analisador de dados automatizado …...eiti kimura maio/2018 qconsp 18 analisador de dados...
TRANSCRIPT

Eiti KimuraMaio/2018
QCONSP 18
ANALISADOR DE DADOS AUTOMATIZADO UTILIZANDO MACHINE LEARNING

SOBRE MIM
● Coordenador de TI e Software Architect na Movile● Msc. in Electrical Engineering● Apache Cassandra MVP (2014/2015 and 2015/2016)● Apache Cassandra Contributor (2015)● Cassandra Summit Speaker (2014 and 2015)● Strata Hadoop World Singapore Speaker (2016)● Spark Summit Speaker (2017)● RedisConf Speaker na Califórnia (2018)
Eiti Kimura
eitikimura

Quem é Movile?
Líder global em marketplaces móveis
A Movile é líder em marketplaces móveis e nosso sonho é fazer a vida de 1 bilhão de pessoas melhor por meio dos nossos apps.
+150MM de pessoas mensalmente
+1.600 pessoas em 15 escritórios
#1 plat. delivery de comida LATAM
#1 plat. de venda de ingressos LATAM
#2 aplicativo rentável globalmente para
crianças

BALANCE INFORMATIONAccount: X3254Balance: $1,564.20
100852
A deposit of $95.00 was made to your account on April 23th at 7:59pm. Your balance is: $1,659.20. Text STOP to cancel or HELP for more information.
BALANCE INFORMATIONAccount: X3254Balance: $1,564.20
100852
A deposit of $95.00 was made to your account on April 23th at 7:59pm. Your balance is: $1,659.20. Text STOP to cancel or HELP for more information.

sumário
sumário
O que veremos hoje?
Caso do sistema de tarifaçãoIntrodução sobre o sistema distribuído para tarifação de usuários dos nossos produtos
Análise de dadosAnalisando os dados de tentativas de tarifação com as operadoras, consolidando
Solução usando aprendizado de máquinaCriando uma analisador de dados automático usando técnicas de aprendizado de máquina e treinamento do modelo com Apache Spark
Resultados do projeto

Sistema de Tarifação e Controle de Assinaturas
SBS
8
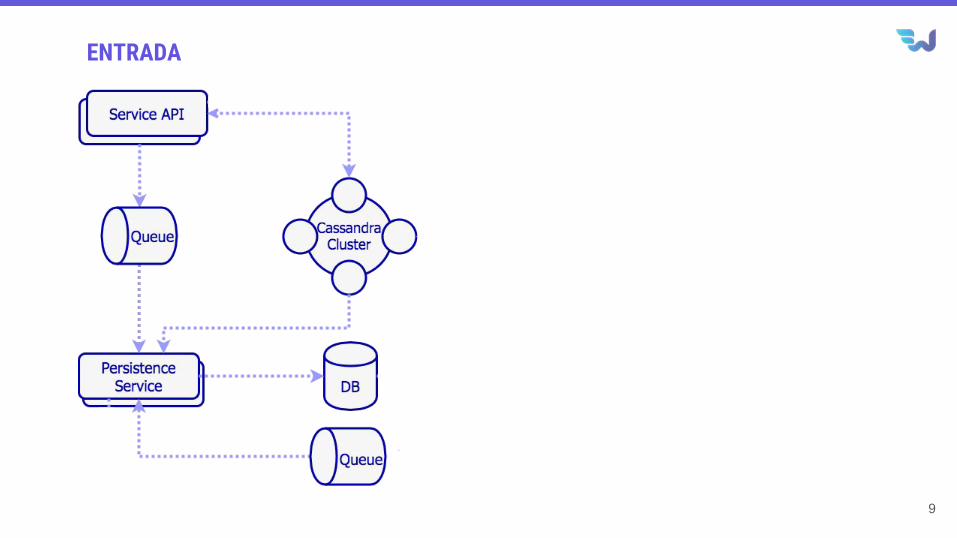
ENTRADA
9
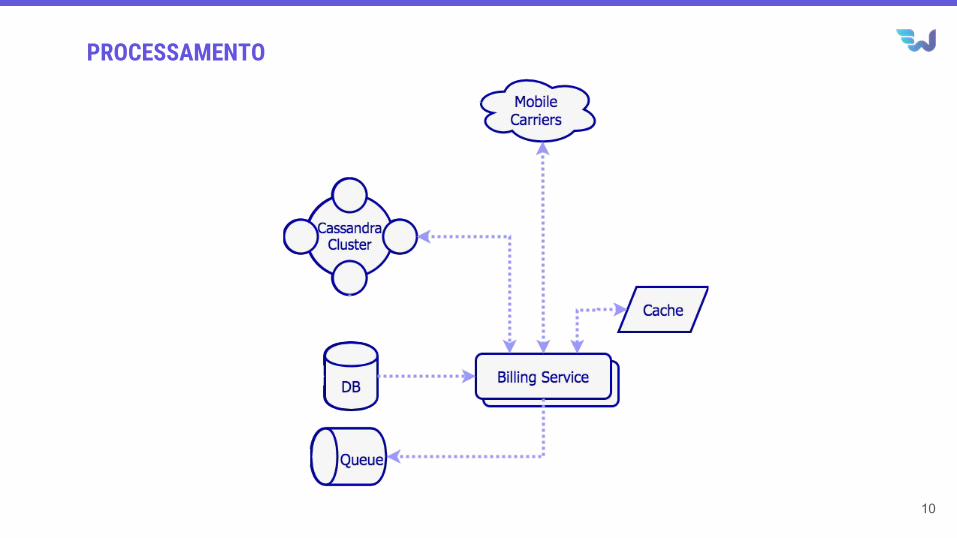
PROCESSAMENTO
10
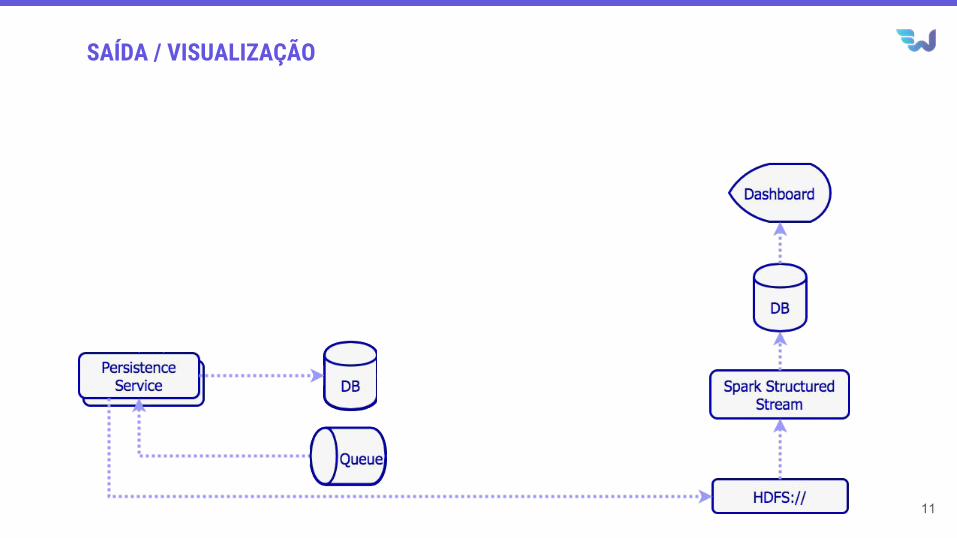
SAÍDA / VISUALIZAÇÃO
11

