anotaÇÃo de dados biolÓgicos jorge...
TRANSCRIPT

ANOTAÇÃO DE DADOSBIOLÓGICOS
Jorge Mondego

Anotação
Em biologia molecular:
Informação adicional vinculada a determinada parte de um documento
Anotar é fornecer informação biológica às seqüências de DNA
Para tal postulação utilizam-se diversos programas de comparação com dados genéticos conhecidos
Anotar é fornecer informação biológica às seqüências de DNAAnotar é postular uma função para um produto de uma ORF

Open Reading Frame (ORF) Open Reading Frame (ORF) Open Reading Frame (ORF) Open Reading Frame (ORF) –––– Matriz aberta de leituraMatriz aberta de leituraMatriz aberta de leituraMatriz aberta de leitura
AUGUUUAAACCCGGGACGTACUGAM F K P G T Y stop
As ORFs são seqüências codificantes em potencial po r possuíremAs ORFs são seqüências codificantes em potencial po r possuírem
-Códon de iniciação-Região codificadora-Códon de terminação
O produto da ORF é a proteína ou polipeptídeo

Anotação e os projetos genomasAnotação e os projetos genomasAnotação e os projetos genomasAnotação e os projetos genomas
O que é um projeto genoma?
Seqüenciamento de material genético deSeqüenciamento de material genético deorganismo e anotação de genes encontrados
Mineração de dados – data mining
Mineração de dados é o processo de caracterização,classificação e extração de informação relevante em um conjuntos de dados.
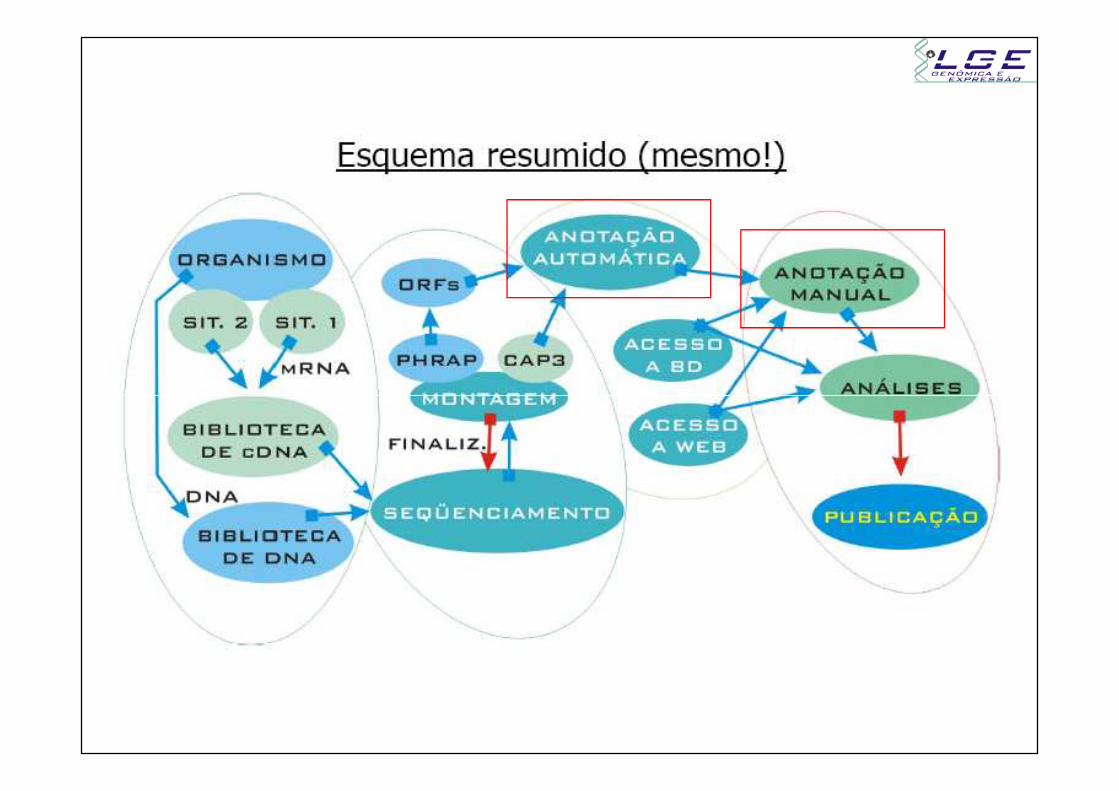

A anotação consiste de duas etapas:
a) Identificar e classificar os elementos no genoma (Gene finding)no genoma (Gene finding)
b) Atrelar informação biológica aos elementos gênicos
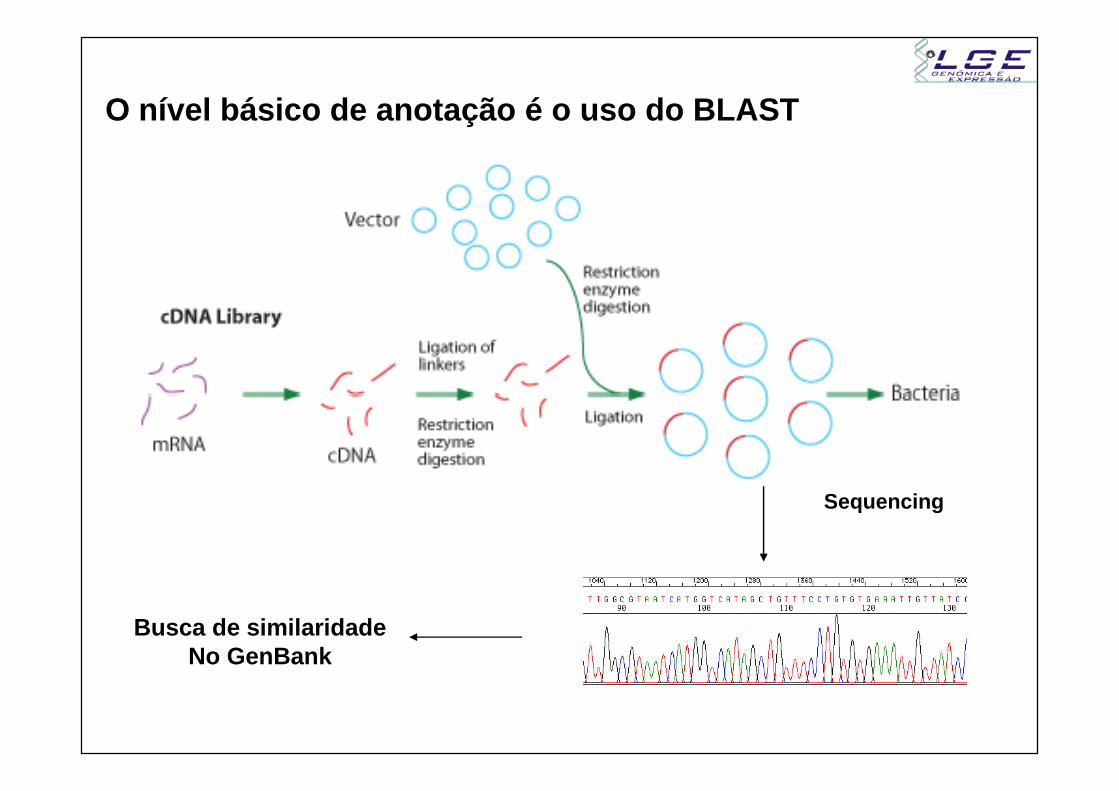
O nível básico de anotação é o uso do BLAST
Sequencing
Busca de similaridadeNo GenBank
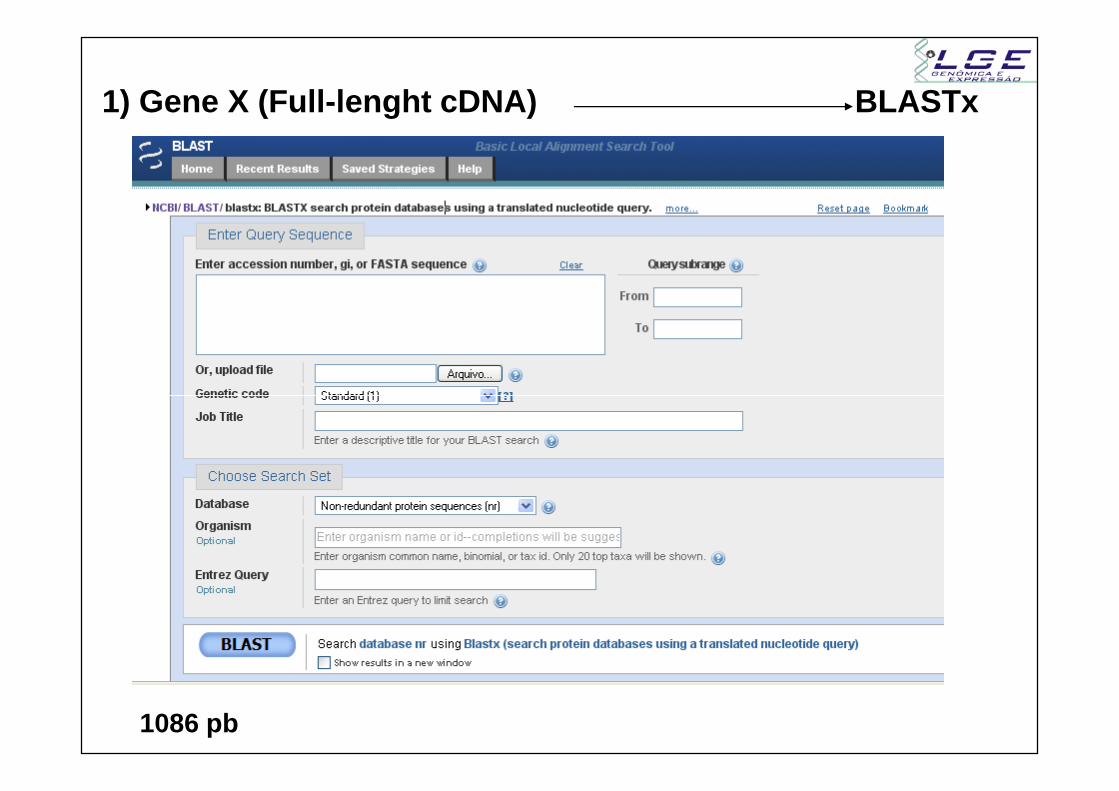
1) Gene X (Full-lenght cDNA) BLASTx
1086 pb
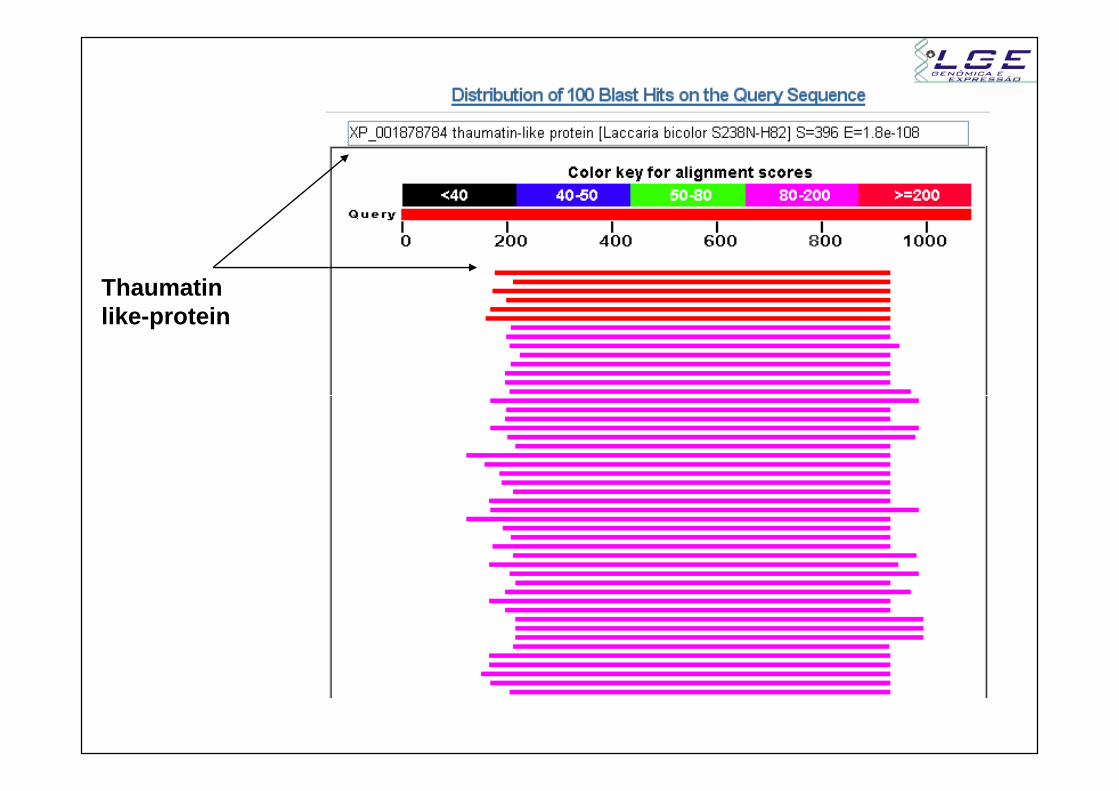
Thaumatinlike-protein

