1. construção da matriz de similaridades com dados binários · 1 6 5 6 1 6 3 6 1 4 6 2 6 2 6 1...
TRANSCRIPT

1. Construção da Matriz de Similaridades com Dados Binários
Num estudo com cinco alunos da disciplina Técnicas Multivariadas, foram avaliadas as seguintes características:
Indivíduo Altura Peso Cor Cor Uso das(polegadas) (libras) Olhos Cabelos mãos Sexo
Fernanda 68 140 verdes loiro destro fem.Adão 73 185 castanhos castanhos canhoto masc.
Francisco 67 165 azuis loiro destro masc.Vera 64 120 castanhos castanhos destro fem.
Cleide 76 210 castanhos castanhos canhoto fem.
Sejam seis variáveis binárias definidas por:
X110
Altura 72pol.Altura 72pol.
X 410
cabelos loiroscabelos não lo iros
X 210
peso 150 lib.peso 150 lib.
X510
destro canhoto
X 310
Olhos castanhos Olhos não cast anhos
X 610
Sexo feminino Sexo masculino
Escores para alunos Cleide e Vera:X1 X2 X3 X4 X5 X6
Cleide 1 1 1 0 0 1Vera 0 0 1 0 1 1
Vera1 0 totais
Cleide 1 2 2 40 1 1 2
totais 3 3 6

a) Indíce de similaridade: 63
p
dasVC
Matriz de similaridades:
1636165611626264
1626410
1
CVFrA
FeCVFrAFe
Maior similadirade: Adão e Cleide (5/6) Menor similaridade: Fernanda e Adão (0)
Matriz de similaridades reorganizadaFr Fe V C A
Fr 1Fe 4/6 1V 2/6 4/6 1C 1/6 1/6 3/6 1A 2/6 0 2/6 5/6 1
2 Grupos: ( I ) alunos Francisco, Fernanda e Vera( II ) alunos Cleide e Adão.

b) Indíce de similaridade com peso duplo para os pares 1-1 e 0-0:
32
33232
)(2)(2
cbdadasVC
Matriz de similaridades:
132721110721212154
1215410
1
CVFrA
FeCVFrAFe
Maior similadirade: Adão e Cleide (10/11) Menor similaridade: Fernanda e Adão (0)
Matriz de similaridades reorganizadaFr Fe V C A
Fr 1Fe 4/5 1V 1/2 4/5 1C 2/7 2/7 2/3 1A 1/2 0 1/2 10/1
11
2 Grupos (mais evidentes): ( I ) alunos Francisco, Fernanda e Vera( II ) alunos Cleide e Adão.

c) Indíce de similaridade com peso duplo para os pares 1-0 e 0-1:
31
3233
)(2
cbda
dasVC
Matriz de similaridades:
131111751111515121
1512110
1
CVFrA
FeCVFrAFe
Maior similadirade: Adão e Cleide (5/7) Menor similaridade: Fernanda e Adão (0)
Matriz de similaridades reorganizadaFr Fe V C A
Fr 1Fe 1/2 1V 1/5 1/2 1C 1/1
11/11
1/3 1A 1/5 0 1/5 5/7 1
4 Grupos (bem evidentes): ( I ) Fernanda( II ) Vera( III ) Francisco( IV ) Cleide e Adão.

2. Medidas de distância e de similaridades
A) Medidas de similaridades
Coeficiente Descrição
pda
Pesos iguais para combinações 1-1 e 0-0.
cbdada
)(2
)(2Pesos duplos para combinações 1-1 e 0-0.
)(2 cbdada
Pesos duplos para combinações 0-1 e 1-0.
pa
Considera apenas combinações 1-1.
cbaa
Desconsidera as combinações 0-0.(que são consideradas irrelevantes)
cbaa2
2 Pesos duplos para as combinações 1-1 e desconsiderando as combinações 0-0
)(2 cbaa
Pesos duplos para as combinações 0-1 e 1-0, desconsiderando as combinações 0-0
cba
Razão entre as combinações 1-1 com as combinações 0-1 e 1-0, desconsiderando as combinações 0-0

B) Medidas de dist�ncia
Coeficiente Nome
p
iii wvwvd
1
22 )(),(
cbwvd ),(2
Quadrado da dist�ncia Euclidiana entre os itens v e w para dados bin�rios.(retorna o n�mero de combina��es 0-1 e1-0)
pcbwvd
),(2 Dist�ncia bin�ria de Sokal.(dist�ncia Euclidiana quadr�tica m�dia).
p
iii wv
1
2)(
)()( wvwv t
Dist�ncia Euclidiana entre os itens v e w.(dados quantitativos)
p
iii wv
1
2)( Dist�ncia Euclidiana e ao quadrado.
)()( 1 wvSwv t Dist�ncia Estat�stica ou
dist�ncia de Mahalanobis.
mp
i
mii wv
/1
1||
Dist�ncia de Minkowski (ou power): para m = 1 � a dist�ncia “city block”; para m = 2 � a dist�ncia Euclidiana.
.,,1|,|max piwv iii
Dist�ncia de Chebychev.

3. Métodos Hierárquicos
Formado por técnicas que procedem por uma série de uniões (ou divisões) sucessivas sendo que, em cada etapa, os objetos são agrupados conforme suas similaridades. Podem ser aglomerativos ou divisivos:
Aglomerativos = agrupamento por uniões; Divisivos = agrupamento por divisões
3.1. Métodos Hierárquicos Aglomerativos
I) Linkagem Simples: mínima distância ou vizinho mais próximo.
A distância entre dois grupos G1 e G2 é dada pela menor distância entre seus objetos.
Agrupar n objetos, itens ou indivíduos.
a) O processo inicia com n clusters, ou grupos, cada um com um objeto, e a respectiva matriz de distâncias ou simiatridades;
b) Identifica-se na matriz o par u e v com a menor distância (maior similaridade, sendo a distância entre u e v dada por duv ;
c) Os objetos u e v são agrupados em um cluster que passa a ser denominado uv e a matriz de distâncias é atualizada:
i) elinando-se a linha e a coluna referenteas aos objetos u e v ;ii) calculando-se as distâncias entre os demais objetos e o grupo uv, tal
que
),min()( vwuwwuv ddd ;

d) Repetir os itens (b) a (c) até que todos os objetos formem um único cluster.
Exemplo 1: Considere a matriz de distâncias entre cinco objetos
a)
08)2(10110956
07309
0
54321
54321
Menor distância: 235 d , novo cluster: (35)
b) Novas distâncias:
3)11,3min(),min( 51311)35( ddd7)10,7min(),min( 52322)35( ddd
8)8,9min(),min( 54344)35( ddd
a') nova matriz:
0568097
0)3(0
4
2
1
)35(
421)35(
Menor distância: 31)35( d , novo cluster: (351)
b') Novas distâncias:
7)9,7min(,min 122)35(2)351( ddd 6)6,8min(,min 144)35(4)351( ddd
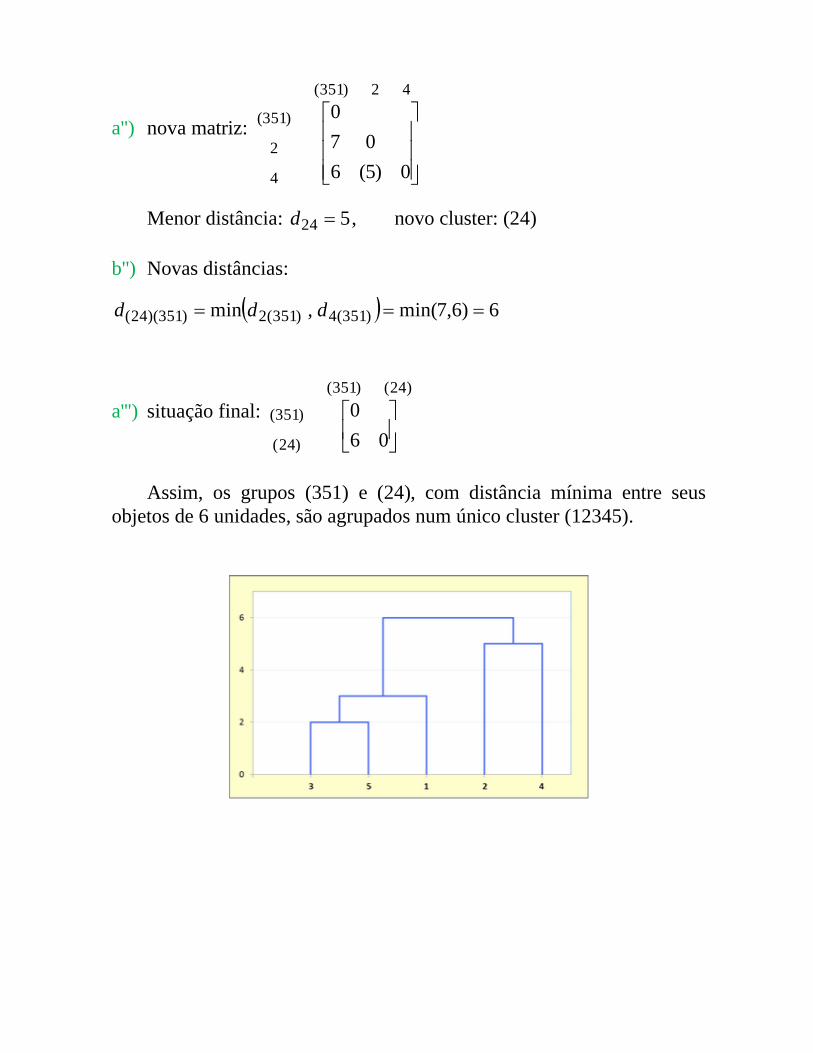
a'') nova matriz:
0)5(607
0
4
2
)351(
42)351(
Menor distância: 524 d , novo cluster: (24)
b'') Novas distâncias:
6)6,7min(,min )351(4)351(2)351)(24( ddd
a''') situação final:
06
0
)24(
)351(
)24()351(
Assim, os grupos (351) e (24), com distância mínima entre seus objetos de 6 unidades, são agrupados num único cluster (12345).

