.627 249.857
Fonte: Anuário Estatístico do Brasil, IBGE,1995
Solução:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
17
Solução:
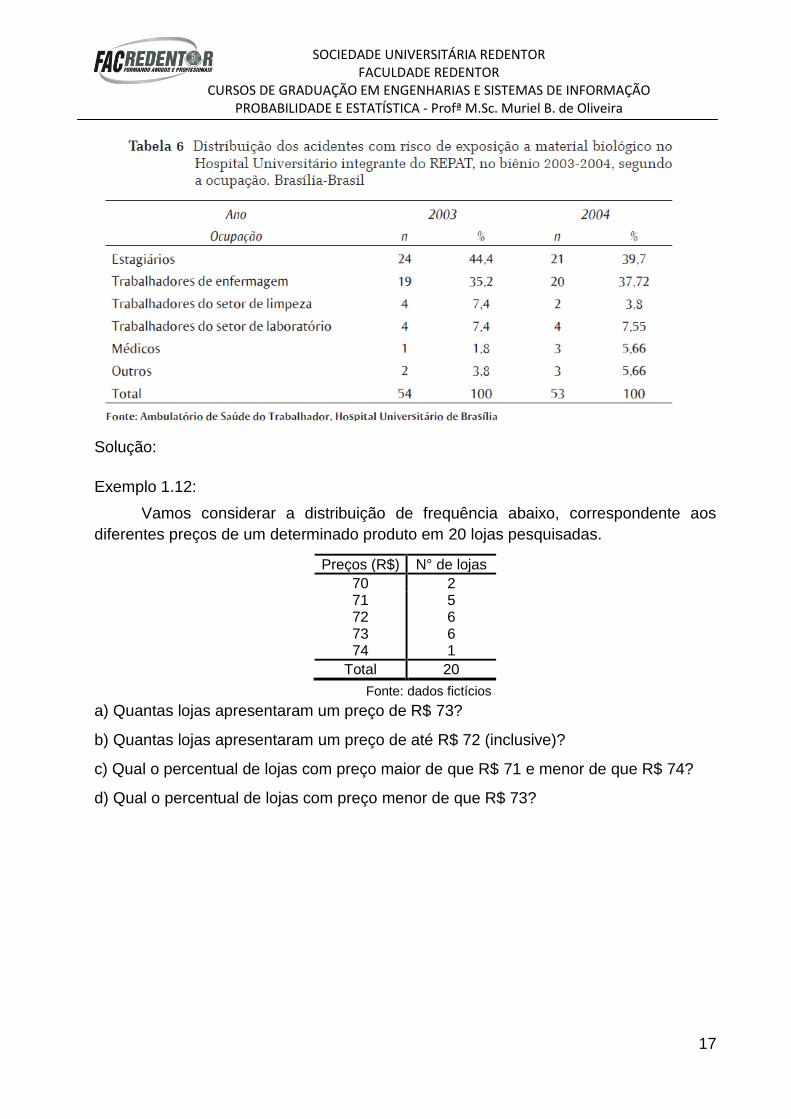
Exemplo 1.12:
Vamos considerar a distribuição de frequência abaixo, correspondente aos
diferentes preços de um determinado produto em 20 lojas pesquisadas.
Preços (R$) N° de lojas
70 2 71 5 72 6 73 6 74 1
Total 20
Fonte: dados fictícios
a) Quantas lojas apresentaram um preço de R$ 73?
b) Quantas lojas apresentaram um preço de até R$ 72 (inclusive)?
c) Qual o percentual de lojas com preço maior de que R$ 71 e menor de que R$ 74?
d) Qual o percentual de lojas com preço menor de que R$ 73?

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
18
Exercícios:
1 – Os dados a seguir, referem-se a estatura (em cm) de 70 funcionários da empresa
NS, que passaram por exames periódicos do trabalho em Nov/2011.
150 156 160 163 167 168 170 172 174 178 150 156
161 163 167 168 170 173 175 179 150 158 161 163
167 169 171 173 175 179 151 158 162 166 168 170
172 173 175 179 152 158 162 166 168 170 172 174
176 181 153 160 162 167 168 170 172 174 176 182
156 160 163 167 168 170 172 174 176 182
Pede-se:
a) montar uma distribuição de frequências segundo as regras de Sturges;
b) o ponto médio da 4° classe;
c) a frequência simples da 3° classe;
d) a frequência relativa da 6° classe;
e) a frequência acumulada da 5° classe;
f) o n° de funcionários cuja altura não atinge 170;
g) a percentagem de funcionários cuja altura não atinge a 165;
h) a percentagem de funcionários cuja altura é maior e igual a 175;
i) a percentagem de funcionários cuja altura é de no mínimo 155 e inferior a 175;
j) interprete os valores da 2° classe;
k) interprete os valores da última classe.
2 – Descreva as etapas do método de engenharia e comente sobre a importância da
estatística na Engenharia.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
19

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
20
II - REPRESENTAÇÃO GRÁFICA DE SÉRIES ESTATÍSTICAS
2.1. INTRODUÇÃO
A representação gráfica das séries estatísticas tem por finalidade dar uma idéia,
a mais imediata possível, dos resultados obtidos, permitindo chegar-se a conclusões
sobre a evolução do fenômeno ou sobre como se relacionam os valores da série em
estudo. Podemos dizer que os gráficos se constituem num recurso visual da Estatística
utilizado para representar um fenômeno.
Embora os gráficos forneçam um menor grau de detalhes do que as tabelas,
estes apresentam um ganho na compreensão global dos dados, permitindo uma visão
geral da situação em estudo sem deixar de evidenciar alguns aspectos particulares que
sejam de interesse do pesquisador.
Uma representação gráfica coloca em evidência as tendências, as ocorrências
ocasionais, os valores mínimos e máximos e também as ordens de grandezas dos
fenômenos que estão sendo observados. Quanto ao uso, temos os gráficos de
informação e os gráficos de análise, como escritos a seguir:
Gráficos de informação: Esses gráficos são usados geralmente quando
queremos proporcionar ao público em geral uma visualização rápida e clara. Como são
gráficos caracteristicamente expositivos, devem ser o mais com pleto possível,
podendo dispensar comentários adicionais. Também podemos omitir as legendas,
desde que as informações relevantes estejam presentes no gráfico.
Gráficos de análise: Esses tipos de gráficos são mais adequados ao trabalho
com o estudo estatístico, pois fornecem elementos úteis para a análise dos dados,
além de serem também informativos. Normalmente, os gráficos de análise são
acompanhados de sua respectiva tabela estatística. Também podemos incluir um texto
explicativo que tem como objetivo esclarecer ao leitor dos pontos principais divulgados
no gráfico.
Contudo, os elementos simplicidade, clareza e veracidade devem ser
considerados quando da elaboração de um gráfico. Devemos ficar atentos, pois um
gráfico mal construído pode transmitir uma informação deturpada em relação à
informação verdadeira. Normalmente isso ocorre por problemas de escala, em que as
proporções entre os dados não são respeitadas.
Nosso objetivo principal aqui não é a construção de gráficos, embora isso seja
muito importante para o desenvolvimento de algumas disciplinas do curso de
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
21
engenharia, mas sim entender melhor um conjunto de dados pelo uso de gráficos
adequados que sejam eficazes na revelação de características importantes.
Encontram-se a seguir os principais tipos de gráficos.
Gráfico de barras
É um gráfico formado por retângulos horizontais de larguras iguais, onde cada
um deles representa a intensidade de uma modalidade ou atributo. É recomendável
que cada coluna conserve uma distância entre si de aproximadamente metade ou 2/3
da largura da base de cada barra, evidenciando deste modo, a não continuidade na
sequência dos dados.
O objetivo deste gráfico é de comparar grandezas e é recomendável para
variáveis cujas categorias tenham designações extensas. É o gráfico mais utilizado
para representar variáveis qualitativas.
Exemplo 2.1:
Acidentes no trecho das cidades de Barbacena e Barroso até a cidade de Itutinga - MG.
Fonte: Dados da 13° CIA PM Ind. de Meio Ambiente e Trânsito, 1° Pelotão PM Rodoviário
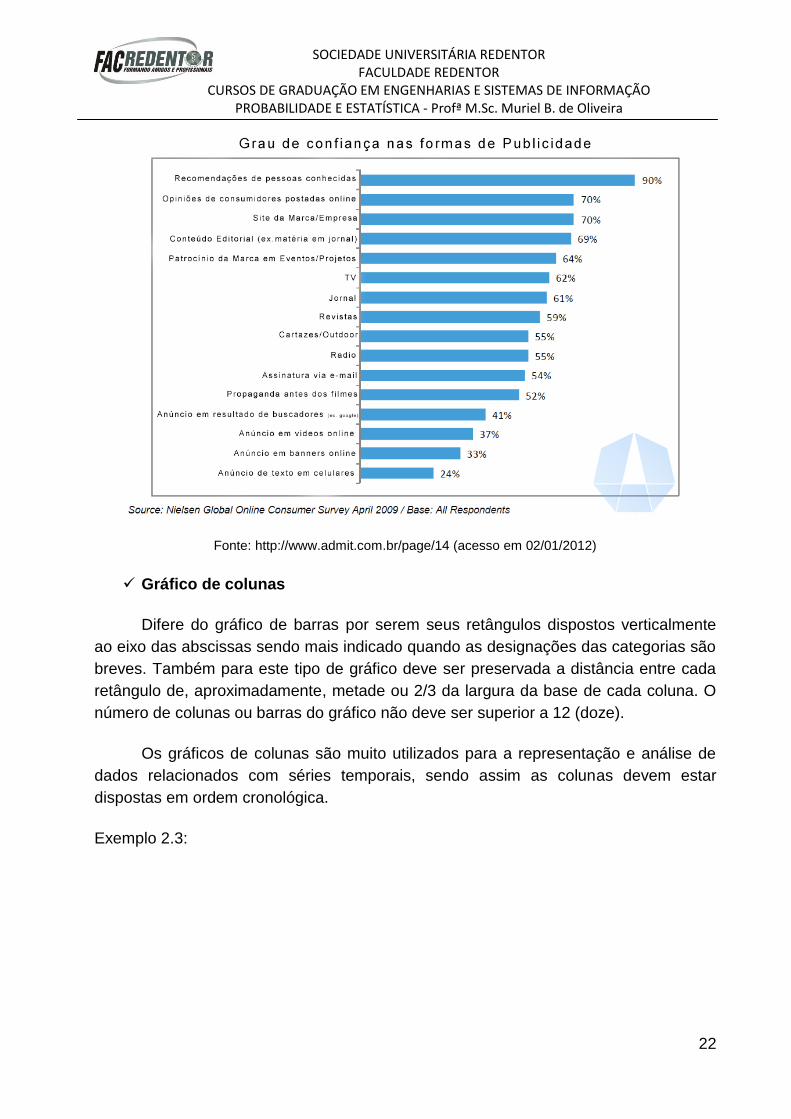
Exemplo 2.2:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
22
Fonte: http://www.admit.com.br/page/14 (acesso em 02/01/2012)
Gráfico de colunas
Difere do gráfico de barras por serem seus retângulos dispostos verticalmente
ao eixo das abscissas sendo mais indicado quando as designações das categorias são
breves. Também para este tipo de gráfico deve ser preservada a distância entre cada
retângulo de, aproximadamente, metade ou 2/3 da largura da base de cada coluna. O
número de colunas ou barras do gráfico não deve ser superior a 12 (doze).
Os gráficos de colunas são muito utilizados para a representação e análise de
dados relacionados com séries temporais, sendo assim as colunas devem estar
dispostas em ordem cronológica.
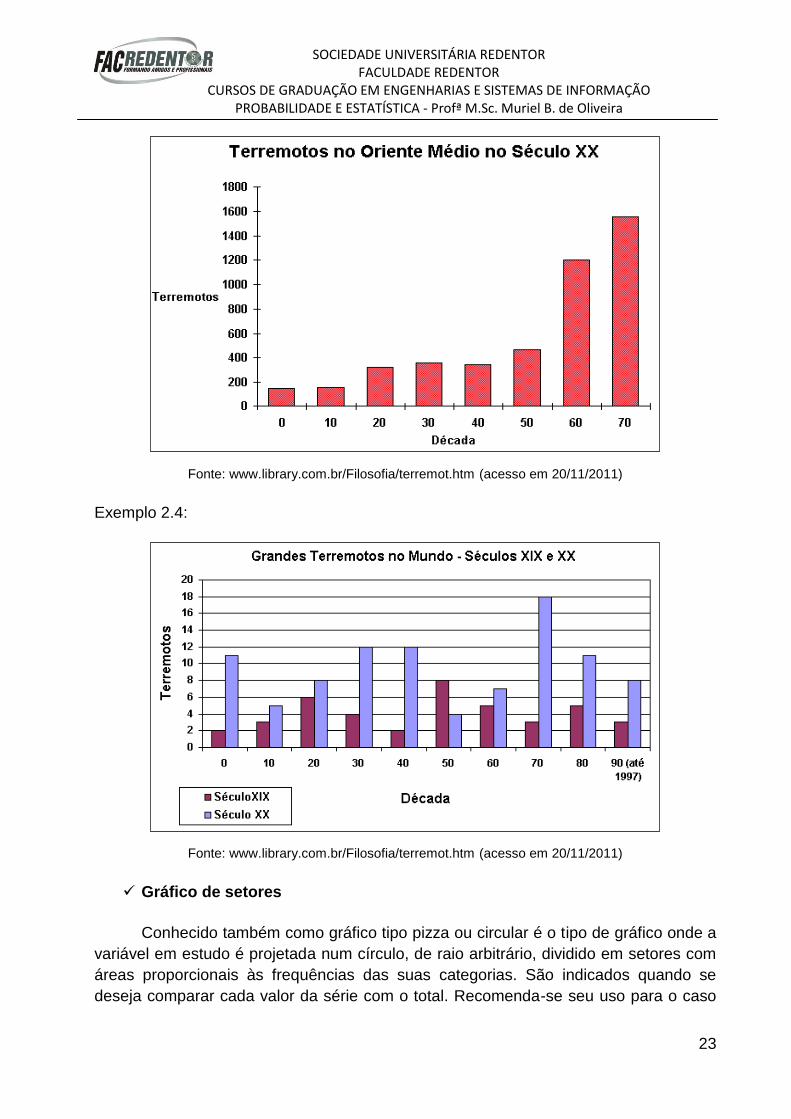
Exemplo 2.3:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
23
Fonte: www.library.com.br/Filosofia/terremot.htm (acesso em 20/11/2011)
Exemplo 2.4:
Fonte: www.library.com.br/Filosofia/terremot.htm (acesso em 20/11/2011)
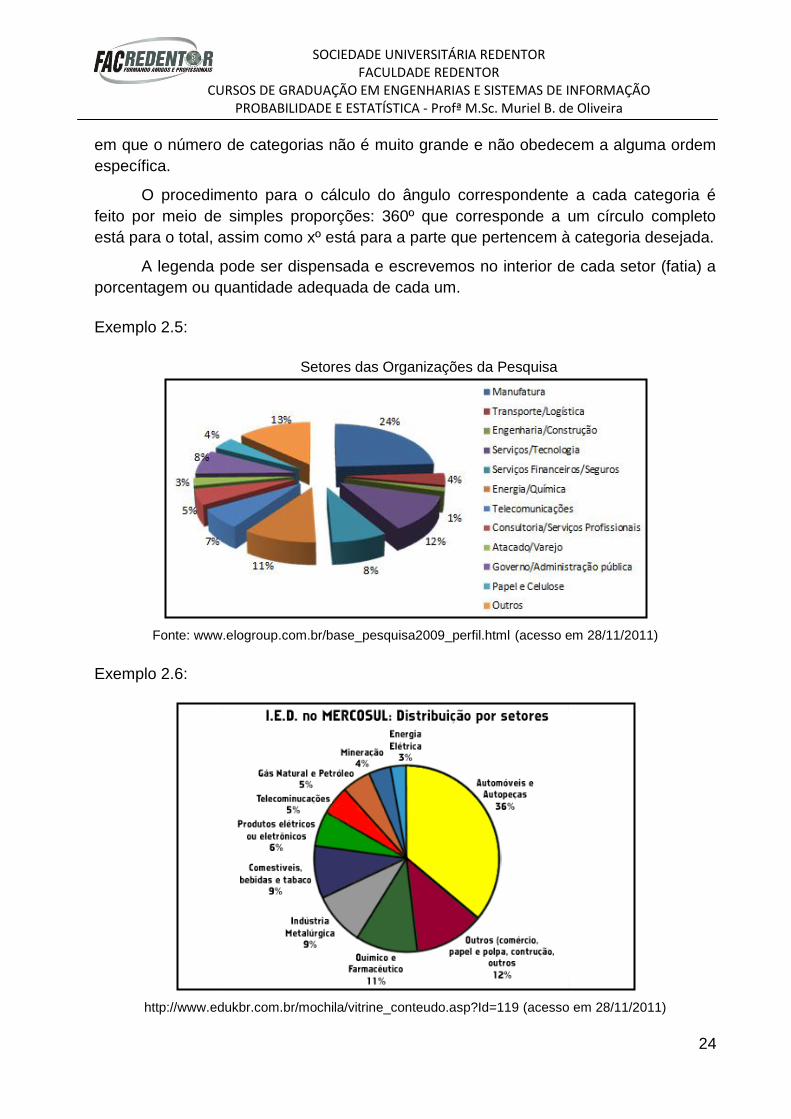
Gráfico de setores
Conhecido também como gráfico tipo pizza ou circular é o tipo de gráfico onde a
variável em estudo é projetada num círculo, de raio arbitrário, dividido em setores com
áreas proporcionais às frequências das suas categorias. São indicados quando se
deseja comparar cada valor da série com o total. Recomenda-se seu uso para o caso
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
24
em que o número de categorias não é muito grande e não obedecem a alguma ordem
específica.
O procedimento para o cálculo do ângulo correspondente a cada categoria é
feito por meio de simples proporções: 360º que corresponde a um círculo completo
está para o total, assim como xº está para a parte que pertencem à categoria desejada.
A legenda pode ser dispensada e escrevemos no interior de cada setor (fatia) a
porcentagem ou quantidade adequada de cada um.
Exemplo 2.5:
Setores das Organizações da Pesquisa
Fonte: www.elogroup.com.br/base_pesquisa2009_perfil.html (acesso em 28/11/2011)
Exemplo 2.6:
http://www.edukbr.com.br/mochila/vitrine_conteudo.asp?Id=119 (acesso em 28/11/2011)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
25
Gráfico Polar
É representação de uma série por meio de um polígono. Geralmente presta-se
para apresentação de séries temporais. Para construí-lo, dividimos uma circunferência
em tantos arcos iguais quantos forem os dados a representar. Pelos pontos de divisas
traçamos os raios. Em cada raio é representado um valor da série, marcamos um ponto
cuja distância ao centro é diretamente proporcional a esse valor. A seguir unimos os
pontos (linhas em laranja e azul).
Exemplo 2.7:
Fonte: besp.mercatura.pt/Pagina.php?codPagina=4 (acesso em 28/11/2011)
Vamos interpretar o gráfico acima:
O gráfico polar é produzido para mostrar simultaneamente os percentuais de
cada um dos exames. Para cada número no gráfico, a legenda mostra a que indicador
se refere e o número de exames por disciplina efetuados na escola. Assim nota-se, por
exemplo, que a média de exame de História está perto do percentil 86% enquanto que
a média das CFD da mesma disciplina encontra–se perto de 78%, observamos
também que na disciplina de matemática, estes alunos tiveram um desempenho inferior
as outras disciplinas.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
26
Exemplo 2.8:
Comparação dos valores do momento torçor (na base do prédio), obtido por meio de
ensaios em túnel de vento e pelo indicado na NBR 6.123, em função da incidência do vento,
para o projeto Brascan Century Staybridge Suites
Fonte: http://www.arcoweb.com.br/tecnologia/aerodinamica-das-construcoes-modelos-reduzidos-02-03-
2006.html (acesso em 28/11/2011)
Gráfico de linhas
Sua aplicação é mais indicada para representações de séries temporais, pois
quando a série cobre um grande número de períodos de tempo, a representação dos
valores através das colunas pode conduzir a uma excessiva concentração de dados.
Sua construção é feita colocando-se no eixo vertical (y) a mensuração da
variável em estudo e na abscissa (x), as unidades da variável numa ordem crescente.
Este tipo de gráfico permite representar séries longas, o que auxilia detectar suas
flutuações tanto quanto analisar tendências. Também podem ser representadas várias
séries em um mesmo gráfico.
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
27
Exemplo 2.9:
Evolução a concorrência no vestibular da FUVEST
Fonte: http://petcivilufjf.wordpress.com/tag/ufjf/ (acesso em 03/01/2012)
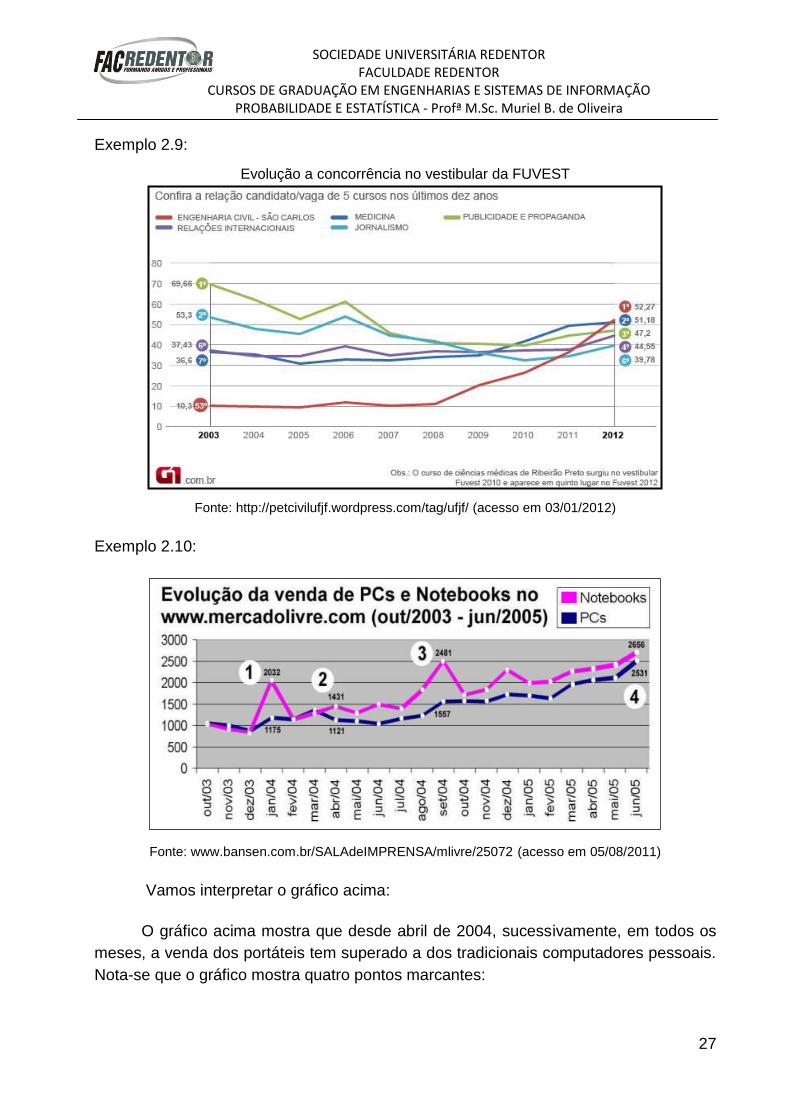
Exemplo 2.10:
Fonte: www.bansen.com.br/SALAdeIMPRENSA/mlivre/25072 (acesso em 05/08/2011)
Vamos interpretar o gráfico acima:
O gráfico acima mostra que desde abril de 2004, sucessivamente, em todos os
meses, a venda dos portáteis tem superado a dos tradicionais computadores pessoais.
Nota-se que o gráfico mostra quatro pontos marcantes:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
28
Ponto 1: Em janeiro de 2004, pela primeira vez a venda de notebooks superou a
de PCs em unidades: 2.032 notebooks e 1.175 PCs; Ponto 2: Em abril de 2004, foram vendidos 1.431 notebooks e 1.121 PCs através
do Mercado Livre. Desde então, as vendas de portáteis têm sempre superado a de PCs;
Ponto 3: Em setembro de 2004, foram vendidos 2.481 notebooks, recorde em
2004; Ponto 4: Em junho de 2005, houve venda recorde de PCs (2.531 unidades), mas
a venda de notebooks também foi recorde (2.656 unidades) e se manteve maior que a
de PCs.
Gráfico de Pontos ou de Dispersão
Os diagramas ou gráficos de pontos fornecem uma apresentação simples, que
reflete a dispersão, os extremos, o centro e as falhas ou picos nos dados. Escolhemos
uma linha horizontal, na qual colocamos a amplitude dos valores dos dados. Plotamos
então cada observação como um ponto diretamente acima dessa linha graduada e,
quando várias observações tem o mesmo valor, os pontos são empilhados
verticalmente naquele ponto da escala.
Exemplo 2.11:
Fonte: Dados fictícios
Quando desejamos conjuntamente resultados para duas variáveis, o equivalente
do gráfico de pontos se chama diagrama de dispersão. Construímos um sistema
retangular de coordenadas associando o eixo horizontal a uma das variáveis e ao eixo
vertical a outra variável, e plotamos cada observação como um ponto desse plano.
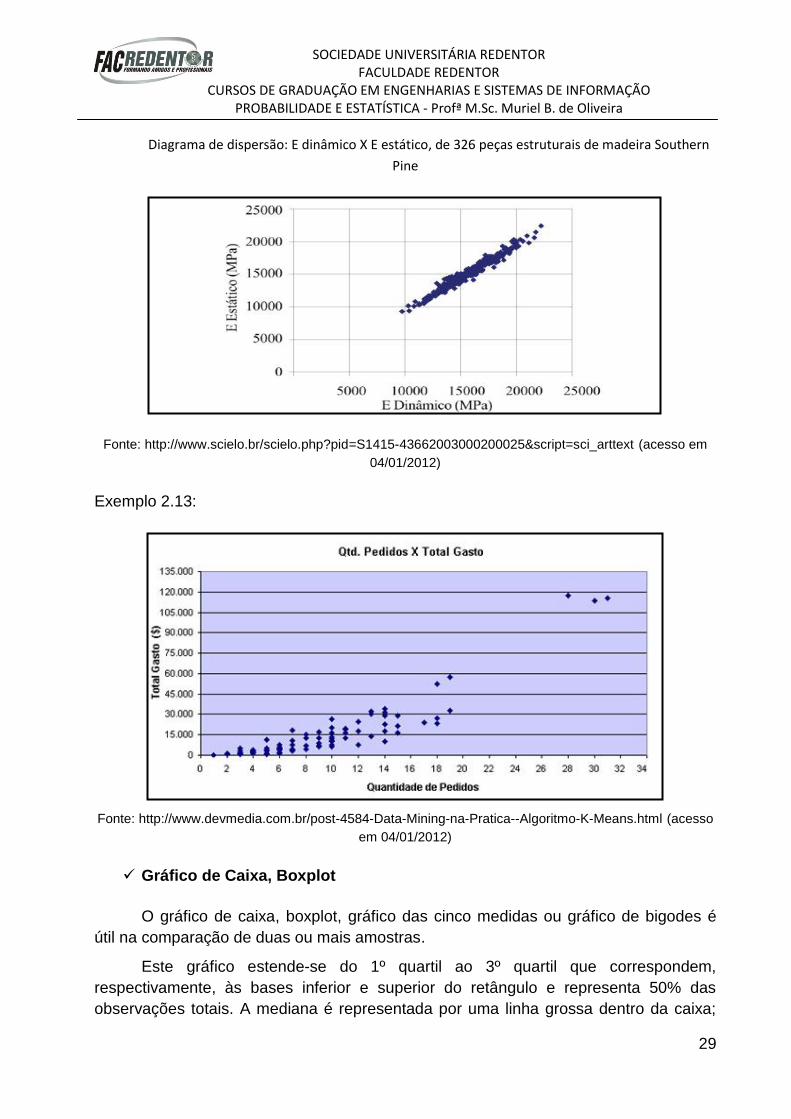
Exemplo 2.12:
Item A Item B
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
29
Diagrama de dispersão: E dinâmico X E estático, de 326 peças estruturais de madeira Southern
Pine
Fonte: http://www.scielo.br/scielo.php?pid=S1415-43662003000200025&script=sci_arttext (acesso em
04/01/2012)
Exemplo 2.13:
Fonte: http://www.devmedia.com.br/post-4584-Data-Mining-na-Pratica--Algoritmo-K-Means.html (acesso
em 04/01/2012)
Gráfico de Caixa, Boxplot
O gráfico de caixa, boxplot, gráfico das cinco medidas ou gráfico de bigodes é
útil na comparação de duas ou mais amostras.
Este gráfico estende-se do 1º quartil ao 3º quartil que correspondem,
respectivamente, às bases inferior e superior do retângulo e representa 50% das
observações totais. A mediana é representada por uma linha grossa dentro da caixa;

