anÁlise da localidade de programas e … · mru – most recently used (algoritmo) npv – número...
TRANSCRIPT

HUGO HENRIQUE CASSETTARI
ANÁLISE DA LOCALIDADE DE PROGRAMAS E DESENVOLVIMENTO DE ALGORITMOS ADAPTATIVOS PARA
SUBSTITUIÇÃO DE PÁGINAS
Dissertação apresentada à Escola Politécnica da Universidade de São Paulo para obtenção do Título de Mestre em Engenharia Elétrica.
São Paulo 2004

HUGO HENRIQUE CASSETTARI
ANÁLISE DA LOCALIDADE DE PROGRAMAS E DESENVOLVIMENTO DE ALGORITMOS ADAPTATIVOS PARA
SUBSTITUIÇÃO DE PÁGINAS
Dissertação apresentada à Escola Politécnica da Universidade de São Paulo para obtenção do Título de Mestre em Engenharia Elétrica. Área de Concentração: Sistemas Digitais Orientador: Prof. Dr. Edson Toshimi Midorikawa
São Paulo 2004

Este exemplar foi revisado e alterado em relação à versão original, sob responsabilidade única do autor e com a anuência de seu orientador. São Paulo, 20 de fevereiro de 2004 Hugo Henrique Cassettari Prof. Dr. Edson Toshimi Midorikawa
FICHA CATALOGRÁFICA
Cassettari, Hugo Henrique Análise da localidade de programas e desenvolvimento de algoritmos
adaptativos para substituição de páginas / Hugo Henrique Cassettari – São Paulo, 2004. Edição Revisada.
118p.
Dissertação (Mestrado) – Escola Politécnica da Universidade de São Paulo. Departamento de Engenharia de Computação e Sistemas Digitais.
1. Gerência de memória 2. Sistemas operacionais 3. Engenharia de computação I. Universidade de São Paulo. Escola Politécnica. Departamento de Engenharia de Computação e Sistemas Digitais II. t

Aos meus pais, Domingos Cassettari e Marlene
Pereira, cuja colaboração para a realização deste
trabalho foi fundamental e inestimável.

AGRADECIMENTOS
Ao meu orientador, Prof. Edson Toshimi Midorikawa, pela amizade, pelos incentivos
constantes, pela dedicação permanentemente ativa e pelo muito que me ensinou em
quase cinco anos de convivência.
À minha família pela atenção, paciência, carinho, apoio participativo e financeiro, e
pela força emocional que me deram nesses dois anos de mestrado.
Aos Profs. João José Neto e Hélio Crestana Guardia pelas críticas sempre
construtivas e pelas valiosas sugestões.
À Profa. Líria Matsumoto Sato e a todos os colegas do Laboratório de Arquitetura e
Software Básico (LASB) pela solidariedade e pelo ambiente de trabalho acolhedor,
produtivo e humano.
Ao meu irmão, Denis Cassettari, pela revisão engajada do texto e pela colaboração
crítica.
À Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES / MEC)
pelo auxílio financeiro na forma de bolsa de fomento.
Aos ex-professores e colegas do Colégio Comercial Nossa Senhora Aparecida,
Escola Técnica Federal de São Paulo, Universidade Presbiteriana Mackenzie e
Escola Politécnica da USP, responsáveis pela minha formação pessoal e acadêmica.
Em especial, por tudo o que fez por mim, meu eterno obrigado ao Prof. Valdim
Santos Alves.

RESUMO
Algoritmos de substituição de páginas influenciam diretamente o desempenho de
sistemas computacionais que utilizam memória virtual paginada. O algoritmo de
substituição mais conhecido e implementado nos sistemas operacionais modernos –
através de versões aproximadas – é o LRU (Least Recently Used). Este algoritmo,
embora seja eficiente na maioria dos casos, demonstra algumas deficiências quando
ocorrem determinados padrões de acesso à memória inerentes aos programas. Tais
padrões estão intrinsecamente ligados à propriedade de localidade de referências que
os processos podem exibir com maior ou menor intensidade. Algoritmos adaptativos
têm a capacidade de modificar o seu comportamento ao longo do tempo, de acordo
com as características de processamento observadas. Este trabalho apresenta um
novo algoritmo adaptativo para substituição de páginas, cujo objetivo é minimizar
falhas detectadas no algoritmo LRU sem perder a sua simplicidade computacional: o
LRU-WAR (LRU with Working Area Restriction / LRU com Confinamento da Área
de Trabalho). Os experimentos realizados indicam que a nova proposta, além de ser
confiável, pode melhorar significativamente o desempenho do algoritmo LRU. A
redução no número de faltas de página em uma simulação chegou a 75%. Análises
comparativas em relação a outros algoritmos recentemente publicados na literatura
científica e um detalhamento minucioso das características dos programas simulados
justificam as conclusões favoráveis a respeito da política de substituição LRU-WAR.

ABSTRACT
Page replacement algorithms have direct influence on the performance of computing
systems which use paged virtual memory. Least Recently Used (LRU) is the best
known replacement algorithm and is widely implemented in modern operating
systems through approximated approaches. Despite being efficient in most cases, it
shows some deficiencies when certain memory access patterns, inherent in specific
programs, occurs. Those patterns are related to the locality property that applications
are able to exhibit more or less intensely. Adaptive algorithms are capable of
modifying their own behavior through time, depending on the execution
characteristics. This work presents a new adaptive algorithm for page replacement:
LRU with Working Area Restriction (LRU-WAR), whose target is to minimize
failures detected in LRU algorithm, preserving its low overhead. Simulation
experiments pointed out that besides being reliable, this new proposal can improve
significantly the performance of LRU. It was achieved a top reduction of 75% in the
number of page faults. Favorable conclusions were justified, concerning the
replacement policy LRU-WAR, both by comparing it to other recently proposed
algorithms and detailing all simulated programs characteristics.

SUMÁRIO
LISTA DE FIGURAS
LISTA DE TABELAS
LISTA DE ABREVIATURAS E SIGLAS
1. INTRODUÇÃO .................................................................................................. 1
1.1. Contexto ........................................................................................................... 1
1.2. Motivação ........................................................................................................ 2
1.3. Objetivos e Contribuições Esperadas .............................................................. 3
1.4. Metodologia ..................................................................................................... 4
1.5. Estrutura do Texto ........................................................................................... 5
2. GERÊNCIA DE MEMÓRIA E ALGORITMOS DE SUBSTITUIÇÃO DE
PÁGINAS .......................................................................................................... 7
2.1. Gerência de Memória ....................................................................................... 7
2.1.1. Alocação Contígua ........................................................................................ 8
2.1.2. Memória Virtual ........................................................................................... 12
2.1.3. Paginação ...................................................................................................... 14
2.1.4. Segmentação ................................................................................................. 17
2.2. Algoritmos de Substituição de Páginas ........................................................... 19
2.2.1. Avaliação de Desempenho ............................................................................ 24
2.2.2. Propostas Adaptativas ................................................................................... 26
2.2.3. Algoritmo SEQ ............................................................................................. 29
2.2.4. Algoritmo EELRU ........................................................................................ 33
3. ANÁLISE DA LOCALIDADE DE PROGRAMAS .......................................... 40
3.1. Ferramentas Desenvolvidas ............................................................................. 42
3.2. Recursos Oferecidos para Análise de Localidade ............................................ 51
3.3. Estudos Realizados .......................................................................................... 57
3.4. Caracterização dos Programas Estudados ........................................................ 59
4. UMA NOVA PROPOSTA PARA SUBSTITUIÇÃO DE PÁGINAS:
O ALGORITMO ADAPTATIVO LRU-WAR ................................................. 66
4.1. Motivação da Proposta ..................................................................................... 66

4.2. Conceitos Básicos ............................................................................................ 69
4.3. Idéia Geral ........................................................................................................ 71
4.4. Aspectos Operacionais ..................................................................................... 72
4.5. Descrição Prática do Algoritmo ....................................................................... 84
4.6. Versão Online .................................................................................................. 87
5. EXPERIÊNCIAS REALIZADAS ...................................................................... 90
5.1. Descrição das Simulações ................................................................................ 90
5.2. Resultados Obtidos .......................................................................................... 93
5.3. Análise dos Resultados .................................................................................... 103
6. CONCLUSÃO .................................................................................................... 110
6.1. Contribuições ................................................................................................... 111
6.2. Trabalhos Futuros ............................................................................................ 112
LISTA DE REFERÊNCIAS .............................................................................. 114

LISTA DE FIGURAS
Figura 1: Metodologia utilizada para a realização de simulações neste trabalho ... 4
Figura 2: Alocação Contígua Simples .................................................................... 8
Figura 3: Exemplo de Alocação Contígua Particionada Estática ........................... 8
Figura 4: Exemplo de Alocação Contígua Particionada Dinâmica e
fragmentação posterior ........................................................................... 10
Figura 5: Espaços de endereçamento virtual e real ................................................. 13
Figura 6: Mapeamento de endereços com o mecanismo de paginação .................. 15
Figura 7: Mapeamento de endereços com o mecanismo de segmentação .............. 18
Figura 8: Exemplo gráfico hipotético com seqüências identificadas pelo
algoritmo SEQ, destacando aquela que teria uma página substituída
nesse instante .......................................................................................... 31
Figura 9: Eixo LRU com os pontos importantes para os algoritmos GLRU e
EELRU ................................................................................................... 33
Figura 10: Interface gráfica da ferramenta TelaTrace (janelas principal e de
aproximação) ........................................................................................ 43
Figura 11: Exemplo de gráficos de acesso bidimensional e tridimensional
(GhostScript) ........................................................................................ 45
Figura 12: Exemplo de visão lateral em gráfico de acessos tridimensional
(GhostScript) ........................................................................................ 46
Figura 13: Exemplo de mapas criados pela ferramenta Trace Explorer (P2C) ...... 49
Figura 14: Exemplo de mapas com dados específicos de uma única página
(P2C, pág. AB) ..................................................................................... 50
Figura 15: Mapas de recência bidimensional e tridimensional com visão lateral
(Netscape) ............................................................................................ 54
Figura 16: Mapa de acessos (Netscape) .................................................................. 55
Figura 17: Recência dos acessos à página 12F com tempo virtual absoluto
(Netscape) ............................................................................................ 56
Figura 18: Mapa de acessos tridimensional (Go) ................................................... 60
Figura 19: Mapas de recência bidimensional e tridimensional (Compress) ........... 61
Figura 20: Mapa de acessos tridimensional (Glimpse) ........................................... 62

Figura 21: Mapa tridimensional de recência dos acessos (2_Pools) ...................... 63
Figura 22: Mapas de acesso bidimensional e tridimensional (Lindsay) ................. 64
Figura 23: Visão lateral tridimensional do mapa de recência dos acessos
(Grobner) .............................................................................................. 65
Figura 24: Exemplos de programas com padrões de acesso seqüenciais
(Gnuplot e Cscope) .............................................................................. 68
Figura 25: Exemplo de área de trabalho, identificando-se o limite W entre
faltas de página .................................................................................... 71
Figura 26: Divisão lógica da fila LRU utilizada pelo algoritmo LRU-WAR ......... 73
Figura 27: Exemplo de utilização do critério de substituição MRU-(W+1) ........... 78
Figura 28: Exemplo de utilização do critério de substituição LRU ........................ 78
Figura 29: Exemplo, em operação seqüencial, de páginas poupadas pelo tempo
de carência ........................................................................................... 81
Figura 30: Gráficos de desempenho referentes aos programas Cscope, Postgres
e Gnuplot .............................................................................................. 99
Figura 31: Gráficos de desempenho referentes aos programas Perl, Photoshop e
Sprite .................................................................................................... 100
Figura 32: Gráficos de desempenho referentes aos programas Acrobat Reader,
Power Point e Espresso ........................................................................ 101
Figura 33: Gráficos de desempenho referentes aos programas Compress,
Multi1 e Grobner .................................................................................. 102
Figura 34: Pontos ótimos de substituição identificados em simulações LRU e
LRU-WAR ........................................................................................... 106
Figura 35: Histogramas de otimalidade das substituições realizadas (LRU e
LRU-WAR) .......................................................................................... 107

LISTA DE TABELAS
Tabela I – Histograma da recência dos acessos na forma tabular (Netscape) ....... 52
Tabela II – Estatísticas gerais dos arquivos de trace utilizados em nossos
estudos .................................................................................................. 59
Tabela III – Características dos estados de execução definidos pelo algoritmo
LRU-WAR ........................................................................................ 79
Tabela IV – Programas e contextos de memória considerados nas simulações
realizadas ........................................................................................... 91
Tabela V – Desempenho dos algoritmos analisados em relação ao caso ótimo ..... 93
Tabela VI – Desempenho do algoritmo LRU-WAR em relação ao algoritmo
LRU ................................................................................................... 95
Tabela VII – Desempenho da versão online do LRU-WAR em relação à versão
offline ................................................................................................. 97

LISTA DE ABREVIATURAS E SIGLAS
3D – Tridimensional
ACROREAD – Adobe Acrobat Reader (programa)
AFC – Application/File-level Characterization (algoritmo)
ARC – Adaptive Replacement Cache (algoritmo)
CPP – Compiler Preprocessor (programa)
CPU – Central Processing Unit
CS – Cscope (programa)
DEAR – Detection-based Adaptive Replacement (algoritmo)
EELRU – Early Eviction LRU (algoritmo)
FBR – Frequency-Based Replacement (algoritmo)
FIFO – First In, First Out (algoritmo)
GCC – GNU Compiler Collection (programa)
GLI – Glimpse (programa)
GLRU – Generalized LRU (algoritmo)
GNU – GNU’s Not Unix (sigla recursiva)
GS – GhostScript (programa)
IRG – Inter-Reference Gap
IRR – Inter-Reference Recency
LFU – Least Frequently Used (algoritmo)
LIRS – Low Inter-reference Recency Set (algoritmo)
LRFU – Least Recently/Frequently Used (algoritmo)
LRU – Least Recently Used (algoritmo)
LRU-WAR – LRU with Working Area Restriction (algoritmo)
MAX – Valor máximo
MFU – Most Frequently Used (algoritmo)
MIN – Valor mínimo
MMU – Memory Management Unit
MRU – Most Recently Used (algoritmo)
NPV – Número da Página Virtual
NRU – Not Recently Used (algoritmo)

OPT – Optimum (algoritmo)
PDF – Portable Document Format
PFF – Page Fault Frequency (algoritmo)
PHOTOSHP – Adobe Photoshop (programa)
POWERPNT – Microsoft Power Point (programa)
PS – Postgres (programa)
RAM – Random Access Memory
SMP – Symmetric MultiProcessor
SPEC – Standard Performance Evaluation Corporation
UBM – Unified Buffer Management (algoritmo)
USP – Universidade de São Paulo
WINWORD – Microsoft Word (programa)
WS – Working Set (algoritmo)

1
1. INTRODUÇÃO
1.1. Contexto
O número cada vez maior de usuários conectados à internet onera
gradativamente a rede mundial, causando sérios problemas de desempenho. O
desenvolvimento de caches para web passou a ser, naturalmente, uma área de
pesquisa muito importante e valorizada no cenário tecnológico atual. Estudos nesta
área trouxeram consigo uma preocupação crescente com as chamadas políticas de
substituição de objetos, fundamentais não apenas no gerenciamento de web caches,
mas também no gerenciamento da memória principal e de outros dispositivos de
cache (memória e disco). A implementação operacional de uma política é feita por
meio de um algoritmo de substituição, cujo grau de eficiência afeta
significativamente o desempenho global do sistema em que atua. Pinheiro (2001), em
sua dissertação de mestrado, discute e avalia políticas de substituição voltadas ao
gerenciamento de caches para web. Diversos outros autores desenvolveram estudos
similares recentemente e continuam trabalhando no assunto.
Contudo, tal enfoque não é o único que ainda desperta interesse da
comunidade científica no que tange ao aperfeiçoamento de políticas de substituição.
Este trabalho visa estudar e discutir especificamente algoritmos de substituição de
páginas de memória. Importante sobretudo no contexto de sistemas que exigem alto
desempenho, o tema se insere no gerenciamento da memória principal, dentro do
escopo de sistemas operacionais. O desenvolvimento do trabalho inclui uma análise
das principais propostas de substituição encontradas na literatura, o levantamento de
aspectos inerentes aos programas que influenciam o desempenho de sistemas de
memória e, por fim, a apresentação de uma nova estratégia adaptativa para
substituição de páginas: o algoritmo LRU-WAR – LRU with Working Area
Restriction.
Além de relatar uma análise do que já foi criado em termos de algoritmos
adaptativos, o trabalho pretende contribuir para o aperfeiçoamento dos sistemas de
memória vigentes. No campo teórico, através da discussão crítica acerca de fatores
que afetam o desempenho das políticas de substituição e alguns meios em potencial

2
para tratá-los. No campo prático, por meio de uma política nova, eficiente e factível,
criada como alternativa ao tradicional algoritmo LRU e suas variações atuais. A
simplicidade computacional da proposta LRU-WAR sugere a sua viabilidade prática,
isto é, incentiva a implementação futura do algoritmo em um sistema operacional
com código aberto, como o Linux por exemplo.
1.2. Motivação
Uma série de estudos, posteriormente detalhados, comprova que a aplicação
do conceito de adaptatividade em algoritmos de substituição de páginas pode trazer
benefícios bastante satisfatórios. Estes benefícios incluem a correção de algumas
deficiências presentes nas políticas tradicionais – ou triviais – e a possibilidade de
otimização nos critérios de substituição empregados. Por conseqüência, algoritmos
adaptativos podem diminuir muito o tempo global de processamento requerido por
um sistema de alto desempenho, uma vez que tornam o gerenciamento da memória
virtual paginada potencialmente mais eficiente.
No entanto, algoritmos adaptativos tendem a onerar o sistema de memória,
seja em termos de processamento complexo ou em termos de estruturas de dados
complexas e expansivas. Muitas propostas relatadas constituem excelentes
alternativas teóricas, porém impraticáveis em um sistema real devido à sobrecarga
que acarretam. Em outras propostas, o aspecto de implementação é muito bem
elaborado e, com isso, consegue-se uma versão online (factível) por meio de alguns
ajustes e aproximações. Mas, ainda assim, perde-se muito da idéia teórica original.
Nossos esforços estão concentrados em projetos adaptativos de substituição
de páginas que, essencialmente, sejam simples e práticos. Ou seja, algoritmos que
tenham uma base teórica fundamentada e engenhosa, mas que sejam viáveis e
eficientes em situações reais de computação. Em 2000, iniciamos estudos que
especulavam a possibilidade de melhorar o desempenho de algoritmos com espaço
de memória variável – especificamente WS e PFF – através de um controle simples e
dinâmico sobre alguns parâmetros de execução adaptativos (MIDORIKAWA et al.,
2000). Os resultados obtidos foram apenas razoáveis. E, em última instância,
algoritmos de substituição com espaço variável possuem uma alta complexidade de

3
implementação inerente à sua filosofia. Por mais que os estudos alcançassem
progressos, eles provavelmente se limitariam a aspectos teóricos.
Em 2002, um novo enfoque foi adotado: a utilização do algoritmo LRU – e
seu respectivo modelo teórico – como base para o desenvolvimento de um novo
projeto adaptativo, caminho explorado pela comunidade científica com alguns
resultados muito positivos. Após um amplo estudo teórico nas propriedades do
modelo LRU, chegou-se à proposta do algoritmo LRU-WAR.
1.3. Objetivos e Contr ibuições Esperadas
O objetivo deste trabalho é buscar novos meios para melhorar o desempenho
de sistemas de gerenciamento de memória, através do estudo e caracterização de
localidade de referências e a pesquisa de algoritmos adaptativos para substituição de
páginas.
Pretende-se contribuir, assim, com as seguintes realizações:
- Estudo sobre o contexto atual de desenvolvimento científico na área de
algoritmos de substituição de páginas e, enfaticamente, algoritmos
adaptativos;
- Associação mais precisa entre localidade de programas e desempenho de
execução dos mesmos, levando-se em consideração diversas políticas de
substituição de páginas;
- Apresentação de novas ferramentas desenvolvidas para facilitar a análise
da localidade de programas em conjunto com outras importantes
características neles encontradas;
- Identificação de formas para reconhecimento de padrões regulares de
acesso e, por decorrência, de critérios dinâmicos para o gerenciamento da
memória virtual paginada;
- Proposta e avaliação de desempenho de uma alternativa adaptativa
original: o algoritmo LRU-WAR de substituição de páginas, quase tão
simples quanto o LRU em termos computacionais, porém mais eficiente
em termos de acerto de previsões.

4
1.4. Metodologia
O estudo de algoritmos de substituição de páginas desenvolvido no
Laboratório de Arquitetura e Software Básico – Departamento de Engenharia de
Computação e Sistemas Digitais da Escola Politécnica da USP – incluiu três etapas:
- Obtenção de traces (arquivos de traços);
- Desenvolvimento de simuladores de sistemas de memória;
- Realização de experimentos, em especial simulações com os traces
obtidos, e análises sobre os resultados.
Um arquivo de traces consiste basicamente na listagem cronológica dos
diversos acessos à memória realizados por um software. Em outras palavras,
descreve passo a passo o comportamento de um dado programa em termos de
utilização da memória. Estes arquivos são obtidos através de um gerador de traces,
que executa o programa alvo e coleta os acessos à memória realizados ao longo de
seu processamento (UHLIG; MUDGE, 1997).
A partir dos dados coletados e armazenados nos arquivos de traces, uma série
de simulações podem ser efetuadas para se avaliar o desempenho de algoritmos de
substituição, no contexto de todos os possíveis tamanhos de memória que se queira
considerar. A figura 1 esquematiza o procedimento adotado nessas avaliações.
Os dados de desempenho obtidos são então analisados em conjunto com as
características de localidade de referências, entre outras, presentes em cada
programa. Ou seja, a eficiência ou não das políticas de substituição de páginas
procura ser explicada de acordo com os padrões de acesso à memória observados nos
programas. Tal análise é feita com o apoio de ferramentas estatísticas e de
visualização desenvolvidas especificamente para este estudo.
Fig. 1: Metodologia utilizada para a realização de simulações neste trabalho
Programaexecutável
Geradorde traces
arquivo de traces
Simuladorresultados

5
As simulações são executadas em equipamentos disponíveis no laboratório,
que incluem duas máquinas multiprocessadoras (com 4 processadores cada) e um
cluster de computadores com 8 nós duais (2 processadores em cada nó).
Aproveitando a estrutura de hardware, foram construídas versões paralelas de
algoritmos de simulação para duas políticas de substituição de páginas: Ótimo e
LRU. O simulador StackPar (CASSETTARI; MIDORIKAWA, 2002b), baseado nas
versões de pilha de ambos os algoritmos (MATTSON et al., 1970), simula a
execução de um único programa, porém divide o processamento do arquivo de traces
correspondente entre os diversos processadores disponíveis na máquina. O tempo de
simulação diminui consideravelmente, mas o simulador implementa apenas estes
dois algoritmos de substituição.
Os demais algoritmos são avaliados através de simuladores simples, em
ambientes com monoprocessamento. Cada algoritmo trivial possui pelo menos um
simulador desenvolvido e implementado por nós. Os simuladores dos algoritmos
adaptativos EELRU (SMARAGDAKIS; KAPLAN; WILSON, 1999) e LIRS
(JIANG; ZHANG, 2002), que complementam nossos estudos, foram cedidos
gentilmente por seus autores.
Com os resultados obtidos através das simulações, procura-se determinar o
melhor algoritmo de substituição de páginas no contexto específico de cada
programa, assim como o porquê de um algoritmo ser mais eficiente que outro na
situação analisada. As características de localidade de um programa explicam a
variação de desempenho observada entre os algoritmos em condições idênticas de
simulação. Mediante a identificação de padrões que representam genericamente
algumas destas características, formas adequadas de tratamento – em termos de
substituição de páginas – procuram ser discutidas e desenvolvidas neste trabalho.
1.5. Estrutura do Texto
O Capítulo 2 da dissertação revisa aspectos básicos sobre gerência de
memória, comentando os diversos tipos de alocação (contígua simples, particionada,
paginada e segmentada) e o conceito de memória virtual. Enfocando a alocação
paginada, base do tema explorado, o Capítulo 2 também relata os principais

6
algoritmos de substituição de páginas existentes, estáticos ou adaptativos,
descrevendo detalhadamente dois importantes algoritmos desta segunda categoria:
SEQ e EELRU. Os dois algoritmos destacados tiveram papel fundamental no
processo de elaboração da proposta LRU-WAR.
No Capítulo 3 é discutida a importância da análise de localidade dos
programas como forma de identificar características de acesso à memória e sua
influência no desempenho das políticas de substituição de páginas, principalmente
aquelas baseadas no modelo LRU. Os programas estudados são descritos e
caracterizados por meio de três ferramentas desenvolvidas para esta finalidade.
As discussões apresentadas no Capítulo 3 motivaram definitivamente o
desenvolvimento do novo algoritmo adaptativo LRU-WAR, cuja concepção é
minuciosamente relatada no Capítulo 4. Os aspectos operacionais do algoritmo são
comentados de forma analítica, justificando-se cada decisão de projeto. A
implementação de suas duas versões – offline (completa, mas teórica) e online
(aproximada, mas factível) – é demonstrada através de pseudo-códigos.
O Capítulo 5 ilustra, por meio de gráficos de desempenho, os resultados
obtidos nas simulações realizadas. A proposta LRU-WAR é comparada com os
algoritmos LRU, EELRU, LIRS e Ótimo, tanto em sua versão offline como em sua
versão online. Uma associação entre as características de localidade dos programas –
analisadas no Capítulo 3 – e o desempenho obtido pelos algoritmos procura ser
sempre traçada.
A conclusão do trabalho é exposta no Capítulo 6, enfatizando suas principais
contribuições e sugerindo trabalhos futuros que o complementem. A bibliografia
utilizada, por fim, é registrada na Lista de Referências.

7
2. GERÊNCIA DE MEMÓRIA E ALGORITMOS DE
SUBSTITUIÇÃO DE PÁGINAS
2.1. Gerência de Memór ia
O sistema de gerenciamento da memória é um dos componentes mais críticos
e importantes do sistema operacional. Na execução de programas que exigem grande
quantidade de processamento – e que, conseqüentemente, requerem alto desempenho
– a gerência de memória tem um papel fundamental.
A memória principal é o local onde ficam armazenados os dados necessários
à execução dos programas, incluindo o seu código de máquina. É nela em que o
processador procura os dados e instruções imprescindíveis à realização de qualquer
tipo de tarefa. O advento da multiprogramação tornou seu gerenciamento uma
atividade complexa e crucial do ponto de vista da eficiência. Um bom gerenciamento
de memória é característica indispensável para um sistema operacional executar
satisfatoriamente tarefas que exigem alto desempenho (MIDORIKAWA, 1991);
(MIDORIKAWA, 1997).
Basicamente, o sistema de gerenciamento da memória deve decidir e
controlar quais dados, quando e por quanto tempo permanecerão residentes na
memória principal do computador. Esta decisão leva em conta uma série de fatores,
como a quantidade e o tamanho dos processos a serem executados, a área de
memória disponível, o ambiente operacional, o tipo de alocação implementada, etc.
A definição e manipulação de mecanismos de blocagem (paginação e segmentação),
o carregamento e alocação física na memória principal dos dados provenientes da
memória secundária e o gerenciamento da memória virtual são atribuições
importantes do sistema.
As informações apresentadas nesta seção são detalhadas de forma didática em
um grande número de publicações. Alguns exemplos em língua portuguesa podem
ser citados: Machado; Maia (1997), Tanenbaum (1999), Oliveira; Carissimi; Toscani
(2001) e Silberschatz; Galvin; Gagne (2001).

8
2.1.1. Alocação Contígua
Os primeiros sistemas operacionais utilizavam uma forma de alocação de
dados na memória denominada alocação contígua simples. Este tipo de sistema
divide a memória principal em dois blocos: em um deles permanece residente o
sistema operacional e no outro é carregado um único programa a ser executado
(figura 2).
O conceito de multiprogramação trouxe consigo a necessidade de um novo
paradigma de alocação, que vislumbrasse a possibilidade de vários programas
estarem alocados na memória principal ao mesmo tempo. O primeiro modelo
proposto foi a alocação contígua particionada, uma evolução incremental no modelo
de alocação contígua simples. Nas implementações iniciais da técnica, a memória era
dividida em partições de tamanho fixo, a chamada alocação particionada estática
(figura 3).
Área para o programa
Sistema Operacional
MEMÓRIA PRINCIPAL
Fig. 2: Alocação Contígua Simples
Partição 3
MEMÓRIA PRINCIPAL
Sistema Operacional
Partição 1
Partição 2
Fig. 3: Exemplo de Alocação Contígua Particionada Estática

9
Neste esquema de alocação, o sistema trabalhava apenas com código absoluto
e cada programa podia ser executado somente em uma única partição pré-
especificada, concorrendo com outros programas que também usavam a mesma
partição, mesmo que as demais estivessem livres. O tamanho e a quantidade de
partições eram flexíveis e variáveis, porém uma mudança de configuração somente
poderia ocorrer na iniciação do sistema operacional. Uma vez configuradas as
partições, permaneciam assim inalteradas durante toda a operação do sistema.
Com o passar do tempo, o sistema evoluiu e os compiladores deixaram de
gerar os limitantes códigos absolutos, passando a gerar códigos relocáveis; este fato
permitiu que os programas fossem alocados, ainda no mesmo modelo estático, em
qualquer partição disponível, não se atendo a apenas uma partição como até então.
A fragmentação interna das partições e a sua baixa flexibilidade eram os dois
principais problemas ainda apresentados pela alocação particionada estática, mesmo
com o advento do código relocável. A alocação particionada dinâmica foi idealizada
com o objetivo de sanar essas pendências. A estratégia dinâmica inovou ao criar uma
forma de gerenciamento na qual a necessidade de uso é o critério para o
particionamento gradativo da memória disponível, metodologia eficiente que
naturalmente se manteve nos sistemas de memória posteriores. Porém, tratando-se
aqui de um sistema de alocação contígua, os programas ainda precisam ser
totalmente carregados em uma única partição para poderem ser processados.
Assim, na alocação particionada dinâmica, os programas alocam a área livre
de memória conforme são disparados. Um programa não ocupa uma partição fixa
pré-definida, e sim aloca o tamanho necessário à sua execução, nem mais nem
menos. Desta forma, programas de qualquer tamanho podem ser executados, desde
que não ultrapassem a área do maior trecho contíguo de memória livre disponível.
Por outro lado, programas pequenos não mais desperdiçam áreas superestimadas,
uma vez que só ocupam o espaço de que efetivamente necessitam. Contudo, o
problema da fragmentação persiste: trechos de memória são liberados
desordenadamente, conforme os programas deixam de rodar (figura 4). Como a
alocação continua sendo contígua, um programa precisa encontrar uma área livre
(partição) maior ou igual ao tamanho de memória do qual necessita para ser
carregado. Mas se os programas possuem tempos distintos de execução – o que

10
praticamente sempre ocorre –, partições limitadas surgem aleatoriamente durante a
operação do sistema, resultando em uma memória possivelmente bastante
fragmentada.
Dentre as partições livres num sistema de alocação dinâmica, a escolha
daquela que será utilizada para carregar um novo programa na memória é feita
basicamente por meio de um dos três seguintes algoritmos:
- Best Fit: Esta estratégia procura pela partição mais adequada ao
programa, em termos de tamanho. Ou seja, escolhe a menor partição
dentre aquelas que comportam o programa e seus dados. Como
dificilmente haverá uma partição com o tamanho exato requerido pelo
processo, uma área livre provavelmente pequena – o trecho da partição
original não ocupado pelo programa – será gerada. Com isso, um conjunto
de partições livres muito pequenas pode infestar a memória no decorrer da
operação do sistema, ocasionando um sério problema de fragmentação,
geralmente crescente. Esta é a principal desvantagem do Best Fit.
- Worst Fit: O método que escolhe a pior partição (inversamente
proporcional ao tamanho do programa) tem como objetivo diminuir a
fragmentação de memória gerada no decorrer do tempo. Seu critério é
escolher sempre a maior partição disponível quando um novo programa
precisa ser carregado. Assim, é maximizada a área da partição original
Programa 3 Partição Livre
Partição Livre Partição Livre
Programa 4
MEMÓRIA PRINCIPAL (depois)
Sistema Operacional
Partição Livre
Programa 4
(programas 1 e 3 deixam de executar)
Programa 1
Programa 2 Programa 2
MEMÓRIA PRINCIPAL (antes)
Sistema Operacional
Fig. 4: Exemplo de Alocação Contígua Particionada Dinâmica e fragmentação posterior

11
que permanecerá livre, transformando-se em outra partição de tamanho
razoável. O grau de fragmentação do sistema normalmente é menor,
porém a execução de um programa grande pode se tornar inviável, visto
que o tamanho das partições livres tende a diminuir com o tempo.
- First Fit: Esta última estratégia não procura qualificar as partições livres
de acordo com o tamanho. Ela simplesmente procura na memória alguma
partição disponível com dimensão suficiente para alocar o programa. A
primeira que for encontrada será aquela utilizada, não importando o
tamanho da subpartição (nova partição livre) que acarretará. É o algoritmo
mais rápido e o que menos consome recursos do sistema, todavia
apresenta um grau de fragmentação menos previsível, aleatório.
Cada um dos algoritmos possui vantagens e desvantagens praticamente
equivalentes em um sistema cujo comportamento seja imprevisível. Entretanto, em
sistemas dedicados, as características de cada um podem determinar qual é o mais
adequado em casos específicos. Para sistemas que operam com poucos programas de
tamanhos determinados, o algoritmo Best Fit deve ser o mais eficiente. Em sistemas
cujo número de programas potencialmente executáveis é alto, a estratégia Worst Fit
talvez seja a mais adequada, desde que o tamanho dos programas seja próximo entre
si. Finalmente, em sistemas imprevisíveis ou com recursos escassos, o First Fit pode
ser o melhor mecanismo.
Na tentativa de minimizar a barreira representada pelo tamanho limitado das
partições, já que em sistemas de alocação contígua os módulos precisam ser
totalmente carregados na memória para poderem rodar, a técnica de overlay foi
criada. Com esta técnica, o processo é dividido em módulos independentes que são
carregados, conforme a necessidade de execução, no bloco de memória reservado ao
programa. Um ou mais módulos podem ocupar o bloco, de acordo com a área livre
disponível. Se um módulo precisa ser carregado para execução e não há espaço, pelo
menos um dos módulos então carregados deve ser sobreposto, isto é, deve ser
descartado da memória. Um módulo pode ser carregado e removido da memória por
uma quantidade ilimitada de vezes enquanto o programa estiver em execução.
Um aperfeiçoamento da técnica de overlay foi posteriormente desenvolvido:
o swapping. Com esse mecanismo, programas que esperam por uma área de memória