Accession number
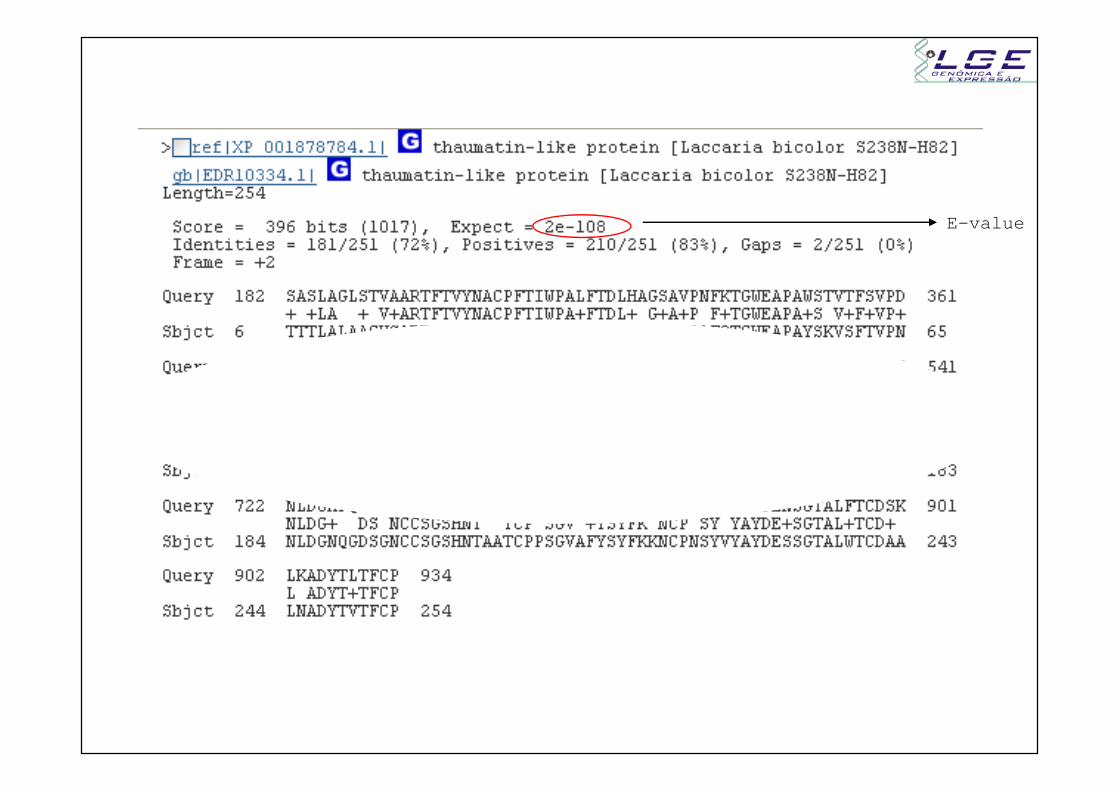
E-value

Anotação estrutural
- ORFs e suas localizações(Quantas ORFs a seqüência possui? As ORFs estão completas?
- Estrutura da seqüência(Apresenta exons e introns? Quantos? Quais suas posições?) (Apresenta exons e introns? Quantos? Quais suas posições?)
- Localização de promotores

1) Seqüência é uma ORF? Ela está completa?
E-value
- Proteína no banco (sbjct) tem 254 aa- Posição 934 do query alinha com posição 254 do su bjct- Final da proteína. Provavelmente Stop codon está presente.

- Proteína no banco (sbjct) tem 254 aa- Posição 182 do query alinha com posição 6 do subj ct- E os outros cinco aminoácidos?- E os outros cinco aminoácidos?

Sinais de secreção são menos conservados que proteí nas maduras.Chance de Start codon estar presente aumenta.
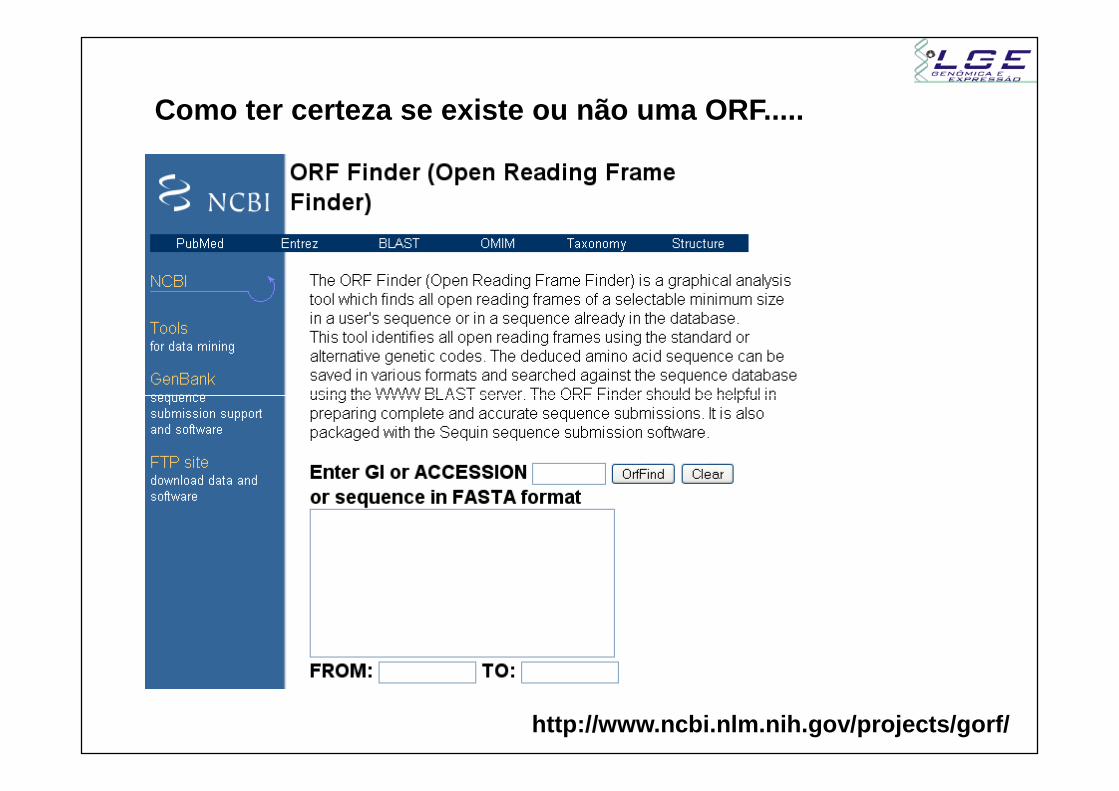
Como ter certeza se existe ou não uma ORF.....
http://www.ncbi.nlm.nih.gov/projects/gorf/

>lcl|Sequence 1 ORF:164..937 Frame +2
MKLFVASASLAGLSTVAARTFTVYNACPFTIWPALFTDLHAGSAVPNFKTGWEAPAWSTVTFSVPDNWTAGRIWARRNCDFSKTGGPTAQCLTGGCNGGLECDRNTGTGVPPATIAEWTLSSNPNIPDNYDVSLVDGYNLPARISNNKGCPVAECAKDLGPDCPAPLKGPFDSTGFPVGCKSACFANLDGHPQDSANCCSGSHNTPQTCPASGVQYYSYFKSNCPRSYAYAYDENSGTALFTCDSKLKADYTLTFCP*
ORF – Seqüência completa!!!