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
30
se a amostra for aproximadamente simétrica, a linha que corresponde à mediana divide
a caixa em duas partes aproximadamente iguais. A caixa esquerda prolonga-se para
baixo do 1º quartil, até ao menor valor da amostra não outlier e a caixa direita prolonga-
se para cima do 3º quartil, até ao maior valor da amostra não outlier (observemos o
exemplo 2.14).
Os outliers, que são assinalados com um círculo, podem representar erros de
introdução de dados, caso em que devemos eliminá-los, ou fazer parte do fenômeno
em estudo, caso em que devemos mantê-los, assinalando-se a sua existência. É
comum fazermos a análise com e sem outliers e registrar as diferenças.
Exemplo 2.14:
Fonte: Prof. Luiz Augusto Pinto Lemos – DMAT – FURG – 2008
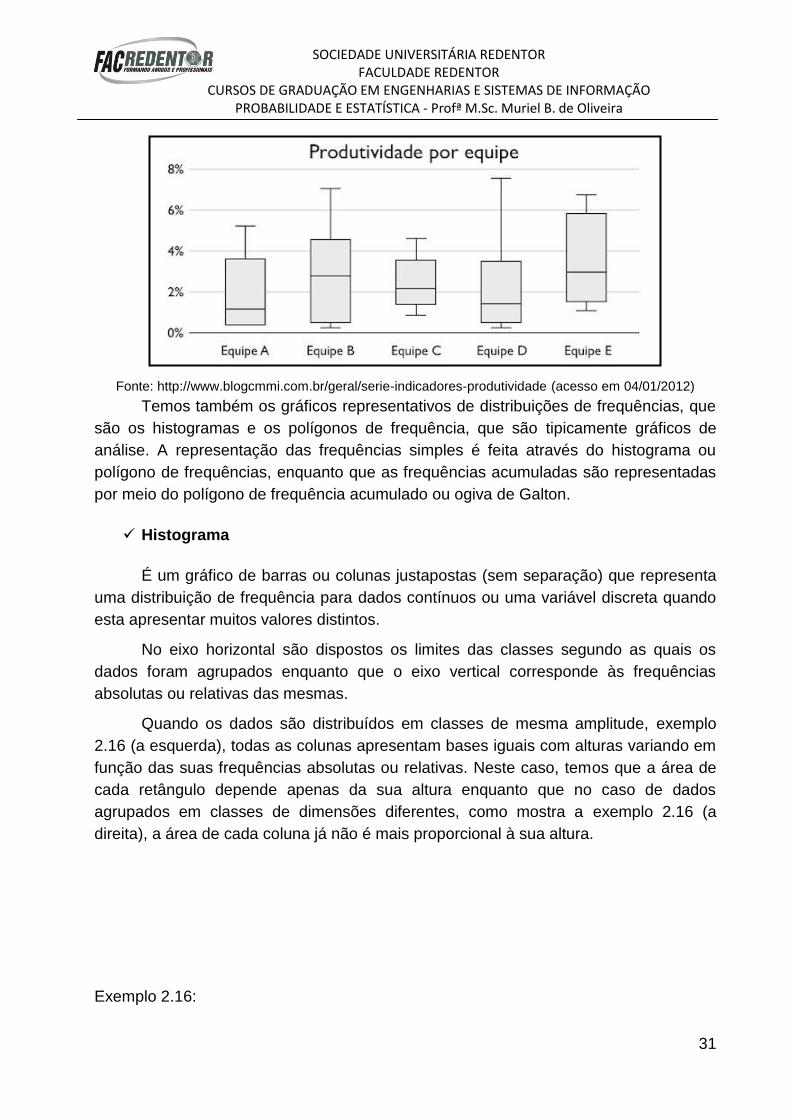
Exemplo 2.15:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
31
Fonte: http://www.blogcmmi.com.br/geral/serie-indicadores-produtividade (acesso em 04/01/2012)
Temos também os gráficos representativos de distribuições de frequências, que
são os histogramas e os polígonos de frequência, que são tipicamente gráficos de
análise. A representação das frequências simples é feita através do histograma ou
polígono de frequências, enquanto que as frequências acumuladas são representadas
por meio do polígono de frequência acumulado ou ogiva de Galton.
Histograma
É um gráfico de barras ou colunas justapostas (sem separação) que representa
uma distribuição de frequência para dados contínuos ou uma variável discreta quando
esta apresentar muitos valores distintos.
No eixo horizontal são dispostos os limites das classes segundo as quais os
dados foram agrupados enquanto que o eixo vertical corresponde às frequências
absolutas ou relativas das mesmas.
Quando os dados são distribuídos em classes de mesma amplitude, exemplo
2.16 (a esquerda), todas as colunas apresentam bases iguais com alturas variando em
função das suas frequências absolutas ou relativas. Neste caso, temos que a área de
cada retângulo depende apenas da sua altura enquanto que no caso de dados
agrupados em classes de dimensões diferentes, como mostra a exemplo 2.16 (a
direita), a área de cada coluna já não é mais proporcional à sua altura.
Exemplo 2.16:
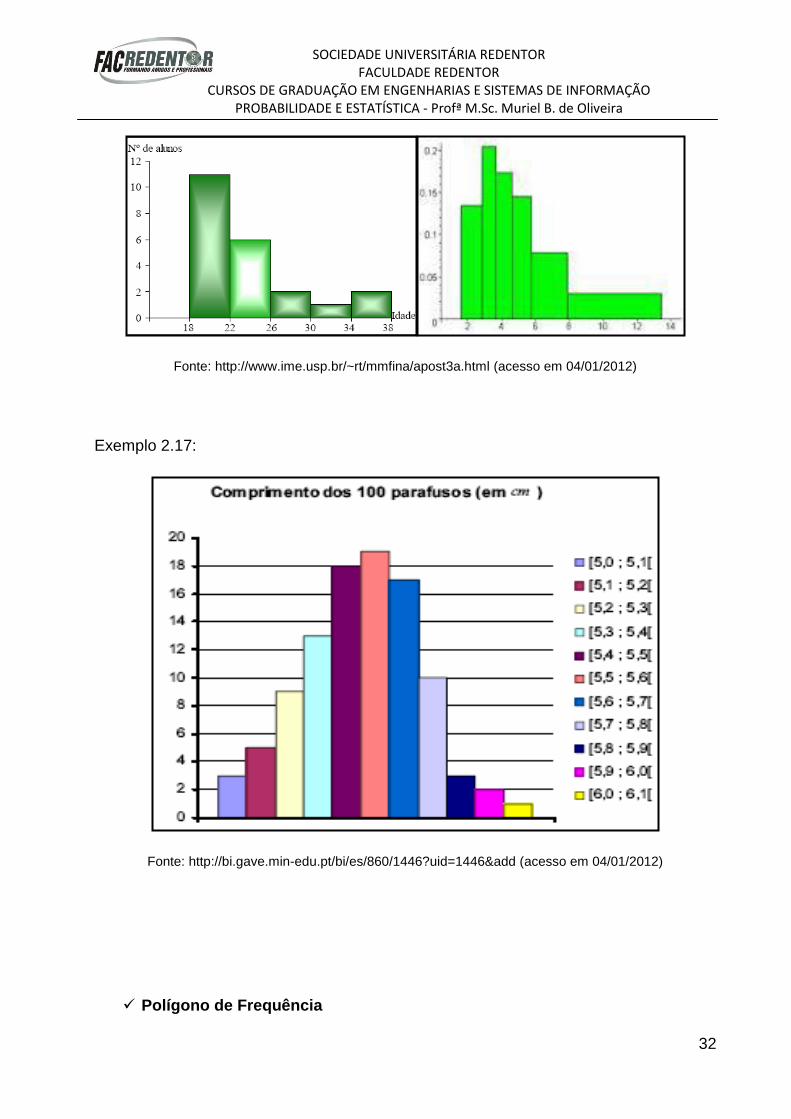
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
32
Fonte: http://www.ime.usp.br/~rt/mmfina/apost3a.html (acesso em 04/01/2012)
Exemplo 2.17:
Fonte: http://bi.gave.min-edu.pt/bi/es/860/1446?uid=1446&add (acesso em 04/01/2012)
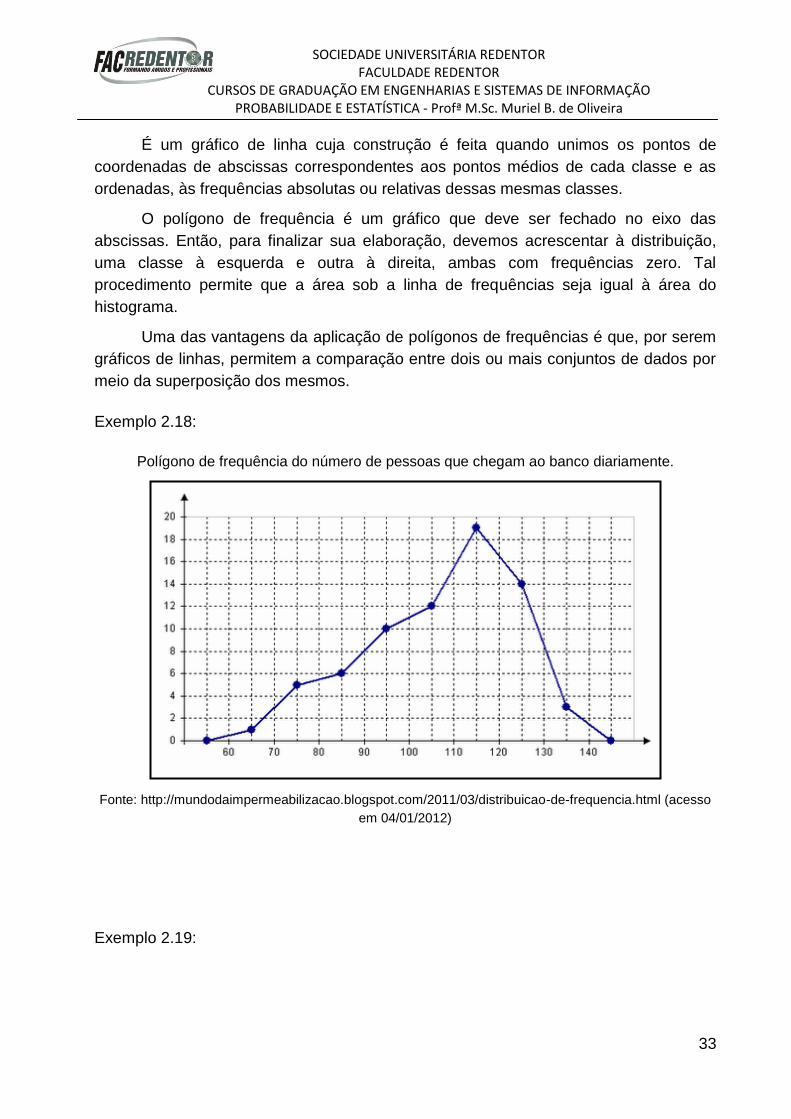
Polígono de Frequência
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
33
É um gráfico de linha cuja construção é feita quando unimos os pontos de
coordenadas de abscissas correspondentes aos pontos médios de cada classe e as
ordenadas, às frequências absolutas ou relativas dessas mesmas classes.
O polígono de frequência é um gráfico que deve ser fechado no eixo das
abscissas. Então, para finalizar sua elaboração, devemos acrescentar à distribuição,
uma classe à esquerda e outra à direita, ambas com frequências zero. Tal
procedimento permite que a área sob a linha de frequências seja igual à área do
histograma.
Uma das vantagens da aplicação de polígonos de frequências é que, por serem
gráficos de linhas, permitem a comparação entre dois ou mais conjuntos de dados por
meio da superposição dos mesmos.
Exemplo 2.18:
Polígono de frequência do número de pessoas que chegam ao banco diariamente.
Fonte: http://mundodaimpermeabilizacao.blogspot.com/2011/03/distribuicao-de-frequencia.html (acesso
em 04/01/2012)
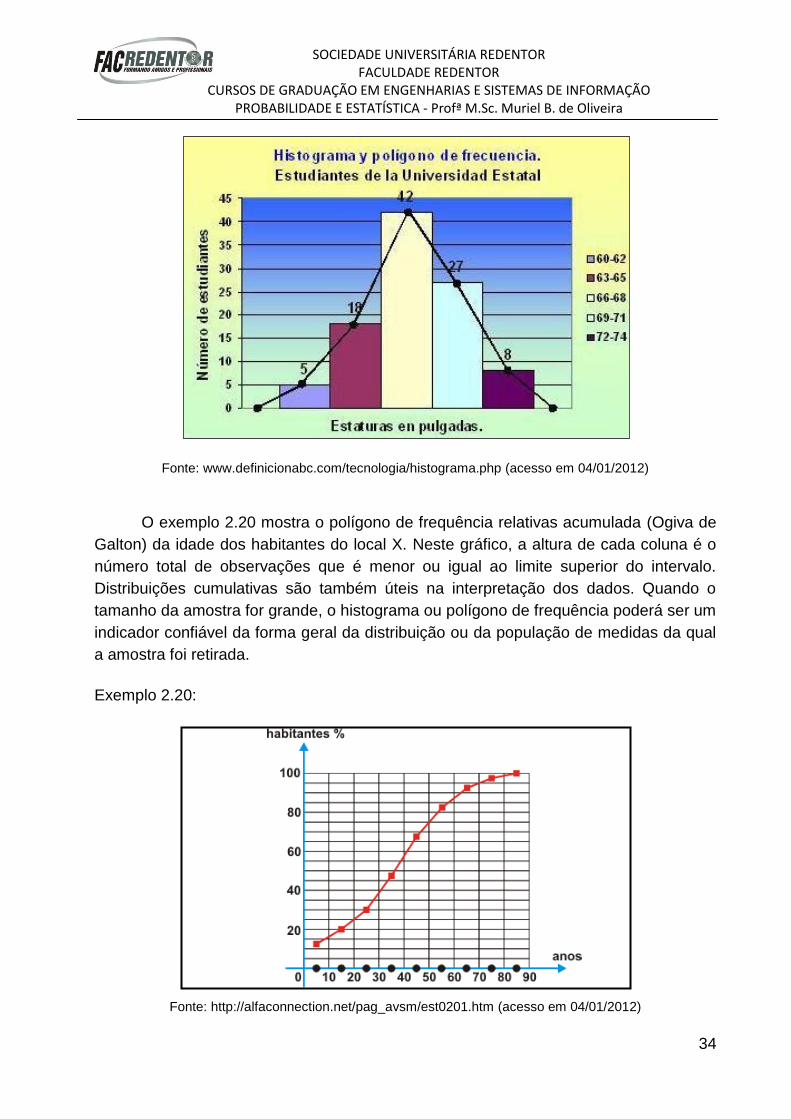
Exemplo 2.19:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
34
Fonte: www.definicionabc.com/tecnologia/histograma.php (acesso em 04/01/2012)
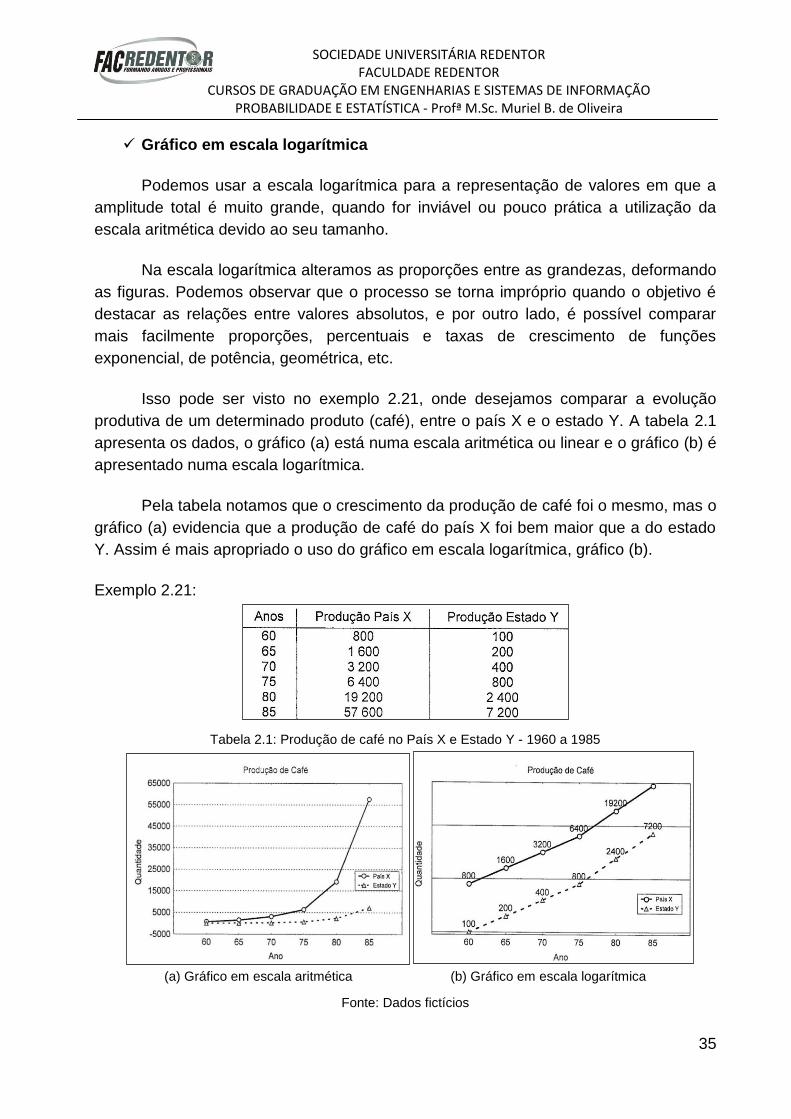
O exemplo 2.20 mostra o polígono de frequência relativas acumulada (Ogiva de
Galton) da idade dos habitantes do local X. Neste gráfico, a altura de cada coluna é o
número total de observações que é menor ou igual ao limite superior do intervalo.
Distribuições cumulativas são também úteis na interpretação dos dados. Quando o
tamanho da amostra for grande, o histograma ou polígono de frequência poderá ser um
indicador confiável da forma geral da distribuição ou da população de medidas da qual
a amostra foi retirada.
Exemplo 2.20:
Fonte: http://alfaconnection.net/pag_avsm/est0201.htm (acesso em 04/01/2012)
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
35
Gráfico em escala logarítmica
Podemos usar a escala logarítmica para a representação de valores em que a
amplitude total é muito grande, quando for inviável ou pouco prática a utilização da
escala aritmética devido ao seu tamanho.
Na escala logarítmica alteramos as proporções entre as grandezas, deformando
as figuras. Podemos observar que o processo se torna impróprio quando o objetivo é
destacar as relações entre valores absolutos, e por outro lado, é possível comparar
mais facilmente proporções, percentuais e taxas de crescimento de funções
exponencial, de potência, geométrica, etc.
Isso pode ser visto no exemplo 2.21, onde desejamos comparar a evolução
produtiva de um determinado produto (café), entre o país X e o estado Y. A tabela 2.1
apresenta os dados, o gráfico (a) está numa escala aritmética ou linear e o gráfico (b) é
apresentado numa escala logarítmica.
Pela tabela notamos que o crescimento da produção de café foi o mesmo, mas o
gráfico (a) evidencia que a produção de café do país X foi bem maior que a do estado
Y. Assim é mais apropriado o uso do gráfico em escala logarítmica, gráfico (b).
Exemplo 2.21:
Tabela 2.1: Produção de café no País X e Estado Y - 1960 a 1985
(a) Gráfico em escala aritmética (b) Gráfico em escala logarítmica
Fonte: Dados fictícios

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
36
Estereogramas
São gráficos geométricos dispostos em três dimensões, pois representam
volume. São usados nas representações gráficas das tabelas de dupla entrada. Em
alguns casos este tipo de gráfico fica difícil de ser interpretado dada a pequena
precisão que oferecem.
Exemplo 2.22:
Fonte: http://globalsistensnews.blogspot.com/2009_04_01_archive.html (acesso em 04/01/2012)
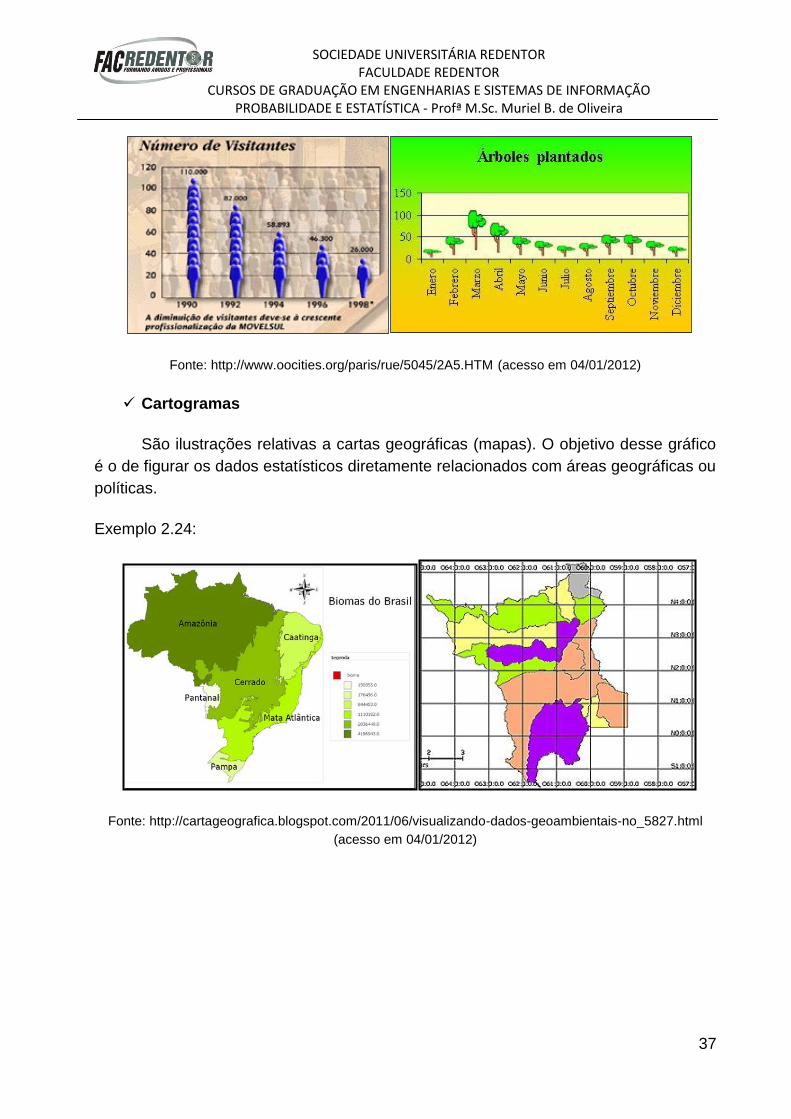
Pictogramas
São construídos a partir de figuras representativas da intensidade do fenômeno.
Este tipo de gráfico tem a vantagem de despertar a atenção do público leigo, pois sua
forma é atraente e sugestiva. Os símbolos devem ser auto-explicativos. A desvantagem
dos pictogramas é que apenas mostram uma visão geral do fenômeno, e não de
detalhes minuciosos.
Exemplo 2.23:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
37
Fonte: http://www.oocities.org/paris/rue/5045/2A5.HTM (acesso em 04/01/2012)
Cartogramas
São ilustrações relativas a cartas geográficas (mapas). O objetivo desse gráfico
é o de figurar os dados estatísticos diretamente relacionados com áreas geográficas ou
políticas.
Exemplo 2.24:
Fonte: http://cartageografica.blogspot.com/2011/06/visualizando-dados-geoambientais-no_5827.html
(acesso em 04/01/2012)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
38
Exemplo 2.25:
Os gráficos podem ser criados em vários programas de computador, como, por
exemplo, Excel, Minitab, Statdisk, Calculadoras Programáveis, etc.
Exemplo 2.26:
Baseando-se no gráfico a seguir, responda as seguintes questões:
a) Que tipo de série estatística o gráfico representa?
b) Que tipo de gráfico é este?
c) Interprete o gráfico:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
39
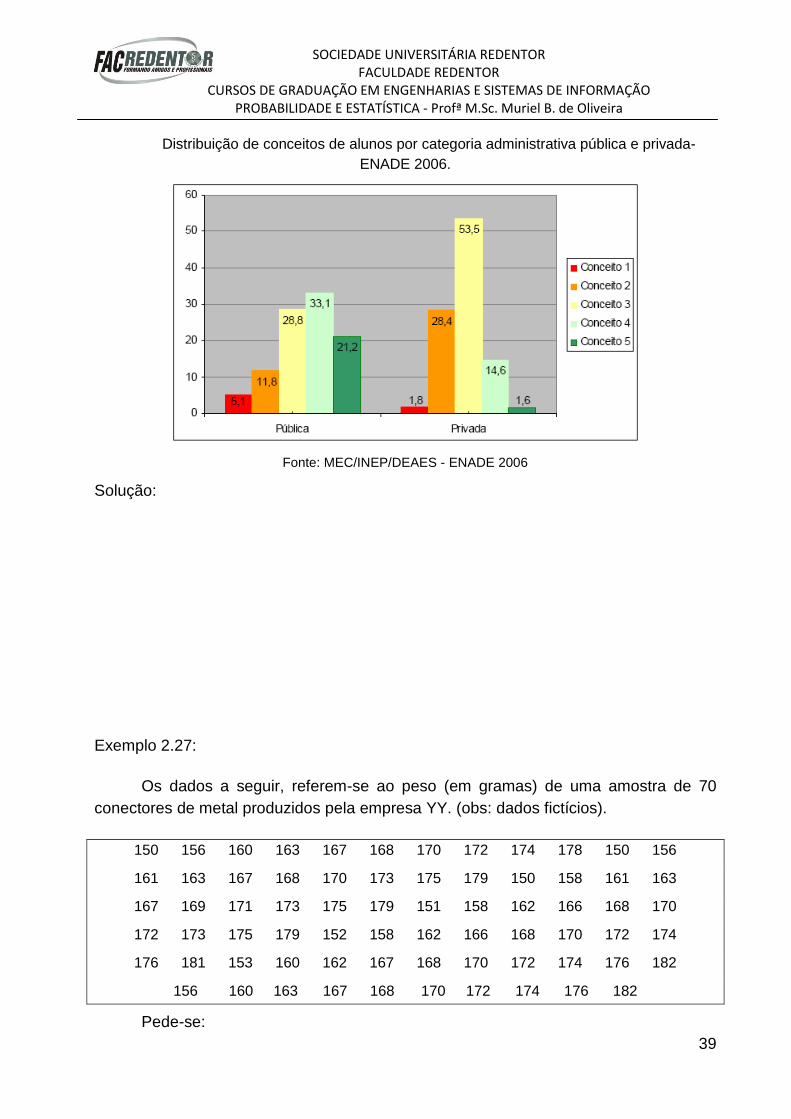
Distribuição de conceitos de alunos por categoria administrativa pública e privada-
ENADE 2006.
Fonte: MEC/INEP/DEAES - ENADE 2006
Solução:
Exemplo 2.27:
Os dados a seguir, referem-se ao peso (em gramas) de uma amostra de 70
conectores de metal produzidos pela empresa YY. (obs: dados fictícios).
150 156 160 163 167 168 170 172 174 178 150 156
161 163 167 168 170 173 175 179 150 158 161 163
167 169 171 173 175 179 151 158 162 166 168 170
172 173 175 179 152 158 162 166 168 170 172 174
176 181 153 160 162 167 168 170 172 174 176 182
156 160 163 167 168 170 172 174 176 182
Pede-se:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
40
a) montar uma distribuição de frequência segundo as regras de Sturges;
b) o ponto médio da 4° classe;
c) a frequência simples da 3° classe;
d) a frequência relativa da 6° classe;
e) a frequência acumulada da 5° classe;
f) o n° de conectores cujo peso não atinge 170;
g) o n° de conectores cujo peso não atinge a 175;
h) a percentagem de conectores cujo peso não atinge a 165;
i) a percentagem de conectores cujo peso é maior e igual a 175;
j) a percentagem de conectores cujo peso é de no mínimo 155 e inferior a 175;
k) interprete os valores da 2° classe;
l) interprete os valores da última classe;
m) o histograma;
n) o polígono de frequências.
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
41