II) Linkagem Completa: máxima distância ou vizinho mais distante.
A distância entre dois grupos G1 e G2 é dada pela maior distância entre seus objetos.
O método da linkagem completa é semelhante ao anterior (linkagem simples) com a diferença de que, neste caso, as distâncias são atualizadas conforme a seguinte relação:
),max()( vwuwwuv ddd .
Exemplo 2: Considere a mesma matriz de distâncias do caso anterior
a)
08)2(10110956
07309
0
54321
54321
Menor distância: 235 d , novo cluster: (35)
b) Novas distâncias:
11)11,3max(),max( 51311)35( ddd10)10,7max(),max( 52322)35( ddd
9)8,9max(),max( 54344)35( ddd

a') nova matriz:
0)5(690910
0110
4
2
1
)35(
421)35(
Menor distância: 524 d , novo cluster: (24)
b') Novas distâncias:
10)9,10max(,max )35(4)35(2)35)(24( ddd 9)6,9max(,max 41211)24( ddd
a'') nova matriz:
0)9(11010
0
1
)24(
)35(
1)24()35(
Menor distância: 9)24( d , novo cluster: (241)
b'') Novas distâncias:
11)11,10max(,max )35(1)35)(24()35)(241( ddd
a''') situação final:
011
0
)241(
)35(
)241()35(
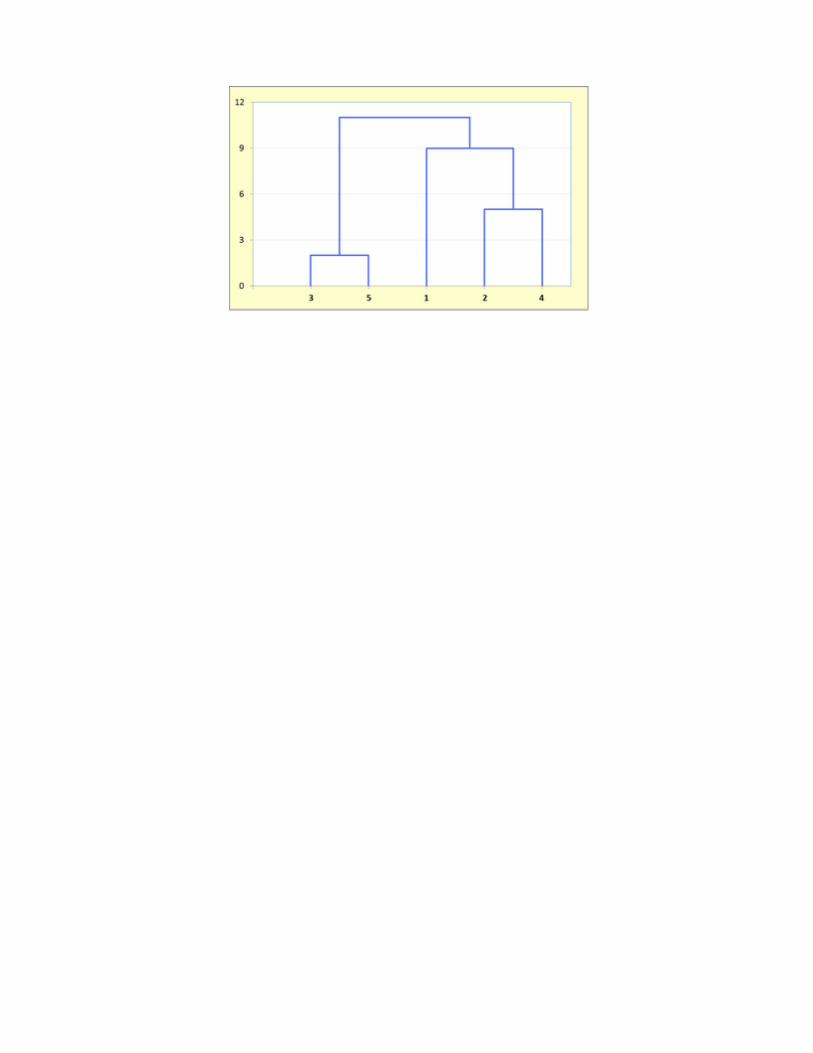
Assim, os grupos (35) e (241), com distância máxima entre seusmenbros de 11 unidades, são agrupados num único cluster (12345).
Observe que na linkagem completa, o objeto 1 foi agrupado ao cluster (24).

III) Linkagem Média: distância média.
A distância entre dois grupos G1 e G2 é dada pela média das distâncias entre seus objetos.
O método da linkagem média é semelhante aos anteriores com a diferença de que, neste caso, as distâncias são atualizadas conforme a seguinte relação:
wuv
i jij
wuv nn
dd
)()(
,
em que: ijd = distância entre o objeto i, do cluster (uv) e o objeto j, do cluster w ;
)(uvn = número de objetos do cluster (uv);
wn = número de objetos do cluster w.
Exemplo 3: Considere a mesma matriz de distâncias dos casos anteriores
a)
08)2(10110956
07309
0
54321
54321
Menor distância: 235 d , novo cluster: (35)
b) Novas distâncias:
72113
25131
1)35(
ddd

5.82107
25232
2)35(
ddd
5.82
892
54344)35(
ddd
a') nova matriz:
0)5(65.8095.8
070
4
2
1
)35(
421)35(
Menor distância: 524 d , novo cluster: (24)
b') Novas distâncias:
5.84
3422
)810()97(22
)()( 54523432)24)(35(
ddddd
5.72
692
41211)24( ddd
a'') nova matriz:
05.7)7(05.8
0
1
)24(
)35(
1)24()35(
Menor distância: 71)35( d , novo cluster: (351)
b'') Novas distâncias:
23)()()( 141254523432
)24)(351(
ddddddd
167.8649
23)69()810()97(
)24)(351(
d
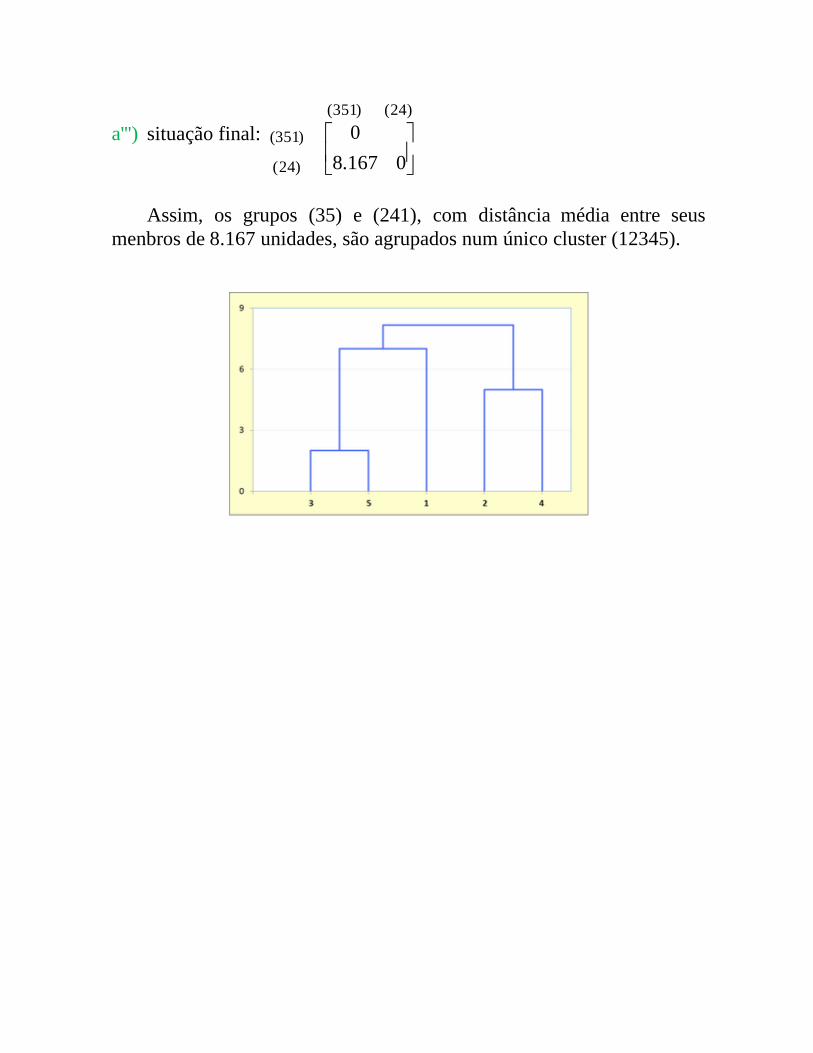
a''') situação final:
0167.8
0
)24(
)351(
)24()351(
Assim, os grupos (35) e (241), com distância média entre seus menbros de 8.167 unidades, são agrupados num único cluster (12345).
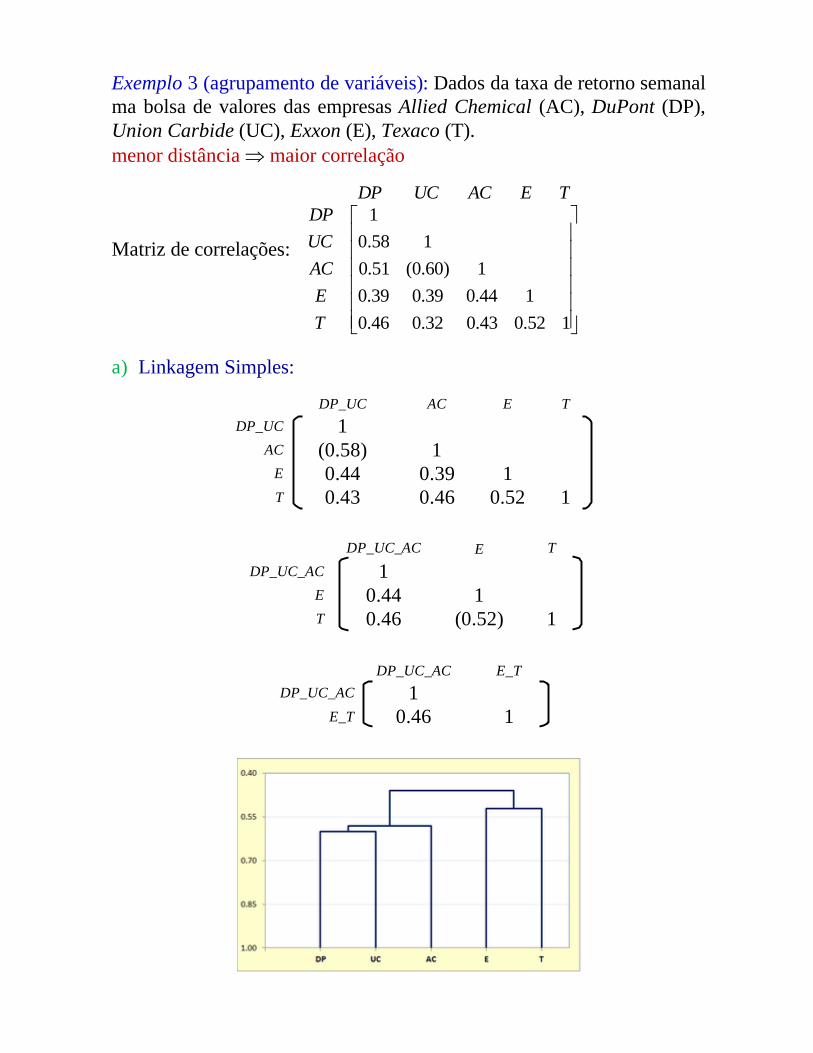
Exemplo 3 (agrupamento de variáveis): Dados da taxa de retorno semanal ma bolsa de valores das empresas Allied Chemical (AC), DuPont (DP), Union Carbide (UC), Exxon (E), Texaco (T).menor distância maior correlação
Matriz de correlações:
152.043.032.046.0144.039.039.0
1)60.0(51.0158.0
1
TE
ACUCDP
TEACUCDP
a) Linkagem Simples:
DP_UC AC E TDP_UC 1
AC (0.58) 1E 0.44 0.39 1T 0.43 0.46 0.52 1
DP_UC_AC E TDP_UC_AC 1
E 0.44 1T 0.46 (0.52) 1
DP_UC_AC E_TDP_UC_AC 1
E_T 0.46 1
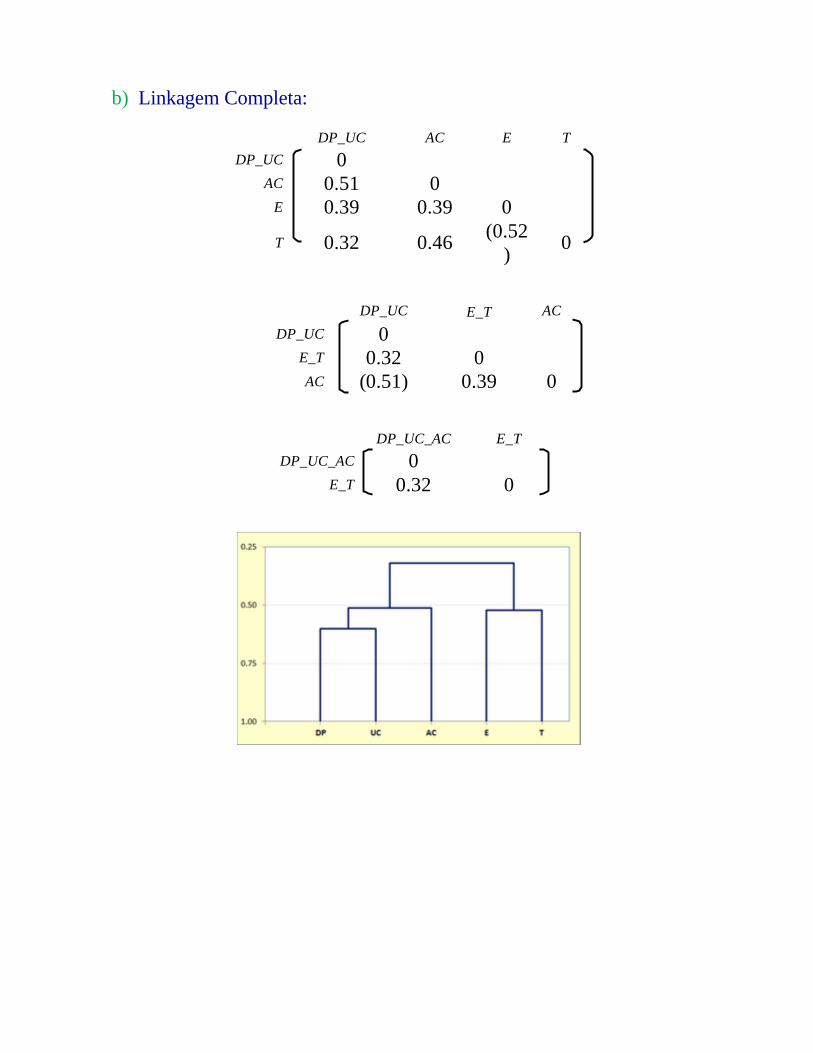
b) Linkagem Completa:
DP_UC AC E TDP_UC 0
AC 0.51 0E 0.39 0.39 0
T 0.32 0.46 (0.52) 0
DP_UC E_T ACDP_UC 0
E_T 0.32 0AC (0.51) 0.39 0
DP_UC_AC E_TDP_UC_AC 0
E_T 0.32 0