E-value
E o final e o início da sequencia?
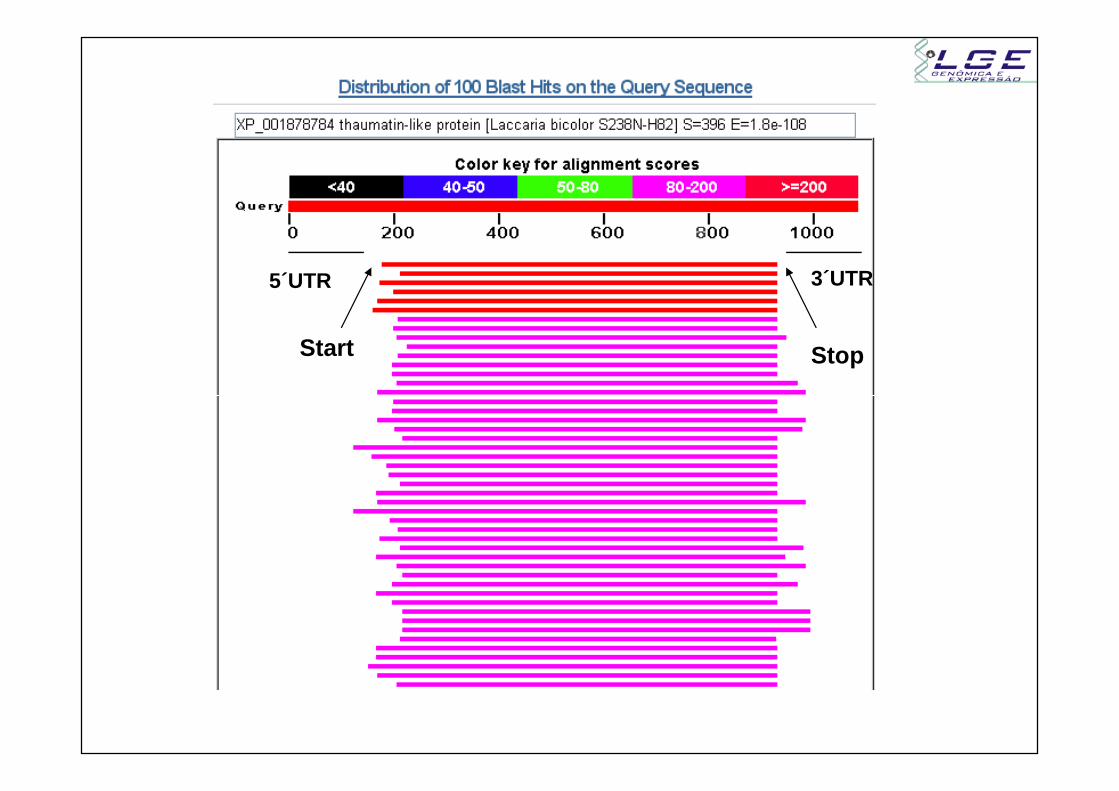
StopStart
5´UTR 3´UTR
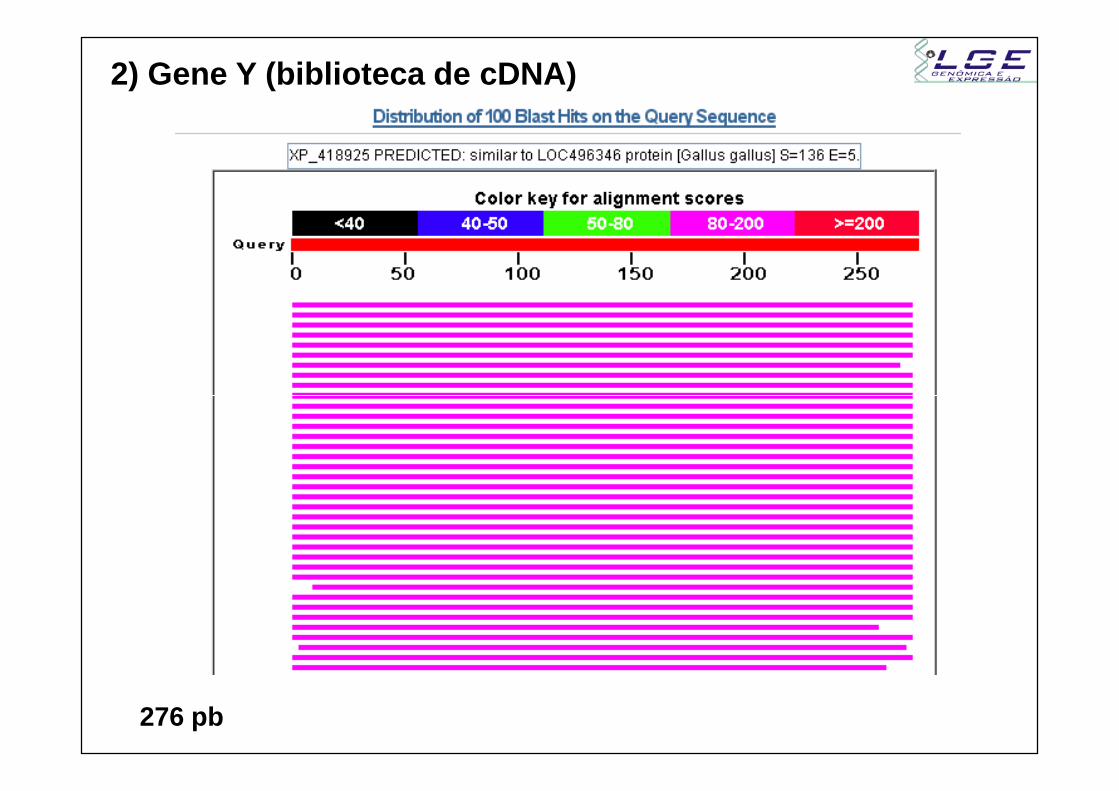
2) Gene Y (biblioteca de cDNA)
276 pb


- Proteína no banco (sbjct) tem 423 aa- Posição 2 do query alinha com posição 150 do subjc t- Posição 274 do query alinha com posição 240 do sub jct- Nem início nem final da proteína estão presentes.
Seqüência incompleta!
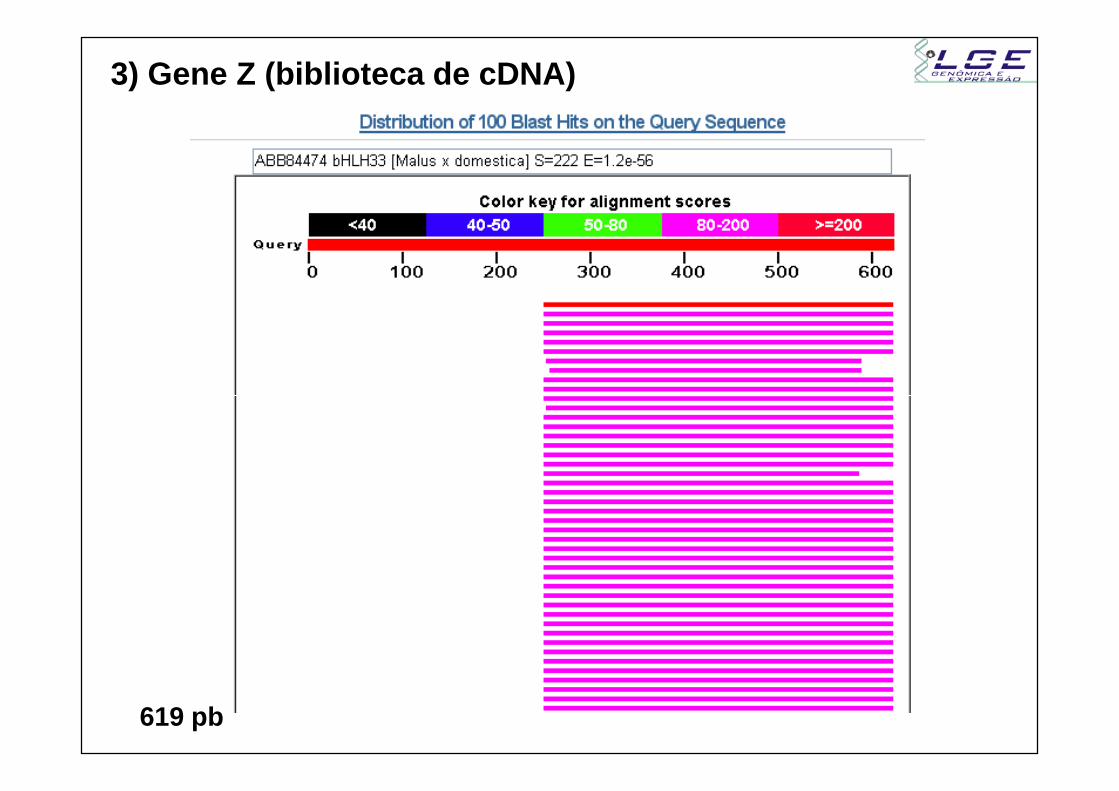
3) Gene Z (biblioteca de cDNA)
619 pb


- Proteína no banco (sbjct) tem 651 aa- Posição 619 do query alinha com posição 529 do subjct- Posição 251 do query alinha com posição 651 do subjct (frame -1)- Final da proteína. Provavelmente está presente- Início da proteína está ausente

http://www.molbiol.ru/eng/scripts/01_13.html
Uso de programa de tradução nas seis frames possíveis
Traduzir na frame -1
SINYDKTKMDNVKKSLLNKRKACDIDETDPYLNRLFPGESLPLDVKVCVKEQEVLIEMRCPYREYILLDIMDAINNLYLDAHSVQSSTLDGVLTLNLKSKFRGAAISPVGMIKQALWKIAGKC*
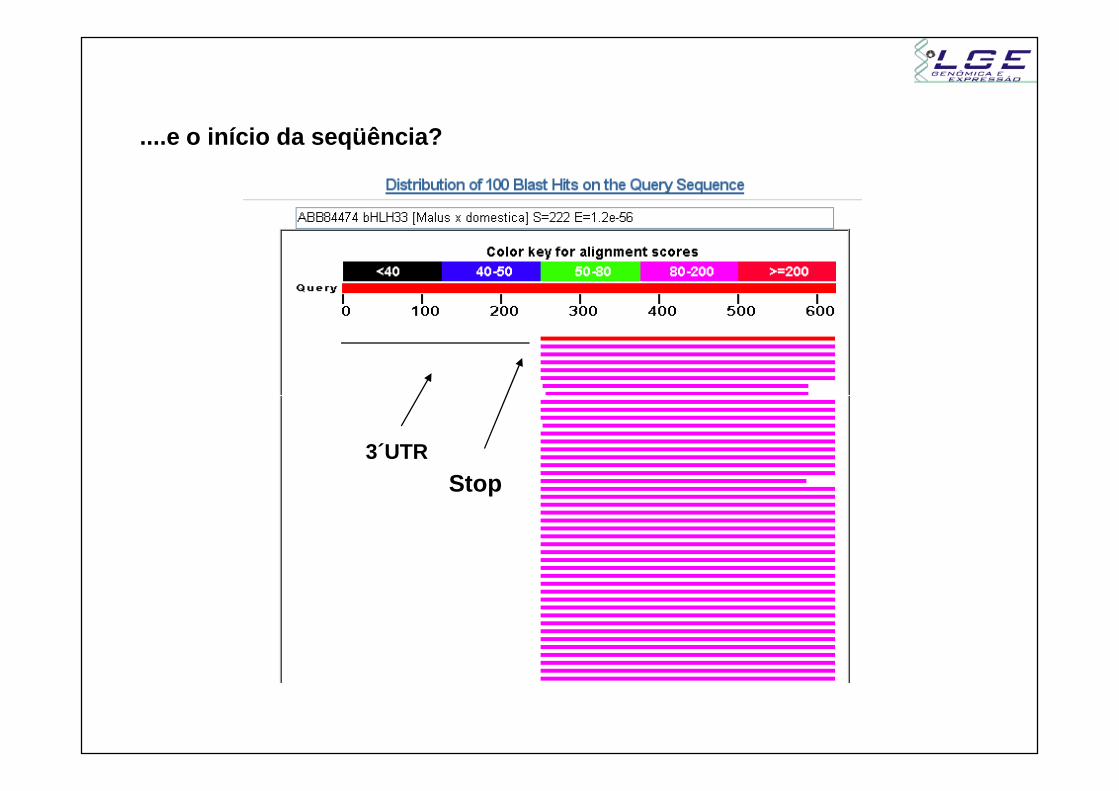
....e o início da seqüência?
3´UTR
Stop