Arquitetura simplificada plataforma de tarifação
12

Desafio: Monitoramento
Como verificar se a plataforma está integralmente funcional baseado somente em análise de dados?
Que tal pedir ajuda a um sistema inteligente?
13
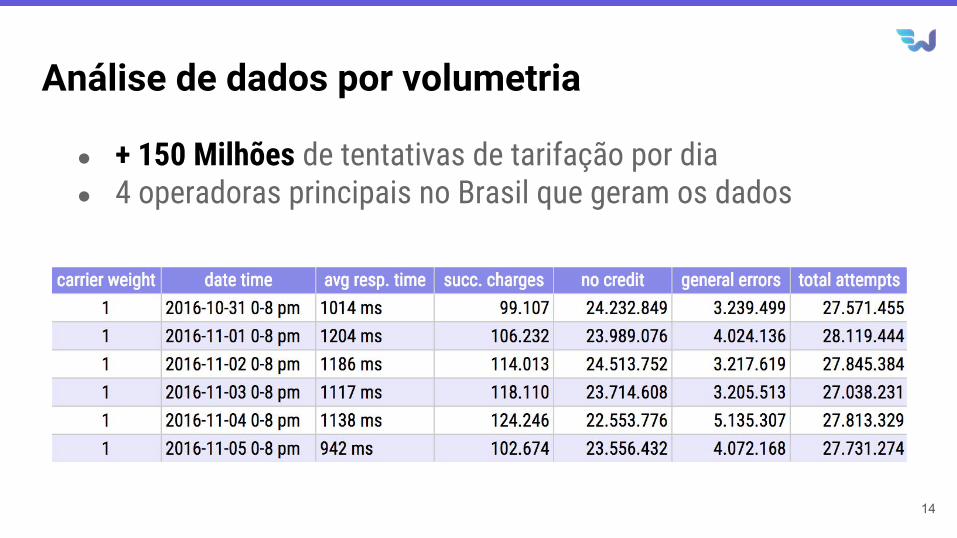
Análise de dados por volumetria
● + 150 Milhões de tentativas de tarifação por dia● 4 operadoras principais no Brasil que geram os dados
14