12
livre para serem processados são mais rapidamente atendidos. Não é necessário que
um programa em execução termine para que o espaço de memória seja liberado. O
sistema de gerenciamento se encarrega de retirar temporariamente um ou mais
programas da memória e alocar o processo em espera. Os programas que saem
permanecem então em estado de espera por algum tempo, até serem novamente
restabelecidos pelo sistema de gerenciamento. Ocorre, assim, uma alternância na
memória entre os processos que concorrem pela ocupação da mesma.
Um programa que deixa a memória, ao retornar, não precisa necessariamente
preencher o mesmo endereço físico que ocupava anteriormente. A relocação
dinâmica permite que o programa seja alocado em qualquer endereço onde haja uma
área contígua suficientemente grande para comportá-lo. Graças à relocação dinâmica,
a utilização da memória é maximizada e a multiprogramação é favorecida.
Contudo, o uso da técnica original implica na movimentação constante de
uma grande quantidade de dados, gerando um custo considerável de entrada e saída e
onerando, por conseguinte, o desempenho global do sistema. A eficiência do
mecanismo somente foi alcançada posteriormente, com o surgimento de um novo
paradigma de gerenciamento de memória: a memória virtual.
2.1.2. Memór ia Vir tual
Memória virtual é uma técnica que utiliza a memória secundária para
produzir o efeito prático de aumentar significativamente o espaço de endereçamento
disponível aos programas. Essa técnica não depende do tamanho da memória
principal – que continua sendo limitado – para ser implementada. A memória
secundária (normalmente um disco rígido) passa a servir como uma espécie de
extensão da memória principal, armazenando a maior parte dos programas e dados
carregados para execução. À memória principal são transferidas, por vez, apenas
algumas partes destes programas e dados, essenciais ao momento pontual da
execução.
Deste modo, criam-se dois espaços de endereçamento de memória: o espaço
de endereçamento virtual e o espaço de endereçamento real (figura 5). Endereços
virtuais são os endereços gerados pelos compiladores e linkers na tradução dos

13
programas. O conjunto de endereços virtuais representa o espaço de endereçamento
do qual os programas necessitam para serem carregados. No entanto, a memória real
– ou memória principal (RAM – Random Access Memory) – pode ser bastante
limitada, possuindo um espaço de endereçamento real normalmente menor, até
mesmo, que um único programa. Um endereço real corresponde a uma célula física
de endereçamento presente na memória principal da máquina.
Obviamente, apenas parte dos programas carregados no espaço de
endereçamento virtual poderá ocupar a memória real num certo instante. Por outro
lado, somente os dados carregados na memória principal são processados pela CPU.
Como vários processos podem estar em execução, concorrendo pela utilização do
processador, uma solução encontrada foi dividir o espaço total de endereçamento dos
programas em pequenos blocos de tamanho fixo, as chamadas páginas de memória.
A implementação dessa estratégia constitui o mecanismo de paginação. Outra
alternativa é dividir o código de um programa com base em critérios lógicos, ou seja,
modularizando o software de acordo com a função dos diversos trechos de código
identificados. Segmentação é o nome que se dá a esta segunda estratégia de
particionamento de memória, em que os segmentos gerados possuem tamanhos
Fig. 5: Espaços de endereçamento virtual e real
.
.
.
.
.
.
ÁREA DE SWAP (disco) MEMÓRIA PRINCIPAL
End. Real 1 End. Real 2
End. Real r
CPU
End. Virtual n
End. Virtual 13 End. Virtual 14 End. Virtual 15 End. Virtual 16
End. Virtual 9 End. Virtual 10 End. Virtual 11 End. Virtual 12
End. Virtual 5 End. Virtual 6
End. Virtual 7 End. Virtual 8
End. Virtual 1 End. Virtual 2 End. Virtual 3 End. Virtual 4

14
independentes e variáveis. Ambos os mecanismos são importantes sobretudo em
ambientes multiusuários e multiprogramáveis. Conforme o momento de execução,
parte dos dados são transferidos temporariamente para a memória principal a fim de
serem processados, retornando à memória secundária quando solicitados pelo
sistema operacional, responsável por este gerenciamento. O mapeamento entre
endereços virtuais e endereços físicos reais é realizado por meio de um dispositivo de
hardware conhecido como MMU (Memory Management Unit – Unidade de
Gerenciamento de Memória).
2.1.3. Paginação
Quando a paginação é o mecanismo de particionamento de dados utilizado, o
espaço de endereçamento virtual de um programa consiste em um conjunto de
páginas de memória. Cada uma dessas páginas armazena uma quantidade fixa de
dados, a qual varia de acordo com o sistema operacional. O tamanho de uma página
normalmente se situa entre 512 bytes e 64 Kbytes, sendo 4 Kbytes um tamanho
médio comum.
Um tamanho de página muito pequeno dificulta o gerenciamento por parte do
sistema operacional, haja vista que cada página corresponde a uma posição na tabela
de páginas, utilizada para o mapeamento do espaço de endereçamento virtual. Logo,
quanto menor uma página, maior a quantidade total de páginas endereçáveis e,
conseqüentemente, maior a dificuldade de mapeamento. Além disso, uma página
muito pequena não permite uma boa exploração da propriedade de localidade
espacial, isto é, pode haver necessidade de acesso ao disco mesmo quando endereços
próximos entre si são referenciados num curto espaço de tempo.
Por outro lado, quando um tamanho de página muito grande é utilizado, a
fragmentação na última página alocada ao processo pode ser maior, além de diminuir
o número de páginas que podem ser carregadas simultaneamente no espaço de
endereçamento real. Ou seja, com uma página de tamanho maior, a necessidade de
localidade espacial passa a ser ainda mais importante no programa, pois se menos
páginas podem ser carregadas simultaneamente, maior será o número de acessos ao
disco quando muitas páginas são referenciadas em um curto espaço de tempo.

15
Cada posição na tabela de páginas representada na figura 6 é composta por
alguns campos que permitem localizar o endereço efetivo de uma página na memória
principal – quando carregada – ou na memória secundária (área de swap). Os campos
principais são os seguintes:
- Número da página virtual (NPV): identifica uma única página virtual
correspondente à posição na tabela; de acordo com o tamanho de página
utilizado, o endereço na memória secundária pode ser calculado.
- Bit de presença: indica se a página está ou não carregada na memória
principal (a página está carregada se o bit possui valor 1).
- Endereço do bloco: se a página estiver carregada na memória principal,
este campo informa o endereço físico em que está alocada; um bloco, ou
janela (frame), é um conjunto de células da memória principal que
comporta dados de uma página.
- Bits de proteção: definem as permissões de acesso à página, normalmente
através de 2 ou 3 bits (leitura, gravação e eventualmente execução).
- Bit de modificação: indica se a página carregada na memória teve ou não
seu conteúdo alterado; se teve, o conteúdo deverá ser atualizado na
memória secundária antes de a página deixar a memória principal.
Posição 1Posição 2Posição 3 .Posição 4 .Posição 5 .Posição 6Posição 7Posição 8
.
.
.Posição v
.
.
.
Pág. Carregada c
TABELA DE PÁGINAS
Pág. Carregada 2
Pág. Virtual 7
Pág. Virtual 8
Pág. Virtual v
Pág. Virtual 5
Pág. Virtual 6
Pág. Virtual 3
Pág. Virtual 4
Pág. Virtual 2
ÁREA DE SWAP (disco) MEMÓRIA PRINCIPAL
Pág. Carregada 1Pág. Virtual 1
Fig. 6: Mapeamento de endereços com o mecanismo de paginação

16
Outros campos também podem fazer parte da tabela de páginas. Um bit de
acesso, por exemplo, pode ser utilizado para identificar as páginas menos ativas
dentre as que estão carregadas na memória principal, o que pode ser essencial para
algumas políticas de substituição de páginas.
Um endereço virtual é obtido através do número da página virtual e de um
deslocamento interno específico. Este deslocamento se refere à distância relativa do
endereço procurado a partir do início da página. Da mesma forma, o endereço físico
da página na memória principal é obtido somando-se o deslocamento interno ao
endereço inicial do bloco onde a página está carregada.
Genericamente, em sistemas de memória virtual paginada, processos
computacionais tendem a explorar, com maior ou menor grau de intensidade, a
propriedade conhecida como localidade de referências. Esta propriedade afirma que
apenas parte das páginas que compõem o espaço de endereçamento virtual de um
programa são efetivamente necessárias à sua execução num certo intervalo de tempo.
Em outras palavras, os dados processados em um determinado momento de execução
normalmente se concentram em algumas poucas páginas. Esta propriedade é o que
fundamenta e valoriza a importância da chamada hierarquia de memória, ou seja, a
forma como os componentes físicos de memória são organizados na arquitetura de
um computador. Dispositivos rápidos, porém dimensionalmente limitados, devem
armazenar temporariamente os dados mais requisitados por um processo. Por outro
lado, dispositivos de memória secundária – lentos, mas com grande capacidade de
armazenamento – alocam a totalidade do espaço de endereçamento utilizado pelo
processo.
O conceito de working set – conjunto de trabalho –, proposto por Denning
(1968), também foi formalizado com base na propriedade de localidade de
referências. O working set de um processo em execução é o conjunto das páginas
requeridas para o seu processamento em um determinado intervalo de tempo. Ele
representa, de certa forma, a concretização da propriedade de localidade: as páginas
que compõem o conjunto retratam, por si só, uma localidade inerente ao momento de
execução do processo.
Dizemos que ocorre uma falta de página quando um dado a ser processado se
encontra em uma página que não está carregada na memória principal e, portanto,

17
inacessível diretamente ao processador. Nesse caso, a página precisa ser
imediatamente alocada na memória para que a execução do processo continue.
Contudo, se a memória principal já está totalmente preenchida, uma das páginas
então carregadas deve ser sobreposta pela página que precisa ser trazida da memória
secundária. Ocorre assim, nesse momento, a necessidade de uma substituição de
página. A dificuldade está em decidir qual página deve deixar a memória, isto é, qual
a página menos importante para a execução do processo no momento da substituição,
aquela que provavelmente não faz mais parte do seu working set corrente. O sistema
operacional é o responsável por esta decisão e, para isso, implementa um algoritmo
de substituição de páginas. O critério utilizado pelo algoritmo elege a página que
deixa a memória quando uma substituição precisa ser efetuada.
A política de substituição de páginas é fator fundamental em qualquer sistema
de memória com paginação. Esse aspecto é posteriormente detalhado na Seção 2.2
deste capítulo, que apresenta e discute os principais algoritmos encontrados na
literatura.
2.1.4. Segmentação
Segmentação é a forma de particionamento de dados que consiste em dividir
um programa em segmentos lógicos, de tamanhos variáveis. O mapeamento dos
segmentos é realizado através de uma tabela de segmentos, similar à tabela de
páginas utilizada na paginação. A figura 7 ilustra simplificadamente o mecanismo.
Um segmento pode representar uma rotina ou estrutura de dados do programa
– desde uma única variável ou constante até estruturas complexas. Qualquer que seja
seu tamanho, cada segmento é carregado na memória apenas quando necessário, isto
é, durante a execução da rotina correspondente ou enquanto a estrutura de dados
estiver sendo utilizada.
As áreas livres de memória são administradas pelo sistema operacional por
meio de uma tabela de controle. Esta tabela armazena os blocos disponíveis e é
utilizada para selecionar um espaço quando um segmento precisa ser carregado. A
seleção pode ser feita utilizando as estratégias de alocação dinâmica Best Fit, Worst
Fit ou First Fit, citadas na Seção 2.1.1 deste capítulo. O que difere a alocação

18
contígua particionada dinâmica da técnica de segmentação é que, na primeira, há a
necessidade de um programa ser integralmente carregado na memória para poder ser
processado; na segunda, por sua vez, apenas partes do programa permanecem
residentes em cada momento de execução. O problema da fragmentação, porém,
ocorre de maneira idêntica em ambas as técnicas. Áreas livres de tamanho muito
pequeno podem infestar a memória durante a operação do sistema. Tais áreas são
geradas pela sobreposição de segmentos menores em áreas até então ocupadas por
segmentos maiores.
Outro problema importante da segmentação é a dificuldade de gerenciamento
da tabela de segmentos, visto que o seu tamanho varia durante a operação do sistema.
A tabela possui basicamente as mesmas informações que a tabela de páginas
utilizada na paginação (número do segmento, bit de presença, endereço físico do
segmento na memória principal, bits de proteção, bit de modificação, etc.), além de
um campo adicional que indica o tamanho de cada segmento. A obtenção de um
endereço virtual ou real específico também é realizada da mesma maneira: um
deslocamento interno é adicionado ao endereço inicial do segmento – real ou virtual
– para localizar o dado correspondente.
Fig. 7: Mapeamento de endereços com o mecanismo de segmentação
Posição 1Posição 2Posição 3 .Posição 4 .Posição 5 .Posição 6Posição 7Posição 8
.
.
.Posição v
.
.
.
Seg. Virtual v
Seg. Virtual 7
Seg. Virtual 8
Seg. Carregado 2
Seg. Virtual 6
Seg. Carregado c
Seg. Virtual 2
Seg. Virtual 3
Seg. Virtual 4
Seg. Virtual 5
ÁREA DE SWAP (disco) MEMÓRIA PRINCIPALTABELA DE
SEGMENTOSSeg. Virtual 1
Seg. Carregado 1

19
O aspecto mais importante de um sistema de memória segmentado, em
termos de eficiência, é a modularização correta e precisa dos programas. Isto nem
sempre ocorre, fato que representa uma desvantagem da segmentação sobre a
paginação, assim como sua maior complexidade de implementação. Mas ela também
possui uma vantagem importante: ao contrário das páginas, os segmentos já estão
logicamente estruturados, garantindo uma exploração ótima da localidade dos
programas e, por conseqüência, uma rapidez maior de execução, com poucos acessos
ao disco.
Há ainda a possibilidade de combinar as duas técnicas de particionamento de
memória virtual, gerando sistemas com segmentação e paginação. Nesses sistemas,
um programa é dividido em segmentos que, por sua vez, são divididos em páginas.
Cada segmento possui sua própria tabela de páginas. A adição de um deslocamento
interno ao endereço inicial de uma página leva a um dado específico do segmento.
Este modelo é eficiente na medida em que permite o processamento simultâneo de
vários segmentos, ainda que o tamanho de memória disponível seja insuficiente para
acomodá-los integralmente: através da paginação interna, um segmento pode estar
parcialmente carregado na memória, alocando-se apenas as páginas imprescindíveis
para o seu momento de execução. Com isso, minimiza-se também o problema da
fragmentação, uma vez que áreas pequenas de memória podem ser bem aproveitadas.
2.2. Algor itmos de Substituição de Páginas
Um dos aspectos mais importantes em um sistema de memória virtual
paginada é a política de substituição de páginas utilizada. Esta política define os
critérios de seleção empregados para a retirada de uma ou mais páginas da memória
principal quando uma outra página precisa ser alocada e não há espaço disponível.
A implementação da política de substituição se dá por meio de um algoritmo
de substituição de páginas, que pode ser basicamente de dois tipos: algoritmos com
espaço fixo e algoritmos com espaço variável. Algoritmos com espaço fixo
trabalham sobre uma área de memória disponível sempre constante. Ao contrário,
algoritmos com espaço variável modificam dinamicamente o tamanho da memória
alocada, conforme o contexto de execução do sistema.

20
As principais propostas de algoritmos com espaço fixo encontradas na
literatura são citadas e comentadas a seguir:
• FIFO: O critério de substituição do algoritmo FIFO – First In, First Out – é
retirar da memória a página carregada há mais tempo, independentemente dos
acessos computados enquanto esteve residente. Este algoritmo apresenta uma
deficiência denominada “anomalia de Belady” (BELADY; NELSON;
SHEDLER, 1969): o número de faltas de página pode eventualmente aumentar
quando o tamanho da memória disponível aumenta. Mas a sua grande vantagem é
a simplicidade e a extrema facilidade de implementação. Uma fila pode ser
naturalmente utilizada para ordenar as páginas de acordo com a idade: uma
página sempre entra no início da fila quando é carregada e a página substituída é
sempre aquela que ocupa a última posição da fila.
• LRU: O algoritmo LRU – Least Recently Used – é simples e normalmente
bastante eficiente. Seu critério é substituir a página acessada há mais tempo, ou
seja, a página residente menos ativa no momento da substituição. Apesar de
apresentar bom desempenho na maioria das situações, o LRU também sofre
algumas deficiências, comentadas no Capítulo 4. Com o objetivo de minimizar
essas deficiências, variações do LRU foram recentemente propostas. Entre os
novos algoritmos publicados, destacam-se o LRU-K e o 2Q. O algoritmo LRU-K
(O’NEIL; O’NEIL; WEIKUM, 1993); (O’NEIL; O’NEIL; WEIKUM, 1999) não
leva em consideração há quanto tempo uma página foi acessada pela última vez e
sim quando ocorreu o seu K-último* acesso. Por exemplo, o LRU-2 verifica qual
a página que realizou seu penúltimo acesso há mais tempo, enquanto o LRU-3
trabalha com o antepenúltimo acesso e assim sucessivamente. Para isso,
informações sobre as últimas K referências realizadas em cada página, residentes
ou não, são mantidas pelo LRU-K. Por sua vez, o algoritmo 2Q (JOHNSON;
SHASHA, 1994) trabalha com duas áreas de gerenciamento de memória: em uma
delas ficam as páginas recém-carregadas e na outra permanecem as páginas
acessadas novamente enquanto estavam na primeira área. As páginas removidas
* A notação n-último é utilizada neste trabalho para designar o n-ésimo termo contado na ordem inversa, do último para o primeiro.

21
da memória pelo 2Q estão normalmente na primeira área e o critério utilizado é o
FIFO. Mas se a primeira área se torna muito pequena – quase todas as páginas
carregadas já foram acessadas pelo menos por duas vezes –, a substituição é feita
sobre uma página da segunda área e o critério utilizado neste caso é o LRU. Ou
seja, a memória é dividida em dois níveis e as páginas são alocadas em cada um
de acordo com sua freqüência de utilização. A partir desta estrutura, o algoritmo
2Q utiliza uma combinação bastante interessante dos algoritmos LRU e FIFO
para substituição das páginas.
• Ótimo: Proposto por Belady (BELADY, 1966), o algoritmo Ótimo – ou OPT –
representa a melhor solução possível a fim de se minimizar o número de faltas de
página. A sua estratégia é retirar da memória, em caso de falta, a página que levar
mais tempo para ser novamente referenciada. O algoritmo “conhece” o futuro,
uma vez que pode ler previamente todos os acessos à memória realizados pelo
programa, o que não ocorreria em uma situação real de execução. Portanto, sua
implementação prática (online) é inviável. Todavia, como solução teórica, é
muito útil em simulações e pode ser utilizado como paradigma na análise de
algoritmos, representando o caso ótimo.
• MRU-n: Este algoritmo escolhe a última página acessada, ou a n-última página,
para ser substituída. O MRU original – Most Recently Used – substitui sempre a
última página referenciada; pode ser chamado também de MRU-1. As variações
MRU-n selecionam, por sua vez, a n-última página mais recentemente acessada
para ser substituída. Por exemplo, o algoritmo MRU-2 substitui sempre a
penúltima página acessada antes de cada falta, enquanto o MRU-3 remove
sempre a antepenúltima e assim sucessivamente. Obviamente, as versões MRU-n
utilizam um critério de substituição pseudo-MRU, normalmente mais eficiente do
que a versão original pelo fato de explorar, com maior ou menor grau de
intensidade, as características de localidade temporal que algumas páginas
apresentam.
• Clock: Uma fila como a do FIFO é utilizada pelo algoritmo do relógio, ou
algoritmo Clock. As páginas são dispostas nesta fila de acordo com a ordem em
que foram carregadas na memória. A página substituída normalmente é aquela
carregada há mais tempo; porém, um bit de acesso é adicionado ao mecanismo de

22
seleção: a página residente mais antiga só é substituída se o seu bit de acesso
estiver zerado, caso contrário a próxima página com bit zerado na seqüência da
fila é selecionada. Um ponteiro circular, que se desloca seqüencialmente – daí o
nome do algoritmo –, indica a página a ser substituída. Em cada falta de página,
este ponteiro se desloca uma posição para frente. No entanto, se o bit da página
apontada estiver acionado, este é zerado e o ponteiro continua a se deslocar até
encontrar uma página inativa (bit zerado). A finalidade do bit de acesso é
informar se uma página foi ou não referenciada desde que foi carregada ou desde
que o ponteiro de substituição a apontou pela última vez. Com este artifício, o
algoritmo não corre o risco de remover páginas acessadas recentemente,
comportando-se de maneira similar ao LRU.
• NRU: O algoritmo NRU – Not Recently Used – tem como critério retirar da
memória uma página não acessada recentemente, isto é, entre as duas últimas
faltas. Além disso, o algoritmo verifica se cada página residente foi ou não
modificada, ou seja, se teve seus dados alterados desde que foi carregada na
memória. Dois bits são utilizados: um para representar a existência ou não de
acessos recentes e outro para sinalizar se a página foi modificada desde o seu
carregamento. A prioridade de substituição segue a seguinte ordem: (1) páginas
não referenciadas e não modificadas, (2) páginas não referenciadas, (3) páginas
não modificadas e (4) páginas referenciadas e modificadas.
• LFU: A página substituída pelo critério LFU – Least Frequently Used – é aquela
menos acessada dentre as que se encontram carregadas na memória. Esta
verificação é feita através de um contador de acessos (hits) associado a cada
página residente. A contagem dos acessos é zerada sempre que uma página deixa
a memória principal. Portanto, a freqüência de utilização se refere apenas aos
acessos recentes e não a todo o histórico de execução do programa. Um problema
que acontece com o LFU é o seguinte: páginas recém-carregadas têm uma
probabilidade de serem substituídas muito maior do que as páginas mais antigas,
pois quanto antes uma página foi carregada, mais tempo ela teve para receber
outros acessos. Visando solucionar o problema, foi proposto o algoritmo FBR
(ROBINSON; DEVARAKONDA, 1990) – Frequency-Based Replacement. Este
algoritmo acrescenta um tempo de carência que toda página recebe após ser

23
referenciada. Somente páginas fora do período de carência podem ser
substituídas e novas referências ocorridas no início desta carência não
incrementam o contador de acessos da página, evitando outro vício do algoritmo
LFU: a valorização de páginas muito acessadas em um único período de
execução.
• MFU: O algoritmo MFU – Most Frequently Used –, por outro lado, substitui
sempre a página residente mais acessada. Da mesma forma que o LFU, utiliza
contadores de acesso para determinar a freqüência de utilização de cada página.
A deficiência deste algoritmo é o fato de ele remover normalmente páginas com
alta localidade temporal, exatamente aquelas com maior tendência a receber
novos acessos.
Dentre os algoritmos com espaço variável, três propostas se destacam:
• WS: O critério da política WS (DENNING, 1968); (DENNING; SCHWARTZ,
1972) – Working Set – é exatamente o mesmo que o da política LRU quando a
memória já está cheia e uma falta de página ocorre: a página acessada há mais
tempo é substituída. No entanto, a atuação deste algoritmo não se restringe a
substituir páginas; ele também estabelece um tempo máximo que cada página
pode permanecer na memória sem ser referenciada. As páginas que atingem esse
tempo máximo de inatividade são sumariamente retiradas da memória principal.
O número de páginas carregadas é, portanto, variável. Este algoritmo explora o
conceito homônimo, também concebido por Denning (1968), o qual afirma que
somente um conjunto limitado de páginas é referenciado pelo programa em um
certo intervalo de tempo qualquer. Definido este tempo – como parâmetro –, o
algoritmo WS assegura que apenas as páginas acessadas no respectivo período
permanecem residentes, isto é, apenas aquelas pertencentes ao working set do
processo no instante considerado.
• PFF: Como o algoritmo WS, o PFF (CHU; OPDERBECK, 1976a); (CHU;
OPDERBECK, 1976b) – Page Fault Frequency – utiliza o critério LRU em caso
de substituição quando o espaço de memória disponível está totalmente ocupado.
Mas também como o WS, ele retira sumariamente páginas da memória quando
detecta inatividade aparente. Sua metodologia é executar esse procedimento
quando a taxa de faltas está baixa, representando um indício de que há mais

24
páginas residentes do que páginas sendo efetivamente acessadas. As páginas
selecionadas para deixar a memória são todas aquelas não referenciadas no
intervalo entre duas faltas de página consecutivas.
• VMIN: O algoritmo VMIN (PRIEVE; FABRY, 1976) representa o caso ótimo de
desempenho – gera o número mínimo de faltas de página – no contexto dos
algoritmos de substituição com espaço variável. Assim como o algoritmo Ótimo,
ele “conhece” todos os acessos futuros que um programa realiza. Sua filosofia é
remover da memória as páginas cujo próximo acesso leve mais tempo para
acontecer do que um parâmetro pré-estabelecido pelo sistema. Desta forma, a
memória gerenciada com a utilização do algoritmo VMIN dificilmente fica
totalmente ocupada, pois só permanecem residentes aquelas páginas que
certamente serão referenciadas em um futuro breve. Obviamente, trata-se
também de um algoritmo offline.
Estudos demonstram que o desempenho médio dos algoritmos com espaço
variável tende a ser superior ao desempenho daqueles com espaço fixo (DENNING,
1980), mas devido à sua maior complexidade de implementação são pouco utilizados
na prática.
2.2.1. Avaliação de Desempenho
Algumas métricas são comumente utilizadas para aferir, do ponto de vista de
algum aspecto de desempenho, a eficiência dos vários algoritmos de substituição de
páginas existentes (ambos os tipos). Podemos citar como métricas potencialmente
relevantes em estudos de desempenho (MIDORIKAWA, 1997):
- Número de faltas de página: quantidade de faltas de página computadas
durante a execução de um processo;
- Taxa de faltas de página: taxa percentual de faltas em relação ao total de
acessos realizados pelo processo num certo intervalo de tempo;
- Produto espaço X tempo: representa uma forma de quantificar a ocupação
real da memória pelo processo, levando em conta seu tempo de execução.
Métricas de desempenho devem ser analisadas sempre em função do tamanho
da memória física disponível e refletem o comportamento dos programas em

25
diferentes visões. Em um nível mais profundo, estão diretamente associadas ao grau
de ocorrência de uma série de fatores, muitas vezes determinantes para o
desempenho do software. Dentre esses fatores, pode-se destacar:
- Localidade de referências: Ocorre quando há uma concentração dos
acessos à memória em determinadas páginas. A localidade pode ser
temporal e/ou espacial. Um caso de localidade temporal é identificado
quando um conjunto de páginas, de tamanho qualquer não nulo, é
continuamente referenciado por um período de tempo considerável. Um
caso de localidade espacial é identificado quando páginas próximas entre
si, em termos de endereçamento virtual, são acessadas continuamente.
- Padrão de acessos à memória: Designa uma regularidade na forma como
os acessos à memória acontecem durante um período de execução do
sistema. Esta regularidade também pode se dar em termos espaciais e/ou
temporais. A seqüência em que determinadas páginas são acessadas, por
exemplo, pode constituir uma regularidade espacial. Por outro lado, o
tempo que decorre entre dois acessos consecutivos a uma mesma página,
se relativamente estável, representa uma regularidade temporal. A
verificação seqüencial de todos os elementos de uma matriz é um
exemplo prático de padrão de acessos à memória cuja regularidade é
espacial. Se a média dos elementos da matriz está sendo calculada, a
página que armazena esta média deve ser constantemente atualizada,
representando um caso de regularidade temporal. Por sua vez, loops
constituem padrões de acesso em que tanto a regularidade espacial como a
temporal estão sempre presentes.
- Características especiais do programa: O tamanho de um processo, por
exemplo, pode influir no desempenho do sistema de memória. Processos
muito pequenos atingem desempenhos ótimos se o seu espaço de
endereçamento virtual puder ser totalmente carregado na memória
principal. Processos muito grandes, por outro lado, geram normalmente
um número de faltas de página muito alto em sua execução, exceto se
houver uma exploração eficiente do conceito de localidade, fato que
depende da maneira como o software foi construído. Programas paralelos

26
ou distribuídos também podem alterar o desempenho do sistema de
memória. O grau de localidade apresentado por esses programas pode ser
diferente daquele apresentado pelos programas tradicionais, fazendo com
que certas premissas de comportamento – em termos de utilização da
memória – às vezes não se confirmem.
2.2.2. Propostas Adaptativas
Recentemente, alguns algoritmos de substituição de páginas foram propostos
apresentando um aspecto inovador em comum: eles modificam seu comportamento
dinamicamente durante uma execução, de acordo com as características de acesso à
memória detectadas. Estes algoritmos, conforme são designados na literatura
científica, pertencem à categoria dos algoritmos adaptativos* , cujo potencial de
exploração é muito grande.
Uma vez identificados os principais fatores que influenciam o desempenho do
sistema de memória, algoritmos adaptativos tentam adequar a política de substituição
de páginas à variação destes fatores em tempo real, independentemente do programa
executado. O comportamento adaptativo pode obedecer a regras fixas ou variáveis
(auto-adaptativas) e, portanto, o número de estados de execução associados ao
algoritmo nem sempre é previsível. Abaixo são listadas algumas ações que um
algoritmo adaptativo de substituição de páginas pode realizar:
- Modificar o tamanho da memória utilizada;
- Modificar o critério de substituição de páginas;
- Modificar os parâmetros associados ao critério vigente;
- Modificar as suas próprias regras de comportamento adaptativo.
Várias propostas de algoritmos adaptativos para substituição de páginas
foram apresentadas à comunidade científica nos últimos anos, a maioria tendo como
* Formalmente, algoritmos adaptativos devem adequar o seu comportamento em qualquer situação genérica de execução de um sistema. No entanto, tal propriedade ainda não foi alcançada em relação aos algoritmos para substituição de páginas. O termo “algoritmo adaptativo” é empregado neste trabalho, em conformidade com a literatura científica correlata, para designar algoritmos dinâmicos, que se adaptam apenas a determinadas situações previamente caracterizadas. Portanto, não é utilizado de forma totalmente precisa.

27
ponto de partida o tradicional e relativamente eficiente algoritmo LRU. Nas
condições em que ele apresenta bom desempenho, sua atuação original é mantida;
nas demais condições, uma alternativa de comportamento é desenvolvida. Entre as
propostas nessa linha se enquadram os algoritmos SEQ e EELRU, detalhados nas
próximas seções deste capítulo (2.2.3 e 2.2.4, respectivamente). Os dois algoritmos
atentam essencialmente para o tratamento de acessos seqüenciais – ponto fraco da
política LRU – e, indiretamente, inspiraram a criação da nova proposta de
substituição apresentada no Capítulo 4.
Outro algoritmo importante é o LIRS (JIANG; ZHANG, 2002) – Low Inter-
reference Recency Set. Seu objetivo é minimizar as deficiências apresentadas pelo
LRU utilizando um critério adicional interessante: a chamada IRR (Inter-Reference
Recency), que representa o número de páginas referenciadas entre os dois últimos
acessos consecutivos a uma mesma página. O algoritmo pressupõe uma inércia
comportamental e, de acordo com as IRRs coletadas, substitui a página que
provavelmente levará mais tempo para ser novamente acessada. Em outras palavras,
o algoritmo LIRS utiliza uma fonte de informação adicional: além do grau de
recência* atual das páginas – isto é, que páginas foram acessadas mais recentemente
que outras –, ele leva em conta também a recência observada entre os dois últimos
acessos realizados em cada página. Isto significa que o LIRS não substitui
necessariamente a página acessada há mais tempo, mas ele utiliza o histórico recente
desta informação para prever quais páginas têm maiores probabilidades de acesso em
um futuro breve.
Três outros algoritmos trouxeram a proposta de identificar certas
características de execução nos processos e se adaptar dinamicamente a elas,
alternando o critério de substituição de acordo com o padrão de acessos constatado.
Estes algoritmos são:
- DEAR (CHOI et al., 1999) – DEtection-based Adaptive Replacement;
- AFC (CHOI et al., 2000) – Application/File-level Characterization;
- UBM (KIM et al., 2000) – Unified Buffer Management.
* O termo “ recência” , um neologismo comumente empregado em trabalhos científicos publicados em língua portuguesa nos últimos anos, é utilizado ao longo desta dissertação como tradução do termo “ recency” (em língua inglesa).

28
As três criações são muito parecidas e seu objetivo comum é empregar
sempre um critério ótimo de substituição para o padrão de acessos vigente na
execução. Os algoritmos DEAR e AFC utilizam vários fatores de decisão – tempo
decorrido entre acessos, instante do K-último acesso, freqüência de acessos – para
chegar à conclusão de qual política de substituição deve prevalecer em cada
momento: LRU, LFU ou MRU. Quatro tipos de padrão de acessos são identificados
por eles: seqüencial (sendo MRU o critério de substituição utilizado); com laços de
processamento ou looping (MRU); probabilístico (LFU); e com localidade de
referências (LRU). O algoritmo UBM faz a mesma detecção, todavia não diferencia
padrão probabilístico – com regularidade de freqüência de acessos – de padrão com
localidade de referências. Para o UBM, existe apenas padrão seqüencial, padrão com
looping e outros padrões, genericamente. Nos dois primeiros casos o critério MRU é
empregado, enquanto o LRU é a opção sugerida, porém deixada em aberto, para o
terceiro caso.
Por fim, há duas propostas que exploram a relação de freqüência e de
recência das páginas em conjunto: LRFU e ARC. O algoritmo LRFU (LEE et al.,
2001) – Least Recently/Frequently Used – faz uma análise direta da união dos fatores
recência temporal e freqüência. Utilizando um processo de quantificação, ele
armazena todo o histórico de acessos que cada página recebeu, estando ela residente
ou não. A quantificação leva em consideração não apenas o aspecto da recência
temporal, isto é, há quanto tempo o acesso ocorreu, mas também o aspecto da
freqüência, uma vez que engloba a totalidade das referências. Todos os acessos são
considerados, no entanto um peso maior é sempre atribuído aos mais recentes,
dinamicamente. Com base no valor quantificado associado a cada página, o
algoritmo seleciona para substituição aquela com a menor relação
recência/freqüência, ou seja, uma página relativamente inativa e pouco acessada.
A última proposta, ARC (MEGIDDO; MODHA, 2003) – Adaptive
Replacement Cache –, é muito parecida com o algoritmo 2Q, citado na Seção 2.2
como uma variação do algoritmo LRU. A diferença é que o ARC é adaptativo e,
além disso, não utiliza o critério FIFO em nenhum momento. Como faz o 2Q, ele
divide a memória em duas áreas de gerenciamento, uma englobando as páginas
recém-carregadas e outra armazenando aquelas que receberam mais de um acesso.