4) Gene W (biblioteca de BAC)
879 pb


HSP1
HSP2
Proteína no banco (sbjct) tem 385 aa- HSP 1 (frame -2)
- 1: Posição 305 do query alinha com posição 90 do subjct- Fim da proteína está ausente
- HSP 1 (frame -3)- 2: Posição 245 do query alinha com posição 659 do subjct- Início da proteína está ausente
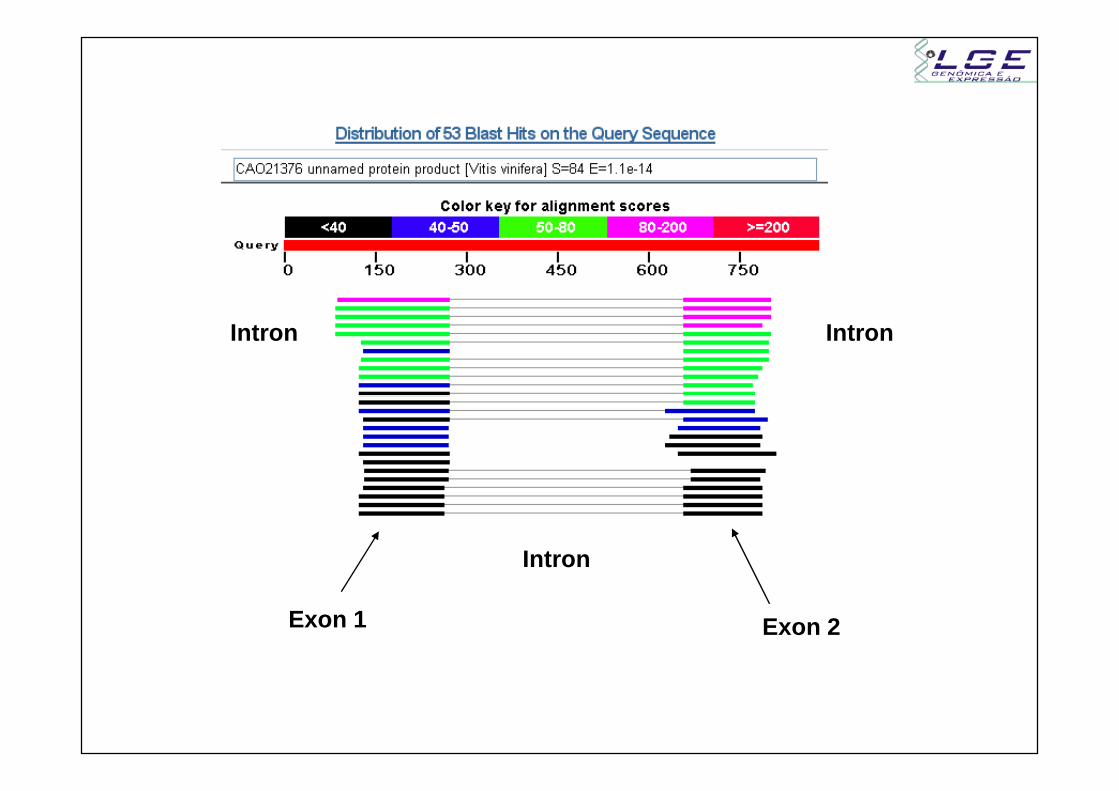
Intron Intron
Exon 1 Exon 2
Intron
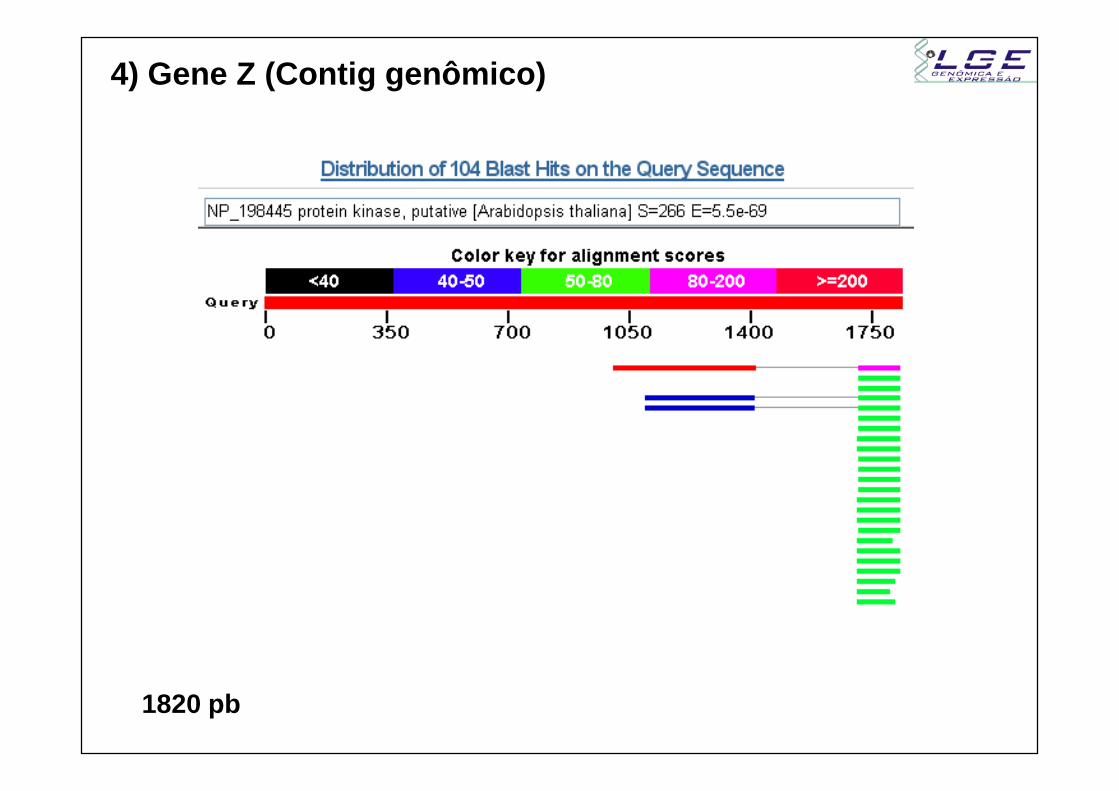
4) Gene Z (Contig genômico)
1820 pb


HSP1
HSP2
Proteína no banco (sbjct) tem 429 aa- HSP 1 (frame +2)
- 1: Posição 1001 do query alinha com posição 1 do subjct- Início da proteína está presente
- HSP 2 (frame +1)- 2: Posição 1821 do query alinha com posição 177 do subjct
- Fim da proteína está presente
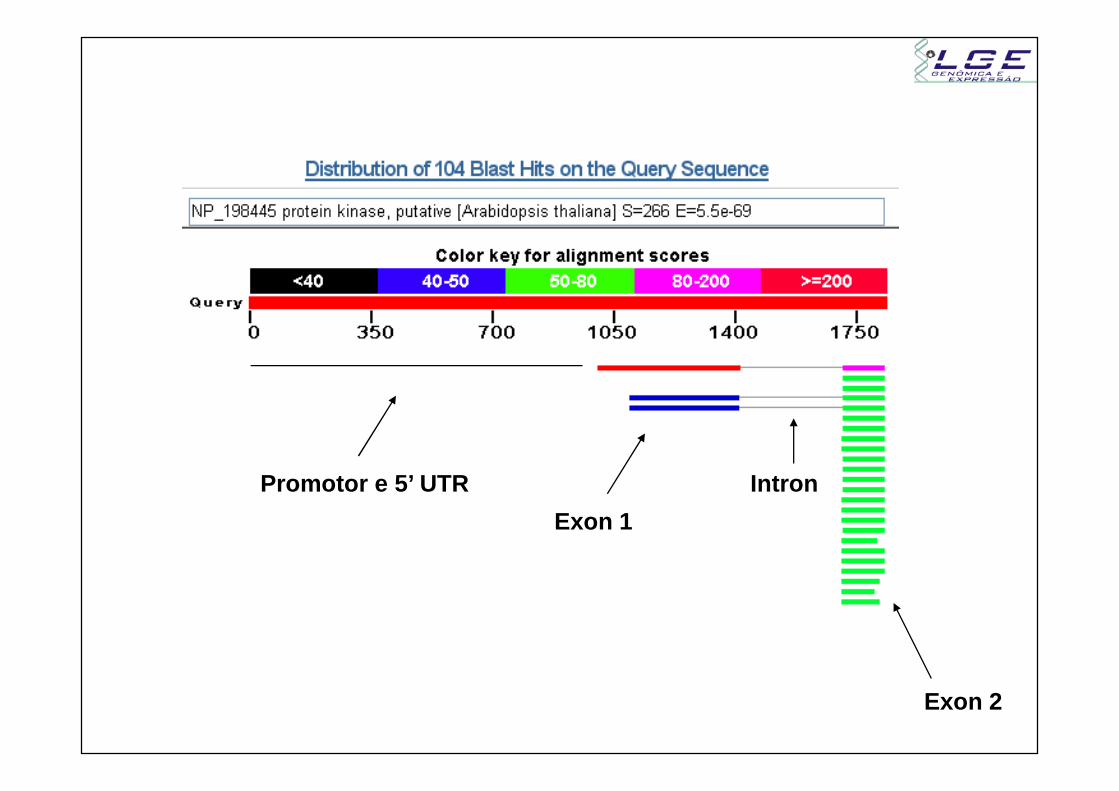
Exon 1
Exon 2
IntronPromotor e 5’ UTR