Entendendo o problema
15
Amostra dos dados (previsão do número de sucessos)
featureslabel/target
# success carrier_weight hour week response_time #no_credit #errors # attempts
61.083, [4.0, 17h, 3.0, 1259.0, 24.751.650, 2.193.67, 26.314.551]
APRENDIZADO SUPERVISIONADO
Regressão Linear
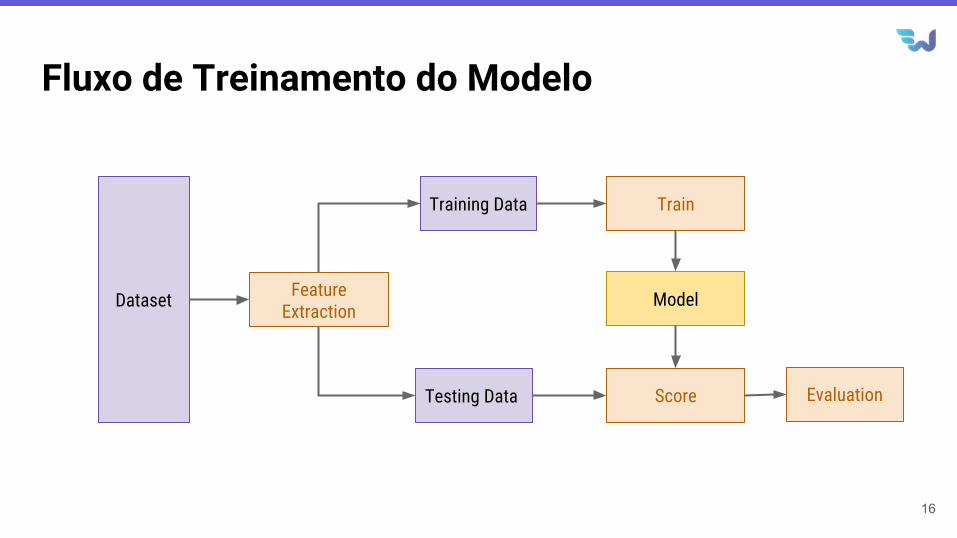
Fluxo de Treinamento do Modelo
16
Training Data
Testing Data
Feature Extraction
Train
Score
Model
Evaluation
Dataset
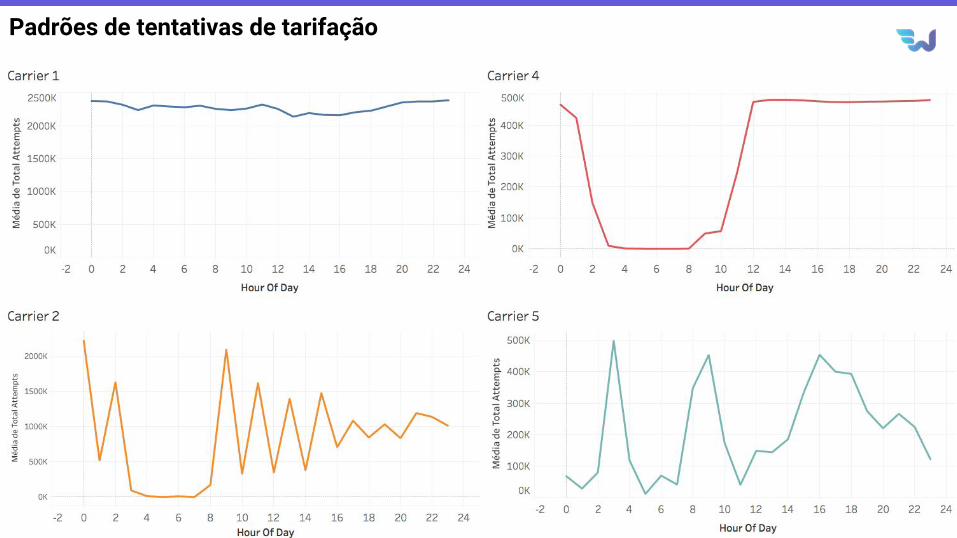
Padrões de tentativas de tarifação
17

Feature Engineering
É o processo de usar o domínio do conhecimento dos dados para criar novos
atributos para que os algoritmos de aprendizado de máquina possam funcionar
com melhor desempenho.
18
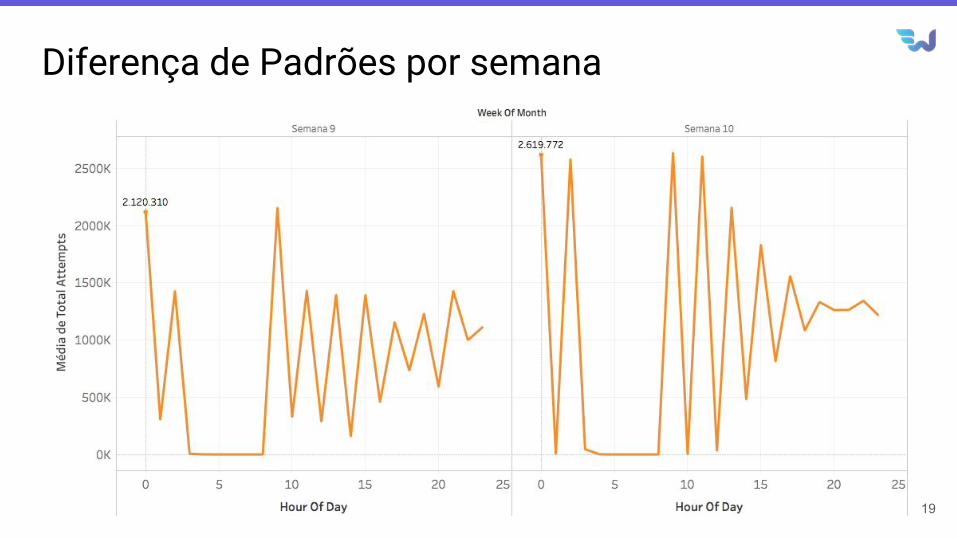
Diferença de Padrões por semana
19