29
Entretanto, a substituição é feita sempre utilizando o critério LRU em uma das duas
áreas. A seleção da área se dá de forma balanceada, de acordo com o estado em que
cada uma delas se encontra nos momentos de substituição, daí o fato de o ARC ser
um algoritmo adaptativo, ao contrário do 2Q – que utiliza um parâmetro fixo para
esta decisão.
2.2.3. Algor itmo SEQ
SEQ (GLASS; CAO, 1997) é um algoritmo adaptativo proposto a partir de
algumas observações a respeito do algoritmo LRU. Notou-se que, apesar de ser um
algoritmo eficiente na maioria das situações, o LRU apresenta deficiência quando o
processo possui determinados padrões de acessos à memória claramente observáveis.
Esses padrões consistem basicamente em conjuntos de acessos seqüenciais realizados
pelo programa no decorrer de sua execução.
Para compreender o funcionamento do SEQ é importante inicialmente definir
o conceito de seqüência: segundo a concepção do algoritmo, uma seqüência é um
conjunto de faltas de página geradas em acessos a endereços consecutivos de
memória, crescentes ou decrescentes em uma mesma direção, sem que haja qualquer
outra falta ocorrida no meio do conjunto. Uma seqüência identifica, pois, um padrão
de acessos linearmente seqüencial.
A metodologia de atuação do algoritmo SEQ pode ser explicada pelos
seguintes passos:
1) Enquanto nenhuma seqüência é detectada durante a execução do programa, o
comportamento do SEQ é idêntico ao comportamento do LRU.
2) Se ao menos uma seqüência é detectada no universo recente de acessos do
programa, o algoritmo passa a considerá-la como componente integrante do
critério de substituição, comportando-se a partir de então como um pseudo-
MRU-n sobre as seqüências identificadas.
3) Constatado um padrão linear de acessos seqüenciais, o SEQ seleciona, em
caso de nova falta de página, uma das seqüências detectadas para que alguma
de suas páginas seja removida da memória. Para isso, uma lista de seqüências
é criada e mantida pelo mecanismo de controle associado ao algoritmo. A

30
seqüência escolhida será, dentre as que possuem um tamanho maior do que L
(parâmetro do algoritmo), aquela que apresentar a maior taxa de crescimento,
independente da direção; isto é, será selecionada a seqüência com mais
páginas recentemente carregadas.
4) Definida a seqüência para substituição, a página removida da memória será a
que ocupa a M-ésima posição na seqüência (sendo M outro parâmetro do
algoritmo); se a M-ésima posição estiver associada a uma página já removida
da memória, será retirada a primeira página residente da seqüência após M.
Portanto, as seqüências se referem a um histórico de todas as faltas de página
em endereços seqüencialmente adjacentes que foram recentemente identificadas,
mesmo que as páginas referentes a estes acessos já não estejam mais carregadas na
memória. O algoritmo SEQ não retira da memória páginas que estejam no fim de
uma seqüência, ou seja, páginas carregadas muito recentemente; daí a importância do
parâmetro M. Isto se deve ao conceito de localidade temporal: as últimas páginas
carregadas podem receber novos acessos por algum tempo mesmo com um padrão
basicamente seqüencial no aspecto espacial.
A seqüência selecionada para substituição é sempre aquela que apresenta a
maior taxa de crescimento. O método para identificá-la consiste na verificação,
seqüência a seqüência, da N-ésima página recém-carregada na mesma (contando do
fim para o começo da seqüência), onde N é o terceiro e último parâmetro do
algoritmo. A seqüência cuja N-ésima página a partir do fim tiver sido carregada por
último é selecionada. O interesse do algoritmo não é verificar em qual seqüência
houve falta pela última vez, e sim em qual seqüência houve mais faltas nos últimos
acessos. Em outras palavras, o objetivo é constatar qual seqüência está mais propícia
a aumentar de tamanho levando em consideração apenas um universo próximo de
acessos.
Os valores padrão especificados pelos criadores do algoritmo SEQ para os
parâmetros L, M e N são, respectivamente, 20, 20 e 5. O parâmetro L tem apenas a
finalidade de descartar seqüências muito pequenas – que podem simplesmente
refletir um caso favorável de localidade espacial, compatível com o tamanho da
memória – ou seqüências em formação, que ainda não afetam significativamente a
política de substituição.
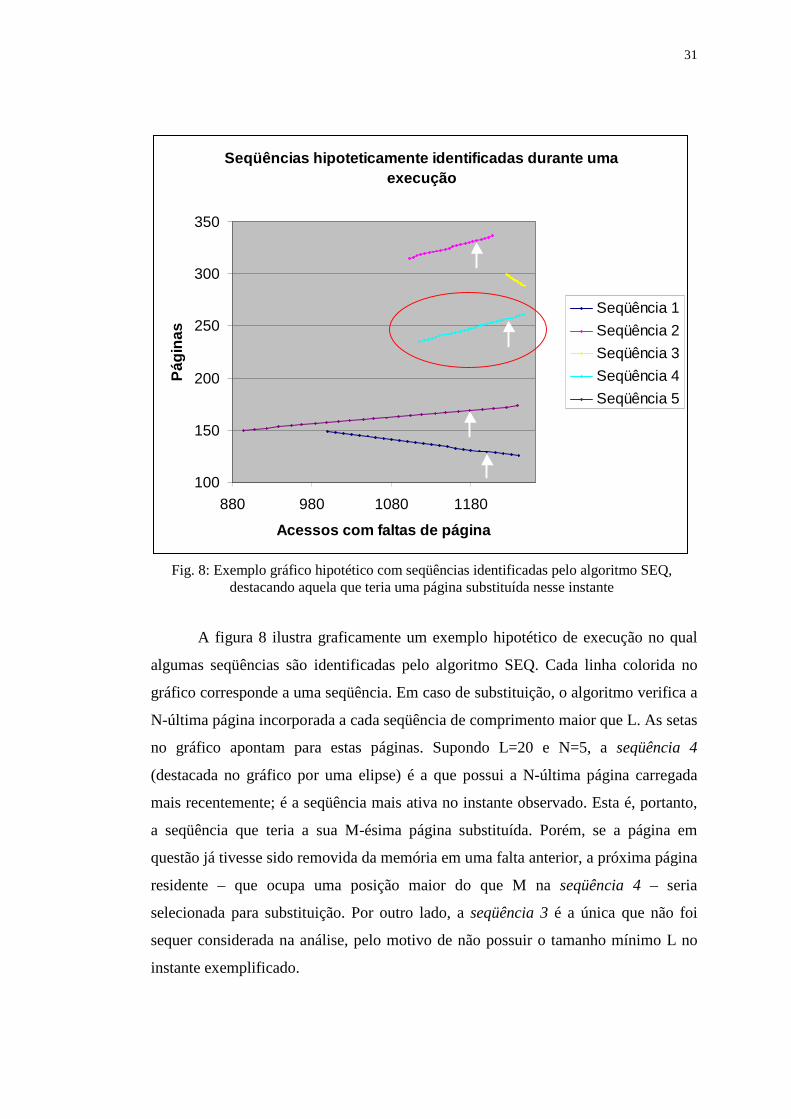
31
A figura 8 ilustra graficamente um exemplo hipotético de execução no qual
algumas seqüências são identificadas pelo algoritmo SEQ. Cada linha colorida no
gráfico corresponde a uma seqüência. Em caso de substituição, o algoritmo verifica a
N-última página incorporada a cada seqüência de comprimento maior que L. As setas
no gráfico apontam para estas páginas. Supondo L=20 e N=5, a seqüência 4
(destacada no gráfico por uma elipse) é a que possui a N-última página carregada
mais recentemente; é a seqüência mais ativa no instante observado. Esta é, portanto,
a seqüência que teria a sua M-ésima página substituída. Porém, se a página em
questão já tivesse sido removida da memória em uma falta anterior, a próxima página
residente – que ocupa uma posição maior do que M na seqüência 4 – seria
selecionada para substituição. Por outro lado, a seqüência 3 é a única que não foi
sequer considerada na análise, pelo motivo de não possuir o tamanho mínimo L no
instante exemplificado.
Fig. 8: Exemplo gráfico hipotético com seqüências identificadas pelo algoritmo SEQ, destacando aquela que teria uma página substituída nesse instante
Seqüências hipoteticamente identificadas durante uma execução
100
150
200
250
300
350
880 980 1080 1180
Acessos com faltas de página
Pág
inas
Seqüência 1
Seqüência 2
Seqüência 3
Seqüência 4
Seqüência 5

32
Genericamente, várias seqüências – com endereços crescentes ou
decrescentes – podem ser identificadas simultaneamente, em qualquer momento de
execução. Não obstante, pode ocorrer também de nenhuma seqüência ser identificada
durante toda a execução de um programa, comportando-se o algoritmo SEQ de forma
idêntica ao algoritmo LRU neste caso.
Uma seqüência permanece armazenada na lista de seqüências até que uma
página não residente e pertencente a ela seja referenciada. Quando isto acontece, a
seqüência é dividida em duas: uma contendo apenas a página acessada e outra
abrangendo o trecho da seqüência original compreendido entre o seu início e a
posição anterior à da página acessada. As duas seqüências normalmente se fundem e
o trecho restante da seqüência original deixa de existir. Entretanto, se a página
acessada puder ser agregada a duas seqüências, terá preferência aquela cuja última
página tenha sido carregada mais recentemente, sendo a outra seqüência excluída.
Exemplificando, se uma falta ocorre na página que inicia uma seqüência, a
nova seqüência passa a ser apenas essa página. Se uma falta ocorre na página que
ocupa a terceira posição de uma seqüência, apenas os seus três elementos iniciais
integrarão a seqüência resultante, desde que nenhuma outra seqüência esteja
competindo para adicionar a página acessada – situação na qual o critério de
desempate seria empregado.
As seqüências, assim, sofrem eventualmente cortes gradativos em seu
tamanho, tornando-se insignificantes ao algoritmo SEQ sempre que seu comprimento
esteja abaixo do parâmetro L. Se todas as seqüências identificadas possuem
tamanhos inferiores a L, é descartada automaticamente a presença de padrões de
acesso seqüenciais e a política LRU volta a ser utilizada nos momentos de
substituição. O critério pseudo-MRU se torna vigente somente quando uma ou mais
seqüências alcança comprimento igual ou superior a L.
O algoritmo demonstra bons resultados em todos os experimentos relatados
por seus autores. O desempenho superior do SEQ em relação ao LRU tradicional é
bastante visível em programas com padrões de acesso linearmente seqüenciais,
aproximando-se muito do algoritmo Ótimo. Em programas sem grande concentração
de acessos seqüenciais, o desempenho do SEQ é similar ao do LRU, não havendo
variações significativas.

33
2.2.4. Algor itmo EELRU
Antes de falar do algoritmo adaptativo EELRU, é importante comentar
brevemente o algoritmo que foi sua inspiração: o GLRU (FERNANDEZ; LANG;
WOOD, 1978); (WOOD; FERNANDEZ; LANG, 1983). O algoritmo GLRU –
Generalized LRU – foi criado com o objetivo de sanar uma deficiência importante
apresentada pelo algoritmo MRU: a manutenção de páginas indefinidamente na
memória, que podem nunca mais serem acessadas.
A idéia do GLRU é trabalhar com dois pontos de substituição de página, isto
é, trabalhar sempre com duas páginas candidatas a deixar a memória em caso de
falta. Uma dessas duas páginas é então selecionada com base em um algoritmo
bastante simples. Podemos considerar o GLRU como mais uma tentativa de mesclar
o LRU e o MRU-n, utilizando uma ou outra política – ou seja, um ou outro ponto de
substituição – de acordo com a situação em que ocorre cada falta.
Os pontos de substituição do algoritmo GLRU podem ser observados na
figura 9, que ilustra o eixo LRU considerado pelo algoritmo. Este eixo é a
representação gráfica de uma fila ordenada de páginas intrínseca ao modelo LRU. A
chamada fila LRU é ordenada sob o critério de recência dos acessos. Assim, a
primeira posição na fila corresponde à página que foi acessada por último. A
próxima posição armazena a segunda página mais recentemente acessada, e assim
sucessivamente.
(late eviction
point: segundo
ponto de
substituição)
As páginas que ocupam estas
posições são candidatas a deixar
a memória em caso de
substituição (falta de página)
(página mais
recentemente
acessada)
(tamanho da
memória
principal)
(early eviction
point: primeiro
ponto de
substituição)
1 e M l
Fig. 9: Eixo LRU com os pontos importantes para os algoritmos GLRU e EELRU

34
O eixo LRU da figura 9 não inclui somente as páginas residentes na memória
principal; ele armazena todas as páginas já acessadas pelo programa, não importando
quais estão ou não residentes. O ponto M corresponde ao tamanho total da memória
considerada. Utilizando o algoritmo LRU tradicional, apenas as páginas entre a
posição 1 e a posição M do eixo estariam residentes; ou seja, uma página nunca
sairia da memória antes de outra acessada há mais tempo. Mas com o GLRU este
fato pode perfeitamente ocorrer. Não é incoerente, pois, que existam páginas
carregadas na memória ocupando posições superiores a M no eixo, já que páginas
não-residentes permanecem em suas posições da fila como se estivessem residentes.
Há sempre um máximo de M páginas carregadas, mas não obrigatoriamente estas
páginas ocupam as M primeiras posições do eixo LRU especificado.
Os pontos e (early eviction point) e l (late eviction point) correspondem aos
dois pontos de substituição citados: o da região inicial e o da região final do eixo. O
primeiro ponto, e, é utilizado quando o critério MRU-n é empregado. Nesta situação,
a e-ésima página mais recentemente acessada é substituída. O outro ponto, l, é
utilizado quando o critério LRU é empregado; neste caso, a página que ocupa a
posição l (aquela acessada há mais tempo) deixa a memória.
A página referenciada em uma determinada posição i do eixo é representada
por r(i). Portanto, r(e) e r(l) representam as páginas que ocupam as posições e e l do
eixo; logo, representam as páginas com potencial para serem substituídas. O
algoritmo GLRU pode ser simplificado através do seguinte pseudo-código,
executado quando uma falta de página ocorre:
� Se r(l) está carregada e a falta acontece em uma página acessada há mais tempo do que a mesma /* após o ponto l * /
Substitua a página r(l) Senão
Substitua a página r(e)
A idéia do GLRU é bastante simples:
- Utiliza o critério MRU-n inicialmente e sempre que a página causadora da
falta tiver sido removida recentemente (acessada pela última vez antes
que, ao menos, uma das páginas residentes);

35
- Utiliza um critério praticamente oposto, LRU, quando todas as páginas
residentes foram acessadas há menos tempo do que a página que causou a
falta, indicando provavelmente um bom aproveitamento de todas estas
páginas.
Porém, o GLRU não é um algoritmo totalmente adaptativo. Os parâmetros
que definem os pontos e e l são fixos. Sua grande vantagem, que é identificar padrões
de acesso seqüenciais não necessariamente contíguos – como listas ligadas e árvores
binárias, que também afetam negativamente o desempenho do LRU –, acaba se
diluindo à medida em que ele não se adapta ao comportamento dinâmico do
programa (padrões de acesso localizados). Enfim, é uma boa idéia, mas que só
funciona de forma ótima se algumas coincidências acontecerem durante a execução.
O algoritmo EELRU, Early Eviction LRU (SMARAGDAKIS; KAPLAN;
WILSON, 1999), foi então proposto como uma versão adaptativa – e otimizada –
baseada nos mesmos princípios do algoritmo GLRU. Agrega o benefício de detectar
mudanças no padrão de acessos do programa e se adaptar automaticamente aos seus
diversos momentos de execução.
O esquema geral do EELRU é basicamente o mesmo do GLRU: um eixo
(eixo LRU) armazena as páginas acessadas pelo programa na ordem decrescente de
recência: a primeira posição do eixo corresponde à página acessada mais
recentemente e a última posição corresponde à página acessada há mais tempo. Os
pontos M, e e l também continuam sendo fundamentais; contudo, com exceção de M,
eles passam a representar posições variáveis, não mais pré-estabelecidas.
Uma análise de custo/benefício, realizada cada vez que ocorre uma falta de
página, determina que posições do eixo melhor correspondem aos pontos e e l, na
situação específica em que ocorreu a falta. Esta análise assegura que os pontos
selecionados representam alternativas ótimas e pode ser considerada como o
mecanismo que efetivamente implementa o aspecto adaptativo do algoritmo.
Uma das propriedades do GLRU dispõe que, quando o algoritmo atinge um
estado estável (a memória alocada ao processo é totalmente preenchida), a
probabilidade P(n) da n-ésima página mais recentemente acessada – aquela que
ocupa a n-ésima posição no eixo LRU – estar residente na memória é dada por:

36
1 , se n ≤ e
P(n) = (M - e) / (l – e) , se e < n ≤ l
0 , se n > l
É importante lembrar que o eixo LRU não armazena apenas páginas
residentes na memória. Ele mantém a ordem das páginas, com base no último acesso,
mesmo quando elas são substituídas. De acordo com o GLRU, todas as páginas
localizadas antes do ponto e certamente se encontram carregadas na memória e o
ponto l representa a página residente acessada há mais tempo. Mas este último
aspecto não é mantido pelo EELRU, cujas propriedades importantes são as seguintes:
os pontos e e l podem variar de posição, desde que e < M, l > M e toda página em
posição igual ou inferior a e no eixo esteja na memória. Isto implica que l não
necessariamente corresponde à página residente acessada há mais tempo.
Quando há páginas residentes situadas – no eixo LRU – após o ponto l, estas
devem ser substituídas antes da página r(l). O ponto l deixa de ser, por conseguinte,
um ponto de substituição em potencial do EELRU, passando a ser somente um ponto
de referência para a análise de custo/benefício realizada pelo algoritmo, análise esta
que irá determinar qual dos dois critérios de substituição será utilizado. Os dois
pontos de substituição são e e a posição do eixo relativa à página LRU, aquela
acessada há mais tempo dentre as que se encontram carregadas na memória principal.
Duas variáveis adicionais são definidas:
- total: armazena o número de hits recentes em páginas localizadas entre os
pontos e e l;
- early: armazena o número de hits recentes em páginas localizadas entre os
pontos e e M.
Um hit – ou acerto – nada mais é do que um acesso realizado em uma página
já residente na memória, ou seja, um acesso em que não há falta de página. Por “hits
recentes” se entende, aqui, acessos ocorridos desde que a página foi carregada na
memória pela última vez.

37
Sendo i uma instância do conjunto de todas as possibilidades de combinações
distintas para a localização dos pontos e e l, o algoritmo EELRU é caracterizado pelo
seguinte pseudo-código:
� benefício = MAX[total i . (M – ei) / (l i – ei) – earlyi] � j = índice i que maximiza benefício � Se benefício ≤ 0
ou (existe uma página r(n) na memória, tal que n > l j) ou (r(l j) está na memória e a falta acontece em uma página acessada menos recentemente do que a mesma) /* após o ponto l j * / Substitua a página acessada há mais tempo /* página LRU * / Senão
Substitua a página r(ej)
O algoritmo procura os pontos e e l que maximizam o desempenho do sistema
de memória, isto é, as posições mais adequadas para que haja uma substituição, de
acordo com o custo/benefício calculado por meio das freqüências de acesso
agregadas em trechos do eixo LRU. A página r(e), referente ao ponto e obtido,
representa a melhor solução para a substituição, exceto nos casos em que:
- Há pelo menos uma página acessada há mais tempo do que r(l) dentre as
que estão carregadas na memória;
- A página r(l) está na memória, é a que está há mais tempo sem ser
acessada dentre as páginas carregadas, mas a página que causou a falta foi
acessada há mais tempo ainda;
- Não foi detectado um padrão de acessos regular e, portanto, não há
benefício em se retirar de memória uma página mais recentemente
acessada.
Em qualquer das hipóteses acima, é substituída a página LRU, ou seja, a
página residente na memória que foi acessada há mais tempo. Na segunda hipótese, a
página LRU é a própria página r(l). Na terceira hipótese, ela pode ou não coincidir
com r(l). O importante é que, antes de substituir uma página r(e), o algoritmo
verifica se o ponto l é anterior à posição ocupada pela página LRU. Se for, a página
LRU deve ser substituída, por mais que o benefício calculado sugira que r(e) seja a
página escolhida. Isto ocorre para garantir que o benefício calculado seja efetivo,

38
pois o mesmo só é válido quando r(l) é a página LRU ou está depois dela no eixo –
fora da memória, nesse último caso.
Uma deficiência do algoritmo EELRU é o fato de ele apresentar fortemente a
chamada “anomalia de Belady” (BELADY; NELSON; SHEDLER, 1969): o
aumento do tamanho da memória física disponível pode acarretar um aumento no
número de faltas de página. Esta deficiência decorre do próprio comportamento
adaptativo do algoritmo, o qual procura predizer acessos futuros através de padrões
detectados em um passado recente (que potencialmente se estende ao presente). Um
exemplo citado pelos autores do algoritmo é o seguinte: em determinadas situações,
o EELRU pode utilizar o critério MRU-n com o intuito de minimizar as faltas
causadas dentro de um loop cujo número de páginas referenciadas é grande, maior
que o da memória disponível. Neste caso, uma página acessada no corpo do loop é
carregada, rapidamente descartada devido à limitação da memória e novamente
carregada pouco tempo depois, na próxima iteração. A situação se repete
continuamente, até o término do loop. A decisão de utilizar o critério MRU-n nesta
situação é correta, mas o benefício de tal critério se mantém somente até a última
iteração, quando o padrão de acessos muda abruptamente. Se o loop não executar
muitas iterações, o benefício almejado se dilui, principalmente quando o tamanho da
memória cresce. Logo, em certos casos, pode haver mais faltas de página quando a
memória aumenta de tamanho, o que não é intuitivo. No entanto, o risco provocado
por estas situações é necessário e inevitável nesse tipo de algoritmo, uma vez que
apenas informações históricas estão disponíveis à sua tomada de decisão.
O desempenho do EELRU, a despeito da anomalia apresentada, é
significativamente positivo. O algoritmo obtém desempenho superior ao do LRU na
maioria dos experimentos relatados por seus autores. E nos casos em que o LRU o
supera, a diferença é pequena, alcançando no máximo um fator constante (pior caso).
Em relação ao algoritmo SEQ, o EELRU também apresenta uma vantagem
importante: ele é muito mais genérico. Em contrapartida, o SEQ demonstra
resultados excelentes quando trabalha com programas que possuem padrões de
acesso linearmente seqüenciais, isto é, programas que apresentam faltas de página
contínuas em acessos a páginas adjacentes. Para exemplificar um padrão linearmente
seqüencial, suponhamos a ocorrência de faltas nas seguintes páginas e na seguinte

39
ordem: página 1000, 550, 200, 1001, 2135, 1002, 1003, 580, 1004, 1831, 310, 1005,
1006... Neste exemplo, empírico e hipotético, as faltas que ocorrem nos acessos às
páginas 1000 até 1006 formam uma seqüência crescente e linear (páginas
adjacentes). Em situações desse tipo, o desempenho do algoritmo SEQ se aproxima e
às vezes se iguala ao desempenho do algoritmo Ótimo, superando claramente o
desempenho do EELRU.
Mas o SEQ se limita a reconhecer acessos seqüenciais lineares. O algoritmo
EELRU, por sua vez, detecta qualquer tipo de acesso seqüencial. Exemplificando,
suponhamos faltas nas seguintes páginas (na ordem em que ocorrem): página 150,
500, 504, 151, 600, 508, 505, 512, 516, 520, 140, 524, 528... As faltas que ocorrem
entre os endereços 500 e 528 (exceto 505, que não faz parte da seqüência) possuem
uma distância constante entre si, podendo representar, por exemplo, acessos a
elementos da coluna de uma matriz – alocada linha a linha. Este é um caso típico de
padrão de acessos regular que o EELRU detecta e manipula eficientemente, ao
contrário do SEQ.
O Capítulo 3 irá apresentar, a seguir, formas de se caracterizar padrões de
acesso à memória inerentes aos programas e também discutirá a importância da
identificação e análise de trechos com localidade de referências. O Capítulo 4, na
seqüência do trabalho, volta a tratar da questão de substituição de páginas, propondo
o novo algoritmo adaptativo LRU-WAR, o qual explora algumas características de
programas visualizadas no Capítulo 3 para melhorar o desempenho do algoritmo
LRU original.

40
3. ANÁLISE DA LOCALIDADE DE PROGRAMAS
Localidade de referências é uma propriedade presente na maioria dos
programas. A propriedade afirma que o processamento de uma tarefa tende a se
concentrar, dentro de um intervalo de tempo qualquer, num conjunto de dados
restrito (DENNING, 1980). Um caso de localidade temporal é observado quando
algumas poucas páginas de memória são continuamente referenciadas durante o
intervalo de tempo considerado. Não obstante, se os acessos à memória se restringem
a uma região específica do espaço de endereçamento virtual, isto é, se as páginas
referenciadas possuem endereços próximos entre si, observamos um caso de
localidade espacial. A importância desta propriedade decorre do seguinte fato: o grau
de localidade apresentado por um programa pode afetar diretamente o seu tempo de
processamento, haja vista a influência que tais características exercem no
desempenho do sistema de memória.
Logo, as políticas de substituição de páginas mais eficientes procuram
explorar, cada uma ao seu modo, as localidades inerentes aos programas, sobretudo
localidade temporal. O algoritmo LRU, por exemplo, procura substituir páginas que
não tenham sido recentemente referenciadas, ou seja, páginas que não apresentem a
tendência de acessos contínuos no momento de execução observado. Por outro lado,
a maioria das propostas adaptativas não somente leva em consideração o aspecto da
localidade temporal, mas também o aspecto espacial. Neste caso, a localidade
espacial em si não é o fator mais importante e sim a quantidade de páginas acessadas
em um determinado período de tempo.
A localidade espacial é positiva quando se restringe a um conjunto de páginas
reduzido, como um loop no qual poucas páginas são referenciadas – em relação ao
tamanho de memória disponível. Um padrão de acessos à memória desse tipo faz
com que o working set do processo também permaneça reduzido, induzindo à
desejada reutilização das páginas residentes. Acompanhada de forte localidade
temporal, portanto, a localidade espacial é interessante. Caso contrário, a presença ou
não de localidade espacial é indiferente à grande maioria das políticas tradicionais de
gerenciamento da memória principal. Ainda assim, pode ser muito importante para o
gerenciamento eficiente de memórias cache, o que a torna relevante.

41
No entanto, o número de páginas distintas referenciadas em determinado
período de tempo é sempre uma informação valiosa porque dimensiona o working set
do processo em tal período. Um working set grande exige maior disponibilidade de
memória para não incorrer em prejuízo ao desempenho do sistema. Portanto, quando
se trata do gerenciamento da memória principal, fica evidente que o aspecto espacial
mais importante para ser analisado é a quantidade de diferentes páginas acessadas em
um mesmo período de tempo, pois o tamanho do working set temporário do processo
é o dado determinante neste contexto.
A análise gráfica dos padrões de acesso à memória apresentados pelos
programas leva a conclusões a respeito do grau da localidade de referências presente
nos mesmos. É muito comum o emprego de gráficos de acesso bidimensionais em
trabalhos que se propõem a analisar características de acesso à memória. Estes
gráficos consistem essencialmente em uma matriz de pontos que informa quais
páginas de memória são acessadas pelo programa estudado em cada momento ao
longo de sua execução (tempo virtual).
Hatfield; Gerald (1971) já utilizavam gráficos desta natureza há mais de 30
anos para analisar otimizações na estrutura de programas que favoreciam o
desempenho de sistemas com memória virtual. Diversos outros trabalhos mais
recentes também introduzem gráficos de acesso para propor novas técnicas de
identificação de padrões (CHOI et al., 1999); (CHOI et al., 2000); (KIM et al., 2000)
ou mesmo para caracterizar cargas de simulação em experimentos (PHALKE, 1995);
(GLASS; CAO, 1997).
Contudo, é natural que haja sempre uma escala reduzindo o tamanho do
gráfico, dimensionando-o de forma que ele ocupe um espaço adequado à sua
visualização global. Desta maneira, muitos pontos são aglutinados, ocasionando
eventualmente enormes perdas de informação. Quanto maior for o número de
acessos à memória realizados pelo programa estudado, e maior o espaço de
endereçamento total de memória que este utiliza, maior será a compressão visual do
gráfico; conseqüentemente, menor será a precisão das informações.
Este capítulo apresenta três ferramentas originais criadas durante o trabalho
desenvolvido. Uma delas gera gráficos de acesso convencionais, bidimensionais, mas
oferece diversas opções de visualização. Uma segunda ferramenta oferece dados para

42
gerar superfícies tridimensionais, minimizando a perda de informações inerente aos
gráficos bidimensionais. A terceira ferramenta processa e fornece uma série de dados
analíticos e gráficos a respeito das características de acesso à memória presentes nos
programas. Este conjunto de ferramentas oferece recursos para um amplo processo
de análise de localidade e para estudos de exploração do modelo LRU.
3.1. Ferramentas Desenvolvidas
TelaTrace foi a primeira ferramenta desenvolvida para este trabalho,
projetada com a finalidade de auxiliar na caracterização de padrões de acesso à
memória presentes em programas típicos e também em programas paralelos
(CASSETTARI; MIDORIKAWA, 2002a). De fato, trata-se basicamente de uma
ferramenta de visualização de acessos. Arquivos de trace fornecem à ferramenta os
dados necessários para a criação de janelas de visualização referentes aos programas
que representam. Os gráficos de acesso – ou mapas de acesso – gerados são
bidimensionais, mas podem ser ampliados. A resolução máxima de uma ampliação é
definida pelo próprio usuário ao iniciar o uso da ferramenta, que é composta de dois
módulos: um módulo de pré-processamento dos traces, codificado em linguagem C;
e um módulo gráfico, codificado em Java. O módulo de pré-processamento produz
uma matriz de pontos com a resolução especificada pelo usuário, enquanto o módulo
gráfico se alimenta desta matriz para construir uma interface gráfica adequada à
visualização completa ou ampliada do comportamento do programa, em termos de
utilização da memória virtual.
A interface gráfica da ferramenta dispõe de duas janelas, conforme ilustra a
figura 10: uma janela principal e outra de aproximação. A janela principal (janela
superior da figura 10) apresenta todos os acessos à memória realizados pelo
programa analisado. Se este for um programa paralelo, cada processador é
diferenciado por uma cor específica e o tipo de acesso (leitura/gravação) é
identificado pela tonalidade de cor. Onde houver sobreposição de acessos, a
ferramenta TelaTrace também realiza uma operação de sobreposição das cores,
permitindo que as características dos acessos sejam identificadas inclusive nestes
casos.

43
A janela inferior da figura 10 é a janela de aproximação, composta por vários
campos: uma janela de aproximação base (à esquerda), uma janela de aproximação
sucessiva (à direita), diversos botões de controle e sensores. A janela de aproximação
base amplia uma determinada região do gráfico completo. Esta região pode ser
selecionada por meio de botões de controle – que servem para avançar ou retroceder
a visualização de um trecho da janela principal – ou diretamente através de um clique
na própria janela principal, que exibe o gráfico completo.
Fig. 10: Interface gráfica da ferramenta TelaTrace (janelas principal e de aproximação)

44
Caso se deseje uma aproximação maior, uma subregião pode ser definida,
bastando um clique na janela de aproximação base para que a área de interesse seja
mostrada na janela de aproximação sucessiva. Cada gráfico exibido nas janelas
descritas informa, em seu eixo horizontal, o tempo virtual de execução do programa
analisado, mensurado em número de acessos. O espaço de endereçamento virtual
utilizado pelo programa é distribuído, por sua vez, no eixo vertical dos gráficos. Para
facilitar a representação do tempo virtual, a notação numérica “nEe” é empregada,
cuja interpretação é n*10e. Assim, por exemplo, a notação 13E6 representa o número
13*106 = 13.000.000 de acessos. As páginas de memória – no eixo vertical – são
identificadas por meio de endereços hexadecimais.
As duas janelas de aproximação possuem ainda sensores que informam a
página e o tempo virtual da posição do gráfico apontada pelo mouse. Outros sensores
indicam se esta posição contém ou não acessos realizados pelos processadores
disponíveis – até 8 processadores –, diferenciando também o tipo de acesso.
Entretanto, apenas a janela principal da ferramenta será exibida ao longo
desta dissertação quando mapas de acesso bidimensionais são apresentados, uma vez
que ela oferece uma visão geral dos padrões de acesso à memória associados aos
programas. Também é importante destacar que todos os arquivos de trace analisados
neste trabalho possuem formato simples. Isto significa que armazenam somente as
páginas referenciadas pelo respectivo programa durante o seu processamento, sem
diferenciar tipos de acesso. Além disso, apenas programas tradicionais (não
paralelos) foram utilizados nos estudos aqui relatados.
Apesar de possuir funcionalidades interessantes e permitir uma análise mais
detalhada dos programas sem perder a praticidade da visualização global, a
ferramenta TelaTrace não gera gráficos tridimensionais. A terceira dimensão é
importante porque agrega a informação de densidade às posições dos gráficos
tradicionais. Para viabilizar este recurso, a ferramenta Mapa3D foi desenvolvida.
Desprovido de interface gráfica, o Mapa3D tem como objetivo formatar um
mapa de acessos tridimensional, gerando dados que possam ser convertidos em
pontos e desenhados por uma ferramenta gráfica genérica. Codificada em linguagem
C, a ferramenta disponibiliza dois tipos de saída: na forma de coordenadas x, y, z; e
na forma de uma matriz numérica. Neste último formato, o eixo x compõe a primeira
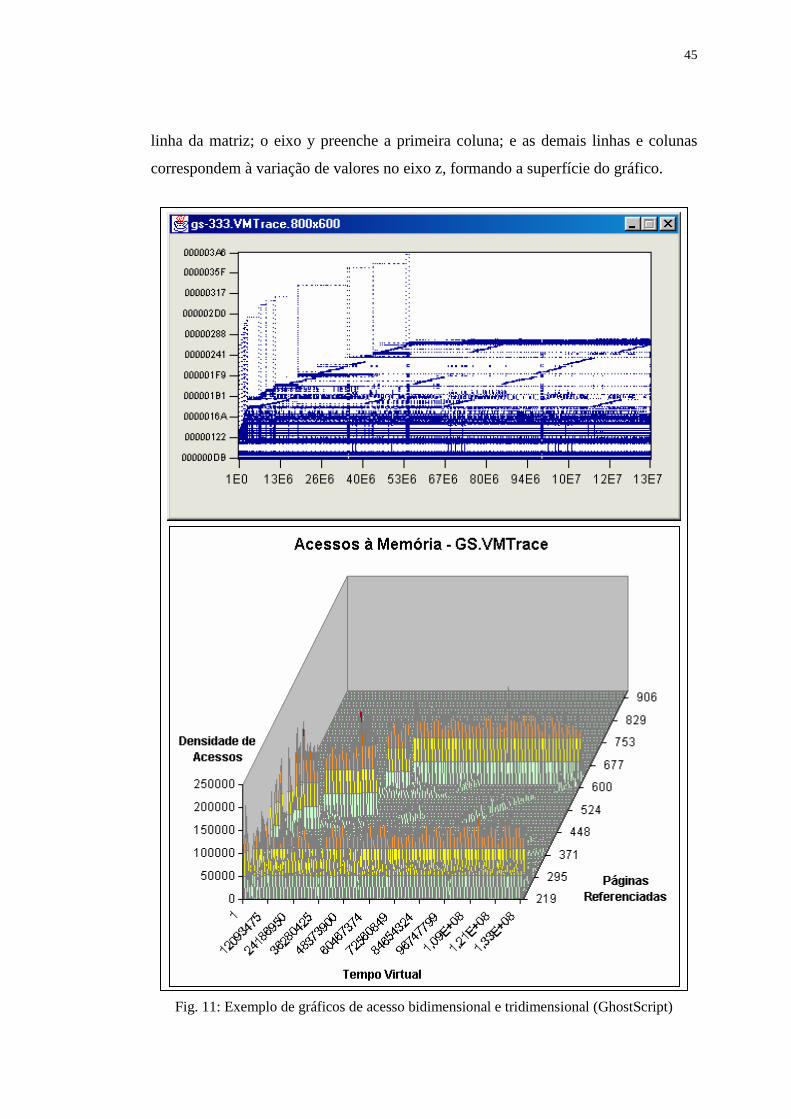
45
linha da matriz; o eixo y preenche a primeira coluna; e as demais linhas e colunas
correspondem à variação de valores no eixo z, formando a superfície do gráfico.
Fig. 11: Exemplo de gráficos de acesso bidimensional e tridimensional (GhostScript)

46
A figura 11 mostra um exemplo de mapa de acessos bidimensional – gerado
pela ferramenta TelaTrace – e um exemplo de mapa de acessos tridimensional –
criado a partir da ferramenta Mapa3D e desenhado pelo Microsoft Excel –, ambos
referentes ao mesmo programa (GhostScript). O gráfico tridimensional oferece
informações muito úteis sobre a distribuição dos acessos entre as diversas posições
de memória referenciadas. Todavia, apesar desta grande vantagem em relação aos
gráficos bidimensionais equivalentes, tal estratégia não é empregada em nenhum
trabalho de análise de localidade encontrado ao longo de nossa revisão bibliográfica.
Portanto, a despeito de sua simplicidade, a ferramenta Mapa3D representa um
recurso inovador que contribui diretamente para a realização de estudos mais
precisos, práticos e completos. Outros ângulos de observação podem ainda ser
utilizados para complementar a visualização tradicional dos gráficos. A figura 12
demonstra a visão lateral do gráfico de acessos tridimensional exibido na figura 11.
Esta variação angular consegue eliminar o problema da ocultação de algumas áreas.
Fig. 12: Exemplo de visão lateral em gráfico de acessos tridimensional (GhostScript)

47
Os mapas de acesso à memória, porém, não fornecem sozinhos todas as
informações necessárias para uma análise completa da localidade dos programas. A
ferramenta Trace Explorer foi então projetada para oferecer um grande número de
dados estatísticos e visuais, que podem ser combinados e investigados de acordo com
o objetivo da pesquisa do usuário. Estes dados basicamente se referem ao volume de
acessos realizados em cada página de memória, ao intervalo de tempo medido entre
os acessos e ao número de outras páginas distintas referenciadas entre os mesmos.
Entre outras informações analíticas sobre os programas, representados por
seus respectivos arquivos de trace, a ferramenta Trace Explorer disponibiliza as
seguintes saídas:
• Mapa de recência dos acessos: Gráfico que indica a posição na fila LRU
ocupada pelas páginas acessadas ao longo do processamento do programa,
considerando uma memória disponível de tamanho ilimitado. Indica também,
por conseqüência, o número de páginas distintas referenciadas entre dois
acessos consecutivos a uma mesma página e pode ser chamado ainda de
mapa de distâncias LRU (stack distance). Apenas a posição da página
pontualmente referenciada é considerada em cada instante. A ferramenta gera
tanto um mapa bidimensional como um mapa tridimensional.
• Histograma da recência dos acessos: Quantifica o número de acessos
ocorridos nas várias posições da fila LRU. Além da forma tradicional – em
colunas –, pode ser apresentado por meio de uma curva, acumulada ou não,
que descreve a quantidade de acessos realizados em função da recência das
páginas neles referenciadas.
• Mapa de variação da recência dos acessos: Calcula a variação de posição na
fila LRU entre dois acessos consecutivos a uma mesma página. Em outras
palavras, subtrai a posição na fila que a página ocupava no último acesso da
posição observada no acesso corrente.
• Mapa de distância entre acessos: Indica a distância entre acessos
consecutivos a uma mesma página, determinada através do tempo virtual, isto
é, do número de acessos realizados em outras páginas, inclusive acessos
repetidos. Este gráfico, portanto, informa o intervalo de tempo que cada
página leva para ser reutilizada durante a execução do programa.