3.1.1. Outros Métodos Hierárquicos:
I) Método Hirárquico do Centróide: a distância entre dois clusters á dada pela distância entre os seus vetores de médias, ou centróides.
Sejam, por exemplos, dois grupos C1 e C2 formados pelos itens (X1, X3, X7) e (X2, X6), respectivamente, então
3731
1XXXX
e 2
622
XXX ,
e, a distância Euclidiana entre C1 e C2 será dada por
)()()C,C( 21t
2121 XXXX d .
Podemos, ainda considerar o seu qyadrado, ou seja,
)()()C,C( 21t
21212 XXXX d
Nesse caso, o centróide de um novo cluster (uv)w será atualizado segunda a relação:
wuv
wuvwuv nn
xxx )(
Nota: o método do centróide pode gerar distorção nos resultados quando o número de elementos dos grupos for muito discrepantes, situação na qual o grupo maior domina a nova média.
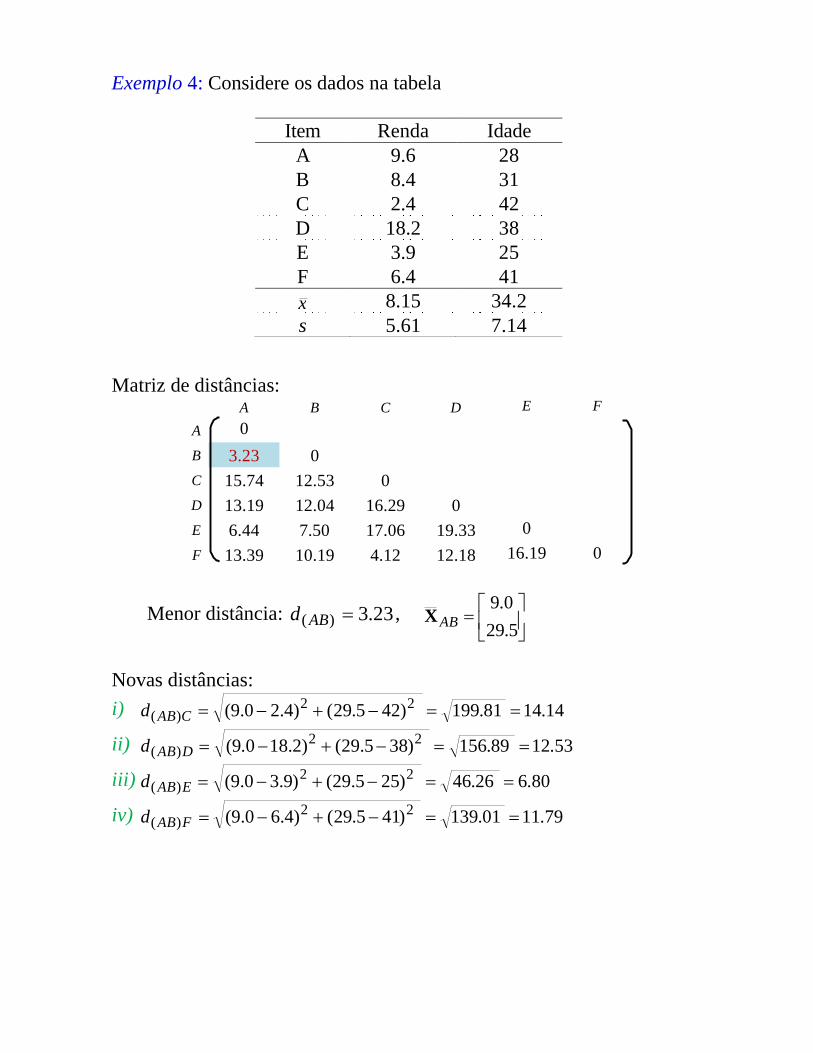
Exemplo 4: Considere os dados na tabela
Item Renda IdadeA 9.6 28B 8.4 31C 2.4 42D 18.2 38E 3.9 25F 6.4 41x 8.15 34.2s 5.61 7.14
Matriz de distâncias:A B C D E F
A 0B 3.23 0C 15.74 12.53 0D 13.19 12.04 16.29 0E 6.44 7.50 17.06 19.33 0F 13.39 10.19 4.12 12.18 16.19 0
Menor distância: 23.3)( ABd ,
5.290.9
ABX
Novas distâncias:i) 14.1481.199)425.29()4.20.9( 22
)( CABd
ii) 53.1289.156)385.29()2.180.9( 22)( DABd
iii) 80.626.46)255.29()9.30.9( 22)( EABd
iv) 79.1101.139)415.29()4.60.9( 22)( FABd

Matriz atualizada:(AB) C D E F
(AB)
0
C 14.14 0D 12.53 16.29 0E 6.80 17.06 19.33 0F 11.79 4.12 12.18 16.19 0
Menor distância: 12.4)( CFd ,
5.414.4
CFX
Novas distâncias:i) 85.1216.165)5.295.41()0.94.4( 22
))(( ABCFd
ii) 24.1469.202)385.41()2.184.4( 22)( DCFd
iii) 51.165.272)255.41()9.34.4( 22)( ECFd
Matriz atualizada:(AB) (CF) D E
(AB) 0(CF) 12.85 0
D 12.53 14.24 0E 6.80 16.51 19.33 0
Menor distância: 80.6)( EABd ,
0.283.7
ABEX
Novas distâncias:i) 81.1366.190)5.410.28()4.43.7( 22
))(( CFABEd
ii) 79.1481.218)0.380.28()2.183.7( 22)( DABEd
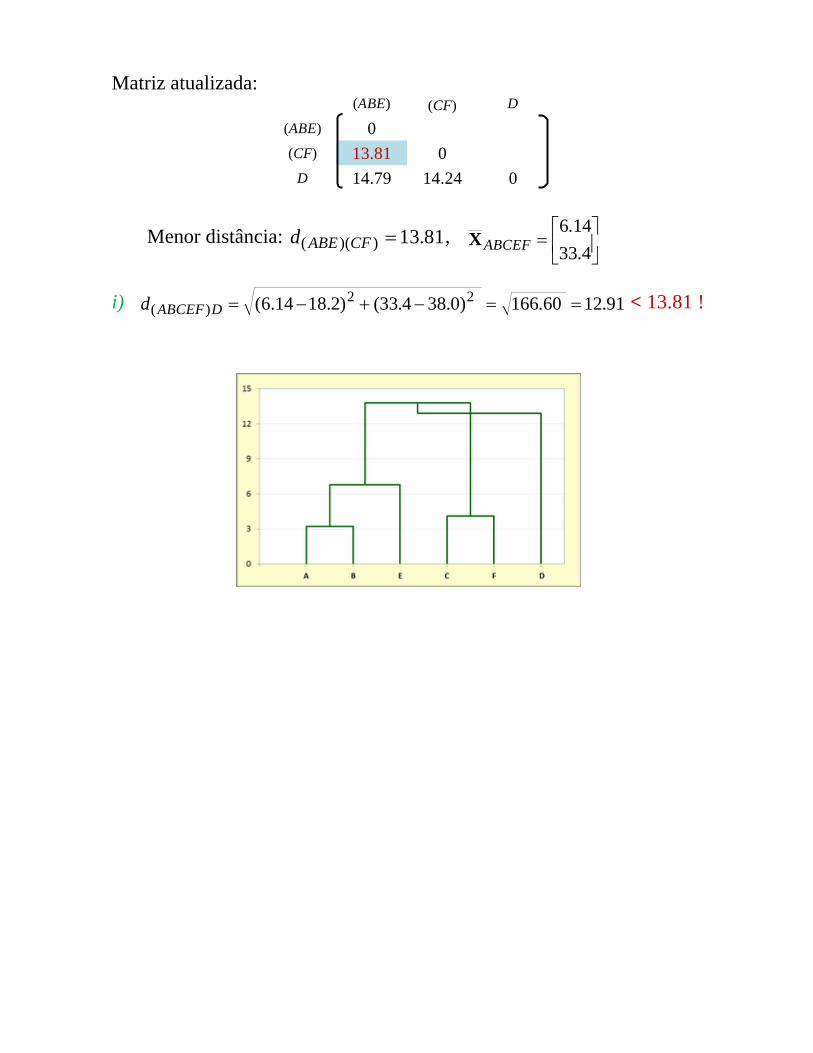
Matriz atualizada:(ABE) (CF) D
(ABE) 0(CF) 13.81 0
D 14.79 14.24 0
Menor distância: 81.13))(( CFABEd ,
4.3314.6
ABCEFX
i) 91.1260.166)0.384.33()2.1814.6( 22)( DABCEFd < 13.81 !