Apache Spark é um motor de análiseunificado para processamento de dados distribuídos em
larga escala.
20

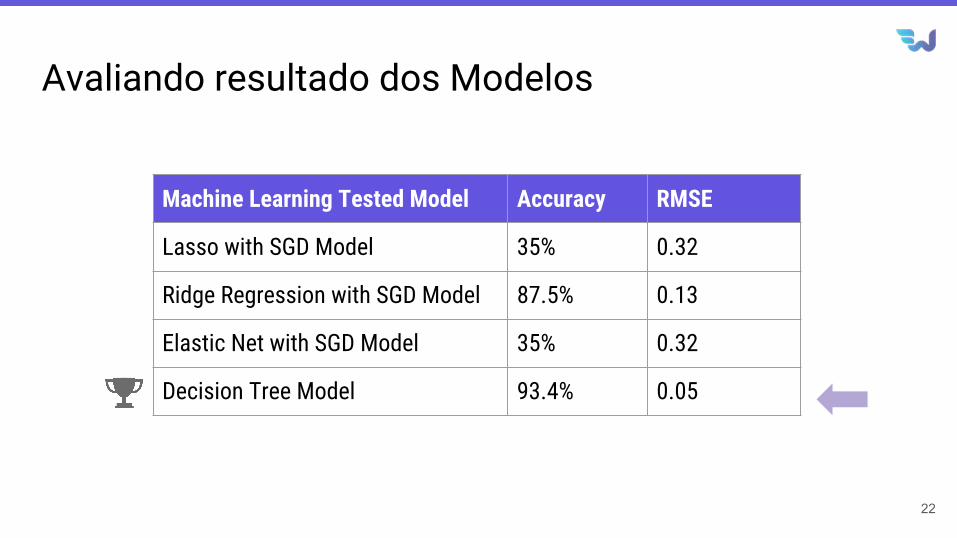
Avaliando resultado dos Modelos
22
Machine Learning Tested Model Accuracy RMSE
Lasso with SGD Model 35% 0.32
Ridge Regression with SGD Model 87.5% 0.13
Elastic Net with SGD Model 35% 0.32
Decision Tree Model 93.4% 0.05