Anotação funcional
- Nome do produto
- Seqüência de qual organismo tem mais similaridade
- Função molecular (atividade)
- Processo biológico (p.e., via metabólica)
- Localização celular
-Domínios proteicos
-Dados de expressão gênica

Anotação funcional
Passos importantes:
- BLASTX : verificar similaridade com proteínas nos b anco de dados
- BLASTN: verificar similaridade com ESTs e RNA ribos somal
- Anotação de domínios proteicos pode fornecer inform açõesimportantes. Bancos de domínios já estão atrelados ao GenBank
- Ontologias de função: relação entre atributos previ amente anotados à seqüência
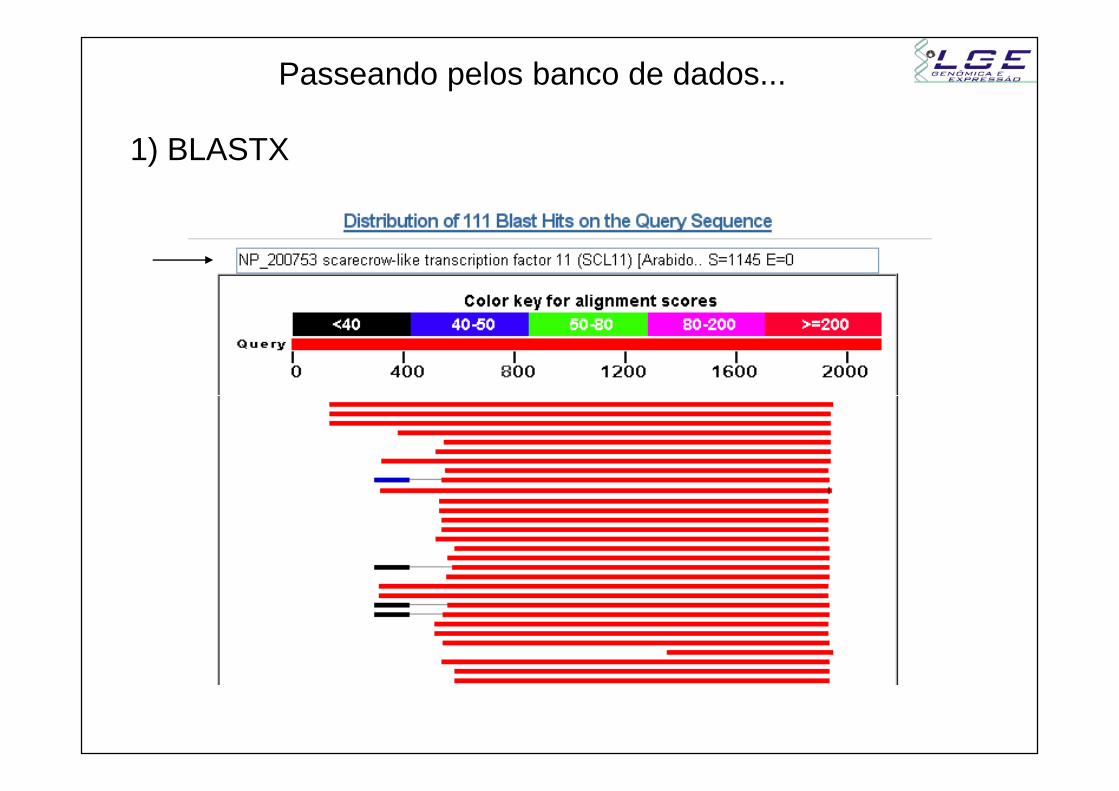
Passeando pelos banco de dados...
1) BLASTX
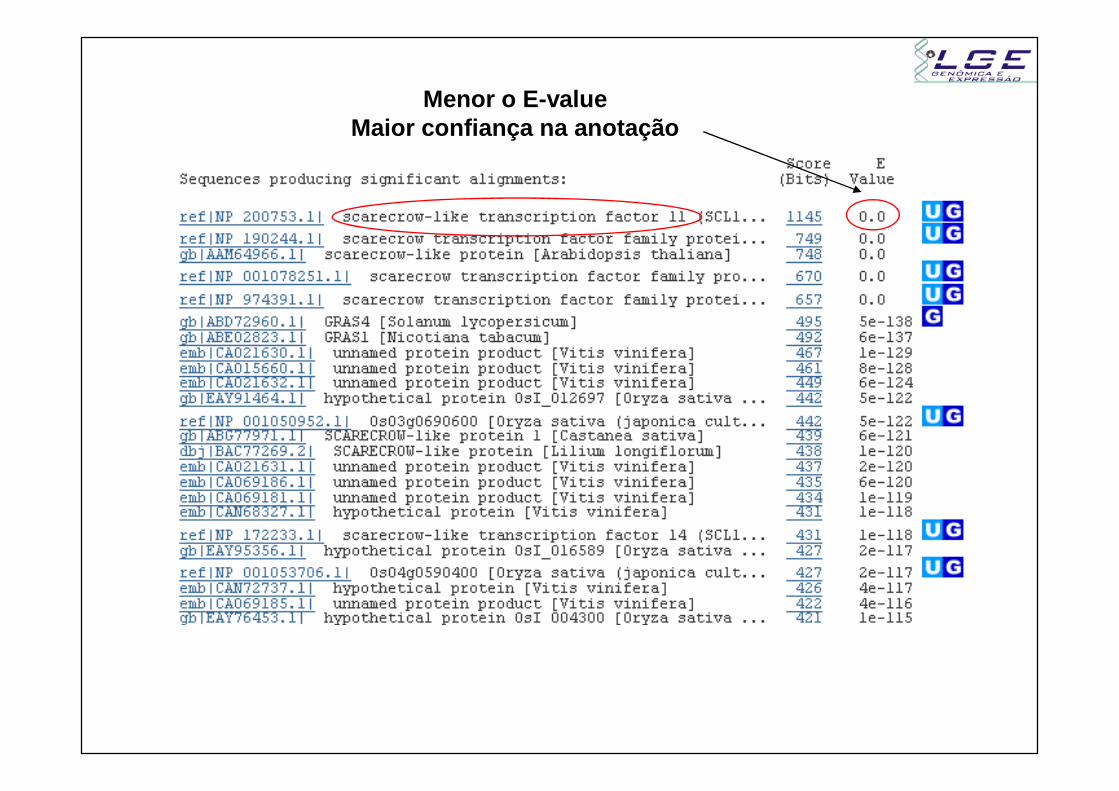
Menor o E-valueMaior confiança na anotação

1.1) Conferir o alinhamento
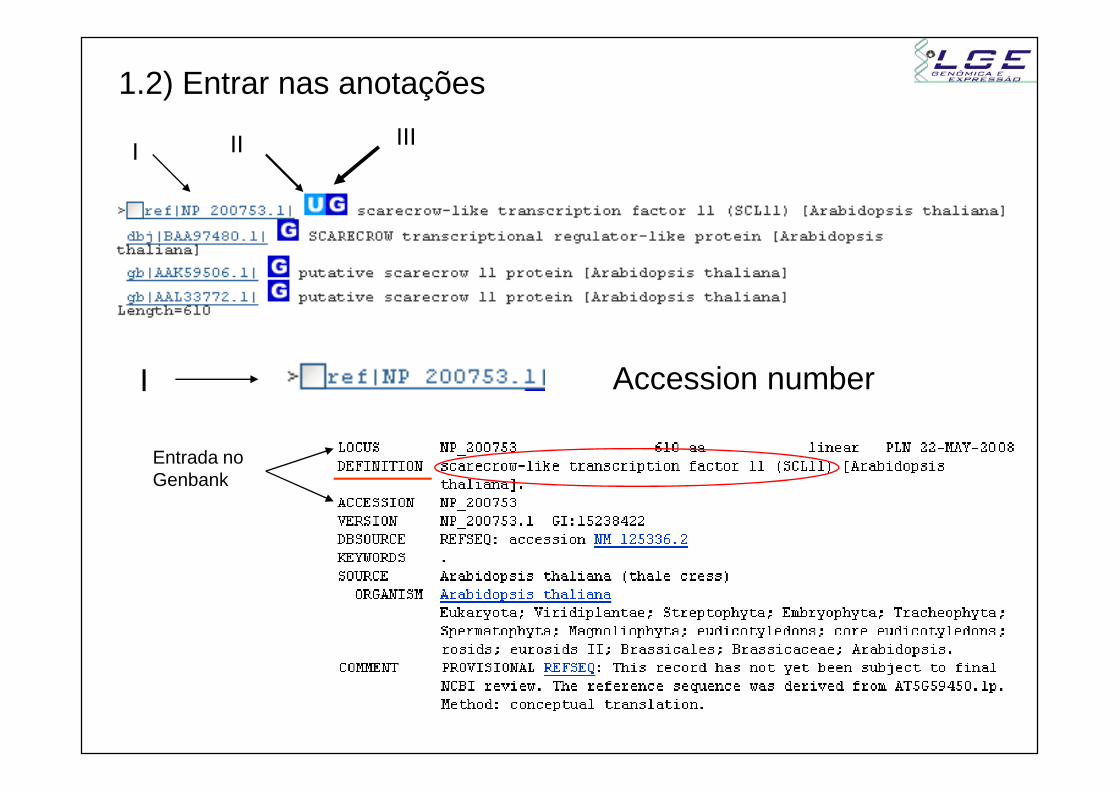
1.2) Entrar nas anotações
IIIII
I
I
Accession numberI
Entrada no Genbank
Accession number