II) Método Hirárquico da Mediana: semelhante ao caso anterior, porém, a atualização dos centróides é feita pela média aritmética sem a ponderação pelo tamanho dos grupos, ou seja, um novo cluster (uv)wserá atualizado por
2)(wuv
wuvxxx
III) Método Hirárquico de Ward: método baseado na análise de variância, utiliza as somas de quadrados (SQ) dentre e entre grupos.Os grupos são formados tal que a SQDentro seja minimizada.
IV) Método Hirárquico Flexível Beta: utiliza uma ponderação na atualização das distâncias com pesos que variam de acordo com o método (Ferreira, DF, pag 382).
vwuwuvvwvuwuwuv dddddd )( ,
com as restrições: 1 vu , vu , 0 , 1 .
Notas:i) segundo as restrições acima, o único parâmetro a ser especificado
seria , pois teríamos 2/)1( u ;ii) os demais métodos hierárquicos podem ser especificados pelo método
flexível beta ecolhendo-se valores adequados para os parâmetros u , v , e (ver tabela).
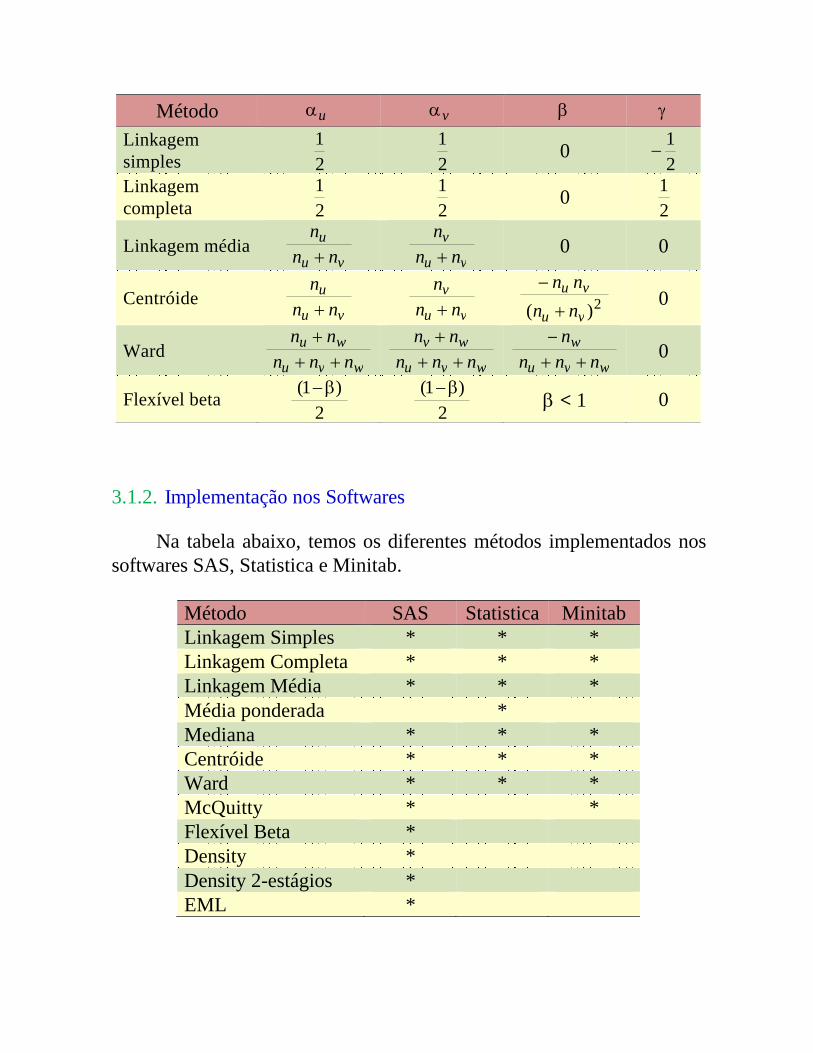
Método u v
Linkagem simples 2
121 0
21
Linkagem completa 2
121 0
21
Linkagem médiavu
unn
n vu
vnn
n 0 0
Centróidevu
unn
n vu
vnn
n 2)( vu
vunnnn
0
Wardwvu
wunnn
nn
wvu
wvnnn
nn
wvu
wnnn
n
0
Flexível beta2
)1( 2
)1( < 1 0
3.1.2. Implementação nos Softwares
Na tabela abaixo, temos os diferentes métodos implementados nos softwares SAS, Statistica e Minitab.
Método SAS Statistica MinitabLinkagem Simples * * *Linkagem Completa * * *Linkagem Média * * *Média ponderada *Mediana * * *Centróide * * *Ward * * *McQuitty * *Flexível Beta *Density *Density 2-estágios *EML *

3.2. Propriedades dos métodos hierárquicos
I) Monotonicidade: segundo a propriedade de monotonicidade, dois grupos serão sempre aglomerados numa junção que é maior do que a anterior.
Os métodos que atendem a essa propriedade são classificados como monotônicos.
i) Os métodos de linkagem simples, linkagem completa, linkagem média e de Ward são todos monotônicos;
ii) O método flexível beta requer que os pesos atendam à condição 1 vu para que seja monotônico;
iii) Os métodos do centróide e da mediana não são monotônicos.
O Exemplo 4, com o agrupamento das variáeis referentes às taxas de retorno das Cias AC, DP, UC, E e T, apresenta uma situação na qual a monotonicidade não foi atendida.
II) Alteração das características do espaço das distâncias: segundo essa propriedade o método de agrupamento pode causar uma contração ou uma dilatação no espaço das distâncias.
i) Nos métodos onde ocorre a contração, os grupos tendem a se juntar com objetos simples.O método da linkagem simples é um método que causa a contração do espaço. Exemplo, Car data (Cars.sta - Statistica):

ii) Nos m�todos onde ocorre a dilatadores, objetos simples tendem a formar grupos com outros objetos simples e n�o com grupos pr� existentes.O m�todo da linkagem completa � um m�todo dilatador do espa�o. Exemplo, Car data (Cars.sta - Statistica):
Obs: os demais m�todos se situam em posi��es intermedi�rias a esses.a) os m�todos do centr�ide e linkagem m�dia s�o, conservativos, n�o
alterandom esta propriedade;b) Ferreira, DF, classifica o m�todo de Ward como um m�todo de
contra��o do espa�o;c) o m�todo flex�vel beta depende do balor do par�metro : se < 0, �
de contra��o; = 0 � conservativo e, para > 1 � dilatador.Ferreira, DF, indica = −0.25 como um bom valor para a qualidade final do agrupamento.
Na pr�tica, recomenda-se a utiliza��o de diversos m�todos, comparando os resultados e, escolher aquele que reflete algum agrupamento natural.

III) Sensibilidade à outliers: é uma propriedade desejada
a) Linkagem simples, linkagem média e Ward são bastante sensíveis;
b) Linkagem completa é sensível;
c) Método do Centróide é robusto à presença de outliers.
Nota: Estudos indicam que, de maneira geral, os métodos da linkagem média e de Ward apresentam os melhores resultados, porém, os resultados dependem muito do comportamento dos dados.