48
• Relatório analítico, que contém diversos dados estatísticos sobre os acessos à
memória realizados pelo programa, como:
− Número total de acessos;
− Número de páginas referenciadas;
− Maior e menor página referenciada (endereços);
− Posição média dos acessos na fila LRU, desvio padrão, menor e maior
posição acessada na fila;
− Variação média da posição dos acessos na fila LRU, desvio padrão,
variação média (em módulo), menor e maior variação.
A ferramenta Trace Explorer não possui interface gráfica própria. Os mapas
citados consistem em coordenadas de pontos gravadas em arquivos de dados. O
conjunto destas coordenadas forma um gráfico, o qual pode ser desenhado por
qualquer ferramenta visual, como Gnuplot ou Microsoft Excel. A figura 13 reúne
dois exemplos de mapas, ambos referentes ao programa P2C e desenhados com o
Gnuplot. O primeiro é um mapa de recência dos acessos realizados e o segundo exibe
a variação desta recência entre acessos a uma mesma página de memória. A variação
em questão pode ser positiva ou negativa, pois a posição de uma página na fila LRU
pode aumentar ou diminuir entre acessos consecutivos a ela.
Alguns arquivos de saída são gerados em duas versões: dados do programa
(visão global) e dados específicos de cada página de memória. O relatório estatístico
também exibe dados individuais relativos às páginas, as quais são listadas tanto por
ordem crescente de endereços, como por ordem decrescente de acessos recebidos. A
figura 14 ilustra dois exemplos de gráficos que se referem ao comportamento de uma
página específica referenciada pelo programa P2C: recência dos acessos à página AB
e distância (intervalo de tempo) entre estes acessos. O eixo horizontal dos gráficos
considera apenas as referências à página analisada e não todos os acessos realizados
pelo programa.
A ferramenta Trace Explorer ainda trabalha com diversos outros dados
analíticos, como o número de páginas distintas referenciadas entre três acessos
consecutivos a uma mesma página, a porcentagem de acessos consecutivos a uma
mesma página em que a variação da recência é zero – freqüência de reutilização
estável –, o número de outras páginas que começam ou deixam de ser referenciadas
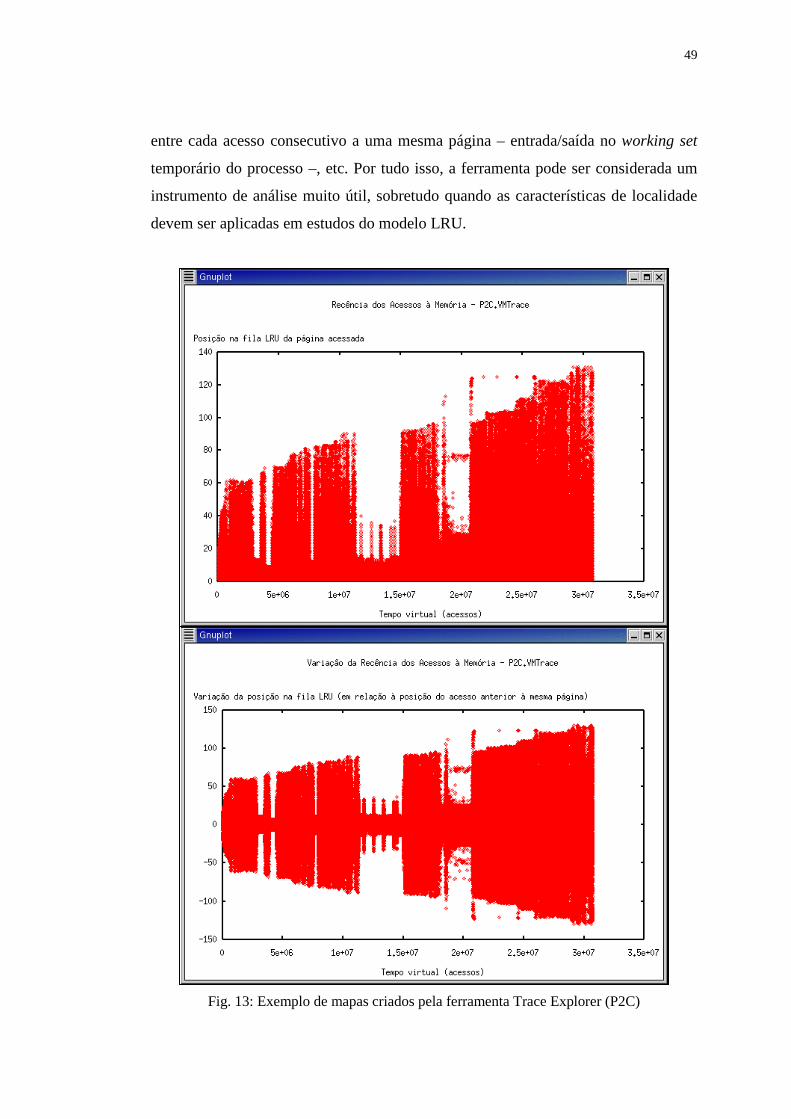
49
entre cada acesso consecutivo a uma mesma página – entrada/saída no working set
temporário do processo –, etc. Por tudo isso, a ferramenta pode ser considerada um
instrumento de análise muito útil, sobretudo quando as características de localidade
devem ser aplicadas em estudos do modelo LRU.
Fig. 13: Exemplo de mapas criados pela ferramenta Trace Explorer (P2C)

50
Fig. 14: Exemplo de mapas com dados específicos de uma única página (P2C, pág. AB)

51
3.2. Recursos Oferecidos para Análise de Localidade
Em conjunto, as três ferramentas detalhadas na seção anterior permitem
diversos tipos de análise em programas. Entre outros aspectos relacionados à
utilização da memória, elas possibilitam identificar:
− Padrões de acesso;
− Localidades de referência temporais e/ou espaciais, além da amplitude e
densidade destas localidades;
− A distribuição de acessos no espaço de endereçamento virtual utilizado pelos
programas;
− A freqüência de reutilização das páginas de memória (distância entre
acessos);
− A interação de uma página com outras, em termos de acessos entrelaçados;
− O tamanho mínimo de memória que cada programa precisa para que não haja
nenhuma necessidade de substituição;
− A posição na fila LRU que as páginas ocupam quando são acessadas.
Este último dado, como se refere a um contexto de memória ilimitada, pode
levar a diversas outras conclusões se for direcionado a estudos específicos. Ao
definirmos um tamanho de memória, por exemplo, todo acesso cuja posição na fila
LRU for maior que este tamanho (baixo grau de recência) resulta necessariamente
em falta de página se a política de substituição LRU, ou mesmo FIFO, é adotada. Um
outro exemplo: é possível estabelecer um tamanho mínimo de memória para que a
taxa de faltas de página permaneça inferior a um certo limite desejado, quando
programas previamente conhecidos e analisados são executados.
A tabela I apresenta dados de um histograma relativo a um estudo de caso
com o programa Netscape. A primeira coluna é composta por intervalos de posições
na fila LRU que, exceto para 0 e 1, seguem a notação “a – b” , a qual deve ser
interpretada como “de a (inclusive) até b” . Ou seja: a � x < b; com x pertencente ao
conjunto de posições analisado na linha correspondente. Por exemplo, a linha cujo
intervalo é apresentado como “2^5 – 2^6” contém os acessos nos quais a página
referenciada ocupava uma posição na fila LRU entre 32 e 63, pois 64 (2^6) não faz
parte do intervalo. As posições na fila LRU, neste tipo de estudo, são contadas a
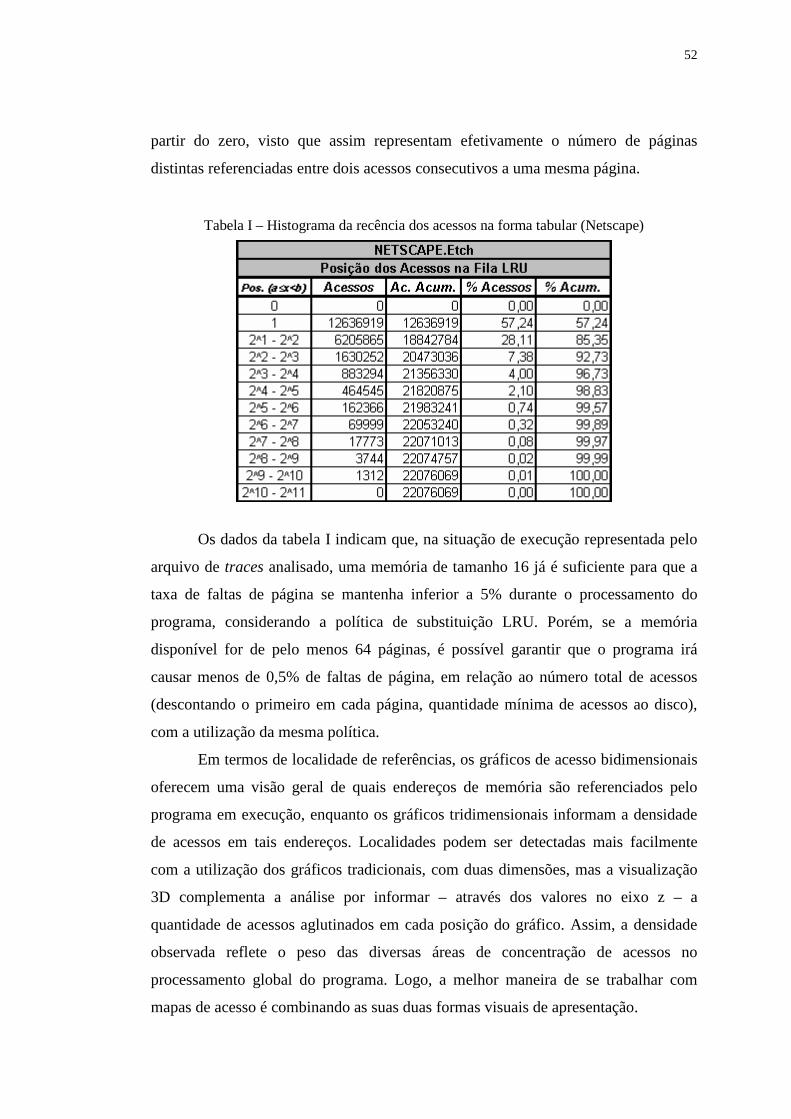
52
partir do zero, visto que assim representam efetivamente o número de páginas
distintas referenciadas entre dois acessos consecutivos a uma mesma página.
Os dados da tabela I indicam que, na situação de execução representada pelo
arquivo de traces analisado, uma memória de tamanho 16 já é suficiente para que a
taxa de faltas de página se mantenha inferior a 5% durante o processamento do
programa, considerando a política de substituição LRU. Porém, se a memória
disponível for de pelo menos 64 páginas, é possível garantir que o programa irá
causar menos de 0,5% de faltas de página, em relação ao número total de acessos
(descontando o primeiro em cada página, quantidade mínima de acessos ao disco),
com a utilização da mesma política.
Em termos de localidade de referências, os gráficos de acesso bidimensionais
oferecem uma visão geral de quais endereços de memória são referenciados pelo
programa em execução, enquanto os gráficos tridimensionais informam a densidade
de acessos em tais endereços. Localidades podem ser detectadas mais facilmente
com a utilização dos gráficos tradicionais, com duas dimensões, mas a visualização
3D complementa a análise por informar – através dos valores no eixo z – a
quantidade de acessos aglutinados em cada posição do gráfico. Assim, a densidade
observada reflete o peso das diversas áreas de concentração de acessos no
processamento global do programa. Logo, a melhor maneira de se trabalhar com
mapas de acesso é combinando as suas duas formas visuais de apresentação.
Tabela I – Histograma da recência dos acessos na forma tabular (Netscape)

53
Na figura 11, por exemplo, várias linhas horizontais estão presentes no
gráfico bidimensional, as quais indicam localidade temporal em diferentes páginas de
memória. Entretanto, a visão tridimensional demonstra que somente em algumas
destas páginas a localidade é realmente forte, formando paredes horizontais na
superfície do gráfico. Da mesma forma, pode-se perceber que os trechos com acessos
seqüenciais (identificados por linhas diagonais nos gráficos) apresentam baixa
densidade de referências e, por decorrência, não são muito significativos no
processamento do programa GhostScript.
Os gráficos de recência também indicam tendências de localidade
importantes. Ding; Zhong (2003) analisam localidade como sendo uma função do
número de páginas distintas referenciadas entre dois acessos consecutivos a uma
mesma página. No modelo LRU, esta medida corresponde à própria posição que a
página ocupa na fila LRU – contada a partir de zero – quando o segundo acesso
ocorre. A exibição tridimensional dos mapas de recência destaca as posições do
gráfico que são maciçamente referenciadas e, conseqüentemente, as posições na fila
LRU em que a maioria dos acessos à memória acontecem. A figura 15 exemplifica
como uma análise conjunta das duas formas de apresentação do mapa – bi e
tridimensional – pode esclarecer muitas dúvidas. O gráfico tridimensional, sozinho,
nem sempre permite a identificação de todas as posições da fila LRU em que páginas
são acessadas. Por sua vez, o mapa com duas dimensões não diferencia uma posição
do gráfico que recebeu apenas um único acesso, por exemplo, de uma posição que
recebeu milhares de acesso – visto que, de acordo com as escalas do gráfico, uma
posição pode concentrar até mesmo milhões de acessos aglutinados.
O que se percebe na figura 15, referente ao programa Netscape, é uma parede
vertical na extremidade esquerda do gráfico tridimensional (com visão lateral),
evidenciando uma forte presença de acessos na porção inicial da fila LRU e,
portanto, a ocorrência constante de localidade temporal, ainda que às vezes
interrompida – fato sugerido pelos picos do gráfico bidimensional. O mapa de
acessos da figura 16 confirma esta constatação: é caracterizado por várias linhas
horizontais que permeiam praticamente toda a execução do programa, cada uma
delas indicando que uma ou mais páginas são continuamente referenciadas, apesar de
conterem alguns intervalos de inatividade, normalmente pequenos.
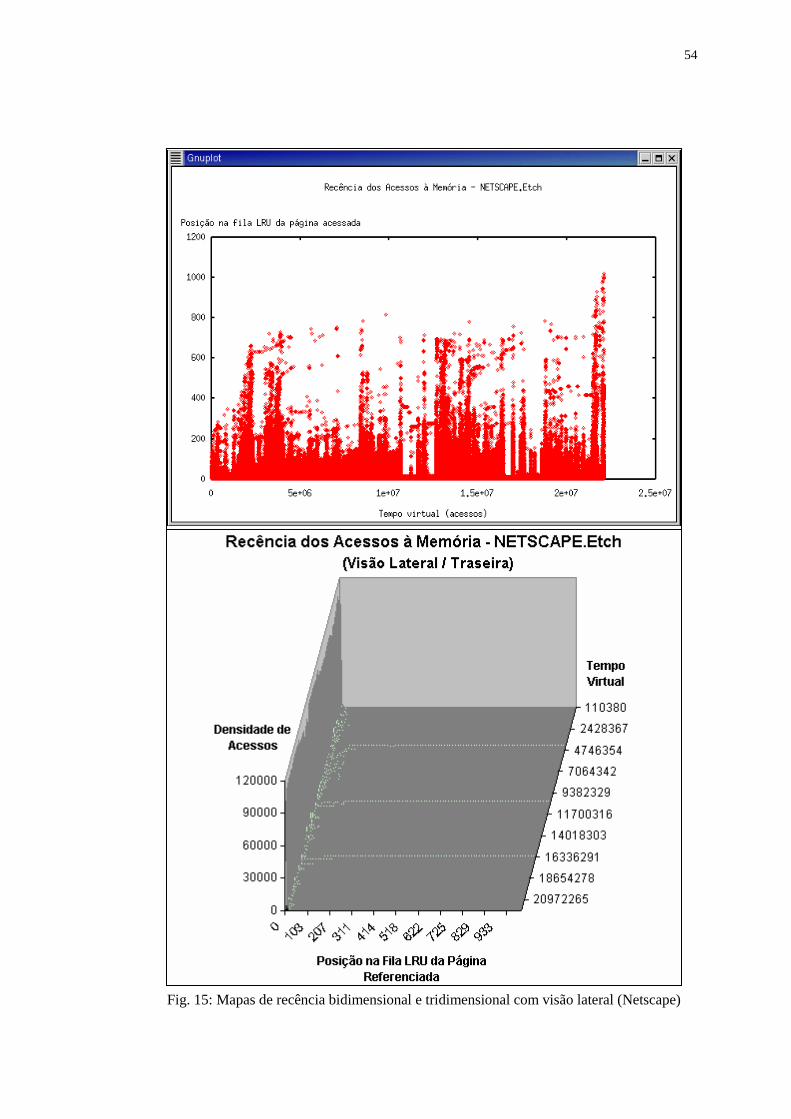
54
Fig. 15: Mapas de recência bidimensional e tridimensional com visão lateral (Netscape)
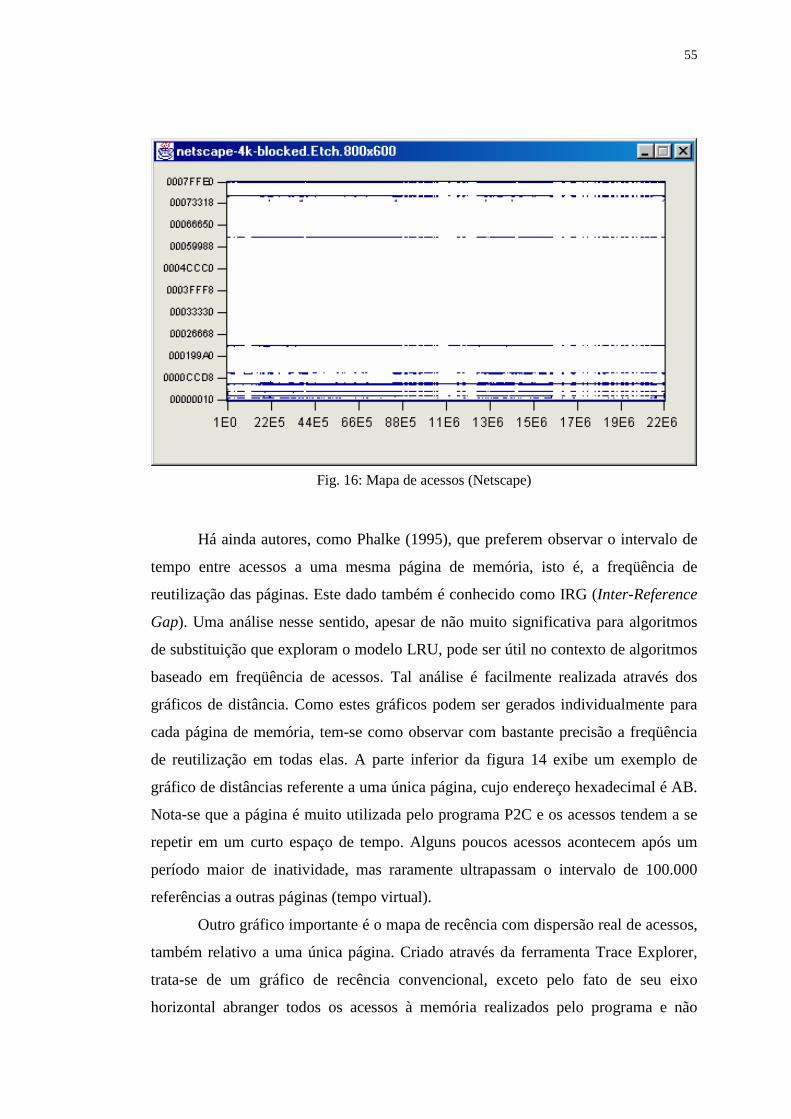
55
Há ainda autores, como Phalke (1995), que preferem observar o intervalo de
tempo entre acessos a uma mesma página de memória, isto é, a freqüência de
reutilização das páginas. Este dado também é conhecido como IRG (Inter-Reference
Gap). Uma análise nesse sentido, apesar de não muito significativa para algoritmos
de substituição que exploram o modelo LRU, pode ser útil no contexto de algoritmos
baseado em freqüência de acessos. Tal análise é facilmente realizada através dos
gráficos de distância. Como estes gráficos podem ser gerados individualmente para
cada página de memória, tem-se como observar com bastante precisão a freqüência
de reutilização em todas elas. A parte inferior da figura 14 exibe um exemplo de
gráfico de distâncias referente a uma única página, cujo endereço hexadecimal é AB.
Nota-se que a página é muito utilizada pelo programa P2C e os acessos tendem a se
repetir em um curto espaço de tempo. Alguns poucos acessos acontecem após um
período maior de inatividade, mas raramente ultrapassam o intervalo de 100.000
referências a outras páginas (tempo virtual).
Outro gráfico importante é o mapa de recência com dispersão real de acessos,
também relativo a uma única página. Criado através da ferramenta Trace Explorer,
trata-se de um gráfico de recência convencional, exceto pelo fato de seu eixo
horizontal abranger todos os acessos à memória realizados pelo programa e não
Fig. 16: Mapa de acessos (Netscape)
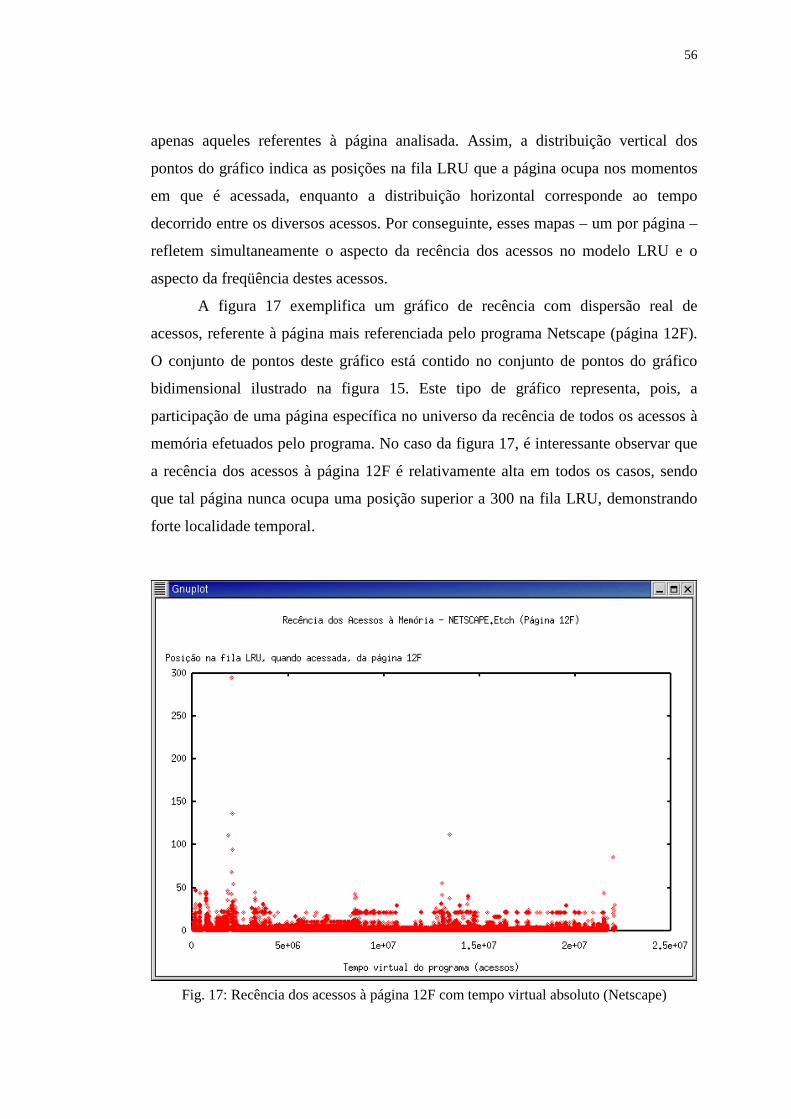
56
apenas aqueles referentes à página analisada. Assim, a distribuição vertical dos
pontos do gráfico indica as posições na fila LRU que a página ocupa nos momentos
em que é acessada, enquanto a distribuição horizontal corresponde ao tempo
decorrido entre os diversos acessos. Por conseguinte, esses mapas – um por página –
refletem simultaneamente o aspecto da recência dos acessos no modelo LRU e o
aspecto da freqüência destes acessos.
A figura 17 exemplifica um gráfico de recência com dispersão real de
acessos, referente à página mais referenciada pelo programa Netscape (página 12F).
O conjunto de pontos deste gráfico está contido no conjunto de pontos do gráfico
bidimensional ilustrado na figura 15. Este tipo de gráfico representa, pois, a
participação de uma página específica no universo da recência de todos os acessos à
memória efetuados pelo programa. No caso da figura 17, é interessante observar que
a recência dos acessos à página 12F é relativamente alta em todos os casos, sendo
que tal página nunca ocupa uma posição superior a 300 na fila LRU, demonstrando
forte localidade temporal.
Fig. 17: Recência dos acessos à página 12F com tempo virtual absoluto (Netscape)

57
3.3. Estudos Realizados
Os programas analisados neste trabalho, utilizados como carga de simulação
nos experimentos apresentados no Capítulo 5, são representados por arquivos de
trace que compõem três pacotes: VMTrace, Etch e Lirs.
O pacote VMTrace inclui 7 arquivos, originalmente aplicados por
Smaragdakis; Kaplan; Wilson (1999) nas simulações do algoritmo EELRU, sendo
também por eles disponibilizados. O nome deste pacote designa a ferramenta de
geração de traces utilizada em sua captação, desenvolvida pelos próprios autores.
A seguir são resumidamente descritos os programas representados por estes 7
arquivos:
- Espresso: Simulador de circuito;
- GCC: Compilador C/C++ do projeto GNU, versão 2.7.2;
- Gnuplot: Gerador de gráficos do projeto GNU;
- Grobner: Programa matemático que trabalha com Bases de Gröbner;
- GS: GhostScript 3.33, interpretador PostScript;
- Lindsay: Simulador de hipercubo;
- P2C: Tradutor de programas em Pascal para C.
A maioria dos traces que integram o pacote VMTrace possui a característica
de não consumir muita memória em sua execução, bastando apenas um pequeno
espaço de endereçamento virtual para armazená-los. Esta característica facilita a
visualização de padrões de acesso presentes em determinados trechos de
processamento, por meio dos gráficos de acesso.
Outros 10 arquivos de trace estão reunidos no pacote Etch, criados por Lee et
al. (1998). São eles:
- Acroread: Adobe Acrobat Reader 3.0, leitor de arquivos no formato PDF;
- CC1: GCC 2.5.3, compilador C do projeto GNU;
- Compress: Compressor de arquivos Unix;
- Go: Implementação do jogo de Go;
- Netscape: Netscape Navigator 3.1, navegador para internet;
- Perl: Interpretador da linguagem de programação homônima;
- Photoshp: Adobe Photoshop 4.0, editor de imagens;