II
UniGene: Grupo de transcritos que parecem advir do mesmo Locus gênico.
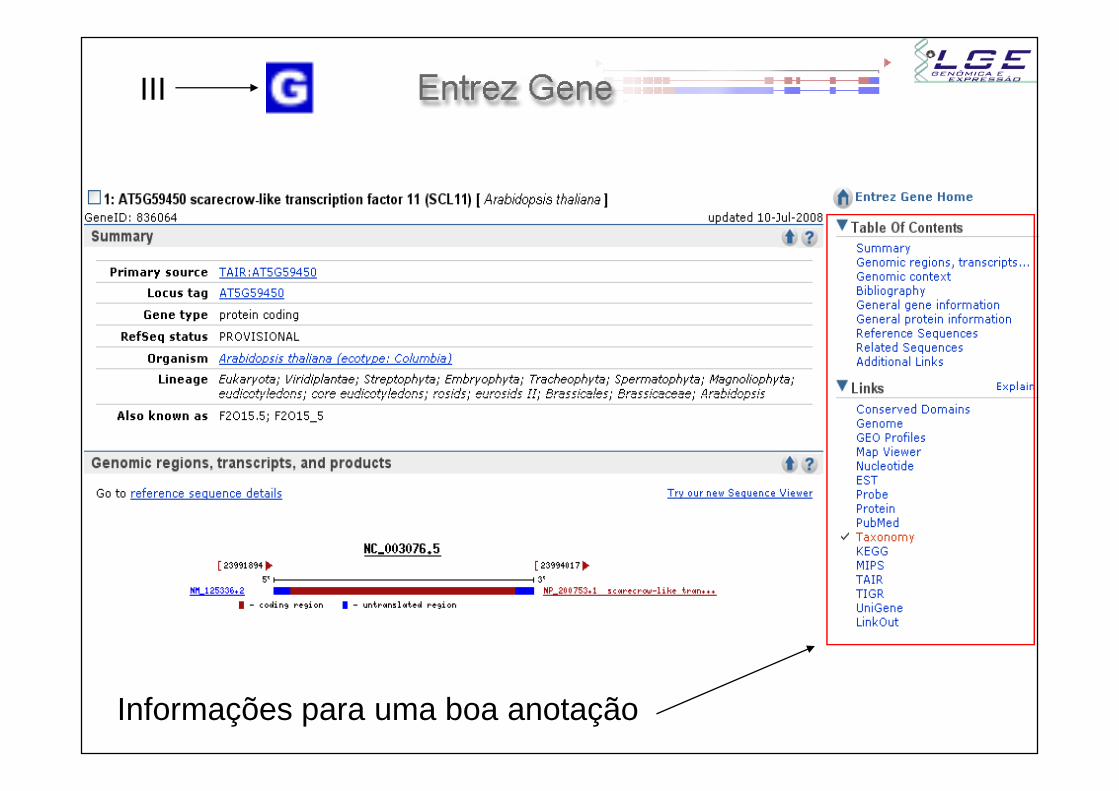
III
Informações para uma boa anotação
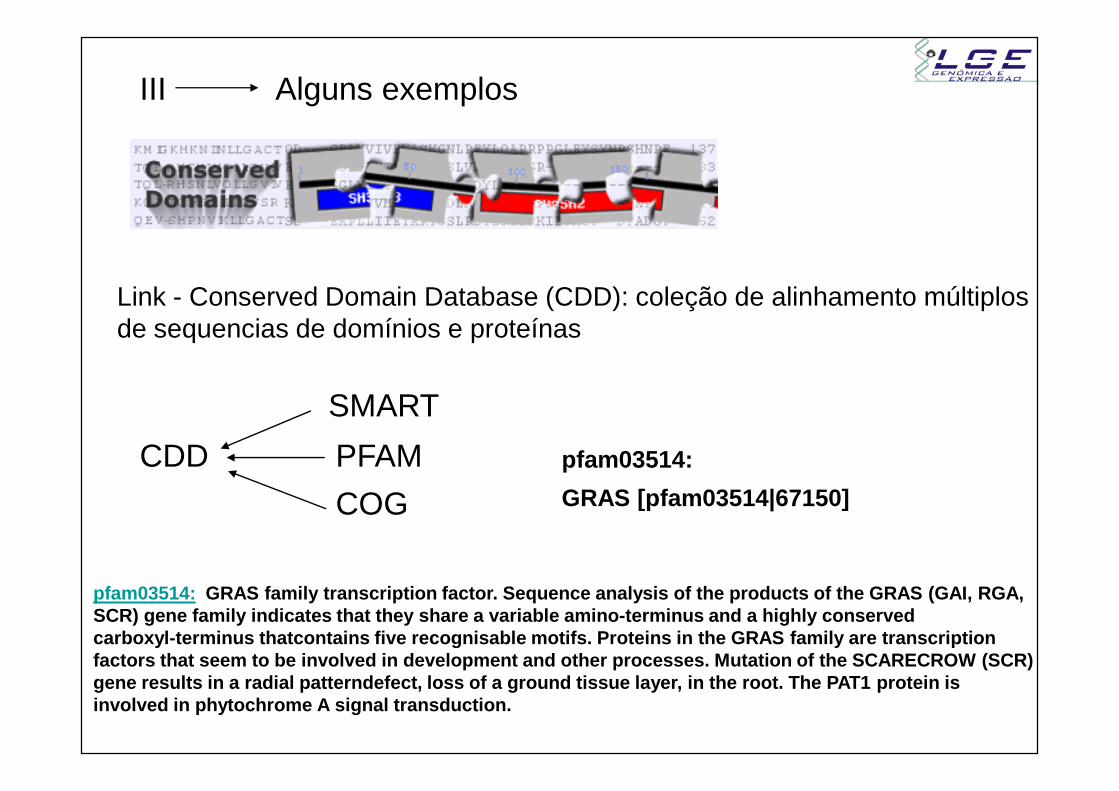
III Alguns exemplos
Link - Conserved Domain Database (CDD): coleção de alinhamento múltiplos de sequencias de domínios e proteínas
SMART
CDD
SMART
PFAM
COG
pfam03514:
GRAS [pfam03514|67150]
pfam03514: GRAS family transcription factor. Sequence analysis of the products of the GRAS (GAI, RGA,SCR) gene family indicates that they share a variab le amino-terminus and a highly conserved carboxyl-terminus thatcontains five recognisable mo tifs. Proteins in the GRAS family are transcriptionfactors that seem to be involved in development and other processes. Mutation of the SCARECROW (SCR)gene results in a radial patterndefect, loss of a g round tissue layer, in the root. The PAT1 protein i s involved in phytochrome A signal transduction.

Link - General Gene Information
GeneOntology Provided by TAIR
Function
transcription factor activitytranscription factor activity
Process
regulation of transcription
Component
undefined

Produto: Scarecrow transcription Factor
Seqüencia mais similar: Arabidopsis thaliana
Função moleular: Fator de transcrição
Processo biológico: Regulação da transcrição
Anotação funcional “básica” da seqüência
Processo biológico: Regulação da transcrição
Domínios proteicos: GRAS
Localização celular: Não definido (?)
Busca na literatura ou em outros bancos de dados

Plant GRAS and metazoan STATs: one family?Donald E. Richards, Jinrong Peng, and Nicholas P. Harberd*Bioessays. 2000 Jun;22(6):573-577.
“According to this proposal, the interaction of a ligand with an intra or extracellular receptor activates the cytoplasmic GRAS protein by phosphorylation. This in turn allows the GRAS protein to homo- or heterodimerize. The GRAS protein then enters the nucleus, binds to DNA, and alters the transcription of genes”.the nucleus, binds to DNA, and alters the transcription of genes”.
NtGRAS1, a novel stress-induced member of the GRAS family in tobacco,localizes to the nucleus.Czikkel BE, Maxwell DP.J Plant Physiol. 2007 Sep;164(9):1220-1230.
Certo ou errado...o anotador tem que decidir.....
Núcleo
Núcleo e citoplasma
Não definido
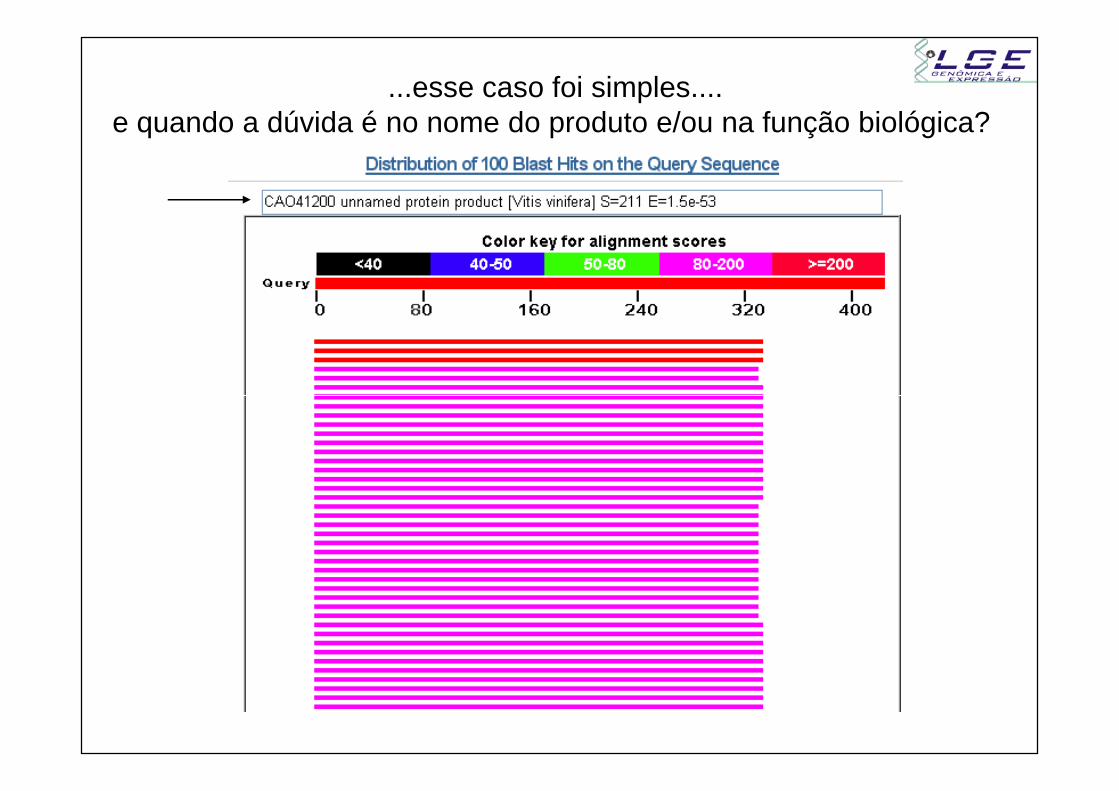
...esse caso foi simples....e quando a dúvida é no nome do produto e/ou na função biológica?

Unnamed protein product – O que isso quer dizer?
Biologicamente não signica nada....