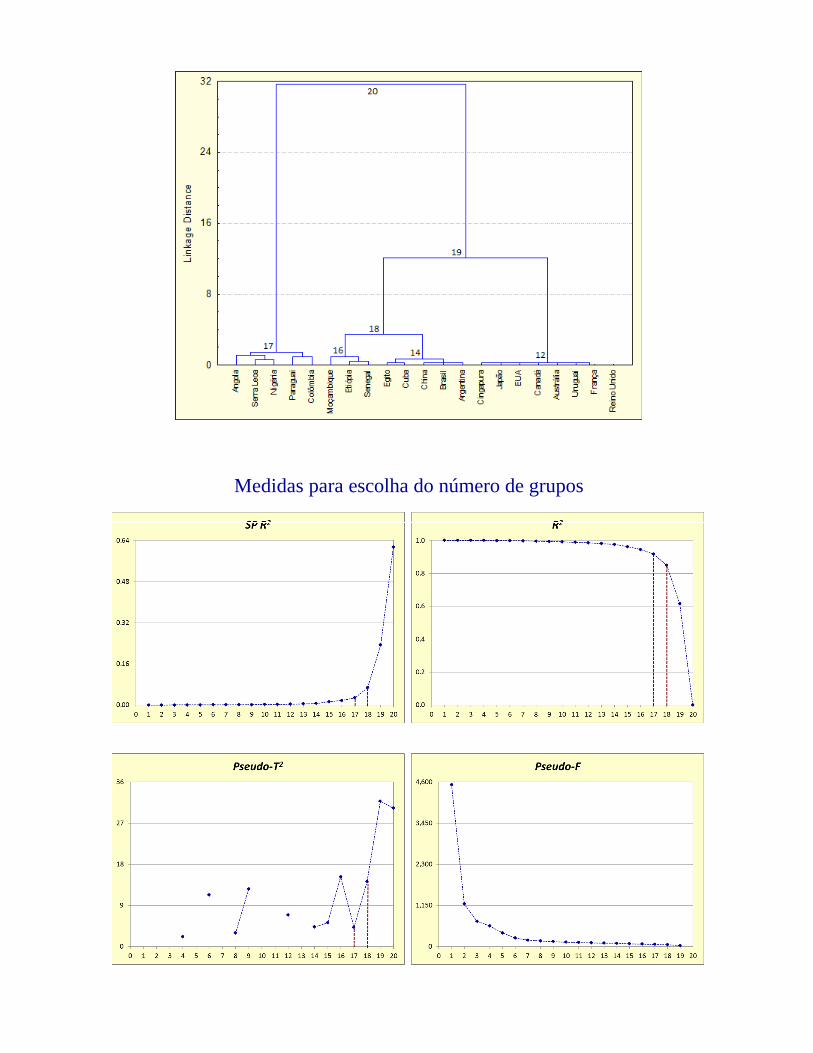
Como determinar o número de grupos
I) Altura entre as junções dos grupos/objetos: a partir do dendrograma, fazer um corte na junção onde se tem um salto ''significativo'' (maior salto).
Esse procedimento pode ser problemático, pois depende da qualidade do agrupamento.
Daniel F. Ferreira introduz o procedimento definido por Mozena (1977), o qual escolhe o maior salto no dendrograma como ponto de corte.
Desta forma, o número de linhas verticais intercepadas definirá o número de grupos.
Exemplo 5: Considerando o dendrograma do agrupamento dos veículos (car data), pela linkagem completa, observamos que o ''maior salto'' se dá entre o nível 4.19 e 2.83, sendo igual a 36.183.219.4 ( Figura)
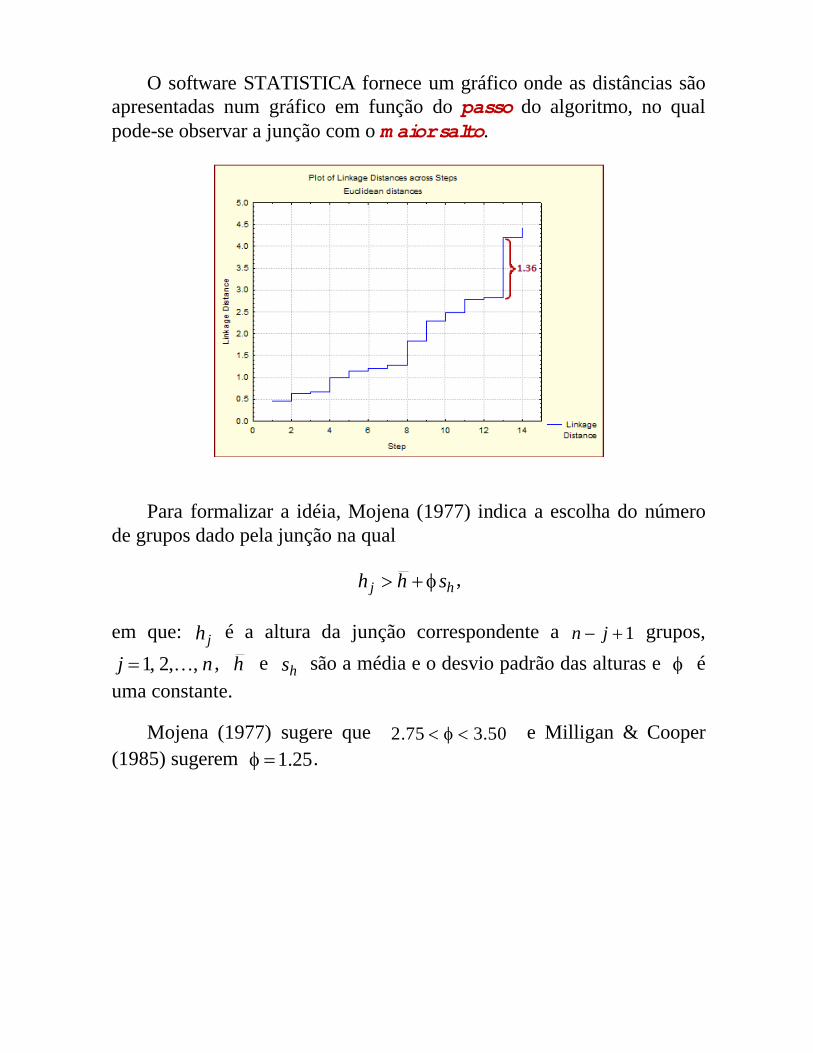
O software STATISTICA fornece um gráfico onde as distâncias são apresentadas num gráfico em função do passo do algoritmo, no qual pode-se observar a junção com o maior salto.
Para formalizar a idéia, Mojena (1977) indica a escolha do número de grupos dado pela junção na qual
hj shh ,
em que: jh é a altura da junção correspondente a 1 jn grupos, nj ,,2,1 , h e hs são a média e o desvio padrão das alturas e é
uma constante.
Mojena (1977) sugere que 50.375.2 e Milligan & Cooper (1985) sugerem 25.1 .
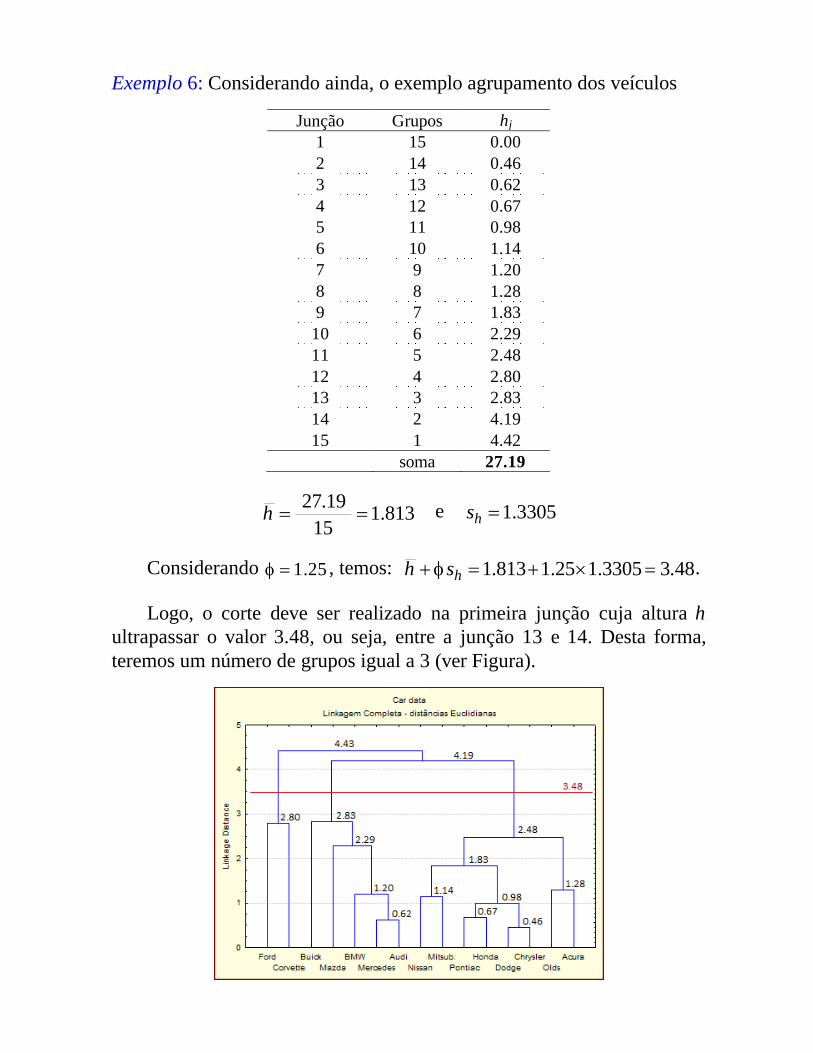
Exemplo 6: Considerando ainda, o exemplo agrupamento dos veículos
Junção Grupos hj1 15 0.002 14 0.463 13 0.624 12 0.675 11 0.986 10 1.147 9 1.208 8 1.289 7 1.83
10 6 2.2911 5 2.4812 4 2.8013 3 2.8314 2 4.1915 1 4.42
soma 27.19
813.115
19.27 h e 3305.1hs
Considerando 25.1 , temos: 48.33305.125.1813.1 hsh .
Logo, o corte deve ser realizado na primeira junção cuja altura hultrapassar o valor 3.48, ou seja, entre a junção 13 e 14. Desta forma, teremos um número de grupos igual a 3 (ver Figura).

II) Somas de quadrados e o coeficiente R2:
Devem ser calculados a cada passo do algoritmo, sendo definidos como:
Soma de quadrados total:
*
1 1)()(
g
i
n
jijij
iSQT xxxx t ;
Soma de quadrados residual (dentro):
*
1 1)()(
g
i
n
jiijiij
iSQRes xxxx t ;
Soma de quadrado entre grupos
*
1)()(
g
iiiinSQB xxxx t ,
em que g* é o número de grupos em cada passo do algoritmo.
O coeficiente R2 é, então, calculado por:
SQTSQBR 2
Quanto mais homogêneos foram os grupos, maior a SQB e nomor a SQRes e, consequentemente, maior será o R2.
Desta forma, devemos procurar um passo do algoritmo com um grande (ou o maior) salto de R2 em relação aos demais.
Obs: a análise pode ser feita por meio de um gráfico passo R2.

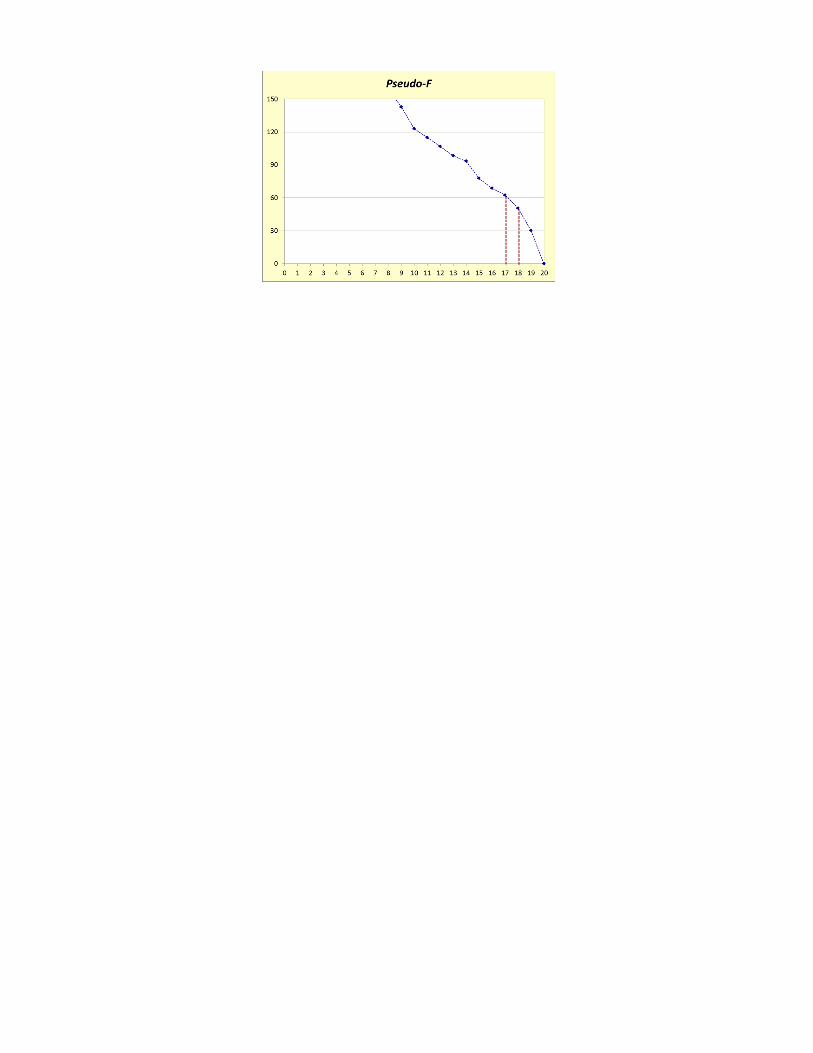
III) Pseudo-F:
Estatística introduzida por Calinski & Harabasz (1974), deve ser calculada passo-a-passo.
2
2
11**
*)/()1*/(
RR
ggn
gnSQTgSQBF
Se F é monotonicamente crescente com g*, então, os dados sugerem que não existe uma partição natural;
Se F apresentar um valor máximo, então, o número de clusters e a partição correspondente no respectivo passo indicam a parti��o ideal.
Pode-se mostrar que, se os dados forem normais p-variados, então:
*)(),1*(~ gnpgpFF .
A idéia do pseudo-F é a de que testes de igualdade entre os vetores de médias dos grupos formados estariam sendo realizados em cada passo do processo. Assim, busca-se o passo com o maior valor do pseudo-F, ou seja, aquele que estaria relacionado com a menor probabilidade de significância do teste, “rejeitando” a igualdade entre os vetores de médias. Nessa situação, os dois conglomerados não deveriam ser unidos, indicando a interrupção do processo.

IV) Estatística CCC - Cubic Clustering Criterium:
Estatística propsta por Sarle (1983) obtrida comparando-se o valor observado do coeficiente 2R com o 2
ER , coeficiente esperado sob a suposição de que os grupos são gerados de acordo com uma distribuição uniforme p-dimensional.
CCC > 0 22ERR , indicando uma estrutura de grupos
diferentes da partição uniforme
O número de grupos finais estaria relacionado com CCC > 3.
Obs: a estatística CCC está implementada no SAS.
V) Pseudo-T 2:
De interpretação semelhante ao pseudo-F, o número de grupos corresponde à junção na qual o pseudo-T 2 alcança o seu valor máximo, ou àquele imediatemente anterior.
Sob as suposições de normalidade, na junção dos clusters u e v, o pseudo-T 2 tem distribuição F com p e )2( vu nn graus de liberdade, podendo ser interpretado como testes de hipóteses entre vetores de médias.
Desta forma, busca-se o maior valor do pseudo-T 2 e, com a igualdade entre os vetores de médias sendo rejeitada, os dois clusters não devem ser unidos.