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
42

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
43
III – MEDIDAS DE POSIÇÃO
3.1- INTRODUÇÃO
As medidas de tendência central mais utilizadas são: média aritmética, moda e
mediana. Outros promédios menos usados são as médias: geométrica, harmônica,
quadrática, cúbica e biquadrática, que não serão vistas nesta unidade.
As outras medidas de posição são as separatrizes.
Temos três formas diferentes (média aritmética, moda e mediana) para três
situações distintas (dados não agrupados, dados agrupados sem intervalo de classe e
dados agrupados com intervalo de classe), como veremos a seguir.
3.2- MÉDIA ARITMÉTICA
Existem duas médias:
Populacional: representada letra grega μ
Amostral: representada por X , sobre a qual as expressões e os cálculos serão
demostrados.
1ª SITUAÇÃO: Dados não agrupados
Sejam os elementos x1, x2, x3,...,xn de uma amostra, portanto n valores da variável X. A média aritmética da variável aleatória de X é definida por,
n
Xi
X
n
i
1 ou
n
XiX
onde n é o número de elementos do conjunto.
Exemplo 3.1:
Suponha que os dados sejam o conjunto de tempo de serviço (em anos) de cinco funcionários: 3, 7, 8, 10 e 11. Determine a média aritmética deste conjunto de dados.
Solução:
8,75
39
5
1110873
n
XiX
Interpretação: o tempo médio de serviço deste grupo de funcionários é de 7,8 anos.
2ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por valores simples

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
44
Quando os dados estiverem agrupados numa distribuição de frequência usaremos a média aritmética dos valores x1, x2, x3,...,xn, ponderados pelas respectivas frequências absolutas: F1, F2, F3, ... , Fn. Assim:
n
i
n
i
Fi
FiXi
X
1
1
. ou
n
FiXiX
.
onde Fin , é o número de elementos do conjunto.
Exemplo 3.2:
A tabela abaixo representa o número de peças de precisão defeituosas desenvolvidas mensalmente pelo controle de qualidade:
Número de peças com defeito (Xi)
Número de meses (Fi)
Xi.Fi
0 2 0
1 3 3
2 6 12
3 8 24
4 4 16
5 2 10
6 1 6
TOTAL 26 71
Determine a média de peças defeituosas por mês.
Solução:
73,226
71.
n
FiXiX
Interpretação: em média, foram encontradas 2,73 peças com defeito por mês.
3ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por intervalos de classes
a) Processo Longo
n
i
i
n
i
iM
F
FP
X
1
1
.
onde PM é o ponto médio de cada intervalo de classe.
b) Processo Breve

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
45
h
F
Fd
PXn
i
i
n
i
ii
MeM
1
1
.
onde PM Me é o ponto médio da mediana e di é o desvio, ou seja, a diferença entre o
ponto médio de cada intervalo de classe e o ponto médio da mediana. Então,
h
PPdi
MeMM .
Em seguida, veremos que a mediana é a medida que divide a distribuição em
duas partes, é a medida do elemento central.
Exemplo 3.3:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos matriculados em uma determinada disciplina. Calcule a média aritmética pelos dois processos:
Escores Alunos (Fi) PM Fac PM .Fi di di. Fi
35 |- 45 5 40 5 200 -2 -10
45 |- 55 12 50 17 600 -1 -12
55 |- 65 18 60 35 1080 0 0
65 |- 75 14 70 49 980 1 14
75 |- 85 6 80 55 480 2 12
85 |- 95 3 90 58 270 3 9
Total 58 3610 13
Solução:
a) 24,6258
3610.
1
1
n
i
i
n
i
iM
F
FP
X
b) 24,6224,2601058
1360
.
1
1
xh
F
Fd
PXn
i
i
n
i
ii
MeM
PMMe é obtido pela Fac, se temos 58 dados, a mediana está no intervalo que contém o 29° dado, logo no intervalo de 55 |- 65, então temos PMMe = 60.
Interpretação: o desempenho médio deste grupo de alunos foi de 62,24 pontos nesta disciplina.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
46
Média Aritmética Ponderada ( PX ) (para dados não agrupados)
Se os elementos x1, x2, x3,...,xn de uma amostra, forem associados a pesos p1,
p2, p3,...,pn , a média aritmética ponderada, representada por PX é calculada por,
in
nnP
p
piXi
pppp
pxpxpxpxX
.
...
.......
321
332211
Exemplo 3.4:
Um professor de Estatística adotou para o ano de 2010 os seguintes pesos para
as notas bimestrais: 1° bimestre peso 1; 2° bimestre peso 2; 3° bimestre peso 3; e, 4°
bimestre peso 4. Qual será a média de um aluno que obteve as seguintes notas em
Estatística: 5, 4, 3 e 2 nos respectivos bimestres ?
Solução:
310
30
10
8985
4321
)4.2()3.3()2.4()1.5(
pX
Interpretação: a nota média deste aluno foi de 3 pontos.
3.2. MODA - Mo
Dentre as principais medidas de posição, destacamos a moda. Moda é o valor
mais frequente da distribuição (aquele que aparece mais vezes).
1ª SITUAÇÃO: Dados não agrupados
Sejam os elementos x1, x2, x3,...,xn de uma amostra, o valor da moda para este tipo de conjunto de dados é simplesmente o valor com maior frequência.
Exemplo 3.5:
Suponha o conjunto de tempo de serviço (em anos) de cinco funcionários: 3, 7, 8, 8 e 11. Determinar a moda deste conjunto de dados.
Solução:
Mo = 8, distribuição unimodal ou modal
Interpretação: o tempo de serviço com maior frequência é de 8 anos.
Exemplo 3.6:
Suponha o conjunto de tempo de serviço (em anos) de cinco funcionários: 3, 3, 7, 8, 8 e 11. Determinar a moda deste conjunto de dados.
Solução:
Mo = 3 e Mo = 8, distribuição bimodal
Interpretação: os tempos de serviço com maior frequência foram de 3 e 8 anos.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
47
Exemplo 3.7:
Suponha o conjunto de tempo de serviço (em anos) de cinco funcionários: 3, 7, 8, 10 e 11. Determinar a moda deste conjunto de dados.
Solução:
Não existe Mo, logo a distribuição é amodal
Interpretação: não existe o tempo de serviço com maior frequência.
2ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por valores simples
Para este tipo de distribuição, a identificação da moda é facilitada pela simples observação do elemento que apresenta maior frequência.
Exemplo 3.8:
A tabela abaixo representa o número de peças de precisão defeituosas desenvolvidas mensalmente pelo controle de qualidade. Determine a moda.
Número de peças com defeito (Xi)
Número de meses (Fi)
0 2
1 3
2 6
3 8
4 4
5 2
6 1
TOTAL 26
Solução:
Se a maior frequência é Fi = 8, logo Mo = 3.
Interpretação: Esse resultado indica que a rejeição de 3 peças defeituosas por
mês foi o resultado mais observado.
3ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por classes
Para dados agrupados em classes, temos diversas fórmulas para o cálculo da
moda. A utilizada será:
Fórmula de Czuber
Procedimento:
a) Identificamos a classe modal (aquela que possuir maior frequência) – CLASSE (Mo).
b) Utiliza-se a fórmula:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
48
hFiFiFi
FiFiLiMo
postantMo
antMo
Mo .)(2
em que:
LiMo : limite inferior da classe modal
FiMo : frequência simples do intervalo da classe modal
Fiant: frequência simples anterior do intervalo da classe modal
Fipost: frequência simples posterior do intervalo da classe modal
h: amplitude do intervalo de classe
Exemplo 3.9:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos
matriculados em uma determinada disciplina. Determine a moda.
Escores Alunos (Fi)
35 |- 45 5
45 |- 55 12
55 |- 65 18
65 |- 75 14
75 |- 85 6
85 |- 95 3
Total 58
Solução:
Classe que contém a Moda: 55 |- 65
hFiFiFi
FiFiLiMo
postantMo
antMo
Mo .)(2
6110.)1412(182
121855
xMo
Interpretação: O escore com maior frequência entre o grupo de 58 alunos foi de
61 pontos.
3.3. MEDIANA – Me ou Md
Após colocarmos os dados em ROL, o valor da mediana é o elemento que
ocupa a posição central, ou seja, é o elemento que divide a distribuição em 50% de
cada lado. É considerada uma separatriz, por ser um promédio que divide o conjunto
de dados em partes iguais:
1ª SITUAÇÃO: Dados não agrupados

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
49
Sejam os elementos x1, x2, x3,..., xn de uma amostra, portanto n valores da
variável X. A mediana da variável aleatória de X é definida por,
- Se n é ímpar, então o valor da mediana será o valor central, localizado na
posição:
2
1nPosMe
- Se n é par, então o valor da mediana será a média das duas observações
adjacentes à posição
2
nPosMe
e 1
2
nPosMe
Exemplo 3.10:
Suponha o conjunto de tempo de serviço (em anos) de cinco funcionários: 3, 7,
8, 10 e 11. Vamos determinar a mediana deste conjunto de dados.
Solução:
Como n = 5, então o valor da mediana estará localizado na posição:
32
15
2
1
nPosMe , ou seja, 3° elemento, portanto, Me = 8
Interpretação: 50% dos funcionários possuem até 8 anos de tempo de serviço,
ou, 50% dos funcionários possuem no mínimo 8 anos de tempo de serviço.
Exemplo 3.11:
Suponha o conjunto de tempo de serviço de cinco funcionários: 3, 7, 8, 10, 11 e
13. Vamos determinar a mediana deste conjunto de dados.
Solução:
Como n = 6, então o valor da mediana estará localizado na posição 32
6MePos ,
(3° elemento), e 412
6PosMe (4° elemento).
E a mediana será calculada como a média aritmética deles.
Assim, no exemplo, teremos: 92
108
Me
Interpretação: 50% dos funcionários possuem até 9 anos de tempo de serviço,
ou, 50% dos funcionários possuem no mínimo 9 anos de tempo de serviço.
2ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por valores simples

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
50
Quando os dados estiverem agrupados numa distribuição de frequência
identificaremos a mediana dos valores x1, x2, x3,...,xn pela posição da mediana
2
nPosMe através da frequência absoluta acumulada (Fac).
Exemplo 3.12:
A tabela abaixo representa o número de peças de precisão defeituosas desenvolvidas mensalmente pelo controle de qualidade. Calcule a mediana.
Número de peças com defeito (Xi)
Número de meses (Fi)
Fac
0 2 2
1 3 5
2 6 11
3 8 19
4 4 23
5 2 25
6 1 26
TOTAL 26
Solução:
132
26
2
nPosMe
Interpretação: em 50% dos meses no máximo 3 peças defeituosas foram
desenvolvidas, ou então, em metade dos meses foram encontradas pelo menos 3
peças defeituosas.
3ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por classes
Procedimento:
1. Calcula-se a posição da mediana: 2
nPosMe
2. Pela Fac identifica-se a classe que contém o valor da mediana – Classe(Me)
3. Utiliza-se a fórmula: h.Fi
Fac)Me(POSLiMe
Me
antMe
onde: LiMe = Limite inferior da classe mediana
Fac,ant = Frequência acumulada anterior à classe mediana
h = Amplitude do intervalo de classe
FiMe = Frequência absoluta simples da classe mediana
n = Tamanho da amostra ou número de elementos
Exemplo 3.13:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
51
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos matriculados em uma determinada disciplina. Calcule a mediana.
Escores Alunos (Fi) Fac
35 |- 45 5 5
45 |- 55 12 17
55 |- 65 18 35
65 |- 75 14 49
75 |- 85 6 55
85 |- 95 3 58
Total 58 -
Solução:
1. 292
58MePos
elemento, observando a Fac temos:
2. Classe(Me) = 55 |− 65
3. 67,6110.18
172955
Me
Interpretação: 50% dos alunos obtiveram escore máximo de 61,67 pontos, ou
então, metade dos alunos obtiveram escore maior que 61,67 pontos.
INDICAÇÕES PARA UTILIZAÇÃO DAS TRÊS PRINCIPAIS MEDIDAS DE
POSIÇÃO
De maneira geral, a média é a mais empregada e a moda é a menos empregada
e a mais difícil de calcular satisfatoriamente. No entanto, a moda é adequada para
caracterizar situações onde estejam em causa os casos ou valores mais usuais. Por
exemplo, em estudos de mercado, o fabricante pode estar interessado nas medidas
que mais se vendem.
A mediana tem vantagens: é mais fácil de calcular do que a média; é mais
resistente do que a média, isto é, a alteração drástica de um só valor do rol reflete-se
substancialmente no valor da média e pode não refletir-se, ou refletir-se muito pouco,
no valor da mediana.
A média tem vantagens: quando a curva de frequência tem forma mais ou
menos simétrica (veremos isso adiante), com abas decaindo rapidamente (valores
erráticos muito improváveis), a média é mais eficiente do que a mediana, isto é, está
menos sujeita à variabilidade de rol para rol (menos sujeita a variações de
amostragem); a média é uma função linear das observações, propriedade que também
pode pesar na sua adoção.
Por fim, uma vantagem da mediana e da moda em relação à média aritmética é
que esta última não pode ser calculada quando ocorrem classes de frequências com

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
52
limites indefinidos (classes abertas). Entretanto, nesta situação, a moda e a mediana
podem ser encontradas sem qualquer dificuldade.
A seguir, na Figura 3.1 podemos ver uma comparação da média, mediana e
moda, as medidas de centro mais utilizadas:
A Figura 3.2 mostra a distribuição dos dados quanto à simetria. Temos que uma
distribuição é assimétrica quando se estende mais para um lado do que para o outro.
Pode ser assimétrica negativa Figura 3.2 (a) ou assimétrica positiva Figura 3.2 (c), ou
ainda simétrica Figura 3.2 (b), quando os dados do histograma não apresentam
diferenças significativas, a esquerda e a direita.
Figura 3.1: Comparação das medidas de centro
Fonte: TRIOLA (2008)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
53
Figura 3.2: Assimetria
Fonte: TRIOLA (2008)
RELAÇÃO EMPÍRICA ENTRE A MÉDIA, A MODA E A MEDIANA
Existe uma fórmula empírica de relação entre as medidas de posição, criada por
Pearson, para distribuições de frequência unimodais:
)(3 MexMox
Calculando cada medida a partir dessa relação temos:
2
3 MoMex
xMeMo 23
3
2 MoxMe
Exemplo 3.14:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos matriculados em uma determinada disciplina:
Escores Alunos (Fi) PM Fac PM .Fi
35 |- 45 5 40 5 200
45 |- 55 12 50 17 600
55 |- 65 18 60 35 1080
65 |- 75 14 70 49 980
75 |- 85 6 80 55 480
85 |- 95 3 90 58 270
Total 58 3610
Nos exemplos 3.3, 3.9 e 3.13, calculamos a média a moda e a mediana obtendo
os seguintes valores:
24,6258
3610.
1
1
n
i
i
n
i
iM
F
FP
X

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
54
6110.)1412(182
121855
xMo
67,6110.18
172955
Me
Agora vamos comparar estes valores com os calculados pela relação empírica:
00,622
61)67,61(3
2
3
MoMex
53,60)24,62(2)67,61(323 xMeMo
83,613
61)24,62(2
3
2
MoxMe
Como vemos não há uma diferença acentuada entre as medidas pelos dois
processos.
3.5. MEDIDAS SEPARATRIZES
Além das medidas de posição que estudamos, há outras que, consideradas
individualmente, não são medidas de tendência central, mas estão ligadas à mediana
relativamente à sua característica de separar a série em duas partes que apresentam o
mesmo número de valores.
Essas medidas - os quartis, os decis e os percentis - são, juntamente com a
mediana, conhecidas pelo nome genérico de separatrizes.
3.5.1. QUARTIS
Os quartis dividem um conjunto de dados em quatro partes iguais. Assim:
Onde:
Q1 = 1° quartil, deixa 25% dos elementos
Q2 = 2° quartil, coincide com a mediana, deixa 50% dos elementos
Q3 = 3° quartil, deixa 75% dos elementos
Procedimento:
1. Calcula-se a posição do quartil: in
QiPos .4
)( , onde: i = 1, 2, 3.
2. Pela Fac identifica-se a classe que contém o valor do quartil - Classe(Qi)
3. Utiliza-se a fórmula: hFi
FacQPOSLiQ
anti
i .)( ,

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
55
onde: Li = Limite inferior da classe quartílica
Fac,ant = Frequência acumulada anterior à classe quartílica
h = Amplitude do intervalo de classe
Fi = Frequência absoluta simples da classe quartílica
n = Tamanho da amostra ou número de elementos
Exemplo 3.15:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos
matriculados em uma determinada disciplina. Calcule o primeiro e o terceiro quartil.
Escores Alunos (Fi) Fac
35 |- 45 5 5
45 |- 55 12 17
55 |- 65 18 35
65 |- 75 14 49
75 |- 85 6 55
85 |- 95 3 58
Total 58 -
Solução:
Primeiro Quartil
1. 5,141.4
58)1( QPos
2. Classe(Q1) = 45 |− 55
3. 92,5292,74510.
12
55,14451
Q
Interpretação: 25% dos alunos obtiveram escore máximo de 52,92 pontos, ou então, 75% dos alunos obtiveram escore maior que 52,92 pontos.
Terceiro Quartil
1. 5,433.4
58)3( QPos
2. Classe(Q3) = 65 |− 75
3. 07,7107,66510.14
355,43653
Q
Interpretação: 75% dos alunos obtiveram escore menor que 71,07 pontos, ou então, 25% dos alunos obtiveram escore de pelo menos 71,07 pontos.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
56
3.5.2. DECIS
São valores que dividem a série em dez partes.
Procedimento:
1. Calcula-se a posição da medida: in
DiPos .10
)(
onde: i = 1,2,3,4,5,6,7,8,9
2. Pela Fac identifica-se a classe que contém o valor do decil - Classe(Di)
3. Utiliza-se a fórmula: hFi
FacDPOSLiD anti
i .)(
onde: Li = Limite inferior da classe do decil
Fac,ant = Frequência acumulada anterior à classe do decil
h = Amplitude do intervalo de classe
Fi = Frequência absoluta simples da classe do decil
n = Tamanho da amostra ou número de elementos
Exemplo 3.16:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos matriculados em uma determinada disciplina. Calcule o sexto decil.
Escores Alunos (Fi) Fac
35 |- 45 5 5
45 |- 55 12 17
55 |- 65 18 35
65 |- 75 14 49
75 |- 85 6 55
85 |- 95 3 58
Total 58 -
Solução:
1. 8,346.10
58)6( DPos
2. Classe(D6) = 55 |− 65
3. 89,6489,95510.18
178,34556
D

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
57
Interpretação: 60% dos alunos obtiveram escore inferior a 64,89 pontos, ou então, 40% dos alunos obtiveram escore mínimo de 64,89 pontos.
3.5.3. PERCENTIS
São as medidas que dividem a amostra em 100 parte iguais.
Procedimento:
1. Calcula-se a posição da medida: in
PiPos .100
)( , onde : i = 1,2,3,..., 98,99
2. Pela Fac identifica-se a classe que contém o valor do percentil - Classe(Pi)
3. Utiliza-se a fórmula: hFi
FacPPOSLiP
anti
i .)( ,
onde:
Li = Limite inferior da classe do percentil
Fac,ant = Frequência acumulada anterior à classe do percentil
h = Amplitude do intervalo de classe
Fi = Frequência absoluta simples da classe do percentil
n = Tamanho da amostra ou número de elementos
Exemplo 3.17:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos matriculados em uma determinada disciplina. Calcule o percentil de ordem 23.
Escores Alunos (Fi) Fac
35 |- 45 5 5
45 |- 55 12 17
55 |- 65 18 35
65 |- 75 14 49
75 |- 85 6 55
85 |- 95 3 58
Total 58 -
Solução:
1. 34,1323.100
58)23( PPos
2. Classe(P23) = 45 |− 55

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
58
3. 95,5195,64510.12
534,134523
P
Interpretação: 23% dos alunos com os menores escores obtiveram pontuação
inferior a 51,95 pontos, ou então, 77% dos alunos obtiveram escore maior que 51,95
pontos.
FÓRMULA GERAL DAS SEPARATRIZES
1° situação: Para dados não agrupados e dados agrupados sem intervalos de classe, uma separatriz genérica “S” de ordem “p” é determinável pela seguinte fórmula:
q
npX
q
npXx
q
npfrac
q
npXSp
)1(int1
)1(int
)1()1(int
Onde:
X: é qualquer elemento de um conjunto ordenado;
q
np )1( : é um índice que indica a posição do elemento X no conjunto ordenado;
q
np )1(int : indica a parte inteira do índice;
frac
q
np )1( : indica a parte fracionária do índice;
q: é o número de partições do conjunto. q N e q>1;
p: é a ordem da separatriz 1< p ≤ q – 1.
2° situação: Para dados agrupados com intervalos de classe, uma separatriz
genérica “S” determinável pela seguinte fórmula:
hFi
FacSPOSLiS
anti.
)( ,
onde: Li = Limite inferior da classe que contém a separatriz
POS(Si): posição da separatriz
Fac,ant = Frequência acumulada anterior à classe que contém a separatriz
h = Amplitude do intervalo de classe
Fi = Frequência absoluta simples da classe que contém a separatriz
Exemplo 3.18:
Suponha o conjunto de tempo de serviço (em anos) de quatro funcionários: 1, 9,
13, 20. Determinar o terceiro quartil (Q3) deste conjunto de dados.
Solução:
Dados em rol: 1, 9, 13, 20

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
59
Q3 = ?, q = 4, p = 3, n = 4
q
np )1( = 75,3
4
)14(3
(posição)
q
npX
q
npXx
q
npfrac
q
npXSp
)1(int1
)1(int
)1()1(int
25,18)7(75,013]1320[75,0133 xQ
Interpretação: 75% funcionários tem tempo de serviço menor ou igual a 18,25
anos e 25% dos funcionários tem tempo de serviço maior ou igual a 18,25 anos.
Exemplo 3.19:
Calcule o Primeiro quartil (Q1) do conjunto de dados abaixo:
2 - 5 - 8 - 5 - 5 - 10 - 1 - 12 - 12 - 11 - 13 - 15.
Solução:
Primeiro, devemos ordenar os dados:
1- 2 - 5 - 5 - 5 - 8 - 10 - 11 - 12 - 12 - 13 – 15.
Assim,
Q1 = ?, q = 4, p = 1, n = 12
q
np )1( = 25,34
)112(1
(posição)
q
npX
q
npXx
q
npfrac
q
npXSp
)1(int1
)1(int
)1()1(int
5]55.[25,051 Q
Interpretação: 25% dos valores são menores ou igual a 5 e 75% dos valores são
maiores ou igual a 5.
Exemplo 3.20:
Calcule o Quarto Decil (D4) da série:
Xi (Fi) Fac
2 1 1
5 4 5
6 3 8
8 2 10
Total 10 -
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
60
D4 = ?, q = 10, p = 4, n = 10
q
np )1( = 40,410
)110(4
(posição)
q
npX
q
npXx
q
npfrac
q
npXSp
)1(int1
)1(int
)1()1(int
5]55.[40,054 D
Interpretação: 40% dos valores são menores ou igual a 5 e 60% dos valores são
maiores ou igual a 5.
Para finalizar este capítulo, vamos observar no diagrama de caixa abaixo as
medidas de posição, incluindo as separatrizes que acabamos de ver:
Fonte: http://www.scielo.br/scielo.php?pid=S0103-84782008000500041&script=sci_arttext
(acesso em 11/01/2012)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
61
4 – MEDIDAS DE VARIAÇÃO
4.1- INTRODUÇÃO
Nesta fase da descrição dos dados, uma análise completa requer muito mais do
que a apresentação dos dados em tabelas ou gráficos, e do cálculo das medidas de
posição. Não podemos apenas caracterizar um conjunto pela sua média, por exemplo,
pois os dados diferem entre si em maior ou menor grau.
As medidas de dispersão ou de variabilidade indicam se os valores estão
relativamente próximos um dos outros, ou separados em torno de uma medida de
posição, geralmente, a média como falamos acima.
As medidas são representadas segundo a sua natureza, sendo divididas em
medidas de dispersão ou de variabilidade absoluta e medidas de dispersão ou de
variabilidade relativa. Consideraremos as seguintes medidas de dispersão absoluta:
Amplitude total (AT), Amplitude semi-interquartílica (IQ), Desvio médio (DM), Variância
(σ2) e Desvio adrão (σ). As medidas de dispersão relativa consideradas são:
Coeficiente de Variação ou Coeficiente de Pearson (CVP) e Coeficiente de Variação ou
Coeficiente de Thorndike (CVT). Ainda serão vistas nessa unidade, medidas de
assimetria e de curtose, que são medidas complementares de dispersão.
4.2. MEDIDAS DE DISPERSÃO ABSOLUTA
4.2.1. AMPLITUDE TOTAL (AT)
Como no caso das medidas de posição, temos três situações diferentes: dados
não agrupados, dados agrupados sem e com intervalo de classe.
1ª SITUAÇÃO: Dados não agrupados
É a diferença entre o maior e menor dos valores da série, ou seja, é a diferença
entre os extremos do conjunto de dados.
mínmáxT XiXiA
A utilização da amplitude total como medida de dispersão é muito restrita, pois é
uma medida que depende apenas dos valores extremos, não sendo afetada pela
variabilidade interna dos valores da série, sendo muito instável.
A amplitude total também é sensível ao tamanho da amostra. Ao aumentar a
amostra, a AT tende a aumentar, ainda que não proporcionalmente. Também apresenta
grande variação de uma amostra para a outra, mesmo que ambas sejam extraídas da
mesma população.
O uso da amplitude total é feito apenas em situações em que ela se apresenta
satisfatória. Um exemplo de aplicação é a amplitude da variação da temperatura em
um dia, um ano, ou num processo de resfriamento. Outras aplicações são encontradas

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
62
quando os dados são raros ou esparsos, que não justificam o uso de uma medida mais
precisa.
Exemplo 4.1:
Sejam as duas series a seguir:
a) 1, 1, 1, 1, 1, 100
b) 1, 30, 32, 45, 75, 100
Ambas possuem AT = 100 – 1 = 99.
2 ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por valores simples
Como na situação anterior, a amplitude total é a diferença entre o maior e menor dos valores da série.
mínmáxT XiXiA
3ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por intervalos de classe
É a diferença entre o limite superior do último intervalo de classe e o limite
inferior do primeiro intervalo de classe, ou seja:
mínmáxT LiLsA
4.2.2. DESVIO-MÉDIO
O desvio-médio ou média dos desvios é a média aritmética dos valores
absolutos dos desvios tomados em relação a média ou a mediana. Sua vantagem é
que leva em conta todos os elementos. Aqui apresentaremos as fórmulas utilizando a
média.
1ª SITUAÇÃO: Dados não agrupados
Sejam os elementos x1, x2, x3,...,xn de uma amostra, portanto n valores da
variável X, com média igual a X . O desvio médio da variável aleatória de X é,
n
XXiD
n
i
m
1
onde n é o número de elementos do conjunto.
Exemplo 4.2:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
63
Suponha o conjunto de tempo de serviço de cinco funcionários: 3, 7, 8, 10 e 11.
Determinar o desvio médio deste conjunto de dados.
Solução:
No exemplo 3.1 calculamos a média, 8,7X
24,25
2,11
5
)8,711()8,710()8,78()8,77()8,73(1
n
XXiD
n
i
m
Interpretação: em média, o tempo de serviço deste grupo de funcionários se
desviou em 2,24 anos em torno dos 7,8 anos de tempo médio de serviço.
2ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por valores simples
Quando os dados estiverem agrupados numa distribuição de frequência
usaremos o desvio médio dos valores x1, x2, x3,...,xn, ponderados pelas respectivas
frequências absolutas: F1, F2, F3, ... , Fn, como no cálculo da média aritmética. Assim,
n
FiXXiD
n
i
m
.1
onde:
ΣFi = n = Frequência absoluta total
Exemplo 4.3:
A tabela abaixo representa o número de peças de precisão defeituosas
desenvolvidas mensalmente pelo controle de qualidade. Calcule o desvio médio.
Número de peças com defeito (Xi)
Número de meses (Fi)
Xi- X Xi- X .Fi
0 2 2,73 5,46
1 3 1,73 5,19
2 6 0,73 4,38
3 8 0,27 2,16
4 4 1,27 5,08
5 2 2,27 4,54
6 1 3,27 3,27
TOTAL 26 30,08
Solução:
A média foi calculada no exemplo 3.2: 73,2X
O cálculo do desvio médio será:
16,126
08,30.1
n
FiXXiD
n
i
m