58
- Powerpnt: Microsoft Power Point 7.0b, editor de apresentações em slides;
- Vortex: Banco de dados orientado a objetos;
- Winword: Microsoft Word 7.0, processador de texto.
Coletados através da ferramenta de geração de traces Etch (ROMER et al.,
1997), estes são os maiores arquivos utilizados em nossos experimentos,
considerando-se o número total de referências à memória. O pacote se divide em
arquivos de programas para Windows – Acrobat Reader, Netscape, Photoshop,
Power Point e Word – e arquivos de programas extraídos do conjunto de benchmarks
SPEC95 (SPEC, 1995) – Compress, GCC, Go, Perl e Vortex. Benchmarks são
programas de teste padronizados, utilizados para avaliação de desempenho.
Por fim, os 9 traces empregados nas simulações descritas pelos autores do
algoritmo LIRS (JIANG; ZHANG, 2002) completam nossos estudos. Além de
2_Pools, um programa sintético criado pelos próprios autores, o pacote Lirs engloba
os seguintes arquivos: CPP, CS, GLI, PS (CHOI et al., 1999); (CHOI et al., 2000);
Multi1, Multi2, Multi3 (KIM et al., 2000); e Sprite (LEE et al., 1999). Tais
programas são descritos abaixo de forma resumida:
- 2_Pools: Simulador sintético que realiza acessos aleatórios em páginas
com diferentes probabilidades de serem referenciadas;
- CPP: Pré-processador do projeto GNU para compilação de programas C;
- CS: Cscope, ferramenta que analisa códigos fonte de programas C;
- GLI: Glimpse, utilitário para busca de texto;
- Multi1: Execução simultânea de CS e CPP;
- Multi2: Execução simultânea de CS, CPP e PS;
- Multi3: Execução simultânea de CPP, Gnuplot (gerador de gráficos do
projeto GNU), GLI e PS;
- PS: Postgres, banco de dados relacional (operações de consulta);
- Sprite: Sistema distribuído (requisições efetuadas por clientes a um
servidor de arquivos).
Apesar de utilizarem espaços de endereçamento virtual relativamente
grandes, os arquivos do pacote Lirs contêm poucos acessos à memória. Dentre todos
os traces aqui analisados, estes são os de menor tamanho.
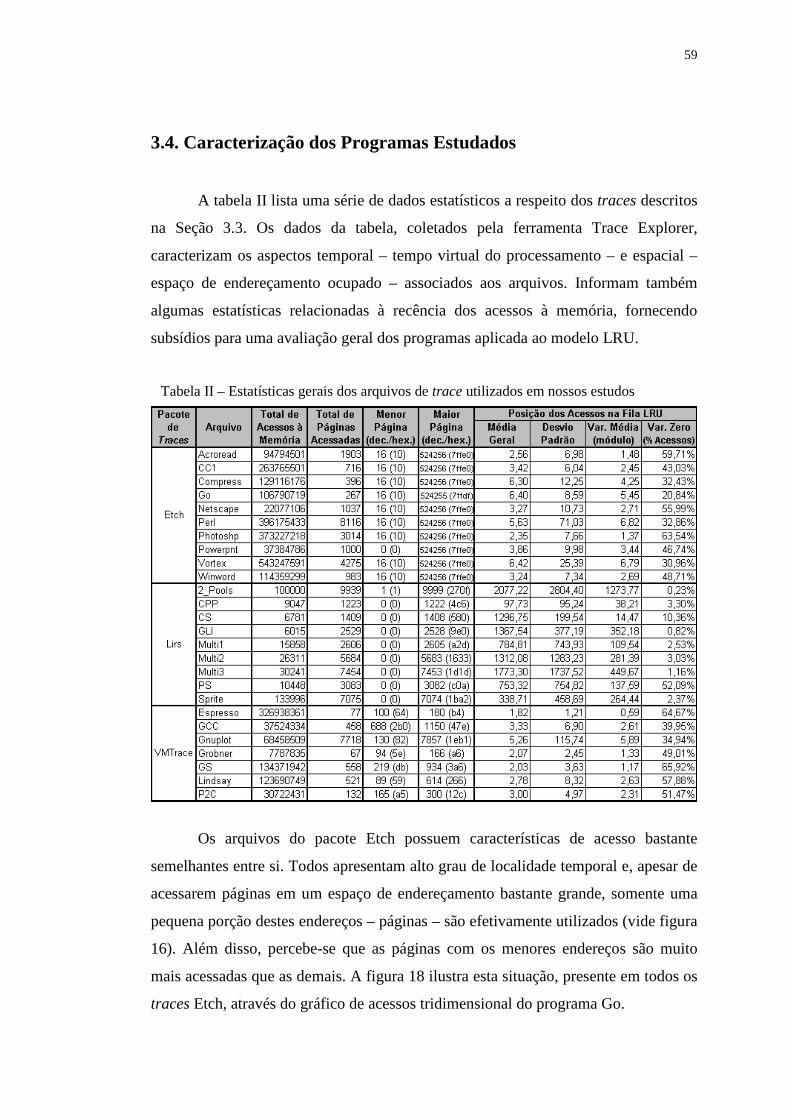
59
3.4. Caracter ização dos Programas Estudados
A tabela II lista uma série de dados estatísticos a respeito dos traces descritos
na Seção 3.3. Os dados da tabela, coletados pela ferramenta Trace Explorer,
caracterizam os aspectos temporal – tempo virtual do processamento – e espacial –
espaço de endereçamento ocupado – associados aos arquivos. Informam também
algumas estatísticas relacionadas à recência dos acessos à memória, fornecendo
subsídios para uma avaliação geral dos programas aplicada ao modelo LRU.
Os arquivos do pacote Etch possuem características de acesso bastante
semelhantes entre si. Todos apresentam alto grau de localidade temporal e, apesar de
acessarem páginas em um espaço de endereçamento bastante grande, somente uma
pequena porção destes endereços – páginas – são efetivamente utilizados (vide figura
16). Além disso, percebe-se que as páginas com os menores endereços são muito
mais acessadas que as demais. A figura 18 ilustra esta situação, presente em todos os
traces Etch, através do gráfico de acessos tridimensional do programa Go.
Tabela II – Estatísticas gerais dos arquivos de trace utilizados em nossos estudos
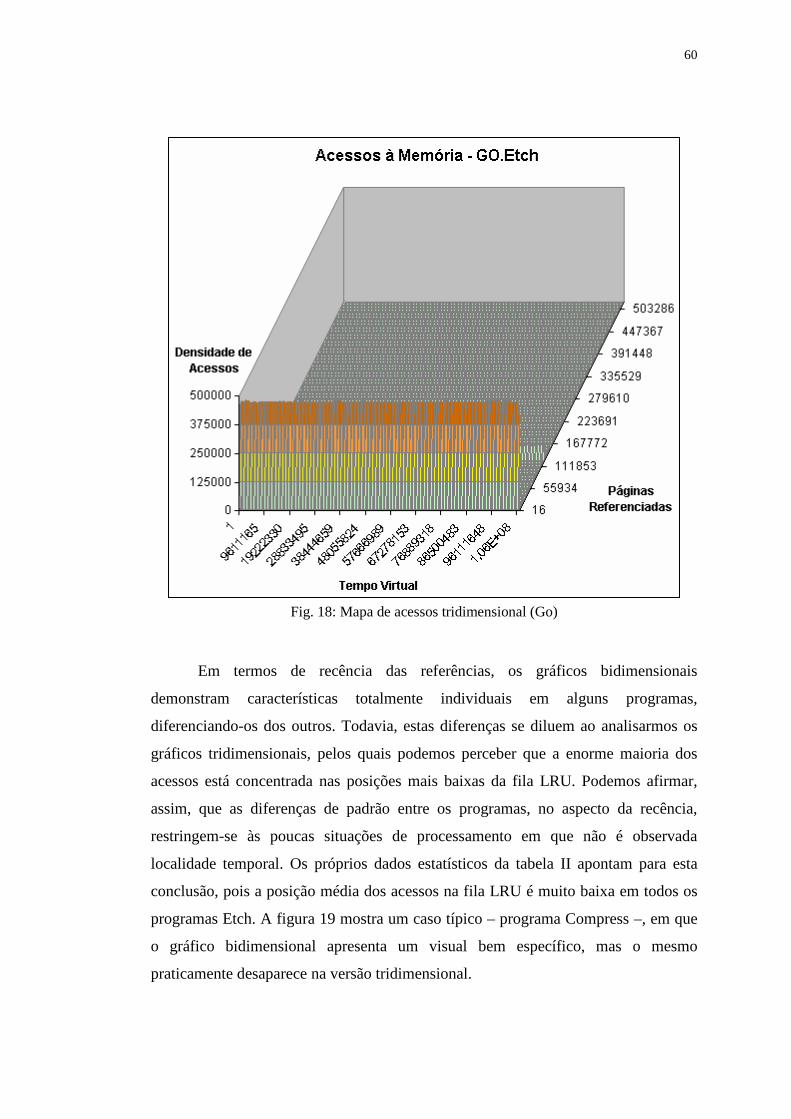
60
Em termos de recência das referências, os gráficos bidimensionais
demonstram características totalmente individuais em alguns programas,
diferenciando-os dos outros. Todavia, estas diferenças se diluem ao analisarmos os
gráficos tridimensionais, pelos quais podemos perceber que a enorme maioria dos
acessos está concentrada nas posições mais baixas da fila LRU. Podemos afirmar,
assim, que as diferenças de padrão entre os programas, no aspecto da recência,
restringem-se às poucas situações de processamento em que não é observada
localidade temporal. Os próprios dados estatísticos da tabela II apontam para esta
conclusão, pois a posição média dos acessos na fila LRU é muito baixa em todos os
programas Etch. A figura 19 mostra um caso típico – programa Compress –, em que
o gráfico bidimensional apresenta um visual bem específico, mas o mesmo
praticamente desaparece na versão tridimensional.
Fig. 18: Mapa de acessos tridimensional (Go)
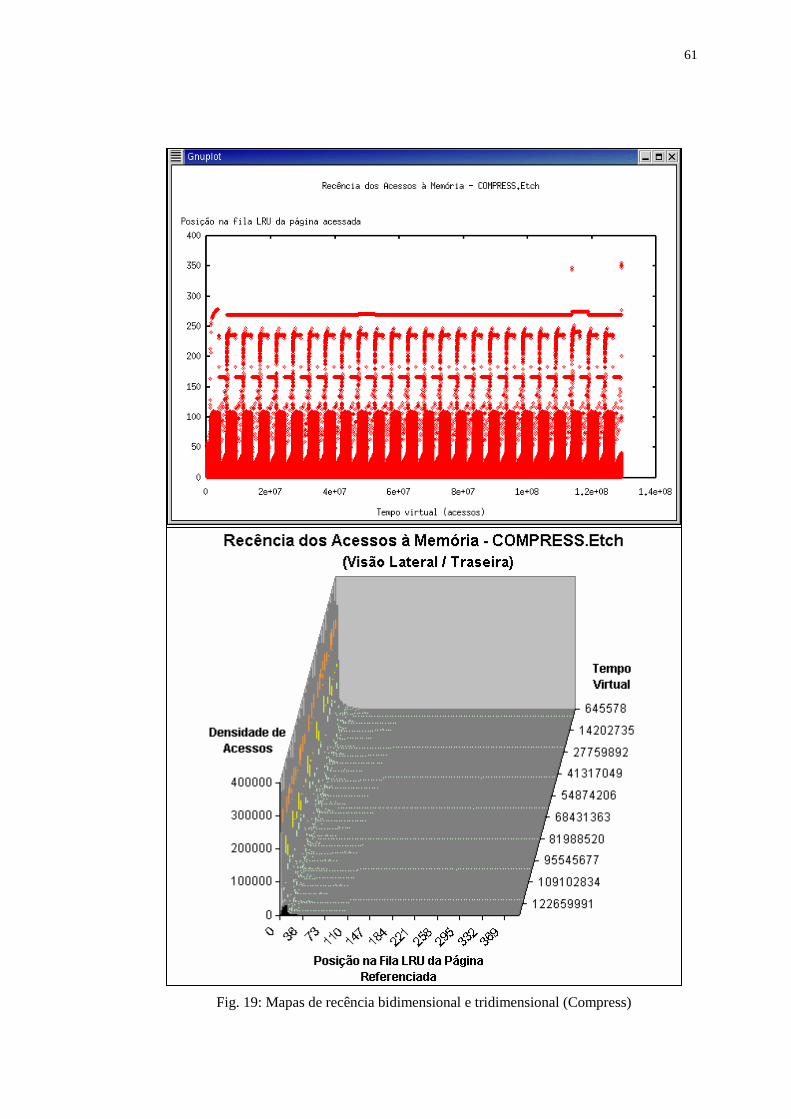
61
Fig. 19: Mapas de recência bidimensional e tridimensional (Compress)
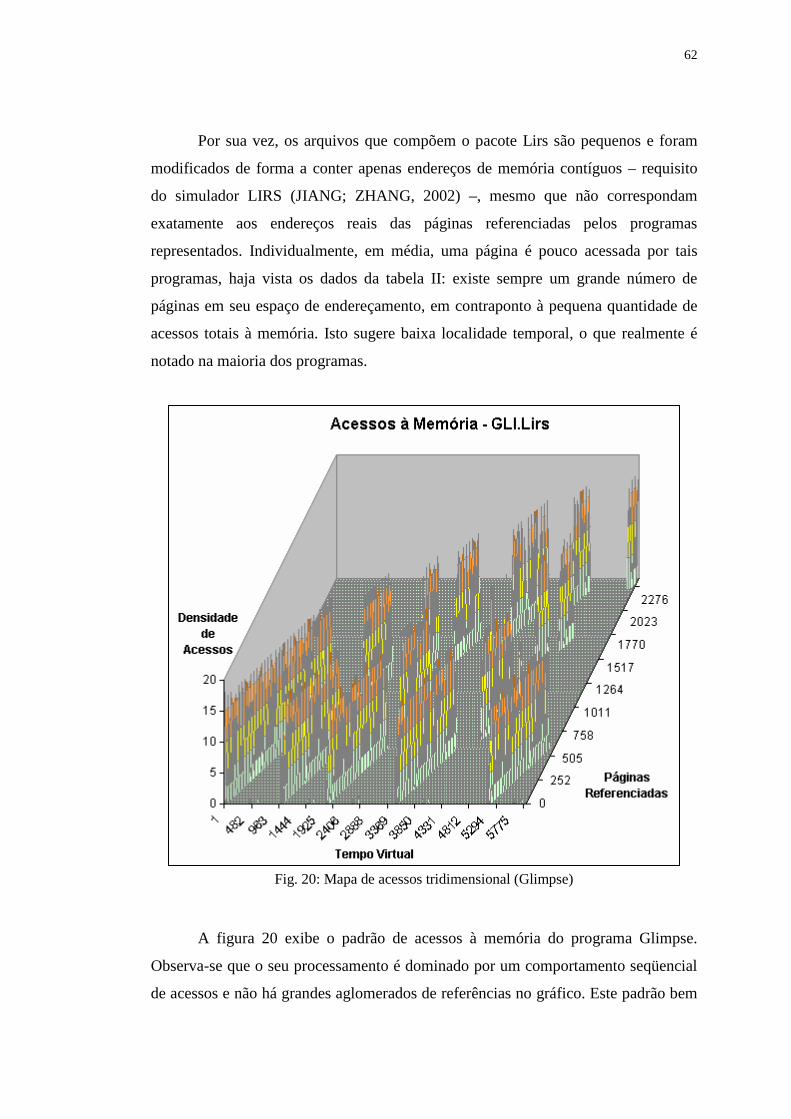
62
Por sua vez, os arquivos que compõem o pacote Lirs são pequenos e foram
modificados de forma a conter apenas endereços de memória contíguos – requisito
do simulador LIRS (JIANG; ZHANG, 2002) –, mesmo que não correspondam
exatamente aos endereços reais das páginas referenciadas pelos programas
representados. Individualmente, em média, uma página é pouco acessada por tais
programas, haja vista os dados da tabela II: existe sempre um grande número de
páginas em seu espaço de endereçamento, em contraponto à pequena quantidade de
acessos totais à memória. Isto sugere baixa localidade temporal, o que realmente é
notado na maioria dos programas.
A figura 20 exibe o padrão de acessos à memória do programa Glimpse.
Observa-se que o seu processamento é dominado por um comportamento seqüencial
de acessos e não há grandes aglomerados de referências no gráfico. Este padrão bem
Fig. 20: Mapa de acessos tridimensional (Glimpse)
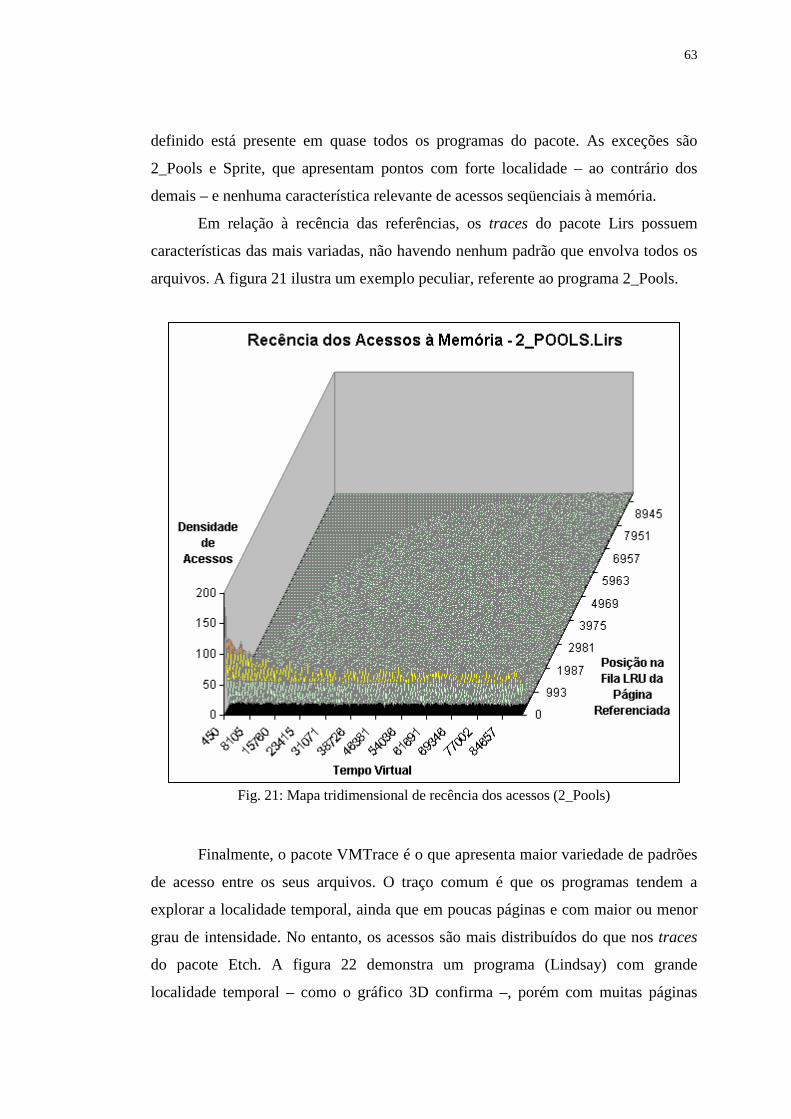
63
definido está presente em quase todos os programas do pacote. As exceções são
2_Pools e Sprite, que apresentam pontos com forte localidade – ao contrário dos
demais – e nenhuma característica relevante de acessos seqüenciais à memória.
Em relação à recência das referências, os traces do pacote Lirs possuem
características das mais variadas, não havendo nenhum padrão que envolva todos os
arquivos. A figura 21 ilustra um exemplo peculiar, referente ao programa 2_Pools.
Finalmente, o pacote VMTrace é o que apresenta maior variedade de padrões
de acesso entre os seus arquivos. O traço comum é que os programas tendem a
explorar a localidade temporal, ainda que em poucas páginas e com maior ou menor
grau de intensidade. No entanto, os acessos são mais distribuídos do que nos traces
do pacote Etch. A figura 22 demonstra um programa (Lindsay) com grande
localidade temporal – como o gráfico 3D confirma –, porém com muitas páginas
Fig. 21: Mapa tridimensional de recência dos acessos (2_Pools)

64
desprovidas desta propriedade também sendo acessadas alternadamente – fato
evidenciado pela própria amplitude espacial do gráfico bidimensional.
Fig. 22: Mapas de acesso bidimensional e tridimensional (Lindsay)

65
Os programas Grobner e Gnuplot são os únicos que apresentam padrões
seqüenciais de acesso à memória bem definidos, o primeiro intercalado com
referências a muitas outras páginas e o segundo intercalado com acessos a poucas
páginas que exibem alta localidade temporal. Em contrapartida, os demais arquivos
VMTrace se caracterizam principalmente pelo aspecto da localidade, sem a presença
de outros padrões regulares facilmente identificáveis.
Devido a esta presença constante de localidade temporal nos programas, a
recência dos acessos é visualizada de forma muito similar em todos os traces do
pacote VMTrace: a grande maioria das referências recai nas primeiras posições da
fila LRU. Um exemplo representativo é apresentado na figura 23, através da visão
lateral do gráfico referente ao programa Grobner.
Fig. 23: Visão lateral tridimensional do mapa de recência dos acessos (Grobner)

66
4. UMA NOVA PROPOSTA PARA SUBSTITUIÇÃO DE
PÁGINAS: O ALGORITMO ADAPTATIVO LRU-WAR
4.1. Motivação da Proposta
O esquema de substituição de páginas mais utilizado nos sistemas
operacionais desenvolvidos ao longo da história é aquele que implementa alguma
forma de aproximação do algoritmo LRU. Esta política se mostra relativamente
eficiente na grande maioria dos casos, em comparação com outras políticas
tradicionais como FIFO, MRU, LFU, etc. Isto porque os programas normalmente não
apresentam padrões de acesso bem definidos, ou seja, é difícil prever que página será
ou não acessada brevemente. Nessa situação, o emprego do critério LRU tende a ser
o mais lógico dentre as políticas de substituição triviais. Afinal, se não há
mecanismos suficientes para se prever qual página levará mais tempo para ser
requisitada pelo processador, substitui-se, em caso de falta, a página que está há mais
tempo sem ser acessada, aquela menos ativa no momento da execução. Em outras
palavras, podemos dizer que a política LRU explora muito bem as características de
localidade temporal presentes na execução de um processo.
Porém, Jiang; Zhang (2002), autores do algoritmo LIRS, apontam situações
em que certamente o algoritmo LRU apresenta deficiências:
- Acessos seqüenciais: situação em que uma estrutura de dados (por
exemplo vetor, matriz, lista ligada, árvore) é percorrida, elemento a
elemento, por um longo intervalo de acessos. Isso pode acontecer por
diversos motivos, como iniciação ou atualização de elementos, busca
seqüencial, processamento consecutivo – como multiplicação de matrizes
–, entre outros. Enquanto a estrutura de dados é percorrida, muitas
páginas distintas são acessadas em um curto intervalo de tempo. Por
conseqüência, o LRU remove sistematicamente páginas recém-
carregadas, visto que geralmente não há reutilização significativa com
este tipo de padrão de acessos. É normal que uma página só seja acessada
novamente quando não está mais residente na memória principal, ou seja,
após toda a estrutura de dados ter sido lida e processada.

67
- Acessos dentro de loops: se as páginas acessadas em cada iteração forem
muitas, numericamente superiores ao tamanho de memória disponível, o
LRU descarta ciclicamente da memória páginas que serão novamente
referenciadas em um futuro breve. Acontece, neste caso, um fenômeno
equivalente ao que ocorre quando o padrão de acessos do programa é
seqüencial: o LRU remove da memória páginas recém-carregadas,
continuamente, antes que possam ser reutilizadas. O motivo também é o
mesmo: no intervalo entre dois acessos consecutivos a uma mesma página
P qualquer, há sempre referências a outras páginas cuja quantidade
ultrapassa o tamanho de memória disponível, fazendo com que a página P
seja substituída pelo LRU antes de ser novamente referenciada.
- Freqüência irregular de acessos: determinadas páginas podem ser muito
pouco acessadas em alguns intervalos de execução e maciçamente
referenciadas em outros, inclusive de forma alternada. Em casos como
este, pode ser interessante que páginas muito referenciadas permaneçam
residentes na memória, ainda que apresentem alguns intervalos grandes de
inatividade. Mas o LRU não leva em conta nenhum dado referente à
freqüência de acessos e, muitas vezes, páginas constantemente acessadas
são removidas da memória indevidamente, o que poderia ser previsto e
evitado por um histórico de freqüência.
Esta terceira situação, no entanto, não apresenta a mesma inércia
comportamental quanto ao padrão de acessos que as duas primeiras. A tentativa de
prever variações na freqüência de acessos às páginas exige estruturas adicionais que
armazenem informações históricas relevantes no decorrer da execução. A alta
complexidade de implementação inerente a essa tentativa (overhead) torna-se um
grande problema e pode torná-la desinteressante.
Por outro lado, as duas primeiras situações – acessos seqüenciais e acessos
dentro de grandes loops – podem ser facilmente detectadas em um processo, pois
possuem uma característica extremamente bem definida: muitas faltas de página em
um curto intervalo de tempo. Outra característica fundamental é o pouco tempo pelo
qual cada página carregada permanece no working set do processo: a página deixa de
ser referenciada rapidamente.

68
A figura 24 ilustra o exemplo de dois programas, o gerador de gráficos
Gnuplot e a ferramenta Cscope, que exibem padrões de acesso visivelmente
seqüenciais. De acordo com o primeiro gráfico, todo o espaço de endereçamento
utilizado pelo programa Gnuplot é seqüencialmente percorrido por três vezes.
Enquanto isso, o espaço de endereçamento referente ao programa Cscope é quase
integralmente referenciado de forma seqüencial por várias vezes, repetidamente. O
fato de as seqüências ocorrerem em páginas de endereços virtuais consecutivos torna
a visualização dos padrões ainda mais clara.
Fig. 24: Exemplos de programas com padrões de acesso seqüenciais (Gnuplot e Cscope)

69
Diversos algoritmos adaptativos foram propostos com o intuito de identificar
e tratar acessos com faltas de página seqüenciais de maneira adequada, sem ignorar o
bom desempenho do algoritmo LRU nos demais casos. O Capítulo 2 descreveu e
discutiu algumas propostas deste tipo, destacando os algoritmos SEQ – que identifica
seqüências procurando adjacências entre as páginas recentemente carregadas na
memória – e EELRU – o qual detecta padrões seqüenciais analisando a concentração
de acessos recentes em páginas que já deixaram a memória. Ambos os algoritmos
agregam benefícios conceituais importantes ao LRU tradicional, mas ambos também
possuem uma complexidade muito maior de implementação.
Uma nova proposta, de conceito e implementação simples, é aqui
apresentada: o algoritmo LRU-WAR (LRU with Working Area Restriction – LRU
com Confinamento da Área de Trabalho). Baseado no tamanho máximo do working
set estimado e validado entre duas faltas de página consecutivas, e na variação deste
tamanho entre as faltas seguintes, o algoritmo utiliza um mecanismo ainda
inexplorado pelas técnicas atuais: a dimensão máxima do working set temporário
como fator decisivo de adaptatividade.
Com desempenho próximo ao do algoritmo LRU no caso médio, o algoritmo
adaptativo LRU-WAR se destaca por detectar e tratar eficientemente períodos com
padrões de acesso predominantemente seqüenciais, mantendo praticamente a mesma
complexidade de implementação que o LRU original.
4.2. Conceitos Básicos
Working set (conjunto de trabalho, normalmente designado pelo termo em
inglês), conforme proposto por Denning (1968), pode ser descrito como o conjunto
das páginas acessadas pelo programa em um determinado intervalo de tempo.
Subentende-se aqui, como working set temporário, o conjunto das páginas acessadas
entre as duas últimas faltas de página ocorridas, qualquer que seja o instante do
processamento. Em outras palavras: é o conjunto das páginas recentemente utilizadas
pelo programa.
Uma estrutura de dados muito utilizada por algoritmos de substituição de
páginas baseados em recência é a chamada fila LRU. Esta fila nada mais é do que a

70
própria representação da memória principal no modelo LRU, ordenada de forma
decrescente sob o critério da recência de acesso das páginas residentes. Como já foi
comentado nos capítulos anteriores, a página mais recentemente acessada ocupa a
primeira posição da fila, seguida pela página acessada imediatamente antes; por
conseqüência, a última posição da fila é ocupada pela página referenciada há mais
tempo, a chamada página LRU (menos recentemente acessada). A página no início
da fila, recém-utilizada, é conhecida como página MRU.
Entendido o princípio da fila LRU e o significado de working set temporário,
um novo conceito pode ser proposto: definimos área de trabalho (working area)
como sendo a região de recência onde o working set temporário está confinado, isto
é, a porção inicial da fila LRU em que todos os acessos realizados entre as duas
últimas faltas de página se concentraram.
O algoritmo LRU-WAR inova ao monitorar os acessos à memória e verificar,
entre duas faltas consecutivas, a página referenciada com menor recência em relação
ao seu último acesso; ou seja, ele identifica a posição mais alta da fila LRU que
recebeu acessos nesse período. Esta posição, representada por W, limita a área de
trabalho. Logo, a área de trabalho consiste no trecho da fila LRU compreendido entre
a última página referenciada – página MRU, início da fila – e a página que ocupa a
W-ésima posição da fila. Uma conclusão importante é que o working set temporário
contém sempre, no máximo, as páginas que ocupam esta área. A figura 25
exemplifica um caso hipotético de execução, no qual W é identificado, assim como a
localização da área de trabalho.
É essencial salientar que as células da fila LRU preenchidas com a cor cinza,
na figura 25, indicam as posições que receberam acessos desde a última falta de
página até o instante vigente. Isto não quer dizer que as páginas referenciadas
continuam nestas mesmas posições. Tampouco quer dizer que as páginas que
atualmente as ocupam foram acessadas no período. De acordo com a política LRU,
toda página referenciada é deslocada imediatamente para o início da fila. Os
destaques em cinza especificam apenas um histórico das posições que tais páginas –
não importa quais são – ocupavam no instante do seu respectivo acesso, antes da
conseqüente reordenação na fila LRU e dentro do período de tempo considerado.

71
4.3. Idéia Geral
O algoritmo LRU-WAR trabalha basicamente com dois critérios de
substituição: o critério LRU, no qual a página acessada há mais tempo é retirada da
memória, e o critério MRU-n, no qual a n-ésima página mais recentemente acessada
é descartada. O critério de substituição padrão é o LRU, que só deixa de ser utilizado
quando uma tendência de padrão seqüencial de acessos se fortalece. O algoritmo
detecta indícios de acesso seqüencial muito rapidamente, porém mantém o critério
LRU e aguarda durante um certo período de carência até que a tendência se
intensifique. O critério de substituição então passa a ser o MRU-n em tal situação.
Para identificar tendências seqüenciais durante uma execução, o LRU-WAR
verifica, a cada falta de página, se o tamanho da área de trabalho é pequeno o
suficiente para sugerir que as páginas residentes estão sendo subutilizadas. Se for,
assume a tendência seqüencial e monitora a variação de tamanho desta área durante
as faltas seguintes. Permanecendo a área de trabalho pequena o suficiente por um
certo número de faltas de página, entra em vigor o modo de operação seqüencial do
algoritmo. Motivo: uma das principais características de padrões de acesso
seqüenciais – incluindo loops de longa abrangência – é o fato de muitas páginas
serem carregadas e logo após removidas da memória pelo critério LRU, com faltas se
sucedendo continuamente. Ou seja, a política LRU passa a se comportar
praticamente como a política FIFO (First-in, First-out). Uma das conseqüências
desse fenômeno é o baixo número de acessos (hits) entre faltas e a insignificante
Fig. 25: Exemplo de área de trabalho, identificando-se o limite W entre faltas de página
Posições onde páginas foram acessadas desde a última falta de página
W1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
...
Fila LRU representando a memória principal
Área de Trabalho (Working Area )
Página MRU Página LRU

72
localidade inerente ao momento de execução. Logo, os poucos acessos realizados em
páginas residentes ficam concentrados em uma pequena porção inicial da fila LRU.
Como, segundo definimos, área de trabalho é a região de recência onde os
últimos acessos à memória estão concentrados, conclui-se facilmente que acessos de
padrão seqüencial geram uma área de trabalho reduzida, ínfima por vezes. E mais:
esta área permanece pequena mesmo após vários acessos com falta de página. Caso
contrário, poderia refletir apenas uma nova localidade de referências, com o
carregamento de algumas páginas não residentes. Mas se muitas faltas ocorrem e
poucas páginas são reutilizadas, a probabilidade de padrão seqüencial aumenta
significativamente.
Criado sob esta reflexão, o algoritmo LRU-WAR procura se valer da
simplicidade e da relativa eficiência do LRU no caso geral, acrescentando a ele uma
forma também simples e viável de detectar tendências de acesso seqüencial, talvez
sua principal deficiência.
4.4. Aspectos Operacionais
A seção anterior destacou as observações que inspiraram a criação do LRU-
WAR e resumiu sua idéia básica. Entretanto, algumas perguntas ainda precisam ser
respondidas para a concretização do algoritmo:
• Quando uma área de trabalho é considerada pequena o suficiente para
indicar uma tendência de acessos seqüenciais?
A figura 26 identifica algumas divisões lógicas na fila LRU que orientam o
algoritmo. Uma área de trabalho é considerada pequena quando está contida na
região seqüencial, porção inicial da fila LRU limitada por L, um dos dois parâmetros
do algoritmo. A região LRU complementa a região seqüencial e consiste,
obviamente, na porção final da fila LRU. Uma subregião também é identificada
dentro da região seqüencial: a chamada região protegida, compreendendo as C
primeiras páginas da fila; C (carência mínima) é o outro parâmetro do algoritmo. A
função desta pequena região será comentada adiante.
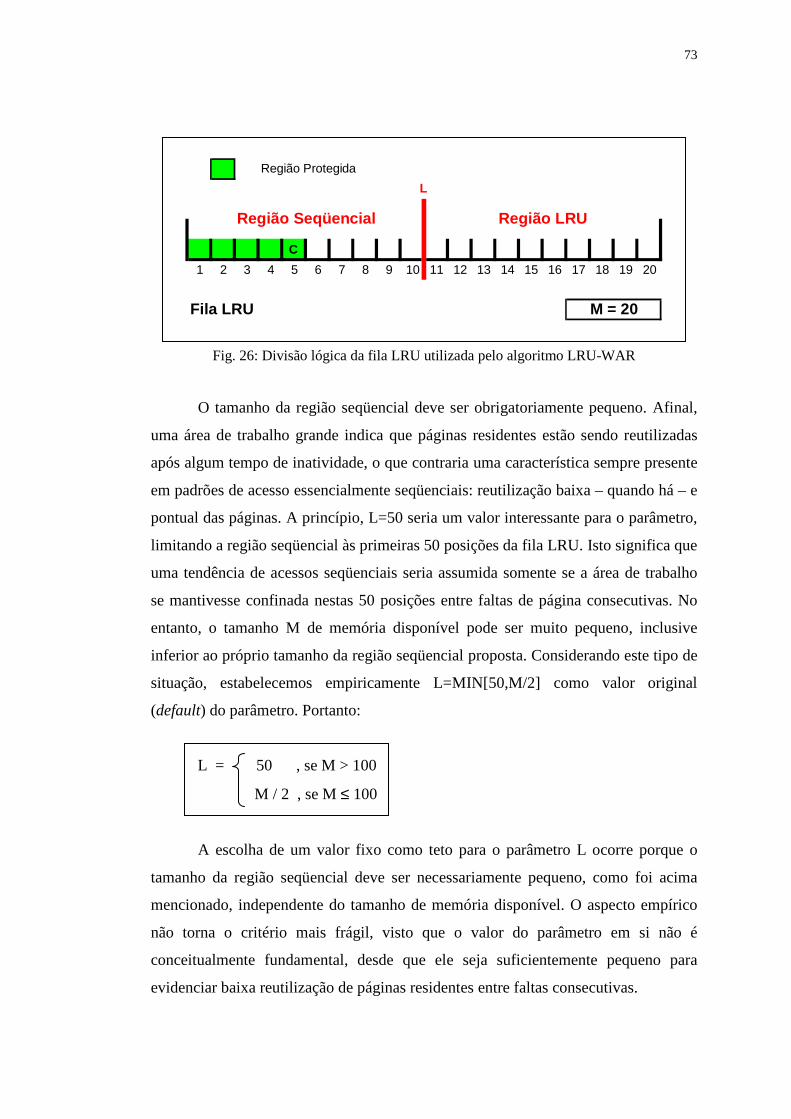
73
O tamanho da região seqüencial deve ser obrigatoriamente pequeno. Afinal,
uma área de trabalho grande indica que páginas residentes estão sendo reutilizadas
após algum tempo de inatividade, o que contraria uma característica sempre presente
em padrões de acesso essencialmente seqüenciais: reutilização baixa – quando há – e
pontual das páginas. A princípio, L=50 seria um valor interessante para o parâmetro,
limitando a região seqüencial às primeiras 50 posições da fila LRU. Isto significa que
uma tendência de acessos seqüenciais seria assumida somente se a área de trabalho
se mantivesse confinada nestas 50 posições entre faltas de página consecutivas. No
entanto, o tamanho M de memória disponível pode ser muito pequeno, inclusive
inferior ao próprio tamanho da região seqüencial proposta. Considerando este tipo de
situação, estabelecemos empiricamente L=MIN[50,M/2] como valor original
(default) do parâmetro. Portanto:
L = 50 , se M > 100
M / 2 , se M ≤ 100
A escolha de um valor fixo como teto para o parâmetro L ocorre porque o
tamanho da região seqüencial deve ser necessariamente pequeno, como foi acima
mencionado, independente do tamanho de memória disponível. O aspecto empírico
não torna o critério mais frágil, visto que o valor do parâmetro em si não é
conceitualmente fundamental, desde que ele seja suficientemente pequeno para
evidenciar baixa reutilização de páginas residentes entre faltas consecutivas.
Fig. 26: Divisão lógica da fila LRU utilizada pelo algoritmo LRU-WAR
C
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
M = 20
Região Protegida
Região Seqüencial Região LRU
L
Fila LRU

74
Tentativas de variação neste parâmetro não obtiveram um melhor valor
genérico. Pode haver um valor ótimo para determinado programa, porém tal número
é imprevisível a priori e volátil no decorrer de seu processamento. Em relação a um
possível ajuste dinâmico, não conseguimos associar o parâmetro L a nenhum fator
que garantisse certa precisão de cálculo sem adicionar uma sobrecarga significativa
ao sistema. Portanto, em um primeiro momento, acreditamos que a atribuição
empírica do valor, desde que sensata, seja a alternativa mais eficiente. Mas quais
valores seriam qualificados como sensatos?
Valores de L muito pequenos podem criar regiões seqüenciais insignificantes,
dificultando a detecção de acessos seqüenciais intercalados por outras páginas de
acesso constante. O exemplo do programa Gnuplot, gráfico superior da figura 24, é
um caso típico: podemos notar a existência de uma linha horizontal permanente na
extremidade inferior do mapa de acessos; esta linha representa uma localidade, no
aspecto espacial – conjunto de endereços adjacentes – e temporal, referenciada
freqüentemente em meio aos acessos de padrão seqüencial. Tanto os acessos
seqüenciais como aqueles não seqüenciais, se intercalados, fazem parte do working
set temporário do processo. As páginas não seqüenciais contribuem, pois, para
aumentar a área de trabalho. Mas se a região seqüencial é muito pequena, esta área
de trabalho pode ultrapassar o seu tamanho, fazendo com que o algoritmo não
detecte tendências de padrão seqüencial efetivas.
Por outro lado, o valor de L precisa ser relativamente pequeno. Caso
contrário, corre-se o risco de uma aproximação maior entre o algoritmo LRU-WAR e
a política MRU-n original, visto que a área de trabalho poderia permanecer contida
na região seqüencial durante quase toda a execução do programa. Isto não é
desejável, pois o algoritmo MRU-n tende a ser menos eficiente que o LRU, exceto
quando acessos seqüenciais predominam. Além disso, uma área de trabalho
constante não significa necessariamente que acessos seqüenciais estão ocorrendo,
pode significar apenas que uma localidade (conjunto de páginas) está sendo bastante
explorada. A tendência seqüencial é válida, de fato, quando a dimensão da área de
trabalho é reduzida, o que não pode ser detectado se a região seqüencial for muito
grande.