VI) Correlação semiparcial:
Considere que num determinado passo ocorra a junção dos clusters Cu e Cv, então, a correlação semiparcial da partição nesse passo é dada por:
SQTnnnnSPR vuvu
vu
vu )()(2
xxxx t
Obs: a SPR2 é uma função não decrescente.
A SPR2 é calculada em cada passo do algoritmo sendo que, deve-se buscar o ponto em que ocorre um salto significativo (maior do que os restantes). Esse ponto indica o número de grupos a ser considerado. A idéia é semelhante ao indicado no item (I), no qual busca-se o passo com a maior altura entre as junções.
Nota: os pontos de corte obtido pelas medidas pseudo-F, pseudo-T2 e SPR2 podem ser encontrados por meio de um gráfico no qual plotamos oi valor da medida versus o passo do algoritmo. Daí, procuramos o pontto de máximo ou o maior salto, conforme o caso.
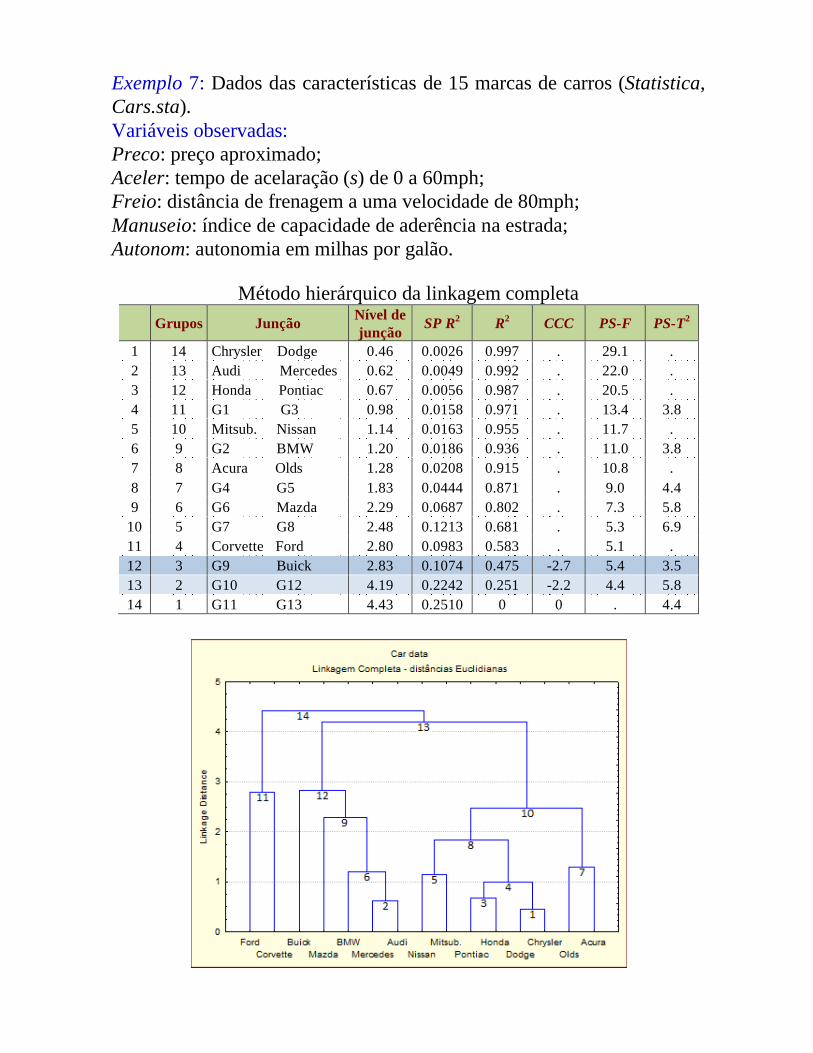
Exemplo 7: Dados das características de 15 marcas de carros (Statistica, Cars.sta).Variáveis observadas:Preco: preço aproximado;Aceler: tempo de acelaração (s) de 0 a 60mph;Freio: distância de frenagem a uma velocidade de 80mph;Manuseio: índice de capacidade de aderência na estrada;Autonom: autonomia em milhas por galão.
Método hierárquico da linkagem completaGrupos Junção Nível de
junção SP R2 R2 CCC PS-F PS-T2
1 14 Chrysler Dodge 0.46 0.0026 0.997 . 29.1 .2 13 Audi Mercedes 0.62 0.0049 0.992 . 22.0 .3 12 Honda Pontiac 0.67 0.0056 0.987 . 20.5 .4 11 G1 G3 0.98 0.0158 0.971 . 13.4 3.85 10 Mitsub. Nissan 1.14 0.0163 0.955 . 11.7 .6 9 G2 BMW 1.20 0.0186 0.936 . 11.0 3.87 8 Acura Olds 1.28 0.0208 0.915 . 10.8 .8 7 G4 G5 1.83 0.0444 0.871 . 9.0 4.49 6 G6 Mazda 2.29 0.0687 0.802 . 7.3 5.8
10 5 G7 G8 2.48 0.1213 0.681 . 5.3 6.911 4 Corvette Ford 2.80 0.0983 0.583 . 5.1 .12 3 G9 Buick 2.83 0.1074 0.475 -2.7 5.4 3.513 2 G10 G12 4.19 0.2242 0.251 -2.2 4.4 5.814 1 G11 G13 4.43 0.2510 0 0 . 4.4
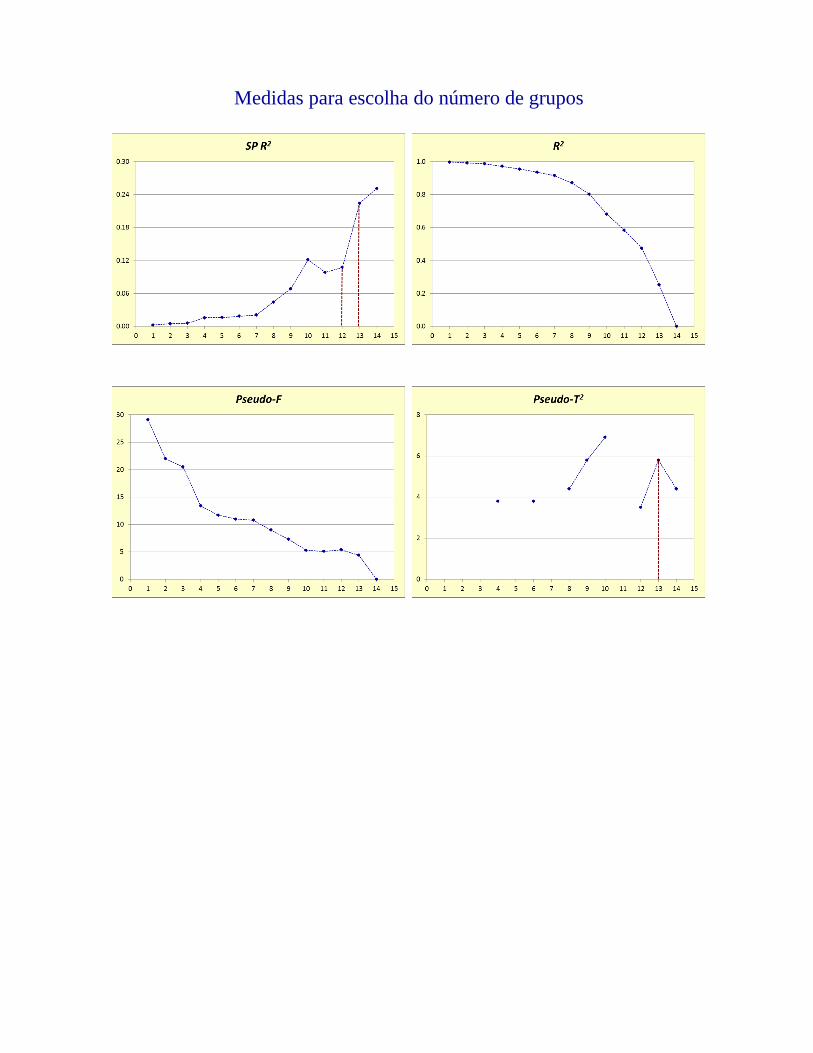
Medidas para escolha do número de grupos
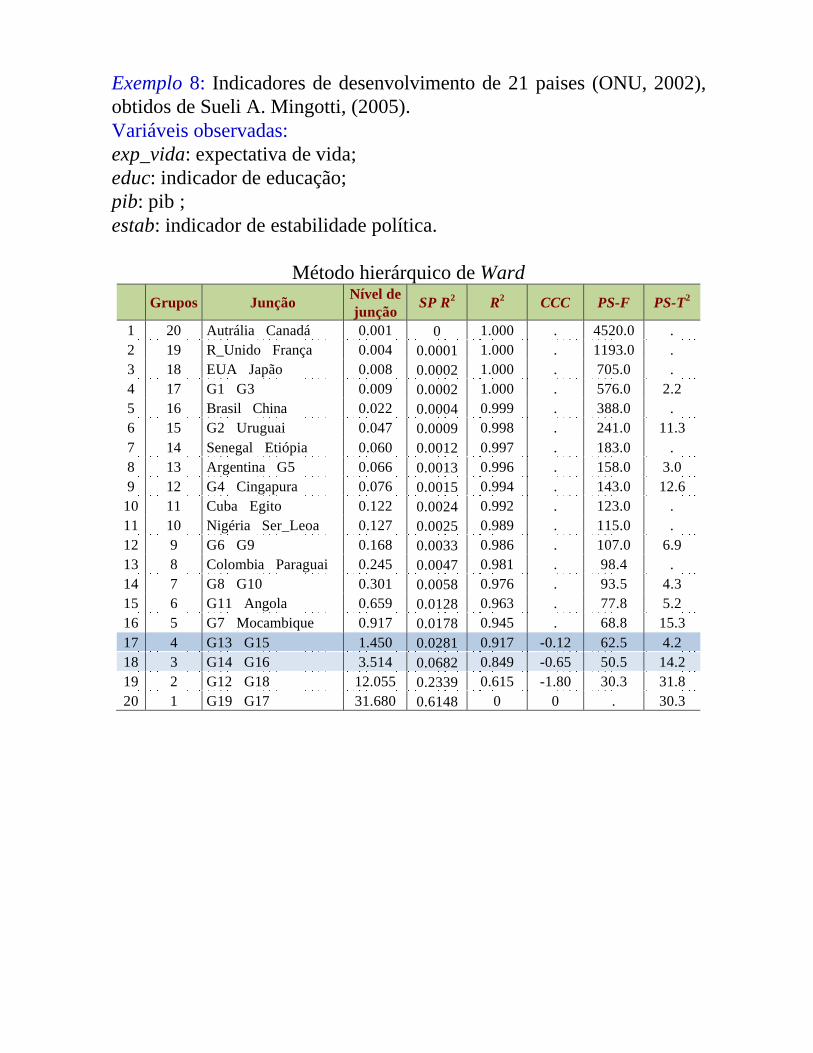
Exemplo 8: Indicadores de desenvolvimento de 21 paises (ONU, 2002), obtidos de Sueli A. Mingotti, (2005). Variáveis observadas:exp_vida: expectativa de vida;educ: indicador de educação;pib: pib ;estab: indicador de estabilidade política.
Método hierárquico de WardGrupos Junção Nível de
junção SP R2 R2 CCC PS-F PS-T2
1 20 Autrália Canadá 0.001 0 1.000 . 4520.0 .2 19 R_Unido França 0.004 0.0001 1.000 . 1193.0 .3 18 EUA Japão 0.008 0.0002 1.000 . 705.0 .4 17 G1 G3 0.009 0.0002 1.000 . 576.0 2.25 16 Brasil China 0.022 0.0004 0.999 . 388.0 .6 15 G2 Uruguai 0.047 0.0009 0.998 . 241.0 11.37 14 Senegal Etiópia 0.060 0.0012 0.997 . 183.0 .8 13 Argentina G5 0.066 0.0013 0.996 . 158.0 3.09 12 G4 Cingapura 0.076 0.0015 0.994 . 143.0 12.6
10 11 Cuba Egito 0.122 0.0024 0.992 . 123.0 .11 10 Nigéria Ser_Leoa 0.127 0.0025 0.989 . 115.0 .12 9 G6 G9 0.168 0.0033 0.986 . 107.0 6.913 8 Colombia Paraguai 0.245 0.0047 0.981 . 98.4 .14 7 G8 G10 0.301 0.0058 0.976 . 93.5 4.315 6 G11 Angola 0.659 0.0128 0.963 . 77.8 5.216 5 G7 Mocambique 0.917 0.0178 0.945 . 68.8 15.317 4 G13 G15 1.450 0.0281 0.917 -0.12 62.5 4.218 3 G14 G16 3.514 0.0682 0.849 -0.65 50.5 14.219 2 G12 G18 12.055 0.2339 0.615 -1.80 30.3 31.820 1 G19 G17 31.680 0.6148 0 0 . 30.3
Medidas para escolha do número de grupos