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
64
Interpretação: em média, o número de peças defeituosas possui uma distância
de 1,16 em torno das 2,73 peças defeituosas em média por mês.
3ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por classes
Quando os dados estiverem agrupados numa distribuição de frequência
usaremos o desvio-médio dos pontos médios x1, x2, x3,...,xn de cada classe,
ponderados pelas respectivas frequências absolutas: F1, F2, F3, ... , Fn. Desta forma, o
cálculo do desvio-médio passa a ser igual ao da 2ª situação. Assim,
n
FiXXiD
n
i
m
.1
, onde
n
i
i
n
i
iM
F
FP
X
1
1
.
Exemplo 4.4:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos
matriculados em uma determinada disciplina. Calcule o desvio médio.
Escores Alunos (Fi) PM PM -X (PM –X). Fi
35 |- 45 5 40 22,24 111,20
45 |- 55 12 50 12,24 146,88
55 |- 65 18 60 2,24 40,32
65 |- 75 14 70 7,76 108,64
75 |- 85 6 80 17,76 106,56
85 |- 95 3 90 27,76 83,28
Total 58 596,88
Solução:
A média foi calculada no exemplo 3.3: 24,62X
O cálculo do desvio-médio será:
29,1058
88,596.1
n
FiXXiD
n
i
m
Interpretação: Em média, a nota de cada aluno deste grupo teve um
distanciamento de 10,29 pontos em torno do desempenho médio deste grupo de
alunos que foi de 62,24 pontos nesta disciplina.
4.2.3. VARIÂNCIA E DESVIO PADRÃO
São as medidas de dispersão mais usadas e conhecidas.
A variância de um conjunto de dados é a média dos quadrados dos desvios dos
valores a contar da média. A fórmula da variância poderá ser calculada de duas
formas:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
65
A populacional: representada letra grega σ2
A amostral: representada por s2
1ª SITUAÇÃO: Dados não agrupados
Sejam os elementos x1, x2, x3,...,xn, portanto n valores da variável X, com média
igual a X . A variância da variável aleatória de X é,
n
Xin
i
1
2
2
ou
1
1
2
2
n
XXi
S
n
i
Obs: Para valores grandes da amostra (n>30), não há grande diferença entre os resultados obtidos com n ou n-1, mas o mais comum é utilizarmos n quando se trata de população e n-1 quando for amostra.
Exemplo 4.5:
Suponha o conjunto de tempo de serviço de cinco funcionários: 3, 7, 8, 10 e 11.
Determinar o desvio-padrão deste conjunto de dados.
Solução:
2
22222
1
2
2 7,94
8,38
15
)8,711()8,710()8,78()8,77()8,73(
1anos
n
XXi
S
n
i
Interpretação: encontramos então uma variância para o tempo de serviço de 9,7
anos2.
Para eliminarmos o quadrado da unidade de medida, extraímos a raiz quadrada
do resultado da variância, que chegamos a outra medida de dispersão, chamada de
DESVIO PADRÃO:
A populacional: representada letra grega 2
A amostral: representada por 2SS
Portanto, o desvio-padrão do exemplo foi de 3,11 anos. Ou seja, se calcularmos
um intervalo utilizando um desvio-padrão em torno da média, encontraremos a
concentração da maioria dos dados.
2ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por valores simples
Quando os dados estiverem agrupados numa distribuição de frequência
usaremos a variância dos valores x1, x2, x3,...,xn, ponderados pelas respectivas
frequências absolutas: F1, F2, F3, ... , Fn. Assim, temos

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
66
n
FiXin
i
1
2
2
.)(
n
FiXiFixi
n
2
22).(
.1 ou
1
.)(1
2
2
n
FiXXi
S
n
i
n
FiXiFixi
nS
2
22).(
.1
1
onde: ΣFi = n = Frequência absoluta total
Exemplo 4.6:
A tabela abaixo representa o número de peças de precisão defeituosas
desenvolvidas mensalmente pelo controle de qualidade. Calcule o desvio padrão.
Número de peças com defeito (Xi)
Número de meses (Fi)
(Xi- X )² (Xi- X )².Fi Xi.Fi Xi².Fi
0 2 7,45 14,91 0,00 0,00
1 3 2,99 8,98 3,00 3,00
2 6 0,53 3,20 12,00 24,00
3 8 0,07 0,58 24,00 72,00
4 4 1,61 6,45 16,00 64,00
5 2 5,15 10,31 10,00 50,00
6 1 10,69 10,69 6,00 36,00
TOTAL 26 55,12 71,00 249,00
Solução:
21
2
2 20,2126
12,55
1
.)(
peçasn
FiXXi
S
n
i
peçasSS 48,120,22
ou
222
22 20,226
71249
126
1).(.
1
1peças
n
FiXiFixi
nS
peçasSS 48,120,22
Interpretação: Portanto, o desvio-padrão do exemplo foi de 1,48 peças em torno
da média, ou seja, se calcularmos um intervalo utilizando um desvio-padrão em torno
da média, encontraremos a concentração da maioria das peças defeituosas por mês.
3ª SITUAÇÃO: Dados agrupados em uma distribuição de frequência por classes

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
67
Quando os dados estiverem agrupados numa distribuição de frequência usaremos a seguinte expressão:
2
22
2 ...
hn
Fidi
n
Fidi
onde:
h
PPdi
MeMM
PM Me: ponto médio da classe que contém mediana
PM : ponto médio do intervalo de classe
Σdi.Fi: somatório do produto da frequência absoluta pelo respectivo desvio
Σdi2.Fi: somatório do produto da frequência absoluta pelo respectivo desvio ao
quadrado
h = Amplitude do intervalo de classe
n= Frequência absoluta total
Obs: Alguns autores utilizam n - 1 no lugar de n, principalmente quando a
amostra é pequena n < 30.
Exemplo 4.7:
A tabela abaixo representa os escores obtidos por um grupo de 58 alunos
matriculados em uma determinada disciplina. Como a média calculada no exemplo 3.3
é 62,24, cálculo do desvio padrão será:
Escores Alunos (Fi) PM di di. Fi di2. Fi
35 |- 45 5 40 -2 -10 20
45 |- 55 12 50 -1 -12 12
55 |- 65 18 60 0 0 0
65 |- 75 14 70 1 14 14
75 |- 85 6 80 2 12 24
85 |- 95 3 90 3 9 27
Total 58 13 97
Como vimos anteriormente, a mediana está no intervalo de classe de 55 |- 65, seu PM é 60, então calculando o di para o primeiro intervalo temos:
210
6040
h
PPdi
MeMM, agora podemos completar e tabela e calcular a
variância para em seguida o desvio padrão:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
68
pontoshn
Fidi
n
Fidi98,16110.
58
13
58
97.
..2
2
2
22
2
pontos73,1298,1612
Interpretação: O desvio-padrão do exemplo foi de 12,73 pontos. Ou seja, se
calcularmos um intervalo utilizando um desvio-padrão em torno do escore médio de
62,24 pontos, encontraremos a concentração da maioria dos alunos dentro deste
intervalo de pontuação.
Sobre o desvio padrão:
Podemos concluir que o desvio padrão S é a medida de dispersão mais usada,
tendo padrão em comum com o desvio médio Dm o fato de ambos serem considerados
os desvios com relação a média. A diferença está que no cálculo do desvio padrão S,
em lugar de serem considerados os valores absolutos dos desvios, calculamos os
quadrados desses. O desvio padrão também se apresenta maior que o desvio médio.
O valor do desvio padrão S é usualmente positivo. É zero quando todos os
valores dos dados são iguais (o mesmo número). S nunca será negativo. Maiores
valores de S indicam uma maior variação.
O valor do desvio padrão pode crescer muito com a inclusão de um ou mais
outliers (valores dos dados que estão muito longe dos demais).
As unidades do desvio padrão S, como por exemplo, metros, polegadas,
minutos, libras, etc. são as mesmas unidades dos dados originais. Quando tivermos a
variância, essas unidades estarão elevadas ao quadrado.
RELAÇÕES EMPÍRICAS ENTRE AS MEDIDAS DE DISPERSÃO
I) Regra prática para a determinação do desvio padrão de dados típicos
Podemos usar uma aproximação para o desvio padrão, visto que a amplitude
mede aproximadamente 4 desvios padrões (= 4S), assim:
4
mínmáx XiXiS
Quando as distribuições são fracamente assimétricas (pequeno enviesamento
da curva), podemos considerar também:
SDm5
4 e SDq
3
2
II) Regra prática “68 95 99,7” ou “Gaussiana”
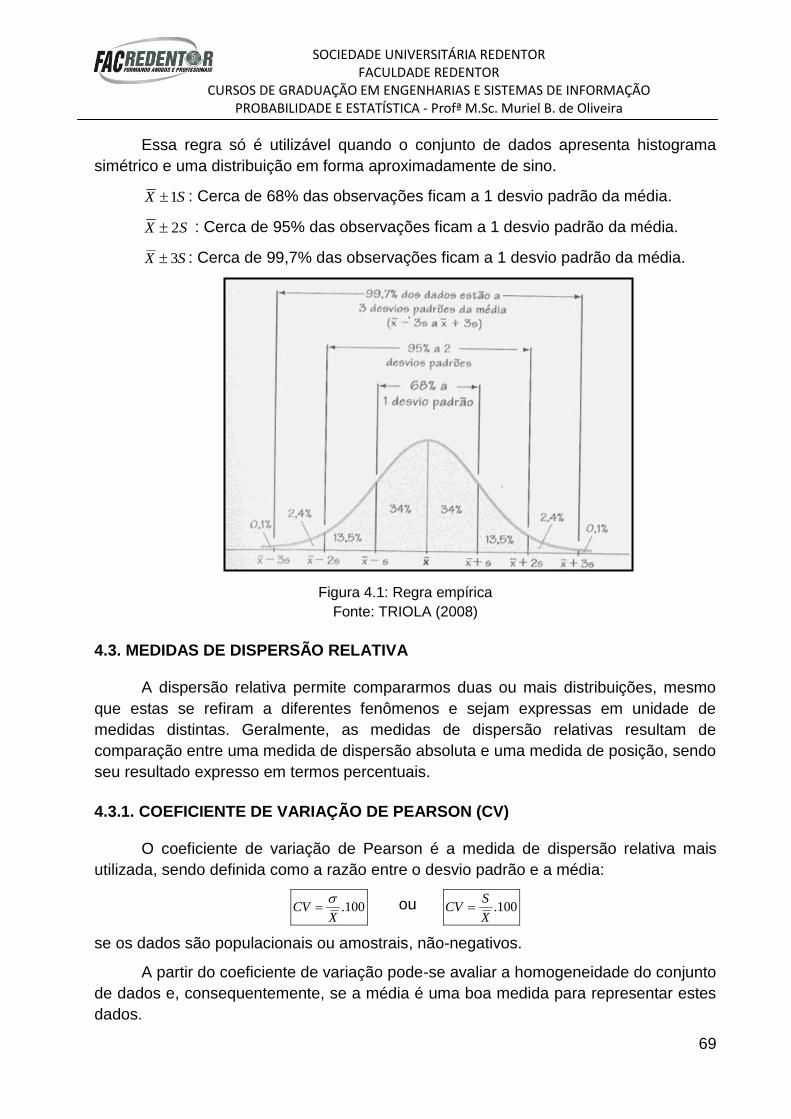
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
69
Essa regra só é utilizável quando o conjunto de dados apresenta histograma
simétrico e uma distribuição em forma aproximadamente de sino.
SX 1 : Cerca de 68% das observações ficam a 1 desvio padrão da média.
SX 2 : Cerca de 95% das observações ficam a 1 desvio padrão da média.
SX 3 : Cerca de 99,7% das observações ficam a 1 desvio padrão da média.
Figura 4.1: Regra empírica
Fonte: TRIOLA (2008)
4.3. MEDIDAS DE DISPERSÃO RELATIVA
A dispersão relativa permite compararmos duas ou mais distribuições, mesmo
que estas se refiram a diferentes fenômenos e sejam expressas em unidade de
medidas distintas. Geralmente, as medidas de dispersão relativas resultam de
comparação entre uma medida de dispersão absoluta e uma medida de posição, sendo
seu resultado expresso em termos percentuais.
4.3.1. COEFICIENTE DE VARIAÇÃO DE PEARSON (CV)
O coeficiente de variação de Pearson é a medida de dispersão relativa mais
utilizada, sendo definida como a razão entre o desvio padrão e a média:
100.X
CV
ou 100.X
SCV
se os dados são populacionais ou amostrais, não-negativos.
A partir do coeficiente de variação pode-se avaliar a homogeneidade do conjunto
de dados e, consequentemente, se a média é uma boa medida para representar estes
dados.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
70
Uma desvantagem do coeficiente de variação é que ele deixa de ser útil quando
a média está próxima de zero. Uma média muito próxima de zero pode inflacionar o
CV. Por outro lado, quanto mais próximo de zero, mais homogêneo é o conjunto de
dados e mais representativa será sua média.
Um coeficiente de variação superior a 50% sugere alta dispersão o que indica
heterogeneidade dos dados. Quanto maior for este valor, menos representativa será a
média. Neste caso, optamos pela mediana ou moda, não existindo uma regra prática
para a escolha de uma destas medidas.
Exemplo 4.8:
Numa empresa o salário médio dos funcionários do sexo masculino é de R$
4.000,00, com um desvio padrão de R$ 1.500,00, e os funcionários do sexo feminino é
em média de R$ 3.000,00, com um desvio padrão de R$ 1.200,00.
Então calculando o coeficiente de variação temos que:
Sexo masculino: %50,37100.4000
1500100.
X
SCV
Sexo feminino: %00,40100.3000
1200100.
X
SCV
Interpretação: Podemos concluir que o salário das mulheres apresenta maior dispersão relativa que o dos homens.
Classificação da distribuição quanto à dispersão:
Dispersão baixa: CV ≤ 15%
Dispersão média: 15% < CV < 30%
Dispersão alta: CV ≥ 30%
4.4. MEDIDAS DE ASSIMETRIA
As medidas de assimetria e de curtose são as últimas que temos para
completarmos o quadro de estatísticas descritivas, que proporcionam, juntamente com
as medidas de posição e de dispersão, a descrição e compreensão completas da
distribuição de frequência em estudo.
A medida de assimetria é um indicador da forma da distribuição dos dados.
Quanto ao grau de deformação ou assimetria, podemos ter três tipos de curvas de
frequência:
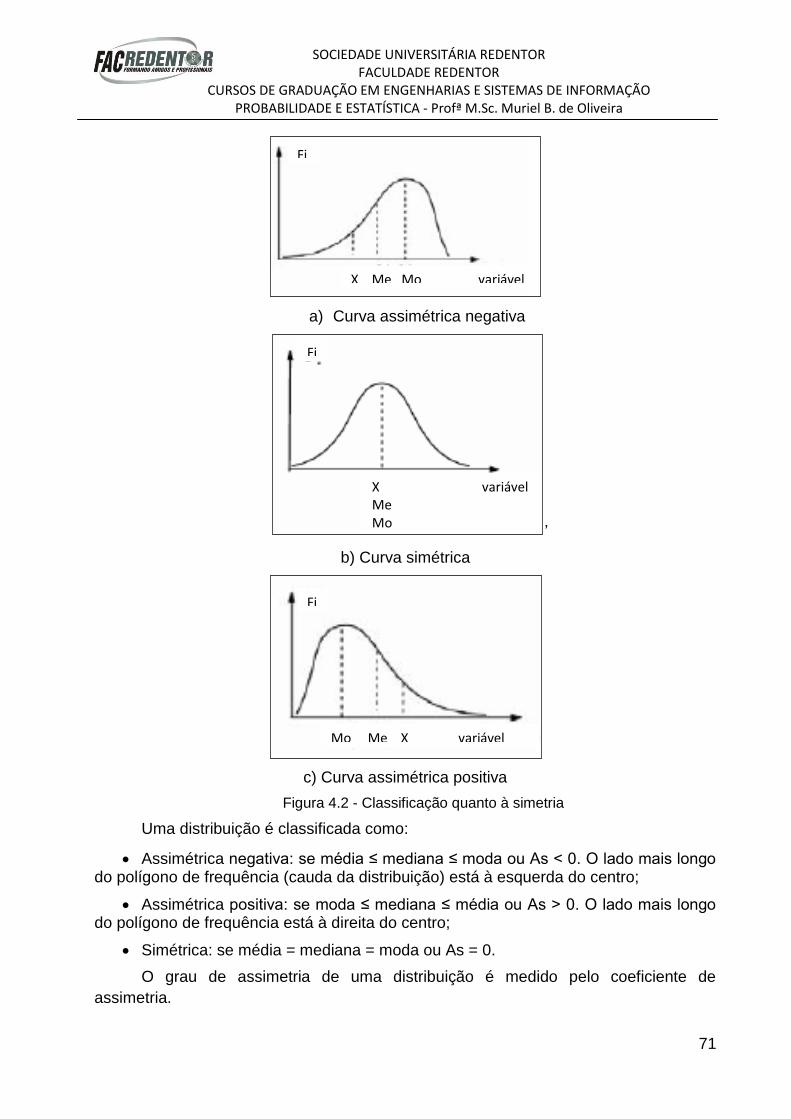
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
71
a) Curva assimétrica negativa
’
b) Curva simétrica
c) Curva assimétrica positiva
Figura 4.2 - Classificação quanto à simetria
Uma distribuição é classificada como:
Assimétrica negativa: se média ≤ mediana ≤ moda ou As < 0. O lado mais longo do polígono de frequência (cauda da distribuição) está à esquerda do centro;
Assimétrica positiva: se moda ≤ mediana ≤ média ou As > 0. O lado mais longo do polígono de frequência está à direita do centro;
Simétrica: se média = mediana = moda ou As = 0.
O grau de assimetria de uma distribuição é medido pelo coeficiente de
assimetria.
Mo Me X variável
Fi
X variável Me Mo
X Me Mo variável
Fi
Fi

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
72
4.4.1. CRITÉRIO DE PEARSON
O coeficiente de assimetria de Pearson (As) definido para dados populacionais e
amostrais, respectivamente, como:
MoAs
ou S
MoXAs
recomendável no caso de distribuições unimodais ou
)(3 MeAs
ou
S
MeXAs
)(3
no caso de distribuições plurimodais.
Classificação do coeficiente de Pearson:
As = 0: distribuição simétrica
0 < As < 1: distribuição assimétrica positiva fraca
As ≥ 1: distribuição assimétrica positiva forte
-1 < As < 0:distribuição assimétrica negativa fraca
As ≤ -1: distribuição assimétrica negativa forte
Fonte: TRIOLA (2008)
4.4.2. CRITÉRIO DE KELLEY
Aqui utilizamos os valores dos 10° e 90° percentis e da mediana. O valor da
assimetria varia entre ±1.
1090
9010 2
PP
MePPAs
4.4.3. CRITÉRIO DE BOWLLEY
Aqui utilizamos os valores dos 1° e 3° quartis e da mediana. O valor da assimetria varia entre ±1.
13
13 2
MeQQAs
4.5. MEDIDAS DE CURTOSE
A medida de curtose é o grau de achatamento ou de afilamento da distribuição,
ou seja, é um indicador da forma desta distribuição.
A medida de curtose é determinada pelo seu coeficiente de curtose k :
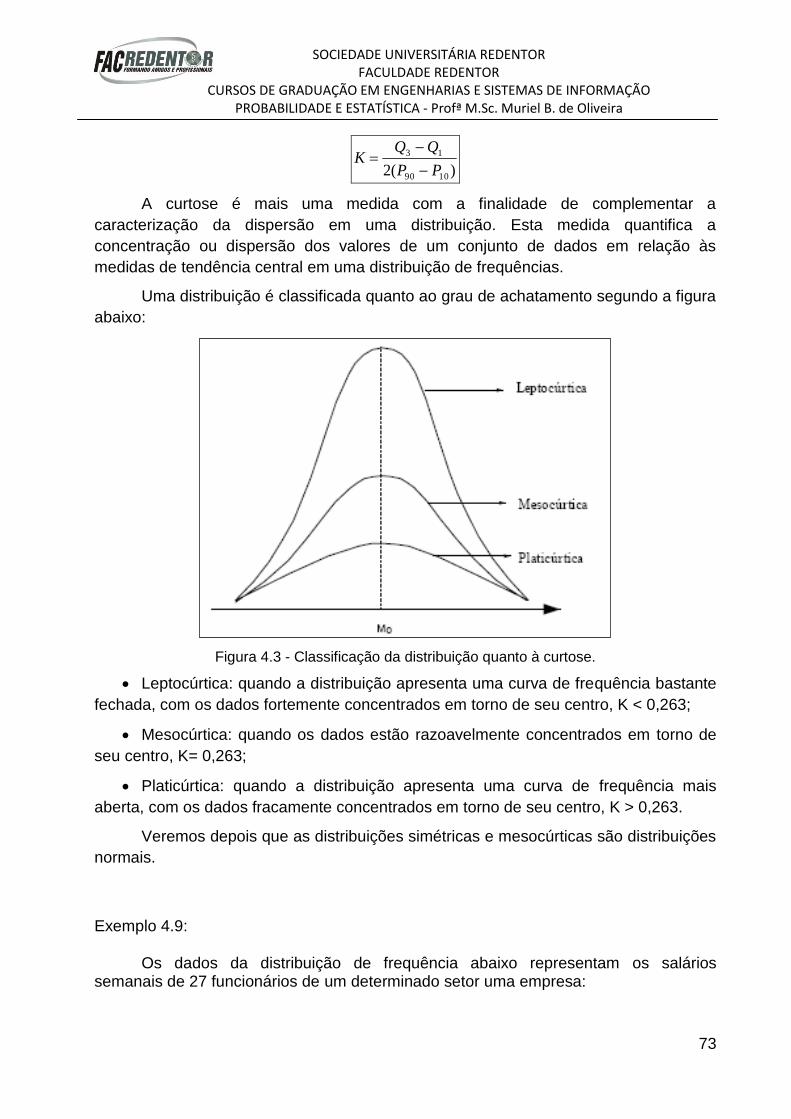
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
73
)(2 1090
13
PP
QQK
A curtose é mais uma medida com a finalidade de complementar a
caracterização da dispersão em uma distribuição. Esta medida quantifica a
concentração ou dispersão dos valores de um conjunto de dados em relação às
medidas de tendência central em uma distribuição de frequências.
Uma distribuição é classificada quanto ao grau de achatamento segundo a figura
abaixo:
Figura 4.3 - Classificação da distribuição quanto à curtose.
Leptocúrtica: quando a distribuição apresenta uma curva de frequência bastante
fechada, com os dados fortemente concentrados em torno de seu centro, K < 0,263;
Mesocúrtica: quando os dados estão razoavelmente concentrados em torno de
seu centro, K= 0,263;
Platicúrtica: quando a distribuição apresenta uma curva de frequência mais
aberta, com os dados fracamente concentrados em torno de seu centro, K > 0,263.
Veremos depois que as distribuições simétricas e mesocúrticas são distribuições
normais.
Exemplo 4.9:
Os dados da distribuição de frequência abaixo representam os salários semanais de 27 funcionários de um determinado setor uma empresa:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
74
Salário (R$) Fi
230,00 2
250,00 4
320,00 6
360,00 8
420,00 4
430,00 2
540,00 1
TOTAL 27
Em relação aos salários vamos calcular:
a) a média;
b) a moda;
c) a mediana;
d) a variância;
e) o desvio padrão;
f) o coeficiente de variação;
g) o coeficiente de assimetria e classificar a distribuição.
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
75

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
76
V – INTRODUÇÃO A PROBABILIDADE
5.1- INTRODUÇÃO
Aqui você será apresentado ao conceito básico e interpretação de probabilidade
de um evento.
Probabilidade ou Possibilidade? A diferença entre as palavras possibilidade e
probabilidade é que a probabilidade mede a possibilidade de em experimento aleatório.
5.2. EXPERIMENTO
Um experimento é qualquer processo que permite fazer observações e que o
resultado está sujeito a incertezas.
Temos como exemplos: o lançamento de um dado para observar a face
vencedora; o comprimento e o peso; a seleção de um eleitor para indicar seu candidato
nas próximas eleições, o levantamento da resistência de compressão em diversas
vigas metálicas, etc.
Os experimentos podem determinísticos ou aleatórios.
Experimentos determinísticos: são aqueles cujos resultados são sempre os mesmos, apesar de se repetirem várias vezes em condições semelhantes. Por exemplo, nascimento de um bebê (é certo que haverá o nascimento).
Experimentos aleatórios: são aqueles cujos resultados não são sempre os mesmos, apesar de se repetirem várias vezes em condições semelhantes, ou ainda, é o experimento que a cada repetição é impossível prever, com absoluta certeza, qual o resultado será obtido, e, além disso, a ocorrência de um deles exclui a possibilidade de ocorrência dos demais (o que chamamos de eventos mutuamente exclusivos). Por exemplo, o sexo do bebê que nasceu (pode ser masculino ou feminino).
5.3. ESPAÇO AMOSTRAL
O espaço amostral (S) de um experimento aleatório (E) é o conjunto de todos os
resultados possíveis desse experimento.
Por exemplo, no lançamento de um dado honesto, temos: S = {1, 2, 3, 4, 5, 6}
5.4. EVENTO
Evento é qualquer resultado possível, obtido da realização de um experimento
E, ou seja, evento é qualquer subconjunto do espaço amostral S. O evento é
denominado simples se consistir em um único resultado e composto se consistir em
mais de um resultado.
Quando o experimento é realizado, um determinado evento A ocorre se o
resultado experimental estiver contido em A. Geralmente, ocorre exatamente um

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
77
evento simples, mas diversos eventos compostos também podem ocorrer
simultaneamente.
Seja, por exemplo, os eventos A, B e C:
A: observar face ímpar no lançamento de um dado. A = {1, 3, 5}
B: observar face maior do que 4. B = {5, 6}
C: observar face par. C = {2, 4, 6}
D: observar face maior do que cinco. D = {6} (evento simples).
5.4.1. Tipos de eventos
Evento Impossível é o evento igual ao conjunto vazio ( ou { }). A probabilidade de ocorrer é zero.
Exemplo: D: observar face maior do que 6. D = { }
Evento certo é o evento igual ao espaço amostral S. A probabilidade de ocorrer é certa, ou seja, igual a 1.
Exemplo: E: observar face menor do que 7. E = {1, 2, 3, 4, 5, 6}
5.4.2. Operação com eventos
Usamos frequentemente diagramas para mostrar a relação entre conjuntos,
sendo estes diagramas também utilizados para descrever a relação entre os eventos.
São os chamados diagramas de Venn.
União: A B é o evento que ocorre se, e somente se, A ocorre ou B ocorre ou ambos ocorrem simultaneamente.
Intersecção: A B é o evento que ocorre se, e somente se, A e B ocorrem simultaneamente.
Obs: se A B = , então A e B são ditos mutuamente exclusivos (excludentes) ou disjuntos.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
78
Complementar: A é o evento que ocorre se, e somente se, A não ocorrer.
5.5. APROXIMAÇÃO DA PROBABILIDADE PELA FREQUÊNCIA RELATIVA
Também chamada de probabilidade empírica, é dada pelo número de vezes em
que ocorreu um determinado evento pelo número de vezes que o procedimento foi
repetido.
Por exemplo, ao tentarmos determinar a probabilidade de uma tachinha cair de
ponta para cima, devemos repetir o procedimento de jogar muitas vezes a tachinha e
depois achar a razão entre o número de vezes que ela caiu de ponta para cima e o
número de jogadas.
5.6. PROBABILIDADE CLÁSSICA (CONCEITO HISTÓRICO)
A probabilidade clássica se aplica a situações em que os resultados que
compõem o espaço amostral tem a mesma possibilidade de ocorrerem, ou seja, os
eventos simples são considerados equiprováveis e o espaço amostral é finito.
Por exemplo, no lançamento de um dado a probabilidade de ocorrer face 2 é
igual a probabilidade de ocorrer qualquer outra face (1, 3, 4, 5 ou 6).
)(
)()(
Sn
AnAP
5.7. PROBABILIDADE SUBJETIVA
Um exemplo é quando os meteorologistas usam seus conhecimentos
específicos de condições do tempo para saber se irá chover no dia de amanhã, então
desenvolvem uma estimativa de probabilidade.
Notação para probabilidades:
P representa a probabilidade
A, B, C,representam eventos específicos
P(A) representa a probabilidade de ocorrer o evento A
n(A) é o número de elementos de A,
n(S) é o número de elementos de S.
0 P(A) 1 ou 1)(1
n
i
iAP

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
79
5.8. TEOREMA DA SOMA
Seja S um espaço amostral e A e B eventos de S. A probabilidade da união
desses eventos é dada por:
P(A B) = P(A) + P(B) – P(A B)
Se A e B são eventos mutuamente exclusivos, então: P(A B) = P(A) + P(B)
P(A B) ou P(A ou B) representa a probabilidade de que ocorra o evento A ou o
evento B (ou ocorram ambos) como um único resultado de um experimento.
A palavra-chave para lembrar é “ou” com adição.
Exemplo 5.1:
Se retirarmos uma carta de um baralho normal de 52 cartas, qual é a
probabilidade de sair um ás ou uma carta de ouros?
Solução:
Exemplo 5.2:
Uma urna contém 4 bolas amarelas, 2 bolas brancas e 3 bolas vermelhas.
Retirando-se uma bola, calcular a probabilidade de ela ser amarela ou branca.
Solução:
5.9. PROBABILIDADE DO COMPLEMENTAR DE UM EVENTO
Se A é o complemento de um evento A, então: P( A ) = 1 – P(A)
Os eventos A e A tem que ser disjuntos, pois como falado, é impossível que o
evento e seu complementar ocorram ao mesmo tempo, assim:
P( A ) + P(A) = 1 e P (A)= 1 – P( A )