Watcher-ai
23
Olá, eu sou Watcher-ai muito prazer!
24
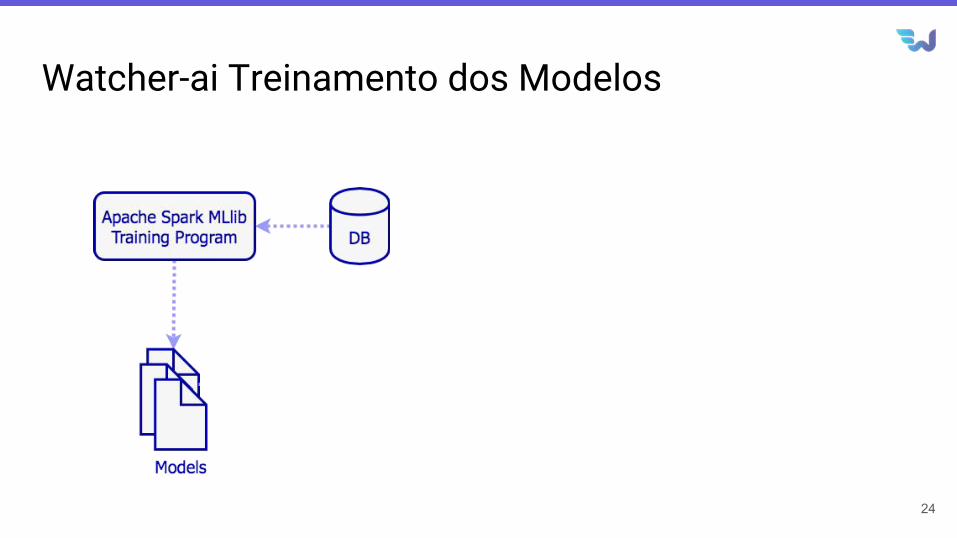
Watcher-ai Treinamento dos Modelos
25
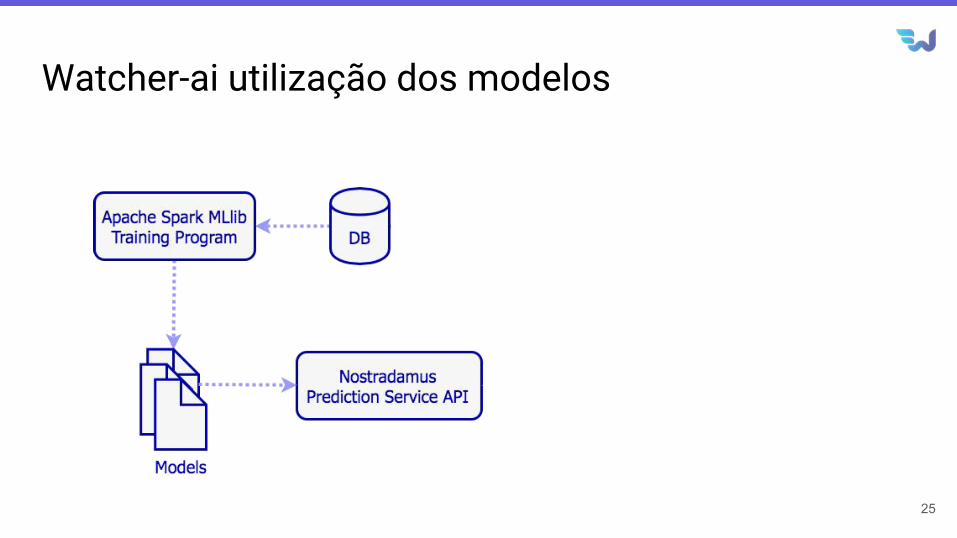
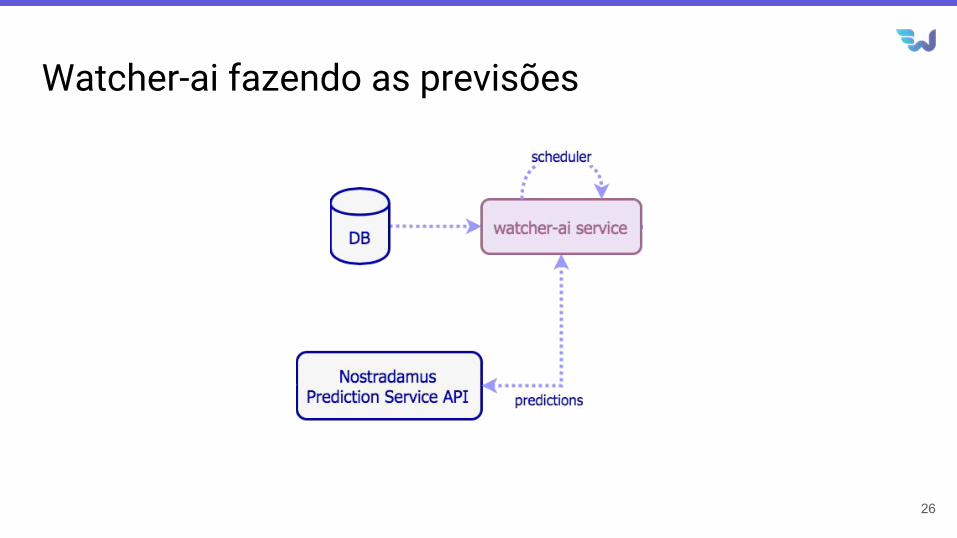
Watcher-ai utilização dos modelos
26
Watcher-ai fazendo as previsões
27
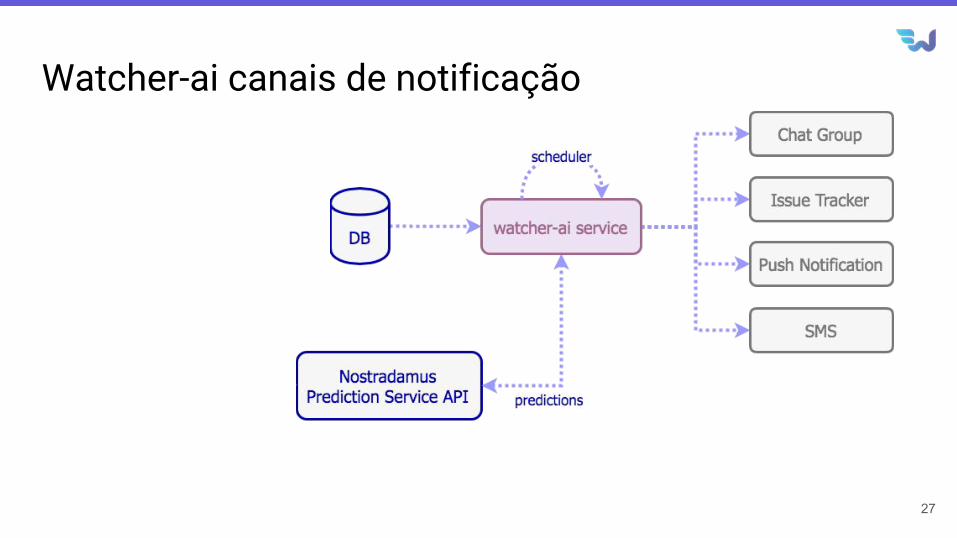
Watcher-ai canais de notificação
28
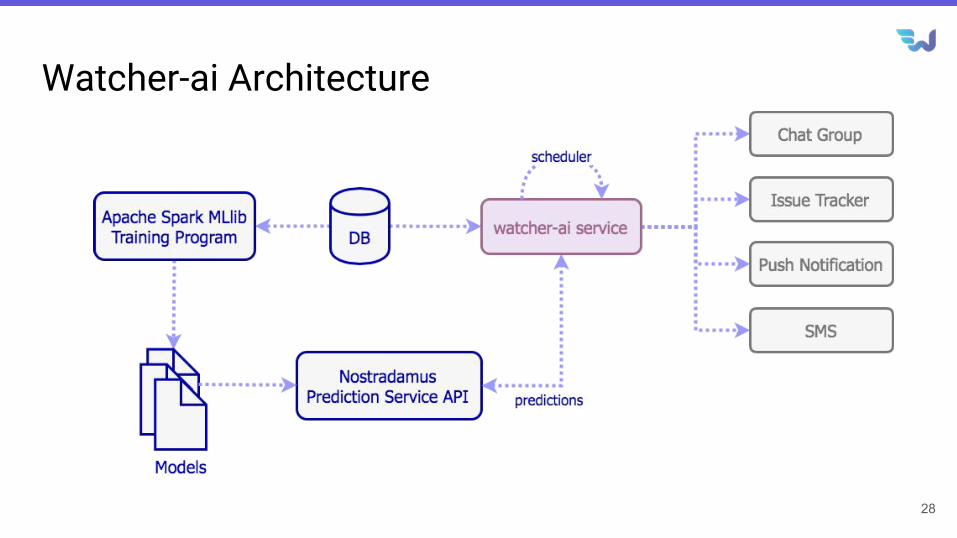
Watcher-ai Architecture