4. Métodos não hierárquicos:
O método das k-médias (k-means) é um método aglomerativo não hierárquico (MNH). Os métodos não hierárquicos podem, ainda, serem baseados em estimações de densidades ou misturas de distribuições, porém o método das k-médias é o mais popular de todos.
Os métodos não hierárquicos são caracterizados por: o número de grupos deve ser estabelecido (conhecido) a priori; utilizam diretamente a matriz de dados, não sendo necessário o
cálculo da matriz de distâncias (vantajoso quando se tem muitos dados);
diferentemente dos métodos hierárquicos, os objetos podem ser realocados diversas vezes durante o processo;
o agrupamento final é obtido ao se atingir um critério de parada que é determinado segundo uma função objetivo (que deve ser otimizada);
devem ser utilizados para agrupamento de objetos (ou itens) e não de variáveis.
Os métodos não hierárquicos podem começar com uma partiçãoinicial dos objetos ou com um grupos de pontos, ou sementes, que serão os núcleos dos clusters. Essa configuração deve ser livre de viés, portanto, é adequado que seja obtida através de escolhas aleatórias das sementes ou partições iniciais.
4.1. Método das k-médias:
O método das k-médias pode utilizar diferentes medidas como função objetivo, como por exemplo, a distância Euclidiana, distância Euclidiana ao quadrado, somas de quadrados dentro e entre grupos.

Algoritmo:
a) Dividir arbitrariamente os n objetos iniciais em g grupos e calcular os seus centróides (vetores de médias);Ou, determinar g sementes arbitrárias como centróides, que podem ser escolhidas dentre os n objetos ou mesmo geradas aleatoriamente;
b) Calcular as distâncias dos n objetos com todos os centróides e: manter o objeto no seu grupo se a sua distância em relação ao
centróide de seu grupo for a menor ou, realocar o objeto para o grupo cuja distância em relação ao
centróide for a menor;
c) Recalcular os centróides para aqueles grupos que sofreram alteração;
d) Repetir os passos (b) e (c) até que não ocorram mais realocações.
Exemplo 9: Sejam as variáveis X1 e X2 medidas para os objetos A, B, C, De E. Dividir os objetos em 2 grupos pelo método das k-médias.
Situação inicial.objeto grupo x1 x2
A G1 5 3B G1 -2 2C G2 -1 -2D G2 -3 -2E G2 1 1
Centróides iniciais:
Grupo 1: 5.2,5.11 x
Grupo 2: 0.1,0.12 x
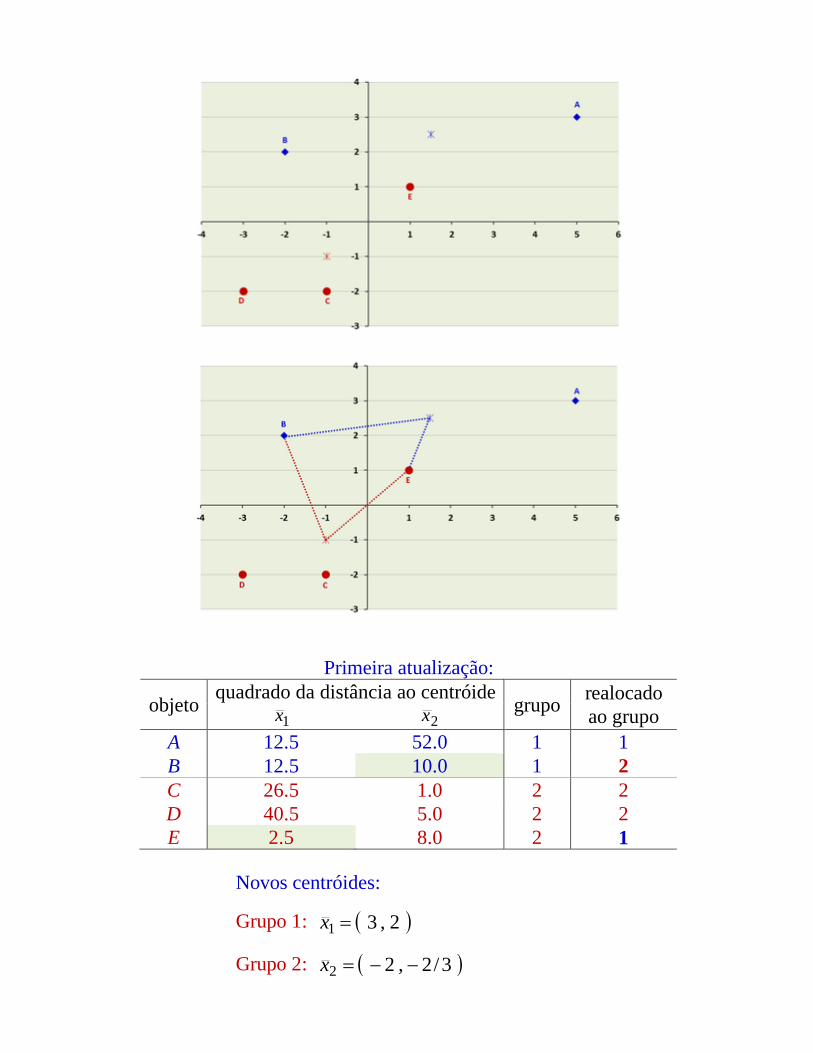
Primeira atualização:
objeto quadrado da distância ao centróide grupo realocadoao grupo1x 2x
A 12.5 52.0 1 1B 12.5 10.0 1 2C 26.5 1.0 2 2D 40.5 5.0 2 2E 2.5 8.0 2 1
Novos centróides:
Grupo 1: 2,31 x
Grupo 2: 3/2,22 x
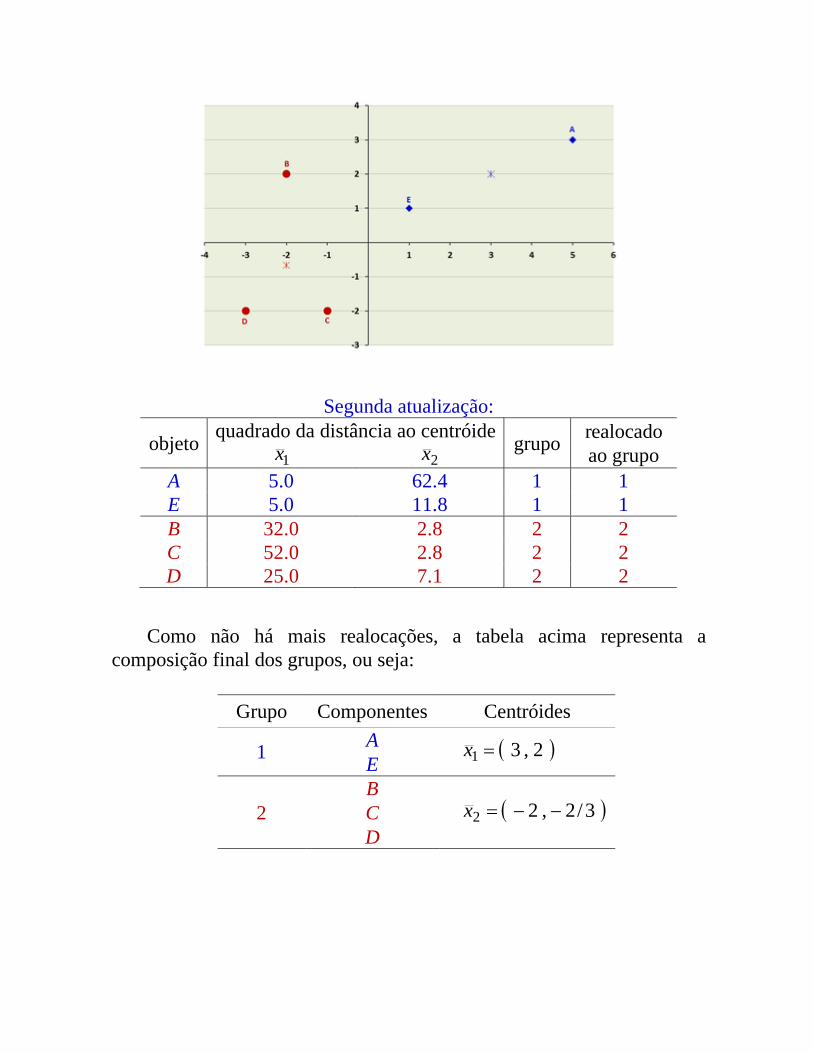
Segunda atualização:
objeto quadrado da distância ao centróide grupo realocadoao grupo1x 2x
A 5.0 62.4 1 1E 5.0 11.8 1 1B 32.0 2.8 2 2C 52.0 2.8 2 2D 25.0 7.1 2 2
Como não há mais realocações, a tabela acima representa a composição final dos grupos, ou seja:
Grupo Componentes Centróides
1 A 2,31 xE
2B
3/2,22 xCD