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
80
5.10. PROBABILIDADE CONDICIONAL
Uma probabilidade condicional é a probabilidade de ocorrer um evento, dado
que um outro evento já ocorreu.
Seja A S e B S. A probabilidade condicional de A dado que B ocorreu (A/B)
é definida como:
)(
)()/(
BP
BAPBAP
se P(B) 0
Como também a probabilidade condicional de B dado que A ocorreu (B/A):
)(
)()/(
AP
ABPABP
se P(A) 0
Exemplo 5.3:
Duas cartas são selecionadas de um baralho comum, sem reposição. Qual a
probabilidade da segunda carta ser uma dama, dado que a primeira foi um rei?
Solução:
Exemplo 5.4:
Lança-se um par de dados não viciados. Se a soma é 6, qual a probabilidade de
ter ocorrido à face 2 em um deles?
Solução:
No lançamento de um par de dados temos 36 possibilidades, para que a soma
das faces seja 6, podemos ter 4 e 2 ou 2 e 4, ou seja, 2 em 36.
Se a soma é 6, temos 5 possibilidades (1 e 5, 5 e 1, 2 e 4, 4 e 2, 3 e 3), em 36.
5.11. TEOREMA DO PRODUTO
Esta regra é utilizada para encontrarmos a probabilidade de o evento A
acontecer em uma primeira prova e o evento B acontecer em uma segunda prova. Se o

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
81
resultado do primeiro evento A afeta a probabilidade do segundo evento B, é
importante que ajustemos a probabilidade de B para refletir a ocorrência de A.
P(A B) = P(A/B).P(B) ou P(A B) = P(B/A).P(A)
Podemos assim dizer que:
P(A1 A2 A3 ... An) = P(A1).P(A2/A1).P(A3/A2 A1)...
A palavra-chave para lembrar é “e” com multiplicação.
Exemplo 5.5:
Num lote de 12 peças, 4 são defeituosas. Três peças são retiradas
aleatoriamente, uma após a outra. Encontre a probabilidade de todas essas 3 peças
serem não defeituosas.
Solução:
5.12. EVENTOS INDEPENDENTES
Dois eventos A e B são ditos independentes caso a probabilidade de um não
influenciar a probabilidade de outro ocorrer ou não, ou seja, se a probabilidade de B
ocorrer é igual à probabilidade condicional de B dado A, tem-se:
P(B) = P(B/A)
Pelo Teorema do Produto tem-se:
P(A B) = P(B/A).P(A)
Substituindo P(B/A) por P(B)
P(A B) = P(B).P(A)
A equação acima é usada como definição formal de independência.
Obs: Se A e B são mutuamente exclusivos, então A e B são dependentes, pois
se A ocorre, B não ocorre, isto é, a ocorrência de um evento condiciona a não-
ocorrência do outro.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
82
Figura 5.1: Aplicando o teorema do produto.
Exemplo 5.6:
Jogamos uma moeda e um dado. Qual a probabilidade de sair cara e depois um
seis?
Solução:
Exemplo 5.7:
Duas cartas são selecionadas de um baralho comum, sem reposição. Qual a
probabilidade de escolhermos um rei e da segunda carta ser uma dama?
Solução:
5.13. PROCESSOS ESTOCÁSTICOS FINITOS E DIAGRAMAS DE ÁRVORE
Um processo estocástico finito é uma sequência finita de experimentos, na qual
cada experimento tem um número finito de resultados. Esses processos podem ser
representados pelo diagrama da árvore e podemos aplicar a seguinte regra prática: a
probabilidade de um ramo da árvore é o produto das probabilidades que o compõem,
as probabilidades entre ramos devem ser somadas quando convier, pois são eventos
mutuamente exclusivos.
Exemplo 5.8:
Início
P(A B) teorema do produto
multiplicaçã
A e B são independentes?
P(A B) = P(B/A).P(A)
P(A B) = P(B).P(A)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
83
Vamos considerar três caixas: A caixa I tem 10 lâmpadas, das quais 4 são
defeituosas; a caixa II tem 6 lâmpadas, das quais 1 é defeituosa; e, a caixa III tem 8
lâmpadas, das quais 3 são defeituosas. Selecionamos uma caixa aleatoriamente e
então retiramos uma lâmpada, também aleatoriamente. Qual a probabilidade da
lâmpada ser defeituosa?
Solução:
Fazendo o diagrama de árvore, temos
Onde, D: lâmpadas defeituosas e P: lâmpadas perfeitas.
314,08
3.
3
1
6
1.
3
1
10
4.
3
1)D(P
)III/D(P).III(P)II/D(P).II(P)I/D(P).I(PP(D)
)DIII(P)DII(P)DI(PP(D)
5.14. TEOREMA DE BAYES
Sejam A1, A2, ..., An uma partição de S e B um evento qualquer. Para qualquer
Ai:
)/().(...)/().()/().(
)/().()/(
2211 nn
ii
iABPAPABPAPABPAP
ABPAPBAP
Exemplo 5.9:
Suponhamos que a pergunta do exemplo 5.8 anterior fosse: Se uma lâmpada for
selecionada ao acaso e for defeituosa, qual a probabilidade de ter vindo da caixa I?
Solução:
D: 4/10 I
P: 6/10 D: 1/6
II P: 5/6 D: 3/8
III P: 5/8
1/3
1/3
1/3

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
84
424,0314,0
133,0
8
3.
3
1
6
1.
3
1
10
4.
3
110
4.
3
1
)D/I(P
)D(P
)I/D(P).I(P
)D(P
)DI(PP(I/D)
Exercícios:
Exemplo 5.10:
Considere a tabela a seguir, que mostra os resultados de um levantamento no
qual foi perguntado a 102 homens e 103 mulheres, trabalhadores, com idade entre 25 e
64 anos, se tinham poupado para emergência pelo menos um mês de salário.
(LARSON, 2007)
Homens Mulheres Total
Menos de um salário mensal 47 59 106
Um salário mensal ou mais 55 44 99
Total 102 103 205
a) Qual é a probabilidade de um(a) trabalhador(a) selecionado(a) ao acaso, ter poupado um mês ou mais para emergência?
Solução:
b) Dado que um trabalhador selecionado ao acaso é homem, qual a
probabilidade dele ter poupado um mês ou menos?
Solução:
c) Dado que um trabalhador poupou um mês ou mais, qual a probabilidade de se
tratar de uma mulher?
Solução:
d) Os eventos de ter poupado um mês ou mais e de ser homem são
dependentes ou independentes? Explique.
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
85
Exemplo 5.11:
Numa certa cidade 40% da população tem cabelos castanhos, 25% tem olhos
castanhos e 15% tem olhos e cabelos castanhos. Uma pessoa da cidade é selecionada
aleatoriamente.
a) Se ela tem cabelos castanhos, qual a probabilidade de ter também olhos
castanhos?
Solução:
b) Se ela tem olhos castanhos, qual a probabilidade de não ter cabelos
castanhos?
Solução:
c) Qual a probabilidade de não ter olhos nem cabelos castanhos?
Solução:
Exemplo 5.12:
São dadas duas urnas. Uma urna A contém 5 bolas vermelhas, 3 brancas e 8
azuis. Uma urna B contém 3 bolas vermelhas e 5 brancas. Lançamos um dado não
viciado: se ocorrer 3 ou 6 uma bola é escolhida de B, caso contrário, uma bola é
escolhida de A.
Para auxiliar na solução vamos esquematizar o problema:
Qual a probabilidade de:
a) Uma bola vermelha ser escolhida?
Solução:
V
A B
A
B V
B
4/6
2/6
8/16
5/8
3/8
3/16
5/16

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
86
b) Uma bola branca ser escolhida?
Solução:
c) Uma bola azul ser escolhida?
Solução:
Exemplo 5.13:
Uma urna contém 7 bolas gravadas com as letras A, A, A, C, C, R, R. Se
extrairmos as bolas uma por uma, qual a probabilidade de se obter a palavra
CARCARA?
Solução:
Exemplo 5.14:
Uma urna A contém 5 bolas vermelhas e 3 brancas. Uma urna B contém 2 bolas
vermelhas e 6 brancas.
Vamos esquematizar:
a) Se uma bola é retirada de cada urna, qual a probabilidade de ambas serem
da mesma cor?
Solução:
b) Se duas bolas são retiradas de cada urna, qual a probabilidade de todas as 4
serem da mesma cor?
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
87
Exemplo 5.15:
Em uma prova caíram 2 problemas. Dos 60 alunos que realizaram a prova,
sabe-se que 37 alunos acertaram o primeiro problema, 40 acertaram o segundo e 25
acertaram ambos. Qual a probabilidade de que um aluno escolhido ao acaso tenha
acertado pelo menos 1 problema?
Solução:
Exemplo 5.16:
Em uma fábrica de parafusos, as máquinas X, Y e Z produzem 25%, 35% e
40%, respectivamente. Da produção de cada máquina, 5%, 4% e 2%, respectivamente,
são parafusos defeituosos. Escolhemos ao acaso um parafuso. Se ele é defeituoso,
qual a probabilidade de que tenha vindo da máquina Y?
Solução:
Fazendo o diagrama de árvore, onde, D: parafusos defeituosos e P: parafusos
perfeitos, temos:
Exemplo 5.17:
Na seção de relações públicas de uma grande loja de departamentos, a
probabilidade de uma queixa de um consumidor se referir a mercadoria defeituosa
(MD) é 0,65, a probabilidade de se referir a atraso na entrega (AE) é 0,30, e a
probabilidade de se referir a erros de faturamento (EF) é 0,05. As queixas sobre
mercadoria defeituosa têm 0,70 de probabilidade de serem resolvidas a contento, as
queixas sobre atraso na entrega têm 0,10 de probabilidade de ser resolvidas

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
88
satisfatoriamente, e as queixas sobre erros no faturamento têm 0,90 de probabilidade
de uma solução satisfatória.
a) Determine a probabilidade de uma queixa ser resolvida satisfatoriamente;
b) Se uma queixa foi resolvida satisfatoriamente, ache a probabilidade de ela se
referir a erro de faturamento.
Solução:
Fazendo o diagrama de árvore, e considerando R: queixa resolvida
satisfatoriamente e NR: queixa não resolvida satisfatoriamente.
Exemplo 5.18:
Um lote é formado por 10 peças boas, 4 com defeitos e 2 com defeitos graves.
Uma peça é escolhida ao acaso. Calcule a probabilidade de que:
a) Ela não tenha defeitos graves;
b) Ela não tenha defeitos;
c) Ela seja boa ou tenha defeitos graves.
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
89
Exemplo 5.19:
Considere o mesmo lote do exemplo 5.18. Retiram-se duas peças ao acaso.
Calcule a probabilidade de que:
a) Ambas sejam perfeitas;
Solução:
b) Nenhuma seja perfeita;
Solução:
c) Nenhuma tenha defeitos graves;
Solução:
d) Pelo menos uma seja perfeita.
Solução:
Exemplo 5.20:
Uma moeda é lançada três vezes. Calcule a probabilidade de obtermos:
a) Três caras;
b) Duas caras e uma coroa;
c) Uma cara somente;
d) Nenhuma cara;
e) Pelo menos uma cara.
Solução:
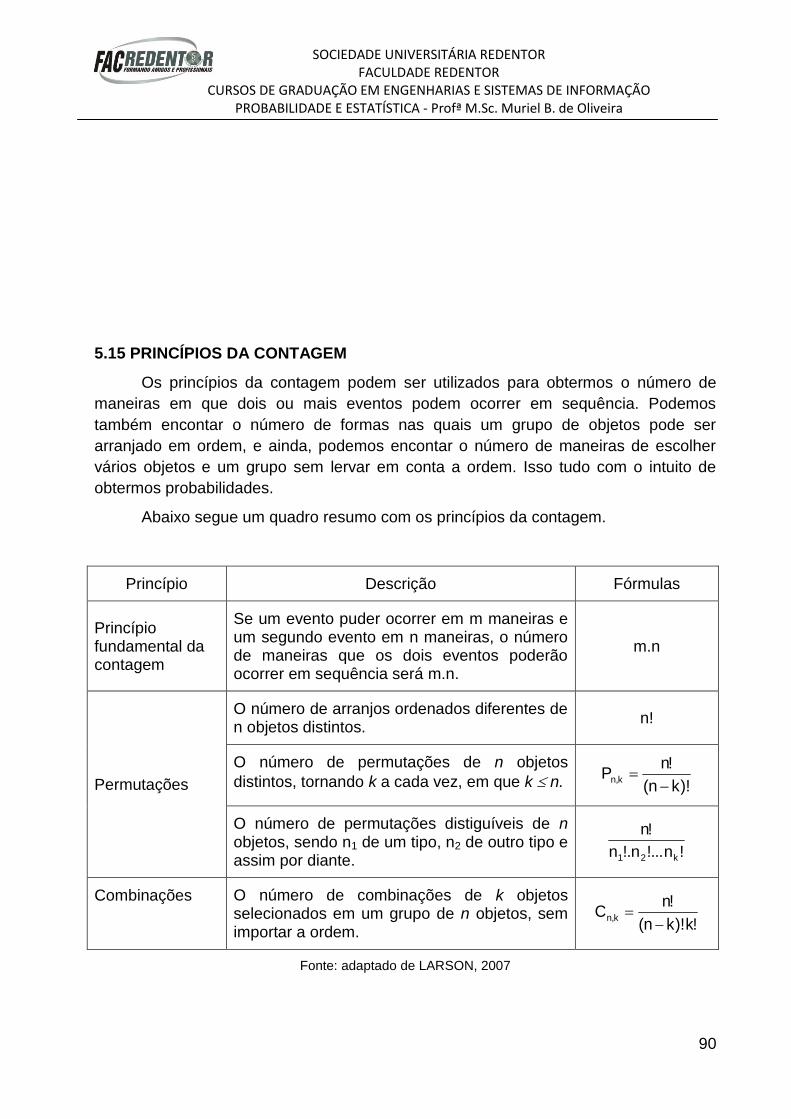
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
90
5.15 PRINCÍPIOS DA CONTAGEM
Os princípios da contagem podem ser utilizados para obtermos o número de
maneiras em que dois ou mais eventos podem ocorrer em sequência. Podemos
também encontar o número de formas nas quais um grupo de objetos pode ser
arranjado em ordem, e ainda, podemos encontar o número de maneiras de escolher
vários objetos e um grupo sem lervar em conta a ordem. Isso tudo com o intuito de
obtermos probabilidades.
Abaixo segue um quadro resumo com os princípios da contagem.
Princípio Descrição Fórmulas
Princípio fundamental da contagem
Se um evento puder ocorrer em m maneiras e um segundo evento em n maneiras, o número de maneiras que os dois eventos poderão ocorrer em sequência será m.n.
m.n
Permutações
O número de arranjos ordenados diferentes de n objetos distintos.
n!
O número de permutações de n objetos
distintos, tornando k a cada vez, em que k n. )!kn(
!nP k,n
O número de permutações distiguíveis de n objetos, sendo n1 de um tipo, n2 de outro tipo e assim por diante.
!n!...n!.n
!n
k21
Combinações O número de combinações de k objetos selecionados em um grupo de n objetos, sem importar a ordem.
!k)!kn(
!nC k,n
Fonte: adaptado de LARSON, 2007

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
91
VI – VARIÁVEIS ALEATÓRIAS
6.1- INTRODUÇÃO
Considere S um espaço amostral. Nem sempre os pontos amostrais de um
espaço amostral são números. Neste caso, é necessário definirmos uma função que
associe ou transforme o espaço amostral não numérico em espaço amostral numérico.
A função que faz essa associação é o que chamamos de variável aleatória.
A palavra aleatória indica que X é determinado por uma possibilidade. As
variáveis aleatórias podem ser discretas ou contínuas.
Se os possíveis valores de X(S) for um conjunto finito (ou infinito numerável) ou
se os possíveis valores de X(S) provém de uma contagem, isto é, possam ser
enumerados, diremos que é variável aleatória discreta (VAD).
Se os possíveis valores de X(S) podem assumir infinitos valores (infinito não
numerável), ou se os possíveis valores de X(S) provém de uma medição, representada
por um intervalo sobre o eixo real, diremos que é variável aleatória contínua (VAC).
Vejamos agora os dois tipos de variáveis aleatórias:
6.2. VARIÁVEL ALEATÓRIA DISCRETA
Vamos iniciar com um exemplo:
Exemplo 6.1:
Lançamento de duas moedas. Seja X: contar o número de caras que ocorrem,
onde, c = cara e k = coroa.
S = {(c, c), (c, k), (k, c), (k, k)}
X = {0, 1, 2}
O número de eventos que correspondem à ocorrência de nenhuma, uma ou
duas caras respectivamente é dado pela seguinte associação:
X Evento
0 A1 = {(k, k)}
1 A2 = {(c, k), (k, c)}
2 A3 = {(c, c)}
Podemos também associar as probabilidades de X assumir um dos valores, as
probabilidades dos eventos correspondentes:
P(X = 0) = P(A1) = 1/4

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
92
P(X = 1) = P(A2) = 2/4
P(X = 2) = P(A3) = 1/4
A cada valor de uma variável aleatória discreta podemos atribuir uma
probabilidade. Ao enumerar cada valor da variável aleatória com a sua probabilidade
correspondente, temos uma distribuição de probabilidade.
A distribuição de probabilidade da variável aleatória X é:
X P(X)
0 1/4
1 1/2
2 1/4
Assim temos:
Definição 1: Uma variável aleatória discreta é uma função que associa a cada ponto amostral um número real.
Definição 2: Uma distribuição discreta de probabilidade enumera cada valor que a variável aleatória pode assumir, ao lado de uma probabilidade. Uma distribuição de probabilidade deve satisfazer as seguintes condições:
0)x(p)i(
1)x(p)ii(
6.2.1. Construção de uma distribuição discreta de probabilidade
Tenha em mente que x é uma variável aleatória discreta com os resultados
possíveis x1, x2, ..., xn.
Estabeleça uma distribuição de frequência para os resultados possíveis.
Obtenha a soma de todas as frequências para os resultados possíveis.
Calcule a probabilidade de cada resultado possível dividindo sua frequência pela soma das frequências.
Verifique se cada probabilidade está entre 0 e 1 e se sua soma é 1.
6.2.2. Média ou valor esperado ou esperança matemática
Dada uma variável aleatória discreta X, com a função de probabilidade p(x),
então a média ou valor esperado de X, denotada por E(X) ou , é definida por:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
93
)(....)(.)(.)(.)( 2211
1
nn
n
i
ii xpxxpxxpxxpxXE
Exemplo 6.2:
Obtenha o número médio de caras da distribuição de probabilidade para o
exemplo de lançamento de 2 moedas e contar o número de caras.
Solução:
A distribuição de probabilidade do exemplo está descrita na tabela a seguir:
X P(X)
0 1/4
1 1/2
2 1/4
Assim, a média (esperança) da distribuição é:
14
12
2
11
4
10)(.)(
2
0
xxxxpxXEi
ii
Propriedades da média:
Sendo X uma variável aleatória e k um número real, então:
1º) E(k) = k
2º) E(k.X) = k . E(X)
3º) E(X Y) = E(X) E(Y)
4º) n21n21
n
1i
i
n
1i
i XE...XEXEX...XXEXEXE
5º) E(aX bY) = a.E(X) b.E(Y)
6.2.3. Variância
A medida de dispersão ou espalhamento da distribuição da variável aleatória X
será dada por:
n
i
ixi XExpxXVAR1
22)(.)(

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
94
Notações utilizadas: VAR(X), V(X), 2(X), 2.
Da definição de variância é possível deduzir uma fórmula mais fácil
operacionalmente de ser aplicada.
22 )()( XEXEXVAR
Onde:
n
1i
i
2
i
2 xp.xXE
O Desvio Padrão é dado por:
)(XVAR
Exemplo 6.3:
Obtenha a variância e o desvio padrão da distribuição de probabilidade para o
exemplo de lançamento de 2 moedas e contar o número de caras.
Solução:
Lembramos que o valor da esperança (média) calculada no exemplo 6.2 foi de
E(X) = 1 e a distribuição de probabilidade encontra-se na tabela a seguir.
X P(X)
0 1/4
1 1/2
2 1/4
Precisamos calcular o valor de E(X2):
2
3
4
12
2
11
4
10)(.)( 222
2
0
22
xxxxpxXEi
ii
Assim:
2
11
2
3)()(
222 XEXEXVAR
71,02
1)( XVAR
Propriedades da Variância:
Sendo X uma variável aleatória e k um número real então:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
95
1º) VAR(k) = 0
2º) VAR(X + k) = VAR(X)
3º) VAR(k.X) = k2.VAR(X)
4º) VAR(aX + b) = a2.VAR(X)
5º) Cov(X,Y) = E(XY) – E(X).E(Y)
6º) VAR(X Y) = VAR(X) + VAR(Y) 2.Cov(X, Y)
Exemplo 6.4:
O psicólogo de uma empresa ministrou um teste de personalidade para
determinar características passivas/agressivas em 150 funcionários. Aos indivíduos
foram atribuídos valores de 1 a 5, em que 1 representava o extremo passivo e 5, o
extremo agressivo. Um escore de 3 indicava não haver nenhuma característica
preponderante. Os resultados constam no quadro abaixo. Estabeleça uma distribuição
de probabilidade para a variável aleatória x, calcule a média, a variância e o desvio
padrão.
x fi
1 24
2 33
3 42
4 30
5 21
Solução:
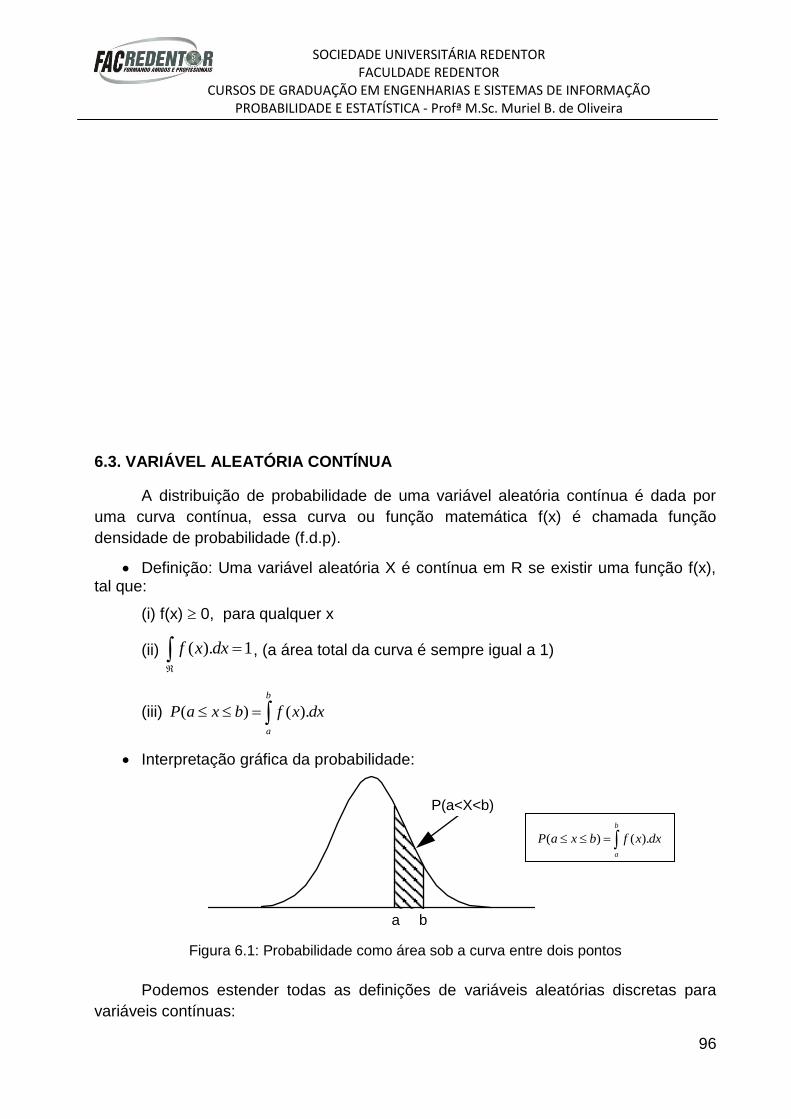
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
96
6.3. VARIÁVEL ALEATÓRIA CONTÍNUA
A distribuição de probabilidade de uma variável aleatória contínua é dada por
uma curva contínua, essa curva ou função matemática f(x) é chamada função
densidade de probabilidade (f.d.p).
Definição: Uma variável aleatória X é contínua em R se existir uma função f(x), tal que:
(i) f(x) 0, para qualquer x
(ii)
1).( dxxf , (a área total da curva é sempre igual a 1)
(iii)
b
a
dxxfbxaP ).()(
Interpretação gráfica da probabilidade:
Figura 6.1: Probabilidade como área sob a curva entre dois pontos
Podemos estender todas as definições de variáveis aleatórias discretas para
variáveis contínuas:
a b
P(a<X<b)
b
a
dxxfbxaP ).()(

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
97
Esperança: R
dx)x(f.x)x(Eμ
Variância: R
2dx)x(f.XEx)x(VAR ou 22 )X(E)X(E)X(VAR
onde dx)x(fx)X(ER
22
Exemplo 6.5:
Verificar se
0
3x2)x(f
2x,0x
2x0
é uma f.d.p.
Solução:
Para que f(x) seja uma f.d.p. é necessário que
1dx).x(f . Assim,
2
0
2
0
2 1064332 xxdxx
Logo f(x) NÃO é uma f.d.p.
6.4. VARIÁVEL ALEATÓRIA PADRONIZADA OU REDUZIDA
Seja X uma variável aleatória com média (µ) e desvio padrão (σ), a variável
resultante da operação:
σ
μXz
é dita variável aleatória padronizada ou reduzida.
Propriedades de Z
Média: 0μμσ
1μEXE
σ
1μXE
σ
1μX
σ
1E
σ
μXEzE
Variância: 1σσ
1μXVAR
σ
1μX
σ
1VAR
σ
μXVARzVAR 2
22
Z: N (0, 1)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
98
6.5. DISTRIBUIÇÕES DE PROBABILIDADE PARA VARIÁVEIS ALEATÓRIAS DISCRETAS
6.5.1. DISTRIBUIÇÃO BINOMIAL
Há muitos experimentos probabilísticos para os quais a conclusão de cada
tentativa pode ser reduzida a dois resultados: sucesso ou fracasso. Quando um jogador
de basquete tente um lançamento livre, por exemplo, das duas, uma: ou ele faz a cesta
ou não. Experimentos probabilísticos como esse são chamados binomiais.
Um experimento binomial tem as seguintes características:
São realizadas n tentativas independentes de um mesmo experimento aleatório;
Cada tentativa admite apenas dois resultados. Os resultados podem ser classificados como um sucesso (p) ou um fracasso (q).
A probabilidade p de sucesso em cada tentativa é constante
Seja X: número de sucessos em n tentativas. A função de probabilidade da
variável X será obtida pela relação:
knk
k,n q.p.C)kX(P , com !kn!k
!nC k,n
Onde:
k: o número de sucessos
n: o número de tentativas ou observações
p: probabilidade de sucesso em cada tentativa
q: probabilidade de fracasso em cada tentativa
A variável X tem distribuição binomial, com parâmetros n e p, e indicaremos pela
notação: X: B ( n, p).
Parâmetros da Distribuição Binomial
Média: E(X) = n.p
Variância: VAR(X) = n.p.q
Exemplo 6.6:
Os registros de uma empresa prestadora de serviços indicam que 40% das
faturas por ela emitidas são pagas após o vencimento. De 14 faturas expedidas,
determine:
a) a probabilidade de nenhuma ser paga após o vencimento;

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
99
b) a probabilidade de no máximo duas serem pagas após o vencimento;
c) a probabilidade de ao menos três serem pagas após o vencimento;
d) o valor esperado do número de faturas pagas após o vencimento e o desvio
padrão.
Solução:
Seja X: número de faturas pagas após o vencimento, então:
a) P(X = 0) = ? temos que: p = 0,40; q = 0,60; k = 0
knk
k,n q.p.C)kX(P
!k)!kn(
!nC k,n
00078,0)0X(P
)60,0.()40,0.(!14
!14)60,0.()40,0.(
!0)!014(
!14)60,0.()40,0.(C)0X(P 1401400140
0,14
b)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
100
6.5.2. DISTRIBUIÇÃO DE POISSON
A distribuição de Poisson é uma distribuição de probabilidade discreta muito
importante para descrever o comportamento de eventos raros, com a probabilidade do
número de ocorrências num intervalo contínuo (tempo ou espaço).
Por exemplo: número de defeitos por lote em determinado produto, número de
chamadas telefônicas em um certo minuto, usuários de internet que tentam entrar em
um certo site.
A unidade de medida (tempo ou espaço) é uma variável contínua, mas a variável
aleatória (número de ocorrências) é discreta. Além disso, as falhas não são contáveis,
por exemplo, não podemos determinar a probabilidade do número de carros que
deixaram de passar num cruzamento.
A função de probabilidade da variável X será obtida pela relação:
!k
μ.e)kX(P
kμ
onde = .t
Onde:
= coeficiente de proporcionalidade
t = tempo ou espaço
A distribuição de Poisson difere da distribuição binomial em dois aspectos
importantes:
i) A distribuição Binomial é afetada pelo n e por p, enquanto que a distribuição
de Poisson é afetada pela média (µ);
ii) Na distribuição Binomial os possíveis valores da variável aleatória x são 0, 1,
2, ..., n; enquanto que na distribuição de Poisson os possíveis valores da variável
aleatória x são 0, 1, 2, ... sem o limite superior.
Parâmetros da Distribuição de Poisson
Média: E(X) =
Variância: VAR(X) =
Exemplo 6.7:
As chamadas de emergência chegam a uma delegacia de polícia a razão de 4
por hora em dias úteis.
a) quantas chamadas de emergência são esperadas num período de 30
minutos?