29
Lições Aprendidas

● Tentar prever e controlar os dados de séries temporais usando simples limiares não funcionaram bem no passado devido a fatores externos
● Nós evitamos (removemos) análises e controles baseados em limiares fixos baseados em desvios padrão, por exemplo
Questão com Séries Temporais
30
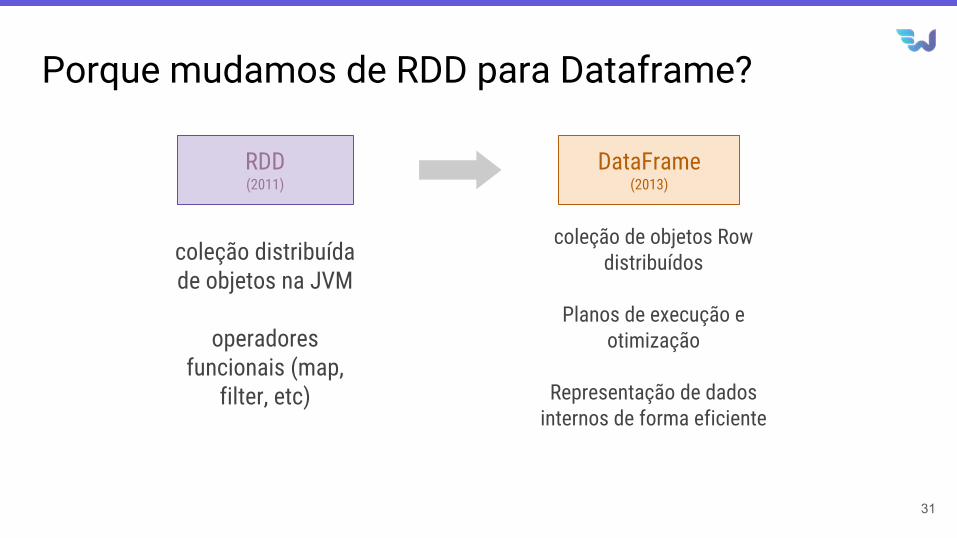
Porque mudamos de RDD para Dataframe?
31
RDD(2011)
DataFrame(2013)
coleção distribuída de objetos na JVM
operadores funcionais (map,
filter, etc)
coleção de objetos Row distribuídos
Planos de execução e otimização
Representação de dados internos de forma eficiente
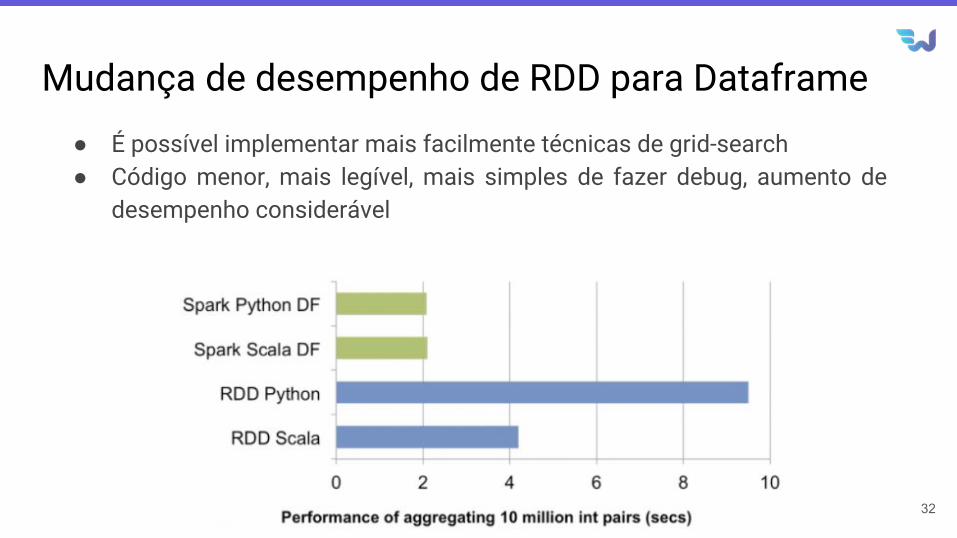
Mudança de desempenho de RDD para Dataframe● É possível implementar mais facilmente técnicas de grid-search● Código menor, mais legível, mais simples de fazer debug, aumento de
desempenho considerável
32