75
Diante do exposto, consideramos o valor L=MIN[50,M/2] bastante razoável e
adequado ao bom funcionamento do algoritmo LRU-WAR Trata-se de um valor
pequeno, mas não tão pequeno ao ponto de invalidar a contribuição do algoritmo.
Logo, este foi o valor adotado em todos os experimentos relatados no Capítulo 5.
• A área de trabalho aumenta e diminui indiscriminadamente entre uma falta
de página e outra?
Uma tendência LRU é assumida quando, entre duas faltas de página
consecutivas, o tamanho da área de trabalho ultrapassa o tamanho da região
seqüencial. Nesta situação, o algoritmo zera a posição W – que representa o tamanho
da área de trabalho – no momento da falta. Se no próximo instante em que uma falta
de página ocorrer, a área de trabalho for maior que a região seqüencial novamente, a
tendência continua sendo LRU e a posição W volta a ser zerada. Caso contrário, uma
tendência seqüencial é detectada – a ser confirmada pela imutabilidade no tamanho
da área de trabalho durante as faltas subseqüentes.
A tendência seqüencial só é confirmada se a área de trabalho permanecer
contida na região seqüencial durante um certo número de faltas de página, quando o
algoritmo entra em operação seqüencial. Enquanto isso não acontece, o critério de
substituição LRU continua a ser utilizado neste período de incerteza.
Porém, fora de tendência LRU, isto é, estando a área de trabalho contida na
região seqüencial, a posição W somente aumenta, nunca diminui. Em outras
palavras: em tendência ou operação seqüencial, a área de trabalho não é sensível à
diminuição de tamanho da região de recência em que o working set temporário está
confinado. Ela só é sensível a um aumento neste tamanho. Pode-se então dizer que,
num instante t qualquer em que ocorra uma falta de página, W=MAX[Wt, Wt-1, Wt-2,
..., Wi], onde i representa o instante em que a tendência deixou de ser LRU pela
última vez. Isto acontece porque o objetivo de W é limitar a região de recência em
que todos os acessos estiveram concentrados desde que a tendência seqüencial foi
detectada. W define, pois, a área de trabalho em que estiveram confinados todos os
working set temporários desde então. Mas é importante lembrar que a área de
trabalho não segrega páginas de memória, e sim posições em que estas páginas –
quaisquer que sejam – foram acessadas.

76
No entanto, um aumento na área de trabalho, mesmo que ela permaneça na
região seqüencial, quebra a estabilidade comportamental da qual o algoritmo
necessita estando em modo de operação seqüencial. Neste caso, a contagem do
número de faltas de página recomeça e uma nova tendência seqüencial é considerada.
• Por quanto tempo a área de trabalho deve permanecer contida na região
seqüencial para que o algoritmo adote o critério MRU-n?
O algoritmo entra em operação seqüencial somente após duas condições
serem satisfeitas:
− A ocorrência de um número de faltas de página proporcional ao
tamanho da área de trabalho – e, portanto, equivalente a W – desde o
instante em que a tendência seqüencial começou;
− A ocorrência de um número adicional de faltas de página, após a
primeira condição ter sido satisfeita, referente a um tempo de carência
complementar.
Isto, claro, se a área de trabalho permanecer na região seqüencial durante todo
este período, configurando uma baixa reutilização de páginas. Por exemplo, se a área
de trabalho tem tamanho 10 em um determinado momento de execução (W=10), o
critério MRU-n só é utilizado caso a área tenha se mantido menor ou igual a este
tamanho durante as últimas 10 faltas de página, incluindo a atual, além do tempo de
carência.
O conceito que emerge é o seguinte: se apenas páginas localizadas em uma
pequena área inicial da fila LRU são acessadas num intervalo de tempo cujo número
de faltas de página é equivalente ao próprio tamanho da área, conclui-se que páginas
estão sendo carregadas e rapidamente se tornando inativas nesse momento de
execução do processo, fato que sugere uma concentração predominante de acessos
seqüenciais.
O tempo de carência citado consiste em um número de faltas de página
adicional que o algoritmo respeita antes de operar em modo seqüencial. Apesar de a
tendência seqüencial já ser bastante forte neste momento, suficiente para o algoritmo
começar a utilizar o critério de substituição MRU-n, o tempo de carência poupa
algumas páginas que seriam substituídas de imediato por tal critério, fazendo com

77
que elas permaneçam residentes na memória. Como o LRU-WAR é baseado em
tendências de execução, e tendências não garantem certeza, o objetivo deste artifício
é permitir que eventuais decisões erradas possam ser detectadas pelo algoritmo.
Se uma das páginas que teriam sido substituídas pelo critério MRU-n,
poupada pelo tempo de carência, for acessada novamente durante a operação
seqüencial (aumentando a área de trabalho), o algoritmo considera que cometeu um
erro. Afinal, pela sua decisão original, aquela página não estaria mais residente. Ela
não foi removida da memória devido exclusivamente ao tempo de carência. Além
disso, o próprio aspecto da reutilização não pontual da página indica que o padrão de
acessos, que aparentava ser seqüencial, de fato não é. Mesmo que existam acessos
seqüenciais, estes estão intercalados com outras páginas que podem ser reutilizadas
após certo tempo, tornando ineficiente a aplicação do critério MRU-n e confirmando
o erro de decisão.
O tempo de carência mínimo é sempre C, parâmetro do algoritmo, utilizado
em situações normais. Entretanto, há casos em que este tempo pode ser muito maior,
o que acontece quando – em operação seqüencial – um erro de decisão é constatado.
A auto-penalidade aplicada pelo algoritmo é a exigência de um tempo de carência
maior para que a operação seqüencial volte a ser adotada, visto que o programa pode
apresentar tendências de execução pouco confiáveis para uma modificação imediata
no critério de substituição.
Durante o tempo de carência, o modo de operação do algoritmo continua
sendo apenas a tendência seqüencial. Logo, o critério LRU permanece em vigor até
que a operação seqüencial se inicie.
• Qual página será removida da memória, em caso de substituição, pelo
algoritmo LRU-WAR?
O critério de substituição MRU-n é aplicado, com efeito, somente quando o
algoritmo está em operação seqüencial. Nesta situação, a página removida é sempre
aquela que ocupa a primeira posição da fila LRU fora da área de trabalho. Logo,
n=W+1; o que permite especificar a versão MRU-n utilizada como sendo MRU-
(W+1). Um exemplo de substituição em operação seqüencial é apresentado na figura
27. A filosofia embutida neste critério é substituir uma página que, por tendência,

78
esteja se tornando inativa; ou seja, uma página que deixou de pertencer ao working
set temporário do processo há pouco tempo. Com este ponto de substituição na
região seqüencial, um grande número de páginas – todas as páginas da região LRU,
além de algumas outras – permanecem residentes na memória até que a tendência
LRU se restabeleça. Isto é, até que uma delas seja referenciada e, por conseguinte, a
área de trabalho aumente. Em operação seqüencial, é pouco provável que uma página
que deixou a memória volte a ser referenciada antes que uma página da região LRU,
uma vez que páginas acessadas seqüencialmente costumam ser requisitadas por um
curto e único período de tempo.
Por outro lado, não estando em operação seqüencial, o critério de substituição
utilizado pelo algoritmo é o da política LRU, que remove a M-ésima página – última
página – da fila. Este critério é aplicado quer esteja o algoritmo em tendência original
(LRU), quer esteja em tendência seqüencial, antes e durante o tempo de carência. A
figura 28 demonstra um exemplo de substituição em tendência LRU.
Fig. 28: Exemplo de utilização do critério de substituição LRU
W LRU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
L Área de TrabalhoExemplo de falta de página em tendência original (LRU) Ponto de Substituição
Fila LRU M = 20
Fig. 27: Exemplo de utilização do critério de substituição MRU-(W+1)
W +1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Fila LRU
Área de Trabalho
Ponto de Substituição
Exemplo de falta de página em operação seqüencial
M = 20
L

79
A utilização do critério LRU quando existe tendência de acessos seqüenciais
é motivada pela incerteza. Se o padrão de acessos pode ser ou não seqüencial em tal
momento de execução, utiliza-se o critério de substituição default, geralmente
eficiente e de conseqüências previsíveis. O LRU só se torna ineficiente quando toda
a memória disponível é ocupada por páginas que foram carregadas em acessos
seqüenciais, o que é evitado pelo algoritmo LRU-WAR graças às operações
seqüenciais. A tabela III destaca os três estados de execução previstos pelo algoritmo
e reitera os critérios de substituição empregados em cada caso.
• Uma página pode ser removida da memória pelo critério de substituição
MRU-n logo após ter sido carregada?
Teoricamente, uma página poderia ser removida da memória muito
rapidamente. Suponhamos que, entre duas faltas consecutivas, somente a página na
segunda posição da fila LRU tenha sido referenciada (W=2). O tempo de carência
vigente, por hipótese, é 5. Imaginemos ainda que, coincidentemente, os seis acessos
seguintes também gerem faltas de página. Isto poderia indicar apenas uma mudança
de localidade e, portanto, não é suficiente para se afirmar com alguma convicção que
o padrão de acessos é seqüencial. Todavia, seria o bastante para que o algoritmo
assim considerasse, de acordo com seu modelo. A página substituída nesta última
falta consecutiva, de fato, seria aquela carregada há somente três acessos antes.
Para evitar que uma operação seqüencial seja precocemente deflagrada, como
no exemplo ilustrado acima, uma área de trabalho mínima foi idealizada. Conforme
destacado na figura 26, a região protegida consiste nas C primeiras posições da fila
LRU. Esta região engloba algumas posições de recência consideradas baixas demais
para conter a área de trabalho, o que permite dizer que a menor área de trabalho
aceita pelo algoritmo LRU-WAR é C+1. Logo, se W ≤ C, o algoritmo atualiza o seu
valor para W = C+1. Com esta condição adicional, C+1 também passa a ser o
Tabela III – Características dos estados de execução definidos pelo algoritmo LRU-WAR

80
número mínimo de faltas de página, somado ao tempo de carência, para que uma
tendência de acessos seqüenciais seja confirmada e o algoritmo adote o modo de
operação seqüencial. Como o menor tempo de carência admitido é C, podemos
concluir que uma operação seqüencial nunca começa sem que a área de trabalho
permaneça com o mesmo tamanho, dentro da região seqüencial, pelo menos por
2C+1 faltas de página consecutivas.
Na grande maioria dos casos, logicamente, a região protegida é uma
subregião contida na região seqüencial. A exceção é quando L é menor ou igual a C,
o que ocorre se, por exemplo, a memória disponível (M) é muito pequena. Nesta
situação, o algoritmo LRU-WAR se comporta exatamente como o algoritmo LRU,
pois não há possibilidade de o critério MRU-n ser utilizado.
O valor original do parâmetro C é 5, pois consideramos que as 5 páginas mais
recentemente acessadas, no mínimo, devem ser sempre preservadas pelo critério de
substituição. Este valor é um ponto médio de equilíbrio, uma vez que o algoritmo
demonstrou certa sensibilidade à sua variação. Variando C tanto para cima como
para baixo, a quantidade de situações beneficiadas é proporcional à quantidade de
situações prejudicadas, em termos de desempenho (número de faltas de página). Isto
significa que, atribuindo a C o valor 10, por exemplo, o algoritmo se mostra mais
eficiente para alguns programas e menos eficiente para outros. O mesmo ocorre se
diminuirmos o seu valor, invertendo-se a situação. O algoritmo obtém melhor
desempenho com padrões seqüenciais quando a região protegida é menor, assim
como o tempo de carência mínimo. Por outro lado, uma região protegida maior evita
que o algoritmo cometa muitos erros de decisão ao tratar acessos que não são
efetivamente seqüenciais, mas que possuem características semelhantes. Para definir
a questão, avaliamos o desempenho do algoritmo MRU-n original com diversos
programas simulados neste trabalho e concluímos, através dos resultados obtidos
com diferentes valores de n, que C=5 é um valor genérico ideal para o parâmetro.
• O que acontece exatamente quando o algoritmo detecta um erro de decisão?
Quais são os procedimentos adotados?
Quando o algoritmo está em operação seqüencial, algumas páginas que
deveriam ter sido substituídas no início da operação certamente foram preservadas

81
devido ao tempo de carência. O número de páginas preservadas é proporcional ao
mesmo, equivalente a um certo número de faltas de página. O tempo de carência
inicial, no momento em que um processo começa a rodar, foi estipulado como sendo
2C (duas vezes C). Isto porque, a princípio, o algoritmo não possui nenhum dado
histórico em relação a tal programa e um tempo de carência superior ao mínimo evita
que alguns erros sejam cometidos caso o processo não apresente forte tendência de
acessos seqüenciais à memória.
A figura 29 ilustra uma situação hipotética de processamento na qual o
algoritmo LRU-WAR opera em modo seqüencial. As posições da fila LRU ocupadas
pelas páginas que foram poupadas da substituição durante o tempo de carência são
destacadas na figura pela cor azul. Neste exemplo, apenas o tempo mínimo de
carência, C=5, foi respeitado pelo algoritmo, provavelmente porque havia um
histórico de operações seqüenciais e nenhum histórico de erros constatados.
Se uma página que está residente graças exclusivamente ao tempo de carência
for novamente acessada em operação seqüencial, três hipóteses são previstas:
− A página ainda não teria sido substituída se a operação seqüencial não
vigorasse: O algoritmo tenta responder à pergunta “se esta operação
seqüencial não estivesse acontecendo e o critério de substituição LRU
continuasse vigente, a tal página reutilizada agora estaria residente?” É
importante lembrar que a mesma só permanece carregada na memória devido
ao tempo de carência, ou seja, como uma exceção à regra da substituição
seqüencial. Se a posição da página na fila LRU é P, o número de páginas
Fig. 29: Exemplo, em operação seqüencial, de páginas poupadas pelo tempo de carência
W +1 +2 +3 +4 +5 +6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Fila LRU M = 20
Páginas não substituídas pela
op. seqüencial devido ao
tempo de carência
LÁrea de Trabalho
Ponto de Substituição

82
substituídas nesta operação seqüencial é N, e M-P � N, pode-se garantir que a
página ainda estaria residente pelo critério LRU, pois o número de outras
páginas referenciadas no período seria insuficiente para deslocá-la até o fim
da fila LRU. Neste tipo de situação, o algoritmo LRU não é ineficiente; pelo
contrário, há um forte indício de que a tendência seqüencial que motivou o
início da respectiva operação refletia apenas uma mudança de localidade ou
mesmo um loop de tamanho menor que o da memória disponível – em termos
de páginas referenciadas por iteração. Qualquer que seja o caso, o algoritmo
cometeu um erro ao adotar o critério MRU-n, afinal não era esperado que
houvesse uma reutilização de páginas em tão curto espaço de tempo. A partir
desta constatação, como forma de auto-penalidade, o algoritmo aumenta o
tempo de carência, dificultando a entrada em vigor de uma próxima operação
seqüencial. Ao tempo de carência atual, é somado o contador N, cujo valor
máximo definido é M (tamanho da memória). Portanto, quanto mais páginas
foram substituídas em operação seqüencial equivocada, maior será o novo
tempo de carência. O motivo deste aumento é o seguinte: se foi necessário
um período de N faltas de página para que o algoritmo detectasse o erro, da
próxima vez estas N faltas ocorrerão antes que a mudança no critério de
substituição se efetive, confirmando ou não se a operação seqüencial deve ser
realmente iniciada. Ou seja, o erro não se repetirá facilmente.
− Muito poucas páginas foram substituídas em operação seqüencial: Às vezes,
o tamanho de memória disponível é muito pequeno e se percebe que a página
reutilizada também teria sido substituída pelo critério LRU, porém
exclusivamente devido à limitação da memória. Por exemplo, se a memória
disponível tem tamanho 20 e a área de trabalho tem tamanho 9, é bastante
provável que as páginas preservadas pelo tempo de carência fossem
rapidamente substituídas se a operação seqüencial não tivesse começado e,
por conseguinte, ela foi teoricamente vantajosa. No entanto, apenas tal
observação não basta. Há um mínimo de faltas de página que devem ocorrer
em operação seqüencial para que o algoritmo considere que o padrão
seqüencial de acessos detectado é realmente legítimo. Senão, prevalece o fato
de a página ter sido reutilizada muito rápido, contrariando a expectativa que

83
orienta o algoritmo. O número mínimo de faltas de página aceitas pelo LRU-
WAR em uma operação seqüencial para que a mesma seja avalizada é N=50
faltas, independente do tamanho de memória disponível. Caso este número
não seja alcançado, um erro é assumido e o procedimento descrito no item
anterior – aumento do tempo de carência – aplica-se igualmente nesta
situação.
− A reutilização foi muito tardia em relação ao tamanho de memória
disponível: Se, por outro lado, a reutilização da página em questão só
aconteceu após a ocorrência de um mínimo de 50 faltas de página em
operação seqüencial e, ainda, a mesma já teria sido substituída pelo critério
LRU em tendência original, o algoritmo considera a referida operação um
sucesso. Pois, embora pelo menos uma página preservada da substituição
seqüencial tenha voltado a ser referenciada, ela não fazia mais parte do
working set do processo pelo modelo LRU em tal momento. Desta forma,
mesmo se tratando de um loop, por exemplo, o número de páginas envolvidas
é superior ao tamanho de memória disponível, evidenciando que se trata, de
fato, de um padrão de acessos basicamente seqüencial. Em situações assim, o
algoritmo apenas aumenta a área de trabalho, reinicia o contador de faltas de
página e volta a operar em tendência LRU ou seqüencial – dependendo do
caso –, sem modificar o tempo de carência para que uma nova operação
seqüencial seja posteriormente deflagrada.
O tempo de carência aumenta, pois, somente quando um erro de decisão é
detectado. Mas ele também pode diminuir, até atingir o valor mínimo. Isto acontece
continuamente em modo de operação seqüencial: enquanto permanece maior que C,
o tempo de carência é decrementado a cada falta de página ocorrida.
A diminuição no tempo de carência permite que o algoritmo se adapte a
variações no padrão de acessos de cada programa. Mesmo que um erro de decisão
seja constatado no início de um processamento, o programa pode apresentar acessos
efetivamente seqüenciais posteriormente. Uma vez confirmada a presença de tais
características e após ser respeitado o tempo de carência estabelecido devido ao erro,
o algoritmo vai se tornando menos rigoroso quanto à prevenção de novos erros na
medida em que os acessos seqüenciais vão se legitimando.

84
4.5. Descr ição Prática do Algor itmo
Agora que todos os aspectos do algoritmo LRU-WAR foram discutidos e
detalhados, é possível descrever de maneira mais objetiva o seu funcionamento
prático. O algoritmo verifica, a cada acesso em páginas residentes na memória, a
posição na fila LRU da página referenciada. Se o valor de W for menor que esta
posição, é imediatamente sobreposto pela mesma, aumentando assim a área de
trabalho; senão, nenhuma alteração é necessária.
O tamanho da área de trabalho (W) só é importante quando uma falta de
página ocorre. Nos casos de falta, se W for maior que o limite L, a última página da
fila – página LRU – é substituída e W é zerado. Se W for menor ou igual ao limite C
da região protegida, a página LRU também é substituída e C+1 passa a ser o novo
valor de W. Finalmente, se W for menor ou igual a L e maior que C, seu valor não é
alterado e duas hipóteses de substituição existem:
- Se W permanece menor ou igual a L há pelo menos W faltas de página
consecutivas, mais o tempo de carência, a página que ocupa a posição
W+1 da fila LRU é substituída;
- Caso contrário, a página LRU é substituída.
O tempo de carência, que inicialmente tem o valor de 2C, aumenta quando
um erro de decisão é detectado pelo algoritmo LRU-WAR, conforme foi explicado
na seção anterior. Em contrapartida, a sua redução é feita apenas em operação
seqüencial, gradativamente, na medida em que faltas de página são computadas.
Uma substituição é efetuada pelo algoritmo exclusivamente quando uma falta
de página acontece e a memória disponível está preenchida por completo. Se uma
página precisa ser carregada na memória principal e o espaço disponível na mesma
não está totalmente ocupado, não há a necessidade de remover qualquer outra página
residente (paginação por demanda).
O algoritmo LRU-WAR pode ser escrito na forma de pseudo-código, onde:
C = tempo mínimo de carência, limite superior da região protegida;
L = limite superior da região seqüencial;
M = tamanho da memória, última posição da fila LRU;
W = limite superior da área de trabalho (working area).

85
1. Se a página acessada está carregada na memória:
2. P = posição da página na fila LRU;
3. Se P > W:
4. Se N > 0: /* Se está em operação seqüencial * /
5. INÉRCIA = 0; /* Encerra a operação seqüencial * /
6. Se P > W+1 e P ≤ W+TC+1 e (N ≤ M-P ou N < 50):
7. /* Detecta erro e aumenta o tempo de carência * /
8. TC = TC + N;
9. N = 0;
10. W = P; /* Aumenta área de trabalho * /
11. Reordena a página na primeira posição da fila.
12. Senão (a página acessada não está carregada na memória):
13. Se a memória está cheia:
14. Se W ≤ L:
15. INÉRCIA = INÉRCIA + 1;
16. Se W ≤ C:
17. W = C + 1;
18. Se INÉRCIA � W+TC: /* Operação seqüencial * /
19. Se N < M ou N < 50:
20. N = N + 1;
21. Se TC > C:
22. TC = TC – 1;
23. Remove a página na posição W+1 da fila;
24. Senão (INÉRCIA < W+TC): /* Tend. seqüencial * /
25. Remove a página na posição M da fila;
26. Senão (W > L): /* Tendência LRU * /
27. INÉRCIA = 0;
28. W = 0;
29. N = 0;
30. Remove a página na posição M da fila;
31. Carrega a página acessada no início da fila.

86
O trecho compreendido entre as linhas de código 2 e 11 é executado somente
quando uma página já residente na memória for acessada (hit). Neste caso, se a
página ocupa uma posição P na fila LRU maior que a área de trabalho, o tamanho da
área é aumentado, passando a englobar esta posição: W = P. Em operação
seqüencial, a contagem de faltas de página é reiniciada, encerrando tal fase. O modo
de operação volta a ser, então, tendência LRU ou tendência seqüencial, de acordo
com o tamanho da nova área de trabalho. Se um erro de decisão é detectado, ou seja,
uma das páginas preservadas da substituição seqüencial pelo tempo de carência foi a
responsável pelo aumento de W, e a sua reutilização foi considerada muito precoce, o
tempo de carência TC aumenta de acordo com o número de substituições realizadas
nesta operação seqüencial.
O trecho de código logo abaixo, entre as linhas 14 e 30, descreve a atuação do
algoritmo quando uma substituição de página precisa ser realizada. Em tendência
original (LRU), a página acessada há mais tempo – que ocupa a posição M, última da
fila – é substituída e a área de trabalho é zerada. Em tendência seqüencial, o critério
de substituição LRU também é empregado e a área de trabalho apenas pode aumentar
de tamanho. Finalmente, se o algoritmo está operando em modo seqüencial, a página
que ocupa a posição W+1 da fila é substituída e a área de trabalho precisa se manter
estável para que a operação não seja interrompida. Ressalte-se que o tamanho da área
de trabalho deve sempre ultrapassar o tamanho da região protegida, condição
garantida pelas linhas 16 e 17. O número de faltas de página, desde o começo de uma
tendência seqüencial, é calculado através do contador INÉRCIA. Por sua vez, o
contador N é responsável pelo armazenamento do número de faltas de página
computadas em operação seqüencial.
A implementação desta versão do algoritmo LRU-WAR, naturalmente offline
– uma vez que realiza operações mesmo quando páginas residentes são acessadas –,
é muito simples: todas as substituições são realizadas com complexidade O(1),
apesar de a fila LRU ser atualizada com complexidade O(n), inerente ao modelo. A
fila é representada por uma lista ligada e dois ponteiros de substituição são definidos:
LRU e SEQ. O ponteiro LRU aponta sempre para a última posição da fila. Já o
ponteiro SEQ, de posição variável, é atualizado sempre que o valor de W se
modifica, passando a apontar para a sua posição seguinte na fila (W+1).

87
4.6. Versão Online
Uma versão online do algoritmo LRU-WAR também foi construída, com a
mesma simplicidade algorítmica da versão offline. Assim como ocorre nas
implementações reais do LRU, esta versão online do LRU-WAR é apenas uma
aproximação da versão offline. A grande diferença está na fila LRU, que não pode
ser atualizada em todos os acessos, apenas durante os momentos de falta de página.
Para a realização deste procedimento, um bit de acesso é associado a cada página
residente. Se, no momento de uma falta de página, o bit vale 1, significa que a página
foi acessada pelo menos uma vez desde a falta anterior. Senão, se o bit contém valor
0, a página obviamente não foi referenciada neste mesmo período. Todos os bits de
acesso são zerados após qualquer falta de página.
Contudo, em relação ao aspecto prático do algoritmo, há pelo menos duas
questões que precisam ser ponderadas:
− A multiprogramação dificulta a detecção de padrões de acesso, pois vários
programas realizam acessos à memória simultaneamente, o que pode tornar as
características individuais de cada processo imperceptíveis ao algoritmo;
− A atualização das posições das páginas na fila LRU pode onerar demais o
sistema, visto que o tempo algorítmico desta operação é de ordem O(n);
quanto maior o tamanho de memória disponível, mais crítica é a situação.
Para minimizar estes problemas e viabilizar a utilização do LRU-WAR em
sistemas reais, propomos uma implementação baseada em filas individuais para cada
processo em execução no sistema (MIDORIKAWA, 1997). O tamanho da memória
M disponível a um processo – que pode variar dinamicamente – passa a ser outro
parâmetro do algoritmo. Desta forma, os procedimentos de substituição são
realizados em um contexto local, manipulando-se apenas a fila referente ao programa
que provocou a falta de página. A definição e atualização do tamanho de memória
destinado a determinado programa seria uma atribuição adicional do sistema
operacional, assim como o gerenciamento das diversas filas LRU em vigor. Tal
solução, portanto, exige modificações específicas em um sistema pré-existente.
O seguinte pseudo-código detalha a implementação do algoritmo LRU-WAR
online, o qual é acionado somente quando uma página não residente é acessada:

88
1. MO = tamanho do espaço de memória ocupado;
2. Com P variando a partir de MO até 1: /* verifica bits de acesso * /
3. Se a página que ocupa a posição P da fila LRU foi acessada:
4. Se P > W:
5. Se N > 0: /* Se está em operação seqüencial * /
6. INÉRCIA = 0; /* Encerra tal operação * /
7. Se P > W+1 e P ≤ W+TC+1 e (N ≤ M-P ou N < 50)
8. /* Detecta erro e aumenta TC * /
9. TC = TC + N;
10. N = 0;
11. W = P; /* Aumenta área de trabalho * /
12. Desativa o bit de acesso associado à página;
13. Reordena a página na primeira posição da fila;
14. P = P + 1;
15. Se MO = M: /* Se a memória está cheia * /
16. Se W ≤ L:
17. INÉRCIA = INÉRCIA + 1;
18. Se W ≤ C: W = C + 1;
19. Se INÉRCIA � W+TC: /* Operação seqüencial * /
20. Se N < M ou N < 50: N = N + 1;
21. Se TC > C: TC = TC – 1;
22. Remove a página na posição W+1 da fila;
23. Senão (INÉRCIA < W+TC): /* Tendência seqüencial * /
24. Remove a página na posição M da fila;
25. Senão (W > L): /* Tendência LRU * /
26. INÉRCIA = 0;
27. W = 0;
28. N = 0;
29. Remove a página na posição M da fila;
30. Senão (MO < M): MO = MO + 1; /* Memória ainda não está cheia * /
31. Carrega a página acessada no início da fila.

89
O procedimento do LRU-WAR online pode ser explicado da seguinte
maneira: em cada falta de página, o algoritmo atualiza W verificando – através dos
bits de acesso – se alguma página referenciada recentemente (entre a falta anterior e
a atual) ocupava uma posição na fila LRU superior ao seu valor. Em caso positivo, o
valor de W passa a corresponder à maior posição acessada. Em caso negativo,
permanece inalterado. Ou seja, W continua a representar a região máxima de
recência onde o working set temporário se mantém confinado.
Os critérios de substituição e os parâmetros do algoritmo online são
exatamente os mesmos que os do algoritmo offline, como pode ser notado no código
entre as linhas 16 e 29, absolutamente inalterado. A única mudança significativa se
refere à reordenação dos elementos na fila LRU que, como ocorre somente durante
as faltas de página, despreza a quantidade de acessos que cada página sofreu e a
ordem destes acessos. A fila LRU do algoritmo online, por conseqüência, é
normalmente pouco precisa em relação à fila LRU do algoritmo offline. A recência
dos acessos representada decrescentemente pela posição das páginas na fila online
constitui apenas uma previsão, uma aproximação da recência efetiva.
O algoritmo LRU-WAR online atualiza a fila mantendo a mesma ordem
relativa entre as páginas que sofreram pelo menos um acesso, porém deslocando-as
para o início. Exemplificando: no momento de uma falta de página, as páginas que
ocupam as posições 3, 6, 8 e 9 da fila LRU são aquelas que receberam acessos desde
a falta anterior. As primeiras posições da fila, após sua atualização, estarão ocupadas
pelas seguintes páginas: página que ocupava a posição 3, seguida pelas páginas que
ocupavam as posições 6, 8 e 9, respectivamente. O trecho entre as linhas de código 2
e 14 é o responsável pela reordenação das páginas na fila, assim como pela eventual
atualização (aumento) no tamanho da área de trabalho e no tempo de carência.
Uma avaliação de desempenho das duas versões do algoritmo LRU-WAR é
apresentada no Capítulo 5. Os resultados obtidos através de simulações realizadas
com os algoritmos LRU-WAR, LRU, EELRU e LIRS são comparados entre si e com
o caso ótimo de substituição de páginas.