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
101
b) qual a probabilidade de nenhuma chamada num período de 30 minutos?
c) qual a probabilidade de ocorrer ao menos duas chamadas no mesmo
período?
Solução:
X: número de chamadas e = 4/h
6.5.3. APROXIMAÇÃO DA DISTRIBUIÇÃO BINOMIAL PELA DISTRIBUIÇÃO DE POISSON
Uma outra aplicação imediata deste modelo foi estudada por Poisson que
verificou o que acontecia com a função Binomial, quando o número de repetições
crescia e p diminuía e concluiu que:
!k
np.eq.p.Clim
knpknk
k,n
0p
n
Onde:
n.p = é a média de sucessos dentro do espaço considerado.
Na distribuição Binomial quando n 100 e n.p 10 a distribuição de Poisson
pode ser utilizada como aproximação de probabilidades Binomiais.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
102
Exemplo 6.8:
A probabilidade de uma lâmpada se queimar ao ser ligada é 1/100. Numa
instalação com 100 lâmpadas, qual a probabilidade de 2 lâmpadas se queimarem ao
serem ligadas?
Solução:
X: número de lâmpadas que queimam ao serem ligadas
Pela distribuição Binomial: p = 0,01 e q = 0,99
184,0)2X(P
)99,0.()01,0.(!2)!2100(
!100)99,0.()01,0.(C)2X(P 98221002
2,100
Pela distribuição de Poisson:
101,0.100p.n
< 5 e n > 30, ok! Podemos aproximar por Poisson
!k
μ.e)kX(P
kμ
184,0!2
1.e)2X(P
21
As distribuições Binomial e Poisson são distribuições discretas de probabilidade.
Agora vamos ver uma distribuição contínua.
6.6. DISTRIBUIÇÃO NORMAL
É uma das mais importantes distribuições de probabilidades (contínua), sendo
aplicada em inúmeros fenômenos e constantemente utilizada para o desenvolvimento
teórico da inferência estatística. É também conhecida como distribuição de Gauss,
Laplace ou Laplace-Gauss.
Foi notado que diversas variáveis contínuas possuíam um comportamento
semelhante independente do experimento de que eram provenientes. Notou-se
também que em diversos experimentos, quando se usavam amostras grandes existia
tendência do comportamento ser semelhante. Este comportamento era senoidal, numa
curva simétrica e mesocúrtica.
O gráfico da função densidade de uma variável normal tem a forma de um sino e
é simétrico em relação à média μ.
Notação: N (, 2).
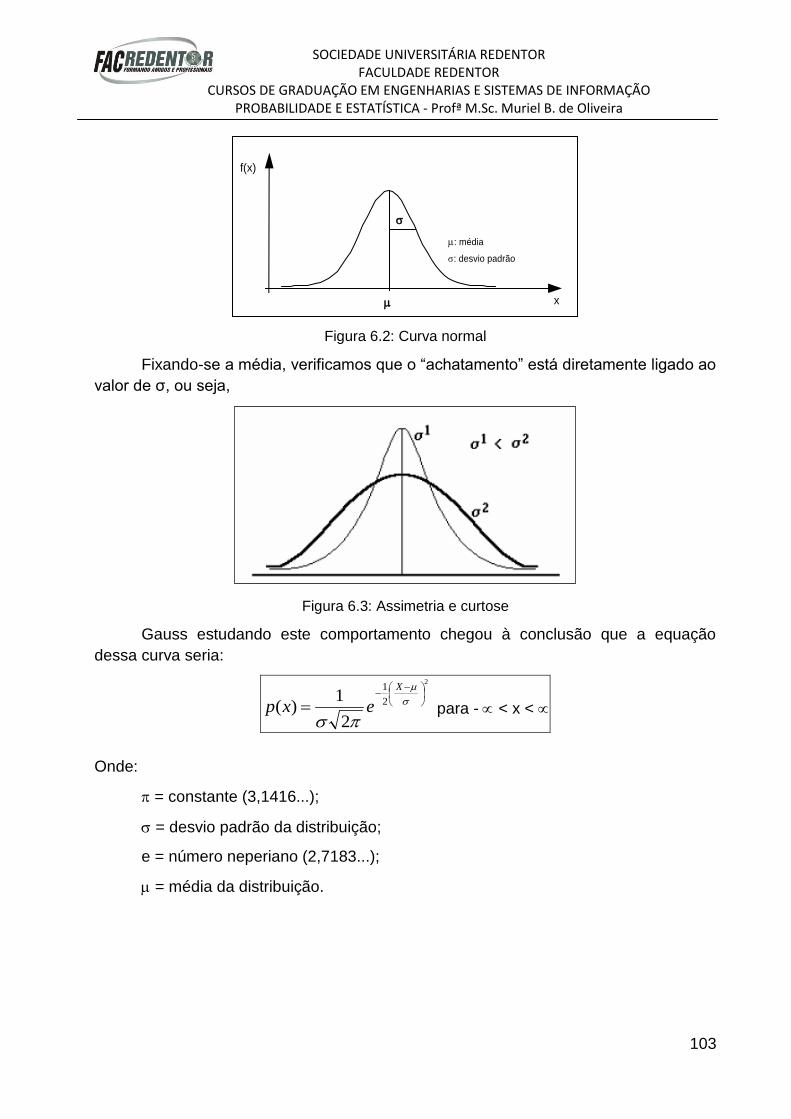
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
103
Figura 6.2: Curva normal
Fixando-se a média, verificamos que o “achatamento” está diretamente ligado ao
valor de σ, ou seja,
Figura 6.3: Assimetria e curtose
Gauss estudando este comportamento chegou à conclusão que a equação
dessa curva seria:
2
2
1
2
1)(
X
exp para - < x <
Onde:
= constante (3,1416...);
= desvio padrão da distribuição;
e = número neperiano (2,7183...);
= média da distribuição.
: média
: desvio padrão
x
f(x)
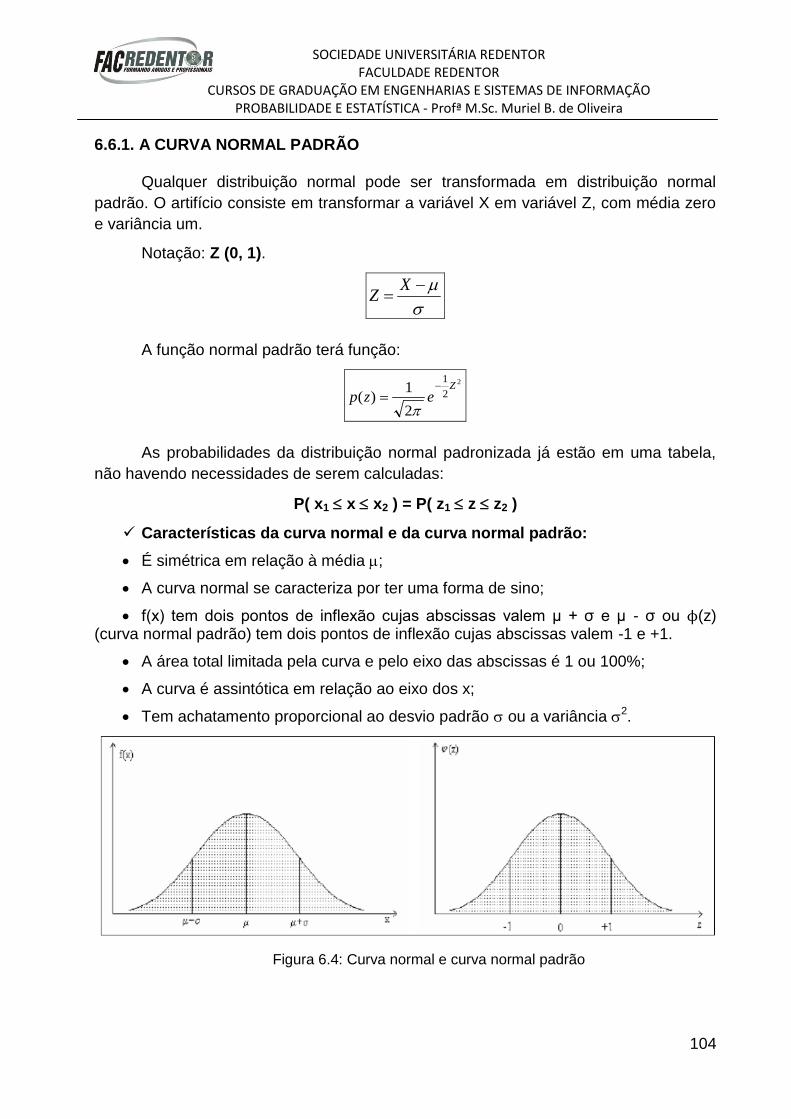
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
104
6.6.1. A CURVA NORMAL PADRÃO
Qualquer distribuição normal pode ser transformada em distribuição normal
padrão. O artifício consiste em transformar a variável X em variável Z, com média zero
e variância um.
Notação: Z (0, 1).
XZ
A função normal padrão terá função:
2
2
1
2
1)(
Z
ezp
As probabilidades da distribuição normal padronizada já estão em uma tabela,
não havendo necessidades de serem calculadas:
P( x1 x x2 ) = P( z1 z z2 )
Características da curva normal e da curva normal padrão:
É simétrica em relação à média ;
A curva normal se caracteriza por ter uma forma de sino;
f(x) tem dois pontos de inflexão cujas abscissas valem μ + σ e μ - σ ou ϕ(z) (curva normal padrão) tem dois pontos de inflexão cujas abscissas valem -1 e +1.
A área total limitada pela curva e pelo eixo das abscissas é 1 ou 100%;
A curva é assintótica em relação ao eixo dos x;
Tem achatamento proporcional ao desvio padrão ou a variância 2.
Figura 6.4: Curva normal e curva normal padrão
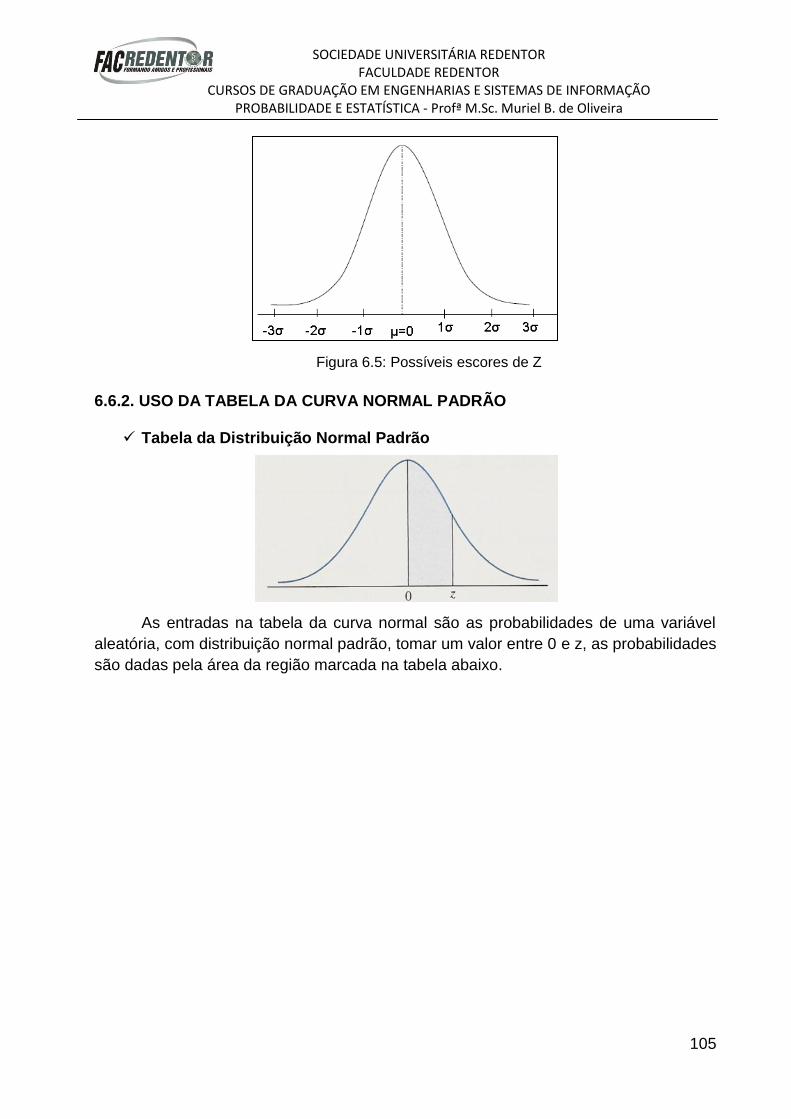
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
105
Figura 6.5: Possíveis escores de Z
6.6.2. USO DA TABELA DA CURVA NORMAL PADRÃO
Tabela da Distribuição Normal Padrão
As entradas na tabela da curva normal são as probabilidades de uma variável
aleatória, com distribuição normal padrão, tomar um valor entre 0 e z, as probabilidades
são dadas pela área da região marcada na tabela abaixo.
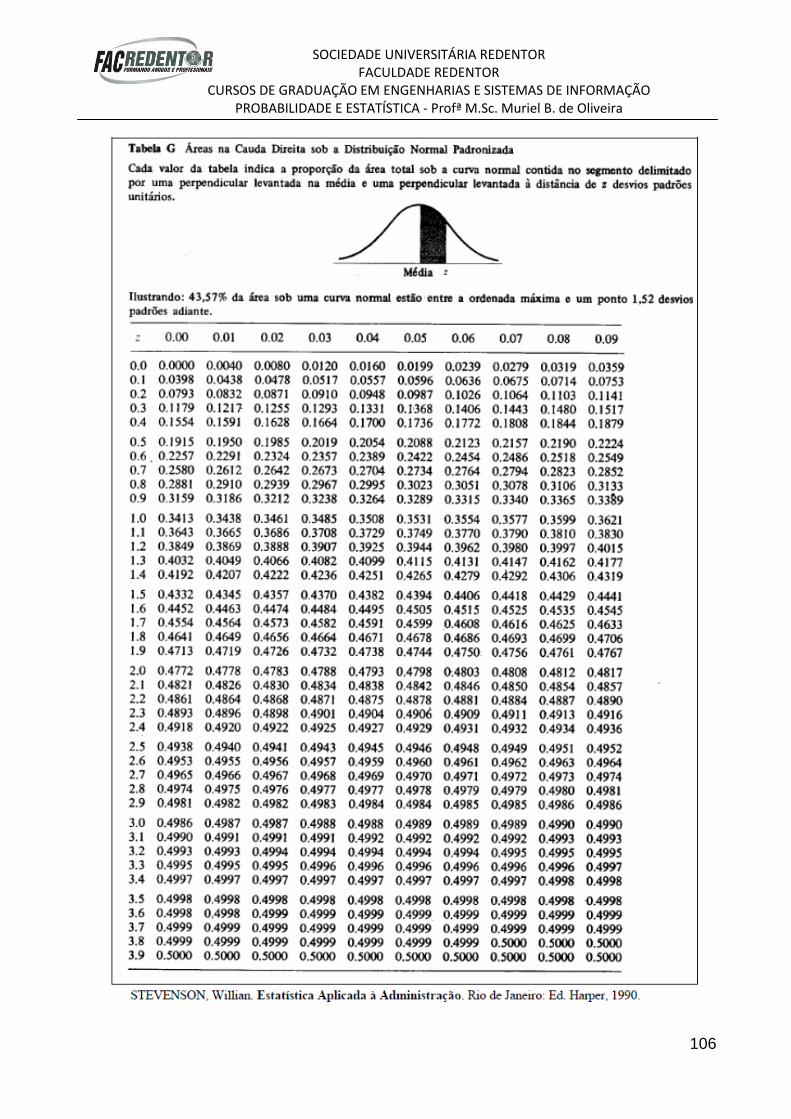
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
106
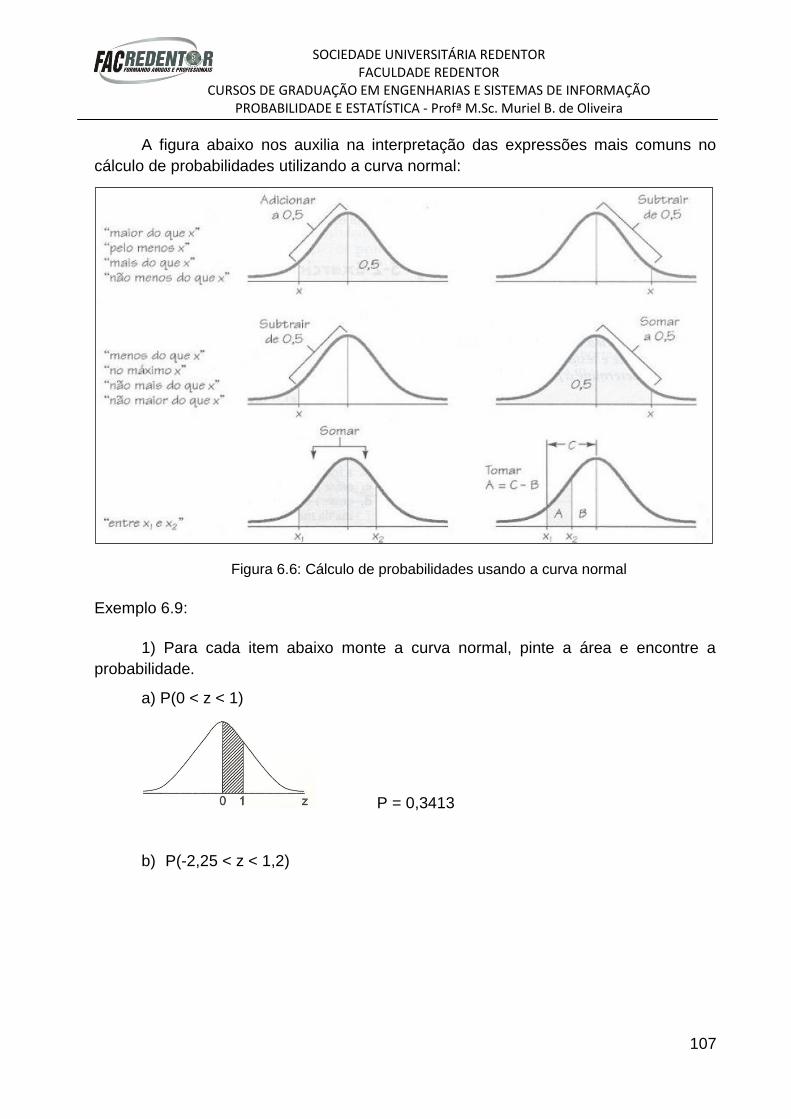
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
107
A figura abaixo nos auxilia na interpretação das expressões mais comuns no
cálculo de probabilidades utilizando a curva normal:
Figura 6.6: Cálculo de probabilidades usando a curva normal
Exemplo 6.9:
1) Para cada item abaixo monte a curva normal, pinte a área e encontre a
probabilidade.
a) P(0 < z < 1)
P = 0,3413
b) P(-2,25 < z < 1,2)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
108
c) P(z > 1,93)
d) z = 0 e z = 2,52
e) z = 1,02 e z = 3,2
f) z -2,67
g) z -1,53

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
109
Exemplo 6.10:
As alturas dos alunos de determinada escola são normalmente distribuídas com
média 1,60m e desvio padrão de 0,30m. Encontre a probabilidade de um aluno medir:
a) Entre 1,50 e 1,80m
b) Mais de 1,75
c) Menos de 1,48
Solução: Temos que a média = 1,60 e o desvio padrão = 0,30 e σ
μxz
a) P(1,50 X 1,80)
33,030,0
60,150,1z1
67,0
30,0
60,180,1z2
Obs: arredondamos o resultado de z para duas casas decimais para entrar na tabela.
Com os valores de z entramos na tabela e calculamos a probabilidade pedida:
P(1,50 X 1,80) = P(-0,33 z 0,67) = 0,1293 + 0,2486 = 0,3779
b)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
110
6.6.3. APROXIMAÇÃO NORMAL PARA DISTRIBUIÇÃO BINOMIAL
Os casos em que o tamanho da amostra é n 30 o cálculo pela distribuição
Binomial começa a ser trabalhoso, no entanto, através do Teorema do Limite Central
as distribuições de probabilidade tendem à normal, quando aumenta o tamanho da
amostra, nesse caso é necessário adaptar uma distribuição discreta a uma contínua.
Teorema Central do Limite
Uma razão para a distribuição Normal ser considerada tão importante é porque
qualquer que seja a distribuição da variável de interesse para grande amostras, a
distribuição das médias amostrais serão aproximadamente normalmente distribuídas, e
tenderão a uma distribuição normal à medida que o tamanho de amostra crescer.
Então podemos ter uma variável original com uma distribuição muito diferente da
Normal (pode até mesmo ser discreta), mas se tomarmos várias amostras grandes
desta distribuição, e então fizermos um histograma das médias amostrais, a forma se
parecerá como uma curva Normal.
A distribuição da média amostral X é aproximadamente Normal com
média e desvio padrão n
σ, onde n é o tamanho da amostra.
A aproximação para a normal melhora à medida que o tamanho amostral cresce.
Este resultado é conhecido como o Teorema Central do Limite e é notável porque nos
permite conduzir alguns procedimentos de inferência sem qualquer conhecimento da
distribuição da população.
Quando usar uma distribuição normal para aproximar uma probabilidade
binomial é necessário mover 0,5 unidades para esquerda e para direita de ponto médio
a fim de incluir todos os valores possíveis de x no intervalo.
Exemplo 6.11:
Consideremos o lançamento de 10 vezes uma moeda e vamos achar a
distribuição de probabilidade do evento cara:
xi 0 1 2 3 4 5 6 7 8 9 10
P(xi) 0,001 0,01 0,045 0,12 0,21 0,25 0,21 0,12 0,045 0,01 0,001
Determine: P(5 x 8)
Solução:
Por Binomial: p= 0,5; q = 0,5; n =10
P(5 x 8) = P(x=5) + P(x=6) + P(x=7) + P(x=8)
P(x=5) = C10,5.(0,5)5.(0,5)5 = 0,25
P(x=6) = C10,6.(0,5)6.(0,5)4 = 0,21
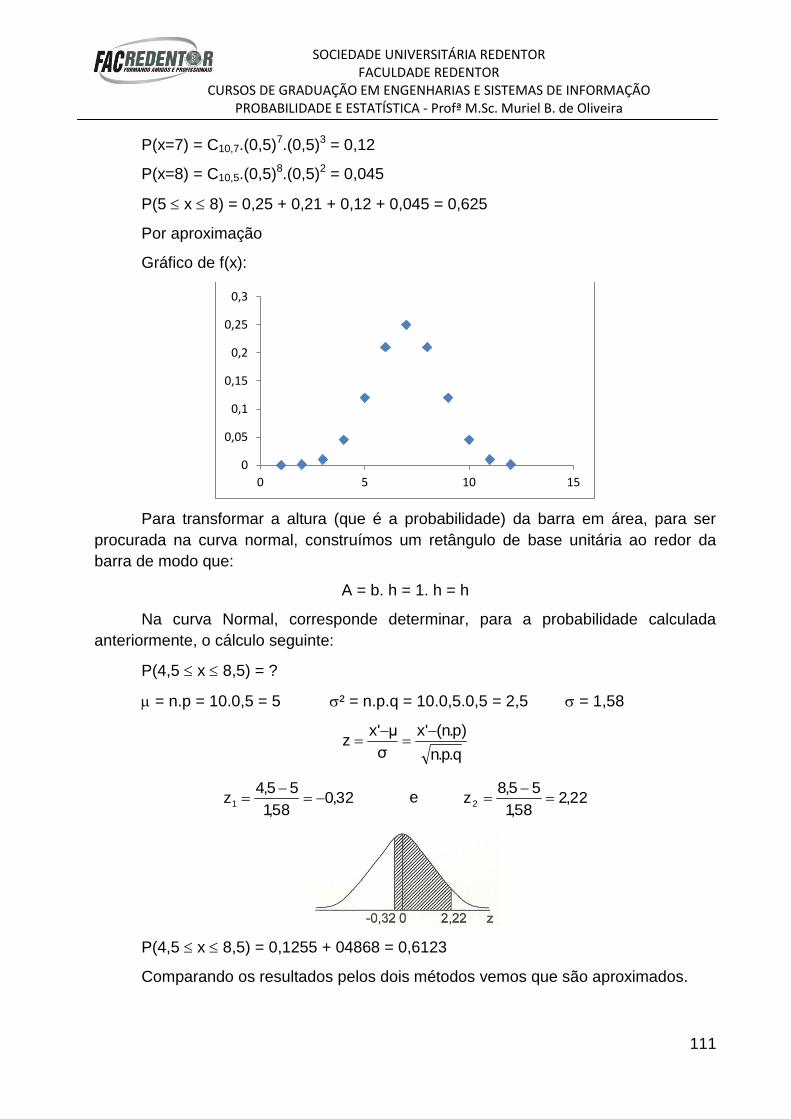
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
111
P(x=7) = C10,7.(0,5)7.(0,5)3 = 0,12
P(x=8) = C10,5.(0,5)8.(0,5)2 = 0,045
P(5 x 8) = 0,25 + 0,21 + 0,12 + 0,045 = 0,625
Por aproximação
Gráfico de f(x):
Para transformar a altura (que é a probabilidade) da barra em área, para ser
procurada na curva normal, construímos um retângulo de base unitária ao redor da
barra de modo que:
A = b. h = 1. h = h
Na curva Normal, corresponde determinar, para a probabilidade calculada
anteriormente, o cálculo seguinte:
P(4,5 x 8,5) = ?
= n.p = 10.0,5 = 5 ² = n.p.q = 10.0,5.0,5 = 2,5 = 1,58
q.p.n
)p.n('x
σ
μ'xz
32,058,1
55,4z1
e 22,2
58,1
55,8z2
P(4,5 x 8,5) = 0,1255 + 04868 = 0,6123
Comparando os resultados pelos dois métodos vemos que são aproximados.
0
0,05
0,1
0,15
0,2
0,25
0,3
0 5 10 15