Nenhuma informação relevante....
Nem sempre o primeiro hit (seqüência mais similar)é o mais informativo
Solução : passe para o próximo

Anotação mais informativa:
Nome do produto bem definido Unigene e Entrez gene
Function
Link - General gene Information (gene onthology)
signal transducer activity
Process
photomorphogenesis
Component
cytoplasm
Link - CDD
pfam03514: GRAS

Será que eu posso anotar minha seqüência como PAT1?
Cuidado!:Lembre-se que quanto menor o E-value maior a confiança na anotação
Levando em conta o exemplo anterior
Duas entradas com o mesmo E-value

Vamos ver os outros Hits....
Muitas seqüências anotadas como Scarecrow protein

Uma anotação mais parcimoniosa.....
Produto: Scarecrow transcription Factor
Seqüencia mais similar: Vitis vinifera
Função moleular: Fator de transcrição
Processo biológico: Regulação da transcriçãoProcesso biológico: Regulação da transcrição
Domínios proteicos: GRAS
Localização celular: núcleo e citoplasma
Nota: Alta Similaridade com proteína PAT1 (Phytochrome A Signal tranduction1)
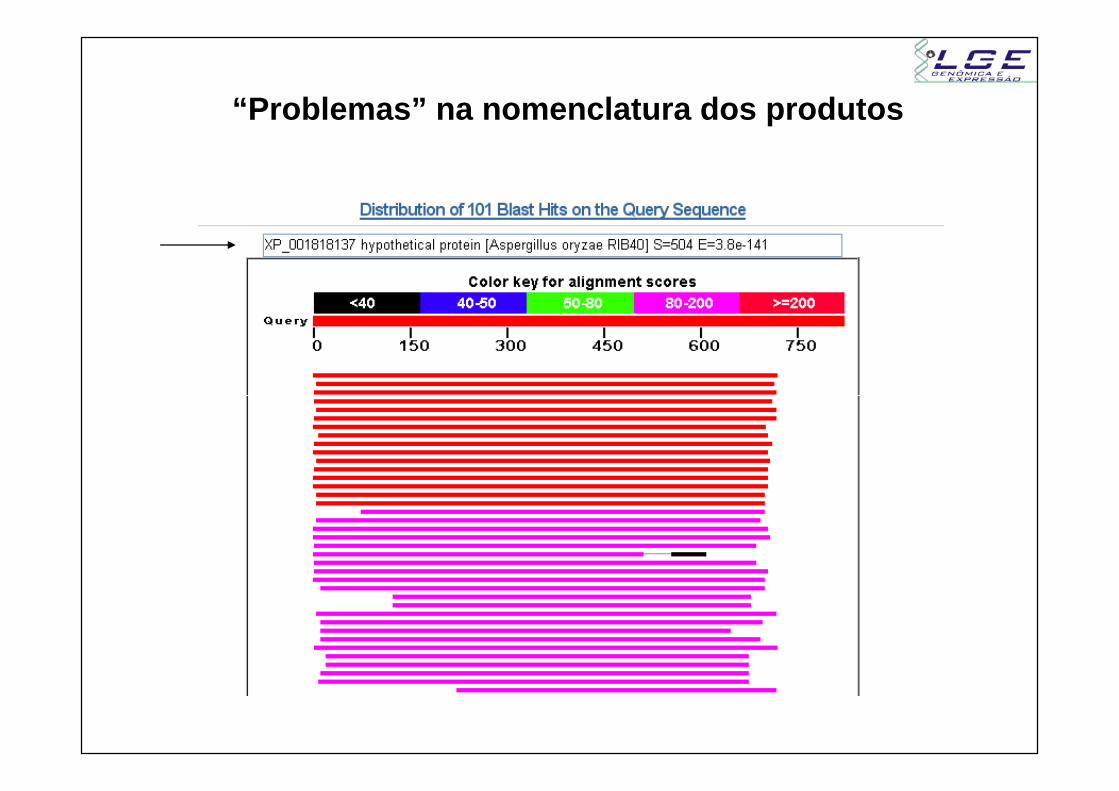
“Problemas” na nomenclatura dos produtos

Hypothetical protein – proteina cuja existência foi preditamas sem evidência experimental (in vivo) de sua expressão.Preditor gênico utilizado para descoberta de genes em genomas encontra uma ORF “grande” sem análogo no banco de dados.
Muitas vezes são chamadas de putative proteins ou predicted
Nomenclaturas importantes
Muitas vezes são chamadas de putative proteins ou predicted proteins
Conserved Hypothetical Protein – proteina cuja existência foi predita mas sem evidência experimental (in vivo) de sua expressão, só que possui similaridade com uma ou mais Hypothetical proteins no banco de dados.

Expressed protein – proteina cuja existência foi comprovadaexperimentalmente (in vivo – bibliotecas de cDNA), mas quenão tem análogos no banco de dados. São os “No-hits”.
Conserved Expressed protein – proteinas cuja existência foi comprovada experimentalmente (in vivo – bibliotecas de cDNA), contendo análogos no banco de dados cuja função não foi comprovada.

Escolha: olhar o Entrez do primeiro hit ou do hit mais informativo?
Os Dois! =]

CDD link: primeiro hit (Hypothetical protein)
Copper-oxidase: Multicopper oxidase. Many of the proteins in this family contain multiple similar copies of this plastocyanin-like domain.
CDD link: primeiro hit (Laccase)
Copper-oxidase: Multicopper oxidase. Many of the proteins in this family contain multiple similar copies of this plastocyanin-like domain.
....Laccases são Multicopper oxidases?

E.C. number

Pela literatura:“Laccases (EC 1.10.3.2) are copper-containing oxidas e enzymes that are foundin many plants, fungi, and microorganisms ….. Laccases act on phenols and
similar molecules, performing a one-electron oxidat ions.... , It is proposed that fungi laccases plays role in the degradation of lig nin...”

Localização celular????
Não tem como inferir pela seqüência...
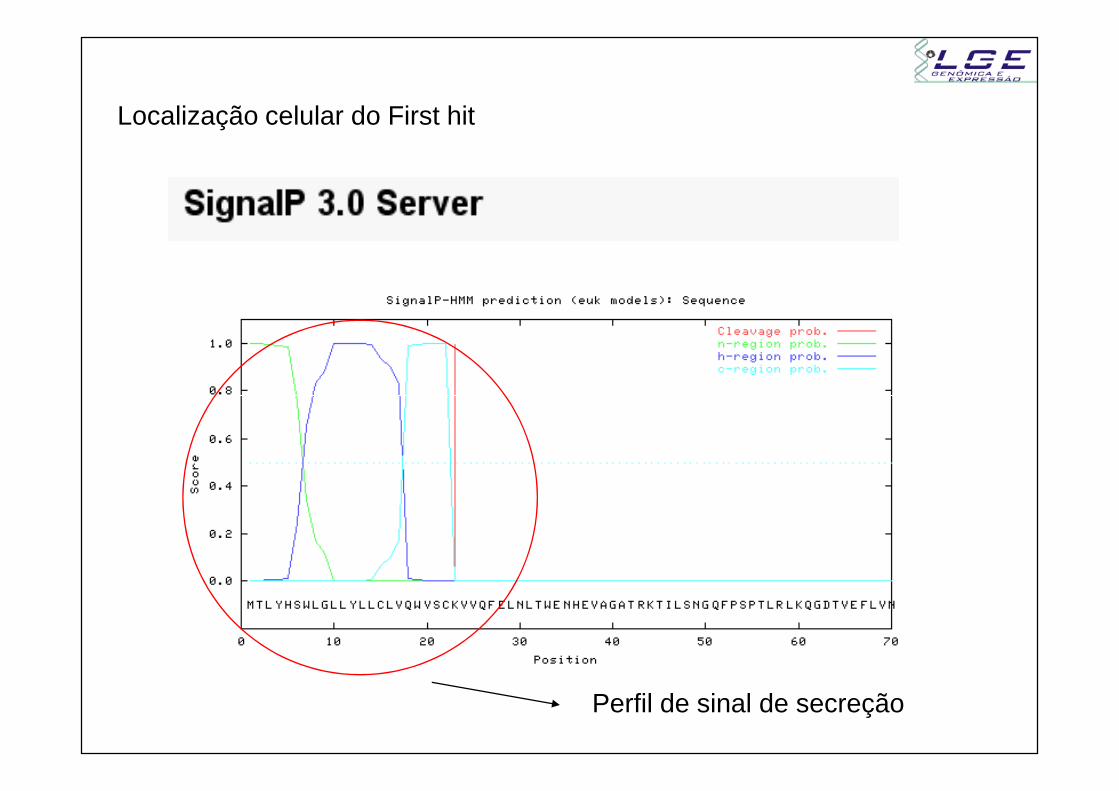
Localização celular do First hit
Perfil de sinal de secreção

Produto: Laccase
Seqüencia mais similar: Aspergillus oryzae
Função molecular: oxidação de fenóis (laccase)
Processo biológico: Degradação de lignina
Uma anotação mais parcimoniosa.....
Processo biológico: Degradação de lignina
Domínios proteicos: Copper oxidase, multicopper oxidase
Localização celular: não definido
E.C. Number – 1.10.3.2
Nota: provavelmente é uma proteína extracelular
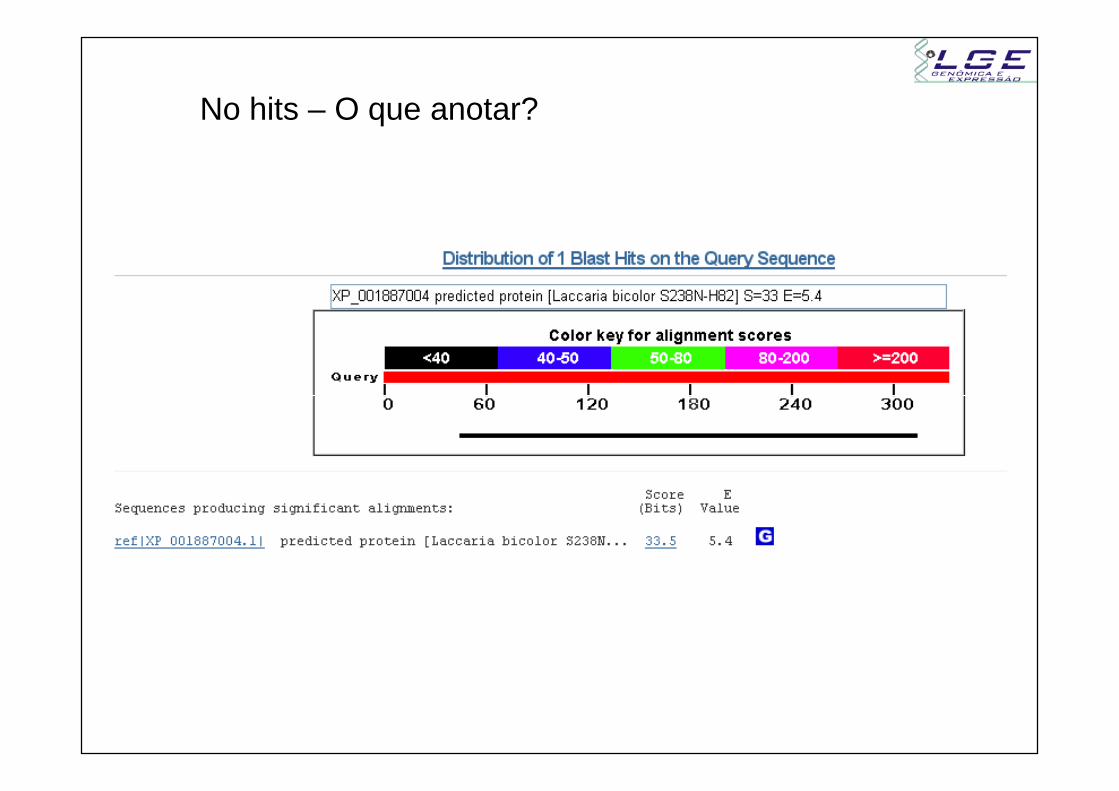
No hits – O que anotar?