Exemplo 10: O m�todo das k-m�dias baseiado na parti��o da soma de quadrados total de uma análise de variância, tal como a aloca��o de Ward, (extra�do do livro de minicurso de L�cia P. Barroso, 2003, Lavras).
O procedimento tem como objetivo a minimiza��o da soma de quadrados da parti��o SQDP (Soma de Quadrados Dentro dos clusters), que � dada por
k
j
n
ivjvji
j
xxvSQD1 1
2)( ,
em que: SQD(v) � a soma de quadrados “dentro” dos grupos para a vari�vel v, v = 1,..., p;
vjx � a m�dia amostral da vari�vel v, no grupo j-ésimo grupo,
vjix � a i-ésima observa��o da vari�vel v, no j-ésimo grupo.
Assim, a soma de quadrados total da parti��o SQDP � dada por:
.1
p
vvSQDSQDP
Dados de Indicadores de viol�ncia de cinco regi�es administrativas do Estado de S�o Paulo considerando duas vari�veis apenas.
Tabela 1: Dados parciais de indicadores de viol�ncia (SSP/SP).
Regi�es Dados Brutos Dados PadronizadosHom. Doloso Furto Hom. Doloso Furto
SJRPreto 10.85 1500.80 -0.6638 0.8475RibPreto 14.13 1496.07 -0.0731 0.8128Bauru 8.62 1448.79 -1.0654 0.4655Campinas 23.04 1277.33 1.5315 -0.7937Sorocaba 16.04 1204.02 0.2709 -1.3321
M�dia 14.54 1385.40 0.00 0.00D.P. 5.55 136.16 1.00 1.00
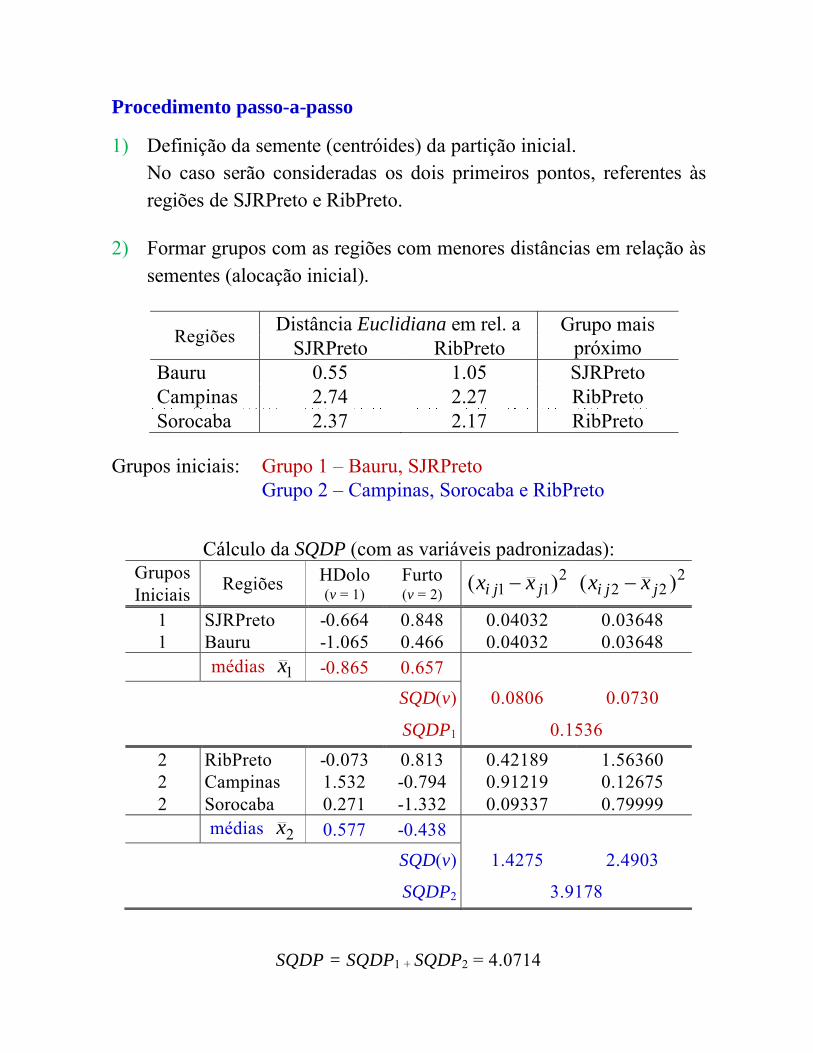
Procedimento passo-a-passo
1) Defini��o da semente (centr�ides) da parti��o inicial.No caso ser�o consideradas os dois primeiros pontos, referentes �s regi�es de SJRPreto e RibPreto.
2) Formar grupos com as regi�es com menores dist�ncias em rela��o �s sementes (aloca��o inicial).
Regi�es Dist�ncia Euclidiana em rel. a Grupo mais pr�ximoSJRPreto RibPreto
Bauru 0.55 1.05 SJRPretoCampinas 2.74 2.27 RibPretoSorocaba 2.37 2.17 RibPreto
Grupos iniciais: Grupo 1 – Bauru, SJRPretoGrupo 2 – Campinas, Sorocaba e RibPreto
C�lculo da SQDP (com as vari�veis padronizadas):Grupos Iniciais Regi�es HDolo
(v = 1)Furto(v = 2)
211 )( jji xx 2
22 )( jji xx
1 SJRPreto -0.664 0.848 0.04032 0.036481 Bauru -1.065 0.466 0.04032 0.03648
m�dias 1x -0.865 0.657SQD(v) 0.0806 0.0730
SQDP1 0.15362 RibPreto -0.073 0.813 0.42189 1.563602 Campinas 1.532 -0.794 0.91219 0.126752 Sorocaba 0.271 -1.332 0.09337 0.79999
m�dias 2x 0.577 -0.438SQD(v) 1.4275 2.4903
SQDP2 3.9178
SQDP = SQDP1 + SQDP2 = 4.0714
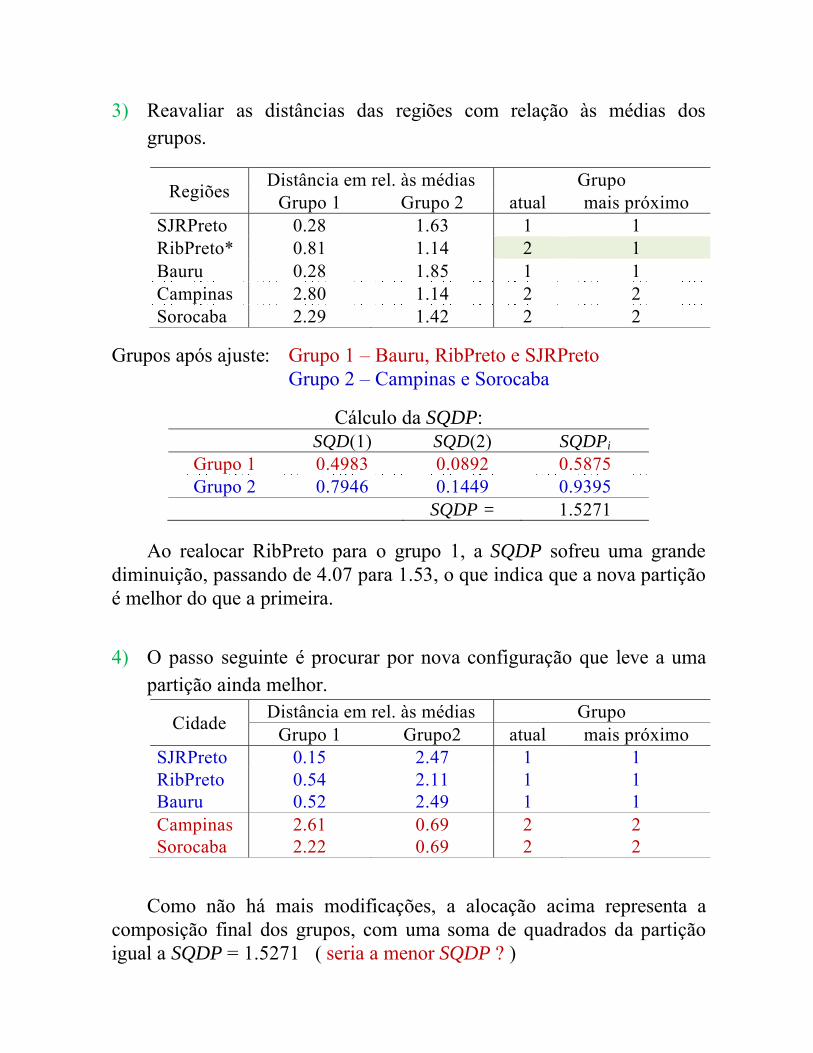
3) Reavaliar as dist�ncias das regi�es com rela��o �s m�dias dosgrupos.
Regi�es Dist�ncia em rel. �s m�dias GrupoGrupo 1 Grupo 2 atual mais pr�ximo
SJRPreto 0.28 1.63 1 1RibPreto* 0.81 1.14 2 1Bauru 0.28 1.85 1 1Campinas 2.80 1.14 2 2Sorocaba 2.29 1.42 2 2
Grupos ap�s ajuste: Grupo 1 – Bauru, RibPreto e SJRPretoGrupo 2 – Campinas e Sorocaba
C�lculo da SQDP:SQD(1) SQD(2) SQDPi
Grupo 1 0.4983 0.0892 0.5875Grupo 2 0.7946 0.1449 0.9395
SQDP = 1.5271
Ao realocar RibPreto para o grupo 1, a SQDP sofreu uma grande diminui��o, passando de 4.07 para 1.53, o que indica que a nova parti��o � melhor do que a primeira.
4) O passo seguinte � procurar por nova configura��o que leve a uma parti��o ainda melhor.
Cidade Dist�ncia em rel. �s m�dias GrupoGrupo 1 Grupo2 atual mais pr�ximo
SJRPreto 0.15 2.47 1 1RibPreto 0.54 2.11 1 1Bauru 0.52 2.49 1 1Campinas 2.61 0.69 2 2Sorocaba 2.22 0.69 2 2
Como n�o h� mais modifica��es, a aloca��o acima representa a composi��o final dos grupos, com uma soma de quadrados da parti��oigual a SQDP = 1.5271 ( seria a menor SQDP ? )

4.1.1. M�todo das k-m�dias no SAS – Procedure FASTCLUS
O m�todo das k-m�dias est� implementado no SAS pelo Procedure FASTCLUS.
Na sequ�ncia s�o apresentadas algumas op��es do FASTCLUS:
- maxcluster = n : define o n�mero de clusters para o agrupamento;
- converge = c : define valor de refer�ncia para a converg�ncia;
- distance: calcula e mostra as dist�ncias entre as m�dias dos clusters;
- least = p : 1 < p < ∞, define a m�trica
▪ se p = 1, o procedimento minimiza a diferen�a absoluta m�dia entre os dados e a mediana do seu grupo;
▪ se p = 2, o procedimento minimiza a raiz quadrada da diferen�a quadr�tica m�dia entre os dados e a m�dia do seu grupo;
▪ se p = max, o procedimento minimiza a m�xima diferen�a absoluta entre os dados e a m�dia do seu grupo;
▪ para 1 < p < ∞, o procedimento minimiza a p-ésima raiz da m�dia das diferen�as absolutas na pot�ncia p.
- maxiter = n : especifica o n�mero m�ximo de itera��es (o default varia com o valor de p);
Valores default:▪ se p = 1, n = 20;▪ se 1 < p < 1.5, n = 50;▪ se 1.5 < p < 2, n = 50;▪ se p = 2, n = 10;▪ se p > 2, n = 20;▪ se p n�o � especificado, n = 1;
- out = sas-data-name: gera arquivo com as sa�das (ver tamb�m outstat);
- replace : especifica a parti��o inicial (ver help do SAS).