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
112
No entanto, se obedecermos à regra que n 30 e n.p 5, o resultado da
aproximação é ainda melhor.
Vale a pena utilizar a aproximação pois dependendo do que quisermos calcular,
a distribuição binomial pode envolver muitos cálculos e se tornar trabalhosa.
Exemplo 6.12:
Vamos fazer a correção para:
a) P(4 < x 7) =
b) P(3 x 8) =
c) P(x 2) =
d) P(x < 5) =
e) P(x = 4) =
Exemplo 6.13:
Sabe-se que 20% das peças produzidas por uma siderurgia são defeituosas.
Selecionam-se, ao acaso e com reposição, 100 peças da produção. Qual é a
probabilidade de encontrarmos de 15 a 30 defeituosas?
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
113
6.6.4. APROXIMAÇÃO NORMAL PARA DISTRIBUIÇÃO DE POISSON
Podemos fazer uso desta aproximação quando: = .t >10
A distribuição de Poisson pode ser aproximada pela curva normal, mas não
podemos esquecer-nos de fazer a correção de continuidade.
Exemplo 6.14:
O SAC de uma empresa recebe em média 6,1 chamadas por minuto. Qual a
probabilidade de chegarem de 700 a 750 chamadas em 2 horas?
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
114
7- TEORIA DA AMOSTRAGEM E DA DECISÃO
7.1- INTRODUÇÃO
A inferência estatística pode ser dividida em estimação de parâmetros e em
teste de hipóteses. É importante destacarmos que sempre que uma estatística seja
uma variável aleatória, ela terá uma distribuição de probabilidades. Chamamos a
distribuição de probabilidades de uma estatística de uma distribuição amostral.
Amostragem é o processo de determinação de uma amostra a ser pesquisada.
Desta forma, a teoria da amostragem estuda as relações existentes entre uma
população e as amostras extraídas dessa população. É útil para avaliação de
grandezas desconhecidas da população (como a média, a variância, etc), ou para
determinar se as diferenças observadas entre duas amostras são devidas ao acaso ou
se são verdadeiramente significativas (Teste de Hipóteses).
A diferença entre censo e amostragem, como vimos no capítulo 1, é que,
enquanto um censo envolve um exame a todos os elementos de um dado grupo, a
amostragem envolve um estudo de apenas uma parte dos elementos. A amostragem
consiste em selecionar parte de uma população e observá-la com vista a estimar uma
ou mais características para a totalidade da população.
7.2. AMOSTRAGEM ALEATÓRIA SIMPLES
É o processo mais elementar e frequentemente utilizado. Esse tipo de
amostragem utiliza uma técnica probabilística. A característica principal é que todos os
elementos da população têm igual probabilidade de pertencer à amostra.
Na prática a amostragem aleatória simples pode ser realizada numerando-se a
população de 1 a N e sorteando-se, a seguir, por meio de um dispositivo aleatório
qualquer, k números dessa sequência, os quais corresponderão aos elementos
pertencentes à amostra.
7.3. AMOSTRAS COM E SEM REPOSIÇÃO
Como vimos, se cada elemento da população pode ser escolhido mais de uma
vez para participar de uma mesma amostra temos a chamada amostra com reposição.
Se cada elemento da população puder ser escolhido apenas uma única vez para
participar de uma mesma amostra, temos a chamada amostra sem reposição.
Na prática, é demonstrado que o uso de amostras sem reposição acarreta em
menores erros do que com amostras com reposição.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
115
7.4. DISTRIBUIÇÕES AMOSTRAIS
Toda a variável aleatória é chamada de uma estatística, logo uma estatística é
qualquer função das observações em uma amostra aleatória.
Consideremos todas as amostras possíveis de tamanho n que podem ser
retiradas de uma população de tamanho N (com ou sem reposição).
Para cada amostra podemos calcular uma grandeza estatística, como a média, o
desvio padrão etc., que varia de amostra para amostra. Com os valores obtidos para
determinada grandeza, podemos construir uma distribuição de probabilidades, que será
denominada de distribuição amostral.
O quadro abaixo mostra as notações mais utilizadas pra algumas medidas:
Medidas População
(Parâmetros)
Amostra
(Estatística)
Tamanho N n
Média Aritmética µ x
Variância 2 s2
Desvio Padrão s
7.5. DISTRIBUIÇÃO AMOSTRAL DAS MÉDIAS
Se os valores da média e do desvio padrão de uma população, de tamanho N,
forem respectivamente µ e , e desta população são retiradas todas as possíveis
amostras de tamanho n, sendo n ≤ N, temos os valores da média e do desvio padrão
da distribuição amostral das médias dados por:
Teorema 1:
A média da distribuição amostral das médias, denotada por x
μ é igual à média
populacional µ. Ou seja:
μμx
Teorema 2:
Se a população é infinita ou se a amostragem é com reposição, então a
variância (2
xσ ) e o desvio-padrão (
xσ ) da distribuição amostral das médias são dados
por:
n
σσ
22
x e
n
σσ
x

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
116
onde n é o número de elementos da amostra.
Teorema 3:
Se a distribuição é finita ou se amostragem é sem reposição, então a variância e
o desvio-padrão da distribuição amostral das médias são dados por:
1N
nN.
n
22
x e
1N
nN.
nx
onde 1N
nN
representa o fator de correção para população finita.
Teorema 4 (Teorema do Limite Central):
Se a população tem ou não distribuição normal com média µ e variância 2,
então a distribuição das médias amostrais será normalmente distribuída com média
μμx e variância
n
σσ
22
x para populações infinitas e
1N
nN.
n
22
x para
populações finitas. Além disso, temos:
Variável aleatória padronizada de x : x
x
σ
μxz
Validade do teorema do limite central:
n > 30, entretanto, em várias situações, dependendo da forma da distribuição da
população, amostras com n < 30 são suficientes para garantir a validade da teoria
central do limite. O teorema central do limite é muito utilizado na inferência estatística.
Obs: O fator de correção para população finita pode ser omitido sempre que
n < 0,05 N.
A distribuição amostral das proporções pode ser considerada como normal para
grandes valores (n ≥ 30). Neste caso, devemos subtrair ou acrescentar de P, uma
correção de continuidade para podermos utilizar a tabela da curva normal. A soma ou
subtração de CC a P ocorre de forma a sempre aumentar a área de probabilidade a ser
calculada.
Correção de continuidade (CC) : n
5,0
n2
1CC

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
117
7.6. DISTRIBUIÇÃO AMOSTRAL DAS PROPORÇÕES
Admita uma população infinita distribuída binomialmente, onde p é a
probabilidade de sucesso da população e q é a probabilidade de fracasso da população
e p + q = 1.
Consideremos todas as possíveis amostras de tamanho n retiradas de uma
população de tamanho N, com reposição. Se para cada amostra calcularmos a
probabilidade de sucesso desta amostra
n
xp onde x é o número de sucessos da
amostra, obtemos desta maneira a distribuição amostral das proporções:
PμP n
pqσ
2
P n
pqσP
ara n ≥ 30, a distribuição amostral de proporções será normal e P
P
σ
μPz
.
Se a população for finita ou se a amostragem for tomada sem reposição, os
valores acima passam a ser:
PμP
1N
nN.
n
pqσ
2
P 1N
nN.
n
pqσP
7.7. ERRO PADRÃO
O desvio padrão da distribuição amostral de uma grandeza estatística é
freqüentemente denominado de seu erro padrão.
Então temos que x
σ é chamado de erro padrão da média e Pσ é chamado de
erro padrão da proporção.
7.8. DISTRIBUIÇÃO AMOSTRAL DAS DIFERENÇAS DAS MÉDIAS OU DAS
PROPORÇÕES
Considere duas populações onde são retiradas amostras de tamanho n1 e n2
cujas médias são 1x e 2x , respectivamente. Sendo as médias e os desvios padrões
das populações μ1, σ1 e μ2, σ2, respectivamente.
Na distribuição amostral das diferenças entre as médias, temos:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
118
21xxμμμ
21
2
2
2
1
2
1xx
2
n
σ
n
σσ 21
2
2
2
1
2
1
xx n
σ
n
σσ
21
21
21
xx
xx21
σ
μxxz
Na distribuição amostral das diferenças entre as proporções, temos:
21PP PPμ21
2
22
1
11PP
2
n
q.p
n
q.pσ
21
2
22
1
11PP
n
q.p
n
q.pσ
21
21
21
PP
PP21
σ
μPPz
Vamos ver agora alguns exemplos de aplicação.
Exemplo 7.1:
Considere a seguinte população x = {2, 3, 4, 5}.
Podemos calcular a média, a variância e o desvio-padrão para a população,
assim:
12,125,1σ
25,14
)5,35()5,34()5,33()5,32(σ
5,34
5432μ
4N
22222
Exemplo 7.2:
A média das notas obtidas na disciplina de Estatística num determinado curso de
graduação tem sido igual a 7,7 e a variância igual a 1,96. Caso sejam extraídas várias
amostras de 49 alunos cada uma, do total de 586 que estão matriculados na disciplina,
determine o desvio padrão da distribuição amostral das médias, levando-se em conta
que a amostra foi efetuada:
a) com reposição;
b) sem reposição.
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
119
a) Com reposição (população finita): 2,049
96,1
n
σσ
x
b) Sem reposição (população infinita)
n < 0,05 N?
49 < 0,05(586)?
49 > 29,3, logo necessita o fator de correção
1916,01586
49586.
49
96,1
1N
nN.
n
σσ
x
Exemplo 7.3:
Numa prova de matemática e física, constante de 80 questões, referente a um
vestibular simulado realizado no Rio de Janeiro, observou-se que a média de acertos
foi de 24,12 com desvio padrão de 9,78. Dos 22102 vestibulandos que participaram da
prova, retirou-se aleatoriamente uma amostra de 200 concorrentes. Determinar:
a) a probabilidade de que a média dessa amostra se localize entre 25 e 26;
b) a probabilidade de que a média dessa amostra apresente um valor inferior a
22.
Solução:
a) P(25 x
μ 26)?
Sem reposição n < 0,05N?
200 < 0,05 (22102)
200 < 1105,1 (podemos omitir o fator de correção)
6916,0200
78,9
n
σσ
x
x
x
σ
μxz
μμ
x
27,16916,0
12,2425z1
72,2
6916,0
12,2426z2

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
120
P(25 x 26) = P(1,27 z 1,72) = 04967 – 0,3980 = 0,0987
b)
Exemplo 7.4:
Verificou-se que 2% das ferramentas produzidas por uma certa máquina são
defeituosas. Qual é a probabilidade de que numa remessa de 400 dessas ferramentas,
revelarem-se;
a) 3% ou mais defeituosas;
b) 2% ou menos defeituosas.
Solução:
p=2% = 0,02; q = 0,98;
n = 400 30 (requer CC) 0125,0400.2
1
n2
1CC
02,0pPμP 007,0400
98,0.02,0
n
pqσP
a) P(P 0,03)?
02875,000125,003,0CC03,0P
25,1007,0
02,002875,0z
P(P 0,03) = P(z 1,25) = 0,5 – 0,3944 = 0,1056
b)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
121
Exemplo 7.5:
Considere duas populações: I - adultos do sexo masculino; II - adultos do sexo
feminino. Supondo que a proporção de pessoas com dificuldades na área de
matemática nessas duas populações seja de 30% e 20%, respectivamente. Qual a
probabilidade de que numa dada amostra de 100 adultos de I e 120 adultos de II,
resultem num valor ( 21 PP ) < 0,18?
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
122
7.9. TEORIA DA DECISÃO
Em Inferência Estatística, a teoria da decisão significa tomar decisões sobre
populações, com base em informações amostrais. Muitos problemas em engenharia
requerem que decidamos entre aceitar ou rejeitar uma afirmação sobre um parâmetro.
A afirmação é chamada de hipótese e o procedimento de tomada de decisão sobre a
hipótese é chamado de teste de hipóteses. Estas decisões estatísticas ocorrem com
relação a qualidade de algum processo, igualdade de parâmetros, igualdade ou
diferença de tratamentos, natureza da população, etc.
7.10. HIPÓTESE ESTATÍSTICA
Podemos dizer que é uma suposição quanto ao valor de um parâmetro
populacional, ou quanto à natureza da distribuição de probabilidade de uma variável
populacional, de uma ou mais populações.
7.11. TESTE DE HIPÓTESE
É uma regra de decisão para aceitar ou rejeitar uma hipótese estatística com
base nos elementos amostrais.
Como vimos, toda avaliação feita sobre um parâmetro populacional, o qual não
possuímos nenhuma informação, pode ser resultado do processo de estimação. Se já
possuímos alguma informação, podemos testá-la no sentido de aceitá-la como
verdadeira ou rejeitá-la.
Os Testes de Significância ou testes de hipóteses tem por finalidade, a partir da
elaboração de uma Hipótese Nula H0 e de uma Hipótese Alternativa H1, verificar a
aceitabilidade ou não da informação, por isso é conhecida como uma Regra de
Decisão.
O objetivo então do teste de hipóteses é determinar se o parâmetro variou.
HIPÓTESE DE NULIDADE OU HIPÓTESE NULA (H0)
É a hipótese estatística a ser testada. O parâmetro populacional a ser testado é
chamado “de referência”, por exemplo, se for a média, será: μ.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
123
HIPÓTESE ALTERNATIVA (H1)
É a hipótese complementar à Hipótese de Nula, isto é, aquela que será aceita
como verdadeira, caso seja rejeitada a hipótese de nula.
7.12. TIPOS DE ERROS DE HIPÓTESE
Quando nos propomos a utilizar tal procedimento, devemos ter em mente que
estamos sujeitos a erros e acertos na decisão. De um modo geral, em qualquer tipo de
decisão, os acertos e os erros podem ser dispostos segundo o quadro a seguir:
Estado da natureza
Decisão H0 é verdadeira H0 é falsa
Aceitamos H0 Decisão correta Erro tipo II
Rejeitamos H0 Erro tipo I Decisão correta
Erro Tipo I: Consiste em rejeitar H0 quando H0 é verdadeira
Erro Tipo II: Consiste em aceitar H0 quando H0 é falsa
Nível de Significância do Teste: é a probabilidade de se cometer o erro Tipo I, ou
seja, rejeitar uma hipótese verdadeira. O nível de significância será denotado por α.
A probabilidade do erro Tipo II não possui um nome em especial mais será
conhecida como erro β.
A fixação da hipótese alternativa é que diferencia os vários tipos de Teste.
Por exemplo, vamos considerar julgar a responsabilidade de um funcionário pela
ocorrência de um acidente do trabalho.
Estado da natureza
Decisão Não Responsável Responsável
Não Responsável Decisão correta Erro tipo II
Responsável Erro tipo I Decisão correta
O erro Tipo I, no caso, seria julgar o funcionário como responsável, quando na
verdade ele não é responsável.
O erro Tipo II, seria julgar o funcionário como não responsável, quando na
verdade ele é responsável.
7.13. TIPOS DE TESTES
Estudaremos testes de hipóteses com uma hipótese nula (H0) e uma hipótese
alternativa (H1). A partir da formulação de H0 e H1, podemos definir o tipo do teste a ser
utilizado.
Consideremos o parâmetro estudado e 0 o valor inicialmente suposto para .

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
124
Seja: AR: área de rejeição (crítica);
AA: área de aceitação;
Za ou Zt: estatística do teste (calculada por nós).
As hipóteses formuladas podem ser dos seguintes tipos:
7.13.1. TESTE BILATERAL
A área crítica está nas duas regiões extremas (caudas) sob a curva.
H0: = 0
H1: ≠ 0
Uma vez que a hipótese nula (H0) determina se o parâmetro analisado é ou não
igual, a hipótese alternativa (H1) especifica valores que poderiam ser maiores ou
menores que o valor do parâmetro analisado.
Em testes bilaterais o nível de significância é dividido igualmente entre as duas
caudas que constituem a região crítica. Por exemplo,um teste bilateral com o nível de
significância igual a 5% ( = 0,05), há uma área de 0,025 em cada uma das caudas.
7.13.2. TESTE UNILATERAL À DIREITA
A área crítica está na região extrema (cauda) direita sob a curva.
H0: = 0 (ou H0: 0)
H1: > 0
Uma vez que a hipótese nula (H0) determina se o parâmetro analisado é menor
ou igual (ou simplesmente igual), a hipótese alternativa (H1) especifica valores que são
maiores que o valor do parâmetro analisado.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
125
7.13.3. TESTE UNILATERAL À ESQUERDA
A área crítica está na região extrema (cauda) esquerda sob a curva.
H0: = 0 (ou H0: 0)
H1: < 0
Uma vez que a hipótese nula (H0) determina se o parâmetro analisado é maior
ou igual (ou simplesmente igual), a hipótese alternativa (H1) especifica valores que são
menores que o valor do parâmetro analisado.
A tabela abaixo apresenta os valores críticos de Z para testes unilaterais e
bilaterais, em vários níveis de significância. Os valores Z para outros níveis de
significância são determinados mediante o emprego das tabelas das áreas da curva
normal.
Nível de significância 0,10 0,05 0,01 0,005 0,002
Valores críticos de Z para testes unilaterais
-1,28 ou 1,28
-1,65 ou 1,65
-2,33 ou 2,33
-2,58 ou 2,58
-2,88 ou 2,88
Valores críticos de Z para testes bilaterais
-1,65 e 1,65
-1,96 e 1,96
-2,58 e 2,58
-2,81 e 2,81
-3,08 e 3,08
7.14. ETAPAS DE UM TESTE DE HIPOTESES
1. Identifique o parâmetro de interesse, a partir do contexto do problema;
2. Estabeleça a hipótese nula H0;
3. Especifique a hipótese alternativa apropriada H1 (atenção, pois H1 define o
tipo de teste a ser empregado);
4. Especifique o nível de significância para o teste, por exemplo, 1% ou 5%;
5. Selecione o teste estatístico ou Z amostral (Za ou Zt (do teste)), que será
usada para decidir rejeitar ou não a hipótese nula, ou seja, estabelecer o(s) “valor(es)
crítico(s)” e Identifique qual o valor da Estatística de Teste necessário para rejeitar H0.
(valor tabelado);

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
126
6. Calcule o estimador e verificar se está na região de aceitação ou na região de
rejeição da hipótese H0. Por exemplo: S
Sa
σ
μSZ
, o valor de S pode ser: x , P ,
21 xx , 21 PP ;
7. Tomada de decisão: O valor observado da medida estatística da amostra é
comparado com o(s) valor(es) crítico(s) estabelecido para o teste estatístico;
8. Decida se H0 deve ou não ser rejeitada e reporte isso no contexto do
problema:
- Se o estimador estiver na área de aceitação, aceita-se H0;
- Se o estimador estiver na área de rejeição, rejeita-se H0;
Assim, agora podem ser emitidas as conclusões.
7.15. TESTE DE HIPOTESES PARA MÉDIAS
xx
0
x
xa
s ou σ
μx
σ
μxZ
7.16. TESTE DE HIPOTESES PARA PROPORÇÕES
p
0a
σ
pPZ
onde
n
xP e
n
)p1(pσ 00
p
x: número de elementos da amostra que possuem características de interesse;
n: tamanho da amostra
7.17. TESTE DE HIPOTESES PARA A DIFERENÇA DAS MÉDIAS
21
21
xx
xx21
aσ
μxxZ
21 xx
21
aσ
xxZ
Neste caso, H0: μ1 = μ2.
7.18. TESTE DE HIPOTESES PARA A DIFERENÇA DAS PROPORÇÕES
Como o valor de p1 e p2 são desconhecidos, devemos substituir por suas
estimativas. Mas H0: p1 = p2, suas estimativas devem ser iguais. Desta forma, tomamos
para as suas estimativas a média aritmética entre P1 e P2, logo:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
127
2
PPp 21^ ou
21
2211^
nn
P.nP.np
ou
21
21^
nn
xxp
e
21
^^
PP
^
n
1
n
1.p1.pσ
21
21
21
PP
^
PP21
a
σ
μPPZ
21 PP
^
21a
σ
PPZ
Exemplo 7.6:
Uma amostra aleatória de 40 elementos retirados de uma população normal com
desvio padrão igual a 3 apresentou um valor médio igual a 60. Teste, ao nível de
significância de 5%, a hipótese de que a média populacional seja igual a 59, supondo a
hipótese alternativa μ >59.
Solução:
Exemplo 7.7:
Uma amostra aleatória de 20 elementos selecionados de uma população normal
com variância 3 apresentou média 53. Teste ao nível de significância de 5% a hipótese
de que μ = 50.
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
128
Exemplo 7.8:
Em um estudo de eficiência do air bag em automóveis, constatou-se que em 821
colisões de carros equipados com airbag, 46 colisões resultaram em hospitalização do
motorista. Ao nível de significância de 0,01, teste a afirmação de que a taxa de
hospitalização nos casos de acidentes com carros com airbag é inferior a taxa de 7,8%
para colisões de carros equipados somente com cinto se segurança.
Solução:
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
129
Exemplo 7.9:
Ao nível de 0,01 de significância, teste a afirmação de que as latas de 0,0109 in
(polegadas) de espessura tem carga axial média inferior a das latas de 0,0111 in de
espessura. As estatísticas resumo estão no quadro abaixo:
Solução:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
130
8 – ANÁLISE DE REGRESSÃO E CORRELAÇÃO
8.1- INTRODUÇÃO
A análise de regressão e correlação é um estudo da relação de uma
determinada variável (dependente) em função de outra ou de outras variáveis
(independente). Por exemplo:
A = {propaganda; vendas de um produto; preço}
B= {resistência de um concreto e relação água/cimento}
C = {investimento em segurança e redução do numero de acidentes}
De maneira geral, queremos encontrar alguma forma de medir a relação entre as
variáveis de cada conjunto, de tal modo que essa medida possa mostrar:
Se há relação entre as variáveis e, caso exista, se é fraca ou forte;
Se essa relação existir, como obter a equação que relacione essas variáveis;
Após obtida a equação, ela poderá ser usada para fins de predição.
Suponhamos que y seja uma variável que nos interessa estudar e prever seu
comportamento. É de se esperar que os valores da variável (dependente) sofram
influência dos valores de um número finito de variáveis: x1, x2 ,...., xk (independentes) e
que exista uma função f que expresse essa dependência. Esta função f pode ser linear,
polinomial, exponencial, logarítmica, etc.
8.2. DIAGRAMA DE DISPERSÃO
É um gráfico que nos fornece o tipo de relação existente entre as variáveis x e y,
isto é, mostra se a relação é linear ou não-linear.
Após determinado o tipo de relação e traçado o gráfico, o próximo passo é
determinar uma equação da reta que represente essa relação. A reta obtida é chamada
de reta de regressão, e sua equação é a equação de regressão.
Figura 8.1: Diagrama de Dispersão e reta de regressão
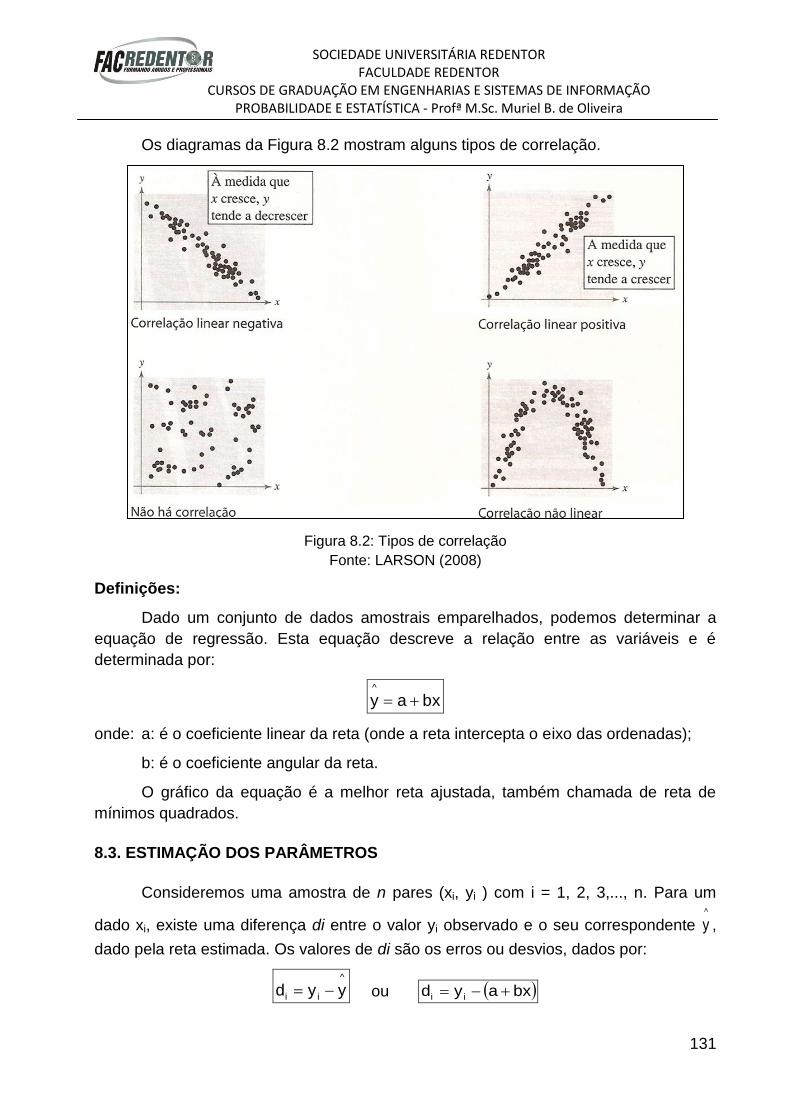
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
131
Os diagramas da Figura 8.2 mostram alguns tipos de correlação.
Figura 8.2: Tipos de correlação
Fonte: LARSON (2008)
Definições:
Dado um conjunto de dados amostrais emparelhados, podemos determinar a
equação de regressão. Esta equação descreve a relação entre as variáveis e é
determinada por:
bxay^
onde: a: é o coeficiente linear da reta (onde a reta intercepta o eixo das ordenadas);
b: é o coeficiente angular da reta.
O gráfico da equação é a melhor reta ajustada, também chamada de reta de
mínimos quadrados.
8.3. ESTIMAÇÃO DOS PARÂMETROS
Consideremos uma amostra de n pares (xi, yi ) com i = 1, 2, 3,..., n. Para um
dado xi, existe uma diferença di entre o valor yi observado e o seu correspondente ^
y ,
dado pela reta estimada. Os valores de di são os erros ou desvios, dados por:
^
ii yyd ou bxayd ii

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
132
O Método dos Mínimos Quadrados é um método pelo qual determinamos os
valores de a e b, de tal forma que a soma dos desvios ao quadrado seja mínima, ou
seja,
2
n
2
2
2
1 d...dd mínima 2
id mínima
Como ^
ii yyd então:
2
i
2
i
2
iii
2
i
2
ii
2
i xbabx2aybx2ay2ybxayd
Por conveniência, vamos abandonar os índices das variáveis x e y.
Derivando Σdj2 em relação aos coeficientes a e b temos:
n
1i
n
1i
2
i
bx2a2y2a
d
(I)
n
1i
2
n
1i
2
i
bx2ax2xy2b
d
(II)
O Σdj2 será um mínimo se as derivadas parciais em relação a a e b forem nulas.
Portanto, a equação (I) é dada por:
0bx2a2y2n
1i
0xbnay
xbnay (III)
Da equação (II) tem-se
0bx2ax2xy2n
1i
2
0xbxaxy 2
2xbxaxy (IV)
As equações (III) e (IV) são as equações normais para a determinação de a e b.
Dividindo todos os termos da equação (III) por n, tem-se:
n
xb
n
na
n
y (V)
onde