Sobre os modelos treinados
33
● criar um modelo único não funcionou
● cada operadora tem um comportamento específico
● foi preciso criar um modelo diferente para cada operadora
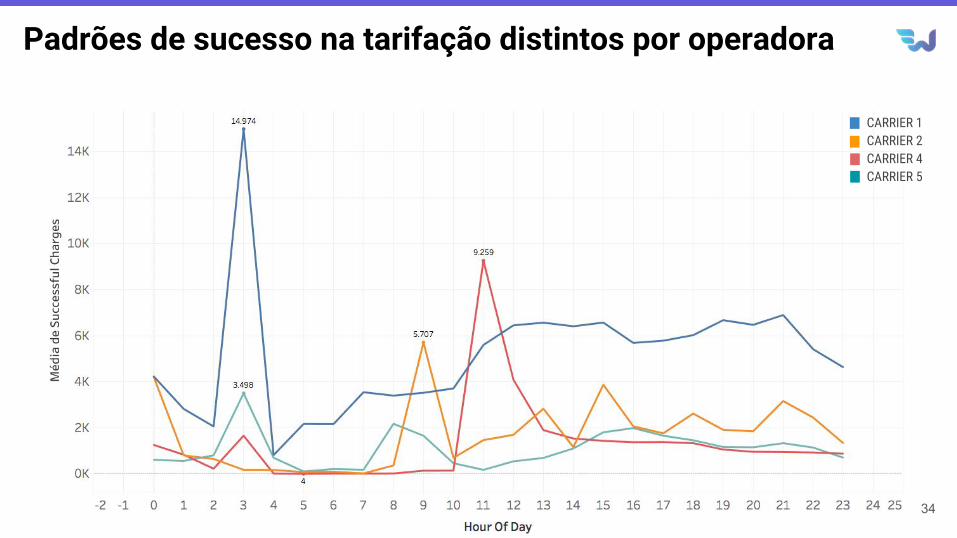
Padrões de sucesso na tarifação distintos por operadora
34
CARRIER 1CARRIER 2CARRIER 4CARRIER 5