90
5. EXPERIÊNCIAS REALIZADAS
Uma metodologia para captação de traces começou a ser definida utilizando o
gerador Augmint (NGUYEN et al., 1996) na fase inicial de nossos estudos. Algumas
técnicas de compressão para estes arquivos também foram estudadas (SAMPLES,
1989); (JOHNSON, 1999); (KAPLAN; SMARAGDAKIS; WILSON, 1999). A
geração de traces próprios é interessante porque aumenta a flexibilidade da pesquisa
e o universo de programas simulados nas avaliações de desempenho. Em
contrapartida, este procedimento exige a manipulação do código fonte de tais
programas – condição imposta ao menos pela ferramenta Augmint – e, dependendo
da forma como é feito, pode gerar arquivos não compatíveis com outros simuladores.
Procurando agilizar a realização de nossas experiências e facilitar a
comparação dos resultados com outros publicados na literatura, optamos por um
caminho alternativo: a utilização de traces já existentes, referenciados em trabalhos
relacionados. Além de representativos, estes arquivos normalmente estão disponíveis
em formatos padronizados, podendo ser experimentados sem a necessidade de
alterações nos simuladores desenvolvidos. Eles também aumentam a credibilidade do
estudo pelo fato de serem heterogêneos e estarem publicamente disponíveis,
representando assim diversas situações de execução previamente analisadas por
outros autores.
5.1. Descr ição das Simulações
Um conjunto de simulações foi organizado para averiguar o desempenho
prático do algoritmo LRU-WAR e compará-lo com outras políticas de substituição
de páginas. O critério de desempenho utilizado é o número de faltas de página
geradas na execução de um processo.
Os experimentos aqui relatados tiveram como carga de simulação os 26
programas descritos e analisados no Capítulo 3, representados por: 10 arquivos de
trace que integram o pacote Etch; 9 arquivos que formam o pacote Lirs; e 7 arquivos
que compõem o pacote VMTrace. Todos os traces possuem um formato trivial, ou
seja, são arquivos texto que somente listam as páginas de memória acessadas pelos
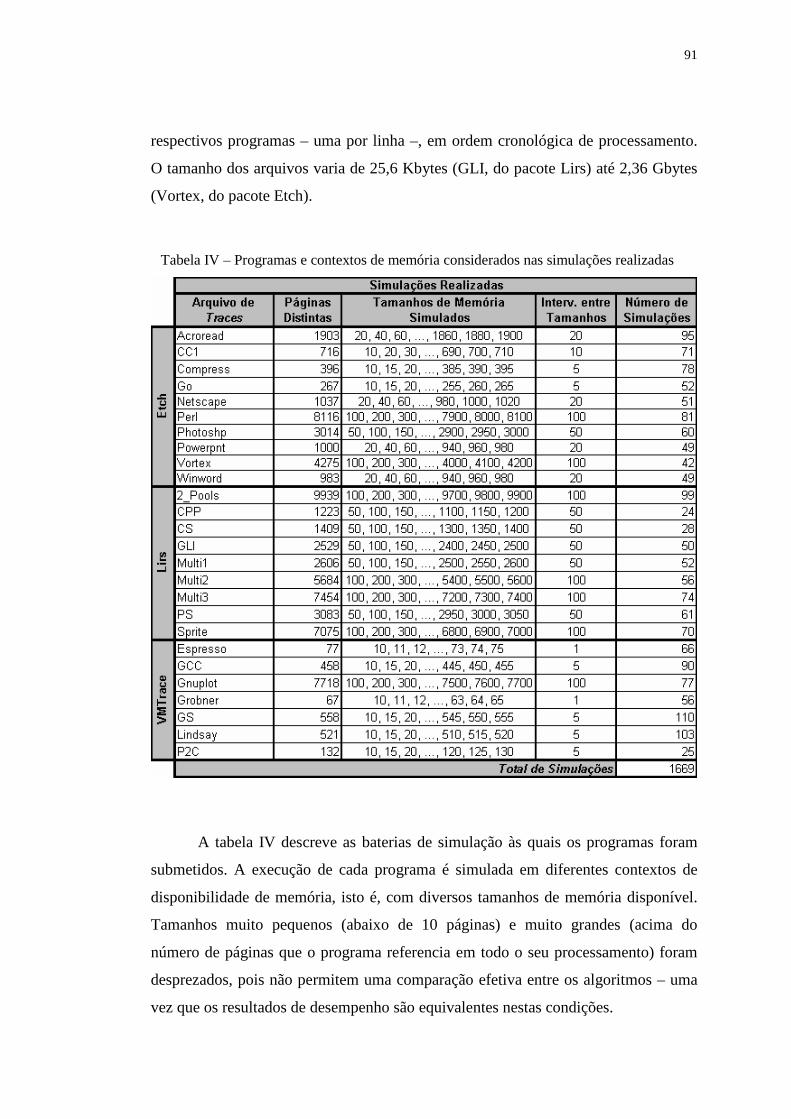
91
respectivos programas – uma por linha –, em ordem cronológica de processamento.
O tamanho dos arquivos varia de 25,6 Kbytes (GLI, do pacote Lirs) até 2,36 Gbytes
(Vortex, do pacote Etch).
A tabela IV descreve as baterias de simulação às quais os programas foram
submetidos. A execução de cada programa é simulada em diferentes contextos de
disponibilidade de memória, isto é, com diversos tamanhos de memória disponível.
Tamanhos muito pequenos (abaixo de 10 páginas) e muito grandes (acima do
número de páginas que o programa referencia em todo o seu processamento) foram
desprezados, pois não permitem uma comparação efetiva entre os algoritmos – uma
vez que os resultados de desempenho são equivalentes nestas condições.
Tabela IV – Programas e contextos de memória considerados nas simulações realizadas

92
A segunda coluna da tabela IV informa o número de páginas distintas
referenciadas pelos programas, enquanto a terceira coluna relata os tamanhos de
memória utilizados em cada simulação e a quarta coluna indica o intervalo entre
estes tamanhos. A última coluna, finalmente, contabiliza o número de simulações
efetuadas. Por exemplo, o programa P2C (pacote VMTrace) foi simulado 25 vezes –
para a avaliação de um único algoritmo de substituição de páginas –, considerando-se
os seguintes tamanhos de memória: M i ∈ { 10,15,20,25,30,35,40,45,50,55,60,65,70,
75,80,85,90,95,100,105,110,115,120,125,130} , 0 < i ≤ 25. Conseqüentemente, o
intervalo entre tamanhos de memória utilizados nas simulações do programa P2C é
de 5 páginas. Cada simulação avalia o desempenho do algoritmo analisado
considerando apenas um destes possíveis tamanhos de memória. O conjunto das
simulações referentes ao programa indica o desempenho médio que o algoritmo
obteve com o mesmo.
Os algoritmos de substituição de páginas que tiveram desempenho aferido
nos experimentos relatados são: Ótimo, LRU, FIFO, EELRU, LIRS, LRU-WAR
Offline e LRU-WAR Online. O algoritmo FIFO, entretanto, apresentou baixa
eficiência em relação a todos os demais e foi desconsiderado nas análises
comparativas. Os simuladores EELRU e LIRS foram criados e disponibilizados pelos
autores dos respectivos algoritmos (SMARAGDAKIS; KAPLAN; WILSON, 1999);
(JIANG; ZHANG, 2002). Todos os demais simuladores foram desenvolvidos por
nós, especificamente para este trabalho de avaliação.
Normalmente, despende-se muito tempo na execução de experiências desta
natureza e, portanto, a construção de simuladores eficientes se torna um fator
importante. O simulador StackPar (CASSETTARI; MIDORIKAWA, 2002b)
desponta como o principal projeto concluído neste sentido. Baseado em algoritmos
de pilha (MATTSON et al., 1970), o StackPar viabiliza a simulação paralela dos
algoritmos de substituição de páginas Ótimo e LRU em máquinas
multiprocessadoras (SMP). Outros simuladores baseados em algoritmos de pilha
também foram desenvolvidos, porém sem a exploração de recursos de paralelismo.
Por fim, alguns simuladores mais simples – que implementam algoritmos como
FIFO, MRU-n, etc. – completam a estrutura de software utilizada em nossas
experiências práticas.
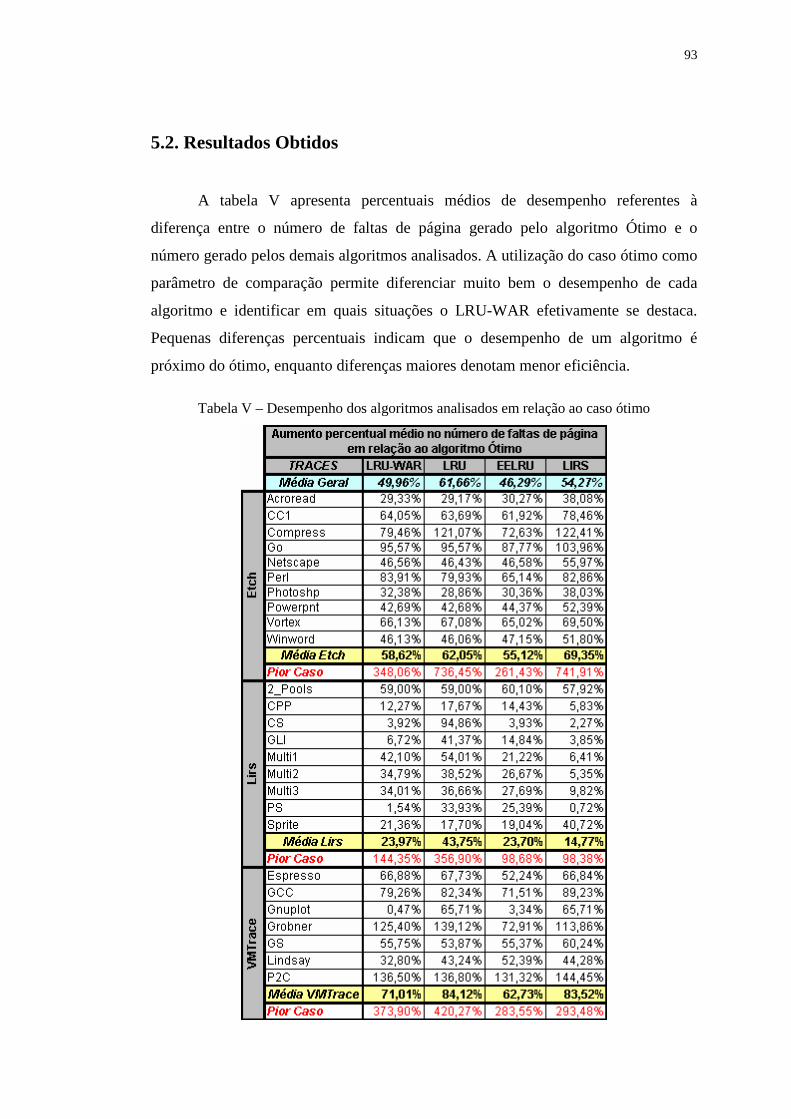
93
5.2. Resultados Obtidos
A tabela V apresenta percentuais médios de desempenho referentes à
diferença entre o número de faltas de página gerado pelo algoritmo Ótimo e o
número gerado pelos demais algoritmos analisados. A utilização do caso ótimo como
parâmetro de comparação permite diferenciar muito bem o desempenho de cada
algoritmo e identificar em quais situações o LRU-WAR efetivamente se destaca.
Pequenas diferenças percentuais indicam que o desempenho de um algoritmo é
próximo do ótimo, enquanto diferenças maiores denotam menor eficiência.
Tabela V – Desempenho dos algoritmos analisados em relação ao caso ótimo

94
O desempenho dos algoritmos relacionado a cada programa é exibido na
forma de percentuais médios. Estes valores representam, naturalmente, a média dos
aumentos percentuais de faltas de página – em relação ao caso ótimo – registrados
pelos algoritmos em cada simulação do programa, ou seja, para cada tamanho de
memória considerado. Exemplificando: o programa Netscape foi simulado 51 vezes
com cada algoritmo, como afirma a tabela IV; assim, o aumento percentual médio,
referente ao acréscimo no número de faltas de página que um algoritmo provoca,
consiste na soma dos 51 aumentos percentuais obtidos em suas simulações, dividida
por 51.
As linhas que informam o pior caso em cada pacote de traces não designam
nenhuma média. Elas destacam, de fato, o maior aumento percentual observado nas
simulações dos respectivos algoritmos com os traces do pacote. Logo, representam o
aumento percentual de faltas de página, em relação ao caso ótimo, calculado em uma
única simulação do algoritmo – envolvendo um programa qualquer do pacote e um
tamanho de memória específico. No caso do pacote Lirs, por exemplo, o pior caso
dos algoritmos EELRU e LIRS acontece na simulação do programa Sprite (com
memórias de tamanho 300 e 500, respectivamente), enquanto o pior caso do
algoritmo LRU-WAR se dá na simulação do programa Multi1 (memória de tamanho
1450) e o pior caso do algoritmo LRU ocorre com o programa Cscope (memória de
tamanho 1300). Como pode ser observado, nem sempre o programa em que é
identificado o pior caso de um algoritmo coincide com o programa no qual a pior
média de desempenho é constatada para o mesmo algoritmo.
Genericamente, os resultados das simulações demonstram um bom
desempenho do algoritmo LRU-WAR. Nos casos em que a ocorrência de acessos
seqüenciais é baixa, o algoritmo apresenta – em termos de faltas de página –, um
desempenho próximo e convergente ao do LRU, às vezes praticamente equivalente.
Isto acontece com programas como 2_Pools, Espresso, P2C e a maioria dos
programas do pacote Etch. Há também programas com os quais o desempenho do
algoritmo LRU-WAR é um pouco pior que o do LRU: Perl, Photoshop, Sprite e
GhostScript.
Por outro lado, quando acessos seqüenciais predominam, a eficiência do
algoritmo proposto é extrema. Quanto maiores os trechos onde acessos seqüenciais
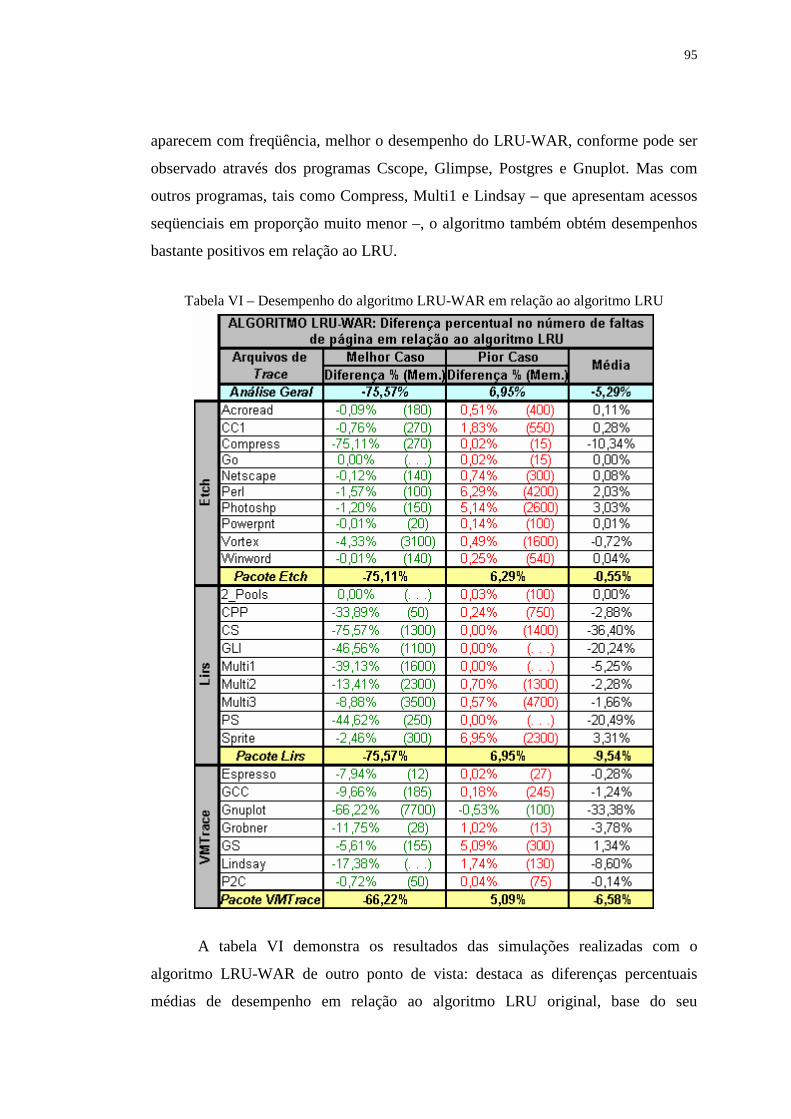
95
aparecem com freqüência, melhor o desempenho do LRU-WAR, conforme pode ser
observado através dos programas Cscope, Glimpse, Postgres e Gnuplot. Mas com
outros programas, tais como Compress, Multi1 e Lindsay – que apresentam acessos
seqüenciais em proporção muito menor –, o algoritmo também obtém desempenhos
bastante positivos em relação ao LRU.
A tabela VI demonstra os resultados das simulações realizadas com o
algoritmo LRU-WAR de outro ponto de vista: destaca as diferenças percentuais
médias de desempenho em relação ao algoritmo LRU original, base do seu
Tabela VI – Desempenho do algoritmo LRU-WAR em relação ao algoritmo LRU

96
desenvolvimento. Valores percentuais positivos indicam que o algoritmo LRU-WAR
apresenta um desempenho pior que o do algoritmo LRU, pois provoca um número
maior de faltas de página. Valores negativos, obviamente, indicam o contrário.
A coluna “melhor caso” representa a situação de execução em que o
algoritmo LRU-WAR obtém o melhor desempenho percentual comparado com o
algoritmo LRU. A situação inversa é representada pela coluna “pior caso” : quando o
LRU obtém o melhor desempenho. A média aritmética das diferenças percentuais
coletadas entre os dois algoritmos, levando-se em conta todas as simulações descritas
na tabela IV – todos os tamanhos de memória considerados –, é calculada na terceira
coluna. Um exemplo: 56 simulações são realizadas para avaliar o desempenho médio
de cada algoritmo na execução do programa Grobner e, portanto, 56 diferenças
percentuais são calculadas entre números de faltas de página gerados pelo algoritmo
LRU e números gerados pelo algoritmo LRU-WAR. A menor destas diferenças
(maior redução no número de faltas de página) representa o melhor caso do
algoritmo LRU-WAR em relação ao LRU original; a maior diferença representa o
pior caso; e a média aritmética entre as 56 diferenças indica uma tendência geral.
Assim, podemos interpretar da seguinte forma os dados relativos ao programa
Grobner: o algoritmo LRU-WAR, em média, atinge um desempenho 3,78% melhor
que o do algoritmo LRU. Porém, ele pode provocar um número de faltas de página
até 1,02% maior que o mesmo; ou seja, em pelo menos uma simulação efetuada com
o programa Grobner, seu desempenho é 1,02% pior que o do algoritmo LRU – neste
caso, isso acontece especificamente com uma memória de tamanho 13. Entretanto,
em uma outra situação de execução (memória disponível de 28 páginas), ele exibe
um resultado 11,75% melhor. A conclusão é que o LRU-WAR pode ser melhor ou
pior que o LRU no processamento de tal programa, dependendo do tamanho de
memória disponível; mas a média sugere que ele tende a apresentar melhores
resultados, o que é confirmado pelas curvas de desempenho comentadas adiante.
O tamanho de memória correspondente ao melhor e ao pior caso –
identificado por um número entre parênteses em cada célula das respectivas colunas
– só não é relatado na tabela VI quando a diferença percentual em questão está
associada a vários tamanhos de memória, sendo o número então substituído pela
indicação de reticências.
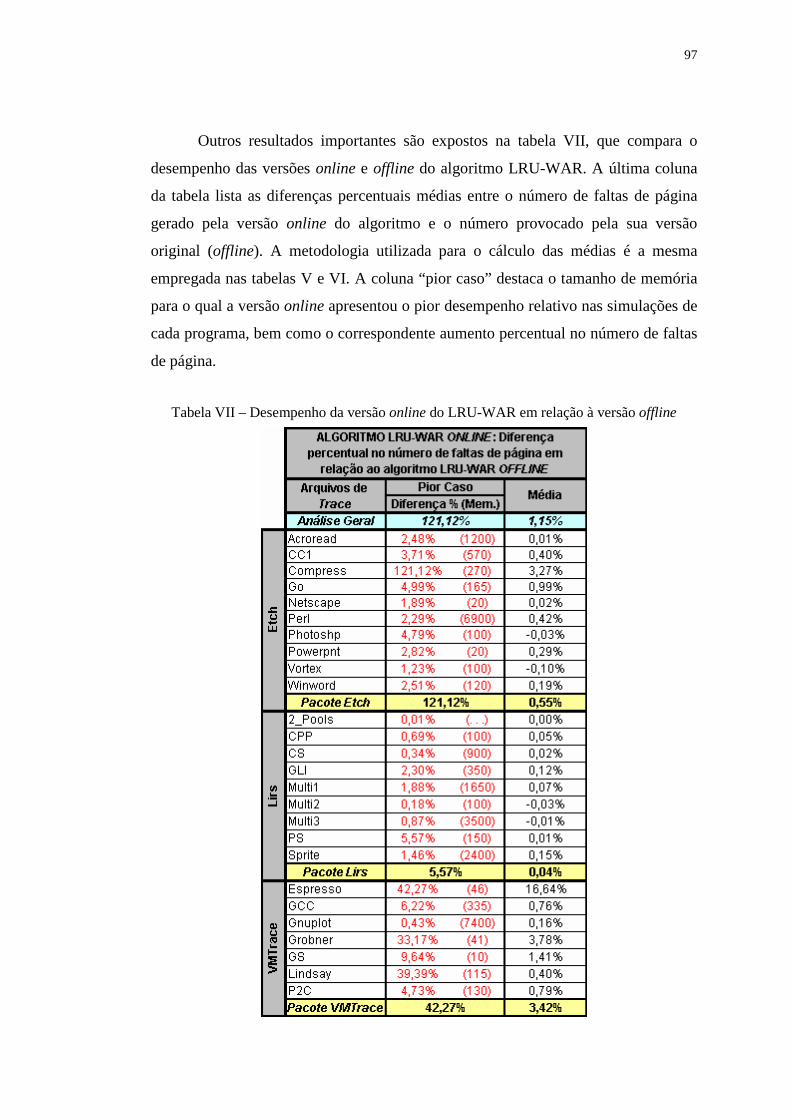
97
Outros resultados importantes são expostos na tabela VII, que compara o
desempenho das versões online e offline do algoritmo LRU-WAR. A última coluna
da tabela lista as diferenças percentuais médias entre o número de faltas de página
gerado pela versão online do algoritmo e o número provocado pela sua versão
original (offline). A metodologia utilizada para o cálculo das médias é a mesma
empregada nas tabelas V e VI. A coluna “pior caso” destaca o tamanho de memória
para o qual a versão online apresentou o pior desempenho relativo nas simulações de
cada programa, bem como o correspondente aumento percentual no número de faltas
de página.
Tabela VII – Desempenho da versão online do LRU-WAR em relação à versão offline

98
De forma genérica, as duas versões alcançam desempenhos próximos entre si.
Considerando todos os experimentos – 1669 simulações realizadas para cada
algoritmo –, a versão online do LRU-WAR consolida um desempenho médio
somente um pouco pior que o da versão offline (1,15%). Há casos, inclusive, em que
a versão online provoca menos faltas de página, em média, do que a versão original:
programas Photoshop, Vortex, Multi2 e Multi3. Aumentos muito significativos no
número de faltas de página são observados apenas em simulações dos programas
Compress, Espresso, Grobner e Lindsay. Todavia, focando-se a análise nas
diferenças percentuais médias de desempenho entre as versões do algoritmo, o
grande destaque negativo da versão online é o programa Espresso.
Algumas curvas de desempenho são finalmente exibidas nas figuras 30, 31,
32 e 33. Estas curvas refletem, de forma gráfica, a quantidade de faltas de página
geradas pelos algoritmos nas simulações dos programas analisados. A figura 30
engloba três programas para os quais o algoritmo LRU-WAR apresenta um melhor
desempenho médio do que o algoritmo LRU. Tais programas possuem uma
característica comum: padrões de acesso seqüenciais à memória que predominam
claramente do começo ao fim de seu processamento. O LRU-WAR é o único
algoritmo adaptativo que demonstra excelente desempenho nos três casos. O
algoritmo EELRU não é muito eficiente no tratamento do programa Postgres e o
algoritmo LIRS falha completamente na execução do programa Gnuplot, igualando
seu desempenho ao do LRU.
Em contrapartida, a figura 31 se refere a programas em que o LRU-WAR
provoca mais faltas de página do que o algoritmo LRU em média. Os três programas
possuem um grande conjunto de páginas com alta freqüência de acessos à memória,
mas nem sempre com intervalos regulares entre esses acessos. Quando encontra tais
características, é comum o algoritmo LRU-WAR cometer decisões equivocadas,
cujas conseqüências são amenizadas em muito pelo seu mecanismo de detecção de
erros. No caso do programa Perl, o EELRU apresenta bons resultados e o LIRS gera
uma curva de desempenho próxima à do algoritmo LRU. Em relação aos outros dois
programas, o desempenho do EELRU é um pouco melhor que o do LRU-WAR e um
pouco pior que o do LRU, enquanto o desempenho do LIRS é inferior ao dos demais
algoritmos em ambos os casos, sobretudo nas simulações do programa Sprite.
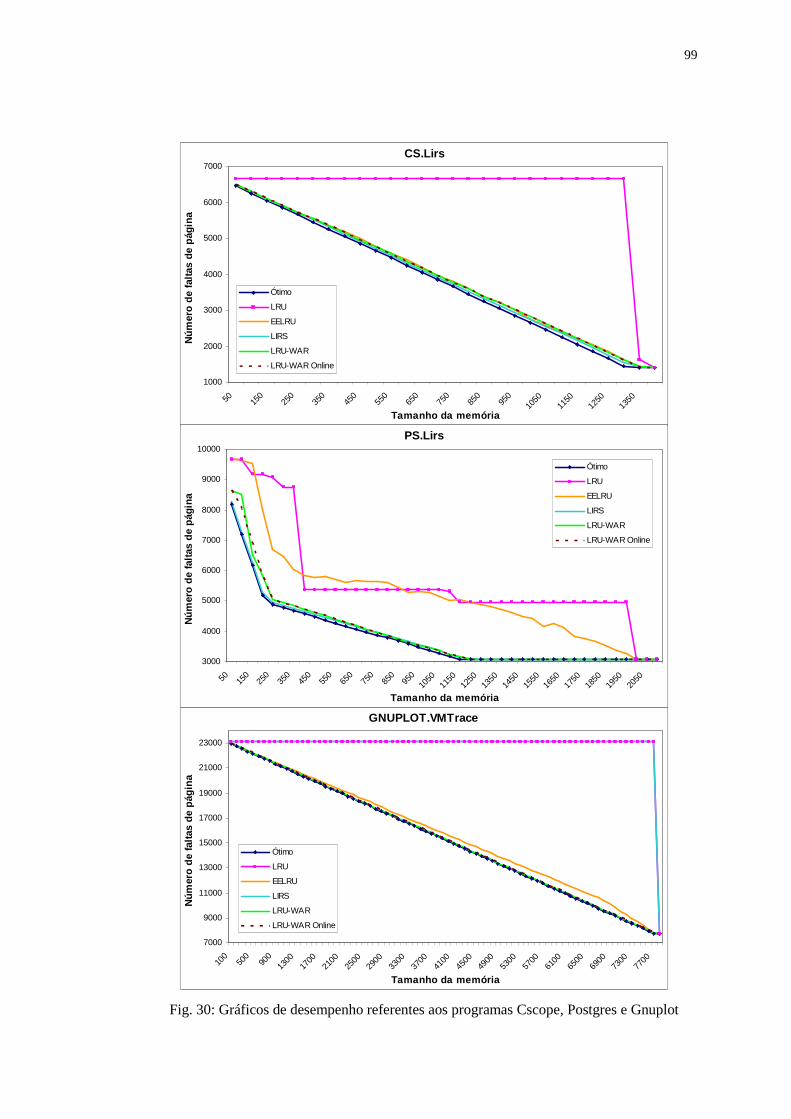
99
CS.Lirs
1000
2000
3000
4000
5000
6000
7000
50 150
250
350
450
550
650
750
850
950
1050
1150
1250
1350
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
PS.Lirs
3000
4000
5000
6000
7000
8000
9000
10000
50 150
250
350
450
550
650
750
850
950
1050
1150
1250
1350
1450
1550
1650
1750
1850
1950
2050
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
GNUPLOT.VMTrace
7000
9000
11000
13000
15000
17000
19000
21000
23000
100
500
900
1300
1700
2100
2500
2900
3300
3700
4100
4500
4900
5300
5700
6100
6500
6900
7300
7700
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
Fig. 30: Gráficos de desempenho referentes aos programas Cscope, Postgres e Gnuplot
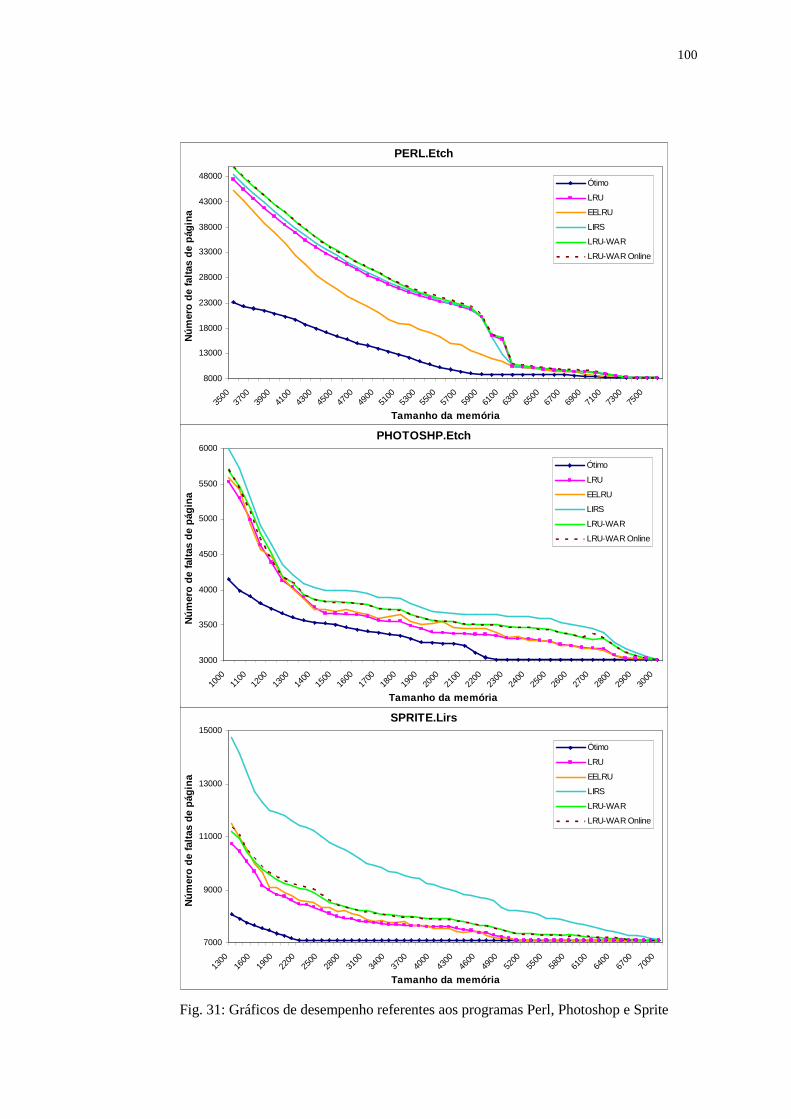
100
SPRITE.Lirs
7000
9000
11000
13000
15000
1300
1600
1900
2200
2500
2800
3100
3400
3700
4000
4300
4600
4900
5200
5500
5800
6100
6400
6700
7000
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
PERL.Etch
8000
13000
18000
23000
28000
33000
38000
43000
48000
3500
3700
3900
4100
4300
4500
4700
4900
5100
5300
5500
5700
5900
6100
6300
6500
6700
6900
7100
7300
7500
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
PHOTOSHP.Etch
3000
3500
4000
4500
5000
5500
6000
1000
1100
1200
1300
1400
1500
1600
1700
1800
1900
2000
2100
2200
2300
2400
2500
2600
2700
2800
2900
3000
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
Fig. 31: Gráficos de desempenho referentes aos programas Perl, Photoshop e Sprite
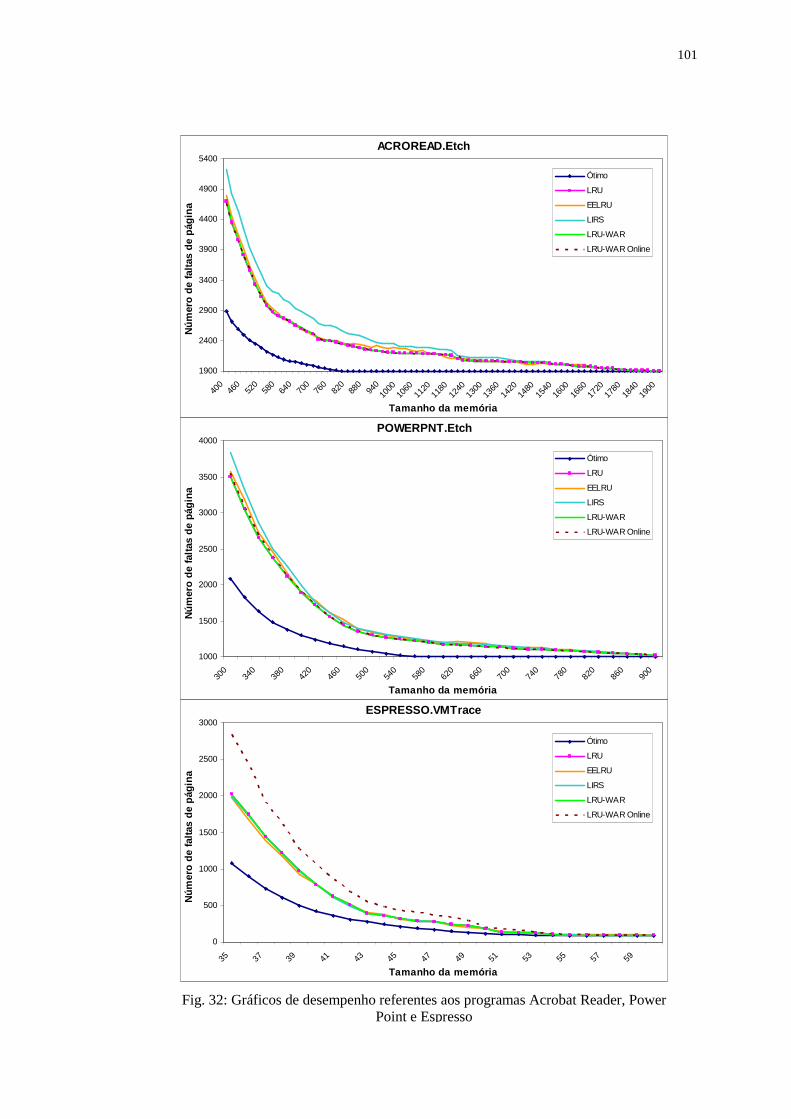
101
ACROREAD.Etch
1900
2400
2900
3400
3900
4400
4900
5400
400
460
520
580
640
700
760
820
880
940
1000
1060
1120
1180
1240
1300
1360
1420
1480
1540
1600
1660
1720
1780
1840
1900
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
POWERPNT.Etch
1000
1500
2000
2500
3000
3500
4000
300
340
380
420
460
500
540
580
620
660
700
740
780
820
860
900
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
ESPRESSO.VMTrace
0
500
1000
1500
2000
2500
3000
35 37 39 41 43 45 47 49 51 53 55 57 59
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
Fig. 32: Gráficos de desempenho referentes aos programas Acrobat Reader, Power Point e Espresso
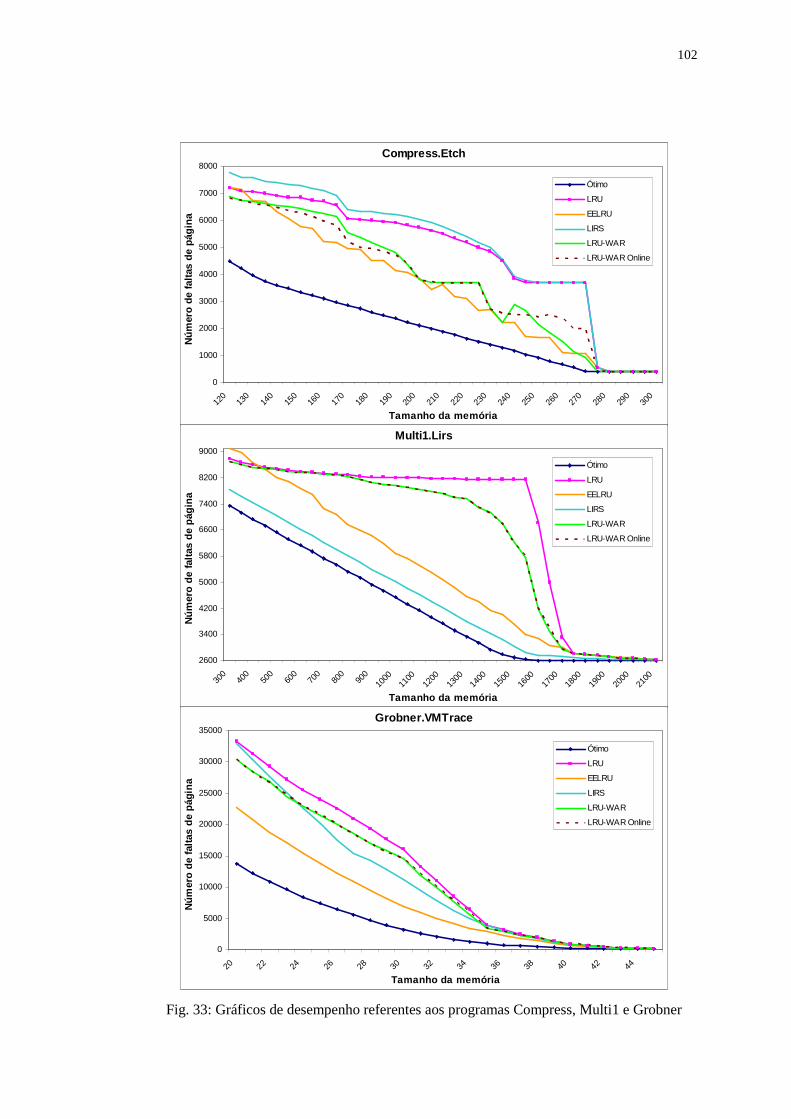
102
Compress.Etch
0
1000
2000
3000
4000
5000
6000
7000
8000
120
130
140
150
160
170
180
190
200
210
220
230
240
250
260
270
280
290
300
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
Multi1.Lirs
2600
3400
4200
5000
5800
6600
7400
8200
9000
300
400
500
600
700
800
900
1000
1100
1200
1300
1400
1500
1600
1700
1800
1900
2000
2100
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
Grobner.VMTrace
0
5000
10000
15000
20000
25000
30000
35000
20 22 24 26 28 30 32 34 36 38 40 42 44
Tamanho da memória
Nú
mer
o d
e fa
ltas
de
pág
ina
Ótimo
LRU
EELRU
LIRS
LRU-WAR
LRU-WAR Online
Fig. 33: Gráficos de desempenho referentes aos programas Compress, Multi1 e Grobner