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
133
yn
y
e
xn
x
(VI)
Substituindo-se (VI) na equação (V) encontra-se:
x.bn
nay
x.bya (VII)
Substituindo o valor de a na equação (IV), tem-se:
2xbxx.byxy
2xbx
n
xb
n
yxy
2
2
xbn
xb
n
yxxy
n
xxb
n
yxxy
2
2
n
xx
n
yxxy
b2
2
(VIII)
Substituindo o numerador da equação (VIII) por yy.xxSSxy e o
denominador por 2
x xxSS temos que:
2x
xy
xx
yy.xx
SS
SSb e x.bya
Exemplo 8.1:
Determinar a reta de mínimos quadrados com os dados da tabela 1, sendo:
x: Despesas com propaganda (milhões de reais)
y: Vendas de um produto (milhares de unidades)
Tabela 1: Dados do exemplo
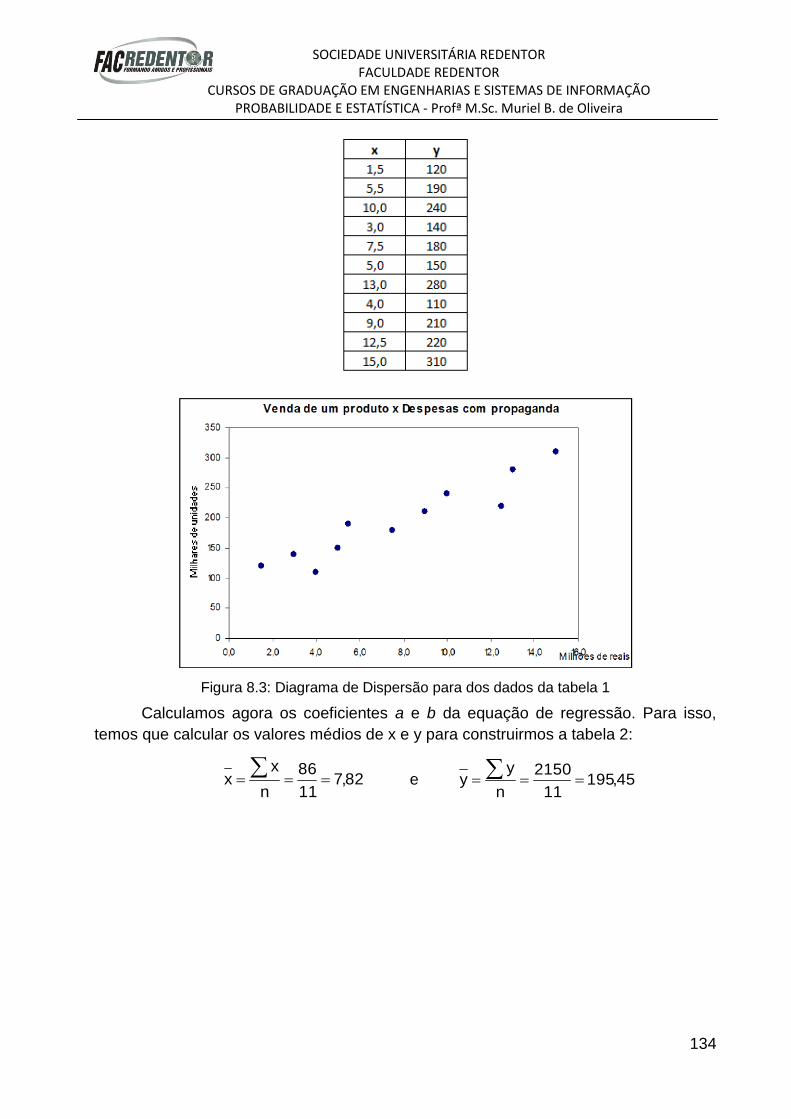
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
134
Figura 8.3: Diagrama de Dispersão para dos dados da tabela 1
Calculamos agora os coeficientes a e b da equação de regressão. Para isso,
temos que calcular os valores médios de x e y para construirmos a tabela 2:
82,711
86
n
xx
e 45,19511
2150
n
yy
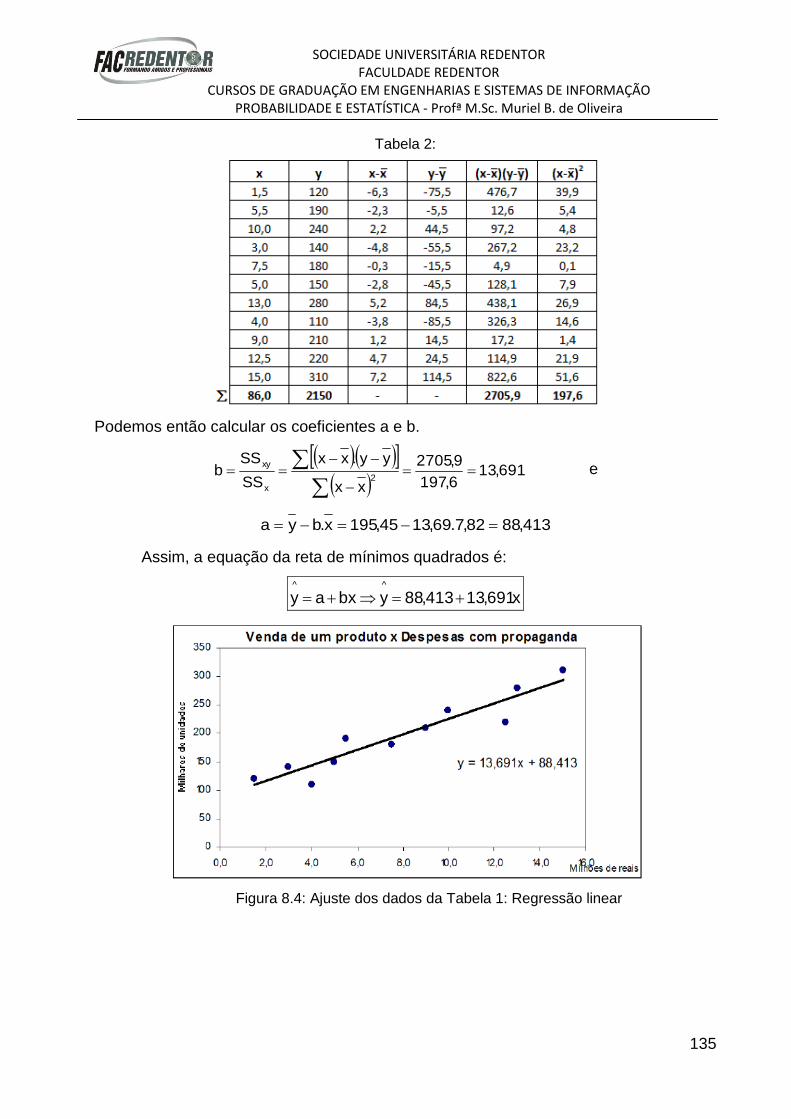
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
135
Tabela 2:
Podemos então calcular os coeficientes a e b.
691,136,197
9,2705
xx
yy.xx
SS
SSb
2x
xy
e
413,8882,7.69,1345,195x.bya
Assim, a equação da reta de mínimos quadrados é:
x691,13413,88ybxay^^
Figura 8.4: Ajuste dos dados da Tabela 1: Regressão linear

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
136
8.4. REGRESSÕES QUE SE TORNAM LINEARES POR TRANSFORMAÇÃO
Há várias funções que, por simples transformações, se tornam lineares, e cujos
parâmetros podem ser estimados pelas fórmulas anteriores. Mostraremos alguns tipos
de transformações mais usados para linearizar a relação entre as variáveis. Assim:
I) Função Exponencial
A linearização da função exponencial é obtida aplicando-se a ela a definição e
as propriedades dos logaritmos. Algebricamente, temos:
Função Exponencial: xaby
Aplicando logaritmo a ambos os termos da igualdade, temos: xablogylog
Daí, considerando as propriedades dos logaritmos, tem-se:
xblogalogylog => blog.xalogylog
Fazendo log y = Y, log a = A e log b = B, resulta: Y = A + B x.
Os processos lineares fornecem A e B. Para obterem-se os valores das
constantes originalmente procuradas, devemos fazer: a = 10A e b = 10B.
Exemplo 8.2:
Determinar a equação da função exponencial que melhor aproxima os dados da
Tabela 1:
Solução:
Devemos calcular os coeficientes a e b da equação xaby .
Precisamos inicialmente substituir a coluna dos valores de y por Y = log y. A
seguir, calculamos os coeficientes A e B como foi calculado para a reta dos mínimos
quadrados.
Calculados então os coeficientes A e B, podemos calcular a e b da equação xaby fazendo A10a e B10b .

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
137
Calculamos agora os coeficientes A e B.
82,711
86
n
xx
e 2691,211
96,24
n
yy
0307,064,197
07,6
xx
yy.xx
SS
SSB
2
x
xy
e
0289,282,7.0307,02691,2x.ByA
Assim temos:
87,1061010a 0289,2A e 0732,11010b 0307,0B .
Logo, a equação exponencial é:
xx 0732,1.87,106aby que pode ser escrita da forma: x0708,0cx e.88,106aey
A Figura 8.5 apresenta a aproximação da função exponencial para os dados da
Tabela 1.
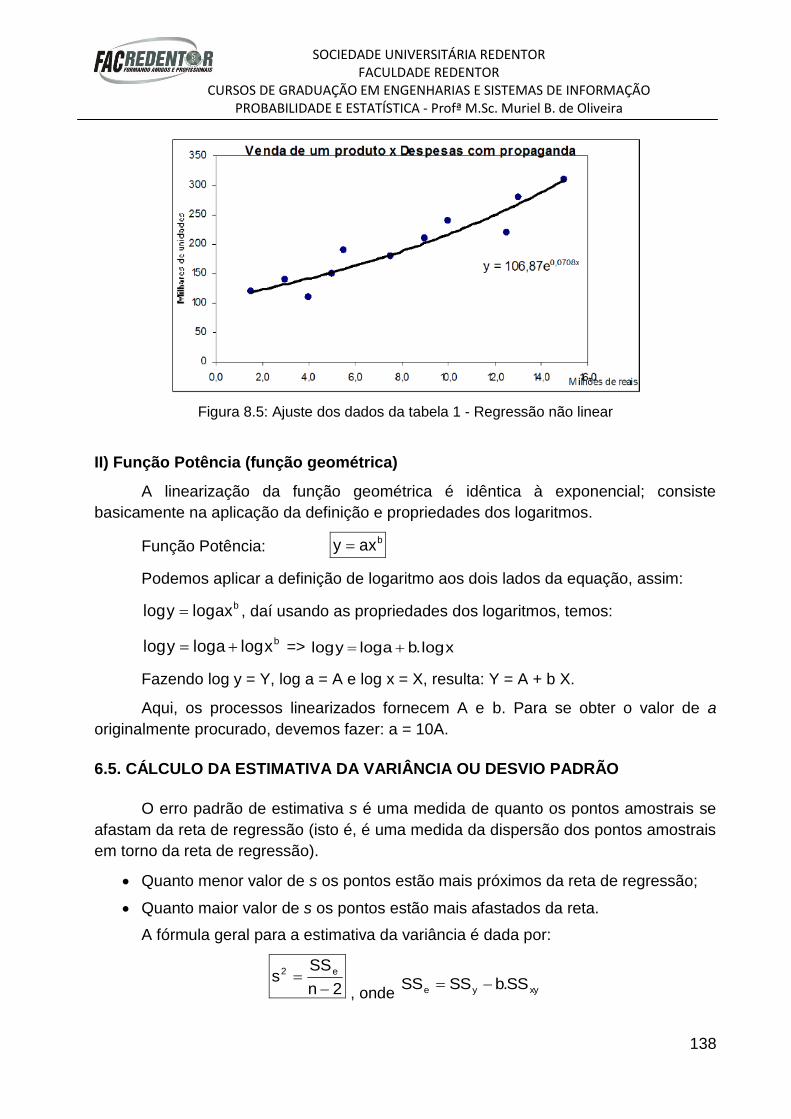
SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
138
Figura 8.5: Ajuste dos dados da tabela 1 - Regressão não linear
II) Função Potência (função geométrica)
A linearização da função geométrica é idêntica à exponencial; consiste
basicamente na aplicação da definição e propriedades dos logaritmos.
Função Potência: baxy
Podemos aplicar a definição de logaritmo aos dois lados da equação, assim:
baxlogylog , daí usando as propriedades dos logaritmos, temos:
bxlogalogylog => xlog.balogylog
Fazendo log y = Y, log a = A e log x = X, resulta: Y = A + b X.
Aqui, os processos linearizados fornecem A e b. Para se obter o valor de a
originalmente procurado, devemos fazer: a = 10A.
6.5. CÁLCULO DA ESTIMATIVA DA VARIÂNCIA OU DESVIO PADRÃO
O erro padrão de estimativa s é uma medida de quanto os pontos amostrais se
afastam da reta de regressão (isto é, é uma medida da dispersão dos pontos amostrais
em torno da reta de regressão).
Quanto menor valor de s os pontos estão mais próximos da reta de regressão;
Quanto maior valor de s os pontos estão mais afastados da reta.
A fórmula geral para a estimativa da variância é dada por:
2n
SSs e2
, onde xyye SS.bSSSS

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
139
n
yySS
2
2
y
ou
2
y yySS e
n
yxxySS xy
ou yy.xxSSxy
A fórmula geral para a estimativa do desvio padrão é dada por:
2ss
Ou ainda por
2n
yy
s
2
i
^
i
onde ii
^
bxay
8.6. DISTRIBUIÇÃO “t” DE STUDENT
ara casos de grandes amostras (n ≥ 30), podemos aplicar o teorema do limite
central para concluir que as médias amostrais se distribuem normalmente,
independente da distribuição da população original. Porém, não podemos utilizar este
teorema quando as amostras são pequenas. Neste caso, deve-se utilizar a distribuição
t de Student.
As condições para usar a Distribuição t de Student são as seguintes:
A amostra é pequena (n < 30);
O desvio padrão () é desconhecido;
A população original tem distribuição essencialmente normal.
Considerando amostras de tamanho n, retiradas de uma população normal de
média μ, e se para cada amostra, calcularmos o valor de:
x
x
s
μxt
obtemos uma distribuição amostral de t. Essa distribuição é dada por:
2
1γ2
0
2
n2
0
γ
t1
y
1n
t1
yy
onde y0 é uma constante que depende de n, de modo que a área subentendida pela
curva é 1, e esta curva distribui-se simetricamente com relação a média zero.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
140
A constante γ = (n - 1) é denominada número de graus de liberdade, definida
como o número de observações independentes da amostra menos o número dos
parâmetros populacionais que devem ser estimados por meio das observações
amostrais.
Quando as três condições citadas acima são satisfeitas, utilizamos a distribuição
t de Student, com a estatística do teste e os valores críticos dados pela tabela a seguir.
(Observação: Na tabela, = df)
8.6.1. PROPORÇÕES DE ÁREAS PARA AS DISTRIBUIÇÕES t
Os valores de t apresentados a seguir indicam a proporção entre o ponto dado e
a cauda superior da distribuição, ao invés da proporção entre a cauda inferior e o ponto
dado, como na distribuição normal.
Após determinar o número de graus de liberdade, recorre-se a tabela e localiza-
se na coluna da esquerda. Com uma determinada linha de valores identificada,
selecionar o valor crítico tc que corresponde ao cabeçalho apropriado. Se um valor está
localizado na cauda esquerda, devemos considerá-lo como negativo.
* Exemplo: Para que a área sombreada represente 0,05 da área total de 1,0, o valor de t
com 10 graus de liberdade é 1,812.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
141
Exemplo 8.3:
Os sete valores relacionados a seguir são cargas axiais (em libras) de latas de
alumínio de 0,0109 in. A carga axial de uma lata é o peso máximo que seus lados
podem suportar, e deve ser superior a 165 libras, visto que esta é a pressão máxima
aplicada quando se fixa a tampa no lugar. Ao nível de 0,01 de significância, teste a
afirmação do engenheiro supervisor de que esta amostra provém de uma população
com média superior a 165 libras.
270; 273; 258; 204; 254; 228; 282
Solução:
= 1%
n = 7
H0: µ1 ≤ 1 5
H1: µ1 > 165
7,2527
282228254204258273270
n
xx
i
63,2776,763s76,763
6
7,252282...7,252270
1n
xxs
222
i2
4439,107
63,27
n
ssx
397,84439,10
1657,252
s
μxt
x
xa
143,301,0 e 6tc tabela
Como ta > tc, rejeita-se a hipótese H0 ao nível de significância de 1%, isto é, a
amostra provém de uma população com µ > 165.
8.7. ESTIMATIVAS
Duas variáveis possuem uma distribuição normal bivariada se, para cada valor
de x, os valores correspondentes de y tem distribuição normal e, para cada valor de y,
os valores correspondentes de x são normalmente distribuídos. Podemos construir um
intervalo de previsão para o verdadeiro valor de y.
As estatísticas amostrais são usadas como estimadores de parâmetros
populacionais. As estimativas obtidas podem ser pontuais ou intervalares:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
142
Estimativa pontual: O parâmetro é estimado unicamente pelo valor do estimador. Por exemplo, a estimativa por ponto para a média populacional é dada através da média da amostra.
Estimativa por intervalo: Quando a partir de uma amostra procuramos calcular um intervalo de variação, chamado intervalo de confiança, de modo que, este intervalo tem uma probabilidade conhecida de conter o verdadeiro parâmetro populacional. Quanto maior a probabilidade do intervalo conter o parâmetro, maior será o intervalo.
Tomando-se S como uma estatística normal N(μS,σS²), temos a equação geral
para os intervalos de confiança, onde (1 - ) determina o nível de confiança:
α1σ.ZSμσ.ZSP scssc
onde Zc é definido como coeficiente de confiança, que é o valor obtido através da
distribuição normal com o nível de confiança especificado.
O nível de confiança (1-) é a probabilidade de que o intervalo construído
contenha o verdadeiro valor do parâmetro que está sendo estimado.
A Distribuição Normal pode ser utilizada, nesse caso, sempre que tivermos uma
das seguintes situações:
Se n = 30, conforme o Teorema do Limite Central;
Se n < 30, sendo a população estudada normalmente distribuída e o desvio padrão populacional conhecido.
.Em termos de distribuição normal Z, o nível de confiança representa a área
central sob a curva normal entre os pontos 2
αZ e 2
αZ .
Figura 8.6: Representação sobre a cura normal
Observe que a área total sob a curva normal é unitária. Se a área central é (1-α),
a notação 2
αZ representa o valor de Z que deixa a sua esquerda 2
α, e a notação
2
αZ
representa o valor de Z que deixa a sua direita a área 2
α.
A tabela abaixo apresenta os valores mais usados do nível de confiança e seu
respectivo coeficiente de confiança:

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
143
Nível de Confiança (1- ) Zc
0,90 1,65
0,95 1,96
0,99 2,58
8.7.1. INTERVALO DE CONFIANÇA PARA ESTIMAR A MÉDIA POPULACIONAL
Um intervalo de estimação para a média populacional é construído, a partir do
valor de x , levando-se em conta ainda um erro de estimativa que considera a
probabilidade de que este intervalo inclua o valor real de µ, e a variabilidade dos dados.
Então o intervalo de estimação, ou confiança, para a média populacional,
utilizando-se a distribuição normal, é dado por:
xS μμμxS
α1σ.Zxμσ.ZxPxcxc
assim:
xc σ.Zx
8.7.2. INTERVALO DE CONFIANÇA PARA ESTIMAR A PROPORÇÃO
POPULACIONAL
PS ^
pn
xP
n
q.pσP
n
p1.p
s
^^
P
α1σ.ZPpσ.ZPP PcPc
assim:
Pc s.ZP
8.7.3. INTERVALO DE CONFIANÇA PARA ESTIMAR A DIFERENÇA ENTRE DUAS
MÉDIAS POLULACIONAIS
21 xxS
α1σ.Zxxμμσ.ZxxP2121 xxc2121xxc21
assim:
21 xxc21 σ.Zxx

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
144
8.7.4. INTERVALO DE CONFIANÇA PARA ESTIMAR A DIFERENÇA ENTRE DUAS
PROPORÇÕES POLULACIONAIS
21 PPS
^
1
1
11 p
n
xP
^
2
2
22 p
n
xP
2
22
1
11PP
n
q.p
n
q.pσ
21
e 2
^
2
^
2
1
^
1
^
1
PPn
p1.p
n
p1.p
s21
α1σ.ZPPppσ.ZPPP2121 PPc2121PPc21
assim:
21 PPc21 s.ZPP
Exemplo 8.4:
A vida média de operação para uma amostra de 10 lâmpadas é 4000 horas, com
desvio padrão da amostra igual à 200 horas. Supõe-se o tempo de operação das
lâmpadas tenha uma distribuição aproximadamente normal. Estime a vida média de
operação para a população de lâmpadas usando um intervalo de confiança de 95%.
Solução:
n = 10; h4000x ; h200s ; = 5%
3,6310
200
n
ss
x
262,2025,02
05,0;9110t2
α;γt cc
horas 4143 a 38573,63.262,24000s.txxc
8.8. INTERVALOS DE PREDIÇÃO
Vamos analisar a seguinte situação:
Para a equação de regressão obtida x.691,13394,88y^
, onde y representa
venda de um produto e x é despesas com propagandas. Portanto, quando x = 2,0
obtemos o valor 115,77 como a melhor venda de um produto de um gasto de 2 milhões
de reais em propagandas. Neste caso, obtemos uma estimativa pontual.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
145
A estimativa pontual tem a desvantagem de não dar qualquer idéia de sua
precisão. Portanto, utilizaremos um intervalo de predição, que é uma estimativa
intervalar de confiança de um valor predito y.
a) Intervalo de confiança para o valor esperado de y para um determinado valor
de x = xp (isto é, predizer a média de todos os valores de y para um dado x = xp).
x
2
p
2
α
^
SS
xx
n
1.s.ty
com = n-2
b) Intervalo de Predição ou Previsão de y para um determinado valor de x (isto é,
para um y individual).
x
2
p
2
α
^
SS
xx
n
11.s.ty
com = n-2
c) Intervalo de Confiança para (coeficiente angular da reta)
x2
αSS
s.tb com = n-2
d) Intervalo de confiança para (coeficiente linear da reta)
x
2
2
αSS
x
n
1.s.ta com = n-2
8.9. TESTE DO COEFICIENTE ANGULAR DA RETA ()
Utilizaremos a seguinte estatística teste:
x
0
teste SS.s
βbt
com = n-2
e as seguintes hipóteses: H0: 0 = 0 e H1: 0 ≠ 0.
8.10. ANÁLISE DE CORRELAÇÃO
8.10.1. INTRODUÇÃO - Coeficiente de correlação de Pearson (r)
A interpretação da existência de uma correlação usando o diagrama de
dispersão pode ser subjetiva. Uma maneira mais precisa de medir o tipo de e o grau de
uma correlação linear entre duas variáveis é por meio do cálculo do coeficiente de
correlação. Desta forma, a correlação ou coeficiente de correlação de Pearson (r) mede
o grau do relacionamento linear entre duas variáveis.

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
146
Podemos destacar algumas características importantes:
Seu valor está sempre entre -1 e 1 e r tem o mesmo sinal do coeficiente angular da reta de regressão.
Um valor de correlação vizinho de +1 ou -1 indica que há uma relação linear muito forte entre as duas variáveis (isto é, existe correlação linear significativa entre x e y). O valor 1 indica uma relação linear perfeita e o valor -1 também indica uma relação linear perfeita mas inversa, ou seja quando uma das variáveis aumenta a outra diminui.
Uma correlação vizinha de zero significa que não há grande relacionamento linear entre as duas variáveis.
O coeficiente de correlação pode ser calculado pela fórmula a seguir:
yx
xy
SS.SS
SSr ou
2
i
2
i
ii
yy.xx
yy.xxr ou
2222 yyn.xxn
y.xxynr
Podemos ver na Figura 8.6 alguns exemplos do valor de r.
Figura 8.6: Exemplos de correlação linear
Fonte: LARSON, (2008)
8.10.2. TESTE PARA CORRELAÇÃO LINEAR
Formulamos as hipóteses, onde ρ é a correlação linear a ser testada.
H0: ρ = 0 (não há correlação linear significativa)
H1: ρ ≠ 0 (há correlação linear significativa)
2n
r1
rt
2teste
com = n-2

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
147
Obs.: Ao predizer um valor de y com base em determinado valor de x pode-se
concluir que:
Se não há correlação linear significativa, o melhor valor predito de y é y .
Se há correlação linear significativa obtém-se o melhor valor predito de y substituindo-se o valor de x na equação de regressão.
8.10.3. COEFICIENTE DE DETERMINAÇÃO OU DE EXPLICAÇÃO
O coeficiente de determinação é igual a razão entre a variação explicada e a
variação total. Ele verifica quanto o modelo adotado explica a realidade. É obtido pela
seguinte fórmula:
100.SS
SS.br
y
xy2
Onde:
2
y yySS e yy.xxSSxy
Tem-se que: 0 ≤ r² ≤ 1
Se r² = 0, o modelo adotado não explica nada da realidade;
Se r² = 1, o modelo adotado explica a realidade com perfeição.
Assim, quanto maior o coeficiente de explicação, melhor o modelo adotado.
É importante interpretar o coeficiente de determinação corretamente. Por exemplo, se o
coeficiente de correlação é r = 0,90, o coeficiente de determinação é r² = 0,90² = 0,81.
Isso significa que 81% da variação de Y pode ser explicada pela relação entre X e Y.
Os 19% restantes da variação são inexplicados e se devem a outros fatores ou a erros
amostrais.
Exemplo 8.5:
Dada a tabela abaixo (do exemplo 8.1), onde:
x: Despesas com propaganda (milhões de reais)
y: Vendas de um produto (milhares de unidades)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
148
a) Determinar a reta de mínimos quadrados.
x69,1341,88ybxay^^
b) Ajustar uma função exponencial aos dados.
xx 0732,1.87,106aby
c) Qual o modelo que você escolheria?
Função linear: %33,89100.7,41472
9,2705.69,13100.
SS
SS.br
y
xy2
Função exponencial: %4,87100.2134,0
0732,6.0307,0100.
SS
SS.br
y
xy2
Devemos escolher a função linear. O modelo está explicando que 89,33% da
variação total das vendas está relacionada com as despesas gastas com propaganda.
d) Determine o coeficiente de correlação de Pearson. Interprete o resultado.
94514,07,41472.63,197
9,2705
SS.SS
SSr
yx
xy
Como o coeficiente de correlação de Pearson é positivo e está próximo de 1,
pode-se dizer que quanto mais se investe em propaganda, mais se vende o produto.
e) Teste a afirmação de que há uma correlação linear entre vendas de um
produto e despesas com propaganda, considere = 5%;
Hipóteses: H0: ρ = 0 (não há correlação linear significativa)
H1: ρ ≠ 0 (há correlação linear significativa)

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
149
= n – 2 = 11 – 2 = 9 262,2025,0;9t2
α
679,8
211
94514,01
94514,0
2n
r1
rt
22teste
Como tteste > tc, rejeita-se a hipótese nula ao nível de significância de 5%, isto é,
há correlação linear significativa.
f) Estimar a quantidade de vendas de um produto para um gasto de 6,0 milhões
de reais com propaganda.
x = 6,0
55,1700,6.69,1341,88yx69,1341,88y^^
Vende-se aproximadamente 170 mil unidades do produto para um gasto de 6,0
milhões de reais com propaganda.
g) Calcule o I.C. para “” (coeficiente angular da reta), sendo = 5%.
262,2025,0;9t2
α
18,221,492s1,4929
9,4428
211
9,2705.69,137,41472
2n
SS.bSSs
xyy2
57,369,13578,1.262,269,136,197
18,22.262,269,13
SS
s.tb
x2
α
Assim, Ic = 10,12 a 17,2 ou (10,12 ≤ ≤ 17,2 ) = 0,95
h) Calcule o I.C. para “” (coeficiente linear da reta), sendo = 5%.
75,3141,886,197
82,7
11
1.18,22.262,241,88
SS
x
n
1.s.ta
2
x
2
2
α
Assim, Ic = 56,66 a 120,16
i) Calcule o I.C. para a média de vendas de um produto com o investimento de 7
milhões de reais.
22,1840,7.69,1341,88yx69,1341,88y^^

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
150
36,1522,184
6,197
82,77
11
1.18,22.262,222,184
SS
xx
n
1.s.ty
2
x
2
p
2
α
^
Assim, Ic = 168,86 a 199,58
j) Calcule o I.C. para y quando x = 7, ou seja, o I.C. para a venda, quando
investimos 7 milhões de reais.
22,1840,7.69,1341,88yx69,1341,88y^^
421,5222,184
6,197
82,77
11
11.18,22.262,222,184
SS
xx
n
11.s.ty
2
x
2
p
2
α
^
Assim, Ic = 131,80 a 236,64

SOCIEDADE UNIVERSITÁRIA REDENTOR FACULDADE REDENTOR
CURSOS DE GRADUAÇÃO EM ENGENHARIAS E SISTEMAS DE INFORMAÇÃO PROBABILIDADE E ESTATÍSTICA - Profª M.Sc. Muriel B. de Oliveira
151
REFERÊNCIAS BIBLIOGRÁFICAS
BUSSAB, W.O. e MORETTIN, P.A. Estatística Básica. São Paulo: Editora Saraiva,
2003.
CRESPO, A. A., Estatística Fácil. 17° ed. São Paulo: Ed. Saraiva, 2002.
DEVORE, J.L. Probabilidade e Estatística para Engenharia e Ciências. São Paulo:
Pioneira Thomson Learning, 2006.
FREUND, J.E.; Estatística Aplicada: economia, administração e contabilidade. 11ª
ed. Porto Alegre: Bookman, 2006.
HINES, W.W. et al. Probabilidade e Estatística na Engenharia. Rio de Janeiro: Livros
Técnicos e Científicos Editora S.A., 2006.
KAZMIER, L. Introdução à Estatística Aplicada à Economia e Administração. Rio
de Janeiro: Mac-Graw Hill, 2007.
LARSON, R.; FARBER, B. Estatística Aplicada. 2ª edição. São Paulo: Editora
Pearson Education. 2008.
MILONE, Giuseppe. Estatística Geral e Aplicada. São Paulo: Pioneira Thomson
Learning, 2004.
MONTGOMERY, D.C. e RUNGER, G.C. Estatística Aplicada e Probabilidade para
Engenheiros. 4ª edição. Rio de Janeiro: Livros Técnicos e Científicos Editora S.A.,
2009.
SPIEGEL, M.R. Estatística. 4ª ed. São Paulo: Pearson Makron Books. 2009.
TOLEDO, G.L, OVALLE, I.I. Estatística Básica. 2º edição. São Paulo: Editora Atlas.
1992.
TRIOLA, M.F. Introdução à Estatística. 10º edição, Rio de Janeiro: Livros Técnicos e Científicos Editora S.A., 2008. icos Editora S.A., 2008.