35
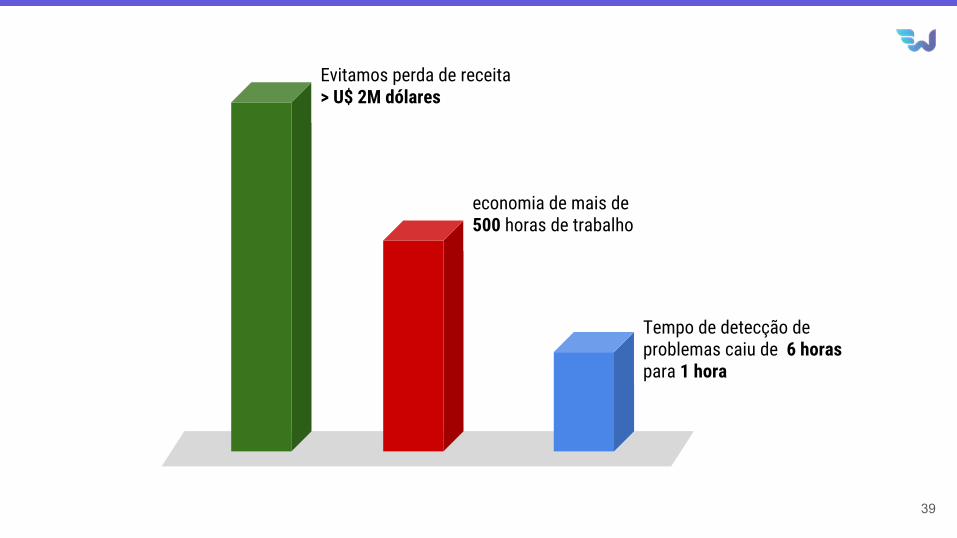
Resultados Obtidos
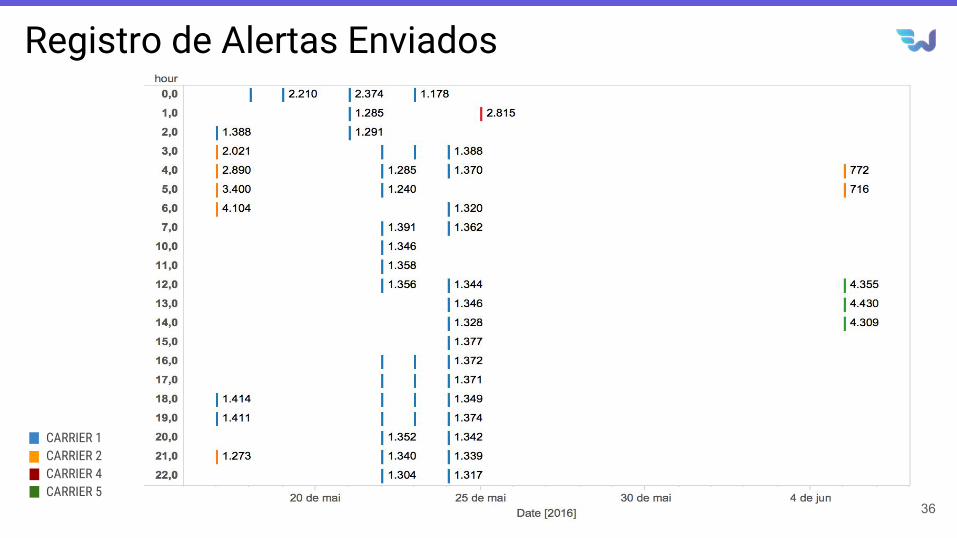
Registro de Alertas Enviados
36
CARRIER 1CARRIER 2CARRIER 4CARRIER 5
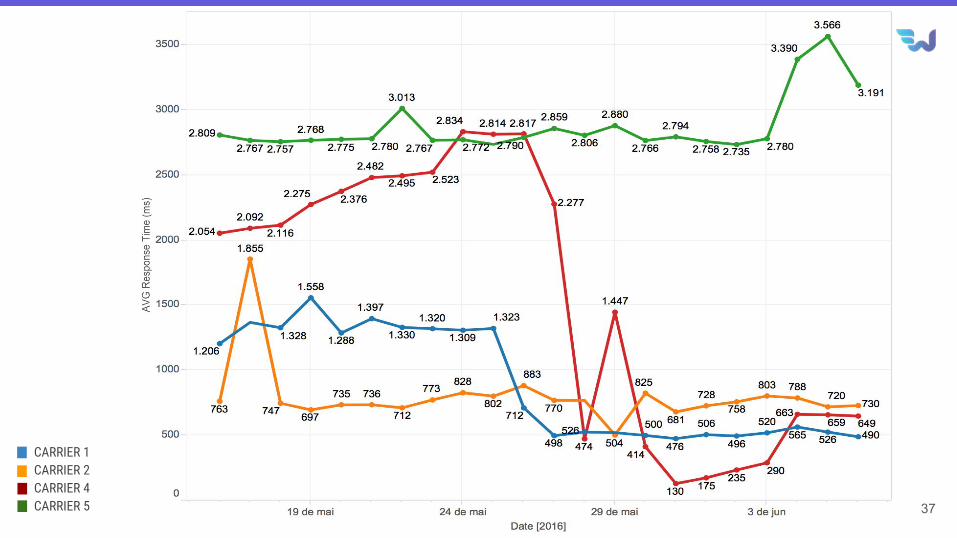
37
CARRIER 1CARRIER 2CARRIER 4CARRIER 5
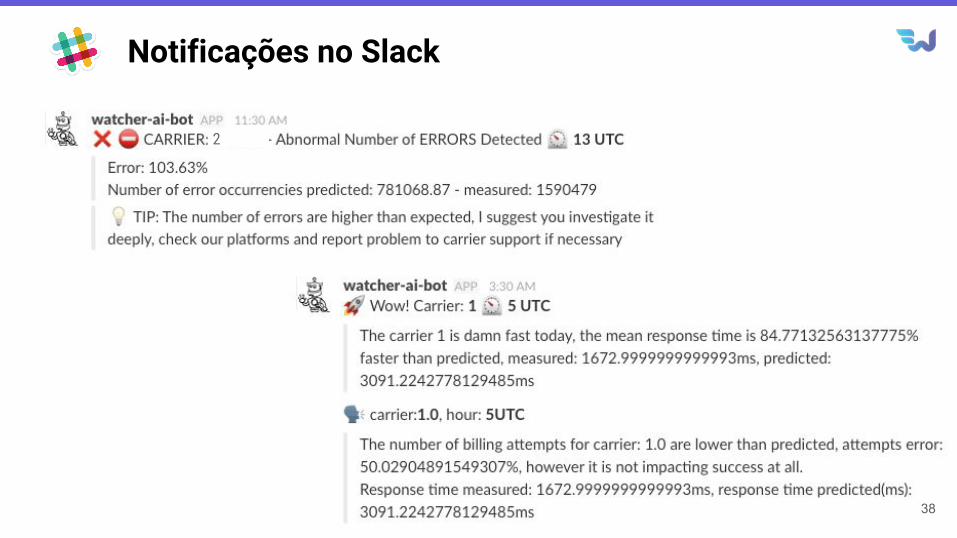
Notificações no Slack
38
2
39
Evitamos perda de receita> U$ 2M dólares
economia de mais de 500 horas de trabalho
Tempo de detecção de problemas caiu de 6 horas para 1 hora

● Prevenção de queda de receita● Um dos sistemas principais de monitoramento● Caso de uso de sucesso de Machine Learning● Solução simples usando o Apache Spark
Resultados Obtidos
40