103
A figura 32, por sua vez, demonstra gráficos nos quais os algoritmos LRU,
EELRU e LRU-WAR exibem resultados próximos entre si. Apesar de o desempenho
médio do algoritmo EELRU ser muito bom com o programa Espresso, sua grande
superioridade em relação aos outros algoritmos está restrita a memórias muito
pequenas (até 20 páginas), desconsideradas no gráfico. Essencialmente, os
programas selecionados possuem forte presença de localidade temporal em certas
páginas de memória, favorecendo a atuação da política de substituição LRU. O
algoritmo LIRS, por outro lado, não costuma obter bons desempenhos em casos
como estes.
Os três programas que compõem a figura 33 representam uma situação
bastante comum: o algoritmo LRU-WAR é melhor do que o algoritmo LRU, mas
não muito melhor. Isto ocorre quando o processo apresenta trechos com acessos
seqüenciais, mas tal padrão não é predominante, o que dificulta a sua detecção por
parte do LRU-WAR. Os algoritmos EELRU e LIRS tendem a obter melhores
resultados com programas que possuem características desse tipo, embora o
desempenho do algoritmo LRU-WAR seja bom em relação ao desempenho do LRU,
cumprindo o seu objetivo fundamental.
Como pode ser notado, os gráficos se restringem a intervalos limitados de
tamanhos de memória. Esta intervenção foi feita para facilitar a visualização das
curvas de desempenho, uma vez que certos trechos ampliados são mais
representativos do que os gráficos completos. O motivo é a grande amplitude do
intervalo de resultados: apesar de a tendência geral ficar evidenciada nos gráficos
completos, as curvas tendem a se comprimir e se aglutinar – em termos visuais –,
dificultando a comparação entre os algoritmos de substituição selecionados.
5.3. Análise dos Resultados
O algoritmo LRU-WAR confirma um desempenho próximo do ótimo quando
trabalha com programas que exibem padrões de acesso basicamente seqüenciais. Por
outro lado, os resultados também demonstram que há algumas situações práticas de
execução em que o desempenho do algoritmo é inferior ao do LRU. Estas situações
acontecem quando, em um determinado momento do processamento de um

104
programa, o LRU-WAR adota o critério de substituição MRU indevidamente. Em
geral, tal problema é causado por uma freqüência irregular de reutilização das
páginas de memória – ora maior, ora menor, alternadamente. Algoritmos baseados
em histórico de freqüência de acessos, como FBR (ROBINSON; DEVARAKONDA,
1990), normalmente obtêm desempenhos melhores neste tipo de situação. Mas o
algoritmo LRU-WAR não chega a ser desastroso em nenhum caso analisado. Graças
ao mecanismo de detecção de erros implementado, seu pior desempenho em relação
ao algoritmo LRU gerou uma diferença percentual máxima de 6,95% no número de
faltas de página, em um universo de 1669 simulações realizadas.
Embora o desempenho do algoritmo LRU-WAR seja, em média, somente
5,29% melhor que o do LRU, há casos em que a sua atuação é marcante. Em seu
melhor caso, o algoritmo reduziu em 75,57% o número de faltas de página
provocadas pelo LRU tradicional. Conseqüentemente, o LRU-WAR demonstrou ser
confiável – atingindo picos negativos previsíveis e aceitáveis – e extremamente
eficiente com determinados programas.
Os resultados também confirmam o bom desempenho do algoritmo EELRU
na grande maioria dos casos. Apesar de possuir uma forma diferente de operação,
este algoritmo foi concebido a partir da mesma constatação que originou o algoritmo
LRU-WAR: acessos seqüenciais provocam muitas faltas de página em um curto
período de tempo e as páginas também permanecem pouco tempo no working set do
processo. Portanto, o objetivo de ambos é o mesmo – otimizar o LRU, tratando
eficientemente padrões seqüenciais de acesso –, diferindo apenas na forma como
cada um procura atingir este objetivo. O LRU-WAR é muito simples em termos
computacionais, mas apresenta uma melhoria de desempenho em relação ao LRU
normalmente menor que a do EELRU. No entanto, é muito difícil que se consiga
desenvolver uma implementação eficiente do algoritmo EELRU para uma versão
online. Este é o grande diferencial positivo do LRU-WAR: sua baixa complexidade
operacional.
A mesma observação se aplica na comparação dos algoritmos LIRS e LRU-
WAR. O algoritmo LIRS, como o EELRU, realiza operações a cada acesso do
programa à memória, independente de tal acesso ocasionar ou não uma falta de
página. Logo, sua implementação prática em um sistema operacional também é

105
inviável, pelo menos em sua versão original. Além disso, o desempenho médio do
algoritmo LIRS foi inferior ao esperado. Seus resultados positivos – apesar de serem
muito bons – estão restritos praticamente ao pacote de traces homônimo.
Quanto à carga de simulação, o programa P2C é um dos mais regulares em
termos de equivalência de desempenho entre os algoritmos baseados no modelo
LRU. Por outro lado, é também o programa em que todos os algoritmos adaptativos
exibem seu pior desempenho médio em relação ao caso ótimo. Isto significa que
nenhum algoritmo consegue um desempenho satisfatório com este programa quando
comparado com o algoritmo Ótimo.
Os dois piores picos de desempenho foram identificados com os algoritmos
LRU e LIRS em uma simulação do programa Compress (memória de tamanho 270):
aumento de 736,45% e 741,91%, respectivamente, no número mínimo de faltas de
página representado pelo algoritmo Ótimo. Em relação ao LRU, o algoritmo que
obteve o melhor pico de desempenho foi o LIRS – simulação do programa Cscope
com memória de tamanho 1300 –, reduzindo o número de faltas de página geradas
pelo primeiro em 76,51%. Mas o pior pico de desempenho relativo ao LRU também
é causado pelo LIRS (37,26%), na simulação do programa Sprite com memória de
tamanho 1300.
O LRU-WAR pode ser considerado a melhor alternativa dentre os algoritmos
analisados – desconsiderando o Ótimo – somente no processamento dos programas
Gnuplot e Lindsay. Entretanto, seu desempenho médio na totalidade das simulações
é melhor que os dos algoritmos LRU e LIRS, sendo superado apenas pelo algoritmo
EELRU. O LRU-WAR também é o algoritmo que apresenta o menor pico negativo –
sinal de estabilidade – em relação ao LRU: 6,95%, contra 37,26% do LIRS e 21,01%
(programa Lindsay, memória de tamanho 120) do EELRU.
Outra forma de analisar a eficiência dos algoritmos em uma simulação é
através da visualização dos pontos ótimos de substituição. A figura 34 ilustra dois
gráficos que indicam tais pontos em simulações do programa Grobner, com memória
de tamanho 28, realizadas com os algoritmos LRU e LRU-WAR. Os pontos
vermelhos dos gráficos informam quais seriam os pontos ótimos de substituição na
fila LRU para cada ocorrência de falta de página. Assim, cada ponto do gráfico
corresponde a uma falta. Não obstante, os pontos verdes do segundo gráfico indicam

106
as posições da fila LRU associadas às páginas substituídas pelo algoritmo LRU-
WAR em tais instantes. As páginas substituídas pelo algoritmo LRU – simulação
analisada no primeiro gráfico –, obviamente, são aquelas que ocupam a última
posição da fila LRU, neste caso a posição 28 (ou 27, se contada a partir do zero), no
momento de cada falta de página.
Fig. 34: Pontos ótimos de substituição identificados em simulações LRU e LRU-WAR
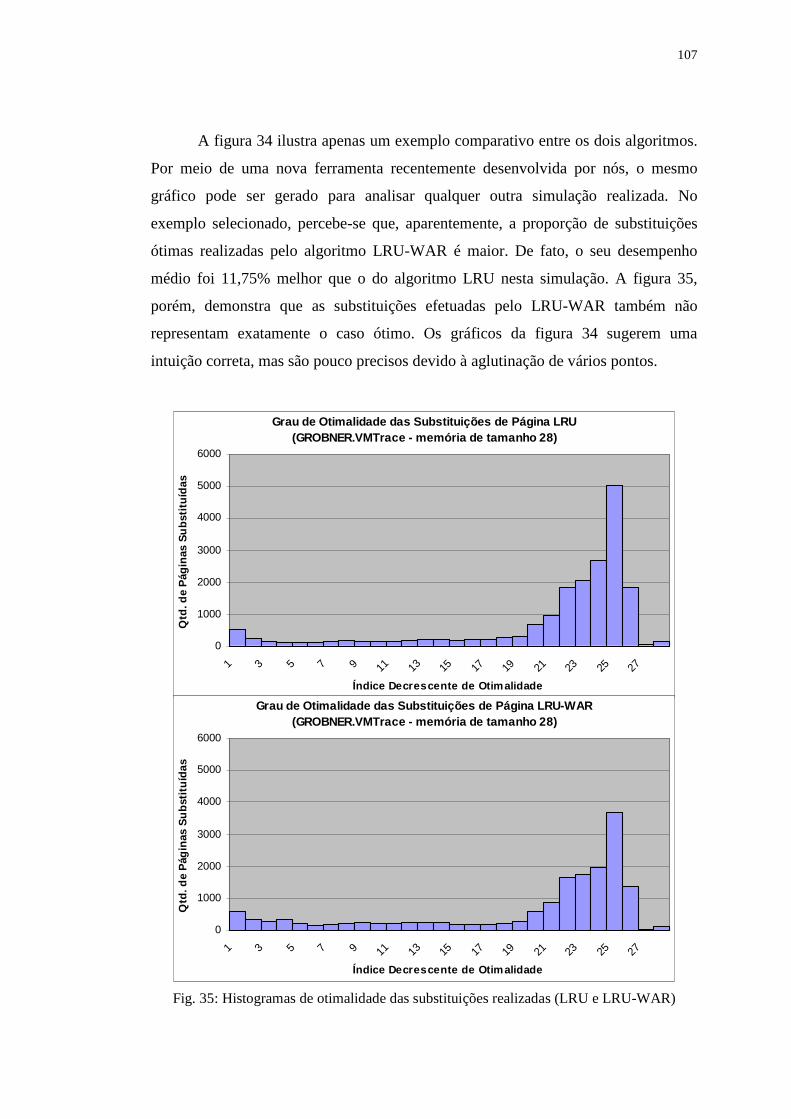
107
A figura 34 ilustra apenas um exemplo comparativo entre os dois algoritmos.
Por meio de uma nova ferramenta recentemente desenvolvida por nós, o mesmo
gráfico pode ser gerado para analisar qualquer outra simulação realizada. No
exemplo selecionado, percebe-se que, aparentemente, a proporção de substituições
ótimas realizadas pelo algoritmo LRU-WAR é maior. De fato, o seu desempenho
médio foi 11,75% melhor que o do algoritmo LRU nesta simulação. A figura 35,
porém, demonstra que as substituições efetuadas pelo LRU-WAR também não
representam exatamente o caso ótimo. Os gráficos da figura 34 sugerem uma
intuição correta, mas são pouco precisos devido à aglutinação de vários pontos.
Fig. 35: Histogramas de otimalidade das substituições realizadas (LRU e LRU-WAR)
Grau de Otimalidade das Substituições de Página LRU(GROBNER.VMTrace - memória de tamanho 28)
0
1000
2000
3000
4000
5000
6000
1 3 5 7 9 11 13 15 17 19 21 23 25 27
Índice Decres cente de Otim alidade
Qtd
. de
Pág
inas
Su
bst
itu
ídas
Grau de Otimalidade das Substituições de Página LRU-WAR(GROBNER.VMTrace - memória de tamanho 28)
0
1000
2000
3000
4000
5000
6000
1 3 5 7 9 11 13 15 17 19 21 23 25 27
Índice Decres cente de Otim alidade
Qtd
. de
Pág
inas
Su
bst
itu
ídas

108
Os dois histogramas reunidos na figura 35 indicam o grau de otimalidade*
das substituições de página realizadas pelos algoritmos LRU e LRU-WAR,
respectivamente. Este grau é determinado por um índice decrescente de otimalidade.
As substituições associadas ao índice 1 representam substituições ótimas. Aquelas
associadas ao índice 2, por sua vez, são substituições um pouco menos eficientes, e
assim sucessivamente. No caso deste exemplo analisado, as substituições cujo índice
de otimalidade é 28 representam justamente a pior escolha possível que o algoritmo
poderia adotar.
O índice de otimalidade é estabelecido de acordo com a distância que cada
página residente apresenta em relação ao seu próximo acesso. Ou seja, a ferramenta
desenvolvida ordena as páginas carregadas na memória em uma fila,
decrescentemente, de acordo com o tempo virtual que cada uma delas vai levar para
ser novamente referenciada. A página que fica na primeira posição da fila é aquela
que irá demorar mais tempo para ser reutilizada e, portanto, deve ser substituída. A
última posição da fila é sempre ocupada pela página que será acessada mais
brevemente dentre as que estão residentes; logo, a substituição desta página seria
uma péssima escolha. O índice de otimalidade proposto reflete a própria ordem de tal
fila imaginária, reconstruída a cada novo momento em que uma falta de página
acontece.
Uma análise conjunta dos dados fornecidos pela nova ferramenta permite
chegar a conclusões interessantes. A observação visual da eficiência de cada
algoritmo, por exemplo, é disponibilizada por histogramas que avaliam as
substituições de página, como os da figura 35. Ao mesmo tempo, os trechos de uma
simulação em que os algoritmos falham mais podem ser determinados pelos gráficos
que confrontam os pontos ótimos de substituição com os pontos selecionados pelos
mesmos.
Finalmente, alguns comentários sobre os resultados apresentados pela versão
online do algoritmo LRU-WAR são importantes para consolidar o trabalho. Ainda
que o seu pico negativo de desempenho provoque 121,12% de faltas de página a
* O termo “otimalidade” é um neologismo utilizado como tradução do termo “optimality” (em língua inglesa), significando o quão próximo do caso ótimo determinado foco de análise se encontra.

109
mais que a versão offline, o algoritmo LRU-WAR online é relativamente estável. Seu
desempenho médio, com poucas exceções, fica muito próximo ao da versão original,
principalmente nas simulações dos arquivos de trace do pacote Lirs. Além disso, ele
não foi comparado com aproximações online de outros algoritmos – que também
tendem a ser menos eficientes em relação às suas versões originais. Como, em
média, o desempenho do LRU-WAR online fica muito próximo ao dos algoritmos
offline estudados, a sua avaliação geral é altamente satisfatória a priori.
A conclusão final a que se chega, a partir dos resultados práticos obtidos, é
que o algoritmo LRU-WAR atende ao seu propósito: é significativamente melhor do
que o algoritmo LRU quando padrões de acesso seqüenciais vigoram e não é muito
pior em nenhuma situação analisada. Seu desempenho médio é superior ou
praticamente equivalente ao do algoritmo LRU em 85% dos programas simulados.
Ainda em média, o LRU-WAR é um pouco pior do que o algoritmo EELRU e um
pouco melhor do que o LIRS, mas é o único dentre os três que possui uma versão
online adequada.

110
6. CONCLUSÃO
Esta dissertação apresentou um estudo sobre gerência de memória focado em
algoritmos de substituição de páginas e, mais especificamente, em algoritmos
adaptativos com tal finalidade. No que concerne à pesquisa, a revisão bibliográfica
procurou ser atualizada e abrangente. Certos algoritmos foram tratados com mais
profundidade do que outros devido à possibilidade que identificamos de explorarmos
algumas de suas idéias com enfoques originais. Após uma importante análise acerca
das propriedades do modelo LRU e de algumas características inerentes a programas
dos mais variados, verificamos que poderíamos reconhecer padrões de acesso
seqüenciais, dinamicamente, somente observando as posições na fila LRU ocupadas
pelas páginas referenciadas ao longo do tempo por um processo. A nova técnica
poderia, assim, contribuir para melhorar o desempenho do algoritmo LRU tradicional
na presença de tais padrões, visto que acessos seqüenciais tendem a romper a
eficiência normalmente observada em sua atuação.
Vários aspectos operacionais foram então definidos, dando origem ao
algoritmo adaptativo de substituição de páginas LRU-WAR (LRU com
Confinamento da Área de Trabalho), uma proposta viável e inédita. Simuladores
online e offline foram desenvolvidos, permitindo a realização de um conjunto de
experiências práticas. A carga de simulação utilizada nestas experiências foi
composta por programas contendo diferentes características de acesso à memória,
previamente estudados e disponibilizados por outros cientistas na forma de arquivos
de trace, o que garante a isenção da pesquisa e a credibilidade dos resultados obtidos.
Os experimentos demonstraram que o algoritmo LRU-WAR alcança
desempenhos excelentes quando trabalha com programas que apresentam padrões de
acesso basicamente seqüenciais. Ao mesmo tempo, o algoritmo se mostrou confiável,
uma vez que o seu desempenho não foi significativamente pior que o do LRU
original em nenhum caso analisado. A versão online do algoritmo LRU-WAR
também confirmou bons resultados de desempenho, o que nos leva a esperar que tais
resultados se repitam em situações reais de processamento. A implementação prática
desta versão pode exigir algumas adaptações no sistema operacional utilizado, mas
isto não a desqualifica de nenhuma maneira.

111
6.1. Contr ibuições
Pretende-se que a contribuição deste trabalho à evolução dos estudos sobre
gerenciamento de memória tenha se dado através das seguintes atividades realizadas:
• Descrição compilada dos principais algoritmos de substituição de páginas,
estáticos e adaptativos, encontrados na literatura científica;
• Detalhamento crítico de dois algoritmos adaptativos: SEQ e EELRU,
propostas interessantes que exploram o modelo LRU;
• Desenvolvimento de ferramentas visuais e de coleta de dados estatísticos
sobre programas (TelaTrace, Mapa3D e Trace Explorer), muito úteis para a
caracterização de cargas de trabalho e em estudos sobre o uso da memória
pelos processos;
• Análise das características de localidade de referências e padrões de acesso à
memória presentes em um conjunto representativo de programas;
• Elaboração de uma metodologia inédita, com baixa complexidade
computacional, para a identificação de padrões de acesso seqüenciais na
execução de processos;
• Proposta de um novo algoritmo adaptativo – LRU-WAR – que utiliza
eficientemente tal metodologia para decidir entre o uso do critério de
substituição LRU e o uso do critério MRU-n durante o processamento de um
programa, introduzindo ainda mecanismos para detecção de erros de decisão;
• Criação de uma versão aproximada e viável do novo algoritmo para ser
futuramente implementada em um sistema operacional: o LRU-WAR online;
• Desenvolvimento de vários simuladores de sistemas de memória, entre eles o
simulador paralelo StackPar;
• Realização de um grande número de experiência práticas que avaliam o
desempenho da proposta LRU-WAR e de outros algoritmos importantes
(LRU, EELRU e LIRS), empregando o algoritmo Ótimo como parâmetro de
eficiência;
• Construção de uma ferramenta que monitora faltas de página em simulações e
calcula o grau de otimalidade das substituições realizadas, além de informar
quais seriam os respectivos pontos ótimos de substituição em cada falta.

112
6.2. Trabalhos Futuros
Diversos trabalhos podem ser propostos para a seqüência de nossos estudos.
O primeiro é a própria implementação prática do algoritmo LRU-WAR online em
um sistema operacional de código aberto, provavelmente o Linux. Gorman (2003),
em sua página na internet, detalha como este sistema operacional realiza cada uma
das tarefas sob sua responsabilidade no âmbito da gerência de memória, entre elas a
política de substituição de páginas e a definição do espaço de endereçamento
destinado a cada processo. O algoritmo LRU-WAR poderia ser modificado para
gerenciar também esta segunda tarefa do sistema operacional: o particionamento
dinâmico da memória disponível entre os processos em execução (MIDORIKAWA,
1997). A alteração viabilizaria o funcionamento eficiente de sua política de
substituição de páginas em ambientes com multiprogramação, ao mesmo tempo em
que aumentaria a responsabilidade do LRU-WAR quanto ao desempenho global e à
confiabilidade do sistema de memória.
O emprego de diretivas inseridas pelo compilador como uma forma eficaz de
orientação ao algoritmo de substituição de páginas, conforme proposto por
Midorikawa (1997), é um tema que também nos interessa bastante. Tal alternativa
evitaria que o algoritmo LRU-WAR cometesse erros de decisão, pois as diretivas
indicariam quando um padrão de acessos é efetivamente seqüencial ou, por exemplo,
acontece apenas uma mudança de localidade.
A exploração de técnicas de inteligência artificial para reconhecimento de
padrões é outra possibilidade que deve ser considerada. Um programa concebido
com esta finalidade, rodando em segundo plano, poderia observar as características
de acesso à memória apresentadas pelos processos e, quando solicitado, orientar as
decisões do sistema operacional * .
Ainda quanto ao reconhecimento de padrões, as ferramentas descritas no
Capítulo 3 oferecem recursos para uma análise mais completa sobre propriedades do
modelo LRU. É importante questionar se outros padrões de acesso à memória
* Sugestão do Prof. João José Neto durante suas argüições no exame de qualificação que precedeu esta dissertação.

113
também podem ser identificados de maneira simples – como faz o algoritmo LRU-
WAR na presença de acessos seqüenciais – a partir do estado encontrado na fila LRU
a cada momento. Características de reutilização das páginas, em especial, devem ser
estudadas com maior profundidade. A continuidade dos estudos sobre localidade de
referências tem como principal objetivo originar um “meta-algoritmo”, que utilizaria
vários critérios de substituição em potencial, de acordo com os padrões de acesso à
memória reconhecidos dinamicamente.
Outras técnicas inventadas para quantificar a presença de localidade temporal
e espacial nos programas, como as chamadas locality surfaces (superfícies de
localidade), merecem um estudo detalhado. As locality surfaces foram originalmente
propostas por Grimsrud et al. (1996) e são utilizadas principalmente em trabalhos
sobre gerenciamento de memórias cache (SORENSON; FLANAGAN, 2001);
(SORENSON; FLANAGAN, 2002). O objetivo da técnica é detectar trechos com
localidade de referências em programas – de acordo com a reutilização das páginas e
de seus endereços físicos – e construir superfícies tridimensionais representativas, as
quais devem ser interpretadas por regras previamente definidas.
Finalmente, como complemento às experiências relatadas no Capítulo 5,
novas simulações podem ser realizadas utilizando traces nos quais ainda não nos
aprofundamos, como os que compõem o pacote Tracebase (JOHNSON, 1999), o
pacote BYU (FLANAGAN et al., 1992), entre outros (ROSEN, 1996); (GLASS;
CAO, 1997). Eventualmente, podemos ainda gerar arquivos próprios, em formato
padrão, simulando programas específicos.

114
LISTA DE REFERÊNCIAS
BELADY, L.A. A study of replacement algorithms for a virtual storage computer. IBM Systems Journal, v.5, n.2, p.78-101, 1966.
BELADY, L.A.; NELSON, R.A.; SHEDLER, G.S. An anomaly in space-time characteristics of certain programs running in a paging machine. Communications of the ACM, v.12, n.6, p.349-353, 1969.
CASSETTARI, H.H.; MIDORIKAWA, E.T. Análise do padrão de acessos à memória de programas paralelos. In: CONGRESSO BRASILEIRO DE COMPUTAÇÃO, 2., Itajaí, 2002. Congresso Brasileiro de Computação. Itajaí: Univali, 2002 (a). 1 CD-ROM.
____. StackPar: um simulador paralelo de sistemas de memória baseado em algoritmos de pilha. In: FÓRUM DE INFORMÁTICA E TECNOLOGIA DE MARINGÁ, 4., Maringá, 2002. IV FITEM: Anais. Maringá: UEM, 2002 (b). 1 CD-ROM.
CHOI, J. et al. An implementation study of a detection-based adaptive block replacement scheme. In: ANNUAL TECHNICAL CONFERENCE, 4., Monterey, 1999. USENIX’ 99: Proceedings. Monterey: USENIX, 1999. p.239-252.
____. Towards application/file-level characterization of block references: a case for fine-grained buffer management. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 25., Santa Clara, 2000. SIGMETRICS’ 00: Proceedings. Santa Clara: ACM, 2000. p.286-295.
CHU, W.W.; OPDERBECK, H. Analysis of the PFF replacement algorithm via a semi-Markov model. Communications of the ACM, v.19, n.5, p.298-304, 1976 (a).
____. Program behavior and the page fault frequency replacement algorithm. Computer, v.9, n.11, p.29-38, 1976 (b).
DENNING, P.J. The working set model for program behavior. Communications of the ACM, v.11, n.5, p.323-333, 1968.
____. Working sets: past and present. IEEE Transactions on Software Engineering, v.SE-6, n.1, p.64-84, 1980.
DENNING, P.J.; SCHWARTZ, S.C. Properties of the working-set model. Communications of the ACM, v.15, n.3, p.191-198, 1972.

115
DING, C.; ZHONG, Y. Predicting whole-program locality through reuse distance analysis. In: CONFERENCE ON PROGRAMMING LANGUAGE DESIGN AND IMPLEMENTATION, 25., San Diego, 2003. PLDI’03: Proceedings. San Diego: ACM, 2003. p.245-257.
FERNÁNDEZ, E.B.; LANG, T.; WOOD, C. Effect of replacement algorithms on a paged buffer database system. IBM Journal of Research and Development, v.22, n.2, p.185-196, 1978.
FLANAGAN, J.K et al. BACH: BYU Address Collection Hardware, the collection of complete traces. In: INTERNATIONAL CONFERENCE ON MODELING TECHNIQUES AND TOOLS FOR COMPUTER EVALUATION, 6., Edinburgh, 1992. Computer Performance Evaluation’92: Proceedings. Edinburgh: Edinburgh University Press, 1992. p.51-65.
GLASS, G.; CAO, P. Adaptive page replacement based on memory reference behavior. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 22., Seattle, 1997. SIGMETRICS’ 97: Proceedings. Seattle: ACM, 1997. p.115-126.
GORMAN, M. Limerick. 2003. Linux VM documentation. Disponível em: <http://www.skynet.ie/~mel/projects/vm>. Acesso em: 30/12/2003.
GRIMSRUD, K. et al. Locality as a visualization tool. IEEE Transactions on Computers, v.45, n.11, p.1319-1326, 1996.
HATFIELD, D.J.; GERALD, J. Program restructuring for virtual memory. IBM Systems Journal, v.10, n.3, p.168-192, 1971.
JIANG, S.; ZHANG, X. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 27., Marina Del Rey, 2002. SIGMETRICS’ 02: Proceedings. Marina Del Rey: ACM, 2002. p.31-42.
JOHNSON, E.E. PDATS II: improved compression of address traces. In: INTERNATIONAL PERFORMANCE, COMPUTING, AND COMMUNICATIONS CONFERENCE, 18., Phoenix, 1999. IPCCC’ 99: Proceedings. Phoenix: IEEE, 1999. p.72-78.
JOHNSON, T.; SHASHA, D. 2Q: a low overhead high performance buffer management replacement algorithm. In: INTERNATIONAL CONFERENCE ON VERY LARGE DATA BASES, 20., Santiago, 1994. VLDB’ 94: Proceedings. Santiago: Morgan Kaufmann, 1994. p.439-450.

116
KAPLAN, S.F.; SMARAGDAKIS, Y.; WILSON, P.R. Trace reduction for virtual memory simulations. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 24., Atlanta, 1999. SIGMETRICS’ 99: Proceedings. Atlanta: ACM, 1999. p.47-58.
KIM, J.M. et al. A low-overhead high-performance unified buffer management scheme that exploits sequential and looping references. In: SYMPOSIUM ON OPERATING SYSTEM DESIGN AND IMPLEMENTATION, 4., San Diego, 2000. OSDI’ 2000: Proceedings. San Diego: USENIX, 2000. p.119-134.
LEE, D.C. et al. Execution characteristics of desktop applications on Windows NT. In: ANNUAL INTERNATIONAL SYMPOSIUM ON COMPUTER ARCHITECTURE, 25., Barcelona, 1998. ISCA’ 98: Proceedings. Barcelona: IEEE/ACM, 1998. p.27-38.
LEE, D. et al. On the existence of a spectrum of policies that subsumes the Least Recently Used (LRU) and Least Frequently Used (LFU) policies. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 24., Atlanta, 1999. SIGMETRICS’ 99: Proceedings. Atlanta: ACM, 1999. p.134-143.
____. LRFU: a spectrum of policies that subsumes the Least Recently Used and Least Frequently Used policies. IEEE Transactions on Computers, v.50, n.12, p.1352-1361, 2001.
MACHADO, F.B.; MAIA, L.P. Arquitetura de sistemas operacionais. 2.ed. Rio de Janeiro: LTC, 1997. 232p.
MATTSON, R.L. et al. Evaluation techniques and storage hierarchies. IBM Systems Journal, v.9, n.2, p.78-117, 1970.
MEGIDDO, N.; MODHA, D.S. ARC: a self-tuning, low overhead replacement cache. In: CONFERENCE ON FILE AND STORAGE TECHNOLOGIES, 2., San Francisco, 2003. FAST’ 03: Proceedings. San Francisco: USENIX, 2003. p.115-130.
MIDORIKAWA, E.T. Gerência de memória para um sistema de computação de alto desempenho. 1991. 208p. Dissertação (Mestrado) – Escola Politécnica, Universidade de São Paulo. São Paulo, 1991.
____. Uma nova estratégia para a gerência de memória para sistemas de computação de alto desempenho. 1997. 193p. Tese (Doutorado) – Escola Politécnica, Universidade de São Paulo. São Paulo, 1997.

117
MIDORIKAWA, E.T. et al. Algoritmos adaptativos de substituição de páginas para a próxima geração de sistemas de memória virtual. In: WORKSHOP DE COMPUTAÇÃO, 3., São José dos Campos, 2000. WORKCOMP’ 2000: Anais. São José dos Campos: ITA, 2000. p.101-107.
NGUYEN, A-T. et al. The Augmint multiprocessor simulation toolkit for Intel x86 architectures. In: INTERNATIONAL CONFERENCE ON COMPUTER DESIGN, 14., Austin, 1996. ICCD’ 96: Proceedings. Austin: IEEE, 1996. p.486-490.
OLIVEIRA, R.S.; CARISSIMI, A.S.; TOSCANI, S.S. Sistemas Operacionais. 2.ed. Porto Alegre: Sagra-Luzzato, 2001. 247p.
O’NEIL, E.T.; O’NEIL P.E.; WEIKUM, G. The LRU-K page replacement algorithm for database disk buffering. In: INTERNATIONAL CONFERENCE ON MANAGEMENT OF DATA, 19., Washington, 1993. SIGMOD’ 93: Proceedings. Washington: ACM, 1993. p.297-306.
____. An optimality proof of the LRU-K page replacement algorithm. Journal of the ACM, v.46, n.1, p.92-112, 1999.
PHALKE, V. Modeling and managing program references in a memory hierarchy. 1995. 151p. Thesis (Doutorado) – Graduate School, Rutgers University. New Brunswick, 1995.
PINHEIRO, J.C. Avaliação de políticas de substituição de objetos em caches na web. 2001. 108p. Dissertação (Mestrado) - Instituto de Ciências Matemáticas e de Computação de São Carlos, Universidade de São Paulo. São Carlos, 2001.
PRIEVE, B.G.; FABRY, R.S. VMIN – an optimal variable-space page replacement algorithm. Communications of the ACM, v.19, n.5, p.295-297, 1976.
ROBINSON, J.T.; DEVARAKONDA, M.V. Data cache management using frequency-based replacement. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 15., Boulder, 1990. SIGMETRICS’ 90: Proceedings. Boulder: ACM, 1990. p.134-142.
ROMER, T. et al. Instrumentation and optimization of Win32/Intel executables using Etch. In: WINDOWS NT WORKSHOP, 1., Seattle, 1997. WINDOWS NT’97: Proceedings. Seattle: USENIX, 1997. p.1-8.
ROSEN, Z. Access graph based heuristics for on-line paging algorithms. 1996. 56p. Thesis (Mestrado) - Raymond and Beverly Sackler Faculty of Exact Science, Tel-Aviv University. Tel-Aviv, 1996.

118
SAMPLES, A.D. Mache: no-loss trace compaction. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 14., Oakland, 1989. SIGMETRICS’ 89: Proceedings. Oakland: ACM, 1989. p.89-97.
SILBERSCHATZ, A.; GALVIN, P.B.; GAGNE, G. Sistemas Operacionais: conceitos e aplicações. Rio de Janeiro: Campus, 2001. 608p.
SMARAGDAKIS, Y.; KAPLAN, S.; WILSON, P. EELRU: simple and effective adaptive page replacement. In: INTERNATIONAL CONFERENCE ON MEASUREMENT AND MODELING OF COMPUTER SYSTEMS, 24., Atlanta, 1999. SIGMETRICS’ 99: Proceedings. Atlanta: ACM, 1999. p.122-133.
SORENSON, E.S.; FLANAGAN, J.K. Cache characterization surfaces and predicting workload miss rates. In: ANNUAL WORKSHOP ON WORKLOAD CHARACTERIZATION, 4., Austin, 2001. WWC-4: Proceedings. Austin: IEEE, 2001. p.129-139.
____. Evaluating synthetic trace models using locality surfaces. In: ANNUAL WORKSHOP ON WORKLOAD CHARACTERIZATION, 5., Austin, 2002. WWC-5: Proceedings. Austin: IEEE, 2002. p.23-33.
SPEC – STANDARD PERFORMANCE EVALUATION CORPORATION. Warrenton. 1995. SPEC CINT95 Benchmarks. Disponível em: <http://www.spec.org/osg/cpu95/CINT95>. Acesso em: 30/12/2003.
TANENBAUM, A.S. Sistemas operacionais modernos. Rio de Janeiro: LTC, 1999. 493p.
UHLIG, R.A.; MUDGE, T.N. Trace-driven memory simulation: a survey. ACM Computing Surveys, v.29, n.2, p-128-170, 1997.
WOOD, C.; FERNÁNDEZ, E.B.; LANG, T. Minimization of demand paging for the LRU stack model of program behavior. Information Processing Letters, v.16, n.2, p.99-104, 1983.