Produto: Conserved expressed protein (EST)Conserved hypothetical protein (genoma)
Seqüencia mais similar: -
Função molecular: desconhecido
Processo biológico: desconhecido Processo biológico: desconhecido
Domínios proteicos: desconhecido
Localização celular: desconhecido
A partir da seqüência buscar localização celular ou outracaracterística interessante (p.e., proteínas ricas em um aminoácido).

A propagação dos erros de anotação....
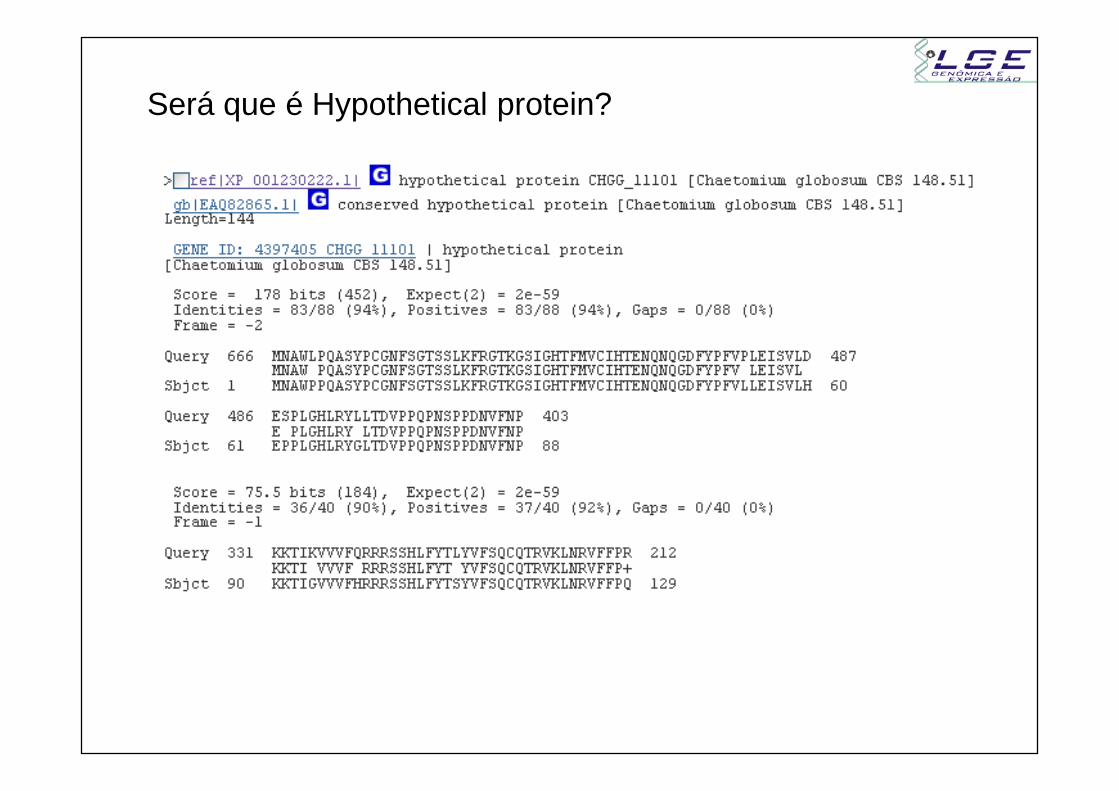
Será que é Hypothetical protein?
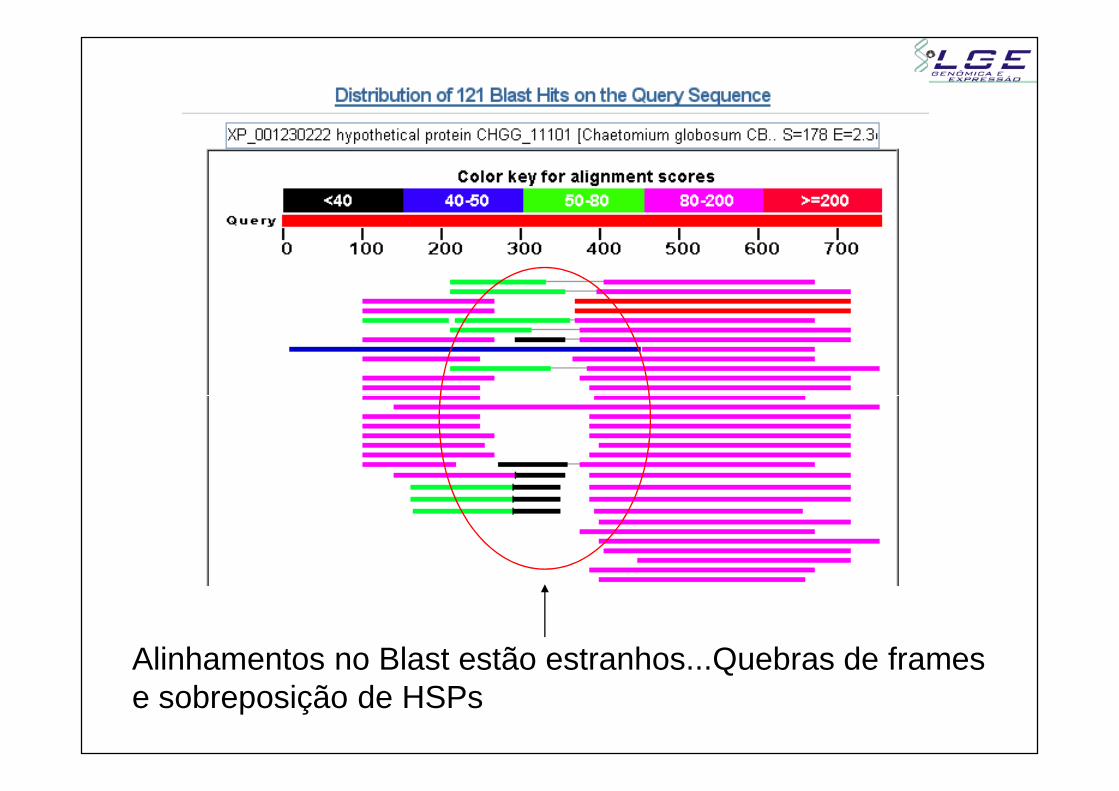
Alinhamentos no Blast estão estranhos...Quebras de framese sobreposição de HSPs
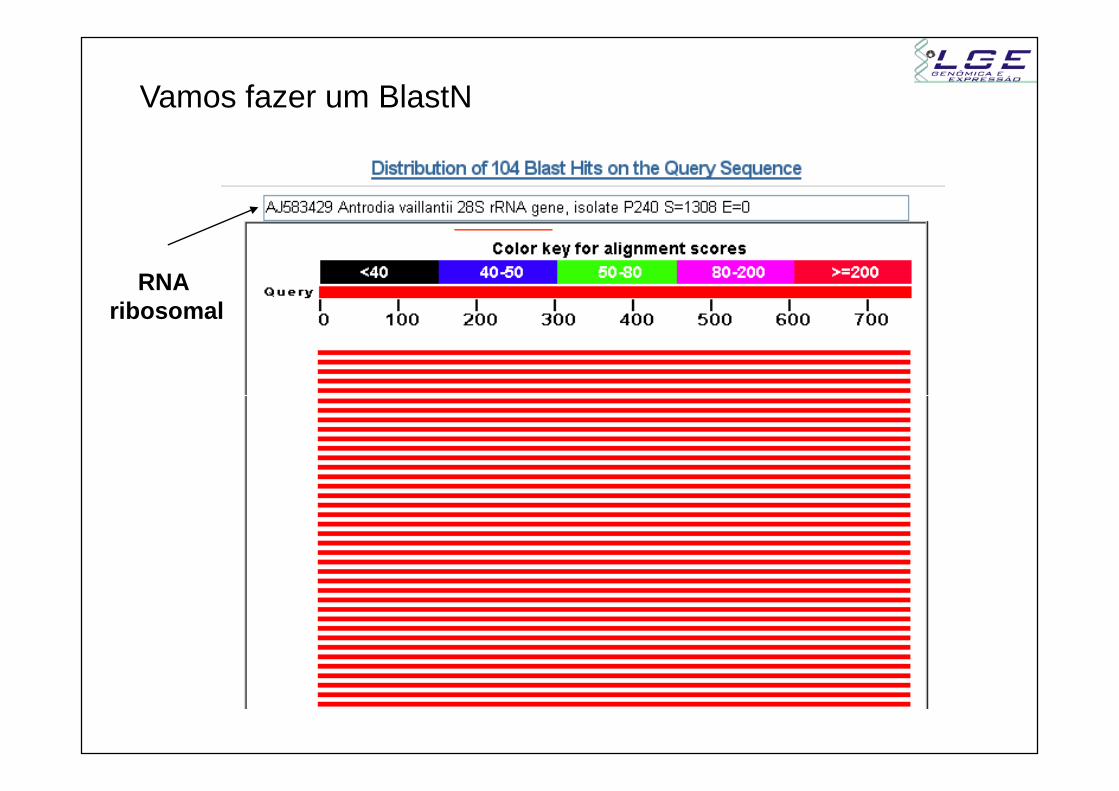
Vamos fazer um BlastN
RNA ribosomal


Explicando o erro:
- Os anotadores desses hits não fizeram um BlastN para conferirsimilaridade com RNA ribossomal
- Pequenas ORFs existem no rRNA mas não codificam nenhuma proteínanenhuma proteína
- Uma “ORF do rRNA” foi anotada como proteína hipotética e oerro foi se propagando.

Para ser anotador é preciso
- Ter um método para anotar (é muito mais fácil anotarcom um pipeline definido)
- Conhecer os bancos de dados. Usar bancos curados(p.e., UniProt) ou mais de um banco para a mesma análise
- Buscar informações na literatura. Nem sempreos bancos de dados vão te dar todas as informaçõesnecessárias
- Gostar de trabalhar na frente do computador (horas à fio)
No início demora...mas com a prática a anotação fica mais rápida.